



Introduction
A considerable body of infancy research has found that exposure to native language input shapes perception. Although infants are born with the ability to discriminate many of the speech sounds found in the world’s languages (for a review see Aslin, Jusczyk, & Pisoni, Reference Aslin, Jusczyk, Pisoni, Kuhn and Siegler1998), during the first year of life this proficiency begins to specialise to their native language. By 6 months of age, infants’ perception of vowel categories has started to narrow on native contrasts (Kuhl, Williams, Lacerda, Stevens, & Lindblom, Reference Kuhl, Williams, Lacerda, Stevens and Lindblom1992; Polka & Werker, Reference Polka and Werker1994), with a narrowing towards native consonant contrasts starting to occur at around 10 to 12 months of age (Best, McRoberts, & Sithole, Reference Best, McRoberts and Sithole1988; Werker & Lalonde, Reference Werker and Lalonde1988; Werker & Tees, Reference Werker and Tees1984). Alongside acquiring the sound structure of their native language, infants are also beginning to recognise frequently heard common and proper nouns. Parental reports suggest that infants already know the meaning of many words by the time they are 6- to 9-months old (Frank, Braginsky, Yurovsky, & Marchman, Reference Frank, Braginsky, Yurovsky and Marchman2017). This is supported by experimental studies which show that infants not only prefer listening to familiar words over unfamiliar words (Hallé & de Boysson-Bardies, Reference Hallé and de Boysson-Bardies1994, Reference Hallé and de Boysson-Bardies1996; Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Swingley, Reference Swingley2005; Vihman, Nakai, DePaolis, & Hallé, Reference Vihman, Nakai, DePaolis and Hallé2004), but can also identify a referent upon hearing a familiar word (Bergelson & Swingley, Reference Bergelson and Swingley2012; Tincoff & Jusczyk, Reference Tincoff and Jusczyk1999).
To understand how infants build phonological representations of words, research has typically focussed on their sensitivity to mispronunciations or deletions of phonemes, and in particular of consonants rather than vowels. However, consonants and vowels have been proposed to have different functions in language processing (Nespor, Peña, & Mehler, Reference Nespor, Peña and Mehler2003) – namely, a consonant bias for lexical processing and a vowel bias for syntactic and prosodic processing. Adult studies on many languages (including English, French, Spanish, Italian, and Dutch) have almost always demonstrated a greater dependence on consonants over vowels in tasks associated with both lexical learning and lexical access (with the possible exception of tone languages, for a review see Nazzi & Cutler, Reference Nazzi and Cutler2019). For example, pseudo-words containing shared consonants with real words create reliable confusion effects, while pseudo-words with shared vowels do not (Creel, Aslin, & Tanenhaus, Reference Creel, Aslin and Tanenhaus2006). Similarly, priming effects are observed when prime and targets share consonants rather than vowels (Delle Luche, Poltrock, Goslin, New, Floccia, & Nazzi, Reference Delle Luche, Poltrock, Goslin, New, Floccia and Nazzi2014). Therefore, given that the privileged role of consonants in adult lexical processing appears to be found irrespective of the language’s phonological inventory, such a bias could assist infants in learning their native language. In particular, a consonant bias could help facilitate both word learning and word recognition in infants.
Although there is extensive evidence for a consonant bias in lexical processing tasks in adults, its developmental trajectory remains unclear (for a review see Nazzi, Poltrock, & Von Holzen, Reference Nazzi, Poltrock and Von Holzen2016). Three distinct accounts concerning its development have been discussed. The initial bias hypothesis (Bonatti, Peña, Nespor, & Mehler, Reference Bonatti, Peña, Nespor and Mehler2007; Nespor et al., Reference Nespor, Peña and Mehler2003) suggests that infants begin to process consonants and vowels as separate linguistic categories from birth. Accordingly, an initial consonant bias would assist infants in building the lexicon of their native language, while an initial vowel bias would provide infants with grammatical and prosodic information. This proposal assumes a limited impact of input characteristics, with neither developmental nor cross-linguistic differences in the development of the consonant bias.
The lexical hypothesis (Keidel, Jenison, Kluender, & Seidenberg, Reference Keidel, Jenison, Kluender and Seidenberg2007) proposes that the consonant advantage in lexical processing tasks is the result of variations in the distribution of consonants and vowels across languages and the extent to which they are advantageous in coding the lexicon. For example, Keidel et al. (Reference Keidel, Jenison, Kluender and Seidenberg2007) analysed 4,943 CVCVCV words, taken from the French corpus Lexique 3 (New, Pallier, Brysbaert, & Ferrand, Reference New, Pallier, Brysbaert and Ferrand2004), to identify the number of unique consonant and vowel tiers present in each word. They found that the words contained 820 specific 3-consonant tiers (e.g., C-S-N- in CASINO) and 562 specific 3-vowel tiers (e.g., A-I-O in CASINO). This means that, on average, each unique consonant tier was found in 6.03 words, whereas each unique vowel tier was found in 8.8 words. Therefore, the vowel tiers for CVCVCV words produced 1.46 times as many possible words compared to consonant tiers and are less informative to code and disambiguate words. Developmentally, this explanation assigns a significant role to the acquired lexical properties of a language, and therefore predicts that the preferential role of consonants may emerge during development due to lexical acquisition, probably in the second year of life. Furthermore, how informative the consonants and vowels of a given language are could also lead to cross-linguistic differences.
Finally, the acoustic-phonetic hypothesis (Floccia, Nazzi, Delle Luche, Poltrock, & Goslin, Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014) also proposes that the consonant bias is learned, but through the exposure to the acoustic-phonetic properties of the consonants and vowels of a language, rather than through its lexical regularities. According to this hypothesis, the increased salience, periodicity and stability of vowels over consonants provides an initial advantage to an infant in processing vowels, with the consonant bias developing before their first birthday. This switch between an initial vowel bias and a subsequent consonant bias may occur as consonants are processed more categorically than vowels, which could highlight to infants that they are more dependable when both recognising and learning new words (Hochmann, Benavides‐Varela, Nespor, & Mehler, Reference Hochmann, Benavides‐Varela, Nespor and Mehler2011). It may also arise due to consonant categories appearing to be more discriminable than vowel categories (Bouchon, Floccia, Fux, Adda-Decker, & Nazzi, Reference Bouchon, Floccia, Fux, Adda‐Decker and Nazzi2015), because of the emerging capacity to process fine temporal information, or due to the development of phonological – as opposed to phonetic – categories throughout the first year of life (Poltrock & Nazzi, Reference Poltrock and Nazzi2015). Together, this could help infants learn to pay more attention to consonants during lexical processing. Within this perspective, cross-linguistic differences due to differential consonantal and vocalic properties between languages may also be found in the development of the consonant bias.
From these hypotheses, it is clear that, to understand the origins of the consonant bias in lexical processing as seen in adults, developmental cross-linguistic data is necessary. Indeed, the three theoretical accounts of the consonant bias predict either that the effect would be observed from the onset of word learning, irrespective of the language being learned (initial bias hypothesis); that it would emerge from the computation of regularities in the early lexicon and would be language dependent (lexical hypothesis); or that it would appear prior to the acquisition of the lexicon but would vary across languages (acoustic-phonetic hypothesis).
Developmental data documenting (or that can be used to document) the emergence of a consonant bias in early childhood come from three types of studies: word learning, word form recognition, and word recognition. Word learning studies explore whether infants use fine phonological information when learning new words. Word form recognition studies typically examine infants’ preference for lists of words presented without visual referents – using, for example, the head turn paradigm (e.g., Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004), and testing their sensitivity to phonological mispronunciations. Word recognition studies explore word processing through a recognition response for a meaningful relationship between a word form and its visual referent, usually through the use of the inter-modal looking paradigm (e.g., Mani & Plunkett, Reference Mani and Plunkett2007) or eyetracking (Von Holzen, van Ommen, White, & Nazzi, Reference Von Holzen, van Ommen, White and Nazzi2022), again testing infants’ sensitivity to mispronunciations. Of course, although word form recognition studies cannot infer any understanding of word meaning, they cannot exclude it either. In what follows, we examine the body of research that can help us understand the origins of the consonant bias, by reviewing all three types of studies.
Initial studies in French-learning infants suggested that a consonant bias is present in lexical processing from an early age. In relation to word learning, Nazzi (Reference Nazzi2005) found that 20-month-old infants successfully learn two novel words if they differ by one of their consonants (e.g., /pize/ vs. /tize/) but not if they differ by one of their vowels (/pize/ vs. /pyze/). Additional studies with French-learning children have found comparable results when using different positions of the consonants within the novel words (Nazzi & Bertoncini, Reference Nazzi and Bertoncini2009), when using different consonants (e.g., /nuk/ vs. /muk/, /rize/ vs. /lize/; Nazzi & New, Reference Nazzi and New2007), as well as consonant changes in coda position (Havy, Bertoncini, & Nazzi, Reference Havy, Bertoncini and Nazzi2011), thus robustly establishing a consonant bias in word learning tasks in French-learning infants. In relation to word form recognition, Poltrock and Nazzi (Reference Poltrock and Nazzi2015), having first established a preference for familiar over novel words in French-learning 11-month-olds, found that infants at that age preferred to listen to vowel alterations over consonant alterations of the familiar words. This finding was found irrespective of the infants’ overall lexicon size. Due to infants’ preferences for familiar words at this age, this finding suggests a reliance on consonant information over vowel information in word form recognition at 11 months. Relatedly, Zesiger and Jöhr (Reference Zesiger and Jöhr2011) found that French-learning 14-month-olds’ recognition of familiar disyllabic target objects was impeded by consonant mispronunciations on the second syllable, but not by mispronunciations on the first syllable, nor vowel changes to the initial or final syllables (though lack of recognition of familiar words in some conditions of this study weakens the evidence of a consonant bias). Convergent evidence was recently found by Von Holzen et al. (Reference Von Holzen, van Ommen, White and Nazzi2022), confirming the consonant bias in word recognition, and additionally showing differential sensitivity to accent change for consonants and vowels. Therefore, the consonant bias appears to be present in word learning, word form recognition and word recognition tasks in French-learning infants from an early age.
Research in even younger French-learning infants also suggests that the consonant bias is not an innate feature of speech perception, but instead develops during the infants’ first year. Infants’ own name recognition (word form) is impeded at 5 months when mispronounced with a vowel change (e.g., ‘Alex’ vs. ‘Elix’) but not with a consonant change (e.g., ‘Victor’ vs. ‘Zictor’), suggesting a vowel bias at this early age (Bouchon et al., Reference Bouchon, Floccia, Fux, Adda‐Decker and Nazzi2015). More recently, Von Holzen and Nazzi (Reference Von Holzen and Nazzi2020) found that both 5- and 8-month-old French-learning infants attended longer to vowel mispronunciations of their own name, but that 11-month-olds attended longer to consonant mispronunciations, a preference that was unrelated to infants’ reported vocabulary size or the proportion of unique consonant and vowel sequences they knew. In a segmentation task, Nishibayashi and Nazzi (Reference Nishibayashi and Nazzi2016) found that 6-month-olds were more sensitive to vowel mispronunciations, whereas 8-month-olds were more sensitive to consonant-mispronunciations in previously segmented words. Together, these findings again indicate that, rather than being an early feature of speech perception, the functional advantage of consonants over vowels in language processing emerges during language acquisition in French-learning infants somewhere between 8 and 11 months.
Interpreting these results in light of the three hypotheses of the origins of the consonant bias points to an advantage of the acoustic-phonetic hypothesis. The initial bias hypothesis would not easily account for the finding that the consonant bias emerges during development, although it could be argued that the consonant bias is a maturational process that appears when infants engage in lexical processing, which would be during the second half of the first year of life. The lexical hypothesis would appear to be discarded by the recurring findings that the consonant bias is observed irrespective of infants’ vocabulary size, although it could be argued that correlations between infants’ responses and estimated vocabulary size are too approximate. The acoustic-phonetic hypothesis, on the other hand, fits nicely with the findings that (1) the bias emerges during development and (2) is independent of word knowledge. Cross-linguistic data are necessary to distinguish further between these hypotheses – recall that only the initial bias hypothesis would claim that the trajectory of emergence of the lexical consonant bias is not language specific.
Studies in other languages strongly suggest that the developmental acquisition of the consonant bias varies cross-linguistically. Firstly, evidence of the early development of the consonant bias remains unclear in British English-learning infants. In relation to word learning, Nazzi, Floccia, Moquet, and Butler (Reference Nazzi, Floccia, Moquet and Butler2009) found that a consonant bias in a word learning task was only present at 30 months of age, with Floccia et al. (Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014) reporting that word pairings differing by one consonant or one vowel were learned equally well by 16- and 24-month-old infants. In relation to word recognition, British English-learning infants appear more sensitive to single-feature consonant than vowel mispronunciations of familiar words at 15 months, but are equally sensitive to both mispronunciations at 12, 18, and 24 months (Mani & Plunkett, Reference Mani and Plunkett2007, Reference Mani and Plunkett2010). At 5 months, Delle Luche, Floccia, Granjon, and Nazzi (Reference Delle Luche, Floccia, Granjon and Nazzi2017) found that, in contrast to Bouchon et al.’s (Reference Bouchon, Floccia, Fux, Adda‐Decker and Nazzi2015) findings in French-learning infants, British English-learning infants did not detect either a consonant or vowel mispronunciation to their own name (word form). However, in a second experiment, infants could detect their own name if it was paired with a name that was phonetically dissimilar (e.g., Sophie vs. Amber). The results from such studies are again in contrast with a language-general initial bias hypothesis. Floccia et al. (Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014) suggest that cross-linguistic differences in either the lexical properties (longer words in early vocabularies in French than English; which might affect the structure of lexical neighbourhoods, an explanation compatible with the lexical hypothesis) or the phonology (e.g., the complexity of syllables in English compared to French; compatible with the acoustic-phonetic hypothesis) may influence the developmental trajectory of the consonant bias. The lexical and phonological properties of a language (depending on the hypothesis) may also lead to a vowel bias that appears to persist in late toddlerhood.
Finally, although adult data point to a predominance of consonant bias across 13 languages (Nazzi & Cutler, Reference Nazzi and Cutler2019), there are languages where toddlers appear to persist into a vowel bias. For example, Højen and Nazzi (Reference Højen and Nazzi2016) found that 20-month-old infants learning Danish, a language where vowels outnumber consonants, demonstrate a vowel rather than a consonant bias in a word learning task. Regarding tone languages, both monolingual Mandarin-learning and bilingual Mandarin–English 24-month-olds were tested on their sensitivity to consonant, vowel, and tone mispronunciations of familiar words (Wewalaarachchi, Wong, & Singh, Reference Wewalaarachchi, Wong and Singh2017). Analyses of proportional looking times revealed that these toddlers were equally sensitive to consonant, vowel and tone mispronunciations, and these effects did not differ across the two language groups, again failing to find a consonant or vowel bias. However, when taking response speed into account, group differences emerged: The monolingual toddlers were most sensitive to tone, then vowel, and then consonant mispronunciations, while the bilingual toddlers were most sensitive to vowel, then consonant, and then tone mispronunciations. While these analyses reveal a vowel bias in both groups of 24-month-olds, these effects were only found on the subset of the data in which the toddlers were initially looking at the distractor object when the target was named, which amounted to only 30% of the data, calling for additional, stronger evidence of such a vowel bias in Mandarin (see also Poltrock, Chen, Kwok, Cheung, & Nazzi, Reference Poltrock, Chen, Kwok, Cheung and Nazzi2018; Wiener, Reference Wiener2020; Wiener & Turnbull, Reference Wiener and Turnbull2016 for related adult data). Lastly, a word learning experiment using eye-tracking in Cantonese learning toddlers found a vowel bias, over consonants and tones, at 30 months (Chen, Lee, Luo, Lai, Cheung & Nazzi, Reference Chen, Lee, Luo, Lai, Cheung and Nazzi2021; see also Gómez, Mok, Ordin, Mehler, & Nespor, Reference Gómez, Mok, Ordin, Mehler and Nespor2018; Poltrock et al., Reference Poltrock, Chen, Kwok, Cheung and Nazzi2018, for related adult data). The results from such studies indicate that the development of consonant and vowel biases is shaped during the first few years of life by an infant’s native language.
Taken together, research suggests that the preferential role of consonants in lexical processing tasks is not an innate bias (discarding the native bias hypothesis), since cross-linguistic variations are found in its developmental course. However, existing data do not fully allow us to determine whether the consonant bias emerges because of lexical regularities or because of acoustic-phonetic information. Both hypotheses account for cross-linguistic variation, but only the lexical regularity hypothesis predicts a link between its acquisition and vocabulary size. Note that such a link has not been found in French-learning infants, but the absence of evidence is not necessarily evidence of absence. To gain more strength, additional cross-linguistic tests of the consonant bias and of its potential links to vocabulary size are required. Therefore, the present study focusses on sensitivity to consonant and vowel mispronunciations of familiar word forms in British English-learning 11-month-olds. British English was chosen because as reviewed above, the evidence so far is inconclusive in that language, with word learning data showing no bias until the age of 30 months (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014; Nazzi et al., Reference Nazzi, Floccia, Moquet and Butler2009), mispronunciation data showing a consonant bias at 15 months, but an equal sensitivity to both consonant and vowel mispronunciations at 12, 18, and 24 months (Mani & Plunkett, Reference Mani and Plunkett2007, Reference Mani and Plunkett2010). The age of 11 months was selected because infants at the end of their first year have begun to acquire their native consonants (Polka & Werker, Reference Polka and Werker1994) and have compiled a receptive vocabulary of about 135 words (Mayor & Plunkett, Reference Mayor and Plunkett2011), providing an ideal moment to examine the role of consonants in lexical processing, and its potential link to vocabulary size.
Note that we will focus on demonstrating the existence (or lack of) a consonant bias in word form recognition, rather than a vowel bias. This is first because, in adulthood, no study has found a vocalic advantage in lexical processing in speakers of non-tonal languages (Nazzi & Cutler, Reference Nazzi and Cutler2019; see Wiener, Reference Wiener2020, for the only evidence of an adult vowel bias, found in the tone language Mandarin). Second, in developmental data, as reviewed above, the languages in which toddlers have shown a vowel bias in lexical processing are either tone languages, or Danish, in which vowels outnumber consonants. The vowel/consonant ratio of English coupled to the absence of tones suggest that English is not expected to elicit an early lexical vowel bias.
The starting point for the current experiments was a paradigm developed by Hallé and de Boysson-Bardies (Reference Hallé and de Boysson-Bardies1996) in French-learning infants (see also Poltrock & Nazzi, Reference Poltrock and Nazzi2015), and then extended to English (Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004) and Dutch (Swingley, Reference Swingley2005). Using a head-turn procedure, the authors examined the impact of mispronunciations of known words on infants’ word form recognition. In 11-month-old English-learning infants, it was found that altering the initial consonants of disyllabic words impeded word recognition (e.g., hearing /vunny/ instead of /bunny/), whereas changing the medial consonant did not (Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004). Replacing either the initial consonant or final consonant in monosyllabic familiar words with a phonetically close consonant also resulted in the familiar word preference disappearing in Dutch-learning 11-month-olds (Swingley, Reference Swingley2005). In French-learning 11-month-olds, Hallé and de Boysson-Bardies (Reference Hallé and de Boysson-Bardies1996) reported that only removing the onset consonant of a familiar disyllabic word resulted in a disappearance of the familiarity preference, although a reanalysis of the data by Vihman et al. (Reference Vihman, Nakai, DePaolis and Hallé2004) found that infants were also sensitive to onset consonant mispronunciations in the first half of the trials but not the second. Together, these results suggest that infants’ recognition of familiar words is at least partially disrupted by consonant changes.
Using the Headturn Preference Procedure (HPP), Experiment 1 aims to replicate the finding that infants prefer listening to lists of familiar over unfamiliar word forms, as has been previously demonstrated in the literature (e.g., Hallé & de Boysson-Bardies, Reference Hallé and de Boysson-Bardies1994; Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004). Having established this familiarity preference, Experiment 2 will follow on from the findings of Poltrock and Nazzi (Reference Poltrock and Nazzi2015) by examining infants’ preferences for onset consonant mispronunciations versus vowel mispronunciations of the familiar word forms presented in Experiment 1. If British English-learning infants behave in the same way as their French-learning counterparts in Poltrock and Nazzi (Reference Poltrock and Nazzi2015), then a preference for lists of word forms with a vowel mispronunciation should emerge, establishing a consonant bias. However, if British English-learning infants do not show a consonant bias, then no preference for either consonant or vowel changes to the familiar word forms will be found.
Across both experiments, infants’ preferences will also be measured in relation to their vocabulary size as estimated by parental reports, in order to examine if there is a link between the acquisition of a consonant bias and lexical development, as done in prior related studies on this issue (e.g., Poltrock & Nazzi, Reference Poltrock and Nazzi2015). In addition, to refine these analyses, infants’ vocabulary knowledge will be used to estimate the number of unique consonant tiers and vowel tiers they have learned at this stage (i.e., /d.d/ and /æ.i/ from ‘daddy’), and examine if those data can predict preference for lists of items, following the same logic as Keidel et al. (Reference Keidel, Jenison, Kluender and Seidenberg2007) who computed vowel and consonant tiers in adult lexicons.
Experiment 1: Familiar Word Forms vs. Pseudowords
To first establish a preference for familiar word forms, Experiment 1 used the HPP to measure 11-month-old British English-learning infants’ preferences for lists of familiar words in comparison to lists of pseudowords. Due to the established findings that infants at 11 months demonstrate a preference for familiar word forms over pseudowords (including for British English, Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004), it was expected that infants would also show such a familiarity effect in the present experiment.
Method
Participants
A total of 24 healthy British English-learning monolingual 11-month old infants were successfully tested (mean age = 10 months; 22 days, range = 10;8 to 11;24, 12 females, 12 males). Sample size was based upon previous research conducted on similar issues and at similar ages (Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020). The data of 17 additional infants were excluded due to non-completion of the 12 trials due to fussiness (N = 3), having 2 consecutive trials with looking times below 2 seconds, or having 3 or more of such trials in total (N = 6), being an outlier (difference score below or above 2 standard deviations from the group mean; N = 4), and technical problems (N = 4). As a measure of infants’ lexical development, caregivers were asked to complete the 100-word Oxford Short Form CDI (Floccia, Sambrook, Delle Luche, Kwok, Goslin, White, Cattani, Sullivan, Abbot–Smith, Krott, Mills, Rowland, Gervain, Plunkett, Hoff, Core, & Patricia, Reference Floccia, Sambrook, Delle Luche, Kwok, Goslin, White, Cattani, Sullivan, Abbot–Smith, Krott, Mills, Rowland, Gervain, Plunkett, Hoff, Core and Patricia2018; Hamilton, Plunkett, & Schafer, Reference Hamilton, Plunkett and Schafer2000), as well as a checklist of the 10 test words presented in the study. All infants were born and raised in the South West of England.
Materials
The lists of familiar words and pseudowords used are presented in Table 1. The 10 disyllabic familiar words were chosen using the Oxford CDI (Hamilton et al., Reference Hamilton, Plunkett and Schafer2000). The selected words were comprehended by 38% (ranging from 14% to 70%) of British English-learning 11-month-olds. This was comparable to the 30% comprehension of familiar words reported by Poltrock and Nazzi (Reference Poltrock and Nazzi2015), and 33% for Vihman et al. (Reference Vihman, Nakai, DePaolis and Hallé2004). The rationale is that the words have a degree of familiarity for children, sufficient to elicit word form recognition.
Table 1. Familiar words and pseudowords used in Experiment 1

The pseudowords were created by making a one-feature change to the first three phonemes of each familiar word (initial consonant, first vowel and middle consonant). For example, in ‘mummy’, the initial consonant was changed to an [n] to form ‘nummy’, and its first vowel to an [ɛ] to form ‘nemmy’. The second consonant (e.g., the second [m] of ‘mummy’) was also changed to avoid too much of an overlap between familiar words and pseudowords (in this example, [m] was changed into [b], so that the resulting pseudoword was ‘nebby’ [nɛbi]). No resulting nonword can be a real word in the dialect spoken in the South West of England where these experiments took place (this also applied to the next two experiments).
The stimuli were recorded in an infant-directed voice by a British English native speaker (from the South West of England) using a Zoom H4N Pro digital recorder in a soundproof booth. One token for each word and nonword was selected. All tokens were normalised for RMS amplitude at 70db using Praat (Boersma & Weenink, Reference Boersma and Weenink2010). Acoustic analysis of the recorded tokens found no statistical differences in duration, or mean, minimum, or maximum fundamental frequency between the words and pseudowords (see Table A1 of the Appendix). Pseudorandomised lists were created for both the words and pseudowords. Lists were made up of two blocks, with each token appearing once in each block, resulting in lists containing a total of 20 tokens. An inter-stimulus interval of 600ms was used between tokens. The position that each token appeared in each list was evenly distributed both within and across each list. The lists were 21.24s in length in both conditions (words versus pseudowords).
Calculating consonant and vowel tiers
The proportion of consonants and vowels in words known by each infant was evaluated using the same method as Von Holzen and Nazzi (Reference Von Holzen and Nazzi2020). Infants’ total word comprehension was determined by combining the parents’ responses to the 100-word Oxford Short Form CDI and the 10 test words on the study checklist. This resulted in a potential 108 unique words (2 words appeared in both the CDI and the study checklist) that infants could be reported to comprehend. Phonetic transcriptions of the known words were then used to create consonant and vowel tier scores. For instance, if an infant understood the words daddy (/dædi/), mummy (/mʌmi/), and bunny (/bʌni/), then they would know three distinct consonant tiers, as all three words contain unique consonant sequences (/d.d/; /m.m/; /b.n/). However, they would only know two distinct vowel tiers, with mummy and bunny containing the same vowel sequence (/ʌ.i/), which is distinctive from the vowel sequence in daddy (/æ.i/). Consonant and vowel proportion scores were then calculated for each infant by dividing the number of unique consonant or vowel tiers they knew by their total word comprehension. These data were then used to correlate with looking times for the different types of word lists.
Procedure
Following informed consent being provided by the parent/caregiver, infants were seated on their caregiver’s lap in a sound-attenuated, darkened booth. A green light at the infants’ eye level, with a video camera used to monitor the infant, was attached to a central panel in the front of the booth. Red lights, with loudspeakers below them, were located on panels either side of the booth. Caregivers were instructed to wear headphones playing a mix of speech and music to mask the auditory stimuli and prevent any inadvertent influence on the infants’ looking behaviour. The experimenter sat outside the booth at the computer and video monitor used to control the stimulus presentation and record the infant looking times. Experimenters were unaware of the sound being played in the booth.
At the start of each trial, the light directly in front of the infant flashed green until the experimenter deemed the infant to be looking at it, at which point the red light on either the left or right would begin to flash. When the experimenter judged the infant to be attending to the side light, the sound file was played until its conclusion or until the infant failed to maintain their gaze toward the corresponding flashing light for 2 consecutive seconds. The cycle would then begin again. In trials where the infants stopped attending to the light for less than 2 seconds before turning back again, the sound file continued to play although the time spent looking away was automatically deducted from the total looking time by the computer program. Therefore, each trial had a maximum looking time of the entire sound file.
The session consisted of two practice trials (passages of classical music), presented on each side, to familiarise the infant to the procedure. This was followed by a test phase consisting of 12 trials, 6 of each condition (familiar word and pseudoword lists). Trials were organised into two blocks. Each block contained 3 lists of familiar words and 3 lists of pseudowords. The order of the lists within each block was randomised.
Results and discussion
Prior to analysing the data, trials with looking times of under 2 seconds in duration were excluded. This led to the removal of 25 of the 288 test trials (8.68%). All infants included in the analysis contributed at least 9 useable trials. Each infant’s mean looking times to the lists of familiar words and pseudowords were calculated and are displayed in Figure 1.

Figure 1. Mean looking times (seconds) in each condition in Experiment 1 (familiar word forms vs pseudowords. Connected dots represent individual infants’ looking times in the two experimental conditions. Error bars represent ±1 standard error, ** indicates significant effect (p = .001).
A repeated measures analysis of variance (ANOVA) on the orientation times with type of list (familiar words vs. pseudowords) and block (first half vs. second half of the experiment) as within-participant factors found a main effect of type of list, F (1, 23) = 15.83, p = .001, ηG2 = .41, with infants listening longer to the lists of familiar words (M = 7.74s, SD = 2.45) than pseudowords (M = 6.33s, SD = 1.74). A significant effect of block was also found, F (1, 23) = 12.11, p = .002, ηG2 = .35, with infants listening longer during the first half of the study. However, there was no type of list by block interaction, F (1, 23) = .68, p = .42, ηG2 = .03.
The reliability of this finding was further examined by performing a paired Bayesian t-test. A Bayes factor over 3 provides support for the strength of the alternative hypothesis (i.e., the presence of an effect) whereas a Bayes factor below 1/3 provides support for the strength of the null hypothesis (i.e., an absence of an effect). Any value that is between 1/3 and 3 is deemed to be inconclusive, providing no clear evidence for either the alternative or null hypothesis (Dienes, 2014; Jeffreys, Reference Jeffreys1961). All Bayesian paired t-tests in the paper were calculated with the default Cauchy prior width of .707 in JASP (JASP Team, 2022; Version 0.16.3). The paired Bayesian t-test, comparing the looking times for familiar words versus pseudowords, found a Bayes factor of BF = 58.01 (t(23) = 4.00, p < .001), providing support for the alternative hypothesis.
Bayesian correlations were also conducted to examine the relationship between infants’ listening preferences (calculated as the difference in mean orientation times to the familiar words and pseudowords) and lexical factors. All Bayesian correlations in the paper were calculated using the default stretched beta prior width of 1.00 in JASP (JASP Team, 2022). Infants had an average CDI comprehension of 7.71 (SD = 5.89) out of 100 words and knew an average of 4.58 (SD = 2.21) out of the 10 test words presented in the study. No correlation was found between infants’ listening preferences and either CDI (r(22) = .12, p = .57, BF = .30) or word checklist scores (r(22) = −.08, p = .70, BF = .27), indicating evidence in favour of the null hypothesis. From the average of 11.00 words (SD = 6.84) that infants understood (from the 108 unique words found when combining the Oxford Short Form CDI and the study checklist), there was an average 10.54 (SD = 6.41) unique consonant tiers and 9.54 (SD = 5.18) unique vowel tiers. The proportion of unique consonant tiers out of known words (M= .97, SD = .05) was significantly higher than the proportion of vowel tiers (M = .90, SD = .10), t (23) = 2.73, p = .01. Neither proportion of consonant (r(22) = −.09, p = .69, BF = .27) or vowel (r(22) = .01, p = .98, BF = .25) tiers out of known words was correlated with infants’ listening preferences, again providing evidence in favour of the null hypothesis. Hence, this analysis fails to find correlations between the proportion of unique consonant or vowel tiers in the words known by each child and their listening preference for familiar words over pseudowords.
The present findings replicate familiar word recognition in British English-learning infants at 11 months, with infants listening longer to word forms over pseudowords. This preference was irrespective of the reported CDI, word checklist scores, or the proportion of unique vowel and consonant tiers in known words. Therefore, infants were able to either comprehend or recognise a sufficient amount of the words presented to them to display an overall preference for familiar word forms over pseudowords. This result replicates previous word recognition studies (Hallé & de Boysson-Bardies, Reference Hallé and de Boysson-Bardies1994, Reference Hallé and de Boysson-Bardies1996; Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Swingley, Reference Swingley2005; Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004), providing further support that, even at this early stage of development, infants can recognise the auditory form of familiar words in their environment.
Experiment 2: Onset consonant changes versus vowel changes
The results of Experiment 1 show that British English 11-month-old infants prefer listening to familiar word forms over pseudowords, irrespective of parental reports of their comprehension of such words. In Experiment 2, British English-learning 11-month-olds’ preference for either an onset consonant mispronunciation or vowel mispronunciation of the familiar word forms presented in Experiment 1 was examined. Given that the majority of disyllabic words in English have a stress that is word initial (Cutler & Carter, Reference Cutler and Carter1987), as is the case for all the familiar words in our stimulus set, it can be predicted that the initial phoneme mispronunciations should be particularly salient to the infants in the present study. This is supported by the finding that English-learning 9-month-olds listen significantly longer to stress-initial over stress-final words (Jusczyk, Cutler, & Redanz, Reference Jusczyk, Cutler and Redanz1993). Furthermore, based on Poltrock and Nazzi’s (Reference Poltrock and Nazzi2015) finding that French-learning 11-month-olds prefer listening to vowel mispronunciations over consonant mispronunciations of familiar word forms, if British English-learning 11-month-olds demonstrate a consonant bias, then we would expect them to show the same preference for vowel mispronunciations compared to consonant mispronunciations of the word forms presented in Experiment 1. However, if they show no bias at this age, then looking times should be equal for both vowel mispronunciations and consonant mispronunciations of such familiar words.
Method
Participants
A further sample of 24 healthy British English-learning monolingual 11-month-old infants was successfully tested (mean age = 11;1, range = 10;11 to 11;28, 8 females, 16 males). The data of 4 additional infants were excluded due to fussiness (N = 1) and having 2 consecutive trials with looking times below 2 seconds, or having 3 or more of such trials in total (N = 3). Caregivers completed both the 100-word Oxford Short Form CDI (Floccia et al., Reference Floccia, Sambrook, Delle Luche, Kwok, Goslin, White, Cattani, Sullivan, Abbot–Smith, Krott, Mills, Rowland, Gervain, Plunkett, Hoff, Core and Patricia2018; Hamilton et al., Reference Hamilton, Plunkett and Schafer2000) and a checklist of the correct pronunciation of the 10 test words presented in the study. All infants were born and raised in the South West of England.
Materials
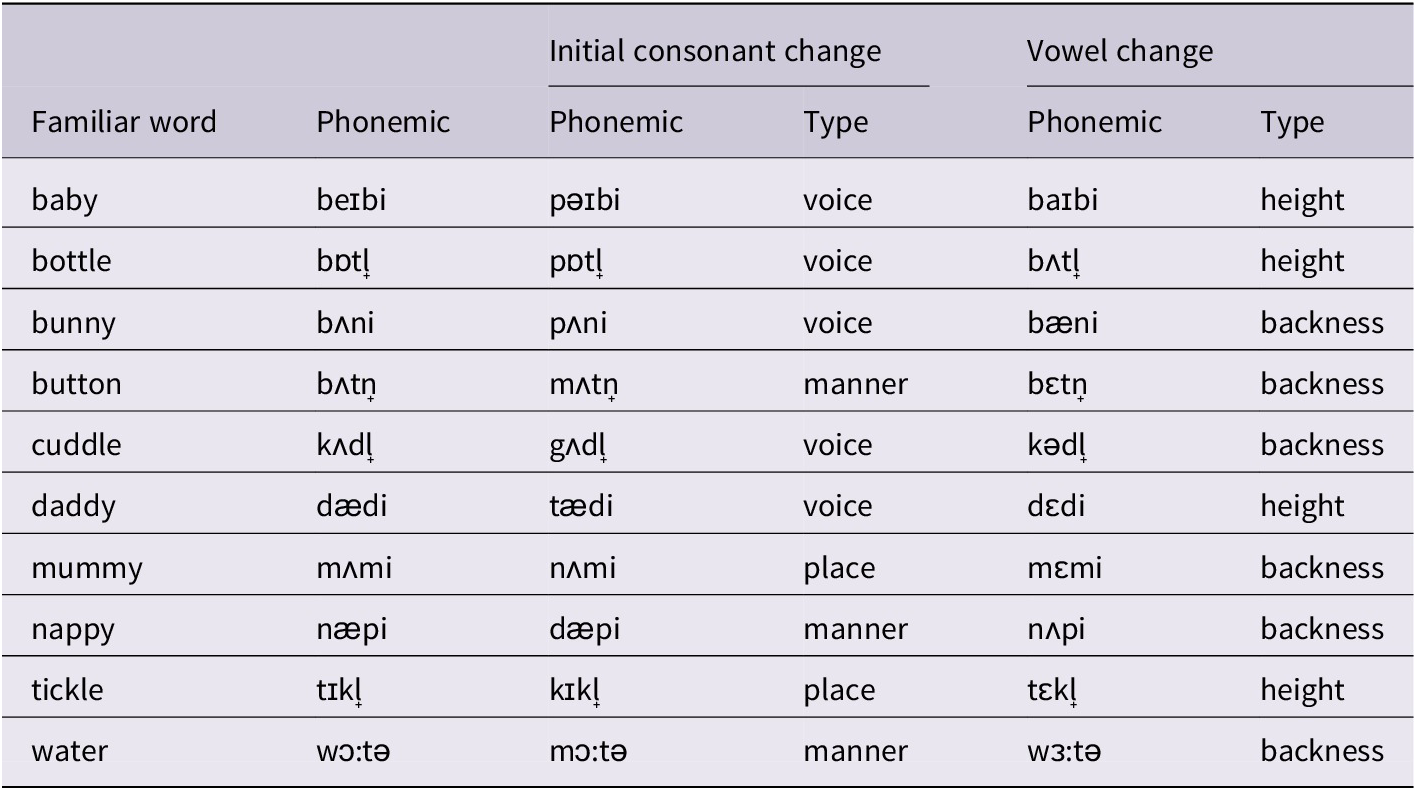
The familiar words from Experiment 1 were modified by one phonological feature, either on the first consonant or the first vowel. The types of changes were the same as those used in Experiment 1 to create pseudowords. That is, whereas the word mummy was changed to ‘nebby’ in Experiment 1 by changing the first three phonemes, here we only changed either the first consonant (‘nummy’) or the first vowel (‘memmy’) by using the same changes. As in Poltrock and Nazzi (Reference Poltrock and Nazzi2015), several types of phonological feature changes were presented in order to reflect consonant and vowel categories as a whole (see Table 2 for the list of consonant and vowel changes to the familiar words and type of phonological feature changes). The tokens were recorded using the same speaker and recording set up as Experiment 1. The acoustic features of the stimuli are listed in Table A2 of the Appendix. There were again no significant differences in duration or mean, minimum, or maximum fundamental frequency in the sound files for each condition. All tokens were normalised for RMS amplitude at 70db using Praat (Boersma & Weenink, Reference Boersma and Weenink2010). The mispronunciations were placed into lists using the same procedure and ISI as Experiment 1, with each list being 21.92s in length in both conditions.
Table 2. Consonant and vowel changes to familiar words used in Experiment 2
Procedure
The procedure and apparatus were identical to those used in Experiment 1. The test phase consisted of 12 trials, 6 of each condition (onset consonant mispronunciation lists and vowel mispronunciation lists). Trials were again organised into two blocks. Each block contained 3 lists of onset consonant mispronunciation words and 3 lists of vowel mispronunciation words. The order of the lists within each block was randomised.
Results and discussion
As in Experiment 1, trials with looking times of under 2 seconds in duration were excluded before analysing the data. This led to the exclusion of 20 of the 288 test trials (6.94%). All infants included in the analysis contributed at least 9 useable trials. Mean looking times to the lists of onset consonant change and vowel change to the familiar words were calculated and are displayed in Figure 2.

Figure 2. Mean looking times (s) in Experiment 2 (onset consonant changes vs. vowel changes). Connected dots represent individual infants’ looking times in the two experimental conditions. Error bars represent ±1 standard error.
A repeated measures ANOVA on the orientation times with type of list (onset consonant change vs. vowel change) and block (first half vs. second half of the experiment) as within-participant factors found a significant effect of block, F (1, 23) = 35.83, p <.001, ηG2 = .61, with infants again listening longer in the first half of the study. However, no main effect of type of list (F (1, 23) = 1.52, p = .23, ηG2 = .06) or an interaction between list and block (F (1, 23) = .05, p = .82, ηG2 = .002) was found. On average, infants listened to the onset consonant change lists for 9.49s (SD = 2.93) and the vowel change for 8.67s (SD = 3.03).
The reliability of the null finding (no effect of condition) was examined with a paired Bayesian t-test, comparing the looking times for vowel mispronunciations versus consonant mispronunciations. This found a Bayes factor of BF = .42 (t(23) = -1.22, p = .23), providing inconclusive evidence for either the alternative or null hypothesis.
Infants had an average CDI comprehension of 6.67 words (SD = 5.02) out of 100 and knew an average of 5.08 (SD = 2.15) of the 10 words presented in the study. No correlation was found between infants’ listening preferences and CDI comprehension (r(22) = −.04, p = .87, BF = .27), providing evidence for the null hypothesis. However, inconclusive evidence for either the alternative or null hypothesis was found for the correlation between infants’ listening preferences and word checklist score (r(22) = .21, p = .32, BF = .41). Infants knew an average of 10.42 words (SD = 6.56) out of the possible 108 unique words found when combining the Oxford Short Form CDI and the study checklist, from which there was an average 10.00 (SD = 6.20) consonant tiers and 9.00 (SD = 4.93) vowel tiers. The proportion of unique consonant tiers out of known words (M = .97, SD = .05) was found to be significantly different to the proportion of vowel tiers (M = .91, SD = .09), t (23) = 2.81, p = .01. However, neither proportion of consonant (r(22) = −.01, p = .97, BF = .25) or vowel tiers (r(22) = .002, p = .99, BF = .25) was correlated with infants’ listening preferences, suggesting evidence in favour of the null hypothesis.
Experiment 1 established that British English 11-month-olds’ word recognition was indexed by longer looking times towards familiar word forms. In this context, the ambiguity regarding infants’ preferences for onset consonant mispronunciations, vowel mispronunciations, or neither, found here in Experiment 2 suggests that infants do not yet have a consonant bias in their word recognition. This is in contrast to Poltrock and Nazzi’s (Reference Poltrock and Nazzi2015) finding that showed a consonant bias in word recognition in French-learning infants of the same age. Our present results thus provide further evidence that infants’ initial word recognition procedures may vary cross-linguistically, as previously found at later ages in word learning tasks (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014; Nazzi et al., Reference Nazzi, Poltrock and Von Holzen2016).
However, the absence of a preference for vowel modified words over consonant modified words is not proof that infants treat the two conditions similarly, and the evidence from the Bayesian analysis only provided inconclusive evidence of this null hypothesis. Thus, it remains unclear whether British English-learning infants display a consonant bias in word form recognition at 11 months. To come to that conclusion, we would need to demonstrate that when presented with a correct pronunciation versus a consonant modification on one hand, and with a correct pronunciation versus a vowel modification on the other hand, infants show a preference for the correct pronunciation in both cases equally. Alternatively, in such a between-participant design, if we can show a preference for the correct pronunciation in the consonant modified version only, this would be taken as evidence that they have learned a consonant bias for lexical processing. This is the aim of Experiment 3, where we tested preference for a single familiar word, ‘mummy’, versus a consonant modified version in one condition, and a vowel modified version in another. This task simplification was introduced to ensure that we would be in the best conditions to observe a consonant bias, if any, at the end of the first year of life. First, we would simplify infants’ working memory load by reducing the number of items. Second, the word ‘mummy’ has been found to elicit sound-to-meaning association from the age of 6 months (Tincoff & Jusczyk, Reference Tincoff and Jusczyk1999), so that we would be more likely to tap into word recognition processes (where consonant information would be predominately used) rather than word form recognition. Third, we also increased slightly the ISI from 600ms to 1 second to provide infants with more time to process information. Finally, we increased the age of children from 11 months to 12 months, so that we could have a slightly larger receptive lexicon to perform correlation analyses on, as well as infants who would have further consolidated their knowledge of native consonants (Polka & Werker, Reference Polka and Werker1994), increasing our chances to observe a consonant bias.
Experiment 3: Consonant versus vowel change in a single familiar word
In the final experiment, a new group of infants was tested in a simplified version of the preceding experiments, with the presentation of only one word known to all infants (‘mummy’). In a between-participant design, infants were presented with ‘mummy’ versus a first consonant change (nummy; /nʌmi/), or a first vowel change (memmy; /mɛmi/) (note that this word and the corresponding changes were used in the previous experiments).
Method
Participants
A new sample of 48 healthy British English-learning 12-month-old infants were tested (mean age = 11;30, range = 11;14 to 13;10, 26 females, 22 males). The data of an additional 18 infants were excluded from the analysis due to crying or being distracted (N = 3), having 2 consecutive trials with looking times below 2 seconds, or having 3 or more of such trials in total (N = 10), parental interference (N = 3), technical issues (N = 2) or being an outlier (i.e., the mean orientation times were 2 SDs below or above the group mean, which was 3). The 100-word Oxford Short Form CDI (Floccia et al., Reference Floccia, Sambrook, Delle Luche, Kwok, Goslin, White, Cattani, Sullivan, Abbot–Smith, Krott, Mills, Rowland, Gervain, Plunkett, Hoff, Core and Patricia2018; Hamilton et al., Reference Hamilton, Plunkett and Schafer2000) was completed by 47 of the 48 caregivers as a measure of their infant’s vocabulary. All infants were born and raised in the South West of England.
Materials
The stimuli were recorded in an infant-directed voice by a British English female native speaker using a Zoom H4N Pro digital recorder in a soundproof booth. She produced a series of tokens for each word (mummy, memmy and nummy), out of which we selected 13 for each item, based primarily on an equal variety of intonation patterns. All tokens were normalised for RMS amplitude at 70db using Praat (Boersma & Weenink, Reference Boersma and Weenink2010). Acoustic analysis of the recorded tokens found no statistical differences in mean, minimum, or maximum fundamental frequency between the three words (see Table A3 of the Appendix), but duration differences were found between the lists, with mummy tokens being the longest (M = 551ms, SD = 106), followed by nummy (M = 547ms, SD = 91) and memmy (M = 472ms, SD = 39). Pseudorandomised lists were created for each word, with an ISI of approximately 1 second between tokens. The lists were 24s in length for each word.
Procedure
The experiment used the same apparatus and procedure as Experiments 1 and 2, with some minor changes. In a between-participant design, the test phase comprised 8 test trials (instead of 12 before, in order to minimise boredom), 4 of each condition (correct pronunciation lists and consonant or vowel mispronunciation lists). Trials were organised into two blocks that each contained two lists of a correct pronunciation of the word “mummy” and two lists of either the consonant (nummy) or vowel (memmy) alteration of the same word. Infants were randomly assigned to one of the two conditions, Consonant Change (24) or Vowel Change (24). The order of the lists within each block was randomised.
Results and discussion
All trials with looking times of under 2 seconds in duration were removed from the analysis. This led to the exclusion of 24 of the 392 test trials (6.12%). All infants included in the analysis provided a minimum of 6 useable trials (the maximum number of trials is 8, against 12 in the previous two experiments). Mean looking times to the correct pronunciation and altered pronunciation were calculated for each infant. Group averages are presented in Figure 3.

Figure 3. Mean looking time (s) in Experiment 3 toward the correct pronunciations of the word mummy versus the altered pronunciations, in the Consonant Change condition (left) and Vowel Change condition (right). Connected dots represent individual infants’ looking times in the two experimental conditions. Error bars represent ±1 standard error, * indicates significant effect (p = .012).
A three-way mixed ANOVA was conducted on infants’ orientation times, with within-participant factors of Pronunciation (Correct, Altered) and Block (first half vs. second half of the experiment) and a between-participant factor of Condition (Consonant, Vowel). There was a significant effect of Pronunciation, F(1, 46) = 6.90, p = .012, ηG2 = .02, but no significant effect of Condition, F(1, 46) = .35, p = .56, ηG2 = .003, or Pronunciation x Condition interaction, F(1, 46) = .40, p = .53, ηG2 = .001.
There was a significant effect of block, F(1, 46) = 39.48, p < .001, ηG2 = .16, with infants displaying longer orientation times in the first half of the study. However, neither the Block x Pronunciation, F(1, 46) = .10, p = .75, ηG2 < .001, Block x Condition, F(1, 46) = .34, p = .56, ηG2 = .002, or Block x Pronunciation x Condition, F(1, 46) = .94, p = .34, ηG2 = .004, interactions were significant.
Bayesian statistics were calculated to estimate the degree of confidence in the null effect of condition. A Bayes independent samples t-test comparing infants’ listening preferences in the Consonant Change and Vowel Change conditions revealed a Bayes factor of BF = .31 (t(46) = −.40, p = .70), providing further support for the null hypothesis.
Due to the non-significant effect of condition on the preference for correct pronunciations, the impact of lexical factors was calculated across both Consonant Change and Vowel Change conditions. Infants had an average CDI comprehension of 12.57 out of 100 (SD = 10.23) words (all children knew the word ‘mummy’). No correlation was found between infants’ listening preferences and the CDI (r(45) = −.10, p = .52, BF = .22), indicating support for the null hypothesis. In relation to consonant and vowel tiers, infants knew an average 12.21 (SD = 9.72) unique consonant tiers and 10.21 (SD = 6.99) unique vowel tiers. The proportion of unique consonant tiers out of known words (M= .99, SD = .03) was found to be significantly different to the proportion of vowel tiers (M = .90, SD = .12), t (46) = 4.47, p < .001. However, neither proportion of consonant (r(45) = −.06, p = .70, BF = .20) or vowel tiers (r(45) = .07, p = .66, BF = .20) was correlated with infants’ listening preferences, again supporting the null hypothesis. No significant differences were found when examining the correlations between infants’ listening preferences and CDI, and proportion to either consonant or vowel tiers in the Consonant Change and Vowel Change conditions separately (p > .05 in all cases, BF = .29 to 1.29)
Results of Experiment 3 show an overall mispronunciation effect, such that infants consistently preferred listening to the correct version of ‘mummy’ over a consonant change or a vowel change. However, there was no evidence of a consonant bias, since preference for the correct version of ‘mummy’ was similar across the two conditions, consonant or vowel change. These findings contrast with the preference for vowel mispronunciations over consonant mispronunciation in French (Poltrock & Nazzi, Reference Poltrock and Nazzi2015), but align with the lack of a consonant bias found in British English word learning data (Floccia et al., 2009) and word recognition data at a later age (Mani & Plunkett, Reference Mani and Plunkett2007, Reference Mani and Plunkett2010).
General discussion
Consonants have been found to be more important than vowels in lexical processing tasks in the adult literature, in most languages (for the original proposal, Nespor et al., Reference Nespor, Peña and Mehler2003; for a review, Nazzi & Cutler, Reference Nazzi and Cutler2019). Research into the development of this consonant bias suggests that cross-linguistic differences, based on phonological and/or lexical properties of an infant’s native language, modulate its acquisition (Nazzi et al., Reference Nazzi, Poltrock and Von Holzen2016). The present study aimed to bridge a gap in the literature by examining if British English-learning 11-month-olds’ recognition of early familiar word forms was more reliant on their consonants than on their vowels. A similar study in French by Poltrock and Nazzi (Reference Poltrock and Nazzi2015) revealed that consonant mispronunciations had a larger impact on word form recognition than vowel mispronunciations. Indeed, whereas data on French-learning infants unequivocally show a consonant bias emerging between 8 and 11 months (Nishibayashi & Nazzi, Reference Nishibayashi and Nazzi2016; Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020), evidence regarding English-learning infants is less straightforward, with studies suggesting a possible consonant bias at 15 months (Mani & Plunkett, Reference Mani and Plunkett2007) and 30 months (Nazzi et al., Reference Nazzi, Floccia, Moquet and Butler2009), but no preference for either consonants or vowels at 12, 16/18, and 23/24 months (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014; Mani & Plunkett, Reference Mani and Plunkett2007, Reference Mani and Plunkett2010). Experiment 1 first measured infants’ preference for listening to familiar word forms over pseudowords. Experiment 2 examined infants’ listening to onset consonant mispronunciations versus vowel mispronunciations of these familiar word forms. Finally, Experiment 3 tested whether infants would prefer a correct pronunciation of a single familiar word, ‘mummy’, over a consonant mispronunciation, ‘nummy’, or a vowel mispronunciation, ‘memmy’.
The results of Experiment 1 established first that 11-month-old British English-learning infants listened longer to lists of correctly pronounced familiar word forms over lists of pseudowords. This preference was found irrespective of parental reports of the number of words their infants knew, and to the phonological properties of infants’ individual vocabularies in terms of consonant/vowel tiers. This finding adds additional support to the literature indicating that, by the time infants reach their first birthday, they are beginning to recognise frequently heard word forms (Hallé & de Boysson-Bardies, Reference Hallé and de Boysson-Bardies1994; Swingley, Reference Swingley2005; Vihman et al., Reference Vihman, Nakai, DePaolis and Hallé2004). Given this result, following the logic in Poltrock and Nazzi (Reference Poltrock and Nazzi2015), any preference for lists of either vowel or consonant mispronounced words would indicate that infants consider one phonetic variation more similar to correctly pronounced familiar words. However, it was inconclusive whether the British English-learning 11-month-old infants tested in Experiment 2 showed a greater dependence on consonants over vowels when recognising familiar word forms. This left us unable to conclude whether or not the infants were treating both consonant and vowel mispronunciations as being equally (un)important, or one as more important than the other. Therefore, in Experiment 3, we used a between-participant design to evaluate directly whether a change from a correct to consonant-modified familiar word would produce a similar preference to a change from a correct to a vowel-modified version. Results were clear cut: infants showed an overall preference for the correctly produced familiar word, which is similar in each condition, and unrelated to the size of their lexicons. In addition, infants’ knowledge of unique consonant or vowel tiers in their vocabulary did not correlate with their listening preferences, indicating that regularities in the early lexicon did not seem to drive the emergence of a processing bias.
Taken together, the last two experiments demonstrate that at 11 months of age, there is no consonant bias for lexical processing in British English-learning infants, but an equal sensitivity to consonants and vowels.
The lack of a consonant bias in British English-learning infants in a word form recognition task contrasts with research conducted in infants learning other languages. Studies on French-learning infants have provided robust evidence for the preferential role of consonants in lexical processing tasks from an early age. Developing from an initial vowel bias present until around 6 months (Bouchon et al., Reference Bouchon, Floccia, Fux, Adda‐Decker and Nazzi2015; Nishibayashi & Nazzi, Reference Nishibayashi and Nazzi2016), French-learning infants have been found to demonstrate a consonant bias from 11 months in familiar word recognition tasks (Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020), and even from 8 months in word segmentation tasks (Nishibayashi & Nazzi, Reference Nishibayashi and Nazzi2016). In particular, the present findings are in contrast to Poltrock and Nazzi (Reference Poltrock and Nazzi2015), who found that French-learning 11-month-olds preferred to listen to the vowel alterations over consonant alterations of familiar word forms. This early consonant bias maintains in French-learning infants, so that, by the time they are between 16 and 20 months, consonants have a privileged role over vowels in word learning tasks (Havy & Nazzi, Reference Havy and Nazzi2009; Nazzi, Reference Nazzi2005; Nazzi & Bertoncini, Reference Nazzi and Bertoncini2009; Nazzi & New, Reference Nazzi and New2007). Similarly, Italian-learning infants appear to follow a comparable development trajectory to French-learning infants, showing a higher sensitivity to vowels over consonants at 6 months, before showing a reverse pattern at 12 months (Hochmann et al., Reference Hochmann, Benavides‐Varela, Nespor and Mehler2011; Hochmann, Benavides‐Varela, Nespor, Mehler, & Flo, Reference Hochmann, Benavides-Varela, Nespor, Mehler and Flo2017).
Instead, the results here appear to add further support to previous research suggesting that British English-learning infants do not demonstrate a consistent consonant bias until later in their development. At 5 months, British English-learning infants can detect their own name versus a phonetically dissimilar name (e.g., Sophie versus Amber) but are unable to do so when either a consonant or vowel mispronunciation is made to their name (Delle Luche et al., 2018). Older infants also fail to show a differential processing of consonants and vowels, showing equal sensitivity to both types: 12-, 18-, and 24-month-old infants are equally impacted by both consonant and vowel mispronunciations of familiar words, with only 15-month-old infants showing a sensitivity to consonant over vowel changes (Mani & Plunkett, Reference Mani and Plunkett2007, Reference Mani and Plunkett2010). A lack of an early consonant bias in British English-learning infants, related to equal sensitivity to consonants and vowels, also extends to word learning tasks. Learning of word pairings that vary by either one consonant or one vowel is comparable in both 16- and 24-month-old infants (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014), with a consonant bias not appearing until 30 months in British English-learning children (Nazzi et al., Reference Nazzi, Floccia, Moquet and Butler2009). The present research adds further weight to these findings, showing that 11-month-old British English-learning infants also do not rely more on consonants in word recognition tasks, instead showing an equal sensitivity to consonant and vowel changes. Taken together, all these results strongly suggest that the observation of a consonant bias at 15 months in Mani and Plunkett (Reference Mani and Plunkett2007) could have been a statistical outlier.
The present study allows further inferences to be made regarding the origin of the functional asymmetry between consonants and vowels. The initial bias hypothesis (Nespor et al., Reference Nespor, Peña and Mehler2003) proposes that a consonant bias should be present in lexical processing tasks from birth, with no developmental or cross-linguistic differences. However, British English-learning 11-month-olds tested here did not show a consonant bias in a word recognition task, a finding that differs from findings in French-learning infants (Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020). Thus, the results here substantiate the idea that the role of consonants in lexical processing emerges during development, as a consequence of language experience (Nazzi et al., Reference Nazzi, Poltrock and Von Holzen2016), which favours an explanation based on acquisition of the native lexicon (Keidel et al., Reference Keidel, Jenison, Kluender and Seidenberg2007) and/or to the acoustic–phonetic properties of the native language (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014).
Firstly, the lexical hypothesis (Keidel et al., Reference Keidel, Jenison, Kluender and Seidenberg2007) proposes that the consonant bias is acquired due to statistical knowledge obtained from an infants’ native lexicon. Accordingly, infants must learn that consonants provide more information than vowels when both identifying and learning words, a process achieved by computation of consonant vs. vowel phonological neighbours of consonant vs. vowel tiers. If this is correct, one would expect the size of the growing lexicon, and/or the proportion of unique consonant tiers versus vowel tiers, to predict the emergence of the consonant bias – in the present study, indexed by a preference for vowel-changed words over consonant-changed words (in Experiment 2), or by a preference for correctly pronounced words over consonant or vowel mispronunciations (Experiment 3). However, the current data in English and those obtained in French at 11 months (Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020) fail to confirm these predictions, as no such correlation was found in all cases. Thus, a purely lexical hypothesis does not appear to account for the cross-linguistic differences found in the development of the consonant bias. However, as suggested by Von Holzen and Nazzi (Reference Von Holzen and Nazzi2020), assessing an infants’ lexicon size (through use of CDI tools, for example) only assesses the words an infant knows, rather than the words they are exposed to in their environment. Our calculations of vocabulary size and phonological tiers relied on such estimates. Furthermore, the CDI assesses only a short list of words an infant knows (100 words), which might not provide a sensitive-enough measure. Consequently, additional research should examine whether the words in an infant’s input or the words an infant understands are more suitable to assess how the structure of an infant’s early lexicon impacts the development of the consonant bias.
In contrast, the acoustic-phonetic hypothesis (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014) suggests that the acoustic and phonetic variations between consonants and vowels may act as an initial indication to infants that such speech sounds need to be processed distinctly. This hypothesis proposes that infants would first show a preference for processing vowels over consonants given their increased salience. However, as they develop, infants learn that consonants, which are processed more categorically (Fry, Abramson, Eimas, & Liberman, Reference Fry, Abramson, Eimas and Liberman1962), are a more reliable and faster cue for word recognition. One potential explanation why British English-learning 11-month-olds may behave differently from their French-learning counterparts is due to the dissimilar phonological properties of the two languages. French has a syllable-timed rhythm, phrase-final lengthening, and contains mainly steady-state vowels (Floccia et al., Reference Floccia, Nazzi, Delle Luche, Poltrock and Goslin2014). Confronted with this, French-learning infants may initially focus on the vowels of their native language (Bouchon et al., Reference Bouchon, Floccia, Fux, Adda‐Decker and Nazzi2015) but, with the expansion of the lexicon and the improvement of temporal resolution abilities (Werner, Marean, Halpin, Spetner, & Gillenwater, Reference Werner, Marean, Halpin, Spetner and Gillenwater1992), would develop a bias for giving more weight to differences between consonants. This would ultimately lead to the development of a consonant bias (Poltrock & Nazzi, Reference Poltrock and Nazzi2015). In comparison, British English-learning infants are exposed to a different range of acoustic cues, with reduced or fully-realised vowels, variable lexical stress and regular diphthongisation in comparison to French. These complex vowel properties may not drive infants’ attention away from vowels to focus on consonants as early as found for French-learning infants. This may explain why British English-learning infants are equally sensitive to consonants and vowels, as demonstrated here at 11 months, before the development of a consonant bias at 30 months (Nazzi et al., Reference Nazzi, Floccia, Moquet and Butler2009).
As proposed by Nazzi et al. (Reference Nazzi, Poltrock and Von Holzen2016), the lexical and acoustic-phonetic hypotheses may also have a combined influence on the development of a consonant bias in lexical processing. Phonological and lexical acquisition do not occur in isolation, with one likely to impact the development of the other (e.g., Yeung, Chen, & Werker, Reference Yeung, Chen and Werker2014; Yeung & Nazzi, Reference Yeung and Nazzi2014; Yeung & Werker, Reference Yeung and Werker2009). Consequently, infants may learn that the acoustic-phonetic properties of consonants and vowels differ in relation to cues for word recognition, as proposed by the acoustic-phonetic hypothesis. However, this will occur alongside infants obtaining statistical knowledge of their native lexicon. Further research should attempt to investigate the combined impact of both lexical and acoustic-phonetic factors on the development of the consonant bias.
In conclusion, the results of this study demonstrate that word form recognition in British English-learning 11-month-olds is equally reliant upon consonants and vowels. This adds further evidence to the finding that a consonant bias in lexical processing tasks is not present in British English-learning infants until approximately 30 months (Nazzi et al., Reference Nazzi, Floccia, Moquet and Butler2009). It also adds additional support to the finding that there are cross-linguistic differences in the acquisition of such a bias, with the present results differing from French-learning infants of a similar age (Poltrock & Nazzi, Reference Poltrock and Nazzi2015; Von Holzen & Nazzi, Reference Von Holzen and Nazzi2020). In order to fully understand the underlying mechanisms of these cross-linguistic differences, further research is needed to explore the role of lexical and acoustic-phonetic factors in shaping the way infants learn the beneficial role of consonants in word recognition and word learning tasks.
Competing interest
The author(s) declare none.
Appendix
Table A1. Acoustic features of stimuli presented in Experiment 1

Note. Standard deviations are reported in parentheses.
Table A2. Acoustic features of stimuli presented in Experiment 2

Note. Standard deviations are reported in parentheses.
Table A3. Acoustic features of stimuli presented in Experiment 3

Note. Standard deviations are reported in parentheses. The first t-test on each line corresponds to the comparison between mummy and memmy, and the second to the comparison between mummy and nummy.









 Open access
Open access