

The sections that follow describe the project’s methodology. All stages of data collection were approved by the Faculty of Arts ethics committee at the University of Bristol.
Data Collection
Survey
The questionnaire responses discussed in Chapters 3, 4 and 5 were collected in 2024 in a survey of over 2,500 professionals based in the UK. I included a summary of the survey methodology in a preliminary report published by the Chartered Institute of Linguists.1 Some of the information provided below first appeared in that report.
I distributed the survey via Prolific (www.prolific.com), a database of pre-registered individuals who can be invited to take part in research. Only studies that offer remuneration to participants can be distributed via this service. Remuneration involves the risk of attracting participants who are only interested in the payment and who are therefore more likely to submit satisficing responses. On the other hand, remuneration can also be considered an ethical principle. It is a way of compensating participants for their time and of recognising the importance of their input. Additionally, recruiting participants through a third-party service allowed me to systematically select members of specific industry sectors, which for this study was desirable.
Drawing on an existing online pool of participants may nevertheless introduce its own types of bias. This method is likely to over-represent frequent internet users who have higher levels of digital literacy. The sample is also inevitably restricted to those who are users of the Prolific service. Internet usage rates are in any case high among UK working-age adults.2 Moreover, one of the study’s main interests was in those with experience of machine translation use, which in most cases involves the use of digital devices. Although the possibility of under-representing machine translation users with low digital literacy cannot be excluded, other recruitment methods would restrict the participant pool in other ways.
To identify participants with the desired profile, I first used the pre-existing demographic information available in the Prolific database to invite potential participants to take a screening questionnaire. Only UK residents who were fluent in English and who belonged to one of five industry categories available on Prolific received the invitation. The industry categories were ‘emergency service’, ‘health care and social assistance’, ‘legal services’, ‘medical/healthcare’ and ‘police’. These pre-existing categories corresponded to participants’ self-identified primary industry, irrespective of their role. Although some of these categories are interchangeable – for example, a nurse could fit under ‘medical/healthcare’ or ‘health care and social assistance’ – using all of them ensured maximum coverage of the key sectors of interest. Based on a search of the Prolific database carried out on 4 March 2024, 4,995 potential participants met the pre-selection criteria just described.
By using demographic details available on Prolific, I was also able to identify those who had a front-line or customer-facing role. Front-line professionals were the first ones to receive the study invitation, but this criterion was eventually relaxed. Those who had not declared working in a front-line role were also invited to participate, and all participants who proceeded to the main questionnaire indicated later how they had used machine translation, including whether they had used it for public-facing communication.
Participants received one pound to complete the screening questionnaire. This questionnaire sought to identify those who had used machine translation at work. It also sought to confirm whether participants indeed worked in one of the selected sectors. Those who had not used machine translation at work were invited to answer an open-text question about whether they would consider using it. This question is analysed in Chapter 5. Those who had used machine translation at work, and who were thereby eligible to proceed, received a further two pounds to complete the main questionnaire. The payments were therefore small tokens of appreciation which helped to incentivise participation without financially inducing it. The questionnaires did not take long to complete – approximately three and ten minutes for the screening and main questionnaires, respectively. Given this small time commitment, all payments were in Prolific’s top tier of fairness.
All participants were given access to a participant information sheet that explained the study’s terms and conditions. Participants were also invited to contact me via Prolific’s anonymous messaging service in case they had any questions. Upon starting either questionnaire, participants were asked to confirm that they had considered the information about the study and were happy to provide their consent. After participating in the study, they were given a month to revoke consent and ask for their data to be destroyed if they so wished.
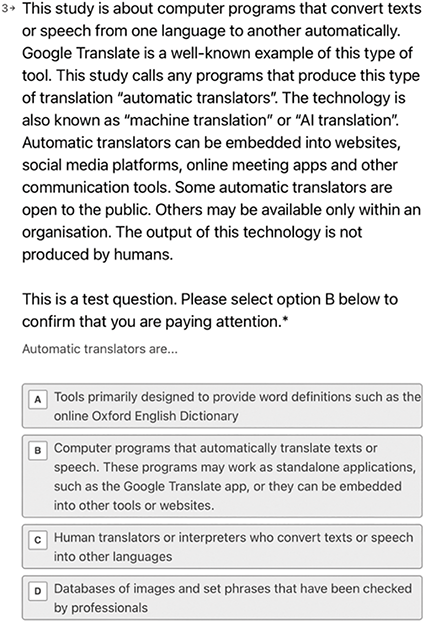
The questionnaires were hosted on the Typeform survey tool. The data was collected between 23 February and 7 April 2024. Those who, in the screening questionnaire, selected an industry category that was inconsistent with their Prolific demographic profile were automatically invited to leave the study. Those who confirmed that they worked in one of the eligible industries proceeded to a question that sought to explain the study’s definition of machine translation. This question is reproduced in Figure M.1. The definition cited Google Translate as an example and explained that machine translation can be embedded in a range of online environments including websites and meeting apps. Participants were then advised that ‘automatic translators’ was the phrase used in the study, a non-technical term used successfully in my previous work involving non-linguists as participants.3 ‘AI translation’ and ‘machine translation’ were also mentioned as other ways of referring to the technology.
Question which defined machine translation and instructed participants to select option B to check that they were reading instructions and paying attention.
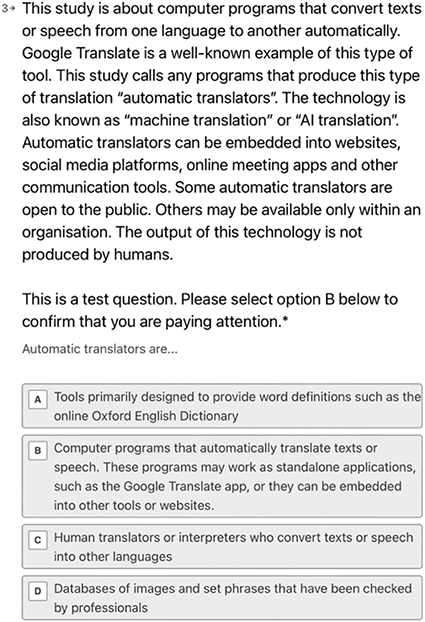
Figure M.1 Long description
The definition reads as follows: This study is about computer programs that convert texts or speech from one language to another automatically. Google Translate is a well-known example of this type of tool. This study calls any programs that produce this type of translation “automatic translators”. The technology is also known as “machine translation” or “AI translation”. Automatic translators can be embedded into websites, social media platforms, online meeting apps and other communication tools. Some automatic translators are open to the public. Others may be available only within an organisation. The output of this technology is not produced by humans.
This is a test question. Please select option B below to confirm that you are paying attention.
Automatic translators are...
A: Tools primarily designed to provide word definitions such as the online Oxford English Dictionary
B: Computer programs that automatically translate texts or speech. These programs may work as standalone applications, such as the Google Translate app, or they can be embedded into other tools or websites.
C: Human translators or interpreters who convert texts or speech into other languages
D: Databases of images and set phrases that have been checked by professionals
After reading the study’s definition of machine translation, participants were provided with a list of options referring to other communication methods that could be confused with machine translation tools. To avoid making them feel like they were being assessed, they were told what option to select. This was therefore an attention rather than a comprehension test. Checking their attention served to confirm that participants were following instructions. It also helped to reinforce the study’s definition of machine translation, although it did not eliminate misunderstandings, as explained below.
Participants who passed the industry and attention checks in the screening questionnaire were asked whether they had used machine translation before. Those who had were asked to select in what situations they had used it. The following options were provided: ‘While travelling on holiday’, ‘For any work-related purpose in the industry you primarily work in’, ‘to study or when learning a new language’, ‘When being interviewed for a job’ and ‘Other’. Participants could select multiple options, and until this point it had not been revealed that the study’s focus was on professional settings. Only those for whom work was one of the selected machine translation use contexts were invited to take part in the study’s main questionnaire.
Further to the steps above, which automatically filtered out ineligible participants, I manually inspected the data to identify invalid submissions. Invalid data fell into one of the following categories: duplicates, timed-out participants, participants with a contradictory employment status and participants who were referring to human language services rather than machine translation or who had not in fact used machine translation at work.
Most duplicates were submitted by participants who initially selected ‘Other industry/none of the above’ on the screening questionnaire. As mentioned, these participants were automatically invited to leave the study, but some of them tried to re-take the questionnaire using an eligible industry option. All these submissions were disregarded since these participants’ first choice was inconsistent with their demographic information available on Prolific. One of these participants was inadvertently allowed to proceed to the main questionnaire. This response was excluded from the main questionnaire sample as a duplicate. Five participants with eligible industry selections resubmitted identical or near-identical responses to the screening questionnaire. These resubmissions were indicative of technical submission difficulties, and their first instance was retained.
Timed-out participants were those who did not confirm the study submission on Prolific within a specified time limit. This limit is automatically set by Prolific based on the researcher’s estimated completion time for the study. For the screening questionnaire, the Prolific limit was 23 minutes. For the main questionnaire, it was 44 minutes. Prolific excludes all timed-out participants by default, so all such participants were excluded even if they submitted a response but failed to confirm the submission on Prolific. Most of them took breaks that were likely to affect data quality, for example due to poor recall of previous questions.
Regarding participants’ employment status, I excluded all those who, according to the Prolific demographics, were not in paid work when they participated in the study. Participants’ employment status in these cases contradicted their industry selection. Where employment status data was not available, I retained the submissions as long as the participant passed the other checks previously described.
An important manual check involved inspecting the nature of the machine translation use which participants described in the main questionnaire. Two participants indicated they had not in fact used machine translation in a professional setting or at all, so these participants were excluded. A few other submissions included evidence of inattention or of a possible misunderstanding of the survey topic. For example, when asked how they thought automatic translators would evolve in the future – a question which I do not analyse in this book – one participant answered, ‘They will be accessible 24 hours a day without the need to pre-book.’ Since machine translation already is available 24 hours a day and does not require pre-booking, this participant was most likely referring to human-mediated services rather than machine translation.
Although participants were told that the survey was not about translations generated by humans, this type of misunderstanding is difficult to eliminate. The language services landscape is quite varied. Human services are themselves technology-supported and mediated. Access to remote interpreters is sometimes provided via an app, for instance,4 so even terms such as ‘translation apps’ can be ambiguous. While blurry distinctions in participants’ understanding are relevant to the broader discussion in this book, responses to the main questionnaire where a misunderstanding of the study was apparent or likely were disregarded in the analysis. I excluded these responses according to the following criteria:
1. There was explicit evidence to suggest, like in the example quoted above, that the participant was referring to a service other than machine translation; or
2. Open-text responses did not compare or distinguish human and non-human services and at least one of the following was also true:
a. The participant provided information about human language services when asked about the machine translation systems used;
b. The participant did not select any option including the name of a specific machine translation tool;
c. The participant declared using a non-publicly available tool and did not provide further information elsewhere;
d. The participant declared that machine translation use was recommended by their employer and did not provide further information elsewhere.
In the absence of explicit distinctions between human and machine, options 2a–2d above were more likely to suggest that technology-mediated human services were being conflated with machine translation.
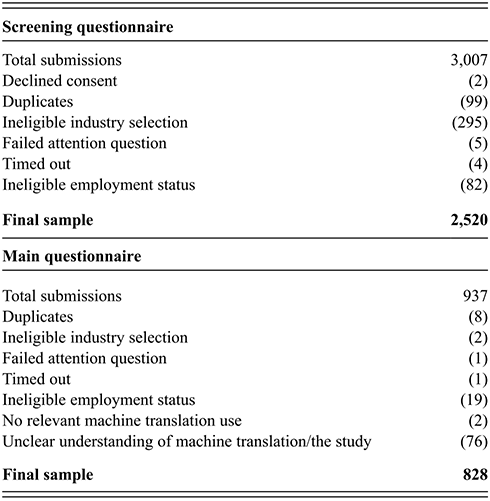
Table M.1 provides a breakdown of total submissions and exclusions.
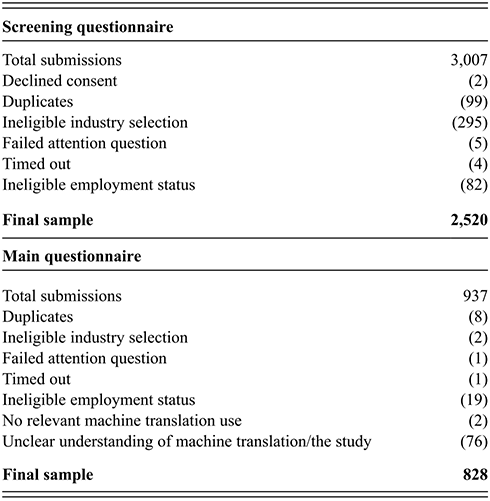
Table M.1 Long description
The table has two columns listing the particulars and the numbers. It reads as follows. Under Screening questionnaire. Total submissions: 3007. Declined consent: 2. Duplicates: 99. Ineligible industry selection: 295. Failed attention question: 5. Timed out: 4. Ineligible employment status: 82. Final sample: 2520.
Under Main questionnaire. Total submissions: 937. Duplicates: 7. Ineligible industry selection: 2. Failed attention question: 1. Timed out: 1. Ineligible employment status: 19. No relevant machine translation use: 2. Unclear understanding of machine translation or the study: 76. Final sample: 829.
A conservative approach was taken to the exclusion of participants, insofar as not all exclusions necessarily reflected a data quality issue. For example, one participant later clarified that they had selected ‘Other’ as their industry option on the screening questionnaire because they worked in health security. As a sector, health security may be more readily associated with government administration than with healthcare, which was the industry category held by Prolific for this participant. Both ‘Medical/Healthcare’ and ‘Other’ were therefore plausible and probably reflected slightly different interpretations of the question in each instance – that is, when the participant provided the information to Prolific and when they answered the question again in the screening questionnaire. It was impractical to verify all such cases to maximise the number of valid submissions. Just attempting to do so could have influenced participants’ responses, so excluding all inconsistencies was preferred. Similarly, not all participants who met the exclusion criteria due to potential misunderstandings necessarily confused human and machine translation. The excluded responses were nevertheless sufficiently ambiguous for their validity to be questioned. I considered the risk of retaining questionable data more serious than the risk of excluding responses unnecessarily, so the exclusions were preferred.
Interviews
I identified social workers to take part in the interviews by contacting UK trade unions and professional associations. I also posted the study’s participant information sheet online on social worker groups on LinkedIn. Recruitment was then amplified by snowball sampling. I asked social workers who had taken part in the study to invite their networks to contact me. Unlike the survey respondents, the interview participants were told from the outset that I was interested in uses of machine translation in their work. The number of machine translation users in the interview sample should not, therefore, be seen as a sector-wide pattern since the topic itself could have attracted machine translation users to the study, even though non-users were also eligible.
The interviews took place between November and December 2024. Their purpose was to gather detailed accounts of machine translation use and of perceptions of the technology within social work. Depth was more important than coverage for the interviews, not least because the survey had already gathered large-scale data. I therefore kept the interview sample to a small size. By the point I had interviewed the eighteen social workers included in the sample, I had been hearing similar stories about their experiences of dealing with language barriers and of using machine translation. Albeit small, the sample was varied. The social workers’ contributions were also richly detailed.
I spoke to all social workers online for convenience and to make it easier to fit the interviews around their busy schedules. I provided them with a participant information sheet to help them decide whether to take part. Those who agreed to get involved sent me a completed consent form. They all received a sixty-pound online gift card in recognition of their contribution.
Research Participants
The mean age of the sample of 2,520 survey respondents was 37.8 years (range 19–76 years). According to the sex data held by Prolific, which mirrors binary categories used in the national census, survey participants were mostly women (75%) although some were men (24.9%) and others (0.1%) preferred not to say. This unbalanced sex distribution is consistent with national data for prominent professions in the survey, such as nurses and social workers.5 Over 90% of the sample had English as a first language. As mentioned in Chapter 3, most of them were from the health and social care sectors. The distribution of industry categories in the sample was as follows: health care and social assistance – 42.7%; medical/healthcare – 38.4%; legal services – 9.8%; emergency service – 5%; police – 4.1%.
The 828 machine translation users largely mirrored this sector distribution (medical/healthcare – 41.9%; health care and social assistance – 37.7%; legal services – 9%; police – 6.9%; emergency service – 4.5%). The machine translation users are described in detail in the Chartered Institute of Linguists 2024 report.6 Nearly a third of them had some knowledge of French. Most of them had a university degree. Nurse, social worker, doctor, police officer and solicitor were, in this order, the five most frequent occupations mentioned by machine translation users in descriptions of their role. In most cases they had held these occupations for one to five years (43%) and for six to fifteen years (35%), although some were significantly more experienced and fell into the ‘sixteen to twenty-five years’ (11.4%) or ‘twenty-six years or more’ (4.4%) brackets. A minority were in the role for less than a year (6%) (and 0.2% skipped the question).
Since the interview participants were a small group that fit a specific professional profile within a single country, I avoided documenting significant detail of their backgrounds to protect their identities. They were all qualified social workers who worked in the UK. They were therefore either native or fully competent users of English. Some of them spoke other languages through heritage and by growing up in multilingual environments. They were predominantly employed by local government authorities. They covered a wide age range, with the youngest in their 20s and the oldest in in their 60s. Nine of them had more than ten years of social work experience. Others had between one and ten years. All bar one were women.
Data Analysis and the Use of Sources
All data collected in the project was analysed inductively. I identified predominant themes and tested these themes against emerging assumptions to arrive at the main arguments and findings. My analysis of the survey focused on the following questions:
Please describe in your own words the type of task(s) or communication where you used automatic translators in your industry.
What advice would you give to a colleague who is thinking of using automatic translators in your industry?
What type of training do you think would have been helpful to have before using automatic translators in your industry?
For non-users of machine translation:
Would you consider using automatic translators in your work in your industry? Please provide brief details of what could influence your decision.
When these questions were presented to the participants, they automatically contained the industry in question; that is, ‘your industry’ was replaced by the industry category that the participant had previously selected. The top two questions above form the basis of Chapter 3 and Chapter 4. My analysis of the answers to these two questions centred on levels of risk and on participants’ risk perceptions. The other questions provided the data for Chapter 5. The analysis for Chapter 5 included general themes that cut across the chapter (and book) but which do not correspond to specific chapter sections or headings, such as machine translation’s convenience and ease of use. Other themes emerging from the analysis largely correspond to the chapter’s sections and subsections, such as privacy and confidentiality and requests for higher levels of accuracy. The questionnaires distributed to participants included other questions which were used to gather contextual information. Two additional open-text questions asked for participants’ visions of the future, an adjacent topic that is not examined in this book.
The interviews featured in Chapter 6 were audio-recorded. I had the audio files fully transcribed by appointing the services of a specialist company. For completion and to facilitate the analysis, the material was transcribed in verbatim style (i.e., including interruptions, repetitions, false starts and speech fillers such as ‘um’, ‘uh’, ‘like’ or ‘you know’). When using the interviews in the text, I removed some of these speech markers from quotes to avoid distraction. On occasion I also slightly edited quotes of either the interview or survey data to correct obvious typos and to improve readability. Any edits involving more than minor corrections are indicated between square brackets.
Like in Chapter 5, some themes emerging from my analysis of the interviews directly correspond to sections and subsections in Chapter 6, such as low-resource languages, accessibility and requests for support. Other themes cut across the entire chapter, such as the standard of care received by service users or social workers’ distrust of professional linguists.
Towards the final stages of writing, I hired a researcher to independently fact-check the book and inspect my analysis. She had access to the full data and cross-checked all chapters against their sources, which included survey and interview data, my research notes and qualitative coding as well as the academic literature and official documents in the public domain.
Data Availability
Data generated in this project are available at the University of Bristol data repository as a restricted dataset due to the sensitivity of the data involved: https://doi.org/10.5523/bris.2lk43ta3ijvba2wwg6o8dclz1d. The metadata record clearly states how the data can be accessed by bona fide researchers. A summary of the survey analysis is openly available at https://doi.org/10.5523/bris.1f2wuj2yd3h6d28ld5t1nrc6u3.

 Open access
Open access