Refine search
Actions for selected content:
48569 results in Computer Science
11 - Probabilistic information retrieval
-
- Book:
- Introduction to Information Retrieval
- Published online:
- 05 June 2012
- Print publication:
- 07 July 2008, pp 201-217
-
- Chapter
- Export citation
Covering Two-Edge-Coloured Complete Graphs with Two Disjoint Monochromatic Cycles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 471-486
-
- Article
- Export citation
Orthogonal Latin Rectangles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 519-536
-
- Article
- Export citation
The Weight and Hopcount of the Shortest Path in the Complete Graph with Exponential Weights
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 537-548
-
- Article
- Export citation
Correlated Matroids
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 511-518
-
- Article
- Export citation
Graph Colouring with No Large Monochromatic Components
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 577-589
-
- Article
- Export citation
-
For a graph G and an integer t we let mcct(G) be the smallest m such that there exists a colouring of the vertices of G by t colours with no monochromatic connected subgraph having more than m vertices. Let
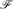
It is also interesting to consider graphs of bounded degrees. Haxell, Szabó and Tardos proved mcc2(G) ≤ 20000 for every graph G of maximum degree 5. We show that there are n-vertex 7-regular graphs G with mcc2(G)=Ω(n), and more sharply, for every ϵ > 0 there exists cϵ > 0 and n-vertex graphs of maximum degree 7, average degree at most 6 + ϵ for all subgraphs, and with mcc2(G) ≥ cϵn. For 6-regular graphs it is known only that the maximum order of magnitude of mcc2 is between
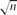 and n.
and n.We also offer a Ramsey-theoretic perspective of the quantity mcct(G).
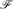
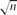 and
and A general feature space for automatic verb classification
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 3 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 337-367
-
- Article
- Export citation
Using automatically labelled examples to classify rhetorical relations: an assessment
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 3 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 369-416
-
- Article
- Export citation
Robust parsing and spoken negotiative dialogue with databases
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 3 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 289-312
-
- Article
- Export citation
On a Question of Bourgain about Geometric Incidences
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 619-625
-
- Article
- Export citation
On the Maximum Degree of a Random Planar Graph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 591-601
-
- Article
- Export citation
On the Minimal Density of Triangles in Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 17 / Issue 4 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 603-618
-
- Article
- Export citation
-
For a fixed ρ ∈ [0, 1], what is (asymptotically) the minimal possible density g3(ρ) of triangles in a graph with edge density ρ? We completely solve this problem by proving that
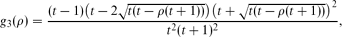 where
where 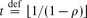 is the integer such that
is the integer such that 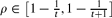 .
.
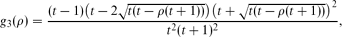
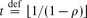 is the integer such that
is the integer such that 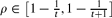 .
.A new PPM variant for Chinese text compression
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 3 / July 2008
- Published online by Cambridge University Press:
- 01 July 2008, pp. 417-430
-
- Article
- Export citation
