Refine search
Actions for selected content:
48558 results in Computer Science
Ontology change: classification and survey
-
- Journal:
- The Knowledge Engineering Review / Volume 23 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 117-152
-
- Article
- Export citation
The 1st international workshop on computational social choice
-
- Journal:
- The Knowledge Engineering Review / Volume 23 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 213-215
-
- Article
- Export citation
Monad compositions II: Kleisli strength
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 613-643
-
- Article
- Export citation
Strong normalisation in two Pure Pattern Type Systems
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 431-465
-
- Article
- Export citation
THE ITERATIVE CONCEPTION OF SET
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 97-110
- Print publication:
- June 2008
-
- Article
- Export citation
Tuplespace-based computing for the Semantic Web: a survey of the state-of-the-art
-
- Journal:
- The Knowledge Engineering Review / Volume 23 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 181-212
-
- Article
- Export citation
HOW APPLIED MATHEMATICS BECAME PURE
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 16-41
- Print publication:
- June 2008
-
- Article
- Export citation
PROBABILISTIC CONDITIONALS ARE ALMOST MONOTONIC
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 73-80
- Print publication:
- June 2008
-
- Article
- Export citation
Fairness in multi-agent systems
-
- Journal:
- The Knowledge Engineering Review / Volume 23 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 153-180
-
- Article
- Export citation
Rewriting calculi, higher-order reductions and patterns: introduction
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 427-429
-
- Article
- Export citation
ON ADOPTING KRIPKE SEMANTICS IN SET THEORY
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 81-96
- Print publication:
- June 2008
-
- Article
- Export citation
Abstracts of Recent PhDs
-
- Journal:
- The Knowledge Engineering Review / Volume 23 / Issue 2 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 217-226
-
- Article
-
- You have access
- HTML
- Export citation
ULTIMATE TRUTH VIS-À-VIS STABLE TRUTH
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 126-142
- Print publication:
- June 2008
-
- Article
- Export citation
-
We show that the set of ultimately true sentences in Hartry Field's Revenge-immune solution model to the semantic paradoxes is recursively isomorphic to the set of stably true sentences obtained in Hans Herzberger's revision sequence starting from the null hypothesis. We further remark that this shows that a substantial subsystem of second-order number theory is needed to establish the semantic values of sentences in Field's relative consistency proof of his theory over the ground model of the standard natural numbers:
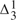 -CA0 (second-order number theory with a
-CA0 (second-order number theory with a 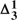 -comprehension axiom scheme) is insufficient. We briefly consider his claim to have produced a ‘revenge-immune’ solution to the semantic paradoxes by introducing this conditional. We remark that the notion of a ‘determinately true’ operator can be introduced in other settings.
-comprehension axiom scheme) is insufficient. We briefly consider his claim to have produced a ‘revenge-immune’ solution to the semantic paradoxes by introducing this conditional. We remark that the notion of a ‘determinately true’ operator can be introduced in other settings.
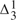 -
-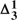 -comprehension axiom scheme) is insufficient. We briefly consider his claim to have produced a ‘revenge-immune’ solution to the semantic paradoxes by introducing this conditional. We remark that the notion of a ‘determinately true’ operator can be introduced in other settings.
-comprehension axiom scheme) is insufficient. We briefly consider his claim to have produced a ‘revenge-immune’ solution to the semantic paradoxes by introducing this conditional. We remark that the notion of a ‘determinately true’ operator can be introduced in other settings.A DECISION PROCEDURE FOR PROBABILITY CALCULUS WITH APPLICATIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 111-125
- Print publication:
- June 2008
-
- Article
- Export citation
Computation with classical sequents
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 555-609
-
- Article
- Export citation
-
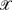 is an untyped continuation-style formal language with a typed subset that provides a Curry–Howard isomorphism for a sequent calculus for implicative classical logic. can also be viewed as a language for describing nets by composition of basic components connected by wires. These features make an expressive platform on which many different (applicative) programming paradigms can be mapped. In this paper we will present the syntax and reduction rules for ; in order to demonstrate its expressive power, we will show how elaborate calculi can be embedded, such as the λ-calculus, Bloo and Rose's calculus of explicit substitutions λx, Parigot's λμ and Curien and Herbelin's
is an untyped continuation-style formal language with a typed subset that provides a Curry–Howard isomorphism for a sequent calculus for implicative classical logic. can also be viewed as a language for describing nets by composition of basic components connected by wires. These features make an expressive platform on which many different (applicative) programming paradigms can be mapped. In this paper we will present the syntax and reduction rules for ; in order to demonstrate its expressive power, we will show how elaborate calculi can be embedded, such as the λ-calculus, Bloo and Rose's calculus of explicit substitutions λx, Parigot's λμ and Curien and Herbelin's 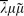 . was first presented in Lengrand (2003), where it was called the λξ-calculus. It can be seen as the pure untyped computational content of the reduction system for the implicative classical sequent calculus of Urban (2000).
. was first presented in Lengrand (2003), where it was called the λξ-calculus. It can be seen as the pure untyped computational content of the reduction system for the implicative classical sequent calculus of Urban (2000).
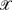 is an untyped continuation-style formal language with a typed subset that provides a Curry–Howard isomorphism for a sequent calculus for implicative classical logic.
is an untyped continuation-style formal language with a typed subset that provides a Curry–Howard isomorphism for a sequent calculus for implicative classical logic. 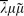 .
.A CUT-FREE SIMPLE SEQUENT CALCULUS FOR MODAL LOGIC S5
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 3-15
- Print publication:
- June 2008
-
- Article
- Export citation
iRho: an imperative rewriting calculus
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 3 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 467-500
-
- Article
- Export citation
THE REVIEW OF SYMBOLIC LOGIC
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 1-2
- Print publication:
- June 2008
-
- Article
- Export citation
TRUTH-FUNCTIONALITY
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 64-72
- Print publication:
- June 2008
-
- Article
- Export citation
RECOGNIZING STRONG RANDOM REALS
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 1 / June 2008
- Published online by Cambridge University Press:
- 01 June 2008, pp. 56-63
- Print publication:
- June 2008
-
- Article
- Export citation
