



Equation balance is of paramount importance in time series analysis. An unbalanced equation is mis-specified and prone to type I error; that is, the rejection of a true null hypothesis. Although this is well known to statisticians, there is confusion in political science about what constitutes balance. Indeed, in his contribution to a recent symposium on time series analysis in Political Analysis, John Freeman (Reference Freeman2016, 50) wrote, “It now is clear that equation balance is not understood by political scientists.” One area of confusion is the tendency to equate equation imbalance with mixing orders of integration. Any time an analysis includes variables with different time series characteristics, we have mixed orders of integration. Consider, for example, an integrated variable, which contains a unit root and is nonstationary, where the mean, variance, and covariance vary over time, an example of which may be the gross domestic product (GDP). By contrast, a stationary series tends to hover around its mean over time, as seems to be the case for presidential approval in the USA, which exhibits autoregressive properties (Beck, Reference Beck1991).Footnote 1 Some research concludes that presidential approval may be fractionally integrated (FI) (which would mean more persistence than an I(0) stationary time series) (Donovan et al., Reference Donovan, Kellstedt, Key and Lebo2020). In either case, given the different time series properties of presidential approval and GDP, an equation relating these variables mixes orders of integration. Importantly, this mixing does not necessarily produce an unbalanced equation.
Enns and Wlezien (Reference Enns and Wlezien2017) review the scholarly debate on the subject and clarify the distinction between imbalance and mixed orders of integration. Following Banerjee et al. (Reference Banerjee, Dolado, Galbraith and Hendry1993), they show that a linear combination of the regressand and of the regressors can produce a balanced equation, even if the variables are of different orders of integration. Using simulations and an applied example of models of income inequality in the United States, Enns and Wlezien (Reference Enns and Wlezien2017) demonstrate that there are situations where estimating general error correction/autoregressive distributed lag (GECM/ADL) models with different orders of integration does not produce an increased risk of spurious results. In this paper, we build on Enns and Wlezien's (Reference Enns and Wlezien2017) findings to further assess the estimation of GECM/ADL models when mixing orders of integration, specifically, to analyze the implications for the risk of type II error; that is, failing to reject a false null hypothesis. With good reason, researchers continue to be worried about type I error (e.g., Philips, this symposium; Kraft, Key, and Lebo, this symposium), and this concern motivated Enns and Wlezien's previous study on the subject. Yet, any recommended methods should be able to identify true relationships in the data when those exist, hence our focus in this paper.
We run simulations of a model with a stationary variable on the right-hand side and a dependent variable that contains both stationary and unit root, that is, integrated, components. As a result, we set up a data generation process in which the variables on the right- and left-hand sides are related but of different orders of integration. This setup is frequently found in social science research, where many variables may involve both stationary and unit root processes, such as people's attitudes over time (Converse, Reference Converse and Apter1964; Achen, Reference Achen1975; Erikson, Reference Erikson1979), party identification (Erikson et al., Reference Erikson, MacKuen and Stimson1998), vote intentions (Erikson and Wlezien, Reference Erikson and Wlezien2012), and global capital mobility (Ahlquist, Reference Ahlquist2006). Thus, focusing on this type of process allows us to demonstrate that mixing orders of integration does not necessarily result in an unbalanced equation, and holds implications for the myriad of published studies in the discipline that model these combined processes with GECMs.
Previous research has shown that the GECM/ADL avoids inflated type I error rates with this data-generating process (DGP). Our goal is to identify whether a GECM/ADL model can detect the true relationship underlying the generated data, and thus avoid type II error. Failure to do so would imply that the GECM/ADL is overly conservative when estimating relationships. By contrast, correctly identifying true relationships would suggest that the GECM/ADL can be appropriate in time series analysis with mixed orders of integration, at least where researchers can establish that equations are balanced (and other modeling assumptions are met).Footnote 2
Our results suggest that the GECM/ADL can indeed identify the true relationship in our data. The mean coefficients also behave as expected, regardless of the autoregressive parameter (ρ) of the stationary component. This is most clear for the asymptotic case. In practice, when T is smaller, analyses are complicated by the fact that the observed time series characteristics of variables do not always match the underlying DGP. However, our simulations show that if researchers base their modeling decisions on the observed time series properties of the data (as is standard practice in time series analysis), they typically will reach sound inferences. Mixing orders of integration in a balanced equation evidently does not compromise the detection of true relationships between series. Our results underscore that pre-whitening data to equalize orders of integration is not always necessary, namely, in the presence of an already balanced equation. This is important, as Enns and Wlezien (Reference Enns and Wlezien2017) show that pre-whitening can come at the expense of identifying true relationships in the data.
This paper thus contributes to an increasing trend in the literature that asserts that there are exceptions to the idea that orders of integration have to be consistent across all series in a model (Grant and Lebo, Reference Grant and Lebo2016, 4). Indeed, GECM/ADL models can be applied with mixed orders of integration, as long as equations are balanced and other assumptions are met as well.
1. Equation balance with mixed orders of integration does not necessarily increase the probability of type I error
Our starting point is the correct assertion that time series analysis requires equations to be balanced. Unbalanced equations suffer from mis-specification and typically result in an increased probability of type I error. Enns and Wlezien (Reference Enns and Wlezien2017) highlight that much of the emphasis in the discussion around equation balance has focused on an overly strict definition that entails having all variables belonging to the same order of integration. Banerjee et al. (Reference Banerjee, Dolado, Galbraith and Hendry1993, 164, italics ours) define an unbalanced equation as one “in which the regressand is not the same order of integration as the regressors, or any linear combination of the regressors.” Relying on Banerjee et al.'s (Reference Banerjee, Dolado, Galbraith and Hendry1993) definition, Enns and Wlezien (Reference Enns and Wlezien2017) show that because of the linear combination, regressors that contain different orders of integration can result in a balanced equation. This clarification is important, for many analyses in the social sciences are modeled with equations that mix orders of integration. Inappropriately restricting the concept of equation balance could thus lead to fruitless contestation of a multitude of published studies that mix orders of integration, but that actually have balanced equations that produce non-spurious results.
Two cointegrated I(1) series, when represented as a single equation GECM,Footnote 3 offer a classic case of a balanced equation with mixed orders of integration (Grant and Lebo, Reference Grant and Lebo2016; Keele et al., Reference Keele, Linn and McLaughlin Webb2016; Enns and Wlezien, Reference Enns and Wlezien2017). The GECM is a balanced equation in this case because ΔY t (the regressand) and ΔX t are both stationary and the integrated regressors (X t−1 and Y t−1) are jointly stationary.Footnote 4 Thus, both sides of the equation are stationary, which is necessary for proper estimation. Although illustrative, cointegration is not exceptional. In this symposium, Kraft, Key, and Lebo also highlight scenarios where linear combinations of integrated X or X and Y yield stationary processes, creating a balanced equation. Enns and Wlezien (Reference Enns and Wlezien2017) also demonstrate cases where it is appropriate to estimate models that mix orders of integration; specifically, as long as the equation is balanced (and others modeling assumptions are met), the GECM/ADL does not inflate the type I error rate.
Yet, some recent studies question the use of GECM/ADL based on type I errors (Grant and Lebo, Reference Grant and Lebo2016; Keele et al., Reference Keele, Linn and McLaughlin Webb2016), which seemingly contrasts with Enns and Wlezien's (Reference Enns and Wlezien2017) findings and other studies showing that when simulations are implemented correctly, the type I error rate follows the expected 5 percent (Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a, Reference Enns, Kelly, Masaki and Wohlfarth2017b; Esarey, Reference Esarey2016). Like all methods, the GECM is only appropriate when relevant assumptions are met. Much of the recent confusion may stem from conducting simulations that violate these assumptions. Even when we specify the DGP in simulations, the observed series will not always reflect the underlying time series properties of the DGP because the simulated data also contain a stochastic component. If the simulations are designed to test a statistical approach that would be appropriate based on the DGP, but some of the simulated data departs from the specified DGP because of the stochastic component—which is especially likely when T is short—conclusions about the statistical approach may be misguided, because the statistical procedure is being evaluated on data it was not intended to be applied to. As Lebo and Grant (2016, 71) state, “Missteps here are easy if we diagnose the properties of our series in terms of some population instead of the sample in hand.”
Indeed, the fact that small sample simulations do not necessarily reflect the time series properties specified in the DGP likely explains some (perhaps all) of the seeming divergent conclusions across this symposium. For example, Kraft, Key, and Lebo in this symposium suggest that they observe inflated type I error rates because of equation imbalance. But equation imbalance cannot fully account for their results. To see why, consider their Figure 2, which shows that the rate of spurious regression declines as T increases. If the type I error rate in their simulations resulted because of equation imbalance in the DGP, we would not expect the false positive rate to decline as the sample size increases. To further evaluate the relationship between sample size and type I error rate in their simulations, we increased the sample size in their simulations to 5000 and then replicated their simulations designed to test the influence of adding unrelated I(1) regressors. We chose T = 5000 so the data more closely follow the asymptotic time series properties of the DGP. Despite using the exact same DGP, increasing the sample size completely changed the conclusions of Kraft, Key, and Lebo's simulations; even with the inclusion of I(1) regressors, the type I error rate drops to 5.2 percent with a mean value of −0.00002 (full results are reported in online Appendix 1).Footnote 5 Although adding unrelated regressors should never be advised in applied settings, doing so does not necessarily create an unbalanced equation.Footnote 6
Since social scientists often confront small samples, it is of course critical to evaluate methods when T is small. However, when conducting these simulations, the series should be diagnosed and model assumptions tested before selecting the model (e.g., Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a, Reference Enns, Kelly, Masaki and Wohlfarth2017b) or else both small and large samples should be simulated to assess whether the small sample properties deviate from the asymptotic results (e.g., Enns and Wlezien, Reference Enns and Wlezien2017). Failure to follow these steps risks misinterpreting simulation results because the statistical model was chosen based on the asymptotic properties of the DGP instead of the properties of the data being analyzed.
Some of Philips’ simulations in this symposium highlight a related concern. He evaluates three separate models (static, LDV (lagged dependent variable), and ARDL/GECM) on the same simulate data. In practice, theory and tests of statistical assumptions would almost always indicate one of these models was appropriate and the other two were inappropriate. What we typically want to know from data simulations is how a model performs when applied as it would be by a researcher. If the sample properties of the simulated data are ignored, and three models that would almost never be applied to the same data are evaluated, we would expect that at least two of the models would consistently perform poorly in the simulations. But the poor performance would be the result of evaluating the models when they should not have been applied (which a researcher could easily avoid with standard time series diagnostics).
In addition to not testing the time series properties of the simulated series to determine which model to estimate, it appears that Philips did not evaluate whether the coefficient on lagged X was significant prior to evaluating the Long Run Multiplier (LRM), which depends on that coefficient. Absent a significant relationship between X t−1 and ΔY t in a GECM, a researcher has no reason to test for a significant LRM. And evaluating the LRM in this context will necessarily inflate the number of type I errors associated with this parameter. These are spurious associations that a practitioner would not encounter, because a practitioner should not estimate an LRM absent evidence of a long-term relationship.
These points offer three insights related to our paper. First, they are a reminder that particularly when T is short, simulations meant to guide applied research cannot be based on asymptotic properties of the DGP. We incorporate this insight into our small sample simulations later in this paper. Second, we believe this discussion helps account for the seemingly divergent findings across the symposium and between the symposium and past research. That is, what may at first look like different conclusions about equation balance and the rate of type I error rates with the GECM/ADL may disappear when simulations base modeling decisions on the observed data (as researchers do in practice). Finally, since Kraft, Key, and Lebo as well as Philips did not base their modeling decisions on the observed data, we should be careful drawing conclusions about published research based on their simulations.
2. Identifying true relationships with mixed orders of integration
As discussed, it has been demonstrated that unrelated stationary and first order integrated time series, that is, non-stationary series, can, in some cases, be analyzed together with a GECM/ADL model without concerns for spurious regressions (i.e., type I error). We now consider whether the GECM/ADL model can identify a true relationship between series that are of different orders of integration. Although time series researchers typically—and understandably—are more concerned about type I error, failing to detect true relationships in the data is also an issue. In the absence of knowledge of the effect of one variable on another, we would like to know that our estimation approach will reveal it.
To address this issue, we evaluate a regression model with a stationary variable on the right-hand side and a dependent variable that includes both stationary and unit root components. Wlezien (Reference Wlezien2000) refers to such a variable as a “combined” time series process. Here, the shock to a combined time series, e t, can be separated into two parts: a series of stationary shocks that cumulate indefinitely (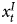 $x^{I}_t$) and another series
$x^{I}_t$) and another series 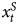 $x^{S}_t$ that decays (Wlezien, Reference Wlezien2000, 79).Footnote 7 In theory, such series are integrated (Granger, Reference Granger1980), as the portion that cumulates over time dominates.
$x^{S}_t$ that decays (Wlezien, Reference Wlezien2000, 79).Footnote 7 In theory, such series are integrated (Granger, Reference Granger1980), as the portion that cumulates over time dominates.
There are many scenarios in the political and economic world that can produce combined time series. To begin with, consider that any process that includes long-term change and measurement error is such a series. But even putting aside measurement error, there are reasons to suppose that numerous processes combine both long-term and short-term change. Theories of people's attitudes over time reflect distinctions between effects that endure versus those that decay (Converse, Reference Converse and Apter1964; Achen, Reference Achen1975; Erikson, Reference Erikson1979). Characterizations of party identification also reflect these distinctions, and some scholars (Erikson et al., Reference Erikson, MacKuen and Stimson1998) explicitly conceive of macro-partisanship as a combined process. The same is true for electoral preferences, which clearly change over time, some of which lasts to impact the outcome and some does not (Erikson and Wlezien, Reference Erikson and Wlezien2012). We also see evidence of short-term and enduring changes in studies of political economy, such as the determinants of global capital mobility (Ahlquist, Reference Ahlquist2006) and its electoral consequences (Tomashevskiy, Reference Tomashevskiy2015). It may be that most seemingly “pure” integrated series actually are combined, where in addition to shocks to the series that cumulate over time there are shocks that decay. Indeed, any series that contains a unit root and is cointegrated with another series must combine integrated and stationary components. This can be seen in Kraft, Key, and Lebo's contribution to this symposium (Equations 5–7), where cointegrated Y combines X, which contains a unit root, and ζ, which is a stationary series. In sum, combined time series are common—and important—for political research, and notice they are substantially quite different to FI series (Box-Steffensmeier and Smith, Reference Box-Steffensmeier and Smith1998b), where all shocks decay, just more slowly than we expect of pure stationary processes.Footnote 8 Combined time series also are ideally suited for GECMs, which estimate both short run (stationary) and long run (integrated) components.
Just as important for our purposes, however, the data generation process of combined time series allow us to conduct simulations where the left- and right-hand side variables are related and of different orders of integration. Not only do researchers often find themselves analyzing series with different orders of integration that are hypothesized to be related, but focusing on cases with different orders of integration offers an opportunity to further clarify the concept of equation balance. For our simulations,
 $$Y_t = x^{I}_t + x^{S}_t$$
$$Y_t = x^{I}_t + x^{S}_t$$ $$x^{I}_t = x^{I}_{t-1} + u1_t,\; \; u1_{t}\, N( 0,\; 1) $$
$$x^{I}_t = x^{I}_{t-1} + u1_t,\; \; u1_{t}\, N( 0,\; 1) $$ $$x^{S}_t = \rho x^{S}_{t-1} + u2_t,\; \; u2_{t}\, N( 0,\; 1) $$
$$x^{S}_t = \rho x^{S}_{t-1} + u2_t,\; \; u2_{t}\, N( 0,\; 1) $$where ρ equals 0.2, 0.5, or 0.8.
Because we want to evaluate whether the GECM/ADL can recover true relationships when the orders of integration on the right- and left-hand side of the equation are mixed, we estimate the equation,Footnote 9
 $$Y_t = \alpha_0 + \alpha_1 Y_{t-1} + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1} + \delta$$
$$Y_t = \alpha_0 + \alpha_1 Y_{t-1} + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1} + \delta$$The equation does not include 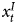 $x^{I}_t$, which means we are mixing a combined time series, Y, which in theory is integrated (Granger, Reference Granger1980), with a stationary time series, x S. Clearly, when analyzing combined time series (as with all data types), researchers should aim to model all explanatory factors. If
$x^{I}_t$, which means we are mixing a combined time series, Y, which in theory is integrated (Granger, Reference Granger1980), with a stationary time series, x S. Clearly, when analyzing combined time series (as with all data types), researchers should aim to model all explanatory factors. If 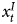 $x^{I}_t$ were correlated with
$x^{I}_t$ were correlated with 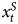 $x^{S}_t$, this omission would create an omitted variable bias problem. Our goal, however, is to model related series that are of different orders of integration and omitting
$x^{S}_t$, this omission would create an omitted variable bias problem. Our goal, however, is to model related series that are of different orders of integration and omitting 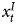 $x^{I}_t$ ensures this scenario. Also keep in mind that time series researchers often face the possibility of omitted variables, either because repeated historical measures do not exist or because they simply do not know the true DGP. Consider research on electoral preferences mentioned earlier, where long-term effects of campaigns are difficult to directly capture on the right-hand side of models of pre-election polls (Erikson and Wlezien, 2012). Equation 4 would not be recommended if we knew the true DGP and had measures of all relevant variables, but it allows us to evaluate the performance of the GECM/ADL with mixed orders of integration and a common but imperfect specification. As a result, our simulations mirror the constraints that researchers may encounter in applied settings.
$x^{I}_t$ ensures this scenario. Also keep in mind that time series researchers often face the possibility of omitted variables, either because repeated historical measures do not exist or because they simply do not know the true DGP. Consider research on electoral preferences mentioned earlier, where long-term effects of campaigns are difficult to directly capture on the right-hand side of models of pre-election polls (Erikson and Wlezien, 2012). Equation 4 would not be recommended if we knew the true DGP and had measures of all relevant variables, but it allows us to evaluate the performance of the GECM/ADL with mixed orders of integration and a common but imperfect specification. As a result, our simulations mirror the constraints that researchers may encounter in applied settings.
Since the true relationship between  $x^{S}_t$ and Y t is 1.0, in our simulations we expect
$x^{S}_t$ and Y t is 1.0, in our simulations we expect 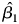 $\hat {\beta _1}$ to equal 1.0. (To be clear, the equation reveals the contribution the independent variable makes to our outcome variable, not the autoregressive parameter of the component.) Relatedly, we expect
$\hat {\beta _1}$ to equal 1.0. (To be clear, the equation reveals the contribution the independent variable makes to our outcome variable, not the autoregressive parameter of the component.) Relatedly, we expect 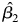 $\hat {\beta _2}$ to equal − 1.0. That this is true can be seen by substituting for Y t−1, which equals
$\hat {\beta _2}$ to equal − 1.0. That this is true can be seen by substituting for Y t−1, which equals 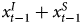 $x^{I}_{t-1} + x^{S}_{t-1}$, as follows:
$x^{I}_{t-1} + x^{S}_{t-1}$, as follows:
 $$Y_t = \alpha_0 + \alpha_1 [ x^{I}_{t-1} + x^{S}_{t-1}] + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1}.$$
$$Y_t = \alpha_0 + \alpha_1 [ x^{I}_{t-1} + x^{S}_{t-1}] + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1}.$$Since Y contains a unit root, α1 = 1, and the equation reduces to
 $$Y_t = \alpha_0 + x^{I}_{t-1} + x^{S}_{t-1} + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1}.$$
$$Y_t = \alpha_0 + x^{I}_{t-1} + x^{S}_{t-1} + \beta_1 x^{S}_t + \beta_2 x^{S}_{t-1}.$$ Given that 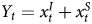 $Y_t = x^{I}_t + x^{S}_t$, by construction, we expect β2 to equal − β1, which cancels the portion of
$Y_t = x^{I}_t + x^{S}_t$, by construction, we expect β2 to equal − β1, which cancels the portion of 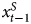 $x^{S}_{t-1}$ in Y t−1 (since
$x^{S}_{t-1}$ in Y t−1 (since 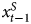 $x^{S}_{t-1}$ does not enter the DGP in Equation 1). Notice that this generalizes across combinations of
$x^{S}_{t-1}$ does not enter the DGP in Equation 1). Notice that this generalizes across combinations of 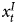 $x^{I}_t$ and
$x^{I}_t$ and  $x^{S}_t$. For example, where the true relationship between
$x^{S}_t$. For example, where the true relationship between 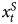 $x^{S}_t$ and Y t equal to 2.0 (and that between
$x^{S}_t$ and Y t equal to 2.0 (and that between 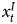 $x^{I}_t$ and Y t equal to 1.0), we would expect β1 in Equation 4 to equal 2 and β2 to equal −2, which would again cancel out the portion of
$x^{I}_t$ and Y t equal to 1.0), we would expect β1 in Equation 4 to equal 2 and β2 to equal −2, which would again cancel out the portion of 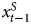 $x^{S}_{t-1}$ in Y t−1. Finally, we expect α0 to equal 0.0. Of course, all of these theoretical expectations are based on the asymptotic case.
$x^{S}_{t-1}$ in Y t−1. Finally, we expect α0 to equal 0.0. Of course, all of these theoretical expectations are based on the asymptotic case.
As previously noted, sometimes political scientists have suggested that it is never acceptable to mix orders of integration and that series should be pre-whitened to ensure the same order of integration for all variables in the model. However, despite different orders of integration on both sides of the equation, we show that the equation is indeed balanced. Substituting Equation 1 for Y, Equation 4 can be rewritten as follows:
 $$x^{S}_t + x^{I}_t = x^{S}_{t-1} + x^{I}_{t-1} + \beta_1x^{S}_t + \beta_2x^{S}_{t-1} + \delta.$$
$$x^{S}_t + x^{I}_t = x^{S}_{t-1} + x^{I}_{t-1} + \beta_1x^{S}_t + \beta_2x^{S}_{t-1} + \delta.$$By rearranging Equation 7, in Equation 8, we see that we now have stationary series on both sides of the equation:
 $$\Delta x^{I}_t + x^{S}_t = \beta_1x^{S}_t + ( 1 + \beta_2) \ast x^{S}_{t-1} + \delta,\; $$
$$\Delta x^{I}_t + x^{S}_t = \beta_1x^{S}_t + ( 1 + \beta_2) \ast x^{S}_{t-1} + \delta,\; $$and so we would expect to be able to identify the true relationships between x S and Y described above.Footnote 10 This does not mean that estimating Equation 4 will correctly represent the DGP, as it clearly does not, since we omit 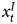 $x^{I}_t$ to ensure that we mix orders of integration. We are intending only to illustrate that, just as an ADL (or GECM) does not necessarily induce spurious results when orders of integration are mixed, it can reveal true relationships with mixed orders of integration, at least when the equation is balanced (and other modeling assumptions are met). As De Boef and Keele (Reference De Boef and Keele2008) have shown, the GECM/ADL does so in a general way, by allowing the data to determine the dynamic structure, that is, settling it empirically not by assumption.
$x^{I}_t$ to ensure that we mix orders of integration. We are intending only to illustrate that, just as an ADL (or GECM) does not necessarily induce spurious results when orders of integration are mixed, it can reveal true relationships with mixed orders of integration, at least when the equation is balanced (and other modeling assumptions are met). As De Boef and Keele (Reference De Boef and Keele2008) have shown, the GECM/ADL does so in a general way, by allowing the data to determine the dynamic structure, that is, settling it empirically not by assumption.
2.1 The asymptotic case
We begin by presenting simulations where T = 5000, only to approximate the asymptotic behavior of the series, before turning to shorter, more realistic T. The asymptotic case is especially important because if equation balance were a concern, it would be evident when T is large. Table 1 presents the results of 2000 simulations where equations are estimated using the ADL, the GECM, and the differenced dependent variable (DV) specification.Footnote 11 Although the simulations employ a single lag, in practice, other lags could be considered and lag structure tested via goodness of fit statistics, such as the Akaike Information Criterion (see also, Hendry, Reference Hendry1995; Wilkins, Reference Wilkins2018). The left part of the table presents the results for the ADL model. There we can see that the estimation almost always recovers the DGP described above. Specifically, the coefficient on 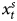 $x^{s}_t$ is consistently near 1.0 and the coefficients on
$x^{s}_t$ is consistently near 1.0 and the coefficients on 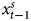 $x^{s}_{t-1}$ and Y t−1 are consistently equal and opposite signed.Footnote 12
$x^{s}_{t-1}$ and Y t−1 are consistently equal and opposite signed.Footnote 12
Table 1. Identifying a true relationship (β1 = 1.0) between 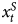 $x^{S}_t$ and Y when
$x^{S}_t$ and Y when  $x^{S}_t$ is stationary and Y combines stationary and unit root properties
$x^{S}_t$ is stationary and Y combines stationary and unit root properties

Notes: coef represents the mean coefficient estimate across 2000 simulations. % represents the percent of simulations for which we (correctly) reject the null hypothesis of no relationship. Consistent with expectations, across all models 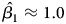 $\hat {\beta _1} \approx 1.0$. As explained in the text, the other parameter estimates also follow expectations. ADL: Y t = α0 + α1Y t−1 +
$\hat {\beta _1} \approx 1.0$. As explained in the text, the other parameter estimates also follow expectations. ADL: Y t = α0 + α1Y t−1 +  $\beta _{1}x^{s}_{t}$ +
$\beta _{1}x^{s}_{t}$ + 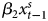 $\beta _{2}x^{s}_{t-1}$ + δ GECM: ΔY t = α0 + α*1Y t−1 +
$\beta _{2}x^{s}_{t-1}$ + δ GECM: ΔY t = α0 + α*1Y t−1 +  $\beta _{1} \Delta x^{s}_{t}$ +
$\beta _{1} \Delta x^{s}_{t}$ + 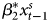 $\beta ^{\ast }_{2}x^{s}_{t-1}$ + γ, where α*1 = α − 1 and β*2 = β1 + β2 from the ADL. First difference: ΔY t = α*0 +
$\beta ^{\ast }_{2}x^{s}_{t-1}$ + γ, where α*1 = α − 1 and β*2 = β1 + β2 from the ADL. First difference: ΔY t = α*0 + 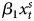 $\beta _{1}x^{s}_{t}$ +
$\beta _{1}x^{s}_{t}$ + 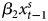 $\beta _{2}x^{s}_{t-1}$ + ɛ, where ΔY t = Y t − α1Y t−1 from the ADL.
$\beta _{2}x^{s}_{t-1}$ + ɛ, where ΔY t = Y t − α1Y t−1 from the ADL.
The GECM is mathematically equivalent to the ADL, so the results based on the former in the middle of Table 1 must be equivalent to the those for the latter (De Boef and Keele, Reference De Boef and Keele2008; Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a). To see this, consider the ADL results in the first column, where α1, the coefficient on y t−1 = 0.9989. If we subtract Y t−1 from both sides of the ADL, the dependent variable becomes ΔY, which matches the GECM and α*1, the coefficient on Y t−1 in the GECM, should equal 0.9989 − 1, or −0.0011, which perfectly matches α*1 in the GECM results. The ADL coefficients on 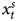 $x^{s}_t$ and
$x^{s}_t$ and 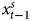 $x^{s}_{t-1}$ (β1 and β2) equal 0.9999 and −0.9983, respectively. To show the equivalency with the GECM results, we can subtract and add 0.9999x t−1 to the right hand side of the ADL results. This produces 0.9999
$x^{s}_{t-1}$ (β1 and β2) equal 0.9999 and −0.9983, respectively. To show the equivalency with the GECM results, we can subtract and add 0.9999x t−1 to the right hand side of the ADL results. This produces 0.9999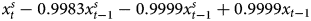 $x^{s}_{t} -0.9983x^{s}_{t-1} - 0.9999x^{s}_{t-1} + 0.9999x_{t-1}$, which equals 0.9999Δx + 0.0016x t−1, exactly the same as the estimates for β1 and β*2 in the GECM results. These results illustrate that the ADL and GECM always produce the exact same numerical information; the only difference is how the two models present this information.
$x^{s}_{t} -0.9983x^{s}_{t-1} - 0.9999x^{s}_{t-1} + 0.9999x_{t-1}$, which equals 0.9999Δx + 0.0016x t−1, exactly the same as the estimates for β1 and β*2 in the GECM results. These results illustrate that the ADL and GECM always produce the exact same numerical information; the only difference is how the two models present this information.
The right side of Table 1 presents the results from a model that first-differences the dependent variable. The model offers an additional way to show that the previously estimated ADL/GECM model is balanced even though the model mixes different orders of integration. To see why, recall that the right hand side of the model (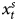 $x^{s}_t$) is stationary and the dependent variable contains a unit root (as well as stationary properties). The standard approach in such a situation is to first-difference Y to make it stationary. Because ΔY = Y t − Y t−1, as the series approaches infinity, subtracting Y t−1 from both sides of the ADL in Equation 4 yields the first-difference model. In other words, given our sample size and DGP, the first-difference model the first-difference model approximates the ADL (and GECM). The results on the far right of Table 1 support this prediction. In most cases the numerical results are identical. The largest difference is 0.001. As can be seen in online Appendix 3, things are nearly identical when T = 200, 100, and 50, although we consider these simulations in more detail below. In other words, in cases where the data could suggest either the GECM/ADL or the first-difference model, both yield nearly identical results.Footnote 13
$x^{s}_t$) is stationary and the dependent variable contains a unit root (as well as stationary properties). The standard approach in such a situation is to first-difference Y to make it stationary. Because ΔY = Y t − Y t−1, as the series approaches infinity, subtracting Y t−1 from both sides of the ADL in Equation 4 yields the first-difference model. In other words, given our sample size and DGP, the first-difference model the first-difference model approximates the ADL (and GECM). The results on the far right of Table 1 support this prediction. In most cases the numerical results are identical. The largest difference is 0.001. As can be seen in online Appendix 3, things are nearly identical when T = 200, 100, and 50, although we consider these simulations in more detail below. In other words, in cases where the data could suggest either the GECM/ADL or the first-difference model, both yield nearly identical results.Footnote 13
As discussed above, Equation 4 is misspecified by construction, because it omits 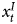 $x^{I}_t$.Footnote 14 Clearly, theory must guide model specification and it would be wrong to conclude that these results imply that the GECM/ADL is always appropriate. They key point is that even with mixed orders of integration, we find that the estimated ADL/GECM in Equation 4 is balanced. Our initial focus, however, has been on an atypically large sample size (T = 5000), so the observed data follow the asymptotic properties.
$x^{I}_t$.Footnote 14 Clearly, theory must guide model specification and it would be wrong to conclude that these results imply that the GECM/ADL is always appropriate. They key point is that even with mixed orders of integration, we find that the estimated ADL/GECM in Equation 4 is balanced. Our initial focus, however, has been on an atypically large sample size (T = 5000), so the observed data follow the asymptotic properties.
2.2 Diagnosing and estimating in practice
In practice, when dealing with finite time series where the true characteristics of the variables and their relationships are unknown, before selecting a model, researchers would first identify the characteristics of the variables. For instance, scholars commonly employ tests, such as the augmented Dickey–Fuller (ADF) test, to diagnose whether series are nonstationary and whether there is drift and/or trend as well.Footnote 15
To illustrate this process, we return to the series we generated for Table A.2 in online Appendix 3. As before, Y always combines unit root and stationary properties and 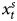 $x^{s}_t$ is always stationary, where the autoregressive parameter ρ = 0.2, 0.5, or 0.8 and T = 50, 100, or 200. Instead of analyzing the data naively, we diagnose the time series properties on each of the simulated combined DVs as well as the stationary independent variables (IVs) with ADF tests, which are particularly relevant for combined time series (see Wlezien, Reference Wlezien2000). To reiterate, while we know the characteristics of the underlying process, researchers in the observational world will not know, so it is important for us to mimic that process, as it has implications for the estimation approaches that are appropriate. As Durr (Reference Durr1992, 193) explains, “empirical diagnoses of time-series data are necessarily a function of a finite sample of a realization of the process in question” (also see Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a; Lebo and Grant, 2016: 71–72).
$x^{s}_t$ is always stationary, where the autoregressive parameter ρ = 0.2, 0.5, or 0.8 and T = 50, 100, or 200. Instead of analyzing the data naively, we diagnose the time series properties on each of the simulated combined DVs as well as the stationary independent variables (IVs) with ADF tests, which are particularly relevant for combined time series (see Wlezien, Reference Wlezien2000). To reiterate, while we know the characteristics of the underlying process, researchers in the observational world will not know, so it is important for us to mimic that process, as it has implications for the estimation approaches that are appropriate. As Durr (Reference Durr1992, 193) explains, “empirical diagnoses of time-series data are necessarily a function of a finite sample of a realization of the process in question” (also see Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a; Lebo and Grant, 2016: 71–72).
To illustrate, let us take the case where the ρ of the stationary component is 0.5 and T = 100. We apply ADF tests using a critical value of 0.05 to each of the 2000 simulated series of both our DV and IV. Table 2 summarizes the results. The first two rows show that we always correctly identify that the IV (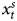 $x^{s}_t$) is stationary but have more difficulty with the combined DV, and identify the underlying integrated process only 78.6 percent of the time (which we see by summing the first and third rows). This pattern comports with previous research (Wlezien, Reference Wlezien2000). By implication, we correctly infer both underlying processes in 78.3 percent of the simulations. Much less frequently—21.4 percent of the time—we conclude that both series are stationary.
$x^{s}_t$) is stationary but have more difficulty with the combined DV, and identify the underlying integrated process only 78.6 percent of the time (which we see by summing the first and third rows). This pattern comports with previous research (Wlezien, Reference Wlezien2000). By implication, we correctly infer both underlying processes in 78.3 percent of the simulations. Much less frequently—21.4 percent of the time—we conclude that both series are stationary.
Table 2. Percent of simulations that identify Y and 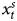 $x^{s}_t$ as I(1) or I(0) with ADF tests when T = 100 and ρ = 0.5
$x^{s}_t$ as I(1) or I(0) with ADF tests when T = 100 and ρ = 0.5

Notes: The first row shows the percent of simulations that correctly identify both series.
These inferences are important, as they matter for estimation. For instance, in the case where both variables appear stationary, we can proceed to estimate an ADL model. Where the DV is nonstationary and the IV stationary, time series practice would recommend regressing the differenced DV on the current and lagged IV. The results of estimating these models are summarized in Table 3. Here we can see that in the 78.3 percent of the simulations where we correctly identify the underlying true processes and estimate a model with a differenced DV, we detect a significant effect of the IV in each of our 2000 simulations, with a mean coefficient of near-perfect 1.0 (0.9999). We also detect the expected β2 (i.e., 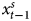 $x^{s}_{t-1}$) in every simulation, the mean estimate of which is −1.0031. The virtually equal and oppositely-signed effects of β1 and β2, which correspond with x s and
$x^{s}_{t-1}$) in every simulation, the mean estimate of which is −1.0031. The virtually equal and oppositely-signed effects of β1 and β2, which correspond with x s and 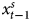 $x^{s}_{t-1}$, imply that the difference in our DV, Y, reflects the difference in
$x^{s}_{t-1}$, imply that the difference in our DV, Y, reflects the difference in 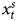 $x^{s}_t$, that is, ΔY = Δx s.Footnote 16 In 21.4 percent of the simulations where both variables appear stationary and we estimate an ADL (as a researcher would do in an applied setting), we obtain similar results, identifying significant current and lagged effects 100 percent of the time and with mean coefficients of 1.0001 and −0.9491, respectively. The estimates do vary, of course, which is important; we nevertheless always detect a true effect of our IV on our DV.
$x^{s}_t$, that is, ΔY = Δx s.Footnote 16 In 21.4 percent of the simulations where both variables appear stationary and we estimate an ADL (as a researcher would do in an applied setting), we obtain similar results, identifying significant current and lagged effects 100 percent of the time and with mean coefficients of 1.0001 and −0.9491, respectively. The estimates do vary, of course, which is important; we nevertheless always detect a true effect of our IV on our DV.
TABLE 3. Results from simulated first difference and ADL models with different combinations of independent and dependent variables

Notes: Consistent with expectations, across all models 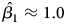 $\hat {\beta _1} \approx 1.0$. As explained in the text, the other parameter estimates also follow expectations. The bottom row (%) shows the percent of simulations that correctly identify the series as Y = I(1),
$\hat {\beta _1} \approx 1.0$. As explained in the text, the other parameter estimates also follow expectations. The bottom row (%) shows the percent of simulations that correctly identify the series as Y = I(1), 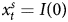 $x^{s}_t = I( 0) $ or Y = I(0),
$x^{s}_t = I( 0) $ or Y = I(0), 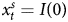 $x^{s}_t = I( 0) $. First difference: ΔY t = α*0 +
$x^{s}_t = I( 0) $. First difference: ΔY t = α*0 + 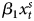 $\beta _{1}x^{s}_{t}$ +
$\beta _{1}x^{s}_{t}$ + 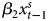 $\beta _{2}x^{s}_{t-1}$ + ɛ ADL: Y t = α0 + α1Y t−1 +
$\beta _{2}x^{s}_{t-1}$ + ɛ ADL: Y t = α0 + α1Y t−1 + 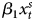 $\beta _{1}x^{s}_{t}$ +
$\beta _{1}x^{s}_{t}$ + 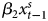 $\beta _{2}x^{s}_{t-1}$ + δ
$\beta _{2}x^{s}_{t-1}$ + δ
Let us now consider different combinations of ρ and T, where the former varies between 0.2, 0.5, and 0.8 and the latter between 50, 100, and 200. Although we know the DGP, we are interested in how researchers would diagnose these series in an applied setting. Table 4 shows the results of our diagnostic analyses for each set of simulations. The patterns are similar to what we saw in Table 2 (and 3), excepting where ρ is large (0.8) and T is low (50). In this case, we frequently identify integration in both the DV and the IV, as the (low) power of the ADF tests make it difficult to reject the null of nonstationarity.Footnote 17 This is important because it implies a different estimate strategy. Specifically, with two I(1) variables, we need to first assess whether they are cointegrated. If they are, we should proceed to a general model suitable for cointegrated series like the GECM; if not, it is necessary to difference both the DV and IV and to estimate a more restricted model.Footnote 18 This is standard time series practice. Furthermore, when we estimate the first-difference models that meet these criteria, we identify the expected relationship in all situations.
Table 4. Percent of simulations that identify Y and X as I(1) or I(0) with ADF tests when T = 50, 100, and 200

Notes: The first row shows the percent of simulations that correctly identify Y as I(1) and X as I(0). ρ indicates the value of the autoregressive parameter in X. Results based on ADF tests on each of the 2000 simulated DVs and IVs using the particular ρ and T, as indicated. Columns may not sum to 100 due to rounding.
In sum, two patterns stand out in these results. First, even in the case where ρ is large (0.8) and T is low (50), most of the time the ADF identifies the time series properties of the DGP. Second, when the ADF indicates the finite series differs from the time series properties of the DGP (which becomes more likely with smaller samples), if we estimate a model based on the observed properties of the data (as indicated by the ADF), we still accurately identify the true relationship between the series in most cases.
3. Conclusion
Time series researchers have understandably focused their studies on the issue of how to avoid spurious correlations. In this paper, we turned our attention to the capacity of GECM/ADL models to detect true relationships between series of different orders of integration, as long as equations are balanced (and other modeling assumptions are met). Although it is known that the GECM/ADL avoids spurious regression in this situation (Enns and Wlezien, Reference Enns and Wlezien2017), if the model cannot detect true relationships in the data, results would not be informative to researchers.
Our simulations show that an equation with a stationary variable on the right-hand side and a dependent variable that combines both unit root and stationary components (a “combined” time series process) can be estimated using a GECM/ADL model. In the simulations, we are able to identify the true relationship between the variables in the asymptotic case. This means that mixing orders of integration not only does not necessarily increase the probability of type I error, as shown by Enns and Wlezien (Reference Enns and Wlezien2017), it also does not necessarily increase the risk of type II error. Of course, things are more complicated when dealing in finite time. As we show in the paper, researchers must first identify the time series properties of the observed data; after doing so, assuming other modeling assumptions are met, the GECM/ADL consistently identifies true relationships.
These findings have important implications for research in most areas in political science. First, they underscore that equation balance and mixed orders of integration, while related, are not one in the same, and that it is possible to have both. Second, we thus need not avoid estimation with mixed orders of integration, or rule out previous research based on such estimation, at least where we have equation balance. Third, and more specifically, with a balanced equation, we can detect true relationships (and eschew spurious ones) even in cases where we cannot correctly represent the DGP. This is of special importance because we often are uncertain about the characteristics of our variables. Although the necessity of pre-testing is encouraged in the literature, including in this symposium (Philips), detecting the properties of series is a difficult task. The findings from our simulations thus assuage some of the problems practitioners often face while also highlighting the importance of the general approach that DeBoef and Keele (2008) recommend. Of course, even when a parsimonious model guided by complete pre-tests fits the data well, standard diagnostics must be evaluated, particularly the characteristics of the residuals. This is (or at least should be) routine in time series analysis, as it provides critical information to researchers.
Finally, we make the additional point that, while there is consensus that the GECM avoids spurious regression when assumptions are met and it is implemented correctly (e.g., Enns et al., Reference Enns, Kelly, Masaki and Wohlfarth2016a, Reference Enns, Kelly, Masaki and Wohlfarth2017b; Grant and Lebo, Reference Grant and Lebo2016), this symposium highlights that there is still some disagreement about how frequently these assumptions are met. We understand that part of the disagreement stems from the application of different approaches to simulations. In our minds, a focus on both large and small samples for simulations, estimating models on simulated data based on the observed data (not naively based on the DGP), and attention to both type I and type II error rates will help advance our understanding of the limits of GECM/ADL models and the use of simulations in time series analysis.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/psrm.2021.38.
Acknowledgments
An earlier version of this paper was presented at the Texas Methods Meeting, University of Houston, 2017. For comments, we thank Neal Beck, Francisco Cantu, Scott Cook, Justin Esarey, Florian Hollenbach, Ryan Kennedy, Tse-Min Lin, Pablo Pinto, Randy Stevenson, Guy Whitten, and the anonymous reviewers.
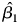
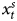

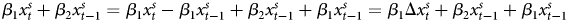










 Open access
Open access