

30.1 Introduction
The scholarly debate around speech rhythm over the last decades has produced a rich literature on its theoretical underpinnings (e.g., Arvaniti, Reference Arvaniti2009; Nolan and Jeon, Reference Nolan and Jeon2014; Gibbon, Reference Gibbon2021), its measurement (using so-called rhythm metrics, for example, Low et al., Reference Low, Grabe and Nolan2000; Deterding, Reference Deterding2001), as well as its applications to a great number of languages and dialects (Szakay, Reference Szakay2006; White and Mattys, Reference White and Mattys2007; Behrman et al., Reference Behrman, Ferguson, Akhund and Moeyaert2019).Footnote 1
Speech rhythm can be defined as ‘the production, for a listener, of a regular recurrence of waxing and waning prominence profiles across syllable chains over time’ (Kohler, Reference Kohler2009, p. 41). While many scholars of speech rhythm might overall agree with this definition, it is in fact much broader in scope than the actual, practical definition and operationalisation of speech rhythm that many studies have used and continue to use. Most research on speech rhythm focuses on duration; that is, Kohler’s ‘waxing and waning’ is operationalised as the alternation of long and short syllables or vowels. However, Kohler refers to alternation in prominence, which might be realised acoustically by duration, but also by pitch, loudness, and potentially other acoustic features. In Section 30.3, the discussion will return to this point and explore ways of measuring rhythmic alternation involving features other than duration.
Speech rhythm was originally conceived as a suprasegmental phenomenon covering three classes of languages (e.g., Pike, Reference Pike1945; Abercrombie, Reference Abercrombie1967, p. 97):
(1) syllable-timed languages, with syllables of equal duration (i.e., isochronous), such as in Spanish (see top panel of Figure 30.1, where syllables are of equal duration and feet vary in duration)
(2) stress-timed languages, with feet, that is, a stressed syllable followed by one or more unstressed syllables, of equal duration (i.e., isochronous), such as in British English (see bottom panel of Figure 30.1, where feet are of equal duration and syllables vary in duration)
(3) mora-timed languages, with morae (a unit smaller than a syllable but often comprising more than one phoneme) of equal duration (i.e., isochronous), such as in Japanese.
Despite attempts to test this rhythm class hypothesis in terms of speech production (e.g., Dankovičová and Dellwo, Reference Dankovičová and Dellwo2007) and perception (e.g., Ramus et al., Reference Ramus, Dupoux and Mehler2003), there is substantial evidence that it lacks empirical support. In particular, two (interlinked) claims of the rhythm class hypothesis have been criticised: (i) the isochrony of specific prosodic units and (ii) the existence of discrete rhythm classes. Note that these two claims are independent – it is possible for the languages of the world to fall into discrete rhythm classes without isochrony.
Idealised syllable-timing and stress-timing.
Idealised syllable-timing involves syllables of equal duration and feet of unequal duration (top), while idealised stress-timing involves syllables of unequal duration and feet of equal duration (bottom).
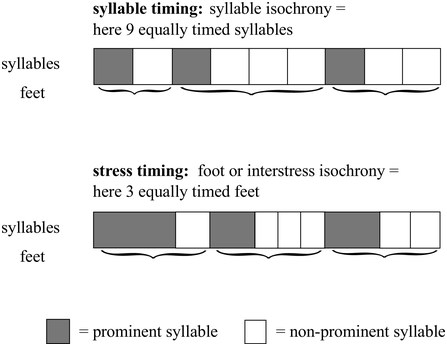
Figure 30.1 Long description
Syllable Timing: In this pattern, the example feet have 9 syllables, and each is represented by a box of equal width. Out of 9, there are 3 prominent syllables that are indicated in a dark shade. Stress Timing: Here, the feet are of equal duration while the some of the syllables are shorter and others are longer. The legends for prominent syllables and non-prominent syllables are given at the bottom.
However, evidence from speech production indicates that the claim of isochrony of syllables in syllable-timed languages, feet in stress-timed languages, and morae in mora-timed languages, respectively, is inaccurate (Dauer, Reference Dauer1983). Moreover, the second claim, that is, that there are distinct rhythm classes, also turns out to be problematic. Evidence from speech production indicates that languages do not fit neatly into rhythm classes (Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002), but that there are gradual instead of categorical differences in timing between languages. Both adult listeners (White et al., Reference White, Mattys and Wiget2012) and infants (Molnar et al., Reference Molnar, Gervain and Carreiras2014; Gasparini et al., Reference Gasparini, Langus, Tsuji and Boll-Avetisyan2021) are sensitive to temporal information rather than to rhythm class in language discrimination.
This evidence prompted a reconceptualisation of speech rhythm as a gradable phenomenon (see White et al., Reference White, Mattys and Wiget2012), with some languages involving greater variability in the duration of syllables (stress-timed languages) and other languages lesser variability (syllable-timed languages). In addition to or instead of syllables, many studies focused on the nuclei of syllables, that is, vowels, similarly identifying greater variability in duration with stress-timing and lesser variability with syllable-timing. Meanwhile, the concept of mora-timing was all but abandoned.
Nevertheless, the original terminology often shines through, with languages or varieties regularly described as syllable- or stress-timed (as in the contributions to Kortmann and Schneider, Reference Kortmann and Schneider2004). Alternatively, in order to reflect the gradable nature of speech rhythm, other terms can be used, such as ‘more stress-timed’, ‘relatively stress-timed’ or ‘stress-based’, and mutatis mutandis for syllable-timing (Dauer, Reference Dauer1983; Braun and Geiselmann, Reference Braun and Geiselmann2011). Nevertheless, possibly because these newer terms are somewhat unwieldy, the older ones are still in use as a shorthand. Moreover, the expression ‘rhythm classes’ can also still be found (e.g., White and Mattys, Reference White and Mattys2007; Gasparini et al., Reference Gasparini, Langus, Tsuji and Boll-Avetisyan2021), though it is now used more rarely and should be entirely avoided (White et al., Reference White, Mattys and Wiget2012) since it inaccurately invokes clear-cut categories instead of reflecting the above-mentioned gradable nature of speech rhythm.
A considerable body of current research attempting to quantify and compare the speech rhythm of languages and dialects, or involving sociolinguistic variation more generally, relies on this notion of greater or lesser variability in the duration of consecutive syllables or vowels, with lesser variability identified with (relative) syllable-timing and greater variability with stress-timing (thus, in Figure 30.1, syllables would not be identical in duration for syllable-timing but just relatively similar, whereas in stress-timing, syllables vary greatly in duration). Returning to Kohler’s definition above, the basic idea behind this approach is that speech with a tendency towards stress-timing involves great variations in prominence (including duration) between prominent (or stressed) and non-prominent (or unstressed) syllables, while a tendency towards syllable-timing involves small variations between prominent and non-prominent syllables.
Overall, in current practice more studies measure speech rhythm with regard to the durational variability of vowels rather than syllables, while other metrics rely on the durations of consonants or yet other phonetic or phonological units. Technically, this method is more complex than discussed so far, since it is not the durational variability of vowel phonemes that is measured but the durational variability of vocalic intervals, that is, one or more consecutive vowels not interrupted by any consonants, possibly spanning word boundaries.
30.2 Duration-Based Metrics
Duration-based rhythm metrics were initially conceived around the aim of quantifying the notion that there are reduced vowels in unstressed syllables in stress-timed languages, while syllable-timed languages have no or little vowel reduction. In addition, stress-timed languages tend to allow consonant clusters with several consonant phonemes, while syllable-timed languages rarely do (Dauer, Reference Dauer1983, pp. 55–58; Ramus et al., Reference Ramus, Nespor and Mehler1999, p. 270; Schiering, Reference Schiering2007).
The considerable number of duration-based rhythm metrics can be classified along three broad distinctions, that is, (1) whether they rely on the durations of vowels, consonants, or syllables, (2) whether they normalise for variation in speech rate, and (3) how they quantify variability (see Figure 30.2). Thus, a distinction can be made between (1) vocalic, consonantal, and syllabic metrics, (2) rhythm metrics normalised for speech rate or not, and (3) global and local metrics.Footnote 2
Taxonomy of common duration-based rhythm metrics.
Duration-based rhythm metrics are classified here according to the segmental unit of measurement (vocalic, consonantal, or syllabic), the operationalisation of variability (local or global), and speech rate normalisation. Theoretically possible but uncommon metrics are shown in brackets.
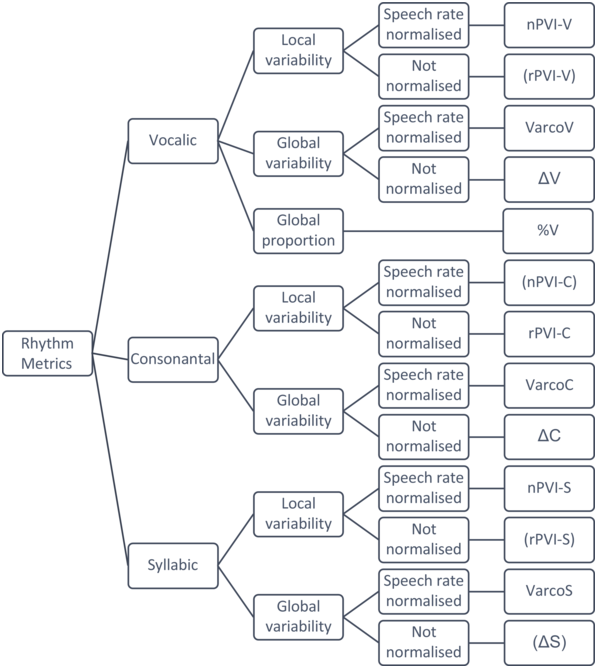
Figure 30.2 Long description
The rhythm is categorized by phonetic segments, namely, Vocalic, Consonantal and Syllabic. Each segment is further classified into local and global variability. Each variability is further classified into speech rate normalised and not normalised. The terminal ends of the tree list the specific metrics calculated, such as n P V I V, r P V I V, Varco V, delta V, % V, and others.
Of these criteria, the global/local distinction requires further explanation. Global rhythm metrics compute a measure of variability of duration of all vocalic, consonantal, or syllabic intervals regardless of their position in the utterance. This can be realised by computing the standard deviation, which yields the measures ΔV (read: ‘Delta V’) and ΔC for vocalic and consonantal intervals, respectively (Ramus et al., Reference Ramus, Nespor and Mehler1999). These metrics can in turn be normalised for speech rate by taking the standard deviation, divided by the mean, multiplied by 100, resulting in metrics known as VarcoV, VarcoC, and VarcoS, respectively (also known as coefficients of variation for vocalic, consonantal, and syllable durations, respectively; Dellwo, Reference Dellwo, Karnowski and Szigeti2006; White and Mattys, Reference White and Mattys2007; Rathcke and Smith, Reference Rathcke and Smith2011).
While global rhythm metrics are computed without regard to the temporal order of the vocal, consonantal, or syllabic units, local metrics are based on differences between adjacent pairs of vocalic intervals (for vocalic metrics), consonantal intervals (for consonantal metrics), or syllables (for syllabic metrics). Finally, the mean of all pairwise comparisons is computed. These metrics are commonly referred to as pairwise variability indices (PVI), where an initial lower case ‘n’ indicates the speech-rate-normalised version and ‘r’ the raw or non-normalised version (Low et al., Reference Low, Grabe and Nolan2000). Of the six theoretically possible PVIs, three, i.e. rPVI-C, nPVI-V, and nPVI-S (Gibbon and Gut, Reference Gibbon and Gut2001),Footnote 3 have been applied in research, while the raw vocalic and syllabic (rPVI-V, rPVI-S) and the normalised consonantal index (nPVI-C, shown in brackets in Figure 30.1) are rarely or never used. Moreover, a rhythm metric that goes beyond this taxonomy, but is often used, accounts for the proportion of vocalic durations relative to total utterance duration, known as %V (Ramus et al., Reference Ramus, Nespor and Mehler1999; %V is technically the inverse of %C, and the convention is to refer to %V). In addition to the duration-based rhythm metrics discussed here, there are others that are less widely used; a comprehensive overview can be found in Fuchs (Reference Fuchs2016, pp. 35–52).
The considerable number of duration-based speech rhythm metrics prompts the question of whether they are all equally reliable or, alternatively, if one or a few of them are superior to the rest. Empirical validity tests indicate that nPVI-V, VarcoV, and %V are the most reliable and should therefore be preferred (White and Mattys, Reference White and Mattys2007; Wiget et al., Reference Wiget, White and Schuppler2010; note, however, that these tests did not include syllabic metrics).Footnote 4 Additional evidence on the validity of these metrics comes from speech perception and indicates that these speech production metrics appear to at least partially capture the human perception of rhythmicity (Fuchs, Reference Fuchs and Fuchs2023a). Finally, given that nPVI-V and VarcoV both measure variability in vocalic durations and are speech-rate-normalised, while %V accounts for the proportion of vocal durations over total utterance duration, it is recommended that studies on speech rhythm relying on duration-based metrics rely on %V as well as, at a minimum, either nPVI-V or VarcoV. With this choice of metrics, two potentially distinct aspects of rhythmicity are captured.
Current practice in the field does not completely follow this advice. Of all duration-based rhythm metrics, the one probably by far most widely used is nPVI-V. For example, a synthesis of previous research on variation in speech rhythm among varieties of English identified 18 relevant studies on 23 varieties of English applying the nPVI-V to samples of read speech (Fuchs, Reference Fuchs and Fuchs2023b). Taken together, these studies support the widely held assumption that so-called Outer Circle varieties (where English is widely used as a second language and local lingua franca, for example, Indian and Nigerian English) tend to be more syllable-timed than Inner Circle varieties (where English is mainly used as a first language, for exmaple, British, American, and Australian English). A major factor that likely accounts for this result is prosodic transfer from relatively syllable-timed languages widely used in countries where Outer Circle varieties of English are spoken. Moreover, so-called Expanding Circle varieties, where English is mainly used as a foreign language but does not enjoy official status or play a large local role (e.g., in Japan and Germany), also tend to be more syllable-timed than Inner Circle varieties. This tendency may in some cases be explained by prosodic transfer as well. However, other reasons are conceivable, too. These include a possible tendency towards syllable-timing in second-language acquisition, and a selection as well as publication bias in the extant publication record. Selection bias may involve researchers selecting research questions that are likely to confirm assumptions they and the field as a whole would consider to be in keeping with the extant research record. Moreover, publication bias may play a role when researchers engaging in such research are more likely to consider manuscripts worth publishing, and more likely to get manuscripts accepted in research outlets, when the results indicate a non-null finding.
The duration-based metrics discussed here have been criticised in several ways (for a more extensive discussion, see Fuchs, Reference Fuchs2016, pp. 57–69). One objection is that duration is only one of several relevant acoustic correlates of prominence, and a more holistic assessment of rhythm should consider additional acoustic measures (see Section 30.3). Another point of contention focuses on a lack of explanatory power, arguing that rhythm metrics quantify rhythm as a surface phenomenon and are influenced by several phonological parameters simultaneously (Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013, p. 109).
Rhythm metrics have also been criticised as empirically inadequate by Arvaniti (Reference Arvaniti2009, Reference Arvaniti2012) because they are influenced by elicitation method and syllable complexity. Arvaniti used sets of sentences that were explicitly designed to elicit a more stress- or more syllable-timed rhythm and showed that this result applies across several languages. However, this approach can in turn be criticised for its circularity. Speech material with specific properties was selected, and the analysis in turn revealed exactly these properties. Moreover, speech rhythm metrics were in fact explicitly designed so as to capture differences in syllable complexity. Finally, Arvaniti’s (Reference Arvaniti2012) results generally go in the expected direction, for example with English and German showing higher nPVI-V values, and lower %V values, than Spanish. In fact, across the three metrics nPVI-V, VarcoV, and %V (shown in previous research to be more reliable than other durational metrics; White and Mattys, Reference White and Mattys2007; Wiget et al., Reference Wiget, White and Schuppler2010) and across five different conditions, the difference between English and Spanish is of a non-negligible size and goes in the expected direction in 12 out of 15 cases. Finally, further empirical evidence supporting duration-based metrics comes from a meta-analysis indicating that language discrimination by infants can be explained by durational rhythm metrics (Gasparini et al., Reference Gasparini, Langus, Tsuji and Boll-Avetisyan2021).
30.3 Acoustic Metrics
While duration-based metrics are widely used in research on speech rhythm, what they actually measure can only partially account for Kohler’s (Reference Kohler2009, p. 41) ‘waxing and waning prominence profiles’ (referred to in Section 30.1). These metrics merely measure variability in duration and neglect any other acoustic correlates of prosodic prominence, the most important of which are intensity and fundamental frequency/f0, alongside their psychoacoustic counterparts loudness and pitch, respectively.
Moreover, range of other proposals do not (directly) rely on a particular acoustic correlate of prosodic prominence but are based on complex transformations of spectral energy or other acoustic information in the speech signal (e.g., Galves et al., Reference Galves, Garcia, Duarte and Galves2002; Tilson and Johnson, Reference Tilsen and Johnson2008; Goswami and Leong, Reference Goswami and Leong2013; Tilsen and Arvaniti, Reference Tilsen and Arvaniti2013; Ravignani and Norton, Reference Ravignani and Norton2017; Gibbon and Li, Reference Gibbon and Li2019; Davis and Jeesun, Reference Davis, Jeesun and Fuchs2023). Some of these approaches to measuring rhythm are difficult to reproduce for other researchers because the code is not publicly available. In the following, the discussion focuses on acoustic rhythm metrics that apply the Varco or PVI concept to acoustic correlates of rhythm beyond duration. The advantage of these approaches is arguably that they present a way of accounting for speech rhythm as a multidimensional acoustic phenomenon (Fuchs, Reference Fuchs2016), realised on multiple acoustic ‘channels’, while at the same time the Varco and PVI indices are mathematically relatively straightforward, and therefore easily interpretable, indices of variability (see Table 30.1 for an overview).
Rhythm metrics based on f0, intensity, and loudness (modified from Fuchs, Reference Fuchs2016: pp. 78–79)
| Metric | Description | Main reference |
|---|---|---|
| nPVI-V(avgInt) | Pairwise variability index for intensity variation between vocalic intervals. Mean of the differences between root mean square amplitude of successive vocalic intervals. | Low (Reference Low1998) |
| nPVI-V(AI) | Pairwise variability index for intensity and duration variation between vocalic intervals. Mean of the differences between the Amplitude Integral of successive vocalic intervals. | Low (Reference Low1998) |
| VarcoS(avgInt) | Coefficient of variation of average intensity in syllables (i.e., standard deviation of average intensity divided by the mean), multiplied by 100. | He (Reference He2012) |
| nPVI-S(avgInt) | Pairwise variability index for variation in average intensity. Mean of the differences between average intensity of adjacent syllables, divided by their sum, multiplied by 100. | He (Reference He2012) |
| nPVI-V(peakInt) | Pairwise variability index for intensity variation between vocalic intervals. Mean of the differences between peak amplitude of successive vocalic intervals. | Fuchs (Reference Fuchs2016) |
| nPVI-V(avgLoud) | Pairwise variability index for variation in average loudness between vocalic intervals. Mean of the differences between average loudness of successive vocalic intervals. | Fuchs (Reference Fuchs2016) |
| nPVI-V(peakLoud) | Pairwise variability index for variation in peak loudness between vocalic intervals. Mean of the differences between peak loudness of successive vocalic intervals. | Fuchs (Reference Fuchs2016) |
| nPVI-V(dur+avgLoud) | Pairwise variability index for combined variation in duration and mean loudness between vocalic intervals. Mean square of the normalised differences between duration and loudness of successive vocalic intervals. | Fuchs (Reference Fuchs2014b, Reference Fuchs2016) |
| nPVI-V(dur+peakLoud) | Pairwise variability index for combined variation in duration and peak loudness between vocalic intervals. Mean square of the normalised differences between duration and peak loudness of successive vocalic intervals. | Fuchs (Reference Fuchs2016) |
| nPVI-V(LI) | Pairwise variability index for loudness and duration variation between vocalic intervals. Mean of the differences between the Loudness Integral of successive vocalic intervals. | Fuchs (Reference Fuchs2016) |
| nPVI-V(f0) | Pairwise variability index for f0 variation between vocalic intervals. Mean of the differences between the pitch excursion of successive vocalic intervals. | Cumming (Reference Cumming2010, Reference Cumming2011) |
| nPVI-V(dur*f0) | Pairwise variability index for variation in duration between vocalic intervals, adjusted for the influence of f0 on duration. Mean of the differences in adjusted duration between successive vocalic intervals. | Fuchs (Reference Fuchs2014a) |
These metrics can be classified according to:
(1) the variability index they use (Varco or PVI)
(2) the phonological unit from which acoustic information is extracted (vowels or syllables)
(3) the acoustic correlate of prominence (f0, intensity, loudness, as well as combinations thereof with duration).
Moreover, variability in the acoustic correlates of prominence can be quantified in different ways:
(4a) For intensity and loudness, there are proposals to quantify variability either in their average, or in their peak value, in the syllable or vocalic interval.
Thus, VarcoS(avgInt) captures variability in the average intensity in syllables. Instead of calculating the standard deviation of syllable duration divided by the mean, multiplied by 100, which is the way the regular VarcoS for syllable duration is calculated (see Section 30.2), for VarcoS(avgInt), average intensity over each syllable is entered into this equation. Thus, VarcoS(avgInt) is calculated as the standard deviation of average intensity for each syllable, divided by the mean, multiplied by 100. Following the same approach, an nPVI-S(avgInt) can be calculated by entering average intensity for each syllable into the nPVI equation. Furthermore, instead of average intensity over a syllable or vocalic interval, peak intensity can be used as a measure, for example, in the vocalic PVI for peak intensity nPVI-V(peakInt). Finally, all these metrics can also be applied to loudness as the psychoacoustic correlate of intensity, for example, the vocalic PVI for average loudness nPVI-V(avgLoud)) and for peak loudness (nPVI-V(peakLoud)).
Based on these proposals, researchers can trace rhythmic variability independently for distinct acoustic correlates of prominence. For example, the regular nPVI-V based on durations (nPVI-V(dur) can be used to quantify the degree of variability in durations between vocalic intervals, while nPVI-V(loud) can be used in parallel to quantify the degree of variability in loudness between vocalic intervals.
(4b) A further refinement of these measures consists in possible combinations of variability in duration with either variability in intensity or loudness. More specifically, it is conceivable that variability in duration and intensity/loudness are tightly correlated with each other; that is, the longer a vowel is, the louder it is at the same time. In other cases, variability in duration and intensity/loudness might not be tightly linked; that is, there might be particularly long vowels that are not necessarily also louder than vowels of average duration.
There are two proposals to account for the potential linkage between variability in duration and intensity/loudness: applying the nPVI formula to both duration and intensity/loudness simultaneously (e.g., nPVI-V(dur+avgLoud), nPVI-V(dur+peakLoud)) or calculating the so-called Amplitude Integral or Loudness Integral (e.g., nPVI-V(AI), nPVI-V(LI)).
Finally, for f0, the existing proposals are not analogous to the rhythm metrics capturing variability in intensity and loudness discussed so far. Instead, the nPVI-V(f0) proposed by Cumming (Reference Cumming2010, Reference Cumming2011) calculated the mean of the differences between the pitch excursion of successive vocalic intervals. Another proposal, by Fuchs (Reference Fuchs2014a), presents an nPVI for vocalic durations that takes into account that differences in f0 also influence perceived duration. In fact, given two vowels of the same duration but different f0, the vowel with higher f0 will be perceived as longer. The proposed nPVI-V(dur*f0) takes this effect into account and thus offers a psychologically more realistic measure of rhythmic variability in perceived duration.
The rhythm metrics proposed for acoustic correlates of prominence do not cover all possible permutations of the various means of computing variability (Varco and nPVI), acoustic correlate (intensity, loudness, f0), and indices of joint variability in duration and another acoustic correlate. Other combinations, such as a joint index of variability in loudness, f0, and duration, might be useful as well.
The rhythm metrics discussed in this section have the advantage of accounting for multiple acoustic correlates of prosodic prominence, thus presenting a more holistic analysis of speech rhythm as a multidimensional phenomenon. For example, in a study comparing read speech in Singapore English and British English, Low (Reference Low1998, pp. 49, 53) was able to confirm the assumption that Singapore English has a more syllable-timed rhythm than British English. In terms of the variability of vocalic durations (nPVI-V(dur)), the analysis indicated that British English had about 1.63 times the durational variability of Singapore English. By contrast, the variability in the Amplitude Integral as a joint measure of amplitude and duration indicated only 1.15 times the variability.Footnote 5
Furthermore, in another study on read speech from Indian English and British English, several rhythm metrics confirmed the assumption that Indian English has a relatively more syllable-timed rhythm than British English (Fuchs, Reference Fuchs2016, pp. 114, 147). However, the magnitude of the differences between the two dialects varied depending on which acoustic correlate of prominence was investigated. Specifically, the PVI for vocalic durations (nPVI-V(dur)) indicated that British English has 1.10 times the rhythmic variability of Indian English in terms of the variability of vocalic durations. By contrast, the difference in rhythmic variability for average loudness (nPVI-V(avgLoud)) was greater – 1.23 times. Finally, the combined index accounting for simultaneous variability in duration and average loudness (nPVI-V(dur+avgLoud)) showed that the rhythmic differences between British and Indian English is in fact even greater, with the former having on average 1.45 times the rhythmic variability of the latter, indicating that duration and loudness may have a compounding effect on perceived rhythmic variability in British English, compared to Indian English.
Finally, turning to the role of f0 in rhythmic variation, an analysis of read speech by Fuchs (Reference Fuchs2014a) found that, in British English, the effect of f0 on perceived duration has a noticeable impact on the degree of rhythmic variability, with a significantly higher nPVI-V(dur*f0) compared to the nPVI-V(dur) that is based on duration only. Importantly, this effect appears to be dialect-specific and was not present for Indian English. In effect, using the nPVI-V(dur*f0) allowed this study to show how the effect of f0 on perceived duration further enhances the differences between relatively more stress-timed British English and relatively more syllable-timed Indian English.
In addition to these metrics, Tilsen and Arvaniti (Reference Tilsen and Arvaniti2013) proposed several rhythm metrics based on ‘empirical mode decomposition of the speech amplitude envelope’, a computationally intensive method from which the authors derive syllabic and supra-syllabic measures. Their approach relies on empirical mode decomposition (Huang et al., Reference Huang, Shen and Long1998) yielding intrinsic mode functions (IMFs), where IMF1 represents the fastest oscillation in the spectral envelope, IMF2 the next fastest, and so on. From these, a total of seven power distribution metrics, rate metrics, and rhythm stability metrics are derived.
These studies clearly indicate that a reduction of speech rhythm to the measurement of variability in duration limits the analysis of speech rhythm to just a single acoustic correlate of prominence and may also underestimate the true degree of rhythmic variation between languages and dialects. For a more comprehensive analysis of speech rhythm as a prosodic phenomenon, variability in multiple acoustic correlates of prominence should be taken into account.
30.4 Conclusion: Applying Acoustic Rhythm Metrics
This chapter started out with a reference to Kohler’s (Reference Kohler2009) definition of speech rhythm in terms of ‘waxing and waning prominence profiles across syllable chains over time’. It then presented several duration-based rhythm metrics. While some of these metrics have been widely used to account for variation in speech rhythm between languages, dialects, as well as sociolinguistic variation, they arguably neglect acoustic correlates of prominence other than duration. The discussion then turned to another class of rhythm metrics, which aim to account for rhythmic variation by quantifying variability in other acoustic correlates of prominence, that is, intensity, loudness, and f0, as well as the interaction between these and their interaction with duration. Several examples from the literature illustrate how these acoustic rhythm metrics can be fruitfully applied in order to provide a more holistic analysis of speech rhythm and to capture its multidimensional nature.
In addition to the theoretical desideratum of a more holistic analysis of speech rhythm, studies in this area should also try to adhere to a set of guidelines in order to provide valid and reproducible results. Such studies should try to compare like with like, that is, carefully select speakers and speech material that are constrained and clearly described. This requirement also includes that variation in speech style needs to be accounted for, for instance by using either read or spontaneous speech or by including both, but including speech style as a variable in the statistical analysis. The annotation and segmentation of the speech data requires clear guidelines in order to enhance comparability between and the reproducibility of studies. Further information on these guidelines as well as a guide towards the statistical analysis of speech rhythm data can be found in Fuchs (Reference Fuchs, Wilson and Westphal2023c).
A final point to consider concerns the computation of rhythm metrics. In order to simplify their application in empirical research and to enhance reproducibility, this chapter is accompanied by a Praat script that computes a large number of the duration-based and acoustic metrics presented in this chapter (available online at https://osf.io/79qyg/).
Summary
The chapter introduces several duration-based and acoustic metrics of speech rhythm. While duration-based metrics are used widely, understanding speech rhythm as relating to variability in prominence opens the door to newer metrics that focus on variability in intensity, loudness, and pitch, in addition and in conjunction with duration.
Implications
Acoustic rhythm metrics have been rarely used in previous research. Their wider application will contribute to a better understanding of cross-linguistic and sociolinguistic variation in speech rhythm. In addition to production studies, research on the perception of speech rhythm promises to reveal additional evidence elucidating the complex nature of speech rhythm.
Gains
The multidimensional analysis of the acoustics of speech rhythm provides important insights for cognitive science and psycholinguistics. By incorporating both duration-based and acoustic metrics, researchers gain a nuanced understanding of the complex nature of speech rhythm and its variation within and across languages.
31.1 Introduction
Models of speech timing must reflect the mechanisms by which speakers communicate linguistic structure to listeners through systematic durational variations (e.g., Klatt, Reference Klatt1976; van Santen and Shih, Reference van Santen and Shih2000; White, Reference White2002, Reference White2014). Such models refer to theories of prosodic structure and to some notion of hierarchically organised prosodic constituents, such as syllables, word, phrases, and so on (e.g., Nespor and Vogel, Reference Nespor and Vogel1986; Selkirk, Reference Selkirk1986). Furthermore, some accounts of observed durational patterns specifically propose direct temporal influences between higher and lower prosodic constituents, for example, between syllables and some form of stress-delimited feet (e.g., O’Dell and Nieminen, Reference O’Dell and Nieminen1999; Port, Reference Port2003), whereby, for example, the number of syllables within the higher-level constituent directly influences the duration of the lower-level constituent (e.g., Lehiste, Reference Lehiste1972). Critical debates remain, however, over the degree to which prosodic constituents are strictly hierarchical and over the nature of the timing constraints that such hierarchical relations impose on speech production (e.g., Shattuck-Hufnagel and Turk, Reference Shattuck-Hufnagel and Turk1996; Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010; White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020).
31.2 Coupled Oscillator Models and Temporal Compression Effects
Arguing against isochronous timing principles in (then extant) notions of ‘rhythm class’, Dauer (Reference Dauer1983) reported positive relationships between inter-stress interval duration and the number of inter-stress syllables for a range of languages, whether, at the time, categorised as ‘stress-timed’ or ‘syllable-timed’.Footnote 1
Reanalysing Dauer’s (Reference Dauer1983) data using linear regression, Eriksson (Reference Eriksson1991) explicitly modelled inter-stress duration as a function of the number of syllables in an inter-stress interval: I = a + nb, where a is the intercept, b is the slope of the regression line, and n is the number of syllables in the inter-stress interval. Eriksson reported that the slope, representing the additional duration due to each new syllable in an inter-stress interval, was similar across languages (approximately 100 ms). He also commented on systematic linguistic differences in the intercept of the regression line: this value clustered around 200 ms in English and Thai (then so-called stress-timed languages), and at 100 ms in (‘syllable-timed’) Spanish, Greek, and Italian.
Eriksson (Reference Eriksson1991) asserted that the ‘natural interpretation’ of intercept value is that it refers to the extra duration of stressed syllables (relative to unstressed syllables) in the inter-stress interval (what we refer to here as the magnitude of durational stress contrast). However, he also observed that the intercept value does not in itself capture the locus of this additional duration, raising the possibility that linguistic variation in intercept values could (alternatively) indicate variable compression of syllables somewhere in the inter-stress interval; that is, the residual intercept durational value could be underpinned by inverse relationships between the number of syllables in the interval and their average duration. In such an account, inter-stress interval duration is a function both of duration added by each new syllable (‘syllable effect’) and syllabic compression due to the composition of the inter-stress interval (‘inter-stress effect’; but see, for example, van Santen, Reference van Santen, Sagisaka, Campbell and Higuchi1997, and White, Reference White2014, for arguments against the syllabic compression interpretation).
Following Eriksson’s second, syllabic compression interpretation of his regression models of cross-linguistic inter-stress-interval duration, O’Dell and Nieminen (Reference O’Dell and Nieminen1999) attempted to capture the hypothesised timing influences on these intervals by positing two interacting oscillators, representing two levels of the prosodic hierarchy: the syllabic oscillator and the inter-stress (or stress-foot) oscillator. These oscillators are proposed to have their own natural frequencies, with the syllabic oscillator higher in frequency than the inter-stress oscillator. Importantly for the generation of observed durational patterns, the oscillators are proposed to interact with each other via a coupling function. As such, the coupled oscillators settle into stable frequency patterns in which the frequency of the faster oscillator is an integer multiple of the frequency of the slower oscillator (see Windmann, Reference Windmann2016). Figure 31.1 shows a schematic representation of a 1:2 ratio of the syllable oscillator to the inter-stress oscillator representing a stable state coupling. It may also be noted that these oscillators are not associated with neural or physiological processes in O’Dell and Nieminen’s purely mathematical models, but there are obvious parallels with accounts of the synchronisation of the temporal structure of speech to endogenous neural oscillations (see, for example, Chapters 3 and 5).
Schematic representation of coupled oscillators.
Stable state between syllabic oscillator (dashed line) and inter-stress oscillator (solid line), where the frequency of the syllabic oscillator is an integer multiple of the frequency of the inter-stress oscillator (here, for illustrative purposes only, a 1:2 ratio).
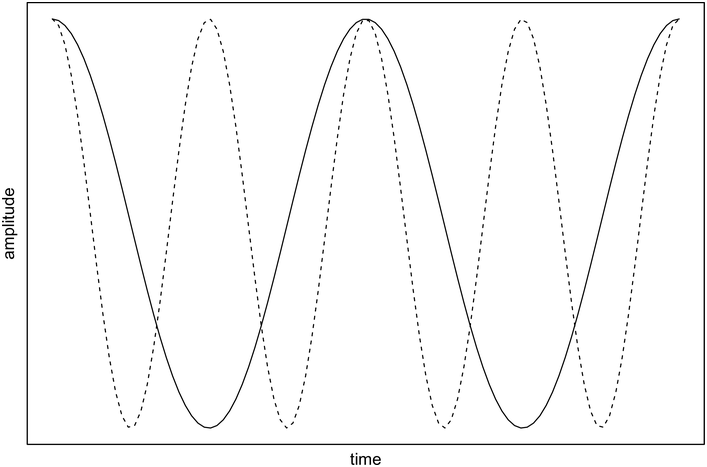
According to O’Dell and Nieminen (Reference O’Dell and Nieminen1999), languages differ in which oscillator dominates as regards timing. In so-called stress-timed languages, the inter-stress oscillator would be the most dominant; thus, as the number of syllables increases in a stress group, the inter-stress oscillator tends to preserve its natural frequency and imposes frequency (and thus durational) changes on the syllabic oscillator. The opposite would be true in so-called syllable-timed languages.
In O’Dell and Nieminen’s (Reference O’Dell and Nieminen1999) model, the relative oscillator strength parameter, r, can be estimated as the ratio of the intercept a (which reflects stress-level timing influence) to the slope b (which reflects the duration due to additional syllables in the inter-stress interval); thus: r = a/b. If r > 1, the stress oscillator dominates, whereas if r ≤ 1, the syllabic oscillator dominates. O’Dell and Nieminen (Reference O’Dell and Nieminen1999) applied the oscillator strength parameter to Dauer’s (Reference Dauer1983) data, as reanalysed in Eriksson (Reference Eriksson1991), with the addition of data from Finnish. The r parameter value (r = a/b) classified languages in accordance with Eriksson (Reference Eriksson1991).
O’Dell and Nieminen (Reference O’Dell and Nieminen2009) discuss ‘polysyllabic shortening’, the postulated inverse relationship between the number of syllables in some constituent and the duration of syllables therein (e.g., Lehiste, Reference Lehiste1972; see, for example, Guba et al., Reference Guba, Mashaqba and Huneety2023, for a recent study on Modern Standard Arabic). O’Dell and Nieminen take polysyllabic shortening (across the inter-stress interval) as a reflection of the interaction between syllabic and inter-stress oscillators. Evidence for polysyllabic shortening is reported, for example, in Kim and Cole (Reference Kim and Cole2005), where stressed syllable durations were shorter as the size of the stress group increased in English (see also, for example, Lehiste, Reference Lehiste1972, regarding word-level polysyllabic shortening). Importantly, however, the coupled oscillators model does not hinge on the assumption of isochronous speech units; rather, compressibility effects only reflect hierarchical nesting, that is, the influence of higher prosodic units on the timing of lower prosodic units and vice versa (see Malisz et al., Reference Malisz, O’Dell, Nieminen and Wagner2016; White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020).
Despite some success in coupled oscillator modelling of such timing effects, it has been argued that observed temporal compression, as is implied by polysyllabic shortening, may be reinterpreted in terms of localised lengthening effects (e.g., Beckman, Reference Beckman, Tohkura, Vatikiotis-Bateson and Sagisaka1992; White, Reference White2002; White and Turk, Reference White and Turk2010). For example, Port (Reference Port1981) reported polysyllabic shortening of stressed syllables such as dib in nonsense sequences like dib … dibber … dibberly. It is important to note, however, that all tokens in this study were realised as the only new material in a fixed carrier phrase: ‘I said [target word] again’. In this (English language) context, the targets will clearly carry phrasal stress (pitch accent), which causes lengthening of constituents within the stressed word (e.g., Cambier-Langeveld and Turk, Reference Cambier-Langeveld and Turk1999; Turk and White, Reference Turk and White1999). The degree of phrasal-stress lengthening of lexically stressed syllables has been shown to vary inversely with word length, with some of the additional length being evidenced on unstressed syllables in disyllabic and trisyllabic words (Turk and White, Reference Turk and White1999; White and Turk, Reference White and Turk2010). Thus, what may appear as polysyllabic shortening can be reinterpreted as due to the redistribution of phrasal-stress lengthening according to word length (White, Reference White2002, Reference White2014; see Beckman, Reference Beckman, Tohkura, Vatikiotis-Bateson and Sagisaka1992, for similar observations with regard to polysyllabic shortening and phrase-final lengthening).
Thus, whilst the coupled oscillators model captures hypothesised timing influences between prosodic units, the implied compressibility effects may not be supported by empirical observations. Rather, prosodic influence on speech timing primarily entails lengthening effects at domain heads (i.e., prominent constituents, such as stressed syllables and pitch-accented words) and edges (i.e., boundaries between prosodic constituents), with distribution and magnitude varying according to language-specific characteristics (for reviews, see Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010; White, Reference White2014; White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020).
There remain, however, aspects of the coupled oscillators model that appear potentially useful in accounting for timing patterns in circumscribed speech contexts, such as in synchronised speech or speech cycling, as discussed below. Next, we consider how phase relations between hierarchical temporal units may offer an account of certain forms of observed timing variation.
31.3 Temporal Coordination between Different Rhythmic Timescales
Our aim in this section is to show that temporal phase relations may modulate the interaction between hierarchical units in synchronised speech or other constrained speech tasks, in particular, speech cycling (Cummins and Port, Reference Cummins and Port1998). Furthermore, cross-linguistic variation in the performance of such tasks may be informative about the localised timing effects that are evident in natural speech.
Regarding synchronised speech, Cummins (Reference Cummins2003) showed that when two speakers read a text together, they synchronise their speech very effectively, often with minimal time lag (between 40 and 60 ms). Cummins further showed that the effect of synchronisation is not the result of one speaker following the speech rate of the other, as there was no consistent leader. Further work suggested that synchronisation is based on a range of suprasegmental sources of information, including fundamental frequency and amplitude envelope modulation, and is not wholly dependent on speech intelligibility (Cummins, Reference Cummins2009); these findings are interpreted as evidence for acoustically based ‘entrainment’ between speakers talking synchronously, although definitions of entrainment vary and typically involve phase-resetting between coupled systems of oscillators (see Obleser and Kayser, Reference Obleser and Kayser2019, for a discussion), which are not precisely defined in Cummins’ account (see Chapter 14 for a discussion of the nature of entrainment with regard to speech).
Speech cycling represents another case of temporal coordination between a speaker and an external stimulus (e.g., Port et al., Reference Port, Cummins and Gasser1995). In speech cycling tasks, speakers repeat phrases to coordinate with metronome beeps, typically starting each new repetition of a phrase synchronously with a beep. The interval between repetition onsets is called the phrase repetition cycle (PRC). It is shown that acoustically salient points, namely stressed vowel onsets, tend to lie at certain privileged phases within the PRC (Figure 31.2). These phases typically divide the PRC into simple integer ratios, such as 1:3, 1:2, and 2:3, reflecting metrical structure within the PRC. These simple ‘phase angles’ (‘harmonic phases’) are said to be attractors for prominence in the PRC that emerge from task constraints, specifically, repeating sentences at a constant period; thus, the organisation of stress beats at privileged time intervals within the PRC reflects a hierarchical structure wherein the lower-level prosodic units, that is, stressed vowel onsets, are nested within a higher-level unit, that is, the PRC (Cummins and Port, Reference Cummins and Port1998).
Schematic representation of speech cycling task.
Interval a, defined as the interval from the first stressed syllable to the final stressed syllable, is divided by interval b – the PRC – to calculate the phase angle of the final stress. Here, the final stress is the second stress of the phrase; in some speech cycling tasks, there are three or more stressed syllables per phrase.
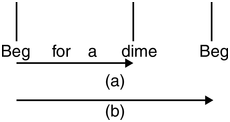
Languages appear to vary in the propensity for speakers to align prominent syllables at metrically important points within the PRC. For example, Cummins (Reference Cummins2002) asked English, Spanish, and Italian speakers to read sentences with two stressed syllables, each followed by an unstressed syllable, and to align the first stressed syllable to a high-tone beep and the second stressed syllable to a low-tone beep. English speakers found the task of metrical coordination easy to perform and showed close and consistent alignment with simple harmonic phases. On the other hand, Italian and Spanish speakers found it more difficult, even after more than 30 minutes of practice, and phase alignment was not close to simple harmonic phase angles. Cummins’ explanation of the easier performance of English speakers referred to the greater salience of stress feet in English than in Italian and Spanish.
Another (alternative or complementary) explanation for these reported cross-linguistic differences in the propensity for speech cycling (Cummins, Reference Cummins2002) may lie in variation in the magnitude of durational contrast between strong and weak syllables. English is known to have a high durational contrast between stressed and unstressed syllables, in part due to a substantial lengthening of (lexically and phrasally) stressed syllables and vowel reduction of unstressed syllables (e.g., Oller, Reference Oller1973; Klatt, Reference Klatt1976). On the other hand, the degree of durational contrast between strong and weak syllables in Italian and Spanish appears lower (than in, for example, English), with lower stress-related lengthening, especially for Spanish, and limited vowel reduction in unstressed syllables (Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002; White and Mattys, Reference White and Mattys2007). The placement of metronome beeps at simple phases – in particular, at the desired phrase onset – leads to the emergence of prominence attractors (Cummins and Port, Reference Cummins and Port1998); therefore, the close alignment of stressed syllables to regular metronome beats is more natural in a language such as English, where stress contrast is high, than in languages with lower stress contrast (e.g., Spanish and Italian). The lower stress contrast in the latter languages tends to make prominences (stressed syllables) less acoustically salient and thus implies less compelling coordination of prominences with attractors; in other words, strong stress contrast affords temporal coordination with regular metronome beats. (Note: this interpretation by no means denies the obvious fact that stress per se is highly salient for speakers of languages such as Spanish, which actually has many more stress-based minimal word pairs than English, but simply suggests that there may be less natural affordance for acoustically based temporal coordination of prominences.)
Zawaydeh et al. (Reference Zawaydeh, Tajima, Kitahara, Parkinson and Benmamoun2002) compared the speech cycling performance of speakers of American English to those of Jordanian Arabic, finding that the English speakers tended to align stressed syllables closer to a simple phase of 1:2 than Arabic speakers (who tended to have later alignment). The vowel reduction of unstressed syllables in Jordanian Arabic is of lower magnitude than English; that is, stressed and unstressed syllables have more similar durations in Jordanian Arabic (Vogel et al., Reference Vogel, Athanasopoulou, Pincus and Ouali2017); thus, by the same argument as for Spanish and Italian (above), there is a lower affordance for alignment of stressed syllables to simple phases in Jordanian Arabic.
Similarly, Ghadanfari (Reference Ghadanfari2022) found dialectal differences in speech cycling between two varieties of Kuwaiti Arabic, Bedouin and Hadari. Specifically, there were smaller phase alignment differences between heavy and light stressed syllables for Hadari speakers than Bedouin speakers. Vowel duration analysis showed that Hadari had greater unstressed syllable reduction than Bedouin. Ghadafari’s interpretation was that unstressed syllable reduction in Hadari leads to stronger stress contrast, which affords more consistent alignment with respect to the PRC.
Ghadanfari (Reference Ghadanfari2022) further showed that speech rate mediates temporal coordination: at shorter metronome periods, where speech rate is likely to be faster, stressed syllables were closer to simple phase angles. This potentially reflects changes in relative durations at faster speaking rate – such as the compression of unstressed syllables – promoting the harmonic alignment of stressed syllables (and see below regarding between-language variation in speech rate influences on phase angles).
Another factor that may promote alignment to simple phases in speech cycling is phonetic compressibility: as discussed by Klatt (Reference Klatt1973), segments may vary in duration according to context but tend to have a minimum duration below which they may not be compressed. The minimum duration of specific segments will depend not only on the manner and place of articulation but also on perceptual factors, that is, what is required to phonetically distinguish sounds within a specific language’s phonemic inventory (see White, Reference White2014, for discussion). Compressibility may also relate to prominence, in particular, whether languages have a high degree of durational stress contrast, with reduction and shortening, or even deletion, of unstressed vowels or whole syllables (such as in Standard Southern British English: e.g., Beckman, Reference Beckman, Otake and Cutler1996).
Tajima (Reference Tajima1999) examined how phase alignment in English and Japanese was affected by manipulation of metronome rate, from slow to fast. English speakers demonstrated consistent alignment of stressed vowel onsets with simple phase angles across different metronome rates, whilst Japanese speakers showed alignment of prominent syllables to incrementally distinct phase angles as metronome rate increased. It is plausible that the more consistent phase alignment in English may be facilitated through relative tolerance of unstressed syllable compression with increasing metronome rate. Note that, regarding the impact of speech rate on temporal coordination, Kuwaiti Arabic dialects behaved more like Japanese than like English, given that phase alignment changed with increased rate (Ghadanfari, Reference Ghadanfari2022). In Kuwaiti Arabic, however, increased rate did not lead to qualitative changes in phase alignment, as for Japanese; rather, in Kuwaiti Arabic, alignment moved closer to a harmonic phase angle with increasing rate. The compressibility of Kuwaiti unstressed syllables may thus be intermediate between those of Japanese and English, although the range of rate variation was higher in the Japanese task (>10 metronome rates (Tajima, Reference Tajima1999) versus three metronome rates in the Kuwaiti task (Ghadanfari, Reference Ghadanfari2022)).
In summary, speech cycling studies show differences between languages, and between dialects of a particular language, in temporal coordination, as evidenced by their differential propensity to generate simple, consistent phase angles of stressed syllable alignment within the phrase repetition angle. As discussed, a plausible interpretation of these cross-linguistic and cross-dialectal differences relates to variation in durational stress contrast. From a top-down perspective, more durationally marked (and thus acoustically more salient) stressed syllables (in languages such as English) are more strongly attracted to metrically stable positions in repeated phrases. From a bottom-up perspective, languages or dialects allowing substantial compression of unstressed syllables (for example, English, in contrast with, for instance, Spanish or Japanese) provide more scope for consistent phase alignment of the stressed syllables, regardless of perturbations due to phonetic content of phrases or variation in metronome rates.
31.4 Temporal Coordination in Natural Dialogues
The nature of temporal coordination in speech cycling, that is, the division of the PRC into simple phases, is clearly specific to the constrained task demands. However, the interaction between interlocutors in natural dialogue has also been suggested to reflect patterns of temporal coordination, as the timing characteristics of a dialogue partner’s speech are proposed to influence the timing of turn-taking of the other interlocutors (e.g., Wilson and Wilson, Reference Wilson and Wilson2005). In this final section, we consider potential commonalities in the timing factors influencing temporal coordination, particularly speech rate and local durational cues, in speech cycling and natural dialogues.
Research on temporal coordination in natural dialogues has focused on the fluent timing of turn transitions between speakers (e.g., Wilson and Zimmerman, Reference Wilson and Zimmerman1986; Couper-Kuhlen, Reference Couper-Kuhlen1993; Benuš, Reference Beňuš2009). The reportedly minimal gaps (suggested to average 200 ms across languages – for example, Stivers et al., Reference Stivers, Enfield and Brown2009; Heldner and Edlund, Reference Heldner and Edlund2010) and relatively rare overlaps in interlocutors’ turns implies adaptation to the current speaker’s rate and anticipation of their utterance termination (Wilson and Wilson, Reference Wilson and Wilson2005). Moreover, Wilson and Wilson suggested a predictive mechanism in conversational turn-taking by which listeners entrain to the syllable oscillation rate of the speaker; thus, to avoid overlap, listeners coordinate the onset of their turns in anti-phase relation to the speaker’s syllable rate.
A related, but distinct, perspective on turn-transition timing was provided in studies of overlapped (i.e., interrupted) conversational transitions (Włodarczak et al., Reference Włodarczak, Simko and Wagner2012a, Reference Włodarczak, Simko and Wagner2012b) using corpora of spontaneous speech of American English, German, and French. They first observed that the initiation of an interrupting turn showed a bias to occur at the end of a vowel-to-vowel (VTV) interval in the preceding speech. Using the normalised pairwise variability index (nPVI; Low et al., Reference Low, Grabe and Nolan2000) of VTV duration, they found that more regular VTV timing was associated – for English dialogues – with this predominant pattern of a late interruption point in the VTV interval (Włodarczak et al., Reference Włodarczak, Simko and Wagner2012a). Reinforcing their conclusions with analyses of French and German dialogues, they interpret this pattern as evidence that coordination of turn-timing is underpinned by temporal entrainment between speakers (Włodarczak et al., Reference Włodarczak, Simko and Wagner2012b). They additionally argue that such entrainment is, in particular, governed by the salient recurrence of the perceptual centre of syllables (p-centre) (Morton et al., Reference Morton, Marcus and Frankish1976; Marcus, Reference Marcus1981).
With regard to durational cues to utterance boundaries, it has long been demonstrated that localised final lengthening may contribute to the salience of phrase or utterance endings (e.g., Price et al., Reference Price, Ostendorf, Shattuck-Hufnagel and Fong1991). It appears surprising, therefore, that Hoogland et al. (Reference Hoogland, White and Knight2023) found that inter-speaker intervals in question-answer sequences in Dutch and English were longer with longer final rhymes. However, they also reported an interaction with articulation rate of the preceding utterance: thus, at faster rates, inter-speaker intervals were shorter when the final rhyme was relatively long. The interpretation of Hoogland et al. of this interaction related to potential listener entrainment to foregoing speaking rate: as segments are shorter at faster speaking rate, the relative length of phrase-final segments is boosted (see Dilley and Pitt, Reference Dilley and Pitt2010; Reinisch et al., Reference Reinisch, Jesse and McQueen2011; Morrill et al., Reference Morrill, Baese-Berk, Heffner and Dilley2015), thus providing a more salient cue to question termination. Thus, local timing cues to turn-ending may potentially be mediated by listener entrainment to the foregoing utterance, at least insofar as it is required to develop expectations regarding segment duration.
31.5 Summary, Future Research, and Conclusions
The review presented here considers various influences on speakers’ temporal coordination patterns in artificial tasks, such as speech cycling, and in natural dialogue turn-taking. Speech cycling indicates cross-linguistic variability in speakers’ propensity to coordinate the occurrence of stressed syllables within an external cycle, with some languages’ greater length of stressed syllables and greater compressibility of unstressed syllables both potentially contributing to the more consistent alignment of stresses with simple phase angles of the PRC (e.g., Tajima, Reference Tajima1999; Cummins, Reference Cummins2002; Ghadanfari, Reference Ghadanfari2022).
Regarding natural dialogue turn-taking, existing accounts point to relative consistency of mean turn-transition time between languages (e.g., Stivers et al., Reference Stivers, Enfield and Brown2009). There are relatively few analyses of the factors that influence the variation of turn-transition time around the reported mean; however, those that have analysed these point to influences of local timing factors towards the ends of utterances, potentially interacting with foregoing articulation rate (e.g., Włodarczak et al., Reference Włodarczak, Simko and Wagner2012a, Reference Włodarczak, Simko and Wagner2012b; Hoogland et al., Reference Hoogland, White and Knight2023). How cross-linguistic variation in local timing effects serves to mediate fluent turn-timing has been little explored to date, not least due to the difficulties of comparing between spontaneous corpora of distinct languages, elicited using different methods and often for distinct research goals.
This review has suggested that findings from artificial tasks, such as speech cycling, may point to influences on coordination in natural conversation. One potential focus of research relates to cross-linguistic and cross-dialectal differences in structural factors influencing coordination. It has been established that speech rate affects the interpretation of local timing cues that signal structure (e.g., word and phrase boundaries). Reinisch et al. (Reference Reinisch, Jesse and McQueen2011) showed that the perception of stress is modulated by speaking rate, with faster foregoing utterance rate increasing the likelihood of listeners perceiving stress contrast. As languages and dialects differ in the magnitude of durational stress contrast, it is worth investigating if speech rate variation differentially influences stress perception between languages and between dialects.
Future cross-linguistic research could likewise benefit from experimentally controlled tasks that probe the influence of specific timing cues on temporal coordination. For example, paradigms requiring coordination of speech with movement (e.g., Allen, Reference Allen1972a, Reference Allen1972b; Rathcke et al., Reference Rathcke, Lin, Falk and Bella2021) offer a means of limiting cross-linguistic task variation in the interests of discerning how native language experience affects listeners’ temporal coordination behaviour. Likewise, artificial language tasks can manipulate timing cues whilst keeping segmental stimuli consistent between languages (e.g., White et al., Reference White, Benavides-Varela and Mády2020).
It is obvious that speakers of all languages are skilled at coordinating the flow of conversation. Artificial speech-based coordination tasks may be an effective means of unpicking the diverse cues that listeners use to achieve such interactional fluency.
Summary
Languages vary in their distribution and realisation of prominent versus less prominent syllables, and in the magnitude of local timing processes such as phrase-final lengthening. These timing differences influence speakers’ performance on temporally constrained artificial tasks such as speech cycling, and may have implications for the coordination of natural conversation.
Implications
It is obvious that speakers of all languages are skilled at coordinating the flow of conversation, but the mechanisms by which this temporal coordination is achieved remain unclear. Artificial speech-based coordination tasks may represent an effective means of unpicking the diverse cues that listeners use to achieve such interactional fluency.
Gains
Making cross-linguistic comparisons of speech timing is challenging given the diversity of structural and realisational differences. The degree to which speakers consistently coordinate prominent syllables within an externally imposed cycle in laboratory tasks is informative about the magnitude of stronger versus weaker syllable contrasts, and – potentially – about temporal coordination in conversation.
32.1 Introduction
32.1.1 Background
Psychological experiments have long shown that when humans hear stimuli sequences alternating in duration or intensity, they tend to group them as iambs (short-long) and trochees (loud-soft), respectively (Bolton, Reference Bolton1894; Woodrow, Reference Woodrow1909). The effect of intensity and duration on grouping biases is known as the iambic–trochaic law (henceforth ITL). It is said to reflect universal cognitive tendencies that lead to subjective rhythmisation and, according to Hayes (Reference Hayes1985, Reference Hayes1995), shape the typology of linguistic stress and consequently rhythm (for alternative views, see Fuchs (Chapter 30) and Barros et al. (Chapter 34)). In particular, Hayes (Reference Hayes1985, Reference Hayes1995) has argued that in unmarked cases, alternating stress will group syllables in accordance with the ITL, and should favour iambs when feet are sensitive to quantity and the positions of heavy syllables (see Hyde, Reference Hyde, van Oostendorp, Ewen, Hume and Rice2011, for a review of the ITL in phonology). The ITL is also said to play a role in language acquisition, as newborn infants exhibit perceptual biases towards the predominant grouping of their native language (e.g., Allen, Reference Allen1975; Abboub et al., Reference Abboub, Nazzi and Gervain2016; Molnar et al., Reference Abboub, Nazzi and Gervain2016). Finally, the ITL is also said to have a hand in processing music (e.g., Drake and Bertrand, Reference Drake and Bertrand2001; Hannon and Trehub, Reference Hannon and Trehub2005; see Crowhurst, Reference Crowhurst2020, for a review).
Recent experimental studies, however, indicate that grouping preferences are not always easy to elicit, resulting in responses that remain only slightly above chance and rarely exceed 70% (Hay and Diehl, Reference Hay and Diehl2007; Iversen et al., Reference Iversen, Patel and Ohgushi2008; Bhatara et al., Reference Bhatara, Boll-Avetisyan, Unger, Nazzi and Höhle2013; Crowhurst and Teodocio, Reference Crowhurst and Teodocio2014). Studies also report asymmetries, with preferences for trochees in response to intensity alternations being stronger and more consistent than duration-based preferences for iambs (Trainor and Adams, Reference Trainor and Adams2000; Iversen et al., Reference Iversen, Patel and Ohgushi2008; de la Mora et al., Reference de la Mora, Nespor and Toro2013; Crowhurst, Reference Crowhurst2016; Crowhurst et al., Reference Crowhurst, Kelly and Teodocio2016; Molnar et al., Reference Molnar, Carreiras and Gervain2016). Finally, responses may be shaped by experience, including musicality (Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara and Höhle2017) and exposure to an L2 (Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara, Unger, Nazzi and Höhle2016), but mostly relating to L1 (first-language) prosody, such as a language’s dominant stress pattern (Crowhurst and Teodocio, Reference Crowhurst and Teodocio2014), the presence of significant pre-boundary lengthening (Molnar et al., Reference Molnar, Carreiras and Gervain2016), and the position of the phrase head (Iversen et al., Reference Iversen, Patel and Ohgushi2008). For instance, unlike native English speakers, Japanese and Zapotec speakers group stimuli alternating in duration into trochees (Iversen et al., Reference Iversen, Patel and Ohgushi2008; Crowhurst and Teodocio, Reference Crowhurst and Teodocio2014, respectively). Cross-linguistic differences also apply to the strength of agreement among participants: in Iversen et al. (Reference Iversen, Patel and Ohgushi2008), Japanese participants agreed less with each other than English participants; similarly, in Bhatara et al. (Reference Bhatara, Boll-Avetisyan, Unger, Nazzi and Höhle2013), French participants agreed less with each other than German participants.
Cross-study discrepancies may be also due to experimental manipulations: responses to linguistic stimuli are more influenced by the participants’ native language (Crowhurst, Reference Crowhurst2016; Molnar et al., Reference Molnar, Carreiras and Gervain2016), while studies using large ratios between alternating stimuli yield stronger preferences (cf., Iversen et al., Reference Iversen, Patel and Ohgushi2008, versus Hay and Diehl, Reference Hay and Diehl2007). Here, we explore possible reasons for such disparities by means of two experiments with native speakers of English, Greek, and Korean.
32.1.2 Prosodic Features of the Tested Languages and Related Predictions
English is a stress accent language (Beckman, Reference Beckman1986). Stressed syllables are hyperarticulated (leading to changes in segmental quality, duration, and intensity), while unstressed syllables are markedly reduced (de Jong, Reference de Jong1995). Stressed syllables are often (but not necessarily) accompanied by changes in pitch as the outcome of intonation (Ladd, Reference Ladd2008). In English, most content words start with a stressed syllable (Cutler and Carter, Reference Cutler and Carter1987; Clopper, Reference Clopper2002; Ernestus and Neijt, Reference Ernestus and Neijt2008), a pattern exploited in perception (e.g., Donselaar et al., Reference Donselaar, Koster and Cutler2005). Stress adjustments, such as the rhythm rule, lead to trochees and a regular alternation of strong and weak metrical constituents (Hayes, Reference Hayes1995), for example, Chìnése éxpert > Chínèse éxpert. In short, English speakers are used to hearing trochees based on large acoustic differences between stressed and unstressed syllables. They are also sensitive to longer duration being associated with phrase-finality (e.g., Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2000; Fletcher, Reference Fletcher, Hardcastle, Laver and Gibbon2010; among many; cf., Iversen et al., Reference Iversen, Patel and Ohgushi2008). Based on the above, we expected English participants to show a preference for trochees and, given the preponderance of trochees in the language, we expected that only large differences in duration would override this preference and lead to iambic grouping.
Greek has stress accent (Arvaniti, Reference Arvaniti2000). Stressed syllables are longer and louder, but the vowels of unstressed syllables are not significantly centralised (Fourakis et al., Reference Fourakis, Botinis and Katsaiti1999; see Arvaniti, Reference Arvaniti2007, for a review). Each word, independently of length, has one stress on one of the last three syllables (Revithiadou and Lengeris, Reference Revithiadou, Lengeris, Heinz, Goedemans and van der Hulst2016).Footnote 1 Penultimate stress is the dominant pattern (approximately 45% of words with two or more syllables have penultimate stress; Protopapas, Reference Protopapas2006), giving rise to frequent trochees. Greek speakers are sensitive to lexical stress during processing (Arvaniti and Rathcke, Reference Arvaniti and Rathcke2015; Protopapas et al., Reference Protopapas, Panagaki, Andrikopoulou, Gutiérrez Palma and Arvaniti2016). Phrase-final lengthening is limited (Arvaniti, Reference Arvaniti2007). In short, Greek speakers are not used to stress-based binary alternations at phrase level but are accustomed to a preponderance of trochees at word level. Based on the above, we expected Greek participants to show a preference for trochees with both intensity and summation sequences, which reflect the integral of duration and intensity (see Section 32.1.3 for details), and a weak preference for iambs with duration sequences, since iambic patterns are not frequently found in the language.
Seoul Korean (the standard variety) has neither lexical stress nor lexical pitch accent (Jun, Reference Jun and Jun2005). Its accentual phrase (AP) is primarily demarcated by the pitch contour (see Jun, Reference Jun and Jun2005, and Jeon, Reference Jeon, Brown and Yeon2015, for reviews). APs are on average 3.2 syllables long and contain on average 1.2 content words, often followed by particles that do not undergo phonetic reduction (Jun and Fougeron, Reference Jun, Fougeron and Botinis2000). The articulation of domain-initial consonants gets stronger at higher levels of the prosodic hierarchy, a phenomenon known as ‘articulatory strengthening’ (Cho and Keating, Reference Cho and Keating2001; Keating et al., Reference Keating, Cho, Fougeron, Hsu, Local, Ogden and Temple2004). It is not clear, however, that articulatory strengthening leads to greater intensity (Cho and Keating, Reference Cho and Keating2001). Domain-final lengthening, on the other hand, is extensive at the intonational phrase level (see Jeon, Reference Jeon, Brown and Yeon2015, for a review) and listeners exploit it for speech segmentation (Jeon and Arvaniti, Reference Jeon and Arvaniti2017). As native Korean speakers show uncertainty in detecting metrical prominence (Lim, Reference Lim2001; Guion, Reference Guion2005) and the intensity cues to the AP are unreliable, they may not show strong grouping preferences with respect to the intensity and summation sequences that reflect metrical strength differences; on the other hand, Korean speakers should prefer iambs with duration sequences, since long duration is a strong group-final cue in Korean.
32.1.3 Experimental Manipulation and Hypotheses
Our hypotheses relate to language-specific influences, discussed in Section 32.1.2, and experimental manipulations that would apply in the absence of language-related differences among groups. Our manipulations are listed below.
First, we used complex tones with three harmonic components and manipulated their duration, intensity, and summation. In the summation sequences, decreases in duration were compensated for by concomitant increases in intensity (see Section 32.2.1.2). This manipulation was based on the observation that amplitude and duration are perceptually integrated, so that a shorter stimulus sounds softer than a longer stimulus of equal average intensity (e.g., Woodrow, Reference Woodrow1909; Beckman, Reference Beckman1986; Moore, Reference Moore2012). There are indications that temporal summation may affect ITL responses: Bolton (Reference Bolton1894) found that sequences in which short but loud sounds alternated with long but soft sounds resulted in a preference for trochees (cf., Crowhurst and Teodocio, Reference Crowhurst and Teodocio2014). Crucially, temporal summation suggests that typical manipulations of duration in ITL experiments – in which intensity stays intact – lead to the longer elements sounding not only longer but also louder. The summation manipulation used here aimed at minimising the auditory boost provided by intensity. If alternating elements in duration sequences must sound both longer and louder to elicit iambic responses, then we would expect typical duration sequences to yield stronger iambic preferences than summation sequences.
Second, we included two inter-stimulus interval (ISI) conditions, such that the duration of the silent interval between tones was either 20 ms (as in Iversen et al., Reference Iversen, Patel and Ohgushi2008) or 200 ms (as in Hay and Diehl, Reference Hay and Diehl2007). Hay and Diehl (Reference Hay and Diehl2007) did not find cross-linguistic differences, while Iversen et al. (Reference Iversen, Patel and Ohgushi2008) did. The difference could be due to the short ISI being temporally more similar to running speech. This is supported by studies using successions of syllables without breaks in between, which also report cross-linguistic differences (e.g., Crowhurst, Reference Crowhurst2016). Thus, we expected to find greater cross-linguistic differences with short ISI.
The third manipulation related to steps, that is, the stepwise increase in acoustic contrast between the alternating tones in a sequence. Based on previous work (e.g., Woodrow, Reference Woodrow1909; Iversen et al., Reference Iversen, Patel and Ohgushi2008; Bhatara et al., Reference Bhatara, Boll-Avetisyan, Unger, Nazzi and Höhle2013; Crowhurst, Reference Crowhurst2016), we anticipated stronger preferences with increased differences between tones.
32.2 Experiment 1
32.2.1 Methods
32.2.1.1 Participants
The analysis is based on responses from 28 speakers of Southern Standard British English (13 females; age mean = 20.27, sd = 1.79), 25 speakers of Athenian Greek (19 females; age mean = 24.08, sd = 4.97), and 30 speakers of Seoul Korean (16 females; age mean = 24.67, sd = 4.25). The data of 13 participants (10 English, two Greek, one Korean) who did not meet the recruitment criteria (e.g., they turned out to be early bilinguals or had language impairments) were excluded. British participants had limited exposure to languages other than English. Greeks and Koreans had learnt at least one other language (mostly English) through formal instruction, as is the norm in Greece and South Korea, respectively. However, none had prolonged contact (> six months) with any language other than their L1. No participants had professional musical training or reported problems with speaking, hearing, or motor control. All participants gave informed consent and were modestly remunerated.
32.2.1.2 Stimuli and Experimental Procedures
The stimuli were sequences of complex tones involving a ‘standard’ alternating with a ‘comparison’ (see Figure A, Supplementary Materials, at https://osf.io/sw3c5/). The tones were generated in Praat (Boersma and Weenink, Reference Boersma and Weenink2014) with a 44.1 kHz sampling rate. As shown in (1), the standard was a complex tone of 200 ms duration and 65 dB intensity, with a rise time of 15 ms, composed of the fundamental frequency (f0) (250 Hz) and the next two odd harmonics.
(1) 1/2 × (sin(2 × pi × 250 × x) + sin(2 × pi × 750 × x) + sin(2 × pi × 1250 × x))
The comparison tones differed from the standard in duration, intensity, or their summation, as shown in Table 32.1. For summation sequences, decreases in duration were compensated for by increases in intensity, using an approximate -3 dB slope for the doubling of duration (Moore, Reference Moore2012). This set-up resulted in five types of tone sequences per acoustic parameter: sequences in which standards alternated with a comparison step, and sequences of standards (controls). Controls were included to investigate grouping biases (see Hay and Diehl, Reference Hay and Diehl2007; Crowhurst, Reference Crowhurst2018).
Acoustic parameters of comparison tones for Intensity (I), Duration (D), and Summation sequences (S) for Steps 1–4 in Experiment 1; f0 was held constant at 250 Hz. The standard (Step 0) was 200 ms in duration, with 65 dB intensity. Items in bold were used in Experiment 2 as well (see Section 32.3.1)
| Duration (ms) | Intensity (dB) | Duration (ms) | Intensity (dB) | Duration (ms) | Intensity (dB) | |||
|---|---|---|---|---|---|---|---|---|
| I1 | 200 | 62 | D1 | 175 | 65 | S1 | 175 | 65.8 |
| I2 | 200 | 59 | D2 | 150 | 65 | S2 | 150 | 66.6 |
| I3 | 200 | 56 | D3 | 125 | 65 | S3 | 125 | 67.4 |
| I4 | 200 | 53 | D4 | 100 | 65 | S4 | 100 | 68.2 |
The ISI manipulation created an ‘ISI-Short’ (ISI = 20 ms) and an ‘ISI-Long’ (ISI = 200 ms) condition. Each sequence was 11–12 s long. To reduce order effects (due to sequences starting or ending in a prominent tone), the intensity in each sequence was gradually increased according to a raised cosine function over the first 2.5 s and decreased over the last 2.5 s. Additionally, for each step, both sequences starting with the standard and ending with the comparison tone and sequences starting with the comparison and ending with the standard were used (referred to below as the ‘standard-comparison order’). Finally, two practice stimuli were constructed per sequence type, using larger differences between standard and comparison.
The stimuli were presented in three blocks (Duration, Intensity, and Summation) in counterbalanced order across participants, resulting in six block orders. Each block started with a practice session of eight trials (two steps × two ISIs × two standard-comparison orders) followed by the test session. Each test session included 54 trials: 48 test trials (four steps × two ISIs × two standard-comparison orders × three repetitions) and six controls (two ISIs × three repetitions), for a total of 162 trials. Trial order was pseudo-randomised per participant so the same sequence was not heard twice in a row.
The experiment ran on DMDX. Participants were tested individually in a quiet room using the same laptop and headphones. Before the experiment, the participants’ hearing was tested by examining whether they could detect a 250 Hz tone of 200 ms duration at 25 dB. All participants passed the test.
Participants were told they would hear tone sequences lasting approximately 10 seconds each. They had to decide how the tones were grouped by selecting one of two pictures, presented to them in counterbalanced order across trials and used to minimise cross-linguistic differences in how terms such as short, long, soft, and loud are expressed and understood (see Figure B, Supplementary Materials, at https://osf.io/sw3c5/; see Bhatara et al., Reference Bhatara, Boll-Avetisyan, Unger, Nazzi and Höhle2013). Iambs were illustrated with two repetitions of a small circle followed by a large circle in a group, trochees by the reverse circle order.
After listening to each stimulus, participants pressed a labelled key on the keyboard to indicate their choice. Choice order was counterbalanced across trials. Following Iversen et al. (Reference Iversen, Patel and Ohgushi2008), participants could respond only after they heard the entire tone sequence. Upon registering their response, the experiment automatically proceeded to the next screen, where participants rated their confidence (3 = completely certain; 2 = somewhat certain; 1 = guessing). If they thought they had chosen the wrong grouping, they could press 0 instead of rating their confidence level. The experiment was self-paced.
After the experiment, the participants completed questionnaires on their musical training and linguistic background. The linguistic background questionnaire was adapted from LEAP-Q (the Language Experience and Proficiency Questionnaire; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) to fit linguistic and cultural expectations of each group. The questionnaires were used to ensure that participants did not have extensive exposure to an L2 or musical training to a professional standard. All instructions and questionnaires were in the speakers’ native language and administered by research assistants who were native speakers of that language.
32.2.2 Results
The experiment yielded 13,446 data points (83 participants × 162 trials) of which 13,373 (English, N = 4496; Greek, N = 4037; Korean, N = 4840) were analysed. The other 73 data points were removed (English, N = 40; Greek, N = 13; Korean, N = 20), as participants had pressed 0 to indicate their choice was invalid. The differences in confidence ratings were minimal, and the only clear trend was that ratings increased along the steps (see supplementary Table A at https://osf.io/sw3c5/). Thus, no data were excluded based on the confidence score.
Mixed-effect logistic models were fitted to the response data using the glmer function in the lme4 package (Bates et al., Reference Bates, Maechler, Bolker and Walker2015b) with R version 3.5.1 (R Core Team, 2018). The models estimated the maximum likelihood of the positively coded trochee response (0: iamb, 1: trochee). Separate models were fit to the data based on STIMULUS TYPE (Intensity, Duration, Summation); each model included LANGUAGE (English, Greek, Korean), ISI (Short, Long), and STEP as predictors. STEP was coded as a continuous variable ranging from 0 to 4 to examine the trend in responses associated with the change of one Step; step 0 corresponded to the control sequences.
We started with the simplest model, which included the aforementioned predictors and random intercepts for participants; interactions and random slopes for ISI and STEP were subsequently added (Bates et al., Reference Bates, Kliegl, Vasith and Baayen2015a). The effects of these were determined by model comparison (anova function, p < 0.05*, p < 0.01**, p < 0.001***). When a convergence error occurred, we used the allFit() function (package optimx, Nash and Varadhan, Reference Nash and Varadhan2011) to check whether all optimisers produced similar values. In identifying the best-fitting model, we added an interaction term to the model only when it significantly improved the model fit from a lower-order model and also referred to the AIC (Akaike information criterion) value. Lower AIC values indicate a better fit.Footnote 2 Below, we focus only on predictors that were statistically significant. Due to space limitations, the figures are provided as online supplementary materials (see Figures C1–C3, https://osf.io/sw3c5/). The model outputs are summarised in Table 32.2.
Experiment 1, best-fitting model summary for Intensity (n = 4460, AIC = 6005.1, PARTICIPANT with random slopes for ISI), Duration (n = 4456, AIC = 5911.6, PARTICIPANT with random slopes for STEP and ISI), and Summation (n = 4455, AIC = 5953.4, PARTICIPANT with random slopes for ISI). Reference level: Language-English, ISI-Short, and Step-Control (0).
| est. | SE | z | p | ||
|---|---|---|---|---|---|
| Intensity | Intercept | −0.19 | 0.12 | −0.16 | 0.87 |
| Step | −0.01 | 0.02 | −0.61 | 0.54 | |
| Language-Greek | 0.23 | 0.14 | 1.64 | 0.1 | |
| Language-Korean | 0.13 | 0.13 | 0.97 | 0.33 | |
| ISI-Long | 0.33 | 0.09 | 3.6 | < 0.001*** | |
| Duration | Intercept | 0.26 | 0.15 | 1.73 | 0.08 |
| Step | −0.20 | 0.04 | −5.18 | < 0.001*** | |
| Language-Greek | −0.06 | 0.20 | −0.30 | 0.76 | |
| Language-Korean | 0.38 | 0.19 | 2.02 | 0.04* | |
| ISI-Long | 0.07 | 0.18 | 0.36 | 0.72 | |
| ISI-Long × Language-Greek | 0.38 | 0.27 | 1.43 | 0.15 | |
| ISI-Long × Language-Korean | −0.06 | 0.25 | −0.25 | 0.80 | |
| Summation | Intercept | 0.16 | 0.15 | 1.06 | 0.29 |
| Step | −0.13 | 0.04 | −3.17 | < 0.01** | |
| Language-Greek | 0.25 | 0.23 | 1.13 | 0.26 | |
| Language-Korean | 0.01 | 0.21 | 0.05 | 0.96 | |
| ISI-Long | 0.23 | 0.17 | 1.33 | 0.18 | |
| Step × Language-Greek | −0.07 | 0.06 | −1.09 | 0.28 | |
| Step × Language-Korean | 0.11 | 0.06 | 1.91 | 0.06 | |
| ISI-Long × Language-Greek | 0.39 | 0.25 | 1.54 | 0.12 | |
| ISI-Long × Language-Korean | −0.04 | 0.24 | −0.15 | 0.88 |
Significance codes: p < 0.05*, p < 0.01**, p < 0.001***.
For Intensity, only ISI (est. = 0.33, p < 0.001) reached statistical significance: participants were more likely to choose trochees for ISI-Long than ISI-Short, for which responses were around chance level in all Steps and for all languages (see Figure C1). For Duration, STEP was significant, with increasingly larger differences between the standard and comparison leading to decreases in trochaic responses (est. = −0.20, p < 0.001). However, the iambic grouping preference was shown only for Step 4 for English and Greek participants (see Figure C2). Korean participants showed an overall preference for trochees (est. = 0.38, p < 0.04), which waned as Step increased. For Summation, only STEP was significant, such that increasingly larger differences between the standard and comparison led to decreases in trochaic responses (est. = −0.13, p < 0.01), though not to a switch to iambs (see Figure C3).
32.2.3 Interim Discussion
The results weakly support the ITL as well as our prediction of a diminished effect of duration when counterbalanced by amplitude changes in the Summation sequences. The results partially support our prediction that preferences would be stronger with larger acoustic differences between standard and comparison; this applied particularly with the Duration sequences. On the other hand, short ISI did not lead to the hypothesised stronger and language-based preferences. However, Language did have an effect: the English and Greek participants, as expected, showed a preference for iambs with the Duration sequences (with Step 4, 100 ms in Figure C2), while Korean participants, against our predictions, did not.
These results are not as striking as those of earlier studies (e.g., Iversen et al., Reference Iversen, Patel and Ohgushi2008, or Crowhurst, Reference Crowhurst2016), even when the stimuli were comparable. A possible reason could be that our experiment lasted approximately an hour and may have fatigued participants or led to habituation. To address this issue, we conducted Experiment 2, which included only sequences with the larger acoustic contrasts from Experiment 1 (Steps 3 and 4).
32.3 Experiment 2
32.3.1 Methods
Recruitment criteria and methods were the same as in Experiment 1. Below, we present only changes made to the experiment.
32.3.1.1 Participants
The results are based on responses from 36 English (19 females; age mean = 23.36, sd = 4.58), 39 Greek (19 females; age mean = 24.03, sd = 3.33), and 35 Korean participants (20 females; age mean = 22.47, sd = 2.64). Data from an additional 15 participants (five English, two Greek, eight Korean) who did not meet the recruitment criteria were discarded.
32.3.1.2 Stimuli and Experimental Procedures
Experiment 2 included the same controls (Step 0) as Experiment 1, plus Steps 3 and 4 of Experiment 1, referred to here as Steps 1 and 2, respectively (see Table 32.1).
The procedures were the same as in Experiment 1 except for two points: Experiment 2 was conducted using PsychoPy version 1.83.01, and participants could change their grouping choice, if they wished, before answering the confidence-rating question. There were 24 practice trials (three sequence types × two steps × two ISIs × two standard-comparison orders). In the main experiment, there were in total 90 trials, 72 test trials (three sequence types × two steps × two ISIs × two standard-comparison orders × three repetitions) and 18 controls (three sequence types × two ISIs × three repetitions). The experiment lasted approximately 30 minutes.
32.3.2 Results
The analysis is based on 9,770 data points; there were 130 missing responses (English, N = 99; Greek, N = 11; Korean, N = 20), yielding 3,141 data points for English, 3,499 for Greek, and 3,130 for Korean. Differences in confidence ratings were minimal across conditions and languages (see supplementary Table B, at https://osf.io/sw3c5/). Thus, no data were excluded based on the confidence score. The modelling procedure was the same as in Experiment 1. The model outputs are summarised in Table 32.3 (see also supplementary Figures D1–D3, at https://osf.io/sw3c5/).
Experiment 2, the best-fitting model summary for Intensity (n = 3255, AIC = 4252), Duration (n = 3250, AIC = 4004.3), and Summation (n = 3265, AIC = 4201.3); for all models, PARTICIPANT with random slopes for ISI and Step. Reference level: Language-English, ISI-Short, and Step-0.
| est. | SE | z | p | ||
|---|---|---|---|---|---|
| Intensity | Intercept | 0.10 | 0.18 | 0.55 | 0.58 |
| Step | −0.13 | 0.13 | −1.05 | 0.29 | |
| Language-Greek | −0.40 | 0.24 | −1.64 | 0.10 | |
| Language-Korean | 0.22 | 0.25 | 0.88 | 0.38 | |
| ISI-Long | 0.38 | 0.13 | 2.93 | < 0.01** | |
| Step × Language-Greek | 0.54 | 0.18 | 3.06 | < 0.01** | |
| Step × Language-Korean | −0.11 | 0.18 | −0.59 | 0.56 | |
| Duration | Intercept | −0.11 | 0.24 | −0.46 | 0.64 |
| Step | −0.61 | 0.16 | -3.94 | < 0.001*** | |
| Language-Greek | −0.09 | 0.33 | −0.29 | 0.77 | |
| Language-Korean | 0.70 | 0.35 | 2.00 | < 0.05* | |
| ISI-Long | −0.21 | 0.35 | −0.6 | 0.55 | |
| Step × Language-Greek | 0.68 | 0.21 | 3.31 | < 0.001*** | |
| Step × Language-Korean | 0.05 | 0.21 | 0.23 | 0.81 | |
| Step × ISI-Long | 0.32 | 0.20 | 1.65 | 0.10 | |
| ISI-Long × Language-Greek | 2.06 | 0.49 | 4.23 | < 0.001*** | |
| ISI-Long × Language-Korean | 0.13 | 0.50 | 0.25 | 0.80 | |
| Step × Language-Greek × ISI-Long | −1.46 | 0.27 | -5.41 | < 0.001*** | |
| Step × Language-Korean × ISI-Long | −0.06 | 0.28 | −0.23 | 0.82 | |
| Summation | Intercept | 0.20 | 0.22 | 0.92 | 0.36 |
| Step | −0.21 | 0.15 | −1.46 | 0.15 | |
| Language-Greek | −0.27 | 0.30 | −0.88 | 0.38 | |
| Language-Korean | 0.18 | 0.21 | 0.86 | 0.39 | |
| ISI-Long | 0.21 | 0.31 | 0.69 | 0.49 | |
| Step × Language-Greek | 0.50 | 0.20 | 2.48 | 0.01* | |
| Step × Language-Korean | 0.18 | 0.21 | 0.86 | 0.39 | |
| Step × ISI-Long | −0.21 | 0.18 | −1.14 | 0.26 | |
| ISI-Long × Language-Greek | 1.24 | 0.43 | 2.86 | < 0.01** | |
| ISI-Long × Language-Korean | 0.29 | 0.44 | 0.66 | 0.51 | |
| Step × Language-Greek × ISI-Long | −0.89 | 0.26 | -3.48 | < 0.001*** | |
| Step × Language-Korean × ISI-Long | −0.14 | 0.26 | −0.54 | 0.59 |
Significance codes: p < 0.05*, p < 0.01**, p < 0.001***.
For Intensity, listeners were more likely to choose trochees with ISI-Long (est. = 0.38, p < 0.01). In addition, the Greek listeners showed an increase in trochee responses with increased STEP (est. = 0.54, p < 0.01), but Korean and English listeners did not (see Figure D1). For Duration, larger STEP differences led to a decrease in trochaic responses (Table 32.3, est. = −0.61, p < 0.001), but this effect depended on LANGUAGE. For English, the effect of STEP was minimal, as participants preferred iambs (Figure D2). For Greek, there was a decrease in trochee responses with each step, particularly for ISI-Long (est. = −1.46, p < 0.001), while the Korean group retained a preference for trochees (est. = 0.7, p < 0.05). For Summation, responses were influenced by LANGUAGE in interaction with STEP and ISI, with the Greek participants showing a decrease in trochaic responses with each step, particularly with ISI-Long (est. = −0.89, p < 0.001). However, the English and Korean participants’ responses showed no consistent and strong group preferences (Figure D3).
32.3.3 Interim Discussion
The expectation that the shorter experiment would lead to stronger preferences was not strongly supported. For Intensity and Summation, the results were largely comparable to those of Experiment 1, although Experiment 2 showed more significant effects related to LANGUAGE. For Duration, English participants showed the expected preference for iambs, as did the Greek group (with the largest step only), while the Korean group retained a preference for trochees. As we found discrepancies in the results of Experiments 1 and 2, we examined individual variation in responses to determine the extent to which it drives aggregate results.
32.4 Individual Differences in Responses
The individual response data (Figure 32.1) revealed variation across participants but overall chance-level responses dominated. When a preference was shown, participants slightly preferred trochees (16% on average) over iambs (12% on average); see Table 32.4 (for raw counts, see Table B, Supplementary Materials, at https://osf.io/sw3c5/).
Individual responses by language and sequence type.
Individual participant responses by language and sequence type in Experiment 1 (a: English, b: Greek, c: Korean) and Experiment 2 (d: English, e: Greek, f: Korean). Each dot represents the mean percentage of trochee responses from one participant. The error bars show ±1 standard error. Responses to controls excluded.
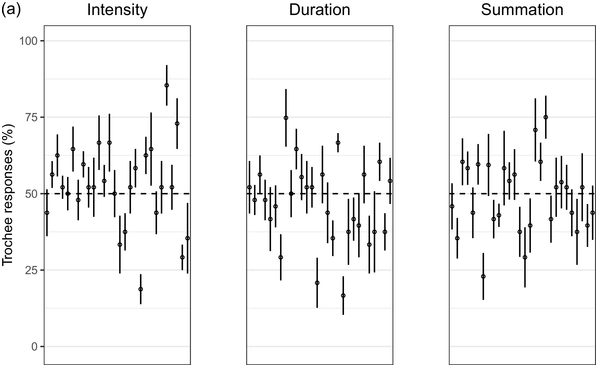
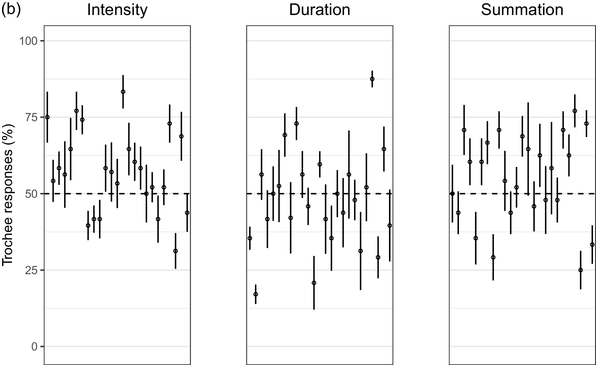
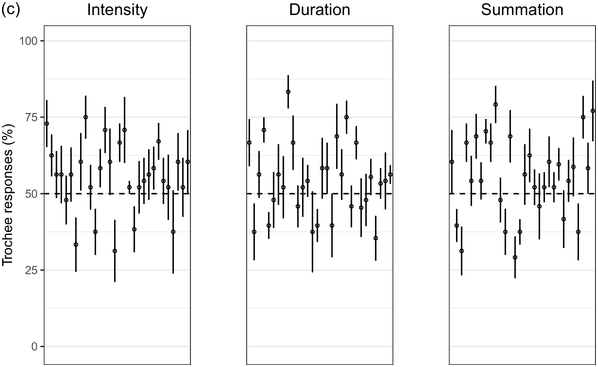
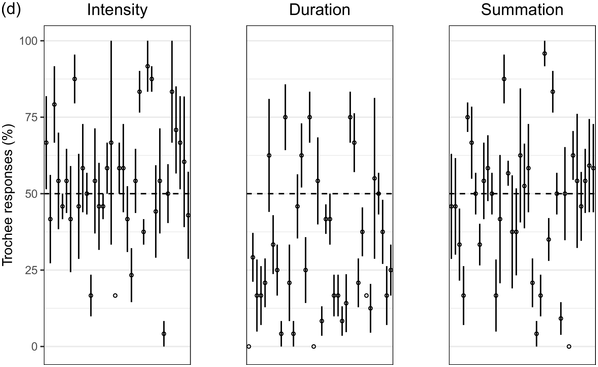
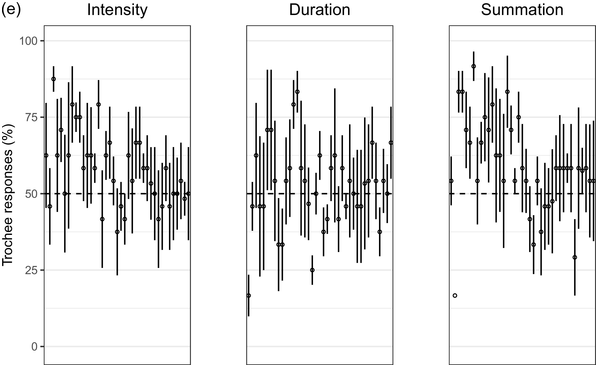
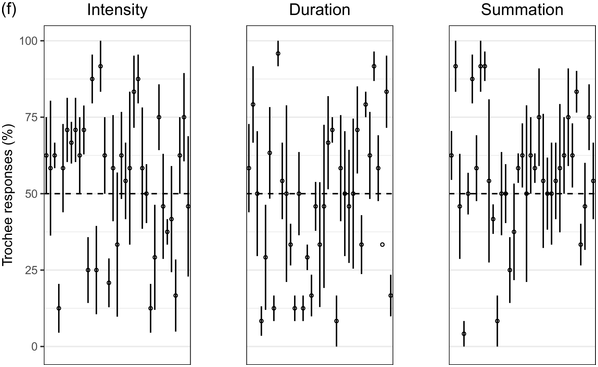
Expressed as percentage of participants from each language showing a (significantly different from chance) preference for trochees, iambs, or no preference in each of the two experiments; data pooled over Step and ISI.
| Sequence | Language | Trochaic preference | Iambic preference | No preference | |||
|---|---|---|---|---|---|---|---|
| Exp 1 | Exp 2 | Exp 1 | Exp 2 | Exp 1 | Exp 2 | ||
| Intensity | English | 14% | 17% | 4% | 11% | 75% | 72% |
| Greek | 28% | 13% | 4% | 0% | 68% | 87% | |
| Korean | 20% | 17% | 7% | 17% | 73% | 66% | |
| Duration | English | 4% | 8% | 14% | 53% | 82% | 39% |
| Greek | 12% | 5% | 16% | 5% | 72% | 90% | |
| Korean | 23% | 14% | 0% | 20% | 77% | 66% | |
| Summation | English | 7% | 11% | 7% | 19% | 86% | 69% |
| Greek | 28% | 18% | 12% | 3% | 60% | 80% | |
| Korean | 27% | 23% | 7% | 9% | 67% | 69% | |
| Control | English | 4% | 17% | 7% | 11% | 89% | 72% |
| Greek | 24% | 5% | 0% | 0% | 76% | 95% | |
| Korean | 20% | 20% | 0% | 11% | 80% | 69% | |
A preference for trochees and individual variation were evident for control sequences as well. We ran binomial tests to determine whether individual participants’ responses were significantly different from chance. The results showed that responses to controls (supplementary Figure E) were significantly different from chance for all three groups in Experiment 1 (for English, p < 0.05; for Greek, p < 0.001; for Korean, p < 0.001), but only for Koreans in Experiment 2 (for English, p = 0.32; for Greek, p < 0.24; for Korean, p < 0.001). However, at the individual level, only a small number of participants, mostly Greek and Korean, showed clear preferences, largely for trochees (Table 32.4; see also supplementary Table C and Figure F). This may explain the preference for trochees with the experimental sequences as well.
32.5 General Discussion
Our results supported the ITL, though not as strongly as those reported elsewhere (e.g., Iversen et al., Reference Iversen, Patel and Ohgushi2008; Bhatara et al., Reference Bhatara, Boll-Avetisyan, Unger, Nazzi and Höhle2013; Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara, Unger, Nazzi and Höhle2016, Reference Boll-Avetisyan, Bhatara and Höhle2017). Some of the differences between our experiments and others may relate to specific experimental manipulations. For example, our results are comparable to those of Hay and Diehl (Reference Hay and Diehl2007), a study using tones. Similarly, our prediction that larger steps would lead to stronger preferences was, to an extent, borne out similarly to Iversen et al. (Reference Iversen, Patel and Ohgushi2008). The weaker effect of Summation relative to Duration indicates that the preference for iambs with duration-varying sequences is reinforced by the perceptual integration of duration and intensity (Moore, Reference Moore2012, inter alia). One way to interpret this finding is that in order to elicit a strong iambic preference, the combined effect of duration and loudness is needed; duration differences alone are not sufficient.Footnote 3 On the other hand, our expectation that short ISI would lead to stronger grouping preferences was not borne out, indicating that different experimental outcomes – such as Hay and Diehl (Reference Hay and Diehl2007) versus Iversen et al. (Reference Iversen, Patel and Ohgushi2008) – cannot plausibly be attributed to this condition.
Our results showed some cross-linguistic differences. English and Greek participants behaved mostly consistently with a weak version of the ITL. For English listeners, in particular, grouping and prominence relations went hand in hand (see London, Reference London2012, Chapter 1), though their preferences were not strong, as in Iversen et al. (Reference Iversen, Patel and Ohgushi2008) or Crowhurst (Reference Crowhurst2016). The Greek results were weaker compared to those of Crowhurst (Reference Crowhurst2016) for Spanish, a language that is prosodically very similar to Greek. These discrepancies suggest that prosodic similarities between languages are not sufficient to predict responses in ITL experiments (see Moghiseh, et al., Reference Moghiseh, Sonderegger and Wagner2023, for a similar discussion, and also Chapter 4.3 on the role of prosody in processing).
The Korean groups, when they showed a preference, preferred trochees. This applied even with Duration sequences, contrary to our predictions. The Korean listeners’ trochee bias for Duration sequences (although not systematic and strong) is reminiscent of Japanese participants’ responses in Iversen et al. (Reference Iversen, Patel and Ohgushi2008). As Korean and Japanese do not have lexical stress, native speakers of these languages may exhibit weak association between acoustic prominence and grouping. Consequently, they may rely on general perceptual principles when engaging in prominence-related tasks (see de la Mora et al., Reference de la Mora, Nespor and Toro2013). This possibility is supported by the responses of the Korean participants to the control sequences: more participants showed trochee (20% for both Experiment 1 and Experiment 2) than iamb preferences (0% for Experiment 1; 11% for Experiment 2; Table 32.4). Trochee preferences are generally considered automatic, as they are easier to induce relative to iambic preferences (de la Mora et al., Reference de la Mora, Nespor and Toro2013).
Finally, both experiments show substantial individual variation, making replication hard to achieve. This is not the first time that ITL results have shown discrepancies. Woodrow (Reference Woodrow1909: 37) describes one participant (out of 13) who heard trochees even when increased duration was coupled with a long silent break between groups of stimuli. Crowhurst and Teodocio (Reference Crowhurst and Teodocio2014) found different results with Zapotec speakers in two experiments. Such findings suggest that reported ITL results may be driven by some participants with strong preferences. This may partly explain the very strong results of Iversen et al. (Reference Iversen, Patel and Ohgushi2008), who analysed only the responses with the highest confidence rating. Alternatively, weak preferences may reflect the fact that experiments on the ITL, including ours, are based on the forced-choice paradigm. Seen in this light, the results may indicate that participants do not find either trochees or iambs an appropriate grouping for the stimuli, possibly reflecting differences in subjective rhythmisation (see Bolton, Reference Bolton1894; Woodrow, Reference Woodrow1909; London, Reference London2012, Chapter 1).
All in all, the present findings indicate that the ITL is at best a tendency, not a rule. Its effects may be strengthened or attenuated by language experience, while they are also susceptible to experimental manipulations (see Moghiseh et al., Reference Moghiseh, Sonderegger and Wagner2023). If so, then it is unlikely that the ITL directly governs language processing, and thus, its role in language acquisition may have been overestimated. Our brief descriptions on English, Greek, and Korean (Section 32.1.2) indicate that the relationship between prominence, grouping, and acoustic parameters differs across languages, and in Korean, which does not have lexical stress, the notion of binary strong–weak alternation is simply not applicable. The cross-linguistic differences question the validity of the ITL as a universal. Furthermore, the relationship between linguistic structure and acoustic parameters is ambiguous within a language; for instance, longer duration can signal both prominence and group finality. The individual differences within each language group in our results suggest that either the ITL experimental paradigm is not suitable for finding a grouping strategy shared by all speakers of a given language or that multiple strategies are employed by its speakers. Recent work has linked such differences to musicality (Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara and Höhle2017) and exposure to languages other than L1 (Boll-Avetisyan et al., Reference Boll-Avetisyan, Bhatara, Unger, Nazzi and Höhle2016). Both hypotheses, with perhaps particular attention to participant rhythm-related abilities, are worth investigating further, as are other potential sources of individual variation (see Orrico et al., Reference Orrico, Gryllia, Kim and Arvaniti2023). What is of importance, however, is that in all instances, the large individual differences indicate that the results are not easy to replicate. At the same time, individual differences are worth investigating further to fully understand the extent of variability within seemingly homogeneous populations.
32.6 Conclusions
We conducted two experiments with English, Korean, and Greek participants to examine whether the ITL is subject to cross-linguistic differences and susceptible to experimental manipulations, such as the duration of the silent intervals between alternating tones. Our results, though overall consistent with the predictions of the ITL, did not provide strong confirmation, in that the participants did not show pronounced grouping preferences. Similarly, the cross-linguistic differences were neither strong nor consistent across the two experiments. Close examination revealed substantial individual variation, which may be critical in explaining the gamut of results reported in the ITL literature, regarding the strength of the effect and cross-linguistic differences. All together, these results indicate that the ITL is susceptible to experimental manipulation and thus may not be readily replicable. In turn, this suggests that, while our findings for Korean highlight the need to test the ITL with more languages that do not have stress, the ITL may be a tendency exhibited by some individuals but is unlikely to hold the universal and central role in speech processing, acquisition, and the development of metrical systems often attributed to it.
32.7 Acknowledgements
We thank Taehong Cho for access to the Hanyang Phonetics and Psycholinguistics Laboratory, Natalie Fecher for assistance in experiment preparation, and Yuna Baek, Jiyoun Choi, Jiyoung Jang, Hyojin Kim, Miru Lee, Jinhee Park, Christina Kanouta, Deepthi Gopal, Heather Rolfe, and Louisa Salhi for assistance with data collection. A preliminary analysis of the first experiment was reported in Jeon and Arvaniti (Reference Jeon and Arvaniti2016). Both authors have contributed equally to this research, and their names are listed here in alphabetical order. The research was supported by an Academy of Korean Studies grant (#AKS-2014-R-13). This support is hereby gratefully acknowledged.
Summary
We tested the ITL with English, Greek, and Korean speakers who responded to tone sequences varying in duration, intensity, or both. We found weak evidence for the ITL, with responses being influenced by the listeners’ native language, as well as substantial inter-speaker variation that casts doubt on ITL replicability.
Implications
The ITL is said to reflect universal cognitive tendencies leading to subjective rhythmisation (moderated by language) and shaping the typology of linguistic (stress and) rhythm. Our findings indicate that not everyone is susceptible to the ITL; results can be driven by a few participants with strong preferences.
Gains
This chapter discusses discrepancies across studies related to the classic idea about binary grouping and how individual differences can influence experimental results and conclusions. Investigating interactions between stimulus properties and listeners’ characteristics in processing complex sounds, rather than overemphasising the role of binary grouping, will lead to more fruitful outcomes.
33.1 Introduction
Abercrombie (Reference Abercrombie1965, Reference Abercrombie1967) proposes that languages can be categorized into three rhythmic groups: mora-timed, stress-timed, and syllable-timed languages (but see Roach, Reference Roach and Crystal1982; Cummins, Reference Cummins2012; Rathcke et al., Reference Rathcke, Lin, Falk and Dalla Bella2021, among others, for critical views). Ramus et al. (Reference Ramus, Nespor and Mehler1999) state that the rhythmic type of a language is associated with its speech segmentation unit. For instance, English, claimed as a representative stress-timed language, involves speech segmentation into feet, whereas Mandarin, a prototypical syllable-timed language, employs syllables for speech segmentation.
Two sets of rhythmic measures have received significant attention: one set proposed by Ramus et al. (Reference Ramus, Nespor and Mehler1999) and the other by Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002).Footnote 1 Ramus et al. (Reference Ramus, Nespor and Mehler1999) segment speech into vowels and consonants, and calculate vocalic and intervocalic intervals. Ramus et al. (Reference Ramus, Nespor and Mehler1999) mainly focus on three measures: %V, ΔV, and ΔC. The measure %V is the proportion of vocalic intervals within a sentence; ΔV refers to the standard deviation of the duration of vocalic intervals within each sentence; and ΔC is the standard deviation of the duration of intervocalic intervals within each sentence. With reference to eight languages, Ramus et al. (Reference Ramus, Nespor and Mehler1999) report that %V and ΔC are in line with the notion of rhythmic classes. For example, according to the authors, English has lower %V than French, because English has reduced vowels and French does not. In addition, English has higher ΔC, because English has more complex onset and coda structures than French. The differences between English and French in terms of %V and ΔC are in line with the supposition that English is a typical stress-timed language and French is a representative syllable-timed language.
One controversial issue not referred to in Ramus et al. (Reference Ramus, Nespor and Mehler1999) is the speech rate factor. Barry et al. (Reference Barry, Andreeva, Russo, Dimitrova and Kostadinova2003) state that both ΔV and ΔC are inversely related to speech rate. Dellwo (Reference Dellwo, Karnowski and Szigeti2006) thus uses a normalized metric VarcoΔC, which is the standard deviation of intervocalic interval duration divided by the mean consonant duration. Dellwo (Reference Dellwo, Karnowski and Szigeti2006) claims that VarcoΔC discriminates better than ΔC between English and French. However, White and Mattys (Reference White and Mattys2007) argue that VarcoΔV appears to be more reliable and discriminative than raw measures, while VarcoΔC seems to remove variation that holds linguistic significance. The pairwise variability index (PVI), proposed by Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002), is the other set of rhythmic measures that has garnered widespread discussion. Different from the rhythmic measures in Ramus et al. (Reference Ramus, Nespor and Mehler1999), the PVI measures capture the sequential variations in intervals. Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002) state that the PVI measures vowel durations and the duration of intervals between vowels (excluding pauses) in speech, followed by the calculation of variability in consecutive measures. They also claim that speech rate should be taken into consideration for the PVI calculation of vocalic intervals, since speech rate may affect their duration. This adjusted metric for vocalic intervals is termed normalized PVI. In contrast, Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002) argue that normalization is not necessary for intervocalic intervals and use the raw PVI. The results reported in their study are as expected for Dutch, English, and German, typical stress-timed languages, and as expected for French and Spanish, typical syllable-timed languages. Their results for Japanese, a mora-timed language, are similar to those for syllable-timed languages.
The most straightforward way to examine the validity of rhythmic classification is to analyze the speech production by native speakers, especially that of monolingual speakers, by use of the rhythmic measures noted above. Another way to approach rhythmic classification is to examine speech by bilinguals with two first languages (hereafter 2L1s). It seems that results from bilinguals with 2L1s should be intermediate between the results from the respective monolingual speakers of their two languages. Examining second-language speakers, particularly the influence of their first language (L1) on their second language (L2), could also provide valuable insights into rhythmic classification. If rhythmic classification is tenable, the effect of the rhythm of L1 on the rhythm of L2 can be expected.
Bilinguals with 2L1s in this chapter are defined as those who have acquired two languages before three years old and can produce fluent and effective speech in both languages. To put it differently, both languages are considered their native languages (see, for example, Haugen, Reference Haugen1953; Weinreich, Reference Weinreich1953). The definition of a bilingual speaker here is not as strict as that of Bloomfield (Reference Bloomfield1933) as a perfect user of two languages in listening, reading, speaking, and writing; however, it is much stricter than that of MacNamara (Reference MacNamara1967) who includes anyone who has minimal competence in listening, reading, speaking, or writing a language other than his/her native language. L2 speakers in this chapter are those who did not acquire the language under discussion in early childhood and have not lived in a country where it is spoken for a long period, but learned it later through formal instruction or self-study (see, for example, Jenkins, Reference Jenkins2000; Mitchell and Myles, Reference Mitchell and Myles2004; Kormos, Reference Kormos2006).
This chapter is structured as follows. Sections 33.2 and 33.3 review rhythmic results from bilinguals with 2L1s and L2 speakers, respectively. Section 33.4 discusses remaining questions in rhythmic classification. Section 33.5 concludes the chapter.
33.2 Rhythms and Bilinguals with 2L1s
If bilinguals with 2L1s (henceforth bilinguals) show results in terms of rhythmic measures somewhere between the results from the monolinguals of their two languages, it demonstrates that the speech production by bilinguals contains the influence of the rhythm of one language on the other. In other words, the rhythmic differences between the two languages can be witnessed and thus support the validity of rhythmic classification.
33.2.1 Rhythmic Measures for Vowels
Bunta and Ingram (Reference Bunta and Ingram2007) compare the speech production by Spanish-English bilingual adults with that of monolingual peers in both languages, of monolingual children in both languages, and of Spanish-English bilingual children. Spanish is considered a syllable-timed language and English a stress-timed language. Bunta and Ingram (Reference Bunta and Ingram2007) mainly employ the normalized vocalic and intervocalic PVI measures (hereafter nPVI-V and nPVI-C, respectively) and find that the nPVI-V measure is effective in distinguishing speech rhythms while the nPVI-C measure does not seem to be an accurate indicator of speech rhythm. According to Bunta and Ingram (Reference Bunta and Ingram2007), the nPVI-V score for speech production in English from the bilingual adults (74.00) is slightly lower than that from the monolingual English adults (79.68), while the nPVI-V value of 43.00 from the bilingual adults in Spanish is marginally higher than the 39.43 from the Spanish monolingual adults. Since a lower nPVI-V score indicates more syllable-timed speech, the speech production in English by the Spanish-English bilingual adults is slightly more syllable-timed than that of the English monolinguals. Similarly, the speech production in Spanish by these bilingual adults is moderately more stress-timed than that of the Spanish monolinguals. This demonstrates that the Spanish-English bilingual adults show an interaction between the two different rhythms of their two languages (see also Mok, Reference Mok2011). In a similar vein, Liu and Takeda (Reference Liu and Takeda2021) focus on the speech production in English by English-Japanese and English-Mandarin bilingual adults and compare their speech production with that of English monolinguals. The proportion of CV (consonant-vowel) syllables in Japanese, a representative mora-timed language, is even higher than that of Mandarin, a typical syllable-timed language. Therefore, the English-Mandarin bilinguals are expected to be closer to the English monolinguals than the English-Japanese bilinguals. Liu and Takeda (Reference Liu and Takeda2021) take %V, ΔV, VarcoΔV, PVI-V, and nPVI-V all into consideration and find out that the English monolinguals, English-Mandarin bilinguals, and English-Japanese bilinguals have decreasing results as expected for two rhythmic measures: (i) 58.41, 48.20, and 46.06 in terms of VarcoΔV; and (ii) 64.80, 63.62, and 59.07 in terms of nPVI-V. Namely, the speech production in English by the two bilingual groups has shown influences of the rhythms of Mandarin and Japanese, respectively. This supports the claim that English, Mandarin, and Japanese each belong to a different rhythmic type. The results from bilingual adults in terms of rhythmic measures for vowels discussed in this subsection have provided support for rhythmic classification (for similar results from bilingual children, see Grabe et al., Reference Grabe, Post and Watson1999a, Reference Grabe, Gut, Post, Watson, Barrière, Morgan, Chiat and Woll1999b; Bunta and Ingram, Reference Bunta and Ingram2007; Kehoe et al., Reference Kehoe, Lleó and Rakow2011; Mok, Reference Mok2011). Section 33.2.2 will turn to rhythmic measures for consonants.
33.2.2 Rhythmic Measures for Consonants
As stated in Section 33.2.1, Bunta and Ingram (Reference Bunta and Ingram2007) have also employed the nPVI-C measure. However, they have not found it as effective as nPVI-V. The nPVI-C value for the speech production in English by English monolinguals is comparable to that by Spanish-English bilingual adults (74.35 versus 73.40). The same pattern can be seen between the nPVI-C values for the speech production in Spanish by Spanish monolinguals and Spanish-English bilingual adults (65.25 versus 67.80). In addition, no statistically significant differences have been found in terms of nPVI-C between Spanish and English spoken by Spanish-English bilingual adults. The only notable difference is between the English and Spanish monolinguals (74.35 versus 67.80). After a comparison with previous studies, Bunta and Ingram (Reference Bunta and Ingram2007) point out that both normalized PVI-C (nPVI-C) and raw PVI-C (rPVI-C) measures are subject to more individual variations than the measures themselves: Both nPVI-C and rPVI-C measures may erase significant differences between groups (see also Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002; Whitworth, Reference Whitworth2002; Knight, Reference Knight2011; but see Arvaniti, Reference Arvaniti2012, for a different interpretation). The results in terms of ΔC, VarcoΔC, rPVI-C, and nPVI-C in Liu and Takeda (Reference Liu and Takeda2021) show an interesting pattern: The English-Japanese bilingual adults have the lowest values in terms of all these four measures among the English-Japanese bilingual adults, English monolinguals, and native Japanese speakers who speak English as an L2. Liu and Takeda (Reference Liu and Takeda2021) further examine the speech production in English by English-Mandarin bilingual adults and find that they have the lowest values in terms of ΔC and rPVI-C and the highest values in terms of VarcoΔC and nPVI-C among the English-Mandarin bilingual adults, English monolinguals, and native Mandarin speakers who speak English as an L2. Liu and Takeda (Reference Liu and Takeda2021) thus conclude that the rhythmic measures for consonants cannot clearly discriminate different rhythmic types. One possible explanation is that the measures of vocalic intervals, especially the nPVI-V measure, reflect rhythm in essence, whereas the measures of intervocalic intervals reflect differences in phonology (Kehoe et al., Reference Kehoe, Lleó and Rakow2011; Liu and Takeda, Reference Liu and Takeda2021). To exemplify, one main characteristic of stress-timed languages is the reduction of unstressed vowels. This seems to partly explain the lack of strong correlation between consonants and rhythmic classes. Another possible explanation is associated with the tendency of compressing the vowel duration to maintain a more regular duration of a syllable (Lehiste, Reference Lehiste1970; Lindblom et al., Reference Lindblom, Lyberg and Holmgren1981). Munhall et al. (Reference Munhall, Fowler, Hawkins and Saltzman1992) tested three native speakers of English and found that all subjects consistently shortened vowels when the durations of codas were increased, whereas the effects of vowel duration on the coda were less consistent. The lack of a consistent pattern of consonant durations partly explains the seemingly unreliable results from rhythmic measures of consonants.
33.3 Rhythms and L2 Speakers
Most studies on L2 speakers agree on L1-to-L2 transfer, resulting in intermediate rhythmic values in the L2, and rhythmic measures for vowels being more discriminative than rhythmic measures for consonants (Taylor, Reference Taylor1981; Bond and Fokes, Reference Bond and Fokes1985; Wenk, Reference Wenk1985; Mochizuki-Sudo and Kiritani, Reference Mochizuki-Sudo and Kiritani1989; Ueyama, Reference Ueyama1996, Reference Ueyama1999; Gut, Reference Gut2003; Jian, Reference Jian2004; Carter, Reference Carter, Gess and Rubin2005; Setter, Reference Setter2006; Coetzee and Wissing, Reference Coetzee and Wissing2007; Yune, Reference Yune2018). In addition, research into L2 speakers has covered more diversified languages and taken account of both the production and perception of rhythm.
33.3.1 Effective Rhythmic Measures
Carter (Reference Carter, Gess and Rubin2005) is perhaps the first to turn attention to the speech rhythm of L2 speakers, using the nPVI measure to examine natural speech production in English and Spanish spoken in North Carolina. According to Carter (Reference Carter, Gess and Rubin2005), Hispanic English is not as stress-timed as English: The mean nPVI-V value of 42.64 is much lower than that of the native English-speaking North Carolinians. Robles-Puente (Reference Robles-Puente2014) asks participants to read the passage The North Wind and the Sun in its English and Spanish versions and finds that his results are in line with those in Carter (Reference Carter, Gess and Rubin2005): The nPVI-V value of 39.7 for the L2 Hispanic English is not as stress-timed as that of the English control group (53.3). White and Mattys (Reference White and Mattys2007) focus on L2 Spanish and L2 English. They find that the VarcoΔV and nPVI-V of L2 Spanish whose native language is English are 52 and 51, respectively, while the VarcoΔV and nPVI-V of L1 Spanish are 41 and 36, respectively. As expected, L2 Spanish speakers have higher VarcoΔV and nPVI-V values than L1 Spanish speakers due to the influence from their L1 English. In a similar vein, the VarcoΔV and nPVI-V of L2 English in those whose native language is Spanish are 54 and 66, respectively, lower than 64 and 73 of L1 English. In terms of %V, L1 Spanish has a lower value than L2 Spanish in those whose native language is English (48 versus 52), which is unexpected. The L1 English has a lower %V value than L2 English in those whose native language is Spanish (38 versus 41) as expected. However, as White and Mattys (Reference White and Mattys2007) report that the %V measure was particularly effective in distinguishing other comparisons in their study, such as L1 Dutch versus L2 Dutch, they conclude that VarcoΔV and nPVI-V seem more reliable and discriminative and %V was particularly satisfactory.
Similarly, Liu and Takeda (Reference Liu and Takeda2021) ask participants to read an English text and note that VarcoΔV and nPVI-V are effective in discriminating the two L2 groups: The L2 English speakers of L1 Mandarin have higher values in terms of these two measures than the L2 English speakers of L1 Japanese as expected. On the other hand, Liu and Takeda (Reference Liu and Takeda2021) also find that the difference in terms of %V between the L2 English speakers whose native languages are Japanese and Mandarin, respectively, is marginal: 40.76 versus 41.41. As the proportion of CV syllables in Japanese is even higher than that of syllable-timed languages (Otake, Reference Otake1990), the L2 English speakers of L1 Japanese are expected to have a slightly higher %V than the L2 English speakers of L1 Mandarin. Therefore, Liu and Takeda’s (Reference Liu and Takeda2021) result does not support the claim that %V is the most discriminative measure (but see Lin and Wang, Reference Lin and Wang2005, for a different conclusion).
Mok and Dellwo (Reference Mok and Dellwo2008) investigate the speech rhythms of Cantonese-accented English and Mandarin-accented English by asking L2 English speakers of L1 Cantonese and Mandarin to read the English version of The North Wind and the Sun at a normal speed and comparing their results with the results from native British English speakers reading a short English passage. The result in terms of nPVI-V shows that Mandarin-accented English has an even higher nPVI-V result than the native British English speakers, while VarcoΔV and %V can distinguish different groups as expected. The result may be interpreted with caution: Since results from different groups are obtained from reading different texts, they may not be entirely comparable.
Jian (Reference Jian2004) compares the L2 English of native Taiwanese Mandarin speakers with the L1 English of native American English speakers by use of nPVI-V. The study concludes that the nPVI-V of L2 English is lower than that of L1 English. Setter (Reference Setter2006) takes a different approach by focusing on the syllable duration in L2 English of native Hong Kong Cantonese speakers. In comparison to British English, Hong Kong English has overall longer syllable durations. Additionally, L2 English speakers show less variation in the relative duration of tonic, stressed, unstressed, and weakened syllables than British English speakers. According to Setter (Reference Setter2006), the limited syllable weakening may prevent these L2 English speakers from exhibiting the native-like pattern of stress-timing and may be a factor in the L2’s syllable-timed rhythm. Coetzee and Wissing (Reference Coetzee and Wissing2007) compare Afrikaans English with Tswana English by asking native speakers of Afrikaans and Tswana to read the English version of The North Wind and the Sun. Afrikaans is a stress-timed language, while Tswana is a syllable-timed language. Therefore, Afrikaans English is estimated to be more stress-timed and Tswana English more syllable-timed. Coetzee and Wissing (Reference Coetzee and Wissing2007) find that Afrikaans English patterns with stress-timed languages and Tswana English with syllable-timed languages as expected. Coetzee and Wissing (Reference Coetzee and Wissing2007) attribute this to the transfer from the L1s of these speakers.
Studies on different languages have generally supported the validity of %V, VarcoΔV, and nPVI-V measures in differentiating L2 rhythms (but see Roach, Reference Roach and Crystal1982; Cummins, Reference Cummins2012; Rathcke et al., Reference Rathcke, Lin, Falk and Dalla Bella2021, for different opinions). This shows the efficacy of these measures in capturing the differences in L2 rhythms. As discussed in Section 33.2, VarcoΔV and nPVI-V are also effective in identifying rhythmic differences between bilinguals with 2L1s and monolinguals. Since both VarcoΔV and nPVI-V are rate-normalized, it suggests that rhythmic measures should take speech rate into consideration. One more note will be made before leaving this subsection. Most studies discussed here have also considered rhythmic measures for consonants. However, similar to the conclusion in Section 33.2, studies on L2 speakers also cast doubt on the validity of rhythmic measures for consonants. To exemplify, Liu and Takeda (Reference Liu and Takeda2021) report that the L2 English of L1 Japanese and the L2 English of L1 Mandarin groups have results much closer to the monolingual English group than the English-Japanese and English-Mandarin bilingual groups in terms of ΔC, VarcoΔC, rPVI-C, and nPVI-C (see also Lin and Wang, Reference Lin and Wang2005; White and Mattys, Reference White and Mattys2007; Mok and Dellwo, Reference Mok and Dellwo2008).
33.3.2 L2 and Perception
A few scholars take a different perspective and explore rhythmic classification from the perception side. Generally speaking, most of them agree that the results show the influence of L1 rhythm on the perception of L2 rhythm (Cutler et al., Reference Cutler, Mehler, Norris and Segui1986; Bertinetto and Fowler, Reference Bertinetto and Fowler1989; Masuko and Kiritani, Reference Masuko and Kiritani1990; Otake et al., Reference Otake, Hatano, Cutler and Mehler1993; Cutler and Otake, Reference Cutler and Otake1994; Erickson et al., Reference Erickson, Akahane-Yamada, Tajima and Matsumoto1999; but see a different conclusion in, for example, Bradley et al., Reference Bradley, Sánchez-Casas and García-Albea1993; Fear et al., Reference Fear, Cutler and Butterfield1995). For example, Bertinetto and Fowler (Reference Bertinetto and Fowler1989) use six pairs of Latinate words to examine the sensitivity of Italian and English speakers to artificially modified durations of unstressed vowels. The results from Bertinetto and Fowler’s (Reference Bertinetto and Fowler1989) study are in line with the classification of English as stress-timed and Italian as syllable-timed, as native English speakers were found to be relatively insensitive to the durational compression of unstressed vowels, while native Italian speakers were more sensitive. Erickson et al. (Reference Erickson, Akahane-Yamada, Tajima and Matsumoto1999) find that it is difficult for native Japanese speakers to count the syllables in each English word read by native American English speakers, which demonstrates that their L1 has made it difficult for them to understand the fundamental rhythmic components of English.
33.4 Remaining Questions
33.4.1 Non-prototypical Languages
One dilemma is the difficulty to classify non-prototypical languages. For example, Dauer (Reference Dauer1983, Reference Dauer1987), Arvaniti (Reference Arvaniti1991, Reference Arvaniti2007), Barry and Andreeva (Reference Barry and Andreeva2001), Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002), and Baltazani (Reference Baltazani2007) find it challenging to decide whether Greek is unclassifiable, syllable-timed, or of a mixed rhythm. Baltazani (Reference Baltazani2007) adopts the rPVI-V and rPVI-C measures and notes that Greek has an intermediate rPVI-V value of 45 between the 30 of Spanish and the 60 of German, while it has a higher rPVI-C value of 68 than both the 58 of Spanish and the 55 of German. Since Spanish and German are respectively representative syllable-timed and stress-timed languages, it is difficult to decide which rhythmic type Greek belongs to exactly (see also Balasubramanian, Reference Balasubramanian1980, for a similar conclusion concerning Tamil). Han (Reference Han1964), Ji (Reference Ji1993), Bond and Stockmal (Reference Bond and Stockmal2002), and Cho (Reference Cho2004) have all debated the classification of Korean’s rhythm as syllable-timed, stress-timed, mora-timed, or somewhere in between the first two categories. Most literature about bilinguals and L2 speakers is mainly limited to a few familiar languages, for example, English, French, German, Japanese, and Mandarin, as discussed in Sections 33.2 and 33.3, and thus cannot shed much light on the understanding of these understudied languages.
33.4.2 Rhythmic Classification: Categorical or Gradient
Some studies on monolinguals have suggested that the distinction between different rhythms appears to be gradient, instead of categorical: Languages appear to be more or less, instead of being absolute, mora-timed, stress-timed, or syllable-timed (Mitchell, Reference Mitchell1969; Port et al., Reference Port, Al-Ani and Maeda1980; Miller, Reference Miller1984; Dauer, Reference Dauer1987; Sato, Reference Sato1993; Minagawa-Kawai, Reference Minagawa-Kawai1999; Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002). To exemplify, Mitchell (Reference Mitchell1969) argues that no language is entirely syllable-timed or stress-timed; rather, all languages exhibit both types of timing, with certain languages favoring one over the other. Dauer (Reference Dauer1987) offers a checklist with eight dimensions for the rhythmic classification of languages. A language is more likely to be called stress-timed if it receives more positive points than negative ones, and syllable-timed if it receives more negative points. English is closer to one end of Dauer’s scale and French is closer to the other. As a result, there is a continuum of rhythmic differences between languages, instead of an absolute difference. To give some language examples, Dimitrova (Reference Dimitrova1997) uses the methods in Dauer (Reference Dauer1987) and finds that the rhythm of Bulgarian is somewhere between stress-timed and syllable-timed. Grabe and Low (Reference Grabe, Low, Gussenhoven and Warner2002) ask their participants to read The North Wind and the Sun in their native languages and demonstrate that English, Dutch, and German are stress-timed and French and Spanish are syllable-timed. However, Malay does not have a statistically significant difference from either representative stress-timed languages or syllable-timed languages in terms of the nPVI-V measure (Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002). The rPVI-C measure provides even smaller differences: No statistically significant difference has emerged between Catalan and Spanish in terms of rPVI-C; Luxembourgish does not have a statistically significant difference from either representative stress-timed languages or syllable-timed languages in terms of rPVI-C (Grabe and Low, Reference Grabe, Low, Gussenhoven and Warner2002). Maddieson (Reference Maddieson, Hyman and Plank2018) argues from a different perspective: Individual variations within a language can be larger than differences between languages of various rhythms. Similarly, according to Arvaniti (Reference Arvaniti2012), the eight native speakers of German range from about 36% to 43% in terms of the %V measure, showing variations larger than the 3.8% difference between English and Spanish in terms of the same measure.
33.4.3 Rhythmic Measures: Beyond Duration
The rhythmic measures discussed in Sections 33.2 and 33.3 assume a direct and straightforward relationship between duration and abstract phonological categories including vowel reduction pattern, vowel weight, syllable structure, and so on. However, the duration of segments may be affected by multiple factors, such as the presence or absence of geminate consonants, the manner of articulation of consonants, vocalic length distinction, the pattern of vowel reduction, syllable structure, syllable position, stress, word type, boundary lengthening, speech rate, accent, intonation, tone, and the syntactic component (Delattre, Reference Delattre1966; Allen, Reference Allen1973; Klatt, Reference Klatt1975, Reference Klatt1976; Bornoze de Manrique and Signorini, Reference Borzone de Manrique and Signorini1983; Dauer, Reference Dauer1983, Reference Dauer1987; Jassem et al., Reference Jassem, Hill, Witten, Gibbon and Richter1984; Laeufer, Reference Laeufer1992; Nooteboom, Reference Nooteboom, Hardcastle and Laver1997; Rietveld et al., Reference Rietveld, Kerkhoff and Gussenhoven1999; Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2000). Roach (Reference Roach and Crystal1982), by comparing six languages, has found little evidence to support that the languages can be differentiated by the timing of inter-stress intervals or syllable durations (see also Wenk and Wioland, Reference Wenk and Wioland1982, using French as a language sample; Den Os, Reference Den Os1988, using Italian and Dutch; Nooteboom, Reference Nooteboom1991, using Swedish). This presents a challenge for rhythmic measures: How does one capture all these different factors in different languages and make a parallel and comprehensive comparison between different languages by use of rhythmic measures? More plainly, it is necessary for rhythmic measures to take not only phonological but also morphological and syntactic components into consideration, for example, morphological processes giving rise to consonant clusters, word order variations in languages, among others. Between the two effective rhythmic measures reviewed in Sections 33.2 and 33.3, VarcoΔV is designed to measure the dispersion of vocalic values and nPVI-V sequential variations. Neither of these two measures can take full account of the phonological components, not to mention the morphological and syntactic components. As far as rhythmic measures remain at the present stage, they cannot provide a full picture of different rhythmic types.
33.5 Conclusion
Although research on bilinguals with 2L1s and L2 speakers has provided support for rhythmic classification, results reviewed in this chapter cannot be claimed as completely satisfactory. Timing processing may operate at several levels – the segment level, the syllable level, and the phrase level – in addition to various factors, such as stress, surrounding context, position, speaking rate, and so on. How to capture all of these levels and factors into rhythmic measures is a challenge that rhythmic classification must solve.
Summary
Rhythmic classification has been subject to scrutiny from various angles, including rhythm production, rhythm perception, and factors influencing rhythm. Despite its long-standing history, questions remain about how to comprehensively, systematically, objectively, and precisely capture all aspects of rhythm in nature and structure.
Implications
Research on bilinguals with 2L1s and L2 speakers has provided some support for rhythmic classification. Future research should explore underrepresented languages and compare data from speakers with diverse language backgrounds, instead of focusing on a few representative languages. Additionally, individual variations, various factors affecting timing processes, and even perception should all be taken into account in rhythmic classification.
Gains
Disputes concerning rhythmic classification may continue. However, it cannot be denied that research on bilinguals with 2L1s and L2 speakers has provided moderate evidence for different rhythms in languages. It has been proposed that aspects of rhythm across cognitive domains overlap at both neural and cognitive levels. Research on language rhythm may provide insights into the neurological, molecular, and evolutionary underpinnings of human cognition.
34.1 Introduction
Linguists specializing in Romance languages have always been intrigued by the extent of diversification brought about by the geographical fragmentation, or Ausgliederung, since the Late Latin period. Cross-linguistic differences within Romance are pervasive, not only in basic vocabulary and fundamental parameters of grammar but also in phonetics and phonology. Vowel inventories, for example, range from just five cardinal phonemes /a, e, i, o, u/ in Spanish to systems boasting between 14 and 16 vowels in French. Reductive sound changes, and in particular vowel weakenings and losses, have also affected the Romance languages and dialects to a different extent, and have yielded phonemic centralized vowels and complex consonant clusters in some parts of the Romance-speaking area, most notably so in European Portuguese (EP). This in turn implies remarkable differences within Romance with respect to the range of admissible syllable structures and to the degree of contrast between accentually prominent and non-prominent syllables. Lexical stress is assigned within a three-syllable window from the right edge of phonological words in most Romance languages, but French stands out in arguably lacking lexical stress altogether (Martin, Reference Martin2015). In view of this diversity of phonological characteristics, anything but homogeneity can also be expected when it comes to the rhythmic organization of utterances.
This contribution offers a reassessment of traditional claims concerning rhythm in the three most widely spoken Romance languages: Spanish, Portuguese, and French. While research has increasingly focused on acoustic rhythm metrics in recent decades, we argue that the rhythmic signature of languages is crucially shaped by their phonological make-up. In Section 34.2, we offer a critical survey of phonetic approaches to rhythmic typology, before moving on to typologies based on phonological parameters. Section 34.3 sketches an account of the behavioural properties of linguistic rhythm, and puts both systemic and behavioural structures to the test in a study of a small sample of elicited speech (Section 34.4). Finally, Section 34.5 will endeavour some conclusions.
34.2 Phonetic and Phonological Approaches to Linguistic Rhythm
Intuitions about rhythmic differences between Germanic and Romance languages have been formulated time and again since the beginnings of comparative poetics and phonetics, albeit under varying terminological guises. English served as the showcase of a stress-timing language in which stressed syllables recur at roughly equal intervals in connected speech. Prosodic timing in Romance languages was felt to be different. According to Pike (Reference Pike1945), ‘many non-English languages (Spanish, for instance) tend to use a rhythm which is more closely related to the syllable than the regular stress-timed type of English’ – a statement that betrays a clear bias by its very wording. Perhaps the most famous development of Pike’s idea can be found in Abercrombie (Reference Abercrombie1967), who considers syllable-timing as the second principal rhythmic type alongside stress-timing. A syllable-timed rhythm would maintain equal duration of all syllables in a speech event. Since nothing prevents the number of syllables in inter-stress intervals to vary, stress-timing and syllable-timing are antagonistic principles. Research failed to find phonetic evidence for isochronous timing of either stresses or syllables in the acoustic signal, even when confounding factors such as speech rate variation or differences between acoustic and perceived syllable onsets were taken into account (see White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020; Arvaniti, Reference Arvaniti, Knight and Setter2021). In particular, evidence for a consistent tendency towards isochrony of syllables in Romance languages was equivocal at best: besides showing significant geographical variation, Spanish, long considered a benchmark for syllable-timing, did exhibit considerable durational differences (see Dufter, Reference Dufter2003; Payne, Reference Payne, Gabriel, Gess and Meisenburg2021). In French, domain-final lengthening militates against syllable uniformity, and syllable reductions and non-realization of schwa likewise obscure strict CVCV (consonant-vowel-consonant-vowel) syllabic uniformity. The situation in Portuguese is characterized by striking differences between the complex syllable structures and reductions found in the European varieties, making European Portuguese a clear case of stress-based rhythm, as opposed to the intermediate rhythmic nature of Brazilian varieties (see Frota and Vigário, Reference Frota and Vigário2001; Payne, Reference Payne, Gabriel, Gess and Meisenburg2021: 284–287). Understandably perhaps, dialectal variation within individual Romance languages has attracted quite some attention among specialists of Italo-Romance (see Schmid, Reference Schmid, Caro Reina and Szczepaniak2014; Bertinetto, Reference Bertinetto2021), but much less so among specialists of Spanish (see, however, Pešková et al., Reference Pešková, Feldhausen, Kireva, Gabriel, Braunmüller and Gabriel2012, on Buenos Aires Spanish) and of French (but see, for Southern French, Meisenburg, Reference Meisenburg2013, and for French spoken in Ontario, Kaminskaïa et al., Reference Kaminskaïa, Tennant and Russell2016).
Nonetheless, scholars remained faithful to stress-timing in English, suggesting that there was a ‘conspiracy’ within the phonetic and phonological structure of the language that favoured such regular distancing of stressed syllables (Ladefoged, Reference Ladefoged1993). Dauer (Reference Dauer1983) was perhaps the first publication within phonetics that explicitly sought to adduce phonological determinants for language-particular rhythmic signatures. By the end of the twentieth century, several studies had elaborated on this idea and proposed phonological prototypes of stress-timing and syllable-timing, respectively (Bertinetto, Reference Bertinetto1988; Auer, Reference Auer1993; Laver, Reference Laver1994: 528–529). Syllable-timing phonology was generally described as adhering more closely to the CV ideal, both with respect to the inventory of syllable types and statistically at the level of syllable tokens. Furthermore, it was argued that, ideally at least, all syllables should be of equal status; that is, no reduced syllables featuring centralized vowels should be allowed, and, conversely, no metrically ‘strong’, and possibly phonologically distinctive, word stresses should disrupt the ‘flat’ prominence contour (see Dufter, Reference Dufter2003, for a critical assessment).
Starting with Ramus et al. (Reference Ramus, Nespor and Mehler1999), the search for acoustic correlates of rhythm classes gained new momentum, and phonetics rather than phonology occupied center stage once again in the study of rhythmic differences. According to Ramus et al., languages traditionally assumed as being syllable-timed do stand out against others, and in particular stress-timed languages, by exhibiting a higher proportion of vocalic intervals, as well as a lower durational variability of consonant intervals. Alternative metrics were proposed to assess rhythmical properties by measuring vocalic and consonantal stretches of the acoustic signal. Grabe and Low (Reference Grabe, Low, Warner and Gussenhoven2002) developed a more sophisticated metric of local durational variability of vocalic and consonantal intervals, which was to inspire much subsequent work in comparative acoustic rhythm research. Prieto et al. (Reference Prieto, del Mar Vanrell, Astruc, Payne and Post2012) even argued that durational metrics were more powerful than phonologically geared phonotactic measurements in the quest to differentiate English, Spanish, and Catalan speech data. Inspired by this line of research, Dufter and Reich (Reference Dufter and Reich2003) proposed a case study on French, Spanish, European, and Brazilian Portuguese using samples of speech obtained by different production tasks (careful reading, fast reading, and elicited unscripted). These speech samples were low-pass filtered to obscure segmental information and provide reasonable approximations of ‘pure prosodic’ stimuli. Subjects familiar with Romance languages then had to try to identify the individual languages in question. Results showed that French signals yielded the highest rates of correct identification, followed by Spanish, while Brazilian and European varieties of Portuguese were less consistently recognized.
Acoustically based rhythm research has recently been subject to criticism. To begin with, no independent justification was provided for the exact definitions of these rhythm metrics. Instead, as Arvaniti (Reference Arvaniti, Knight and Setter2021) points out, their selection from among a range of conceivable alternative measures was essentially circular: they were selected because they turned out to group together languages that were assumed to belong together on intuitive and typological grounds. Worse still, the values obtained proved to depend more strongly on the method of speech data elicitation than on the individual languages, read speech differing crucially from more spontaneous productions (Bertinetto, Reference Bertinetto2021), in which variability in timing is much greater and thus may override ‘underlying’ rhythmic regularities. On the perception side, Dufter and Reich (Reference Dufter and Reich2003) found better rates of correct language identification for low-pass-filtered spontaneous speech data as compared to stimuli created on the basis of read speech. Inter-speaker variation within individual languages also loomed large (Wiget et al., Reference Wiget, White and Schuppler2010), and sometimes had even greater effects than cross-linguistic variation. Again, speaker dependence was also clearly at play in Dufter and Reich (Reference Dufter and Reich2003). Finally, cultural differences in rhythm perception are demonstrable (Cameron and Grahn, Reference Cameron, Grahn, Hartenberger and McClelland2020), so that an exclusive reliance on acoustic measurements may not be sufficient to capture stable intuitions about cross-linguistic rhythmic similarities and differences in the first place.
Against the diminishing confidence in local acoustic measures of rhythm, two trends seem to be emerging. Within phonetics, models of timing have been proposed that seek to reconcile local and utterance-level determinants of timing, and relate durational properties to more abstract metrical patternings (Gibbon and Lin, Reference Gibbon, Lin, Wrembel, Kiełkiewicz-Janowiak and Gąsiorowski2020; White and Malisz, Reference White, Malisz, Gussenhoven and Chen2020; Gibbon, Reference Gibbon2023). Also, a somewhat rueful return to phonological considerations seems to be discernible in recent years (see Caro Reina, Reference Caro Reina2019; Bertinetto, Reference Bertinetto2021).
Yet, a phonological approach to rhythmic types will likely not yield discrete rhythm classes either. We suggest that phonological distinctions – or their absence – in a given language contribute to shaping its rhythmic signature in systematic ways. Not only the temporal dimension must be considered but also accentual metrical structure. As Jakobson (Reference Jakobson and Jakobson1962: 135) already recognized, distinctive quantity and distinctions in accent position come into conflict, since accentual prominence tends to be phonetically expressed by durational modifications as well (see Dufter, Reference Dufter2003: 126–129). Romance languages have almost entirely lost the distinctive vowel quantities of Classical Latin. Distinctive quantity in consonants has also been largely lost in Romance languages and in particular in the languages under consideration here, French, Spanish, and Portuguese. In contrast, word accent, whose position was clearly predictable in Classical Latin, has acquired some distinctive potential in all modern standard Romance languages except French (see Spanish término ‘term’ with antepenultimate stress versus termino ‘I finish’ with penultimate stress versus terminó ‘he/she/it finished’ with stress on the last syllable). In French, on the other hand, higher-level accentual prominence seems to serve primarily to demarcate phonological phrases, leading to a striking anisochrony of final lengthened syllables and phrase-internal syllables (see Figure 34.5). In this sense, we would like to echo Bertinetto’s (Reference Bertinetto2021) call for ‘studies targeting phonotactics and accentual texture’ for a better understanding of rhythmic differences between Romance languages and dialects.
To us, this indicates that although rhythmic metrics make a contribution of their own to the field, the phonetic realization is little more than the tip of a phonological iceberg. The intuitions and cognitive impacts of rhythm are related to an underlying principle that guides the phonetic surface rather than a constraint in the realization itself. Therefore, understanding accent and phrasing differences provides clues to the blueprint used by speakers to produce speech, which can be sometimes more or sometimes less rhythmic.
34.3 Rhythmic Performance
Perceived rhythmic differences in Romance may be explained partly as an outcome of the different phonological constellations employed to exploit time and prominence for systemic functions (demarcative lengthening of phrase-final syllables in French, distinctive stress in most other Romance languages). Nevertheless, we need to address the prosodic differences between Romance languages that are not related to those functions. Thus, we are dealing with prosodic configurations that are not tied to the construction of propositions and their discursive management but to preferences in timing and prominence relations, which should be regarded as rhythmic on the productive side of linguistic utterances.
We focus the discussion on Ibero Romance varieties and French, which are well documented and show a broad range of variation, due both to systemic differences and to rhythmic preferences (Vaissière, Reference Vaissière, Sundberg, Nord and Carlson1991; Abaurre and Galves, Reference Abaurre and Galves1998; Frota and Vigário, Reference Frota and Vigário2001; Reich, Reference Reich2002, Reference Reich, Meisenburg and Selig2004; Dufter, Reference Dufter2003, Dufter and Reich, Reference Dufter and Reich2003; Vigário, Reference Vigário2003; Reich and Rohrmeier, Reference Reich, Rohrmeier, Caro Reina and Szczepaniak2014, this volume; Caro Reina, Reference Caro Reina2019). The configurations of time and prominence work pretty much in the same way in these languages: lexical stress carries a few distinctive functions (both lexical and morphological) but is restricted to a three-syllable window at the end of words (see Roca, Reference Roca and van der Hulst1999).Footnote 1 In Ibero-Romance languages, lengthening is not a phonological rule, as in French, but a phonetic correlate of stressed and phrase-final syllables.
Rhythm has been treated in metrical phonology and related frameworks (Liberman and Prince, Reference Liberman and Prince1977; Hayes, Reference Hayes1995; Kager, Reference Kager1999) as a simple principle that attributes alternating strength to syllables or morae to construct metrical feet, such as trochees, iambs, or dactyls. In a more elaborated sense that spans different cognitive domains, rhythm refers to the optional performative behaviour with respect to abstract grids of relative prominence. Musicians, for example, may choose the level of a metrical grid they play on to vary the rhythmic characteristics of a piece of music (see Chapter 27). To put this into a simple schema, we can represent a four-quarter beat in a metrical grid in which musicians may play notes or beat a drum either on the base or any other level of a bar without violating the abstract representation of the metrical grid. It is possible to play on all, on the first and the third, or only on the first of a group of four beats in time, without changing the abstract grid (Figure 34.1).Footnote 2
Three levels of prominence.
In many languages, lexical stress is not projected by metrical algorithms but by lexical and morphological distinctivity, which is essential for the construction of meaning. Secondary prominence, however, gives rise to metrical feet, which are not involved in the construction of meaning.
Thus, speakers are almost as free as musicians, but with other instruments. By manipulating the sonority of vowels, speakers can pronounce all vowels maintaining all prominence levels, or pronounce only metrically strong vowels at the foot level by reducing or eliding metrically weak vowels, or, more radically, keep only the vowels that carry lexical stress. As long as the distinctive form of the phonological word can still be processed by hearers, all these options are in principle available.
European Portuguese (henceforth, EP) and Spanish from Bogotá, taken here as polar prototypes, differ the most in the phonetic realization of unstressed syllables. The preference for reduced, devoiced, and even elided vowels in non-prominent syllables in varieties of EP contrasts sharply with the strikingly stable vocalism across all metrical positions in Spanish.
If we take firstly an example from the IPA illustration of EP (Cruz-Ferreira, Reference Cruz-Ferreira1995) and contrast it with its correspondent form in Spanish, we see that an analogue analysis is possible.
In Figure 34.2, the words desistiu and desistió (‘gave up’) are schematically described regarding their phonetic realization and phonological structure. Note that in both versions of this word, the distinctive stress on the last syllable is not derived by the metrical assignment of strength but by a morphological rule that assigns values for tense, mood, aspect, person, and number based upon it: nearly all verb forms of third-person past perfect indicative carry final stress in both languages.Footnote 3 Therefore, it must be respected in order to construct meaning. All other levels are open for variation. The preference for the stress level in the rhythmic performance of word forms (indicated by the box at the stress level for EP and at the syllabic level for Spanish) leads speakers to omit the vowels of unstressed syllables. This, in turn, results in highly complex syllable structures with onsets that violate the sonority principle, since fricatives should not precede stops in onsets (Vennemann, 1988). Most speakers of Spanish select the base level and pronounce all syllabic nuclei, resulting in preferred syllable structures. The level of the foot may be selected as well, leading to the reduction/elision of weak vowels at the foot level, but we do not see evidence of this possibility in our data. In general, since rhythmic preferences in this sense are not involved in the lexical and morphosyntactic construction of meaning, they are less constrained by language-specific conventional rules (see Chapter 27). Thus, they should be accessible in all languages and free for individual and stylistic variation. Nevertheless, speech communities converge in preferred patterns.
Elision versus stability of sonority in unstressed syllables.

34.4 Experimental Data
To understand the variation of rhythmic performance as a conspiracy of systemic configurations and the selection of levels of prominence, we need to extend our study beyond undifferentiated consonantal and vocalic stretches of speech to the sonority of syllabic nuclei in different metrical positions. We conducted a production experiment to collect spoken data with participants who were born in the cities of Madrid, Bogotá, São Paulo, Lisbon, and Paris, and who spent at least their first 15 years there. In this experiment, they were asked to provide a short self-introduction, make touristic recommendations, and describe a recipe. Out of the 26 subjects (six for Madrid, six for Bogotá, two for São Paulo, six for Lisbon, six for Paris), we selected two recordings from each city, one from a female speaker, one from a male speaker, in which the productions were the most comparable (similar age and educational level of speakers, similar duration, same recipes). We chose such parts of our tasks that showed relaxed, semi-spontaneous speech and cross-linguistically comparable discourse traditions such as recipes, descriptions of walks, and introductions.
This interaction lasted around three minutes, of which short excerpts between 10 and 30 seconds were selected for annotation. We chose passages that were comparable with regard to their actual discourse move: explaining successive procedures in cooking, leading to a series of phrases with continuation rises. We further trimmed these excerpts in sequences of at least 18 randomly selected stressed syllables. The annotation was made up of five layers:Footnote 4
1. orthographic transcription;
2. basic differences of the sonority of syllabic nuclei on different metrical positions in two categories: full and reduced;Footnote 5
3. number of realized syllables among all canonical syllables to measure elision rates;
4. lexical stresses: in the case of French, we treated phrase-final syllables as stressed in order to make the data more comparable;
5. edges of phonological phrases (without further differentiation).
Sonority was perceptually assigned by the first two authors. The annotated data was processed through Praat (Boersma and Weenink, Reference Boersma and Weenink2023) and RStudio (RStudio Team, 2023) to extract the following measures, which will be presented in Section 34.4.2:
(i) number of canonical syllables;
(ii) number of realized syllables;
(iii) proportion of realized syllables among all canonical syllables;
(iv) number of reduced unstressed syllables;Footnote 6
(v) number of non-reduced unstressed syllables;
(vi) proportion of reduction among all unstressed syllables;
(vii) minimum and maximum of fundamental frequency (F0) before stressed, in stressed, and after stressed syllables;
(viii) intensity before stressed, in stressed, and after stressed syllables.
We start with examples before we turn to a quantitative overview. We show spectrograms, intensity, and F0 contours, the targets of which we annotated in standard ToBI (tones and break indices) labels. We added an IPA transcription, labelled the nuclei of syllables as ‘full (f)’ or ‘reduced (r)’, and indicated the positions of stresses and edges of phonological phrases.
34.4.1 Examples
Our first example is taken from a speaker from Lisbon (Figure 34.3).
An utterance from a speaker from Lisbon.

Figure 34.3 Long description
The levels are as follows. Spectrogram: It plots a fluctuating line of sound's frequency and intensity over time. Text. It includes a spoken sentence in a foreign language. Tones: This includes L percent, L asterisk H and H percent. I P A Transcription: This shows the precise phonetic representation of each sound. Stress: Indicates the stressed syllables in the sentence that are marked with asterisks. Edges: Includes symbols like hyphen and percentage.
This example shows a preference for prominence at the word stress level: all other nuclei are centralized or devoiced in articulation and thus reduced in sonority. Intonation and intensity seem to not contribute to a regular rhythmic pattern: only the nuclear configuration at the right boundary shows salient tonal events, with a rising pitch accent and a high boundary tone. Intensity does not seem to vary between sonority peaks. The fact that the duration of unstressed cor is longer than stressed ta in cortada seems to suggest that duration in this case is correlated more to conversational hesitation (just as in the following em) than to metrical positions. In all other cases, unstressed syllables are shorter or show similar duration. Clearly, it is the sonority of syllabic nuclei that shows rhythmic alternation of strength.
This configuration is very different to what we find in Spanish from Bogotá (Figure 34.4).
An utterance from a speaker from Bogotá.
Figure 34.4 Long description
The levels are as follows. Spectrogram: It plots a fluctuating line and a broken line of sound's frequency and intensity over time. Text. It includes a spoken sentence in a foreign language. Tones: This includes L asterisk and H percent. I P A Transcription: This shows the precise phonetic representation of each sound. Stress: Indicates the stressed syllables in the sentence that are marked with asterisks. Edges: Includes symbols like hyphen and percentage.
All but one syllabic nuclei are realized with full sonority. We see late rising pitch accents (L*+H) and high tones at both final boundaries. Both papa (‘potato’) and especias (‘spices’) show differences with respect to intensity, the stressed syllables being clearly louder than the following unstressed syllables. Just as in the example from EP, though, intonation is basically limited to the nuclear configurations at the final edges of phonological phrases.
Figure 34.5 illustrates yet another configuration in an utterance by a Parisian speaker.
An utterance from a speaker from Paris.
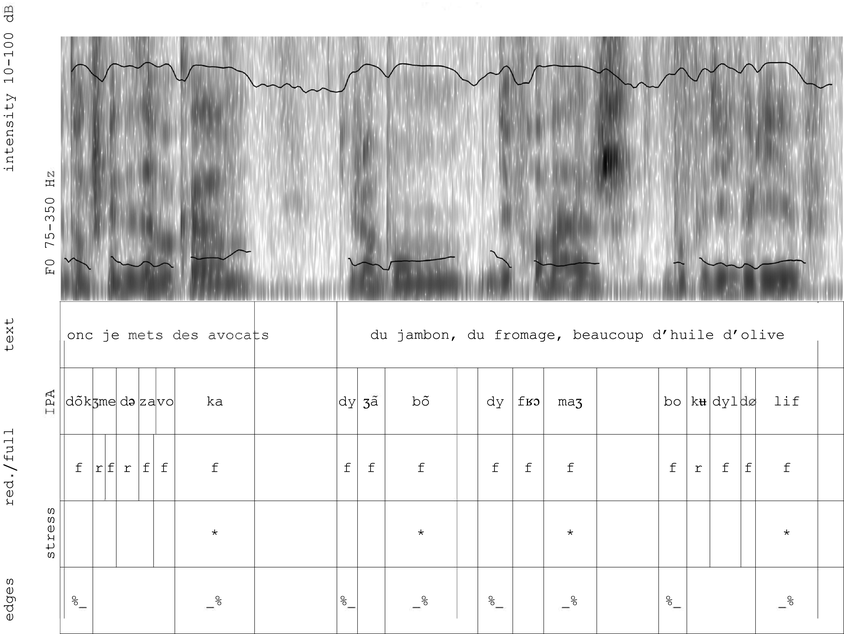
Figure 34.5 Long description
The levels are as follows. Spectrogram: It plots a fluctuating line and a broken line of sound's frequency and intensity over time. Text. It includes a spoken sentence in a foreign language. Tones: This includes L asterisk and H percent. I P A Transcription: This shows the precise phonetic representation of each sound. Stress: Indicates the stressed syllables in the sentence that are marked with asterisks. Edges: Includes symbols like hyphen and percentage.
The most salient feature of this chain of four phonological phrases is the lengthening of their final syllables. With the exception of the final fall, no tonal movement can be analyzed here, which is why we dropped the analytical line for tones. Only three out of 17 syllable nuclei have been reduced and only one (the clitic subject pronoun je) has been elided. The intensity also shows no interpretable contrasts. This is a radical example of the phonology sketched above: lengthening is the decisive cue for edges of phrases and the most salient feature of the rhythm of French, setting it clearly apart from other Romance languages.
34.4.2 Quantitative Overview
No inferential statistics have been carried out, due primarily to the small sample but also to the high variation between speakers of the same language that reflects the optional nature of rhythmic preferences. The rhythmic design of utterances as such (set apart from perceived rhythm due to systemic functions of time and prominence outlined in Section 34.1.2) is a prosodic option that shows only preferences within linguistic communities and should not be treated as a rule of grammar. This is probably one of the reasons why the Portuguese utterances in Dufter and Reich (Reference Dufter and Reich2003) were confused with Spanish: due to the similarity of the systemic functions of prominence and timing, speakers are free to make individual choices between different rhythmic options.
A descriptive quantification of the parameters of our data partly shows the expected configurations but also yields some unexpected results, as shown in Table 34.1.
| Paris | Lisbon | São Paulo | Bogotá | Madrid | |
|---|---|---|---|---|---|
| (i) number of canonical syllables | 118 | 104 | 86 | 86 | 104 |
| (ii) number of realized syllables | 97 | 90 | 82 | 85 | 93 |
| (iii) proportion of realized/all canonical syllables | 0.822 | 0.865 | 0.953 | 0.988 | 0.894 |
| (iv) number of non-reduced unstressed syllables | 63 | 23 | 27 | 51 | 49 |
| (v) number of reduced unstressed syllables | 6 | 30 | 21 | 7 | 10 |
| (vi) proportion of reduced/all unstressed syllables | 0.087 | 0.566 | 0.429 | 0.121 | 0.169 |
The first two lines count possible syllables projected onto the segemental string (i), the syllables that speakers elided from this projection (ii). The third line informs about the proportion of elided out of all possible syllables (iii), independent of their metrical position. Interestingly, the variety that elides most is not EP, taken to be the most ‘stress-timed’ within the Romance languages, but Parisian French, a language that represented a prototype for ‘syllable-timing’ in many early approaches (see Section 34.1). This might find an explanation in the phrase-based prosody of French. Recall that we labeled phrase-final syllables as ‘stressed’, as it has become the practice in many works on French phonology (see Gendrot et al., Reference Gendrot, Adda-Decker, Santiago, Gibson and Gil2019, among many others). These occur less often than the lexical stresses of Spanish and Portuguese. Thus, there are fewer syllables that may be elided in these languages than in French.Footnote 7 Our speakers from Bogotá are those who elided fewer syllabic nuclei than all others, followed by the speakers from São Paulo. The measures from (iv) to (vi) shows us the reduction rate in unstressed syllables. As expected, both varieties of Portuguese show far more vowel reduction processes than both varieties of Spanish and French, with Lisbon leading the whole group (values (iv) and (v) and the proportion in (vi)). Thus, taking elision and reduction together, the Bogotá speakers’ performance most closely resembles that of a ‘syllable-timed language’ (see Section 34.1). We may refer to this configuration as a baseline rhythm.
If we look at the mean progression of F0 in different metrical positions (viii), we basically find differences in scaling but not in the overall picture of uptrends and downtrends, which would be required to motivate different regular patterns. The data presented in Table 34.2 are F0 values for minimum and maximum values before, during, and after stressed syllables for male and female speakers combined in each variety.
| Paris | Lisbon | São Paulo | Bogotá | Madrid | |
|---|---|---|---|---|---|
| Min F0 before stressed | 144,987 | 160,87 | 174,872 | 140,172 | 155,862 |
| Max F0 before stressed | 253,613 | 185,743 | 214,955 | 232,881 | 168,116 |
| Min F0 stressed | 155,091 | 162,333 | 170,069 | 154,802 | 157,046 |
| Max F0 stressed | 338,446 | 193,206 | 222,884 | 193,288 | 193,669 |
| Min F0 after stressed | 169,514 | 173,649 | 185,511 | 157,037 | 164,294 |
| Max F0 after stressed | 363,214 | 201,488 | 229,715 | 214,937 | 191,876 |
The fact that all languages show a rising general contour may partly be due to the fact that many utterances in our corpus correspond to lists (of ingredients and procedures for recipes) couched in phonological phrases with cross-linguistically expectable continuation rises at the edges following a focused content word: the tones show rises through the accented syllables, in the case of French, also initial rises (Max F0 after stressed), which prove to be far from optional. This configuration again corroborates that both boundaries of the phonological phrase are salient positions in the prosodic configuration of this language. All Iberian varieties show also a smooth rise through the stressed syllables, with the exception of Bogotá, where our data seem to suggest a fall, since maximum F0 is higher before stressed syllables than on them. What is important in the observation of F0 in our data is that the intonational contour follows pragmatic rather than rhythmic functionality and thus may not serve to entrain rhythmic patterns.
The observation of intensity reveals some interesting results. As before, Table 34.3 presents values for male and female speakers of each variety combined, in this case for intensity regarding the stressed syllable and its adjacent syllables.
| Paris | Lisbon | São Paulo | Bogotá | Madrid | |
|---|---|---|---|---|---|
| before stressed | 68,64 | 68,396 | 66,832 | 71,046 | 68,218 |
| stressed | 70,352 | 73,231 | 69,596 | 72,533 | 71,673 |
| after stressed | 71,439 | 70,474 | 67,185 | 71,436 | 70,654 |
The data from Lisbon and São Paulo show the sharpest difference between unstressed and stressed syllables, while the speakers from Bogotá exhibit the smallest difference for this parameter. Our data from Madrid show less intensity before stress than the data from Bogotá, thus corroborating the results from the observation of sonority. Again, the data from Paris confirm our observation of F0: it is not only final lengthening but also the salient configuration of initial edges that set up the phrase as the pivotal domain of French, as is evidenced by the high value for syllables after ‘stressed’ syllables that refer to phrase-initial syllables. With respect to rhythm, we see that parameters that are not related to systemic functions, such as sonority and intensity, are the best parameters for eurhythmic performance.
34.5 Conclusions and Outlook
We traced phonetic and phonological approaches to linguistic rhythm through nearly a century of research and projected their perspectives on to Romance languages. What should have become clear is the fact that this family of languages contains very different siblings that employ very different types of rhythm. In many respects, French appears as the odd one out within the modern Romance languages, and its rhythm is no exception. It has lost the lexical stress that other Romance languages inherited from Latin and uses timing and tuning to profile the phonological phrase as its most salient domain. By contrast, Spanish and Portuguese both exhibit similar phonological regularities in word stress placement and lack segmental quantity distinctions. Even so, they turn out to differ strikingly in the degree of accentual prominence. In our data from Lisboan Portuguese, unstressed syllables are more likely to undergo weakening or elision than in São Paulo Portuguese and far more than in the Spanish varieties from Madrid and especially from Bogotá.
Many questions arise from this general picture. Firstly, weakening and elision are not processes that may apply without restrictions, since they blur the distinctive potential of word forms that may then no longer be understood. The thresholds at which rhythmic reduction begins to impair comprehensibility are far from well understood, but they represent an important perspective for studies in second-language acquisition and contact linguistics. Also, more refinement of our analysis is needed. Thus, the need to control for the role of foot construction in the reduction processes across Romance is imperative, since it could suggest that metrically weak unstressed syllables are more prone to reduction than strong unstressed syllables. Italian is a language with very-well-documented dialects that offers promising empirical grounds for research in this direction. In a more theoretical perspective, rhythmic variation that is not a consequence of phonological timing and distinctive prominence. Instead it might be a consequence of speaker-specific choices, similar to the performance changes in music. The selection of levels of prominence in the performance of a piece of music can be, as shown, compared to the strengthening and weakening of unstressed vowels in language.
Summary
Our contribution offers an overview of phonetic and phonological approaches to linguistic rhythm and their application to the study of rhythmic differences within Romance. We argue that systematic cross-linguistic and cross-dialectal differences partly follow from different phonological functions of prominence and timing and partly from routinized rhythmic interpretations of metrical prominence structure.
Implications
We argue for a distinction between systemic and behavioral parameters to describe linguistic rhythm. The rhythm of individual utterances results both from the phonological functions of prominence and timing tiers, and the language-specific interpretations of prominent and non-prominent positions. Romance languages and dialects provide an ideal testing ground for studying rhythmic macro- and micro-variation.
Gains
An approach to linguistic rhythm that seeks to disentangle (i) functional phonological determinants (such as contrastive stress and distinctive segment and syllable duration), (ii) language-specific rhythmic preferences, and (iii) performance at the level of individual utterances may advance our understanding of underlying cognitive rhythmic preferences, despite ubiquitous variation related to speaker, speech style, and other facets of speech.
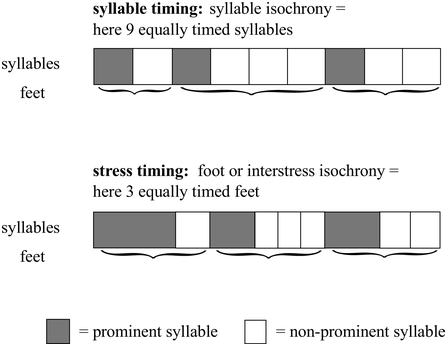
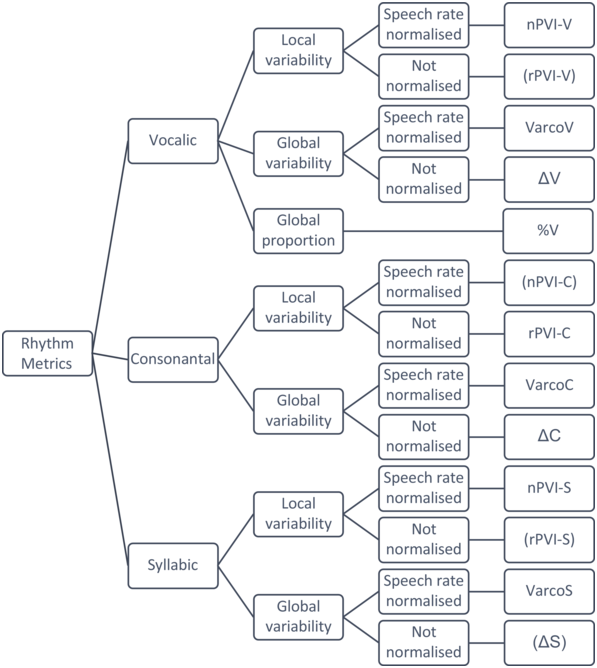
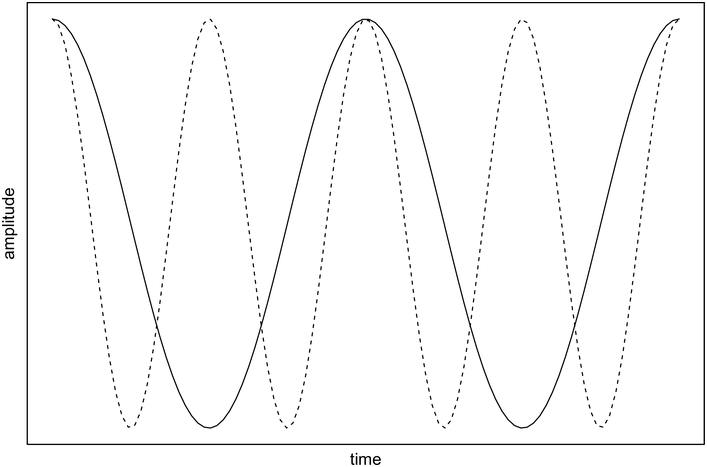
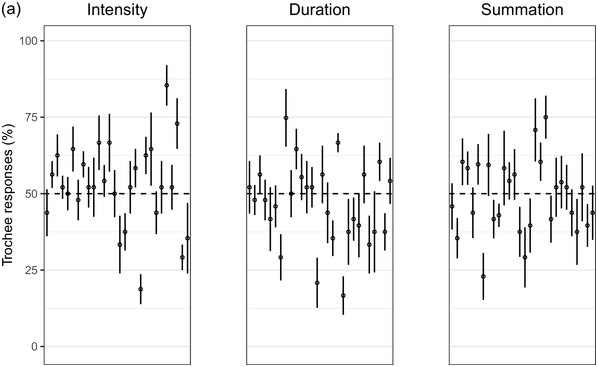
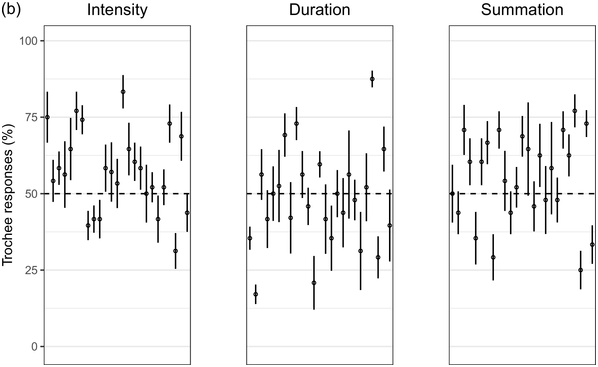
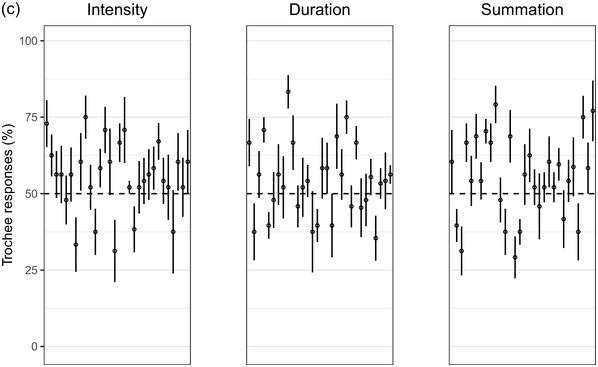
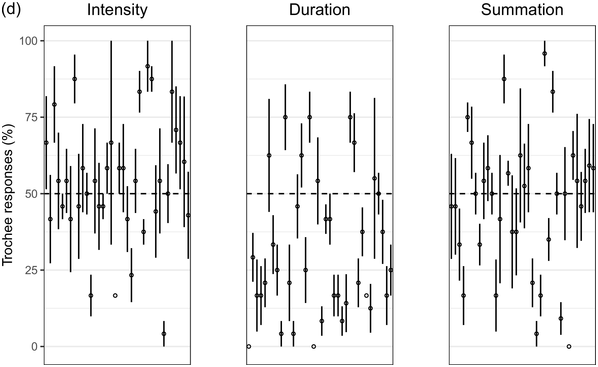
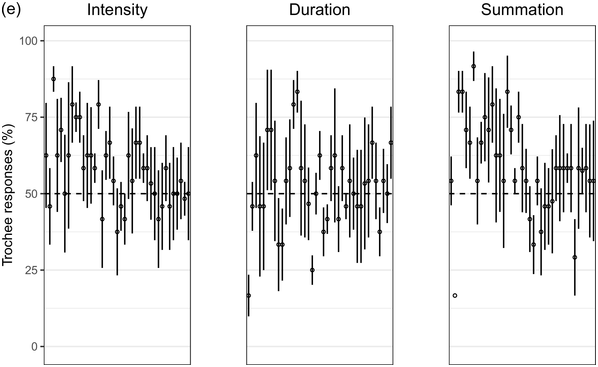
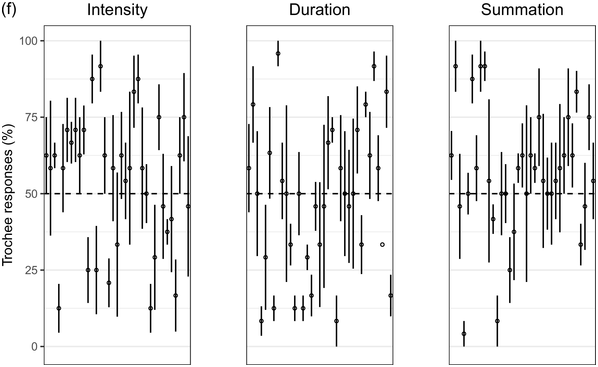


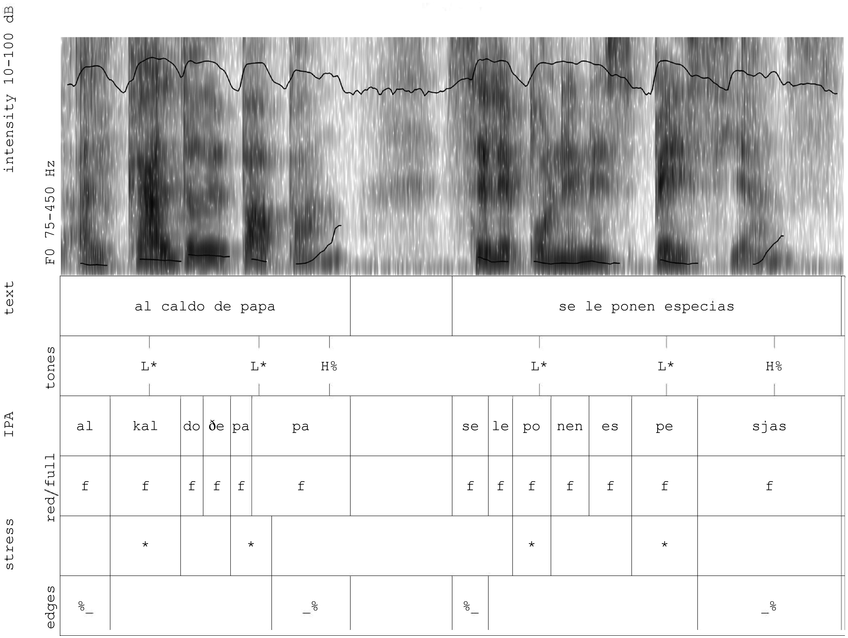
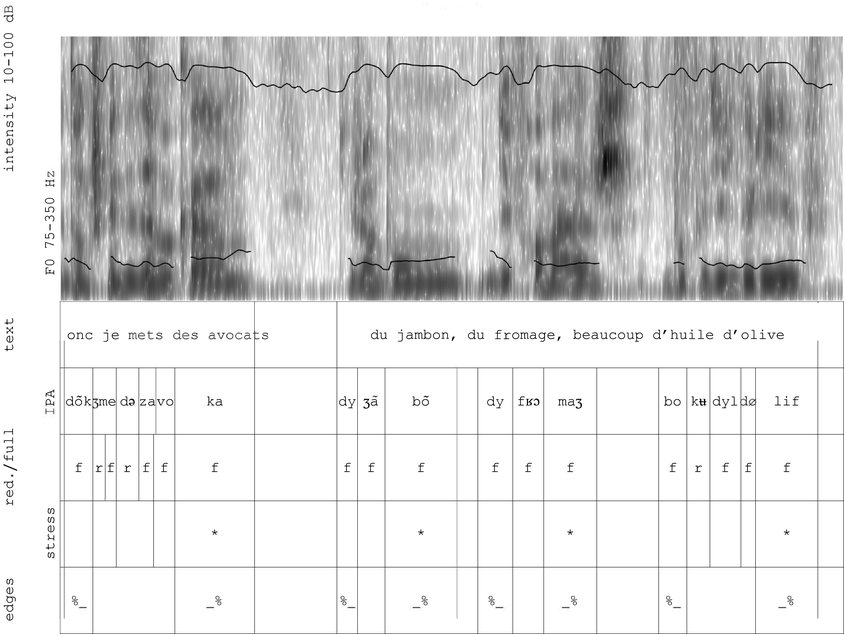

 Open access
Open access