


1. Introduction
The upcoming Solvency II directive regulates the amount of capital that insurance companies must hold to reduce the risk of insolvency. In the directive’s standard model, capital charges are calculated using a scenario-based approach, and the solvency capital requirement (SCR) is given as the difference between the present value under best estimate assumptions and the present value under a certain stress scenario. The SCR is computed on a risk-by-risk level, and then aggregated using predetermined correlation matrices.
For disability insurance, perhaps the most important risk is recovery risk, i.e., the risk that the policy holder receives the payments for a longer period of time than anticipated, i.e. that claim termination rates are lower than anticipated. The Revised Technical Specifications for the Solvency II Valuation and Solvency Capital Requirements Calculations (Part I) (European insurance and occupational pensions authority (EIOPA), 2012) include shocks to disability inception and termination rates. The suggested shock for recovery risk involves a decrease of 20% in termination rates for the following 12 months and for all years thereafter.
As an alternative to the standard stress scenario, insurers may adopt an internal model, which should be based on a value-at-risk approach. The SCR is then given by the difference between the best estimate, which corresponds to the expected value, and the 99.5% quantile of the value of the benefits in 1 year, including benefits paid during the 1st year. Determining this quantile is typically a high-dimensional problem that requires simulation techniques. Levantesi & Menzietti (Reference Levantesi and Menzietti2012) estimate SCR under stochastic disability and mortality using simulation methods. Their approach covers both systematic and idiosyncratic risk, and is suitable for small portfolios.
In order to reduce the computational complexity of the problem, scenario analysis and approximation methods may be used. Christiansen & Steffensen (Reference Christiansen and Steffensen2013) and Christiansen et al. (Reference Christiansen, Henriksen, Schomacker and Steffensen2016) develop a safe-side scenario approach for the estimation of SCR using dynamic programming techniques. Christiansen et al. (Reference Christiansen, Denuit and Lazar2012) suggest an internal model for Solvency II based on linearisation and Gaussian approximations.
In this paper, we consider an extension of the conditional independence model suggested in Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014 b), where the individuals in a large life insurance portfolio are assumed independent, conditional on a stochastic process representing the economic–demographic environment. Using the conditional law of large numbers (CLLN), we show that if the portfolio becomes large enough, the future liability value can be approximated by a functional of the environment process. This result indicates that the idiosyncratic risks can be diversified away, so that only the systematic risk, i.e. the risk that the environment changes, remains. Based on this representation, we derive a semi-analytical approximation of the systematic risk quantiles of the future liability value for a homogeneous portfolio when the environment is represented by a one-factor diffusion process. For the multi-factor diffusion case, we propose two different risk aggregation techniques for a portfolio consisting of large and homogeneous pools based on the variance–covariance method and convex optimisation techniques, respectively. Finally, we present numerical results based on disability claims data from the Swedish insurance company Folksam, and compare the resulting capital charges with the Solvency II standard method.
The paper is organised as follows: in section 2, we introduce a conditional independence model with associated payment streams and calculate the value of the liabilities at a general δ-year horizon. In section 3, we consider aggregation of δ-year risks for large insurance portfolios based on the CLLN. In section 4, we derive a semi-analytical approximation for homogeneous portfolios. In section 5, we propose two different SCR aggregation methods for portfolios consisting of large, homogeneous pools. In section 6, we present numerical results based on disability claims data from the Swedish insurance company Folksam.
2. A Conditional Independence Model
In this section, we extend the conditional independence model suggested in Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014 b). Let τ 1, τ 2, … be random event times (e.g. times of death or recovery from disability), and let
 $$N_{t}^{k} {\,\equals\,}I\{ \tau ^{k} \leq t\} ,\,\,\,\,\,k\geq 1$$
$$N_{t}^{k} {\,\equals\,}I\{ \tau ^{k} \leq t\} ,\,\,\,\,\,k\geq 1$$
so that
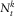 $$N_{t}^{k} $$
denotes the state of an insured individual at time t (e.g. alive/dead or disabled/recovered). Further, define the processes
$$N_{t}^{k} $$
denotes the state of an insured individual at time t (e.g. alive/dead or disabled/recovered). Further, define the processes
 $$N^{k} {\,\equals\,}(N_{t}^{k} )_{{t\geq 0}} ,\,\,\,\,\,k\geq 1$$
$$N^{k} {\,\equals\,}(N_{t}^{k} )_{{t\geq 0}} ,\,\,\,\,\,k\geq 1$$
and let
 $${\cal F}^{N} {\,\equals\,}({\cal F}_{t}^{N} )_{{t\geq 0}} {\,\equals\,}({\cal F}_{t}^{{N^{1} }} \vee{\cal F}_{t}^{{N^{2} }} \vee\,\!\ldots\!)_{{t\geq 0}} $$
$${\cal F}^{N} {\,\equals\,}({\cal F}_{t}^{N} )_{{t\geq 0}} {\,\equals\,}({\cal F}_{t}^{{N^{1} }} \vee{\cal F}_{t}^{{N^{2} }} \vee\,\!\ldots\!)_{{t\geq 0}} $$
denote the filtration generated by N
1, N
2, … . Let Z be a càdlàg process taking values in
 $${\Bbb R}^{m} $$
with natural filtration
$${\Bbb R}^{m} $$
with natural filtration
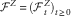 $${\cal F}^{Z} {\,\equals\,}({\cal F}_{t}^{Z} )_{{t\geq 0}} $$
. We let Z
t
represent the state of the economic–demographic environment at time t. Define the filtration
$${\cal F}^{Z} {\,\equals\,}({\cal F}_{t}^{Z} )_{{t\geq 0}} $$
. We let Z
t
represent the state of the economic–demographic environment at time t. Define the filtration
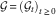 $${\cal G}{\,\equals\,}({\cal G}_{t} )_{{t\geq 0}} $$
by
$${\cal G}{\,\equals\,}({\cal G}_{t} )_{{t\geq 0}} $$
by
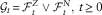 $${\cal G}_{t} {\,\equals\,}{\cal F}_{t}^{Z} \vee{\cal F}_{t}^{N} ,\;t\geq 0$$
. We assume that N
1, N
2, … are independent, conditional on
$${\cal G}_{t} {\,\equals\,}{\cal F}_{t}^{Z} \vee{\cal F}_{t}^{N} ,\;t\geq 0$$
. We assume that N
1, N
2, … are independent, conditional on
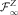 $${\cal F}_{\infty}^{Z} $$
, and that the
$${\cal F}_{\infty}^{Z} $$
, and that the
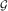 $${\cal G}$$
intensity of N
k
is the process
$${\cal G}$$
intensity of N
k
is the process
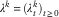 $$\lambda ^{k} {\,\equals\,}(\lambda _{t}^{k} )_{{t\geq 0}} $$
defined by
$$\lambda ^{k} {\,\equals\,}(\lambda _{t}^{k} )_{{t\geq 0}} $$
defined by
 $$\lambda _{t}^{k} {\,\equals\,}q_{x} (t,Z_{{t^{{\minus}} }} \!)(1{\minus}N_{{t^{{\minus}} }}^{k} \!),\,\,\,\,\,t\geq 0$$
$$\lambda _{t}^{k} {\,\equals\,}q_{x} (t,Z_{{t^{{\minus}} }} \!)(1{\minus}N_{{t^{{\minus}} }}^{k} \!),\,\,\,\,\,t\geq 0$$
where x is a parameter representing e.g. the age of the insured and
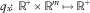 $$q_{x} \!\colon\,{\Bbb R}^{{\!\plus}} {\times}{\Bbb R}^{m} \,\mapsto\,{\Bbb R}^{{\!\plus}} $$
is the transition rate function corresponding to x, here assumed continuous. Now, consider an insurance policy with payment stream A
k
given by
$$q_{x} \!\colon\,{\Bbb R}^{{\!\plus}} {\times}{\Bbb R}^{m} \,\mapsto\,{\Bbb R}^{{\!\plus}} $$
is the transition rate function corresponding to x, here assumed continuous. Now, consider an insurance policy with payment stream A
k
given by
 $$dA_{t}^{k} {\,\equals\,}g_{x} (t,Z_{t} )(1{\minus}N_{t}^{k} )dt{\plus}h_{x} (t,Z_{{t^{{\minus}} }} \!)dN_{t}^{k} ,\,\,\,\,\,t\leq T_{x} $$
$$dA_{t}^{k} {\,\equals\,}g_{x} (t,Z_{t} )(1{\minus}N_{t}^{k} )dt{\plus}h_{x} (t,Z_{{t^{{\minus}} }} \!)dN_{t}^{k} ,\,\,\,\,\,t\leq T_{x} $$
The policy pays g
x
(t, Z
t
) continuously, as long as
 $$N_{t}^{k} {\,\equals\,}0$$
, until a fixed future time T
x
. In addition, if the event time τ
k
is reached before T
x
, the policy immediately pays a lump sum of
$$N_{t}^{k} {\,\equals\,}0$$
, until a fixed future time T
x
. In addition, if the event time τ
k
is reached before T
x
, the policy immediately pays a lump sum of
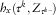 $$h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)$$
. This type of policy allows for payments from the contract to depend on time as well as on the state of the economic–demographic environment and the age of the insured. For example, the contract could be inflation linked and contain a deferred period.
$$h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)$$
. This type of policy allows for payments from the contract to depend on time as well as on the state of the economic–demographic environment and the age of the insured. For example, the contract could be inflation linked and contain a deferred period.
When considering insurance portfolios, it is often convenient to form pools or sub-populations consisting of individuals with similar descriptive statistics, e.g. age, gender, income, etc. Reserves and risk measures for the portfolio can then be obtained by calculating the corresponding quantity for each pool, and then aggregating the results in a suitable way. To this end, let X denote a finite set of age groups, and let
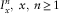 $$I_{x}^{n} ,\;x\inX,\;n\geq 1$$
denote the index set of individuals with disability inception age x in a portfolio of n policies. Obviously, we must have
$$I_{x}^{n} ,\;x\inX,\;n\geq 1$$
denote the index set of individuals with disability inception age x in a portfolio of n policies. Obviously, we must have
 $$\mathop{\sum}\limits_{x \in X} {\left| {I_{x}^{n} } \right|{\,\equals\,}n} $$
$$\mathop{\sum}\limits_{x \in X} {\left| {I_{x}^{n} } \right|{\,\equals\,}n} $$
Now, define the random present value
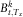 $$B_{{t,T_{x} }}^{k} $$
of a single policy by
$$B_{{t,T_{x} }}^{k} $$
of a single policy by
 $$B_{{t,T_{x} }}^{k} {\,\equals\,}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} dA_{s}^{k} } $$
$$B_{{t,T_{x} }}^{k} {\,\equals\,}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} dA_{s}^{k} } $$
where the short rate r is assumed to be adapted to
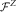 $${\cal F}^{Z} $$
. The random present value
$${\cal F}^{Z} $$
. The random present value
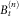 $$B_{t}^{{(n)}} $$
of the portfolio can then be defined by
$$B_{t}^{{(n)}} $$
of the portfolio can then be defined by
 $$B_{t}^{{(n)}} {\,\equals\,}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,T_{x} }}^{k} } $$
$$B_{t}^{{(n)}} {\,\equals\,}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,T_{x} }}^{k} } $$
For some δ≥0 denoted by
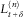 $$L_{{t{\plus}\delta }}^{{(n)}} $$
, the expected value of the portfolio liabilities at time t+δ, given information about the population and environment processes up to time t+δ. We have
$$L_{{t{\plus}\delta }}^{{(n)}} $$
, the expected value of the portfolio liabilities at time t+δ, given information about the population and environment processes up to time t+δ. We have
 $$\eqalignno{ L_{{t{\plus}\delta }}^{{(n)}} = & E\left[ {B_{t}^{{(n)}} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & =\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,t{\plus}\delta }}^{k} } {\plus}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle \kappa \in I_{x}^{n} \hfill} {e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {r_{u} du} }} } E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] $$
$$\eqalignno{ L_{{t{\plus}\delta }}^{{(n)}} = & E\left[ {B_{t}^{{(n)}} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & =\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,t{\plus}\delta }}^{k} } {\plus}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle \kappa \in I_{x}^{n} \hfill} {e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {r_{u} du} }} } E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] $$
where the first term represents the payments from t to t+δ, and the second term represents the value of the liabilities payable from t+δ until the end of the contracts. Using the martingale property of the compensated processes
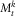 $$M_{t}^{k} $$
defined by
$$M_{t}^{k} $$
defined by
 $$M_{t}^{k} {\,\equals\,}N_{t}^{k} {\minus}{\int}_0^t {\lambda _{s}^{k} ds} $$
$$M_{t}^{k} {\,\equals\,}N_{t}^{k} {\minus}{\int}_0^t {\lambda _{s}^{k} ds} $$
together with the assumption that Z is càdlàg, we obtain
 $$\eqalignno{ E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & \quad {\plus}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } h_{x} (s,Z_{{^{{s^{{\minus}} }} }} \!)dN_{s}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & \quad {\plus}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } h_{x} (s,Z_{{^{{s^{{\minus}} }} }} \!)\lambda _{s}^{k} ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } (1{\minus}N_{s}^{k} )\tilde{g}_{x} (s,Z_{s} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] $$
$$\eqalignno{ E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & \quad {\plus}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } h_{x} (s,Z_{{^{{s^{{\minus}} }} }} \!)dN_{s}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & \quad {\plus}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } h_{x} (s,Z_{{^{{s^{{\minus}} }} }} \!)\lambda _{s}^{k} ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } (1{\minus}N_{s}^{k} )\tilde{g}_{x} (s,Z_{s} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] $$
where
 $$\tilde{g}_{x} (s,Z_{s} ){\,\equals\,}g_{x} (s,Z_{s} ){\plus}h_{x} (s,Z_{s} )q_{x} (s,Z_{s} )$$
$$\tilde{g}_{x} (s,Z_{s} ){\,\equals\,}g_{x} (s,Z_{s} ){\plus}h_{x} (s,Z_{s} )q_{x} (s,Z_{s} )$$
If the environment process Z is Markov, it follows from (Djehiche & Löfdahl, Reference Djehiche and Löfdahl2014 b, proposition 1) that
 $$\eqalignno{ E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e\,^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } (1{\minus}N_{s}^{k} )\tilde{g}_{x} (s,Z_{s} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}(1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
$$\eqalignno{ E\left[ {B_{{t{\plus}\delta ,T_{x} }}^{k} \left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] & {\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {e\,^{{{\minus}{\int}_{t{\plus}\delta }^s {r_{u} du} }} } (1{\minus}N_{s}^{k} )\tilde{g}_{x} (s,Z_{s} )ds\left| {{\cal G}_{{t{\plus}\delta }} } \right.} \right] \cr & {\,\equals\,}(1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
where
 $$v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ){\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {\tilde{g}_{x} (s,Z_{s} )e^{{{\minus}{\int}_{t{\plus}\delta }^s {(q_{x} (u,Z_{u} ){\plus}r_{u} )du} }} } ds\left| {Z_{{t{\plus}\delta }} } \right.} \right]$$
$$v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ){\,\equals\,}E\left[ {{\int}_{t{\plus}\delta }^{T_{x} } {\tilde{g}_{x} (s,Z_{s} )e^{{{\minus}{\int}_{t{\plus}\delta }^s {(q_{x} (u,Z_{u} ){\plus}r_{u} )du} }} } ds\left| {Z_{{t{\plus}\delta }} } \right.} \right]$$
Let
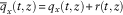 $\bar{q}_{x} (t,z){\,\equals\,}q_{x} (t,z){\plus}r(t,z)$
, and assume that
$\bar{q}_{x} (t,z){\,\equals\,}q_{x} (t,z){\plus}r(t,z)$
, and assume that
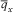 $\bar{q}_{x} $
is lower bounded,
$\bar{q}_{x} $
is lower bounded,
 $\tilde{g}_{x} $
is continuous and bounded, and that Z is a Markov process with infinitesimal generator
$\tilde{g}_{x} $
is continuous and bounded, and that Z is a Markov process with infinitesimal generator
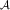 $${\cal A}$$
. Then, v
x
(t, z) given by (6) satisfies the Feynman–Kac partial differential equation (PDE)
$${\cal A}$$
. Then, v
x
(t, z) given by (6) satisfies the Feynman–Kac partial differential equation (PDE)
 $$\left\{\! \matrix{ {\minus}{{\partial v_{x} } \over {\partial s}}{\plus}\bar{q}_{x} (s,z)v_{x} {\,\equals\,}{\cal A}v_{x} {\plus}\tilde{g}_{x} (s,z),\quad t{\plus}\delta \leq s\,\lt\,T_{x} \hfill \cr v_{x} (T_{x} ,z){\,\equals\,}0 \hfill \cr} \right.$$
$$\left\{\! \matrix{ {\minus}{{\partial v_{x} } \over {\partial s}}{\plus}\bar{q}_{x} (s,z)v_{x} {\,\equals\,}{\cal A}v_{x} {\plus}\tilde{g}_{x} (s,z),\quad t{\plus}\delta \leq s\,\lt\,T_{x} \hfill \cr v_{x} (T_{x} ,z){\,\equals\,}0 \hfill \cr} \right.$$
Using (4) and (5), the portfolio value at the δ-year horizon is given by
 $$L_{{t{\plus}\delta }}^{{(n)}} =\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,t{\plus}\delta }}^{k} } {\plus}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {r_{u} du} }} } (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} )$$
$$L_{{t{\plus}\delta }}^{{(n)}} =\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {B_{{t,t{\plus}\delta }}^{k} } {\plus}\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {r_{u} du} }} } (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} )$$
The first sum represents the discounted payments between t and t+δ. The second sum represents the following: for each policy that has not reached its corresponding event time τ k before t+δ, the value of the remaining liabilities is given by v x (t+δ, Z t+δ ). This value is then discounted back to time t.
Having computed the future value of the portfolio, we turn to the task of determining the capital requirement, i.e. determining the corresponding conditional quantiles.
3. SCR and the CLLN
In this section, we consider the problem of calculating the SCR for a large insurance portfolio. In the Solvency II directive, the key quantity of interest is a particular conditional quantile of
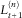 $$L_{{t{\plus}1}}^{{(n)}} $$
, the value of the portfolio in 1 year from now, defined by (8) with δ=1. Determining this quantile is an infinite-dimensional problem, since
$$L_{{t{\plus}1}}^{{(n)}} $$
, the value of the portfolio in 1 year from now, defined by (8) with δ=1. Determining this quantile is an infinite-dimensional problem, since
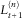 $$L_{{t{\plus}1}}^{{(n)}} $$
depends on
$$L_{{t{\plus}1}}^{{(n)}} $$
depends on
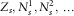 $$Z_{s} ,N_{s}^{1} ,N_{s}^{2} ,\,\ldots\!$$
, for each s∈[t, t+1]. In general, it is not possible to determine the quantiles exactly. They can sometimes be estimated by simulation methods, at least if the portfolio is small enough. For a large portfolio with conditionally independent policies, it is convenient to disregard the idiosyncratic risks associated with each individual policy, and focus on estimating the systematic risk carried by the environment process Z. This idea is formalised by the following version of the CLLN. We state the result on a general δ-year horizon.
$$Z_{s} ,N_{s}^{1} ,N_{s}^{2} ,\,\ldots\!$$
, for each s∈[t, t+1]. In general, it is not possible to determine the quantiles exactly. They can sometimes be estimated by simulation methods, at least if the portfolio is small enough. For a large portfolio with conditionally independent policies, it is convenient to disregard the idiosyncratic risks associated with each individual policy, and focus on estimating the systematic risk carried by the environment process Z. This idea is formalised by the following version of the CLLN. We state the result on a general δ-year horizon.
Proposition 1 Assume that q
x
and r are non-negative, that |g
x
|≤m
g
<∞, |h
x
|≤m
h
<∞, |T
x
|≤m
T
<∞, and that Z is a Markov process with infinitesimal generator
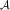 $${\cal A}$$
. Then, for δ≥0, conditional on
$${\cal A}$$
. Then, for δ≥0, conditional on
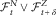 $${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
$${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
 $$\mathop {{\rm lim}}\limits_n \left( {{1 \over n}L_{{t{\plus}\delta }}^{{(n)}} \,{\minus}\,E\left[ {{1 \over n}L_{{t{\plus}\delta }}^{{(n)}} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]} \right){\,\equals\,}0\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
$$\mathop {{\rm lim}}\limits_n \left( {{1 \over n}L_{{t{\plus}\delta }}^{{(n)}} \,{\minus}\,E\left[ {{1 \over n}L_{{t{\plus}\delta }}^{{(n)}} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]} \right){\,\equals\,}0\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
Proof: Let
 $L_{{t{\plus}\delta }}^{k} {\,\equals\,}E[B_{{t,T_{x} }}^{k} \!\mid\!{\cal G}_{{t{\plus}\delta }} ]$
. Using (5)
$L_{{t{\plus}\delta }}^{k} {\,\equals\,}E[B_{{t,T_{x} }}^{k} \!\mid\!{\cal G}_{{t{\plus}\delta }} ]$
. Using (5)
 $$\eqalignno{ L_{{t{\plus}\delta }}^{k} & {\,\equals\,}B_{{t,t{\plus}\delta }}^{k} {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {r_{u} du} }} (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) \cr & {\,\equals\,}{\int}_t^{t{\plus}\delta } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } \left[ {(1{\minus}N_{s}^{k} )g_{x} (s,Z_{s} )ds{\plus}h_{x} (s,Z_{{s^{{\minus}} }} \!)dN_{s}^{k} } \right] \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } r_{u} du}} (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
$$\eqalignno{ L_{{t{\plus}\delta }}^{k} & {\,\equals\,}B_{{t,t{\plus}\delta }}^{k} {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {r_{u} du} }} (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) \cr & {\,\equals\,}{\int}_t^{t{\plus}\delta } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } \left[ {(1{\minus}N_{s}^{k} )g_{x} (s,Z_{s} )ds{\plus}h_{x} (s,Z_{{s^{{\minus}} }} \!)dN_{s}^{k} } \right] \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } r_{u} du}} (1{\minus}N_{{t{\plus}\delta }}^{k} )v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
where the function v
x
solves (7). From the model assumption
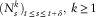 $(N_{s}^{k} )_{{t\leq s\leq t{\plus}\delta }} ,\;k\geq 1$
are independent conditional on
$(N_{s}^{k} )_{{t\leq s\leq t{\plus}\delta }} ,\;k\geq 1$
are independent conditional on
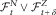 $${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
. It follows that
$${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
. It follows that
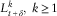 $$L_{{t{\plus}\delta }}^{k} ,\;k\geq 1$$
are independent conditional on
$$L_{{t{\plus}\delta }}^{k} ,\;k\geq 1$$
are independent conditional on
 $${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
. Further, if we are able to show that
$${\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} $$
. Further, if we are able to show that
 $$\mathop{\sum}\limits_{k{\,\equals\,}1}^\infty {{1 \over {k^{2} }}} E\left[ {\left( {L_{{t{\plus}\delta }}^{k} {\minus}E\left[ {L_{{t{\plus}\delta }}^{k} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]} \right)^{2} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]\,\lt\,\infty\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
$$\mathop{\sum}\limits_{k{\,\equals\,}1}^\infty {{1 \over {k^{2} }}} E\left[ {\left( {L_{{t{\plus}\delta }}^{k} {\minus}E\left[ {L_{{t{\plus}\delta }}^{k} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]} \right)^{2} \left| {{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} } \right.} \right]\,\lt\,\infty\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
then the claim follows from the CLLN (Prakasa Rao, Reference Prakasa Rao2009, theorem 6). Since
 $$E[(L_{{t{\plus}\delta }}^{k} {\minus}E[L_{{t{\plus}\delta }}^{k} \!\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ])^{2} \!\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ]\leq E[\,\mid\,L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} \,\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ]\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
$$E[(L_{{t{\plus}\delta }}^{k} {\minus}E[L_{{t{\plus}\delta }}^{k} \!\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ])^{2} \!\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ]\leq E[\,\mid\,L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} \,\mid\!{\cal F}_{t}^{N} \vee{\cal F}_{{t{\plus}\delta }}^{Z} ]\,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
it is sufficient to show that
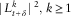 $$\!\mid\!L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} ,\,k\geq 1$$
, are uniformly bounded. From Jensen’s inequality, it follows immediately that
$$\!\mid\!L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} ,\,k\geq 1$$
, are uniformly bounded. From Jensen’s inequality, it follows immediately that
 $$\,\mid\!L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} {\!\equals\!}\,\mid\!E[B_{{t,T_{x} }}^{k} \!\mid\!{\cal G}_{{t{\plus}\delta }} ]\!\mid\,^{2} \leq E[\,\mid\!B_{{t,T_{x} }}^{k} \!\mid\,^{2} \,\mid\!{\cal G}_{{t{\plus}\delta }} ]\,\,\,\,\,\rm a.s.$$
$$\,\mid\!L_{{t{\plus}\delta }}^{k} \!\mid\,^{2} {\!\equals\!}\,\mid\!E[B_{{t,T_{x} }}^{k} \!\mid\!{\cal G}_{{t{\plus}\delta }} ]\!\mid\,^{2} \leq E[\,\mid\!B_{{t,T_{x} }}^{k} \!\mid\,^{2} \,\mid\!{\cal G}_{{t{\plus}\delta }} ]\,\,\,\,\,\rm a.s.$$
Hence, it is sufficient to show that
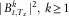 $$\,\mid\!B_{{t,T_{x} }}^{k} \!\mid^{2} ,\,k\geq 1$$
are uniformly bounded. Using (1), (2), and (3)
$$\,\mid\!B_{{t,T_{x} }}^{k} \!\mid^{2} ,\,k\geq 1$$
are uniformly bounded. Using (1), (2), and (3)
 $$\eqalignno{ \left| {B_{{t,T_{x} }}^{k} } \right|^{2} & {\,\equals\,}\left| {{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds} \right. \cr & \quad \left. {{\plus}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } h_{x} (s,Z_{{s^{{\minus}} }} \!)dN_{s}^{k} } \right|^{2} \cr & {\,\equals\,}\left| {{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds} \right. \cr & \left. {{\plus} e^{{{\minus}{\int}_t^{\tau ^{k} } {r_{u} du} }} h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)I\{ t\leq \tau ^{k} \leq T_{x} \} } \right|^{2} $$
$$\eqalignno{ \left| {B_{{t,T_{x} }}^{k} } \right|^{2} & {\,\equals\,}\left| {{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds} \right. \cr & \quad \left. {{\plus}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } h_{x} (s,Z_{{s^{{\minus}} }} \!)dN_{s}^{k} } \right|^{2} \cr & {\,\equals\,}\left| {{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds} \right. \cr & \left. {{\plus} e^{{{\minus}{\int}_t^{\tau ^{k} } {r_{u} du} }} h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)I\{ t\leq \tau ^{k} \leq T_{x} \} } \right|^{2} $$
Define I 1 and I 2 by
 $$\eqalignno{ & I_{1} {\,\equals\,}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds \cr & I_{2} {\,\equals\,}e^{{{\minus}{\int}_t^{\tau ^{k} } {r_{u} du} }} h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} )I\{ t\leq \tau ^{k} \leq T_{x} \} $$
$$\eqalignno{ & I_{1} {\,\equals\,}{\int}_t^{T_{x} } {e^{{{\minus}{\int}_t^s {r_{u} du} }} } g_{x} (s,Z_{s} )(1{\minus}N_{s}^{k} )ds \cr & I_{2} {\,\equals\,}e^{{{\minus}{\int}_t^{\tau ^{k} } {r_{u} du} }} h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} )I\{ t\leq \tau ^{k} \leq T_{x} \} $$
We have
 $$\,\mid\!I_{1} {\plus}I_{2} \!\mid^{2} \leq 2I_{1}^{2} {\plus}2I_{2}^{2} \,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
$$\,\mid\!I_{1} {\plus}I_{2} \!\mid^{2} \leq 2I_{1}^{2} {\plus}2I_{2}^{2} \,\,\,\,\,{\rm a}{\rm .s}{\rm .}$$
By assumption, r is non-negative, so that
 $$\eqalignno{ & I_{1}^{2} \leq {\int}_t^{T_{x} } {\left| {g_{x} (s,Z_{s} )} \right|} ^{2} ds\leq m_{g}^{2} (m_{T} {\minus}t) \cr & I_{2}^{2} \leq \left| {h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)} \right|^{2} \leq m_{h}^{2} $$
$$\eqalignno{ & I_{1}^{2} \leq {\int}_t^{T_{x} } {\left| {g_{x} (s,Z_{s} )} \right|} ^{2} ds\leq m_{g}^{2} (m_{T} {\minus}t) \cr & I_{2}^{2} \leq \left| {h_{x} (\tau ^{k} ,Z_{{\tau ^{{k{\minus}}} }} \!)} \right|^{2} \leq m_{h}^{2} $$
Hence
 $$\,\mid\!B_{{t,T_{x} }}^{k} \!\mid^{2} \leq 2m_{g}^{2} (m_{T} {\minus}t){\plus}2m_{h}^{2} \,\lt\,\infty$$
$$\,\mid\!B_{{t,T_{x} }}^{k} \!\mid^{2} \leq 2m_{g}^{2} (m_{T} {\minus}t){\plus}2m_{h}^{2} \,\lt\,\infty$$
and the proof is complete.□
Evaluating the conditional expectation in (9), we arrive at the following corollary.
Corollary 2 The CLLN approximation to
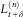 $$L_{{t{\plus}\delta }}^{{(n)}} $$
is given by
$$L_{{t{\plus}\delta }}^{{(n)}} $$
is given by
 $$L_{{t{\plus}\delta }}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {(1{\minus}N_{t}^{k} )V^{x} } $$
$$L_{{t{\plus}\delta }}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{\scriptstyle x\in X \hfill \atop \scriptstyle k\in I_{x}^{n} \hfill} {(1{\minus}N_{t}^{k} )V^{x} } $$
where
 $$\eqalignno{ V^{x} & {\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}_{x} (s,Z_{s} )e^{{{\minus}{\int}_t^s {\bar{q}_{x} (u,Z_{u} )du} }} ds} \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(u,Z_{u} )du} }} v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
$$\eqalignno{ V^{x} & {\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}_{x} (s,Z_{s} )e^{{{\minus}{\int}_t^s {\bar{q}_{x} (u,Z_{u} )du} }} ds} \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(u,Z_{u} )du} }} v_{x} (t{\plus}\delta ,Z_{{t{\plus}\delta }} ) $$
The first term of (10) corresponds to the discounted payments between t and t+δ. The second term corresponds to the following: for the fraction of contracts still active at time t+δ, the value of the remaining liabilities is given by v x (t+δ, Z t+δ ). This value is then discounted back to time t.
Corollary 2 implies that we can diversify away the idiosyncratic risk, so that only the systematic risk remains. This means that we can approximate the portfolio quantiles by the computationally much simpler systematic risk quantiles, i.e.
 $$F_{{L_{{t{\plus}\delta }}^{{(n)}} }}^{{{\minus}1}} \,(p)\,\approx\,F_{{\mathop{\sum}\limits_{x,k} {(1{\minus}N_{t}^{k} )V^{x} } }}^{{{\minus}1}} (p)$$
$$F_{{L_{{t{\plus}\delta }}^{{(n)}} }}^{{{\minus}1}} \,(p)\,\approx\,F_{{\mathop{\sum}\limits_{x,k} {(1{\minus}N_{t}^{k} )V^{x} } }}^{{{\minus}1}} (p)$$
This result is a generalisation of the CLLN for ultimate risk (δ→∞) obtained in (Djehiche & Löfdahl, Reference Djehiche and Löfdahl2014 b). The main difference is that (12) provides an approximation for risks on a general δ-year horizon. In particular, it allows for approximating the 1-year risks associated with the Solvency II framework. Further, we relax the homogeneity assumptions, which allows for more realistic modelling of insurance portfolios. It should be stressed that Proposition 1 holds for even more general portfolios, where the payment functions g and h may be unique for each contract, as long as they satisfy some boundedness conditions. Forming homogeneous pools is simply a convenient tool that will help us with calculating the portfolio SCR. This is the topic of the next sections.
4. SCR for Homogeneous Portfolios
In this section, we consider a semi-analytical approximation for a homogeneous portfolio under a one-factor diffusion model. The methods used in this section are best suited for the case where the time horizon δ is small relative to the duration of the liabilities. This is typically the case with disability or pension annuities and the 1-year horizon of the Solvency II framework.
Assuming a one-factor model need not be a serious limitation, as we may, e.g., use one of the mimicking techniques from Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014 b). This procedure is illustrated in section 4.1, where we use the Markov projection technique to mimic a multi-factor model with a one-factor model.
To simplify notation, we suppress the dependence on x, and define the random variable V by
 $$V{\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}(s,Z_{s}^{{t,z}} )e^{{{\minus}{\int}_t^s {\bar{q}(u,Z_{u}^{{t,z}} )du} }} } ds{\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(s,Z_{s}^{{t,z}} )ds} }} v(t{\plus}\delta ,Z_{{t{\plus}\delta }}^{{t,z}} )$$
$$V{\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}(s,Z_{s}^{{t,z}} )e^{{{\minus}{\int}_t^s {\bar{q}(u,Z_{u}^{{t,z}} )du} }} } ds{\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(s,Z_{s}^{{t,z}} )ds} }} v(t{\plus}\delta ,Z_{{t{\plus}\delta }}^{{t,z}} )$$
where the process Z t,z has dynamics given by the stochastic differential equation (SDE)
 $$\left\{\! \matrix{ dZ_{s}^{{t,z}} {\,\equals\,}\alpha (s,Z_{s}^{{t,z}} )ds{\plus}\sigma (s,Z_{s}^{{t,z}} )dW_{s} ,\,\,\,\,\,s\geq t \hfill \cr Z_{s}^{{t,z}} {\,\equals\,}z,\,\,\,\,\,s\leq t \hfill \cr} \right.$$
$$\left\{\! \matrix{ dZ_{s}^{{t,z}} {\,\equals\,}\alpha (s,Z_{s}^{{t,z}} )ds{\plus}\sigma (s,Z_{s}^{{t,z}} )dW_{s} ,\,\,\,\,\,s\geq t \hfill \cr Z_{s}^{{t,z}} {\,\equals\,}z,\,\,\,\,\,s\leq t \hfill \cr} \right.$$
Recall that the function v(s, z) satisfies the PDE
 $$\left\{ \!\matrix{ {\minus}{{\partial v} \over {\partial s}}{\plus}\bar{q}(s,z)v{\,\equals\,}\alpha (s,z){{\partial v} \over {\partial z}}{\plus}{1 \over 2}\sigma ^{2} (s,z){{\partial ^{2} v} \over {\partial z^{2} }}{\plus}\tilde{g}(s,z),\,\,\,\,\,t{\plus}\delta \leq s\,\lt\,T \hfill \cr v(T,z){\,\equals\,}0 \hfill \cr} \right.$$
$$\left\{ \!\matrix{ {\minus}{{\partial v} \over {\partial s}}{\plus}\bar{q}(s,z)v{\,\equals\,}\alpha (s,z){{\partial v} \over {\partial z}}{\plus}{1 \over 2}\sigma ^{2} (s,z){{\partial ^{2} v} \over {\partial z^{2} }}{\plus}\tilde{g}(s,z),\,\,\,\,\,t{\plus}\delta \leq s\,\lt\,T \hfill \cr v(T,z){\,\equals\,}0 \hfill \cr} \right.$$
In the light of (12), in order to determine the portfolio quantiles, it is enough to determine the quantiles of V.
Typically, liabilities such as disability or pension annuities tend to have a long duration. Hence, for a δ that is small relative to the duration of the liability, the value of the remaining liabilities at t+δ should dominate the value of the benefits paid between t and t+δ. Hence, the exact path of Z
t,z
from z to
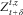 $$Z_{{t{\plus}\delta }}^{{t,z}} $$
is not as important as the value of
$$Z_{{t{\plus}\delta }}^{{t,z}} $$
is not as important as the value of
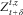 $$Z_{{t{\plus}\delta }}^{{t,z}} $$
, since, by the Markov property of Z
t,z
, the value of the remaining liabilities at t+δ does only depend on
$$Z_{{t{\plus}\delta }}^{{t,z}} $$
, since, by the Markov property of Z
t,z
, the value of the remaining liabilities at t+δ does only depend on
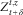 $$Z_{{t{\plus}\delta }}^{{t,z}} $$
. This observation provides motivation for using the comonotonic approximation proposed by Dhaene et al. (Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke2002) and others: let
$$Z_{{t{\plus}\delta }}^{{t,z}} $$
. This observation provides motivation for using the comonotonic approximation proposed by Dhaene et al. (Reference Dhaene, Denuit, Goovaerts, Kaas and Vyncke2002) and others: let
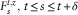 $$F_{s}^{{t,z}} ,\,t\leq s\leq t{\plus}\delta $$
denote the distribution function of
$$F_{s}^{{t,z}} ,\,t\leq s\leq t{\plus}\delta $$
denote the distribution function of
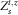 $$Z_{s}^{{t,z}} $$
and let the uniformly distributed random variable U be defined by
$$Z_{s}^{{t,z}} $$
and let the uniformly distributed random variable U be defined by
 $$U{\,\equals\,}F_{{t{\plus}\delta }}^{{t,z}} (Z_{{t{\plus}\delta }}^{{t,z}} )$$
$$U{\,\equals\,}F_{{t{\plus}\delta }}^{{t,z}} (Z_{{t{\plus}\delta }}^{{t,z}} )$$
Define the stochastic process
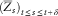 $$(\bar{Z}_{s} )_{{t\leq s\leq t{\plus}\delta }} $$
by
$$(\bar{Z}_{s} )_{{t\leq s\leq t{\plus}\delta }} $$
by
 $$\bar{Z}_{s} {\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (U){\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (F_{{t{\plus}\delta }}^{{t,z}} (Z_{{t{\plus}\delta }}^{{t,z}} ))$$
$$\bar{Z}_{s} {\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (U){\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (F_{{t{\plus}\delta }}^{{t,z}} (Z_{{t{\plus}\delta }}^{{t,z}} ))$$
and note that
 $$\bar{Z}_{s} \:\mathop{{\,\equals\,}}\limits^{d} \:Z_{s}^{{t,z}} \,\,\,\,\,t\leq s\leq t{\plus}\delta $$
$$\bar{Z}_{s} \:\mathop{{\,\equals\,}}\limits^{d} \:Z_{s}^{{t,z}} \,\,\,\,\,t\leq s\leq t{\plus}\delta $$
Further, define the random variable
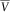 $$\bar{V}$$
by
$$\bar{V}$$
by
 $$\bar{V}{\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}(s,\bar{Z}_{s} )e^{{{\minus}{\int}_t^s {\bar{q}(u,\bar{Z}_{u} )du} }} } ds{\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(s,\bar{Z}_{s} )ds} }} v(t{\plus}\delta ,\bar{Z}_{{t{\plus}\delta }} )$$
$$\bar{V}{\,\equals\,}{\int}_t^{t{\plus}\delta } {\tilde{g}(s,\bar{Z}_{s} )e^{{{\minus}{\int}_t^s {\bar{q}(u,\bar{Z}_{u} )du} }} } ds{\plus}e^{{{\minus}{\int}_t^{t{\plus}\delta } {\bar{q}(s,\bar{Z}_{s} )ds} }} v(t{\plus}\delta ,\bar{Z}_{{t{\plus}\delta }} )$$
Under the comonotonic approximation, the random variable
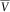 $$\bar{V}$$
is simply a function of
$$\bar{V}$$
is simply a function of
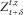 $$Z_{{t{\plus}\delta }}^{{t,z}} $$
, i.e.
$$Z_{{t{\plus}\delta }}^{{t,z}} $$
, i.e.
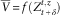 $$\bar{V}{\,\equals\,}f(Z_{{t{\plus}\delta }}^{{t,z}} )$$
, with the function
$$\bar{V}{\,\equals\,}f(Z_{{t{\plus}\delta }}^{{t,z}} )$$
, with the function
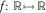 $$f\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$$
defined by (15) and (16). By reducing the dimensionality, determining the quantiles of
$$f\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$$
defined by (15) and (16). By reducing the dimensionality, determining the quantiles of
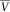 $$\bar{V}$$
is a much simpler task than determining those of V. We suggest the approximation
$$\bar{V}$$
is a much simpler task than determining those of V. We suggest the approximation
 $$F_{V}^{{{\minus}1}} (p)\,\approx\,F_{{\bar{V}}}^{{{\minus}1}} (p)$$
$$F_{V}^{{{\minus}1}} (p)\,\approx\,F_{{\bar{V}}}^{{{\minus}1}} (p)$$
for calculating capital requirements for a large portfolio, whenever δ is sufficiently small. The performance of the comonotonic approximation is investigated in section 6.
In Proposition 5, we show that, under reasonable assumptions, the mapping x ↦ f(x) is monotone, which makes it trivial to calculate the quantiles of
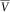 $$\bar{V}$$
. First, we need the following propositions.
$$\bar{V}$$
. First, we need the following propositions.
Proposition 3 (cf. Friedman (Reference Friedman1964), theorem 3.10) Assume that
 $${{\partial \alpha } \over {\partial z}},\,{{\partial \sigma ^{2} } \over {\partial z}},\,{{\partial \bar{q}} \over {\partial z}},\,{{\partial \tilde{g}} \over {\partial z}}$$
$${{\partial \alpha } \over {\partial z}},\,{{\partial \sigma ^{2} } \over {\partial z}},\,{{\partial \bar{q}} \over {\partial z}},\,{{\partial \tilde{g}} \over {\partial z}}$$
are continuous functions and that v is a solution to the PDE (14). Then
 $${{\partial ^{3} v} \over {\partial z^{3} }},\,{\partial \over {\partial t}}{{\partial v} \over {\partial z}}$$
$${{\partial ^{3} v} \over {\partial z^{3} }},\,{\partial \over {\partial t}}{{\partial v} \over {\partial z}}$$
exist and are continuous.
Proposition 4 Assume that the conditions of Proposition 3 are satisfied, and that
 $${{\partial \tilde{g}(s,z)} \over {\partial z}}{\minus}{{\partial \bar{q}(s,z)} \over {\partial z}}v(s,z)\leq 0,\,\,t\leq s\leq T,\,z\in{\Bbb R}$$
$${{\partial \tilde{g}(s,z)} \over {\partial z}}{\minus}{{\partial \bar{q}(s,z)} \over {\partial z}}v(s,z)\leq 0,\,\,t\leq s\leq T,\,z\in{\Bbb R}$$
Then, the mapping z ↦ v(·, z) is non-increasing.
Proof: Let
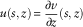 $$u(s,z){\,\equals\,}{{\partial v} \over {\partial z}}(s,z)$$
. Taking the derivative with respect to z on both sides of (14), we obtain the following PDE for u(s, z):
$$u(s,z){\,\equals\,}{{\partial v} \over {\partial z}}(s,z)$$
. Taking the derivative with respect to z on both sides of (14), we obtain the following PDE for u(s, z):
 $$\left\{ \!\matrix{ {\minus}{{\partial u} \over {\partial s}}{\plus}\left( {\bar{q}{\minus}{{\partial \alpha } \over {\partial z}}} \right)u{\,\equals\,}\left( {\alpha {\plus}{1 \over 2}{{\partial \sigma ^{2} } \over {\partial z}}} \right){{\partial u} \over {\partial z}}{\plus}{1 \over 2}\sigma ^{2} {{\partial ^{2} u} \over {\partial z^{2} }}{\plus}{{\partial \tilde{g}} \over {\partial z}}{\minus}{{\partial \bar{q}} \over {\partial z}}v,\,\,\,\,\,t\leq s\,\lt\,T \hfill \cr u(T,z){\,\equals\,}0 \hfill \cr} \right.$$
$$\left\{ \!\matrix{ {\minus}{{\partial u} \over {\partial s}}{\plus}\left( {\bar{q}{\minus}{{\partial \alpha } \over {\partial z}}} \right)u{\,\equals\,}\left( {\alpha {\plus}{1 \over 2}{{\partial \sigma ^{2} } \over {\partial z}}} \right){{\partial u} \over {\partial z}}{\plus}{1 \over 2}\sigma ^{2} {{\partial ^{2} u} \over {\partial z^{2} }}{\plus}{{\partial \tilde{g}} \over {\partial z}}{\minus}{{\partial \bar{q}} \over {\partial z}}v,\,\,\,\,\,t\leq s\,\lt\,T \hfill \cr u(T,z){\,\equals\,}0 \hfill \cr} \right.$$
From Proposition 3, all partial derivatives exist and are continuous. It is immediate that the function u(s, z) satisfying the PDE (18) has the Feynman–Kac representation
 $$u(t,z){\,\equals\,}E\left[ {{\int}_t^T {\left( {{{\partial \tilde{g}} \over {\partial z}}(s,\widehat{Z}_{s} ){\minus}{{\partial \bar{q}} \over {\partial z}}(s,\widehat{Z}_{s} )v(s,\widehat{Z}_{s} )} \right)} e^{{{\minus}{\int}_t^s {(\bar{q}(u,\widehat{Z}_{u} ){\minus}{{\partial \alpha } \over {\partial z}}(u,\widehat{Z}_{u} ))du} }} ds\left| {\widehat{Z}_{t} {\,\equals\,}z} \right.} \right]$$
$$u(t,z){\,\equals\,}E\left[ {{\int}_t^T {\left( {{{\partial \tilde{g}} \over {\partial z}}(s,\widehat{Z}_{s} ){\minus}{{\partial \bar{q}} \over {\partial z}}(s,\widehat{Z}_{s} )v(s,\widehat{Z}_{s} )} \right)} e^{{{\minus}{\int}_t^s {(\bar{q}(u,\widehat{Z}_{u} ){\minus}{{\partial \alpha } \over {\partial z}}(u,\widehat{Z}_{u} ))du} }} ds\left| {\widehat{Z}_{t} {\,\equals\,}z} \right.} \right]$$
where the process
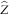 $$\widehat{Z}$$
is the Itô diffusion defined by
$$\widehat{Z}$$
is the Itô diffusion defined by
 $$d\widehat{Z}_{s} {\,\equals\,}\left( {\alpha (s,\widehat{Z}_{s} ){\plus}{1 \over 2}{{\partial \sigma ^{2} } \over {\partial z}}(s,\widehat{Z}_{s} )} \right)ds{\plus}\sigma (s,\widehat{Z}_{s} )d\widehat{W}_{s} $$
$$d\widehat{Z}_{s} {\,\equals\,}\left( {\alpha (s,\widehat{Z}_{s} ){\plus}{1 \over 2}{{\partial \sigma ^{2} } \over {\partial z}}(s,\widehat{Z}_{s} )} \right)ds{\plus}\sigma (s,\widehat{Z}_{s} )d\widehat{W}_{s} $$
and
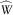 $$\widehat{W}$$
is a Wiener process. Since we assumed the integrand to be non-positive, it is clear that u(t, z) is non-positive. Hence, z ↦ v(·, z) is non-increasing.□
$$\widehat{W}$$
is a Wiener process. Since we assumed the integrand to be non-positive, it is clear that u(t, z) is non-positive. Hence, z ↦ v(·, z) is non-increasing.□
Proposition 5 Assume that the conditions of Proposition 3 are satisfied. Further, assume that
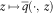 $$z\,\mapsto\,\bar{q}( \cdot ,\,z)$$
is non-decreasing and that
$$z\,\mapsto\,\bar{q}( \cdot ,\,z)$$
is non-decreasing and that
 $$z\,\mapsto\,\tilde{g}( \cdot , \,z)$$
is non-negative and non-increasing. For δ≥0, define the function
$$z\,\mapsto\,\tilde{g}( \cdot , \,z)$$
is non-negative and non-increasing. For δ≥0, define the function
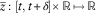 $$\bar{z}\,\colon\,[t,t{\plus}\delta ]{\times}{\Bbb R}\,\mapsto\,{\Bbb R}$$
by
$$\bar{z}\,\colon\,[t,t{\plus}\delta ]{\times}{\Bbb R}\,\mapsto\,{\Bbb R}$$
by
 $$\bar{z}(s,x){\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (F_{{t{\plus}\delta }}^{{t,z}} (x))$$
$$\bar{z}(s,x){\,\equals\,}(F_{s}^{{t,z}} )^{{{\minus}1}} (F_{{t{\plus}\delta }}^{{t,z}} (x))$$
Then, the mapping x ↦ f(x) is defined by
 $$f(x)\!\!:=\,\,\,\mathop{\int}\nolimits_t^{t{\plus}\delta } {\tilde{g}(s,\bar{z}(s,x))} e^{{{\minus}\mathop{\int}\nolimits_t^s \bar{q}(u,\bar{z}(u,x))du}} ds{\plus}e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {\bar{q}(s,\bar{z}(s,x))ds} }} v(t{\plus}\delta ,x)$$
$$f(x)\!\!:=\,\,\,\mathop{\int}\nolimits_t^{t{\plus}\delta } {\tilde{g}(s,\bar{z}(s,x))} e^{{{\minus}\mathop{\int}\nolimits_t^s \bar{q}(u,\bar{z}(u,x))du}} ds{\plus}e^{{{\minus}\mathop{\int}\nolimits_t^{t{\plus}\delta } {\bar{q}(s,\bar{z}(s,x))ds} }} v(t{\plus}\delta ,x)$$
is non-increasing.
Proof: First, note that
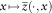 $$x\,\mapsto\,\bar{z}( \cdot ,x)$$
is non-decreasing. From the Feynman–Kac representation (6) for v(t, z), it is immediate that
$$x\,\mapsto\,\bar{z}( \cdot ,x)$$
is non-decreasing. From the Feynman–Kac representation (6) for v(t, z), it is immediate that
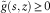 $$\tilde{g}(s,z)\geq 0$$
implies v(t, z)≥0. This, together with the assumptions that
$$\tilde{g}(s,z)\geq 0$$
implies v(t, z)≥0. This, together with the assumptions that
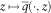 $$z\,\mapsto\,\bar{q}( \cdot ,z)$$
is non-decreasing and
$$z\,\mapsto\,\bar{q}( \cdot ,z)$$
is non-decreasing and
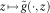 $$z\,\mapsto\,\tilde{g}( \cdot ,z)$$
is non-increasing, means that the conditions of Proposition 4 are satisfied. Further, since
$$z\,\mapsto\,\tilde{g}( \cdot ,z)$$
is non-increasing, means that the conditions of Proposition 4 are satisfied. Further, since
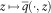 $$z\,\mapsto\,\bar{q}( \cdot ,z)$$
is non-decreasing, the second term in (19) is a product of two non-negative, non-increasing factors, and so it is non-increasing. The same argument holds for the integrand in the first term in (19). Hence, x ↦ f(x) is non-increasing.□
$$z\,\mapsto\,\bar{q}( \cdot ,z)$$
is non-decreasing, the second term in (19) is a product of two non-negative, non-increasing factors, and so it is non-increasing. The same argument holds for the integrand in the first term in (19). Hence, x ↦ f(x) is non-increasing.□
In the light of Proposition 5, it is immediate that the quantiles of
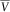 $$\bar{V}$$
are given by
$$\bar{V}$$
are given by
 $$F_{{\bar{V}}}^{{{\minus}1}} (p){\,\equals\,}F_{{f(Z_{{t{\plus}\delta }}^{{t,z}} )}}^{{{\minus}1}} (p){\,\equals\,}f((F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p))$$
$$F_{{\bar{V}}}^{{{\minus}1}} (p){\,\equals\,}F_{{f(Z_{{t{\plus}\delta }}^{{t,z}} )}}^{{{\minus}1}} (p){\,\equals\,}f((F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p))$$
Using (12), (17), and (20), the p quantile of the portfolio liabilities can be approximated by
Corollary 6
 $$F_{{L_{{t{\plus}\delta }}^{{(n)}} }}^{{{\minus}1}} (p)\,\approx\,\mathop{\sum}\limits_{k{\,\equals\,}1}^n {(1{\minus}N_{t}^{k} )f((F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p))} $$
$$F_{{L_{{t{\plus}\delta }}^{{(n)}} }}^{{{\minus}1}} (p)\,\approx\,\mathop{\sum}\limits_{k{\,\equals\,}1}^n {(1{\minus}N_{t}^{k} )f((F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p))} $$
We conclude that, for the homogeneous case, we can approximate the portfolio quantiles and capital requirements without resorting to simulation techniques: it is enough to compute
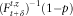 $$(F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p)$$
, solve the Feynman–Kac PDE for v(s, z), and evaluate the right hand side of (21) using numerical integration.
$$(F_{{t{\plus}\delta }}^{{t,z}} )^{{{\minus}1}} (1{\minus}p)$$
, solve the Feynman–Kac PDE for v(s, z), and evaluate the right hand side of (21) using numerical integration.
Using the CLLN approximation (12), we are able to diversify away the idiosyncratic risks, given that the portfolio is large enough, leaving only the systematic risk. Further, using the comonotonic approximation (21), we are able to project the systematic risk onto a single random variable, provided that δ is small relative to the duration of the liabilities. The comonotonic approximation relies on a one-factor model. When the population disability is described by a multi-factor model, the methods from this section cannot be used directly. We now give an example of how the Markov projection technique can be used to approximate a multi-factor model with a one-factor model.
4.1. Application to disability insurance
We consider the disability model from Aro et al. (Reference Aro, Djehiche and Lofdahl2015), as adapted in Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014 b, section 4.1). The transition rate is given by
 $$q(s,\nu _{s}^{{t,\xi }} ){\,\equals\,}c\,{\rm log}(1{\plus}{\rm exp}\{ a(x,s)^{T} \nu _{s}^{{t,\xi }} \} )$$
$$q(s,\nu _{s}^{{t,\xi }} ){\,\equals\,}c\,{\rm log}(1{\plus}{\rm exp}\{ a(x,s)^{T} \nu _{s}^{{t,\xi }} \} )$$
where
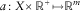 $$a\,\colon\,X{\times}{\Bbb R}^{{\plus}} \mapsto{\Bbb R}^{m} $$
and
$$a\,\colon\,X{\times}{\Bbb R}^{{\plus}} \mapsto{\Bbb R}^{m} $$
and
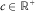 $$c\in{\Bbb R}^{{\plus}} $$
represent modelling choices. The process v
t,ξ
is defined by
$$c\in{\Bbb R}^{{\plus}} $$
represent modelling choices. The process v
t,ξ
is defined by
 $$\nu _{s}^{{t,\xi }} {\,\equals\,}\xi {\plus}\mu (s{\minus}t){\plus}A(W_{s} {\minus}W_{t} ),s\geq t$$
$$\nu _{s}^{{t,\xi }} {\,\equals\,}\xi {\plus}\mu (s{\minus}t){\plus}A(W_{s} {\minus}W_{t} ),s\geq t$$
where
 $$\xi \in{\Bbb R}^{m} $$
, W is m-dimensional standard Brownian motion with independent components,
$$\xi \in{\Bbb R}^{m} $$
, W is m-dimensional standard Brownian motion with independent components,
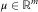 $$\mu \in{\Bbb R}^{m} $$
a drift vector, and
$$\mu \in{\Bbb R}^{m} $$
a drift vector, and
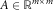 $$A\in{\Bbb R}^{{m{\times}m}} $$
is the Cholesky factorisation of the covariance matrix ∑ of v
t,ξ
. Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014
b) suggested that this multi-factor model can be approximated by a one-factor model using the Markov projection, or mimicking technique first introduced by Krylov (Reference Krylov1984): for a fixed x∈X, let
$$A\in{\Bbb R}^{{m{\times}m}} $$
is the Cholesky factorisation of the covariance matrix ∑ of v
t,ξ
. Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014
b) suggested that this multi-factor model can be approximated by a one-factor model using the Markov projection, or mimicking technique first introduced by Krylov (Reference Krylov1984): for a fixed x∈X, let
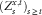 $$(Z_{s}^{{x,t}} )_{{s\geq t}} $$
denote the Markov projection of the scalar valued process
$$(Z_{s}^{{x,t}} )_{{s\geq t}} $$
denote the Markov projection of the scalar valued process
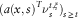 $$(a(x,s)^{T} \nu _{s}^{{t,\xi }} )_{{s\geq t}} $$
with dynamics given by
$$(a(x,s)^{T} \nu _{s}^{{t,\xi }} )_{{s\geq t}} $$
with dynamics given by
 $$\left\{\! \matrix{ dZ_{s}^{{x,t}} {\,\equals\,}(\theta ^{x} (s){\minus}\kappa ^{x} (s)Z_{s}^{{x,t}} )ds{\plus}\sigma ^{x} (s)dW_{s} ,\,\,\,\,\,s\geq t \hfill \cr Z_{s}^{{x,t}} {\,\equals\,}a(x,t)^{T} \nu _{t}^{{t,\xi }} {\,\equals\,}a(x,t)^{T} \xi ,\,\,\,\,\,s\leq t \hfill \cr} \right.$$
$$\left\{\! \matrix{ dZ_{s}^{{x,t}} {\,\equals\,}(\theta ^{x} (s){\minus}\kappa ^{x} (s)Z_{s}^{{x,t}} )ds{\plus}\sigma ^{x} (s)dW_{s} ,\,\,\,\,\,s\geq t \hfill \cr Z_{s}^{{x,t}} {\,\equals\,}a(x,t)^{T} \nu _{t}^{{t,\xi }} {\,\equals\,}a(x,t)^{T} \xi ,\,\,\,\,\,s\leq t \hfill \cr} \right.$$
where
 $$\eqalignno{ \kappa ^{x} (s) & {\,\equals\,}{\minus}{{a(x,s)^{T} \Sigma \dot{a}(x,s)} \over {a(x,s)^{T} \Sigma a(x,s)}} \cr & \theta ^{x} (s){\,\equals\,}a(x,s)^{T} \mu {\plus}\dot{a}(x,s)^{T} (\xi {\plus}\mu (s{\minus}t)) \cr & {\minus}a(x,s)^{T} (\xi {\plus}\mu (s{\minus}t)){{a(x,s)^{T} \Sigma \dot{a}(x,s)} \over {a(x,s)^{T} \Sigma a(x,s)}} \cr & \sigma ^{x} (s){\,\equals\,}\sqrt {a(x,s)^{T} \Sigma a(x,s)} $$
$$\eqalignno{ \kappa ^{x} (s) & {\,\equals\,}{\minus}{{a(x,s)^{T} \Sigma \dot{a}(x,s)} \over {a(x,s)^{T} \Sigma a(x,s)}} \cr & \theta ^{x} (s){\,\equals\,}a(x,s)^{T} \mu {\plus}\dot{a}(x,s)^{T} (\xi {\plus}\mu (s{\minus}t)) \cr & {\minus}a(x,s)^{T} (\xi {\plus}\mu (s{\minus}t)){{a(x,s)^{T} \Sigma \dot{a}(x,s)} \over {a(x,s)^{T} \Sigma a(x,s)}} \cr & \sigma ^{x} (s){\,\equals\,}\sqrt {a(x,s)^{T} \Sigma a(x,s)} $$
The Markov projection method ensures that Z x,t is Markov, and that
 $$Z_{s}^{{x,t}} \:\mathop{{\,\equals\,}}\limits^{d} \:a(x,s)^{T} \nu _{s}^{{t,\xi }} ,\,s\geq t$$
$$Z_{s}^{{x,t}} \:\mathop{{\,\equals\,}}\limits^{d} \:a(x,s)^{T} \nu _{s}^{{t,\xi }} ,\,s\geq t$$
Let
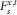 $$F_{s}^{{x,t}} $$
denote the distribution function of
$$F_{s}^{{x,t}} $$
denote the distribution function of
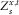 $$Z_{s}^{{x,t}} $$
. From the property (23),
$$Z_{s}^{{x,t}} $$
. From the property (23),
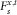 $$F_{s}^{{x,t}} $$
is then also the distribution function of
$$F_{s}^{{x,t}} $$
is then also the distribution function of
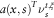 $$a(x,s)^{T} \nu _{s}^{{t,\xi }} $$
. Since Z
x,t
is a Hull–White process,
$$a(x,s)^{T} \nu _{s}^{{t,\xi }} $$
. Since Z
x,t
is a Hull–White process,
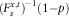 $$(F_{s}^{{x,t}} )^{{{\minus}1}} (1{\minus}p)$$
is obtained analytically as
$$(F_{s}^{{x,t}} )^{{{\minus}1}} (1{\minus}p)$$
is obtained analytically as
 $$(F_{s}^{{x,t}} )^{{{\minus}1}} (1{\minus}p){\,\equals\,}\delta ^{x} (t,s,z^{x} ){\plus}\gamma ^{x} (t,s)\Phi ^{{{\minus}1}} (1{\minus}p)$$
$$(F_{s}^{{x,t}} )^{{{\minus}1}} (1{\minus}p){\,\equals\,}\delta ^{x} (t,s,z^{x} ){\plus}\gamma ^{x} (t,s)\Phi ^{{{\minus}1}} (1{\minus}p)$$
where
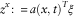 $$z^{x} \colon\,{\,\equals\,}a(x,t)^{T} \xi $$
, and δ
x
and γ
x
are obtained as the following explicit expressions of the coefficients of the Hull–White process:
$$z^{x} \colon\,{\,\equals\,}a(x,t)^{T} \xi $$
, and δ
x
and γ
x
are obtained as the following explicit expressions of the coefficients of the Hull–White process:
 $$\eqalignno{ & \delta ^{x} (t,s,z^{x} ){\,\equals\,}z^{x} e^{{{\minus}{\int}_t^s {\kappa ^{x} (v)dv} }} {\plus}{\int}_t^s {e^{{{\minus}{\int}_u^s {\kappa ^{x} (v)dv} }} \theta ^{x} } (u)du \cr & (\gamma ^{x} (t,s))^{2} {\,\equals\,}{\int}_t^s {e^{{{\minus}2{\int}_u^s {\kappa ^{x} (v)dv} }} } (\sigma ^{x} (u))^{2} du $$
$$\eqalignno{ & \delta ^{x} (t,s,z^{x} ){\,\equals\,}z^{x} e^{{{\minus}{\int}_t^s {\kappa ^{x} (v)dv} }} {\plus}{\int}_t^s {e^{{{\minus}{\int}_u^s {\kappa ^{x} (v)dv} }} \theta ^{x} } (u)du \cr & (\gamma ^{x} (t,s))^{2} {\,\equals\,}{\int}_t^s {e^{{{\minus}2{\int}_u^s {\kappa ^{x} (v)dv} }} } (\sigma ^{x} (u))^{2} du $$
From now on we suppress x to simplify notation. It turns out that, against all odds, it is possible to compute δ and γ analytically in this model. Using the fact that
 $$\kappa (v){\,\equals\,}{\minus}{1 \over {2\sigma ^{2} (v)}}{{d\sigma ^{2} } \over {dv}}{\,\equals\,}{\minus}{1 \over 2}{d \over {dv}}{\rm log}\sigma ^{2} (v)$$
$$\kappa (v){\,\equals\,}{\minus}{1 \over {2\sigma ^{2} (v)}}{{d\sigma ^{2} } \over {dv}}{\,\equals\,}{\minus}{1 \over 2}{d \over {dv}}{\rm log}\sigma ^{2} (v)$$
we immediately obtain
 $$e^{{{\minus}{\int}_u^s {\kappa (v)dv} }} {\,\equals\,}{{\sigma (s)} \over {\sigma (u)}}$$
$$e^{{{\minus}{\int}_u^s {\kappa (v)dv} }} {\,\equals\,}{{\sigma (s)} \over {\sigma (u)}}$$
It follows that
 $$\gamma ^{2} (t,s){\,\equals\,}\sigma ^{2} (s)(s{\minus}t)$$
$$\gamma ^{2} (t,s){\,\equals\,}\sigma ^{2} (s)(s{\minus}t)$$
Further, define
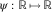 $\psi \,\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$
by
$\psi \,\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$
by
 $$\psi (v){\,\equals\,}a(v)^{T} (\xi {\plus}\mu (v{\minus}t))$$
$$\psi (v){\,\equals\,}a(v)^{T} (\xi {\plus}\mu (v{\minus}t))$$
It is easy to check that
 $${d \over {dv}}\left( {{{\psi (v)} \over {\sigma (v)}}} \right){\,\equals\,}{{\dot{\psi }(v)} \over {\sigma (v)}}{\minus}{{\psi (v)a(v)^{T} \Sigma \dot{a}(v)} \over {\sigma ^{3} (v)}}$$
$${d \over {dv}}\left( {{{\psi (v)} \over {\sigma (v)}}} \right){\,\equals\,}{{\dot{\psi }(v)} \over {\sigma (v)}}{\minus}{{\psi (v)a(v)^{T} \Sigma \dot{a}(v)} \over {\sigma ^{3} (v)}}$$
which is exactly the integrand of δ. Hence, we obtain
 $$\eqalignno{ \delta (t,s,z) & {\,\equals\,}z{{\sigma (s)} \over {\sigma (t)}}{\plus}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)){\minus}{{\sigma (s)} \over {\sigma (t)}}a(t)^{T} \xi \cr & {\,\equals\,}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)) $$
$$\eqalignno{ \delta (t,s,z) & {\,\equals\,}z{{\sigma (s)} \over {\sigma (t)}}{\plus}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)){\minus}{{\sigma (s)} \over {\sigma (t)}}a(t)^{T} \xi \cr & {\,\equals\,}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)) $$
Finally, the quantiles of
 $$Z_{s}^{{t,z}} $$
are given by
$$Z_{s}^{{t,z}} $$
are given by
 $$(F_{s}^{{t,z}} )^{{{\minus}1}} (1{\minus}p){\,\equals\,}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)){\plus}\sigma (s)\sqrt {s{\minus}t} \Phi ^{{{\minus}1}} (1{\minus}p)$$
$$(F_{s}^{{t,z}} )^{{{\minus}1}} (1{\minus}p){\,\equals\,}a(s)^{T} (\xi {\plus}\mu (s{\minus}t)){\plus}\sigma (s)\sqrt {s{\minus}t} \Phi ^{{{\minus}1}} (1{\minus}p)$$
Inserting (24) into (21) allows for efficient approximation of the portfolio risk. This is very useful, since it completely removes the need for costly Monte Carlo simulations.
It should be noted that while the Markov projection technique preserves the marginal distributions of the environment process, the finite-dimensional distributions are in general not preserved, see e.g. Borkar (Reference Borkar1989). This implies that the distribution of the δ-year liability value V defined by (13) is not necessarily preserved. However, for the comonotonic approximation
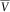 $$\bar{V}$$
, this is of less importance. To see this, consider
$$\bar{V}$$
, this is of less importance. To see this, consider
 $$\bar{V}$$
defined by (16): in view of (15) and (23), conditional on the value of the environment process at time t+δ, the trajectories of the comonotonic processes based on the original environment process and its mimicked process will agree. Hence, the Markov projection only alters
$$\bar{V}$$
defined by (16): in view of (15) and (23), conditional on the value of the environment process at time t+δ, the trajectories of the comonotonic processes based on the original environment process and its mimicked process will agree. Hence, the Markov projection only alters
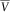 $$\bar{V}$$
through the function v which satisfies (14). Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014
b) numerically investigated the sensitivity of v with respect to the Markov projection technique. Their results indicate that while some precision is lost, the effect is rather small. We suggest that using Markov projections together with the comonotonic approximation should not significantly alter the distribution of
$$\bar{V}$$
through the function v which satisfies (14). Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014
b) numerically investigated the sensitivity of v with respect to the Markov projection technique. Their results indicate that while some precision is lost, the effect is rather small. We suggest that using Markov projections together with the comonotonic approximation should not significantly alter the distribution of
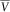 $$\bar{V}$$
, although further research is needed to confirm this claim.
$$\bar{V}$$
, although further research is needed to confirm this claim.
5. SCR for Inhomogeneous Portfolios Under Multi-Factor Models
For inhomogeneous portfolios under multi-factor models, we generally need to resort to simulations or scenario generation techniques. In this section, we consider two simplified calculation procedures for obtaining estimates of SCR for portfolios consisting of large homogeneous pools, using the disability model from section 4.1. Recall that the CLLN approximation of the portfolio value
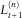 $$L_{{t{\plus}1}}^{{(n)}} $$
is given by
$$L_{{t{\plus}1}}^{{(n)}} $$
is given by
 $$L_{{t{\plus}1}}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{x\in X} {c_{x}^{n} V^{x} } $$
$$L_{{t{\plus}1}}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{x\in X} {c_{x}^{n} V^{x} } $$
where, for each x∈X, V
x
is given by (11), and
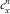 $$c_{x}^{n} $$
is defined by
$$c_{x}^{n} $$
is defined by
 $$c_{x}^{n} {\,\equals\,}\mathop{\sum}\limits_{k\in I_{x}^{n} } {(1{\minus}N_{t}^{k} )} $$
$$c_{x}^{n} {\,\equals\,}\mathop{\sum}\limits_{k\in I_{x}^{n} } {(1{\minus}N_{t}^{k} )} $$
Further, the comonotonic approximation of V x corresponding to (15)–(16) is given by
 $$V^{x} \,\approx\,\bar{V}^{x} {\,\equals\,}f^{x} (Z_{{t{\plus}1}}^{{x,t}} )$$
$$V^{x} \,\approx\,\bar{V}^{x} {\,\equals\,}f^{x} (Z_{{t{\plus}1}}^{{x,t}} )$$
where
 $$\eqalignno{ f^{x} (Z_{{t{\plus}1}}^{{x,t}} ) & {\,\equals\,}{\int}_t^{t{\plus}1} {\tilde{g}_{x} (s,\bar{Z}_{s}^{{x,t}} )} e^{{{\minus}{\int}_t^s {\bar{q}_{x} (u,\bar{Z}_{u}^{{x,t}} )du} }} ds \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}1} {\bar{q}_{x} (s,\bar{Z}_{s}^{{x,t}} )ds} }} v_{x} (t{\plus}1,\bar{Z}_{{t{\plus}1}}^{{x,t}} ) $$
$$\eqalignno{ f^{x} (Z_{{t{\plus}1}}^{{x,t}} ) & {\,\equals\,}{\int}_t^{t{\plus}1} {\tilde{g}_{x} (s,\bar{Z}_{s}^{{x,t}} )} e^{{{\minus}{\int}_t^s {\bar{q}_{x} (u,\bar{Z}_{u}^{{x,t}} )du} }} ds \cr & \quad {\plus}e^{{{\minus}{\int}_t^{t{\plus}1} {\bar{q}_{x} (s,\bar{Z}_{s}^{{x,t}} )ds} }} v_{x} (t{\plus}1,\bar{Z}_{{t{\plus}1}}^{{x,t}} ) $$
The corresponding approximation for the portfolio value is given by
 $$L_{{t{\plus}1}}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{x\in X} {c_{x}^{n} \bar{V}^{x} } $$
$$L_{{t{\plus}1}}^{{(n)}} \,\approx\,\mathop{\sum}\limits_{x\in X} {c_{x}^{n} \bar{V}^{x} } $$
It is easy to see that the random vector
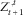 $$Z_{{t{\plus}1}}^{{ \cdot ,t}} $$
defined by
$$Z_{{t{\plus}1}}^{{ \cdot ,t}} $$
defined by
 $$Z_{{t{\plus}1}}^{{ \cdot ,t}} {\,\equals\,}(Z_{{t{\plus}1}}^{{x,t}} )_{{x\in X}} $$
$$Z_{{t{\plus}1}}^{{ \cdot ,t}} {\,\equals\,}(Z_{{t{\plus}1}}^{{x,t}} )_{{x\in X}} $$
follows a multivariate normal distribution. Therefore, the random vector
 $$V^{ \cdot } $$
defined by
$$V^{ \cdot } $$
defined by
 $$V^{ \cdot } {\,\equals\,}(f^{x} (Z_{{t{\plus}1}}^{{x,t}} ))_{{x\in X}} $$
$$V^{ \cdot } {\,\equals\,}(f^{x} (Z_{{t{\plus}1}}^{{x,t}} ))_{{x\in X}} $$
has a Gaussian copula. In the following subsections, we will suggest aggregation methods that exploit this particular structure.
5.1. Variance–covariance aggregation
For a portfolio consisting of large and homogeneous pools, we suggest a risk aggregation analogous to that of the SCR standard formula. The basic idea is to calculate the SCR for each pool and aggregate the results to obtain the portfolio SCR. Using Corollary 6, the SCR for each pool can be obtained as
 $$SCR_{p}^{x} \,\approx\,c_{x}^{n} (f^{x} ((F_{{t{\plus}1}}^{{x,t}} )^{{{\minus}1}} (1{\minus}p)){\minus}v_{x} (t,a(x,t)^{T} \xi )),\,\,x\in X$$
$$SCR_{p}^{x} \,\approx\,c_{x}^{n} (f^{x} ((F_{{t{\plus}1}}^{{x,t}} )^{{{\minus}1}} (1{\minus}p)){\minus}v_{x} (t,a(x,t)^{T} \xi )),\,\,x\in X$$
i.e., the SCR for each pool x can be represented as a function of a quantile of the random variable
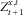 $$Z_{{t{\plus}1}}^{{x,t}} $$
. The Gaussian copula of
$$Z_{{t{\plus}1}}^{{x,t}} $$
. The Gaussian copula of
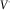 $$V^{ \cdot } $$
leads us to suggest the natural risk aggregation formula
$$V^{ \cdot } $$
leads us to suggest the natural risk aggregation formula
 $$SCR_{p} \,\approx\,\sqrt {\mathop{\sum}\limits_{x,y\in X} {\rho _{{xy}} SCR_{p}^{x} SCR_{p}^{y} } } $$
$$SCR_{p} \,\approx\,\sqrt {\mathop{\sum}\limits_{x,y\in X} {\rho _{{xy}} SCR_{p}^{x} SCR_{p}^{y} } } $$
where the correlation coefficients ρ xy are determined by
 $$\rho _{{xy}} {\,\equals\,}\rho (Z_{{t{\plus}1}}^{{x,t}} ,Z_{{t{\plus}1}}^{{y,t}} ){\,\equals\,}{{a(x,t{\plus}1)^{T} \Sigma a(y,t{\plus}1)} \over {\sqrt {a(x,t{\plus}1)^{T} \Sigma a(x,t{\plus}1)a(y,t{\plus}1)^{T} \Sigma a(y,t{\plus}1)} }}$$
$$\rho _{{xy}} {\,\equals\,}\rho (Z_{{t{\plus}1}}^{{x,t}} ,Z_{{t{\plus}1}}^{{y,t}} ){\,\equals\,}{{a(x,t{\plus}1)^{T} \Sigma a(y,t{\plus}1)} \over {\sqrt {a(x,t{\plus}1)^{T} \Sigma a(x,t{\plus}1)a(y,t{\plus}1)^{T} \Sigma a(y,t{\plus}1)} }}$$
The approximation (27) provides a computationally easy way of aggregating the risks. Moreover, its natural association to the SCR standard formula should make it easier for the regulatory experts to accept it as an internal model formula. However, it should be stressed that (27) only holds with equality if
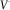 $$V^{ \cdot } $$
has an elliptical distribution, which is typically not the case. It is possible that this ad hoc method is too simplistic to adequately reflect the true risk of the portfolio in all situations. Therefore, we will suggest an alternative way of calculating the portfolio risk based on scenario generation and convex optimisation.
$$V^{ \cdot } $$
has an elliptical distribution, which is typically not the case. It is possible that this ad hoc method is too simplistic to adequately reflect the true risk of the portfolio in all situations. Therefore, we will suggest an alternative way of calculating the portfolio risk based on scenario generation and convex optimisation.
5.2. Stress scenario generation
Estimating the SCR from the portfolio value in a suitably chosen extreme scenario provides a computationally tractable approach to the SCR problem. Christiansen & Steffensen (Reference Christiansen and Steffensen2013) suggest that an upper bound for SCR p may be obtained by finding the worst outcome for the portfolio over a confidence set, i.e. a set of transition rates with mass p. This section is dedicated to constructing such a confidence set for a portfolio value of the form (26).
Recall that
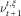 $$\nu _{{t{\plus}1}}^{{t,\xi }} $$
has the representation
$$\nu _{{t{\plus}1}}^{{t,\xi }} $$
has the representation
 $$\nu _{{t{\plus}1}}^{{t,\xi }} {\,\equals\,}\xi {\plus}\mu {\plus}A(W_{{t{\plus}1}} {\minus}W_{t} )\:\mathop{{\,\equals\,}}\limits^{d} \:\xi {\plus}\mu {\plus}AY$$
$$\nu _{{t{\plus}1}}^{{t,\xi }} {\,\equals\,}\xi {\plus}\mu {\plus}A(W_{{t{\plus}1}} {\minus}W_{t} )\:\mathop{{\,\equals\,}}\limits^{d} \:\xi {\plus}\mu {\plus}AY$$
where Y is an m-dimensional vector of independent standard normal random variables. Hence, for each x∈X, the random variable
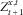 $$Z_{{t{\plus}1}}^{{x,t}} $$
has the representation
$$Z_{{t{\plus}1}}^{{x,t}} $$
has the representation
 $$Z_{{t{\plus}1}}^{{x,t}} \:\mathop{{\,\equals\,}}\limits^{d} \:a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}AY)$$
$$Z_{{t{\plus}1}}^{{x,t}} \:\mathop{{\,\equals\,}}\limits^{d} \:a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}AY)$$
Based on (28), constructing a confidence set for
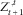 $$Z_{{t{\plus}1}}^{{ \cdot ,t}} $$
is equivalent to constructing a confidence set for Y. The latter alternative is more convenient due to the spherical symmetry of the distribution of Y. Consider e.g. the scenarios defined by
$$Z_{{t{\plus}1}}^{{ \cdot ,t}} $$
is equivalent to constructing a confidence set for Y. The latter alternative is more convenient due to the spherical symmetry of the distribution of Y. Consider e.g. the scenarios defined by
 $$\,\mid\!Y\!\mid\,^{2} \leq R^{2} $$
$$\,\mid\!Y\!\mid\,^{2} \leq R^{2} $$
for a suitable
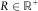 $$R\in{\Bbb R}^{{\plus}}\!$$
. The worst outcome for the portfolio liabilities among these scenarios is given by
$$R\in{\Bbb R}^{{\plus}}\!$$
. The worst outcome for the portfolio liabilities among these scenarios is given by
 $$\mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,^{2} \leq R^{2} } \mathop{\sum}\limits_{x\in X} {c_{x}^{n} f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay))} $$
$$\mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,^{2} \leq R^{2} } \mathop{\sum}\limits_{x\in X} {c_{x}^{n} f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay))} $$
Finding a set of transition rates with mass p is analogous to choosing the radius R such that
 $${\Bbb P}(\,\mid\!Y\!\mid\,^{2} \,\gt\,R^{2} ){\,\equals\,}1{\minus}p$$
$${\Bbb P}(\,\mid\!Y\!\mid\,^{2} \,\gt\,R^{2} ){\,\equals\,}1{\minus}p$$
Noting that
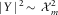 $$\,\mid\!Y\!\mid\,^{2} \,\sim\,{\cal X}_{m}^{2} $$
, we obtain
$$\,\mid\!Y\!\mid\,^{2} \,\sim\,{\cal X}_{m}^{2} $$
, we obtain
 $$R(p){\,\equals\,}\sqrt {({\cal X}_{m}^{2} )^{{{\minus}1}} (p)} $$
$$R(p){\,\equals\,}\sqrt {({\cal X}_{m}^{2} )^{{{\minus}1}} (p)} $$
If y* is an argmax of (29), then a conservative SCR estimate is given by
 $${\rm SCR}_{p} \leq \mathop{\sum}\limits_{x\in X} {c_{x}^{n} (f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay^{{\asterisk}} )){\minus}v_{x} (t,a(x,t)^{T} \xi ))} $$
$${\rm SCR}_{p} \leq \mathop{\sum}\limits_{x\in X} {c_{x}^{n} (f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay^{{\asterisk}} )){\minus}v_{x} (t,a(x,t)^{T} \xi ))} $$
In other words, to compute the capital requirement it is enough to find a maximiser y* of (31). However, determining y* is a matter of solving a high-dimensional, possibly non-convex, optimisation problem, which may indeed be challenging.
A natural question is how sharp the upper bound given by (31) is. We give a partial answer to this question in the special case where
(H1) the liability value function
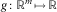 $$g\,\colon\,{\Bbb R}^{m} \,\mapsto\,{\Bbb R}$$
is quasi-concave, i.e., for each p∈(0,1), the set A
p
is defined by
$$g\,\colon\,{\Bbb R}^{m} \,\mapsto\,{\Bbb R}$$
is quasi-concave, i.e., for each p∈(0,1), the set A
p
is defined by
 $$A_{p} {\,\equals\,}\{ y\,\colon\,g(y)\geq F_{{g(Y)}}^{{{\minus}1}} (p)\} $$
$$A_{p} {\,\equals\,}\{ y\,\colon\,g(y)\geq F_{{g(Y)}}^{{{\minus}1}} (p)\} $$
is convex.
Define y* by
 $$y^{{\asterisk}} {\,\equals\,}\mathop {{\rm arg}{\rm min}}\limits_{y\in A_{p} } \,\mid\!y\!\mid\,$$
$$y^{{\asterisk}} {\,\equals\,}\mathop {{\rm arg}{\rm min}}\limits_{y\in A_{p} } \,\mid\!y\!\mid\,$$
i.e., y* is the boundary point of A p which is closest to the origin. We make the further assumption that
(H2) for p close to 1, A p does not contain the origin.
This assumption is quite reasonable for any insurance portfolio, which is seen when we consider the opposite case: if g(0), which in some sense represents the most probable outcome for the insurance portfolio, belongs to the (1−p)% worst case scenarios, then the insurer has much bigger problems to worry about. One may think of a “Gaussian lottery” where the insurer gains a lot of money whenever a certain tail event is exceeded, and loses a small amount of money otherwise. This is typically the opposite of most sound insurance strategies used in practice. The case with a constant g is trivial and not considered here. Moving on, we define the set C p by
 $$C_{p} {\,\equals\,}\{ y\,\colon\,\,\mid\!y\!\mid\,\leq \,\mid\!y^{{\asterisk}} \!\mid\} $$
$$C_{p} {\,\equals\,}\{ y\,\colon\,\,\mid\!y\!\mid\,\leq \,\mid\!y^{{\asterisk}} \!\mid\} $$
i.e. C p is the ball with radius |y*| centred at the origin. By the Separating Hyperplanes Theorem, there is a hyperplane containing y* that separates A p and C p and, by the Hilbert Projection Theorem, the half-space H p given by
 $$H_{p} {\,\equals\,}\{ y\,\colon\,(y^{{\asterisk}} )^{T} (y{\minus}y^{{\asterisk}} )\geq 0\} $$
$$H_{p} {\,\equals\,}\{ y\,\colon\,(y^{{\asterisk}} )^{T} (y{\minus}y^{{\asterisk}} )\geq 0\} $$
contains A p . This, together with the spherical property of the distribution of Y, implies
 $$1{\minus}p{\,\equals\,}{\Bbb P}(A_{p} )\leq {\Bbb P}(H_{p} ){\,\equals\,}{\Bbb P}((y^{{\asterisk}} )^{T} (Y{\minus}y^{{\asterisk}} )\geq 0){\,\equals\,}1{\minus}\Phi (\,\mid\!y^{{\asterisk}} \!\mid\,)$$
$$1{\minus}p{\,\equals\,}{\Bbb P}(A_{p} )\leq {\Bbb P}(H_{p} ){\,\equals\,}{\Bbb P}((y^{{\asterisk}} )^{T} (Y{\minus}y^{{\asterisk}} )\geq 0){\,\equals\,}1{\minus}\Phi (\,\mid\!y^{{\asterisk}} \!\mid\,)$$
where Φ denotes the normal distribution function. This is equivalent to
 $$\,\mid\!y^{{\asterisk}} \!\mid\,\leq \Phi ^{{{\minus}1}} (p){\,\equals\,}R(p)$$
$$\,\mid\!y^{{\asterisk}} \!\mid\,\leq \Phi ^{{{\minus}1}} (p){\,\equals\,}R(p)$$
which means that we should search for y* among the vectors in
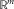 $${\Bbb R}^{m} $$
with length at most Φ−1(p). We have obtained the following conservative quantile estimate:
$${\Bbb R}^{m} $$
with length at most Φ−1(p). We have obtained the following conservative quantile estimate:
Lemma 7
 $$F_{{g(Y)}}^{{{\minus}1}} (p){\,\equals\,}g(y^{{\asterisk}} )\leq \mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,\leq \Phi ^{{{\minus}1}} (p)} g(y)$$
$$F_{{g(Y)}}^{{{\minus}1}} (p){\,\equals\,}g(y^{{\asterisk}} )\leq \mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,\leq \Phi ^{{{\minus}1}} (p)} g(y)$$
The radius given by (33) is significantly smaller than (30), which implies that Lemma 7 gives an improved upper bound for SCR p under the comonotonic approximation.
The assumption that g is quasi-concave is restrictive, but holds for some interesting special cases. For example, if g is a linear combination of the elements of y, or a monotone function of such a linear combination, then g is quasi-concave. Further, in this special case, (32) holds with equality: for a non-increasing
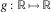 $$g\,\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$$
and
$$g\,\colon\,{\Bbb R}\,\mapsto\,{\Bbb R}$$
and
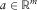 $$a\in{\Bbb R}^{m} $$
$$a\in{\Bbb R}^{m} $$
 $$F_{{g(a^{T} Y)}}^{{{\minus}1}} (p){\,\equals\,}g(F_{{a^{T} Y}}^{{{\minus}1}} (1{\minus}p)){\,\equals\,}g(\,\mid\!a\!\mid\,\Phi ^{{{\minus}1}} (1{\minus}p))$$
$$F_{{g(a^{T} Y)}}^{{{\minus}1}} (p){\,\equals\,}g(F_{{a^{T} Y}}^{{{\minus}1}} (1{\minus}p)){\,\equals\,}g(\,\mid\!a\!\mid\,\Phi ^{{{\minus}1}} (1{\minus}p))$$
Setting
 $$F_{{g(a^{T} Y)}}^{{{\minus}1}} (p){\,\equals\,}g(a^{T} y^{{\asterisk}} )$$
$$F_{{g(a^{T} Y)}}^{{{\minus}1}} (p){\,\equals\,}g(a^{T} y^{{\asterisk}} )$$
yields
 $$y^{{\asterisk}} {\,\equals\,}{\minus}{a \over {\,\mid\!a\!\mid\,}}\Phi ^{{{\minus}1}} (p)$$
$$y^{{\asterisk}} {\,\equals\,}{\minus}{a \over {\,\mid\!a\!\mid\,}}\Phi ^{{{\minus}1}} (p)$$
which satisfies (33). In the light of Proposition 5, this holds for each f
x
defined by (25) under the comonotone approximation. Hence, we may use (34) with equality to calculate
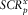 $$SCR_{p}^{x} $$
for each age group separately. Regarding the portfolio liabilities, the liability value function g is given by
$$SCR_{p}^{x} $$
for each age group separately. Regarding the portfolio liabilities, the liability value function g is given by
 $$g(y){\,\equals\,}\mathop{\sum}\limits_{x\in X} {c_{x}^{n} f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay))} $$
$$g(y){\,\equals\,}\mathop{\sum}\limits_{x\in X} {c_{x}^{n} f^{x} (a(x,t{\plus}1)^{T} (\xi {\plus}\mu {\plus}Ay))} $$
Unfortunately, g defined by (35) need not be quasi-concave even if it holds for each f x separately. Even the weaker condition that only A 0.995 is convex is hard to verify without introducing further assumptions. This is left as a topic for future research.
The numerical results in the next section indicate that there might be some connection between the scenario generation method and the variance–covariance method. To shed some light on this, let y* be the maximiser of (35) over the set (33), let y x be the maximiser of f x . Abusing notation, we write v x =v x (t,a(x,t) T ξ) and f x (y)=f x (a(x,t+1) T (ξ+μ+Ay)). Then
 $$\eqalignno{ \mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,\leq \Phi ^{{{\minus}1}} (p)} & \mathop{\sum}\limits_x {c_{x}^{n} f^{x} (y)} {\minus}\mathop{\sum}\limits_x {c_{x}^{n} v_{x} } \cr & {\,\equals\,}\mathop{\sum}\limits_x {c_{x}^{n} (f^{x} (y^{{\asterisk}} ){\minus}v_{x} )} \cr & \leq \mathop{\sum}\limits_x {c_{x}^{n} (f^{x} (y_{x} ){\minus}v_{x} )} \cr & {\,\equals\,}\sqrt {\mathop{\sum}\limits_{j,k} {c_{j}^{n} (f^{j} (y_{j} ){\minus}v_{j} )c_{k}^{n} (f^{k} (y_{k} ){\minus}v_{k} )} } \cr & {\,\equals\,}\sqrt {\mathop{\sum}\limits_{j,k} {SCR_{p}^{j} SCR_{p}^{k} } } $$
$$\eqalignno{ \mathop {{\rm max}}\limits_{y\,\colon\,\,\mid\,y\,\mid\,\leq \Phi ^{{{\minus}1}} (p)} & \mathop{\sum}\limits_x {c_{x}^{n} f^{x} (y)} {\minus}\mathop{\sum}\limits_x {c_{x}^{n} v_{x} } \cr & {\,\equals\,}\mathop{\sum}\limits_x {c_{x}^{n} (f^{x} (y^{{\asterisk}} ){\minus}v_{x} )} \cr & \leq \mathop{\sum}\limits_x {c_{x}^{n} (f^{x} (y_{x} ){\minus}v_{x} )} \cr & {\,\equals\,}\sqrt {\mathop{\sum}\limits_{j,k} {c_{j}^{n} (f^{j} (y_{j} ){\minus}v_{j} )c_{k}^{n} (f^{k} (y_{k} ){\minus}v_{k} )} } \cr & {\,\equals\,}\sqrt {\mathop{\sum}\limits_{j,k} {SCR_{p}^{j} SCR_{p}^{k} } } $$
which bears strong resemblance to the simple variance–covariance aggregation formula (27). The only difference is that the correlation coefficients ρ jk are not taken into account. Unfortunately
 $$\sqrt {\mathop{\sum}\limits_{j,k} {SCR_{p}^{j} SCR_{p}^{k} } } \geq \sqrt {\mathop{\sum}\limits_{j,k} {\rho _{{jk}} SCR_{p}^{j} SCR_{p}^{k} } } $$
$$\sqrt {\mathop{\sum}\limits_{j,k} {SCR_{p}^{j} SCR_{p}^{k} } } \geq \sqrt {\mathop{\sum}\limits_{j,k} {\rho _{{jk}} SCR_{p}^{j} SCR_{p}^{k} } } $$
i.e., reintroducing the correlations yields an inequality in the other direction, which means that it is difficult to directly relate the two risk aggregation schemes to each other.
6. Numerical Results
We perform a simulation study over a range of age groups, from 25 to 60 years of age. We have chosen the interest rate r=0.02, and the contracts are simple annuity contracts with
 $$g_{x} (s,z){\,\equals\,}1,\,\,\,\,\,h_{x} (s,z){\,\equals\,}0,\,\,\,\,\,z\in{\Bbb R},\,\,\,\,\,0{\,\equals\,}t\leq s\leq T_{x} {\,\equals\,}65{\minus}x,\,\,\,\,\,x\in X$$
$$g_{x} (s,z){\,\equals\,}1,\,\,\,\,\,h_{x} (s,z){\,\equals\,}0,\,\,\,\,\,z\in{\Bbb R},\,\,\,\,\,0{\,\equals\,}t\leq s\leq T_{x} {\,\equals\,}65{\minus}x,\,\,\,\,\,x\in X$$
We employ the four-factor disability termination model and fitting method from Djehiche & Löfdahl (Reference Djehiche and Löfdahl2014 a, section 5.1), and the model parameters are estimated from disability claims data for the years 2000–2011. The transition rate function is of the form (22) from section 4.1.
6.1. Quantile approximations for homogeneous portfolios
First, we investigate the convergence of the CLLN approximation. Paths of the underlying stochastic process Z, as well as each individual contract, are simulated over the interval [t,t+1], and
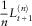 $${1 \over n}L_{{t{\plus}1}}^{{(n)}} $$
and V
x
are computed for each trajectory. Figure 1 displays the convergence of the portfolio 99.5% quantile to the CLLN 99.5% quantile, for age groups 25, 30, 35, … , 60. The y-axis is normalised to the value obtained from the CLLN simulation. As we can see, it suffices to have only a few hundred individuals to obtain a very good approximation.
$${1 \over n}L_{{t{\plus}1}}^{{(n)}} $$
and V
x
are computed for each trajectory. Figure 1 displays the convergence of the portfolio 99.5% quantile to the CLLN 99.5% quantile, for age groups 25, 30, 35, … , 60. The y-axis is normalised to the value obtained from the CLLN simulation. As we can see, it suffices to have only a few hundred individuals to obtain a very good approximation.

Figure 1 Convergence of portfolio 99.5% quantiles to conditional law of large numbers approximation.
Next, the 99.5% quantiles from the simulation are compared with the quantiles from the comonotonic approximation, for age groups 25, 30, 35, … , 60. The results are displayed in Figure 2. The solid line corresponds to the simulated law of large number approximation. The dotted line corresponds to a portfolio simulation of 2,000 contracts, and the dashed line corresponds to the comonotonic approximation (20). The y-axis is normalised to the simulated law of large number approximation.

Figure 2 Portfolio 99.5% quantile per age group, normalized. Solid: conditional law of large numbers. Dotted: 2,000 contracts. Dashed: comonotonic approximation.
From this simulation study, we see that the comonotonic approximation performs fairly well. It seems to provide slightly conservative quantile estimates, ranging from 1% to 5% above the simulated quantiles.
6.2. Capital requirements for homogeneous portfolios
In this section, we compare four different SCR calculation procedures for a large portfolio: the standard SCR, the CLLN SCR approximation, the comonotonic approximation, and the scenario method with radius R(p)=Φ−1(p). For reference, these are compared with two historical stress scenarios that reverse the changes from 2006–2007 and 2007–2008, respectively. The yearly change from 2006–2007 was minor, while the change from 2007–2008 represents a major shock to the system due to regulation changes. Table 1 displays the SCR values, as a fraction of the standard SCR, for the age groups 25, 30, … , 60. Comparing the standard 20% stress to the historical scenarios, we can see that, as expected, the reversed change from 2006–2007 yields a very low SCR. Meanwhile, the reversed change from 2007–2008 yields an SCR which is several times larger than the SCR of the standard model. Bearing in mind that the SCR should match the risk of a 200-year event, these results suggest that the standard stress scenario is far too lenient, at least for Swedish insurance companies. The Swedish sickness insurance system is quite volatile due to political reasons, and this fact may not be properly reflected in the calibration of the standard stress scenario.
Table 1 Solvency capital requirement (SCR) in relation to the standard method SCR.

MC CLLN, Monte Carlo conditional law of large numbers.
The SCR from the Monte Carlo CLLN approximation and the comonotonic approximation are similar, with the latter seeming slightly more conservative. The SCR obtained from the comonotonic approximation and the scenario method are identical. This is expected, since, in the light of Proposition 5, the liability value function for each pool is monotone, which implies that (34) holds with equality. All three approaches propose a lower SCR for young people, and a higher SCR for ages 40 and over, compared with the standard model. The SCR from all models are significantly lower compared with the 2007–2008 stress SCR for each groups.
It could be argued that the political risk should be included in the operational risk module, to be applied on top of the standard 20% stress of the recovery rates, which would then only account for the biometric part of the disability and recovery risk. However, for disability insurance, it is important to realise that we are dealing with economic disability, in the sense that, for the purpose of receiving benefits, it does not matter whether the policy holder is actually ill; the only thing that matters is whether she has the right to obtain benefits. Hence, we argue that, for the purpose of claims reserving and risk management, the economic disability rates should be used over the actual biometric disability rates. Further, from a statistics point of view, it may be difficult to isolate the political effects from fluctuations in the biometric rates, which suggests that, for simplicity, they should be modelled as one. This implies that every factor that affects the economic disability rates must be included in the standard stress scenario, be it political or biometric.
6.3. SCR aggregation
In this section, we consider a large portfolio, partitioned into eight pools of equal size corresponding to the age groups 25, 30, … , 60. We investigate the performance of the risk aggregation schemes from sections 5.1–5.2, and compare the results to a CLLN Monte Carlo simulation approach. The scenario method SCR is calculated using the radii R
1(p)=Φ−1(p) and
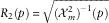 $$R_{2} (p){\,\equals\,}\sqrt {({\cal X}_{m}^{2} )^{{{\minus}1}} (p)} $$
. For reference, the results are compared with two historical stress scenarios that reverse the changes from 2006–2007 and 2007–2008, respectively. Table 2 displays portfolio SCR values, scaled by the SCR obtained from the standard method.
$$R_{2} (p){\,\equals\,}\sqrt {({\cal X}_{m}^{2} )^{{{\minus}1}} (p)} $$
. For reference, the results are compared with two historical stress scenarios that reverse the changes from 2006–2007 and 2007–2008, respectively. Table 2 displays portfolio SCR values, scaled by the SCR obtained from the standard method.
Table 2 Portfolio solvency capital requirement (SCR) in relation to the standard method SCR.

MC CLLN, Monte Carlo conditional law of large numbers.
Bearing in mind the results from the previous section, we are not surprised to find that the portfolio SCR is higher for both aggregation approximations compared with the standard model. The same holds for the CLLN Monte Carlo simulation. The simple variance–covariance aggregation formula (27) provides an estimate that is only slightly larger that the Monte Carlo estimates. As expected, the scenario method with radius R 2 provides a highly conservative estimate compared with the Monte Carlo simulation. However, it is interesting to note that this upper bound is only slightly lower than the 2008–2007 stress scenario.
Surprisingly, the SCR estimates from the scenario method with R 1 and the variance–covariance method are almost identical. The reason for this is unclear, but, in the light of (36)–(37), our best guess would be that the increase from removing the correlations is balanced by the reduction caused by replacing the individual maximisers y j with the global maximiser y*. Still, this result suggests that such simple aggregation procedures as the standard-type formula (27) may indeed be used to estimate SCR. Since this method is computationally attractive, it seems feasible to implement it as an internal model.
Acknowledgements
Financial support from the Filip Lundberg and Eir’s 50 Years foundations is gratefully acknowledged. The authors thank the anonymous referee for insightful remarks that helped to improve the content of the paper.




