

35.1 Introduction
The importance of rhythm for language processing is a core theme throughout this volume. Both the acoustic structure of the speech signal and the physiology of speech perception and production are intimately tied to rhythm, and so the proposal that rhythm is also at the centre of language acquisition is perhaps unsurprising. Rhythm can be understood as a kind of hidden glue that underpins the acoustic structure of human languages and the representation of sensory structure by human brains. Indeed, almost four decades ago, Mehler et al. (Reference Mehler, Jusczyk and Lambertz1988) proposed that sensitivity to rhythm was a universal precursor to language acquisition by young infants. Here, I adapt temporal sampling (TS) theory (Goswami, Reference Goswami2011) to provide a rhythm-based framework for explaining language acquisition by infants (see also Goswami, Reference Goswami2019, Reference Goswami2020, Reference Goswami2022a). TS theory was originally proposed as a causal framework for integrating the acoustic and motor difficulties with rhythm found in children with dyslexia with an oscillatory model of sensory encoding. The acoustic rhythmic difficulties in dyslexia were indexed primarily by sensory difficulties in discriminating changes in speech energy called amplitude rise times (ARTs, depicted in Figure 35.1), and by perceptual difficulties in discriminating syllable stress patterns and musical rhythm patterns, along with problems in tapping in time with a regular metronome beat (e.g., Thomson and Goswami, Reference Thomson and Goswami2008; Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011; Goswami et al., Reference Goswami and Leong2013). The rhythmic neural encoding aspects of TS theory were focused on low-frequency oscillations in the delta (0.5–4 Hz) and theta (4–8 Hz) neurophysiological bands, thought to play a core role in rhythmic entrainment (Ghitza and Greenberg, Reference Ghitza and Greenberg2009; see Chapter 3). These features were integrated into a sensory/neural explanatory system for understanding the phonological difficulties that characterise children with dyslexia, and that also characterise many children with what was previously termed specific language impairment (SLI – now termed developmental language disorder, DLD). Since 2011, TS theory has been developed further in the light of experimental data. Following an outline of TS theory drawing on sensory/neural data from adults and children, two longitudinal studies testing the theory with infant participants will be described in detail.
A schematic depiction of ARTs.
Panel 1A depicts the amplitude envelope for the sentence ‘drive round, pick my children back up’, and Panel 1B shows the rise time for the syllable ‘my’, taken from the longer sentence.
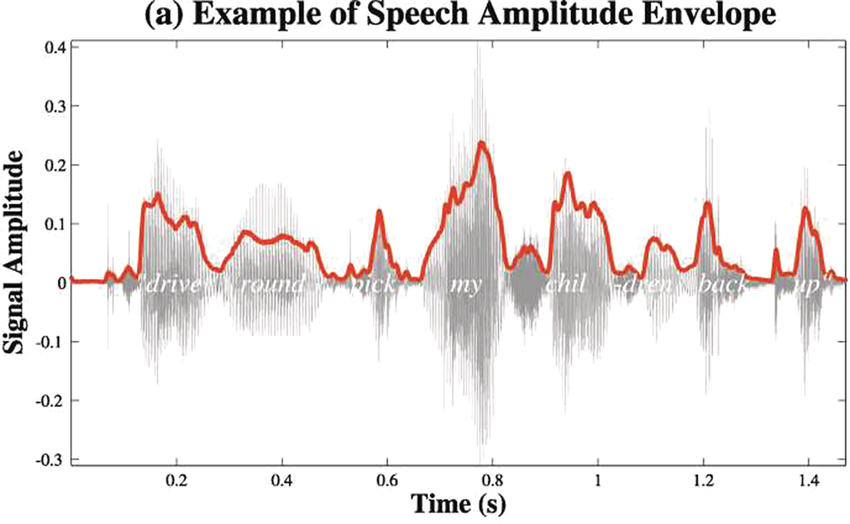
Figure 35.1(a) Long description
The horizontal axis represents time ranging from 0.2 to 1.4 seconds. The vertical axis represents signal amplitude, which ranges from minus 0.3 through 0.4. The waveform of speech reads, drive round, pick my children back up. A solid line outlines the waveform. The values are estimated.
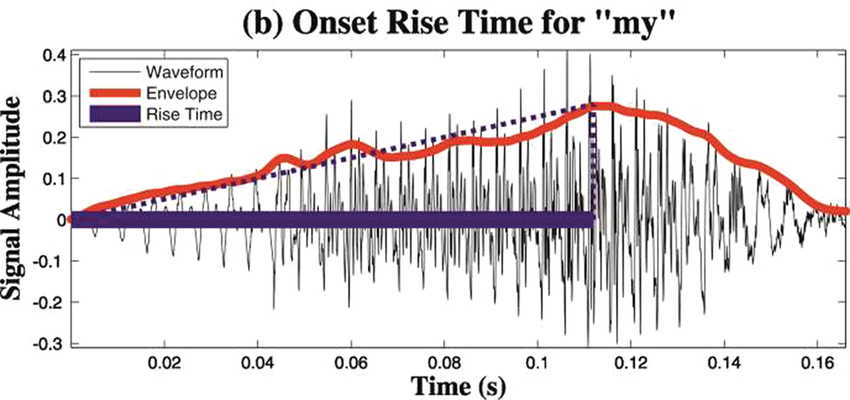
Figure 35.1(b) Long description
The horizontal axis represents time ranging from 0.02 through 0.16 seconds. The vertical axis represents signal amplitude, which ranges from minus 0.3 through 0.4. This graph displays a waveform which originates at (0.00, 0) and terminates at (0.16, 0). A solid line for the envelope overlaps the waveform and originates at (0.00, 0) and terminates at (0.16, 0). A dotted line indicates the rising amplitude of the onset. A vertical horizontal line also overlaps the waveform to indicate computation of the rise time, originates at (0.00, 0) and terminates at (0.7, 0). The values are estimated.
35.2 Temporal Sampling Theory
Temporal ‘sampling’ refers to the fact that the brain depends on networks of neurons that oscillate between excitation and inhibition to encode sensory information (‘brain waves’). Temporal coding is an important aspect of information coding in the brain (Buzsáki and Draghun, Reference Buzsáki and Draguhn2004), and for encoding the complex speech signal, the synchronous activity of oscillating networks of neurons at different timescales (frequency bands, primarily delta, 0.5–4 Hz, theta, 4–8 Hz, beta, 15–25 Hz, and gamma, 30–80 Hz) is thought to be critical (Giraud and Poeppel, Reference Giraud and Poeppel2012; see also Obleser et al., Reference Obleser, Herrmann and Henry2012). Neurophysiology shows that these frequency bands are ubiquitous throughout the brain and encode many aspects of sensory information (Buzsáki, Reference Buzsáki2006). The acoustic speech signal can be modelled as the summation of a number of frequency bands fluctuating in intensity (amplitude) over time (the amplitude envelope, AE; Drullman, Reference Drullman, Greenberg and Ainsworth2006). The auditory system codes amplitude modulations (AMs) in natural sounds across different frequency channels and at different timescales (Joris et al., Reference Joris, Schreiner and Rees2004; Turner, Reference Turner2010), and there is systematic AM structure in the AE of all natural sounds, not just speech (Turner, Reference Turner2010; see Daikoku and Goswami, Reference Daikoku and Goswami2022, for AM structure of music, birdsong, wind, and rain). The AE of both child-directed speech (CDS) such as nursery rhymes and infant-directed speech (IDS) or BabyTalk can be analysed in terms of its constituent temporal modulation frequencies (Leong and Goswami, Reference Leong and Goswami2015; Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017). This computational modelling shows that the dominant modulation frequency bands for these highly rhythmic speech registers cluster into three AM bands, with centre frequencies around ~2 Hz, ~5 Hz, and ~20 Hz, thereby approximately matching the electrophsyiological bands of delta, theta, and beta/low gamma. These insights concerning the AM structure of CDS and IDS fit well with adult multi-time resolution speech processing models (MTRMs) (see Poeppel, Reference Poeppel2003; Poeppel et al., Reference Poeppel, Idsardi and van Wassenhove2008; also see Chapters 3 and 5), models that played a core role in the development of TS theory (see Goswami, Reference Goswami2011).
35.2.1 TS Theory: Sensory Data
Adult MTRMs proposed that the different temporal integration windows characterised by the different oscillatory networks yielded packets of information at different linguistic grain sizes that were matched to stored representations of words in the mental lexicon (Poeppel et al., Reference Poeppel, Idsardi and van Wassenhove2008). Adult MTRMs focused on the linguistic units of the syllable and the phoneme, thought to be captured by temporal integration windows in the theta and gamma bands, respectively. The infant and child speech modelling studies discussed in Section 35.2 showed that the stressed syllable is also an important linguistic grain size, and is captured by temporal integration windows in the delta band (Leong and Goswami, Reference Leong and Goswami2015). Leong and Goswami’s speech modelling revealed that if one cycle of AM at each temporal rate (delta (~2 Hz), theta (~5 Hz), and beta/low gamma (~20 Hz)) in English nursery rhymes is assumed to match one level of linguistic structure (stressed syllable, syllable, onset-rime), then the AM structure in the AE of CDS provides sufficient sensory information for the brain to extract phonological units of different sizes with over 80–90% efficiency (the spectral-amplitude modulation hierarchy model, S-AMPH, Leong and Goswami, Reference Leong and Goswami2015). This suggests that applying an MTRM approach to the simplified rhythmic genres of IDS and CDS, which underpin language acquisition across cultures, could enable ‘acoustic-emergent’ phonology. When brain rhythms and speech rhythms at these different rates (delta, theta, beta/low gamma) are in temporal alignment, then an emergent phonological system can be extracted from the speech signal by automatic acoustic statistical learning processes (see Goswami, Reference Goswami2022a, for detail; statistical learning is required as speech–brain alignment is only probabilistically accurate in yielding phonological units). This automatic learning can, in principle, enable perceptual organisation of the acoustic speech stream into syllable stress patterns (prosodic feet), syllables, and onset-rime units (m-ash, cr-ash, spl-ash). Further, automatic learning of higher-level acoustic prosodic hierarchies that are also present in the sensory signal could enable the perceptual organisation of acoustic information relevant to extracting syntax and grammar, such as prosodic and intonational phrasing (the ‘prosodic phrasing’ hypothesis; see Cumming et al., Reference Cumming, Wilson and Goswami2015). Perceptual detection of prosodic hierarchies also depends on accurate ART perception (Cumming et al., Reference Cumming, Wilson and Goswami2015).
In TS theory, rhythm patterns are hypothesised to be core to these organisational processes. The S-AMPH computational modelling work based on nursery rhymes further revealed that each AM band is in temporal synchronicity with its adjacent band, via phase relations. Phase relations are temporal relations between different cycles of rhythmic timing, such as slower versus faster bands of AM. In IDS and CDS, these phase relations are governed by the delta AM band (Leong et al., Reference Leong, Stone, Turner and Goswami2014). In particular, phase relations between the delta (~2 Hz) and theta (~5 Hz) AM bands in nursery rhymes are critical to perceiving their ‘beat’ structure or metrical structure (e.g., trochaic versus iambic; Leong et al., Reference Leong, Stone, Turner and Goswami2014, Leong and Goswami, Reference Leong and Goswami2015). Delta–theta AM phase alignment is also core to perceiving rhythm in music (Daikoku and Goswami, Reference Daikoku and Goswami2022). Indeed, the finding that the delta AM band sits at the top of the phase hierarchy in CDS and IDS is thought-provoking, as its centre rate of ~2 Hz matches the dominant beat rate of music (120 bpm) (Fraisse, Reference Fraisse and Deutsch1982; see also Chapters 26 and 27). Temporal analyses of the lullabies sung by mothers to their infants across cultures reveals a cross-cultural convergence on this beat rate of ~2 Hz (Trehub and Trainor, Reference Trehub, Trainor, Rovee-Collier, Lipsitt and Hayne1998). Accordingly, AM-based modelling of the speech signal suggests that cultural practices such as BabyTalk and lullabies may facilitate the automatic extraction of phonology and possibly syntax via the AM phase hierarchy, by statistical sensory learning beginning in the cradle. Infant auditory statistical learning is already known to be highly efficient (e.g., Saffran, Reference Saffran2001), and while IDS and CDS are simplified speech registers, they nevertheless encompass more rhythmic categories than trochaic versus iambic, for example anapest rhythms.
TS theory proposes that this automatic statistical learning depends intimately on ART discrimination, as different ARTs are associated with different temporal modulation rates. TS theory (Goswami, Reference Goswami2011) was in part developed because psychoacoustic studies had repeatedly demonstrated impaired ART discrimination by children with dyslexia, across languages (to date English, French, Finnish, Dutch, Spanish, Chinese, and Hungarian, summarised in Goswami, Reference Goswami2015). Difficulties in discriminating ARTs (which index the rate of change of AMs) could be expected to cause impairments in distinguishing the different modulation frequency ranges in speech, which would result in inefficient phase-locking to these frequency ranges by neuronal oscillatory networks (Goswami, Reference Goswami2011). Adult neuroscience studies were able to demonstrate that ARTs (called ‘speech edges’ in that literature) played a key mechanistic role in the alignment of brain rhythms and speech rhythms (Gross et al., Reference Gross, Hoogenboom and Thut2013; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Chapter 8). For example, ARTs in the theta band provide sensory landmarks that automatically trigger brain rhythms and speech rhythms into temporal alignment, via phase-resetting ongoing neural activity (Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014). Further, the oscillatory networks that are responsive to speech inputs are also hierarchically organised, with delta at the top (Gross et al., Reference Gross, Hoogenboom and Thut2013). Accordingly, prior research with children and adults shows that there is a mechanistic neural hierarchy of oscillations, an AM phase hierarchy in IDS and CDS, and a linguistic hierarchy of phonological units that all match in terms of their intrinsic relational structure. This provides a sensory/neural framework for language acquisition via automatic statistical learning of this relational AM structure, which is depicted in simplified form in Figure 35.2.
TS theory and infant language acquisition.
The schematic depiction of TS theory emphasises the core role of ART and rhythm processing via automatic neural entrainment to AMs at ~2 Hz (delta) and ~5 Hz (theta) rates, sensory-neural processes that support the developing lexicon. Although only briefly discussed in this chapter, individual differences in rhythmic entrainment to visual speech and motor entrainment may also have an impact on the developing lexicon.
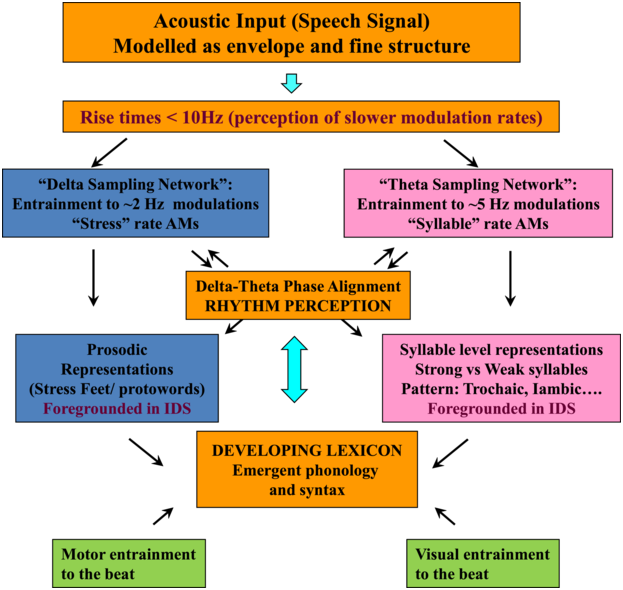
Figure 35.2 Long description
The flowchart starts with the acoustic input, which is followed by delta sampling network and theta sampling network, a box for delta theta phase alignment helping to determine prosodic representations or syllable level representations and a box indicating the developing lexicon. Motor entertainment to the beat and visual entertainment to the beat also contribute to developing the lexicon.
35.2.2 TS Theory: Neural Data
Children with dyslexia have phonological impairments at many levels of the linguistic hierarchy, showing difficulties in identifying and manipulating phonological units such as stressed syllables, syllables, onset-rimes, and phonemes in oral tasks (Goswami, Reference Goswami and Skeide2022b, for a recent review). If automatic statistical learning of AM phase relations supports acoustic-emergent phonology, and given the well-established sensory discrimination difficulties with ARTs found in children with dyslexia, it is logical to expect atypical oscillatory responses to natural speech in these children. The first studies investigating the neural aspects of TS theory in children predicted atypical responding in both the delta and theta bands. These early studies used a rhythmic speech paradigm, in which a ‘talking head’ repeated the syllable ‘ba’ at 2 Hz while an electroencephalogram (EEG) was recorded (Power et al., Reference Power, Mead, Barnes and Goswami2012, Reference Power, Mead, Barnes and Goswami2013). Children were listening for oddball syllables that were slightly out of time with the 2 Hz rhythm, and pressed a button when this occurred. Even when children with dyslexia were equated to control children without dyslexia for their performance in the button-press task, their brains were out of time regarding the delta-band response (but not the theta-band response; Power et al., Reference Power, Mead, Barnes and Goswami2013). The key finding was that the oscillatory response in the delta band had a different preferred phase (preferred phase refers to the point in time when most neurons are discharging their electrical potentials). Brain excitation in the delta band was maximal at a different point in time for the group of children with dyslexia compared to control children. By TS theory, this would suggest that the peak delta-band neural response for dyslexic children was aligned with less informative points in the speech stimulus, a phase difference that might be expected to impair the neural representation of phonological information.
Subsequent dyslexia studies testing TS theory in English indicated that the dyslexic brain encoded a less accurate representation of delta-band envelope information (Power et al., Reference Power, Colling, Mead, Barnes and Goswami2016; Keshavarzi et al., Reference Keshavarzi, Mandke and Macfarlane2022; Mandke et al., Reference Mandke, Flanagan and Macfarlane2022). These investigations recorded either EEG or MEG (magnetoencephalography) during speech listening tasks, and either used a method called the multivariate temporal response function (mTRF) to estimate different features of the heard speech such as the speech AE from the EEG responses (generating a correlational r value; Di Liberto et al., Reference Di Liberto, O’Sullivan and Lalor2015; Crosse et al., Reference Crosse, di Liberto, Bednar and Lalor2016), or other methods such as phase-locking values (PLVs) in MEG to estimate the cortical encoding of speech in different frequency bands. These developmental studies showed that neural representation in the delta band was less accurate (exhibiting a significantly lower mTRF r value) in a sentence-listening task for children with dyslexia compared to both age-matched control children and younger reading-level-matched control children using EEG (Power et al., Reference Power, Colling, Mead, Barnes and Goswami2016). It was also less accurate in a story-listening task compared to age-matched control children in neuroimaging studies using MEG (exhibiting a significantly lower PLV; Mandke et al., Reference Mandke, Flanagan and Macfarlane2022) and EEG (exhibiting a significantly lower mTRF r value; Keshavarzi et al., Reference Keshavarzi, Mandke and Macfarlane2022). In the English EEG studies, neural accuracy was significantly related to measures of phoneme awareness and non-word reading, and in the MEG study, to vocabulary development. Neuroimaging studies in other languages have also found impaired low-frequency envelope encoding for children with dyslexia (in both the delta and theta bands; see Destoky et al., Reference Destoky, Bertels and Niesen2020, Reference Destoky, Bertels and Niesen2022, French) and atypical speech–brain synchronisation in the delta band (see Molinaro et al., Reference Molinaro, Lizarazu, Lallier, Bourguignon and Carreiras2016, Spanish). Importantly, speech reconstruction studies with infants, children, and adults (in which EEG recorded during speech listening is used to reconstruct low-frequency speech information <8 Hz using mTRFs) show that delta-band information yields phonetic information as well as prosodic (syllable stress) information (Di Liberto et al., Reference Di Liberto, O’Sullivan and Lalor2015, Reference Di Liberto, Peter and Kalashnikova2018, Reference Di Liberto, Attaheri and Cantisani2023). Accordingly, this review of neural data supporting TS theory indicates that low-frequency envelope information is encoded less accurately by children with dyslexia, and that this impaired encoding affects the quality of their phonological development at many levels of the linguistic hierarchy, including the phoneme level.
35.2.3 Implications for a TS Theory of Language Acquisition
The sensory and neural data with children gathered to test TS theory have a number of implications for language acquisition. Regarding sensory factors, if ART sensitivity could be measured in infancy, it would be expected to be a significant predictor of linguistic development. As infants get older and become able to participate in metrical rhythm tasks, individual differences in rhythm perception and production might also be expected to relate to ART discrimination and to predict linguistic development. These sensory predictions of TS theory were investigated in the SEEDS project. Regarding neural factors, both the accuracy of continuous speech encoding in the delta and theta bands as measured by mTRFs and the timing of oscillatory responses (such as preferred phase) in the delta band to rhythmic inputs might be expected to predict later language outcomes. These predictions of TS theory were investigated in the Cambridge UK BabyRhythm project. Both were longitudinal infant projects, one with an at-risk sample (SEEDS) and one with a typically developing sample (BabyRhythm), and an overview of their findings is presented here.
35.3 SEEDS: Infants at Family Risk for Dyslexia
The SEEDS (of Literacy) project recruited a group of infants at family risk for dyslexia (FR group) and a group of infants not at family risk for dyslexia (NFR group) in Australia, and followed their development from the age of five months. One aim of SEEDS was to investigate whether infant measures of auditory sensitivity to rhythm would be related to subsequent linguistic and phonological skills and, eventually, to reading achievement (Kalashnikova et al., Reference Kalashnikova, Goswami and Burnham2018, Reference Kalashnikova, Goswami and Burnham2019, Reference Kalashnikova, Burnham and Goswami2020a, Reference Kalashnikova, Burnham and Goswami2020b, Reference Kalashnikova, Burnham and Goswami2020c, Reference Kalashnikova, Burnham and Goswami2021). Children were assigned to the FR and NFR groups at the beginning of the project based on a parent having a pre-existing dyslexia diagnosis and/or their performance on a comprehensive parental screening battery that included language, reading, and cognitive tasks. This targeted sample proved difficult to recruit; hence, most publications are based on samples of 50 infants or fewer.
An infant behavioural procedure for assessing sensitivity to ART was developed based on the psychoacoustic stimuli used to measure ART discrimination in younger children (Corriveau et al., Reference Corriveau, Goswami and Thomson2010). An infant version of a two-alternative forced choice (2AFC) adaptive threshold procedure was created based on looking preference. Infants sat on their parent’s lap facing three monitors in a sound-attenuated infant-testing booth. Once infants fixated the central monitor, the images of a chequerboard appeared on the right and left screens. Infants’ fixations to the monitor on one side produced a repeating auditory stimulus with a fixed rise time (e.g., 15 ms, 15 ms, 15 ms, 15 ms …), while fixations to the monitor on the other side produced an auditory stimulus with alternating rise times (15 ms, 300 ms, 15 ms, 300 ms …). Greater fixation to the alternating stimulus was taken as a measure of discrimination, and step size was reduced accordingly (e.g., 15 ms, 270 ms, 15 ms, 270 ms …), enabling a threshold (a just noticeable difference in ART) to be established (see Kalashnikova et al., Reference Kalashnikova, Goswami and Burnham2018, for a full description). When the FR and NFR groups were aged 10 months, they already showed a significant difference in ART discrimination in this task (Kalashnikova et al., Reference Kalashnikova, Goswami and Burnham2018), as would be expected by TS theory.
Early auditory rhythm sensitivity as indexed by the ART measure administered at 10 months was a significant predictor of subsequent vocabulary development (Kalashnikova et al., Reference Kalashnikova, Goswami and Burnham2019). When they were aged 36 months, the SEEDS cohort were given a standardised vocabulary measure from the Stanford-Binet (Roid, Reference Roid2003). They were also given two experimental measures of phonological development at 42 months. These were a mispronunciation detection task (e.g., ‘abble’ for apple) and a non-word repetition task (the children orally copied items such as ‘sep’, ‘gattom’, and ‘katapet’). A linear mixed-effects analysis showed that ART discrimination at age 10 months was a predictor of vocabulary at 36 months of age, but not (contrary to hypothesis) of phonological development at 42 months (Kalashnikova et al., Reference Kalashnikova, Goswami and Burnham2019). The phonological tasks did not yet show group differences, possibly due to reduced sensitivity at this age. By contrast, infants who were less sensitive to ART had smaller vocabularies, and reduced vocabulary development is known to be an early hallmark of risk for dyslexia. Prospective longitudinal studies of children at family (genetic) risk of dyslexia frequently report deficits in expressive vocabulary (e.g., at 17 months; Koster et al., Reference Koster, Been and Krikhaar2005), and van Viersen et al. (Reference van Viersen, de Bree and Verdam2017) showed that children at risk for dyslexia exhibit delayed growth patterns of both receptive and expressive vocabulary sizes from 17 to 35 months. In the latter study, these early vocabulary scores reliably discriminated between at-risk children who later did and did not develop dyslexia.
One explanation for reduced vocabulary development in FR samples could be that reduced sensitivity to ARTs impairs the learning of new words. This would be predicted by TS theory if infants with poorer rise time sensitivity process the speech signal less effectively. Prior research with children with dyslexia has shown a significant relationship between ART discrimination and the ability to learn novel words (Thomson and Goswami, Reference Thomson and Goswami2010). Thomson and Goswami reported that children with dyslexia were worse at learning novel words in a paired associate learning (PAL) task compared to both age-matched and younger reading-level-matched control children. Within the dyslexic group, children with better ART sensitivity performed better in the PAL task. To test the possibility that reduced ART sensitivity impairs novel word learning, a ‘fast mapping’ task was administered when the SEEDS cohort were aged 19 months (Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2020a). Two non-word items, ‘lif’ and ‘wug’, were presented repeatedly along with two novel visual objects in a habituation paradigm, and word learning was tested in a subsequent preferential looking paradigm. Both groups of infants showed similar patterns of habituation, and similar engagement and attention during the learning component of the task. However, while the NFR infants showed increased looking time to the correct novel referent at test, the FR infants did not. The FR infants were hence less successful at learning new words early in the language acquisition process, as would be expected on the basis of TS theory.
Of course, it could be argued that the FR infants were simply poorer at PAL. This explanation was ruled out by a subsequent study of PAL when the SEEDS sample were aged 48 and 54 months (Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2020b). In the later PAL task, the SEEDS children were required to learn associations between four novel words and four novel objects, with learning assessed by (1) finding the correct object in response to its label, and (2) producing the novel word when shown the corresponding object. Their letter knowledge was also assessed as a measure of pre-reading skill at both ages, and vocabulary was measured again at 48 months. Kalashnikova et al. (Reference Kalashnikova, Burnham and Goswami2020b) found no deficit in PAL for the FR children on either measure of learning, and no relationship between PAL and letter knowledge. However, the FR children still had significantly smaller vocabularies than the NFR children. Accordingly, linguistic development is still compromised, even though the difficulties in novel word learning present at 19 months for the FR children could no longer be demonstrated using the later PAL task at 48 and 54 months. Further analyses revealed that it was earlier performance in the non-word repetition task given at 42 months that predicted PAL. This suggests developmental continuity between early auditory difficulties, subsequent early word-learning difficulties, individual differences in later phonological sensitivity, and subsequent vocabulary learning.
By four years of age (48 months), the SEEDS sample were able to complete some of the measures of rhythmic sensitivity used in the TS studies of children with dyslexia. These measures comprised a rhythm discrimination task based on musical beats (following Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011, hereafter musical beat perception) and a measure of rhythm production based on tapping to a 2 Hz metronome beat (following Thomson and Goswami, Reference Thomson and Goswami2008; see Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2021). By TS theory, both measures of rhythmic processing should be related to phonological development and should be impaired in the FR group. The non-word repetition data gathered at 42 months was thus studied in relation to rhythm discrimination and rhythm production at 48 months. When aged four years, the FR group showed significantly poorer rhythm discrimination (significantly lower ‘d’ scores) in the musical beat perception task compared to the NFR group (Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2021). There was no group difference in rhythm production (tapping accuracy), although the FR group displayed more variable performance (Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2021; Figure 35.2). As noted above, when aged four years the SEEDS sample also received measures of letter knowledge and vocabulary. The FR and NFR children showed significant group differences in all three linguistic tasks (non-word repetition, letter knowledge, and vocabulary development), with the FR children showing consistently worse performance. Correlation analyses showed that tapping variability was significantly related to performance on all three linguistic tasks, whereas variability in musical beat perception was not. A mediation analysis showed that metronome tapping was a significant predictor of non-word repetition, and non-word repetition was a significant predictor of letter knowledge (Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2021). Accordingly, the link between rhythm and pre-literacy skills (letter knowledge) is mediated by phonological processing (non-word repetition). Again, these longitudinal relations are consistent with TS theory. In future SEEDS analyses, we plan to investigate developmental continuities between ART discrimination, phonological development, and early literacy.
35.4 Cambridge UK BabyRhythm Project: Typically Developing Infants
In order to test neural predictions of TS theory with infants, large samples are required. EEG data collected from infants is quite noisy, and there can be substantial loss of data. The Cambridge UK BabyRhythm project was able to recruit 122 typically developing infants, who were followed from the age of two months to 42 months with very little drop-out. Infants attended for eight EEG sessions at the ages of two, four, five, six, seven, nine, and 11 months, and language outcomes were measured at 12, 15, 18, 24, 30, and 42 months. To date, only language analyses up to 24 months are available (see also Chapter 36). Based on TS theory, three tasks were selected for the EEG recordings: a nursery rhyme task and two rhythmic tasks. Infants watched videos of a ‘talking head’ singing nursery rhymes in IDS, of a ‘talking head’ saying ‘ta’ repeatedly at 2 Hz in IDS, and of a visual presentation of a ball dropping on to a drum accompanied by a metronome beat at 2 Hz. These three audiovisual tasks enabled us to assess cortical tracking of natural speech in the delta and theta bands by applying mTRF analyses to the nursery rhyme EEG, and to generate measures of preferred phase using the EEG recorded to both speech (‘ta’) and non-speech (drumbeat) rhythmic inputs.
These neural measures were used to predict a range of language outcomes. Although many different experimental measures of phonology and grammar were employed, along with standardised measures such as the UK version of the CDI (communicative development inventory; Alcock et al., Reference Alcock, Meints and Rowland2020), the Covid-19 pandemic had a very disruptive effect on data collection, and only some of the language outcome measures could be used for the neural prediction analyses. The most robust measures were the UK-CDI, in which parents estimated their infants’ word comprehension and production, an infant-led vocabulary measure called the CCT (computerised comprehension task; Friend and Keplinger, Reference Friend and Keplinger2003), in which infants selected a named object on a tablet screen to indicate comprehension, and a non-word repetition task introduced as a game about naming toys. The vocabulary measures were administered from 12 months of age, and the non-word repetition task from 18 months of age (see Rocha et al., Reference Rocha, Ní Choisdealbha and Attaheri2024, for full analyses).
On the basis of prior TS studies with children with dyslexia, it was expected that the accuracy of encoding of envelope information in the delta band along with individual differences in preferred phase in the delta band could be predictors of language outcomes. Regarding the accuracy of low-frequency envelope encoding, the EEG recorded in response to the sung nursery rhymes presented at the four-, seven-, and 11-month laboratory sessions was analysed using the mTRF method. These longitudinal analyses compared the accuracy of the speech envelope information encoded in the delta (0.5–4 Hz), theta (4–8 Hz), and alpha (8–12 Hz, a control band) bands at each age. Encoding accuracy was estimated for the first 60 infants in the UK BabyRhythm sample (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Di Liberto2022), and is currently being replicated with the remaining infants (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024). In Attaheri et al. (Reference Attaheri, Ní Choisdealbha and Di Liberto2022), delta-band encoding was significantly stronger (significantly larger r values) than theta-band encoding at four months, and continued to be stronger at all subsequent ages, with no evidence for significant alpha-band encoding at any age. Other neural factors related to speech encoding by adults, such as phase-amplitude coupling (PAC) measures, were also present from the earliest measurement point (four months). Adult speech-encoding studies have highlighted theta–gamma PAC as particularly relevant for speech processing (Hyafil et al., Reference Hyafil, Fontolan, Kabdebon, Gutkin and Giraud2015). Our infant data showed that delta-led PAC was equally important as theta-led PAC during the nursery rhyme listening task, with delta–beta, delta–gamma, theta–beta, and theta–gamma PAC all significant at all ages (four, seven, and 11 months) (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Di Liberto2022). In ongoing analyses (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024), language data collected between 12 and 24 months is being related to the neural data. Currently, only theta–gamma PAC appears to be a significant source of individual differences. Stronger theta–gamma PAC is related to better language outcomes, while delta-related PAC is not (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024). The other neural predictor of better language outcomes as measured by the mTRF analyses was the accuracy of delta-band encoding at 11 months (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024). Worse language outcomes were related to the theta–delta power ratio (higher ratios were associated with worse outcomes), and to the overall amount of theta power (higher theta power spectral density was associated with worse language outcomes; Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024). Accordingly, both delta-band and theta-band oscillatory responses and their dynamic interactions are important for language acquisition, as would be expected on the basis of TS theory.
Given the earlier data collected with children with dyslexia (Power et al., Reference Power, Mead, Barnes and Goswami2013), the preferred phase of entrainment in the delta band to rhythmic speech should also relate to individual differences in language outcomes. Preferred phase analyses were conducted for the two rhythmic tasks (‘ta’ and drumbeat), which were administered at two, six, and nine months in the auditory-only or auditory-visual (AV) domain, and at five and eight months as visual-only (VO) speech. Phase analyses revealed that infants already exhibited phase consistency to rhythmic syllables and drumbeats at two months of age, when most participants were sleeping and hence experienced auditory-only input (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2023). Individual phase angles in the syllable task at two months were a significant predictor of later vocabulary outcomes as measured by the CCT at 18 months. By the time the infants were aged nine months, phase angles in the syllable task were associated with the number of parent-estimated known words at 24 months on the UK-CDI, for both comprehension and production. Regarding the drumbeat task, phase angles at nine months were predictive of non-word repetition skills at the age of 24 months, an early measure of phonological sensitivity (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2023).
For VO speech, similar results were obtained (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2024). At five months, infants already exhibited an increased cortical response to the stimuli at the stimulus frequency (thereby showing cortical tracking at 2 Hz), but phase consistency was variable. At eight months, the infants showed significant phase consistency to VO speech, and oscillatory responses were moving towards a common preferred phase angle. Individual differences in phase angle at eight months were significantly related to later vocabulary at 24 months. Taken together, the analyses reported by Ní Choisdealbha et al. show that individual differences in the phase angle of the neural response to rhythmic speech stimuli are predictive of later language outcomes, for auditory-only, VO, and AV speech. Accordingly, key neural parameters of TS theory explain some of the individual variation in children’s later language outcomes.
Ideally, the Cambridge UK BabyRhythm study would have explored whether there was an association between individual differences in ART sensitivity and these different neural outcome measures. However, the 2AFC behavioural paradigm from the SEEDS study did not yield reliable data with the UK BabyRhythm infants. As the infants were still wearing the EEG cap when they received the 2AFC paradigm, instead of using behavioural thresholds we used their ERPs as an index of ART sensitivity (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2022). The ERP data revealed that the infants showed robust mismatch responses to all the steps on the thresholding staircase, including the ones that we had expected to be below threshold on the basis of the SEEDS data. Even the smallest just noticeable difference of 161 ms in rise time (15 ms versus 176 ms) was discriminated by 85% of the sample at seven months of age, and there was no consistent pattern to the presence or absence of a mismatch response across the 10 values used for the staircase. This finding shows that infants are able to discriminate ARTs with high accuracy, revealing the readiness of the infant brain to process speech rhythm. The ART data also demonstrate the value of neural measures in assessing the parameters of TS theory. Future studies will need to present more fine-grained differences between ART stimuli in order to find individual infant thresholds and relate them to language outcomes.
35.5 Conclusions
Applying TS theory to infant language acquisition appears to be a promising avenue for future research. Referring back to Figure 35.2, the SEEDS and the Cambridge UK BabyRhythm projects have provided evidence for a number of factors theorised to be critical to language acquisition. The UK BabyRhythm project has shown that the infant brain is highly sensitive to ART differences (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2022), and entrains to delta-band and theta-band speech envelope information from four months of age (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Di Liberto2022, Reference Attaheri, Ní Choisdealbha and Rocha2024). Hence, the delta and theta sampling networks shown in Figure 35.2 are gaining information about AMs at the ‘stress’ and ‘syllable’ rates from early in language learning. Computational speech analyses of IDS collected in the SEEDS project showed that delta–theta phase alignment of AMs is foregrounded in BabyTalk (Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017), and although phase-phase analyses have yet to be completed, the UK BabyRhythm neural data showed that phase-amplitude mechanisms are already in play during speech processing (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Di Liberto2022). Hence, phase-phase mechanisms may also be online. The effects of individual differences in these sensory/neural variables on the developing lexicon were documented by both projects. The SEEDS data showed that infant rise time sensitivity at 10 months predicted vocabulary development at three years, with behavioural rhythm measures at four years subsequently predicting pre-literacy variables, mediated by phonological sensitivity (non-word repetition). The UK BabyRhythm data suggested that the accuracy of delta-band cortical tracking of speech envelope information at 11 months predicted later vocabulary, as did theta–gamma PAC (Attaheri et al., Reference Attaheri, Ní Choisdealbha and Rocha2024), while individual differences in neural phase angle to rhythmic speech and non-speech stimuli also predicted both later vocabulary and non-word repetition (Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2023). This suggests that both neural phase alignment in the delta band and the accuracy of speech envelope encoding are critical for later language outcomes (see also Rios-Lopez et al., Reference Rios-Lopez, Molinaro, Bourguignon and Lallier2022). Accordingly, data from both infant projects converge in showing that the sensory/neural factors foregrounded by TS theory make important contributions to later language outcomes for English-learning infants.
Summary
This chapter presents a theoretical overview of how rhythm may be important for language development, using the framework of TS theory. Sensory and neural data for TS theory from children are reviewed, and the TS-proposed causal sensory/neural mechanisms are assessed by utilising recent infant longitudinal data.
Implications
Amplitude ‘rise time’ discrimination and neural entrainment to rhythmic acoustic signals are physical characteristics of the nervous system and not under conscious control, yet they govern in part the efficiency of language acquisition. Future projects in other languages are now required to test the language universality of TS theory and these sensory/neural factors.
Gains
Deeper understanding of the sensory and neural mechanisms that govern individual differences in language acquisition may open the door to novel interventions, possibly based on rhythm, that may enhance language development.
36.1 Introduction
Language acquisition is a multimodal phenomenon. Within the womb, the fetus is exposed to the rhythm of their mother’s speech via a low-pass filter. They hear the rumbling of their mother talking; they feel her movements. At birth, infants can recognise their mother’s voice (Mehler et al., Reference Mehler, Bertoncini, Barriere and Jassik-Gerschenfeld1978) and show familiarity with stories read to them in utero (Decasper and Spence, Reference Decasper and Spence1986). They are not just passive recipients; in their earliest communications, their cries follow the pattern of the language they are exposed to (Mampe et al., Reference Mampe, Friederici, Christophe and Wermke2009). At birth, even with months of auditory experience under their belt, their language system is flexible and open to the input it receives. Young infants can discriminate between sounds in languages they have never been exposed to before, an ability that is lost over the first year of life as the system acquires expertise for its language(s) (Maurer and Werker, Reference Maurer and Werker2014). The journey towards adult-like language expertise is long; infants have to learn vocabulary, syntax, and grammar. All these elements have been extensively studied in infants and young children, and we have a wealth of knowledge of key roles of, for example, ostension (Csibra, Reference Csibra2010) or statistical learning (Romberg and Saffran, Reference Romberg and Saffran2010).
In recent decades, fuelled in part by observations from language disorders, adult speech perception, and music perception, a new contender on the block has emerged as a critical component of linguistic success – rhythm perception. The grossly oversimplified story (discussed with the detail it deserves in other chapters of this edition in Section 6) is that speech is a rhythmic signal, and that efficient processing of the rhythm of speech facilitates language acquisition. The patterning of syllables and stress syllables gives anchors, or perceptual edges, in the speech signal that allow the listener to attend to important information in speech (Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014). Rhythmic cues give structure to the speech signal for the listener to follow. What is intriguing is that when we speak to infants (see Chapters 23 and 38), we emphasise this rhythm, slowing down and adding greater emphasis. Our voices take on a sing-song quality that is not a reflection of the expert speaker but is attuned to our novice listeners. This phenomenon is known as infant-directed speech (IDS). IDS is linked to enhanced word learning. Infants learn new words better when they are presented in IDS than adult-directed speech (ADS) (Ma et al., Reference Ma, Golinkoff, Houston and Hirsh-Pasek2011), and this benefit is also true for adults learning a new language (Ma et al., Reference Ma, Golinkoff, Houston and Hirsh-Pasek2011). Critically, IDS is not necessary for learning throughout the acquisition journey – once a language has been sufficiently mastered, older infants learn well without it (Ma et al., Reference Ma, Golinkoff, Houston and Hirsh-Pasek2011). Caregivers are therefore responsive to the needs of their infant, modulating the acoustic properties of the IDS they produce according to infant age, and likely reflecting infant attention to different acoustic cues, within the bidirectional and dynamic caregiver–infant speech interactions (Cox et al., Reference Cox, Bergmann and Fowler2023). Similarities in prosody have been demonstrated amongst diverse societies (Broesch and Bryant, Reference Broesch and Bryant2018), and IDS is largely considered universal, at least in form if not quantity (Cox et al., Reference Cox, Bergmann and Fowler2023). Adults can distinguish IDS from ADS in non-native languages from short, contextless audio excerpts (Hilton et al., Reference Hilton, Moser and Bertolo2022). If the greater rhythmicity of IDS is a critical universal property, we must settle on some core understandings of what we mean by rhythm. In music, rhythm describes a series of temporal intervals (see Chapter 27). It is often characterised by isochrony or equal spacing between event onsets. Whilst naturalistic speech never has the regularity of a metronome or click track, IDS has greater isochrony than ADS. We can consider the proximate mechanisms that may be at play whilst infants are listening to this special rhythmic signal, the most intuitive being that infants are (neurophysiologically) tracking the rhythm of IDS. For this to be the case, we must meet two criteria. First, that the infants can neurally track an auditory rhythm, and second, that the speech contains an auditory rhythm for infants to track.
36.1.1 Criterion 1: Infants Perceive Auditory Rhythm
There is good evidence from the field of music cognition that infants can perceive auditory rhythms. We see this behaviourally, for example in habituation studies where we see that infants discriminate tempo changes (Baruch and Drake, Reference Baruch and Drake1997) and metre (Hannon and Johnson, Reference Hannon and Johnson2005). Through infancy, infants’ spontaneous movement behaviour changes in response to music, and whilst infants cannot reliably synchronise to music, they show tempo-flexibility, moving faster to faster auditory tempi and slower to slower tempi (Rocha and Mareschal, Reference Rocha and Mareschal2017; Yu and Myowa, Reference Yu and Myowa2021; Zentner and Eerola, Reference Zentner and Eerola2010). We are also able to measure rhythm perception neurally, with electroencephalographic (EEG) mismatch responses showing that infants detect a missing beat (Winkler et al., Reference Winkler, bor Há den, Ladinig, Sziller and Honing2009) and interpret metrical structure (Flaten et al., Reference Flaten, Marshall, Dittrich and Trainor2022). A more direct approach to measuring infant neural responses to musical beats has used steady-state evoked potentials (SSEPs), which reflect the amount of neural energy at different frequencies. An established measure in adult music cognition (Nozaradan et al., Reference Nozaradan, Peretz, Missal and Mouraux2011), this approach has been used to show that infants have enhanced energy at the perceived beat and metre frequencies of auditory rhythmic patterns (Cirelli et al., Reference Cirelli, Spinelli, Nozaradan and Trainor2016; Flaten et al., Reference Flaten, Marshall, Dittrich and Trainor2022).
36.1.2 Criterion 2: IDS Contains Auditory Rhythm
If we are therefore happy to proceed with our argument that infants perceive critical timing information in auditory rhythmic stimuli such as repeated tones or real music, the next criterion for rhythm as a key to language acquisition is to show that there is indeed rhythm in the speech signal for infants to track (see Chapter 23). Studies of the acoustic signal of naturalistic IDS show increased amplitude modulations around 2 Hz (Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017). To investigate this, Leong et al. applied a computational model to child-directed speech (CDS) and revealed that the speech is hierarchically organised, known as the spectral-amplitude modulation phase hierarchy (S-AMPH). The approach consists of a set of algorithms that are used to derive underlying spectral characteristics of the speech signal. It uses probabilistic demodulation to model the rhythm patterns in speech, giving a low-dimensional representation of the acoustic and temporal properties of the speech envelope (Goswami and Leong, Reference Goswami and Leong2013; Leong and Goswami, Reference Leong and Goswami2014, Reference Leong and Goswami2015; Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017). This data-driven modelling approach allows us to identify various amplitude modulations corresponding to linguistic boundaries. For example, in the first report on S-AMPH (Leong and Goswami, Reference Leong and Goswami2015), the application of the modelling approach to CDS revealed amplitude modulations corresponding to prosodic stress (stress AM ~2 Hz), syllables (~5 Hz), and phoneme rate (~20 Hz). Furthermore, they argued that this nested hierarchy of speech rhythms could be used by an infant to build stimulus-driven phonological maps of a speech system in any given language. Particularly in CDS, these amplitude modulations are exaggerated, and possibly provide the essential acoustic landmarks for children.
Given the above support for our core criteria, it is not surprising that there has been increased focus in recent years on understanding the mechanisms by which rhythmic processing of speech may support typical and atypical language acquisition. The human auditory cortex has been shown to reliably track the amplitude envelope of the speech signal. This is achieved by phase aligning endogenous neural oscillations with the amplitude envelope of the temporally regular auditory information. The speech envelope refers to the amplitude fluctuations over time, typically occurring in low frequencies (< 10 Hz), which help the listener track the speech rhythm. Using magnetoencephalography (MEG), speech tracking of the amplitude envelope was demonstrated in healthy adult listeners (e.g., Gross et al., Reference Gross, Hoogenboom and Thut2013; Peelle et al., Reference Peelle, Gross and Davis2013) but since then has been revealed in infant EEG (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022a; Jessen et al., Reference Jessen, Obleser and Tune2021; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022). There is evidence that this speech envelope-tracking ability develops from childhood to adulthood, and even supports better performance in speech in noise (Destoky et al., Reference Destoky, Bertels and Niesen2020; Vander Ghinst et al., Reference Vander Ghinst, Bourguignon and Niesen2019). The speech-tracking literature has predominantly used measures such as speech–brain coherence, phase-locking value, and mutual information. These methods essentially measure statistical dependency between the speech signal and underlying neurophysiological data. In the rest of this chapter, we aim to provide an account of the state-of-the-art methods being developed to elucidate the relationship between rhythm and language, summarise where the literature converges and diverges, highlight open questions, and discuss the developments in our field that can enhance understanding of these phenomena.
36.2 A Primer on Neural Measures of Rhythm Processing Suitable for Use with Infants
Neural measurements from the earliest moments in life have been possible for some decades now, including via EEG, MEG, and near-infrared spectroscopy (fNIRS). Most relevant studies to this chapter use M/EEG for its excellent temporal resolution. EEG measures spontaneous neuronal activity generated by ensembles of neurons, from the surface of the scalp. MEG on the other hand measures the magnetic components of this underlying neuronal activity. Infant EEG often comprises high-density (64–128-channel) recording using water-based geodesic sensor nets that need little preparation, aiding infant compliance (Figure 36.1a). Modern systems are improving traditional issues with signal-to-noise ratio (SNR), with infant active electrode caps that can be pre-gelled and applied almost as quickly as nets.
Infant neural activity can be measured passively using EEG or MEG systems.
An infant wearing a geodesic sensor net.
Figure 36.11A. Long description
Photo A presents a child seated in the lap of an adult wearing a specialized cap on their head with many small electrodes attached. This procedure is known as electroencephalography or E E G, which measures electrical activity of the brain.
MEG adapted with lightweight optically pumped magnetometers.

Figure 36.11B. Long description
Photo B presents a child seated in a specialized chair inside a room wearing an electrode cap similar to the E E G cap in photo A. This procedure is known as magnetoencephalography M E G, which uses specialised sensors to measure magnetic fields of the brain. There are a bunch of wires on the floor of the room.
Infant EEG has further benefited from technological advances in signal processing post data collection. As it is challenging to ensure infants remain stationary during an experiment, data can suffer from non-canonical movement artefacts, difficult to remove using standard adult-defined techniques. However, recent noteworthy advancements in toolboxes and tutorials specifically for infant EEG data allow greater precision in the analysis of noisy data (Gabard-Durnam et al., Reference Gabard-Durnam, Leal, Wilkinson and Levin2018; Lopez et al., Reference Lopez, Monachino and Morales2022). These general technological advancements have facilitated the growth in complex methodologies suitable for answering questions on infant speech perception. On the other hand, MEG offers the same temporal resolution as EEG and has a reasonable spatial resolution allowing us to investigate activity between networks of brain regions. A crucial limitation of the traditional cryogenically cooled MEG system is that it has a fixed array of sensors, making head movements a confound in typical experiments. As the sensor array is fixed, any head motion relative to the sensor array can cause changes in the SNR and spatial blurring of the underlying sources. Recognising this limitation, several algorithms are now available to correct head movement artefacts. However, changes in the SNR (as sources move relative to the array) during recording place a limit on the amount of movement that can be compensated (Medvedovsky et al., Reference Medvedovsky, Taulu, Bikmullina and Paetau2007). The problem of head movement is much more pronounced in the paediatric population, where infants and/or toddlers find it very difficult to stay still in unnatural (i.e., laboratory) environments. This limitation is better overcome by EEG and fNIRs, which involves placing the sensors directly on the participants’ heads. Recent exciting developments in MEG hardware have led to the development of room temperature MEG sensors, which involve the use of optically pumped magnetometers (OPMs) (Boto et al., Reference Boto, Meyer and Shah2017, Reference Boto, Holmes and Leggett2018). The lightweight sensors (OPMs) can be mounted in a helmet, making the scanner a wearable device. This new approach is gaining traction, and early adoption with children demonstrates significant improvements in the SNR with OPMs when testing children with epilepsy (Feys et al., Reference Feys, Corvilain and Aeby2022), cortical tracking of speech (de Lange et al., Reference de Lange, Boto and Holmes2021), and hyper-scanning during play (Holmes et al., Reference Holmes, Rea and Hill2023). Being able to place the OPMs directly over a participant’s head has two distinct advantages: (1) improved SNR, and (2) improved spatial resolution. This makes a compelling use case in developmental populations, particularly during naturalistic experiments. For example, in a study by Hill et al. (Reference Hill, Boto and Holmes2019), the OPM-MEG system was used to measure somatosensory activity underlying maternal touch in two- and five-year-olds. Therefore, whilst this chapter mostly discusses infant EEG, we see great potential for MEG research in the coming years.
36.3 Methodological Overview
Human speech is intrinsically rhythmic. This is mainly the result of coordinated movement by the oro-musculature involved in speech production. In a stress-timed language such as English, the rhythm in speech typically translates to the occurrence of stress and unstressed syllables in connected speech (Cummins and Port, Reference Cummins and Port1998; Nespor et al., Reference Nespor, Shukla, Mehler, Oostendorp, Ewen, Hume and Rice2011). The speech rhythm (i.e., prosody), indexed by the changes in the amplitude envelope of the signal, offers critical cues for speech segmentation (see Chapter 11 for an alternative perspective). Whilst there are variations in the rate of speech, both within and between speakers, healthy adult listeners change their ongoing neural oscillations to match the incoming speech signal. This is a key mechanism for speech perception. Nevertheless, how the auditory cortex achieves this impressive feat, and the precise oscillatory mechanisms underlying it, remain largely elusive. Moreover, and of particular interest to developmental neuroscientists, there are the questions, what does this mechanism look like in infancy and childhood? (How) does it aid language acquisition? And what happens when these mechanisms break down early in childhood? Progress towards answering these questions has been made through measurement of the associations between the speech signal and ongoing neural oscillations using M/EEG. Owing in large part to these speech-tracking methods, the mechanism of ‘neural entrainment’ as a basis for speech processing and language acquisition has also received considerable support. Here, we look at speech–brain coherence, phase-locking value (PLV), mutual information (MI), and multivariate temporal response function (mTRF) as examples of methods that have been used to study neural entrainment.
36.3.1 Speech–Brain Coherence
Coherence is a statistical measure that is used to identify statistical dependency between two signals, x(t) (e.g., speech time series) and y(t) (e.g., neural time series). It is given by:
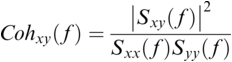
where 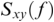 is cross-spectral density between x and y, and
is cross-spectral density between x and y, and 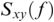 and
and 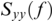 are the auto-spectral density of x and y, respectively. The spectral densities are estimated using Fourier transform. Values of coherence range between 0 (random coupling) and 1 (perfect synchronisation) (Pascual-Marqui et al., Reference Pascual-Marqui, Lehmann and Koukkou2011).
are the auto-spectral density of x and y, respectively. The spectral densities are estimated using Fourier transform. Values of coherence range between 0 (random coupling) and 1 (perfect synchronisation) (Pascual-Marqui et al., Reference Pascual-Marqui, Lehmann and Koukkou2011).
36.3.2 Phase-Locking Value (PLV)
PLV measures frequency-specific phase synchronisation between two signals. It is computed by calculating the distribution of phase difference extracted from two source time series x(t) and y(t). It is formally given by:
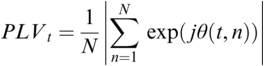
where 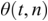 gives the phase difference
gives the phase difference 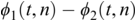 . The phase information is typically extracted using the Hilbert transform. PLV provides a summary statistic of the phase difference at t (Lachaux et al., Reference Lachaux, Rodriguez, Martinerie and Varela1999).
. The phase information is typically extracted using the Hilbert transform. PLV provides a summary statistic of the phase difference at t (Lachaux et al., Reference Lachaux, Rodriguez, Martinerie and Varela1999).
36.3.3 Mutual Information (MI)
MI serves as a measure of mutual dependence between two random variables. It is used to quantify the amount of information that can be obtained about one variable by observing the other variable. Unlike speech–brain coherence or PLV, MI captures both linear and non-linear interactions between the two signals. An additional advantage of the method is that the same framework can be extended to study different aspects of the underlying signals (e.g., phase-phase, amplitude-amplitude, phase-amplitude, or cross-frequency coupling). The MI between two random variables 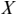 and
and  is mathematically given as follows:
is mathematically given as follows:
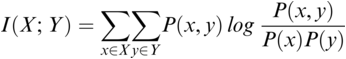
where 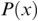 and
and 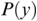 are the marginal distributions of variables
are the marginal distributions of variables 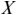 and
and 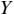 , respectively, and
, respectively, and 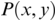 is the joint distribution of these variables.
is the joint distribution of these variables.
The general steps involved in all three above methods include: (1) band-pass filtering of the neural time series and the speech signal in the same frequency bands; (2) extraction of the relevant quantity (e.g., spectral density, phase, or amplitude information); before (3) subjecting it to the relevant mathematical operation.
36.3.4 Multivariate Temporal Response Function (mTRF)
The mTRF is a novel method for investigating the neurophysiological processing of the auditory signal. Unlike the methods mentioned above, the mTRF method involves decoding the patterns of neural activity related to a particular stimulus feature using a set of linear filters, which could include acoustic envelope, spectrogram, phonemes, or phonetic features (Crosse et al., Reference Crosse, Di Liberto, Bednar and Lalor2016; Di Liberto et al., Reference Di Liberto, O’Sullivan and Lalor2015). These filters are trained on, for example, 80% of the data and then applied to the remaining 20% to generate predictions (or the time course) of the stimulus feature in question. The mTRF approach has some advantages. First, an explicit pre-selection of channels (or ROIs) is not required as data from all the channels is used to create a stimulus reconstruction. Second, the commonly used backward modelling approach can maximise sensitivity to key signal differences between highly correlated sensors. This is achieved by mapping data from all sensor locations simultaneously and by detecting correlations in the data.
36.3.5 Comparison of Approaches
Relevant developmental research in the auditory domain has historically been dominated by the use of non-speech sounds as stimuli, such as amplitude-modulated or frequency-modulated tones, to measure auditory steady-state response (ASSR). These approaches remain very popular because the neural responses to such stimuli are very robust and can reliably be recorded across the lifespan. However, such experiments suffer from a lack of ecological validity and don’t allow us to measure the development of neural responses in a naturalistic setting. Experiments with the use of naturalistic, immersive paradigms have recently started to increase, using the methods described above. Such paradigms using audiovisual stories, nursery rhymes, or IDS allow us to study how multiple streams of information are processed by the infant’s brain. This gives a clear benefit of increased generalisability of the findings.
All the methods outlined in our chapter (coherence, PLV, MI, and mTRF) generally suffer from the same limitations; that is, developmental studies tend to have smaller sample sizes and noisier data than the adult studies from which these techniques have been developed. The ability of each method to deal with inherent low SNR should be considered by the researcher. Further, all the methods briefly reviewed here (except for MI) rely on linear relationships between the speech signal and the neurophysiological data. This assumption may not be sufficient to fully encapsulate the brain’s response to speech stimuli. A further limitation specific to mTRF concerns model selection, as the researcher must define the specific speech parameter that they are interested in studying (e.g., speech envelope, spectrogram, or phonetic features). Choosing the right model for the mTRF can be challenging, and different models may perform differently for different types of stimuli or neural responses. The set of models that generate statistically significant results for one research group may not generalise to other tasks/conditions/datasets. We also think it is important to highlight that the mTRF reconstruction values are often very small. This might be partly to do with the noisy nature of M/EEG signals. Whilst the effects reported in the literature using the mTRF method show statistical significance when compared to a null distribution, their clinical significance remains under-explored, and this will be a critical next step for the field.
Finally, it is worth noting that the brain’s responses to rhythmic stimulation can be a mixture of series of evoked responses and non-phase-aligned oscillatory (or induced) responses (David et al., Reference David, Kilner and Friston2006). It is important to disentangle the two when studying oscillatory responses in infants as researchers risk attributing oscillatory functions to evoked activity. This can be achieved by removing the averaged evoked response from the data before analysing it or by incorporating computational models (e.g., Doelling et al., Reference Doelling, Assaneo, Bevilacqua, Pesaran and Poeppel2019) with theoretical models of language acquisition.
36.4 Synthesis of Infant Rhythmic Processing Literature
As identified in Table 36.1, we are now well equipped to ask and answer questions on the neural underpinnings of rhythmic speech processing. The studies outlined below offer a snapshot of ‘neural entrainment’ research in infants and how this mechanism may aid language acquisition. The precise definition of neural entrainment remains hotly debated (Giraud, Reference Giraud2020; Haegens, Reference Haegens2020; Meyer et al., Reference Meyer, Sun and Martin2020), and we prefer the term speech tracking. Here, speech tracking is defined as the neural process by which the ongoing neurophysiological activity follows the patterns of the speech signal. However, a causal link has yet to be established.
To our knowledge, the first study to investigate the differential neural substrates of IDS and ADS tracking measured neurophysiological (EEG) responses to recordings of naturalistic IDS and ADS in seven-month-old, pre-verbal infants (Kalashnikova et al., 2018). In this study, spectral analysis revealed that the theta-band power over the left hemisphere was significantly larger than the right hemisphere. The hemispheric differences provide compelling evidence in support of the asymmetric sampling hypothesis (AST) (Hickok and Poeppel, Reference Hickok and Poeppel2007; Poeppel, Reference Kalashnikova2003). It is possible that the functional asymmetry postulated by AST may have origins as early as seven months of age, when infants are at the beginnings of language production, producing babbling. Furthermore, analysis using mTRF showed that theta-band (4–8 Hz) cortical tracking of the speech envelope was greater for IDS than ADS. Here, the authors investigated theta tracking as they were interested in how the exaggerated prosodic features of IDS, such as higher pitch and slower tempo, may enhance the salience of speech sounds for infants and make them easier to process. These findings are in line with the literature outlined in our introduction, which suggests that these unique characteristics of IDS may play an important role in early language acquisition in infants. That amplitude envelope was tracked gives a first insight into the idea that it is indeed the rhythm of IDS that is a critical component. However, the choice of investigating theta-band oscillations in response to the envelope reflects the authors’ interest in IDS directing the infants’ attentional spotlight, and it would be very interesting to understand how different saliency cues drive cortical tracking. Without additional manipulations, it is not possible to know if it specifically or exclusively the enhanced low-frequency rhythms of IDS driving cortical tracking.
In a longitudinal study, Attaheri et al. (Reference Attaheri, Choisdealbha and Di Liberto2022a) measured cortical tracking of sung speech in infants at four, seven, and 11 months of age using mTRF applied to EEG data in canonical delta, theta, and alpha bands. Audiovisual stimuli were used of a woman performing various British nursery rhymes (e.g., ‘Twinkle Twinkle Little Star’). The results revealed that infants had above-chance performance cortical tracking in delta and theta bands across the three time points. They also identified the presence of strong phase-amplitude coupling with delta–theta bands as the drivers. More details on this study and its functional interpretation can be found in Chapter 35. Whilst the current data cannot provide direct evidence for the involvement of this neural process in the extraction of linguistically meaningful information, the data form part of a longitudinal study that continued to track infants into the third year of life with detailed language assessments. Through this design, it is possible to see the extent to which early processing of the amplitude envelope of sung speech predicts language acquisition (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022a, Reference Attaheri, Choisdealbha and Rocha2024). However, what is also intriguing about these results is a complex developmental pattern. The original longitudinal findings show the strongest mTRF values of cortical tracking at four months of age, with significantly lower levels at 11 months. Attaheri et al. (Reference Attaheri, Panayiotou and Phillips2022b) also replicated their findings with adults. This study used identical stimuli and the same analysis pipeline to that of the infant study. Here, their findings revealed that adult cortical responses to sung speech reflected very similar underlying processes, showing increased delta- and theta-band tracking, with similar mTRF values for adults as for the infants at the youngest time point tested (four months). The suggested overall trajectory may therefore be an inverted U shape, with younger infants performing similarly to adults, but with weaker tracking in the intervening period. Such interpretation remains speculative, especially as it is not clear from these results whether greater tracking at four months than 11 months is the result of a true developmental characteristic (e.g., increased salience of the stressed syllable amplitude modulation at this early age), or a physical or methodological characteristic (e.g., cleaner EEG data at the earlier age whilst the infant is less mobile).
In another study of how natural IDS facilitates the neural processing of prosody in infants, Menn et al. (Reference Menn, Michel, Meyer, Hoehl and Männel2022) used EEG to measure speech–brain coherence in seven–nine-month-old infants. The infants listened to either IDS or ADS presented live by their caregiver. The results showed statistically significant speech–brain coherence for IDS and ADS at prosodic rates. However, the speech–brain coherence was significantly greater for IDS compared to ADS, specifically in the prosodic rates. The authors suggest that natural IDS may facilitate infants’ ability to track and learn the rhythmic features of speech, which could in turn support language development. The rhythmic patterns of IDS, which are characterised by exaggerated intonation, slower tempo, and higher pitch, are thought to aid in infant attention and arousal, as well as in the formation of speech representations in the brain. The main contribution of this study is the ecological validity of the naturalistic speech, with the design set up such that the caregiver and infant were communicating as they would at home, in the IDS condition. However, Menn et al. also draw our attention to the fact that the ADS condition was not exactly matched to the IDS, as caregivers were instructed to additionally remove all ostensive cues, such as mutual gaze. It would be of great interest to understand the additive benefit of such cues in future work.
Across the studies and techniques discussed thus far, it is worth noting that most use non-specific linguistic timescales and assume that there is a one-to-one mapping between speech rhythms and canonical neural oscillations (e.g., delta, theta, gamma bands). Of significant importance is the inter-speaker variability or different registers of speech such as ADS or IDS that can produce speech rhythms across a broad range (see chapters in Section 6). Therefore, it is important to first identify the specific linguistic timescales of interest in the speech material before studying the corresponding neural oscillations. This question was first addressed in adults (Keitel et al., Reference Keitel, Gross and Kayser2018) by manually annotating their stimulus material, and by applying data-driven filtering to CDS (Mandke et al., Reference Mandke, Flanagan and Macfarlane2022). Both these studies identified prosodic features < 5 Hz. These statistical regularities are noticeably lower than assumptions made in the literature; for example, syllable rate is reflected in the theta band (4–8 Hz) and phoneme rate in the gamma band (> 30 Hz). Constraining the neural oscillations by linguistic boundaries identified in the stimulus material will improve the precision of interpretation, particularly in the language acquisition literature.
Overall, these studies provide valuable insights into the neural mechanisms underlying the processing of prosody in infants and highlight the importance of natural IDS in supporting early language development. However, speech envelope tracking alone may not be sufficient to account for language acquisition, as it oversimplifies the computations undertaken by the infant brain. It fails to consider the role of other features contained in the speech signal, such as phonetic features, formant transitions, temporal fine structure, and so on. For example, Inbar et al. (Reference Inbar, Genzer, Perry, Grossman and Landau2023) recently investigated the neurophysiological basis of intonation units (IUs), a fundamental unit of human languages (Inbar et al., Reference Inbar, Grossman and Landau2020). In their naturalistic listening study using EEG, Inbar et al. (Reference Inbar, Genzer, Perry, Grossman and Landau2023) demonstrated robust evoked responses to IU in adult listeners. For further details, we direct the reader to Chapter 15. The evidence from the adult speech-tracking literature strengthens proposals that as the acoustic information travels along the auditory pathway, higher-order structures extract more complex representations from the speech signal. This representational hierarchy receives support from the fact that the anatomy of the auditory system is also hierarchically organised. Future work to account for how meaning is assigned to these speech features (e.g., amplitude envelope), and how these are further used by the developing brain in speech production, will be valuable next steps (see Chapters 17 and 18).
36.5 Multimodal Rhythm Perception and Production in Relation to Language Acquisition
In our introduction, we highlighted that speech is a multimodal act, and in this section, we wish to stress that the rhythm in speech is multimodal. Typically, when infants are exposed to speech, they are not only hearing the auditory signal but also gaining rich visual information. For example, when singing to an infant, adults’ metrically strong moments involve temporally aligned eye-widening and blinking, in addition to the movement of the mouth (Lense et al., Reference Lense, Shultz, Ast Esano and Jones2022). Infants are receptive to this and their looking at the eyes of the singer is coordinated with these eye movements (Lense et al., Reference Lense, Shultz, Ast Esano and Jones2022). IDS is produced with larger mouth movements than ADS (Green et al., Reference Green, Nip, Wilson, Mefferd and Yunusova2010) and more head movements (Smith and Strader, Reference Smith and Strader2014). Eyebrow movements and head nods are particularly useful cues to phrase boundaries and are again more prominent in IDS than ADS (de la Cruz-Pavía et al., Reference de la Cruz-Pavía, Gervain, Vatikiotis-Bateson and Werker2020). Such inter-sensory redundancies (i.e., synchronous information across modalities) facilitate the detection of changes in prosody above an auditory cue alone (Bahrick et al., Reference Bahrick, McNew, Pruden and Castellanos2019). For more details on the multimodal nature of the speech input that infants receive, we direct the reader to Chapter 38.
Aside from the focus on the rich multimodality of the language stimulus directed to infants, it is also critical that we do not forget the multimodality of infants’ attempts at language production. The relationship between gross motor actions across limbs and the development of speech is well recognised. Early repetitive motor movements, such as kicking or hand-waving, in which infants can spend 40% of their time, have been described as stereotypies, reflexive or rhythmic actions that precede more deliberately controlled movement (Thelen, Reference Thelen1981). We can think of these rhythmic movements as a ‘passive’ response to the speech, with seminal studies showing that neonates’ earliest movements are associated with the timing of adult speech (Condon and Sander, Reference Condon and Sander1974). However, we can also think further about rhythmic movements whilst infants are actively generating speech sounds themselves. From a dynamic systems theory approach, rhythmic motor actions produced with the mouth and hand may entrain each other, such that the generation of a well-practised action such as hand-banging may ‘pull in’ the timing of vocalisations (Iverson and Thelen, Reference Iverson and Thelen1999). It is well documented that fluent speech is preceded by canonical babbling, where the infant produces repetitions of consonant-vowel syllables (Kuhl, Reference Kuhl2004). Rhythmic movements such as shaking a rattle reach their peak around the time that infants begin canonical babbling, and drop off once babbling is established (Ejiri, Reference Ejiri1998; Iverson et al., Reference Iverson, Hall, Nickel and Wozniak2007). Infant babbling is frequently temporally coordinated with rhythmic movement such as hand-banging, and the vocalisations that co-occur with such movement show more mature properties, which sustain after the movement ends (Ejiri and Masataka, Reference Ejiri and Masataka2001).
Therefore, in addition to considering infants’ neural tracking of speech rhythm, we believe it is critical to also consider infants’ motoric rhythmic responses to speech. Whilst the cortical tracking methods described above give fine-grained temporal information, the seminal studies of infant movement discussed thus far largely rely on micro-coding of video data, constrained by the frame rate of the video collected. The advancement of motion capture technology now facilitates nuanced analysis of infant movement without the need for the frame-by-frame hand coding of video. Optical 3D motion capture uses reflective markers placed at strategic points on the infant, from which x-, y-, and z-coordinates can be derived. In Figure 36.2a, the infant is wearing rigid bodies (prearranged unique combinations of markers stuck to a firm board), attached to the limbs and head via soft, elasticated, fabric straps. Optical motion capture systems can record infant movement at up to 2,000 frames per second, allowing incredibly high precision measurement. However, these systems are still relatively expensive, requiring the use of multiple near-infrared cameras to measure the reflection of light from the markers. The recent emergence of markerless motion-tracking technology for 2D pose estimation can allow even more naturalistic recording of infant movement via normal video. Markerless motion tracking uses deep-learning models trained on large video datasets to tag key points such as wrist, elbow, or shoulder, and even facial features. Figure 36.2b shows the application of an open-source markerless motion capture model to an infant drumming.
Motion capture methods.
Infant wearing rigid body reflective marker arrangements for optical motion tracking.
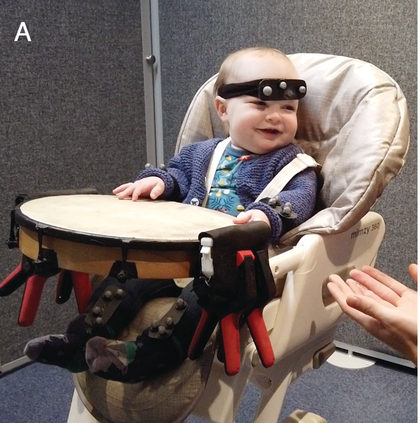
Infant recorded on home webcam and analysed offline using OpenPose open-source markerless motion capture.
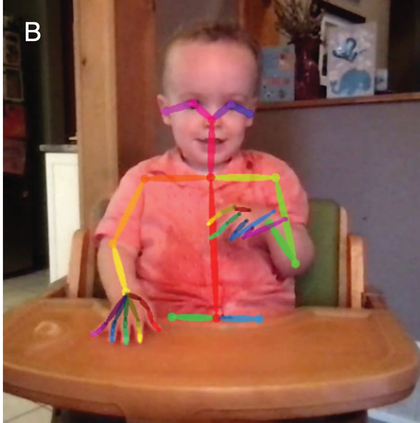
Motion capture studies of infants’ rhythmic movement whilst listening to rhythmic stimuli provide interesting insights. Whilst as a group they do not show sensorimotor synchronisation to the rate of auditory presentation at an adult level, over the first two years of life, infants show tempo-flexibility or move faster to faster auditory tempi and slower to slower tempi (Rocha and Mareschal, Reference Rocha and Mareschal2017; Zentner and Eerola, Reference Zentner and Eerola2010). Case studies show that some infants may show such adaptation to the rate of music as early as three to four months of age (Fujii et al., Reference Fujii, Watanabe and Oohashi2014). Due to the convincing evidence that infants are tracking the amplitude envelope of speech sounds and other rhythmic auditory stimuli (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022a; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022), it is tempting to conceive of infant rhythmic movement as a reflection of the strength of the tracking of the signal (i.e., to hypothesise that those who are tracking the stimulus well will also show better temporal matching of their movement to that stimulus). However, infants’ spontaneous rhythmic movements are found equally in silence as they are to a rhythmic musical stimulus (de l’Etoile et al., Reference de l’Etoile, Bennett and Zopluoglu2020; Fujii et al., Reference Fujii, Watanabe and Oohashi2014). Zentner and Eerola (Reference Zentner and Eerola2010) showed equal rates of rhythmic movements for a simple drumbeat as naturalistic music, but less for IDS or ADS. Whilst the relationship between infants’ quantity and rate of rhythmic movement is therefore not directly tied to what they are hearing, it is very interesting to consider how the development of rhythmic movement and sensorimotor synchronisation may unfold. For example, in the Cambridge UK BabyRhythm longitudinal study, where infant drumming to speech and non-speech rhythmic stimuli was recorded using motion capture, Rocha et al. (Reference Rocha, Attaheri and Choisdealbha2024) show that infant drumming becomes more rhythmic with age. This was particularly true when infants were drumming in a silent control condition, which mirrors previous findings that infants’ spontaneous motor tempo becomes faster and more regular over the first years of life (Rocha et al., Reference Rocha, Southgate and Mareschal2021). The Cambridge UK BabyRhythm study compared infant drumming in silence to an isochronous 2 Hz drumbeat, an isochronous 2 Hz repetition of the syllable ‘ta’, and naturalistic sung nursery rhymes. Rocha et al. found that infant drumming in the presence of a drumbeat showed a similar maturation as their spontaneous motor tempo, becoming faster and more rhythmic with age. However, infants did not show the same pattern of becoming more regular with age in the linguistic conditions (repeated syllables and sung nursery rhymes). It is possible that infants are upregulating variability, in response to more complex auditory stimuli, perhaps reflecting a trade-off between greater adaptation to the stimulus with age and rhythmicity.
36.6 Conclusion
This chapter aimed to unpack how rhythm supports language acquisition. Furthermore, we have provided an overview of the methods and highlighted some open questions. It will be of great interest to better understand gross motor rhythmic action in the context of speech perception and production, and the interplay between the seemingly good early cortical tracking, with the emphasis on neural alignment, and less precise or more variable behavioural tracking.
The focus of this chapter on neural tracking of the rhythmic auditory information in speech reflects cutting-edge neuroscience, using ever more sophisticated techniques to drill into the minutiae of perception. The focus is undoubtedly on the auditory modality, but even where this focus is being broadened to consider, for example, visual information present on the face (Lense et al., Reference Lense, Shultz, Ast Esano and Jones2022; Ní Choisdealbha et al., Reference Ní Choisdealbha, Attaheri and Rocha2024), it is still often measuring the unidirectional impact of features of speech, often presented on a screen, to the neural firing of the infant. In the final section, we make several recommendations as to how we can integrate diverse areas of knowledge and capitalise on the rapid technological developments, to consider the role of rhythm in infant language acquisition more holistically.
We outlined how methodological advancements have provided insight into the way that the infant brain processes language. Recent years have shown that the rhythmic information carried by the amplitude envelope of the speech signal is a core characteristic of IDS that infants are indeed processing. However, it is important to acknowledge other low-level features (e.g., envelope, spectrogram, temporal fine structure) and high-level features (e.g., phonetic features) that are part of the speech signal and are reflected in the EEG signal (Di Liberto et al., Reference Di Liberto, O’Sullivan and Lalor2015). To what extent are these additional timing or landmark cues important? To what extent are these cues more or less important in the special case of IDS? It is important that we do not simply apply our learning from adult speech studies to developmental problems. In the coming years, we can add thorough consideration of the other rhythmic properties of IDS that may be critical, for example, in the visual, touch, or motor domains. In doing so, and without constraining our focus on rhythm to only reflect the amplitude envelope, we can fully consider the breadth of developmental scaffolding that IDS provides.
Finally, in addition to understanding the rich multimodality of spoken language, it is critical to note that outside of the lab, exposure to IDS occurs in bidirectional social interactions (Menn et al., Reference Menn, Männel and Meyer2023), within a wider conversational context (Golinkoff et al., Reference Golinkoff, Can, Soderstrom and Hirsh-Pasek2015). Regarding the infant as simply a passive receiver of (auditory) information does a great disservice to how we know that infants develop language. For example, neonates vocalise more when a parent is present (Caskey et al., Reference Caskey, Stephens, Tucker and Vohr2011). Other strands of research into early communication are taking a hyper-scanning approach, where the neural activity of both the infant and the caregiver is recorded simultaneously (e.g., Nguyen et al., Reference Nguyen, Abney, Salamander, Bertenthal and Hoehl2021a, Reference Nguyen, Schleihauf and Kayhan2021b, Reference Nguyen, Schleihauf and Kungl2021c). The M/EEG methods we have described in this chapter can handle the complexity of this kind of information, and we should attempt to embrace this complexity to further centre the infant as a participator in, rather than the recipient of, IDS.
Summary
The chapter synthesises the current evidence supporting infants’ ability to track speech rhythms and underscores the importance of IDS in language acquisition. We advocate for widening the scope of IDS to include visual, somatosensory, and motor rhythms (in addition to auditory), which additionally shape early language acquisition.
Implications
Understanding how infants track incoming sensory information in different modalities has broad implications. The current literature posits rhythm perception as a critical element of language acquisition. Advancements in studying multimodal infant responses will deepen insights into this pivotal aspect of early language development.
Gains
The chapter provides a summary of the state of the art in speech and rhythm processing and how it relates to early language acquisition. We identify avenues for future research and provide a commentary on the suitability of the most popular methods.
37.1 Introduction
To learn about their world, infants have to make sense of the ‘great blooming, buzzing confusion’ of their environment (James, Reference James1890). They have to learn that the streams of sound that their caregivers emit are communicative and meaningful. Acquiring language is a key developmental milestone that children reach in their early years. Already before their first birthday, infants learn many things about speech and language. For example, in their first year of life, infants discover which sounds are meaningful in their native language (Kuhl, Reference Kuhl2004; Werker and Tees, Reference Werker and Tees1984), they learn to segment words from the continuous speech stream (Jusczyk, Reference Jusczyk1999), and they start to link these word forms to meaning (Johnson, Reference Johnson2016). Infants’ brains are ‘language-ready’ (Hagoort, Reference Hagoort2017), but their brains are also still rapidly developing in interaction with their environment (Westermann, Reference Westermann2016). The environment in which language learning needs to occur is usually noisy, with many possible referents, cluttered visual information (Yu et al., Reference Yu, Zhang, Slone and Smith2021), and auditory background noise. We now know that children are active learners (Bazhydai et al., Reference Bazhydai, Westermann and Parise2020; Begus et al., Reference Begus, Gliga and Southgate2016; Kidd et al., Reference Kidd, Piantadosi and Aslin2012; Stahl and Feigenson, Reference Stahl and Feigenson2015): they selectively attend to important information. Being able to select the relevant information for language learning enables language growth (D’souza et al., Reference D’souza, D’souza and Karmiloff-Smith2017). It is essential to know what neural processes help children in this attentional selection for language learning and how environmental cues and neural maturation influence these processes. This insight will help us understand individual differences in language development and give clues for providing an optimal learning situation in both typical and atypical development.
The current chapter will showcase the potential importance of neural tracking, that is, the alignment between neural activity and rhythmic speech patterns, for attentional selection during speech processing development. We will review recent research on neural speech tracking in infants and its relation to later language development. Finally, we will discuss how electrophysiological maturation across infancy may change neural tracking in infancy and influence the trajectory of both typical and atypical language development.
37.1.1 Using Rhythm for First-Language Acquisition
One important cue that infants use for language learning is rhythm (Gleitman and Wanner, Reference Gleitman and Wanner1982). Newborns can already distinguish different languages based on their rhythmic characteristics (Nazzi et al., Reference Nazzi, Floccia and Bertoncini1998; Ramus and Mehler, Reference Ramus and Mehler1999; Ramus et al., Reference Ramus and Mehler1999). Seven- to eight-month-olds use rhythmic properties to segment words from a continuous speech stream (Johnson and Jusczyk, Reference Johnson and Jusczyk2001; Jusczyk et al., Reference Jusczyk1999). This has been proposed to be an important bootstrapping mechanism for language learning (Gervain et al., Reference Gervain, Christophe, Mazuka, Gussenhoven and Chen2020; Höhle, Reference Höhle2009).
Our hypothesis is that the oscillatory properties of the human brain are particularly suited to pick up rhythmic properties of language. In the current chapter, we specify how the neural tracking of rhythmic speech properties might help children to selectively attend to important information in their input, thus paving the way for language learning.
37.1.2 Proposal: Importance of Neural Tracking for Temporal Attention and Impact Maturation
We here propose that rhythmic neural tracking of speech (Giraud and Poeppel, Reference Giraud and Poeppel2012), that is, the synchronisation between neural oscillations and speech rhythm, is central to active language learning. Neural oscillations provide temporal windows of alternating reduced and enhanced excitability (Buzsáki and Watson, Reference Buzsáki and Watson2022; Fries, Reference Fries2015; VanRullen, Reference VanRullen2016), enabling more effective processing at high-excitability states (Lakatos et al., Reference Lakatos, Musacchia and O’Connel2013; VanRullen, Reference VanRullen2016). Neural synchronisation to external stimuli has been proposed to allow for sensory selection (Schroeder and Lakatos, Reference Schroeder and Lakatos2009). During speech processing, neural tracking of speech acoustics might help to group information into analysable units such as words and phrases (Ding and Simon, Reference Ding and Simon2014; Goswami, Reference Goswami2018; Keitel and Gross, Reference Keitel and Gross2016; see also Chapters 3, 5, and 35). We here propose that neural tracking assists language development by guiding infants’ attention towards informative units in speech, helping infants to learn to segment the continuous speech signal into informative units and from there bootstrap language learning (Gervain et al., Reference Gervain, Christophe, Mazuka, Gussenhoven and Chen2020; Höhle, Reference Höhle2009). It is important to realise that the infant brain is still rapidly developing, with electrophysiological brain activity speeding up with infant development (Anderson and Perone, Reference Anderson and Perone2018; Cellier et al., Reference Cellier, Riddle, Petersen and Hwang2021; Menn et al., Reference Menn, Männel and Meyer2023a). We hypothesise that this electrophysiological maturation gives rise to different processing constraints and opportunities at different points in development, with optimal analysis time windows shifting with development.
37.2 Neural Tracking of Speech
In adults, it is now well established that rhythmic properties of speech set up a predictive context (Rothermich and Kotz, Reference Rothermich and Kotz2013) that is crucial for speech decoding (Gagnepain et al., Reference Gagnepain, Henson and Davis2012; Rimmele et al., Reference Rimmele, Morillon, Poeppel and Arnal2018; Zion Golumbic et al., Reference Zion Golumbic, Poeppel and Schroeder2012). Rhythm in speech is most obvious in the amplitude envelope modulation of the speech waveform (see Figure 37.1; Giraud and Poeppel, Reference Giraud and Poeppel2012; Goswami, Reference Goswami2012), with clear peaks from 2 to 10 Hz across languages, corresponding to the syllable rate (see Poeppel and Assaneo, Reference Poeppel and Assaneo2020, for a recent review). At a higher frequency (~30–50 Hz), modulations are associated with phonemic features, and at a lower temporal modulation rate (<4 Hz) with prosodic stress and lexical and phrasal structure, for example through the intonation contour (Giraud and Poeppel, Reference Giraud and Poeppel2012; Rosen et al., Reference Rosen, Carlyon, Darwin and Russell1992).
Illustration of neural tracking of speech.
Electrophysiological activity in the delta and theta range is assumed to synchronise to amplitude modulations in speech (see also Chapter 35). The line above the speech signal displays the amplitude envelope. Note that the delta and theta band is lower in infants compared to the canonical frequency bands in adults (Anderson and Perone, Reference Anderson and Perone2018; Cellier et al., Reference Cellier, Riddle, Petersen and Hwang2021), and that the speech rates in infant-directed speech are typically slower than in adult-directed speech, with ~3–6 Hz as the typical infant-directed syllable rate (Cox et al., Reference Cox, Bergmann and Fowler2023; Raneri et al., Reference Raneri, Von Holzen, Newman and Ratner2020).
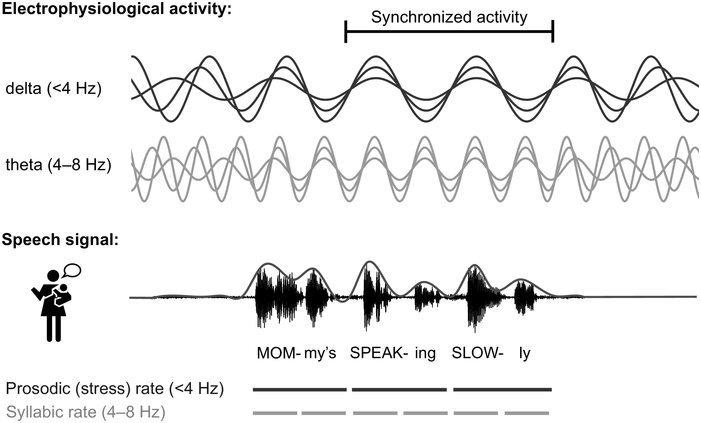
Figure 37.1 Long description
Two types of brain waves are depicted; delta is less than 4 hertz and theta is between 4 through 8 hertz. A waveform of speech is shown. The text below the speech signal reads, Mom my's Speaking Slowly. Prosodic rate and syllabic rate are denoted with broken lines.
By now, it is well established that electrophysiological brain activity tracks the temporal modulations in speech (Figure 37.1; Gross et al., Reference Gross, Hoogenboom and Thut2013; Luo and Poeppel, Reference Luo and Poeppel2007; see Poeppel and Assaneo, Reference Poeppel and Assaneo2020, for a review). In the brain, alternating periods of excitation and inhibition result in rhythmic fluctuations of neuronal activity. The speed of fluctuation depends on internal neuronal frequency properties and differs between neuronal populations (Buzsáki, Reference Buzsáki2006; Buzsáki and Watson, Reference Buzsáki and Watson2022; Hutcheon and Yarom, Reference Hutcheon and Yarom2000). Rhythmic fluctuations across larger groups of neurons can be measured as neural oscillations at different frequencies on the scalp using electroencephalography (EEG). Neural oscillations provide windows of alternating reduced and enhanced excitability, giving temporal windows for analysing and grouping information (Buzsáki and Watson, Reference Buzsáki and Watson2022; Fries, Reference Fries2015; VanRullen, Reference VanRullen2016). At rest, oscillations in the auditory cortex are hierarchically organised into the delta (< 4 Hz), theta (4–8 Hz), and gamma (> 30 Hz) range (Giraud et al., Reference Giraud, Kleinschmidt and Poeppel2007; Keitel and Gross, Reference Keitel and Gross2016), and thus closely match the frequencies of stress patterns, syllables, and phonemes. This resulted in the proposal that rhythmic properties of speech entrain neuronal firing (Giraud and Poeppel, Reference Giraud and Poeppel2012; Gross et al., Reference Gross, Hoogenboom and Thut2013; Lalor and Foxe, Reference Lalor and Foxe2010; Luo and Poeppel, Reference Luo and Poeppel2007; Peelle and Davis, Reference Peelle and Davis2012), causing neurons to align both the frequency and the phase of their firing patterns to the input (Regan, Reference Regan1977; Zaehle et al., Reference Zaehle, Lenz, Ohl and Herrmann2010). This rhythmical neural tracking enables the forming of temporal predictions about salient events in the input, ensuring the brain is most excitable at times when the speech signal carries the most information (Lakatos et al., Reference Lakatos, Musacchia and O’Connel2013; Large and Jones, Reference Large and Jones1999; Rimmele et al., Reference Rimmele, Morillon, Poeppel and Arnal2018; Schroeder and Lakatos, Reference Schroeder and Lakatos2009). This helps in grouping information in analysable units such as words, syllables, and phrases (Ding and Simon, Reference Ding and Simon2014; Goswami, Reference Goswami2018; Keitel et al., Reference Keitel, Gross and Kayser2018) and facilitates speech processing (Cason and Schön, Reference Cason and Schön2012; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Henry and Obleser, Reference Henry and Obleser2012; Keitel et al., Reference Keitel, Gross and Kayser2018; Peelle et al., Reference Peelle, Gross and Davis2013; see Meyer, Reference Meyer2018, for a review) by assisting the segmentation and identification of linguistic units from speech.
Natural speech is not perfectly rhythmic, and bottom-up cues alone might be insufficient to explain the synchronisation between neural activity and the speech envelope (Meyer et al., Reference Meyer, Sun and Martin2020). Indeed, speech tracking has been found to be influenced by cross-modality influences as well as to be top-down-modulated by linguistic knowledge and attention. The influence of linguistic knowledge on neural tracking has, for example, been shown by Ding et al. (Reference Ding, Melloni, Zhang, Tian and Poeppel2016), while other studies have confirmed that neural tracking is modulated by semantic content (Broderick et al., Reference Broderick, Anderson and Lalor2019; Kaufeld et al., Reference Kaufeld, Bosker and Ten Oever2020).
In addition to linguistic knowledge, visual information also affects neural tracking of speech (Crosse et al., Reference Crosse, Butler and Lalor2015; Power et al., Reference Power, Mead, Barnes and Goswami2012a; Zion Golumbic et al., Reference Zion Golumbic, Cogan, Schroeder and Poeppel2013). Rhythmic movements of the mouth, lips, and jaw often occur in synchrony with the auditory signal, even slightly preceding it (Chandrasekaran et al., Reference Chandrasekaran, Trubanova, Stillittano, Caplier and Ghazanfar2009). This makes facial cues important for following or even predicting the rhythm of speech and thus likely aiding speech tracking (Bourguignon et al., Reference Bourguignon, Baart, Kapnoula and Molinaro2020; Park et al., Reference Park, Kayser, Thut and Gross2016, Reference Park, Ince, Schyns, Thut and Gross2018; Zoefel, Reference Zoefel2021). Indeed, visual information from mouth movements aids in synchronising neural oscillations in both adults (Bauer et al., Reference Bauer, Debener and Nobre2020; Biau et al., Reference Biau, Wang, Park, Jensen and Hanslmayr2021; Bourguignon et al., Reference Bourguignon, Baart, Kapnoula and Molinaro2020; Peelle and Sommers, Reference Peelle and Sommers2015; Thézé et al., Reference Thézé, Giraud and Mégevand2020; Zoefel, Reference Zoefel2021) and children (Power et al., Reference Power, Foxe, Forde, Reilly and Lalor2012b; but see Çetinçelik et al., Reference Çetinçelik, Rowland and Snijders2023, Reference Çetinçelik, Jordan-Barros, Rowland and Snijders2024).
Finally, neural tracking is also modulated by attention. Speech is rarely heard under ideal acoustic conditions, so listeners must selectively attend to the relevant speech stream and filter out irrelevant noise. Neural entrainment has been proposed to be a core mechanism for attentional selection, maximising temporal attention on to the behaviourally important parts of the signal (Lakatos et al., Reference Lakatos, Karmos, Mehta, Ulbert and Schroeder2008; Obleser and Kayser, Reference Obleser and Kayser2019; Zion Golumbic et al., Reference Zion Golumbic, Poeppel and Schroeder2012). Indeed, when presented with multiple talkers simultaneously, rhythmic neural tracking helps in attending to one of multiple speech streams and synchronisation reflects the attended speaker (O’Sullivan et al., Reference O’Sullivan, Power and Mesgarani2015; Power et al., Reference Power, Foxe, Forde, Reilly and Lalor2012b; Zion Golumbic et al., Reference Zion Golumbic, Poeppel and Schroeder2012).
It is good to realise that the speech–brain synchronisation measured in most studies needs not to arise from an alignment of ongoing endogenous neural oscillations, that is, from underlying oscillatory activity that is shifted in phase due to the rhythmical input (Figure 37.1). Instead, the synchronisation may reflect a series of auditory responses evoked by acoustic extrema in the speech signal, which are superimposed on neural activity and thus appear in the same frequency as the speech rhythm (see, for example, Keitel et al., Reference Keitel, Obleser, Jessen and Henry2021). Recent evidence regarding the involvement of genuine oscillations in speech tracking suggests that, at least in some cases, rhythmic responses persist even after stimulation has ended (van Bree et al., Reference van Bree, Sohoglu, Davis and Zoefel2021; Zoefel et al., Reference Zoefel, ten Oever and Sack2018). This suggests an involvement of oscillatory entrainment in speech tracking, likely in combination with evoked responses (Doelling et al., Reference Doelling, Florencia Assaneo, Bevilacqua, Pesaran and Poeppel2019).
It is important to keep the distinction between evoked and oscillatory accounts in mind when interpreting findings from neural tracking. However, oscillations have been argued to reflect basic operating mechanisms of the brain, which are employed by specialised cognitive processes (Friederici and Singer, Reference Friederici and Singer2015; Fries, Reference Fries2015). During speech processing, the brain needs to flexibly adapt its operating frequencies to the speech characteristics. Even evoked responses will therefore necessarily, at least to a certain degree, occur within the frequency ranges that the brain is able to process and communicate in. As we will argue below, maturation of underlying oscillatory circuits during infancy constrains the information that infants can process and thus affects neural tracking – even if the underlying mechanism were evoked rather than entrained.
37.3 Neural Speech Tracking in Infants
In recent years, there has been increasing evidence that electrophysiological activity in the infant brain already tracks the rhythm of speech (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022a; Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). In particular, it has been shown that newborns track the syllable rate (3–6 Hz) of simple repeated sentences in the native and non-native language (Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). This study did not test the tracking of other rhythms, therefore leaving it unclear whether newborns already track the slow prosodic (stress) rate and the fast phoneme rate in speech. The youngest age for which tracking of prosodic stress has been shown is for four-month-olds, who were found to track sung nursery rhymes in the delta and theta rate (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022). However, infants’ early focus on prosody (Nazzi et al., Reference Nazzi, Jusczyk and Johnson2000) makes it likely that they already track prosodic stress earlier. The youngest age tested for phoneme-rate tracking is 10-month-olds by Menn et al. (Reference Menn, Ward and Braukmann2022b), who found significant tracking of the phoneme rate of spoken nursery rhymes in these infants. More research is needed to investigate the onset of neural tracking of speech in the prosodic stress rate and the phonemic rate.
At least by seven months of age, infants do not require perfectly rhythmic speech for neural tracking but can also track natural speech, such as cartoons (Jessen et al., Reference Jessen, Fiedler, Münte and Obleser2019), maternal speech in natural interactions (Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022a), and live maternal singing (Nguyen et al., Reference Nguyen, Reisner and Lueger2023). Given that natural speech can at most be considered quasi-rhythmic (Jadoul et al., Reference Jadoul, Ravignani, Thompson, Filippi and de Boer2016; Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013), robust synchronisation of neural activity to speech likely requires continuous updating through top-down modulation. Similar to adults, there is some evidence for a modulation of infants’ neural tracking of speech by visual information, linguistic knowledge, and attention.
Tan et al. (Reference Tan, Kalashnikova, Di Liberto, Crosse and Burnham2022) compared neural tracking in visual-only, auditory-only, and audiovisual speech, finding an audiovisual speech benefit for five-month-old infants and adults, but not for four-year-olds. Another study did not find a benefit of visual cues in 10-month-olds (in ideal listening conditions with slow infant-directed speech (IDS) without background noise), showing equally robust neural tracking of audiovisual speech when visual cues were present versus when they were blocked (Çetinçelik et al., Reference Çetinçelik, Jordan-Barros, Rowland and Snijders2024). Possibly, infant brains particularly rely on audiovisual information prior to the onset of linguistic knowledge. At later ages the audiovisual speech benefit is largest in relatively noisy and challenging conditions (Ross et al., Reference Ross, Saint-Amour, Leavitt, Javitt and Foxe2006; Sumby and Pollack, Reference Sumby and Pollack1954).
Evidence for an influence of linguistic knowledge on neural tracking of speech acoustics in infants currently only comes from artificial language studies showing that statistical learning modulates tracking of artificial speech. Choi et al. (Reference Choi, Batterink, Black, Paller and Werker2020) presented six-month-old infants with trisyllabic pseudowords concatenated to syllable strings, which were presented at a fixed syllable rate while the infants’ EEG was recorded. While the infants initially showed synchronisation to the syllable rate only, they transitioned to neural tracking of both the syllable rate and the rate of the trisyllabic pseudowords by the end of the experiment. This progression to tracking of the pseudoword rate indicates a top-down influence of newly acquired knowledge on neural tracking of the artificial speech stream, though studies on naturalistic speech are currently still lacking.
In addition to visual information and linguistic knowledge, infants’ neural tracking also likely benefits from attentional selection. Kalashnikova et al. (Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018) observed stronger tracking to IDS compared to adult-directed speech (ADS) in seven-month-old infants. The authors attribute this IDS tracking benefit to infants’ increased attention to IDS (Cooper and Aslin, Reference Cooper and Aslin1990; Frank et al., Reference Frank, Alcock and Arias-Trejo2020). It should be noted, though, that the studies by Tan et al. (Reference Tan, Kalashnikova, Di Liberto, Crosse and Burnham2022) and Çetinçelik et al. (Reference Çetinçelik, Jordan-Barros, Rowland and Snijders2024) observed no relationship between attention (to visual cues) and neural tracking. It is also possible that the IDS tracking benefit is based on increased amplitude modulations at the rate of prosodic stress in IDS over ADS (Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022a; Räsänen et al., Reference Räsänen, Kakouros and Soderstrom2018).
37.4 Infants’ Neural Tracking and Their Later Language Development
Multiple studies suggest that infants’ rhythmic neural tracking of speech relates to language abilities. Snijders (Reference Snijders2020) demonstrated that 7.5-month-olds’ neural tracking of spoken nursery rhymes at the rhythm of stressed syllables (1.5–2 Hz) relates to their word segmentation abilities at nine months. Expanding on this finding, neural tracking at the stressed-syllable rate at 10 months has been found to predict vocabulary development at two years (Menn et al., Reference Menn, Ward and Braukmann2022b) and at 18 months (Çetinçelik et al., Reference Çetinçelik, Jordan-Barros, Rowland and Snijders2024). The predictive effect of the tracking of slow rhythms (0.5–4 Hz) in speech for vocabulary development was replicated by Attaheri et al. (Reference Attaheri, Choisdealbha and Rocha2024) using spoken nursery rhymes.
Interestingly, some studies provide evidence for a relationship between neural tracking at the syllable rate, rather than the stressed-syllable rate, and vocabulary acquisition. Both Hahn and Snijders (Reference Hahn and Snijders2023) and Çetinçelik et al. (Reference Çetinçelik, Rowland and Snijders2023) found a positive relationship between 10-month-olds’ neural tracking of speech in the syllable rate and vocabulary growth until 18 months. Note that the syllable rates in these studies were relatively low, as they were based on the syllable rate of the actual IDS stimuli used in the experiments – resulting in a syllable rate within the canonical delta frequency range (2.5–3.5 Hz both in Hahn and Snijders, Reference Hahn and Snijders2023, and in the studies of Çetinçelik et al.).
Taken together, recent studies provide evidence that rhythmic neural tracking of speech predicts word segmentation and later vocabulary, but further studies are needed to establish whether tracking of specific frequency ranges related to stimulus characteristics is especially relevant for language acquisition or whether there is a more general role for neural tracking in the delta frequency range.
37.5 Possible Mechanisms
As presented above, speech tracking at specific frequency ranges might be related to later language development. One interpretation would be that infants who preferably track in that specific frequency range are somehow at an advantage for language development. This may be a result of their individual ‘electrophysiological profile’, that is, the location and power distribution of prominent peaks (and potentially also non-rhythmic, aperiodic activity) in the infant’s electrophysiological spectrum (Ostlund et al., Reference Ostlund, Donoghue and Anaya2022). In particular, individual differences in electrophysiological maturation between infants will lead to differences in spectral characteristics of brain rhythms, which will allow them to process information at different frequencies. Infants whose electrophysiological profile leads them to preferentially track at the stressed-syllable rate may benefit in their use of rhythmic cues for word segmentation. Another interpretation would be that tracking is flexible, with infants adapting the frequency they are tracking depending on which parts of the input signal they currently pay attention to. In this interpretation, tracking at specific frequency ranges for specific stimuli might be beneficial for language development. Neural speech tracking would then reflect infants’ attention to specific parts of the speech signal (e.g., stressed syllables), simultaneously acting as a core mechanism for maximising temporal attention on these parts (Lakatos et al., Reference Lakatos, Karmos, Mehta, Ulbert and Schroeder2008; Obleser and Kayser, Reference Obleser and Kayser2019; Zion Golumbic et al., Reference Zion Golumbic, Poeppel and Schroeder2012). We would like to argue for a combination of the two interpretations: neural speech tracking maximises the uptake of relevant information from the noisy multimodal environment, while being constrained by the maturation of the underlying oscillatory circuits (see Haegens and Zion Golumbic, Reference Haegens and Zion Golumbic2017; Meyer et al., Reference Meyer, Sun and Martin2020; Rimmele et al., Reference Rimmele, Morillon, Poeppel and Arnal2018, for related accounts of adult speech processing). Successful speech processing and language learning require neural activity to adapt flexibly to the quasi-rhythmic input, which can only occur within the limits of the developing neural system (Menn et al., Reference Menn, Männel and Meyer2023a).
37.5.1 Maturational Constraints
To understand the mechanistic role of neural tracking in language development and how this changes with age, we need to take brain maturation into account. The system’s constraints change with maturation, which will impact language processing possibilities. The infant brain is not fully developed at birth and maturational aspects of the brain are reflected in its electrophysiology (Hill et al., Reference Hill, Clark, Bigelow, Lum and Enticott2022; Schaworonkow and Voytek, Reference Schaworonkow and Voytek2021; Vanhatalo and Kaila, Reference Vanhatalo and Kaila2006). In infancy, slow neural oscillations are predominant and there is a general speed-up of electrophysiological rhythms across early childhood (Anderson and Perone, Reference Anderson and Perone2018; see Figure 37.2).Footnote 1 The individual alpha peak frequency (iAPF) is one of the most robust markers of cerebral maturation (Rodríguez-Martínez et al., Reference Rodríguez-Martínez, Ruiz-Martínez, Barriga Paulino and Gómez2017; Valdés-Sosa et al., Reference Valdés-Sosa, Biscay and Galán1990). In the developing brain at posterior sites, the dominant alpha rhythm gradually shifts from 3–6 Hz in infants to 8–12 Hz in adulthood (Cellier et al., Reference Cellier, Riddle, Petersen and Hwang2021; Gable et al., Reference Gable, Miller and Bernat2022; Marshall et al., Reference Marshall, Bar-Haim and Fox2002; Schaworonkow and Voytek, Reference Schaworonkow and Voytek2021; Stroganova et al., Reference Stroganova, Orekhova and Posikera1999). The gradual increase of the iAPF is possibly a product of increased myelination (i.e., the formation of white matter tracts in the brain, especially between thalamus and cortex; Freschl et al., Reference Freschl, Azizi, Balboa, Kaldy and Blaser2022; Segalowitz et al., Reference Segalowitz, Santesso and Jetha2010). Faster iAPF has been related to increases in speed of information processing (Klimesch et al., Reference Klimesch, Doppelmayr, Schimke and Pachinger1996; Surwillo, Reference Surwillo1961) and attentional performance (Tröndle et al., Reference Tröndle, Popov, Dziemian and Langer2022). In particular, the iAPF has been hypothesised to reflect the size of the temporal integration window (Bastiaansen et al., Reference Bastiaansen, Berberyan, Stekelenburg, Schoffelen and Vroomen2020; Cecere et al., Reference Cecere, Rees and Romei2015; VanRullen, Reference VanRullen2016; White, Reference White1963; but see Buergers and Noppeney, Reference Buergers and Noppeney2022; London et al., Reference London, Benwell and Cecere2022; Ruzzoli et al., Reference Ruzzoli, Torralba, Morís Fernández and Soto-Faraco2019). The temporal integration window is the time needed to separate two events (either cross-modal or within modality). This means that a faster iAPF will make it easier to segregate information occurring in quick temporal succession, indicating that the acceleration in iAPF across infancy and childhood will allow children to dissociate information at smaller temporal intervals as they mature. In line with this, infants initially have very long temporal integration windows (Hochmann and Kouider, Reference Hochmann and Kouider2022; Tsurumi et al., Reference Tsurumi, Kanazawa, Yamaguchi and Kawahara2021): while adults can differentiate tones if they are separated by at least 20 ms (Giraud, Reference Giraud2020; Joliot et al., Reference Joliot, Ribary and Llinás1994), 7.5-month-old infants need a total of ~150 ms difference in tone onsets in order to process two tones as separate (Benasich and Tallal, Reference Benasich and Tallal2002). The iAPF might thus reflect processing constraints that change with development, determining the limits of neural temporal processing. Notably, alpha activity is not classically associated with neural tracking during speech processing (see Meyer, Reference Meyer2018, for a review). However, the acceleration of alpha and the corresponding decrease in temporal integration windows has been associated with higher audiovisual integration abilities (Ronconi et al., Reference Ronconi, Vitale and Federici2023; Zhou et al., Reference Zhou, Cui and Yang2022). Given the importance of visual cues for infants’ language acquisition (Çetinçelik et al., Reference Çetinçelik, Rowland and Snijders2021; Hollich et al., Reference Hollich, Newman and Jusczyk2005) and potentially also the neural tracking of audiovisual speech (Power et al., Reference Power, Foxe, Forde, Reilly and Lalor2012b), maturation in peak alpha frequency may be especially related to the development of audiovisual speech processing.
Overview of EEG maturation in infancy.
Electrophysiological activity during speech processing during infancy (modelled from Menn et al., Reference Menn, Männel and Meyer2023b). Slow electrophysiological activity (< 5–10 Hz) is initially prevalent. There is a general acceleration in the frequencies of electrophysiological activity across early childhood (A). High-frequency activity starts to emerge around six months of age (B).
Figure 37.2(A) Long description
The darker shades of gray represent higher levels of activity. The horizontal axis is age in months, and the vertical axis is frequency. A color gradient scale ranges from minus 20 to 30. The values are estimated.
Figure 37.2(B) Long description
It plots four declining lines that originate at (2, 40) and terminate at (48, minus 10), (48, minus 8) and (48, minus 40). The legends for 1 month, 6 months, 12 months and 18 months are given at the top right of the graph. The values are estimated.
In addition to the increase in iAPF, fast oscillatory activity (i.e., gamma-band rhythms) only gradually emerges in the infant brain, based on continuous changes in the excitation–inhibition balance across development. In the adult brain, there is a balance between excitatory and inhibitory activity, and neural excitation is followed by somewhat proportional inhibition (Shu et al., Reference Shu, Hasenstaub and McCormick2003). The excitation–inhibition balance in the brain matures with development, giving rise to windows of plasticity in which the excitation–inhibition balance is optimal for neural plasticity and learning, thus enabling a sensitive period during childhood (Werker and Hensch, Reference Werker and Hensch2015). The excitation–inhibition balance is also crucial for the emergence of neural oscillations (Buzsáki, Reference Buzsáki2006; Buzsáki and Watson, Reference Buzsáki and Watson2022; Poil et al., Reference Poil, Hardstone, Mansvelder and Linkenkaer-Hansen2012), which arise from alternating periods of excitation and inhibition. Slow electrophysiological activity in the delta and theta range is already present in the auditory language areas prenatally (Arichi et al., Reference Arichi, Whitehead and Barone2017; Chipaux et al., Reference Chipaux, Colonnese and Mauguen2013; Moghimi et al., Reference Moghimi, Shadkam and Mahmoudzadeh2020; Routier et al., Reference Routier, Mahmoudzadeh and Panzani2017; Vecchierini et al., Reference Vecchierini, André and d’Allest2007). In contrast, faster oscillatory rhythms (i.e., gamma-range activity), which require the rapid interaction between excitatory neurons and inhibitory interneurons, only gradually emerge towards the second half of the first year (Le Van Quyen et al., Reference Le Van Quyen, Khalilov and Ben-Ari2006; Pivik et al., Reference Pivik, Andres and Tennal2019). This is potentially caused by the delayed migration of inhibitory interneurons until after birth (Xu et al., Reference Xu, Broadbelt and Haynes2011). It has recently been proposed that this trajectory of electrophysiological development from slow to fast affects infants’ processing of temporal information in speech (Menn et al., Reference Menn, Männel and Meyer2023a; see Figure 37.2). The developing brain might be initially well suited for picking up especially the low-frequency rhythmic regularities in the environment (such as prosodic stress and syllable rhythms) but struggles with information at shorter timescales, such as individual phonemes. Indeed, it has been shown that infants still struggle to segment individual speech sounds from fluent speech. Bijeljac-Babic et al. (Reference Bijeljac-Babic, Bertoncini and Mehler1993) tested newborns’ ability to discriminate short speech sequences. While newborns showed significant discrimination of bisyllabic versus trisyllabic sequences, they showed no evidence for discriminating bisyllabic utterances that only differ in the number of phonemes within a syllable. This indicates that newborns’ speech processing initially focuses on larger units of speech, but they are not yet able to process the fast pace of the phoneme rhythm. Young infants’ inability to process phoneme-rate information in fluent speech may seem at odds with countless studies demonstrating their remarkable ability to discriminate between unfamiliar phonemes (Kuhl, Reference Kuhl2007; see Werker et al., Reference Werker, Yeung and Yoshida2012, for a comprehensive review). However, these studies typically present to-be-distinguished phonemes individually with long inter-stimulus intervals, which may suit infants’ long temporal integration windows. Infants learn phonemes from fluent speech, and they show the first signs of native phoneme acquisition around 6–12 months of age, coinciding with the emergence of high-frequency electrophysiological activity. This activity would potentially allow them to segment phonemes from fluent speech. It is therefore likely that the emergence of high-frequency electrophysiological activity constrains phonological acquisition towards the second half of the first year. Studies investigating young infants’ phoneme recognition in fluent speech are currently scarce (but see Menn et al., Reference Menn, Männel and Meyer2023b).
Taken together, there is strong evidence for a maturation of electrophysiological processing speed across infancy and early childhood, as indexed by both the acceleration of iAPF and the emergence of high-frequency activity. This maturation in electrophysiological processing abilities may provide infants with novel possibilities to process speech as they age (see Elman, Reference Elman1996, for a similar idea on chronotopic constraints). We hypothesise that developmental constraints on speech processing may guide infants’ attention to specific parts of the speech signal, namely those at timescales the infant is equipped to process based on their electrophysiological capabilities. This will be reflected in their neural tracking. As a result, different input rhythms are important across development, initially slow prosodic rhythms and later also the faster phonological rhythms (also see Menn et al., Reference Menn, Männel and Meyer2023a).
37.6 Implications for Language Acquisition Research
Children are active learners, selectively attending to important information. We argue that this is reflected in their neural tracking of speech, with neural tracking reflecting their temporal attention. Neural tracking maximises the uptake of relevant information from the noisy multimodal environment while being constrained by the maturation of the underlying oscillatory circuits. While it has been shown that infants track speech from an early age, it is currently still unclear which factors affect infants’ neural tracking. More research is needed to establish the modulation of infants’ neural tracking by neural maturation, as well as by cross-modal influences, linguistic knowledge, and attention. We expect neural tracking to change with development (due to both maturational constraints and developing linguistic knowledge), but also with, for instance, task demands and motivational or attentional state.
Our proposal has several consequences for language acquisition research. It is important to take individual differences in electrophysiological profile into account, both maturational differences as well as individual differences (neurodiversity, see below in Section 37.6.1) and changes in attentional or motivational state. First of all, we hypothesise changes in tracking based on neural development. Electrophysiological maturation constrains infants’ possibilities for speech processing, initially only allowing them to focus on slow prosodic and syllable rhythms of speech. In line with electrophysiological acceleration, we hypothesise that neural tracking will transition to faster speech rhythms across the first year of life, as electrophysiological maturation allows them also to process speech information at this timescale. We hope that more awareness of and knowledge about maturational constraints in language acquisition will further our understanding of speech processing, including interpretations about phonemic processing in continuous speech, and how larger units and chunks might be most effectively processed there (Menn et al., Reference Menn, Männel and Meyer2023a, Reference Menn, Männel and Meyer2023b).
Secondly, neural tracking will be influenced by linguistic and cognitive development. As linguistic knowledge is built up, different rhythms will be more important for infants’ speech processing, affecting neural tracking. Furthermore, linguistic knowledge will serve as a top-down influence on tracking (Choi et al., Reference Choi, Batterink, Black, Paller and Werker2020). In addition, cognitive processes such as working memory and executive functioning are developing and may affect neural tracking. When assessing developmental differences, it is important to distinguish general brain maturation effects from effects due to the development of cognitive processing and representations (with brain maturation and cognitive development obviously also having mutual influences).
Thirdly, besides the developmental effects due to electrophysiological maturation and cognitive development, we expect that infants’ focus on different timescales in speech is also affected by task demands and infant state. Above, we already discussed possible influences of multimodal input, but also other characteristics of the input might affect neural tracking. For instance, while we assume that infants initially employ information in the slow prosodic stress rhythm for higher-level linguistic abstraction, there may be situations in which this information is not informative. This could, for instance, be the case in studies with artificially rhythmic stimulus materials. We then expect infants to shift their attention to different rates providing more informative cues, which would be reflected in an increase of neural tracking in the attended rate and a decrease of tracking in the normally expected prosodic rate. Also, in natural speech, different language and stimulus characteristics can determine whether it is important for the child to track specific rhythms, for example depending on whether the stressed-syllable rhythm gives cues to segment words from continuous speech in the particular language or stimulus set. Cross-linguistic differences in rhythmic cues and their informativeness for linguistic inference may also lead to different results in studies investigating different languages. Additionally, neural tracking may shift depending on the infant’s current state. It may be easier to process bottom-up cues provided by acoustic amplitude modulations compared to top-down influences on tracking, which may require more effort (Song and Iverson, Reference Song and Iverson2018). Infants may therefore resort to bottom-up tracking at the rate of strong acoustic modulations in cases of low ‘motivation’ (e.g., if the infant is tired).
Thus, it is important to take stimulus characteristics into account. Researchers often use generic frequency bands to establish neural tracking, while it is crucial to report and use stimulus-specific frequency characteristics of the speech input (see Keitel et al., Reference Keitel, Gross and Kayser2018). Only then can we discover how stimulus characteristics interact with underlying oscillatory possibilities in establishing neural tracking, and the mechanisms through which neural tracking might be related to successful language acquisition. Besides stimulus-specific speech regularities, stimulus variability also needs to be taken into account. We expect different properties of neural tracking when stimuli are repeated over and over again (such as in Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021), compared to when there is more variability (in both content and prosody) in natural speech.
37.6.1 Implications for Atypical Language Acquisition: Autism
Besides maturational differences, individual differences in neural make-up (‘neurodiversity’) are also expected to be important for neural tracking and its relation with language acquisition. Neurodevelopmental conditions often give rise to variation in attentional selection capabilities, which can enable language growth or result in language delay (D’souza et al., Reference D’souza, D’souza and Karmiloff-Smith2017; Grice et al., Reference Grice, Wehrle and Krüger2023). We argue that differences in neural constraints will result in different neural tracking possibilities, which might be reflections of how attentional processes influence language acquisition, possibly through differences in the mechanistic constraints that are in place. Here, we will work out how neural constraints and their maturation might relate to variability in language development in autism (see Chapter 47 for an overview of behavioural entrainment in autism).
One current hypothesis about biological mechanisms in autism states that the balance of neural excitation and inhibition (E/I balance) is altered in autistics (Bruining et al., Reference Bruining, Hardstone and Juarez-Martinez2020; Dickinson et al., Reference Dickinson, Jones and Milne2016; Rubenstein and Merzenich, Reference Rubenstein and Merzenich2003; Snijders et al., Reference Snijders, Milivojevic and Kemner2013) and that this E/I imbalance may lead to differences in neural oscillations. Indeed, autistic children show differential development in EEG oscillations and non-oscillatory electrophysiological activity (Tierney et al., Reference Tierney, Gabard-Durnam, Vogel-Farley, Tager-Flusberg and Nelson2012), and these electrophysiological differences relate to language development (Romeo et al., Reference Romeo, Choi and Gabard-Durnam2021; Shuffrey et al., Reference Shuffrey, Pini and Potter2022; Wilkinson et al., Reference Wilkinson, Gabard-Durnam and Kapur2020). In a recent study, it has been shown that the development of E/I imbalances across childhood and adolescence are associated with individual differences in listening comprehension in both autistic and non-autistic children (Plueckebaum et al., Reference Plueckebaum, Meyer, Beck and Menn2023). Additionally, there are some indications that the maturation of iAPF is atypical in autistic children (Edgar et al., Reference Edgar, Dipiero and McBride2019; Green et al., Reference Green, Dipiero and Koppers2022; but see Carter Leno et al., Reference Carter Leno, Pickles and van Noordt2021; Lefebvre et al., Reference Lefebvre, Delorme and Delanoë2018). Individual differences in iAPF development for autistic individuals have been related to atypicalities in temporal audiovisual integration. In particular, there are indications that autistic individuals may show a widened temporal-binding window for integration and consequently decreased sensitivity to asynchrony in audiovisual speech (Zhou et al., Reference Zhou, Cui and Yang2022). This suggests that autistic individuals employ visual information to a much lesser degree for generating auditory predictions. Indeed, Ronconi et al. (Reference Ronconi, Vitale and Federici2023) showed that audiovisual integration in autistic children is primarily driven by auditory processing, which phase-resets visual activity. Whether reduced reliance on visual information in autism impacts neural tracking of speech is an open issue.
In a recent study assessing infants with a family history of autism, we did not identify differences in neural tracking of sung audiovisual nursery rhymes compared to infants with no autism family history (Menn et al., Reference Menn, Ward and Braukmann2022b), although the identified relation between an increase in stressed-syllable tracking at 10 months with a later larger vocabulary was stronger for infants with an autism family history. In contrast, in a small sample of adults, reduced neural tracking of auditory-only speech in autistic versus non-autistic individuals has been identified (Jochaut et al., Reference Jochaut, Lehongre and Saitovitch2015). Differences between these studies might reflect developmental differences, or might be due to different stimuli (song versus speech, audio versus audiovisual). In future work, it is important to establish how neural tracking of speech is related to neural development, and how that might result in variability in language acquisition also in other E/I-atypical populations. Research investigating the development of E/I balance in infancy is only just emerging, but recent studies have reported early imbalances also for infants with genetic risks for ADHD (Begum-Ali et al., Reference Begum‐Ali, Goodwin and Mason2022; Carter Leno et al., Reference Carter Leno, Pickles and van Noordt2021), and their relationship to language development poses an exciting venue for future research.
37.7 Conclusion
In this chapter we reviewed current evidence on infants’ neural tracking of speech. Neural oscillations in the infant brain synchronise with the rhythm of speech, tracking it at different frequencies. This predicts word segmentation and later language abilities. We present the hypothesis that rhythmic neural speech tracking reflects infants’ attention to specific parts of the speech signal (e.g., stressed syllables), and simultaneously acts as a core mechanism for maximising temporal attention on to those parts. Neural constraints on speech tracking might be influenced by neural maturation, and we set out how this might be reflected in both typical and atypical language development.
Summary
This chapter reviews research on infants’ neural tracking of speech, and how this process predicts later language abilities. We hypothesise that neural speech tracking reflects infants’ temporal attention to specific parts of the speech signal. Neural maturation in typical and atypical development might influence constraints on neural tracking.
Implications
Future research on neural tracking of speech should take maturational constraints into account, as well as individual differences herein. Temporal stimulus characteristics should always be specifically described to understand the interaction between environmental input, brain and language development, and infant state.
Gains
Understanding underlying neural mechanisms in the developing brain and their interaction with the environment is crucial for understanding individual differences in speech perception and language development.
38.1 Introduction
Young infants are sensitive to the rhythmic patterns and regularities in their auditory input, which is primarily composed of the speech and singing that they hear from their caregivers (Hilton et al., Reference Hilton, Moser and Bertolo2022). This sensitivity is considered to play a fundamental role in the process of early language acquisition in the first years of life (Gervain, Reference Gervain2018; Gervain and Mehler, Reference Gervain and Mehler2010; Jusczyk, Reference Jusczyk1997; Nazzi and Ramus, Reference Nazzi and Ramus2003), as well as support development of more advanced language processing abilities in childhood such as phonological awareness and reading. Infants begin learning the rhythmic patterns of their native language or languages in utero when they perceive limited segmental but intact suprasegmental information from ambient speech (Moon and Fifer, Reference Moon and Fifer2000). This equips them with the ability to differentiate their native language(s) from rhythmically different nonnative languages already at birth (DeCasper and Fifer, Reference DeCasper and Fifer1980; Nazzi et al., Reference Nazzi, Bertoncini and Mehler1998). This initial language-specific rhythmic sensitivity becomes further fine-tuned and extended over infants’ first year of life. This is observed in the emerging abilities to discriminate between rhythmically similar languages (Bosch and Sebastián-Gallés, Reference Bosch and Sebastián-Gallés1997; Molnar et al., Reference Molnar, Gervain and Carreiras2014) and to detect native prosodic patterns at the utterance, lexical, and sub-lexical levels (Friederici et al., Reference Friederici, Friedrich and Christophe2007; Höhle et al., Reference Höhle, Bijeljac-Babic, Herold, Weissenborn and Nazzi2009; Weber et al., Reference Weber, Hahne, Friedrich and Friederici2004). These early prosodic abilities, in turn, support the processing and segmentation of incoming continuous speech (e.g., Jusczyk et al., Reference Jusczyk, Cutler and Redanz1993; Hallé and de Boysson-Bardies, Reference Hallé and de Boysson-Bardies1996; Mattys et al., Reference Mattys, Jusczyk, Luce and Morgan1999; Morgan and Saffran, Reference Morgan and Saffran1995; and refer to Chapter 39 for a detailed discussion of infants’ early perception of native language rhythm).
In this chapter, we discuss how infants’ environments are optimized for supporting their challenging task of identifying and learning the prosodic and rhythmic patterns of their native language(s). We review findings showing that this optimization is not manifested as an enhancement of language-specific rhythmic cues in infant-directed speech. Instead, we discuss evidence for the presence of language-general rhythmic regularities in natural caregiver–infant interactions, in which caregivers do not only communicate with infants through speech but also music, touch, and movement. We show that infants are exposed to multiple rhythmic input modalities that combined comprise optimized intersensory rhythmic input that infants enjoy from their first months of gestation and after birth. This optimized multisensory stimulation fosters infants’ early ability to extract rhythmic regularities from their environment, supporting subsequent language acquisition.
38.2 Infant-Directed Speech: Rhythmic Information in Infants’ Early Language Input
Infants’ early linguistic environment consists primarily of infant-directed (ID) speech, which refers to the speech style or register that adults spontaneously use in interactions with young infants (Golinkoff et al., Reference Golinkoff, Can, Soderstrom and Hirsh-Pasek2015; Soderstrom, Reference Soderstrom2007). Compared to speech used in interactions among adults or adult-directed (AD) speech, ID speech is characterized by affective, acoustic, and linguistic properties proposed to serve specific functions such as regulating infants’ emotional states (Papoušek et al., Reference Papoušek, Bornstein, Nuzzo, Papoušek and Symmes1990), capturing and maintaining infants’ attention during communicative interactions (Fernald and Simon, Reference Fernald and Simon1984), and facilitating early language development (Kuhl, Reference Kuhl2000). Evidence for ID speech has been documented across languages and language families, and adult listeners are highly accurate at differentiating it from AD speech even in unfamiliar languages, suggesting universality in the acoustic properties of ID speech (Hilton et al., Reference Hilton, Moser and Bertolo2022). Even though ID speech is produced by adults for an infant audience, infants are not passive perceivers of this speech register. From their first months of life, infants prefer listening to ID compared to AD speech (Byers-Heinlein et al., Reference Byers-Heinlein, Tsui and Bergmann2021; Cooper and Aslin, Reference Cooper and Aslin1990), and their active feedback shapes the acoustic properties of the ID speech produced by their caregivers (Lam and Kitamura, Reference Lam and Kitamura2012; Murray and Trevarthen, Reference Murray and Trevarthen1986; Smith and Trainor, Reference Smith and Trainor2008). Caregivers are also sensitive to their infants’ developmental needs and evolving listening preferences (Kitamura and Burnham, Reference Kitamura and Burnham1998, Reference Kitamura and Burnham2003; Kitamura and Lam, Reference Kitamura and Lam2009), and adjust their speech accordingly. For instance, ID speech to newborns is highly soothing and comforting, while ID speech to six–nine-month-olds acquires more directive and attention-grabbing qualities (Kitamura and Burnham, Reference Kitamura and Burnham2003), reflecting infants’ readiness to actively engage with objects and people in their environment and attend to linguistic information in their speech input (Newman and Hussain, Reference Newman and Hussain2006). Similarly, as infants approach their second birthday, ID speech becomes faster and exhibits a reduction in mean pitch and pitch range (Cox et al., Reference Cox, Bergmann and Fowler2023), progressively approximating the less prosodically exaggerated child-directed and AD speech registers.
Several acoustic and prosodic adaptations in ID relative to AD speech have been proposed to directly support early language processing and subsequent language acquisition. For instance, phonetic exaggeration, typically indexed by the expansion of the acoustic distance between the three corner vowels /i/, /u/, and /a/ (Burnham et al., Reference Burnham, Kitamura and Vollmer-Conna2002; Kuhl et al., Reference Kuhl, Andruski and Chistovich1997), has been proposed to directly foster early speech perception abilities by providing infants with exposure to clear speech and more distinct phonetic categories (Kuhl, Reference Kuhl2000). Indeed, infants show more efficient vowel processing and word recognition when presented with ID speech containing acoustically exaggerated vowels (Lovcevic et al., Reference Lovcevic, Burnham and Kalashnikova2022; Peter et al., Reference Peter, Kalashnikova, Santos and Burnham2016; Song et al., Reference Song, Demuth and Morgan2010), and the extent to which individual mothers exaggerate vowels in ID speech correlates with their infants’ concurrent speech perception abilities and future vocabulary size (Hartman et al., Reference Hartman, Ratner and Newman2017; Kalashnikova and Burnham, Reference Kalashnikova and Burnham2018; Kalashnikova and Carreiras, Reference Kalashnikova and Carreiras2022; Liu et al., Reference Liu, Kuhl and Tsao2003; but see Martin et al., Reference Martin, Schatz and Versteegh2015; McMurray et al., Reference McMurray, Kovack-Lesh, Goodwin and McEchron2013, for findings contradicting this claim). Prosodic characteristics of ID speech including expanded pitch range and slow speech rate have also been linked to enhanced speech processing. In experimental paradigms, infants are more successful at segmenting continuous ID speech characterized by expanded pitch range (Floccia et al., Reference Floccia, Keren-Portnoy and DePaolis2016; Schreiner and Mani, Reference Schreiner and Mani2017; Thiessen et al., Reference Thiessen, Hill and Saffran2005) and recognizing words produced in slow ID speech (Song et al., Reference Song, Demuth and Morgan2010).
Based on this evidence linking the characteristics of caregivers’ ID speech to language outcomes, several studies have hypothesized that specific acoustic cues to the rhythmic patterns of infants’ native language would also be exaggerated compared to AD speech, and that this would support the development of native prosodic competence and speech segmentation abilities. Traditionally, the world’s languages have been classified as belonging to one of three rhythmic classes defined by the size of their prosodic units, which include the metrical foot in stress-timed languages (e.g., English), the syllable in syllable-timed languages (e.g., Spanish), and the mora in mora-timed languages (e.g., Japanese) (Abercrombie, Reference Abercrombie1967). More recently, this classification has been debated (e.g., Turk and Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013), but there is evidence that a language’s rhythmic structure can be defined by several durational measures that represent the proportion and variability of duration with which consonantal and vocalic intervals occur in that language (e.g., Ramus et al., Reference Ramus, Nespor and Mehler1999, Reference Ramus, Hauser, Miller, Morris and Mehler2000; and refer to Chapter 11 for a discussion of other measures of speech rhythm). A recent meta-analysis shows that infants rely on these durational cues in language differentiation tasks, whereby smaller differences in vocalic variability and larger differences in consonantal variability between languages lead to better discrimination performance from birth to 12 months (Gasparini et al., Reference Gasparini, Langus, Tsuji and Boll-Avetisyan2021).
These language-specific durational cues may be difficult to extract for a novice language-learner, so they would be expected to be exaggerated in the slower and prosodically exaggerated ID speech. To test this, Payne et al. (Reference Payne, Post, Astruc, Prieto and Vanrell2009) compared durational rhythmic cues in English, Spanish, and Catalan ID speech to two-, four-, and six-year-olds (a register also referred to as child-directed speech, reflecting the recipient children’s ages). These three languages differ significantly in their rhythmic structure (English is stress-timed, Spanish is syllable-timed, and Catalan falls in between). Results showed that even though ID speech differed acoustically from AD speech in each language, instead of enhancing cross-linguistic differences, the ID adaptations resulted in greater rhythmic similarities. Across languages, ID speech was more vocalic and had reduced variability in consonantal segments. Lee et al. (Reference Lee, Kitamura, Burnham and McAngus Todd2014) assessed the same cues in English ID speech to infants from 0 to 12 months but failed to replicate the ID versus AD speech differences reported by Payne et al. However, using a modelling approach that assessed the sonorant structure of ID and AD speech (which measures the regularity with which syllables occur in speech based on prominence cues such as intensity, pitch, spectral balance, and duration; Lee and Todd, Reference Lee and Todd2004), this study also reported that stressed and unstressed syllables were differentiated to a lesser extent in ID compared to AD speech. Finally, Tajima et al. (Reference Tajima, Tanaka, Martin and Mazuka2013) investigated the durational cues of ID and AD speech in Japanese, a mora-timed language. Their analyses also failed to reveal any ID adjustments that would support the identification of mora segments in continuous speech. As can be seen, there are some inconsistencies across these studies, which are likely due to cross-dialectal and cross-linguistic differences and assessments of speech directed to infants and children spanning a wide age range. Despite this issue, this evidence suggests that ID speech does not enhance, and may even distort, durational cues that signal language-specific rhythm structure, potentially in favor of the prosodic adjustments that serve the affective and attention-grabbing functions of this speech register (Kempe et al., Reference Kempe, Brooks and Gillis2005).
Even if caregivers do not exaggerate language-specific rhythmic properties in ID speech, the findings reviewed above indicate that the segmental and suprasegmental properties of this register result in a temporal structure that is significantly different from AD speech (Nencheva and Lew-Williams, Reference Nencheva and Lew-Williams2022). Specifically, ID speech exhibits greater rhythmic regularities, resulting in a more isochronous signal. At first glance, this may appear to contradict the notion that ID speech is optimized for promoting the acquisition of language-specific rhythmic competence, but it may be the case that rhythmic regularization leads to more efficient neural encoding and processing of speech by young infants. This argument is based on extensive evidence from neurophysiological studies for entrainment between endogenous oscillatory neural activity and incoming sensory information (Ding et al., Reference Ding, Patel and Chen2017; and see Chapters 3, 5, 35, 36, and 37).
In the case of speech, specifically, linguistic information across multiple timescales is conveyed by the energy fluctuations of the amplitude envelope (i.e., the lexical and phrasal rate 1–4 Hz, the syllabic rate 5–8 Hz, and the phonological rate 30–50 Hz), which are tracked by corresponding frequency bands of neural oscillations in the auditory cortex (delta, theta, and gamma bands, respectively) (Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Ding and Simon, Reference Ding and Simon2014; Ghitza, Reference Ghitza2012; Peelle and Davis, Reference Peelle and Davis2012; Poeppel and Assaneo, Reference Poeppel and Assaneo2020; and refer to Chapter 35 for a detailed discussion of cortical tracking of speech). Speech processing is primarily governed by efficient entrainment to the slowly occurring information in the speech envelope (delta and theta oscillation bands) (Ghitza, Reference Ghitza2012; Gross et al., Reference Gross, Hoogenboom and Thut2013; Luo and Poeppel, Reference Luo and Poeppel2007), which significantly correlates with speech intelligibility and successful comprehension (Arnal and Giraud, Reference Arnal and Giraud2012; Vanthornhout et al., Reference Vanthornhout, Decruy, Wouters, Simon and Francart2018). Both top-down processes and bottom-up information contribute to the efficiency of cortical entrainment in individual listeners (Di Liberto et al., Reference Di Liberto, Lalor and Millman2018; Doelling et al., Reference Doelling, Arnal, Ghitza and Poeppel2014; Peelle et al., Reference Peelle, Gross and Davis2013). Entrainment is more efficient when listeners have higher proficiency in the language in which the stimuli are presented (Lizarazu et al., Reference Lizarazu, Carreiras and Molinaro2023), and when they actively attend to the stimulus string (Golumbic et al., Reference Zion Golumbic, Ding and Bickel2013; Obleser and Kayser, Reference Obleser and Kayser2019). The bottom-up cues that modulate entrainment include speech rate and rhythmic regularity (Aubanel et al., Reference Aubanel, Davis and Kim2016; Lizarazu et al., Reference Lizarazu, Lallier and Molinaro2019). Thus, it is plausible that young infants who have limited access to top-down information during speech processing particularly benefit from exposure to ID speech, which is precisely a slow, attention-grabbing, and more isochronous speech signal.
Several studies support this proposal. Falk and Kello (Reference Falk and Kello2017) analyzed the temporal structure of the amplitude envelope of German ID speech and singing to six-month-old infants. They found that acoustic energy across frequencies corresponding to different units in the linguistic hierarchy were clustered to a greater extent in ID than AD registers. That is, the hierarchical temporal structure of ID registers was more regular compared to AD counterparts. Leong et al. (Reference Leong, Kalashnikova, Burnham and Goswami2014) assessed naturally produced English ID and AD speech to infants from seven to 11 months, focusing specifically on low-frequency information in the amplitude envelope. Their findings revealed greater delta–theta phase synchronization in ID speech compared to greater theta–gamma synchronization in AD speech. These results indicate greater rhythmic regularity in ID compared to AD speech, in particular at the rates at which stressed and unstressed syllables occur. Pérez-Navarro et al. (Reference Pérez-Navarro, Lallier, Clark, Flanagan and Goswami2022) recently replicated this result for Spanish child-directed speech to four-year-olds, suggesting that these adjustments extend across rhythm classes (i.e., in stress-timed English and syllable-timed Spanish) and may be preserved as children develop more advanced language abilities over time. Critically, the benefits of these rhythmic adjustments in ID and child-directed speech are reflected in direct measures of infant speech processing: Infants show more efficient neural entrainment to ID compared to AD speech (Kalashnikova et al., Reference Kalashnikova and Burnham2018; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022a). Thus, the language-general rhythmic regularities in ID speech play an important role in facilitating early processing and encoding of speech, which may in turn promote infants’ subsequent learning of the specific rhythmic patterns of their native language and the extraction of meaningful linguistic units from continuous speech.
38.3 ID Singing: A Multimodal Source of Rhythmic Information
The temporal adjustments approximate ID speech to the rhythmically regular and melodic structure of music (Daikoku and Goswami, Reference Daikoku and Goswami2022). Music is another highly prominent auditory signal available to infants before and after birth (Kisilevsky et al., Reference Kisilevsky, Hains, Jacquet, Granier-Deferre and Lecanuet2004), and provides them with valuable rhythmic information (Papadimitriou et al., Reference Papadimitriou, Smyth, Politimou, Franco and Stewart2021). After birth, the most common source of music for most infants is their caregivers’ singing (Trehub et al., Reference Trehub, Unyk and Kamenetsky1997). Caregivers across the world’s cultures have been documented to sing to their infants (Trehub and Russo, Reference Trehub, Russo, Russo, Ilari and Cohen2020), and their ID singing differs from AD singing by a number of acoustic and prosodic properties including higher pitch, increased amplitude, and greater frequency variation. ID singing has been proposed to serve primarily an affective function by regulating infants’ arousal and emotional states (Cirelli et al., Reference Cirelli, Trehub and Trainor2018; Salimpoor et al., Reference Salimpoor, Benovoy, Longo, Cooperstock and Zatorre2009; Trainor, Reference Trainor2006) as well as promoting social bonding in caregiver–infant interactions (Cirelli and Trehub, Reference Cirelli and Trehub2019), crucial for healthy socio-emotional development (Poćwierz-Marciniak and Harciarek, Reference Poćwierz-Marciniak and Harciarek2021). As it is the case for ID speech, caregivers dynamically adjust the characteristics of ID singing according to their infants’ emotional and developmental needs and their own intention to capture and maintain their infants’ attention or modify the infants’ emotional state (Delavenne et al., Reference Delavenne, Gratier and Devouche2013; Rock et al., Reference Rock, Trainor and Addison1999). Lullabies, for instance, have a slower tempo, simpler melodies, and a reduced pitch range, and they aim to calm and soothe the infant. Play songs, on the other hand, have a faster tempo, more complex and varied melodies, and a wider pitch range, and their aim is to engage and animate the infant (Trainor and Trehub, Reference Trainor and Trehub1998). Infants, in turn, enjoy listening to ID singing by relaxing, manifesting less distress, and exhibiting more positive emotions (Shannon, Reference Shannon2006; Trehub et al., Reference Trehub, Ghazban and Corbeil2015). Interestingly, infants’ responses are also molded by the type of songs that they hear. Infants direct attention internally, focusing on self-regulation, during lullabies, but direct their attention externally toward the caregiver through mutual gaze during rhythmic play songs (Rock et al., Reference Rock, Trainor and Addison1999).
Critically, the exaggerated acoustic features of ID singing delineate its hierarchical beat structure, helping infants process phrase boundaries, rhythm, and grouping structures (Longhi, Reference Longhi2009). This means that not only the musical but also the linguistic information encountered in this register can be processed more effectively, supporting language acquisition. Several recent studies have assessed neural entrainment in young infants in response to pre-recorded sung ID speech and live, naturally produced ID singing and found efficient tracking at the delta and theta frequencies, relevant for speech encoding (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022a; Nguyen et al., Reference Nguyen, Reisner and Lueger2023). Nguyen et al. (Reference Nguyen, Reisner and Lueger2023) measured neural entrainment of seven-month-old infants in response to lullabies and play songs, which display different acoustic and prosodic properties, as discussed above. Infants tracked lullabies more efficiently, which was primarily related to the slow tempo and beat clarity in this song type. However, infants were more likely to produce rhythmic movements when listening to play songs, which was related to the perceived loudness of these stimuli. Thus, it appears that these different types of ID songs not only elicit different attentional responses from infants (Rock et al., Reference Rock, Trainor and Addison1999) but may also have differential functions in facilitating infants’ encoding of the linguistic information in these songs (Franco et al., Reference Franco, Suttora, Spinelli, Kozar and Fasolo2022). Evidence is starting to emerge with several studies showing moderate but significant correlations between individual infants’ efficiency of neural entrainment to ID songs measured in the first year of life and language outcomes, in particular, vocabulary size in the second year (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Menn et al., Reference Menn, Ward and Braukmann2022b; Nguyen et al., Reference Nguyen, Reisner and Lueger2023). Thus, the regular prosodic and rhythmic structure of ID singing, similarly to ID speech, may play a significant role in fostering infants’ speech processing and supporting later acquisition of the specific rhythmic properties of their native language and subsequent language acquisition.
ID speech and singing convey auditory-only information that facilitates infants’ auditory processing. However, solely focusing on the auditory modality misrepresents the true multimodal nature of caregiver–infant communication and fails to capture the facilitative role that ID adjustments in other sensory modalities may play in supporting language development, to which we now turn.
Infants are typically exposed to ID speech and singing in the context of active face-to-face interactions with their caregivers, in which the auditory input is supported by rich multimodal information that can also foster the process of encoding and segmenting incoming speech input. For instance, infants attend to the speaker’s face when listening to ID speech and singing, which leads to enhanced neural entrainment and greater interpersonal synchronization with their caregivers (Lense et al., Reference Lense, Shultz, Astésano and Jones2022; Tan et al., Reference Tan, Kalashnikova, Di Liberto, Crosse and Burnham2022). Caregivers also employ touch and gesture to emphasize relevant linguistic information when interacting with their young infants (Abu-Zhaya et al., Reference Abu-Zhaya, Seidl and Cristia2017; O’Neill et al., Reference O’Neill, Bard, Linnell and Fluck2005). Furthermore, and particularly relevant to infants’ perception of rhythmic information in the input, ID singing (but not ID speech; Zentner and Eerola, Reference Zentner and Eerola2010) elicits active rhythmic movement from the infants themselves. Therefore, in addition to perceiving rhythmic information in the auditory modality, infants have the opportunity to experience it in their own passive and active body movements.
Similarly to adults, infants are enticed to move when they hear music (Gordon, Reference Gordon2003). Several studies show that infants in their first year of life are more likely to produce rhythmic movements in response to ID singing and musical sequences compared to other stimuli, including ID speech (e.g., Ilari, Reference Ilari2015; Nguyen et al., Reference Nguyen, Reisner and Lueger2023; Zentner and Eerola, Reference Zentner and Eerola2010). Most importantly, there is also evidence to suggest that infants’ movements are coordinated with the temporal structure of the input, signalling a connection between infants’ rhythmic perception and rhythmic movement production (de l’Etoile et al., Reference de l’Etoile, Bennett and Zopluoglu2020; Longhi, Reference Longhi2009; Zentner and Eerola, Reference Zentner and Eerola2010). For instance, a recent study by de l’Etoile et al. (Reference de l’Etoile, Bennett and Zopluoglu2020) assessed whether infants’ movements related to rhythmic regularities in the stimuli, and whether infants were sensitive to rhythmic training. Six–10-month-old infants’ movements were recorded in response to silence, irregular auditory stimuli, and rhythmically regular song recordings. Infants’ movements were more regularly timed in response to the rhythmically regular songs. While infants’ ability to precisely time their rhythmic movements to the tempo of musical stimuli that they hear seems to emerge much later in preschool years (Drake et al., Reference Drake, Jones and Baruch2000; Eerola et al., Reference Eerola, Luck and Toiviainen2006), they show early sensitivity to the rhythmic structure of music, which is observed in the greater quantity and higher regularity of their rhythmic movements.
38.4 Early Vestibular, Tactile, and Somatosensory Experiences with Rhythm
Movement plays a significant role in processing rhythm, so it is evident that hearing is not the only sensory modality involved in processing rhythm in music and speech. Most importantly, infants start perceiving rhythm through vestibular, tactile, and somatosensory (VTS) experiences (Provasi et al., Reference Provasi, Anderson and Barbu-Roth2014) well before they start moving in response to music and ID singing. Specifically, the first experiences with rhythm occur already in utero, encompassing multiple sources of rhythmic stimulation produced by the mother’s body movements (Lecanuet and Schaal, Reference Lecanuet and Schaal2002). As a consequence, vestibular and somatosensory input has been found to be central to rhythm perception after birth and during early development (Phillips-Silver and Trainor, Reference Phillips-Silver and Trainor2005; Tichko et al., Reference Tichko, Kim and Large2022; Trainor et al., Reference Trainor, Gao, Lei, Lehtovaara and Harris2009; and refer to Chapter 4 for a sensorimotor account of multimodal prosody, including the role of the vestibular system). The VTS system is the first to develop in the human fetus: Cutaneous and trigeminal somatosensory receptors mature at around four to seven weeks of gestation (Humphrey, Reference Humphrey1964). While the early emergence of somatosensory anatomy and function is shortly followed by vestibular and chemosensory functioning, auditory and visual functioning are first observed much later in prenatal development (Bremner and Spence, Reference Bremner and Spence2017). From the third trimester of gestation, fetuses perceive rhythmic signals coming from the intrauterine and extrauterine environment through bone conduction (Sohmer et al., Reference Sohmer, Perez, Sichel, Priner and Freeman2001). Specifically, the maternal voice is transmitted directly to the amniotic fluid via body tissues and bones, with pitch and the first overtones being fully conducted through the spine and the pelvic arch (Petitjean, Reference Petitjean1989). External low frequencies (corresponding to the first four octaves of the piano) are perceived in utero, with bone conduction allowing for intelligibility of both speech and music rhythmic patterns (Granier-Deferre et al., Reference Granier-Deferre and Busnel2011; Mampe et al., Reference Mampe, Friederici, Christophe and Wermke2009).
VTS mechanisms, crucial for early rhythmic experiences, also provide the context in which fetal “hearing” occurs. Maternal heartbeat, breathing, and walking all produce movement together with sound (Kisilevsky et al., Reference Kisilevsky, Killen, Muir and Low1991), so it is probably the cross-modal temporal synchrony generated by the coupling of VTS and auditory signals that is crucial in shaping rhythm processing in utero (Provasi et al., Reference Provasi, Anderson and Barbu-Roth2014). Consistently, premature infants who receive VTS stimulation adapt their breathing to the rate and acceleration of VTS stimuli (Zimmerman and Barlow, Reference Zimmerman and Barlow2012). The very early exposure to the isochronous pulse of maternal heartbeat and breathing patterns may shape the development of neural and physiological systems supporting rhythm perception after birth toward familiar patterns (Teie, Reference Teie2016). Memory of these experiences is maintained after birth (Ullal-Gupta et al., Reference Ullal-Gupta, Vanden Bosch der Nederlanden, Tichko, Lahav and Hannon2013), with newborns preferring to listen to music and nursery rhymes heard prenatally compared to unfamiliar tracks (DeCasper and Spence, Reference DeCasper and Spence1986; Hepper, Reference Hepper1991). That is, experience of VTS stimulation combines with auditory input to comprise the prenatal experience of rhythm. The effects of these early multimodal experiences are seen in the infant preferences toward regular, binary rhythms after birth and throughout development (DeCasper and Sigafoos, Reference DeCasper and Sigafoos1983; Doheny et al., Reference Doheny, Hurwitz, Insoft, Ringer and Lahav2012; Lahav et al., Reference Lahav, Saltzman and Schlaug2007; Tichko et al., Reference Tichko, Kim and Large2022).
Passive experience with movements that generate VTS stimulation continues after birth, significantly influencing the perception of auditory rhythm in infants (Phillips-Silver and Trainor, Reference Phillips-Silver and Trainor2005). Across cultures, caregivers use VTS rhythms to calm their newborns, for instance by moving them back and forth or by rocking them while singing or walking (Provasi et al., Reference Provasi, Anderson and Barbu-Roth2014). A recent study demonstrated that the cadence of parent movements and walking is related to the spontaneous motor tempo of young infants (Rocha et al., Reference Rocha, Southgate and Mareschal2021). Furthermore, studies with adult and infant participants showed that body movement can bias the auditory encoding of ambiguous rhythms (Phillips-Silver and Trainor, Reference Phillips-Silver and Trainor2005, Reference Phillips-Silver and Trainor2007). Phillips-Silver and Trainor (Reference Phillips-Silver and Trainor2005) exposed infants to a rhythmically ambiguous auditory pattern while they were bounced in time with a duple or a triple meter. After this exposure, infants preferred the meter pattern to which they were bounced. Watching someone else moving in time with a meter, however, was not sufficient to elicit similar effects in infants or adults, demonstrating that the active movement of the body is crucial in rhythm encoding and processing (Phillips-Silver and Trainor, Reference Phillips-Silver and Trainor2007, Reference Phillips-Silver and Trainor2008). These findings confirm that active and passive motion generating VTS experience not only shapes the early development of structural and functional mechanisms underlying rhythm processing, but that it also influences rhythm processing right after birth and throughout development.
VTS experiences continue to mediate the interaction between rhythm ability and language development throughout infancy and early childhood. VTS and auditory rhythmic abilities have been proposed as a potential scaffold for early interpersonal synchrony between mothers and infants (Trehub, Reference Trehub2003), and VTS–auditory coupling has an impact in sustaining early language acquisition. For instance, synchronous tactile cues were shown to help four- and five-month-olds to find words in continuous speech, promoting word learning (Abu-Zhaya et al., Reference Abu-Zhaya, Seidl and Cristia2017; Seidl and Cristià, Reference Seidl and Cristià2008). Moreover, audio-tactile stimulation resulted in enhanced event related potentials (ERPs) and higher beta-band activity (at 15−16 Hz) recorded using electroencephalography (EEG), compared to auditory-only stimulation in eight-month-old infants (Tanaka et al., Reference Tanaka, Kanakogi, Kawasaki and Myowa2018). Consistently, parents tend to spontaneously synchronize the location and timing of their touches on the infant’s body with word rhythm in ID speech (Custode and Tamis-LeMonda, Reference Custode and Tamis-LeMonda2020; Lew-Williams et al., Reference Lew-Williams, Ferguson, Abu-Zhaya and Seidl2019; Tincoff et al., Reference Tincoff, Seidl, Buckley, Wojcik and Cristia2019). Later in development, preschoolers who can entrain their motion to an external beat display more faithful neural encoding of temporal modulations in speech and achieve higher scores on tests of early language skills (Woodruff Carr et al., Reference Woodruff Carr, White-Schwoch, Tierney, Strait and Kraus2014).
On the other hand, rhythmic deficits including VTS and sensorimotor abilities are shared by different atypically developing populations, including developmental dyslexia (Beker et al., Reference Beker, Foxe and Molholm2021; Goswami, Reference Goswami2002; Power et al., Reference Power, Mead, Barnes and Goswami2013), attention deficit disorder (Carrer, Reference Carrer2015; Puyjarinet et al., Reference Puyjarinet, Bégel, Lopez, Dellacherie and Dalla Bella2017), autism (Fitzpatrick et al., Reference Fitzpatrick, Romero and Amaral2017; Franich et al., Reference Franich, Wong, Yu and To2021, see also Chapter 47 on rhythmic-prosodic synchrony in speakers with and without autism), and developmental coordination disorder (Chang et al., Reference Chang, Li and Chan2021; Puyjarinet et al., Reference Puyjarinet, Bégel, Lopez, Dellacherie and Dalla Bella2017; Trainor et al., Reference Trainor, Chang, Cairney and Li2018). For instance, individuals with dyslexia who exhibit weaker performance in rhythm perception and production tasks also tend to show weaker phonological awareness (Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2014; Forgeard et al., Reference Forgeard, Schlaug and Norton2008; Goswami et al., Reference Goswami, Gerson and Astruc2010; Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011; Kalashnikova et al., Reference Kalashnikova, Burnham and Goswami2021; Lee et al., Reference Lee, Sie, Chen and Cheng2015; Thomson and Goswami, Reference Thomson and Goswami2008) and poorer reading skills (Dellatolas et al., Reference Dellatolas, Watier, Le Normand, Lubart and Chevrie-Muller2009; Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015; Goswami et al., Reference Goswami, Gerson and Astruc2010, Reference Goswami, Huss, Mead, Fosker and Verney2013; Muneaux et al., Reference Muneaux, Ziegler, Truc, Thomson and Goswami2004; Thomson and Goswami, Reference Thomson and Goswami2008). Furthermore, individuals with dyslexia also demonstrate impaired processing of auditory rise times, which has been linked to inefficient entrainment between the neural oscillatory activity and the speech signal (Huss et al., Reference Huss, Verney, Fosker, Mead and Goswami2011; Leong et al., Reference Leong, Hämäläinen, Soltész and Goswami2011; Chapter 35).
38.5 Directions for Future Research
This chapter highlights the need for research on early rhythm development to focus on understanding how infants’ rhythmic experiences intertwine across modalities, with VTS, auditory, visual, and sensorimotor inputs being simultaneously perceived and processed in an integrated manner. Specifically, it is vital to understand how these different input modalities interact and are integrated, as well as their combined effects on infants’ language development. Recent methodological and technological advances offer the opportunity to investigate this multimodal integration in increasingly more ecologically valid paradigms (see Chapter 36). This can be achieved by using infant-friendly neurophysiological and neuroimaging techniques (e.g., EEG, functional near infrared spectroscopy) combined with behavioral online measures of infants’ gaze or motion tracking (e.g., Nguyen et al., Reference Nguyen, Reisner and Lueger2023; Rocha et al., Reference Rocha, Attaheri and Choisdealbha2024), which provide temporally precise indices of infants’ rhythm perception and production. These measures can now be successfully assessed in the context of live caregiver–infant interactions (e.g., Haresign et al., Reference Haresign, Phillips and Whitehorn2022; Nguyen et al., Reference Nguyen, Abney, Salamander, Bertenthal and Hoehl2021; Piazza et al., Reference Piazza, Hasenfratz, Hasson and Lew-Williams2020; Wass et al., Reference Wass, Whitehorn, Haresign, Phillips and Leong2020), which also capture the interpersonal synchrony during rhythm production and the dynamic changes in caregivers’ behaviors produced in response to the infants’ communicative cues.
This research will also lead to significant practical applications such as the development of rhythm-based intervention programs for infants with developmental or neurological disorders given that rhythm training has been shown to improve language and reading-related abilities (Bonacina et al., Reference Bonacina, Cancer, Lanzi, Lorusso and Antonietti2015; Flaugnacco et al., Reference Flaugnacco, Lopez and Terribili2015; Habib et al., Reference Habib, Lardy and Desiles2016; Overy, Reference Overy2000; Thomson et al., Reference Thomson, Leong and Goswami2013). Evidence for the effectiveness of rhythmic training outside the auditory and visual modalities, which remains highly limited to date, will also provide key information for optimizing the early rhythmic experiences of infants affected by sensory deprivation early in life (e.g., Hidalgo et al., Reference Hidalgo, Falk and Schön2017; Holland et al., Reference Holland, Bouwer, Dalgelish and Hurtig2010; Karam et al., Reference Karam, Russo, Branje, Price and Fels2008; Özcan et al., Reference Özcan, Caligiore, Sperati, Moretta and Baldassarre2016; Petitto et al., Reference Petitto, Holowka, Sergio and Ostry2001; Russo, Reference Russo2023).
38.6 Conclusion
This chapter has reviewed the growing evidence that ID communication is rich in rhythmic information, and supports the development of infants’ early rhythm perception and production abilities and plays a fundamental role in the process of early language development. This evidence demonstrates that compared to AD speech, rhythmic information in ID speech, infants’ primary source of linguistic information, exhibits higher rhythmic regularity, which facilitates infants’ encoding and processing of this register. This rhythmic regularity is also a characteristic of ID singing, a prominent signal used in natural caregiver–infant interactions. Most importantly, these auditory signals are not the only sources of regular rhythmic information available to infants. Young infants experience rhythm passively and actively across multiple modalities, including auditory, visual, tactile, and sensorimotor. The integration of rhythmic information from these different sources sustains the encoding of auditory rhythmic stimuli from the earliest stages of development and supports infants in the task of extracting rhythmic information specific to the language or languages spoken in their environment.
38.7 Acknowledgements
This work was supported by the Basque Government through the BERC 2022–2025 program and funded by the Spanish State Research Agency through BCBL Severo Ochoa excellence accreditation CEX2020–001010/AEI/10.13039/501100011033. Marina Kalashnikova’s work was supported by the Spanish State Research Agency through the Ramon y Cajal research fellowship, RYC2018–024284-I. Laura Fernández-Merino’s work was supported by a Predoctoral Grant from the Spanish Ministry of Science, Innovation and Universities and the European Social Fund, PRE2019–087623. Sofia Russo’s work was supported by a Postdoctoral Grant from the Department of Developmental Psychology and Socialization, Università degli Studi di Padova Rif. 2022ASSDPSS14.
Summary
Sensitivity to their native language’s rhythmic patterns allows infants to segment continuous speech. ID speech contains rhythmic cues, but it is not the only mode of ID communication to do so. Early development of rhythmic skills is supported by infants’ experience with rhythm across auditory, visual, tactile, and sensorimotor modalities.
Implications
Infants’ rhythm experience is not restricted to the auditory domain. Future research should investigate how infants’ rhythmic experiences intertwine and become integrated across sensory modalities involved in ID communication. This understanding is vital for defining the environmental factors that facilitate the development of early rhythmic abilities and language acquisition.
Gains
Infants experience optimized intersensory rhythmic input. This multisensory stimulation plays an important role in facilitating efficient entrainment between infants’ oscillatory neural activity and the input signal as well as in promoting intra-personal synchronization within the caregiver–infant dyad, both critical for successful language acquisition and healthy socio-cognitive development.
39.1 Introduction
To acquire language, infants need to extract information from speech and develop an understanding of the relationship between sounds and their meaning. When observing infants and young children in everyday life, this seems like a gradually developing and effortless task, but the underlying process is likely more complex and currently not completely understood. For the language learner, some form of tracking of the stream is arguably needed for language acquisition to take off, for word and grammar learning to proceed. The question arises as to what features of the phonetically rich, but lexically and grammatically opaque input, provide an entry point into, and facilitate, the acquisition of the structure of language in its full complexity, including words and grammar. Here we take a closer look at prosody and its role in early development of auditory neural oscillations, focusing on a model in which synchronization to the slow fluctuations associated with the prosodic phrase level scaffold grammar learning in infancy (Nallet and Gervain, Reference Nallet and Gervain2021).
39.2 The Prenatal Prosodic-Shaping Model
According to the prenatal prosodic-shaping model (Nallet and Gervain, Reference Nallet and Gervain2021), infants’ prenatal experience with the speech signal lays the foundation for subsequent grammar learning after birth. Developing fetuses are exposed to speech as early as from week 24 to 28 of gestation (Eggermont and Moore, Reference Eggermont, Moore, Werner, Fay and Popper2011). However, due to the intrauterine environment, sounds are low-pass filtered, essentially providing the fetus with the prosodic contour of the speech signal (Gerhardt and Abrams, Reference Gerhardt and Abrams2000; Menn et al., Reference Menn, Männel and Meyer2023).
Prosodic cues contribute to the parsing of the speech stream in the form of intonational phrase boundaries (Thompson and Balkwill, Reference Thompson and Balkwill2006), dynamic pitch changes (Watson and Gibson, Reference Watson and Gibson2005), metrical information (Liu et al., Reference Liu, Jiang, Wang, Xu and Patel2015), and so on. In terms of its function, prosody may be used as a grammatical marker, for example, of focus or interrogatives, and can also provide meaning to an utterance above and beyond the lexical and grammatical content by nuancing the speaker’s intent in communicating affect, emphasis, irony, and so on (Coutinho and Dibben, Reference Coutinho and Dibben2013; Scherer, Reference Scherer1986; Zentner et al., Reference Zentner, Grandjean and Scherer2008). As such, the above-mentioned linguistic phenomena associated with prosodic cues provide an anchor to the underlying structure of language and, importantly to the topic of this chapter, may thus bootstrap the development of grammar (Gervain and Werker, Reference Gervain and Werker2013; Nazzi and Ramus, Reference Nazzi and Ramus2003; Soderstrom et al., Reference Soderstrom, Seidl, Nelson and Jusczyk2003).
How such regularities are processed by the brain has been a much-debated topic (e.g., Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Giraud and Poeppel, Reference Giraud and Poeppel2012). Recent advances have established that adults’ brain responses simultaneously track the different timescales of the speech signal. Bottom-up processing of units in the speech signal is supported by neural oscillations in the delta (0.5–3.5 Hz), theta (4–8 Hz), and low-gamma (>35 Hz) frequency bands (Ding et al., Reference Ding, Melloni, Zhang, Tian and Poeppel2016; Giraud and Poeppel, Reference Giraud and Poeppel2012). These bands, respectively, underlie the processing of prosodic phrases, syllables, and (sub-)phonemic units of speech (Giraud and Poeppel, Reference Giraud and Poeppel2012), as their frequencies match those of the relevant linguistic units. For further details, we direct the reader to Chapters 3 and 5. However, it is still unclear how the neural tracking of the speech and, in particular, the oscillatory hierarchy develop during the first year of life.
The prenatal prosodic-shaping model proposes that this development starts already prior to birth. In utero, the fine-grained phonemic information (i.e., the gamma band) is mostly suppressed in the low-passed auditory signal that reaches the fetus, while syllabic and prosodic phrase information is preserved, as the spectral content fluctuates at slower frequencies (corresponding to theta and delta frequency bands) (Gerhardt and Abrams, Reference Gerhardt and Abrams2000). Given this prenatal experience with the speech signal, the neural tracking of larger linguistic units may already start prenatally, while oscillations tracking (sub-)phonemic information may not be operational until after birth (Nallet and Gervain, Reference Nallet and Gervain2021). Postnatally, infants are exposed to the full-band speech signal, at which point the neural tracking of fine-grained phonemic elements may start being shaped by experience with the (unfiltered) speech signal.
Due to their prenatal exposure to parts of the speech signal, fetuses are born with a certain familiarity with language. It has been attested that neonates prefer sounds to which they have been exposed in the womb (DeCasper and Fifer, Reference DeCasper and Fifer1980; Mehler et al., Reference Mehler, Jusczyk and Lambertz1988; Moon, Reference Moon, Filippa, Kuhn and Westrup2017; Moon et al., Reference Moon, Cooper and Fifer1993), which suggests that they do have the ability to learn from the low-passed signal available to them, and that some shaping of the language system takes place already in utero. For example, newborns show a preference for their mother’s voice compared to an unknown female voice (DeCasper and Fifer, Reference DeCasper and Fifer1980; Moon, Reference Moon, Filippa, Kuhn and Westrup2017), and for their native language over unfamiliar languages (Mehler et al., Reference Mehler, Jusczyk and Lambertz1988; Moon et al., Reference Moon, Cooper and Fifer1993). Following these results, a growing body of research suggests that prenatal experience, with the prosodic features preserved in the low-passed speech signal, might lay the foundations for even more complex language acquisition.
Newborns can, for example, distinguish well-formed from ill-formed prosodic sequences based on duration, pitch, or intensity, but only if the varying element is contrastive in the language they heard before birth (Abboub et al., Reference Abboub, Nazzi and Gervain2016). Specifically, French newborns can discriminate between short-long and long-short sequences (variation in duration), which mark contrastive distinctions, but not between loud-soft and soft-loud (variation in intensity) or high-low and low-high sequences (variation in pitch), which are not markers of contrastive distinctions in French prosody (Nespor et al., Reference Nespor, Shukla and van de Vijver2008; Nespor and Vogel, Reference Nespor and Vogel2007). In addition, even though consonants are likely not perceivable by the fetus, some information about vowels might be available, because vowels, which are the main carriers of prosodic information, are high-energy events in the speech signal. Accordingly, Moon et al. (Reference Moon, Lagercrantz and Kuhl2013) observed opposite preferences between American and Swedish newborns for the vowel with which they had prenatal experience (the American /i:/ versus the Swedish /y/ vowel).
It thus becomes evident that infants are born with a certain familiarity with the prosodic features of their native language. Importantly, as prosody also carries lexical, morphosyntactic, and pragmatic information, it is highly relevant to language development overall. In older infants, prosody provides cues to, for example, word boundaries (Shukla et al., Reference Shukla, White and Aslin2011) and word order (Gervain and Werker, Reference Gervain and Werker2013), and is thus an important bootstrapping mechanism for lexical and grammatical development. However, already newborns display the ability to utilize prosodic features to gain access to more complex aspects of their native language. For instance, they can discriminate between function words (marking morphosyntactic structure) and content words (carrying lexical meaning) (Shi et al., Reference Shi, Werker and Morgan1999), and they are sensitive to word order and its violations (Benavides-Varela and Gervain, Reference Benavides-Varela and Gervain2017). In addition, newborns are sensitive to prosodic violations at the utterance level, in that they discriminate between well-formed and ill-formed prosodic contours (Martinez-Alvarez et al., Reference Martinez‐Alvarez, Benavides‐Varela, Lapillonne and Gervain2023).
According to the prenatal prosodic-shaping model (Nallet and Gervain, Reference Nallet and Gervain2021), prosody provides the earliest experience with language, and is one of the mechanisms that links innate predispositions and soon-to-be relevant input from the environment. In other words, as prosodic features of spoken language fluctuate at slower frequencies, they are likely to be preserved in utero, as suggested by newborns’ familiarity with these features. This prenatal prosodic experience is hypothesized to shape the neural architecture, meaning that neural entrainment to prosody is already operational at birth (Menn et al., Reference Menn, Männel and Meyer2023; Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). When newborns get exposed to the full-band speech signal after birth, which includes the fine-grained acoustic information at the phonemic level, oscillations in the delta and theta bands are already fine-tuned, at least to some extent, to the rhythm of the prenatally heard language. After months of exposure to the full speech signal, phoneme perception becomes attuned to the native language, and neural activity in its corresponding frequency band, gamma, is fine-tuned and hierarchically embedded in the delta- and theta-band oscillations. This model can thus offer a theoretical account in which prenatal experience with prosody is the foundation on which subsequent language development is built, in that, with postnatal exposure, oscillations in the gamma band are gradually embedded in the prenatally acquired delta- and theta-band oscillations. In other words, the developmental chronology of experience with speech, first filtered then full-band, explains the hierarchical organization of oscillations. However, see also Menn et al. (Reference Menn, Männel and Meyer2023) for a related perspective in which electrophysical maturation and the emergence of gamma-band activity shapes the acquisition of phonological knowledge.
39.3 Evidence for the Model
Recent research on the development of neural tracking suggests that delta-band tracking is operational in the first year of life. Infants at six and nine months of age, presented with streams of rhythmic stimuli in the form of the syllable “ta” or a drumbeat at a presentation rate of 2 Hz, displayed local peaks in electroencephalography (EEG) power at the presentation rate for both stimulus types, compared to a silent baseline condition (Choisdealbha et al., Reference Choisdealbha, Attaheri and Rocha2022). The response was entrained to the stimuli, namely time-locked to the onset of the stimulus, as observed through a relative increase in phase consistency. The response in the 4 Hz (harmonic frequency of the presentation rate) and 7 Hz (not-harmonic frequency of the presentation rate) was also assessed and compared to the response at the presentation rate. An increase in power at the harmonic frequency was observed, regardless of stimulus type, but a time-locked response similar to the 2 Hz response was only observed to the speech stimulus at the 4 Hz harmonic frequency. The infants were tested longitudinally, but, importantly, no evidence of improved tracking as a function of age was observed (Choisdealbha et al., Reference Choisdealbha, Attaheri and Rocha2022).
Similarly, when longitudinally following four-, seven-, and 11-month-old infants’ tracking of sung speech (nursery rhymes), a peak in power in the delta band (at ~2.2 Hz) and the theta band (at ~4.3 Hz) was observed (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022). However, delta-band tracking stayed significantly higher compared to theta-band tracking at each age, and was specifically strong at four months, while theta-band tracking increased over the course of the first year of life. The alpha band (8–12 Hz) was used as a control condition, in which no reliable tracking was observed (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022). Given the results of these studies, infants appear to faithfully track auditory speech-related stimuli in the theta and delta bands, a mechanism that is operational from at least four months of age (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Choisdealbha et al., Reference Choisdealbha, Attaheri and Rocha2022).
Interestingly, in terms of the predictions made by the prenatal prosodic-shaping hypothesis, Attaheri et al. (Reference Attaheri, Choisdealbha and Di Liberto2022) also observed delta- and theta-band-driven phase amplitude coupling with higher-frequency amplitudes. Namely, the phase of delta- and theta-band activity acted as a carrier of amplitude in higher-frequency bands, both beta and gamma frequencies, although greatest for gamma-band activity. This finding is consistent with the model as it suggests that the prenatally unavailable higher frequencies associated with phonemes will become embedded in the delta-band oscillations when the infant is exposed to these frequencies after birth. In other words, the prenatal experience with the phases of delta- and theta-band frequencies is likely to play an important role in the temporal organization of the amplitude of higher-frequency bands in the infant brain, that is, in their nesting within the slower bands.
Another branch of research on early neural tracking of speech focuses on infant-directed speech (IDS) compared to adult-directed speech (ADS) (Kalashnikova et al., Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022). IDS, a type of speech often used by adults when speaking to infants, is characterized by a higher pitch, more variability in intonation, and a slower tempo compared to ADS. This is reflected in amplified slow-frequency modulations as compared to ADS, and has been shown to be preferred by infants, offering potential benefits in language development (Song et al., Reference Song, Demuth and Morgan2010). Seven-month-old infants have been found to track both naturally produced IDS and ADS, as measured in the increases in power in the theta band (Kalashnikova et al., Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018). Furthermore, significant correlations were found between the pattern of neural activity and the envelope of the speech signal for IDS, but not for ADS, meaning that the envelope of the speech signal was more strongly reflected in the neural signal when infants were presented with IDS compared to ADS (Kalashnikova et al., Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018).
Menn et al. (Reference Menn, Michel, Meyer, Hoehl and Männel2022) extend on these results by estimating whether the effect for IDS is driven by the syllabic rate or the prosodic stress for IDS compared to ADS in nine-month-olds, namely, which frequency band causes the effect (theta versus delta band, respectively). The infants listened to their mothers describe items in either an IDS- or ADS-like way. In addition to significant speech–brain coherence at the syllabic and prosodic stress rate for both IDS and ADS, a significantly higher coherence was found for IDS at the prosodic stress rate, but not at the syllabic rate, a difference driven by a left-central cluster. As such, their results indicate that prosodic stress (greater coherence at delta-band frequencies), but not syllable rhythm, might be the facilitator of greater neural tracking of IDS (Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022). These results might arise as a consequence of the differences in attentional salience between IDS and ADS, as the prosodic differences may contribute to increased attention to the speech sounds.
The results reviewed above come from somewhat older infants (between four and 11 months of age). However, are these abilities already present at birth? When assessing tracking of syllables, that is, activity in the theta band, no differences were found between newborns and six-month-old infants presented with short sentences read in IDS: Both groups similarly track the phase and amplitude of the envelope of familiar (native language) and unfamiliar (different rhythmic class and same rhythmic class as the first language [L1]) languages (Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). Interestingly, while phase tracking continues to be universal, amplitude tracking is only kept up for the unfamiliar language, especially the rhythmically different one. As such, phase and amplitude tracking might be differentially modulated over the course of the first year, which may be reflective of a perceptual narrowing following infants’ experience with their native language (Kuhl, Reference Kuhl2004; Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). More recent results with newborns (Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2023) suggest that newborns show enhanced power in the delta and theta bands in response to the language heard prenatally and, to some extent, to a rhythmically similar unfamiliar language, as compared to a rhythmically different unfamiliar language, whereas no such language differences were present in the gamma band, where no enhanced power was found for speech in any of the languages tested. These results also confirm the hypothesis that slower oscillations are fine-tuned already at birth (Nallet and Gervain, Reference Nallet and Gervain2021; see also Menn et al., Reference Menn, Männel and Meyer2023).
39.4 General Discussion
To acquire their native language, infants need to develop sensitivity to the phonological properties and contrasts characteristic of that language. These skills are a necessary first step on the path to word learning and grammar acquisition. Several models have been proposed to account for the relatively fast and seemingly effortless accomplishment of this challenging task. One such model, the native language model (Kuhl, Reference Kuhl2004; Kuhl et al., Reference Kuhl, Williams, Lacerda, Stevens and Lindblom1992), focuses on developmental changes in early infant auditory perception and aims to incorporate social and communicative factors in recent versions of the model (Kuhl et al., Reference Kuhl, Conboy and Coffey-Corina2008). The prenatal prosodic-shaping model offers a novel perspective on perceptual narrowing from the point of view of recent advances in the neurobiology of language and its alignment with neural structures and mechanisms that support its development in human infants. Development of synchronization of neural oscillations to speech at different levels of granularity offers a possible format for such an account.
Seen together, the current literature indicates that infants from four to 11 months of age reliably track speech in both the delta (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Choisdealbha et al., Reference Choisdealbha, Attaheri and Rocha2022; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022) and theta (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022; Kalashnikova et al., Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022) frequency bands. Syllabic tracking, as reflected in the theta band, shows a developmental increase between four and 11 months (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022). However, in terms of the phase of the signal, tracking appears to remain relatively stable from birth until around six months of age for both familiar and unfamiliar languages (Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). Amplitude tracking, on the other hand, is universal at birth, but only manifests for unfamiliar languages at six months of age (Ortiz Barajas et al., Reference Ortiz Barajas, Guevara and Gervain2021). Between four and 11 months, prosodic tracking in the delta band has been found to remain greater than syllabic tracking throughout these ages. In addition, IDS may facilitate neural tracking (Kalashnikova et al., Reference Kalashnikova, Peter, Di Liberto, Lalor and Burnham2018; Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022), an effect primarily driven by prosodic stress as reflected in stronger delta-band coherence for IDS compared to ADS (Menn et al., Reference Menn, Michel, Meyer, Hoehl and Männel2022).
In terms of the prenatal prosodic-shaping model, the low-frequency parts of the speech signal that are available prenatally are successfully tracked by the infant brain during the first year of life, although some developmental changes can also be observed. Based on extant research, both syllabic tracking and tracking of larger prosodic units are present from birth. Interestingly, in terms of nested oscillations, the phases of both delta- and theta-band oscillations do act as carriers of amplitude in higher-frequency bands, especially in the gamma band (Attaheri et al., Reference Attaheri, Choisdealbha and Di Liberto2022). While the currently available evidence supports the prenatal prosodic-shaping model, the number of available studies is still very small. In particular, few studies have tested newborn infants and fetuses. Studying newborns and fetuses poses a challenge compared to adults. Specifically with EEG, newborns’ data tend to have a lower signal-to-noise ratio, which limits the analysis methods that can be used. During the first months of life, the electrophysiological activity is less structured than in later development and in adulthood, and evidence can as such be of a more indirect nature. Applying the same oscillatory models as with adults and older infants can therefore be somewhat challenging.
Taken together, and considering future empirical word in the field, the prenatal prosodic-shaping model has the potential to explain how available brain mechanisms interface with the infant environment, both at prenatal and neonatal/postnatal stages. As such, this model offers predictable hypotheses concerning the hierarchical nesting of neural oscillations in concert with increased complexity of the acquired language skills, from word learning to advanced grammar.
39.5 Acknowledgements
ERC Consolidator Grant “BabyRhythm” nr. 773202 to Judit Gervain and a FARE grant nr. R204MPRHKE from the Italian Ministry for Universities and Research to Judit Gervain.
Summary
The current chapter reviews recent findings of infants’ neural tracking of speech and relates these findings to subsequent grammar acquisition. Specifically, we discuss the potential role of prenatal exposure to speech for speech-tracking abilities at birth and its potential as an entry point into language structure in early language acquisition, in light of the prenatal prosodic-shaping model.
Implications
There is a gap in the literature when it comes to newborns’ tracking of speech in the gamma band, corresponding to (sub-)phonemic elements of speech. Although several recent results are consistent with the predictions of the prenatal prosodic-shaping model, it can be empirically approached by addressing this gap.
Gains
Understanding the neural mechanisms that support grammar development is highly relevant to psycholinguistics/neurolinguistics, as much is yet unknown. The model presented in this chapter represents a potential framework for interpretation of the growing body of research on the role of neural oscillations in early speech processing.
40.1 Introduction
Rhythm in speech emerges from the systematic alternation of stronger and weaker elements across several layers of prosodic organization. Yet, defining and quantifying speech rhythm remains challenging, with multiple competing frameworks and metrics proposed over the years. These efforts reflect the absence of consensus on how best to capture rhythmic structure in the speech signal and the need for continued refinement of analytic tools.
Deloche et al. (Reference Deloche, Bonnasse-Gahot and Gervain2024) provide a historical overview of perspectives and analytical methods for capturing rhythmic structure in speech, which we paraphrase in the next two paragraphs. Afterwards, we introduce our current objective.
Early accounts of rhythm emphasized the principle of isochrony—the idea that speech is organized into equally timed units, whether measured by syllables or by the intervals between stresses (Pike, Reference Pike1945; Abercrombie, Reference Abercrombie1967). This view motivated the familiar classification of languages into “syllable-timed” and “stress-timed” types (see also Chapters 30 in this volume). Subsequent empirical studies showed that natural speech rarely maintains equal timing across these units (Roach, Reference Roach1982; Dauer, Reference Bartelds, de Vries, Richter, Liberman and Wieling1983), leading to a rejection of strict isochrony. Even so, the term speech rhythm and the associated typology persist because alternations in prominence at multiple prosodic levels still give rise to the perception of rhythm (Langus et al., Reference Langus, Mehler and Nespor2017), which depends on physical dimensions such as intensity, duration, pitch, and vowel quality (Terken & Hermes, Reference Terken, Hermes and Horne2000). For typology and modeling alike, this broader view keeps rhythm anchored in observable timing and prominence patterns rather than in idealized equal units.
Following this paradigm shift, the field moved from searching for perfectly timed intervals to characterizing subtler regularities distributed across multiple temporal and spectral dimensions (Bertinetto, Reference Bertinetto1989; Kohler, Reference Kohler2009; Cumming & Nolan, Reference Cumming2010; Turk & Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2013). Dauer (Reference Bartelds, de Vries, Richter, Liberman and Wieling1983) proposed linking rhythmic classes to structural properties of languages—such as syllable complexity and the presence of vowel reduction—laying the foundation for duration-based rhythm metrics. These metrics, which quantify the variability of consonantal and vocalic intervals, offered the first large-scale quantitative evidence supporting rhythm classes (Ramus et al., Reference Ramus, Nespor and Mehler1999; Grabe & Low, Reference Grabe and Low2002; see also Chapter 30 for an overview). Despite their ability to distinguish prototypical stress-timed and syllable-timed languages, these measures are highly sensitive to changes in speech rate, style, and task, sometimes producing within-language variability greater than cross-linguistic differences (Arvaniti, Reference Arvaniti2009, Reference Arvaniti2012; Wiget et al., Reference Wiget, White and Schuppler2010). As noted by Deloche et al. (Reference Deloche, Bonnasse-Gahot and Gervain2024), these limitations underscore the need for approaches that go beyond interval statistics to reassess the acoustic basis of rhythm and to connect linguistic intuitions with stable statistical regularities in real speech.
In our own current work, we focus on how listeners acquire the rhythm of a non-native language, which has historically received less attention than studies of segmental learning. A key question we are interested in is whether having an L1 with similar rhythmic structure facilitates acquisition of an L2’s rhythm. Evidence to date suggests that shared rhythmic patterns in the L1 can support learning of the L2 rhythm, whereas a mismatch can pose persistent challenges. For instance, German learners of English often achieve a degree of durational variability similar to native British English, while French learners show lower variability even at advanced proficiency (Ordin & Polyanskaya, Reference Ordin and Polyanskaya2015). Yet, as Van Maastricht et al. (Reference Van Maastricht, Krahmer, Swerts and Prieto2019) note, such findings must be interpreted cautiously, as differences may also arise from segmental, phonotactic, or prosodic disparities between the languages being compared.
The present study seeks to extend this work by testing whether rhythm similarity facilitates acquisition both across distinct L1–L2 pairings and within the same pairing at different proficiency levels. Specifically, we analyze English rhythm acquisition by native speakers of German and French, and German rhythm acquisition by native speakers of English and French. Within the German–English pairing, we further examine how English and French are acquired by native German speakers. A key methodological advance of this study is that L2 proficiency is indexed not merely by self-report or exposure but by the degree of acoustic distance between L1 and L2, following Bartelds et al. (Reference Bartelds, de Vries, Richter, Liberman and Wieling2021, Reference Bartelds, de Vries and Sanal2022). Crucially, rather than focusing exclusively on the variability of consonantal and vocalic intervals, we assess temporal regularities by measuring amplitude-envelope modulations aligned with syllabic and higher-order rhythmic patterns, providing a direct window on the alternations of prominence that constitute rhythm and offering a principled bridge between acoustic structure and perceived prosodic organization.
40.2 Methods
40.2.1 Stimuli
The stimuli for this study were extracted from the BonnTempo corpus (Dellwo et al., Reference Dellwo, Aschenberner, Wagner, Dancovicova and Steiner2004). The L1 dataset consists of read speech recordings from 15 native speakers of German, seven of English, and six of French. The L2 dataset encompasses recordings of German-accented English (N=8), German-accented French (N=8), French-accented English (N=2), English-accented German (N=3), and French-accented German (N=1). The selection of these languages is based on prior research indicating distinctions in speech rhythm among English, German, and French (Ramus et al., Reference Ramus, Nespor and Mehler1999; Loukina et al., Reference Loukina, Kochanski, Rosner, Keane and Shih2011). Specifically, English and German are characterized as stress-timed languages, where the rhythm tends to be based on regular intervals between stressed syllables. French, on the other hand, is described as a syllable-timed language, where each syllable is perceived to have approximately the same duration.
For German speakers, a short German passage from a novel by Bernhard Schlink (Selbs Betrug) of 76 syllables long served as reading material. This text was then translated into English (77 syllables) and French (93 syllables) for English and French speakers, respectively. The subjects were asked to become familiar with the text before reading in five reading rates: slowest, slow, normal, fast, and fastest. The passage was divided into seven utterances and saved as separate files. The English versions of the utterances are:
1. The next day, I went to Falmouth.
2. It is a voyage to the end of the world.
3. After Lincoln, the hills and woods become monotonous.
4. After Bristol, the town gets boring.
5. And near Saints Bury, the countryside becomes flat and monotonous.
6. If dissidents were banned in our country,
7. They would be banned to the Portishead bay.
All five versions of each utterance were then annotated according to phonological syllable durations and consonantal and vocalic intervals on two separate tiers using Praat software (Boersma and Weenink, Reference Boersma and Weenink2001).
40.2.2 L2 Proficiency Measure
To estimate L2 proficiency, we utilized word-based pronunciation differences using self-supervised neural models, as explained by Bartelds et al. (Reference Bartelds, de Vries and Sanal2022). In this approach, the neural acoustic distance was computed for pairs of audio files, representing a reference speaker (L1) and a target speaker (L2). The calculation involved averaging the distances between corresponding tokens (words/subwords) that form the given sentence. This procedure was carried out for all combinations of audio from the L1 and L2 groups, considering a specific sentence spoken at a particular rate. It is important to note that the neural model representations are sensitive not only to differences in how individual speech sounds are produced (segmental differences) but also to capturing variations in speech melody (intonation) and timing (duration), as described by Bartelds et al. (Reference Bartelds, de Vries and Sanal2022).
Mean acoustic distances at all five speaking rates between L1 and L2 English, German, and French (for native German speakers only) are presented in Table 40.1. It is evident that the distance from L1 English is greater for French-accented English than for German-accented English. Similarly, French-accented German is less similar to German than English-accented German.
Means and standard deviations (SDs) of acoustic distance between L1 and L2 English and German.
| Language pair | Speaking rate | Mean | SD |
|---|---|---|---|
| English vs. German-accented English | slowest | 2.95 | 0.05 |
| slow | 2.83 | 0.04 | |
| normal | 2.77 | 0.08 | |
| fast | 2.72 | 0.08 | |
| fastest | 2.68 | 0.06 | |
| English vs. French-accented English | slowest | 3.09 | 0.08 |
| slow | 3.02 | 0.07 | |
| normal | 2.97 | 0.10 | |
| fast | 2.87 | 0.08 | |
| fastest | 2.83 | 0.06 | |
| German vs. English-accented German | slowest | 3.03 | 0.10 |
| slow | 2.90 | 0.12 | |
| normal | 2.84 | 0.11 | |
| fast | 2.75 | 0.08 | |
| fastest | 2.77 | 0.08 | |
| German vs. French-accented German | slowest | 3.42 | 0.07 |
| slow | 2.75 | 0.08 | |
| normal | 3.16 | 0.08 | |
| fast | 3.28 | 0.07 | |
| fastest | 2.84 | 0.09 | |
| French vs. German-accented French | slowest | 3.04 | 0.06 |
| slow | 2.94 | 0.05 | |
| normal | 2.89 | 0.06 | |
| fast | 2.76 | 0.05 | |
| fastest | 2.73 | 0.09 |
One-way ANOVAs confirm the statistical significance of these differences, indicating that native German speakers are significantly more proficient in English than French speakers [F(1, 68) = 35.48, p < .001], and that native English speakers are significantly more proficient in German than French speakers [F(1, 68) = 64.81, p < .001]. Additionally, the distinction between German-accented English and English, compared to German-accented French and French, was significant [F(1, 68) = 7.89, p = 0.006], indicating the superior English proficiency of German speakers over their French proficiency.
40.2.3 Amplitude Envelope Modulation Spectrum (AEMS)
AEMS involves the spectral analysis of low-rate amplitude modulations within the envelope of the speech signal. The analysis covers the entire amplitude modulation spectrum as well as specific frequency bands of amplitude modulations. Fourier analysis is applied to the speech envelopes to identify the dominant amplitude modulation rate (Figure 40.1) (for different metrics, see Chapters 9, 10, and 30).
AEMS.
The left graph shows the amplitude-normalized waveform and the amplitude envelope (dark solid line) of a male saying “paPapa” four times. The right graph is its corresponding down-sampled envelope modulation spectrum (in dB).
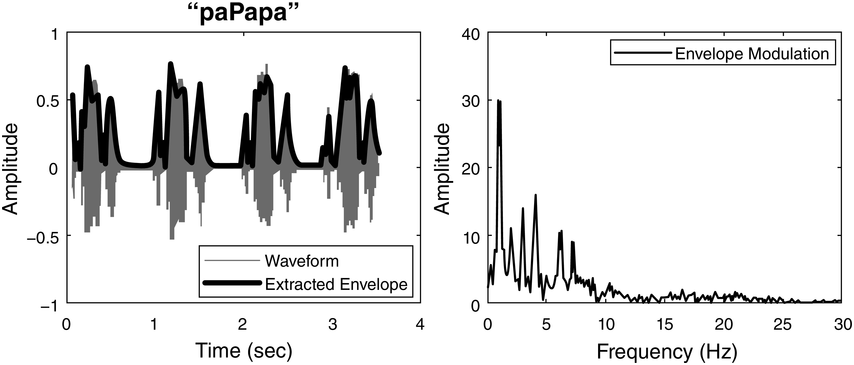
Figure 40.1 Long description
Left. The horizontal axis represents time, which ranges from 0 to 4 seconds. The vertical axis represents an amplitude which ranges from minus 1 to 1. It plots a waveform. The waveform is outlined with the extracted waveform. Right. The horizontal axis represents frequency, which ranges from 0 to 30 hertz. The vertical axis represents the amplitude, which ranges from 0 through 40. It plots a fluctuating line for envelope modulation.
In Figure 40.1, the left graph illustrates the amplitude envelope of a speech waveform (composed of four repetitions of /paPApa/ tri-syllabic nonsense words). This envelope captures temporal fluctuations in amplitude, including those corresponding to syllabic patterns. Regular patterns such as stressed-unstressed rhythms are also discernible. These regularities can be quantified by subjecting the envelope to Fourier analysis, resulting in a depiction of the dominant amplitude modulation rates present in the signal, as shown in the right graph. Note that the highest energy peak (in decibels) occurs at 1 Hz, with additional peaks observable at higher rates.
To generate the AEMS, the signal undergoes several processing steps. First, it is filtered into seven-octave bands using eighth-order Chebyshev digital filters, with center frequencies of 125, 250, 500, 1,000, 2,000, 4,000, and 8,000 Hz. Next, the amplitude envelope is extracted (half-wave rectified, then low-pass filtered at 30 Hz using a fourth-order Butterworth filter), and down-sampled to 80 Hz (mean subtracted) from the full signal and each of the seven-octave bands.
For each down-sampled envelope, a power spectrum analysis is performed using a 512-point fast Fourier transform, applying a Tukey window. The results are converted to decibels for frequencies up to 10 Hz (normalized to maximum autocorrelation). Consequently, seven EMS metrics are computed for each band and one metric from the full signal, resulting in a total of 56 metrics [(7 octave bands + 1 full signal) × 7 metrics]. All amplitude measures are normalized to the average amplitude across the spectrum. Table 40.2 illustrates the seven metrics and their descriptions.
Description of AEMS metrics.
| Metric | Description |
|---|---|
| Centroid | The frequency at which the amplitude of the spectrum is balanced. The period of this frequency corresponds to the duration of the dominant repetitive amplitude pattern. |
| Peak frequency | The frequency of the peak in the spectrum with the greatest amplitude. |
| Peak amplitude | The amplitude of the peak frequency described above (normalized by the overall amplitude of energy in the spectrum). This measurement indicates the extent to which the rhythm is influenced by a single frequency. |
| E3–6 | Energy in the region of 3–6 Hz (normalized). This corresponds to the approximate spectral range around 4 Hz, which has shown correlations with intelligibility (Houtgast and Steeneken, Reference Houtgast and Steeneken1985) and an inverse correlation with segmental deletions (Tilson and Johnson, Reference Tilsen and Johnson2008). |
| Below4 | Energy in spectrum from 0–4 Hz (normalized). The spectrum was divided at 4 Hz, as it has been suggested that the energy below and above 4 Hz exhibited relatively low correlation across diverse speakers and sentences. |
| Above4 | Energy in spectrum from 4–10 Hz (normalized). |
| Ratio4 | Energy below 4 Hz/energy above 4 Hz (normalized). |
40.2.4 Data Processing and Analysis
The values of each AEMS for each sentence and frequency band underwent outlier examination (± 2SD) based on group and speaking rate. Outliers were excluded before proceeding with statistical analyses. In total, 4.1% of the data (N=93,967) were eliminated. All statistical analyses were conducted using SPSS (Version 29).
40.2.5 Analysis: Stepwise Discrimination Analysis
Stepwise discriminant function analyses were carried out to evaluate the categorization of German-accented and French-accented English as native English utterances; English-accented German and French-accented German as native German utterances; and native German-accented French utterances as native French. These analyses were performed for each of the five speaking rates as well as for all rates combined.
Following the methodologies outlined by Liss et al. (Reference Liss, LeGendre and Lotto2010) and Wayland and Nozawa (Reference Wayland and Nozawa2019), in each step of the analysis, the parameter that minimized Wilks’ lambda was incorporated if the change’s F statistic was statistically significant at p < 0.05. Furthermore, any parameter that ceased to significantly decrease Wilks’ lambda (p > 0.10) upon adding a new variable was excluded from the discriminant function analysis. The outcome of this analysis yielded canonical functions, which signify linear combinations of the chosen predictor variables. These functions were subsequently utilized to establish classification rules for determining group membership, encompassing categories such as native English, German-accented English, French-accented English, native German, English-accented German, and French-accented German. The accuracy rate was expressed as a percentage.
To assess the robustness of the classification rules, leave-one-out cross-validation was employed. This involved classifying the excluded utterances based on the functions derived from all other utterances.
Finally, positive predictive values (PPVs) were calculated for the L2-accented utterances. These values represent the percentage of correctly predicted cases with the observed characteristic compared to the total number of cases predicted as having the characteristic. For example, PPVs for German-accented English indicate the percentage of German-accented English utterances that were correctly predicted to be native English, as a percentage of all utterances in the analysis classified as native English.
40.3 Results
Table 40.3 displays the cross-validated PPVs for German-accented English and French-accented English across the five speaking rates, as well as when all rates were considered together. The PPVs for German-accented English are consistently higher than those for French-accented English across all five rates. This suggested that a larger proportion of German-accented English utterances were categorized as English. A two-tailed independent T-test was conducted comparing PPVs across the five rates and confirmed that the difference was statistically significant [t(8) = 5.94, p < .001].
PPVs for German-accented English and French-accented English in terms of their classification as English based on EMS metrics.
| Metric | Accented type | Speaking rate | PPV (%) |
|---|---|---|---|
| EMS | German-accented English | slowest | 34.0 |
| slow | 36.1 | ||
| normal | 37.5 | ||
| fast | 42.4 | ||
| fastest | 51.2 | ||
| all rates combined | 32.2 | ||
| French-accented English | slowest | 6.0 | |
| slow | 5.6 | ||
| normal | 25.0 | ||
| fast | 12.1 | ||
| fastest | 2.4 | ||
| all rates combined | 9.1 |
PPVs for English-accented German and French-accented German are shown in Table 40.4. English-accented German was classified as German at a higher percentage than French-accented German for each rate and when all the rates were combined. The difference was statistically significant [t(8) = 6.02, p<.001].
PPVs for English-accented German and French-accented German in terms of their classification as German based on EMS metrics
| Metric | Accented type | Speaking rate | PPV (%) |
|---|---|---|---|
| EMS | English-accented German | slowest | 12.2 |
| slow | 10.0 | ||
| normal | 18.4 | ||
| fast | 16.7 | ||
| fastest | 14.7 | ||
| all rates combined | 11.7 | ||
| French-accented German | slowest | 1.1 | |
| slow | 1.4 | ||
| normal | 5.7 | ||
| fast | 4.9 | ||
| fastest | 4.9 | ||
| all rates combined | 6.1 |
Out of the 56 predictors, 11 were found to be statistically significant in the combined-rate discriminant function analysis (DFA) model. The primary predictor among these was Ratio4_125, denoting the normalized energy below 4 Hz to the energy above 4 Hz in the 125 Hz frequency band. In the DFA models for each of the five rates, the number of significant predictors varied: one for the normal rate, three for the fast rate, four for both the slow and fastest rates, and five for the slowest rate, with no overlap in the top predictor.
In the combined-rate DFA model, nine significant predictors emerged, with E3–6_2000, which represents energy in the range of 3–6 Hz (normalized by overall spectrum amplitude) from the 2,000 Hz band, being the top predictor. In the individual rate models, three–nine significant predictors were identified.
Table 40.5 shows PPVs for German-accented English as English and German-accented French as French. The difference was statistically significant [t(8) = 3.46, p = .009], indicating that German-accented English was classified as English significantly more frequently than German-accented French as French.
PPVs for German-accented English and German-accented French in terms of their classification as English and French, respectively, based on EMS metrics.
| Metric | Accented type | Speaking rate | PPV (%) |
|---|---|---|---|
| EMS | German-accented English | slowest | 28.9 |
| slow | 39.0 | ||
| normal | 44.4 | ||
| fast | 36.6 | ||
| fastest | 42.6 | ||
| all rates combined | 41.5 | ||
| German-accented French | slowest | 12.0 | |
| slow | 18.2 | ||
| normal | 28.9 | ||
| fast | 24.1 | ||
| fastest | 31.3 | ||
| all rates combined | 20.6 |
The combined-rate DFA model resulted in 14 significant predictors, with Peak amplitude-4000 being the top predictor. This predictor represents the amplitude of the frequency peak in the spectrum from the 4,000 Hz band. In the separate rate models, a varying combination of six–nine significant predictors was identified for the five different rates.
40.4 Discussion
The aim of the study was to examine the potential influence of shared linguistic rhythm on the acquisition of rhythm in an L2. The employed rhythm metrics analyzed temporal regularities extracted from the AEMS. These metrics capture low-rate temporal variations in spectral envelope amplitude, corresponding to prosodic units such as syllables, and regular durational variations such as stressed-unstressed intervals. Both different L1–L2 language combinations (German-accented versus French-accented English, and English-accented German versus French-accented German) and the same L1–L2 combination (German-accented English versus German-accented French) were explored.
The findings strongly support the advantage of the shared-L1 rhythm hypothesis, demonstrating that German-accented English is consistently more likely to be classified as English compared to French-accented English. Furthermore, German-accented English is classified as being closer to native English than German-accented French is to native French.
Interestingly, the results align with the word-based acoustic distance estimations derived from self-supervised neural models. These suggest that the word-level pronunciation of English by German speakers is closer to native English than that of French speakers. Similarly, English speakers show a closer word-based pronunciation to native German than to French. Furthermore, German speakers exhibit a closer pronunciation to English than to French. Together, the findings suggest that rhythm planning may be influenced by the words and their segmental makeup in the utterance (Myers and Watson, Reference Myers and Watson2021).
The significance of various predictors identified in the DFA models offers valuable insights into the acoustic features that contribute to the observed rhythmic classification patterns. For example, energy below 4 Hz was the primary predictor for differentiating between German-accented and French-accented English. Notably, predictor values were 1.9 for German-accented English and 2.8 for French-accented English. This indicates that in the 125 Hz octave band frequency (ranging from 88 to 177 Hz), the spectral envelope amplitude modulation rates below 4 Hz are more pronounced (relative to those above 4 Hz) in English spoken by French speakers than in that spoken by German speakers. An amplitude modulation rate of 4 Hz is typically associated with syllable-pattern information in speech, as noted by Greenberg et al. (Reference Greenberg, Carvey, Hitchcock and Chang2003) and Greenberg (Reference Greenberg, Greenberg and Ainsworth2006). These findings suggest that French-accented English exhibits a stronger presence of regular temporal patterns associated with prosodic units of or closer to a syllable size, reflecting a possible influence from French’s traditionally classified syllable-timed rhythm.
On the other hand, energy in the range of 3–6 Hz emerged as the top predictor for English-accented versus French-accented German. The 3–6 Hz range roughly corresponds to the spectral region around 3–4 Hz, which has been shown to correlate with vowel deletions, particularly in English (Tilsen and Johnson, Reference Tilsen and Johnson2008). Crucially, the predictor value was higher for English-accented German compared to French-accented German (4.5 versus 3.8). The higher values for English-accented German may thus be due to a greater amount of vowel deletion in German produced by English speakers compared to French-accented German.
Lastly, it is worth noting that top predictors and various combinations of significant predictors were identified for different speaking rates, indicating potential variations in rhythm articulation adjustments across varying rates of speech production. Further research is necessary to fully elucidate the relationship between these predictor patterns and the dynamic nature of speech rhythm under different speech tempos.
In conclusion, despite its extensive history of progress, research on speech rhythm continues to be exploratory due to the complexity of the underlying phenomena and the lack of an effective tool that bridges the gap between linguists’ intuition and tangible statistical patterns in the speech signal (Deloche et al., Reference Deloche, Bonnasse-Gahot and Gervain2024). Our findings not only support the facilitating roles of shared linguistic rhythm in L2 speech learning but also underscore the AEMS’s significant potential as a powerful tool for analyzing speech rhythms, both within and across languages. Its ability to capture regular patterns across various speech unit sizes uniquely positions it to reveal nuanced rhythmic differences overlooked by traditional methods focused solely on segmental intervals. In addition, the AEMS approach is automated, thus avoiding the labor-intensive and error-prone process required for segmenting speech into vocalic and consonantal intervals.
40.5 Acknowledgments
We express our gratitude to Professor Volker Dellwo for his generosity in sharing the BonnTempo corpus. We also extend our appreciation to Professor Andrew Lotto for providing the MatLab codes for the EMS metrics, and to Professor Yonghee Oh for providing Figure 40.1.
Summary
Using metrics extracted from the AEMS, this study demonstrated the facilitating roles of shared linguistic rhythm and established the AEMS as a powerful tool for analyzing speech rhythms, both within and across languages.
Implications
To fully understand the complexity of linguistic rhythm, it is crucial to employ metrics capable of quantifying temporal patterns across various speech unit sizes. Automated tools such as the AEMS significantly enhance our ability to examine rhythm within and across languages, facilitating a more nuanced understanding of the connection between linguists’ intuition and tangible statistical patterns in the speech signal.
Gains
The acquisition of L2 rhythm is facilitated by a shared L1 rhythm, with improved L2 rhythm production correlating to enhanced word/subword production in L2. This observation supports the notion that planning metrical representations for rhythm also depends on the words and their segmental composition in the spoken utterance.
41.1 The Segmentation Problem
A crucial step in language acquisition is to learn to segment the continuous speech stream into possible word candidates. To solve this problem, infants rely on a variety of perceptual and computational mechanisms. During the first year of life, infants can segment speech with the help of phonotactic regularities (Mattys et al., Reference Mattys, Jusczyk, Luce and Morgan1999), lexical constraints (Jusczyk et al., Reference Jusczyk, Cutler and Norris2003), rhythmic structure (Houston et al., Reference Houston, Jusczyk, Kuljpers, Coolen and Cutler2000; Nazzi et al., Reference Nazzi, Iakimova, Bertoncini, Frédonie and Alcantara2006), statistical cues (Saffran et al., Reference Saffran, Newport and Aslin1996), and prosodic cues (Jusczyk et al., Reference Jusczyk, Cutler and Redanz1993, Reference Jusczyk, Houston and Newsome1999; Johnson and Jusczyk, Reference Johnson and Jusczyk2001; Marimon et al., Reference Marimon, Höhle and Langus2022). The prosodic cues that support infants’ speech segmentation are commonly assumed to be language-specific and consist of rhythmic-grouping cues (e.g., Abboub et al., Reference Abboub, Nazzi and Gervain2016), intonational contours (e.g., Shukla et al., Reference Shukla, White and Aslin2011), and stress patterns (e.g., Echols et al., Reference Echols, Crowhurst and Childers1997; Jusczyk et al., Reference Jusczyk, Houston and Newsome1999). However, there is also evidence that more general cues such as transitional probabilities aid early speech segmentation (Thiessen and Saffran, Reference Thiessen and Saffran2003). Understanding how the use of these cues develops and how they interact is a central question in early language development.
Here, we argue that infants’ ability to segment speech, including the ability to exploit all the cues to word boundaries, may be mediated by their ability to build expectations of how the speech signal will unfold. For example, infants exposed to bisyllabic or trisyllabic words in isolation will subsequently only learn words from a continuous speech stream that match the length of the words they first heard in isolation (Lew-Williams and Saffran, Reference Lew-Williams and Saffran2012). Infants exposed to a list of nonwords following a specific stress pattern (either iambic or trochaic) will consequently segment a continuous speech stream following that specific stress pattern (Thiessen and Saffran, Reference Thiessen and Saffran2007). Importantly, infants who are familiarized with words of equal length tend to perform better in a speech segmentation task than infants who are exposed to continuous speech with varied word length (Johnson and Tyler, Reference Johnson and Tyler2010; Mersad and Nazzi, Reference Mersad and Nazzi2012). Also, adult participants listening to passages of sentences that follow a predictable prosodic structure will only segment words defined by statistical regularities if these fall within the prosodic boundaries of the primed sentence structure (Wang et al., Reference Wang, Zevin and Mintz2017, Reference Wang, Zevin, Trueswell and Mintz2020). These studies therefore suggest the ability to use rhythmic expectations in speech, such as syllabic length and stress patterns, to effectively segment and anticipate word boundaries.
41.2 Methodological Considerations
To better understand how infants predict how the speech signal will unfold, we need to move beyond the behavioral methods generally used to investigate speech segmentation abilities in infancy. Typically, speech segmentation experiments first familiarize participants with continuous speech that contains words that follow specific statistical regularities or prominence patterns. Participants are then tested on words that occurred in the familiarization phase, words that violate the regularities of interest, and/or words that did not occur in the familiarization phase. This typically involves measuring infants’ attention in looking-time paradigms such as the head-turn preference procedure (Hirsh-Pasek et al., Reference Hirsh-Pasek, Kemler Nelson and Jusczyk1987) and querying adults whether they remember and can distinguish words from nonwords. However, these experiments rely on different responses in infants and adults that hinder direct comparisons between participants at different ages of development. Furthermore, the familiarization phase that unfolds in a matter of minutes can be taxing to younger infants who have a limited focus, thus limiting the amount of test trials and conditions that can be included in a single experiment. Finally, behavioral methods have also failed to tap into the process of speech perception and segmentation that occurs as the familiarization phase unfolds (but see Gómez et al., Reference Gómez and Mehler2011).
To overcome these limitations, we have explored the use of pupillometry. Under constant lightning conditions, pupils dilate as the result of a variety of perceptual and cognitive processes (Loewenfeld, Reference Loewenfeld1958). In adults, pupil dilation has been linked to a greater cognitive load as well as violations of expectation (Hess and Polt, Reference Hess and Polt1960; Kahneman and Beatty, Reference Kahneman and Beatty1966; Karatekin, Reference Karatekin2007; Jackson and Sirois, Reference Jackson and Sirois2009; Laeng et al., Reference Laeng, Sirois and Gredebäck2012; Fritzsche and Höhle, Reference Fritzsche and Höhle2015; Tromp et al., Reference Tromp, Haagort and Meyer2016; Vogelzang et al., Reference Vogelzang, Van Rijn and Hendriks2016). Similarly, in infants and young children, pupils dilate as the result of surprise and cognitive effort (Karatekin, Reference Karatekin2007; Jackson and Sirois, Reference Jackson and Sirois2009; Gredebäck and Melinder, Reference Gredebäck and Melinder2010; Hepach and Westermann, Reference Hepach and Westermann2013; Hochmann and Papeo, Reference Hochmann and Papeo2014; Langus et al., Reference Langus, Boll-Avetisyan, van Ommen and Nazzi2023) and can provide a more sensitive measure than behavioral methods such as looking time (Jackson and Sirois, Reference Jackson and Sirois2009; Hepach and Westermann, Reference Hepach and Westermann2013, Reference Hepach and Westermann2016). In fact, a growing body of literature suggests that pupillometry can be used to study speech perception throughout infancy into adulthood (Hochmann and Papeo, Reference Hochmann and Papeo2014; Fritzsche and Höhle, Reference Fritzsche and Höhle2015; Tamási et al., Reference Tamási, McKean, Gafos, Fritzsche and Höhle2017; Marimon et al., Reference Marimon, Höhle and Langus2022; Langus et al., Reference Langus, Boll-Avetisyan, van Ommen and Nazzi2023). In speech perception experiments, pupillometry can therefore provide a noninvasive physiological measure that can be used to compare infants and adults directly in the same paradigm using the same stimuli.
Pupillometry may also reveal how listeners perceive and parse continuous speech as the signal unfolds. In particular, changes in pupil size can also entrain to rhythmic auditory stimuli as the auditory stimuli unfold – that is, dilate and constrict in synchrony with acoustic or structural patterns in the auditory stimuli. For example, changes in pupil size can synchronize to repeating musical instrument sounds in adult listeners (Fink et al., Reference Fink, Hurley, Geng and Janata2018). Furthermore, studies with primates show that changes in pupil size can entrain to repeating patterns of tone sequences defined by statistical regularities and that these entrained pupillary responses are comparable to neural entrainment in the auditory cortex (Barczak et al., Reference Barczak, O’Connell and McGinnis2018) (see Chapter 3). These findings are not only remarkable because the relatively slow changes in pupil size spontaneously synchronize to auditory stimuli, but they also suggest that the entrained pupillary responses can reveal how listeners parse continuous auditory stimuli. This is particularly interesting for infant speech segmentation experiments where the stimuli often occur with a predictable regular rhythm (Thiessen and Saffran, Reference Thiessen and Saffran2007; Johnson and Tyler, Reference Johnson and Tyler2010; Mersad and Nazzi, Reference Mersad and Nazzi2012). Measuring pupil size may therefore not only be informative about which words infants and adults remember in speech segmentation experiments, but could also reveal how the process of speech segmentation in the familiarization phase unfolds.
41.3 Methodological Considerations: Pupil Dilation as a Measure for Speech Segmentation
To explore whether pupillary changes can be used to investigate speech segmentation in infants and adults, we carried out a cue-weighting experiment while we measured participants’ pupil size with an eye-tracker. Participants were familiarized with a continuous speech stream in which statistical words signaled by transitional probabilities straddled prosodic word boundaries (see Figure 41.1C). Specifically, in the familiarization stream, every other syllable carried lexical stress that both German-learning infants and German-speaking adults would perceive as word-initial (Höhle, Reference Höhle2002). However, the syllables used to create the familiarization stream were combined in a way that the transitional probabilities between syllables were higher at prosodic word boundaries (between weak-strong syllable pairs) than within prosodic words (i.e., between strong-weak syllable pairs). After the familiarization phase, participants were presented with prosodic words (which followed a lexical stress pattern in the familiarization string, but had low transitional probabilities between the two syllables i.e., 0.2–0.4), statistical words (which had high transitional probabilities between the syllables, i.e., 1.0), and nonwords (which consisted of syllables that never occurred adjacently in the familiarization stream; the transitional probability was 0.0). We measured infants’ and adults’ pupil sizes with an eye-tracker throughout the experiment. Adult participants were additionally asked to indicate with a key press if they had heard the specific test word during the familiarization.
Frequency tagging the pupillary response.
(A) The pupillary response during the familiarization phase is transformed from the time domain to the frequency domain through fast Fourier transform (FFT). The FFT decomposes the pupillary response into sine-wave components of different frequencies by determining their amplitude and phase. (B) One of these sinusoidal components will correspond to word frequency (2.08 Hz), that is, pupils dilating and constricting once during the occurrence of each word. (C) To determine whether infants’ pupils entrain to statistical or prosodic words, we will look at the temporal alignment (i.e., phase) of the pupillary response at word frequency. Because the familiarization stream started with a statistical word, if infants’ pupils entrain to statistical words, then the pupillary response at word frequency (2.08 Hz) would be temporally aligned with the familiarization stream onset (solid line, upper side of the panel). In contrast, if infants’ pupils entrain to prosodic words, then the pupillary response at word frequency should be temporally shifted from the onset of the familiarization stream by one syllable that corresponds to half a cycle (π) of the 2.08 Hz response (dashed line, lower side of the panel).
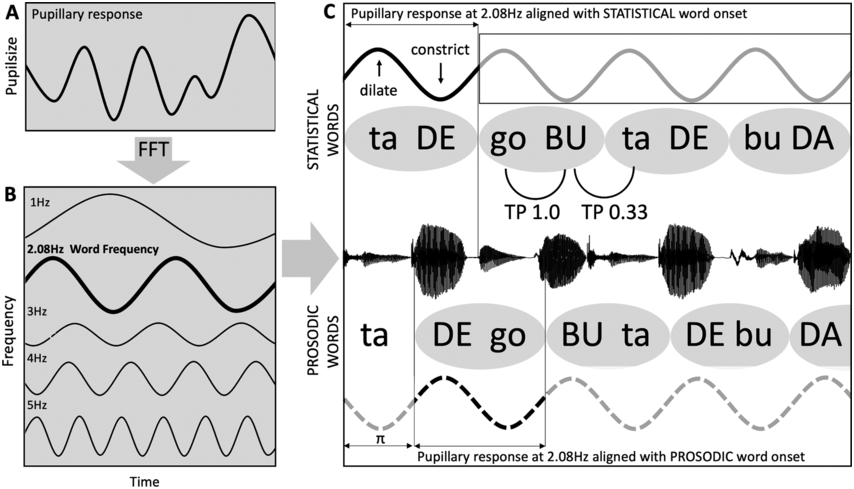
Figure 41.1 Long description
Panel A: A graph of pupillary response over time. The horizontal-axis is time, and the vertical-axis is pupillary size. The graph shows fluctuations in pupil size. Panel B: A graph of frequency over time. It plots five lanes for 1 hertz, 2.08 hertz, 3 hertz, 4 hertz, and 5 hertz. Panel C: Shows the speech signal, acoustic waveform which is aligned with the pupillary response. The top part shows the acoustic waveform with the words, ta De go Bu ta De bu Da and the corresponding pupillary response. The bottom part shows the words, ta De go Bu ta DE bu Da again, but this time aligned with the prosodic aspects of the speech.
Results showed that adults segmented the familiarization stream into prosodic words. Behavioral responses indicated that they had heard prosodic words but not statistical words or nonwords in the familiarization stream. The same results were obtained also from their pupillary response: Their pupils dilated significantly more to nonwords and to statistical words than to prosodic words. The comparison of adult participants’ behavioral and pupillary responses therefore shows that changes in pupil size can reveal recognition of words in speech segmentation experiments also with a spontaneous physiological response that does not require an overt response. In contrast, we failed to find any evidence for consistent segmentation of the familiarization phase with either prosodic or statistical cues in nine-month-old German-learning infants. Infants’ pupillary response at test showed no significant differences between prosodic words, statistical words, and nonwords. This suggests that, as a group, nine-month-olds failed to segment the familiarization stream consistently with either prosodic or statistical cues, replicating previous studies with nine-month-old German-learning infants in a behavioral paradigm (Marimon, Reference Marimon2019).
However, the overall failure of nine-month-old infants as a group to show a preference for prosodic or statistical words does not mean that infants failed to segment the familiarization stream altogether. It is also possible that some infants were segmenting the familiarization stream into prosodic words and others into statistical words. To explore this possibility, we used frequency tagging on infants’ and adults’ pupillary response during the familiarization phase (see Figure 41.1). By decomposing the pupillary response during the whole familiarization phase into different frequency components using a fast Fourier transform, we observed that changes in pupil size at stimulus frequency in adults were temporally aligned with prosodic word onsets. Furthermore, the variability in the phase of the pupillary response was predictive of participants’ performance at test – namely, those participants’ whose pupils were more aligned with prosodic word boundaries during the familiarization were better at recognizing prosodic words in test. In contrast, the temporal alignment of the pupillary response during the familiarization in infants showed considerable variability, with those infants who were more entrained to prosodic words showing better recognition of prosodic words at test and those infants who were more entrained to statistical words showing better recognition of statistical words at test. Pupillary entrainment to temporal regularities in continuous speech is therefore informative about how adults and infants segment words from continuous speech and provides insights about the segmentation process that is difficult to discern with behavioral methods (Marimon et al., Reference Marimon, Höhle and Langus2022).
41.4 Pupils Rapidly Entrain to Auditory Rhythms
The results of the cue-weighting experiments suggest that pupillary entrainment can be informative about how infants and adults parse a continuous speech stream into possible word candidates. However, since the FFT in these analyses considered the familiarization phase as a whole, it did not reveal the dynamics of entrainment as it unfolded during the familiarization phase. This raises the question of whether the pupils can become entrained to rhythmic stimuli fast enough to provide more detailed information about the time course of the perception of rhythmic auditory stimuli. In fact, there is some evidence that nonhuman primates’ pupils can entrain to repetitive auditory patterns within only a few repetitions of the pattern (Barczak et al., Reference Barczak, O’Connell and McGinnis2018). However, because primates in these studies were presented with hundreds of trials, which is impossible with young infants, it remains unknown whether temporally more fine-grained entrained responses could also be observed in younger infants. To answer this question, we reanalyzed data specifically for this chapter from one of our recent speech perception experiments in young infants (Langus et al., Reference Langus, Boll-Avetisyan, van Ommen and Nazzi2023).
This study tested whether German-learning infants (N=31) perceive lexical stress as categorical by presenting infants with short trials consisting of four instances of the nonword “gaba” while we recorded their pupil size with an eye-tracker. The words were chosen from a lexical stress continuum that covaried pitch, duration, and intensity cues ranging from trochaic (i.e., word-initial: strong-weak) to iambic (i.e., word-final: weak-strong). The first three instances of the word in each trial always consisted of the same item from the acoustic continuum and provided the prosodic context that varied across trials. The fourth instance provided the test (trochaic or iambic) that was identical across trials, and it could be the same as the context (i.e., standard trials), be from the opposite category as the context (i.e., between-category trials; it had the same prominence as the standard trials but in the opposite category), or from the same category as the context (i.e., within-category trials; it had the same prominence as the standard trials but the acoustic cues were more prominent). We reasoned that evidence for categorical perception would entail infants’ pupil dilations showing: (a) discrimination of between-category trials from within-category and standard trials, and (b) no discrimination between within-category and standard trials. The analysis of the pupillary response following the fourth word – that is, the test word – showed that only those six-month-old infants who had above-average exposure to various linguistic and/or musical activities at home showed differences in pupil size between rhythmic patterns that span category boundaries. These results reinforce the idea that pupillometry can be used to study linguistic phenomena in very young infants.
For this chapter, we carried out an additional exploratory analysis to investigate whether infants’ changes in pupil size synchronize to the occurrence of the word “gaba” in these short trials, that is, whether and when the pupillary response at stimulus frequency became aligned with the occurrence of the words in the trial. Following the analysis outlined in Barzack et al. (Reference Barczak, O’Connell and McGinnis2018), we bandpass-filtered the pupillary response throughout the trial into a narrow frequency band centered around 1.72Hz (+/− 25%). This frequency corresponded to the frequency at which the words occurred in the trial. To determine whether infants’ pupillary response at stimulus frequency was consistent across trials, we calculated the inter-trial pupillary coherence (ITPC) of the pupillary response at stimulus frequency across all the good trials for a given infant (M = 24.48). The ITC is bounded between 0 and 1, with 1 corresponding to perfect coherence of the pupillary response across trials and 0 corresponding to no inter-trial coherence. We baseline-corrected the ITC by subtracting the average ITC during 500 ms before first-word onset from the ITC throughout the trial.
The results of this exploratory analysis indicate that the phase of the pupillary response at stimulus frequency during the trial showed significant phase clustering from the second repetition of the word in the trial (Figure 41.2). To investigate the evolution of the ITC of the pupillary response during the trial, we also ran a linear regression with the ITC values as the dependent variable and the position of the word in the trial (first to fourth) as a categorical fixed factor. The pupillary response at stimulus frequency did not differ significantly from zero at first-word onset (Intercept: β = .074, SE = .054, t = 1.356, p = .177), and there was no significant increase in ITC by the second-word onset (β = .113, SE = .077, t = 1.468, p = .114). However, a significant increase in coherence when compared to first-word onset was observed at the third- (β =.252, SE = .077, t = 3.279, p < 0.01) and fourth-word (β = 0.374, SE = .077, t = 4.873, p < .0001) onsets (Figure 41.2B and 41.2C). Taken together, the phase of the pupillary response at stimulus frequency shows a significant increase in inter-trial coherence by the third word in the trial. These results suggest that infants’ pupils can rapidly entrain to the occurrence of temporally predictable patterns in auditory stimuli. This indicates that by the second repetition of the word, the pupillary response has entrained to the occurrence of words in the stimuli.
Pupillary synchrony to the words in the trial.
(A) The pupillary response at stimulus frequency (1.72 Hz) averaged across trials and infants. The shaded area corresponds to the duration of the words in the trial. Pupil size is negative because of narrow-band filtering. (B) Evolution of the baseline-corrected inter-trial coherence (averaged ITC across infants) of the pupillary response at stimulus frequency during the whole trial. (C) Comparison of ITC at each word onset.
Figure 41.2 Long description
Panel a: A bar and line graph depicts pupil size versus time in seconds. It plots a fluctuating line which originates at (minus 1, 0.00) and terminates at (6, 0.00). The line overlaps the bars labeled baseline first word, second word, third word, and fourth word. Panel b: A line graph of I T C versus time in seconds. It plots a curve which originates at (minus 1, 0.00), rises and peaks at (2.5, 0.35), falls and terminates at (6, 0.08). Panel c: A violin plot of I T C values for each of the four words. The box plots show the distribution of I T C values for each word presentation. The horizontal lines above the box plots indicate statistical significance. The asterisks are marked above the violin plots. The median values of I T C are as follows. Fourth word, 0.27. Third word, 0.25. Second word, 0.18. First word, 0.10. The values are estimated.
41.5 The Role of Rhythm in Speech Perception and Segmentation in Infancy
Rhythm may play an important role in how young infants acquire language as infants are sensitive to rhythmic properties of speech from birth (Jusczyk, Reference Jusczyk1997; Langus et al., Reference Langus, Mehler and Nespor2017; Chapters 11, 35, 36, and 38). Previous studies have shown that the regular occurrence of words of equal length or knowledge of the rhythmic structure of words may mediate young infants’ and adults’ ability to parse continuous speech into possible word candidates (Johnson and Tyler, Reference Johnson and Tyler2010; Mersad and Nazzi, Reference Mersad and Nazzi2012; Wang et al., Reference Wang, Zevin and Mintz2017, Reference Wang, Zevin, Trueswell and Mintz2020). This suggests that temporal regularities in continuous speech may lead listeners to build expectations of when word boundaries are likely to occur. The results outlined in this chapter complement this line of research by showing that adults’ and infants’ changes in pupil size track temporal regularities (i.e., possible word candidates) signaled by statistical or prosodic cues, and that this ability may facilitate the segmentation of continuous speech already during the first year of life. Furthermore, the analysis of six-month-old infants’ pupil size in short trials consisting of only four words further suggests that pupils entrain to auditory stimuli very rapidly, that is, within two repetitions of words. This raises the question of what role rapid entrainment to auditory stimuli that are kept artificially rhythmic may play in language acquisition.
The suprasegmental rhythm of spoken language is contained within intonational contours that correspond to prosodic units with boundaries marked by acoustic cues such as pauses and final lengthening (Nespor and Vogel, Reference Nespor and Vogel1986). This means that rhythm will be most informative about the underlying structure of spoken language within the bounds of a prosodic unit that typically corresponds to a single sentence or a phrase. Infant-directed speech typically uses three–five words per utterance (Saksida et al., Reference Saksida, Langus and Nespor2017), limiting rhythmic units for infants to entrain to. The sentence length (as with the word length; Johnson and Tyler, Reference Johnson and Tyler2010; Mersad and Nazzi, Reference Mersad and Nazzi2012) likely influences rhythmic predictions’ benefit in speech learning. Infants in our analysis entrained by third-word onset, implying that early entrainment allows more learning time as sentences unfold. Rapid entrainment may help infants in extracting structure from relatively short acoustic signals, such as single sentences in spoken language.
However, most studies use highly rhythmic stimuli, unlike naturally occurring speech, which raise questions about the role of entrainment in infants’ real speech perception. It is possible that the natural language temporal variability might hinder entrainment, limiting its applicability from controlled experiments to everyday speech. However, infants seem particularly adept at learning from the rhythmic speech signal that surrounds them (e.g., Kuhl, Reference Kuhl2010; Leong et al., Reference Leong, Kalashnikova, Burnham and Goswami2017; Chapter 35), which includes a variety of rhythmic stimuli – such as nursery rhymes, singing, instrumental music, as well as infant-directed speech – that boost infants’ ability to detect structure from linguistic stimuli (see Suppanen et al., Reference Suppanen, Huotilainen and Ylinen2019; Langus et al., Reference Langus, Boll-Avetisyan, van Ommen and Nazzi2023; see also Chapter 23). This suggests that infants might grasp language effectively from predictably rhythmic stimuli including songs, nursery rhymes, and structured speech (spoken language with relatively regular and temporally predictive rhythmic structure).
41.6 Why Pupils Are Interesting
In contrast to methods commonly used in infant research, the pupillary response can be evoked in a passive listening procedure and does not need an overt behavioral response. Because infants’ pupil size can be measured with an eye-tracker automatically from around 3.5 months of age (Hochmann and Papeo, Reference Hochmann and Papeo2014; Saksida and Langus, Reference Saksida and Langus2024), the pupillary response is one of the few experimental methods that allows for testing speech perception in adults and infants using the same experimental paradigms. While the paradigms used for pupillometry are like those used in electroencephalography (EEG), pupillometry does not require placement of electrodes that can be time-consuming and fastidious for infants. Experiments using pupillometry are, therefore, likely to yield more data and result in less data loss when dealing with young infants. While the analysis of the pupillary response is similar to EEG data, it is computationally less demanding due to lower sampling rate and fewer channels (i.e., only two: the left eye and the right eye). Furthermore, eye-trackers are considerably cheaper than equipment for recording electrophysiological brain responses. As such, pupillometry may be more beginner-friendly in an experimental field that has primarily focused on behavioral paradigms.
Pupillometry is also interesting for measuring rhythm perception. Rhythmic entrainment is characterized by sensorimotor synchronization, that is, spontaneous neural and behavioral synchronization to the rhythmic beat (see Chapter 6). Rhythm perception is therefore often measured in terms of neural entrainment (for an overview: Lakatos et al., Reference Lakatos, Gross and Thut2019; Obleser and Kayser, Reference Obleser and Kayser2019) or by asking participants to tap their finger to the rhythm of auditory stimuli (Repp, Reference Repp2005; Iversen and Patel, Reference Iversen and Patel2008). Evidence for changes in pupil size synchronizing to auditory rhythms are therefore interesting because pupil size is both a correlate of underlying neural activity as well as a spontaneous motor output. For example, studies in primates suggest that neural ensembles in the primary auditory cortex entrain to repeating auditory patterns in a comparable time and manner as changes in pupil size (Barczack et al., Reference Barczak, O’Connell and McGinnis2018). Pupil size could therefore function as a proxy for underlying neural entrainment. However, changes in pupil size are also caused by pupillary muscles in the oculomotor system (Mathôt, Reference Mathôt2018). Similar to spontaneous tapping of the finger to regular rhythm, pupillary entrainment is also evidence for sensorimotor synchronization that results in motor output. While synchronizing changes in pupil size is likely to involve quite different neural pathways than finger tapping, it has the advantage of emerging spontaneously without explicit instruction. This means that pupillary entrainment to auditory rhythms may provide a unique – if not the only – way to study spontaneous sensorimotor synchronization in the laboratory across the lifespan.
Finally, it is also possible that pupil dilation, as the result of cognitive and/or perceptual processing, is physiologically relevant for audiovisual perception. Similar to the effect of varying the size of the aperture in photo cameras, larger pupil size will result in shallower depth of vision and consequently limit the visual detail that is perceived (e.g., a portrait photo with a blurred background: Marcos et al., Reference Marcos, Moreno and Navarro1999; Ebitz and Moore, Reference Ebitz and Moore2019). Because speech is an audiovisual experience where auditory and visual cues are integrated online (McGurk effect; McGurk and MacDonald, Reference McGurk and MacDonald1976; Guellai et al., Reference Guellai, Langus and Nespor2014; Peña et al., Reference Peña, Langus, Gutiérrez, Huepe-Artigas and Nespor2016), pupil size changes elicited by auditory processing may facilitate the visual perception of the speaker’s face by blending out unnecessary visual background information. Further studies could explore whether changes in pupil size due to surprise, cognitive load, or entrainment to auditory stimuli affect depth of field to facilitate visual perception. Since speech is rarely perfectly rhythmic, it is necessary to confirm if pupil changes also entrain to natural speech. While it is uncertain how much pupil size alterations impact audiovisual perception, results suggest that rapid pupil size changes linked to auditory processing may facilitate integration of audiovisual signals. If validated, pupillometry will not just correlate but also significantly contribute to understanding how we perceive and acquire audiovisual information.
41.7 Conclusion
In this chapter we argued that rhythm plays an important role in speech perception and word segmentation by showing results from different studies using pupillometry. The first study showed that both infants’ and adults’ pupils can entrain to a continuous speech stream and that this is informative about their word segmentation abilities. In the second study, a reanalysis of Langus et al. (Reference Langus, Boll-Avetisyan, van Ommen and Nazzi2023), we demonstrated that pupils can rapidly entrain to rhythmic stimuli within only a few repetitions of the words in a trial. Our results show that pupillometry can be a useful tool when investigating speech perception, potentially revealing the dynamics of how continuous speech is parsed into words as the speech signal unfolds. However, the question of whether pupil entrainment can also capture and synchronize to the rhythmic variability of natural speech still remains open, and further research is needed. Furthermore, we suggested that pupillometry can be a great method to complement behavioral responses and to be used to investigate speech perception from early infancy to adulthood. Therefore, it can allow us to gain further knowledge on the underlying perceptual and cognitive mechanisms in word segmentation and speech perception.
41.8 Acknowledgements
This work was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) funding for the Sonderforschungsbereich (Collaborative Research Center) “Limits of Variability in Language” (grant number 317633480, SFB 1287, collaboration between projects C03 and C07), by the European Union’s Horizon 2020 Individual Marie-Curie Fellowship to Alan Langus (grant number 748909; “RHYTHMSYNC”), and the Postdoc Prize of Brandenburg 2022 (Ministerium für Wissenschaft, Forschung und Kultur Brandenburg) to Mireia Marimon.
Summary
A crucial step in language acquisition is to learn to segment the continuous speech stream into possible word candidates. To solve this problem, infants rely on a variety of perceptual and computational mechanisms. We argue that infants’ ability to segment speech, including the ability to exploit all the cues to word boundaries, may be mediated by their ability to build rhythmic expectations of how the speech signal will unfold. We showcase that pupillary entrainment to auditory stimuli is a novel way of investigating speech perception and segmentation. Synchronized changes in pupil size can reveal much about the perception of rhythmic regularities in spoken language.
Implications
Further research is needed to answer the question about whether pupil entrainment can also capture and synchronize to the rhythmic variability of natural speech. Using eye-tracking rather than electrophysiology might be an advantage, especially for investigating babies, toddlers, and infants.
Gains
We propose a new methodological perspective for rhythm perception in infancy and adulthood, which can allow us to gain further knowledge on the underlying perceptual and cognitive mechanisms in acquiring word segmentation abilities.
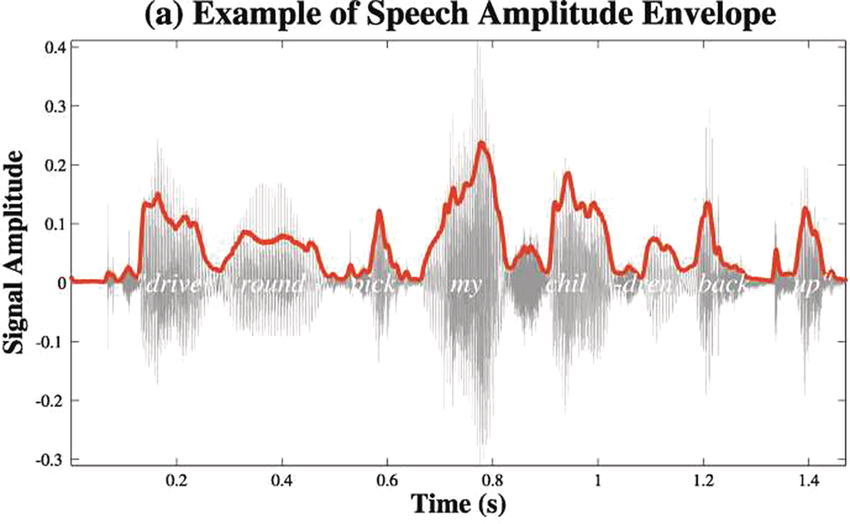
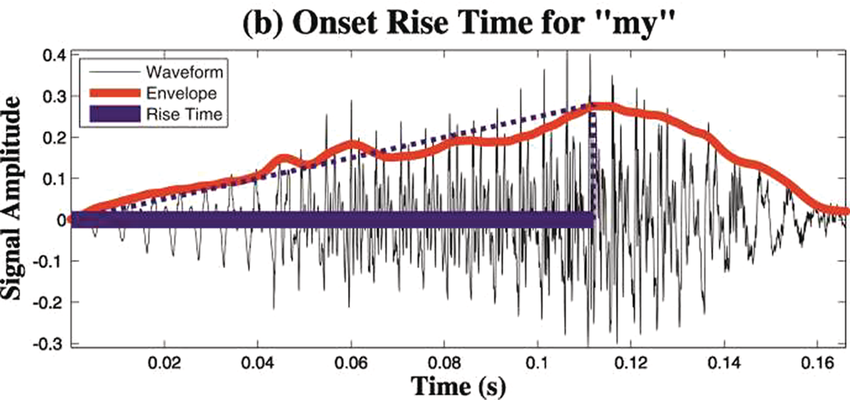
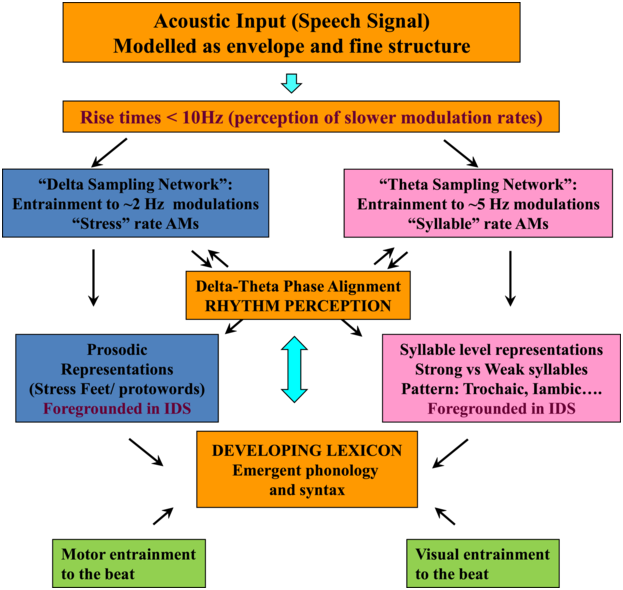

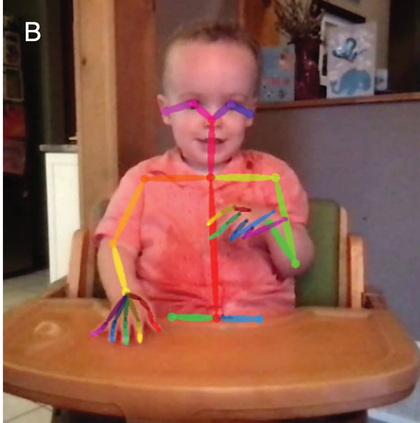
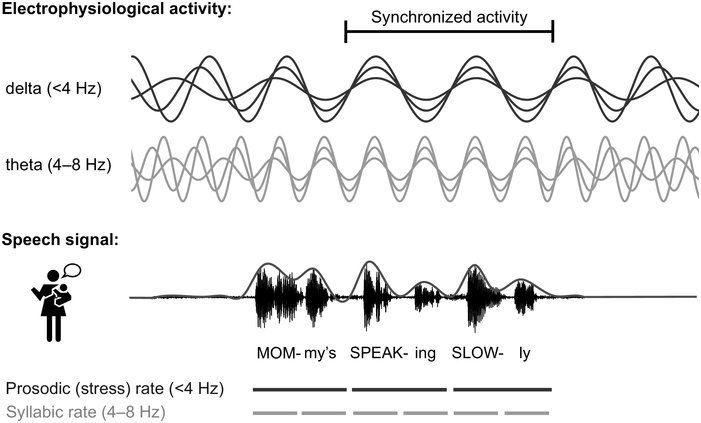
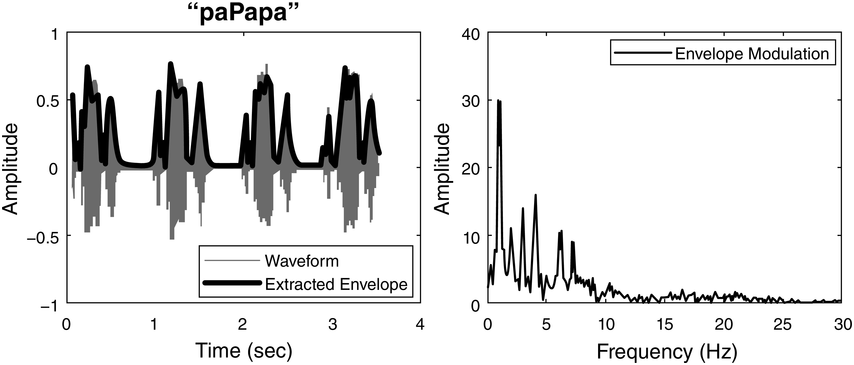
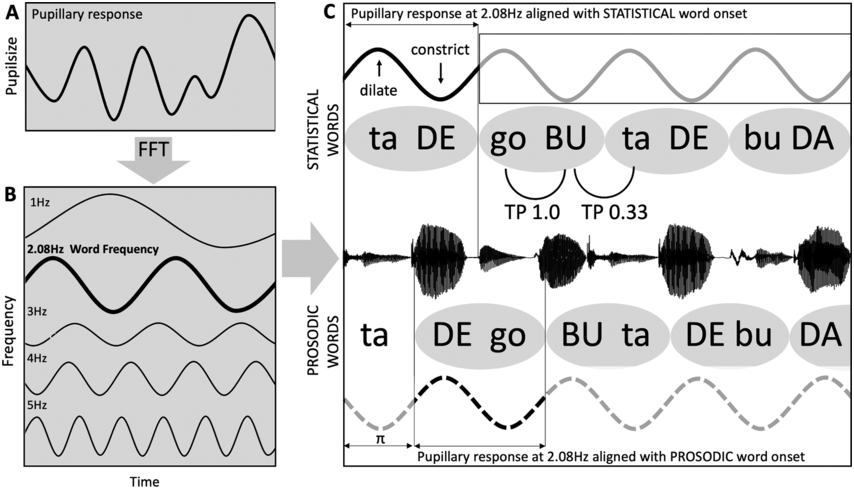

 Open access
Open access