We study minimax regret treatment rules under matched treatment assignment in a setup where a policymaker, informed by a sample of size N, needs to decide between T different treatments for a 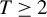 . Randomized rules are allowed for. We show that the generalization of the minimax regret rule derived in Schlag (2006, ELEVEN—Tests needed for a recommendation, EUI working paper) and Stoye (2009, Journal of Econometrics 151, 70–81) for the case
. Randomized rules are allowed for. We show that the generalization of the minimax regret rule derived in Schlag (2006, ELEVEN—Tests needed for a recommendation, EUI working paper) and Stoye (2009, Journal of Econometrics 151, 70–81) for the case  is minimax regret for general finite
is minimax regret for general finite 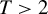 and also that the proof structure via the Nash equilibrium and the “coarsening” approaches generalizes as well. We also show by example, that in the case of random assignment the generalization of the minimax rule in Stoye (2009, Journal of Econometrics 151, 70–81) to the case
and also that the proof structure via the Nash equilibrium and the “coarsening” approaches generalizes as well. We also show by example, that in the case of random assignment the generalization of the minimax rule in Stoye (2009, Journal of Econometrics 151, 70–81) to the case 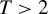 is not necessarily minimax regret and derive minimax regret rules for a few small sample cases, e.g., for
is not necessarily minimax regret and derive minimax regret rules for a few small sample cases, e.g., for 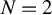 when
when 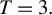
In the case where a covariate x is included, it is shown that a minimax regret rule is obtained by using minimax regret rules in the “conditional-on-x” problem if the latter are obtained as Nash equilibria.
]]>