This study shows the impact of black carbon (BC) aerosol atmospheric rivers (AAR) on the Antarctic Sea ice retreat. We detect that a higher number of BC AARs arrived in the Antarctic region due to increased anthropogenic wildfire activities in 2019 in the Amazon compared to 2018. Our analyses suggest that the BC AARs led to a reduction in the sea ice albedo, increased the amount of sunlight absorbed at the surface, and a significant reduction of sea ice over the Weddell, Ross Sea (Ross), and Indian Ocean (IO) regions in 2019. The Weddell region experienced the largest amount of sea ice retreat (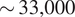 km2) during the presence of BC AARs as compared to
km2) during the presence of BC AARs as compared to 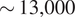 km2 during non-BC days. We used a suite of data science techniques, including random forest, elastic net regression, matrix profile, canonical correlations, and causal discovery analyses, to discover the effects and validate them. Random forest, elastic net regression, and causal discovery analyses show that the shortwave upward radiative flux or the reflected sunlight, temperature, and longwave upward energy from the earth are the most important features that affect sea ice extent. Canonical correlation analysis confirms that aerosol optical depth is negatively correlated with albedo, positively correlated with shortwave energy absorbed at the surface, and negatively correlated with Sea Ice Extent. The relationship is stronger in 2019 than in 2018. This study also employs the matrix profile and convolution operation of the Convolution Neural Network (CNN) to detect anomalous events in sea ice loss. These methods show that a higher amount of anomalous melting events were detected over the Weddell and Ross regions.
km2 during non-BC days. We used a suite of data science techniques, including random forest, elastic net regression, matrix profile, canonical correlations, and causal discovery analyses, to discover the effects and validate them. Random forest, elastic net regression, and causal discovery analyses show that the shortwave upward radiative flux or the reflected sunlight, temperature, and longwave upward energy from the earth are the most important features that affect sea ice extent. Canonical correlation analysis confirms that aerosol optical depth is negatively correlated with albedo, positively correlated with shortwave energy absorbed at the surface, and negatively correlated with Sea Ice Extent. The relationship is stronger in 2019 than in 2018. This study also employs the matrix profile and convolution operation of the Convolution Neural Network (CNN) to detect anomalous events in sea ice loss. These methods show that a higher amount of anomalous melting events were detected over the Weddell and Ross regions.