


I Introduction
This chapter introduces the basic concepts of artificial intelligence (AI) to assist lawyers in understanding in what way, if any, the private law framework needs to be updated to enable systems employing AI to be treated in an ‘appropriate’ manner. What ‘appropriate’ means is a matter for legal experts and ethicists, insofar as the law reflects ethical principles, so the chapter seeks to identify the technological challenges which might require a legal response, not to prejudge what such a response might be.
AI is a complex topic, and it is also moving very fast, with new methods and applications being developed all the timeFootnote 1. Consequently, this chapter focuses on principles that are likely to be stable over time, and this should help lawyers to appreciate the capabilities and limitations of AI. Further, it illustrates the insights with ‘concrete’ examples from current applications of AI. In particular, it discusses the state of the art in application of AI and machine learning (ML) and identifies a range of challenges relating to use of the technology where it can have an impact on human health and wellbeing.
The rest of the chapter is structured as follows. Section II introduces the key concepts of AI including ML and identifies some of the main types and uses of ML. Section III sets out a view of the current ‘state of the art’ in AI applications, the strengths and weaknesses of the technology and the challenges that this brings. This is supported by concrete examples. Section IV presents conclusions including arguing that a multidisciplinary approach is needed to evolve the legal framework relating to AI and ML.
II Artificial Intelligence: Key Concepts
The concept of AI is generally said to originate with Alan TuringFootnote 2 who proposed an ‘imitation game’ where a human held a conversation through a textual interface either with another human or a computer (machine).Footnote 3 If a human cannot distinguish the machine from another human, then the machine is said to have ‘passed the test’ – we now refer to this as the ‘Turing Test’,Footnote 4 although Turing didn’t use that term himself. Technology has advanced to an enormous degree in the seventy years since Turing’s original paper but the concept of a machine imitating a human remains valid and indicative of the aims of AI.Footnote 5
A Artificial Intelligence and Machine Learning
First, we give a more direct definition of what is meant by AI and then introduce the concept of ML:
AI involves developing computer systems to perform tasks normally regarded as requiring human intelligence, for example, deciding prison sentences,Footnote 6 or medical diagnosis.Footnote 7
At the moment, there is no consensus on a standard definition of AI.Footnote 8 The European Commission’s Communication on AI proposed the following definition of AI:
Artificial intelligence (AI) refers to systems that display intelligent behaviour by analysing their environment and taking actions – with some degree of autonomy – to achieve specific goals. AI-based systems can be purely software-based, acting in the virtual world (e.g., voice assistants, image analysis software, search engines, speech and face recognition systems) or AI can be embedded in hardware devices (e.g., advanced robots, autonomous cars, drones or Internet of Things applications).Footnote 9
Some other definitions of AI tend to describe the technology in terms of its most widely used techniques, for example, ML, logic, and statistical approaches.Footnote 10
Early AI systems, often called expert systems,Footnote 11 were generally based on well-defined rules, and these rules were normally defined by humans reflecting knowledge of the domain in which the system was to be used, for example, clinical decision-support tools that utilise a knowledge repository and a predefined ruleset for the prescribing of medications for common conditions.Footnote 12
ML is a form of AI, developing computer systems that learn to perform a task from training data, guided by performance measures, for example, accuracy.Footnote 13
ML is intended to generalise beyond the training data so the resultant systems can work effectively in situations on which they were not trained, for example, learning to identify the presence or absence of diabetic retinopathy from thousands of historic retinal scans labelled with outcomes.Footnote 14 We will use the term AI to include ML, but not vice versa.
It is common to distinguish ‘narrow AI’ from ‘general AI’, often referred to as artificial general intelligence (AGI).Footnote 15 The key difference is that ‘narrow AI’ is focused on a specific task, for example, recognising road signs, whereas AGI is not – indeed we would expect AGI to have the breadth of capabilities of humans including the ability to hold conversations, drive a car, interpret legal judgments, and so on. Modern AI systems can be classed as ‘narrow’ and some view AGI as unattainableFootnote 16 (see also the discussion of the ‘state of the art’ later).
ML is used in most modern AI systems as a cost-effective way of solving problems that would be prohibitively expensive or impossible to develop using conventional programming – and the key to this is the ability of ML to generalise beyond training data.Footnote 17 For example, an ML-based system used for medical diagnosis should work for any patient in the system’s intended scope of application. This is similar to the way that humans apply their knowledge – doctors can treat patients they have not seen before, we can drive on new roads, including those that weren’t built when we learnt to drive. This can be seen as generalising Turing’s imitation game to a wider range of capabilities than textual communication.
B Types of Machine Learning
There are many different ML methods, but they can generally be divided into three classes.Footnote 18 We provide some contextual information then give descriptions of these three classes before giving some examples of different ML methods.Footnote 19
Data plays a key role in ML and learning algorithms are used to discover knowledge or patterns from data without explicit (human) programming.Footnote 20 The result of learning is referred to as the ML model. The dataset used for training may be labelled, saying what each datum means, for example, a cat or a dog in an image, or it may be unlabelled.Footnote 21 The data is normally complex, and we will refer to the elements of each datum as features. The dataset is often split into a training set and a test set, with the test set used to assess the performance, for example, accuracy, of the learnt ML model.Footnote 22
1 Supervised Learning
Supervised learning uses a labelled dataset and this a priori knowledge is used to guide the learning process. Supervised learning tries to find the relationships between the feature set and the label set. The knowledge extracted from supervised learning is often utilised for classification or for regression problems. Where the labels are categorical, the learning problem is referred to as classification.Footnote 23 On the other hand, if the labels correspond to numerical values, the learning problem is defined as regression problem.Footnote 24

Figure 1.1 Object classification
Note: Assuring Autonomy International Programme at the University of York, funded by the Lloyd’s Register Foundation.
Figure 1.1 gives a simple illustration of the use of ML for object identification and classification. The ML models have classified dynamic objects in the image and placed bounding boxes around them; in general, such algorithms will distinguish different classes of vehicle, for example, vehicles from people, as this helps in predicting their movement. Here, regression may be used for predicting the future position or trajectory of a vehicle based on its past positions.Footnote 25
2 Unsupervised Learning
Unsupervised learning uses unlabelled data and can draw inferences from the dataset to identify hidden patterns.Footnote 26 Unsupervised learning is often used for clustering (grouping together related data) and finding associations among features. An active area of work is so-called ‘self-supervised learning’ (the self here is a computer, not a person) which learns good generic features from an enormous unlabelled dataset.Footnote 27 These features can then be used to solve a specific task with a smaller labelled dataset, that is, feeding into supervised learning.
The ‘recommender’ systems for online shopping systems produce outputs such as: ‘people who bought this item also bought…’.Footnote 28 Practical recommender systems use a mixture of ML methods, and this may include unsupervised learning.Footnote 29 Thus, it is likely that most readers of this chapter will have used a system that employs unsupervised learning, without being aware of it.
3 Reinforcement Learning
Reinforcement learning (RL) is a learning method that interacts with its environment by producing actions and discovering errors or receiving rewards.Footnote 30 Trial-and-error search and delayed reward are the most relevant characteristics of RL. In this class of learning, there are three primary components: the agent (the learner or decision-maker), the environment (everything the agent interacts with) and actions (what the agent can do).
The environment gives the agent a state (e.g., moving or stationary), the agent takes an action, then the environment gives back a reward as well as the next state. By analogy, this is like a children’s game where one child is blindfolded (the agent), this child can move forwards, backwards, left and right (the actions) in a room (the environment) to find an object and is given hints (rewards), for example, warm, hot, cold, freezing, depending on how close they are to the object, by other children.
This loop continues until the environment gives back a terminal state and a final reward (perhaps some chocolate in the children’s game), which ends the episode. The objective is for the agent to automatically determine the ideal behaviour in this environment to maximise its performance. Normally RL development is carried out in a simulated environment or on historical data before the agent is used in real-world applications, for example, optimising the treatment of sepsis.Footnote 31
RL can be used in planning and prediction problems, for example, identifying safe paths for a robot to move around a factory, and recommending medication for a patient.Footnote 32 In constrained environments with concrete rules, for example, board games, RL has demonstrated outstanding performance. This is best illustrated by DeepMind’s AlphaGo computer program that utilised RL, amongst other ML models, and defeated the world champion in the game of Go, which is much more complex than chess.Footnote 33
C Developing ML Models
Following the identification and analysis of a problem in a specific context, ML models can be developed through three primary phases: data management, model learning and model testing.Footnote 34 Data management involves collecting or creating, for example, by simulation, data on which to train the models. The data needs to be representative of the situation of interest, for example, roads for autonomous vehicles (AVs),Footnote 35 patient treatments and outcomes in healthcare, and perhaps successful and unsuccessful cases for a legal assistant. As well as splitting a dataset into a training dataset and a test data set, a validation dataset can also be used for model parameter tuning during model learning. For model learning itself, it is necessary to consider how to represent the knowledge derived from the training data, that is, what type of ML method to use, how to evaluate the ML model performance and then how to optimise the learning process. This is illustrated in Figure 1.2.

Figure 1.2 A simple illustration of machine learning process
Jia, ‘Embracing Machine Learning in Safety Assurance in Healthcare’ (n 19).
In model testing, the performance of the ML models is assessed using various metrics on the test dataset. It is easiest to explain this concept by considering classification of objects for an AV. The ML model output is therefore the assessed class for the observed object. For simplicity, assume we are only interested in identifying dynamic objects, that is, those that can move, and distinguishing them from static objects. In this case, we can have:
True positive – correct classification, for example, a person is identified as a dynamic object.
True negative – correct classification, for example, a lamppost is not identified as dynamic.
False positive – incorrect classification, for example, a statueFootnote 36 is classified as dynamic.
False negative – incorrect classification, for example, a person is not classified as dynamic.
It is common to convert these cases into rates and measures,Footnote 37 for example, a true positive rate (TPR), which is the proportion of positives correctly identified, that is, true positives, out of all the positives. Similarly, other measures are defined, for example, accuracy, which is the proportion of correct outputs (true positives plus true negatives) out of all the ML model outputs.
Some ML methods, for example neural networks (NNs), produce a score or probability qualifying the output,Footnote 38 for example, dynamic object with 0.6 probability. If the threshold in this case was 0.5, then the output would be interpreted as saying that the object was dynamic. However, if the threshold was set at 1, then the use of the NN would never give a positive output (saying the object was dynamic), thus the TPR would be 0, and so would the false positive rate (FPR). Similarly, a threshold of 0 would mean that everything was treated as positive, so both TPR and FPR would be 1. Intermediate thresholds, for example 0.5, would give a different value for TPR and FPR. TPR and FPR are combined into a measure known as the receiver operating characteristic (ROC)Footnote 39 which plots TPR vs. FPR as the threshold varies with different values, see Figure 1.3 for an example. It is also common to use the area under the curve ROC (AUC-ROC) to report the model performance, and the closer the AUC is to 1, the better the performance is.Footnote 40
The AUC-ROC can be used to compare different ML models to choose the best one for a particular application. Figure 1.3 illustrates the use of a ROC curve for this purpose, comparing a convolutional neural network (CNN) with a fully connected deep neural network (DNN).Footnote 41 A random ML model (prediction) would produce a diagonal line on the ROC and the AUC-ROC would be 0.5. A perfect ML model would give an AUC-ROC of 1, and the ‘curve’ would follow the axes in the diagram. The example in Figure 1.3 shows that the two ML models have similar performance as measured by the AUC-ROC.

Figure 1.3 Illustration of ROC
JA McDermid, Y Jia, Z Porter and I Habli, ‘Artificial Intelligence Explainability: The Technical and Ethical Dimensions’ (2021) 379(2207) Phil. Trans. R. Soc. A.
The intent of the evaluation criteria for ML models is to illuminate how well the model performs, contrasting desired behaviour with erroneous or undesirable behaviour.
In practice, development of ML models is highly iterativeFootnote 42 and model developers frequently build and test new models, evaluating them to see if the performance has improved. Once ML models are put into operation they may still be updated, for example if new data is available.
D Examples of ML Methods
There are many ML methods as we mentioned earlier. The aim here is to illustrate the variety and their capabilities to inform the discussion on the use of ML methods later, and on strengths, limitations, the state of the art and challenges in Section III.
Some of the more widely used ML methods are:
NNs – a network of artificial (computer models of) neurons, inspired by the human brain.Footnote 43 NNs are good at analysing complex data, for example images, and can be used supervised, for example, with labelled images, or unsupervised.Footnote 44 There are many variants, for example, CNN and fully connected DNN as illustrated in Figure 1.3.
Random forest (RF) – a collection of decision trees which is normally more robust (less susceptible to error in a single input) than a single decision tree.Footnote 45 Usually, RF is developed using supervised learning, and they are well-suited to decision problems, for example, for clinical diagnosis.Footnote 46
Probabilistic graphical models (PGMs) – a graph of variables (features) of interest in the problem domain and probabilistic relationships between them. There are several types of PGM including Bayesian networks (BNs) and Markov networks.Footnote 47 They can be used both supervised and unsupervised.
Generally, the learnt models, most notably DNNs, are very complex and ‘opaque’ to humans, that is, not open to scrutiny. PGMs are more amenable to human inspection, and it is possible to integrate human domain knowledge into PGMs. The primary difference between DNNs and PGMs lies in the structure of the machine learnt model in that PGMs tend to reflect human reasoning more explicitly, including causation.Footnote 48 This aids the process of interrogating the model for understanding the basis of its output. This level of transparency is harder to achieve with DNNs and therefore the majority of the techniques that are used to explain the output of DNN models rely on indirect means,Footnote 49 for example, examples and counterfactual explanations.Footnote 50
E Uses of ML Models
There are many uses of ML models. Some are embedded in engineered systems, for example, AVs, whereas others are IT systems, that is, operating on a computer, phone, or similar device.
AVs are an example of embedded ML. AVs often use ML for camera image analysis and understanding, for example classifying ‘objects’ into dynamic vs static, and identifying subclasses of dynamic objects – cars, bicycles, pedestrians, and so on. Typically, the systems employ a form of NN, for example, CNNs.Footnote 51 Many employ conventional computational methods of path planning (local navigation) but some use RL to determine safe and optimal paths.Footnote 52
ML is increasingly being proposed for use in healthcare for both diagnosis and treatment;Footnote 53 most of such applications are IT systems. Some of the systems also involve image analysis, for example, identifying tumours in images, with performance exceeding that of clinicians in some cases.Footnote 54 There are online systems, for example, from Babylon Health,Footnote 55 which employs an ML-based symptom checker. Applications which recommend treatments are also being explored, for example, delivery of vasopressors as part of sepsis treatment.Footnote 56
Legal uses of AI are also IT systems. The applications include predicting the outcome of tax appealsFootnote 57 and helping with the production of legal letters which correctly phrase non-expert text in support of claims, and other legal actions.Footnote 58 Some of the benefit of such tools arises from currently available computational power to trawl large volumes of documents, and there are now commercially available tools that use ML (including supervised and unsupervised learning) to find appropriate legal documentation to support a case.Footnote 59
III State of the Art and Challenges
AI, particularly ML, has enormous potential. As noted above, this arises out of its ability to generalise from the data used for training to new situations; this is perhaps the strongest justification for the use of the term ‘intelligence’. However, some would argue that the potential hasn’t been fully realised.Footnote 60 The aim in this section is to try to characterise the state of the art in the use of ML, noting that it differs across application domains, and to identify some of the challenges in achieving more widespread use of the technology. The focus here is on technical and ethical issues, rather than on legal challenges.
A State of the Art
ML is already pervasive in a range of online applications (IT systems). As indicated above, online platforms, which many use daily, such as Google search and online shopping, make massive use of ML.Footnote 61 Arguably, Google’s search engine is one of the most impressive applications of ML providing extensive results to arbitrary textual queries in a very short space of time. This is all the more impressive as the learning is necessarily unsupervised. As well as good algorithms, this is made possible by access to massive computational power in data centres (sometimes referred to as ‘cloud computing’).Footnote 62
Such capabilities are becoming ‘commoditised’ and companies, for example, Amazon Web Services,Footnote 63 now provide access to data centres as a commercial offering. Further, the software to build ML applications is now widely available. For example, TensorFlow,Footnote 64 originally developed by Google is readily available; it can be used to build applications with a wide range of ML models including NNs, although it still requires extensive programming skills; there is also support for developing popular classes of system such as recommenders.
Further, there is a growing availability of skills to develop such systems with most computer science departments in universities teaching ML at undergraduate and postgraduate level. Thus, the ingredients are there for widespread development of AI and ML applications.
Most application domains where ML is being applied can be viewed as emergent or nascent. Whilst there are examples of systems, for example, in healthcare and legal practice, their adoption is not widespread. We will illuminate some of the reasons for this when we consider challenges.
There has been work on ML in embedded systems for some time, for example, in robotics, but the ‘autonomous vehicle challenge’ set up by the US Defense Advanced Research Projects Agency (‘DARPA’) about fifteen years ago can perhaps be seen as prompting a step-change in research in this area.Footnote 65 Although there is work using ML systems across transportation and in other sectors, for example, factory automation,Footnote 66 miningFootnote 67 and robotic surgery,Footnote 68 perhaps the greatest investment and development has been seen in AVs. Waymo (a spin off from Google) is now offering a ‘ride hailing’ service known as Waymo One;Footnote 69 whilst this service is only available in limited areas, for example, in Phoenix Arizona,Footnote 70 the service does operate without a human driver and the vehicles have now operated for about 20 million miles on the roads.Footnote 71 Waymo has also now forged partnerships with several automotive Original Equipment Manufacturers (‘OEMs’), for example, Jaguar Land Rover.Footnote 72 However, whilst extremely impressive, the systems are not ‘perfect’, and there have been several examples of vehicles getting confused or ‘stuck’, for example, by traffic cones.Footnote 73
Note that these systems are computationally expensive (particularly for image analysis)Footnote 74 and are only practicable because of the availability of super-computer levels of performance at affordable prices.Footnote 75 Further, computational power is doubling roughly every eighteen monthsFootnote 76 which should facilitate the broader adoption of ML.
B Challenges
There are many challenges in developing ML-based systems, so that they can be used with confidence that their behaviour will be sound, safe, legal, and so on, where their use can give rise to harm. The aim here is to identify some of the key technical challenges and to outline some of the possible approaches to addressing these challenges.
First, and most fundamentally, there is a transfer of decision-making or responsibility for recommending a course of action from a human to a computer and its ML components. From a legal perspective, this raises issues about agency and liability which are discussed elsewhere in this volume.
Second, humans have a semantic model, for example, know what a bicycle is and its likely behaviour; computers, even those incorporating ML, do not have these models.Footnote 77 Similarly, humans have contextual models, for example, know what a roundabout is and the effects on driver behaviour, and the ML does not.Footnote 78 These semantic and contextual models allow humans to generalise beyond their experience to reliably deal with new situations. However, for systems using ML the lack of such models can contribute to ‘gaps’ between what is required and what is achieved, which may be significant in engineering, ethical and legal terms.Footnote 79 The solution to this is to encode enough additional information in the systems to cope with the limitations in the ML components to enable effective operation – note that this is potentially feasible as we are considering ‘narrow AI’ not AGIFootnote 80 – but, as the example of the Waymo getting stuck encountering traffic cones shows, doing this remains a major challenge.
Third, the way the ML systems work, generalising from training data, identifies correlations not causation.Footnote 81 A recent studyFootnote 82 used ML to assess the relationship between body shape and income, and identified correlations which differ across genders, for example that obesity in females correlates with lower income. It would be a mistake, however, to infer that body shape causes low income – it may be that those on low income cannot afford a good diet and that might lead to obesity. Further, there may be other causally relevant factors that have not been considered in the ML model. This does not mean that the ML model is wrong; just that care needs to be taken when acting on the outputs of the ML model.
Fourth, the learnt ML models are ‘opaque’, that is not amenable to human scrutiny.Footnote 83 This means that it is hard to understand why the ML models produce their outputs. This can, in turn, give rise to doubts – why was that recommendation made, and was it biased? This has legal implications, for example, in terms of complying with the General Data Protection Regulations,Footnote 84 as well as ethical ones in terms of fairness. A partial solution is via so-called explainable AI methods, where simpler approaches are used to make the workings of the ML model human interpretable.Footnote 85 One of the most commonly used explainable AI methods is feature importance which illustrates the relative weight of each input feature for the ML model as a whole (global importance) or for a particular output (local importance).Footnote 86 This is illustrated in Figure 1.4, for a system concerned with weaning intensive care patients from mechanical ventilation. Here, the longer bars show greater influence of that input feature on the ML model output, with those bars close to zero length being of least importance.
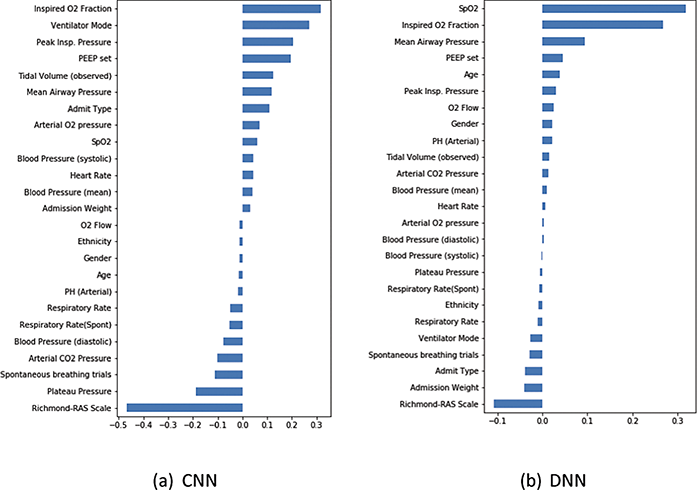
Figure 1.4 Global feature importance for CNN and fully connected DNN
McDermid, Jia, Porter and Habli, ‘Artificial Intelligence Explainability: The Technical and Ethical Dimensions’ (n 49).
This figure is for the two ML models shown in Figure 1.3. The two ML models have similar performance as shown in Figure 1.3, but the feature importance is quite different. Clinicians can judge the relevance and validity of these weightings to see which, if either, of the ML models is preferable. It is also notable that gender, ethnicity, and age are close to zero (low importance) for the CNN but age and gender in the fully connected DNN are relatively important, so this model might be thought to show bias. Care needs to be taken here. Age and gender might be clinically relevant, so a judgement about whether a system is biased or not needs to be considered carefully; in this case, ethical considerations need to be treated alongside clinical ones.
Fifth, there is an issue of trust and human control over the system employing ML. As noted above, some ML systems produce outputs with a probability; in all cases, there is uncertainty in the accuracy of the results.Footnote 87 Users should be (made) aware of this intrinsic uncertainty. However, even if they are aware, there can be automation bias where users tend to trust the system’s outputs without questioning them.Footnote 88 Further, the user might have no practical way of cross-checking the output of the ML system – they might not have access to the ‘raw’ data and there may simply be insufficient time to assess the data and to intervene. Such issues might, in part, be addressed using techniques such as explainable AI methods but there remain legal and ethical issues, for example, the ethical conditions for carrying responsibility might not be met for those who carry legal responsibility for the effects of using the systemFootnote 89.
Sixth, many embedded systems operate in situations where they can pose a threat to human health or safety, for example, in unmanned aircraft for reconnaissance.Footnote 90 However, this is perhaps most apparent with AVs although it can arise in other cases, for example, robotic surgery. Figure 1.5 presents a partial timeline for the accident caused by an Uber ATG vehicle in March 2018 in Tempe Arizona that led to the death of Elaine Herzberg.Footnote 91 This example enables us to illustrate the importance of some of the concepts introduced earlier.

Figure 1.5 Partial timeline in Uber Tempe accident
Figure 1.5 shows the positions of Elaine Herzberg and her bicycle (labelled as pedestrian) and the Uber ATG vehicle (shown in green) at four times prior to the impact. The Highway Accident Report published by the National Transportation Safety Board stated that the Automated Driving System ‘never accurately classified her as a pedestrian or predicted her path’.Footnote 92 Critically, the predicted motion depended on the classification so when she was on one of the left turn lanes and classified as a car, she was predicted to leave the main road. Her movement history was discarded each time the vehicle reclassified her so at no time was her trajectory predicted as crossing the road. An impending collision was predicted 1.2S before the actual accident took place but the system did not act automatically (due to a concern over false positives leading to unnecessary emergency braking) with the expectation that the safety driver would respond. The safety driver (Rafaela Vasquez) didn’t initiate timely braking – reportedly she was not paying attention, perhaps due to lack of training or due to automation bias (the vehicle had already successfully navigated the ‘circuit’ on which she was driving once). However, it may have been the case that she had insufficient time to react – see the previous discussion about legal and ethical responsibility. Uber was found to have no (legal) (criminal) case to answer for the accident, but the safety driver is facing a trial for negligent homicide.Footnote 93 There is no currently accepted solution to assuring the safety of autonomous systems.Footnote 94 There is relevant work on the assurance of the ML components of autonomous systemsFootnote 95 but this remains an active area of research.
Finally, ML models can be set up to continue learning in operation – sometimes referred to as online learning.Footnote 96 This is, of course, analogous to the way humans learn. Most current ML-based systems learn off-line with the ML models being updated periodically by the developers (perhaps via over-the-air updates in the case of AVs).Footnote 97 As systems move towards online learning this introduces new challenges including how to assure continued safety, and it raises further questions about human control and agency.
IV Conclusions
AI, especially ML, is already a key component of many systems affecting society – not least online search and other online services. The capability of current ML systems and the trends in the power of computer systems means that these uses are likely to expand over time from current applications which are predominantly IT systems to include embedded systems, for example, in AVs, implantable medical devices and manufacturing. Further, the range of application domains is likely to expand. These capabilities bring with them challenges in technical, ethical and legal terms.
Technically, the biggest challenge is to develop and assure systems employing ML models so that they can be used with confidence that they are safe and have other desirable properties, including being free from bias. This links to the broader issues of trust and the ability for humans to exercise informed control or consent when this is appropriate. There are many legal questions, including those around the notion of agency and liability. This is a complex and intellectually challenging area, but also one requiring urgent attention since systems employing ML models are already being used and there is potential for considerable growth in applications.
This chapter has tried to give an accessible (gentle) introduction to the concepts of AI and ML for lawyers. Some technical details have been presented, for example, explaining the concept of feature importance for ML models, to give an idea of the depth and subtlety of the issues raised by the use of AI and ML models. It is hoped that this makes clear the need to take a multi-disciplinary approach to studying and evolving the legal framework relating to AI and ML and gives an adequate basis to help lawyers engage in constructive discussions with technical specialists.





