


1 Introduction
Names are associated with group identity around the world. An important marker of identity is religion which shapes preferences, attitudes, and political and economic outcomes (Guiso, Sapienza, and Zingales Reference Guiso, Sapienza and Zingales2003; Iyer Reference Iyer2016). In India too, it is associated with socioeconomic status, health outcomes, electoral behavior, and conflict (Bhalotra, Valente, and Van Soest Reference Bhalotra, Valente and Van Soest2010; Chhibber and Shastri Reference Chhibber and Shastri2014; Iyer Reference Iyer2018). Despite its salience, there is a lack of fine-grained data on religion in South Asia.Footnote 1 Therefore, much of the research relies partly or wholly on manual classification. For example, Sachar et al. (Reference Sachar2006) infer religion using person names to highlight economic and social deprivations faced by Indian Muslims. Others use electoral candidate names to examine the effect of co-religiosity on voting behavior and of Muslim representation on education and health outcomes of constituents (Bhalotra et al. Reference Bhalotra, Clots-Figueras, Cassan and Iyer2014; Heath, Verniers, and Kumar Reference Heath, Verniers and Kumar2015). Similarly, Field et al. (Reference Field, Levinson, Pande and Visaria2008) use names in electoral rolls to examine the effect of residential segregation on Hindu–Muslim violence during the 2002 Gujarat riots. This dependence on manual classification limits studies on religious demography to coarse or small scale analyses.
In this paper, we bridge this gap by training character-sequence-based machine-learning models that infer religion using person names alone. While our methods are more generally applicable for predicting other markers of group identity such as race, gender, ethnicity, caste, and nationality, we demonstrate their strength by inferring religion in the Indian context as a case in point.Footnote 2 In India, names are well known to signify religious identity. This is evident in Gaikwad and Nellis (Reference Gaikwad and Nellis2017) who assign Hindu or Muslim sounding names to fictitious internal migrants and elicit attitudes of natives toward them in a face to face survey in Mumbai. Moreover, name lists along with precise addresses or locations are often publicly available. Sources such as electoral rolls, below poverty line (BPL) lists, land records, and beneficiary lists of social security programs such as job cards for Mahatma Gandhi National Rural Employment Guarantee Act (MGNREGA), Swachh Bharat Mission (SBM), etc. provide multiple related names and locations for millions of households but do not disclose religion. Our work, therefore, can be used to construct individual level datasets incorporating names to study religious demography and uncover discrimination in the allocation of targeted welfare programs.Footnote 3 Inferring religion from names on social media platforms that lack demographic attributes can also guide network and sentiment analysis, and detect religious polarization.
Currently the only viable alternative to manual classification of names into religion is provided by Susewind (Reference Susewind2015), who uses a string matching algorithm to predict religion based on a reference list. However, being a dictionary based method, the algorithm suffers from low coverage; it cannot classify unseen names and is not resilient to spelling variations. We show that character-based machine-learning models outperform the existing work while being orders of magnitude faster. Our models can also classify unseen names with high accuracy and account for spelling variations.
Due to their distinct linguistic origins, Muslim and non-Muslim names are particularly interesting. While Classical Arabic is the liturgical language of Islam, Sanskrit is the principal liturgical language of Hinduism. Buddhism, Sikhism, and Jainism are also rooted in Sanskrit or Indic languages Pali, Punjabi, and Magadhi Prakrit, respectively. The distinct orthographies of the linguistic roots manifest in person names too. Islamic names are derived from Classical Arabic, Persian, and Turkish whereas non-Muslim names are rooted in Sanskrit or Dravidian languages (Emeneau Reference Emeneau1978; Schimmel Reference Schimmel1997). We explain the classification decisions of one of our models and systematically uncover prominent linguistic differences between Muslim and non-Muslim names by applying the layer-wise relevance propagation (LRP) technique from the field of explainable artificial intelligence (Bach et al. Reference Bach, Binder, Montavon, Klauschen, Müller and Samek2015). The model associates typical character patterns, meaningful prefixes, and suffixes in Classical Arabic and Sanskrit/Dravidian languages with Muslim and non-Muslim names, respectively.
The politics and economics of Hindu–Muslim relationship is also of interest to social scientists (Bhalotra et al. Reference Bhalotra, Clots-Figueras, Iyer and Vecci2021; Mitra and Ray Reference Mitra and Ray2014; Nellis et al. Reference Nellis2016). Indian Muslims, despite being a sizable minority (14% of population), are persistently under-represented in office at both the state and national levels. Consequently, they suffer economic and social backwardness (Sachar et al. Reference Sachar2006). Compared to the Hindu majority, Indian Muslims have lower access to publicly provided goods such as tap water (64% vs. 70% for Hindus; NSS 69th round, 2012) and healthcare (2.1% vs. 5.1% for Hindus; NFHS-3), and have lower education attainment (Kundu Reference Kundu2014). We apply our model to candidates’ names from large-scale data on national- and state-level elections in India and highlight the puzzling trend of declining Muslim representation despite a consistent increase in their population share.
2 Names and Group Identity
A substantial literature leverages names as signals of group identity. Several studies use fictitious resumes to find evidence of labor market penalty associated with African-American or foreign sounding names in North America (Bertrand and Mullainathan Reference Bertrand and Mullainathan2004; Oreopoulos Reference Oreopoulos2011) and Arabic names in France (Adida, Laitin, and Valfort Reference Adida, Laitin and Valfort2010). In response, the discriminated minorities might change their names to signal an intent to assimilate (Algan et al. Reference Algan, Malgouyres, Mayer and Thoenig2022; Biavaschi, Giulietti, and Siddique Reference Biavaschi, Giulietti and Siddique2017; Fouka Reference Fouka2019) or assert their cultural identity via names (Fouka Reference Fouka2020).
Our work is related to the literature that infers group identity from names. Harris (Reference Harris2015) uses geocoded person names to estimate local ethnic compositions in Kenya by modeling the ethnic proportions of each unique observation in a surname list. Elliott et al. (Reference Elliott, Morrison, Fremont, McCaffrey, Pantoja and Lurie2009) introduce Bayesian Improved Surname Geocoding (BISG) which infers an individual’s race given their surname and geolocation using Bayes’ rule.Footnote 4 Imai and Khanna (Reference Imai and Khanna2016) improve upon this by combining surnames and geolocation with age, gender, and party registration using Florida voter registration data.Footnote 5 BISG requires information on racial/ethnic compositions at each precise geolocation. This might be useful when identity groups are spatially segregated.Footnote 6 Given residential segregation along religious lines in India, geographic information might be useful in this context as well.Footnote 7 However, geocoding can be expensive and is often inaccurate. For reference, Google API costs $5.00/1,000 addresses. Clark, Curiel, and Steelman (Reference Clark, Curiel and Steelman2021) use ESRI 2013 street address geocoder which was unable to geocode 4.6% of addresses in Georgia, United States. Moreover, outside the United States—especially in developing countries—information on group composition may not even be available at geographically precise levels making geocoding infeasible. In such contexts, inferring group identity only from names may be useful. When geocoding is feasible, our character-based models can be incorporated within the existing BISG packages to improve performance over the surname dictionaries.
In contrast to race/ethnicity inference, religion inference has only received a limited attention. The case of religion is distinctive, especially given that people can have multiple races or ethnicities when they descend from more than one racial group, but only a single religion even in case of interfaith marriages.Footnote 8 Moreover, in India, interfaith marriages are rare. A second distinction that makes religion inference from names interesting is that, unlike race, religion entails codified sets of beliefs and practices for its adherents. This is also reflected in personal names for which there are prescriptive guidelines across different religions. For example, in South Asia, Islamic naming guidelines prescribe Arabic names taken from the Quran and recommend avoiding resemblance to Hindu names (Metcalf Reference Metcalf2009). On the other hand, there has been a shift in naming conventions across racial groups in the United States over the past few decades. Fryer Jr and Levitt (Reference Fryer and Levitt2004) discuss how Blacks living in predominantly White neighborhoods increasingly adopt White sounding names than Blacks in racially segregated neighborhoods. Therefore, we expect names across religions to remain more distinctive than across racial/ethnic groups.
Our approach is also related to several papers in machine learning that infer demographic attributes from names. Early papers in this literature almost exclusively use dictionary-based methods which suffer from lack of coverage on unseen names or spelling variations (Mateos Reference Mateos2007). To address this, others use sub-name features such as character n-grams, prefixes, suffixes, and phonetic patterns. These are used to infer nationality, gender, and ethnicity using hierarchical decision trees and hidden Markov models (Ambekar et al. Reference Ambekar, Ward, Mohammed, Male and Skiena2009), Bayesian inference (Chang et al. Reference Chang, Rosenn, Backstrom and Marlow2010), multinomial logistic regression (LR) (Torvik and Agarwal Reference Torvik and Agarwal2016; Treeratpituk and Giles Reference Treeratpituk and Giles2012), and support vector machine (SVM) (Knowles, Carroll, and Dredze Reference Knowles, Carroll and Dredze2016). Lee et al. (Reference Lee, Kim, Ko, Choi, Choi and Kang2017) and Wood-Doughty et al. (Reference Wood-Doughty, Andrews, Marvin and Dredze2018) avoid manually crafting sub-name features and use neural networks that learn these features automatically from the character sequence in names. While Bayesian inference and hidden Markov models are generative classifiers that model the probability of an output class, decisions trees, LR, SVM, and neural networks are discriminative classifiers that learn a boundary separating the classes and are well suited to classification tasks. Our experiments reaffirm that discriminative classifiers outperform dictionary-based and generative model baselines.
3 Data
3.1 REDS
We use the Rural Economic & Demographic Survey (REDS) data collected by the National Council of Applied Economic Research to train our models. It constitutes a nationally representative sample of over 115,000 rural households from 17 major Indian states surveyed in 2006. We use the respondent’s and their parent/spouse’s name and self-reported religion. We label a person as Muslim or non-Muslim and split the data into training, validation, and test sets in the ratio 80:10:10.Footnote 9
3.2 U.P. Rural Households
One concern with self-reporting in REDS could be that some people might not accurately reveal their religion, for example, due to fear of persecution. This might be a source of noise, and we expect that our models would have been even more accurate if there was no misreporting. Therefore, we use a second test set to further validate our models. Due to a lack of publicly available datasets mapping names to religion, we annotate the religion of 20,000 randomly selected household heads from a dataset comprising over 25 million households in rural Uttar Pradesh (U.P.)—the largest state of India.Footnote 10 Hindus (comprising 83.66%) and Muslims (15.55%) are the predominant religious groups in rural U.P. and form over 99.2% of the population. Therefore, the annotators classify the religion as either non-Muslim (largely comprising Hindus) or Muslim.
The annotations are done independently by the two annotators using the names of household heads and their parent/spouse. The inter-annotator agreement rate is 99.91% (Kohen’s Kappa
 $\kappa $
= 0.9959) indicating that names strongly reflect perceived religion.Footnote 11 We further validate the veracity of annotations by manually classifying randomly selected 1,000 person names in REDS as Muslim or non-Muslim. The annotations are accurate for 99.2% cases indicating large overlap between self-reported religion and annotations.
$\kappa $
= 0.9959) indicating that names strongly reflect perceived religion.Footnote 11 We further validate the veracity of annotations by manually classifying randomly selected 1,000 person names in REDS as Muslim or non-Muslim. The annotations are accurate for 99.2% cases indicating large overlap between self-reported religion and annotations.
Table 1 shows descriptive statistics for both the datasets. REDS contains nearly 99,000 unique names (
 $\approx 86\%$
of observations) while the corresponding figure is over 12,000 (
$\approx 86\%$
of observations) while the corresponding figure is over 12,000 (
 $\approx 62\%$
) for U.P. Rural Households dataset. The average name length is 15.6 and 8.8 characters in the two datasets, respectively. The shorter name length for the U.P. Rural Households dataset is due to nearly 60% observations containing information only on an individual’s first name. In contrast, REDS includes both first and last names for 95% individuals.Footnote 12 The religious composition in the REDS data closely mirrors the national level rural composition.Footnote 13
$\approx 62\%$
) for U.P. Rural Households dataset. The average name length is 15.6 and 8.8 characters in the two datasets, respectively. The shorter name length for the U.P. Rural Households dataset is due to nearly 60% observations containing information only on an individual’s first name. In contrast, REDS includes both first and last names for 95% individuals.Footnote 12 The religious composition in the REDS data closely mirrors the national level rural composition.Footnote 13
Table 1 Descriptive statistics.

Figure 1 shows relative character frequency distributions representing the ratio of average frequency of each character to average name length across a religious group in REDS. The alphabets “F”, “Q”, and “Z” are characteristic of Muslim names. They represent phonemes [f], [q], and [z], respectively, that do not exist in the Sanskrit phonemic inventory. On the other hand, “P”, “V”, and “X” are rare among Muslim names owing to the absence of phonemes [p], [ʋ], and [ʂ] in Classical Arabic. Hindu, Sikh, Jain, and Buddhist names have similar distributions owing to their common linguistic origins.Footnote 14

Figure 1 Relative character frequency heatmaps for REDS data.
4 Models
We make predictions using single and two names (i.e., primary and parent/spouse’s name) in each household. We preprocess the raw data by upper-casing and removing special characters, numbers, and extra spaces. For single name models, we also include parent/spouse’s name as a primary name to enrich our training set as it is highly likely that they share the same religion. Since REDS is a nationally representative survey, we keep duplicates to account for frequency of each name within a religion. We describe our models below and defer technical details to Section B of the Supplementary Material.
4.1 Baseline: Name2community
We use a dictionary-based classification algorithm Name2community proposed by Susewind (Reference Susewind2015) as our first baseline. The algorithm first counts the frequency of each name part (i.e., the first name, last name, etc.) within a reference list specific to each religion based on spelling and pronunciation. These two frequencies are combined to obtain a certainty index for each name part for each religion. These indices are then aggregated over all the name parts to get the certainty index for the entire name. Finally, each name is assigned the religion having the highest certainty index.Footnote 15
4.2 Baseline: Language Models
For our second baseline, we follow Jensen et al. (Reference Jensen, Karell, Tanigawa-Lau, Habash, Oudah and Fairus Shofia Fani2021) who train language models to infer religiosity from Indonesian names. A language model computes the probabilities of n-grams from a training corpus. It then uses a method such as maximum likelihood estimation to predict the probability of the next character or word in a given sequence. Language models have previously been used for a distinct task of language and dialect identification from text pioneered by Cavnar and Trenkle (Reference Cavnar and Trenkle1994) and improved upon by Vatanen, Väyrynen, and Virpioja (Reference Vatanen, Väyrynen and Virpioja2010) and Jauhiainen, Lindén, and Jauhiainen (Reference Jauhiainen, Lindén and Jauhiainen2017, Reference Jauhiainen, Lindén and Jauhiainen2019a).Footnote 16 We train two separate language models
 $LM_M$
and
$LM_M$
and
 $LM_{NM}$
on the set of Muslim and non-Muslim names, respectively. We then compute perplexity—a standard metric for evaluating language models—of both the models for a given name. Perplexity measures how surprised a model is on seeing a name in the test set. Therefore, we classify a name as Muslim if the perplexity score of
$LM_{NM}$
on the set of Muslim and non-Muslim names, respectively. We then compute perplexity—a standard metric for evaluating language models—of both the models for a given name. Perplexity measures how surprised a model is on seeing a name in the test set. Therefore, we classify a name as Muslim if the perplexity score of
 $LM_M$
is less than that of
$LM_M$
is less than that of
 $LM_{NM}$
for that name and non-Muslim otherwise.Footnote 17
$LM_{NM}$
for that name and non-Muslim otherwise.Footnote 17
4.3 Bag-of-n-Grams Models
For bag-of-n-grams models, we first convert each name to its character n-gram feature representation using term frequency-inverse document frequency (TF-IDF).Footnote 18 TF-IDF captures the importance of each character n-gram (or token) in a document normalized by its importance in the entire corpus without taking into account its relative position in the document. We then use linear SVM and LR classifiers with L2 regularization to predict religion from these feature vectors. Since the classes are highly imbalanced, we use balanced class weights.
4.4 Convolutional Neural Network
We experiment with several neural network architectures popular in text classification based on Convolutional Neural Network (CNN) and Long Short-Term Memory network (LSTM). We find that character-based CNN gives better performance on our task. Originally designed for computer vision, CNN is known for its ability to extract important local features using far fewer parameters compared to other neural models (LeCun et al. Reference LeCun1989). Its architecture is also highly parallelizable making it faster. CNN has attained much success in natural language processing research since Collobert et al. (Reference Collobert, Weston, Bottou, Karlen, Kavukcuoglu and Kuksa2011) who apply it to multiple NLP tasks for improved speed and accuracy.Footnote 19 Our model takes character sequence in a name as input using an architecture similar to Zhang, Zhao, and LeCun (Reference Zhang, Zhao and LeCun2015) and outputs the probabilities of the name belonging to each religion.Footnote 20
5 Model Decisions and Linguistic Roots
Machine-learning models are often black boxes—they are good at predicting an outcome, but the reason for their predictions is unknown. It is important to explain how a model arrives at a decision to assess its validity and generalizability, and to foster trust in it. We apply LRP on the REDS test set to identify the character patterns distinguishing Muslim and non-Muslim names in India.
LRP maps the output of a classifier back to the input characters and computes the contribution of each input character to the final prediction of a machine-learning model. In our context, it answers what character patterns make a name Islamic or non-Islamic. Arras et al. (Reference Arras, Horn, Montavon, Müller and Samek2017) apply LRP to text data and show that though both SVM and CNN models performed comparably in terms of classification accuracy, the explanations from CNN were more human interpretable. Therefore, we study the decisions of our CNN model using the LRP implementation of Ancona et al. (Reference Ancona, Ceolini, Öztireli and Gross2018).Footnote 21
Table 2 reports LRP heatmaps showing classification decisions of CNN model on distinctive names from REDS test set. Characters with positive relevance scores with respect to Muslim class are labeled red, while those with negative relevance scores are blue, that is, they have positive relevance for non-Muslims. The left panel shows examples of correctly classified Muslim names. The LRP relevance scores are able to identify phonemes characteristic in Classical Arabic such as “F” (column 1, examples 1, 4–6), “Q” (column 1, examples 2 and 4), “Z” (column 1, example 7), and “KH” (column 1, examples 8 and 9). Meaningful suffixes such as “UDDIN” (column 1, example 3) meaning “(of) the religion/faith/creed” that are highly characteristic of Arabic names are also detected as relevant for the Muslim class. The right panel shows correctly classified non-Muslim names. The characters “P” (column 2, example 1), “V” (column 2, example 2), and “X” (column 2, example 9) are highly relevant for non-Muslims.
Table 2 Heatmaps for Muslim and non-Muslim names using LRP on distinctive REDS test set names.

The relevance of a character toward a class also depends on its context. For example, the neutral character “D” is highly relevant to the Muslim class when it is a part of “UDDIN”, while it becomes highly relevant to non-Muslim class when it forms the word “DEV” (meaning god in Sanskrit) (column 2, examples 2, 3, and 8).Footnote 22 We notice that the relevance of the characters “{” and “}” signifying the beginning and end of a name part, respectively, is also modulated by the character sequences following and preceding them.
In Table 3, we show 10 most relevant unigrams, bigrams, and trigrams for both the classes conditional on n-grams not being rare, that is, occurring at least 25 times in the test set. For this, we apply LRP on all test set names and average the relevance scores of each n-gram. The linguistic differences discussed in Section 3 are indeed systematically captured by the model. Unigrams “F”, “Q”, and “Z” are most predictive of the Muslim class, whereas “X”, “V”, and “P” are most relevant for the non-Muslim class. The bigram “KH” corresponding to phoneme [x] is highly relevant for the Muslim class. The character positions are also important in a name part. We find that “F}” and “B}” are highly relevant to the Muslim class implying that the characters “B” or “F” at the end of a name part characterize Muslim names. On the other hand, the bigram “PR” is a distinguishing feature of the non-Muslim class, especially at the beginning of a name part, denoted by the trigram “{PR”. This is meaningful as “PR” is a Sanskrit prefix which when added to an adjective or a noun accentuates its quality. Similarly, the bigram “VV” has positive relevance for non-Muslim class as it forms part of the Dravidian honorific suffix “AVVA” added to female names. The trigram “DDI” is considered highly relevant by our model and forms part of the suffix “UDDIN” in Arabic names. These examples illustrate that LRP relevances are very reliable at finding meaningful character n-grams that distinguish the two classes and highlight the linguistic differences depicted by the names.Footnote 23
Table 3 Most relevant n-grams among Muslim and non-Muslim names.

6 Results
We report the results in Table 4 for both REDS and U.P. Rural Households test sets. For evaluation, we use Precision (P), Recall (R), and their harmonic mean (
 $F_1$
) defined as follows:
$F_1$
) defined as follows:
 $$ \begin{align*} P = \frac{TP}{TP+FP}, \quad R = \frac{TP}{TP+FN}, \quad F_1 = \frac{2*P*R}{P+R}, \end{align*} $$
$$ \begin{align*} P = \frac{TP}{TP+FP}, \quad R = \frac{TP}{TP+FN}, \quad F_1 = \frac{2*P*R}{P+R}, \end{align*} $$
where TP = #True Positives, FP = #False Positives, and FN = #False Negatives. In our context, precision measures what percentage of individuals predicted to have a particular religion actually belong to that religion. Recall measures what fraction of members actually belonging to a religion is classified under that religion. The two metrics are especially useful for imbalanced classes. Precision will be low if there are too many false positives and recall will be low in case of too many false negatives. Their harmonic mean
 $F_1$
captures the trade-off between the two types of errors.
$F_1$
captures the trade-off between the two types of errors.
Table 4 Results on test sets. Standard errors are reported in parentheses. The highest score for a metric within a panel is marked in bold. The evaluation for Name2community and Language Model is based on names classified unambiguously.
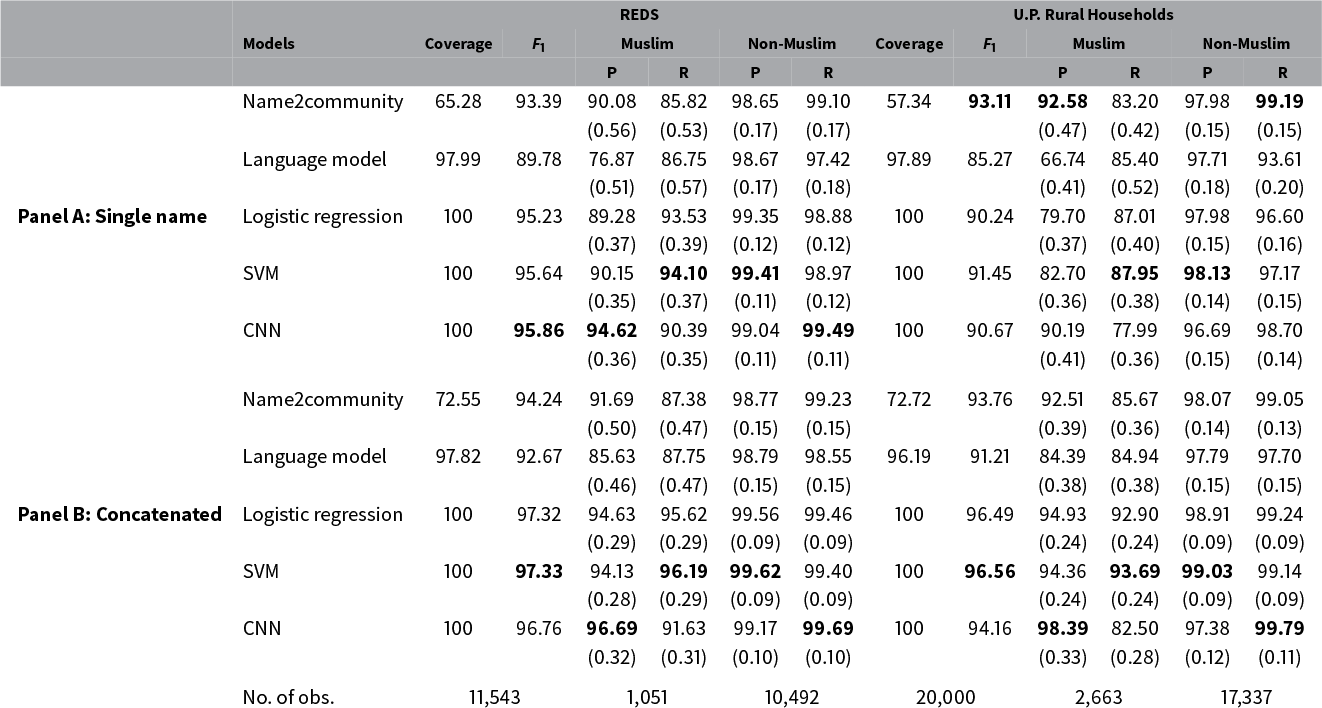
Panel A of Table 4 shows the results when predicting religion using only a single name. Name2community can only classify less than two-thirds of observations in both the test sets. The scores in the table are based on the observations classified unambiguously. We also experiment by assigning the majority religion to the ambiguous predictions of Name2community for tie-breaking. This reduces the macro-average
 $F_1$
score to 82% and 75% for the two datasets, respectively.
$F_1$
score to 82% and 75% for the two datasets, respectively.
On the other hand, bag-of-n-grams models perform exceptionally well and have 100% coverage. Among the names that could be assigned a class using Name2community, the overall accuracy is significantly higher for LR, SVM, and CNN for both the test sets. In our experiments, Name2community was also orders of magnitude slower than character-based models. It could only predict 0.4 names/second. In contrast, LR, SVM, and CNN predicted 50,000–500,000 names/second. Therefore, predicting religion for the entire REDS test set comprising 11,543 names took over 8 hours using Name2community for single name model and nearly 13 hours with concatenated names. On the other hand, LR, SVM, and CNN only took 0.035–0.4 seconds to predict all the names. This makes Name2community less scalable to large datasets that may comprise millions of observations and further limits its viability as a general religion detector for South Asia. The coverage for language model is almost perfect, except in a few cases where the perplexity is infinity. It could predict approximately 2,500 names/second, which is slower than other character-based models but reasonable compared to Name2community. However, the performance of language model is worse for both the test sets with much lower
 $F_1$
scores. Comparing among the bag-of-n-grams models and CNN reveals that the accuracy of SVM and CNN is significantly higher than LR at the 5% level of significance. The performance of SVM and CNN is comparable. They also have higher macro-average
$F_1$
scores. Comparing among the bag-of-n-grams models and CNN reveals that the accuracy of SVM and CNN is significantly higher than LR at the 5% level of significance. The performance of SVM and CNN is comparable. They also have higher macro-average
 $F_1$
scores than LR, though the difference is small.
$F_1$
scores than LR, though the difference is small.
We note that performance is lower on U.P. Rural Households data compared to REDS. This might be due to the difference in name length distributions across the two datasets.Footnote 24 To verify this, we restrict our sample to observations having only a first name representing 60% of the U.P. Rural Households data and 5% of the REDS test set. The
 $F_1$
score for LR, SVM, and CNN reduces to approximately 85% and is now comparable for both datasets.Footnote 25 For observations having both first and last names, the
$F_1$
score for LR, SVM, and CNN reduces to approximately 85% and is now comparable for both datasets.Footnote 25 For observations having both first and last names, the
 $F_1$
score is around 96% and is again comparable for the two datasets. This leads us to expect that including the name of a relative such as parent/spouse might improve the performance of the models—especially for the U.P. Rural Households data for which a majority of individuals only have information on the first name.
$F_1$
score is around 96% and is again comparable for the two datasets. This leads us to expect that including the name of a relative such as parent/spouse might improve the performance of the models—especially for the U.P. Rural Households data for which a majority of individuals only have information on the first name.
The results improve when we enrich our data by concatenating individual names with their parent/spouse’s name (Panel B of Table 4). This is primarily driven by better identification of individuals for whom we only have the first name. The language model continues to perform worse than other character-based models. The
 $F_1$
score for CNN is now lower than LR and SVM. The overall accuracy is also lower for CNN with the difference being statistically significant at the 1% level. The recall for Muslim names is worse for CNN resulting in less balanced predictions. We also note that the coverage for Name2community increases by 7 percentage points for REDS and 15 percentage points for the U.P. Rural Households data. However, this is accompanied by only a marginal increase in the macro-average
$F_1$
score for CNN is now lower than LR and SVM. The overall accuracy is also lower for CNN with the difference being statistically significant at the 1% level. The recall for Muslim names is worse for CNN resulting in less balanced predictions. We also note that the coverage for Name2community increases by 7 percentage points for REDS and 15 percentage points for the U.P. Rural Households data. However, this is accompanied by only a marginal increase in the macro-average
 $F_1$
score. Thus, there are limited gains from providing richer data to Name2community.
$F_1$
score. Thus, there are limited gains from providing richer data to Name2community.
Figure 2 shows the performance across models in predicting the aggregate Muslim share. For this, we follow the approach in Clark et al. (Reference Clark, Curiel and Steelman2021) and bootstrap 10,000 draws with a sample size of 1,000 per draw (
 $\approx $
population in a typical polling station in India). We then take the absolute difference between actual Muslim count and estimated Muslim count. We find that Name2community and language model almost always perform worse in estimating aggregate religious composition. In contrast, SVM and LR perform better and both have similar accuracy. The performance of CNN is comparable to LR and SVM for REDS. However, LR and SVM slightly outperform CNN for the U.P. Rural Households dataset. The differences in median accuracy between SVM and Name2community are 4.37 and 27.68 per 1,000 for REDS and U.P. Rural Households datasets, respectively, for single name models. The corresponding differences are 4.72 and 19.04 for concatenated models. These differences are sizeable and indicate that improved coverage and accuracy of the character-based models are meaningful even when estimating aggregate Muslim shares. We report the density plots of effective number of imputed religions, defined as the inverse of Herfindahl index, at the individual level in Figures 6 and 7 in Section E of the Supplementary Material. They show that the level of uncertainty for Name2community is higher than character-based models. The variation of error rates with effective number of imputed religions, shown in Figures 8 and 9 in Section E of the Supplementary Material, indicates that average error increases with uncertainty in model predictions.
$\approx $
population in a typical polling station in India). We then take the absolute difference between actual Muslim count and estimated Muslim count. We find that Name2community and language model almost always perform worse in estimating aggregate religious composition. In contrast, SVM and LR perform better and both have similar accuracy. The performance of CNN is comparable to LR and SVM for REDS. However, LR and SVM slightly outperform CNN for the U.P. Rural Households dataset. The differences in median accuracy between SVM and Name2community are 4.37 and 27.68 per 1,000 for REDS and U.P. Rural Households datasets, respectively, for single name models. The corresponding differences are 4.72 and 19.04 for concatenated models. These differences are sizeable and indicate that improved coverage and accuracy of the character-based models are meaningful even when estimating aggregate Muslim shares. We report the density plots of effective number of imputed religions, defined as the inverse of Herfindahl index, at the individual level in Figures 6 and 7 in Section E of the Supplementary Material. They show that the level of uncertainty for Name2community is higher than character-based models. The variation of error rates with effective number of imputed religions, shown in Figures 8 and 9 in Section E of the Supplementary Material, indicates that average error increases with uncertainty in model predictions.

Figure 2 Density plots of absolute difference in reported and estimated religious counts per 1,000 people.
One might expect bias against women who take up their husbands’ names—especially in interfaith marriages. However, according to the 2019–2020 PEW Research Center survey less than 1% marriages in India are interfaith.Footnote 26 Furthermore, we restrict the sample to women for both the test sets and report the results in Table 10 in Section F of the Supplementary Material. The
 $F_1$
score is lower for single name models owing to a small fraction (10%) of women in the training data. However, LR, SVM, and CNN continue to outperform the baseline models. Therefore, character-based models have an advantage even when inferring the religion of women from names is of particular interest (as in Field, Jayachandran, and Pande Reference Field, Jayachandran and Pande2010). The performance improves substantially when we include the name of parent/spouse—who usually share the same religion—and becomes comparable to that of the unrestricted sample.
$F_1$
score is lower for single name models owing to a small fraction (10%) of women in the training data. However, LR, SVM, and CNN continue to outperform the baseline models. Therefore, character-based models have an advantage even when inferring the religion of women from names is of particular interest (as in Field, Jayachandran, and Pande Reference Field, Jayachandran and Pande2010). The performance improves substantially when we include the name of parent/spouse—who usually share the same religion—and becomes comparable to that of the unrestricted sample.
Summing up, character-based models perform better than Name2community and language model and can accurately infer religion at the individual/household level. Single name SVM and CNN perform slightly better than LR at the individual level. However, when estimating the aggregate composition, SVM and LR are comparable, while CNN performs slightly worse. Our preferred model is SVM given that CNN also requires extensive hyperparameter tuning, and therefore, might be harder to train. However, when probabilities are of interest, LR is preferable as SVM does not directly return probabilities. We also perform multi-religion classification. The character-based models still outperform Name2community across all the classes. See Section G of the Supplementary Material for a detailed discussion.

Figure 3 Muslim representation in Indian Politics during 1962–2021.
To illustrate the applicability of our methods in a different context, we also apply them to the task of race/ethnicity inference in the United States. We find that character-based models are substantially better than BISG at estimating the counts of Black voters who are the largest minority group, and therefore, more vulnerable to discrimination (Cikara, Fouka, and Tabellini Reference Cikara, Fouka and Tabellini2022). This may be especially useful for guiding studies on Black voter behavior and political representation (Cascio and Washington Reference Cascio and Washington2014; Washington Reference Washington2006). We discuss this in detail in Section A of the Supplementary Material.
7 Muslim Representation in India
In this section, we discuss an application of our work in the electoral context. We examine the temporal patterns of Muslim representation in the Indian legislature during 1962–2021. For this, we use the Indian Elections Dataset compiled by Agarwal et al. (Reference Agarwal2021). The dataset contains information on all the candidates and their electoral outcomes in the national- and state-level elections. The national elections data comprise 71,799 candidates in 8,277 races (4,524 unique winners), whereas the state-level data have 373,290 candidates in 54,143 races (34,924 unique winners). We classify candidate names using the binary SVM classifier. We exclude constituencies reserved for scheduled castes and scheduled tribes in our analysis.Footnote 27
We report the results in Figure 3. Figure 3a shows the results for the national elections. We find that the Muslim candidate share increased commensurately with the Muslim population share in India (based on the Census data). In contrast, the Muslim vote share stagnated and the share of Muslim legislators steadily declined. One possible explanation for this could be splitting of votes among different Muslim candidates. Figure 3b shows the aggregate results for state elections across India. Again, the share of Muslim candidates has increased with the overall Muslim population share. However, the vote share of Muslim contestants has remained almost constant. Muslims are underrepresented at both levels but the extent of under-representation is lower in state assemblies than at the national level. This could be explained by a combination of a higher Muslim vote share and a more proportionate mapping of vote share into seat share due to the smaller size of assembly constituencies in comparison to parliamentary constituencies.
8 Ethical Implications
Religion is a sensitive issue and religious minorities face unfair treatment in many parts of the world. For example, the 2004 French headscarf ban adversely affected the educational attainment and labor market outcomes of Muslim women (Abdelgadir and Fouka Reference Abdelgadir and Fouka2020). Characterized by strong communal politics, India is no exception to this. India’s Independence from colonial rule was accompanied by large-scale violence between Hindus and Muslims, and the underlying social tensions have persisted to date (Jha Reference Jha2013; Varshney and Wilkinson Reference Varshney and Wilkinson2016). Politicians have frequently weaponized these tensions for electoral gains (Wilkinson Reference Wilkinson2006). There is evidence of religious discrimination beyond politics too, for instance, in urban housing rental markets (Thorat et al. Reference Thorat, Banerjee, Mishra and Rizvi2015) and labor markets (Thorat and Attewell Reference Thorat and Attewell2007). Therefore, it is of utmost importance to include a discussion on ethical implications of our work.
A potential risk that comes with any new technology is that it may be used by nefarious actors. In our case, one could argue that the inferences made by our models could exacerbate religious discrimination and violence. This might also pose a risk to people incorrectly classified among the targeted group. However, as discussed, religious connotations of names are well known in India. This means that while making individual level decisions such as hiring or renting property, employers, and landlords do not require an algorithm to identify religion. Likewise, local rioters can easily use publicly available name-lists to manually identify religion with near perfect accuracy. Moreover, government actors already have access to detailed information on religion through the Indian Census and other sources. Therefore, the algorithm is less relevant for individual actors or the government.
On the other hand, by making data more accessible to researchers, we expect our work will help highlight any discrimination and deprivations experienced by minorities. This could, in turn, help formulate policies to protect vulnerable groups. Therefore, we expect the benefits of such a technology to outweigh the potential harms. We caution that names may not strictly correspond to religious or other identity groups. Therefore, our classification exercise should be interpreted as a probabilistic rather than a rigid mapping.
9 Conclusion
We infer religion from South Asian names using character-based machine-learning models. While dictionary-based methods suffer from slow speed, low coverage, and low accuracy, character-based models perform exceptionally well and can easily be scaled to massive datasets. Given the lack of fine-grained data on religion and abundance of public name lists, this is a viable way to generate individual level data on group identity and also obtain precise group composition estimates. We apply our methods to the question of Muslim representation in India and observe a declining trend despite a rise in their population share. We use LRP to explain the predictions of one of our models and detect linguistic differences in names across religions. More than 40 years back, Emeneau (Reference Emeneau1978) observed that exhaustive studies on South Asian onomastics could only be undertaken with the aid of sophisticated computer programs due to the sheer size of the population. We hope that our analysis motivates more in-depth linguistic studies.
More broadly, this work can serve as a methodological guide outside South Asia to identify groups for whom the underlying names might have different linguistic roots. For example, in Latin America, White names reflect the predominant language (Spanish) spoken by them while the indigenous names strongly reflect indigenous languages (Guarani, Quechua, Nahuatl, and Aymara, etc.). Similarly, in Nigeria, Hausa names belonging to the Afro-Asiatic family are distinct from Yoruba and Igbo names having roots in Niger-Congo linguistic family. We also demonstrate that our models can aid the existing BISG packages in the United States—replacing surname dictionaries for calculating prior probabilities of an individual’s race/ethnicity and reduce bias in estimating Black voter count. Thus, our work can contribute toward a richer understanding of economic conditions of various groups, discrimination, residential segregation, conflict, and identity politics; it can also facilitate research on group behavior on social media platforms.
Acknowledgments
We are indebted to Mithilesh Chaturvedi, Sabyasachi Das, Sudha Rao, and Feyaad Allie for helpful feedback and suggestions. We also thank the editorial team at Political Analysis and four anonymous reviewers for their detailed engagement and suggestions toward the improvement of the manuscript.
Data Availability Statement
The replication code for this article is available at https://doi.org/10.7910/DVN/JOEVPN (Chaturvedi and Chaturvedi Reference Chaturvedi and Chaturvedi2023). Instructions for accessing Rural Economic & Demographic Survey (REDS) data are available at http://adfdell.pstc.brown.edu/arisreds_data/readme.txt.
Conflict of Interest
The authors report no conflict of interest.
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2023.6.











 Open access
Open access