


The traditional approach to nutritional epidemiology is to relate single nutrients to particular diseases, a classic example being the link between vitamin C and scurvy( Reference Fawns 1 ). This reductionist approach however has many limitations, particularly when applied to outcomes with complex, multifactoral aetiologies such as obesity, diabetes and CVD. Focusing on individual nutrients ignores the fact that people eat foods and meals that include many nutrients and that there are possible synergies among these( Reference Hu 2 ). It is also difficult to address collinearly among individual nutrient intakes and the approach can encourage multiple testing in search of modest effect sizes( Reference Hu 2 ), which in turn leads to a high number of type 1 errors in published research( Reference Ioannidis 3 ).
Consequently, there has been a recent emphasis on research which identifies holistic dietary patterns in populations as determinants of disease( Reference Hu 2 , Reference Anderson, Harris and Houston 4 – Reference Villegas, Salim and Collins 16 ). Investigating dietary patterns better reflects the real-life scenario that foods are not consumed in isolation and allows us to look at the impact of overall diet on health. Furthermore, studying dietary patterns could have greater public health impact since results may be more easily translated into public health messages than research on specific nutrients( Reference Hu 17 , Reference Fahey, Ferrari and Slimani 18 ). However, the key challenge to dietary pattern research lies in reducing the complexity of human diets down to a manageable set of observed patterns in a principled manner.
In 1982, Schwerin et al.( Reference Schwerin, Stanton and Smith 19 ) introduced the concept of food patterns when they examined food habits and health. Slattery et al.( Reference Slattery and Boucher 20 , Reference Slattery, Boucher and Caan 21 ) expanded on this and laid the foundations for future data-driven, empirical approaches work when they used factor analysis to identify dietary patterns and assess the relationship between these patterns and colon cancer. Methodological development has continued as various research groups have turned to other statistical models( Reference Villegas, Salim and Collins 16 , Reference Bailey, Gutschall and Mitchell 22 – Reference Sotres-Alvarez, Herring and Siega-Riz 29 ). As such, the use of multivariate statistical models to identify dietary patterns is now fairly well established in nutritional epidemiology( Reference Fahey, Ferrari and Slimani 18 ). Methods aimed at reducing the dimensionality of dietary data, such as factor analysis or principal components analysis, are more common. Cluster analyses aimed at identifying mutually exclusive groups of people based on a shared dietary pattern are less so, even though they may lead to more widely interpretable results. Among cluster methods, algorithmic approaches such as k-means clustering have been more popular, while model-based cluster methods such as latent class analysis (LCA) have been used sparingly( Reference Sotres-Alvarez, Herring and Siega-Riz 28 , Reference Fahey, Thane and Bramwell 30 , Reference Padmadas, Dias and Willekens 31 ) despite their relative advantages. Further, we are only aware of one published study that employed latent class modelling to explore dietary changes over time( Reference Sotres-Alvarez, Herring and Siega-Riz 29 ).
Using latent class modelling of multiple food-item intakes, we aimed to describe the change in dietary patterns over a 10-year period among a cohort of middle-aged Irish adults. We were particularly interested in the implications of the stability (or change) in the patterns over time in relation to health outcomes.
Methods
Study population
Data are from the Cork and Kerry Diabetes and Heart Disease Study, a cohort of adults recruited from seventeen general practices in the Cork and Kerry region of Ireland in 1998. All practices affiliated with the Cork training programme for general practice were invited and seventeen of eighteen practices agreed to participate in the study. These practices were broadly representative of the socio-economic profile of the area, with six urban and twelve rural practices. Fifteen practices were in Co. Cork and two were in Co. Kerry. The average list size is approximately 2500 people and this includes both public and private patients.
In summary, a stratified random sampling approach by age and sex was employed across four age strata between the ages of 50 and 69 years. Individuals with CVD, known diabetes mellitus or other diseases or those receiving medication were included in the sampling process. With an anticipated prevalence of type 2 diabetes of 5 %, we estimated that 1000 individuals would be needed to estimate the prevalence with a precision of ±3 %. The sampling strategy for the original cohort has been detailed previously( Reference Creagh, Neilson and Collins 32 – Reference Kearney, Harrington and McCarthy 34 ).
In total, 1473 potential participants were identified and invited to participate in the study. Of these, 1018 attended for the physical examination yielding a 69·1 % response rate. Allowing for those who could not attend by reason of being hospitalized (n 6), out of the country (n 5), no longer alive (n 3), outside the target age group (n 2), too confused (n 1) and untraceable (n 3), the effective response rate was 70·1 %.
The baseline study was originally designed as a cross-sectional survey, but in 2008 additional funding was obtained to re-contact survey participants and undertake a 10-year rescreen. As the study was not designed as a cohort study, contact had not been maintained with participants during the decade between the first survey and the rescreen. Before making contact with the individual participants, contact was made with the general practices to check whether the participants were still alive and to ascertain whether the rescreening examination was appropriate. Allowing for mortality rate of 12 % (n 121), 16 % (n 166) loss to follow-up (not currently with the general practice, moved from area) and a further 4 % (n 41) classified as too unwell to participate, an available sample of 690 individuals were invited to participate in the rescreen. After follow-up with and review of vital status and causes of death through linkage with the National Cancer Registry, the rescreen response rate was 52 % (n 359). Non-responders for the follow-up were slightly older than the responders (aged 60·1 years v. 58·4 years), more likely to be retired (30 % v. 17 %) and less likely to be married (71 % v. 80 %, P = 0·02).
Willing participants at each time point provided fasting blood samples, underwent a series of physical measurements and completed a detailed general health and lifestyle questionnaire. Study methods and protocols have previously been described( Reference Villegas 33 – Reference Creagh, Neilson and Perry 35 ). All procedures were carried out with reference to the detailed guidelines outlined in the ‘Standard Operating Procedures Manual’( 36 , 37 ). The Clinical Research Ethics Committee of the Cork Teaching Hospitals granted ethical permission for the study.
Physical measurements
Anthropometric measurements
Physical measurements included height, weight and waist circumference. All physical measurements were taken by a qualified research nurse trained in the study protocols. In 1998 and 2008 respectively, height was measured using a Harpenden stadiometer and a portable Seca Leicester height measure to the nearest 0·1 cm and weight was measured using a Soehnle digital weighing scales and a portable electronic Tanita WB100MA weighing scale to the nearest 0·1 kg; at both time points waist circumference was measured using a Seca 200 measuring tape to the nearest 0·1 cm.
Participants were classified as overweight or obese based on a BMI of ≥25 kg/m2 or ≥30 kg/m2, respectively. Risk of central obesity was classified based on the WHO categorization of waist-to-hip ratio of ≥0·90 for men and ≥0·85 for women( 38 ).
Other physical measurements
At both time points, blood pressure was measured according to the study's standard operating procedures. In summary, blood pressure was measured in a seated position. Three readings were taken 1 min apart. The average of the second and third readings was noted. Clinical hypertension was defined as systolic blood pressure ≥140 mmHg and/or diastolic blood pressure ≥90 mmHg.
Biochemical and haematological measurements
At both time points participants provided fasting blood samples. Sample processing has been described previously( Reference Kearney, Harrington and McCarthy 34 ). Diabetes status based on glycated Hb (HbA1c) was defined as per the International Expert Committee Report( 39 ): diabetes, HbA1c ≥ 6·5 %; prediabetes, HbA1c =6·0–6·5 %; normal, HbA1c < 6·0 %. Insulin resistance was defined on the basis of fasting glucose and insulin using the glucose homeostasis model assessment of insulin sensitivity (HOMA-IR)( Reference Matthews, Hosker and Rudenski 40 ). It derives an estimate of insulin sensitivity from the mathematical modelling of fasting plasma glucose and insulin concentrations. HOMA-IR scores were calculated by the formula (fasting insulin × fasting glucose)/22·5. Participants were defined as having insulin resistance if they had a HOMA-IR score >4·65.
Health and lifestyle questionnaire
A health and lifestyle questionnaire was distributed to participants with their examination appointment at baseline and follow-up. The themes of the questionnaire were past medical history (specifically CVD and diabetes), use of medication and lifestyle behaviours including smoking, alcohol use and physical activity. The socio-economic, behavioural and lifestyle characteristics categorized from the questionnaire have been described previously( Reference Kearney, Harrington and McCarthy 34 ). In summary, for the current analysis, based on questionnaire responses at baseline and follow-up, the following categories were defined.
-
1. Socio-economic status was classified according to education attainment, marital status and car ownership.
-
2. Physical activity was classified at baseline based on the British Regional Heart Study Physical Activity instrument( Reference Shaper, Wannamethee and Weatherall 41 ) and grouped into three physical activity categories: inactive to occasional (‘low’), light to moderate (‘moderate’) and moderate to high (‘high’)( Reference Villegas 33 ). At follow-up physical activity was assessed using the International Physical Activity Questionnaire (http://www.ipaq.ki.se/scoring.pdf)( Reference Morgan, McGee and Watson 42 ). Participant scores were classified as high (over 10 000 steps/d), moderate (5000–10 000 steps/d) or low (less than 5000 steps/d). For the current analysis a categorical variable was created: ‘low’, ‘moderate’ or ‘high’.
-
3. Smoking status was categorized as ‘never smoker’, ‘current smoker’ or ‘ex smoker’.
-
4. Alcohol status was classified into one of four categories based on participants’ current average weekly intake: ‘never’ (no drink), ‘occasional/light’ (1–<14 units/week), ‘moderate/heavy’ (>14 units/week)’ and ‘ex drinker’ (former drinker but not a current drinker).
-
5. Self-rated general health status was classified at baseline as ‘excellent’, ‘good’, ‘fair’ or ‘poor’ and at follow-up as ‘excellent’, ‘very good’, ‘good’, ‘fair’ or ‘poor’.
Dietary assessment questionnaire
At both time points, participants completed a semi-quantitative FFQ( Reference Harrington, Perry and Lutomski 43 ) in which they were asked to indicate their average consumption of food items over the last year. In 1998 there were 159 items in the FFQ. Eight food items were added to the 2008 FFQ to reflect changes in food availability. These were vegetarian lasagne, cholesterol-lowering spreads, frozen fruit, sugar substitutes, homemade vegetable soup, homemade meat soup, curry sauce and alcopops. Frequency of consumption of a medium serving or common household unit was asked for each food and then converted into quantities using standard portion sizes. The frequency categories were ‘never or less than once a month’, ‘1–3 times per month’ ‘once a week’, ‘2–4 per week’, ‘5–6 per week’, ‘once a day’, ‘2–3 per day’, ‘4–5 per day’ and ‘6+ per day’. Items in the FFQ were then expressed in terms of quantities of food/beverage consumed (g/d or ml/d). Nine hundred and twenty-five individuals (91 %) completed the FFQ in 1998, while 320 (89 %) completed it in 2008; 303 individuals completed it at both time points.
DASH scores
Based on validated work( Reference Fung, Chiuve and McCullough 44 ), we constructed a DASH (Dietary Approaches to Stop Hypertension) score for each completed FFQ( Reference Harrington, Fitzgerald and Layte 45 ). For each food group, consumption was divided into quintiles and participants were classified according to their intake ranking. Consumption of healthy food components was rated on a scale of 1–5, with higher scores reflecting more frequent consumption. Less healthy dietary constituents, where low consumption is desired, were scored on a reverse scale with lower consumption receiving higher scores. Component scores were summed and an overall DASH score was calculated for each person. Overall DASH score was subsequently collapsed to quintiles for analysis – lower quintiles indicated a poorer dietary quality.
Latent class analysis
To identify data-driven dietary patterns using LCA, food items were first aggregated into twenty-three mutually exclusive food groups based previously published work from this cohort( Reference Villegas, Salim and Collins 16 ) (Table 1). For each food group, participants were categorized as those reporting zero intake, with the remainder divided into tertiles of consumption, based on the 1998 distributions (thus a change in category between 1998 and 2008 reflects a change in an individual's intake, not a change in the distribution of intake).
Table 1 Food groups

Information from completed FFQ from each time point was stacked into a single analytical data set, with a total of 1245 observations (n 925 from 1998, n 320 from 2008, n 303 at both time points). Using this stacked data set, the observed distribution of the categorized food groups was then modelled as a function of a single multinomial latent class variable, with the assumption that the food group distributions were independent, conditional on class membership. We estimated models ranging from two to eight classes using Mplus 6·11. All thresholds were freely estimated across classes for each food group (i.e. no constraints were made on estimated parameters). Models were not adjusted for energy, sex, age or any other covariates. Because some individuals contributed two observations to the analytical sample, the CLUSTER option was used to adjust standard errors of parameter estimates to account for within-person correlations.
The optimum number of classes was determined based on a combination of: (i) model fit (the Bayesian Information Criterion (BIC), the BIC adjusted for the number of parameters in the model (BICa), the Akaike Information Criterion (AIC) and the log likelihood (LL)); (ii) classification quality, based on the mean probability of class membership among individuals modally assigned to a given class; and (iii) substantive interpretation.
In assessing the dietary transitions, the post hoc analysis was confined to participants who had diet recorded at two time points (n 303). While the latent class model is probabilistic with respect to class membership, individuals were categorized by their modal class assignment for the post hoc analyses. This decision was supported by the high classification quality characterizing the models. All dietary transitions were relative the 1998 patterns.
All post hoc analysis was conducted using the statistical software package Stata 12 IC. ANOVA was used to describe associations between latent class group and continuous variables, while cross-tabulation with a χ 2 significance test was used to test associations with categorical variables. A P value <0·05 was considered statistically significant.
Results
Fit indices for latent class models including two to eight latent classes are given in Fig. 1. The AIC and LL indicated monotonically improving fit as the number of classes included in the model was increased; BICa indicated that model fit was best for the six-class model, but fit was not qualitatively different among the three- to eight-class solutions; BIC indicated that model fit was best for the three- and four-class solutions, with monotonically decreasing fit when more classes were added. For all models and respective classes, the mean probability of class membership given modal class assignment was >80 %. For the three-class model, this probability approached 90 % for all three classes. Based on this information, preference for model parsimony and the interpretation detailed below, we chose to report results from the three-class model.
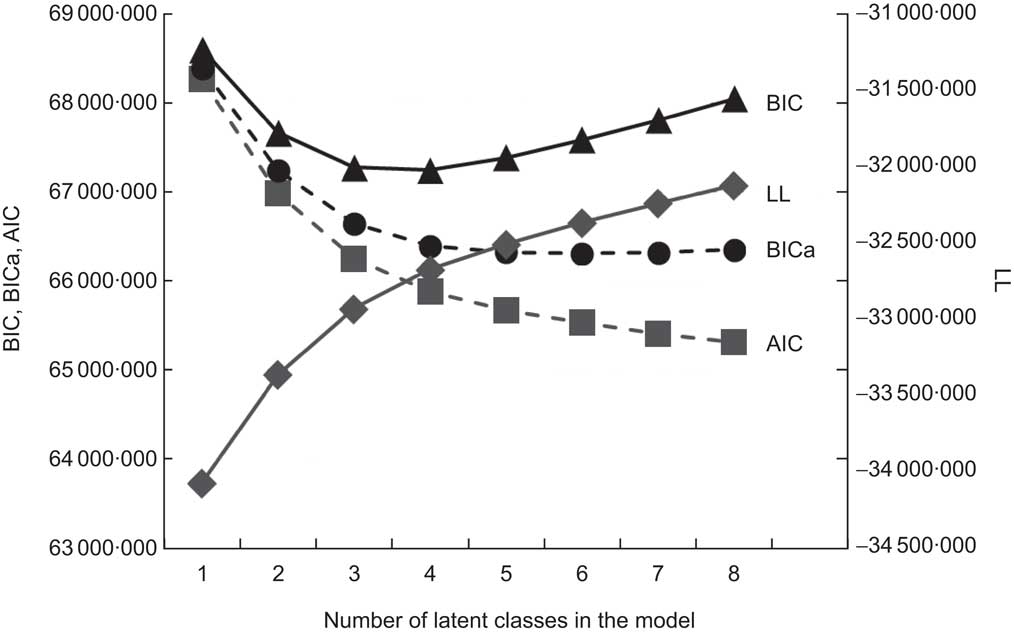
Fig 1 Model fit for latent class models including two to eight latent classes (BIC, Bayesian Information Criterion; BICa, BIC adjusted for the number of parameters in the model; AIC, Akaike Information Criterion; LL, log likelihood)
Class 1, which we have labelled Western, was characterized by higher consumption of cereals, breads and potatoes, dairy products, meats (in particular red and processed meats) and foods from the top shelf of the food pyramid, especially sweet snacks. Participants in this class had higher dietary salt and overall energy intakes, and were the group with the lowest DASH dietary score (indicating a poorer quality diet compared with the other classes). Class 2, labelled Healthy, was characterized by significantly higher intakes of fruits and vegetables, higher intakes of low-fat dairy products and the highest DASH dietary score. Class 3, labelled Low-Energy, was distinguished from class 1 in having lower consumption of red meat, sweet snacks and overall energy.
Table 2 shows gives a summary of mean daily servings of the food groups which constitute the DASH dietary score for each latent class at baseline and follow-up, and distinguishes one class from another by highlighting the DASH food groups consumed at significantly higher or lower levels relative to the other classes. A clear distinction between dietary groups was evident particularly with respect to the consumption of fruit, vegetables, red meats and confectionery.
Table 2 Food group intakes by latent class group; men and women aged 50–69 years at baseline in 1998 and at 10-year follow up in 2008, Cork and Kerry Diabetes and Heart Disease Study, Republic of Ireland
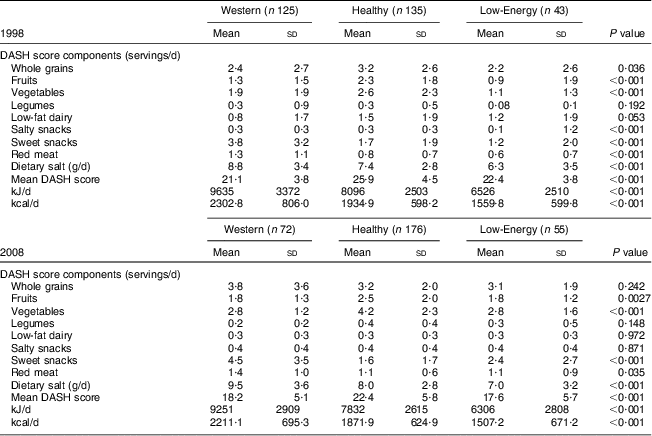
DASH, Dietary Approaches to Stop Hypertension.
Lifestyle characteristics associated with each class at baseline and follow-up
Differences in food patterns were associated with differences in demographic, health and lifestyle characteristics at baseline and follow-up (Table 3). At baseline, differences were seen in sex, marital status, car ownership, alcohol status, self-rated health, central obesity and HDL-cholesterol. In relation to CVD risk factors, participants in the Healthy class were less likely to have diabetes, less likely to be at risk of central obesity and more likely to have higher HDL-cholesterol concentration. Higher proportions of non-smokers, non-drinkers and high physical activity participation rates were seen in the Healthy class. At follow-up differences were seen in sex, age, marital status, education, hypertension status, HDL-cholesterol and homocysteine levels. Higher proportions of Healthy class participants (although not significant differences at P < 0·05) rated their health as ‘excellent’, were non-smokers, were occasional/light drinkers and had higher levels of physical activity. Although not significant at P < 0·05, the Low-Energy class had a disproportionate number of current smokers. Significant differences (P < 0·004) were seen in follow-up class membership in relation to hypertension status. A lower proportion of respondents in the Western class had hypertension compared with the Healthy and Low-Energy classes. Homocysteine levels were lower in the Healthy class than in the Western and Low-Energy classes.
Table 3 Demographic and lifestyle characteristics by class group at baseline and follow-up; men and women aged 50–69 years at baseline in 1998 and at 10-year follow up in 2008, Cork and Kerry Diabetes and Heart Disease Study, Republic of Ireland
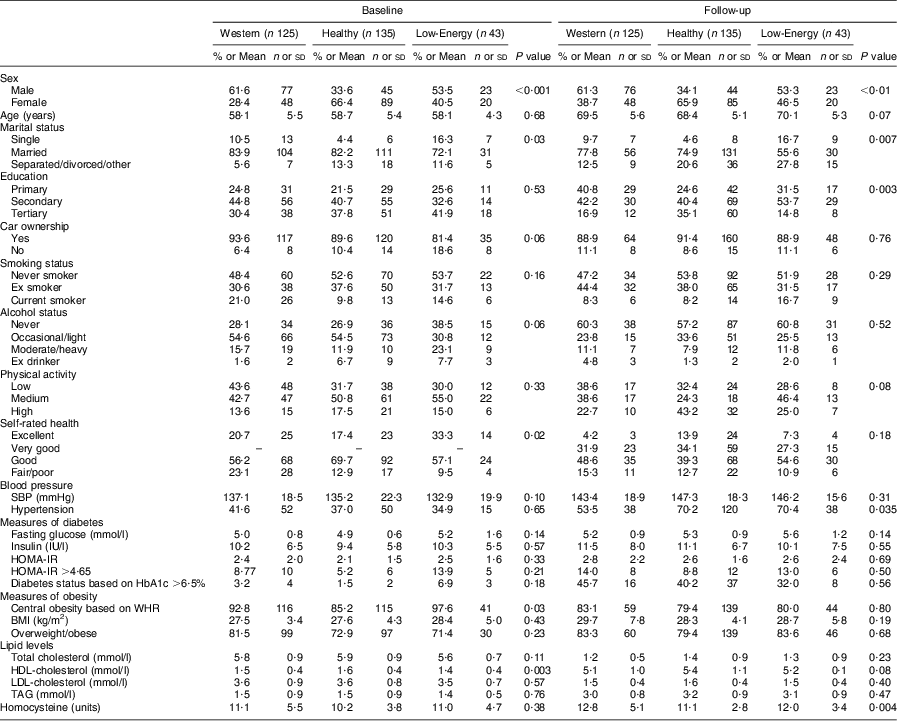
SBP, systolic blood pressure; HOMA-IR, homeostasis model assessment of insulin sensitivity; HbA1c, glycated Hb; WHR, waist-to-hip ratio.
Data are presented as % and n for categorical variables or as mean and sd for continuous variables.
Diet stability and transitions
Of the total sample (n 303), at follow-up 16 % remained in the Western class, 33 % remained in the Healthy class and 6 % remained in the Low-Energy class (Table 4). Within-class stability was highest in the Western class; of those in the Western class at baseline, 68 % remained in this class, while 57 % remained in the Healthy class and 35 % remained in the Low-Energy class. A further 25 % moved from either the Western (19 %) or Low-Energy class (6 %) to the Healthy class between 1998 and 2008.
Table 4 Breakdown of respondents remaining in baseline class (class stability) or transitioning to a different class between 1998 and 2008; men and women aged 50–69 years at baseline in 1998 and at 10-year follow up in 2008, Cork and Kerry Diabetes and Heart Disease Study, Republic of Ireland

*Percentage stable in each class; denominator is class n at baseline.
Table 5 shows the health outcomes for participants whose dietary pattern remained stable over the 10-year period. In terms of stability, there were significant differences between men and women (P < 0·001), education group (P < 0·05), marital status (P < 0·01) and homocysteine levels (P < 0·05). More men were stable in the Western class while more women remained stable in the Healthy class. Those who remained stable in the Western class had significantly higher homocysteine levels at follow-up compared with those who remained stable in either the Healthy class or the Low-Energy class.
Table 5 Lifestyle behaviours and health outcomes at follow-up for dietary stable participantsFootnote *; men and women aged 50–69 years at baseline in 1998 and at 10-year follow up in 2008, Cork and Kerry Diabetes and Heart Disease Study, Republic of Ireland
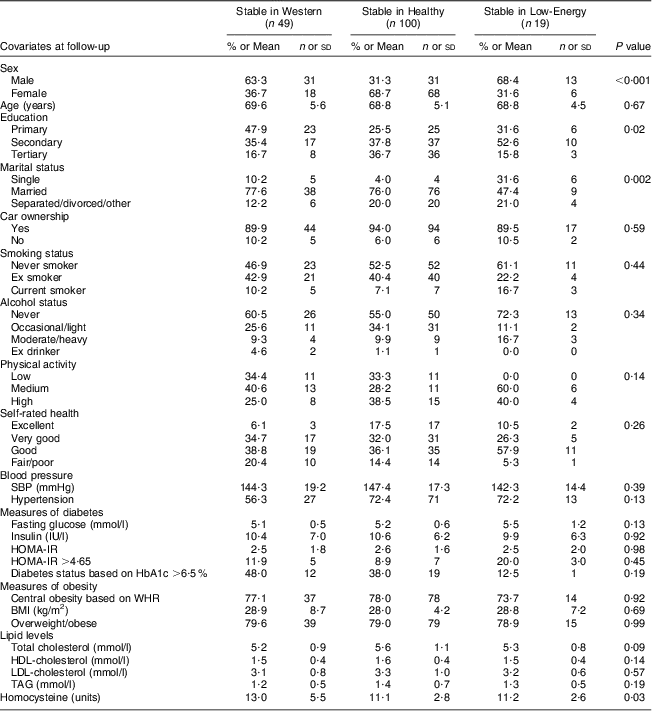
SBP, systolic blood pressure; HOMA-IR, homeostasis model assessment of insulin sensitivity; HbA1c, glycated Hb; WHR, waist-to-hip ratio.
Data are presented as % and n for categorical variables or as mean and sd for continuous variables.
* This analysis relates only to participants who remained stable in their dietary class from baseline to follow-up.
Analysis of CVD risk factors assessed at baseline and associations with stability or diet transitions (stable in Western, stable in Healthy and transition from Western/Low-Energy to Healthy) at follow-up are shown in Table 6. Sociodemographic characteristics were significantly associated with class membership. Men were significantly more likely to be in the Western stable group, while women were significantly more likely to be in the Healthy stable group (P < 0·001). Participants with primary education were more likely to be in the Western stable group, while participants with tertiary education were more likely to be in the ‘transition to healthy diet’ group. Significant differences were seen in group membership by smoking status (P = 0·05). Current smokers (at baseline) were more likely to be in the ‘transition to healthy diet’ group. The Healthy stable group had fewer current smokers (at baseline) compared with the Western and Low-Energy groups. Participants in the Healthy stable group had lower baseline levels of homocysteine and central obesity (based on waist-to-hip ratio, P = 0·01) compared with the other two groups.
Table 6 Univariate analysis of CVD factors at baseline as predictors of diet transitions/diet stability at follow-up; men and women aged 50–69 years at baseline in 1998 and at 10-year follow up in 2008, Cork and Kerry Diabetes and Heart Disease Study, Republic of Ireland

SBP, systolic blood pressure; HOMA-IR, homeostasis model assessment of insulin sensitivity; HbA1c, glycated Hb; WHR, waist-to-hip ratio.
Data are presented as % and n for categorical variables or as mean and sd for continuous variables.
*Relates to participants who moved from either the Western or Low-Energy class to the Healthy class.
Analysis of health outcomes at follow-up by class pattern showed that the demographic variations seen with baseline risk factors persisted at follow-up, with significant variations seen across sex, education and marital status (results not shown). Significant differences were seen in homocysteine and cholesterol levels between the classes. At follow-up, homocysteine levels for the Western stable group were higher than those for the Healthy stable and ‘transition to healthy diet’ groups. The Healthy stable group had higher total cholesterol and HDL-cholesterol concentrations than the other two groups.
Discussion
Principal findings
The current study was an exploratory one to evaluate the use of LCA as a method to assess dietary patterns and dietary transitions in a free-living population. Three primary results are evident from this research. First, three distinct dietary patterns emerged from the analysis: Western, Healthy and Low-Energy classes. These patterns were broadly similar to clusters derived in the original 1998 baseline study using k-means clustering( Reference Villegas, Salim and Collins 16 ), and were associated with significant differences in demographic and health outcomes at baseline and follow-up. Second, over half of all participants remained ‘stable’ in their dietary class at follow-up. Third, stability in a Western dietary pattern was associated with increased homocysteine levels, while stability in a Healthy diet pattern was associated with lower rates of central obesity.
Study implications
Three previous studies have used LCA in modelling dietary patterns in cross-sectional analyses( Reference Sotres-Alvarez, Herring and Siega-Riz 28 , Reference Fahey, Thane and Bramwell 30 , Reference Padmadas, Dias and Willekens 31 ). It is interesting to note that these three other studies found one group with considerably higher mean consumption of meat, similar to our class 1 group (Western). Many epidemiological studies investigating dietary patterns rely on one dietary assessment and assume that dietary patterns remain stable. To our knowledge, the present study is the first to use LCA to model longitudinal dietary transitions in older adults. Sotres-Alvarez et al.( Reference Sotres-Alvarez, Herring and Siega-Riz 29 ) documented dietary transition from pregnancy to postpartum. While some studies have investigated dietary stability, many of these use dietary scores based on a limited number of foods or food behaviours and results between studies are inconsistent. Mulder et al.( Reference Mulder, Ranchor and Sanderman 46 ) used a dietary score based on seven food behaviours and found great variability over a 4-year period, while Mishra et al.( Reference Mishra, McNaughton and Bramwell 47 ) used a dietary pattern score based on factor analysis and found that healthier eating behaviours were more stable than other behaviours. In contrast, van Dam et al. ( Reference van Damm, Rimm and Willett 48 ) found higher stability with the Western pattern in comparison to the ‘Prudent’ dietary pattern. The present study, similar to Mishra et al.( Reference Mishra, McNaughton and Bramwell 47 ), shows high dietary stability over time, particularly for the healthy diet pattern.
The sociodemographic determinants of diet are well documented( Reference Villegas, Salim and Collins 16 , Reference Harrington, Fitzgerald and Layte 45 , Reference Layte, Harrington and Sexton 49 – Reference Lutomski, Van den Broeck and Harrington 55 ), particularly the relationship between diet and educational status( Reference Mishra, Ball and Arkbuckle 56 , Reference Schulze, Hoffmann and Kroke 57 ). We found that educational status is also an important predictor of dietary stability and transition. Those with higher levels of education were more likely to have a healthy diet and to remain stable in the healthy diet group over time. Those who transitioned to the healthy diet class from the Western class were more likely to be participants with higher education, while those with lower education tended to remain in the Western class.
Many studies which use a posteriori methods to determine dietary patterns adjust for energy intake, age and sex in their model estimations. Our models did not adjust for these variables. We chose not to adjust for energy intake as total energy intake has been shown to be poorly estimated using FFQ. In relation to age, all participants were in a very narrow age band and few differences were seen by age category in univariate analysis. Further, we believed that adjustment for sex would limit the distinction between classes. Inclusion of these variables in the model estimation would reduce the opportunity to explore the determinants of dietary patterns and the stability/transitions over time.
Study strengths and limitations
We chose an LCA over algorithmic approaches to cluster detection such as k-means. Like most other cluster methods, the key challenge lies in choosing the ‘correct’ number of classes. However, because LCA is a model-based method, it is possible to use goodness-of-fit tests to help identify the ideal number of subgroups. This is especially important given that the external validity of the model cannot be assessed since the class labels are not known. Furthermore, once the model has been estimated, posterior probabilities of class membership for each observation can be calculated, providing additional information for model selection. Further, latent class models can be more easily extended under a structural equation modelling framework to explicitly incorporate longitudinal data, additional covariates, multiple outcomes and other latent variables in the model.
The manner in which we dealt with the longitudinal nature of our data bears some consideration. We chose not to use a latent class transition model( Reference Sotres-Alvarez, Herring and Siega-Riz 29 ), which would be composed of a separate latent class variable at each time point connected by a multinomial regression model. Our primary concern with this approach, given the exploratory nature of our investigation, was that small differences in parameter estimates between the two time points could risk being over-interpreted. Equality constraints could certainly be imposed on a latent class transition model to help address this, but lacking strong a priori knowledge, this can lead to a slippery slope of model testing and optimization that can lead to model overfit. It also requires one to specify the number of latent classes at each time point.
Instead we ‘stacked’ the observations from each time point into a single analytical data set and used this to estimate a single latent class variable. Viewing this single variable as a mix of classes from 1998 and 2008, the model is conservative in that minor differences in the parameters would be ignored, with the larger number of observations from 1998 appropriately having a greater influence on parameter estimates. Conversely, any substantial differences such as the emergence or disappearance of a class would still be evident in the model. Compared with the latent class transition approach, our model is considerably more parsimonious and requires fewer decisions to be made by the researcher, such as specifying the number of latent classes for two time points and setting parameter constraints. The key limitation to our approach, however, was that we were not able to explicitly estimate class transition probabilities between years. We instead had to assign observations to their modal class assignment based on posterior probabilities of class membership and analyse these assignments post hoc in individuals observed at each time point.
There are limitations to the study which need to be considered in interpreting the results. The Cork and Kerry Diabetes and Heart Disease Study (baseline and follow-up) was conducted in a general practice setting. In Ireland, there is no register of general practices, and individuals are free to move between practices if they so wish without notification. Coupled with the ageing cohort this can increase loss to follow-up for studies of this nature. One of the problems in surveying older people is the high proportion of non-responders, but also of drop-outs largely due to deaths( Reference Van Staveren, de Groot and Haveman-Nies 58 ). However, due to the nature of the study, the healthier population also yields advantages. In less healthy elderly populations, the relatively rapid decline in functional status as a result of progressive illness is likely to be evident.
Further limitations are associated with measurement error in relation to the exposure (diet). The FFQ is associated with random error and there is likely some recall bias. However, the FFQ used in these studies has been validated for use in the Irish population( Reference Harrington 59 ) and has been used repeatedly in the National Health and Lifestyle Studies( Reference Harrington, Perry and Lutomski 43 , Reference Friel, Nic Gabhainn and Kelleher 60 , Reference Kelleher, Nic Gabhainn and Friel 61 ) to monitor trends in the population. Although the numbers are low, the current study is strengthened by the completion of the same dietary measurement instrument at both time points by participants. Our study is one of the few studies to track dietary patterns over a 10-year period in an older population. Retrospective dietary assessment is difficult, particularly in an ageing population where cognitive ability might be diminished; however, because of the method of recruitment, the participants in our study were probably more healthy, mobile and socially outgoing than would occur in a representative sampling of this age group in the community. Further, each participant was met by the study team as part of the physical examination component of the study and, where necessary, a member of the research team provided assistance with the questionnaires.
The current study was based on food consumption data at two time points. It did not take account of the possible changes in food supply over this time period, and changes in dietary patterns could potentially be due to food supply changes. The report from the European Heart Network( 62 ) indicates that between 1998 and 2008, supplies in vegetable oils and fruits increased, animal fats decreased, sugar supplies fluctuated and the supply of vegetables remained stable. While there were changes in the food supply, the cross-sectional food consumption patterns reflect the dietary patterns of the Irish population at these two time periods( Reference Harrington, Perry and Lutomski 43 , Reference Friel, Nic Gabhainn and Kelleher 60 , Reference Kelleher, Nic Gabhainn and Friel 61 ).
Conclusions
The present study confirms that LCA is a useful method for estimating dietary patterns and their stability/transition over time. Using these methods, it was possible to confirm that healthy dietary patterns are associated with sociodemographic characteristics and that educational status is associated with both healthy diet stability and transition to healthy diets. Given the strong evidence for the role of diet in the development of chronic diseases, in particular hypertension, diabetes and CVD, it is important to reliably identify the predictors of dietary transitions and stability. Robust methods are required to determine the predictors of these transitions and we propose that LCA is a useful complement to more commonly applied a posteriori methods.
Acknowledgements
Sources of funding: This work was supported by the HRB Centre for Health and Diet Research and funded by the Irish Health Research Board (HRC 2007/13). The Irish Health Research Board had no role in the design, analysis or writing of this article. Conflicts of interest: No conflict of interest declared. Ethics: The study was approved by the Clinical Research Ethics Committee of the Cork University Teaching Hospitals. Authors’ contributions: J.M.H. worked as a senior researcher on the study and had a major role in data analysis and interpretation; she worked on the statistical analysis and had primary responsibility for the final content of the paper; she is the guarantor. D.L.D. conducted the latent class modelling and contributed to the interpretation of the models; he co-wrote the paper. A.P.F. is a Senior Lecturer in Biostatistics in the Department of Epidemiology & Public Health; he provided statistical advice and made revisions to the paper. M.S.G. is Professor of Biostatistics and provided advice on the latent class modelling. I.J.P. was the Principal Investigator of the Cork and Kerry Diabetes and Heart Disease Study and contributed to the study design, data analysis and interpretation, and made revisions to the paper. All authors approved the final version of the paper for publication. Acknowledgements: The authors thank the study participants for giving their time and all participating general practices.







