


1 Introduction
It’s a commonplace nowadays that beliefs come in degrees, though this isn’t universally accepted. There are some holdouts – those who say the recent uptick of interest in ‘credences’ and ‘subjective probabilities’ is yet another philosophical fad that will eventually run its course. But that’s hardly plausible. A very large body of work across a wide range of disciplines developed over many decades depends on the presumption that our beliefs – or something closely linked to our beliefs – admit of degrees and, moreover, that it makes good sense to represent those degrees numerically. These numerical representations of belief are far too useful for far too much to be just a passing trend.
I expect most readers will agree with me about that. But what we’re much less likely to agree on is what the numbers mean. What is the underlying psychological reality to which these numerical representations supposedly correspond? Perspectives on this matter vary wildly. For some, degrees of belief are understood to be explicit, on-the-fly judgements about the probability of an event, or a conscious attempt to put a number on the weight of one’s evidence, or the intensity of some confidence phenomenology when contemplating a possibility. Others will, like myself, think of degrees of belief as implicit attitudes – attitudes that may be present and playing a role in your cognitive economy even if you’re not consciously aware of their doing so, and even if they’re not readily accessible to conscious introspection. But there’s a substantial variety of perspectives, too, on how these attitudes are to be understood. If I say that Ramsey believes
 to degree 0.69, does that ‘0.69’ tell us something about
to degree 0.69, does that ‘0.69’ tell us something about
 ’s location in Ramsey’s subjective confidence ordering over possibilities? Does it tell us something about Ramsey’s willingness to bet on
’s location in Ramsey’s subjective confidence ordering over possibilities? Does it tell us something about Ramsey’s willingness to bet on
 ? About the centrality of
? About the centrality of
 to Ramsey’s web of belief, or his dispositions to revise his opinions regarding
to Ramsey’s web of belief, or his dispositions to revise his opinions regarding
 in the face of new evidence? All of the above? None of the above?
in the face of new evidence? All of the above? None of the above?
An intimately related (but more constrained) question concerns what’s meaningful in a numerical representation of belief. What, in other words, does it take for numerically distinct representations to nevertheless represent the same system of beliefs? Most are happy to suppose there’s no uniquely correct way to represent degrees of belief within a numerical framework, just as there’s clearly no uniquely correct way to numerically represent lengths, or temperatures, or desirabilities. As Reference Builes, Horowitz and SchoenfieldBuiles et al. (2022) recently put it,
there’s nothing ‘0.69-ish’ about my degree of confidence in
 , beyond the fact that 0.69 can serve as an adequate representation of my degree of confidence within a particular representational system. But 69, for example, or 732.6 for that matter, would work just as well, provided the system was structured in the right way.
, beyond the fact that 0.69 can serve as an adequate representation of my degree of confidence within a particular representational system. But 69, for example, or 732.6 for that matter, would work just as well, provided the system was structured in the right way.
But what it is for the representational system to be ‘structured in the right way’ is about as clear as mud. Here, as before, we find plentiful variation and disagreement. The most common numerical representations of belief make use of credence functions – mappings from propositions to real values between 0 and 1. It usually goes without saying that the relation induced over the propositions by their numerical ordering in a credence function is intended to correspond to relative strengths of belief regarding those propositions. But is that the extent of the meaningful information captured in a credence function? That is, if two credence functions are ordinally equivalent, does it follow that they are therefore equivalent in meaning? If so, then we’d probably better get started on revising the many theories of rational belief and decision making that presuppose meaningful differences between ordinally equivalent credence functions! On the other hand, if there’s more to the meaning than just the numerical orderings, then exactly what additional structure is relevant – and why?
These are questions about the measurement of belief, which is the subject of this Element. In summary: what do our numerical representations of belief actually represent, how exactly do they represent it, and under what conditions are such representations meaningful?Footnote 1
Broadly speaking, there are two main approaches to the measurement of belief. According to what I’ll be calling the epistemic approach, a system of beliefs admits of numerical representation just in case that system has a certain kind of internal structure that can be mirrored in an appropriate numerical framework. A rather different tack – the decision-theoretic approach – focuses not so much on the internal structure of the belief system but instead on the relationship between beliefs, desires, and preferences in the context of decision making. Both the epistemic approach and the decision-theoretic approach can be spelled out in many different ways, but very roughly the difference between them amounts to whether the numerical representability of a system of beliefs is (a) a matter of those beliefs having a certain kind of internal coherence, or (b) a matter of those beliefs relating to preferences and desires in a coherent way. These approaches can have very different implications regarding what should and should not be considered meaningful in our numerical representations of belief, and they can likewise diverge significantly when it comes to what an agent must be like in order for their beliefs to admit of such representations in the first place.
Cards on the table: I prefer the decision-theoretic approach. More cautiously, I would say that the decision-theoretic approach generally supplies us with the best way to interpret numerical representations of belief in the Bayesian tradition, especially in decision-theoretic contexts but also in the context of much (if not most) traditional Bayesian epistemology.Footnote 2 The basic reason for this is that standard Bayesian theories and models, and many arguments in that tradition, routinely make assumptions about meaningfulness that are hard to make sense of given the most common epistemic approaches. Further, while there are some less common epistemic approaches that can in principle support richer claims about meaningfulness (e.g., the multiprimitive structures discussed in Section 5.3), these are still very underdeveloped and ultimately strike me as comparatively unmotivated.
But I’ll not spend a great deal of time arguing in favour of my own approach, nor arguing against the competitors. I mean – I’ll do a little of that here and there, and my biases will surely be apparent in parts of the discussion, but the main purpose of this work is expositional rather than argumentative. So I’ll focus much more on explaining what the epistemic and decision-theoretic approaches are, highlighting some of the possible variation within those two approaches, and the implications they have regarding what kinds of numerical representations are possible, when they’re possible, and what ought to be considered meaningful in those representations.
The remainder of the discussion proceeds as follows. Section 2 introduces some key concepts from the representational theory of measurement, while Section 3 provides some clarifications and general assumptions regarding a theory of belief measurement. We then turn to the epistemic approaches: Section 4 covers the simplest version of the epistemic approach, built around binary comparative confidence relations, while Section 5 gives an overview of several alternatives. Finally, Section 6 gives an overview of the decision-theoretic approach, discusses one particular version (due to Frank Ramsey) in some detail, and addresses some common misunderstandings and objections.
2 Representation and Measurement
We find it abundantly useful to express many physical facts using numbers and numerical relations. There’s no great mystery to this, even for the mathematical Platonist who thinks that numbers and numerical relations are abstracta and not present in the physical world in the same manner as electrons or chairs or gravitational attraction. When I say I’ve gained at least 2 pounds thanks to all the nice food at a recent conference, which is more than twice as much as what I gained at the last conference, I’m using those numbers and numerical relations to refer to and reason about my ever-increasing weight. These claims aren’t made true by virtue of any little numbers attached somewhere to my body, slowly and inevitably going up over time. Rather, the numbers and numerical relations serve as abstract stand-ins for physical properties and physical relations, and they do this by virtue of some structural similarity between them.
What we call quantities are determinable properties whose determinates have a certain salient relational structure that renders them ripe for numerical representation. Length, for instance, is a determinable attribute, with determinates – the specific lengths – sharing higher-order relations between them that can be usefully represented within a numerical framework. For any two physical objects
 and
and
 and a fixed orientation for each, either (a)
and a fixed orientation for each, either (a)
 will be at least as long as
will be at least as long as
 , or (b)
, or (b)
 will be at least as long as
will be at least as long as
 , or (c) both (i.e., they’ll be as long as each other). Here, the at least as long relation holds between physical objects, but we can also understand it as a second-order relation between the length attributes directly. Say that any two objects have the same length,
, or (c) both (i.e., they’ll be as long as each other). Here, the at least as long relation holds between physical objects, but we can also understand it as a second-order relation between the length attributes directly. Say that any two objects have the same length,
 , if each is at least as long as the other. Say next that
, if each is at least as long as the other. Say next that
 is at least as long as
is at least as long as
 just in case any object with property
just in case any object with property
 is at least as long as any object with property
is at least as long as any object with property
 . We can then associate the lengths
. We can then associate the lengths
 and
and
 with numbers
with numbers
 and
and
 in such a manner that
in such a manner that
 is at least as long as
is at least as long as
 just in case
just in case
 .
.
In this example, the lengths
 and the at least as long relation between them are said to be qualitative, whereas the numbers
and the at least as long relation between them are said to be qualitative, whereas the numbers
 and the
and the
 relation between them serve as their numerical representations. Think of a qualitative property or relation as one that can be characterised without explicit reference to numbers or numerical relations. So ‘qualitative’ here contrasts with ‘numerical’, not with ‘quantitative’ – the idea being that quantities can be characterised either in qualitative terms or in numerical terms, with the latter being possible precisely because the abstract numerical stuff shares a structure in common with the real-world qualitative stuff it represents.Footnote 3
relation between them serve as their numerical representations. Think of a qualitative property or relation as one that can be characterised without explicit reference to numbers or numerical relations. So ‘qualitative’ here contrasts with ‘numerical’, not with ‘quantitative’ – the idea being that quantities can be characterised either in qualitative terms or in numerical terms, with the latter being possible precisely because the abstract numerical stuff shares a structure in common with the real-world qualitative stuff it represents.Footnote 3
The purpose of this section is to expand on that initial idea and make it more precise. More generally, the goal is to introduce some key concepts for discussing the numerical representation of quantities. I start with the fundamentals of the Representational Theory of Measurement (RTM).Footnote 4
2.1 Preliminary Concepts
I presume familiarity with predicate logic, and with the elementary concepts and notation of set theory. Much of what follows will revolve around properties of binary relations and operations, though, so the following are worth stating:
Definition 1. An
 -ary relation on a set
-ary relation on a set
 is a subset of
is a subset of
 . Where
. Where
 , by convention,
, by convention,
 if and only if
if and only if
 and
and
 if and only if
if and only if
 . We say that
. We say that
 is
is
transitive if and only if
 and
implies
, for all
,
and
implies
, for all
,complete if and only if
or
for all
,reflexive if and only if
, for all
,symmetric if and only if
implies
, for all
,asymmetric if and only if
implies not
, for all
,antisymmetric if and only if
and
implies
, for all
,a preorder if and only if
is transitive and reflexive,a weak order if and only if
is a complete preorder,a total order if and only if
is an antisymmetric weak order, andan equivalence relation if and only if
is transitive, reflexive, and symmetric.























Furthermore, where
 is defined on a set
is defined on a set
 , then
, then
 is said to be
is said to be
minimal (in
) if and only if
for all
, andmaximal (in
) if and only if
for all
.






Preorders – especially weak orders – will be important. Throughout, I’ll use
 to represent a number of qualitative preorder relations, and I’ll use
to represent a number of qualitative preorder relations, and I’ll use
 and
and
 for the symmetric and asymmetric parts of
for the symmetric and asymmetric parts of
 respectively. That is, I’ll henceforth take it as read that
respectively. That is, I’ll henceforth take it as read that
-
if and only if
and
, and
-
if and only if
and
.






Definition 2. An
 -ary operation on a set
-ary operation on a set
 is a (total or partial) function from
is a (total or partial) function from
 into
into
 . Suppose
. Suppose
 is a binary operation on
is a binary operation on
 . By convention,
. By convention,
 if and only if
if and only if
 , and
, and
 is defined if and only if
is defined if and only if
 is defined. Furthermore, we say that
is defined. Furthermore, we say that
 is
is
total if and only if
is defined for all
, otherwise partial,commutative if and only if
is total and for all
,
, andassociative if and only if
is total and for all
,
.








Note that properties are just the special case of
 -ary relations where
-ary relations where
 , and every
, and every
 -ary operation can be recast as an
-ary operation can be recast as an
 -ary relation. For example, addition is a total binary operation on the set of real numbers
-ary relation. For example, addition is a total binary operation on the set of real numbers
 , since it maps
, since it maps
 back into
back into
 ; it is also the ternary relation
; it is also the ternary relation
 on
on
 such that
such that
 if and only if
if and only if
 . As such, for what follows I’ll usually just write ‘relations’ rather than ‘properties and relations’ or ‘relations and operations’ – but wherever I intend to refer to operations in particular, this will be explicitly marked.
. As such, for what follows I’ll usually just write ‘relations’ rather than ‘properties and relations’ or ‘relations and operations’ – but wherever I intend to refer to operations in particular, this will be explicitly marked.
Next we need the generic notion of a relational system. This is a system comprising a set, one or more distinguished relations on that set, and zero or more distinguished binary operations:
Definition 3. Let
 (
(
 ) and
) and
 (
(
 ) be index sets. Then
) be index sets. Then
 is a relational system if and only if
is a relational system if and only if
 is a non-empty set, the
is a non-empty set, the
 are relations on
are relations on
 , and the
, and the
 are binary operations on
are binary operations on
 .
.
The relations and operations used to characterise a relational system are known as the primitives of that system. Note the semi-colon, used to explicitly separate the primitive relations from the primitive operations.Footnote 5
An example of a simple relational system is
 , comprising the set
, comprising the set
 and the primitive at least as great relation
and the primitive at least as great relation
 on
on
 . A richer relational system would be
. A richer relational system would be
 , which includes also the primitive binary operation
, which includes also the primitive binary operation
 . These are what we’ll call numerical systems – they’re comprised of a set of numbers and one or more relations thereupon. More generally, we take a numerical system to be any relational system constructed from numerical stuff. (There’s no need to be very precise here – some relational systems have a numerical feel about them, and that’ll suffice for referring to them as numerical systems.) In contrast are qualitative systems, or systems constructed from qualitative stuff. For example, if
. These are what we’ll call numerical systems – they’re comprised of a set of numbers and one or more relations thereupon. More generally, we take a numerical system to be any relational system constructed from numerical stuff. (There’s no need to be very precise here – some relational systems have a numerical feel about them, and that’ll suffice for referring to them as numerical systems.) In contrast are qualitative systems, or systems constructed from qualitative stuff. For example, if
 is the set of determinate length properties (as described at the beginning of the section), and
is the set of determinate length properties (as described at the beginning of the section), and
 is the at least as long relation between them, then
is the at least as long relation between them, then
 will count as a qualitative system. Likewise, for any two lengths
will count as a qualitative system. Likewise, for any two lengths
 and
and
 , we let their end-to-end concatenation,
, we let their end-to-end concatenation,
 , be the length
, be the length
 of any object that’s as long as what you get when you take two disjoint rigid objects of length
of any object that’s as long as what you get when you take two disjoint rigid objects of length
 and
and
 and attach them end-to-end. (See Figure 1.) Then
and attach them end-to-end. (See Figure 1.) Then
 will be a binary operation on
will be a binary operation on
 , and
, and
 will also be a qualitative system.
will also be a qualitative system.

Figure 1
 is the end-to-end concatenation of
is the end-to-end concatenation of
 and
and
 (i.e.,
(i.e.,
 ).
).
Henceforth, I’ll use
 for numerical systems and
for numerical systems and
 for qualitative systems. We need then a way of expressing when a qualitative relational system possesses a similar structure to that of some numerical system, such that the latter might be exploited to represent the former. For this we make use of structure-preserving mappings, or homomorphisms:
for qualitative systems. We need then a way of expressing when a qualitative relational system possesses a similar structure to that of some numerical system, such that the latter might be exploited to represent the former. For this we make use of structure-preserving mappings, or homomorphisms:
Definition 4. Let
 and
and
 , where
, where
 and
and
 . Then
. Then
 is a weak homomorphism from
is a weak homomorphism from
 into
into
 if and only if
if and only if
1.
is an
-ary relation if and only if
is an
-ary relation2.
if and only if
3.







 is a strong homomorphism from
is a strong homomorphism from
 into
into
 if, in addition,
if, in addition,
4.

Corresponding to the distinction between weak homomorphisms and strong homomorphisms, we can say that
 weakly maps
weakly maps
 into
into
 whenever
whenever

and strongly maps
 into
into
 whenever the converse also holds.
whenever the converse also holds.
An example will help to make this clearer. Start first with the simple qualitative system
 . A function
. A function
 is a homomorphism from
is a homomorphism from
 into
into
 when
when

Since there are no primitive operations in
 , conditions 3 and 4 are trivially satisfied and so we don’t bother with the weak/strong distinction. Next, consider the richer system
, conditions 3 and 4 are trivially satisfied and so we don’t bother with the weak/strong distinction. Next, consider the richer system
 , this time endowed with a primitive concatenation operation. This time, then, a function
, this time endowed with a primitive concatenation operation. This time, then, a function
 counts as a weak homomorphism from
counts as a weak homomorphism from
 into
into
 whenever, in addition to the preceding, it weakly maps
whenever, in addition to the preceding, it weakly maps
 into
into
 :
:

And
 is a strong homomorphism if it strongly maps
is a strong homomorphism if it strongly maps
 into
into
 :
:

If
 is a total operation and
is a total operation and
 is antisymmetric, then every weak homomorphism from
is antisymmetric, then every weak homomorphism from
 into
into
 will be a strong homomorphism – but otherwise this needn’t be the case.
will be a strong homomorphism – but otherwise this needn’t be the case.
2.2 Representation Theorems and Uniqueness
A homomorphism maps the primitive relations and operations of one relational system into the primitive relations and operations of another. When at least a weak homomorphism from
 into
into
 exists, we can say that
exists, we can say that
 has – or otherwise includes as a proper part – a structure similar to that of
has – or otherwise includes as a proper part – a structure similar to that of
 . A strong homomorphism establishes a slightly stronger similarity of structure. In either case, it is this similarity that justifies representing
. A strong homomorphism establishes a slightly stronger similarity of structure. In either case, it is this similarity that justifies representing
 using (or ‘in’)
using (or ‘in’)
 . Because of this, the central theoretical objects of the RTM are results that establish precise conditions for when an arbitrary qualitative system
. Because of this, the central theoretical objects of the RTM are results that establish precise conditions for when an arbitrary qualitative system
 can be represented in some specific numerical system
can be represented in some specific numerical system
 . These are known as representation theorems.
. These are known as representation theorems.
Let
 denote the set of all weak homomorphisms from
denote the set of all weak homomorphisms from
 into
into
 . Then, for a prespecified
. Then, for a prespecified
 , a representation theorem supplies (at least) sufficient conditions on
, a representation theorem supplies (at least) sufficient conditions on
 to guarantee that some such homomorphism exists. The conditions are usually called the axioms of that theorem. Typically, the axioms will be chosen such that (at least) most of them are individually necessary for representability – that is, they’re direct consequences of the assumption that
to guarantee that some such homomorphism exists. The conditions are usually called the axioms of that theorem. Typically, the axioms will be chosen such that (at least) most of them are individually necessary for representability – that is, they’re direct consequences of the assumption that
 is non-empty. Axioms that are not necessary for representability are usually known as structural axioms.Footnote 6 For example:
is non-empty. Axioms that are not necessary for representability are usually known as structural axioms.Footnote 6 For example:
Theorem 5 (Krantz et al. 1971, 15) Let
 be a set and
be a set and
 a binary relation on
a binary relation on
 . Then there is at least one homomorphism from
. Then there is at least one homomorphism from
 into
into
 if
if
| 1. |
 is finite
is finite | (finitude) |
| 2. |
 is a weak order
is a weak order | (weak order) |
The weak order axiom is necessary: since
 is a weak order on
is a weak order on
 , if
, if
 is to be mapped into
is to be mapped into
 then
then
 must itself be a weak order if it’s to be mapped into
must itself be a weak order if it’s to be mapped into
 . The finitude axiom is structural – it’s possible to represent
. The finitude axiom is structural – it’s possible to represent
 in
in
 even if
even if
 is infinite, though in that case additional axioms are needed to ensure representability. (See Reference Krantz, Luce, Suppes and TverskyKrantz et al. (1971), 40–1, for details.)
is infinite, though in that case additional axioms are needed to ensure representability. (See Reference Krantz, Luce, Suppes and TverskyKrantz et al. (1971), 40–1, for details.)
A representation theorem will also usually include or otherwise be associated with a uniqueness result. In the ideal case, the uniqueness result tells us about the relationship between homomorphisms belonging to
 for all
for all
 satisfying the axioms of the associated representation theorem. Continuing the example, it’s plain to see that if
satisfying the axioms of the associated representation theorem. Continuing the example, it’s plain to see that if
 is any homomorphism from
is any homomorphism from
 into
into
 , then so too is
, then so too is
 if and only if
if and only if

Any
 satisfying this condition is related to
satisfying this condition is related to
 by a strictly increasing (or order-preserving) transformation. So the kind of uniqueness result we’d expect to find attached to Theorem 5 would say that given weak order and finitude, the homomorphisms in
by a strictly increasing (or order-preserving) transformation. So the kind of uniqueness result we’d expect to find attached to Theorem 5 would say that given weak order and finitude, the homomorphisms in
 are unique up to an order-preserving transformation. The ‘unique up to’ phrasing is another way to say that the homomorphism set is constrained by the specified transformation – hence it designates a property shared by all and only the functions in the set.
are unique up to an order-preserving transformation. The ‘unique up to’ phrasing is another way to say that the homomorphism set is constrained by the specified transformation – hence it designates a property shared by all and only the functions in the set.
Two points of caution. First: a uniqueness result applies to all systems satisfying the axioms of the associated representation theorem – not necessarily to all systems that are representable in the specified numerical system simpliciter. This is important if the representation theorem includes structural axioms, which are sometimes used to strengthen the uniqueness result. As a rule of thumb, the more structural constraints imposed on
 , the more restricted the potential homomorphisms from
, the more restricted the potential homomorphisms from
 into
into
 , leading to a stronger uniqueness result. Second: many uniqueness results apply only to a proper subset of the possible homomorphisms in
, leading to a stronger uniqueness result. Second: many uniqueness results apply only to a proper subset of the possible homomorphisms in
 . For example, the uniqueness result may assert that there is only one homomorphism from
. For example, the uniqueness result may assert that there is only one homomorphism from
 into
into
 which satisfies such-and-such properties (e.g., is a probability measure), even while there are infinitely many homomorphisms in
which satisfies such-and-such properties (e.g., is a probability measure), even while there are infinitely many homomorphisms in
 that do not. For these reasons, one must be careful when interpreting a uniqueness result – some results that on first glance appear rather impressive may end up only really reflecting the strength of the structural conditions employed in the representation theorem and/or arbitrary restrictions to a particular representational format.
that do not. For these reasons, one must be careful when interpreting a uniqueness result – some results that on first glance appear rather impressive may end up only really reflecting the strength of the structural conditions employed in the representation theorem and/or arbitrary restrictions to a particular representational format.
Table 1 Scale types and uniqueness conditions
| Scale type | Uniqueness condition | Relations preserved |
|---|---|---|
| Ordinal | Strictly increasing transformations | Orderings |
| Interval | Positive affine transformations | Difference ratios |
| Ratio | Positive similarity transformations | Ratios |
| Absolute | Identity | Everything |
Moving on – the final thing to do in this section is outline the major scale types. (See Table 1.) In the preceding example, the
 in
in
 are unique up to order-preserving transformations. In that case, the set
are unique up to order-preserving transformations. In that case, the set
 is said to be an ordinal scale of
is said to be an ordinal scale of
 , and the
, and the
 in
in
 are also called ordinal scales of
are also called ordinal scales of
 . (The ambiguity is unfortunate, but context usually suffices for disambiguation.) Three other scale types are also important. The next is an interval scale:
. (The ambiguity is unfortunate, but context usually suffices for disambiguation.) Three other scale types are also important. The next is an interval scale:
 is an interval scale when the
is an interval scale when the
 are unique up to a positive affine (or interval-preserving) transformation – that is, if
are unique up to a positive affine (or interval-preserving) transformation – that is, if
 then so is
then so is
 , for any
, for any
 defined such that for some real values
defined such that for some real values
 and
and
 , with
, with
 ,
,

Whereas order-preserving transformations merely preserve orderings, interval-preserving transformations preserve ratios of differences (and thus also orderings). So, if
 and
and
 are related by an interval-preserving transformation, then
are related by an interval-preserving transformation, then

Next are ratio scales:
 is a ratio scale when the
is a ratio scale when the
 are unique up to a positive similarity (or ratio-preserving) transformation – that is, if
are unique up to a positive similarity (or ratio-preserving) transformation – that is, if
 is in
is in
 , then so is
, then so is
 , for any
, for any
 defined such that for some real value
defined such that for some real value
 ,
,

Ratio-preserving transformations preserve ratios (and thus also ratios of differences, and thus also orderings). So, if
 and
and
 are related by a ratio-preserving transformation, then
are related by a ratio-preserving transformation, then

Finally, there are absolute scales. This is just the case where
 contains exactly one homomorphism.
contains exactly one homomorphism.
The foregoing classification scheme originates with Reference StevensStevens (1946). It’s the most widely known means of classifying scale types by a wide margin. It works well for most purposes, and it’ll suffice for ours, though it’s not the only classification scheme nor is it the most general. (A more general classification scheme, though also more complicated, can be found in Reference NarensNarens (1981).)
2.3 Extensive and Conjoint Measurement
Of special interest to the theory of measurement are ‘additive’ representations. Roughly, these are representations that make use of addition in some important way. It can be a little hard to define precisely, though, as what it takes for a representation to count as ‘additive’ can vary across measurement structures. The simplest case is that of extensive measurement. Here, we can say that a homomorphism from
 into
into
 is weakly additive when it weakly maps one of
is weakly additive when it weakly maps one of
 ’s primitives into addition; strong additivity can then be defined in the obvious parallel way. The qualitative operation that gets mapped into addition is usually referred to as a concatenation operation.
’s primitives into addition; strong additivity can then be defined in the obvious parallel way. The qualitative operation that gets mapped into addition is usually referred to as a concatenation operation.
Let’s discuss one example of an extensive measurement structure in more detail – a positive concatenation structure. Since it doesn’t make sense to speak of lengths shorter than no length at all, we conventionally measure length using additive homomorphisms from
 into
into
 , where
, where
 is the set of real numbers not smaller than zero. The metre scale is one such homomorphism. Let
is the set of real numbers not smaller than zero. The metre scale is one such homomorphism. Let
 be the metre length, defined as the length of the path light travels in a vacuum in 1/
be the metre length, defined as the length of the path light travels in a vacuum in 1/
 of a second. Then the metre scale,
of a second. Then the metre scale,
 , corresponds to the (unique) strong homomorphism from
, corresponds to the (unique) strong homomorphism from
 into
into
 that assigns the unit value to
that assigns the unit value to
 . In other words,
. In other words,
1.
and
2.
if and only if
3.
if and only if






This method of measuring length is possible precisely because the behaviour of
 and
and
 is mirrored by the behaviour of
is mirrored by the behaviour of
 and
and
 over the non-negative reals. The most important conditions are as follows:
over the non-negative reals. The most important conditions are as follows:
| 1. |
 is a weak order
is a weak order | (weak order) |
| 2. |

| (associativity) |
| 3. |

| (commutativity) |
| 4. |

| (monotonicity) |
| 5. |

| (weak positivity) |
| 6. |
 only if
only if
 is minimal in
is minimal in

| (identity element) |
Compare, for
 :
:
| 1. |
 is a weak order
is a weak order | (weak order) |
| 2. |

| (associativity) |
| 3. |

| (commutativity) |
| 4. |

| (monotonicity) |
| 5. |

| (weak positivity) |
| 6. |
 only if
only if

| (identity element) |
Epistemic approaches to the measurement of belief focus on representing the internal structure of the belief system, and typically posit systems that look a great deal like positive concatenation structures. However, not all ‘additive’ representations follow the same model – they do not all require a primitive concatenation operation that gets mapped into addition. An alternative way to generate ‘additive’ representations employs conjoint measurement structures, wherein multiple quantities are represented simultaneously and the additive structure of the representation is derived from the nature of their lawlike relationships. Since conjoint measurement is important for decision-theoretic approaches to the measurement of belief, it’s worth considering an example in a bit of detail. The procedure is more complicated than the case of extensive measurement (see Figure 2).Footnote 7

Figure 2 Conjoint measurement structure
We start with a single weak ordering,
 , defined for some quantity
, defined for some quantity
 that’s determined by two independent factors
that’s determined by two independent factors
 and
and
 . For example, suppose
. For example, suppose
 is discomfort as determined by temperature
is discomfort as determined by temperature
 and humidity
and humidity
 (Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 17–18), momentum as determined by mass and velocity (Reference Luce and TukeyLuce & Tukey 1964, 4–5), or overall value as determined by monetary and sentimental value.
(Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 17–18), momentum as determined by mass and velocity (Reference Luce and TukeyLuce & Tukey 1964, 4–5), or overall value as determined by monetary and sentimental value.
In any case, we suppose
 on
on
 is determined by these two factors
is determined by these two factors
 and
and
 , whatever they may all be. Formally we can represent this by reconstructing
, whatever they may all be. Formally we can represent this by reconstructing
 as an ordering not over
as an ordering not over
 directly but instead over
directly but instead over
 . So, for example,
. So, for example,

is understood to mean that the level of
 determined by the combination of
determined by the combination of
 and
and
 is at least as great as the level of
is at least as great as the level of
 determined by
determined by
 and
and
 , where the
, where the
 and
and
 are levels of
are levels of
 and
and
 respectively.
respectively.
The next step is to extract from
 two extensive ‘subsystems’ for
two extensive ‘subsystems’ for
 and
and
 separately. We start by defining an ordering
separately. We start by defining an ordering
 over
over
 , by comparing the levels of
, by comparing the levels of
 that result from varying the
that result from varying the
 factor while holding the
factor while holding the
 factor fixed. That is,
factor fixed. That is,

So
 is greater than
is greater than
 when
when
 contributes more to
contributes more to
 than
than
 does, holding the level of
does, holding the level of
 fixed. Note, of course, that the definition alone doesn’t guarantee
fixed. Note, of course, that the definition alone doesn’t guarantee
 will be a weak order – for that we need to suppose that if changing from
will be a weak order – for that we need to suppose that if changing from
 to
to
 increases the level of
increases the level of
 while holding the level of
while holding the level of
 fixed for any particular level of
fixed for any particular level of
 , then the same should hold for all levels of
, then the same should hold for all levels of
 . Essentially this amounts to saying that the contribution
. Essentially this amounts to saying that the contribution
 makes to
makes to
 is independent of the contribution made by
is independent of the contribution made by
 . This is established by the independence axiom, which will be explained in a later paragraph. An exactly parallel definition gets us an ordering
. This is established by the independence axiom, which will be explained in a later paragraph. An exactly parallel definition gets us an ordering
 over
over
 .
.
At this point we’ve got two very simple subsystems,
 and
and
 . But we should like to construct extensive structures so as to enable a richer numerical representation. Thus we will need to define a concatenation operation as well. Assume that
. But we should like to construct extensive structures so as to enable a richer numerical representation. Thus we will need to define a concatenation operation as well. Assume that
 and
and
 combine in an intuitively ‘additive’ fashion. (This will be qualitatively expressed by means of the independence and double cancellation axioms.) Then, it will be possible to draw meaningful correlations in size between intervals in
combine in an intuitively ‘additive’ fashion. (This will be qualitatively expressed by means of the independence and double cancellation axioms.) Then, it will be possible to draw meaningful correlations in size between intervals in
 and in
and in
 by comparing the effects on the level of
by comparing the effects on the level of
 that result from varying one factor while holding the other fixed. For suppose there are
that result from varying one factor while holding the other fixed. For suppose there are
 such that
such that

We can read this as saying that changing from
 to
to
 (while holding the
(while holding the
 -level fixed) has the same effect on
-level fixed) has the same effect on
 as changing from
as changing from
 to
to
 (while holding the
(while holding the
 -level fixed). If we let
-level fixed). If we let
 designate the interval between
designate the interval between
 and
and
 as observed in the effect on
as observed in the effect on
 , and likewise for
, and likewise for
 mutatis mutandis, then what we’ve said is that
mutatis mutandis, then what we’ve said is that
 is equal to
is equal to
 , and thus we compare the size of intervals in one factor to intervals in the other. Given that, if there also are minimal levels
, and thus we compare the size of intervals in one factor to intervals in the other. Given that, if there also are minimal levels
 and
and
 of
of
 and
and
 , then we can define concatenation operations
, then we can define concatenation operations
 and
and
 for each of
for each of
 and
and
 . Starting with
. Starting with
 , we say
, we say

just in case the effect on
 that results from increasing
that results from increasing
 to
to
 while holding the level of
while holding the level of
 fixed at
fixed at
 is equal to the effect on
is equal to the effect on
 that results from increasing the level of
that results from increasing the level of
 from
from
 to
to
 and increasing the level of
and increasing the level of
 from
from
 to some level
to some level
 such that the result is equal in effect on
such that the result is equal in effect on
 as observed from an increase from
as observed from an increase from
 to
to
 . That is, if
. That is, if

then
 is equal to
is equal to
 plus
plus
 , where the latter is known to be equal to
, where the latter is known to be equal to
 . Treating
. Treating
 and
and
 as ‘zero’ points, then, the ‘size’ of the interval
as ‘zero’ points, then, the ‘size’ of the interval
 gives the absolute ‘size’ of
gives the absolute ‘size’ of
 alone, and so this essentially amounts to saying that
alone, and so this essentially amounts to saying that
 equals
equals
 plus
plus
 .
.
The upshot is that, with the appropriate axioms on
 , we can extract extensive subsystems
, we can extract extensive subsystems
 and
and
 out of the initial system
out of the initial system
 , which will admit of separate additive representations
, which will admit of separate additive representations
 and
and
 . The final step is to then show that there exists some numerical operation,
. The final step is to then show that there exists some numerical operation,
 , that combines
, that combines
 and
and
 so as to represent
so as to represent
 on
on
 ; that is,
; that is,

The function
 may take a wide variety of forms depending on the shape of
may take a wide variety of forms depending on the shape of
 , but one simple case is when
, but one simple case is when
 and
and
 combine additively to determine a final value that represents
combine additively to determine a final value that represents
 :
:

The result is a conjoint representation of all three quantities
 ,
,
 , and
, and
 simultaneously, achieved via a two-component vector homomorphism
simultaneously, achieved via a two-component vector homomorphism
 from
from
 into
into
 that ‘decomposes’ into
that ‘decomposes’ into
 and
and
 via
via
 .
.
All of this obviously requires that
 will satisfy the axioms required for the existence of such a representation. These axioms will together essentially assert that
will satisfy the axioms required for the existence of such a representation. These axioms will together essentially assert that
 behaves in the manner one would expect if levels of
behaves in the manner one would expect if levels of
 were determined by the sum of two independent factors
were determined by the sum of two independent factors
 and
and
 . For instance, the following are very typical necessary axioms for additive conjoint measurement structures:
. For instance, the following are very typical necessary axioms for additive conjoint measurement structures:
| 1. | For all
 and
and
 ,
,
 if and only if
if and only if
 , and
, and
 if and only if
if and only if

| (independence) |
| 2. | For all
 and
and
 ,
,
 and
and
 implies
implies

| (double cancellation) |
Again, it’s helpful to compare the qualitative axiom with the intended numerical representation. The independence axiom is straightforward:
 for some
for some


 for all
for all
 The double cancellation axiom is a little less obvious; it concerns cases in which the common terms of two inequalities cancel out to determine a third:
The double cancellation axiom is a little less obvious; it concerns cases in which the common terms of two inequalities cancel out to determine a third:




Let’s sum up. In the example of a conjoint measurement structure I’ve just outlined, the numerical representations of
 ,
,
 , and
, and
 are a package deal. Or, more accurately, they’re three parts of a single representational system comprising several functions and an operation that ties them together. Note in particular – and this will be important – that the two constructed subsystems are defined such that they only make sense as parts of the larger system. The primitives of
are a package deal. Or, more accurately, they’re three parts of a single representational system comprising several functions and an operation that ties them together. Note in particular – and this will be important – that the two constructed subsystems are defined such that they only make sense as parts of the larger system. The primitives of
 , for instance, are characterised in terms of how
, for instance, are characterised in terms of how
 relates to
relates to
 in the determination of
in the determination of
 . Likewise, the operation
. Likewise, the operation
 needn’t correspond to any ‘natural’ concatenation operation that can be readily defined in terms of
needn’t correspond to any ‘natural’ concatenation operation that can be readily defined in terms of
 alone, without reference to how
alone, without reference to how
 interacts with
interacts with
 and
and
 . To the extent that
. To the extent that
 is represented as having an ‘additive’ structure in this manner, then, that structure is manifest in its relationship with
is represented as having an ‘additive’ structure in this manner, then, that structure is manifest in its relationship with
 and
and
 . This is all to say that the meaning of the representation
. This is all to say that the meaning of the representation
 in this context can only be fully grasped by reference to its relation to
in this context can only be fully grasped by reference to its relation to
 as specified by the rule
as specified by the rule
 by which they combine to represent
by which they combine to represent
 . The three numerical representations are, in that sense, inseparable.
. The three numerical representations are, in that sense, inseparable.
Contrast this with the extensive measurement of
 , where the primitives of that system can be characterised without any direct reference to other quantities. One can appreciate what it is for the system of lengths to have an ‘additive’ structure just by considering how determinate length attributes relate to other determinate length attributes. One needn’t embed the system of lengths into a larger relational structure involving multiple quantities in order to comprehend what it is for one length to be twice as long as another, for example, since one can just see it directly by placing the lengths alongside one another. An intuitive way to characterise the difference between the two kinds of measurement structure, then, is to say extensive measurement is geared towards representing the internal relational structure of a single determinable attribute, whereas the conjoint measurement is geared more towards representing the relationships between several attributes.
, where the primitives of that system can be characterised without any direct reference to other quantities. One can appreciate what it is for the system of lengths to have an ‘additive’ structure just by considering how determinate length attributes relate to other determinate length attributes. One needn’t embed the system of lengths into a larger relational structure involving multiple quantities in order to comprehend what it is for one length to be twice as long as another, for example, since one can just see it directly by placing the lengths alongside one another. An intuitive way to characterise the difference between the two kinds of measurement structure, then, is to say extensive measurement is geared towards representing the internal relational structure of a single determinable attribute, whereas the conjoint measurement is geared more towards representing the relationships between several attributes.
2.4 Conventionality
One of the more important lessons of the RTM concerns the extent to which our use of numbers to represent the world is grounded in convention. (By ‘conventional’, I mean unforced from a purely mathematical point of view, and so setting aside pragmatic considerations.) It’s useful to divide it up into three distinct grades of conventionality.
Most will be plenty familiar already with conventionality of the first grade, choice of scale – that is, in the choice of homomorphism from
 , for a fixed choice of
, for a fixed choice of
 and
and
 . This arises, for instance, when we are free to choose between metres, inches, light-years, or beard-seconds (the amount a typical beard grows in one second) as our units for measuring length.
. This arises, for instance, when we are free to choose between metres, inches, light-years, or beard-seconds (the amount a typical beard grows in one second) as our units for measuring length.
A rather deeper and not as widely appreciated form of conventionality arises in the choice of numerical system. A very simple example is the choice to use
 to represent a weak order
to represent a weak order
 , rather than
, rather than
 . Either would obviously work just as well as the other – and just as well as any other weak order on the reals. But a more complicated example is also worth mentioning. As I noted in the previous section, conventional measures of length are almost always additive homomorphisms from
. Either would obviously work just as well as the other – and just as well as any other weak order on the reals. But a more complicated example is also worth mentioning. As I noted in the previous section, conventional measures of length are almost always additive homomorphisms from
 to
to
 . On any such measure, the value assigned to
. On any such measure, the value assigned to
 will always be twice the value assigned to
will always be twice the value assigned to
 . Our overwhelming familiarity with these additive measures can lead to the sense that there’s something uniquely correct about this representation – that the qualitative relation holding between
. Our overwhelming familiarity with these additive measures can lead to the sense that there’s something uniquely correct about this representation – that the qualitative relation holding between
 and
and
 is an essentially twice-ish relation. As Brian Reference EllisEllis (1968, 83) put it, there’s a common sense that the ‘twice’ in ‘twice as long’ has a significance independent of the conventions of measurement. (‘Clearly, 2 meters is twice as long as long as 1 meter – that is the natural and obvious way to describe their relation!’) However, the axioms that justify the additive measurement of length – associativity, commutativity, monotonicity, and so on – are consistent with a multitude of non-additive representations whereby
is an essentially twice-ish relation. As Brian Reference EllisEllis (1968, 83) put it, there’s a common sense that the ‘twice’ in ‘twice as long’ has a significance independent of the conventions of measurement. (‘Clearly, 2 meters is twice as long as long as 1 meter – that is the natural and obvious way to describe their relation!’) However, the axioms that justify the additive measurement of length – associativity, commutativity, monotonicity, and so on – are consistent with a multitude of non-additive representations whereby
 need not be assigned a value twice that which is assigned to
need not be assigned a value twice that which is assigned to
 .
.
Consider multiplicative measures, which map
 not into
not into
 but into
but into
 instead (see Reference HölderHölder 1901; Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 11–12, 99ff; Reference NarensNarens 1985, 27–31). Let the multiplicative (base 2) version of the metre scale be called the schmetre scale; it corresponds to a homomorphism
instead (see Reference HölderHölder 1901; Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 11–12, 99ff; Reference NarensNarens 1985, 27–31). Let the multiplicative (base 2) version of the metre scale be called the schmetre scale; it corresponds to a homomorphism
 that maps
that maps
 onto
onto
 such that
such that
1.
and
2.
if and only if
3.
if and only if






On the schmetre scale, the value assigned to
 will always be equal to the square of the value assigned to
will always be equal to the square of the value assigned to
 . Since 1 metre is 2 schmetres, then, 2 metres is 4 schmetres and 4 metres is 16 schmetres. Hence, if 4 metres is twice as long as 2 metres, it follows that 16 schmetres is twice as long as 4 schmetres. The point is not that there’s some sort of contradiction here – there isn’t. Rather, it’s that the qualitative relation between
. Since 1 metre is 2 schmetres, then, 2 metres is 4 schmetres and 4 metres is 16 schmetres. Hence, if 4 metres is twice as long as 2 metres, it follows that 16 schmetres is twice as long as 4 schmetres. The point is not that there’s some sort of contradiction here – there isn’t. Rather, it’s that the qualitative relation between
 and
and
 is no more a twice-ish relation than it is a square-ish relation. Our use of ‘twice as long’ to refer to and describe the relation between
is no more a twice-ish relation than it is a square-ish relation. Our use of ‘twice as long’ to refer to and describe the relation between
 and
and
 reflects only a conventional preference for additive representations over an infinite variety of alternative representational formats that are, from a mathematical point of view, equally adequate to the task.
reflects only a conventional preference for additive representations over an infinite variety of alternative representational formats that are, from a mathematical point of view, equally adequate to the task.
But the conventionality runs deeper still, for it arises also in the choice of qualitative system. Again, length supplies a useful example. Earlier I characterised
 on
on
 in terms of laying objects end-to-end. However, there are other ways of concatenating lengths that we might have employed as primitives instead. One alternative (also discussed by Reference EllisEllis 1968, 80–1) is right-angled concatenation. Say that
in terms of laying objects end-to-end. However, there are other ways of concatenating lengths that we might have employed as primitives instead. One alternative (also discussed by Reference EllisEllis 1968, 80–1) is right-angled concatenation. Say that
 just when
just when
 is the length of the hypotenuse of the right-angled triangle with catheti of lengths
is the length of the hypotenuse of the right-angled triangle with catheti of lengths
 and
and
 . (See Figure 3; I did have to look that word up.) Right-angled concatenation has all the same key properties as end-to-end concatenation which permit additive measurement. In an alternative history, then, we might have chosen to measure length by mapping
. (See Figure 3; I did have to look that word up.) Right-angled concatenation has all the same key properties as end-to-end concatenation which permit additive measurement. In an alternative history, then, we might have chosen to measure length by mapping
 into
into
 . (Or
. (Or
 , or
, or
 , or …) This would have simplified how we express the relationships between sides of a right-angled triangle, though it would also have made calculating end-to-end concatenations of distances slightly more difficult.
, or …) This would have simplified how we express the relationships between sides of a right-angled triangle, though it would also have made calculating end-to-end concatenations of distances slightly more difficult.

Figure 3
 is the right-angled concatenation of
is the right-angled concatenation of
 and
and
 (i.e.,
(i.e.,
 ).
).
With that said, I don’t want to give the impression that anything goes. A minimal constraint on the choice of qualitative system is that the primitives must be natural. Without some such constraint, we trivialise the whole endeavour. For instance, assuming no more than that
 can be mapped into
can be mapped into
 , we know already that there exists a binary relation
, we know already that there exists a binary relation
 on
on
 that maps into
that maps into
 , in the sense that
, in the sense that

Likewise, supposing only that
 maps into
maps into
 , we know already that there will exist at least one ternary relation
, we know already that there will exist at least one ternary relation
 such that
such that

So the fact that we can then find some relations on
 corresponding to
corresponding to
 and
and
 is thoroughly uninteresting. We can derive such relations from any mapping of
is thoroughly uninteresting. We can derive such relations from any mapping of
 into
into
 , so long as we’re permissive enough about what counts as a relation. It’s a matter of convention what we take the primitive relations in our qualitative systems to be, that is true, but measurement is only interesting when those relations are natural.
, so long as we’re permissive enough about what counts as a relation. It’s a matter of convention what we take the primitive relations in our qualitative systems to be, that is true, but measurement is only interesting when those relations are natural.
2.5 Meaningfulness
A focus of the discussion to follow involves differentiating what is meaningful from what is not in the measurement of belief. The most common strategy for drawing such distinctions goes via invariance. Essentially, the idea is that a numerical property or relation is meaningful only if it’s invariant across alternative numerical representations; otherwise, it’s a mere artefact of convention.
Compare the case of temperature. When represented in
 C, water freezes at 0 and boils at 100, the hottest temperature recorded in Australia is almost exactly half way between these values (50.7) and more than double the hottest temperature recorded in Antarctica (19.8). But not all of the numerical properties and relations just mentioned are meaningful. Measured in
C, water freezes at 0 and boils at 100, the hottest temperature recorded in Australia is almost exactly half way between these values (50.7) and more than double the hottest temperature recorded in Antarctica (19.8). But not all of the numerical properties and relations just mentioned are meaningful. Measured in
 F, water freezes at 32 and boils at 212, the hottest recorded temperature in Australia (123) is less than twice the hottest temperature in Antarctica (68), though it’ll still be just over halfway between the freezing and boiling points of water. Celsius and Fahrenheit are equally legitimate interval scale measures of temperature – they’re numerically distinct but they’re not meaningfully distinct. The particular values associated with each temperature and the ratios between those values vary between alternative scales, and they are therefore not meaningful. Ratios of differences are invariant, on the other hand, and so we call them meaningful.
F, water freezes at 32 and boils at 212, the hottest recorded temperature in Australia (123) is less than twice the hottest temperature in Antarctica (68), though it’ll still be just over halfway between the freezing and boiling points of water. Celsius and Fahrenheit are equally legitimate interval scale measures of temperature – they’re numerically distinct but they’re not meaningfully distinct. The particular values associated with each temperature and the ratios between those values vary between alternative scales, and they are therefore not meaningful. Ratios of differences are invariant, on the other hand, and so we call them meaningful.
So far, so good. But consider again the additive measures of
 . If
. If
 and
and
 are any two additive measures of that system, then
are any two additive measures of that system, then

But this, too, is an artefact of conventions – in the choice of numerical system. As we’ve just discussed, the qualitative relation that holds between
 and
and
 whenever
whenever
 is twice as long as
is twice as long as
 isn’t itself a ratio relation in any deep sense, and if
isn’t itself a ratio relation in any deep sense, and if
 is a multiplicative measure of length, then
is a multiplicative measure of length, then

In that broader sense, almost all the information in any numerical representation of
 is an artefact of convention. There’s approximately nothing that’s invariant across all numerical representations of a qualitative system, and what is preserved is far too little to be of much interest.
is an artefact of convention. There’s approximately nothing that’s invariant across all numerical representations of a qualitative system, and what is preserved is far too little to be of much interest.
The upshot is that meaningfulness needs to be understood relative to a fixed choice of numerical system. A more precise account of meaningfulness, and one that incorporates this lesson, originates with Reference PfanzaglPfanzagl (1968). I present it here in lightly modified form:
Definition 6. Suppose that
 is non-empty, where
is non-empty, where
 and
and
 . For any
. For any
 and any
and any
 -ary relation
-ary relation
 on
on
 ,
,
 is the relation induced on
is the relation induced on
 by
by
 and
and
 if and only if
if and only if

 is
is
 -meaningful relative to
-meaningful relative to
 when
when
 doesn’t depend on the choice of
doesn’t depend on the choice of
 in
in
 .
.
Where the
 and
and
 are obvious given context, we simply say that
are obvious given context, we simply say that
 is meaningful. Note one: if
is meaningful. Note one: if
 is among the primitive relations
is among the primitive relations
 of
of
 , then
, then
 is just the corresponding primitive relation
is just the corresponding primitive relation
 in
in
 and thus
and thus
 is automatically
is automatically
 -meaningful relative to
-meaningful relative to
 . So we’re only interested in the case where
. So we’re only interested in the case where
 isn’t among the primitives relations of
isn’t among the primitives relations of
 . Note two: if
. Note two: if
 is one of the primitive operations of
is one of the primitive operations of
 , then it doesn’t automatically follow that
, then it doesn’t automatically follow that
 is meaningful, except in the special case where every homomorphism in
is meaningful, except in the special case where every homomorphism in
 is a strong homomorphism. So being a primitive relation in
is a strong homomorphism. So being a primitive relation in
 suffices for being meaningful, being a primitive operation doesn’t.
suffices for being meaningful, being a primitive operation doesn’t.
To get a grip on Definition 6, it’s helpful to compare cases where a numerical relation isn’t meaningful. Observe first of all that every numerical property or relation
 induces a corresponding property or relation
induces a corresponding property or relation
 on the qualitative system relative to each
on the qualitative system relative to each
 . So, if some ordinal scale
. So, if some ordinal scale
 maps
maps
 into
into
 , the 2:1 ratio relation induces a corresponding relation on
, the 2:1 ratio relation induces a corresponding relation on
 that holds for
that holds for
 whenever
whenever
 . But that relation isn’t
. But that relation isn’t
 -meaningful relative to
-meaningful relative to
 , precisely because
, precisely because
 needn’t equal
needn’t equal
 for every other
for every other
 in
in
 . By contrast, the 2:1 ratio is meaningful relative to the additive measures of
. By contrast, the 2:1 ratio is meaningful relative to the additive measures of
 , since
, since
 equals
equals
 for any two additive measures
for any two additive measures
 and
and
 . (Why does that matter? Because if the 2:1 ratio is meaningful with respect to the additive measurement of length, then we can draw generalisations and formulate laws involving that ratio without worrying that it all depends on an arbitrary choice of scale.)
. (Why does that matter? Because if the 2:1 ratio is meaningful with respect to the additive measurement of length, then we can draw generalisations and formulate laws involving that ratio without worrying that it all depends on an arbitrary choice of scale.)
In general, the idea is that a numerical relation is meaningful inasmuch as it always corresponds to the same qualitative relation regardless of what homomorphism we care to use, given a fixed choice of numerical system. That’s just what ‘meaningful’ means in this context: always picks out the same thing independent of the choice of scale. So to make some headway on the matter of what should be considered meaningful in our numerical representations of belief, we need to say more about the kinds of qualitative structures these representations are supposed to be representations of.
3 Clarifications and Desiderata
The central questions to be addressed by an account of the measurement of belief are, in relation to a given purported numerical representation of belief: (i) what is the qualitative system being represented, (ii) what is the numerical system in which it’s represented, and (iii) under what conditions are such representations possible? Answer these, and you’ll have a complete theory of the measurement of belief; don’t answer them, and all you’ll have are numbers.
An epistemic approach, I said, is one that explains the measurement of belief by appeal to the internal structure of the belief system. Better: an epistemic approach is one according to which the qualitative system being represented can be characterised fully in terms of doxastic states and the relations between them, where a doxastic state is any type of mental state with a belief-ish flavour. This might include states of all-or-nothing belief, levels of confidence, judgements of comparative probability, judgements of when one thing is evidence for another thing or when they are independent, and so on. In sum, doxastic states are the sorts of mental states that have a mind-to-world direction of fit, broadly construed; or the sorts of things that reflect our opinions regarding what the world is like and what it might be like, and that ought to be responsive to evidence independent of our preferences. Epistemic approaches are covered in Section 4 and Section 5.
Decision-theoretic approaches appeal instead to relations between doxastic states and conative states (read: states with a desire-ish flavour) to explain what the numbers mean. Roughly, a paradigmatic decision-theoretic approach is one where the qualitative system is comprised of a conjoint system of beliefs and basic desires (as opposed to derivative or instrumental desires), related via their joint determination of a preference ordering over a space of actions according to some decision rule; the numerical representation of the preference relation is then constructed to capture the systematic relations holding between the three. Decision-theoretic approaches are covered in Section 6.
But before we delve into the details, this section provides some background clarifications on what a theory of belief measurement is and what it is not (section 3.1 and section 3.2), followed by some simplifying assumptions (section 3.3) and general desiderata (section 3.4) that will be relevant to the discussion throughout.
3.1 Quantitation, Not Elicitation
In the classic presentations of the RTM, qualitative systems are understood to be empirical relational systems. These systems are built around primitives that are directly and publicly observable in the context of some experimental procedure. For example, rather than characterising the length system
 as a set of attributes and higher-order relations between them, if I were doing things in the classical manner, then I’d have characterised it as a set of rigid physical objects, the observable at least as long relation between them, and a concatenation operation interpreted as the physical process of taking two rigid objects and joining them to form a new composite object. Essentially, empirical relational systems are systems in which nothing is hidden from view – the relations should be open to observation, the relata should be things we can touch and see and poke and prod, and the operations are physical procedures on or processes observed in the entities being measured.
as a set of attributes and higher-order relations between them, if I were doing things in the classical manner, then I’d have characterised it as a set of rigid physical objects, the observable at least as long relation between them, and a concatenation operation interpreted as the physical process of taking two rigid objects and joining them to form a new composite object. Essentially, empirical relational systems are systems in which nothing is hidden from view – the relations should be open to observation, the relata should be things we can touch and see and poke and prod, and the operations are physical procedures on or processes observed in the entities being measured.
There are some obvious problems that arise when measurement is understood this way. (These problems were not unknown to the founders of the representational theory; cf. Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 27–31.) In violation of ubiquitous transitivity axioms, for example, one might have a series of objects each longer than the preceding by an imperceptible amount, such that adjacent objects will be observed to be of the same length even while the last is much longer than the first. Similar problems arise for all empirical relational systems, and will be familiar from the history of operationalism. They all point to the same basic issue: quantities cannot be perfectly characterised in terms of the experimental procedures by which they’re measured, since no such procedure is ever perfect. Instead, measurement procedures are developed on the basis of what our best theories imply about the conditions under which observable experimental outcomes will reliably (albeit imperfectly) correlate with variations in some limited range of magnitudes of the quantity we desire to measure.Footnote 8
But it would be a mistake to dismiss the classical RTM focus on empirical relational systems as mere offshoots of some outdated operationalism. Much more illuminating to say that the mathematical framework of the theory was built to play two separable explanatory roles. On the one hand, it’s there to explain how we might use numerical properties and relations to represent and reason about bits of the world that aren’t themselves numerical in nature. That explanation appeals to structure-preserving mappings between qualitative and numerical systems, and matters of observability are irrelevant here. On the other hand, the very same formalisms were supposed to help guide the design of actual measurement procedures. The empirical relational system for the measurement of length, for instance, was supposed to be formulated in such a way that it might feasibly be implemented in some empirical procedure for measuring lengths – hence the pervasiveness of error in all realistic measurement practices was taken to present a serious problem for the RTM (cf. Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 1–9, 25, 27–31).
We can – and should – keep these roles separate. The RTM is great for the first, not so great for the second.Footnote 9 As Reference KyburgKyburg (1984) once said, the ‘theory of measurement is difficult enough without bringing in the theory of making measurements’ (p. 7). Unfortunately, ambiguity in how we use the term ‘measurement’ can obscure this point. Compare the ‘measurement of mass’ qua abstract pairing of determinate mass attributes with numbers, such that relations between the latter usefully mirror relations between the former; versus the ‘measurement of mass’ qua empirical procedure for determining the mass of particular objects by means of an equal-armed pan balance. The original intention was that the RTM will be a theory of both – and the sad result has been that it’s routinely criticised for being of little relevance to the actual measurement practices of working scientists (e.g., Reference BorsboomBorsboom 2005; Reference MariMari 2005; Reference ReissReiss 2016). Such criticisms lack bite when we recognise that the RTM was always better understood as a framework for understanding meaning and meaningfulness in our numerical representations of systems of determinable attributes as posited by a scientific theory.
In light this, let me emphasise firmly that a theory of belief measurement as presently understood is not in the business of explaining how we might gather empirical evidence as to the strength of an agent’s beliefs through the observation of their behaviour, nor how we might elicit their beliefs by any other means. Mario Reference BungeBunge (1973) once recommended avoiding the ambiguity of ‘measurement’ by referring to the abstract sense as quantitation. The terminological suggestion never much caught on, but in those terms our topic is the quantitation of beliefs rather than their elicitation.
Consequently, I also suggest we make no presumptions regarding the observability of the qualitative primitives posited within a theory of belief measurement. These systems posit psychological relations – things like is more confident than, is more desirable than, is indifferent between – and it would be an error to presume that such relations will be directly observable in behaviour.Footnote 10 It would be a deeper error still to assume that these relations must be observable, if we’re to justify theses about the structure of the qualitative systems involving them. Quantities are posits of our scientific theories, and like any other posits they need not be directly observable. The justification for the hypothesis that a qualitative system has a certain formal structure that permits a certain format of numerical representation need not derive from any direct observations of that structure, but can instead derive indirectly from the broader empirical and theoretical virtues of the theories that presuppose a system of quantities endowed with that structure. In this respect the measurement of belief is no different in kind than the measurement of any other quantity.
3.2 Measurement, Not Metaphysics
This is an work on measurement, not metaphysics. Experience teaches that these can be hard to keep separate, but separate them we should – lest we end up rejecting perfectly reasonable approaches to the measurement of belief by mixing them up with hideously implausible views on the metaphysics of belief.
The core questions dealt with by a theory of belief measurement concern the specific matter of quantitation: in relation to a purported numerical representation of some doxastic state or set of such states,
1. what is the qualitative system
being represented,2. what is the numerical system
in which it’s represented, and3. under what conditions are such representations possible?


By contrast, a metaphysics of belief is concerned with much broader questions about the kinds of ontological and/or conceptual dependence relations that hold between doxastic states of different kinds, and between doxastic states and the wider world.Footnote 11 The core task of such a metaphysics is, in short, to explain what kinds of doxastic state-types there are, and where they ought to be situated relative to one another and relative to the rest of the world within some general conceptual framework and/or global ontology of the universe.
One major division in the metaphysics of belief is between realist and anti-realist views. Broadly speaking, the former says that the correct attribution of a doxastic state to an agent depends on objective facts about the agent, and the latter says that correct attribution depends somehow on who’s doing the attributing. Some versions of interpretivism fall into the anti-realist camp; such will typically say that an agent’s beliefs are just those an interpreter can usefully employ to explain the agent’s behaviour. Among realists, a major division is between representational and non-representational theories. The former explains what it is to have a doxastic state with such-and-such content by hypothesising the existence of some internal mental representation of that content. Non-representational theories link doxastic states instead to not-necessarily-representational states of the agent that are systematically related to the contents thereof. Among non-representational views are behaviourist theories, which analyse doxastic states as patterns of behaviour; dispositionalist theories, which analyse doxastic states via a suite of associated (and not-necessarily-behavioural) dispositions; and functionalist theories, which analyse doxastic states by reference to a functional role that typically revolves around relations between beliefs over time given evidence and between beliefs, desires and behaviour.
While there are some connections between measurement and metaphysics – some ways of approaching the former will fit more or less naturally with different ways of approaching the latter – in general, one cannot read metaphysics off of measurement. Every epistemic and decision-theoretic approach to the measurement of belief that’s considered in the following sections is compatible with a wide range of views on the metaphysics of belief – including all of those just mentioned. There’s nothing intrinsically realist or anti-realist, or representationalist or non-representationalist, or behaviourist or dispositionalist or functionalist (and so on) about any of these measurement theories.
This point is especially worth emphasising in the case of decision-theoretic accounts of belief measurement. Historically there has been a close connection between the decision-theoretic representation theorems that underlie those accounts, and behaviourist (or behaviourist-lite) metaphysical theories which propose to reduce beliefs to preferences as revealed by choices. Since this kind of behaviourism is nowadays treated like a bad smell, decision-theoretic approaches to the measurement of belief seem to have been tainted by association and are thereby often dismissed without much consideration. So I want to consider that case in a bit more detail, as on reflection there’s not much reason to link the decision-theoretic approaches specifically to behaviourism.
A typical decision-theoretic representation theorem establishes sufficient conditions for the conjoint measurement of beliefs, desires, and preferences. The general idea is that an agent’s preference ordering will be determined by their beliefs and desires via some decision rule (e.g., expected utility maximisation), and so we want to construct a numerical representation of those preferences which ‘decomposes’ into independent representations of belief and desire via that decision rule. (Compare the example in section 2.3, with the representation of C ‘decomposing’ into representations of its determinants A and B via some rule f.) These theorems don’t tell us anything about the metaphysical relationship between beliefs, desires, and preferences. Consider: if I describe a structure for the conjoint measurement of momentum as determined by mass and velocity, then no one leaps to the conclusion that mass and velocity are ontologically dependent on momentum. Likewise, if I describe a structure for the conjoint measurement of discomfort as determined by temperature and humidity, no one infers that the concepts of temperature and humidity ought to be analysed in terms of discomfort. Such inferences would be obviously fallacious – so why would we draw parallel inferences from decision-theoretic representation theorems?
According to the decision-theoretic approach, the conjoint representation is supposed to capture a systematic relation or relations between beliefs, desires, and preferences that is explanatorily relevant to the quantitation of belief. Nothing about this implies that beliefs depend conceptually or ontologically on preferences. Moreover, the explanatorily relevant relations may not be dependence relations at all. For example, the approach would be consistent with a functionalist metaphysics according to which beliefs, desires and preferences are interrelated posits in a psychological theory such that none are reducible to the others, and such that their statistically or biologically normal causal interactions can be systematically represented within a decision-theoretic framework.
Observe, also, that such a functionalist might say the relation between beliefs and preferences is critical for explaining the quantitation of belief, even while saying that the characteristic functional role of belief isn’t exhausted by those relations. One might suppose that an important part of the functional role of belief concerns the connection between beliefs and sensory evidence – a state cannot rightly be said to ‘play the belief-role’ if it isn’t appropriately sensitive to perceived changes in the environment. Such relationships will be crucial when providing a functionalist analysis of what beliefs are, but that doesn’t imply they need also be mentioned in an explanation of why it makes sense to represent a system of beliefs within a certain numerical framework. These are related issues, to be sure, but nevertheless clearly distinct.
Compare the case of mass. Our concept of mass can be plausibly analysed in terms of its theoretical role: mass is the property that best satisfies the total role associated with ‘mass’ within contemporary physics. But mass does many things. The mass of an object is proportionate to its resistance to acceleration as measured by an observer at rest with respect to it. It’s also proportionate to the strength of the gravitational field the object exerts on others, and its total rest energy. Mass is tied to momentum and velocity, density and volume, and to how fast a transverse wave travels through a string attached to a fixed point at each end. Mass also plays a role in stellar evolution; for instance, a white dwarf with mass exceeding about 1.4 solar masses will succumb to electron degeneracy pressure and collapse into either a neutron star or a black hole. So if you want to analyse mass by reference to its total theoretical role, then there’s a lot you need to mention – but if you just want to give an explanation of why it makes sense to measure mass on a ratio scale, then not all of that is going to be necessary or relevant. In sum: the relations we use to analyse the concept of a quantity can come apart from the typically narrower class of relations we use to explain the quantitation of that quantity.
An account of the measurement of belief just isn’t in the business of explaining ontological or conceptual dependence relations that hold between different kinds of doxastic states, nor between doxastic states and non-doxastic states. It would be wise, then, to be very careful when drawing metaphysical conclusions from measurement-theoretic premises.
3.3 Simplifying Assumptions
Having said some things about the sorts of things we shouldn’t be assuming, let me now talk about the things I will be assuming. There are three assumptions in total; the first two are simplifying assumptions about how we model contents:
- Assumption 1
Degrees of belief have propositional contents, where propositions can be modelled as subsets of some non-empty space of possible worlds (henceforth denoted
).- Assumption 2
For each agent and all propositions
, there exists an algebra of propositions
on
such that the agent has some degree of belief towards
if and only if
belongs to
.







By ‘possible’, I mean at least consistent with classical logic. An algebra of propositions is defined like so:
Definition 7.
 is an algebra of propositions on
is an algebra of propositions on
 if and only if it is a non-empty set of subsets of
if and only if it is a non-empty set of subsets of
 , and for all
, and for all
 ,
,
1. If
is in
, then
(henceforth
) is in
2. If
and
are in
, then
is in










Furthermore, an element
 is an atom of the algebra if and only if
is an atom of the algebra if and only if
 and for every
and for every
 , either
, either
 or
or
 .
.
These are substantive assumptions indeed, and I’m not super confident they’re true – but they’re also both very standard assumptions in the present context, and each does a great deal to help simplify many matters.Footnote 12
Still, I should say a bit more about these two assumptions, since they’ll play an important role at some points of the discussion. An immediate consequence of Assumption 1 is that the contents of belief are coarse-grained: if
 and
and
 are logically equivalent, then
are logically equivalent, then
 . But I did not call it a ‘simplifying’ assumption due to this fact – there’s a lot to be said in favour of coarse-grained content! (e.g., Reference StalnakerStalnaker 1984; Reference LewisLewis 1986; Reference Chalmers, Egan and WeathersonChalmers 2011.) Rather, I consider Assumption 1 to be a simplifying assumption because it (in effect) has us ignore so-called de se content and certain common strategies for the representation thereof that require going a little ways beyond the standard possible worlds framework (e.g., Reference LewisLewis 1979).
. But I did not call it a ‘simplifying’ assumption due to this fact – there’s a lot to be said in favour of coarse-grained content! (e.g., Reference StalnakerStalnaker 1984; Reference LewisLewis 1986; Reference Chalmers, Egan and WeathersonChalmers 2011.) Rather, I consider Assumption 1 to be a simplifying assumption because it (in effect) has us ignore so-called de se content and certain common strategies for the representation thereof that require going a little ways beyond the standard possible worlds framework (e.g., Reference LewisLewis 1979).
Opponents of coarse-grained content often suppose we can model more fine-grained contents using impossible worlds. Roughly, the idea is that wherever we want to differentiate between logically equivalent contents
 and
and
 , we can include in our space of worlds
, we can include in our space of worlds
 one or more impossible worlds where one of these holds but the other doesn’t; hence the set of
one or more impossible worlds where one of these holds but the other doesn’t; hence the set of
 -worlds will come apart from the set of
-worlds will come apart from the set of
 -worlds. But matters are not quite so easy. One cannot simply throw a bunch of impossible worlds into
-worlds. But matters are not quite so easy. One cannot simply throw a bunch of impossible worlds into
 without potentially breaking something elsewhere, especially in the presence of Assumption 2.
without potentially breaking something elsewhere, especially in the presence of Assumption 2.
To explain why, it’ll help to have a specific account of what impossible worlds are and how they’re used to model contents. For the purposes of the discussion I’ll adopt the modal ersatz approach found in Reference NolanNolan (1997), though essentially the same points can be made for other popular accounts of impossible worlds (e.g., linguistic ersatzism or extended modal realism, see Reference ElliottElliott 2019b for discussion). Following Nolan’s preferred terminology, take propositions – the potential objects of our beliefs and the meanings of our declarative sentences, whatever they may be – to be ontological primitives. Given that, we let a world
 be any set of propositions, and we say that
be any set of propositions, and we say that
 is true at a world
is true at a world
 just in case
just in case
 . There is, of course, a one-to-one correspondence between each primitive proposition
. There is, of course, a one-to-one correspondence between each primitive proposition
 and the set of worlds containing
and the set of worlds containing
 (the
(the
 -worlds). We say a world is possible just in case it’s complete (contains either
-worlds). We say a world is possible just in case it’s complete (contains either
 or its negation, for every proposition
or its negation, for every proposition
 ) and consistent (has no logically inconsistent subsets); otherwise, it’s impossible. If
) and consistent (has no logically inconsistent subsets); otherwise, it’s impossible. If
 contains only possible worlds, then if
contains only possible worlds, then if
 logically implies
logically implies
 then every
then every
 -world in
-world in
 will be a
will be a
 -world. But if
-world. But if
 isn’t restricted to possible worlds, then it may be that
isn’t restricted to possible worlds, then it may be that
 implies
implies
 even while there are some impossible
even while there are some impossible
 -worlds in
-worlds in
 that aren’t
that aren’t
 -worlds. Much therefore depends on what kinds of worlds get to go into
-worlds. Much therefore depends on what kinds of worlds get to go into
 ; the richer the space of worlds, the more distinctions we can draw between logically-equivalent contents modelled as sets of worlds.
; the richer the space of worlds, the more distinctions we can draw between logically-equivalent contents modelled as sets of worlds.
Impossible worlds theorists will often assume a very rich space of worlds characterised by an unrestricted comprehension principle: for any complete set of primitive propositions
 , there is a world
, there is a world
 such that
such that
 . Roughly, for any possibility or impossibility, there’s a world that verifies it; and the principle thereby ensures there are always some
. Roughly, for any possibility or impossibility, there’s a world that verifies it; and the principle thereby ensures there are always some
 -worlds that aren’t
-worlds that aren’t
 -worlds even when
-worlds even when
 logically implies
logically implies
 . However, unrestricted comprehension also has the consequence that many subsets of
. However, unrestricted comprehension also has the consequence that many subsets of
 are meaningless. These are sets of worlds that correspond to no primitive proposition whatever, and so are not fit (by hypothesis) to serve as the objects of belief. There is nothing that’s true at all and only the worlds in a meaningless set – they are just artefacts of the construction of contents as sets of sets of primitive propositions. For example, and as Reference NolanNolan (1997, 563) points out, any set containing only possible worlds will be meaningless in this sense given unrestricted comprehension. For any set of possible worlds
are meaningless. These are sets of worlds that correspond to no primitive proposition whatever, and so are not fit (by hypothesis) to serve as the objects of belief. There is nothing that’s true at all and only the worlds in a meaningless set – they are just artefacts of the construction of contents as sets of sets of primitive propositions. For example, and as Reference NolanNolan (1997, 563) points out, any set containing only possible worlds will be meaningless in this sense given unrestricted comprehension. For any set of possible worlds
 there will be some propositions they all have in common. Given that, let
there will be some propositions they all have in common. Given that, let
 be a world such that everything true at all the worlds in
be a world such that everything true at all the worlds in
 is also true at
is also true at
 , but the negation of one or more of those things is also true at
, but the negation of one or more of those things is also true at
 . It follows that
. It follows that
 is an impossible world. So, there is nothing true at all and only a set of possible worlds – such sets are meaningless.
is an impossible world. So, there is nothing true at all and only a set of possible worlds – such sets are meaningless.
The existence of meaningless subsets of
 isn’t intrinsically problematic. However, it does not play nicely with Assumption 2. An algebra of propositions is closed under relative complements and binary unions, and in the presence of unrestricted comprehension two facts follow. First, the relative complement of any meaningful proposition is meaningless: for any
isn’t intrinsically problematic. However, it does not play nicely with Assumption 2. An algebra of propositions is closed under relative complements and binary unions, and in the presence of unrestricted comprehension two facts follow. First, the relative complement of any meaningful proposition is meaningless: for any
 and
and
 there will be impossible worlds where both
there will be impossible worlds where both
 and
and
 hold, hence there’s no
hold, hence there’s no
 such that the set of
such that the set of
 -worlds doesn’t intersect with the set of
-worlds doesn’t intersect with the set of
 -worlds. Second, the union of any two meaningful propositions is meaningless: for any
-worlds. Second, the union of any two meaningful propositions is meaningless: for any
 and
and
 there can be no
there can be no
 such that the set of
such that the set of
 -worlds is the union of the
-worlds is the union of the
 -worlds and the
-worlds and the
 -worlds, since then every
-worlds, since then every
 -world would be an
-world would be an
 -world but for any
-world but for any
 and
and
 there will be some
there will be some
 -worlds that aren’t
-worlds that aren’t
 -worlds. In short, then: any algebra of propositions defined on a sufficiently rich space of possible and impossible worlds will consist mostly of meaningless sets – and we shouldn’t want to represent agents as having beliefs towards entities that correspond to no proper object of belief.
-worlds. In short, then: any algebra of propositions defined on a sufficiently rich space of possible and impossible worlds will consist mostly of meaningless sets – and we shouldn’t want to represent agents as having beliefs towards entities that correspond to no proper object of belief.
You might think there’s an easy response: the main premises of the foregoing reasoning are unrestricted comprehension and Assumption 2, so we can simply deny one or both of those and avoid the problem – right? Again, though, matters aren’t so simple. For one thing, unrestricted comprehension or something in the nearby vicinity is required for the most attractive results that impossible worlds are advertised to have in relation to fine-grained content and logical omniscience (see Reference NolanNolan 2013 for an overview). But moreover, it’s a mistake to suppose that unrestricted comprehension is necessary for the conclusion – as if the problem would simply disappear were we to adopt a more restricted principle. As shown in Reference ElliottElliott (2019b), the real problem is that Assumption 2 imposes a Boolean algebraic structure over meaningful subsets of
 , which forces the worlds in
, which forces the worlds in
 to conform to a Boolean logic. Under quite minimal richness conditions on what kinds of possible worlds go into
to conform to a Boolean logic. Under quite minimal richness conditions on what kinds of possible worlds go into
 , either (a) every algebra of sets on
, either (a) every algebra of sets on
 will contain meaningless sets of worlds or (b) the worlds in
will contain meaningless sets of worlds or (b) the worlds in
 will be closed under the
will be closed under the
 -fragment of Boolean logic (or something to the same effect).
-fragment of Boolean logic (or something to the same effect).
Nor is it easy to deny Assumption 2 since – as we’ll see – many theories for the measurement of belief make important use of that assumption. This includes all of the epistemic approaches that I will discuss in what follows, and a large number of decision-theoretic approaches too. The reason why the assumption is important ultimately boils down to the fact that representation of any quantity on anything stronger than an ordinal scale requires a qualitative structure richer than what can be provided by a single weak ordering over the magnitudes thereof – basically, some additional relation will be required for the extra-ordinal structure of the numerical representation to grock on to. Thus, in the measurement of length we require not only the at least as long relation, but also a concatenation operation that can be mapped into addition. Likewise for conjoint measurement, where the additional structure is supplied by reconstructing
 on the single quantity
on the single quantity
 as a quarternary relation over
as a quarternary relation over
 and then using induced relations between the factors
and then using induced relations between the factors
 and
and
 to supply the additional structure for the representation. For theories of belief measurement, the additional structure that allows for the possibility of more-than-merely-ordinal measurement is often characterised by set-theoretic relations between contents (qua sets of worlds) in such a way that presupposes the algebraic structure guaranteed by Assumption 2.
to supply the additional structure for the representation. For theories of belief measurement, the additional structure that allows for the possibility of more-than-merely-ordinal measurement is often characterised by set-theoretic relations between contents (qua sets of worlds) in such a way that presupposes the algebraic structure guaranteed by Assumption 2.
The point here is not that there’s no hope for impossible worlds, or that we shouldn’t make use of them. Rather, the point is that incorporating impossible worlds into contemporary theories of belief measurement will require careful consideration about the nature of content and likely some further adjustments to our formal models and their interpretation. The common thought among many philosophers is that impossible worlds present an easy fix to the problems of coarse-grained content – just throw some impossible worlds into
 and you’re done. But it is not so easy. In that sense, then, the conjunction of Assumption 1 and Assumption 2 can be considered a simplifying assumption as well.
and you’re done. But it is not so easy. In that sense, then, the conjunction of Assumption 1 and Assumption 2 can be considered a simplifying assumption as well.
One more simplifying assumption:
- Assumption 3
Degrees of belief are precise.
 be the proposition that the coin lands heads, and
be the proposition that the coin lands heads, and
 that the card is red. If degrees of belief are precise (represented by real values), and you have some positive degree of confidence in each of
that the card is red. If degrees of belief are precise (represented by real values), and you have some positive degree of confidence in each of
 and
and
 , then there must be some precise value
, then there must be some precise value
 such that you’re exactly
such that you’re exactly
 times as confident in
times as confident in
 as you are in
as you are in
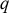 . Plausibly, though, there is no such
. Plausibly, though, there is no such
 , or at least there needn’t be.
, or at least there needn’t be.Over the past few decades, something of a consensus has emerged regarding the representation of ‘imprecise’ degrees of belief (see, e.g., Reference WalleyWalley 1991; Reference KaplanKaplan 2010; Reference JoyceJoyce 2010). Instead of the real-valued functions employed in classical models of graded belief, we use a set of real-valued functions – a credal set, or as it’s often known in philosophy, a representor. The rough idea is that what a representor represents is what’s true according to all functions in the set. Thus, for example, we say the subject has at least as much confidence in
 as she does in
as she does in
 just when every function in her representor assigns a value to
just when every function in her representor assigns a value to
 that’s at least as great as the value assigned to
that’s at least as great as the value assigned to
 . Moreover, a general strategy exists for the construction of these ‘representor’ representations that can be applied to the different epistemic and decision-theoretic approaches discussed in what follows (e.g., Reference Evren and OkEvren & Ok 2011; Reference Alon and LehrerAlon & Lehrer 2014; Reference Alon and SchmeidlerAlon & Schmeidler 2014; Reference Augustin, Coolen, Cooman and TroffaesAugustin et al. 2014; Reference Hawthorne, Hájek and HitchcockHawthorne 2016). The main move is to replace the common weak order axiom that’s used to construct a precise real-valued representation with a strictly weaker preorder axiom, thus allowing for incompleteness in the primitive psychological relations being represented. The ‘imprecise’ representation is then constructed from the many precise representations of the various possible completions of that preorder.
. Moreover, a general strategy exists for the construction of these ‘representor’ representations that can be applied to the different epistemic and decision-theoretic approaches discussed in what follows (e.g., Reference Evren and OkEvren & Ok 2011; Reference Alon and LehrerAlon & Lehrer 2014; Reference Alon and SchmeidlerAlon & Schmeidler 2014; Reference Augustin, Coolen, Cooman and TroffaesAugustin et al. 2014; Reference Hawthorne, Hájek and HitchcockHawthorne 2016). The main move is to replace the common weak order axiom that’s used to construct a precise real-valued representation with a strictly weaker preorder axiom, thus allowing for incompleteness in the primitive psychological relations being represented. The ‘imprecise’ representation is then constructed from the many precise representations of the various possible completions of that preorder.
Since this is a general strategy that works more or less the same way across epistemic and decision-theoretic approaches, I’ve neglected to include details. Instead, I’ll take it as read that the real-valued measures of belief considered in what follows are idealisations – and relatively harmless idealisations, in that we have a good sense of how to do away with them. (See also section 6.4 for a little more discussion on this.)
3.4 Desiderata
The remainder of this section will outline four desiderata for a theory of belief measurement. To be clear: I will not be explicitly evaluating the theories of belief measurement by reference to these desiderata. Evaluation is left to the reader, and you may take issue with some (or all) of what I take to be theoretically desirable. Rather, the desiderata are here offered by way of explanation for why I’ve chosen to focus on certain topics in the chapters that follow – namely the meaningfulness of extra-ordinal information, probabilistic and non-probabilistic representations, and logical omniscience.
Again I’ll need to start with some terminology. We take a probability measure to be defined as follows:
Definition 8. Where
 is an algebra of propositions on
is an algebra of propositions on
 ,
,
 is a probability measure if and only if, for all
is a probability measure if and only if, for all
 ,
,
| 1. |

| (non-negativity) |
| 2. |

| (normalisation) |
| 3. | If
 , then
, then

| (
 -additivity)
-additivity) |
According to probabilism, ideally rational agents are those whose beliefs can be accurately represented by some probability measure. Now, exactly what it is for a system of beliefs to be represented by a probability measure is a question to be settled by an account of the measurement of belief – so probabilism is a thesis that only makes sense against the backdrop of some measurement theory. But set that aside. A weaker version of the thesis, what Reference KaplanKaplan (2010) calls modest probabilism, requires that an ideally rational system of beliefs can be represented by a non-empty set of probability measures.
I want something even weaker: at least some rational systems of belief are represented by (sets of) probability measures. Call it really modest probabilism. While there are occasional arguments against (modest) probabilism, these usually highlight surprising exceptions to the thesis that ideally rational agents must always be represented by (sets of) probability measures. So I take it that really modest probabilism will be generally uncontroversial, and as such we should desire a theory of belief measurement that’s in a position to make sense of it:
- Desideratum 1
A theory of the measurement of belief should be consistent really modest probabilism.
That is, the theory should be able to explain how a system of beliefs might be accurately represented by some probability measure (or a set thereof).Footnote 13
For the next, let’s say that a measure of belief is cardinal (as opposed to merely ordinal) if it’s unique up to something stronger than an order-preserving transformation. So, for example, interval-scale and ratio-scale measures will count as cardinal measures in this sense. Given that,
- Desideratum 2
Probabilistic representations of belief are (at least in some theoretical contexts) cardinal measures of those beliefs.
One reason to accept this desideratum is intuition. Most will be happy to say that a rational agent ought to have about 50 per cent confidence that a fair coin will land heads on a single toss, which should be half as much confidence as they have regarding it landing either heads or tails, and twice as much confidence as they ought to have regarding it landing heads twice in a row. Or, more straightforwardly, it’s clearly sensible to say that a person can have much more confidence in one thing than in another. Such claims makes sense only if beliefs are measurable on something stronger than an ordinal scale.
I’m inclined to take these intuitions seriously, as indicative of how we pre-theoretically (and post-theoretically) tend to think about confidence. But I wouldn’t want to rest my case on such intuitions alone. A stronger reason to accept Desideratum 2 arises from the fact that more-than-merely-ordinal information has a theoretical role to play in our standard (and non-standard) theories of rational decision-making. Consider the following example. We imagine first that Ramsey has to choose between two gambles:
α : receive $1 if
is true, nothing otherwiseβ : receive $2 if
is false, nothing otherwise


Suppose also that Ramsey considers
 less probable than
less probable than
 but more probable than
but more probable than
 . Without loss of generality, let the algebra
. Without loss of generality, let the algebra
 be
be
 . A probability measure will be a merely ordinal representation of Ramsey’s confidences just in case it assigns a value to
. A probability measure will be a merely ordinal representation of Ramsey’s confidences just in case it assigns a value to
 that’s strictly between
that’s strictly between
 and
and
 . As such, there’s at least two ordinally equivalent probability measures,
. As such, there’s at least two ordinally equivalent probability measures,
 and
and
 , such that
, such that

If confidence is measured on nothing stronger than an ordinal scale, then there should be no difference in meaning between
 and
and
 . But according to expected utility theory, there is a difference: Ramsey should prefer
. But according to expected utility theory, there is a difference: Ramsey should prefer
 if and only if his confidence in
if and only if his confidence in
 is more than twice his confidence in
is more than twice his confidence in
 . At that point, the higher probability of winning with
. At that point, the higher probability of winning with
 outweighs the promise of a larger prize with
outweighs the promise of a larger prize with
 . So expected utility theory is inconsistent with the thesis that confidence is measured on a merely ordinal scale. (I’ll say more about this in Section 6.3.)
. So expected utility theory is inconsistent with the thesis that confidence is measured on a merely ordinal scale. (I’ll say more about this in Section 6.3.)
The same holds for most alternatives to expected utility theory, including normative theories (for representing ideally rational agents) and descriptive theories (for representing realistic agents). And we needn’t rest the case on decision-theoretic examples either. Much the same holds in contemporary epistemology, where a great deal of theory and argument presumes the more-than-merely-ordinal measurement of belief. Two brief examples; I’m sure if you start looking you’ll find more. First, the relation of probabilistic independence is crucially important for Bayesian theories of evidence and learning, but independence relations can vary between ordinally equivalent numerical representations (see Section 5.3). Second, epistemic utility theory appeals to numerical properties that differentiate ordinally equivalent probability measures (see Reference Mayo-Wilson and WheelerMayo-Wilson & Wheeler 2019, p. 19). In sum: if our numerical representations of belief are to play the roles that they are in fact generally taken to play in contemporary theories of rational belief and rational decision-making, then they cannot be mere ordinal-scale measures. That’s not a conclusive reason for accepting Desideratum 2, of course, but it is a reason, and a potent one.
Together, Desideratum 1 and Desideratum 2 imply that at least some possible agents have beliefs that are representable by a probability measure, where that probability measure isn’t merely an ordinal scale. But for all that’s said, it may be that cardinal measurement is only possible in the special case of ideally rational agents – everyone else is stuck with mere ordinal measures. The next desideratum is aimed at denying this. Say that an agent is logically omniscient just in case, if
 logically entails
logically entails
 , then the agent has no more confidence in
, then the agent has no more confidence in
 than they do in
than they do in
 . In other words, their confidences are ordered coherently with respect to logical implication. Then:
. In other words, their confidences are ordered coherently with respect to logical implication. Then:
- Desideratum 3
Logical omniscience is not a prerequisite for the cardinal measurement of belief.
The argument I’ll provide for Desideratum 3 is just based on intuition. I’m not ideally rational, and neither are you. We are less-than-ideally rational, and one likely manifestation of this fact is that we aren’t logically omniscient. But this doesn’t prevent us from believing one proposition much more than another, or about half as much as another, and so on. (If there are any Moorean facts in the theory of belief measurement, this ought to be one of them.) Furthermore, given Assumption 1, any probabilistic representation of beliefs will automatically determine a logically omniscient confidence ordering. So, consequence: probabilistic representation is not a prerequisite for cardinal representation either.
The joint effect of the three desiderata so far will be that we should want a theory of how beliefs can be measured on something stronger than an ordinal scale, which is consistent with really modest probabilism but isn’t limited to representing the beliefs of the logically omniscient. We want a theory of cardinal belief measurement for ideal and non-ideal agents. The final desideratum is an anti-disjunctiveness condition:
- Desideratum 4
A theory of belief measurement should not be fundamentally different for ideal versus non-ideal agents.
If we’re going to say that both ideally rational and non-ideally rational agents can have degrees of belief that are measured on something stronger than an ordinal scale, then we should also want an explanation that makes sense in both cases – a unifying theory is a better theory. There doesn’t appear to be any difference in meaning when we say (e.g.) that Jules is much more confident in one proposition over another, depending on whether Jules is ideally rational or non-ideal like us. If that’s right, then fundamentally the same explanation of quantitatability should apply in either case.
I intend for Desideratum 4 to be compatible with the idea that there might be more than one adequate approach to the measurement of belief. It might be, for example, that a decision-theoretic approach is apt for the purposes of decision theory, and that an epistemic approach is apt for certain other theoretical contexts, with no fact of the matter as to which is the correct way of doing things. It’s not unusual that there might be complementary ways of explaining the quantitation of a given quantity. For example, the ratio-scale measurement of mass can be explained as an instance of fundamental extensive measurement, or conjoint measurement, or (given an appropriate choice of base quantities) derived measurement – there is no fact of the matter as to which is the right way to do it. But the key term there is complementary. The various ways to explain the quantitation of mass are not disjunctive in the sense of giving one explanation for how mass is measured that applies to a certain subset of masses, and a fundamentally distinct explanation for other magnitudes. That’s the kind of disjunctiveness we should avoid.
4 Epistemic Approaches: Comparative Confidence
The most straightforward and best-known of the epistemic approaches involves the probabilistic representation of (complete) binary comparative confidence relations. For ease of reference, I’ll call this the standard epistemic approach. This section begins with an overview of the standard epistemic approach (Section 4.1), after which we consider the problem of logical omniscience and non-probabilistic generalisations (Section 4.2). Several further varieties of epistemic approach are discussed in the next section.
For the present section, we take
 be interpreted relative to some agent
be interpreted relative to some agent
 , and we read
, and we read
 as saying that
as saying that
 has at least as much confidence in
has at least as much confidence in
 as she has in
as she has in
 . Supposing that
. Supposing that
 is a weak order, it’s then natural to interpret
is a weak order, it’s then natural to interpret
 as more confidence, and
as more confidence, and
 as equal confidence. Where
as equal confidence. Where
 , I’ll sometimes say that
, I’ll sometimes say that
 and
and
 are equiprobable; this shouldn’t be understood to presuppose that
are equiprobable; this shouldn’t be understood to presuppose that
 has a probabilistic representation.
has a probabilistic representation.
4.1 Probabilistic Representations
The main results in this area concern the conditions under which a system comprised of an algebra of propositions and a comparative confidence relation,
 , can be represented in the numerical system
, can be represented in the numerical system
 by means of some probability measure. Reference SavageSavage (1954) established sufficient conditions, based on earlier work from Reference de Finettide Finetti (1931). Reference Kraft, Pratt and SeidenbergKraft, Pratt, and Seidenberg (1959) were the first to provide necessary and sufficient conditions for the case of finite algebras, which were presented then in simpler form by Dana Reference ScottScott (Reference Scott1964).
by means of some probability measure. Reference SavageSavage (1954) established sufficient conditions, based on earlier work from Reference de Finettide Finetti (1931). Reference Kraft, Pratt and SeidenbergKraft, Pratt, and Seidenberg (1959) were the first to provide necessary and sufficient conditions for the case of finite algebras, which were presented then in simpler form by Dana Reference ScottScott (Reference Scott1964).
For the following definition, we take
 to be the indicator function of
to be the indicator function of
 . The indicator function of a proposition simply distinguishes those worlds that belong to the proposition from those that don’t, by assigning 1 to the former and 0 to the latter; namely,
. The indicator function of a proposition simply distinguishes those worlds that belong to the proposition from those that don’t, by assigning 1 to the former and 0 to the latter; namely,
 is a function on
is a function on
 such that
such that

Definition 9. Let
 be an algebra of propositions on
be an algebra of propositions on
 , and
, and
 a binary relation on
a binary relation on
 . Then
. Then
 is a finite system of qualitative probability if and only if
is a finite system of qualitative probability if and only if
1.
is finite (finitude)2.
is complete (completeness)3.
(
-minimality)4.
(non-triviality)5. If
and
are two sequences of propositions in
, then, for
, if
i)
, andii)
for all
,
then
(Scott’s axiom)













Theorem 10 (Scott 1964)
⟨A,≿⟩
is a finite system of qualitative probability if and only if at least one probability measure
 is a homomorphism from
is a homomorphism from
 into
into
 .
.
Much of the work is done by Scott’s axiom, but what that axiom says isn’t transparent. Roughly, it tells us that if two collections of propositions
 and
and
 contain the same number of truths as a matter of logical necessity, then if the agent is more confident of
contain the same number of truths as a matter of logical necessity, then if the agent is more confident of
 propositions in the first collection than they are of the corresponding propositions in the second, there must be an
propositions in the first collection than they are of the corresponding propositions in the second, there must be an
 th proposition in the second collection of which they have more confidence than the corresponding proposition in the first collection – they must balance out. (Compare: for real values, if
th proposition in the second collection of which they have more confidence than the corresponding proposition in the first collection – they must balance out. (Compare: for real values, if
 , and
, and
 ,
,
 , then
, then
 .) But we needn’t worry about what Scott’s axiom says exactly; more illuminating for present purposes is to consider what the axiom implies in the context of the others.Footnote 14
.) But we needn’t worry about what Scott’s axiom says exactly; more illuminating for present purposes is to consider what the axiom implies in the context of the others.Footnote 14
If we use
 henceforth to represent the union of disjoint sets – that is, the restriction of set-theoretic union
henceforth to represent the union of disjoint sets – that is, the restriction of set-theoretic union
 to those pairs of sets with no elements in common – then for any finite system of qualitative probability,
to those pairs of sets with no elements in common – then for any finite system of qualitative probability,
| 1. |
 is a weak order
is a weak order | (weak order) |
| 2. |

| (associativity) |
| 3. |

| (commutativity) |
| 4. |
 if and only if, if
if and only if, if
 then
then

| (
 -monotonicity)
-monotonicity) |
| 5. |

| (weak positivity) |
| 6. |
 only if
only if

| (minimal identity) |
These should remind you of the properties that permit the additive measurement of length (Section 2.3), with
 playing something similar to role played by end-to-end concatenation in a positive concatenation structure. The weak order axiom is, as discussed earlier, necessary for
playing something similar to role played by end-to-end concatenation in a positive concatenation structure. The weak order axiom is, as discussed earlier, necessary for
 to be mapped into
to be mapped into
 . The associativity and commutativity axioms fall out of the associativity and commutativity of
. The associativity and commutativity axioms fall out of the associativity and commutativity of
 . Finally, weak positivity and minimal identity correspond to the non-negativity condition in Definition 8 (the definition of a probability measure), while
. Finally, weak positivity and minimal identity correspond to the non-negativity condition in Definition 8 (the definition of a probability measure), while
 -monotonicity corresponds to the
-monotonicity corresponds to the
 -additivity condition.
-additivity condition.
Indeed, we can make the analogy with the measurement of length more explicit by restating Theorem 10 thus:
Theorem 10’
⟨A,≿⟩
is a finite system of qualitative probability if and only if there is at least one probability measure
 that is also a weak homomorphism from
that is also a weak homomorphism from
 into
into
 .
.
This way of stating Scott’s result better captures the point of the probabilistic representation of comparative confidence. After all, if the goal was to show how a system
 might be represented in
might be represented in
 , then the finitude and weak order axioms would have sufficed – everything beyond that just serves to restrict the kinds of qualitative systems under consideration without making any difference to their representability in
, then the finitude and weak order axioms would have sufficed – everything beyond that just serves to restrict the kinds of qualitative systems under consideration without making any difference to their representability in
 . What makes it worthwhile to represent comparative confidence using a probability measure is that the characteristic properties of such measures (namely:
. What makes it worthwhile to represent comparative confidence using a probability measure is that the characteristic properties of such measures (namely:
 -additivity) are reflected in the ‘additive’ behaviour of
-additivity) are reflected in the ‘additive’ behaviour of
 in relation to
in relation to
 , thus giving rise to meaning beyond just the ordering information. If not for this, then there’s no apparent reason to care about probabilistic representations of
, thus giving rise to meaning beyond just the ordering information. If not for this, then there’s no apparent reason to care about probabilistic representations of
 over any number of non-probabilistic but ordinally equivalent representations.
over any number of non-probabilistic but ordinally equivalent representations.
With that said, there’s a couple important disanalogies with the case of length that should be noted. First, additive measures of
 are 1-point unique – that is, fixing the numerical value of any non-minimal length
are 1-point unique – that is, fixing the numerical value of any non-minimal length
 will uniquely determine the remainder of the scale. The same needn’t always be true for probabilistic measures of
will uniquely determine the remainder of the scale. The same needn’t always be true for probabilistic measures of
 . Consider a finite algebra with atoms
. Consider a finite algebra with atoms
 , where
, where

A probability measure
 will represent
will represent
 just in case
just in case

Obviously, choosing a measure
 such that
such that
 , for instance, won’t yet determine the values for
, for instance, won’t yet determine the values for
 and
and
 – it only determines that they’ll take distinct positive values summing to
– it only determines that they’ll take distinct positive values summing to
 . So the measure isn’t 1-point unique. Essentially similar examples can be constructed to show that there will be systems of finite probability such that the additive measures of
. So the measure isn’t 1-point unique. Essentially similar examples can be constructed to show that there will be systems of finite probability such that the additive measures of
 are not
are not
 -point unique for arbitrarily large
-point unique for arbitrarily large
 .
.
Second,
 is meaningful relative to the additive measures of
is meaningful relative to the additive measures of
 , but the same needn’t be true for probabilistic measures of
, but the same needn’t be true for probabilistic measures of
 . In other words, where
. In other words, where
 and
and
 are distinct probabilistic representations of the same system
are distinct probabilistic representations of the same system
 , the relation
, the relation
 induced on
induced on
 by
by
 relative to
relative to
 need not be the relation
need not be the relation
 induced on
induced on
 by
by
 relative to
relative to
 . (Recall from Definition 6 that
. (Recall from Definition 6 that
 if and only if
if and only if
 .) Consider again the previous example, where
.) Consider again the previous example, where
 , and so
, and so

Now suppose that
 is such that
is such that
 ; hence
; hence

Though both
 and
and
 are weakly additive measures of
are weakly additive measures of
 , the qualitative relation corresponding to
, the qualitative relation corresponding to
 under
under
 isn’t identical to the qualitative relation corresponding to
isn’t identical to the qualitative relation corresponding to
 under
under
 . So addition isn’t
. So addition isn’t
 -meaningful relative to
-meaningful relative to
 .
.
Both disanalogies are a result of the fact that probabilistic representations of a system of qualitative probability need not be unique. This situation can be remedied if we add more axioms, such as
-
only if
for some
. (solvability)



Supposing that
 is a finite system of qualitative probability satisfying solvability, then the analogy with the additive measurement of length is considerably stronger. In that case, the set of weakly additive measures of
is a finite system of qualitative probability satisfying solvability, then the analogy with the additive measurement of length is considerably stronger. In that case, the set of weakly additive measures of
 will include all and only those
will include all and only those
 that are related to
that are related to
 by a positive similarity transformation, and hence they will be 1-point unique (Reference SuppesSuppes 1969, 6–7). Furthermore,
by a positive similarity transformation, and hence they will be 1-point unique (Reference SuppesSuppes 1969, 6–7). Furthermore,
 for any
for any
 related to
related to
 by a positive similarity transformation, and so
by a positive similarity transformation, and so
 will be meaningful relative to any set of weakly additive measures of
will be meaningful relative to any set of weakly additive measures of
 .
.
Another way to make that analogy clear is to generalise
 slightly, and then show that this generalised relation can be (strongly) mapped into
slightly, and then show that this generalised relation can be (strongly) mapped into
 . Start with the following:
. Start with the following:
Definition 11. Where
 is an equivalence relation and
is an equivalence relation and
 is a binary operation,
is a binary operation,
 is the relation induced by
is the relation induced by
 and
and
 if and only if
if and only if
 whenever
whenever
 for some
for some
 and
and
 such that
such that
 and
and
 .
.
In the special case where
 is antisymmetric, there’s no difference between
is antisymmetric, there’s no difference between
 and
and
 . For example,
. For example,
 is just the same as
is just the same as
 . But since the equiprobability of
. But since the equiprobability of
 and
and
 need not imply the identity of
need not imply the identity of
 and
and
 , in many cases it will be impossible to construct a system
, in many cases it will be impossible to construct a system
 that admits of an additive measure in the stronger sense. For suppose
that admits of an additive measure in the stronger sense. For suppose
 , but there also exists some
, but there also exists some
 such that
such that
 . Then, if
. Then, if
 maps
maps
 into
into
 , then
, then
 will strongly map into
will strongly map into
 only if
only if
 implies
implies
 , which by hypothesis is false. But this isn’t a deep problem – we dissolve it entirely by mapping the very slightly more general ternary relation
, which by hypothesis is false. But this isn’t a deep problem – we dissolve it entirely by mapping the very slightly more general ternary relation
 into
into
 instead (where the latter is construed this time as a ternary relation). Thus,
instead (where the latter is construed this time as a ternary relation). Thus,
Theorem 12 Suppose that
 is a finite system of qualitative probability satisfying solvability. Then there exists a homomorphism
is a finite system of qualitative probability satisfying solvability. Then there exists a homomorphism
 from
from
 into
into
 . Furthermore, the set of all homomorphisms from
. Furthermore, the set of all homomorphisms from
 into
into
 is unique up to positive similarity transformations, and exactly one of them is a probability measure.
is unique up to positive similarity transformations, and exactly one of them is a probability measure.
Proof. Suppose that
 is the unique probability representation of
is the unique probability representation of
 , guaranteed by the hypothesis of the theorem. The relation
, guaranteed by the hypothesis of the theorem. The relation
 always maps into
always maps into
 by definition, so for the existence result we need only establish
by definition, so for the existence result we need only establish
 . To that end, note
. To that end, note
 if and only if there exist
if and only if there exist
 such that
such that
 ,
,
 ,
,
 , and
, and
 . The right-to-left of that biconditional is trivial, given that
. The right-to-left of that biconditional is trivial, given that
 represents
represents
 and that
and that
 satisfies
satisfies
 -additivity. For the left-to-right, suppose
-additivity. For the left-to-right, suppose
 . Where
. Where
 , let
, let
 ,
,
 and
and
 . Where
. Where
 , let
, let
 be a proposition such that
be a proposition such that
 and
and
 . Using solvability it can be shown some such
. Using solvability it can be shown some such
 exists. Now let
exists. Now let
 ,
,
 , and
, and
 . The proof of the uniqueness result is straightforward and omitted. ☐
. The proof of the uniqueness result is straightforward and omitted. ☐
Note, though, that solvability isn’t necessary for unique probabilistic representation. This is a good thing, since the axiom is very restrictive – in the context of the other axioms, it requires every atom of
 that’s non-minimal in
that’s non-minimal in
 to be equiprobable with every other such atom. In other words, it forces all non-minimal atoms into a single
to be equiprobable with every other such atom. In other words, it forces all non-minimal atoms into a single
 -equivalence class (Reference SuppesSuppes 1969, 6–7). A more general condition that also suffices for unique probabilistic representability can be formulated in terms of scalability.
-equivalence class (Reference SuppesSuppes 1969, 6–7). A more general condition that also suffices for unique probabilistic representability can be formulated in terms of scalability.
Definition 13. Suppose
 is any sequence of pairwise disjoint and equiprobable propositions where
is any sequence of pairwise disjoint and equiprobable propositions where
 . Then,
. Then,
1. If
, for
, then
is directly scaled by
2. If
is directly scaled by
, then
is scaled by
3. If
is scaled by
, and
is scaled by
, then
is scaled by














In other words, the scaling relation is the ancestral of the direct scaling relation. The more general axiom can now be stated with ease:
For any non-minimal atom
,
is scaled by
. (scalability)



The difference between solvability and scalability is represented in Figure 4. We assume in each case that
 is a finite system of qualitative probability, with the
is a finite system of qualitative probability, with the
 -ordering over the atoms of
-ordering over the atoms of
 represented by the relative size of the corresponding areas inside the box. On the left, case (a), solvability is satisfied, and hence also scalability. There are four equiprobable non-minimal atoms,
represented by the relative size of the corresponding areas inside the box. On the left, case (a), solvability is satisfied, and hence also scalability. There are four equiprobable non-minimal atoms,
 to
to
 , all directly scaled by
, all directly scaled by
 . Since
. Since
 , each atom must be assigned
, each atom must be assigned
 by any probability measure
by any probability measure
 . Case (b) violates solvability, since
. Case (b) violates solvability, since

Figure 4 Solvability (a) versus scalability (b)

but there’s no
 such that
such that

However, case (b) still satisfies scalability, and has a unique probabilistic representation. There are four atoms. The largest,
 , is directly scaled by
, is directly scaled by
 , since
, since
 and
and
 are disjoint, equiprobable, and their union is identical to and thus equiprobable with
are disjoint, equiprobable, and their union is identical to and thus equiprobable with
 . So
. So
 . The second largest atom
. The second largest atom
 is then directly scaled by
is then directly scaled by
 :
:

Finally,
 and
and
 are both directly scaled by
are both directly scaled by
 and thus assigned
and thus assigned

As with solvability, scalability isn’t necessary for unique probabilistic representability either. It turns out that necessary and sufficient conditions for unique probabilistic representations here are not easy to express (for reasons explained in Reference NarensNarens 1980), and we’ll need to wait until we’ve introduced extended indicator functions in Section 5.2.
4.2 The Problem of Logical Omniscience
A probability measure on an algebra of sets
 will always represent a comparative confidence ordering that extends the superset relation over the propositions in
will always represent a comparative confidence ordering that extends the superset relation over the propositions in
 , in the sense that
, in the sense that
 implies
implies
 . Given Assumption 1,
. Given Assumption 1,
 includes only logically possible worlds. The combination of these facts presents a problem, since if
includes only logically possible worlds. The combination of these facts presents a problem, since if
 is restricted to possible worlds then
is restricted to possible worlds then
 if and only if
if and only if
 implies
implies
 . In other words, in the presence of Assumption 1, a probability measure can represent only logically omniscient agents – agents whose comparative confidence orderings invariably respect the logical relations between propositions.
. In other words, in the presence of Assumption 1, a probability measure can represent only logically omniscient agents – agents whose comparative confidence orderings invariably respect the logical relations between propositions.
Given the desiderata discussed in Section 3.4, it’s therefore worth considering whether and how the standard epistemic approach might be generalised – or better, de-idealised – so as to apply also to agents who aren’t logically ideal. The generalisation I have in mind involves a tweak to how we understand the ‘concatenation’ operation. Basically, what we need to do is replace
 with a strictly more general operation that still allows for the same kind of additivity results that make the standard probabilistic approach interesting, while not also forcing logical omniscience.
with a strictly more general operation that still allows for the same kind of additivity results that make the standard probabilistic approach interesting, while not also forcing logical omniscience.
Let me start by noting two important constraints. First, the concatenation operation ought to be natural. As explained in Section 2.4, without naturalness in the choice of qualitative primitives, the very idea of measurement is trivialised. Second, to avoid disjunctiveness (Desideratum 4), we are looking for a generalisation of the standard epistemic approach – specifically in the sense that we want a qualitative system
 that can be represented in
that can be represented in
 , which includes qualitative probability structures as a special case, but which also allows for the non-probabilistic representation of structures that are not probabilistically representable. So we need a natural relation
, which includes qualitative probability structures as a special case, but which also allows for the non-probabilistic representation of structures that are not probabilistically representable. So we need a natural relation
 that’s an extension of
that’s an extension of
 in those cases (or at least some of those cases) where
in those cases (or at least some of those cases) where
 does admit probabilistic representation.
does admit probabilistic representation.
These are not trivial constraints. It’s not easy to find a natural relation that has the aforementioned properties, and which doesn’t lead us right back in to the problem of logical omniscience. To appreciate the difficulty here, consider what happens when
 . In this case,
. In this case,
 is guaranteed to be an extension of
is guaranteed to be an extension of
 , as desired. However, mapping
, as desired. However, mapping
 into
into
 leads inevitably to logical omniscience. Since
leads inevitably to logical omniscience. Since
 and
and
 are always disjoint,
are always disjoint,
 is always defined; moreover,
is always defined; moreover,
 will be the identity element with respect to
will be the identity element with respect to
 (i.e., for all
(i.e., for all
 ,
,
 ). Consequently, if
). Consequently, if
 is any additive measure of
is any additive measure of
 , then
, then
 implies
implies
 implies
implies
 . In other words, the identity element of
. In other words, the identity element of
 will need to be mapped to the identity element of
will need to be mapped to the identity element of
 , which is zero. Furthermore, for any
, which is zero. Furthermore, for any
 , if
, if
 then there will exist some
then there will exist some
 such that
such that
 , hence
, hence
 and so
and so
 and so
and so
 . The result:
. The result:
 implies
implies
 ; logical omniscience.
; logical omniscience.
If we’re to avoid logical omniscience, then
 cannot be what ‘plays the concatenation role’. We do better if we consider instead the union of subjectively incompatible propositions. Henceforth, let
cannot be what ‘plays the concatenation role’. We do better if we consider instead the union of subjectively incompatible propositions. Henceforth, let
 designate this operation, defined relative to
designate this operation, defined relative to
 as the restriction of
as the restriction of
 to those pairs of propositions
to those pairs of propositions
 such that
such that
 is minimal in
is minimal in
 . Intuitively,
. Intuitively,
 and
and
 are subjectively incompatible whenever the subject has at least as much confidence in any proposition whatsoever as they do in the conjunction of
are subjectively incompatible whenever the subject has at least as much confidence in any proposition whatsoever as they do in the conjunction of
 and
and
 . Then,
. Then,
 is an extension of
is an extension of
 whenever
whenever
 can be represented probabilistically, as required. In other cases, though,
can be represented probabilistically, as required. In other cases, though,
 needn’t imply
needn’t imply
 . Hence, it’s possible to have an additive mapping from
. Hence, it’s possible to have an additive mapping from
 into
into
 that needn’t satisfy
that needn’t satisfy
 -additivity in all cases, but which is also guaranteed to satisfy
-additivity in all cases, but which is also guaranteed to satisfy
 -additivity in those cases where a probabilistic representation of
-additivity in those cases where a probabilistic representation of
 exists.Footnote 15
exists.Footnote 15
I’ll start with a simple example, chosen to demonstrate that none of
 -minimality, non-triviality, or Scott’s axiom are required for the desired homomorphisms to exist. (As such, this is intended to be an extreme example, not a realistic one.) We suppose that
-minimality, non-triviality, or Scott’s axiom are required for the desired homomorphisms to exist. (As such, this is intended to be an extreme example, not a realistic one.) We suppose that
 contains exactly four atoms,
contains exactly four atoms,
 through
through
 . We then label the non-atomic propositions via the indices of the atomic propositions from which they’re constructed; so, for instance,
. We then label the non-atomic propositions via the indices of the atomic propositions from which they’re constructed; so, for instance,

Given that, consider the following non-omniscient confidence ranking:

We want to show there’s at least one
 such that for all
such that for all
 ,
,
i.
, andii.
.


It’s clear the following assignment would satisfy property i:

So we just need to show that this assignment also satisfies property ii. To that end, note that
 and
and
 are subjectively incompatible only if they both include the minimal proposition
are subjectively incompatible only if they both include the minimal proposition
 ; for all the other propositions, it matters not where they sit in the
; for all the other propositions, it matters not where they sit in the
 ordering (so long as they don’t sit at the bottom). Hence, we need only consider the ordering of the concatenable propositions:
ordering (so long as they don’t sit at the bottom). Hence, we need only consider the ordering of the concatenable propositions:

It’s then easy to check that
 ; and whenever
; and whenever
 , then
, then
 . Thus, it’s possible to have a weakly additive (but not
. Thus, it’s possible to have a weakly additive (but not
 -additive) measure of
-additive) measure of
 . More generally, it’s possible to have a (strong) homomorphism from
. More generally, it’s possible to have a (strong) homomorphism from
 into
into
 , even while
, even while
 is not logically omniscient.
is not logically omniscient.
The construction makes use of the same general notion of scaling from the previous section, though this time understood in terms of pairwise subjectively incompatible propositions rather than pairwise disjoint propositions. For example,
 and
and
 are equiprobable and subjectively incompatible, and their union is
are equiprobable and subjectively incompatible, and their union is
 ; hence, they’re directly scaled by
; hence, they’re directly scaled by
 :
:

Then,
 and
and
 are equiprobable and subjectively incompatible, and their union is
are equiprobable and subjectively incompatible, and their union is
 ; hence, they’re scaled by
; hence, they’re scaled by
 and derivatively scaled by
and derivatively scaled by
 :
:

The value for
 can then be determined by summing the values for the subjectively incompatible propositions
can then be determined by summing the values for the subjectively incompatible propositions
 and
and
 ; that is,
; that is,

Similar applies to
 . And, finally, the value for every other proposition is determined via equiprobability with some proposition whose value has already been fixed via scaling relative to
. And, finally, the value for every other proposition is determined via equiprobability with some proposition whose value has already been fixed via scaling relative to
 . So what makes the avoidance of logical omniscience possible here is that subjective incompatability needn’t coincide with logical incompatibility. They will coincide whenever
. So what makes the avoidance of logical omniscience possible here is that subjective incompatability needn’t coincide with logical incompatibility. They will coincide whenever
 can be represented probabilistically, but not always. Thus we can generalise the case of probabilistic representations by swapping out
can be represented probabilistically, but not always. Thus we can generalise the case of probabilistic representations by swapping out
 as the concatenation operation for the more general
as the concatenation operation for the more general
 operation.
operation.
Sufficient conditions for the existence of such representations are established in the following definition and associated theorem. There are three structural conditions – finitude, richness, and weak solvability – all of which are satisfied in the foregoing example.
Definition 14. Let
 be an algebra of propositions on
be an algebra of propositions on
 , and
, and
 a binary relation on
a binary relation on
 . Then
. Then
 is a finite system of additive confidence if and only if
is a finite system of additive confidence if and only if
 is finite and for all
is finite and for all
 ,
,
| 1. |
 is a weak order
is a weak order | (weak order) |
| 2. | If
 is defined,
is defined,
 and
and
 , then there are
, then there are
 and
and
 such that
such that
 is defined,
is defined,
 , and
, and

| (richness) |
| 3. | If
 , then there are
, then there are
 and
and
 such that
such that
 is defined,
is defined,
 and
and

| (weak solvability) |
| 4. | If
 and
and
 are defined and
are defined and
 , then
, then

| (
 -monotonicity)
-monotonicity) |
| 5. | If
 is defined, then
is defined, then
 , with
, with
 only if
only if
 is minimal
is minimal | (
 -positivity)
-positivity) |
Theorem 15 If
 is a finite system of additive confidence, then there exists a homomorphism from
is a finite system of additive confidence, then there exists a homomorphism from
 into
into
 ; furthermore, the set of all such homomorphisms is unique up to positive similarity transformations.
; furthermore, the set of all such homomorphisms is unique up to positive similarity transformations.
Proof. The finer details of the proof are not especially illuminating, so I provide a summary. The strategy is to reconstruct
 as a system for which strongly additive measures are known to exist. First we let
as a system for which strongly additive measures are known to exist. First we let
 be the set of
be the set of
 -equivalence classes in
-equivalence classes in
 , with the minimal elements excised; that is,
, with the minimal elements excised; that is,
 , with
, with
 only if
only if
 . We then let
. We then let
 be the total order induced on
be the total order induced on
 by
by
 ; that is,
; that is,
 whenever
whenever
 .
.
 is to be interpreted as the set of concatenable pairs in
is to be interpreted as the set of concatenable pairs in
 , so
, so
 just when
just when
 is defined for some
is defined for some
 and
and
 , or (same thing) when
, or (same thing) when
 for some
for some
 . Finally,
. Finally,
 is an operation on
is an operation on
 such that
such that
 if and only if
if and only if
 , and so a function from
, and so a function from
 into
into
 . We then want to show that
. We then want to show that
 satisfies:
satisfies:
A.
is a total order.B. If
,
, and
, then
.C. If
, then if
,
.D. If
, then if
,
.E.
if and only if
, and when both hold then
F. If
, then
.G. If
, then there exists an
such that
and
.




















Condition A follows from weak order, and B from richness. Given B, conditions C and D follow from
 -monotonicity and the commutativity of
-monotonicity and the commutativity of
 and
and
 . The first conjunct of E falls out of how
. The first conjunct of E falls out of how
 has been defined, and the second conjunct follows from the associativity of
has been defined, and the second conjunct follows from the associativity of
 and
and
 . Condition F is fixed by
. Condition F is fixed by
 -positivity, and G by weak solvability. From these seven conditions plus finitude, it follows that the system
-positivity, and G by weak solvability. From these seven conditions plus finitude, it follows that the system
 is a Archimedean, regular, positive, ordered local semigroup (Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 44–5). This suffices for the existence of a homomorphism
is a Archimedean, regular, positive, ordered local semigroup (Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 44–5). This suffices for the existence of a homomorphism
 from
from
 into
into
 , and the set of such homomorphisms is unique up to positive similarity transformations. (This is a corollary of Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 44–6, theorem 4 and theorem
, and the set of such homomorphisms is unique up to positive similarity transformations. (This is a corollary of Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 44–6, theorem 4 and theorem
 .) We then let
.) We then let
 be defined on
be defined on
 such that
such that
 for all non-minimal
for all non-minimal
 , and
, and
 otherwise, which gives us a homomorphism from
otherwise, which gives us a homomorphism from
 into
into
 , and inherits the uniqueness properties mentioned earlier. ☐
, and inherits the uniqueness properties mentioned earlier. ☐
If
 is a finite system of qualitative probability that also satisfies solvability, then it will be a finite system of additive confidence. In that case, the unique representation
is a finite system of qualitative probability that also satisfies solvability, then it will be a finite system of additive confidence. In that case, the unique representation
 of
of
 in
in
 that satisfies normalisation just is the unique probability representation of
that satisfies normalisation just is the unique probability representation of
 . From the perspective of the desiderata in Section 3.4, these are all good things.
. From the perspective of the desiderata in Section 3.4, these are all good things.
However, it’s not all happy news. While Theorem 15 offers a step forward in dealing with logical omniscience, it’s no great leap. We’ve managed to avoid the strictest form of logical omniscience – that is, where
 always implies
always implies
 – but the additive representation of
– but the additive representation of
 is perhaps not as flexible as one might like. For one thing, note that
is perhaps not as flexible as one might like. For one thing, note that
 will always be maximal in
will always be maximal in
 . To see why, suppose it isn’t. A proposition
. To see why, suppose it isn’t. A proposition
 is concatenable just in case it’s a superset of
is concatenable just in case it’s a superset of
 for some
for some
 that’s minimal in
that’s minimal in
 . The concatenable propositions are those that can stand in relations of subjective incompatibility, and in a finite system of additive confidence, every proposition must be equiprobable with a concatenable proposition. So, if
. The concatenable propositions are those that can stand in relations of subjective incompatibility, and in a finite system of additive confidence, every proposition must be equiprobable with a concatenable proposition. So, if
 isn’t maximal in
isn’t maximal in
 , then at least one other concatenable proposition must be. Let
, then at least one other concatenable proposition must be. Let
 be that proposition, or one of them, and let
be that proposition, or one of them, and let
 be any minimal proposition that implies
be any minimal proposition that implies
 . Now suppose
. Now suppose
 is
is
 . So
. So
 and
and
 are subjectively incompatible, and we should have
are subjectively incompatible, and we should have
 ; but
; but
 , so
, so
 , contradicting the hypothesis that
, contradicting the hypothesis that
 .
.
More generally, in any finite system of additive confidence,
 will always entail
will always entail
 with respect to pairs of concatenable propositions
with respect to pairs of concatenable propositions
 and
and
 . So while we’ve shown that it’s possible to maintain the analogy with the measurement of length while avoiding logical omniscience, the results here are still quite limited. What we really have in the end is not non-omniscience but a restricted form of omniscience. Moreover, this means that any time
. So while we’ve shown that it’s possible to maintain the analogy with the measurement of length while avoiding logical omniscience, the results here are still quite limited. What we really have in the end is not non-omniscience but a restricted form of omniscience. Moreover, this means that any time
 is minimal, then the stricter form of logical omniscience follows immediately – since in that case every proposition in the algebra is automatically concatenable.
is minimal, then the stricter form of logical omniscience follows immediately – since in that case every proposition in the algebra is automatically concatenable.
Other generalisations of the standard epistemic approach might be possible, though the relevant work has yet to be done. The difficulty, as I said, is locating an appropriately natural operation to ‘play the concatenation role’, which generalises the probabilistic case but doesn’t force logical omniscience (or something near as bad). Not an easy thing to find, when the most natural operations in the vicinity seem to be set-theoretic relations between contents that, given Assumption 1, correspond directly to their logical relationships. Maybe that’s a good reason to revisit Assumption 1. But if it is, then it’s also a good reason to consider alternative measurement structures that don’t rely so much on set-theoretic relations between belief contents.
5 Epistemic Approaches: Alternatives
Epistemic approaches to the measurement of belief aren’t limited to those involving a single binary confidence relation. In this section, I briefly look at several other epistemic approaches. The first involves quarternary (or conditional) confidence relations (Section 5.2); then qualitative expectation relations (Section 5.1); then structures involving multiple primitive doxastic relations (Section 5.3).
5.1 Conditional Confidence
A theory of belief measurement that makes use of a binary confidence relation will be well-suited for representations that assign a single numerical value to each proposition, where this is intended to represent the agent’s unconditional confidence regarding that proposition. However, it’s sometimes thought that the more fundamental concept in epistemology is not unconditional confidence but rather conditional confidence – the level of confidence one has in
 given some hypothesis
given some hypothesis
 (e.g., Reference HájekHájek 2003). A common motivation for this thought is that, while it’s standard to define conditional probabilities out of unconditional probabilities like so,
(e.g., Reference HájekHájek 2003). A common motivation for this thought is that, while it’s standard to define conditional probabilities out of unconditional probabilities like so,

that definition only makes sense when
 ; yet there appear to be cases where it makes sense to speak of the probability of
; yet there appear to be cases where it makes sense to speak of the probability of
 conditional on
conditional on
 even while the unconditional probability of
even while the unconditional probability of
 is zero.
is zero.
There is an epistemic approach to the measurement of belief that fits nicely with this perspective. It involves replacing the binary confidence relation of the standard epistemic approach with a quarternary relation – or, same thing, a binary relation
 on
on
 , interpreted
, interpreted
 if and only if
if and only if
 is at least as confident in
is at least as confident in
 given
given
 as she is in
as she is in
 given
given
 .
.
To make things a little easier, let’s write
 instead. The goal, then, is to lay down axioms on this quarternary
instead. The goal, then, is to lay down axioms on this quarternary
 that will suffice for the ‘probabilistic’ representation thereof. Much of the work done on this matter is owing to Koopman – see especially his (Reference Koopman1940a) and (Reference Koopman1940b); see also (Reference LuceLuce 1968). For this section, however, I will briefly summarise a more recent (but closely related) result in Reference Hawthorne, Hájek and HitchcockHawthorne (2016).Footnote 16
that will suffice for the ‘probabilistic’ representation thereof. Much of the work done on this matter is owing to Koopman – see especially his (Reference Koopman1940a) and (Reference Koopman1940b); see also (Reference LuceLuce 1968). For this section, however, I will briefly summarise a more recent (but closely related) result in Reference Hawthorne, Hájek and HitchcockHawthorne (2016).Footnote 16
Since we are treating conditional probabilities as basic, the numerical representation cannot consist in probability measures strictly so-called (i.e., as per Definition 8). Instead, we employ Popper functions, which generalise the classic definition of a probability measure:
Definition 16.
 is a Popper function if and only if
is a Popper function if and only if
1. For some
,
2. For all
,
3. If
, then
4.
unless
for all
5.










Relative to a fixed condition, a Popper function behaves essentially like a probability measure. For instance, fixing the condition to
 , the definition implies:
, the definition implies:
-
,
-
, and
if
, then
.




Moreover, if
 is the probability measure corresponding to
is the probability measure corresponding to
 , then for any
, then for any
 such that
such that
 ,
,
 will behave just like
will behave just like
 . The difference, though, is that
. The difference, though, is that
 can still be defined even when
can still be defined even when
 . In this case,
. In this case,
 also behaves just like a probability measure
also behaves just like a probability measure
 , different from
, different from
 , in the same way that
, in the same way that
 behaves like
behaves like
 . And likewise, there may be some
. And likewise, there may be some
 such that
such that
 , and
, and
 might behave in turn like yet another probability measure different again from
might behave in turn like yet another probability measure different again from
 and
and
 . Thus the Popper function
. Thus the Popper function
 can act like an ordered hierarchy of probability measures. As Hawthorne helpfully puts it,
can act like an ordered hierarchy of probability measures. As Hawthorne helpfully puts it,
a Popper function may consist of a ranked hierarchy of classical probability functions, where conditionalization on a probability 0 sentence induces a transition from one classical probability function to another classical function at a lower rank. The idea is that probability 0 need not mean ‘absolutely impossible’. Rather, it means something like, ‘not a viable possibility unless (and until) the more plausible alternatives are refuted.’
See also Reference van Fraassenvan Fraassen (1976), Reference SpohnSpohn (1986), Reference HalpernHalpern (2001), and Reference Brickhill and HorstenBrickhill and Horsten (2018) for detailed discussion on the close relationship between Popper functions, lexicographic probability measures (lexically ordered sequences of probabilities), and non-Archimedean probability measures (probabilities that can take infinitesimal numerical values).
As one might naturally expect, the additional complexity of the numerical representation – with Definition 16 including both an additive component in condition 4, and a multiplicative component in condition 5 – corresponds to significant increased complexity in the required axioms on
 :
:
Definition 17. Let
 be an algebra of propositions on
be an algebra of propositions on
 , and
, and
 a binary relation on
a binary relation on
 . We say that
. We say that
 is a system of qualitative conditional probability if and only if the following are satisfied:
is a system of qualitative conditional probability if and only if the following are satisfied:
1.
is a weak order (weak order)2. For some
,
(non-triviality)3. For all
,
(maximality)4. For all
, if
, then
(implication)5. For all
, if
and
, then
(negation-symmetry)6. For all
, if
i)
and
, orii)
and
,
then
(composition)7. For all
, if
and
, and
i) if
, then
ii) if
, then
(decomposition-a)
8. For all
, if
and
, then
i) if
, then
ii) if
, then
(decomposition-b)
9. For all
, if
, then for some
there exist
such that
i)
,ii) for distinct
,
and
,iii)
,iv) for some
,
(Archimedean)











































Theorem 18 Hawthorne (2016) If
 is a system of qualitative conditional probability, there exists a homomorphism from
is a system of qualitative conditional probability, there exists a homomorphism from
 into
into
 , and exactly one such homomorphism is a Popper function.
, and exactly one such homomorphism is a Popper function.
The non-triviality, maximality, and implication axioms directly correspond to conditions 1, 2, and 3 of Definition 16. The negation-symmetry axiom is the main axiom corresponding to the additivity condition 4, while the composition and decomposition axioms correspond to the multiplicative condition. The Archimedean axiom says that whenever
 , there is a finite number of mutually exclusive and equiprobable propositions such that the conditional probability of their union (relative to some condition) is strictly between that of
, there is a finite number of mutually exclusive and equiprobable propositions such that the conditional probability of their union (relative to some condition) is strictly between that of
 and
and
 . In terms of the representation: if
. In terms of the representation: if
 , then the difference between
, then the difference between
 and
and
 is not infinitesimal, ensuring
is not infinitesimal, ensuring
 can be represented in
can be represented in
 .
.
5.2 Qualitative Expectations
A rather different epistemic approach – originating with Reference Suppes and ZanottiSuppes and Zanotti (1976), see also Reference ClarkClark (2000) and Reference Suppes and PedersonSuppes and Pederson (2016) – takes the primitive ordering relation
 to be defined not over an algebra of propositions, but instead over an algebra of extended indicator functions.
to be defined not over an algebra of propositions, but instead over an algebra of extended indicator functions.
Extended indicator functions are a generalisation of indicator functions. In the broadest terms, an extended indicator function is a certain kind of random variable – an integer-valued function
 defined on
defined on
 such that for some positive integer
such that for some positive integer
 , propositions
, propositions
 , and non-negative integers
, and non-negative integers
 ,
,

But that’s unlikely to be intuitive, so it’ll help to consider how extended indicator functions can be built up via the pointwise summation of ordinary indicator functions. Start with the indicator function of
 , or
, or
 , which in Section 4 was defined as the function that takes each world
, which in Section 4 was defined as the function that takes each world
 in
in
 and returns the value 1 if
and returns the value 1 if
 belongs to
belongs to
 , and 0 otherwise. Now consider its
, and 0 otherwise. Now consider its
 th iteration,
th iteration,
 , defined:
, defined:

For any integer
 , the
, the
 th iteration of any indicator function will count as an extended indicator function. Clearly, where
th iteration of any indicator function will count as an extended indicator function. Clearly, where
 , then
, then
 ; and where
; and where
 , then
, then
 can be expressed as the pointwise sum of
can be expressed as the pointwise sum of
 and
and
 (or
(or
 ) for
) for
 . More generally, the pointwise sum of any two extended indicator functions will also count as an extended indicator function. So, for example,
. More generally, the pointwise sum of any two extended indicator functions will also count as an extended indicator function. So, for example,
 is an extended indicator function:
is an extended indicator function:

In the same fashion,
 is an extended indicator function, and so on. Hence we can construct a space of extended indicator functions by starting with a set of propositions, taking the set of indicator functions corresponding to those propositions, and closing it under pointwise summation:
is an extended indicator function, and so on. Hence we can construct a space of extended indicator functions by starting with a set of propositions, taking the set of indicator functions corresponding to those propositions, and closing it under pointwise summation:
Definition 19.
 is the algebra of extended indicator functions generated by
is the algebra of extended indicator functions generated by
 iff
iff
1. For all
,
2. If
, then
3. Nothing else is in





This algebra of extended indicator functions will comprise the domain of the primitive binary relation
 – a so-called qualitative expectations relation – with the goal being to represent
– a so-called qualitative expectations relation – with the goal being to represent
 via an expectation function:
via an expectation function:
Definition 20. Where
 is the algebra of extended indicator functions generated by
is the algebra of extended indicator functions generated by
 , a function
, a function
 is an expectation function if and only if for all
is an expectation function if and only if for all
 ,
,
1.
2.


So we’re mapping
 into
into
 , in other words. Sufficient conditions for the existence of such representations are provided by the following theorem. Given the additive structure of the representation, these axioms should come as no surprise:
, in other words. Sufficient conditions for the existence of such representations are provided by the following theorem. Given the additive structure of the representation, these axioms should come as no surprise:
Definition 21. Let
 be an algebra of propositions on
be an algebra of propositions on
 , and
, and
 a binary relation on the algebra
a binary relation on the algebra
 of extended indicator functions generated by
of extended indicator functions generated by
 . Then
. Then
 is a system of qualitative expectations if and only if it satisfies the following, for all
is a system of qualitative expectations if and only if it satisfies the following, for all
 ,
,
| 1. |
 is a weak order
is a weak order | (weak order) |
| 2. |

| (
 -minimality)
-minimality) |
| 3. |

| (non-triviality) |
| 4. |
 if and only if
if and only if

| (
 -monotonicity)
-monotonicity) |
| 5. | If
 , then there are
, then there are
 with
with

| (Archimedean) |
Theorem 22 Suppes (2016) If
 is a system of qualitative expectations, then there is an expectation function that maps
is a system of qualitative expectations, then there is an expectation function that maps
 into
into
 ; furthermore, the set of homomorphisms from
; furthermore, the set of homomorphisms from
 into
into
 that are also expectation functions is unique up to positive similarity transformations.
that are also expectation functions is unique up to positive similarity transformations.
Note that any expectation function which maps
 into
into
 is ipso facto a weakly additive representation of
is ipso facto a weakly additive representation of
 in
in
 , and vice versa. Indeed, similar to the reformulation Theorem 10 as Theorem 10
, and vice versa. Indeed, similar to the reformulation Theorem 10 as Theorem 10
 earlier, it would be straightforward to re-write Theorem 22 so as to make the connection with extensive measurement more transparent. Essentially: if
earlier, it would be straightforward to re-write Theorem 22 so as to make the connection with extensive measurement more transparent. Essentially: if
 satisfies the stated axioms, then there is a weak homomorphism, unique up to a positive similarity transformation, from
satisfies the stated axioms, then there is a weak homomorphism, unique up to a positive similarity transformation, from
 into
into
 .
.
There is a direct connection between expectation representations of qualitative expectation relations and the probabilistic representation of comparative confidence relations. Note that any expectation function
 is related by a positive similarity transformation to exactly one normalised expectation function
is related by a positive similarity transformation to exactly one normalised expectation function
 , with
, with
 . This
. This
 describes a probability measure
describes a probability measure
 if, for all
if, for all
 , we let
, we let
 . In other words, the weakly additive measures of
. In other words, the weakly additive measures of
 correspond to a unique probability measure on
correspond to a unique probability measure on
 . Indeed, Reference Suppes and ZanottiSuppes and Zanotti (1976, 435–7) were able to establish that
. Indeed, Reference Suppes and ZanottiSuppes and Zanotti (1976, 435–7) were able to establish that
 has a unique probabilistic representation if and only if there exists a system of qualitative expectations
has a unique probabilistic representation if and only if there exists a system of qualitative expectations
 such that
such that
 on
on
 is the weak order induced by
is the weak order induced by
 on
on
 , defined like so:
, defined like so:

So, a (complete) binary confidence relation is uniquely probabilistically representable just when it can be extended to a qualitative expectations relation which satisfies Suppes and Zanotti’s five axioms.
So much for the formalities, now for the hard part: the interpretation of
 over
over
 isn’t entirely transparent, and I suspect this is main reason why there’s been comparatively little work done on this approach. In the usual case, random variables are functions from the outcomes of an experiment-type to numerical values of those outcomes. For instance, if we say the experiment is tossing two six-sided die, there are 36 possible outcomes corresponding to the different combinations, and 11 possible numerical values from 2 to 12 they might sum to. Letting
isn’t entirely transparent, and I suspect this is main reason why there’s been comparatively little work done on this approach. In the usual case, random variables are functions from the outcomes of an experiment-type to numerical values of those outcomes. For instance, if we say the experiment is tossing two six-sided die, there are 36 possible outcomes corresponding to the different combinations, and 11 possible numerical values from 2 to 12 they might sum to. Letting
 be the corresponding random variable, the expected value
be the corresponding random variable, the expected value
 of
of
 is the probability-weighted average value of the outcomes (under the supposition the experiment is run), and the sum of the expected value of
is the probability-weighted average value of the outcomes (under the supposition the experiment is run), and the sum of the expected value of
 with itself
with itself
 times can be interpreted as the expected total value of
times can be interpreted as the expected total value of
 independent runs of the same experiment under the same conditions. If the die are fair, then
independent runs of the same experiment under the same conditions. If the die are fair, then
 , and
, and

For this to make sense, though, it should be possible for those 36 outcomes to recur across independent instances of the same experiment. It is much less clear how to make sense of the iterated variables where the ‘outcomes’ are maximally specific possible worlds and the ‘experiment’, as such, can only be run once. Suppose
 is the proposition there are dogs, and
is the proposition there are dogs, and
 the proposition most roses are red. Presumably we should be able to find both propositions in
the proposition most roses are red. Presumably we should be able to find both propositions in
 , given the intended interpretation of that set. Each corresponds to a random variable over
, given the intended interpretation of that set. Each corresponds to a random variable over
 , namely
, namely
 and
and
 , and there’s no difficulty in interpreting
, and there’s no difficulty in interpreting
 as an expectation relation in this case. But the interpretations of
as an expectation relation in this case. But the interpretations of
 and
and
 are not similarly transparent, and still less the interpretation of
are not similarly transparent, and still less the interpretation of
 .
.
In connection to this, it’s noteworthy that Reference SuppesSuppes (2014, 53) later flagged interpretive difficulties as a distinctive cost for the approach, particularly vis-à-vis the mixed indicator functions
 . Reference Suppes and ZanottiSuppes and Zanotti (1982) explain one possible way to interpret their mixed non-iterated functions
. Reference Suppes and ZanottiSuppes and Zanotti (1982) explain one possible way to interpret their mixed non-iterated functions
 thus:
thus:
Suppose Smith is considering two locations to fly to for a weekend vacation. Let
 be the event of sunny weather at location
be the event of sunny weather at location
 and
and
 be the event of warm weather at location
be the event of warm weather at location
 . The qualitative comparison Smith is interested in is the expected value of
. The qualitative comparison Smith is interested in is the expected value of
 versus the expected value of
versus the expected value of
 . It’s natural to insist that the utility of the outcomes has been too simplified by the sums
. It’s natural to insist that the utility of the outcomes has been too simplified by the sums
 . The proper response is that the expected values of the two functions are being compared as a matter of belief, not value or utility. Thus it would seem quite natural to bet that the expected value of
. The proper response is that the expected values of the two functions are being compared as a matter of belief, not value or utility. Thus it would seem quite natural to bet that the expected value of
 will be greater than that of
will be greater than that of
 , no matter how one feels about the relative desirability of sunny versus warm weather.
, no matter how one feels about the relative desirability of sunny versus warm weather.
And in regards to the non-mixed iterated indicator functions,
 where
where
 , Reference SuppesSuppes (2014) offers the following interpretation:
, Reference SuppesSuppes (2014) offers the following interpretation:
From an intuitive estimation or gambling standpoint, it’s much easier to reflect on the subjective probability of
 than of
than of
 . For example, if
. For example, if
 means ‘heads’ in a toss of a coin with unknown bias, then
means ‘heads’ in a toss of a coin with unknown bias, then
 is just the estimate of 5 such tosses being ‘heads’.
is just the estimate of 5 such tosses being ‘heads’.
The ‘heads’ example is selectively chosen. Supposing
 is a set of possible worlds,
is a set of possible worlds,
 in general means that the proposition
in general means that the proposition
 is true at the world
is true at the world
 . It is not clear to me how something along the lines of Suppes’ suggested reading will make intuitive sense when
. It is not clear to me how something along the lines of Suppes’ suggested reading will make intuitive sense when
 is there are dogs or most roses are red.
is there are dogs or most roses are red.
5.3 Multiprimitive Structures
Suppose we identify an agent’s unconditional probabilities with their probabilities conditional on the necessary proposition
 . Given that, we can usefully see the two epistemic accounts just discussed as alternative ways of enriching the relatively simple systems of unconditional comparative confidence
. Given that, we can usefully see the two epistemic accounts just discussed as alternative ways of enriching the relatively simple systems of unconditional comparative confidence
 that were characterised by Definition 9. The account in Section 5.1 extends the domain of the confidence relation to
that were characterised by Definition 9. The account in Section 5.1 extends the domain of the confidence relation to
 , such that the agent’s unconditional confidence ordering falls out as a special case. The qualitative expectations account in Section 5.2 instead extends the domain from
, such that the agent’s unconditional confidence ordering falls out as a special case. The qualitative expectations account in Section 5.2 instead extends the domain from
 to
to
 , again with the unconditional confidence ordering being a special part of the richer relation. The following alternative also enriches the simple
, again with the unconditional confidence ordering being a special part of the richer relation. The following alternative also enriches the simple
 systems, though in a different way again: by adding more psychological primitives to the system.
systems, though in a different way again: by adding more psychological primitives to the system.
Of course, there is an absurd variety of ways this might go, depending on what primitives we choose to add and the structures we take them to have. One might conceivably add a primitive unary property corresponding to certainty, for example. Definitions of ‘certainty’ in terms of comparative confidence will usually equate it with maximal confidence, but one might imagine that being certain that
 can sometimes come apart from being at least as confident that
can sometimes come apart from being at least as confident that
 as any other proposition – and so an independent primitive for qualitative certainty would be useful. Similarly, if one supposes that all-or-nothing belief is related but not reducible to comparative confidence, and therefore seeks to represent all-or-nothing beliefs alongside degrees of belief within a single numerical framework, then one might try adding a primitive all-or-nothing believes relation by which to do so. There’s all sorts of things one might conceivably do.
as any other proposition – and so an independent primitive for qualitative certainty would be useful. Similarly, if one supposes that all-or-nothing belief is related but not reducible to comparative confidence, and therefore seeks to represent all-or-nothing beliefs alongside degrees of belief within a single numerical framework, then one might try adding a primitive all-or-nothing believes relation by which to do so. There’s all sorts of things one might conceivably do.
Probably the most commonly suggested additional primitive, however, is an independence relation (e.g., Reference Domotor, Hintikka and SuppesDomotor 1970; Reference FineFine 1973; Reference Kaplan and FineKaplan & Fine 1977; Reference LuceLuce 1978; Reference Luce and NarensLuce & Narens 1978; Reference JoyceJoyce 2010). Per usual, we say
 and
and
 are independent relative to a probability measure
are independent relative to a probability measure
 whenever
whenever

In cases where a comparative confidence relation can be represented by more than one probability measure, which propositions will count as probabilistically independent of one another can sometimes vary depending on which measures are chosen. An example: suppose
 contains four atoms,
contains four atoms,
 –
–
 , and the probability measures
, and the probability measures
 and
and
 are defined like so:
are defined like so:


The resulting measures correspond to the same overall confidence ordering, as represented in the following table:

|

|

|

| ||
|---|---|---|---|---|---|

| 1 | 1 |

| 0.28 | 0.29 |

| 0.98 | 0.97 |

| 0.26 | 0.26 |

| 0.92 | 0.92 |

| 0.20 | 0.21 |

| 0.90 | 0.89 |

| 0.18 | 0.18 |

| 0.82 | 0.82 |

| 0.10 | 0.11 |

| 0.80 | 0.79 |

| 0.08 | 0.08 |

| 0.74 | 0.74 |

| 0.02 | 0.03 |

| 0.72 | 0.71 |

| 0 | 0 |
Observe that
 and
and
 are independent relative to
are independent relative to
 , not relative to
, not relative to
 :
:

So probabilistic independence is not, in general, meaningful relative to the probabilistic measurement of comparative confidence.
Since independence is one of the more central concepts in probability theory, and does important theoretical work, we should want to rectify this situation. One might suppose we can simply solve the problem by imposing further axioms on
 , thus ensuring a unique probabilistic representation. But this response is inadequate. For one thing, it doesn’t solve the problem. Even supposing that
, thus ensuring a unique probabilistic representation. But this response is inadequate. For one thing, it doesn’t solve the problem. Even supposing that
 has a unique probabilistic representation in
has a unique probabilistic representation in
 , there will still be many non-probabilistic representations of that system in
, there will still be many non-probabilistic representations of that system in
 whereby
whereby
 needn’t equal 1 – so independence will not be meaningful relative to the natural class of additive homomorphisms into
needn’t equal 1 – so independence will not be meaningful relative to the natural class of additive homomorphisms into
 .Footnote 17 Moreover, there will still be ordinally equivalent probability measures that plausibly represent distinct systems of belief – as evidenced by their differentiable roles in epistemology and decision theory – and we should like to be able to account for them too.
.Footnote 17 Moreover, there will still be ordinally equivalent probability measures that plausibly represent distinct systems of belief – as evidenced by their differentiable roles in epistemology and decision theory – and we should like to be able to account for them too.
The better response is to find a system of primitives that will guarantee meaningfulness for independence. Most obviously, we can include a primitive qualitative independence relation alongside comparative confidence. Let
 designate a binary relation on
designate a binary relation on
 . The goal is then to supply conditions on an enriched system
. The goal is then to supply conditions on an enriched system
 sufficient for the existence of a measure
sufficient for the existence of a measure
 such that
such that
i.
if and only if
ii. If
, then
iii.
if and only if






If
 is finite, then such a measure will exist only if
is finite, then such a measure will exist only if
 satisfies the axioms from Definition 9. Necessary axioms for
satisfies the axioms from Definition 9. Necessary axioms for
 on this interpretation are provided by Reference SuppesSuppes (2014); each directly corresponds to basic properties of probabilistic independence:
on this interpretation are provided by Reference SuppesSuppes (2014); each directly corresponds to basic properties of probabilistic independence:
1.
2. If
, then
or
3. If
, then
4. If
, then
5. If
, and
,
, then












Including a primitive independence relation with these constraints into a system of qualitative probability will in some cases be enough to let us meaningfully differentiate between ordinally equivalent probability measures. It does for the preceding example, for instance, depending on whether
 or not. But it’s not always enough. Consider again the case that was earlier discussed in Section 3.4, where
or not. But it’s not always enough. Consider again the case that was earlier discussed in Section 3.4, where
 and
and

Suppose that the
 and
and
 in
in
 have this structure. Then
have this structure. Then
 can be represented by numerous measures satisfying properties i and ii, provided
can be represented by numerous measures satisfying properties i and ii, provided

The addition of property iii forces those measures to satisfy normalisation, and hence forces them all to be probability measures. However, it does nothing to sort between the many ordinally equivalent probability measures that fit with those comparative confidences.
It is possible to add yet further primitives that will help to guarantee unique probabilistic representability even where the conditions on
 and
and
 alone are not enough. Reference SuppesSuppes (2014: 49–50) shows that if one adds a primitive entropic uncertainty relation
alone are not enough. Reference SuppesSuppes (2014: 49–50) shows that if one adds a primitive entropic uncertainty relation
 (defined over partitions of
(defined over partitions of
 ) alongside appropriate axioms relating
) alongside appropriate axioms relating
 ,
,
 , and
, and
 , then one can guarantee a unique (absolute scale) representation of the resulting system that also happens to be a probability measure. No doubt there are many other primitives that one could try including alongside
, then one can guarantee a unique (absolute scale) representation of the resulting system that also happens to be a probability measure. No doubt there are many other primitives that one could try including alongside
 and
and
 that might work too. The matter has so far only undergone the most cursory exploration.
that might work too. The matter has so far only undergone the most cursory exploration.
6 Decision-Theoretic Approaches
A decision-theoretic representation is a kind of conjoint representation, typically of a single binary preference relation that decomposes into a representation of beliefs and a representation of (basic) desires that pairwise determine those preferences according to a pre-specified decision rule.
Decision-theoretic representations can differ along several dimensions, depending on the primitives used to construct the qualitative system, the desired constraints on the numerical representations of belief and desire, or the details of the decision rule. By far the most well-known theorems in this space are those for subjective expected utility theory; here we find the seminal works of Reference Ramsey and BraithwaiteRamsey (1931), Reference SavageSavage (1954), and Reference JeffreyJeffrey (1965). But there are dozens of variations on these theorems, and many more indeed for the huge number of non-expected utility theories that have been proposed as descriptive or normative rivals to the orthodox expected utility theory.
I won’t attempt to cover all the variety in this section. Instead, I’ll start with a brief overview of the main frameworks in which decision-theoretic representations tend to be constructed (Section 6.1), after which I’ll go into more detail on (a version of) Ramsey’s theorem (Section 6.2). Then I discuss meaningfulness in the conjoint measurement of belief and desire (Section 6.3), and finally rebut some common objections and concerns about the decision-theoretic approach (Section 6.4).
6.1 The Objects of Preference
Before we can build a conjoint representation of preferences as determined by beliefs and desires, we require an appropriate means of formalising the objects over which the preference relation is to be defined. These objects are variably referred to as gambles, bets, prospects, options, acts, decisions, choices, and more, depending on the intended interpretation of the theorem and the personal inclinations of its authors. But, broadly speaking, there are three main ways to formalise the objects of preference. These can be roughly ordered by the degree of internal structure they represent those objects as having – that is, from those that posit very richly structured objects of preference to those that define preferences over unstructured sets.
At the ‘richly structured’ end of the spectrum will be theorems that, like Reference SavageSavage’s (Reference Savage1954), employ more or less arbitrary associations between states of nature and consequences. In this context, preferences are usually understood as a relation over actions the agent might perform, or perhaps intentions to perform those actions, with the idea being that actions can be represented by their possible consequences relative to the states of the world under which the action brings them about. Where
 is a partition of
is a partition of
 representing different states the world might be in, and
representing different states the world might be in, and
 is a set of consequences that some potential action could bring about depending on which state happens to be true, we let each action be represented by a function from
is a set of consequences that some potential action could bring about depending on which state happens to be true, we let each action be represented by a function from
 to
to
 . (So if
. (So if
 is the function that pairs
is the function that pairs
 with
with
 , then it represents the action such that were it performed, then if
, then it represents the action such that were it performed, then if
 is the true state then
is the true state then
 would result, and if
would result, and if
 is the true state then
is the true state then
 would result, and so on.) The preference relation is defined over a set of these functions, and a conjoint representation is constructed that (typically, not always) decomposes into two measures – a function on the set of consequences
would result, and so on.) The preference relation is defined over a set of these functions, and a conjoint representation is constructed that (typically, not always) decomposes into two measures – a function on the set of consequences
 (corresponding to the desirability of those consequences); and a function on an algebra of propositions (usually called ‘events’) constructed from the states in
(corresponding to the desirability of those consequences); and a function on an algebra of propositions (usually called ‘events’) constructed from the states in
 (corresponding to the agent’s beliefs).
(corresponding to the agent’s beliefs).
For example, suppose
 is finite, and the set of events
is finite, and the set of events
 is the algebra of propositions with atoms given by
is the algebra of propositions with atoms given by
 . Then, an ordinary expected utility theorem provides axioms on a preference relation
. Then, an ordinary expected utility theorem provides axioms on a preference relation
 defined over the space of actions
defined over the space of actions
 sufficient for the existence of a probability measure
sufficient for the existence of a probability measure
 on
on
 (‘
(‘
 ’ for beliefs) and a real-valued function
’ for beliefs) and a real-valued function
 on
on
 (‘
(‘
 ’ for desires), such that for any actions
’ for desires), such that for any actions
 and
and
 ,
,

Note that
 and
and
 must here be defined on distinct sets – indeed, in Savage’s original construction
must here be defined on distinct sets – indeed, in Savage’s original construction
 and
and
 are disjoint. The reason is that a proposition counts as an event just in case it’s logically equivalent to a disjunction of states; hence any proposition that’s consistent with any state and its negation cannot be an event. Given that, observe that consequences cannot in general be events, if the functional representation of actions is to be coherent. We cannot say that
are disjoint. The reason is that a proposition counts as an event just in case it’s logically equivalent to a disjunction of states; hence any proposition that’s consistent with any state and its negation cannot be an event. Given that, observe that consequences cannot in general be events, if the functional representation of actions is to be coherent. We cannot say that
 is the action that brings consequence
is the action that brings consequence
 at state
at state
 , whereas
, whereas
 is the action that brings some other consequence
is the action that brings some other consequence
 at
at
 , if the state logically determines that a particular consequence obtains. So consequences need to be logically independent of states. For a similar reason, states cannot in general determine actions. Hence, the domain of the belief function cannot include propositions that determine the actions under deliberation nor the consequences thereof. For some this is seen as a good-making feature of Savage’s construction (e.g., Reference SpohnSpohn 1977); for others, not so much (e.g., Reference HájekHájek 2016; Reference ElliottElliott 2017a).
, if the state logically determines that a particular consequence obtains. So consequences need to be logically independent of states. For a similar reason, states cannot in general determine actions. Hence, the domain of the belief function cannot include propositions that determine the actions under deliberation nor the consequences thereof. For some this is seen as a good-making feature of Savage’s construction (e.g., Reference SpohnSpohn 1977); for others, not so much (e.g., Reference HájekHájek 2016; Reference ElliottElliott 2017a).
At the other end of the spectrum are theorems that, like Reference JeffreyJeffrey’s (Reference Jeffrey1965; Reference Jeffrey1978; see also Reference BolkerBolker 1967 and Reference DomotorDomotor 1978), define preferences over an algebra of propositions (qua sets of worlds) that simultaneously serves as the domain of both the belief and desire functions. For this reason they are sometimes called ‘monoset theorems’. Jeffrey’s theorem supplies axioms on a preference relation
 defined over an algebra of propositions
defined over an algebra of propositions
 sufficient for the existence of a probability measure
sufficient for the existence of a probability measure
 and a real-valued
and a real-valued
 where
where
 if and only if
if and only if
 , and for
, and for
 , if
, if
 is any finite partition of
is any finite partition of
 , then:
, then:

It makes little sense to interpret the objects of Jeffrey’s preference relation as actions. Some of the propositions in
 may very well correspond to actions that the agent may choose to perform – these Reference JeffreyJeffrey (1968, 170) refers to as actual propositions – but many more of the propositions over which
may very well correspond to actions that the agent may choose to perform – these Reference JeffreyJeffrey (1968, 170) refers to as actual propositions – but many more of the propositions over which
 is defined will correspond to no plausible object of choice in any realistic decision context. So
is defined will correspond to no plausible object of choice in any realistic decision context. So
 is much better seen in this case as a relative desirability relation:
is much better seen in this case as a relative desirability relation:
To say that
 is ranked higher than
is ranked higher than
 [in the agent’s preference ordering] means that the agent would welcome the news that
[in the agent’s preference ordering] means that the agent would welcome the news that
 is true more than he would the news that
is true more than he would the news that
 is true:
is true:
 would be better news than
would be better news than
 .
.
Given this, the axioms of Jeffrey’s theorem constrain the agent’s relative desirabilities for propositions in general, and decision-making is construed as selecting between actual propositions on the basis of their desirabilities in contexts where one is able to make one or another of them true.
The difference in how the objects of preference are represented is also important from a measurement-theoretic perspective. For any numerical representation of any weak order, if that representation is going to be more than just an ordinal scale then one needs posit some additional structure when characterising the qualitative system – else there will be nothing for the extra-ordinal structure of the representation to be a representation of. In the Savage framework, the additional structure can be found mostly in the objects of preference. For example, Savage’s theorem requires:
If
and
for all
, and
, then if
for all
, and otherwise
and
, then
.









In other words, if two acts
 and
and
 have identical consequences for a subset of the states, and for all other states
have identical consequences for a subset of the states, and for all other states
 has better consequences, then
has better consequences, then
 should be preferred to
should be preferred to
 . In the Jeffrey framework, however, the relata of
. In the Jeffrey framework, however, the relata of
 have no internal structure; they are just sets of worlds. Hence, we need to appeal instead to logical (or set-theoretic) relations between propositions to get an interesting (more-than-merely-ordinal) representation. For example:
have no internal structure; they are just sets of worlds. Hence, we need to appeal instead to logical (or set-theoretic) relations between propositions to get an interesting (more-than-merely-ordinal) representation. For example:
If
for some
such that
and either
or
, then
for all
.







In other words, if
 makes no contribution to the desirability of
makes no contribution to the desirability of
 for disjoint
for disjoint
 and
and
 of distinct desirabilities, then the agent must presumably have zero confidence in
of distinct desirabilities, then the agent must presumably have zero confidence in
 , and hence for consistency
, and hence for consistency
 should make no contribution to the desirability of
should make no contribution to the desirability of
 for any other
for any other
 .
.
An interesting middle ground is provided by the third kind of framework, originating with Reference Ramsey and BraithwaiteRamsey (1931), where preferences are defined over a domain of very simple prospects of the form ‘
 if
if
 ,
,
 otherwise’. These are typically interpreted as conjunctions of conditionals, perhaps corresponding to potential choices or gambles the agent might take. They are typically formalised as
otherwise’. These are typically interpreted as conjunctions of conditionals, perhaps corresponding to potential choices or gambles the agent might take. They are typically formalised as
 -tuples of conditions and consequences – for example,
-tuples of conditions and consequences – for example,
 . Most such theorems focus on binary prospects like the one just described. In some cases preferences are also defined for ternary prospects ‘
. Most such theorems focus on binary prospects like the one just described. In some cases preferences are also defined for ternary prospects ‘
 if
if
 ,
,
 if
if
 ,
,
 otherwise’, or sometimes even quarternary prospects, but nothing so richly structured as the (potentially infinitary) act-functions we find in the Savage-style frameworks. (For examples of theorems in the Ramseyan framework, see Reference DebreuDebreu 1959; Reference Davidson and SuppesDavidson & Suppes 1956; Reference Davidson, Suppes and SiegelDavidson et al. 1957; Reference FishburnFishburn 1967; Reference ElliottElliott 2017b; Reference Elliott2017c.) The theorem discussed in the next section belongs to this third class.
otherwise’, or sometimes even quarternary prospects, but nothing so richly structured as the (potentially infinitary) act-functions we find in the Savage-style frameworks. (For examples of theorems in the Ramseyan framework, see Reference DebreuDebreu 1959; Reference Davidson and SuppesDavidson & Suppes 1956; Reference Davidson, Suppes and SiegelDavidson et al. 1957; Reference FishburnFishburn 1967; Reference ElliottElliott 2017b; Reference Elliott2017c.) The theorem discussed in the next section belongs to this third class.
It’s worth noting that the Ramseyan approach is extremely limited as a framework for formalising decision theory – especially in contrast to either of the Savagean or Jeffreyan frameworks just discussed. Most decision situations involve choices between options that cannot plausibly be reduced to simple
 -ary prospects, for very small
-ary prospects, for very small
 . Our decisions usually have more than two or three possible consequences. Savage and Jeffrey sought to achieve a complete and fully general axiomatisation of a decision theory in terms of preferences, and from this perspective the Ramseyan framework is grossly inadequate.
. Our decisions usually have more than two or three possible consequences. Savage and Jeffrey sought to achieve a complete and fully general axiomatisation of a decision theory in terms of preferences, and from this perspective the Ramseyan framework is grossly inadequate.
But for a theory of measurement we needn’t ask so much. The goal here is to isolate a qualitative conjoint psychological system with a relational structure that suffices to explain the quantitation of belief. With that in mind, we needn’t assume that the qualitative system should include all of the agent’s preferences over all possible actions and/ propositions, nor that the decision rule should be generally applicable to every conceivable decision situation.
6.2 Ramsey’s Theorem
Here’s the goal: from a single preference ordering over a space of binary prospects (e.g, of the form ‘
 if
if
 ,
,
 otherwise’), we want to extract numerical representations of belief and desire that conjointly represent those preferences according to a version of the expected utility rule.
otherwise’), we want to extract numerical representations of belief and desire that conjointly represent those preferences according to a version of the expected utility rule.
The first step is to be more precise about the form of the intended numerical representation. We let
 be a preference relation defined over a set
be a preference relation defined over a set
 of prospects. Where
of prospects. Where
 is an algebra of propositions and
is an algebra of propositions and
 is a set of consequences, we formalise prospects as 3-tuples
is a set of consequences, we formalise prospects as 3-tuples
 in
in
 . Footnote 18 For simplicity, we will be assuming that both
. Footnote 18 For simplicity, we will be assuming that both
 and
and
 are finite. This just lets us ignore a complicated ‘Archimedean’ axiom that’s trivially satisfied in finite contexts. Given that, we desire a function
are finite. This just lets us ignore a complicated ‘Archimedean’ axiom that’s trivially satisfied in finite contexts. Given that, we desire a function
 that represents
that represents
 in the sense that
in the sense that

where
 itself decomposes into two functions
itself decomposes into two functions
 (for beliefs) and
(for beliefs) and
 (for desires) such that
(for desires) such that

Call this the simplified formula.
Note an immediate complication: the simplified formula is too simple! It implies that the three factors contributing to the value of a prospect are independent of one another. In particular, according to the simplified formula,

However, the desirability of
 – as supposedly represented by
– as supposedly represented by
 – may vary depending on whether it obtains in a context where
– may vary depending on whether it obtains in a context where
 is true versus a context where
is true versus a context where
 is true, which could imply a difference in desirability between
is true, which could imply a difference in desirability between
 and
and
 . In general, the value of a prospect’s consequences ought to be judged relative to the conditions under which those consequences obtain. Consequently, the value of
. In general, the value of a prospect’s consequences ought to be judged relative to the conditions under which those consequences obtain. Consequently, the value of
 isn’t always given by the simplified formula, but by the slightly more complicated one:
isn’t always given by the simplified formula, but by the slightly more complicated one:

The implication is that if
 is determined by this more complicated decision rule, then either it cannot be represented in the desired manner, or
is determined by this more complicated decision rule, then either it cannot be represented in the desired manner, or
 cannot be defined for all possible prospects in
cannot be defined for all possible prospects in
 . The resolution to this little problem is to restrict
. The resolution to this little problem is to restrict
 to those prospects
to those prospects
 such that the agent is indifferent between
such that the agent is indifferent between
 and
and
 , and likewise between
, and likewise between
 and
and
 , since in these cases the complicated formula will just reduce to the simplified formula. If propositions are coarsely individuated – if they are sets of logically possible worlds, as per Assumption 1 – then one way to achieve this restriction is to suppose that a prospect can be found in
, since in these cases the complicated formula will just reduce to the simplified formula. If propositions are coarsely individuated – if they are sets of logically possible worlds, as per Assumption 1 – then one way to achieve this restriction is to suppose that a prospect can be found in
 only if its consequences entail the conditions under which they obtain, so
only if its consequences entail the conditions under which they obtain, so
 and
and
 . More precisely:
. More precisely:
| 1. |
 only if
only if
 implies
implies
 and
and
 implies
implies
 ; and
; and
 is inconsistent only if
is inconsistent only if
 is inconsistent, and
is inconsistent, and
 is inconsistent only if
is inconsistent only if
 is inconsistent
is inconsistent | (restricted prospects) |
But this only tells us what kinds of prospects aren’t in
 . We will also need to ensure that the domain of
. We will also need to ensure that the domain of
 is rich enough to ensure the existence of the desired representation. There are five richness axioms in total, starting with:
is rich enough to ensure the existence of the desired representation. There are five richness axioms in total, starting with:
| 2. | For every
 , there is a prospect
, there is a prospect

| (trivial prospects) |
The purpose of this axiom is to let us extend the preference ordering
 to the set of consequences
to the set of consequences
 , in the obvious way:
, in the obvious way:

Axioms 7–10, presented later, will ensure that
 on
on
 is a weak order. This trivial prospects axiom isn’t necessary if we treat preferences over consequences as a primitive relation. That is what Ramsey did. However, letting preferences be defined in the first instance only over gambles, rather than both gambles and their consequences, makes some parts of the construction slightly more natural.
is a weak order. This trivial prospects axiom isn’t necessary if we treat preferences over consequences as a primitive relation. That is what Ramsey did. However, letting preferences be defined in the first instance only over gambles, rather than both gambles and their consequences, makes some parts of the construction slightly more natural.
Before I state the four remaining richness axioms, some notation will prove useful. First, let
 designate the set of consequences
designate the set of consequences
 in
in
 such that
such that
 . In terms of the intended representation,
. In terms of the intended representation,
 contains all and only those
contains all and only those
 such that
such that
 . We then use
. We then use
 for a prospect conditional on
for a prospect conditional on
 with consequences equal in desirability to
with consequences equal in desirability to
 and
and
 . Next, suppose that, for
. Next, suppose that, for
 ,
,

Supposing
 is represented in the desired format, this can hold only if
is represented in the desired format, this can hold only if
 . Consequently, if
. Consequently, if

then
 . In this fashion we can isolate the half-probability propositions in
. In this fashion we can isolate the half-probability propositions in
 . We use
. We use
 for a prospect with consequences equal in desirability to
for a prospect with consequences equal in desirability to
 and
and
 conditional on one or another of these half-probability propositions. These prospects can be used to define halfway points between the desirabilities of
conditional on one or another of these half-probability propositions. These prospects can be used to define halfway points between the desirabilities of
 and
and
 . Finally, we characterise a qualitative ordering
. Finally, we characterise a qualitative ordering
 over
over
 like so:
like so:

Defined as such,
 represents the relative size of intervals in desirability – in the final representation, we will see
represents the relative size of intervals in desirability – in the final representation, we will see

We can now state the remaining richness axioms with comparative ease:
| 3. | If
 , then there is some
, then there is some

| (halfway prospects) |
| 4. | If
 , then there are
, then there are
 such that
such that

| (
 -solvability)
-solvability) |
| 5. | For every
 , there’s some
, there’s some
 such that
such that
 , or some
, or some
 such that
such that

| (extendibility) |
| 6. | For every
 , there’s some
, there’s some
 such that
such that
 or
or

| (non-trivial prospects) |
The halfway prospects axiom ensures that we can always define halfway points between the desirabilities of any two consequences.
 -solvability is a non-necessary condition used to guarantee that for any non-zero interval in desirability between two consequences, there will be another interval of the same size to which it can be ‘added’. This allows ratios of differences to be defined, which is what ultimately allows the construction of an interval-scale measure
-solvability is a non-necessary condition used to guarantee that for any non-zero interval in desirability between two consequences, there will be another interval of the same size to which it can be ‘added’. This allows ratios of differences to be defined, which is what ultimately allows the construction of an interval-scale measure
 . The extendibility axiom is then used to extend
. The extendibility axiom is then used to extend
 on
on
 to all of
to all of
 , and hence define
, and hence define
 . Finally, non-trivial prospects ensures there are enough prospects around such that a degree of belief can be defined for every proposition in
. Finally, non-trivial prospects ensures there are enough prospects around such that a degree of belief can be defined for every proposition in
 .
.
Definition 23. Where
 is a finite algebra of propositions and
is a finite algebra of propositions and
 is a finite set of propositions,
is a finite set of propositions,
 is a finite Ramseyan structure if and only if
is a finite Ramseyan structure if and only if
 satisfying restricted prospects, trivial prospects, halfway prospects,
satisfying restricted prospects, trivial prospects, halfway prospects,
 -solvability, extendability and non-trivial prospects.
-solvability, extendability and non-trivial prospects.
What remains is to specify conditions on a finite Ramsey structure sufficient for the existence of the desired representation. We proceed in three stages, starting with the construction of the desirability function
 . This uses:
. This uses:
| 7. |
 is a weak order
is a weak order | (weak order) |
| 8. |
 is transitive
is transitive | (
 -transitivity)
-transitivity) |
| 9. | For all
 ,
,

| (reversibility) |
| 10. | For all
 , if
, if
 , then
, then

| (averaging) |
In overview,
 is derived as follows. (For details, see Reference ElliottElliott 2017c and Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 145–52.) First, we use weak order,
is derived as follows. (For details, see Reference ElliottElliott 2017c and Reference Krantz, Luce, Suppes and TverskyKrantz et al. 1971, 145–52.) First, we use weak order,
 -transitivity and reversibility, in conjunction with halfway prospects and
-transitivity and reversibility, in conjunction with halfway prospects and
 -solvability, to define a concatenation operation
-solvability, to define a concatenation operation
 over desirability intervals, such that
over desirability intervals, such that
 is an additive extensive structure. This allows for a ratio-scale measure of desirability intervals. Given averaging, we can define an interval-scale measure
is an additive extensive structure. This allows for a ratio-scale measure of desirability intervals. Given averaging, we can define an interval-scale measure
 such that:
such that:
i.
if and only if
ii.
if and only if




Next, we define
 on
on
 using
using
 , like so:
, like so:

The extendibility axiom ensures the definition is adequate. Note, of course, that
 . Finally, we extract the belief function
. Finally, we extract the belief function
 out of
out of
 . Where
. Where
 , reorganising the simplified formula gets us
, reorganising the simplified formula gets us
 as a ratio of differences in desirability:
as a ratio of differences in desirability:

This last step requires the non-trivial prospects axiom, plus one more axiom which asserts that the contribution
 makes to the overall value of a prospect is independent of the desirabilities of its consequences. Expressed directly in terms of preferences, this axiom is rather complicated and not at all intuitive. The interested reader should refer to Reference Davidson and SuppesDavidson and Suppes’ (Reference Davidson and Suppes1956) axiom A10 and the associated definitions for how it goes. We can simplify matters greatly by ‘cheating’ and expressing the axiom in terms of the intended representation:
makes to the overall value of a prospect is independent of the desirabilities of its consequences. Expressed directly in terms of preferences, this axiom is rather complicated and not at all intuitive. The interested reader should refer to Reference Davidson and SuppesDavidson and Suppes’ (Reference Davidson and Suppes1956) axiom A10 and the associated definitions for how it goes. We can simplify matters greatly by ‘cheating’ and expressing the axiom in terms of the intended representation:
11. For all
, if
,
, and
, then
(independence)





The upshot is that the foregoing definition of
 won’t depend on the particular choice of prospect. It is a consistency requirement, on how the agent values different prospects conditional on the same proposition.
won’t depend on the particular choice of prospect. It is a consistency requirement, on how the agent values different prospects conditional on the same proposition.
Putting that all together:
Theorem 24 Ramsey (1931); Elliott (2017c) If
 is a finite Ramseyan structure satisfying weak order,
is a finite Ramseyan structure satisfying weak order,
 -transitivity, reversibility, averaging, and independence, then there are functions
-transitivity, reversibility, averaging, and independence, then there are functions
 ,
,
 and
and
 , such that
, such that
i.
if and only if
ii.



Furthermore,
 is unique up to a positive affine transformation, while
is unique up to a positive affine transformation, while
 is unique and for all
is unique and for all
 ,
,
iii.
.

Note that
 is unique simpliciter – an absolute scale. The uniqueness clause applies to all representations satisfying properties i and ii. (Property iii, by contrast, is not an explicit stipulation on the form of the representation but is rather derived as a consequence of the representation.) The uniqueness of
is unique simpliciter – an absolute scale. The uniqueness clause applies to all representations satisfying properties i and ii. (Property iii, by contrast, is not an explicit stipulation on the form of the representation but is rather derived as a consequence of the representation.) The uniqueness of
 is a result of how it was defined – as a dimensionless ratio of differences in desirability – and the fact that
is a result of how it was defined – as a dimensionless ratio of differences in desirability – and the fact that
 is unique up to an interval-preserving transformation.
is unique up to an interval-preserving transformation.
6.3 Uniqueness and Meaning
It’s a point often noted that the expected utility representations of a preference ordering are not unique. Theorem 24 implies, for example, that if
 has an expected utility representation involving the pair of belief and desire functions
has an expected utility representation involving the pair of belief and desire functions
 and
and
 , then there will be another such representation involving
, then there will be another such representation involving
 and
and
 , where
, where

Since it’s widely held that desirabilities can be measured on nothing stronger than an interval scale (similar to temperatures as measured in Celsius or Fahrenheit), the usual response to this fact is that there is no meaningful difference between
 and
and
 .
.
Now consider the following example, from Reference ZyndaZynda (2000). Where
 is an
is an
 -ary prospect with consequences
-ary prospect with consequences
 conditional on which element of a partition
conditional on which element of a partition
 happens to be true, then
happens to be true, then
 has an expected utility representation involving
has an expected utility representation involving
 and
and
 whenever
whenever
 if and only if
if and only if

If any such representation exists, then there will be another representation of
 involving the functions
involving the functions
 and
and
 , where
, where

In this case, though, the belief and desire functions will be combined by a different decision rule – the valuation maximisation rule. This rule tells us that
 just in case
just in case

It is straightforward to show that an expected utility representation of
 (with
(with
 and
and
 ) exists if and only if a valuation maximisation representation of
) exists if and only if a valuation maximisation representation of
 (with
(with
 and
and
 ) likewise exists. The key step is then just to note that the transformation from
) likewise exists. The key step is then just to note that the transformation from
 to
to
 is bijective and so invertible:
is bijective and so invertible:

So, substituting into the inequality for expected utility representations just presented:

Then dropping the constant factor:

which is just another way to write the valuation maximisation rule.
By analogy with desirabilities, one might imagine this tells us something about meaningfulness in
 and
and
 : that in just the same way as we wanted to say that
: that in just the same way as we wanted to say that
 and
and
 are not meaningfully distinct, so too should we want to say that
are not meaningfully distinct, so too should we want to say that
 and
and
 are not meaningfully distinct. As Reference ZyndaZynda (2000) has suggested,
are not meaningfully distinct. As Reference ZyndaZynda (2000) has suggested,
One might point out that
 is simply a linear transformation of
is simply a linear transformation of
 , and argue that in the case of probabilities (like utilities and temperatures) this is a difference that makes no difference. This approach commits [the theorist] to taking as real properties of degrees of belief at most those properties that are common to both
, and argue that in the case of probabilities (like utilities and temperatures) this is a difference that makes no difference. This approach commits [the theorist] to taking as real properties of degrees of belief at most those properties that are common to both
And a little further on, Zynda argues that
 and
and
 will share a common ordering, and thus represent the same comparative confidences. Hence,
will share a common ordering, and thus represent the same comparative confidences. Hence,
According to this solution, people really have properties that can properly be called ‘degrees of belief’, though these are more abstract in nature than subjective probabilities, being purely qualitative … the concept of degree of belief on this strategy becomes a purely ordinal notion.
However, while there is an important lesson about meaningfulness to be gleaned from this example, this is not it.
First note that
 and
and
 will have more than just their orderings in common. The linear transformation which relates
will have more than just their orderings in common. The linear transformation which relates
 to
to
 also preserves difference ratios, and those ratios are not decision-theoretically superfluous. Again, the example from Section 3.4 suffices to make this point. Where
also preserves difference ratios, and those ratios are not decision-theoretically superfluous. Again, the example from Section 3.4 suffices to make this point. Where
 , we imagine that Ramsey has a choice between:
, we imagine that Ramsey has a choice between:
α : receive $1 if
is true, nothing otherwiseβ : receive $2 if
is false, nothing otherwise


According to expected utility theory, Ramsey should prefer
 if and only if
if and only if

As there are numerically distinct but ordinally equivalent probability measures that differ with respect to this inequality, expected utility theory requires that there are meaningful differences between those measures. The same is therefore true for the valuation maximisation rule, according to which Ramsey should prefer
 if and only if
if and only if

Do not be tempted, though, to infer from these facts that difference ratios are meaningful in
 . (They are meaningful; the mistake is to think the reason has anything to do with what’s common to
. (They are meaningful; the mistake is to think the reason has anything to do with what’s common to
 and
and
 .) For consider yet another decision-theoretic representation. Define
.) For consider yet another decision-theoretic representation. Define
 such that
such that

Now
 has an expected utility representation involving
has an expected utility representation involving
 and
and
 if and only if it also has an ‘equivalent’ schmaluation maximisation representation involving
if and only if it also has an ‘equivalent’ schmaluation maximisation representation involving
 and
and
 , where this time we say
, where this time we say
 if and only if
if and only if

However, difference ratios are not preserved in the transformation from
 to
to
 . So if earlier we were tempted to say that difference ratios are meaningful in
. So if earlier we were tempted to say that difference ratios are meaningful in
 only if they’re shared with
only if they’re shared with
 , then by the same token they should be shared with
, then by the same token they should be shared with
 as well – but then difference ratios wouldn’t be meaningful after all.
as well – but then difference ratios wouldn’t be meaningful after all.
The proof that a schmaluation maximisation representation exists just in case an expected utility representation exists is near identical to that for the valuation maximisation representations presented earlier, and relies mostly on the fact that the transformation from
 to
to
 is bijective and so invertible:
is bijective and so invertible:

And it generalises easily: if the transformation from
 to
to
 is bijective, then we’ll be able to construct a representation of
is bijective, then we’ll be able to construct a representation of
 which makes use of
which makes use of
 and
and
 , where that representation exists if and only if an expected utility representation with
, where that representation exists if and only if an expected utility representation with
 and
and
 exists. This includes transformations that do not preserve ratios, or difference ratios, or even orderings. In fact, there’s virtually nothing that’s shared across all possible decision-theoretic representations of
exists. This includes transformations that do not preserve ratios, or difference ratios, or even orderings. In fact, there’s virtually nothing that’s shared across all possible decision-theoretic representations of
 . But it would be a gross error to infer that almost all the information in
. But it would be a gross error to infer that almost all the information in
 is meaningless.
is meaningless.
Clearly, whether something is meaningful in
 has nothing much to do with what kind of information
has nothing much to do with what kind of information
 shares or doesn’t share with
shares or doesn’t share with
 and
and
 . And hopefully you can see the problem: the valuation and schmaluation maximisation representations are ‘equivalent’ to the expected utility representation in the sense that they are equally legitimate ways to numerically represent a system of preferences, but they are representations within distinct numerical systems – and meaningfulness in the representation of any quantity is only sensibly defined relative to a fixed choice of numerical format (§2.5). Indeed, for any real-valued representation
. And hopefully you can see the problem: the valuation and schmaluation maximisation representations are ‘equivalent’ to the expected utility representation in the sense that they are equally legitimate ways to numerically represent a system of preferences, but they are representations within distinct numerical systems – and meaningfulness in the representation of any quantity is only sensibly defined relative to a fixed choice of numerical format (§2.5). Indeed, for any real-valued representation
 of any quantity, if
of any quantity, if
 and
and
 are related by an invertible transformation on the reals, then
are related by an invertible transformation on the reals, then
 will also be a way of representing that quantity in some numerical system or other. This includes transformations that do not preserve ratios, or difference ratios, or even orderings.
will also be a way of representing that quantity in some numerical system or other. This includes transformations that do not preserve ratios, or difference ratios, or even orderings.
What Zynda-style examples actually establish is that ratios in
 are meaningful relative to expected utility representations, precisely because any transformation of
are meaningful relative to expected utility representations, precisely because any transformation of
 that doesn’t preserve ratios must therefore employ a different combination rule. Since ratios are meaningful, therefore difference ratios and orderings are also meaningful. But there is a deeper lesson here too: the conjoint structure being represented isn’t any structure internal to the system of beliefs itself, considered in isolation from anything else, but relates instead to the connection between beliefs, desires, and preferences. The belief functions
that doesn’t preserve ratios must therefore employ a different combination rule. Since ratios are meaningful, therefore difference ratios and orderings are also meaningful. But there is a deeper lesson here too: the conjoint structure being represented isn’t any structure internal to the system of beliefs itself, considered in isolation from anything else, but relates instead to the connection between beliefs, desires, and preferences. The belief functions
 ,
,
 , and
, and
 do have something in common – they all play similar roles in the respective numerical models of decision-making that employ them. (Essentially: these beliefs interact with those desires to produce such-and-such preferences.) That is what’s invariant, and that is why we cannot transform the belief function without making adjustments to the decision rule: because the meaning of
do have something in common – they all play similar roles in the respective numerical models of decision-making that employ them. (Essentially: these beliefs interact with those desires to produce such-and-such preferences.) That is what’s invariant, and that is why we cannot transform the belief function without making adjustments to the decision rule: because the meaning of
 is tied up with how it interacts with
is tied up with how it interacts with
 to produce preferences. Of course there are many ways to represent that conjoint system – there are always many ways to represent any system. But however we do so, the three components of the representation – the belief function, the desire function, and the decision rule – need to be interpreted together.
to produce preferences. Of course there are many ways to represent that conjoint system – there are always many ways to represent any system. But however we do so, the three components of the representation – the belief function, the desire function, and the decision rule – need to be interpreted together.
For an analogy, consider the relationship between force, mass, and acceleration. If those quantities are represented in Newtons, kilograms, and metres per second squared (respectively), then the connection between them can be neatly captured with the usual formula:

But if we start playing around with the numerical representation of the different components, then we can easily come up with many numerically distinct but ‘equivalent’ representations of the very same relationship. Where mass is measured in pounds, acceleration in schmetres per second squared,Footnote 19 and force in negative Newtons, then we get:

The superficial form of the rule has changed, but not the underlying relational system between the three quantities. What’s happening with the different ways of expressing the connection between beliefs, desires, and preferences is no different in kind than what’s happening with these different ways of expressing the connection between force, mass, and acceleration.
6.4 An Apology
Theorem 24 describes a very flexible representation of belief –
 must be such that
must be such that
 and
and
 , but otherwise there are few constraints on the shape it must take. It’s possible to construct finite Ramseyan structures such that
, but otherwise there are few constraints on the shape it must take. It’s possible to construct finite Ramseyan structures such that
 is logically non-omniscient, and it’s also possible to construct finite Ramseyan structures such that
is logically non-omniscient, and it’s also possible to construct finite Ramseyan structures such that
 is a probability measure. Given the desiderata of Section 3.4, I take it that this flexibility is a good-making feature. It allows for a non-disjunctive theory of belief measurement that’s consistent with a range of probabilistic and non-probabilistic representations, on a more-than-merely ordinal scale, without forcing logical omniscience.
is a probability measure. Given the desiderata of Section 3.4, I take it that this flexibility is a good-making feature. It allows for a non-disjunctive theory of belief measurement that’s consistent with a range of probabilistic and non-probabilistic representations, on a more-than-merely ordinal scale, without forcing logical omniscience.
The reason for this flexibility is that the degree of belief assigned to
 is determined independently of almost any other proposition, aside from
is determined independently of almost any other proposition, aside from
 . This contrasts with epistemic approaches (and Jeffrey-style decision-theoretic approaches). The quantitation of belief on the Ramseyan approach requires no particular appeal to relations between belief states or the contents thereof, but instead depends primarily on systematic relationships between the agent’s degree of belief in
. This contrasts with epistemic approaches (and Jeffrey-style decision-theoretic approaches). The quantitation of belief on the Ramseyan approach requires no particular appeal to relations between belief states or the contents thereof, but instead depends primarily on systematic relationships between the agent’s degree of belief in
 and the value they attach to prospects conditional on
and the value they attach to prospects conditional on
 . As Reference Ramsey and BraithwaiteRamsey (1931) put it,
. As Reference Ramsey and BraithwaiteRamsey (1931) put it,
[The] degree of a belief is a causal property of it, which we can express vaguely as the extent to which we are prepared to act on it.
A rough way to express the difference: on the epistemic approach, the strength of Sally’s belief towards
 is twice that of
is twice that of
 when
when
 is equiprobable with the disjunction of two incompatible
is equiprobable with the disjunction of two incompatible
 and
and
 equiprobable with
equiprobable with
 ; on the Ramseyan approach, if
; on the Ramseyan approach, if
 is believed to twice the degree as
is believed to twice the degree as
 , then this will be connected to the difference in desirability between
, then this will be connected to the difference in desirability between
 and
and
 being twice the difference between
being twice the difference between
 and
and
 (for
(for
 ).
).
It’s worth emphasising again that the connection between belief and preference needn’t be constitutive. Many have claimed to find in Ramsey’s essay the thesis that beliefs are nothing over and above preferences as manifest in choice dispositions. Ramsey himself never said that, and instead characterised the relationship between them in causal terms. But in any case, nothing about Theorem 24 implies that beliefs are reducible to preferences. It’s true that in the proof of the theorem we first characterise a desirability function that represents preferences and from that go on to derive a belief function – but one cannot infer any kind of ontological or conceptual dependence relations between quantities just from the order in which their numerical representations happen to be constructed in a conjoint representation thereof. That would be fallacious. The numerical representation requires a qualitative interpretation involving some systematic connection between beliefs and preferences, but that connection may take many possible forms.
Recognising this fallacy helps in dealing with some common objections to the decision-theoretic approach. An exemplar here is Reference Eriksson and HájekEriksson and Hájek’s (Reference Eriksson and Hájek2007) Zen monk. A ‘Zen monk’ is an agent who is indifferent between all consequences, and therefore indifferent between all prospects. The preferences of such an agent would violate non-trivial prospects in such a way that the belief function
 cannot be derived from the agents’ desirabilities. Yet, presumably, such an agent could still have determinate degrees of belief, and two Zen monks could have distinct degrees of belief between them. If such beings could exist, then they are a counterexample to the thesis that an agent’s degrees of belief are nothing over and above their preferences. But the Zen monk is much less problematic if we take the strength of an agent’s belief to be ‘a causal property of it’ which need not be manifest in all cases (Reference ElliottElliott 2019a). Even if a Zen monk is actually indifferent among all consequences, she may still be in a state of belief the typical causal role of which would only become apparent if she were no longer universally indifferent. What it is to believe
cannot be derived from the agents’ desirabilities. Yet, presumably, such an agent could still have determinate degrees of belief, and two Zen monks could have distinct degrees of belief between them. If such beings could exist, then they are a counterexample to the thesis that an agent’s degrees of belief are nothing over and above their preferences. But the Zen monk is much less problematic if we take the strength of an agent’s belief to be ‘a causal property of it’ which need not be manifest in all cases (Reference ElliottElliott 2019a). Even if a Zen monk is actually indifferent among all consequences, she may still be in a state of belief the typical causal role of which would only become apparent if she were no longer universally indifferent. What it is to believe
 to degree
to degree
 , on this picture, is to be in a state whose typical causal role in connection to preferences and desire is reflected in the class of systems with representations such that
, on this picture, is to be in a state whose typical causal role in connection to preferences and desire is reflected in the class of systems with representations such that
 .
.
Another common objection is that Ramsey’s theorem (and the like) only establishes conditions under which a preference relation behaves as if it’s determined by such-and-such beliefs and desires combined according to the expected utility rule – it doesn’t guarantee that the agent really has those beliefs and desires (cf. Reference ZyndaZynda 2000; Reference ChristensenChristensen 2001; Reference Eriksson and HájekEriksson & Hájek 2007; Reference Meacham and WeisbergMeacham & Weisberg 2011). The observation is correct, of course, just as it would also be correct to say that a representation theorem for the conjoint measurement of momentum as determined by mass and velocity only supplies conditions under which momentum behaves as if it’s determined by mass and velocity. But so what? If the point of a decision-theoretic representation theorem were to show that an agent whose preferences satisfy the axioms must therefore have the beliefs and desires they are represented as having, then it would be safe to say that no such theorem has ever succeeded in that task. It’s not the sort of thing they can show. Lucky, then, that this isn’t the only way to interpret Theorem 24!
A much more fruitful interpretation is in terms of measurement. The aptness of the conjoint representation is presupposed as part of the theoretical background on which the account of measurement is founded, not magically derived from the representation theorem. Reference Ramsey and BraithwaiteRamsey (1931) knew this:
I propose to take as a basis a general psychological theory, which … comes, I think, fairly close to the truth in the sorts of cases with which we are most concerned. I mean the theory that we act in the way we think most likely to realize the objects of our desires, so that a person’s actions are completely determined by his desires and opinions.
What Ramsey’s theorem supplies is an explanation of the quantitation of belief and desire in the context of that model of decision-making. There’s nothing unusual about this – the quantitation of any quantity is always explained against a backdrop of theoretical models and presuppositions.
So we shouldn’t be worried about that objection. However, a natural followup concern is that the expected utility model of decision making is unrealistic – and if that’s the case, then the qualitative systems these models represent may fail to capture any explanatorily relevant relations at all. Addressing this concern will take a little more work, since the response depends on where the lack of realism originates. There are two main sources, which I’ll discuss in turn.
The first is the extremely precise nature of the numerical representation – it involves real-valued degrees of belief and desire, combined with perfect consistency according to a precise decision rule. To achieve such a precise representation, we require strong assumptions about the richness of the domain over which the preferences are defined and about the structure of the preferences over that domain. That’s hardly surprising – infinite precision is a strong property for a representation to have. For the same reason, I do not think we should be too concerned with any lack of realism arising from this source. Such is an inevitable consequence of trying to model a squishy psychological system in a rigid numerical framework, and any feasible theory of belief measurement needs to allow for some idealisations that make the topic tractable. It’s enough if the systems we characterise are in the ballpark of realism. More importantly, it’s usually possible to isolate and weaken or remove the axioms (or parts of the axioms) that are required in fixing the precision of the representation, if we’re willing to accept somewhat weaker uniqueness conditions as a result.
I said ‘somewhat weaker’ for a reason. Critics of decision-theoretic representation theorems tend to write as though failing to establish a unique real-valued belief function is the same as establishing no bounds on degrees of belief at all – as if any lack-of-uniqueness implies radical non-uniqueness. More often, though, one can weaken the very strong axioms required for unique real-valued representation and while still establishing tight bounds on that representation. Consider some examples. I’ve already talked about how the weak order axiom can be replaced with a weaker preorder axiom so as to allow for incompleteness, leading to a representation of ‘imprecise’ beliefs and desires (Section 3.3). So consider instead the extendibility axiom. This (structural) axiom helps us to pinpoint precise degrees of belief by fixing a precise
 -value for some appropriate prospect
-value for some appropriate prospect
 conditional on
conditional on
 ; it does so either by setting that value equal to the desirability of a consequence or equal to the midway point between two consequences. But where extendibility is violated and the required prospects don’t exist, we can still characterise bounds on degrees of belief provided there are
; it does so either by setting that value equal to the desirability of a consequence or equal to the midway point between two consequences. But where extendibility is violated and the required prospects don’t exist, we can still characterise bounds on degrees of belief provided there are
 such that
such that

In this case, the value of
 will be bound like so:
will be bound like so:

More or less the same effect can be achieved if the independence axiom is violated. That axiom requires perfect consistency across how every prospect conditional on
 is evaluated relative to its consequences, which is necessary if
is evaluated relative to its consequences, which is necessary if
 is to be defined as a ratio of differences in real-valued desirabilities. But it’s possible to weaken independence to allow for a bit of fuzziness in the evaluation of prospects, with corresponding fuzziness in the characterisation of
is to be defined as a ratio of differences in real-valued desirabilities. But it’s possible to weaken independence to allow for a bit of fuzziness in the evaluation of prospects, with corresponding fuzziness in the characterisation of
 . Essentially, where the axiom is violated then for every
. Essentially, where the axiom is violated then for every
 there’s still a unique – and potentially very narrow – interval
there’s still a unique – and potentially very narrow – interval
 such that every prospect on
such that every prospect on
 is valued as if
is valued as if
 .
.
In like fashion we can define bounds on the desirabilities of consequences where any or all of trivial gambles, halfway prospects, and/or
 -solvability are violated. In general, the point here is that some of the axioms (or some parts of some axioms) in a decision-theoretic representation theorem primarily serve to ensure a precise numerical representation – and while they tend to be quite unrealistic, it is not so hard to weaken them. The effect of doing so is a little less precision in the numbers obtained, but nothing more substantially affecting the basic explanatory structure being represented. I suspect Reference Ramsey and BraithwaiteRamsey (1931) understood this point well, and was expressing as much when he wrote:
-solvability are violated. In general, the point here is that some of the axioms (or some parts of some axioms) in a decision-theoretic representation theorem primarily serve to ensure a precise numerical representation – and while they tend to be quite unrealistic, it is not so hard to weaken them. The effect of doing so is a little less precision in the numbers obtained, but nothing more substantially affecting the basic explanatory structure being represented. I suspect Reference Ramsey and BraithwaiteRamsey (1931) understood this point well, and was expressing as much when he wrote:
I have not worked out the mathematical logic of this in detail, because this would, I think, be rather like working out to seven places of decimals a result only valid to two.
That, I think, is the right attitude. It’s not realistic to suppose that degrees of belief (and desire) have all the precision of the real numbers. However, we gain some insight into their quantitation by pretending otherwise, and lose nothing of great import in the fiction.
The second source of potential irrealism will be the more fundamental structure of the expected utility model itself – even after accounting for imprecision in degrees of belief and desirability. Perhaps we do not simply evaluate prospects by weighing the values of its consequences against our confidence that those consequences will obtain, but instead also take risk into account in a manner that cannot properly be captured by the expected utility rule (or any ‘equivalent’ decision rule). If so, then again there is a concern that the model fails to capture any explanatorily relevant relations between beliefs and preferences. We’re looking for those relations in the wrong place, because we’ve been presupposing the wrong psychological picture.
We must be a little careful here. Suppose that ordinary decision-makers systematically violate the expected utility rule when evaluating prospects. Still, that rule may serve as a rational ideal, and Theorem 24 may still prove useful in explaining the quantitation of belief by reference to the role one’s beliefs regarding
 ought to play in connection to how they ought to evaluate prospects conditional on
ought to play in connection to how they ought to evaluate prospects conditional on
 . I said earlier that we don’t have to interpret the systematic relationship between belief and preference that explains the conjoint quantitation thereof as a constitutive relation; we don’t have to interpret it as a descriptive relation either. Similarly, an analytic functionalist might say that the expected utility rule captures the essence of folk psychology (a la Reference LewisLewis 1974), and hence a theorem like Ramsey’s can help explain how beliefs are quantitated according to folk psychology. Since it’s no commitment of analytic functionalism that folk psychology provides a perfect descriptive account of decision-making, concerns about the adequacy of expected utility theory are largely irrelevant to this interpretation. The theory is uncontroversially close to the truth in either case, and the analytic functionalist needs nothing stronger than this.
. I said earlier that we don’t have to interpret the systematic relationship between belief and preference that explains the conjoint quantitation thereof as a constitutive relation; we don’t have to interpret it as a descriptive relation either. Similarly, an analytic functionalist might say that the expected utility rule captures the essence of folk psychology (a la Reference LewisLewis 1974), and hence a theorem like Ramsey’s can help explain how beliefs are quantitated according to folk psychology. Since it’s no commitment of analytic functionalism that folk psychology provides a perfect descriptive account of decision-making, concerns about the adequacy of expected utility theory are largely irrelevant to this interpretation. The theory is uncontroversially close to the truth in either case, and the analytic functionalist needs nothing stronger than this.
Still, one may be concerned that the expected utility rule is neither descriptively nor normatively adequate, and may not be satisfied with the analytic functionalist’s interpretation. In that case, we will need a theory of quantitation formulated against the backdrop of some alternative to expected utility theory. Not to worry, for there are many essentially similar theorems for a wide range of these alternatives. The details change, but in outline the general approach to explaining the quantitation of belief remains more or less the same.
Representation theorems for the huge number of non-expected utility theories are too numerous to discuss in detail, but it’s worth looking at one example – Reference Kahneman and TverskyKahneman and Tversky’s (Reference Kahneman and Tversky1979) prospect theory.Footnote 20 I’ll start by describing the theory. We designate a special (non-)consequence the status quo; in the representation, the desirability of the status quo will be fixed at zero, hence we’ll label it ‘0’. We then focus in on ternary prospects of the form ‘
 if
if
 ,
,
 if
if
 , and 0 otherwise’, where
, and 0 otherwise’, where
 and
and
 are mutually exclusive. We assume that degrees of belief are values between zero and one that sum to one for sets of mutually exclusive and jointly exhaustive propositions. Fixing the desirability of the status quo at zero, according to the expected utility rule:
are mutually exclusive. We assume that degrees of belief are values between zero and one that sum to one for sets of mutually exclusive and jointly exhaustive propositions. Fixing the desirability of the status quo at zero, according to the expected utility rule:

In other words, the part of the prospect corresponding to the status quo makes no contribution to the value of the prospect, which is a weighted average of the desirabilities of the remaining consequences. According to prospect theory, however, the weights aren’t given by the agent’s degrees of belief directly. Instead they’re given by a decision weight corresponding to the agent’s beliefs in combination with their attitudes towards risk, where the latter modify the impact the agent’s degrees of belief have on the overall value of a gamble. Where
 and
and
 and
and
 ,
,

For example, suppose
 ,
,
 , and that
, and that
 is halfway between
is halfway between
 and
and
 . According to expected utility theory, the desirability of
. According to expected utility theory, the desirability of
 should be halfway between the desirabilities of
should be halfway between the desirabilities of
 and
and
 , so equal to the desirability of
, so equal to the desirability of
 . However, if
. However, if
 , then according to prospect theory the desirability of
, then according to prospect theory the desirability of
 will be less than that of
will be less than that of
 . In this case, the decision weight reflects a ‘risk averse’ attitude whereby the agent would prefer a guaranteed
. In this case, the decision weight reflects a ‘risk averse’ attitude whereby the agent would prefer a guaranteed
 to a risky prospect with an expected value equal to
to a risky prospect with an expected value equal to
 .
.
For our purposes, the thing to note is the close similarity between the expected utility formula for evaluating
 and prospect theory’s formula for evaluating
and prospect theory’s formula for evaluating
 . Suppose
. Suppose
 ; then in both cases we’re looking for a pair of functions,
; then in both cases we’re looking for a pair of functions,
 and
and
 , such that the value of the prospect is given by
, such that the value of the prospect is given by

The difference between them is that, for expected utility theory,
 is interpreted as the agent’s degrees of belief; whereas for prospect theory
is interpreted as the agent’s degrees of belief; whereas for prospect theory
 is interpreted as a decision weight that reflects the agent’s degrees of belief and their attitudes towards risk.Footnote 21 Thus is it possible, as Reference Kahneman and TverskyKahneman and Tversky observe (Reference Kahneman and Tversky1979, 280), to infer decision weights from preferences over simple prospects in a manner that’s not dissimilar from how we go about inferring degrees of belief in the original Ramseyan approach. Moreover, and with the appropriate additional axioms on preference, those decision weights can in turn be decomposed into a belief function and a risk function (e.g., Reference WakkerWakker 2004).
is interpreted as a decision weight that reflects the agent’s degrees of belief and their attitudes towards risk.Footnote 21 Thus is it possible, as Reference Kahneman and TverskyKahneman and Tversky observe (Reference Kahneman and Tversky1979, 280), to infer decision weights from preferences over simple prospects in a manner that’s not dissimilar from how we go about inferring degrees of belief in the original Ramseyan approach. Moreover, and with the appropriate additional axioms on preference, those decision weights can in turn be decomposed into a belief function and a risk function (e.g., Reference WakkerWakker 2004).
The end result is only a light modification on the Ramseyan theme: the degree of a belief is not quite a measure of the extent to which we are prepared to act on it, but instead a measure of the extent we’re prepared to act on it given our attitudes towards risk. Either way, the meaning of the numerical representation of belief is manifest in the role that representation plays in a decision-theoretic context, and such representations tend to play very much the same kind of role regardless of the precise details of the decision theory in question. Expected utility theory may be unrealistic in some ways, or it may not be, but that doesn’t mean the theory of quantitation we get out of it isn’t fundamentally on the right track.
Martin Peterson
Texas A&M University
Martin Peterson is Professor of Philosophy and Sue and Harry E. Bovay Professor of the History and Ethics of Professional Engineering at Texas A&M University. He is the author of four books and one edited collection, as well as many articles on decision theory, ethics and philosophy of science.
About the Series
This Cambridge Elements series offers an extensive overview of decision theory in its many and varied forms. Distinguished authors provide an up-to-date summary of the results of current research in their fields and give their own take on what they believe are the most significant debates influencing research, drawing original conclusions.

























