


Introduction
Data-intensive science has been described as the “fourth paradigm” for scientific exploration, with the first three being experiments, theory, and simulation.Reference Tolle, Tansley and Hey1 While the value of data-intensive research approaches are becoming more apparent, the field of materials science has not yet experienced the same widespread adoption of these methods (as has occurred in biosciences,Reference Ramsundar, Kearnes, Riley, Webster, Konerding and Pande2 astronomy,Reference Banerji, Lahav, Lintott, Abdalla, Schawinski, Bamford, Andreescu, Murray, Raddick, Slosar, Szalay, Thomas and Vandenberg3 and particle physics4). Nonetheless, the potential impact of data-driven materials science is tremendous: Materials informatics could reduce the typical 10–20 year development and commercialization cycleReference White5 for new materials. We see plentiful opportunities to use data and data science to radically reduce this timeline and generally advance materials research and development (R&D) and manufacturing.
In this article, we discuss the current state of affairs with respect to data and data analytics in the materials community, with a particular emphasis on thorny challenges and promising initiatives that exist in the field. We conclude with a set of near-term recommendations for materials-data stakeholders. Our goal is to demystify data analytics and give readers from any subdiscipline within materials research enough information to understand how informatics techniques could apply to their own workflows.
Challenges surrounding data: The status quo in materials
There are five principal barriers to broader data sharing and large-scale meta-analysis within the field of materials science. This section enumerates and discusses the following barriers in depth: (1) opaque buzzwords in materials informatics, which prevent a typical materials scientist from readily seeing how data-driven methods could apply to their work; (2) idiosyncrasies in individual researchers’ preferred data workflows; (3) a wide variety of stakeholders, who often have conflicting goals, hailing from corresponding diverse research areas; (4) limited availability of structured data and agreed-upon data standards; and (5) a lack of clear incentives to share data.
Proliferation of buzzwords
Like many areas of science, materials informatics is unfortunately hamstrung by the proliferation of buzzwords whose meanings are not clear to researchers in the broader materials community. To a first approximation, machine learning, data mining, and artificial intelligence are roughly interchangeable and refer to the use of algorithms to approximately model patterns in data. Materials informatics, in analogy to bioinformatics, refers to developing an understanding of materials using data and algorithms. Thus, machine learning is a key tool for researchers in the materials informatics domain.
While “big data” has become a fashionable term in the materials informatics and broader materials communities, the reality is that very few materials researchers outside of large user facilities and some specialized communities such as tomography and combinatorial chemistry generate data that meet the traditional “3V’s” big-data definition of high volume, velocity, and variety.Reference Zikopoulos, Eaton, deRoos, Deutsch and Lapis6 Real-world examples of big data include YouTube streaming four billion hours of video per month (which is over six exabytes, or six billion gigabytes, at 1080p resolution), and Twitter receiving about half a million tweets per minute during the Brazil–Germany soccer match in the 2014 World Cup. To give a contrasting example from materials science, performing 100,000 density functional simulations to predict the electronic structures of many known crystalline materials—while scientifically very useful—is not the domain of big data. To store all of the meaningful scientific outputs of the simulations would not require more than a few terabytes of storage, which fits easily on a single hard drive (considered low volume); the simulations finish relatively slowly (i.e., low velocity—completed calculations arrive at the rate of a few results per hour, perhaps, and not thousands of results per second); and the output data are all completely uniform (i.e., no variety by definition). YouTube, Twitter, Google, and Facebook deal with big data; most materials researchers do not, although that fact takes nothing away from the unique data challenges facing the materials community.
We also wish to draw a clear distinction between computational materials science and materials informatics. The former generally refers to using physics-based tools, such as density functional theory (DFT), molecular dynamics, or phase-field simulations, to model behavior of materials. In contrast, models developed by materials informatics are data based, not physics based (i.e., there is no underlying governing equation, such as the Schrödinger equation), nor is informatics specific to “computational” researchers. For example, experimentalists performing tomographic or high-throughput x-ray diffraction studies generate tremendous quantities of data and may thus turn to algorithmic approaches to process and understand these data at scale. We would designate such activities as materials informatics.
Finally, many researchers, especially those who study structural metals, may be familiar with the subdiscipline of computational materials science called integrated computational materials engineering (ICME).Reference Allison, Backman and Christodoulou7 This framework involves connecting physics-based models at various length scales (e.g., atomistic simulation, dislocation modeling, thermodynamic modeling, continuum modeling) to predictively model alloy systems. Materials informatics can complement ICME in two ways: (1) by predictively supplying key materials property parameters for underlying ICME models, if those parameters are not known a priori; and (2) by integrating the outputs of an ICME workflow into higher-level machine learning-based models of materials behavior.
Idiosyncratic data workflows
Data workflows in materials vary considerably and depend on a number of factors, such as specific research focus, data-acquisition techniques, and individual researcher’s personal preferences. While materials researchers have long been producing a wealth of knowledge relating to the processing–structure–properties–performance relationships of materials, this information is generated, analyzed, and disseminated in such a wide variety of ways that researchers face tremendous difficulties in reusing and repurposing others’ data. We have found in the course of software usability interviews with materials researchers at universities and companies that virtually every individual makes a unique set of choices among characterization or simulation tools, data warehousing methods, data analysis methods, and data reporting avenues. This fragmentation among workflows makes centralization and standardization of materials data far more challenging; we visualize the situation in Figure 1.

Figure 1. Flowchart illustrating only a fraction of the tremendous variety in how materials researchers generate, manipulate, write about, distribute, and discover data. Note: USB, universal serial bus; PC, personal computer.
Wide variety of stakeholders and research areas
Materials science is a broad and interdisciplinary field in which progress emerges from complex interactions between producers of data (i.e., researchers at universities, government labs, and industry), funding agencies, makers of equipment and software, and distributors of research results (often journal publishers). These stakeholders are all instrumental in the materials field, but often do not share aligned incentives when it comes to making materials data broadly available.
For example, researchers may wish to keep particularly exciting results private for extended periods to avoid the risk of others publishing those results, and they even withhold negative results from publication altogether; industrial researchers generally withhold their most interesting results as trade secrets; characterization equipment-makers often design proprietary data formats in an effort to differentiate their tools through software; and publishers have the incentive to generate revenue from controlling access to materials publications and data, for example, by offering for-pay databases.8,9 Figure 2 lists some of the stakeholders in the materials-data landscape, broken down by category.
Figure 2. A partial list of the hundreds of organizations that all play important roles in the generation, distribution, and storage of materials data. Note: AFLOW, Automatic-FLOW for Materials Discovery; APS, American Physical Society; ACS, American Chemical Society; MRS, Materials Research Society; TMS, The Minerals, Metals and Materials Society; ASM, American Society for Metals; NIMS, National Institute for Materials Science; ICSD, Inorganic Crystal Structure Database; AFLOWLIB, Repository associated with the AFLOW project.
Data decentralization, limited access to structured data, and missing data standards
Decentralization
The substantial diversity among subdisciplines within materials science and engineering is often cited as a reason why a unified data infrastructure for materials research is impractical; instead, the community will be forced to adopt a federated system of smaller databases.Reference Bhat, Bartolo, Kattner, Campbell and Elliott10 One can make the counterargument, however, that enabling cross-pollination among different areas of materials and creating a “one-stop-shop,” comprehensive data clearinghouse is crucial to the advancement of materials research, and hence, we should focus on building such a system in spite of the inherent challenges of doing so. The National Institute of Standards and Technology (NIST) Materials Data Curation System11 and Citrine Informatics’ Citrination platform12 are two such very broad materials-data infrastructures whose goal is to structure and store a wide variety of materials research data.
The current materials data landscape is a highly fragmented patchwork quilt of smaller databases, each customized to present information from a specific subdiscipline. We have created an extensive, yet inevitably incomplete, list of materials-data resources (see Table I).
Table I. A list of some notable materials-data resources.
Note: AFLOWLIB, Automatic-FLOW for Materials Discovery; AIST, National Institute of Advanced Industrial Science and Technology (Japan); ASM, American Society for Metals; CALPHAD, CALculation of PHAse Diagrams; SGTE, Scientific Group Thermodata Europe; CINDAS, Center for Information and Numerical Data Analysis and Synthesis; CRC, Chemical Rubber Company; DOE, US Department of Energy; CES, Cambridge Engineering Selector; NIMS, National Institute for Materials Science; NIST, National Institute of Standards and Technology; KIM, Knowledge Database of Interatomic Models; UCSB MRL, University of California, Santa Barbara Materials Research Laboratory.
Limited access to structured data
The vast majority of materials-data resources available today are optimized for “low-throughput” human consumption (e.g., via a graphical interface). Modern data analytics techniques, however, rely on systematic computational access to very large stores of data through an application programming interface (API).Reference Taylor, Rose, Toher, Levy, Yang, Nardelli and Curtarolo13,Reference Ong, Cholia, Jain, Brafman, Gunter, Ceder and Persson14 While systematic access to large data sets is widespread (e.g., the genomics community),15 the current status quo in materials data is fundamentally incompatible with state-of-the-art methods of computationally extracting insights from data. In Table I, we note that the vast majority of data resources are not bulk downloadable, which essentially renders them unavailable to data analytics unless they are first scraped or extracted by other software methods. For example, the Inorganic Crystal Structure Database (ICSD)Reference Belkly, Helderman, Karen and Ulkch16 is an invaluable, authoritative collection of crystallographic data on tens of thousands of materials; because it is not bulk downloadable, however, researchers face significant barriers to analyzing its contents in aggregate.
Missing data standards
Data standards are another key to revolutionizing the materials data landscape. Data decentralization in materials has led to a wide variety of choices in terms of data storage techniques. Most of the data resources in Table I employ idiosyncratic data formats under the hood, and the materials community has few widely adopted data standards (the Crystallographic Information File, or CIF, is a notable exception; it is the gold standard for representing crystal structure data).Reference Hall, Allen and Brown17 There are general repositories, such as Dryad and Figshare, that store data from a large number of unrelated scientific fields.18,19 Repositories such as these allow data to be uploaded in any format. While this broadens public access to raw scientific data, it does not necessarily facilitate reuse and analytics, as the information is often formatted in such a way that other researchers would have tremendous difficulty interpreting it.
The lack of data standards in materials greatly complicates the task of gaining useful insight from large-scale materials data. Flexible, uniform, computer-readable data standards should be established to enable data to be shared and systematically mined. Task forces and working groups have been convened to address this issue, but achieving broad agreement on data standards among diverse stakeholders has proven challenging. Citrine Informatics is working to nucleate grassroots support for a flexible JavaScript Object Notation (JSON)-based materials-data format20 that provides a semistructured means to represent a wide range of materials data, but success with this initiative will depend strongly on uptake by the materials community at large. We provide a more detailed overview of some existing standards in our recommendations for key next steps. Here, we simply note that organizations such as IEEE and W3C are potential hardware, software, and Internet-focused models for promulgating data standards in materials.
Lack of incentives
The typical materials researcher today experiences minimal incentive for sharing data. Other research communities, such as biological sciences and astronomy, are often used as exemplars of data-dissemination practices; however, these groups have unique sets of data sharing requirements, norms, and incentives that may not directly transfer to materials.Reference Borgman21 In the materials community specifically, it is not clear that making one’s research data broadly available will lead to any of the following: (1) enhanced impact and more citations for one’s work; (2) improved funding opportunities; or (3) improved chances at professional advancement and promotion. The National Science Foundation (NSF) and US Department of Energy (DOE) are two major funding agencies that now require a data management plan for funded research,22,23 though it is not clear what the consequences might be for researchers who do not make a good-faith effort to deliver on these plans. Going forward, it will be vital for funding agencies and journal publishers to encourage data sharing by rewarding researchers who offer their data to the community or by prescribing data warehousing practices as does the National Institutes of Health and many biological sciences journals.
Not only does the materials community lack incentives for data sharing, it also lacks an obvious forcing function that necessitates a culture of structured data access and advanced analytics. In genomics, for example, the volumes of data produced even in routine laboratory experiments are so great that data-driven approaches are essential in the field. In contrast, many materials science and engineering researchers have been able to continue using traditional “small data” generation and analysis approaches, in spite of the potential advantages of harnessing large-scale data analytics techniques to inform research in many sub-fields.
The situation is gradually changing. We believe that researchers who adopt data standards and make their research widely available via data repositories will win in several important ways by: (1) getting ahead of competitors by integrating machine learning and data analytics in their workflows; (2) making their research more discoverable—on the Citrine Informatics’ Citrination materials data platform, for example, a highly accessed data set from the Open Quantum Materials DatabaseReference Saal, Kirklin, Aykol, Meredig and Wolverton24 can attract 50–100 views per week (see Figure 3), comparable engagement to a high-profile paper in a reputed journal two to three months after publication; and (3) saving time in finding and analyzing data by taking advantage of automation and software. McKinsey estimated that knowledge workers, which include materials scientists, spend about 20% of their time looking for information;Reference Chui, Manyika, Bughin, Dobbs, Roxburgh, Sarrazin, Sands and Westergren25 establishing a materials data infrastructure can help reduce this overhead time burden.
Figure 3. Access statistics (page views/month) for the Open Quantum Materials Database (OQMD) paper after it appeared on the Citrination platform. The spike in August 2015 resulted from Google indexing the OQMD data set on Citrination.
New thinking around materials data
Having outlined the very real barriers facing widespread adoption of data-driven materials science, we now take a more encouraging tone: the data status quo in materials science is changing for the better. Specifically, more data and research outputs are becoming available as open-access content; funding agencies are acknowledging meta-analyses of data as key to progress in materials research; several notable projects have emerged to unite software, data, and web infrastructure for the benefit of the materials community; and industrial stakeholders are beginning to recognize that a pressing need exists for open manufacturing data.
Open-access movement
The open-access (OA) paradigm, in which readers are able to view and (sometimes) repurpose published research at no cost, is gaining traction as key stakeholders jump on board. More publishers are adopting OA models, and increasing numbers of papers are appearing under a creative commons license, which makes content and data freely available. The Nature Publishing Group, for example, launched the journal Scientific Data in 2014, which is OA and dedicated specifically to redistributing important scientific data sets. Unfortunately, among the journal’s 60+ recommended repositories, fewer than five are dedicated to materials and chemical data, illustrating just how badly materials is lagging other disciplines in terms of data warehousing. By contrast, the biological sciences have over 40 approved repositories across subdomains ranging from omics to taxonomy.
Governments around the world are intensifying their efforts to make research data more widely available. In the United Kingdom, the Royal Society has outlined recommendations that address the issues surrounding data sharing within the scientific community. They believe research data should be accessible, intelligible, assessable, and usable.26 The United Kingdom and Ireland have also committed to improve copyright law to facilitate text and data mining (TDM), as they recognize it as an important technique for extracting insight from existing data.27 In June 2014, the UK parliament passed a law that allows TDM of copyrighted materials for noncommercial purposes, as long as sufficient reference is made to the original work. The US White House’s Office of Science and Technology Policy in 2013 directed national research agencies to prepare to make federally funded research outputs publicly accessible, and since 2012, the European Commission has been pushing for broader access to government-funded research. Thus, many agencies directly involved in financing the research enterprise are advancing initiatives to encourage wider dissemination of scientific data.
Data as a critical materials R&D enabler
Data-intensive approaches are proving to be valuable for materials discovery, reducing the time needed to search for new materials with desirable properties by shortlisting promising candidates. Recently, stakeholders have shown an interest in promoting activities that encourage the use of modern data-centric approaches to solve materials problems.Reference Holdren28,29 One notable example is the US Materials Genome Initiative (MGI), launched in 2011, to accelerate materials development and commercialization.Reference Kalil and Wadia30–Reference Simon, Kim, Gomez-Gualdron, Camp, Chung, Martin, Mercado, Deem, Gunter, Haranczyk, Sholl, Snurr and Smit32 Specifically, the MGI aims to halve the time and money needed to shepherd novel materials from the laboratory to widespread commercial deployment. In a similar vein, in 2015, the US Air Force Research Laboratory, NIST, and NSF launched a Materials Science and Engineering Data Challenge to encourage the use of publicly available data to discover or model new material properties.29 The purpose of this challenge is to demonstrate that researchers can extract entirely novel insights from already-published materials data sets; the challenge submission period ended in March 2016, and the winners will present their results at the Materials Science and Technology 2016 Conference in Salt Lake City.
Using data to scale from the laboratory to manufacturing
The goal of accelerating materials development and deployment, as expressed by the US MGI, does not end with fundamental materials discovery. Reliably manufacturing those materials at scale is frequently an even greater challenge, and both industry and government see opportunities for data to accelerate materials scale-up to manufacturing. Numerous efforts to address this challenge have emerged, from the Advanced Manufacturing Plan 2.0 report by the President’s Council on Science and Technology33 to the National Network for Manufacturing Innovation (NNMI) funded by several US government agencies.34 While manufacturing broadly has always been a data-intensive endeavor, given that data-historian software has been ubiquitous in the manufacturing environment to log process data for at least two decades, modern analytics can now crunch these data to identify more complex relationships between environmental conditions, processing parameters, product quality, materials wear and lifetime characteristics, and many other metrics. Optimizing these parameters promises to yield more product, at lower cost, using less energy.
While manufacturing faces some of the same challenges as the materials R&D community, it also suffers from a unique and severe constraint: lack of publicly available data. Proprietary data exist in abundance, but many producers of materials carefully guard their manufacturing data as trade secrets; so while the nascent open-access movement grows, the sharing of manufacturing data lags substantially. To combat this, consortia are forming around precompetitive research in efficient, smart manufacturing. Three examples of these are the Smart Manufacturing Leadership Coalition at the University of Texas, the Digital Manufacturing node of the NNMI system, and the recent call for proposals for a Manufacturing Innovation Institute on Smart Manufacturing.35–37 Critically, each of these includes substantial industrial involvement and sponsorship, ensuring that the tools and methods developed within them are relevant to real-world manufacturing challenges.
Case studies: Demonstrating the potential of materials data and analytics
Materials Project
The Materials ProjectReference Jain, Ong, Hautier, Chen, Richards, Dacek, Cholia, Gunter, Skinner, Ceder and Persson38,39 was instituted at Lawrence Berkeley National Laboratory in 2011 with the goal to create an open, collaborative, and data-rich ecosystem for accelerated materials design. The Project uses high-performance computing within a sophisticated integrated infrastructure comprising an open-source python-based analysis library, pymatgen,Reference Ong, Richards, Jain, Hautier, Kocher, Cholia, Gunter, Chevrier, Persson and Ceder40 a document-based schema-less database, and automated open-source workflow software, Fireworks,Reference Jain, Hautier, Moore, Ong, Fischer, Mueller, Persson and Ceder41,Reference Jain, Ong, Chen, Medasani, Qu, Kocher, Brafman, Petretto, Rignanese, Hautier, Gunter and Persson42 to determine structural, thermodynamic, electronic, and mechanical properties of over 65,000 inorganic compounds by means of high-throughput ab initio calculations. More compounds and properties (e.g., elastic tensors, band structures, dielectric tensors, x-ray diffraction, piezoelectric constants, etc.)Reference de Jong, Chen, Angsten, Jain, Notestine, Gamst, Sluiter, Ande, van der Zwaag, Plata, Toher, Curtarolo, Ceder, Persson and Asta43,Reference de Jong, Chen, Geerlings, Asta and Persson44 are being added on a daily basis. The Materials Project, and related data-driven ab initio screening efforts, have led to a number of advances in energy materials discovery.Reference Jain, Shin and Persson45
A series of web applications provide users with the capability to perform advanced searches and useful analyses (e.g., phase diagrams, reaction-energy computations, band-structure decomposition, novel structure prediction, Pourbaix diagrams).Reference Jain, Ong, Hautier, Chen, Richards, Dacek, Cholia, Gunter, Skinner, Ceder and Persson38,Reference Ong, Richards, Jain, Hautier, Kocher, Cholia, Gunter, Chevrier, Persson and Ceder40,Reference Persson, Waldwick, Lazic and Ceder46 The calculated results and analysis tools are freely disseminated to the public via a searchable online web application, and the data are easily accessed and downloaded through the first implemented Materials Application Programming Interface (Materials API).Reference Ong, Cholia, Jain, Brafman, Gunter, Ceder and Persson14 A high-level interface to the Materials API has been built into the pymatgen analysis library that provides a powerful way for users to programmatically query and analyze large quantities of materials information. While most of the available data are computed and produced in-house, the Project recently launched MPComplete, which allows Project users to submit desired structures to be simulated within DFT and MPContribs,Reference Huck, Gunter, Cholia, Winston, N’Diaye and Persson47,Reference Huck, Jain, Gunter, Winston and Persson48 a software framework within which users may upload external materials data—either computed or measured—and develop apps within the Project’s infrastructure. Today, the Project has more than 18,000 registered users and attracts 300+ distinct users every day to the site, spanning industry, academia, and government.Reference Jain, Ong, Hautier, Chen, Richards, Dacek, Cholia, Gunter, Skinner, Ceder and Persson38
The Open Quantum Materials Database
The Open Quantum Materials Database (OQMD)Reference Saal, Kirklin, Aykol, Meredig and Wolverton24,Reference Kirklin, Saal, Meredig, Thompson, Doak, Aykol, Rühl and Wolverton49 is a high-throughput database currently consisting of ∼400,000 DFT total energy calculations of compounds from the ICSD and decorations of commonly occurring crystal structures. OQMD is open (without restrictions) and is online.50,51 Users can (1) search for materials by composition, (2) create phase diagrams (T = 0K), (3) determine ground-state compositions, (4) determine whether equilibrium (any two-phase tie line) exists between any two phases, (5) visualize crystal structures, or (6) download the entire database for their own use. The OQMD has been used to perform high-throughput computational screening of many types of materials, such as structural metal alloys,Reference Kirklin, Saal, Hegde and Wolverton52 Li battery materials,Reference Kirklin, Meredig and Wolverton53 and high-efficiency nanostructured thermoelectrics.Reference Zhao, Hao, Lo, Wu, Zhou, Lee, Li, Biswas, Hogan, Uher, Wolverton, Dravid and Kanatzidis54 Much of the software and tooling surrounding the OQMD is open source and available for anyone to use and build upon.
Expert-led database building from literature
The practice and effectiveness of aggregation of experimental data is exemplified in two widely used databases of crystal structures. The ICSD, hosted by the Fachinformationszentrum (FIZ) Karlsruhe in Germany contains over 180,000 entries on the crystal structures of minerals, metals, and other extended solid–inorganic compounds.Reference Belkly, Helderman, Karen and Ulkch16 The older Cambridge Crystallography Data Centre in the United Kingdom compiles and distributes the Cambridge Structural Database (CSD), a repository of experimentally determined organic and metal–organic crystal structures that currently exceeds 800,000 entries.Reference Allen55 Both of these databases owe their success to some combination of early and widespread adoption, encouragement from journal publishers, and the clarity and utility of the .cif crystal structure format.Reference Hall, Allen and Brown17,Reference Brown and McMahon56 A third example of a careful and useful compilation of structural data is the Protein DataBank.Reference Berman57 In materials science, the recent proliferation of computationally generated databases of materials structures and some of their computed properties have all been rooted in the ICSD.
Similar searchable online databases of materials properties, particularly those related to functional materials, are not as readily available. For example, no repository exists even for something as simple as the magnetic or ferroic ordering temperatures of inorganic compounds. Perhaps the resource that comes closest to what is required is the Landolt–Börnstein handbook series, which dates to the late 19th century and is now available electronically at the for-pay SpringerMaterials database.
Going forward, it is clear that the impetus for the creation of such databases must be associated with journal-mandated requirements for the deposition of relevant property data, appropriately curated and formatted, in precisely the same manner that is mandated for crystal structure information. Recognizing the need and utility of such databases, there have been recent attempts to physically mine the literature to better understand the landscape of thermoelectric materialsReference Gaultois, Sparks, Borg, Seshadri, Bonificio and Clarke58 and lithium- and lithium-ion-battery materials (Figure 4).Reference Sparks, Ghadbeigi, Harada and Lettiere59 The process involves gathering appropriate publications, deciding the key data in the publications, and then employing a combination of students and postdoctoral fellows to perform data extractions. Quantitative experimental and simulation results reported in publications must be physically entered into a text file, frequently through the process of manually digitizing plots in the publications by using freeware tools such as DataThief. At this stage, metadata such as the unit-cell volume of the compound being measured, the elemental abundance of the constituents, or the preparation method are also entered. Finally, the text file is read into web-based visualization suites using software such as HighCharts, which is freely available for use to academic, not-for-profit entities.
Figure 4. Screenshot of a battery data-mining resource,Reference Ghadbeigi, Harada, Lettiere and Sparks72 displaying the average potential of the electrode as a function of the calculated discharge capacity after the 25th cycle. Such visualizations make it easier for materials scientists to identify important patterns in very large data sets. The symbol size is proportional to the percentage capacity that is retained after 25 cycles (larger is better), and the color indicates the crystal structure type of the active electrode material. Hovering the mouse over data points allows metadata to be read, and clicking on the points takes the reader to the original literature.73 For thermoelectrics, see Reference 71. Note: CB, carbon black; PVDF&DMP, poly(vinylidene fluoride) & dimethyl phthalate; EC, ethylene carbonate; DMC, dimethyl carbonate; C, charge rate.
The data, once available for visualization, can be highly useful for further prediction,Reference Gaultois and Sparks60 including through machine learning.Reference Sparks, Gaultois, Oliynyk, Brgoch and Meredig61 The insight that can be gained simply by looking at the data, appropriately plotted, cannot be overstated. As an example, the previous exercise as applied to thermoelectric materials quickly illustrates the large regions of parameter space where searching for new high-performing materials would be futile.
Citrination materials-data analytics platform
Citrination12 is a materials data platform that extracts new insights from large-scale materials data. The platform ingests messy materials data sources, such as papers, patents, or existing databases, and extracts clean, structured facts from these files (e.g., 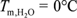 ${T_{m,{H_2}O}} = 0^\circ C$, where
${T_{m,{H_2}O}} = 0^\circ C$, where 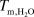 ${T_{m,{H_2}O}}$ is the melting temperature of water). The resulting data can be used to train machine learning models of materials behavior, which Citrine deploys as web apps to accelerate R&D, manufacturing, and sales efforts in the materials industry. Citrination also represents one of the world’s largest collections of completely free and open materials data, usable by any researcher worldwide, with over three million records and counting.12,62,63
${T_{m,{H_2}O}}$ is the melting temperature of water). The resulting data can be used to train machine learning models of materials behavior, which Citrine deploys as web apps to accelerate R&D, manufacturing, and sales efforts in the materials industry. Citrination also represents one of the world’s largest collections of completely free and open materials data, usable by any researcher worldwide, with over three million records and counting.12,62,63
Two forms of data exist within Citrination: (1) structured data, which contain clearly defined and formatted data points, and (2) unstructured data, which include images, PDFs, and documents in other formats. The data represent a collection of information from a wide variety of sources, both experimental and computational, and have been added either by the company or by the site’s users themselves. The platform supports a wide variety of materials metadata, using an underlying hierarchical data standard. This makes it easy for data to be understood, evaluated, and cited. The structured data is searchable and can be programmatically accessed using the site’s API. Thus, Citrination makes it easier for researchers to access and analyze materials data at a scale that has not been previously possible.
Key next steps
Nucleation around data standards
The amount of data in the materials community, as in many other areas of science and human endeavor, is increasing exponentially, making data management an urgent priority. To enable seamless data sharing and increase the usability of published data, data standards are required. Historically, efforts to create standards for materials data storage have focused on XML schemas. Over a decade ago, NIST developed MatML for storing materials data.Reference Sturrock, Begley and Kaufman64 Other examples of XML schema, developed specifically for materials data storage, are MatDB and NMC-MatDB.Reference Austin and Over65 However, none of these has achieved wide adoption in the field.Reference Zhang, Zhao and Wang66 We hypothesize that the greatest barrier to adoption to any proposed new data standard is that users do not see the value in adopting a standard that is not already widespread. “Seeding” a new data standard with a large quantity of useful materials data could help mitigate this problem.
JSON67 has emerged alongside XML as a preferred file format for hierarchical data formatting, and JSON is now used for asynchronous browser/server communication among other applications. The JSON format is similar to XML in many ways and provides good flexibility in terms of the scope of data that can be structured in this format. Most modern computer programming languages provide native parsing and generation of JSON files. This makes it a good candidate to be used to store materials data of varying types and for various purposes. The Materials Information File (MIF) is an open JSON-based file format, created by Citrine Informatics, to store diverse materials data ranging from standard entropy curves to x-ray diffraction patterns to DFT simulation outputs.20 A number of key objects have already been defined to encompass common materials concepts (e.g., materials, measurements, phases, phase diagrams), and new objects can be readily created as needed.20 The MIF format can thus evolve to accommodate materials data from every subdiscipline of materials. With this potential flexibility and ability to store various types of data, Citrine’s goal is to build broad support for the MIF as a data standard within the materials community, and has been tackling the data standards problem by generating millions of MIF records and making them publicly available.
Data consolidation
Given the inherently diverse nature of materials data, consolidation is a major challenge. At present, most data repositories focus on a specific subset of materials data, and while this allows them to specialize, it means that it is often difficult to extract value across numerous data resources. In addition, different repositories structure data idiosyncratically, and the ease of access is highly variable; a single unified infrastructure would greatly streamline data analysis.
Data-intensive visualization
Data visualization is a key research activity that conveys information efficiently. Visualizations assist with highlighting patterns within data and identifying useful and important trends. Some classic examples of materials-related visualizations are Ashby plots, relating density and modulus across classes of materials, and Pettifor mapsReference Pettifor68 of intermetallic crystal structures. We believe that improved systematic access to materials data will dramatically enhance the community’s ability to generate such information-rich visualizations. Figure 5 illustrates how a Python script can be used to programmatically generate an Ashby plot using public data from the Citrination platform.
Figure 5. An Ashby plot auto-generated using structured data accessed via the Citrination API. Programmatic data access allows for the construction of key materials data visualizations, such as Ashby plots, without tens of hours of manual data entry. Note: AISI, American Iron and Steel Institute; GFRP, glass-fiber-reinforced plastic; CFRP, carbon-fiber-reinforced plastic.
Better software
Generally, materials informatics is only accessible to those who have deep experience in computer programming and data science. This is because the most currently available informatics tools rely on some degree of programming ability to analyze and manipulate data. As there are many materials scientists without such a background, it is vital that materials informatics are democratized in order to allow widespread access to the benefits of large-scale materials data analysis. For this to become a reality, software must be developed that will be intuitive and easy to use for materials experts who do not also possess training in computer science or data science. Such a goal requires the development of sophisticated user interfaces that expose the power of materials data without miring the user in jargon, arcane tuning parameters, or unfamiliar syntax. Such tools are just now emerging for widespread consumption by the materials community; examples include Citrine’s thermoelectric materials recommendation engine,Reference Sparks, Gaultois, Oliynyk, Brgoch and Meredig61,Reference Gaultois, Oliynyk, Mar, Sparks, Mulholland and Meredig69 Materials Project’s Pourbaix diagram generator,Reference Persson, Waldwick, Lazic and Ceder46 OQMD’s grand canonical linear programming-basedReference Akbarzadeh, Ozoliņš and Wolverton70 phase stability evaluator, and the University of California, Santa Barbara Materials Research Laboratory and The University of Utah’s thermoelectric data visualizer.Reference Gaultois, Sparks, Borg, Seshadri, Bonificio and Clarke58
Summary
This article discusses the challenges and opportunities associated with data-intensive materials research. With respect to its integration of large-scale data analysis, materials science lags behind other scientific disciplines; however, the situation is rapidly changing for the better. In particular, funding agencies, journal publishers, industry, government labs, and university researchers are aligning to make materials research data more accessible and useful to the community. We highlighted four specific efforts within the materials research community—Materials Project,39 Open Quantum Materials Database,50 expert database curation at the University of California, Santa Barbara and The University of Utah,71 and the Citrination platform—12 all of which involve aggregating, analyzing, or visualizing large quantities of materials research data at no cost to users. We expect these and related efforts to gather momentum as materials research continues to benefit from broader access to large data sets.
Acknowledgment
K.P. was supported by the Materials Project (Grant # EDCBEE), supported by the US Department of Energy Office of Science, Office of Basic Energy Sciences Department under Contract No. DE-AC02-05CH11231. R.S. thanks the National Science Foundation for support of this research through NSF-DMR 1121053 (MRSEC). C.W. gratefully acknowledges funding support from DOC NIST award 70NANB14H012 (CHiMaD).
Joanne Hill studied chemistry and materials science at the University of Cape Town, South Africa. She now works as a data engineer at Citrine Informatics, focusing on automated data extraction and ingestion with the goal of making materials data more accessible and useful to everyone. Hill can be reached by email at jo@citrine.io.
Gregory Mulholland is the Chief Operating Officer at Citrine Informatics, the data platform for the physical world. He works with partners along the materials value chain to use state-of-the-art data science techniques to accelerate advanced materials discovery and deployment. He earned an MBA degree from Stanford University’s Graduate School of Business, MPhil degree in materials science from the University of Cambridge, and a BS degree in electrical and computer engineering from North Carolina State University. Mulholland can be reached by email at greg@citrine.io.
Kristin Persson studies the physics and chemistry of materials using atomistic computational methods and high-performance computing technology, particularly for clean-energy production and storage applications. She is director of the Materials Project at Lawrence Berkeley National Laboratory, a multi-institution, multinational effort to compute the properties of all inorganic materials and provide the data and associated analysis algorithms to researchers free of charge. This project has been used to design novel photocatalysts, multivalent battery electrode materials, Li-ion battery electrode materials, and electrolytes for beyond-Li energy storage solutions. Persson can be reached by email at kapersson@lbl.gov.
Ram Seshadri is a professor in the Department of Chemistry and Biochemistry at the University of California, Santa Barbara (UCSB), and director of the UCSB Materials Research Laboratory: an NSF MRSEC. His group is active in the area of functional materials for energy conversion and storage, in addition to researching fundamental aspects of electronic, magnetic, and polar materials. He is also interested in materials education and outreach. Seshadri can be reached by email at seshadri@mrl.ucsb.edu.
Christopher Wolverton is a professor of materials science and engineering at Northwestern University. Before joining the faculty, he worked at the Research and Innovation Center at Ford Motor Company, where he was group leader for the Hydrogen Storage and Nanoscale Modeling Group. His research interests include computational studies of a variety of energy-efficient and environmentally friendly materials via first-principles atomistic calculations, high-throughput and data mining tools to accelerate materials discovery, and “multiscale” methodologies for linking atomistic and microstructural scales. Wolverton can be reached by email at c-wolverton@northwestern.edu.
Bryce Meredig is a co-founder and the Chief Executive Officer of Citrine Informatics. His goal is to build software that enables every materials researcher to harness the world’s entire corpus of materials data to accelerate their work. He earned a PhD degree in materials science from Northwestern University, an MBA degree from Stanford University, and a BAS degree in materials science and German from Stanford University. In addition to his role at Citrine, he is a consulting assistant professor of materials science at Stanford University. Meredig can be reached by email at bryce@citrine.io.

