


1. Introduction
Coreference resolution (Sukthanker et al. Reference Sukthanker, Poria, Cambria and Thirunavukarasu2020) is the task of identifying and clustering mentions in a document that refer to the same entity. Coreference resolution has important applications in areas such as question answering and relation extraction. Traditional coreference resolution models (Popescu-Belis, Reference Popescu-Belis2003; Raghunathan et al. Reference Raghunathan, Lee, Rangarajan, Chambers, Surdeanu, Jurafsky and Manning2010; Durrett and Klein, Reference Durrett and Klein2013; Wiseman, Rush, and Shieber, Reference Wiseman, Rush and Shieber2016; Clark and Manning, Reference Clark and Manning2016a, Reference Clark and Manning2016b) work in a pipelined fashion. They usually process the task in two stages: mention detection and coreference resolution. Mention detection identifies the entity mentions in a document; coreference resolution clusters mentions that refer to the same entity. At both stages, syntactic parsers are relied on to build complicated hand-engineered features. Consequently, traditional pipelines suffer from cascading errors and are difficult to generalize to new datasets and languages (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b).
To overcome the shortcomings of pipeline models, Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b) proposed the first end-to-end model that tackles mention detection and coreference resolution simultaneously. They consider all spans as mention candidates and use two scoring functions to learn which spans are entity mentions and which are their coreferential antecedents. The training objective is to optimize the marginal log-likelihood of all correct antecedents implied by the gold-standard clustering. To control model complexity, they use a unary mention scoring function to prune the space of spans and antecedents and a pairwise antecedent scoring function to compute the softmax distribution over antecedents for each span. Both scoring functions are simple feed-forward neural networks, and the inputs to both scoring functions are the learned span embeddings. Thus, the core of end-to-end neural coreference resolution models is the learning of span embeddings. A bi-directional LSTM was used to generate the embedded representations of spans (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b; Zhang et al. Reference Zhang, Nogueira dos Santos, Yasunaga, Xiang and Radev2018).
The aforementioned end-to-end coreference resolution model (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b) is a “first-order” model that only considers local context and does not directly incorporate any information about the entities to which the spans might refer. Thus, first-order models may suffer from consistency errors. Higher-order inference (HOI) methods were therefore proposed to incorporate some document-level information. Most such HOI methods, such as Attended Antecedent (AA) (Lee, He, and Zettlemoyer, Reference Lee, He and Zettlemoyer2018; Joshi et al. Reference Joshi, Levy, Zettlemoyer and Weld2019, Reference Kantor and Globerson2020), Entity Equalization (Kantor and Globerson, Reference Kantor and Globerson2019), and Span Clustering (Xu and Choi, Reference Xu and Choi2020), are based on span refinement. These methods iteratively refine span embeddings using global context from the other spans. Following the success of contextualized representations, ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018; Lee et al., Reference Lee, He and Zettlemoyer2018), BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019; Joshi et al. Reference Joshi, Levy, Zettlemoyer and Weld2019; Kantor and Globerson, Reference Kantor and Globerson2019), and SpanBERT (Joshi et al. Reference Joshi, Chen, Liu, Weld, Zettlemoyer and Levy2020) have been used to build span embeddings for higher-order models.
This research is motivated by the following three recent findings: (i) It was shown that HOI methods have marginal or even negative impact on coreference resolution (Xu and Choi, Reference Xu and Choi2020), but the reason is not clear. (ii) Contextualized representations have recently been shown to be anisotropic (i.e., not directionally uniform in the vector space) (Ethayarajh, Reference Ethayarajh2019), especially the representations in the topmost layer. (iii) It has been found that isotropy is beneficial and that less-anisotropic embeddings could lead to large improvements on downstream NLP tasks (Mu, Bhat, and Viswanath, Reference Mu, Bhat and Viswanath2018; Ethayarajh, Reference Ethayarajh2019).
In this paper, we reveal the reasons for the negative impact of HOI on coreference resolution. We show that HOI actually increases and thus worsens the anisotropy (i.e., lack of directional uniformity) of span embeddings and makes it difficult to distinguish between related but distinct entities (e.g., pilots and flight attendants). We propose two methods, Less-Anisotropic Internal Representations (LAIR) and Data Augmentation with Document Synthesis and Mention Swap (DSMS), to learn less-anisotropic span embeddings. LAIR uses the linear aggregation of the first layer and the topmost layer of contextualized embeddings. DSMS generates more diversified examples of related but distinct entities by synthesizing documents and mention swap. We conduct comprehensive experiments to understand the reasons behind HOI’s negative impact on end-to-end coreference resolution using various state-of-the-art contextualized representations based span embeddings:
-
1. The discrepancy of HOI impact on ELMo (Lee et al., Reference Lee, He and Zettlemoyer2018; Peters et al., Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), BERT (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019; Joshi et al., Reference Joshi, Levy, Zettlemoyer and Weld2019; Kantor and Globerson, Reference Kantor and Globerson2019), SpanBERT (Joshi et al., Reference Joshi, Chen, Liu, Weld, Zettlemoyer and Levy2020), and ELECTRA (Clark et al. Reference Clark, Luong, Le and Manning2020) can be explained by their degree of anisotropy and contextualization. The span embeddings from SpanBERT and ELECTRA are more anisotropic and are encoded with longer context than ELMo and BERT.
-
2. The span embeddings from SpanBERT and ELECTRA without higher-order refinement are thus less anisotropic and more effective than high-order span embeddings.
-
3. Furthermore, the less-anisotropic span embeddings from SpanBERT and ELECTRA can significantly improve performance. Using LAIR and DSMS, SpanBERT and ELECTRA gained + 0.7 F1 and + 2.8F1 on the OntoNotes benchmark respectively.
-
4. LAIR directly builds less-anisotropic span embeddings and achieves significant improvements over HOI-based methods, while DSMS alone achieves only marginal improvements without the incorporation of LAIR.
2. Background of end-to-end neural coreference resolution
2.1. Task formulation
End-to-end coreference resolution is the state-of-the-art approach based on deep learning. It tackles mention detection and coreference resolution simultaneously by span ranking; thus, it is formulated as a task of assigning antecedents
 $a_i$
for each span
$a_i$
for each span
 $i$
. A possible span candidate is any continuous N-gram within a sentence. The set of possible assignments
$i$
. A possible span candidate is any continuous N-gram within a sentence. The set of possible assignments
 $a_i$
is
$a_i$
is
 $\mathcal{A}_i=\{1,\dots, i-1,\varepsilon \}$
, where
$\mathcal{A}_i=\{1,\dots, i-1,\varepsilon \}$
, where
 $\varepsilon$
is a “dummy” antecedent. If span
$\varepsilon$
is a “dummy” antecedent. If span
 $i$
is assigned to a non-dummy antecedent, span
$i$
is assigned to a non-dummy antecedent, span
 $j$
, then we have
$j$
, then we have
 $a_i = j$
. If span
$a_i = j$
. If span
 $i$
is assigned to a dummy antecedent
$i$
is assigned to a dummy antecedent
 $\varepsilon$
, then it indicates one of two scenarios: (1) span
$\varepsilon$
, then it indicates one of two scenarios: (1) span
 $i$
is not an entity mention; (2) span
$i$
is not an entity mention; (2) span
 $i$
is the first mention of a new entity (cluster). Through transitivity of coreferent antecedents, these assignment decisions induce clusters of entities over the document.
$i$
is the first mention of a new entity (cluster). Through transitivity of coreferent antecedents, these assignment decisions induce clusters of entities over the document.
2.2. First-order coreference resolution
The first-order end-to-end coreference resolution model (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b) independently ranks each pair of spans using a pairwise scoring function
 $s(i,j)$
. These scores are used to compute the antecedent distribution
$s(i,j)$
. These scores are used to compute the antecedent distribution
 $P(a_i)$
for each span
$P(a_i)$
for each span
 $i$
:
$i$
:
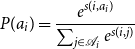 \begin{equation} P(a_i) = \frac{e^{s(i, a_i)}}{\sum _{j \in \mathcal{A}_i} e^{s(i,j)}} \end{equation}
\begin{equation} P(a_i) = \frac{e^{s(i, a_i)}}{\sum _{j \in \mathcal{A}_i} e^{s(i,j)}} \end{equation}
The coreferent score
 $s(i,j)$
for a pair of spans includes three factors: (1)
$s(i,j)$
for a pair of spans includes three factors: (1)
 $s_m(i)$
, the score of span
$s_m(i)$
, the score of span
 $i$
for being a mention, (2)
$i$
for being a mention, (2)
 $s_m(j)$
, the score of span
$s_m(j)$
, the score of span
 $j$
for being a mention, (3)
$j$
for being a mention, (3)
 $s_a(i,j)$
, the score of span
$s_a(i,j)$
, the score of span
 $j$
for being an antecedent of
$j$
for being an antecedent of
 $i$
:
$i$
:
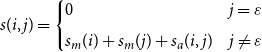 \begin{equation} \begin{aligned} s(i,j)= \begin{cases} 0& j=\varepsilon \\[5pt] s_m(i)+s_m(j)+s_a(i,j) & j \neq \varepsilon \\ \end{cases} \end{aligned} \end{equation}
\begin{equation} \begin{aligned} s(i,j)= \begin{cases} 0& j=\varepsilon \\[5pt] s_m(i)+s_m(j)+s_a(i,j) & j \neq \varepsilon \\ \end{cases} \end{aligned} \end{equation}
The scoring functions
 $s_m$
and
$s_m$
and
 $s_a$
take span representations
$s_a$
take span representations
 $\textbf{g}$
as input:
$\textbf{g}$
as input:
 \begin{equation} \begin{aligned} s_m(i)&=\textbf{w}_m \cdot FFNN_m(\textbf{g}_i) \\[3pt] s_a(i,j)&=\textbf{w}_a \cdot FFNN_a\left(\left[\textbf{g}_i,\textbf{g}_j,\textbf{g}_i \circ \textbf{g}_j,\phi (i,j)\right]\right) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} s_m(i)&=\textbf{w}_m \cdot FFNN_m(\textbf{g}_i) \\[3pt] s_a(i,j)&=\textbf{w}_a \cdot FFNN_a\left(\left[\textbf{g}_i,\textbf{g}_j,\textbf{g}_i \circ \textbf{g}_j,\phi (i,j)\right]\right) \end{aligned} \end{equation}
where
 $ \cdot$
denotes the dot product;
$ \cdot$
denotes the dot product;
 $ \circ$
denotes element-wise multiplication;
$ \circ$
denotes element-wise multiplication;
 $FFNN$
denotes a feed-forward neural network; and
$FFNN$
denotes a feed-forward neural network; and
 $\phi (i,j)$
represents speaker and meta-data features (e.g., genre information and the distance between the two spans).
$\phi (i,j)$
represents speaker and meta-data features (e.g., genre information and the distance between the two spans).
However, it is intractable to score every pair of spans in a document. There are
 $O(W^2)$
spans of potential mentions in a document (
$O(W^2)$
spans of potential mentions in a document (
 $W$
is the number of words). Comparing every pair would be
$W$
is the number of words). Comparing every pair would be
 $O(W^4)$
complexity. Thus, pruning is performed according to the mention scores
$O(W^4)$
complexity. Thus, pruning is performed according to the mention scores
 $s_m(i)$
to reduce the spans that are unlikely to be an entity mention.
$s_m(i)$
to reduce the spans that are unlikely to be an entity mention.
2.3. Higher-order coreference resolution
The first-order coreference resolution model only considers pairs of spans, and does not directly incorporate any information about the entities to which the spans might belong. Thus, first-order models may suffer from consistency errors. HOI methods were proposed to incorporate some document-level information. Span-refinement-based HOI methods, such as AA (Lee et al., Reference Lee, He and Zettlemoyer2018; Joshi et al. Reference Joshi, Levy, Zettlemoyer and Weld2019, Reference Kantor and Globerson2020), Entity Equalization (Kantor and Globerson, Reference Kantor and Globerson2019), and Span Clustering (Xu and Choi, Reference Xu and Choi2020), iteratively refine span embeddings
 $\textbf{g}_i$
using global context. Cluster Merging (Xu and Choi, Reference Xu and Choi2020) is a score-based HOI method. It does not update span embeddings directly, but updates the coreferent scores using a latent cluster score.
$\textbf{g}_i$
using global context. Cluster Merging (Xu and Choi, Reference Xu and Choi2020) is a score-based HOI method. It does not update span embeddings directly, but updates the coreferent scores using a latent cluster score.
AA (Lee et al., Reference Lee, He and Zettlemoyer2018) was the first HOI method. It iteratively refines the span representations
 $\textbf{g}^n_i$
of span
$\textbf{g}^n_i$
of span
 $i$
at the
$i$
at the
 $n$
th iteration, using information from antecedents. The refined span representations are used to compute the refined antecedent distribution
$n$
th iteration, using information from antecedents. The refined span representations are used to compute the refined antecedent distribution
 $P_n(a_i)$
:
$P_n(a_i)$
:
 \begin{equation} P_n(a_i) = \frac{e^{s\left(\textbf{g}_i^n, \textbf{g}^n_{a_i}\right)}}{\sum _{j\in \mathcal{A}_i} e^{s\left(\textbf{g}_i^n, \textbf{g}^n_j\right)}} \end{equation}
\begin{equation} P_n(a_i) = \frac{e^{s\left(\textbf{g}_i^n, \textbf{g}^n_{a_i}\right)}}{\sum _{j\in \mathcal{A}_i} e^{s\left(\textbf{g}_i^n, \textbf{g}^n_j\right)}} \end{equation}
At each iteration, the expected antecedent representation
 $\textbf{a}^n_i$
of each span
$\textbf{a}^n_i$
of each span
 $i$
is computed using the current antecedent distribution
$i$
is computed using the current antecedent distribution
 $P_n(a_i)$
as an attention mechanism:
$P_n(a_i)$
as an attention mechanism:
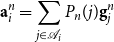 \begin{equation} \textbf{a}_i^n = \sum \limits _{j \in \mathcal{A}_i} P_n(j) \textbf{g}_j^n \end{equation}
\begin{equation} \textbf{a}_i^n = \sum \limits _{j \in \mathcal{A}_i} P_n(j) \textbf{g}_j^n \end{equation}
The current span representation
 $\textbf{g}_i^n$
is then updated via interpolation with its expected antecedent representation
$\textbf{g}_i^n$
is then updated via interpolation with its expected antecedent representation
 $\textbf{a}_i^n$
:
$\textbf{a}_i^n$
:
 \begin{equation} \textbf{g}_i^{n+1} = \textbf{f}_i^n \circ \textbf{g}_i^n + \left(1-\textbf{f}_i^n\right) \circ \textbf{a}_i^n \end{equation}
\begin{equation} \textbf{g}_i^{n+1} = \textbf{f}_i^n \circ \textbf{g}_i^n + \left(1-\textbf{f}_i^n\right) \circ \textbf{a}_i^n \end{equation}
where
 $\textbf{f}_i^n = \sigma \left(\textbf{W}_f\left[ \textbf{g}_i^n, \textbf{a}_i^n\right]\right)$
is a learned gate vector, and
$\textbf{f}_i^n = \sigma \left(\textbf{W}_f\left[ \textbf{g}_i^n, \textbf{a}_i^n\right]\right)$
is a learned gate vector, and
 $\circ$
denotes element-wise multiplication. Thus, the span representation
$\circ$
denotes element-wise multiplication. Thus, the span representation
 $\textbf{g}_i^{n+1}$
at iteration
$\textbf{g}_i^{n+1}$
at iteration
 $n+1$
is an element-wise weighted average of the current span representation
$n+1$
is an element-wise weighted average of the current span representation
 $\textbf{g}_i^n$
and its direct antecedents.
$\textbf{g}_i^n$
and its direct antecedents.
2.4. Building span embeddings from contextualized representations
The core of end-to-end neural coreference resolution is the learning of vectorized representations of text spans. The span representation
 $\textbf{g}_i$
of span
$\textbf{g}_i$
of span
 $i$
is usually the concatenation of four vectors (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b) as follows:
$i$
is usually the concatenation of four vectors (Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b) as follows:
 \begin{equation} \textbf{g}_i=\left[\textbf{g}^*_{START(i)},\textbf{g}^*_{END(i)},\hat{\textbf{g}}_i,\phi (i)\right] \end{equation}
\begin{equation} \textbf{g}_i=\left[\textbf{g}^*_{START(i)},\textbf{g}^*_{END(i)},\hat{\textbf{g}}_i,\phi (i)\right] \end{equation}
where
 $START(i)$
and
$START(i)$
and
 $END(i)$
are the start position and end position of span
$END(i)$
are the start position and end position of span
 $i$
, respectively, Boundary representations
$i$
, respectively, Boundary representations
 $\textbf{g}^*_{START(i)},\textbf{g}^*_{END(i)}$
are the vector representations of word
$\textbf{g}^*_{START(i)},\textbf{g}^*_{END(i)}$
are the vector representations of word
 $START(i)$
and
$START(i)$
and
 $END(i)$
, respectively. Internal representation
$END(i)$
, respectively. Internal representation
 $\hat{\textbf{g}}_i$
is a weighted sum of word vectors in span
$\hat{\textbf{g}}_i$
is a weighted sum of word vectors in span
 $i$
, and
$i$
, and
 $\phi (i)$
is a feature vector encoding the size of span
$\phi (i)$
is a feature vector encoding the size of span
 $i$
.
$i$
.
Assuming the vector representations of each word are
 $\{\textbf{x}_1,\cdots, \textbf{x}_T\}$
(
$\{\textbf{x}_1,\cdots, \textbf{x}_T\}$
(
 $T$
is the length of the document), Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b), Zhang et al. (Reference Zhang, Nogueira dos Santos, Yasunaga, Xiang and Radev2018) and Lee et al. (Reference Lee, He and Zettlemoyer2018) use a bi-directional LSTM to build the first three vectors of the span representation
$T$
is the length of the document), Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b), Zhang et al. (Reference Zhang, Nogueira dos Santos, Yasunaga, Xiang and Radev2018) and Lee et al. (Reference Lee, He and Zettlemoyer2018) use a bi-directional LSTM to build the first three vectors of the span representation
 $\textbf{g}_i$
:
$\textbf{g}_i$
:
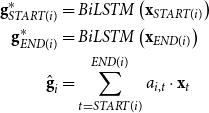 \begin{equation} \begin{aligned} \textbf{g}^*_{START(i)} &= BiLSTM\left(\textbf{x}_{START(i)}\right) \\ \textbf{g}^*_{END(i)} &= BiLSTM\left(\textbf{x}_{END(i)}\right)\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot \textbf{x}_t \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \textbf{g}^*_{START(i)} &= BiLSTM\left(\textbf{x}_{START(i)}\right) \\ \textbf{g}^*_{END(i)} &= BiLSTM\left(\textbf{x}_{END(i)}\right)\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot \textbf{x}_t \end{aligned} \end{equation}
where
 $a_{i,t}$
is a learned weight computed from
$a_{i,t}$
is a learned weight computed from
 $BiLSTM(\textbf{x}_t)$
, and
$BiLSTM(\textbf{x}_t)$
, and
 $\textbf{x}_t$
can be GloVe (Jeffrey Pennington, Socher, and Manning, Reference Pennington, Socher and Manning2014; Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b), ELMo (Lee et al., Reference Lee, He and Zettlemoyer2018; Peters et al., Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), or the concatenation of GloVe and CNN character embeddings (Santos and Zadrozny, Reference Santos and Zadrozny2014; Zhang et al., Reference Zhang, Nogueira dos Santos, Yasunaga, Xiang and Radev2018).
$\textbf{x}_t$
can be GloVe (Jeffrey Pennington, Socher, and Manning, Reference Pennington, Socher and Manning2014; Lee et al. Reference Lee, He, Lewis and Zettlemoyer2017b), ELMo (Lee et al., Reference Lee, He and Zettlemoyer2018; Peters et al., Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), or the concatenation of GloVe and CNN character embeddings (Santos and Zadrozny, Reference Santos and Zadrozny2014; Zhang et al., Reference Zhang, Nogueira dos Santos, Yasunaga, Xiang and Radev2018).
Following the success of contextualized representations, Kantor and Globerson (Reference Kantor and Globerson2019), and Joshi et al. (Reference Joshi, Levy, Zettlemoyer and Weld2019) replace the LSTM-based encoder with BERT (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019). They either use BERT in a convolutional mode (Kantor and Globerson, Reference Kantor and Globerson2019) or split the documents into fixed length before applying BERT (Joshi et al., Reference Joshi, Levy, Zettlemoyer and Weld2019). Kantor and Globerson (Reference Kantor and Globerson2019) use a learnable weighted average of the last four layers of BERT to build span representations. Joshi et al. (Reference Joshi, Levy, Zettlemoyer and Weld2019) use the topmost layer output of BERT to build span representations:
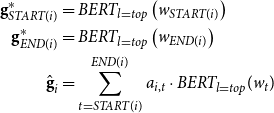 \begin{equation} \begin{aligned} \textbf{g}^*_{START(i)} &= BERT_{l=top}\left(w_{START(i)}\right) \\ \textbf{g}^*_{END(i)} &= BERT_{l=top}\left(w_{END(i)}\right)\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot BERT_{l=top}(w_t) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \textbf{g}^*_{START(i)} &= BERT_{l=top}\left(w_{START(i)}\right) \\ \textbf{g}^*_{END(i)} &= BERT_{l=top}\left(w_{END(i)}\right)\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot BERT_{l=top}(w_t) \end{aligned} \end{equation}
where
 $BERT_l(w_i)$
is the
$BERT_l(w_i)$
is the
 $l$
th layer contextualized embeddings of token
$l$
th layer contextualized embeddings of token
 $w_i$
, and
$w_i$
, and
 $a_{i,t}$
is a learned weight computed from the topmost layer output. Documents are split into segments of fixed length and BERT is applied to each segment. Two variants of splitting were proposed: overlap and independent (non-overlapping). Surprisingly, independent splitting performs better.
$a_{i,t}$
is a learned weight computed from the topmost layer output. Documents are split into segments of fixed length and BERT is applied to each segment. Two variants of splitting were proposed: overlap and independent (non-overlapping). Surprisingly, independent splitting performs better.
3. Related work
3.1. Effectiveness of higher-order inference
Lee et al. (Reference Lee, He and Zettlemoyer2018) propose the first HOI method, AA, for coreference resolution. Their experiments show that AA improved ELMo’s performance on OntoNotes by + 0.4 F1. Kantor and Globerson (Reference Kantor and Globerson2019) show that removing AA improved BERT’s performance slightly. Experiments by Xu and Choi (Reference Xu and Choi2020) show that span-refinement-based HOI methods, AA, Entity Equalization (Kantor and Globerson, Reference Kantor and Globerson2019), and Span Clustering (Xu and Choi, Reference Xu and Choi2020), have a negative impact on contextualized encoders, such as SpanBERT. However, the reasons behind this are not clear. In particular, the discrepancy of HOI impact among ELMo, BERT, and SpanBERT is not explained.
3.2. Measures of anisotropy and contextuality
Ethayarajh (Reference Ethayarajh2019) proposes to measure how contextual and anisotropic a word representation is using three different metrics: self-similarity, intra-sentence similarity, and random similarity. We adopt their measures to gauge how anisotropic and how contextual a word representation or a span embedding is and show that the HOI methods actually increase the anisotropy of span embeddings.
3.3. Data augmentation for coreference resolution
Wu et al. (Reference Wu, Wang, Yuan, Wu and Li2020) use existing question answering datasets for out-of-domain data augmentation for coreference resolution by transforming the coreference resolution task into a question answering task. To reduce anisotropy with examples of related but distinct entities, we use synthesized documents for in-domain data augmentation.
3.4. Embeddings aggregation
Arora et al. (Reference Arora, Li, Liang, Ma and Risteski2018) hypothesize that the global word embedding is a linear combination of its sense embeddings. They show that senses can be recovered through sparse coding. Mu et al. (Reference Mu, Bhat and Viswanath2017) show that senses and word embeddings are linearly related and sense sub-spaces tend to intersect along a line. Yaghoobzadeh et al. (Reference Yaghoobzadeh, Kann, Hazen, Agirre and Schütze2019) probe the aggregated word embeddings of polysemous words for semantic classes. They created a WIKI-PSE corpus, where word and semantic class pairs were annotated using Wikipedia anchor links, for example “apple” has two semantic classes: food and organization. A separate embedding for each semantic class was learned based on the WIKI-PSE corpus. They find that the linearly aggregated embeddings of polysemous words represent their semantic classes well. Our previous work (Hou et al. Reference Hou, Wang, He and Zhou2020) shows that linearly aggregated entity embeddings can improve the performance of entity linking. In this research, we use linear aggregations of contextualized representations from different layers of Transformer (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017)-based encoders to learn less-anisotropic span embeddings.
4. Revealing the reason for the negative impact of HOI
4.1. What is anisotropy
Anisotropy means that the elements of vectorized representations are not uniformly distributed with respect to direction. Instead, they occupy a narrow cone in the vector space. Its opposite, isotropy, has both theoretical and empirical benefits, for example it allows for stronger “self-normalization” during training (Arora, Liang, and Ma, Reference Arora, Liang and Ma2017) and improves performance on downstream tasks (Mu et al., Reference Mu, Bhat and Viswanath2018).
4.2. Measure of anisotropy of span embeddings
For contextualized word representations, the degree of anisotropy is measured by the average cosine similarity between the representations of randomly sampled words from different contexts (Ethayarajh, Reference Ethayarajh2019). We adopt this to measure the anisotropy,
 $RandomSim(D)$
, of span embeddings in a document
$RandomSim(D)$
, of span embeddings in a document
 $D$
, as follows.
$D$
, as follows.
Let
 $D$
be a document that contains
$D$
be a document that contains
 $m$
spans of entity mentions
$m$
spans of entity mentions
 $\{s_1, s_2, \dots, s_m\}$
. Let
$\{s_1, s_2, \dots, s_m\}$
. Let
 $\textbf{g}_i$
be the span embedding of span
$\textbf{g}_i$
be the span embedding of span
 $s_i$
. The random similarity between these spans is
$s_i$
. The random similarity between these spans is
 \begin{equation} RandomSim(D) = \frac{1}{m^2-m}\sum \limits _{i} \sum \limits _{j\neq i}cos\left(\textbf{g}_i, \textbf{g}_j\right) \end{equation}
\begin{equation} RandomSim(D) = \frac{1}{m^2-m}\sum \limits _{i} \sum \limits _{j\neq i}cos\left(\textbf{g}_i, \textbf{g}_j\right) \end{equation}
where
 $cos$
denotes the cosine similarity.
$cos$
denotes the cosine similarity.
4.3. HOI generates more anisotropic span embeddings
In this subsection, we prove and show that HOI makes the generated span embeddings more anisotropic. According to Equation (10), we need to prove that the HOI refined span embeddings
 $\textbf{g}_i^{n+1}, \textbf{g}_j^{n+1}$
at iteration
$\textbf{g}_i^{n+1}, \textbf{g}_j^{n+1}$
at iteration
 $n+1$
are more similar than
$n+1$
are more similar than
 $\textbf{g}_i^{n}, \textbf{g}_j^{n}$
at iteration
$\textbf{g}_i^{n}, \textbf{g}_j^{n}$
at iteration
 $n$
. Based on the definition
$n$
. Based on the definition
 $cos(\textbf{a}, \textbf{b})=\textbf{a}\cdot \textbf{b}/\|\textbf{a}\|\times \|\textbf{b}\|$
and the supposition that
$cos(\textbf{a}, \textbf{b})=\textbf{a}\cdot \textbf{b}/\|\textbf{a}\|\times \|\textbf{b}\|$
and the supposition that
 $\|\textbf{g}_i^{n+1}\|=\|\textbf{g}_i^n\|$
, we can say that
$\|\textbf{g}_i^{n+1}\|=\|\textbf{g}_i^n\|$
, we can say that
 $\textbf{g}_i^{n+1}, \textbf{g}_j^{n+1}$
are more similar than
$\textbf{g}_i^{n+1}, \textbf{g}_j^{n+1}$
are more similar than
 $\textbf{g}_i^{n}, \textbf{g}_j^{n}$
if
$\textbf{g}_i^{n}, \textbf{g}_j^{n}$
if
 $\textbf{g}_i^{n+1}\cdot \textbf{g}_j^{n+1} \gt \textbf{g}_i^{n}\cdot \textbf{g}_j^{n}$
.
$\textbf{g}_i^{n+1}\cdot \textbf{g}_j^{n+1} \gt \textbf{g}_i^{n}\cdot \textbf{g}_j^{n}$
.
Combining Equations (5) and (6) and treat vector
 $\textbf{f}_i^n$
as scalar
$\textbf{f}_i^n$
as scalar
 $f_i^n$
, we get
$f_i^n$
, we get
 \begin{equation} \begin{aligned} \textbf{g}_i^{n+1} &= f_i^n \textbf{g}_i^n + \left(1-f_i^n\right) \sum _{k=1}^{m} P_n(k) \textbf{g}_k^n \approx f_i^n \textbf{g}_i^n + \left(1-f_i^n\right) \Big (P_n(i) \textbf{g}_i^n + P_n(j) \textbf{g}_j^n\Big )\\[5pt] \textbf{g}_j^{n+1} &= f_j^n \textbf{g}_j^n + \left(1-f_j^n\right) \sum _{k=1}^{m} P^{\prime}_n(k) \textbf{g}_k^n \approx f_j^n \textbf{g}_j^n + \left(1-f_j^n\right) \Big (P^{\prime}_n(i) \textbf{g}_i^n + P^{\prime}_n(j) \textbf{g}_j^n\Big ) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \textbf{g}_i^{n+1} &= f_i^n \textbf{g}_i^n + \left(1-f_i^n\right) \sum _{k=1}^{m} P_n(k) \textbf{g}_k^n \approx f_i^n \textbf{g}_i^n + \left(1-f_i^n\right) \Big (P_n(i) \textbf{g}_i^n + P_n(j) \textbf{g}_j^n\Big )\\[5pt] \textbf{g}_j^{n+1} &= f_j^n \textbf{g}_j^n + \left(1-f_j^n\right) \sum _{k=1}^{m} P^{\prime}_n(k) \textbf{g}_k^n \approx f_j^n \textbf{g}_j^n + \left(1-f_j^n\right) \Big (P^{\prime}_n(i) \textbf{g}_i^n + P^{\prime}_n(j) \textbf{g}_j^n\Big ) \end{aligned} \end{equation}
Treating
 $f_i^n$
and
$f_i^n$
and
 $f_j^n$
equally as
$f_j^n$
equally as
 $f$
,
$f$
,
 $P_n(i)$
and
$P_n(i)$
and
 $P^{\prime}_n(j)$
equally as
$P^{\prime}_n(j)$
equally as
 $P$
,
$P$
,
 $P_n(j)$
and
$P_n(j)$
and
 $P^{\prime}_n(i)$
equally as
$P^{\prime}_n(i)$
equally as
 $\hat{P}$
, we get
$\hat{P}$
, we get
 \begin{equation} \textbf{g}_i^{n+1} \cdot \textbf{g}_j^{n+1} \approx \Big (f\textbf{g}_i^n + (1-f)\left(P\textbf{g}_i^n+\hat{P}\textbf{g}_j^n\right)\Big ) \cdot \Big (f\textbf{g}_j^n + (1-f)\left(\hat{P}\textbf{g}_i^n+P\textbf{g}_j^n\right)\Big ) \end{equation}
\begin{equation} \textbf{g}_i^{n+1} \cdot \textbf{g}_j^{n+1} \approx \Big (f\textbf{g}_i^n + (1-f)\left(P\textbf{g}_i^n+\hat{P}\textbf{g}_j^n\right)\Big ) \cdot \Big (f\textbf{g}_j^n + (1-f)\left(\hat{P}\textbf{g}_i^n+P\textbf{g}_j^n\right)\Big ) \end{equation}
and
 \begin{align} \textbf{g}_i^{n+1} \cdot \textbf{g}_j^{n+1} \approx & \Big (f^2+2f(1-f)P+(1-f)^2P^2+(1-f)^2\hat{P}^2\Big ) \textbf{g}_i^n\cdot \textbf{g}_j^n\nonumber\\[4pt] &+2f(1-f)\hat{P}+2(1-f)^2P\hat{P} \end{align}
\begin{align} \textbf{g}_i^{n+1} \cdot \textbf{g}_j^{n+1} \approx & \Big (f^2+2f(1-f)P+(1-f)^2P^2+(1-f)^2\hat{P}^2\Big ) \textbf{g}_i^n\cdot \textbf{g}_j^n\nonumber\\[4pt] &+2f(1-f)\hat{P}+2(1-f)^2P\hat{P} \end{align}
Figure 1 shows the histogram distribution of the
 $f$
and
$f$
and
 $P$
values. Practically, as shown in Figure 1,
$P$
values. Practically, as shown in Figure 1,
 $f,P\rightarrow 1$
, and as
$f,P\rightarrow 1$
, and as
 $P,\hat{P}$
are the elements of a softmax list,
$P,\hat{P}$
are the elements of a softmax list,
 $P+\hat{P}\approx 1$
,
$P+\hat{P}\approx 1$
,
 $\hat{P}\rightarrow 0$
. Thus, in Equation (13), the former part approximately equals
$\hat{P}\rightarrow 0$
. Thus, in Equation (13), the former part approximately equals
 $\textbf{g}_i^n\cdot \textbf{g}_j^n$
, and the latter part is not zero. Thus,
$\textbf{g}_i^n\cdot \textbf{g}_j^n$
, and the latter part is not zero. Thus,
 $\textbf{g}_i^{n+1}\cdot \textbf{g}_j^{n+1} \gt \textbf{g}_i^{n}\cdot \textbf{g}_j^{n}$
. This proves that the HOI methods tend to generate more anisotropic span embeddings. From Equation (13), we can see that the more iterations we refine the span embeddings for, the more anisotropic the span embeddings will become.
$\textbf{g}_i^{n+1}\cdot \textbf{g}_j^{n+1} \gt \textbf{g}_i^{n}\cdot \textbf{g}_j^{n}$
. This proves that the HOI methods tend to generate more anisotropic span embeddings. From Equation (13), we can see that the more iterations we refine the span embeddings for, the more anisotropic the span embeddings will become.
The histogram distributions of
 $f$
and
$f$
and
 $P$
values. We recorded 6564
$P$
values. We recorded 6564
 $f$
and
$f$
and
 $P$
values respectively during the last two epochs of training C2F+BERT-base+AA.
$P$
values respectively during the last two epochs of training C2F+BERT-base+AA.
 $f$
is the average across the embedding dimension;
$f$
is the average across the embedding dimension;
 $P$
is the max value of antecedents.
$P$
is the max value of antecedents.
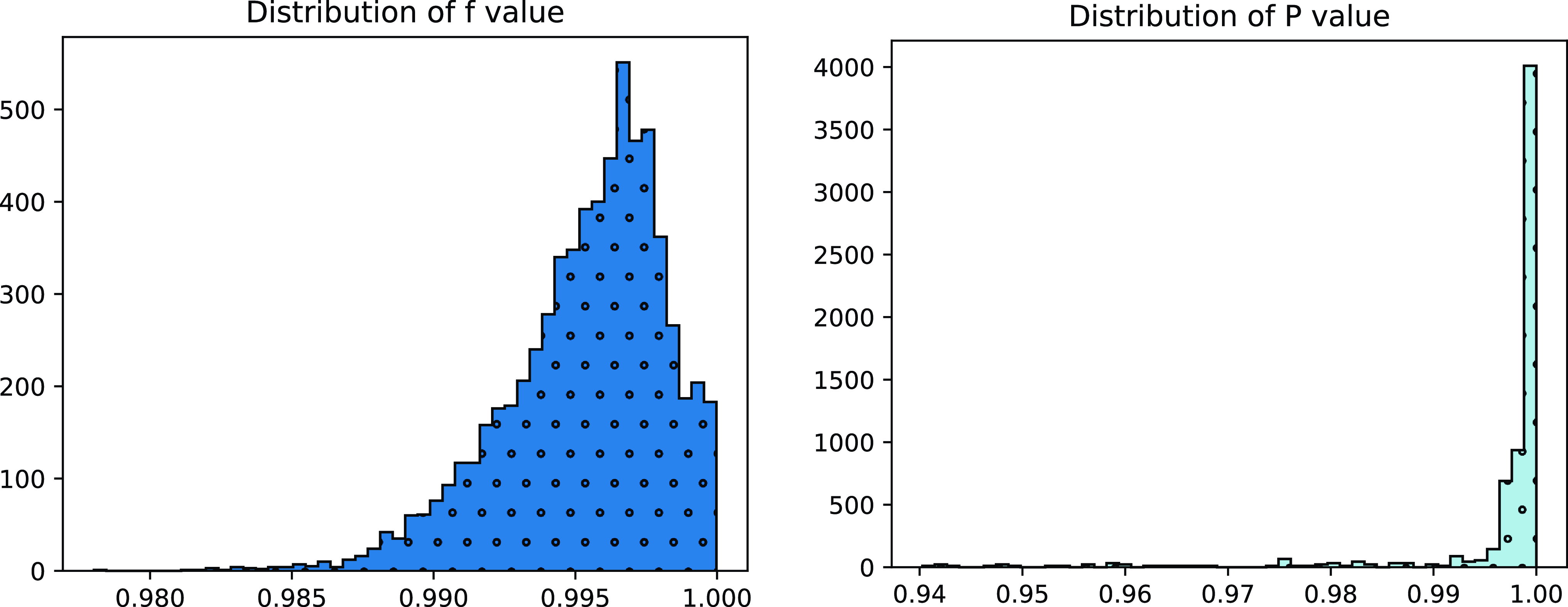
To concretely show the degree of anisotropy of span embeddings generated by different HOI methods, we compute and record the random similarity (Equation (10)) at each epoch during training. Figure 2 displays the recorded average cosine similarity of each epoch. As shown in Figure 2, the span embeddings generated by HOI methods are always more anisotropic than the span embeddings generated without HOI.
The degree of anisotropy of span embeddings is measured by the average cosine similarity between uniformly randomly sampled spans. (Figures 2-6 are generated using the method of Ethayarajh (Reference Ethayarajh2019)).
For contextualized word representations, the degree of anisotropy is measured by the average cosine similarity between uniformly randomly sampled words. The higher the layer, the more anisotropic. Embeddings of layer 0 are the input layer word embeddings.
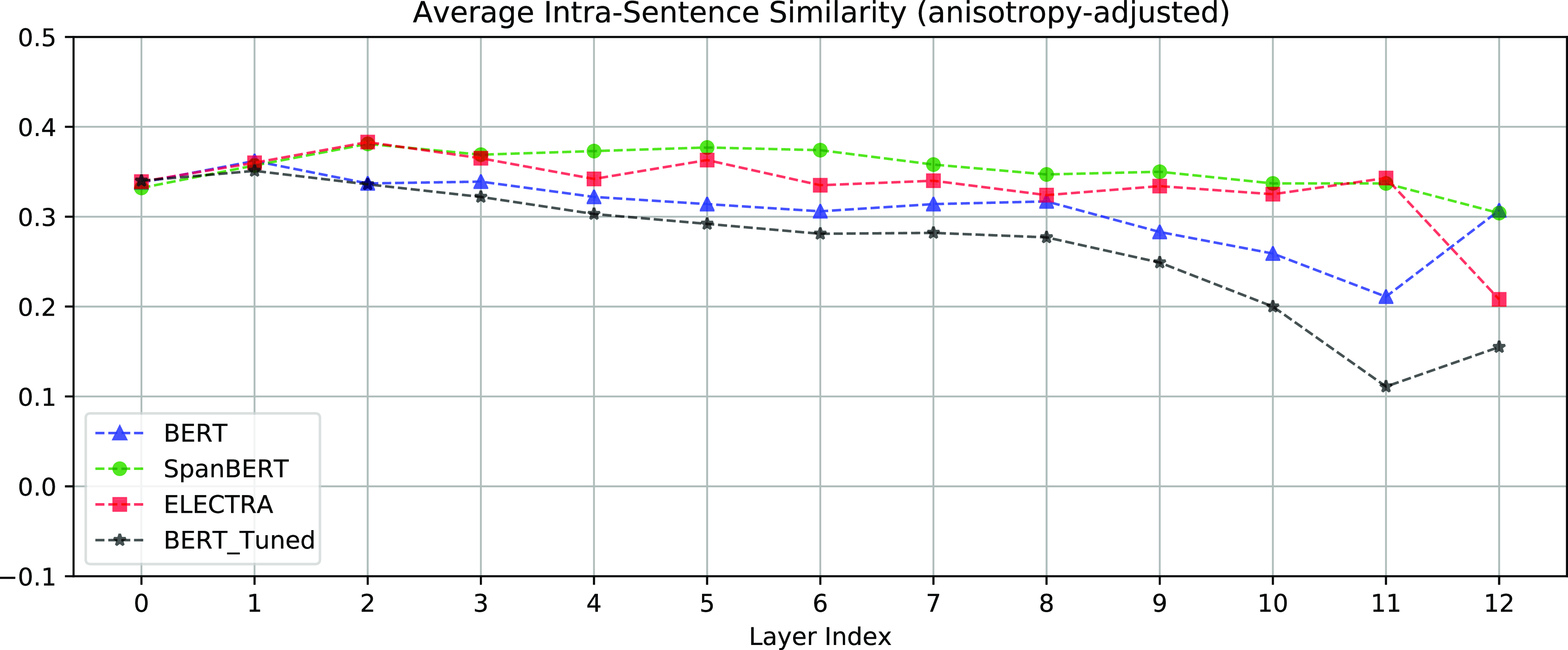
Intra-sentence similarities of contextualized representations. The intra-sentence similarity is the average cosine similarity between each word representation in a sentence and their mean.
Self-similarities of contextualized representations. Self-similarity is the average cosine similarity between representations of the same word in different contexts.

According to Equations (5) and (6), higher-order span refinement is essentially injecting information from other spans into a span’s embedding. Thus, unrelated spans may become more similar (and hence, more anisotropic).
4.4. Why anisotropic span embeddings are undesirable
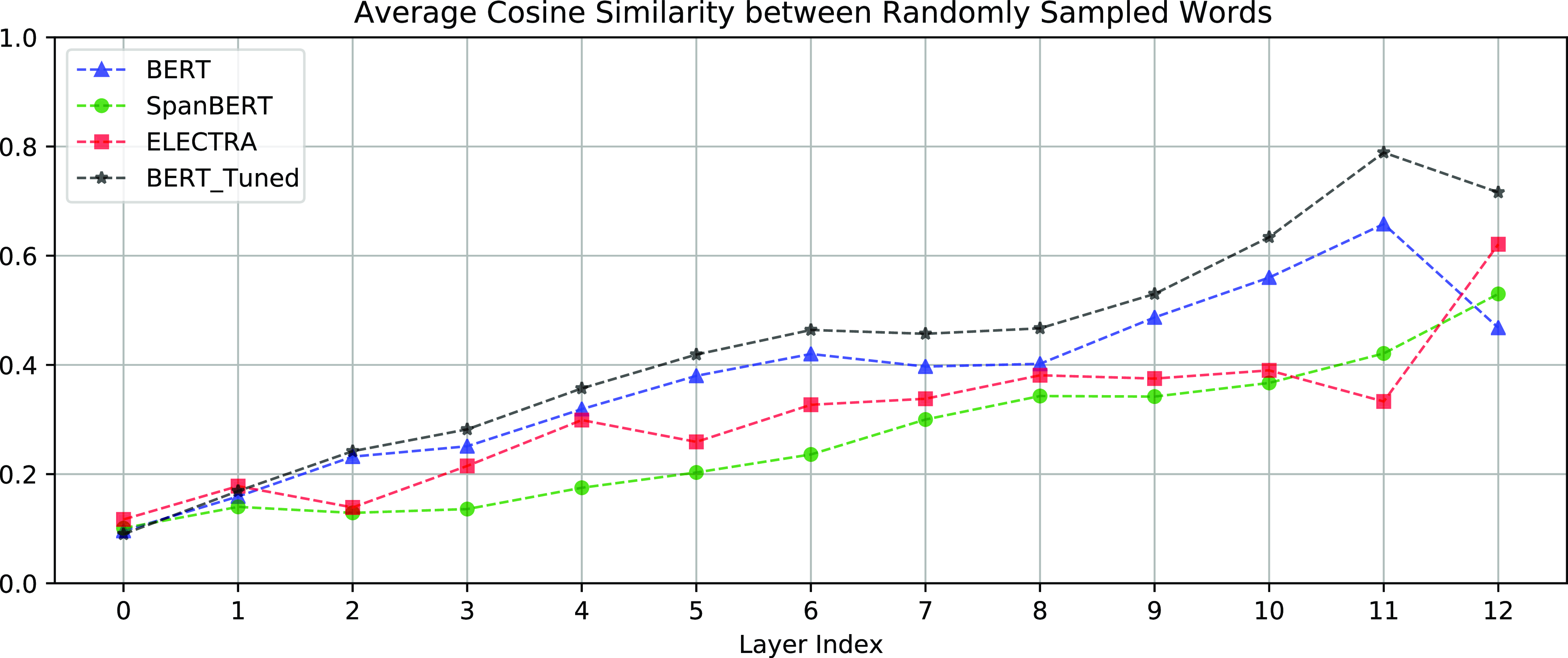
Span embeddings encode the contextual information (and some meta-information about spans) of the textual spans that are potentially an entity mention. Spans in the same sentence or segment will have similar span embeddings. Thus, some degree of anisotropy is also an indicator of contextuality (Ethayarajh, Reference Ethayarajh2019). To explain this, we compute the measures of contextualization and anisotropy proposed by Ethayarajh (Reference Ethayarajh2019) and visualize these measures in Figures 3, 4, and 5. Figure 3 shows the random cosine similarities (the degree of anisotropy) of each layer. Figures 4 and 5 show the intra-sentence similarities and self-similarities of each layer, respectively. Both the intra-sentence similarity and the self-similarity are contextualization measures proposed by Ethayarajh (Reference Ethayarajh2019). As shown in Figures 4 and 5, the higher layer representations are more context-specific, that is the top layer representations are more contextualized. As shown in Figure 3, the top layer representations are also more anisotropic. However, if the embeddings of the spans in the same document are too anisotropic, that is the span embeddings occupy a narrow cone in the vector space, related but distinct entities (e.g., pilots and flight attendants) will become difficult to distinguish.
This can be explained by the example of pilots and flight attendants by Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b). As Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b) analyzed, related but distinct entities appear in similar contexts and likely have nearby word (span) embeddings. Thus, their neural coreference resolution model predicts a false positive link between pilots and flight attendants. Related entities are grouped in a local cluster in the vector space, while unrelated entities in different contexts are grouped in different clusters in the vector space. Thus, unrelated entities are more distinguishable than the related entities. However, extremely isotropic (not anisotropic) embeddings are also undesirable. For a vocabulary with
 $V$
words, the extremely isotropic embeddings would be the embeddings in a
$V$
words, the extremely isotropic embeddings would be the embeddings in a
 $|V|$
dimension with each word occupying a single dimension. Such extremely isotropic embeddings cannot capture the similarity between words and lose contextualization. As more contextualized representations tend to be anisotropic (Ethayarajh, Reference Ethayarajh2019), we need to achieve a trade-off between isotropy and contextualization.
$|V|$
dimension with each word occupying a single dimension. Such extremely isotropic embeddings cannot capture the similarity between words and lose contextualization. As more contextualized representations tend to be anisotropic (Ethayarajh, Reference Ethayarajh2019), we need to achieve a trade-off between isotropy and contextualization.
In summary, we believe that the negative impact of HOI is caused by worsening the anisotropy of span embeddings without incorporating more contexts. We propose methods that learn less-anisotropic span embeddings in Section 5 and perform comprehensive experimental analysis in Section 6.
5. Learning less-aniostropic span embeddings
5.1. Less-anisotropic internal representations (LAIR)
Contextualized word representations are more context-specific in the higher layers. However, Ethayarajh (Reference Ethayarajh2019) shows that these contextualized word representations are anisotropic, especially in the higher layers. Building span embeddings directly from the output-layer contextualized word representations will cause anisotropy. To reduce the degree of anisotropy while retaining contextual information, we use a linear aggregation of the contextualized embeddings of the first layer and the topmost layer. As the boundary representations need to encode more contextual information, we only use aggregated embeddings for the internal representation
 $\hat{\textbf{g}}_i$
:
$\hat{\textbf{g}}_i$
:
 \begin{equation} \begin{aligned} AT(w_t) &= \alpha \circ T_{l=1}(w_t) + (1-\alpha ) \circ T_{l=top}(w_t)\\ \textrm{a}_{t} &= \textbf{w}_{\textrm{a}} \cdot FFNN_{\textrm{a}}(AT(w_t))\\ a_{i,t} &= \frac{exp(\textrm{a}_t)}{\sum \limits ^{END(i)}_{k=START(i)}exp(\textrm{a}_k)}\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot AT(w_t) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} AT(w_t) &= \alpha \circ T_{l=1}(w_t) + (1-\alpha ) \circ T_{l=top}(w_t)\\ \textrm{a}_{t} &= \textbf{w}_{\textrm{a}} \cdot FFNN_{\textrm{a}}(AT(w_t))\\ a_{i,t} &= \frac{exp(\textrm{a}_t)}{\sum \limits ^{END(i)}_{k=START(i)}exp(\textrm{a}_k)}\\ \hat{\textbf{g}}_i&=\sum \limits ^{END(i)}_{t=START(i)} a_{i,t} \cdot AT(w_t) \end{aligned} \end{equation}
where
 $T_l(w)$
is the
$T_l(w)$
is the
 $l$
th layer Transformer-based (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) contextualized embedding of token
$l$
th layer Transformer-based (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) contextualized embedding of token
 $w$
,
$w$
,
 $AT$
is the aggregated representation, and the scalar
$AT$
is the aggregated representation, and the scalar
 $\alpha$
is the weight of the first layer embedding.
$\alpha$
is the weight of the first layer embedding.
Aggregating the first layer and the topmost layer embeddings can reduce anisotropy without substantial loss of contextual information, because the topmost layer encodes the most contextual information, and the first layer is the least anisotropic (Ethayarajh, Reference Ethayarajh2019).
5.2. Data augmentation with document synthesis and mention swap (DSMS)
As we mentioned in Section 4.4, anisotropic span embeddings make it difficult to distinguish related but distinct entities. We propose to learn less-anisotropic span embeddings by using a more diversified set of examples of related but distinct entities, generated by synthesizing documents and by mention swapping. Algorithm 1 describes the complete process for this data augmentation method, the details of which are as follows.
Data augmentation for learning less-anisotropic span embeddings

5.2.1. synthesizing documents
We split each training document into segments of 512 word pieces (Wu et al. Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao and Macherey2016) and then combine segments from two different documents to synthesize two-segment-long training “documents.” The process is as follows:
-
1) For each pair of documents
 $(d_1,d_2)$
of the same genre, compute their TF-IDF cosine similarity
$s$
. Sort the list of
$(d_1,d_2, s)$
from the largest to the smallest according to similarity
$s$
.
$(d_1,d_2)$
of the same genre, compute their TF-IDF cosine similarity
$s$
. Sort the list of
$(d_1,d_2, s)$
from the largest to the smallest according to similarity
$s$
. -
2) Sequentially select a pair of documents
$(d_1,d_2)$
from the ordered list
$[(d_1,d_2,s)]$
. If both documents have not been selected, then build a synthesized document of two segments using the second segment of
$d_1$
and the first segment of
$d_2$
. Mentions and clusters are updated to sew both segments together. These steps are detailed below. -
3) Repeat step 2) until no documents can be generated.








The two documents used to synthesize a new document possibly contain coreferent mentions. Such documents can be viewed as noisy examples. Such noisy examples help reduce the similarity of span embeddings (e.g., reduce the similarity of the two span embeddings of “Biden”) and improve the generalization of resolution models.
Why sort the list of
$(d_1,d_2, s)$
by similarity?

By synthesizing documents using segments from similar real documents, we can create training examples with distinct (non-coreferent) entities of similar contexts. Our hypothesis is that we can learn less-anisotropic span embeddings from such training examples.
Selecting documents for synthesis
We select documents of the same genre to synthesize documents; a document is used only once for synthesizing documents. Since a synthesized document consists of two segments from different documents,
 $N$
documents of a genre will generate
$N$
documents of a genre will generate
 $N/2$
synthesized documents.
$N/2$
synthesized documents.
Updating mentions and clusters
A synthesized document consists of two segments from different documents, which are sewn together by simply updating the start and end positions of the mentions. Mentions that are not in the selected segments are removed from the clusters.
5.2.2. Mention swap
For a synthesized document, we randomly select a cluster with more than one mention and then randomly select two different mentions from that cluster and swap them. We hypothesize that more swaps might introduce noisy information. Thus, we do only one swap in a synthesized document. Mention swapping is performed as follows:
-
1) Randomly select 2 mentions in the same cluster;
-
2) Swap the token IDs of these mentions;
-
3) Update the start and end positions of both mentions.
5.2.3. Learning less-anisotropic span embeddings
Data augmentation can help learn less-anisotropic span embeddings in the following two ways:
-
• The synthesized documents consist of two independent (no coreferences) segments with similar contexts. The pairwise score function (Equation (3)) computes the coreference scores of all pairs of spans in the documents. Thus, the synthesized documents provide examples of non-coreferential mentions (spans) in similar contexts. Such examples help learn less-anisotropic span embedding for spans in similar contexts (anisotropic embeddings are too similar to distinguish).
-
• Mention swap changes the contexts of a pair of mentions and thus can provide different combinations of boundary representations and internal representations (Equation (7)) of a span.
6. Experiments
6.1. Data sets and evaluation metrics
6.1.1. Document level coreference resolution: ontoNotes
OntoNotes (English) is a document-level dataset from the CoNLL-2012 shared task (Pradhan et al. Reference Pradhan, Moschitti, Xue, Uryupina and Zhang2012) on coreference resolution. It consists of 2,802/343/348 train/development/test documents of different genres, such as newswire, magazine articles, broadcast news, broadcast conversations, etc.
Evaluation metrics
The main evaluation metric is the average F1 of three metrics (Recasens and Hovy, Reference Recasens and Hovy2011): MUC (Vilain et al. Reference Vilain, Burger, Aberdeen, Connolly and Hirschman1995), B
 $^3$
(Bagga and Baldwin, Reference Bagga and Baldwin1998), and CEAF
$^3$
(Bagga and Baldwin, Reference Bagga and Baldwin1998), and CEAF
 $_{\phi 4}$
(Luo, Reference Luo2005) on the test set according to the official CoNLL-2012 evaluation scripts.
$_{\phi 4}$
(Luo, Reference Luo2005) on the test set according to the official CoNLL-2012 evaluation scripts.
6.1.2. Paragraph level coreference resolution: GAP
GAP (Webster et al. Reference Webster, Recasens, Axelrod and Baldridge2018) is a human-labeled corpus of ambiguous pronoun-name pairs derived from Wikipedia snippets. Examples in the GAP dataset fit within a single segment, thus obviating the need for cross-segment inference.
Evaluation metrics
The metrics are the F1 score on Masculine and Feminine examples, Overall, and the Bias factor (i.e., F/M). Following Webster et al. (Reference Webster, Recasens, Axelrod and Baldridge2018) and Joshi et al. (Reference Joshi, Levy, Zettlemoyer and Weld2019), the coreference resolution system is trained on OntoNotes and only the testing is performed on GAP. The dataset and scoring script are available on GitHub.Footnote a
6.1.3. Data sets for gauging contextualized representations
Like Ethayarajh (Reference Ethayarajh2019), we use the data from the SemEval Semantic Textual Similarity tasks from the years 2012–2016 (Agirre et al. Reference Agirre, Cer, Diab and Gonzalez-Agirre2012, Reference Agirre, Cer, Diab, Gonzalez-Agirre and Guo2013, Reference Agirre, Banea, Cardie, Cer, Diab, Gonzalez-Agirre, Guo, Mihalcea, Rigau and Wiebe2014, Reference Agirre, Banea, Cardie, Cer, Diab, Gonzalez-Agirre, Guo, Lopez-Gazpio, Maritxalar, Mihalcea, Rigau, Uria and Wiebe2015). The other settings remain the same.
6.2. Implementation and hyperparameters
Before performing the experiments on coreference resolution, we gauged the anisotropy and contextuality of the contextualized representations from BERT, SpanBERT, and ELECTRA using the codeFootnote b from Ethayarajh (Reference Ethayarajh2019) on the data sets mentioned in Section 6.1.3. The results for anisotropy are shown in Figure 3. The measures of contextuality are intra-sentence similarity and self-similarity, shown in Figures 4 and 5 respectively.
We split the OntoNotes English documents into segments of 512 word pieces (Wu et al., Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao and Macherey2016), performing data augmentation only on the training set. To compare the effects of our methods on multiple encoders, we also carried out experiments on ELECTRA with uncased vocabulary, using the HuggingFace PyTorch version of ELECTRAFootnote c (discriminator).
Our code is based on the implementation in Joshi et al. (Reference Joshi, Levy, Zettlemoyer and Weld2019) and Xu and Choi (Reference Xu and Choi2020). We use similar hyperparameters, except that we introduce a new hyperparameter: the weight of the first layer embeddings,
 $\alpha$
, in Equation (14). We chose
$\alpha$
, in Equation (14). We chose
 $\alpha$
as follows: For SpanBERT, we tried
$\alpha$
as follows: For SpanBERT, we tried
 $\alpha$
over the range from 0.1 to 0.6 with a 0.1 increment. Since ELECTRA is more anisotropic than SpanBERT (as shown in Figure 3), we tried larger values of
$\alpha$
over the range from 0.1 to 0.6 with a 0.1 increment. Since ELECTRA is more anisotropic than SpanBERT (as shown in Figure 3), we tried larger values of
 $\alpha$
for ELECTRA. All the
$\alpha$
for ELECTRA. All the
 $\alpha$
values are chosen based on the development set of OntoNotes. These hyperparameters for our experiments are listed in Table 1.
$\alpha$
values are chosen based on the development set of OntoNotes. These hyperparameters for our experiments are listed in Table 1.
Hyperparameter settings for our experiments

6.3. Baselines
To validate our methods for reducing anisotropy, we compared our methods with systems that combine coarse-to-fine antecedent pruning (C2F) (Lee et al., Reference Lee, He and Zettlemoyer2018) with the following HOI modules: AA (Lee et al., Reference Lee, He and Zettlemoyer2018), Entity Equalization (Kantor and Globerson, Reference Kantor and Globerson2019), Span Clustering (Xu and Choi, Reference Xu and Choi2020), and cluster merging (CM) (Xu and Choi, Reference Xu and Choi2020).
We also applied LAIR + DSMS to C2F+SpanBERT+CM, but found this approach did not improve performance and therefore removed the CM module (i.e., LAIR + DSMS + C2F+SpanBERT). This not only could improve performance, but could also significantly accelerate training.
6.4. Results
The results on OntoNotes are listed in Table 2. For SpanBERT, (LAIR + DSMS) offers an improvement of + 0.7 F1 over the system that does not use any HOI; the improvement over the system that uses AA is + 1.0 F1. For ELECTRA, (LAIR + DSMS) boosts the performance by + 2.8 F1 over the system that does not use any HOI. The results also show that DSMS alone achieves only marginal improvements without the incorporation of LAIR. We analyze the reasons for this phenomenon in Section 6.5.1.
Results on the test set of the OntoNotes English data from the CoNLL-2012 shared task. HOI modules are in bold. The rightmost column is the main evaluation metric, the average F1 of MUC,
 $B^3$
,
$B^3$
,
 $CEAF_{\phi _{4}}$
. BERT, SpanBERT, and ELECTRA are the large model. The results of the models with citations are copied verbatim from the original papers
$CEAF_{\phi _{4}}$
. BERT, SpanBERT, and ELECTRA are the large model. The results of the models with citations are copied verbatim from the original papers
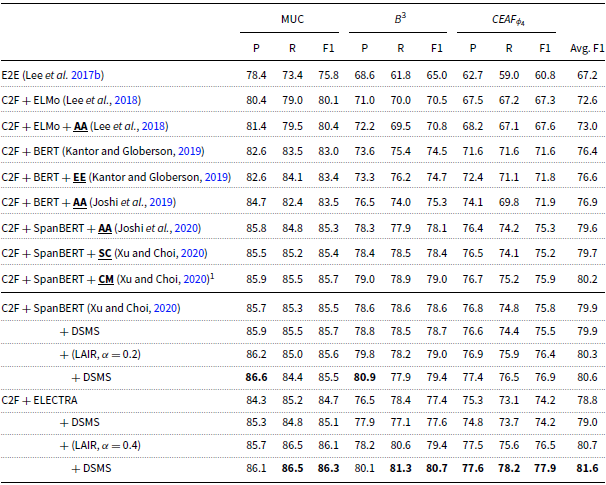
1 CM is not a span-refinement-based HOI method. The results here are copied verbatim from the original paper. However, we cannot reproduce the reported results (Avg. F1 80.2). When we train “C2F+SpanBERT+CM,” we found the training is extremely slow and can achieve only marginal even negative improvements (Avg. F1 80.0 over 79.9). The marginal improvement of CM is not worth its extreme complexity.
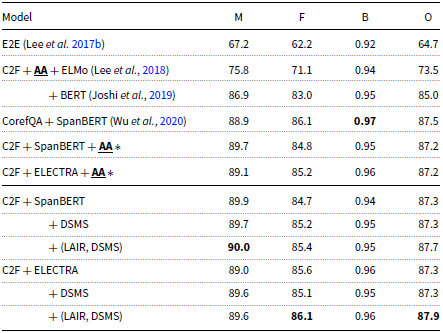
The results on GAP are listed in Table 3. Combined with (LAIR + DSMS), ELECTRA achieves new state-of-the-art for performance on the GAP dataset.
Performance on the test set of GAP corpus. The metrics are F1 scores on Masculine and Feminine examples, Overall F1 score, and a Bias factor(F/M). BERT, SpanBERT, and ELECTRA are the large model. The models are trained using OntoNotes and tested on the test set of GAP.
 $\ast$
denotes the model is re-implemented following Joshi et al. (Reference Joshi, Chen, Liu, Weld, Zettlemoyer and Levy2020)
$\ast$
denotes the model is re-implemented following Joshi et al. (Reference Joshi, Chen, Liu, Weld, Zettlemoyer and Levy2020)
6.5. Analysis and findings
6.5.1. Effects of LAIR and DSMS
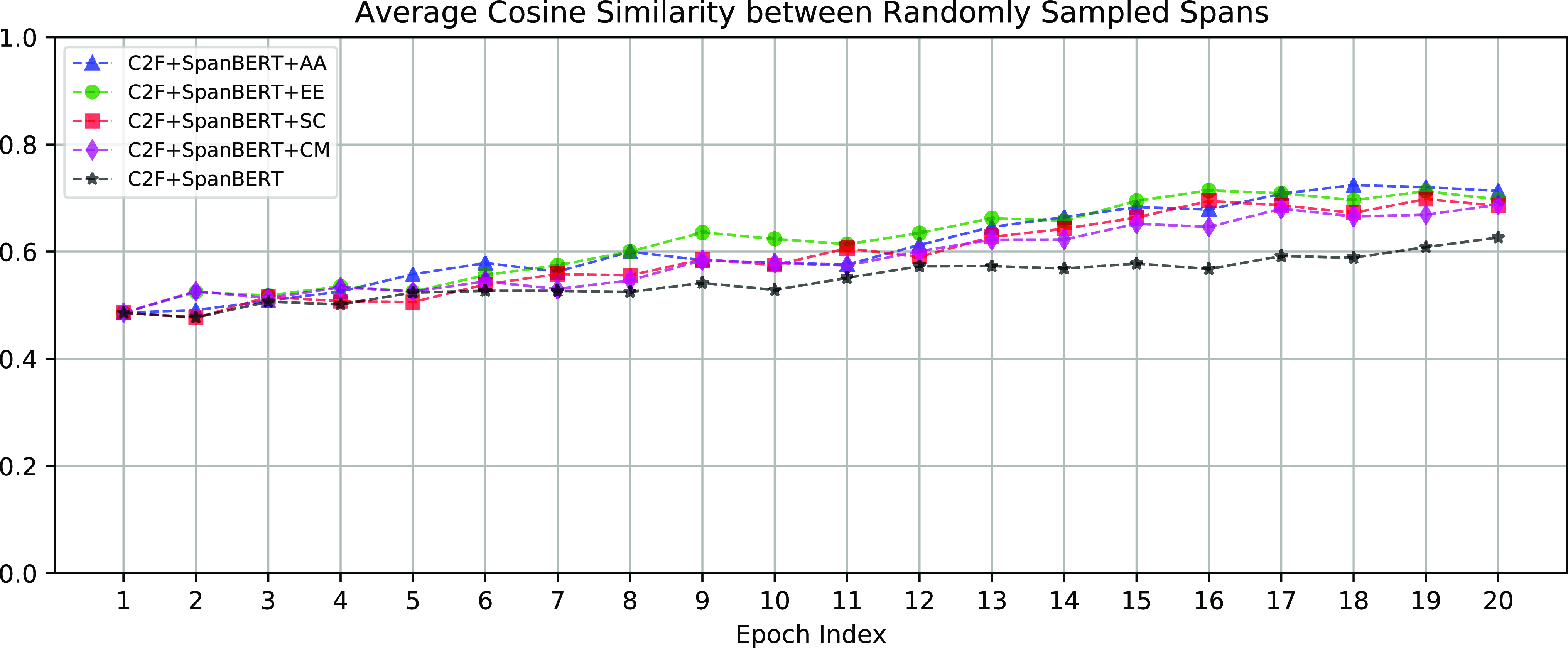
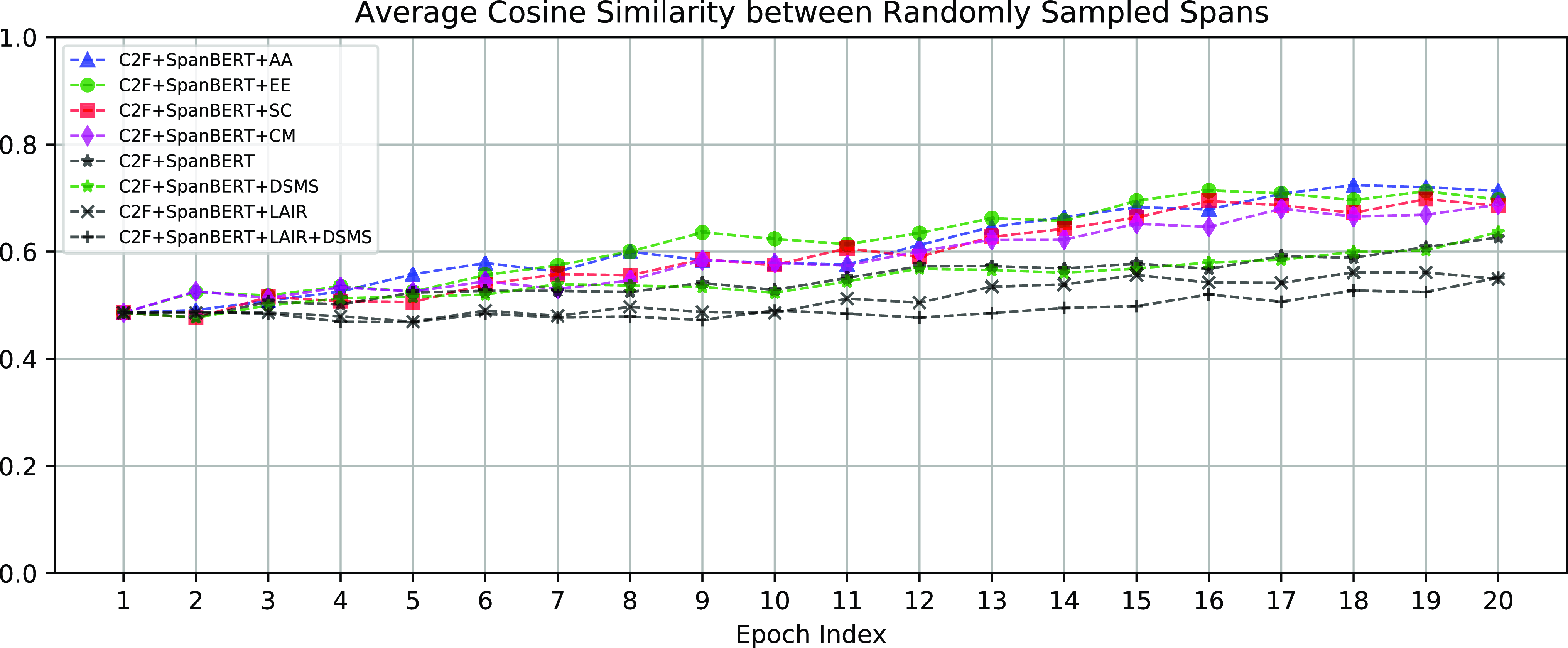
The effects of LAIR and DSMS for learning less-anisotropic span embeddings can be assessed by measuring the degree of anisotropy in those learned span embeddings and relating this to performance. Figure 6 shows the average cosine similarity between randomly sampled spans based on the span embeddings generated by SpanBERT with different settings. The similarities are the measure of anisotropy defined in Equation (10). The less similar the spans are, the less anisotropic are the span embeddings. We can see that LAIR and DSMS effectively reduce the anisotropy of span embeddings. As shown in Table 2 and Figure 6, LAIR + DSMS achieved the best performance with the least anisotropic span embeddings.
The average cosine similarity between randomly sampled spans. The less similar between spans, the less anisotropic are the span embeddings. LAIR and DSMS help learn less-anisotropic span embeddings.
Case study
We perform a case study on the cosine similarity between The pilots’ and The flight attendants to verify our method further. This is an example in Lee et al. (Reference Lee, He, Lewis and Zettlemoyer2017b) from the OntoNotes dev set (document number: bn/cnn/02/cnn_0210_0). As shown in Figure 7, our LAIR method can effectively make the span embeddings of The pilots’ and The flight attendants less similar, that is less anisotropic.
The cosine similarity between The pilots’ and The flight attendants, an example from OntoNotes dev set.

We find that applying DSMS alone achieves only marginal improvement for both SpanBERT and ELECTRA
As shown in Table 2 ( 11th and 15th rows) and Table 3 (8th and 11th rows), applying solely DSMS can only achieve marginal improvement. Figure 6 shows that DSMS cannot effectively reduce the degree of anisotropy of span embeddings. DSMS is essentially a data augmentation method; training with the augmented examples can only fine-tune span embeddings yet cannot significantly reduce anisotropy (as shown in Figure 6). In contrast, LAIR builds less-anisotropic span embeddings directly by incorporating the embeddings of the bottom layer, that is the least anisotropic layer. Combining DSMS with LAIR can further fine-tune the less-anisotropic span embeddings and improve performances.
We also experimented with less-anisotropic boundary representations, but achieved slightly worse results. This is in line with the fact that the boundary representations were designed to encode a span’s contextual information, while the internal representation was designed to encode the internal information of a span. Replacing first layer embeddings with input layer word embeddings also did not lead to improvement, indicating that the internal representation
 $\hat{\textbf{g}}_i$
still needs contextual information to better encode a span’s internal structure.
$\hat{\textbf{g}}_i$
still needs contextual information to better encode a span’s internal structure.
6.5.2. LAIR and DSMS are ineffective for BERT
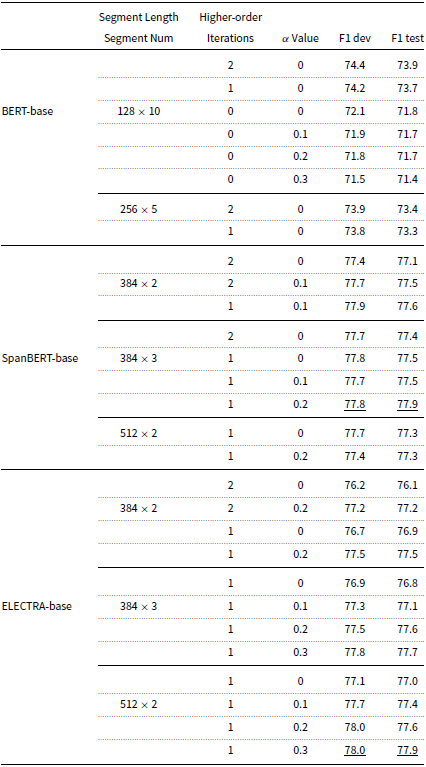
We could not achieve any improvement for BERT by using LAIR or DSMS. The 1st-3rd rows of Table 4 show that decreasing the HOI iterations causes the performance of BERT-base drop significantly. The 3rd-6th rows of Table 4 show that LAIR has negative impact for BERT. BERT has the following two characteristics:
-
• The contextualized embeddings from BERT are highly anisotropic. The embeddings of every layer are more anisotropic than those of SpanBERT and ELECTRA, as shown in Figure 3. BERT fine-tuned for coreference resolution becomes even more anisotropic.
-
• BERT is not capable of encoding longer contexts effectively (Joshi et al., Reference Joshi, Levy, Zettlemoyer and Weld2019). Figures 4 and 5 also corroborate that BERT-base does not encode sufficient contextual information.
Although LAIR can directly reduce the anisotropy of BERT word embeddings, applying LAIR also depletes the contextual information needed for coreference resolution. Thus, LAIR and DSMS are not effective for BERT.
Ablation studies of higher-order inference for BERT-base, ELECTRA-base, and SpanBERT-base. The metric is the average F1 score on the OntoNotes dev set and test set using different combinations of hyperparameters. The HOI method used is the Attended Antecedent Lee et al. (Reference Lee, He and Zettlemoyer2018)
6.5.3. Degree of anisotropy and
$\alpha$

Figure 3 shows that the bottom layer is the least anisotropic. This means increasing
 $\alpha$
(i.e., increasing the proportion of the bottom layer) will make the span embeddings less anisotropic. However, Figures 4 and 5 also show that the bottom layer contains the least contextual information. Thus, increasing
$\alpha$
(i.e., increasing the proportion of the bottom layer) will make the span embeddings less anisotropic. However, Figures 4 and 5 also show that the bottom layer contains the least contextual information. Thus, increasing
 $\alpha$
will also deplete the contextual information for coreference resolution. The results in Table 5 show that settings with
$\alpha$
will also deplete the contextual information for coreference resolution. The results in Table 5 show that settings with
 $\alpha \geq 0.5$
perform poorly. Increasing
$\alpha \geq 0.5$
perform poorly. Increasing
 $\alpha$
worsens performance. Entirely using the bottom layer (
$\alpha$
worsens performance. Entirely using the bottom layer (
 $\alpha =1.0$
) achieves the worst results.
$\alpha =1.0$
) achieves the worst results.
Ablation studies on different
 $\alpha$
values for different models
$\alpha$
values for different models

As we mentioned in Section 4.4, we need to choose the best
 $\alpha$
to achieve a trade-off between isotropy and contextualization. According to Figure 3, ELECTRA is more anisotropic than SpanBERT. In Table 2, the 11th and 14th rows show that LAIR performs the best when
$\alpha$
to achieve a trade-off between isotropy and contextualization. According to Figure 3, ELECTRA is more anisotropic than SpanBERT. In Table 2, the 11th and 14th rows show that LAIR performs the best when
 $\alpha$
is set to 0.2 for SpanBERT and 0.4 for ELECTRA, respectively. We can say that the more anisotropic the embeddings are, larger the
$\alpha$
is set to 0.2 for SpanBERT and 0.4 for ELECTRA, respectively. We can say that the more anisotropic the embeddings are, larger the
 $\alpha$
(Equation 14) is needed for LAIR.
$\alpha$
(Equation 14) is needed for LAIR.
6.5.4. Discrepancy of higher-order inference effectiveness for ELMo, BERT, SpanBERT, and ELECTRA
We perform ablation studies to test the effectiveness of HOI and LAIR. Table 4 shows the trend of performance with the increase of
 $\alpha$
and the number of HOI iterations. Considering the tiny change of
$\alpha$
and the number of HOI iterations. Considering the tiny change of
 $\alpha$
and HOI iterations, the marginal but consistent change of performance is meaningful. When a larger
$\alpha$
and HOI iterations, the marginal but consistent change of performance is meaningful. When a larger
 $\alpha$
is applied, the change of F1 is manifest. HOI methods are computationally expensive. Reducing the number of HOI iterations can reduce computational complexity. A marginal improvement of F1 with a smaller number of HOI iterations is worthwhile.
$\alpha$
is applied, the change of F1 is manifest. HOI methods are computationally expensive. Reducing the number of HOI iterations can reduce computational complexity. A marginal improvement of F1 with a smaller number of HOI iterations is worthwhile.
As shown in Table 4, SpanBERT-base (the 10th-13th rows) and ELECTRA-base (the 18th and 20th rows) achieve better results when using fewer iterations of HOI. While BERT-base (the 1st and 2nd rows) still needs a deeper higher-order refinement of span embeddings to get the best result using segments of 128 word pieces (Wu et al., Reference Wu, Schuster, Chen, Le, Norouzi, Macherey, Krikun, Cao, Gao and Macherey2016). Lee et al. (Reference Lee, He and Zettlemoyer2018) showed that combining ELMo with HOI achieved + 0.4 F1 improvement. There is a discrepancy between the HOI effectiveness for ELMo, BERT, SpanBERT, and ELECTRA.
Why is HOI effective for ELMo and BERT?
For ELMo, we find ELMo is much less anisotropic and less contextualized than BERT, SpanBERT, and ELECTRA. HOI does not increase the anisotropy of ELMo-based span embeddings to a threshold where the negative effect can be seen; at the same time, it does incorporate global information.
For BERT, BERT-base achieves the best performance when using segments of 128 word pieces, as shown in Table 4 (the 1st and 7th rows). This shows BERT is not capable of encoding longer contexts (Joshi et al., Reference Joshi, Levy, Zettlemoyer and Weld2019). Figures 4 and 5 also show that BERT-base generates less contextualized word (span) embeddings than SpanBERT-base and ELECTRA-base. HOI helps BERT incorporate document-level contextual information from longer contexts, without greatly increasing anisotropy.
Why is HOI negative for spanBERT and ELECTRA?
SpanBERT and ELECTRA achieve the best results using segments of 512 word pieces. Thus, they are capable of encoding longer contextual information. Their measures of contextuality (Ethayarajh, Reference Ethayarajh2019) in Figures 4 and 5 also show they are not only highly contextualized but also highly anisotropic. Applying HOI to SpanBERT or ELECTRA does not incorporate much global information but it worsens the anisotropy of the span embeddings. As Table 4 (the 12th-13th rows and the 18th-20th rows) shows, the more iterations we refine span embeddings for, the worse performance we achieve for SpanBERT and ELECTRA. This supports our analysis in Section 4.3.
6.5.5. Document segment length and contextualization
The results in Table 4 show that SpanBERT-base and ELECTRA-base can use longer document segments (384 tokens or 512 tokens) for coreference resolution, while BERT-base can only use short document segments (only 128 tokens). Figures 4 and 5 demonstrate that SpanBERT-base and ELECTRA-base can generate more contextualized representations than BERT-base. This means SpanBERT and ELECTRA are more effective for encoding longer contexts. Thus, our methods can reduce anisotropy without depleting contextualization for SpanBERT and ELECTRA.
6.5.6. Word embeddings vs Layer 1 embeddings
Figure 3 shows that the layer 0 embeddings (the input layer word embeddings) and the layer 1 embeddings are the least anisotropic; we therefore also experimented with the input layer word embeddings, but without improvement. The difference is that the layer 1 embeddings encode contextual information, showing that the internal representation
 $\hat{\textbf{g}}_i$
still needs contextual information to better encode a span’s internal structure.
$\hat{\textbf{g}}_i$
still needs contextual information to better encode a span’s internal structure.
7. Conclusions
In this paper, we revealed the reasons for the negative impact of HOI on coreference resolution. We showed that HOI actually increases and thus worsens the anisotropy of span embeddings and makes it difficult to distinguish between related but distinct entities (e.g., pilots and flight attendants). We proposed two methods, LAIR and DSMS, to learn less-anisotropic span embeddings for coreference resolution. LAIR uses the linear aggregation of the first layer and the topmost layer of the Transformer-based contextualized embeddings, such as SpanBERT and ELECTRA. DSMS generates more diversified examples of related but distinct entities by synthesizing documents and by mention swapping.
We evaluated LAIR and DSMS on the OntoNotes benchmark for document-level coreference resolution and the GAP data sets for paragraph-level coreference resolution. Our experiments showed that less-anisotropic span embeddings improve the performance significantly (+2.8 F1 gain on OntoNotes benchmark), achieving new state-of-the-art for performance on the GAP dataset.
We performed ablation studies to test the effectiveness of HOI and LAIR, revealing the reason for the negative impact of HOI methods. We found that (i) HOI-negative encoders such as ELECTRA and SpanBERT output longer-context-encoded contextualized but anisotropic representations, and LAIR can reduce anisotropy without depleting contextual information; (ii) HOI-positive encoders such as ELMo and BERT only encode shorter contexts, and HOI helps incorporate global contextual information from longer contexts.
Acknowledgments
This work was supported by the 2020 Catalyst: Strategic NZ-Singapore Data Science Research Programme Fund, MBIE, New Zealand.
Competing interests
The authors declare none.
























 Open access
Open access