
84 results
Community respiratory viral metrics to inform masking in healthcare settings: A regional consensus approach
-
- Journal:
- Infection Control & Hospital Epidemiology , First View
- Published online by Cambridge University Press:
- 12 February 2024, pp. 1-3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Figures
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp vii-viii
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp xv-xvi
-
- Chapter
- Export citation
Chapter 5 - Benford Agreement Analysis of the Sea Around Us Project’s Fish-Landings Data
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 94-130
-
- Chapter
- Export citation
Chapter 4 - Data Characteristics and the Workflow of Benford Agreement Analysis
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 74-93
-
- Chapter
- Export citation
Chapter 7 - Assessing the Impacts of Problematic Benford Validity
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 169-187
-
- Chapter
- Export citation
Index
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 204-208
-
- Chapter
- Export citation
Chapter 3 - Benford’s Law and Assessing Conformity
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 24-73
-
- Chapter
- Export citation
Preface
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp xiii-xiv
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp iv-iv
-
- Chapter
- Export citation
Chapter 6 - Benford Agreement Analysis of US and Global COVID-19 New Cases Data
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 131-168
-
- Chapter
- Export citation
References
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 196-203
-
- Chapter
- Export citation
Tables
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp ix-xii
-
- Chapter
- Export citation
Chapter 1 - Introduction
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 1-10
-
- Chapter
-
- You have access
- HTML
- Export citation
Contents
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp v-vi
-
- Chapter
- Export citation
Chapter 2 - Validity and Self-Reported Data
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 11-23
-
- Chapter
-
- You have access
- HTML
- Export citation
Chapter 8 - Conclusion
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 188-195
-
- Chapter
- Export citation

Applying Benford's Law for Assessing the Validity of Social Science Data
-
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023
Optimising MWA EoR data processing for improved 21-cm power spectrum measurements—fine-tuning ionospheric corrections
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 39 / 2022
- Published online by Cambridge University Press:
- 14 October 2022, e047
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The redshifted cosmological 21-cm signal emitted by neutral hydrogen during the first billion years of the universe is much fainter relative to other galactic and extragalactic radio emissions, posing a great challenge towards detection of the signal. Therefore, precise instrumental calibration is a vital prerequisite for the success of radio interferometers such as the Murchison Widefield Array (MWA), which aim for a 21-cm detection. Over the previous years, novel calibration techniques targeting the power spectrum paradigm of EoR science have been actively researched and where possible implemented. Some of these improvements, for the MWA, include the accuracy of sky models used in calibration and the treatment of ionospheric effects, both of which introduce unwanted contamination to the EoR window. Despite sophisticated non-traditional calibration algorithms being continuously developed over the years to incorporate these methods, the large datasets needed for EoR measurements require high computational costs, leading to trade-offs that impede making use of these new tools to maximum benefit. Using recently acquired computation resources for the MWA, we test the full capabilities of the state-of-the-art calibration techniques available for the MWA EoR project, with a focus on both direction-dependent and direction-independent calibration. Specifically, we investigate improvements that can be made in the vital calibration stages of sky modelling, ionospheric correction, and compact source foreground subtraction as applied in the hybrid foreground mitigation approach (one that combines both foreground subtraction and avoidance). Additionally, we investigate a method of ionospheric correction using interpolated ionospheric phase screens and assess its performance in the power spectrum space. Overall, we identify a refined RTS calibration configuration that leads to an at least 2 factor reduction of the EoR window power contamination at the
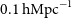 $0.1 \; \textrm{hMpc}^{-1}$
scale. The improvement marks a step further towards detecting the 21-cm signal using the MWA and the forthcoming SKA low telescope.
$0.1 \; \textrm{hMpc}^{-1}$
scale. The improvement marks a step further towards detecting the 21-cm signal using the MWA and the forthcoming SKA low telescope.
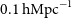
A comparison of grazing v. zero-grazing on early-lactation dairy cow performance
-
- Journal:
- The Journal of Agricultural Science / Volume 160 / Issue 1-2 / February 2022
- Published online by Cambridge University Press:
- 19 April 2022, pp. 127-136
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
