


INTRODUCTION
Disease surveillance in both animal and public health fields involves the ongoing systematic collection, analysis, interpretation and timely communication of health-related data [Reference Thacker and Berkelman1]. The purpose of surveillance activities may include monitoring of endemic diseases and the impact of control measures or the identification of (re-)emerging and exotic diseases that may have a significant impact upon public health, animal health, welfare and international trade [Reference Stärk2]. Animal health surveillance includes animal conditions which may pose a threat to human health – either directly or via food products – even where such conditions are unapparent in the animal itself [3]. The output of surveillance programmes assists in setting priorities and guiding effective prevention and control strategies. It also helps to monitor the progress and success of intervention programmes and, in the animal health field, to demonstrate the infection- and hazard-free status of animals and animal-derived products [4]. Ensuring that surveillance programmes are fit for purpose is therefore paramount.
The costs of obtaining surveillance information need to be balanced against the benefits derived. The importance of ensuring that public health systems are efficient and effective is increasingly being recognized [Reference Bravata5–Reference Meynard7] and this applies equally to animal health surveillance systems [Reference Hu6, Reference Knight-Jones8]. Improving the efficiency of surveillance is a key goal of the UK's Veterinary Surveillance Strategy [3]. Evaluation of surveillance programmes is essential to ensure that limited resources are effectively used to provide the evidence required for protecting animal (and human) health. Such evaluations can lead to changes in surveillance methods, resulting in considerable financial savings [Reference Hesterberg, Cook and Stack9]. Evaluation of surveillance can play an essential part in establishing and maintaining international trust [Reference Nabarro, Relman, Choffnes and Mack10]. Quality assurance is essential to maintain credibility, which is particularly important for inter-community and international trade with animals and animal-derived products.
Evaluation is defined as the systematic and objective assessment of the relevance, adequacy, progress, efficiency, effectiveness and impact of a course of actions, in relation to objectives and taking into account the resources and facilities that have been deployed [11]. Currently, there is no universally accepted standard for evaluation of animal health surveillance. Many different approaches have been applied [e.g. Reference Stärk2, Reference Birch12–Reference Vidal Diez, Arnold and Del Rio Vilas16] without consistency or apparent agreement on what is optimal. Evaluation of human health surveillance systems is more commonly practised and several generic guidelines exist for public health surveillance evaluation [17–20]. These typically include the assessment of a series of attributes such as flexibility, acceptability and timeliness, using a combination of qualitative and quantitative techniques. Probably the most well-established guidelines for evaluating public health surveillance systems are those published by the Centers for Disease Control and Prevention (CDC) in the USA [17]. The CDC guidelines suggest ten attributes that may be assessed as part of a balanced evaluation process: simplicity, flexibility, data quality, acceptability, sensitivity, positive predictive value, representativeness, timeliness, stability and usefulness. However, the applicability of these human health guidelines to animal health surveillance is unclear given differences in emphasis and prioritization of surveillance objectives between the disciplines. For example, cost-effectiveness might be considered to be most important in animal health surveillance programmes whereas diagnostic accuracy may be more valued in public health schemes because of the consequences of classification errors for the individual case. An animal health-specific evaluation framework that is both comprehensive and generic is required but not currently available.
The aim of this systematic review is to identify and examine existing frameworks for surveillance evaluation in animal health, public health and allied disciplines, to discover which techniques are currently being used across the globe and to assess their strengths and weaknesses. This information will be used to inform the development of a generic evaluation framework for animal health surveillance systems in Great Britain.
METHODS
We sought to identify published and unpublished reports of evaluations conducted on surveillance systems in the following areas: animal health/disease; public health; environmental health; bioterrorism; and public security.
Literature sources and search strategies
Three sources were searched by one author (J.A.D.) for relevant reports: Web of Science databases of peer-reviewed articles; Google search of grey literature; and conference proceedings of the International Society for Veterinary Epidemiology and Economics, and the Society for Veterinary Epidemiology and Preventive Medicine. Additionally, we identified additional articles from the bibliographies of included articles. We searched for literature containing combinations of the terms ‘surveillance’, ‘evaluation’, ‘analysis’ and ‘performance’ using the Boolean query: Topic=surveillance AND Title=(surveillance AND (evaluat* OR analy* OR perform*)) OR (evaluat* AND perform*). The use of wildcards (*) ensured that articles containing any variation of each of the search terms were identified (e.g. evaluat* would detect evaluate, evaluates, evaluation, evaluations, evaluating, evaluative and evaluator). We used identical search terms for all sources. We restricted the searches of Web of Science and Google to articles published in the last 15 years (i.e. 1995–2010) and that of the conference proceedings to articles published in the last 10 years (i.e. 2000–2010).
Study selection and data abstraction
The literature retrieval process is illustrated in Figure 1. Articles were screened using the criteria detailed in Figure 1. Primary exclusion criteria were applied to the titles and abstracts of articles. The full texts of these articles were then obtained and the secondary exclusion criteria applied. Data extracted from the articles about each surveillance system included: aim of evaluation exercise, surveillance system evaluated, location, species involved, disease/condition, data collected, collection method, analysis method performed, specific attributes assessed, use of performance indicators (PIs), and the perceived strengths and weaknesses of each evaluation approach. Articles were included in this review if they presented data from the estimation of at least one attribute of a surveillance system.
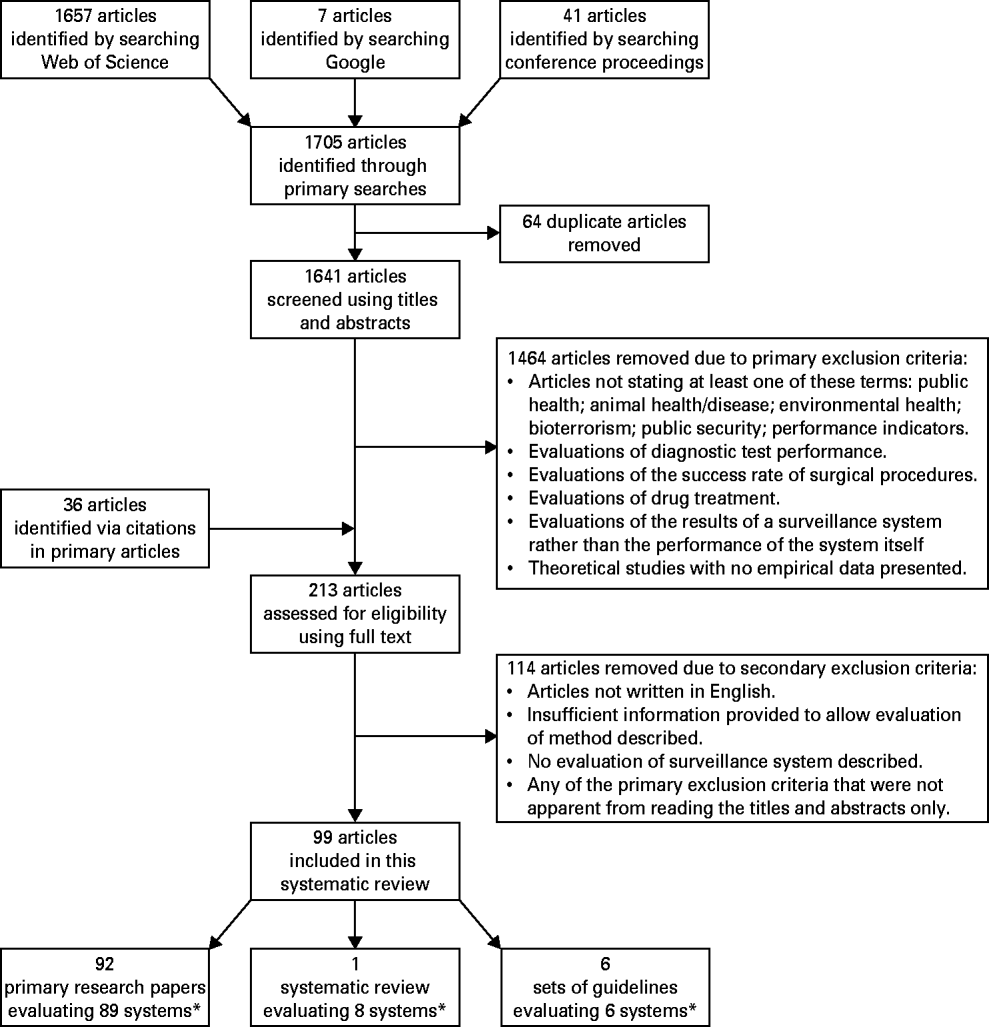
Fig. 1. Flow chart documenting literature retrieval and criteria used to select articles for inclusion in the systematic review of frameworks for evaluating human and animal health surveillance systems. * The total number of surveillance system evaluations was 101: one system included in the systematic review, and another that was included in one of the sets of guidelines, were both already identified and included in this review as primary research papers.
RESULTS
A total of 1741 articles were screened for this review: 1705 primary articles identified through searching Web of Science, Google and epidemiology conference proceedings, and 36 additional articles identified by examining the citation lists of these primary articles (Fig. 1). Nineteen articles written in languages other than English were excluded. After applying all exclusion criteria (Fig. 1), 99 articles remained. Of these, 92 were primary research papers [Reference Hu6–Reference Hesterberg, Cook and Stack9, Reference Birch12–Reference Vidal Diez, Arnold and Del Rio Vilas16, Reference Aavitsland, Nilsen and Lystad21–Reference Yih103], one was a systematic review [Reference Jajosky and Groseclose104], and six were sets of guidelines for evaluating surveillance systems [17, Reference Buehler105–Reference Sosin109] (Fig. 1). Data from these 99 articles were extracted and included in this review.
Health conditions for which surveillance systems were evaluated
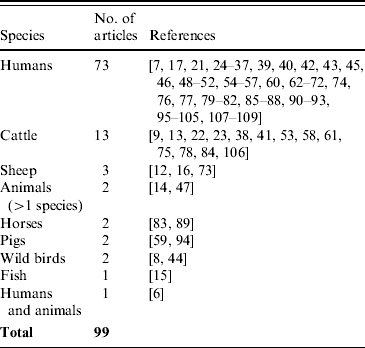
The 99 articles included evaluations of 101 different surveillance systems: some articles evaluated more than one system and some systems were evaluated (in different ways) by more than one article. Most (73/99) of the articles on surveillance system evaluations were for human diseases, with far fewer for animal diseases: cattle were the most frequent subject of the animal health surveillance systems that had been evaluated (13/99) (Table 1). Only one article integrated the evaluation of human and animal health surveillance, in a study of West Nile virus epidemiology [Reference Hu6].
Table 1. Species for which health surveillance systems were evaluated
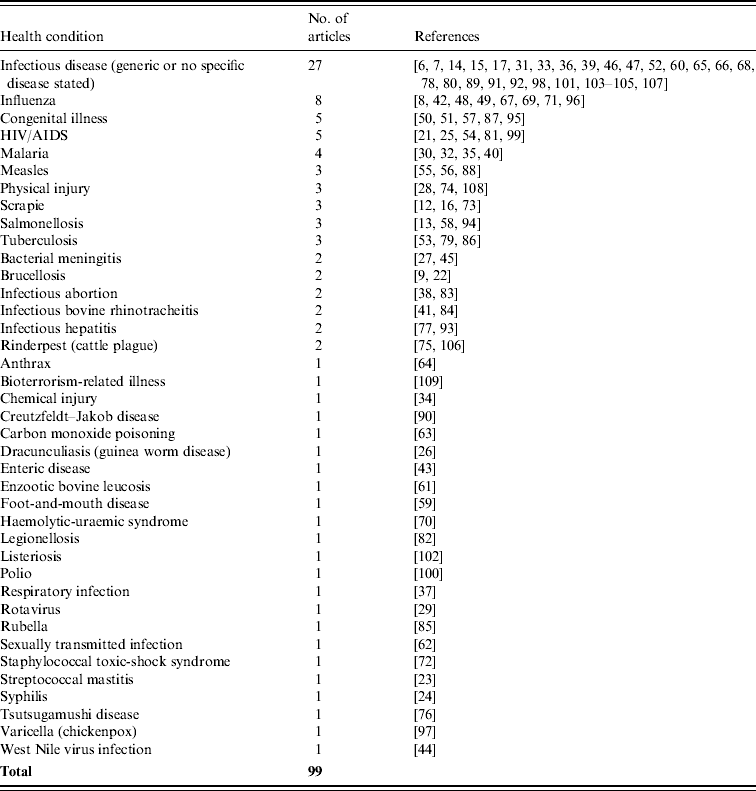
Surveillance systems for 38 named diseases (27 infectious and 11 non-infectious) were evaluated within the 99 articles (Table 2). Influenza was the disease for which surveillance was most frequently evaluated (eight articles: seven in humans and one in wild birds). While the majority of surveillance system evaluations focused on a single disease, about one quarter (27/101) did not specify a particular disease with the implication that the evaluation was applied generically across a range of conditions. Of those that could be considered generic, a variety of information sources were exploited. Two evaluations were internet-based, using the web as an automated system for real-time monitoring of online information about emerging diseases [Reference Hu6, Reference Brownstein and Freifeld36]. One evaluated system logged and rapidly analysed telephone calls made by members of the public to the NHS Direct helpline [Reference Doroshenko46]. Four evaluations focused on the ability of surveillance systems to detect disease outbreaks early, including two dedicated to illnesses among military personnel engaged in battle [Reference Meynard7, Reference Izadi65, Reference Jefferson66, Reference Buehler105]. Finally, three sets of generic guidelines were presented from which more specific frameworks could be developed [17, Reference Romaguera, German, Klaucke, Teutsch and Churchill91, Reference Malecki, Resnick and Burke107]. Of these, one outlined a novel stepwise process by which a prioritized list of evaluation criteria may be generated for any chosen disease or health indicator [Reference Malecki, Resnick and Burke107]. Although this system was developed for the selection and evaluation of public health indicators from environmental threats, its high flexibility suggests it should be adaptable for the evaluation of animal health surveillance.
Table 2. Health conditions for which surveillance systems were evaluated
Locations of surveillance systems evaluated
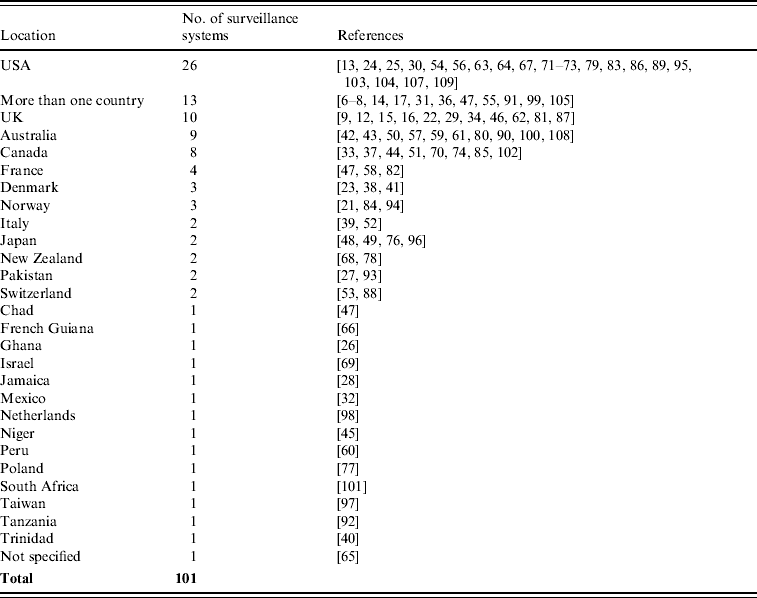
The 99 evaluations included in this review covered 101 surveillance systems located unevenly across the globe and dominated by the USA (Table 3). Most evaluations related to surveillance systems implemented in North America (35/101), followed by Europe (26/101), Australasia (11/101), Asia (6/101), Africa (5/101) and South America (4/101). Thirteen articles described the evaluation of surveillance systems located in more than one country (Table 3).
Table 3. Locations where the 101 surveillance systems whose evaluations were included in this review were implemented
Methods employed to evaluate surveillance systems
Quantitative approaches were applied far more commonly than qualitative approaches, and this was especially true for evaluations of animal health surveillance. A summary of the methods used for evaluating surveillance systems appears in Table 4. The commonest method (employed in 39/101 evaluations) was to apply simple quantitative approaches such as measuring the proportion of actual cases reported or the percentage of record cards completed [e.g. Reference Carrieri39, Reference Harpaz56, Reference Mariner75, Reference Mazurek77, Reference Rumisha92, Reference van Benthem and van Vliet98, Reference Weber101]. Comparison of one surveillance system with another to estimate the relative sensitivity of each (the proportion of cases in the population under surveillance that are detected by the surveillance system) was also frequently done [e.g. Reference Hesterberg, Cook and Stack9, Reference Betanzos-Reyes32, Reference Fujii49, Reference Hutchison and Martin61, Reference Lesher72, Reference McIntyre78]. Several advanced statistical approaches were employed to evaluate surveillance systems. These included 19 articles that employed simulation modelling (used far more commonly in evaluations of animal than human health surveillance), seven articles on stochastic scenario tree modelling [Reference Knight-Jones8, Reference Hesterberg, Cook and Stack9, Reference Hadorn14, Reference Hadorn and Stark53, Reference Herndandez-Jover59, Reference Hutchison and Martin61, Reference Watkins100], five articles using the capture–recapture (CRC) technique [Reference Barat30, Reference Chadee40, Reference Guasticchi52, Reference Nardone82, Reference Rahi and Dezateux87] and one article which quantified the effort applied in looking for infection (expressed as the number of negative measles test results per 100 000 population) which gave an indication of the confidence that could be associated with the conclusion of infection being absent if it were not found [Reference Harpaz and Papania55]. Qualitative approaches based on subjective scoring systems or expert opinion were less commonly used and mainly restricted to evaluations of human health surveillance [e.g. Reference He, Zurynski and Elliott57, Reference Ihekweazu62, Reference Jefferson66, Reference Robotin90, Reference Sandberg94, Reference Weber101]. Many articles used more than one approach to evaluate a surveillance system, for example combining quantitative measures of data completeness (an indication of quality) with qualitative impressions of acceptability of the system to users [e.g. Reference Doroshenko46, Reference He, Zurynski and Elliott57, Reference Ihekweazu62, Reference Jefferson66, Reference Miller80, Reference Weber101].
Table 4. Summary and distribution of methods for evaluating surveillance systems used in the 99 articles included in this review
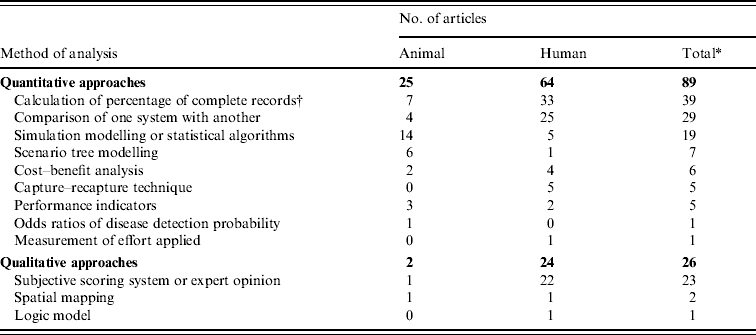
* Figures do not sum to 99 because several articles used more than one approach.
† One article using this approach evaluated health surveillance in both animals and humans.
Attributes of surveillance systems
The range and number of attributes assessed by the different studies varied widely. In total, 23 different attributes of surveillance systems were assessed across the 99 articles (Fig. 2). These attributes are defined in Table 5. The most frequently assessed attributes were sensitivity, timeliness and data quality (Fig. 2). The frequency distribution of the number of attributes assessed per article was positively skewed, with approximately half the articles (48/99) assessing one or two attributes only and very few articles assessing more than ten attributes (Fig. 3). Twenty-four articles reported on the assessment of a single attribute: sensitivity (13 articles); cost-effectiveness (four articles); representativeness (three articles); timeliness (three articles); and acceptability (one article). Attributes such as consistency of performance over time [Reference Walker99], system security [Reference Mitchell, Williamson and O'Connor108], and surveillance feasibility [Reference Meynard7] were assessed in a single article each (Fig. 2).
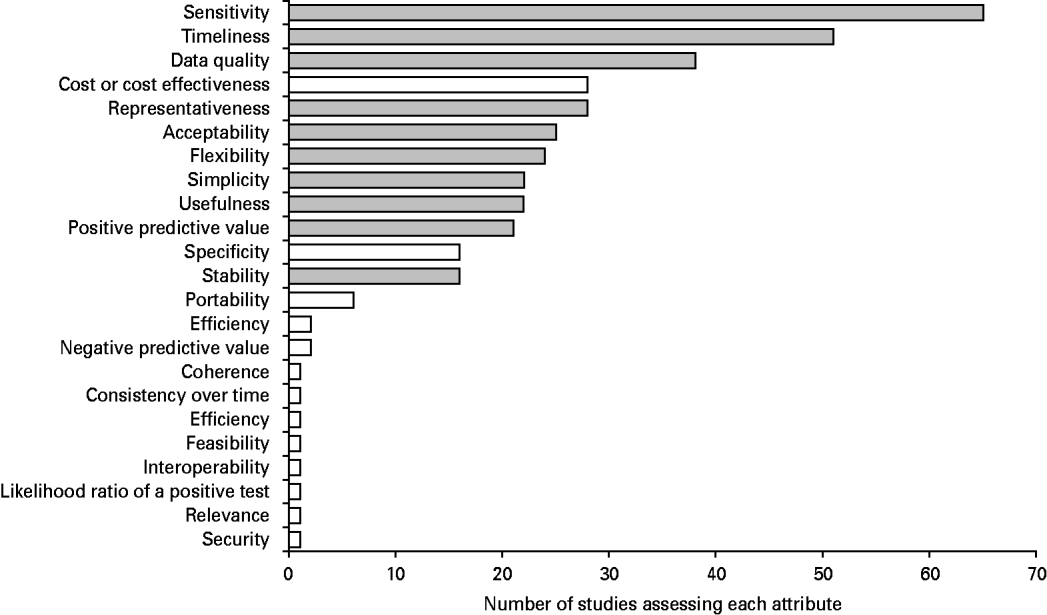
Fig. 2. Surveillance system attributes assessed by the 99 studies included in this review. Attributes recommended for evaluation in the Centers for Disease Control and Prevention guidelines [17] are shaded in grey.
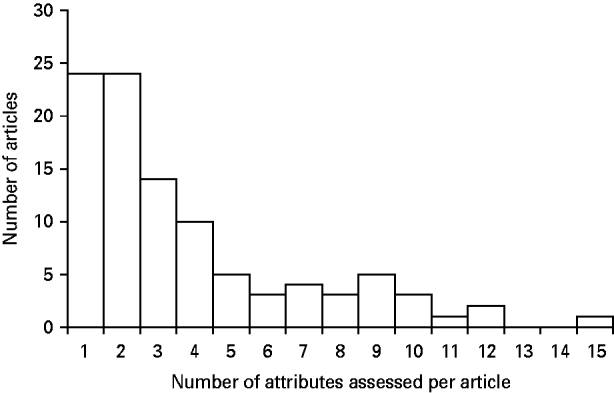
Fig. 3. Frequency distribution of the number of surveillance attributes assessed per article.
Table 5. Definitions of surveillance system attributes assessed in the 99 articles included in this review (sources of definitions: [Reference Meynard7, 17, Reference Walker99, Reference Buehler105, Reference Mitchell, Williamson and O'Connor108])

Almost a quarter (23/99) of the articles specifically stated as an objective to assess one or more of the ten attributes recommended in the CDC guidelines for evaluating public health surveillance systems [17]. Only five articles [Reference Moran and Fofana15, Reference Betanzos-Reyes32, Reference Carpenter, Chriel and Greiner38, Reference Morris81, Reference Phillips86] did not assess any of the ten attributes recommended by CDC and all of these five articles assessed the cost-effectiveness of surveillance programmes. A variety of ways was used to assess cost-effectiveness. By determining the relative costs of several regimens to each generate a 1% increase in surveillance sensitivity, a comparison of efficacy was achieved which allowed the most cost-effective regimen to be recommended for surveillance of influenza in wild birds [Reference Knight-Jones8]. A slightly different approach was employed in an evaluation of human tuberculosis surveillance, where cost per 1% increase in PIs was used to determine the most efficient use of resources programmes [Reference Phillips86]. While comparing the cost-effectiveness of two or more surveillance regimens may be relatively straightforward, conducting a cost–benefit analysis may prove more difficult. Costs may be difficult to estimate [Reference Phillips86] and social benefits may be difficult to quantify [Reference Morris81] which means precise cost–benefit evaluations may not always be possible.
Other non-CDC attributes that were commonly assessed included specificity (the proportion of true non-events correctly classified as such, the inverse being the false alarm rate: assessed in 16/99 articles) and portability (how well the system can be duplicated in another setting: assessed in 6/99 articles). Several articles described schemes which set out to assess more attributes than were subsequently possible due to lack of reliable data. This was particularly apparent for specificity [Reference Arscott-Mills, Holder and Gordon28, Reference Brownstein and Freifeld36], sensitivity [Reference Gazarian50, Reference Hendrikx58] and representativeness [Reference Doroshenko46, Reference Gazarian50], where accurate data on the presence/absence of infection and the demographic heterogeneity is needed if these attributes are to be calculated. Representativeness in particular is rarely assessed fully [Reference Lynn73, Reference Del Rio Vilas and Pfeiffer110].
Relationships between attributes were rarely investigated. An exception was a Bayesian network model for analysis of detection performance in surveillance systems, an approach which offered insights into the trade-offs between sensitivity, specificity and timeliness [Reference Izadi65].
Performance indicators
Five articles described the development and calculation of PIs to evaluate surveillance systems for tuberculosis in humans [Reference McNabb79, Reference Phillips86], rinderpest (cattle plague) [Reference Mariner75, 106] and bovine clinical salmonellosis [Reference Hendrikx58]. PIs are time-delimited, denominator-based statistics [Reference Mariner75] which can be used to monitor the implementation of surveillance systems rather than for the periodic evaluation of surveillance activities to determine whether these activities are meeting their objectives. They allow the progress of surveillance to be monitored by providing quantitative comparisons of elements of the activity over time [106]. An example of a PI would be the number of cases of the condition of interest properly reported within 7 days of diagnosis, per 100 000 population. In the case of the rinderpest eradication programme, PIs were further subdivided into diagnostic indicators [106]. Diagnostic indicators are more detailed than PIs and measure specific sub-steps in the surveillance process [Reference Mariner75]. Examples of diagnostic indicators include the number of individuals sampled for which results were reported, or the percentage of districts with up-to-date report registries.
Generic evaluation frameworks
Four articles described three generic evaluation frameworks which could be applied to a range of diseases and situations [Reference Meynard7, 17, Reference Buehler105, Reference Malecki, Resnick and Burke107]. The generic nature of these frameworks comes about from their common structure which allows priorities to be varied according to the specific objectives of each surveillance programme. A series of core elements (such as zoonotic importance or public concern) reflect the different purposes of surveillance and may be chosen accordingly. Each of these core elements contains a selection of criteria to be evaluated (such as strength of evidence). The criteria are judged through assessment of attributes of the surveillance system. By varying the priority of the core elements depending on the surveillance objectives and choosing a different selection of criteria to be evaluated using a range of attributes each time, these frameworks appear flexible and truly generic.
DISCUSSION
A distinct lack of standardization exists regarding the best approach for evaluating surveillance systems in order to facilitate decision-making in the fields of animal or public health. The ten attributes recommended for evaluation by CDC [17] – simplicity, flexibility, data quality, acceptability, sensitivity, positive predictive value, representativeness, timeliness, stability and usefulness – were often assessed but usually singly or in pairs rather than all ten together. An evaluation based on only one or two attributes is not likely to provide a complete, unbiased evaluation of a surveillance system since multiple indicators are needed for tracking the implementation and effects of a programme [17]. Given that evaluation is defined as the systematic assessment of the quality of something, the large proportion of articles included in this review that assessed only one or two attributes cannot be considered complete evaluations. Indeed, it could be argued that only about one quarter of the articles in this review (27/99) performed a systematic assessment, by addressing five or more attributes (Fig. 3) to form a balanced evaluation of a surveillance system. While the optimal number of attributes for assessment is likely to vary depending on the objectives of each evaluation, between five and 10 attributes per evaluation are likely to be required to provide a complete evaluation. Defining too few will not result in a systematic assessment and defining too many can detract from the evaluation's goal by making it a huge task to gather data and making interpretation difficult. In some cases a complete evaluation may not be required to achieve the objectives of the evaluation process. For example, an evaluation of a limited number of parameters allowed the relative value of different surveillance strategies to be assessed resulting in recommendations that allowed substantial cost savings [Reference Hesterberg, Cook and Stack9].
Focusing on the relative value and relationships between attributes may allow the identification of a limited number of ‘core’ characteristics which when all considered will allow for a holistic evaluation. For example, simplicity appears to be positively related to acceptability, with staff willingness to participate in surveillance being high if the system is simple and easy to use [Reference Buehler105]. In the same way, a reliable system (one that functions without failure, which often means absence of complex technology) is likely to have higher acceptability to users than a system that frequently fails [Reference Jefferson66]. Thus, assessment of acceptability should capture much of the essence of simplicity and reliability too. Similarly, the three attributes sensitivity, specificity and positive predictive value all give related information and so assessment of one or two might be sufficient. Some authors have made suggestions for grouping related or comparable attributes [Reference Malecki, Resnick and Burke107, Reference Sosin109]. However, it may still be important to evaluate several related attributes individually. For example, a system could be extremely sensitive (detecting all cases of a disease) but if specificity was low, many of the apparently positive cases would in fact be false positives. This would dilute any benefit provided by the high sensitivity. Because sensitivity and specificity are related, but provide different information, they ought to be estimated simultaneously [Reference Bravata5], taking into account the evaluation objectives. Theoretical work indicates it may be possible to incorporate sensitivity, specificity and timeliness into a single metric [Reference Kleinman and Abrams111] although interpretation of the combined measure is not straightforward. In addition, some attributes may provide information that is more relevant to the assessment of the worth of a surveillance system than other related attributes. For example, it has been suggested that the number of lives saved could be used rather than timeliness to evaluate surveillance systems for outbreak detection [Reference Kleinman and Abrams112].
At best, only moderate agreement seems to exist concerning which attributes of a surveillance system should be assessed. This may be because the value of each attribute to decision-makers varies depending on the surveillance objectives. A surveillance system designed to prove freedom from infection will require a higher sensitivity than a system which tracks the prevalence of a widespread endemic disease, for example. Although sensitivity and timeliness were each assessed in over half of the studies included in this review, this may be as much due to data availability and their ease of calculation rather than their particular usefulness to decision-makers in facilitating early detection of infection. Surveillance objectives were often not stated in the articles reviewed and so the reasons for choosing certain attributes for assessment were not always apparent. The objective of the evaluation process should be clearly stated and the evaluation designed accordingly, rather than being dictated by convenience. An assessment of the purpose of the surveillance activity should be included as part of the evaluation process.
Both quantitative and qualitative methods were used as part of the evaluation process. The commonest approach to evaluation used in the systems reviewed – comparing surveillance output (such as the number of reported cases of the disease under surveillance) with another dataset (e.g. official records of the incidence of the same disease) – should be applied with caution. In the absence of a reliable gold standard against which to compare, this approach has the potential to introduce significant bias [Reference Del Rio Vilas and Pfeiffer110]. In such situations, relative sensitivity rather than true sensitivity of the surveillance system is being determined [e.g. Reference Lynn73, Reference Phillips86, Reference Tan97]. These figures may be very different, and artificially inflate the apparent sensitivity of the system. Sensitivity need not be high for a surveillance system to be useful (exactly how high it needs to be will vary with surveillance objectives) but the surveillance methodology must remain stable over time if trends in sensitivity are to be interpreted meaningfully [17, Reference Magnani113]. A single measurement of relative sensitivity is on its own arguably of little use.
A possible solution to under-ascertainment is the use of CRC methods to estimate the unobserved population with the event under study. This gives information on the size of the ‘true’ population against which surveillance output can be assessed. This approach, commonly used in ecological studies [Reference Jolly114], is increasingly being applied to evaluate public health surveillance [Reference Barat30, Reference Chadee40, Reference Guasticchi52, Reference Nardone82, Reference Rahi and Dezateux87], but has rarely been applied in animal health surveillance evaluation [Reference Del Rio Vilas115]. The aim of CRC models is to estimate the number of individuals with the characteristics of interest that are not detected by any of the surveillance sources in place. Once this estimate is obtained, it is possible to compute the total population with that characteristic, as well as the sensitivity of the surveillance system [Reference Del Rio Vilas and Pfeiffer110]. Greater application of CRC methods would enhance animal health surveillance evaluation by improving the accuracy of sensitivity estimates. It is likely to be beneficial to use a combination of quantitative (e.g. CRC) and qualitative (e.g. interviewing the surveillance actors) techniques to assess each attribute so that information is captured on the possible reasons for a certain measured level and perhaps indicate actions which may be undertaken to improve it.
It is surprising that economic evaluation is not an integral part of more surveillance evaluation programmes: only 28/99 articles included an assessment of cost or cost-effectiveness. The cost of obtaining surveillance information needs to be balanced against the benefits derived, so examining the outputs of surveillance is only half the process. The most commonly followed guidelines – those of CDC [17] – suggest that costs may be judged relative to benefits but do not explicitly advocate that this be an integral part of all surveillance evaluations nor indicate how this may be done. This is an area that could usefully be expanded, since the CDC guidelines were the source most frequently referred to by articles included in the present review. While ensuring cost-effectiveness might be expected to be of higher priority in animal rather than human health surveillance (where social factors might be valued higher), there appears to be no difference between human and animal surveillance schemes, with 29% (21/73) of human studies and 27% (7/26) of animal studies including cost-effectiveness as part of the surveillance evaluation process.
PIs were used in the evaluation of only four surveillance programmes covering three diseases (two of animals and one of humans). Given that PIs allow continuous monitoring – as opposed to periodic evaluation – of a surveillance system, it is perhaps surprising that they are not more widely documented. One reason may be a perception that they require the collection and analysis of lots of detailed data. However, this need not – in fact, should not – be the case [106]. PIs should reduce the wide range of quantitative information to one or two measures. Such measures can be even more informative if they include a measure of cost-effectiveness, such as cost per percentage point increase in PIs [Reference Phillips86]. PIs should be set at a realistic target balancing minimal requirements with objectives for improvement [Reference Mariner75]. Another possible reason for the scarcity of PIs in the literature could be if they are used as part of an ongoing internal monitoring programme but not published as part of a formal evaluation. Proof that PIs are a valuable and effective tool comes from their pivotal role in the recent announcement of global rinderpest elimination, the first ever animal disease to be wiped out [116]. Increased use – and reporting – of PIs would enhance animal health surveillance evaluation by providing robust summary quantitative measures of changes in disease patterns over time.
Clear definitions and agreement on what each attribute, indicator or criterion actually measure is essential if surveillance evaluations are to be comparable and universally understood. The most accepted reference for definitions of attributes appears to be the CDC guidelines for evaluating public health surveillance systems [17], although not everyone appears to follow these. For example, completeness and accuracy are included under the definition of sensitivity in one paper [Reference Sekhobo and Druschel95] while they are taken to indicate quite different things elsewhere [17]. Use of non-standard terms can also lead to confusion. The distinction between ‘reporting efficiency’ and sensitivity is not clear in one article [Reference Atchison29]. Similarly, the difference between generalizability and portability is not explicit in an evaluation framework [Reference Sosin109]. Last, the use of the word ‘quality’ to describe surveillance schemes in a general sense [Reference Walker99] (as opposed to meaning the completeness and accuracy of data) has the potential to introduce misunderstanding. Definitions for the terms used in this review are included in Table 5 and discussions have been initiated within the veterinary surveillance community to clarify and where possible standardize terminology [Reference Hoinville117]; these discussions continued at a workshop prior to the International Conference on Animal Health Surveillance in May 2011 (http://www.animalhealthsurveillance.org/).
In conclusion, there is currently no universally accepted standardized process to evaluate surveillance systems for animal and human health. The most commonly cited guidelines for evaluating public health surveillance systems – those of CDC [17] – have been adapted for specific situations in the public health field [Reference Meynard7] and could be adapted for animal health use as they were to produce an evaluation protocol that was applied to evaluate scrapie surveillance in the USA [Reference Lynn73]. However, the CDC guidelines do not provide an ‘off-the-shelf’ framework; rather they include a broad selection of attributes whose use needs to be tailored to each surveillance evaluation, a process which may be far from straightforward. Due to the wide range of system attributes that may be assessed, methods which collapse these down into a small number of grouped characteristics by focusing on the relationships between attributes and their links to the objectives of the surveillance system should be explored further. The application of methods such as CRC and scenario-tree analysis to improve sensitivity estimates is advised. A generic and comprehensive evaluation framework could then be developed consisting of a limited number of common attributes together with several sets of secondary attributes which could be selected depending on the disease or range of diseases under surveillance. If there is to be a benefit to decision-makers, and ultimately result in maximum impact, the outputs of the surveillance need to be interpreted correctly and communicated clearly to all who make use of the system. Economic evaluation should be an integral part of the surveillance evaluation process. This would provide a significant benefit to decision-makers who often need to make choices based on limited or diminishing resources.
ACKNOWLEDGEMENTS
Funding provided by the Department for Food, Environment and Rural Affairs (project code SE4302).
DECLARATION OF INTEREST
None.








