


1 Introduction
This paper aims to find out whether and how speakers track the relative frequency of different patterns of alternation in the lexicon, by investigating speakers’ behavior when they are faced with unpredictability in allomorph selection. Unpredictability may arise when there is phonological neutralization in certain parts of the paradigm, and it may also arise in cases of exceptional (or ‘irregular’) processes. In both cases, the language contains some stems that alternate in a certain way within their paradigms, while other stems show different (or no) alternations, but this difference cannot be attributed to the phonological context. It is then unpredictable based on phonological properties of a stem whether and how it alternates. For instance, in Dutch, open syllable lengthening does not apply to all noun stems, e.g. [xɑt]
 $\tilde{~}$
[xa:.tən] ‘hole, sg
$\tilde{~}$
[xa:.tən] ‘hole, sg
 $\tilde{~}$
pl’ but [kɑt]
$\tilde{~}$
pl’ but [kɑt]
 $\tilde{~}$
[ka.tən], not *[ka:. tən] ‘cat, sg
$\tilde{~}$
[ka.tən], not *[ka:. tən] ‘cat, sg
 $\tilde{~}$
pl’ (Coetzee Reference Coetzee2008). Thus, if a speaker is faced with a new or unknown stem in the singular, it is not predictable whether the plural form has a lengthened vowel or not.
$\tilde{~}$
pl’ (Coetzee Reference Coetzee2008). Thus, if a speaker is faced with a new or unknown stem in the singular, it is not predictable whether the plural form has a lengthened vowel or not.
There are numerous theoretical devices for lexically encoding which stems undergo unpredictable alternations, such as attributing them to underlying phonological differences, marking certain stems as exceptions to phonological processes (Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977, Pater Reference Pater2000, Becker Reference Becker2009), or lexically listing alternants (Pinker & Prince Reference Pinker and Prince1988, Pinker Reference Pinker1999, Albright & Hayes Reference Albright and Hayes2003, Zuraw Reference Zuraw2010). However, lexical encoding/listing alone is not sufficient to explain speakers’ knowledge of unpredictable alternations, since such processes often show some degree of productivity. Productivity shows that speakers have extrapolated knowledge that goes beyond the specific stems involved; speakers must also have grammatical rules or constraint rankings for exceptionful or irregular processes (Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977; Zuraw Reference Zuraw2000, Reference Zuraw2010; Albright & Hayes Reference Albright and Hayes2003; Hayes & Londe Reference Hayes and Londe2006; Pater et al. Reference Pater, Staubs, Jesney and Smith2012). Furthermore, it has been observed that in many cases, the productivity of an alternation reflects the relative frequency of that pattern in the lexicon. This is most directly captured by positing that grammars are probabilistic, and speakers apply rules (or constraint rankings) stochastically.
From this stochastic approach, some basic predictions can be made. First, when speakers must provide an inflected form of a novel stem, as in a wug test (Berko Reference Berko1958), we expect that competing output forms should be generated with probabilities approximating the lexical frequencies of the relevant patterns. In addition, when speakers are asked to judge the acceptability of novel forms, they should have gradient well-formedness intuitions that correlate with statistical trends in the lexicon. This frequency matching prediction has been confirmed in numerous studies of unpredictable allomorphy, including Zuraw (Reference Zuraw2000, Reference Zuraw2002, Reference Zuraw2007, Reference Zuraw2010), Albright, Andrade & Hayes (Reference Albright, Andrade, Hayes, Albright and Cho2001), Bybee (Reference Bybee2001), Albright (Reference Albright2002a, Reference Albrightb), Albright & Hayes (Reference Albright and Hayes2003), Ernestus & Baayen (Reference Ernestus and Baayen2003), Hayes & Londe (Reference Hayes and Londe2006), Jun & Lee (Reference Jun and Lee2007), Becker (Reference Becker2009), Jun (Reference Jun2010) and others.
It is thus clear that speakers have knowledge of at least some statistical lexical patterns. At the same time, there is evidence that speakers do not apply all processes as productively as their frequency in the lexicon would lead one to expect. This, too, is expected under a probabilistic grammatical approach, in which the probability of a rule or constraint ranking may be modulated by constraints on grammars and by prior expectations about likely processes or grammars. A number of recent studies on this issue focus on comparison between ‘natural’ vs. ‘unnatural’ patterns, testing whether speakers are less likely to generalize processes that have complex or phonetically unmotivated conditioning environments (Wilson Reference Wilson2006, Moreton Reference Moreton2008, Hayes et al. Reference Hayes, Zuraw, Siptar and Londe2009, Becker, Ketrez & Nevins Reference Becker, Ketrez and Nevins2011, Do Reference Do2013, Hayes & White Reference Hayes and White2013, Jun Reference Jun2015). In this study, we will focus on a different constraint, concerning the directionality of processes relating allomorphs. We test the single base hypothesis (Albright Reference Albright2002a, Reference Albright, Downing, Alan Hall and Raffelsiefen2005, Reference Albright and Good2008), according to which speakers identify a designated base form in the paradigm, and are constrained to learn rules that project other allomorphs based on this privileged base allomorph. In order to test this, we performed wug tests on Seoul Korean verbal paradigms. For reasons to be discussed in Section 1.1, we assume that the base form of Seoul Korean verbal paradigms is a pre-vocalic allomorph, found before a particular vowel-initial suffix. Adopting this assumption, we performed wug tests in two directions. In the forward formation test, speakers were presented with nonce verb stimuli in the pre-vocalic (pre-V) base form and were required to generate a pre-consonant (pre-C) non-base response, whereas in backward formation test, the stimulus–response relation was switched. The prediction is that responses in the forward (base
 $\rightarrow$
non-base) direction should accurately reflect statistical trends in the lexicon, whereas responses in the reverse (non-base
$\rightarrow$
non-base) direction should accurately reflect statistical trends in the lexicon, whereas responses in the reverse (non-base
 $\rightarrow$
base) direction should not.
$\rightarrow$
base) direction should not.
The results show that in the forward direction, speakers do indeed generalize patterns in a way that approximates the probability of different pre-vocalic to pre-consonantal (base
 $\rightarrow$
non-base) correspondences in the Seoul Korean verbal lexicon. This result confirms that speakers do have the capacity to match lexical frequencies, as reported in many previous studies. However, speakers’ responses in the backward formation test do not correlate closely with the probability of pre-consonantal to pre-vocalic (non-base
$\rightarrow$
non-base) correspondences in the Seoul Korean verbal lexicon. This result confirms that speakers do have the capacity to match lexical frequencies, as reported in many previous studies. However, speakers’ responses in the backward formation test do not correlate closely with the probability of pre-consonantal to pre-vocalic (non-base
 $\rightarrow$
base) correspondences. Instead, we will show that responses in the backward formation test are best modeled using probabilities of mappings in the forward (base
$\rightarrow$
base) correspondences. Instead, we will show that responses in the backward formation test are best modeled using probabilities of mappings in the forward (base
 $\rightarrow$
non-base) direction. This asymmetry is predicted by the single base hypothesis (Albright Reference Albright2002a, Reference Albrightb, Reference Albright, Downing, Alan Hall and Raffelsiefen2005, Reference Albright and Good2008), in which forward, as opposed to backward formation rules play a privileged role in speakers’ morphological grammar.
$\rightarrow$
non-base) direction. This asymmetry is predicted by the single base hypothesis (Albright Reference Albright2002a, Reference Albrightb, Reference Albright, Downing, Alan Hall and Raffelsiefen2005, Reference Albright and Good2008), in which forward, as opposed to backward formation rules play a privileged role in speakers’ morphological grammar.
The rest of this paper is organized as follows. In the remainder of this section, we provide background information about Seoul Korean verbal paradigms, presenting the probabilities of forward and backward formation rules for the alternation classes of Seoul Korean verbs, based on Albright & Hayes’s (Reference Albright, Hayes and Maxwell2002, Reference Albright and Hayes2003) minimal generalization learner. We then discuss potential models of allomorph selection and their predictions for wug tests on Seoul Korean verbal paradigms. Section 2 describes the method and procedure of the experiments, and reports the results. In Section 3, we compare different models of the experimental results, and show that the results of the backward formation test are more consistent with the predictions of forward formation rules than those of backward formation rules. In Sections 4 and 5, we discuss alternative accounts and remaining puzzles. The final section concludes this study.
1.1 Seoul Korean verbal paradigms
Seoul Korean has a three-way laryngeal contrast between lenis, aspirated and tense (or glottalized) obstruents, as shown in Table 1.
Table 1 Three-way laryngeal distinction among obstruents in Korean.
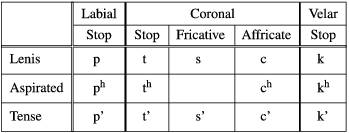
All obstruents neutralize to their homorganic lenis stop counterparts in coda position: coronal stops, affricates and fricatives neutralize to [t], labial stops to [p] and velar stops to [k]. This coda neutralization process applies with no exception, often yielding stem-final alternations in the verbal paradigm, which will be illustrated shortly.
All verb forms in Korean are suffixed, and verb stems never occur in isolation. Verbal suffixes may be classified into the following four types, based on Choi (Reference Choi1985) and Kang (Reference Kang, Kuno, Lee, Whitman, Maling, Kang, Sells and Sohn2006).

With respect to stem-final (non-)alternation, (ɨ)C-initial and (Cɨ)C-initial suffixes behave like V-initial and C-initial suffixes, respectively, and thus we will focus on the latter two suffix types.
The process of coda neutralization creates unpredictable alternations in Seoul Korean verbal paradigms. Since stem-final obstruents are neutralized before C-initial suffixes but remain distinct before V-initial suffixes, stems may exhibit allomorphy, as shown in (2).

Coda neutralization is an exceptionless and fully productive process, and thus the pre-C form of a stem is fully predictable based on its corresponding pre-V form. In contrast, the stem-final segment of pre-V forms is unpredictable based on the pre-C form. Thus, even though the process of coda neutralization is exceptionless, the resulting allomorphy may involve unpredictability, depending on which form a speaker is presented with.
Coda neutralization is not the only source of alternations in Seoul Korean verbal paradigms. Additional cases in which pre-V forms are unpredictable based on their corresponding pre-C forms are shown in (3).

In the traditional literature, the alternating classes (3a–c) are called ‘p, s, t-irregular’. The characterization as irregular reflects the fact that if these alternations are analyzed as intervocalic lenition (p-to-w spirantization, s-elision, and t-flapping), they have numerous exceptions, exemplified in (3a
 $^{\prime }$
, b
$^{\prime }$
, b
 $^{\prime }$
, c
$^{\prime }$
, c
 $^{\prime }$
).Footnote
[5]
Footnote
[6]
Stem-finally, each alternating class and its corresponding ‘regular’ class are distinct before V-initial suffixes whereas the two classes are neutralized before C-initial suffixes. Thus, as in the cases involving coda neutralization in (2) above, there is asymmetric (un)predictability: the pre-V forms here are unpredictable based on their corresponding pre-C forms.
$^{\prime }$
).Footnote
[5]
Footnote
[6]
Stem-finally, each alternating class and its corresponding ‘regular’ class are distinct before V-initial suffixes whereas the two classes are neutralized before C-initial suffixes. Thus, as in the cases involving coda neutralization in (2) above, there is asymmetric (un)predictability: the pre-V forms here are unpredictable based on their corresponding pre-C forms.
Conversely, there are alternations in which the pre-C forms are unpredictable based on their corresponding pre-V forms, since neutralization occurs among pre-V forms. Some examples are shown in (4).

Stem-final /u/ becomes [w] when a verb is conjugated with V-initial suffixes (glide formation), and thus the u-final stem class in (4a) would be indistinguishable pre-vocalically from the w
 $\tilde{~}$
p alternating class (4a
$\tilde{~}$
p alternating class (4a
 $^{\prime }$
), which is traditionally called p-irregular. Similarly, the l-final stem class in (4b) is indistinguishable from the l
$^{\prime }$
), which is traditionally called p-irregular. Similarly, the l-final stem class in (4b) is indistinguishable from the l
 $\tilde{~}$
t alternating class in (4b
$\tilde{~}$
t alternating class in (4b
 $^{\prime }$
) (traditionally called t-irregular) in the pre-V context, where both class stems end in a flap.
$^{\prime }$
) (traditionally called t-irregular) in the pre-V context, where both class stems end in a flap.
Thus far, we have presented cases in Seoul Korean verbal paradigms in which allomorphic alternations may be unpredictable, depending on which form of the verb is presented. In (2) and (3) above, pre-V forms are unpredictable based on their corresponding pre-C forms, whereas the opposite is true in (4). A consequence of this is that no single part of the paradigm suffices to tell a learner about whether and how all verb stems alternate. Nevertheless, many morphological and phonological analyses posit that a certain part of a paradigm is designated as the inflectional base for the entire paradigm, for all lexical items. The evidence for this hypothesis comes from acquisition errors (Do Reference Do2013), historical change (Kuryłowicz Reference Kuryłowicz1947, Mańczak Reference Mańczak1958), and phonological paradigm uniformity effects (Kenstowicz Reference Kenstowicz, Durand and Laks1996), all of which show that a single form in the paradigm may act as the ‘pivot’ or ‘base’ of reanalysis or paradigm uniformity. Albright (Reference Albright2002a) advances the ‘single surface base’ hypothesis, according to which learners choose a base form that maximizes predictability, by undergoing as few neutralizations as possible.
According to this hypothesis, the choice of the base form must be determined separately for each part of speech in each language. Kang (Reference Kang, Kuno, Lee, Whitman, Maling, Kang, Sells and Sohn2006) provides empirical evidence from historical change and acquisition errors that pre-V forms act as the base of Korean verbal paradigms, and Albright & Kang (Reference Albright and Kang2009) present learning simulation results showing that the pre-V form is indeed more informative than the pre-C form. If this is correct, then the grammar of Korean would consist of rules generating pre-C forms on the basis of the pre-V base, and not vice versa. Accordingly, we call the pre-V
 $\rightarrow$
pre-C direction of inference ‘forward formation’, and pre-C
$\rightarrow$
pre-C direction of inference ‘forward formation’, and pre-C
 $\rightarrow$
pre-V inference ‘backward formation’. We should emphasize that the distinction between forward and backward formation follows from asymmetrical grammatical models with a designated base. The goal of this study is to test the hypothesis that grammar is asymmetrical, and consists only of knowledge of ‘forward’ mappings. In the wug tests described in Section 2 below, participants were presented with forms of nonce verbs showing neutralizations in pre-V and pre-C contexts, and asked to generate unpredictable forms. If the single base hypothesis is correct, speakers would learn the statistical trends governing pre-V
$\rightarrow$
pre-V inference ‘backward formation’. We should emphasize that the distinction between forward and backward formation follows from asymmetrical grammatical models with a designated base. The goal of this study is to test the hypothesis that grammar is asymmetrical, and consists only of knowledge of ‘forward’ mappings. In the wug tests described in Section 2 below, participants were presented with forms of nonce verbs showing neutralizations in pre-V and pre-C contexts, and asked to generate unpredictable forms. If the single base hypothesis is correct, speakers would learn the statistical trends governing pre-V
 $\rightarrow$
pre-C projection, but not the reverse. The wug test results in Section 3 will provide evidence in favor of this hypothesis.
$\rightarrow$
pre-C projection, but not the reverse. The wug test results in Section 3 will provide evidence in favor of this hypothesis.
1.2 Morphological correspondence rules in Seoul Korean verbal paradigms
In this section, we first describe the statistical trends governing (non-)alternation in Seoul Korean verbal paradigms, in both the forward and backward formation directions. We then compare several models of how speakers may select allomorphs based on these trends, and their predictions for the wug tests that we carried out on Seoul Korean verbal paradigms.
1.2.1 The minimal generalization learner
For the purpose of obtaining probabilistic rules relating surface allomorphs in Seoul Korean verbal paradigms, we employed the minimal generalization learner proposed by Albright & Hayes (Reference Albright, Hayes and Maxwell2002, Reference Albright and Hayes2003) and Albright (Reference Albright, Downing, Alan Hall and Raffelsiefen2005). To illustrate, consider the following pairs of Seoul Korean verb forms (designated here with numerals to relate them to the rules in (6) below).

The goal of the model is to learn a set of rules mapping one form (such as the pre-V form) to another (such as the pre-C form). Rules have the form A
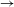 $\rightarrow$
B / C__D, consisting of a structural change (A
$\rightarrow$
B / C__D, consisting of a structural change (A
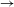 $\rightarrow$
B) and context, or structural description (C__D). In order to identify the structural change and context, morphologically related pairs of forms are compared, e.g. [ipə] and [ipc’a]. The substring that the two forms have in common is taken as the context, and the part that differs as the change. This initial comparison for the paradigms in (5), in both the pre-V
$\rightarrow$
B) and context, or structural description (C__D). In order to identify the structural change and context, morphologically related pairs of forms are compared, e.g. [ipə] and [ipc’a]. The substring that the two forms have in common is taken as the context, and the part that differs as the change. This initial comparison for the paradigms in (5), in both the pre-V
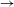 $\rightarrow$
pre-C and pre-C
$\rightarrow$
pre-C and pre-C
 $\rightarrow$
pre-V directions, yields the set of word-specific rules in (6).
$\rightarrow$
pre-V directions, yields the set of word-specific rules in (6).

These word-specific rules are in turn compared, and if a pair of rules share the structural change, their contexts are compared in order to create a more general rule. For instance, the rules in (6a.ii, iii) share the change [ə]
 $\rightarrow$
[c’a], so they are compared to determine more general ways to characterize the environments in which the change occurs, as illustrated below:
$\rightarrow$
[c’a], so they are compared to determine more general ways to characterize the environments in which the change occurs, as illustrated below:
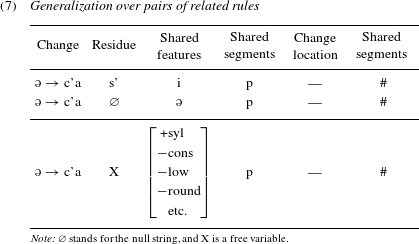
Common properties on the left and right sides of the ‘change location’, shown under ‘shared segments/features’ above, form the context of a new generalized rule. The remaining material with no common properties, shown under ‘residue’ above, is represented as a free variable (X). Some resulting generalized rules for the paradigms in (5) would be the following:


Comparisons of this type are iterated, yielding multiple rules for the same change. The resulting contexts can be very general, if the pairs of rules being compared do not share many segments or features in the context.
This comparison procedure yields many rules for the same change, and frequently a given word will be covered by multiple rules. For example, (5i) [ipə] is covered in the backward formation direction by rules (6b.i), (8b.i), and (8b.ii). However, these rules differ in their statistical validity: the rule in (6b.i) narrowly and accurately characterizes (5i) ‘wear’, but it does not generalize to any other lexical items. Rules (8b.i) and (8b.ii), on the other hand, are more broadly applicable, but at the cost of including some exceptions, such as (5vi) [kipc’a], which is [kiwə], not *[kipə] in the pre-V form. It is hypothesized that learners seek rules that cover as many items and include as few exceptions as possible. In order to determine this, the model calculates the reliability of each rule, as defined in (9).

For instance, as shown below, the structural description of the generalized rule in (8b.i) is met in eight forms in the Seoul Korean verb lexicon employed in the present study, but only six of them, shown in (10a), take the structural change of the rule. (We explain how the verb lexicon was constructed later in this section, before example (11).) Two verbs, presented in (10b, c), show different changes involving p
 $\rightarrow$
w and p
$\rightarrow$
w and p
 $\rightarrow$
p
$\rightarrow$
p
 $^{\text{h}}$
, respectively, and thus count as exceptions, rather than as hits, for rule (8b.i).
$^{\text{h}}$
, respectively, and thus count as exceptions, rather than as hits, for rule (8b.i).

As a result, rule (8b.i) has a reliability of 6/8 = 0.75.
The reliability of a rule indicates the probability of the rule’s application in the lexicon. Recall that the objective of the model is to find those rules that cover as many forms as possible; however, rules that cover just a single word, such as the rules in (6) above, have very high reliability (typically, 1/1 = 1). Therefore, the raw reliability values are adjusted using lower confidence limit statistics (Mikheev Reference Mikheev1997) to yield confidence values. In the calculation of confidence, ratios that are based on smaller amounts of data (i.e. reliabilities with smaller scope) are penalized more than rules based on larger amounts of data (higher scope). For instance, a rule with 5/5 reliability is assigned a lower confidence value than the one with 1000/1000 reliability. When a confidence level of
 $\unicode[STIX]{x1D6FC}$
= 0.95 is adopted, the former has a confidence of 0.825 and the latter has a confidence of 0.999. The confidence of the rule in (8bi), which has a reliability of 0.75, is 0.609.
$\unicode[STIX]{x1D6FC}$
= 0.95 is adopted, the former has a confidence of 0.825 and the latter has a confidence of 0.999. The confidence of the rule in (8bi), which has a reliability of 0.75, is 0.609.
We assume that speakers select the best rule for each change, i.e. the one with highest confidence among those that can apply, when they produce output forms of an unknown stem and rate its well-formedness. Accordingly, speakers’ well-formedness ratings on the output forms are determined by the confidence value of the best rule. When a nonce form is covered by a rule that has high scope and few exceptions, the relevant change will apply with high confidence; thus, high lexical frequency supports confident generalization, or high productivity, of a pattern of allomorphy.
In order to construct a full set of rules for deriving pre-V and pre-C allomorphs in Seoul Korean verbal paradigms and calculate their reliability/confidence values, we need a lexicon of Seoul Korean verbs. To construct this, we started with a list of Korean verbs provided by Kang & Kim (Reference Kang and Kim2004), which is based on a 5.5 million word text corpus of Sejong Project (http://www.sejong.or.kr/). Since the Seoul dialect may roughly be considered the standard dialect of Korean, we used the Standard Korean Dictionary (Kwuklip kwuke yenkwuwen 1999) to exclude typographical and classification errors, non-standard dialectal and polymorphemic verbs. We also excluded those whose token frequencies are below 10 in the Sejong Corpus, since the first author, who is a native speaker of Seoul Korean, mostly did not recognize these low-frequency verbs, which we take to suggest that these are sufficiently rare and should therefore be excluded from the construction of a lexicon of Seoul Korean verbs. The resulting database included inflected pre-C and pre-V forms of 722 verbs. This set of verbs was then submitted to the minimal generalization learner, in order to obtain lexical frequencies of each (non-)alternation class and a full set of forward and backward formation rules. Some of the resulting rules are shown in (11).


Recall from Section 1.1 that the pre-V forms of the w
 $\tilde{~}$
p and l
$\tilde{~}$
p and l
 $\tilde{~}$
t alternating classes are not distinguishable with respect to stem-final segments from those of the regular u-final stems (w
$\tilde{~}$
t alternating classes are not distinguishable with respect to stem-final segments from those of the regular u-final stems (w
 $\tilde{~}$
u) and l-final stems (l
$\tilde{~}$
u) and l-final stems (l
 $\tilde{~}$
l), respectively. Thus, as can be seen in the last column of (11a.i, ii), the u- and l-final stems are exceptions to the forward formation rules for the w
$\tilde{~}$
l), respectively. Thus, as can be seen in the last column of (11a.i, ii), the u- and l-final stems are exceptions to the forward formation rules for the w
 $\tilde{~}$
p and l
$\tilde{~}$
p and l
 $\tilde{~}$
t alternating classes, which accounts for their relatively low confidence values (0.389 and 0.073). In contrast, the forward formation rules for non-alternation, i.e. (11a.iii) p
$\tilde{~}$
t alternating classes, which accounts for their relatively low confidence values (0.389 and 0.073). In contrast, the forward formation rules for non-alternation, i.e. (11a.iii) p
 $\tilde{~}$
p and (11a.iv) t
$\tilde{~}$
p and (11a.iv) t
 $\tilde{~}$
t, and that for the s
$\tilde{~}$
t, and that for the s
 $\tilde{~}$
t alternation (11a.v) resulting from coda neutralization all have high confidence values, since none of these classes involve neutralization in the base (pre-V) form. Therefore, all stems ending with [p], [t], or [s] in pre-V position have [p], [t] and [t] in pre-C position, and there are no exceptions to the rules in (11a.iii–v). (The alternations involved in /c/- and /ci/-final verbs in (11a.vi, vii) will be discussed later in this section.)
$\tilde{~}$
t alternation (11a.v) resulting from coda neutralization all have high confidence values, since none of these classes involve neutralization in the base (pre-V) form. Therefore, all stems ending with [p], [t], or [s] in pre-V position have [p], [t] and [t] in pre-C position, and there are no exceptions to the rules in (11a.iii–v). (The alternations involved in /c/- and /ci/-final verbs in (11a.vi, vii) will be discussed later in this section.)
It was also noted in Section 1.1 that in pre-C position, the w
 $\tilde{~}$
p alternating class is neutralized with the p
$\tilde{~}$
p alternating class is neutralized with the p
 $\tilde{~}$
p and p
$\tilde{~}$
p and p
 $^{\text{h}}$
$^{\text{h}}$
 $\tilde{~}$
p (non-)alternating classes, and similarly, the l
$\tilde{~}$
p (non-)alternating classes, and similarly, the l
 $\tilde{~}$
t alternating class is neutralized with (non-)alternations like s
$\tilde{~}$
t alternating class is neutralized with (non-)alternations like s
 $\tilde{~}$
t, c
$\tilde{~}$
t, c
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $\tilde{~}$
t, etc. Thus, in the backward formation direction, there is stiff competition between several different patterns for each place of articulation, which leads to exceptions. Thus, backward formation rules, some of which are shown in (11b) above, tend to have relatively low confidence values; the values 0.106–0.302 in (11b) are typical.
$\tilde{~}$
t, etc. Thus, in the backward formation direction, there is stiff competition between several different patterns for each place of articulation, which leads to exceptions. Thus, backward formation rules, some of which are shown in (11b) above, tend to have relatively low confidence values; the values 0.106–0.302 in (11b) are typical.
There are two points that merit comment. First, the rules for an alternation class may have drastically different confidence values depending on the direction of the derivation. For instance, the forward formation rule for the s
 $\tilde{~}$
t alternation (11a.v) has a high confidence of 0.872, whereas its backward formation counterpart (11b.iii) has a low confidence of 0.106. This is because different parts of the paradigm are affected by different neutralizations, so a given alternation class may compete with different sets of alternation classes in forward and backward formations. In the forward formation, as mentioned above, the s
$\tilde{~}$
t alternation (11a.v) has a high confidence of 0.872, whereas its backward formation counterpart (11b.iii) has a low confidence of 0.106. This is because different parts of the paradigm are affected by different neutralizations, so a given alternation class may compete with different sets of alternation classes in forward and backward formations. In the forward formation, as mentioned above, the s
 $\tilde{~}$
t alternation class has no competition, since all stems, ending with [s] before V-initial suffixes, must end with [t] before C-initial suffixes. Thus, the forward formation rule for the s
$\tilde{~}$
t alternation class has no competition, since all stems, ending with [s] before V-initial suffixes, must end with [t] before C-initial suffixes. Thus, the forward formation rule for the s
 $\tilde{~}$
t alternation has no exceptions, resulting in high confidence. In contrast, in the backward formation direction, the s
$\tilde{~}$
t alternation has no exceptions, resulting in high confidence. In contrast, in the backward formation direction, the s
 $\tilde{~}$
t alternation class competes with many other classes, including t
$\tilde{~}$
t alternation class competes with many other classes, including t
 $\tilde{~}$
t, c
$\tilde{~}$
t, c
 $\tilde{~}$
t, and l
$\tilde{~}$
t, and l
 $\tilde{~}$
t, which end with coronal consonants other than [s] before V-initial suffixes. Thus, the backward formation rules for coronal-final classes usually have many exceptions, obtaining low confidence values. Cases like this, where forward and backward formation rules have distinct reliability/confidence values, will be crucial in the testing of possible models of allomorph selection.
$\tilde{~}$
t, which end with coronal consonants other than [s] before V-initial suffixes. Thus, the backward formation rules for coronal-final classes usually have many exceptions, obtaining low confidence values. Cases like this, where forward and backward formation rules have distinct reliability/confidence values, will be crucial in the testing of possible models of allomorph selection.
In addition, it can happen that an alternation is relatively unreliable in general, but highly reliable in a specific environment. In the above, the forward formation rule for the c
 $\tilde{~}$
t alternation, shown in (11a.vi), with a relatively broad rule context, has a medium confidence value of 0.423, because almost as many verb stems show the c
$\tilde{~}$
t alternation, shown in (11a.vi), with a relatively broad rule context, has a medium confidence value of 0.423, because almost as many verb stems show the c
 $\tilde{~}$
ci alternation where stem-final /i/ before a suffix-initial vowel undergoes glide formation nearly obligatorily, and the resulting [j] deletes after an affricate (post-affricate /i/-deletion). But, if we limit ourselves to pre-V forms where final /c/ follows /i/, the relevant rule for the c
$\tilde{~}$
ci alternation where stem-final /i/ before a suffix-initial vowel undergoes glide formation nearly obligatorily, and the resulting [j] deletes after an affricate (post-affricate /i/-deletion). But, if we limit ourselves to pre-V forms where final /c/ follows /i/, the relevant rule for the c
 $\tilde{~}$
t alternation, shown in (11a.vii), has a relatively high confidence value of 0.740 since seven out of eight stems that end with [it] in their pre-C forms are /c/-final, not /ci/-final. This context-specific rule predicts that Seoul Korean speakers will choose [t]-final forms for wug verb stimuli with final [ic] before V-initial suffixes to an above-average extent. This is what Albright (Reference Albright2002b) calls an ‘island of reliability’. The prediction is that an alternation pattern may be more productive in those specific contexts, where the proportion of items undergoing the rule is especially high in the lexicon. Thus, it is possible that the speakers’ responses for wug stems with identical final segments will differ depending on the specific quality of non-final segments.
$\tilde{~}$
t alternation, shown in (11a.vii), has a relatively high confidence value of 0.740 since seven out of eight stems that end with [it] in their pre-C forms are /c/-final, not /ci/-final. This context-specific rule predicts that Seoul Korean speakers will choose [t]-final forms for wug verb stimuli with final [ic] before V-initial suffixes to an above-average extent. This is what Albright (Reference Albright2002b) calls an ‘island of reliability’. The prediction is that an alternation pattern may be more productive in those specific contexts, where the proportion of items undergoing the rule is especially high in the lexicon. Thus, it is possible that the speakers’ responses for wug stems with identical final segments will differ depending on the specific quality of non-final segments.
1.2.2 Single base hypothesis and backward formation
The single base hypothesis states that one form, i.e. the privileged base form, is memorized and the rest of the paradigm is derived from it. (See Albright Reference Albright2002a, Reference Albright, Downing, Alan Hall and Raffelsiefen2005 for details of the single base hypothesis.) Under the strictest version of this hypothesis, speakers have only forward formation rules deriving non-base forms from the base, and no backward formation rules deriving the base form from a non-base form are available to them. (Under a more relaxed version of a single base hypothesis, backward formation rules exist, but are limited in their application in some way.)
To illustrate the consequences of this hypothesis, consider a case in which the confidence values of the rules deriving a particular alternation are very different in the forward and backward formation directions. Recall that the forward formation rule for the s
 $\tilde{~}$
t alternation has a relatively high confidence of 0.872 whereas its corresponding backward formation counterpart has a low confidence of 0.106. In a fully symmetrical model, in which all forms can be derived directly from each other, both sets of forward and backward formation rules accompanied with their probability of application, i.e. reliability/confidence, are available. The expected productivities of the s
$\tilde{~}$
t alternation has a relatively high confidence of 0.872 whereas its corresponding backward formation counterpart has a low confidence of 0.106. In a fully symmetrical model, in which all forms can be derived directly from each other, both sets of forward and backward formation rules accompanied with their probability of application, i.e. reliability/confidence, are available. The expected productivities of the s
 $\tilde{~}$
t alternation are then different depending on the direction of the wug test. Participants in the forward formation test, given a stimulus ending with [s] should be relatively likely to produce responses ending with [t], while participants in a backward formation test, given a stimulus ending with [t], should be relatively unlikely to produce [s]. We will call this model a ‘bi-directional’ model. We also note in passing that a number of theoretical approaches to encoding alternations with underlying forms (rather than rules encoding surface mappings) are also ‘bi-directional’, in that they allow speakers to consider information from any part of the paradigm when projecting other forms.Footnote
[8]
If the distribution of responses in the backward formation test matches well the confidence of backward formation rules, it would lead us to reject the single base hypothesis, in favor of a bi-directional model.
$\tilde{~}$
t alternation are then different depending on the direction of the wug test. Participants in the forward formation test, given a stimulus ending with [s] should be relatively likely to produce responses ending with [t], while participants in a backward formation test, given a stimulus ending with [t], should be relatively unlikely to produce [s]. We will call this model a ‘bi-directional’ model. We also note in passing that a number of theoretical approaches to encoding alternations with underlying forms (rather than rules encoding surface mappings) are also ‘bi-directional’, in that they allow speakers to consider information from any part of the paradigm when projecting other forms.Footnote
[8]
If the distribution of responses in the backward formation test matches well the confidence of backward formation rules, it would lead us to reject the single base hypothesis, in favor of a bi-directional model.
In contrast, under the single base hypothesis, the grammar contains no backward formation rules. Thus, we must ask what speakers do in a situation where they must provide a base form for the given non-base form of an unknown stem, such as in a backward formation wug test. Lacking rules to derive base forms directly, there are several mechanisms that speakers might employ to infer base forms, when given a non-base stimulus. Some possibilities are listed in (12).

The first possibility is that speakers employ forward, not backward, formation rules, even when doing a ‘backward formation’ task. If, as suggested by the single base hypothesis, no other rules than forward formation rules are available, speakers might rely on them even in a backward formation test by undoing them. In forward application, speakers take a given stimulus as input, and check which rules it could undergo (i.e. meets the structural description). In order to apply forward rules to a backward formation, speakers would need to determine which rules a given stimulus could have been produced by, as the output for the rule. Thus, inference in both directions employs the same set of rules, but sometimes through regular application (forward formation) and sometimes by inferring possible outputs (backward formation). We will call this a ‘uni-directional model’. For example, given a Seoul Korean verb stem ending with [t] before a consonant (a non-base form), speakers would need to identify rules that have [t] as their output, such as the t
 $\rightarrow$
t rule in (11a.iv) (confidence = 0.916), the s
$\rightarrow$
t rule in (11a.iv) (confidence = 0.916), the s
 $\rightarrow$
t rule in (11a.v) (confidence = 0.872) and many others. If speakers’ task in the wug test is to rate the well-formedness of possible inflected forms, they would assign high scores, close to 0.872 (out of 1.0), to the forms ending with [s]. Note that this well-formedness rating is very different from the corresponding backward formation rule’s prediction, 0.106. This kind of result would strongly support the single base hypothesis over the bi-directional model. If speakers have both forward and backward formation rules, there would be no plausible reason for using forward formation rules in the backward formation test. It will be shown that the uni-directional model makes better predictions about the distribution of the participants’ response patterns of the present experiment than the bi-directional model and other alternatives, supporting the single base hypothesis.
$\rightarrow$
t rule in (11a.v) (confidence = 0.872) and many others. If speakers’ task in the wug test is to rate the well-formedness of possible inflected forms, they would assign high scores, close to 0.872 (out of 1.0), to the forms ending with [s]. Note that this well-formedness rating is very different from the corresponding backward formation rule’s prediction, 0.106. This kind of result would strongly support the single base hypothesis over the bi-directional model. If speakers have both forward and backward formation rules, there would be no plausible reason for using forward formation rules in the backward formation test. It will be shown that the uni-directional model makes better predictions about the distribution of the participants’ response patterns of the present experiment than the bi-directional model and other alternatives, supporting the single base hypothesis.
There are other conceivable approaches to projecting base forms in the backward direction, even if backward formation rules are not available. One straightforward and uninteresting possibility is random guessing; this predicts that speakers should simply assign equal probability to all possible patterns. Alternatively, speakers might choose the response that best satisfies paradigm uniformity constraints (Kenstowicz Reference Kenstowicz1995, Reference Kenstowicz, Durand and Laks1996; Benua Reference Benua1997; Steriade Reference Steriade, Broe and Pierrehumbert2000; Coetzee Reference Coetzee2009). If speakers were found to mirror lexical statistics in the forward direction, while employing random guessing or favoring uniformity only in the backward formation direction, this would also support an asymmetrical model such as the single base hypothesis. However, if speakers behave randomly or based on Paradigm Uniformity in both forward and backward formation tests, it would simply mean that speakers do not know any statistical patterns in the lexicon, providing counter-evidence to all stochastic approaches relying on lexical patterns. (See Coetzee Reference Coetzee2009 for the claim that Paradigm Uniformity is the default option in learning the relation between surface forms in a paradigm.)
In order to collect data to test the alternative models just discussed, we performed wug tests on Seoul Korean verbal paradigms.
2 Experiment: Wug test
2.1 Participants
Forty-two paid native speakers of Seoul-Gyeonggi dialects were recruited from the community at Seoul National University. Twenty-two and twenty participated in forward and backward formation tests, respectively. No one participated in both tests. See Appendix A for details of the experiment.
2.2 Materials
Korean wug verbs were created through minor modification of Middle Korean verbs and adjectives listed in Lee (Reference Lee2008).Footnote [9] The same set of wug stems was employed in both forward and backward formation tests. In order to test the productivity of alternations, the stem-final segments were varied in the pre-V (base) and pre-C (derived) forms in order to create novel members of each target alternation class. All of the wug verbs were inflected with verbal endings such as imperative and hortative markers, which can only attach to verbs and not to other categories such as nouns and adjectives. All the inflected forms employed in the experiment can be seen in Appendix B.
In both the forward and backward formation tests, 20 test stems and 20 fillers (10 k-final and 10 m-final) were employed. The test stems were designed to test the productivity of alternations such as w
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
t,
$\tilde{~}$
t,
 $\varnothing$
$\varnothing$
 $\tilde{~}$
t, s
$\tilde{~}$
t, s
 $\tilde{~}$
t, and c
$\tilde{~}$
t, and c
 $\tilde{~}$
t. In the forward formation test, half of the test stems ended in [w] and the rest ended in [l], allowing us to test the productivity of the alternations w
$\tilde{~}$
t. In the forward formation test, half of the test stems ended in [w] and the rest ended in [l], allowing us to test the productivity of the alternations w
 $\tilde{~}$
p and l
$\tilde{~}$
p and l
 $\tilde{~}$
t. In the backward formation test, half of the test stems ended in [p] and the rest ended in [t], allowing us to test the productivity of not only the alternations w
$\tilde{~}$
t. In the backward formation test, half of the test stems ended in [p] and the rest ended in [t], allowing us to test the productivity of not only the alternations w
 $\tilde{~}$
p and l
$\tilde{~}$
p and l
 $\tilde{~}$
t but also those involving coronal neutralizations such as
$\tilde{~}$
t but also those involving coronal neutralizations such as
 $\varnothing$
$\varnothing$
 $\tilde{~}$
t, s
$\tilde{~}$
t, s
 $\tilde{~}$
t, and c
$\tilde{~}$
t, and c
 $\tilde{~}$
t.
$\tilde{~}$
t.
2.3 Method
In the present experiment, modeled on Albright & Hayes (Reference Albright and Hayes2003), participants were required to perform the following three tasks:

Task (i) was adopted for two purposes: to hide the intention of the experiment from the participants and to confirm that the stimuli sounded phonologically natural to them.
For task (ii), participants produced inflected forms of the given wug verbs. In forward formation test, the wug verb stimuli were presented in their pre-V forms, and the participants produced pre-C forms as responses. Both pre-V and pre-C forms were placed in a frame consisting of four sentences as shown below:

In backward formation test, the opposite applied: stimuli were presented in their pre-C forms, and participants produced the corresponding pre-V forms.
For task (iii), the participants rated various possible inflected forms of the given wug verbs according to how acceptable they sounded as inflected forms of the given stimuli. In forward formation test, participants were given wug verbs in pre-V forms, and provided acceptability ratings of possible pre-C forms. Conversely, in the backward formation test, participants were given wug verbs in their pre-C form, and provided acceptability ratings of possible pre-V forms. In this part of the experiment, each wug verb was embedded in a frame consisting of two sentences, as can be seen in (15)–(16) below. The inflected form of a wug verb in the first sentence can be considered as a stimulus, and the one in the second sentence, a ‘response’, conditioned on the first form that was presented. In forward formation test, test stems ending in [w] in the base form were presented with [p] and [u] for rating, while stems ending in [l] were presented with [t] and [l] for rating, as in (15).

In backward formation test, test stems ending in [p] in the non-base (pre-C) form were presented with [p] and [w] for rating, while test stems ending in [t] were presented with the five possible segments [l, t,
 $\varnothing$
, s, c] for rating.
$\varnothing$
, s, c] for rating.

In the experiment, items were ordered such that pairs of sentences for competing (non-)alternation classes were never adjacent to each other. For instance, the pairs in (16a.i) and (16a.ii) were presented as far from each other as possible. The experimenter also emphasized that the participants must rate the goodness of the second occurrence of the wug verb, considering how good it was as a hortative form (or imperative form in backward formation test) of the novel verb presented in the first sentence. For each wug verb, the experimenter produced the two frame sentences, using an appropriate intonation. Throughout the experiment, only spoken forms of wug verbs were used by both the experimenter (the first author or his assistant) and participants. The remaining details of the experimental procedure are given in Appendix A.
2.4 Results
In this section, we first report participants’ phonological well-formedness judgments for the experimental stimuli, and then their productions and acceptability judgments for possible inflected forms of the wug verbs.
2.4.1 Phonological well-formedness
In order to minimize the possibility that the experimental stimuli contain phonologically unnatural sequences, most stimuli were created through minor modification of real but obsolete Middle Korean verbs or adjectives, which are phonotactically similar to words that survived into Modern Korean. This helped to ensure that the items would be legal Korean words, but it is still important to confirm that the invented Korean wug verbs were considered phonologically natural by speakers of Modern Korean. Furthermore, by collecting phonological well-formedness ratings of each verb, we were able to control statistically for any effect that small differences in phonotactic wellformedness between the verbs may have had on participants’ ratings on the goodness of the inflected forms of the verbs.
The average of participants’ phonological ratings for our wug verbs is 4.09 (mean rating of pre-C forms = 4.21, SD = 0.90, n = 20; mean rating of pre-V forms = 3.98, SD = 0.57, n = 20). These phonological ratings can be compared to those of Albright & Hayes’s (Reference Albright and Hayes2003) wug verbs, which were designed to be well-formed English words. On the same 1–7 scale (1 = completely bizarre; 7 = completely normal), their English wug verbs received 4.68 (SD = 1.62, n = 58) and ill-formed foils, 2.97 (SD = 1.46, n = 29). Thus, although Korean wug verbs in general received lower phonological ratings than English wug verbs, their ratings are closer to those of English wug verbs and clearly higher than those of English ill-formed foils.
In addition, three low-frequency real words were mistakenly employed as wug verb stimuli in the present experiment (see footnote 9), allowing us to compare phonological ratings for ‘truly’ nonce verbs against a few actual Korean verbs. The mean phonological rating for one of the real verbs [kamjəl-ə] is 3.36, which is lower than the ratings of most of the wug verbs (16 out of 20 pre-V forms). In other words, most of the wug verbs received higher phonological ratings than at least one real word. This suggests that participants in general found the wug verb stimuli to be relatively acceptable, on par with actual (but obsolete) Korean verbs.
Recall that our primary reason for wanting wug stimuli to sound like ordinary Korean verbs is that we do not want speakers to reject inflected forms because they contain phonotactically improbable sequences (rather than improbable alternations). Thus, it is relevant to observe that participants’ phonological ratings of the wug verbs are not strongly correlated with their ratings of the inflected forms. The correlation values, which are not statistically significant, are quite low, as shown in (17).

Consequently, we can be sure that participants did not rate the goodness of the inflected forms according to their phonological well-formedness. In Section 3 below, the influence of phonological well-formedness of a word onto participants’ rating of its goodness will be examined and controlled for in a more systematic way.
2.4.2 The wug test: Elicited production and goodness judgment
This section reports the results from both elicited productions and goodness judgments. Here we consider only overall patterns of the results, providing a somewhat informal comparison between uni- and bi-directional models. In the next section, we provide a statistical analysis of the results, focusing on those of the goodness judgment task.
Table 2 Wug test results: forward formation.
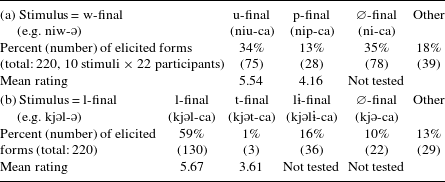
Note: ‘Other’ refers to errors elsewhere in the verb, and uninterpretable responses.
The forward formation test results are summarized in Table 2.Footnote
[10]
All of the so-called ‘irregular’ alternation classes are clearly less productive, both in terms of the proportion of elicited forms and also the mean goodness ratings scores. For the w-final stimuli, participants produced 75 u-final forms (34%) and assigned a mean goodness score of 5.54 to u-final outputs, whereas they produced 28 p-final forms (13%) and assigned a mean score of 4.16 to p-final outputs. Thus, it can be said that the w
 $\tilde{~}$
u class of verbs is more productive than the w
$\tilde{~}$
u class of verbs is more productive than the w
 $\tilde{~}$
p class. For the l-final stimuli, participants produced 130 l-final forms (59%) and assigned a mean goodness rating of 5.67 to l-final outputs, whereas they produced only three t-final forms (1%) and assigned a mean score of 3.61 to t-final outputs. This suggests that the l
$\tilde{~}$
p class. For the l-final stimuli, participants produced 130 l-final forms (59%) and assigned a mean goodness rating of 5.67 to l-final outputs, whereas they produced only three t-final forms (1%) and assigned a mean score of 3.61 to t-final outputs. This suggests that the l
 $\tilde{~}$
l (non-alternating l) class of verbs is more productive than the l
$\tilde{~}$
l (non-alternating l) class of verbs is more productive than the l
 $\tilde{~}$
t class. Finally, the productions contained a considerable number of outputs that were completely unexpected, because they do not mirror any existing alternations. This included 78 w-deletion responses (35%) for the w-final stimuli and 36 lɨ-final ones (16%) for the l-final stimuli. These relatively frequent but unexpected results will be discussed in Section 5.
$\tilde{~}$
t class. Finally, the productions contained a considerable number of outputs that were completely unexpected, because they do not mirror any existing alternations. This included 78 w-deletion responses (35%) for the w-final stimuli and 36 lɨ-final ones (16%) for the l-final stimuli. These relatively frequent but unexpected results will be discussed in Section 5.
Table 3 Wug test results: backward formation.

Note: ‘Other’ refers to errors elsewhere in the verb, and uninterpretable responses.
The backward formation test results are summarized in Table 3. As above, the ‘irregular’ patterns of alternation are clearly less productive, both in terms of the proportion of elicited forms and in terms of mean goodness ratings. For p-final stimuli, participants produced 184 p-final forms (92%) and assigned a mean goodness rating of 6.12 to p-final forms, whereas they produced only four w-final forms (2%) and assigned a mean score of 3.92 to w-final forms. Thus, the non-alternating p
 $\tilde{~}$
p class of verbs is more productive than the w
$\tilde{~}$
p class of verbs is more productive than the w
 $\tilde{~}$
p class. For t-final stimuli, [c, t, s]-final responses are frequent in the elicited production portion and received relatively high goodness scores, compared to [
$\tilde{~}$
p class. For t-final stimuli, [c, t, s]-final responses are frequent in the elicited production portion and received relatively high goodness scores, compared to [
 $\varnothing$
, l]-final forms. Thus, it can be said that the c
$\varnothing$
, l]-final forms. Thus, it can be said that the c
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $\tilde{~}$
t, and s
$\tilde{~}$
t, and s
 $\tilde{~}$
t classes of verbs are more productive than the
$\tilde{~}$
t classes of verbs are more productive than the
 $\varnothing$
$\varnothing$
 $\tilde{~}$
t and l
$\tilde{~}$
t and l
 $\tilde{~}$
t classes.
$\tilde{~}$
t classes.
Taken together, these results show that the same alternations are productive regardless of the direction of the wug test. The highly productive group includes the w
 $\tilde{~}$
u, p
$\tilde{~}$
u, p
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
l, c
$\tilde{~}$
l, c
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $\tilde{~}$
t, and s
$\tilde{~}$
t, and s
 $\tilde{~}$
t classes, whereas the relatively unproductive group includes the w
$\tilde{~}$
t classes, whereas the relatively unproductive group includes the w
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
t,
$\tilde{~}$
t,
 $\varnothing$
$\varnothing$
 $\tilde{~}$
t, and l
$\tilde{~}$
t, and l
 $\tilde{~}$
t classes.
$\tilde{~}$
t classes.
The results in Table 3 show that the distribution of elicited forms and the mean goodness ratings scores in the backward formation test are not consistent with the predictions of the bi-directional model. Recall that under the bi-directional model, we expect asymmetries in the production of alternations, due to differences in the reliability of forward formation rules and their backward formation counterparts. Specifically, we showed in Section 1.2.1 that the backward formation rules for coronal-final verb stems in Seoul Korean tend to have low reliability/confidence values. This is due to the fact that stem-final coronal obstruents are neutralized to [t] before C-initial suffixes, so the pre-V realization of a given stem is unpredictable. Nonetheless, participants frequently produced [c, t, s]-final forms, and gave such outputs high ratings. This is unexpected, if speakers were using backward formation rules, since those rules should have low confidence. In contrast, the results are consistent with a uni-directional model in which only forward formation rules are available. Recall that the forward formation rules for the s
 $\tilde{~}$
t and t
$\tilde{~}$
t and t
 $\tilde{~}$
t alternation class verbs in (11a.iv–v) have relatively high confidence values (0.872 and 0.916, respectively), so these alternations are predicted to be highly productive. The confidence value for the c
$\tilde{~}$
t alternation class verbs in (11a.iv–v) have relatively high confidence values (0.872 and 0.916, respectively), so these alternations are predicted to be highly productive. The confidence value for the c
 $\tilde{~}$
t alternation class is not generally as high; for instance, rule (11a.vi) has a confidence score of 0.423. However, as discussed in Section 1.2.1, island of reliability effects may play a role here. Recall that the c
$\tilde{~}$
t alternation class is not generally as high; for instance, rule (11a.vi) has a confidence score of 0.423. However, as discussed in Section 1.2.1, island of reliability effects may play a role here. Recall that the c
 $\tilde{~}$
t alternation is dominant in the post-[i] context (7/8 verbs), and thus the relevant forward formation rule in (11a.vii) has a high confidence value of 0.740. Among ten t-final wug verb stimuli adopted in the backward formation test, three verbs end with [it]. As shown below, their c-final class forms received high goodness scores (mean = 6.0 out of 7.0), compared to those of the rest of the t-final stimuli.
$\tilde{~}$
t alternation is dominant in the post-[i] context (7/8 verbs), and thus the relevant forward formation rule in (11a.vii) has a high confidence value of 0.740. Among ten t-final wug verb stimuli adopted in the backward formation test, three verbs end with [it]. As shown below, their c-final class forms received high goodness scores (mean = 6.0 out of 7.0), compared to those of the rest of the t-final stimuli.

It is obvious that the c
 $\tilde{~}$
t alternation was not applied evenly across all /t/-final wug stems, but rather, was favored specifically for the three verbs with a preceding /i/. Thus, once we take detailed rule contexts into account, the confidence values of forward formation rules can explain much of why c
$\tilde{~}$
t alternation was not applied evenly across all /t/-final wug stems, but rather, was favored specifically for the three verbs with a preceding /i/. Thus, once we take detailed rule contexts into account, the confidence values of forward formation rules can explain much of why c
 $\tilde{~}$
t alternations enjoyed a modest degree of productivity. In conclusion, the overall pattern of results is consistent with the predictions of the uni-directional model. In the next section, we provide a more systematic evaluation of possible accounts of the test results.
$\tilde{~}$
t alternations enjoyed a modest degree of productivity. In conclusion, the overall pattern of results is consistent with the predictions of the uni-directional model. In the next section, we provide a more systematic evaluation of possible accounts of the test results.
3 Discussion
In this section, we provide a more detailed comparison of the predictions of the bi- and uni-directional models.
3.1 Word-by-word comparison
In order to test how closely participants’ responses mirror the probability of alternation in the lexicon, we calculated predicted scores for all of the test items. We trained the minimal generalization model on the lexicon of Seoul Korean, in both the forward and backward formation directions, and used the resulting grammar to derive predicted scores for each candidate output for the test items. As discussed above, the minimal generalization model usually induces multiples rules that could all apply to a given form to produce the same change or alternation. We assume that from the set of potentially applicable rules, the best rule, i.e. the one with highest confidence, is chosen to apply, and determines the goodness of the alternation. As a result, we have provided a single confidence for each of the test forms employed in the wug test. However, it can also happen that there are no rules that can apply to a given form to produce a particular alternation. This happens because the minimal generalization learner, as described above, constructs the most specific rules possible. Consequently, if all of the existing words that undergo a particular alternation share certain properties, the resulting rules will also share those properties. In such cases, the alternation is predicted to be inapplicable to nonce words that do not share the relevant properties. For instance, all existing w
 $\tilde{~}$
p alternating stems have [–low] final vowels, so test forms with stem-final [+low] vowels, such as [golaw] and [golap], do not meet the structural description of the rules for the w
$\tilde{~}$
p alternating stems have [–low] final vowels, so test forms with stem-final [+low] vowels, such as [golaw] and [golap], do not meet the structural description of the rules for the w
 $\tilde{~}$
p alternation. In such cases, we assigned a predicted confidence score of zero to the relevant test forms. For all the inflected forms employed in the goodness ratings task of the current wug test, confidence values of the best forward and backward formation rules are provided in Appendix B, alongside the mean goodness ratings.
$\tilde{~}$
p alternation. In such cases, we assigned a predicted confidence score of zero to the relevant test forms. For all the inflected forms employed in the goodness ratings task of the current wug test, confidence values of the best forward and backward formation rules are provided in Appendix B, alongside the mean goodness ratings.
In order to evaluate how well different sets of rules can explain wug test results, we will compare the rules’ confidence values with the mean goodness ratings of the test forms. If goodness ratings scores vary proportionately with the confidence values, the relevant rules would be considered as a good predictor of the test results. The following shows the correlations of goodness scores to confidence values of the forward and backward formation rules:

For the forward wug test, participants’ goodness ratings show a strong positive correlation with the confidence scores of the forward formation rules. This shows that in the forward direction, speakers are sensitive to the same statistical trends in the lexicon that are encoded by probabilistic grammar induced by the minimal generalization model. We therefore reject models based solely on random guessing or paradigm uniformity, in favor of a model that tracks at least some lexical statistics concerning the relative frequency of different alternations.
The comparison between (19b) and (19c) above shows that participants’ ratings do not reflect all lexical statistics, however. Crucially, in the backward formation task, participant ratings do not correlate as strongly with the predictions of the backward formation rules; instead, they correlate more strongly with the confidence of forward formation rules. In other words, the best model of speakers’ judgments is one that contains only forward formation rules, and no backward formation rules. This supports the uni-directional model over the bi-directional model.
Before we proceed to a more detailed comparison of the uni- and bi-directional models, let us consider exactly which aspects of the results of the backward formation test can be better explained by the forward formation rules. As can be seen in Appendix B.2, cases where forward and backward formation rules have distinct confidence values involve [p, t, s, c]-final response forms which correspond to the p
 $\tilde{~}$
p, t
$\tilde{~}$
p, t
 $\tilde{~}$
t, s
$\tilde{~}$
t, s
 $\tilde{~}$
t and c
$\tilde{~}$
t and c
 $\tilde{~}$
t (non-)alternating classes, respectively. For these cases, forward formation rules have significantly higher confidence values than their backward formation counterpart rules. (Recall the relevant discussion about the rules for the s
$\tilde{~}$
t (non-)alternating classes, respectively. For these cases, forward formation rules have significantly higher confidence values than their backward formation counterpart rules. (Recall the relevant discussion about the rules for the s
 $\tilde{~}$
t alternating class in Section 1.2 above.) The relatively higher confidence values of the forward formation rules provide a better match to the high goodness scores given to the test forms of the p
$\tilde{~}$
t alternating class in Section 1.2 above.) The relatively higher confidence values of the forward formation rules provide a better match to the high goodness scores given to the test forms of the p
 $\tilde{~}$
p, t
$\tilde{~}$
p, t
 $\tilde{~}$
t, s
$\tilde{~}$
t, s
 $\tilde{~}$
t and c
$\tilde{~}$
t and c
 $\tilde{~}$
t classes. In sum, the productivity of the p
$\tilde{~}$
t classes. In sum, the productivity of the p
 $\tilde{~}$
p, t
$\tilde{~}$
p, t
 $\tilde{~}$
t, s
$\tilde{~}$
t, s
 $\tilde{~}$
t and c
$\tilde{~}$
t and c
 $\tilde{~}$
t classes is predicted by the forward formation, but not the backward formation rules.
$\tilde{~}$
t classes is predicted by the forward formation, but not the backward formation rules.
3.2 Mixed effects analysis
Thus far, we have considered only mean ratings scores, abstracting away from differences of individual participants. In this section, for a more stringent test, we take into consideration individual participant (and item) differences. The results of the present wug test were fitted with the lmer function from the lme4 package (Bates, Maechler & Bolker Reference Bates, Maechler and Bolker2011) in R (R Development Core Team 2014). Specifically, we provide a mixed effects analysis, taking the goodness rating of the inflected form as the dependent variable, confidence values, phonological well-formedness ratings and the final segment type of the stem (coronal vs. labial) as fixed factors, and participants and wug stems as random factors.
3.2.1 Results of the forward formation test
The mixed effects analysis of goodness ratings in the forward formation test shows significant effects of both random and fixed factors. Specifically, as can be seen in Table 4, the random effects for this model shows that there are fairly large estimates given to the slopes for confidence values of forward formation rules, labeled as ‘forward confidence’, with participant, labeled as ‘participant’, and test verb stem, labeled as ‘verb’, meaning that different participants and wug verb stems show greater/lesser effects of the model’s confidence score.
Table 4 Random effects: forward–forward comparison.
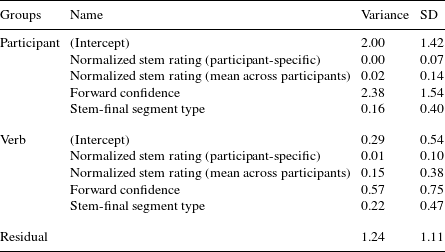
Note: Number of observations: 880. Groups: participant, 22; verb, 20.
Table 5 Fixed effects: forward–forward comparison.

Even once these random factors are taken into account, as can be seen in Table 5, the confidence values of forward formation rules still have a sizable effect on the goodness ratings (t = 6.75), which holds independently of the specific participant.
In contrast, phonological well-formedness factors – including both stem well-formedness ratings normalized by participant and averaged across all participants – have a very weak effect on the goodness ratings (t = –0.11, 1.24). This analysis suggests that participants’ ratings are due to knowledge of the relative probability of different alternations in the lexicon, as encoded by the forward formation rules’ confidences. This result is consistent with both the uni- and bi-directional models, since both posit rules relating base forms to non-base forms. The next section concerns predictions of the two models with respect to the backward formation test results.
3.2.2 Results of the backward formation test
To find out whether results of the backward formation test are more consistent with the predictions of the backward or forward formation rules, we constructed two mixed effects models, one with backward confidence (confidence values provided by backward formation rules) as a fixed factor (which we will call ‘backward only’ model) and the other with forward confidence as a fixed factor (which we will call ‘forward only’ model). As can be seen in Tables 6 and 7, just like the mixed effect model presented in the previous section, both of these models show the confidence’s sizable effect on the goodness ratings (t = 10.90, 10.43), which holds independently of the specific participant.
This means that participants’ ratings are significantly correlated with the confidence values of both the forward and backward formation rules. This is not surprising, given the positive correlations seen in the previous section, and the fact that the confidence scores in the two directions are often correlated with each other. The question, then, is whether one set of rules provides a better model than the other. We then compared the log likelihood and the Akaike Information Criterion (AIC) values of the two models in order to determine which model provides a better fit to the goodness ratings data. As shown in Table 8, the log likelihood (logLik) for the ‘forward-only’ model is higher (better fit), and the AIC value is lower (again, better fit).
Table 6 Fixed effects: ‘backward only’ model.

Table 7 Fixed effects: ‘forward only’ model.

Table 8 Model comparison: ‘forward-only’ vs. ‘backward-only’.
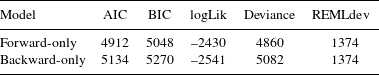
This model comparison confirms that participant ratings in the backward formation test are better modeled using the confidence scores of forward formation rules than backward formation rules. This interpretation is confirmed by a correlation test between participants’ goodness ratings of the backward formation test and the predicted values of the models. The test shows that the predicted values of ‘forward-only’ model (R
 $^{2}$
= 0.764) are correlated more strongly with the goodness ratings of the backward formation test, compared to those of ‘backward-only’ model (R
$^{2}$
= 0.764) are correlated more strongly with the goodness ratings of the backward formation test, compared to those of ‘backward-only’ model (R
 $^{2}$
=
0.711).
$^{2}$
=
0.711).
We therefore conclude that the ‘forward-only’ model provides a more accurate account of the ratings data than the ‘backward-only’ model. Consequently, the mixed effects analyses presented above provide support for the uni-directional model over the bi-directional model.
4 Alternatives
In the previous section, we discussed how well the bi- and uni-directional models explain the results of the wug test, focusing on the backward formation test. In this section, we consider other possible accounts.
4.1 Generality of phonological processes
As reported in Section 2.4.2 above, participant productions and goodness ratings indicate that a particular set of (non-)alternation classes is productive, regardless of the direction of the wug test. The high productive group includes the w
 $\tilde{~}$
u, p
$\tilde{~}$
u, p
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
l, c
$\tilde{~}$
l, c
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $\tilde{~}$
t, and s
$\tilde{~}$
t, and s
 $\tilde{~}$
t classes, whereas the low productive group includes the w
$\tilde{~}$
t classes, whereas the low productive group includes the w
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
t,
$\tilde{~}$
t,
 $\varnothing$
$\varnothing$
 $\tilde{~}$
t, and l
$\tilde{~}$
t, and l
 $\tilde{~}$
t classes.
$\tilde{~}$
t classes.
In order to explain the observed difference in productivity between the two groups, one might consider the possibility that the alternations of the high productive classes are phonologically more predictable than those of low productive ones. Note that the alternations of the high productive classes are the result of applying automatic phonological processes such as coda neutralization and glide formation. In contrast, if we follow the traditional phonological analyses, mentioned in Section 1.1, the alternations of the low productive classes would be the result of applying lenition processes with exceptions, which have been called ‘irregular’ processes.
Note, however, that there are many other alternation classes which are due to the same automatic processes, but nonetheless show low productivity. Note that the c
 $^{\text{h}}$
$^{\text{h}}$
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $^{\text{h}}$
$^{\text{h}}$
 $\tilde{~}$
t, and p
$\tilde{~}$
t, and p
 $^{\text{h}}$
$^{\text{h}}$
 $\tilde{~}$
p alternation class verbs, like the highly productive w
$\tilde{~}$
p alternation class verbs, like the highly productive w
 $\tilde{~}$
u, p
$\tilde{~}$
u, p
 $\tilde{~}$
p, l
$\tilde{~}$
p, l
 $\tilde{~}$
l, c
$\tilde{~}$
l, c
 $\tilde{~}$
t, t
$\tilde{~}$
t, t
 $\tilde{~}$
t, and s
$\tilde{~}$
t, and s
 $\tilde{~}$
t classes, involve the automatic process of coda neutralization. Nonetheless, inflected forms involving these alternations were rarely chosen by the experiment participants, as can be seen in the results of elicited production reported in Table 3 above. Thus, we cannot simply attribute the observed differences in productivity to the generality of the phonological processes involved in their alternations.
$\tilde{~}$
t classes, involve the automatic process of coda neutralization. Nonetheless, inflected forms involving these alternations were rarely chosen by the experiment participants, as can be seen in the results of elicited production reported in Table 3 above. Thus, we cannot simply attribute the observed differences in productivity to the generality of the phonological processes involved in their alternations.
4.2 Influence from the noun lexicon
As discussed in Section 2.4.2, one prominent pattern of the backward formation test results which is not consistent with the predictions of backward formation rules is the frequent occurrence and high ratings of s-final forms. The productivity of s
 $\tilde{~}$
t alternations is interesting, because verbs with s
$\tilde{~}$
t alternations is interesting, because verbs with s
 $\tilde{~}$
t alternations are greatly outnumbered by verbs with other alternations (e.g. t
$\tilde{~}$
t alternations are greatly outnumbered by verbs with other alternations (e.g. t
 $\tilde{~}$
t and t
$\tilde{~}$
t and t
 $\tilde{~}$
c) in Seoul Korean. We have attributed this productivity to the fact that in the forward direction, pre-V /s/ does consistently correspond with pre-C /t/. However, another possibility that must be considered is that s
$\tilde{~}$
c) in Seoul Korean. We have attributed this productivity to the fact that in the forward direction, pre-V /s/ does consistently correspond with pre-C /t/. However, another possibility that must be considered is that s
 $\tilde{~}$
t alternations in verbs are encouraged by their prevalence in noun paradigms. In Seoul Korean noun paradigms, stem-final /s/ is very frequent among coronal-final stems. It has been pointed out in the literature on Korean phonology and morphology (Ko Reference Ko1989; Hayes Reference Hayes1998; Albright Reference Albright2002a, Reference Albright, Downing, Alan Hall and Raffelsiefen2005; Kang Reference Kang and McClure2003; Jun Reference Jun2010 among others) that /s/ is in fact the most frequent stem-final coronal obstruent in nouns, as shown below, and it is thus adopted as an innovative variant among nouns with stem-final coronal obstruents, for instance /pat
$\tilde{~}$
t alternations in verbs are encouraged by their prevalence in noun paradigms. In Seoul Korean noun paradigms, stem-final /s/ is very frequent among coronal-final stems. It has been pointed out in the literature on Korean phonology and morphology (Ko Reference Ko1989; Hayes Reference Hayes1998; Albright Reference Albright2002a, Reference Albright, Downing, Alan Hall and Raffelsiefen2005; Kang Reference Kang and McClure2003; Jun Reference Jun2010 among others) that /s/ is in fact the most frequent stem-final coronal obstruent in nouns, as shown below, and it is thus adopted as an innovative variant among nouns with stem-final coronal obstruents, for instance /pat
 $^{\text{h}}$
-ɨl/ [pat
$^{\text{h}}$
-ɨl/ [pat
 $^{\text{h}}$
ɨl]
$^{\text{h}}$
ɨl]
 $\tilde{~}$
[pasɨl] ‘field (acc)’.
$\tilde{~}$
[pasɨl] ‘field (acc)’.

In the experiment, wug stems were placed in frames where only verbs can appear, so this result could not be due to misanalysis of the wug items as nouns. However, one might still consider the possibility that the observed high productivity of s-final forms is due to the influence of the noun lexicon. If the participants considered not only the verb lexicon but also the noun lexicon in the test, they are expected to produce s-final forms as frequently as they did in the test since a large number of nouns with final /s/ would contribute to the reliability/confidence of backward formation rules deriving s-final forms.
We consider this possibility quite unlikely for the following two reasons. First, as can be seen in (20), stem-final /c
 $^{\text{h}}$
/ is also frequent in the noun lexicon, and this frequent occurrence of stem-final /c
$^{\text{h}}$
/ is also frequent in the noun lexicon, and this frequent occurrence of stem-final /c
 $^{\text{h}}$
/ has been adopted as the basis for the occurrence of innovative forms involving them (Jun Reference Jun2010): for instance, /mit
$^{\text{h}}$
/ has been adopted as the basis for the occurrence of innovative forms involving them (Jun Reference Jun2010): for instance, /mit
 $^{\text{h}}$
-ɨl/ [mit
$^{\text{h}}$
-ɨl/ [mit
 $^{\text{h}}$
ɨl]
$^{\text{h}}$
ɨl]
 $\tilde{~}$
[mic
$\tilde{~}$
[mic
 $^{\text{h}}$
ɨl] ‘bottom (acc)’. Thus, if the participants were influenced by lexical frequencies of alternations among nouns, c
$^{\text{h}}$
ɨl] ‘bottom (acc)’. Thus, if the participants were influenced by lexical frequencies of alternations among nouns, c
 $^{\text{h}}$
-final forms should be expected to be at least partly productive. However, in the production test, participants never volunteered c
$^{\text{h}}$
-final forms should be expected to be at least partly productive. However, in the production test, participants never volunteered c
 $^{\text{h}}$
-final forms. This low productivity of c
$^{\text{h}}$
-final forms. This low productivity of c
 $^{\text{h}}$
-final forms undermines the possibility that the noun lexicon was considered by the participants of the current wug test.
$^{\text{h}}$
-final forms undermines the possibility that the noun lexicon was considered by the participants of the current wug test.
More importantly, if alternations among nonce verbs are influenced by other lexical categories, we would expect adjectives to play a role as well. In fact, because verbs and adjectives have a great deal of morphological overlap in Korean, it is controversial whether the two even belong to separate categories. The distinction between the two is mainly based on restrictions on a couple of suffixes such as -(nɨ)n ‘non-past indicative’ that can be attached only to verb stems, not adjectives (Sohn Reference Sohn1999, Mok Reference Mok2003). Since the category distinction between verbs and adjectives in Korean is at best weak, we might expect lexical statistics of alternations among adjectives to influence responses at least as much as nouns. The results of the present experiment show no such indication. Note below that the w
 $\tilde{~}$
p alternation class is much more frequent than the p
$\tilde{~}$
p alternation class is much more frequent than the p
 $\tilde{~}$
p class in the adjective lexicon, and thus even after combining verbs and adjectives, the w
$\tilde{~}$
p class in the adjective lexicon, and thus even after combining verbs and adjectives, the w
 $\tilde{~}$
p class is still dominant.Footnote
[11]
If both verbs and adjectives contribute to the rule reliability/confidence, the rule for the w
$\tilde{~}$
p class is still dominant.Footnote
[11]
If both verbs and adjectives contribute to the rule reliability/confidence, the rule for the w
 $\tilde{~}$
p alternation should have very high reliability/confidence, predicting high productivity of the w
$\tilde{~}$
p alternation should have very high reliability/confidence, predicting high productivity of the w
 $\tilde{~}$
p class forms. This is not what we found; instead, w
$\tilde{~}$
p class forms. This is not what we found; instead, w
 $\tilde{~}$
p alternations are dispreferred, consistent with their low frequency in the verb lexicon.
$\tilde{~}$
p alternations are dispreferred, consistent with their low frequency in the verb lexicon.

Thus, we conclude that the high degree of productivity for s
 $\tilde{~}$
t alternations should be attributed to the high confidence of forward s
$\tilde{~}$
t alternations should be attributed to the high confidence of forward s
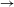 $\rightarrow$
t rules, and not to the independent existence of t
$\rightarrow$
t rules, and not to the independent existence of t
 $\tilde{~}$
s alternations in nouns.
$\tilde{~}$
s alternations in nouns.
4.3 Paradigm uniformity and Bayes’ theorem
In Section 3, we showed that although the forward formation test results are consistent with the predictions of the forward formation rules, the backward formation test results are not so consistent with the predictions of the backward formation rules. This is problematic for the bi-directional model of inferring alternations. We also showed that the backward formation test results are better explained by the forward formation rules than the backward formation rules. This helps support the uni-directional model, which includes only forward formation rules. In this section, we discuss some other mechanisms that have the potential to explain the backward formation test results.
Let us first consider the possibility that results of the backward formation test are due to paradigm uniformity. Recall from Section 1.2.2, this option makes more sense under the single base hypothesis, since such asymmetrical models have a ready-made explanation for why speakers would use different strategies in different directions. As shown below, the strongly favored [p, t]-final responses are almost identical to the p, t-final stimuli (except for allophonic voicing, not shown in the phonetic transcription of this paper). Thus, these forms satisfy paradigm uniformity, and could potentially be favored by paradigm uniformity constraints.

Paradigm uniformity cannot explain the high productivity of s
 $\tilde{~}$
t and c
$\tilde{~}$
t and c
 $\tilde{~}$
t alternations, however. For t-final stimuli, paradigm uniformity unequivocally favors [ɾ, t
$\tilde{~}$
t alternations, however. For t-final stimuli, paradigm uniformity unequivocally favors [ɾ, t
 $^{\text{h}}$
]-final outputs over [s, c]-final outputs. Thus, we find that paradigm uniformity is not a good predictor of participant responses, in either the forward or backward direction. (See Coetzee Reference Coetzee2009 for the claim that paradigm uniformity is the default option, if other things, including lexical frequency, are equal.)
$^{\text{h}}$
]-final outputs over [s, c]-final outputs. Thus, we find that paradigm uniformity is not a good predictor of participant responses, in either the forward or backward direction. (See Coetzee Reference Coetzee2009 for the claim that paradigm uniformity is the default option, if other things, including lexical frequency, are equal.)
As suggested by an anonymous referee, another possible option under the single base hypothesis is use of forward formation rules, together with Bayes’ Theorem, in the explanation of the backward formation test results. Bayes’ theorem is typically used for deriving a conditional probability from its reverse conditional probability: P(x|y) = P(y|x)*P(x)/P(y). Thus, if we know only the confidence of forward formation rules, which can be considered as the conditional probability of having a pre-C form given its corresponding pre-V form, we would be able to derive, through Bayes’ theorem, the confidence of backward formation rules, i.e. the conditional probability of having a pre-V form given its corresponding pre-C form. However, the resulting model’s prediction about the results of the wug test would be no different from that of the bi-directional model since the two models’ predictions are based on the same set of confidence values. As shown in the previous section, the bi-directional model does not provide a satisfactory explanation of the results of the backward formation test; thus, a model based on Bayes’ theorem does not intrinsically solve the problem of how to invert forward formation rules to apply them in backward formations.
4.4 A superset model with both forward and backward confidence
In Section 3, we compared a grammar containing rules in only one direction (base
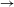 $\rightarrow$
derived) with a grammar that contains different rules for each direction of derivation (base
$\rightarrow$
derived) with a grammar that contains different rules for each direction of derivation (base
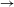 $\rightarrow$
derived, and derived
$\rightarrow$
derived, and derived
 $\rightarrow$
base). In order to test which grammar provides a better account of the current wug test results, we constructed two mixed effects models: ‘forward-only’ and ‘backward-only’. These models include, as fixed factors, confidence values provided by forward formation rules (forward confidence) and those provided by backward formation rules (backward confidence), respectively. It was shown that the ‘forward-only’ model provides a more accurate account of the ratings data of the backward formation test than the ‘backward-only’ model. This provides support for the hypothesis that grammars contain rules in only one direction, and speakers use these rules ‘in reverse’ to do backward formation, when necessary.
$\rightarrow$
base). In order to test which grammar provides a better account of the current wug test results, we constructed two mixed effects models: ‘forward-only’ and ‘backward-only’. These models include, as fixed factors, confidence values provided by forward formation rules (forward confidence) and those provided by backward formation rules (backward confidence), respectively. It was shown that the ‘forward-only’ model provides a more accurate account of the ratings data of the backward formation test than the ‘backward-only’ model. This provides support for the hypothesis that grammars contain rules in only one direction, and speakers use these rules ‘in reverse’ to do backward formation, when necessary.
An alternative possibility, suggested by an anonymous referee, is that grammars contain rules in both directions, and that speakers can access both simultaneously. In order to test this possibility, we constructed a superset model with both sets of confidence values (provided by forward and backward formation rules), as fixed factors. As can be seen in Table 9, this superset mixed effects model shows that the forward and backward confidence values both have a noticeable effect on the goodness ratings of the backward formation test, which holds independently of the specific participant.
Table 9 Fixed effects: a superset model.

We did a likelihood ratio test on the nested comparison of this superset model and the ‘forward-only’ model. The result shows that the superset model is significantly better (
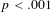 $p<.001$
) than the ‘forward-only’ model, indicating that the backward confidence values explain some variance in the ratings that the forward confidence values do not.
$p<.001$
) than the ‘forward-only’ model, indicating that the backward confidence values explain some variance in the ratings that the forward confidence values do not.
This result appears to support a model in which speakers have simultaneous access to rules in both directions. However, crucially, they do not support a symmetrical bi-directional model, in which rules in all directions have equal status. Recall from Section 3.2.2 that a model with forward confidence values provided a better account of the ratings data in the backward formation test than backward confidence values; that is, even if both play some role in predicting ratings in the backward formation test, the forward confidence rules are the primary determinant. This asymmetry is also seen clearly in the magnitudes of the coefficients for the two predictors in Table 9. As mentioned in Section 1.2.2, under a relaxed version of a single base hypothesis, backward formation rules may exist, but are limited in their application in some way. Given that the base form has a privileged status, it is expected under this relaxed version of a single base hypothesis that forward formation rules would play a larger role in explaining the mapping in each direction. This expectation is consistent with the result of the statistical analyses presented above.
This result raises a deeper question about the role and status of ‘backwards’ direction rules: if speakers rely primarily on forward rules, why would the grammar additionally contain backward rules that are used simultaneously, but to a lesser extent? We can only offer tentative speculation on this point. One possibility is that the ‘backward’ effect, although significant, has a fundamentally different source than the ‘forward’ effect. For example, perhaps the grammar contains only forward rules, as in the single surface base hypothesis, but speakers also make recourse to non-grammatical analogical comparisons when they are forced to use the rules in reverse to do backward (derived
 $\rightarrow$
base) derivations. Alternatively, perhaps the grammar does contain rules in both directions, as suggested by the relaxed version of the single surface base hypothesis, but the forward direction rules are ‘privileged’: speakers are more likely to use them, or trust them more, in cases where the outcomes conflict.
$\rightarrow$
base) derivations. Alternatively, perhaps the grammar does contain rules in both directions, as suggested by the relaxed version of the single surface base hypothesis, but the forward direction rules are ‘privileged’: speakers are more likely to use them, or trust them more, in cases where the outcomes conflict.
5 Remaining puzzles
In Section 2.4.2, we reported two unexpected response patterns from the elicited production portion of the experiment. First, many responses for the w-final stimuli (e.g. [naluw-ə]) involve w-deletion (e.g. [nalu-ca]). Forms of this type (78 occurrences) were even more frequent than u-final forms (75 occurrences). Second, for the l-final stimuli (e.g. [kjəl-ə]), 36 ɨ-insertion forms (e.g. [kjəlɨ-ca]) were produced. These two patterns were not expected to occur, and thus they were not even included in the goodness ratings task. We will first discuss the w-deletion and then ɨ-insertion forms.
There are two potential explanations for the frequent deletion of the stem-final [w] attested in the current wug test: optional w-epenthesis and stem-final [u]-deletion.Footnote
[12]
As mentioned above, stem-final [u] typically undergoes glide formation before V-initial suffixes, but an additional hiatus-avoidance process is reported to occur variably (Kim Reference Kim2000). [w] is sometimes inserted between the stem-final /u/ (and /o/) and the suffix-initial vowel, e.g. /katu-ə/ [katwə]
 $\tilde{~}$
[katuwə] ‘block in (imp)’. It may be the case that participants considered the stem-final [w] to be an epenthetic consonant, and thus they omitted it before C-initial suffixes (e.g. [nalu-ca]). This analysis is supported by the fact that for the two test stems ending in the sequence [uw], [naluw-ə] and [nasuw-ə], more than half of the participants deleted [w] with the -ca suffix: 15 [nalu-ca] and 12 [nasu-ca].
$\tilde{~}$
[katuwə] ‘block in (imp)’. It may be the case that participants considered the stem-final [w] to be an epenthetic consonant, and thus they omitted it before C-initial suffixes (e.g. [nalu-ca]). This analysis is supported by the fact that for the two test stems ending in the sequence [uw], [naluw-ə] and [nasuw-ə], more than half of the participants deleted [w] with the -ca suffix: 15 [nalu-ca] and 12 [nasu-ca].
The rest of [w]-deletion forms may be attributed to another optional process in which stem-final /u/ deletes in some Seoul Korean verbs, as shown in (23).

In Kim’s (Reference Kim2000) description of this process, its application domain is not specifically limited to the pre-C context. But, insofar as this deletion can occur before C-initial suffixes, and Korean speakers are aware of it, it would not be surprising that the participants applied this deletion while responding to the [w]-final stimuli in the current experiment.
Consequently, the phonological processes of glide epenthesis and deletion may explain why speakers’ productions frequently showed w
 $\tilde{~}$
$\tilde{~}$
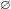 $\varnothing$
alternation. Both of these are relatively minor processes in Korean, and the details of their occurrence bear further investigation; however, the facts above are consistent with a phonological explanation for this unexpected pattern.
$\varnothing$
alternation. Both of these are relatively minor processes in Korean, and the details of their occurrence bear further investigation; however, the facts above are consistent with a phonological explanation for this unexpected pattern.
Let us now consider ɨ-insertion forms (e.g. [kjəlɨ-ca]) for the l-final stimuli (e.g. [kjəl-ə]). Given that there are only six lɨ-final verb stems with the
 $\varnothing$
$\varnothing$
 $\tilde{~}$
ɨ alternation in the Seoul Korean verb lexicon, forms of this type were not expected to be produced as often as they were. We think that this unexpected pattern can be attributed to the experimenter’s careful articulation of the stimuli. Recall that a flap and a lateral are in an allophonic relationship in Korean, as shown below.
$\tilde{~}$
ɨ alternation in the Seoul Korean verb lexicon, forms of this type were not expected to be produced as often as they were. We think that this unexpected pattern can be attributed to the experimenter’s careful articulation of the stimuli. Recall that a flap and a lateral are in an allophonic relationship in Korean, as shown below.

A flap is allowed to occur only as a single onset, whereas a lateral may occur as a coda or a geminate. The stem-final /l/ of the l-final stimuli occurs between vowels, and thus it should be pronounced as a flap in Korean. However, during the experiment, the experimenter attempted to pronounce the stimuli clearly, in order to avoid segmental misperceptions. This attempt may occasionally have lead the experimenter to pronounce the morphemes separately, causing the /l/ to be pronounced in the coda of the stem. This coda lateral may have been interpreted as a geminate by Korean listeners, since a pre-V lateral must be a geminate according to Korean phonotactics.
Stems with a geminate [l] before V-initial suffixes are mostly the ll
 $\tilde{~}$
lɨ alternating verbs which have been called ‘lɨ-irregular’ in the traditional literature:
$\tilde{~}$
lɨ alternating verbs which have been called ‘lɨ-irregular’ in the traditional literature:

There are many verbs of this alternation type, 38 in the Seoul Korean verb lexicon adopted in the present study. If participants heard /l/-final stimuli such as /kjəl-ə/ as involving a geminate lateral (e.g. [kjəllə]), they would be very likely to produce ll
 $\tilde{~}$
lɨ forms (e.g. [kjəɾɨ-ca]).
$\tilde{~}$
lɨ forms (e.g. [kjəɾɨ-ca]).
The above explanations of the two unexpected response patterns are tentative, but consistent with the data. Crucially, whatever the best explanation for these outputs ultimately is, these unexpected patterns do not threaten to undermine our conclusions about bi- and uni-directional models, for the following reasons. First, the unexpected patterns were observed from results of the elicited production portion of the experiment, while most of the statistical tests presented here concern the goodness judgment task. In addition, the unexpected response patterns were confined to the forward formation test, about which both bi- and uni-directional models make the same predictions. Therefore, although it is true that the occurrence of those unexpected response patterns must be fully understood in order to obtain a final account of how Seoul Korean speakers apply the full range of alternations, we leave an in-depth investigation of them for future research.
6 Conclusion
In the present study, we have performed two-way wug tests on Seoul Korean verbal paradigms, in order to probe how speakers make inferences about unpredictable allomorph selection in unknown stems. We have considered several possible models of the inference about the allomorph selection, focusing on those relying on probabilistic rules that track lexical frequencies.
Adopting the minimal generalization learner, we have first constructed two sets of rules, those deriving non-base surface allomorphs of Seoul Korean verbs from their base forms (forward formation) and those responsible for the derivation of the opposite direction (backward formation). These rules are accompanied with reliability/confidence values, i.e. rule application probabilities, which are determined by the relevant lexical frequencies.
The results are broadly consistent with a model in which speakers infer alternations based on rules, rather than based on paradigm uniformity or random guessing. In addition, we find support for the hypothesis that grammar is asymmetrical, and speakers do not learn rules for all logically possible mappings. In particular, correlation tests and mixed effects analyses showed that the results of the backward formation test are more consistent with the prediction of the forward formation rules than that of the backward formation rules. This supports Albright’s (Reference Albright2002a et seq.) single base hypothesis, where only forward formation rules are available.
APPENDIX A
Experiment procedure
Two sheets for pen-and-paper tests were prepared to give instructions and collect responses: the first one is for tasks (i) and (ii), and the second for task (iii).

The first sheet consisted of three parts, A, B and C shown in (27).


APPENDIX B
Mean ratings and model confidence values







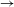














 Open access
Open access