

A large part of public opinion research is dedicated to studying whether individuals in different groups understand survey questions in similar ways (see Davidov, Muthén, and Schmidt Reference Davidov, Muthén and Schmidt2018, for an overview). However, while those using expert surveys have been concerned for a while with systematic differences in experts’ response patterns (e.g., Bakker et al. Reference Bakker, Edwards, Jolly, Polk, Rovny and Steenbergen2014), few studies to date applied measurement invariance (MI) techniques from public opinion research to expert surveys (for a recent exception, see Marquardt and Pemstein Reference Marquardt and Pemstein2018). Due to respondents’ homogeneity and usage of anchoring vignettes, one expects these problems to be minor or absent. Nevertheless, since measuring and comparing country averages is their main goal, if specialists on different countries or regions answer questions differently, comparison becomes impossible.
We show how MI techniques from mass surveys can be applied to analyze differing response patterns from experts using the Perceptions of Electoral Integrity dataset (PEI, Norris, Wynter, and Grömping Reference Norris, Wynter and Grömping2017). Results indicate that direct mean comparisons of countries’ electoral integrity across regions are biased across most integrity’s dimensions. We conclude with recommendations for those using this dataset and for the elaboration of better expert surveys in general.
1 Data
The PEI datasetFootnote
1
asks experts, since 2013, to evaluate whether national elections all around the world can be considered free and fair.Footnote
2
It has 49 questions capturing eleven dimensions of electoral integrity. With the exception of North Africa (
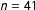 $n=41$
), all regions have at least 100 expert respondents.Footnote
3
The dimensions of electoral integrity are: 1. Electoral Laws (3 questions); 2. Electoral Procedures (4); 3. Boundaries for Voting Districts (3); 4. Voter Registration (3); 5. Party and Candidate Registration (5); 6. Media Coverage (5); 7. Campaign Finance (5); 8. Voting Process (8); 9. Vote Count (5); 10. Voting Results (4); 11. Election Authorities (4). Responses have a 1–5 Likert scale, from “Strongly disagree” to “Strongly agree.” For example, on “Election Authorities,” the first indicator reads “The election authorities were impartial.”Footnote
4
$n=41$
), all regions have at least 100 expert respondents.Footnote
3
The dimensions of electoral integrity are: 1. Electoral Laws (3 questions); 2. Electoral Procedures (4); 3. Boundaries for Voting Districts (3); 4. Voter Registration (3); 5. Party and Candidate Registration (5); 6. Media Coverage (5); 7. Campaign Finance (5); 8. Voting Process (8); 9. Vote Count (5); 10. Voting Results (4); 11. Election Authorities (4). Responses have a 1–5 Likert scale, from “Strongly disagree” to “Strongly agree.” For example, on “Election Authorities,” the first indicator reads “The election authorities were impartial.”Footnote
4
2 Measurement Invariance
With Likert scales, MI is obtained if two respondents who have the same level of a latent construct give the same answer to a question measuring it, regardless of group membership (Millsap Reference Millsap2011).Footnote 5 We test two types of invariance: metric and scalar (Millsap Reference Millsap2011). Metric invariance means that an increase of 1 unit in the latent trait corresponds to the exact same increase in the response for any individual, regardless of group identity. It yields comparable coefficients when used in regression analysis. Scalar invariance requires, on top of metric, that two individuals with the same level of the construct would give the exact same answer. Scalar invariance is more demanding, but necessary for comparison of group means.
We test MI using multigroup confirmatory factor analysis (MGCFA, Jöreskog Reference Jöreskog1971). In a CFA model, indicators theorized to measure each dimension should load together into a single latent variable. MGCFA considers that observations might be nested into qualitatively different groups. It allows researchers to test if some estimated model parameters differ across the groups: for example, a factor loading may have one value for respondents from region A and another for B, while other model parameters are estimated as the same across all regions. If the measurement instrument is invariant across groups, freely estimated loadings should be similar: if the loading of an indicator is high for one region but low for another, it suggests that the items function differently. We apply MGCFA with three nested invariance models: configural, metric (factor loadings are constrained to be equal across groups) and scalar (loadings and intercepts are constrained to be equal across groups), testing invariance by comparing the
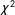 $\unicode[STIX]{x1D712}^{2}$
-distributed difference in the -2*log-likelihoods.
$\unicode[STIX]{x1D712}^{2}$
-distributed difference in the -2*log-likelihoods.
The
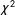 $\unicode[STIX]{x1D712}^{2}$
invariance test in MGCFA has been criticized for finding noninvariance even in the presence of substantively minor deviations (Oberski Reference Oberski2014). Therefore, we also present the Root Mean Squared Error of Approximation (RMSEA), and the Comparative Fit Index (CFI). These are less sensitive to large samples and indicate whether the more restricted models have acceptable fit. Next we use the Alignment method (Asparouhov and Muthén Reference Asparouhov and Muthén2014). This is an optimization approach to invariance which minimizes overall noninvariance of the model while allowing noninvariance of a few indicators or groups (Asparouhov and Muthén Reference Asparouhov and Muthén2014). While these may increase the odds of Type II errors (not finding noninvariance that exists), combining both methods gives us a good overview of actual (non)invariance levels.Footnote
6
$\unicode[STIX]{x1D712}^{2}$
invariance test in MGCFA has been criticized for finding noninvariance even in the presence of substantively minor deviations (Oberski Reference Oberski2014). Therefore, we also present the Root Mean Squared Error of Approximation (RMSEA), and the Comparative Fit Index (CFI). These are less sensitive to large samples and indicate whether the more restricted models have acceptable fit. Next we use the Alignment method (Asparouhov and Muthén Reference Asparouhov and Muthén2014). This is an optimization approach to invariance which minimizes overall noninvariance of the model while allowing noninvariance of a few indicators or groups (Asparouhov and Muthén Reference Asparouhov and Muthén2014). While these may increase the odds of Type II errors (not finding noninvariance that exists), combining both methods gives us a good overview of actual (non)invariance levels.Footnote
6
We test MI in each of the eleven electoral integrity dimensions, each modeled as a latent variable with three to eight indicators as denoted in the codebook. Invariance is tested across two clustering options: five continents, or nine regions (defined by PEI itself). Instead of using the original responses, we run the analyses on DIF-corrected rank ordered responses obtained with PEI’s anchoring vignettes, following the nonparametric model by King et al. (Reference King, Murray, Salomon and Tandon2004).Footnote 7
Table 1. MGCFA test of measurement invariance.

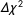 $\unicode[STIX]{x1D6E5}\unicode[STIX]{x1D712}^{2}$
: difference between the configural and metric invariance models’
$\unicode[STIX]{x1D6E5}\unicode[STIX]{x1D712}^{2}$
: difference between the configural and metric invariance models’
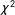 $\unicode[STIX]{x1D712}^{2}$
statistics;
$\unicode[STIX]{x1D712}^{2}$
statistics;
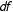 $df$
: difference in the number of free parameters between the two models, and
$df$
: difference in the number of free parameters between the two models, and
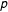 $p$
-values for this difference. RMSEA and CFI from the metric invariance models;
$p$
-values for this difference. RMSEA and CFI from the metric invariance models;
 $\unicode[STIX]{x1D6E5}$
RMSEA and
$\unicode[STIX]{x1D6E5}$
RMSEA and
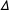 $\unicode[STIX]{x1D6E5}$
CFI are the difference in RMSEA and CFI from that model to the configural. All fit statistics are calculated with the Satorra and Bentler (Reference Satorra and Bentler2001) correction for robust estimation.
$\unicode[STIX]{x1D6E5}$
CFI are the difference in RMSEA and CFI from that model to the configural. All fit statistics are calculated with the Satorra and Bentler (Reference Satorra and Bentler2001) correction for robust estimation.
3 Results
Table 1 has results of metric invariance tests with MGCFA. We do not report scalar invariance because no dimension even approaches it.Footnote 8 For no dimensions of electoral integrity can we directly compare mean values of countries across regions. A few dimensions fare well in metric invariance: “Boundaries,” “Voter Registration,” and “Electoral authorities,” in both regions and continents. Most others not only display significant differences between the configural and metric models, but the models with constrained loadings have very poor fit, as denoted by RMSEAs greater than 0.05 and CFIs less than 0.95 (recommended thresholds for good fit by Hu and Bentler Reference Hu and Bentler1999). It is important to highlight that noninvariance remains after incorporating anchoring vignettes into the model,Footnote 9 confirming the finding by von Davier et al. (Reference von Davier, Shin, Khorramdel and Stankov2017) that vignette questions themselves can be understood differently by respondents in different groups, ultimately just moving the noninvariance problem one step further.
With the alignment analysis (Table 2), we find that noninvariance in some dimensions is restricted to a few items, and mostly concentrated in some regions. For example, the first indicator for “Electoral Laws” has a noninvariant intercept in Africa, while the third has noninvariant loading and intercept in Western Europe. These indicators, however, work well in all other continents or regions to measure the integrity of electoral laws in a cross-regionally comparable way. In these cases, users of PEI could drop problematic regions or items from their analyses. The best performing dimension is “Voter registration,” where all items have good cross-regional validity and can be used without problems in comparative research. Western Europe is the most problematic region overall, with the highest number of indicators that are noninvariant for loadings and intercepts. We may hypothesize that specialists in Western Europe have different anchors for inappropriate electoral conduct, resulting in different response styles even after accounting for DIF with anchoring vignettes.
Table 2. Alignment method: loadings and intercepts invariance.

Numbers indicate the standardized difference between the noninvariant group intercept and the weighed average intercept between invariant groups. Continents: 1: Africa; 2: Americas; 3: Asia; 4: Europe; 5: Oceania. Regions: 1: East & Southern Africa; 2: West & Central Africa; 3: East Asia & Pacific; 4: South Asia; 5: Eastern Europe; 6: Western Europe; 7: Middle East; 8: North Africa; 9: Americas.
Noninvariance of indicators’ intercepts is considered the least problematic, since if loadings are invariant one can still get unbiased regression estimates. To check the magnitude of the (smallest possible) problem we look at the size of noninvariance for intercepts. Numbers in the light gray cells are the standardized difference between that indicator’s intercept for that group and the weighed average intercept for invariant groups. Looking again at the noninvariant intercept for the third indicator in “Boundaries” in Europe, the estimate means that, for an election with the exact same level of integrity of boundaries for voting districts, an European respondent would give an answer 0.21 standard deviations below the average of respondents from other regions. There are larger differences in other dimensions and regions: for example, experts in Africa evaluating whether “fraudulent votes were cast” (“Voting Process”) would give answers 0.42 SDs below the average of other respondents evaluating exactly the same elections. Considering how these questions are aggregated, biases add up to substantively different evaluations of elections across regions.
4 Conclusion
In this letter we perform MI tests in the PEI dataset (Norris, Wynter, and Grömping Reference Norris, Wynter and Grömping2017), and show that experts have different response styles depending on the region where their countries of specialty are located. These results reinforce findings that one should not use aggregate means of expert surveys (Marquardt and Pemstein Reference Marquardt and Pemstein2018). The problem persists after using anchoring vignettes, which are supposed to account for DIF. Consequently, it is unlikely that the issue could be solved by increasing the number of experts, or perhaps crowdsourcing (Maestas, Buttice, and Stone Reference Maestas, Buttice and Stone2014): if all specialists on Western Europe or West European citizens have a systematically different understanding of electoral integrity than experts of other regions, errors are not random and will not cancel out by increasing the pool size. Due to this systematic bias on answers to each individual question, using other measures of central tendency (as suggested by Lindstädt, Proksch, and Slapin Reference Lindstädt, Proksch and Slapin2018) would still yield incomparable estimates across regions. Beyond incomparable averages, lack of loadings’ invariance also compromises these dimensions’ use in regression analysis. For instance, the solutions proposed by Marquardt and Pemstein (Reference Marquardt and Pemstein2018) can help correcting for scalar invariance and yield cross-regionally comparable country means. They might not, however, solve the lack of metric invariance for linear models and the biased regression estimates that follow. The only solution, given available data, would be to use Bayesian multilevel structural equation models with random factor loadings (Muthén and Asparouhov Reference Muthén and Asparouhov2018; Castanho Silva, Bosancianu, and Littvay Reference Castanho Silva, Bosancianu and Littvay2019). Such methods can model the cross-regional noninvariance and should be applied by researchers who use the electoral integrity dimensions in their regression analyses.
There might be a few ways to alleviate noninvariance problems when designing expert surveys. First, following PEI’s exemplary lead and having (a) constructs with a strong theoretical foundation, (b) multiple questions per construct, and (c) anchoring vignettes. This allows, at least, to test whether the measurement is cross-regionally valid. Second, one could also collect pilot data with quasi-experts (e.g., internationally diverse groups of social science graduate students) who are likely to respond similarly to the targeted respondents. Following the analytical steps presented here, one can identify, adjust or eliminate problematic items, and, if needed, even drop entire regions. We call for better design of expert survey batteries and more rigorous pretests, leading to comparative measurement of relevant concepts where results can actually be compared.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2019.24.




