1 Introduction
In February of 2017, the Trump Administration issued an executive order that banned the entry of people from seven majority-Muslim countries into the U.S. and unleashed chaos in airports all over the world. Legal challenges were swift and, within two weeks, the 9th Circuit Court of Appeals had scheduled oral arguments concerning the order. Public interest in how the court would rule was significant. More than 130,000 people listened to the arguments, and hundreds of experts weighed in on how the judges would vote. Many of these predictions relied on the three judges’ emotional reactions and vocal expressions during oral argument. For example, the New York Times provided a live analysis of the judges’ reactions, assessing whether they were “pretty skeptical” or “friendly.”Footnote 1 Ultimately, the three-judge panel ruled unanimously against the travel ban, but it was not without days of uncertainty for those affected.
In this paper, we do what observers of the 9th Circuit oral argument were attempting by asking whether we can systematically detect how judges will vote based on emotional responses at oral argument. We address this by examining the U.S. Supreme Court, which has decades of audio data. Specifically, we explore audio from nearly 3,000 hours of oral arguments from the last 30 years and find that vocal pitch alone is strongly predictive of Supreme Court Justices’ votes. The results are robust to the inclusion of other factors and predict outcomes at least as well as more complex models accounting for substantive features of the actors and cases, suggesting that vocal pitch predicts decisions in ways that characteristics like ideology or legal issue areas do not. In results presented in the Supplemental Information, moreover, we extend our findings to the 9th Circuit’s travel ban argument, suggesting that our approach has good external validity.
As we discuss below, our findings are consistent with several causal narratives. For example, it could be the case that Justices actively rely on their emotions in reaching important decisions. It may also be that judges experience aroused responses during oral arguments because they receive information conflicting with previously made decisions. Although we cannot disaggregate these explanations, our results clearly show that nonsubstantive and implicit signals, even among elite actors such as federal judges and Supreme Court Justices, can provide additional meaningful information on their attitudes beyond what can be found in their textual pronouncements.
2 Description of Supreme Court Oral Arguments Audio Data, Emotional Arousal, and Vocal Pitch
We are not the first to suggest that emotion plays an important role in judicial oral arguments (e.g., Shullman Reference Shullman2004; Johnson et al. Reference Johnson, Black, Goldman and Treul2009). For example, Black et al. (Reference Black, Treul, Johnson and Goldman2011) argue that the “tenor” of oral arguments can be used as a barometer of how Justices will rule in a given case. While others have utilized the number of questions directed toward each side (Roberts, Jr. Reference Roberts2005; Epstein, Landes, and Posner Reference Epstein, Landes and Posner2010), Black et al. (Reference Black, Treul, Johnson and Goldman2011) captured the emotions expressed during oral arguments using the number of “pleasant” and “unpleasant” words. They find that the more unpleasant words Justices use toward an attorney, the less likely that attorney will prevail in the case. Even though we acknowledge the importance of what Justices say, we suggest how they say those words may be of equal, if not greater, predictive importance.
Why might vocal pitch predict the behavior of even elite actors like Supreme Court Justices and why might the emotion signaled by vocal pitch be more important than the substantive content? First, changes in vocal inflections, like pitch, often occur unbeknownst to the speaker (Ekman et al. Reference Ekman, O’Sullivan, Friesen and Scherer1991). For the Justices, emotional arousal may be more likely when interacting with someone with whom they disagree. When this occurs, the heart begins to race, palms begin to sweat, and all muscles, including the vocal cords, tighten (Posner, Russell, and Peterson Reference Posner, Russell and Peterson2005). This is the primary reason why “the most consistent association reported in the literature is between arousal and vocal pitch, such that higher levels of arousal have been linked to higher-pitched vocal samples” (Mauss and Robinson Reference Mauss and Robinson2009, 222). For example, Laukka, Juslin, and Bresin (Reference Laukka, Juslin and Bresin2005) asked actors to portray “weak” and “strong” versions of a variety of emotions that were later judged by amateur and expert judges on the degree to which the actors were displaying an “activated” or “intense” emotional state. Not only was vocal pitch correlated with both activation and intensity, but the “patterns of vocal cues for activation and emotion intensity showed numerous similarities,” suggesting both may be capturing the same “physiological reaction” (648).Footnote 2
Moreover, due to the automatic nature of this response, a speaker’s vocal pitch will often provide insights into a speaker’s level of activation beyond their conscious communication. Indeed, “several studies have shown, that like the body, the tone of a person’s voice leaks information that is not revealed by the verbal content or facial expressions associated with the message” (Zuckerman and Driver Reference Zuckerman, Driver, Siegman and Feldstein1985, 129). (Additional discussion of this literature can be found in the Supplemental Information.) For these reasons, verbal and nonverbal behavior should be thought of in terms of a “leakage hierarchy” with “verbal content” located in the “controllable end of the continuum, whereas the body and tone of voice may be classified as less controllable and more leaky channels” (Zuckerman and Driver Reference Zuckerman, Driver, Siegman and Feldstein1985, 130). This suggests that Justices may subconsciously indicate their ultimate preferences toward a case by raising their vocal pitch toward either the petitioner or respondent. This is the case regardless of whether the Justice formulates her response contemporaneously or whether she is reacting on the basis of predispositions about the case.
Second, some Justices, like Antonin Scalia, may be more willing to express emotion as compared to others. Such differences are problematic for text-based measures since they only capture emotion that is verbalized. According to Russell (Reference Russell2003), this ignores a range of emotions which occur prior to conscious awareness. As analogy, consider felt body temperature. Even though our body’s temperature changes all the time, we do not always identify those changes as being hot or cold. For some, a small decrease in temperature may be enough to say, “I am cold!” For others, that same decrease may not even be recognized. Emotional expression on the Supreme Court functions in a similar way—some is verbal, some is nonverbal. For some Justices, an attorney’s error may be egregious enough to warrant calling it “idiotic,” while for others that same error may not even raise an eyebrow, verbal or otherwise. Text-based measures are extraordinarily useful when one is interested in understanding the former, but struggle with latter.Footnote 3
To achieve this end, we collected audio recordings from oral arguments in 1,773 cases, beginning in 1982 and ending in 2014.Footnote 4 Using the timestamps provided by the Oyez Project,Footnote 5 we further parsed these cases into discrete segments of audio uttered by (1) the Justices themselves, (2) the lawyer/s representing the petitioner, and (3) the lawyer/s representing the respondent.Footnote 6 Lawyers spoke for 2,137 hours. Justices spoke for 502 hours. For the Justices, this represented 146,335 discrete utterances. Additional descriptive statistics are provided in the Supplemental Information, Tables S1–S2.
3 Results: How Emotion Arousal Predicts Supreme Court Justices’ Voting
We expect that a Justice who is more emotionally activated when speaking toward an attorney will be more likely to vote against that attorney. If this is correct, a higher vocal pitch will predict a stronger negative response. To analyze this, we code whether a Justice votes in favor of the petitioner, a 1 or 0 variable.Footnote 7 We construct a measure of “Pitch Difference” by subtracting vocal pitch in questions directed toward petitioners from vocal pitch in questions directed toward respondents. (Vocal pitch was measured using Praat, a speech synthesis program that estimates the fundamental frequency by dividing the autocorrelation of a windowed signal by the autocorrelation of the window itself. To estimate the fundamental frequency we only use voiced speech. More details can be found in the Supplemental Information.) For each Justice, we converted vocal pitch to standard deviations above and below his or her average vocal pitch, which accounts for systematic differences between Justices (for example between male and female Justices) as well as any measurement error associated with extracting the fundamental frequency.Footnote 8
The main results are presented in Table 1, Model 2. All models are multilevel logistic regressions with random intercepts for each Justice.Footnote
9
These results show that the higher emotional arousal or excitement directed at an attorney compared to his or her opponent, the less likely that attorney is to win the Justice’s vote (
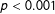 $p<0.001$
).Footnote
10
From Model 1, when the vocal pitch of questions directed to both sides is the same, the predicted probability of a Justice voting for the petitioner is 0.55. However, the probability of a Justice voting for the petitioner drops by 7 percentage points if the difference between the vocal pitch directed to the petitioner is one standard deviation higher than the vocal pitch directed at the respondent. The overall prediction rate is also reported.Footnote
11
Here, we are able to predict 57.50 percent of Justices’ votes accurately (see Table 1) and 66.55 percent of overall case outcomes accurately (see Table S4) using only pitch difference, suggesting that vocal pitch predicts not only how individual Justices vote but also the eventual disposition of the case.Footnote
12
$p<0.001$
).Footnote
10
From Model 1, when the vocal pitch of questions directed to both sides is the same, the predicted probability of a Justice voting for the petitioner is 0.55. However, the probability of a Justice voting for the petitioner drops by 7 percentage points if the difference between the vocal pitch directed to the petitioner is one standard deviation higher than the vocal pitch directed at the respondent. The overall prediction rate is also reported.Footnote
11
Here, we are able to predict 57.50 percent of Justices’ votes accurately (see Table 1) and 66.55 percent of overall case outcomes accurately (see Table S4) using only pitch difference, suggesting that vocal pitch predicts not only how individual Justices vote but also the eventual disposition of the case.Footnote
12
Table 1. Does vocal pitch predict votes in favor of the petitioner?

Note: Each model is a multilevel logistic regression with a random intercept for each Justice. Outcome is whether the Justice voted in favor of petitioner. Unit of analysis is each Justice’s vote. Models include statements with question marks. The average vocal pitch in questions directed toward the petitioner (“Petitioner Pitch”) minus the average vocal pitch in questions directed toward the respondent (“Respondent Pitch”) is captured in “Pitch Difference” (Petitioner Pitch - Respondent Pitch). Model 2 uses the Dictionary of Affect in Language (DAL). Model 3 uses the Harvard IV dictionary. Model 4 uses the Linguistic Inquiry and Word Count (LIWC) dictionary. The rest of the controls are the same as Black et al. (2011). Please refer to the Supplemental Information for more details about each dictionary, the controls, and our cross-validation approach.
Models 2, 3, and 4 include the controls used by Black et al. (Reference Black, Treul, Johnson and Goldman2011), as well as the differences in the use of “pleasant” and “unpleasant” words as defined by the Dictionary of Affect in Language (DAL), the Harvard IV dictionary (also known as the General Inquirer), and the Linguistic Inquiry and Word Count (LIWC) dictionary, respectively. Since the Harvard IV dictionary is publicly available, we provide the words used for Model 3 in the Supplemental Information. For Models 2 and 4, we provide some examples of “positive” and “negative” words. Unlike Black et al. (Reference Black, Treul, Johnson and Goldman2011), we use the Martin–Quinn scores estimated in the previous term, as Martin–Quinn scores are dynamically estimated within each term using Justices’ votes, which would introduce endogeneity if not lagged. These are continuous measures from liberal (
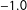 $-1.0$
) to conservative (
$-1.0$
) to conservative (
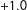 $+1.0$
) and vary from Justice to Justice and from term to term.
$+1.0$
) and vary from Justice to Justice and from term to term.
After accounting for vocal pitch, including these other variables only increases the predictive power of the model by around seven percentage points, suggesting that vocal pitch has unique predictive value. To further assess the substantive importance of vocal pitch, we compared the performance of vocal pitch (and of only vocal pitch) to a widely known algorithm developed by Katz, Bommarito, and Blackman (Reference Katz, Bommarito and Blackman2014), known as
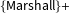 $\{\text{Marshall}\}+$
. This algorithm uses 95 variables to predict Supreme Court Justices’ voting and is known as one of the most predictive algorithms currently available.Footnote
13
As explained in the Supplemental Information, we restricted our analysis to the period from 1998 to 2012. In total,
$\{\text{Marshall}\}+$
. This algorithm uses 95 variables to predict Supreme Court Justices’ voting and is known as one of the most predictive algorithms currently available.Footnote
13
As explained in the Supplemental Information, we restricted our analysis to the period from 1998 to 2012. In total,
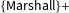 $\{\text{Marshall}\}+$
successfully predicts 64.76 percent of cases correctly, which is 1.79 percentage points lower than our prediction rate of 66.55 percent of cases. A simple
$\{\text{Marshall}\}+$
successfully predicts 64.76 percent of cases correctly, which is 1.79 percentage points lower than our prediction rate of 66.55 percent of cases. A simple
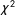 $\unicode[STIX]{x1D712}^{2}$
test reveals the models are similarly predictive (
$\unicode[STIX]{x1D712}^{2}$
test reveals the models are similarly predictive (
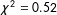 $\unicode[STIX]{x1D712}^{2}=0.52$
,
$\unicode[STIX]{x1D712}^{2}=0.52$
,
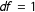 $df=1$
,
$df=1$
,
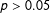 $p>0.05$
), suggesting we are able to equal the predictive power of a model that uses 95 predictors using only one—vocal pitch.
$p>0.05$
), suggesting we are able to equal the predictive power of a model that uses 95 predictors using only one—vocal pitch.
Model 1 also outperforms traditional petitioner-based models in which a “plaintiff always wins” rule is applied. Although seemingly simple, such a rule is actually fairly sophisticated and takes into account a lot of what scholars know about strategic planning, the rule of four, and principles of precedent. Using only vocal pitch, Model 1 significantly (
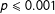 $p\leqslant 0.001$
) outperforms this baseline by 2.58 percentage points. Even though Models 2, 3, and 4 all perform better, when one only uses the number of “positive” and “negative” words, the prediction rates are substantially worse. For example, when the only predictors are the percent more positive and negative words directed at the petitioner, the model successfully predicts 0.81 and 0.72 percentage points better than the “plaintiff always wins” model, depending on whether one uses the DAL or LIWC dictionaries, respectively. The Harvard IV dictionary actually predicts 8.25 percentage points less than this baseline. As we show in the Supplemental Information, regardless of the text-based measure one uses, vocal pitch does substantially better at predicting both cases and votes. These results are not meant to suggest that vocal pitch is the only variable that should be incorporated into models of oral arguments. Nor do our results suggest text-based measures have no place in the study of emotional expression on the Supreme Court. Rather, our results demonstrate vocal pitch should be one of many variables that should be taken into consideration when assessing oral arguments.
$p\leqslant 0.001$
) outperforms this baseline by 2.58 percentage points. Even though Models 2, 3, and 4 all perform better, when one only uses the number of “positive” and “negative” words, the prediction rates are substantially worse. For example, when the only predictors are the percent more positive and negative words directed at the petitioner, the model successfully predicts 0.81 and 0.72 percentage points better than the “plaintiff always wins” model, depending on whether one uses the DAL or LIWC dictionaries, respectively. The Harvard IV dictionary actually predicts 8.25 percentage points less than this baseline. As we show in the Supplemental Information, regardless of the text-based measure one uses, vocal pitch does substantially better at predicting both cases and votes. These results are not meant to suggest that vocal pitch is the only variable that should be incorporated into models of oral arguments. Nor do our results suggest text-based measures have no place in the study of emotional expression on the Supreme Court. Rather, our results demonstrate vocal pitch should be one of many variables that should be taken into consideration when assessing oral arguments.
4 Discussion
For scholars interested in predicting Justice votes weeks, if not months, before the Court’s ruling is released, oral arguments “provide a barometer of how justices will rule in a given case” (Black et al.
Reference Black, Treul, Johnson and Goldman2011, 574). While we are not the first to suggest emotional expressions are an important part of such prognostications, the vast majority of these studies have only considered text-based measures (for important exceptions, see Schubert et al.
Reference Schubert, Peterson, Schubert and Wasby1992; Knox and Lucas Reference Knox and Lucas2017). We show vocal pitch on its own is about as predictive of Justices’ votes and overall case outcomes as models that use all publicly available quantitative legal and nonlegal information, including additional textual information related to emotion. These comparisons are not meant to suggest that vocal pitch is the only variable scholars should use when assessing emotional expression on the Supreme Court. We argue the
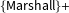 $\{\text{Marshall}\}+$
algorithm, text-based measures, and the “petitioner always wins” rule can (and should) be used to predict Justice votes. However, nonverbal signals, including changes in vocal pitch, also carry considerable weight. Justices choose their words carefully, but have far less control over how those words are spoken—and these subconscious vocal cues, our findings show, carry important information about eventual rulings.
$\{\text{Marshall}\}+$
algorithm, text-based measures, and the “petitioner always wins” rule can (and should) be used to predict Justice votes. However, nonverbal signals, including changes in vocal pitch, also carry considerable weight. Justices choose their words carefully, but have far less control over how those words are spoken—and these subconscious vocal cues, our findings show, carry important information about eventual rulings.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2018.47.