




Language learners must develop the ability to vary language according to linguistic and situational factors to produce context-appropriate utterances. Likewise, interpreting the additional meaning conveyed through language variation to interact effectively across multiple interactional contexts is essential. The study of communicative competence (e.g., Canale & Swain, Reference Canale and Swain1980; Sun, Reference Sun2014; van Compernolle & Williams, Reference van Compernolle and Williams2012) is long-standing and was initially explored to understand what language teachers must do beyond assisting learners in the development of grammatical competence to foster the acquisition of language abilities through which learners could participate fully in the target language. Over the past decades, this field of research has also led to an increasingly large and sophisticated body of work demonstrating how factors specific to the linguistic components of a language, the characteristics of individual speakers, and the context of interaction all come to influence the production and interpretation of the variable elements in language in context. Much of this work has been conducted within usage-based, functional, and variationist approaches to language acquisition and use. Within these frameworks, we see that patterns of language use drive acquisition and that these patterns are influenced by factors ranging from how often a given lexical item occurs in a language to the social identities of the speaker and hearer. In the context of second language (L2) acquisition, we see that even if production of variable structures indicating particular social, situational, or geographic characteristics is optional for individual speakers, targetlike interpretation of these forms is integral to advanced linguistic competence. The study contributes to this body of work through an examination of the copula contrast in Spanish, a variable structure in native and L2 populations, by exploring the development of interpretative abilities of English-speaking learners of Spanish, and the extent to which interpretation is differential across adjective classes and individual adjectives.
THE RESEARCH CONTEXT
The current investigation lies at the intersection of several subfields of the study of language acquisition and use. It is contextualized within usage-based frameworks that recognize language variation and the multiple factors that influence these variable patterns of use. Likewise, the study employs a variationist analysis and is part of a growing body of research on L2 variation. We focus specifically on interpretative abilities, an area of study that remains relatively small. Finally, the test case to which we apply our research questions is the copula contrast in L2 Spanish, and this is among the structures about which we have the most empirical information in the Spanish language, both among native speakers (NSs) and L2 learners. In the review that follows, we summarize relevant research in these domains to contextualize the study and identify the contributions that our research makes for each of these areas of investigation.
USAGE-BASED APPROACHES TO LANGUAGE PRODUCTION AND ACQUISITION
Generally speaking, usage-based approaches are characterized by their attention to patterns attested in the language to which a speaker is exposed. These patterns drive language acquisition and contextualize language structures within their linguistic, social, and interactional settings (e.g., Bybee, Reference Bybee2007, Reference Bybee2010; Goldberg, Reference Goldberg, Hoffmann and Trousdale2013). Likewise, usage-based approaches view language as a series of connections between lexical, structural, and social factors, rather than as an isolated entity. These approaches attend to the role of the frequency of occurrence of particular lexical items, or collocations thereof, in processes of language change and language acquisition. Research shows that highly frequent grammatical items resist changes that result from processes such as analogy, whereas less frequent forms are less resistant to such change. Thus, language change is diffused through the lexicon differentially, affecting items to varying extents based on their overall frequency. Moreover, the patterns that are the most lexically diffuse (i.e., that extend to the greatest number of lexical items) are more likely to attract members from other classes in a type of pattern regularization. In this sense, both lexical (i.e., token) frequency and type frequency play a role in acquisition. In contrast to patterns of syntactic change, phonological change is generally led by the more frequent forms, which tend to reduce more often and to greater degrees (Bybee, Reference Bybee2007, Reference Bybee2010). Despite the importance of frequency in these approaches, it is a valuable starting point for the current discussion to note that most usage-based approaches also allow for a level of abstraction. Thus, it is not necessary to argue that frequency, or any other factor, is the sole determiner of change or acquisition, nor that languages operate in the absence of generalization.
Usage-based approaches have been applied profitably to the study of L2 acquisition. This body of work demonstrates the importance of constructs such as lexical frequency, collocational frequency, lexical density, and lexical deployment and their relationship to L2 learning. For example, we know that learners exhibit sensitivity to lexical frequency in a variety of ways. Ellis and Schmidt (Reference Ellis and Schmidt1997) showed that learners of an artificial grammar were more accurate with past tense forms for high-frequency verbs, and Wulff, Ellis, Römer, Bardovi-Harlig, and Leblanc (Reference Wulff, Ellis, Römer, Bardovi-Harlig and Leblanc2009) showed that those verb forms that occurred most frequently in the progressive and past tense in their NS corpus were the first to emerge in those same forms in the L2 of adult learners. Ellis and Ferreira-Junior (Reference Ellis and Ferreira-Junior2009) studied verb/argument constructions among native and L2 speakers of English, showing that those forms that occur most frequently among NSs were even more strongly represented by the nonnatives and were often the first to emerge. The implication is that frequency may lead to prototypes that foster the development within a particular category. Durrant and Schmitt (Reference Durrant and Schmitt2009) examined collocation type, where collocation is defined as a relationship that a lexical item has with items that co-occur with greater than random probability (following Hoey, Reference Hoey1991, p. 7), and showed that learners produced highly frequent collocations at an even higher rate than NSs while underusing collocations with lower frequencies of occurrence. Crossley, Subtirelu, and Salsbury (Reference Crossley, Subtirelu and Salsbury2013) identified word frequency as the strongest predictor in early noun production in an L2 (see also Wolter & Gyllstad, Reference Wolter and Gyllstad2013 for similar work on collocations). These results have been further corroborated across several tasks, showing that frequency affects speed of reading, accuracy in acceptance on grammaticality judgment tasks, spoken articulation, the degree to which reading the beginning of the formula primed recognition of the second word (i.e., primed production), and speed of comprehension (e.g., Ellis, Simpson-Vlach, & Maynard, Reference Ellis, Simpson-Vlach and Maynard2008). Recent research on language processing has also shown that the facilitative effects among bilinguals that result from higher frequency are greater in the L2 than the first language (L1), perhaps due to smaller vocabulary size as a result of less exposure to the target (Diependaele, Lemhöfer, & Brysbaert, Reference Diependaele, Lemhöfer and Brysbaert2013; see also Yi, Reference Yi2018, for collocations) and that this effect is not mediated by L2 proficiency (Cop, Keuleers, Drieghe, & Duyck, Reference Cop, Keuleers, Drieghe and Duyck2015), although it is mediated by some factors, such as age and other individual differences (Whitford & Titone, Reference Whitford and Titone2017; see also Wolter & Yamashita, Reference Wolter and Yamashita2018, for collocations).
THE SLA OF VARIABLE STRUCTURES
Research on the L2 acquisition of variable structures covers many languages and a range of grammatical properties, extending from phonetic to morphosyntactic to lexico-semantic (see Geeslin & Long, Reference Geeslin and Long2014, and De Vogelaer & Katerbow, Reference De Vogelaer and Katerbow2017, for overviews). For example, while research on English (e.g., Adamson & Regan, Reference Adamson and Regan1991; Major, Reference Major2004) and French (e.g., Regan, Howard, & Lemée, Reference Regan, Howard and Lemée2009; Rehner, Mougeon, & Nadasdi, Reference Rehner, Mougeon and Nadasdi2003) once dominated, we now see examples of research on variation in Spanish (e.g., Kanwit, Reference Kanwit2017), Norwegian (Karlsen, Geva, & Lyster, Reference Karlsen, Geva and Lyster2016), Arabic (Raish, Reference Raish2015), and Mandarin (Li, Reference Li2014), to name a few. In general, this field explores the linguistic, social, and individual factors that predict patterns of use and is characterized by complex statistical modeling that details the relative importance of these many factors. In general, for L2 learners at least, research demonstrates that the linguistic factors have greater influence than the social characteristics of the speaker, the hearer, or the interactional context.
Within this field of study, some work addresses the connection between the properties of individual lexical items (e.g., lexical frequency) and variable patterns of use. As with the usage-based studies, the underlying question is whether patterns of lexical diffusion, which reveal that change (or acquisition) does not affect all words at the same time or to the same degree, are attested among L2 learners. Building on work by Erker and Guy (Reference Erker and Guy2012), who showed the effect of lexical frequency on the patterns of use of subject forms by NSs of Spanish, Linford and colleagues explored both the way lexical frequency was measured (within corpus vs. across corpora and native vs. nonnative datasets) and the role that this factor played in the patterns of use for adult bilinguals, both Spanish and English dominant (Linford & Shin, Reference Linford, Shin, Cabrelli Amaro, Lord, de Prada Pérez and Aaron2013; Linford, Long, Solon, & Geeslin, Reference Linford, Long, Solon, Geeslin, Ortega, Tyler, Park and Uno2016). The role of frequency differs across studies. Frequency may play a role as a main effect in predicting subject pronoun use (Bayley, Holland, & Ware, Reference Bayley, Greer and Holland2013), it may mediate the effect of other variables (e.g., revealing significant differences within tense-mood-aspect and semantic class when those variables are divided according to frequency, as in Erker & Guy, Reference Erker and Guy2012; Linford & Shin, Reference Linford, Shin, Cabrelli Amaro, Lord, de Prada Pérez and Aaron2013; Linford et al., Reference Linford, Long, Solon, Geeslin, Ortega, Tyler, Park and Uno2016), or it may reveal neither effect (e.g., in native Mandarin subject expression in Li & Bayley, Reference Li and Bayley2018). Likewise, Solon, Linford, and Geeslin (Reference Solon, Linford and Geeslin2018) examined the phenomenon of /d/-deletion in intervocalic contexts in Spanish among native and advanced nonnative speakers and showed that the role of frequency was different for these two groups and, in fact, that frequency had an even greater effect on the nonnatives than the NSs. In light of these diverse findings, we view frequency as a useful tool, rather than a single-factor explanation.
RESEARCH ON INTERPRETATION
Research on L2 learners has further shown that differences may exist between the language produced by learners and their own patterns of interpretation. Furthermore, studies of interpretation in L2s across multiple theoretical approaches show that linguistic and individual characteristics influence patterns of processing, and that these patterns of influence change over the course of development (e.g., Borgonovo, Bruhn de Garavito, & Prévost, Reference Borgonovo, Bruhn de Garavito and Prévost2015; Cheng & Almor, Reference Cheng and Almor2017). Additionally, L2 processing and interpretation patterns are often different from those of NSs (e.g., Clahsen & Felser, Reference Clahsen and Felser2006; Grüter, Lew-Williams, & Fernald, Reference Grüter, Lew-Williams and Fernald2012). As would be expected, given what is known about variable structures in L2s, interpretation may further be affected by implicit language attitudes, by individual identities, and by experiences and contact with particular speech communities (Schmidt, Reference Schmidt2018; Schoonmaker-Gates, Reference Schoonmaker-Gates2017). It is important to note that the term interpretation may be used to refer to online processing as well as more deliberate interpretation of meaning (or implied meaning), both linguistic and social, and this range of constructs further contributes to the variety of studies included under the umbrella term. Henceforth, we narrow our scope to include studies of interpretation of variable structures conducted within variationist or usage-based frameworks, as these most closely inform the current project.
Within the variationist framework, we have seen that individual lexical items do play a role in interpretation, and this role varies across levels of experience. One set of studies that has explored this issue for L2 Spanish focuses on the interpretation of verb forms in subjunctive and indicative moods in adverbial clauses. Prescriptively, for a given set of adverbs, verb forms in the subjunctive mood in adverbial clauses are predicted to have a “not yet completed” interpretation whereas those in the indicative are predicted to be interpreted as habitual events that are regularly occurring. Kanwit and Geeslin (Reference Kanwit and Geeslin2014) used a written interpretation task that asked participants to indicate whether an event was habitual, had not yet occurred, or if both interpretations were possible. They examined the role of the verb form (subjunctive or indicative mood), the position of the main clause relative to the adverbial clause, the regularity of the verb form, and the adverb, showing that lower-level learners did not use mood to interpret the utterances. Compared to NSs, the learners in general demonstrated less use of lexically specific patterns of interpretation and less distinction across different adverbs (cuando “when,” hasta que “until,” después de que “after”). To more effectively investigate the role of individual adverbs and their patterns of co-occurrence, Kanwit and Geeslin (Reference Kanwit and Geeslin2018) created a new written instrument that manipulated three of the same factors (verbal mood, verbal morphological regularity, and the adverbial conjunction), but they increased the number of adverbs included from three to six and classified these adverbs according to their degree of variability and their frequency of occurrence, based on corpus data. Their analysis showed the influence of verbal mood from the intermediate level upward, as well as a high degree of variability based on individual lexical items and their patterns of co-occurrence with subjunctive and indicative moods. From these two studies, we see that learners are able to move toward nativelike patterns of interpretation. We further see that the particular variable structure, its linguistic context, and the type of variation attested in native speech all influence the path of L2 acquisition. These findings signal the need for a careful look at these same factors in other variable structures.
THE COPULA CONTRAST IN SPANISH
To further the study of the relationship between patterns of use, including lexical frequency, and the acquisition of the ability to interpret meaning from variable structures in an L2, we have selected the copula contrast in attributive contexts in Spanish as the variable structure for examination. In what follows, we provide a brief overview of how this structure operates in native Spanish, including attested patterns of variation and an account of what is known to date about the role that particular lexical items (i.e., adjectives) play in the patterns of use. We continue with an overview of what has been discovered for the L2 acquisition of this structure while highlighting the attributive context.
A copular verb is a connecting element and is attested in a variety of forms in the world’s languages. In Spanish, the verbs ser and estar both mean “to be” and are used to connect a referent with an attributive adjective. This is illustrated in examples (1a‒b) in the following text. In this same context, there are other verbs, such as parecer “to seem” and sentirse “to feel,” that carry additional lexical meaning, which can also fulfill the role of connecting a referent with an attribute (1c‒d).
(1a) Ella es alegre.
She is a happy person.
(1b) Ella está alegre.
She is happy/in a good mood/looks happy.
(1c) Ella parece inteligente.
She seems intelligent.
(1d) Ella se siente triste.
She feels sad.
In addition to extensive theoretical research, which has attempted to define the role of these verbs and to delimit the contexts in which each appears (e.g., Camacho, Reference Camacho, Hualde, Olarrea and O’Rourke2012), the field enjoys substantial empirical work on the variation attested for the copula contrast. Most studies focus on ser and estar (leaving verbs like parecer aside) and define the context of analysis by the function of attribution, although these contexts can be defined syntactically as the [copula + adjective] context as well (e.g., Brown & Cortés-Torres, Reference Brown, Cortés-Torres, Geeslin and Díaz-Campos2012; Díaz-Campos & Geeslin, Reference Díaz-Campos and Geeslin2011; Geeslin, Reference Geeslin, J. Huang and Liu2014; Geeslin & Guijarro-Fuentes, Reference Geeslin and Guijarro-Fuentes2008; Gutiérrez, Reference Gutiérrez2003). Across studies, periods, and geographic regions, the most generalizable result is that Spanish is undergoing a process of language change through which the use of estar is extending into contexts where ser was previously the only form attested. In other words, contexts that were formerly categorical are now variable, allowing both copulas. The selection between these two forms has been associated with a range of factors, including social characteristics, geography, elicitation task, as well as linguistic factors, such as predicate type, experience with the referent, adjective class, frame of reference, and the referent’s animacy and changeability (see, for example, Díaz-Campos & Geeslin, Reference Díaz-Campos and Geeslin2011, for Caracas; Gutiérrez, Reference Gutiérrez2003, for Michoacán, Mexico, and Houston; Brown & Cortés-Torres, Reference Brown, Cortés-Torres, Geeslin and Díaz-Campos2012, for Puerto Rico; Malaver, Reference Malaver2012, for Mexico and Guatemala; Geeslin & Guijarro-Fuentes, Reference Geeslin and Guijarro-Fuentes2008, for varieties of Peninsular Spanish; and Silva-Corvalán, Reference Silva-Corvalán1986, for Los Angeles). In the review that follows, we highlight studies that explore the relationship of individual adjectives to patterns of use.
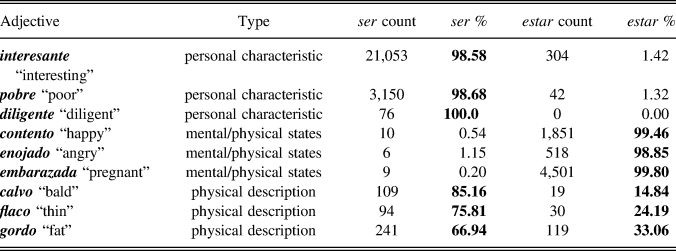
In an analysis of patterns of co-occurrence between individual adjectives and the copulas in Spanish, Geeslin (Reference Geeslin, J. Huang and Liu2014) found that in her U.S.-based NS corpus of 764 examples of [copula + adjective] structures, only 9 of 26 adjectives that were used five or more times occurred with both ser and estar. In the face of earlier work that suggested that up to 80 percent of all adjectives allowed variation between ser and estar (e.g., Mesa Alonso, Domínguez Herrera, Padrón Sánchez, & Morales Aguilera, Reference Mesa Alonso, Domínguez Herrera, Padrón Sánchez and Morales Aguilera1993), this was somewhat surprising. In related work, Brown and Cortés-Torres (Reference Brown, Cortés-Torres, Geeslin and Díaz-Campos2012), in an analysis of 2,566 tokens extracted from informal conversations in Puerto Rican Spanish, argued that [ser + adjective] and [estar + adjective] are constructions and that specific [copula + adjective] constructions have definitive pragmatic and semantic uses. Their analysis showed that estar occurs with an individual frame of reference, mental and physical state adjectives, resultant states, and immediate experience with the referent. However, there were 116 additional uses of [estar + adjective] that were not explained by these factors. A closer analysis of these cases showed that more than half of the tokens (n = 60) were produced using just seven adjectives, such as brutal “excellent,” bueno “good,” and bonito “pretty.” They argue that these adjectives, which have high token frequency, are derived from analogical extensions to speakers’ previous experience with the construction. They then act as prototypes for other similar adjectives. Another important finding is that individual adjectives showed different rates of use with estar. For example, fuerte “strong,” grande “big,” difícil “difficult,” and nuevo “new” occurred with both copulas, but less than 25 percent of their occurrences were with estar. However, loco “crazy” and malo “bad” occurred with both verbs but with estar 51‒75% of the time, while brutal “excellent” and seguro “sure” were used with estar more than 75% of the time. Together these studies suggest that variability may be a function of the individual lexical item as well as the semantic class of these adjectives (e.g., prototypical meanings) and each of these factors may interact with the overall lexical frequency of the adjective to influence patterns of use.
SLA RESEARCH ON COPULA CONTRAST
The body of L2 research addressing this grammatical structure is robust. Early research focused on all functions of the copula, and generally sought to confirm, refute, and refine the attested stages of acquisition across learners and learning contexts (e.g., Ryan & Lafford, Reference Ryan and Lafford1992). The Spanish copula contrast has further been examined to advance theoretical perspectives (e.g., Bruhn de Garavito & Valenzuela, Reference Bruhn de Garavito and Valenzuela2008; Perpiñán, Marín, & Moreno Villamar, Reference Perpiñán, Marín and Moreno Villamar2019), pedagogical approaches (Cheng, Reference Cheng2002; VanPatten, Reference VanPatten2010), and inquiry into understudied language pairs (e.g., Korean [Geeslin & Long, Reference Geeslin, Long, Pérez-Jiménez, Leonetti and Gumiel-Molina2015]; Dutch [Pinto & Guerra Rivera, Reference Pinto, Guerra Rivera, Judy and Perpiñán2015]), the role of tasks in research on learner language (Geeslin, Reference Geeslin, Klee and Face2006), and L2 processing (Dussias, Contemori, & Román, Reference Dussias, Contemori and Román2014). Contemporary research has also isolated particular copular functions (e.g., locative [Dussias et al., Reference Dussias, Contemori and Román2014]; stative and eventive passives [Bruhn de Garavito & Valenzuela, Reference Bruhn de Garavito and Valenzuela2008]). Consistent with this development, many studies limit their analysis to the attributive function (i.e., the [copula + adjective] context) (e.g., Geeslin, Reference Geeslin2003).
Most studies that focus on the attributive function recognize the variability that exists in this context. This work has revealed that learners do not limit themselves to only ser and estar in these attributive contexts, but rather, they produce a range of forms, including parecer “to seem,” sentirse “to feel,” and verse “to look,” just as NSs do (Geeslin & Gudmestad, Reference Geeslin and Gudmestad2010). Additionally, at lower levels of proficiency, attributive uses of buscar “to look” and mirar “to watch” are also attested for English-speaking learners (Geeslin, Reference Geeslin, Leow and Sanz2000) as are hacer “to do” and poner “to place” for Korean-speaking learners of Spanish (Geeslin & Long, Reference Geeslin, Long, Pérez-Jiménez, Leonetti and Gumiel-Molina2015). What is particularly interesting about these results when considered together is that they suggest a role for each lexical item and, further, that some of these may reflect L1 influences while others appear to be attested in native and nonnative language patterns, regardless of learner backgrounds.
This research demonstrates changes in the distribution of these forms across the time course of L2 acquisition. The general finding that ser is initially overgeneralized and then estar is gradually integrated into the learner grammar (e.g., Ryan & Lafford, Reference Ryan and Lafford1992) holds true in the attributive context (e.g., see Cheng, Lu, & Giannakouros, Reference Cheng, Lu and Giannakouros2008, for L1 Chinese; Geeslin, Reference Geeslin, Leow and Sanz2000, for L1 English; and Geeslin & Long, Reference Geeslin, Long, Pérez-Jiménez, Leonetti and Gumiel-Molina2015, for L1 Korean). In each of those studies, estar use increases with proficiency, gradually replacing ser in the contexts where the latter had been overgeneralized. In most cases, the more proficient learners approximate nativelike rates of use of estar (e.g., Geeslin, Reference Geeslin2003), but there are examples of highly advanced learners yielding significantly different rates of use or selection of estar (see Geeslin & Guijarro-Fuentes, Reference Geeslin and Guijarro-Fuentes2006, for Portuguese-speaking learners who significantly exceed the native norms). Given the varying elicitation tasks and L1 backgrounds across studies, it is difficult to pinpoint the source of the differences without further investigation.
Finally, the studies in the variationist research paradigm have identified several independent factors that generally predict the patterns of copula use for L2 learners. Firstly, the influence of linguistic factors appears to outweigh that of social, interactional, or individual background factors. Thus far, factors such as learning context (e.g., study abroad vs. at-home classroom) or speaker gender do not appear to hold the same predictive power that the morphosyntactic, semantic, or pragmatic factors do. A second common finding is that the pragmatic constraints on patterns of use override the semantic ones, even at higher levels of proficiency. For example, Geeslin (Reference Geeslin, Leow and Sanz2000), in a study of four levels of English-speaking learners of Spanish, found that constraints such as whether the referent + adjective combination was susceptible to change (i.e., a semantic factor) were a significant predictor of learner language patterns in early levels, but frame of reference, which is a pragmatic constraint, was only significant at higher levels. Likewise, Geeslin (Reference Geeslin2003) showed that for very advanced learners, but not for NSs, pragmatic constraints, such as experience with the referent and frame of reference, were significant predictors of estar. Building on this, Cheng, Lu, and Giannakouros (Reference Cheng, Lu and Giannakouros2008) showed a gradual shift from formulaic use to lexically based strategies to more semantic and pragmatically driven strategies at the highest level.
The role of lexical patterns attested in corpora and their relationship to learner patterns of use was investigated in Geeslin (2013). Analyzing interview data collected from graduate-level English-speaking learners and native Spanish speakers, she identified all adjectives used more than five times and categorized them by patterns of co-occurrence. Her analysis showed that while NSs produced both ser and estar with nine of the most frequently used adjectives, nonnative speakers only produced three adjectives with both ser and estar: amable “friendly,” feliz “happy,” and mejor “better.”Footnote 1 Geeslin further showed that the patterns of co-occurrence were not the result of lesser lexical diversity in the patterns of nonnative speakers, as they used approximately as many different adjectives as NSs. Instead, the author suggests that these findings indicate that learners rely more on the individual lexical item (adjective) than NSs when determining patterns of copula use.
SUMMARY: PATTERNS OF USE AND THE INTERPRETATION OF THE COPULA CONTRAST
The preceding review identifies a relative lag in research assessing the L2 acquisition of the interpretation of sociolinguistically variable structures. We know that usage-based models provide a foundation through which the role of type and token frequency in L2 interpretation can be explored, and also that this issue has been addressed with success in studies of the Spanish subjunctive. In the case of the copula contrast, research suggests that the type (e.g., semantic class of an adjective, such as physical description) and the token (i.e., the individual adjective) influence production of the [copula + adjective] structure. We further know that even adjectives within the same semantic class do not always pattern in the same way. Instead, it may be the case that L2 learners follow item-based strategies (i.e., based on individual lexical items such as adjectives), and it is further likely that other factors, both linguistic and social, are also at play. The goal of the present study is to connect these findings to explore the interpretation of the copulas in Spanish when paired with adjectives that differ by adjective class and by attested patterns of co-occurrence.
THE CURRENT STUDY
Given the important role attested for individual lexical items and the gap in research examining the L2 interpretation of variable structures, the study was designed to answer the following questions:
1. How do learners and native speakers of Spanish interpret the copulas ser and estar with adjectives?
a. How do interpretations change as level of experience with Spanish increases?
b. How are interpretations influenced by the copula, grammatical gender, adjective class, and lexical item?
c. How do interpretations differ based on individual lexical items within the co-occurrence classes?
PARTICIPANTS
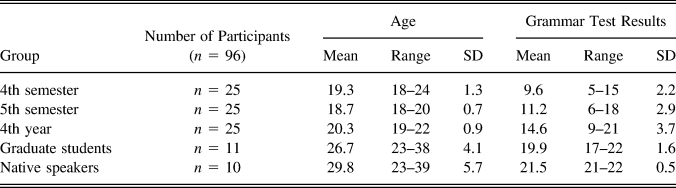
We collected data from 86 English-speaking learners of Spanish at four levels of enrollment and from a group of 10 NSs of Spanish, who were living in the United States (i.e., also bilingual) at the time of the study. The native speakers were from several regions in the Spanish-speaking world and were deliberately invited because they represent the range of varieties of Spanish to which U.S.-based students are exposed and the bilingual norm that constitutes the target for our classroom learners. Their results are intended to provide a view of the range of possibilities that exist for NSs of Spanish rather than a characterization of any single variety of Spanish. Their countries of origin included Colombia (3), Spain (3), Mexico (2), Argentina, and Puerto Rico, and all had resided in the contiguous United States for at least one year. The learners were enrolled at a large, midwestern public university and were drawn from fourth-semester classes (i.e., the final course required to meet the language requirement), fifth-semester classes (i.e., the bridge for all majors and minors), advanced courses (i.e., for fourth-year students majoring in Spanish), and also from the graduate student population (i.e., students who are also generally assigned to teach language courses as part of their degree program). As with our other learners, the graduate students were all U.S. born to monolingual English-speaking families. Whereas 0/25, 2/25, and 11/25 of the learners in the first three groups had spent more than three weeks abroad in a Spanish-speaking country,Footnote 2 all graduate students reported extensive experience (six months to 2.5 years, M = 17.5 months) studying or working abroad in Spain, Mexico, Argentina, Puerto Rico, Chile, or Peru. The graduate group approximated the age range of the NSs. The characteristics of each of these groups, including age and grammar test results are summarized in Table 1.
TABLE 1. Description of participants
INSTRUMENTS
Each participant completed three tasks. The first was a written interpretation task, described in greater detail in the following text. The second task was a language background questionnaire designed to provide a snapshot of the learner characteristics that might be a source of difference between learners. This questionnaire asked about the collegiate courses taken thus far; the years of high school study completed by each participant; the purpose, location, and length of time spent abroad; and experience with other languages aside from English and Spanish. Finally, the third task was a discrete-point grammar test that included 22 multiple-choice items. The items assess formal knowledge of grammar topics generally covered in instructed settings. The scores on this test do not provide a comprehensive view of learner proficiency but they do serve to confirm the original placement of our learners into groups according to level of enrollment.
Written Interpretation Task
The linguistic data analyzed in the study come from a written interpretation task containing 24 items, each of which asked the participant to select the sentence ending that best matched their interpretation of the main clause, or to indicate that both were possible.Footnote 3 The response options were two clauses, one of which represented a class frame interpretation (i.e., comparing the referent to a class of other individuals) and the other that represented an individual frame interpretation (i.e., comparing the referent to himself/herself at another point in time). Each item on the instrument manipulated the adjective, which was classified by its semantic class (i.e., personal characteristic, physical description, or mental/physical state) and its pattern of co-occurrence with the copular verbs (ser for personal characteristics, estar for states, ser and estar for physical descriptions). Three personal characteristic adjectives were used (interesante “interesting,” pobre “poor,” and diligente “diligent”), along with three states (contento “happy,” enojado “angry,” and embarazada “pregnant”), and three physical descriptions (flaco “thin,” gordo “fat,” and calvo “bald”). Only felicitous combinations were included in the instrument, and adjectives were selected based on their rates of co-occurrence with the copulas in the corpus search, as described in the next section. Grammatical gender was also manipulated, creating one masculine and one feminine context for the nine adjectives included. There are two exceptions to this: we used only masculine referents with calvo “bald” and only feminine referents with embarazada “pregnant” and there are two such contexts of these physical description adjectives on the instrument so that each adjective occurs twice. This yielded a total of 24 items reflected in Table 2.
TABLE 2. Design of items in written interpretation task

In addition to the factors that were manipulated, we controlled several other linguistic variables to avoid introducing additional sources of variability into the instrument. All items contained third-person singular referents, all referents were human, and all verb forms were in the present indicative. Markers that indicate surprise or that promote a reading that is either momentary or ongoing were avoided as these also contribute to copula interpretation. A sample item is shown in (2), along with how it was coded according to the linguistic variables manipulated in the instrument design.Footnote 4
(2) Sample item from written interpretation task
Blanca está flaca ...
a. ____ y siempre ha querido ser modelo.
b. ____ y los tíos creen que puede ser por el estrés.
c. Las dos son posibles.
“Blanca looks thin ...
a. ____ and she has always wanted to be a model.
b. ____ and our aunt and uncle think it could be due to stress.
c. Both are possible.”
Coding: [physical description adjective], [feminine gender], [estar].
For all items in the instrument, the prescriptive prediction is that if estar occurs in the main clause, the referent is presented in an individual frame and if ser occurs in the main clause the interpretation should correspond to a class frame. However, based on the previous literature on variation and the copula contrast, we anticipate that this trend is not categorical. We further expect that differences in patterns of interpretation may be attested at the level of the individual adjective and also that the grammatical gender factor will hold greater influence at lower levels of proficiency because of the attested tendency to overgeneralize masculine forms at early stages of development (see Alarcón, Reference Alarcón and Geeslin2014 for overview).
Corpus Search to Select Adjectives for the Instrument
To represent diverse semantic classes and to select adjectives within each class that empirically occur nearly exclusively with ser, with estar, or that occur with both, we searched the two-billion-word web/dialect version of the Corpus del español (Davies, 2015‒2016) for tokens of the verb forms es (from ser) and está (from estar) with 50 different adjectives, noting which occurred nearly exclusively with only one copula and which were well attested with both (Table 3).Footnote 5 We identified adjectives belonging to the semantic class “personal characteristic” that occurred nearly exclusively with ser, adjectives in the semantic class “mental/physical state” that occurred nearly exclusively with estar, and adjectives in the class “physical description” that exhibited variability in co-occurrence with ser and estar. We further ensured that these adjectives are relatively frequent and are known to learners even at relative lower levels of enrollment. There are, of course, adjectives in these semantic classes that may exhibit different patterns and, thus, these preliminary steps are important in making inferences from our results about the role of individual lexical items and general classifications based on patterns of co-occurrence.
TABLE 3. Partial summary of search of es/está + ADJ in Corpus del español (Davies, 2015‒2016 two-billion-word web corpus)
RESULTS
We present the overall rates of selection for our interpretation response options before turning our attention to mixed-effects regression models. The first model includes all task items. The next two analyze the subset of items that conveyed physical descriptions through both copulas.
Overall Rates of Interpretation
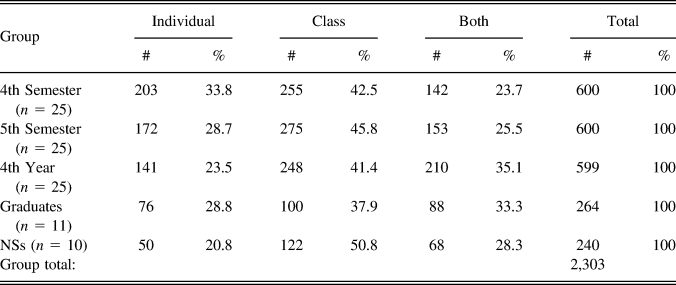
For NSs, the class response was the most popular followed by the “both” response. This was the case for the graduates and fourth-year learners as well (Table 4). Although the class frame was the most common response for the fourth- and fifth-semester learners, the individual frame was a more frequent interpretation than the “both” response.
TABLE 4. Distribution of interpretation responses
Our mixed-effects models evaluate the linguistic elements that influence these distributions.
Mixed-Effect Models: All Items
In all regression models we present, we have combined the individual frame interpretation with the response that both interpretations were possible because (a) increased acceptance of the individual interpretation (i.e., the interpretation traditionally associated with estar) is in the direction of language change (i.e., extension of estar) and (b) the individual and “both” responses patterned similarly in cross-tabulations, unlike the class response, indicating that participants treated the former two responses differently from the latter.Footnote 6 For each participant group, we first ran a mixed-effects model in Rbrul (Johnson, Reference Johnson2009) that considered all items from the task. In this model, the two applicable independent linguistic variables were adjective class and grammatical gender, which were run as main effects, and the individual participant and the adjective were run as random effects. In all models, acceptance of the individual frame was entered as the input value, meaning that factor weights closer to 1 indicate a favoring effect for the individual frame, whereas values closer to 0 indicate a disfavoring effect (i.e., favoring of the class frame). The range is provided for significant variables and is the difference between the factors that most and least favored the individual frame response. P-values for each variable indicate whether the model selected that variable as significant (i.e., for values < .05) and a correspondence between low p-values and high ranges can be noted. The overall rate of individual frame allowance can be found at the bottom of the table.
When all items from the task were considered (Table 5), adjective class was significant for NSs, with mental states (which occurred with estar) favoring the individual frame interpretation. For learners, adjective class was not significant for fourth-semester learners but was at each subsequent level. Although adjective class was not significant at the fourth semester, learners selected the individual interpretation less with mental states than their overall response rate, whereas at the later levels, this context favored the individual response, as it did for NSs, with factor weights increasing at each learner level until slightly overshooting the NS weight. Personal characteristics (with ser) disfavored the individual interpretation for NSs, which was also the case for all learner groups after the third semester, with factor weights again moving toward and eventually surpassing those of the NSs. For all participant groups, physical descriptions (which occurred half with ser and half with estar) fell between these extremes. For the NSs and fifth-semester and graduate learners, participants allowed the individual interpretation less with these items than with the average item (i.e., these slightly disfavored the individual response), whereas for fourth-year learners this context slightly favored the individual interpretation.
TABLE 5. Factors predicting allowance of individual frame (all items)
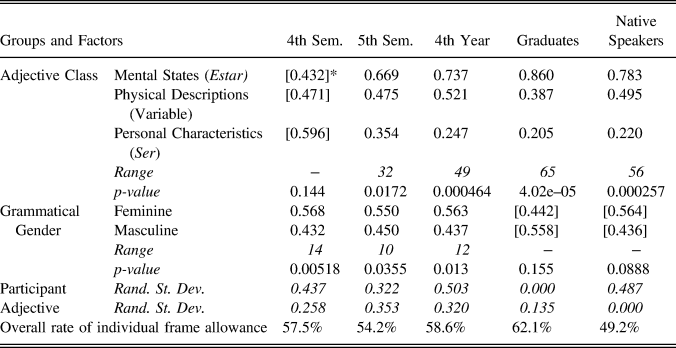
* Bracketed numbers indicate that the factor was not significant in the regression.
The grammatical gender variable, which applied to all items, was not significant for NSs or graduate learners, but did significantly constrain responses for the three lower levels. In each of those cases, feminine referents favored the individual interpretation and masculine referents disfavored the response, meaning that these groups responded that a female referent was more likely to be compared to herself than a male referent was. This variable was most predictive at the lowest level, at which adjective class was not significant.
Mixed-Effects Models: Items Divided by Copula
Because NSs and learners (after fourth semester) interpreted sentences differently based on which copula appeared, we now divide our data in half, first considering only those items that contained ser and then only those containing estar. This enables us to determine whether additional factors constrained interpretation when the copula is controlled and whether participants responded differently for different adjectives within the same copula category. For these subsets, the independent variables evenly represented across the items were the adjective used and grammatical gender of the referent. These two independent variables were entered into a mixed-effects model for each group, along with individual participant as a random effect.Footnote 7
For the subset of items that included ser (Table 6), NSs were constrained by the individual adjective used, as were the fourth- and fifth-semester and fourth-year learners. The fourth-semester learners were also constrained by grammatical gender. For overall rates of interpretation (final row of the table), participants reduced allowance of the individual frame in these items containing ser across groups, beginning with 58.3% at the fourth-semester level and reaching a low of 36.7% in the NS group.
TABLE 6. Factors predicting allowance of individual frame for ser items
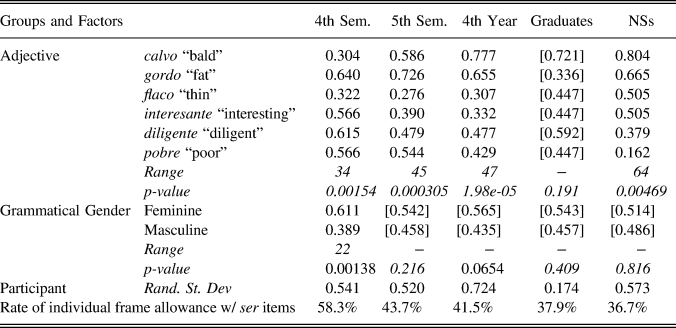
Examining the individual adjective used, the NS data revealed two interesting results that show sensitivity to adjective class, but also to the individual adjective. Firstly, the physical description adjectives (calvo “bald,” gordo “fat,” flaco “thin”) roughly grouped together as those that most favored the individual frame interpretation, as opposed to the personal characteristics adjectives (interesante “interesting,” diligente “diligent,” pobre “poor”) that generally disfavored this response, although interesante behaved similarly to flaco from the former group. Secondly, NSs showed difference within the two adjective classes, as, for example, calvo favored the individual interpretation much more than flaco, and pobre disfavored the response much more than interesante. Similarly, whereas diligente and pobre (personal characteristic adjectives) disfavored the individual interpretation for NSs, they both favored this response for the fourth-semester group and one of them (pobre) favored it for the fifth-semester learners. Adjective class was not significant for the graduate students, who tended to treat adjectives that occurred with ser more similarly to each other than the other groups did.
Although the individual adjective was significant for the first three learner levels, none of those groups behaved like the NSs, as the adjective rankings did not coincide with adjective class, with at least one physical description adjective disfavoring the individual interpretation for these groups (and two doing so for the fourth-semester learners). Grammatical gender was only significant for the least experienced learner group, for whom feminine referents favored the individual interpretation. Although grammatical gender was not significant for the other groups, the individual interpretation was selected more with female referents than male referents for the remaining groups.
For the other half of task items, which included the verb estar, NSs were again constrained according to the individual adjective, as were fourth- and fifth- semester learners (Table 7). NSs and fourth-year learners were also constrained by grammatical gender for these items. Overall rates of individual frame interpretation also revealed a pattern across groups, as learners increasingly allowed the individual interpretation, beginning at 57.3% at the fourth semester and ending at 86.4% for the graduates. Nevertheless, all of these rates exceeded that of the NSs beginning at the fifth semester.
TABLE 7. Factors that predict allowance of individual frame for estar items
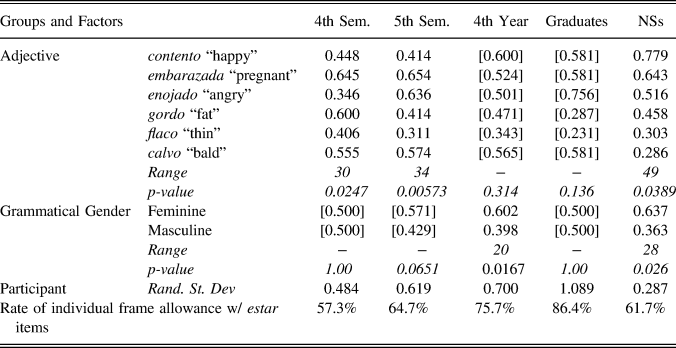
Once again, and even more clearly than with the ser subset, NSs responded to adjectives differently according to adjective class, with the three mental state adjectives (contento “happy,” embarazada “pregnant,” enojado “angry”) favoring the individual interpretation and the three physical description adjectives disfavoring the response. Also similar to the ser items, although adjectives patterned along these classes, NSs still demonstrated a sizable range within each class, for example favoring the individual interpretation much more with contento “happy” than enojado “angry,” and disfavoring it more with calvo “bald” than gordo “fat.” As with the ser items, learner groups did not match this NS patterning for adjectives. This variable was significant at the fourth- and fifth- semester levels, although fourth-semester learners showed opposite directions of effect than the NSs (i.e., favoring instead of disfavoring of the individual interpretation and vice versa) for four of the six adjectives, and fifth semesters differed from the NSs for two directions of effect. For fourth-year learners and graduates, adjective was not significant, perhaps due to their overall high selection of the individual frame response that varied less across adjectives.
Finally, grammatical gender was significant for the NSs and fourth-year learners, with both groups favoring the individual interpretation with female referents and disfavoring it with male referents. For the NSs, this likely reflects the favoring effect that embarazada “pregnant” (which only appeared in the feminine) had on the individual interpretation and the disfavoring effect that held for calvo “bald” (only masculine in the data). For the fourth-year learners, this explanation does not apply because those two adjectives were treated similarly and the adjective was not significant for items with estar.
DISCUSSION
Our study was designed to answer research questions about how learners and NSs of Spanish interpreted the copulas ser and estar with attributive adjectives, along with how such interpretations changed as level of experience with Spanish increased. Results indicated that NSs selected the class frame interpretation most often overall, followed by the response that both interpretations were possible, which was the same ordering for fourth-year and graduate learners. Fourth- and fifth-semester learners shared with the other groups that the class interpretation was the most popular but selected the individual frame interpretation at higher rates than the “both” response.
Mixed-effects analyses of all items revealed that for NSs and all learner groups after the fourth semester, adjective class was the most predictive independent linguistic variable of interpretation, with mental states indicated by estar favoring the individual frame interpretation and physical descriptions indicated by ser disfavoring this interpretation. Across the learner groups, this variable became increasingly predictive, as indicated by lower p-values and higher ranges, with graduate learners eventually overshooting NS patterns by more strongly favoring the individual interpretation with mental states (estar) and disfavoring it with personal characteristics (ser), indicating greater prescriptivism on their part than that of NSs. This has been reported for interpretation of other variable structures (e.g., the mood contrast in Kanwit & Geeslin, Reference Kanwit and Geeslin2014), and could be related to the greater proportion of formal contexts usually represented in advanced learner as opposed to NS input (Tarone, Reference Tarone2007).
In contrast, fourth-semester learners were not constrained by adjective class across the copulas when all items were considered, and instead had interpretation predicted by the grammatical gender of the referent, favoring the individual interpretation when referents were feminine. Although gender did not significantly affect NSs or graduate learners, it did maintain significance at the fifth-semester and fourth-year levels. To some extent, these findings are consistent with past work on interpretation, which has shown less experienced learners to be unaffected by the variables that most influence NS interpretation and to be influenced instead by factors that do not constrain NSs. For example, Kanwit and Geeslin (Reference Kanwit and Geeslin2014) found that although NSs and more experienced learners were primarily influenced by mood in interpreting whether an action had already occurred, the least experienced learners were not significantly constrained by mood and instead were influenced by clause order and verbal morphological regularity, which were not significant for the other groups when all items were considered. Like that study, the current results support more general claims that in determining how to interpret a given structure, learner comprehension strategies may involve prioritizing cues that are less meaningful for NSs. For instance, chronological ordering of sentential elements occurs commonly cross-linguistically, but in determining which actions occur before others, NSs are likely to attend to temporality expressed in verbal morphology (Bardovi-Harlig, Reference Bardovi-Harlig2000; Kanwit & Geeslin, Reference Kanwit and Geeslin2014, Reference Kanwit and Geeslin2018), whereas learners may instead rely on the ordering of elements, assuming that information has been presented chronologically, which is especially the case at earlier, premorphological stages (i.e., pragmatic stages, Bardovi-Harlig, Reference Bardovi-Harlig2000).
Because NSs and most learners were constrained by the copula used, we ran additional analyses holding the copulas constant to determine whether participants treated individual adjectives divergently for a single copula and whether grammatical gender played a role. To answer these questions, additional mixed-effects regressions were run, which only included the half of the items containing ser and then the half containing estar. Overall rates of interpretation within each copula subset revealed development, with learners decreasing selection of the individual interpretation with ser at each level from the fourth semester (58.3%) to the graduate level (37.9%), who most approximated NS rates (36.7%), and increasing the interpretation with estar across levels, although this meant overshooting NS rates. The graduates’ greater selection of the individual interpretation with estar provides further evidence for NS interpretations that are less prescriptive than those of advanced learners (Kanwit & Geeslin, Reference Kanwit and Geeslin2014).
The individual adjective was significant in both the ser and estar regressions for the NSs, indicating that adjectives patterned together by class but within each class NSs also demonstrated lexical effects in treating individual adjectives rather distinctly in spite of the general pattern. For example, in the estar model, the three mental state adjectives all favored the individual interpretation, while the three physical description adjectives all disfavored it, and yet the favoring effect for contento “happy” was much stronger than for enojado “angry,” with the disfavoring effect for calvo “bald” much stronger than that of gordo “fat.” Thus, the NSs did treat the adjectives according to classes, but they did not respond uniformly within a given adjective class. This means that NSs showed a combination of constraint-based and lexically based interpretation. They demonstrated the former in differentiating according to adjective class when all items were considered and, when items were divided by copula, in showing results that grouped according to adjective class in both of the additional models. Nevertheless, they also demonstrated lexically based interpretation in these smaller models, as they treated each adjective divergently within a given class, showing a rather sizable range within classes. In tandem, these results support prior work that has shown NSs to use patterns of collocation and to have a lexical basis for interpretation (Bybee, Reference Bybee2007, Reference Bybee2010; Edmonds & Gudmestad, Reference Edmonds and Gudmestad2014; Goldberg, Reference Goldberg, Hoffmann and Trousdale2013; Kanwit & Geeslin, Reference Kanwit and Geeslin2014, Reference Kanwit and Geeslin2018).
Learners did not match NSs in grouping adjectives according to type within the individual verb regressions, although they did demonstrate development in no longer being significantly constrained according to directions of effect that opposed the NSs’. For example, for the estar models, the fourth-semester learners had opposite directions of effect vis-à-vis the NSs for four of the six adjectives (and also for the ser models), whereas this was the case for only two of the adjectives for the fifth-semester group, and then this variable was not significant for fourth-year and graduate learners, although each only diverged from the NSs for one adjective’s (calvo “bald”) direction of effect.
Like the NSs, as early as the fifth semester, learners also tended toward constraint-based interpretation when all items were considered, as they differentiated according to adjective class. Unlike the NSs, graduate learners did not further differentiate within adjective classes, as individual adjective was not significant in either verb-specific model. Thus, the more experienced learners seem to have systems that are the most similar to what would be predicted by constraint-based interpretation: adjective class is highly predictive when all items are considered and individual adjective is not significant in either copula’s model for the graduate learners and is not significant in the estar model for the fourth-year learners. The learner tendencies to interpret estar as expressing the individual frame and to overshoot NS norms support prior research on the copula contrast (Geeslin, Reference Geeslin2003; Geeslin & Guijarro-Fuentes, Reference Geeslin and Guijarro-Fuentes2006). Learners overshooting NS norms in interpretation is also consistent with work on other structures (e.g., mood interpretation in Kanwit & Geeslin, Reference Kanwit and Geeslin2014, Reference Kanwit and Geeslin2018). Less differentiation based on individual adjectives for graduate learners is similar to prior work that has shown NSs to rely on collocations more than learners (Edmonds & Gudmestad, Reference Edmonds and Gudmestad2014) and for advanced learners to depend more on class than lexical item in interpretation (e.g., significant results for both individual adverb and mood for NSs, but only for mood for graduates in Kanwit & Geeslin, Reference Kanwit and Geeslin2014).
The least experienced learners are not constrained by adjective class when all items are considered and select the individual interpretation less with mental states than with personal characteristics or physical descriptions. This means that they have not yet developed constraint-based interpretation for the copula contrast. Rather than constraint-based interpretation, they respond according to the adjective used, although they do so in ways that usually diverge from the NSs (for four of the six adjectives for each copula’s model). In the absence of other cues for interpretation, they also afford a larger role for grammatical gender, which shapes their interpretation when all items are considered and in the ser model.
The learners with intermediate experience (i.e., fifth semester and fourth year) fell between the two extremes presented. They demonstrated more constraint-based interpretation than the fourth-semester learners because adjective class achieved significance for them. Nevertheless, for them, the individual adjective is also significant, with individual adjectives increasingly behaving like they do for NSs in each verb’s models, rather than yielding opposing directions of effect. Thus, the data seem to indicate that learners have to develop constraint-based interpretations (i.e., they do not yet have them at the lowest level), that such interpretations give way to lexical effects with more language experience, but that differential treatment within an adjective class may be reduced as participants behave in a more prescriptive fashion and even overshoot NS conditioning. The fact that fourth-year learners demonstrate some of the just-described qualities of the intermediate groups and also some of what was described for the graduates in the preceding text (e.g., lack of significance for individual adjectives in the estar model) indicates that the proposed changes may indeed occur in the order proposed.
Although grammatical gender constrained the least proficient learners in the main model, it mostly did not constrain interpretation in the models that were divided by copula, with three exceptions. For the items with ser, grammatical gender was significant only for the least experienced learners (fourth semester), who showed a pattern similar to when all items were considered. For the items with estar, NSs were constrained by gender, but this was likely also an effect of individual adjectives because the feminine adjective embarazada “pregnant” highly favored the individual interpretation and the masculine adjective calvo “bald” highly disfavored it. Feminine adjectives also favored the individual interpretation for fourth-year learners, although the same discrepancy for embarazada vis-à-vis calvo did not hold for this group, with the two adjectives treated rather similarly (both favoring the individual interpretation).
The discussion thus far has provided a detailed account of how the interpretation of [copula + adjective] structures develops with increasing proficiency and how the predictive models of such interpretation differ across levels and from NSs. As we have argued, this research sits at the intersection of several subfields of inquiry and, consequently, has numerous implications across these fields. The study of the L2 acquisition of the copula contrast in Spanish benefits from new knowledge related to interpretation (vis-à-vis production) as well as new findings related to the role of semantic groups (i.e., adjective class) and individual lexical items. The varying importance of these factors between groups further connects these findings to broader questions about the degree to which linguistic behavior is rule governed (i.e., influenced by generalized patterns) or item based (i.e., specific to a given lexical item or collocation). Our findings are consistent with existent research, such as Durrant and Schmitt (Reference Durrant and Schmitt2009), who found that learners produce frequent collocations at higher rates than NSs and less frequent collocations at comparatively lower rates. In the case of interpretation, our NNSs showed a lesser effect for individual lexical items than the NSs did. One key difference between Durrant and Schmitt and the current study is the manner in which lexical frequency was operationalized. In the former, the researchers compared relatively more and less frequent collocations to one another, whereas we ensured that all collocations on the instrument were regularly occurring (i.e., rather frequent). Despite this, our results point to comparable differences between NSs and NNSs. We hypothesize that this reflects differing ranges and depths of experience between traditional classroom L2 learners and NSs. Studies like Linford et al. (Reference Linford, Long, Solon, Geeslin, Ortega, Tyler, Park and Uno2016) suggest that group-specific corpora may be a better source for measuring lexical or collocational frequency for learners. Their study of subject form production showed that while NS patterns of use generally reflected patterns in other larger corpora, the learner patterns were less generalizable between group-specific and larger, publicly available corpora. Taken together, we hypothesize that the use of group-specific corpora can be used profitably to further study patterns of interpretation.
These findings also expand our knowledge of interpretation more broadly. Doing so helps to address the current bias in the literature toward analyses of production. In the case of L2 variable structures, this is especially important, as sociolinguistic competence is generally understood to place greater burdens on accurate interpretation of sociolinguistically variable forms than on producing the full range of forms available in the input, some of which may not reflect the identity of an individual learner. With these implications in mind, we see that in addition to improving our knowledge of the development of a particular variable structure, the present study contributes more broadly to our understanding of L2 interpretive abilities, as well as usage-based and corpus research approaches to the patterning of language use more broadly.
CONCLUSIONS, LIMITATIONS, AND FUTURE DIRECTIONS
Our findings build on the existing work on the L2 acquisition of variable structures by expanding the relatively scarce knowledge of interpretation to the Spanish copula. They further connect this area of study to research on the roles of type and token frequency in native and nonnative patterns of use. We see evidence of differences between production and perception and also that the role of frequency may differ between NSs and learners in systematic ways. Because this is one of few studies examining the L2 interpretation of a variable structure in this way, many paths for future inquiry remain. Firstly, while the written instrument is held constant across participants and the individual was considered as a random effect, the participants likely also contribute to the variability attested. Future studies might examine individual results in greater detail, along with individuals’ varied social characteristics and experiences. Likewise, our learner groups differ considerably in proficiency from one another and additional data from intermediate-level learners or longitudinal data will provide greater detail about developmental paths. We see great possibility in expansion through supplementary interpretive tasks (e.g., picture matching), additional adjectives and classes, and further variable structures, including those associated with particular geographic varieties. In sum, the present study lays the foundation for future research into the L2 acquisition of interpretation of sociolinguistically variable structures.
SUPPLEMENTARY MATERIAL
To view supplementary material for this article, please visit https://doi.org/10.1017/S0272263119000718








