
33 results
Adverse childhood experiences and craving: Results from an Italian population in outpatient addiction treatment
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 12 May 2023, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embolic Stroke of Undetermined Source: Role of Implantable Loop Recorder in Secondary Prevention
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 50 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 03 June 2022, pp. 529-534
-
- Article
- Export citation
A pragmatic controlled trial to improve the appropriate prescription of drugs in adult outpatients: design and rationale of the EDU.RE.DRUG study
-
- Journal:
- Primary Health Care Research & Development / Volume 21 / 2020
- Published online by Cambridge University Press:
- 09 July 2020, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Ebola virus disease outbreak in Tonkolili district, Sierra Leone: a retrospective analysis of the Viral Haemorrhagic Fever surveillance system, July 2014–June 2015
-
- Journal:
- Epidemiology & Infection / Volume 147 / 2019
- Published online by Cambridge University Press:
- 26 February 2019, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
GROUPS OF FINITE NORMAL LENGTH
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 97 / Issue 2 / April 2018
- Published online by Cambridge University Press:
- 01 February 2018, pp. 229-239
- Print publication:
- April 2018
-
- Article
-
- You have access
- Export citation
-
Let
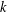 $k$ be a nonnegative integer. A subgroup
$k$ be a nonnegative integer. A subgroup 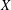 $X$ of a group
$X$ of a group 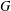 $G$ has normal length
$G$ has normal length 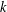 $k$ in
$k$ in 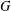 $G$ if all chains between
$G$ if all chains between 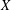 $X$ and its normal closure
$X$ and its normal closure 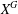 $X^{G}$ have length at most
$X^{G}$ have length at most 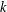 $k$, and
$k$, and 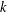 $k$ is the length of at least one of these chains. The group
$k$ is the length of at least one of these chains. The group 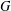 $G$ is said to have finite normal length if there is a finite upper bound for the normal lengths of its subgroups. The aim of this paper is to study groups of finite normal length. Among other results, it is proved that if all subgroups of a locally (soluble-by-finite) group
$G$ is said to have finite normal length if there is a finite upper bound for the normal lengths of its subgroups. The aim of this paper is to study groups of finite normal length. Among other results, it is proved that if all subgroups of a locally (soluble-by-finite) group 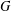 $G$ have finite normal length in
$G$ have finite normal length in 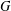 $G$, then the commutator subgroup
$G$, then the commutator subgroup 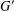 $G^{\prime }$ is finite and so
$G^{\prime }$ is finite and so 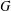 $G$ has finite normal length. Special attention is given to the structure of groups of normal length
$G$ has finite normal length. Special attention is given to the structure of groups of normal length 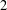 $2$. In particular, it is shown that finite groups with this property admit a Sylow tower.
$2$. In particular, it is shown that finite groups with this property admit a Sylow tower.
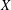
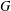
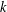
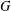
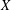
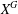
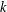
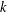
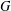
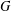
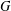
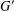
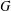
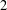
Epigraph
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp xxiii-xxiv
-
- Chapter
- Export citation
2 - Centrality Measures
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 31-68
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp xi-xi
-
- Chapter
- Export citation
4 - Small-World Networks
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 107-150
-
- Chapter
- Export citation
References
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 535-549
-
- Chapter
- Export citation
10 - Weighted Networks
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 374-409
-
- Chapter
- Export citation
7 - Degree Correlations
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 257-293
-
- Chapter
- Export citation
5 - Generalised Random Graphs
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 151-205
-
- Chapter
- Export citation
1 - Graphs and Graph Theory
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 1-30
-
- Chapter
- Export citation
Introduction
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp xii-xxii
-
- Chapter
- Export citation
Contents
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp vii-x
-
- Chapter
- Export citation
9 - Community Structure
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 332-373
-
- Chapter
- Export citation
6 - Models of Growing Graphs
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 206-256
-
- Chapter
- Export citation
3 - Random Graphs
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 69-106
-
- Chapter
- Export citation
Author Index
-
- Book:
- Complex Networks
- Published online:
- 11 October 2017
- Print publication:
- 28 September 2017, pp 550-551
-
- Chapter
- Export citation
