
90 results
Bound by Borders: Voter Mobilization Through Social Networks
-
- Journal:
- British Journal of Political Science , First View
- Published online by Cambridge University Press:
- 30 April 2024, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
65 Verbal and Visual-Spatial Abilities Differ by Ethnicity in a Referred Pediatric Sample
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 29 / Issue s1 / November 2023
- Published online by Cambridge University Press:
- 21 December 2023, pp. 741-742
-
- Article
-
- You have access
- Export citation
Statistically Valid Inferences from Privacy-Protected Data
-
- Journal:
- American Political Science Review / Volume 117 / Issue 4 / November 2023
- Published online by Cambridge University Press:
- 08 February 2023, pp. 1275-1290
- Print publication:
- November 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Statistically Valid Inferences from Differentially Private Data Releases, with Application to the Facebook URLs Dataset
-
- Journal:
- Political Analysis / Volume 31 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 20 April 2022, pp. 1-21
-
- Article
- Export citation
An Improved Method of Automated Nonparametric Content Analysis for Social Science
-
- Journal:
- Political Analysis / Volume 31 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 07 January 2022, pp. 42-58
-
- Article
- Export citation
Rejoinder: Concluding Remarks on Scholarly Communications
-
- Journal:
- Political Analysis / Volume 31 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 02 December 2021, pp. 335-336
-
- Article
- Export citation
The Essential Role of Statistical Inference in Evaluating Electoral Systems: A Response to DeFord et al.
-
- Journal:
- Political Analysis / Volume 31 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 02 December 2021, pp. 325-331
-
- Article
- Export citation
Flipping My Research Methods Course: Video Lectures, OERs & The Hybrid Classroom
-
- Journal:
- Political Science Today / Volume 1 / Issue 3 / August 2021
- Published online by Cambridge University Press:
- 18 August 2021, pp. 5-6
- Print publication:
- August 2021
-
- Article
-
- You have access
- HTML
- Export citation
The “Math Prefresher” and the Collective Future of Political Science Graduate Training
-
- Journal:
- PS: Political Science & Politics / Volume 53 / Issue 3 / July 2020
- Published online by Cambridge University Press:
- 28 February 2020, pp. 537-541
- Print publication:
- July 2020
-
- Article
-
- You have access
- HTML
- Export citation
Theoretical Foundations and Empirical Evaluations of Partisan Fairness in District-Based Democracies
-
- Journal:
- American Political Science Review / Volume 114 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 23 October 2019, pp. 164-178
- Print publication:
- February 2020
-
- Article
- Export citation
A New Model for Industry–Academic Partnerships
-
- Journal:
- PS: Political Science & Politics / Volume 53 / Issue 4 / October 2020
- Published online by Cambridge University Press:
- 19 August 2019, pp. 703-709
- Print publication:
- October 2020
-
- Article
-
- You have access
- HTML
- Export citation
Ecological Regression with Partial Identification
-
- Journal:
- Political Analysis / Volume 28 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 02 August 2019, pp. 65-86
-
- Article
- Export citation
-
Ecological inference (EI) is the process of learning about individual behavior from aggregate data. We relax assumptions by allowing for “linear contextual effects,” which previous works have regarded as plausible but avoided due to nonidentification, a problem we sidestep by deriving bounds instead of point estimates. In this way, we offer a conceptual framework to improve on the Duncan–Davis bound, derived more than 65 years ago. To study the effectiveness of our approach, we collect and analyze 8,430
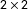 $2\times 2$ EI datasets with known ground truth from several sources—thus bringing considerably more data to bear on the problem than the existing dozen or so datasets available in the literature for evaluating EI estimators. For the 88% of real data sets in our collection that fit a proposed rule, our approach reduces the width of the Duncan–Davis bound, on average, by about 44%, while still capturing the true district-level parameter about 99% of the time. The remaining 12% revert to the Duncan–Davis bound.
$2\times 2$ EI datasets with known ground truth from several sources—thus bringing considerably more data to bear on the problem than the existing dozen or so datasets available in the literature for evaluating EI estimators. For the 88% of real data sets in our collection that fit a proposed rule, our approach reduces the width of the Duncan–Davis bound, on average, by about 44%, while still capturing the true district-level parameter about 99% of the time. The remaining 12% revert to the Duncan–Davis bound.
Why Propensity Scores Should Not Be Used for Matching
-
- Journal:
- Political Analysis / Volume 27 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 07 May 2019, pp. 435-454
-
- Article
- Export citation
A Theory of Statistical Inference for Matching Methods in Causal Research
-
- Journal:
- Political Analysis / Volume 27 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 04 October 2018, pp. 46-68
-
- Article
- Export citation
Assessing a National Collaborative Program To Prevent Catheter-Associated Urinary Tract Infection in a Veterans Health Administration Nursing Home Cohort
-
- Journal:
- Infection Control & Hospital Epidemiology / Volume 39 / Issue 7 / July 2018
- Published online by Cambridge University Press:
- 10 May 2018, pp. 820-825
- Print publication:
- July 2018
-
- Article
- Export citation
How the Chinese Government Fabricates Social Media Posts for Strategic Distraction, Not Engaged Argument
-
- Journal:
- American Political Science Review / Volume 111 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 27 July 2017, pp. 484-501
- Print publication:
- August 2017
-
- Article
-
- You have access
- HTML
- Export citation
Isolating Spatial Autocorrelation, Aggregation Bias, and Distributional Violations in Ecological Inference: Comment on Anselin and Cho
-
- Journal:
- Political Analysis / Volume 10 / Issue 3 / Summer 2002
- Published online by Cambridge University Press:
- 04 January 2017, pp. 298-300
-
- Article
- Export citation
Explaining Systematic Bias and Nontransparency in U.S. Social Security Administration Forecasts
-
- Journal:
- Political Analysis / Volume 23 / Issue 3 / Summer 2015
- Published online by Cambridge University Press:
- 04 January 2017, pp. 336-362
-
- Article
-
- You have access
- Open access
- Export citation
On Political Methodology
-
- Journal:
- Political Analysis / Volume 2 / 1990
- Published online by Cambridge University Press:
- 04 January 2017, pp. 1-29
-
- Article
- Export citation
Comparing Incomparable Survey Responses: Evaluating and Selecting Anchoring Vignettes
-
- Journal:
- Political Analysis / Volume 15 / Issue 1 / Winter 2007
- Published online by Cambridge University Press:
- 04 January 2017, pp. 46-66
-
- Article
-
- You have access
- Export citation
