
51 results
Contributors
-
-
- Book:
- The Cambridge Dictionary of Philosophy
- Published online:
- 05 August 2015
- Print publication:
- 27 April 2015, pp ix-xxx
-
- Chapter
- Export citation
Functional architecture and free will
-
- Journal:
- Behavioral and Brain Sciences / Volume 3 / Issue 1 / March 1980
- Published online by Cambridge University Press:
- 04 February 2010, pp. 143-146
-
- Article
- Export citation
Rational belief
-
- Journal:
- Behavioral and Brain Sciences / Volume 6 / Issue 2 / June 1983
- Published online by Cambridge University Press:
- 04 February 2010, pp. 231-245
-
- Article
- Export citation
Induction and probability
-
- Journal:
- Behavioral and Brain Sciences / Volume 9 / Issue 4 / December 1986
- Published online by Cambridge University Press:
- 04 February 2010, p. 660
-
- Article
- Export citation
Probabilistic fallacies
-
- Journal:
- Behavioral and Brain Sciences / Volume 19 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 04 February 2010, p. 31
-
- Article
- Export citation
Knowledge and the absolute
-
- Journal:
- Behavioral and Brain Sciences / Volume 6 / Issue 1 / March 1983
- Published online by Cambridge University Press:
- 04 February 2010, pp. 72-73
-
- Article
- Export citation
Intuition, competence, and performance
-
- Journal:
- Behavioral and Brain Sciences / Volume 4 / Issue 3 / September 1981
- Published online by Cambridge University Press:
- 04 February 2010, pp. 341-342
-
- Article
- Export citation
The role of logic in reason, inference, and decision
-
- Journal:
- Behavioral and Brain Sciences / Volume 6 / Issue 2 / June 1983
- Published online by Cambridge University Press:
- 04 February 2010, pp. 263-273
-
- Article
- Export citation
Probability intervals and rational norms
-
- Journal:
- Behavioral and Brain Sciences / Volume 8 / Issue 4 / December 1985
- Published online by Cambridge University Press:
- 04 February 2010, pp. 753-754
-
- Article
- Export citation
Keynes's Philosophical Development, John B. Davis. Cambridge University Press, 1994, 196 + xii pages.
-
- Journal:
- Economics & Philosophy / Volume 12 / Issue 2 / October 1996
- Published online by Cambridge University Press:
- 05 December 2008, pp. 230-234
-
- Article
- Export citation
15 - Inductive Logic and Inductive Reasoning
-
-
- Book:
- Reasoning
- Published online:
- 05 June 2012
- Print publication:
- 05 May 2008, pp 291-301
-
- Chapter
- Export citation
7 - Vexed Convexity
-
-
- Book:
- Knowledge and Inquiry
- Published online:
- 05 March 2010
- Print publication:
- 13 February 2006, pp 97-110
-
- Chapter
- Export citation
Belief, Evidence, and Conditioning
-
- Journal:
- Philosophy of Science / Volume 73 / Issue 1 / January 2006
- Published online by Cambridge University Press:
- 01 January 2022, pp. 42-65
- Print publication:
- January 2006
-
- Article
- Export citation
-
Since Ramsey, much discussion of the relation between probability and belief has taken for granted that there are degrees of belief, i.e., that there is a real-valued function, B, that characterizes the degree of belief that an agent has in each statement of his language. It is then supposed that B is a probability. It is then often supposed that as the agent accumulates evidence, this function should be updated by conditioning:
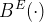 $B^{E}(\cdot) $
should be
$B^{E}(\cdot) $
should be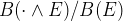 $B(\cdot \wedge E) / B(E) $
. Probability is also important in classical statistics, where it is generally supposed that probabilities are frequencies, and that inference proceeds by controlling error and not by conditioning. I will focus on the tension between these two approaches to probability, and in the main part of the paper show where and when Bayesian conditioning conflicts with error based statistics and how to resolve these conflicts.
$B(\cdot \wedge E) / B(E) $
. Probability is also important in classical statistics, where it is generally supposed that probabilities are frequencies, and that inference proceeds by controlling error and not by conditioning. I will focus on the tension between these two approaches to probability, and in the main part of the paper show where and when Bayesian conditioning conflicts with error based statistics and how to resolve these conflicts.
David Christensen. Putting logic in its place: formal constraints on rational belief. Oxford University Press, Oxford, 2004 xii + 187 pp.
-
- Journal:
- Bulletin of Symbolic Logic / Volume 11 / Issue 4 / December 2005
- Published online by Cambridge University Press:
- 15 January 2014, pp. 534-535
- Print publication:
- December 2005
-
- Article
- Export citation
6 - Nonmonotonic Reasoning
-
- Book:
- Uncertain Inference
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001, pp 117-151
-
- Chapter
- Export citation

Uncertain Inference
-
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001
Names Index
-
- Book:
- Uncertain Inference
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001, pp 291-292
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Uncertain Inference
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001, pp i-iv
-
- Chapter
- Export citation
Preface
-
- Book:
- Uncertain Inference
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001, pp xi-xii
-
- Chapter
- Export citation
4 - Interpretations of Probability
-
- Book:
- Uncertain Inference
- Published online:
- 07 December 2009
- Print publication:
- 06 August 2001, pp 68-97
-
- Chapter
- Export citation
