

1 Peer Review and Its Discontents
What Is Peer Review and Is It Any Good?
‘Peer review’ is the system by which manuscripts and other scholarly objects are vetted for validity, appraised for originality, and selected for publication as articles in academic journals, as academic books (‘monographs’), and in different forms.Footnote 1 Since an editor of an academic title cannot be expected to be an expert in every single area covered by a publication and since it appears undesirable to have a single person controlling the publication’s flow of scientific and humanistic knowledge, there is a need for input from more people. Manuscripts submitted for consideration are shown to external expert advisers (‘peers’) who deliver verdicts on the novelty of the work, criticisms or praise of the piece, and a judgement of whether or not to proceed to publication. A network of experts with appropriate degrees of knowledge and experience within a field are coordinated to yield a set of checks and balances for the scientific and broader research landscapes. Editors are then bound, with some caveats and to some extent, to respect these external judgements in their own decisions, regardless of how harsh the mythical ‘reviewer 2’ may be (Reference Bakanic, McPhail and SimonBakanic, McPhail, and Simon 1989; Reference Bornmann and DanielBornmann and Daniel 2008; Reference Fogg and FiskeFogg and Fiske 1993; Reference LockLock 1986; Reference Petty, Fleming and FabrigarPetty, Fleming, and Fabrigar 1999; Reference Sternberg, Hojjat, Brigockas and GrigorenkoSternberg et al. 1997; Reference Zuckerman and MertonZuckerman and Merton 1971).
The premise behind peer review may appear sound, even incontrovertible. Who could object to the best in the world appraising one another, nobly ensuring the integrity of the world’s official research record? Yet, considering the system for even a few moments leads to several questions. What is a peer and who decides? What does it mean when a peer approves somebody else’s work? How many peers are required before a manuscript can be properly vetted? What happens if peers disagree with one another? Does (or should) peer review operate in the same fashion in disciplines as distinct as neuroscience and sculpture? Particle physics and social geography? Math and literary criticism? When academics rely on publications for their job appointments and promotions, how does peer review interact with other power structures in universities? Do reviewers act with honour and integrity in their judgements within this system?
Consider, as just one example, the question of anonymity in the peer-review process. Review is meant to assess the work itself, not the authors. If the identity of the authors is available to reviewers, though, then might not they give an easy ride to people they know or allow personal disputes to affect their judgement negatively? It is also possible that radically incorrect work might be erroneously perceived as truthful when it comes from an established figure within a discipline or that bold new and correct work might be incorrectly rejected because it comes from new or unusual quarters (Reference CampanarioCampanario 2009).
Yet simply removing the names of authors is not itself necessarily a solution. When one is dealing with small pools of experts, this can provide a false sense of security (Reference Fisher, Friedman and StraussFisher, Friedman, and Strauss 1994; Reference Godlee, Gale and MartynGodlee, Gale, and Martyn 1998; Reference SandströmSandström 2009; Reference Wang and UlfWang and Sandström 2015). If a reviewer knows that the work was part of a publicised funded project, for instance, it could be possible to guess with some accuracy the authors’ identities. In niche sub-fields, researchers usually all know one another and the areas in which their colleagues are working (Reference Mom, Sandström and PeterMom, Sandström, and Besselaar 2018; Reference Sandström and MartinSandström and Hällsten 2008).
On the other side of this process, what about the identity of the reviewer? Should the authors (or even the readership of the final piece) be told who has reviewed the manuscript (Reference PullumPullum 1984; Reference van Rooyen, Delamothe and Evansvan Rooyen, Delamothe, and Evans 2010)? There are arguments for both positive and negative answers to this question. When people are anonymous, they may be more able to speak without constraint. A junior postdoctoral researcher may be capable of reviewing the work of a senior professor but might not be able to criticise extensively the work for fear of career reprisals were their identity to be revealed (this also raises the question, though, of what we mean by ‘peer’). Yet we also know that the cover of anonymity can be abused. Anonymous reviewers, it is assumed, may be more aggressive in their approach and can even write incredibly hurtful ad hominem attacks on papers (Reference Silbiger and StublerSilbiger and Stubler 2019).
Further, how can we tell the standards demanded of a publisher without knowledge of the individuals used to assess the manuscripts? As Kathleen Fitzpatrick notes, conditions of anonymity limit our ability to investigate the review process thoroughly. For ‘in using a human filtering system’, she writes, ‘the most important thing to have information about is less the data that is being filtered, than the human filter itself: who is making the decisions, and why’ (Reference FitzpatrickFitzpatrick 2011, 38). It is also clear that errors are only likely to be caught if the selection of peers is up to scratch (although as we note later, there are even some problems with this assumption). Group social dynamics may also affect decision-making in this area (Reference Olbrecht and BornmannOlbrecht and Bornmann 2010; Reference van Arensbergen, van der Weijden and van den Besselaarvan Arensbergen, van der Weijden, and van den Besselaar 2014). Gender biases also play a role (Reference van den Besselaar, Sandström and SchiffbaenkerBesselaar et al. 2018; Reference Biernat, Tocci and WilliamsBiernat, Tocci, and Williams 2012; Reference Helmer, Schottdorf, Neef and BattagliaHelmer et al. 2017; Reference Kaatz, Gutierrez and CarnesKaatz, Gutierrez, and Carnes 2014). Anonymity in the review process, just the first of many concerns, is far more complicated than it might at first appear (for more on this debate, see Reference BrownBrown 2003; Reference DeCourseyDeCoursey 2006; Reference Eve, Vincent and WickhamEve 2013; Reference GodleeGodlee 2002; Reference Ross-HellauerRoss-Hellauer 2017; Reference Seeber and BacchelliSeeber and Bacchelli 2017; R. Reference SmithSmith 1999; Reference TattersallTattersall 2015; Reference van Rooyen, Godlee, Evans, Black and Smithvan Rooyen et al. 1999).
It also seems abundantly clear that the peer-review process is far from infallible. Every year, thousands of articles are retracted (withdrawn) for containing inaccuracies (Reference Brainard and YouBrainard and You 2018), for conducting unethical research practices, and for many other reasons (for more on this, see the ‘Retraction Watch’ site; see Reference Brembs, Button and MarcusBrembs, Button, and Munafò 2013 for a study that found that impact factor correlates with retraction rate). On occasion, this has had devastating consequences in spaces such as public health. Andrew Wakefield’s notorious retracted paper claiming a link between the mumps, measles, and rubella (MMR) vaccine and the development of autism in children was published in perhaps the most prestigious medical journal in the world, The Lancet (Reference Wakefield, Murch, Anthony, Linnell, Casson, Malik and BerelowitzWakefield et al. 1998). The work was undoubtedly subject to stringent pre-publication review and was cleared for publication. Yet the article was later retracted and branded fraudulent, having caused immense and ongoing damage to public health (Reference Godlee, Smith and MarcovitchGodlee, Smith, and Marcovitch 2011). It is, alas, always easier to make an initial statement than subsequently to retract or to correct it. As a result, a worldwide anti-vaccination movement has seized upon this circumstance as evidence of a conspiracy. The logic uses the supposed initial validation of peer review and the prestige of The Lancet as evidence that Wakefield was correct and that he is the victim of a conspiratorial plot to suppress his findings. Hence, when peer review goes wrong, the general belief in its efficacy, coupled with the prestige of journals founded on the supposed expertise of peer review, has damaging real-world effects.
In other cases, peer review is problematic for the delays it introduces. Consider research around urgent health emergencies, such as the Zika virus or newly proposed treatments for the 2019 novel coronavirus. Is it appropriate and ethical to wait several days, weeks, or even months for expert opinion on whether this information should be published when people are dying during the lag period? The answer to this depends on the specific circumstances and the outcome, which can only be known after publication. On the one hand, if the information is published, without peer review, and it turns out to be correct and solid without revision, then the checks and balances of peer review would have cost lives. On the other hand, if the information published is wrong or even actively harmful, and there is even a chance that peer review could have caught this, one might feel differently. These are but a few of the problems, dilemmas, and ethical conundrums that circulate around that apparently ‘simple’ concept of peer review.
In this opening chapter, we describe the broad background histories of peer review and its study. This framing chapter is designed to give the reader the necessary surrounding context to understand the historical evolution and development of peer review. It also introduces much of the secondary criticism of peer review that has emerged in recent years, questioning the usual assumption that the objectivity (or intersubjectivity) of review is universally accepted as the best course of action to ensure standards. Finally, we address the merits of innovative new peer-review practices and disciplinary differences in their take-up (or otherwise). While there are certainly cross-disciplinary implications for our work, it has been in the natural sciences that the benefits and rewards of these new approaches have been most heavily sold.
The Study of Peer Review
Despite the aforementioned challenges, the role of peer review in improving the quality of academic publications and in predicting the impact of manuscripts through criteria of ‘excellence’ is widely seen as essential to the research endeavour. As a term that first entered critical and popular discourse around 1960 but also as a practice that only became commonplace far later than most suspect, ‘peer review’ is sometimes described as the ‘gold standard’ of quality control, and the majority of researchers consider it crucial to contemporary science (Reference Alberts, Hanson and KelnerAlberts, Hanson, and Kelner 2008; Reference BaldwinBaldwin 2017, Reference Baldwin2018; Reference Enslin and HedgeEnslin and Hedge 2018; Reference Fyfe, Squazzoni, Torny and DondioFyfe et al. 2019; Reference HamesHames 2007, 2; Reference Moore, Neylon, Eve, O’Donnell and PattinsonMoore et al. 2017; Reference Mulligan, Hall and RaphaelMulligan, Hall, and Raphael 2013, 132; Reference ShatzShatz 2004, 1). Indeed, peer review is much younger than many suspect. In 1936, for instance, Albert Einstein was outraged to learn that his unpublished submission to Physical Review had been sent out for review (Reference BaldwinBaldwin 2018, 542). Yet, despite its relative youth, peer review has nonetheless become a fixture of academic publication. This raises the question, though, of why this might be the case. For surprisingly little evidence exists to support the claim that peer review is the best way to pre-audit work, leading Michelle Lamont and others to note the importance of ensuring that ‘peer review processes … [are] themselves subject to further evaluation’ (Reference LamontLamont 2009, 247; see also Reference LaFolletteLaFollette 1992). Indeed, there are long-standing criticisms of the validity of peer review, exemplified in Franz J. Ingelfinger’s notorious statement that the process is ‘only moderately better than chance’ (Reference IngelfingerIngelfinger 1974, 686; see also Reference DanielDaniel 1993, 4; Reference Rothwell and MartynRothwell and Martyn 2000) and Drummond Rennie’s (then deputy editor of the Journal of the American Medical Association) ‘if peer review was a drug it would never be allowed onto the market’ (cited in Richard Reference SmithSmith 2006a, Reference Smith2010). However, the status function declaration, as John Reference SearleSearle (2010) puts it, of peer review is to institute a set of institutional practices that allow for the selection of quality by a group of empowered, qualified experts (see also Reference RacharRachar 2016). Peer review as conducted within universities resonates, in many senses, as a type of ‘total institution’ as defined by Christie Davies and Erving Goffman: a ‘distinctive set of organizations that are both part of and separate from modern societies’ (Reference DaviesDavies 1989, 77) and a ‘social hybrid’ that is ‘part residential community, part formal organization’ (Reference GoffmanGoffman 1968, 22).
Yet research into peer review processes can be difficult to conduct. At least one of the challenges with such studies is that there is always the risk of seeking explanations for the accepted constructions and logics of peer review, rather than recognising the contingency of their emergence. This has not, however, prevented a burgeoning field from emerging around the topic (Reference Batagelj, Ferligoj and SquazzoniBatagelj, Ferligoj, and Squazzoni 2017; Reference Tennant and Ross-Hellauer.Tennant and Ross-Hellauer 2019). Certainly, following the influential work of John Reference SwalesSwales (1990), an ever-increasing number of studies have examined the language and mood of published academic articles, grant proposals, and editorials (Reference Aktas and CortesAktas and Cortes 2008; Reference Connor and MauranenConnor and Mauranen 1999; Reference GiannoniGiannoni 2008; Reference HarwoodHarwood 2005a, Reference Harwood2005b; Reference Shehzad and FitzpatrickShehzad 2015; these examples are drawn from Reference Lillis and CurryLillis and Curry 2015, 128). This is not surprising; after all, as van den Besselaar, Sandström, and Schiffbaenker note, ‘[l]anguage embodies normative views about who/where we communicate about, and stereotypes about others are embedded and reproduced in language’ (Reference van den Besselaar, Sandström and Schiffbaenker2018, 314; see also Reference Beukeboom and BurgersBeukeboom and Burgers 2017; Reference Burgers and BeukeboomBurgers and Beukeboom 2016). Indeed, a number of existing studies have examined the linguistic properties of peer review reports written by the authors themselves (Reference ConiamConiam 2012; Reference WoodsWoods 2006, 140–6; for more, see Reference PaltridgePaltridge 2017, 49–50).
Yet, as examples of some of the difficulties that hinder the study of these documents, consider that peer-review reports are often owned and guarded by organisations that wish to protect not only the anonymity of reviewers but also the systems of review that bring them an operational advantage – anonymous review comes with several benefits for organisations that are in commercial competition with one another. In particular, and as just one instance, since reviewers often work for multiple publication outlets (that is, the same reviewers can review for more than one journal), the claim of one publisher to have a more rigorous standard of review or better quality of reviewer than other outlets could be damaged were review processes open, non-anonymous, and subject to transparent verification. (It is also clear that top presses can publish bad and incorrect work and that excellent work can appear in less prestigious venues (Reference ShatzShatz 2004, 130).) Further, these organisations often do not have conditions in place that will allow research to be conducted upon peer-review reports. The earliest studies of peer review, therefore, generally used survey methodologies rather than directly interrogating the results of the process (Reference ChaseChase 1970; Reference Lindsey and LindseyLindsey and Lindsey 1978; Reference Lodahl and GordonLodahl and Gordon 1972). As an occluded genre of writing that nonetheless underpins scientific publication, relatively little is known about the ways in which academics write and behave, at scale, in their reviewing practices.
As another example, an absence of rules and guidelines around ownership of peer-review comments certainly contributes to the challenges. The lack of financial incentives in many cases and, therefore, contracts and agreements with reviewers have meant that no clear ownership of reviews has been established (for more on the economics and financials of scholarly communications in the digital era, see Reference GansGans 2017; Reference HoughtonHoughton 2011; Reference Kahin and VarianKahin and Varian 2000; Reference McGuigan and RussellMcGuigan and Russell 2008; Reference MorrisonMorrison 2013; Reference WillinskyWillinsky 2009). In the absence of such statements, it can be assumed that copyright remains with the author of the reports in most jurisdictions. Publishers often do not wish to exert any dominance in this area for fear of dissuading future referees, who can be hard enough to persuade at the best of times. Reviews, therefore, exist in a world of grace and favour rather than one with any clear legal framework. Publishers also benefit from opacity in this domain in other ways. For example, by keeping poor-quality reviews hidden from sight, journals are able to build their reputations on other, less direct, criteria such as citation indices and editorial board celebrity (for more on the occluded nature of peer review, see Reference GosdenGosden 2003). A journal’s reviewer database can also provide competitive advantage and bring value to a publishing stable beyond the status of the title itself.
That said, in spite of these difficulties, a substantial number of studies have examined peer review (for just a selection, consider Reference Bonjean and HullumBonjean and Hullum 1978; Reference Mustaine and TewksburyMustaine and Tewksbury 2008; Reference Smigel and RossSmigel and Ross 1970; Reference Tewksbury and MustaineTewksbury and Mustaine 2012), and it would be a mistake to call the field under-researched, although the methods used are diverse and disaggregated (Reference Grimaldo, Marušić and SquazzoniGrimaldo, Marušić, and Squazzoni 2018; Reference Meruane, González Vergara and Pina-StrangerMeruane, González Vergara, and Pina-Stranger 2016, 181). Indeed, Reference Meruane, González Vergara and Pina-StrangerMeruane, González Vergara, and Pina-Stranger (2016, 183) provide a good history of the disciplinary specialisations of the study of peer-review processes (PRP) since the 1960s noting that while ‘PRP has been a prominent object of study, empirical research on PRP has not been addressed in a comprehensive way.’ The precise volume of research varies by the way that one searches, but there appears to be up to 23,000 articles on the topic between 1969 and 2013 by one count – and this does not even include the so-called grey literature of blogs (Reference Meruane, González Vergara and Pina-StrangerMeruane, González Vergara, and Pina-Stranger 2016, 181). It is, then, well beyond the scope of this book to provide a comprehensive meta-review of the secondary literature on peer review. The interested reader, though, could consult one of the many other studies that have conducted such an exercise (Reference BornmannBornmann 2011b; Reference Meruane, González Vergara and Pina-StrangerMeruane, González Vergara, and Pina-Stranger 2016; Reference Silbiger and StublerSilbiger and Stubler 2019; Reference WellerWeller 2001). Much, although by no means all, of this research has been critical of peer-review processes, finding our faith in the practice to be misplaced (Reference SquazzoniSquazzoni 2010, 19; Reference Sugimoto and CroninSugimoto and Cronin 2013, 851–2; for more positive opinions on the process, see Reference Bornmann, Shin, Toutkoushian and TeichlerBornmann 2011a; Reference GoodmanGoodman 1994; Reference Pierie, Walvoort and OverbekePierie, Walvoort, and Overbeke 1996). Critics of peer review usually point to its poor reliability and lack of predictive validity (Reference Fang, Bowen and CasadevallFang, Bowen, and Casadevall 2016; Reference Fang and CasadevallFang and Casadevall 2011; Reference HerronHerron 2012; Reference Kravitz, Franks, Feldman, Gerrity, Byrne and TierneyKravitz et al. 2010; Reference MahoneyMahoney 1977; Reference Schroter, Black, Evans, Carpenter, Godlee and SmithSchroter et al. 2004; Richard Reference SmithSmith 2006b); biases and subversion within the process (Reference BardyBardy 1998; Reference Budden, Tregenza, Aarssen, Koricheva, Leimu and LortieBudden et al. 2008; Reference Ceci and PetersCeci and Peters 1982; Reference ChawlaChawla 2019; Reference Chubin and HackettChubin and Hackett 1990; Reference CroninCronin 2009; Reference Dall’AglioDall’Aglio 2006; K. Reference Dickersin, Chan, Chalmers, Sacks and SmithDickersin et al. 1987; Reference Dickersin, Min and MeinertKay Dickersin, Min, and Meinert 1992; Reference Ernst and KienbacherErnst and Kienbacher 1991; Reference FanelliFanelli 2010, Reference Fanelli2011; Reference Gillespie, Chubin and KurzonGillespie, Chubin, and Kurzon 1985; Reference IoannidisIoannidis 1998; Reference LinkLink 1998; Reference LloydLloyd 1990; Reference MahoneyMahoney 1977; Reference Ross, Gross, Desai, Hong, Grant, Daniels, Hachinski, Gibbons, Gardner and KrumholzRoss et al. 2006; Reference ShatzShatz 2004, 35–73; Reference Travis and CollinsTravis and Collins 1991; Reference TregenzaTregenza 2002); the inefficiency of the system (Reference Ross-HellauerRoss-Hellauer 2017, 4–5); and the personally damaging nature of the process (Reference BornmannBornmann 2011b, 204; Reference Chubin and HackettChubin and Hackett 1990). For instance, and as just a sample, when Reference Rothwell and MartynRothwell and Martyn (2000, 1964) studied the reproducibility of peer-review reports, they repeated Ingelfinger’s assertion that ‘although recommendations made by reviewers have considerable influence on the fate of both papers submitted to journals and abstracts submitted to conferences, agreement between reviewers in clinical neuroscience was little greater than would be expected by chance alone.’ As another example, more recent work by Reference Okike, Hug, Kocher and LeopoldOkike et al. (2016) unveiled a strong unconscious bias among reviewers in favour of known or famous authors and institutions in the discipline of orthopaedics when using a single-blind mode of review. This casts serious doubt on claims to be able to ‘put aside’ one’s knowledge of an author or to act objectively in the face of conflicts of interest, although in other disciplinary spaces, it has been argued that the definition of merit, as defined in a discipline, is constructed by particular figures and that this identity should play a part in the evaluation of their work (Reference FishFish 1988). Additionally, Reference Murray, Siler, Lariviére, Chan, Collings, Raymond and SugimotoMurray et al. (2018, 25) explore the relationship between gender and international diversity and equity in peer review, concluding that ‘[i]ncreasing gender and international representation among scientific gatekeepers may improve fairness and equity in peer review outcomes, and accelerate scientific progress.’
Special mention should also be made of the PEERE Consortium, which has, in particular, achieved a great deal in opening up datasets for study (PEERE Consortium n.d.). Aiming, with substantial European research funding, to ‘improve [the] efficiency, transparency and accountability of peer review through a trans-disciplinary, cross-sectorial collaboration’, the consortium has been one of the most prolific centres for research into peer review in the past half decade. Publications from the group have spanned the author perspective on peer review (Reference Drvenica, Bravo, Vejmelka, Dekanski and OlgicaDrvenica et al. 2019), the reward systems of peer review (Reference Zaharie and SeeberZaharie and Seeber 2018), the links between reputation and peer review (Reference Grimaldo, Paolucci and Sabater-Mir.Grimaldo, Paolucci, and Sabater-Mir 2018), the role that artificial intelligence might play in future structures of review (Reference 97Mrowinski, Fronczak, Fronczak, Ausloos and NedicMrowinski et al. 2017), the timescales involved in review (Reference Huisman and SmitsHuisman and Smits 2017; Reference Mrowinski, Fronczak, Fronczak, Nedic and AusloosMrowinski et al. 2016), the reasons why people cite retracted papers (Reference Bar-Ilan and HaleviBar-Ilan and Halevi 2017), the fate of rejected manuscripts (Reference Casnici, Grimaldo, Gilbert and SquazzoniCasnici, Grimaldo, Gilbert, Dondio et al. 2017), and the ways in which referees act in multidisciplinary contexts (Reference Casnici, Grimaldo, Gilbert and SquazzoniCasnici, Grimaldo, Gilbert, and Squazzoni 2017).
In terms of the language used in peer review reports, work by Brian Reference PaltridgePaltridge (2015) has examined the ways in which reviewers request revisions of authors, using a mixed-methods approach. Paltridge studied review reports for the peer-reviewed journal English for Specific Purposes finding a mixture of implicit and explicit directions for revision used by reviewers, making for a confusing environment in which ‘what might seem like a suggestion is not at all a suggestion’ but ‘rather, a direction’ (Reference PaltridgePatridge 2015, 14), a view echoed by Reference GosdenGosden (2001, 16). Somewhat in contrast to this, though, Reference KourilovaKourilova (1998) found that non-native users of English often wrote with an honest, or brutal, bluntness in their reports for a range of sociocultural reasons. While this may come with its own challenges and be painful for authors, such bluntness is far less subject to misinterpretation than hedged attempts at avoiding offence. Comments with such a negative tone can also appear in published book reviews (Reference Salager-Meyer and AndrásSalager-Meyer 2001), but these are often more complimentary than behind-the-scenes peer-review reports (Reference HylandHyland 2004, 41–62). The ‘out of sight’ or occluded nature of peer review (Reference Swales and FeakSwales and Feak 2000, 229) tends, then, to lend itself to more critical judgements.
New Modalities of Peer Review
For some commentators, peer review is the least bad option, and any intervention is only likely to result in poorer outcomes. Others, though, have proposed a range of new methods and operational modes that are designed to address the perceived shortcomings in existing review protocols. Certainly, for the most part, this has taken place within the natural sciences and, as David Shatz remarks, ‘the paucity of humanities literature on peer review … [is] truly striking’, although he is unable to explain why this should be (Reference Shatz2004, 4). In this section of this chapter, we outline these new experiments, mostly within this disciplinary space.
Post-Publication Review
The twenty-first century is characterised by what Clay Shirky has famously called ‘filter failure’ (Reference Shirky2008). In the face of an ever-increasing abundance of material – be that scholarly, information, or news – it is apparent that we face severe difficulties in knowing where to spend our scarce attention (Reference BhaskarBhaskar 2016; Reference Eve and TabbiEve 2017; Reference NielsenNielsen 2011). Various solutions have been posed for how this might be remedied, most of which centre on what Michael Bhaskar calls a culture of ‘curation’, in which whether by algorithm or by human selection, the ‘wheat is sorted from the chaff’ (Reference BhaskarBhaskar 2016). What it might mean to do so appropriately is, of course, a matter of some contention. Algorithms that surface only mainstream content when we are looking for outliers represent just another problematic case of filter failure, as opposed to any viable solution.
The same problems apply to the scholarly and research literature (Reference Eve, Eve and GrayEve 2020). We exist in a world where more is published than it is possible for a person to read, even in almost every niche sub-discipline. Some solutions have taken the algorithmically curated route. Hence, there have been, on the reader side, several attempts to provide automatic summaries of articles, condensing these otherwise large artefacts down into bite-size, digestible chunks (‘Get The Research’ n.d.; Reference McKenzieMcKenzie 2019; Reference Nikolov, Pfeiffer and HahnloserNikolov, Pfeiffer, and Hahnloser 2018). Yet, we actually exist within a model of digital authorship that R. Lyle Reference SkainsSkains (2019) has dubbed ‘the attention economy’. It is a model where we only discover material that can float above the otherwise amorphous mass of scholarship. Simply shortening the material itself can help, but it does not resolve the discoverability deficit (Reference NeylonNeylon 2010).
This is problematic for scholarly research writing in a way that it is not for, say, works of fiction. While nobody enjoys a badly researched novel, the degree of comprehensiveness required remains considerably less for fiction than for science and scholarship. Writers of historical fiction, for example, conduct research to provide themselves with historically plausible details – appropriate language, modes of transportation, manners of dress, and so on. They seek evidence and descriptions, rather than resolving long-standing debates.
Scientists and scholars, on the other hand, are held to a much higher, though often more narrow, standard. While they are not responsible, as the novelist is, for the construction of an entire world, they are responsible in most cases for the entire range of professional opinion on their topic: what other researchers have found, where they have disagreed, and where the gaps are among them. To conduct new, rigorous research (or even a well-designed replication study), researchers need to have read everything that is pertinent to their topic. Domain mastery is essential and many see the mitigation of this problem as the role of peer review. If there is too much to read and too little time, perhaps too much is being published, the reasoning goes. By subdividing fields into topical journals – even if these do, then, mutate into ‘club goods’, rather than mere subject-based discoverability aids (Reference Hartley, Potts, Montgomery, Rennie and NeylonHartley et al. 2019; Reference Potts, Hartley, Montgomery, Neylon and RenniePotts et al. 2017) – and then by limiting the volume that is published, the idea is that researchers have an easy way to keep abreast of their field: simply read that journal.
This model has become untenable and problematic for many reasons. The first is that most high-status journals, which act as poor proxies for quality in institutional hiring and promotion metrics, publish across a range of fields. In addition to monitoring The Journal of Incredibly Niche Studies, authors must also regularly check Nature, Cell, Science, PMLA, New Literary History, the journals of the Royal Society and so on, depending upon their field, all of which publish across sub-disciplinary spaces. In this context, most of the content in these publications will not be relevant to a reader who aims to work on a specific project. But they also cannot be dismissed and must be checked. Hence, journal brand does not work well as a filter for subject, even if one believes that it can work as a filter for quality (that is, one might assume – although this assumption is not, in itself, non-problematic – that work published in Nature is good but it may not be relevant) (see Reference Moore, Neylon, Eve, O’Donnell and PattinsonMoore et al. 2017).
In light of this discussion, though, we can also query whether the work that is published is necessarily good. This is the second problem: given the critiques and failures of peer review to act as a reliably predictive arbiter of quality; if the review system is used as an exclusionary filter, we know that some good work will not be published and that some bad work will nonetheless appear. For although the logic of the system seems sound – the more important and rigorous a work appears to be, when appraised by experts, the more prominence it should be given through publication in a ‘top’ venue – it is not clear that expert preselection is able accurately to determine, in advance, whether work is important or even correct (Reference Brembs, Button and MarcusBrembs, Button, and Munafò 2013). In this sense, then, peer review cannot act universally well as a filter for quality, either, admitting both Type I (false positive) and Type II (false negative) errors.
What, though, if there were another way of surfacing relevant material that was also good? Given that we only seem to know whether material was accurate and true after the fact, some publications have speculated that post-publication peer review might be a sound way of ensuring that correct material is not excluded, while also seeking expert judgement on the accuracy of work. The basic premise of such systems works as follows:
1. The work is made available online, before a review is conducted;
2. Expert reviews are either solicited or volunteered on the publicly available manuscript;
3. These reviews are either made public or used as evidence to remove the piece from the public record if they are unanimously negative.
One of the challenges with point three is that retractions are less effective than work not entering the public space at all, as we have also seen in the case of the traditionally vetted, but problematic, work by Wakefield. Further, for technical and preservation reasons, retracted articles are not removed but merely marked as retracted. Post review may, if anything, make the problem of fraudulent or incorrect work entering the public record – a major reason for establishing a vetting system in the first place – worse and even more difficult to correct.
Proposals for post-publication peer review arise as a recognition of the fact that we are not very good at determining, ahead of publication, what is important and good. However, it comes with its own challenges. When a publisher seeks a traditional pre-publication review, they could argue that they are conducting a form of due diligence, in which they have done the best they could to ensure the accuracy of material. This could be important in specific biomedical sciences and the applied medical literature, even if we know that peer review has flaws. In a model that uses post-publication peer review, it is not clear that the same could be said. If material is published that then causes harm, it is not clear that a publisher could argue that they had done everything they could to prevent this, even when they do not endorse the material. Further, it is unclear who would take the legal blame here. While authors usually must sign a waiver for negligence due to inaccuracy, publishers are the ones displaying the material and claiming that they add value to the truth of the work. In addition, in many jurisdictions one cannot disclaim negligence for death or injury. Further, if one believes that peer review does do at least some good in filtering out bad material, then it is clear that this model of peer review will be one in which readers would ‘have to trek through enormous amounts of junk’ to find true material and one in which inundation frustrates truth (Reference ShatzShatz 2004, 16, 25). This is also a type of ‘post-truth’ system in which, it is claimed, all competing views are equally legitimated: ‘flat earth theories now can be said to enjoy “scholarly support”’ (Reference ShatzShatz 2004, 16; see also Reference Holmwood, Eve and GrayHolmwood 2020).
PLOS ONE, the journal that is the subject of the study to which most of this book is devoted, uses a system of post-publication review with an initial review on grounds of ‘technical soundness’. In other words, there is a filtering system of pre-review at PLOS ONE, but it is not predicated on novelty, importance, or significance (although reviewers are free to alert editors to the potential significance of work if it is proved to be correct). Rather it is supposed to examine purely whether the experiment was established in a sound fashion and executed according to that plan, whether it is technically sound. Whether or not reviewers actually assess according to these criteria is something to which we will later turn. Whether or not post-publication peer review even actually happens with any regularity is another problematic matter (Reference PoynderPoynder 2011, 17).
Most systems of post-publication peer review, such as that piloted at F1000, present a ‘tick box’ mechanism, where readers can easily see the review status on an article. This usually takes the form of marking the work as ‘approved’ (‘The paper is scientifically sound in its current form and only minor, if any, improvements are suggested’), ‘approved with reservations’ (‘Key revisions are required to address specific details and make the paper fully scientifically sound’), or ‘not approved’ (‘Fundamental flaws in the paper seriously undermine the findings and conclusions’). In this way, F1000 gives clear signals to its readership on the opinions of reviewers towards the material, while not preselecting in advance. This allows for an evaluation of both the article and the review process, especially since the reviewer names and comments are publicly available, the subject of the next section.
Open Peer Review
There is little to no standardised consensus on what is meant by the term ‘open peer review’, even within the self-identifying ‘open science’ community (Reference FordFord 2013; Reference HamesHames 2014; Reference Ross-HellauerRoss-Hellauer 2017; Reference WareWare 2011). As Tony Ross-Hellauer notes:
While the term is used by some to refer to peer review where the identities of both author and reviewer are disclosed to each other, for others it signifies systems where reviewer reports are published alongside articles. For others it signifies both of these conditions, and for yet others it describes systems where not only ‘invited experts’ are able to comment. For still others, it includes a variety of combinations of these and other novel methods.
Indeed, for Ross-Hellauer, seven types of open peer review are identified in the secondary scholarly literature on the subject:
Open identities (‘Authors and reviewers are aware of each other’s identity.’)
Open reports (‘Review reports are published alongside the relevant article.’)
Open participation (‘The wider community are [sic] able to contribute to the review process.’)
Open interaction (‘Direct reciprocal discussion between author(s) and reviewers, and/or between reviewers, is allowed and encouraged.’)
Open pre-review manuscripts (‘Manuscripts are made immediately available (e.g., via pre-print servers like arXiv) in advance of any formal peer review procedures.’)
Open final-version commenting (‘Review or commenting on final “version of record” publications.’)
Open platforms (‘Review is facilitated by a different organizational entity than the venue of publication.’) (Reference Ross-HellauerRoss-Hellauer 2017, 7; for an alternative taxonomy, see Reference Butchard, Rowberry, Squires and TaskerButchard et al. 2017, 28–32)
While ‘open pre-review manuscripts’ were covered in the earlier section on the temporality of review, any of these other areas are up for grabs under the heading ‘open review’. As such, we will treat each here in turn.
We have already given some attention to issues of anonymity in review, but one of the definitions of open peer review seeks to make public the names of reviewers, either to authors or to the readership at large. It is worth adding to the previous discussion, though, that a series of studies in the 1990s showed, counter-intuitively, that revealing the identity of reviewers makes no difference to the detection and reporting of errors in the review process (Reference Fisher, Friedman and StraussFisher, Friedman, and Strauss 1994; Reference Godlee, Gale and MartynGodlee, Gale, and Martyn 1998; Reference Justice, Cho, Winker, Berlin and RennieJustice et al. 1998; Reference McNutt, Evans, Fletcher and FletcherMcNutt et al. 1990; Reference van Rooyen, Godlee, Evans, Black and Smithvan Rooyen et al. 1999). Nonetheless, in the early 2020s many venues were experimenting with forms of open or signed reviews, most notably, again, F1000, which also provides platforms for major funders such as the Wellcome Trust. Such venues also extend into the ‘open reports’ category, as it is possible to read the reviews provided by each named reviewer. This comes with a type of reputational benefit to reviewers, surfacing an otherwise hidden form of labour for which credit is not usually forthcoming.
Models of ‘open participation’ in which anyone may review a manuscript are more contentious, for they might stretch the bounds of the term ‘peer’ to the breaking point (for more on which, see Reference FullerFuller 1999, 293–301; Reference TsangTsang 2013), although some systems such as Science Open require that a prospective referee show they are an author on at least five published articles (as demonstrated through their ORCID profile) to qualify (Reference Ross-HellauerRoss-Hellauer 2017, 10). It is also the case that such open participation efforts can see low levels of uptake when reviewers are not explicitly invited (Reference Bourke-WaiteBourke-Waite 2015). That said, there have been extensive calls for greater interactivity that would replace the judgemental and potentially exclusionary characteristics of peer review with dialogue between researchers but also with a wider community (Reference KennisonKennison 2016). Furthermore, the development of external review framework sites such as Pubpeer and Retraction Watch have fulfilled a genuine community need for scrutiny of work, after it has been published. These are community-run sites, often with anonymous commenting, and so suffer, technically, from the same drawbacks as other open participation platforms. However, several high-profile instances of misconduct have been identified in recent years through such platforms, demonstrating substantial value even as these mechanisms sit outside the mainstream practices of peer review.
Finally, sites such as Publons, RUBRIQ, Axios Review, and Peerage of Science offer or have offered independent services whereby reviews can be ‘transferred’ between journals. In theory, this makes sense; as the same reviewers often work for different publications; behind the scenes, there is a mass duplication of labour in the event of resubmission to a new venue. It is even possible that the same reviewers may be asked to appraise work at a different journal if work is resubmitted elsewhere. In practice, though, this portability poses substantial challenges for journals. For example, one might ask, what is the point of a journal if peer review is decoupled from the venue? If the work has been reviewed, why could it not appear in an informal venue, such as a blog or personal website, and merely point back to the peer-review reports? This would be particularly potent if the names of the reviewers were also available. There are also questions of versioning. Ensuring that it is clear to which version each peer review points is critical in such situations.
New Media Formats
Finally, while it might seem, at first glance, that the media form of the object under review is irrelevant to a review process, this is not the case. Despite debates over the fixity of print (Reference EisensteinEisenstein 2009; Reference HudsonHudson 2002; Reference JohnsJohns 1998), the fundamentally unfinished and even incompletable nature of interactive, collaborative, and born-digital scholarship poses new challenges for peer review (Reference RisamRisam 2014). For if work continues to go through iteration after iteration, as just one example, how are review processes to be managed, at a point when peer review already appears to be buckling beneath the burden of unsustainable time demands (Reference Bourke-WaiteBourke-Waite 2015)? Further, one might also consider how new types of output – software, data, non-linear artefacts with user-specific navigational pathways (interactive visualisations, for instance), practice-based work – would fare under conventional review mechanisms (Reference HannHann 2019).
Conclusions
Since its rise to prominence in the late twentieth century, peer review has occupied a leading place in the cultural scientific imaginary. It has been enshrined as the gold standard for the arbitration of quality and is often falsely thought to be a timeless element of scientific intersubjectivity. Yet, despite its seventeenth-century or eighteenth-century origins (Reference Butchard, Rowberry, Squires and TaskerButchard et al. 2017, 7; Reference FitzpatrickFitzpatrick 2011, 21) and its evolution to become ‘sanctified through long use’ (Reference 78BaverstockBaverstock 2016, 65), the wide-scale adoption of peer review is nowhere near so old as many people imagine and, as this chapter has shown, there is also much disquiet about its efficacy, accuracy, and negative consequences. This has led to a range of new, experimental practices that attempt to modify the peer-review workflow, changing the temporalities (pre- vs post-), visibilities (open identities vs anonymity), and positional relationalities (at-venue vs portability) of these practices. Given the speed of ascent with which peer review has moved to claim its crown, though, it would not be surprising if another modality of practice could rise as swiftly to supplant it. Surely, though, any new method would also be subject to fresh critique. For none of the mentioned methods is perfect and peer review is likely always to have its discontents.
This leads to the obvious question: in relation to process and procedure, does change actually happen? If changes to processes are mooted, does this lead to substantive change in practices or indeed broader cultural and intellectual change? What opportunities are there to test such questions?
In the remainder of this book, we turn to these questions through a focal lens on the Public Library of Science (PLOS). We present this organisation as a case study in attempted radicalism in peer-review practice and unearth the degree to which it has been successful in initiating institutional change in academia. In Chapter 2, we examine the ways in which PLOS sought to reshape review and the challenges that it faced. We give a background history of the organisation and its mission, which are crucial to understanding PLOS’s strategy for change. We also detail the sensitivities of and difficulties faced in studying a confidential peer-review report database and the protocols that we had to develop to conduct this work. We finally look at the overarching structure of the database, detailing how much reviewers write and the subjects on which they centre their analysis.
In Chapter 3 we turn to a set of specific questions around PLOS’s supposedly changed practice. In this chapter, we ask whether PLOS’s guidelines yield a new format of review; whether reviewers in PLOS ONE ignore novelty, as they are supposed to; whether reviews in PLOS ONE are more critically constructive than one might expect; how much of a role an author’s language plays in the evaluation of a manuscript; how much of a reviewer’s behaviour can be controlled or anticipated; and to what extent reviewers understand new paradigms of peer review. The last part of this chapter details our only partially successful efforts to use computational classification methods to ‘distant read’ the corpus. Finally, in Chapter 4 we turn to an appraisal of the extent to which PLOS has managed to change the standards for peer review in a broader fashion.
As a final note, the subtitle of this book makes reference to ‘institutional change in academia’ more widely. Isn’t it presumptuous to assume that PLOS and its niche crafting of new modalities of peer review can act as a synecdoche for all types of change within academia? Perhaps. Yet PLOS has been incredibly influential. It has grown to house the largest single journal on the planet, and it was founded from a position espousing radical change. We believe, therefore, that valuable lessons can be drawn from PLOS’s experience. We now move to set out the background against which these lessons can be taught.
2 The Radicalism of PLOS
A New Hope
We closed the introduction with a set of questions. These can be summarised as follows: given an agenda for new practice, what opportunities are there to observe and critique interventions intended to drive change?
The Public Library of Science (PLOS) can safely be characterised as an organisation that shared the concerns about peer review that we outlined earlier and that has sought to drive such change through a radical approach. Instigated in the year 2000 as a result of a petition by the Nobel Prize–winning scientist Harold Varmus, Patrick O. Brown of Stanford, and Michael Eisen of the University of California, Berkeley, PLOS – or ‘PLoS’ as it was initialled until 2012 (PLOS 2012) – was originally established with the support of a $9 million grant from the Gordon and Betty Moore Foundation. The vision here was one of a radically open publication platform in which PLoS Biology and PLoS Medicine, their two initial publications, would ‘allow PLoS to make all published works immediately available online, with no charges for access or restrictions on subsequent redistribution or use’ (Gordon and Betty Moore Foundation 2002).
Yet open access to published content, itself a fairly outlandish proposition at the time, was not enough for PLOS. Frustration was growing among the founders and board that peer review was returning essentially arbitrary results. As Catriona J. MacCallum put it, ‘[t]he basis for such decisions’ in peer review ‘is inevitably subjective. The higher-profile science journals are consequently often accused of “lottery reviewing,” a charge now aimed increasingly at the more specialist literature as well. Even after review, papers that are technically sound are often rejected on the basis of lack of novelty or advance’ (Reference MacCallum2006). PLOS wanted to do something different.
Specifically, in 2006 PLOS established PLOS ONE (again, originally PLoS ONE), a flagship journal that works differently from many other venues. The peer-review procedure at PLOS ONE is predicated on the idea of ‘technical soundness’ in which papers are judged according to whether or not their methods and procedures are thought to be solid, rather than on the basis of whether their contents are judged to be important (PLOS 2016b). Notably, though, even this definition is contentious: subjectivity is involved in the assessment of whether a methodology is rigorous and sound (Reference PoynderPoynder 2011, 25–26). For instance, to understand whether a methodology is suitable, one must not only know and understand its mechanics but also imagine potential problems and alternative experiments. Even while the aim of an experimental set-up is to eradicate subjectivity from observation, it takes imagination and subjectivity to create and then to appraise good experimental design. PLOS ONE was nonetheless designed to ‘initiate a radical departure from the stifling constraints of this existing system’. In this new model, it was claimed, ‘acceptance to publication [would] be a matter of days’ (Reference MacCallumMacCallum 2006).
At the time of its inception, this was a fairly radical idea (Reference GilesGiles 2007; The Editors of The New Atlantis 2006). Dubbed ‘peer-review lite’, the mechanism was nonetheless still far from the more innovative, pure post-publication approaches that we earlier described. Instead, it offered a lowered threshold for publication on the grounds that replication studies (‘not novel’), pedestrian basic science (‘not significant’, or otherwise framed as Kuhnian ‘normal science’), and even failed experiments (‘not successful’) should all have their place in the complete scientific record. Of course, one might ask how far PLOS would really be willing to take this. Would a well-designed replication study of the boiling point of water be published? It appears to fulfil the criteria of technical soundness while also replicating a well-known result. We doubt, however, that such an article would, in reality, make it through even peer-review lite.
As it was described at the time, the plan was for PLOS ONE to use ‘a two-stage assessment process starting when a paper is submitted but continuing long after it has been published’. A handling editor – of which PLOS had assembled a vast pool – could ‘make a decision to reject or accept a paper (with or without revision) on the basis of their own expertise, or in consultation with other editorial board members or following advice from reviewers in the field’ (Reference MacCallumMacCallum 2006). The fact that handling editors could make their own judgement internally was indeed particularly controversial (Reference PoynderPoynder 2011, 26). This review process was supposed to focus ‘on objective and technical concerns to determine whether the research has been sufficiently well conceived, well executed, and well described to justify inclusion in the scientific record’ (Reference MacCallumMacCallum 2006).
PLOS also asserted at the time that ‘peer review doesn’t, and shouldn’t, stop’ at publication (for more on this, see Reference Spezi, Wakeling, Pinfield, Fry, Creaser and WillettSpezi et al. 2018). Although disallowing anonymous commenting and having a code of conduct with civility criteria for reviewers, the idea for PLOS ONE was that ‘[o]nce a paper is in the public domain post-publication, open peer review will begin.’ This was explicitly driven by technological capacity. It was an area ‘where the increasing sophistication of web-based tools [could] begin to play a part’ and PLOS’s new partnership with the TOPAZ platform at the time drove the capacity for post-publication review (Reference MacCallumMacCallum 2006). In this sense, the radicalism of PLOS was pushed in part by technological capacity – a technogenetic source made ‘possible because some of the limitations and costs of traditional publishing begin to go away on the Internet’ (Reference PoynderPoynder 2006a). It was also fuelled, though, by the social concerns about peer review, its (lack of) objectivity, and its relative slowness.
Critics further pointed out, though, that the broad scope of PLOS ONE, coupled with its high acceptance rate, could be construed as a revenue model for the organisation (Reference PoynderPoynder 2011, 9). This was one of the main concerns of an economic situation that rested upon the acceptance of papers for a revenue stream: that it might introduce a perverse incentive to accept work. For those with greater faith in conventional peer review, the experiment in peer-review lite was a cynical economic means by which PLOS could cross-subsidise its selective titles, while propounding an ethical argument about the good of science.
In addition to its culture of radical experiment, PLOS ONE is, further, an interesting venue as, unlike many other journals, it has a long-standing clause that makes reviews available for research, provided that the research in question has obtained internal ethical approval (PLOS 2016a). And this is where we step in. PLOS provided us with a database consisting of 229,296 usable peer-review reports written between 2014 and 2016 from PLOS ONE. While the two-year period gap does contain potential for heterogeneity of policy to cause challenges for analysis, the relatively short time span should, we hope, provide some coherence between analysed units. There were other reports in this database, but the identifiers assigned to them made it impossible to group these reports by review round and so these data were discarded. We wanted to know the following: How have the radical propositions that led to the creation of PLOS ONE affected actual practices on the ground in the title? Do PLOS reviewers behave as one might expect given the radicalism on which PLOS ONE was premised? And what can we learn about organisational change and its drivers?
As we have already touched upon, papers in PLOS ONE span various disciplinary remits, albeit mainly in the natural sciences (where the majority of research into peer review has already found itself focused (Reference Butchard, Rowberry, Squires and TaskerButchard et al. 2017). ‘From the start’, wrote MacCallum, ‘PLoS ONE will be open to papers from all scientific disciplines.’ This was because, it was believed, ‘links’ of commonality ‘can be made between all the sciences’: an interesting argument that stops short of asserting that this might also apply to humanistic inquiry (Reference MacCallum2006). Varmus, indeed, conceived of PLOS ONE as ‘an encyclopedic, high volume publishing site’ across disciplines (Reference Varmus2009, 264). As an early staffer at PLOS ONE put it, the general view was that ‘science subjects developed in a pretty arbitrary way. The boundaries have effectively been imposed as a consequence of the way that journals work, and the way that universities are structured’, and PLOS ONE was designed, from the outset, to counter such disciplinary siloing (Reference PoynderPoynder 2006b). This multidisciplinarity yields opportunities but at the same time also creates evaluative challenges (Reference CollinsCollins 2010). Indeed, we must acknowledge early on that our study will be unable to draw discipline-specific conclusions, even while it may be able to speak generally across a relatively broad remit.
While it is unlikely, then, that a large-scale, mass review of peer-review practices across the academic funding and publishing sectors will emerge at any point in the near future, in the descriptive portions of this book, we report on our access to the PLOS ONE review corpus and thereby take the smaller step of interrogating a very large dataset that focuses only on the components of peer review concerned with technical soundness and that is ethically cleared for this type of research project. Specifically, in this chapter we describe the data-handling protocol, data-handling risks, and high-level composition of the database, our own aspects of ‘technical soundness’. We then move to outline the content types of the reports according to a coding taxonomy that we developed for this exercise and that was used to attempt to train a neural-network text classifier. Finally, we report on the stylometric properties of the reports and the correlations of different language use with recommended outcome.
The Peer Review Database and Its Sensitivities
Securing this database of peer-review reports meant accepting restrictions on its future use and on the extent to which the underlying dataset would need to remain private – a delicate matter to negotiate when one is working in a field of ‘open science’. Reviewers have an expectation that their reviews will be used in confidence within the review process and that they can remain anonymous. However, referees agree as part of the PLOS review process that their contributions may be used for research purposes:
In our efforts to improve the peer review system and scientific communication, we have an ongoing research program on the processes we use in the course of manuscript handling at the PLOS journals. If you are a reviewer, author or editor at PLOS, and you wish to opt out of this research, please contact the relevant journal office. Participation does not affect the editorial consideration of submitted manuscripts, nor PLOS’ policies relating to confidentiality of authors, reviewers or manuscripts.
Individual research projects will be subject to appropriate ethical consideration and approval and if necessary individuals will be contacted for specific consent to participate.
In order to minimise the risks of identification of referees from any analysis conducted (and associated reputational risks to PLOS, authors, and reviewers), our protocol required removal of all identifying data prior to release from PLOS to the project team. The project team never held email addresses or names of referees and all records that relate to submissions or publications in the relevant PLOS journals from any member of the project team were removed from the corpus by PLOS prior to the transfer of the dataset to the team. Where a project member was an academic or professional editor, rather than a reviewer, we did not consider that this posed a risk of reidentification of confidential information. We note that Cameron Neylon was an academic editor for PLOS ONE from 2009–12 and a PLOS staff member from 2012–15 but played no editorial role over the latter time period. Sam Moore worked at PLOS from 2009–12 and on PLOS ONE specifically from 2011–12.
The dataset was treated as sensitive and analysed only on project computers running the latest distribution of Ubuntu Linux using hard disks encrypted with the crypto-luks system and a minimum key-length of thirty characters. Backups were stored on two non-co-located computers with encrypted hard drives and data were never transferred via email, cloud storage, or other insecure online transmission mechanisms, instead using the secure copy facility (scp) using RSA key-based authentication. Data were only accessed by the researchers charged directly with actual analysis and with Martin Paul Eve or Daniel Paul O’Donnell as their direct supervisor. Other members of the project team had access to summaries that included snippets of representative text. The original dataset was destroyed at the end of the project and unfortunately cannot be shared. To obtain the original dataset, third-party researchers would need to contact PLOS directly. As a consequence, useful data sharing on this project is extremely limited in scope and relates only to compositional matters without any original citation. This, of course, causes substantial challenges for those who wish to replicate and/or verify our findings, and we regret that we are unable to be of much help here. Further, citation of the reports in this article are restricted to generic non-identifying statements and to versions of statements that are either redacted or have had their subject matter replaced or made synonymous. In this way, though, we are able to comment on the ways in which reviewers write and behave, without compromising anonymity and without linking any report to a final published or rejected article.
How Much Do Reviewers Write?
An initial fundamental quantitative question that can be asked of the database is the following: How much do peer reviewers write per review? This is an important question because it bears on the extent to which peer review is a gatekeeping mechanism as against a mechanism for constructive feedback. It takes very few words to say ‘accept’ or ‘reject’, but many more to help an author improve a paper. With PLOS’s early radicalism and belief that peer review could be a positive force in the new context, it was hard to know what to expect in terms of volume. Figure 1 plots the character counts of reviews in the database and shows a strongly positive skewed distribution peaking around the 2,000 to 4,000 character bands. This is approximately 500 words per report as the most common length (depending on the tokenisation method that is used to delimit words).
Character count frequency distributions across the PLOS ONE peer-review database
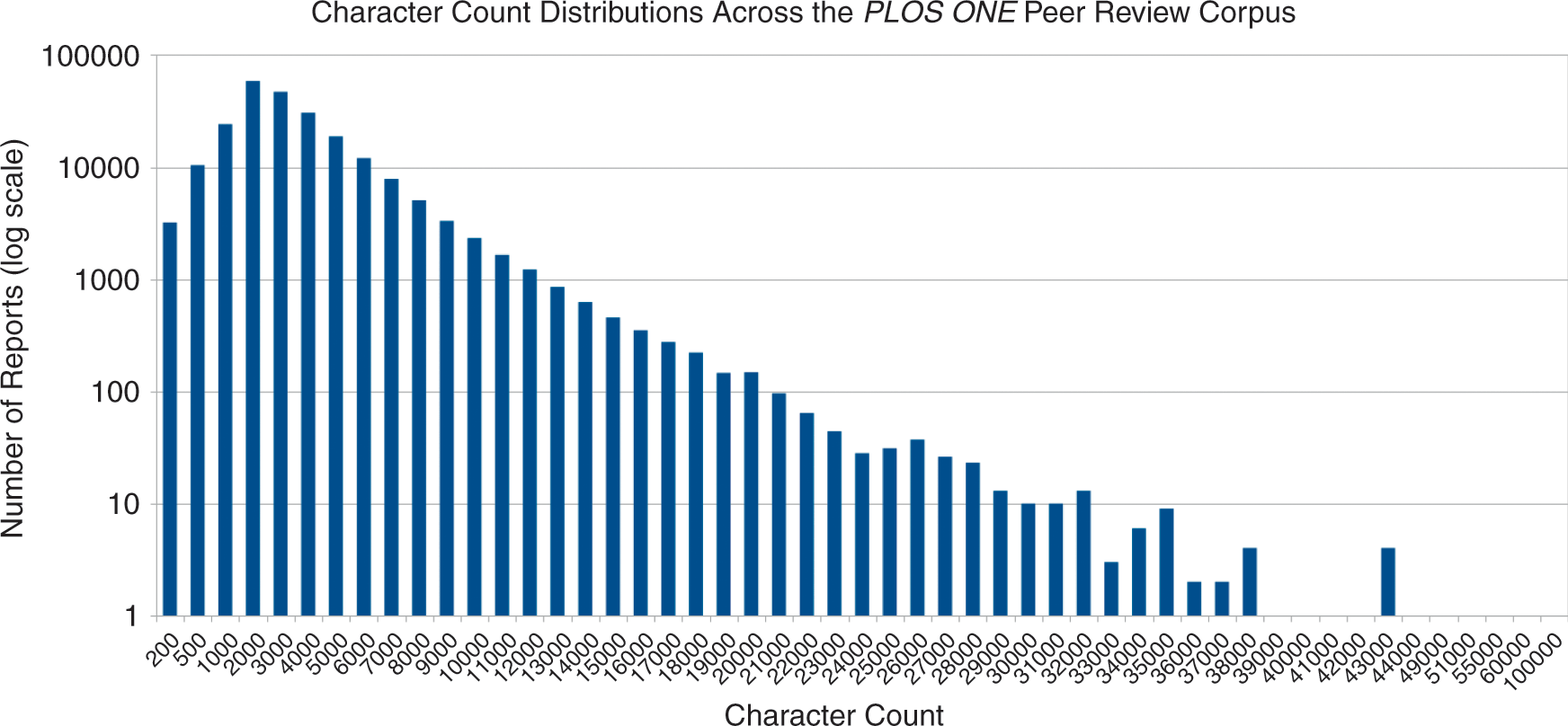
There are some significant outliers within this distribution (clear from the very long tail of Figure 1). The mean character count for reports (with an attempt to exclude conflict of interest statements) is 3,081. The median character count is 2,350. The longest report in the corpus, however, is 90,155 characters long, or just under 14,000 words; in all likelihood, this is longer than the article on which it comments (a study showed that for medical journals the mean length of article is 7.88 pages, or roughly 2,000–4,000 words at 250–500 words per page (Reference Falagas, Zarkali, Karageorgopoulos, Bardakas and MavrosFalagas et al. 2013)). The second-longest review is 59,946 characters, or approximately 5,000 words. Indeed, at the upper end of the distribution among those reviewers whose reports are voluminous, there appears to be roughly an inverse proportionality to rank in the frequency table. (That is, the first report is twice the length of the second, etc.)
However, some anomalies are masked by the apparent simplicity of this visualisation. For instance, one might assume that second-round reports, where a reviewer appraises whether or not a set of revisions has been accepted, would fall at the shorter end of the spectrum with a stronger positive skew. In our manual-tagging exercise, however, we often found substantive comments in subsequent rounds: indeed, reviewers frequently apologised for introducing additional criticisms in second- and third-round reviews that were not picked up in the original. In the overall amalgamation, we pulled together all sets of comments by the same reviewers on the same manuscript into single documents. Hence, Figure 1 gives a misleading picture of the corpus shape.
A more accurate way of classifying this is perhaps only to look at the first round of review. This distribution of first-round-only reports can be seen in Figure 2.
Character count frequency distributions across the PLOS ONE peer-review database, first-round reviews only

Plotting the first-round reviews as opposed to the general corpus makes little difference to the overall distribution pattern of the length of reviews. In general, most peer-review reports at PLOS ONE are less than 2,351 characters long and the addition of comments appraising whether revisions have been made, as in Figure 2, does not significantly affect the skew. These findings correlate with previous studies of the peer-review process, which found average report lengths to range from 304 to 1,711 words in other disciplinary spaces (Reference BolívarBolívar 2011; Reference FortanetFortanet 2008, 30; Reference GosdenGosden 2003; Reference SamrajSamraj 2016). Of course, other studies have concluded that the length of report is not proportional to its quality, when measured by the ‘level of directness of comments used in a referee report’ (Reference Fierro, Meruane, Varas Espinoza and González HerreraFierro et al. 2018, 213). An initial glance at the quantity written, though, shows no difference in practice to more conventional journals.
The higher bound for the average length of peer-review reports that we found in a multidisciplinary database has several consequences. For one, it may be indicative of an uneven distribution of length of report between disciplinary spaces. That is, some disciplines may have greater expected norms for the length of report that must be returned to be considered rigorous. At a time when peer review is thought to be growing at an unsustainable rate (Reference Bourke-WaiteBourke-Waite 2015), this may have different consequences in those disciplines where much longer reports are expected. Indeed, the labour time involved in conducting a peer review inheres not just in the length of the submitted artefact that must be appraised – although, superficially, it is quantitatively more effort to read a monograph of 80,000 words than an article of 2,000 words – but also in the expected volume of returned comments and the level of analytical detail that is anticipated by an editor both to signal that a proper and thorough review has been conducted and to ensure the usefulness of the report. To more accurately appraise the potential strains on the peer-review system, we would urge publishers with access to report databases to make public the average length of their reports by disciplinary breakdown to help disaggregate our findings.
What Do Reviewers Write?
To understand the composition of the database and to communicate these findings in a way that does not cite any material directly, we undertook a qualitative coding exercise (specifically domain and taxonomic descriptive coding (Reference McCurdy, Spradley and ShandyMcCurdy, Spradley, and Shandy 2005, 44–45)) in which three research assistants (RAs) collaboratively built a taxonomy of statements derived from the longer reviews. Two of the research assistants were native English speakers based in London in the United Kingdom (Gadie and Odeniyi), although we note that the policed boundary of ‘native’ and ‘non-native’ speakers comes with both challenges for the specific study of peer review and postcolonial overtones (Reference Lillis and CurryLillis and Curry 2015, 130; see also Reference EnglanderEnglander 2006). The third research assistant is an L2 English speaker based in Lethbridge in Canada (Parvin) with significant social scientific background experience, including with this kind of coding work. Eve and O’Donnell oversaw coordination between the research groups.
The goal of our coding exercise was to delve into the linguistic structures and semantic comment types that are used by reviewers, following previous work by Reference FortanetFortanet (2008). This would allow us to disseminate a description of some of the peer-review database without compromising the strict criteria of anonymity and privacy that the database demanded.
Qualitative coding techniques are always inherently subjective to some degree (Reference MerriamMerriam 1998, 48; Reference Sipe and GhisoSipe and Ghiso 2004, 482–3). Indeed, as Saldaña notes, there are many factors that affect the results of qualitative coding procedures:
The types of questions you ask and the types of responses you receive during interviews (Reference KvaleKvale 1996; Reference Rubin and RubinRubin and Rubin 1995), the detail and structuring of your field notes (Reference Emerson, Fretz and ShawEmerson, Fretz, and Shaw 1995), the gender and race/ethnicity of your participants – and yourself (Reference Behar and GordonBehar and Gordon 1995; Reference Stanfield and DennisStanfield and Dennis 1993), and whether you collect data from adults or children (Reference Greene and HoganGreene and Hogan 2005; Reference Zwiers and MorrissetteZwiers and Morrissette 1999).
We mitigated some of the language, race, and gender problems by ensuring diversity among the coding and research team. As just one instance of this across one identity axis, without Parvin’s input, we would have been confined to a British English anglophonic perspective, a stance that matches the profile of neither PLOS authors nor their reviewers. The triplicate process of coding that we undertook – in which each RA worked at first individually but then regrouped to build collaborative consensus among the group on both sentiment and thematic classification – also helped to construct an intersubjective agreement on the labels assigned for each term. Reference Bornmann, Weymuth and DanielBormann et al. (2010, 499) also used such a triplicate system. The downside of this approach is that, clearly, we traded accuracy for volume. It is also possible that a different group of coders would have used different terms, and part of our coding exercise involved a process of synonym checking. Such partial and subjectively situated knowledges are, however, an essential and well-recognised part of post-structuralist social-scientific studies, and we acknowledge explicitly our active involvement in the shaping and building of such knowledges (Reference CrottyCrotty 1998; Reference DenzinDenzin 2010; Reference HarawayHaraway 1988).
There are also debates as to the quantity of material that should be coded (Reference SaldañaSaldaña 2009, 15). We opted to use our RAs’ time to work initially on the richer reports, as a preliminary survey of the database did not reveal any types of statement in the shortest reviews that were not present, in some form, in the longer entries. Once the initial taxonomy had been constructed from the tagging of the longest reviews, we then took a random sample of reports from around the median character count length with the number of documents tagged determined by the funding constraints on the time of the RAs. This resulted in 78 triplicate tagged reports, consisting of 2,049 statements. The coding process resulted in the development of a taxonomy of statements found within the PLOS ONE review database. At the broadest level these pertained to the following:
the ‘field of knowledge’ to which the statement referred
‘references to data’
‘section analyses’
comments on ‘omission’
comments on ‘methodology’
comments on ‘expression/language’
Each of these categories had a range of specific sub-tags, which are shown and explicated in Table 1.
| High-Level Category | Fine-Grained Category | Explication |
|---|---|---|
| Data | Data | A reference to results and/or data. |
| Data | data-commentary | A description of or commentary upon data, for instance, a reference to a chart’s legend. |
| Data | Interpretation | Extrapolation from data. This category can overlap with data analysis/treatment. |
| Data | Analysis/treatment | How data are treated after collection. This includes data analysis and statistical analysis. It can also refer to secondary data (sets). |
| Data | Presentation | Includes reference to data display. Also includes comments on formatting, size of tables, redundancy of images, visibility of images, and size of the images. |
| Field of Knowledge | (Knowledge) Statement | A statement that the reviewer makes (about fact or community agreed notions). Does not apply to the reviewer paraphrasing the original article. Relates to knowledge claims by the reviewer and/or authors. |
| Field of Knowledge | Information for author(s) | Statements that indicate a reviewer’s subjective opinion, for example, ‘I consider it appropriate to … ’ |
| Field of Knowledge | Positioning | Reference to ways in which/to what extent the authors position concepts/ideas in relation to others. Can also imply/require the Literature tag (see following). |
| Field of Knowledge | Literature | Explicit reference to secondary literature. Negative sentiment score in this category refers to misinterpretation or misrepresentation of literature, or lack of relevance of references employed. |
| Field of Knowledge | Revision | A comment on whether revisions have been made. A positive sentiment score in this category indicates revisions met while a negative means the opposite. This category also includes corrections and reference to subsequent/previous revisions. |
| Field of Knowledge | Holistic revision | Reviewer signals a range of issues to be fixed through revisions (referring to multiple categories). |
| Field of Knowledge | Fallibility | Instances where the reviewer admits they may not be correct in their opinion/criticism or admits inadequacy of and uncertainty around judgement. |
| Field of Knowledge | Tone | Tone of reviewer exhibits bias against non-Western submission/language (patronising). Tone of reviewer exhibits ad hominem attack on author or team of researchers. Also used to denote overly familiar personal register/tone. Awarded appropriate sentiment score if tone implies praise or critique of manuscript. |
| Field of Knowledge | Potential/significance | A remark upon the significance of findings/data/results/work. This also includes the potential of contribution to knowledge or research; references to reproduction of experiments. Also used to flag poor scholarship and auto-plagiarism via a lack of novelty. Note that this category of ‘significance’ should not be a criterion used for judgement of admission within the PLOS ONE ecosystem. |
| Expression | (English) Language | Reference to use of English, languages other than English, native/non-native speakers. |
| Expression | Typographical errors | Reference to surface-level errors, including grammatical errors. Lack of consistency denotes strongly negative sentiment. Trivial typos are low sentiment score. Comments on punctuation are attributed using this tag. |
| Expression | Expression | Communicative quality – coherence of style and academic/scientific register. Choice of language. Rewording. Definitions of terms/acronyms. |
| Expression | Terminology | Use/deployment of subject-specific terminology. Can refer to accessibility of terms. |
| Expression | Cohesion | Comments on linkage between sections of paper in terms of correlation, structure, and organisation. |
| Expression | Style | Comments on adhesion to house style. |
| Expression | Citation | Referencing and citation practice; includes lack of appropriate citation. |
| Expression | Summary | When a reviewer summarises or signals a section of paper. Also used as a form of transition before critique. Includes quotations from original text, including title. |
| Expression | Transition | A transitive statement which makes no reference to the manuscript. Includes notes to editors. |
| Methodology | Methodology | Broader approach to methods adopted. Also refers to rationale, justification, or basis for research. Ethical issues/concerns. |
| Methodology | Statistics | In general and/or explicit reference to statistics including statistical tests. Explicit reference or use of statistical tests such as Analysis of Variance (ANOVA), Student’s T-Test, Pearson, correlation coefficients, Mann Whitney (package). |
| Methodology | Experimental design | Reference to a series of experiments, hypotheses, sample size, control groups, parameters, data collection tools, inferential/descriptive statistics, correlation, data modelling. |
| Methodology | Method | Refers to the description of method, including procedures, techniques, and discussion of advantageous alternatives. |
| Methodology | Limitations | Discussion of limitations. |
| Omission | Implied omission | Implies that something is missing without explicitly stating it. |
| Omission | Omission | Explicitly states that something is missing. |
| Omission | Accuracy | Comments on the accuracy of (data) description (& definitions). Can refer to factual or descriptive inaccuracy. Can also refer to (lack of) precision. |
| Omission | Elaboration | Request for more detail, information, clarification, or precision. Different to omission in the sense that omission is about something that isn’t there at all whereas this tag calls for supplementation. |
| Omission | Argument/analysis | Missing discussion of data/results. |
| Omission | Ambiguity | Reference to clarity, vagueness. Can connote positive (as clear, well worded, etc.) as well as negative sentiment. Instances where something is unclear to the reviewer. |
| Omission | Argument | Pertains to clarity of argument – exposing point of view. Distinct from ‘argument/analysis’ in that it deals with literature. Can also refer to the phrasing of an argument. Negative sentiment can refer to redundant or unconvincing argument. Explicit reference to logic or logical can imply this category. Also refers to the coherence of an argument. Claims implying criticism/agreement. |
| Omission | Implied criticism | Used for tagging questions from reviewers. Negative meaning/critique implicit. For instance, ‘Would this manuscript benefit from X?’ |
| Section | Outcome | Publishability and suitability of results/data/findings. Relates to publishability of specific paper. Usually with reference to the admissibility criteria of PLOS ONE. |
| Section | Overarching comment | Used for tagging comments that broadly apply to the whole manuscript. |
| Section | Conclusion | Reference to the results of interpretation and/or analysis. Can also refer to results/findings. Reference to implications of results. Also refers to limitations of study. |
| Section | Abstract | Reference to the work’s abstract. |
| Section | Appendix | Reference to an appendix in a work. |
In addition to coding against the taxonomy to categorise statements, each statement was also assigned a sentiment score (again negotiated among the three coders). The sentiment scale used ran from −10 (strongly negative) to +10 (strongly positive) with zero (0) denoting a neutral statement. Certainly, sentiment was, at first, the most contentious element of the coders’ practice with little agreement among readers. By the end of the process, reviewers found themselves broadly in agreement on sentiment markers with little negotiation required.
An interesting phenomenon that demonstrates some of the limitations of our sample size can be seen in the fact that no statements in our taxonomy pertain to ethics and Institutional Review Board procedures (rather than to the ethics of peer review itself (for more on the latter, see Reference George and Woodwardde George and Woodward 1994; reprinted in Reference ShatzShatz 2004)). This is not the case in the corpus as a whole, where reports contain notes expressing diverse sentiments such as ‘[t]he description of the human research ethics and informed consent process is confusing. Was the research protocol reviewed and approved by an institutional review board (IRB)? If yes, which one?’; ‘I have sincere reservations about the authors [sic] lack of independent review by an ethics committee’; ‘[t]hus, review by an ethics board is not needed’; and ‘an ethics statement is required in the method section.’ While these statements would have been tagged as remarks upon ‘expression’ and ‘omission’, they would also have been marked as pertaining to ethics had we encountered any such reports in our tagging exercise. This is important since some reviewers dubbed ethics problems as major concerns with certain manuscript submissions, such as a lack of ethical clearance for work upon vertebrates or cephalopods, one of PLOS ONE’s ethics criteria. There are several clear reasons for this. The first is that ethical issues in PLOS policies only apply to a subset of articles and, therefore, only a subset of the random sample. Second, PLOS ONE editorial staff screen major ethics issues before assigning papers to academic editors and so we would expect that in the subset of papers for which ethics is relevant, many issues may already have been cleared with authors before the work is sent to peer review.
On the other hand, there were occasionally also statements that merely confirmed that ethics procedures had been followed: ‘[t]he research meets all applicable standards for the ethics of experimentation and research integrity’, for instance. Although reviewers are asked, explicitly, to consider ethical issues in any paper in a separate question, it is notable that our sample did not find any statements on this matter. This could be interpreted to mean that the ‘missing’ statements on ethics in our sample indicate implicit assent that all ethical matters have been satisfactorily addressed. However, a sociology of absences means that it remains important to continue to pay attention to what might be expected but is not found (Reference SantosSantos 2002). For an important point that informs all of our analysis herein is that PLOS ONE editors attempt to screen for policy matters before sending to peer review in any case. This is meant to ensure that work that is not in line with PLOS’s publishing policy and could not be published anyway is not sent to reviewers. Such work is incredibly hard to investigate; nonetheless, it sits as an invisible substrata to the reports that are visible.
In the next chapter, we turn to what we can learn about reviewing practices under supposedly radical conditions, and the extent to which this institutional policy can be seen as a driver of academic practice.
3 New Technologies, Old Traditions?
At the end of our year-long coding project, we had tagged 2,049 statements across 78 reports in triplicate consensus. While this constitutes a small proportion of the total dataset, the specific reports were selected using a computational random number generator to ensure that our results came from across the spectrum of review types and represented accurately the underlying database. This chapter details the composition and congruence of the reports that we studied. We also attempt to show whether or not our findings match those made by others in different journal spaces.
More specifically, this chapter aims to appraise whether reviewers in PLOS ONE, a journal with radical criteria for peer review, behave in radical ways or stick to tried-and-tested norms. In other words, our investigation here is into the difficulties of organisational change in academia. What does it take, we ask, to change practices? Are policies enough? Is technology sufficient? Or are there broader and deeper social requirements?
Did PLOS’s Guidelines Yield a New Review Format?
In line with existing studies on the commonality of report structures and the ‘moves’ within them (Reference BornmannBornmann 2011b, 201; Reference GosdenGosden 2003; Reference PaltridgePaltridge 2017, 39–40), which we here confirm, most reviewers for PLOS ONE begin their reports with a summary of the manuscript on which they have been asked to comment. That is, reports open by describing the contents of the paper with statements such as ‘this manuscript investigates the relationship between t-cells and inflammatory markers in rheumatoid arthritis.’
Indeed, the strongest structural homophily between reports emerges in the opening gambits: sixty-eight of the seventy-eight (87 per cent) reports that we studied contained a summary statement within the first six sentences of the reviews. Of the ten reports that did not contain a summary within the first six sentences, four (40 per cent) were second-round reviews (appraisals of revisions that just cut to the chase), and four (40 per cent) contained at least one summary statement somewhere later in the report. In other words, only six (7.7 per cent) of the reports that we examined contained no statement summarising the research work on which the reviewers were commenting. Such statements usually restate the aim of the paper under review.
In broad terms, these restatements appear to serve three purposes. First, they demonstrate that the reviewer has read the manuscript and can concisely summarise its subject to the editor. This serves a legitimation function in demonstrating the reviewer’s understanding of the paper (and that the reviewer has done the required reading) but also as a check on the quality of the paper as a communicative instrument. Of course, this can also be a delegitimation function should a reviewer inaccurately summarise a paper – a good example of an instance where the editor may wish to discard or ignore the contents of a report. In fact, this is evidence for the need for continuing editorial oversight of peer review and a demonstration of an occasion where simply relaying the verdict or accepting the opinion of reviewers is insufficient to conduct a proper review. In pre-review modes, though, this can lead to timing frustrations. If an author has waited a long time for reports to be returned and one of these reports is then shown to be based on a misreading of the paper, it may be necessary to seek an additional reader, leading to further delays to the process.
Second, such statements confirm intersubjectively between the editor and reviewer that they are speaking of the same manuscript, a way of ensuring that reports do not become confused between submissions. Although, we presume, rare in the age of comprehensive technological workflow management solutions, anybody who has ever used email can identify with the mortifying sensation of having attached the wrong file. By summarising the manuscript at the very beginning of the report, reviewers give the editor a clear and easy way of checking that no administrative oversight has compromised the review process. This is perhaps a reflection of the review report as a genre that is internalised and continually rehearsed with every review; that is, it is so common to read reviews with summary statements at the beginning that academics assume that all reviews require them.
Third, and finally (while also being linked to the first function), such a restatement of the paper’s intent serves as a self-offered check of the reviewer’s understanding and fitness to review. This differs slightly from the previous points, although it also carries a legitimation function. It works more as a conditional check that states ‘if you accept my interpretation of this paper, then you should accept my verdict as follows.’ This hermeneutic statement thereby gives the editor much greater room for interventionist manoeuvre if they believe that the reviewer has read the paper from a different disciplinary or sub-disciplinary standpoint. This differs from a factually incorrect statement – ‘this paper is about X’ – and is usually of the form ‘however, if we take Smith and Smith’s 2006 results into account, then surely there is a problem with X.’ Approximately 20 per cent of the reports that we examined contain statements in which reviewers admit to their own fallibility in the appraisal of the piece under discussion; hence, this third category is important.
Indeed, despite the legitimation function detailed above, in eleven (16.2 per cent) of the examined reports that contain an early summary (and in a total of fifteen (19.2 per cent) examined reports), reviewers also admit their own lack of knowledge or understanding (‘fallibility’). Such expressions of self-fallibility varied in their composition. In some cases, this took the form of an implicit and conditional criticism of the communication of the work: ‘If I’m understanding the construction of [studied phenomenon]’. In other cases, such statements were warnings to the editor that the reviewer did not feel entirely competent to appraise the work, sometimes followed by a conjunctive adverb (‘but’ or ‘however’) to legitimate continued comment on the piece: ‘I am not an expert in this field, but …’; ‘I am not an expert. … However’; ‘Unfortunately, I cannot comment on [redacted] aspects.’ That such statements are widely present indicates that reviewers do not always believe that they are being assigned work that they are able to evaluate. Of course, as research is niche and specialised to particular laboratories, it may be that there is no reviewer in the world who would be totally competent to appraise a piece of work; hence, every reviewer has the potential to share the opinion that they are out of their depth. That said, in only one instance did a reviewer decline to comment entirely on these grounds: ‘Unfortunately, the current reviewer is not an expert in the analytical methods used to analyze and characterize the [subject matter] highlighted in this manuscript to give an appropriate review.’ We note, though, that other reviewers may have declined invitations on the ground that they were unqualified to comment and that the statement we found was only one of partial fallibility. That is, in this instance, the reviewer was simply noting that they could not comment on a particular aspect of the paper rather than the manuscript in its entirety. This may emphasise the importance of using multidisciplinary review teams, including dedicated statisticians. Again, though, this amplifies the labour and time required as well as overburdening statistical reviewers.
On occasion, we tagged instances of such ‘hedging’ from reviewers as admissions of fallibility. For example, when asking for specific reruns of experiments, terms such as ‘perhaps’ or ‘probably’ indicated a level of uncertainty in the recommendation that could lead to such a classification. While there is no universally agreed upon definition of ‘hedging’ (Reference CromptonCrompton 1997; Reference HylandHyland 1996, Reference Hyland1998, Reference Hyland2000, Reference Hyland2004; Reference MyersMyers 1989; Reference NashNash 1990; Reference PrasithrathsintPrasithrathsint 2015; Reference Salager-MeyerSalager-Meyer 1994), previously it has been considered as a strategy for politeness (for instance, Reference Brown and LevinsonBrown and Levinson 1987; Reference Dressen-HammoudaDressen-Hammouda 2013; Reference FernándezFernández 2005; Reference HeldHeld 2010; Reference Spencer-Oatey and FranklinSpencer-Oatey and Franklin 2009; Reference TangTang 2013; Reference VarttalaVarttala 2001) with cross-cultural and gender differences in usage (Reference CoatesCoates 2013; Reference HinkelHinkel 2005; Reference Scollon and ScollonScollon and Scollon 2001). In academic writing, hedges imply ‘that a statement is based on plausible reasoning rather than certain knowledge’ (Reference HylandHyland 1998, 4), allowing the reader either to become complicit in accepting such a statement or to contest it (Reference Kim and LimKim and Lim 2015). Again, such hedging in review statements gives the editor lateral freedom to accept or decline a review’s perspective. It also gives the author of the paper the opportunity to argue back against the report. Sometimes, reviewers apologise to editors and authors in their reviews, with one report saying ‘sorry for a rather unstructured list of too many comments in the attached pdf’, admitting fallibility of the organisation of their recommendations. From time to time, such self-appraisals were related to comments on language where the reviewer admits not to speak the language of the paper as their first language or not to know of the linguistic appropriateness of a certain way of writing: ‘I am not a native speaker myself’; ‘I am not sure that sentences can be started with numeric values or abbreviations.’ Interestingly, given anecdotal reports that non-native English speakers are judged more harshly by peer reviewers (that is, peer reviewers often see the language as a block to an actual evaluation of the science), it is unclear whether editors take reader reports written by non-native English speakers less seriously. It is also true that editors may be non-native English speakers.Footnote 2
This all coheres to paint a picture of reviewer uncertainties that nonetheless act as functional elements of the peer-review system. Reviewers’ admissions of fallibility are not simply statements of a factual inability to comment but also play a part of the discursive dynamics of negotiation between reviewers and editors. Occurring in one in five papers, such statements are often conditionally hedged to allow for flexibility in review processes. Of course, this is itself a rhetorical strategy, daring the author or editor to question the judgement of the external reviewer (‘I am not sure that sentences can be started with X … are you?’), while still leaving open the possibility of error. Such statements of fallibility are a good example of the ways in which peer review, when conducted behind the scenes, is a delicate social negotiation, rooted in language practices and communities of practice (Reference Lave and WengerLave and Wenger 1991), with their own expected rules of behaviour and linguistic codes.
In many ways, this finding is not unexpected: PLOS ONE asks reviewers to comment on the technical soundness of manuscripts and, for the reasons listed earlier, reviewers have a relatively standard set of legitimation moves in which they can establish their competence to comment and to identify the manuscript. These elements do not disappear under PLOS’s criteria for review. Further, the delicate negotiation of reviewer authority continues in the new peer-review environment of PLOS ONE, hence the persistence of hedging and of reviewer admissions of fallibility.
Do Reviewers in PLOS ONE Ignore Novelty?
Reviewers for PLOS ONE frequently comment on the novelty of the papers that they are reviewing, but they do not usually remark upon reproducibility. This is important, as previous work has shown that reviews expressing concerns about a ‘lack of originality’ were ‘likely to be associated with rejection’ (Reference Turcotte, Drolet and GirardTurcotte, Drolet, and Girard 2004, 549). Thus, although the review criteria of PLOS ONE are set at a strict boundary of ‘technical soundness’ and we expected that reviewers would understand this, sixty out of the seventy-eight reports that we tagged (77 per cent) commented either positively or negatively on (and, on some occasions, both positively and negatively upon different aspects of) the potential, novelty, and significance of the paper under review. Thirteen (21.7 per cent) of these assertions around originality and significance explicitly used the term ‘novel’ or ‘novelty’ in the coded statement, for instance, ‘the findings presented are both novel and interesting’; ‘the novelty and impact of the current study is low’; ‘furthermore, [redacted] has already been shown to influence [redacted] ([redacted reference]) limiting the novelty of this manuscript’; ‘there is essentially no novelty in the findings’; ‘the novelty of [redacted] is rather low’; ‘while the paper is well written and easy to follow, its current shape seems not close to publication, mainly due to lack of novelty.’ On one occasion, a reviewer asked explicitly for revisions in which the authors should describe the novelty of the paper: ‘the novelty and significance of the study should be clearly described in the Introduction.’
There are three explanations for this. The first is that at least part of the PLOS ONE review process does request that reviewers comment on the significance, novelty, or importance of the work, albeit not as a criterion for acceptance but rather to assist the editors in highlighting work – after publication – that reviewers believe merits especial attention. Most instances of commentary of novelty in our sample, however, treated this as a positive or negative attribute and used this appraisal within the review as an evaluation criterion, rather than as guidance markers to editors, as part of what Stefan Hirschauer has called the ‘reciprocal observations of judgments that complement and compete, control and court one another’ during the peer-review process (Reference Hirschauer2010, 74). A second explanation is that when authors remark on the novelty or significance of a portion of their work, they are signposting to the reviewer that this is an important part of the paper – and reviewers’ comments reflect this back. That is, within a limited time economy, authors’ own remarks upon what is ‘new’ or ‘significant’ serve to guide the reader’s attention. Finally, though, such statements often appear to indicate, as the third explanation for this phenomenon, that the quest for significance is so ingrained in academic reviewing culture that even when asked specifically not to comment on originality, significance, or novelty, reviewers cannot help themselves.
Such comments on originality and significance stand in contrast to the goals of PLOS ONE. As Adam Eyre-Walker and Nina Stoletzki have shown, scientists are poor at evaluating whether a paper will go on to have significant effects (Reference Eyre-Walker and Stoletzki2013). Several studies have also shown that work that went on to achieve high recognition and status could equally well have been rejected at earlier or later parts of significance-based peer-review processes and fared poorly as a benchmarking measure of career success (Reference Azoulay, Graff Zivin and MansoAzoulay, Zivin, and Manso 2011; Reference Calcagno, Demoinet, Gollner, Guidi, Ruths and de MazancourtCalcagno et al. 2012; Reference CampanarioCampanario 2009, Reference Campanario1993, Reference Campanario1996; Reference Campanario and AcedoCampanario and Acedo 2007; Reference Ceci and PetersCeci and Peters 1982; Reference CostelloCostello 2010; Reference Fang, Bowen and CasadevallFang, Bowen, and Casadevall 2016; Reference Gans and ShepherdGans and Shepherd 1994; Reference Lindner, Nakamura and SmalheiserLindner and Nakamura 2015; Reference MengMeng 2016; Reference Nicholson and IoannidisNicholson and Ioannidis 2012; Reference PaganoPagano 2006; Reference Siler, Lee and BeroSiler, Lee, and Bero 2015; Reference WellerWeller 2001). While there is some evidence that reviewers find greater consensus in distinguishing non-acceptable from acceptable work (that is, reviewers find agreement in work that should not be published) (Reference CicchettiCicchetti 1991; Reference WellerWeller 2001), debates around the roles of novelty and significance in gatekeeping processes continue to rage and, as noted, appear thoroughly embedded within academic expectations and norms. It takes an incredibly long time for things to change. Indeed, given the ongoing prevalence of comment on novelty and significance in the PLOS ONE review corpus, there may be some truth to Max Planck’s adage about the pace of change in academia. Perhaps science really does advance ‘one funeral at a time’ (Reference Azoulay, Fons-Rosen and Graff ZivinAzoulay, Fons-Rosen, and Graff Zivin 2019).
Hearteningly for the goals of PLOS ONE, though, we did encounter reports where reviewers remarked unfavourably upon claims for novelty within the paper (that is, not remarking that a paper’s novelty was poor but rather chastising authors for making their own claims for novelty): ‘the study is novel, but is that necessarily important?’ ‘the authors make much ado about the fact that the study is the first of its kind, but is it better to be first or to make an important contribution?’ and ‘I am concerned about the author’s insistence on the uniqueness of this study.’ On occasion, reviewers praised the modesty of authors, noting that they ‘make reasonable and humble claims about the finding with a well-balanced explanation of the limitations of the study’.
In fact, statements on novelty are occasionally used to ask authors to temper their claims: ‘while I recognize that this is a novel study, the rhetoric that is being used to sell the message is a little extreme.’ Such remarks on novelty, then, are appropriate within the criteria set by PLOS ONE when used to ensure that authors do not overstate their claims. There is thus a complicated relationship between significance and soundness that editors have to navigate and a simple edict that ‘reviewers should not remark on novelty’ is neither appropriate nor sufficient. These, though, were few and far between and not found systematically in the reports that we examined. Of course, without the manuscripts themselves, we cannot appraise how often such criticisms arise compared with how often claims for novelty are made in the respective PLOS ONE papers on which the reviews were conducted. It is also the case that PLOS ONE editors have the ability to overrule the comments of reviewers that violate policy, such as those on novelty. This applies at both the academic editorial and staff/managing editorial levels. Hence, even if reviewer behaviour has not changed ‘under the hood’, it is possible that the outcomes of the review process are changed.
Given also that one of the goals of PLOS ONE’s review criterion of technical soundness is to ensure reproducibility and replication, we were interested to see how often these phenomena were mentioned. There has been much debate in recent years over the fact that most publications do not value replication and reproducibility as conditions of admittance, for a variety of reasons (Reference AldhousAldhous 2011; Reference GoldacreGoldacre 2011; Reference LawrenceLawrence 2007; Reference Lundh, Barbateskovic, Hróbjartsson and GøtzscheLundh et al. 2010; Reference Nosek, Spies and MotylNosek, Spies, and Motyl 2012; Reference RothsteinRothstein 2014; Reference WilsonWilson 2011; Reference YongYong 2012a, Reference Yong2012b, Reference Yong2012c, Reference Yong2012d), but we note that, in theory, PLOS ONE will publish such work. Of the seventy-eight reports that we studied, only three (3.8 per cent) mentioned reproducibility in their feedback. That said, reviewers commented with great frequency both on matters of experimental design and on methodological aspects. Among the seventy-eight reports coded, forty-four (56.4 per cent) commented on the design of the studies they were reviewing, while fifty-four (69.2 per cent) remarked upon the methods used. Comments on method, though, were overwhelmingly negative, with only three (3.8 per cent) of the reports we studied remarking favourably upon this aspect. The ‘experimental design’ category fared little better, with only six (7.7 per cent) of the reports that we studied commenting positively upon the way that experiments were designed.
This is indicative of a further set of assumptions in reviewing practice. It is not common to comment upon experimental design and method unless problems are found. This is important as one of the challenges here is that the assumption that method and experimental design are acceptable – even if not remarked upon positively – means that it is impossible to know whether a reviewer has truly considered these elements. The fact that such comments only come through in a negative context demonstrates the extent to which familiar patterns of behaviour are replicated – but also the degree to which PLOS’s criteria must be seen as more radical. The use of structured review forms may mitigate this risk, however, and provide a way to ensure that there are comments both positive and negative on all aspects of a paper and to verify that reviewers have evaluated these aspects of a study’s design.
Despite, then, PLOS’s intention to modify radically the conditions under which peer review is conducted, reviewers’ behaviours turn out to be far more resistant to change. When allowed to make free-form comment, reviewers revert to the practices seen elsewhere. In a context in which reviewers are working under severe time constraints, it is easier and pragmatic for them to behave in ways to which they are already accustomed. Next we speculate more on the complex drivers of institutional change and the ways in which PLOS does or does not fulfil the actual conditions necessary for radical practice to emerge.
Are Reviews in PLOS ONE More Critically Constructive?
The viciousness and power dynamics of peer-review feedback are often noted anecdotally and in formal studies (Reference BelluzBelluz 2015; Reference BerkenkotterBerkenkotter 1995; Reference Ceci and PetersCeci and Peters 1982; Reference Eve, Vincent and WickhamEve 2013; Reference Moore, Neylon, Eve, O’Donnell and PattinsonMoore et al. 2017; Reference ShatzShatz 1996; Reference Silbiger and StublerSilbiger and Stubler 2019), particularly when conducted under conditions of anonymity. Recent work has also shown that reviewers relay unprofessional, damaging, or even racist comments that may disproportionately affect traditionally underrepresented groups in the sciences (e.g. Reference Silbiger and StublerSilbiger and Stubler 2019). We found plenty of evidence in our tagging exercise at PLOS ONE to support the assertion that peer-review comments can be extremely direct (and likely emotionally bruising for authors). This included blunt appraisals but also instances where reviewers attempted to assume the career status of the authors or postulate that the work was ‘salami slicing’ of a PhD thesis. Statements with negative sentiment written by reviewers for the consumption of authors attached to the ‘outcome’ tag included the following: ‘in summary, this manuscript as currently conceived and written should not be published in any reputable peer reviewed journal’; ‘this paper has serious problems and needs to be completely rewritten’; ‘[this] manuscript is in many ways unclear and not suitable for publication’; ‘these findings alone represent a minimal manuscript with effectively no major selling points to warrant publication’; ‘the manuscript reads very much like a portion of a thesis rather than a self-contained manuscript for public dissemination’; ‘the bulk of the writing is conjecture, speculation, unsupported theories, statements that lack data, etc.’; ‘there is essentially no possibility of publication in the current format’; ‘these findings are not worth much of a publication, much less a publication in PLoS’; ‘the text is ridiculously unsupported, to the point where I would have been embarrassed to submit such a manuscript’; ‘I could complain more and more … but this manuscript is so poor that I am surprised it made it past editorial review’; and ‘this is a poorly conceived paper with muddled logic which has no point.’
While such feedback is direct, its ire is aimed at a range of different actors within the manuscript environment. Some of these remarks attempt to deflect direct criticism of the authors themselves, commenting on the ‘the manuscript’, ‘the text’, and the ‘the paper’. That is, by focusing remarks on the document, such statements can avoid personal insinuations. This is not to say that such feedback actually does this; as can be seen, personal attack and author comment are rife. Remarking, for instance, that ‘I would have been embarrassed to submit such a manuscript’ realigns the criticism at the author, rather than at the work. Finally, it is interesting to note the instances where criticism is directed at the editorial process and the assumptions that sit behind such assertions. The note that ‘this manuscript is so poor that I am surprised it made it past editorial review’ squarely places the blame for pre-filtering on the editors at PLOS ONE. It also assumes that the role of the first-stage editorial sweep is to ensure that reviewers’ time is not wasted in the appraisal of extremely poor manuscripts. Of course, the prerequisite for this is implicit consensus between the general editor and a subject specialist about what constitutes a ‘bad’ manuscript. In turn, this relies upon the reviewers understanding the unique review criteria of PLOS ONE in the same way as the general editor. It also relies on a congruence of expectation around language and expression, which are, of course, particular to the authors’ linguistic proficiency in English as well as the stylistic predilections of the home discipline of the subject specialist.
The sentiment arc of negative feedback also did not conform to our structural expectations. The secondary literature in organisational studies has, in recent years, evaluated whether the widespread practice of sugar-coated negative feedback is an effective strategy for managers (Reference Von Bergen, Bressler and CampbellBergen, Bressler, and Campbell 2014; Reference DanielsDaniels 2009). We speculated that reviewers might adopt such an approach – colloquially referred to as a ‘shit sandwich’ – based on previous studies in the field (Reference FortanetFortanet 2008; Reference SamrajSamraj 2016, 79–80). Such feedback would be described by a sentiment arc that began with positive remarks, and then moved to criticisms, before finally ending by returning to positive appraisals. This approach is designed to make it easier for reviewers to deliver hard-hitting feedback without appearing uncharitable while also recognising any positive aspects of the paper under review. It is a model of feedback desired by at least some early-career researchers who want to see ‘some points for improvement’ but who believe that it can ‘help improve articles if the positives are also clearly highlighted’ (Reference O’Brien, Graf and McKellarO’Brien, Graf, and McKellar 2019, 8). However, of the fourteen papers that we tagged that scored between −7 and −10 sentiment in the ‘outcome’ or ‘overarching comment’ categories – that is, papers that were strongly rejected – not a single one received a positive sentiment of greater than +3 at any point in any other category. (For the purposes of aggregation, where a single statement received multiple tag assignations and, therefore, multiple sentiment scores, we took the mean of these scores and plotted this as a single point.)
More broadly, reviews that scored in this range for these categories generally exhibited consistently negative sentiment throughout, with the majority (nine) never scoring above the neutral zero point at all. Although the sample size here is small, from this, we conclude that at least some reviewers in PLOS ONE who deliver unfavourable verdicts are direct and unambiguous in their negative feedback and do not tend to ‘sandwich’ their statements. This is in contrast to previous studies which located instances of sandwiching practices, albeit noting that ‘a good news opening is no guarantee … of a happy ending for the author’ (Reference BelcherBelcher 2007, 10). The lack of sugar-coating of feedback may be perceived as discouraging, but from the previously cited literature in other domains, such as business management, direct and unambiguous comments, even if negative, are more useful in delivering clear, actionable, and interpretable reports that are less subject to miscomprehension (such ambiguity in reports was a key finding of Reference Bakanic, McPhail and SimonBakanic, McPhail, and Simon 1989).
That said, some commonalities in sentiment arc appear among the very most negative reviews that we tagged, but these are potentially occurring by chance since they are few in number. Specifically, reviews that scored a −10 in the ‘outcome’ or ‘overarching comment’ category tended to show a decline in sentiment approximately one-third of the way through the review, with an upwards spike at the two-thirds point, as seen in Figure 3.
Extremely negative review sentiment arcs, plotted on a normalised x-axis for location within the review document against sentiment on the y-axis. Each line represents a report.

By contrast, the strongly positive reports that we tagged – those that yielded a score of between +7 and +10 for ‘outcome’ or ‘overarching comment’ – tended to exhibit much wider variance in their sentiment markers. There was also a greater commonality in their sentiment arcs, as shown in Figure 4.
Extremely positive review sentiment arcs, plotted on a normalised x-axis for location within the review document against sentiment on the y-axis. Each line represents a report.

All of the strongly positive reports that we tagged began with glowing praise and their most positive remarks before falling down the sentiment scale. Indeed, it is the reports that recommend a positive outcome (including requests for minor revisions) that appear most likely to exhibit the shit-sandwich formulation, although this turns out to be misleading. The sandwich shape is actually due to the fact that extremely positive sentiment scores for ‘outcome’ and ‘overarching comment’ are almost always comments on the fact that revisions have been addressed, before going into more minor quibbles, and then encountering the rest of the original, more critical review. For instance, most of these reports begin by remarking favourably upon the revisions that have been undertaken on the manuscripts: ‘The authors have addressed the review comments I made completely and effectively and I look forward to seeing the completed manuscript in press’; ‘The authors have successfully address all the comments highlighted in the previous review of the manuscript’; ‘This manuscript is significantly improved over the previous version’; ‘The authors have made revisions and answered all the questions the review raised’; and ‘The authors have adequately addressed the comments raised in a previous round of review and I think this manuscript is now acceptable for publication.’ Indeed, we only encountered one report that scored highly positive for ‘outcome’ and ‘overarching comment’ sentiment that was not a statement about revision: ‘I don’t have anything to add or suggest to this manuscript and for the first time, I will accept this paper just as it is.’ Although again deduced from a low sample size, this suggests that almost all highly positive outcomes are the result of a revisions process and that first-round acceptance at PLOS ONE is a rare occurrence. In contrast to the most negative reports that we examined, these reviews, although positive, straddled the neutral line and contained many more critical comments.
If PLOS’s criteria aimed to create a more constructive review environment – one in which comments were more objective and less ad hominem – then it is not clear that it has yet succeeded. Reviewers appear to be as blunt and direct as in any other title. Comments are frequently bruising but do at least, as a result, avoid interpretational ambiguity.
How Much of a Role Does the Authors’ Language Play in Reviewers’ Verdicts?
Many reviews focused their critique upon expression (that is, the way a paper was written). This varied hugely by reviewer, but one review that we evaluated contained 106 separate line-by-line recommendations for often minor or trivial adjustments of expression. This level of detail was certainly rare; in this case, it was often a combination of typo errors (‘smaple should be sample’) and clarifications of expression (‘I wasn’t sure what the authors meant by X’). Clearly, though, it is also a mistake to regard the scholarly communications workflow as a steady, linear progression from peer review (encompassing a ‘pure’ intellectual and objective appraisal of the work), through copyediting (language changes), into typesetting (producing galleys), before proofing (a final check that no further errors have been introduced), and publication.
Instead, peer review often seems to cross over with copyediting, in particular. As PLOS ONE does not perform copyediting, this is actually, also, an element on which reviewers are specifically invited to comment. Sixty per cent (47) of the reports that we studied made some comment on expression or pointed out typos in the manuscript under review. While some disciplines, such as history, have argued that the form of expression in their field is more central to their intellectual concerns (Reference MandlerMandler 2013, 556), the natural sciences, exemplified here in PLOS ONE, also take expression extremely seriously. On the one hand, this is at least in part because imprecision of language can lead to misunderstanding of the underlying scientific facts that a paper intends to communicate. Indeed, linguistics and language cannot wholly be separated from the intellectual content of a paper. As one reviewer remarked, with their own expressive errors in the sentence: ‘nonthless [sic] the article is not well write [sic], with many ambiguous sentence’s and interpretations, that makes difficult the understanding.’ While this type of statement can appear careless and hypocritical, it could be that this reviewer is a non-native English speaker as it is widely acknowledged that it is easier to read second languages than to produce new and correct statements in them, but we do not presume this here.
On the other hand, though, often the language ‘errors’ that are corrected by peer reviewers go far further than would be necessary merely to understand the work and veer into the realm of preference: ‘Also be careful about split infinitives: “experimentally shown” is grammatically incorrect even though it is used in casual English’ (although in this case the example given could only be a borderline instance of a split complement, unless ‘shown’ is a typo for ‘show’). In any case, this reviewer continues: “You ‘show experimentally’ much the same that you do not ‘boldly go’ rather than ‘go boldly.’” The specific reference to Star Trek in ‘boldly go’ is also culturally contingent. This type of pedantic (although not necessarily unhelpful) correction by a type of reviewer that we call ‘peer copyeditors’ extends all the way down to the placement of commas: ‘represented, whereas is an incorrect use of a comma’. Further the advice given in this space of language editing appears often to be less thorough than in other areas. On some occasions in our corpus, native English speakers believe that simply drawing attention to an inaccuracy of language – without any supporting statements – is sufficient to make an error apparent. This is not always true, though. For instance, one comment simply read: ‘Line 130: Piece-by-piece’ and it was not clear to us precisely what error was being highlighted.
The detection of language errors in peer-review reports was also used to police the tone of manuscripts, ensuring that the scientific record remains one couched in a formal level of written discourse: ‘Line 305: the inclusion of a suspension point [ellipsis] in the text is too casual for a main body of text within a peer-reviewed manuscript.’ Certainly, this speaks to the fact that peer review is a process that sees itself as protecting the public perception of science, and the ways in which language registers may confer reputational advantage or damage. Much in the same way that radio presenters in the United Kingdom were once expected to speak only with received pronunciation, in ensuring presentational care over manuscripts, peer reviewers often consider the challenging matter of public, or even just intra-scientific, presentation (Reference SangsterSangster 2008; Reference TrudgillTrudgill 2000, 7). This comes with the advantage of not only ensuring that papers use the ‘correct’ linguistic expression for their object of study and are, as a result, accurate (while also maintaining an acceptability and appropriateness of register) but also ensuring that the language of science has a formal mimetic quality. There seems to be an underlying concern that if the language of and expression within a paper is sloppy, the team could also have been careless in their scientific practice. Judgements over the use of English language are thus made or used supposedly to reflect the quality of science and thought beneath a paper.
As we noted in Chapter One, though, this can be problematic. It is perfectly possible to construct and conduct a sound scientific experiment without being a fluent writer or speaker of English. The prevalence of comment on expression suggests, though, that peer reviewers in PLOS ONE regard the communication of scientific research as part of the research process itself. Expressive language is both deemed within the evaluative remit of reviewers and seen as integrally entwined both with the reputation of scientific discourse (and its seriousness) and with a mimetic quality that must somehow reflect the accuracy of the underpinning science. Given that modes of expression are preferential and rooted within the pragmatic language community of the reader, this puts some strain on the argument that PLOS’s review criteria result in a process that is designed to efface subjectivity.
How Much of Reviewer Behaviour Can Be Controlled/Anticipated?
The recent literature around peer review has suggested many ways in which policies and procedures might improve our practices (Reference Allen, Cury, Gaston, Graf, Wakley and WillisAllen et al. 2019). Many of the reports contained sentences that requested additional information that was expected, but not found, in the manuscript. In our taxonomy, the tags ‘elaboration’ and ‘omission’ are emblematic of this phenomenon in which an absence is detected within the paper and additional information is requested. This is different, in some cases, from a missing ethics section, for instance, and can pertain more to an imprecision in the language used within a manuscript. For example, one reviewer asked ‘what was the nature of the protein samples?’ while another specified that ‘it would be better to add a table listing the main methods published in the literature.’
In these cases, there is an obvious question: How do reviewers come to any conclusion about what is missing or what should be present? Sometimes this is based on subject knowledge. As noted, a subject specialist wanted to know more detail on the particular nature of protein samples under discussion, presumably because specific types of proteins might have behaved differently under the experimental conditions. Another example of this in our tagged corpus was the statement that ‘in the absence of this information, it is difficult to ascertain whether [this genetic marker] is an independent prognostic factor in the [condition under discussion].’ Such omission in this case is related to interpretation and method. The requested addition to the manuscript in this instance would allow the reader to link clearly the outcome in the patient group to a single expressive genetic marker. However, this could be seen as much as a critique of method as a simple statement on omission depending on whether the absent information is actually available. In other words: if the manuscript author(s) is (are) unable to provide the missing information, because it is unknown and unaccounted for in their experiment, then this is a failure of method. If the information is available, but has simply been omitted from the manuscript, then this is simply an issue of presentation of necessary context in the document. Other instances of this method/presentation ambiguity in omission statements abound. For instance: ‘for example, [redacted] status is known in only a few patients, [genetic] mutation status is not reported and cytogenetics/molecular cytogenetic classification is missing’ and ‘important information are [sic] missing preventing the comprehension of the results.’
On the other hand, the earlier second example – on listing the methods in a table – is a presentational comment as much as an omission. Certainly, it recommends the insertion of an artefact that was not present in the manuscript at the time of review. However, this is not linked, as in the previous cases, to any matter of interpretation or method but rather to the clarity of expression of the manuscript. Such matters are preferential to each reviewer but may also be linked to expectations of presentational norms within disciplinary sub-communities. In smaller, more niche journals, such presentational styles might be explicitly specified: ‘a summary of relevant methods from the secondary literature should be presented in a tabular form’, for example. However, in larger ‘mega-journals’ such as PLOS ONE, it is far more difficult to police intra-disciplinary norms except through tacit reviewer expectations that are rarely made explicit. Junior scholars who consult the journal and read previous articles for presentational context may be confused by variance of styles within a single venue, as they will be unable to spot coherence between spaces (because it does not exist).
Omission and requests for elaboration were clearly linked in our taxonomy and usually these tags occurred together. This indicates that in most cases there is overlap between omissions and hermeneutic contexts that can be clarified by additional explanation. Statements tagged purely with ‘omission’ or those in conjunction with ‘presentation’ were usually more of the presentational (and perhaps superficial) nature described earlier. In this way, it is often the case that multidimensional appraisals of intersecting labels/tags can give a better context for understanding the function of a specific statement.
In these instances of absence, we suggest that it may be worthwhile for journals to think about explicit matters that require consideration. Just as a conflict of interest statement is overtly required and requested of reviewers, a clear delineation of elements that should be present in a manuscript could help to foster reviewing practice with greater homogeneity of requests for additional information. Such comments on omission, though, also draw attention to the unspoken assumptions made by reviewers. They are remarks upon expectation, which can only be drawn by those familiar with an outside environment. For venues that wish to change cultures of review, this presents some severe difficulties in anticipating what reviewers will want to see, but that new criteria may rule out. How does one account for the Rumsfeldian ‘unknown unknowns’ under such a paradigm?
To What Extent Do Reviewers Understand New Paradigms of Review?
To close this chapter, we want briefly to comment on the occasional references that we found that pertain to processes of scholarly communications within peer-review reports. We have already noted that occasionally reviewers remark on the unique novelty criteria of PLOS ONE. However, very occasionally reviewers refer to more unusual practices in a type of scientific meta-commentary.
A good example of this is a remark on grey literature that we encountered, in which a reviewer wrote: ‘I consider it acceptable to take key results from grey literature and to submit the material for peer review and publication in an archival journal.’ ‘Grey literature’ refers to material that is publicly or internally available but has not been published in conventional academic channels (Reference Adams, Hillier-Brown, Moore, Lake, Araujo-Soares, White and SummerbellAdams et al. 2016; Reference Saleh, Ratajeski and BertoletSaleh, Ratajeski, and Bertolet 2014). It can refer to blog posts, internal corporate reports, pamphlets, and other forms. Of interest in this particular statement is that the reviewer expresses an opinion on the acceptability of submitting such material as reference sources within peer-reviewed venues. However, it is notable that the reviewer then goes on to state that if such practices are conducted, the paper itself must be of an extremely high quality and of significance. That is, in this reviewer’s view, only papers of the highest quality and significance should be permitted to cite grey literature.
Similarly, there were comments on the functioning of referencing and how such systems should serve within scholarly communication environments. For instance, one reviewer remarked that ‘this reference is advertising, not science.’ Such a statement relies on an understanding of the functions of both referencing and citation – a complex subject that varies from discipline to discipline (with a diverse set of motivations underpinning the reasons why people make reference to or cite work) (Reference CroninCronin 1984, Reference Cronin1998, Reference Cronin2000; Reference Erikson and ErlandsonErikson and Erlandson 2014) – and a definition of science that is not immediately clear from the context of this sentence. It is possible that the reviewer believes that there is a conflict of interest here and that the citation is being used merely to inflate the citation counts of the author. Alternatively, the phrase ‘advertising not science’ has found a prominent place in various open science movements that promote the sharing of data. Indeed, Graham Steel has remarked that ‘publishing research without data is simply advertising, not science’, the implication being that without the means to verify the underlying study, most scientific content is worthless (Reference SteelSteel 2013).Footnote 3
It is not possible, in this second instance, to determine which of these possibilities is under consideration, but such comments nonetheless open a fascinating window into the ways in which reviewers can begin to challenge established scientific practices through their comments. We did not specifically tag these statements with any kind of ‘meta’ label, but we would suggest that future studies – or work at publishing houses – consider the ways in which reviewers may, cumulatively and over time, exert pressures on the usual norms of reviewing practices through such meta-scientific statements about scholarly communications. In this way, it may become feasible to chart the extent to which institutional diktats of change are enacted on the ground. It should become possible, over time, to see the changing expectations of reviewers’ cultural practice embedded in their implicit demands of manuscripts and what they deem to be missing, thus giving a benchmark as to the permeation of new cultures of review.
Commonalities between Reviews
In our tagging exercise, we were only able to explore a very small proportion of the review database. Indeed, the effort involved in team-tagging the reports was substantial. The process involved detailed negotiations between team members and a triplicate replication of labour in each case. Recent developments in natural language processing, however, have led to various practices of ‘distant’ or ‘machine’ reading (see Reference DaDa 2019; Reference EveEve 2019; Reference MorettiMoretti 2013, Reference Moretti2007; Reference PiperPiper 2018; Reference UnderwoodUnderwood 2017, Reference Underwood2019).
We wondered whether it might be possible, thinking within such paradigms, to train a predictive model that was able to identify and to tag accurately peer-review statements, thereby allowing us to extrapolate our quantitative findings across the entire PLOS ONE review corpus. To conduct this test, we built a multi-class and multi-label text classifier based on the TenCent NeuralClassifier toolkit (An Open-Source Neural Hierarchical Multi-Label Text Classification Toolkit: Tencent/ NeuralNLP-NeuralClassifier 2019).
Although multi-class and multi-label text classification is a difficult task and even though we were only possessed of a relatively minimal, albeit robust, training set, the neural network was good at classifying certain types of input text. In particular, the network performed well at recognising requests for revision and/or outcome statements. For example, the generic statement ‘I do not recommend publication’ was tagged by the network as pertaining to ‘revision’ and ‘outcome’. Some other types of broad statements were also accurately classified: ‘In particular I am left confused as to how the results fit in here’ was marked as ‘ambiguity’ and ‘cohesion’ by the software.
However, the specific challenges of implementing an accurate classification system were many. First, the tagged data proved insufficient for these purposes. The labour-intensive processes of triplicate tagging gave us the confidence that we needed in the material that had been tagged, but this came at the expense of volume. Further, since each tagged statement was relatively short, it was difficult to train natural-language processing toolkits to identify salient features; there is not a huge volume in each case for the network to identify. As noted, there are also instances where we did not find and tag particular types of statements, such as those pertaining to ethics. Finally, since each statement was written by a different author (reviewer), with different primary languages, the strength of these linguistic differentiations – as opposed to the words used within different types of classificatory statements – appears to be pulled to the fore (for more on authorship signals against others, see Reference Allison, Heuser, Jockers, Moretti and WitmoreAllison et al. 2011; Reference JockersJockers 2013). As such, this study is limited to a relatively small sample size with a relatively good accuracy level within that sample.
Hence, while the network appears to work well at classifying statements that have appeared in almost all reviews – for instance, the outcome example given – it performed poorly at identifying less frequent types, such as ‘fallibility’. The network was unable, for example, to ascribe a label to the statement ‘I must confess that I am not an expert with respect to these methods’, a clear assertion of fallibility. Further, various statements around originality were not tagged with any accuracy. For instance, ‘There is nothing technically wrong with the paper, but it is not that original’ was marked as an ‘overarching comment’, which is a fair assessment. However, no label noting that this was a statement about originality or novelty was ascribed, regardless of the training parameters that we fed to the network.
In short, while our experiment in using machine learning to examine the entire corpus of reviews might have worked well for certain types of statements, such as those pertaining to outcome, the uncertainty around and low levels of accuracy mean that any quantitative analysis based on the broader corpus, read at distance, would be unacceptably imprecise. Nonetheless, the moments of success in the network seem to indicate that those with broader resources for tagging and access to a large corpus of review reports might, in future, see some benefit in using this approach. For instance, we can envisage situations where such a network could detect hostile tone and warn the reviewer that they are being overly harsh or ad hominem. We could also imagine situations in which such a classifier could distinguish reviews that were structured in an unusual/idiosyncratic manner. While this would not rule out the review from being useful, it could give an indication that the reviewer is inexperienced or working away from norms of the form. That said, if publishers used the network to insist on normative practices in review, then this could stifle new ways of writing and operating.
A further method for distant reading the corpus is, of course, to conduct a simple text search through the reviews. This is how we identified the ‘missing’ statements on ethics to which we earlier referred. This can be useful to find examples of specific kinds of practice. For instance, to identify overly aggressive reports we used a simple tool, ‘grep’ (globally search a regular expression and print), to look for instances of the word ‘useless’ in the top-800 longest reports. This yielded harsh reports that included phrases such as ‘Fig 12 is almost useless’; ‘the null model seems somewhat useless’; ‘remove the repeated useless sentences’; ‘I found the [secondary subject matter] results to be EXTREMELY distracting, and essentially useless’; ‘this work appears to be all but useless’ and so on. What such searching cannot tell us, though, is the prevalence of such practices. For instance, the previous examples were found using an extremely simple keyword search pulled from the top of our heads. There will be many instances of ad hominem or vicious attacks that use different terms and the only reliable way, at present, to identify these is to read and to tag the reports themselves.
In addition to this, capital letters (such as ‘EXTREMELY’ in the given example) are relatively easy to detect and sometimes indicate strong sentiment of one kind or another. However, detection of these is not as simple as a regular expression (‘\b[A-Z][A-Z]+\b’) as this will also pull out the many acronyms used in scientific practice (‘BDNF’, ‘ROC’, etc.). It is also not clear that capital letters denote strong sentiment in one direction or another; ‘WOW’ can indicate ‘WOW this is a brilliant paper’, but it can equally likely specify ‘WOW, this paper was terrible.’ Furthermore, on occasion, capital letters are used to denote section headings and/or specific portions of a paper (‘in the METHOD section’). In this way, the extraction of capital letters – without a pre-built blacklist of words to exclude – is likely to result in many false positives.
Another way of exploring the corpus at scale is to use the techniques of topic modelling. Topic modelling generally uses a process called ‘latent Dirichlet allocation’ (LDA) to cluster terms that probabilistically co-occur in similar contexts. This is a useful way to explore a dataset and to infer the groups of terms that most frequently crop up together, that is, which ‘topics’ are explored within a corpus (‘a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics’) (Reference Blei, Ng and JordanBlei, Ng, and Jordan 2003, 993). As Ben Schmidt notes, this approach ‘does a good job giving an overview of the contents of large textual collections; it can provide some intriguing new artifacts to study; and it even holds … some promise for structuring non-lexical data like geographic points’ (Reference Schmidt2012).
However, LDA is also a dangerous method: there is no way to infer why topics have been grouped together. In particular, surprising groupings that appear to exhibit coherence may not be as well bound as we would like to think. As Schmidt continues:
[S]till, excitement about the use of topic models for discovery needs to be tempered with skepticism about how often the unexpected juxtapositions LDA creates will be helpful, and how often merely surprising. A poorly supervised machine learning algorithm is like a bad research assistant. It might produce some unexpected constellations that show flickers of deeper truths; but it will also produce tedious, inexplicable, or misleading results.
That said, as an exploratory exercise that others may wish to take further, we produced a twenty-topic model using the MALLET tool based on the same corpus of 800 reports using the default hyperparameters and with stop words excluded. The results for this are shown in Table 2.
| Topic Number | Topic Terms |
|---|---|
| 1 | authors manuscript paper study comments data review results current previous discussion work addressed major provide reviewer research information important studies |
| 2 | interests competing samples genetic dna populations population gene pcr table strains sequences figure structure loci sequencing individuals analysis chromosomes number |
| 3 | paper data case make point time clear important find fact understand general evidence e.g. i.e. model number high approach literature |
| 4 | line lines page sentence paragraph change suggest section figure results text table discussion reference manuscript remove delete add replace information |
| 5 | genes gene expression analysis number sequences sequence genome rna authors expressed species biological fig methods transcripts data results transcriptome proteins |
| 6 | model method models paper approach parameters system distribution set network number dataset parameter distributions author proposed performance simulations equation networks |
| 7 | species study habitat lines area model spatial population areas line fish variables sites models distance size individuals data prey year |
| 8 | study treatment patients group participants trial intervention studies outcome pain analysis groups clinical outcomes research control care reported patient measures |
| 9 | patients study blood clinical studies disease plasma levels authors activity acute group tissue serum negative ace sensitivity mir cortisol healthy |
| 10 | social behavior females males male authors individuals scer_scrt lcl study female group behaviors human sex calls behaviour pointing sexual attention |
| 11 | fire area page e.g. subject trees specific stand bone signals motion intensity study science frequency subjects biochemistry atmospheric stands fires |
| 12 | food hsv animals infection mice diet authors bees response dose resistance treatment weight pigs bacteria immune intake group larvae virus |
| 13 | participants task authors condition experiment effect stimuli results memory performance responses effects experiments stimulation response conditions experimental visual trials learning |
| 14 | cells authors cell figure fig expression data shown protein experiments levels control show mrna mice state manuscript results effect antibody |
| 15 | species phylogenetic taxa tree xxx based diversity sequences analysis clade character genus specimens support trees present phylogeny group taxonomic found |
| 16 | age health risk table page women population study prevalence model factors children results years variables cases analysis paragraph hiv year |
| 17 | null partly disease n/a cancer vaccine hpv page cervical women vaccination safety doi group gardasil adverse rate don’t map human |
| 19 | data results authors analysis table methods study differences significant discussion statistical figure time section values effect test information sample size |
| 19 | species water soil temperature change growth plant plants concentrations climate samples concentration biomass sites fish site study conditions carbon community |
| 20 | fig protein binding manuscript light proteins figure structure shown images domain mutant site sequence image residues cry region structures pax |
Some of these topics appear easy to interpret. Group one, composed of ‘authors’, ‘manuscript’, and ‘paper’ and so on cluster meta-statements about the paper, its submission, the review process. It is curious, though, that ‘important’ should find its way into the work here (although ‘not important’ would also trigger this, so no sentiment value should be inferred). Certainly, the word ‘important’ can appear in multiple contexts. For instance, ‘it is important that the author address these points’ is as likely a statement as ‘this paper is extremely important.’ Nonetheless, given that PLOS ONE specifically disavows ‘importance’ from its criteria, it is significant that the term should appear so prominently among statements that are otherwise common in opening gambits.
Topic four, by contrast, clearly pertains to the mechanics of a paper and suggested corrections. Its functional emphasis on the ‘line’, ‘sentence’, ‘page’, ‘figure’, ‘table’, and so forth – coupled with ‘suggest’, ‘add’, ‘replace’, and ‘delete’ – is the archetypical set of terms that we find in revision requests. In our experience of tagging, such language is prevalent during line-by-line commentaries that usually take the form of ‘line 123: suggest adding X’.
Several of the topics relate to subject matter that is clearly of disciplinary interest to and prominent within PLOS ONE. Topics two and five, for instance, are concerned with genetics. Topic seven appears to be biology; topics eight and nine circle around medicine and clinical trials; topic ten relates to reproduction, mating, and sexuality; topic twelve seems to indicate dietary behaviours; topic fifteen is about biological taxonomies; topic sixteen is on ageing.
Of course, anyone who knows anything about PLOS ONE might have guessed that such terms would cluster and be found as separate strata. For us, the more useful indicators are not the subject groupings, which one would expect, but the functional parameters. We can anticipate scenarios under which knowledge of the distinct linguistic layer of line-by-line corrections, for instance, could be extracted and formed into editorial ‘to-do’ lists. We could also imagine automatic detection of appraisal of novelty and importance and a flagging system that could warn the editor of such an approach (and that it should not be used in the judgement of articles). The challenge, as ever with topic modelling, is that the topics that seem clearly thematically clustered are obvious, while the ones that exhibit less coherence (say, topic twenty) are baffling.
4 PLOS, Institutional Change, and the Future of Peer Review
How Successful Was PLOS in Changing Peer Review?
While this book has focused specifically on the analysis of peer review, its histories, and its futures, the implications in reality are far wider. We have actually been speaking about broader institutional change and its drivers. A key point on such institutional change was voiced by Harold Varmus, one of the original proponents of PLOS, who, when asked what he might have done differently, noted ‘just how much effort it takes to convince the scientific community to make a change in their publication practices’ (Reference PoynderPoynder 2006a). Yet PLOS set out to change the way that review was conducted. It saw the flaws in the existing system and aimed to create a better structure, a utopianism in the non-pejorative sense of the word. How successful, though, was PLOS in changing the world?
One of the most notable impacts of PLOS’s practice has been the proliferation of new venues adopting novel peer-review mechanisms. For instance, as noted earlier, the F1000 platforms that power systems such as Wellcome Open Research run on post-publication mechanisms. PLOS’s early radicalism paved the road for these types of platforms in ways that would not have otherwise been possible. Further, although we argue that PLOS’s impact must be evaluated in distributed terms across the heterogeneous set of new organisations that it has spawned, PLOS ONE itself continues to receive a high volume of annual submissions, indicating a demand for its systems of peer review that facilitate rapid publication of results that do not necessarily claim to be earth shattering.
However, in terms of reviewer behaviour, our work shows that PLOS’s readers have not wholly gotten the message of change. For instance, one of the core goals of the new PLOS review model was to change appraisal from novelty and significance to technical soundness, reproducibility, and scientific accuracy. Yet it is clear from our analysis that reviewers still frequently mention novelty and significance (albeit not always as a discriminator for publication and with the caveats set out earlier in the section on topic modelling) but that they rarely remark upon reproducibility. In other words: changing the criteria of peer review to ask reviewers to appraise aspects of science different from those with which they are familiar appears a necessary but insufficient condition of change. The norms of gatekeeping creep back in, despite such changes.
Reviewer civility is a harder aspect to appraise. Certainly, one of the extant criticisms of the peer-review system is that it is aggressive, oppressive, and ad hominem. Reviews in PLOS ONE continue to exhibit remarkable directness and use language that is likely to be upsetting to authors. However, whether this is bad practice is unclear. In cutting to the chase, such reviews provide unambiguous feedback as to the acceptability or otherwise of the manuscript. Hence, it may be that strong, direct statements avoid future disappointment for authors who might misinterpret sandwiched or hedged reports. That said, judgements based on language can be prejudicial to non-native English speakers, which can extend outwards into a coloniality of gatekeeping (Reference Eve and GrayEve and Gray 2020). Balancing the need for accurate expression against merely preferential considerations, in an environment where there is no round of professional copyediting, can prove difficult.
Why, though, do such instances of policy change not translate into real-world action? In some ways, this is a collective action problem. The unspoken but shared belief among reviewers that they should act according to broader community norms, rather than the ‘outsider’ logic of a single venue, could partly account for this. Such external pressures are even clearer in the case of new journals that wish to get off the ground but, at the same time, alter social systems. This is because journals are, to some degree, knowledge clubs (Reference BuchananBuchanan 1965; Reference HartleyHartley 2015; Reference Potts, Hartley, Montgomery, Neylon and RenniePotts et al. 2017; Reference Sandler and TschirhartSandler and Tschirhart 1980). A club is, in the classic definition, ‘a voluntary group deriving mutual benefits from sharing one or more of the following: production costs, the members’ characteristics, or a good characterized by excludable benefits’ (Reference Sandler and TschirhartSandler and Tschirhart 1997, 335). The binding commonalities of the intellectual communities that use academic publishing systems make club theory a compelling way to describe such structures.
If we accept the assertion that a journal is a club, a different question arises: Is/was PLOS ONE even a journal? As Hartley et al. note, ‘[a]t launch, PLOS ONE had no community beyond enthusiastic supporters of its publishing organization’ (Reference Hartley, Potts, Montgomery, Rennie and Neylon2019, 31). Its brand – the excludable benefit – that it offered to authors was radicalism. Within academia, this is a very small club indeed. Certainly, other members’ characteristics were not shared by the broader population of the academy. Academics schooled in conventional models of peer review and who believe(d) in the filtering mechanisms of peer review as a valid way to reduce reading load did not share characteristics with the radicals who supported PLOS ONE. The very idea of diluting scarcity by publishing replication studies and anything that was technically sound also abolished any shared competitive quest for prestige, the excludable benefit of publication in many titles. PLOS ONE also failed to bind academics by discipline. Again, as Hartley et al. put it, ‘the quality assurance associated with the prestige good is no longer efficiently provided by an informed knowledge club. A journal covering sociology and neuroscience invokes a community that is too broad, diffuse, and uncertain to ensure that quality assurance is consistent’ (Reference Hartley, Potts, Montgomery, Rennie and Neylon2019, 32). Add to this that many academics were – and still are – opposed to open access and one has the perfect storm. Given that the radicals who valued PLOS ONE at the start were opposed to many of the characteristics that apply to most journals, it is almost the case that they had created the venue as a club whose membership could be described by Groucho Marx’s famous quip: ‘I don’t want to belong to any club that would accept me as one of its members.’
In short, perhaps the reason that PLOS ONE’s edicts on peer reviewers’ behaviours seem to have had less effect than one might believe (or hope depending on one’s inclinations) is that it tried to hit so many moving targets at once. By demolishing disciplinarity, peer review for significance and novelty, copyediting, print publication, and paywalls – all at the same time – PLOS ONE almost destroyed any binding notion of community that might have survived. Perhaps a better question is the following: How has PLOS’s vision had so much of an impact on the world, given the shortcomings of its community model?
Several answers present themselves. First, the club model for understanding journals has limitations. Other kinds of goods and clubs are in play beyond those tied directly to scholarly communities that are capable of providing sufficient benefits to be sustained. Journals like Nature do not serve a specific identifiable community with common scholarly norms and practices. Rather, they create a ‘social network market’ where the club good is the prestige of being in a selective group of authors. It is possible that PLOS ONE did in fact provide a similar kind of community, albeit at a lower level of prestige, based on a recognised brand that signifies sufficient publication to be of value. This would mean that recognisable scholarly communities do not matter as much to the lifecycle of journals as Reference Hartley, Potts, Montgomery, Rennie and NeylonHartley et al. (2019) want to claim. It is likely that the simple club theoretic model is an incomplete way of thinking about journals.
A second possibility is that PLOS came along at the right time and that there was more of a radical community lurking than suspected. In this case, PLOS ONE served a pent-up demand. This is an interesting assertion with respect to group dynamics, as the BMC Series of journals could be argued to have had a similar if less explicit model within a more traditional set of separate journals. If PLOS ONE was serving a nascent community with pent-up demand, that community must have been spread too thinly within the disciplines that the BMC Series was serving separately; therefore, the cross-disciplinary nature was actually an advantage. Of course, it is also possible that the BMC Series laid the groundwork that made PLOS ONE seem less radical to certain communities, which in turn may have also encouraged engagement from latent radicals, willing to emerge once the concept had proven itself.
Third, shifting funder attitudes at the governmental, philanthropic, and institutional levels adopted similar rhetorics to PLOS and, as such, changed the desirable club membership criteria among academics. It could be that by having a good idea and getting it in front of the people with the money, PLOS created a community using soft power. Another way of putting this is that PLOS was made safe as its radicalisms around peer review, disciplinarity, process, and open access became normalised within institutions. That said, however one spins it at the broader level of authorship, we also have clear evidence from our work that reviewers have not internalised such radicalism. PLOS may have won over the bodies of its authors as a new community, but their souls seem to remain firmly in extant camps.
There is also the possibility that our expectations around timescales are poorly calibrated here. Several figures in recent years have lamented the ‘slow’ pace of change (Reference CockerillCockerill 2014; Reference PoynderPoynder 2017, Reference Poynder2019), marking almost twenty years since the signing of the three initial declarations on open access (Reference Chan, Cuplinskas, Eisen, Friend, Genova, Guédon and HagemannChan et al. 2002; ‘Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities’, 2003; Reference Suber, Brown, Cabell, Chakravarti, Cohen, Delamothe and EisenSuber et al. 2003). A comparison with the timescale for the original uptake of peer review is both enlightening and frustrating. As Aileen Fyfe notes, ‘[t]he practice that we now recognise as “peer review” (but not the term itself) emerged in the early 19th century.’ It was not until the 1830s that the systemic use of peer review came to the fore – almost two hundred years after the establishment of the Philosophical Transactions journal – even if ‘[t]hereafter, refereeing quickly became a normal part of the publication process at the learned societies’ (Reference FyfeFyfe 2015; see also Reference Moxham and FyfeMoxham and Fyfe 2018).
The original development of ‘peer review’, then, went through a series of evolutionary changes. However, more important to note is that, at the time of the emergence of refereeing, the academic world was much smaller. It was not the globalised system of hyperconnected interchange that it is today, and fewer papers were published per year than there are now sometimes authors on a single paper. This created a systemic flexibility that does not exist in our time. Consensus building for change between 200 people is easier than among 200,000; when the number of journals was extremely limited, executive editorial decisions about process would have widespread, near-total system-wide effects.
This is not the case in the current environment. A disaggregated system of publishing in which thousands of journal titles are spread among hundreds of corporate entities with differing mission goals means that interventions are always partial. Singular interventions must normally be considered as either attempts at consensus-building or as disruptions (Reference ChristensenChristensen 1997). PLOS, clearly, aimed at the latter and certainly succeeded in showing an alternative that is now cascading through the echelons of new publication venues. An example of a consensus-building approach might be seen in an organisation such as Crossref, which is composed of a member board of publishers and acts as an intermediate and governed third party to implement new metadata deposit and preservation infrastructures.
There is also the idea, however, of ‘scaling small’ (Reference AdemaAdema 2018). In such efforts, the idea of systemic centralised change is abandoned in favour of accepting limited capacity but with the potential for – albeit no expectation of – horizontal spread, a kind of archipelago of radical practice. Examples of such small-scale rethinkings, radical reworkings, or demonstrations of practice can be found in groups such as the ScholarLed collective, and in entities such as punctum books, Goldsmiths Press, Open Book Publishers, Open Humanities Press, the Open Library of Humanities, and others. Usually not driven by top-down imperatives, although sometimes attracting grant funding from private and government sources, such initiatives create alternative spaces of publishing possibility, perhaps at more manageable scales than the transformative attempts of PLOS ONE.
Our study presented in this book has also charted some of the technical, privacy, and labour implications that we faced in our attempt to understand better the peer-review corpus at PLOS ONE. However, we have only really been able to scratch the surface. The time resources we expended in triplicate tagging our subset of the review corpus were substantial; yet, even with this investment, we were unable to obtain a large enough sample size/training set for machine-learning approaches to classify the corpus at scale. This resource problem also comes with some worrying future consequences. Many large multinational publishing companies have substantial access to peer-review reports from the portfolios of thousands of journals. With yearly revenues in the billions of dollars, their resources far exceed those that universities can afford. This means that if we are not careful, the people who will know the most about the peer-review processes in the academy will be corporate entities that do not necessarily share the values that we prize (see Reference FitzpatrickFitzpatrick 2019 for a good articulation of the direction in which universities should consider heading; see also Reference Montgomery, Hartley, Neylon, Gillies, Gray, Herrmann-Pillath and HuangMontgomery et al. 2018). Given the ever-increasing metrification of evaluation processes and the conversion of large publishers to full-stack data-controlling entities, providing evaluative dashboards to university managers, this is a potentially damaging situation. We must take care to ensure that research into peer review is not market or private-corporate research, but research conducted for its own sake, in the open.
All is not lost, though. Even while portions of this book have expressed scepticism at peer review’s predictive powers, we have managed both to confirm the findings of some existing studies and to refute some others. We have also been privileged to be the first group to work with PLOS ONE’s corpus of reviews, which differs substantially from other corpora in its criterion of ‘technical soundness’. This differentiation made it possible for us to appraise the extent to which organisational change can be driven by changes to policy and guidelines. Academia may or may not advance one funeral at a time, but peer review is certainly slower to change than publisher policies in the digital age.
It is difficult, at our time of writing, to predict what peer review will look like in a decade’s time. That Einstein in 1936 was surprised by a review of his work shows us the speed at which practices can change, and we exist today in a period in which digital accelerationism is nearly omnipresent. While we should not succumb to technological determinism, we also should not underestimate the power of new digital capabilities to create feedback loops that alter behavioural expectations. Technology can drive social change as much as social change can alter technology. Indeed, as Janis Jefferies and Sarah Kember put it, ‘[w]e might point to a consensual technological determinism that both undermines and structures the opposition between a culture that is free (and freely shared) and one that is, necessarily, proprietorial’ (Reference Jefferies, Kember, Jefferies and Kember2019, 3). At the same time, it is important to note the extent to which academia has naturalised the story of peer review, transforming it into a supposedly timeless phenomenon, when really it is not as old as might be suspected.
Perhaps, though, one of the key takeaway points with which we wish to leave the reader is the question of digital abundance, scarcity, and the problematic powers of filtering and discovery. PLOS ONE is premised on the notion that in the age of the Internet, the scarcity of academic publication through high levels of filtering selection based on novelty or significance is a false scarcity. To some extent, this is true. There are not the constraints of page space and budget in the digital age. But there is still a cost to publishing per paper and PLOS charges to cover it. While high rejection rates based on an artificial scarcity have been blamed for exorbitant publisher costs, one could equally say the same of high-output volume publications such as PLOS ONE, in which universities will pay because something has passed review, rather than paying a higher cost in a subscription ecosystem for material not to appear in exclusive venues, as was the case under exclusive review criteria. The low levels of filtering also have a human cost. How we can deal with ever-rising levels of published material, even within small sub-disciplines, remains unresolved. More is published every day than can ever be read by a single person in a lifetime. This is not to say that exclusive peer review is the solution to such a problem: if we are no good at selecting what to publish, then there is no point claiming that this saves people time. What is clear is that value signals, communicated through various forms of peer review, will become ever more important over time – alongside machine learning and classification approaches – in directing where we spend our attention. A combined value attribution through machine curation and human sentiment seems to be the future direction of travel.
In all, though, we hope that this study will be of interest in informing future discussion on peer review but also on future change in the academy. PLOS developed a groundbreaking new paradigm that, over the course of a decade and a half, has come to increasing prominence. Its ideas have found their way into government policies, funder mandates, and even the economics of scholarly communications. PLOS ONE continues to attract a high volume of submissions. Yet the ‘old system’ of review persists, mentally and in practice, side by side with the new. It could be that we are only at the start of a cascade in which PLOS’s arguments will eventually win out. Or perhaps such proposed changes are destined to be a flash-in-the-pan experiment, no more than a brief moment of experiment in the long-evolving history of refereeing and peer review. We do not possess the historical vantage point yet to see this, but we do propose that future projects that wish to enact institutional change within academia and the university can learn from PLOS’s radicalism. As we have argued, the lessons PLOS teaches provide both positive guidelines and negative warnings; it is a beacon of change and at the same time a lighthouse of rocks to avoid. And we believe it will remain a good while longer before Reviewer Two absorbs the arguments, strictures, and demands that PLOS makes, lays down, and asks.
Acknowledgements
This book would not have been possible without the generous support of too many individuals to name. However, the authors are grateful, in particular, to Veronique Kiermer and Damian Pattinson, both of whom facilitated access to the underlying dataset; to Joerg Heber for valuable comments; and to Jennifer Lin, who worked on the original research proposal. We are extremely grateful to Don Waters, Patricia Hswe, and Michael Gossett at the Andrew W. Mellon Foundation. The authors also wish to thank Gurpreet Singh, who assisted us in technical coordination across the Atlantic. We are grateful also to PLOS as a whole for access to the dataset and for supporting this project.
This study was funded by the Andrew W. Mellon Foundation under grant #21700692 for which we are most grateful. Martin Paul Eve’s work on this project was also supported by a Philip Leverhulme Prize from The Leverhulme Trust grant PLP-2019–023.

Martin Paul Eve is Professor of Literature, Technology and Publishing at Birkbeck, University of London. He holds a PhD from the University of Sussex and is the author of five other books: Pynchon and Philosophy: Wittgenstein, Foucault and Adorno (Palgrave, 2014); Open Access and the Humanities: Contexts, Controversies and the Future (Cambridge University Press, 2014); Password [a cultural history] (Bloomsbury, 2016); Literature Against Criticism: University English and Contemporary Fiction in Conflict (Open Book Publishers, 2016); and Close Reading with Computers: Textual Scholarship, Computational Formalism and David Mitchell’s Cloud Atlas (Stanford University Press, 2019). Martin is a member of the UK English Association’s Higher Education Committee and the Universities UK Open Access Monographs Working Group; with support from the Andrew W. Mellon Foundation, he founded the Open Library of Humanities. In 2017, Martin was named as one of The Guardian’s five UK finalists for higher education’s most inspiring leader, alongside the vice chancellors of Cambridge, Liverpool, and Sheffield Hallam Universities and Oxford’s politics professor Karma Nabulsi. In 2018, Martin was awarded the KU Leuven Medal of Honour in the Humanities and Social Sciences. In 2019, he was awarded the Philip Leverhulme Prize. Martin is Principal Investigator on the Reading Peer Review project. https://orcid.org/0000–0002-5589–8511
Robert Gadie is a PhD candidate at University of the Arts London, whose doctoral research focuses on the policy implications of artists’ epistemological practice. As Principal Editor for the Journal of Arts Writing by Students (2015–19), Robert developed a novel peer review framework to accommodate creative submissions and fostered an international reviewer network of MA and PhD students in the arts.
Samuel A. Moore is a Research Fellow in the Centre for Postdigital Cultures at Coventry University. He has a PhD in Digital Humanities from King’s College London and over a decade’s experience as a publisher and researcher with a focus on open access and the digital commons. His research and teaching sit at the intersections of information studies, critical theory, and science and technology studies (STS). He is also one of the organisers of the Radical Open Access Collective and blogs at www.samuelmoore.org/.
Cameron Neylon is Professor of Research Communication at the Centre for Culture and Technology at Curtin University, where he co-leads the Curtin Open Knowledge Initiative, a multi-million-dollar project examining the future of universities in a networked world. He is also Director of KU Research and an advocate of open research practice who has worked in research and support areas including chemistry, advocacy, policy, technology, publishing, political economy, and cultural studies. He was a contributor to the Panton Principles for Open Data, the Principles for Open Scholarly Infrastructure, and the altmetrics manifesto. He is a founding board member and past president of FORCE11 and served on the boards and advisory boards of organisations including Impact Story, Crossref, altmetric.com, OpenAIRE, the LSE Impact Blog, and various editorial boards. His previous positions include Advocacy Director at PLOS, Senior Scientist (Biological Sciences) at the STFC, and tenured faculty at the University of Southampton. Along with his earlier work in structural biology and biophysics, his research and writing focus on the culture of researchers; the political economy of research institutions; and how these interact, and collide with, the changing technology environment.
Victoria Odeniyi has a Masters in English Language Teaching (University of Sheffield, UK) and completed her doctoral studies in Applied Linguistics (Canterbury Christ Church University, UK). She was a calibrator on the Reading Peer Review project (Birkbeck, University of London) and a co-researcher on a Developing Educators project at Queen Mary University of London, which investigated academic practices and their impact on learning in the Faculty of Science and Engineering. Currently, Victoria is a senior teaching fellow at UCL Institute of Education, London, where she supervises MA Applied Linguistics, TESOL, and MA English Education students. Victoria is also a committee member for the British Association of Applied Linguistics’ Professional Academic and Work-based Literacies Special Interest Group, undertakes peer review regularly, and is an editorial adviser for the International Journal of Multicultural Education. Current research and professional interests include academic practice, the sociolinguistics of identity, critical intercultural communication, and ethnographic approaches to research. https://orcid.org/0000–0002-1555–7763.
Daniel Paul O’Donnell is Professor of English at the University of Lethbridge, where he is responsible for teaching courses in medieval English language and literature, digital humanities, and grammar. His research interests focus on the practice of the humanities in the age of open science, digital humanities, and early medieval England. He is Principal Investigator of the Future Commons partnership and the Visionary Cross Project, a data-centric study of the representation of the crucifix in early medieval English art and literature. O’Donnell is past president of FORCE11, Global Outlook::Digital Humanities, Digital Medievalist, and the Text Encoding Initiative. He is the editor-in-chief of Digital Studies/Le champ numérique. O’Donnell is chair of the steering committee of the FORCE11 Scholarly Communications Institute (FSCI), which is held each August in Los Angeles.
Shahina Parvin is a PhD candidate in Cultural, Social, and Political Thought at the University of Lethbridge, Alberta, Canada, and Assistant Professor (on study leave) in the Department of Anthropology at Jahangirnagar University, Savar, Dhaka, Bangladesh. Her research interests focus on the questions of gender and power. Until 2016, her research questioned biomedical and health professionals’ control over Bangladeshi women’s reproductive bodies through the discourses of well-being, freedom, and empowerment. Shahina also significantly contributed to women’s scholarship by investigating the impacts of micro-finance banking loans on impoverished Bangladeshi women’s lives. In her PhD project, she has explored stories of immigrant racialised women’s use of mental health services in Lethbridge, Canada, analysing their stories within a broader discussion of gender, race, imperialism, and regulatory aspects associated with biopsychiatric knowledge. Shahina also worked with ethnic minority people in Bangladesh to examine the ways they became economically, socially, and politically marginalised. Additionally, she has been exploring the political history of impoverished Bangladeshi women’s migration to the Gulf countries and their post-immigration vulnerabilities.
Series Editor
Samantha Rayner
University College London
Samantha Rayner is a Reader in UCL’s Department of Information Studies. She is also Director of UCL’s Centre for Publishing, co-Director of the Bloomsbury CHAPTER (Communication History, Authorship, Publishing, Textual Editing and Reading) and co-editor of the Academic Book of the Future BOOC (Book as Open Online Content) with UCL Press.
Associate Editor
Leah Tether
University of Bristol
Leah Tether is Professor of Medieval Literature and Publishing at the University of Bristol. With an academic background in medieval French and English literature and a professional background in trade publishing, Leah has combined her expertise and developed an international research profile in book and publishing history from manuscript to digital.
Advisory Board
Simone Murray, Monash University
Claire Squires, University of Stirling
Andrew Nash, University of London
Leslie Howsam, Ryerson University
David Finkelstein, University of Edinburgh
Alexis Weedon, University of Bedfordshire
Alan Staton, Booksellers Association
Angus Phillips, Oxford International Centre for Publishing
Richard Fisher, Yale University Press
John Maxwell, Simon Fraser University
Shafquat Towheed, The Open University
Jen McCall, Emerald Publishing
About the Series
This series aims to fill the demand for easily accessible, quality texts available for teaching and research in the diverse and dynamic fields of Publishing and Book Culture. Rigorously researched and peer-reviewed Elements will be published under themes, or ‘Gatherings’. These Elements should be the first check point for researchers or students working on that area of publishing and book trade history and practice: we hope that, situated so logically at Cambridge University Press, where academic publishing in the UK began, it will develop to create an unrivalled space where these histories and practices can be investigated and preserved.
Academic Publishing
Gathering Editor: Jane Winters
Jane Winters is Professor of Digital Humanities at the School of Advanced Study, University of London. She is co-convenor of the Royal Historical Society’s open-access monographs series, New Historical Perspectives, and a member of the International Editorial Board of Internet Histories and the Academic Advisory Board of the Open Library of Humanities.





 Open access
Open access