

Differences in when, how, and with whom bilingual children interact in each of their two languages entail that there is considerable variation in both the quantity and the quality of bilingual experience from one child to the next. Numerous studies over recent years have shown that these differences in experience predict children’s rate of acquisition across a range of language skills (see Unsworth, Reference Unsworth, Nicoladis and Montanari2016, for review). The vast majority of these studies have focussed on variation in input quantity. Input quantity refers to the amount of exposure available to a child. This may be expressed as a relative or absolute value (e.g., number of hours per week or number of tokens; Grüter, Hurtado, Marchman, & Fernald, Reference Grüter, Hurtado, Marchman, Fernald, Grüter and Paradis2014; De Houwer, Reference De Houwer, Grüter and Paradis2014), and it may gauge the extent of exposure at the current time or cumulatively over time (e.g., Gutiérrez-Clellen & Kreiter, Reference Gutiérrez-Clellen and Kreiter2003; Thordardottir, Reference Thordardottir2011; Unsworth, Reference Unsworth2013). Typically, input quantity is indexed as the percentage of a child’s waking hours in which interlocutors speak a given language to the child, and is usually derived from parental questionnaire data (see Unsworth, Reference Unsworth, Schmid and Köpke2018, for a review of such questionnaires).
Comparatively little is known about the role of variation in input quality on bilingual children’s language outcomes. Input quality refers to the type of exposure available to a child. It typically involves some measure of diversity or “richness” (Jia & Fuse, Reference Jia and Fuse2007). There is evidence to suggest that various qualitative properties of bilingual children’s input may impact on their rate of acquisition. These include, for example, the availability of speakers of the language in question (e.g., Gollan, Starr, & Ferreira, Reference Gollan, Starr and Ferreira2015), the range of (early) literacy-related activities (e.g., Scheele, Leseman, & Mayo, Reference Scheele, Leseman and Mayo2010), and whether children are exposed to language mixing (e.g., Byers-Heinlein, Reference Byers-Heinlein2013). As with input quantity, measures of input quality may be absolute (e.g., the number of different conversational partners; Place & Hoff, Reference Place and Hoff2011) or relative (e.g., the proportion of parental utterances containing code switches; Bail, Morini, & Newman, Reference Bail, Morini and Newman2015), and as noted by Paradis (Reference Paradis2011, p. 217), they often incorporate some index of frequency, with the consequence that they are not exclusively qualitative in nature.
The aim of this study is to investigate which aspects of input quality best predict bilingual children’s performance on a range of standardized language tests, with particular focus on the role of non-native input.
Effects of input quality on bilingual language development
The quality of input to which bilingual children are exposed may vary depending on a number of factors. These include the richness or intensity of the input, the context in which input is provided, variety in the number and type of sources providing input, as well as whether it is from native or non-native speakers.
A number of studies on the early child second language (L2) acquisition of English (Jia & Fuse, Reference Jia and Fuse2007; Paradis, Reference Paradis2011) have found that input richness, usually a composite measure comprising the frequency and density of activities such as computer games, television, book reading, and playing with friends, predicted children’s scores on verbal morphology and vocabulary.
Input in a given language may be tied to a specific context or location. Hearing a language in different locations, and specifically at home compared to at school, may result in qualitative differences in the lexical and morphosyntactic diversity and complexity of input in a child’s two languages. Such differences may contribute to what has been referred to as the “distributed characteristic” of bilingual (lexical) knowledge (Bialystok, Luk, Peets, & Yang, Reference Bialystok, Luk, Peets and Yang2010; Oller, Pearson, & Cobo-Lewis, Reference Oller, Pearson and Cobo-Lewis2007). They may also affect the (rate of) development of different types of linguistic and academic skills (e.g., Cummins, Reference Cummins1979).
Input from a variety of sources has been found to positively affect bilingual children’s developing language skills. In one of the few studies to address this question, Place and Hoff (Reference Place and Hoff2011) observed that the number of different speakers providing input was a significant predictor of Spanish–English toddlers’ vocabulary and grammar scores in English (see also Place & Hoff, Reference Place and Hoff2016). Citing work by Richtsmeier, Gerken, Goffman, and Hogan (Reference Richtsmeier, Gerken, Goffman and Hogan2009) and Singh (Reference Singh2008), Place and Hoff (Reference Place and Hoff2011, p. 1835) suggest that hearing language from multiple speakers may help children to identify features relevant for the acquisition of (phonological) categories and words.
Input from a variety of sources may also increase the range of syntactic structures available in the input (Huttenlocher, Waterfall, Vasilyeva, Vevea, & Hedges, Reference Huttenlocher, Waterfall, Vasilyeva, Vevea and Hedges2010) as well as the functional significance of the language (Fishman, Cooper, & Ma, Reference Fishman, Cooper and Ma1971; Gathercole & Thomas, Reference Gathercole and Thomas2009). Variation in lexical and morphosyntactic diversity and complexity across individual speakers has been shown to predict variation in bilingual children’s (rate of) acquisition. More specifically, it has been shown that children whose parents and teachers offer more diverse and complex input have a faster rate of acquisition (Bowers & Vasilyeva, Reference Bowers and Vasilyeva2011; Huttenlocher, Vasilyeva, Cymeran, & Levine, Reference Huttenlocher, Vasilyeva, Cymerman and Levine2002). In studies on monolingual acquisition, variation in input quality in these terms has in turn been linked to differences in socioeconomic status (Hart & Risley, Reference Hart and Risley1995; Hoff, Reference Hoff2006).
Finally, the quality of bilingual children’s input may vary as a result of who exactly is providing that input. Unlike most monolinguals, many bilinguals may hear input from native and non-native speakers (Fernald, Reference Fernald, Hoff and McCardle2006). Compared with (some) native speakers, non-native speakers are likely to have less diverse and less sophistica-ted vocabulary, less accurate and sophisticated morphosyntax, and not be as phonologically accurate (e.g., Core & Hoff, Reference Core and Hoff2014, qtd. in Place & Hoff, Reference Place and Hoff2016). There is some evidence from monolingual children that in the early years, the quality of parental input in these terms predicts children’s later language development. More specifically, using data from child–caregiver interactions at 18, 30, and 42 months, Rowe (Reference Rowe2012) found that after controlling for input quantity, quality of caregiver input at 18 months, operationalized as lexical diversity (number of different words), lexical sophistication (number of “rare” words), and number of decontextualized utterances (i.e., utterances that refer to objects, events, or people not present in the context), was a significant predictor of children’s vocabulary scores at later ages.
If non-native-speaker parents provide input in their non-native language to children, then this could in principle have a similar effect. Non-native input or exposure to a specific, non-native variety of the target language has been claimed to lead to incomplete acquisition or fossilisation in some bilingual child populations (Cornips & Hulk, Reference Cornips and Hulk2008; Driessen, van der Slik, & De Bot, Reference Driessen, van der Slik and De Bot2002). The proficiency level of the input provider has also been argued to modulate the effect of input quantity: in a study on the early child L2 acquisition of vocabulary and tense morphology in English, Paradis (Reference Paradis2011) found that overall amount of input at home was not a significant predictor of children’s outcomes (see also Chondrogianni & Marinis, Reference Chondrogianni and Marinis2011). She argued that this was most likely due to the low proficiency level of the speakers providing this input. In other words, her study provides indirect evidence for the proficiency level of input providers impacting on children’s language outcomes.
The role of native versus non-native input in child bilingualism has been investigated more directly in two studies by Place and Hoff (Reference Place and Hoff2011, Reference Place and Hoff2016). Both studies used the Language Diary method (De Houwer, Reference De Houwer2011) to derive a number of measures of input quantity and quality, namely, the number of single-language conversational partners, the number of different speakers as sources of exposure, as well as the proportion of language exposure from native speakers. These input measures were then used to predict bilingual English–Spanish toddlers’ scores for vocabulary and grammar. In both studies, native input predicted children’s scores in English, even after controlling for amount of input, although the amount of variance explained by native input was limited (e.g., between 4% and 5% in Place and Hoff, Reference Place and Hoff2016). The authors speculate that this might be due to the relative high proficiency of the non-native speakers in their sample. They conclude that non-native input “is less beneficial [to language development] than native input” (p. 17; in line with, e.g., Hammer et al., Reference Hammer, Komaroff, Rodriguez, Lopez, Scarpino and Goldstein2012), although which specific properties of native input lead to these benefits remains unclear.
In sum, bilingual children’s (rate of) language development has been shown to be affected by specific properties of the input, including its richness and the number of different speakers. However, previous results are mixed, and effects are often limited in scope. There is some evidence that exposure to non-native versus native input is related to children’s rate of acquisition, although this relation may be indirect in the sense that expected effects of input quantity were not found when the proficiency level of the speakers providing said input was low. It remains unclear, however, whether it is the amount of native rather than non-native input that matters, or the quality of any non-native input. Previous studies have incorporated measures of one or the other, but not both at the same time. Furthermore, studies incorporating measures of parental proficiency have thus far focussed on maternal proficiency only. Given the heterogeneity in family constellations often present in studies on bilingual language development, it makes sense to consider the impact of non-native proficiency on children’s developing skills more broadly.
The relation between family constellation, input quality/quantity, and language development
Bilingual families come in many shapes and sizes. Patterns of parental language use vary. Sometimes parents consciously adopt a particular “language strategy,” often as part of their own family’s “language policy” (King & Fogle, Reference King, Fogle, McCarty and May2017), whereas for other parents, the language or languages they use is more the result of happenstance than anything else. Irrespective of how parents’ patterns of language use emerge, they offer us another way of tapping into the relation between properties of language input and children’s language development.
The most well-known approach to raising bilingual children is the “one parent, one language” approach. In many cases, one of these two languages is the same as the majority language spoken by the wider community and consequently, bilingual children raised within such a family constellation will typically hear more majority-language input than children raised in what is often referred to as a “minority language at home” situation, where majority-language exposure is in principle restricted to outside the home. Needless to say, there is considerable variation within these two types of family constellation, and other types exist, too, including, for example, constellations where one or both parents use two languages.
In a large-scale survey on the impact of parental language use on bilingual children’s development in their two languages, De Houwer (Reference De Houwer2007) observed that children were most likely to speak both the minority and the majority language when both parents spoke the minority language and at most one parent spoke the majority language at home. In their study on Spanish–English bilingual 25-month-olds, Place and Hoff (Reference Place and Hoff2011) documented how family constellation (“native English mother + native Spanish father” vs. “native Spanish mother + native English father” vs. “native Spanish mother + native Spanish father”) impacted on the quantity and quality of input available to children. For example, they found that two-thirds of the English input to children with a native English-speaking mother came from native speakers, whereas when the father was a native speaker of English and the mother a native speaker of Spanish, native-speaker input in English was reduced to 28%. Furthermore, children’s language skills were also related to family constellation; for example, children without any native English-speaking parent had significantly smaller vocabularies than children with a native-speaker mother, and this finding was partially mediated by input quantity and the number of different speakers providing English input.
There is thus evidence to suggest that both quantitative and qualitative aspects of bilingual children’s input may vary as a function of family constellation and, no doubt to a certain extent as a result of this variation, family constellation is also a predictor of bilingual children’s language outcomes.
This study
The aim of the present study was to examine the relation between specific quality-oriented properties of bilingual children’s input and measures of children’s language development across a number of skills. The properties in question were
the proportion of input from native speakers;
the degree of non-nativeness in the input; and
input richness.
The proportion of input from native speakers consisted of an estimation of the relative amount of target language input at home provided by native speakers as opposed to non-native speakers, whereas the degree of non-nativeness focussed on the proficiency level of any such non-native speakers. Input richness reflected the extent to which families engaged in language and literacy activities in the target language (following Jia & Fuse, Reference Jia and Fuse2007; Paradis, Reference Paradis2011). Specific details concerning the operationalisation of these three variables are given below in the Method section.
Given that family constellation has been shown to affect the quantity and quality of input available to bilingual children, we first documented the influence of family constellation on these three properties of dual language exposure (following Place & Hoff, Reference Place and Hoff2011). Family constellation was operationalized in two ways. First, we divided children into groups based on whether their parents were native speakers (i.e., a more quality-based division, along the lines of Place & Hoff, Reference Place and Hoff2011). Second, we divided children into groups based on the extent to which the parents used the two languages (i.e., a more quantity-based analysis, along the lines of De Houwer, Reference De Houwer2007). Subsequently, we analyzed the impact of the relative proportion of native versus non-native input, the degree of non-nativeness in the input, and the input richness on children’s acquisition of the majority language, in this case Dutch, while taking family constellation into account. In both analyses, we used these three variables of interest as predictors while controlling for input quantity and for other background variables known to affect bilingual language acquisition, namely, socioeconomic status (SES; e.g., Cobo-Lewis, Pearson, Eilers, & Umbel, Reference Cobo-Lewis, Pearson, Eilers, Umbel, Oller and Eilers2002), working memory (e.g., Gangopadhyay, Davidson, Weisman, & Kaushanskaya, Reference Gangopadhyay, Davidson, Weismer and Kaushanskaya2016), and gender (e.g., Place & Hoff, Reference Place and Hoff2016). Two other factors that have been shown to play a role in bilingual/early child L2 acquisition, namely, L1 transfer (e.g., Blom & Baayen, Reference Blom and Baayen2013) and age of onset (e.g., Meisel, Reference Meisel2009), were not included here. This is because for the sample of children in this study, the considerable variation in other languages precluded any analysis of this variable, and all children were exposed to the target language before the age of 3, which meant that to the extent that a specific age of onset could be pinpointed, there was hardly any relevant variation for this variable.
We administered tests tapping into a number of language skills (i.e., receptive and productive one-word vocabulary, semantic fluency, and receptive and productive morphosyntax). Our expectations were that more native input, non-native input from more proficient speakers, as well as richer input more generally would be associated with a faster rate of acquisition and hence would predict children’s scores on these tests.
Method
Participants
Participants were 50 bilingual children aged 3 years (M = 41 months, SD = 5.1, range: 31 to 49 months; 26 girls, 24 boys), recruited from preschools in the Netherlands. An additional 3 children were also tested, but they were excluded from analyses because they failed to complete most of the tasks (n = 2) or because their parent did not participate (n = 1). These centers are attended by 2- to 3-year-old children, on average for 4 half-days a week (see, e.g., Slot, Reference Slot2014, for more information about and an evaluation of such centers and their educational programs). Eligibility is determined by local authorities, usually via baby and toddler clinics. Children who attend are usually considered at risk of a language disadvantage, either because one or both of their parents speak a language other than Dutch and/or because their parents have a low level of education. By and large, this was also the case for the children in our sample, although they came from families from a whole range of socioeconomic backgrounds, as measured by maternal education on a scale from 0 = preprimary to 6 = postgraduate degree (M = 3.4, SD = 1.3).
The bilingual children were all acquiring Dutch plus one of a range of other languages: Armenian (2), Berber (12), Chinese (1), English (3), Farsi (3), Greek (3), Indonesian (1), Italian (1), Kurdish (1), Polish (5), Russian (2), Serbian (1), Spanish (4), Surinamese (1), Turkish (9), or Vietnamese (1). Three children were also exposed to a third language via their parents (Russian, Kurdish, and Greek), 4 by other members of their family (Bulgarian, English, Kurdish, and Greek), and 1 child had been exposed to Spanish at daycare (in addition to English/Dutch) until the age of 2.5 years. Parental report of home language skills suggested that there was a wide range of ability in the non-Dutch language(s) (using a modified version of the Alberta Language and Development Questionnaire; Paradis, Emmerzael, & Sorenson Duncan, Reference Paradis, Emmerzael and Sorenson Duncan2010; M = 24 [out of 33], SD = 5.4).
The main selection criterion for participation was that at least one parent was a non-native speaker of Dutch and used Dutch with the child at least some of the time. In the process of recruiting participants, the non-native speaker was operationalized as being a speaker with an age of onset later than birth and (self-)reporting as having non-native proficiency in a detailed parent questionnaire (see Language Exposure and Use section below for further information). This resulted in a sample including family constellations that varied in terms of the number of non-native speakers, the level of Dutch language proficiency of these non-native speakers, and the amount of Dutch language input provided at home overall. The sample was thus heterogeneous in nature but ecologically valid in that it was typical for the type of early childhood education center from which it was drawn.
Language tasks
Receptive vocabulary
A shortened version of the third edition of the Dutch Peabody Picture Vocabulary Test (PPVT-III-NL; Dunn & Dunn, Reference Dunn and Dunn2005) was used to assess receptive vocabulary (cf. Verhagen, Boom, Mulder, de Bree, & Leseman, in press; Verhagen, de Bree, Mulder, & Leseman, Reference Verhagen, de Bree, Mulder and Leseman2017). In this task, children were asked to select one out of four pictures that best matched an orally presented word, following the standard protocol. A shortened version was used to reduce testing time and fatigue. Specifically, items were removed from the original test on the basis of pilot data showing that they did not differentiate well across 3-year-old children (Verhagen et al., Reference Verhagen, de Bree, Mulder and Leseman2017, in press). To facilitate administration and scoring, the task was administered on a laptop and responses recorded with a button press by the experimenter. A fixed number of 24 items were presented to all children. Internal consistency of the task was sufficient (α = .73; Verhagen et al., Reference Verhagen, de Bree, Mulder and Leseman2017). The dependent variable used in the analyses was total number of items correct.
Active vocabulary
The active vocabulary subtest of the CELF Preschool-2-NL (Wigg, Secord, Semel, & de Jong, Reference Wigg, Secord, Semel and de Jong2012) was used to measure expressive vocabulary skill in Dutch. In this test, children name pictures in response to questions asked by the assessor, such as “What is this?” or “What is the girl doing?” The test contains 20 items, but testing is adaptive, such that administration is stopped when a child makes six consecutive errors. Raw scores rather than standard scores were used in the analysis, for the following reasons: first, the standard scores are normed for monolinguals only; second, some of the children in the current sample fell (just) under the age for which standard scores can be calculated and would have to be excluded from analysis; third, using total (raw) scores allowed for the full range of variability to be included in the analysis. On this subtest, children were awarded 2 points when their answer was completely correct, and for 8 of the 20 items they received 1 point for responses that were approximating the right answer (e.g., babykoe “baby cow” instead of kalf “calf”). The test–retest reliability coefficient for 3-year-old children is excellent (r = .90; Wigg et al., Reference Wigg, Secord, Semel and de Jong2012). The dependent variable used in the analyses was total number of items correct.
Semantic fluency
Semantic fluency or category fluency involves the ability to quickly generate items belonging to a certain semantic category within a given time frame. It is thought to tap into lexical knowledge and retrieval and semantic (memory) organization (Ardila, Ostrosky-Solís, & Bernal, Reference Ardila, Ostrosky-Solís and Bernal2006) and has been found to correlate with general language proficiency (Bialystok, Craik, & Luk, Reference Bialystok, Craik and Luk2008). Two categories were used (food and animals), and children were given 1 min to name as many items as they could think of (following the protocol used in Peña et al., Reference Peña, Bedore and Zlatic-Giunta2002). Children’s answers were recorded and scored afterward by the experimenter following a predetermined set of criteria as the total number of responses for each child within 1 min, minus repetitions, words from another semantic category, and unintelligible responses. Scoring for all children was subsequently checked by the first author. Given that this task was included to measure lexical knowledge in Dutch, responses in the child’s other language were excluded from the analysis. When children responded in a language other than Dutch, they were encouraged to produce the same (or another) word in Dutch. The dependent variable used in the analyses was the sum total of unique answers in both categories.
Sentence comprehension
Children’s ability to understand spoken sentences in Dutch was assessed with the sentence comprehension subtest of the CELF Preschool-2-NL (Wigg et al., Reference Wigg, Secord, Semel and de Jong2012). In this test, children choose which one out of four pictures best matches a spoken sentence. The test contains 22 items, but testing is stopped when a child makes five consecutive errors. Again, for the reasons mentioned above, raw rather than standard scores were used, and the dependent variable used in the analyses was total number of items correct. The test–retest reliability coefficient for 3-year-old children is acceptable (r = .73; Wigg et al., Reference Wigg, Secord, Semel and de Jong2012).
Morphosyntax
The word structure subtest of the CELF Preschool-2-NL (Wigg et al., Reference Wigg, Secord, Semel and de Jong2012) was used to assess morphosyntax in Dutch. Specifically, this subtest assesses children’s knowledge of subject–verb agreement, adjectival inflection, diminutives, noun plurals, and pronouns. The test contains 23 items, but testing is discontinued after seven consecutive errors. As for the other CELF subtests, the dependent variable used in the analyses was total number of items correct. The test–retest reliability coefficient for 3-year-old children is acceptable (r = .74; Wigg et al., Reference Wigg, Secord, Semel and de Jong2012).
Other measures
Nonverbal working memory
Nonverbal working memory, or the ability to manipulate nonverbal information stored in memory, was assessed with the hand movements subtest of the Kaufman Assessment Battery for Children (Kaufman & Kaufman, Reference Kaufman and Kaufman2004). In this subtest, children imitate a series of taps the assessor makes on the table with the fist, palm, or side of the hand. The test contains 12 items, divided into units of 3 or 4 items. The subtest is adaptive, such that testing stops when children fail on all items in a unit or when children fail on 1 item after having provided correct answers to all items in the last unit intended for their age. The resulting score is the total number of items for which children imitated the research assistant’s hand movements in the correct order. No information is available about the reliability of this subtest with this age group.
Language exposure and use
Bilingual children’s current and previous patterns of language exposure and use were estimated using a detailed parental questionnaire (Bilingual Language Experience Calculator; BiLEC; Unsworth, Reference Unsworth2013). Following Gutiérrez-Clellen and Kreiter (Reference Gutiérrez-Clellen and Kreiter2003), this questionnaire asks parents to indicate where and with whom the child spends time on an average day in the week and an average day during the weekend, for how long, and which language(s) each person uses when addressing the child and how well he or she speaks that language, as well as time spent on extracurricular activities and the language(s) in which these occurred. Using this information, we calculated a general measure of input quantity, namely, the child’s relative exposure to Dutch at the current time, including sources at home, preschool, and elsewhere, such as television, tablets, and friends, and a measure of their exposure over time (i.e., cumulative length of exposure, following Unsworth, Reference Unsworth2013). In addition, we calculated the proportion of exposure at home that was from native (NS) versus non-native (NNS) speakers (% NS input), as well as the average proficiency level of any input provided by NNS, on a scale from 0 = no fluency to 5 = native fluency. The latter variable was calculated in two different ways: first by simply averaging the proficiency level of all input providers at home aged 4 years and older (average quality NNS input), and second by weighting the relative contribution of each depending on the amount of time he or she spent with the child (weighted quality NNS input). For more details, see Unsworth (Reference Unsworth2013) and the manual available for download via the IRIS online instrument repository at www.iris-database.org.
Data collected from non-native parents as part of the wider project indicated that the (self-)reported proficiency used to derive our predictor variables was valid. More specifically, when the data collected from non-native parents (n = 33) using a film retell task (Dimroth, Andorno, Benazzo, & Verhagen, Reference Dimroth, Andorno, Benazzo and Verhagen2010) were evaluated by 11 native-speaker judges with extensive experience in teaching Dutch as an L2, the interclass correlation was in the excellent range (Cicchetti, Reference Cicchetti1994) for all variables (i.e., vocabulary, grammar, accent, fluency, and overall proficiency), and of particular importance for present purposes, there was a strong, positive correlation between the average rating by the native-speaker judges and the (self-)reported proficiency data collected using the BiLEC questionnaire, r (33) = .69, p < .001.
Participating parents were categorized as a native speaker if they met the following criteria: age of onset was below 4 years old (following the broad consensus in the literature; McLaughlin, Reference McLaughlin1978; Meisel, Reference Meisel2009; Unsworth, Reference Unsworth2013) and the (self-)reported proficiency provided in the BiLEC questionnaire was nativelike (i.e., 5 on the scale given above). For the most part, these two criteria coincided. There were, however, a number of parents (n = 12) who reported nativelike proficiency in the questionnaire but who had an age of onset older than 4. In these cases, we allowed (self-)reported proficiency to “trump” age of onset for two reasons: first, there exist individual late learners, albeit not many, who achieve nativelike competence (Hyltenstam & Abrahamsson, Reference Hyltenstam and Abrahamsson2008); and second, (self-)reported proficiency, albeit not entirely unproblematic, is probably a more accurate estimation of parents’ abilities than a more general premise based on the literature, and as such likely provides a better characterization of input quality, the variable we were ultimately trying to operationalize. Native-speaker judgments, available for 7 of the 12 cases, supported this decision. All but two of these parents had scores that placed them in the top 20% of our sample (i.e., >6.0, on a scale from 0 to 9, where the highest score obtained was 7.0); they and the five parents for whom no native-speaker judgment data were available were classified as native speakers. The remaining two parents, who had considerably lower native-speaker ratings (i.e., 3.0 and 4.2) were classified as non-native speakers. The potential risk here is that there will be parents who were categorized as native speaker but who were not. We return to this question in the Discussion. This categorization resulted in 14 mothers and 14 fathers being categorized as native-speakers of Dutch. The average age of onset to Dutch for the non-native speaker parents who spoke Dutch to their child was 18.1 years for the mothers (SD = 8.0; range: 0 to 32) and 12.3 years for the fathers (SD = 11.1; range: 0 to 36).
To gain a better understanding of the families’ language and literacy practices at home, especially those in Dutch, a second questionnaire was administered. This Daily Communication Questionnaire (Mayo & Leseman, Reference Mayo and Leseman2006; Scheele et al., Reference Scheele, Leseman and Mayo2010) consists of 32 questions about the frequency of various language and literacy activities (on a scale from 0 = never to 5 = daily) and the language in which such activities take place (as a proportion of the total amount of time dedicated to said activities). These activities include watching (specific kinds of) television, reading/being read to, parent–child interactions, singing and storytelling, and educational conversations (e.g., talking about shapes and colors). Cronbach’s alpha (α = .84) indicated good internal consistency. Responses were averaged across all questions and subsequently weighted for the extent to which they took place in Dutch by multiplying the average score for a given activity by the proportion of time the activity was carried out in Dutch.
Procedure
Informed consent was obtained from all parents. Children were tested individually by trained research assistants in a quiet room at preschool or at their homes, depending on the family’s preference. Tests were administered in a fixed order (i.e., PPVT, CELF subtests, Kaufman Hand Movements, and semantic fluency) and interspersed with a number of other tasks assessing children’s knowledge of specific grammatical phenomena (i.e., definiteness and word order) as part of a larger project. Children received a sticker after each task, and a small gift at the end of the session. Parents completed both the BILEC questionnaire and the Daily Communication Questionnaire via an interview with a trained assistant. In addition to the film retell task mentioned briefly above, parents also performed a number of other language tasks not reported here.
Analysis
To determine which properties of bilingual children’s language experience predicted their receptive and productive skills in vocabulary and morphosyntax, we conducted a series of multiple linear regression analyses with children’s accuracy scores as dependent variable using the lm function in the lme4 package (Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015) in R (R Core Team, 2017). For each task, we first entered the “baseline” predictors (i.e., age, gender, working memory, and SES). Subsequently, we added our predictors of interest in several separate models. These were
the proportion of input from native (rather than non-native) speakers (% NS input);
the degree of non-nativeness of any non-native input (either average quality NNS input or weighted quality NNS input);
the extent to which families engaged in language and literacy activities in Dutch (input richness);
overall proportion of exposure to Dutch (input quantity); and
family constellation.
With respect to the latter variable, family constellation, two series of analyses were performed. In the first, family constellation was operationalized as the presence or absence of a Dutch native-speaker parent (NS parent). In the second, family constellation was based on parental language use, that is, whether one, both, or neither parent mostly used Dutch as language of communication with the child. For degree of non-nativeness, analyses were conducted with both variables, but only one at a time.
Other variables that were potential predictors of interest, namely, past exposure (indexed by cumulative length of exposure) and children’s own language use, showed multicollinearity with input quantity (r = .48, p < .001 and r = .74, p < .001, respectively), and hence only input quantity was included in the analysis, as outlined above. We return to this issue of multicollinearity in the Discussion.
In all models, orthogonal sum-to-zero contrast coding was applied to our categorical fixed effects (i.e., SES, gender, and family constellation), and all continuous variables were centered around zero (Baguley, Reference Baguley2012, pp. 590–621). For gender, girls (coded as 0.5) were contrasted with boys (reference, coded as –0.5). For SES, there were two contrasts: the first contrast compared primary (reference, coded as 0) with secondary (–0.5) and university-level education (0.5), and in the second contrast, secondary and university level were compared to each other. For NS parent (at least) “one NS parent” (coded as 0.5) was compared to “no NS parent” (reference, coded as –0.5).Footnote 1 Finally, for parental language strategy, there were also two contrasts: in the first contrast the group where both parents mostly speak heritage language (i.e., “mostly HL”; the reference group and as such coded a 0) was compared with the group where one parent mostly speaks Dutch, the other mostly speaks HL (i.e., “HL + Dutch”; coded as –0.5) and the group where both parents mostly speak Dutch (i.e., “mostly Dutch”; coded as 0.5), and in the second, the latter two groups were compared with each other.
For each model, a stepwise variable selection procedure was conducted in which nonsignificant predictors were removed to obtain the most parsimonious model. Model complexity was increased by including interaction effects between the predictors of interest and the baseline predictors and between different predictors of interest. In order to compare models, likelihood ratio tests were performed that compared the goodness of fit using the anova function in the base package (R Core Team, 2017). In this way, the final model was selected by checking whether the p value from the likelihood ratio test was significant.
Results
Descriptives (all children)
Table 1 presents an overview of the experiential variables derived from the parental questionnaires. To provide a more complete picture of the sample, this overview includes more general measures of bilingual experience in addition to the variables used in the analyses below.
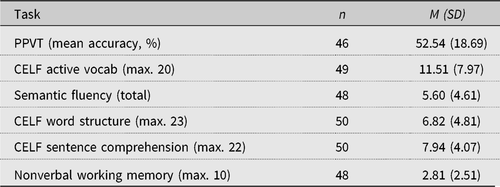
Table 1. Descriptive statistics for experiential variables (all children, n = 50)

The data in Table 1 show that, on average, the bilingual children in our sample heard and used Dutch at home more often than their other language, that about half of their Dutch input was from non-native speakers, and that the average (self-)reported proficiency level of these non-native speakers was “quite fluent.”Footnote 2
Table 2 provides the descriptive statistics for children’s scores on the five Dutch language tasks and the nonverbal working memory task. The standard deviations on all tasks were high, indicating considerable individual variation.
Table 2. Children’s (raw) scores on language tasks and working memory task: All children
Family constellation based on parents’ native speaker status
Children were divided into two groups based on whether their parents were native or non-native speakers of Dutch: a group where neither parent was a NS (n = 20) and a group where at least on parent was a NS (n = 30). The characteristics of these two groups with respect to our predictors of interest are given in Table 3.
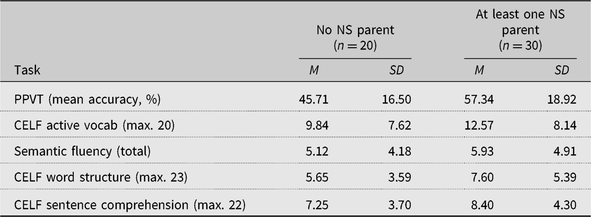
Table 3. Descriptive statistics for predictors of interest for family constellation groups based on parents’ native speaker status

The groups were comparable in terms of input quantity, t (32.0) = –1.33, p = .194, although there was more variation in the group without any NS parents. (The alpha level here was corrected, from .05 to .01, to prevent Type 1 errors resulting from the multiple t tests [n = 5] carried out with the same groups.) Children in both groups were exposed to NNS input but not surprisingly, the proportion of NS input was lower in the No NS parent group, t (48) = 3.47, p = .001. The average quality of any NNS input did not significantly differ across groups, however, irrespective of how this was measured: average quality NNS input, t (43) = –2.03, p = .048; weighted quality NNS input, t (43) = –2.07, p = .044. There was also no significant difference in terms of input richness, t (48) = –0.81, p = .420.
Table 4 provides the descriptive statistics for children’s scores on the five Dutch language tasks for the two family constellation groups based on parents’ native speaker status. The most parsimonious regression models for each task are given in Table 5.
Table 4. Children’s (raw) scores on language tasks and working memory task: Family constellation groups based on parents’ native speaker status
The results for the three vocabulary tasks were as follows. For the PPVT, the results showed that children of university-level-educated mothers had significantly higher scores than the children with mothers educated to secondary level. Furthermore, the difference between children of primary-level-educated mothers and children of mothers educated to at least secondary level was approaching significance. In addition, the degree of non-nativeness was also a significant predictor of children’s scores. For the active vocabulary subtest of the CELF, age and input quantity were significant predictors of children’s scores, with older children and children with more overall exposure to Dutch obtaining higher scores. Finally, on the semantic fluency task, older children and children with a richer input named significantly more words than younger children and children with a less diverse input. Note, however, that when input richness was not included in the model for semantic fluency, input quantity became a significant predictor (cf. Table A.1 in Appendix A). This was most likely the result of the strong correlation between these two variables, r (50) = .71, p < .001.
Turning to the two morphosyntactic tasks (in Table 5), on the word structure subtest girls scored significantly higher than boys. In addition, nonverbal working memory and the degree of non-nativeness (average quality NNS input) were also significant predictors of children’s scores on this subtest. The latter two variables were also significant predictors of children’s scores on the sentence comprehension subtest, as was age.
Table 5. Predictors of total scores identified through a multiple regression analysis in which family constellation group is based on parents’ native speaker status

Family constellation (i.e., no NS parent vs. NS parent) was not a significant predictor of children’s scores for any of the five tasks. Furthermore, replacing average quality NNS input with weighted quality NNS input did not change the results, except for sentence comprehension, where the weighted measure was not significant; in other words, degree of non-nativeness remained a significant predictor for the PPVT and the word structure subtest irrespective of whether this was based on a simple average of all non-native input providers at home, or whether the contribution of input providers was weighted according to how much time they spent with the child.
To summarize, these results show that the amount of Dutch language input was a significant predictor of both productive vocabulary tasks. Input quality, when operationalized as the extent to which parents undertook language and literacy activities with their children (input richness), was a significant predictor of children’s semantic fluency when input quantity was not included in the model. Neither the proportion of input at home from native speakers nor whether children had (at least) one or no parents providing native input predicted children’s scores on any of the skills tested. The degree of non-nativeness was, however, significantly related to children’s scores on receptive vocabulary and the two morphosyntactic tasks. Finally, age, SES, and nonverbal working memory were significant predictors for several of the tasks. The models explained between 30% and 40% of the variance in children’s scores.
Family constellation based on parental language use
For the second analysis, children were divided into three groups based on whether their parents both mostly spoke the heritage language (HL) at home (n = 13), one parent mostly spoke the HL and the other mostly Dutch (n = 12), or whether both parents mostly spoke Dutch (n = 24), where “mostly” was operationalized as ≥ 50%. The characteristics of these three groups with respect to our predictors of interest are given in Table 6.
Table 6. Descriptive statistics for predictors of interest for family constellation groups based on patterns of parental language use

The groups by definition differed in terms of input quantity, F (2, 46) = 17.14, p < .001; as the SD in Table 6 indicate, there was, however, considerable variation within and overlap between the Mostly HL group and the HL + Dutch groups. Again, somewhat not surprisingly, the three groups differed in terms of % NS input, F (2, 46) = 3.45, p = .040: when both parents mostly spoke the HL, most of Dutch input at home came from non-native speakers, whereas in the other two groups (i.e., where at least one parent mostly spoke Dutch), a comparable proportion of input in Dutch came from native speakers. Post hoc (least significant difference) tests confirmed that children in the Mostly HL group heard significantly less NS input than children in the HL + Dutch (MD = –14.85%, p = .033) and the Mostly Dutch (MD = –33.34%, p < .001) groups. Note, however, that once again, there was considerable variation among families in all groups. The degree of non-nativeness was also significantly different across groups, F (2, 41) = 3.42, p = .042, with more proficient non-native speakers providing input in the Mostly Dutch families when compared with the Mostly HL families (MD = 0.66, p = .012); the degree of non-nativeness in the HL + Dutch families did not, however, differ from either of the other two groups. When the same variable was weighted for the amount of time each non-native speaker spoke Dutch to the child, the mean values per group increased, suggesting that the more proficient non-native speakers provided more input. Furthermore, for weighted quality NNS input, there were no statistically significant differences between family constellation groups, F (2, 41) = 1.03, p = .177. For input richness, F (2, 46) = 9.60, p < .001, families where both parents spoke mostly Dutch engaged in more language and literacy activities in Dutch than families where both parents mostly spoke the HL (MD = 0.88, p < .001); once again, the children in HL + Dutch families were not significantly different from either of the other two groups.
Table 7 provides the descriptive statistics for children’s scores on the five Dutch language tasks for the three family constellation groups based on parental language use. The most parsimonious regression models for each task are given in Table 8.
Table 7. Children’s (raw) scores on language tasks: Family constellation groups based on patterns of parental language use
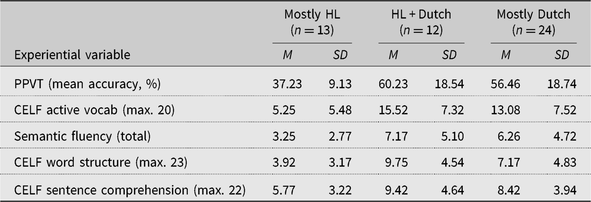
Table 8. Predictors of total scores identified through a multiple regression analysis in which family constellation group is based on patterns of parental language use
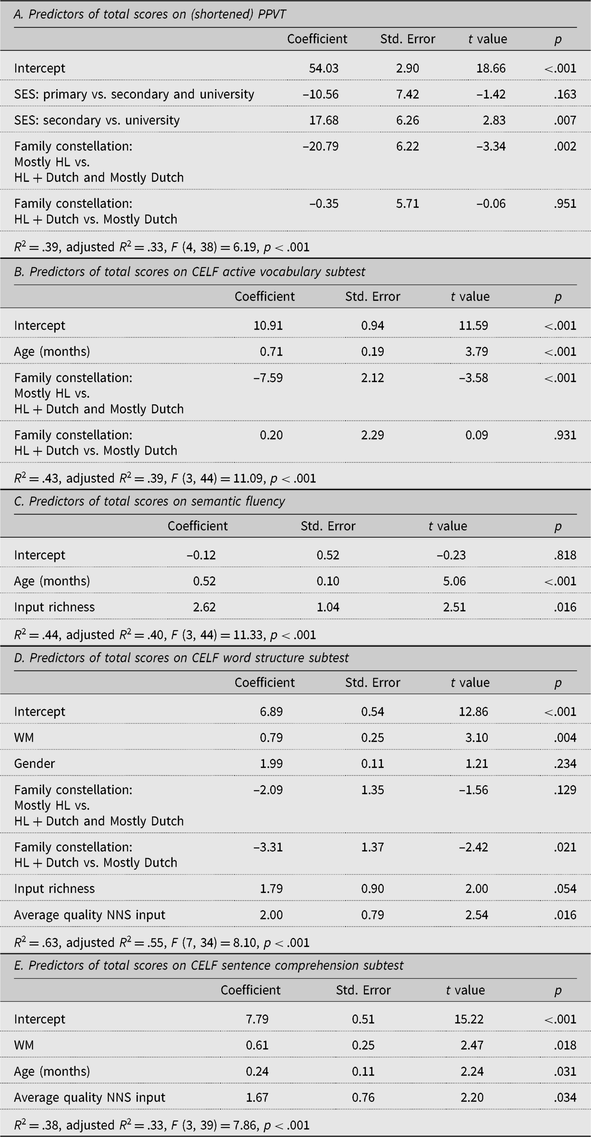
The results for the three vocabulary tasks were as follows. For the PPVT, SES and family constellation were the only significant predictors. Children of university-educated mothers scored significantly higher than children of mothers educated to secondary level only. Children in the Mostly HL group scored significantly lower than the children in the other two groups, who did not significantly differ from each other. Rerunning the analysis such that the contrast between the Mostly HL and the HL + Dutch groups was included confirmed that there was a significant difference between these two groups (see Table A.2 in Appendix A for complete model). Variation in input quantity and quality did not account for any additional variance.
Family constellation was also a significant predictor of active vocabulary (Table 8); once again, the children in the Mostly HL group scored significantly lower than the children in the other two groups, who did not significantly differ from each other, and rerunning the analysis with the contrasts between the Mostly HL and the HL + Dutch groups confirmed that there was a significant difference between these two groups (see Table A.3 in Appendix A for complete model). In addition to family constellation, age was also a significant predictor for active vocabulary.
For the final vocabulary task, semantic fluency, the predictors which were added to the model once again affected the results: in the model reported in Table 6, older children and children whose families engaged in more language and literacy activities named significantly more words than younger children and children with less rich input. Given that this is the same model as in the previous set of analyses (i.e., Table 5), the same caveat with respect to input richness holds here: as a result of multicollinearity between this variable and input quantity, input quantity was a significant predictor when input richness was omitted from the analysis (see Table A.1 in Appendix A).
For word structure, there was a significant but slightly different effect of family constellation: children in the Mostly HL group did not significantly differ from the other two groups, but there was a significant difference between these two groups, with the children in the HL + Dutch group scoring significantly higher than the children in the Mostly Dutch group. Rerunning the analysis such that the contrast between the Mostly HL and the HL + Dutch groups was included confirmed that the children in the HL + Dutch group also scored significantly higher than the children in the Mostly NL group (see Table A.4 in Appendix A). The quality of any NNS input was also a significant predictor (either average quality NNS input or weighted quality NNS input), as was non-verbal working memory, with input richness approaching significance (p = .054). Quality of NNS input and nonverbal working memory were also significant predictors of children’s scores for sentence comprehension (Table 8), as was age.
To summarize, family constellation, when operationalized as parental language use, was a significant predictor of children’s scores on all tasks except sentence comprehension. Variation in input quantity within the three family constellation groups did not capture any additional variance. Neither did the proportion of input from native speakers (% NS input). Input quality, when operationalized as the degree of non-nativeness, was a significant predictor of children’s scores on the two morphosyntactic tasks only. Our other measure of input quality, input richness, predicted children’s scores on word structure, and when input quantity was not included in the model, on semantic fluency. Finally, age, SES, and nonverbal working memory were significant predictors for several tasks. The various models explained between 30% and 55% of the variance in children’s scores. Table 9 provides an overview of the findings from both analyses.
Table 9. Summary of significant predictors

Note: NNS, non-native speaker; WM, nonverbal working memory; SES, socioeconomic status; HL, heritage language.
Discussion
This study investigated the relationship between the quality of young bilingual children’s language input and their developing productive and receptive skills in vocabulary and morphosyntax in the majority language (Dutch). More specifically, taking children’s family constellations as our starting point, we examined the extent to which three different quality-oriented properties of children’s input in Dutch would predict their language outcomes while taking into account their age, gender, nonverbal working memory, and SES, as well as overall amount of Dutch input. The three properties were (a) the proportion of input from native (rather than non-native) speakers, (b) the degree of non-nativeness in the input, and (c) input richness, measured as the extent to which families engaged in language and literacy activities in Dutch. Two sets of analyses were conducted on the same five tasks, a shortened version of the PPVT, a semantic fluency task, and the active vocabulary, word structure, and sentence comprehension subtests of the CELF-2. In the first analysis, family constellation was operationalized as the number of native- versus non-native-speaker parents, and in the second in terms of parental language use, whereby both parents mostly spoke the same language (i.e., Dutch or the heritage language) or different languages.
Native versus non-native input
After controlling for the effect of the background variables age, gender, SES and working memory, and the effects of input quantity, neither the presence of a native-speaker parent nor the proportion of Dutch input from native speakers was found to predict children’s performance on any of the five tasks. Taken at face value, this result seems to suggest that exposure to (some) non-native input may matter less for acquisition than often thought. Evidence from the acquisition of American Sign Language and from artificial language learning suggests that children are able to overcome inconsistencies in input (Hudson Kam & Newport, Reference Hudson Kam and Newport2005; Singleton & Newport, Reference Singleton and Newport2004).
Our findings contrast with those of Place and Hoff (Reference Place and Hoff2011, Reference Place and Hoff2016), who found that the proportion of exposure provided by native speakers was significantly related to bilingual toddlers’ outcomes in the majority language, English. There are a number of possible reasons for both our null finding and for the discrepancy between our study and this earlier work. First, while there was quite some variation in the proficiency level of the non-native speakers in our sample (see below), their level of proficiency was on the whole quite high (cf. Table 1). This meant that the categorical distinction made between native and non-native speaker in this study was based on a relatively small difference in proficiency; the extent of this difference may also have been smaller than in the Place and Hoff studies.Footnote 3
Second, there are other sources of (potentially high quality) input (e.g., preschool teachers and television) that were not included in the calculation of %NS input. Consequently, at least some children may have been exposed to more native-speaker input than reported. Third, the operationalization of this variable across the two studies differed. We used a parental questionnaire to elicit information about who spent time with the child, for how long, and which language(s) they used, whereas Place and Hoff (Reference Place and Hoff2011, Reference Place and Hoff2016) made use of a language diary (De Houwer, Reference De Houwer2011) in which parents noted who was interacting with the child during 30-min blocks and whether they spoke English, Spanish, or both languages; only the single-language blocks were included when calculating the proportion of NS input. How exactly these differences may have impacted on our respective results is hard to say, but it is clear that while similar, the two measures were not exactly the same.
Fourth, our operationalization of native speaker (age of age of onset < 4 years, (self-)reported nativelike proficiency) may have been too conservative. As outlined in the Method section, where there was a discrepancy in the values for these two variables, we allowed (self-)reported proficiency to “trump” age of onset, and we used native-speaker judgments as arbiter wherever possible. For a handful of parents, however, no such native-speaker judgment data were available, and hence, we essentially had to make an educated guess based on the patterns observed in the data we did have. It is possible that, as a result, several parents were classified as native speakers while they should have been classified as non-native speakers.
Rather than the amount of native or non-native input at home, it was the degree of non-nativeness that mattered. More specifically, the degree of non-nativeness in children’s input predicted their scores on receptive vocabulary and on the two productive morphosyntactic tasks (in line with Hammer et al., Reference Hammer, Komaroff, Rodriguez, Lopez, Scarpino and Goldstein2012). Following previous work (e.g., Core & Hoff, 2014 qtd. in Place & Hoff, Reference Place and Hoff2016; Rowe, Reference Rowe2012), we speculate that this is likely due to more proficient non-native speakers providing more morphosyntactically complex and lexically diverse input. Future work examining the productive data we have from parents, reported on here in the context of the native-speaker judgments, will be able to address this question directly. Based on the present data alone, the question of whether continued exposure to low proficiency non-native input will lead to incomplete acquisition or fossilisation, as has been claimed by some (Cornips & Hulk, Reference Cornips and Hulk2008; Driessen et al., Reference Driessen, van der Slik and De Bot2002), remains unclear.
Input richness
In addition to the two variables concerning non-native exposure, input quality was also examined in terms of input richness (i.e., the extent to which families engaged in language and literacy activities in Dutch). The finding that richer input from a range of different sources helps (second) language development is in line with previous work (e.g., Jia & Fuse, Reference Jia and Fuse2007; Paradis, Reference Paradis2011), including research using the same parental questionnaire (Scheele et al., Reference Scheele, Leseman and Mayo2010). In particular, exposure to narratives written in the third person through, for example, shared-book reading not only provides children with more input but also, more concretely, to more types and tokens of the kind of verbal morphology elicited in the word structure task. It is important to note, however, that for this task, input richness was only a marginally significant predictor (p = .05). Furthermore, for semantic fluency, a model almost comparable to the most parsimonious one contained input quantity rather than input richness. In other words, it is hard to know whether it is the relative amount of input in Dutch more generally or participation in language and literacy-related activities that is the decisive factor in predicting children’s ability to name as many different objects as possible.
Patterns of parental language use
In our second set of analyses, family constellation was operationalized in terms of parental language use. Two different findings emerged. First, on the receptive and productive vocabulary, children with at least one (mostly) Dutch-speaking parent had higher scores than children whose parents mostly spoke the HL and children with one (mostly) Dutch-speaking parent and one (mostly) HL-speaking parent. The observation that having one or more parents who speak Dutch leads to better performance replicates the well-established finding that amount of exposure matters (e.g., Gathercole & Thomas, Reference Gathercole and Thomas2009; Hoff et al., Reference Hoff, Core, Place, Rumiche, Senor and Parra2012), although given the correlation with input richness, it is impossible to say whether what matters is how much parents use a given language or how they use that language. Note that this problem is likely to hold for many studies, not just this one.
Despite the observation that parental language use correlated (sometimes highly) with input richness and input quantity, we believe analyzing our data using this variable is insightful for two reasons. First, which language parent(s) mostly speak with their children is something more tangible than an overall measure of input quantity, and hence it can be more readily translated into recommendations for raising bilingual children (see below). Second, operationalizing aspects of bilingual children’s language experience in a range of different ways allows us to gain a better understanding of how these aspects (and the various terms used to describe them in the literature) relate to one other.
The second finding concerning parental language use was that children whose parents mostly spoke different languages (i.e., children in the HL + Dutch group) had significantly better scores on the word structure task than children whose parents mostly spoke the same language (i.e., children in the Mostly HL and Mostly Dutch groups). This finding cannot be accounted for in terms of amount of input. One possible explanation is that simultaneous exposure to both languages at home sensitizes children to the differences between the two languages, and this, in turn, may be beneficial to learning (Kuo & Anderson, Reference Kuo and Anderson2010).
The observation that, for word structure and sentence comprehension at least, the degree of any non-native input accounted for variance above and beyond that captured by parental language use emphasizes the importance of including not only parents but also other conversational partners at home, most notably siblings, who have been shown to have both a direct and an indirect impact on toddlers’ developing language skills (Bridges & Hoff, Reference Bridges and Hoff2014).
Input quantity
In the present study, input quantity was operationalized as the proportion of Dutch spoken to the child both inside and outside the home. Input quantity was found to predict bilingual children’s active vocabulary scores, in line with earlier research showing input effects in this domain (e.g., Gathercole & Thomas, Reference Gathercole and Thomas2009; Hoff et al., Reference Hoff, Core, Place, Rumiche, Senor and Parra2012; Thordardottir, Reference Thordardottir2011). Furthermore, for receptive vocabulary, this effect held after controlling for SES, confirming earlier research showing that input effects on bilingual vocabulary development exist independently of differences related to SES (Buac, Gross, & Kaushanskaya, Reference Buac, Gross and Kaushanskaya2014; Scheele et al., Reference Scheele, Leseman and Mayo2010).
It is important to note that the findings reported here as effects of input quantity could, as in many earlier studies, equally be effects of children’s output (i.e., language use). The very nature of bilingual language interaction means that when bilingual children use one of their two languages more frequently, they likely elicit more input in that language; similarly, hearing more input in a given language may contribute to better proficiency and subsequently more output in that language (Pearson, Reference Pearson2007). In short, children’s patterns of language input and language use, while not identical, are closely related to each other. Of particular interest, input quantity was a significant predictor of children’s vocabulary on the two productive tasks only. If this finding is indicative of an effect of output rather than input, it could reflect either a modality-specific relationship between language use and expressive skills or a more general influence of language use, affecting expressive skills more readily than receptive skills because the former are harder to achieve, as argued in a recent study by Ribot, Hoff, and Burridge (Reference Ribot, Hoff and Burridge2018). As previous research has shown, however, it is possible that input and output may relate to bilingual children’s language outcomes differently (e.g., Bohman, Bedore, Pena, Mendez-Perez, & Gillam, Reference Bohman, Bedore, Pena, Mendez-Perez and Gillam2010; Ribot et al., Reference Ribot, Hoff and Burridge2018; Unsworth, Reference Unsworth, Silva- and Treffers-Daller2015; Unsworth, Chondrogianni, & Skarabela, Reference Unsworth, Chondrogianni and Skarabela2018). Because of the multicollinearity between these two variables in the present data set, it was not possible to investigate this possibility here.
Input quantity, as indexed by a general measure incorporating input inside and outside the home, was not related to children’s performance on the two morphosyntactic tasks. This contrasts with previous research, where such a relationship has been observed (e.g., Chondrogianni & Marinis, Reference Chondrogianni and Marinis2011; Place & Hoff, Reference Place and Hoff2016). This may be because the tasks were not sensitive enough to detect the relevant effects. This may hold for the sentence comprehension subtest of the CELF, which may be more sensitive to children’s cognitive than their linguistic skills (see below), but it seems unlikely for the word structure subtest given that it targets many of the same linguistic structures (e.g., subject–verb agreement, adjectival inflection, and noun plurals) as the tasks used in earlier studies where input effects were observed (e.g., Paradis, Reference Paradis2011; Thomas, Williams, Jones, Davies, & Binks, Reference Thomas, Williams, Jones, Davies and Binks2014).
A second explanation for the lack of input quantity effects in the morphosyntactic domain is that many of the children in the present study were beyond the relevant input threshold, that is, their input in Dutch was enough for variation to no longer matter. A number of studies have shown that once more than half their language exposure is in one language, bilingual children are likely to score as well as monolingual peers of that language (Bedore et al., Reference Bedore, Peña, Summers, Boerger, Resendiz, Greene and Gillam2012; Hoff et al., Reference Hoff, Core, Place, Rumiche, Senor and Parra2012). While there are some differences between these studies in terms of the exact percentage at which bilingual–monolingual differences disappear, all report figures around the 50% to 70% mark. On average, the children in our sample were exposed to Dutch for 65% of the time (SD = 22%), which means that input quantity may for many children have nonetheless been at a level at which it is less likely to predict morphosyntactic development. At the same time, however, such an explanation does not square with the findings for vocabulary, given that the majority of the children in our sample would be beyond the relevant threshold for vocabulary (e.g., Thordardottir, Reference Thordardottir2011), and yet a significant relation was observed there.
The contribution of working memory and other background variables to language outcomes
One of the other factors that emerged as an equally and sometimes more important predictor of children’s scores than input quality and quantity was nonverbal working memory. The observation that nonverbal working memory is related to bilingual children’s morphosyntactic development is in line with a recent study by Gangopadhyay et al. (Reference Gangopadhyay, Davidson, Weismer and Kaushanskaya2016), who found that nonverbal working memory predicted bilingual children’s ability to detect morphosyntactic violations whereas no such relationship was observed for the monolinguals. While the children in that study were older (8 to 10 years old) than the children in the present study, and the task (grammaticality judgment) was different from the one used here, the authors’ conclusion that limited proficiency may result in increased reliance on domain-general working memory skills fits nicely with the findings from the present study (see De Cat, Reference De Cat2018).
Most studies addressing the role of working memory in bilingual language development or including working memory as a covariate in their analysis focus on verbal rather than nonverbal working memory, and while the results are mixed, there is some evidence to suggest that verbal working memory is a predictor of children’s sentence comprehension abilities (e.g., Engel de Abreu & Gathercole, Reference Engel de Abreu and Gathercole2012; McDonald, Reference McDonald2008; Verhagen & Leseman, Reference Verhagen and Leseman2016; see Kidd, Reference Kidd2013, for review). It has been suggested that the working memory task used here, the Kaufman Hand Movements test, in part relies on verbal encoding strategies (Frencham, Fox, & Mayberry, Reference Frencham, Fox and Mayberry2003), and as such, its relation with language outcomes observed here may to some extent reflect an effect of verbal rather than nonverbal working memory. More specifically, when performing this task, adults have been found to create language-based labels to describe each hand movement and subsequently use these to recall the correct sequence (Frencham et al., Reference Frencham, Fox and Mayberry2003). Whether children, especially those as young as the participants in the present study, make use of a similar strategy remains unknown.
In terms of other background variables, SES as indexed by maternal education was found to predict children’s scores, although only on receptive vocabulary. This is in line with many earlier studies demonstrating an effect of SES on bilingual children’s language development for vocabulary (e.g., Cobo-Lewis et al., Reference Cobo-Lewis, Pearson, Eilers, Umbel, Oller and Eilers2002; Hoff, Reference Hoff2006). Similarly, the effect of gender observed here for the CELF word structure test, albeit only in the first analysis, is in line with other studies that have observed more advanced language skills in girls than in boys (e.g., Place & Hoff, Reference Place and Hoff2016), although it remains unclear why this effect should be found for this task only.
Implications
The findings of the present study provide further evidence that variation in input quantity and quality matters in bilingual language acquisition. More specifically, the extent to which simultaneous and early sequential bilingual children are exposed to input from non-native speakers impacts on their developing language skills. The present study provides new evidence that what matters is not necessarily the amount of non-native input relative to native input, but the degree of non-nativeness. Place and Hoff (Reference Place and Hoff2016, p. 17) note in their discussion that “the finding is not that non-native input is harmful; the finding is that it is less beneficial than native input.” Our findings are consonant with this claim. At the same time, our findings also show that non-native input from lower proficiency speakers is less beneficial than non-native input from higher proficiency speakers.
One implication of this finding is that the advice regularly given to immigrant parents that they should speak Dutch to their children may not be good advice. When parents do not speak Dutch well, our findings suggest that they had better not speak Dutch to the children but rather seek out opportunities for their children to interact with either more proficient non-native speakers or native speakers. Not only will investing valuable “language time” as a low-proficiency non-native speaker likely not have the desired effect on a child’s development of the majority language, several studies have shown that it is likely to have a negative impact on the development of the heritage language (De Houwer, Reference De Houwer2007; Paradis & Nicoladis, Reference Paradis and Nicoladis2007).
Limitations
There are a number of limitations to the present study. First, input quality was indexed using self-report only. While this is by no means uncommon in the field, and available data from a film retell task from a subset of the non-native parents suggested self-report was a valid means of operationalizing proficiency level, including more objective measures in future analyses may allow for a more accurate evaluation of the impact of this variable. Second, the sample was small given the heterogeneity of the group, in particular the subgroups in the family constellation analyses, and this likely reduced the study’s power. Third, the heterogeneous nature of the sample in terms of home languages meant that it was not possible to account for any effects of language transfer.
Conclusion
Bilingual children’s language experience varies in a multitude of ways, not only in how much they hear (or use) their two languages but also in terms of the quality of this language input. The results of the present study show that the impact of this variation on bilingual children’s (rate of) language development is multifaceted in that not all linguistic domains are affected similarly, background variables such as SES and working memory are sometimes equally good or better predictors of patterns of behavior, and the effects of input quantity and quality are intertwined. Which specific properties of non-native input are key in predicting bilingual children’s outcomes and whether some are more important than others has yet to be determined. The findings of the present study suggest that the impact of non-native input in bilingual children’s language is a matter of degree.
Acknowledgments
This research was supported by funding from the Education and Learning Sciences research impulse at Utrecht University, where all authors were previously employed. We are grateful to all participating preschools and their teachers, the children and their families, and to the various research assistants who helped with data collection and coding. Finally, we would like to acknowledge the constructive and informative comments provided by the reviewers.
Appendix A
Table A. Predictors of total scores on semantic fluency identified through a multiple regression analysis in which family constellation groups is based on parents’ native speaker status (cf. Table 5C)

Table B. Predictors of total scores on PPVT identified through a multiple regression analysis in which family constellation groups is based on parental language use (cf. Table 8A)

Table C. Predictors of total scores on CELF active vocabulary subtest identified through a multiple regression analysis in which family constellation groups is based on parental language use (cf. Table 8B)
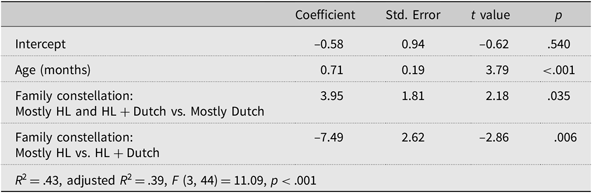
Table D. Predictors of total scores on CELF word structure subtest identified through a multiple regression analysis in which family constellation groups is based on parental language use (cf. Table 8D)















 Open access
Open access