


Recent research has established that written input can play a powerful role in the acquisition of a second language (L2) sound system (Bassetti, Reference Bassetti2006; Escudero, Hayes-Harb, & Mitterer, Reference Escudero, Hayes-Harb and Mitterer2008; Escudero, Simon, & Mulak, Reference Escudero, Simon and Mulak2014; Hayes-Harb & Cheng, Reference Hayes-Harb and Cheng2016; Hayes-Harb, Nicol, & Barker, Reference Hayes-Harb, Nicol and Barker2010; Showalter, Reference Showalter2018; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013). To date, the literature on the role of orthography in L2 word form learning has focused almost exclusively on the acquisition of phonemic contrasts in the target language. However, attaining target-like knowledge of a language entails acquiring not only its phoneme inventory, but also its phonological processes. For example, in German and many other languages (including Dutch, Russian, Turkish, and Catalan), obstruent voicing contrasts are neutralized in syllable-final position (e.g., hun[d]e dogs vs. hun[t] dog, both written with <d>). That is, these languages exhibit an alternation between voiced (e.g., [d]) and voiceless (e.g., [t]) phones such that the underlying forms of alternating words (and the way they are spelled) will not always match their surface forms.
It is important to note that the acquisition of a phonological process depends on the learner’s ability to make inferences about the relationship between the phonolexical (i.e., underlying) forms of words and their surface realizations based on information available in the linguistic input. For second language learners, this input often includes both auditory and written forms. To the extent that adult learners make use of written input to infer the phonological structure of L2 words, we might expect written forms to exert influence over the acquisition of alternations such as those produced by final devoicing processes. For example, for native English-speaking learners of German, the spelled forms of alternating words (i.e., words that undergo the final devoicing process) are potentially misleading with respect to the surface voicing of the final obstruents.
Some researchers have reported that adult native English speakers have difficulty acquiring German final devoicing, and have attributed the observed difficulty to the learners’ exposure to written input (Young-Scholten, Reference Young-Scholten, Burmeister, Piske and Rohde2002, Reference Young-Scholten2004; Young-Scholten & Langer, Reference Young-Scholten and Langer2015). In a recent study, Hayes-Harb, Brown, and Smith (Reference Hayes-Harb, Brown and Smith2018) provided direct empirical evidence for the causal relationship hypothesized by Young-Scholten and colleagues, demonstrating that exposure to words’ written forms can interfere with native English speakers’ ability to remember the surface voicing of final obstruents in a set of unsuffixed words exemplifying a German-like pattern of voicing neutralization. Crucially, however, this study focused on the acquisition of target-like patterns of surface voicing in final position only (e.g., learners were exposed to /tȿob/ [tȿop] and /tȿop/ [tȿop]). Their learners were not also exposed to (or tested on) word forms with the target obstruent in nonfinal position where the underlying voicing value is maintained (i.e., they did not also learn suffixed forms like /tȿobən/ [tȿobən]). As Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018) did not examine participants’ knowledge of alternating forms, the study was not informative as to the acquisition of the process of German final devoicing. As a result, it remains unclear whether orthographic input was helpful or detrimental with respect to the acquisition of the final devoicing process. Moreover, as van de Vijver and Baer-Henney (Reference van de Vijver and Baer-Henney2014) note, knowledge of phonological processes, such as German final devoicing, involves not only knowledge of both the words that alternate (and those that do not) but also productive knowledge of the process that extends to novel words. The present study thus represents a logical next step in advancing our understanding of the role of orthographic input in the acquisition of German final devoicing by adult L2 learners by focusing not on the ability to remember a trained set of (non-alternating) surface forms (as in Hayes-Harb et al., Reference Hayes-Harb, Brown and Smith2018) but rather on the ability to remember a set of alternating surface forms (Experiment 1) and on the ability to apply the devoicing process to new word forms (i.e., generalization; Experiment 2).
Orthographic input in L2 phonolexical development
A growing body of research has examined the influence of orthographic input on the acquisition of L2 segmental contrasts. Some researchers have observed that learners can benefit from written input when learning the phonological forms of L2 words containing novel contrasts that are difficult to perceive on the basis of auditory input alone. In particular, learners exposed to systematic graphemic information representing a novel contrast exhibited more accurate memory for the words’ phonological forms than learners who were not exposed to orthographic information (Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013). These studies typically employ a mini-lexicon paradigm, wherein naïve adult participants are taught a set of L2 words (and/or nonwords) involving the novel contrast of interest, and exposure to the words’ spelled forms is manipulated between groups of participants. These studies have demonstrated that for some novel contrasts, the availability of written input can support the establishment of phonolexical representations for newly learned words that encode the contrast. Examples include the English /æ/-/ε/ contrast for native Dutch speakers (Escudero et al., Reference Escudero, Hayes-Harb and Mitterer2008), Dutch vowel contrasts for native Spanish speakers (Escudero et al., Reference Escudero, Simon and Mulak2014), and Mandarin tone contrasts for native English speakers (Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2013).
By contrast, other researchers have reported no beneficial effect of exposure to orthographic input on the acquisition of a novel phonological contrast (Durham, Hayes-Harb, Barrios, & Showalter, Reference Durham, Hayes-Harb, Barrios and Showalter2016; Hayes-Harb & Hacking, Reference Hayes-Harb and Hacking2015; Pytlyk, Reference Pytlyk2011; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2015; Simon, Chambless, & Kickhöfel Alves, Reference Simon, Chambless and Kickhöfel Alves2010) or have demonstrated that orthographic input may interfere with the acquisition of target-like L2 phonological representations, particularly when the written input provides learners with “misleading” information about the phonological forms of new words. Interference effects have been reported when L2 orthographic conventions differ from those of the native language (L1; Bassetti, Reference Bassetti2006), when grapheme–phoneme correspondences (i.e., the mapping[s] between grapheme and phoneme) are different in the L1 and L2 (Hayes-Harb & Cheng, Reference Hayes-Harb and Cheng2016; Hayes-Harb et al., Reference Hayes-Harb, Nicol and Barker2010; Showalter, Reference Showalter2018), or when the L1 and L2 differ in whether or not familiar graphemes signal a contrast (Escudero et al., Reference Escudero, Simon and Mulak2014). Other factors, including the degree of perceptual difficulty posed by the contrast (Escudero, Reference Escudero2015) and the transparency of the L2 writing system (Mok, Lee, Li, & Xu, Reference Mok, Lee, Li and Xu2018), have also been found to modulate written input effects.
To date, this literature has focused almost exclusively on the acquisition of phonological contrasts; few studies have examined its influence on the acquisition of L2 phonological processes. In the following section, we review literature on the acquisition of morphophonological alternations, in particular voicing alternations in German, and what is presently known about the role of orthography in the acquisition of these alternations by adult L2 learners.
The acquisition of German final devoicing
Like English, the German phoneme inventory contains both voiced and voiceless obstruents (e.g., /p/-/b/, /f/-/v/, etc.). However, while obstruents can contrast in voicing in other positions, only voiceless obstruents are permitted in syllable-final position in German (Grantham O’Brien & Fagan, Reference Grantham O’Brien and Fagan2016). In final position, underlyingly voiced obstruents are produced as their voiceless counterparts (e.g., the word verb is spelled <verben> and <verb> in the plural and singular form and is pronounced [vεɐ̯bən] and [vεɐ̯p], respectively). This phonological pattern has traditionally been treated as one of final obstruent devoicing (cf. Jessen & Ringen, Reference Jessen and Ringen2002). It is worth noting that there has been considerable debate about the completeness of the voicing neutralization, with many researchers providing evidence from production or perception that underlying voicing contrasts are preserved to some extent in surface forms (Kleber, John, & Harrington, Reference Kleber, John and Harrington2010; Port & O’Dell, Reference Port and O’Dell1985; Roettger, Winter, Grawunder, Kirby, & Grice, Reference Roettger, Winter, Grawunder, Kirby and Grice2014). Nevertheless, the phonological process of final obstruent devoicing in German introduces a morphophonological alternation in voicing (i.e., variation in the surface phonetic form of certain stems as a result of the application of a morphological process) across various morphological paradigms in German that is not found and English and, thus, must be acquired by an English learner of German if he or she is to attain target-like knowledge of German.
In non-alternating words, the underlying and surface forms of morphemes are identical in both the singular and the plural (e.g., the word stain is spelled <flecken> and <fleck> in the plural and singular form and is pronounced [flεkən] and [flεk], respectively). In alternating words, however, the underlying voicing is preserved in morphologically complex forms (e.g., [vεɐ̯bən] verb.plural where the /b/ is resyllabified as an onset), but is devoiced in final position (e.g., [vεɐ̯p], verb.singular). The traditional account from generative phonology is that observing alternations in the ambient language should lead language learners to posit underlying representations that are different from surface forms, as well as a phonological process that allows the surface forms to be derived from the underlying forms. Moreover, the existence of non-alternating forms, in which nonfinal obstruents surface as voiceless, should provide the learner with important evidence that a process of intervocalic voicing is untenable. It is important to note that the German final devoicing process is not indicated orthographically. That is, despite the neutralization of voicing in the auditory input, the written form of verb <verb> represents the underlying voicing value of the stem-final obstruent phoneme. As a result, for learners with access to written input, orthography is potentially misleading with respect to the surface voicing of underlyingly voiced final obstruents. Alternatively, written input may provide a clue to the underlying voicing of alternating forms; we return to this point in more detail in the Discussion section.
Morphophonological alternations, such as German final devoicing, are productive in adult native speakers of a language. That is, adults have tacit knowledge of these processes as demonstrated by their ability to extend the pattern of alternation to other known lexical items, as well as to nonce items (Berko, Reference Berko1958). However, as morphophonological alternations vary cross-linguistically, language learners (L1 and L2) must acquire knowledge of them through exposure to the language. The discovery and encoding of alternations by language learners is a complex task that requires “comparison of morphologically related forms, choosing a basic or underlying form, and learning a grammar that can generate the various surface realizations” (Albright & Hayes, Reference Albright, Hayes, Goldsmith, Riggle and Yu2011, p. 672). While some researchers report that certain morphophonemic alternations are acquired relatively early (e.g., vowel harmony in the accusative suffix in Turkish, Aksu-Koç, & Slobin, Reference Aksu-Koç, Slobin and Slobin1985; vowel and consonant alternations in Northern Saami, Bals, Reference Bals2004; vowel alternations in European Portuguese, Fikkert & Freitas, Reference Fikkert and Freitas2006), others have claimed that adult-like mastery does not emerge until relatively late (Pierrehumbert, Reference Pierrehumbert2003). A number of factors, such as phonetic grounding, frequency, locality, amount of exposure, and knowledge of abstract features, have been shown to influence the acquisition process and generalization behavior (Baer-Henney & van de Vijver, Reference Baer-Henney and van de Vijver2012; Cristia & Seidl, Reference Cristia and Seidl2008; van de Vijver & Baer-Henney, Reference van de Vijver and Baer-Henney2014; Wilson, Reference Wilson2006).
Buckler and Fikkert (Reference Buckler and Fikkert2016) investigated how voicing alternations are represented in the lexicon of Dutch and German 3-year-olds. Like German, Dutch also exhibits final obstruent devoicing and voicing alternations across morphological paradigms. That is, a syllable-final voiceless obstruent in the singular of a noun may correspond in the plural to a voiced obstruent (e.g., <bed> [bεt] bed – <bedden> [bεdən] beds). The authors employed a visual fixation procedure to measure the child’s sensitivity to mispronunciations of voicing word-medially in both monomorphemic words and both alternating and non-alternating bimorphemic plural forms. They hoped that this method would allow them to detect learners’ knowledge about the voicing alternations in the two languages in advance of their production ability. The German children demonstrated robust representation of voicing alternations within morphological paradigms (i.e., they demonstrated knowledge of which lexical items alternated and which did not, and word recognition was inhibited by mispronunciations). The Dutch children, in contrast, exhibited evidence of overgeneralization of the voicing alternation (e.g., they showed more recognition of plural words with [d], regardless of whether this was the correct pronunciation of the words or a mispronunciation), suggesting that they were aware of the voicing alternation, but preferred for the alternation to occur across all words. The authors attribute the earlier mastery of the voicing alternation by German than Dutch peers to differences in the robustness of cues to voicing and the voicing alternation in the phonological system and across the lexicon.
Other researchers have employed “wug tests” (Berko, Reference Berko1958) to investigate the productive mastery of voicing alternations in children learning German and Dutch. These studies have typically observed generalization errors, even when the same child can correctly deploy variants of familiar words (Kerkhoff, Reference Kerkhoff2007; van de Vijver & Baer-Henney, Reference van de Vijver and Baer-Henney2011; Zamuner, Kerkhoff, & Fikkert, Reference Zamuner, Kerkhoff and Fikkert2006, Reference Zamuner, Kerkhoff and Fikkert2012). For example, van de Vijver and Baer-Henney (Reference van de Vijver and Baer-Henney2011) examined the acquisition of voicing and vowel alternations in German-learning children. In the first experiment involving a reverse wug test, a group of 5-year-old German-learning children were asked to produce the singular form for plural words and nonwords from either a voicing alternation context, a vowel alternation context, or both. The children were largely successful in providing the singular form for known plural words, demonstrating they know which lexical items alternate and which do not, as well as which type of alternation the words undergo. However, they failed to provide a singular for plural nonwords (repeating the plural form instead), suggesting that their knowledge of the alternations is not yet productive at this age. In a second experiment, the children were asked to provide the plural for singular words and nonwords. While they were more accurate at providing a plural for a word than a nonword, they were able to provide a plural for some nonword stimuli as well, generalizing alternations from pairs of words to nonwords. They were, however, more likely to generalize the voicing alternation, which is phonetically motivated, than the vowel alternation, which is not. However, alternations were dispreferred in nonwords across both experiments. Similar findings have been reported from wug tests examining the productivity of Dutch-learning children’s knowledge of final obstruent devoicing (Kerkhoff, Reference Kerkhoff2007; Zamuner et al., Reference Zamuner, Kerkhoff and Fikkert2006, Reference Zamuner, Kerkhoff and Fikkert2012).
L2 learners have been found to devoice word-final consonants in speech production even when devoicing is not part of either the L1 or the L2 grammars (see, e.g., Broselow, Chen, & Wang, Reference Broselow, Chen and Wang1998; Eckman, Reference Eckman1981; Hayes-Harb, Smith, Bent, & Bradlow, Reference Hayes-Harb, Smith, Bent and Bradlow2008). This phenomenon has been attributed to the relative “unmarkedness” of final devoicing, with relevant predictions formalized in the markedness differential hypothesis (Eckman, Reference Eckman1977). Nonetheless, studies that have investigated the acquisition of German final devoicing by adult L2 learners have typically reported non-target-like mastery (e.g., Hayes-Harb et al., Reference Hayes-Harb, Brown and Smith2018; Smith & Peterson, Reference Smith and Peterson2012; Young-Scholten, Reference Young-Scholten, Burmeister, Piske and Rohde2002). Smith and Peterson (Reference Smith and Peterson2012) investigated the acquisition of German final devoicing by native English adult learners of German as a L2. Learners’ productions of orthographically similar English and German words were compared along several relevant acoustic measures known to vary with the voicing of final segments. As a group, the learners performed differently in German and English, suggesting that they (or at least some of them) had learned the final devoicing pattern to some degree and had modified one or more relevant acoustic parameters in their German production. There was considerable individual variation, however. Only a few participants performed within the native range, while most showed only limited progress.
Young-Scholten (Reference Young-Scholten, Burmeister, Piske and Rohde2002) reported longitudinal data on the phonological acquisition of three native-English-speaking adolescents at various points during their stay in Germany as exchange students. She observed that the learners differed in their success in acquiring the German final devoicing pattern. She noted that the individuals who exhibited the most progress in learning the pattern were those who reported the least amount of exposure to written input. While this research did not establish a causal relationship between orthographic input and failure to acquire German final devoicing, it is consistent with the hypothesis that the transfer of native English speakers’ final voicing contrast is reinforced by misleading orthographic representations of German words.
Building on Young-Scholten’s finding, Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018) directly investigated the hypothesis that exposure to German written forms interferes with learners’ ability to establish target-like surface forms for underlyingly voiced final obstruents. Twenty-six native English speakers with no prior German language learning experience were taught a German-like mini-lexicon consisting of 12 auditory nonwords forming six minimal pairs differing in the underlying voicing of the word-final obstruents. Subjects were randomly assigned to one of two word learning conditions: No Spell and Spell. During the word learning phase, each nonword was associated with a pictured “meaning.” The Spell group additionally saw the written form of each word displayed below the image. At test, participants in the Spell group were more likely than participants in the No Spell group to produce the words that were spelled with final voiced obstruent letters with a voiced final obstruent, suggesting that orthographic input may have overridden the auditory input for participants in this group. Moreover, this finding was replicated in a second group of participants even though these participants received explicit instruction about German spelling in an effort to prevent the interference from written input in Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018, Experiment 2). Their study thus established a causal link between knowledge of a words’ spelled forms and non-target-like surface voicing in L2 German acquisition by native English speakers. However, it did not investigate the acquisition of the process of final obstruent devoicing in German. As Young-Scholten (Reference Young-Scholten, Burmeister, Piske and Rohde2002, p. 268) noted, it is not possible to determine what a learner’s underlying representations are on the basis of her or his production of just one of the alternants. To this end, in the present study we investigate the influence of orthographic input in the L2 acquisition of the German final devoicing process by native English speakers. In Experiment 1, we ask whether naïve adult learners demonstrate a German-like pattern of final devoicing when there is evidence in the auditory input for both the voiced and the voiceless alternants (Research Question 1; RQ1), and whether orthographic input interferes with the acquisition of the phonological process even when evidence of the alternation is available in the auditory input (Research Question 2; RQ2). In Experiment 2, we replicate the findings from Experiment 1 with a new set of participants, then ask whether these naïve adult learners can extend their knowledge of a German-like pattern of final devoicing to new word forms (Research Question 3; RQ3), and whether orthographic input interferes with the generalization of the phonological process to novel forms (Research Question 4; RQ4).
Experiment 1: acquisition of the final devoicing alternation
Participants
Twenty native speakers of English (4 male, 16 female; mean age = 22.3 years; range = 18–29 years) with no prior experience learning German or any other final-devoicing language were recruited from undergraduate linguistics courses at the University of Utah and earned course credit for their participation. An additional 2 participants (one from each word learning condition) completed the study, but their data is not considered here because these 2 participants did not pass the criterion test (details below). None of the participants reported having a hearing, speech, language processing, or neurological disorder. Subjects were randomly assigned to one of two word learning conditions: the Orthography group or the No Orthography group.
Stimuli
Stimuli consisted of 12 German-like words, including some actual German words as well as nonwords. All words were of the form consonant–consonant–vowel–consonant (CCVC), with the onsets [kȿ], [tȿ], or [ʃt], the vowels [o], [i], [a], or [aɪ], and the codas [t/d], [p/b], and [k/g] (see Appendix A). Half of the words were alternating (i.e., ending in a voiced stop consonant) and the other half were non-alternating (i.e., ending in a voiceless stop consonant). Previous artificial lexicon studies have included minimal pairs in their stimulus sets, typically for the purpose of emphasizing the relevant phonological contrasts in the input to participants. Here, we did not include final voiced and voiceless minimal pairs, as Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018) noted that doing so may have artificially enhanced the influence of orthographic input in their study. To create morphologically complex forms that provide evidence for the underlying voicing of the words, we also presented words in their “pseudo-plural” forms. German-like plural forms of each of the words were created by adding the suffix /-en/ to the singular form (e.g., /kȿak/ [kȿak] penguin – /kȿaken/ [kȿakən] penguins; /tȿob/ [tȿop] fork – /tȿoben/ [tȿobən] forks). Two female native speakers of German were recorded reading the words in their singular and plural forms four times each; two tokens (the second and third production) of the singular and plural forms of each word were selected from each talker for the experiment, for a total of four auditory tokens of each word in the singular and four in the plural form. The words were randomly paired with visual referents portraying their meanings (line drawings of vehicles, animals, clothing, etc.; Snodgrass & Vanderwart, Reference Snodgrass and Vanderwart1980). Participants in the Orthography group additionally saw the written form of each word below the image. The full set of auditory and visual stimuli is provided in Appendix A. Auditory and visual stimuli for both experiments have been made available at http://www.iris-database.org.
Procedure
We employed an artificial lexicon study format consisting of a word learning phase, a criterion test, and a final production test. During the experimental procedure, the participant was seated in a sound-attenuated booth. Auditory stimuli were played at a comfortable listening level over headphones while visual stimuli were presented on a computer screen in front of them. The visual and auditory stimuli were presented using DMDX experiment presentation software (Forster & Forster, Reference Forster and Forster2003). A keyboard and a microphone were used to record the responses during the criterion test and the final test, respectively. Following the experimental task, participants completed a language background questionnaire. The entire visit lasted 40–50 min.
Word learning phase
During the word learning phase, participants were exposed to the auditory forms of the words and saw a corresponding image depicting the words’ meanings. Participants in the Orthography group additionally saw the spelled form of the word displayed immediately below the image. In a given exposure trial, participants first heard the singular form of the word and saw its corresponding meaning displayed for 2000 ms. Then, 500 ms later, the auditory and visual for the plural form of the same word were displayed for 2000 ms. This was followed by a 1500 ms break before the next trial began. Figure 1 provides an example of a word learning trial for the Orthography group. Participants in the No Orthography condition did not see the written forms displayed below the images during word learning.
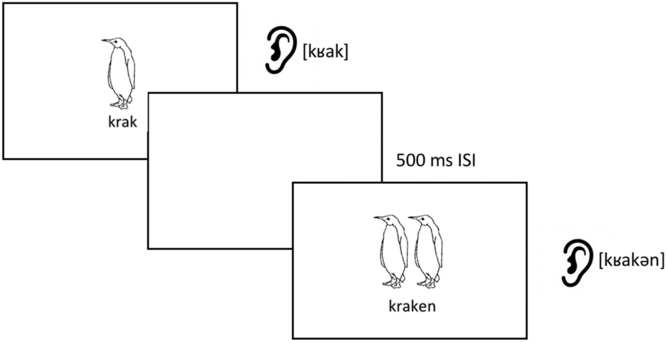
Figure 1. Example word learning trial for the Orthography group for Experiment 1 and Experiment 2A.
A word learning block consisted of the random-ordered presentation of each of the 12 words 4 times (once with each of 4 unique auditory word tokens; 2 speakers × 2 tokens/speaker) in both their singular and plural forms, for a total of 48 singular and 48 plural forms per block. The block was presented 4 times, for a total of 192 singular and 192 plural forms per iteration of the word learning phase. Each block was separated by a participant-controlled break. No response was required of participants during this phase. Participants were instructed to learn the new words and their meanings.
Criterion test phase
Following the word learning phase, participants completed a criterion test to ensure that they had sufficient knowledge of the words to complete the final test. The criterion test consisted of a two-way forced-choice auditory word-picture matching task, in which participants heard the singular form of a word and saw an image and were asked to decide if the auditory form and the image matched or not by pressing keys labeled YES or NO on a keyboard. The criterion test consisted of each of the 12 singular forms presented once in a match trial and once in a mismatch trial (24 trials total), with trials presented in a random order. Figure 2 illustrates a match and mismatch trial from the criterion test. It is important to note that the criterion test only tested participants’ ability to detect mismatches among very different words. Subjects passed the criterion test when they reached 90% accuracy or better.

Figure 2. Example of a match and a mismatch trial from the criterion test for Experiment 1 and Experiment 2A.
Picture naming test
In the final test, participants completed a picture naming task. On a given trial, participants saw an image and were asked to produce the auditory form that corresponded to that image. They had 6 s to produce the word before the next trial commenced. The test consisted of two blocks. In the first block, two productions of each of the 12 singular forms were elicited in a random order. In the second block, two productions of each of the 12 plural forms were elicited, for a total of 48 productions per participant. Figure 3 provides an example of the singular and plural test trials.

Figure 3. Examples of the singular and plural test trials for Experiment 1 and Experiment 2A.
Coding
Each of the 960 productions (12 words × 2 morphological conditions × 2 tokens × 20 speakers) elicited during the final test was extracted from the long sound file with the help of PRAAT software (Boersma & Weenink, Reference Boersma and Weenink2018) and were coded by the authors for their “global correctness.” Globally correct productions contained final consonants with the target place and manner, and differed from the target by no more than one segment (added, deleted, or substituted) beyond the voicing of the final segment (e.g., for the target /ʃtop/ the following productions were accepted as globally correct: [ʃtop], [stop], [ʃtob], [ʃtɑp], [stob], but not [stɑp]). Both authors separately judged each auditory token for global correctness. When there were disagreements, the conflict was resolved by consulting a third individual. Out of 960 total speech tokens produced, 801 (83.4%) were judged to be globally correct and were submitted to coding. There was no difference between the average percentage of globally correct productions for the Orthography group (84.4%) and the No Orthography group (82.5%); t (18) = –0.29, p = .778.
In order to determine whether participants produced singular (final) and plural (nonfinal) segments as voiced or voiceless, an additional 32 participants from the same population (15 male, 17 female; mean age = 22.03 years; range = 18–27 years) were recruited as “coders” and were asked to identify the target consonant in each production. The choice to use native English-speaking coders with similar phonetic/phonological systems to categorize the productions as voiced or voiceless, as opposed to native German-speaking coders or acoustic analyses, reflects our interest not in whether our initial-state learners have acquired the phonetics of German final devoicing, but rather whether they have learned the phonological pattern of alternation and produced what they intended to be voiced or voiceless final obstruent categories. All globally correct productions from each participant were presented to coders in a two-way forced-choice task. Coders heard the productions of the German-like words ending in either a voiced or a voiceless final obstruent and were asked to judge whether the final segment was voiced or voiceless (e.g., heard tro[b/p] and judged whether the final segment was a <b> or a <p>). They completed four practice trials with additional words and final/nonfinal consonants not related to the task (e.g., heard [pel] and judged whether the final segment was a <l> vs. <r>) prior to completing the test in order to ensure their understanding of the task. In order to reduce the tokens judged by each coder to a manageable number, not all tokens were presented to all coders. Each globally accurate production of a singular form was randomly assigned to one of four “singular” lists. Globally accurate productions of each plural form were also distributed randomly and equally across four “plural” lists. Which singular and which plural lists were coded, as well as the order of presentation among lists, was counterbalanced across coders, such that each of the four singular lists was paired with each of the four plural lists twice (once preceding it, and once following it). Ultimately, each token was coded by eight coders, and each coder coded 200 or 201 tokens.
Results of Experiment 1
Experiment 1 was designed to address two research questions:
RQ1: Do naïve adult learners demonstrate a German-like pattern of final devoicing when there is evidence in the auditory input for both the voiced and the voiceless alternants?
RQ2: Does orthographic input interfere with the acquisition of the phonological process even when evidence of the alternation is available in the auditory input?
The answer to the first research question lies in a differential effect of morphological condition on the two levels of underlying voicing, and crucially, more voiceless productions in the singular (unsuffixed) than the plural (suffixed) forms of the underlyingly voiced words.
The answer to the second research question comes from a comparison of the performance of the Orthography and No Orthography groups with respect to evidence of the acquisition of devoicing. A three-way interaction (Underlying Voicing × Morphological Condition × Word Learning Condition), where the Orthography group does not acquire the final devoicing process as the No Orthography group does, would provide evidence of interference from written input.
Figure 4 presents the mean proportion of voiceless productions by word learning condition, underlying voicing, and morphological condition for Experiment 1. As expected, participants in both groups produced underlyingly voiceless obstruents as voiceless the majority of the time. Moreover, underlyingly voiceless (non-alternating) words varied little as a function of morphological condition (underlyingly voiceless singular = .89, plural = .82 for the No Orthography group and singular = .94, plural = .89 for the Orthography group). Relative to the non-alternating words, words containing underlyingly voiced consonants were produced as voiceless relatively less often and the proportion of voiceless productions varied considerably more as a function of word learning group and morphological condition (No Orthography, singular = .52, plural = .29; Orthography, singular = .25, plural = .11).

Figure 4. Mean proportion voiceless productions by word learning group, underlying voicing, and morphological condition for Experiment 1. Error bars represent one SE of the mean.
To analyze the data from our two word learning groups of interest, we first performed an omnibus analysis using generalized mixed-effects models with crossed random effects for speaker, word, and coder using the lme4 package (version 1.1–15; Bates, Maechler, Bolker, & Walker, Reference Bates, Maechler, Bolker and Walker2015) of R (version 3.3.1). The model was fit with voiceless productions as the dependent variable (coded as voiceless = 1, voiced = 0 for each observation) for which a logistic linking function was used. The analysis included contrast coded fixed effects for word learning condition (–.5 = No Orthography, .5 = Orthography), underlying voicing (–.5 = voiced, .5 = voiceless), and morphological condition (–.5 = plural, .5 = singular) in a 2 × 2 × 2 factorial design. Random effects were fit using a “maximal” random effects structure (Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013), including random intercepts for speaker, word, and coder, by-speaker random slopes for underlying voicing and morphological condition, by-word random slopes for word learning condition and morphological condition, and by-coder random slopes for underlying voicing, morphological condition, and word learning condition. Models were fit using a maximum likelihood technique. Planned comparisons were conducted using simultaneous tests for general linear hypotheses with the multcomp package in R (Hothorn, Bretz, & Westfall, Reference Hothorn, Bretz and Westfall2008). P-values were adjusted using the single-step method and a family-wise error rate protection via Bonferroni correction. Data and analysis code for both experiments have been made available at https://dataverse.org/.
Results indicated that participants produced more voiceless productions for underlyingly voiceless than for underlyingly voiced words (main effect of underlying voicing) and for unsuffixed (singular) than for suffixed (plural) forms (main effect of morphological condition). These main effects were qualified by a two-way interaction of word learning condition and underlying voicing and a three-way interaction of word learning condition, underlying voicing, and morphological condition, suggesting that the magnitude of the devoicing effect varied as a function of word learning group. No other main effects or interactions were significant. The results of the omnibus analysis are reported in Table 1a.
Table 1. (a) Mixed effects model omnibus analysis examining the effects of underlying voicing, morphological condition, and word learning condition, and individual mixed effects analyses for (b) the No Orthography group and (c) the Orthography group for Experiment 1

Note: All factors were coded using contrast coding, as follows: word learning condition (–.5 = No Orthography, .5 = Orthography), underlying voicing (–.5 = voiced, .5 = voiceless), morphological condition (–.5 = plural, .5 = singular).
a Omnibus analysis model formula: Voiceless ~ Underlying Voicing * Morphological Condition * Word Learning Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Word Learning Condition + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition + Word Learning Condition | CoderID).
b No Orthography group model formula: Voiceless ~ Underlying Voicing * Morphological Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition | CoderID).
c Orthography group model formula: Voiceless ~ Underlying Voicing * Morphological Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition | CoderID).
To better understand this three-way interaction and to directly address our first research question, we conducted follow-up analyses to examine the effects of underlying voicing and morphological condition separately for the No Orthography and Orthography groups. The model of the data subset by word learning group included fixed effects underlying voicing and morphological condition and their interaction, as well as random intercepts for speaker, word, coder, and by-speaker and by-coder random slopes for underlying voicing and morphological condition, and by-word random slopes for morphological condition.
Fixed effects for the No Orthography group indicated that more voiceless productions were observed for underlyingly voiceless than for underlyingly voiced words (main effect of underlying voicing) and for unsuffixed (singular) than for suffixed (plural) forms (main effect of morphological condition). The interaction of morphological condition and underlying voicing was marginal. Although this interaction was not significant, it was the case that the simple effect of morphological condition within the No Orthography group was significant for underlyingly voiced words (estimate = 1.32, SE = 0.37, z = 3.53, p = .003) and nonsignificant for underlyingly voiceless words (estimate = 1.56, SE = 1.39, z = 1.449, p = .62), suggesting that a differential effect of morphological condition was observed for the two levels of underlying voicing. The results of the No Orthography group analysis are reported in Table 1b.
Significant main effects of underlying voicing and of morphological condition were also observed for the Orthography group. Of importance here, the interaction of morphological condition and underlying voicing was not significant, nor were the simple effects of morphological condition observed for underlyingly voiced (estimate = 0.75, SE = 0.38, z = 1.972, p = .28) or underlyingly voiceless words (estimate = 0.74, SE = 0.42, z = 1.785, p = .39), suggesting that, unlike the Orthography group, no statistical evidence for the acquisition of the final devoicing process was observed for the Orthography group. The results of the Orthography group analysis are reported in Table 1c.
Pairwise comparisons of the word learning groups confirmed that the two groups differed in the voiceless productions made for the underlyingly voiced words in the singular (estimate = –2.61, SE = 0.61, z = –4.269, p < .001) and plural (estimate =–2.04, SE = 0.62, z = –3.274, p < .01), with the Orthography group producing fewer voiceless productions than the No Orthography group in each case. As expected, the groups did not differ in the voiceless productions made for the underlyingly voiceless words in the singular (estimate = 0.95, SE = 0.59, z = 1.616, p = .50) or the plural (estimate = 0.77, SE = 0.61, z = 1.265, p = .75).
Discussion of Experiment 1
In Experiment 1 we asked whether native English-speaking adult L2 learners acquire a German-like pattern of final devoicing when they have auditory evidence for both the voiced and the voiceless alternants (RQ1). We observed that both groups of participants produced more underlyingly voiced forms as voiceless in the singular than the plural condition, suggesting that they picked up on the alternation in the auditory input to some degree. However, the pattern was only significant for the No Orthography group.
We also asked whether orthographic input interferes with the acquisition of the phonological process even when evidence of the alternation is available in the auditory input (RQ2). The answer to this question appears to be “yes.” The significant three-way interaction of word learning condition, morphological condition, and underlying voicing indicates that the alternation was learned differentially as a result of exposure (or not) to written input. In particular, our follow-up analyses suggest that the No Orthography group, but not the Orthography group, showed evidence of having acquired the final devoicing process. Moreover, a comparison of the two word learning groups revealed that learners who had been exposed to written forms erroneously produced more underlyingly voiced stops as voiced word-finally (i.e., in the singular) than those who did not see written forms, corroborating past findings (Hayes-Harb et al., Reference Hayes-Harb, Brown and Smith2018). However, the Orthography group correctly produced more underlyingly voiced obstruents as voiced in the plural than did participants in the No Orthography group. This pattern suggests a potential trade-off of exposure to written input, which will be taken up in further detail in the General Discussion section.
Our findings thus far are restricted to learners’ performance on trained items. That is, participants were exposed to words in both their suffixed (plural) and unsuffixed (singular) forms and were tested on the same set of singular and plural words. As a result, we cannot conclude that participants have necessarily acquired a phonological process. Instead, they may have simply memorized which auditory forms match which images. The hallmark of having learned a phonological process is productivity, or the ability to generalize a pattern beyond known forms. In order to ensure the robustness of our findings from Experiment 1, as well as to investigate whether learners have acquired knowledge of a phonological process that generalizes to a set of untrained items, we conducted a second experiment. Experiment 2A involves a direct replication of Experiment 1 in a new group of learners and coders, with the exception that coding was carried out online rather than in the laboratory. Experiment 2B addresses the nature of the knowledge acquired by the learners. In Experiment 2B, participants were exposed to a new set of words in only their plural forms (which provides evidence for the underlying form of the target obstruents). At test, they were asked to name the words in their singular forms, providing an opportunity to produce final devoicing for underlyingly voiced final obstruents. If learners inferred a phonological process that extends across the lexicon, rather than memorized patterns of surface voicing for trained items, underlyingly voiced obstruents in new plural words should be devoiced in their unsuffixed (i.e., singular) form when they occur in word-final position.
Experiment 2: generalization of the final devoicing alternation
Participants
Participants were 20 new native English speakers with no prior experience with German or any other final devoicing language (8 male, 11 female, 1 other; mean age = 24.5 years; range = 18–51 years). They met the same inclusionary criteria as participants in Experiment 1. They were randomly assigned to one of two word learning conditions: Orthography or No Orthography.
Stimuli
The stimuli used in Experiment 2A were identical to those used in Experiment 1. Only one of the two speakers from Experiment 1 was able to return to record the new words for Experiment 2B, so the generalization words in Experiment 2B were produced by one familiar and one new female speaker. The new words were paired with six new images portraying their meanings. The full set of stimuli used in Experiment 2B is provided in Appendix B. Experiment 2B stimuli consisted of six German-like words of the form C(C)VC, with the onsets [fȿ], [bȿ], [gl], [f], or [sm], the vowels [o], [i], [a], or [u], and the codas [t/d], [p/b], or [k/g].
Procedure
The procedure for Experiment 2A was identical to that of Experiment 1. Following Experiment 2A, participants immediately participated in Experiment 2B.
Word learning phase (Experiment 2B)
During the word learning phase, participants were exposed to the auditory forms of the six new German-like words in their plural forms, and a picture depicting the word’s meaning would appear on the screen in front of them. As for Experiment 2A, participants in the Orthography group additionally saw the spelled form of the word below the image. Figure 5 provides an example of a word learning trial for the Orthography group.

Figure 5. Example of a word learning trial for the Orthography group in Experiment 2B.
Each of the six words was presented in its plural form in a random order four times per block, with each presentation of a word involving a unique production from the two female German speakers. There were four blocks per word learning cycle separated by a participant-controlled break for a total of 96 trials.
Criterion test phase (Experiment 2B)
Participants completed a criterion test of 12 trials (6 match and 6 mismatch) presented in a random order to ensure that they had sufficient knowledge of the new words to complete the final test. Figure 6 shows an example of a match and a mismatch trial from the criterion test for Experiment 2B.

Figure 6. An example of a match and a mismatch trial from the criterion test for Experiment 2B.
Picture naming test (Experiment 2B)
Two productions of each of the 6 singular forms followed by the 6 plural forms were elicited for a total of 24 productions per participant for Experiment 2B. Figure 7 provides an example of the singular and plural test trials.

Figure 7. An example of the singular and plural test trials for Experiment 2B.
Coding
PRAAT software (Boersma & Weenink, Reference Boersma and Weenink2018) was used to extract each of the 1,440 productions (18 words × 2 morphological conditions × 2 tokens × 20 speakers) elicited during the final tests of Experiments 2A and 2B. Globally correct productions (1,076/1,440 or 74.7% of productions) again had the target place and manner of the final consonant and differed from the target by no more than one segment (added/changed/deleted) beyond the voicing of the final segment. Global accuracy for Experiment 2A was 76.7% (737/960 productions), and for Experiment 2B it was 70.6% (339/480). It is worth noting that this is somewhat lower than global accuracy in Experiment 1; however, the mean global accuracy in Experiments 2A/2B for the No Orthography group (71.8%) did not differ significantly from the Orthography group (77.6%); t (18) = –0.99, p = .33.
All globally correct productions from each participant were presented to a new group of 75 coders (40 male, 35 female; mean age = 22.09 years; range = 18–46 years) in a two-way forced-choice task. Data was collected online via Qualtrics (www.qualtrics.com), and tokens were randomly assigned to coders. Each coder judged approximately 200 productions total (mean = 196; range = 192–199), and each individual production was coded by between 6 and 21 coders (mean = 14). Twelve non-test items involving three-syllable English words (4 words × 3 repetitions) were interspersed among the test items in both the singular and the plural blocks as a sound check and to ensure that the participants were attending sufficiently to the task. The words were presented auditorily, and subjects were required to select the word that they heard from among four options: arrival, tornado, determine, and seventeen. Only a single error was made on these items by one participant, allowing us to be fairly confident that all the coders performed the task with care.
Results of Experiment 2
Experiment 2A
The mean proportion of voiceless productions by word learning condition, underlying voicing, and morphological condition for Experiment 2A are shown in Figure 8. As expected, participants in both groups produced underlyingly voiceless obstruents as voiceless the majority of the time and the proportion of voiceless consonants produced in underlyingly voiceless (non-alternating) words varied little as a function of morphological condition (underlyingly voiceless singular = .92, plural = .85 for the No Orthography group and singular = .94, plural = .93 for the Orthography group). Relative to the non-alternating words, words containing underlyingly voiced consonants were produced as voiceless relatively less often and the proportion of voiceless productions varied considerably more as a function of word learning group and morphological condition (No Orthography, singular = .79, plural = .54; Orthography, singular = .43, plural = .35).

Figure 8. Mean proportion voiceless productions by word learning group, underlying voicing, and morphological condition for Experiment 2A. Error bars represent one SE of the mean.
It is also worth noting that the data look quite similar to the data from Experiment 1, particularly for the No Orthography group, with a few minor differences. Relative to the participants in the Orthography group in Experiment 1, the participants in the Orthography group in Experiment 2A produced numerically more voiceless productions for three of the four conditions. The magnitude of the difference between the two morphological conditions for the underlyingly voiced words is also smaller in Experiment 2A than in Experiment 1. It is likely that these differences reflect individual variation in how evidence from written input impacts learners’ inferences about the phonolexcial representation of new words, and/or individuals’ inferences about whether or not particular words alternate. If this is true, then it may be the case that participants in Experiment 2A relied less on written input and/or were less likely to infer that alternating words undergo an alternation.
The statistical analysis consisted of an omnibus analysis following the analysis procedures detailed for Experiment 1. As in Experiment 1, more voiceless productions were observed for underlyingly voiceless than for underlyingly voiced words (a main effect of underlying voicing) and for unsuffixed (singular) than for suffixed (plural) forms (a main effect of morphological condition). The two-way interactions of word learning condition and underlying voicing, and word learning condition and morphological condition, were also significant. A significant three-way interaction of word learning condition, underlying voicing, and morphological condition was also observed, suggesting that the magnitude of the devoicing effect varied as a function of word learning group and underlying voicing. No other main effects or interactions reached significance. The results of the omnibus model are reported in Table 2.
Table 2. (a) Mixed effects model omnibus analysis examining the effects of underlying voicing, morphological condition, and word learning condition, and individual mixed effects analyses for (b) the No Orthography group and (c) the Orthography group for Experiment 2A

Note: All factors were coded using contrast coding, as follows: word learning condition (–.5 = No Orthography, .5 = Orthography), underlying voicing (–.5 = voiced, .5 = voiceless), morphological condition (–.5 = plural, .5 = singular).
a Omnibus analysis model formula: Voiceless ~ Underlying Voicing * Morphological Condition * Word Learning Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Word Learning Condition + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition + Word Learning Condition | CoderID).
b No Orthography group model formula: Voiceless ~ Underlying Voicing * Morphological Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition | CoderID).
c Orthography group model formula: Voiceless ~ Underlying Voicing * Morphological Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition | CoderID).
To follow up on the three-way interaction and answer RQ1, we examined the effects of underlying voicing and morphological condition separately for the No Orthography and Orthography groups. If either of the groups has acquired a German-like pattern of final devoicing, we should observe an interaction of morphological condition and underlying voicing and/or a simple effect of morphological condition in underlyingly voiced forms but not underlyingly voiceless forms. The model of the data subset by word learning group included fixed effects underlying voicing and morphological condition and their interaction, as well as random intercepts for speaker, word, coder, and by-speaker and by-coder random slopes for underlying voicing and morphological condition, and by-word random slopes for morphological condition (Table 2a and 2b).
For the No Orthography group, fixed effects indicated that more voiceless productions were observed for the underlyingly voiceless than for the underlyingly voiced words (a main effect of underlying voicing) and for unsuffixed (singular) than for suffixed (plural) forms (a main effect of morphological condition). To our surprise, the interaction of morphological condition and underlying voicing was not significant. However, the simple effect of morphological condition within the No Orthography group was significant for underlyingly voiced words (estimate = 1.63, SE = 0.30, z = 5.49, p < .001), but was marginal for underlyingly voiceless words (estimate = 0.84, SE = 0.31, z = 2.71, p = .05).
For the Orthography group, the main effects of underlying voicing and of morphological condition were again observed. The interaction of morphological condition and underlying voicing was not significant, nor was the simple effect of morphological condition observed for underlyingly voiced words (estimate = 0.33, SE = 0.29, z = 1.12, p = .84) or underlyingly voiceless pairs (estimate = 0.24, SE = 0.31, z = 0.76, p = .96), suggesting that, unlike the No Orthography group, we do not find evidence for the acquisition of a German-like final devoicing process by the Orthography group.
Pairwise comparisons of the two word learning conditions confirmed that the groups differed in the number of voiceless productions they produced for the underlyingly voiced words in the singular (estimate = –2.20, SE = 0.53, z = –4.14, p < .001), but not for the underlyingly voiced words in the plural (estimate = –0.91, SE = 0.45, z = –2.02, p = .25). As expected, no difference between the groups was observed for the underlyingly voiceless words in the singular (estimate = 0.39, SE = 0.45, z = 0.87, p = .94) or in the plural (estimate = 0.99, SE = 0.44, z = 2.26, p = .15). Together, the three-way interaction, the significant two-way interaction between morphological condition and underlying voicing for the No Orthography group but not the Orthography group, and the pairwise comparisons just described provide evidence for an interfering effect of written input (RQ2).
Experiment 2B
Experiment 2B was designed to examine whether knowledge of a German-like final devoicing process acquired during Experiment 2A extended to new words. We addressed two research questions:
RQ3: Do naïve adult learners generalize knowledge of a German-like pattern of final devoicing to new words?
RQ4: Does orthographic input interfere with the generalization of the phonological process to novel forms?
The answer to RQ3 lies in a differential effect of morphological condition on the two levels of underlying voicing, and crucially, more voiceless productions in the singular (unsuffixed) than the plural (suffixed) forms of the underlyingly voiced words. This could be observed as an interaction of morphological condition by underlying voicing and/or a simple effect of morphological condition in underlyingly voiced forms but not underlyingly voiceless forms.
The answer to RQ4 comes from a comparison of the performance of the Orthography and No Orthography groups with respect to evidence of the generalization of devoicing. A three-way interaction (Underlying Voicing × Morphological Condition × Word Learning Condition), where the Orthography group exhibits less robust generalization of the final devoicing process, relative to the No Orthography group, would provide evidence of interference from written input.
Figure 9 presents the mean proportion of voiceless productions by word learning condition, underlying voicing, and morphological condition for Experiment 2B. As expected, participants in both groups produced underlyingly voiceless obstruents as voiceless the majority of the time. Moreover, the proportion of voiceless productions for the underlyingly voiceless (non-alternating) words varied very little as a function of morphological condition (No Orthography, singular = .86, plural = .83; Orthography, singular = .88, plural = .84). Relative to the underlyingly voiceless consonants, underlyingly voiced consonants produced as voiceless relatively less often and the proportion of voiceless productions varied more as a function of word learning group and morphological condition (No Orthography, singular = .52, plural = .29; Orthography, singular = .25, plural = .11).

Figure 9. Mean proportion voiceless productions by word learning group, underlying voicing, and morphological condition for Experiment 2B. Error bars represent one SE of the mean.
It is also worth noting that the data from Experiment 2B look quite similar to the data from Experiments 1 and 2A. However, while the magnitude of the difference between the two morphological conditions for the underlyingly voiced words for the No Orthography group is similar across experiments, relatively fewer voiceless productions were observed for underlyingly voiced words overall in Experiment 2B. This may reflect the frequency of voiced and voiceless consonants in the auditory input during the word learning phase. Voiceless consonants were less frequent in Experiment 2B (.5) than in Experiments 1 and 2A (.75) due to exposure to only suffixed (plurals) forms.
The statistical analysis again consisted of an omnibus analysis following the analysis procedures detailed for Experiment 1. The results indicated that participants produced more voiceless productions for underlyingly voiceless words than underlyingly voiced words (a main effect of underlying voicing). Participants also produced more voiceless productions for unsuffixed (singular) than for suffixed (plural) forms (a main effect of morphological condition). There were no other significant main effects or interactions. The omnibus model results are reported in Table 3.
Table 3. Mixed effects model omnibus analysis examining the effects of underlying voicing, morphological condition, and word learning condition, and individual mixed effects analyses for the No Orthography group and the Orthography group for Experiment 2B

Note: All factors were coded using contrast coding, as follows: word learning condition (–.5 = No Orthography, .5 = Orthography), underlying voicing (–.5 = voiced, .5 = voiceless), morphological condition (–.5 = plural, .5 = singular)
a Omnibus analysis model formula: Voiceless ~ Underlying Voicing * Morphological Condition * Word Learning Condition + (1 + Underlying Voicing + Morphological Condition | SpkrID) + (1 + Word Learning Condition + Morphological Condition | Word) + (1 + Underlying Voicing + Morphological Condition + Word learning Condition | CoderID).
Discussion of Experiment 2
Experiment 2 set out to investigate the robustness of the pattern observed in Experiment 1, as well as to test the productivity of learners’ knowledge of the German final devoicing pattern. The results of Experiment 2A generally replicate the findings of Experiment 1 in a new group of participants and with a new group of coders who completed the coding task online. In particular, we observed that both the participants who were exposed to words’ written forms and those who were not produced more voiceless productions for underlyingly voiced words in the singular than in the plural. However, the difference between the two morphological conditions for the underlyingly voiced words was again only significant for the No Orthography group, providing additional evidence that naïve adult learners demonstrate knowledge of a German-like final devoicing process when their auditory input contains both the voiced and the voiceless variants of alternating words (RQ1). Moreover, the unexpected marginal simple effect of morphological condition for underlyingly voiceless (non-alternating words) may reflect knowledge of this final devoicing process. Participants may have picked up on the devoicing pattern but have imperfect knowledge of which words alternate (and which do not), causing them to overgeneralize the devoicing rule to some non-alternating words.
With respect to RQ2, the magnitude of the devoicing effect for the two word learning groups varied as a function of morphological condition and underlying voicing, resulting in a three-way interaction of word learning group, morphological condition, and underlying voicing. Moreover, while both groups of learners demonstrate some sensitivity to the alternation in their input, statistical evidence of robust devoicing was only observed for the No Orthography group, suggesting that written input interfered with the acquisition of the final devoicing process by the Orthography group. In addition, the Orthography group again produced significantly more voiced productions (non-targetlike surface forms) for the underlyingly voiced singulars than did the No Orthography group in this condition, replicating Experiment 1. It is worth noting that results for the so-called singular condition exhibit the pattern previously reported in Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018).
As participants in both groups appeared to acquire some knowledge of the German final devoicing process, in Experiment 2B we asked whether adult L2 learners generalize a German-like pattern of final devoicing to newly learned words that they are exposed to only in their suffixed (i.e., plural) forms. While we observe a pattern similar to that found in Experiments 1 and 2A, there is no statistical support for generalization of the final devoicing process to new words (RQ3), and thus no evidence that written input interferes in the generalization of the final devoicing process (RQ4).
General Discussion
Here we have reported the results of two experiments exploring the acquisition of a German-like final devoicing process by adult native English speakers. In Experiments 1 and 2A, we observed differential voicing of alternating (underlyingly voiced) words in their unsuffixed (singular) and suffixed (plural) forms by participants in the No Orthography groups, but not the Orthography groups, suggesting that participants exposed to auditory evidence for the alternation acquire some knowledge of the final devoicing process (RQ1). This finding is consistent with the results reported by Smith and Peterson (Reference Smith and Peterson2012), who found limited devoicing in German words relative to orthographically similar English words by native English-speaking learners in their second semester of German. The fact that the effect was only significant for the No Orthography group speaks to RQ2 (whether access to written input during word learning interfered with the acquisition of the German-like final devoicing process). We observed a significant three-way interaction of word learning condition, underlying voicing, and morphological condition, suggesting differential acquisition of the final devoicing process and providing evidence that access to words’ written forms interfered with participants’ ability to learn the alternation. We have thus provided evidence of an effect of orthographic input on the acquisition of the final devoicing process, building on earlier findings reported by Hayes-Harb et al. (Reference Hayes-Harb, Brown and Smith2018).
In Experiment 2B, we examined whether participants acquired knowledge of the final devoicing process that generalizes to a set of untrained items. The lack of evidence for generalization in Experiment 2B (RQ3; and thus a lack of evidence that written input interferes with generalization; RQ4) is consistent with previous findings suggesting that productive generalized knowledge of morphophonological alternations emerges late in first language acquisition (Kerkhoff, Reference Kerkhoff2007; van de Vijver & Baer-Henney, Reference van de Vijver and Baer-Henney2011; Zamuner et al., Reference Zamuner, Kerkhoff and Fikkert2006, Reference Zamuner, Kerkhoff and Fikkert2012). The difficulty associated with generalization is ubiquitous in L1 and L2 acquisition more generally. For example, perceptual training studies have demonstrated that generalization beyond trained stimuli (e.g., to new tokens, talkers, phonological environments, etc.) requires both a high degree of variability in the training stimuli and substantial training duration (see, e.g., Bradlow, Pisoni, Akahane-Yamada, & Tohkura, Reference Bradlow, Pisoni, Akahane-Yamada and Tohkura1997), neither or which was involved in the present study. Moreover, as Pierrehumbert (Reference Pierrehumbert2003) states, “generalization about word-forms depends on knowing sufficient number or words. Knowledge of morphophonological relations likewise depends on having sufficient vocabulary, and a sufficient knowledge of syntactic and semantic relations amongst words, for relevant word pairs to be identified and for generalizations to be formed over these pairs” (p. 116). Future studies should consider the acquisition of other morphophonological alternations, as well as explore the factors that influence their acquisition and generalization by adult learners of a L2.
In order to acquire alternations, learners must infer both the underlying representations of the alternating words and the phonological rule that will allow them to derive the surface forms from those underlying forms. By investigating the influence of written input during the acquisition of a phonological process, we observed that written input plays a more complex role in phonolexical acquisition than previously thought. Our data suggests there may be an orthographic input trade-off. In both Experiments 1 and 2A we observed that participants in the Orthography group were at a disadvantage relative to the No Orthography group with respect to producing target-like surface voicing for underlyingly voiced words in their singular forms. That is, exposure to written input during word learning interfered with the acquisition of target-like surface voicing in this morphological condition. However, the Orthography group appeared to have an advantage over participants in the No Orthography group with respect to underlyingly voiced plural words (Experiment 1), where the devoicing process does not apply and written input provides a helpful clue to the words’ underlying forms. That is, learners who had access to written forms while they learned the words were more likely than those who did not to correctly produce underlyingly voiced plurals as voiced. The Orthography group demonstrated a bias to represent the alternating (underlyingly voiced) words as non-alternating and voiced throughout the paradigm (consistent with the orthographic representations), whereas the No Orthography participants, who did not have access to the biasing effect of written forms, were more likely to infer that the words are underlyingly voiceless (and thus produced underlyingly voiced forms, both singular and plural, more often as voiceless, at >75% and >50%, respectively) in Experiments 1 and 2A. That both groups (to some extent) favored uniformity across the morphological paradigm is in line with previous research on the child acquisition of final devoicing languages, such as German and Dutch (Kerkhoff, Reference Kerkhoff2007; van de Vijver & Baer-Henney, Reference van de Vijver and Baer-Henney2011; Zamuner et al., Reference Zamuner, Kerkhoff and Fikkert2006, Reference Zamuner, Kerkhoff and Fikkert2012), and suggests that paradigm uniformity (Steriade, Reference Steriade, Broe and Pierrehumbert2000) may generally be favored at early stages of acquisition regardless of whether learners are acquiring a L1 or L2. As the present study focused on the acquisition of a German-like pattern of alternation within a simplified plural paradigm by naïve participants, additional research focused on the acquisition of morphophonological alternations by adult L2 learners will be needed to assess the robustness of these findings for other types of phonological alternations. Moreover, research that looks at phonological acquisition over time will also be important to understand the impact of orthographic input for individual learners and the short- and long-term consequences of exposure to written input for learners’ phonolexical acquisition more generally. For example, it is possible that for phonological alternations, such as German final devoicing, the advantage of having established target-like underlying forms early on outweighs the disadvantage of not producing target-like surface voicing early in the acquisition process, or viceversa. We expect these will prove to be fruitful avenues for future research on the influences of written input in the acquisition of phonological alternations. Ultimately, the findings of this line of research should support language teachers’ decisions regarding the use of written input at early stages of L2 instruction: understanding how and why written forms encourage or discourage the development of target-like lexicophonological representations is essential to leveraging written input effectively in instructed settings.
Acknowledgments
We are grateful to the members of the Speech Acquisition Lab, the audiences of PSLLT 2016 and SLRF 2017, Johanna Watzinger-Tharp, Dave Kush, Veronika Mayerhofer, and Natalia Muller, as well as the editor and two anonymous reviewers for their contributions to this research.
Conflict of Interest
Author Rachel Hayes-Harb currently serves as Editor of Applied Psycholinguistics, and played no role in the editorial process for this manuscript, which was handled by the journal’s previous Editor.
Appendix A: Experimental stimuli used in Experiment 1 and Experiment 2a
 |
Appendix B: Experimental stimuli for Experiment 2B
 |











