

1 Introduction
The task of modeling claim severities is a well known and difficult challenge in actuarial science, and their correct description is of large interest for the practicing actuary or risk manager. In some lines of business, the size of claims may manifest features which are difficult to capture correctly by simple distributional assumptions, and ad hoc solutions are very often used to overcome this practical drawback. In particular, heavy-tailed and multimodal data may be present, which together with a high count of small claim sizes, produces an odd-shaped distribution.
In this paper, we introduce phase-type (PH) distributions as a powerful vehicle to produce probabilistic models for the effective description of claim severities. PH distributions are roughly defined as the time it takes for a pure-jump Markov processes on a finite state space to reach an absorbing state. Their interpretation in terms of traversing several states before finalizing is particularly appealing actuarial science, since one may think of claim sizes as the finalized “time” after having traversed some unobserved states to reach such magnitude, for instance, legal cases, disabilities, unexpected reparation costs, etc. Many distributions such as the exponential, Erlang, Coxian, and any finite mixture between them fall into PH domain, and they possess a universality property in that they are dense (in the sense of weak convergence, cf. Asmussen, Reference Asmussen2008) on the set of probability measures with positive support.
Despite many particular instances of PH being classical distributions, a unified and systematic approach was only first studied in Neuts (Reference Neuts1975, Reference Neuts1981), which laid out the modern foundations of matrix analytic methods (see Bladt and Nielsen, Reference Bladt and Nielsen2017 for a recent comprehensive treatment). Since then, they have gained popularity in applied probability and statistics due to their versatility and closed-form formulas in terms of matrix exponentials. A key development for their use in applied statistics was the development of a maximum likelihood estimation (MLE) procedure via the expectation–maximization (EM) algorithm (cf. Asmussen et al., Reference Asmussen, Nerman and Olsson1996), which considers the full likelihood arising from the path representation of a PH distribution. Ahn et al. (Reference Ahn, Kim and Ramaswami2012) explore the case of exponentially transformed PH distributions to generate heavy-tailed distributions. Furthermore, transforming PH distributions parametrically has been considered in Albrecher and Bladt (Reference Albrecher and Bladt2019) and Albrecher et al. (Reference Albrecher, Bladt and Yslas2020b), resulting in inhomogeneous phase-type (IPH) distributions, which leads to non-exponential tail behaviors by allowing for the underlying process to be time-inhomogeneous (see also Bladt and Rojas-Nandayapa, Reference Bladt and Rojas-Nandayapa2017; Albrecher et al. Reference Albrecher, Bladt and Bladt2020a for alternative heavy-tailed PH specifications). The latter development allows to model heavy- or light-tailed data with some straightforward adaptations to the usual PH statistical methods.
Incorporating rating factors, or covariates, is particularly relevant when segmentation of claims is sought for, for example, for insurance pricing, and is known to be problematic when the underlying model does not belong to the exponential dispersion family, i.e. when a Generalized Linear Model (GLM) is not sufficiently flexible. Regression models for PH distributions have been considered in the context of survival analysis, cf. McGrory et al. (Reference McGrory, Pettitt and Faddy2009) and references therein for the Coxian PH case, and more recently (Albrecher et al., Reference Albrecher, Bladt, Bladt and Yslas2021) for IPH distributions with applications to mortality modeling. The current work uses the specification of the model within the latter contribution but applied to claim severity modeling for insurance. The methodology is simpler, since we treat the fully observed case, allowing for some closed-form formulas for, for example, mean estimation or inferential tools.
Several other statistical models for insurance data can be found in the literature, with the common theme being constructing a global distribution consisting of smaller simpler components, either by mixing, splicing (also referred to as composite models), or both. In Lee and Lin (Reference Lee and Lin2010), a mixture of Erlang (ME) distributions with common scale parameter was proposed and subsequently extended to more general mixture components in Tzougas et al. (Reference Tzougas, Vrontos and Frangos2014), Miljkovic and Grün (Reference Miljkovic and Grün2016), and Fung et al. (Reference Fung, Badescu and Lin2020). Concerning composite models, many different tail and body distribution combinations have been considered, and we refer to Grün and Miljkovic (Reference Grün and Miljkovic2019) for a comparison of some of them, where a substantial body of the relevant literature can be found as well. Global models is dealt with a combination of mixtures and splicing, with Reynkens et al. (Reference Reynkens, Verbelen, Beirlant and Antonio2017) being the main reference (see also Fung et al., Reference Fung, Tzougas and Wuthrich2021 for a feature selection approach).
Our present PH regression model is not only mathematically but also conceptually different to all previous approaches. With the use of matrix calculus, it allows to specify multimodal and heavy-tailed distributions without the need of threshold selection or having to specify the number of mixture components. Instead, an inhomogeneity function and the size of the underlying state space have to be specified. The former is usually straightforward according to the tail behavior of the data, and the latter can be chosen either in a data-driven way or in a more dogmatic way if there is a certain belief of a specific number of unobserved states driving the data-generating process.
The structure of the remainder of the paper is as follows. In Section 2, we provide the necessary preliminaries on IPH distributions and formulate our PH regression model including their parametrizations, their estimation procedure, statistical inference, and dimension and structure selection. We then perform a simulation study in Section 3 to illustrate its effectiveness in a synthetic heterogeneous dataset. Subsequently, we perform the estimation on a real-life French insurance dataset in Section 4. Finally, Section 5 concludes.
2 Model specifications
In this section, we lay down some preliminaries on IPH distributions which are needed in order to introduce the relevant key concepts to be used in our regression and subsequently proceed to introduce the specifications of the claim severity models. We skip the proofs, and the interested reader can find a comprehensive treatment of the marginal models in the following references: Bladt and Nielsen (Reference Bladt and Nielsen2017) and Albrecher and Bladt (Reference Albrecher and Bladt2019), the latter taking a more abstract approach. We will, however, tailor and emphasize the most relevant features of the models with respect to claim severity modeling for insurance.
2.1 Mathematical formulation of IPH distributions
Let
 $ ( J_t )_{t \geq 0}$
be a time-inhomogeneous Markov pure-jump process on the finite state space
$ ( J_t )_{t \geq 0}$
be a time-inhomogeneous Markov pure-jump process on the finite state space
 $\{1, \dots, p, p+1\}$
, where states
$\{1, \dots, p, p+1\}$
, where states
 $1,\dots,p$
are transient and
$1,\dots,p$
are transient and
 $p+1$
is absorbing. In our setting, such a process can be regarded as an insurance claim evolving through different states during its lifetime until the absorbing state is reached, which determines the total size of the claim. In its most general form, the transition probabilities of the jump process:
$p+1$
is absorbing. In our setting, such a process can be regarded as an insurance claim evolving through different states during its lifetime until the absorbing state is reached, which determines the total size of the claim. In its most general form, the transition probabilities of the jump process:
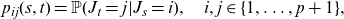 \begin{align*}p_{ij}(s,t)={\mathbb P}(J_t=j|J_s=i),\quad i,j\in\{1,\dots,p+1\},\end{align*}
\begin{align*}p_{ij}(s,t)={\mathbb P}(J_t=j|J_s=i),\quad i,j\in\{1,\dots,p+1\},\end{align*}
may be written in succinct matrix form in terms of the product integral as follows:
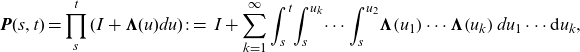 \begin{align*}\textbf{P}(s,t)=\prod_{s}^{t}(\boldsymbol{I}+\boldsymbol{\Lambda}(u) d u)\;:=\;\boldsymbol{I}+\sum_{k=1}^{\infty} \int_{s}^{t}\! \int_{s}^{u_{k}} \!\cdots \int_{s}^{u_{2}}\! {\boldsymbol\Lambda}\!\left(u_{1}\right) \cdots {\boldsymbol\Lambda}\!\left(u_{k}\right) d u_{1} \cdots \textrm{d} u_{k},\end{align*}
\begin{align*}\textbf{P}(s,t)=\prod_{s}^{t}(\boldsymbol{I}+\boldsymbol{\Lambda}(u) d u)\;:=\;\boldsymbol{I}+\sum_{k=1}^{\infty} \int_{s}^{t}\! \int_{s}^{u_{k}} \!\cdots \int_{s}^{u_{2}}\! {\boldsymbol\Lambda}\!\left(u_{1}\right) \cdots {\boldsymbol\Lambda}\!\left(u_{k}\right) d u_{1} \cdots \textrm{d} u_{k},\end{align*}
for
 $s<t,$
where
$s<t,$
where
 $\boldsymbol{\Lambda}(t)$
is a matrix with negative diagonal elements, nonnegative off-diagonal elements, and rows sums equal to 0, commonly referred to as an intensity matrix. Since the process
$\boldsymbol{\Lambda}(t)$
is a matrix with negative diagonal elements, nonnegative off-diagonal elements, and rows sums equal to 0, commonly referred to as an intensity matrix. Since the process
 $ ( J_t )_{t \geq 0}$
has a decomposition in terms of transient and absorbing states, we may write
$ ( J_t )_{t \geq 0}$
has a decomposition in terms of transient and absorbing states, we may write
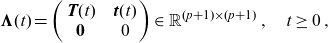 \begin{align*} \boldsymbol{\Lambda}(t)= \left( \begin{array}{c@{\quad}c} \textbf{T}(t) & \textbf{t}(t) \\ \textbf{0} & 0 \end{array} \right)\in\mathbb{R}^{(p+1)\times(p+1)}\,, \quad t\geq0\,,\end{align*}
\begin{align*} \boldsymbol{\Lambda}(t)= \left( \begin{array}{c@{\quad}c} \textbf{T}(t) & \textbf{t}(t) \\ \textbf{0} & 0 \end{array} \right)\in\mathbb{R}^{(p+1)\times(p+1)}\,, \quad t\geq0\,,\end{align*}
where
 $\textbf{T}(t) $
is a
$\textbf{T}(t) $
is a
 $p \times p$
sub-intensity matrix and
$p \times p$
sub-intensity matrix and
 $\textbf{t}(t)$
is a p-dimensional column vector providing the exit rates from each state directly to
$\textbf{t}(t)$
is a p-dimensional column vector providing the exit rates from each state directly to
 $p+1$
. The intensity matrix has this form, since there are no positive rates from the absorbing state to the transient ones, and since the rows should sum to 0, we have that for
$p+1$
. The intensity matrix has this form, since there are no positive rates from the absorbing state to the transient ones, and since the rows should sum to 0, we have that for
 $t\geq0$
,
$t\geq0$
,
 $\textbf{t} (t)=- \textbf{T}(t) \, \textbf{e}$
, where
$\textbf{t} (t)=- \textbf{T}(t) \, \textbf{e}$
, where
 $\textbf{e} $
is a p-dimensional column vector of ones. Thus,
$\textbf{e} $
is a p-dimensional column vector of ones. Thus,
 $\textbf{T}(t)$
is sufficient to describe the dynamics of process after time zero. We write
$\textbf{T}(t)$
is sufficient to describe the dynamics of process after time zero. We write
 $\textbf{e}_k$
in the sequel for the k-th canonical basis vector of
$\textbf{e}_k$
in the sequel for the k-th canonical basis vector of
 $\mathbb{R}^p$
, so in particular
$\mathbb{R}^p$
, so in particular
 $\textbf{e}=\sum_{k=1}^p\textbf{e}_k$
.
$\textbf{e}=\sum_{k=1}^p\textbf{e}_k$
.
If the matrices
 $\textbf{T}(s)$
and
$\textbf{T}(s)$
and
 $\textbf{T}(t)$
commute for any
$\textbf{T}(t)$
commute for any
 $s<t$
, we may write
$s<t$
, we may write
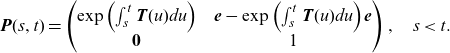 \begin{align*}\textbf{P}(s,t)=\begin{pmatrix} \exp\left(\int_s^t\textbf{T}(u)du\right)\;\;\;\; & \textbf{e}-\exp\left(\int_s^t\textbf{T}(u)du\right) \textbf{e} \\ \textbf{0}\;\;\;\; & 1 \end{pmatrix},\quad s<t.\end{align*}
\begin{align*}\textbf{P}(s,t)=\begin{pmatrix} \exp\left(\int_s^t\textbf{T}(u)du\right)\;\;\;\; & \textbf{e}-\exp\left(\int_s^t\textbf{T}(u)du\right) \textbf{e} \\ \textbf{0}\;\;\;\; & 1 \end{pmatrix},\quad s<t.\end{align*}
The matrices
 $(\textbf{T}(t))_{t\ge0}$
together with the initial probabilities of the Markov process,
$(\textbf{T}(t))_{t\ge0}$
together with the initial probabilities of the Markov process,
 $ \pi_{k} = {\mathbb P}(J_0 = k)$
,
$ \pi_{k} = {\mathbb P}(J_0 = k)$
,
 $k = 1,\dots, p$
, or in vector notation:
$k = 1,\dots, p$
, or in vector notation:
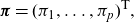 \begin{align*}\boldsymbol{\pi} = (\pi_1 ,\dots,\pi_p )^{\textsf{T}},\end{align*}
\begin{align*}\boldsymbol{\pi} = (\pi_1 ,\dots,\pi_p )^{\textsf{T}},\end{align*}
fully parametrize IPH distributions, and with the additional assumption that
 ${\mathbb P}(J_0 = p + 1) = 0$
we can guarantee that absorption happens almost surely at a positive time. We thus define the positive and finite random variable given as the absorption time as follows:
${\mathbb P}(J_0 = p + 1) = 0$
we can guarantee that absorption happens almost surely at a positive time. We thus define the positive and finite random variable given as the absorption time as follows:
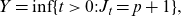 \begin{align*} Y = \inf \{ t > 0 : J_t = p+1 \},\end{align*}
\begin{align*} Y = \inf \{ t > 0 : J_t = p+1 \},\end{align*}
and say that it follows an IPH distribution with representation
 $(\boldsymbol{\pi},(\textbf{T}(t))_{t\ge0})$
. For practical applications, however, we focus on a narrower class which allows for effective statistical analysis. We make the following assumption regarding the inhomogeneity of the sub-intensity matrix:
$(\boldsymbol{\pi},(\textbf{T}(t))_{t\ge0})$
. For practical applications, however, we focus on a narrower class which allows for effective statistical analysis. We make the following assumption regarding the inhomogeneity of the sub-intensity matrix:
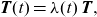 \begin{align*}\textbf{T}(t) = \lambda(t)\,\textbf{T},\end{align*}
\begin{align*}\textbf{T}(t) = \lambda(t)\,\textbf{T},\end{align*}
with
 $\lambda(t)$
some parametric and positive function such that the map:
$\lambda(t)$
some parametric and positive function such that the map:
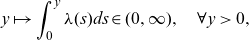 \begin{align*}y\mapsto\int_0^y \lambda(s)ds\in(0,\infty),\quad\forall y>0,\end{align*}
\begin{align*}y\mapsto\int_0^y \lambda(s)ds\in(0,\infty),\quad\forall y>0,\end{align*}
converges to infinity as
 $y\to\infty$
, and
$y\to\infty$
, and
 $\textbf{T}$
is a sub-intensity matrix that does not depend on time t. When dealing with particular entries of the sub-intensity matrix, we introduce the notation:
$\textbf{T}$
is a sub-intensity matrix that does not depend on time t. When dealing with particular entries of the sub-intensity matrix, we introduce the notation:
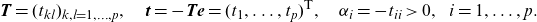 \begin{align*}\textbf{T}=(t_{kl})_{k,l=1,\dots,p},\quad \textbf{t}=-\textbf{T}\textbf{e}=(t_1,\dots,t_p)^{{\textsf{T}}},\quad \alpha_i=-t_{ii}>0,\:\:\: i=1,\dots,p.\end{align*}
\begin{align*}\textbf{T}=(t_{kl})_{k,l=1,\dots,p},\quad \textbf{t}=-\textbf{T}\textbf{e}=(t_1,\dots,t_p)^{{\textsf{T}}},\quad \alpha_i=-t_{ii}>0,\:\:\: i=1,\dots,p.\end{align*}
We then write
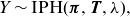 \begin{align*}Y \sim \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda ),\end{align*}
\begin{align*}Y \sim \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda ),\end{align*}
where IPH stands for inhomogeneous phase type. Similarly, we write PH in place of phase type in the sequel, that is, for the case when
 $\lambda$
is a constant.
$\lambda$
is a constant.
IPH distributions are the building blocks to model claim severity for two reasons. Firstly, they have the interpretation of being absorption times of an underlying unobserved multistate process evolving through time, which can be very natural if the losses are linked with an evolving process, such as a lifetime or a legal case; and secondly, PH distributions are the archetype generalization of the exponential distribution in that many closed-form formulas are often available in terms of matrix functions, and thus, when armed with matrix calculus and a good linear algebra software, a suite of statistical tools can be developed Please provide the expansions for BFGS, AIC, BIC, GLM, and IBNR if necessary.explicitly.
It is worth mentioning that PH distributions possess a universality property, since they are known to be dense on the set of positive-valued random variables in the sense of weak convergence. Consequently, they possess great flexibility for atypical histogram shapes that the usual probabilistic models struggle to capture. Do note, however, that the tail can be grossly misspecified if no inhomogeneity function is applied, since weak convergence does not guarantee tail equivalence between the approximating sequence and the limit.
Another feature of IPH distributions is that they can have a different tail behavior than their homogeneous counterparts, allowing for non-exponential tails. To see this, first note that if
 $Y \sim \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda )$
, then we may write
$Y \sim \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda )$
, then we may write
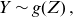 \begin{equation}Y \sim g(Z) \,,\end{equation}
\begin{equation}Y \sim g(Z) \,,\end{equation}
where
 $Z \sim \mbox{PH}(\boldsymbol{\pi} , \textbf{T} )$
and g is defined in terms of
$Z \sim \mbox{PH}(\boldsymbol{\pi} , \textbf{T} )$
and g is defined in terms of
 $\lambda$
by:
$\lambda$
by:
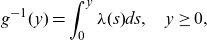 \begin{equation*}g^{-1}(y) = \int_0^y \lambda (s)ds,\quad y\ge0, \end{equation*}
\begin{equation*}g^{-1}(y) = \int_0^y \lambda (s)ds,\quad y\ge0, \end{equation*}
which is well defined by the positivity of
 $\lambda$
, or equivalently (see for instance Theorem 2.9 in Albrecher and Bladt, Reference Albrecher and Bladt2019):
$\lambda$
, or equivalently (see for instance Theorem 2.9 in Albrecher and Bladt, Reference Albrecher and Bladt2019):
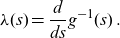 \begin{equation*}\lambda (s) = \frac{d}{ds}g^{-1}(s) \,. \end{equation*}
\begin{equation*}\lambda (s) = \frac{d}{ds}g^{-1}(s) \,. \end{equation*}
Since the asymptotic behavior of PH distributions can be deduced from its Jordan decomposition, the following result in the inhomogeneous case is available. It is a generalization of the theory developed in Albrecher et al. (Reference Albrecher, Bladt, Bladt and Yslas2021), and the proof is hence omitted.
Proposition 2.1 Let
 $ Y \sim\mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda )$
. Then the survival function
$ Y \sim\mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda )$
. Then the survival function
 $S_Y=1-F_Y(y)$
, density
$S_Y=1-F_Y(y)$
, density
 $f_Y$
, hazard function
$f_Y$
, hazard function
 $h_Y$
, and cumulative hazard function
$h_Y$
, and cumulative hazard function
 $H_Y$
of Y satisfy, respectively, as
$H_Y$
of Y satisfy, respectively, as
 $t\to \infty$
,
$t\to \infty$
,
 \begin{align*} S_Y(y)&= {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( \int_0^y \lambda (s)ds\ \textbf{T} \right)\textbf{e} \sim c_1 [g^{-1}(y)]^{n -1} e^{-\chi [g^{-1}(y)]},\\f_Y(y) &=\lambda (y)\, {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( \int_0^y \lambda (s)ds\ \textbf{T} \right)\textbf{t}\sim c_2 [g^{-1}(y)]^{n -1} e^{-\chi [g^{-1}(y)]}\lambda(y),\\ h_Y(y) &\sim c \lambda(y) ,\\ H_Y(y)& \sim k g^{-1}(y), \end{align*}
\begin{align*} S_Y(y)&= {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( \int_0^y \lambda (s)ds\ \textbf{T} \right)\textbf{e} \sim c_1 [g^{-1}(y)]^{n -1} e^{-\chi [g^{-1}(y)]},\\f_Y(y) &=\lambda (y)\, {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( \int_0^y \lambda (s)ds\ \textbf{T} \right)\textbf{t}\sim c_2 [g^{-1}(y)]^{n -1} e^{-\chi [g^{-1}(y)]}\lambda(y),\\ h_Y(y) &\sim c \lambda(y) ,\\ H_Y(y)& \sim k g^{-1}(y), \end{align*}
where
 $c_1$
,
$c_1$
,
 $c_2$
, c, and k are positive constants,
$c_2$
, c, and k are positive constants,
 $-\chi$
is the largest real eigenvalue of
$-\chi$
is the largest real eigenvalue of
 $\textbf{T}$
, and n is the dimension of the Jordan block associated with
$\textbf{T}$
, and n is the dimension of the Jordan block associated with
 $\chi$
.
$\chi$
.
In particular, we observe that the tail behavior is determined almost entirely by function g. We also note that any model based on the intensity of the process (as will be the case for our regression model below) is asymptotically a model on the hazard of the distribution.
If g is the identity, we get Erlang tails, but for other choices, we move away from the exponential domain. The choice of g is typically determined according to the desired tail behavior required for applications. For heavy-tailed claim severities in the Fréchet max-domain of attraction, the exponential transformation
 $g(z)=\eta \left( \exp(z)-1\right),\:\:\eta>0$
leading to Pareto tails is the simplest choice, although the log-logistic can also have such a behavior. When data are moderately heavy-tailed, as understood by being in the Gumbel max-domain of attraction, heavy-tailed Weibull
$g(z)=\eta \left( \exp(z)-1\right),\:\:\eta>0$
leading to Pareto tails is the simplest choice, although the log-logistic can also have such a behavior. When data are moderately heavy-tailed, as understood by being in the Gumbel max-domain of attraction, heavy-tailed Weibull
 $g(z)=z^{1/\eta},\:\:\eta>0$
, or Lognormal
$g(z)=z^{1/\eta},\:\:\eta>0$
, or Lognormal
 $g(z)=\exp(z^{1/\gamma})-1,\:\:\gamma>1$
transforms can provide useful representations. In life insurance applications, the Matrix-Gompertz distribution with
$g(z)=\exp(z^{1/\gamma})-1,\:\:\gamma>1$
transforms can provide useful representations. In life insurance applications, the Matrix-Gompertz distribution with
 $g(z)=\log( \eta z + 1 ) / \eta,\:\: \eta>0$
can be particularly useful to model human lifetimes.
$g(z)=\log( \eta z + 1 ) / \eta,\:\: \eta>0$
can be particularly useful to model human lifetimes.
One tool which is particularly useful to deal with expressions involving IPH distributions is matrix calculus. Here, the main tool is Cauchy’s formula for matrices, which is as follows. If u is an analytic function and
 $\textbf{A}$
is a matrix, we define
$\textbf{A}$
is a matrix, we define
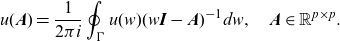 \begin{align*} u( \textbf{A})=\dfrac{1}{2 \pi i} \oint_{\Gamma}u(w) (w \textbf{I} -\textbf{A} )^{-1}dw ,\quad \textbf{A}\in \mathbb{R}^{p\times p}.\end{align*}
\begin{align*} u( \textbf{A})=\dfrac{1}{2 \pi i} \oint_{\Gamma}u(w) (w \textbf{I} -\textbf{A} )^{-1}dw ,\quad \textbf{A}\in \mathbb{R}^{p\times p}.\end{align*}
where
 $\Gamma$
is a simple path enclosing the eigenvalues of
$\Gamma$
is a simple path enclosing the eigenvalues of
 $\textbf{A}$
, and
$\textbf{A}$
, and
 $\textbf{I}$
is the p-dimensional identity matrix. This allows for functions of matrices to be well defined, which in turn gives explicit formulas for IPH distributions, simplifying calculations and numerical implementation alike.
$\textbf{I}$
is the p-dimensional identity matrix. This allows for functions of matrices to be well defined, which in turn gives explicit formulas for IPH distributions, simplifying calculations and numerical implementation alike.
Example 2.2 Consider the following underlying Markov process parameters:
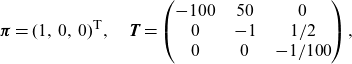 \begin{align*}\boldsymbol{\pi}=(1,\,0,\,0)^{{\textsf{T}}},\quad\textbf{T}=\begin{pmatrix}-100\;\;\;\; & 50\;\;\;\; & 0 \\0\;\;\;\; & -1\;\;\;\; & 1/2\\0\;\;\;\; & 0\;\;\;\; & -1/100 \\\end{pmatrix},\end{align*}
\begin{align*}\boldsymbol{\pi}=(1,\,0,\,0)^{{\textsf{T}}},\quad\textbf{T}=\begin{pmatrix}-100\;\;\;\; & 50\;\;\;\; & 0 \\0\;\;\;\; & -1\;\;\;\; & 1/2\\0\;\;\;\; & 0\;\;\;\; & -1/100 \\\end{pmatrix},\end{align*}
and a Weibull inhomogeneity parameter
 $\eta=8$
, which was chosen significantly light-tailed for visualization purposes. Compared to a conventional Weibull distribution, with
$\eta=8$
, which was chosen significantly light-tailed for visualization purposes. Compared to a conventional Weibull distribution, with
 $\boldsymbol{\pi}=1$
,
$\boldsymbol{\pi}=1$
,
 $\textbf{T}=-1/10$
, and
$\textbf{T}=-1/10$
, and
 $\eta=8$
, we see in Figure 1 that just a few additional parameters in the augmented matrix version of a common distribution can result in very different behavior in the body of the distribution (the tail behavior is guaranteed to be the same). For this structure, the case
$\eta=8$
, we see in Figure 1 that just a few additional parameters in the augmented matrix version of a common distribution can result in very different behavior in the body of the distribution (the tail behavior is guaranteed to be the same). For this structure, the case
 $p=3$
shows that the Markov process can traverse three states before absorption, resulting in three different modes of the density. For other matrix structures or parameters, there is in general no one-to-one correspondence between p and the number of modes of the resulting density.
$p=3$
shows that the Markov process can traverse three states before absorption, resulting in three different modes of the density. For other matrix structures or parameters, there is in general no one-to-one correspondence between p and the number of modes of the resulting density.
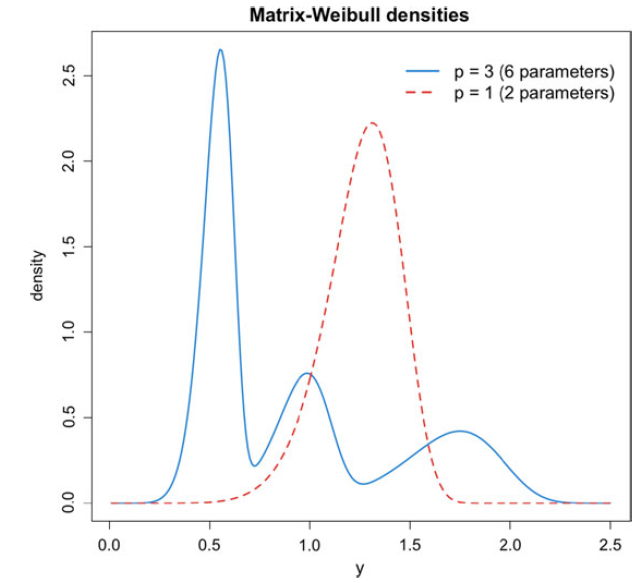
Figure 1. Densities corresponding to a scalar Weibull distribution and a Matrix-Weibull distribution.
2.2 The PH regression model
We now introduce a regression model based on IPH distributions and use it to provide a segmentation model for claim severities. Classically, for pure premium calculation, the mean is the main focus. Presently, we do not aim to improve on other data-driven procedures for pure mean estimation but instead focus on the entire distribution of the loss severities. That said, a consequence of a well-fitting global model is a reasonable mean estimate in the small sample case. However, when considering large sample behavior, any scoring rule in terms of means is not a proper scoring rule for target distributions that are not fully characterized by their first moment (see Gneiting and Raftery, Reference Gneiting and Raftery2007), and thus model choice is less important in this case.
Let
 $\textbf{X} = (X_1, \dots, X_d)^{\textsf{T}}$
be a d-dimensional vector of rating factors associated with the loss severity random variable Y. We keep the convention that
$\textbf{X} = (X_1, \dots, X_d)^{\textsf{T}}$
be a d-dimensional vector of rating factors associated with the loss severity random variable Y. We keep the convention that
 $\textbf{X}$
does not contain the entry of 1 associated with an intercept in order to obtain an identifiable regression specification (the intercept is included in the matrix
$\textbf{X}$
does not contain the entry of 1 associated with an intercept in order to obtain an identifiable regression specification (the intercept is included in the matrix
 $\textbf{T}$
). Let
$\textbf{T}$
). Let
 $\boldsymbol{\beta}$
be a d-dimensional vector of regression coefficients so that
$\boldsymbol{\beta}$
be a d-dimensional vector of regression coefficients so that
 $\textbf{X}^{\textsf{T}}\boldsymbol{\beta}$
is a scalar. Then, we define the conditional distribution of
$\textbf{X}^{\textsf{T}}\boldsymbol{\beta}$
is a scalar. Then, we define the conditional distribution of
 $Y|\textbf{X}$
as having density function, see Proposition 2.1,
$Y|\textbf{X}$
as having density function, see Proposition 2.1,
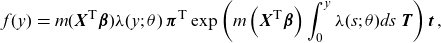 \begin{eqnarray} f(y) &=& m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) \lambda (y;\; \theta )\, {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}\right)\int_0^y \lambda (s;\; \theta )ds\ \textbf{T} \right)\textbf{t} \,, \end{eqnarray}
\begin{eqnarray} f(y) &=& m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) \lambda (y;\; \theta )\, {\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}\right)\int_0^y \lambda (s;\; \theta )ds\ \textbf{T} \right)\textbf{t} \,, \end{eqnarray}
where
 $m:\mathbb{R}\to \mathbb{R}_+$
is any positive function (monotonicity is not required). We call this the phase-type regression model. In particular, we recognize an IPH distribution
$m:\mathbb{R}\to \mathbb{R}_+$
is any positive function (monotonicity is not required). We call this the phase-type regression model. In particular, we recognize an IPH distribution
 $ \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda(\cdot \mid \textbf{X} , \boldsymbol{\beta}, \theta ) )$
, where
$ \mbox{IPH}(\boldsymbol{\pi} , \textbf{T} , \lambda(\cdot \mid \textbf{X} , \boldsymbol{\beta}, \theta ) )$
, where
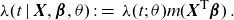 \begin{align} \lambda(t \mid \textbf{X} , \boldsymbol{\beta},\theta )\;:=\;\lambda (t;\; \theta ) m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) \,.\end{align}
\begin{align} \lambda(t \mid \textbf{X} , \boldsymbol{\beta},\theta )\;:=\;\lambda (t;\; \theta ) m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) \,.\end{align}
One possible interpretation of this model is that covariates act multiplicatively on the underlying Markov intensity, thus creating proportional intensities among different policies. In fact, since the intensity of an IPH distribution is asymptotically equivalent to its hazard function, we have that covariates satisfy a generalized proportional hazards specification in the far-right tail.
The conditional mean can be written in the form:
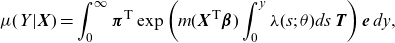 \begin{align}\mu(Y|\textbf{X})=\int_0^\infty \boldsymbol{\pi}^{\textsf{T}}\exp\left(m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})\int_0^y \lambda(s;\; \theta )ds\,\textbf{T} \right)\textbf{e} \,dy,\end{align}
\begin{align}\mu(Y|\textbf{X})=\int_0^\infty \boldsymbol{\pi}^{\textsf{T}}\exp\left(m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})\int_0^y \lambda(s;\; \theta )ds\,\textbf{T} \right)\textbf{e} \,dy,\end{align}
which is simply obtained by integrating the survival function over
 $\mathbb{R}_+$
, see Proposition 2.1. A simple special case is obtained by the following choices, giving a Gamma GLM with canonical link: take
$\mathbb{R}_+$
, see Proposition 2.1. A simple special case is obtained by the following choices, giving a Gamma GLM with canonical link: take
 $\textbf{T}=-1$
, and
$\textbf{T}=-1$
, and
 $\lambda\equiv 1$
to receive
$\lambda\equiv 1$
to receive
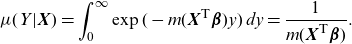 \begin{align*}\mu(Y|\textbf{X})=\int_0^\infty \exp(-m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) y ) \,dy=\frac{1}{ m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})}.\end{align*}
\begin{align*}\mu(Y|\textbf{X})=\int_0^\infty \exp(-m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta}) y ) \,dy=\frac{1}{ m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})}.\end{align*}
Another slightly more complex special case is that of regression for Matrix-Weibull distributions, which contains the pure PH specification (when
 $\lambda\equiv1$
). In this setting, it is not hard to see that
$\lambda\equiv1$
). In this setting, it is not hard to see that
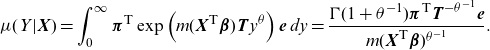 \begin{align}\mu(Y|\textbf{X})=\int_0^\infty \boldsymbol{\pi}^{\textsf{T}}\exp\left(m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})\textbf{T} y^{ \theta }\right)\textbf{e} \,dy =\frac{\Gamma(1+ \theta ^{-1}) \boldsymbol{\pi}^{\textsf{T}}\textbf{T}^{- \theta ^{-1}}\textbf{e}}{ m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})^{ \theta ^{-1}}}.\end{align}
\begin{align}\mu(Y|\textbf{X})=\int_0^\infty \boldsymbol{\pi}^{\textsf{T}}\exp\left(m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})\textbf{T} y^{ \theta }\right)\textbf{e} \,dy =\frac{\Gamma(1+ \theta ^{-1}) \boldsymbol{\pi}^{\textsf{T}}\textbf{T}^{- \theta ^{-1}}\textbf{e}}{ m(\textbf{X}^{\textsf{T}}\boldsymbol{\beta})^{ \theta ^{-1}}}.\end{align}
Figure 2 shows (2.4) as a function of a unidimensional
 $\textbf{X}$
for various inhomogeneity functions
$\textbf{X}$
for various inhomogeneity functions
 $\lambda$
, and fixing the underlying Markov parameters at
$\lambda$
, and fixing the underlying Markov parameters at
 $\boldsymbol{\pi}=(1/2,1/4,1/4)^{{\textsf{T}}}$
and
$\boldsymbol{\pi}=(1/2,1/4,1/4)^{{\textsf{T}}}$
and
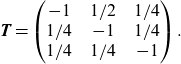 \begin{align*}\textbf{T}=\begin{pmatrix}-1\;\;\;\; & 1/2\;\;\;\; & 1/4 \\1/4\;\;\;\; & -1\;\;\;\; & 1/4\\1/4\;\;\;\; & 1/4\;\;\;\; & -1 \\\end{pmatrix}.\end{align*}
\begin{align*}\textbf{T}=\begin{pmatrix}-1\;\;\;\; & 1/2\;\;\;\; & 1/4 \\1/4\;\;\;\; & -1\;\;\;\; & 1/4\\1/4\;\;\;\; & 1/4\;\;\;\; & -1 \\\end{pmatrix}.\end{align*}
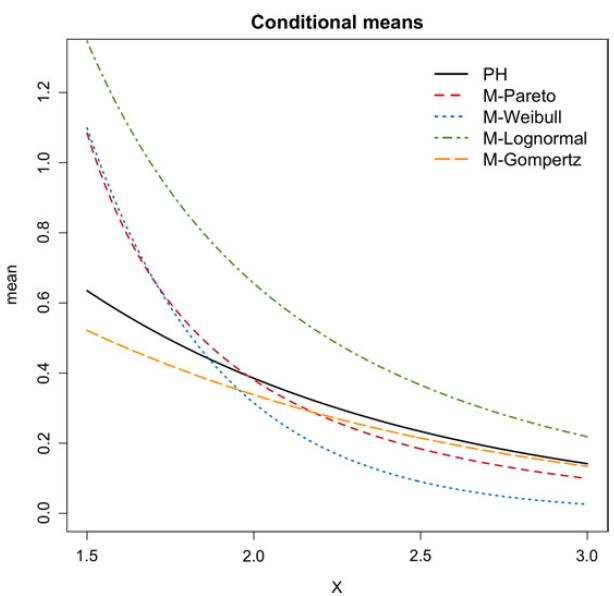
Figure 2. Mean functions of the PH regression model, as a function of a univariate regressor and for different specifications of the inhomogeneity function
 $\lambda$
.
$\lambda$
.
2.3 Estimation
Claim severity fitting can be done by MLE in much the same way whether there are rating factors or not, and hence we exclusively present the more general case. For this purpose, we adopt a generalization of the EM algorithm, which we outline below. Such an approach is much faster to converge than naive multivariate optimization, provided a fast matrix exponential evaluation is available (see Moler and Van Loan, Reference Moler and Van Loan1978).
A full account of the EM algorithm for ordinary PH distributions can be found in Asmussen et al. (Reference Asmussen, Nerman and Olsson1996) which led to the subsequent developments and extensions to censored and parameter-dependent transformations in Olsson (Reference Olsson1996) and Albrecher et al. (Reference Albrecher, Bladt and Yslas2020b). Further details are provided in Appendix 6, since the formulas therein are the building blocks of the EM algorithm for the PH regression model.
By defining
 $g(\cdot;\; \theta)$
and
$g(\cdot;\; \theta)$
and
 $g(\cdot|\textbf{X}, \boldsymbol{\beta}, \theta)$
as follows in terms of their inverse functions
$g(\cdot|\textbf{X}, \boldsymbol{\beta}, \theta)$
as follows in terms of their inverse functions
 $g^{-1}(y;\; \theta )=\int_{0}^{y}\lambda(s;\; \theta )ds$
and
$g^{-1}(y;\; \theta )=\int_{0}^{y}\lambda(s;\; \theta )ds$
and
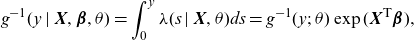 \begin{align*}g^{-1}(y \,|\, \textbf{X}, \boldsymbol{\beta}, \theta )=\int_{0}^{y}\lambda(s \,|\, \textbf{X}, \theta )ds = g^{-1}(y;\; \theta ) \exp(\textbf{X}^{\textsf{T}}\boldsymbol{\beta} ),\end{align*}
\begin{align*}g^{-1}(y \,|\, \textbf{X}, \boldsymbol{\beta}, \theta )=\int_{0}^{y}\lambda(s \,|\, \textbf{X}, \theta )ds = g^{-1}(y;\; \theta ) \exp(\textbf{X}^{\textsf{T}}\boldsymbol{\beta} ),\end{align*}
we note the simple identity:
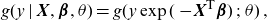 \begin{align} g(y \,|\, \textbf{X}, \boldsymbol{\beta},\theta )=g(y \exp(-\!\textbf{X}^{\textsf{T}}\boldsymbol{\beta} ) \,;\, \theta ) \,,\end{align}
\begin{align} g(y \,|\, \textbf{X}, \boldsymbol{\beta},\theta )=g(y \exp(-\!\textbf{X}^{\textsf{T}}\boldsymbol{\beta} ) \,;\, \theta ) \,,\end{align}
which yields that
 $g^{-1}( Y \,|\, \textbf{X}, \boldsymbol{\beta}, \theta ) \sim \mbox{PH}(\boldsymbol{\pi} , \textbf{T} )$
. In other words, there is a parametric transformation, depending both on the covariates and regression coefficients, which brings the PH regression model into a conventional PH distribution. The generalized EM algorithm hinges on this fact and optimizes the transformed PH distribution and the transformation itself in alternating steps.
$g^{-1}( Y \,|\, \textbf{X}, \boldsymbol{\beta}, \theta ) \sim \mbox{PH}(\boldsymbol{\pi} , \textbf{T} )$
. In other words, there is a parametric transformation, depending both on the covariates and regression coefficients, which brings the PH regression model into a conventional PH distribution. The generalized EM algorithm hinges on this fact and optimizes the transformed PH distribution and the transformation itself in alternating steps.
Algorithm 1 Generalized EM algorithm for phase-type regression
Input:: positive data points
 $\textbf{y}=(y_1,y_2,\dots,y_N)^{{\textsf{T}}}$
, covariates
$\textbf{y}=(y_1,y_2,\dots,y_N)^{{\textsf{T}}}$
, covariates
 $\textbf{x}_1,\dots,\textbf{x}_N$
, and initial parameters
$\textbf{x}_1,\dots,\textbf{x}_N$
, and initial parameters
 $( \boldsymbol{\pi} , \textbf{T} ,\theta)$
$( \boldsymbol{\pi} , \textbf{T} ,\theta)$
-
(1) Transformation: transform the data into
 $z_i=g^{-1}(y_i;\; \theta ) \exp(\textbf{x}_i^{\textsf{T}} \boldsymbol{\beta})$
,
$i=1,\dots,N$
.
$z_i=g^{-1}(y_i;\; \theta ) \exp(\textbf{x}_i^{\textsf{T}} \boldsymbol{\beta})$
,
$i=1,\dots,N$
. -
(2) E-step: compute the statistics (see Appendix 6 for precise definitions of the random variables
$B_k$
,
$Z_k$
,
$N_{ks}$
, and
$N_k$
):
\begin{align*} \mathbb{E}(B_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} \frac{\pi_k {\textbf{e}_k}^{{\textsf{T}}}\exp( \textbf{T} z_i) \textbf{t} }{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} x_i) \textbf{t} }\end{align*}
\begin{align*} \mathbb{E}(Z_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} \frac{\int_{0}^{z_i}{\textbf{e}_k}^{{\textsf{T}}}\exp( \textbf{T} (z_i-u)) \textbf{t} \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} u)\textbf{e}_kdu}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}
\begin{align*}\mathbb{E}(N_{ks}\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N}t_{ks} \frac{\int_{0}^{z_i}{\textbf{e}_s}^{{\textsf{T}}}\exp( \textbf{T} (z_i-u)) \textbf{t} \, \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} u)\textbf{e}_kdu}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}
\begin{align*}\mathbb{E}(N_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} t_k\frac{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i){\textbf{e}}y_k}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }.\end{align*}
-
(3) M-step: let
\begin{align*}\hat \pi_k=\frac{\mathbb{E}(B_k\mid \textbf{Z}=\textbf{z})}{N}, \quad \hat t_{ks}=\frac{\mathbb{E}(N_{ks}\mid \textbf{Z}=\textbf{z})}{\mathbb{E}(Z_{k}\mid \textbf{Z}=\textbf{z})}\end{align*}
\begin{align*}\hat t_{k}=\frac{\mathbb{E}(N_{k}\mid \textbf{Z}=\textbf{z})}{\mathbb{E}(Z_{k}\mid \textbf{Z}=\textbf{z})},\quad \hat t_{kk}=-\sum_{s\neq k} \hat t_{ks}-\hat t_k.\end{align*}
-
(4) Maximize
\begin{align*} (\hat{\theta},\hat{\boldsymbol{\beta}}) & = argmax_{(\theta ,\boldsymbol{\beta})} \sum_{i=1}^N \log (f_{Y}(y_i;\; \hat{\boldsymbol{\pi}}, \hat{\textbf{T}}, \theta ,\boldsymbol{\beta} )) \\ & = argmax_{(\theta ,\boldsymbol{\beta})} \sum_{i=1}^N \log\left(\!m(\textbf{x}_i \boldsymbol{\beta}) \lambda (y;\; \theta )\, {\boldsymbol{\pi}^{\textsf{T}}}\exp \!\left(\!m(\textbf{x}_i \boldsymbol{\beta}\!)\int_0^y \lambda (s;\; \theta )ds\ \textbf{T}\!\right)\!\textbf{t}\!\right) \end{align*}
-
(5) Update the current parameters to
$({\boldsymbol{\pi}},\textbf{T}, \theta ,\boldsymbol{\beta}) =(\hat{{\boldsymbol{\pi}}},\hat{\textbf{T}}, \hat{ \theta },\hat{\boldsymbol{\beta}})$
. Return to step 1 unless a stopping rule is satisfied.














Output: fitted representation
 $( \boldsymbol{\pi} , \textbf{T} ,\theta, \boldsymbol{\beta})$
.
$( \boldsymbol{\pi} , \textbf{T} ,\theta, \boldsymbol{\beta})$
.
A standard fact of the above procedure, which is not hard to verify directly, is the following result.
Proposition 2.3 The likelihood function is increasing at each iteration of Algorithm 1. Thus, for fixed p, since in that case the likelihood is also bounded, we obtain convergence to a (possibly local) maximum.
Remark 2.1 (Computational remarks) Algorithm 1 is simple to comprehend and very often will converge not only to a maximum but to a global maximum. However, its implementation can quickly turn prohibitively slow, if one fails to implement fast matrix analytic methods. The main difficulty is the computation of matrix exponentials, which appears in the E-step of step 1, and then repeatedly in the optimization of step 2. This problem is by no means new, with Moler and Van Loan (1978) already providing several options on how to calculate the exponential of a matrix.
In Asmussen et al. (Reference Asmussen, Nerman and Olsson1996), matrix exponentiation was done for PH estimation by converting the problem into a system of ordinary differential equations (ODEs) and then subsequently solved by the Runge–Kutta method of order 4. The C implementation, called EMpht, is still available online, cf. Olsson (Reference Olsson1998). Using the same ODE approach, Albrecher et al. (Reference Albrecher, Bladt, Bladt and Yslas2021) implemented a C++ based algorithm available from the matrixdist package in R (cf. Bladt and Yslas, Reference Bladt and Yslas2021). However, when extended to IPH distributions, this approach requires reorderings and lacks the necessary speed to estimate datasets of the magnitude of those found in insurance.
For this reason, we presently choose to make use of the uniformization method, which expresses the dynamics of a continuous-time Markov jump process in terms of a discrete-time chain where jumps occur at a Poisson intensity. Please check the usage of the term ‘consists on’ in the sentence ‘For this reason, we..’ and correct if necessary.More precisely, taking
 $\phi= \max_{k=1,\dots,p} (\!-\!t_{kk})$
and
$\phi= \max_{k=1,\dots,p} (\!-\!t_{kk})$
and
 $\textbf{Q} = {\phi}^{-1}\left( \phi \textbf{I} + \textbf{T} \right)$
, which is a transition matrix, we have that
$\textbf{Q} = {\phi}^{-1}\left( \phi \textbf{I} + \textbf{T} \right)$
, which is a transition matrix, we have that
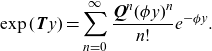 \begin{align*} \exp( \textbf{T} y)= \sum_{n=0}^{\infty} \frac{\textbf{Q} ^{n} (\phi y)^{n}}{n !} e^{-\phi y }. \end{align*}
\begin{align*} \exp( \textbf{T} y)= \sum_{n=0}^{\infty} \frac{\textbf{Q} ^{n} (\phi y)^{n}}{n !} e^{-\phi y }. \end{align*}
and a truncated approximation of this series has error smaller than
 \begin{align*} \sum_{n=M+1}^{\infty} \frac{(\phi y)^{n}}{n !} e^{-\phi y } = \mathbb{P}(N_{\phi y}>M) \,, \end{align*}
\begin{align*} \sum_{n=M+1}^{\infty} \frac{(\phi y)^{n}}{n !} e^{-\phi y } = \mathbb{P}(N_{\phi y}>M) \,, \end{align*}
with
 $N_{\phi y} \sim \mbox{Poisson}(\phi y) $
. In other words, with the introduction of the regularization parameter
$N_{\phi y} \sim \mbox{Poisson}(\phi y) $
. In other words, with the introduction of the regularization parameter
 $\phi$
, we are able to tame the error incurred in the truncation approximation by considering M large enough according to a Poisson law. Further improvements can be achieved by artifacts as the following one: since trivially
$\phi$
, we are able to tame the error incurred in the truncation approximation by considering M large enough according to a Poisson law. Further improvements can be achieved by artifacts as the following one: since trivially
 $e^{\textbf{T} y}=(e^{\textbf{T} y/2^{m}})^{2^m}$
, then the Poisson law with mean
$e^{\textbf{T} y}=(e^{\textbf{T} y/2^{m}})^{2^m}$
, then the Poisson law with mean
 $\phi y /2^{m} <1 $
implies good approximations with small M for
$\phi y /2^{m} <1 $
implies good approximations with small M for
 $e^{\textbf{T} y/2^{m}}$
and then
$e^{\textbf{T} y/2^{m}}$
and then
 $e^{\textbf{T} y}$
is obtained by simple sequential squaring.
$e^{\textbf{T} y}$
is obtained by simple sequential squaring.
Integrals of matrix exponentials can be computed using an ingenious result of Van Loan (Reference Van Loan1978), which states that
 \begin{align*} \exp \left( \left( \begin{array}{c@{\quad}c} \textbf{T} & \textbf{t} \, \boldsymbol{\pi} \\ \textbf{0} & \textbf{T} \end{array} \right) y \right)= \left( \begin{array}{c@{\quad}c} \textrm{e}^{\textbf{T} y } & \int_{0}^{y} \textrm{e}^{ \textbf{T} (y-u)} \textbf{t} \boldsymbol{\pi} \textrm{e}^{ \textbf{T} u}du \\ \textbf{0} & \textrm{e}^{\textbf{T} y } \end{array} \right)\,. \end{align*}
\begin{align*} \exp \left( \left( \begin{array}{c@{\quad}c} \textbf{T} & \textbf{t} \, \boldsymbol{\pi} \\ \textbf{0} & \textbf{T} \end{array} \right) y \right)= \left( \begin{array}{c@{\quad}c} \textrm{e}^{\textbf{T} y } & \int_{0}^{y} \textrm{e}^{ \textbf{T} (y-u)} \textbf{t} \boldsymbol{\pi} \textrm{e}^{ \textbf{T} u}du \\ \textbf{0} & \textrm{e}^{\textbf{T} y } \end{array} \right)\,. \end{align*}
Hence, integrals of the form
 $\int_{0}^{y} \textrm{e}^{ \textbf{T} (y-u)} \textbf{t} \boldsymbol{\pi} \textrm{e}^{ \textbf{T} u}du$
can easily be computed at a stroke by one single matrix exponential evaluation of the left-hand-side expression and extracting the corresponding upper-right sub-matrix.
$\int_{0}^{y} \textrm{e}^{ \textbf{T} (y-u)} \textbf{t} \boldsymbol{\pi} \textrm{e}^{ \textbf{T} u}du$
can easily be computed at a stroke by one single matrix exponential evaluation of the left-hand-side expression and extracting the corresponding upper-right sub-matrix.
Bundled together with a new RcppArmadillo implementation (which is now also part of the latest Github version of matrixdist), the increase in speed was of about two to three orders of magnitude. Consequently, larger datasets with more covariates can be estimated in reasonable time. Naturally, the methods are still slower than those for simple regression models such as GLMs.
2.4 Inference and goodness of fit
Inference and goodness of fit can always be done via parametric bootstrap methods. However, re-fitting a PH regression can be too costly. Consequently, we will take a more classical approach and derive certain quantities of interest which will allow us to perform variable selection and assess the quality of a fitted model.
2.4.1 Inference for phase-type regression models
For the following calculations, we focus only in the identifiable parameters of the regression, which are the relevant ones in terms of segmentation. Furthermore, we now make the assumption that m is differentiable and write
 $\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)$
for the joint log-likelihood function of the observed severities
$\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)$
for the joint log-likelihood function of the observed severities
 $\textbf{y}=(y_1,\dots,y_N)$
with corresponding rating factors
$\textbf{y}=(y_1,\dots,y_N)$
with corresponding rating factors
 $\overline{\textbf{x}}=(\textbf{x}_1,\dots,\textbf{x}_N)$
.
$\overline{\textbf{x}}=(\textbf{x}_1,\dots,\textbf{x}_N)$
.
From (2.2), we obtain for
 $j = 1,\dots,d$
and
$j = 1,\dots,d$
and
 $h(y;\; \theta )\;:=\;\int_0^y \lambda (s;\; \theta )ds$
,
$h(y;\; \theta )\;:=\;\int_0^y \lambda (s;\; \theta )ds$
,
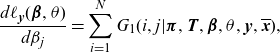 \begin{align}\frac{d\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)}{d\beta_j}&= \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}),\end{align}
\begin{align}\frac{d\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)}{d\beta_j}&= \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}),\end{align}
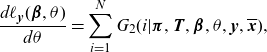 \begin{align}\frac{d\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)}{d \theta }&= \sum_{i=1}^N G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}),\end{align}
\begin{align}\frac{d\ell_{\textbf{y}}(\boldsymbol{\beta},\theta)}{d \theta }&= \sum_{i=1}^N G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}),\end{align}
where
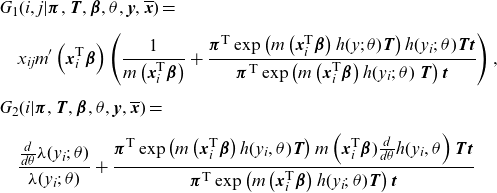 \begin{align*}& G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}})=\\[5pt] & \quad x_{ij}m'\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right) \left(\frac{1}{m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right) }+\frac{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y;\; \theta )\textbf{T} \right)h(y_i;\; \theta )\textbf{T}\textbf{t}}{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i;\; \theta )\ \textbf{T} \right)\textbf{t}}\right),\\[5pt]& G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}})=\\[5pt] & \quad \frac{\frac{d}{d \theta }\lambda(y_i;\; \theta )}{\lambda(y_i;\; \theta )}+\frac{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i, \theta ) \textbf{T} \right)m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta})\frac{d}{d \theta }h(y_i, \theta \right)\textbf{T}\textbf{t}}{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i;\; \theta ) \textbf{T} \right)\textbf{t}}\end{align*}
\begin{align*}& G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}})=\\[5pt] & \quad x_{ij}m'\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right) \left(\frac{1}{m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right) }+\frac{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y;\; \theta )\textbf{T} \right)h(y_i;\; \theta )\textbf{T}\textbf{t}}{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i;\; \theta )\ \textbf{T} \right)\textbf{t}}\right),\\[5pt]& G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}})=\\[5pt] & \quad \frac{\frac{d}{d \theta }\lambda(y_i;\; \theta )}{\lambda(y_i;\; \theta )}+\frac{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i, \theta ) \textbf{T} \right)m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta})\frac{d}{d \theta }h(y_i, \theta \right)\textbf{T}\textbf{t}}{{\boldsymbol{\pi}^{\textsf{T}}}\exp \left( m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta} \right)h(y_i;\; \theta ) \textbf{T} \right)\textbf{t}}\end{align*}
Such expressions should be equal to 0 whenever convergence is achieved in step 2 of Algorithm 1.
In general, the score functions (2.7) and (2.8) will not have an explicit solution when equated to 0. Concerning the
 $(d+1)\times(d+1)$
-dimensional Fisher information matrix, we may write it as:
$(d+1)\times(d+1)$
-dimensional Fisher information matrix, we may write it as:
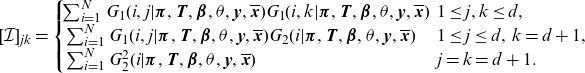 \begin{align}[\mathcal{I}]_{jk}&= \begin{cases}\! \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) G_1(i,k|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! 1\le j,k \le d,\\ \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! 1\le j \le d,\;k=d+1,\\ \sum_{i=1}^N G_2^2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! j=k=d+1.\end{cases}\end{align}
\begin{align}[\mathcal{I}]_{jk}&= \begin{cases}\! \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) G_1(i,k|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! 1\le j,k \le d,\\ \sum_{i=1}^N G_1(i,j|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) G_2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! 1\le j \le d,\;k=d+1,\\ \sum_{i=1}^N G_2^2(i|\boldsymbol{\pi},\textbf{T},\boldsymbol{\beta},\theta,\textbf{y},\overline{\textbf{x}}) & \!\!\! j=k=d+1.\end{cases}\end{align}
Then, we may use the asymptotic MLE approximation, as
 $N\to\infty$
,
$N\to\infty$
,
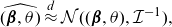 \begin{align*}\widehat{(\boldsymbol{\beta},\theta)}\stackrel{d}{\approx}\mathcal{N}((\boldsymbol{\beta},\theta),\mathcal{I}^{-1}),\end{align*}
\begin{align*}\widehat{(\boldsymbol{\beta},\theta)}\stackrel{d}{\approx}\mathcal{N}((\boldsymbol{\beta},\theta),\mathcal{I}^{-1}),\end{align*}
which can be used to compute standard errors and Neyman-type confidence intervals. For instance,
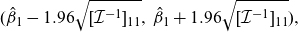 \begin{align*}(\hat\beta_1-1.96 \sqrt{[\mathcal{I}^{-1}]_{11}},\:\hat\beta_1+1.96 \sqrt{[\mathcal{I}^{-1}]_{11}}),\end{align*}
\begin{align*}(\hat\beta_1-1.96 \sqrt{[\mathcal{I}^{-1}]_{11}},\:\hat\beta_1+1.96 \sqrt{[\mathcal{I}^{-1}]_{11}}),\end{align*}
constitutes an approximate 95% confidence interval for the parameter
 $\beta_1$
. We obtain p-values in much the same manner.
$\beta_1$
. We obtain p-values in much the same manner.
Observe that we have deliberately omitted inference for the PH parameters
 $\boldsymbol{\pi}$
and
$\boldsymbol{\pi}$
and
 $\textbf{T}$
. The reason being, this is a particularly difficult task due to the non-identifiability issue of PH distributions, namely that several representations can result in the same model. Papers such as Bladt et al. (Reference Bladt, Esparza and Nielsen2011) and Zhang et al., Reference Zhang, Zheng, Okamura and Dohi2021 provide methods of recovering the information matrix for these parameters, but the validity of the conclusions drawn from such approach are not fully understood. Consequently, and similarly to other regression models, we will only perform estimation on the regression coefficients themselves and use the distributional parameters merely as a vehicle to obtain
$\textbf{T}$
. The reason being, this is a particularly difficult task due to the non-identifiability issue of PH distributions, namely that several representations can result in the same model. Papers such as Bladt et al. (Reference Bladt, Esparza and Nielsen2011) and Zhang et al., Reference Zhang, Zheng, Okamura and Dohi2021 provide methods of recovering the information matrix for these parameters, but the validity of the conclusions drawn from such approach are not fully understood. Consequently, and similarly to other regression models, we will only perform estimation on the regression coefficients themselves and use the distributional parameters merely as a vehicle to obtain
 $\boldsymbol{\beta}$
.
$\boldsymbol{\beta}$
.
Remark 2.2 We performed estimation using numerical optimization, with and without using the gradient of the log-likelihood for step 2 in Algorithm 1. Not using the gradient was always faster, since when dealing with matrix exponentials the evaluation of the derivatives is equally costly as the objective function itself, and thus best avoided. In practice, the Fisher information matrix may be near-singular when large numbers of covariates are considered. The negative of the the Hessian matrix obtained by numerical methods such as the Broyden-Fletcher-Goldfarb-Shanno algorithm is a more reliable alternative in this case, whose inverse may also be used to approximate the asymptotic covariance matrix.
2.4.2 Goodness of fit for phase-type regression models
Below is a brief description of a goodness-of-fit diagnostic tool for the above models, which, when ordered and plotted against theoretical uniform order statistics, constitute a PP plot. The idea is to transform the covariate-specific data into a parameter-free scale using the probability integral transformation (PIT).
Indeed, by applying the PIT transform to the data:
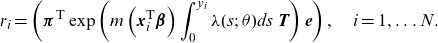 \begin{align}r_i=\left({\boldsymbol{\pi}^{\textsf{T}}}\exp \left(m\left(\textbf{x}_i^{\textsf{T}} \boldsymbol{\beta} \right) \int_0^{y_i} \lambda (s;\; \theta )ds\ \textbf{T} \right)\textbf{e}\right),\quad i=1,\dots N.\end{align}
\begin{align}r_i=\left({\boldsymbol{\pi}^{\textsf{T}}}\exp \left(m\left(\textbf{x}_i^{\textsf{T}} \boldsymbol{\beta} \right) \int_0^{y_i} \lambda (s;\; \theta )ds\ \textbf{T} \right)\textbf{e}\right),\quad i=1,\dots N.\end{align}
The null hypothesis under the PH regression model is
 \begin{align*}\mathcal{H}_0:Y_i\sim \mbox{IPH}\left({\boldsymbol{\pi}},\textbf{T},m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta}\right)\lambda\right),\quad i=1,\dots,N,\end{align*}
\begin{align*}\mathcal{H}_0:Y_i\sim \mbox{IPH}\left({\boldsymbol{\pi}},\textbf{T},m\left(\textbf{x}_i^{\textsf{T}}\boldsymbol{\beta}\right)\lambda\right),\quad i=1,\dots,N,\end{align*}
and it standard see that the dataset:
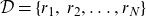 \begin{align*}\mathcal{D}=\{r_1,\:r_2,\dots, r_N\}\end{align*}
\begin{align*}\mathcal{D}=\{r_1,\:r_2,\dots, r_N\}\end{align*}
constitutes a sample of uniform variables.
Thus, it only remains to assess the goodness of fit of
 $\mathcal{D}$
against a standard uniform distribution, for which a suite of statistical tests and visual tools can be applied.
$\mathcal{D}$
against a standard uniform distribution, for which a suite of statistical tests and visual tools can be applied.
2.5 On the choice of matrix dimension and structure
Often a general sub-intensity matrix structure is too general to be either practical or parsimonious, and special structures can do the job almost as well with fewer parameters (see, e.g., Bladt and Nielsen, Reference Bladt and Nielsen2017, Section 3.1.5, and also Section 8.3.2). This is because IPH distributions are not identifiable: two matrices of different dimension and/or structure may yield exactly the same distribution.
A zero in the off-diagonal of the sub-intensity matrix
 $\textbf{T}$
indicates absence of jumps between two states, whereas a zero in the diagonal is not possible. Below we describe the most commonly used special structures for
$\textbf{T}$
indicates absence of jumps between two states, whereas a zero in the diagonal is not possible. Below we describe the most commonly used special structures for
 $\textbf{T}$
(and its corresponding
$\textbf{T}$
(and its corresponding
 $\boldsymbol{\pi}$
). Note that we borrow the names of the structures from the homogeneous case, but the resulting distribution will in general not be linked to such name. For instance, a Matrix-Pareto of exponential structure will yield a Pareto distribution, and not an exponential one.
$\boldsymbol{\pi}$
). Note that we borrow the names of the structures from the homogeneous case, but the resulting distribution will in general not be linked to such name. For instance, a Matrix-Pareto of exponential structure will yield a Pareto distribution, and not an exponential one.
Exponential structure. This is the simplest structure one can think of and applies only for
 $p=1$
, that is, the scalar case. We have
$p=1$
, that is, the scalar case. We have
 $\boldsymbol{\pi}^{\textsf{T}}=1$
,
$\boldsymbol{\pi}^{\textsf{T}}=1$
,
 $\textbf{T}=-\alpha<0$
, and so
$\textbf{T}=-\alpha<0$
, and so
 $\textbf{t}=\alpha$
. The corresponding stochastic process is schematically depicted in the top-left panel of Figure 3.
$\textbf{t}=\alpha$
. The corresponding stochastic process is schematically depicted in the top-left panel of Figure 3.
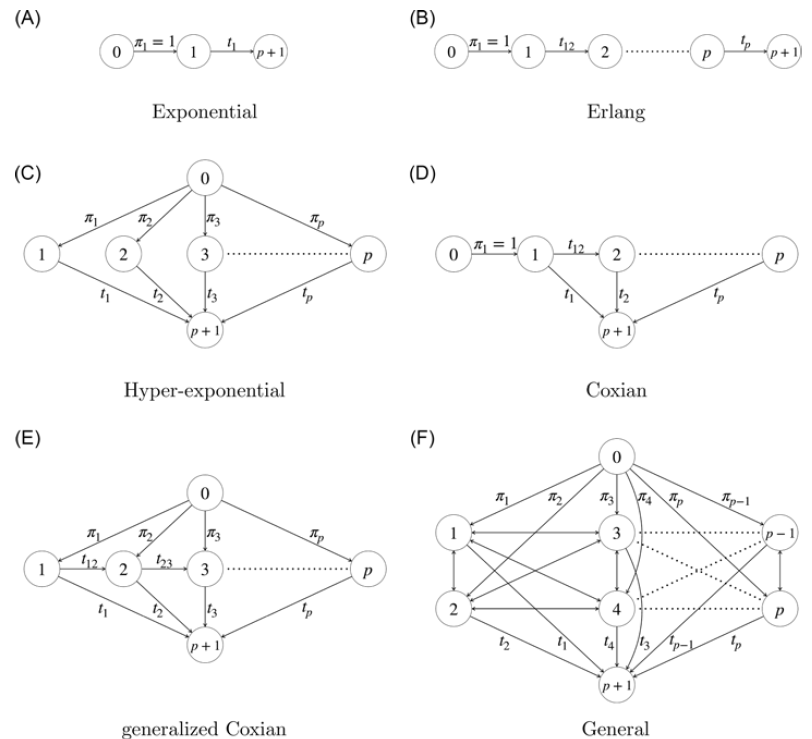
Figure 3. Underlying Markov structures. Names are borrowed from the corresponding PH representations but apply to our inhomogeneous setup as well. The state 0 is added for schematic reasons but is not part of the actual state space of the chain. The (F) general case has the intensities
 $t_{ij}$
and
$t_{ij}$
and
 $t_{ji}$
between each pair of states
$t_{ji}$
between each pair of states
 $i,j\in\{0,\dots,p\}$
omitted for display purposes.
$i,j\in\{0,\dots,p\}$
omitted for display purposes.
Erlang structure. This structure traverses p identical states consecutively from beginning to end, or in matrix notation:
 \[ \boldsymbol{\pi}^{\textsf{T}} =(1, \:0, \dots, \:0 ),\]
\[ \boldsymbol{\pi}^{\textsf{T}} =(1, \:0, \dots, \:0 ),\]
 \[ \textbf{T} = \begin{pmatrix} -\alpha\;\;\;\; & \alpha\;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & \ddots\;\;\;\; &\ddots\;\;\;\; & \vdots\\ \;\;\;\; & \;\;\;\; & -\alpha\;\;\;\; & \alpha\\ 0\;\;\;\; & \;\;\;\; & \;\;\;\; &-\alpha \end{pmatrix}, \, \quad \textbf{t}= \begin{pmatrix}0 \\ \vdots \\ 0 \\\alpha \end{pmatrix},\quad \alpha>0. \]
\[ \textbf{T} = \begin{pmatrix} -\alpha\;\;\;\; & \alpha\;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & \ddots\;\;\;\; &\ddots\;\;\;\; & \vdots\\ \;\;\;\; & \;\;\;\; & -\alpha\;\;\;\; & \alpha\\ 0\;\;\;\; & \;\;\;\; & \;\;\;\; &-\alpha \end{pmatrix}, \, \quad \textbf{t}= \begin{pmatrix}0 \\ \vdots \\ 0 \\\alpha \end{pmatrix},\quad \alpha>0. \]
The corresponding stochastic process is schematically depicted in the top-right panel of Figure 3.
Hyperexponential PH distribution. This structure will always give rise to a mixture of scalar distributions, since it starts in one of the p states but has no transitions between them thereafter. The matrix representation is the following:
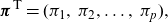 \[ \boldsymbol{\pi}^{\textsf{T}} =(\pi_1, \: \pi_2, \dots, \: \pi_p),\]
\[ \boldsymbol{\pi}^{\textsf{T}} =(\pi_1, \: \pi_2, \dots, \: \pi_p),\]
 \[ \textbf{T} = \begin{pmatrix} -\alpha_1\;\;\;\; & \;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & \;\;\;\; & \ddots\;\;\;\; & \\ 0\;\;\;\; & \;\;\;\; & \;\;\;\; & -\alpha_p \end{pmatrix}, \, \quad \textbf{t} = \begin{pmatrix}\alpha_1 \\ \vdots \\\alpha_p \end{pmatrix},\quad \alpha_i>0, \:\:\: i=1,\dots,p. \]
\[ \textbf{T} = \begin{pmatrix} -\alpha_1\;\;\;\; & \;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & \;\;\;\; & \ddots\;\;\;\; & \\ 0\;\;\;\; & \;\;\;\; & \;\;\;\; & -\alpha_p \end{pmatrix}, \, \quad \textbf{t} = \begin{pmatrix}\alpha_1 \\ \vdots \\\alpha_p \end{pmatrix},\quad \alpha_i>0, \:\:\: i=1,\dots,p. \]
The corresponding stochastic process is schematically depicted in the center-left panel of Figure 3.
Coxian structure. This structure is a generalization of the Erlang one, where different parameters are allowed for the diagonal entries, and also absorption can happen spontaneously from any intermediate state. The parametrization is as follows:
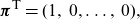 \[ \boldsymbol{\pi}^{\textsf{T}} =(1,\: 0, \dots,\: 0),\]
\[ \boldsymbol{\pi}^{\textsf{T}} =(1,\: 0, \dots,\: 0),\]
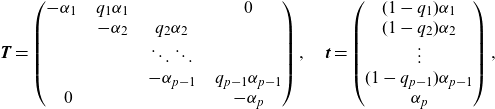 \[ \textbf{T} = \begin{pmatrix} -\alpha_1\;\;\;\; & q_1\alpha_1\;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & -\alpha_2\;\;\;\; & q_2\alpha_2\;\;\;\; & \\ \;\;\;\; & \;\;\;\; & \ddots \ddots\;\;\;\; & \\\;\;\;\; & \;\;\;\; & -\alpha_{p-1}\;\;\;\; & q_{p-1}\alpha_{p-1} \\ 0 & & & -\alpha_p \end{pmatrix}, \quad \textbf{t} = \begin{pmatrix}(1-q_1)\alpha_1 \\ (1-q_{2})\alpha_{2} \\ \vdots \\ (1-q_{p-1})\alpha_{p-1} \\\alpha_p \end{pmatrix},\]
\[ \textbf{T} = \begin{pmatrix} -\alpha_1\;\;\;\; & q_1\alpha_1\;\;\;\; & \;\;\;\; & 0 \\ \;\;\;\; & -\alpha_2\;\;\;\; & q_2\alpha_2\;\;\;\; & \\ \;\;\;\; & \;\;\;\; & \ddots \ddots\;\;\;\; & \\\;\;\;\; & \;\;\;\; & -\alpha_{p-1}\;\;\;\; & q_{p-1}\alpha_{p-1} \\ 0 & & & -\alpha_p \end{pmatrix}, \quad \textbf{t} = \begin{pmatrix}(1-q_1)\alpha_1 \\ (1-q_{2})\alpha_{2} \\ \vdots \\ (1-q_{p-1})\alpha_{p-1} \\\alpha_p \end{pmatrix},\]
with
 $\alpha_i>0,\:q_i\in[0,1], \:i=1,\dots,p$
. The corresponding stochastic process is schematically depicted in the center-right panel of Figure 3.
$\alpha_i>0,\:q_i\in[0,1], \:i=1,\dots,p$
. The corresponding stochastic process is schematically depicted in the center-right panel of Figure 3.
Generalized Coxian structure. This structure has the same
 $\textbf{T}$
and
$\textbf{T}$
and
 $\textbf{t}$
parameters as in the Coxian case, the only difference being that the initial vector is now distributed among all p states, that is,
$\textbf{t}$
parameters as in the Coxian case, the only difference being that the initial vector is now distributed among all p states, that is,
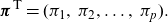 \[ \boldsymbol{\pi}^{\textsf{T}} =(\pi_1, \: \pi_2,\dots, \:\pi_p ).\]
\[ \boldsymbol{\pi}^{\textsf{T}} =(\pi_1, \: \pi_2,\dots, \:\pi_p ).\]
The corresponding stochastic process is schematically depicted in the bottom-left panel of Figure 3.
Remark 2.3 One convenient feature of having zeros in a sub-intensity matrix is that the EM algorithm will forever keep those zeros in place, effectively searching only within the subclass of IPH distributions of a given special structure. A prevalent observation which has nearly become a rule of thumb is that Coxian structures perform nearly as well as general structures and are certainly much faster to estimate.
Remark 2.4 When dealing with matrices whose entries are the parameters of the model, the usual systematic measures such as Akaike’s Information Criteria (AIC) or Bayesian Information Criteria (BIC) are overly conservative (yielding too simple models), and the appropriate amount of penalization is a famous unsolved problem in the PH community, and out of the scope of the current work. The selection of the number of phases and the special substructure of such matrix is commonly done by trial and error, much in the same manner as is done for the tuning of hyperparameters of a machine learning method, or the selection of the correct combination of covariates in a linear regression. Such approach is also taken presently. Despite this disadvantage, there is one advantage from a purely statistical standpoint, which is that standard errors (and thus significance of regression coefficients) arising from asymptotic theory are more truthful if no automatic selection procedure is used.
Hence, when selecting between fitted dimensions and structures, it is advised to keep track of the negative log-likelihood (rather than AIC or BIC) and its decrease when increasing the number of phases or changing the structure. Theoretically, larger matrices will always yield better likelihood, but in practice, it is often the case that the likelihood stops increasing (effectively getting stuck in a good local optimum), or increases are not so significant. Usually, EM algorithms for PH distributions for marginal distributions estimate effectively and in reasonable time up to about 20–30 phases, while for a PH regression the number is closer to 5–10. The additional inhomogeneity function of IPH distributions, however, makes models more parsimonious than the PH counterparts, and usually less than 10 phases are needed.
Once the dimension and structure is chosen, one can perform model selection with respect to the regression coefficients. These fall into the usual framework, and the AIC or BIC criteria can then be used to compare and select between various models.
3 A simulation study
Before applying the above models to a real-life insurance dataset, we would first like to confirm that PH regression is an effective tool for estimating data exhibiting features which are common in insurance. Namely, claim severity can exhibit multimodality and different behavior in the body and tails of the distribution, the latter being heavy-tailed in some lines of business. In order to create synthetic data with these features, we take the following approach.
We simulate
 $N=1000$
times from a bivariate Gaussian copula
$N=1000$
times from a bivariate Gaussian copula
 $\textbf{X}=(X_1,X_2)^{\textsf{T}}$
with correlation coefficient
$\textbf{X}=(X_1,X_2)^{\textsf{T}}$
with correlation coefficient
 $0.7$
, which will play the role of sampling from a bivariate feature vector with uniform marginals. Then, we create three mean specifications based on the first entry of such vector:
$0.7$
, which will play the role of sampling from a bivariate feature vector with uniform marginals. Then, we create three mean specifications based on the first entry of such vector:
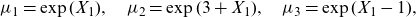 \begin{align*}\mu_1=\exp(X_1),\quad \mu_2=\exp(3+X_1), \quad \mu_3=\exp(X_1-1),\end{align*}
\begin{align*}\mu_1=\exp(X_1),\quad \mu_2=\exp(3+X_1), \quad \mu_3=\exp(X_1-1),\end{align*}
in a sense individually specifying a log-link function. We finally sample with probabilities
 $0.4$
,
$0.4$
,
 $\,0.4$
, and
$\,0.4$
, and
 $\,0.2$
from three different regression specifications:
$\,0.2$
from three different regression specifications:
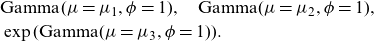 \begin{align*}& \text{Gamma}(\mu=\mu_1, \phi=1),\quad \text{Gamma}(\mu=\mu_2, \phi=1),\\ & \exp(\text{Gamma}(\mu=\mu_3, \phi=1)).\end{align*}
\begin{align*}& \text{Gamma}(\mu=\mu_1, \phi=1),\quad \text{Gamma}(\mu=\mu_2, \phi=1),\\ & \exp(\text{Gamma}(\mu=\mu_3, \phi=1)).\end{align*}
The data are depicted in Figure 4.
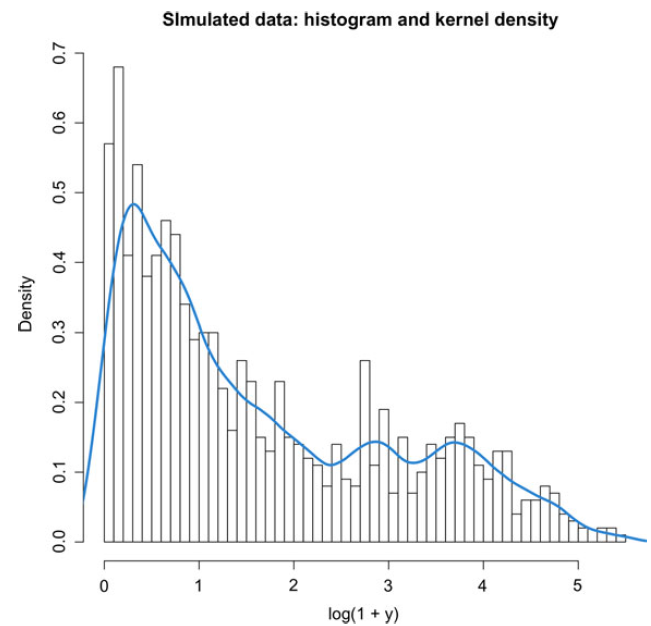
Figure 4. Histogram and kernel density estimate of the log-transformed simulated data.
Observe that the third component implies Pareto-type tails, although this component has the smallest probability of occurrence. We also remark that the true driver of the regression is
 $X_1$
, and thus we would ideally like to obtain the nonsignificance of
$X_1$
, and thus we would ideally like to obtain the nonsignificance of
 $X_2$
from the inference.
$X_2$
from the inference.
Next, consider four model specifications:
-
(1) a Gamma GLM with log-link function and considering
$X_1$
as covariate. -
(2) a Gamma GLM with log-link function and considering
$X_1$
and
$X_2$
as covariates. -
(3) a Matrix-Pareto PH regression of Coxian type and dimension 3, considering
$X_1$
as covariate. -
(4) a Matrix-Pareto PH regression of Coxian type and dimension 3, considering
$X_1$
and
$X_2$
as covariates.






The analysis was carried using the matrixdist package in R, Bladt and Yslas (Reference Bladt and Yslas2021). The results are Please define/explain the relevance of the use of boldface in Tables 1, 2 and 4.given in Table 1 (observe that the IPH models do not have intercept since it is included in their sub-intensity matrices), showing good segmentation for the matrix-based methods. Uninformative covariates can play the role of mixing in the absence of a correctly specified probabilistic model, and thus we see that
 $X_2$
is significant for the GLM model, whereas this is no longer the case for the PH regression. The AIC and BIC select the overall best model to be the Matrix-Pareto with only
$X_2$
is significant for the GLM model, whereas this is no longer the case for the PH regression. The AIC and BIC select the overall best model to be the Matrix-Pareto with only
 $X_1$
as rating factor. In terms of goodness of fit, we visually confirm from Figure 5 that the distributional features of the data are captured substantially better by considering an underlying Markov structure.
$X_1$
as rating factor. In terms of goodness of fit, we visually confirm from Figure 5 that the distributional features of the data are captured substantially better by considering an underlying Markov structure.
Table 1. GLMs and PH regression models.
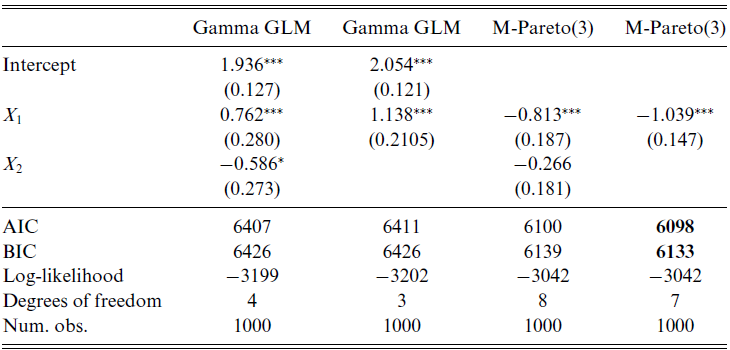
The smallest AIC and BIC values are given in boldface.
 $^{***}p<0.001$
;
$^{***}p<0.001$
;
 $^{**}p<0.01$
;
$^{**}p<0.01$
;
 $^{*}p<0.05$
$^{*}p<0.05$
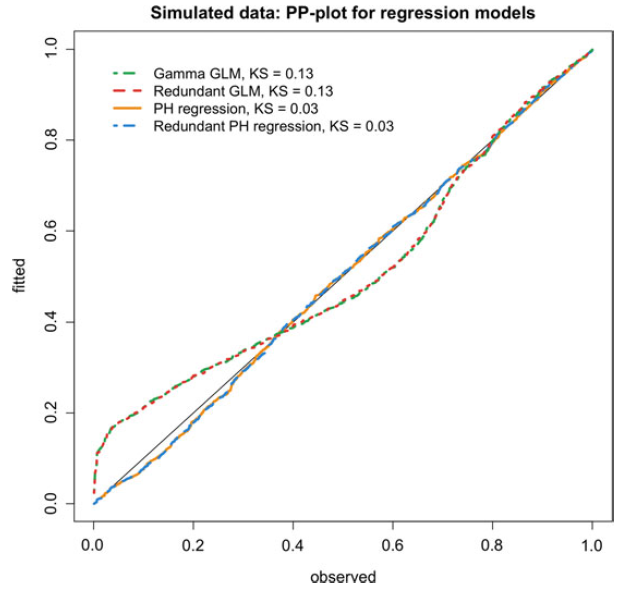
Figure 5. Ordered PITs from equation (2.10) versus uniform order statistics for the simulated dataset. KS refers to the Kolmogorv–Smirnov statistic for testing uniformity.
4 Application to a the French Motor Personal Line dataset
In this section, we consider a real-life insurance dataset: the publicly available French Motor Personal Line dataset. We apply the IPH and PH regression estimation procedures to the distribution of claim severities, illustrating how the theory and algorithms from the previous sections can be effectively applied to model claim sizes.
We consider jointly the four datasets freMPL1, freMPL2, freMPL3, and freMPL4, from the CASdatasets package in R. These data describe claim frequencies and severities pertaining to four different coverages in a French motor personal line insurance for about 30,000 policies in the year 2004. The data have 18 covariates, which are described in the Supplementary Material. The 7008 observations with positive claim severity possess a multimodal density, arising from mixing different types of claims.
4.1 Marginal estimation
In the first step, we estimate the marginal behavior of the data, without rating factors. The model we choose to estimate is an IPH distribution with the exponential transform, namely, a Matrix-Pareto distribution. This choice is motivated by a preliminary analysis of the data by which a Hill plot indicated the presence of regularly varying tails, indicating heavy-tailedness. Since the data on the log-scale have a pronounced hump in the middle, a dimension larger than 1 or 2 is needed, so we chose 5. Finally, since there are no particular specificities in the right or left tail, a Coxian sub-matrix structure can do an equally good job as a general structure, and thus we select the former in the name of parsimony.
We also estimate a 20-dimensional Matrix-Weibull distribution on the data to illustrate the denseness property of IPH distributions. The Matrix-Weibull distribution generates modes more easily than the Matrix-Pareto, and we choose such a high dimension in order to illustrate the denseness of IPH distributions. However, this model is over-parametrized and thus mainly of academic interest.
As the first reference, we also fit a two-parameter Gamma distribution to the data. We also consider a splicing (or composite) model, cf. Albrecher et al. (Reference Albrecher, Beirlant and Teugels2017) and Reynkens et al. (Reference Reynkens, Verbelen, Beirlant and Antonio2017) (see also Miljkovic and Grün, Reference Miljkovic and Grün2016), defined as follows. Let
 $f_1$
and
$f_1$
and
 $\:f_2$
be two densities supported on the positive real line. A spliced density based on the the latter components is then given by:
$\:f_2$
be two densities supported on the positive real line. A spliced density based on the the latter components is then given by:
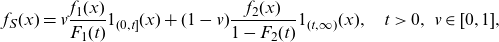 \begin{align*}f_S(x)=v \frac{f_1(x)}{F_1(t)} 1_{(0,t]}(x) + (1-v) \frac{f_2(x)}{1- F_2(t)} 1_{(t,\infty)}(x), \quad t>0,\:\: v\in[0,1],\end{align*}
\begin{align*}f_S(x)=v \frac{f_1(x)}{F_1(t)} 1_{(0,t]}(x) + (1-v) \frac{f_2(x)}{1- F_2(t)} 1_{(t,\infty)}(x), \quad t>0,\:\: v\in[0,1],\end{align*}
where t is the splicing location. We consider a popular implementation found in the ReIns package in R, Reynkens and Verbelen (Reference Reynkens and Verbelen2020), where
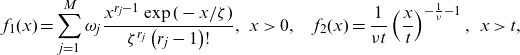 \begin{align*}f_1(x)=\sum_{j=1}^{M} \omega_{j} \frac{x^{r_{j}-1} \exp (-x / \zeta)}{\zeta^{r_{j}}\left(r_{j}-1\right) !},\:\:x>0,\quad f_2(x)=\frac{1}{\nu t}\left(\frac{x}{t}\right)^{-\frac{1}{\nu}-1},\:\:x>t,\end{align*}
\begin{align*}f_1(x)=\sum_{j=1}^{M} \omega_{j} \frac{x^{r_{j}-1} \exp (-x / \zeta)}{\zeta^{r_{j}}\left(r_{j}-1\right) !},\:\:x>0,\quad f_2(x)=\frac{1}{\nu t}\left(\frac{x}{t}\right)^{-\frac{1}{\nu}-1},\:\:x>t,\end{align*}
are, respectively, a ME densities with common scale parameter and a Pareto density, which we call the ME-Pareto specification.
The parameter estimates are the following for the Gamma distribution, found by MLE,
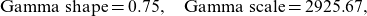 \begin{align*}\text{Gamma shape}= 0.75, \quad \text{Gamma scale} = 2925.67,\end{align*}
\begin{align*}\text{Gamma shape}= 0.75, \quad \text{Gamma scale} = 2925.67,\end{align*}
while for the splicing model we obtain, selecting
 $\nu$
through EVT techniques (Hill estimator) and the remaining parameters through MLE (using an EM algorithm), and choosing M from 1 to 10 according to the best AIC:
$\nu$
through EVT techniques (Hill estimator) and the remaining parameters through MLE (using an EM algorithm), and choosing M from 1 to 10 according to the best AIC:
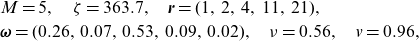 \begin{align*}&M=5, \quad \zeta=363.7,\quad \textbf{r}=(1,\, 2 ,\, 4,\, 11,\, 21),\\ &\boldsymbol{\omega}=(0.26,\, 0.07,\, 0.53,\, 0.09,\, 0.02),\quad \nu =0.56,\quad v=0.96,\end{align*}
\begin{align*}&M=5, \quad \zeta=363.7,\quad \textbf{r}=(1,\, 2 ,\, 4,\, 11,\, 21),\\ &\boldsymbol{\omega}=(0.26,\, 0.07,\, 0.53,\, 0.09,\, 0.02),\quad \nu =0.56,\quad v=0.96,\end{align*}
and
 $t\approx10,000$
was selected by visual inspection according to when the Hill plot stabilizes for the sample. Finally, for the IPH Matrix-Pareto distribution, we obtain the following estimates by applying Algorithm 1 without covariates (which is implemented in the matrixdist package in R, Bladt and Yslas, Reference Bladt and Yslas2021):
$t\approx10,000$
was selected by visual inspection according to when the Hill plot stabilizes for the sample. Finally, for the IPH Matrix-Pareto distribution, we obtain the following estimates by applying Algorithm 1 without covariates (which is implemented in the matrixdist package in R, Bladt and Yslas, Reference Bladt and Yslas2021):
 \begin{align*}\boldsymbol{\pi}=\textbf{e}_1, \quad \textbf{T}= \begin{pmatrix}-12.61\;\;\;\; & 12.48\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & 0\\0\;\;\;\; & -12.61\;\;\;\; & 10.33\;\;\;\; & 0\;\;\;\; & 0\\0\;\;\;\; & 0\;\;\;\; & -1.99\;\;\;\; & 1.99\;\;\;\; & 0\\0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & -7.34\;\;\;\; & 7.34\\0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & -7.34\\\end{pmatrix},\quad \eta = 1149.57,\end{align*}
\begin{align*}\boldsymbol{\pi}=\textbf{e}_1, \quad \textbf{T}= \begin{pmatrix}-12.61\;\;\;\; & 12.48\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & 0\\0\;\;\;\; & -12.61\;\;\;\; & 10.33\;\;\;\; & 0\;\;\;\; & 0\\0\;\;\;\; & 0\;\;\;\; & -1.99\;\;\;\; & 1.99\;\;\;\; & 0\\0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & -7.34\;\;\;\; & 7.34\\0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & 0\;\;\;\; & -7.34\\\end{pmatrix},\quad \eta = 1149.57,\end{align*}
where
 $\textbf{e}_1=(1,\,0,\,0,\,0,\,0)^{\textsf{T}}.$
The 404 fitted parameters of the Matrix-Weibull, most of the zero, are omitted, since they do not provide further intuition on IPH fitting.
$\textbf{e}_1=(1,\,0,\,0,\,0,\,0)^{\textsf{T}}.$
The 404 fitted parameters of the Matrix-Weibull, most of the zero, are omitted, since they do not provide further intuition on IPH fitting.
Table 2 provides numerical results on the three fitted models, and in particular it shows that an IPH Matrix-Pareto distribution is well aligned with the state-of-the-art models for severity modeling in insurance such as composite methods. The AIC and BIC are not good measures for IPH distributions, since they can over-penalize them when the underlying sub-intensity matrix is not of minimal order. However, we see that even with this hinderance, the performance in terms of information criteria is positive.
Table 2. Summary of fitted marginal models to severities from the freMPL dataset.
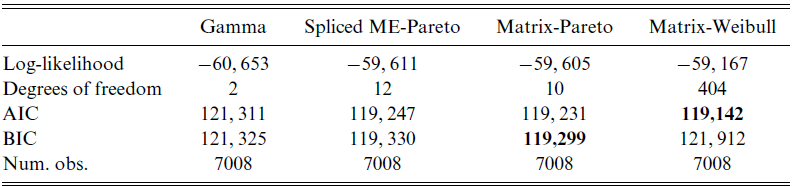
The smallest AIC and BIC values are given in boldface.
The quality of the fit is also assessed in Figure 6. In particular, we observe that the data have a big spike at the log-severity around the value
 $7.3$
, which poses problems to the first three distributions. This disturbance manifests itself in the PP plot as a slight “S” shape. Not surprisingly, the visual quality of the fit of the splicing and IPH models is, as expected, far superior to its Gamma counterpart, while the difference between the two Pareto-tailed models is not very noticeable. Their implied tail indices agree, as given respectively by the formulas
$7.3$
, which poses problems to the first three distributions. This disturbance manifests itself in the PP plot as a slight “S” shape. Not surprisingly, the visual quality of the fit of the splicing and IPH models is, as expected, far superior to its Gamma counterpart, while the difference between the two Pareto-tailed models is not very noticeable. Their implied tail indices agree, as given respectively by the formulas
 $\hat\xi=\nu=0.56,$
and
$\hat\xi=\nu=0.56,$
and
 \begin{align*}\hat\xi = -1/\max\{\Re\text{Eigen}(\hat{\textbf{T}})\} = 0.50,\end{align*}
\begin{align*}\hat\xi = -1/\max\{\Re\text{Eigen}(\hat{\textbf{T}})\} = 0.50,\end{align*}
where
 $\Re\text{Eigen}(\textbf{A})$
denotes the set of real eigenvalues of a matrix
$\Re\text{Eigen}(\textbf{A})$
denotes the set of real eigenvalues of a matrix
 $\textbf{A}$
. For reference, recall that in terms of the Pareto tail parameter, the following relationship holds
$\textbf{A}$
. For reference, recall that in terms of the Pareto tail parameter, the following relationship holds
 $\alpha = 1/\xi$
. As a sanity check, we see that both estimates for the tail index fall perfectly within the Hill estimator’s bounds. In particular, the estimated models have finite mean (their tail index is less than 1; alternatively, their Pareto index is larger than 1). We would like to remark that fitting a conventional Pareto distribution as a global model will result in a particularly bad fit, such that in the IPH case we have managed use matrix parameters to our advantage, in order to automatically engineer an all-inclusive model, featuring no threshold selection.
$\alpha = 1/\xi$
. As a sanity check, we see that both estimates for the tail index fall perfectly within the Hill estimator’s bounds. In particular, the estimated models have finite mean (their tail index is less than 1; alternatively, their Pareto index is larger than 1). We would like to remark that fitting a conventional Pareto distribution as a global model will result in a particularly bad fit, such that in the IPH case we have managed use matrix parameters to our advantage, in order to automatically engineer an all-inclusive model, featuring no threshold selection.
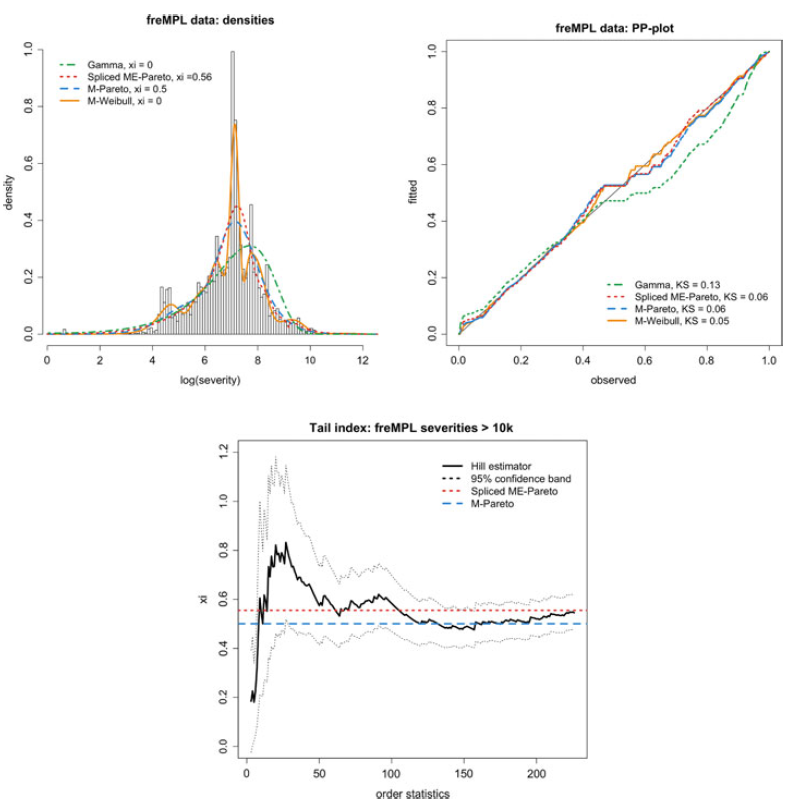
Figure 6. Fitted distributions to claim severities from the MPL dataset. The log-transform is used exclusively for visual purposes, the estimation having been carried out in the usual scale. KS refers to the Kolmogorv–Smirnov statistic for testing uniformity.
4.2 Incorporating rating factors
Having already analyzed the marginal behavior of the French MPL data, we proceed to incorporate rating factors through the PH regression model that we have presented above. In Table 3, we show summarizing statistics for claim severity, while two further tables of summarizing statistics for continuous rating factors and categorical rating factors, respectively, can be found in Supplementary Material.
Table 3. Summary statistics of the French MPL dataset: claim severity.

To reduce the large number of categories and variables, we perform a preprocessing step where we individually, for each categorical variable, prune a regression tree according to the best predictive performance on the mean of the log-severities (since the variables exhibit heavy-tails). We then merge categories together according to the resulting optimal tree. For all the continuous variables, we perform a simple shift-and-scale transformation.
The Matrix-Pareto is the only distribution which according to the Hill estimator will have the correct tail behavior, and thus we consider it as a good target model for PH regression. However, we also consider a model which does not have the correct tail behavior, namely the Matrix-Weibull distribution. The latter is convenient since it has a closed-form formula for mean prediction as per Equation (2.5).
The result of the fit using all the processed rating factors is given in Table 4 and Figure 7, with all the coefficients of the five-dimensional IPH models multiplied by
 $-1$
, to be comparable with the log-link Gamma GLM. The significance is obtained from a normal approximation using the implied Fisher matrix based on the Hessian matrix from the numerical optimization, as detailed in the goodness-of-fit subsection above. When considering less covariates, Equation (2.9) can be equivalently used, yielding very close results. The AIC and BIC are well below what the corresponding GLM can achieve, even if this is not a generous metric for IPH models.
$-1$
, to be comparable with the log-link Gamma GLM. The significance is obtained from a normal approximation using the implied Fisher matrix based on the Hessian matrix from the numerical optimization, as detailed in the goodness-of-fit subsection above. When considering less covariates, Equation (2.9) can be equivalently used, yielding very close results. The AIC and BIC are well below what the corresponding GLM can achieve, even if this is not a generous metric for IPH models.
Table 4. Summary for GLM and PH regression models for the freMPL dataset.
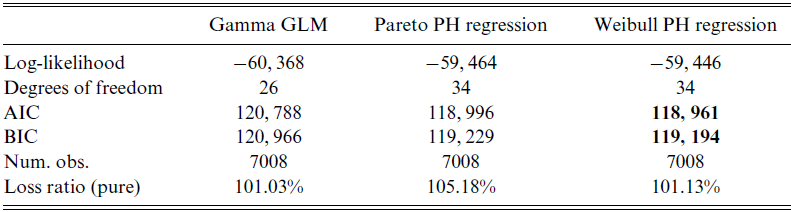
The smallest AIC and BIC values are given in boldface.
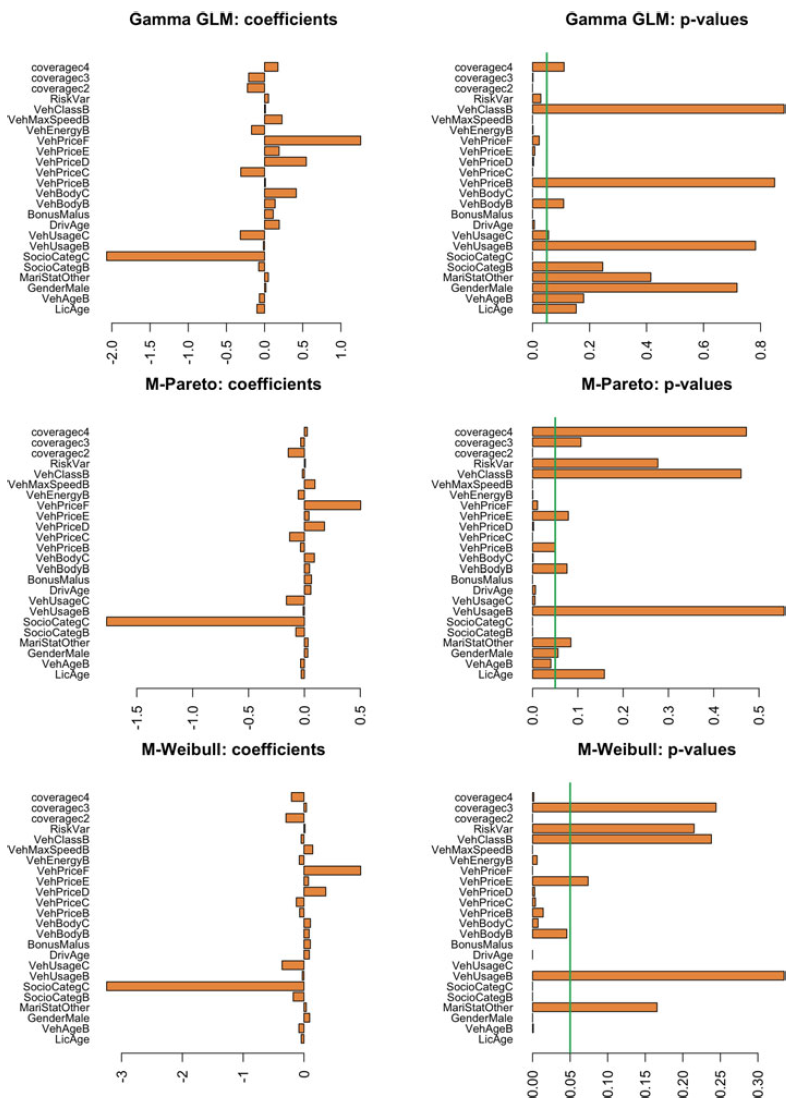
Figure 7. Coefficients and p-values of IPH and GLM regression. For display: IPH coefficients multiplied by
 $-1$
and intercept of GLM omitted.
$-1$
and intercept of GLM omitted.
We observe that the loss ratio (where we understand as losses the claim severities, i.e., disregarding frequencies) is kept much better for the Weibull variant than for the Pareto, despite the latter being a better model for large claims. In practice, this inconvenience can be amended by regressing the losses with respect to the premium. Since estimation is done via MLE, it is not uncommon for a model with misspecified tail behavior to globally perform better. The fact that the Weibull PH regression performs almost as well as the GLM when predicting the mean is remarkable, since the former model does not specifically target averages, and the latter does.
In Figure 8, we illustrate the behavior of the aggregation of the implied mean predictions across all policies. We consider prediction from all three models, for selected rating factors and their categories, as computed by the general formula (2.4) in the Pareto case, and the explicit formula (2.5) in the Weibull case. Each of the aggregate predictions are normalized to sum to 1 for display purposes. We again see that despite the Weibull PH regression not being specifically designed for such task, it comes very close to the performance of the GLM.
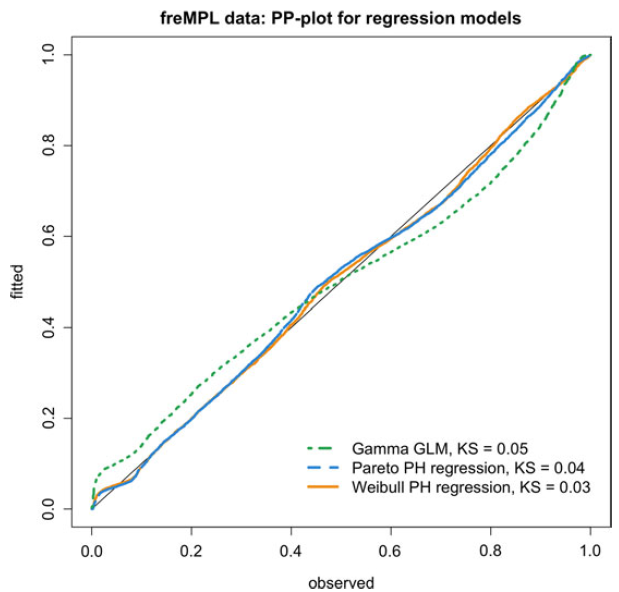
Figure 8. Left panels: aggregate observed losses versus aggregate implied model premia (expected value), normalized to sum to 1, for the Gamma GLM, and Pareto and Weibull PH regressions; right panels: number of claims within each category (right).
In Figure 9, we illustrate the prediction of quantiles, as implied by the fitted conditional distribution functions of each model. We average the quantile estimates across policies corresponding to each of the rating factors and their categories. We observe that matrix distributions perform much better in this respect, and the correct specification of the Pareto tail can be appreciated in the bottom right panel, corresponding to the quantile at level
 $0.9$
. Figure 10 further supports the global estimation improvement in terms of the PP plot goodness-of-fit diagnostic.
$0.9$
. Figure 10 further supports the global estimation improvement in terms of the PP plot goodness-of-fit diagnostic.
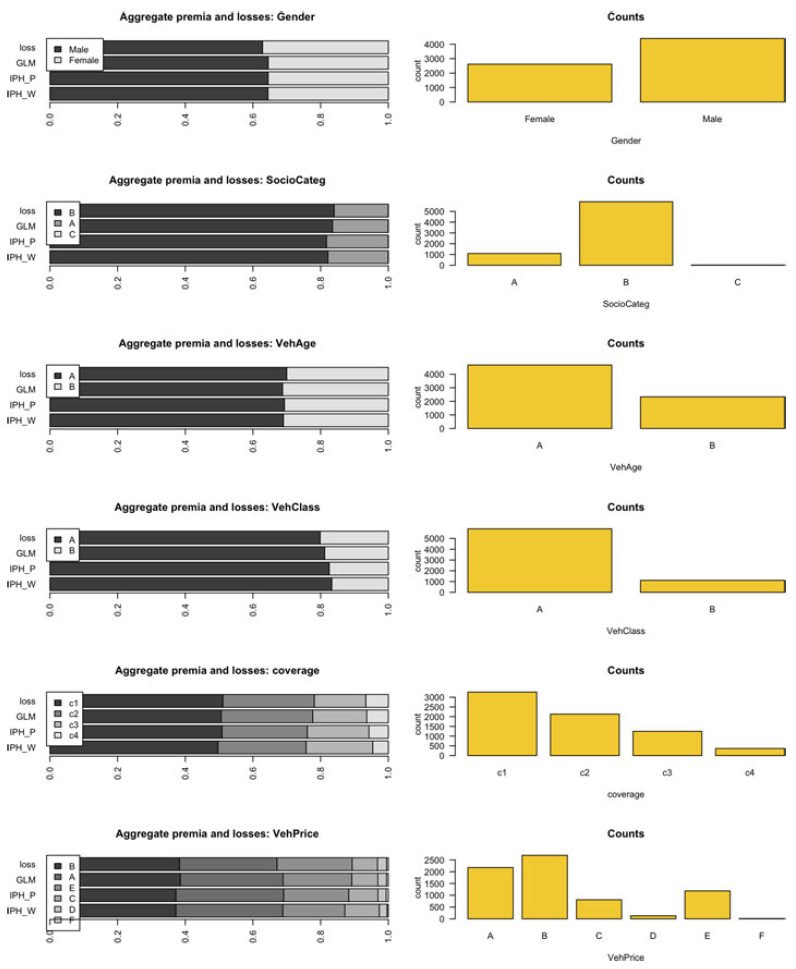
Figure 9. Empirical quantiles by coverage category versus mean (accoss all other covariates) quantiles implied by the Gamma GLM, and Pareto and Weibull PH regressions.
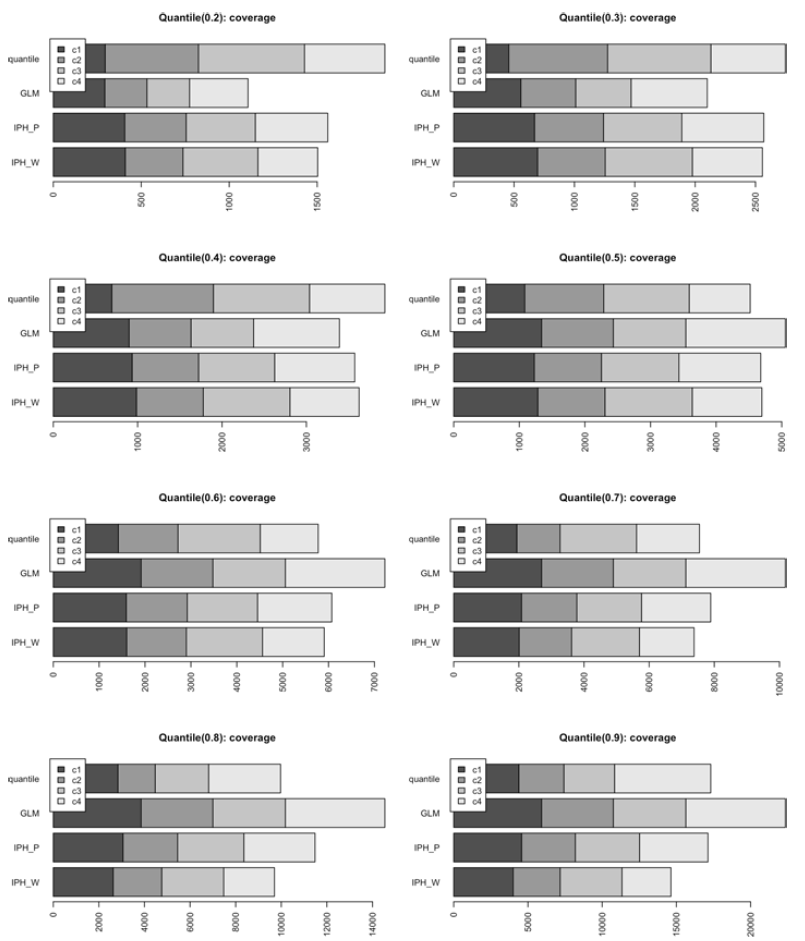
Figure 10. Ordered PITs from Equation (2.10) versus uniform order statistics for the French MPL dataset. KS refers to the Kolmogorv–Smirnov statistic for testing uniformity.
In terms of out-of-sample sample predictive performance, the mean square error (MSE) when holding out the first 20% of the observations and training on the remaining 80% is given by
Footnote 1
 $3.66$
,
$3.66$
,
 $3.69$
, and
$3.69$
, and
 $3.70$
, for the Gamma GLM, Pareto, and Weibull PH regression models, respectively. In general, if the risk manager is solely interested in mean prediction, our experiments suggest that other data-driven methods may outperform PH regression models, although the advantage is usually small. However, the tables turn when considering the entire distribution of loss severities. Thus, a key takeaway here is that PH regression models should be used when the aim is to capture the entire distributional properties of claim severities correctly. In contrast, models specifically designed for mean prediction may be more appropriate if only the average is of interest.
$3.70$
, for the Gamma GLM, Pareto, and Weibull PH regression models, respectively. In general, if the risk manager is solely interested in mean prediction, our experiments suggest that other data-driven methods may outperform PH regression models, although the advantage is usually small. However, the tables turn when considering the entire distribution of loss severities. Thus, a key takeaway here is that PH regression models should be used when the aim is to capture the entire distributional properties of claim severities correctly. In contrast, models specifically designed for mean prediction may be more appropriate if only the average is of interest.
5 Conclusion
We have presented a novel claim severities model based on PH distributions, which implicitly assumes an underlying and unobservable multistate Markov structure. The inhomogeneity function is Table citations were not sequential, so both citations and the respective tables have been renumbered according to the order in which they were cited. Please check and confirm this has been done correctly.the key ingredient for translating the exponential tails of PH distributions to other tail domains, which is particularly useful for modeling of insurance data. We have shown that the use of a generalized EM algorithm performs effective estimation on the marginal distribution of severities, both with and without rating factors, the former being backed up by a simulation study. The flexibility of the PH regression model is particularly advantageous when data are multimodal, heavy- or light-tailed, and generally more heterogeneous than what the classical regression methods require. The practical implementation of PH, IPH, and PH regression can be carried out using the matrixdist (Bladt and Yslas, Reference Bladt and Yslas2021) package in R.
Several questions remain open for further research, for instance, the incorporation of multi-parameter PH regression models, or using IPH models to describe data exhibiting incurred but not reported claims. A faster implementation of the generalized EM algorithms is needed, mainly in the case when numerous categorical rating factors are present, for widespread and systematic use of the PH regression model. Alternative estimation methods have not been explored and could prove competitive to MLE.
Acknowledgment
MB would like to acknowledge financial support from the Swiss National Science Foundation Project 200021_191984.
Conflicts of interest
MB declares no conflict of interest related to the current manuscript.
Supplementary Material
To view supplementary material for this article, please visit https://doi.org/10.1017/asb.2021.40.
Appendix A. Details on the EM algorithm for PH distributions
Here, we assume that
 $Z\sim\mbox{PH}( \boldsymbol{\pi} , \textbf{T} ).$
Let
$Z\sim\mbox{PH}( \boldsymbol{\pi} , \textbf{T} ).$
Let
 $B_k$
be the number of times that the process
$B_k$
be the number of times that the process
 $\{J_t\}_{t\geq0}$
starts in state k,
$\{J_t\}_{t\geq0}$
starts in state k,
 $N_{ks}$
is the total number of jumps from state k to s,
$N_{ks}$
is the total number of jumps from state k to s,
 $N_k$
is the number of times that we reach the absorbing state
$N_k$
is the number of times that we reach the absorbing state
 $p+1$
from state k, and let
$p+1$
from state k, and let
 $Z_k$
be the total time that the underlying Markov jump process spends in state k prior to absorption. These statistics are not recoverable from Z. Given a sample of absorption times
$Z_k$
be the total time that the underlying Markov jump process spends in state k prior to absorption. These statistics are not recoverable from Z. Given a sample of absorption times
 $\textbf{z}$
, the completely observed likelihood can be written in terms of these sufficient statistics as follows:
$\textbf{z}$
, the completely observed likelihood can be written in terms of these sufficient statistics as follows:
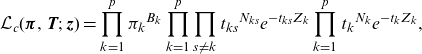 \begin{equation}\mathcal{L}_c( \boldsymbol{\pi} , \textbf{T} ;\;\textbf{z})=\prod_{k=1}^{p} {\pi_k}^{B_k} \prod_{k=1}^{p}\prod_{s\neq k} {t_{ks}}^{N_{ks}}e^{-t_{ks}Z_k}\prod_{k=1}^{p}{t_k}^{N_k}e^{-t_{k}Z_k},\end{equation}
\begin{equation}\mathcal{L}_c( \boldsymbol{\pi} , \textbf{T} ;\;\textbf{z})=\prod_{k=1}^{p} {\pi_k}^{B_k} \prod_{k=1}^{p}\prod_{s\neq k} {t_{ks}}^{N_{ks}}e^{-t_{ks}Z_k}\prod_{k=1}^{p}{t_k}^{N_k}e^{-t_{k}Z_k},\end{equation}
which is seen to conveniently fall into the exponential family of distributions, and thus has explicit maximum likelihood estimators.
However, the full data are not observed, and hence we employ the EM algorithm as an iterative way to obtain the maximum likelihood estimators. At each iteration, the conditional expectations of the sufficient statistics
 $B_k$
,
$B_k$
,
 $N_{ks}$
,
$N_{ks}$
,
 $N_k$
, and
$N_k$
, and
 $Z_k$
given the absorption times
$Z_k$
given the absorption times
 $\textbf{z}$
are computed, commonly referred to as the E-step. Subsequently,
$\textbf{z}$
are computed, commonly referred to as the E-step. Subsequently,
 $\mathcal{L}_c( \boldsymbol{\pi} , \textbf{T} ,\textbf{z})$
is maximized using the estimates of the sufficient statistics from the previous step, in this way obtaining
$\mathcal{L}_c( \boldsymbol{\pi} , \textbf{T} ,\textbf{z})$
is maximized using the estimates of the sufficient statistics from the previous step, in this way obtaining
 $( \boldsymbol{\pi} , \textbf{T} )$
, commonly known as the M-step. The latter maximization is simple to perform because of the closed-form maximum likelihood estimators of exponential families.
$( \boldsymbol{\pi} , \textbf{T} )$
, commonly known as the M-step. The latter maximization is simple to perform because of the closed-form maximum likelihood estimators of exponential families.
Below are the explicit formulas needed for the E- and M-steps for a sample of size N. We denote by
 ${\textbf{e}}_k$
the column vector with all elements equal to 0 besides the
${\textbf{e}}_k$
the column vector with all elements equal to 0 besides the
 $k\textrm{th}$
entry which is equal to 1, that is, the
$k\textrm{th}$
entry which is equal to 1, that is, the
 $k\textrm{th}$
element of the canonical basis of
$k\textrm{th}$
element of the canonical basis of
 $\mathbb{R}^d$
.
$\mathbb{R}^d$
.
-
(1) E-step, conditional expectations:
\begin{align*} \mathbb{E}(B_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} \frac{\pi_k {\textbf{e}_k}^{ {\textsf{T}}}\exp( \textbf{T} z_i) \textbf{t} }{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}
\begin{align*} \mathbb{E}(Z_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} \frac{\int_{0}^{x_i}{\textbf{e}_k}^{ {\textsf{T}}}\exp( \textbf{T} (z_i-u)) \textbf{t} \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} u)\textbf{e}_kdu}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}


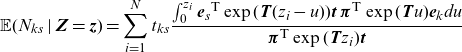 \begin{align*}\mathbb{E}(N_{ks}\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N}t_{ks} \frac{\int_{0}^{z_i}{\textbf{e}_s}^{{\textsf{T}}}\exp( \textbf{T} (z_i-u)) \textbf{t} \, \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} u)\textbf{e}_kdu}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}
\begin{align*}\mathbb{E}(N_{ks}\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N}t_{ks} \frac{\int_{0}^{z_i}{\textbf{e}_s}^{{\textsf{T}}}\exp( \textbf{T} (z_i-u)) \textbf{t} \, \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} u)\textbf{e}_kdu}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }\end{align*}
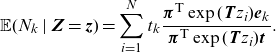 \begin{align*}\mathbb{E}(N_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} t_k\frac{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i){\textbf{e}}_k}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }.\end{align*}
\begin{align*}\mathbb{E}(N_k\mid \textbf{Z}=\textbf{z})=\sum_{i=1}^{N} t_k\frac{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i){\textbf{e}}_k}{ \boldsymbol{\pi}^{\textsf{T}} \exp( \textbf{T} z_i) \textbf{t} }.\end{align*}
-
(2) M-step, explicit maximum likelihood estimators:
\begin{align*}\hat \pi_k=\frac{\mathbb{E}(B_k\mid \textbf{Z}=\textbf{z})}{N }, \quad \hat t_{ks}=\frac{\mathbb{E}(N_{ks}\mid \textbf{Z}=\textbf{z})}{\mathbb{E}(Z_{k}\mid \textbf{Z}=\textbf{z})}\end{align*}
We set
\begin{align*}\hat t_{k}=\frac{\mathbb{E}(N_{k}\mid \textbf{Z}=\textbf{z})}{\mathbb{E}(Z_{k}\mid \textbf{Z}=\textbf{z})},\quad \hat t_{kk}=-\sum_{s\neq k} \hat t_{ks}-\hat t_k.\end{align*}
\begin{align*} \hat{\boldsymbol{\pi}}=(\hat{\pi}_1, \dots,\: \hat{\pi}_p)^{{\textsf{T}}},\quad \hat{\textbf{T}} =\{{ \hat{t}}_{ks}\}_{k,s=1,2,\dots,p},\quad\hat{\textbf{t}}=( \hat{t}_1,\dots,\: \hat{t}_p)^{{\textsf{T}}}.\end{align*}



If we repeat the above two steps, it can be shown that the likelihood increases at each iteration, and thus convergence to a possibly local maximum is guaranteed.























 Open access
Open access