


Impact Statement
The bioimage analysis community consists of software developers, imaging experts, and users, all with different expertise, scientific background, and computational skill levels. The NIH-funded Center for Open Bioimage Analysis (COBA) was launched in 2020 to serve the cell biology community’s growing need for sophisticated open-source software and workflows for light microscopy image analysis. This paper shares the result of a COBA survey to assess the most urgent ongoing needs for software and training in the community and provide a helpful resource for software developers working in this domain. Here, we describe the state of open-source bioimage analysis, developers’ and users’ requests from the community, and our resulting view of common goals that would serve and strengthen the community to advance imaging science.
Results
Participants
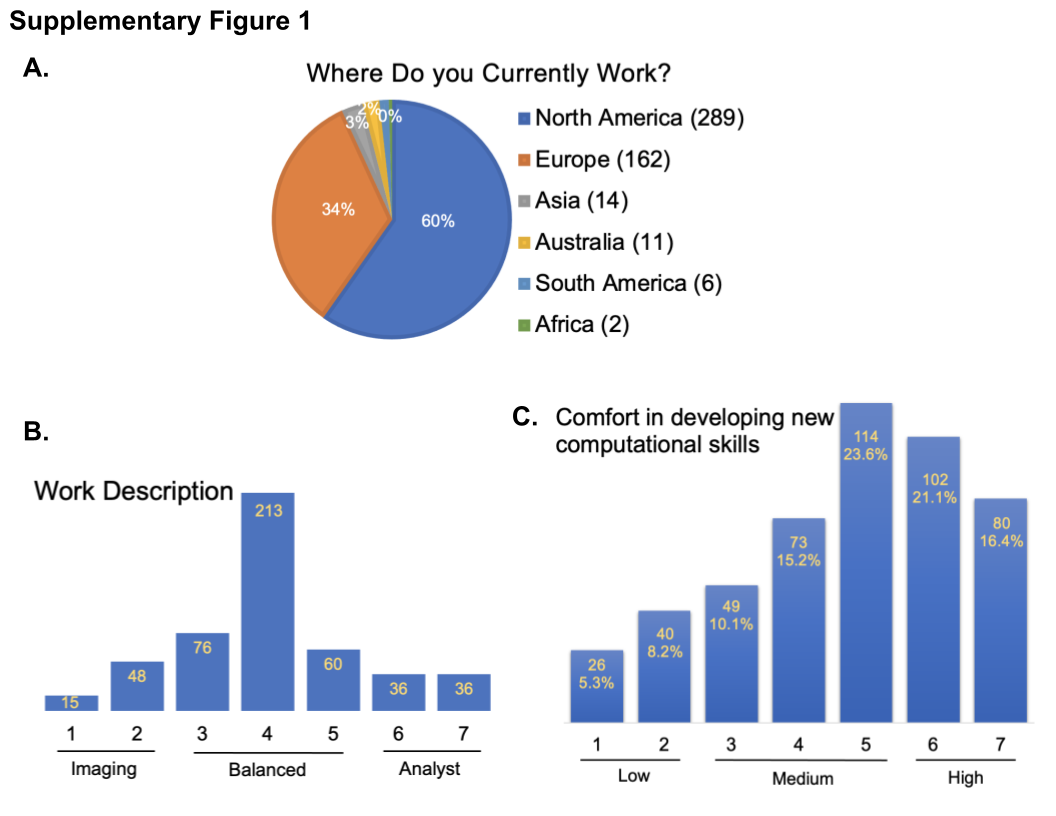
Of the 484 survey participants, the majority were from North America (60%) and Europe (34%), followed by Asia, Australia, South America, and Africa (Supplementary Figure 1a). Forty-three percentage of participants were in training (either “Postdoctoral Fellows” or “Undergraduate/Graduate Students,” hereafter described as “Trainees”; Figure 1a). Most participants described experience and/or training in the biological sciences, including cell/molecular biology, chemistry/biochemistry, followed by physics and developmental biology (Figure 1b), although the small proportion of participants whose role was “Image Analyst” or “Other” reported computational backgrounds more often. This is consistent with a 2015 survey from the Network of European BioImage Analysts (NEUBIAS)(Reference Miura 1 ), which is a network working toward bridging the efforts between life science, computer science, and digital image processing( 2 ).

Figure 1. (a) Responses to the multiple-choice question of “Which of the following roles best describe you?” Respondents had the option to provide additional answers. (b) Responses to the checkbox question of “Which of the following do you have significant formal training in or experience with? Select all that apply.” Responses were broken down by the major categories from part (a).
We next asked participants to describe their work along a linear scale of 1–7, with 1 representing mainly imaging (sample preparation, optimizing/deciding on imaging modalities, acquiring images, etc.) and 7 representing mainly image analysis (finding the right tools to analyze a particular experiment, optimizing the analysis, and data mining). The group of respondents with scores of 1 and 2 are hereafter described as “imaging,” the group with scores of 3–5 as “balanced,” and the group with scores of 6 and 7 as “analysts.” The majority of respondents fell into the “balanced” category (Supplementary Figure 1b).
We also asked participants about both their current level of computational skills and comfort developing new skills on a scale of 1–7, with 1 representing very poor and 7 representing excellent for current skills and 1 representing very uncomfortable and 7 representing very comfortable. Computational skills tracked somewhat with job roles, with the imaging, balanced, and analyst groups showing mean computational skills of 3.59, 4.17, and 5.40, respectively (Figure 2). On average, the community feels they are more comfortable than not in developing new computational skills, rating themselves a 4.73 out of 7 (Supplementary Figure 1c).

Figure 2. Responses to the question of “How would you rate your computational skills?” along a linear scale with 1 representing very poor and 7 representing excellent. Responses were crossmatched with the work duties (graphed in Supplementary Figure 1b).
Since almost half of the survey participants were from the trainee group and because trainees may have particular requests that need to be addressed, we wanted to know how our measures of job class, computational skill, and computational comfort differed for trainees versus nontrainees. Crossmatching the work duties, as shown in Supplementary Figure 1b, with the role description, as shown in Figure 1a, showed the trainee group was relatively evenly drawn from the imaging, balanced, and analyst groups. A large number of survey respondents were from the balanced group, regardless of their trainee status (Figure 3a). While trainees were missing from the highest self-reported skill level, reported comfort in developing new computational skills increased with reported existing skill level and was comparable between trainees and nontrainees (Figure 3b).

Figure 3. (a) The trainee versus nontrainee groups’ job descriptions were drawn by a crossmatch of the work duties (graphed in Supplementary Figure 1b) and role descriptions (graphed in Figure 1a). (b) Responses to the question of “How would you rate your comfort in developing new computational skills?” (graphed in Supplementary Figure 1c), crossmatched with the responses to the question of “How would you rate your computational skills?” and separated based on the trainee group.
Needs and commonly used tools
Types of images analyzed (modality, technique, specimen, etc.)
In response to our question “What kinds of images do you commonly want to analyze?,” bright-field, differential interference contract [DIC], and phase images (BF/DIC/Phase) and fluorescent two-dimensional (2D) images from cells and organisms were the top most-commonly analyzed images among the survey participants (Figure 4), which were mainly captured by manual field selection as opposed to an automated system. Overall, the majority of images to be analyzed were 2D, followed by 2D time-lapse images, 3D volumes, and then 3D time-lapse images.

Figure 4. Responses to the checkbox grid question of “What kinds of images do you commonly want to analyze?” Respondents had the option to provide additional answers.
Types of analysis tools used
When we asked “What image analysis tools do you use the most?,” the vast majority of respondents reported the category of “open-source point and click software.” The question described such tools to include ImageJ(Reference Schneider, Rasband and Eliceiri 3 , Reference Schindelin, Rueden, Hiner and Eliceiri 4 ), Fiji(Reference Schindelin, Arganda-Carreras and Frise 5 ), CellProfiler(Reference Stirling, Swain-Bowden, Lucas, Carpenter, Cimini and Goodman 6 ), Icy(Reference de Chaumont, Dallongeville and Chenouard 7 ), and so forth, all of which are the most commonly used tools among participants (Figure 5a). The next most common tools were “computational libraries and scripts” (such as scikit-image(Reference van der Walt, Schönberger and Nunez-Iglesias 8 ) and MATLAB( 9 ) libraries), followed by commercial software on the user’s microscope and other commercial software. While these may be representative of the broader community, we note that most promotion of the survey was via a forum for open-source tools (forum.image.sc)(Reference Rueden, Ackerman and Arena 10 ) and by Twitter accounts related to open-source tools, presumably increasing their final representation in the survey.

Figure 5. (a) Responses to the multiple-choice question of “What image analysis tools do you use the most?” Respondents had the option to provide additional options. (b) Responses to the checkbox question of “How do you generally go about solving an image analysis problem? Check the approach(es) you use them the most.” Respondents had the option to provide additional options.
Approaches, image analysis problems, and tips for developers and users
Commonly used approaches to solve image analysis problems
We next wanted to better understand what approaches our participants take to solve their image analysis problems. The most popular approaches are: sit down with a familiar tool, search the web, look up solutions in the scientific literature, ask a friend or colleague, and/or ask on the Scientific Community Image Forum (forum.image.sc; Figure 5b).
Well-solved image analysis issues and those needing better solutions
To assess the community’s thoughts on the success of currently existing tools, we next asked participants via open-ended questions to describe which image analysis problems they thought were already well solved and which they wished had better solutions. We analyzed the free-text responses by parsing them using Python scripts as described in the Methods section. Responses containing “detection” and/or “segmentation” were the most common for both questions; likely this reflects the huge diversity of biological objects our participants are trying to detect (Figure 6a,b). The answers with a much higher relative rank in the “well-solved” category were “Nuclei” and “2D” and in the “wish were better solved” category were “3D/Volume” and “Tissue/Histology.”

Figure 6. (a) Keyword analysis of the open-ended question of “What image analysis problems (i.e., finding nuclei, tissue analysis, analysis of super-resolution data, etc.) do you think are generally well solved?” (b) Keyword analysis of the open-ended question of “What image analysis problems (i.e., finding nuclei, tissue analysis, analysis of super-resolution data, etc.) do you wish had easier/better solutions?”
Tips for image analysis for users and developers
Suggestions for the open-source tool creators/what creators can do?
We asked the community to provide open-ended feedback for the tool developers: “What do you think analysis tool CREATORS (such as software developers) could/should do to make image analysis better and more successful? How best could we encourage them to do it?” Through our analysis of keywords, we conclude that all groups encouraged developers to improve documentations and manuals, user interface, plugins and packages, as well as providing easy-to-follow workshops and tutorials (Figure 7a). They suggested that tool creators form a tight-knit community, in which they could collaborate, review software, and improve documentation. Other suggestions included prizes for best tool instructions and frequent reminders for users to cite analysis tools in publications.

Figure 7. (a) Keyword analysis of the open-ended question of “What do you think analysis tool CREATORS (such as software developers) could/should do to make image analysis better and more successful? How best could we encourage them to do it?” (b) Keyword analysis of the open-ended question of “What do you think analysis tool USERS (such as microscopists) could/should do to make image analysis better and more successful? How best could we encourage them to do it?”
As we expected, users who self-reported spending more time on imaging than on analysis have different perspectives on the greatest needs. We therefore binned the answers into the “imaging,” “balanced,” and “analyst” categories. The “imaging” group’s most common suggestions were for more user-friendly tools, better documentation, and more video tutorials. The “balanced” group emphasized a need for clear documentation with detailed explanations of the parameters, as well as asking for tools that perform better in real-world conditions when ability to improve sample acquisition is limited. The “analysts” also highlighted a need for better documentation, an ecosystem with fewer and more multifunctional tools over a plethora of single-use scripts, and more interoperability between the current open-source tools; they also encouraged developers to communicate with users early and often.
Suggestions for the open-source tool users
We also asked, “What do you think analysis tool USERS (such as microscopists) could/should do to make image analysis better and more successful? How best could we encourage them to do it?,” allowing the community to provide feedback for the tool users. Overall, as shown in Figure 7b, the community asked users to seek out existing tutorials and workshops and learn the tools and basics of image analysis, follow the best practice guidelines for imaging, and ask their image analysis questions on the image.sc forum. By using a single, central forum for image analysis questions, all members could benefit from every user’s questions, feedback, and suggestions, which makes it easier for tool creators to provide answers. Respondents also encouraged users to start image analysis when performing pilot imaging and condition optimization experiments, rather than waiting until the completion of larger-scale experiments. Participants also suggested that principal investigators encourage their trainees to take image analysis courses and try new image analysis tools.
Breaking down the answers by role, we found that the “imaging” group asked the users to pay attention to sample quality, to have an understanding of why particular image analysis methods are applied in certain cases, and to reach out to experts and provide detailed feedback to tool developers with examples. The “balanced” group responded that users should provide analysis workflow details in publications, keep settings consistent during acquisition and analysis, and they encouraged tool users to think about the analysis before and during image acquisition, testing their approach on early data rather than leaving all the analysis for the end. They also emphasized providing feedback for the developers, exploring new tools, and posting questions on the image.sc forum. “Analysts” particularly asked users to take advantage of available tutorials and workshops about the basics of image analysis and open-source tools. They also encouraged tool users to clarify their image analysis needs to the developers, provide feedback, request new features, and report bugs, including detailed information and sample images in their bug reports.
Learning materials and their components
Interest in learning new topics
We next asked users to rate their interest in learning more about each of several topics. Participants showed the highest level of interest in learning about image analysis practices specifically related to their own field (Figure 8a). The remaining four areas to be rated, image analysis theories, general image analysis practices, learning to use different software tools, and deep learning approaches for image analysis, showed a similar pattern to each other with a plurality of users stating they were “very interested” followed by “moderately,” “a little,” and “not at all” interested. These results emphasize that the community shows an appetite for image analysis educational materials.

Figure 8. (a) Responses to the multiple-choice grid question of “How interested are you in learning more about the following topics?” (b) Responses to the multiple-choice grid question of “For any topic(s) you are interested in, how interested would you be in learning about them in the following ways?”
Delivery format of learning material
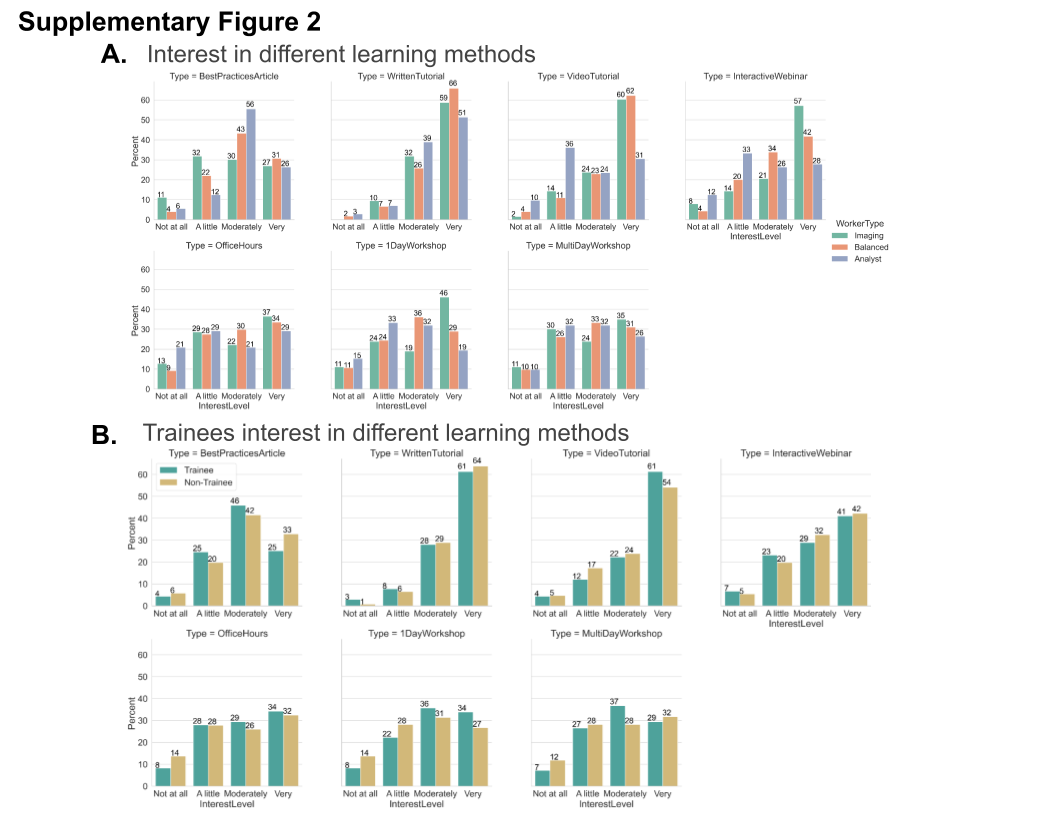
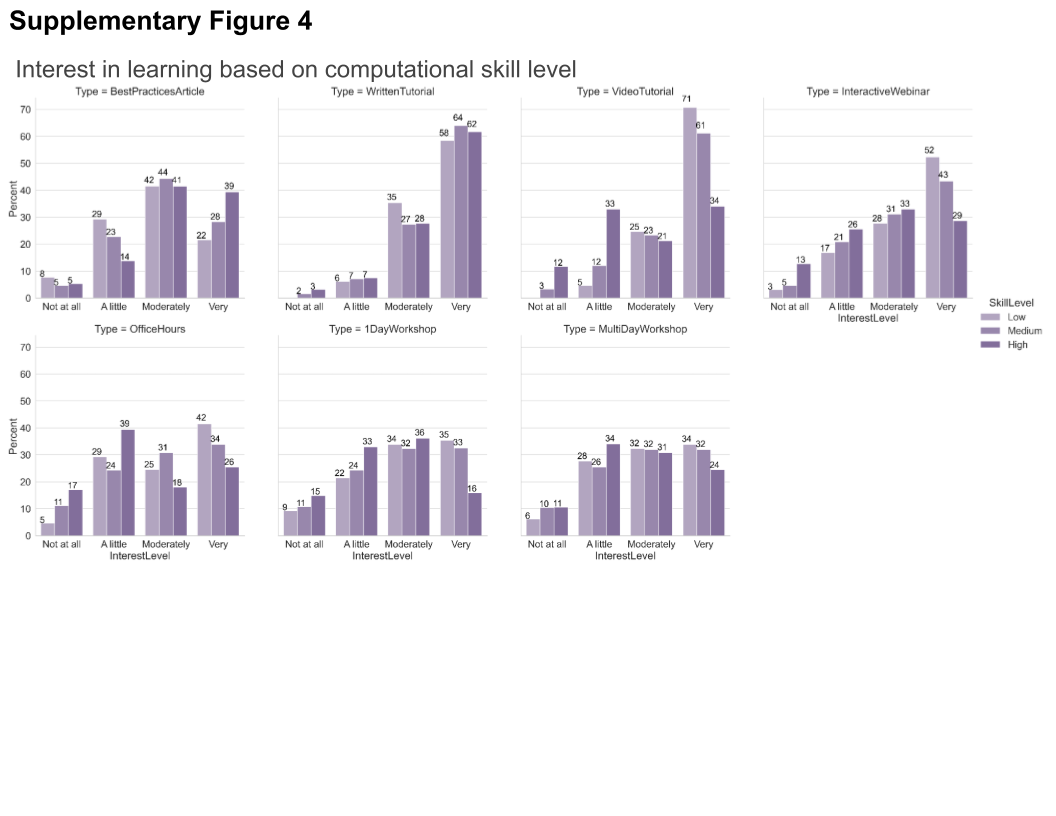
To help trainers and developers better prioritize particular types of educational material, we asked “For any topic(s) you are interested in, how interested would you be in learning about them in the following ways?,” via a multiple-choice grid question. Survey participants in general prefer written step-by-step and video tutorials. The next most preferred methods of learning in order were interactive webinars, best practice articles, and office hours with an expert (Figure 8b). While we hypothesized that we would see differences in preferred format among our “imaging,” “balanced,” and “analyst” groups, we saw fewer differences than we expected between those groups (Supplementary Figure 2a). The results indicated the interest for the written and video tutorials, and interactive webinars are higher between the “imaging” and “balanced” groups at the “moderately” and “very” interested levels, while the “analyst” group preferred written tutorial and best practice articles the most. The preferences did not substantially differ between trainees and nontrainees (Supplementary Figure 2b). As we know job role did not perfectly correlate with either existing computational skills or comfort in developing new computational skills, we also wanted to assess how those attributes drove interest in particular types of content; we therefore binned users for each of these categories into “Low” (answers of 1 and 2), “Medium” (answers of 3–5), or “High” (answers of 6 and 7). We did not find as much variation in interest level when broken down by comfort level in developing new computational skills (Supplementary Figure 3) as when broken down by computational skills (Supplementary Figure 4); the interest in written material remains high across all demographics, but as the level of computational skills increases, the preference for best practice articles increases while the preference for video tutorials or more interactive offerings such as office hours and interactive webinars decreases.
Components of well-received learning materials
We asked participants about their past experiences with workshops and conferences. Survey participants have mostly attended workshops, tutorials, and conferences on imaging and image analysis, and they specifically found NEUBIAS, Fiji/ImageJ, Open Microscopy Environment, CellProfiler, and Imaris workshops very helpful (Figure 9a). Robert Haase’s workshops on YouTube, along with the Analytical and Quantitative Light Microscopy course at Marine Biology Laboratory and the Quantitative Imaging course at Cold Spring Harbor Laboratory, were among the responses as well. When asked what made those particular resources beneficial, respondents highlighted that those workshops provided image analysis basics and theory, step-by-step and hands-on approaches, real-time feedback, and access to experts while developing a workflow.

Figure 9. (a) Keyword analysis of the open-ended question of “Are there any image analysis workshops, tutorials, or conferences that you have participated in and found particularly helpful? If yes, what made them beneficial?” (b) Keyword analysis of the open-ended question of “Are there any conferences you have attended in the past that you think would particularly benefit from the addition/expansion of image analysis offerings?” (c) Keyword analysis of the open-ended question of “What specific topics (i.e., overviews of a particular tool, comparisons between pieces of software, or how to use a certain tool for a certain kind of experiment) would you like to see prioritized for future image analysis workshop and tutorial offerings?” (d) Responses to the multiple-choice question of “How would you prefer to be notified about image analysis workshops, sessions, or conferences being planned?”
When asked to name conferences that could benefit from the addition/expansion of image analysis offerings, the most common responses included the following: the American Society for Cell Biology, Society for Neuroscience, NEUBIAS, European Light Microscopy Initiative, and Microscience Microscopy Congress (Figure 9b). Microscopy and Microanalysis, Developmental Biology, and European Molecular Biology Organization scientific conferences were among the responses. We also asked respondents which subjects they would like to see prioritized for the workshops and tutorials. Most—unsurprisingly—wanted materials for the particular tool with which they work, indicating a strong appetite for practical training, but general suggestions, included machine and deep learning, coding, Python, different libraries, ImageJ macro writing, overview of different tools, best practices, and different examples (Figure 9c). Finally, the community’s preferred methods of notification for the image analysis conferences and workshops are through email lists, forums (such as image.sc and the microforum [forum.microlist.org]), Twitter, and their local microscopy facility (Figure 9d).
In the final “Any other thoughts?” open answer response, the community asked for easy-to-follow (at your own pace) beginner’s guides, better clarification of best practices, a centralized location to find available image analysis tools, various types of example workflows, interoperable platforms to create a workflow combining different tools, and better tools for hyperspectral image analysis.
Methods
The 2020 BioImage Analysis Questionnaire was developed using Google Forms and was distributed in the bioimage community around the world using the image.sc forum; microforum; Twitter; and confocal, ImageJ, and BioImaging North America listservs. Responses were exported via tables, and duplicates were removed; the results were then graphed in Jupyter Notebook (version 6.1.1)(Reference Kluyver, Ragan-Kelley, Pérez, Loizides and Schmidt 11 ) using Python3(Reference Van Rossum and Drake 12 ), matplotlib(Reference Hunter 13 ), numpy(Reference Harris, Millman and van der Walt 14 ), pandas(Reference Reback and McKinney 15 ), and seaborn(Reference Waskom 16 ) libraries or Microsoft Excel (2016 and 2021).
To analyze the short- and long-answer survey questions, the answers to a specific question were parsed with a Python (3.7) script using PyCharm (2019.3) to find the number of words used in the answers, excluding some commonly used words, such as I, that, in, or, of, and at. The outcome file was then checked, and depending on the question, the most used and meaningful words were chosen to create a tag list. The responses were parsed again using the tag list, searching for the number of keywords from the tag list. The final results showed the number of keywords (from the tag list) used in the answers. The corresponding figure was then created based on the counts and tags using Microsoft Excel. The tag names used in the figure were sometimes shortened to fit the figure.
Future Needs
In this survey, we strove to include as many participants as possible from as wide a range of biological training backgrounds and computational skill levels as possible. We posted in venues such as FuturePISlack and microscopy listservs; however, the fact that much of the promotion of the survey was via the Scientific Community Image Forum (forum.image.sc) and Twitter accounts related to open-source tools means it is probable that the group of biologists least exposed to image analysis may also be least represented in this survey. While we have attempted to address this data limitation by breaking down responses to key questions by a number of variables, this limitation points to a larger issue: How can the bioimage analysis community best reach out to the subset of the biology community that is most computationally uncomfortable or unaware and therefore needs user-friendly tools the most? We hope that this work, in addition to other recent works describing bioimage analysis surveys(Reference Miura 1 ), will also drive community conversation on the most critical questions to quantify and assess the field going forward.
Image analysis is an essential part of microscopy, and in the same way that users learn to optimize their staining, enhance sample preparation, and select appropriate microscope modalities and settings, image analysis method selection, optimization, and building suitable image analysis workflows must be seen as an integral part of the creation of a successful experimental design. Microscopy core facilities are critical for microscopy knowledge at their various institutions; we therefore hope to increase targeted outreach to those core facility staff to improve their access to high-quality image analysis resources to then pass onto their users as an essential part of their microscopy training. Since experimental and quantitative biological courses are sometimes the first exposure of trainees to such concepts, we hope to increase our collaborations with instructors to develop the image analysis section of their curricula.
We broadly encourage scientific meetings and conferences to offer image analysis workshops and introduce their various communities to topics such as imaging and image analysis and promote resources such as the microforum (forum.microlist.org) and the Scientific Community Image Forum. While bioimage analysis experts need and benefit from their own internal conferences to share techniques and best practices, especially in the light of users’ preferences to hear more tailored presentations about the kinds of analyses done in their field, we hope in the future to be able to partner with both large, broad scientific conferences and small subfield meetings. These partnerships could be used not only to educate attendees, but to promote future attempts to better gauge the biology community’s needs, allowing our bioimage analysis community to hopefully capture a broader perspective. It would also be helpful for funding agencies and journals where tools are published to incentivize creation of “beginner” resources as a standard part of bioimage analysis tool creation, but at the same time, tool developers must be given the resources to learn to create such materials. Efforts to “train trainers,” such as The Carpentries (https://carpentries.org/) and Life Science Trainers (https://lifescitrainers.org/), exist and can hopefully be expanded. Finally, we encourage biology graduate and post-graduate training organizations to encourage their trainees to think of microscopy images not just as qualitative, but as truly quantitative data sources. Their enthusiastic participation in the image analysis community from the beginning of their use of microscopy will encourage improved community engagement.
The Scientific Community Image Forum, which is sponsored by the Center for Open Bioimage Analysis (COBA), partners with more than 50 open-source image analysis tools and scientific organizations devoted to biological imaging. It was designed to be a central “go-to” place for the community to ask questions and share updates, news, and ideas. While membership in the forum has grown from approximately 10,000 to 17,000 users in 2 years, fewer than one-fourth of users in our survey identified it as something they “generally” use to solve image analysis problems, indicating the forum can still have an even larger impact among the community. Anecdotal responses from the survey, as well as our experience training users in image analysis, suggest some users find asking questions on the forum intimidating. To ensure the forum lives up to its fullest potential, the community could consider a number of more systematic steps to reduce barriers to participation, such as expanding the existing templates for common questions to make it even easier for users to know which information developers and experts most likely need to answer their questions or creating a stickied “metadescription” post describing all the tools to make choosing a tool easier for new users. Suggestions for improving the forum are always welcome via the various communication routes for COBA via Twitter (@COBA_NIH), contact forms on our website (https://openbioimageanalysis.org/), and email (COBA@broadinstitute.org).
While the broad expansion of open-source image analysis tools has been an incredible benefit to the community at large, such an “embarrassment of riches” can make it overwhelming for a new user to find the most appropriate tool for their image analysis needs. We applaud efforts for cataloguing existing tools, such as the BioImage informatics index from NEUBIAS(Reference Martins, Cordelières and Colombelli 17 ), and hope that efforts in this space can be expanded. While the image analysis community is already an exceptionally collaborative space, we encourage tool creators to continue to work to make their tools either directly interoperable with popular existing platforms or easily accessed via well-documented application programming interfaces, as well as to provide other tools with constructive feedback. Together, this will continue to create a rising tide that lifts all boats and gives users easier entry points into the image analysis ecosystem. We encourage forum members to advertise their outreach activities, such as upcoming trainings and links to their previously recorded workshops. We encourage those who are developing bioimage analysis training resources, especially for new users, to reserve a few minutes to introduce users to forum.image.sc, demonstrating how to search for a specific question and find relevant threads, and how to submit an issue or feature improvement request on GitHub for a specific tool. In addition, event organizers can advertise upcoming conferences and workshops to specifically target their appropriate audience.
There is a clear need for a more centralized online location for the training material related to image analysis tools and resources for best practices. COBA is working toward creating a centralized place for the currently available training resources and best practice guidelines for the community and look forward to collaborating with others looking to do the same.
Conclusion
Nearly 500 members of the imaging community from around the world participated in the BioImage Analysis Survey, conducted in 2020 through the NIH COBA. The most common requests from the participants were for general improvement of tool documentation and for access to easy-to-follow tutorials. There is demand for the community to focus on centralizing and publicizing existing educational resources, as well as improving tutorials for the imaging community. Our data on user preferences for particular formats and types of material should help COBA and other developers decide how to structure and prioritize their efforts.
The growth and increased stability of the bioimage analysis community in the last several years is both a triumph and a testament to the many hours that countless members of the community have contributed. With these survey data, COBA hopes to aid the entire community in celebrating its successes and in prioritizing its goals in both the short and longer terms. While individual tools and approaches will no doubt wax and wane in popularity over time, if we share common goals and plans for achieving them, our community will only continue to grow stronger in the years to come.
Acknowledgments
We would like to thank the biology and microscopy community for providing answers to the survey questions. We would also like to thank Rebecca L. Ledford for her help in opening and publicizing the survey. We would also like to thank the members of the Eliceiri, Carpenter-Singh, and Cimini labs for their input on the questionnaire and assessment of needs in the bioimaging community.
Supplementary Materials
To view supplementary material for this article, please visit http://doi.org/10.1017/S2633903X21000039.
Competing Interests
The authors declare that there are no competing interests associated with the manuscript.
Authorship Contributions
B.A.C. and E.T.A.D. created the survey with editorial input from N.J., K.W.E., and A.E.C. N.J. performed analyses with help and supervision from B.A.C. The manuscript was written by N.J. and B.A.C., with editorial contributions from E.T.A.D., A.E.C., and K.W.E. All authors have read and approved the manuscript.
Funding Statement
This work was supported by the COBA which is supported by the National Institutes of Health, National Institute of General Medical Sciences P41 GM135019 to A.E.C. and K.W.E. This project has been made possible in part by Grant No. 2020-225720 to B.A.C. from the Chan Zuckerberg Initiative DAF, an advised fund of Silicon Valley Community Foundation. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Data Availability Statement
The survey questions, responses to each individual question (sorted independently for each question to ensure deidentification), and all code used in creating the results are available at https://github.com/ciminilab/2021_Jamali_submitted. This study was exempt from IRB approval based on Category 2 (Surveys, interviews, educational tests, and public observations). Full exemption was granted because we agreed to de-identify the data, so the subjects’ identity could not be readily obtained.












 Open access
Open access