

1. Introduction
Random regular graphs, where each vertex has the same degree d, are among the most well-known examples of expanders: graphs with high connectivity and which exhibit rapid mixing. Expanders are of particular interest in computer science, from sampling and complexity theory to design of error-correcting codes. For an extensive review of their applications, see [Reference Hoory, Linial and Wigderson35]. What makes random regular graphs particularly interesting expanders is the fact that they exhibit all three existing types of expansion properties: edge, vertex, and spectral.
The study of regular random graphs took off with the work of [Reference Bender7, Reference Bender and Rodney Canfield8, Reference Bollobás10], and slightly later [Reference McKay52] and [Reference Wormald64]. Most often, their expanding properties are described in terms of the existence of the spectral gap, which we define below.
Let A be the adjacency matrix of a simple graph, where
 $A_{ij} = 1$
if i and j are connected and zero otherwise. Denote
$A_{ij} = 1$
if i and j are connected and zero otherwise. Denote
 $\sigma(A) = \{\lambda_1 \geq \lambda_2 \geq \ldots \}$
as its spectrum. For a random d-regular graph,
$\sigma(A) = \{\lambda_1 \geq \lambda_2 \geq \ldots \}$
as its spectrum. For a random d-regular graph,
 $\lambda_1 = \max_{i} |\lambda_i| = d$
, but the second largest eigenvalue
$\lambda_1 = \max_{i} |\lambda_i| = d$
, but the second largest eigenvalue
 $\eta = \max (|\lambda_2|, |\lambda_{n}| )$
is asymptotically almost surely of much smaller order, leading to a spectral gap. Note that we will always use
$\eta = \max (|\lambda_2|, |\lambda_{n}| )$
is asymptotically almost surely of much smaller order, leading to a spectral gap. Note that we will always use
 $\eta$
to be the second largest eigenvalue of the adjacency matrix A. For a list of important symbols see Appendix A.
$\eta$
to be the second largest eigenvalue of the adjacency matrix A. For a list of important symbols see Appendix A.
Spectral expansion properties of a graph are, strictly speaking, defined with respect to the smallest nonzero eigenvalue of the normalised Laplacian,
 $\mathcal{L} = I - D^{-1/2} A D^{-1/2}$
, where I is the identity and D is the diagonal matrix of vertex degrees. In the case of a d-regular graph,
$\mathcal{L} = I - D^{-1/2} A D^{-1/2}$
, where I is the identity and D is the diagonal matrix of vertex degrees. In the case of a d-regular graph,
 $\sigma(\mathcal{L})$
is a scaled and shifted version of
$\sigma(\mathcal{L})$
is a scaled and shifted version of
 $\sigma(A)$
. Thus, a spectral gap for A translates directly into one for
$\sigma(A)$
. Thus, a spectral gap for A translates directly into one for
 $\mathcal{L}$
.
$\mathcal{L}$
.
The study of the second largest eigenvalue in regular graphs had a first breakthrough in the Alon-Boppana bound [Reference Alon1], which states that the second largest eigenvalue satisfies
 \begin{equation*} \eta \geq 2 \sqrt{d-1} - \frac{c_d}{\log n} .\end{equation*}
\begin{equation*} \eta \geq 2 \sqrt{d-1} - \frac{c_d}{\log n} .\end{equation*}
Graphs for which the Alon–Boppana bound is attained are called Ramanujan. Friedman [Reference Friedman27] proved the conjecture of [Reference Alon1] that almost all d-regular graphs have
 $\eta \leq 2 \sqrt{d-1} + \epsilon$
for any
$\eta \leq 2 \sqrt{d-1} + \epsilon$
for any
 $\epsilon > 0$
with high probability as the number of vertices goes to infinity. This result was simultaneous simplified and deepened in [Reference Friedman and Kohler29]. More recently, [Reference Bordenave12] gave a different proof that
$\epsilon > 0$
with high probability as the number of vertices goes to infinity. This result was simultaneous simplified and deepened in [Reference Friedman and Kohler29]. More recently, [Reference Bordenave12] gave a different proof that
 $\eta \leq 2 \sqrt{d-1}+\epsilon_n$
for a sequence
$\eta \leq 2 \sqrt{d-1}+\epsilon_n$
for a sequence
 $\epsilon_n \rightarrow 0$
as n, the number of vertices tends to infinity; the new proof is based on the non-backtracking operator and the Ihara-Bass identity.
$\epsilon_n \rightarrow 0$
as n, the number of vertices tends to infinity; the new proof is based on the non-backtracking operator and the Ihara-Bass identity.
1.1. Bipartite biregular model
In this paper, we prove the analog of Friedman and Bordenave’s result for bipartite, biregular random graphs. These are graphs for which the vertex set partitions into two independent sets
 $V_1$
and
$V_1$
and
 $V_2$
, such that all edges occur between the sets. In addition, all vertices in set
$V_2$
, such that all edges occur between the sets. In addition, all vertices in set
 $V_i$
have the same degree
$V_i$
have the same degree
 $d_i$
. See Figure 1 for a schematic of such a graph. Along the way, we also bound the smallest positive eigenvalue and the rank of the adjacency matrix.
$d_i$
. See Figure 1 for a schematic of such a graph. Along the way, we also bound the smallest positive eigenvalue and the rank of the adjacency matrix.

Figure 1. The structure of a bipartite, biregular graph. There are
 $n = |V_1|$
left vertices,
$n = |V_1|$
left vertices,
 $m=|V_2|$
right vertices, each of degree
$m=|V_2|$
right vertices, each of degree
 $d_1$
and
$d_1$
and
 $d_2$
, with the constraint that
$d_2$
, with the constraint that
 $n d_1 = m d_2$
. The distribution
$n d_1 = m d_2$
. The distribution
 $\mathcal{G}(n,m,d_1,d_2)$
is taken uniformly over all such graphs.
$\mathcal{G}(n,m,d_1,d_2)$
is taken uniformly over all such graphs.
Let
 $\mathcal{G}(n,m,d_1,d_2)$
be the uniform distribution of simple, bipartite, biregular random graphs. Any
$\mathcal{G}(n,m,d_1,d_2)$
be the uniform distribution of simple, bipartite, biregular random graphs. Any
 $G \sim \mathcal{G}(n,m,d_1,d_2)$
is sampled uniformly from the set of simple bipartite graphs with vertex set
$G \sim \mathcal{G}(n,m,d_1,d_2)$
is sampled uniformly from the set of simple bipartite graphs with vertex set
 $V=V_1 \bigcup V_2$
, with
$V=V_1 \bigcup V_2$
, with
 $|V_1|=n$
,
$|V_1|=n$
,
 $|V_2|=m$
and where every vertex in
$|V_2|=m$
and where every vertex in
 $V_i$
has degree
$V_i$
has degree
 $d_i$
. Note that we must have
$d_i$
. Note that we must have
 $n d_1 = m d_2 = |E|$
. Without any loss of generality, we will assume
$n d_1 = m d_2 = |E|$
. Without any loss of generality, we will assume
 $n \leq m$
and thus
$n \leq m$
and thus
 $d_1 \geq d_2$
when necessary. Sometimes we will write that G is a
$d_1 \geq d_2$
when necessary. Sometimes we will write that G is a
 $(d_1, d_2)$
-regular graph, when we want to explicitly state the degrees. Let X be the
$(d_1, d_2)$
-regular graph, when we want to explicitly state the degrees. Let X be the
 $n \times m$
matrix with entries
$n \times m$
matrix with entries
 $X_{ij}=1$
if and only if there is an edge between vertices
$X_{ij}=1$
if and only if there is an edge between vertices
 $i \in V_1$
and
$i \in V_1$
and
 $j \in V_2$
. Using the block form of the adjacency matrix
$j \in V_2$
. Using the block form of the adjacency matrix
 \begin{equation}A=\left(\begin{array}{c@{\quad}c} 0 & X \\[4pt] X^* & 0 \end{array}\right ),\end{equation}
\begin{equation}A=\left(\begin{array}{c@{\quad}c} 0 & X \\[4pt] X^* & 0 \end{array}\right ),\end{equation}
It is well known that
 $\mathcal{G}(n,m,d_1,d_2)$
is connected with high probability, as long as
$\mathcal{G}(n,m,d_1,d_2)$
is connected with high probability, as long as
 $d_i\geq 3$
. From (1), it can be verified that all eigenvalues of A occur in pairs
$d_i\geq 3$
. From (1), it can be verified that all eigenvalues of A occur in pairs
 $\lambda$
and
$\lambda$
and
 $-\lambda$
, where
$-\lambda$
, where
 $|\lambda|$
is a singular value of X, along with at least
$|\lambda|$
is a singular value of X, along with at least
 $|n - m|$
zero eigenvalues. For these reasons, the second largest eigenvalue is
$|n - m|$
zero eigenvalues. For these reasons, the second largest eigenvalue is
 $\eta = \lambda_2(A) = -\lambda_{n+m-1} (A)$
. Furthermore, the leading or Perron eigenvalue of A is always
$\eta = \lambda_2(A) = -\lambda_{n+m-1} (A)$
. Furthermore, the leading or Perron eigenvalue of A is always
 $\sqrt{d_1 d_2}$
, matched to the left by
$\sqrt{d_1 d_2}$
, matched to the left by
 $-\sqrt{d_1d_2}$
, which reduces to the result for d-regular when
$-\sqrt{d_1d_2}$
, which reduces to the result for d-regular when
 $d_1 = d_2$
.
$d_1 = d_2$
.
We will focus on the spectrum of the adjacency matrix. Similar to the case of the d-regular graph, in the bipartite, biregular graph, the spectrum of the normalized Laplacian is a scaled and shifted version of the adjacency matrix: Because of the structure of the graph,
 $D^{-1/2} A D^{-1/2} = \frac{1}{\sqrt{d_1 d_2}} A$
. Therefore, a spectral gap for A again implies that one exists for
$D^{-1/2} A D^{-1/2} = \frac{1}{\sqrt{d_1 d_2}} A$
. Therefore, a spectral gap for A again implies that one exists for
 $\mathcal{L}$
.
$\mathcal{L}$
.
Previous work on bipartite, biregular graphs includes the work of [Reference Feng and Li25] and [Reference Li and Solé43], who proved the analog of the Alon–Boppana bound. For every
 $\epsilon >0$
,
$\epsilon >0$
,
 \begin{eqnarray}\eta \geq \sqrt{d_1-1} + \sqrt{d_2 - 1} - \epsilon\end{eqnarray}
\begin{eqnarray}\eta \geq \sqrt{d_1-1} + \sqrt{d_2 - 1} - \epsilon\end{eqnarray}
as the number of vertices goes to infinity. This bound also follows immediately from the fact that the second largest eigenvalue cannot be asymptotically smaller than the right limit of the asymptotic support for the eigenvalue distribution, which is
 $\sqrt{d_1-1} + \sqrt{d_2 - 1}$
and was first computed by [Reference Godsil and Mohar32]. They found the spectral measure
$\sqrt{d_1-1} + \sqrt{d_2 - 1}$
and was first computed by [Reference Godsil and Mohar32]. They found the spectral measure
 $\mu(\lambda)$
has a point mass at
$\mu(\lambda)$
has a point mass at
 $\lambda=0$
of size
$\lambda=0$
of size
 $\frac{1}{2} |d_1 - d_2| / (d_1 + d_2)$
and a continuous part given by the density
$\frac{1}{2} |d_1 - d_2| / (d_1 + d_2)$
and a continuous part given by the density
 \begin{equation} \textrm{d}\mu(\lambda) = \frac{d_1 d_2 \sqrt{(- \lambda^2 + d_1 d_2 - (z - 1)^2) (\lambda^2 - d_1 d_2 + (z + 1)^2)}} {\pi (d_1 + d_2) (d_1 d_2 - \lambda^2) |\lambda|} , \end{equation}
\begin{equation} \textrm{d}\mu(\lambda) = \frac{d_1 d_2 \sqrt{(- \lambda^2 + d_1 d_2 - (z - 1)^2) (\lambda^2 - d_1 d_2 + (z + 1)^2)}} {\pi (d_1 + d_2) (d_1 d_2 - \lambda^2) |\lambda|} , \end{equation}
supported on
 \begin{equation*}|\sqrt{d_1-1} - \sqrt{d_2 - 1}| \leq |\lambda| \leq \sqrt{d_1-1} + \sqrt{d_2 - 1} , \mbox{where}\ z=\sqrt{(d_1 - 1)(d_2 - 1)} .\end{equation*}
\begin{equation*}|\sqrt{d_1-1} - \sqrt{d_2 - 1}| \leq |\lambda| \leq \sqrt{d_1-1} + \sqrt{d_2 - 1} , \mbox{where}\ z=\sqrt{(d_1 - 1)(d_2 - 1)} .\end{equation*}
Graphs where
 $\eta$
attains the Alon–Boppana bound, equation (2), are also called Ramanujan. Complete graphs are always Ramanujan but not sparse, whereas d-regular or bipartite
$\eta$
attains the Alon–Boppana bound, equation (2), are also called Ramanujan. Complete graphs are always Ramanujan but not sparse, whereas d-regular or bipartite
 $(d_1, d_2)$
-regular graphs are sparse. Our results show that almost every
$(d_1, d_2)$
-regular graphs are sparse. Our results show that almost every
 $(d_1, d_2)$
-regular graph is ‘almost’ Ramanujan.
$(d_1, d_2)$
-regular graph is ‘almost’ Ramanujan.
Beyond the first two eigenvalues, we should mention that [Reference Bordenave and Lelarge13] studied the limiting spectral distribution of large sparse graphs. They obtained a set of two coupled equations that can be solved for the eigenvalue distribution of any
 $(d_1, d_2)$
-regular random graph. The solution of the coupled equations for fixed
$(d_1, d_2)$
-regular random graph. The solution of the coupled equations for fixed
 $d_1$
and
$d_1$
and
 $d_2$
shows convergence of the spectral distribution of a random regular bipartite graph to the Marčenko–Pastur law. This was first observed by [Reference Godsil and Mohar32]. For
$d_2$
shows convergence of the spectral distribution of a random regular bipartite graph to the Marčenko–Pastur law. This was first observed by [Reference Godsil and Mohar32]. For
 $d_1, d_2 \to \infty$
with
$d_1, d_2 \to \infty$
with
 $d_1/d_2$
converging to a constant, [Reference Dumitriu and Johnson24] showed that the limiting spectral distribution converges to a transformed version of the Marčenko–Pastur law. When
$d_1/d_2$
converging to a constant, [Reference Dumitriu and Johnson24] showed that the limiting spectral distribution converges to a transformed version of the Marčenko–Pastur law. When
 $d_1 = d_2 = d$
, this is equal to the Kesten–McKay distribution [Reference McKay51], which becomes the semicircular law as
$d_1 = d_2 = d$
, this is equal to the Kesten–McKay distribution [Reference McKay51], which becomes the semicircular law as
 $d \to \infty$
[Reference Godsil and Mohar32, Reference Dumitriu and Johnson24]. Notably, [Reference Mizuno and Sato53] obtained the same results when they calculated the asymptotic distribution of eigenvalues for bipartite, biregular graphs of high girth. However, their results are not applicable to random bipartite biregular graphs as these asymptotically almost surely have low girth [Reference Dumitriu and Johnson24].
$d \to \infty$
[Reference Godsil and Mohar32, Reference Dumitriu and Johnson24]. Notably, [Reference Mizuno and Sato53] obtained the same results when they calculated the asymptotic distribution of eigenvalues for bipartite, biregular graphs of high girth. However, their results are not applicable to random bipartite biregular graphs as these asymptotically almost surely have low girth [Reference Dumitriu and Johnson24].
Our techniques borrow heavily from the results of [Reference Bordenave, Lelarge and Massoulié14] and [Reference Bordenave12], who simplified the trace method of [Reference Friedman27] by counting non-backtracking walks built up of segments with at most one cycle, and by relating the eigenvalues of the adjacency matrix to the eigenvalues of the non-backtracking one via the Ihara–Bass identity. The combinatorial methods we use to bound the number of such walks are similar to how [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran15] counted self-avoiding walks in the context of community recovery in a regular stochastic block model.
Finally, we should mention that similar techniques have been employed by [Reference Coste20] to study the spectral gap of the Markov matrix of a random directed multigraph. The non-backtracking operator of a bipartite biregular graph could be seen as the adjacency matrix of a directed multigraph, whose eigenvalues are a simple scaling away from the eigenvalues of the Markov matrix of the same. However, the block structure of our non-backtracking matrix means that the corresponding multigraph is bipartite, and this makes it different from the model used in [Reference Coste20].
1.2. Configuration versus random lift model
Random lifts are a model that allows the construction of large, random graphs by repeatedly lifting the vertices of a base graph and permuting the endpoints of copied edges. See [Reference Bordenave12] for a recent overview. A number of spectral gap results have been obtained for random lift models, e.g. [Reference Friedman27, Reference Angel, Friedman and Hoory2, Reference Friedman and Kohler29, Reference Bordenave12].
Random lift models are contiguous with the configuration model in very particular cases. See Section 4.1 for a definition of the configuration model; this is a useful substitute for the uniform model and is practically equivalent. For even d, random n-lifts of a single vertex with
 $d/2$
self-loops are equivalent to the d-regular configuration model. For odd d, no equivalent lift construction is known or even believed to exist.
$d/2$
self-loops are equivalent to the d-regular configuration model. For odd d, no equivalent lift construction is known or even believed to exist.
For
 $(d_1, d_2)$
-biregular, bipartite graphs, the situation is more complicated. A celebrated result due to [Reference Marcus, Spielman and Srivastava48] showed the existence of infinite families of
$(d_1, d_2)$
-biregular, bipartite graphs, the situation is more complicated. A celebrated result due to [Reference Marcus, Spielman and Srivastava48] showed the existence of infinite families of
 $(d_1, d_2)$
-regular bipartite graphs that are Ramanujan. That is, with
$(d_1, d_2)$
-regular bipartite graphs that are Ramanujan. That is, with
 $\eta = \sqrt{d_1-1} + \sqrt{d_2 - 1}$
by taking repeated lifts of the complete bipartite graph on
$\eta = \sqrt{d_1-1} + \sqrt{d_2 - 1}$
by taking repeated lifts of the complete bipartite graph on
 $d_1$
left and
$d_1$
left and
 $d_2$
right vertices
$d_2$
right vertices
 $K_{d_1,d_2}$
. If
$K_{d_1,d_2}$
. If
 $d_1=d_2=d$
, then the configuration model is contiguous to the random lift of the multigraph with two vertices and d edges connecting then. Certainly, for a biregular bipartite graph with
$d_1=d_2=d$
, then the configuration model is contiguous to the random lift of the multigraph with two vertices and d edges connecting then. Certainly, for a biregular bipartite graph with
 $n/d_2=m/d_1=k$
not an integer, we cannot construct it by lifting
$n/d_2=m/d_1=k$
not an integer, we cannot construct it by lifting
 $K_{d_1, d_2}$
as considered by [Reference Marcus, Spielman and Srivastava48]. But even for k integer, it seems likely the two models are not contiguous, for the reasons we now explain.
$K_{d_1, d_2}$
as considered by [Reference Marcus, Spielman and Srivastava48]. But even for k integer, it seems likely the two models are not contiguous, for the reasons we now explain.
Suppose there were a base graph G that could be lifted to produce any (3,2)-biregular, bipartite graph. Consider another graph H which is a union of 2 complete bipartite graphs
 $K_{2,3}$
. Then H is a (3,2)-biregular, bipartite graph and occurs in the configuration model with nonzero probability. The only G that H could be a lift of is
$K_{2,3}$
. Then H is a (3,2)-biregular, bipartite graph and occurs in the configuration model with nonzero probability. The only G that H could be a lift of is
 $K_{2,3}$
, because it is a disconnected union and
$K_{2,3}$
, because it is a disconnected union and
 $K_{2,3}$
itself is not a lift of any graph or multigraph (note that
$K_{2,3}$
itself is not a lift of any graph or multigraph (note that
 $2+3=5$
is prime). Therefore, G would have to be
$2+3=5$
is prime). Therefore, G would have to be
 $K_{2,3}$
. Figure 2 shows an example of another graph H’ with the same number of vertices as H which is (3,2)-biregular, bipartite but is not a lift of
$K_{2,3}$
. Figure 2 shows an example of another graph H’ with the same number of vertices as H which is (3,2)-biregular, bipartite but is not a lift of
 $K_{2,3}$
. Now, H and H’ both occur in the configuration model with equal, nonzero probability. Therefore, we cannot construct every example of a (3,2)-biregular, bipartite graph by repeatedly lifting a single base graph G.
$K_{2,3}$
. Now, H and H’ both occur in the configuration model with equal, nonzero probability. Therefore, we cannot construct every example of a (3,2)-biregular, bipartite graph by repeatedly lifting a single base graph G.

Figure 2. The (3,2)-bipartite, biregular graph on the right is not a 2-lift of
 $K_{2,3}$
. Every pair of left vertices shares a neighbour on the right.
$K_{2,3}$
. Every pair of left vertices shares a neighbour on the right.
Since the eventual goal of any argument based on lifts that also applies to the configuration model would have to show that almost all bipartite, biregular graphs can be obtained by lifting and are sampled asymptotically uniformly from the lift model, the above considerations suggest this argument would be highly non-trivial. We in fact doubt such an argument can be made. Intuitively, in the configuration model edges occur ‘nearly independently,’ whereas for random lifts there are strong dependencies due to the fact that many edges are not allowed; see [Reference Bordenave12].
1.3. Structure of the paper
Briefly, we now lay out the method of proof that the bipartite, biregular random graph is Ramanujan. The proof outline is given in detail in Section 5.1, after some important preliminary terms and definitions given in Section 4. The bulk of our work builds to Theorem 3.1, which is actually a bound on the second eigenvalue of the non-backtracking matrix B, as explained in Section 2. The Ramanujan bound on the second eigenvalue of A then follows as Theorem 3.2. As a side result, we find that row- and column-regular, rectangular matrices (the off-diagonal block X of the adjacency matrix in equation (1)) with aspect ratio smaller than one (
 $d_1 \neq d_2$
) have full rank with high probability.
$d_1 \neq d_2$
) have full rank with high probability.
To find the second eigenvalue of B, we subtract from it a matrix S that is formed from the leading eigenvectors and examine the spectral norm of the ‘almost-centered’ matrix
 $\bar{B} = B - S$
. We then proceed to use the trace method to bound the spectral norm of the matrix
$\bar{B} = B - S$
. We then proceed to use the trace method to bound the spectral norm of the matrix
 $\bar{B}^\ell$
by its trace. However, since
$\bar{B}^\ell$
by its trace. However, since
 $\bar{B}$
is not positive definite, this leads us to consider
$\bar{B}$
is not positive definite, this leads us to consider
 \begin{equation*}\mathbb{E}\left(\|\bar{B}^{\ell}\|^{2k}\right)\leq \mathbb{E}\left( \textrm{Tr} \left( (\bar{B}^{\ell}) (\bar{B}^{\ell})^* \right)^{k} \right).\end{equation*}
\begin{equation*}\mathbb{E}\left(\|\bar{B}^{\ell}\|^{2k}\right)\leq \mathbb{E}\left( \textrm{Tr} \left( (\bar{B}^{\ell}) (\bar{B}^{\ell})^* \right)^{k} \right).\end{equation*}
On the right-hand side, the terms in
 $\bar{B}^\ell$
refer to circuits built up of 2k segments, each of length
$\bar{B}^\ell$
refer to circuits built up of 2k segments, each of length
 $\ell+1$
, since an entry
$\ell+1$
, since an entry
 $B_{ef}$
is a walk on two edges. Because the degrees are bounded, it turns out that, for
$B_{ef}$
is a walk on two edges. Because the degrees are bounded, it turns out that, for
 $\ell = O(\log (n))$
, the depth
$\ell = O(\log (n))$
, the depth
 $\ell$
neighbourhoods of every vertex contain at most one cycle—they are ‘tangle-free.’ Thus, we can bound the trace by computing the expectation of the circuits that contribute, along with an upper bound on their multiplicity, taking each segment to be
$\ell$
neighbourhoods of every vertex contain at most one cycle—they are ‘tangle-free.’ Thus, we can bound the trace by computing the expectation of the circuits that contribute, along with an upper bound on their multiplicity, taking each segment to be
 $\ell$
-tangle-free.
$\ell$
-tangle-free.
Finally, to demonstrate the usefulness of the spectral gap, we highlight three applications of our bound. In Section 6, we show a community detection application. Finding communities in networks is important for the areas of social network, bioinformatics, neuroscience, among others. Random graphs offer tractable models to study when detection and recovery are possible.
We show here how our results lead to community detection in regular stochastic block models with arbitrary numbers of groups, using a very general theorem by [Reference Wan, Meilă, Cortes, Lawrence, Lee, Sugiyama and Garnett62]. Previously, [Reference Newman and Martin54] studied the spectral density of such models, and the community detection problem of the special case of two groups was previously studied by [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran15] and [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran15].
In Section 7, we examine the application to linear error correcting codes built from sparse expander graphs. This concept was first introduced by [Reference Gallager30] who explicitly used random bipartite biregular graphs. These ‘low-density parity-check’ codes enjoyed a renaissance in the 1990s, when people realised they were well suited to modern computers. For an overview, see [Reference Richardson and Urbanke57, Reference Richardson and Urbanke58]. Our result yields an explicit lower bound on the minimum distance of such codes, i.e. the number of errors that can be corrected.
The final application, in Section 8, leads to generalised error bounds for matrix completion. Matrix completion is the problem of reconstructing a matrix from observations of a subset of entries. Heiman et al. [Reference Heiman, Schechtman and Shraibman33] gave an algorithm for reconstruction of a square matrix with low complexity as measured by a norm
 $\gamma_2$
, which is similar to the trace norm (sum of the singular values, also called the nuclear norm or Ky Fan n-norm). The entries that are observed are at the non-zero entries of the adjacency matrix of a bipartite, biregular graph. The error of the reconstruction is bounded above by a factor which is proportional to the ratio of the leading two eigenvalues, so that a graph with larger spectral gap has a smaller generalization error. We extend their results to rectangular graphs, along the way strengthening them by a constant factor of two. The main result of the paper gives an explicit bound in terms of
$\gamma_2$
, which is similar to the trace norm (sum of the singular values, also called the nuclear norm or Ky Fan n-norm). The entries that are observed are at the non-zero entries of the adjacency matrix of a bipartite, biregular graph. The error of the reconstruction is bounded above by a factor which is proportional to the ratio of the leading two eigenvalues, so that a graph with larger spectral gap has a smaller generalization error. We extend their results to rectangular graphs, along the way strengthening them by a constant factor of two. The main result of the paper gives an explicit bound in terms of
 $d_1$
and
$d_1$
and
 $d_2$
.
$d_2$
.
As this paper was being prepared for submission, we became aware of the work of [Reference Deshpande, Montanari, O’Donnell, Schramm and Sen22]. In their interesting paper, they use the smallest positive eigenvalue of a random bipartite lift to study convex relaxation techniques for random not-all-equal-3SAT problems. It seems that our main result addresses the configuration model version of this constraint satisfaction problem, the first open question listed at the end of [Reference Deshpande, Montanari, O’Donnell, Schramm and Sen22].
2. Non-backtracking matrix B
Given
 $G \sim \mathcal{G}(n,m,d_1,d_2)$
, we define the non-backtracking operator B. This operator is a linear endomorphism of
$G \sim \mathcal{G}(n,m,d_1,d_2)$
, we define the non-backtracking operator B. This operator is a linear endomorphism of
 $\mathbb{R}^{|\vec{E}|}$
, where
$\mathbb{R}^{|\vec{E}|}$
, where
 $\vec{E}$
is the set of oriented edges of G and
$\vec{E}$
is the set of oriented edges of G and
 $|\vec{E}| = 2|E|$
. Throughout this paper, we will use V(H), E(H), and
$|\vec{E}| = 2|E|$
. Throughout this paper, we will use V(H), E(H), and
 $\vec{E}(H)$
to denote the vertices, edges, and oriented or directed edges of a graph, subgraph, or path H. For oriented edges
$\vec{E}(H)$
to denote the vertices, edges, and oriented or directed edges of a graph, subgraph, or path H. For oriented edges
 $e=(u,v)$
, where u and v are the starting and ending vertices of e, and
$e=(u,v)$
, where u and v are the starting and ending vertices of e, and
 $f=(s,t)$
, define:
$f=(s,t)$
, define:
 \begin{equation*}B_{ef}=\begin{cases} 1,&\textrm{if $v=s$ and $u\neq t$};\\[2pt] 0,& \textrm{otherwise}.\end{cases}\end{equation*}
\begin{equation*}B_{ef}=\begin{cases} 1,&\textrm{if $v=s$ and $u\neq t$};\\[2pt] 0,& \textrm{otherwise}.\end{cases}\end{equation*}
We order the elements of
 $\vec{E}$
as
$\vec{E}$
as
 $\{e_1, e_2,\cdots,e_{2|E|}\}$
, so that the first
$\{e_1, e_2,\cdots,e_{2|E|}\}$
, so that the first
 $|E|$
have end point in the set
$|E|$
have end point in the set
 $V_2$
. In this way, we can write
$V_2$
. In this way, we can write
 \begin{equation*}B =\left(\begin{array}{c@{\quad}c}0 & B^{(12)} \\B^{(21)} & 0\end{array}\right)\!.\end{equation*}
\begin{equation*}B =\left(\begin{array}{c@{\quad}c}0 & B^{(12)} \\B^{(21)} & 0\end{array}\right)\!.\end{equation*}
for
 $|E| \times |E|$
matrices
$|E| \times |E|$
matrices
 $B^{(12)}$
and
$B^{(12)}$
and
 $B^{(21)}$
with entries equal to 0 or 1.
$B^{(21)}$
with entries equal to 0 or 1.
We are interested in the spectrum of B. Denote by
 $\textbf{1}_{\alpha}$
the vector with first
$\textbf{1}_{\alpha}$
the vector with first
 $|E|$
coordinates equal to 1 and the last
$|E|$
coordinates equal to 1 and the last
 $|E|$
equal to
$|E|$
equal to
 $\alpha = \sqrt{d_1-1}/\sqrt{d_2-1}$
. We can check that
$\alpha = \sqrt{d_1-1}/\sqrt{d_2-1}$
. We can check that
 \begin{equation*}B \textbf{1}_{\alpha} = B^* \textbf{1}_{\alpha} =\lambda \textbf{1}_{\alpha}\end{equation*}
\begin{equation*}B \textbf{1}_{\alpha} = B^* \textbf{1}_{\alpha} =\lambda \textbf{1}_{\alpha}\end{equation*}
for
 $\lambda=\sqrt{(d_1-1)(d_2-1)}$
. By the Perron–Frobenius Theorem, we conclude that
$\lambda=\sqrt{(d_1-1)(d_2-1)}$
. By the Perron–Frobenius Theorem, we conclude that
 $\lambda_1=\lambda$
and the associated eigenspace has dimension one. Also, one can check that if
$\lambda_1=\lambda$
and the associated eigenspace has dimension one. Also, one can check that if
 $\lambda$
is an eigenvalue of B with eigenvector
$\lambda$
is an eigenvalue of B with eigenvector
 $v=(v_1,v_2)$
,
$v=(v_1,v_2)$
,
 $v_i\in \mathbb{R}^{|E|}$
, then
$v_i\in \mathbb{R}^{|E|}$
, then
 $-\lambda$
is also an eigenvalue with eigenvector
$-\lambda$
is also an eigenvalue with eigenvector
 $v'=(-v_1,v_2)$
. Thus,
$v'=(-v_1,v_2)$
. Thus,
 $\sigma(B)=-\sigma(B)$
and
$\sigma(B)=-\sigma(B)$
and
 $\lambda_{2|E|}=-\lambda_1$
.
$\lambda_{2|E|}=-\lambda_1$
.
2.1 Connecting the spectra of A and B
Understanding the spectrum of B turns out to be a challenging question. A useful result in this direction is the following theorem proved by [Reference Bass6], and subsequently in [Reference Watanabe and Fukumizu63] and [Reference Kotani and Sunada40]; see also Theorem 3.3 in [Reference Angel, Friedman and Hoory3].
Theorem 2.1 (Ihara–Bass formula). Let
 $G=(V,E)$
be any finite graph and B be its non-backtracking matrix. Then
$G=(V,E)$
be any finite graph and B be its non-backtracking matrix. Then
 \begin{equation*}\textrm{det}(B-\lambda I) = \left(\lambda^2-1\right)^{|E|-|V|} \textrm{det}\left(D-\lambda A+\lambda^2 I\right),\end{equation*}
\begin{equation*}\textrm{det}(B-\lambda I) = \left(\lambda^2-1\right)^{|E|-|V|} \textrm{det}\left(D-\lambda A+\lambda^2 I\right),\end{equation*}
where D is the diagonal matrix with
 $D_{vv}=d_v - 1$
and A is the adjacency matrix of G.
$D_{vv}=d_v - 1$
and A is the adjacency matrix of G.
We use the Ihara–Bass formula to analyse the relationship of the spectrum of B to the spectrum of A in the case of a bipartite biregular graph. It will turn out that this relationship can be completely unpacked. From Theorem 2.1, we get that
 \begin{equation*}\sigma(B)=\{\pm 1\}\bigcup\{\lambda: D-\lambda A+\lambda^2 I\ \textrm{is not invertible}\}.\end{equation*}
\begin{equation*}\sigma(B)=\{\pm 1\}\bigcup\{\lambda: D-\lambda A+\lambda^2 I\ \textrm{is not invertible}\}.\end{equation*}
Note that there are precisely
 $2(m+n)$
eigenvalues of B that are determined by A, and that
$2(m+n)$
eigenvalues of B that are determined by A, and that
 $\lambda = 0$
is not in the spectrum of B, since the graph has no isolated vertices (
$\lambda = 0$
is not in the spectrum of B, since the graph has no isolated vertices (
 $\det(D) \neq 0$
).
$\det(D) \neq 0$
).
We use the special structure of G to get a more precise description of
 $\sigma(B)$
. The matrices A and D are equal to:
$\sigma(B)$
. The matrices A and D are equal to:
 \begin{equation*}A=\left(\begin{array}{c@{\quad}c} 0 & X \\
X^* & 0 \end{array}\right ),\ \ D=\left(\begin{array}{c@{\quad}c} (d_1-1)I_n & 0 \\0 & (d_2-1)I_m \end{array}\right ),\end{equation*}
\begin{equation*}A=\left(\begin{array}{c@{\quad}c} 0 & X \\
X^* & 0 \end{array}\right ),\ \ D=\left(\begin{array}{c@{\quad}c} (d_1-1)I_n & 0 \\0 & (d_2-1)I_m \end{array}\right ),\end{equation*}
where
 $I_k$
is the
$I_k$
is the
 $k\times k$
identity matrix. Let
$k\times k$
identity matrix. Let
 $\lambda\in \sigma(B)\backslash\{-1,1\}$
. Then there exists a nonzero vector v such that
$\lambda\in \sigma(B)\backslash\{-1,1\}$
. Then there exists a nonzero vector v such that
 \begin{equation*}(D-\lambda A+\lambda^2 I)v = 0 .\end{equation*}
\begin{equation*}(D-\lambda A+\lambda^2 I)v = 0 .\end{equation*}
Writing
 $v=(v_1,v_2)$
with
$v=(v_1,v_2)$
with
 $v_1\in \mathbb{C}^n$
,
$v_1\in \mathbb{C}^n$
,
 $v_2\in \mathbb{C}^m$
, we obtain:
$v_2\in \mathbb{C}^m$
, we obtain:
 \begin{eqnarray}Xv_2 & =& \frac{d_1-1+\lambda^2}{\lambda}v_1, \end{eqnarray}
\begin{eqnarray}Xv_2 & =& \frac{d_1-1+\lambda^2}{\lambda}v_1, \end{eqnarray}
 \begin{eqnarray}X^*v_1 & = &\frac{d_2-1+\lambda^2}{\lambda}v_2 .\end{eqnarray}
\begin{eqnarray}X^*v_1 & = &\frac{d_2-1+\lambda^2}{\lambda}v_2 .\end{eqnarray}
The above imply that, provided that the right-hand side is non-zero,
 \begin{eqnarray}\xi^2=\frac{(d_1-1+\lambda^2)(d_2-1+\lambda^2)}{\lambda^2}\end{eqnarray}
\begin{eqnarray}\xi^2=\frac{(d_1-1+\lambda^2)(d_2-1+\lambda^2)}{\lambda^2}\end{eqnarray}
is a nonzero eigenvalue of both
 $XX^*$
with eigenvector
$XX^*$
with eigenvector
 $v_1$
and
$v_1$
and
 $X^*X$
, with eigenvector
$X^*X$
, with eigenvector
 $v_2$
. We can rewrite equation (6) as
$v_2$
. We can rewrite equation (6) as
 \begin{eqnarray}\lambda^4 - (\xi^2 - d_1 - d_2+2) \lambda^2 + (d_1-1)(d_2-1) = 0 .\end{eqnarray}
\begin{eqnarray}\lambda^4 - (\xi^2 - d_1 - d_2+2) \lambda^2 + (d_1-1)(d_2-1) = 0 .\end{eqnarray}
We will now detail how the eigenvalues of A (denoted
 $\xi$
here) map to eigenvalues of B and vice-versa. Let us examine the special case
$\xi$
here) map to eigenvalues of B and vice-versa. Let us examine the special case
 $\xi = 0$
. Assume
$\xi = 0$
. Assume
 $n \leq m$
for simplicity. Assume that the rank of X is r. Then X has
$n \leq m$
for simplicity. Assume that the rank of X is r. Then X has
 $m-r$
independent vectors in its nullspace. Let u be one such vector. Now, if we pick
$m-r$
independent vectors in its nullspace. Let u be one such vector. Now, if we pick
 $v_2 = u$
,
$v_2 = u$
,
 $v_1 = 0$
, and
$v_1 = 0$
, and
 $\lambda = \pm i \sqrt{d_2-1}$
, equations (4) and (5) are satisfied. Hence,
$\lambda = \pm i \sqrt{d_2-1}$
, equations (4) and (5) are satisfied. Hence,
 $\pm i \sqrt{d_2-1}$
are eigenvalues of B, both with multiplicity
$\pm i \sqrt{d_2-1}$
are eigenvalues of B, both with multiplicity
 $m-r$
.
$m-r$
.
Since the rank of X is r, it follows that the nullity of
 $X^*$
is
$X^*$
is
 $n-r$
, so there are
$n-r$
, so there are
 $n-r$
independent vectors w for which
$n-r$
independent vectors w for which
 $X^*w = 0$
. Now, note that picking
$X^*w = 0$
. Now, note that picking
 $v_1 = w$
,
$v_1 = w$
,
 $v_2 = 0$
, and
$v_2 = 0$
, and
 $\lambda = \pm i \sqrt{d_1 -1}$
, we satisfy equations (4) and (5). Thus,
$\lambda = \pm i \sqrt{d_1 -1}$
, we satisfy equations (4) and (5). Thus,
 $\pm i \sqrt{d_1-1}$
are eigenvalues of B, both with multiplicity
$\pm i \sqrt{d_1-1}$
are eigenvalues of B, both with multiplicity
 $n-r$
.
$n-r$
.
The remaining 4r eigenvalues of B determined by A come from nonzero eigenvalues of A. For each
 $\xi^2$
with
$\xi^2$
with
 $\xi$
a nonzero eigenvalue of A, we will have precisely 4 complex solutions to equation (6). Since there are 2r such eigenvalues, coming in pairs
$\xi$
a nonzero eigenvalue of A, we will have precisely 4 complex solutions to equation (6). Since there are 2r such eigenvalues, coming in pairs
 $\pm \xi$
, they determine a total of 4r eigenvalues of B, and the count is complete. To summarise the discussion above, we have the following Lemma:
$\pm \xi$
, they determine a total of 4r eigenvalues of B, and the count is complete. To summarise the discussion above, we have the following Lemma:
Lemma 2.2. Any eigenvalue of B belongs to one of the following categories:
-
1.
 $\pm 1$
are both eigenvalues with multiplicities
$|E|-|V| = nd_1 - m -n$
,
$\pm 1$
are both eigenvalues with multiplicities
$|E|-|V| = nd_1 - m -n$
, -
2.
$\pm i \sqrt{d_1-1}$
are eigenvalues with multiplicities
$n-r$
, where r is the rank of the matrix X, -
3.
$\pm i \sqrt{d_2-1}$
are eigenvalues with multiplicities
$m-r$
, and -
4. every pair of non-zero eigenvalues
$(-\xi, \xi)$
of A generates exactly 4 eigenvalues of B.







3. Main result
We spend the bulk of this paper in the proof of the following:
Theorem 3.1. If B is the non-backtracking matrix of a bipartite, biregular random graph
 $G \sim \mathcal{G}(n,m,d_1,d_2)$
, then its second largest eigenvalue
$G \sim \mathcal{G}(n,m,d_1,d_2)$
, then its second largest eigenvalue
 \begin{equation*}|\lambda_2 (B)| \leq ((d_1-1)(d_2-1))^{1/4}+\epsilon_n\end{equation*}
\begin{equation*}|\lambda_2 (B)| \leq ((d_1-1)(d_2-1))^{1/4}+\epsilon_n\end{equation*}
asymptotically almost surely, with
 $\epsilon_n \to 0$
as
$\epsilon_n \to 0$
as
 $n \to \infty$
. Equivalently, there exists a sequence
$n \to \infty$
. Equivalently, there exists a sequence
 $\epsilon_n \rightarrow 0$
as
$\epsilon_n \rightarrow 0$
as
 $n \rightarrow \infty$
so that
$n \rightarrow \infty$
so that
 \begin{equation*}\mathbb{P}\left [ |\lambda_2(B)| - ((d_1-1)(d_2-1))^{1/4} >\epsilon_n \right ] \rightarrow 0 \mbox{as} n \rightarrow \infty .\end{equation*}
\begin{equation*}\mathbb{P}\left [ |\lambda_2(B)| - ((d_1-1)(d_2-1))^{1/4} >\epsilon_n \right ] \rightarrow 0 \mbox{as} n \rightarrow \infty .\end{equation*}
Remark. For the random lift model, Theorem 3.1 was proved by [Reference Bordenave12], which applies to random bipartite graphs only when
 $d_1=d_2=d$
as discussed in Section 1.2.
$d_1=d_2=d$
as discussed in Section 1.2.
We combine Theorems 2.1 and 3.1 to prove our main result concerning the spectrum of A.
Theorem 3.2 (Spectral gap). Let
 $A=\left(\begin{array}{cc} 0 & X \\X^* & 0 \end{array}\right )$
be the adjacency matrix of a bipartite, biregular random graph
$A=\left(\begin{array}{cc} 0 & X \\X^* & 0 \end{array}\right )$
be the adjacency matrix of a bipartite, biregular random graph
 $G \sim \mathcal{G}(n,m,d_1,d_2)$
. Without loss of generality, assume
$G \sim \mathcal{G}(n,m,d_1,d_2)$
. Without loss of generality, assume
 $d_1 \geq d_2$
or, equivalently,
$d_1 \geq d_2$
or, equivalently,
 $n \leq m$
. Then:
$n \leq m$
. Then:
-
i. Its second largest eigenvalue
$\eta = \lambda_2 (A)$
satisfies
asymptotically almost surely, with
\begin{equation*}\eta \leq \sqrt{d_1-1}+\sqrt{d_2-1}+ \epsilon^{\prime}_n\end{equation*}
$\epsilon^{\prime}_n \to 0$
as
$n \to \infty$
.
-
ii. Its smallest positive eigenvalue
$\eta^+_{\textrm{min}} = \min ( \{\lambda \in \sigma(A): \lambda > 0\} )$
satisfies
asymptotically almost surely, with
\begin{equation*}\eta_{\textrm{min}}^+\geq \sqrt{d_1-1}-\sqrt{d_2-1}- \epsilon^{\prime\prime}_n\end{equation*}
$\epsilon^{\prime\prime}_n\to 0$
as
$n \to \infty$
. (Note that this will be almost surely positive if
$d_1>d_2$
; no further information is gained if
$d_1 = d_2$
.)
-
iii. If
$d_1 \neq d_2$
, the rank of X is n with high probability.











Remark. Since the first draft of this work came out, considerable advances have been made regarding the question of singularity of random regular graphs. It was conjectured in [Reference Costello and Vu21] that, for
 $3\leq d\leq n-3$
, the adjacency matrix of uniform d-regular graphs is not singular with high probability as n grows to infinity. For directed d-regular graphs and growing d, this is now known to be true, following the results of [Reference Cook19] and [Reference Litvak, Lytova, Tikhomirov, Tomczak-Jaegermann and Youssef45, Reference Litvak, Lytova, Tikhomirov, Tomczak-Jaegermann and Youssef46]. For constant degree d, [Reference Huang36, Reference Huang37] proved the asymptotic non-singularity of the adjacency matrix for both undirected and directed d-regular graphs. The last case can be interpreted as singularity of the adjacency matrix of random d-regular bipartite graph. To the best of our knowledge, Theorem 3.2(iii) is the first result concerning the rank of rectangular random matrices with
$3\leq d\leq n-3$
, the adjacency matrix of uniform d-regular graphs is not singular with high probability as n grows to infinity. For directed d-regular graphs and growing d, this is now known to be true, following the results of [Reference Cook19] and [Reference Litvak, Lytova, Tikhomirov, Tomczak-Jaegermann and Youssef45, Reference Litvak, Lytova, Tikhomirov, Tomczak-Jaegermann and Youssef46]. For constant degree d, [Reference Huang36, Reference Huang37] proved the asymptotic non-singularity of the adjacency matrix for both undirected and directed d-regular graphs. The last case can be interpreted as singularity of the adjacency matrix of random d-regular bipartite graph. To the best of our knowledge, Theorem 3.2(iii) is the first result concerning the rank of rectangular random matrices with
 $d_1$
nonzero entries in each row and
$d_1$
nonzero entries in each row and
 $d_2$
in each column.
$d_2$
in each column.
Remark. The analysis of the Ihara-Bass formula for Markov matrices of bipartite biregular graph appeared before in [Reference Kempton39]. We have independently proven Lemma 2.2 and extracted from it more information than is given in [Reference Kempton39], including Theorem 3.2(iii).
Proof. Equation (7), describing those eigenvalues of B which are neither
 $\pm 1$
and do not correspond to 0 eigenvalues of A is equivalent to
$\pm 1$
and do not correspond to 0 eigenvalues of A is equivalent to
 \begin{eqnarray}0 = x^2 + \alpha \beta - (y - \alpha - \beta ) x,\end{eqnarray}
\begin{eqnarray}0 = x^2 + \alpha \beta - (y - \alpha - \beta ) x,\end{eqnarray}
where
 $x = \lambda^2$
,
$x = \lambda^2$
,
 $y = \xi^2$
,
$y = \xi^2$
,
 $\alpha = d_1 - 1$
, and
$\alpha = d_1 - 1$
, and
 $\beta = d_2 -1$
. A simple discriminant calculation and analysis of equation (8), keeping in mind that
$\beta = d_2 -1$
. A simple discriminant calculation and analysis of equation (8), keeping in mind that
 $y \neq 0$
, leads to a number of cases in terms of y:
$y \neq 0$
, leads to a number of cases in terms of y:
-
Case 1:
$y \in ((\sqrt{\alpha} -\sqrt{\beta})^2, (\sqrt{\alpha} + \sqrt{\beta})^2)$
, i.e. roughly speaking,
$\eta$
is in the bulk, means that x is on the circle of radius
$\sqrt{\alpha \beta}$
and the corresponding pair of eigenvalues
$\lambda$
are on a circle of radius
$(\alpha \beta)^{1/4}$
. -
Case 2:
$y \in (0, (\sqrt{\alpha} - \sqrt{\beta})^2]$
means that x is real and negative, so
$\lambda$
is purely imaginary.In this case, one may also show that the smaller of the two possible values for x is increasing as a function of y and
$x_{-} \in (-\alpha, -\sqrt{\alpha \beta}]$
. The larger of the two values of x is decreasing and
$x_{+} \in [-\sqrt{\alpha \beta}, - \beta)$
. Correspondingly, the largest in absolute value that
$\lambda$
could be in this case is
$\pm i \alpha^{1/4} = \pm i (d_1-1)^{1/4}$
. -
Case 3:
$y \geq (\sqrt{\alpha} + \sqrt{\beta})^2$
means that both solutions
$x_{\pm}$
are real, and the larger of the two is larger than
$\sqrt{\alpha \beta}$
.














Note that equation (8) shows there is a continuous dependence between x and y, and consequently between
 $\xi$
and
$\xi$
and
 $\lambda$
. Putting these cases together with Lemma 2.2, a few things become apparent:
$\lambda$
. Putting these cases together with Lemma 2.2, a few things become apparent:
-
1.
$\xi>\sqrt{d_1-1}+ \sqrt{d_2-1}$
means that
$\lambda> ((d_1-1)(d_2-1))^{1/4}$
. -
2.
$|\lambda_2| \leq ((d_1-1)(d_2-1))^{1/4} + \epsilon$
implies that all eigenvalues except for the largest two will be either 0, or in a small neighbourhood
$[\sqrt{\alpha} -\sqrt{\beta} - \delta,\sqrt{\alpha} + \sqrt{\beta} + \delta]$
of the bulk, with
$\delta$
small if
$\epsilon$
is small since the dependence of
$\delta$
on
$\epsilon$
can be deduced from equation (8). -
3.
$|\lambda_2| \leq ((d_1-1)(d_2-1))^{1/4} + \epsilon$
with high probability implies that if
$d_1 \neq d_2$
,
$r=n$
with high probability. Otherwise, we would have eigenvalues of B with absolute value
$\sqrt{d_1-1}$
and this is larger than
$((d_1-1)(d_2-1))^{1/4}$
.













This completes the proof, with results (i) and (ii) following from the point 2 and (iii) following from point 3.
In Figure 3, we depict the spectra of A and B for a sample graph
 $G \sim \mathcal{G}(120,280,7,3)$
. Looking at the non-backtracking spectrum, we observe the two leading eigenvalues
$G \sim \mathcal{G}(120,280,7,3)$
. Looking at the non-backtracking spectrum, we observe the two leading eigenvalues
 $\pm \sqrt{(d_1 - 1 )(d_2 - 1)}$
(blue crosses) outside the circle of radius
$\pm \sqrt{(d_1 - 1 )(d_2 - 1)}$
(blue crosses) outside the circle of radius
 $((d_1 - 1)(d_2 - 1))^{1/4}$
along with a number of zero eigenvalues (black dots). There are also multiple purely imaginary eigenvalues which can arise from
$((d_1 - 1)(d_2 - 1))^{1/4}$
along with a number of zero eigenvalues (black dots). There are also multiple purely imaginary eigenvalues which can arise from
 $|\xi| \in (0, \sqrt{d_1 - 1} - \sqrt{d_2 - 1}]$
as well as
$|\xi| \in (0, \sqrt{d_1 - 1} - \sqrt{d_2 - 1}]$
as well as
 $\xi = 0$
. However, due to Theorem 3.2, only the smaller of
$\xi = 0$
. However, due to Theorem 3.2, only the smaller of
 $i \sqrt{d_1 - 1}$
and
$i \sqrt{d_1 - 1}$
and
 $i \sqrt{d_2 - 1}$
is observed with non-negligible probability, implying that X has rank
$i \sqrt{d_2 - 1}$
is observed with non-negligible probability, implying that X has rank
 $r = n$
with high probability (shown as blue stars). Furthermore, we observe two pairs of real eigenvalues of B which are connected to a pair of eigenvalues of A from ‘above’ the bulk, as well as two pairs of imaginary eigenvalues of B which are connected to a pair of eigenvalues of A from ‘below’ the bulk.
$r = n$
with high probability (shown as blue stars). Furthermore, we observe two pairs of real eigenvalues of B which are connected to a pair of eigenvalues of A from ‘above’ the bulk, as well as two pairs of imaginary eigenvalues of B which are connected to a pair of eigenvalues of A from ‘below’ the bulk.

Figure 3. Example spectra for a sample graph
 $G \sim \mathcal{G}(120, 280, 7, 3)$
. Left, we depict the spectrum of the adjacency matrix A. The dash-dotted line marks the leading eigenvalue, while the dashed line marks our bound for the second eigenvalue, Theorem (3.2). The Marčenko–Pastur limiting spectral density, equation (3), is shown in black. Right, we depict the spectrum of the non-backtracking matrix B for the same graph. Each eigenvalue is shown as a transparent orange circle, the leading eigenvalues are marked with blue crosses, and the eigenvalues arising from zero eigenvalues of A are marked with blue stars. Our main result, Theorem 3.1, proves that with high probability the non-leading eigenvalues are inside, on, or very close to the black dashed circle. In this case, there are 8 outliers of the circle, which arise from 2 pairs of eigenvalues below and above the Marčenko–Pastur bulk.
$G \sim \mathcal{G}(120, 280, 7, 3)$
. Left, we depict the spectrum of the adjacency matrix A. The dash-dotted line marks the leading eigenvalue, while the dashed line marks our bound for the second eigenvalue, Theorem (3.2). The Marčenko–Pastur limiting spectral density, equation (3), is shown in black. Right, we depict the spectrum of the non-backtracking matrix B for the same graph. Each eigenvalue is shown as a transparent orange circle, the leading eigenvalues are marked with blue crosses, and the eigenvalues arising from zero eigenvalues of A are marked with blue stars. Our main result, Theorem 3.1, proves that with high probability the non-leading eigenvalues are inside, on, or very close to the black dashed circle. In this case, there are 8 outliers of the circle, which arise from 2 pairs of eigenvalues below and above the Marčenko–Pastur bulk.
4. Preliminaries
We describe the standard configuration model for constructing such graphs. We then define the ‘tangle-free’ property of random graphs. Since small enough neighbourhoods are tangle-free with high probability, we only need to count tangle-free paths when we eventually employ the trace method.
4.1. The configuration model
The configuration or permutation model is a practical procedure to sample random graphs with a given degree distribution. Let us recall its definition for bipartite biregular graphs. Let
 $V_1=\{v_1,v_2,\dots,v_n\}$
and
$V_1=\{v_1,v_2,\dots,v_n\}$
and
 $V_2=\{w_1,w_2,\dots, w_m\}$
be the vertices of the graph. We define the set of half edges out of
$V_2=\{w_1,w_2,\dots, w_m\}$
be the vertices of the graph. We define the set of half edges out of
 $V_1$
to be the collection of ordered pairs
$V_1$
to be the collection of ordered pairs
 \begin{equation*}\vec{E}_1=\{(v_i,j) \mbox{for $1\leq i\leq n$ and $1\leq j\leq d_1$}\}\end{equation*}
\begin{equation*}\vec{E}_1=\{(v_i,j) \mbox{for $1\leq i\leq n$ and $1\leq j\leq d_1$}\}\end{equation*}
and analogously the set of half edges out of
 $V_2$
:
$V_2$
:
 \begin{equation*}\vec{E}_2=\{(w_i,j) \mbox{for $1\leq i\leq m$ and $1\leq j\leq d_2$}\},\end{equation*}
\begin{equation*}\vec{E}_2=\{(w_i,j) \mbox{for $1\leq i\leq m$ and $1\leq j\leq d_2$}\},\end{equation*}
see Figure 1. Note that
 $|\vec{E}_1|=|\vec{E}_2|=nd_1=md_2 = |E|$
. To sample a graph, we choose a random permutation
$|\vec{E}_1|=|\vec{E}_2|=nd_1=md_2 = |E|$
. To sample a graph, we choose a random permutation
 $\pi$
of
$\pi$
of
 $[n d_1]$
. We put an edge between
$[n d_1]$
. We put an edge between
 $v_i$
and
$v_i$
and
 $w_j$
in the G whenever
$w_j$
in the G whenever
 \begin{equation*}\pi((i-1)d_1+s)=(j-1)d_2+t\end{equation*}
\begin{equation*}\pi((i-1)d_1+s)=(j-1)d_2+t\end{equation*}
for any pair of values
 $1\leq s\leq d_1$
,
$1\leq s\leq d_1$
,
 $1\leq t\leq d_2$
. For specific half edges
$1\leq t\leq d_2$
. For specific half edges
 $e = (v_i, j)$
and
$e = (v_i, j)$
and
 $f = (w_s, t)$
, we use the notation
$f = (w_s, t)$
, we use the notation
 $\pi(e) = f$
as shorthand for
$\pi(e) = f$
as shorthand for
 $\pi((i-1)d_1 + j) = (s-1)d_2 + t$
and say that “e matches to f.”
$\pi((i-1)d_1 + j) = (s-1)d_2 + t$
and say that “e matches to f.”
The graph obtained may not be simple, since multiple half edges may be matched between any pair of vertices. However, conditioning on a simple graph outcome, the distribution is uniform in the set of all simple bipartite biregular graphs. Furthermore, for fixed
 $d_1, d_2$
and
$d_1, d_2$
and
 $n,m \to \infty$
, the probability of getting a simple graph is bounded away from zero [Reference Bollobás11].
$n,m \to \infty$
, the probability of getting a simple graph is bounded away from zero [Reference Bollobás11].
Consider the random
 $B \in \mathbb{R}^{2 |E|\times 2 |E|}$
whose first
$B \in \mathbb{R}^{2 |E|\times 2 |E|}$
whose first
 $|E|$
rows are indexed by the elements of
$|E|$
rows are indexed by the elements of
 $\vec{E}_1$
and the last
$\vec{E}_1$
and the last
 $|E|$
rows are indexed by those of
$|E|$
rows are indexed by those of
 $\vec{E}_2$
, in lexicographic order. Columns are indexed in the same way. Entry
$\vec{E}_2$
, in lexicographic order. Columns are indexed in the same way. Entry
 $B_{ef}$
with
$B_{ef}$
with
 $e=(v_i,j) \in \vec{E}_1$
and
$e=(v_i,j) \in \vec{E}_1$
and
 $f=(w_s,t) \in \vec{E}_2$
is defined as
$f=(w_s,t) \in \vec{E}_2$
is defined as
 \begin{equation*}B_{ef}=\begin{cases} 1,& \mbox{if $\pi(e) = f' = (w_s, t')$ and $t'\neq t$};\\ 0,& \textrm{otherwise}.\end{cases}\end{equation*}
\begin{equation*}B_{ef}=\begin{cases} 1,& \mbox{if $\pi(e) = f' = (w_s, t')$ and $t'\neq t$};\\ 0,& \textrm{otherwise}.\end{cases}\end{equation*}
This defines the upper half of B. We define the lower half similarly, by putting
 \begin{equation*}B_{fe}=\begin{cases} 1,&\textrm{if $\pi^{-1}(f) = e' = (v_i, j')$ and $j'\neq j$};\\ 0,& \textrm{otherwise}.\end{cases}\end{equation*}
\begin{equation*}B_{fe}=\begin{cases} 1,&\textrm{if $\pi^{-1}(f) = e' = (v_i, j')$ and $j'\neq j$};\\ 0,& \textrm{otherwise}.\end{cases}\end{equation*}
This is the same definition used in [Reference Bordenave12]. In words, it says that the directed edge given by e followed by the directed edge given by f are connected by some half edge
 $f' = (w_s, t')$
, and the path they form does not backtrack. This is therefore the same matrix introduced in Section 2, ordered according to the half edges. Notice that the randomness comes from the matching only.
$f' = (w_s, t')$
, and the path they form does not backtrack. This is therefore the same matrix introduced in Section 2, ordered according to the half edges. Notice that the randomness comes from the matching only.
We consider two symmetric matrices
 $M = M(\pi)$
and N, indexed the same as B, and defined by:
$M = M(\pi)$
and N, indexed the same as B, and defined by:
 \begin{equation*}M_{ef} = 1_{ \{ \pi(e) = f \} }\mbox{ and }M_{fe} = 1_{ \{ \pi^{-1} (f) = e \} } \mbox{ for $e\in \vec{E}_1$ and $f\in \vec{E}_2$}\end{equation*}
\begin{equation*}M_{ef} = 1_{ \{ \pi(e) = f \} }\mbox{ and }M_{fe} = 1_{ \{ \pi^{-1} (f) = e \} } \mbox{ for $e\in \vec{E}_1$ and $f\in \vec{E}_2$}\end{equation*}
and
 \begin{equation*}N_{gh} = 1_{ \{u = v \mbox{ and } i\neq j \}} \mbox{ for $g = (u,i), h = (v,j) \in \vec{E}_1 \cup \vec{E}_2$} .\end{equation*}
\begin{equation*}N_{gh} = 1_{ \{u = v \mbox{ and } i\neq j \}} \mbox{ for $g = (u,i), h = (v,j) \in \vec{E}_1 \cup \vec{E}_2$} .\end{equation*}
We see that a term like
 $M_{eg} N_{gf}$
corresponds to M matching the directed edge e to g by
$M_{eg} N_{gf}$
corresponds to M matching the directed edge e to g by
 $\pi$
, and N taking us out of the vertex of g along the directed edge f, which is different from g. Thus, the rule of matrix multiplication means that
$\pi$
, and N taking us out of the vertex of g along the directed edge f, which is different from g. Thus, the rule of matrix multiplication means that
 \begin{align}B=MN.\end{align}
\begin{align}B=MN.\end{align}
This equality will be useful in Section 5.2 when working with products of the matrix B.
4.2. Tangle-free paths
Sparse random graphs, including bipartite graphs, have the important property of being ‘tree-like’ in the neighbourhood of a typical vertex. Formally, consider a vertex
 $v \in V_1 \cup V_2$
. For a natural number
$v \in V_1 \cup V_2$
. For a natural number
 $\ell$
, we define the ball of radius
$\ell$
, we define the ball of radius
 $\ell$
centered at v to be:
$\ell$
centered at v to be:
 \begin{equation*}B_{\ell}(v) = \{w \in V_1 \cup V_2 : d_{G}(v,w) \leq \ell\}\end{equation*}
\begin{equation*}B_{\ell}(v) = \{w \in V_1 \cup V_2 : d_{G}(v,w) \leq \ell\}\end{equation*}
where
 $d_G(\cdot ,\cdot )$
is the graph distance.
$d_G(\cdot ,\cdot )$
is the graph distance.
Definition 4.1. A graph G is
 $\ell$
-tangle-free if
$\ell$
-tangle-free if
 $B_{\ell}(v)$
contains at most one cycle for any vertex v.
$B_{\ell}(v)$
contains at most one cycle for any vertex v.
The next lemma says that most bipartite biregular graphs are
 $\ell$
-tangle-free up to logarithmic sized neighbourhoods.
$\ell$
-tangle-free up to logarithmic sized neighbourhoods.
Lemma 4.2. Let
 $G \sim \mathcal{G}(n,m,d_1,d_2)$
be a bipartite, biregular random graph. Let
$G \sim \mathcal{G}(n,m,d_1,d_2)$
be a bipartite, biregular random graph. Let
 $\ell < \frac{1}{8} \log_d (n)$
, for
$\ell < \frac{1}{8} \log_d (n)$
, for
 $d=\max\{d_1, d_2\}$
. Then G is
$d=\max\{d_1, d_2\}$
. Then G is
 $\ell$
-tangle-free with probability at least
$\ell$
-tangle-free with probability at least
 $1-n^{-1/2}$
.
$1-n^{-1/2}$
.
Proof. This is essentially the proof given in [Reference Lubetzky and Sly47], Lemma 2.1. Fix a vertex v. We will use the so called exploration process to discover the ball
 $B_{\ell}(v)$
. More precisely, we order the set
$B_{\ell}(v)$
. More precisely, we order the set
 $\vec{E}_1$
lexicographically:
$\vec{E}_1$
lexicographically:
 $(v_i,j) < (v_{i'},j')$
if
$(v_i,j) < (v_{i'},j')$
if
 $i\leq i'$
and
$i\leq i'$
and
 $j\leq j'$
. The exploration process reveals
$j\leq j'$
. The exploration process reveals
 $\pi$
one edge at the time, by doing the following:
$\pi$
one edge at the time, by doing the following:
-
A uniform element is chosen from
$\vec{E}_2$
, and it is declared equal to
$\pi(1)$
. -
A second element is chosen uniformly, now from the set
$\vec{E}_2\backslash\{\pi(1)\}$
and set equal to
$\pi(2)$
. -
Once we have determined
$\pi(i)$
for
$i\leq k$
, we set
$\pi(k+1)$
equal to a uniform element sampled from the set
$\vec{E}_2\backslash\{\pi(1),\pi(2),\dots,\pi(k)\}$
.








We use the final
 $\pi$
to output a graph as we did in the configuration model. The law of these graphs is the same. With the exploration process, we expose first the neighbours of v, then the neighbours of these vertices, and so on. This breadth-first search reveals all vertices in
$\pi$
to output a graph as we did in the configuration model. The law of these graphs is the same. With the exploration process, we expose first the neighbours of v, then the neighbours of these vertices, and so on. This breadth-first search reveals all vertices in
 $B_k (v)$
before any vertices in
$B_k (v)$
before any vertices in
 $B_{j > k} (v)$
. Note that, although our bound is for the family
$B_{j > k} (v)$
. Note that, although our bound is for the family
 $\mathcal{G}(n,m,d_1,d_2)$
, the neighbourhood sizes are bounded above by those of the d-regular graph with
$\mathcal{G}(n,m,d_1,d_2)$
, the neighbourhood sizes are bounded above by those of the d-regular graph with
 $d=\max(d_1,d_2)$
.
$d=\max(d_1,d_2)$
.
Consider the matching of half edges attached to vertices in the ball
 $B_i(v)$
at depth i (thus revealing vertices at depth
$B_i(v)$
at depth i (thus revealing vertices at depth
 $i+1$
). In this process, we match a maximum
$i+1$
). In this process, we match a maximum
 $m_i \leq d^{i+1}$
pairs of half edges total. Let
$m_i \leq d^{i+1}$
pairs of half edges total. Let
 $\mathcal{F}_{i,k}$
be the filtration generated by matching up to the kth half edge in
$\mathcal{F}_{i,k}$
be the filtration generated by matching up to the kth half edge in
 $B_i(v)$
, for
$B_i(v)$
, for
 $1 \leq k \leq m_i$
. Denote by
$1 \leq k \leq m_i$
. Denote by
 $A_{i,k}$
the event that the kth matching creates a cycle at the current depth. For this to happen, the matched vertex must have appeared among the
$A_{i,k}$
the event that the kth matching creates a cycle at the current depth. For this to happen, the matched vertex must have appeared among the
 $k-1$
vertices already revealed at depth
$k-1$
vertices already revealed at depth
 $i+1$
. The number of unmatched half edges is at least
$i+1$
. The number of unmatched half edges is at least
 $nd - 2 d^{i+1}$
. We then have that:
$nd - 2 d^{i+1}$
. We then have that:
 \begin{equation*}\mathbb{P}(A_{i,k})\leq \frac{(k-1) (d-1)}{nd - 2 d^{i+1}}\leq \frac{(d-1) m_i}{(1 - 2 d^{i+1} n^{-1}) nd}\leq \frac{m_i}{n}.\end{equation*}
\begin{equation*}\mathbb{P}(A_{i,k})\leq \frac{(k-1) (d-1)}{nd - 2 d^{i+1}}\leq \frac{(d-1) m_i}{(1 - 2 d^{i+1} n^{-1}) nd}\leq \frac{m_i}{n}.\end{equation*}
So, we can stochastically dominate the sum
 \begin{equation*}\sum_{i=1}^{\ell-1}\sum_{k=1}^{m_i} A_{i,k}\end{equation*}
\begin{equation*}\sum_{i=1}^{\ell-1}\sum_{k=1}^{m_i} A_{i,k}\end{equation*}
by
 $Z \sim \textrm{Bin} \left( d^{\ell+1},\ n^{-1} d^{\ell} \right)$
. So the probability that
$Z \sim \textrm{Bin} \left( d^{\ell+1},\ n^{-1} d^{\ell} \right)$
. So the probability that
 $B_{\ell}(v)$
is
$B_{\ell}(v)$
is
 $\ell$
-tangle-free has the bound:
$\ell$
-tangle-free has the bound:
 \begin{equation*}\mathbb{P} ( \mbox{$B_{\ell}(v)$ is not $\ell$-tangle-free} ) =\mathbb{P} \left( \sum_{i=1}^{\ell-1}\sum_{k=1}^{m_i} A_{i,k}> 1 \right) \leq \mathbb{P} (Z>1) =O\left( \frac{d^{4\ell+1}}{n^2} \right) =O\left( n^{-3/2} \right) ,\end{equation*}
\begin{equation*}\mathbb{P} ( \mbox{$B_{\ell}(v)$ is not $\ell$-tangle-free} ) =\mathbb{P} \left( \sum_{i=1}^{\ell-1}\sum_{k=1}^{m_i} A_{i,k}> 1 \right) \leq \mathbb{P} (Z>1) =O\left( \frac{d^{4\ell+1}}{n^2} \right) =O\left( n^{-3/2} \right) ,\end{equation*}
which follows using that
 $\ell = c \log_d n$
with
$\ell = c \log_d n$
with
 $c < 1/8$
. The Lemma follows by taking a union bound over all vertices.
$c < 1/8$
. The Lemma follows by taking a union bound over all vertices.
5. Proof of Theorem 3.1
5.1. Outline
We are now prepared to explain the main result. To study the second largest eigenvalue of the non-backtracking matrix, we examine the spectral radius of the matrix obtained by subtracting off the dominant eigenspace. We use for this:
Lemma 5.1
([Reference Bordenave, Lelarge and Massoulié14], Lemma 3). Let T and R be matrices such that
 $\textrm{Im}(T)\subset \textrm{Ker}(R)$
,
$\textrm{Im}(T)\subset \textrm{Ker}(R)$
,
 $\textrm{Im}(T^*)\subset \textrm{Ker}(R)$
. Then all eigenvalues
$\textrm{Im}(T^*)\subset \textrm{Ker}(R)$
. Then all eigenvalues
 $\lambda$
of
$\lambda$
of
 $T+R$
that are not eigenvalues of T satisfy:
$T+R$
that are not eigenvalues of T satisfy:
 \begin{equation*}|\lambda|\leq \max_{x\in \textrm{Ker}(T)}\frac{\|(T+R)x\|}{\|x\|} .\end{equation*}
\begin{equation*}|\lambda|\leq \max_{x\in \textrm{Ker}(T)}\frac{\|(T+R)x\|}{\|x\|} .\end{equation*}
Throughout the text,
 $\| \cdot \|$
is the spectral norm for matrices and
$\| \cdot \|$
is the spectral norm for matrices and
 $\ell^2$
-norm for vectors. Recall that the leading eigenvalues of B, in magnitude, are
$\ell^2$
-norm for vectors. Recall that the leading eigenvalues of B, in magnitude, are
 $\lambda_1 = \sqrt{(d_1 -1)(d_2-1)}$
and
$\lambda_1 = \sqrt{(d_1 -1)(d_2-1)}$
and
 $\lambda_{2|E|} = -\lambda_1$
with corresponding eigenvectors
$\lambda_{2|E|} = -\lambda_1$
with corresponding eigenvectors
 $\textbf{1}_{\alpha}$
and
$\textbf{1}_{\alpha}$
and
 $\textbf{1}_{-\alpha}$
. Applying Lemma 5.1 with
$\textbf{1}_{-\alpha}$
. Applying Lemma 5.1 with
 $T=\frac{\lambda_1^{\ell}}{\textbf{1}_{\alpha}^* \textbf{1}_{\alpha}}(\textbf{1}_{\alpha} \textbf{1}_{\alpha}^* +(-1)^\ell \textbf{1}_{-\alpha} \textbf{1}_{-\alpha}^*)$
and
$T=\frac{\lambda_1^{\ell}}{\textbf{1}_{\alpha}^* \textbf{1}_{\alpha}}(\textbf{1}_{\alpha} \textbf{1}_{\alpha}^* +(-1)^\ell \textbf{1}_{-\alpha} \textbf{1}_{-\alpha}^*)$
and
 $R = B^\ell - T$
, we get that
$R = B^\ell - T$
, we get that
 \begin{align}\lambda_2(B)\leq \max_{\begin{array}{c}x \in \textrm{Ker}(T) \\\|x\| = 1\end{array}}\left( \| B^{\ell}x \| \right)^{1/\ell}.\end{align}
\begin{align}\lambda_2(B)\leq \max_{\begin{array}{c}x \in \textrm{Ker}(T) \\\|x\| = 1\end{array}}\left( \| B^{\ell}x \| \right)^{1/\ell}.\end{align}
It will be important later to have a more precise description of the set
 $\textrm{Ker}(T)$
. It is not hard to check that
$\textrm{Ker}(T)$
. It is not hard to check that
 \begin{align*}\textrm{Ker}(T) &= \{x: \langle x, \textbf{1}_{\alpha} \rangle = \langle x, \textbf{1}_{-\alpha} \rangle=0\} \\& =\{(v,w)\in \mathbb{R}^{2|E|}: \langle v, \textbf{1} \rangle = \langle w, \textbf{1} \rangle=0\}.\end{align*}
\begin{align*}\textrm{Ker}(T) &= \{x: \langle x, \textbf{1}_{\alpha} \rangle = \langle x, \textbf{1}_{-\alpha} \rangle=0\} \\& =\{(v,w)\in \mathbb{R}^{2|E|}: \langle v, \textbf{1} \rangle = \langle w, \textbf{1} \rangle=0\}.\end{align*}
In the last line, the vectors v, w and
 $\textbf{1}$
are
$\textbf{1}$
are
 $|E|-$
dimensional, and
$|E|-$
dimensional, and
 $\textbf{1}$
is the vector of all ones.
$\textbf{1}$
is the vector of all ones.
In order to use equation (10), we must bound
 $\| B^\ell x \|$
for large powers
$\| B^\ell x \|$
for large powers
 $\ell$
and
$\ell$
and
 $x \in \textrm{Ker}(T)$
. This amounts to counting the contributions of certain non-backtracking walks. We will use the tangle-free property in order to only count
$x \in \textrm{Ker}(T)$
. This amounts to counting the contributions of certain non-backtracking walks. We will use the tangle-free property in order to only count
 $\ell$
-tangle-free walks. We break up
$\ell$
-tangle-free walks. We break up
 $B^\ell$
into two parts in Section 5.2, an ‘almost’ centered matrix
$B^\ell$
into two parts in Section 5.2, an ‘almost’ centered matrix
 $\bar{B}^\ell$
and the remainder
$\bar{B}^\ell$
and the remainder
 $\sum_j R^{\ell,j}$
and we bound each term independently.
$\sum_j R^{\ell,j}$
and we bound each term independently.
To compute these bounds, we need to count the contributions of many different non-backtracking walks. We will use the trace technique, so only circuits which return to the starting vertex will contribute. In Section 5.3, we compute the expected contribution of products of B along such circuits, employing a result from [Reference Bordenave12].
Section 5.4 covers the combinatorial component of the proof. The total contributions
 $\| B^\ell x \|$
come from many non-backtracking circuits of different flavours, depending on their number of vertices, edges, cycles, etc. Each circuit is broken up into 2k segments of tangle-free walks of length
$\| B^\ell x \|$
come from many non-backtracking circuits of different flavours, depending on their number of vertices, edges, cycles, etc. Each circuit is broken up into 2k segments of tangle-free walks of length
 $\ell$
. We need to compute not only the expectation along the circuit, but also upper-bound the number of circuits of each flavor. We introduce an injective encoding of such circuits that depends on the number of vertices, length of the circuit, and, crucially, the tree excess of the circuit. An important part of these calculations is to keep track of the imbalance between left and right vertices visited in the circuit, since this controls the powers of
$\ell$
. We need to compute not only the expectation along the circuit, but also upper-bound the number of circuits of each flavor. We introduce an injective encoding of such circuits that depends on the number of vertices, length of the circuit, and, crucially, the tree excess of the circuit. An important part of these calculations is to keep track of the imbalance between left and right vertices visited in the circuit, since this controls the powers of
 $d_1$
and
$d_1$
and
 $d_2$
in the result.
$d_2$
in the result.
Finally, in Section 5.8, we put all of these ingredients together and use Markov’s inequality to bound each matrix norm with high probability. We find that
 $\| \bar{B}^\ell \|$
contributes a factor that goes as
$\| \bar{B}^\ell \|$
contributes a factor that goes as
 $((d_1 - 1)(d_2 - 1))^{\ell/4}$
, whereas
$((d_1 - 1)(d_2 - 1))^{\ell/4}$
, whereas
 $\| R^{\ell,j} \|$
contributes only a factor of
$\| R^{\ell,j} \|$
contributes only a factor of
 $(d-1)^\ell/n$
, up to polylogarithmic factors in n. Thus, the main contribution to the circuit counts comes from the mean and, in fact, comes from circuits which are exactly trees traversed forwards and backwards. Interestingly, this is analogous to what happens when using the trace method on random matrices of independent entries.
$(d-1)^\ell/n$
, up to polylogarithmic factors in n. Thus, the main contribution to the circuit counts comes from the mean and, in fact, comes from circuits which are exactly trees traversed forwards and backwards. Interestingly, this is analogous to what happens when using the trace method on random matrices of independent entries.
In the proof, we are forced to consider tangled paths but which are built up of tangle-free components. This delicate issue was first made clear by [Reference Friedman28] who introduced the idea of tangles and a ‘selective trace.’ Bordenave et al. [Reference Bordenave, Lelarge and Massoulié14], who we follow closely in this part of our analysis, also has a good discussion of these issues and their history. We use the fact that
 \begin{equation}\mathbb{E}\left(\|\bar{B}^{\ell}\|^{2k}\right)\leq \mathbb{E}\left(\textrm{Tr}\left[\left( (\bar{B}^{\ell}) (\bar{B}^{\ell})^* \right)^{k}\right]\right),\end{equation}
\begin{equation}\mathbb{E}\left(\|\bar{B}^{\ell}\|^{2k}\right)\leq \mathbb{E}\left(\textrm{Tr}\left[\left( (\bar{B}^{\ell}) (\bar{B}^{\ell})^* \right)^{k}\right]\right),\end{equation}
and so deal with circuits built up of 2k segments which are
 $\ell$
-tangle-free. Notice that the first segment comes from
$\ell$
-tangle-free. Notice that the first segment comes from
 $\bar{B}^\ell$
, the second from
$\bar{B}^\ell$
, the second from
 $(\bar{B}^{\ell})^*$
, etc. Because of this, the directionality of the edges along each segment alternates. See Figure 4 for an illustration of a path which contributes for
$(\bar{B}^{\ell})^*$
, etc. Because of this, the directionality of the edges along each segment alternates. See Figure 4 for an illustration of a path which contributes for
 $k=2$
and
$k=2$
and
 $\ell=2$
. Also, while each segment is
$\ell=2$
. Also, while each segment is
 $\ell$
-tangle-free, the overall circuit may be tangled.
$\ell$
-tangle-free, the overall circuit may be tangled.

Figure 4. An example circuit that contributes to the trace in equation (11), for
 $k = 2$
and
$k = 2$
and
 $\ell = 2$
. Edges are numbered as they occur in the circuit. Each segment
$\ell = 2$
. Edges are numbered as they occur in the circuit. Each segment
 $\{ \gamma_i \}_{i=1}^4$
is of length
$\{ \gamma_i \}_{i=1}^4$
is of length
 $\ell + 1 = 3$
and made up of edges
$\ell + 1 = 3$
and made up of edges
 $3(i-1)+1$
through 3i. The last edge of each
$3(i-1)+1$
through 3i. The last edge of each
 $\gamma_i$
is the first edge of
$\gamma_i$
is the first edge of
 $\gamma_{i+1}$
, and these are shown in purple. Every path
$\gamma_{i+1}$
, and these are shown in purple. Every path
 $\gamma_{i}$
with i even follows the edges backwards due to the matrix transpose. However, this detail turns out not to make any difference since the underlying graph is undirected. Our example has no cycles in each segment for clarity, but, in general, each segment can have up to one cycle, and the overall circuit may be tangled.
$\gamma_{i}$
with i even follows the edges backwards due to the matrix transpose. However, this detail turns out not to make any difference since the underlying graph is undirected. Our example has no cycles in each segment for clarity, but, in general, each segment can have up to one cycle, and the overall circuit may be tangled.
5.2. Matrix decomposition
We start this section by defining the set of paths that will be relevant to bound the norm of
 $\|\bar{B}^{\ell}\|$
. We closely follow [Reference Bordenave12].
$\|\bar{B}^{\ell}\|$
. We closely follow [Reference Bordenave12].
Definition 5.2. Define
 $\Gamma^{\ell}_{ef}$
to be the set of all non-backtracking paths of
$\Gamma^{\ell}_{ef}$
to be the set of all non-backtracking paths of
 $2\ell+1$
half edges, starting at e and ending at f. A path in this set will be denoted by
$2\ell+1$
half edges, starting at e and ending at f. A path in this set will be denoted by
 $\gamma= (e_1,e_2,\dots,e_{2\ell},e_{2\ell+1})$
, where
$\gamma= (e_1,e_2,\dots,e_{2\ell},e_{2\ell+1})$
, where
 $e_1 = e$
and
$e_1 = e$
and
 $e_{2\ell + 1} = f$
. The non-backtracking property means that, for all
$e_{2\ell + 1} = f$
. The non-backtracking property means that, for all
 $1\leq i\leq \ell$
,
$1\leq i\leq \ell$
,
 $e_{2i}$
and
$e_{2i}$
and
 $e_{2i+1}$
share the same vertex but
$e_{2i+1}$
share the same vertex but
 $e_{2i}\neq e_{2i+1}$
. Similarly, let
$e_{2i}\neq e_{2i+1}$
. Similarly, let
 $\Gamma^\ell = \bigcup_{e,f} \Gamma^\ell_{ef}$
.
$\Gamma^\ell = \bigcup_{e,f} \Gamma^\ell_{ef}$
.
Each path in
 $\Gamma^\ell_{ef}$
uses
$\Gamma^\ell_{ef}$
uses
 $2 \ell + 1$
half edges, corresponding to
$2 \ell + 1$
half edges, corresponding to
 $\ell + 1$
edges in the graph. To be clear, the above definition counts all possible non-backtracking sequences of half edges. These are different than the usual non-backtracking paths and do not necessarily exist in the graph. Some of these paths might backtrack along a duplicate edge which utilizes a different half edge.
$\ell + 1$
edges in the graph. To be clear, the above definition counts all possible non-backtracking sequences of half edges. These are different than the usual non-backtracking paths and do not necessarily exist in the graph. Some of these paths might backtrack along a duplicate edge which utilizes a different half edge.
We now have
 \begin{equation}(B^{\ell})_{ef} =\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} B_{e_{2t-1} e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} M_{e_{2t-1} e_{2t}}N_{e_{2t}e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} M_{e_{2t-1} e_{2t}}\end{equation}
\begin{equation}(B^{\ell})_{ef} =\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} B_{e_{2t-1} e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} M_{e_{2t-1} e_{2t}}N_{e_{2t}e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell} M_{e_{2t-1} e_{2t}}\end{equation}
where we used equation (9) and the fact that
 $\Gamma^{\ell}_{ef}$
is non-backtracking, so
$\Gamma^{\ell}_{ef}$
is non-backtracking, so
 $N_{e_{2t}e_{2t+1}}=1$
.
$N_{e_{2t}e_{2t+1}}=1$
.
Recall that we will use equation (10) and Lemma 5.1 to bound
 $\lambda_2$
. Denote by
$\lambda_2$
. Denote by
 $\bar{B}$
the matrix with entries equal to
$\bar{B}$
the matrix with entries equal to
 $\bar{B} = B - S$
, where
$\bar{B} = B - S$
, where
 \begin{equation*} S = \frac{1}{|E|} \left( \begin{array}{c@{\quad}c} 0 & (d_2 - 1) \textbf{1} \textbf{1}^* \\[4pt]
(d_1 - 1) \textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
\begin{equation*} S = \frac{1}{|E|} \left( \begin{array}{c@{\quad}c} 0 & (d_2 - 1) \textbf{1} \textbf{1}^* \\[4pt]
(d_1 - 1) \textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
Note that
 $\bar{B}$
is an almost centred version of B, and
$\bar{B}$
is an almost centred version of B, and
 $\textrm{Ker} ( S ) = \textrm{Ker}(T) = \textrm{span} (\textbf{1}_{\alpha}, \textbf{1}_{-\alpha} ) $
, where T is the matrix from Lemma 5.1. To apply the lemma, we wish to get an expression like equation (12) for
$\textrm{Ker} ( S ) = \textrm{Ker}(T) = \textrm{span} (\textbf{1}_{\alpha}, \textbf{1}_{-\alpha} ) $
, where T is the matrix from Lemma 5.1. To apply the lemma, we wish to get an expression like equation (12) for
 $\bar{B}^{\ell}$
. To do so, we write:
$\bar{B}^{\ell}$
. To do so, we write:
 \begin{equation*}\bar{B} = B - S = M N - S = (M - S') N\end{equation*}
\begin{equation*}\bar{B} = B - S = M N - S = (M - S') N\end{equation*}
the above matrix equation in the unknown S’ can be solved by simple manipulations. We get
 \begin{equation*}S'=\frac{1}{|E|} \left( \begin{array}{c@{\quad}c} 0 & \textbf{1} \textbf{1}^* \\[4pt]
\textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
\begin{equation*}S'=\frac{1}{|E|} \left( \begin{array}{c@{\quad}c} 0 & \textbf{1} \textbf{1}^* \\[4pt]
\textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
Using again that N is identically one over the elements of the set
 $\Gamma^{\ell}_{ef}$
, we find a similar formula to equation (12):
$\Gamma^{\ell}_{ef}$
, we find a similar formula to equation (12):
 \begin{align}(\bar{B}^\ell)_{ef}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell}\left( B - S \right)_{e_{2t-1} e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell}\bar{M}_{e_{2t-1} e_{2t}},\end{align}
\begin{align}(\bar{B}^\ell)_{ef}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell}\left( B - S \right)_{e_{2t-1} e_{2t+1}}=\sum_{\gamma \in \Gamma^\ell_{ef}}\prod_{t=1}^{\ell}\bar{M}_{e_{2t-1} e_{2t}},\end{align}
where
 $\bar{M}=M-S'$
.
$\bar{M}=M-S'$
.
The following telescoping sum formula is a simple algebraic manipulation and appears in [Reference Massoulie50] and [Reference Bordenave, Lelarge and Massoulié14]:
 \begin{equation*}\prod_{s=1}^\ell x_s = \prod_{s=1}^\ell y_s +\sum_{j=1}^\ell \prod_{s=1}^{j-1} y_s (x_j - y_j) \prod_{t=j+1}^\ell x_t .\end{equation*}
\begin{equation*}\prod_{s=1}^\ell x_s = \prod_{s=1}^\ell y_s +\sum_{j=1}^\ell \prod_{s=1}^{j-1} y_s (x_j - y_j) \prod_{t=j+1}^\ell x_t .\end{equation*}
Using this, with
 $x_s = B_{e_{2s-1} e_{2s+1}}$
and
$x_s = B_{e_{2s-1} e_{2s+1}}$
and
 $y_s = \bar{B}_{e_{2s-1} e_{2s+1}}$
, we obtain the following relation:
$y_s = \bar{B}_{e_{2s-1} e_{2s+1}}$
, we obtain the following relation:
 \begin{align}( B^{\ell} )_{ef}=( \bar{B}^{\ell} )_{ef}+\sum_{\gamma\in \Gamma^{\ell}_{ef}}\sum_{j=1}^{\ell}\prod_{s=1}^{j-1} \bar{B}_{e_{2s-1} e_{2s+1}}S_{e_{2j-1} e_{2j+1}}\prod_{t=j+1}^{\ell} B_{e_{2t-1} e_{2t+1}}.\end{align}
\begin{align}( B^{\ell} )_{ef}=( \bar{B}^{\ell} )_{ef}+\sum_{\gamma\in \Gamma^{\ell}_{ef}}\sum_{j=1}^{\ell}\prod_{s=1}^{j-1} \bar{B}_{e_{2s-1} e_{2s+1}}S_{e_{2j-1} e_{2j+1}}\prod_{t=j+1}^{\ell} B_{e_{2t-1} e_{2t+1}}.\end{align}
This decomposition breaks the elements in
 $\Gamma^{\ell}_{ef}$
into two subpaths, also non-backtracking, of length j and
$\Gamma^{\ell}_{ef}$
into two subpaths, also non-backtracking, of length j and
 $\ell-j$
, respectively.
$\ell-j$
, respectively.
Definition 5.3. Let
 $F_{ef}^\ell \subset \Gamma^\ell_{ef}$
denote the subset of paths which are tangle-free, with
$F_{ef}^\ell \subset \Gamma^\ell_{ef}$
denote the subset of paths which are tangle-free, with
 $F^\ell = \bigcup_{e,f} F^\ell_{ef}$
.
$F^\ell = \bigcup_{e,f} F^\ell_{ef}$
.
We will take the parameter
 $\ell$
to be small enough so that the path
$\ell$
to be small enough so that the path
 $\gamma$
is tangle-free with high probability. Thus, the sums in equations (12) or (13) need only be over the paths
$\gamma$
is tangle-free with high probability. Thus, the sums in equations (12) or (13) need only be over the paths
 $\gamma \in F_{ef}^\ell$
. However, to recover the matrices B and
$\gamma \in F_{ef}^\ell$
. However, to recover the matrices B and
 $\bar{B}$
by rearranging equation (14), we need to also count those tangle-free subpaths that arise from splitting tangled paths. While breaking a tangle-free path will necessarily give us two new tangle-free subpaths, the converse is not always true. This extra term generates a remainder that we define now.
$\bar{B}$
by rearranging equation (14), we need to also count those tangle-free subpaths that arise from splitting tangled paths. While breaking a tangle-free path will necessarily give us two new tangle-free subpaths, the converse is not always true. This extra term generates a remainder that we define now.
Definition 5.4. Let
 $T^{\ell,j}_{ef}$
be the set of non-backtracking paths containing
$T^{\ell,j}_{ef}$
be the set of non-backtracking paths containing
 $2\ell+1$
half edges, starting at e and ending at f, such that overall the path is tangled but the first
$2\ell+1$
half edges, starting at e and ending at f, such that overall the path is tangled but the first
 $2j-1$
, middle three, and last
$2j-1$
, middle three, and last
 $2(\ell - j)+1$
half edges form tangle-free subpaths:
$2(\ell - j)+1$
half edges form tangle-free subpaths:
 $\gamma = (e_1, \ldots, e_{2\ell + 1}) \in T^{\ell,j}$
if and only if
$\gamma = (e_1, \ldots, e_{2\ell + 1}) \in T^{\ell,j}$
if and only if
 $\gamma' = (e_1, \ldots, e_{2j-1}) \in F^{j-1}$
,
$\gamma' = (e_1, \ldots, e_{2j-1}) \in F^{j-1}$
,
 $\gamma'' = (e_{2j-1}, e_{2j}, e_{2j+1}) \in F^{1}$
, and
$\gamma'' = (e_{2j-1}, e_{2j}, e_{2j+1}) \in F^{1}$
, and
 $\gamma''' = (e_{2j+1}, \ldots, e_{2\ell + 1}) \in F^{\ell - j}$
. Set
$\gamma''' = (e_{2j+1}, \ldots, e_{2\ell + 1}) \in F^{\ell - j}$
. Set
 $T^{\ell,j} = \bigcup_{e,f} T^{\ell,j}_{ef}$
.
$T^{\ell,j} = \bigcup_{e,f} T^{\ell,j}_{ef}$
.
Set the remainder
 \begin{align} R^{\ell,j}_{ef} &= \sum_{\gamma\in T^{\ell,j}_{ef}} \sum_{j=1}^{\ell} \prod_{s=1}^{j-1} \bar{B}_{e_{2s-1} e_{2s+1}} S_{e_{2j-1} e_{2j+1}} \prod_{t=j+1}^{\ell} B_{e_{2t-1} e_{2t+1}} \nonumber \\ &= \sum_{\gamma\in T^{\ell,j}_{ef}} \sum_{j=1}^{\ell} \prod_{s=1}^{j-1}\ \bar{M}_{e_{2s-1} e_{2s}} S_{e_{2j-1} e_{2j+1}} \prod_{t=j+1}^{\ell} M_{e_{2t-1} e_{2t}}.\end{align}
\begin{align} R^{\ell,j}_{ef} &= \sum_{\gamma\in T^{\ell,j}_{ef}} \sum_{j=1}^{\ell} \prod_{s=1}^{j-1} \bar{B}_{e_{2s-1} e_{2s+1}} S_{e_{2j-1} e_{2j+1}} \prod_{t=j+1}^{\ell} B_{e_{2t-1} e_{2t+1}} \nonumber \\ &= \sum_{\gamma\in T^{\ell,j}_{ef}} \sum_{j=1}^{\ell} \prod_{s=1}^{j-1}\ \bar{M}_{e_{2s-1} e_{2s}} S_{e_{2j-1} e_{2j+1}} \prod_{t=j+1}^{\ell} M_{e_{2t-1} e_{2t}}.\end{align}
Since the paths are non-backtracking, the N terms are all unity.
Adding and subtracting
 $\sum_{j=1}^{\ell} R^{\ell,j}_{ef}$
to equation (14) and rearranging the sums, we obtain
$\sum_{j=1}^{\ell} R^{\ell,j}_{ef}$
to equation (14) and rearranging the sums, we obtain
 \begin{align}B^{(\ell)} =\bar{B}^{(\ell)} +\sum_{j=1}^{\ell}\bar{B}^{(j)} S B^{(\ell-j)}-\sum_{j=1}^{\ell} R^{\ell,j},\end{align}
\begin{align}B^{(\ell)} =\bar{B}^{(\ell)} +\sum_{j=1}^{\ell}\bar{B}^{(j)} S B^{(\ell-j)}-\sum_{j=1}^{\ell} R^{\ell,j},\end{align}
where the matrices
 $B^{(\ell)}$
and
$B^{(\ell)}$
and
 $\bar{B}^{(\ell)}$
are tangle-free versions of
$\bar{B}^{(\ell)}$
are tangle-free versions of
 $B^\ell$
and
$B^\ell$
and
 $\bar{B}^\ell$
, i.e. element ef in both matrices only counts paths
$\bar{B}^\ell$
, i.e. element ef in both matrices only counts paths
 $\gamma \in F_{ef}^\ell$
. Multiplying equation (16) on the right by
$\gamma \in F_{ef}^\ell$
. Multiplying equation (16) on the right by
 $x \in \textrm{Ker} (T)$
and using that
$x \in \textrm{Ker} (T)$
and using that
 $B^{(\ell - j)} x$
is also within
$B^{(\ell - j)} x$
is also within
 $\textrm{Ker}(S)$
, since it is just the space spanned by the leading eigenvectors, we find that the middle term is identically zero. Thus, for
$\textrm{Ker}(S)$
, since it is just the space spanned by the leading eigenvectors, we find that the middle term is identically zero. Thus, for
 $x \in \textrm{Ker}(T)$
,
$x \in \textrm{Ker}(T)$
,
 \begin{equation}\| B^{(\ell)}x \|\leq \| \bar{B}^{(\ell)} x \|+\left\|\sum_{j=1}^{\ell}R^{\ell,j} x\right\|\leq \| \bar{B}^{(\ell)} \|+\sum_{j=1}^{\ell} \| R^{\ell,j} \| .\end{equation}
\begin{equation}\| B^{(\ell)}x \|\leq \| \bar{B}^{(\ell)} x \|+\left\|\sum_{j=1}^{\ell}R^{\ell,j} x\right\|\leq \| \bar{B}^{(\ell)} \|+\sum_{j=1}^{\ell} \| R^{\ell,j} \| .\end{equation}
5.3 Expectation bounds
Our goal is to find a bound on the expectation of certain random variables which are products of
 $\bar{B}_{ef}$
along a circuit. To do this, we will need to bound the probabilities of different subgraphs when exploring G. This requires us to introduce the concept of consistent edges and their multiplicity.
$\bar{B}_{ef}$
along a circuit. To do this, we will need to bound the probabilities of different subgraphs when exploring G. This requires us to introduce the concept of consistent edges and their multiplicity.
Definition 5.5. Let
 $\gamma = (e_1, \ldots, e_{2k})$
be a sequence of half edges of even length, with
$\gamma = (e_1, \ldots, e_{2k})$
be a sequence of half edges of even length, with
 $\vec{E}(\gamma)$
its set of half edges, and
$\vec{E}(\gamma)$
its set of half edges, and
 $E(\gamma) = \{ \{e_{2i-1}, e_{2i}\}\ for\ i [k]\} $
its set of edges (unordered pairs, thus undirected).
$E(\gamma) = \{ \{e_{2i-1}, e_{2i}\}\ for\ i [k]\} $
its set of edges (unordered pairs, thus undirected).
-
The multiplicity of a half edge
$e \in \vec{E}(\gamma)$
is
$m_\gamma(e) = \sum_{t=1}^{2k} 1_{\{ e_t = e \}}$
. -
The multiplicity of an edge
$\{h_1, h_2\} \in E(\gamma)$
, is
$m_\gamma(\{h_1,h_2\}) = \sum_{t=1}^k 1_{\{ \{e_{2t-1}, e_{2t}\} = \{h_1, h_2\} \}}$
. -
An edge
$\{h_1, h_2\}$
is consistent if
$m_\gamma(h_1) = m_\gamma(h_2) = m_\gamma(\{h_1, h_2\})$
.






Lemma 5.6. Let
 $\gamma = (e_1, \ldots, e_{2k})$
be a sequence of half edges of even length, with M and
$\gamma = (e_1, \ldots, e_{2k})$
be a sequence of half edges of even length, with M and
 $\bar{M}$
the matching matrix and its centred version generated by a uniform matching in the configuration model. Then for
$\bar{M}$
the matching matrix and its centred version generated by a uniform matching in the configuration model. Then for
 $1 \leq k \leq \sqrt{|E|}$
and
$1 \leq k \leq \sqrt{|E|}$
and
 $0 \leq t_0 \leq k$
we have that
$0 \leq t_0 \leq k$
we have that
 \begin{equation*}\left|\mathbb{E}\prod_{t=1}^{t_0} \bar{M}_{e_{2t - 1} e_{2t}}\prod_{t=t_0+1}^{k} M_{e_{2t - 1} e_{2t}}\right|\leq C \cdot 2^b \cdot \left( \frac{1}{|E|} \right)^\mathcal{E}\left( \frac{3 k}{\sqrt{|E|}} \right)^{\mathcal{E}_1}\end{equation*}
\begin{equation*}\left|\mathbb{E}\prod_{t=1}^{t_0} \bar{M}_{e_{2t - 1} e_{2t}}\prod_{t=t_0+1}^{k} M_{e_{2t - 1} e_{2t}}\right|\leq C \cdot 2^b \cdot \left( \frac{1}{|E|} \right)^\mathcal{E}\left( \frac{3 k}{\sqrt{|E|}} \right)^{\mathcal{E}_1}\end{equation*}
where
 $b = $
number of inconsistent edges of multiplicity one occurring before
$b = $
number of inconsistent edges of multiplicity one occurring before
 $t_0$
,
$t_0$
,
 $\mathcal{E}_1 = $
number of consistent edges with multiplicity one occurring before
$\mathcal{E}_1 = $
number of consistent edges with multiplicity one occurring before
 $t_0$
,
$t_0$
,
 $\mathcal{E} = |E(\gamma)|$
, and C is a universal constant.
$\mathcal{E} = |E(\gamma)|$
, and C is a universal constant.
Proof. Recall the form of the matrices
 \begin{equation*} M = \left( \begin{array}{c@{\quad}c} 0 & M_1 \\[4pt]
M_1^* & 0 \end{array} \right ) \quad \mbox{and} \quad \bar{M} = M - \frac{1}{|E|} \left( \begin{array}{cc} 0 & \textbf{1} \textbf{1}^* \\[4pt]
\textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
\begin{equation*} M = \left( \begin{array}{c@{\quad}c} 0 & M_1 \\[4pt]
M_1^* & 0 \end{array} \right ) \quad \mbox{and} \quad \bar{M} = M - \frac{1}{|E|} \left( \begin{array}{cc} 0 & \textbf{1} \textbf{1}^* \\[4pt]
\textbf{1} \textbf{1}^* & 0 \end{array} \right ).\end{equation*}
Matrix
 $M_1 \in \mathbb{R}^{|E| \times |E|}$
is a random permutation matrix between
$M_1 \in \mathbb{R}^{|E| \times |E|}$
is a random permutation matrix between
 $n d_1 = |E|$
and
$n d_1 = |E|$
and
 $m d_2 = |E|$
half edges. Therefore,
$m d_2 = |E|$
half edges. Therefore,
 $M_1$
is distributed exactly the same as a matching matrix of a random
$M_1$
is distributed exactly the same as a matching matrix of a random
 $|E|$
-lift of a single edge, and the same holds for its centered version
$|E|$
-lift of a single edge, and the same holds for its centered version
 $M_1 - \frac{1}{|E|} \textbf{1} \textbf{1}^*$
. The only paths
$M_1 - \frac{1}{|E|} \textbf{1} \textbf{1}^*$
. The only paths
 $\gamma$
that contribute in this bipartite setting must alternate between the bipartite sets and avoid the 0 blocks, otherwise the bound holds trivially. For one of these paths
$\gamma$
that contribute in this bipartite setting must alternate between the bipartite sets and avoid the 0 blocks, otherwise the bound holds trivially. For one of these paths
 $\gamma$
assume, without loss of generality, that the path starts in set
$\gamma$
assume, without loss of generality, that the path starts in set
 $V_1$
. Then define the transformed path
$V_1$
. Then define the transformed path
 $\gamma' = (e^{\prime}_1, \ldots, e^{\prime}_{2k}) = (e_1, e_2, e_4, e_3, e_5, \ldots)$
, i.e. with every other pair in
$\gamma' = (e^{\prime}_1, \ldots, e^{\prime}_{2k}) = (e_1, e_2, e_4, e_3, e_5, \ldots)$
, i.e. with every other pair in
 $\gamma$
in reverse order. Note that
$\gamma$
in reverse order. Note that
 \begin{equation}\prod_{t=1}^{t_0} \bar{M}_{e_{2t - 1} e_{2t}}\prod_{t=t_0+1}^{k} M_{e_{2t - 1} e_{2t}}=\prod_{t=1}^{t_0} (\bar{M}_1)_{e^{\prime}_{2t - 1} e^{\prime}_{2t}}\prod_{t=t_0+1}^{k} (M_1)_{e^{\prime}_{2t - 1} e^{\prime}_{2t}} .\end{equation}
\begin{equation}\prod_{t=1}^{t_0} \bar{M}_{e_{2t - 1} e_{2t}}\prod_{t=t_0+1}^{k} M_{e_{2t - 1} e_{2t}}=\prod_{t=1}^{t_0} (\bar{M}_1)_{e^{\prime}_{2t - 1} e^{\prime}_{2t}}\prod_{t=t_0+1}^{k} (M_1)_{e^{\prime}_{2t - 1} e^{\prime}_{2t}} .\end{equation}
Then the Lemma holds by [Reference Bordenave12], Proposition 28.
5.4. Path counting
This section is devoted to counting the number of ways non-backtracking walks can be concatenated to obtain a circuit as in Section 5.2. We will follow closely the combinatorial analysis used in [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16]. In that paper, the authors needed a similar count for self-avoiding walks. We make the necessary adjustments to our current scenario.
Our goal is to find a reasonable bound for the number of circuits that contribute to the trace bound, equation (11) and shown graphically in Figure 4. Define
 $\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
as those circuits which visit exactly
$\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
as those circuits which visit exactly
 $\mathcal{V} = |V(\gamma)|$
different vertices,
$\mathcal{V} = |V(\gamma)|$
different vertices,
 $\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
$\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
 $\mathcal{E} = |E(\gamma)|$
different edges. Note, these are undirected edges in E(G). This is a set of circuits of length
$\mathcal{E} = |E(\gamma)|$
different edges. Note, these are undirected edges in E(G). This is a set of circuits of length
 $2 k \ell$
obtained as the concatenation of 2k non-backtracking, tangle-free walks of length
$2 k \ell$
obtained as the concatenation of 2k non-backtracking, tangle-free walks of length
 $\ell$
. We denote such a circuit as
$\ell$
. We denote such a circuit as
 $\gamma= ( \gamma_1,\gamma_2,\cdots, \gamma_{2k} )$
, where each
$\gamma= ( \gamma_1,\gamma_2,\cdots, \gamma_{2k} )$
, where each
 $\gamma_j$
is a length
$\gamma_j$
is a length
 $\ell$
walk.
$\ell$
walk.
To bound
 $C_{\mathcal{V}, \mathcal{E}}^\mathcal{R} = | \mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R} |$
, we will first choose the set of vertices and order them. The circuits that contribute are indeed directed non-backtracking walks. However, by considering undirected walks along a fixed ordering of vertices, that ordering sets the orientation of the first and thus the rest of the directed edges in
$C_{\mathcal{V}, \mathcal{E}}^\mathcal{R} = | \mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R} |$
, we will first choose the set of vertices and order them. The circuits that contribute are indeed directed non-backtracking walks. However, by considering undirected walks along a fixed ordering of vertices, that ordering sets the orientation of the first and thus the rest of the directed edges in
 $\gamma$
. Thus, we are counting the directed walks which contribute to equation (11). We relabel the vertices as
$\gamma$
. Thus, we are counting the directed walks which contribute to equation (11). We relabel the vertices as
 $1,2, \ldots, \mathcal{V}$
as they appear in
$1,2, \ldots, \mathcal{V}$
as they appear in
 $\gamma$
. Denote by
$\gamma$
. Denote by
 $\mathcal{T}_{\gamma}$
the spanning tree of those edges leading to new vertices as induced by the path
$\mathcal{T}_{\gamma}$
the spanning tree of those edges leading to new vertices as induced by the path
 $\gamma$
. The enumeration of the vertices tells us how we traverse the circuit and thus defines
$\gamma$
. The enumeration of the vertices tells us how we traverse the circuit and thus defines
 $\mathcal{T}_{\gamma}$
uniquely.
$\mathcal{T}_{\gamma}$
uniquely.
We encode each walk
 $\gamma_j$
by dividing it into sequences of subpaths of three types, which in our convention must always occur as type 1
$\gamma_j$
by dividing it into sequences of subpaths of three types, which in our convention must always occur as type 1
 $\to$
type 2
$\to$
type 2
 $\to$
type 3, although some may be empty subpaths. Each type of subpath is encoded with a number, and we use the encoding to upper bound the number of such paths that can occur. Given our current position on the circuit, i.e. the label of the current vertex, and the subtree of
$\to$
type 3, although some may be empty subpaths. Each type of subpath is encoded with a number, and we use the encoding to upper bound the number of such paths that can occur. Given our current position on the circuit, i.e. the label of the current vertex, and the subtree of
 $\mathcal{T}_{\gamma}$
already discovered (over the whole circuit
$\mathcal{T}_{\gamma}$
already discovered (over the whole circuit
 $\gamma$
not just the current walk
$\gamma$
not just the current walk
 $\gamma_j$
), we define the types and their encodings:
$\gamma_j$
), we define the types and their encodings:
-
Type 1: These are paths with the property that all of their edges are edges of
$\mathcal{T}_{\gamma}$
and have been traversed already in the circuit. These paths can be encoded by their end vertex. Because this is a path contained in a tree, there is a unique path connecting its initial and final vertex. We use 0 if the path is empty. -
Type 2: These are paths with all of their edges in
$\mathcal{T}_{\gamma}$
but which are traversed for the first time in the circuit. We can encode these paths by their length, since they are traversing new edges, and we know in what order the vertices are discovered. We use 0 if the path is empty. -
Type 3: These paths are simply a single edge, not belonging to
$\mathcal{T}_\gamma$
, that connects the end of a path of type 1 or 2 to a vertex that has been already discovered. Given our position on the circuit, we can encode an edge by its final vertex. Again, we use 0 if the path is empty.



Now, we decompose
 $\gamma_j$
into an ordered sequence of triples to encode its subpaths:
$\gamma_j$
into an ordered sequence of triples to encode its subpaths:
 \begin{equation*}(p_1,q_1,r_1) (p_2,q_2,r_2) \cdots (p_t,q_t,r_t),\end{equation*}
\begin{equation*}(p_1,q_1,r_1) (p_2,q_2,r_2) \cdots (p_t,q_t,r_t),\end{equation*}
where each
 $p_i$
characterises subpaths of type 1,
$p_i$
characterises subpaths of type 1,
 $q_i$
characterises subpaths of type 2 and
$q_i$
characterises subpaths of type 2 and
 $r_i$
characterizes subpaths of type 3. These subpaths occur in the order given by the triples. We perform this decomposition using the minimal possible number of triples.
$r_i$
characterizes subpaths of type 3. These subpaths occur in the order given by the triples. We perform this decomposition using the minimal possible number of triples.
Now,
 $p_i$
and
$p_i$
and
 $r_i$
are both numbers in
$r_i$
are both numbers in
 $\{0,1,...,\mathcal{V} \}$
, since our cycle has
$\{0,1,...,\mathcal{V} \}$
, since our cycle has
 $\mathcal{V}$
vertices. On the other hand,
$\mathcal{V}$
vertices. On the other hand,
 $q_i \in \{ 0,1,...,\ell \}$
since it represents the length of a subpath of a non-backtracking walk of length
$q_i \in \{ 0,1,...,\ell \}$
since it represents the length of a subpath of a non-backtracking walk of length
 $\ell$
. Hence, there are
$\ell$
. Hence, there are
 $(\mathcal{V} + 1)^2 (\ell+1)$
possible triples. Next, we want to bound how many of these triples occur in
$(\mathcal{V} + 1)^2 (\ell+1)$
possible triples. Next, we want to bound how many of these triples occur in
 $\gamma_j$
. We will use the following lemma.
$\gamma_j$
. We will use the following lemma.
Lemma 5.7. Let
 $(p_1,q_1,r_1) (p_2,q_2,r_2) \cdots (p_t,q_t,r_t)$
be a minimal encoding of a non-backtracking walk
$(p_1,q_1,r_1) (p_2,q_2,r_2) \cdots (p_t,q_t,r_t)$
be a minimal encoding of a non-backtracking walk
 $\gamma_j$
, as described above. Then
$\gamma_j$
, as described above. Then
 $r_i = 0$
can only occur in the last triple
$r_i = 0$
can only occur in the last triple
 $i = t$
.
$i = t$
.
Proof. We can check this case by case. Assume that for some
 $i<t$
we have
$i<t$
we have
 $(p_i,q_i,0)$
and consider the concatenation with
$(p_i,q_i,0)$
and consider the concatenation with
 $(p_{i+1},q_{i+1},r_{i+1})$
. First, notice that both
$(p_{i+1},q_{i+1},r_{i+1})$
. First, notice that both
 $p_{i+1}$
and
$p_{i+1}$
and
 $q_{i+1}$
cannot be zero since then we will have
$q_{i+1}$
cannot be zero since then we will have
 $(p_i,q_i,0)(0,0,v^*)$
which can be written as
$(p_i,q_i,0)(0,0,v^*)$
which can be written as
 $(p_i,q_i,v^*)$
. If
$(p_i,q_i,v^*)$
. If
 $q_i\neq 0$
, then we must have
$q_i\neq 0$
, then we must have
 $p_{i+1} \neq 0$
. Otherwise, we split a path of new edges (type 2), and the decomposition is not minimal. This implies that we visit new edges and move to edges already visited, hence we need to go through a type 3 edge, implying that
$p_{i+1} \neq 0$
. Otherwise, we split a path of new edges (type 2), and the decomposition is not minimal. This implies that we visit new edges and move to edges already visited, hence we need to go through a type 3 edge, implying that
 $r_i \neq 0$
. Finally, if
$r_i \neq 0$
. Finally, if
 $p_i \neq 0$
and
$p_i \neq 0$
and
 $q_i = 0$
, then we must have
$q_i = 0$
, then we must have
 $p_{i+1}=0$
; otherwise, we split a path of old edges (type 1). We also require
$p_{i+1}=0$
; otherwise, we split a path of old edges (type 1). We also require
 $q_{i+1} \neq 0$
, but
$q_{i+1} \neq 0$
, but
 $(p_i,0,0)(0,q_{i+1},r_{i+1})$
is the same as
$(p_i,0,0)(0,q_{i+1},r_{i+1})$
is the same as
 $(p_i,q_{i+1},r_{i+1})$
, which contradicts the minimality condition. This covers all possibilities and finishes the proof.
$(p_i,q_{i+1},r_{i+1})$
, which contradicts the minimality condition. This covers all possibilities and finishes the proof.
Using the lemma, any encoding of a non-backtracking walk
 $\gamma_j$
has at most one triple with
$\gamma_j$
has at most one triple with
 $r_i=0$
. All other triples indicate the traversing of a type 3 edge. We now give a very rough upper bound for how many of such encodings there can be. To do so, we will use the tangle-free property and slightly modify the encoding of the paths with cycles. Consider the two cases:
$r_i=0$
. All other triples indicate the traversing of a type 3 edge. We now give a very rough upper bound for how many of such encodings there can be. To do so, we will use the tangle-free property and slightly modify the encoding of the paths with cycles. Consider the two cases:
-
Case 1: Path
$\gamma_j$
contains no cycle. This implies that we traverse each edge within
$\gamma_j$
once. Thus, we can have at most
$\chi= \mathcal{E} - \mathcal{V} + 1$
many triples with
$r_i\neq 0$
. This gives a total of at most
many ways to encode one of these paths.
\begin{equation*} \left((\mathcal{V}+1)^2 (\ell+1) \right)^{\chi+1}\end{equation*}
-
Case 2: Path
$\gamma_j$
contains a cycle. Since we are dealing with non-backtracking, tangle-free walks, we enter the cycle once, loop around some number of times, and never come back. We change the encoding of such paths slightly. Let
$\gamma_j^{a}$
,
$\gamma_j^{b}$
, and
$\gamma_j^{c}$
be the segments of the path before, during, and after the cycle. We mark the start of the cycle with
$|$
and its end with
$\|$
. The new encoding of the path is
where we encode the segments separately. Observe that each a subpath is connected and self-avoiding. The above encoding tells us all we need to traverse
\begin{equation*}(p^a_1,q^a_1,r^a_1) \cdots (p^a_{t^a},q^a_{t^a},r^a_{t^a})\, | \,(p^b_1,q^b_1,r^b_1) \cdots (p^b_{t^b},q^b_{t^b},r^b_{t^b})\, \| \,(p^c_1,q^c_1,r^c_1) \cdots (p^c_{t^c},q^c_{t^c},r^c_{t^c}),\end{equation*}
$\gamma_j$
, including how many times to loop around the cycle: since the total length is
$\ell$
, we can back out the number of circuits around the cycle from the lengths of
$\gamma_j^{a}$
,
$\gamma_j^{b}$
, and
$\gamma_j^{c}$
, see Figure 5. Following the analysis made for Case 1, the subpaths
$\gamma_j^{a}$
,
$\gamma_j^{b}$
,
$\gamma_j^{c}$
are encoded by at most
$\chi + 1$
triples, but we also have at most
$\ell$
choices each for our marks
$|$
and
$\|$
. We are left with at most
ways to encode any path of this kind.
\begin{equation*} \ell^2 \left((\mathcal{V}+1)^2 (\ell+1) \right)^{\chi+1}\end{equation*}


















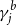







Figure 5. Encoding an
 $\ell$
-tangle-free walk, in this case the first walk in the circuit
$\ell$
-tangle-free walk, in this case the first walk in the circuit
 $\gamma_1$
, when it contains a cycle. The vertices and edges are labeled in the order of their traversal. The segments
$\gamma_1$
, when it contains a cycle. The vertices and edges are labeled in the order of their traversal. The segments
 $\gamma^a$
,
$\gamma^a$
,
 $\gamma^b$
, and
$\gamma^b$
, and
 $\gamma^c$
occur on edges numbered (1, 2, 3);
$\gamma^c$
occur on edges numbered (1, 2, 3);
 $(4 + 6i, 5+6i, 6+6i, 7+6i, 8+6i, 9+6i)$
for
$(4 + 6i, 5+6i, 6+6i, 7+6i, 8+6i, 9+6i)$
for
 $i = 0, 1, \ldots c$
; and
$i = 0, 1, \ldots c$
; and
 $(10+6c)$
, respectively. The encoding is
$(10+6c)$
, respectively. The encoding is
 $(0,3,0) | (0,4,3)(4,0,0) \| (0,1,0)$
. Suppose
$(0,3,0) | (0,4,3)(4,0,0) \| (0,1,0)$
. Suppose
 $c = 1$
. Then
$c = 1$
. Then
 $\ell = 22$
and the encoding is of length
$\ell = 22$
and the encoding is of length
 $3 + (4+1+1)(c+1) + 1$
, we can back out c to find that the cycle is repeated twice. The encodings become more complicated later in the circuit as vertices see repeat visits.
$3 + (4+1+1)(c+1) + 1$
, we can back out c to find that the cycle is repeated twice. The encodings become more complicated later in the circuit as vertices see repeat visits.
Together, these two cases mean there are less than
 $2 \ell^2 \left((\mathcal{V}+1)^2 (\ell+1) \right)^{\chi+1}$
such paths.
$2 \ell^2 \left((\mathcal{V}+1)^2 (\ell+1) \right)^{\chi+1}$
such paths.
Now we conclude by encoding the entire circuit
 $\gamma = (\gamma_1, \ldots, \gamma_{2k})$
. We first choose
$\gamma = (\gamma_1, \ldots, \gamma_{2k})$
. We first choose
 $\mathcal{V}$
vertices,
$\mathcal{V}$
vertices,
 $\mathcal{R}$
in the set
$\mathcal{R}$
in the set
 $V_2$
, and order them, which can occur in
$V_2$
, and order them, which can occur in
 $(m)_\mathcal{R} (n)_{\mathcal{V}-\mathcal{R}} \leq m^\mathcal{R} n^{\mathcal{V} - \mathcal{R}}$
different ways. Finally, in the whole path
$(m)_\mathcal{R} (n)_{\mathcal{V}-\mathcal{R}} \leq m^\mathcal{R} n^{\mathcal{V} - \mathcal{R}}$
different ways. Finally, in the whole path
 $\gamma$
we are counting concatenations of 2k paths which are
$\gamma$
we are counting concatenations of 2k paths which are
 $\ell$
-tangle-free. Therefore, we conclude with the following Lemma:
$\ell$
-tangle-free. Therefore, we conclude with the following Lemma:
Lemma 5.8. Let
 $\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
be the set of circuits
$\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
be the set of circuits
 $\gamma = (\gamma_1, \ldots, \gamma_{2k})$
of length
$\gamma = (\gamma_1, \ldots, \gamma_{2k})$
of length
 $2 k \ell$
obtained as the concatenation of 2k non-backtracking, tangle-free walks of length
$2 k \ell$
obtained as the concatenation of 2k non-backtracking, tangle-free walks of length
 $\ell$
, i.e.
$\ell$
, i.e.
 $\gamma_s \in F^\ell$
for all
$\gamma_s \in F^\ell$
for all
 $s \in [2k]$
, which visit exactly
$s \in [2k]$
, which visit exactly
 $\mathcal{V} = |V(\gamma)|$
different vertices,
$\mathcal{V} = |V(\gamma)|$
different vertices,
 $\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
$\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
 $\mathcal{E} = |E(\gamma)|$
different edges. If
$\mathcal{E} = |E(\gamma)|$
different edges. If
 $C_{\mathcal{V}, \mathcal{E}}^\mathcal{R} = |\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}|$
, then
$C_{\mathcal{V}, \mathcal{E}}^\mathcal{R} = |\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}|$
, then
 \begin{equation}C_{\mathcal{V}, \mathcal{E}}^\mathcal{R}\leq m^\mathcal{R} n^{\mathcal{V} - \mathcal{R}} (2 \ell)^{4k}\left( (\mathcal{V}+1)^2 (\ell+1) \right)^{2k (\chi + 1)},\end{equation}
\begin{equation}C_{\mathcal{V}, \mathcal{E}}^\mathcal{R}\leq m^\mathcal{R} n^{\mathcal{V} - \mathcal{R}} (2 \ell)^{4k}\left( (\mathcal{V}+1)^2 (\ell+1) \right)^{2k (\chi + 1)},\end{equation}
where
 $\chi = \mathcal{E} - \mathcal{V} + 1$
.
$\chi = \mathcal{E} - \mathcal{V} + 1$
.
The circuits that contribute to the remainder term
 $R^{\ell, j}$
are slightly different. In this case, each length
$R^{\ell, j}$
are slightly different. In this case, each length
 $\ell$
segment is an element of
$\ell$
segment is an element of
 $T^{\ell, j}$
rather than
$T^{\ell, j}$
rather than
 $F^{\ell}$
. We have to slightly modify the previous argument for this case.
$F^{\ell}$
. We have to slightly modify the previous argument for this case.
Lemma 5.9. Let
 $\mathcal{D}_{\mathcal{V},\mathcal{E}}^\mathcal{R}$
be the set of circuits
$\mathcal{D}_{\mathcal{V},\mathcal{E}}^\mathcal{R}$
be the set of circuits
 $\gamma = (\gamma_1, \ldots, \gamma_{2k})$
of length
$\gamma = (\gamma_1, \ldots, \gamma_{2k})$
of length
 $2k\ell$
obtained as the concatenation of 2k elements
$2k\ell$
obtained as the concatenation of 2k elements
 $\gamma_s \in T^{\ell, j}$
for
$\gamma_s \in T^{\ell, j}$
for
 $s = 1, \ldots, 2k$
, that visit exactly
$s = 1, \ldots, 2k$
, that visit exactly
 $\mathcal{V}$
vertices,
$\mathcal{V}$
vertices,
 $\mathcal{R}$
of which are in
$\mathcal{R}$
of which are in
 $V_2$
, and
$V_2$
, and
 $\mathcal{E}$
different edges. Then for
$\mathcal{E}$
different edges. Then for
 $D_{\mathcal{V},\mathcal{E}}^\mathcal{R} = | \mathcal{D}_{\mathcal{V},\mathcal{E}}^\mathcal{R} |$
, we have
$D_{\mathcal{V},\mathcal{E}}^\mathcal{R} = | \mathcal{D}_{\mathcal{V},\mathcal{E}}^\mathcal{R} |$
, we have
 \begin{align}D_{\mathcal{V},\mathcal{E}}^\mathcal{R}\leq m^\mathcal{R} n^{\mathcal{V}-\mathcal{R}}(2 \ell)^{6k}( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} .\end{align}
\begin{align}D_{\mathcal{V},\mathcal{E}}^\mathcal{R}\leq m^\mathcal{R} n^{\mathcal{V}-\mathcal{R}}(2 \ell)^{6k}( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} .\end{align}
Proof. Since each
 $\gamma^s = (e_1, \ldots, e_{2\ell + 1}) \in T^{\ell,j}$
, we have that
$\gamma^s = (e_1, \ldots, e_{2\ell + 1}) \in T^{\ell,j}$
, we have that
 $\gamma' = (e_1, \ldots, e_{2j-1}) \in F^{j-1}$
,
$\gamma' = (e_1, \ldots, e_{2j-1}) \in F^{j-1}$
,
 $\gamma'' = (e_{2j-1}, e_{2j}, e_{2j+1}) \in F^{1}$
, and
$\gamma'' = (e_{2j-1}, e_{2j}, e_{2j+1}) \in F^{1}$
, and
 $\gamma''' = (e_{2j+1}, \ldots, e_{2\ell + 1}) \in F^{\ell - j}$
. Encoding
$\gamma''' = (e_{2j+1}, \ldots, e_{2\ell + 1}) \in F^{\ell - j}$
. Encoding
 $\gamma'$
,
$\gamma'$
,
 $\gamma''$
, and
$\gamma''$
, and
 $\gamma'''$
as before, we have the generous upper bound of at most
$\gamma'''$
as before, we have the generous upper bound of at most
 \begin{equation*}\left[ (2\ell) ((\mathcal{V} + 1)^2(\ell+1))^{\chi+1} \right]^3\end{equation*}
\begin{equation*}\left[ (2\ell) ((\mathcal{V} + 1)^2(\ell+1))^{\chi+1} \right]^3\end{equation*}
many encodings for each
 $\gamma_s$
. Choosing and ordering the vertices, then concatenating 2k of these paths gives the final result.
$\gamma_s$
. Choosing and ordering the vertices, then concatenating 2k of these paths gives the final result.
5.5. Half edge isomorphism counting
We have constructed the circuits in
 $\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
and
$\mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
and
 $\mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
by choosing the vertices and edges that participate in them. However, the expectation bound applies to matchings of half-edges in the configuration model. Since there are multiple ways to configure the half edges into such a circuit, this must be taken into account in the combinatorics.
$\mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
by choosing the vertices and edges that participate in them. However, the expectation bound applies to matchings of half-edges in the configuration model. Since there are multiple ways to configure the half edges into such a circuit, this must be taken into account in the combinatorics.
Lemma 5.10. Let
 $I_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
be the number of half edge choices for the graph induced by
$I_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
be the number of half edge choices for the graph induced by
 $\gamma \in \mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}\cup \mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
. Then,
$\gamma \in \mathcal{C}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}\cup \mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R}$
. Then,
 \begin{equation} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \leq d_1^{\mathcal{V} - \mathcal{R}} (d_1 - 1)^{\mathcal{E} - \mathcal{V} + \mathcal{R}} d_2^{\mathcal{R}} (d_2 - 1)^{\mathcal{E} - \mathcal{R}} . \end{equation}
\begin{equation} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \leq d_1^{\mathcal{V} - \mathcal{R}} (d_1 - 1)^{\mathcal{E} - \mathcal{V} + \mathcal{R}} d_2^{\mathcal{R}} (d_2 - 1)^{\mathcal{E} - \mathcal{R}} . \end{equation}
Proof. For every left vertex v, with degree
 $g_v$
on the graph induced by
$g_v$
on the graph induced by
 $\gamma$
, the number of choices of half edges is
$\gamma$
, the number of choices of half edges is
 $d_1(d_1-1)\dots(d_1- g_v+1)\leq d_1 (d_1-1)^{g_v-1}$
. Note that the choice of half edges are independent for the left vertices. We then get that there are
$d_1(d_1-1)\dots(d_1- g_v+1)\leq d_1 (d_1-1)^{g_v-1}$
. Note that the choice of half edges are independent for the left vertices. We then get that there are
 $d_1^{\mathcal{V}-\mathcal{R}} (d_1-1)^{\mathcal{E} - \mathcal{V}+\mathcal{R}}$
many choices, where we used that the sum of all the degrees on one component of a bipartite graph equals the number of edges:
$d_1^{\mathcal{V}-\mathcal{R}} (d_1-1)^{\mathcal{E} - \mathcal{V}+\mathcal{R}}$
many choices, where we used that the sum of all the degrees on one component of a bipartite graph equals the number of edges:
 $\mathcal{E} = \sum_v g_v$
. Similarly, for right vertices we get
$\mathcal{E} = \sum_v g_v$
. Similarly, for right vertices we get
 $d_2^{\mathcal{R}}(d_2-1)^{(\mathcal{E}-\mathcal{R})}$
.
$d_2^{\mathcal{R}}(d_2-1)^{(\mathcal{E}-\mathcal{R})}$
.
Corollary 5.11. We have that
 \begin{equation} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \leq (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}} (d_2 (d_2 - 1))^\mathcal{R} (d - 1)^{2 (\chi - 1)}.\end{equation}
\begin{equation} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \leq (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}} (d_2 (d_2 - 1))^\mathcal{R} (d - 1)^{2 (\chi - 1)}.\end{equation}
5.6. Bounding the imbalance
$\psi$

We focus now on the quantity defined as
 $\psi = \mathcal{R} - \mathcal{E} / 2 $
. Informally,
$\psi = \mathcal{R} - \mathcal{E} / 2 $
. Informally,
 $\psi$
captures the imbalance between the number of vertices on each partition of the bipartite graph visited by the circuit
$\psi$
captures the imbalance between the number of vertices on each partition of the bipartite graph visited by the circuit
 $\gamma$
. We show that this imbalance is not too large.
$\gamma$
. We show that this imbalance is not too large.
Lemma 5.12. Let
 $\ell < \frac{1}{32} \log_d(n)$
, then
$\ell < \frac{1}{32} \log_d(n)$
, then
 $\psi \leq 16 k^2$
with high probability.
$\psi \leq 16 k^2$
with high probability.
Proof. For any subgraph H define
 $\psi(H) = \mathcal{R}(H)-\mathcal{E}(H)/2$
. We set
$\psi(H) = \mathcal{R}(H)-\mathcal{E}(H)/2$
. We set
 $\psi=\psi(\gamma)$
. To bound this quantity, we analyse the subgraph
$\psi=\psi(\gamma)$
. To bound this quantity, we analyse the subgraph
 $\gamma_{\leq i}$
, obtained by the concatenation of the first i walks in
$\gamma_{\leq i}$
, obtained by the concatenation of the first i walks in
 $\gamma$
, i.e. the union of the graphs induced by
$\gamma$
, i.e. the union of the graphs induced by
 $\gamma_1, \ldots, \gamma_i$
. Our choice of
$\gamma_1, \ldots, \gamma_i$
. Our choice of
 $\ell$
implies that every neighbourhood of radius
$\ell$
implies that every neighbourhood of radius
 $4\ell$
is tangle-free with high probability. Hence, every non-backtracking walk
$4\ell$
is tangle-free with high probability. Hence, every non-backtracking walk
 $\gamma_j$
is either a path or a path with exactly one loop. It is not hard to conclude that
$\gamma_j$
is either a path or a path with exactly one loop. It is not hard to conclude that
 $\psi(\gamma_j) \leq 2$
for all j and
$\psi(\gamma_j) \leq 2$
for all j and
 $\psi(\gamma_{\leq 1}) = \psi(\gamma_1) \leq 2$
. We now proceed inductively to add walks to our graph, one by one, as they appear on the circuit. We will upper bound the increment
$\psi(\gamma_{\leq 1}) = \psi(\gamma_1) \leq 2$
. We now proceed inductively to add walks to our graph, one by one, as they appear on the circuit. We will upper bound the increment
 $\psi(\gamma_{\leq i+1}) - \psi(\gamma_{\leq i})$
by looking at how the addition of
$\psi(\gamma_{\leq i+1}) - \psi(\gamma_{\leq i})$
by looking at how the addition of
 $\gamma_{i+1}$
changes the imbalance.
$\gamma_{i+1}$
changes the imbalance.
To analyse this, consider the intersection of
 $\gamma_{i+1}$
and each
$\gamma_{i+1}$
and each
 $\gamma_j$
,
$\gamma_j$
,
 $1\leq j\leq i$
. Notice that
$1\leq j\leq i$
. Notice that
 $\psi$
may increase only if there are vertices at which the two walks split apart. We claim that there are at most two such vertices. Assume that at
$\psi$
may increase only if there are vertices at which the two walks split apart. We claim that there are at most two such vertices. Assume that at
 $v_1,v_2$
and
$v_1,v_2$
and
 $v_3$
the two walks split. Then there are two disjoint cycles in the union of
$v_3$
the two walks split. Then there are two disjoint cycles in the union of
 $\gamma_{i+1}$
and
$\gamma_{i+1}$
and
 $\gamma_j$
, obtained by following each first from
$\gamma_j$
, obtained by following each first from
 $v_1$
to
$v_1$
to
 $v_2$
and then from
$v_2$
and then from
 $v_2$
to
$v_2$
to
 $v_3$
. But this is a contradiction, since the diameter of this union is less than
$v_3$
. But this is a contradiction, since the diameter of this union is less than
 $2 \ell < \frac{1}{8} \log(n)$
, which implies that their union is tangle-free. We conclude that
$2 \ell < \frac{1}{8} \log(n)$
, which implies that their union is tangle-free. We conclude that
 $\psi(\gamma_{i+1} \cup \gamma_j) \leq 8$
since there are at most two splits and each split contributes at most four to the imbalance. Then
$\psi(\gamma_{i+1} \cup \gamma_j) \leq 8$
since there are at most two splits and each split contributes at most four to the imbalance. Then
 $\psi(\gamma_{\leq i+1}) \leq \psi(\gamma_{\leq i}) + 8i + 2$
, which implies that
$\psi(\gamma_{\leq i+1}) \leq \psi(\gamma_{\leq i}) + 8i + 2$
, which implies that
 $\psi(\gamma)\leq 16k^2$
, as desired.
$\psi(\gamma)\leq 16k^2$
, as desired.
5.7. Bounding the inconsistent edges
We will need a bound on the number of inconsistent edges of multiplicity one, which we get in the following lemma. Recall Definition 5.5, which introduced inconsistent edges.
Lemma 5.13. Let
 $b_\mathcal{C}$
denote the number of inconsistent edges of multiplicity one on a circuit
$b_\mathcal{C}$
denote the number of inconsistent edges of multiplicity one on a circuit
 $\gamma = (\gamma_1, \ldots, \gamma_{2k})$
consisting of 2k non-backtracking walks of length
$\gamma = (\gamma_1, \ldots, \gamma_{2k})$
consisting of 2k non-backtracking walks of length
 $\ell$
each. It holds that
$\ell$
each. It holds that
 $ b_\mathcal{C} \leq 4 (k + \chi)$
, where
$ b_\mathcal{C} \leq 4 (k + \chi)$
, where
 $\chi=\mathcal{E}-\mathcal{V}+1$
.
$\chi=\mathcal{E}-\mathcal{V}+1$
.
Proof. Let
 $\{e,f\}$
be an inconsistent edge of multiplicity one, where e and f are its half edges. For inconsistency and without loss of generality, there must exist another edge
$\{e,f\}$
be an inconsistent edge of multiplicity one, where e and f are its half edges. For inconsistency and without loss of generality, there must exist another edge
 $\{e,f'\}$
in
$\{e,f'\}$
in
 $\gamma$
, so that
$\gamma$
, so that
 $m_\gamma (e) \neq 1$
. We may assume that
$m_\gamma (e) \neq 1$
. We may assume that
 $\{e,f\}$
is traversed before
$\{e,f\}$
is traversed before
 $\{e,f'\}$
. Let v be the vertex of e and consider the two possible scenarios:
$\{e,f'\}$
. Let v be the vertex of e and consider the two possible scenarios:
-
Case 1: There is no cycle containing v in
$\gamma$
. Then the edge
$\{e,f\}$
may only be inconsistent if v is visited at the end of one of the 2k non-backtracking walks
$\gamma_i$
and
$\{e,f'\}$
is at the beginning of
$\gamma_{i+1}$
. Hence, in this case, we have at most two inconsistent edges of multiplicity one. This yields at most 4k such edges. -
Case 2: There is a cycle passing through v. For each such cycle, there is an edge that does not belong to the tree
$T_{\gamma}$
(defined in Section 5.4). Furthermore, each cycle creates at most four inconsistent edges. Combining these two facts we get at most
$4\chi$
and the proof follows.







Lemma 5.14. Consider a circuit
 $\gamma = (\gamma_1, \ldots, \gamma_{2k})$
with
$\gamma = (\gamma_1, \ldots, \gamma_{2k})$
with
 $\gamma_s \in T^{\ell,j}$
for
$\gamma_s \in T^{\ell,j}$
for
 $j \in [2k]$
, with
$j \in [2k]$
, with
 $\gamma_s$
decomposed as
$\gamma_s$
decomposed as
 $\gamma^{\prime}_s, \gamma^{\prime\prime}_s, \gamma^{\prime\prime\prime}_s$
as in the Definition 5.4. Let
$\gamma^{\prime}_s, \gamma^{\prime\prime}_s, \gamma^{\prime\prime\prime}_s$
as in the Definition 5.4. Let
 $b_\mathcal{D}$
denote the number of inconsistent edges of multiplicity one in the union of segments
$b_\mathcal{D}$
denote the number of inconsistent edges of multiplicity one in the union of segments
 $\bigcup_{s=1}^{2k} (\gamma^{\prime}_s \cup \gamma^{\prime\prime}_s)$
. Then
$\bigcup_{s=1}^{2k} (\gamma^{\prime}_s \cup \gamma^{\prime\prime}_s)$
. Then
 $b_\mathcal{D}\leq 16k+4 \chi$
, where
$b_\mathcal{D}\leq 16k+4 \chi$
, where
 $\chi = \mathcal{E} - \mathcal{V} + 1$
.
$\chi = \mathcal{E} - \mathcal{V} + 1$
.
Proof. The argument is similar to the above; however, now there are 4k segments in
 $\bar\gamma = \bigcup_{s=1}^{2k} (\gamma^{\prime}_s \cup \gamma^{\prime\prime}_s)$
, counting
$\bar\gamma = \bigcup_{s=1}^{2k} (\gamma^{\prime}_s \cup \gamma^{\prime\prime}_s)$
, counting
 $\gamma^{\prime}_s$
and
$\gamma^{\prime}_s$
and
 $\gamma^{\prime\prime}_s$
separately. As above, each of these 4k segments may yield at most 2 inconsistent edges. Furthermore, the graph induced by
$\gamma^{\prime\prime}_s$
separately. As above, each of these 4k segments may yield at most 2 inconsistent edges. Furthermore, the graph induced by
 $\bar\gamma$
may not be connected; let C be the number of connected components. Each edge that creates a cycle may yield at most 4 inconsistent edges, and there are at most
$\bar\gamma$
may not be connected; let C be the number of connected components. Each edge that creates a cycle may yield at most 4 inconsistent edges, and there are at most
 $\mathcal{E} - \mathcal{V} + C$
non-tree edges. Then, we have that
$\mathcal{E} - \mathcal{V} + C$
non-tree edges. Then, we have that
 \begin{equation*}b_\mathcal{D}\leq 8 k + 4 (\mathcal{E} - \mathcal{V} + C)\leq 8k + 4 (\mathcal{E} - \mathcal{V} + 2k)\leq 16 k + 4 \chi,\end{equation*}
\begin{equation*}b_\mathcal{D}\leq 8 k + 4 (\mathcal{E} - \mathcal{V} + C)\leq 8k + 4 (\mathcal{E} - \mathcal{V} + 2k)\leq 16 k + 4 \chi,\end{equation*}
as claimed.
5.8. Bounds on the norm of
$\bar{B}^{\ell}$
and
$R^{\ell,j}$


All of the ingredients are gathered to bound the matrix norms.
Theorem 5.15. Let
 $\ell = \lfloor c\log(n) \rfloor$
where
$\ell = \lfloor c\log(n) \rfloor$
where
 $c < \frac{1}{32}$
is a universal constant. It holds that
$c < \frac{1}{32}$
is a universal constant. It holds that
 \begin{equation*}\|\bar{B}^{(\ell)}\|\leq \left((d_1-1)(d_2-1)\right)^{\ell/4}\exp( \log^{3/4} n )\end{equation*}
\begin{equation*}\|\bar{B}^{(\ell)}\|\leq \left((d_1-1)(d_2-1)\right)^{\ell/4}\exp( \log^{3/4} n )\end{equation*}
asymptotically almost surely.
Proof. The following holds for any natural number k, but for our proof, we will take
 \begin{equation} k = \lfloor \log (n)^{1/3} \rfloor \quad \mbox{ and } \quad \ell = \lfloor c \log n \rfloor \mbox{ for some } c
< \frac{1}{32}.\end{equation}
\begin{equation} k = \lfloor \log (n)^{1/3} \rfloor \quad \mbox{ and } \quad \ell = \lfloor c \log n \rfloor \mbox{ for some } c
< \frac{1}{32}.\end{equation}
We have
 \begin{align}\mathbb{E} \left(\| \bar{B}^{(\ell)} \|^{2k} \right)\leq \mathbb{E}\left(\textrm{Tr} \left[ \left( \bar{B}^{(\ell)} \bar{B}^{(\ell)^*} \right)^{k} \right]\right)=\mathbb{E}\left(\sum_{\gamma \in \mathcal{C}}\prod_{t=1}^{2 k \ell} \bar{B}_{e_{2t-1} e_{2t+1}}\right).\end{align}
\begin{align}\mathbb{E} \left(\| \bar{B}^{(\ell)} \|^{2k} \right)\leq \mathbb{E}\left(\textrm{Tr} \left[ \left( \bar{B}^{(\ell)} \bar{B}^{(\ell)^*} \right)^{k} \right]\right)=\mathbb{E}\left(\sum_{\gamma \in \mathcal{C}}\prod_{t=1}^{2 k \ell} \bar{B}_{e_{2t-1} e_{2t+1}}\right).\end{align}
The sum is taken over the set
 $\mathcal{C}$
of all circuits
$\mathcal{C}$
of all circuits
 $\gamma$
of length
$\gamma$
of length
 $2k\ell$
, where
$2k\ell$
, where
 $\gamma= ( \gamma_1, \gamma_2, \ldots, \gamma_{2k} )$
is formed by concatenation of 2k tangle-free segments
$\gamma= ( \gamma_1, \gamma_2, \ldots, \gamma_{2k} )$
is formed by concatenation of 2k tangle-free segments
 $\gamma_s \in F^{\ell}$
, with the convention
$\gamma_s \in F^{\ell}$
, with the convention
 $e^{s+1}_1=e^s_{\ell+1}$
. Again, refer to Figure 4 for clarification.
$e^{s+1}_1=e^s_{\ell+1}$
. Again, refer to Figure 4 for clarification.
As in Section 5.4, we will break these into circuits which visit exactly
 $\mathcal{V} = |V(\gamma)|$
different vertices,
$\mathcal{V} = |V(\gamma)|$
different vertices,
 $\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
$\mathcal{R} = |V(\gamma) \cap V_2|$
of them in the right set, and
 $\mathcal{E} = |E(\gamma)|$
different edges. We define three disjoint sets of circuits:
$\mathcal{E} = |E(\gamma)|$
different edges. We define three disjoint sets of circuits:
 \begin{align*} \mathcal{C}_1 & = \{\gamma \in \mathcal{C}: \mbox{all edges in $\gamma$ are traversed at least twice} \}, \\ \mathcal{C}_2 & = \{\gamma \in \mathcal{C}: \mbox{at least one edge in $\gamma$ is traversed exactly once and $\mathcal{V} \leq kl+1$} \}, \mbox{and} \\ \mathcal{C}_3 & = \{\gamma \in \mathcal{C}: \mbox{at least one edge in $\gamma$ is traversed exactly once and $\mathcal{V} > kl+1$} \} .\end{align*}
\begin{align*} \mathcal{C}_1 & = \{\gamma \in \mathcal{C}: \mbox{all edges in $\gamma$ are traversed at least twice} \}, \\ \mathcal{C}_2 & = \{\gamma \in \mathcal{C}: \mbox{at least one edge in $\gamma$ is traversed exactly once and $\mathcal{V} \leq kl+1$} \}, \mbox{and} \\ \mathcal{C}_3 & = \{\gamma \in \mathcal{C}: \mbox{at least one edge in $\gamma$ is traversed exactly once and $\mathcal{V} > kl+1$} \} .\end{align*}
Define the quantities
 \begin{equation*}I_j=\left|\mathbb{E} \sum_{\gamma\in \mathcal{C}_j} \prod_{t=1}^{2k\ell} \bar{B}_{e_{2t-1} e_{2t+1}}\right|\leq \sum_{\gamma \in \mathcal{C}_j}\left|\mathbb{E}\prod_{t=1}^{2k\ell}\bar{M}_{e_{2t-1} e_{2t}}\right|\end{equation*}
\begin{equation*}I_j=\left|\mathbb{E} \sum_{\gamma\in \mathcal{C}_j} \prod_{t=1}^{2k\ell} \bar{B}_{e_{2t-1} e_{2t+1}}\right|\leq \sum_{\gamma \in \mathcal{C}_j}\left|\mathbb{E}\prod_{t=1}^{2k\ell}\bar{M}_{e_{2t-1} e_{2t}}\right|\end{equation*}
for
 $j = 1, 2$
and 3, so that (24) can be bounded as
$j = 1, 2$
and 3, so that (24) can be bounded as
 \begin{align}\mathbb{E}\left(\|\bar{B}^{(\ell)}\|^{2k}\right)\leq I_1+I_2+I_3.\end{align}
\begin{align}\mathbb{E}\left(\|\bar{B}^{(\ell)}\|^{2k}\right)\leq I_1+I_2+I_3.\end{align}
We will bound each term on the right-hand side above. The reason for this division is that, by Theorem 5.6, when we have any two-path traversed exactly once, the expectation of the corresponding circuit is smaller, because the matrix
 $\bar{B}$
is nearly centered. We will see that the leading order terms in equation (24) will come from circuits in
$\bar{B}$
is nearly centered. We will see that the leading order terms in equation (24) will come from circuits in
 $\mathcal{C}_1$
. From Lemmas 5.6 and 5.8 and Corollary 5.11, we get that
$\mathcal{C}_1$
. From Lemmas 5.6 and 5.8 and Corollary 5.11, we get that
 \begin{align} I_j&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}\sum_{\gamma\in \mathcal{C}_j \cap \mathcal{C}_{\mathcal{V},\mathcal{E}}^\mathcal{R}}\left|\mathbb{E}\prod_{t=1}^{2k\ell} \bar{M}_{e_{2t-1} e_{2t}}\right|\nonumber\\
&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}C_{\mathcal{V},\mathcal{E}}^\mathcal{R} \,I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \,\left|\mathbb{E}\prod_{t=1}^{2k\ell} \bar{M}_{e_{2t-1} e_{2t}}\right|\nonumber\\
&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}n^{\mathcal{V} - \mathcal{R}}m^{\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)} \nonumber \\
& \qquad\qquad\cdot (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}}(d_2 (d_2 - 1))^\mathcal{R}(d - 1)^{2(\chi - 1)} \nonumber \\& \qquad\qquad\cdot C2^{b_\mathcal{C}} \left( \frac{1}{|E|} \right)^\mathcal{E}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1} \nonumber \\&\leq C\sum_{\mathcal{V},\mathcal{E},\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}(d_1 - 1)^{\mathcal{V} - \mathcal{R}}(d_2 - 1)^\mathcal{R}(d - 1)^{2(\chi - 1)} \nonumber \\& \qquad\qquad\cdot 2^{b_\mathcal{C}}\left( \frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1} \nonumber \\&\leq C\sum_{\mathcal{V},\mathcal{E},\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( (d_1 - 1)(d_2 - 1) \right)^{\mathcal{E} / 2}\nonumber \\& \qquad\qquad\cdot \left( \frac{d_2 - 1}{d_1 - 1} \right)^\psi(d_1 - 1)^{1-\chi}(d - 1)^{2(\chi - 1)}2^{b_\mathcal{C}}\left( \frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1}\nonumber \\&\leq c_0 n\ell^{4k}c_1^{k^2}c_2^k\sum_{\mathcal{V},\mathcal{E}}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\left( \frac{c_4 k \ell}{\sqrt{n}} \right)^{\mathcal{E}_1}\end{align}
\begin{align} I_j&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}\sum_{\gamma\in \mathcal{C}_j \cap \mathcal{C}_{\mathcal{V},\mathcal{E}}^\mathcal{R}}\left|\mathbb{E}\prod_{t=1}^{2k\ell} \bar{M}_{e_{2t-1} e_{2t}}\right|\nonumber\\
&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}C_{\mathcal{V},\mathcal{E}}^\mathcal{R} \,I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \,\left|\mathbb{E}\prod_{t=1}^{2k\ell} \bar{M}_{e_{2t-1} e_{2t}}\right|\nonumber\\
&\leq \sum_{\mathcal{V},\mathcal{E},\mathcal{R}}n^{\mathcal{V} - \mathcal{R}}m^{\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)} \nonumber \\
& \qquad\qquad\cdot (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}}(d_2 (d_2 - 1))^\mathcal{R}(d - 1)^{2(\chi - 1)} \nonumber \\& \qquad\qquad\cdot C2^{b_\mathcal{C}} \left( \frac{1}{|E|} \right)^\mathcal{E}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1} \nonumber \\&\leq C\sum_{\mathcal{V},\mathcal{E},\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}(d_1 - 1)^{\mathcal{V} - \mathcal{R}}(d_2 - 1)^\mathcal{R}(d - 1)^{2(\chi - 1)} \nonumber \\& \qquad\qquad\cdot 2^{b_\mathcal{C}}\left( \frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1} \nonumber \\&\leq C\sum_{\mathcal{V},\mathcal{E},\mathcal{R}}(2\ell)^{4k} ((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( (d_1 - 1)(d_2 - 1) \right)^{\mathcal{E} / 2}\nonumber \\& \qquad\qquad\cdot \left( \frac{d_2 - 1}{d_1 - 1} \right)^\psi(d_1 - 1)^{1-\chi}(d - 1)^{2(\chi - 1)}2^{b_\mathcal{C}}\left( \frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}}\left( \frac{6 k \ell}{\sqrt{|E|}} \right)^{\mathcal{E}_1}\nonumber \\&\leq c_0 n\ell^{4k}c_1^{k^2}c_2^k\sum_{\mathcal{V},\mathcal{E}}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\left( \frac{c_4 k \ell}{\sqrt{n}} \right)^{\mathcal{E}_1}\end{align}
We use
 $C, c_0, c_1, c_2, c_3, c_4$
to denote constant terms and set
$C, c_0, c_1, c_2, c_3, c_4$
to denote constant terms and set
 $\alpha = ((d_1-1)(d_2-1))^{1/4}$
. In the last line, we used Lemmas 5.12 and 5.13 to bound
$\alpha = ((d_1-1)(d_2-1))^{1/4}$
. In the last line, we used Lemmas 5.12 and 5.13 to bound
 $\psi$
and
$\psi$
and
 $b_\mathcal{C}$
in terms of k and
$b_\mathcal{C}$
in terms of k and
 $\chi$
and remove the sum over
$\chi$
and remove the sum over
 $\mathcal{R}$
, which contains at most
$\mathcal{R}$
, which contains at most
 $\mathcal{V}$
terms. We will use equation (26) to bound each
$\mathcal{V}$
terms. We will use equation (26) to bound each
 $I_j$
.
$I_j$
.
5.8.1
Bounding
$I_1$

Here,
 $\mathcal{E}_1 = 0$
since every edge is traversed twice. We then have that
$\mathcal{E}_1 = 0$
since every edge is traversed twice. We then have that
 $\mathcal{V} - 1 \leq \mathcal{E} \leq k\ell$
. Since
$\mathcal{V} - 1 \leq \mathcal{E} \leq k\ell$
. Since
 $\gamma$
is connected, we have
$\gamma$
is connected, we have
 $1 \leq \mathcal{V} \leq k\ell+1$
. Thus, on the right-hand side of equation (26) we get
$1 \leq \mathcal{V} \leq k\ell+1$
. Thus, on the right-hand side of equation (26) we get
 \begin{align*}I_1&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\sum_{\mathcal{E}=\mathcal{V}-1}^{k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\alpha^{2(\mathcal{V} - 1)}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k}\sum_{\chi= 0}^{k\ell - \mathcal{V} + 1}\left( \alpha^2 ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n}\right)^\chi\end{align*}
\begin{align*}I_1&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\sum_{\mathcal{E}=\mathcal{V}-1}^{k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\alpha^{2(\mathcal{V} - 1)}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k}\sum_{\chi= 0}^{k\ell - \mathcal{V} + 1}\left( \alpha^2 ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n}\right)^\chi\end{align*}
The second sum is upper bounded by
 $\sum_{\chi=0}^\infty\left( C \frac{ ((\mathcal{V}+1)^2 (\ell+1) )^{2k} }{n} \right)^\chi$
, where C is some constant, which we show next is bounded by a common constant for our choices of k and
$\sum_{\chi=0}^\infty\left( C \frac{ ((\mathcal{V}+1)^2 (\ell+1) )^{2k} }{n} \right)^\chi$
, where C is some constant, which we show next is bounded by a common constant for our choices of k and
 $\ell$
and all
$\ell$
and all
 $\mathcal{V} \in [k\ell + 1]$
. To see this, it will suffice to show that
$\mathcal{V} \in [k\ell + 1]$
. To see this, it will suffice to show that
 $((\mathcal{V}+1)^2 (\ell+1) )^{2k}=o(n)$
. But
$((\mathcal{V}+1)^2 (\ell+1) )^{2k}=o(n)$
. But
 $((\mathcal{V}+1)^2 (\ell+1) ) = O(k^2 \ell^3)$
which, for our choices of k and
$((\mathcal{V}+1)^2 (\ell+1) ) = O(k^2 \ell^3)$
which, for our choices of k and
 $\ell$
, yields
$\ell$
, yields
 \begin{equation*}2k \log( (\mathcal{V}+1)^2 (\ell+1) )=O({\log(n)^{1/3}}\log(\log(n)))=o(\log(n))\end{equation*}
\begin{equation*}2k \log( (\mathcal{V}+1)^2 (\ell+1) )=O({\log(n)^{1/3}}\log(\log(n)))=o(\log(n))\end{equation*}
as desired.
Finally, the first summand is maximised for
 $\mathcal{V} = k\ell + 1$
and there are at
$\mathcal{V} = k\ell + 1$
and there are at
 $k\ell + 1$
many terms in that sum. Therefore, modifying the constant
$k\ell + 1$
many terms in that sum. Therefore, modifying the constant
 $c_0$
yields
$c_0$
yields
 \begin{align}I_1\leq c^{\prime}_0 n\ell^{4k}c_1^{ k^2}c_2^k(k \ell + 1)^2\left( (k\ell+2)^2 (\ell+1) \right)^{2k}\alpha^{2 k \ell}.\end{align}
\begin{align}I_1\leq c^{\prime}_0 n\ell^{4k}c_1^{ k^2}c_2^k(k \ell + 1)^2\left( (k\ell+2)^2 (\ell+1) \right)^{2k}\alpha^{2 k \ell}.\end{align}
5.8.2
Bounding
$I_2$

Here there is at least one edge traversed exactly once, so we have
 $\mathcal{E} \geq \mathcal{V}$
for
$\mathcal{E} \geq \mathcal{V}$
for
 $\gamma\in \mathcal{C}_2$
. Taking
$\gamma\in \mathcal{C}_2$
. Taking
 $\mathcal{E}_1 = 0$
only increases the right-hand side on equation (26); it becomes
$\mathcal{E}_1 = 0$
only increases the right-hand side on equation (26); it becomes
 \begin{align*}I_2&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V}=1}^{k\ell+1} \sum_{\mathcal{E}=\mathcal{V}}^{2k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\alpha^{2(\mathcal{V}-1)}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k}\sum_{\chi= 1}^{2k\ell - \mathcal{V} + 1}\left( \alpha^2 ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n}\right)^\chi\end{align*}
\begin{align*}I_2&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V}=1}^{k\ell+1} \sum_{\mathcal{E}=\mathcal{V}}^{2k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V} = 1}^{k\ell+1}\alpha^{2(\mathcal{V}-1)}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k}\sum_{\chi= 1}^{2k\ell - \mathcal{V} + 1}\left( \alpha^2 ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n}\right)^\chi\end{align*}
Notice that this last term is almost identical to the one in the bound of
 $I_1$
, except that now we start the second sum at
$I_1$
, except that now we start the second sum at
 $\chi=1$
, which leads to an extra factor of
$\chi=1$
, which leads to an extra factor of
 $O( ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} / n )$
. This allow us to factor out another geometric series and proceed as we did for
$O( ((\mathcal{V} + 1)^2 (\ell + 1))^{2k} / n )$
. This allow us to factor out another geometric series and proceed as we did for
 $I_1$
. This yields
$I_1$
. This yields
 \begin{align}I_2\leq c^{\prime}_0\ell^{4k}c_1^{ k^2}c_2^k(k \ell+1)^2\left( (k\ell+2)^2 (\ell+1) \right)^{4k}\alpha^{2k\ell},\end{align}
\begin{align}I_2\leq c^{\prime}_0\ell^{4k}c_1^{ k^2}c_2^k(k \ell+1)^2\left( (k\ell+2)^2 (\ell+1) \right)^{4k}\alpha^{2k\ell},\end{align}
since there are
 $k\ell+1$
terms in the first sum.
$k\ell+1$
terms in the first sum.
5.8.3
Bounding
$I_3$

This set will require more delicate treatment, since circuits in
 $\mathcal{C}_3$
visit potentially many vertices and edges, yet we need to keep the power of
$\mathcal{C}_3$
visit potentially many vertices and edges, yet we need to keep the power of
 $\alpha$
at most
$\alpha$
at most
 $2k\ell$
.
$2k\ell$
.
We first show that, in this case,
 $\mathcal{E}_1$
is also large. We have
$\mathcal{E}_1$
is also large. We have
 $\mathcal{E} \geq \mathcal{V}$
, and let
$\mathcal{E} \geq \mathcal{V}$
, and let
 $\mathcal{V} = k\ell + t$
. Define
$\mathcal{V} = k\ell + t$
. Define
 $\mathcal{E}^{\prime}_1$
as the number of edges traversed once in
$\mathcal{E}^{\prime}_1$
as the number of edges traversed once in
 $\gamma$
, so that
$\gamma$
, so that
 $\mathcal{E}^{\prime}_1 = b + \mathcal{E}_1$
. Since
$\mathcal{E}^{\prime}_1 = b + \mathcal{E}_1$
. Since
 $\gamma$
has length
$\gamma$
has length
 $2k \ell$
, we deduce that
$2k \ell$
, we deduce that
 $2 (\mathcal{E} - \mathcal{E}^{\prime}_1) + \mathcal{E}^{\prime}_1 \leq 2k\ell$
, which implies that
$2 (\mathcal{E} - \mathcal{E}^{\prime}_1) + \mathcal{E}^{\prime}_1 \leq 2k\ell$
, which implies that
 $\mathcal{E}^{\prime}_1 \geq 2t$
. Finally, Lemma 5.13 yields
$\mathcal{E}^{\prime}_1 \geq 2t$
. Finally, Lemma 5.13 yields
 $\mathcal{E}_1 \geq (2t - 4 (\chi + k))_+$
. equation (26) then gives,
$\mathcal{E}_1 \geq (2t - 4 (\chi + k))_+$
. equation (26) then gives,
 \begin{align*}I_3&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V}=k\ell+1}^{2k\ell}\sum_{\mathcal{E}=\mathcal{V}}^{2k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\left( \frac{(c_4 k \ell)^2}{n} \right)^{(\mathcal{V} - k\ell - 2(\chi+k))_+}\nonumber \\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{t=1}^{k\ell}\sum_{\chi=1}^{k\ell - t+1}\alpha^{2 (k\ell + \chi + t-1)}(k\ell + t)((k\ell + t + 1)^2 (\ell + 1))^{2k(\chi + 1)}\\& \qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \cdot \left( \frac{c_3}{n} \right)^{\chi}\left( \frac{(c_4 k \ell)^2}{n} \right)^{(t - 2(\chi+k))_+}\nonumber \\&=c_0n\ell^{4k}c_1^{ k^2}c_2^k\alpha^{2 (k\ell-1)}\sum_{t=1}^{k\ell}(k\ell + t)((k\ell + t + 1)^2 (\ell + 1))^{2k}\alpha^{2t}\\& \qquad\qquad\qquad\qquad\qquad\qquad \cdot \sum_{\chi=1}^{k\ell - t+1}\left( \alpha^2 ((k\ell + t + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n} \right)^{\chi}\left( \frac{(c_4 k \ell)^2}{n} \right)^{(t - 2(\chi+k))_+}.\end{align*}
\begin{align*}I_3&\leq c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{\mathcal{V}=k\ell+1}^{2k\ell}\sum_{\mathcal{E}=\mathcal{V}}^{2k\ell}\alpha^{2\mathcal{E}}\mathcal{V}((\mathcal{V} + 1)^2 (\ell + 1))^{2k(\chi + 1)}\left( \frac{c_3}{n} \right)^\chi\left( \frac{(c_4 k \ell)^2}{n} \right)^{(\mathcal{V} - k\ell - 2(\chi+k))_+}\nonumber \\&=c_0 n\ell^{4k}c_1^{ k^2}c_2^k\sum_{t=1}^{k\ell}\sum_{\chi=1}^{k\ell - t+1}\alpha^{2 (k\ell + \chi + t-1)}(k\ell + t)((k\ell + t + 1)^2 (\ell + 1))^{2k(\chi + 1)}\\& \qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad \cdot \left( \frac{c_3}{n} \right)^{\chi}\left( \frac{(c_4 k \ell)^2}{n} \right)^{(t - 2(\chi+k))_+}\nonumber \\&=c_0n\ell^{4k}c_1^{ k^2}c_2^k\alpha^{2 (k\ell-1)}\sum_{t=1}^{k\ell}(k\ell + t)((k\ell + t + 1)^2 (\ell + 1))^{2k}\alpha^{2t}\\& \qquad\qquad\qquad\qquad\qquad\qquad \cdot \sum_{\chi=1}^{k\ell - t+1}\left( \alpha^2 ((k\ell + t + 1)^2 (\ell + 1))^{2k} \frac{c_3}{n} \right)^{\chi}\left( \frac{(c_4 k \ell)^2}{n} \right)^{(t - 2(\chi+k))_+}.\end{align*}
To simplify our notation, we will write
 \begin{equation*}F(k,\ell)=c_0n\ell^{4k}c_1^{ k^2}c_2^k\alpha^{2 (k\ell-1)}(2k\ell)((2k\ell + 1)^2 (\ell + 1))^{2k}.\end{equation*}
\begin{equation*}F(k,\ell)=c_0n\ell^{4k}c_1^{ k^2}c_2^k\alpha^{2 (k\ell-1)}(2k\ell)((2k\ell + 1)^2 (\ell + 1))^{2k}.\end{equation*}
Observe now that we can write
 \begin{equation*}I_3\leq F(k,\ell)\sum_{t=1}^{k\ell} \alpha^{2t}\sum_{\chi=1}^{k\ell-t+1} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2\chi)_+}\end{equation*}
\begin{equation*}I_3\leq F(k,\ell)\sum_{t=1}^{k\ell} \alpha^{2t}\sum_{\chi=1}^{k\ell-t+1} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2\chi)_+}\end{equation*}
where
 $c(k,\ell)=c_3\alpha^2((2k\ell+1)^2(\ell+1))^{2k}$
. To bound the double sum on the right-hand side above, we start by removing a factor of
$c(k,\ell)=c_3\alpha^2((2k\ell+1)^2(\ell+1))^{2k}$
. To bound the double sum on the right-hand side above, we start by removing a factor of
 $\frac{c(k,\ell)}{n}$
, which leaves
$\frac{c(k,\ell)}{n}$
, which leaves
 \begin{equation}I_3\leq F(k,\ell)\frac{c(k,\ell)}{n} \sum_{t=1}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2-2\chi)_+}\end{equation}
\begin{equation}I_3\leq F(k,\ell)\frac{c(k,\ell)}{n} \sum_{t=1}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2-2\chi)_+}\end{equation}
The n in the denominator is crucial to cancel the linear term in
 $F(k,\ell)$
, keeping the upper bound for
$F(k,\ell)$
, keeping the upper bound for
 $I_3$
small. We focus on bounding the double sum. We split the sum in t in two parts.
$I_3$
small. We focus on bounding the double sum. We split the sum in t in two parts.
Case 1:
 $t< 2k+2$
. For these values of t, we have
$t< 2k+2$
. For these values of t, we have
 $(t-2k-2-2\chi)_+=0$
, hence
$(t-2k-2-2\chi)_+=0$
, hence
 \begin{equation}\sum_{t=1}^{2k+1} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2-2\chi)_+}=\sum_{t=1}^{2k+1} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=O(\alpha^{4k})\end{equation}
\begin{equation}\sum_{t=1}^{2k+1} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi} \left(\frac{(c_4k\ell)^2}{n}\right)^{(t-2k-2-2\chi)_+}=\sum_{t=1}^{2k+1} \alpha^{2t}\sum_{\chi=0}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=O(\alpha^{4k})\end{equation}
where the last equality uses again the same geometric upper bound for the sum over
 $\chi$
.
$\chi$
.
Case 2:
 $t\geq 2k+2$
. We split the second sum, from
$t\geq 2k+2$
. We split the second sum, from
 $\chi=0$
to
$\chi=0$
to
 $N=\lfloor t/2-k-1\rfloor$
and the terms with
$N=\lfloor t/2-k-1\rfloor$
and the terms with
 $\chi > N$
and analyse the two separately. The first can be upper bounded by
$\chi > N$
and analyse the two separately. The first can be upper bounded by
 \begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{N}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k \ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)}\leq \alpha^{4k+4} \sum_{t=0}^{k\ell-2k-2}\alpha^{2t} (N+1)\left( \frac{c_4 k \ell}{\sqrt{n}} \right)^{\frac{t}{2}}.\end{equation*}
\begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{N}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k \ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)}\leq \alpha^{4k+4} \sum_{t=0}^{k\ell-2k-2}\alpha^{2t} (N+1)\left( \frac{c_4 k \ell}{\sqrt{n}} \right)^{\frac{t}{2}}.\end{equation*}
The last inequality can be checked in two steps: We first factor out the power of
 $\alpha^{4k+4}$
, and then use that
$\alpha^{4k+4}$
, and then use that
 $\frac{c(k,\ell)}{n}\leq \frac{c_4 k \ell}{\sqrt{n}}$
, which holds for large enough n, to simplify the second sum to the addition of
$\frac{c(k,\ell)}{n}\leq \frac{c_4 k \ell}{\sqrt{n}}$
, which holds for large enough n, to simplify the second sum to the addition of
 $N+1$
equal terms. To bound the right hand side, we one more time upper bound by a geometric series of ratio less than one to get
$N+1$
equal terms. To bound the right hand side, we one more time upper bound by a geometric series of ratio less than one to get
 \begin{equation}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{N}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k\ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)}\leq O(k\ell\alpha^{4k}).\end{equation}
\begin{equation}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=0}^{N}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k\ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)}\leq O(k\ell\alpha^{4k}).\end{equation}
We are left with the terms
 $\chi > N$
. In this case, we get
$\chi > N$
. In this case, we get
 $(t-2k-2-2\chi)_+=0$
, so
$(t-2k-2-2\chi)_+=0$
, so
 \begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k \ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)_+}=\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}.\end{equation*}
\begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t}\left(\frac{c(k,\ell)}{n}\right)^{\chi}\left(\frac{c_4 k \ell}{\sqrt{n}}\right)^{(t/2-k-1-\chi)_+}=\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}.\end{equation*}
The sum over
 $\chi$
is of the order of
$\chi$
is of the order of
 $\left(\frac{c(k,\ell)}{n}\right)^{N+1}\leq \left(\frac{c(k,\ell)}{n}\right)^{t/2-k-1}$
. Substituting this into the above, we are left with
$\left(\frac{c(k,\ell)}{n}\right)^{N+1}\leq \left(\frac{c(k,\ell)}{n}\right)^{t/2-k-1}$
. Substituting this into the above, we are left with
 \begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=C\sum_{t=2k+2}^{k\ell} \alpha^{2t}\left(\frac{c(k,\ell)}{n}\right)^{t/2-k-1}\end{equation*}
\begin{equation*}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=C\sum_{t=2k+2}^{k\ell} \alpha^{2t}\left(\frac{c(k,\ell)}{n}\right)^{t/2-k-1}\end{equation*}
for some universal constant C. After factoring
 $\alpha^{4k+4}$
and changing variables in the summation, we conclude that
$\alpha^{4k+4}$
and changing variables in the summation, we conclude that
 \begin{equation}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=C\alpha^{4k+4}\sum_{t=0}^{k\ell-2k-2} \alpha^{2t}\left(\frac{c(k,\ell)}{n}\right)^{t/2}=O(\alpha^{4k}).\end{equation}
\begin{equation}\sum_{t=2k+2}^{k\ell} \alpha^{2t}\sum_{\chi=N+1}^{k\ell-t} \left(\frac{c(k,\ell)}{n}\right)^{\chi}=C\alpha^{4k+4}\sum_{t=0}^{k\ell-2k-2} \alpha^{2t}\left(\frac{c(k,\ell)}{n}\right)^{t/2}=O(\alpha^{4k}).\end{equation}
Using (29) and the results for case 1 (30) and case 2 (31) and (32), we conclude that
 \begin{equation}I_3\leq F(k,\ell)\frac{c(k,\ell)}{n}O(k\ell \alpha^{4k})=c^{\prime}_0\ell^{4k}c_1^{ k^2}(c^{\prime}_2)^k(k\ell)^2((2k\ell + 1)^2 (\ell + 1))^{4k}\alpha^{2k\ell}\end{equation}
\begin{equation}I_3\leq F(k,\ell)\frac{c(k,\ell)}{n}O(k\ell \alpha^{4k})=c^{\prime}_0\ell^{4k}c_1^{ k^2}(c^{\prime}_2)^k(k\ell)^2((2k\ell + 1)^2 (\ell + 1))^{4k}\alpha^{2k\ell}\end{equation}
5.8.4 Finishing the proof of Theorem 5.15
We have bounded the three pieces we need to prove the theorem. From (27), (28), and (33), with n sufficiently large, we get
 \begin{align*}\mathbb{E} \left( \| \bar{B}^{(\ell)} \|^{2k}\right)&\leq I_1 + I_2 + I_3 \\&\leq \alpha^{2k\ell}n\cdot Cc_1^{ k^2}c_5^k\ell^{4k}(k \ell)^{4}\left(k^2\ell^3 \right)^{4k}\\&\leq \alpha^{2k\ell}n\cdot C'c_1^{(\log n)^{2/3}}c_6^{(\log n)^{1/3}}(\log n)^{4 (\log n)^{1/3}}(\log n)^{16/3}\,((\log n)^{11/3})^{4 (\log n)^{1/3}}\\&\leq \alpha^{2k\ell}n\cdot C''c_1^{(\log n)^{2/3}}c_6^{(\log n)^{1/3}}(\log n)^{20 (\log n)^{1/3} + 6}\\& :=\alpha^{2k\ell} n \cdot f(n) ,\end{align*}
\begin{align*}\mathbb{E} \left( \| \bar{B}^{(\ell)} \|^{2k}\right)&\leq I_1 + I_2 + I_3 \\&\leq \alpha^{2k\ell}n\cdot Cc_1^{ k^2}c_5^k\ell^{4k}(k \ell)^{4}\left(k^2\ell^3 \right)^{4k}\\&\leq \alpha^{2k\ell}n\cdot C'c_1^{(\log n)^{2/3}}c_6^{(\log n)^{1/3}}(\log n)^{4 (\log n)^{1/3}}(\log n)^{16/3}\,((\log n)^{11/3})^{4 (\log n)^{1/3}}\\&\leq \alpha^{2k\ell}n\cdot C''c_1^{(\log n)^{2/3}}c_6^{(\log n)^{1/3}}(\log n)^{20 (\log n)^{1/3} + 6}\\& :=\alpha^{2k\ell} n \cdot f(n) ,\end{align*}
where
 $c_5, c_6, C, C', C''$
are universal constants.
$c_5, c_6, C, C', C''$
are universal constants.
Take any
 $\epsilon > 0$
. It can be checked that
$\epsilon > 0$
. It can be checked that
 $(\log n)^{20 (\log n)^{1/3} + 6}= o(n^{\epsilon})$
, and
$(\log n)^{20 (\log n)^{1/3} + 6}= o(n^{\epsilon})$
, and
 $f(n) = o(n^{\epsilon})$
as well. Let
$f(n) = o(n^{\epsilon})$
as well. Let
 $g(n) = \exp((\log n)^{3/4})$
; then
$g(n) = \exp((\log n)^{3/4})$
; then
 $g(n) = o(n^\epsilon)$
but
$g(n) = o(n^\epsilon)$
but
 $g(n)^{2k} \gg n^\epsilon$
. We apply Markov’s inequality, so that
$g(n)^{2k} \gg n^\epsilon$
. We apply Markov’s inequality, so that
 \begin{align}\mathbb{P} \left[\| B^{(\ell)} \|\geq\alpha^{\ell} g(n)\right]&\leq \frac{ \mathbb{E} \left( \| \bar{B}^{(\ell)} \|^{2k} \right) }{ \alpha^{2k\ell} g(n)^{2k}}\leq \frac{n f(n)}{g(n)^{2k}}=o(1),\end{align}
\begin{align}\mathbb{P} \left[\| B^{(\ell)} \|\geq\alpha^{\ell} g(n)\right]&\leq \frac{ \mathbb{E} \left( \| \bar{B}^{(\ell)} \|^{2k} \right) }{ \alpha^{2k\ell} g(n)^{2k}}\leq \frac{n f(n)}{g(n)^{2k}}=o(1),\end{align}
which is the statement of the theorem.
Theorem 5.16. Let
 $1\leq j\leq \ell = \lfloor c \log(n) \rfloor$
where
$1\leq j\leq \ell = \lfloor c \log(n) \rfloor$
where
 $c < \frac{1}{32}$
is a universal constant. Then
$c < \frac{1}{32}$
is a universal constant. Then
 \begin{equation*}\|R^{\ell,j}\|\leq \frac{(d-1)^\ell}{n} \exp((\log n)^{3/4})\end{equation*}
\begin{equation*}\|R^{\ell,j}\|\leq \frac{(d-1)^\ell}{n} \exp((\log n)^{3/4})\end{equation*}
asymptotically almost surely.
Proof. The proof is analogous to the proof of Theorem 5.15. Recall the definition of
 $R^{\ell,j}$
in equation (15). For any integer k, we have that
$R^{\ell,j}$
in equation (15). For any integer k, we have that
 \begin{align}\mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right)&\leq \mathbb{E}\left(\textrm{Tr}\left[ \left( (R^{\ell,j}) (R^{\ell,j})^* \right)^{k}\right]\right)\nonumber \\&\leq \sum_{ \gamma \in \mathcal{D} }\prod_{s=1}^{2k}\left|\mathbb{E}\prod_{i=1}^{j-1} \bar{B}_{e^s_{2i-1} e^s_{2i+1}}S_{e^s_{2j-1} e^s_{2j+1}}\prod_{i=j+1}^{\ell} B_{e^s_{2i-1} e^s_{2i+1}}\right|\nonumber \\&=\sum_{ \gamma \in \mathcal{D} }\prod_{s=1}^{2k}\left|\mathbb{E}\prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}}S_{e^s_{2j-1} e^s_{2j+1}}\prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}}\right|\end{align}
\begin{align}\mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right)&\leq \mathbb{E}\left(\textrm{Tr}\left[ \left( (R^{\ell,j}) (R^{\ell,j})^* \right)^{k}\right]\right)\nonumber \\&\leq \sum_{ \gamma \in \mathcal{D} }\prod_{s=1}^{2k}\left|\mathbb{E}\prod_{i=1}^{j-1} \bar{B}_{e^s_{2i-1} e^s_{2i+1}}S_{e^s_{2j-1} e^s_{2j+1}}\prod_{i=j+1}^{\ell} B_{e^s_{2i-1} e^s_{2i+1}}\right|\nonumber \\&=\sum_{ \gamma \in \mathcal{D} }\prod_{s=1}^{2k}\left|\mathbb{E}\prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}}S_{e^s_{2j-1} e^s_{2j+1}}\prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}}\right|\end{align}
Now, the sum is over the set
 $\mathcal{D}$
of circuits
$\mathcal{D}$
of circuits
 $\gamma= (\gamma_1,\gamma_2,\dots,\gamma_{2k})$
of length
$\gamma= (\gamma_1,\gamma_2,\dots,\gamma_{2k})$
of length
 $2k\ell$
formed from 2k elements of
$2k\ell$
formed from 2k elements of
 $T^{\ell,j}$
,
$T^{\ell,j}$
,
 $\gamma_s = (e^s_1, e^s_2, \ldots, e^s_{2\ell+1} )$
for
$\gamma_s = (e^s_1, e^s_2, \ldots, e^s_{2\ell+1} )$
for
 $s \in [2k]$
, with the convention
$s \in [2k]$
, with the convention
 $e^{s+1}_1 = e^s_{2\ell+1}$
(see Definition 5.4).
$e^{s+1}_1 = e^s_{2\ell+1}$
(see Definition 5.4).
Proceeding as before, using Lemma 5.9 and Corollary 5.11, we get that
 \begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} \sum_{\gamma \in \mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R} } \prod_{s=1}^{2k} \left| \mathbb{E} \prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}} S_{e^s_{2j-1} e^s_{2j+1}} \prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}} \right| \\ &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} D_{\mathcal{V}, \mathcal{E}}^\mathcal{R} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \prod_{s=1}^{2k} \left| \mathbb{E} \prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}} S_{e^s_{2j-1} e^s_{2j+1}} \prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}} \right| \\ &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} m^\mathcal{R} n^{\mathcal{V}-\mathcal{R}} (2 \ell)^{6k} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} \\ & \qquad \qquad \cdot (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}} (d_2 (d_2 - 1))^\mathcal{R} (d - 1)^{2 (\chi - 1)} \\ & \qquad \qquad \cdot \prod_{s=1}^{2k} \left( \frac{d-1}{|E|} \right) C 2^{b_s} \left(\frac{1}{|E|} \right)^{\mathcal{E}_s} \left( \frac{6\ell}{\sqrt{|E|}} \right)^{\mathcal{E}_{1,s}} .\end{align*}
\begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} \sum_{\gamma \in \mathcal{D}_{\mathcal{V}, \mathcal{E}}^\mathcal{R} } \prod_{s=1}^{2k} \left| \mathbb{E} \prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}} S_{e^s_{2j-1} e^s_{2j+1}} \prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}} \right| \\ &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} D_{\mathcal{V}, \mathcal{E}}^\mathcal{R} I_{\mathcal{V}, \mathcal{E}}^\mathcal{R} \prod_{s=1}^{2k} \left| \mathbb{E} \prod_{i=1}^{j-1} \bar{M}_{e^s_{2i-1} e^s_{2i}} S_{e^s_{2j-1} e^s_{2j+1}} \prod_{i=j+1}^{\ell} M_{e^s_{2i-1} e^s_{2i}} \right| \\ &\leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} m^\mathcal{R} n^{\mathcal{V}-\mathcal{R}} (2 \ell)^{6k} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} \\ & \qquad \qquad \cdot (d_1 (d_1 - 1))^{\mathcal{V} - \mathcal{R}} (d_2 (d_2 - 1))^\mathcal{R} (d - 1)^{2 (\chi - 1)} \\ & \qquad \qquad \cdot \prod_{s=1}^{2k} \left( \frac{d-1}{|E|} \right) C 2^{b_s} \left(\frac{1}{|E|} \right)^{\mathcal{E}_s} \left( \frac{6\ell}{\sqrt{|E|}} \right)^{\mathcal{E}_{1,s}} .\end{align*}
The last inequality uses Lemma 5.6 on each path
 $\gamma_s$
, with
$\gamma_s$
, with
 $\mathcal{E}_s$
,
$\mathcal{E}_s$
,
 $b_s$
, and
$b_s$
, and
 $\mathcal{E}_{1,s}$
defined analogous to the quantities
$\mathcal{E}_{1,s}$
defined analogous to the quantities
 $\mathcal{E}$
, b, and
$\mathcal{E}$
, b, and
 $\mathcal{E}_1$
in the same lemma. Note that
$\mathcal{E}_1$
in the same lemma. Note that
 $S_{ef} \leq \frac{d-1}{|E|}$
for any e,f and
$S_{ef} \leq \frac{d-1}{|E|}$
for any e,f and
 $\sum_{s=1}^{2k} b_s \leq b_\mathcal{D} \leq 16 (k + \chi)$
by Lemma 5.14. Setting
$\sum_{s=1}^{2k} b_s \leq b_\mathcal{D} \leq 16 (k + \chi)$
by Lemma 5.14. Setting
 $\mathcal{E} = \sum_{s=1}^{2k} \mathcal{E}_s$
, taking
$\mathcal{E} = \sum_{s=1}^{2k} \mathcal{E}_s$
, taking
 $\mathcal{E}_1 = \sum_{s=1}^{2k} \mathcal{E}_{1,s} \geq 0$
, using
$\mathcal{E}_1 = \sum_{s=1}^{2k} \mathcal{E}_{1,s} \geq 0$
, using
 $d_1, d_2 \leq d$
, and combining terms, we find that
$d_1, d_2 \leq d$
, and combining terms, we find that
 \begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) & \leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} (2 \ell)^{6k} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} \\ & \qquad \qquad \cdot (d_1 - 1)^{\mathcal{V} - \mathcal{R}} (d_2 - 1)^\mathcal{R} (d - 1)^{2 (\chi - 1)} \\ & \qquad \qquad \cdot \left( \frac{C'}{|E|} \right)^{2k} 2^{b_\mathcal{D}} \left(\frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V}, \mathcal{E}} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} (d - 1)^{\mathcal{V}} \left( \frac{c_2}{n} \right)^{\chi} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V} = 1}^{2k\ell} \sum_{\mathcal{E} = \mathcal{V} - 1}^{2k\ell} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} (d - 1)^{\mathcal{V}} \left( \frac{c_2}{n} \right)^{\chi} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V} = 1}^{2k\ell} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} (d - 1)^{\mathcal{V}} \sum_{\chi = 0}^{2k\ell} \left( ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} \frac{c_2}{n} \right)^{\chi} , \end{align*}
\begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) & \leq \sum_{\mathcal{V}, \mathcal{E}, \mathcal{R}} (2 \ell)^{6k} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} \\ & \qquad \qquad \cdot (d_1 - 1)^{\mathcal{V} - \mathcal{R}} (d_2 - 1)^\mathcal{R} (d - 1)^{2 (\chi - 1)} \\ & \qquad \qquad \cdot \left( \frac{C'}{|E|} \right)^{2k} 2^{b_\mathcal{D}} \left(\frac{1}{|E|} \right)^{\mathcal{E} - \mathcal{V}} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V}, \mathcal{E}} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} (d - 1)^{\mathcal{V}} \left( \frac{c_2}{n} \right)^{\chi} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V} = 1}^{2k\ell} \sum_{\mathcal{E} = \mathcal{V} - 1}^{2k\ell} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k(\chi + 1)} (d - 1)^{\mathcal{V}} \left( \frac{c_2}{n} \right)^{\chi} \\ &\leq c_0 \ell^{6k} c_1^k n^{1 - 2k} \sum_{\mathcal{V} = 1}^{2k\ell} \mathcal{V} ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} (d - 1)^{\mathcal{V}} \sum_{\chi = 0}^{2k\ell} \left( ( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} \frac{c_2}{n} \right)^{\chi} , \end{align*}
for some constants
 $c_0, c_1, c_2$
. Note that the important
$c_0, c_1, c_2$
. Note that the important
 $n^{-2k}$
comes from the
$n^{-2k}$
comes from the
 $|E|^{-2k}$
deterministic term. Now, like before we have that
$|E|^{-2k}$
deterministic term. Now, like before we have that
 $( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} = o(n)$
, so for sufficiently large n we can bound the sum over
$( (\mathcal{V} + 1)^2 (\ell + 1) )^{6k} = o(n)$
, so for sufficiently large n we can bound the sum over
 $\chi$
by a constant. The sum over
$\chi$
by a constant. The sum over
 $\mathcal{V}$
is easily bounded as before, leading to
$\mathcal{V}$
is easily bounded as before, leading to
 \begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) &\leq (d-1)^{2k\ell} n^{1-2k} \cdot c^{\prime}_0 \ell^{6k} c_1^k (2k\ell)^2 ((2k\ell + 1)^2 (\ell + 1))^{6k} \\
&\leq (d-1)^{2k\ell} n^{1-2k} \cdot c^{\prime\prime}_0 c^{\prime(\log n)^{1/3}}_1 (\log n)^{6(\log n)^{1/3}} (\log n)^{8/3} ((\log n)^{11/3})^{6(\log n)^{1/3}} \\ &:= (d-1)^{2k\ell} n^{1-2k} \cdot f(n).\end{align*}
\begin{align*} \mathbb{E}\left(\|R^{\ell,j}\|^{2k}\right) &\leq (d-1)^{2k\ell} n^{1-2k} \cdot c^{\prime}_0 \ell^{6k} c_1^k (2k\ell)^2 ((2k\ell + 1)^2 (\ell + 1))^{6k} \\
&\leq (d-1)^{2k\ell} n^{1-2k} \cdot c^{\prime\prime}_0 c^{\prime(\log n)^{1/3}}_1 (\log n)^{6(\log n)^{1/3}} (\log n)^{8/3} ((\log n)^{11/3})^{6(\log n)^{1/3}} \\ &:= (d-1)^{2k\ell} n^{1-2k} \cdot f(n).\end{align*}
To finish the proof, we note that
 $f(n) = o(n^\epsilon)$
for any
$f(n) = o(n^\epsilon)$
for any
 $\epsilon > 0$
. Take
$\epsilon > 0$
. Take
 $g(n) = \exp((\log n)^{3/4})$
. Then, applying Markov’s inequality,
$g(n) = \exp((\log n)^{3/4})$
. Then, applying Markov’s inequality,
 \begin{equation} \mathbb{P} \left[ \| R^{\ell,j} \| \geq \frac{(d - 1)^{\ell} }{n} g(n) \right] \leq \frac{\mathbb{E} \left( \| R^{\ell,j} \|^{2k} \right) n^{2k}} { (d-1)^{2k\ell} g(n)^{2k} } \leq \frac{n f(n)}{g(n)^{2k}} = o(1).\end{equation}
\begin{equation} \mathbb{P} \left[ \| R^{\ell,j} \| \geq \frac{(d - 1)^{\ell} }{n} g(n) \right] \leq \frac{\mathbb{E} \left( \| R^{\ell,j} \|^{2k} \right) n^{2k}} { (d-1)^{2k\ell} g(n)^{2k} } \leq \frac{n f(n)}{g(n)^{2k}} = o(1).\end{equation}
5.9. Proof of the main result, Theorem 3.1
We will again take
 $\ell = \lfloor c \log n \rfloor$
, with c chosen so that the graph is
$\ell = \lfloor c \log n \rfloor$
, with c chosen so that the graph is
 $\ell$
-tangle-free with high probability. By equations (10) and (17),
$\ell$
-tangle-free with high probability. By equations (10) and (17),
 \begin{equation*}|\lambda_2|^{\ell}\leq \| \bar{B}^{(\ell)}\|+\sum_{k=1}^{\ell} \| R^{\ell,j}\|.\end{equation*}
\begin{equation*}|\lambda_2|^{\ell}\leq \| \bar{B}^{(\ell)}\|+\sum_{k=1}^{\ell} \| R^{\ell,j}\|.\end{equation*}
Notice that
 $(d-1)^\ell \leq (d-1)^{c \log n} \leq n^{c \log d}$
, so take
$(d-1)^\ell \leq (d-1)^{c \log n} \leq n^{c \log d}$
, so take
 $c < \min \left(\frac{1}{32}, \frac{1}{\log d} \right)$
. Then
$c < \min \left(\frac{1}{32}, \frac{1}{\log d} \right)$
. Then
 $(d-1)^\ell = O(n^\epsilon)$
for some
$(d-1)^\ell = O(n^\epsilon)$
for some
 $0 < \epsilon < 1$
, and recall that
$0 < \epsilon < 1$
, and recall that
 $\exp((\log n)^{3/4}) = o(n^{\epsilon'})$
for any
$\exp((\log n)^{3/4}) = o(n^{\epsilon'})$
for any
 $\epsilon' > 0$
. We apply Theorems 5.15 and 5.16 to get
$\epsilon' > 0$
. We apply Theorems 5.15 and 5.16 to get
 \begin{eqnarray}\nonumber|\lambda_2|& \leq &\left(\exp((\log n)^{3/4}) \left( (d_1-1)(d_2-1) \right)^{\ell/4}+\ell\exp((\log n)^{3/4})\frac{(d-1)^\ell}{n}\right)^{1/\ell} \\\nonumber& = & \left( (d_1-1)(d_2-1) \right)^{1/4}+\epsilon_n,\end{eqnarray}
\begin{eqnarray}\nonumber|\lambda_2|& \leq &\left(\exp((\log n)^{3/4}) \left( (d_1-1)(d_2-1) \right)^{\ell/4}+\ell\exp((\log n)^{3/4})\frac{(d-1)^\ell}{n}\right)^{1/\ell} \\\nonumber& = & \left( (d_1-1)(d_2-1) \right)^{1/4}+\epsilon_n,\end{eqnarray}
where
 $\epsilon_n \to 0$
as
$\epsilon_n \to 0$
as
 $n \to \infty$
.
$n \to \infty$
.
6. Application: community detection
In many cases, such as online networks, we would like to be able to recover specific communities in those graphs. In the typical setup, a community is a set of vertices that are more densely connected together than to the rest of the graph.
The model we present here is inspired by the planted partition or stochastic blockmodel (SBM, [Reference Holland, Laskey and Leinhardt34]). In the SBM, each vertex belongs to a class or community, and the probability that two vertices are connected is a function of the classes of the vertices. It is a generalisation of the ErdÖs-Rényi random graph. The classes or blocks in the SBM make it a good model for graphs with community structure, where nodes preferentially connect to other nodes depending on their communities [Reference Newman55].
There are many methods for detecting a community given a graph. For an overview of the topic, see [Reference Fortunato26]. Spectral clustering is a common method which can be applied to any set of data
 $\{ \zeta_i \}_{i=1}^n$
. Given a symmetric and non-negative similarity function S, the similarity is computed for every pair of data points, forming a matrix
$\{ \zeta_i \}_{i=1}^n$
. Given a symmetric and non-negative similarity function S, the similarity is computed for every pair of data points, forming a matrix
 $A_{ij} = S(\zeta_i, \zeta_j ) = S(\zeta_j, \zeta_i ) \geq 0$
. The spectral clustering technique is to compute the leading eigenvectors of A, or matrices related to it, and use the eigenvectors to cluster the data. In our case, the matrix in question is just the Markov matrix of a graph, defined soon. We will show that we can guarantee the success of the technique if the degrees are large enough.
$A_{ij} = S(\zeta_i, \zeta_j ) = S(\zeta_j, \zeta_i ) \geq 0$
. The spectral clustering technique is to compute the leading eigenvectors of A, or matrices related to it, and use the eigenvectors to cluster the data. In our case, the matrix in question is just the Markov matrix of a graph, defined soon. We will show that we can guarantee the success of the technique if the degrees are large enough.
Our graph model is a regular version of the SBM. We build it on a ‘frame,’ which is a small, weighted graph that defines the community structure present in the larger, random graph. Each class is represented by a vertex in the frame. The edge weights in the frame define the number of edges between classes. What makes our model differ from the SBM is that the connections between classes are described by a regular random graph rather than an ErdÖs-Rényi random graph. However, the graph itself is not necessarily regular.
A number of authors have studied similar models. Our model is a generalisation of a random lift of the frame, which is said to cover the random graph (e.g. [Reference Marcus, Spielman and Srivastava49, Reference Angel, Friedman and Hoory3, Reference Bordenave, Lelarge and Massoulié14]). This type of random graph was also studied by [Reference Newman and Martin54], who called it an equitable random graph, since the community structure is equivalent to an equitable partition. This partition induces a number of symmetries across vertices in each community which are useful when studying the eigenvalues of the graph. Barrett et al. [Reference Barrett, Francis and Webb4] studied the effect of these symmetries from a group theory standpoint. The work of [Reference Barucca5] is closest to ours: they consider spectral properties of such graphs and their implications for spectral community clustering. In particular, they show that the spectrum of what we call the ‘frame’ (in their words, the discrete spectrum, which is deterministic) is contained in that of the random graph. They use the resolvent method (called the cavity method in the physics community) to analyse the continuous part of the spectrum in the limit of large graph size and argue that community detection is possible when the deterministic frame eigenvalues all lie outside the bulk. However, this analysis assumes that there are no stochastic eigenvalues outside the bulk, which will only hold with high probability if the graph is Ramanujan. Our analysis shows that, if a set of pairwise spectral gaps hold between all communities, then this will be the case.
6.1. The frame model
We define the random regular frame graph distribution
 $\mathcal{G}(n,H)$
as a distribution of simple graphs on n vertices parametrised by the ‘frame’ H. The frame
$\mathcal{G}(n,H)$
as a distribution of simple graphs on n vertices parametrised by the ‘frame’ H. The frame
 $H=(V,E,p,D)$
is a weighted, directed graph. Here, V is the vertex set,
$H=(V,E,p,D)$
is a weighted, directed graph. Here, V is the vertex set,
 $E \subseteq \{(i,j): i,j \in V\}$
is the directed edge set, the vertex weights are p, and the edge weights are D. Note that we drop the arrows on the edge set in this section, since it will always be directed. The vertex weight vector
$E \subseteq \{(i,j): i,j \in V\}$
is the directed edge set, the vertex weights are p, and the edge weights are D. Note that we drop the arrows on the edge set in this section, since it will always be directed. The vertex weight vector
 $p \in \mathbb{R}^{|V|}$
, where
$p \in \mathbb{R}^{|V|}$
, where
 $\sum_{i \in V} p_i = 1$
, sets the relative sizes of the classes. The edge weights are a matrix of degrees
$\sum_{i \in V} p_i = 1$
, sets the relative sizes of the classes. The edge weights are a matrix of degrees
 $D \in \mathbb{N}^{|V| \times |V|}$
. These assign the number of edges between each class in the random graph:
$D \in \mathbb{N}^{|V| \times |V|}$
. These assign the number of edges between each class in the random graph:
 $D_{ij}$
is the number of edges from each vertex in class i to vertices in class j. The degrees must satisfy the balance condition
$D_{ij}$
is the number of edges from each vertex in class i to vertices in class j. The degrees must satisfy the balance condition
 \begin{equation} p_i D_{ij} = p_j D_{ji}\end{equation}
\begin{equation} p_i D_{ij} = p_j D_{ji}\end{equation}
for all
 $i,j \in V$
where (i,j) or (j,i) are in E. This requires that, for every edge
$i,j \in V$
where (i,j) or (j,i) are in E. This requires that, for every edge
 $e \in E$
, its reverse orientation also exists in H. We also require that
$e \in E$
, its reverse orientation also exists in H. We also require that
 $n_i = n p_i \in \mathbb{N}$
for every
$n_i = n p_i \in \mathbb{N}$
for every
 $i \in V$
, so that the number of vertices in each type is integer.
$i \in V$
, so that the number of vertices in each type is integer.
Given the frame H, a random regular frame graph
 $G \sim \mathcal{G}(n,H)$
is a simple graph on n vertices with
$G \sim \mathcal{G}(n,H)$
is a simple graph on n vertices with
 $n_i$
vertices in class i. It is chosen uniformly among graphs with the constraint that each vertex in class i makes
$n_i$
vertices in class i. It is chosen uniformly among graphs with the constraint that each vertex in class i makes
 $D_{ij}$
connections among the vertices in class j. In other words, if
$D_{ij}$
connections among the vertices in class j. In other words, if
 $i = j$
, we sample that block of the adjacency matrix as the adjacency matrix of a
$i = j$
, we sample that block of the adjacency matrix as the adjacency matrix of a
 $D_{ii}$
-regular random graph on
$D_{ii}$
-regular random graph on
 $n_i$
vertices. For off-diagonal blocks
$n_i$
vertices. For off-diagonal blocks
 $i \neq j$
, these are sampled as bipartite, biregular random graphs
$i \neq j$
, these are sampled as bipartite, biregular random graphs
 $\mathcal{G} (n_i, n_j, D_{ij}, D_{ji})$
.
$\mathcal{G} (n_i, n_j, D_{ij}, D_{ji})$
.
Sampling from
 $\mathcal{G}(n,H)$
can be performed similar to the configuration model, where each node is assigned as many half-edges as its degree, and these are wired together with a random matching [Reference Newman55]. The detailed balance condition equation (37) ensures that this matching is possible. Practically, we often have to generate many candidate matchings before the resulting graph is simple, but the probability of a simple graph is bounded away from zero for fixed D.
$\mathcal{G}(n,H)$
can be performed similar to the configuration model, where each node is assigned as many half-edges as its degree, and these are wired together with a random matching [Reference Newman55]. The detailed balance condition equation (37) ensures that this matching is possible. Practically, we often have to generate many candidate matchings before the resulting graph is simple, but the probability of a simple graph is bounded away from zero for fixed D.
An example of a random regular frame graph is the bipartite, biregular random graph. The family
 $\mathcal{G}(n, m, d_1, d_2)$
is a random regular frame graph
$\mathcal{G}(n, m, d_1, d_2)$
is a random regular frame graph
 $\mathcal{G}(n + m, H)$
, where the frame H is the directed path on two vertices:
$\mathcal{G}(n + m, H)$
, where the frame H is the directed path on two vertices:
 $V= \{ 1, 2 \}$
and
$V= \{ 1, 2 \}$
and
 $E = \{ (1,2), (2,1) \}$
. The weights are taken as
$E = \{ (1,2), (2,1) \}$
. The weights are taken as
 $p_1 = n/(n+m)$
,
$p_1 = n/(n+m)$
,
 $p_2 = m/(n+m)$
,
$p_2 = m/(n+m)$
,
 $D_{12} = d_1$
, and
$D_{12} = d_1$
, and
 $D_{21} = d_2$
.
$D_{21} = d_2$
.
Another example random regular frame graph is shown in Figure 6. In this case, the frame H has
 $V= \{ A, B, C \}$
and
$V= \{ A, B, C \}$
and
 $E = \{ (A,B), (A,C), (B,A), (B,C), (C,A), (C,B) \}$
with weights p and D as shown in Figure 6A. We see that this generates a random tripartite graph with regular degrees between vertices in different independent sets, shown in Figure 6B.
$E = \{ (A,B), (A,C), (B,A), (B,C), (C,A), (C,B) \}$
with weights p and D as shown in Figure 6A. We see that this generates a random tripartite graph with regular degrees between vertices in different independent sets, shown in Figure 6B.

Figure 6. Schematic and realisation of a random regular frame graph. A, The frame graph. The vertices of the frame (red = A, green = B, blue = C) are weighted according to their proportions p in the random regular frame graph. The edge weights
 $D_{ij}$
set the between-class vertex degrees in the random regular frame graph. This frame will yield a random tripartite graph. B, Realisation of the graph on 72 vertices. In this instance, there are
$D_{ij}$
set the between-class vertex degrees in the random regular frame graph. This frame will yield a random tripartite graph. B, Realisation of the graph on 72 vertices. In this instance, there are
 $1/8 \times 72=9$
green and red vertices and
$1/8 \times 72=9$
green and red vertices and
 $3/4 \times 72=54$
blue vertices. Each blue vertex connects to
$3/4 \times 72=54$
blue vertices. Each blue vertex connects to
 $k_{CA}=1$
red vertex and
$k_{CA}=1$
red vertex and
 $k_{CB}=2$
green vertices. This is actually a multigraph; with so few vertices, the probability that the configuration model algorithm yields parallel edges is high.
$k_{CB}=2$
green vertices. This is actually a multigraph; with so few vertices, the probability that the configuration model algorithm yields parallel edges is high.
6.2. Markov and related matrices of frame graphs
Now, we define a number of matrices associated with the frame and the sample of the random regular frame graph.
Let G be a simple graph. Define
 $D_G = \textrm{diag}(d_G)$
, the diagonal matrix of degrees in G. The Markov matrix
$D_G = \textrm{diag}(d_G)$
, the diagonal matrix of degrees in G. The Markov matrix
 $P=P(G)$
is defined as
$P=P(G)$
is defined as
 \begin{equation*}P = D_G^{-1} A,\end{equation*}
\begin{equation*}P = D_G^{-1} A,\end{equation*}
where
 $A=A(G)$
is the adjacency matrix. The Markov matrix is the row-normalized adjacency matrix, and it contains the transition probabilities of a random walker on the graph G. Let
$A=A(G)$
is the adjacency matrix. The Markov matrix is the row-normalized adjacency matrix, and it contains the transition probabilities of a random walker on the graph G. Let
 $L = I - \mathcal{L} = D_G^{-1/2} A \, D_G^{-1/2}$
be a matrix simply related to the normalized Laplacian. We call this the symmetrized Markov matrix. Then P and L have the same eigenvalues, but L is symmetric, since
$L = I - \mathcal{L} = D_G^{-1/2} A \, D_G^{-1/2}$
be a matrix simply related to the normalized Laplacian. We call this the symmetrized Markov matrix. Then P and L have the same eigenvalues, but L is symmetric, since
 $L_{ij} = \frac{A_{ij}}{ \sqrt{ d_i d_j } }$
.
$L_{ij} = \frac{A_{ij}}{ \sqrt{ d_i d_j } }$
.
Suppose
 $G \sim \mathcal{G}(n, H)$
, where the frame
$G \sim \mathcal{G}(n, H)$
, where the frame
 $H = (V,E,p, D)$
. Another matrix that will be useful is what we call the Markov matrix of the frame R, where
$H = (V,E,p, D)$
. Another matrix that will be useful is what we call the Markov matrix of the frame R, where
 $R_{ij} = \frac{ D_{ij} }{\sum_j D_{ij}}$
. Thus, R is a row-normalized D, in the same way that the Markov matrix P is the row-normalized adjacency matrix A. Furthermore, R is invariant under any uniform scaling of the degrees. Because of this equitable partition property of random regular frame graphs, eigenvectors of the frame matrices
$R_{ij} = \frac{ D_{ij} }{\sum_j D_{ij}}$
. Thus, R is a row-normalized D, in the same way that the Markov matrix P is the row-normalized adjacency matrix A. Furthermore, R is invariant under any uniform scaling of the degrees. Because of this equitable partition property of random regular frame graphs, eigenvectors of the frame matrices
 $D=D(H)$
or
$D=D(H)$
or
 $R=R(H)$
lift to eigenvectors of
$R=R(H)$
lift to eigenvectors of
 $A = A(G)$
or
$A = A(G)$
or
 $P=P(G)$
, respectively. Suppose
$P=P(G)$
, respectively. Suppose
 $D x = \lambda x$
, then it is a straightforward exercise to check that
$D x = \lambda x$
, then it is a straightforward exercise to check that
 $A \tilde{x} = \lambda \tilde{x}$
for the piecewise constant vector
$A \tilde{x} = \lambda \tilde{x}$
for the piecewise constant vector
 \begin{equation*}\tilde{x} =\left[\begin{array}{c}\textbf{1}_{n_1} x_1 \\\textbf{1}_{n_2} x_2 \\\vdots\end{array}\right] .\end{equation*}
\begin{equation*}\tilde{x} =\left[\begin{array}{c}\textbf{1}_{n_1} x_1 \\\textbf{1}_{n_2} x_2 \\\vdots\end{array}\right] .\end{equation*}
Using the same procedure, we can lift any eigenpair of R to an eigenpair of P with the same eigenvalue.
6.2.1 Bounds on the eigenvalues of frame graphs in terms of blocks
The following result is due to [Reference Wan, Meilă, Cortes, Lawrence, Lee, Sugiyama and Garnett62]:
Proposition 6.1. Let G be a random regular frame graph G(n,H), P its Markov matrix, and L the Laplacian with vertices ordered by class in both cases. Let R be the Markov matrix of the frame
 $H=(V,E,p,D)$
, with
$H=(V,E,p,D)$
, with
 $|V(H)| = K$
classes. Define the matrices
$|V(H)| = K$
classes. Define the matrices
 $L^{(kl)}$
as the (k,l) block of L with respect to the clustering of vertices by class. For
$L^{(kl)}$
as the (k,l) block of L with respect to the clustering of vertices by class. For
 $l \neq k$
, let
$l \neq k$
, let
 \begin{equation*}M^{(kl)} =\left(\begin{array}{cc}0 & L^{(kl)} \\L^{(kl)} & 0\end{array}\right)=\left(\begin{array}{cc}0 & L^{(kl)} \\L^{(lk)*} & 0\end{array}\right).\end{equation*}
\begin{equation*}M^{(kl)} =\left(\begin{array}{cc}0 & L^{(kl)} \\L^{(kl)} & 0\end{array}\right)=\left(\begin{array}{cc}0 & L^{(kl)} \\L^{(lk)*} & 0\end{array}\right).\end{equation*}
For
 $l=k$
, let
$l=k$
, let
 $M^{(kk)} = L^{(kk)}$
. Assume that all eigenvalues of D are nonzero and pick a constant C such that
$M^{(kk)} = L^{(kk)}$
. Assume that all eigenvalues of D are nonzero and pick a constant C such that
 \begin{equation*} \frac{| \lambda_2^{(kl)} |}{\lambda_1^{(kl)}} \le C
< 1\end{equation*}
\begin{equation*} \frac{| \lambda_2^{(kl)} |}{\lambda_1^{(kl)}} \le C
< 1\end{equation*}
for every
 $k,l = 1, \ldots K$
, where
$k,l = 1, \ldots K$
, where
 $\lambda_1^{(kl)}$
and
$\lambda_1^{(kl)}$
and
 $\lambda_2^{(kl)}$
are the leading and second eigenvalues of
$\lambda_2^{(kl)}$
are the leading and second eigenvalues of
 $M^{(kl)}$
. Under these conditions, the eigenvalues of P which are not eigenvalues of R are bounded by
$M^{(kl)}$
. Under these conditions, the eigenvalues of P which are not eigenvalues of R are bounded by
 \begin{equation*}C \max_{k=1,\ldots, K} \left( R_{kk} + \sum_{l \neq k} \sqrt{R_{kl} R_{lk}} \right)\leq \frac{C}{2} \left(1 + \max_{k=1,\ldots, K} \sum_{l=1}^K R_{lk} \right) .\end{equation*}
\begin{equation*}C \max_{k=1,\ldots, K} \left( R_{kk} + \sum_{l \neq k} \sqrt{R_{kl} R_{lk}} \right)\leq \frac{C}{2} \left(1 + \max_{k=1,\ldots, K} \sum_{l=1}^K R_{lk} \right) .\end{equation*}
The spectrum of the Markov matrix
 $\sigma(P)$
enjoys a simple connection to
$\sigma(P)$
enjoys a simple connection to
 $\sigma(A)$
when A is the adjacency matrix of a graph drawn from
$\sigma(A)$
when A is the adjacency matrix of a graph drawn from
 $G(n,m,d_1,d_2)$
. In this case,
$G(n,m,d_1,d_2)$
. In this case,
 $L = \frac{ A }{ \sqrt{d_1 d_2} }$
, so the eigenvalues of P are just the scaled eigenvalues of A. This and the spectral gap for bipartite, biregular random graphs, Theorem 3.2, lead to the following remark:
$L = \frac{ A }{ \sqrt{d_1 d_2} }$
, so the eigenvalues of P are just the scaled eigenvalues of A. This and the spectral gap for bipartite, biregular random graphs, Theorem 3.2, lead to the following remark:
Remark. For a random regular frame graph,
 $M^{(kl)}$
corresponds to the symmetrized Markov matrix L of a bipartite biregular graph
$M^{(kl)}$
corresponds to the symmetrized Markov matrix L of a bipartite biregular graph
 $G(n_k, n_l, D_{kl}, D_{lk})$
. Thus,
$G(n_k, n_l, D_{kl}, D_{lk})$
. Thus,
 \begin{equation*}\frac{| \lambda_2^{(kl)} |}{\lambda_1^{(kl)}}\leq \frac{\sqrt{D_{kl} - 1} +\sqrt{D_{lk} - 1}}{\sqrt{D_{kl} D_{lk}}} + \epsilon .\end{equation*}
\begin{equation*}\frac{| \lambda_2^{(kl)} |}{\lambda_1^{(kl)}}\leq \frac{\sqrt{D_{kl} - 1} +\sqrt{D_{lk} - 1}}{\sqrt{D_{kl} D_{lk}}} + \epsilon .\end{equation*}
Suppose we are given a frame that fits the conditions of Proposition 6.1; namely, D cannot have any zero eigenvalues. Then we can uniformly grow the degrees, which leaves R invariant, but allows us to reach an arbitrarily small C. This ensures that the leading K eigenvalues of P are equal to the eigenvalues of R. Note that this actually means that the entire random regular frame graph satifsfies a weak Ramanujan property. We now show that this guarantees spectral clustering.
6.3. Spectral clustering
Spectral clustering is a popular method of community detection. Because some eigenvectors of P, the Markov matrix of a random regular frame graph, are piecewise constant on classes, we can use them to recover the communities so long as those eigenvectors can be identified. Suppose there are K total classes in our random regular frame graph. Then, given the eigenvectors
 $x^1, x^2, \ldots, x^K$
, which are piecewise constant across classes, we can cluster vertices by class. For each vertex
$x^1, x^2, \ldots, x^K$
, which are piecewise constant across classes, we can cluster vertices by class. For each vertex
 $v \in V(G)$
, associate the vector
$v \in V(G)$
, associate the vector
 $y^v \in \mathbb{R}^K$
where
$y^v \in \mathbb{R}^K$
where
 $y^v_j = x^j_v$
. Then if
$y^v_j = x^j_v$
. Then if
 $y^v = y^u$
for
$y^v = y^u$
for
 $u, v \in V(G)$
, vertices u and v belong to the same class.Footnote a It is simple to recover these piecewise constant vectors
$u, v \in V(G)$
, vertices u and v belong to the same class.Footnote a It is simple to recover these piecewise constant vectors
 $x^1, x^2, \ldots, x^K$
when they are the leading eigenvectors. These facts lead to the following theorem:
$x^1, x^2, \ldots, x^K$
when they are the leading eigenvectors. These facts lead to the following theorem:
Theorem 6.2
(Spectral clustering guarantee in frame graphs). Let G be a random regular frame graph G(n,H) and P its Markov matrix. Let R be the Markov matrix of the frame
 $H=(V,E,p,D)$
, with
$H=(V,E,p,D)$
, with
 $|V(H)| = K$
classes and
$|V(H)| = K$
classes and
 $\lambda_1 \ge \ldots \ge \lambda_K$
the eigenvalues of R and
$\lambda_1 \ge \ldots \ge \lambda_K$
the eigenvalues of R and
 $|\lambda_K| > 0$
. Then we can scale the degrees by some
$|\lambda_K| > 0$
. Then we can scale the degrees by some
 $\kappa \in \mathbb{N}$
,
$\kappa \in \mathbb{N}$
,
 $D \to \kappa D$
, so that the vertex classes are recoverable by spectral clustering of the leading K eigenvectors of P.
$D \to \kappa D$
, so that the vertex classes are recoverable by spectral clustering of the leading K eigenvectors of P.
Remark. The conditions of Theorem 6.2, while very general, are also weaker than may be expected using more sophisticated methods tailored to the specific frame model. We illustrate this with the following example.
6.3.1 Example: The regular stochastic block model
Brito et al. [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16] and Barucca [Reference Barucca5] studied a regular stochastic block model, which can be seen as a special case of our frame model. Let the frame H be the complete directed graph on two vertices, including self loops, where
 \begin{equation*}D = \left(\begin{array}{cc}d_1 & d_2\\d_2 & d_1\end{array}\right)\end{equation*}
\begin{equation*}D = \left(\begin{array}{cc}d_1 & d_2\\d_2 & d_1\end{array}\right)\end{equation*}
and
 $p = (1/2, 1/2)$
. Define the regular stochastic block model as
$p = (1/2, 1/2)$
. Define the regular stochastic block model as
 $\mathcal{G} (2n, H)$
. This is a graph with two classes of equal size, representing two communities of vertices, with within-class degree
$\mathcal{G} (2n, H)$
. This is a graph with two classes of equal size, representing two communities of vertices, with within-class degree
 $d_1$
and between-class degree
$d_1$
and between-class degree
 $d_2$
. We assume
$d_2$
. We assume
 $d_1 > d_2$
, since communities are more strongly connected within. Brito et al. [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16] proved the following theorem:
$d_1 > d_2$
, since communities are more strongly connected within. Brito et al. [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16] proved the following theorem:
Theorem 6.3. If
 $(d_1-d_2)^2 > 4 (d_1 + d_2 -1)$
, then there is an efficient algorithm for strong recovery, i.e. recovery of the exact communities with high probability as
$(d_1-d_2)^2 > 4 (d_1 + d_2 -1)$
, then there is an efficient algorithm for strong recovery, i.e. recovery of the exact communities with high probability as
 $n \to \infty$
.
$n \to \infty$
.
Theorem 6.3 gives a sharp bound on the degrees for recovery, which we can compare to our spectral clustering results. The eigenvalues of D are
 $d_1 + d_2$
and
$d_1 + d_2$
and
 $d_1 - d_2$
, and the Markov matrix of the frame R has eigenvalues 1 and
$d_1 - d_2$
, and the Markov matrix of the frame R has eigenvalues 1 and
 $(d_1 - d_2) / (d_1 + d_2)$
. The diagonal blocks
$(d_1 - d_2) / (d_1 + d_2)$
. The diagonal blocks
 $L^{(11)}$
and
$L^{(11)}$
and
 $L^{(22)}$
each correspond to the Laplacian matrix of a
$L^{(22)}$
each correspond to the Laplacian matrix of a
 $d_1$
-regular random graph on n vertices, whereas the off-diagonal block term
$d_1$
-regular random graph on n vertices, whereas the off-diagonal block term
 $M^{(12)}$
corresponds to the Laplacian of a
$M^{(12)}$
corresponds to the Laplacian of a
 $d_2$
-regular bipartite graph on 2n vertices. Using our results and the previously known results for regular random graphs [Reference Friedman27, Reference Friedman28, Reference Bordenave, Lelarge and Massoulié14], we can pick some
$d_2$
-regular bipartite graph on 2n vertices. Using our results and the previously known results for regular random graphs [Reference Friedman27, Reference Friedman28, Reference Bordenave, Lelarge and Massoulié14], we can pick some
 $C > 2 \sqrt{d_2 - 1}/d_2$
since
$C > 2 \sqrt{d_2 - 1}/d_2$
since
 $d_1 > d_2$
and we will eventually take the degrees to be large. Using Proposition 6.1, we find that the spurious eigenvalues of P come after the leading 2 eigenvalues if
$d_1 > d_2$
and we will eventually take the degrees to be large. Using Proposition 6.1, we find that the spurious eigenvalues of P come after the leading 2 eigenvalues if
 \begin{equation*}\frac{2 \sqrt{d_2 - 1}}{d_2}
< \frac{d_1 - d_2}{d_1 + d_2},\end{equation*}
\begin{equation*}\frac{2 \sqrt{d_2 - 1}}{d_2}
< \frac{d_1 - d_2}{d_1 + d_2},\end{equation*}
to leading order in the degrees. Rearranging, we obtain the condition
 \begin{equation*}(d_1 - d_2)^2 > 4 (d_2 - 1) \left( \frac{d_1 + d_2}{d_2} \right)^2 .\end{equation*}
\begin{equation*}(d_1 - d_2)^2 > 4 (d_2 - 1) \left( \frac{d_1 + d_2}{d_2} \right)^2 .\end{equation*}
Assuming
 $d_2/d_1 = \beta < 1$
fixed, and taking the limit
$d_2/d_1 = \beta < 1$
fixed, and taking the limit
 $d_1, d_2 \to \infty$
, we find that the result of [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16] becomes
$d_1, d_2 \to \infty$
, we find that the result of [Reference Brito, Dumitriu, Ganguly, Hoffman and Tran16] becomes
 \begin{equation*}d_1 > 4 \frac{1+\beta}{(1-\beta)^2} + o(1),\end{equation*}
\begin{equation*}d_1 > 4 \frac{1+\beta}{(1-\beta)^2} + o(1),\end{equation*}
whereas our result becomes
 \begin{equation*}d_1 > \frac{4}{\beta} \left( \frac{1+\beta}{1-\beta} \right)^2 + o(1),\end{equation*}
\begin{equation*}d_1 > \frac{4}{\beta} \left( \frac{1+\beta}{1-\beta} \right)^2 + o(1),\end{equation*}
illustrating that the spectral threshold is a factor of
 $(1+\beta)/\beta$
weaker.
$(1+\beta)/\beta$
weaker.
7. Application: low density parity check or expander codes
Another useful application of random graphs is as expanders, loosely defined as graphs where the neighbourhood of a small set of nodes is large. Expander codes, also called low-density parity-check (LDPC) codes, were first introduced by Gallager in his PhD thesis [Reference Gallager30]. These are a family of linear error correcting codes whose parity-check matrix is encoded in an expander graph. A linear code is a set
 $\mathcal{C} \subset \Sigma^L$
, where a length L codeword
$\mathcal{C} \subset \Sigma^L$
, where a length L codeword
 $x \in \mathcal{C}$
if and only if
$x \in \mathcal{C}$
if and only if
 $H x = 0$
. The alphabet
$H x = 0$
. The alphabet
 $\Sigma$
is typically a finite field, and
$\Sigma$
is typically a finite field, and
 $H \in \Sigma^{P \times L}$
is the parity check matrix. In the simplest case,
$H \in \Sigma^{P \times L}$
is the parity check matrix. In the simplest case,
 $\Sigma = \mathbb{F}_2$
and each row of H can be interpreted as a parity constraint on codewords. The performance of such codes depends on how good an expander that graph is, which in turn can be shown to depend on the separation of eigenvalues. For a good introduction and overview of the subject, see [Reference Richardson and Urbanke58].
$\Sigma = \mathbb{F}_2$
and each row of H can be interpreted as a parity constraint on codewords. The performance of such codes depends on how good an expander that graph is, which in turn can be shown to depend on the separation of eigenvalues. For a good introduction and overview of the subject, see [Reference Richardson and Urbanke58].
Following [Reference Tanner61], we construct a code
 $\mathcal{C}$
from a
$\mathcal{C}$
from a
 $(d_1,d_2)$
-regular bipartite graph G on
$(d_1,d_2)$
-regular bipartite graph G on
 $n + m$
vertices and two smaller linear codes
$n + m$
vertices and two smaller linear codes
 $\mathcal{C}_1$
and
$\mathcal{C}_1$
and
 $\mathcal{C}_2$
of length
$\mathcal{C}_2$
of length
 $d_1$
and
$d_1$
and
 $d_2$
, respectively. We write
$d_2$
, respectively. We write
 $\mathcal{C}_1 = [d_1, k_1, \delta_1]$
and
$\mathcal{C}_1 = [d_1, k_1, \delta_1]$
and
 $\mathcal{C}_2 = [d_2, k_2, \delta_2]$
with the usual convention of length, dimension, and minimum distance. We assume that the codes are all binary, using the finite field
$\mathcal{C}_2 = [d_2, k_2, \delta_2]$
with the usual convention of length, dimension, and minimum distance. We assume that the codes are all binary, using the finite field
 $\mathbb{F}_2$
the codeword is
$\mathbb{F}_2$
the codeword is
 $x \in \mathcal{C} \subset \mathbb{F}_2^{|E|}$
where
$x \in \mathcal{C} \subset \mathbb{F}_2^{|E|}$
where
 $|E| = n d_1 = m d_2$
. That is, we associate a bit to each edge in the graph bipartite graph G. Let
$|E| = n d_1 = m d_2$
. That is, we associate a bit to each edge in the graph bipartite graph G. Let
 $( e_i(v) )_{i=1}^{d_v}$
represent the set of edges incident to a vertex v in some arbitrary, fixed order. Then the vector
$( e_i(v) )_{i=1}^{d_v}$
represent the set of edges incident to a vertex v in some arbitrary, fixed order. Then the vector
 $x \in \mathcal{C}$
if and only if the vectors
$x \in \mathcal{C}$
if and only if the vectors
 $( x_{e_1(u)}, x_{e_2(u)}, \ldots, x_{e_{d_1}(u)} )^T \in \mathcal{C}_1$
for all
$( x_{e_1(u)}, x_{e_2(u)}, \ldots, x_{e_{d_1}(u)} )^T \in \mathcal{C}_1$
for all
 $u \in V_1$
and
$u \in V_1$
and
 $( x_{e_1(v)}, x_{e_2(v)}, \ldots, x_{e_{d_2}(v)} )^T \in \mathcal{C}_2$
for all
$( x_{e_1(v)}, x_{e_2(v)}, \ldots, x_{e_{d_2}(v)} )^T \in \mathcal{C}_2$
for all
 $v \in V_2$
. The final code
$v \in V_2$
. The final code
 $\mathcal{C}$
is also linear. With this construction, the code
$\mathcal{C}$
is also linear. With this construction, the code
 $\mathcal{C}$
has rate at least
$\mathcal{C}$
has rate at least
 $k_1 / d_1 + k_2/d_2 - 1$
[Reference Tanner61].
$k_1 / d_1 + k_2/d_2 - 1$
[Reference Tanner61].
Furthermore, [Reference Janwa and Lal38] proved the following bound on the minimum distance of the resulting code:
Theorem 7.1. Suppose
 $\delta_1 \geq \delta_2 > \eta/2$
, where
$\delta_1 \geq \delta_2 > \eta/2$
, where
 $\eta$
is the second largest eigenvalue of the adjacency matrix of G. Then the code
$\eta$
is the second largest eigenvalue of the adjacency matrix of G. Then the code
 $\mathcal{C}$
has minimum distance
$\mathcal{C}$
has minimum distance
 \begin{equation*}\delta \geq \frac{n}{d_2} \left( \delta_1 \delta_2 - \frac{\eta}{2} (\delta_1 + \delta_2 ) \right).\end{equation*}
\begin{equation*}\delta \geq \frac{n}{d_2} \left( \delta_1 \delta_2 - \frac{\eta}{2} (\delta_1 + \delta_2 ) \right).\end{equation*}
Corollary 7.2. Suppose the code
 $\mathcal{C}$
is constructed from a biregular, bipartite random graph
$\mathcal{C}$
is constructed from a biregular, bipartite random graph
 $G \sim \mathcal{G}(n,m, d_1, d_2)$
and the conditions of Theorem 7.1 hold. Then the minimum distance of
$G \sim \mathcal{G}(n,m, d_1, d_2)$
and the conditions of Theorem 7.1 hold. Then the minimum distance of
 $\mathcal{C}$
satisfies
$\mathcal{C}$
satisfies
 \begin{equation*}\delta \geq \frac{n}{d_2} \left( \delta_1 \delta_2 -\frac{\sqrt{d_1 - 1} + \sqrt{d_2 - 1}}{2} (\delta_1 + \delta_2 ) - \epsilon_n \right) .\end{equation*}
\begin{equation*}\delta \geq \frac{n}{d_2} \left( \delta_1 \delta_2 -\frac{\sqrt{d_1 - 1} + \sqrt{d_2 - 1}}{2} (\delta_1 + \delta_2 ) - \epsilon_n \right) .\end{equation*}
We see that these Tanner codes will have maximal distance for smallest
 $\eta$
and used our main result, Theorem 3.2, to obtain the explicit bound in Corollary 7.2. By growing the graph, the above shows a way to construct arbitrarily large codes whose minimum distance remains proportional to the code size
$\eta$
and used our main result, Theorem 3.2, to obtain the explicit bound in Corollary 7.2. By growing the graph, the above shows a way to construct arbitrarily large codes whose minimum distance remains proportional to the code size
 $n d_1$
. That is, the relative distance
$n d_1$
. That is, the relative distance
 $\delta / (n d_1)$
is bounded away from zero as
$\delta / (n d_1)$
is bounded away from zero as
 $n \to \infty$
. However, the above bound will only be useful if it yields a positive result, which depends on the codes
$n \to \infty$
. However, the above bound will only be useful if it yields a positive result, which depends on the codes
 $\mathcal{C}_1$
and
$\mathcal{C}_1$
and
 $\mathcal{C}_2$
as well as the degrees.
$\mathcal{C}_2$
as well as the degrees.
Remark. In general, the performance guarantees on LDPC codes that are obtainable from graph eigenvalues are weaker than those that come from other methods. Although our method does guarantee high distance for some high degree codes, analysis of specific decoding algorithms or a probabilistic expander analyses yield better bounds that work for lower degrees [Reference Richardson and Urbanke58].
7.1 Example: An unbalanced code based on a (14,9)-regular bipartite graph
We illustrate the applicability of our distance bound with an example. Let
 $\mathcal{C}_1 = [14, 8, 7]$
and
$\mathcal{C}_1 = [14, 8, 7]$
and
 $\mathcal{C}_2 = [9, 4, 6]$
. These can be achieved by using a Reed–Salomon code on the common field
$\mathcal{C}_2 = [9, 4, 6]$
. These can be achieved by using a Reed–Salomon code on the common field
 $\mathbb{F}_{q}$
for any
$\mathbb{F}_{q}$
for any
 $q > 14$
[Reference Richardson and Urbanke58]. We take
$q > 14$
[Reference Richardson and Urbanke58]. We take
 $q = 2^4 = 16$
for inputs that are actually binary, and this means each edge in the graph actually contains 4 bits of information. Employing Corollary 7.2, the Tanner code
$q = 2^4 = 16$
for inputs that are actually binary, and this means each edge in the graph actually contains 4 bits of information. Employing Corollary 7.2, the Tanner code
 $\mathcal{C}$
will have relative minimum distance
$\mathcal{C}$
will have relative minimum distance
 $\delta / (n d_1) \geq 0.0014$
and rate at least
$\delta / (n d_1) \geq 0.0014$
and rate at least
 $0.016$
. Taking
$0.016$
. Taking
 $n = 216$
and
$n = 216$
and
 $m = 336$
gives the code a minimum distance of at least 4.
$m = 336$
gives the code a minimum distance of at least 4.
8. Application: matrix completion
Assume that we have some matrix
 $Y \in \mathbb{R}^{n \times m}$
which has low ‘complexity.’ Perhaps it is low-rank or simple by some other measure. If we observe
$Y \in \mathbb{R}^{n \times m}$
which has low ‘complexity.’ Perhaps it is low-rank or simple by some other measure. If we observe
 $Y_{ij}$
for a limited set of entries
$Y_{ij}$
for a limited set of entries
 $(i,j) \in E \subset [n] \times [m]$
, then matrix completion is any method which constructs a matrix
$(i,j) \in E \subset [n] \times [m]$
, then matrix completion is any method which constructs a matrix
 $\hat{Y}$
so that
$\hat{Y}$
so that
 $\| \hat{Y} - Y\|$
is small, or even zero. Matrix completion has attracted significant attention in recent years as a tractable algorithm for making recommendations to users of online systems based on the tastes of other users (a.k.a. the Netflix problem). We can think of it as the matrix version of compressed sensing [Reference Candès and Tao18, Reference Candes and Plan17].
$\| \hat{Y} - Y\|$
is small, or even zero. Matrix completion has attracted significant attention in recent years as a tractable algorithm for making recommendations to users of online systems based on the tastes of other users (a.k.a. the Netflix problem). We can think of it as the matrix version of compressed sensing [Reference Candès and Tao18, Reference Candes and Plan17].
Recently, a number of authors have studied the performance of matrix completion algorithms where the index set E is the edge set of a regular random graph [Reference Heiman, Schechtman and Shraibman33, Reference Bhojanapalli and Jain9, Reference Gamarnik, Li and Zhang31]. Heiman et al. [Reference Heiman, Schechtman and Shraibman33] describe a deterministic method of matrix completion, where they can give performance guarantees for a fixed observation set E over many input matrices Y. The error of their reconstruction depends on the spectral gap of the graph. We expand upon the result of [Reference Heiman, Schechtman and Shraibman33], extending it to rectangular matrix and improving their bounds in the process.
8.1. Matrix norms as measures of complexity and their relationships
We will employ a number of different matrix and vector norms in this section. These are all related by the properties of the underlying Banach spaces. The complexity of Y is measured using a factorisation norm (also called the max-norm):
 \begin{equation*} \gamma_2 (Y) = \min_{UV^* = Y} \|U\|_{\ell_2 \to \ell_\infty^n} \|V\|_{\ell_2 \to \ell_\infty^m}.\end{equation*}
\begin{equation*} \gamma_2 (Y) = \min_{UV^* = Y} \|U\|_{\ell_2 \to \ell_\infty^n} \|V\|_{\ell_2 \to \ell_\infty^m}.\end{equation*}
The minimum is taken over all possible factorisations of
 $Y = UV^*$
, and the norm
$Y = UV^*$
, and the norm
 $\| X \|_{\ell_2 \to \ell_\infty^n} = \max_i \sqrt{\sum_j X^2_{ij}}\ $
returns the largest
$\| X \|_{\ell_2 \to \ell_\infty^n} = \max_i \sqrt{\sum_j X^2_{ij}}\ $
returns the largest
 $\ell_2$
norm of a row. So, equivalently,
$\ell_2$
norm of a row. So, equivalently,
 \begin{equation*} \gamma_2 (Y) = \min_{U V^* = Y} \max_{i,j} \|u_i \|_2 \, \|v_j \|_2 ,\end{equation*}
\begin{equation*} \gamma_2 (Y) = \min_{U V^* = Y} \max_{i,j} \|u_i \|_2 \, \|v_j \|_2 ,\end{equation*}
where
 $u_i$
and
$u_i$
and
 $v_i$
are the rows of U and V. See [Reference Linial, Mendelson, Schechtman and Shraibman44] for a number of results about the norm
$v_i$
are the rows of U and V. See [Reference Linial, Mendelson, Schechtman and Shraibman44] for a number of results about the norm
 $\gamma_2$
. In particular, note that
$\gamma_2$
. In particular, note that
 \begin{align}\gamma_2(A \circ B) \leq \gamma_2(A) \gamma_2(B) \end{align}
\begin{align}\gamma_2(A \circ B) \leq \gamma_2(A) \gamma_2(B) \end{align}
 \begin{align} \frac{1}{\sqrt{n m}} \| Y \|_{\textrm{Tr}} \leq \gamma_2(Y) \end{align}
\begin{align} \frac{1}{\sqrt{n m}} \| Y \|_{\textrm{Tr}} \leq \gamma_2(Y) \end{align}
 \begin{align} \gamma_2(Y) \leq \sqrt{\textrm{rank} (Y) } \| Y \|_{\infty}.\end{align}
\begin{align} \gamma_2(Y) \leq \sqrt{\textrm{rank} (Y) } \| Y \|_{\infty}.\end{align}
Property (38) says that
 $\gamma_2$
is sub-multiplicative under the Hadamard product [Reference Lee, Shraibman and Špalek42, Reference De Winter, Schillewaert and Verstraete23] and will be used in our proof. Properties (39) and (40) relate
$\gamma_2$
is sub-multiplicative under the Hadamard product [Reference Lee, Shraibman and Špalek42, Reference De Winter, Schillewaert and Verstraete23] and will be used in our proof. Properties (39) and (40) relate
 $\gamma_2$
to two common complexity measures of matrices, the trace norm (sum of singular values, i.e. the
$\gamma_2$
to two common complexity measures of matrices, the trace norm (sum of singular values, i.e. the
 $\ell^m_2 \to \ell^n_2$
nuclear norm) and rank. Note also the well-known fact that
$\ell^m_2 \to \ell^n_2$
nuclear norm) and rank. Note also the well-known fact that
 \begin{equation*}\| Y \|_{\textrm{Tr}} = \min_{UV^* = Y} \| U \|_F \|V \|_F ,\end{equation*}
\begin{equation*}\| Y \|_{\textrm{Tr}} = \min_{UV^* = Y} \| U \|_F \|V \|_F ,\end{equation*}
where
 $\| X \|_F = \sqrt{\sum_{ij} X_{ij}^2}$
is the Frobenius norm. We see that the trace norm constrains factors U and V to be small on average via
$\| X \|_F = \sqrt{\sum_{ij} X_{ij}^2}$
is the Frobenius norm. We see that the trace norm constrains factors U and V to be small on average via
 $\| \cdot \|_F$
, whereas the norm
$\| \cdot \|_F$
, whereas the norm
 $\gamma_2$
is similar but constrains factors uniformly via
$\gamma_2$
is similar but constrains factors uniformly via
 $\| \cdot \|_{\ell_2 \to \ell_\infty^n}$
. However, we should note that computing
$\| \cdot \|_{\ell_2 \to \ell_\infty^n}$
. However, we should note that computing
 $\gamma_2(Y)$
is more costly than the trace norm, which can be performed with just the singular value decomposition, although still possible in polynomial time with convex programming [Reference Heiman, Schechtman and Shraibman33].
$\gamma_2(Y)$
is more costly than the trace norm, which can be performed with just the singular value decomposition, although still possible in polynomial time with convex programming [Reference Heiman, Schechtman and Shraibman33].
8.2. Matrix completion generalisation bounds
The method of matrix completion that we study is to return the matrix X which is the solution to:
 \begin{equation}\begin{aligned}& \underset{X}{\text{minimise}}& & \gamma_2(X) \\& \text{subject to}& & X_{ij} = Y_{ij}, \; (i,j) \in E .\end{aligned}\end{equation}
\begin{equation}\begin{aligned}& \underset{X}{\text{minimise}}& & \gamma_2(X) \\& \text{subject to}& & X_{ij} = Y_{ij}, \; (i,j) \in E .\end{aligned}\end{equation}
The
 $\gamma_2$
norm was first proposed by [Reference Srebro and Shraibman60, Reference Srebro, Rennie, Jaakkola, Saul, Weiss and Bottou59] as a robust complexity measure, and it was shown to be an effective and practical regularisation on real data sets [Reference Lee, Recht, Srebro, Tropp and Salakhutdinov41, Reference Recht and Ré56].
$\gamma_2$
norm was first proposed by [Reference Srebro and Shraibman60, Reference Srebro, Rennie, Jaakkola, Saul, Weiss and Bottou59] as a robust complexity measure, and it was shown to be an effective and practical regularisation on real data sets [Reference Lee, Recht, Srebro, Tropp and Salakhutdinov41, Reference Recht and Ré56].
Heiman et al. [Reference Heiman, Schechtman and Shraibman33] analyse the performance of the convex program (41) for a square matrix Y using an expander argument, assuming that E is the edge set of a d-regular graph with second eigenvalue
 $\eta$
. They obtain the following theorem:
$\eta$
. They obtain the following theorem:
Theorem 8.1
([Reference Heiman, Schechtman and Shraibman33]). Let E be the set of edges of a d-regular graph with second eigenvalue bound
 $\eta$
. For every
$\eta$
. For every
 $Y \in \mathbb{R}^{n \times n}$
, if
$Y \in \mathbb{R}^{n \times n}$
, if
 $\hat{Y}$
is the output of the optimization problem (38), then
$\hat{Y}$
is the output of the optimization problem (38), then
 \begin{equation*} \frac{1}{n^2} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{d},\end{equation*}
\begin{equation*} \frac{1}{n^2} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{d},\end{equation*}
where
 $c = 8 K_G \leq 14.3$
is a universal constant and
$c = 8 K_G \leq 14.3$
is a universal constant and
 $\| \cdot \|_F$
is the Frobenius norm.
$\| \cdot \|_F$
is the Frobenius norm.
Considering sampling following the biadjacency matrix of a bipartite graph, we find a similar result which also applies to rectangular matrices. If
 $n=m$
and
$n=m$
and
 $d_1 = d_2 = d$
, our bound is equivalent to that of Theorem 8.1, but with constants improved by a factor of two due to stronger mixing in bipartite graphs. Intuitively, using a biadjacency matrix is a ‘more random’ way of sampling than using an adjacency matrix, since it is not symmetric.
$d_1 = d_2 = d$
, our bound is equivalent to that of Theorem 8.1, but with constants improved by a factor of two due to stronger mixing in bipartite graphs. Intuitively, using a biadjacency matrix is a ‘more random’ way of sampling than using an adjacency matrix, since it is not symmetric.
Theorem 8.2. Let E be the set of edges of a
 $(d_1, d_2)$
-regular graph with second eigenvalue bound
$(d_1, d_2)$
-regular graph with second eigenvalue bound
 $\eta$
. For every
$\eta$
. For every
 $Y \in \mathbb{R}^{n \times m}$
, if
$Y \in \mathbb{R}^{n \times m}$
, if
 $\hat{Y}$
is the output of the optimization problem (41), then
$\hat{Y}$
is the output of the optimization problem (41), then
 \begin{equation*} \frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} ,\end{equation*}
\begin{equation*} \frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} ,\end{equation*}
where
 $c = 4 K_G \leq 7.13$
.
$c = 4 K_G \leq 7.13$
.
Proof. We start by considering a rank-1 sign matrix
 $S=u v^*$
, where
$S=u v^*$
, where
 $u\in\{-1,1\}^{n}, v\in\{-1,1\}^{m}$
. Let
$u\in\{-1,1\}^{n}, v\in\{-1,1\}^{m}$
. Let
 $S' = \frac{1}{2} (S + J)$
, where J is the all-ones matrix, so that S’ has the entries of -1 in S replaced by zeros. Then
$S' = \frac{1}{2} (S + J)$
, where J is the all-ones matrix, so that S’ has the entries of -1 in S replaced by zeros. Then
 $S' = 1_A 1_B^* + 1_{A^c} 1_{B^c}^*$
for subsets
$S' = 1_A 1_B^* + 1_{A^c} 1_{B^c}^*$
for subsets
 $A \subset V_1 = [n]$
and
$A \subset V_1 = [n]$
and
 $B \subset V_2 = [m]$
, where
$B \subset V_2 = [m]$
, where
 $A = \{ i:\, u_i = 1 \} $
and
$A = \{ i:\, u_i = 1 \} $
and
 $B = \{ j :\, v_j = 1 \}$
. Consider the expression
$B = \{ j :\, v_j = 1 \}$
. Consider the expression
 \begin{align*}\left| \frac{1}{n m} \sum_{i,j} s_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s_{ij} \right|&=\left| \frac{1}{n m} \sum_{i,j} (2 s^{\prime}_{ij} - 1) -\frac{1}{|E|} \sum_{(i,j) \in E} (2 s^{\prime}_{ij} - 1) \right| \\&=2 \left| \frac{1}{n m} \sum_{i,j} s^{\prime}_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s^{\prime}_{ij} \right| \\&= 2 \left| \frac{|A||B| + |A^c| |B^c|}{n m} -\frac{E(A,B) + E(A^c, B^c)}{|E|} \right| \\&\leq 2 \left| \frac{|A||B|}{nm} - \frac{E(A,B)}{|E|} \right|+2 \left| \frac{|A^c| |B^c|}{n m} -\frac{E(A^c, B^c)}{|E|} \right|.\end{align*}
\begin{align*}\left| \frac{1}{n m} \sum_{i,j} s_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s_{ij} \right|&=\left| \frac{1}{n m} \sum_{i,j} (2 s^{\prime}_{ij} - 1) -\frac{1}{|E|} \sum_{(i,j) \in E} (2 s^{\prime}_{ij} - 1) \right| \\&=2 \left| \frac{1}{n m} \sum_{i,j} s^{\prime}_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s^{\prime}_{ij} \right| \\&= 2 \left| \frac{|A||B| + |A^c| |B^c|}{n m} -\frac{E(A,B) + E(A^c, B^c)}{|E|} \right| \\&\leq 2 \left| \frac{|A||B|}{nm} - \frac{E(A,B)}{|E|} \right|+2 \left| \frac{|A^c| |B^c|}{n m} -\frac{E(A^c, B^c)}{|E|} \right|.\end{align*}
The following is a bipartite version of the expander mixing lemma [Reference De Winter, Schillewaert and Verstraete23]:
 \begin{equation*}\left| \frac{E(A,B)}{|E|} - \frac{|A||B|}{n m} \right|\leq \frac{\eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B|}{nm}\left(1- \frac{|A|}{n} \right) \left( 1- \frac{|B|}{m} \right) } \\=\frac{\eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B||A^c||B^c|}{(nm)^2}} .\end{equation*}
\begin{equation*}\left| \frac{E(A,B)}{|E|} - \frac{|A||B|}{n m} \right|\leq \frac{\eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B|}{nm}\left(1- \frac{|A|}{n} \right) \left( 1- \frac{|B|}{m} \right) } \\=\frac{\eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B||A^c||B^c|}{(nm)^2}} .\end{equation*}
We find that
 \begin{align*}\left| \frac{1}{n m} \sum_{i,j} s_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s_{ij} \right|& \leq \frac{4 \eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B||A^c||B^c|}{(nm)^2}}\\& = \frac{4 \eta}{\sqrt{d_1 d_2}}\sqrt{ x y (1-x) (1-y) }\\& \leq \frac{\eta}{\sqrt{d_1 d_2}},\end{align*}
\begin{align*}\left| \frac{1}{n m} \sum_{i,j} s_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} s_{ij} \right|& \leq \frac{4 \eta}{\sqrt{d_1 d_2}}\sqrt{\frac{|A||B||A^c||B^c|}{(nm)^2}}\\& = \frac{4 \eta}{\sqrt{d_1 d_2}}\sqrt{ x y (1-x) (1-y) }\\& \leq \frac{\eta}{\sqrt{d_1 d_2}},\end{align*}
since
 $x y (1-x) (1-y)$
attains a maximal value of
$x y (1-x) (1-y)$
attains a maximal value of
 $2^{-4}$
for
$2^{-4}$
for
 $0 \leq x,y \leq 1$
.
$0 \leq x,y \leq 1$
.
The rest of the proof develops identical to the results of [Reference Heiman, Schechtman and Shraibman33], which we include for completeness. We apply the result for rank-1 sign matrices to any matrix R. Let
 $R = \sum_i \alpha_i S^i$
, where
$R = \sum_i \alpha_i S^i$
, where
 $S^i$
is a rank-1 sign matrix and
$S^i$
is a rank-1 sign matrix and
 $\alpha_i \in \mathbb{R}$
. For a general matrix R, this might require many rank-1 sign matrices. Define the sign nuclear norm
$\alpha_i \in \mathbb{R}$
. For a general matrix R, this might require many rank-1 sign matrices. Define the sign nuclear norm
 $\nu (R) = \sum_i |\alpha_i|$
. Then,
$\nu (R) = \sum_i |\alpha_i|$
. Then,
 \begin{equation*}\left| \frac{1}{n m} \sum_{i,j} r_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} r_{ij} \right|\leq \nu(R) \frac{\eta}{\sqrt{d_1 d_2}} .\end{equation*}
\begin{equation*}\left| \frac{1}{n m} \sum_{i,j} r_{ij} -\frac{1}{|E|} \sum_{(i,j) \in E} r_{ij} \right|\leq \nu(R) \frac{\eta}{\sqrt{d_1 d_2}} .\end{equation*}
It is a consequence of Grothendieck’s inequality, a well-known theorem in functional analysis, that there exists a universal constant
 $1.5 \leq K_G \leq 1.8$
so that
$1.5 \leq K_G \leq 1.8$
so that
 $\gamma_2 (X) \leq \nu(X) \leq K_G \gamma_2(X)$
for any real matrix X; see [Reference Heiman, Schechtman and Shraibman33].
$\gamma_2 (X) \leq \nu(X) \leq K_G \gamma_2(X)$
for any real matrix X; see [Reference Heiman, Schechtman and Shraibman33].
Now, let the matrix of residuals
 $R = (\hat{Y}-Y) \circ (\hat{Y} - Y)$
, where
$R = (\hat{Y}-Y) \circ (\hat{Y} - Y)$
, where
 $\circ$
is the Hadamard entry-wise product of two matrices, so that
$\circ$
is the Hadamard entry-wise product of two matrices, so that
 $R_{ij} = (\hat{Y}_{ij} - Y_{ij})^2$
. Since
$R_{ij} = (\hat{Y}_{ij} - Y_{ij})^2$
. Since
 \begin{equation*}\frac{1}{|E|} \sum_{(i,j) \in E} r_{ij} = 0 ,\end{equation*}
\begin{equation*}\frac{1}{|E|} \sum_{(i,j) \in E} r_{ij} = 0 ,\end{equation*}
we conclude that
 \begin{equation*}\frac{1}{n m} \sum_{i,j} r_{ij}\leq \nu(R) \frac{\eta}{\sqrt{d_1 d_2}}\leq K_G \gamma_2(R) \frac{\eta}{\sqrt{d_1 d_2}}.\end{equation*}
\begin{equation*}\frac{1}{n m} \sum_{i,j} r_{ij}\leq \nu(R) \frac{\eta}{\sqrt{d_1 d_2}}\leq K_G \gamma_2(R) \frac{\eta}{\sqrt{d_1 d_2}}.\end{equation*}
Furthermore,
 $\gamma_2 (R) \leq \gamma_2 (\hat{Y}-Y)^2 \leq ( \gamma_2(\hat{Y}) + \gamma_2(Y) ) ^2 $
by (38) and the triangle inequality. Since
$\gamma_2 (R) \leq \gamma_2 (\hat{Y}-Y)^2 \leq ( \gamma_2(\hat{Y}) + \gamma_2(Y) ) ^2 $
by (38) and the triangle inequality. Since
 $\hat{Y}$
is the output of the algorithm and Y is a feasible solution,
$\hat{Y}$
is the output of the algorithm and Y is a feasible solution,
 $\gamma_2 (\hat{Y}) \leq \gamma_2 (Y)$
. Thus,
$\gamma_2 (\hat{Y}) \leq \gamma_2 (Y)$
. Thus,
 $\gamma_2(R) \leq 4 \gamma_2(Y)^2$
and the proof is finished.
$\gamma_2(R) \leq 4 \gamma_2(Y)^2$
and the proof is finished.
8.3. Noisy matrix completion bounds
Furthermore, our analysis easily extends to the case where the matrix we observe is corrupted with noise. As mentioned in the above remark, similar results will hold for the trace norm. In the noisy case, we solve the problem
 \begin{equation}\begin{aligned}& \underset{X}{\text{minimize}}& & \gamma_2(X) \\& \text{subject to}& & \frac{1}{|E|} \sum_{(i,j) \in E} ( X_{ij} - Z_{ij})^2 \leq \delta^2\end{aligned}\end{equation}
\begin{equation}\begin{aligned}& \underset{X}{\text{minimize}}& & \gamma_2(X) \\& \text{subject to}& & \frac{1}{|E|} \sum_{(i,j) \in E} ( X_{ij} - Z_{ij})^2 \leq \delta^2\end{aligned}\end{equation}
and obtain the following theorem:
Theorem 8.3. Suppose we observe
 $Z_{ij} = Y_{ij} + \epsilon_{ij}$
with bounded error
$Z_{ij} = Y_{ij} + \epsilon_{ij}$
with bounded error
 \begin{equation*} \frac{1}{|E|} \sum_{(i,j) \in E} \epsilon_{ij}^2 \leq \delta^2 .\end{equation*}
\begin{equation*} \frac{1}{|E|} \sum_{(i,j) \in E} \epsilon_{ij}^2 \leq \delta^2 .\end{equation*}
Then solving the optimization problem (42) will yield a bound of
 \begin{equation*}\frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} + 4 \delta^2,\end{equation*}
\begin{equation*}\frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} + 4 \delta^2,\end{equation*}
where
 $c = 4 K_G \leq 7.13$
.
$c = 4 K_G \leq 7.13$
.
Proof. Denote
 $\hat{Y}$
the solution to P42. It will be useful to introduce the sampling operator
$\hat{Y}$
the solution to P42. It will be useful to introduce the sampling operator
 $\mathcal{P}_E : \mathbb{R}^{n \times m} \to \mathbb{R}^{n \times m}$
, where
$\mathcal{P}_E : \mathbb{R}^{n \times m} \to \mathbb{R}^{n \times m}$
, where
 $(\mathcal{P}_E (X) )_{ij} = X_{ij}$
if
$(\mathcal{P}_E (X) )_{ij} = X_{ij}$
if
 $(i,j) \in E$
and 0 otherwise. Again let
$(i,j) \in E$
and 0 otherwise. Again let
 $R = (\hat{Y} - Y) \circ (\hat{Y} - Y)$
be the matrix of squared errors, then
$R = (\hat{Y} - Y) \circ (\hat{Y} - Y)$
be the matrix of squared errors, then
 \begin{align*}\left|\frac{1}{nm} \| \hat{Y} - Y \|_F^2 -\frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\right|&=\left| \frac{1}{n m} \sum_{i,j} (\hat{Y}_{ij} - Y_{ij})^2 -\frac{1}{|E|} \sum_{(i,j) \in E} (\hat{Y}_{ij} - Y_{ij})^2 \right| \\& \leq K_G \gamma_2(R) \frac{\eta}{\sqrt{d_1 d_2}}.\end{align*}
\begin{align*}\left|\frac{1}{nm} \| \hat{Y} - Y \|_F^2 -\frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\right|&=\left| \frac{1}{n m} \sum_{i,j} (\hat{Y}_{ij} - Y_{ij})^2 -\frac{1}{|E|} \sum_{(i,j) \in E} (\hat{Y}_{ij} - Y_{ij})^2 \right| \\& \leq K_G \gamma_2(R) \frac{\eta}{\sqrt{d_1 d_2}}.\end{align*}
However, since Y is a feasible solution to P42, we have
 \begin{equation*}\gamma_2 (\hat{Y}) \leq \gamma_2 (Y).\end{equation*}
\begin{equation*}\gamma_2 (\hat{Y}) \leq \gamma_2 (Y).\end{equation*}
Applying (38) and the triangle inequality,
 \begin{equation*}\gamma_2 (R) \leq \left( \gamma_2(\hat{Y} - Y) \right)^2\leq \left( \gamma_2(\hat{Y}) + \gamma_2(Y) \right)^2\leq 4 \gamma_2(Y)^2 .\end{equation*}
\begin{equation*}\gamma_2 (R) \leq \left( \gamma_2(\hat{Y} - Y) \right)^2\leq \left( \gamma_2(\hat{Y}) + \gamma_2(Y) \right)^2\leq 4 \gamma_2(Y)^2 .\end{equation*}
Using the triangle inequality again gives
 \begin{equation*}\| \mathcal{P}_E (\hat{Y} - Y) \|_F\leq \| \mathcal{P}_E (\hat{Y} - Z) \|_F+\| \mathcal{P}_E (Z - Y) \|_F\leq 2 \delta \sqrt{|E|},\end{equation*}
\begin{equation*}\| \mathcal{P}_E (\hat{Y} - Y) \|_F\leq \| \mathcal{P}_E (\hat{Y} - Z) \|_F+\| \mathcal{P}_E (Z - Y) \|_F\leq 2 \delta \sqrt{|E|},\end{equation*}
taking into account the bound on the observation errors. Because
 \begin{equation*}\frac{1}{nm} \| \hat{Y} - Y \|_F^2\leq \left| \frac{1}{nm} \| \hat{Y} - Y \|_F^2 - \frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\right|+\frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\end{equation*}
\begin{equation*}\frac{1}{nm} \| \hat{Y} - Y \|_F^2\leq \left| \frac{1}{nm} \| \hat{Y} - Y \|_F^2 - \frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\right|+\frac{1}{|E|} \| \mathcal{P}_E (\hat{Y} - Y) \|_F^2\end{equation*}
we get the final bound
 \begin{equation*}\frac{1}{n m} \| \hat{Y} - Y \|_F^2\leq 4 K_G \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} + 4 \delta^2.\end{equation*}
\begin{equation*}\frac{1}{n m} \| \hat{Y} - Y \|_F^2\leq 4 K_G \gamma_2(Y)^2 \frac{\eta}{\sqrt{d_1 d_2}} + 4 \delta^2.\end{equation*}
8.4. Application of the spectral gap
Theorem 8.2 provides a bound on the mean squared error of the approximation X. Directly applying Theorem 3.2, we obtain the following bound on the generalisation error of the algorithm using a random biregular, bipartite graph:
Corollary 8.4. Let E be sampled from a
 $\mathcal{G}(n,m, d_1, d_2)$
random graph. For every
$\mathcal{G}(n,m, d_1, d_2)$
random graph. For every
 $Y \in \mathbb{R}^{n \times m}$
, if
$Y \in \mathbb{R}^{n \times m}$
, if
 $\hat{Y}$
is the output of the optimization problem (38), then
$\hat{Y}$
is the output of the optimization problem (38), then
 \begin{equation*} \frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\sqrt{d_1 - 1} + \sqrt{d_2 - 1} + \epsilon_n }{\sqrt{d_1 d_2}} ,\end{equation*}
\begin{equation*} \frac{1}{n m} \| \hat{Y} - Y \|_F^2 \leq c \gamma_2(Y)^2 \frac{\sqrt{d_1 - 1} + \sqrt{d_2 - 1} + \epsilon_n }{\sqrt{d_1 d_2}} ,\end{equation*}
where
 $c = 4 K_G \leq 7.13$
is a universal constant.
$c = 4 K_G \leq 7.13$
is a universal constant.
Acknowledgements
We would like to thank Marina Meilă for sharing Proposition 6.1 and for suggestions and comments. Thank you also to Pierre Youssef, Simon Coste, and Subhabrata Sen for helpful comments and connections. We are grateful to our anonymous reviewers for useful comments and suggestions, and at least in one case for pointing out errors in an earlier version of this manuscript (which have since been fixed). K. D. H. was supported by the Big Data for Genomics and Neuroscience NIH training grant, Washington Research Foundation postdoctoral fellowship, as well as NSF grants DMS-1122105 and DMS-1514743. G. B. was partially supported by NSF CAREER award DMS-1552267. I. D. was supported by NSF DMS-1712630 and NSF CAREER award DMS-0847661.
Appendix A. List of symbols










































 Open access
Open access