


Plain language summary
Many texts produced at the medieval universities did not originate as literary works but were instead gradually and collaboratively developed from records of oral teaching, known as reportationes. While this practice was likely widespread, there are very few sources detailing its daily operation, forcing scholars to rely on indirect evidence deducible from preserved works. In this context, this article proposes a study exploring computational analysis of style as a way to track layers of editorial work in scholastic collections, potentially revealing the actual scope of authors’ control over these works. This approach draws from earlier studies which successfully employed computational techniques in the context of medieval Latin letter collections and Old French hagiographies. I discuss applying similar methods to the collection of Stephen Langton’s (d. 1228) theological quaestiones. Langton’s collection is particularly interesting for it is known to depend on reportationes, and it transmits most of its material in more than one version, in some cases allowing us to track the development from raw records of oral teaching to fully developed literary forms. Initial analysis of Langton’s corpus shows that by measuring the frequencies of the most common words – a common stylometric method – it is possible to differentiate its stylistic signal from other contemporary scholastic collections, as well as to observe some stylistic diversity within Langton’s corpus. However, the key limitation in the context of Langton’s quaestiones stems from their length, as most of quaestiones are too short to provide representative samples. This issue can be addressed by including additional stylistic features: sequences of Part of Speech tags, which capture syntactic structures, and pseudo-affixes (the few opening and closing characters of each word), which represent morphological information. These features have been shown to provide good results with automatically generated transcriptions; consequently, I plan to compare tests performed on manually composed editions and automatically extracted data. The key gain offered by automated transcription lies in providing a feasible way of extending analysed corpora by including unedited material.
Introduction
This article proposes a study employing stylometric techniques of authorship attribution to assess the scope of anonymous contributions to the collection of Stephen Langton’s Quaestiones Theologiae. In this, it follows studies which demonstrated the robustness of stylometric methods applied to the analysis of collaborative authorship in comparable medieval Latin literary traditions (Kestemont, Moens, and Deploige Reference Kestemont, Moens and Deploige2013; De Gussem Reference De Gussem2017). In particular, I draw heavily on the methods of unsupervised cluster analysis offered in Camps and Cafiero (Reference Camps and Cafiero2013), Cafiero and Camps (Reference Cafiero and Camps2019), Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021). The central goal of the proposed study is to analyse stylistic signals observable within a collection known to originate from anonymous reportationes – the collection of Stephen Langton’s Quaestiones Theologiae – aiming to locate any internal stylistic clusters. The hypothesis is that, if discernible, such clusters may be representative of the activity of non-authorial contributors. While the proposed study’s design is informed by recent editorial work on Langton’s collection (Langton, ed. Bieniak et al. 2014–2024), these methods can be expected to apply to other scholastic corpora displaying similar traces of collaborative work. To further explore this potential transfer of methods, the proposed study will involve a direct comparison of the performance of the stylometric tests on both manually edited and HTR-extracted data, adapting the pipeline constructed in Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021). Below, I discuss the philological motivation of the problem, followed by a discussion of the selected methods and potential results.
State of research on early scholastic reportationes
Dating back at least to the 1920s, the scholarly interest in the production of reportationes gradually led to their recognition as a salient feature of the scholastic intellectual practice.Footnote 1 Generally speaking, a reportatio is a note recording oral teaching, usually taken from a master’s lecture by one of its participants. The proliferation of reportationes was closely associated with the growth of universities, and many attempts were made to analyse reportationes in the context of specifically medieval didactic forms. Thus, for example, reportationes prove uniquely valuable as testimonies of the practice of formal public debate, disputatio, in the 13th and 14th centuries.Footnote 2 Still, reportatio as such was neither a genre nor a transmission method but a technique applied in many different contexts and with varying aims.Footnote 3 In many cases, the primary goal of such note-taking may have been private, intended to aid the student’s memory. However, there are also documented cases in which the teaching collected through reportationes formed the foundation of a master’s regular literary works. It is not always easy to establish whether a particular text originated from reportationes, and thus the scope of such oral-to-literary transfer is not fully understood. While the literary production based on reportationes dates back at least to the 1120s, for the entire 12th century scholars have identified only two testimonies describing the process of reporting and its later literary refinement.Footnote 4 Consequently, the existing research on the earliest usage of reportationes for literary production – that is, the production stemming from the cathedral schools and universities before c. 1250 – largely extrapolates from these two testimonies and the more comprehensive information available for later scholastic tradition.
Two basic types of evidence provide insight into the actual scope of the early scholastic literary production based on reportationes. First, scholars identified marks of oral communication in some otherwise inconspicuous literary works. These marks can be lexical or pragmatic. Examples include the prevalence of second-person verb forms, ellipses, or context-specific references to the audience – e.g., singling out lecture participants by name or recalling earlier exchanges of arguments, not preserved in the written testimony.Footnote 5 Another type of indirect evidence is stemmatical. It is not uncommon for traditions dating back to 12th-century Paris to transmit multiple partially collatable versions, likely indicating independent strands of transmission in the text’s early history. Transmission via reportationes is a likely cause behind at least some of this variance,Footnote 6 especially when more than one record of a lecture was created and when the master did not supervise the process. Taken together, available evidence suggests that already in the early stages of the scholastic tradition, it was fairly common for a master to produce his works from reportationes.
Different general accounts of the practice of reportatio can be largely traced back to scholars’ interest in corpora exhibiting different consequences of transmission via reportationes. Some collections, while demonstrably stemming from classroom reports, are stemmatically regular – that is, the stemmatical evidence suggests the existence of a single archetype at the origin of the tradition – leading their editors to assume a higher degree of reportatorial professionalisation and master’s control over the process.Footnote 7 On the other end of the spectrum, we find collections compiling and reworking scattered reportatorial material, possibly with little or no magisterial control, and at a considerable time distance from the initial lecture.Footnote 8 Overall, the reportatio seems to be less of a formalised and unified phenomenon in the 12th century than in its later practice, and thus many basic questions relating to its operation remain open. In particular, in most cases we do not know how many actors – and with what exact roles – stand behind the preserved collections. A model transmission would involve the reportator reworking his record shortly after the class or debate, presumably mostly to supplement the details missing due to the hastiness of the initial record,Footnote 9 and then the master authenticating the testimony, likely extensively interfering in the text – this final correction is known as an ordinatio.Footnote 10 How closely the daily operation of textual production based on reportationes resembled this schema is not clear, but we can safely assume that the preserved records are skewed on the side of more regular instances of reporting, as these were more likely to enter into wider circulation requiring ample scribal work.
Corpus: Stephen Langton’s Quaestiones Theologiae
The collection of Stephen Langton’s Quaestiones provides a particularly convenient vantage point for the study of the practice of reportatio in the early university setting. Stemming from Langton’s Parisian teaching sometime during the last decades of the 12th century up to 1206, this collection was never given a final shape, despite some clear traces of attempted editorial work. Around 70% of the quaestiones listed in the contemporary index of the collection are transmitted in multiple substantially different versions, preserved at varying stages of production.Footnote 11 Some of these include exceptionally concise discussions – presumably unedited transcripts of reportationes – which correspond with some of the fully developed quaestiones, either preserving the structure of the argumentation or being partially collatable, suggesting that these versions represent different accounts of one oral quaestio.
The collection is transmitted by eight major manuscript witnesses (Figure 1). The discernible subcollections (mss. C,Footnote
12
H / K, and families
 $\alpha $
and
$\alpha $
and
 $\beta $
) likely represent parallel, partially overlapping compilations of Langton’s material. They transmit vastly different sets of quaestiones, mostly in varying order. Part of the collection may have been reviewed by Langton – especially in ms. C – but most of the quaestiones were almost certainly edited by someone else, possibly by unknown students or secretaries from Langton’s milieu after 1206. How many editors worked on this collection remains unclear. Similarly, we have no estimate of the number of reportatores involved in recording Langton’s teaching.
$\beta $
) likely represent parallel, partially overlapping compilations of Langton’s material. They transmit vastly different sets of quaestiones, mostly in varying order. Part of the collection may have been reviewed by Langton – especially in ms. C – but most of the quaestiones were almost certainly edited by someone else, possibly by unknown students or secretaries from Langton’s milieu after 1206. How many editors worked on this collection remains unclear. Similarly, we have no estimate of the number of reportatores involved in recording Langton’s teaching.
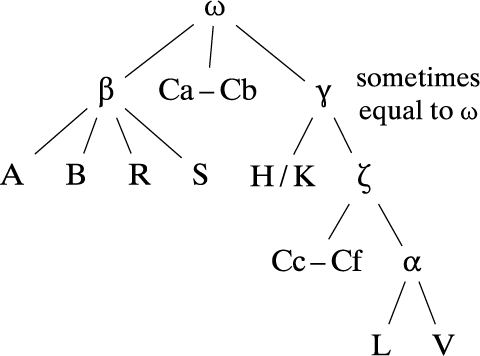
Figure 1. General transmission pattern of Langton’s Quaestiones Theologiae.
Exploratory stylometric analysis
The basic premise of the proposed study stems from the results of Kestemont, Moens, and Deploige (Reference Kestemont, Moens and Deploige2013) and De Gussem (Reference De Gussem2017). Both these studies applied techniques of stylometric authorship attribution in the context of 12th-century collaborative Latin writing, showing that it is possible to track with these tools stylistic variance which can be linked to the contributions of secretaries working with, respectively, Hildegard of Bingen and Bernard of Clairvaux. Our hypothesis – to some extent validated by the exploratory analysis – is that it is similarly possible to map the layers of reportatorial and editorial activity in scholastic corpora.
Both these studies employed to a good effect a widely accepted metric of style: the frequencies of function words, that is, the most common subject-independent lemmas observed in a given corpus.Footnote 13 While, as discussed below, the specific stylometric tests applied in these studies do not transfer well into the problem at hand, it can certainly be confirmed that function words provide a reliable marker of style for scholastic corpora. For example, Figure 2 shows a comparison of 3,000-word samples from Langton’s quaestiones, Robert of Courson’s Summa,Footnote 14 and Aquinas’ Summa Theologiae, prima pars.Footnote 15 From each text, we draw 50 continuous samples. All samples are represented by the relative frequencies of the 200 most frequent words (unlemmatised), which largely align with function words. The data was transformed by primary component analysis (PCA), with the two top components capturing a little over 25% of the total variance. As apparent in the plot, all samples cluster according to their text of origin, showing that these authorial signals can be identified based on the usage of the most frequent words. It is not surprising – function words prove to be effective across many languages and genres – but also not entirely trivial, since theological quaestiones of the period belong to a highly technical and formulaic genre, and thus can be expected to display overall fainter stylistic signals than the related epistolary or sermon corpora.
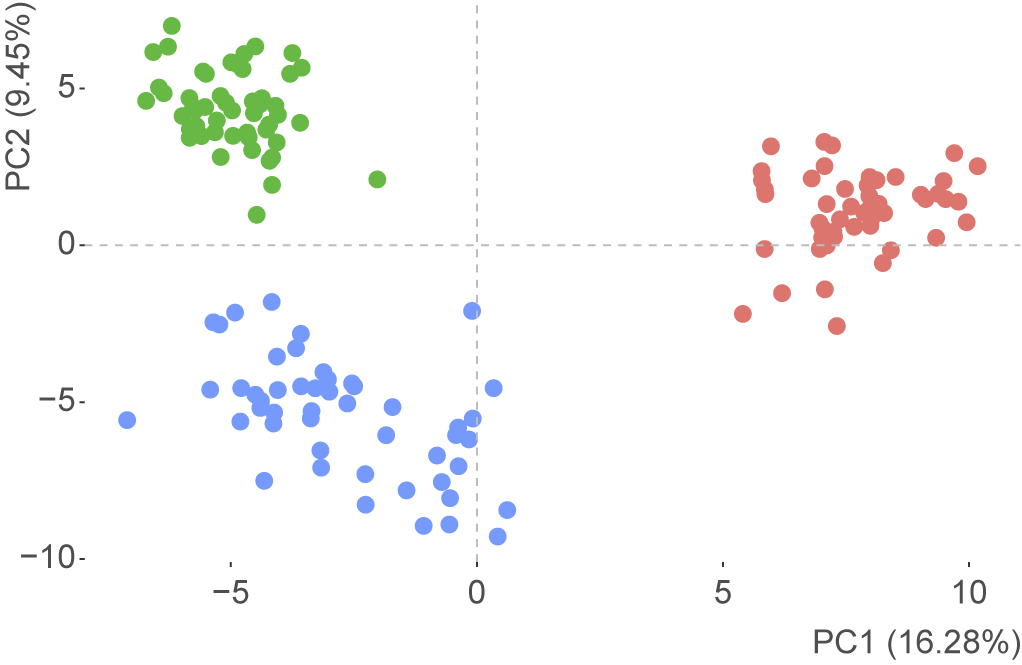
Figure 2. PCA of samples from Aquinas (red), Courson (green), and Langton (blue).
Two factors limit the usefulness of the above test for the analysis of stylistic clusters within Langton’s collection. First, since we have no reliable estimate of the number of expected classes, PCA alone is not a suitable clustering mechanism, as it can conflate some clusters discernible in the initial data. The second limitation is related to the samples’ length. For the distributions of the most frequent words to be representative of the authorial signal, the sample length needs to reach a threshold of 2,000–5,000 words, with the exact required length varying depending on genre and language (Eder Reference Eder2013). Meanwhile, the average length of a single quaestio in Langton’s collection is around 1,400 words, with the extreme values of 166 and 7,385 words.Footnote 16 We can reach the reliable sample’s length by concatenating the quaestiones – as in the above test – but this effectively averages over the stylistic signal of all quaestiones included in a given sample, obscuring the signals of shorter texts and under-representing the actual stylistic variance of the collection.
While the most promising way to address this issue seems to be by extending the set of analysed features – see the discussion in the “Methods” section below – this problem can be to some extent mitigated by bundling the quaestiones according to the information obtained from stemmatical analysis. As already noted, the quaestiones are transmitted in four subcollections, which contain different, partially overlapping sets of quaestiones. Since these subcollections most likely originated as compilations of dispersed Langtonian material, it makes sense to analyse smaller classes of quaestiones organised by the set of manuscripts in which they are transmitted. In this way, we end up with 10 disjoint classes, as detailed in Table 1. This organisation of material accounts for major stemmatical relations, including the shifting relation between ms. C and family
 $\gamma $
.Footnote
17
$\gamma $
.Footnote
17
Table 1. Grouping Langton’s Quaestiones by shared codices.
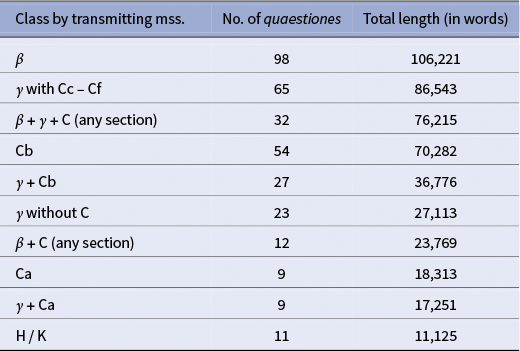
Note: For more details on this data, consult the supplementary files – see the Data Availability Statement below.
Figure 3 shows the results of PCA conducted for these classes, based on the distribution of the 200 most frequent words. While most classes expectedly cluster around the average for the entire collection, there are two clear outliers: the material transmitted exclusively in section Ca of ms. C, as well as quaestiones proper to the Chartres collection H / K.Footnote 18 In the case of Ca, this notably aligns with a long-standing palaeographic observation: the final folios of Ca – the ones transmitting material not found in any other codices – were copied by a different hand (Gregory Reference Gregory1930). Similarly, the bulk of quaestiones transmitted solely by H / K is positioned on its final folios (ms. K, f. 152ra–153va), possibly also copied alia manu.Footnote 19 Thus, the exploratory analysis shows that even based on this admittedly unrefined set of features, it is possible to distinguish stylistic signal characteristic of this collection, as well as locate some stylistic heterogeneity within its boundaries.
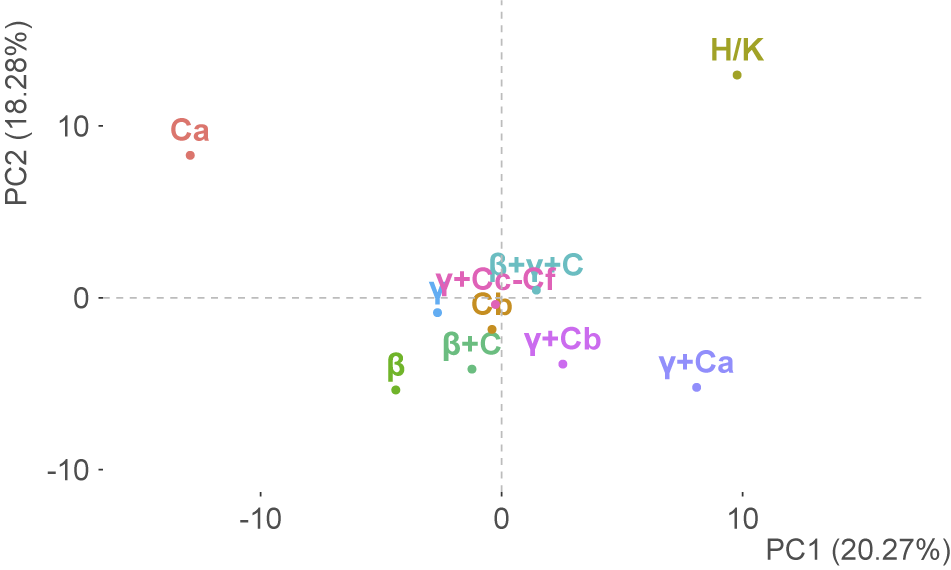
Figure 3. PCA for Langton’s Quaestiones, grouped by transmitting codices.
Methods
The proposed study relies heavily on the methods applied in the context of similar research questions in Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021), where a corpus of short and mostly anonymous Old French texts was analysed to uncover original authorial series obscured by layers of compilatory work. Moreover, this study demonstrated the validity of HTR-based data extraction pipelines for stylometric analysis. Below, I discuss the key implementation details of relevant stylometric tests and data preparation.
Extended features: POS n-grams and pseudo-affixes
While some stylometric tests proposed in recent literature perform well in authorship attribution tasks for samples much shorter than 3,000 words, these solutions largely rely on word embeddings and training author-specific classifiers.Footnote 20 These techniques, in turn, require framing the problem as a supervised scenario based on a dataset of securely labelled samples, which is not feasible in this case. Instead, I plan to extend the set of analysed features, aiming to obtain richer representations of samples and thus enhance the performance on shorter quaestiones.
A strategy suggested in some recent literature is to incorporate Part-of-Speech (POS) n-grams (Chen et al. Reference Chen, Burns, Bolt, Chaudhuri and Dexter2024). Of many possible extended features, the POS three-grams are especially promising as a simple representation of syntactic structures mostly ignored in the bag-of-words approach of tests based solely on word distributions. Incorporating POS three-grams is further facilitated by the availability of efficient morphological taggers for Latin. For the proposed study, I intend to use the LatinPipe (Straka, Straková, and Gamba Reference Straka, Straková and Gamba2024) or closely related UDPipe 2, both of which provide API access and report very high performance on POS tagging (over 99% accuracy), including on scholastic Latin corpora.Footnote 21 Moreover, following Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021), I will extend analysed features by pseudo-affixes, i.e., character three-grams representing each word’s boundaries,Footnote 22 which have been shown to provide valuable stylistic signals (Sapkota et al. Reference Sapkota, Bethard, Montes and Solorio2015).
For each individual feature (most frequent words, POS three-grams, prefixes), the minimal statistically reliable sample length will be assessed implementing the test proposed by Moisl (Reference Moisl2011), in which once more I follow Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021). Establishing this threshold is the study’s primary goal and will condition the later analysis of the data since it determines the exact set of quaestiones which can be reliably subjected to cluster analysis.
Data preparation
For the proposed study, I will benefit from access to the machine-readable text of most or all of Langton’s quaestiones. Nevertheless, I also intend to perform tests on HTR-extracted transcriptions. It can be expected that no significant difference in performance will be observed, with the critical edition being effectively a denoising procedure, although we cannot a priori rule out the possibility that editorial interventions left some systematic stylistic trace. The primary goal in experimenting with automated transcriptions is to develop workflows facilitating the inclusion of relevant unedited sources (or manuscript-specific versions of edited material) in further stylometric studies. In the immediate context of Langton’s corpus, this would offer great aid in the survey of his vast and mostly unstudied scriptural commentaries.
I intend to test in this study the relatively recent transformer-based HTR solutions (TrOCR), which have been successfully applied to historical material (Ströbel et al. Reference Ströbel, Clematide, Hodel and Volk2022). These architectures rely on a vision transformer for feature extraction and a BERT-type decoder for the translation of visual tokens into characters, offering a few relevant advantages over widely applied solutions based on convolutional neural networks. First, they work exceptionally well with normalised transcriptions, largely facilitating the preparation of ground truth. This comes with a significant advantage in the context of university-based Latin literary production, which features a high density of often idiosyncratic abbreviations. In this case, framing the abbreviation expansion as a downstream task performed on HTR-extracted (semi-)diplomatic transcription is considerably more complex than for vernacular corpora, which generally confer less frequent and more regular abbreviations.Footnote 23 Moreover, the reliance on a transformer decoder is likely to result in noise reduction: since the model has a high preference for regular forms, it will likely at least partially normalize orthography, facilitating the later lemmatisation task. Even where the transcription is inaccurate, the produced form can be sufficiently close to ground truth to enable correct assignment of POS tags and prefixes. Consequently, the task-specific accuracy of extracted features is likely to be significantly higher than suggested by the reported Character Error Rate of the model, which can be expected to score around 2%–3%.
For ground truth preparation, I plan to rely on Kraken’s blla model for text segmentation.Footnote 24 While Camps, Clérice, and Pinche (Reference Camps, Clérice and Pinche2021) reported low performance for segmentation with Kraken’s legacy model (default at the time), initial tests show that currently blla outperforms Transkribus’ Universal Lines in polygonisation, creating overall more spacious line polygons and capturing relevant abbreviation markers. I will reuse the transcriptions provided by the collection’s editors, manually aligning a portion of the material (c. 20 pages), after which I will train a provisional Kraken model and automatically align the transcription for remaining pages.Footnote 25 While it would be convenient to prepare in this way ground truth for all major codices transmitting Langton’s collection, I will prioritize workflow exploration over providing a comprehensive dataset.
Potential results
As noted above, the final results of this study will depend heavily on the exact value of the minimal sample length established in statistical tests. It should be noted that this threshold is calculated for every individual feature and depends on the feature’s overall probability in the corpus. Consequently, it will be necessary to balance out the exact set of features and corpus composition, almost certainly resulting in the exclusion of some of the shortest quaestiones. Depending on the composition of the final corpus, the study will address three questions:
-
– Can we discern some distinct clusters among longer quaestiones? Such clusters would likely correspond to the activity of different editors, potentially including a cluster of quaestiones directly corrected by Langton.
-
– In general, do short and long versions of one quaestio tend to cluster together? Such clusters could indicate cases in which either the original reportator developed the longer version or in which the longer version preserved verbatim most of the reportatio. If no clusters of this type are observed, this would suggest a systematic stylistic difference between reportationes and literary quaestiones beyond the obvious difference in length.
-
– Finally, if it will be possible to include most of the short quaestiones, can we observe any clusters of reportationes? Such clusters could be linked to the activity of individual reportatores.
Acknowledgements
I am thankful to Magdalena Bieniak and Wojciech Wciórka for reading an earlier version of this article and sharing their helpful remarks. I would also like to thank Gary Macy for sharing his transcription of ms. Bruges 247.
Author Contributions
Jan Maliszewski — Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Software, Visualization, Writing – original draft, Writing – review & editing.
Data availability statement
The data and code used in this study are available at: https://github.com/jtmaliszewski/CHR-2025-It-takes-a-village. Please note that due to unresolved copyright concerns, the plain text data was masked: all but the top 200 most frequent words were replaced with a “MASKEDTOKEN” placeholder. This allows for full reproduction of the exploratory analysis presented in this article, and the unmasked data was disclosed for peer review. I am currently seeking permission from relevant parties to publish the entire unmasked corpus as part of the final research report. In the meantime, if you are interested in inspecting the unmasked corpus, please contact me at j.maliszewski@uw.edu.pl. The stylometric analysis employed in this article was implemented with the stylo package for R – Eder, Rybicki, and Kestemont (Reference Eder, Rybicki and Kestemont2016).
Ethical standards
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Funding statement
This work was supported by the National Science Centre, Poland, project 2022/45/N/HS1/03747.
Competing interests
The author declares none.
Primary sources
Manuscripts
Stephen Langton, Quaestiones theologiae
-
A Avranches, Bibliothèque municipale, 230, ff. 12ra–294rb
-
B Arras, Bibliothèque municipale, 965 (394), ff. 70ra–157vb
-
C Cambridge, St. John’s College Library, C.7 (57), ff. 171ra–352rb
-
(Ca = C, ff. 171–218; Cb = C, ff. 219–282; Cc = C, ff. 283–306; Cd = C, ff. 307–322; Ce = C, ff. 323–346; Cf = C, ff. 347–352)
-
H Chartres, Bibliothèque municipale, 430, ff. 3r–73v
-
K Chartres, Bibliothèque municipale, 430, ff. 74ra–154vb
-
L Oxford, Bodleian Library, Lyell 42
-
R Città del Vaticano, Biblioteca Apostolica Vaticana, Vat. lat. 4297
-
S Paris, Bibliothèque nationale de France, lat. 16385
-
V Paris, Bibliothèque nationale de France, lat. 14556
Robert of Courson, Summa
-
Bruges 247 = Brugge, Hoofdbibliotheek Biekorf (Stadsbibliotheek), 247
Editions
-
Hugh of St. Victor, Sententiae de divinitate. In Ambrogio Piazzoni, “Ugo di San Vittore auctor delle Sentetiae de divinitate”, Studi Medievali 23 (1982), 912–55.
-
Peter Abelard, Historia Calamitatum, ed. Jacques Monfrin, Paris: Vrin, 1959.
-
Peter Comestor, Lectures on the Glossed Gospel of John, ed. and tr. David M. Foley, Reference Foley2024, The Catholic University of America Press: Washington, DC.
-
Stephen Langton, Quaestiones theologiae, Auctores Britannici Medii Aevi (ABMA):
-
Vol. I, ed. Riccardo Quinto, Magdalena Bieniak, 2014,
(ABMA 22)
-
Vol. II, ed. Wojciech Wciórka, in preparation
-
Vol. III.1, ed. Magdalena Bieniak, Wojciech Wciórka, 2021,
(ABMA 36)
-
Vol. III.2, ed. Magdalena Bieniak, Marcin Trepczyński, Wojciech
Wciórka, 2022, (ABMA 40)
-
Vol. III.3, ed. Magdalena Bieniak, Andrea Nannini, 2024,
(ABMA 45)
-
Vol. IV, ed. Magdalena Bieniak, Jan Maliszewski, in preparation
-
-
Thomas Aquinas, Summa Theologiae, prima pars (= Opera omnia iussu impensaque Leonis XIII P. M. edita, t. 4-5, Roma 1888–1889). Digitised text by R. Busa, E. Alarcón is available from Corpus Thomisticum.








 Open access
Open access
Rapid Responses
No Rapid Responses have been published for this article.