


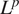

Impact Statement
The Poisson equation is one of the most computationally intensive partial differential equations to solve, requiring very expensive iterative methods. We propose a novel and flexible CNN architecture which can either serve as an alternative to existing iterative methods on Cartesian grids, or augment them. Outperforming existing NN models, the proposed framework can deal with different boundary conditions and domain aspect ratios, without the need for re-training as long as boundary condition types (Dirichlet, Neumann, etc.) are unchanged. The proposed model can enable engineers to run simulations faster, for instance in computational fluid dynamics, where a Poisson equation must to be solved at each time step of the simulation for incompressible flows.
1. Introduction
Partial differential equations (PDEs) describe complex systems in many fields of engineering and science, ranging from fluid flows to options pricing. Despite their ubiquity, they can be very costly to solve accurately. One of the most important PDEs in engineering is the Poisson equation, expressed mathematically as
 $$ {\nabla}^2\phi =f, $$
$$ {\nabla}^2\phi =f, $$where  $ f $ is a forcing term and
$ f $ is a forcing term and  $ \phi $ is the variable for which a solution is sought. Appearing in a diverse range of problems including heat conduction, gravitation, simulating fluid flows, and electrodynamics, the Poisson problem plays a central role in the design of many modern technologies. However, solving the Poisson equation numerically for large problems involving millions of degrees of freedom is only tractable by employing iterative methods. For example, it is well known that the treatment of incompressibility is a real difficulty to obtain solutions of the incompressible Navier–Stokes equations, the mathematical model used to describe the motions of a turbulent flow. Any algorithm must ensure a divergence-free flow field at any given time during the calculation. The unavoidable step of solving the Poisson equation, as introduced by a fractional step method per Chorin (Reference Chorin1967, Reference Chorin1968, 9) can be computationally very expensive (it can represent up to 90% of the computational effort), since it is often based on the said complex iterative techniques.
$ \phi $ is the variable for which a solution is sought. Appearing in a diverse range of problems including heat conduction, gravitation, simulating fluid flows, and electrodynamics, the Poisson problem plays a central role in the design of many modern technologies. However, solving the Poisson equation numerically for large problems involving millions of degrees of freedom is only tractable by employing iterative methods. For example, it is well known that the treatment of incompressibility is a real difficulty to obtain solutions of the incompressible Navier–Stokes equations, the mathematical model used to describe the motions of a turbulent flow. Any algorithm must ensure a divergence-free flow field at any given time during the calculation. The unavoidable step of solving the Poisson equation, as introduced by a fractional step method per Chorin (Reference Chorin1967, Reference Chorin1968, 9) can be computationally very expensive (it can represent up to 90% of the computational effort), since it is often based on the said complex iterative techniques.
One of the fastest algorithms for solving the Poisson equation iteratively, with  $ O(n) $ complexity per Lui (Reference Lui2011), is the multigrid algorithm whereby the problem is solved using a number of successively coarser grids to eliminate low wavenumber error in a few iterations. However, even the multigrid algorithm can take prohibitively long amounts of time to iterate for very large problems. Convolutional neural networks (CNNs) are well positioned to accelerate such iterative methods; they are already in use in various areas of engineering and applied mathematics for complex regression and image-to-image translation tasks, have
$ O(n) $ complexity per Lui (Reference Lui2011), is the multigrid algorithm whereby the problem is solved using a number of successively coarser grids to eliminate low wavenumber error in a few iterations. However, even the multigrid algorithm can take prohibitively long amounts of time to iterate for very large problems. Convolutional neural networks (CNNs) are well positioned to accelerate such iterative methods; they are already in use in various areas of engineering and applied mathematics for complex regression and image-to-image translation tasks, have  $ O(n) $ runtime complexityFootnote 1 and can be run very efficiently on graphics processing units (GPUs) and other floating point acceleration hardware.
$ O(n) $ runtime complexityFootnote 1 and can be run very efficiently on graphics processing units (GPUs) and other floating point acceleration hardware.
Leveraging these strengths, our principal motivation is to develop a CNN-based Poisson equation solver that does not require re-training to perform inference on inputs with different types of boundary conditions (BCs) within a given range of grid resolutions and sizes in the context of Cartesian grids. In this work, we present a novel CNN architecture capable of handling arbitrary right-hand side (RHS) functions  $ f $ and BCs of a given type on rectangular two-dimensional grids of different aspect ratios but uniform grid spacing
$ f $ and BCs of a given type on rectangular two-dimensional grids of different aspect ratios but uniform grid spacing  $ \Delta $. The proposed model is also included in a CFD solver to demonstrate its potential to provide an accurate initial guess (more accurate than the first step of conventional iterative methods), so that the rate of convergence can be dramatically increased.
$ \Delta $. The proposed model is also included in a CFD solver to demonstrate its potential to provide an accurate initial guess (more accurate than the first step of conventional iterative methods), so that the rate of convergence can be dramatically increased.
The outline of this paper is as follows: in Section 2, we provide a brief summary of the recent advancements and ongoing challenges in applying neural networks (NNs) to solve the Poisson equation and more broadly to solve general PDEs. Then, we propose a novel BC handling strategy in Section 3 and the related model architecture in Section 4. The details of our dataset generation method, novel loss and training process are provided in Section 5, Section 6, and Section 7, respectively. The results and performance of the new model are showcased and discussed in Section 8. Finally, conclusions are drawn and plans for future work are outlined.
2. Related Work
Interest in solving PDEs using NN-based methods has a relatively long history, beginning in the 1990s with efforts by Lee and Kang (Reference Lee and Kang1990), Dissanayake and Phan-Thien (Reference Dissanayake and Phan-Thien1994), and Lagaris et al. (Reference Lagaris, Likas and Fotiadis1998). A significant proportion of early works on using NNs to approximate the solutions of PDEs focus on approximating the solution  $ \phi $ given the variables it depends on, such as spatial coordinates, treating the NN as a continuous function. Training is performed to minimize the solution residuals inside the domain and on the boundaries. For example, Lagaris et al. (Reference Lagaris, Likas and Fotiadis1998) utilize a single layer perceptron (constrained by the computational power limitations of the time) to augment trial functions known to satisfy the equation in question to solve a number of benchmark problems in numerical analysis, such as the Poisson equation subject to both (fixed) Dirichlet and Neumann BCs using various RHS functions.
$ \phi $ given the variables it depends on, such as spatial coordinates, treating the NN as a continuous function. Training is performed to minimize the solution residuals inside the domain and on the boundaries. For example, Lagaris et al. (Reference Lagaris, Likas and Fotiadis1998) utilize a single layer perceptron (constrained by the computational power limitations of the time) to augment trial functions known to satisfy the equation in question to solve a number of benchmark problems in numerical analysis, such as the Poisson equation subject to both (fixed) Dirichlet and Neumann BCs using various RHS functions.
This rather intuitive application of NNs greatly benefits from their differentiability via the backpropagation algorithm since it provides a very accurate method to compute the residuals. Combined with other factors such as the accurate results achieved for specific problems using relatively few parameters, the computational constraints of the era and the relative infancy of more advanced NN architectures in use today, this method became the dominant approach in the early attempts to bring the fields of PDEs and NNs together. However, it suffered from the rather severe drawback of each set of trained weights being able to handle only a specific RHS function and set of BCs.
With the increase in computation power through the 2000s, more complicated models with more parameters and multiple layers became the norm. Smaoui and Al-Enezi (Reference Smaoui and Al-Enezi2004) used the greater amounts of computational power available to investigate deeper models, utilizing multilayer perceptrons to predict the proper orthogonal decomposition modes of the one-dimensional (1D) Kuramoto–Sivashinsky equation and the two-dimensional (2D) Navier–Stokes equation. Similarly, Baymani et al. (Reference Baymani, Kerayechian and Effati2010) used multilayer perceptrons to compute the solution of the Stokes equation by decomposing it into multiple Poisson problems and solving the Poisson problems with a procedure similar to the works discussed above. Furthermore, research into different neural computation methods became more popular, leading to works such as those using Radial Basis Function NNs by Jianyu et al. (Reference Jianyu, Siwei, Yingjian and Yaping2003) and by Mai-Duy and Tran-Cong (Reference Mai-Duy and Tran-Cong2001). A more detailed survey of the methods of the era was published by Kumar and Yadav (Reference Kumar and Yadav2011).
Research into the applications of NNs to solve PDEs is still gaining significant momentum, driven by a number of factors providing a supporting ecosystem for deep learning research in general. Substantial improvements in the hardware used to run NN training and inference, discovery of better practices to train NNs, a culture of making publications available in open-access repositories and releasing source code using free and open-source licences in the research community help maintain a substantial growth rate. A brief overview of notable approaches being investigated in a modern setting is provided in the following subsections.
2.1. Modern approaches to solving PDEs using NNs
The above factors led to great strides in models using the older, “continuous” paradigm of training multilayer perceptron-style NNs to minimize solution residuals. Such models can now tackle a much greater variety of PDEs, solved in complex domains with a variety of BCs. A prominent example of advances in this area in recent years is the advent of “physics informed neural networks (PINNs)” by Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2017a) who demonstrated the use of such a methodology to solve the Schrödinger and Burgers equations, the latter of which is of particular note due to the presence of discontinuities. Based on that paradigm, Lu et al. (Reference Lu, Meng, Mao and Karniadakis2021) developed the DeepXDE library, capable of solving a wide range of differential equations including partial- and integro-differential equations, providing a more user-friendly way of using NNs in this context. Furthermore, Meng and Karniadakis (Reference Meng and Karniadakis2019) proposed a method to help PINNs predict the correct values in a problem when given a combination of abundant yet less accurate “low-fidelity” plus sparse yet more accurate “high-fidelity” data.
Another subject that attracted substantial attention in the recent years is using NNs to “discover” the underlying PDE describing (e.g., a physical system) from an existing dataset. In such a system, the NN tries to find the numerical coefficients of a previously assumed PDE form by minimizing residuals. Notable examples include works by Long et al. (Reference Long, Lu, Ma and Dong2018), who adopted a convolutional methodology to first discover the coefficients for and then predict the time evolution of a 2D linear diffusion equation, and also a number of works by Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2017b) and Raissi (Reference Raissi2018), with examples of applications to, among others, the Burgers and Navier–Stokes equations. It is further noteworthy that interest in this subject extends beyond the use of NNs, as evidenced by works such as those from Rudy et al. (Reference Rudy, Brunton, Proctor and Kutz2016) using sparse regression.
Meanwhile, separate from the initial approaches to applying NNs to PDEs described above, fully convolutional models that capitalize on significant strides made in computer vision using CNNs began to gain traction. Utilizing common techniques in computer vision by treating the known terms and solutions of PDEs on rectangular grids as though they were images, such methods approach the task of solving a PDE as an image-to-image translation problem similar to the pix2pix method by Isola et al. (Reference Isola, Zhu, Zhou and Efros2016).
2.2. CNNs and the Poisson equation
A significant proportion of the efforts to use CNNs to solve PDEs has focused on the Poisson equation, considering its status as a well-understood benchmark problem with applications to many fields as mentioned earlier.
In the fluid mechanics community, works of Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2016) and Xiao et al. (Reference Xiao, Zhou, Wang and Yang2018) pioneered the usage of CNNs to solve the Poisson equation. While both use their models within the framework of a complete CFD solver to simulate the motion of smoke plumes around objects, the architectures used and training methodologies are different. The former developed a model which takes a 3D array containing the velocity divergence and geometry information on cubic  $ 128\times 128\times 128 $ grids while the latter adopt a multigrid-like strategy with multiple discretizations to make predictions on larger
$ 128\times 128\times 128 $ grids while the latter adopt a multigrid-like strategy with multiple discretizations to make predictions on larger  $ 384\times 384\times 384 $ grids. Moreover, the former approach trains the NN to minimize the divergence of the velocity field only while the latter adopts a more direct strategy by trying to instead minimize a linear combination of the L2 norms of the velocity divergence and the discrepancy between the predicted and ground truth pressure correction values by leveraging the additional data available from the specific methodology. Building on the strategy developed in these works, Ajuria Illarramendi et al. (Reference Ajuria Illarramendi, Alguacil, Bauerheim, Misdariis, Cuenot and Benazera2020) used a CNN to handle the Poisson solver step of CFD simulations of plumes and flows around cylinders, demonstrating stable and accurate time evolution even for Richardson numbers greater than in the training data when applied in combination with several Jacobi iterations. Outside fluid mechanics, Shan et al. (Reference Shan, Tang, Dang, Li, Yang, Xu and Wu2017) investigated the application of a fully convolutional NN to predict the electric potential on cubic
$ 384\times 384\times 384 $ grids. Moreover, the former approach trains the NN to minimize the divergence of the velocity field only while the latter adopts a more direct strategy by trying to instead minimize a linear combination of the L2 norms of the velocity divergence and the discrepancy between the predicted and ground truth pressure correction values by leveraging the additional data available from the specific methodology. Building on the strategy developed in these works, Ajuria Illarramendi et al. (Reference Ajuria Illarramendi, Alguacil, Bauerheim, Misdariis, Cuenot and Benazera2020) used a CNN to handle the Poisson solver step of CFD simulations of plumes and flows around cylinders, demonstrating stable and accurate time evolution even for Richardson numbers greater than in the training data when applied in combination with several Jacobi iterations. Outside fluid mechanics, Shan et al. (Reference Shan, Tang, Dang, Li, Yang, Xu and Wu2017) investigated the application of a fully convolutional NN to predict the electric potential on cubic  $ 64\times 64\times 64 $ grids given the charge distributions and (constant) permittivities, claiming average relative errors below
$ 64\times 64\times 64 $ grids given the charge distributions and (constant) permittivities, claiming average relative errors below  $ 3\% $ and speedups compared to traditional methods.
$ 3\% $ and speedups compared to traditional methods.
In general, all of these works attempt to predict the solution of the Poisson equation given an array containing the values of the RHS function on a grid. In the present study, we propose a fully convolutional NN architecture that can handle arbitrary BCs, on grids with different aspect ratios and uniform grid spacing. The mathematical formulation and the neural architecture of the proposed approach are discussed in the next two sections.
3. Mathematics of the Proposed NN Architecture
Since the Poisson problem does not have a unique solution when BCs are absent, a way to include and process BC information alongside the RHS is required to obtain a model that is able to solve the Poisson problem with arbitrary BCs (as opposed to training different models tailored for one specific set of BCs). Matrix-based methods such as successive over-relaxation and direct solution handle the BCs by augmenting the RHS vector. Conversely, an NN must process boundary information more explicitly by integrating it into the model architecture. Following from John (Reference John1982) and assuming arbitrary Dirichlet or Neumann BCs, the proposed methodology involves splitting the original (2D) Poisson problem into one Poisson problem with homogeneous (zero Dirichlet) BCs plus four Laplace problems where each Laplace problem has three homogeneous BCs plus one inhomogeneous Dirichlet or Neumann BC identical to one of the BCs in the original problem on the corresponding boundary.
Formally, for Dirichlet BCs, if we consider the original problem on a rectangular domain  $ D $, denoting an edge of the domain with the index
$ D $, denoting an edge of the domain with the index  $ k $ as
$ k $ as  $ {\left[\partial D\right]}_k $ and the corresponding boundary condition on the edge as
$ {\left[\partial D\right]}_k $ and the corresponding boundary condition on the edge as  $ {g}_k $,
$ {g}_k $,
 $$ {\nabla}^2\phi =f\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_1\right)={g}_1\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_2\right)={g}_2\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_3\right)={g}_3\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_4\right)={g}_4, $$
$$ {\nabla}^2\phi =f\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_1\right)={g}_1\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_2\right)={g}_2\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_3\right)={g}_3\hskip0.5em \wedge \hskip0.5em \phi \left({\left[\partial D\right]}_4\right)={g}_4, $$we can rewrite it in the following form, exploiting the linearity of the Laplace operator
 $$ {\nabla}^2\left({\phi}_h+{\phi}_{BC0}+{\phi}_{BC1}+{\phi}_{BC2}+{\phi}_{BC3}\right)=f, $$
$$ {\nabla}^2\left({\phi}_h+{\phi}_{BC0}+{\phi}_{BC1}+{\phi}_{BC2}+{\phi}_{BC3}\right)=f, $$such that
 $$ {\mathrm{\nabla}}^2{\phi}_h= f\hskip0.5em \wedge \hskip0.5em {\phi}_h(\mathrm{\partial}D)=0, $$
$$ {\mathrm{\nabla}}^2{\phi}_h= f\hskip0.5em \wedge \hskip0.5em {\phi}_h(\mathrm{\partial}D)=0, $$ $$ {\nabla}^2{\phi}_{BCk}=0\hskip0.5em \wedge \hskip0.5em {\phi}_{BCk}\left({\left[\partial D\right]}_j\right)=\left\{\begin{array}{cc}{g}_k& j=k\\ {}0& j\ne k\end{array}\right.,j,k\in \left[\mathrm{0,1,2,3}\right]. $$
$$ {\nabla}^2{\phi}_{BCk}=0\hskip0.5em \wedge \hskip0.5em {\phi}_{BCk}\left({\left[\partial D\right]}_j\right)=\left\{\begin{array}{cc}{g}_k& j=k\\ {}0& j\ne k\end{array}\right.,j,k\in \left[\mathrm{0,1,2,3}\right]. $$ Thus, it is possible to solve the original problem by first solving the Poisson equation with the original RHS but zero BCs to find  $ {\phi}_h $, then solving Laplace problems for each BC to find
$ {\phi}_h $, then solving Laplace problems for each BC to find  $ {\phi}_{BCk} $ and summing these results. Similarly, the proposed NN architecture will be composed of two parts—one which solves the homogeneous Poisson problem and another which solves the Laplace problem given one BC. It will be shown in Section 8.6 that this approach is superior to designing a single NN for an inhomogeneous Poisson problem. It also offers more flexibility for handling various types of BCs. Such a feature is not available in the geometry-restricted strategies seen in previous works. It means that the proposed model can tackle any Poisson problem with the appropriate BCs.
$ {\phi}_{BCk} $ and summing these results. Similarly, the proposed NN architecture will be composed of two parts—one which solves the homogeneous Poisson problem and another which solves the Laplace problem given one BC. It will be shown in Section 8.6 that this approach is superior to designing a single NN for an inhomogeneous Poisson problem. It also offers more flexibility for handling various types of BCs. Such a feature is not available in the geometry-restricted strategies seen in previous works. It means that the proposed model can tackle any Poisson problem with the appropriate BCs.
4. Proposed NN Architecture
Figure 1 provides an overview of the high-level structure of the NN architecture proposed in the current study. The NN components of the model are the blocks marked as Dirichlet BC NN (DBCNN), which approximates the solution of the Laplace equation with one inhomogeneous Dirichlet boundary, and the homogeneous Poisson NN (HPNN) which approximates the solution of the Poisson equation with homogeneous BCs. The architecture mirrors the decomposition in Equations (2)–(5). First, the DBCNN submodel makes predictions for the four Laplace problems and applies reflection and rotation operations such that the inhomogeneous boundaries align with the corresponding boundary in the original problem. Then, the HPNN model makes a prediction for the Poisson problem with homogeneous BCs. Finally, these results are summed to obtain the final prediction for a Poisson problem with four inhomogeneous DBCs.

Figure 1. High-level diagram of Poisson convolutional neural network (CNN). Variable names in parentheses in each block indicate the shape of the output of the block.
4.1. Homogeneous Poisson NN (HPNN)
The HPNN estimates the solution of the Poisson problem with homogeneous BCs and was inspired by the Fluidnet architecture by Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2016). The model has two inputs: the RHS and the domain information (grid spacing, domain sizes per spatial dimension). Figure 2 provides an overview of the model architecture. Our model expands upon the Fluidnet model by adding ResNet blocks (first proposed by He et al., Reference He, Zhang, Ren and Sun2015) after most convolutions, incorporating a substantially larger number of independent pooling operations and using dense layers as well as positional embeddingsFootnote 2 to handle different grid resolutions, grid sizes, and aspect ratios.

Figure 2. Homogeneous Poisson neural network (NN) diagram. Variable names in parentheses in each block indicate the shape of the output of the block. Variables named “HP*” are hyperparameters.
In the present study, it was found that the additional model architecture features lead to substantial gains in accuracy for relatively little increases in runtime. A more detailed investigation of the improvements afforded by the novel model features can be found in Section 8.6 with an ablation study. Further investigations indicated that without incorporating a mechanism to handle domain and grid spacing information as with the positional embeddings and the feedforward layers, the model learns to merely reproduce the solution profile with an average peak magnitude value, substantially reducing its usefulness. The necessity to supply the grid spacing is evident from the fact that this is necessary for classical methods as well; on a grid, the finite difference approximation for the Laplacian operator depends on the  $ {\Delta}^2 $ factors in the denominator and hence this information is needed to reverse the operation. On the other hand, while there is no such similar absolute necessity to supply the domain size information (and indeed classical methods do not require this information at all), in practice it was found to greatly boost the performance of the model since it enables the model to adjust its output to different aspect ratios more easily.
$ {\Delta}^2 $ factors in the denominator and hence this information is needed to reverse the operation. On the other hand, while there is no such similar absolute necessity to supply the domain size information (and indeed classical methods do not require this information at all), in practice it was found to greatly boost the performance of the model since it enables the model to adjust its output to different aspect ratios more easily.
When processing the RHS, first the data are passed through several convolutions. Then, the computation is split into multiple independent pooling operations, each of which applies average pooling of progressively larger pool sizes to capture lower-wavenumber modes and applies further convolutions to the pooled results. Then, the pooled results are upsampled using either a polynomial reconstruction method (in the case of the pooling threads with the largest two pool sizes) or transposed convolutions (for branches with smaller pool sizes). Using polynomial interpolation based upsampling methods for pooling branches with large pool sizes was observed to reduce artefacting in the output; upsampling, for example, a  $ 2\times 2 $ input generated using
$ 2\times 2 $ input generated using  $ 128\times 128 $ pooling from a
$ 128\times 128 $ pooling from a  $ 200\times 200 $ source image requires using a strideFootnote 3 of 128 for the transposed convolution to upsample to the original size, which is excessively large. Finally, the results from all branches are summed and are divided by the number of branches times the number of channels in each branch.
$ 200\times 200 $ source image requires using a strideFootnote 3 of 128 for the transposed convolution to upsample to the original size, which is excessively large. Finally, the results from all branches are summed and are divided by the number of branches times the number of channels in each branch.
The domain information (i.e.,  $ \Delta $,
$ \Delta $,  $ {L}_x $, and
$ {L}_x $, and  $ {L}_y $) is processed by several dense layers. The RHS and domain information branches are subsequently merged by multiplying every channel from the RHS branch by one of the outputs of the domain information branch, expressed using tensor notation (without the implicit summation) as
$ {L}_y $) is processed by several dense layers. The RHS and domain information branches are subsequently merged by multiplying every channel from the RHS branch by one of the outputs of the domain information branch, expressed using tensor notation (without the implicit summation) as
 $$ {A}_{ij kl}{B}_{ij}={C}_{ij kl}, $$
$$ {A}_{ij kl}{B}_{ij}={C}_{ij kl}, $$where index  $ i $ is the batch dimension, index
$ i $ is the batch dimension, index  $ j $ is the channel dimension, and the remaining indices are for the spatial dimensions. Finally, several more convolutions are applied to the result from Equation (6), reducing the final number of channels to 1 to produce the solution.
$ j $ is the channel dimension, and the remaining indices are for the spatial dimensions. Finally, several more convolutions are applied to the result from Equation (6), reducing the final number of channels to 1 to produce the solution.
4.2. Dirichlet boundary condition NN (DBCNN)
The DBCNN estimates the solution of the Laplace equation with one inhomogeneous DBC. As inputs, it takes one 1D array containing the BC information, the same domain information used for the HPNN and the number of grid points in the direction orthogonal to the provided BC. Figure 3 further details the operation of the model.

Figure 3. Dirichlet boundary condition neural network (NN) diagram. Variable names in parentheses in each block indicate the shape of the output of the block. Variables named “HP*” are hyperparameters.
The difficulty of solving this problem is constructing the solution, which is a 2D scalar field, from the BC information which is only a 1D scalar field. To overcome this issue, a known mathematical property of the solutions of the Laplace equation in this setting is exploited; given homogeneous DBCs on three boundaries plus one inhomogeneous Dirichlet BC on another on a rectangular domain, the solution of the Laplace equation on the domain  $ \left[0,{L}_x\right]\times \left[0,{L}_y\right] $ can be written as a series of the form
$ \left[0,{L}_x\right]\times \left[0,{L}_y\right] $ can be written as a series of the form
 $$ \phi =\sum \limits_{m=1}^{\infty }{A}_m\sinh \left(\frac{m\pi \left(x-{L}_x\right)}{L_x}\right)\sin \left(\frac{m\pi y}{L_y}\right), $$
$$ \phi =\sum \limits_{m=1}^{\infty }{A}_m\sinh \left(\frac{m\pi \left(x-{L}_x\right)}{L_x}\right)\sin \left(\frac{m\pi y}{L_y}\right), $$when the nonhomogeneous boundary is placed at  $ x=0 $. Thus, we can say that the solution along any constant
$ x=0 $. Thus, we can say that the solution along any constant  $ y=\tilde{y} $ can be written as
$ y=\tilde{y} $ can be written as
 $$ \phi \left(x,\tilde{y}\right)=\sum \limits_{m=1}^{\infty }{B}_m\sinh \left(\frac{m\pi \left(x-{L}_x\right)}{L_x}\right). $$
$$ \phi \left(x,\tilde{y}\right)=\sum \limits_{m=1}^{\infty }{B}_m\sinh \left(\frac{m\pi \left(x-{L}_x\right)}{L_x}\right). $$ Thus, to reconstruct the solution, the  $ {B}_m $ values for each gridpoint in the
$ {B}_m $ values for each gridpoint in the  $ y $ direction are required. Naturally, as is common practice for numerical algorithms, a cutoff point
$ y $ direction are required. Naturally, as is common practice for numerical algorithms, a cutoff point  $ {n}_c $ is chosen for the series. The DBCNN model works by first performing a series of 1D convolutions on the BC data to increase the number of channels to
$ {n}_c $ is chosen for the series. The DBCNN model works by first performing a series of 1D convolutions on the BC data to increase the number of channels to  $ {n}_c $. Following that, spatial pyramid pooling as introduced by He et al. (Reference He, Zhang, Ren, Sun, Fleet, Pajdla, Schiele and Tuytelaars2014) is performed on this result and the fixed-size vector from this operation is concatenated with the domain/grid information. This vector is processed through a feedforward neural network, the final layer of which has
$ {n}_c $. Following that, spatial pyramid pooling as introduced by He et al. (Reference He, Zhang, Ren, Sun, Fleet, Pajdla, Schiele and Tuytelaars2014) is performed on this result and the fixed-size vector from this operation is concatenated with the domain/grid information. This vector is processed through a feedforward neural network, the final layer of which has  $ {n}_c $ units. As the third step, the
$ {n}_c $ units. As the third step, the  $ \sinh $ modes
$ \sinh $ modes  $ \sinh \left( m\pi \left(x-{L}_x\right)/{L}_x\right) $ are constructed and are normalized such that the maximum absolute value in each mode is
$ \sinh \left( m\pi \left(x-{L}_x\right)/{L}_x\right) $ are constructed and are normalized such that the maximum absolute value in each mode is  $ 1.0 $. Finally, a tensor product between the results in the first three steps is performed to create a batch of
$ 1.0 $. Finally, a tensor product between the results in the first three steps is performed to create a batch of  $ \left({n}_c,{n}_x,{n}_y\right) $ sized tensors and a number of 2D convolutions are performed to reduce the number of “channels”
$ \left({n}_c,{n}_x,{n}_y\right) $ sized tensors and a number of 2D convolutions are performed to reduce the number of “channels”  $ {n}_c $ to 1.
$ {n}_c $ to 1.
It should be noted that this model returns results such that the inhomogeneous BC is always on the left boundary of the domain. However, a series of rotations and reflections are sufficient to modify the result such that any other boundary is the inhomogeneous boundary instead.
5. Dataset
The dataset plays a fundamental role when training NNs, since NNs learn to reproduce the conditional probability distribution of the data as outlined by Bishop (Reference Bishop2006). Hence, training on a dataset that does not reflect the probability distribution of the problem in question will give inaccurate results when performing inference. This is especially important when the model will be trained on synthetic data as with our approach, since the onus is on the user to ensure the training set reflects the conditional PDF of the “real” data.
Furthermore, the Poisson problem in the most general case will have source functions and solutions that are finite yet unbounded, which present significant obstacles for NNs. Hence, there is a need to normalize the dataset in a way that does not lead to a loss of generality in the predictive performance of the model while constraining the range of the inputs and outputs to a well-defined and consistent interval. Fortunately, the linearity of the Laplace operator allows us to do this by merely scaling the RHS and the solution by some coefficient  $ \alpha $:
$ \alpha $:
 $$ {\nabla}^2\phi =f\Rightarrow \alpha {\nabla}^2\phi ={\nabla}^2\left(\alpha \phi \right)=\alpha f. $$
$$ {\nabla}^2\phi =f\Rightarrow \alpha {\nabla}^2\phi ={\nabla}^2\left(\alpha \phi \right)=\alpha f. $$ A similar argument may be made to show that scaling the DBCs for such a Poisson problem by a constant results in the solution of the corresponding Laplace problem (as shown in Equation 5) being scaled by the same constant. In this work, it was chosen to constrain the source functions and BCs such that their maximum absolute value is always  $ 1.0 $. Different training data generation methods were adopted for the two sub-models, detailed below.
$ 1.0 $. Different training data generation methods were adopted for the two sub-models, detailed below.
5.1. Training data for HPNN
The HPNN submodel was trained on an analytically generated dataset, composed of synthetically generated solution-RHS pairs based on truncated Fourier and polynomial series. First, the solutions were generated as the sum of a Fourier series and a polynomial, both with random coefficients
 $$ \phi ={\phi}_F+{\phi}_P. $$
$$ \phi ={\phi}_F+{\phi}_P. $$Given homogeneous DBCs, the Poisson equation on a rectangular domain can be shown to have solutions of the form
 $$ \phi =\sum \limits_{m,n}{A}_{m n}\sin \left(\frac{m\pi x}{L_x}\right)\sin \left(\frac{n\pi y}{L_y}\right), $$
$$ \phi =\sum \limits_{m,n}{A}_{m n}\sin \left(\frac{m\pi x}{L_x}\right)\sin \left(\frac{n\pi y}{L_y}\right), $$where, for example,  $ {L}_x $ indicates the domain length in the
$ {L}_x $ indicates the domain length in the  $ x $ direction. It should be noted that that the Laplacian of such a function will correspond to an RHS which is also the sum of products of sine waves. Using such a truncated Fourier series however results in RHS=0 for all grid points on the boundary—a loss of generality. The RHS need not be zero on the boundaries when solving a Poisson problem analytically as an infinite Fourier series can be fitted for a discontinuous function, Gibbs’ phenomenon notwithstanding. However, since a truly infinite series cannot be computed on a computer, the solution was instead augmented by a polynomial component
$ x $ direction. It should be noted that that the Laplacian of such a function will correspond to an RHS which is also the sum of products of sine waves. Using such a truncated Fourier series however results in RHS=0 for all grid points on the boundary—a loss of generality. The RHS need not be zero on the boundaries when solving a Poisson problem analytically as an infinite Fourier series can be fitted for a discontinuous function, Gibbs’ phenomenon notwithstanding. However, since a truly infinite series cannot be computed on a computer, the solution was instead augmented by a polynomial component
 $$ {\phi}_P=\prod \limits_i{p}_i\left({x}_i\right)={p}_x(x){p}_y(y). $$
$$ {\phi}_P=\prod \limits_i{p}_i\left({x}_i\right)={p}_x(x){p}_y(y). $$ The multidimensional polynomial  $ {\phi}_P $ is generated by multiplying 1D polynomials together, benefiting from the variable separable nature of the Poisson equation. Each polynomial component was created by randomly choosing roots
$ {\phi}_P $ is generated by multiplying 1D polynomials together, benefiting from the variable separable nature of the Poisson equation. Each polynomial component was created by randomly choosing roots  $ r $ within the extent of the domain in the respective dimension plus a random coefficient
$ r $ within the extent of the domain in the respective dimension plus a random coefficient  $ B $, reserving two of the roots for the extrema of the domain
$ B $, reserving two of the roots for the extrema of the domain
 $$ {p}_i\left({x}_i\right)={B}_i\left({x}_i-0\right)\left({x}_i-{L}_i\right)\left({x}_i-{r}_{i,0}\right)\left({x}_i-{r}_{i,1}\right)\dots $$
$$ {p}_i\left({x}_i\right)={B}_i\left({x}_i-0\right)\left({x}_i-{L}_i\right)\left({x}_i-{r}_{i,0}\right)\left({x}_i-{r}_{i,1}\right)\dots $$A similar methodology was followed for the Fourier series counterpart with random coefficients C, again utilizing the variable separability
 $$ {\phi}_F=\prod \limits_i{s}_i({x}_i), $$
$$ {\phi}_F=\prod \limits_i{s}_i({x}_i), $$ $$ {s}_i({x}_i)=\sum \limits_k{C}_{k, i}\mathrm{sin}\left(\frac{k\pi {x}_i}{L_i}\right). $$
$$ {s}_i({x}_i)=\sum \limits_k{C}_{k, i}\mathrm{sin}\left(\frac{k\pi {x}_i}{L_i}\right). $$ Subsequently, the peak magnitudes of the two components  $ \max \left(|{\phi}_F|\right) $ and
$ \max \left(|{\phi}_F|\right) $ and  $ \max \left(|{\phi}_P|\right) $ were equalized to ensure neither component dominates the generated dataset. The corresponding right hand sides were calculated by appropriately adjusting the coefficients in the case of
$ \max \left(|{\phi}_P|\right) $ were equalized to ensure neither component dominates the generated dataset. The corresponding right hand sides were calculated by appropriately adjusting the coefficients in the case of  $ {\phi}_F $ and using autodifferentiation to compute
$ {\phi}_F $ and using autodifferentiation to compute  $ {p_i}^{\prime \prime}\left({x}_i\right) $ in the case of
$ {p_i}^{\prime \prime}\left({x}_i\right) $ in the case of  $ {\phi}_P $.
$ {\phi}_P $.
As a final step, normalization was carried out on the dataset to improve model performance. Both the right hand side and the solution are divided by  $ \max \left(|\mathrm{RHS}|\right) $ to set the RHS’ maximum absolute value to 1. Furthermore, the solutions were divided by an additional
$ \max \left(|\mathrm{RHS}|\right) $ to set the RHS’ maximum absolute value to 1. Furthermore, the solutions were divided by an additional  $ \max {\left(\left[{L}_x,{L}_y\right]\right)}^2 $ factor, that is square of the longest domain extent, to ensure that both the RHS and the solution are properly nondimensionalizedFootnote 4.
$ \max {\left(\left[{L}_x,{L}_y\right]\right)}^2 $ factor, that is square of the longest domain extent, to ensure that both the RHS and the solution are properly nondimensionalizedFootnote 4.
During the dataset synthesis process, the number of terms for each sample in the Fourier and Taylor series components were chosen randomly from a uniform distribution within a predetermined range. Overall, this methodology to generate synthetic homogeneous Poisson problems provides four parameters per spatial dimension to control the roughness of the RHS—two parameters for both series components prescribing the range to draw the number of terms from—for a sum of eight parameters for the two dimensional problems investigated in Section 8. The grid parameters were similarly chosen randomly from uniform distributions within predetermined ranges. This necessitates two parameters to choose the range of grid spacings, plus a further two parameters per spatial dimension for the maximum and minimum number of grid points across each dimension, for a total of six parameters for a 2D problem. Note that grid spacings were randomly chosen per-batch instead of per-sample.
5.2. Training data generation for the DBCNN
A different approach to generating training data for the DBCNN submodel was chosen, eschewing the series based approach for the HPNN submodel in favor of a purely numerical approach. This was motivated by the fact that the peak magnitude of the  $ \sinh $ component in the series for the solution of the Laplace equation shown in Equation (7) grows exponentially as the series index
$ \sinh $ component in the series for the solution of the Laplace equation shown in Equation (7) grows exponentially as the series index  $ m $ grows. To avoid having to artificially skew the distribution of the coefficients, instead it was chosen to randomly generate the boundary conditions which necessitates the usage of a numerical method to obtain the solutions to the Laplace problems.
$ m $ grows. To avoid having to artificially skew the distribution of the coefficients, instead it was chosen to randomly generate the boundary conditions which necessitates the usage of a numerical method to obtain the solutions to the Laplace problems.
However, since the boundary conditions of interest are continuous, generating, for example, 200 random values for a 200 gridpoint boundary results in extremely noisy BCs that do not reflect the typical use case for Poisson solvers and are very difficult for NNs to learn from. To rectify this issue, it was instead chosen to generate lower resolution random BCs and then upscale these to the desired resolution using cubic interpolation. Owing to the  $ {C}^2 $ continuity of cubic upscaling, this ensures that the resulting BCs are smooth when the ratio of the final resolution to initial resolution is high enough. The drawback of this method is the addition of this lower resolution to the list of user-defined parameters. To prevent the NN from overfitting for a specific value of this parameter, this value was chosen randomly from a uniform distribution for each batch. This methodology requires
$ {C}^2 $ continuity of cubic upscaling, this ensures that the resulting BCs are smooth when the ratio of the final resolution to initial resolution is high enough. The drawback of this method is the addition of this lower resolution to the list of user-defined parameters. To prevent the NN from overfitting for a specific value of this parameter, this value was chosen randomly from a uniform distribution for each batch. This methodology requires  $ 2\left({N}_D-1\right) $ user-defined parameters to choose the minimum and maximum possible quantities of control points, where
$ 2\left({N}_D-1\right) $ user-defined parameters to choose the minimum and maximum possible quantities of control points, where  $ {N}_D $ is the number of spatial dimensions. The number of parameters needed to control the grid size is identical to Section 5.1.
$ {N}_D $ is the number of spatial dimensions. The number of parameters needed to control the grid size is identical to Section 5.1.
Solutions to the resulting linear systems were computed using the Python algebraic multigrid package PyAMG by Olson and Schroder (Reference Olson and Schroder2018). Specifically, the “classical” Ruge–Stuben algebraic multigrid method with a tolerance of  $ {10}^{-10} $ was chosen. Calculations were done on a 32-core 64-thread AMD Threadripper 2990WX CPU, using 64 threads. Table 6 in Section 8.7 outlines the wall-clock runtime needed to solve single problems at various grid sizes, excluding the time needed to generate the RHS and BCs, along with a comparison to the multigrid method running on the GPU based on the pyamgx Python bindings by Srinath (Reference Srinath2018) to the AMGX library by Nvidia Corporation (2020). In this work, the coarse grid sizes (across each dimension) were set between 2 and 10. To avoid overfitting on specific examples, the datasets are generated on-the-go before each batch is fed to the training routine.
$ {10}^{-10} $ was chosen. Calculations were done on a 32-core 64-thread AMD Threadripper 2990WX CPU, using 64 threads. Table 6 in Section 8.7 outlines the wall-clock runtime needed to solve single problems at various grid sizes, excluding the time needed to generate the RHS and BCs, along with a comparison to the multigrid method running on the GPU based on the pyamgx Python bindings by Srinath (Reference Srinath2018) to the AMGX library by Nvidia Corporation (2020). In this work, the coarse grid sizes (across each dimension) were set between 2 and 10. To avoid overfitting on specific examples, the datasets are generated on-the-go before each batch is fed to the training routine.
6. Loss Function and Approximation of Loss Value
In typical regression applications, it is common to use the mean squared error (MSE) as the loss function. However, as shown in multiple studies on image-to-image translation using convolutional models such as those by Isola et al. (Reference Isola, Zhu, Zhou and Efros2016), MSE loss does not typically lead to good results. As an alternative, since the targets are strictly smooth functions, the continuous version of the  $ {L}^p $ norm between the output and the target presents a more meaningful loss for a pair of continuous functions. The norm is defined as
$ {L}^p $ norm between the output and the target presents a more meaningful loss for a pair of continuous functions. The norm is defined as
 $$ {\left[\frac{1}{A}{\int}_A{\left(y-t\right)}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}, $$
$$ {\left[\frac{1}{A}{\int}_A{\left(y-t\right)}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}, $$where  $ y $ is the prediction,
$ y $ is the prediction,  $ t $ is the target, and
$ t $ is the target, and  $ A $ is a finite region of
$ A $ is a finite region of  $ {\mathrm{\mathbb{R}}}^n $. However, we know the functions’ values only on a rectangular grid. In a naive approach, we could evaluate the expression in Equation (16) by using a polynomial reconstruction method and integrating the piecewise polynomial. In fact, MSE loss can be interpreted as doing this with the midpoint rule. A more accurate alternative is Gauss–Legendre quadrature. In practice, this methodology can be written down for a function
$ {\mathrm{\mathbb{R}}}^n $. However, we know the functions’ values only on a rectangular grid. In a naive approach, we could evaluate the expression in Equation (16) by using a polynomial reconstruction method and integrating the piecewise polynomial. In fact, MSE loss can be interpreted as doing this with the midpoint rule. A more accurate alternative is Gauss–Legendre quadrature. In practice, this methodology can be written down for a function  $ h:{\mathrm{\mathbb{R}}}^n\to \mathrm{\mathbb{R}} $ as
$ h:{\mathrm{\mathbb{R}}}^n\to \mathrm{\mathbb{R}} $ as
 $$ {\int}_Vh\left({x}_1,{x}_2,\dots, {x}_n\right)\hskip0.1em \mathrm{d}{x}_1\dots \mathrm{d}{x}_n\hskip0.5em \approx \hskip0.5em \sum \limits_{i_1=1}^{k_1}\dots \sum \limits_{i_n=1}^{k_n}\left(\prod \limits_{j=1}^n{w}_{i_j}\right)h\left({\overline{x}}_{1_{i_1}},\dots, {\overline{x}}_{n_{i_n}}\right), $$
$$ {\int}_Vh\left({x}_1,{x}_2,\dots, {x}_n\right)\hskip0.1em \mathrm{d}{x}_1\dots \mathrm{d}{x}_n\hskip0.5em \approx \hskip0.5em \sum \limits_{i_1=1}^{k_1}\dots \sum \limits_{i_n=1}^{k_n}\left(\prod \limits_{j=1}^n{w}_{i_j}\right)h\left({\overline{x}}_{1_{i_1}},\dots, {\overline{x}}_{n_{i_n}}\right), $$where  $ {k}_l $ is the order of the quadrature in the lth direction,
$ {k}_l $ is the order of the quadrature in the lth direction,  $ {\overline{x}}_{l_{i_l}} $ is the ilth quadrature point (i.e., Legendre polynomial root) in the lth direction and
$ {\overline{x}}_{l_{i_l}} $ is the ilth quadrature point (i.e., Legendre polynomial root) in the lth direction and  $ w $ is a vector containing the quadrature weights (hence
$ w $ is a vector containing the quadrature weights (hence  $ {w}_{i_j} $ denotes the ilth weight in the jth direction). Applying this formula to Equation (16) for
$ {w}_{i_j} $ denotes the ilth weight in the jth direction). Applying this formula to Equation (16) for  $ y,t:{\mathrm{\mathbb{R}}}^2\to \mathrm{\mathbb{R}} $ with
$ y,t:{\mathrm{\mathbb{R}}}^2\to \mathrm{\mathbb{R}} $ with  $ k $ weights in both directions, we can write
$ k $ weights in both directions, we can write
 $$ {\left[\frac{1}{A}{\int}_A\left(y\left({x}_1,{x}_2\right)-t\right({x}_1,{x}_2\left)\right){}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}\approx {\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j\left[y\left({\overline{x}}_{1_i},{\overline{x}}_{2_j}\right)-t\right({\overline{x}}_{1_i},{\overline{x}}_{2_j}\left)\right]{}^p\right]}^{1/p}. $$
$$ {\left[\frac{1}{A}{\int}_A\left(y\left({x}_1,{x}_2\right)-t\right({x}_1,{x}_2\left)\right){}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}\approx {\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j\left[y\left({\overline{x}}_{1_i},{\overline{x}}_{2_j}\right)-t\right({\overline{x}}_{1_i},{\overline{x}}_{2_j}\left)\right]{}^p\right]}^{1/p}. $$ This approach, however, relies on knowing the values of  $ y $ and
$ y $ and  $ t $ at the quadrature points
$ t $ at the quadrature points  $ {\overline{x}}_1,{\overline{x}}_2 $ which are not equispaced and therefore cannot be made to coincide with the grid points using a simple affine transformation as is the common practice for utilizing Gauss–Legendre quadrature for domains other than the canonical
$ {\overline{x}}_1,{\overline{x}}_2 $ which are not equispaced and therefore cannot be made to coincide with the grid points using a simple affine transformation as is the common practice for utilizing Gauss–Legendre quadrature for domains other than the canonical  $ \left[-1,1\right] $ domain. To overcome this issue,
$ \left[-1,1\right] $ domain. To overcome this issue,  $ y\left({\overline{x}}_1,{\overline{x}}_2\right) $ and
$ y\left({\overline{x}}_1,{\overline{x}}_2\right) $ and  $ t\left({\overline{x}}_1,{\overline{x}}_2\right) $ were approximated using bilinear interpolation within the “cell” enclosing each quadrature point. In practice, for each quadrature point, the value is a linear combination of the four known values on the corners
$ t\left({\overline{x}}_1,{\overline{x}}_2\right) $ were approximated using bilinear interpolation within the “cell” enclosing each quadrature point. In practice, for each quadrature point, the value is a linear combination of the four known values on the corners
 $$ y\left({\overline{x}}_1,{\overline{x}}_2\right)\approx \left[{b}_{00}\hskip0.5em {b}_{01}\hskip0.5em {b}_{10}\hskip0.5em {b}_{11}\right]\left[\begin{array}{c}{y}_{i,j}\\ {}{y}_{i+1,j}\\ {}{y}_{i,j+1}\\ {}{y}_{i+1,j+1}\end{array}\right]={\overrightarrow{b}}^{\top}\overrightarrow{y}, $$
$$ y\left({\overline{x}}_1,{\overline{x}}_2\right)\approx \left[{b}_{00}\hskip0.5em {b}_{01}\hskip0.5em {b}_{10}\hskip0.5em {b}_{11}\right]\left[\begin{array}{c}{y}_{i,j}\\ {}{y}_{i+1,j}\\ {}{y}_{i,j+1}\\ {}{y}_{i+1,j+1}\end{array}\right]={\overrightarrow{b}}^{\top}\overrightarrow{y}, $$where the weight vector  $ \overrightarrow{b} $ depends on the coordinates of the quadrature point and the grid points. Denoting
$ \overrightarrow{b} $ depends on the coordinates of the quadrature point and the grid points. Denoting  $ {\overrightarrow{\cdot}}_{ij} $ as the vector containing the values of the variable in question for the
$ {\overrightarrow{\cdot}}_{ij} $ as the vector containing the values of the variable in question for the  $ i $th quadrature point in the
$ i $th quadrature point in the  $ {x}_1 $ direction and the
$ {x}_1 $ direction and the  $ j $th quadrature point in the
$ j $th quadrature point in the  $ {x}_2 $ direction, we can rewrite Equation (18) as
$ {x}_2 $ direction, we can rewrite Equation (18) as
 $$ {\left[\frac{1}{A}{\int}_A\left(y\left({x}_1,{x}_2\right)-t\right({x}_1,{x}_2\left)\right){}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}\approx {\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j{\left[{\overrightarrow{b}}_{ij}^{\top}\left({\overrightarrow{y}}_{ij}-{\overrightarrow{t}}_{ij}\right)\right]}^p\right]}^{1/p}. $$
$$ {\left[\frac{1}{A}{\int}_A\left(y\left({x}_1,{x}_2\right)-t\right({x}_1,{x}_2\left)\right){}^p\hskip0.1em \mathrm{d}A\right]}^{1/p}\approx {\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j{\left[{\overrightarrow{b}}_{ij}^{\top}\left({\overrightarrow{y}}_{ij}-{\overrightarrow{t}}_{ij}\right)\right]}^p\right]}^{1/p}. $$During training, it was found that augmenting the integration with a mean absolute error (MAE) loss component sped up the loss minimization. Hence, the final expression for the loss is
 $$ L={\lambda}_1{\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j{\left[{\overrightarrow{b}}_{ij}^{\top}\left({\overrightarrow{y}}_{ij}-{\overrightarrow{t}}_{ij}\right)\right]}^p\right]}^{1/p}+\frac{\lambda_2}{N}\sum \limits_i^N\mid {y}_i-{t}_i\mid . $$
$$ L={\lambda}_1{\left[\frac{1}{A}\sum \limits_i^k\sum \limits_j^k{w}_i{w}_j{\left[{\overrightarrow{b}}_{ij}^{\top}\left({\overrightarrow{y}}_{ij}-{\overrightarrow{t}}_{ij}\right)\right]}^p\right]}^{1/p}+\frac{\lambda_2}{N}\sum \limits_i^N\mid {y}_i-{t}_i\mid . $$ Experimentation during training indicated that values of  $ {\lambda}_1=0.4 $,
$ {\lambda}_1=0.4 $,  $ {\lambda}_2=1.0 $ and
$ {\lambda}_2=1.0 $ and  $ p=2 $ provide good performance. A benchmark of training the DBCNN model with and without this novel loss function can be found in Section 8.6.
$ p=2 $ provide good performance. A benchmark of training the DBCNN model with and without this novel loss function can be found in Section 8.6.
Training the model by using the root mean square (RMS) solution residual as the loss as in works by Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2017a, Reference Raissi, Perdikaris and Karniadakis2017b) was also tried, both on its own and as an extra term in the loss expression in Equation (21). It was found that, when used by itself, the residual loss leads to unstable training. This issue can be overcome by starting training with an MAE and/or integral loss and introducing the residual component after several epochs of training. Unfortunately this leads to higher MSE than the loss function in Equation (21), albeit resulting in smoother solutions that may in some cases look qualitatively better. However, it was chosen to focus on numerical measures of error in this work.
7. NN Training
The model was implemented using Tensorflow 2.3. The submodels were trained independently; no further end-to-end training was carried out for the full model configuration shown in Figure 1. Adam was chosen as the optimizer method, with an initial learning rate of  $ {10}^{-4} $ for the DBCNN and
$ {10}^{-4} $ for the DBCNN and  $ {10}^{-5} $ for the HPNN. Learning rate was dynamically tapered to
$ {10}^{-5} $ for the HPNN. Learning rate was dynamically tapered to  $ {10}^{-7} $ as loss plateaued. To determine when to stop the training, early stopping based on the mean squared error with 20-epoch patience was used. Table 1 summarizes the information regarding the number of samples used to train each model.
$ {10}^{-7} $ as loss plateaued. To determine when to stop the training, early stopping based on the mean squared error with 20-epoch patience was used. Table 1 summarizes the information regarding the number of samples used to train each model.
Table 1. Details of the number of samples used to train each submodel.

Abbreviations: DBCNN, Dirichlet boundary conditions neural network; HPNN, homogeneous Poisson neural network.
Furthermore, a number of best practice guidelines for both training and tweaking the model architecture were established for ensuring the best model performance:
• Final layers should have small kernels to prevent artefacting near the domain edges since smaller kernels require less padding to retain the input shape, while initial layers should have large kernels to propagate information from each gridpoint to every other gridpointFootnote 5 using fewer convolutional layers.
• Randomizing input domain shapes by independently picking the size of each dimension from a uniform distribution leads to a nonuniform distribution of aspect ratios (ARs), as the ratio of two uniform distributions is known to result in a highly nonuniform distribution per Marsaglia (Reference Marsaglia1965). This leads to poor performance with ARs which are less commonly encountered in the dataset. To rectify this, instead the ARs themselves can be picked from a uniform distribution and the grid sizes generated based on the ARs.
• Using large batch sizes is critical for ensuring good model performance. In the case of the HPNN submodel, increasing the batch size from 13 to 50 led to a
 $ 45\% $ reduction in loss with an identical number of samples and a $ 78\% $ reduction at the end of training.
$ 45\% $ reduction in loss with an identical number of samples and a $ 78\% $ reduction at the end of training.• Adding as many pooling levels to the HPNN as possible is crucial to allow the model to capture information at multiple scales.
• Deconvolutional upsampling in the HPNN provides superior results when reversing pooling operations with small pool sizes, while bilinear/nearest neighbor are better for very large pool sizes (e.g.,
$ 64\times 64 $).• Increasing the number of spatial pyramid pooling (SPP) levels in the DBCNN was found to reduce prediction accuracy beyond a certain level; increasing the number of output values from the SPP layer to 123 from 58 reduced loss by
$ 41\% $, but further increasing it to 228 led to a $ 32\% $ increase relative to 123 outputs.• Using Rectified Linear Unit (ReLU) activations in the intermediate layers for this task was observed to cause the dying ReLU problem. Other activations such as tanh or leaky ReLUs were observed to result in higher accuracy.
• Residual connections boost performance of both the DBCNN and the HPNN.





8. Results and Performance
In this section we show the performance of a Poisson CNN model, the submodels of which were trained independently on problems with grids containing 192–384 grid points in each direction and  $ \Delta $ values between 0.005 and 0.05. Sections 8.1 and 8.2 outline the test cases chosen and give greater detail regarding the performance of the model in each test case. Moving outside the “comfort zone” of the model, Section 8.3 investigates the performance of the model with problem sizes outside the training data. Section 8.4 details ways to work around artefacting that can show up in the model’s predictions, and demonstrates the usage of Poisson CNN predictions as initial guesses for the multigrid algorithm. Building on that demonstration, Section 8.5 showcases the usage of the Poisson CNN within a CFD simulation and compares the accuracy obtained with a fully conventional simulation. Finally, Section 8.6 explores the impact of key innovations in the model architecture on the predictive performance of the model and 8.7 compares the wall-clock runtime of the model against a conventional iterative solver algorithm. Furthermore, to demonstrate the flexibility of our approach, we present in Appendix A a gallery of results with a greater range of aspect ratios.
$ \Delta $ values between 0.005 and 0.05. Sections 8.1 and 8.2 outline the test cases chosen and give greater detail regarding the performance of the model in each test case. Moving outside the “comfort zone” of the model, Section 8.3 investigates the performance of the model with problem sizes outside the training data. Section 8.4 details ways to work around artefacting that can show up in the model’s predictions, and demonstrates the usage of Poisson CNN predictions as initial guesses for the multigrid algorithm. Building on that demonstration, Section 8.5 showcases the usage of the Poisson CNN within a CFD simulation and compares the accuracy obtained with a fully conventional simulation. Finally, Section 8.6 explores the impact of key innovations in the model architecture on the predictive performance of the model and 8.7 compares the wall-clock runtime of the model against a conventional iterative solver algorithm. Furthermore, to demonstrate the flexibility of our approach, we present in Appendix A a gallery of results with a greater range of aspect ratios.
Table 2 outlines the number of parameters for the models with the specific choice of hyperparameters (e.g., kernel sizes and number of channels) made. It should be noted that our choice does not represent a necessarily optimal choice for these hyperparameters, as this work is meant as a feasibility study.
Table 2. Summary of the number of parameters.

Abbreviations: BC, boundary condition; CNN, convolutional neural network.
Table 3 gives an overview of the performance of the models in terms of the MAE, mean absolute percentage error (MAPE) and the percentage of grid points in each case for which the model made a prediction within 10% of the target. Supplementing the selected test cases, averaged results for larger sets of similar examples are also available where applicable.
Table 3. Summary of the results presented in this section, plus averaged figures for larger numbers of examples for each case where applicable.

Note that grid points with absolute percentage errors above 200% were excluded from the MAPE calculation due to MAPE values approaching infinity near the zero solution contours. Baseline cases are denoted in italics. Average figures were computed over 600 randomly generated samples. Peak error figures were normalized by the maximal absolute value of the ground truth.
In addition to our models, we provide an overview of the performance of two baseline models trained on the same datasets using identical loss functions and optimizers to illustrate the strength of our individual sub-models on their respective tasks. A four-level U-Net, proposed by Ronneberger et al. (Reference Ronneberger, Fischer and Brox2015), with leaky ReLU activations and 7.5 million parameters serves as the baseline case for the HPNN submodel. Meanwhile, the baseline case for the DBCNN sub-model is a stack of six bidirectional Long Short-Term Memory (LSTM) layers (see Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997) with 100 units per layer and  $ \tanh $ activations containing approximately 440,000 parameters, plus bilinear upscaling applied to the final LSTM output to match the target shape.
$ \tanh $ activations containing approximately 440,000 parameters, plus bilinear upscaling applied to the final LSTM output to match the target shape.
Detailed results from the baseline experiments are omitted for brevity, however our models greatly outperformed the naive baseline implementations; both the HPNN and the DBCNN model achieved MAEs an order of magnitude smaller than their respective baselines. Particularly, the U-Net produced results with the kind of severe checkerboard artefacting patterns associated with transpose convolutions, in line with the observations of Odena et al. (Reference Odena, Dumoulin and Olah2016), displaying the advantage of using both transpose convolutions and traditional upsampling techniques in the HPNN architecture. Meanwhile, compared to the LSTM stack, the DBCNN model’s specifically tailored architecture leveraging the mathematical properties of the investigated problem produces results which exhibit substantially less high-frequency noise in the direction orthogonal to the boundary. Another striking result is the percentages of grid points for which the prediction is within 10% of the target value, which are much higher for our models when compared to the baselines.
8.1. Examples similar to the training set
It is crucial for machine learning (ML) algorithms to be able to make correct predictions on previously unseen data that comes from a dataset with the same conditional probability distribution between the inputs and outputs as the training data. In typical ML applications, this is tested for by splitting the dataset (of e.g., photos) into a training and a validation set and observing if a model that performs well on the training set does equally well on the validation set. In our approach, since each batch of training data is generated from random noise synthetically just before being fed to the training loop, analogously we can test the model’s performance on new random samples generated in an identical manner. This section presents the models’ performance on examples generated in the same manner as the training data first for each submodel individually in Sections 8.1.1 and 8.1.2, finally presenting an example for a Poisson problem with four inhomogeneous DBCs in Section 8.1.3.
8.1.1. Homogeneous Poisson NN
Figures 4 and 5 depict the performance of the HPNN on two random examples generated in the same manner as the training data, with different ARs. The model displays good predictive accuracy with the majority of the predictions lying within 10% of the target for the example in Figure 4, rising to over three quarters for the example in Figure 5. A substantial proportion of the predictions that lie outside this 10% band are clustered around the contours where the solution  $ \phi =0 $, where high percentage errors occur despite good predictions in terms of the numerical value. The most notable inaccuracies (in terms of the absolute values) lie near points where the ground truth has a local maximum or minimum due to slight mispredictions of both the location and the value of these local extrema.
$ \phi =0 $, where high percentage errors occur despite good predictions in terms of the numerical value. The most notable inaccuracies (in terms of the absolute values) lie near points where the ground truth has a local maximum or minimum due to slight mispredictions of both the location and the value of these local extrema.

Figure 4. Performance of the homogeneous Poisson neural network (HPNN) model on an example with grid size  $ 365\times 365 $ and
$ 365\times 365 $ and  $ \Delta =1.81\times {10}^{-2} $. The HPNN submodel performs well, producing a prediction within 10% of the target for over half of the grid points.
$ \Delta =1.81\times {10}^{-2} $. The HPNN submodel performs well, producing a prediction within 10% of the target for over half of the grid points.

Figure 5. Performance of the homogeneous Poisson neural network (HPNN) model on an example with grid size  $ 384\times 192 $ and
$ 384\times 192 $ and  $ \Delta =3.47\times {10}^{-2} $. The HPNN submodel can handle a variety of different aspect ratios well, including in this case where it predicts values within 10% of the target for almost three-quarters of the grid points.
$ \Delta =3.47\times {10}^{-2} $. The HPNN submodel can handle a variety of different aspect ratios well, including in this case where it predicts values within 10% of the target for almost three-quarters of the grid points.
The example in Figure 5, when juxtaposed against Figure 4, showcases the capability of the HPNN submodel to deal with problems involving vastly differing ARs and grid sizes without retraining. This capability is crucial for Poisson CNN’s intended aim as an acceleration step for iterative algorithms, as reusability for different grid parameters greatly enhances the attractiveness for this purpose.
8.1.2. Dirichlet BC NN
As shown in Figures 6 and 7, the DBCNN reproduces the multigrid solution with a good degree of accuracy, replicating the hyperbolic sine solution profile well. The largest absolute errors occur due to some oscillatory behaviour near the left boundary, caused by the padding-related issues explained in Section 7 being magnified by the large solution magnitudes in this region. Section 8.4 discusses the application of Jacobi post-smoothing to resolve this issue. Jacobi smoothing substantially reduces the peak normalized error down to  $ 2.49\times {10}^{-1} $ and
$ 2.49\times {10}^{-1} $ and  $ 1.96\times {10}^{-1} $ for Figures 6 and 7, respectively—an almost three quarter reduction compared to the values in Table 3. The performance in terms of the percentage of grid points with predictions within 10% of the target are 41 and
$ 1.96\times {10}^{-1} $ for Figures 6 and 7, respectively—an almost three quarter reduction compared to the values in Table 3. The performance in terms of the percentage of grid points with predictions within 10% of the target are 41 and  $ 31\% $ for the two cases, slightly worse than the HPNN submodel. Conversely, the MAE for the case in Figure 6 is
$ 31\% $ for the two cases, slightly worse than the HPNN submodel. Conversely, the MAE for the case in Figure 6 is  $ 84\% $ lower than the MAE for the HPNN submodel in Figure 4 as shown in Table 3.
$ 84\% $ lower than the MAE for the HPNN submodel in Figure 4 as shown in Table 3.

Figure 6. Performance of the Dirichlet boundary condition neural network (DBCNN) model on an example generated in the same manner as its training data, with a grid size of  $ 384\times 384 $ and
$ 384\times 384 $ and  $ \Delta =2.63\times {10}^{-2} $. The DBCNN submodel replicates the hyperbolic sine solution profile successfully.
$ \Delta =2.63\times {10}^{-2} $. The DBCNN submodel replicates the hyperbolic sine solution profile successfully.

Figure 7. Performance of the Dirichlet boundary condition neural network (DBCNN) model on an example generated in the same manner as its training data, with a grid size of  $ 382\times 197 $ and
$ 382\times 197 $ and  $ \Delta =1.59\times {10}^{-2} $. Similar to the homogeneous Poisson neural network (HPNN), the DBCNN can handle different aspect ratios effectively, replicating the solution profile properly.
$ \Delta =1.59\times {10}^{-2} $. Similar to the homogeneous Poisson neural network (HPNN), the DBCNN can handle different aspect ratios effectively, replicating the solution profile properly.
The seemingly contradictory MAPE and MAE values are explained by the observation that  $ \% $ errors increase progressively as we move in the positive horizontal direction. For the DBCNN,
$ \% $ errors increase progressively as we move in the positive horizontal direction. For the DBCNN,  $ \% $ errors rise toward the right boundary since the sinh-shaped solution profile in this direction rapidly reduces the solution magnitudes. Thus, absolute errors remain very small despite large relative errors. ARs further complicates this comparison as the solution decays quicker in terms of normalized horizontal coordinates
$ \% $ errors rise toward the right boundary since the sinh-shaped solution profile in this direction rapidly reduces the solution magnitudes. Thus, absolute errors remain very small despite large relative errors. ARs further complicates this comparison as the solution decays quicker in terms of normalized horizontal coordinates  $ x/{L}_x $ for high AR domains as seen in Figure 7. Hence, MAPEs are relatively small and MAEs are relatively large for low AR cases and the opposite is true for higher ARs.
$ x/{L}_x $ for high AR domains as seen in Figure 7. Hence, MAPEs are relatively small and MAEs are relatively large for low AR cases and the opposite is true for higher ARs.
8.1.3. Poisson CNN (full model)
Figure 8 depicts the performance of the full model on a randomly generated Poisson problem. The performance of the model in terms of MAPE is  $ 9.81\% $ and over two thirds of grid points have predictions within
$ 9.81\% $ and over two thirds of grid points have predictions within  $ 10\% $ of the target. The decomposition of the Poisson problem as shown in Equation (5) performs well and the Poisson CNN architecture proposed is capable of providing good estimates for solutions to Poisson problems with four inhomogeneous BCs, substantially exceeding the performance of the individual submodels on their respective subproblems.
$ 10\% $ of the target. The decomposition of the Poisson problem as shown in Equation (5) performs well and the Poisson CNN architecture proposed is capable of providing good estimates for solutions to Poisson problems with four inhomogeneous BCs, substantially exceeding the performance of the individual submodels on their respective subproblems.

Figure 8. Performance of the Poisson convolutional neural network (CNN) model on an example with grid size  $ 263\times 311 $ and
$ 263\times 311 $ and  $ \Delta =4.91\times {10}^{-2} $. The components predicted by the submodels reconstruct the solution accurately, demonstrating the flexibility of the decomposition.
$ \Delta =4.91\times {10}^{-2} $. The components predicted by the submodels reconstruct the solution accurately, demonstrating the flexibility of the decomposition.
8.2. Taylor–Green vortex problem
The Taylor–Green vortex (TGV) in two-dimensions is a well-known analytical solution to the Navier–Stokes equations. The pressure component of the TGV, with the time-dependent term and density set as unity for simplicity, presents an easy-to-construct analytical test case. It is a benchmark frequently used in CFD community and is representative of Poisson equations encountered in practical applications. We can construct a Poisson problem in the domain  $ \left[0,\pi \right]\times \left[0,\pi \right] $ by setting the solution
$ \left[0,\pi \right]\times \left[0,\pi \right] $ by setting the solution  $ \phi $ as the TGV pressure field
$ \phi $ as the TGV pressure field
 $$ \phi =-\frac{1}{4}(\mathrm{cos}(2 x)+\mathrm{cos}(2 y)) $$
$$ \phi =-\frac{1}{4}(\mathrm{cos}(2 x)+\mathrm{cos}(2 y)) $$ $$ \therefore \mathrm{R}\mathrm{H}\mathrm{S}={\mathrm{\nabla}}^2\phi =\mathrm{cos}(2 x)+\mathrm{cos}(2 y), $$
$$ \therefore \mathrm{R}\mathrm{H}\mathrm{S}={\mathrm{\nabla}}^2\phi =\mathrm{cos}(2 x)+\mathrm{cos}(2 y), $$with the BC along each boundary defined as
 $$ b(t)=-\left(\cos (2t)+1\right)/4, $$
$$ b(t)=-\left(\cos (2t)+1\right)/4, $$where  $ t $ is the coordinate along the boundary. As a benchmark case, we investigate the performance of the model on this problem with a grid size towards the middle of the range the model has seen during training—
$ t $ is the coordinate along the boundary. As a benchmark case, we investigate the performance of the model on this problem with a grid size towards the middle of the range the model has seen during training— $ 255\times 255 $.
$ 255\times 255 $.
Figures 9, 10, and 11 show the performance of the HPNN, DBCNN, and Poisson CNN models, respectively. The HPNN submodel performed at a level in line with the results displayed in Section 8.1.1 when predicting on the RHS function. The model achieved predictions within 10% of the target at over half of the grid points and reproduced key solution features such as symmetricity about the  $ x=y $ line. Mirroring the previous cases, largest absolute errors are concentrated near local extrema, particularly near the local minimum in the middle of the domain, and largest percentage errors are near the
$ x=y $ line. Mirroring the previous cases, largest absolute errors are concentrated near local extrema, particularly near the local minimum in the middle of the domain, and largest percentage errors are near the  $ \phi =0 $ contours.
$ \phi =0 $ contours.

Figure 9. Prediction of the homogeneous Poisson neural network (HPNN) submodel on the Taylor–Green vortex (TGV) case, compared to multigrid. Although the problem is materially dissimilar to the training set, the HPNN submodel performs in line with the 600 example average in Table 3.

Figure 10. Prediction of the Dirichlet boundary condition neural network (DBCNN) submodel on the Taylor–Green vortex (TGV) case, compared to multigrid. The DBCNN submodel performs well in this test case, marginally better than the 600 example average in Table 3, although mild artefacting is visible near the corners.

Figure 11. Prediction of the full model on the Taylor–Green vortex (TGV) case. Overall, the Poisson convolutional neural network (CNN) exhibits good performance only slightly behind the performance shown on the problems similar to the ones encountered in the dataset, highlighting the generalization performance of the model.
The DBCNN submodel performed slightly better in this case compared to the 600-sample average shown in Table 3. Although providing somewhat grainy results and underpredicting the peak magnitude of the solution along the  $ y=\left(2k+1\right)\pi /2 $ contours where the BC value approaches 0, the predictions along the midsection of the domain are very good. Highest absolute errors are seen near the left boundary by the corners while the highest percentage errors are by the right boundary, mirroring the previous sample shown in Section 8.1.2.
$ y=\left(2k+1\right)\pi /2 $ contours where the BC value approaches 0, the predictions along the midsection of the domain are very good. Highest absolute errors are seen near the left boundary by the corners while the highest percentage errors are by the right boundary, mirroring the previous sample shown in Section 8.1.2.
The performance of the full Poisson CNN model exceeds that of the individual submodels. The MAPE of the full model lies below that of the two submodels and is just above the previous 600-sample average shown in Table 3. Important solution features such as the sharp contours along the  $ x+y=\left(2k+1\right)\pi /2 $ lines are present. However, from a purely qualitative perspective, some artefacting is visible near the corners, stemming from the artefacting seen in the DBCNN prediction.
$ x+y=\left(2k+1\right)\pi /2 $ lines are present. However, from a purely qualitative perspective, some artefacting is visible near the corners, stemming from the artefacting seen in the DBCNN prediction.
Overall, both submodels as well as the overall Poisson CNN model demonstrate solid performance in this analytical test case, giving further evidence that the model did not overfit on the training data.
8.3. Performance with previously unseen grids
An important aspect of the generalization performance of the model is whether it is able to handle grids with parameters (such as grid spacing and sizes) outside the range encountered during training. Figure 12 shows the RMS error of the model prediction relative to the analytical solution on the same TGV case shown in Section 8.2 with progressively denser grids.

Figure 12. Root mean square (RMS) error model output w.r.t. the analytical solution versus grid density for the Taylor–Green vortex (TGV) case. Interval of grid sizes encountered in training is marked by red lines. Yellow dot indicates the results presented in Section 8.2.

Figure 13. Poisson convolutional neural network (CNN) predictions on  $ 120\times 120 $ (left),
$ 120\times 120 $ (left),  $ 500\times 500 $ (middle) and
$ 500\times 500 $ (middle) and  $ 750\times 750 $ (right) grids for the Taylor–Green vortex (TGV) case. Although the model does not perform well for grids smaller than those seen during training, its predictive ability diminishes only gradually for larger grids.
$ 750\times 750 $ (right) grids for the Taylor–Green vortex (TGV) case. Although the model does not perform well for grids smaller than those seen during training, its predictive ability diminishes only gradually for larger grids.
The results clearly indicate that while the model is struggling to handle grids that are coarser than the training data, the quality of the predictions degrade more gradually for larger grids. In addition, even within the range seen in the training data, the NN model behaves unlike a traditional numerical algorithm where a linear decrease of the RMS error with a slope equal to the order of the method is expected.
In the  $ 120\times 120 $ case, the model gives an answer completely dissimilar to the analytical solution due to severe mispredictions by the HPNN submodel as seen in the midsection of the domain. For the
$ 120\times 120 $ case, the model gives an answer completely dissimilar to the analytical solution due to severe mispredictions by the HPNN submodel as seen in the midsection of the domain. For the  $ 500\times 500 $ and
$ 500\times 500 $ and  $ 750\times 750 $ cases however, the general solution profile is retained despite gradually increasing under-prediction of the local maximum at
$ 750\times 750 $ cases however, the general solution profile is retained despite gradually increasing under-prediction of the local maximum at  $ \left(\pi /2,\pi /2\right) $ and over-prediction of the local minima at the corners.
$ \left(\pi /2,\pi /2\right) $ and over-prediction of the local minima at the corners.
Although the model’s performance when predicting on smaller grids than the training data is substantially worse, this is a use case with far narrower use cases than the converse. The fact that the model retains the ability to reproduce the general solution profile, albeit with lower accuracy, is very promising as this can enable the model to supply initial guesses for iterative algorithms for problems with larger grids than encountered during training. The capability of the model to do that for the multigrid algorithm will be explored in Section 8.4.
8.4. Post-smoothing and comparison versus one multigrid cycle
Considering the primary envisioned use case for our model is accelerating iterative Poisson solvers, one problematic issue is the presence of high-frequency artefacting which can occasionally manifest itself as seen in Figure 11. Applying five Jacobi postsmoothing iterations to the predicted field eliminates most of the high frequency artefacting, greatly reducing the roughness of the produced solution surface as shown in Figure 14.

Figure 14. Comparison of the model’s performance versus multigrid with a single cycle, with five Jacobi post-smoothing iterations applied to each. The Poisson convolutional neural network (CNN) prediction clearly outperforms the single-cycle multigrid prediction.
The post-smoothing applied modestly improved the MAPE of the solution, lowering it to  $ 11.61\% $. With the same post-smoothing applied, the multigrid method with eight levels was able to achieve a MAPE of
$ 11.61\% $. With the same post-smoothing applied, the multigrid method with eight levels was able to achieve a MAPE of  $ 21.08\% $. Hence, the post-smoothing resolves the issue of high-frequency oscillations created by the model near the edges as can be seen by comparing Figures 11 and 14.
$ 21.08\% $. Hence, the post-smoothing resolves the issue of high-frequency oscillations created by the model near the edges as can be seen by comparing Figures 11 and 14.
The preliminary results in Figure 14 demonstrate that it should be possible to increase the convergence rate of conventional iterative methods by using the present CNN architecture as the first step of an iterative strategy. Figure 15 serves as a more detailed demonstration of that capability, juxtaposing the RMS error after a single multigrid iteration with a zero initial guess, two multigrid iterations with a zero initial guess and a single multigrid iteration with the model prediction as the initial guess for the TGV case over a number of grid resolutions, including those outside the training data range.

Figure 15. Root mean square (RMS) error comparison for multigrid iterations with zero, single cycle multigrid and Poisson convolutional neural network (CNN) prediction initial guesses on the Taylor–Green vortex (TGV) snapshot case. Red lines indicate the grid parameter range seen by the model during training.
The model shows remarkable capability in this task, being able to reduce the RMS error after a single multigrid iteration by a massive  $ 94\% $ relative to an initial zero guess when utilized on a problem with a previously encountered
$ 94\% $ relative to an initial zero guess when utilized on a problem with a previously encountered  $ 384\times 384 $ grid size. A reduction of
$ 384\times 384 $ grid size. A reduction of  $ 74\% $ is achieved on a 4,500 × 4,500 problem, a grid over an order of magnitude larger than the largest problem in the training set. It is further noteworthy that a single multigrid iteration with the model prediction as the initial guess is able to beat two multigrid iterations in accuracy even for the same 4,500 × 4,500 grid with
$ 74\% $ is achieved on a 4,500 × 4,500 problem, a grid over an order of magnitude larger than the largest problem in the training set. It is further noteworthy that a single multigrid iteration with the model prediction as the initial guess is able to beat two multigrid iterations in accuracy even for the same 4,500 × 4,500 grid with  $ 22\% $ lower RMS error. This suggests that the Poisson CNN model can provide very substantial increases of accuracy to the multigrid algorithm. Moreover, the model is capable of undertaking this task for problems much larger than the examples encountered during training.
$ 22\% $ lower RMS error. This suggests that the Poisson CNN model can provide very substantial increases of accuracy to the multigrid algorithm. Moreover, the model is capable of undertaking this task for problems much larger than the examples encountered during training.
This capability is especially important tn light of the results in Table 6 which clearly display that our model increases the runtime gap versus multigrid as the problem size grows. Eventually, our model catches up to even a single cycle of multigrid for large problems while beating the accuracy of the said initial cycle, providing a substantial boost to the convergence rate of the multigrid method from the time perspective as well.
8.5. NN-assisted pressure projection method
Given the solid performance of the model on a single snapshot as shown in Sections 8.2 and 8.4, we present the results from a TGV simulation, where the pressure projection step is assisted by a variant of the proposed NN. To ensure boundary condition compatibility with this CFD problem, we require a variant of the model capable of handling Neumann as opposed to DBCs. Considering the analytical solution for the TGV presented in Equation (23), sticking to the domain previously investigated in this section, we only require a model capable of handling homogeneous Neumann BCs.
Hence, the variant of our model used in this sub-section comprises of only the HPNN component, with the only change being the application of “symmetric” padding in the final convolution layer as opposed to zero padding to ensure that the boundary conditions are naturally applied by the model. The dataset used to train this model also incorporates a corresponding modification to accommodate the change in the BCs, switching to homogeneous Neumann BCs as opposed to DBCs. In effect, this is achieved by replacing the sine series in Section 5.1 with a cosine series. The training on this dataset was done in a manner similar to the model with DBCs in Sections 8.1–8.4, but with smaller grid sizes ranging between 80 and 120 on each side. In addition, the physics-informed loss from Raissi et al. (Reference Raissi, Perdikaris and Karniadakis2017a) was found to reduce validation MSE with Neumann BCs, unlike the DBC case, and thus was used as a loss function component in addition to Equation (21).
The simulation itself was performed within the framework of the MIT licensed Navier_Stokes_2D codebase by Roberts and Zhang (Reference Roberts and Zhang2014), a simple 2D finite-difference code incorporating a range of projection methods, including an implementation of the gauge method proposed by Weinan and Liu (Reference Weinan and Liu2003) which was utilized in this investigation. The codebase was modified to ensure inter-operability with the HPNN model and recent versions of Python3.
The nondimensionalised Navier–Stokes equations require a choice of Reynolds numberFootnote 6  $ \mathit{\operatorname{Re}}=1/\nu $, where
$ \mathit{\operatorname{Re}}=1/\nu $, where  $ \nu $ is the kinematic viscosity of the fluid. Additionally, an appropriate Courant–Friedrichs–Lewy number
$ \nu $ is the kinematic viscosity of the fluid. Additionally, an appropriate Courant–Friedrichs–Lewy number  $ C=\frac{\Delta t}{\Delta}\left(u+v\right) $ must be chosen to ensure that the time step
$ C=\frac{\Delta t}{\Delta}\left(u+v\right) $ must be chosen to ensure that the time step  $ \Delta t $ is sufficiently small to prevent numerical instabilities given the grid spacing
$ \Delta t $ is sufficiently small to prevent numerical instabilities given the grid spacing  $ \Delta $ and the
$ \Delta $ and the  $ x- $ and
$ x- $ and  $ y- $direction velocities
$ y- $direction velocities  $ u $ and
$ u $ and  $ v $. The results presented in this section were obtained from a simulation run with the default parameters of
$ v $. The results presented in this section were obtained from a simulation run with the default parameters of  $ \mathit{\operatorname{Re}}=1.0 $ and
$ \mathit{\operatorname{Re}}=1.0 $ and  $ C=0.2 $ in the Navier_Stokes_2D codebase. The domain was kept identical to the one in Section 8.2, but was discretised with
$ C=0.2 $ in the Navier_Stokes_2D codebase. The domain was kept identical to the one in Section 8.2, but was discretised with  $ 100\times 100 $ grid points. Similar to the “hybrid” strategy applied by Ajuria Illarramendi et al. (Reference Ajuria Illarramendi, Alguacil, Bauerheim, Misdariis, Cuenot and Benazera2020), designed to reduce the accumulation of errors during the time marching process, traditional solver iterations are applied to the output of the model.
$ 100\times 100 $ grid points. Similar to the “hybrid” strategy applied by Ajuria Illarramendi et al. (Reference Ajuria Illarramendi, Alguacil, Bauerheim, Misdariis, Cuenot and Benazera2020), designed to reduce the accumulation of errors during the time marching process, traditional solver iterations are applied to the output of the model.
Table 4 displays the  $ {L}_2 $ error norms of the velocities and the pressure compared to the analytical result at the end of the simulation (
$ {L}_2 $ error norms of the velocities and the pressure compared to the analytical result at the end of the simulation ( $ t=1.0 $). Figure 16 juxtaposes the ground truth result with the predictions of the HPNN for the pressure at
$ t=1.0 $). Figure 16 juxtaposes the ground truth result with the predictions of the HPNN for the pressure at  $ t=1.0 $, both raw and when assisted by a single iteration of the biconjugate gradient stabilized (BiCGSTAB) method.
$ t=1.0 $, both raw and when assisted by a single iteration of the biconjugate gradient stabilized (BiCGSTAB) method.

Figure 16. Raw Neumann boundary condition (BC) homogeneous Poisson neural network (HPNN) prediction (left), Poisson convolutional neural network (CNN) prediction with one traditional solver iteration (middle) and ground truth solution (right) of the Taylor–Green vortex (TGV) simulation at  $ t=1.0 $ (time step 637). The raw HPNN prediction displays artefacting near the edges and overshoot at local extrema, however, a single traditional solver iteration aids it to achieve a high degree of accuracy.
$ t=1.0 $ (time step 637). The raw HPNN prediction displays artefacting near the edges and overshoot at local extrema, however, a single traditional solver iteration aids it to achieve a high degree of accuracy.
Table 4.  $ {L}_2 $ error norms for the velocities
$ {L}_2 $ error norms for the velocities  $ \left(u,v\right) $ and the pressure
$ \left(u,v\right) $ and the pressure  $ p $ at the end of the Navier–Stokes simulation (
$ p $ at the end of the Navier–Stokes simulation ( $ t=1.0 $).
$ t=1.0 $).

Overall, the HPNN aided by a single BiCGSTAB prediction achieves a level of pressure error comparable to the level achieved by two iterations of BiCGSTAB with an initial zero guess, a massive  $ {L}_2 $ error reduction compared to a single zero-initial-guess BiCGSTAB iteration. This is in line with our comparison with multigrid solvers in Section 8.4 using the Dirichlet BC variant of the Poisson CNN model, showing strong evidence that our model performs well in practical applications for acceleration of Poisson problems.
$ {L}_2 $ error reduction compared to a single zero-initial-guess BiCGSTAB iteration. This is in line with our comparison with multigrid solvers in Section 8.4 using the Dirichlet BC variant of the Poisson CNN model, showing strong evidence that our model performs well in practical applications for acceleration of Poisson problems.
8.6. Ablation studies
The proposed NN architecture incorporates many features which improve performance for the Poisson equation task relative to other CNN architectures commonly used in image-to-image translation tasks. This is clearly demonstrated by the order-of-magnitude difference in validation MAE achieved on various cases relative to the baseline models in Table 3. To open a path for future advances in developing CNN architectures for this task, it is important to understand the contribution of each architectural feature to the performance of the model. One of the most common methods to investigate this in machine learning is via an ablation study, whereby certain features of the model under investigation are disabled in isolation and the performance is compared against the full model. Table 5 presents the results of our ablation study conducted with five key improvements of our model compared to previous works by considering the rise in validation MSE as well as change in the inference speed of the model.
Table 5. Percentage change to the validation MSE and inference speed of the Poisson CNN when key model architecture features are removed.

Abbreviations: CNN, convolutional neural network; DBCNN, Dirichlet boundary condition neural network; HPNN, homogeneous Poisson neural network; MSE, mean squared error.
The ablation study clearly highlights the magnitude of the improvements Poisson CNN offers compared to previous architectures. Most significant advantage of the proposed model is the utilization of the decomposition approach presented in Section 3, which enables it to achieve a more than six-fold reduction in validation MSE at zero cost in terms of inference time. Next in terms of importance comes the almost halving of validation MSE enabled by the inclusion of positional embeddings, a feature critical to enable good performance when handling variable input shapes to the model. Then, we see the approximately one-third reduction in validation MSE afforded by employing our novel loss function, the  $ {L}^p $ integral loss, and the addition of more pooling blocks compared to the Fluidnet architecture by Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2016). Finally, the inclusion of residual connections in convolutional layers enables a more modest further
$ {L}^p $ integral loss, and the addition of more pooling blocks compared to the Fluidnet architecture by Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2016). Finally, the inclusion of residual connections in convolutional layers enables a more modest further  $ 5\% $ reduction in MSE values. Combined, these features enable our model to tackle the generalized form of the Poisson problem effectively, enabling a marked improvement over models previously employed on the Poisson problem or in more general image-to-image translation tasks.
$ 5\% $ reduction in MSE values. Combined, these features enable our model to tackle the generalized form of the Poisson problem effectively, enabling a marked improvement over models previously employed on the Poisson problem or in more general image-to-image translation tasks.
8.7. Wall-clock runtime
The practical applicability of Poisson CNN’s ability to boost the accuracy of multigrid iterations is contingent on its wall-clock runtime. Table 6 outlines the wall-clock runtime of both the sub-models and the full model using single precision run on an Nvidia V100 GPU, versus multigrid run on 64 threads on a 32-core/64-thread AMD Threadripper 2990WX CPU and the same GPU. Note that the model architecture and weights were not changed compared to the results presented above and the accuracy of the model was not evaluated.
Table 6. Wall clock runtimes of the multigrid solver versus the DBCNN, HPNN, and Poisson CNN models (in seconds).

Abbreviations: CNN, convolutional neural network; CPU, central processing unit; DBCNN, Dirichlet boundary condition neural network; GPU, graphics processing unit; HPNN, homogeneous Poisson neural network.
The Poisson CNN model begins to outperform both CPU and GPU multigrid around grid sizes approaching  $ 500\times 500 $, eventually building up to five times the speed of CPU multigrid at 4,500 × 4,500, and over twice that of GPU multigrid. While in the case of CPU multigrid there likely exists a severe memory bandwidth bottleneckFootnote 7 for such large problems, as the performance of the multigrid algorithm was demonstrated to be memory bandwidth limited by various authors such as Goodnight et al. (Reference Goodnight, Woolley, Lewin, Luebke and Humphreys2005), our model performs favorably runtime-wise against GPU multigrid as well.
$ 500\times 500 $, eventually building up to five times the speed of CPU multigrid at 4,500 × 4,500, and over twice that of GPU multigrid. While in the case of CPU multigrid there likely exists a severe memory bandwidth bottleneckFootnote 7 for such large problems, as the performance of the multigrid algorithm was demonstrated to be memory bandwidth limited by various authors such as Goodnight et al. (Reference Goodnight, Woolley, Lewin, Luebke and Humphreys2005), our model performs favorably runtime-wise against GPU multigrid as well.
These results show that the NN model proposed in the current study has the potential to offer substantial speedups to solve the Poisson equation for practical applicatons especially in light of the results shown in Sections 8.4 and 8.5.
It is noteworthy that no hyperparameter optimization efforts were conducted for our model. It is likely that by tuning the number of hyperparameters (by e.g., reducing the number of channels in the intermediate layers or the number convolution layers altogether) substantial speedups could be achieved while making little or no compromise in terms of the predictive accuracy of the model, albeit larger model sizes may be necessary for larger problems. The extreme similarity of many of the feature maps in the initial layers of the model is supportive of this possibility. Finally, further very substantial speedups are possible by taking full advantage of quickly developing deep learning acceleration hardware. For example, the “Tensor Cores” on the V100 GPU (which require half-precision operations and specific programming to properly utilize) theoretically offer up to 125TFlops of performance as opposed to 15.2 TFlops of standard single-precision performance as explained in Nvidia Corporation (2019).
9. Conclusion and Future Work
A CNN model to estimate the solution of the 2D Poisson equation with DBCs was developed, based on splitting the problem into a homogeneous Poisson problem and four Laplace problems with one inhomogeneous BC each, with envisioned practical applications to accelerate iterative Poisson solvers by providing initial guesses that are both faster and more accurate than a single iteration of multigrid. Training was done on synthetic, random datasets generated to replicate the smooth functions a Poisson solver would be expected to handle in real world use cases. In order to achieve good convergence during training, the novel  $ {L}^p $ integral loss was developed and found to be superior for this task to the MSE.
$ {L}^p $ integral loss was developed and found to be superior for this task to the MSE.
The model developed can estimate solutions with pointwise deviations below 10% even when given inputs that are materially different from both training and validation data, based on analytical test cases. The predictions are accurate enough such that the model can be used in the pressure projection step of a Navier–Stokes simulation in conjunction with a traditional solver iteration, beating the accuracy of a classical simulation with more iterations per projection step. Comparison of the runtime performance of the model indicates that the runtime at the grid sizes used to generate results for this work is similar to that of multigrid, though with superior accuracy compared to a single cycle. Theoretical speedups up to 5× were observed when using the model with larger inputs. Hence, our model provides a solid foundation to substantially accelerate the solution of the Poisson equation.
Based on the successes showcased in this work, in future work we intend to improve our model by incorporating the following features:
Predicting on larger, previously unseen grids. By fixing the scaling issue demonstrated in the predictions made by the model when encountering larger grids than previously seen, the need for training on a specific range of grid sizes may be completely eliminated.
BC combinations. Many applications require solving the Poisson equation with different combinations of BCs. Though all-Dirichlet and all-Neumann cases were investigated in this work, one possible approach for tackling more complicated combinations can be adopting a strategy similar to the one outlined in Section 3, but since the BCs must retain their respective types in the homogeneous problem as well, having multiple models to solve the homogeneous problem with each combination of BCs possible. The number of separate models can be minimized by grouping BC combinations that are identical under rotations/reflections.
3D grids. The work presented focused on less memory- and time-intensive 2D problems, but most problems of interest in CFD are 3D. It is not expected that vast architectural changes will be necessary for a 3D version of this work since most convolutions etc. can be easily made 3D, however the greater number of parameters and much larger inputs can make training difficult and more memory intensive, necessitating work on model parallelism across GPUs.
Domain adaptation/transfer learning for different domain sizes. As seen in Figure 12, currently the Poisson CNN model’s predictions degrade in quality for grids larger than those encountered in training. This problem is analogous to the domain mismatch problem encountered in many deep learning applications such as computer vision, as explored in a survey by Wang and Deng (Reference Wang and Deng2018). Adapting transfer learning techniques can be a way to overcome this weakness by training a Poisson CNN model on a very diverse range of data and then fine-tuning for more specific domain ranges as necessary for increased accuracy.
Objects inside domain. Currently our model works only with BCs imposed on the edges of a rectangular domain. Objects inside the domain are commonly encountered in CFD and electrodynamics, requiring imposition of BCs on the surface of these objects. A possible way to tackle this problem is adding a “mask” channel to the inputs with 1.0 values for points lying inside the objects placed in the domain and 0.0 values for points outside, similar to the approach in Tompson et al. (Reference Tompson, Schlachter, Sprechmann and Perlin2016).
Hyperparameter optimization. The hyperparameters of an NN model such as kernel sizes and number of convolution layer channels play an important role in the accuracy, inference speed and training time of deep NNs. Choosing an optimal size for the model will be crucial to obtain maximum performance especially in comparison to multigrid on GPUs. Gaussian Process based Bayesian hyperparameter search or tree-structured Parzen estimators as explored by Bergstra et al. (Reference Bergstra, Bardenet, Bengio and Kégl2011) are two systematic approaches common in literature for this task.
Funding Statement
This work was supported by a PhD studentship funded by the Department of Aeronautics, Imperial College London.
Competing Interests
The authors declare no competing interests exist.
Data Availability Statement
Readers interested in replicating the results in this work may find the code available on Github, which has been tested to work on AMD64 and IBM POWER9 systems with Nvidia GPUs. We strongly recommend running the code by building a Docker image using the Dockerfile appropriate for your system, under the docker/directory in the development branch.
Author Contributions
Conceptualization, A.G.Ö., A.H., S.L., B.S., G.R., and P.T.; Formal analysis, A.G.Ö.; Investigation, A.G.Ö.; Methodology, A.G.Ö., A.H., B.S., G.R., and P.T.; Validation, A.G.Ö.; Visualization, A.G.Ö.; Software, A.G.Ö.; Data Curation, A.G.Ö.; Resources, S.L.; Supervision, S.L. and B.S.; Project administration, S.L.; Funding acquisition, S.L.; Writing-original draft, A.G.Ö., S.L., and G.R.; Writing-review & editing, A.G.Ö., A.H., S.L., and G.R.
Appendix. Higher Aspect Ratio Examples
Below are further examples obtained from a HPNN model, trained with a range of aspect ratios ranging from 0.25 to 4.0. Despite slightly lower performance compared to the models the results of which are investigated in Section 8.1.1, overall performance is still high, demonstrating that our model can adapt to a wide range of aspect ratios similar to those commonly encountered in many applications like computational fluid dynamics.

Figure 17. Prediction of a homogeneous Poisson neural network (NN) model on an example with grid size  $ 384\times 96 $ and
$ 384\times 96 $ and  $ \Delta =2.64\times {10}^{-2} $. As shown, when trained on an appropriate dataset, the model architecture is capable of handling aspect ratios well above the results in Section 8.
$ \Delta =2.64\times {10}^{-2} $. As shown, when trained on an appropriate dataset, the model architecture is capable of handling aspect ratios well above the results in Section 8.

Figure 18. Prediction of a homogeneous Poisson neural network (NN) model on an example with grid size  $ 96\times 384 $ and
$ 96\times 384 $ and  $ \Delta =3.26\times {10}^{-2} $. The same model can handle domains that have low aspect ratios as well as those with large ones.
$ \Delta =3.26\times {10}^{-2} $. The same model can handle domains that have low aspect ratios as well as those with large ones.






















































 Open access
Open access
Comments
No Comments have been published for this article.