


Introduction
The first phase of the coronavirus disease 2019 (COVID-19) pandemic in Germany was managed relatively successfully in comparison to other countries in Europe. Therefore, it is worth taking a closer look at the course of the pandemic in Germany, which has already led to controversial discussions in the public. This particularly concerns the important question about the effectiveness of various control measures. Several publications discuss the effects of control measures in different countries, see, e.g., [Reference Flaxman1–Reference Li3]. As [Reference Floyd and Endowed4] point out, however, many of such studies are undermined by unreliable data on incidence. Many papers use data provided by the Johns Hopkins University (JHU) [Reference Dong, Du and Gardner5]. These data are based on cumulative registered cases in different countries, which induces several problems, particularly the fact that not all cases are reported and that there is delay between the day of infection and the reporting day. Furthermore, the systems of reporting vary between countries, which makes comparisons between countries difficult.
In a recent paper on Germany [Reference Dehning6], the authors use a complex Bayesian modelling approach based on the daily registrations in the JHU data for Germany. An important claim in [Reference Dehning6] is that the lock-down-like measures on 23 March were necessary to stop exponential growth. However, this claim is contradicted for example by results from the RKI [7]. Furthermore, these approaches were critically questioned by [Reference Bryant and Elofsson8, Reference Wieland9], where the latter emphasised the importance of taking into account the delay by reporting and incubation time, when analysing the possible effect of non-pharmaceutical interventions.
In our analysis we focus on the curve of infection at two geographical levels: the federal state of Bavaria and all of Germany and on four age-strata. The paper is organised as follows. In section ‘Data and methods’, we present the data and the strategy of estimating the relevant daily counts. Then the segmented regression model, which is the basis for further analyses, is presented. The penultimate section presents the results followed by a discussion.
Data and methods
Estimation of diseases onset
For the analysis of the Bavarian data, we use the COVID-19 reporting data of the Bavarian State Office for Health and Food Safety (LGL) that is collected within the framework of the German Infection Control Act (IfSG). At the case level, these data include the reporting date (the date at which the case was reported to the LGL) as well as the time of disease onset (here: symptom onset). However, the latter is not always known: partly because it could not be determined and partly because the case did not (yet) have any symptoms at the time of entry into the database. A procedure for imputation of missing values regarding the disease onset has been developed by [Reference Günther10], using a flexible generalised additive model for location, scale and shape (GAMLSS; [Reference Stasinopoulos11]), assuming a Weibull distribution for the time period between disease onset and reporting date. The model includes gender, age, as well as calendar time and day of the week of reporting as covariates. We estimate the delay time distribution from data with disease onset and impute missing disease onsets based on this model.
For the German data, no individual case data were available, so instead we used publicly available aggregated case reporting data published on a daily basis by the RKI [12]. These data contain aggregated numbers of reported cases for all observed combinations of disease onset date and reporting date at local health authorities as well as the numbers of reported cases per day without information on disease onset date. Information is aggregated on district level in different age and sex groups. Based on this aggregated data, we estimated a similar model as described above for the imputation of missing disease onset dates, replacing the smooth associations of age and reporting delay by a categorical effect of the age group of the cases. To account for differences in reporting behaviour in the different federal states, the model was estimated separately for each state and daily onset counts were aggregated after imputation.
We estimated the imputation model for the German data based on all cases reported up until 1 June. The percentage of imputed values was 37% for the Bavarian data and 28% for the German data. Since this percentage is rather high, we performed a sensitivity analysis using (1) only data with a documented disease onset and (2) utilising the reporting date of cases as disease onset date when the actual onset date is unknown.
Back-projection
To interpret the course of the pandemic and possible effects of interventions, case-based data on time of infection is essential. However, as such data are generally not available, one simple approach is to shift the curve of disease onsets to the past by the average incubation period. The average incubation period for COVID-19 is about five days [Reference Lauer13]. A more sophisticated approach, however, is to use the incubation period distribution as part of an inverse convolution, also known as back-projection, in order to estimate the number of infections per day from the time series of disease onsets [Reference Becker, Watson and Carlin14, Reference Werber15]. We assume a log-normal distribution for the incubation time with a median of 5.1 days and a 97.5% percentile at 11.5 days [Reference Lauer13]. These are the same values as used by [Reference Dehning6]. For our calculation, we use the back-projection procedure implemented in the R package surveillance [Reference Salmon, Schumacher and Höhle16].
The segmented regression model
To analyse the temporal course of the infection, we use the following regression model and change points (see [Reference Muggeo17, Reference Muggeo, Sottile and Porcu18]):
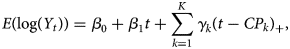
where Yt is the number of detected COVID-19 cases by time t of infection, K is the number of change points and x + = max(x, 0) is the positive part of x. The change points CPk, k = 1, …, K are used to partition the epidemic curve Yt into K + 1 phases. These are characterised by different growth parameters. In the phase before the first change point CP 1 the growth is characterised by the parameter β 1, in the 2nd phase between CP 1 and CP 2 by β 2 = β 1 + γ 1. The next change is then at time CP 2. In the 3rd phase between CP 2 and CP 3 the growth parameter is given by β 3 = β 1 + γ 1 + γ 2. This applies accordingly until the last phase after CPK. The quantities exp(βj), j = 1, …, K + 1 can be interpreted as daily growth factors. Since we use estimated, non-integer values Yt from the back-projection procedure as outcome, we assume a (conditional) Gaussian distribution for log(Yt). Furthermore, we assume an AR(1) error term for the regression model, since serial correlation occurs due to smoothing in the backprojection procedure.
Since model (1) is a generalised linear model given the change points, the parameters of the model (including the change points) can be estimated by minimising the respective likelihood function. However, due to the estimation of the change points, the numerical optimisation problem is not straightforward. For the estimation of the model we use the R package segmented, see [Reference Muggeo19]. The starting values are partly estimated by discrete optimisation. The number of change points K is increased from K = 1 up to a maximum of K = 6. It is examined whether the increase of the number of change points leads to a lower value of the Bayesian information criterion (BIC). Since the considered time series consist of only 61 data points, we exclude models with more than 6 change points, since they are hardly interpretable and the danger of overfitting is high.
We apply the segmented regression model to time series of the estimated daily counts of infections for detected COVID-19 cases in Bavaria and all of Germany. Since the back-projection algorithm yields an estimate for the expected values of the number of daily infections and does so by inducing a smoothing effect, as a sensitivity analysis for the location of the breakpoints, we also apply a regression model to the time series of the daily counts of disease onsets. The results of this sensitivity analysis are presented in the supplementary material. Furthermore, as a more detailed analysis, we apply our procedure to data stratified by age groups. A special focus is on the age group 80 + , as this group has the highest risk for a critical course of the disease.
Results
In Figure 1, the three different time series of daily case counts (newly reported, disease onset and estimated infection date) are presented. The time delay between the three time series for Bavaria and Germany is evident. Furthermore, the curves do not just differ by a constant shift on the x-axis, instead there is also a notable change in the structure of the curves. The curve relating to the date of infection is clearly smoothed due to the back-projection procedure (cf. Section 2.2) and has a clear maximum both for Bavaria and Germany.
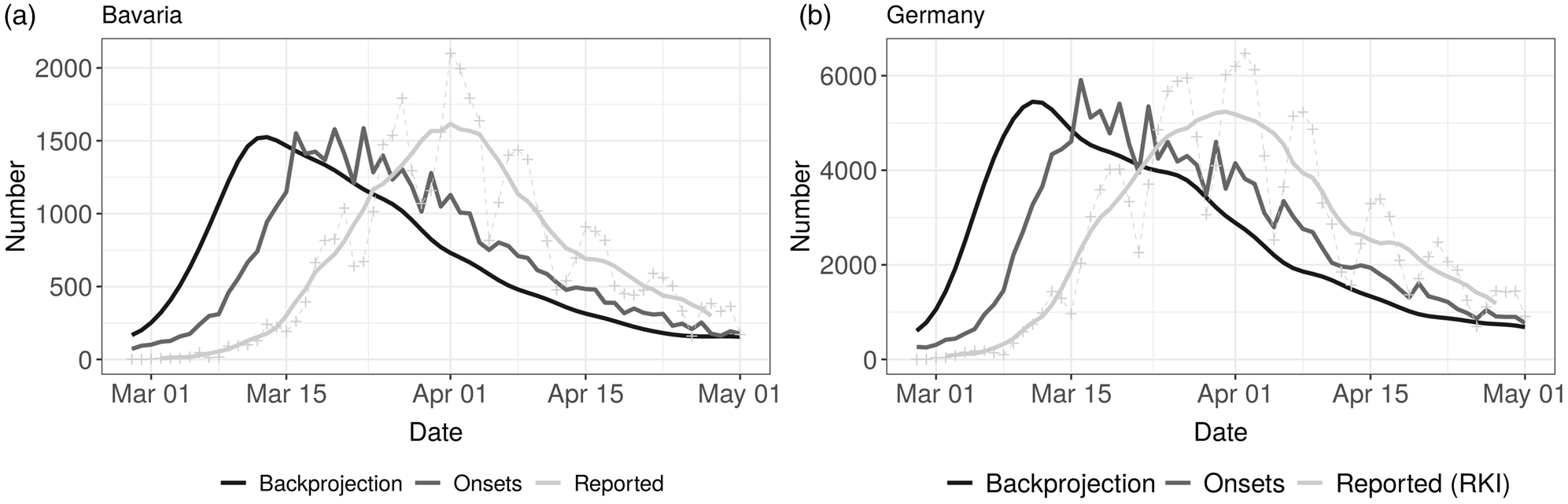
Fig. 1. Comparison of time series of daily reported cases (7 day average and daily reported numbers, light grey), disease onsets (reported and imputed, grey) and backprojection (derived number of infections, dark grey) for Bavaria (left panel) and Germany (right panel).
Bavarian data
The overall Bavarian model includes five change points. The result can be seen in Figure 2 (left panel) and in Table 1.
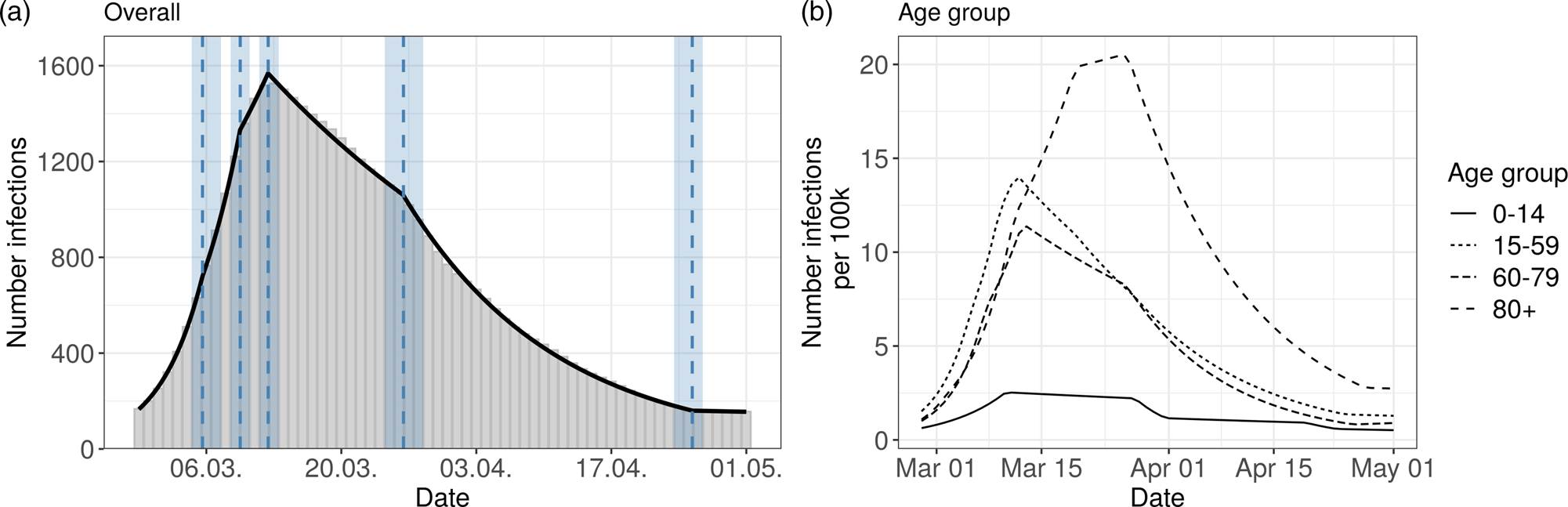
Fig. 2. Segmented regression models for Bavaria. The left panel shows results for all reported cases from Bavaria. The solid line is the fitted curve ac cording to the segmented regression model (1) with five change points (K = 5) selected based on BIC. The bars are the expected numbers of detected COVID- 19 cases by time of infection (cf. Section 2.2). Dashed lines and surrounding shaded ribbons indicate estimated change points and respective, approximate 95% confidence intervals. The right panel shows results of the segmented regression in four age groups based on the back-projected number of infections per 100 000 individuals. The back-projection and segmented regression was estimated in each age group separately and the selected number of change points varies between groups.
Table 1. Summary table of the segmented regression model for the expected number of daily infections in Bavaria with five change points
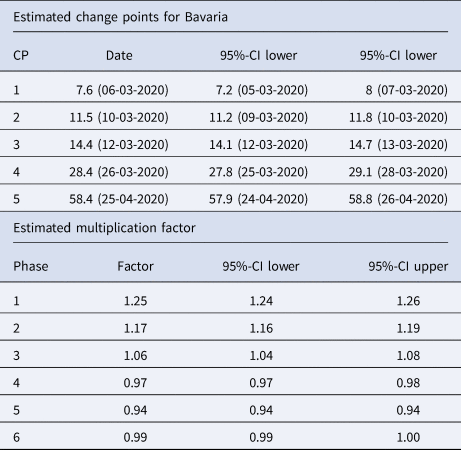
The dates of the estimated change points and the corresponding 95% confidence intervals are given. For the date of the lower/upper limit of the confidence intervals, the values were rounded up or down to the more extreme value. In the second part of the table the estimated multiplication factors of the number of cases per day with the confidence intervals for the six phases are given
The resulting six phases are:
1st phase: There is a substantial increase in new infections with a high daily multiplication factor of 1.25. The first phase ends on 6th March.
2nd phase: The increase slows down to a daily multiplication factor of 1.17.
This phase lasts to the 10th of March.
3rd phase: For a short time the multiplication factor further goes down to 1.06
4th phase: The change point on 12th March marks a clearly visible change in the course of the pandemic. It is the turning point of the curve (change of the multiplication factor to 0.97).
5th phase: A further change point is found around 26th March. There is an accelerated decrease in the infections with a daily factor of 0.94.
6th phase: On 25th April the estimated number of infections of reported cases is rather low and there is no further decrease after this change point (multiplication factor close to 1).
The age-stratified analysis gives some interesting further insights about the course of the pandemic, see Figure 2 (right panel) and Table S1 in the supplementary material. The age groups 15–59 and 60–79 years show a similar pattern as the overall analysis. However, in the 80 + age group there are clear differences compared to the other groups. There, the turning point of the pandemic is considerably later on 22nd March. Furthermore, the number of estimated infections per 100 000 is higher than in the other groups. The age group 0–14 years has a much lower number of reported infections, and change points similar to the overall analysis.
German data
The results for the German data are presented in Figure 3 and in Table 2. The model for Germany has four change points inducing five phases:
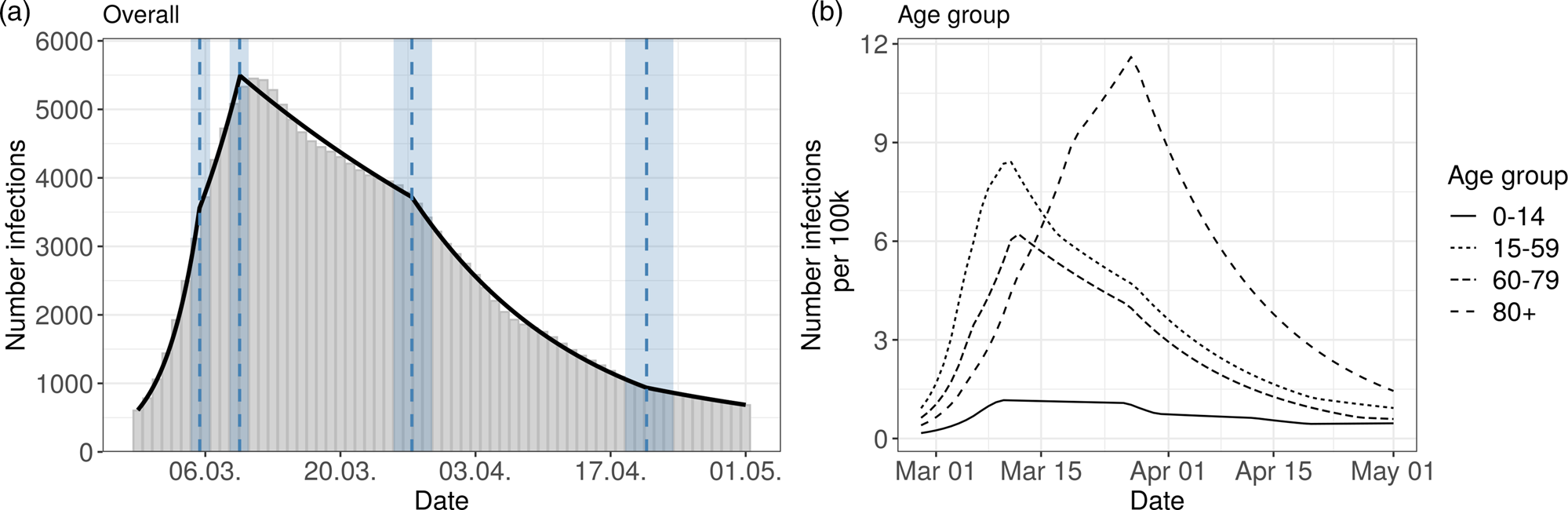
Fig. 3. Segmented regression models for Germany. The left panel shows results for all reported cases. The solid line is the fitted curve according to the segmented regression model (1) with three change points (K = 3) selected based on BIC. The bars are the expected numbers of detected COVID-19 cases by time of infection (cf. Section 2.2). Dashed lines and surrounding shaded ribbons indicate estimated change points and respective, approximate 95% confidence intervals. The right panel shows results of the segmented regression in four age groups based on the back-projected number of infections per 100 000 individuals. The back-projection and segmented regression was estimated in each age-group separately and the selected number of change points varies between groups.
Table 2. Summary table of the segmented regression model for the expected number of daily infections in Germany with four change points
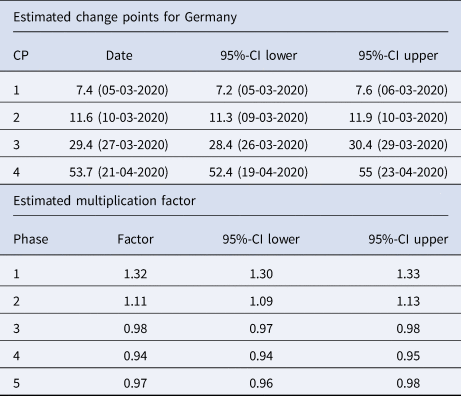
The dates of the estimated change points and the corresponding 95% confidence intervals are given. For the date of the lower/upper limit of the confidence intervals, the values were rounded up or down to the more extreme value. In the second part of the table the estimated multiplication factors of the number of cases per day with the confidence intervals for the 5 phases are given.
1st phase: There is a strong increase (multiplication factor 1.32 per day) in new infections in the beginning of the pandemic until 5th March, where the increase decreases.
2nd phase: From 5th March to 10th March there is still a substantial increase of infections with a daily multiplication factor around 1.1.
3rd phase: After the change point on 10th March, there is a clearly visible change in the course of the pandemic. There is change from an increasing to a decreasing curve with a daily multiplication factor of about 0.98. This phase lasts until 27th March.
4th phase: An acceleration of the decrease can be seen from 27th March onward. The daily multiplication factor is 0.94.
5th phase After 21st April, the number of infections is rather low with a slow decrease.
The results of the age stratified analysis are similar to the results for Bavaria (cf. Figure 3, right panel and Supplement Table S2). The age group 80 + once again differs substantially from the other age groups. The turning point for the 80 + group is on 25th March. The other age groups show a structure similar to the overall analysis.
Discussion
The current analysis is a retrospective, exploratory analysis of the German and Bavarian COVID-19 reporting data during Mar–Apr 2020.
Limitations
The analysis only includes reported cases. If the proportion of undetected cases changes over time, e.g., due to different test criterion, this can distort the curve and thus the determination of the change points. Therefore, additional data on daily deaths and hospital admissions and the number of tests performed should be considered. Furthermore, it is possible to estimate the proportion of undetected cases with the help of representative studies such as the one currently conducted in Munich, see [Reference Radon20]. In a recent paper [Reference Schneble21] performed a time-varying estimation of the case detection ratio (CDR) for different age groups. They find a linear decreasing CDR from 2 March until 12 April in the main age groups. The CDR was only half as large at the end of the period as it was at the beginning. This can only partly explain the curve, where we observe a much higher increase.
Our analysis is based to a considerable extent on imputed data, see [Reference Günther10], which is a result of missing data w.r.t. the disease onset. We have performed a sensitivity analysis using only cases with available disease onset date and based on imputing missing disease onset dates by the reporting date of the cases (Figure S2 in the supplementary material).
The back-projection procedure is based on an assumption of the distribution of the incubation time. There are some recent papers showing some evidence for a longer incubation time in elderly cases, see [Reference Dai, Yang and Zhao22, Reference Tan23]. There-fore, we performed an additional sensitivity analysis comparing the results for the 80 + age group for different assumptions about the incubation time distribution, see supplementary material Figure S3. We find in this sensitivity analysis that the curve of the new infections is shifted to the left by about 2–3 days. However, the structure of the curve does not change considerably. Altogether, the much later peak in the 80 + compared to the other population strata cannot only be due to a different incubation time.
Furthermore, our estimation of the change points and the corresponding confidence intervals is based on the estimated curve of the number of detected COVID-19 cases by time of infection. Due to the additional uncertainty of the curve induced by imputation, back-projection and model selection, the confidence intervals for the change points might not reflect the full extent of uncertainty in our modelling. However, even somewhat wider confidence intervals would not fundamentally change the interpretation of our results.
Since changes in behaviour do not occur abruptly, the assumption of change points is also problematic in itself. Therefore, the interpretation of change points should always be done in conjunction with a direct observation of the epidemic curve.
Interpretation of results
Our analysis is based on the onset of the disease (more precisely: the onset of symptoms) and a back-projection to the date of infections, and therefore, despite its limitations, is better suited to describe the course of the pandemic than the more common analysis of daily or cumulative reported case numbers. In the analysis of the Bavarian and the German data our main result is the change point, where the exponential growth was stopped: this clearly happened already between 9 and 13 March. The timing of this change point coincides with the implementation of the first control measures: the partial ban of mass events with more than 1000 people. Furthermore, in a press conference on March 11th chancellor Merkel and the president of the RKI appealed to self-enforced social distancing [24]. Furthermore, the extended media coverage from Bergamo, Italy, as well as the voluntary transition to home-office work could be related to this essential change in the course of the pandemic.
In Bavaria and in Germany, the change point at 26/27th March of the infection date is apparent. This change point is associated with different measures taken in March (closing of schools and stores on 16th March and the shut- down including contact ban on 22nd March in Germany including Bavaria). Other measures were similar in timing in Bavaria and all over Germany. In Bavaria, some measures were implemented a little earlier. Since there were many measures administered simultaneously and since – as described above – other factors beyond the measures itself contributed, we do not think is not possible to quantify the effect of individual measures to the development of the epidemic curve.
The results for the 80 + age group indicate an infection curve which is delayed by about one week compared to the other age groups. This is possibly due to the fact that the disease was first introduced into Germany by younger holiday makers and business travellers. Hence, it likely took some additional generations of transmission before the infections mitigated into the 80 + group. Furthermore, many infections in the age group 80 + are due to outbreaks in nursing homes and homes for the elderly, where very different mechanisms of contact occur compared to the rest of the population. Many of the restrictions were targeted at the younger age groups (school closings, mobility restrictions), hence, the effect of these interventions is only indirect for the 80 + group and thus the impact is delayed. This underlines the need for more direct measures for this group. For the age group of 0–14 the breakpoints are similar to the other age groups. The much lower infection rate could be partly due to lower case detection ratio, since infected children show less symptoms, see e.g. [Reference Ludvigsson25].
The claim by Dehning et al. [Reference Dehning6], that the shutdown on 21st March was necessary to stop the growth of the pandemic is not supported by our analysis. There is a change point in the epidemic curve after that date, but the major change from an exponential growth to a decrease was before the shutdown. The difference in results can be explained by the different data bases used for the respective analyses. While Dehning et al. [Reference Dehning6] used data bases on daily registered cases, in our analysis, data on disease onset are included. As can be seen from Figure 1 and from the results of our data analysis, the delay distribution of the time between disease onset and reporting day changed over time. This makes a crucial difference. In a recent technical addendum [Reference Dehning26] the authors re-fit their model on more appropriate data. These analysis – in our opinion – clearly show that the effective reproduction number decreased earlier than in their initial analysis, however, they attribute the decrease to a SIR model peculiarity, where a linear decrease in the contact rate can lead to the incidence curve dropping despite R(t) > 1.
The above discussions illustrate how complex the interpretation of even simple SIR models is and the question is, if such SIR modelling is not too simple to really allow for questions to be answered model based (no age structure, no time-varying reporting delay, no incubation period). In contrast, our approach is more data driven with a minimum of modelling assumptions and without the need to include strong prior information about the change points. Directly using a segmented curve with exponential growth (decline) is in line with common models of infectious diseases in its early stages, where the limitation of the spread by immune persons plays no role. The problem of using complex models with many parameters for the evaluation of governmental measures has also been highlighted by [Reference Bryant and Elofsson8].
Our approach is similar to that of [Reference Wieland9] who performs a change point analysis for the cumulative reported numbers as well as the estimated R(t). The use of the time-varying reproduction number R(t), a standard measure to describe the course of an epidemic is challenging, as different definitions have been proposed in the literature that also imply different interpretations (see [Reference Cori27, Reference Lipsitch, Joshi and Cobey28]). However, the analysis of R(t) as a relative measure can be useful, when one wants to analyse data from different countries with non-comparable reporting systems, see [Reference Li3].
Altogether, the effect of governmental measures as a whole is clearly documented in the literature, see, e.g., [Reference Flaxman1] and [Reference Islam2]. Our results are in line with that of [Reference Wood29], where a stop of exponential growth in Great Britain was also observed before the lockdown. Our result on a possible effect of the ban of mass events is also in line with the results of [Reference Li3].
The temporal connection between the change points in our analysis and various control measures should be interpreted as an association, rather than a direct causal relationship. In the end many other explanations exists and from a simple time-series analysis it is not possible to say to what extent the population already had changed their behaviour voluntarily, as for example observed in mobility data [Reference Bryant and Elofsson30, Reference Schlosser31], and in what way the measures contributed to this. More speculative alternative explanations would include the possibility of a seasonal effect on coronavirus activity (e.g. related to temperature) or changes in test capacity or the case detection ratio. However, given the re-emergence of the pandemic in the fall of 2020 at high test capacity and at relatively high temperatures shows that contact behaviour is the major explanatory factor for virus activity. Nevertheless, any analysis of observational
Time-series data including only a limited amount of explanatory factors has to be interpreted with care and with respect to the many uncertainties which remain regarding COVID-19 [Reference Davey Smith, Blastland and Munafò32].
Despite the limitations of the approach, we argue that it is advantageous and important to directly interpret the epidemic curve and the absolute number of cases, rather than indirect measures like the R(t). Furthermore, the reproduction rate does not contain information about how many people are currently affected, or whether the infected persons belong to risk groups. The course of the time-varying reproduction number calculated by us for Bavaria fits well with the change point analysis [Reference Günther10]. A value of R(t) > 1 corresponds to a rate of increase >1, noting that the time delays in the interpretation of R(t) must be kept in mind.
It should be noted, that the presented analysis is retrospective. Control measures have to be decided based on a completely different level of information than what the retrospectively established epidemic curve suggests. The simple observation of the course of the reported case numbers by reporting date is also problematic because this course is strongly influenced by the reporting behaviour and the methods and capacities of the test laboratories. Typically, substantially fewer cases are reported at weekends than during the week. Therefore, the estimation proposed by Günther et al. [Reference Günther10] is an important step to estimate the better interpretable curve of new cases, but is limited by assumptions and limitations itself, that need to be considered when interpreting the results.
Since the impact of the measures also depends on how they are implemented by the population (compliance), the results cannot be directly transferred to the future. Nevertheless, it remains a remarkable result that the clear turning point of the early COVID-19 infection data in Germany is associated with non-drastic measures (no shutdown) and strong appeals by politicians.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268821000558
Acknowledgements
We would like to thank Katharina Katz and Manfred Wildner from the Bavarian State Office for Health and Food Safety (LGL) for providing the data and for useful discussions. We also thank Nadja Sauter and Daniel Schlichting for help with visualisations. We thank two reviewers whose comments helped to improve the work significantly.
Data and code availability
Data used for the analyses and all code to reproduce the models, figures and tables in the manuscript are openly and freely available from [Reference Günther33]. All analyses were performed using the R programming language [34].







 Open access
Open access