

No CrossRef data available.
Article contents
Asymptotically optimal policies for weakly coupled Markov decision processes
Part of:
Stochastic systems and control
Published online by Cambridge University Press: 25 March 2026
Abstract
We consider the problem of maximizing the expected average reward obtained over an infinite time horizon by n weakly coupled Markov decision processes. Our setup is a substantial generalization of the multi-armed restless bandit problem that allows for multiple actions and constraints. We establish a connection with a deterministic and continuous-variable control problem where the objective is to maximize the average reward derived from an occupancy measure that represents the empirical distribution of the processes when 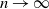 $n \to \infty$. We show that a solution of this fluid problem can be used to construct policies for the weakly coupled processes that achieve the maximum expected average reward as
$n \to \infty$. We show that a solution of this fluid problem can be used to construct policies for the weakly coupled processes that achieve the maximum expected average reward as 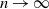 $n \to \infty$, and we give sufficient conditions for the existence of solutions. Under certain assumptions on the constraints, we prove that these conditions are automatically satisfied if the unconstrained single-process problem admits a suitable unichain and aperiodic policy. In particular, the assumptions include multi-armed restless bandits and a broad class of problems with multiple actions and inequality constraints. Also, the policies can be constructed in an explicit way in these cases. Our theoretical results are complemented by several concrete examples and numerical experiments, which include multichain setups that are covered by the theoretical results.
$n \to \infty$, and we give sufficient conditions for the existence of solutions. Under certain assumptions on the constraints, we prove that these conditions are automatically satisfied if the unconstrained single-process problem admits a suitable unichain and aperiodic policy. In particular, the assumptions include multi-armed restless bandits and a broad class of problems with multiple actions and inequality constraints. Also, the policies can be constructed in an explicit way in these cases. Our theoretical results are complemented by several concrete examples and numerical experiments, which include multichain setups that are covered by the theoretical results.
MSC classification
Secondary:
93E03: Stochastic systems, general
Information
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2026. Published by Cambridge University Press on behalf of Applied Probability Trust.
References
Adelman, D. and Mersereau, A. J. (2008). Relaxations of weakly coupled stochastic dynamic programs. Operat. Res. 56, 712–727.10.1287/opre.1070.0445CrossRefGoogle Scholar
Altman, E. (2021). Constrained Markov Decision Processes. Routledge, Abingdon.10.1201/9781315140223CrossRefGoogle Scholar
Billingsley, P. (1999). Convergence of Probability Measures. John Wiley, Chichester.10.1002/9780470316962CrossRefGoogle Scholar
Brown, D. B. and Smith, J. E. (2020). Index policies and performance bounds for dynamic selection problems. Manag. Sci. 66, 3029–3050.10.1287/mnsc.2019.3342CrossRefGoogle Scholar
Brown, D. B. and Zhang, J. (2022). Dynamic programs with shared resources and signals: Dynamic fluid policies and asymptotic optimality. Operat. Res. 70, 3015–3033.10.1287/opre.2021.2181CrossRefGoogle Scholar
Brown, D. B. and Zhang, J. (2023). Fluid policies, reoptimization, and performance guarantees in dynamic resource allocation. Operat. Res. 73, 583–1150.Google Scholar
Gast, N., Gaujal, B. and Khun, K. (2023). Testing indexability and computing Whittle and Gittins index in subcubic time. Math. Meth. Operat. Res. 97, 391–436.10.1007/s00186-023-00821-4CrossRefGoogle Scholar
Gast, N., Gaujal, B. and Yan, C. (2020). Exponential convergence rate for the asymptotic optimality of Whittle index policy. Preprint, arXiv:2012.09064.Google Scholar
Gast, N., Gaujal, B. and Yan, C. (2023). Exponential asymptotic optimality of Whittle index policy. Queueing Systems 104, 107–150.10.1007/s11134-023-09875-xCrossRefGoogle Scholar
Gast, N., Gaujal, B. and Yan, C. (2023). Linear program-based policies for restless bandits: Necessary and sufficient conditions for (exponentially fast) asymptotic optimality. Math. Operat. Res. 49, 2468–2491.10.1287/moor.2022.0101CrossRefGoogle Scholar
Gast, N., Gaujal, B. and Yan, C. (2024). Reoptimization nearly solves weakly coupled Markov decision processes. Preprint, arXiv:2211.01961.Google Scholar
Gocgun, Y. and Ghate, A. (2012). Lagrangian relaxation and constraint generation for allocation and advanced scheduling. Comput. Operat. Res. 39, 2323–2336.10.1016/j.cor.2011.11.017CrossRefGoogle Scholar
Goldsztajn, D., Borst, S. C. and Van Leeuwaarden, J. S. (2026). Fluid limits for interacting queues in sparse dynamic graphs. Stoch. Process. Appl. 192, 104794.10.1016/j.spa.2025.104794CrossRefGoogle Scholar
Hawkins, J. T. (2003). A Langrangian decomposition approach to weakly coupled dynamic optimization problems and its applications. PhD thesis, Massachusetts Institute of Technology.Google Scholar
Hodge, D. J. and Glazebrook, K. D. (2015). On the asymptotic optimality of greedy index heuristics for multi-action restless bandits. Adv. Appl. Prob. 47, 652–667.10.1239/aap/1444308876CrossRefGoogle Scholar
Hong, Y., Xie, Q., Chen, Y. and Wang, W. (2023). Restless bandits with average reward: Breaking the uniform global attractor assumption. In Proc. 37th Conf. Neural Information Processing Systems. Curran Associates, Inc., New York, pp. 12810–12844.Google Scholar
Hong, Y., Xie, Q., Chen, Y. and Wang, W. (2024). When is exponential asymptotic optimality achievable in average-reward restless bandits? Preprint, arXiv:2405.17882.Google Scholar
Hong, Y., Xie, Q., Chen, Y. and Wang, W. (2025). Unichain and aperiodicity are sufficient for asymptotic optimality of average-reward restless bandits. To appear in Math. Operat. Res. DOI: https://doi.org/10.1287/moor.2024.0678.Google Scholar
Meuleau, N., Hauskrecht, M., Kim, K.-E., Peshkin, L., Kaelbling, L. P., Dean, T. and Boutilier, C. (1998). Solving very large weakly coupled markov decision processes. In Proc. 15th Nat. Conf. Artificial Intelligence, pp. 165–172.Google Scholar
Patrick, J., Puterman, M. L. and Queyranne, M. (2008). Dynamic multipriority patient scheduling for a diagnostic resource. Operat. Res. 56, 1507–1525.10.1287/opre.1080.0590CrossRefGoogle Scholar
Puterman, M. L. (2014). Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley, Chichester.Google Scholar
Salemi Parizi, M. (2018). Approximate dynamic programming for weakly coupled Markov decision processes with perfect and imperfect information. PhD thesis, University of Washington.Google Scholar
Verloop, I. M. (2016). Asymptotically optimal priority policies for indexable and nonindexable restless bandits. Ann. Appl. Prob. 26, 1947–1995.10.1214/15-AAP1137CrossRefGoogle Scholar
Weber, R. R. and Weiss, G. (1990). On an index policy for restless bandits. J. Appl. Prob. 27, 637–648.10.2307/3214547CrossRefGoogle Scholar
Whittle, P. (1988). Restless bandits: Activity allocation in a changing world. J. Appl. Prob. 25, 287–298.10.2307/3214163CrossRefGoogle Scholar
Xiong, G., Li, J. and Singh, R. (2021). Reinforcement learning for finite-horizon restless multi-armed multi-action bandits. Preprint, arXiv:2109.09855.Google Scholar
Yan, C. (2024). An optimal-control approach to infinite-horizon restless bandits: Achieving asymptotic optimality with minimal assumptions. In Proc. 63rd IEEE Conf. Decision and Control. IEEE, New York, pp. 6665–6672.Google Scholar
Zayas-Caban, G., Jasin, S. and Wang, G. (2019). An asymptotically optimal heuristic for general nonstationary finite-horizon restless multi-armed, multi-action bandits. Adv. Appl. Prob. 51, 745–772.10.1017/apr.2019.29CrossRefGoogle Scholar
Zhang, X. and Frazier, P. I. (2021). Restless bandits with many arms: Beating the central limit theorem. Preprint, arXiv:2107.11911.Google Scholar