

Introduction
In the last ten years, digital media have become more easily accessible and increasingly used among pre-schoolers (Ofcom, 2019), in large part due to their intuitive design (Ólafsson, Livingstone, & Haddon, Reference Ólafsson, Livingstone and Haddon2013). According to a UK Ofcom report (Ofcom, 2019), by 2018 tablets were used by 58% of children aged 3 and 4; with 19% of them having their own tablet. Young children are thus surrounded by educational technology, and are native users of smart phones, tablets and computers; they have hence been referred to as digitods (Holloway, Green, & Stevenson, Reference Holloway, Green and Stevenson2015), a term that highlights the fact that digital media is present in their lives from birth. A huge number of apps for language development are currently available for children in app stores (Callaghan & Reich, Reference Callaghan and Reich2018; Vaala, Ly, & Levine, Reference Vaala, Ly and Levine2015). However, few of these meet standards for being effectively educational from a developmental psychology perspective (Callaghan & Reich, Reference Callaghan and Reich2018; Hirsh-Pasek, Zosh, Golinkoff, Gray, Robb, & Kaufman, Reference Hirsh-Pasek, Zosh, Golinkoff, Gray, Robb and Kaufman2015; Kolak, Norgate, Monaghan, & Taylor, Reference Kolak, Norgate, Monaghan and Taylor2021; Papadakis, Kalogiannakis, & Zaranis, Reference Papadakis, Kalogiannakis and Zaranis2018; Vaala et al., Reference Vaala, Ly and Levine2015). Increasing exposure to touchscreens means there is potential for educational apps to provide supplementary opportunities to support language development – for example, by exposing children to new words in a similar way to storybooks; especially when apps are co-used between parent and child. Co-use of media between parent and child makes time spent with media more interactive and can improve learning, especially for children under the age of 5 (Neumann, Reference Neumann2018; Wood, Petkovski, De Pasquale, Gottardo, Evans, & Savage, Reference Wood, Petkovski, De Pasquale, Gottardo, Evans and Savage2016). Consequently, language in touchscreen apps, when co-used between parent and child, could be useful as an additional source of children’s language input, alongside child directed speech (CDS), books and some TV programmes. However, it is worth noting that only 20% of parents report co-using apps with 2- to 4-year-olds most of the time (Rideout & Robb, Reference Rideout and Robb2020), though this rises to 49% for children 0-2-years-old, and overall for children aged 0-8-years-old 80% of parents report co-use of apps most or some of the time with their child.
Importantly, touchscreens – compared to other types of passive media, such as TV – might benefit language learning because they give the child autonomy and agency to select their activities and to directly interact with and manipulate the digital content, which might increase the child’s intrinsic motivation and subsequently also increase their engagement and learning (Hirsh-Pasek et al., Reference Hirsh-Pasek, Zosh, Golinkoff, Gray, Robb and Kaufman2015; Kervin, Reference Kervin2016; Nacher, Jaen, Navarro, Catala & González, Reference Nacher, Jaen, Navarro, Catala, Navarro and González2015). Moreover, the multimodal attributes of touchscreen apps (e.g., audio sound, animations, highlighted texts) deliver immediate feedback to child’s actions and have the potential to stimulate children’s auditory, visual and tactile senses (Neumann, Reference Neumann2020). Apps – contrary to passive forms of digital media – can have the potential to promote scaffolded learning experience by offering various settings to adjust to the child’s age and skills, or by automatically adjusting the level of difficulty of the activities contingently. However, studies show that apps currently popular in the app market could provide substantially more scaffolding opportunities (e.g., Papadakis et al., Reference Papadakis, Kalogiannakis and Zaranis2018; Kolak et al., Reference Kolak, Norgate, Monaghan and Taylor2021). While engaged with carefully selected apps, ideally co-used with parents, children might have a chance to use and expand their language repertoire for meaningful purposes, especially when learning in the app is nested within authentic, meaningful and purposeful context (Hirsh-Pasek et al., Reference Hirsh-Pasek, Zosh, Golinkoff, Gray, Robb and Kaufman2015; Kervin, Reference Kervin2016). Indeed, a number of studies to date have shown that children can learn new words from touchscreen apps (Arnold, Chary, Gair, Helm, Herman, Kang, & Lokhandwala, Reference Arnold, Chary, Gair, Helm, Herman, Kang and Lokhandwala2021; Dore, Shirilla, Hopkins, Collins, Scott, Schatz, Lawson-Adams, Valladares, Foster, Puttre, Toub, Hadley, Golinkoff, Dickinson, & Hirsh-Pasek, Reference Dore, Shirilla, Hopkins, Collins, Scott, Schatz, Lawson-Adams, Valladares, Foster, Puttre, Toub, Hadley, Golinkoff, Dickinson and Hirsh-Pasek2019; Kirkorian, Choi, & Pempek, Reference Kirkorian, Choi and Pempek2016; Russo-Johnson, Troseth, Duncan, & Mesghina, Reference Russo-Johnson, Troseth, Duncan and Mesghina2017).
All these features make the experience with touchscreens different to the passive experience of watching TV, which for decades has been the main source of digital media input for children. One of the key features promoting active learning is contingent responses, which touchscreen apps are readily able to provide (alongside parent-child interaction during app co-use). Social contingency is key to facilitating children’s attention and arousal and to supporting language learning (Kuhl, Reference Kuhl2007). Children’s interactive experience with touchscreens places media use alongside two other key interactive forms of language input: child-directed speech and shared book reading. Although studies to date show that children can learn new words from touchscreens (Arnold et al., Reference Arnold, Chary, Gair, Helm, Herman, Kang and Lokhandwala2021; Dore et al., Reference Dore, Shirilla, Hopkins, Collins, Scott, Schatz, Lawson-Adams, Valladares, Foster, Puttre, Toub, Hadley, Golinkoff, Dickinson and Hirsh-Pasek2019; Kirkorian et al., Reference Kirkorian, Choi and Pempek2016; Russo-Johnson et al., Reference Russo-Johnson, Troseth, Duncan and Mesghina2017) and learn new content in general (see Xie, Peng, Qin, Huang, Tian, & Zhou, Reference Xie, Peng, Qin, Huang, Tian and Zhou2018, for a meta-analysis), little attention has been devoted to investigating touchscreen media as a more general source of language input. Thus, in this paper we investigate the potential of touchscreen apps to enrich preschoolers’ language environment, when used between parent and child, in comparison to CDS and shared book reading.
The role of CDS in supporting children’s language learning
Children’s language development is strongly related to the number of words that they hear everyday in their environment (Hart & Risley, Reference Hart and Risley1995; Huttenlocher, Haight, Bryk, Seltzer, & Lyons, Reference Huttenlocher, Haight, Bryk, Seltzer and Lyons1991; Weisleder & Fernald, Reference Weisleder and Fernald2013). To learn language, children must hear a broad range of vocabulary and sentence structure (Dickinson, Griffith, Golinkoff, & Hirsh-Pasek, Reference Dickinson, Griffith, Golinkoff and Hirsh-Pasek2012; Rowe & Zuckerman, Reference Rowe and Zuckerman2016). Exposure to CDS, as opposed to adult-directed speech, supports children’s language development (Weisleder & Fernald, Reference Weisleder and Fernald2013), and the greater its lexical and grammatical diversity, the stronger its positive influence on children’s vocabulary acquisition (e.g., Hoff & Naigles, Reference Hoff and Naigles2002; Rowe, Reference Rowe2012). The particular type of grammatical constructions, as well as their variety, are also important for supporting language learning. Fernald and Hurtado (Reference Fernald and Hurtado2006) found that item-based sentence frames (e.g., It’s a X; Where’s the Y; Look at the X) occur regularly in CDS, and help children identify familiar nouns, meaning CDS is tuned to enhancing early language development.
However, CDS may be somewhat limited in the linguistic structures that it contains. Cameron-Faulkner, Lieven, and Tomasello (Reference Cameron-Faulkner, Lieven and Tomasello2003) noted that speech directed to children aged 2 in monolingual English speakers included a low proportion of canonical constructions (i.e., constructions with a Subject, Verb and Object) and complex sentences (i.e., sentences with more than one lexical verb), constituting only 15% of the whole CDS sample analysed by Cameron-Faulkner et al. (Reference Cameron-Faulkner, Lieven and Tomasello2003). Instead, the language children hear from their caregivers includes a high proportion of fragments (utterances without subject and predicate), copulas (utterances in which the main verb is some form of to be) and questions. The findings from these studies suggest that CDS might be well suited to early vocabulary development, but less supportive, at least initially, of children’s development of more structurally rich constructions, which is part of later stages of language development.
The potential of books to support children’s language learning
While CDS is to some extent constrained, children’s books provide an additional source that can support the enhanced richness of input. Shared book reading has been directly linked to children’s language development (Farrant & Zubrick, Reference Farrant and Zubrick2012; Mol, Bus, Jong, & Smeets, Reference Mol, Bus, Jong and Smeets2008; Raikes, Pan, Luze, Tamis-LeMonda, Brooks-Gunn, Constantine, Tarullo, Raikes, & Rodriguez, Reference Raikes, Pan, Luze, Tamis-LeMonda, Brooks-Gunn, Constantine, Tarullo, Raikes and Rodriguez2006; Robb, Richert, & Wartella, Reference Robb, Richert and Wartella2009; Taylor, Monaghan, & Westermann, Reference Taylor, Monaghan and Westermann2018). Shared storybook reading plays an important role in early word learning; the frequency of shared book reading predicts the size of both child’s receptive and expressive vocabulary in children under the age of 5 (Arterberry, Bornstein, Midgett, Putnick, & Bornstein, Reference Arterberry, Bornstein, Midgett, Putnick and Bornstein2007; Sénéchal, Reference Sénéchal1997). Books provide decontextualized language (referencing people or events that are outside of child’s immediate environment) and more diverse vocabulary than that used in everyday conversations at home, embedded in a greater diversity of grammatical constructions (Dickinson et al., Reference Dickinson, Griffith, Golinkoff and Hirsh-Pasek2012). Montag, Jones, and Smith (Reference Montag, Jones and Smith2015) compared word type and token counts to a matched sample of CDS and found more unique word types in books than in CDS. Importantly, they also found that individual picture books include more unique word types than length-matched conversations from CDS. Dawson, Hsiao, Tan, Banerji, and Nation (Reference Dawson, Hsiao, Tan, Banerji and Nation2021) also found that language in children’s books is more lexically diverse than CDS. Their analysis was based on a book corpus comprising 160 books commonly read to children aged 0-5 (320,000 words) and 10 corpora from the CHILDES UK database (around 3.8 million words). Furthermore, the authors found that language in children’s books includes a larger proportion of rarer word types compared to CDS. Nouns and adjectives occur more frequently in the books whereas pronouns occur more frequently in CDS. Dawson and colleagues also found that words included in children’s books are more structurally complex with respect to number of phonemes and morphological structure. Words in books also have later age of acquisition, are more abstract, and more emotionally arousing than words in CDS. Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013) found that books targeting 2-year-olds provide a different, enriching language input than speech directed to children of that age, because they present children with proportionally more canonical utterances and complex constructions than are present in CDS. Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013) thus concluded that the language used in children’s books has the potential to support children’s grammatical development. Similarly, shared book reading might also positively affect the language parents use with their children, by increasing lexical and syntactic diversity in CDS (Noble, Cameron-Faulkner, & Lieven, Reference Noble, Cameron-Faulkner and Lieven2018).
The potential of touchscreen apps to support language learning
Less is known about the effectiveness of digital content, such as touchscreen apps, for language learning. Studies investigating language in books and CDS use language transcripts (from a book text or from a naturalistic play between a parent and a child). Studies to date have not investigated language in touchscreen apps (especially audio and onscreen language, i.e., all the language available in the app when it is co-used by parent and child), instead studies analysed children’s language learning from apps by using experimental designs or randomised control trials. Experimental studies using a lab-designed app found that 2-4-year-olds were able to learn labels for novel objects (Kirkorian et al., Reference Kirkorian, Choi and Pempek2016; Russo-Johnson et al., Reference Russo-Johnson, Troseth, Duncan and Mesghina2017) or new vocabulary (Dore et al., Reference Dore, Shirilla, Hopkins, Collins, Scott, Schatz, Lawson-Adams, Valladares, Foster, Puttre, Toub, Hadley, Golinkoff, Dickinson and Hirsh-Pasek2019). This suggests that developmentally appropriate apps can have potential to teach children new vocabulary. Interactive digital media may therefore be a valuable source of language input for young children. Arnold and colleagues (Reference Arnold, Chary, Gair, Helm, Herman, Kang and Lokhandwala2021) conducted a randomised controlled trial of the effect of home use of Khan Academy app (teaching children sounds, letters and words) on literacy skills of 4- and 5-year-olds from low SES households. They showed that educational apps with a clear learning goal have the potential to foster academic success and narrow the language gap that is associated with SES (e.g., Hart & Risley, Reference Hart and Risley1995).
A recent systematic review and meta-analysis by Madigan, McArthur, Anhorn, Eirich, and Christakis (Reference Madigan, McArthur, Anhorn, Eirich and Christakis2020) focused on associations between screen use and children’s language skills based on data from 42 studies. Their analysis revealed that greater quantity of screen use (measured as hours per day/week) was negatively linked to child language skills, whereas better quality of screen use (co-viewing with caregivers and educational programs) was positively linked to child language skills. The findings of this meta-analysis highlight the need for media to be of high quality in order to benefit children’s language development. However, little is known about the content of the language used in educational touchscreen media, and, consequently, about how touchscreen media might support preschoolers’ language learning. To date, the majority of studies analysing vocabulary of educational media (e.g., the language of instruction presented in digital media) have focused on only one TV program or segment of a program, but not on the language used during the course of operating touchscreen apps. For example, Larson and Rahn (Reference Larson and Rahn2015) found that Sesame Street’s Word on the Street initiative used appropriately designed, research based instructional strategies for teaching new words, such as repeated word exposures and examples, and provided large variability across episodes in terms of how many opportunities children had to learn the words. In a more recent study, Danielson, Wong, and Neuman (Reference Danielson, Wong and Neuman2019) presented a content analysis of vocabulary instruction from a larger representative sample of educational media available on DVD and streaming platforms and found that educational media programs rarely included sophisticated words or the type of support that might facilitate deeper learning (e.g., repeating words or providing a definition). To date, there are no studies analysing the language features of touchscreen apps to understand whether they have the potential to enrich a child’s language environment. Thus, in the present study we aim to remedy this by analysing language available to parent and child during app co-use in the most popular children’s apps targeting preschoolers, and comparing the features of that language to language in children’s books and CDS targeting 2-year-olds.
The role of psycholinguistic properties of language in supporting children’s language learning
As a marker of quality and appropriateness of language, the psycholinguistic properties of language can be linked to language development. Some of the psycholinguistic properties that could potentially influence language learning include (at the sentence level) mean length of utterance (MLU), and (at the word level) word frequency, concreteness, age of acquisition (AoA).
Mean length of utterance (MLU) – the number of words the utterance contains – increases in both child-directed speech and children’s own productions according to age (Snow, Reference Snow1972) and is also related to grammatical complexity of structures (Dickinson & Porche, Reference Dickinson and Porche2011).
Low frequency words tend to be learned by children later than high frequency words (Cameirão & Vicente, Reference Cameirão and Vicente2010; Ferrand, Brysbaert, Keuleers, New, Bonin, Méot, Augustinova, & Pallier, Reference Ferrand, Brysbaert, Keuleers, New, Bonin, Méot, Augustinova and Pallier2011; Moors, De Houwer, Hermans, Wanmaker, van Schie, Van Harmelen, De Schryver, De Winne, & Brysbaert, Reference Moors, De Houwer, Hermans, Wanmaker, van Schie, Van Harmelen, De Schryver, De Winne and Brysbaert2013), and lower-frequency words tend to be more prevalent in books than in CDS (Dickinson & Tabors, Reference Dickinson and Tabors2001).
Concrete words tend to be easier to remember (Paivio, Reference Paivio2013) and learned better than more abstract words (Kaushanskaya & Rechtzigel, Reference Kaushanskaya and Rechtzigel2012), and high concrete words are also more likely to be directed to young children than abstract words (Philips, Reference Philips1973). Constructivist theories of development (e.g., Inhelder & Piaget, Reference Inhelder and Piaget1958) claim that development advances from the concrete to the abstract and recommend that learning and teaching should follow the same pathway. Indeed, Gleitman, Cassidy, Nappa, Papafragou, and Trueswell (Reference Gleitman, Cassidy, Nappa, Papafragou and Trueswell2005) argue that there is a degree of word concreteness that makes words easier or more difficult to acquire. More concrete object labels are acquired first and other, more abstract words (such as verbs or non-object terms, including colour, number and time words) require more information for the child to ascertain their meaning. Abstract words pose a challenge for word learning due to their non-obvious word-referent mappings (Tare, Shatz, & Gilbertson, Reference Tare, Shatz and Gilbertson2008).
Furthermore, words that are more commonly acquired early in children’s development (words with lower age AoA) are more likely to be accessible to children.
Word repetition is another feature of input that affects word learning. Although some learning occurs when words are encountered for the first time, i.e., during fast mapping (Axelsson & Horst, Reference Axelsson and Horst2014; Carey, Reference Carey2010), single presentation of a word is rarely enough for robust word learning to happen (Horst & Samuelson, Reference Horst and Samuelson2008; Mather & Plunkett, Reference Mather and Plunkett2009). The repetitiveness of caregivers’ speech predicts later vocabulary (Newman, Rowe, & Bernstein Ratner, Reference Newman, Rowe and Bernstein Ratner2016). Repeated exposure to a word provides additional opportunities to store relevant information about the word, which enables the formation of a more robust representation (Horst, Reference Horst2013; McMurray, Horst, & Samuelson, Reference McMurray, Horst and Samuelson2012; Yu & Smith, Reference Yu and Smith2007). Caregivers’ tendency to use the same words repeatedly in consecutive sentences is likely to influence young children’s word learning (Brodsky, Waterfall, & Edelman, Reference Brodsky, Waterfall, Edelman, McNamara and Trafton2007; Hills, Reference Hills2013; Onnis, Waterfall, & Edelman, Reference Onnis, Waterfall and Edelman2008; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016). Similarly, repeatedly being read the same storybook fosters children’s word learning through contextual repetition (Horst, Parsons, & Bryan, Reference Horst, Parsons and Bryan2011; McLeod & McDade, Reference McLeod and McDade2010). We suggest that high quality language input would offer repetitions of words and phrases that can also enhance the range of words that children experience. That is, an enriching environment would offer words with lower frequency repeated more often than words with higher frequency, words with later AoA more often than words with earlier AoA, and words of lower concreteness more often than words of higher concreteness.
Finally, lexical diversity in language input has a major influence on language learning. Lexical diversity is commonly operationalised as the ratio of different unique words to the total number of words. Children who are exposed to a large amount of lexically diverse speech (compared to children who are not) are reported to learn language more quickly and have larger vocabularies (see Hoff, Reference Hoff2006, for a review). Based on computational modelling, Jones and Rowland (Reference Jones and Rowland2017) envision that the quantity of language children hear in their environment is more important in early learning, but diversity is crucial for later language development. Lexical diversity and repetitions may be seen as diametrically opposite, but they capture different aspects of the quality of input. For instance, the repetitions analysis detects the properties of words that are repeated, whereas the lexical diversity study detects the extent to which there is broader repetition in the sample. We distinguish lexical diversity from (the inverse of) repetitions, because repetitions have a special status in child-directed speech, and are particularly important for children learning vocabulary as well as grammar (Cameron-Faulkner et al., Reference Cameron-Faulkner, Lieven and Tomasello2003; Matychuk, Reference Matychuk2005; Newman et al., Reference Newman, Rowe and Bernstein Ratner2016; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016). We therefore investigated the prevalence of repetitions but also the characteristics of those repeated utterances in the apps to determine their potential role in supporting language learning.
As the literature presented above suggests, input features, such as psycholinguistic properties of language (frequency, concreteness, AoA and MLU) as well as word repetition and lexical diversity, are important factors supporting language learning. These factors should therefore be investigated in detail when assessing whether different language input sources that children are exposed to (e.g., books and touchscreen apps) have the potential to enrich children’s language experience. Investigating language features also enables us to assess whether a certain input source is age-appropriate and whether the words that the child is exposed to have the potential to add to child’s everyday language experience.
Importantly, high quality language input is seen as providing variety of vocabulary (see Rowe, Reference Rowe2012, for a review), which will be reflected on:
-
(a) an input source level (each sample of CDS, each book, and each app): more range and complexity of grammatical constructions;
-
(b) a sentence level: longer MLU;
-
(c) a word level: overall lower frequency, later AoA, and lower concreteness of words.
These features of input have the potential for introducing a richer language environment.
The present study
To date, no research has been conducted to compare the properties of language available to parent and child during app co-use in educational apps, to CDS and children’s books. To fill this gap, the current study aims to examine the differences between the language in top educational apps, best-selling children’s books, and CDS, targeting preschool children. Both books and educational apps (when read/used together by parent and child) might constitute sources of additional language input and expose children to words or grammatical constructions that they do not hear frequently in child directed speech. Thus, this study focuses on how educational apps can potentially contribute to children’s language exposure, when co-used with parents. In our analyses we aimed to expand on Cameron-Faulkner and Noble’s (Reference Cameron-Faulkner and Noble2013) study that compared proportions of different construction types used in CDS and in children’s books targeting children aged 2, by adding to their comparison a sample of the most popular educational apps in the app markets. Apps for young children in the app markets can be found in the categories for under 5-year-olds only (there are no separate categories with apps for 2-year-olds only). Thus, in our study we looked at the apps for wider age range than the books and CDS in our sample were targeting. However, these are the apps that are also experienced by 2-year-olds.
The analyses regarding construction types are performed on an input source level (i.e., proportion of different construction types across each of the app, book and CDS samples). To add to the analyses on a sample level, we also analyse lexical diversity between the three input sources.
To provide further detail to the comparison, we performed a fine-grained language analysis of vocabulary use by investigating psycholinguistic properties of language in CDS, children’s books and educational apps. Specifically, we performed an analysis on the sentence level by comparing MLU in the three input sources, and an analysis on the word level by comparing word frequency, concreteness and AoA between the input sources. These psycholinguistic variables are known to influence language learning (e.g., Ferrand et al., Reference Ferrand, Brysbaert, Keuleers, New, Bonin, Méot, Augustinova and Pallier2011; Kaushanskaya & Rechtzigel, Reference Kaushanskaya and Rechtzigel2012), and will thus help determine whether the language used in educational apps is age-appropriate, pedagogically effective, and the extent to which it is more varied than language in CDS and children’s books. Finally, repeated exposure to words facilitates learning (Brodsky et al., Reference Brodsky, Waterfall, Edelman, McNamara and Trafton2007; Hills, Reference Hills2013; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016; Onnis et al., Reference Onnis, Waterfall and Edelman2008) and therefore in our analyses on the word level, we also focus on the extent to which the more advanced words are repeated across the three input sources. Specifically, we were interested in the differences between apps, books and CDS with respect to how often they repeat words potentially enriching children’s language environment (of low frequency, later AoA and low concreteness) compared to high frequency, early AoA, and high concreteness words.
We address the broad question of the extent to which apps can be viewed as a possible form of enriched linguistic input by investigating the following research questions:
-
1. Do apps provide enriched linguistic input compared to children’s book text and CDS with respect to the proportion of use of various grammatical constructions (i.e., lower proportion of fragments, copulas and imperatives, and higher proportion of questions, subject-predicate and complex utterances)?
-
2. Do apps provide enriched linguistic input in terms of psycholinguistic variables (i.e., higher lexical diversity, longer MLU, words of lower frequency, lower concreteness and later age of acquisition) compared to books and CDS?
-
3. Are there differences between apps, books and CDS in terms of whether they repeat words of lower frequency, lower concreteness and later age of acquisition more frequently than words of higher frequency, higher concreteness and earlier AoA?
Method
Data collection
Educational apps
Apps were identified from the top 10 charts for ages 5 and under in the Apple, Google and Amazon app stores on 7th June 2018. In each app market we aimed to find the most relevant category within the charts, i.e., related to very young children. The names of the app categories in the top charts differed between the app markets; in Apple and Google app stores the relevant app category was called ‘Apps for ages 5 and under’ while in Amazon app store it was called ‘Best sellers in kids apps’. After removing duplicates and video-based apps, 18 apps were identified as educational – i.e., following our definition of an educational app (Kolak et al., Reference Kolak, Norgate, Monaghan and Taylor2021), apps that had a learning goal targeting early skills development, e.g., linking sounds and letters, counting, learning shapes and colours, teaching about people, places and environment (see Table 1 for the names and characteristics of those apps). Apps that were not identified as educational were, for example, PJ Masks (a gaming app in which user’s task is to run on the rooftops and collect diamonds on the way, by jumping up and down) or My Very Hungry Caterpillar (a gaming app in which user can move freely across the screens and try different activities, such as watering the plants). Each app was downloaded and a five-minute screen recording was taken while the first author used the appFootnote 1. All the utterances that were presented either as (a) audio, (b) onscreen, or (c) audio & onscreen simultaneously during app use were transcribed (N = 1,632).
Table 1. Characteristics of the app sample.

Books
We used the same book sample as Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013). This comprised 20 books taken from the best seller list of picture books aimed at 2-year-olds from the Amazon UK website in April and May 2011. Books were excluded if the same style of book or books with the same author had been selected already, or if the book was clearly inappropriate for the target age group (see Cameron-Faulkner & Noble, Reference Cameron-Faulkner and Noble2013 for more details on the selected sample). All utterances from the books were transcribed (N = 1,405) by the first author of the present paper to enable the analysis of psycholinguistic measures.
CDS
We used the same CDS sample as Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013) and Cameron-Faulkner et al. (Reference Cameron-Faulkner, Lieven and Tomasello2003). The sample comprised corpus data (scripts available for each mother-child dyad) taken from the Manchester corpus (Theakston, Lieven, Pine, & Rowland, Reference Theakston, Lieven, Pine and Rowland2001), available from the CHILDES website (MacWhinney & Snow, Reference MacWhinney and Snow1990). The corpus contains the transcribed interactions of 12 mother-child dyads (six girls, six boys), all monolingual English speakers. The analyses were based on two hours of recordings for each dyad. In the present analyses, in line with Cameron-Faulkner et al., Reference Cameron-Faulkner, Lieven and Tomasello2003, we focussed only on maternal speech, and not on the child’s own language production. The age of the children in those recordings ranged between 1;9.28 and 2;6.23 and the mean length of utterance of each child was between 2.00 and 2.49. We used the raw transcripts available through the CHILDES website (N of utterances = 27,117) to calculate the psycholinguistic measures.
Data coding
Input source level: Construction types and linguistic diversity
Each utterance from the apps was coded for its grammatical construction types by the first author according to the taxonomy used in Cameron-Faulkner et al. (Reference Cameron-Faulkner, Lieven and Tomasello2003) and Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013), which is based on standard linguistic criteria. For the construction types and their definitions, as well as the examples for each of the construction types from apps, books and CDS, see Table 2. For construction types coding in the apps, reliability was conducted on 15% of data rated by an independent rater, trained in the coding of linguistic criteria. Inter-rater reliability was high (κ = 0.889, p < .0001). To remain consistent with Cameron-Faulkner and Noble’s (Reference Cameron-Faulkner and Noble2013) methodology, we excluded formulaic performatives (such as hello, good-morning, good-bye, please, thank-you, yes, no) from the app data. The data regarding proportional frequency of different construction types (means and SE) for the book and CDS sample was obtained from Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013).
Table 2. Construction types and their definitions together with examples from apps, books and CDS.

On the input source level, we also measured lexical diversity, which is reflected in the ratio of different unique words to the total number of words. To calculate lexical diversity, we used the Guiraud index (Guiraud, Reference Guiraud1954). The Guiraud index is proposed as the most adequate measure of lexical diversity, in contrast to a commonly used type/token ratio, which is reported to yield erroneous outcomes when the number of tokens between the different sources vary substantially (see Hout & Vermeer, Reference Hout, Vermeer, Daller, Milton and Treffers-Daller2007). The formula for calculating the index is c = V / √ N, where V stands for the number of types, and N for the number of tokens. The higher the index, the larger the lexical diversity.
Sentence and word level: Psycholinguistic properties of the words
To analyse the psycholinguistic properties of the words used in the apps, books and CDS, we looked at several psycholinguistic measures. On the sentence level, we examined MLU, which measures the length of language production in terms of the number of words the utterance contains. On the word level, we took frequency of the words in a corpus of child-appropriate speech from television programmes. The corpus was derived from transcripts of 5,848,083 words from a UK public broadcast television channel – CBeebies – directed to children aged up to 6 years (van Heuven, Mandera, Keuleers, & Brysbaert, Reference van Heuven, Mandera, Keuleers and Brysbaert2014). The frequency dataset based on children’s TV shows is a large database that is representative of children’s wider oral language experience. It is also highly correlated in terms of frequencies of words from a corpus of 1001 books for children (Masterson, Stuart, Dixon, & Lovejoy, Reference Masterson, Stuart, Dixon and Lovejoy2010), r = .76 (correlation between adult frequency counts and this book corpus is lower, r=.66).
We also took information on concreteness ratings of words. Concreteness ratings were obtained from Brysbaert, Warriner, and Kuperman (Reference Brysbaert, Warriner and Kuperman2014) on a scale from 1 (abstract word) to 5 (concrete word). We also assessed words’ age of acquisition. AoA ratings for words were obtained from Kuperman, Stadthagen-Gonzalez, and Brysbaert (Reference Kuperman, Stadthagen-Gonzalez and Brysbaert2012). Frequency, concreteness and AoA were assigned separately for each word in each utterance.
Data analyses
Analyses on the input source level
With respect to the data on the proportional frequency of utterances from Cameron-Faulkner and Noble (Reference Cameron-Faulkner and Noble2013), the authors shared the summary of means and SE for each utterance type with us. Thus, to investigate whether apps, books and CDS differ with respect to proportional frequency of each utterance type, we computed ANOVAs based on the data summary available to us.
Lexical diversity was calculated using the Guiraud index separately for each app, book and CDS dyad, and a one-way ANOVA was conducted to compare lexical diversity across apps, books and CDS. The Guiraud index is not reliable when computed over a single utterance within an app, book, or CDS dyad, and so an item-level analysis, such as generalised linear mixed effects, was not applicable for analysing lexical diversity.
Analyses on the sentence and word level
In the case of analyses on the sentence and word level, we performed mixed-effects models analyses with each sentence or word as a separate observation.
Results
Analyses on the input source level: Construction types and lexical diversity
To compare the occurrence of the different construction types in the apps, books and CDS samples, we used proportional frequency of each construction type in the samples (see Figure 1) and performed a series of one-way ANOVAs separately for each construction type. The results, including the main effects of each construction type, and Tukey HSD post-hoc tests investigating comparisons between the different input sources, are summarised in Table 3.
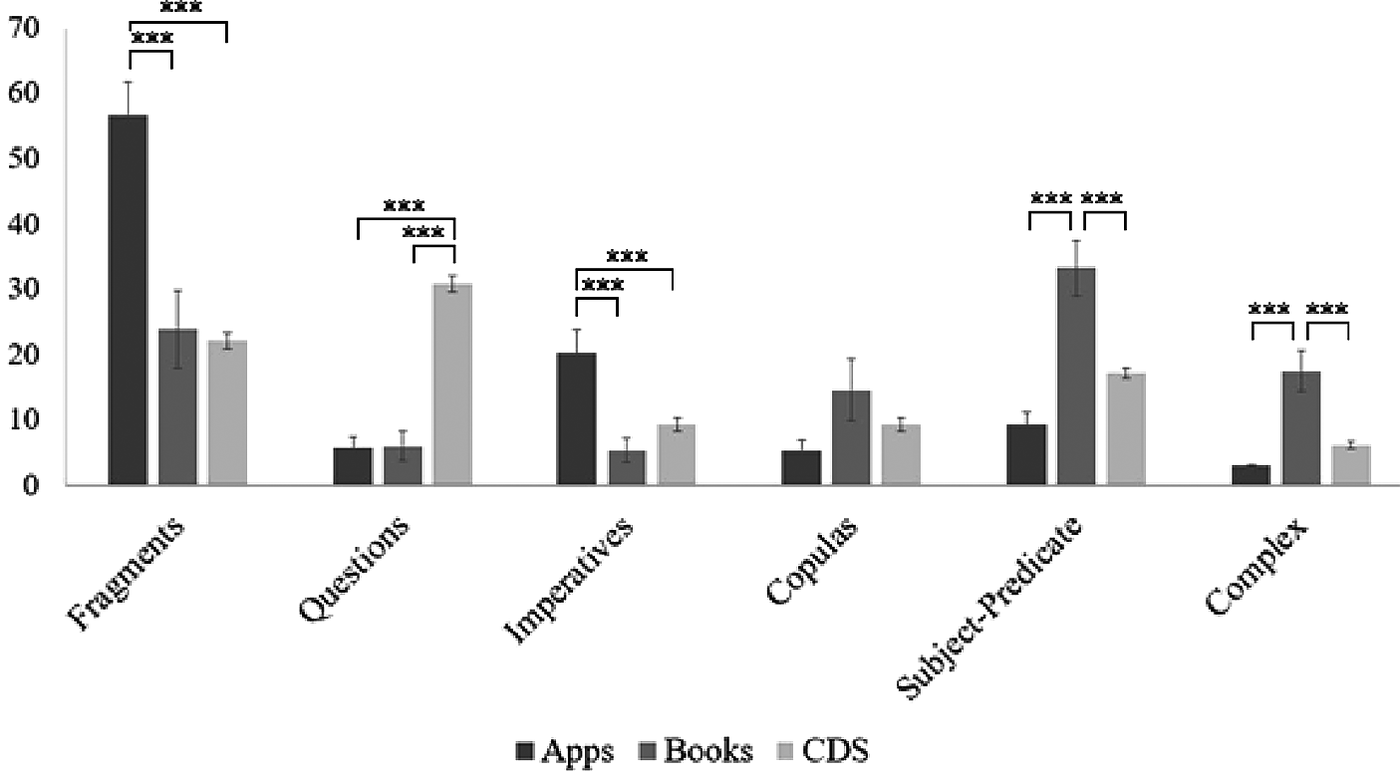
Figure 1. Proportional frequency of construction type in apps, books and CDS (+/- 1 SE).
Table 3. Summary of main effects of construction types and comparisons between the input sources.

Apps had higher proportional frequency of fragments than books (p = 0.001) and CDS (p = 0.0003), with no difference between books and CDS. Apps also had higher proportional frequency of imperatives than books (p = 0.0001) and CDS (p =0.0001), with no difference between books and CDS. CDS had higher proportional frequency of questions than apps (p < 0.001) and books (p < 0.001), with no difference between apps and books. Books contained higher proportional frequency of subject-predicate than apps (p = 0.0001) and CDS (p = 0.006), with no difference between apps and CDS. Books had also higher proportion of complex sentences than apps (p = 0.0001) and CDS (p = 0.006), with no difference between apps and CDS. Finally, apps, books and CDS did not differ with respect to the proportional frequency of copulas that they included.
For lexical diversity, the one-way ANOVA demonstrated a significant effect of input source, F(2,47) = 5.047, p = 0.010, ηp2 = .307. Bonferroni post-hoc tests revealed that CDS had statistically significantly higher lexical diversity than apps, p = 0.008 (see Table 3). There was no difference between apps and books, nor between CDS and books with respect to lexical diversity.
Analyses on the sentence and word level: Psycholinguistic properties of words
To investigate how apps, books and CDS differ in terms of the psycholinguistic measures of the words they contain, and whether this was general across sources within each input type, we ran four mixed-effects models, separately with each of MLU, frequency, concreteness and AoA as dependent variables. Each model included a fixed effect of input source (apps, books or CDS) and random intercept for individual sources (particular app, book, or CDS dyad; called ‘subject’ in R syntax for the models), with psycholinguistic measure (MLU, frequency, concreteness or AoA) as the dependent variable. For the MLU analysis, each utterance was counted as a separate observation. For the analyses of frequency, concreteness and AoA, each word type in an individual source was counted as a separate observation, with words weighted according to the number of repetitions within the source. We fitted frequency and AoA with a Gaussian distribution – however, the Gaussian distribution was not an effective fit for MLU and concreteness, reflected in model non-convergence, and so the better-fitting inverse-Gaussian function was used to model these variables. As frequency, concreteness, and AoA are intercorrelated (e.g., Balota, Cortese, Sergent-Marshall, Spieler, & Yap, Reference Balota, Cortese, Sergent-Marshall, Spieler and Yap2004), we included all the other variables as predictors to determine whether input source related to the dependent variable once variance associated with the other variables was accounted for. For instance, we predicted whether input source related to differences in frequency of the words the sources contained when variance in frequency associated with concreteness and AoA was also accommodated. This enabled us to ensure that a significant relation between the psycholinguistic variable and input source was particular to that variable and not due to intercorrelations with other psycholinguistic variables.
The model results for MLU are presented in Table 5. The results show a significant main effect of input source, with books having higher MLU than apps and CDS (see Table 4). There was no significant difference between apps and CDS.
Table 4. Descriptive results for the psycholinguistic measures in the sample of apps, books and CDS.
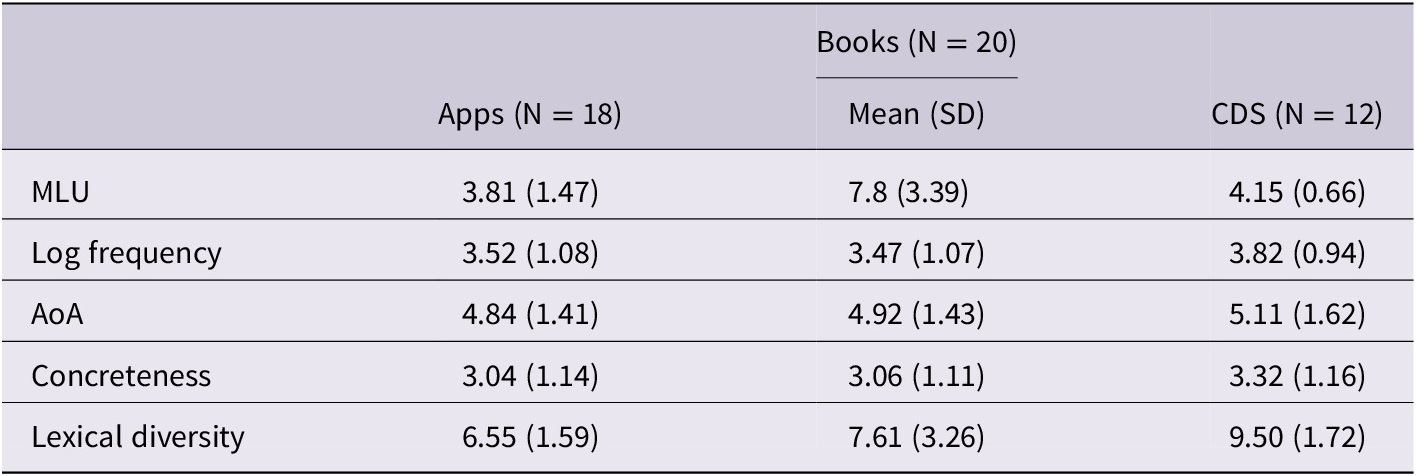
Table 5. Mixed model results for the analysis of MLU. Comparing books and CDS to apps.

R syntax for the model:glmer(MLU ~ (1 | subject) + input source, data=data1, glmerControl(optimizer="bobyqa", optCtrl = list(maxfun = 10000)), family=inverse.gaussian(link = "identity"))
The frequency model results are presented in Table 6. The results show a significant main effect of input source, with CDS having higher word frequency than apps and books (see Table 6). There was no significant difference between apps and books.
Table 6. Mixed effects model results for the analysis of log frequency.

R syntax for the model:lmer(log_frequency ~ (1 | subject) + input source + aoa + concreteness, data=data1, weight = repetitions)
There were no significant differences in AoA with respect to input source, once frequency and concreteness were taken into account. For concreteness, the distribution of words in CDS was significantly higher in mean concreteness than words in books, but the words in apps were not significantly different than CDS or books. The results of the model are shown in Table 7.
Table 7. Mixed effects model results for the analysis of concreteness.

R syntax for the model:glmer(concreteness ~ (1 | subject) + input source + frequency + aoa, data = data1, glmerControl(optimizer="bobyqa", optCtrl = list(maxfun = 10000)), weight = repetitions, family = inverse.gaussian(link = "identity"))
Psycholinguistic properties in relation to the number of repetition of words
We also wanted to test if the three input sources differ in the extent to which they repeat certain types of words. We investigated whether, across the input sources, words that are generally less frequent, less concrete and acquired later in language development are repeated to different extents across these sources than words that are more frequent, more concrete and acquired earlier in development. To test this, we ran a linear mixed-effects model with subject as random effect, fixed effects of log frequency, AoA and concreteness, and three interactions between each of these psycholinguistic variables and input source. The initial model also included by-subject random slopes for all the fixed effects and interactions, and a random intercept for word. However, due to the convergence issues, random structure had to be simplified and the final model included only random slope for subject (each individual source). Because of large differences in the number of types (distinct words in a sample) across the input sources (N = 1829 in apps, N = 3626 in books and N = 9966 in CDS), the mean number of repetitions in CDS (M = 10.79, SD = 36.90) was much higher than in apps (M = 2.66, SD = 3.94) and books (M = 2.93, SD = 6.06). Therefore, to avoid skewing the mixed model results, we generated z-scores for the number of repetitions of words for each input source in order to avoid skewing the results of the model. The model was fitted with an inverse Gaussian functionFootnote 3 and had the z-score of number of repetitions as a continuous dependent variable.
The model showed a positive main effect of log frequency, indicating that across the input sources the higher the frequency of a word, the more often a given word was repeated (see Table 8). This was as expected: words that are found to be high-frequency in other corpora also tend to be used more across the input sources. Critically, this pattern was more emphatic for CDS than for apps and books (see Figure 2a). There was no difference in the pattern of repetitions between apps and books. This suggests that apps have greater representation of lower-frequency words than are found in CDS.
Table 8. Mixed model results: the effects of psycholinguistic variables and input source for the number of repetitions.

R syntax for the model:glmer(repetitions_zscores ~ (1 | subject) + frequency + aoa + concreteness + frequency:input source + aoa:input source + concreteness:input source, data=data1, glmerControl(optimizer="bobyqa", optCtrl = list(maxfun = 10000)), family = inverse.gaussian(link = "identity"))
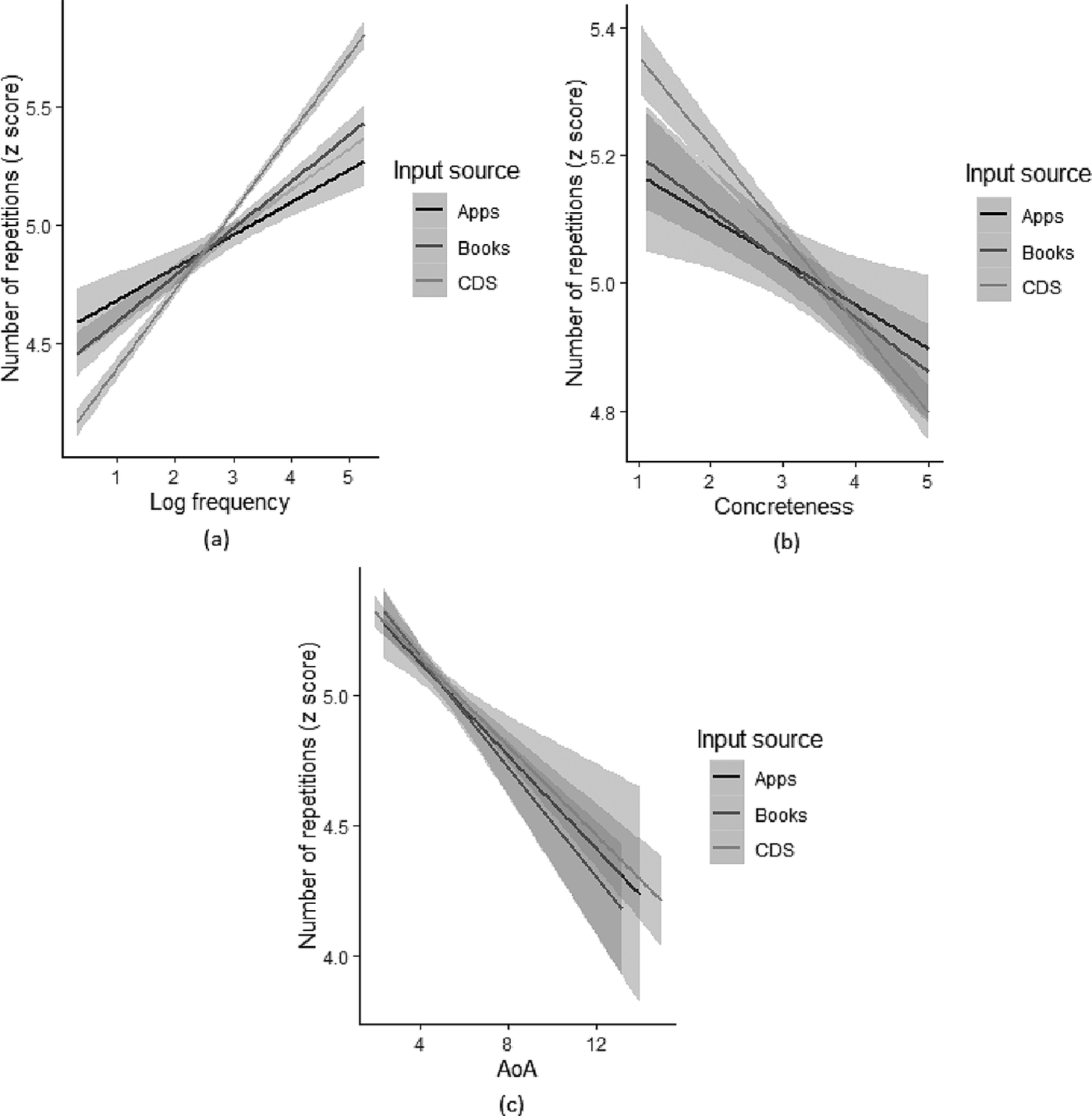
Figure 2. Interactions between (a) log frequency and input source, (b) concreteness and input source and (c) AoA and input source, for the number of repetitions (z scores).
The model also showed a negative main effect of concreteness, indicating that across the input sources the higher the concreteness of a word, the less often a given word was repeated. Thus, words of lower concreteness were repeated most often across the input sources. This is as expected, because high-frequency words tend to be function words, which are low in concreteness. The pattern described above was more emphatic for CDS than for apps and books. There was no difference between apps and books with respect to the extent to which they tend to repeat less concrete words more often than more concrete words. As can be seen in Figure 2b, apps, books and CDS do not differ in how often they contain repetitions of words of high concreteness, but there is a difference in how often they include repetitions of words of low concreteness; those words occur less often in apps and books than in CDS.
Finally, the results showed a negative main effect of AoA, indicating that across the input sources the later the age of acquisition of a word, the less often a given word was repeated. Thus, words with early age of acquisition were repeated most often across the input sources. This is anticipated because early AoA words tend to occur more often in language directed to children than do later acquired words. As can be seen in Figure 2c, apps, books and CDS do not differ in how often they contain repetitions of words of low AoA, but there is a difference in how often they include repetitions of words of high AoA; those words occur more often in CDS than in books, with no difference between apps and CDS, or apps and books.
Discussion
Interactive opportunities provided by touchscreen apps, such as controlling the app activities, directing the outcome of the experience, obtaining timely feedback and opportunities for scaffolded learning, can provide an additional supportive context for language learning (Kervin, Reference Kervin2016). The aim of the present study was to investigate whether the language used in educational apps, when co-used between parent and child, can be considered a contribution as a form of linguistic input for children aged 2- to 5-year-old. This is the first study offering a detailed analysis of language features in children’s touchscreen apps. To situate language in apps in relation to other interactive sources of input that children are exposed to daily, we compared the language available to the child in co-use of apps with a parent, to the maternal language used in CDS, and the text in a set of the most popular children’s books.
First, we expanded on Cameron-Faulkner and Noble’s (Reference Cameron-Faulkner and Noble2013) research, by comparing proportional frequency of construction types in the three input sources. To add to the analyses on the input source level, we also tested whether the three input sources differ with respect to lexical diversity. Then, to make our language analysis more detailed, we also conducted a fine-grained analysis of language on sentence and word level, testing the difference between the language in the three input sources in terms of the MLU, frequency, concreteness and AoA of words. Finally, we investigated whether, across the input sources, words that have potential to introduce richer language environment (i.e., words that are of lower frequency and concreteness, and acquired later in language development), are repeated more often than words that do not have potential to introduce richer language environment (i.e., words that are more frequent, more concrete and acquired earlier in development). Crucially, we tested whether the three input sources differ with respect to how often they repeat words that introduce richer language environment, compared to the words that do not introduce richer language environment.
The results form a complex picture of the language used in educational apps, when directly compared to other sources of children’s language input. They demonstrate that apps provide children with a higher proportion of fragments of constructions than books and CDS, and consequently have a lower MLU than books, which suggests that the language used in apps is simpler than the language in books and CDS. However, the results also show that at the same time apps present children with lower frequency words than CDS and have words of similar frequency to books. Apps were also found to have significantly lower lexical diversity than CDS but did not differ with respect to lexical diversity from books, which indicates that apps present children with lower variety of words than CDS.
The fact that apps contain lower frequency words, less lexical diversity (fewer unique words) compared to CDS, and shorter utterances compared to books, might make them a suitable input source for younger children (2-3-years old, who are at the phase of rapidly building their vocabulary) and, at the same time, an enriched form of input for that age group, in addition to language available from other sources. Presenting children with words that occur in their environment less frequently will increase the quantity and quality of language in the child’s environment when combined with CDS and books. Younger children with a shorter memory span and limited cognitive processing capacities might experience difficulties with processing long complex sentences. Exposing them to shorter sentences with lower frequency words might make them more capable of focussing their attention on the less frequent and – potentially – new words. Indeed, the presence of isolated words promotes statistical word segmentation (Lew-Williams, Pelucchi, & Saffran, Reference Lew-Williams, Pelucchi and Saffran2011), and the frequency with which a child hears a word in isolation has been shown to predict word learning better than the child’s total frequency of exposure to that word (Brent & Siskind, Reference Brent and Siskind2001).
Additionally, the analysis of repetitions showed that although all sources of input tend to repeat words of high frequency more often than words of low frequency, apps repeat those words to a lesser extent than CDS. In contrast, apps repeat low frequency words more often than CDS. This suggests that apps give more opportunities for children to hear low frequency words repeated during app use, compared to CDS. Examples of such low frequency words repeated often within the apps are: ‘invitation’ (Peppa Pig Party Time app), ‘badge’ (Hey Duggee app), ‘sticker’ (Phonics Island app), ‘conveyor’ (Peppa Pig Holiday app) and ‘phoneme’ (PP Phonics). All the examples come from the apps targeting children under the age of 5. Repeated exposure to words facilitates learning (Brodsky et al., Reference Brodsky, Waterfall, Edelman, McNamara and Trafton2007; Hills, Reference Hills2013; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016; Onnis et al., Reference Onnis, Waterfall and Edelman2008), thus repeatedly exposing children to words that they hear less frequently in their environment is a potential strength of the language in educational apps.
Regarding other properties of words, the analysis showed that apps do not differ from books and CDS with respect to the concreteness of words that they include. The analysis of word repetitions showed that all input sources repeat words of low concreteness more often than words of high concreteness. Shatz (Reference Shatz1993) suggested that exposure to words of low concreteness in varied conversational contexts might facilitate their acquisition. The fact that words of low concreteness – which are more difficult to learn – are repeated more often than words of high concreteness across the three different input sources, might give children the opportunity to hear abstract words repeated in different contexts, which might consequently aid their acquisition. While there is no difference with respect to how often all three input sources repeat words of high concreteness, CDS repeats words of low concreteness more often than apps and books. This means that children have more opportunities to hear abstract words repeated several times during an interaction when they spend time interacting with their caregivers than when they are being read to or when they use educational apps. As mentioned in the results section, one category of words low in concreteness, frequently repeated in CDS, comprises function words (articles, conjunctions, quantifiers, prepositions, pronouns). However, the other categories of words that are repeated more often in CDS than in books and apps comprise words relating to emotions (e.g., happy, sad, angry), states (e.g., tired, sleepy, hungry) or time of the events (e.g., yesterday, in a moment, tomorrow). The regression line for the analysis of the repetition of words in relation to their concreteness for apps and books is less steep than for CDS. This is presumably because apps and picture books depict their action and plotline in pictures or videos with concrete and imaginable words, rather than abstract concepts. Therefore, the words children hear throughout book reading or app use might vary less in their concreteness (most of them have to be concrete enough to be presented as pictures) than words in CDS, and thus there is a smaller difference in the number of repetitions for high vs low concrete words in apps and books.
Regarding AoA of words, the analysis showed that the three sources of input do not differ with respect to the mean AoA of words that they include. The analysis of repetitions showed that apps, books and CDS repeat words acquired early in life more often than words acquired later in life. Thus, similarly to books and CDS, apps present children with age-appropriate words and more often repeat the words that are more likely to be known by children, compared to the words that children acquire later in the development. This makes the language in apps equally child appropriate as the language in books and CDS. However, we observed a difference with respect to how often books and CDS repeat words acquired later in life, with CDS repeating those words more often than is found in books. This might seem counterintuitive, though it is a consequence of the lower overall levels of repetition that occur in books. Thus, the early AoA words are repeated less often – meaning that the effect of repetitions of later AoA words (which are rarer in both CDS and apps/books) is seen as having more of an impact in CDS. There were no differences with respect to the number of repetitions of words acquired later in life between apps and books, or apps and CDS.
To summarise the findings relating to the psycholinguistic properties of words, what apps have in common with books and CDS is the mean concreteness and AoA of words. The words that children are exposed to from the three sources of input are on average of medium concreteness and acquired at the age of 5. The words that are repeated most often across apps, books and CDS are of high frequency, low concreteness and early age of acquisition. Considering that word repetition supports word learning (Brodsky et al., Reference Brodsky, Waterfall, Edelman, McNamara and Trafton2007; Hills, Reference Hills2013; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016; Onnis et al., Reference Onnis, Waterfall and Edelman2008), children seem to have more opportunities to learn abstract words from CDS, since CDS repeats abstract words more often than apps and books. Apps, on the other hand, seem to be an enriched input source of less frequently used words, including on average lower frequency words than CDS and similar frequency of words to books, and repeating low frequency words more often than CDS.
Regarding more sophisticated constructions, like CDS, apps have a lower proportion of subject-predicate and complex sentences than books, suggesting that apps might not be well designed to support child’s development of structurally rich constructions. Due to their lower lexical diversity, when compared to CDS, apps are also not well designed to teach a wide variety of words. Thus, educational apps targeting children aged 2 to 5 might be better suited to early multi-word development than to later stages of children’s grammatical development. To make apps an enriched source of language input for older children, app developers should focus on integrating more grammatically complex language content within their apps, as well as a wider variety of words.
Some features of apps are helpful for learning, but other features will contribute less to a rich language environment. Lexical diversity and longer utterances are particularly useful for expanding vocabulary (Rowe, Reference Rowe2012) and learning more complex syntactic constructions (Cameron-Faulkner et al., Reference Cameron-Faulkner, Lieven and Tomasello2003), but the dovetailing of the apps with properties of individual words that support their acquisition will mean these words can be acquired more effectively. Therefore, some features that we found in apps (shorter utterances, lower frequency words, higher proportion of fragments) might be more beneficial for children starting to build their vocabulary at pace (aged 2-3 years). These features might help enrich children’s vocabulary acquisition alongside CDS. However, apps in the UK app market aimed at preschoolers should include more complex language (more lexical diversity, longer and complex utterances) if they wish to enrich older preschoolers’ (4-5 years old) language development.
Another potential area for improvement in apps is the social interaction role of language: apps were found to have a lower proportion of questions than CDS. Asking children questions stimulates socially contingent interaction, which supports word learning (Roseberry, Hirsh-Pasek, & Golinkoff, Reference Roseberry, Hirsh-Pasek and Golinkoff2014; Tamis-LeMonda, Kuchirko, & Song, Reference Tamis-LeMonda, Kuchirko and Song2014). On the other hand, we found that apps contain a higher proportion of imperatives than books and CDS. One possible way of improving apps’ social interactivity could be for app developers to replace some of the subjectless requests for a child’s action with questions – for example, instead of saying “Let’s find them!”, the narrator in the pre-recorded audio in the app could ask the child “Where do you think they are hiding?”, making the language more socially interactive. Apps could also benefit from having questions asked by interactive game characters, testing child’s knowledge acquired during app use, such as “What else starts from letter ‘k’”? A large number of questions in the apps are actually hidden commands, e.g., “Can you say ‘dog’?” is operationally similar to “Say ‘dog”. Though apps also involve some questions that are not commands, such as “Did you know which dinosaur had the largest teeth?”, apps could benefit from replacing the questions that are ‘hidden commands’ with more socially interactive questions.
Our study provides key insights into the features of language in educational apps, which are currently a potential additional source of children’s language input, alongside CDS and books. However, we also identify several avenues for future research, which would enable a more in-depth understanding of the potential of educational apps for enriching children’s language input. Investigating interactions between the psycholinguistic features of words (frequency, concreteness and AoA) and construction types (fragments, questions, imperatives, copulas, subject-predicate, complex) could help us understand whether low frequency words that children are repeatedly exposed to from educational apps occur more often in fragments (which would make the words more easily distinguished for children), or in complex constructions. Another insightful exploration could be analysing how closely word repetitions follow each other and whether they occur in consecutive sentences, since exposing children to the same words repeatedly in consecutive sentences is likely to influence young children’s word learning (Brodsky et al., Reference Brodsky, Waterfall, Edelman, McNamara and Trafton2007; Hills, Reference Hills2013; Schwab & Lew-Williams, Reference Schwab and Lew-Williams2016; Onnis et al., Reference Onnis, Waterfall and Edelman2008). It would also be of use to test whether word repetitions occur in different contexts, since exposure to words in varied conversational contexts might facilitate their acquisition (Shatz, Reference Shatz1993). Future studies could also investigate what are the most often repeated types of words (nouns, pronouns, verbs, adjectives, adverbs) in the three input sources.
Another key aspect of children’s language exposure is TV. This aspect has not been investigated in this study because of its passive nature (as opposed to the interactive nature of apps, shared book reading and CDS). However, future studies could analyse language in the most popular children’s programmes with respect to utterance types and psycholinguistic properties. Finally, a controlled experimental study measuring how children learn new words from educational apps depending on the presence of different apps’ language features could be a natural continuation of this research.
Limitations
This study comes with several limitations. First, there are differences between the three input sources in our sample with respect to the age range focus and sample size of the input sources. While the books in our sample target two year olds and the CDS dyads involve speech directed to children aged between 2;6 and 2;9, the apps in the sample were designed to target mainly children aged 2-5, with 4 apps targeting children under 8 years old. However, the way apps are categorised in the app markets did not allow us to select a specific sample of apps targeting only 2-year-olds. Where age is concerned, the app markets offer app categories such as ‘Ages up to 5’, but will not allow users to select apps for a specific age group (e.g., 2-year-olds only). Therefore, the apps from the categories chosen by us from the most popular app markets are most likely the ones that the 2-year-old children will be exposed to. It is likely that books in our sample, suitable for 2-year-olds, also recur throughout children’s preschool experience, and are thus likely to be used also with older children (e.g., “Goldilocks and Three Bears”, “Three Little Pigs”). Another discrepancy between the samples lies in the difference of the number of utterances and number of word types across the input sources, though this was controlled in the statistical analyses by investigating z-scores of repetitions rather than raw repetition frequencies within the sources.
Second, by inclusion of both audio and onscreen transcripts from the apps we might risk getting an inaccurate representation of language input from this source given that young children are mostly unable to read written text and the language they are truly exposed to is only audio. However, in this paper we aimed to look at the potential of apps to enhance the language environment, rather than the content of apps accessible to 2-year-olds independently. Young children sometimes co-use apps with their parents (Connell, Lauricella, & Wartella, Reference Connell, Lauricella and Wartella2015) who might read the onscreen text to them, in a similar way that they read a book to their child. Thus, both in the case of book texts and apps, we analyse the potential of those sources to support language, rather than just the content accessible to the children independently. However, as Rideout and Robb (Reference Rideout and Robb2020) point out, only 20% of 2- to 4-year-olds co-use apps with their parents most of the time (though 80% of 0-8-year-olds do co-use apps with parents at least some of the time).
Conclusion
To the best of our knowledge, the present study is the first to provide an analysis of the language available to parent and child in educational apps, based on a sample of the most popular apps available in the app stores. The study provides information for caregivers, educators and app designers on the potential of apps for enriching young children’s language environment. Our analysis suggests that, although apps should not replace other forms of interaction (see Taylor et al., Reference Taylor, Monaghan and Westermann2018 for a similar argument), they can potentially introduce children to words heard less frequently than in CDS during early multi-word development (i.e., when children benefit from hearing shorter grammatical constructions). However, there are certain areas for improvement for app developers, should they wish for their apps to constitute a source of enriched language input for older children. Currently, apps do not expose children to a high proportion of questions and complex sentences, both of which are crucial for supporting child’s development of structurally rich constructions before school entrance. Nevertheless, alongside multiple other sources of language in children’s early environments, apps may constitute a role that can extend children’s language experience in new and potentially useful directions.
Acknowledgments
This work was supported by the Economic and Social Research Council [grant number ES/R004129/1]. The authors would like to thank Shenitta Anderson and Kathryn Johnson for help with data coding. The data that support the findings of this study are openly available on the Open Science Framework at https://osf.io/a8rcm/.











 Open access
Open access