

Introduction
The Shiji (史記) is the first systematic history covering the period before 94 BCE and sets the model for subsequent dynastic histories. Relations between persons and places are key issues in traditional historiography. However, character-based text search is inadequate for the study of such relationships, as Classical texts are not easy to read in this way. First, Chinese texts are written without word boundaries, lacking the “white space” that separates words in contemporary Western language texts. Moreover, there is no parser for literary Chinese that has the precision of parsers for contemporary Chinese. Third, a person may appear in the same text with different names, and the same name may be used by different persons. And finally, mapping people and events to places is impeded by the need to locate ancient place names.
In this article, we explore a novel approach to the computational analysis of Chinese historical texts. First, we segment each word from the text and tag its part-of-speech (such as nouns, verbs, adjectives, person names, place names). Second, each person in the text is given a unique ID, which applies to all names by which a person was known, and personal information, enabling person search and social relation discovery. Third, each place name in the text is given a unique ID and locational information, which makes possible visualizations such as personal travel maps. Once the text is tagged in this way it is possible to conduct multi-purpose retrieval system and quantitative analysis of the Shiji.
As a first step, we chose the Basic Annals (本紀), which makes up the first twelve chapters of the Shiji, to build the database. The Basic Annals record important persons and events and thus may be seen as an abstract of the Shiji. We created the database the Basic Annals to provide full-text retrieval, to calculate occurrences, and to visualize person and place relations.Footnote 1 By querying the database, the social relations between persons and the personal travelling routes can be visualized and calculated. Data analysis also identifies the key locations and key persons as well as heat maps. The database of the whole Shiji is still under construction.
Related Work
The digital humanities constitute a rapidly developing field. There are already important textual, biographical, and spatial databases. In the field of classical historical works, a well-known example is Hestia,Footnote 2 a database of Herodotus's Histories. Hestia is based on the Perseus text's semi-automated identification of places in the Histories and supplies visualized search of time and place in the Histories.
Aside from searchable text databases, there are two important databases for research on Chinese history. The China Biographical Database Project (CBDB) contains data on 427,000 individuals, currently primarily from the seventh through the nineteenth centuries.Footnote 3 The China Historical GIS (CHGIS)Footnote 4 is a historical geography database with the granularity of a year. It collects populated places and historical administrative units for the period from 221 BCE to 1911 CE. CHGIS also provides basic geographic data. CHGIS can be used as a common GIS for many applications, such as a geographic information system of literary history, census data, and historical events.Footnote 5
Our Shiji database contributes to creating a digital history of early China. Unfortunately, neither CBDB nor CHGIS currently is adequate for tagging the Shiji, which extends back 1,500 years before 94 BCE and also records ancient legends. Moreover, those two utilities extract the person, place, and event information from historical texts, indexes, and other materials, but do not link that information to relevant passages in the original texts. In our view, annotating persons and places in each sentence in the text with IDs for unique persons and places is of crucial importance: it is accurate, and it makes it much easier to trace persons and places. If all the persons and locations in the historical record can be tagged with unique IDs, then the relations between the persons and the travels of each person will be immediately accessible. We have also built such a database of the Zuozhuan (左傳),Footnote 6 which covers the period 722 to 468 BCE. Once the Shiji database is completed we will be able to make interesting comparisons between the two.
The Construction of Shiji Basic Annals Database
For the base of the Shiji we used the new revised version.Footnote 7 The text, totaling 92,994 characters, has punctuation but lacks word segmentation. Our first task was word segmentation and part-of-speech tagging. The next step was to manually assign IDs to person names and IDs and GIS coordinates to place names using Baidu Map.Footnote 8 We thus built up a database for multi-search data retrieval. The database is available online for public use with many of the functions introduced here. With the database it becomes possible to find the number of persons, their genders, home states, social relations, etc. recorded in the text.
Word Segmetation and POS Tagging
To enable word-based retrieval, we imposed word segmentation and part-of-speech (POS) tagging using the Suiyuan (隨園) SEG annotation toolFootnote 9 developed by Shi Min and colleagues.Footnote 10 The F-score of the tool is around 85–90 percent on early Chinese texts. Although this saved considerable time and labor, it still required manual checking. In the example below, each word is assigned a POS tag, such as verb, noun, person, location and conjunction. Finally, the 92,994 characters are segmented into 78,542 words.Footnote 11
黄帝 person 居 verb 軒轅 person 之 aux 丘 loc, punc 而 conj 娶 verb 於 prep 西陵 loc 之 aux 女 noun, punc 是 pronoun 爲 verb 嫘祖 person 。punc
Person
Person names in the text cannot be used directly in data analysis, because a person may have different names and the same name may refer to different persons. We assign each person in the Basic Annals a unique ID and then tag each occurrence of the names of a person with the same ID, so that although names vary the unique person is constant. This enhances the person retrieval function of the database. In the user interface, however, an ID number would be opaque, and listing all possible names would be confusing, especially when projected onto a map, thus we use the most well-known name as a person's key name. We then annotate the person's gender and state or tribe. Table 1 is an example of the detailed information on each person in the Basic Annales, including the person's ID, key name, alternative names, gender and state.
Table 1. Person Information in the Database

There are 1,497 names and 5,908 instances in the database corresponding to 958 unique persons. Each person has 1.56 names on average. The persons in the Basic Annals offer possibilities for information that has not been well studied. Among the 958 persons, 918 are males and 40 are females; men dominated this history.
Location
For the place names in the text, we tagged each unique place with a single ID as we did for person names. Each place ID is also annotated with the current name and the geographical location in Baidu Map. The places are classified into several categories, such as mountain, river, tribal area, state, etc. The coordinates of the location's central point are manually taken via Baidu Map. Table 2 shows the details of the location information in the database. Each location is annotated with the state, the current location, and its coordinates.
Table 2. The Location Information in the Database

There are 894 locations in the database, including 503 locations within states, 93 rivers, 76 mountains, and so forth. Moreover, the frequency of the appearance of a place name also indicates its importance. Table 3 shows the locations with most occurrences. The states Chu (楚) and Qin (秦) are the key states in this, while the Yellow River and Mount Tai (泰山) are important too.
Table 3. Places Appearing with the Highest Frequency (> 20)

With geographic information, it is possible to search a location on the map. We developed the search function, which could also search a state or country according to places mentioned as being within it. Figure 1 shows twelve places occurring within the state of Han (韓國). Given that states at the time did not have clear boundaries, maximizing the point locations allows us to learn about its territorial extent.
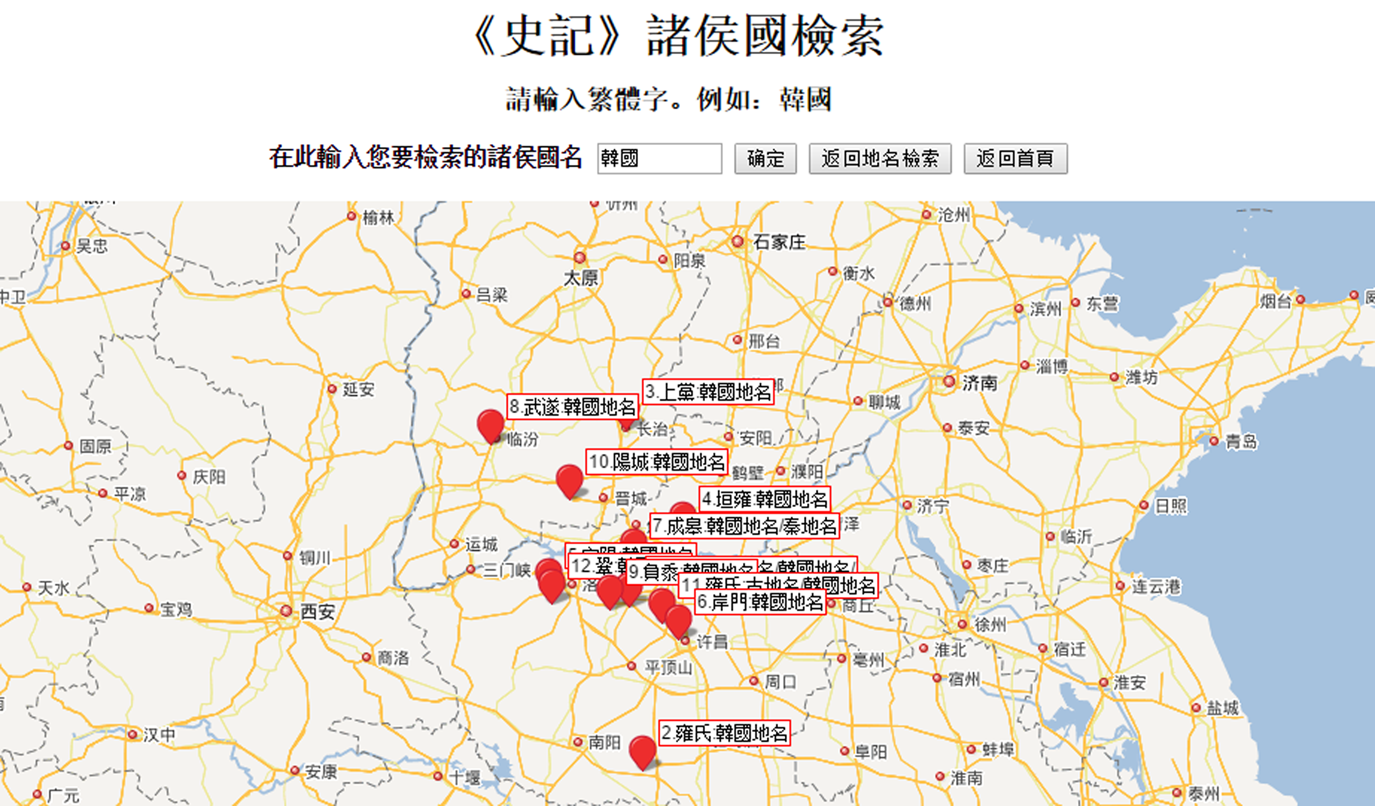
Figure 1. Map Search for 韓國 (State Of Han)
Heat maps can illustrate the density of people and events. We have created heat maps of place name occurrences of the locations for each of the Basic Annals. Figure 2 shows the heat map for the basic annals of the First Emperor, Qin Shihuang (秦始皇), from which we can see that the center of Qin's dominion is along the Yellow River, with some hot spots along the Yangtze River.

Figure 2. Heat Map Places Appearing in the Basic Annals of Qin Shihuang (秦始皇)
Social Relations
Social relations and activities are key issues in historical research. However, automating the discovery and classification of the association between people is extremely challenging. Instead we have used a simple method to compute and visualize relations and activities: co-occurrence. Given that each occurrence of a person name is tagged with a unique ID, it is possible to count the co-occurrence of two persons within a text strong demarcated by commas or periods in a punctuated text. Table 4 shows the examples of the co-occurrences of three pairs of persons with their person IDs.
Table 4. Co-Occurrences of Two Persons

The co-occurrence is only an estimated measure of the relations between two persons. We manually checked the 4,528 co-occurrences, finding that the precision or accuracy is 84.73 percent. By accuracy we mean that there was a relationship between the two persons. In this case 322 co-occurrences were not actual relations, and the relationship in another 374 co-occurrences was unclear. Although the accuracy is not particularly high, in aggregate these figures are useful. Table 5 lists the ten persons with the largest number of relations in the Basic Annals, an indicator of the importance of these persons and the amount of information about their activities in the text.
Table 5. The Ten Persons with Most Relations

Travel Routes
We can map the place names in the order that they appear in the Basic Annals. As the co-occurrence of two persons in one sentence is used to simulate the relations between them, the co-occurrence of person and location would imply the relation between the two entities. We might assume that, as is usually the case with Basic Annals, the place name appears at the moment a report from that place is received at court. But we might also assume that the order of appearance of places names can represent places to which a person traveled. This is more likely to be so in biographies. We can use the Baidu Map Application Programming Interface (API) to visualize a person's travels. The Baidu Map API is a set of JavaScript protocols embedded in the web application program interface that supplies both walking and driving routes between two locations. We choose the walking routes as more likely to simulate travel in the premodern world. Figure 3 maps places that co-occurred with Emperor Shun (舜帝, also referred to as Yudi 虞帝) in the Basic Annals. This alone is useful for illustrating how the Shiji gives substance to a history that many today would regard as legendary. In this case we have taken the sequence of places mentioned and used the Baidu Map API's walking route to tie the locations together.Footnote 12

Figure 3. Places Appearing in the Annals of Emperor Shun 舜帝
This is an approach to counting the places a person has visited and comparing the routes of different persons. We do not think this represents the travels of an individual in Figure 3, but because the database allows the recall of the passage in question, we can see how each place appears in the text and the order of places mentioned.
The sequence of places mentioned may be used to calculate the travel distance. We compute the straight-line distance between two locations by Formula 1. We can sum all the distances with Formula 2. The notions ϕ i and λ i are the longitude and latitude of location i.
 $$\eqalign{&\lpar {{\rm Formula\;}1} \rpar {\rm \;LineDist}\;\lpar {\phi_1\comma \;\lambda_1\semicolon \;\phi_2\comma \;\lambda_2} \rpar = \cr &\quad\quad 111.199{\rm \ast }\root 2 \of {{\lpar {\phi_1-\phi_2} \rpar }^2 + {\lpar {\lambda_1-\lambda_2} \rpar }^2\ast cos{\left({\displaystyle{{\phi_1 + \phi_2} \over 2}} \right)}^2} }$$
$$\eqalign{&\lpar {{\rm Formula\;}1} \rpar {\rm \;LineDist}\;\lpar {\phi_1\comma \;\lambda_1\semicolon \;\phi_2\comma \;\lambda_2} \rpar = \cr &\quad\quad 111.199{\rm \ast }\root 2 \of {{\lpar {\phi_1-\phi_2} \rpar }^2 + {\lpar {\lambda_1-\lambda_2} \rpar }^2\ast cos{\left({\displaystyle{{\phi_1 + \phi_2} \over 2}} \right)}^2} }$$ $$\lpar {{\rm Formula\;}2} \rpar {\rm \;SumDist} = \mathop \sum \limits_{i = 1}^{n-1} LineDist\lpar {\phi_i\comma \;\lambda_i\semicolon \;\phi_{i + 1}\comma \;\lambda_{i + 1}} \rpar $$
$$\lpar {{\rm Formula\;}2} \rpar {\rm \;SumDist} = \mathop \sum \limits_{i = 1}^{n-1} LineDist\lpar {\phi_i\comma \;\lambda_i\semicolon \;\phi_{i + 1}\comma \;\lambda_{i + 1}} \rpar $$Table 6 lists the ten persons who travelled the longest travelling distances. The distances have been calculated by summing up all the route lengths between the locations, although real travelling distances are always longer than straight line distances.
Table 6. Top Ten Persons with Travelling Information

Although we have created routes and distances for the places mentioned in the Basic Annals, what the map shows are places in communication with the court. Our goal here is use this to show the possibilities for the analysis of the biographies in the Shiji we are currently working on.
Future Work
This article introduces the framework of our digital humanities database of the Basic Annals of the Shiji. This open access online database consists of three parts: full-text, person, and location retrieval. In the future, we plan to refine the data with the help of historians and put it online for public use. Furthermore, we will add more functions for the word-based full-text and visualized retrieval. We hope this kind of database with rich information on persons and locations can be applied to more historical texts.
Acknowledgment
We are grateful for the comments and revision by the reviewers and editors. We also thank Liang Qiao and Ke Yang for their data annotation of the database. This work is supported in part by National Social Science Funds of China (No. 18BYY127), and China Scholarship Council.








