


1 Introduction
Over the past two decades, modal logic’s notion of necessity and possibility has provided precise characterizations for a wide range of computational phenomena: from reasoning about different stages of computation (Davies & Pfenning, Reference Davies and Pfenning2001; Jang et al., Reference Jang, Gélineau, Monnier and Pientka2022) and (Schürmann et al., Reference Schürmann, Despeyroux and Pfenning2001; Pientka et al., Reference Pientka, Abel, Ferreira, Thibodeau and Zucchini2019) to homotopy type theory (Licata et al., Reference Licata, Orton, Pitts and Spitters2018; Shulman, Reference Shulman2018) and guarded recursions (Nakano, Reference Nakano2000; Clouston et al., Reference Clouston, Bizjak, Grathwohl and Birkedal2015). One might say that these applications bear witness to the unusual effectiveness of modalities in programming languages and logic.
To support these applications in various areas, the foundational study of the necessity modality (
 $\square$
) has started in the early 1990s. The study was primarily driven by the computational interpretation of modal logics from a proof-theoretic point of view. In his PhD thesis, Borghuis (Reference Borghuis1994) gives a formulation of pure type system with a
$\square$
) has started in the early 1990s. The study was primarily driven by the computational interpretation of modal logics from a proof-theoretic point of view. In his PhD thesis, Borghuis (Reference Borghuis1994) gives a formulation of pure type system with a
 $\square$
modality. Similarly, Pfenning &Wong (Reference Pfenning and Wong1995) and Davies & Pfenning (Reference Davies and Pfenning2001) propose an intuitionistic formulation of the all sublogics of the modal logic S4. Martini & Masini (Reference Martini and Masini1996) explore reading modal proofs from various modal logics as programs. All the prior work mentioned uses a context stack structure to organize modal assumptions in order to incorporate the
$\square$
modality. Similarly, Pfenning &Wong (Reference Pfenning and Wong1995) and Davies & Pfenning (Reference Davies and Pfenning2001) propose an intuitionistic formulation of the all sublogics of the modal logic S4. Martini & Masini (Reference Martini and Masini1996) explore reading modal proofs from various modal logics as programs. All the prior work mentioned uses a context stack structure to organize modal assumptions in order to incorporate the
 $\square$
modality.
$\square$
modality.
In this work, we contribute to the foundational landscape of modal type theories using context stacks by investigating Mint, a Modal INtuitionistic Type theory, which directly extends the simply typed Kripke-style modal lambda-calculus by Davies & Pfenning (Reference Davies and Pfenning2001) to the dependently typed setting. In particular, Mint adds to the usual Martin-Löf type theory (MLTT) the necessity modality (
 $\square$
) and supports a full hierarchy of cumulative universes, inductive types, and large eliminations. Mint captures dependently typed variants of modal Systems K, T,
Footnote 1
K4, and S4, complementing previous work by Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019), which only supports idempotent S4.
$\square$
) and supports a full hierarchy of cumulative universes, inductive types, and large eliminations. Mint captures dependently typed variants of modal Systems K, T,
Footnote 1
K4, and S4, complementing previous work by Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019), which only supports idempotent S4.
The Kripke style and context stacks. Following Davies & Pfenning (Reference Davies and Pfenning2001), Mint uses a context stack where each context corresponds to a Kripke world to model the Kripke semantics (Kripke, 196). A term t is then typed in a context stack
 ${\overrightarrow{\Gamma}}$
, which at the beginning is a singleton with an empty context (i.e.
${\overrightarrow{\Gamma}}$
, which at the beginning is a singleton with an empty context (i.e.
 $\varepsilon;\cdot$
).
$\varepsilon;\cdot$
).
where the topmost context denotes the current world. Subsequently, we use “context” and “world” interchangeably.
In the simply typed setting, the rules for
 $\square$
introduction and elimination are as follows:
$\square$
introduction and elimination are as follows:

In the
 $\square$
introduction rule, we enter a new world by appending an empty context to the context stack. The
$\square$
introduction rule, we enter a new world by appending an empty context to the context stack. The
 $\square$
elimination rule allows us to use the fact that
$\square$
elimination rule allows us to use the fact that
 $\square T$
is true. In particular, if
$\square T$
is true. In particular, if
 $\square T$
holds in a context stack
$\square T$
holds in a context stack
 ${\overrightarrow{\Gamma}}$
, then we can use T in any world that is accessible from it. Which previous world can be reached is controlled by the
${\overrightarrow{\Gamma}}$
, then we can use T in any world that is accessible from it. Which previous world can be reached is controlled by the
 ${{{{{\texttt{unbox}}}}}}$
level n, which we call modal offset. Modal offsets eliminate the need of explicit structural rules to manage the context stack structure as done by Borghuis (Reference Borghuis1994) and Pfenning & Wong (Reference Pfenning and Wong1995). Following Davies & Pfenning (Reference Davies and Pfenning2001), we refer to the systems with context stacks and
${{{{{\texttt{unbox}}}}}}$
level n, which we call modal offset. Modal offsets eliminate the need of explicit structural rules to manage the context stack structure as done by Borghuis (Reference Borghuis1994) and Pfenning & Wong (Reference Pfenning and Wong1995). Following Davies & Pfenning (Reference Davies and Pfenning2001), we refer to the systems with context stacks and
 ${{{{{\texttt{unbox}}}}}}$
for elimination as the Kripke-style systems.
${{{{{\texttt{unbox}}}}}}$
for elimination as the Kripke-style systems.
There are two reasons why we are investigating a modal dependent type theory in the Kripke style:
• Firstly, the Kripke style, as indicated by its name and our previous introduction, corresponds to the Kripke semantics directly. In other words, the Kripke-style systems provide syntactic theories for the corresponding Kripke semantics. Moreover, in the Kripke style, we can elegantly and uniformly capture various modal systems such as K, T, K4, and S4 simply by restricting modal offsets (Davies & Pfenning, Reference Davies and Pfenning2001; Reference Hu and PientkaHu & Pientka, 2022a ). Modal offsets enable us to study properties such as normalization uniformly for all subsystems of S4 and give rise to a fresh perspective of corresponding semantic concepts that internalize this syntactic context stack structure.
• Secondly, from a practical point of view, the Kripke style provides a foundation for the usual meta-programming style of quasi-quoting, as observed by Davies & Pfenning (Reference Davies and Pfenning2001). We are interested in reasoning directly about meta-programs for languages such as MetaML (Taha & Sheard, Reference Taha and Sheard1997; Taha, Reference Taha2000) and similar staged- or meta-programming systems (see also Brady & Hammond, Reference Brady and Hammond2006) that use quasi-quotation. In this work, we hence develop the equational theory of the Kripke style formulation of the
 $\square$
modality. This allows Mint’s S4 variant to be used as a program logic for reasoning directly about meta-programs. We give an example in Section 3.3.
$\square$
modality. This allows Mint’s S4 variant to be used as a program logic for reasoning directly about meta-programs. We give an example in Section 3.3.

Overview. In this paper, we establish normalization of Mint using normalization by evaluation (NbE) (Martin-Löf, Reference Martin-Löf, Rose and Shepherdson1975; Berger & Schwichtenberg, Reference Berger and Schwichtenberg1991). This yields an algorithm that can be directly implemented. An NbE algorithm typically consists of two steps: (1) we evaluate terms from the type theory in a chosen mathematical model and (2) we extract normal forms from that model. Here, we follow work by Abel (Reference Abel2013) and choose an untyped domain as the mathematical model. In the literature, there are other possible choices like presheaf categories (Altenkirch et al., Reference Altenkirch, Hofmann and Streicher1995; Kaposi & Altenkirch, Reference Kaposi and Altenkirch2017), but untyped domains are simpler to work with and mechanize. Further, they allow us to derive an actual normalization algorithm that can be implemented. In fact, as we will show, such an implementation of NbE can be extracted from our mechanization in Agda.
One problem in NbE is how we should model the Kripke structure introduced by
 $\square$
in the semantics. This is intimately related to how we characterize
$\square$
in the semantics. This is intimately related to how we characterize
 $\square$
elimination. In our constructions, the Kripke structure is captured by a novel algebra truncoid and is internalized in the semantics. Due to the internalization, our proof structure is just a moderate extension of Abel (Reference Abel2013). Since truncoids precisely capture various meta-theoretical structures in Mint including substitutions and evaluation environments, as a bonus, this allows us to elegantly and uniformly capture the differences across all subsystems. Further, the soundness and completeness proofs of NbE can easily be re-used for all the subsystems of S4 mentioned above without change.
$\square$
elimination. In our constructions, the Kripke structure is captured by a novel algebra truncoid and is internalized in the semantics. Due to the internalization, our proof structure is just a moderate extension of Abel (Reference Abel2013). Since truncoids precisely capture various meta-theoretical structures in Mint including substitutions and evaluation environments, as a bonus, this allows us to elegantly and uniformly capture the differences across all subsystems. Further, the soundness and completeness proofs of NbE can easily be re-used for all the subsystems of S4 mentioned above without change.
Contributions. Our main contributions in this paper are:
• We present a core modal dependent type theory, Mint, as an explicit substitution calculus (Section 4) together with an equational theory. We successfully scale the concept of Kripke-style substitutions from Reference Hu and PientkaHu & Pientka (2022a ) to dependent types, so that we obtain a unified representation of the modal and local structural properties of Kripke-style context stacks.
• Following Abel (Reference Abel2013), we develop an NbE algorithm (Section 5) for Mint which we prove complete (Section 6) and sound (Section 7). It builds on an untyped domain model. Central to the models and the NbE algorithm is the algebra of truncoid (Section 4.2). Truncoid provides an algebraic description of the Kripke structure of Mint, so that the Kripke structure in the semantics is internalized in the model as untyped modal transformations (UMoTs). As a result, our constructions are very adaptive, accommodating all four subsystems of S4 without change.
• The NbE algorithm of Mint with a full cumulative universe hierarchy and its soundness and completeness proofs are fully mechanized in Agda. Our mechanization of the NbE algorithm only relies on two standard extensions: induction–recursion (Dybjer, Reference Dybjer2000) and function extensionality, which are more familiar than the advanced combination of induction–induction (Nordvall Forsberg & Setzer, Reference Nordvall Forsberg and Setzer2010) and quotient inductive types exploited by Reference Altenkirch and KaposiAltenkirch & Kaposi (2016b ,a) and Kaposi & Altenkirch (Reference Kaposi and Altenkirch2017).
• We adjust our models so that they explicitly maintain universe levels and no longer fundamentally rely on cumulativity as in Abel (Reference Abel2013), Abel et al. (Reference Abel, Vezzosi and Winterhalter2017), and Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019). On the one hand, this adjustment directly enables a type-theoretic mechanization, as former on-paper approaches require taking limits of universe levels to infinity due to cumulativity. On the other hand, this adjustment also seems to suggest a more robust model construction that applies for both cumulative and non-cumulative universe hierarchies.
• Last, we extract from our Agda mechanization a Haskell implementation of NbE for Mint (Section 8), which may serve as a verified kernel of an implementation of Mint. We also provide an executable example for normalizing programs in Mint in our mechanization.
Our Agda mechanization consists of
 $\sim$
11k LoC. This is close to or fewer than existing mechanizations (Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Kaposi & Altenkirch, Reference Kaposi and Altenkirch2017; Pujet & Tabareau, Reference Pujet and Tabareau2022, Reference Pujet and Tabareau2023). Please refer to our technical report (Reference Hu and PientkaHu & Pientka, 2022b
) and Agda mechanization for full details. The paper contains
$\sim$
11k LoC. This is close to or fewer than existing mechanizations (Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Kaposi & Altenkirch, Reference Kaposi and Altenkirch2017; Pujet & Tabareau, Reference Pujet and Tabareau2022, Reference Pujet and Tabareau2023). Please refer to our technical report (Reference Hu and PientkaHu & Pientka, 2022b
) and Agda mechanization for full details. The paper contains ![]() to an online artifact for an easy correspondence between code and discussions.
to an online artifact for an easy correspondence between code and discussions.
2 The Kripke style in the landscape of modal type theories
Over the past three decades, modal type systems have been studied from different perspectives. For example, Bierman & de Paiva (Reference Bierman and de Paiva1996, Reference Bierman and de Paiva2000) use a regular context by requiring a substitution for modal assumptions during the introduction of
 $\square$
. In 2001, Davies & Pfenning (Reference Davies and Pfenning2001) and Pfenning & Davies (Reference Pfenning and Davies2001) propose an alternative to the Kripke-style formulation where they separate modal assumptions and regular (or local) assumptions into two contexts. Hence, this formulation is often referred to as dual-context style. They also provide a translation for simply typed terms between the Kripke-style and the dual-context formulation. This translation can be viewed as compiling Kripke-style representations which corresponds to meta- or staged programming idioms under Curry–Howard correspondence to the dual-context representation which makes evaluation order more clear.
$\square$
. In 2001, Davies & Pfenning (Reference Davies and Pfenning2001) and Pfenning & Davies (Reference Pfenning and Davies2001) propose an alternative to the Kripke-style formulation where they separate modal assumptions and regular (or local) assumptions into two contexts. Hence, this formulation is often referred to as dual-context style. They also provide a translation for simply typed terms between the Kripke-style and the dual-context formulation. This translation can be viewed as compiling Kripke-style representations which corresponds to meta- or staged programming idioms under Curry–Howard correspondence to the dual-context representation which makes evaluation order more clear.
In recent years, the dual-context representation of modal logic has been well studied. For example, Kavvos (Reference Kavvos2017) looks into the dual-context style and gives formulations for systems K, T, K4, and GL. Shulman (Reference Shulman2018) uses spatial type theory, a dependently typed variant of the dual-context style, to separate discrete and continuous assumptions to establish Brouwer’s fixed-point theorem in HoTT. Licata et al. (Reference Licata, Orton, Pitts and Spitters2018) restrict spatial type theory and obtain crisp type theory to internally represent universes in HoTT. The implementation of crisp type theory, Agda-flat, is also in the dual-context style. A recent general framework for modal type theories, multi-mode type theory (MTT) (Gratzer et al., Reference Gratzer, Kavvos, Nuyts and Birkedal2020; Gratzer, Reference Gratzer2022), is a generalization of the dual-context style due to its elimination principle of the modalities. We therefore review here the dual-context style formulation and discuss differences between both styles.
The Kripke and dual-context styles differ in the organization of assumptions and the elimination principle of
 $\square$
. As opposed to context stacks in the Kripke style, a dual-context-style system has precisely two contexts. One context stores modal (or global) assumptions, while the other one stores regular (or local) assumptions. The defining difference between both styles is the elimination principle of the
$\square$
. As opposed to context stacks in the Kripke style, a dual-context-style system has precisely two contexts. One context stores modal (or global) assumptions, while the other one stores regular (or local) assumptions. The defining difference between both styles is the elimination principle of the
 $\square$
modality. In simply typed S4, the introduction and elimination rules for
$\square$
modality. In simply typed S4, the introduction and elimination rules for
 $\square$
are defined as follows:
$\square$
are defined as follows:

In the judgments,
 $\Psi$
is the global context while
$\Psi$
is the global context while
 $\Gamma$
is the local one. The introduction rule requires that t is well typed only with the global assumptions. In the elimination rule,
$\Gamma$
is the local one. The introduction rule requires that t is well typed only with the global assumptions. In the elimination rule,
 $s : \square T$
is eliminated by
$s : \square T$
is eliminated by
 ${{{{{\texttt{letbox}}}}}}$
; essentially
${{{{{\texttt{letbox}}}}}}$
; essentially
 ${{{{{\texttt{letbox}}}}}}$
is a form of pattern matching.
Footnote 2
The body t is type-checked with a global context extended with an extra global assumption
${{{{{\texttt{letbox}}}}}}$
is a form of pattern matching.
Footnote 2
The body t is type-checked with a global context extended with an extra global assumption
 $u : T$
. This elimination principle implies that
$u : T$
. This elimination principle implies that
 $\square$
is viewed as sums. One shortcoming of sum types is the lack of extensionality. Extensionality of sum types including
$\square$
is viewed as sums. One shortcoming of sum types is the lack of extensionality. Extensionality of sum types including
 $\square$
in the dual-context style requires a set of special equivalences like commuting conversions to be included (Lindley, Reference Lindley2007). Such commuting conversions are usually absent with dependent types. On the other hand, in the Kripke style, we use
$\square$
in the dual-context style requires a set of special equivalences like commuting conversions to be included (Lindley, Reference Lindley2007). Such commuting conversions are usually absent with dependent types. On the other hand, in the Kripke style, we use
 ${{{{{\texttt{unbox}}}}}}$
for elimination.
${{{{{\texttt{unbox}}}}}}$
for elimination.
 ${{{{{\texttt{unbox}}}}}}$
is a projection and treats
${{{{{\texttt{unbox}}}}}}$
is a projection and treats
 $\square$
as products.
$\square$
as products.
 $\square$
in the Kripke style is therefore extensional due to its
$\square$
in the Kripke style is therefore extensional due to its
 $\eta$
equivalence rule. This difference in elimination principles finds a very close resemblance in the two styles of defining
$\eta$
equivalence rule. This difference in elimination principles finds a very close resemblance in the two styles of defining
 $\Sigma$
types. When we define
$\Sigma$
types. When we define
 $\Sigma$
inductively, its elimination is pattern matching.
Footnote 3
If
$\Sigma$
inductively, its elimination is pattern matching.
Footnote 3
If
 $\Sigma$
is defined as a product, then we use projections for elimination. These two styles are not always equivalent and we may even clearly distinguish them in some settings, e.g., a substructural system. Moreover, even in regular MLTT,
$\Sigma$
is defined as a product, then we use projections for elimination. These two styles are not always equivalent and we may even clearly distinguish them in some settings, e.g., a substructural system. Moreover, even in regular MLTT,
 $\Sigma$
as a product is extensional, because products admit
$\Sigma$
as a product is extensional, because products admit
 $\eta$
equivalence, while inductive types usually do not. Furthermore, the situation of
$\eta$
equivalence, while inductive types usually do not. Furthermore, the situation of
 $\square$
is more complex. Davies & Pfenning (Reference Davies and Pfenning2001) only show a translation between the Kripke and the dual-context styles in the simply typed case. This translation in fact is not preserved by equivalence. Due to type-level computation, the translation given by Davies & Pfenning (Reference Davies and Pfenning2001) seems very challenging to extend to dependent types. In fact, due to the lack of extensionality in the dual-context style, we do not currently think that such a translation is possible between the Kripke-style and the dual-context style system.
$\square$
is more complex. Davies & Pfenning (Reference Davies and Pfenning2001) only show a translation between the Kripke and the dual-context styles in the simply typed case. This translation in fact is not preserved by equivalence. Due to type-level computation, the translation given by Davies & Pfenning (Reference Davies and Pfenning2001) seems very challenging to extend to dependent types. In fact, due to the lack of extensionality in the dual-context style, we do not currently think that such a translation is possible between the Kripke-style and the dual-context style system.
Though the Kripke style presents appealing advantages of extensionality and uniformity in formulation, it is technically more challenging to study than the dual-context style. For example, direct normalization proofs of the simply typed Kripke-style systems were established (Reference Hu and PientkaHu & Pientka, 2022a ; Valliappan et al., Reference Valliappan, Ruch and Tomé Cortiñas2022) only recently. The ultimate reason why the Kripke style is more challenging than the dual-context style is the lack of a proper notion of simultaneous substitutions. In the dual-context style, its notion of simultaneous substitutions is clear: there are two list of terms, one substituting the global context and the other for the local one. The obvious definition of simultaneous substitutions in the dual-context style is a significant advantage, both when implementing and when reasoning about these systems. In the Kripke style, it is less obvious how to define simultaneous substitutions. Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019) have given a substitution calculus for the dependently typed idempotent S4 and Reference Birkedal, Clouston, Mannaa, Møgelberg, Pitts and SpittersBirkedal et al. (2020a ) have given a version for dependently typed K, but the general cases for other modal systems like T and non-idempotent S4 remain unknown. In our previous work (Reference Hu and PientkaHu & Pientka, 2022a ), we propose the Kripke-style substitutions (or K-substitutions), which is shown to be a proper notion of simultaneous substitutions for the Kripke style with simple types. By introducing Mint and its foundational study, we have shown that K-substitutions and our normalization proof scale to the dependently typed settings. Therefore, our work is a significant step forward to a deeper understanding of the Kripke-style systems.
3 Introducing Mint by examples
Before introducing Mint and its NbE proof, we illustrate how to write programs that exploit the
 $\square$
modality. In particular, we will use these programs to highlight different design decisions. We use an Agda-like syntax as our front-end language.
$\square$
modality. In particular, we will use these programs to highlight different design decisions. We use an Agda-like syntax as our front-end language.
3.1 Axioms in S4
Mint is a system that captures dependently typed variants of four different modal systems: K, T, K4, and S4. These systems are distinguished by the logical axioms that they admit. In Mint, we can implement the following modal axioms generically:
K:
$\square (A \to B) \to \square A \to \square B$
T:
$\square A \to A$
4:
$\square A \to \square \square A$



In these axioms, A and B refer to any propositions and hence are generic. Recall that in all four subsystems of S4, Axiom K is mandatory. The system that only admits K is System K. If Axiom T is added to System K, then we obtain System T. If we further add Axiom 4 to System T, then we have S4. System K4 only admits Axioms K and 4, but not T. To actually write down these axioms in Mint, intuitively we would like to give T, for example, the following type in Mint:
Here we use Ty to denote universes to avoid clashing with Agda’s terminology. Unfortunately, this type does not type-check, because A is in the current world, but ![]() requires the type A to be meaningful in the next world. The correct implementation of T states that A is a type that is universally accessible by giving it the kind
requires the type A to be meaningful in the next world. The correct implementation of T states that A is a type that is universally accessible by giving it the kind ![]() . This ensures that A remains accessible. When we want to use A in the definition of
. This ensures that A remains accessible. When we want to use A in the definition of ![]() , we now need to first
, we now need to first ![]() it with a proper level.
it with a proper level.
It might appear counter-intuitive at first glance, why we distinguish between a type of kind ![]() Ty and a type of kind Ty. This distinction is necessary, as Mint does not support cross-stage persistence (Taha & Sheard, Reference Taha and Sheard1997), i.e., the axiom R:
Ty and a type of kind Ty. This distinction is necessary, as Mint does not support cross-stage persistence (Taha & Sheard, Reference Taha and Sheard1997), i.e., the axiom R:
 $A \to \square A$
or more specifically
$A \to \square A$
or more specifically
 $\texttt{Ty} \to \square \texttt{Ty}$
. In particular, there is no way to implement a function that would lift any type of kind
$\texttt{Ty} \to \square \texttt{Ty}$
. In particular, there is no way to implement a function that would lift any type of kind
 $\texttt{Ty}$
such that it would have kind
$\texttt{Ty}$
such that it would have kind
 $\square \texttt{Ty}$
. As a consequence, to ensure that all our types, in particular types such as
$\square \texttt{Ty}$
. As a consequence, to ensure that all our types, in particular types such as
 $\square A,$
are well kinded, we need to ensure that A is globally meaningful. A similar design decision has been taken by Jang et al. (Reference Jang, Gélineau, Monnier and Pientka2022) in their work on developing a polymorphic modal type system that supports the generation of polymorphic code.
$\square A,$
are well kinded, we need to ensure that A is globally meaningful. A similar design decision has been taken by Jang et al. (Reference Jang, Gélineau, Monnier and Pientka2022) in their work on developing a polymorphic modal type system that supports the generation of polymorphic code.
We are now in a position to also implement the other two axioms similarly:

3.2 Lifting of natural numbers
As previously discussed, Mint does not support cross-stage persistence and the axiom
 $A \to \square A$
is not admissible for all A. Nevertheless, there are types where we can explicitly lift an element of type A to
$A \to \square A$
is not admissible for all A. Nevertheless, there are types where we can explicitly lift an element of type A to
 $\square A$
. The type for natural numbers is one such example. In Mint, we need to implement such lifting functions when required to ensure cross-stage persistence. Since Mint supports inductive types just as MLTT does, we define natural numbers, Nat, in the usual way, with zero and succ as the constructors. Then, we define its lift function, which shows that natural numbers do admit Axiom
$\square A$
. The type for natural numbers is one such example. In Mint, we need to implement such lifting functions when required to ensure cross-stage persistence. Since Mint supports inductive types just as MLTT does, we define natural numbers, Nat, in the usual way, with zero and succ as the constructors. Then, we define its lift function, which shows that natural numbers do admit Axiom
 $A \to \square A$
:
$A \to \square A$
:

Note that this function is implemented by recursion on the input number. If the input is just zero, then the solution is easy: it is just ![]() . We can refer to zero inside of a
. We can refer to zero inside of a ![]() , which requires a term in the next world, because Nat is a closed definition, which can be automatically lifted to any other world. In the succ case, we first provide a
, which requires a term in the next world, because Nat is a closed definition, which can be automatically lifted to any other world. In the succ case, we first provide a ![]() as required by the output type obligation. Then, we must perform a recursion somehow. Luckily,
as required by the output type obligation. Then, we must perform a recursion somehow. Luckily, ![]() brings us back to the current world, which allows us access to n, which is precisely needed for a structural recursion.
brings us back to the current world, which allows us access to n, which is precisely needed for a structural recursion.
Just as pure MLTT, Mint can be used to prove properties about a definition. For example, we can show that ![]() is an inverse of lift:
is an inverse of lift:

In the base case, the left-hand side evaluates to ![]() , which is just equivalent to zero. Therefore, reflexivity (refl) suffices to prove this goal. In the step case, we need to prove
, which is just equivalent to zero. Therefore, reflexivity (refl) suffices to prove this goal. In the step case, we need to prove
The left-hand side is reduced to ![]() based on the equivalence rules that we describe in the next section. Note the recursive call
based on the equivalence rules that we describe in the next section. Note the recursive call ![]() . Therefore, we can conclude the goal by the recursive call modulo an extra congruence of succ.
. Therefore, we can conclude the goal by the recursive call modulo an extra congruence of succ.
3.3 Generating N-ary sum
According to Davies & Pfenning (Reference Davies and Pfenning2001), the modal logic S4 corresponds to staged computation under Curry–Howard correspondence, where
 $\square A$
denotes the type of a computation of type A, the result of which is only available in some future stages of computation. Effectively,
$\square A$
denotes the type of a computation of type A, the result of which is only available in some future stages of computation. Effectively,
 $\square$
segments different computational stages, so that variables in past stages cannot be directly referred to in the current stage. The
$\square$
segments different computational stages, so that variables in past stages cannot be directly referred to in the current stage. The
 $\square$
modality provides a logical foundation for multi-staged programming systems like MetaML (Taha & Sheard, Reference Taha and Sheard1997; Taha, Reference Taha2000). By integrating
$\square$
modality provides a logical foundation for multi-staged programming systems like MetaML (Taha & Sheard, Reference Taha and Sheard1997; Taha, Reference Taha2000). By integrating
 $\square$
into MLTT, we can use Mint as a program logic to model dependently typed staged computations and use Mint’s equational theory to prove that the programs satisfy certain specifications. In this section, we show how the S4 variant of Mint can model staged programming and in the next, we prove that this program is correctly implemented. Proving the correctness of a staged or meta-program in MetaML or a similar system has not been previously considered, but with Mint, this capability comes very naturally. For more practicality, we postulate that certain extraction mechanisms can be employed here to extract the code to a mature staged programming system such as MetaML (Taha & Sheard, Reference Taha and Sheard1997) with proper type-level magic to erase the dependent types as commonly practiced in Coq and Agda.
$\square$
into MLTT, we can use Mint as a program logic to model dependently typed staged computations and use Mint’s equational theory to prove that the programs satisfy certain specifications. In this section, we show how the S4 variant of Mint can model staged programming and in the next, we prove that this program is correctly implemented. Proving the correctness of a staged or meta-program in MetaML or a similar system has not been previously considered, but with Mint, this capability comes very naturally. For more practicality, we postulate that certain extraction mechanisms can be employed here to extract the code to a mature staged programming system such as MetaML (Taha & Sheard, Reference Taha and Sheard1997) with proper type-level magic to erase the dependent types as commonly practiced in Coq and Agda.
Our task here is to model a meta-program that generates code for an n-ary sum function that sums up n numbers. If n is zero, then we return zero; if it is one, then we return the identity function; if it is two, then we return the function that sums up two arguments, i.e., ![]() . Writing such an n-ary sum function in a type-safe manner can be achieved by exploiting large elimination in MLTT.
. Writing such an n-ary sum function in a type-safe manner can be achieved by exploiting large elimination in MLTT.
We first define a type-level function nary n, which computes the type of an n-ary function:

We then define the type of nary-sum as taking in a natural number n : Nat and intuitively returning code of type nary n. This, however, does not quite work, as ![]() (nary n) is ill-typed. Note that n is defined in the current world, but we need to use it inside
(nary n) is ill-typed. Note that n is defined in the current world, but we need to use it inside ![]() (i.e. in the next world). We hence need to first lift the n : Nat to
(i.e. in the next world). We hence need to first lift the n : Nat to ![]() Nat using the previously defined lift function to then be able to splice it in. The need to lift values such as natural numbers to have access to both their values and their code representations is a common theme when writing staged programs. In a dependently typed setting, we need to use such lifting functions also on the type level to support a form of cross-stage persistence of values. We hence arrive at the type
Nat using the previously defined lift function to then be able to splice it in. The need to lift values such as natural numbers to have access to both their values and their code representations is a common theme when writing staged programs. In a dependently typed setting, we need to use such lifting functions also on the type level to support a form of cross-stage persistence of values. We hence arrive at the type ![]() for the nary-sum function. Its implementation follows, in fact, directly from our intention.
for the nary-sum function. Its implementation follows, in fact, directly from our intention.

Note that in the base case of zero, the return type is ![]() Nat; in the case of succ zero, we return the boxed identity function; in the case of succ (succ n), nary-sum (succ (succ n)) returns a term of type
Nat; in the case of succ zero, we return the boxed identity function; in the case of succ (succ n), nary-sum (succ (succ n)) returns a term of type ![]() . The recursive call nary-sum (succ n) has type
. The recursive call nary-sum (succ n) has type ![]()
![]() . Further, we have
. Further, we have

To compute the final result of nary-sum (succ (succ n)), we first unbox the code generated by nary-sum (succ n), which has type ![]() , and apply it to the sum of the first two arguments. For convenience, we use numeric literals 0, 1, etc. for natural numbers zero, succ zero, etc. interchangeably. To illustrate, let us normalize nary-sum 3:
, and apply it to the sum of the first two arguments. For convenience, we use numeric literals 0, 1, etc. for natural numbers zero, succ zero, etc. interchangeably. To illustrate, let us normalize nary-sum 3:

The last equation shows in Mint that nary-sum 3 and the code of x y z -> (x + y) + z are definitionally equal due to the congruence of ![]() :
:
Mint admits the congruence of ![]() and as a result, reductions occur freely even inside of a
and as a result, reductions occur freely even inside of a ![]() as in MetaML (Taha, Reference Taha2000). The congruence of
as in MetaML (Taha, Reference Taha2000). The congruence of ![]() is essential to model MetaML and particularly helpful when using Mint as a program logic, for the same reason as having the congruence of
is essential to model MetaML and particularly helpful when using Mint as a program logic, for the same reason as having the congruence of ![]() . Moreover, the congruence of
. Moreover, the congruence of ![]() allows a significantly simpler semantic model leading to a straightforward normalization proof.
allows a significantly simpler semantic model leading to a straightforward normalization proof.
3.4 Soundness of N-ary sum
Previously, we have shown a specific proof for the ternary sum. Mint can take one step further: we can prove general properties about nary-sum. In particular, we can prove that given a list xs of natural numbers, which has length n, adding up all numbers in xs returns the same result as using the code generated by nary-sum n to add them up. To make this theorem precise, we first define the function sum, which sums up all the numbers in a list xs of length n, and the function ap-list, which applies a function f : nary n to all the numbers in xs:

where omitted-eq has type ![]() when eq has type
when eq has type ![]() . We omit it to avoid being distracted by equational reasoning. The slightly unorthodox definition of sum is defined by recursion on n just as ap-list, so that auxiliary lemmas such as the associativity of addition are avoided in our subsequent soundness theorem. Proving it equal to the standard definition is an easy exercise in pure MLTT, which we omit here. We now can state and prove our target theorem:
. We omit it to avoid being distracted by equational reasoning. The slightly unorthodox definition of sum is defined by recursion on n just as ap-list, so that auxiliary lemmas such as the associativity of addition are avoided in our subsequent soundness theorem. Proving it equal to the standard definition is an easy exercise in pure MLTT, which we omit here. We now can state and prove our target theorem:

nary-sum-sound takes two equality proofs to simplify the formulation of this lemma. When using nary-sum-sound, eq’ can be derived from eq and unbox-lift defined above. The first two base cases are easy. In the last case, a recursive call suffices. We reason as follows. The expected return type is

By simplifying the left-hand side, we obtain

On the other hand, the recursive call gives us:

By again simplifying the left-hand side, we conclude

Therefore by definitional equality, nary-sum-sound is a valid proof.
4 Definition of Mint
In this section, we formally introduce Mint. We introduce its syntax, typing rules, and equivalence rules. To manipulate the modal structure, we introduce two operations on Kripke-style substitutions, truncation and truncation offset, to the system. Both operations turn out to be components of an algebraic structure, called truncoid, which captures the Kripke structure of Mint generically. We use this algebraic structure throughout our technical development and have corresponding definitions in the semantics.
4.1 Syntax and judgments of Mint
Mint has the following syntax:

Mint extends MLTT with context stacks and the
 $\square$
modality. As discussed in Section 1, Mint models and reasons about the Kripke semantics (Kripke, Reference Kripke1963). In particular, we use context stacks to keep track of assumptions in all accessed worlds. Mint has natural numbers (
$\square$
modality. As discussed in Section 1, Mint models and reasons about the Kripke semantics (Kripke, Reference Kripke1963). In particular, we use context stacks to keep track of assumptions in all accessed worlds. Mint has natural numbers (
 ${{{{{\texttt{Nat}}}}}}$
,
${{{{{\texttt{Nat}}}}}}$
,
 $\texttt{zero}$
,
$\texttt{zero}$
,
 $\texttt{succ }t$
),
$\texttt{succ }t$
),
 $\Pi$
types, cumulative universes, written as
$\Pi$
types, cumulative universes, written as
 $\texttt{Ty}_i$
, and explicit Kripke-style substitutions, which model the mapping between context stacks. Here, the cumulativity of universes means if a type is in the universe of level i, then it is also in the universe of level 1+i, not a stronger notion of cumulativity based on universe subtyping working even for function types and others. We also include a recursor on natural numbers
$\texttt{Ty}_i$
, and explicit Kripke-style substitutions, which model the mapping between context stacks. Here, the cumulativity of universes means if a type is in the universe of level i, then it is also in the universe of level 1+i, not a stronger notion of cumulativity based on universe subtyping working even for function types and others. We also include a recursor on natural numbers
 $(\texttt{elim}\ M\ s\ s'\ t)$
. In this expression, t is the scrutinee describing a natural number, and s and s’ are referring to the two possible cases where t is
$(\texttt{elim}\ M\ s\ s'\ t)$
. In this expression, t is the scrutinee describing a natural number, and s and s’ are referring to the two possible cases where t is
 $\texttt{zero}$
and the successor, respectively; M is the motive describing essentially the overall type skeleton of the recursor. As the overall type of the recursor depends on t, we model the motive M as a type with one free variable. Subsequently, we omit most discussions of natural numbers for brevity and refer the interested readers to our technical report and our mechanization. To construct and use a term of
$\texttt{zero}$
and the successor, respectively; M is the motive describing essentially the overall type skeleton of the recursor. As the overall type of the recursor depends on t, we model the motive M as a type with one free variable. Subsequently, we omit most discussions of natural numbers for brevity and refer the interested readers to our technical report and our mechanization. To construct and use a term of
 $\Pi$
type, we have
$\Pi$
type, we have
 $\lambda$
abstraction and function application as usual. We have discussed
$\lambda$
abstraction and function application as usual. We have discussed
 ${{{{{\texttt{box}}}}}}$
and
${{{{{\texttt{box}}}}}}$
and
 ${{{{{\texttt{unbox}}}}}}$
, the constructor and eliminator of
${{{{{\texttt{unbox}}}}}}$
, the constructor and eliminator of
 $\square$
types, in Section 3. When
$\square$
types, in Section 3. When
 ${{{{{\texttt{unbox}}}}}}$
’ing a term t, we must specify a number n, i.e.,
${{{{{\texttt{unbox}}}}}}$
’ing a term t, we must specify a number n, i.e.,
 $\texttt{unbox}_{n}\ t$
, to describe the Kripke world we travel back to when type-checking t. By restricting n, Mint is specialized to one of the dependently typed generalizations of four different modal systems: K, T, K4, and S4. For example, if the modal offset must be 1, i.e., only
$\texttt{unbox}_{n}\ t$
, to describe the Kripke world we travel back to when type-checking t. By restricting n, Mint is specialized to one of the dependently typed generalizations of four different modal systems: K, T, K4, and S4. For example, if the modal offset must be 1, i.e., only
 $\texttt{unbox}_{1}\ t$
is possible, then we obtain the System K. By allowing the modal offset to be either 0 or 1, we obtain the System T. If the modal offset must be positive, we obtain the System K4. If there is no restriction at all, then we obtain the most general System S4. The Kripke style has the advantage of being specialized to different modal systems by controlling the modal offsets. This observation has been made by Pfenning &Wong (Reference Pfenning and Wong1995), Davies & Pfenning (Reference Davies and Pfenning2001), and Reference Hu and PientkaHu & Pientka (2022a
). At last, since Mint is formulated with explicit Kripke-style substitutions, the substitution closure
$\texttt{unbox}_{1}\ t$
is possible, then we obtain the System K. By allowing the modal offset to be either 0 or 1, we obtain the System T. If the modal offset must be positive, we obtain the System K4. If there is no restriction at all, then we obtain the most general System S4. The Kripke style has the advantage of being specialized to different modal systems by controlling the modal offsets. This observation has been made by Pfenning &Wong (Reference Pfenning and Wong1995), Davies & Pfenning (Reference Davies and Pfenning2001), and Reference Hu and PientkaHu & Pientka (2022a
). At last, since Mint is formulated with explicit Kripke-style substitutions, the substitution closure
 $t[{\overrightarrow{\sigma}}]$
is defined as a form of syntax. We emphasize that the
$t[{\overrightarrow{\sigma}}]$
is defined as a form of syntax. We emphasize that the
 $t[{\overrightarrow{\sigma}}]$
has a very low binding precedence in our representation. For example, when we write
$t[{\overrightarrow{\sigma}}]$
has a very low binding precedence in our representation. For example, when we write
 $t~s[{\overrightarrow{\sigma}}]$
, we mean
$t~s[{\overrightarrow{\sigma}}]$
, we mean
 $(t~s)[{\overrightarrow{\sigma}}]$
. If we want
$(t~s)[{\overrightarrow{\sigma}}]$
. If we want
 ${\overrightarrow{\sigma}}$
to be applied to s only, we add explicit parentheses
${\overrightarrow{\sigma}}$
to be applied to s only, we add explicit parentheses
 $t~(s[{\overrightarrow{\sigma}}])$
. Similarly,
$t~(s[{\overrightarrow{\sigma}}])$
. Similarly,
 $\texttt{unbox}_{n}\ t [{\overrightarrow{\sigma}}]$
denotes
$\texttt{unbox}_{n}\ t [{\overrightarrow{\sigma}}]$
denotes
 $(\texttt{unbox}_{n}\ t)[{\overrightarrow{\sigma}}]$
.
$(\texttt{unbox}_{n}\ t)[{\overrightarrow{\sigma}}]$
.
Moreover, in this paper, we explicitly work with de Bruijn indices to stay close to our mechanization. The de Bruijn index of a variable is to be understood relative to the topmost context in a context stack, keeping in mind that
 ${{{{{\texttt{box}}}}}}$
and
${{{{{\texttt{box}}}}}}$
and
 ${{{{{\texttt{unbox}}}}}}$
modify the context stack and change the topmost context. For example, given a context stack
${{{{{\texttt{unbox}}}}}}$
modify the context stack and change the topmost context. For example, given a context stack ![]() the term
the term ![]() ) is well formed, but the first occurrence of
) is well formed, but the first occurrence of ![]() refers to the function
refers to the function ![]() , while the second occurrence in
, while the second occurrence in ![]() refers to
refers to ![]() , as
, as ![]() refers to a term in the prior world. Notationally, we consistently use upper cases for types and lower cases otherwise.
refers to a term in the prior world. Notationally, we consistently use upper cases for types and lower cases otherwise.
We turn the formulation of Kripke-style substitutions (or just K-substitutions) from our previous work at Mathematical Foundations of Programming Semantics (MFPS) (Reference Hu and PientkaHu & Pientka, 2022a
) between context stacks into explicit K-substitutions. K-substitutions are a generalization of the usual simultaneous substitutions. Instead of representing a mapping between two contexts in the typical case, a K-substitution is a mapping between two context stacks. In our explicit K-substitutions, the following syntax directly replicates the usual formulation of simultaneous substitutions:
 $\overrightarrow{I}$
is the identity K-substitutions between two context stacks;
$\overrightarrow{I}$
is the identity K-substitutions between two context stacks;
 ${\overrightarrow{\sigma}}, t$
extends a K-substitution with a term;
${\overrightarrow{\sigma}}, t$
extends a K-substitution with a term;
 $\mathsf{wk}$
is local weakening supporting weakening of the topmost context of a context stack; and
$\mathsf{wk}$
is local weakening supporting weakening of the topmost context of a context stack; and
 ${\overrightarrow{\sigma}} \circ {\overrightarrow{\delta}}$
composes
${\overrightarrow{\sigma}} \circ {\overrightarrow{\delta}}$
composes
 ${\overrightarrow{\sigma}}$
with
${\overrightarrow{\sigma}}$
with
 ${\overrightarrow{\delta}}$
. Furthermore, a K-substitution is no longer simply a list of terms. Modal extension
${\overrightarrow{\delta}}$
. Furthermore, a K-substitution is no longer simply a list of terms. Modal extension
 ${\overrightarrow{\sigma}};\Uparrow^{n}$
is added and unique in Kripke-style modal type theories, and models modal weakening of context stacks. The modal offset n originates from the modal transformation operation (MoT) (Davies & Pfenning, Reference Davies and Pfenning2001) and is used to keep track of the number of contexts, which are added to the codomain context stack as in the following rule. A modal extension only introduces one empty context to the domain context stack:
${\overrightarrow{\sigma}};\Uparrow^{n}$
is added and unique in Kripke-style modal type theories, and models modal weakening of context stacks. The modal offset n originates from the modal transformation operation (MoT) (Davies & Pfenning, Reference Davies and Pfenning2001) and is used to keep track of the number of contexts, which are added to the codomain context stack as in the following rule. A modal extension only introduces one empty context to the domain context stack:

Please refer to our previous work at MFPS (Reference Hu and PientkaHu & Pientka, 2022a
) for a complete motivation for modal extensions.
 ${\overrightarrow{\sigma}}$
provides a mapping from
${\overrightarrow{\sigma}}$
provides a mapping from
 ${\overrightarrow{\Gamma}}$
to
${\overrightarrow{\Gamma}}$
to
 ${\overrightarrow{\Delta}}$
, while
${\overrightarrow{\Delta}}$
, while
 ${\overrightarrow{\sigma}};\Uparrow^{n}$
maps from
${\overrightarrow{\sigma}};\Uparrow^{n}$
maps from
 ${\overrightarrow{\Gamma}}; {\overrightarrow{\Gamma}'}$
to
${\overrightarrow{\Gamma}}; {\overrightarrow{\Gamma}'}$
to
 ${\overrightarrow{\Delta}}; \cdot$
where the number of contexts in
${\overrightarrow{\Delta}}; \cdot$
where the number of contexts in
 ${\overrightarrow{\Gamma}'}$
is n. This modal weakening is crucial to characterize the
${\overrightarrow{\Gamma}'}$
is n. This modal weakening is crucial to characterize the
 $\beta$
rule of
$\beta$
rule of
 $\square$
in a type-safe manner (see
$\square$
in a type-safe manner (see ![]() ). Hence, we incorporate modal weakening into our definition of K-substitution.
). Hence, we incorporate modal weakening into our definition of K-substitution.
We give some selected typing rules in Figure 1. The full set of rules can be found in Appendix A. The definition of Mint consists of six judgments: ![]() denotes that the context stack
denotes that the context stack
 ${\overrightarrow{\Gamma}}$
is well formed;
${\overrightarrow{\Gamma}}$
is well formed; ![]() denotes that
denotes that
 ${\overrightarrow{\Gamma}}$
and
${\overrightarrow{\Gamma}}$
and
 ${\overrightarrow{\Delta}}$
are equivalent context stacks;
${\overrightarrow{\Delta}}$
are equivalent context stacks; ![]() denotes that term t has type T in context stack
denotes that term t has type T in context stack
 ${\overrightarrow{\Gamma}}$
;
${\overrightarrow{\Gamma}}$
; ![]() denotes that terms t and s of type T are equivalent in context stack
denotes that terms t and s of type T are equivalent in context stack
 ${\overrightarrow{\Gamma}}$
;
${\overrightarrow{\Gamma}}$
; ![]() denotes that
denotes that
 ${\overrightarrow{\sigma}}$
is a K-substitution susbtituting terms in
${\overrightarrow{\sigma}}$
is a K-substitution susbtituting terms in
 ${\overrightarrow{\Delta}}$
into ones in
${\overrightarrow{\Delta}}$
into ones in
 ${\overrightarrow{\Gamma}}$
; and
${\overrightarrow{\Gamma}}$
; and ![]() denotes that
denotes that
 ${\overrightarrow{\sigma}}$
and
${\overrightarrow{\sigma}}$
and
 ${\overrightarrow{\delta}}$
are equivalent in K-substituting terms in
${\overrightarrow{\delta}}$
are equivalent in K-substituting terms in
 ${\overrightarrow{\Delta}}$
into ones in
${\overrightarrow{\Delta}}$
into ones in
 ${\overrightarrow{\Gamma}}$
. Due to explicit K-substitutions, there needs to be more judgments than usual. The equivalence between context stacks
${\overrightarrow{\Gamma}}$
. Due to explicit K-substitutions, there needs to be more judgments than usual. The equivalence between context stacks
 $\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
is necessary, because we must specify a conversion rule for the equivalence between K-substitutions:
$\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
is necessary, because we must specify a conversion rule for the equivalence between K-substitutions:

Fig. 1. Selected rules for Mint.

In turn, we need the equivalence between K-substitutions ![]() due to the following congruence rule for the K-substitution closure:
due to the following congruence rule for the K-substitution closure:

Without explicit (K-)substitutions, both
 $\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
and
$\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
and ![]() are defined after the typing judgments, instead of mutually defined. This style of definitions follows Abel (Reference Abel2013) closely.
are defined after the typing judgments, instead of mutually defined. This style of definitions follows Abel (Reference Abel2013) closely.
Following Harper & Pfenning (Reference Harper and Pfenning2005), we introduce ![]() in the rules in order to establish syntactic properties like context stack conversion and presupposition. Context stack conversion states that all syntactic judgments respect context stack equivalence
in the rules in order to establish syntactic properties like context stack conversion and presupposition. Context stack conversion states that all syntactic judgments respect context stack equivalence
 $\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
. Presupposition (or syntactic validity) includes for example facts such as if
$\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
. Presupposition (or syntactic validity) includes for example facts such as if ![]() then
then
 $\vdash {\overrightarrow{\Gamma}}$
and
$\vdash {\overrightarrow{\Gamma}}$
and ![]() for some i.
for some i.
Theorem 4.1 (Context stack conversion). Given
 $\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
,
$\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
,
• if
, then ;• if
, then ;
• if
then ;
• if
then .
Theorem 4.2 (Presupposition).
• If
$\vdash {\overrightarrow{\Gamma}} \approx {\overrightarrow{\Delta}}$
, then
$\vdash {\overrightarrow{\Gamma}}$
and
$\vdash {\overrightarrow{\Delta}}$
.• If
, then
$\vdash {\overrightarrow{\Gamma}}$
and for some i.
• If
then
$\vdash {\overrightarrow{\Gamma}}$
, and for some i.
• If
, then
$\vdash {\overrightarrow{\Gamma}}$
and
$\vdash {\overrightarrow{\Delta}}$
.• If
, then
$\vdash {\overrightarrow{\Gamma}}$
, and
$\vdash {\overrightarrow{\Delta}}$
.









After proving these two properties, we remove the ![]() and call the resulting judgments the true and golden definition of Mint. These two definitions are equivalent:
and call the resulting judgments the true and golden definition of Mint. These two definitions are equivalent:
Theorem 4.3. The two sets of rules of Mint given above are equivalent.
4.2. Truncoid: Algebra of truncation and truncation offset
Mint fundamentally relies on two operations, ![]() and
and ![]() to handle its Kripke structure. Given
to handle its Kripke structure. Given ![]() and some
and some
 $n < |{\overrightarrow{\Delta}}|$
, truncation of a K-substitution, written as
$n < |{\overrightarrow{\Delta}}|$
, truncation of a K-substitution, written as
 ${\overrightarrow{\sigma}} \mid {n}$
, returns a prefix of
${\overrightarrow{\sigma}} \mid {n}$
, returns a prefix of
 ${\overrightarrow{\sigma}}$
with domain context stack
${\overrightarrow{\sigma}}$
with domain context stack
 ${\overrightarrow{\Delta}} \mid {n}$
where n modal extensions and accordingly n contexts from
${\overrightarrow{\Delta}} \mid {n}$
where n modal extensions and accordingly n contexts from
 ${\overrightarrow{\Delta}}$
are dropped. The main question then is, what is the codomain context stack of this K-substitution? – Since we drop modal extensions including their modal offsets from
${\overrightarrow{\Delta}}$
are dropped. The main question then is, what is the codomain context stack of this K-substitution? – Since we drop modal extensions including their modal offsets from
 ${\overrightarrow{\sigma}}$
, the codomain context stack
${\overrightarrow{\sigma}}$
, the codomain context stack
 ${\overrightarrow{\Gamma}}$
must also be adjusted. Recall that each modal offset in a modal extension accounts for a number of contexts in
${\overrightarrow{\Gamma}}$
must also be adjusted. Recall that each modal offset in a modal extension accounts for a number of contexts in
 ${\overrightarrow{\Gamma}}$
. Hence, intuitively, we should drop k contexts from
${\overrightarrow{\Gamma}}$
. Hence, intuitively, we should drop k contexts from
 ${\overrightarrow{\Gamma}}$
where k is the sum of all dropped modal offsets.
${\overrightarrow{\Gamma}}$
where k is the sum of all dropped modal offsets.
For example, let
 ${\overrightarrow{\sigma}}$
be
${\overrightarrow{\sigma}}$
be
 $({\overrightarrow{\delta}};\Uparrow^{1} , t;\Uparrow^{2} , s)$
where
$({\overrightarrow{\delta}};\Uparrow^{1} , t;\Uparrow^{2} , s)$
where ![]() . Truncation
. Truncation
 ${\overrightarrow{\sigma}} \mid {2}$
then returns the prefix
${\overrightarrow{\sigma}} \mid {2}$
then returns the prefix
 ${\overrightarrow{\delta}}$
after dropping everything up to two modal extensions
${\overrightarrow{\delta}}$
after dropping everything up to two modal extensions
 $\Uparrow^1$
and
$\Uparrow^1$
and
 $\Uparrow^2$
. This resulting K-substitution intuitively must have domain context stack
$\Uparrow^2$
. This resulting K-substitution intuitively must have domain context stack
 ${\overrightarrow{\Delta}}$
and codomain context stack
${\overrightarrow{\Delta}}$
and codomain context stack
 ${\overrightarrow{\Gamma}}$
, i.e.,
${\overrightarrow{\Gamma}}$
, i.e., ![]() . How do we obtain
. How do we obtain
 ${\overrightarrow{\Gamma}}$
from
${\overrightarrow{\Gamma}}$
from
 ${\overrightarrow{\Gamma}}; \Gamma_0;\Gamma_1; \Gamma_2$
? – The answer is by simply dropping the top 3 contexts where 3 is exactly the sum of the modal offsets in the dropped part of
${\overrightarrow{\Gamma}}; \Gamma_0;\Gamma_1; \Gamma_2$
? – The answer is by simply dropping the top 3 contexts where 3 is exactly the sum of the modal offsets in the dropped part of
 ${\overrightarrow{\sigma}}$
.
${\overrightarrow{\sigma}}$
.
To compute the sum of modal offsets, we define the truncation offset
 $\mathcal{O}({{\overrightarrow{\sigma}}}, {n})$
below. In general, we have
$\mathcal{O}({{\overrightarrow{\sigma}}}, {n})$
below. In general, we have ![]() .
.
Our syntax of explicit K-substitutions is carefully designed such that truncation and truncation offset can be defined by recursion on the structure of the inputs:

These two operations satisfy the following two coherence conditions:
Lemma 4.4 (Coherence conditions).
• Coherence of addition: for all
${\overrightarrow{\sigma}}$
, m and n,
${\overrightarrow{\sigma}} \mid {(n + m)} = ({\overrightarrow{\sigma}} \mid {n}) \mid {m}$
and
$\mathcal{O}({{\overrightarrow{\sigma}}}, {n + m}) = \mathcal{O}({{\overrightarrow{\sigma}}}, {n}) + \mathcal{O}({{\overrightarrow{\sigma}} \mid {n}}, m)$
.• Coherence of addition: for all
${\overrightarrow{\sigma}}$
,
${\overrightarrow{\delta}}$
and m,
$({\overrightarrow{\sigma}} \circ {\overrightarrow{\delta}}) \mid {n} = ({\overrightarrow{\sigma}} \mid {n}) \circ ({\overrightarrow{\delta}} \mid {} {\mathcal{O}({{\overrightarrow{\sigma}}}, {n}) })$
and
$\mathcal{O}({{\overrightarrow{\sigma}} \circ {\overrightarrow{\delta}}}, {n}) = \mathcal{O}({{\overrightarrow{\delta}}}, {\mathcal{O}({{\overrightarrow{\sigma}}}, {n})})$
.







These two operations describe how K-substitutions interact with the Kripke structure of Mint so that the whole system remains coherent, e.g., in the following rule:

When applying a K-substitution
 ${\overrightarrow{\sigma}}$
to
${\overrightarrow{\sigma}}$
to
 ${{{{{\texttt{unbox}}}}}}$
, the K-substitution is pushed recursively inside with a truncated K-substitution and the
${{{{{\texttt{unbox}}}}}}$
, the K-substitution is pushed recursively inside with a truncated K-substitution and the
 ${{{{{\texttt{unbox}}}}}}$
level adjusted by truncation offset.
${{{{{\texttt{unbox}}}}}}$
level adjusted by truncation offset.
Truncation and truncation offset turn out to be very general concepts and are central to modeling the Kripke structure in both syntax and semantics. In particular, truncation and truncation offset form an algebra, which we call a truncoid. The following gives a concrete and the most basic algebraic characterization of a truncoid:
Definition 4.1. A truncoid is a triple
 $(S, \_ \mid {\_}, \mathcal{O}({\_}, {\_}))$
, where
$(S, \_ \mid {\_}, \mathcal{O}({\_}, {\_}))$
, where
• S is a set;
• the truncation operation
$\_ \mid {\_}$
takes an S and a natural number and returns an S;• the truncation offset operation
$\mathcal{O}({\_}, {\_})$
takes an S and a natural number and returns a natural number.


where the coherence of addition holds:
 \begin{equation*} s \mid { }{(n + m)} = (s \mid {n}) \mid {m} \, \mathrm{and} \, \mathcal{O}({s}, {n + m}) = \mathcal{O}({s}, {n}) + \mathcal{O}({s \mid {n}}, m) \end{equation*}
\begin{equation*} s \mid { }{(n + m)} = (s \mid {n}) \mid {m} \, \mathrm{and} \, \mathcal{O}({s}, {n + m}) = \mathcal{O}({s}, {n}) + \mathcal{O}({s \mid {n}}, m) \end{equation*}
Following the common mathematical practice, we directly call S a truncoid if it has coherent truncation and truncation offset. We have already shown that K-substitutions are a truncoid. In Section 5 and later sections, we will describe other instances of truncoids on the semantic side. Essentially, the normalization proof is just a study of interactions among different truncoids. In fact, most truncoids we encounter in the normalization proof are more specific, so it is worth organizing a few important and special truncoids ahead of time. The first kind is applicative truncoids, which allows a truncoid to be applied to another:
Definition 4.2. An applicative truncoid consists of a triple of truncoids
 $(S_0, S_1, S_2)$
and an additional apply operation
$(S_0, S_1, S_2)$
and an additional apply operation
 $\_[\_]$
which takes
$\_[\_]$
which takes
 $S_0$
and
$S_0$
and
 $S_1$
and returns
$S_1$
and returns
 $S_2$
. Moreover, the apply operation satisfies an extra coherence condition:
$S_2$
. Moreover, the apply operation satisfies an extra coherence condition:
 \begin{align*} s[s'] \mid {n} = (s \mid {n})[s' \mid {\mathcal{O}({s}, {n})}] \mathrm{and} \mathcal{O}({s[s']}, {n}) = \mathcal{O}({s'}, {\mathcal{O}({s}, {n})}) \end{align*}
\begin{align*} s[s'] \mid {n} = (s \mid {n})[s' \mid {\mathcal{O}({s}, {n})}] \mathrm{and} \mathcal{O}({s[s']}, {n}) = \mathcal{O}({s'}, {\mathcal{O}({s}, {n})}) \end{align*}
Most semantic models that we depend on in the normalization proof are also applicative. For example, evaluation environments in Section 5 are applicative. K-substitutions are also applicative, as we can just let the apply operation be composition. Following this intuition, we define a specialized applicative truncoid as a substitutional truncoid by asking the apply operation to behave like composition:
Definition 4.3. A substitutional truncoid S is an applicative truncoid (S, S, S) with an identity
 ${\mathsf{id}} \in S$
. Note that the apply operation is essentially composition, which we just write as
${\mathsf{id}} \in S$
. Note that the apply operation is essentially composition, which we just write as
 $\_\circ\_$
. The extra coherence conditions are for identity:
$\_\circ\_$
. The extra coherence conditions are for identity:
 \begin{align*} {\mathsf{id}} \mid {n} = {\mathsf{id}}, \mathcal{O}({{\mathsf{id}}}, {n}) = n, {\mathsf{id}} \circ s = s \mathrm{and} s \circ {\mathsf{id}} = s \end{align*}
\begin{align*} {\mathsf{id}} \mid {n} = {\mathsf{id}}, \mathcal{O}({{\mathsf{id}}}, {n}) = n, {\mathsf{id}} \circ s = s \mathrm{and} s \circ {\mathsf{id}} = s \end{align*}
and associativity:
 \begin{align*} (s_0 \circ s_1) \circ s_2 = s_0 \circ (s_1 \circ s_2) \end{align*}
\begin{align*} (s_0 \circ s_1) \circ s_2 = s_0 \circ (s_1 \circ s_2) \end{align*}
As expected, K-substitutions are a substitutional truncoid. We will see very soon that the UMoTs, which model the Kripke structure in the semantics, are also substitutional. There is another way to specialize applicative truncoid. Starting from an applicative truncoid, if we allow
 $S_1$
to be substitutional, then we obtain a closed truncoid:
$S_1$
to be substitutional, then we obtain a closed truncoid:
Definition 4.4. A closed truncoid
 $(S_0, S_1)$
is an applicative truncoid triple
$(S_0, S_1)$
is an applicative truncoid triple
 $(S_0, S_1, S_0)$
where
$(S_0, S_1, S_0)$
where
 $S_1$
is a substitutional truncoid. We write
$S_1$
is a substitutional truncoid. We write
 ${\mathsf{id}}$
and
${\mathsf{id}}$
and
 $\_\circ\_$
for identity and composition of
$\_\circ\_$
for identity and composition of
 $S_1$
. The following additional coherence conditions are required:
$S_1$
. The following additional coherence conditions are required:
• coherence of identity:
$s[{\mathsf{id}}] = s$
.• coherence of composition:
$s[s_1 \circ s_2] = s [s_1] [s_2]$


We say that
 $S_0$
is closed under
$S_0$
is closed under
 $S_1$
. The apply operation of a closed truncoid must return
$S_1$
. The apply operation of a closed truncoid must return
 $S_0$
as required by the definition. In the semantics, the evaluation environments are closed under UMoTs. Note that K-substitutions are also closed under themselves. The laws of applicative and closed truncoids cover all the properties we need to reason about the normalization process. There are also non-closed applicative truncoids. The evaluation operation of K-substitutions to be shown in Section 5 is one such example.
$S_0$
as required by the definition. In the semantics, the evaluation environments are closed under UMoTs. Note that K-substitutions are also closed under themselves. The laws of applicative and closed truncoids cover all the properties we need to reason about the normalization process. There are also non-closed applicative truncoids. The evaluation operation of K-substitutions to be shown in Section 5 is one such example.
5 Untyped domain
Starting from this section, we begin to prove the normalization of Mint. The plan is as follows:
1. In this section, we define the untyped domain to which we evaluate valid programs of Mint and the NbE algorithm.
2. In Section 6, we establish the completeness theorem, which states that equivalent terms evaluate to syntactically equal normal forms by our algorithm. Completeness is proved by constructing a partial equivalence relation (PER) model, which relates two values from the untyped domain.
3. In Section 7, we establish the soundness theorem, which states that a well-typed term is equivalent to the normal form returned by the NbE algorithm. The model to prove soundness is more sophisticated as it relies on the PER model defined for completeness. The model for soundness must glue both values in the untyped domain and the syntactic terms, so conventionally, we call this model a gluing model.
In our NbE algorithm, we first evaluate a well-typed syntactic term into an untyped semantic domain, D. This domain contains no
 $\beta$
redex, so the evaluation process performs all
$\beta$
redex, so the evaluation process performs all
 $\beta$
reductions. After obtaining a value in the untyped domain, we must convert this value back to the syntax as a normal form. This process is done by the readback functions. The readback functions also perform
$\beta$
reductions. After obtaining a value in the untyped domain, we must convert this value back to the syntax as a normal form. This process is done by the readback functions. The readback functions also perform
 $\eta$
expansion, so we eventually obtain a
$\eta$
expansion, so we eventually obtain a
 $\beta\eta$
normal form.
$\beta\eta$
normal form.
In this section, we give the definition of the untyped domain in which we operate and the NbE algorithm. For brevity, we omit most of discussion about natural numbers and recursion. We refer interested readers to our technical report and our Agda code. For mathematical accuracy, we use
 $:=$
for assignments and
$:=$
for assignments and
 $=$
for equality. We use
$=$
for equality. We use
 $::$
to denote a meta-level name binding, i.e., Agda level.
$::$
to denote a meta-level name binding, i.e., Agda level.
5.1 Definition of untyped domain
The untyped domain has the following syntax. :

In the untyped domain, variables are represented by de Bruijn levels. Consider a topmost context
 $\Gamma.T.\Delta$
in some stack. If a variable
$\Gamma.T.\Delta$
in some stack. If a variable
 $v_x$
is bound to type T, in the syntax, we use a de Bruijn index and
$v_x$
is bound to type T, in the syntax, we use a de Bruijn index and
 $x = |\Delta|$
. Its corresponding de Bruijn level z, on the other hand, equals to
$x = |\Delta|$
. Its corresponding de Bruijn level z, on the other hand, equals to
 $|\Gamma|$
. De Bruijn levels assign a unique absolute name to each variable in each context, so that we can avoid handling local weakening of variables in the semantics. Evidently, these two representations satisfy
$|\Gamma|$
. De Bruijn levels assign a unique absolute name to each variable in each context, so that we can avoid handling local weakening of variables in the semantics. Evidently, these two representations satisfy
 $z + x + 1 = |\Gamma.T.\Delta|$
. This equation will be used in the readback functions to correspond syntactic and semantic variables.
$z + x + 1 = |\Gamma.T.\Delta|$
. This equation will be used in the readback functions to correspond syntactic and semantic variables.
In this untyped domain, values are effectively partially
 $\beta$
-reduced values and classified into three categories: values (D), neutral values (
$\beta$
-reduced values and classified into three categories: values (D), neutral values (
 $D^\mathsf{Ne}$
), and normal values (
$D^\mathsf{Ne}$
), and normal values (
 $D^\mathsf{Nf}$
). Same as before, we consistently use upper cases for semantic types and lower cases otherwise. In D,
$D^\mathsf{Nf}$
). Same as before, we consistently use upper cases for semantic types and lower cases otherwise. In D,
 $\blacksquare$
models
$\blacksquare$
models
 $\square$
semantically and
$\square$
semantically and
 $\mathsf{U}_i$
models a universe at level i.
$\mathsf{U}_i$
models a universe at level i.
 $\texttt{ze}$
models
$\texttt{ze}$
models
 $\texttt{zero}$
and
$\texttt{zero}$
and
 $\texttt{su}(a)$
models successors. A neutral value c is embedded into D when annotated with a type A. Following Abel (Reference Abel2013), we use defunctionalization (Reynolds, Reference Reynolds1998; Ager et al., Reference Ager, Biernacki, Danvy and Midtgaard2003) to capture open syntactic terms in the domain together with their surrounding evaluation environments, which enables formalization in Agda.
$\texttt{su}(a)$
models successors. A neutral value c is embedded into D when annotated with a type A. Following Abel (Reference Abel2013), we use defunctionalization (Reynolds, Reference Reynolds1998; Ager et al., Reference Ager, Biernacki, Danvy and Midtgaard2003) to capture open syntactic terms in the domain together with their surrounding evaluation environments, which enables formalization in Agda.
For example, a domain type
 $Pi(A, T, \overrightarrow{\rho})$
models a
$Pi(A, T, \overrightarrow{\rho})$
models a
 $\Pi$
type and consists of a domain type A as the input type and a syntactic type T as the output type together with its ambient environment
$\Pi$
type and consists of a domain type A as the input type and a syntactic type T as the output type together with its ambient environment
 $\overrightarrow{\rho,}$
which provides instantiations for all the free variables in T except the topmost one bound by
$\overrightarrow{\rho,}$
which provides instantiations for all the free variables in T except the topmost one bound by
 $\Pi$
in the syntax. Similarly, a domain value
$\Pi$
in the syntax. Similarly, a domain value
 $\Lambda(t, \overrightarrow{\rho})$
models a
$\Lambda(t, \overrightarrow{\rho})$
models a
 $\lambda$
term and describes a syntactic body t together with an environment
$\lambda$
term and describes a syntactic body t together with an environment
 $\overrightarrow{\rho,}$
which provides values for all the free variables in t except the topmost one bound by
$\overrightarrow{\rho,}$
which provides values for all the free variables in t except the topmost one bound by
 $\lambda$
in the syntax. For a neutral domain value for the recursor of natural numbers
$\lambda$
in the syntax. For a neutral domain value for the recursor of natural numbers
 $\mathsf{rec}(M, a, t, c, \overrightarrow{\rho})$
, the neutral domain value c describes the scrutinee, which is intended to be a natural number, while a describes the domain value for the base case. Next, t is an open syntactic term because it describes the term for the step-case. Last, M describes the motive in the syntax with one free variable expressing the dependency on the natural number c. Due to defunctionalization, we thus capture
$\mathsf{rec}(M, a, t, c, \overrightarrow{\rho})$
, the neutral domain value c describes the scrutinee, which is intended to be a natural number, while a describes the domain value for the base case. Next, t is an open syntactic term because it describes the term for the step-case. Last, M describes the motive in the syntax with one free variable expressing the dependency on the natural number c. Due to defunctionalization, we thus capture
 $\overrightarrow{\rho}$
, the surrounding environment of M and t.
$\overrightarrow{\rho}$
, the surrounding environment of M and t.
The NbE algorithm relies on local and global environments in the evaluation process. Local evaluation environments (
 $\mathsf{Env}$
) are functions mapping de Bruijn indices to domain values. Global evaluation environments (
$\mathsf{Env}$
) are functions mapping de Bruijn indices to domain values. Global evaluation environments (
 $\mathsf{Envs}$
), or just environments, are functions mapping modal offsets to tuples
$\mathsf{Envs}$
), or just environments, are functions mapping modal offsets to tuples
 $\mathbb{N} \times \mathsf{Env}$
where the first projection is a modal offset, thereby allowing us to model different modal logics. An environment can be viewed as a stream of local environments paired with modal offsets. In the NbE algorithm, when evaluating a well-typed term, only a finite prefix of an environment is used, which is ensured by soundness.
$\mathbb{N} \times \mathsf{Env}$
where the first projection is a modal offset, thereby allowing us to model different modal logics. An environment can be viewed as a stream of local environments paired with modal offsets. In the NbE algorithm, when evaluating a well-typed term, only a finite prefix of an environment is used, which is ensured by soundness.
We use ![]() for the empty local environment and
for the empty local environment and ![]() for the global environment.
for the global environment.

 $\texttt{emp}$
and
$\texttt{emp}$
and
 $\texttt{empty}$
are the empty local and global evaluation environments. Their definitions do not matter here because they only provide default values, which are guaranteed to be never used by soundness. Instead, we focus on how to extend local and global environments. First, we can modally extend an environment with a modal offset n:
$\texttt{empty}$
are the empty local and global evaluation environments. Their definitions do not matter here because they only provide default values, which are guaranteed to be never used by soundness. Instead, we focus on how to extend local and global environments. First, we can modally extend an environment with a modal offset n:

We write
 ${{{{{\texttt{ext}}}}}}(\overrightarrow{\rho})$
for
${{{{{\texttt{ext}}}}}}(\overrightarrow{\rho})$
for
 ${{{{{\texttt{ext}}}}}}(\overrightarrow{\rho}, 1)$
.
${{{{{\texttt{ext}}}}}}(\overrightarrow{\rho}, 1)$
.
 ${{{{{\texttt{ext}}}}}}$
models modal extension of a K-substitution (
${{{{{\texttt{ext}}}}}}$
models modal extension of a K-substitution (
 ${\overrightarrow{\sigma}};\Uparrow^{n}$
), so n is not associated with any local environment, hence
${\overrightarrow{\sigma}};\Uparrow^{n}$
), so n is not associated with any local environment, hence
 $\texttt{emp}$
.
$\texttt{emp}$
.
We can locally extend an environment with a value by inserting it into the topmost local environment.
 ${{{{{\texttt{lext'}}}}}}$
conses a value to a local environment, and
${{{{{\texttt{lext'}}}}}}$
conses a value to a local environment, and
 ${{{{{\texttt{lext}}}}}}$
just extends a value to its topmost local environment by calling
${{{{{\texttt{lext}}}}}}$
just extends a value to its topmost local environment by calling
 ${{{{{\texttt{lext'}}}}}}$
:
${{{{{\texttt{lext'}}}}}}$
:

The
 ${{{{{\texttt{drop}}}}}}$
operation drops the zeroth mapping from the topmost
${{{{{\texttt{drop}}}}}}$
operation drops the zeroth mapping from the topmost
 $\mathsf{Env}$
. It is needed for the interpretation of
$\mathsf{Env}$
. It is needed for the interpretation of
 $\mathsf{wk}$
:
$\mathsf{wk}$
:

Last, environments form a truncoid,
Footnote 4
and we define truncation and truncation offset on
 $\overrightarrow{\rho}$
:
$\overrightarrow{\rho}$
:

5.2 Untyped Modal Transformations
To model
 $\square$
, we must consider how to model the Kripke structure of Mint. In our untyped domain model, we employ the internal approach, where the Kripke structure is internalized by
$\square$
, we must consider how to model the Kripke structure of Mint. In our untyped domain model, we employ the internal approach, where the Kripke structure is internalized by ![]() , ranged over by
, ranged over by
 $\kappa$
. Formally, a UMoT is just an (Agda) function of type
$\kappa$
. Formally, a UMoT is just an (Agda) function of type
 $\mathbb{N} \to \mathbb{N}$
, modeling a stream of modal offsets. Given a domain value
$\mathbb{N} \to \mathbb{N}$
, modeling a stream of modal offsets. Given a domain value
 $a \in D$
and a UMoT
$a \in D$
and a UMoT
 $\kappa$
, the UMoT application operation
$\kappa$
, the UMoT application operation
 $a[\kappa]$
applies
$a[\kappa]$
applies
 $\kappa$
to a and denotes sending a to another world according to
$\kappa$
to a and denotes sending a to another world according to
 $\kappa$
. The internalization further requires subsequent models to satisfy monotonicity w.r.t. UMoTs (see Sections 6.2.3 and 7.3.1), which is the root of other properties involving UMoTs. The internalization seems to provide certain modularity, and we conjecture that our proof can be adapted to other modalities in Kripke style by only adjusting the definition of UMoTs and the proof of monotonicity. In fact, UMoTs have sufficiently captured the Kripke structures of all Systems K, T, K4, and S4, so as a bonus, their normalization is established simultaneously.
$\kappa$
. The internalization further requires subsequent models to satisfy monotonicity w.r.t. UMoTs (see Sections 6.2.3 and 7.3.1), which is the root of other properties involving UMoTs. The internalization seems to provide certain modularity, and we conjecture that our proof can be adapted to other modalities in Kripke style by only adjusting the definition of UMoTs and the proof of monotonicity. In fact, UMoTs have sufficiently captured the Kripke structures of all Systems K, T, K4, and S4, so as a bonus, their normalization is established simultaneously.
Our approach is in contrast to the external approach by Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019), where the model is parameterized by an extra layer of poset. Subsequent proofs thus must explicitly quantify over this poset, making their proof more difficult to adapt to other modalities (Gratzer et al., Reference Gratzer, Kavvos, Nuyts and Birkedal2020).
Before defining applications of UMoTs, we first define the following operations:

Cons of UMoTs is defined in a way similar to environments. UMoTs have composition, and we use
 $\overrightarrow{1}$
to represent the identity UMoT in our setting. As previously mentioned, UMoTs form a substitutional truncoid. A quick intuition is that UMoTs behave like substitutions in the semantics, except that it only brings values from one world to another without touching the variables. In the following, we give the
$\overrightarrow{1}$
to represent the identity UMoT in our setting. As previously mentioned, UMoTs form a substitutional truncoid. A quick intuition is that UMoTs behave like substitutions in the semantics, except that it only brings values from one world to another without touching the variables. In the following, we give the ![]() for applying a UMoT to domain values and environments:
for applying a UMoT to domain values and environments:

Following our previous convention, we let
 $a[\kappa]$
take a very low parsing precedence. Most cases just recursively push
$a[\kappa]$
take a very low parsing precedence. Most cases just recursively push
 $\kappa$
inwards, except the
$\kappa$
inwards, except the
 $\blacksquare$
,
$\blacksquare$
,
 ${{{{{\texttt{box}}}}}}$
and
${{{{{\texttt{box}}}}}}$
and
 ${{{{{\texttt{unbox}}}}}}$
cases. The cases for
${{{{{\texttt{unbox}}}}}}$
cases. The cases for
 $\blacksquare$
and
$\blacksquare$
and
 ${{{{{\texttt{box}}}}}}$
are similar.
${{{{{\texttt{box}}}}}}$
are similar.
 $\kappa;\Uparrow^{1}$
instructs their recursions to enter a new world, indicated by cons’ing 1 to
$\kappa;\Uparrow^{1}$
instructs their recursions to enter a new world, indicated by cons’ing 1 to
 $\kappa$
. The
$\kappa$
. The
 ${{{{{\texttt{unbox}}}}}}$
case is similar to the rule in Section 4.2. The recursion is
${{{{{\texttt{unbox}}}}}}$
case is similar to the rule in Section 4.2. The recursion is
 $c[\kappa \mid {n}]$
because c is in the n-th previous world. The
$c[\kappa \mid {n}]$
because c is in the n-th previous world. The
 ${{{{{\texttt{unbox}}}}}}$
level is adjusted to
${{{{{\texttt{unbox}}}}}}$
level is adjusted to
 $\mathcal{O}({\kappa}, {n})$
for coherence with the Kripke structure. The apply operation for a local environment
$\mathcal{O}({\kappa}, {n})$
for coherence with the Kripke structure. The apply operation for a local environment
 $\rho$
is just defined by applying
$\rho$
is just defined by applying
 $\kappa$
to all values within pointwise. The apply operation for
$\kappa$
to all values within pointwise. The apply operation for
 $\overrightarrow{\rho}$
can be motivated by making the triple
$\overrightarrow{\rho}$
can be motivated by making the triple
 $(\mathsf{Envs}, \text{UMoT}, \mathsf{Envs})$
an applicative truncoid. Indeed, this is the unique definition (up to isomorphism) to prove
$(\mathsf{Envs}, \text{UMoT}, \mathsf{Envs})$
an applicative truncoid. Indeed, this is the unique definition (up to isomorphism) to prove
 $\overrightarrow{\rho}[\kappa] \mid {n} = (\overrightarrow{\rho} \mid {n})[\kappa \mid {\mathcal{O}({\overrightarrow{\rho}}, {n})}]$
. From here, we can see the formulation of truncoids does guide us very quickly to the right definition of operations. Moreover, since UMoTs are substitutional, we would hope that
$\overrightarrow{\rho}[\kappa] \mid {n} = (\overrightarrow{\rho} \mid {n})[\kappa \mid {\mathcal{O}({\overrightarrow{\rho}}, {n})}]$
. From here, we can see the formulation of truncoids does guide us very quickly to the right definition of operations. Moreover, since UMoTs are substitutional, we would hope that
 $\mathsf{Envs}$
is closed under UMoTs. Indeed, this fact can be examined by checking the necessary laws imposed by a closed truncoid.
$\mathsf{Envs}$
is closed under UMoTs. Indeed, this fact can be examined by checking the necessary laws imposed by a closed truncoid.
5.3 Evaluation
Next we consider the ![]() , which, given
, which, given
 $\overrightarrow{\rho}$
, evaluates a syntactic term to a domain value or evaluates a K-substitution to another environment. In the following sections, we will define a number of partial functions (denoted by
$\overrightarrow{\rho}$
, evaluates a syntactic term to a domain value or evaluates a K-substitution to another environment. In the following sections, we will define a number of partial functions (denoted by
 $\rightharpoonup$
), which cannot be directly formalized in Agda. Instead, we define them as relations between inputs and outputs, and we prove that given the same inputs, the outputs are equal. When we refer to a result of a partial function, we implicitly existentially quantify this result for brevity.
$\rightharpoonup$
), which cannot be directly formalized in Agda. Instead, we define them as relations between inputs and outputs, and we prove that given the same inputs, the outputs are equal. When we refer to a result of a partial function, we implicitly existentially quantify this result for brevity.

Note that here
 $(\mathsf{Substs}, \mathsf{Envs}, \mathsf{Envs})$
forms an applicative truncoid when the evaluation terminates. In the evaluation of
$(\mathsf{Substs}, \mathsf{Envs}, \mathsf{Envs})$
forms an applicative truncoid when the evaluation terminates. In the evaluation of
 $\mathsf{Trm}$
, we make use of partial functions, which evaluate
$\mathsf{Trm}$
, we make use of partial functions, which evaluate
 ${{{{{\texttt{box}}}}}}$
and
${{{{{\texttt{box}}}}}}$
and
 $\Lambda$
. These partial functions are defined below:
$\Lambda$
. These partial functions are defined below:

Effectively, these partial functions remove all
 $\beta$
redexes.
$\beta$
redexes.
5.4 Readback functions
After evaluating a
 $\mathsf{Trm}$
to D, we have already got the corresponding
$\mathsf{Trm}$
to D, we have already got the corresponding
 $\beta$
normal form in D. We need one last step, readback functions, to read from D back to normal form and do the
$\beta$
normal form in D. We need one last step, readback functions, to read from D back to normal form and do the
 $\eta$
expansion at the same time to obtain a
$\eta$
expansion at the same time to obtain a
 $\beta\eta$
normal form:
$\beta\eta$
normal form:

A readback function takes as an argument
 $\overrightarrow{z} :: \overrightarrow{\mathbb{N}}$
, which is a nonempty list of natural numbers. Each number in this list records the length of the context in that position of the context stack. This list supplies new de Bruijn levels (i.e. new absolute and fresh names) as the readback process continues. In the
$\overrightarrow{z} :: \overrightarrow{\mathbb{N}}$
, which is a nonempty list of natural numbers. Each number in this list records the length of the context in that position of the context stack. This list supplies new de Bruijn levels (i.e. new absolute and fresh names) as the readback process continues. In the
 $\blacksquare$
case, since we enter a new world, 0 is pushed to the list because the new world has no assumption. In the Pi case, the topmost context is extended by one due to the argument of
$\blacksquare$
case, since we enter a new world, 0 is pushed to the list because the new world has no assumption. In the Pi case, the topmost context is extended by one due to the argument of
 $\lambda$
, so we also increment the topmost de Bruijn level by one. In the
$\lambda$
, so we also increment the topmost de Bruijn level by one. In the
 ${{{{{\texttt{unbox}}}}}}$
case, we must truncate
${{{{{\texttt{unbox}}}}}}$
case, we must truncate
 $\overrightarrow{z}$
in order to correctly keep track of the lengths of contexts in the stack because the context stack is also truncated. In the variable case in
$\overrightarrow{z}$
in order to correctly keep track of the lengths of contexts in the stack because the context stack is also truncated. In the variable case in
 $\mathsf{R}^{\mathsf{Ne}}$
, we use the aforementioned formula
$\mathsf{R}^{\mathsf{Ne}}$
, we use the aforementioned formula
 $z' - z - 1$
to compute the corresponding de Bruijn index in the syntax. If we begin with a well-typed term, then this formula is always non-negative, so we do not have to consider the case where we are cut off at 0.
$z' - z - 1$
to compute the corresponding de Bruijn index in the syntax. If we begin with a well-typed term, then this formula is always non-negative, so we do not have to consider the case where we are cut off at 0.
The readback process consists of three functions:
 $\mathsf{R}^{\mathsf{Nf}}$
reads back a normal form;
$\mathsf{R}^{\mathsf{Nf}}$
reads back a normal form;
 $\mathsf{R}^{\mathsf{Ne}}$
reads back a neutral form; and
$\mathsf{R}^{\mathsf{Ne}}$
reads back a neutral form; and
 $\mathsf{R}^{\mathsf{Ty}}$
reads back a normal type. Note that
$\mathsf{R}^{\mathsf{Ty}}$
reads back a normal type. Note that
 $\mathsf{R}^{\mathsf{Nf}}$
is type-directed, so
$\mathsf{R}^{\mathsf{Nf}}$
is type-directed, so
 $\eta$
expansion is performed. With evaluation and readback, we are ready to give the definition of the NbE algorithm by first evaluating a term and its type to the domain and then read back as a normal form:
$\eta$
expansion is performed. With evaluation and readback, we are ready to give the definition of the NbE algorithm by first evaluating a term and its type to the domain and then read back as a normal form:
Definition 5.1. For ![]() , the NbE algorithm is
, the NbE algorithm is
where the initial environment
 $\uparrow^{{\overrightarrow{\Gamma}}}$
is defined by the structure of
$\uparrow^{{\overrightarrow{\Gamma}}}$
is defined by the structure of
 ${\overrightarrow{\Gamma}}$
:
${\overrightarrow{\Gamma}}$
:

We have an elaborated example for running the NbE algorithm in Appendix B.
6 PER model and completeness
In the previous section, we have given the full definition of the NbE algorithm. In this section, we follow Abel (Reference Abel2013) and define a PER model for the untyped domain and prove the completeness theorem, which states that equivalent terms evaluate to an equal normal form. There are two steps to establish completeness: (1) the fundamental theorems, which prove soundness of the PER model, and (2) the realizability theorem, which states that values related by the PER model have an equal normal form. Similar to other NbE proofs for dependent types (Abel, Reference Abel2013; Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Kaposi & Altenkirch, Reference Kaposi and Altenkirch2017; Wieczorek & Biernacki, Reference Wieczorek and Biernacki2018; Gratzer et al., Reference Gratzer, Sterling and Birkedal2019), the soundness proof of NbE relies on the fundamental theorems of the PER model, so the PER model is a prerequisite for the next section.
Due to our intention of staying close to our mechanization, we assign names to judgments, ranging from
 ${{{{{\mathcal{D}}}}}}$
,
${{{{{\mathcal{D}}}}}}$
,
 ${{{{{\mathcal{E,}}}}}}$
and
${{{{{\mathcal{E,}}}}}}$
and
 ${{{{{\mathcal{J}}}}}}$
.
${{{{{\mathcal{J}}}}}}$
.
6.1 PER model
We follow Abel (Reference Abel2013) and first introduce the following relations.

where
 $Nf \subseteq D^{\mathsf{Nf}} \times D^{\mathsf{Nf}}$
,
$Nf \subseteq D^{\mathsf{Nf}} \times D^{\mathsf{Nf}}$
,
 $Ty \subseteq D \times D$
and
$Ty \subseteq D \times D$
and
 $Ne \subseteq D^{\mathsf{Ne}} \times D^{\mathsf{Ne}}$
. Nf relates two normal domain values iff their readbacks are equal given any context stack and UMoT. Ty and Ne are defined similarly. We will show by realizability (Section 6.2.5) that all forthcoming PERs are subsumed by Nf, so any two related values have equal readbacks as normal forms, through which completeness is established. These relations are part of dependently typed candidate space introduced by Abel (Reference Abel2013). Since these relations are defined by equality, they are indeed PERs.
$Ne \subseteq D^{\mathsf{Ne}} \times D^{\mathsf{Ne}}$
. Nf relates two normal domain values iff their readbacks are equal given any context stack and UMoT. Ty and Ne are defined similarly. We will show by realizability (Section 6.2.5) that all forthcoming PERs are subsumed by Nf, so any two related values have equal readbacks as normal forms, through which completeness is established. These relations are part of dependently typed candidate space introduced by Abel (Reference Abel2013). Since these relations are defined by equality, they are indeed PERs.
The premises of these PERs are all universally quantified over UMoTs. This universal quantification is and continues to be crucial in our PERs. Due to the substitutional truncoid structure of UMoTs, particularly composition, universally quantifying UMoTs allows us to internalize the Kripke structure and delegate the handling of the said structure to UMoTs, so that the proof structure is completely oblivious to the exact structure
 $\square$
possesses, making our constructions very adaptive as explained in Section 5.2.
$\square$
possesses, making our constructions very adaptive as explained in Section 5.2.
Now we move on to define the actual PERs that relate domain values. The PER model consists of two PERs:
 $\mathcal{U}_i$
which denotes a universe and relates two domain types at level i, and
$\mathcal{U}_i$
which denotes a universe and relates two domain types at level i, and
 $\textbf{El}_i({{{{{\mathcal{D}}}}}})$
which given
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
which given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
relates two domain values of domain types A and B. The PER model resembles Tarski-style universes (Palmgren, Reference Palmgren1998), in which universes contain “codes” and
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
relates two domain values of domain types A and B. The PER model resembles Tarski-style universes (Palmgren, Reference Palmgren1998), in which universes contain “codes” and
 $\textbf{El}$
converts these codes into actual types which contain values. Following Abel (Reference Abel2013) and Abel et al. (Reference Abel, Vezzosi and Winterhalter2017),
$\textbf{El}$
converts these codes into actual types which contain values. Following Abel (Reference Abel2013) and Abel et al. (Reference Abel, Vezzosi and Winterhalter2017),
 $\mathcal{U}_i$
and
$\mathcal{U}_i$
and
 $\textbf{El}_i$
are defined inductive-recursively (Dybjer, Reference Dybjer2000). Moreover, due to cumulative universes, they must in addition be defined with the well-foundedness of the universe levels. We refer interested readers to our Agda code for our actual formalization of these two relations.
$\textbf{El}_i$
are defined inductive-recursively (Dybjer, Reference Dybjer2000). Moreover, due to cumulative universes, they must in addition be defined with the well-foundedness of the universe levels. We refer interested readers to our Agda code for our actual formalization of these two relations.
Definition 6.1. The equivalence for domain types ![]() and the equivalence for domain values
and the equivalence for domain values ![]() are defined as follows:
are defined as follows:
• Neutral types and neutral values:

Then
 $a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff
 $a \approx b \in Neu$
, where Neu relates two values only when they are actually neutral:
$a \approx b \in Neu$
, where Neu relates two values only when they are actually neutral:

Note that the annotating domain types
 $A_1$
and
$A_1$
and
 $A_2$
do not matter as long as c and c’ are related by Ne.
$A_2$
do not matter as long as c and c’ are related by Ne.
• Universes:

Then
 $a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff
 $a \approx b \in \mathcal{U}_j$
. Note that here
$a \approx b \in \mathcal{U}_j$
. Note that here
 $\textbf{El}_i({{{{{\mathcal{D}}}}}})$
is defined in terms of
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
is defined in terms of
 $\mathcal{U}_j$
. This is fine because of
$\mathcal{U}_j$
. This is fine because of
 $j < i$
and the well-foundedness of universe levels.
$j < i$
and the well-foundedness of universe levels.
• Semantic
$\blacksquare$
types:


Then
 $a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff for any UMoT
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff for any UMoT
 $\kappa$
and
$\kappa$
and
 ${{{{{\texttt{unbox}}}}}}$
level n, the
${{{{{\texttt{unbox}}}}}}$
level n, the
 ${{{{{\texttt{unbox}}}}}}$
ing’s of
${{{{{\texttt{unbox}}}}}}$
ing’s of
 $a[\kappa]$
and
$a[\kappa]$
and
 $b[\kappa]$
remain related:
$b[\kappa]$
remain related:
 ${{{{{\texttt{unbox}}}}}} \cdot (n, a[\kappa]) \approx {{{{{\texttt{unbox}}}}}} \cdot (n, b[\kappa]) \in \textbf{El}_i({{{{{\mathcal{J}}}}}}(\kappa;\Uparrow^{n}))$
. In other words, if a and b are still related no matter how they travel in Kripke worlds and then are
${{{{{\texttt{unbox}}}}}} \cdot (n, a[\kappa]) \approx {{{{{\texttt{unbox}}}}}} \cdot (n, b[\kappa]) \in \textbf{El}_i({{{{{\mathcal{J}}}}}}(\kappa;\Uparrow^{n}))$
. In other words, if a and b are still related no matter how they travel in Kripke worlds and then are
 ${{{{{\texttt{unbox}}}}}}$
’ed, then they are related by
${{{{{\texttt{unbox}}}}}}$
’ed, then they are related by
 $\textbf{El}_i({{{{{\mathcal{D}}}}}})$
.
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
.
• Semantic Pi types:

Then
 $a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff for any UMoT
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
iff for any UMoT
 $\kappa$
and related a’ and b’, i.e.,
$\kappa$
and related a’ and b’, i.e.,
 ${{{{{\mathcal{E}}}}}} :: a' \approx b' \in \textbf{El}_i({{{{{\mathcal{J}}}}}}_1(\kappa))$
, the results of applying
${{{{{\mathcal{E}}}}}} :: a' \approx b' \in \textbf{El}_i({{{{{\mathcal{J}}}}}}_1(\kappa))$
, the results of applying
 $a[\kappa]$
and
$a[\kappa]$
and
 $b[\kappa]$
remain related:
$b[\kappa]$
remain related:
 $a[\kappa] \cdot a' \approx b[\kappa] \cdot b' \in \textbf{El}_i({{{{{\mathcal{J}}}}}}_2(\kappa, {{{{{\mathcal{E}}}}}}))$
. That is, a and b are related if all results of applying them in other worlds to related values are still related.
$a[\kappa] \cdot a' \approx b[\kappa] \cdot b' \in \textbf{El}_i({{{{{\mathcal{J}}}}}}_2(\kappa, {{{{{\mathcal{E}}}}}}))$
. That is, a and b are related if all results of applying them in other worlds to related values are still related.
6.2 Properties for PERs
During mechanization, we are forced to make everything precise and type theory friendly and observe certain gaps between a set-theoretic proof and a type-theoretic one. In this section, we discuss how properties of our PERs are formulated and proved in a type-theoretic flavor. Our mechanization also exposes some oversimplifications about universes that are common in on-paper, set theoretic NbE proofs (Abel, Reference Abel2013; Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Gratzer et al., Reference Gratzer, Sterling and Birkedal2019) in Section 6.2.4.
6.2.1
$\mathcal{U}$
irrelevance

While it comes for free in paper proofs, we must prove the intuition that
 $\textbf{El}_i$
only relies on A and B in
$\textbf{El}_i$
only relies on A and B in
 $A \approx B \in \mathcal{U}_i$
, not how exactly they are related by
$A \approx B \in \mathcal{U}_i$
, not how exactly they are related by
 $\mathcal{U}_i$
. Effectively, we would like to show that
$\mathcal{U}_i$
. Effectively, we would like to show that
 $\mathcal{U}$
is proof-irrelevant:
$\mathcal{U}$
is proof-irrelevant:
Lemma 6.1 ![]() . Given
. Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
 $a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
,
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
,
• if
${{{{{\mathcal{E}}}}}}_1 :: A \approx B' \in \mathcal{U}_i$
, then
$a \approx b \in \textbf{El}_i({{{{{\mathcal{E}}}}}}_1)$
;• if
${{{{{\mathcal{E}}}}}}_2 :: A' \approx B \in \mathcal{U}_i$
, then
$a \approx b \in \textbf{El}_i({{{{{\mathcal{E}}}}}}_2)$
.




This lemma matches our set-theoretic intuition and states that a and b are related as long as we know they are related by one “representative” domain type.
6.2.2
$\mathcal{U}$
and
$\textbf{El}$
are PERs


When proving
 $\mathcal{U}$
and
$\mathcal{U}$
and
 $\textbf{El}$
being PERs, we were already facing strong scrutiny from Agda’s termination checker, so we must adjust our statements to more type-theoretic ones. To even state symmetry, we have to introduce an extra premise
$\textbf{El}$
being PERs, we were already facing strong scrutiny from Agda’s termination checker, so we must adjust our statements to more type-theoretic ones. To even state symmetry, we have to introduce an extra premise
 ${{{{{\mathcal{D}}}}}}_2$
. This extra assumption
${{{{{\mathcal{D}}}}}}_2$
. This extra assumption
 ${{{{{\mathcal{D}}}}}}_2$
exposes a clearer termination measure and allows Agda to admit our proof just by recognizing decreasing structures.
${{{{{\mathcal{D}}}}}}_2$
exposes a clearer termination measure and allows Agda to admit our proof just by recognizing decreasing structures.
Lemma 6.2 (Symmetry). Given
 ${{{{{\mathcal{D}}}}}}_1 :: A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}}_1 :: A \approx B \in \mathcal{U}_i$
,
•
$B \approx A \in \mathcal{U}_i$
;• if
${{{{{\mathcal{D}}}}}}_2 :: B \approx A \in \mathcal{U}_i$
, and
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}}_1)$
, then
$b \approx a \in \textbf{El}_i({{{{{\mathcal{D}}}}}}_2)$
.




Proof Induction on i and
 ${{{{{\mathcal{D}}}}}}_1$
and inversion on
${{{{{\mathcal{D}}}}}}_1$
and inversion on
 ${{{{{\mathcal{D}}}}}}_2$
in the second statement.
${{{{{\mathcal{D}}}}}}_2$
in the second statement.
The symmetry of
 $\textbf{El}$
requires two
$\textbf{El}$
requires two
 $\mathcal{U}_i$
derivations:
$\mathcal{U}_i$
derivations:
 ${{{{{\mathcal{D}}}}}}_1$
relating A and B, and
${{{{{\mathcal{D}}}}}}_1$
relating A and B, and
 ${{{{{\mathcal{D}}}}}}_2$
relating B and A. They are used in the premise and the conclusion, respectively.
${{{{{\mathcal{D}}}}}}_2$
relating B and A. They are used in the premise and the conclusion, respectively.
 ${{{{{\mathcal{D}}}}}}_2$
is important to handle the contravariance of the input and the output in the function case.
${{{{{\mathcal{D}}}}}}_2$
is important to handle the contravariance of the input and the output in the function case.
 ${{{{{\mathcal{D}}}}}}_2$
can be eventually discharged by combining the symmetry of
${{{{{\mathcal{D}}}}}}_2$
can be eventually discharged by combining the symmetry of
 $\mathcal{U}_i$
and irrelevance, but it is necessary to prove the lemma in a type-theoretic flavor.
$\mathcal{U}_i$
and irrelevance, but it is necessary to prove the lemma in a type-theoretic flavor.
Transitivity also requires a similar treatment but more complex:
Lemma 6.3 (Transitivity). Given
 ${{{{{\mathcal{D}}}}}}_1 :: A_1 \approx A_2 \in \mathcal{U}_i$
and
${{{{{\mathcal{D}}}}}}_1 :: A_1 \approx A_2 \in \mathcal{U}_i$
and
 ${{{{{\mathcal{D}}}}}}_2 :: A_2 \approx A_3 \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}}_2 :: A_2 \approx A_3 \in \mathcal{U}_i$
,
•
$A_1 \approx A_3 \in \mathcal{U}_i$
;• if
${{{{{\mathcal{D}}}}}}_3 :: A_1 \approx A_3 \in \mathcal{U}_i$
,
$A_1 \approx A_1 \in \mathcal{U}_i$
, and
$a_1 \approx a_2 \in \textbf{El}_i({{{{{\mathcal{D}}}}}}_1)$
and
$a_2 \approx a_3 \in \textbf{El}_i({{{{{\mathcal{D}}}}}}_2)$
, then
$a_1 \approx a_3 \in \textbf{El}_i({{{{{\mathcal{D}}}}}}_3)$
.






In addition to
 ${{{{{\mathcal{D}}}}}}_3$
which is used in
${{{{{\mathcal{D}}}}}}_3$
which is used in
 $\textbf{El}_i({{{{{\mathcal{D}}}}}}_3)$
in conclusion, reflexivity of
$\textbf{El}_i({{{{{\mathcal{D}}}}}}_3)$
in conclusion, reflexivity of
 $A_1$
,
$A_1$
,
 $A_1 \approx A_1 \in \mathcal{U}_i$
, is also a required assumption. This is again due to the function case. Prior to establishing transitivity, we do not have reflexivity, so it is easier to make
$A_1 \approx A_1 \in \mathcal{U}_i$
, is also a required assumption. This is again due to the function case. Prior to establishing transitivity, we do not have reflexivity, so it is easier to make
 $A_1 \approx A_1 \in \mathcal{U}_i$
an extra assumption. Again, Agda admits our proof just by decreasing structures.
$A_1 \approx A_1 \in \mathcal{U}_i$
an extra assumption. Again, Agda admits our proof just by decreasing structures.
6.2.3 Monotonicity
As explained in Section 5.2, our PERs must respect UMoTs, i.e., are monotonic. Monotonicity ensures that the Kripke structure is successfully internalized, so subsequent proofs are unaware of the exact modality we are handling, making our proof structure very general. Due to the composition of UMoTs, all properties describing the Kripke structure eventually boil down to monotonicity.
Lemma 6.4 (Monotonicity). Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and a UMoT
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and a UMoT
 $\kappa$
,
$\kappa$
,
•
$A[\kappa] \approx B[\kappa] \in \mathcal{U}_i$
;• if
${{{{{\mathcal{E}}}}}} :: A[\kappa] \approx B[\kappa] \in \mathcal{U}_i$
and
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
, then
$a[\kappa] \approx b[\kappa] \in \textbf{El}_i({{{{{\mathcal{E}}}}}})$
.




Similar to symmetry and transitivity, we also require
 ${{{{{\mathcal{E}}}}}}$
in the second statement to ease termination checking in Agda.
${{{{{\mathcal{E}}}}}}$
in the second statement to ease termination checking in Agda.
6.2.4 Cumulativity and lowering
While there is existing work on NbE proofs of dependent type theories (Abel, Reference Abel2013; Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Gratzer et al., Reference Gratzer, Sterling and Birkedal2019) which considers full cumulative universe hierarchies, they all slightly oversimplify the proofs of the cumulativity of their PER models. Cumulativity states that if two types or values are related at level i, then they are also related at level
 $1 + i$
. At first glance, this property is too intuitive to be worth looking into. However, if we carefully consider the function case, we see that in the proof, we assume two related values at level
$1 + i$
. At first glance, this property is too intuitive to be worth looking into. However, if we carefully consider the function case, we see that in the proof, we assume two related values at level
 $1+i$
, but our premise requires them to be related at level i, and we are stuck. To correctly prove cumulativity, we must mutually prove a lowering lemma:
$1+i$
, but our premise requires them to be related at level i, and we are stuck. To correctly prove cumulativity, we must mutually prove a lowering lemma:
Lemma 6.5 (Cumulativity and lowering). If
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
• then
${{{{{\mathcal{D}}}}}}' :: A \approx B \in \mathcal{U}_{i+1}$
;• if
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
, then
$a \approx b \in \textbf{El}_{i+1}({{{{{\mathcal{D}}}}}}')$
;• if
$a \approx b \in \textbf{El}_{i+1}({{{{{\mathcal{D}}}}}}')$
, then
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
.





Note that according to the last statement, we can lower from
 $\textbf{El}_{1+i}$
to
$\textbf{El}_{1+i}$
to
 $\textbf{El}_i$
if we know A and B are related at level i. In general, lowering is necessary for type constructors in which types can occur in negative positions. It is this lowering property that is being somewhat glossed over in prior work.
$\textbf{El}_i$
if we know A and B are related at level i. In general, lowering is necessary for type constructors in which types can occur in negative positions. It is this lowering property that is being somewhat glossed over in prior work.
6.2.5 Realizability
Following Abel (Reference Abel2013), we prove the realizability theorem, which states that related values are read back equal. Realizability of the PER model is essential to establish the completeness and the soundness theorems. More formally,
Theorem 6.6 (Realizability). Given
 ${{{{{\mathcal{D}}}}}} ::\ A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}} ::\ A \approx B \in \mathcal{U}_i$
,
•
$A \approx B \in Ty$
;• if
$c \approx c' \in Ne$
, then
$\uparrow^A(c) \approx \uparrow^B(c') \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
;• if
$a \approx b \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
, then
$\downarrow^A(c) \approx \downarrow^B(c') \in Nf$
.





Proof Induction on i and
 ${{{{{\mathcal{D}}}}}}$
.
${{{{{\mathcal{D}}}}}}$
.
The first statement says that if A and B are related, then they are always read back as an equal normal type in syntax. The third statement says that if a and b are related, then they are always read back as an equal normal form in syntax. Combined with the fundamental theorems which we are about to give in Section 6.4, we prove completeness.
6.3 PER model for context stacks and environments
To define semantic judgments that are used to state fundamental theorems, we extend the PER model to context stacks and environments.
Definition 6.2 The equivalence of context stacks ![]() and the equivalence of evaluation environments
and the equivalence of evaluation environments ![]() are defined inductive-recursively as follows:
are defined inductive-recursively as follows:
•
Then ![]() is always true.
is always true.
•
Then
iff - truncations of
$\overrightarrow{\rho}$
and
$\overrightarrow{\rho}'$
by one are recursively related: , and- first modal offsets are equal:
$n = n'$
where
$(n, \_) := \overrightarrow{\rho}(0)$
and
$(n', \_) := \overrightarrow{\rho}'(0)$
.
•
Then
$\overrightarrow{\rho} \approx \overrightarrow{\rho}' \in {{{{{[\![ {{{{{\mathcal{D}}}}}} ]\!]}}}}}$
iff -
${{{{{\texttt{drop}}}}}}(\overrightarrow{\rho})$
and
${{{{{\texttt{drop}}}}}}(\overrightarrow{\rho}')$
are recursively related: , and- the topmost values are related by the evaluations of T:
$\rho(0) \approx \rho'(0) \in \textbf{El}_i({{{{{\mathcal{J}}}}}}_2({{{{{\mathcal{E}}}}}}))$
where
$ (\_, \rho) := \overrightarrow{\rho}(0) $
and
$ (\_, \rho') := \overrightarrow{\rho}'(0) $
.













We can extend properties in Section 6.2 to context stacks and environments as well, e.g., ![]() .
.
6.4 Semantic judgments, fundamental theorems, and completeness
Having defined all PER models, we are ready to define the semantic judgments:
Definition 6.3. We define ![]() as follows:
as follows:

where ![]() iff
iff
•
${\overrightarrow{\Gamma}}$
is semantically well formed:
${{{{{\mathcal{D}}}}}} ::\ \vDash {\overrightarrow{\Gamma}}$
, and• there exists a universe level i, such that for any related
$\overrightarrow{\rho}$
and
$\overrightarrow{\rho}'$
, i.e., , - evaluations of T are related types:
and- evaluations of t and t’ are related values:
;




and ![]() iff
iff
•
${\overrightarrow{\Gamma}}$
and
${\overrightarrow{\Delta}}$
are semantically well formed:
${{{{{\mathcal{D}}}}}} ::\ \vDash {\overrightarrow{\Gamma}}$
and
${{{{{\mathcal{E}}}}}} ::\ \vDash {\overrightarrow{\Delta}}$
, and• for any related
$\overrightarrow{\rho}$
and
$\overrightarrow{\rho}'$
, i.e., ,
${\overrightarrow{\sigma}}$
and
${\overrightarrow{\sigma}'}$
evaluate to related environments: .








The fundamental theorem states that the semantic judgments are sound w.r.t. the syntactic judgments:
Theorem 6.7 (Fundamental).

Proof Mutual induction on all premises (see the mechanization for full details)
The completeness theorem states that syntactic equivalent terms evaluate to equal normal forms:
Theorem 6.8 ![]() . If
. If ![]() , then
, then
 $\mathsf{nbe}^T_{{\overrightarrow{\Gamma}}}(t) = \mathsf{nbe}^T_{{\overrightarrow{\Gamma}}}(t')$
.
$\mathsf{nbe}^T_{{\overrightarrow{\Gamma}}}(t) = \mathsf{nbe}^T_{{\overrightarrow{\Gamma}}}(t')$
.
Proof By the fundamental theorems, we have ![]() from which we know
from which we know
 ${{{{{\mathcal{D}}}}}} ::\ \vDash {\overrightarrow{\Gamma}}$
. We have that the initial environment is related:
${{{{{\mathcal{D}}}}}} ::\ \vDash {\overrightarrow{\Gamma}}$
. We have that the initial environment is related: ![]() . We further learn that
. We further learn that ![]() are related, and due to realizability, they have equal normal forms.
are related, and due to realizability, they have equal normal forms.
6.5 Consequences of completeness
From the fundamental theorems of the PER model, we can derive a few consequences, which are useful but very challenging to prove syntactically:
Lemma 6.9 ![]() , then
, then
 $i = j$
.
$i = j$
.
Proof Completeness says that
 $\texttt{Ty}_i$
and
$\texttt{Ty}_i$
and
 $\texttt{Ty}_j$
have equal normal form, which implies
$\texttt{Ty}_j$
have equal normal form, which implies
 $i = j$
.
$i = j$
.
Due to the previous lemma, we can prove the following “exact inversion” lemma:
Lemma 6.10 ![]() .
.
• If
.• If
.
If we proceed by induction on the premise, the universe levels in the conclusion cannot be made exactly i. However, this is now possible with the fundamental theorems.
7 Kripke gluing model and soundness
In the previous section, we have established the completeness theorem. In this section, we present the soundness proof for the NbE algorithm, which states that a well-typed term is equivalent to its evaluated normal form. Central to the proof is a Kripke gluing model. The model glues the syntax and the semantics (Coquand & Dybjer, Reference Coquand and Dybjer1997) and is Kripke because it is monotonic w.r.t. a special class of K-substitutions, restricted weakenings. Similar to completeness, the proof of soundness also has two steps: (1) the fundamental theorems and (2) the realizability theorem stating that a term is equivalent to the readback of its related value. We first give the definitions of restricted weakenings and the gluing model.
7.1 Restricted weakening
Restricted weakenings are a special class of K-substitutions, which characterize the possible changes in context stacks during evaluation. Therefore, if a term and a value are related, their relation must be stable under restricted weakenings, hence introducing a Kripke structure to the gluing model.
Definition 7.1. A K-substitution
 ${\overrightarrow{\sigma}}$
is a
${\overrightarrow{\sigma}}$
is a ![]() if it inductively satisfies
if it inductively satisfies

Effectively, a restricted weakening can only do either local weakenings (
 $\mathsf{wk}$
) or modal extensions (
$\mathsf{wk}$
) or modal extensions (
 $\_;\Uparrow^{n}$
), because only these two cases are possible during evaluation. Since restricted weakenings form a category, we require the gluing model to respect them.
$\_;\Uparrow^{n}$
), because only these two cases are possible during evaluation. Since restricted weakenings form a category, we require the gluing model to respect them.
7.2 Gluing model
Restricted weakenings are already K-substitutions, so they naturally apply to syntactic terms. However, to define the gluing model, we must also apply them to domain values. This is achieved by ![]() ,Footnote 5 which extracts a UMoT from a K-substitution (not just a restricted weakening).
,Footnote 5 which extracts a UMoT from a K-substitution (not just a restricted weakening).

Moreover, for conciseness, given a K-substitution
 ${\overrightarrow{\sigma}}$
and a domain value a, we write
${\overrightarrow{\sigma}}$
and a domain value a, we write
 $a[{\overrightarrow{\sigma}}]$
for
$a[{\overrightarrow{\sigma}}]$
for
 $a[\texttt{mt}({\overrightarrow{\sigma}})]$
unless the distinction is worth emphasizing. Next, we define the gluing model that relates syntactic and domain terms and types. For a PER P, we write
$a[\texttt{mt}({\overrightarrow{\sigma}})]$
unless the distinction is worth emphasizing. Next, we define the gluing model that relates syntactic and domain terms and types. For a PER P, we write
 $p \in P$
for
$p \in P$
for
 $p \approx p \in P$
:
$p \approx p \in P$
:
Definition 7.2 Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
•
says that T is related to domain types A and B in
${\overrightarrow{\Gamma}}$
as a type at level i.•
says that in
${\overrightarrow{\Gamma}}$
, t of type T is related to domain value a in
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
.



![]() and
and ![]() are defined mutually by first well-founded recursion on i and then recursion on
are defined mutually by first well-founded recursion on i and then recursion on
 ${{{{{\mathcal{D}}}}}}$
:
${{{{{\mathcal{D}}}}}}$
:
•
iff - T is a type at level i:
.- For any restricted weakening
${\overrightarrow{\sigma}}$
, that is , s.t.
iff-
$c \in Ne$
.- T is a type at level i:
.- t is well typed:
.- For any restricted weakening
${\overrightarrow{\sigma}}$
, that is , s.t. and
•
iff . iff - t is well typed:
.- T is equivalent to
$\texttt{Ty}_j$
: .- a is in PER
$\mathcal{U}_j$
:
${{{{{\mathcal{E}}}}}} :: a \in \mathcal{U}_j$
.- t and a are recursively related as types by well-foundedness:
.
Note that
refers to , so the definition requires a well-founded recursion on i.•
iff there exists some T’, such that- T is equivalent to
.- For any
${\overrightarrow{\Delta}'}$
such that
$\vdash {\overrightarrow{\Delta}}; {\overrightarrow{\Delta}'}$
and any restricted weakening and
${{{{{\mathcal{E}}}}}}({\overrightarrow{\sigma}};\Uparrow^{|{\overrightarrow{\Delta}'}|})$
are recursively related as types:
iff there exists some T’, such that- t is well typed:
.- a is in
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
:
$a \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
.- T is equivalent to
$\square T'$
: .- For any
${\overrightarrow{\Delta}'}$
such that
$\vdash {\overrightarrow{\Delta}}; {\overrightarrow{\Delta}'}$
and any restricted weakening , the results of eliminating
$t[{\overrightarrow{\sigma}}]$
and
$a[{\overrightarrow{\sigma}}]$
are recursively related as terms:
•
iff there exist
$T_1$
and
$T_2$
, such that- T and
$\Pi T_1. T_2$
are equivalent:
-
$T_2$
is well typed: .- For any restricted weakening
,*
$T_1[{\overrightarrow{\sigma}}]$
and
${{{{{\mathcal{E}}}}}}_1({\overrightarrow{\sigma}})$
are recursively related: , and* For any related s and b, i.e.
, and
${{{{{\mathcal{E}}}}}}_3 :: b \in \textbf{El}_i({{{{{\mathcal{E}}}}}}_1({\overrightarrow{\sigma}}))$
,
$T_2[{\overrightarrow{\sigma}}, s]$
and
${{{{{\mathcal{E}}}}}}_2({\overrightarrow{\sigma}},{{{{{\mathcal{E}}}}}}_3)$
are recursively related as types:
Note that here we require
${{{{{\mathcal{E}}}}}}_3 :: b \in \textbf{El}_i({{{{{\mathcal{E}}}}}}_1({\overrightarrow{\sigma}}))$
as an assumption, which technically from . However, this fact requires a proof and thus cannot be used at the time of definition. Adding this assumption simplifies our definition. iff there exist
$T_1$
and
$T_2$
, such that- t is well typed:
.- a is in the PER
$\textbf{El}_i({{{{{\mathcal{D}}}}}})$
:
$ a \in \textbf{El}_i({{{{{\mathcal{D}}}}}})$
.- T and
$\Pi T_1. T_2$
are equivalent: .-
$T_2$
is well typed: .- For any restricted weakening
, *
$T_1[{\overrightarrow{\sigma}}]$
and
${{{{{\mathcal{E}}}}}}_1({\overrightarrow{\sigma}})$
are recursively related: , and* For any related s and b, i.e.,
, and
${{{{{\mathcal{E}}}}}}_3 :: b \in \textbf{El}_i({{{{{\mathcal{E}}}}}}_1({\overrightarrow{\sigma}}))$
, the results of eliminating
$t[{\overrightarrow{\sigma}}]$
and
$a[{\overrightarrow{\sigma}}]$
are recursively related as terms:










































7.3 Properties of gluing model
In this section, we discuss some properties of the gluing model. For conciseness, we focus on monotonicity, realizability, and cumulativity.
7.3.1 Monotonicity
Monotonicity ensures that the gluing model is stable under restricted weakenings. Restricted weakenings apply to both syntax and semantics because they contain modal extensions to instruct both sides to travel among Kripke worlds. Following a similar strategy as in the PER model, we add the additional typing derivations
 ${{{{{\mathcal{D}}}}}}$
and
${{{{{\mathcal{D}}}}}}$
and
 ${{{{{\mathcal{E,}}}}}}$
which characterize
${{{{{\mathcal{E,}}}}}}$
which characterize
 $A\approx B$
and
$A\approx B$
and
 $A[{\overrightarrow{\sigma}}] \approx B[{\overrightarrow{\sigma}}],$
resp., to expose more clearly the proof structure and simplify the termination argument.
$A[{\overrightarrow{\sigma}}] \approx B[{\overrightarrow{\sigma}}],$
resp., to expose more clearly the proof structure and simplify the termination argument.
Lemma 7.1 (Monotonicity). Given a restricted weakening ![]() ,
,
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
 ${{{{{\mathcal{E}}}}}} :: A[{\overrightarrow{\sigma}}] \approx B[{\overrightarrow{\sigma}}] \in \mathcal{U}_i$
,
${{{{{\mathcal{E}}}}}} :: A[{\overrightarrow{\sigma}}] \approx B[{\overrightarrow{\sigma}}] \in \mathcal{U}_i$
,
• if
then ;
• if
7.3.2 Realizability
In completeness, realizability morally states that
 $\textbf{El}$
is subsumed by Nf. In soundness, realizability has a similar structure. We first need to give three definitions, which serve a purpose similar to Ty, Ne, and Nf in completeness:
$\textbf{El}$
is subsumed by Nf. In soundness, realizability has a similar structure. We first need to give three definitions, which serve a purpose similar to Ty, Ne, and Nf in completeness:
Definition 7.3. Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,

The first judgment ![]() states that T is equivalent to the readback of A (or equally the readback of B) under all valid restricted weakenings. Similarly, the third judgment
states that T is equivalent to the readback of A (or equally the readback of B) under all valid restricted weakenings. Similarly, the third judgment ![]() states that t is equivalent to the readback of a under all valid restricted weakenings. The realizability theorem states that the gluing models of types and terms are subsumed by these two judgments, respectively, which constitutes our second step to the soundness proof. Then, we state the realizability for the gluing model:
states that t is equivalent to the readback of a under all valid restricted weakenings. The realizability theorem states that the gluing models of types and terms are subsumed by these two judgments, respectively, which constitutes our second step to the soundness proof. Then, we state the realizability for the gluing model:
Theorem 7.2 (Realizability). Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
,
• if
• if
• if
7.3.3 Cumulativity and lowering
Similar to the PER model, cumulativity of the gluing model also requires a lowering statement to handle the function cases and contravariant occurrences in type constructors in general:
Lemma 7.3 ![]() . Given
. Given
 ${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
${{{{{\mathcal{D}}}}}} :: A \approx B \in \mathcal{U}_i$
and
 ${{{{{\mathcal{E}}}}}} :: A \approx B \in \mathcal{U}_{1+i}$
which we obtain by applying Lemma 6.5 to
${{{{{\mathcal{E}}}}}} :: A \approx B \in \mathcal{U}_{1+i}$
which we obtain by applying Lemma 6.5 to
 ${{{{{\mathcal{D}}}}}}$
,
${{{{{\mathcal{D}}}}}}$
,
• if
• if
• if
.
The first two statements are just cumulativity. However, there is one more complication here in the lowering: we cannot simply derive ![]() from
from ![]() ! This is because the gluing model contains syntactic information about types so the lowering statement must in addition have an assumption about T and
! This is because the gluing model contains syntactic information about types so the lowering statement must in addition have an assumption about T and
 ${{{{{\mathcal{D}}}}}}$
’s relation at a lower level, which is introduced by
${{{{{\mathcal{D}}}}}}$
’s relation at a lower level, which is introduced by ![]() . With this assumption, we successfully establish the cumulativity for the gluing model.
. With this assumption, we successfully establish the cumulativity for the gluing model.
7.4 Gluing model for K-substitutions and environments
In this section, we generalize the gluing model to K-substitutions and evaluation environments. Our gluing model is in fact more complex than existing proofs on paper (Abel, Reference Abel2013; Abel et al., Reference Abel, Vezzosi and Winterhalter2017; Gratzer et al., Reference Gratzer, Sterling and Birkedal2019), in that our gluing model is again defined through induction–recursion, while existing proofs directly proceed by recursion on the structure of the domain contexts (or context stacks in our case). This existing proof technique will not work in mechanization, because this technique heavily relies on cumulativity to bring the gluing model for terms and values to a limit, so the generalization to K-substitutions and environments does not care about universe levels. Evidently, in Agda, we cannot really take limits, so we must always keep track of universe levels. In our definition, we have an inductive definition
 $\Vdash {\overrightarrow{\Gamma}}$
of semantic well formedness of context stacks, in which universe levels are maintained. We speculate that this extra inductive predicate allows an easy adaptation to non-cumulative settings, an NbE proof of which remains unseen to date.
$\Vdash {\overrightarrow{\Gamma}}$
of semantic well formedness of context stacks, in which universe levels are maintained. We speculate that this extra inductive predicate allows an easy adaptation to non-cumulative settings, an NbE proof of which remains unseen to date.
Definition 7.4. The semantic well formedness of context stacks ![]() and the gluing model for K-substitutions and environments
and the gluing model for K-substitutions and environments ![]() are defined inductive-recursively:
are defined inductive-recursively:
•
.•
-
${\overrightarrow{\sigma}}$
is well typed: .- There exists a K-substitution
${\overrightarrow{\sigma}'}$
and an modal offset n, such that *
${\overrightarrow{\sigma}'}$
is
${\overrightarrow{\sigma}}$
’s truncation: ,* modal offsets are equal:
$\mathcal{O}({{\overrightarrow{\sigma}}}, 1) = \mathcal{O}({\overrightarrow{\rho}}, 1) = n$
, and*
${\overrightarrow{\sigma}'}$
and
$\overrightarrow{\rho} \mid { }1$
are recursively related: .
•
iff-
${\overrightarrow{\sigma}}$
is well typed: .- There exists a K-substitution
${\overrightarrow{\sigma}'}$
and t, such that *
${\overrightarrow{\sigma}'}$
is
${\overrightarrow{\sigma}}$
with the topmost term dropped: ,* t is that topmost term:
.* T evaluates in
${{{{{\texttt{drop}}}}}}(\overrightarrow{\rho})$
and the result is in
$\mathcal{U}_i$
:* t and
$\overrightarrow{\rho}(0)$
are related at level i: , where
$(\_, \rho) := \overrightarrow{\rho}(0)$
,*
${\overrightarrow{\sigma}'}$
and
${{{{{\texttt{drop}}}}}}(\overrightarrow{\rho})$
are recursively related: .



















We can then prove ![]() like monotonicity, which we omit here in favor of space. We refer the readers to our Agda development. We then give the definitions for semantic judgments.
like monotonicity, which we omit here in favor of space. We refer the readers to our Agda development. We then give the definitions for semantic judgments.
Definition 7.5. Semantic judgments for soundness are defined as follows:

7.5 Fundamental theorems and soundness
Finally, we are ready to establish the fundamental theorems and soundness:
Theorem 7.4 (Fundamental).
• If
$\vdash {\overrightarrow{\Gamma}}$
, then
$\Vdash {\overrightarrow{\Gamma}}$
.• If
.• If
.


Theorem 7.5 (Soundness). If ![]() .
.
Proof We first apply the fundamental theorems and obtain ![]() . Moreover, we know
. Moreover, we know ![]() , t and
, t and ![]() are related. The goal is concluded by further applying realizability.
are related. The goal is concluded by further applying realizability.
7.6 Consequences
The fundamental theorems for the gluing model allow us to establish a few more consequences, which are difficult to prove syntactically. We show that the standard injectivity and canonicity hold in Mint.
Lemma 7.6 (Injectivity of Type Constructors).
• If
• If
and .
Lemma 7.7 (Canonicity of N). If ![]() , then
, then ![]() for some number n.
for some number n.
The following lemma about universe levels is also interesting. It says that if two types are equivalent and they are well typed at a different level, then they are equivalent also at that level. This lemma is intuitive but very challenging to prove syntactically.
Lemma 7.8 (Type equivalence). If ![]() , then
, then ![]() .
.
Proof From ![]() and completeness, we know
and completeness, we know
 $T_1$
and
$T_1$
and
 $T_2$
have equal normal form. We conclude the goal by soundness and transitivity.
$T_2$
have equal normal form. We conclude the goal by soundness and transitivity.
As the final and conclusive theorem, we show that Mint is consistent.
Theorem 7.9 (Consistency). There is no closed term of type
 $\Pi \texttt{Ty}_i . v_0$
. That is, there is no t such that the following judgment holds:
$\Pi \texttt{Ty}_i . v_0$
. That is, there is no t such that the following judgment holds:
In Agda’s syntax, the type is written as (A : Set_i) -> A and consistency requires that this type does not have a closed inhabitant. In other words, there is no generic way to construct a term for an arbitrary type. If Mint has a bottom type, then the consistency proof is immediately reduced to the consistency of our meta-language (i.e. Agda) and hence significantly simplifies the proof. For the current definition of Mint, we can still prove this theorem with a bit more technical setup.
Proof Note that consistency is equivalent to proving that there is no t’ such that
Note that, by soundness, t’ must be equivalent to some neutral term u by NbE, because its type (
 $v_0$
) is neutral. So our goal is to show that this u also does not exist:
$v_0$
) is neutral. So our goal is to show that this u also does not exist:
Now we do induction on u. We show that in
 $\varepsilon;\texttt{Ty}_i$
, there does not exist a neutral term of any type other than
$\varepsilon;\texttt{Ty}_i$
, there does not exist a neutral term of any type other than
 $\texttt{Ty}_j$
(i and j are not necessarily equal due to cumulativity), and thus it is impossible for u to have type
$\texttt{Ty}_j$
(i and j are not necessarily equal due to cumulativity), and thus it is impossible for u to have type
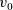 $v_0$
. Otherwise, that would require
$v_0$
. Otherwise, that would require
 $\texttt{Ty}_i$
and
$\texttt{Ty}_i$
and
 $v_0$
to be equivalent, which can be rejected by completeness as they do not evaluate to the same normal form.
$v_0$
to be equivalent, which can be rejected by completeness as they do not evaluate to the same normal form.
8 Extraction of the NbE algorithm
To use our NbE algorithm as a verified kernel of a proof assistant, we want to execute our mechanization. Even though we cannot directly execute our mechanization in Agda, we can obtain a Haskell implementation of our NbE algorithm from it using Agda’s extraction facility.
To illustrate how to use and run this extracted algorithm, we provide an example of executable code of the ubiquitous power function (see Appendix B). This Agda file contains the representation of the power function, its typing derivation, and use cases in Mint. We also apply the NbE algorithm to these use cases. Once extracted into Haskell, we can run the NbE algorithm on these use cases to obtain their normal forms and print them. For ease of use and reproducibility, we also provide the extracted Haskell code itself.
This shows that our formalization in principle can serve as an implementation of a verified kernel of a proof assistant equipped with the necessity modality.
9 Related work
9.1 Applications of modalities in multi-staged programming
As previously mentioned, the modal system S4 corresponds to multi-staged programming under Curry–Howard correspondence (Davies & Pfenning, Reference Davies and Pfenning2001) and Mint provides a dependently typed variant of S4. There are other applications of dependent typed systems to multi-staged programming. Kawata & Igarashi (Reference Kawata and Igarashi2019) study
 $\lambda^{\text{MD}}$
, a logical framework with stages.
$\lambda^{\text{MD}}$
, a logical framework with stages.
 $\lambda^{\text{MD}}$
uses stage variables to keep track of stages, while Mint uses context stacks and
$\lambda^{\text{MD}}$
uses stage variables to keep track of stages, while Mint uses context stacks and
 ${{{{{\texttt{unbox}}}}}}$
levels for the same purpose. Pasalic et al. (Reference Pasalic, Taha and Sheard2002) propose Meta-D to remove administrative redexes introduced in a staged interpreter. Brady & Hammond (Reference Brady and Hammond2006) improve Pasalic et al. (Reference Pasalic, Taha and Sheard2002) by also extending MLTT with stages. Fundamentally, the type theory in Brady & Hammond (Reference Brady and Hammond2006) is the dependently typed system T with cross-stage persistence. Extending the T variant of Mint with cross-stage persistence would constitute Brady&Hammond (Reference Brady and Hammond2006)’ system Though the authors claim that their type theory is strongly normalizing, they do not provide any proof, whereas Mint’s normalization proof naturally adapts to all subsystems of S4, including T.
${{{{{\texttt{unbox}}}}}}$
levels for the same purpose. Pasalic et al. (Reference Pasalic, Taha and Sheard2002) propose Meta-D to remove administrative redexes introduced in a staged interpreter. Brady & Hammond (Reference Brady and Hammond2006) improve Pasalic et al. (Reference Pasalic, Taha and Sheard2002) by also extending MLTT with stages. Fundamentally, the type theory in Brady & Hammond (Reference Brady and Hammond2006) is the dependently typed system T with cross-stage persistence. Extending the T variant of Mint with cross-stage persistence would constitute Brady&Hammond (Reference Brady and Hammond2006)’ system Though the authors claim that their type theory is strongly normalizing, they do not provide any proof, whereas Mint’s normalization proof naturally adapts to all subsystems of S4, including T.
9.2 Modal type theories
One of the first “propositions-as-types”-interpretations of modal logics was given by Borghuis (Reference Borghuis1994) in his PhD thesis, which studies the modal natural deduction with the modality S4 and modal pure type system. His work, similar to Pfenning & Wong (Reference Pfenning and Wong1995) and Davies & Pfenning (Reference Davies and Pfenning2001), also introduces a context stack structure (called generalized contexts). However, in contrast to Davies & Pfenning (Reference Davies and Pfenning2001) where the elimination rule (
 ${{{{{\texttt{unbox}}}}}}_n$
) integrates both modal and local weakening, Borghuis’ elimination rule has explicit rules for both local weakening and modal weakening. As a consequence, weakening is not a property of the overall system in Borghuis’ work. Further, Borghuis studies strong normalization via a translation of the modal pure type system to a pure type system. In contrast, we give a direct normalization proof that yields an algorithm for normalizing objects in Mint.
${{{{{\texttt{unbox}}}}}}_n$
) integrates both modal and local weakening, Borghuis’ elimination rule has explicit rules for both local weakening and modal weakening. As a consequence, weakening is not a property of the overall system in Borghuis’ work. Further, Borghuis studies strong normalization via a translation of the modal pure type system to a pure type system. In contrast, we give a direct normalization proof that yields an algorithm for normalizing objects in Mint.
Most closely related to our work is the line of research by Clouston (Reference Clouston2018), Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019), Reference Birkedal, Clouston, Mannaa, Møgelberg, Pitts and SpittersBirkedal et al. (2020b
), and Valliappan et al. (Reference Valliappan, Ruch and Tomé Cortiñas2022). This line of work explores various modal dependent type theories where different stages are separated by locks ![]() . Kripke- and Lock-style (sometimes also referred to as Fitch-style) systems are fundamentally the same, although we manage the context stack structure slightly differently. Syntactically, the Kripke style simply uses a stack of contexts, while the Lock-style uses locks
. Kripke- and Lock-style (sometimes also referred to as Fitch-style) systems are fundamentally the same, although we manage the context stack structure slightly differently. Syntactically, the Kripke style simply uses a stack of contexts, while the Lock-style uses locks ![]() to segment one context into sections. Therefore, Lock-style systems typically rely on external side conditions such as “delete all of the locks that occur in the context” or “no lock occurs in context
to segment one context into sections. Therefore, Lock-style systems typically rely on external side conditions such as “delete all of the locks that occur in the context” or “no lock occurs in context
 $\Gamma$
”. These checks and operations on contexts with locks correspond in fact to modal structural properties in the Kripke-style formulation. For example, “deleting all of the locks” corresponds to the property of modal fusion. The condition that “no locks occur in context
$\Gamma$
”. These checks and operations on contexts with locks correspond in fact to modal structural properties in the Kripke-style formulation. For example, “deleting all of the locks” corresponds to the property of modal fusion. The condition that “no locks occur in context
 $\Gamma$
” is naturally captured simply by the stack structure of the context stack in Kripke-style systems. Hence, while the lock-based treatment of contexts and the use of context stacks are related (see also Clouston, Reference Clouston2018), context stacks reflect more directly the underlying Kripke semantics. As a consequence, structural properties of context stacks are more clearly formulated as general logical principles on those context stacks. This also allows us to characterize the context stack structure by a truncoid algebra and internalize it in our semantics. One consequence of that approach is that it allows us to directly adapt existing NbE algorithms such as Abel (Reference Abel2013). The end result is a clean and general NbE proof that captures all four subsystems of S4 without change. The fact that our NbE algorithm can be compactly and elegantly mechanized in Agda further emphasizes the benefit of the Kripke-style structure of context stacks and its corresponding semantic characterizations.
$\Gamma$
” is naturally captured simply by the stack structure of the context stack in Kripke-style systems. Hence, while the lock-based treatment of contexts and the use of context stacks are related (see also Clouston, Reference Clouston2018), context stacks reflect more directly the underlying Kripke semantics. As a consequence, structural properties of context stacks are more clearly formulated as general logical principles on those context stacks. This also allows us to characterize the context stack structure by a truncoid algebra and internalize it in our semantics. One consequence of that approach is that it allows us to directly adapt existing NbE algorithms such as Abel (Reference Abel2013). The end result is a clean and general NbE proof that captures all four subsystems of S4 without change. The fact that our NbE algorithm can be compactly and elegantly mechanized in Agda further emphasizes the benefit of the Kripke-style structure of context stacks and its corresponding semantic characterizations.
In comparison, Valliappan et al. (Reference Valliappan, Ruch and Tomé Cortiñas2022) give four (similar but) different formulations for all four subsystems of simply typed S4 and provide their normalization proofs separately. Our previous work (Reference Hu and PientkaHu & Pientka, 2022a ) considers the Kripke style and gives one NbE proof based on a presheaf model that handles all four subsystems. The NbE proof given by Gratzer et al. (Reference Gratzer, Sterling and Birkedal2019) for dependently typed, idempotent S4 cannot be easily adapted to all four subsystems of S4 and it is also not fully mechanized.
Last, the work by Gratzer (Reference Gratzer2022) gives a NbE proof for a richer MTT. However, its relationship to Kripke-style formulations is less clear, as it uses a very different formulation of the
 $\square$
elimination rule. As such, it is closer in spirit to the dual-context formulation of modal S4 given by Davies & Pfenning (Reference Davies and Pfenning2001) and further developed by Jang et al. (Reference Jang, Gélineau, Monnier and Pientka2022) (see also discussion below). Disregarding the differences in the underlying formulation of the modal elimination rule, the NbE proof described in Gratzer (Reference Gratzer2022) builds on the idea of synthetic Tait’s computability introduced by Sterling (Reference Sterling2022). This framework is much less understood than, for example, Abel (Reference Abel2013). In particular, it is less clear how one would mechanize the NbE proof given by Gratzer (Reference Gratzer2022) or how one would extract an algorithm that can be implemented in a conventional programming language. Hence, while Mint is less powerful than MTT, our work has direct practical benefits: it simply relies on well-understood techniques and approaches and we can extract an NbE algorithm from our Agda mechanization.
$\square$
elimination rule. As such, it is closer in spirit to the dual-context formulation of modal S4 given by Davies & Pfenning (Reference Davies and Pfenning2001) and further developed by Jang et al. (Reference Jang, Gélineau, Monnier and Pientka2022) (see also discussion below). Disregarding the differences in the underlying formulation of the modal elimination rule, the NbE proof described in Gratzer (Reference Gratzer2022) builds on the idea of synthetic Tait’s computability introduced by Sterling (Reference Sterling2022). This framework is much less understood than, for example, Abel (Reference Abel2013). In particular, it is less clear how one would mechanize the NbE proof given by Gratzer (Reference Gratzer2022) or how one would extract an algorithm that can be implemented in a conventional programming language. Hence, while Mint is less powerful than MTT, our work has direct practical benefits: it simply relies on well-understood techniques and approaches and we can extract an NbE algorithm from our Agda mechanization.
An alternative formulation of modal type systems is the dual-context formulation, which also goes back to Davies & Pfenning (Reference Davies and Pfenning2001) and where the authors gave a translation between the implicit (or Kripke-style) modal
 $\lambda$
-calculus using context stacks and the explicit using dual contexts to distinguish between global assumptions and local assumptions. This translation shows that both styles have the same logical strength. However, the translation does not give a correspondence between the equivalence relations of both styles. In fact, we speculate that the translation from the Kripke style to the dual-context style does not preserve equivalence. This further implies that the translation cannot be scaled to dependent types, because of the mutual definition of typing and equivalence judgments, and that both styles may not have the same expressive power in the dependently typed setting. In recent years, modal type systems in the dual-context style have found a wide range of seemingly unconnected applications: from reasoning about universes in homotopy type theory (Licata et al., Reference Licata, Orton, Pitts and Spitters2018; Shulman, Reference Shulman2018) to mechanizing meta-theory (Pientka, Reference Pientka2008), to reasoning about effects (Zyuzin & Nanevski, Reference Zyuzin and Nanevski2021), and meta-programming (Jang et al., Reference Jang, Gélineau, Monnier and Pientka2022). It would hence be interesting to further explore the relationship between implicit and explicit formulations of modal type theories in the future.
$\lambda$
-calculus using context stacks and the explicit using dual contexts to distinguish between global assumptions and local assumptions. This translation shows that both styles have the same logical strength. However, the translation does not give a correspondence between the equivalence relations of both styles. In fact, we speculate that the translation from the Kripke style to the dual-context style does not preserve equivalence. This further implies that the translation cannot be scaled to dependent types, because of the mutual definition of typing and equivalence judgments, and that both styles may not have the same expressive power in the dependently typed setting. In recent years, modal type systems in the dual-context style have found a wide range of seemingly unconnected applications: from reasoning about universes in homotopy type theory (Licata et al., Reference Licata, Orton, Pitts and Spitters2018; Shulman, Reference Shulman2018) to mechanizing meta-theory (Pientka, Reference Pientka2008), to reasoning about effects (Zyuzin & Nanevski, Reference Zyuzin and Nanevski2021), and meta-programming (Jang et al., Reference Jang, Gélineau, Monnier and Pientka2022). It would hence be interesting to further explore the relationship between implicit and explicit formulations of modal type theories in the future.
9.3 Mechanization of normalization for dependent type theory
From the 1990s, the question of how to mechanize the normalization proof for dependent type theory has been fundamental to gain trust in the type-theoretic foundation proof assistants such as Coq or Agda are built on. One of the earliest works is, for example, by Barras & Werner (Reference Barras and Werner1997). Barras and Werner formalized the strong normalization for the calculus of construction in Coq using reducibility candidates. More recently, Abel et al. (Reference Abel, Vezzosi and Winterhalter2017) mechanize a normalization proof for Martin-Löf logical framework in Agda. Instead of NbE, they first reduce terms to weak head normal forms and then use a type-directed algorithmic convertibility checking algorithm to check the equivalence of terms. In their development, they also rely on induction–recursion to give a semantics to dependent types. The algorithmic convertibility checking algorithm is shown to be complete and sound w.r.t. the equivalence rules. The completeness and soundness proofs are parameterized by a relation, reducing the size of the proofs. Pujet & Tabareau (Reference Pujet and Tabareau2022) extend the work by Abel et al. (Reference Abel, Vezzosi and Winterhalter2017) by mechanizing observational equality and two-level cumulative universe hierarchy. In their work, they did not need a lowering lemma for related cumulative properties. Instead, they make the following adjustments:
• In their logical relations, they added an extra case to represent the embedding from the lower universe to the higher one. This adjustment turns the cumulativity lemmas into a case in the logical relations.
• Moreover, in addition to the level 0 and level 1 universes, they have an extra level
$\infty$
universe, which subsumes both level 0 and 1 universes. Then, the proof can simply lift all types to the
$\infty$
level and completely avoid explicit discussions of universe levels entirely. This treatment resembles the typical paper proof.


This work is further superseded by Pujet & Tabareau (Reference Pujet and Tabareau2023), which mechanizes impredicative observational equality. In this work, however, cumulativity is removed from the universe hierarchy.
In contrast, mechanizations of NbE algorithms in dependent type theory are less common and remain challenging. Danielsson (Reference Danielsson2006) presents the first mechanization of NbE for Martin-Löf logical framework using induction–recursion in AgdaLight. As pointed out by Chapman (Reference Chapman2009), Danielsson (Reference Danielsson2006)’s formulation contains non-strictly positive predicates, which compromise the trust in this work.
Chapman (Reference Chapman2009) formalizes Martin-Löf logical framework in the style of categories with families (Dybjer, Reference Dybjer1996) in Agda and presents a sound normalizer. However, the normalizer is not shown complete whereas our paper has shown both completeness and soundness.
Altenkirch & Kaposi (Reference Altenkirch and Kaposi2016b,a) and Kaposi & Altenkirch (Reference Kaposi and Altenkirch2017) mechanize an NbE algorithm for Martin-Löf logical framework in Agda and prove completeness and soundness using a presheaf formulation akin to categories with families. Their development explores an advanced combination of intrinsic syntactic representations and involved features like induction–induction (Nordvall Forsberg & Setzer, Reference Nordvall Forsberg and Setzer2010) and quotient inductive types. In comparison, our development is simpler and only relies on two standard extensions: induction–recursion and functional extensionality. The simplicity leads to a formalization of a full hierarchy of universes. We hope that our mechanization of NbE in Agda, while focused on a modal type theory, also provides more general guidance on how to deal with a full universe hierarchy in the mechanization and implementation of NbE in type theory.
Most work in this area is done in Agda, as it supports induction–recursion, which strengthens the logical power of the meta-language and allows us to define the semantics for universes. Nevertheless, Agda is not the only choice. Wieczorek & Biernacki (Reference Wieczorek and Biernacki2018) mechanize an NbE algorithm for Martin-Löf logical framework in Coq. Since Coq does not support induction–recursion, they universally quantify over the impredicative universe Prop in their models. Their algorithm can also be extracted to and run in Haskell or OCaml. One benefit of using Coq is that Prop is automatically removed during extraction. Hence, their extraction code is cleaner than the one generated from Agda. While the readability of our extracted code could be improved by adding compiler auxiliary pragmas, the root cause for the verbosity of our extracted code lies in Agda’s extraction facilities. In the future, it would be interesting to adapt Wieczorek & Biernacki (Reference Wieczorek and Biernacki2018)’s work to mechanize the NbE algorithm for Mint in Coq, which would allow us to take advantage of Coq’s extraction facilities.
10 Conclusions and future work
In this paper, we introduce Mint, a foundation for dependently typed variants of Systems K, T, K4, and S4. This work adds a further piece to the landscape of combining modalities and dependent types. To justify Mint, we provide an NbE algorithm and its completeness and soundness proofs. To further strengthen our confidence in the theoretical development, we fully mechanize our constructions in safe Agda, with the standard extensions of functional extensionality and induction–recursion. In our proof, we introduce the notion of truncoids, a special algebra that characterizes structures appearing in both syntax and semantics. It serves as a guiding principle throughout our proof. We further exploit the notion of UMoTs to modularize our constructions so that our normalization result applies to all aforementioned systems without modifications.
As part of future work, we will explore the application of the dependently typed variant of S4 to multi-staged and meta-programming. This direction allows us to develop a type theory that is capable of proving and meta-programming in the same language. To achieve this goal, we would like to have the power of doing pattern matching on code as demonstrated by Jang et al. (Reference Jang, Gélineau, Monnier and Pientka2022). Having pattern matching on code will allow Mint to write meta-programs that construct proofs based on the goal types. As such it would provide a general foundation for boot-strapping proof assistants.
Acknowledgments
We would like to thank the anonymous reviewers for their suggestions and feedbacks. This work was funded by the Natural Sciences and Engineering Research Council of Canada (grant number 206263), Fonds de recherche du Québec – Nature et technologies (grant number 253521). Postgraduate Scholarship – Doctoral by the Natural Sciences and Engineering Research Council of Canada was awarded to the first author. A graduate fellowship from Fonds de recherche du Québec – Nature et technologies (grant number 304215) was awarded to the second author.
Conflicts of Interest
None.
A Full set of rules for Mint
![]() Context stack
Context stack
 ${\overrightarrow{\Gamma}}$
is well formed.
${\overrightarrow{\Gamma}}$
is well formed.

![]()
 ${\overrightarrow{\Gamma}}$
and
${\overrightarrow{\Gamma}}$
and
 ${\overrightarrow{\Delta}}$
are equivalent context stacks.
${\overrightarrow{\Delta}}$
are equivalent context stacks.

![]()
 ${\overrightarrow{\sigma}}$
is a K-substitution substituting terms in
${\overrightarrow{\sigma}}$
is a K-substitution substituting terms in
 ${\overrightarrow{\Delta}}$
into ones in
${\overrightarrow{\Delta}}$
into ones in
 ${\overrightarrow{\Gamma}}$
.
${\overrightarrow{\Gamma}}$
.

![]()
 ${\overrightarrow{\sigma}}$
and
${\overrightarrow{\sigma}}$
and
 ${\overrightarrow{\delta}}$
are equivalent in K-substituting terms in
${\overrightarrow{\delta}}$
are equivalent in K-substituting terms in
 ${\overrightarrow{\Delta}}$
into ones in
${\overrightarrow{\Delta}}$
into ones in
 ${\overrightarrow{\Gamma}}$
.
${\overrightarrow{\Gamma}}$
.
Congruence rules:

Categorical rules:

Other rules:

To define the variable rule for the typing judgment, we need to define the lookup judgment
 $x : T \in {\overrightarrow{\Gamma}}$
:
$x : T \in {\overrightarrow{\Gamma}}$
:

![]() Term t has type T in context stack
Term t has type T in context stack
 ${\overrightarrow{\Gamma}}$
.
${\overrightarrow{\Gamma}}$
.

![]() Terms t and s of type T are equivalent in context stack
Terms t and s of type T are equivalent in context stack
 ${\overrightarrow{\Gamma}}$
.
${\overrightarrow{\Gamma}}$
.
Congruence rules:

 $\beta$
and
$\beta$
and
 $\eta$
rules:
$\eta$
rules:

General K-substitution rules:

Variable rules:

 $\Pi$
rules:
$\Pi$
rules:
To describe how K-substitutions are propagated into different constructs, we need to define the weakening of a K-substitution:
 \begin{align*} q_T({\overrightarrow{\sigma}}) := ({\overrightarrow{\sigma}} \circ \mathsf{wk}) , v_0\end{align*}
\begin{align*} q_T({\overrightarrow{\sigma}}) := ({\overrightarrow{\sigma}} \circ \mathsf{wk}) , v_0\end{align*}
where the subscript T is needed for the following typing rule:

We often omit this subscript when it can be inferred from the context.

 ${{{{{\texttt{Nat}}}}}}$
rules:
${{{{{\texttt{Nat}}}}}}$
rules:

 $\square$
rules:
$\square$
rules:

 $\texttt{Ty}$
rule:
$\texttt{Ty}$
rule:

Other rules:

B Generating power functions
In this section, we give one more example for a program in Mint and run our NbE algorithm on it. The program that we use is a quintessential example of staged programming: the staged power function, which generates code of the n-th power of another number that will be given in a later stage. Recall that the S4 variant of Mint models staged computation. Following Davies & Pfenning (Reference Davies and Pfenning2001), we use the box modality to ascribe the type ![]() to generated code. The implementation of the power function in Mint then follows familiar ideas.
to generated code. The implementation of the power function in Mint then follows familiar ideas.

In the zero case, pow returns a constant function always returning 1. Otherwise, if the input is succ n, pow recurses on n to generate code for pow n. To build our final result, i.e., the code for pow (succ n), we need to splice in the code from the recursive call. We use ![]() to obtain code of type
to obtain code of type ![]() . We then apply this function to x to obtain the code for n-th power of x and then multiply it with x to obtain the final result. The following is an execution of pow 2:
. We then apply this function to x to obtain the code for n-th power of x and then multiply it with x to obtain the final result. The following is an execution of pow 2:

In the rest of this section, we will run pow 2 using our NbE algorithm. To normalize pow 2, let us redefine pow in Mint syntax:

We assume multiplication is defined in the syntax and the semantics in the usual way. In this definition, we rewrite pattern matching into an elimination of a natural number and change named variables to de Bruijn indices. Instead of using explicit names, we associate binders and variables using colors. First,
 $\mathsf{pow}$
is a function, so we start with a
$\mathsf{pow}$
is a function, so we start with a ![]() . It introduces a variable, which we mark in
. It introduces a variable, which we mark in ![]() . Then we eliminate that variable
. Then we eliminate that variable ![]() using
using
 $\textsf{elim}$
. We supply the motive (
$\textsf{elim}$
. We supply the motive (
 $\square (\Pi {{{{{\texttt{Nat}}}}}} . {{{{{\texttt{Nat}}}}}})$
), the base case (
$\square (\Pi {{{{{\texttt{Nat}}}}}} . {{{{{\texttt{Nat}}}}}})$
), the base case (
 ${{{{{\texttt{box}}}}}}\ (\lambda 1)$
), the step case, and the scrutinee
${{{{{\texttt{box}}}}}}\ (\lambda 1)$
), the step case, and the scrutinee ![]() . The step case introduces two more variables marked in
. The step case introduces two more variables marked in ![]() , one for the predecessor (which we do not use) and the result of the recursive call. Then, we introduce another
, one for the predecessor (which we do not use) and the result of the recursive call. Then, we introduce another ![]() in
in
 ${{{{{\texttt{box}}}}}}$
for constructing
${{{{{\texttt{box}}}}}}$
for constructing
 $\Pi {{{{{\texttt{Nat}}}}}}. {{{{{\texttt{Nat}}}}}}$
. Inside, we first
$\Pi {{{{{\texttt{Nat}}}}}}. {{{{{\texttt{Nat}}}}}}$
. Inside, we first
 ${{{{{\texttt{unbox}}}}}}$
the result of the recursive call
${{{{{\texttt{unbox}}}}}}$
the result of the recursive call ![]() and obtain a function of type
and obtain a function of type
 $\Pi {{{{{\texttt{Nat}}}}}} . {{{{{\texttt{Nat}}}}}}$
. We apply that function to
$\Pi {{{{{\texttt{Nat}}}}}} . {{{{{\texttt{Nat}}}}}}$
. We apply that function to ![]() to obtain a
to obtain a
 ${{{{{\texttt{Nat}}}}}}$
and then multiply that by an
${{{{{\texttt{Nat}}}}}}$
and then multiply that by an ![]() again. Note that although there are three
again. Note that although there are three
 $v_0$
’s in the code, they refer to two different variables, as distinguished by their colors.
$v_0$
’s in the code, they refer to two different variables, as distinguished by their colors.
Now let us first examine our evaluation process. For simplicity, we use 0, 1, and 2 for
ze
,
su(ze) , and
su(su(ze)) . To simplify the evaluation of ![]() , we first define a few sub-evaluations. Let
, we first define a few sub-evaluations. Let
 $\overrightarrow{\rho}$
be
$\overrightarrow{\rho}$
be
 ${{{{{\texttt{lext}}}}}}({{{{{\uparrow^{\varepsilon; \cdot}}}}}}, \mathbf{2})$
:
${{{{{\texttt{lext}}}}}}({{{{{\uparrow^{\varepsilon; \cdot}}}}}}, \mathbf{2})$
:

Here
 $P_0$
represents the evaluation of the body of
$P_0$
represents the evaluation of the body of
 $\mathsf{pow}$
in the case of 0. The
$\mathsf{pow}$
in the case of 0. The
 $\lambda$
of the base case is evaluated to a
$\lambda$
of the base case is evaluated to a
 $\Lambda$
, in which the first component is still a syntactic term of Mint and the second component is the surrounding environment. The environment is extended modally because of the outer
$\Lambda$
, in which the first component is still a syntactic term of Mint and the second component is the surrounding environment. The environment is extended modally because of the outer
 ${{{{{\texttt{box}}}}}}$
. We define
${{{{{\texttt{box}}}}}}$
. We define
 $P_1$
similarly:
$P_1$
similarly:

Similarly, in the final result, the function body ![]() is captured. The environment is extended with
is captured. The environment is extended with
 $\mathbf{0}$
and
$\mathbf{0}$
and
 $P_0$
because the step case has two open variables: the predecessor and the recursive call. Then, we define
$P_0$
because the step case has two open variables: the predecessor and the recursive call. Then, we define ![]() :
:
Note that this only evaluates the term. To perform NbE, we must also evaluate its type:
Note that the first component of Pi is evaluated and in the domain while the second one is still syntax. Now, we compute ![]() , which expands to
, which expands to
We have computed the evaluations above and now move on to the readback:

Thus, we obtain a normal form as we previously claimed.



 Open access
Open access
Discussions
No Discussions have been published for this article.