


1 Introduction
The primitive operations associated with certain data types can be separated into constructors and destructors. For example, over the natural numbers, the successor (or increment) function and the constant 0 are constructors, whereas the predecessor (or decrement) function and equals-zero test are destructors. Over strings on some fixed alphabet
 $\Sigma$
, the cons function, which prepends a given character onto a given string, is a constructor, as is the constant naming the empty string. On the other hand, the head function, which isolates the first character of a given string, and the tail function, which deletes it, are destructors, as is the relation which tests whether a string is empty. Similarly, one can define constructors and destructors for trees, heaps, nested lists, and all sorts of other common data types.
$\Sigma$
, the cons function, which prepends a given character onto a given string, is a constructor, as is the constant naming the empty string. On the other hand, the head function, which isolates the first character of a given string, and the tail function, which deletes it, are destructors, as is the relation which tests whether a string is empty. Similarly, one can define constructors and destructors for trees, heaps, nested lists, and all sorts of other common data types.
A cons-free program over any one of these data types is a program in which no constructors occur. For example, consider the following cons-free natural number program, which decides whether its input is even:
 \begin{align*} \mathtt{even}(\mathtt{n}) = &\mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{zero}(\mathtt{n}\mathtt{-1})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{even}(\mathtt{n}\mathtt{-2}).\end{align*}
\begin{align*} \mathtt{even}(\mathtt{n}) = &\mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{zero}(\mathtt{n}\mathtt{-1})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{even}(\mathtt{n}\mathtt{-2}).\end{align*}
In other words, to check whether a given number is even, we return “true” if it is equal to zero, return “false” if it is equal to one, and otherwise subtract two and recurse. (Here,
 $\mathtt{n}\mathtt{-2}$
abbreviates
$\mathtt{n}\mathtt{-2}$
abbreviates
 $\mathtt{n}\mathtt{-1\!-\!1}$
.) This program is clearly cons-free, as 0 and
$\mathtt{n}\mathtt{-1\!-\!1}$
.) This program is clearly cons-free, as 0 and
 $+\mathtt{1}$
do not occur within.
$+\mathtt{1}$
do not occur within.
Cons-free programs clearly do not form a Turing complete language. Given their somewhat severe limitations, it is perhaps surprising that cons-free programs retain significant computational power: by a seminal result of Neil Jones (Reference Jones1999), cons-free string programs in a simple first-order functional language capture exactly the class P of polynomial-time relations. In other words, every language in P is decided by some cons-free program, and every language decided by a cons-free program is in P. Moreover, if we restrict our attention to tail-recursive programs, we capture the class L of logarithmic-space relations in exactly the same sense.
Cons-free programs, however, fail to capture the functional versions of any complexity class, e.g., the classes FP and FL of polynomial-time and logarithmic-space functions respectively. Indeed, they cannot even define the simplest function which increases the size of the input. To remedy this deficiency, we introduce the notion of an read/write-factorizable program. Such programs extend the destruct-only (or read-only) variables of cons-free programs with construct-only (or write-only) variables. For example, the following addition program is RW-factorizable:
 \begin{align*} \mathtt{add}(\mathtt{n},\mathtt{m})=\mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{m}\ \mathtt{else}\ \mathtt{add}(\mathtt{n}\mathtt{-1},\mathtt{m}\mathtt{+1}).\end{align*}
\begin{align*} \mathtt{add}(\mathtt{n},\mathtt{m})=\mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{m}\ \mathtt{else}\ \mathtt{add}(\mathtt{n}\mathtt{-1},\mathtt{m}\mathtt{+1}).\end{align*}
Here
 $\mathtt{n}$
is a read-only variable of type R,
$\mathtt{n}$
is a read-only variable of type R,
 $\mathtt{m}$
is a write-only variable of type W, and
$\mathtt{m}$
is a write-only variable of type W, and
 $\mathtt{add}:R \times W \to W$
. Similarly, we can define a string concatenation function of type
$\mathtt{add}:R \times W \to W$
. Similarly, we can define a string concatenation function of type
 $R \times W \to W$
by
$R \times W \to W$
by
 \begin{align*} \mathtt{cat}(\mathtt{x},\mathtt{w}) = \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
\begin{align*} \mathtt{cat}(\mathtt{x},\mathtt{w}) = \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
where
 $\mathtt{x}$
is a read-only variable of type R,
$\mathtt{x}$
is a read-only variable of type R,
 $\mathtt{w}$
is a write-only variable of type W,
$\mathtt{w}$
is a write-only variable of type W,
 $\mathtt{null} : R \to 2$
tests whether read-only string is empty,
$\mathtt{null} : R \to 2$
tests whether read-only string is empty,
 $\mathtt{cons} : \Sigma \times W \to W$
prepends a character in the alphabet
$\mathtt{cons} : \Sigma \times W \to W$
prepends a character in the alphabet
 $\Sigma$
to a write-only string,
$\Sigma$
to a write-only string,
 $\mathtt{hd} : R \to \Sigma$
is the head function, and
$\mathtt{hd} : R \to \Sigma$
is the head function, and
 $\mathtt{tl} : R \to R$
is the tail function.
$\mathtt{tl} : R \to R$
is the tail function.
Consider the problem of programming a RW-factorizable identity function of type
 $R \to W$
. Notice that the trivial program
$R \to W$
. Notice that the trivial program
 $\mathtt{id}(\mathtt{x}) = \mathtt{x}$
cannot be consistently typed as
$\mathtt{id}(\mathtt{x}) = \mathtt{x}$
cannot be consistently typed as
 $R \to W$
; instead, we have to destruct the input and construct it again. Over strings, this would look something like
$R \to W$
; instead, we have to destruct the input and construct it again. Over strings, this would look something like
 $\mathtt{id}(\mathtt{x}) = \mathtt{cat}(\mathtt{x},\mathtt{nil})$
. This shows that information can flow from R values to W values; however, the reverse is not possible.
$\mathtt{id}(\mathtt{x}) = \mathtt{cat}(\mathtt{x},\mathtt{nil})$
. This shows that information can flow from R values to W values; however, the reverse is not possible.
Finally, let us try to define the base-2 exponential function
 $n \mapsto 2^n$
. The program
$n \mapsto 2^n$
. The program
 \begin{align*} \mathtt{exp}(\mathtt{n}) &= \mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{1}\ \mathtt{else}\ \mathtt{double}(\mathtt{exp}(\mathtt{n}\mathtt{-1})) \\ \mathtt{double}(\mathtt{n}) &= \mathtt{add}(\mathtt{n},\mathtt{n})\end{align*}
\begin{align*} \mathtt{exp}(\mathtt{n}) &= \mathtt{if}\ \mathtt{zero}(\mathtt{n})\ \mathtt{then}\ \mathtt{1}\ \mathtt{else}\ \mathtt{double}(\mathtt{exp}(\mathtt{n}\mathtt{-1})) \\ \mathtt{double}(\mathtt{n}) &= \mathtt{add}(\mathtt{n},\mathtt{n})\end{align*}
is not RW-factorizable, because
 $\mathtt{double}:R \to W$
, and
$\mathtt{double}:R \to W$
, and
 $\mathtt{exp}$
cannot be well-typed, as its output must agree with both the input and output of
$\mathtt{exp}$
cannot be well-typed, as its output must agree with both the input and output of
 $\mathtt{double}$
. However,
$\mathtt{double}$
. However,
is a perfectly legitimate RW-factorizable definition of
 $n \mapsto 2^n$
, with
$n \mapsto 2^n$
, with
 $\mathtt{f} : R \times W \to W$
.
$\mathtt{f} : R \times W \to W$
.
1.1 Our contribution
The central results of this paper are that
-
RW-factorizable string programs of type
 $R \to W$
which are non-nested capture exactly the class FP of polynomial-time functions, and
$R \to W$
which are non-nested capture exactly the class FP of polynomial-time functions, and -
RW-factorizable strings programs of type
$R \to W$
which are tail-recursive capture exactly the class FL of logarithmic-space functions.


In other words, the passage from cons-free to RW-factorizable programs is exactly what allows us to extend the results of Jones (Reference Jones1999) from relational to functional classes. The purpose of the non-nested stipulation is to exclude nested recursive programs like leap from line (1), whose outputs can have length exponential in the length of the inputs. Footnote 1
A foundational lesson of implicit computational complexity going back to Bellantoni & Cook (Reference Bellantoni and Cook1992) is that any Turing-complete programming language must allow for the same piece of data to be both read and written. Our results illustrate this phenomenon in a particularly clear way. Footnote 2
A natural question to ask about RW-factorizable programs is how to (syntactically) compose them, i.e., produce a program which computes the sequential composition of two given programs. Naive attempts fail: you cannot stick an output of type W directly into an input of type R. So the problem is nontrivial; however, we solve it at the end of this paper.
Both the capturing and composition results utilize the same technical device, namely bit-length computability of a function, which is introduced in this paper. This essentially means computability by two cons-free programs, one computing the bits, the other the length, of a given function on each input. Our results suggest that this idea might have some “legs” and be worthy of further study in its own right.
1.2 Organization of this paper
In Section 2, we review some technical background. We then introduce RW-factorizable programs over strings, our main object of study, in Section 3. In Section 4, we introduce bit-length programs, a dialect of cons-free programs, and define bit-length computability in Section 5. That section also states that FL and FP are captured by pairs of bit-length programs; a sketch of the proofs is postponed to Appendix B.
Sections 6 defines a compiling function from RW-factorizable to (pairs of) bit-length programs; Section 7 defines a compiling function in the other direction. These two sections establish the equivalence of the two models of computation and thus prove our desired capturing results for RW-factorizable programs. Section 8 treats syntactic composition of bit-length programs and hence of RW-factorizable programs by proxy. Finally in Section 9, we discuss further directions for research.
The beating technical heart of this paper consists of four program transformations in Section 6, two in Section 7, and one in Section 8. Some of these are simple and others more intricate, but each transformation implements a conceptually simple idea which we outline at the top of its respective section. We advise that the reader read these first before diving into the details.
We develop most transformations according to a common template: first describing a transformation of types, then of variables and values, then of terms and programs, and finally proving correctness. In the interests of space, we postpone all the proofs of correctness to Appendix A.
1.3 Related work
The present paper falls squarely into a long tradition of characterizing complexity classes by function algebras, programming languages, and related models of computation, a topic known as implicit computational complexity (ICC). ICC has been an area of interest since, at least, the 1960s (Cobham, 1965), with a resurgence in the last 30 years since the groundbreaking work of Bellantoni & Cook (Reference Bellantoni and Cook1992). There are multiple approaches to ICC, see, e.g., the survey (Hofmann, Reference Hofmann2000) for early developments pre-2000, and Dal Lago (Reference Dal Lago2022) for a recent survey about methods involving higher-order programs. Recently, implicit characterizations have been furnished for complexity classes using different modes of computation, or using different modes of computation as a means of characterizing standard complexity classes; in particular, this includes probabilistic computation (Lago & Toldin, Reference Lago and Toldin2015; Lago et al., Reference Lago, Kahle, Oitavem, Tallinn, Bonchi and Puglisi2021), reversible computation (Kristiansen, Reference Kristiansen2022), parallel computation (Baillot & Ghyselen, Reference Baillot and Ghyselen2022), and higher-order complexity (Hainry et al., Reference Hainry, Kapron, Marion and Péchoux2022).
Many of these results are obtained by imposing a type system on a base programming language, as we do in this paper. Of the multitude of different flavors of implicit characterizations, we briefly review the most well-known ones with connections to our work:
-
Data ramification. By this, we mean factoring the base data into two or more copies, and restricting how we can access or modify data in each copy. (Our approach of RW-factorization falls into this broad category.) The most common of these is the normal/safe factorization, which underlies many of the foundational papers in the field, e.g., Bellantoni & Cook (Reference Bellantoni and Cook1992), Leivant (Reference Leivant1995), and has a wide variety of applications. Our work is distinguished from these by our use of a general-purpose programming language with flexible recursive definitions, rather than function algebras based off of primitive recursion. There are other instances of data ramification, for example the secure information flow of Marion (Reference Marion2011), which partitions data into “higher” and “lower” security tiers. This bears resemblance to W- and R-data respectively, but ultimately yields different results: higher-security data does allow a limited amount of destruction, and FP is characterized by a class of tail-recursive programs. Still, this is perhaps the characterization closest to our own in spirit.
-
Linearity. By linearity we mean (very roughly) restricting the reuse of variables or primitive operations, e.g., controlling the number of times a constructor can occur in the right-hand side of a recursive definition. Approaches to ICC based on linear logic include proof-theoretic approaches like light linear logic (Girard, Reference Girard1998) and soft linear logic (Lafont, Reference Lafont2004), as well as the type-based approach of non-size-increasing computation (Hofmann, Reference Hofmann2002). From a practical perspective, they seem to yield more intensionally expressive languages than safe primitive recursion and have been applied to, e.g., cryptographic protocols (Baillot et al,. Reference Baillot, Barthe and Lago2019). There does not seem to be any real technical connection between our work and this approach, except perhaps that our “non-nested” restriction of RW-factorizable programs carries a whiff of a linear typing discipline.
-
Restricted termination. This is (roughly) the study of measures or bounds on programs or computation states, such that only those programs having execution that terminates within the bound, are part of the characterization. This is a flourishing field, both for traditional programs (Bonfante et al., Reference Bonfante, Marion and Moyen2011; Aubert et al., Reference Aubert, Seiller, Rubiano and Rusch2022) and for non-deterministic models such as term rewriting systems (Avanzini et al., Reference Avanzini, Eguchi and Moser2011, Reference Avanzini, Eguchi and Moser2015; Avanzini & Moser, Reference Avanzini and Moser2016). The approach of the present paper does not use restricted termination in any technical sense, and the characterizations we provide are not reliant on termination; there is, however, a tenuous connection in the sense that we use programs with very restricted ability to construct data structures, and this might be amenable to analysis by methods devised for ICC using restricted termination.
-
Cons-free programs. This is the particular line of inquiry which the present paper belongs to. Jones (Reference Jones1999) was the first to observe that eschewing constructors yields a simple method of capturing polynomial-time and logarithmic-space relations. This paradigm has since been extended to obtain many capturing results in a variety of contexts, e.g., higher types (Jones, Reference Jones2001), non-determinism (Bonfante, Reference Bonfante2006), simultaneous higher types and non-determinism (Kop & Simonsen, Reference Kop and Simonsen2017), treelike data (Ben-Amram & Petersen, Reference Ben-Amram, Petersen, Larsen, Skyum and Winskel1998), term rewriting systems (de Carvalho & Simonsen, 2014; Czajka, Reference Czajka2018), and cons-free time complexity classes (Bhaskar et al., Reference Bhaskar, Kop and Simonsen2022; Jones et al., Reference Jones, Kop, Bhaskar, Simonsen, Fribourg and Heizmann2020). The present paper is the first to consider computability of function classes.
2 Preliminaries
We assume a basic familiarity with syntax and semantics of first-order functional programming languages, Turing machines, the Turing machine complexity classes P (polynomial time) and L (logarithmic space), and their functional variants FP and FL. Note that when defining a functional space class, the space bound only applies to the work tapes and not the output tape. Hence, the length of the output of function in FL may in general grow polynomially in the length of the input.
Following the set-theoretic convention, we identify any natural number n with its set of predecessors
 $\{0,1,\dots,n-1\}$
and we denote the set of all natural numbers by
$\{0,1,\dots,n-1\}$
and we denote the set of all natural numbers by
 $\omega$
. Therefore,
$\omega$
. Therefore,
 $1 = \{0\}$
,
$1 = \{0\}$
,
 $2 = \{0,1\}$
, and
$2 = \{0,1\}$
, and
 $1^n$
and
$1^n$
and
 $2^n$
are the sets of unary and binary strings of length n, respectively. We also identify 0 and 1 with
$2^n$
are the sets of unary and binary strings of length n, respectively. We also identify 0 and 1 with
 $\bot$
(false) and
$\bot$
(false) and
 $\top$
(true), respectively, so 2 is also the set of boolean values.
$\top$
(true), respectively, so 2 is also the set of boolean values.
We denote the set of all finite unary and binary strings by
 $1^\star$
and
$1^\star$
and
 $2^\star,$
respectively, following the convention in computer science.
Footnote 3
The empty string is denoted
$2^\star,$
respectively, following the convention in computer science.
Footnote 3
The empty string is denoted
 $\varepsilon$
; its underlying alphabet must be inferred from context. The head of a string is its first character, and its tail is the remainder. The head and tail of
$\varepsilon$
; its underlying alphabet must be inferred from context. The head of a string is its first character, and its tail is the remainder. The head and tail of
 $\varepsilon$
are undefined. If x is a string, then
$\varepsilon$
are undefined. If x is a string, then
 $|x|$
is its length.
$|x|$
is its length.
We typically use lowercase Latin letters such as m,n,u,v,w,x,y for variables that range over “type-0 objects” such as natural numbers and strings. By, e.g., a “n-ary relation on strings,” we mean a subset of
 $(2^\star)^n$
. We use capital Latin letters, e.g., P,Q,X,Y, for variable that range over relations, and f,g,h for variables that range over functions. We use lowercase Greek letters for variables that range over types. We use typewriter script for program syntax.
$(2^\star)^n$
. We use capital Latin letters, e.g., P,Q,X,Y, for variable that range over relations, and f,g,h for variables that range over functions. We use lowercase Greek letters for variables that range over types. We use typewriter script for program syntax.
A partial function
 $f : X \rightharpoonup Y$
is a function
$f : X \rightharpoonup Y$
is a function
 $f : X' \to Y$
for some
$f : X' \to Y$
for some
 $X' \subseteq X$
; X’ is the domain of convergence of f. If x is in the domain of convergence of f, we write
$X' \subseteq X$
; X’ is the domain of convergence of f. If x is in the domain of convergence of f, we write
 $f(x) \downarrow$
, otherwise
$f(x) \downarrow$
, otherwise
 $f(x) \uparrow$
, and say that f “converges” or “diverges” on x, respectively. Partial functions converge strictly, meaning that
$f(x) \uparrow$
, and say that f “converges” or “diverges” on x, respectively. Partial functions converge strictly, meaning that
 $f(g(x)) \downarrow$
implies, in particular, that
$f(g(x)) \downarrow$
implies, in particular, that
 $g(x) \downarrow$
. For two partial functions
$g(x) \downarrow$
. For two partial functions
 $f,f':X \rightharpoonup Y$
, we say that
$f,f':X \rightharpoonup Y$
, we say that
 $f' \sqsubseteq f$
in case
$f' \sqsubseteq f$
in case
 $f'(x) = y \implies f(x) = y$
for all
$f'(x) = y \implies f(x) = y$
for all
 $(x,y) \in X \times Y$
. Finally, note that by “partial function” we do mean a possibly total function, otherwise we will say properly partial.
$(x,y) \in X \times Y$
. Finally, note that by “partial function” we do mean a possibly total function, otherwise we will say properly partial.
The semantics of a program p is the partial function denoted by
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
. A program p computes a partial function f in case
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
. A program p computes a partial function f in case
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is identical to f as a partial function. A program p accepts a set X in case X is the domain of convergence of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is identical to f as a partial function. A program p accepts a set X in case X is the domain of convergence of
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
. Finally, a boolean-valued program p decides a set X if it computes the characteristic function of X.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
. Finally, a boolean-valued program p decides a set X if it computes the characteristic function of X.
A partial function computed by a program may in general have a dependent type. Given a type
 $\alpha$
and family of types
$\alpha$
and family of types
 $\beta(x)$
indexed by
$\beta(x)$
indexed by
 $x : \alpha$
, we will refer to the dependent sum type
$x : \alpha$
, we will refer to the dependent sum type
 $\sum_{x : \alpha} \beta(x)$
and the dependent product type
$\sum_{x : \alpha} \beta(x)$
and the dependent product type
 $\prod_{x : \alpha} \beta(x)$
. (When
$\prod_{x : \alpha} \beta(x)$
. (When
 $\beta$
does not depend on x, these reduce to
$\beta$
does not depend on x, these reduce to
 $\alpha\times\beta$
and
$\alpha\times\beta$
and
 $\alpha \to \beta$
respectively.) The language of dependent types provides an elegant formulation for counting modules, but we do not use the machinery of dependent types in any essential way.
$\alpha \to \beta$
respectively.) The language of dependent types provides an elegant formulation for counting modules, but we do not use the machinery of dependent types in any essential way.
A note on functional complexity. Suppose that
 $f : 2^\star \to 2^\star$
is contained in the class FP of polynomial-time computable functions. Consider the function
$f : 2^\star \to 2^\star$
is contained in the class FP of polynomial-time computable functions. Consider the function
 $f_\ell : 2^\star \to 1^\star$
defined by
$f_\ell : 2^\star \to 1^\star$
defined by
 $f_\ell (x) = |f(x)|$
, i.e., the length of f(x). Then,
$f_\ell (x) = |f(x)|$
, i.e., the length of f(x). Then,
 $f_\ell$
is also in FP; take, for example, any Turing machine computing f in polynomial time and identify all the characters of its output alphabet. Similarly, consider the function
$f_\ell$
is also in FP; take, for example, any Turing machine computing f in polynomial time and identify all the characters of its output alphabet. Similarly, consider the function
 $f_b : 2^\star \times 1^\star \to 2$
defined by
$f_b : 2^\star \times 1^\star \to 2$
defined by
 $f_b(x,i) = \big( f(x) \big)_i$
, meaning the
$f_b(x,i) = \big( f(x) \big)_i$
, meaning the
 $i^{\mathrm{th}}$
-bit of f(x), for any
$i^{\mathrm{th}}$
-bit of f(x), for any
 $x \in 2^\star$
and
$x \in 2^\star$
and
 $i < |f(x)|$
. This relation is computable in polynomial time as well: on input (x,i), write f(x) on a work tape and extract the
$i < |f(x)|$
. This relation is computable in polynomial time as well: on input (x,i), write f(x) on a work tape and extract the
 $i{\mathrm{th}}$
-bit.
Footnote 4
$i{\mathrm{th}}$
-bit.
Footnote 4
All this is to say, roughly speaking, that if a function of type
 $2^\star \to 2^\star$
is computable in polynomial time, then so is its length function and its bits relation. We note that the converse implication is valid too. In other words, if
$2^\star \to 2^\star$
is computable in polynomial time, then so is its length function and its bits relation. We note that the converse implication is valid too. In other words, if
 $f_\ell$
and
$f_\ell$
and
 $f_b$
are both computable in polynomial time, then we can compute f in polynomial time by concatenating the bits
$f_b$
are both computable in polynomial time, then we can compute f in polynomial time by concatenating the bits
 $f_b(x,i)$
for each
$f_b(x,i)$
for each
 $i < f_\ell(x)$
.
$i < f_\ell(x)$
.
In other words, we have reduced the notion of polynomial-time computability of functions of type
 $2^\star \to 2^\star$
to polynomial-time computability of relations and of functions
$2^\star \to 2^\star$
to polynomial-time computability of relations and of functions
 $2^\star \to 1^\star$
. What do we gain from this? We get some characterization of polynomial-time computability of functions
$2^\star \to 1^\star$
. What do we gain from this? We get some characterization of polynomial-time computability of functions
 $2^\star \to 2^\star$
in terms of cons-free programs. (Cons-free programs can handle data of type
$2^\star \to 2^\star$
in terms of cons-free programs. (Cons-free programs can handle data of type
 $1^\star$
with counting modules, a device for reckoning with natural number quantities bounded by a polynomial in the length of the input.) So the polynomial-time computability of
$1^\star$
with counting modules, a device for reckoning with natural number quantities bounded by a polynomial in the length of the input.) So the polynomial-time computability of
 $f : 2^\star \to 2^\star$
may be witnessed by two cons-free programs: one with string input and counting module output computing the length and another with string and counting module input and boolean outputs, computing the bits. We shall elaborate on this later.
$f : 2^\star \to 2^\star$
may be witnessed by two cons-free programs: one with string input and counting module output computing the length and another with string and counting module input and boolean outputs, computing the bits. We shall elaborate on this later.
The observations we have made about polynomial time apply respectively to logarithmic space and tail-recursive cons-free programs. The proof is slightly different: notice that if
 $f : 2^\star \to 2^\star$
is in FL, then we cannot compute
$f : 2^\star \to 2^\star$
is in FL, then we cannot compute
 $f_b(x,i)$
by writing f(x) on a work tape, because it will be too long, in general. However, there is a well-known trick in space complexity to circumvent this, viz., replacing the write-only output tape by a work tape that records only the position of the head. Similarly, when computing f(x) using
$f_b(x,i)$
by writing f(x) on a work tape, because it will be too long, in general. However, there is a well-known trick in space complexity to circumvent this, viz., replacing the write-only output tape by a work tape that records only the position of the head. Similarly, when computing f(x) using
 $f_b$
and
$f_b$
and
 $f_\ell$
, we compute
$f_\ell$
, we compute
 $f_\ell(x)$
in binary, which compresses it enough to stick it on a work tape.
$f_\ell(x)$
in binary, which compresses it enough to stick it on a work tape.
We compile these observations into an official and easily referenced theorem.
Theorem 1. A function
 $f:2^\star \to 2^\star$
is computable in polynomial time, respectively, logarithmic space, iff there are functions
$f:2^\star \to 2^\star$
is computable in polynomial time, respectively, logarithmic space, iff there are functions
 $f_\ell : 2^\star \to 1^\star$
and
$f_\ell : 2^\star \to 1^\star$
and
 $f_b : 2^\star \times 1^\star \to 2$
computing the length and bits of f which are computable in polynomial time, respectively logarithmic space.
$f_b : 2^\star \times 1^\star \to 2$
computing the length and bits of f which are computable in polynomial time, respectively logarithmic space.
3 RW-factorizable programs
Let us work over the set
 $2^\star$
of binary strings. Consider the following set of string primitives
Footnote 5
$2^\star$
of binary strings. Consider the following set of string primitives
Footnote 5
-
$\mathtt{hd}$
, denoting the head function, of type
$2^\star \rightharpoonup 2$
,
-
$\mathtt{tl}$
, the tail function, of type
$2^\star \rightharpoonup 2$
-
$\mathtt{null}$
, the empty test, of type
$2^\star \to 2$
-
$\mathtt{nil}$
, a constant naming the empty string, of type
$2^\star$
, and
-
$\mathtt{cons}$
, a binary function prepending a given character onto a given string, of type
$2 \times 2^\star \to 2$
.










Now, consider two separate copies of
 $2^\star$
, viz., R, whose strings are read-only, and W, whose strings are write-only. Then, we may retype these primitives, replacing each occurrence of
$2^\star$
, viz., R, whose strings are read-only, and W, whose strings are write-only. Then, we may retype these primitives, replacing each occurrence of
 $2^\star$
by either R or W as follows:
$2^\star$
by either R or W as follows:
 $$ \mathtt{hd} : R \rightharpoonup 2,\hspace{5pt} \mathtt{tl} : R \rightharpoonup R,\hspace{5pt}\mathtt{null} : R \to 2,\hspace{5pt} \mathtt{nil} : W,\hspace{5pt} \mathtt{cons}: 2 \times W \to W.$$
$$ \mathtt{hd} : R \rightharpoonup 2,\hspace{5pt} \mathtt{tl} : R \rightharpoonup R,\hspace{5pt}\mathtt{null} : R \to 2,\hspace{5pt} \mathtt{nil} : W,\hspace{5pt} \mathtt{cons}: 2 \times W \to W.$$
Note that this typing is consistent with strings in R being “read-only” and strings in W being “write-only.”
From these primitives, we construct a simple first-order programming language. First we define the types, then terms, of our programming language, then we define the programs themselves; finally, we equip these programs with an environment-based big-step semantics.
Definition 1. The three atomic types are 2, R, and W, denoting the type of booleans, read-only strings, and write-only strings, respectively. A product type is any expression of the form
 $\tau_0 \times \dots \times \tau_{n-1}$
, for
$\tau_0 \times \dots \times \tau_{n-1}$
, for
 $n \ge 0$
, where each
$n \ge 0$
, where each
 $\tau_i$
is either 2 or R. (W is excluded from product formation.) When
$\tau_i$
is either 2 or R. (W is excluded from product formation.) When
 $n=0$
, the product is empty. We extend the type constructor
$n=0$
, the product is empty. We extend the type constructor
 $\times$
to apply to product types by
$\times$
to apply to product types by
 $$ (\tau_0 \times \dots \times \tau_{n-1}) \times (\tau_n \times \dots \times \tau_{m-1}) = \tau_0 \times \dots \times \tau_{m-1} . $$
$$ (\tau_0 \times \dots \times \tau_{n-1}) \times (\tau_n \times \dots \times \tau_{m-1}) = \tau_0 \times \dots \times \tau_{m-1} . $$
A function type symbol is an expression of one of the following forms
 $$ \beta \to \alpha,\hspace{5pt} \beta \to W,\hspace{5pt} \beta \times W \to W, $$
$$ \beta \to \alpha,\hspace{5pt} \beta \to W,\hspace{5pt} \beta \times W \to W, $$
where
 $\beta$
and
$\beta$
and
 $\alpha$
are product types, and
$\alpha$
are product types, and
 $\alpha$
is nonempty.
$\alpha$
is nonempty.
Definition 2. For each product type
 $\alpha$
, fix an infinite set
$\alpha$
, fix an infinite set
 $\mathtt{Var}_\alpha$
of variables of type
$\mathtt{Var}_\alpha$
of variables of type
 $\alpha$
. For each product type
$\alpha$
. For each product type
 $\beta$
, fix infinite sets
$\beta$
, fix infinite sets
 $\mathtt{RFsymb}_{\beta \to W}$
and
$\mathtt{RFsymb}_{\beta \to W}$
and
 $\mathtt{RFsymb}_{\beta \times W \to W}$
of function symbols of type
$\mathtt{RFsymb}_{\beta \times W \to W}$
of function symbols of type
 $\beta \to W$
and
$\beta \to W$
and
 $\beta \times W \to W,$
respectively; similarly define
$\beta \times W \to W,$
respectively; similarly define
 $\mathtt{RFsymb}_{\beta \to \alpha}$
for each pair or product types
$\mathtt{RFsymb}_{\beta \to \alpha}$
for each pair or product types
 $(\alpha,\beta)$
.
$(\alpha,\beta)$
.
By a variable, we mean any member of any
 $\mathtt{Var}_\alpha$
, or the symbol
$\mathtt{Var}_\alpha$
, or the symbol
 $\mathtt{w}$
, which is the sole variable of type W. By a recursive function symbol, we mean any member of one of the sets
$\mathtt{w}$
, which is the sole variable of type W. By a recursive function symbol, we mean any member of one of the sets
 $\mathtt{RFsymb}_{\beta \to W}$
or
$\mathtt{RFsymb}_{\beta \to W}$
or
 $\mathtt{RFsymb}_{\beta \times W \to W}$
, for any
$\mathtt{RFsymb}_{\beta \times W \to W}$
, for any
 $\beta, W$
.
$\beta, W$
.
Definition 3. An RW term is any expression that can be derived according to the inference rules in Figure 1.
RW-terms. Letters
 $\alpha$
,
$\alpha$
,
 $\beta$
, and each
$\beta$
, and each
 $\alpha_i$
range over product types and each
$\alpha_i$
range over product types and each
 $\tau_i$
ranges over the atomic types 2 and R.
$\tau_i$
ranges over the atomic types 2 and R.

It is straightforward to show that any RW term has a unique derivation from these inference rules, and that if an RW term contains any subterm of type W, it must itself have type W.
Notice that we restrict the way that W terms can occur: there is only one variable of type W and recursive function symbols of output type W have at most one W input. This restriction, which we may refer to as the W-thinness of RW terms, does not ultimately limit the expressive power of the resulting language. Roughly speaking, this is because a W datum is a sort of black box: no information can flow out of it and it cannot affect the shape of a computation. Think of it as a write-only output tape of a Turing machine: a single write-only output tape suffices.
Definition 4 We identify a few important properties of RW terms.
-
An RW term is explicit if it contains no occurrence of a recursive function symbol.
-
An RW term is cons-free if it is not of type W; equivalently, if it does not contain any subterm of type W.
-
An RW term is non-nested in case it contains no occurrence of a recursion function symbol of type W inside another occurrence of a recursive function symbol of type W. More precisely, in any application of the bottom-most rule of Figure 1, the second hypothesis S must be explicit.
-
An RW term is tail-recursive in case there is no occurrence of a recursive function symbol inside any other occurrence of a recursive function symbol, or any primitive call, or in the if clause of any
$\mathtt{if}\ /\ \mathtt{then}\ /\ \mathtt{else}\ $
term. More precisely, in any application of a rule in the second row of Figure 1, or any application of the three recursive function calls at the bottom of 1, the terms in the hypotheses must be explicit; when forming
$\mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
,
$T_0$
must be explicit.



Remark 1. Notice that every tail-recursive term is also non-nested. Tail recursive RW-factorizable programs will end up capturing FL and non-nested programs will end up capturing FP; the program leap of Section 1 is witness to the necessity of this restriction.
Notice also that to be non-nested we only forbid nested recursive calls of output type W. (Surprisingly, we can always eliminate nested recursive calls in the purely cons-free part of a program, though we will not need this result in the present paper.)
Remark 2. We will actually silently use a slightly more general formulation of tail recursion. Notice that tail recursion affords more flexibility to calls to the primitives over recursive calls. For example, it is perfectly legal to write phrases such as
 $\mathtt{hd}( \mathtt{tl}( \dots ))$
but not
$\mathtt{hd}( \mathtt{tl}( \dots ))$
but not
 $\mathtt{hd}(\mathtt{f}( \dots ))$
, in a tail-recursive program.
$\mathtt{hd}(\mathtt{f}( \dots ))$
, in a tail-recursive program.
However, consider a transformation
 $T \mapsto T^\diamond$
on terms that uses the recursive functions of a previously defined tail-recursive program
$T \mapsto T^\diamond$
on terms that uses the recursive functions of a previously defined tail-recursive program
 $p^ \unicode{x2020}$
. In arguing that
$p^ \unicode{x2020}$
. In arguing that
 $T \mapsto T^\diamond$
preserves tail recursion, it suffices to treat calls to the recursive functions of
$T \mapsto T^\diamond$
preserves tail recursion, it suffices to treat calls to the recursive functions of
 $p^ \unicode{x2020}$
like calls to the primitives as opposed to other recursive calls.
Footnote 6
$p^ \unicode{x2020}$
like calls to the primitives as opposed to other recursive calls.
Footnote 6
Definition 5. An RW-factorizable program consists of a finite list of distinct recursive function symbols
 $(\mathtt{f}_0,\dots,\mathtt{f}_k)$
and a definition for each one, which takes one of the following two forms:
$(\mathtt{f}_0,\dots,\mathtt{f}_k)$
and a definition for each one, which takes one of the following two forms:
 $$ \mathtt{f}_i(\mathtt{x}_i,\mathtt{w}) = T_i \ \text{ or }\ \mathtt{f}_i(\mathtt{x}_i) = T_i,$$
$$ \mathtt{f}_i(\mathtt{x}_i,\mathtt{w}) = T_i \ \text{ or }\ \mathtt{f}_i(\mathtt{x}_i) = T_i,$$
where
 $T_i$
is a RW-term,
$T_i$
is a RW-term,
 $\mathtt{x}_i$
is a variable, and every recursive function symbol that occurs in
$\mathtt{x}_i$
is a variable, and every recursive function symbol that occurs in
 $T_i$
must be one of
$T_i$
must be one of
 $(\mathtt{f}_0,\dots,\mathtt{f}_k)$
. Furthermore
$(\mathtt{f}_0,\dots,\mathtt{f}_k)$
. Furthermore
-
If the definition of
$\mathtt{f}_i$
is of the form
$\mathtt{f}_i(\mathtt{x}_i,\mathtt{w}) = T_i$
, then
$\mathtt{f}_i(\mathtt{x}_i,\mathtt{w})$
must be a well-formed RW term of the same type as
$T_i$
, and the only variables that may occur in
$T_i$
are
$\mathtt{x}_i$
and
$\mathtt{w}$
. -
If the definition of
$\mathtt{f}_i$
is of the form
$\mathtt{f}_i(\mathtt{x}_i) = T_i$
, then
$\mathtt{f}_i(\mathtt{x}_i)$
must be a well-formed RW term of the same type as
$T_i$
, and the only variable that may occur in
$T_i$
is
$\mathtt{x}_i$
.













The head (term) of a program is the left-hand side of its first line, e.g.,
 $\mathtt{f}_0(\mathtt{x}_0)$
or
$\mathtt{f}_0(\mathtt{x}_0)$
or
 $\mathtt{f}_0(\mathtt{x}_0,\mathtt{w})$
. A program is cons-free in case all terms occurring within are cons-free.
$\mathtt{f}_0(\mathtt{x}_0,\mathtt{w})$
. A program is cons-free in case all terms occurring within are cons-free.
Remark 3 Any RW-factorizable program can be split into a “purely cons-free part” and a “W-part.” The purely cons-free part consists of all recursive function symbols of output type other than W and their definitions. This part is a self-contained “sub-program”: it does not contain any recursive function calls of type W, and its semantics is independent of the rest of the program. The W part of the program consists of all recursive function symbols of output type W and their definitions. It lies on top of the purely cons-free part, using it as a black box.
We equip programs with a standard, call-by-value, environment-based big-step semantics. By a value, we mean an element of the domain of some type, and by an environment, we mean a finite function mapping variables to values.
Definition 6. For a program p, term T, value v of the same type as T, and environment
 $\rho$
, we define the relation
$\rho$
, we define the relation
 $\rho \vdash_p T \to v$
according to the inference rules in Figure 2. We typically suppress the subscript p from
$\rho \vdash_p T \to v$
according to the inference rules in Figure 2. We typically suppress the subscript p from
 $\vdash$
for legibility.
$\vdash$
for legibility.
Program Semantics. In the bottom two rules,
 $\mathtt{f}(\mathtt{x}) = T^\mathtt{f}$
or
$\mathtt{f}(\mathtt{x}) = T^\mathtt{f}$
or
 $\mathtt{f}(\mathtt{x},\mathtt{w}) = T^\mathtt{f}$
is the recursive definition of
$\mathtt{f}(\mathtt{x},\mathtt{w}) = T^\mathtt{f}$
is the recursive definition of
 $\mathtt{f}$
in p. Also, w ranges over values of type W; r and r’ range over values of type R; b ranges over values of type 2; the
$\mathtt{f}$
in p. Also, w ranges over values of type W; r and r’ range over values of type R; b ranges over values of type 2; the
 $a_i$
range over values of type 2 and R; v, v’,
$a_i$
range over values of type 2 and R; v, v’,
 $v_i$
range over values of any product type; and u ranges over values of any type. The value
$v_i$
range over values of any product type; and u ranges over values of any type. The value
 $v_0 \circ \dots \circ v_{n-1}$
denotes concatenation of the constituent tuples. For example if
$v_0 \circ \dots \circ v_{n-1}$
denotes concatenation of the constituent tuples. For example if
 $v_0 = (a_0,a_1)$
and
$v_0 = (a_0,a_1)$
and
 $v_1 = (a_2,a_3,a_4)$
then
$v_1 = (a_2,a_3,a_4)$
then
 $v_0 \circ v_1 = (a_0, a_1, a_2, a_3, a_4)$
. In general we will not carefully maintain this correspondence between variable names and their types.
$v_0 \circ v_1 = (a_0, a_1, a_2, a_3, a_4)$
. In general we will not carefully maintain this correspondence between variable names and their types.

Definition 7 Given a program p, define
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
iff there is a derivation of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
iff there is a derivation of
 $[\mathtt{x} = x] \vdash_p \mathtt{f}_0(\mathtt{x}) \to v$
, where
$[\mathtt{x} = x] \vdash_p \mathtt{f}_0(\mathtt{x}) \to v$
, where
 $\mathtt{f}_0(\mathtt{x})$
is the head of p. (If the head of p is of the form
$\mathtt{f}_0(\mathtt{x})$
is the head of p. (If the head of p is of the form
 $\mathtt{f}_0(\mathtt{x},\mathtt{w})$
, then
$\mathtt{f}_0(\mathtt{x},\mathtt{w})$
, then
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,w) = v$
iff there is a derivation of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,w) = v$
iff there is a derivation of
 $[\mathtt{x} = x, \mathtt{w} = w] \vdash_p \mathtt{f}_0(\mathtt{x},\mathtt{w}) \to v$
.) Since p is deterministic,
$[\mathtt{x} = x, \mathtt{w} = w] \vdash_p \mathtt{f}_0(\mathtt{x},\mathtt{w}) \to v$
.) Since p is deterministic,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is easily seen to be a partial function.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is easily seen to be a partial function.
Note that the relation
 $\vdash_p$
is independent of the head of p; it is only when defining
$\vdash_p$
is independent of the head of p; it is only when defining
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
that we care what the head is.
Footnote 7
Aside from specifying the head, neither
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
that we care what the head is.
Footnote 7
Aside from specifying the head, neither
 $\vdash_p$
nor
$\vdash_p$
nor
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is sensitive to the particular order of the recursive function symbols in a program; it is only because of overwhelming programming intuition that we say a list instead of a set of function symbols.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
is sensitive to the particular order of the recursive function symbols in a program; it is only because of overwhelming programming intuition that we say a list instead of a set of function symbols.
In subsequent sections, we will define programs by extending previously defined programs with additional recursive function symbols and their definitions. This simply means: take the old program, forget what its head is, add new lines to the program—we don’t care in what order—and pick a new head according to the definition at hand. If q is the old program and p the new one, notice that
 $\vdash_p$
extends
$\vdash_p$
extends
 $\vdash_q$
.
$\vdash_q$
.
4 Bit-length programs
In this section, we construct a dialect of cons-free programs and use them to define function computability in the manner sketched in Section 2. In other words, two programs are needed to witness the computability of a function
 $f:2^\star \to 2^\star$
in polynomial time: one that computes the bits of f and the other that computes the length. Hence, we call these programs (rather unimaginatively) bit-length (or BL) programs.
$f:2^\star \to 2^\star$
in polynomial time: one that computes the bits of f and the other that computes the length. Hence, we call these programs (rather unimaginatively) bit-length (or BL) programs.
The bit-length dialect differs from the standard cons-free language in two ways. The first difference is to replace R-data with string indices as follows. Imagine a cons-free program with a single string input. Then any string constructed during computation will be a suffix of that input. Instead, we might as well consider indices of the input string. Instead of querying the head of the various string suffixes, we query the bit of the input string at the given index.
The second difference is that counting modules—a type of natural numbers with magnitude bounded polynomially in the length of the input—are treated as a separate data type, a dependent type which varies with the length of the input string, as opposed to syntactic sugar.
Each of these modifications confers an advantage. Replacing R values by string indices lends a sort of extensional compositionality to bit-length programs that RW-factorizable programs lack. Meaning, the pair of programs computing a function transforms the same type of information about the input (its bits and length, given by the index primitives) into the same type of information about the output (its bits and length, given by the two programs). Moreover, a careful treatment of counting modules allows for cleaner representation strings in
 $1^\star$
. (The relevance of unary strings to computation of functions was discussed in Section 2.)
$1^\star$
. (The relevance of unary strings to computation of functions was discussed in Section 2.)
We note that the original paper (Jones, Reference Jones1999) contains a language called
 $\mathtt{CM}$
for counter machine, which was used as a technical tool in the proofs of the main results of that paper. A variant,
$\mathtt{CM}$
for counter machine, which was used as a technical tool in the proofs of the main results of that paper. A variant,
 $\mathtt{CM}^\mathit{rec-poly}$
, is basically identical to our bit-length language. However, our presentation is different enough to justify a separate treatment. For one, CM and its variants are imperative instead of functional. Secondly, indices and counting modules are conflated in CM, whereas we treat them as different types. A glossary between the present paper and (Jones, Reference Jones1999) can be found in Table 1.
Footnote 8
$\mathtt{CM}^\mathit{rec-poly}$
, is basically identical to our bit-length language. However, our presentation is different enough to justify a separate treatment. For one, CM and its variants are imperative instead of functional. Secondly, indices and counting modules are conflated in CM, whereas we treat them as different types. A glossary between the present paper and (Jones, Reference Jones1999) can be found in Table 1.
Footnote 8
A correspondence between languages in the present paper on the left and Jones (Reference Jones1999) on the right. A bit-length program is C-free if it contains no counting modules

As for RW programs, we explain bit-length programs first by discussing types, then terms, then programs, and finally semantics.
Definition 8. For any
 $n \in \omega$
, the counting module C(n) is a data type whose domain is the set
$n \in \omega$
, the counting module C(n) is a data type whose domain is the set
 $n = \{0,1,\dots,n-1\}$
, and whose primitives consist of constants naming the maximum (
$n = \{0,1,\dots,n-1\}$
, and whose primitives consist of constants naming the maximum (
 $n - 1$
), minimum (0), and 1, plus operations of addition, subtraction, and comparison and equality tests. Addition and subtraction “top out” and “bottom out” at the maximum and minimum element, respectively.
$n - 1$
), minimum (0), and 1, plus operations of addition, subtraction, and comparison and equality tests. Addition and subtraction “top out” and “bottom out” at the maximum and minimum element, respectively.
Definition 9. For any string
 $x \in 2^\star$
, the set of indices I(x) is a data type whose domain is
$x \in 2^\star$
, the set of indices I(x) is a data type whose domain is
 $|x| + 1 = \{0,1,\dots,|x|\}$
, and whose primitives consist of constants naming the maximum (
$|x| + 1 = \{0,1,\dots,|x|\}$
, and whose primitives consist of constants naming the maximum (
 $|x|$
), minimum (0), predecessor (which decrements the index), equality to zero, and bit (which returns the bit of the input at the given index).
$|x|$
), minimum (0), predecessor (which decrements the index), equality to zero, and bit (which returns the bit of the input at the given index).
Remark 4. We index strings such that the leftmost character has index the length of the string, and the rightmost character has index 1. That is, for any string x,
 $x = x_{|x|}x_{|x|-1} \dots x_2 x_1$
. The bit
$x = x_{|x|}x_{|x|-1} \dots x_2 x_1$
. The bit
 $x_0$
is undefined. This funny indexing makes the compiling between bit-length and cons-free programs cleaner, as identifying indices with suffixes identifies
$x_0$
is undefined. This funny indexing makes the compiling between bit-length and cons-free programs cleaner, as identifying indices with suffixes identifies
 $\mathtt{tl}$
with the predecessor function.
$\mathtt{tl}$
with the predecessor function.
Notice that C and I are dependent types; namely, they are families of types indexed by some other value (natural numbers or binary strings). Now we introduce program syntax.
Definition 10. There are three atomic type symbols, 2, I, and C, denoting the type of booleans, indices, and counting modules respectively. A BL-type symbol is any expression of the form
 $\tau_0 \times \dots \times \tau_{n-1}$
, for
$\tau_0 \times \dots \times \tau_{n-1}$
, for
 $n \ge 0$
, where each
$n \ge 0$
, where each
 $\tau_i$
is an atomic type symbol. When
$\tau_i$
is an atomic type symbol. When
 $n=0$
, the product is empty, and when
$n=0$
, the product is empty, and when
 $n=1$
, we recover the atomic type symbols. A BL-function type symbol is an expression of the form
$n=1$
, we recover the atomic type symbols. A BL-function type symbol is an expression of the form
 $\beta \to \alpha$
, where
$\beta \to \alpha$
, where
 $\beta$
and
$\beta$
and
 $\alpha$
are product types, and
$\alpha$
are product types, and
 $\alpha$
is nonempty.
$\alpha$
is nonempty.
Definition 11. For a BL-type symbol
 $\alpha$
, we write
$\alpha$
, we write
 $\alpha(x,n)$
to denote the type obtained by specializing each coordinate of
$\alpha(x,n)$
to denote the type obtained by specializing each coordinate of
 $\alpha$
to x or n as appropriate. (Similarly for BL-function types.)
$\alpha$
to x or n as appropriate. (Similarly for BL-function types.)
Remark 5. In the context of a single computation of a bit-length program, x and n will be fixed. Therefore, it is fine to type variables by type symbols, like 2, I, C,
 $2 \times I \times C$
, etc., since we do not have multiple instantiations of these types in a single computation. In contrast, values have types like I(x),
$2 \times I \times C$
, etc., since we do not have multiple instantiations of these types in a single computation. In contrast, values have types like I(x),
 $I(x) \times C(n)$
, etc., where x is a string and n a number.
$I(x) \times C(n)$
, etc., where x is a string and n a number.
Definition 12. Fix an infinite set
 $\mathtt{Var}_\alpha$
of variables of type
$\mathtt{Var}_\alpha$
of variables of type
 $\alpha$
, for each BL-type
$\alpha$
, for each BL-type
 $\alpha$
, and an infinite set
$\alpha$
, and an infinite set
 $\mathtt{RFsymb}_{\beta \to \alpha}$
of BL-function symbols of type
$\mathtt{RFsymb}_{\beta \to \alpha}$
of BL-function symbols of type
 $\beta \to \alpha$
, for each function type
$\beta \to \alpha$
, for each function type
 $\beta \to \alpha$
. Then, a bit-length term is any expression which can be derived according to the inference rules in Figure 3.
$\beta \to \alpha$
. Then, a bit-length term is any expression which can be derived according to the inference rules in Figure 3.
Bit/length terms. Here
 $\alpha$
ranges over product types and
$\alpha$
ranges over product types and
 $\tau$
over atomic types.
$\tau$
over atomic types.

Definition 13. A bit-length term is explicit in case it contains no occurrence of a recursive function symbol. It is tail-recursive in case no recursive function symbol occurs inside any other recursive call, primitive call, or if clause. (We are not concerned with non-nested bit-length terms.)
Definition 14. A bit-length program is a finite list of lines of the form
 $\mathtt{f}_i(\mathtt{x}_i) = T_i$
, for
$\mathtt{f}_i(\mathtt{x}_i) = T_i$
, for
 $0 \le i \le k$
, where
$0 \le i \le k$
, where
 $\mathtt{x}_i$
is a variable whose type agrees with the domain of
$\mathtt{x}_i$
is a variable whose type agrees with the domain of
 $\mathtt{f}$
, and the type of
$\mathtt{f}$
, and the type of
 $T_i$
agrees with the codomain of
$T_i$
agrees with the codomain of
 $\mathtt{f}_i$
. In addition, the only variable that occurs in
$\mathtt{f}_i$
. In addition, the only variable that occurs in
 $T_i$
must be
$T_i$
must be
 $\mathtt{x}_i$
, and the only recursive function symbols that occur in
$\mathtt{x}_i$
, and the only recursive function symbols that occur in
 $T_i$
must be one of
$T_i$
must be one of
 $(\mathtt{f}_0,\dots,\mathtt{f}_k)$
.
$(\mathtt{f}_0,\dots,\mathtt{f}_k)$
.
Definition 15. For any bit-length program p, input string
 $x \in 2^\star$
, seed
$x \in 2^\star$
, seed
 $n \in \omega$
, term T of type
$n \in \omega$
, term T of type
 $\alpha$
, environment
$\alpha$
, environment
 $\rho$
binding the free variables of T, and value v of type
$\rho$
binding the free variables of T, and value v of type
 $\alpha(x,n)$
, we define the relation
$\alpha(x,n)$
, we define the relation
 $$ x, n, \rho \vdash_p T \to v$$
$$ x, n, \rho \vdash_p T \to v$$
according to the inference rules in Figure 4. Note that there is at most one v satisfying the above relation for each x, n,
 $\rho$
, p, and T, which means that p is deterministic.
$\rho$
, p, and T, which means that p is deterministic.
Semantics for bit-length programs. Dependence of
 $\vdash$
on x, n, and
$\vdash$
on x, n, and
 $\rho$
is suppressed for legibility.
$\rho$
is suppressed for legibility.
 $\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
is the recursive definition of
$\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
is the recursive definition of
 $\mathtt{f}$
in p and
$\mathtt{f}$
in p and
 $x_i$
is the i-th bit of
$x_i$
is the i-th bit of
 $x = x_{|x|} \dots x_1$
. Variables c and d range over C(n), i ranges over I(x), the
$x = x_{|x|} \dots x_1$
. Variables c and d range over C(n), i ranges over I(x), the
 $a_i$
range over values in any atomic type, and v, v’ and the
$a_i$
range over values in any atomic type, and v, v’ and the
 $v_i$
range over values of any type. In general we will not carefully maintain this correspondence between variables and their types. As in RW-factorizable programs, note that while we can form larger tuples from smaller proper tuples, we can only decompose tuples into atomic types.
$v_i$
range over values of any type. In general we will not carefully maintain this correspondence between variables and their types. As in RW-factorizable programs, note that while we can form larger tuples from smaller proper tuples, we can only decompose tuples into atomic types.

Remark 6. Note the extra two parameters x and n in the definition of semantics of bit-length programs. These may be viewed as analogous to a global variable if you’re a programmer or the structure on the left-hand side of the satisfiability relation if you’re a logician. Without them, the function symbols
 $\mathtt{max}$
,
$\mathtt{max}$
,
 $+$
, and
$+$
, and
 $\mathtt{bit}$
are ill defined.
$\mathtt{bit}$
are ill defined.
Definition 16. For any program p and function
 $\lambda : \omega \to \omega$
, we define the relation
$\lambda : \omega \to \omega$
, we define the relation
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = w$
by
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = w$
by
 $$x,\lambda(|x|),[\mathtt{x}_0 = y] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to w,$$
$$x,\lambda(|x|),[\mathtt{x}_0 = y] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to w,$$
where
 $\mathtt{f}_0(\mathtt{x}_0) = T_0$
is the head of p. By the determinism of p,
$\mathtt{f}_0(\mathtt{x}_0) = T_0$
is the head of p. By the determinism of p,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
is a partial function.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
is a partial function.
Note that the string variable x becomes the first argument of
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
. Therefore, if we want to compute a function which has a single string input by a bit-length program, the head of that program must be nullary, i.e., have zero inputs.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
. Therefore, if we want to compute a function which has a single string input by a bit-length program, the head of that program must be nullary, i.e., have zero inputs.
Definition 17. Fix a string x, natural number n, and program p, and let
 $\rho \vdash T \to v$
mean
$\rho \vdash T \to v$
mean
 $x,n,\rho \vdash_p T \to v$
. A collision is an occurrence of an inference rule of the form
$x,n,\rho \vdash_p T \to v$
. A collision is an occurrence of an inference rule of the form

such that
 $\min\{v+w,n\} = n$
, in a derivation formed from the inference rules in Figure 4. We say a derivation of
$\min\{v+w,n\} = n$
, in a derivation formed from the inference rules in Figure 4. We say a derivation of
 $\rho \vdash T \to v$
is collision-free in case it contains no collisions.
$\rho \vdash T \to v$
is collision-free in case it contains no collisions.
Informally, a collision occurs when an addition operation attempts to overstep (or even meet) the maximum integer bound n in a derivation. The nice thing about collision-free derivations is that they are oblivious to this bound.
Lemma 1. If
 $x,n,\rho\vdash_p T \to v$
by a collision-free derivation and
$x,n,\rho\vdash_p T \to v$
by a collision-free derivation and
 $n' \ge n$
, then
$n' \ge n$
, then
 $x,n',\rho \vdash_p T \to v$
.
$x,n',\rho \vdash_p T \to v$
.
Proof. Notice that in the inference rules of Figure 4, a collision is the only instance in which the conclusion depends on n. Hence if we take a collision-free derivation and increase n, it is still a valid derivation.
Remark 7. As a consequence of Lemma 1, if
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) =w$
by a collision-free derivation and
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) =w$
by a collision-free derivation and
 $\lambda(n) \le \lambda'(n)$
for all
$\lambda(n) \le \lambda'(n)$
for all
 $n \in \omega$
, then
$n \in \omega$
, then
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda'}(x,y) = w$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda'}(x,y) = w$
.
Finally, let us discuss the type of the partial function computed
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
by a bit-length program p, which will in general be a dependent product type. Suppose the recursive function symbol
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
by a bit-length program p, which will in general be a dependent product type. Suppose the recursive function symbol
 $\mathtt{f}_0$
in the head of program p has type
$\mathtt{f}_0$
in the head of program p has type
 $\beta \to \alpha$
. Then, the type of
$\beta \to \alpha$
. Then, the type of
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
is
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda$
is
 $$\prod_{x:2^\star} \big( \beta(x,\lambda(|x|)) \to \alpha(x,\lambda(|x|)) \big).$$
$$\prod_{x:2^\star} \big( \beta(x,\lambda(|x|)) \to \alpha(x,\lambda(|x|)) \big).$$
We identify two important special cases. When
 $\beta$
is the empty tuple and
$\beta$
is the empty tuple and
 $\alpha = C$
, then
$\alpha = C$
, then
 $$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : \prod_{x : 2^\star} C(\lambda(|x|)).$$
$$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : \prod_{x : 2^\star} C(\lambda(|x|)).$$
On the other hand, when
 $\alpha = 2$
and
$\alpha = 2$
and
 $\beta = C$
, then
$\beta = C$
, then
 $$ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : \sum_{x:2^\star} C(\lambda(|x|)) \to 2. $$
$$ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : \sum_{x:2^\star} C(\lambda(|x|)) \to 2. $$
(Note that when both
 $\beta$
is empty and
$\beta$
is empty and
 $\alpha =2$
, then
$\alpha =2$
, then
 $ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : 2^\star \to 2$
.)
$ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda : 2^\star \to 2$
.)
5 Bit-length computability of functions
The following theorem is a restatement of the theorems
 $\mathtt{TM}^\mathit{ptime} \equiv \mathtt{CM}^\mathit{rec-poly}$
and
$\mathtt{TM}^\mathit{ptime} \equiv \mathtt{CM}^\mathit{rec-poly}$
and
 $\mathtt{TM}^\mathit{logspace} \equiv \mathtt{CM}^\mathit{poly}$
from Jones (Reference Jones1999).
$\mathtt{TM}^\mathit{logspace} \equiv \mathtt{CM}^\mathit{poly}$
from Jones (Reference Jones1999).
Theorem. Let f be any function of type
 $2^\star \to 2$
. Then, the following are equivalent:
$2^\star \to 2$
. Then, the following are equivalent:
-
f is computable in polynomial time.
-
There is a polynomially bounded function
$\lambda : \omega \to \omega$
and bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
$x \in 2^\star$
.



We get an analogous result by replacing FP with FL and “bit-length program” with “tail-recursive bit-length program” throughout.
We use the following extension of this theorem. The basic observation is that the simulations of Turing machines by programs can be augmented by counting modules that keep track of the lengths of tapes or what comes to the same thing, unary strings. So the simulation extends to Turing machines which return unary strings as output. We sketch the proof in Appendix B.
Theorem 2. For any function
 $f : 2^\star \to 1^\star$
, the following are equivalent:
$f : 2^\star \to 1^\star$
, the following are equivalent:
-
f is computable in polynomial time.
-
There is a polynomially bounded function
$\lambda : \omega \to \omega$
and a bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
$x \in 2^\star$
.



For any function
 $f : 2^\star \times 1^\star \to 2$
and polynomially bounded function
$f : 2^\star \times 1^\star \to 2$
and polynomially bounded function
 $\pi : \omega \to \omega$
, the following are equivalent:
$\pi : \omega \to \omega$
, the following are equivalent:
-
There is a polynomial-time computable function
$g : 2^\star \times 1^\star \to 2$
such that
$g(x,y) = f(x,y)$
for any string
$x \in 2^\star$
and
$y \le \pi(|x|)$
. -
There is a polynomially bounded function
$\lambda : \omega \to \omega$
and a bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = f(x,y)$
, without collisions, for any
$x \in 2^\star$
and
$y \le \pi(|x|)$
.








Moreover, we get an analogous result by replacing FP with FL and “bit-length program” with “tail-recursive bit-length program” throughout.
Note that the recursive function symbol
 $\mathtt{f}_0$
in the head of the program p should have type C if
$\mathtt{f}_0$
in the head of the program p should have type C if
 $f : 2^\star \to 1^\star$
and type
$f : 2^\star \to 1^\star$
and type
 $C \to 2$
if
$C \to 2$
if
 $f : 2^\star \times 1^\star \to 2$
.
$f : 2^\star \times 1^\star \to 2$
.
Combining Theorems 1 and 2, we are able to show the fundamental property of bit-length programs; namely that a function is computable in polynomial time iff there is a pair of bit-length programs computing the length and bits of f, respectively. Similarly, a function is computable in logarithmic space iff there is a pair of tail-recursive bit-length programs computing the length and bits of f respectively.
Theorem 3. For any function
 $f : 2^\star \to 2^\star$
, f is computable in polynomial time if and only if there is a polynomially bounded function
$f : 2^\star \to 2^\star$
, f is computable in polynomial time if and only if there is a polynomially bounded function
 $\lambda : \omega \to \omega$
such that
$\lambda : \omega \to \omega$
such that
 $|f(x)| < \lambda(|x|)$
for all
$|f(x)| < \lambda(|x|)$
for all
 $x \in 2^\star$
and a pair of bit-length programs p and q such that
$x \in 2^\star$
and a pair of bit-length programs p and q such that
 $$ |f(x)| = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) $$
$$ |f(x)| = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) $$
without collisions, for all
 $x \in 2^\star$
, and additionally for any
$x \in 2^\star$
, and additionally for any
 $i < |f(x)|$
,
$i < |f(x)|$
,
 $$ \big( f(x) \big)_i = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x,i) $$
$$ \big( f(x) \big)_i = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x,i) $$
without collisions, where
 $\big( f(x) \big)_i$
is the
$\big( f(x) \big)_i$
is the
 $i\mathrm{th}$
-bit of f(x).
$i\mathrm{th}$
-bit of f(x).
Furthermore, we get the analogous result for logarithmic space by requiring that p and q be tail-recursive.
Proof We go through the proof in the polynomial-time case; the proof for the logarithmic-space case is verbatim, replacing “program” by “tail-recursive program” throughout.
Suppose
 $f : 2^\star \to 2^\star$
is computable in polynomial time. By Theorem 1, there exist polynomial-time computable functions
$f : 2^\star \to 2^\star$
is computable in polynomial time. By Theorem 1, there exist polynomial-time computable functions
 $f_\ell: 2^\star \to 1^\star$
and
$f_\ell: 2^\star \to 1^\star$
and
 $f_b:2^\star \times 1^\star \to 2$
such that, for all
$f_b:2^\star \times 1^\star \to 2$
such that, for all
 $x \in 2^\star$
$x \in 2^\star$
 $f_\ell(x) = |f(x)|$
, and additionally for each
$f_\ell(x) = |f(x)|$
, and additionally for each
 $i < |f(x)|$
,
$i < |f(x)|$
,
 $f_b(x,i) = \big( f(x) \big)_i$
. Let
$f_b(x,i) = \big( f(x) \big)_i$
. Let
 $\pi$
be a polynomially bounded function such that
$\pi$
be a polynomially bounded function such that
 $|f(x)|< \pi(|x|)$
.
$|f(x)|< \pi(|x|)$
.
By Theorem 2 applied to
 $f_\ell,$
there is a polynomially bounded function
$f_\ell,$
there is a polynomially bounded function
 $\lambda_1$
and a bit-length program q such that
$\lambda_1$
and a bit-length program q such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda_1}(x) = f_\ell(x)$
, without collisions, for any string x. By Theorem 2 applied to
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda_1}(x) = f_\ell(x)$
, without collisions, for any string x. By Theorem 2 applied to
 $f_b$
, there is a polynomially bounded function
$f_b$
, there is a polynomially bounded function
 $\lambda_2$
and a bit-length program p such that
$\lambda_2$
and a bit-length program p such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda_2}(x,i) = f_b(x,i)$
, without collisions, for any string x and
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_{\lambda_2}(x,i) = f_b(x,i)$
, without collisions, for any string x and
 $i < \pi(|x|)$
. Let
$i < \pi(|x|)$
. Let
 $\lambda$
be a polynomially bounded function dominating both
$\lambda$
be a polynomially bounded function dominating both
 $\lambda_1$
and
$\lambda_1$
and
 $\lambda_2$
. By Remark 7 concerning collision-free computation, we can replace
$\lambda_2$
. By Remark 7 concerning collision-free computation, we can replace
 $\lambda_1$
and
$\lambda_1$
and
 $\lambda_2$
by
$\lambda_2$
by
 $\lambda$
in the statements above. By definition of
$\lambda$
in the statements above. By definition of
 $f_\ell$
,
$f_\ell$
,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |f(x)|$
, for any string x. By definition of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |f(x)|$
, for any string x. By definition of
 $f_b$
and since
$f_b$
and since
 $\pi(|x|)$
dominates
$\pi(|x|)$
dominates
 $|f(x)|$
,
$|f(x)|$
,
 n the other direction, suppose we ha
for any string x and
n the other direction, suppose we ha
for any string x and
 $i < |f(x)|$
. This concludes the forward direction.
$i < |f(x)|$
. This concludes the forward direction.
In the other direction, suppose we have a bound
 $\lambda$
and programs p and q satisfying the desired properties. Then by Theorem 2, the function
$\lambda$
and programs p and q satisfying the desired properties. Then by Theorem 2, the function
 $x \mapsto |f(x)| : 2^\star \to 1^\star$
is computable in polynomial time. Fix a polynomially bounded function
$x \mapsto |f(x)| : 2^\star \to 1^\star$
is computable in polynomial time. Fix a polynomially bounded function
 $\pi$
such that
$\pi$
such that
 $|f(x)| < \pi(|x|)$
. Then by Theorem 2 again, there is a function
$|f(x)| < \pi(|x|)$
. Then by Theorem 2 again, there is a function
 $g : 2^\star \times 1^\star \to 2$
, computable in polynomial time, such that
$g : 2^\star \times 1^\star \to 2$
, computable in polynomial time, such that
 $g(x,i) = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,i)$
for every string x and
$g(x,i) = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,i)$
for every string x and
 $i < \pi(|x|)$
. (In particular,
$i < \pi(|x|)$
. (In particular,
 $g(x,i) = \big( f(x) \big)_i $
for every string x and
$g(x,i) = \big( f(x) \big)_i $
for every string x and
 $i < |f(x)|$
.) Finally, by applying Theorem 1 to
$i < |f(x)|$
.) Finally, by applying Theorem 1 to
 $x \mapsto |f(x)|$
and g, we conclude that f is computable in polynomial time.
$x \mapsto |f(x)|$
and g, we conclude that f is computable in polynomial time.
Theorem 3 suggests the following definition.
Definition 18. Let
 $f : 2^\star \to 2^\star$
,
$f : 2^\star \to 2^\star$
,
 $\lambda : \omega \to \omega$
, p be a bit-length program whose head recursive function symbol has type
$\lambda : \omega \to \omega$
, p be a bit-length program whose head recursive function symbol has type
 $C \to 2$
, and q be a bit-length program whose head recursive function symbol has type C.
$C \to 2$
, and q be a bit-length program whose head recursive function symbol has type C.
Then we say
 $(\lambda,p,q)$
properly computes f in case
$(\lambda,p,q)$
properly computes f in case
 $\lambda$
is increasing,
$\lambda$
is increasing,
 $|f(x)| < \lambda(|x|)$
for all
$|f(x)| < \lambda(|x|)$
for all
 $x \in 2^\star$
,
$x \in 2^\star$
,
 $ \big( f(x) \big)_i = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x,i) $
without collisions.
$ \big( f(x) \big)_i = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x,i) $
without collisions.
Then, Theorem 3 can be succinctly restated as follows: membership in FP is equivalent to being properly computed by some triple
 $(\lambda,p,q)$
with polynomially bounded
$(\lambda,p,q)$
with polynomially bounded
 $\lambda$
, and membership in FL is equivalent to being properly computed by some triple
$\lambda$
, and membership in FL is equivalent to being properly computed by some triple
 $(\lambda,p,q)$
with polynomially bounded
$(\lambda,p,q)$
with polynomially bounded
 $\lambda$
and p and q tail-recursive.
$\lambda$
and p and q tail-recursive.
6 Compiling RW-factorizable to bit-length programs
We now show how to compile an RW-factorizable program into a pair of bit-length programs that properly computes the same function. This consists of four program transformations:
-
1. The “dagger” transformation
$ \unicode{x2020}$
, that translates the RW-terms without W into the bit-length variant without counting modules. (So, substrings of the input string are reinterpreted as indices,
$\mathtt{hd}$
is reinterpreted as
$\mathtt{bit}$
,
$\mathtt{tl}$
is reinterpreted as
$\mathtt{P}$
, etc.) -
2. The “diamond” transformation
$\diamond$
that takes an RW-term T of type W into a bit-length term
$T^\diamond$
of type 2, which detects whether T denotes a string built up from
$\mathtt{w}$
or built up from
$\mathtt{nil}$
. -
3. A “length” transformation
$\ell$
that takes an RW-term T of type W into a bit-length term
$T^\ell$
of type C computing the length of T. -
4. A “bit” transformation b that takes an RW-term T of type W into a bit-length term
$T^b$
of type 2, which has an extra variable
$\mathtt{c}$
and computes the bit of T at
$\mathtt{c}$
.














Each of these transformations requires a translation of types, then terms and values, then programs, and finally a proof of correctness. Footnote 9 Moreover, we need to observe that each transformation preserves tail recursion. For that reason, this section is long, even though the main idea of each translation is easy to intuit:
-
The dagger transformation is straightforward, essentially amounting to a “renaming” of primitives.
-
Operationally, when we evaluate a RW-term T of type W into a value v according to an environment
$\rho$
, v is constructed by starting with either the empty string
$\varepsilon$
or the string
$w = \rho(\mathtt{w})$
and
$\mathtt{cons}$
-ing various bits in front. The term
$T^\diamond$
detects which of
$\varepsilon$
or w v is “built up” from. -
Suppose p is an RW-factorizable program that contains a recursive function symbol
$\mathtt{f}$
of type
$\beta \times W \to W$
. Suppose that
$\rho \vdash_p \mathtt{f}(T,S) \to v$
,
$\rho \vdash_p \mathtt{f}(T,\mathtt{nil}) \to u$
and
$\rho \vdash_p S \to w$
. Then, there are two possibilities. Either
$v = uw$
, in which case-
•
$|v| = |u| + |w|$
, and -
•
$v_i = w_i$
(if
$i \le |w|$
), and otherwise is
$u_{i - |w|}$
.
-
















Otherwise
 $v = u$
, in which case
$v = u$
, in which case
 $|v| = |u|$
and
$|v| = |u|$
and
 $v_i = u_i$
. Which case we are in is given to us by the diamond transformation.
$v_i = u_i$
. Which case we are in is given to us by the diamond transformation.
The rest of the section essentially consists of making these intuitions formal.
6.1 The dagger transformation
The types in an RW-factorizable program are 2, R, and W. The types in a bit-length program are 2, I, and C. We first define a map from W-free types to bit-length types and then extend it to variables, recursive function symbols, terms, and programs.
Definition 19. Let
 $2^ \unicode{x2020} = 2$
and
$2^ \unicode{x2020} = 2$
and
 $R^ \unicode{x2020} = I$
, and extend this to product and function types coordinate-wise.
$R^ \unicode{x2020} = I$
, and extend this to product and function types coordinate-wise.
Definition 20. For RW variables
 $\mathtt{x}$
not of type W and function symbols
$\mathtt{x}$
not of type W and function symbols
 $\mathtt{f}$
not containing any type W, let
$\mathtt{f}$
not containing any type W, let
 $\mathtt{x} \mapsto \mathtt{x}^ \unicode{x2020}$
and
$\mathtt{x} \mapsto \mathtt{x}^ \unicode{x2020}$
and
 $\mathtt{f} \mapsto \mathtt{f}^ \unicode{x2020}$
be a map from RW-factorizable variables and function symbols into bit-length variables and function symbols, so that for example, if
$\mathtt{f} \mapsto \mathtt{f}^ \unicode{x2020}$
be a map from RW-factorizable variables and function symbols into bit-length variables and function symbols, so that for example, if
 $\mathtt{x}$
is of type
$\mathtt{x}$
is of type
 $\tau$
, then
$\tau$
, then
 $\mathtt{x}^ \unicode{x2020}$
is of type
$\mathtt{x}^ \unicode{x2020}$
is of type
 $\tau^ \unicode{x2020}$
. (We may assume these maps are injective.)
$\tau^ \unicode{x2020}$
. (We may assume these maps are injective.)
Definition 21. Define a map
 $T \mapsto T^ \unicode{x2020}$
from W-free RW-factorizable terms to bit-length terms by:
$T \mapsto T^ \unicode{x2020}$
from W-free RW-factorizable terms to bit-length terms by:
-
If
$T \equiv \mathtt{true}$
or
$T \equiv \mathtt{false,}$
, then
$T^ \unicode{x2020} \equiv T$
. -
If
$T \equiv \mathtt{x}$
, then
$T^ \unicode{x2020} \equiv \mathtt{x}^ \unicode{x2020}$
. -
If
$T \equiv \mathtt{hd}(S)$
then
$T^ \unicode{x2020} \equiv \mathtt{bit}(S^ \unicode{x2020})$
. -
If
$T \equiv \mathtt{tl}(S)$
then
$T^ \unicode{x2020} \equiv \mathtt{P}(S^ \unicode{x2020})$
. -
If
$T \equiv \mathtt{null}(S)$
then
$T^ \unicode{x2020} \equiv \mathtt{null}(S^ \unicode{x2020})$
. -
If
$T \equiv T_0 \oplus \dots \oplus T_{n-1}$
then
$T^ \unicode{x2020} \equiv T^ \unicode{x2020}_0 \oplus \dots \oplus T^ \unicode{x2020}_{n-1}$
. -
If
$T \equiv S[i]$
then
$T^ \unicode{x2020} \equiv S^ \unicode{x2020} [i]$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then
$T^ \unicode{x2020} \equiv \mathtt{if}\ T^ \unicode{x2020}_0\ \mathtt{then}\ T^ \unicode{x2020}_1\ \mathtt{else}\ T^ \unicode{x2020}_2$
. -
If
$T \equiv \mathtt{f}(S)$
then
$T^ \unicode{x2020} \equiv \mathtt{f}^ \unicode{x2020}(S^ \unicode{x2020})$
.



















Notice that this transformation trivially preserves tail recursion.
Definition 22. For a cons-free program
 $p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)_{0 \le i \le k}$
, let the bit-length program
$p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)_{0 \le i \le k}$
, let the bit-length program
 $p^ \unicode{x2020}$
be
$p^ \unicode{x2020}$
be
 $ (\mathtt{f}^ \unicode{x2020}_i(\mathtt{x}_i^ \unicode{x2020}) = T^ \unicode{x2020}_i)_{0 \le i \le k}$
. Note that
$ (\mathtt{f}^ \unicode{x2020}_i(\mathtt{x}_i^ \unicode{x2020}) = T^ \unicode{x2020}_i)_{0 \le i \le k}$
. Note that
 $p^ \unicode{x2020}$
is a well-formed program which is tail-recursive if p is.
$p^ \unicode{x2020}$
is a well-formed program which is tail-recursive if p is.
Finally, we extend
 $ \unicode{x2020}$
to a map on values. Note that the type of the map
$ \unicode{x2020}$
to a map on values. Note that the type of the map
 $y \mapsto y^ \unicode{x2020} : R \to I(x)$
depends on an “ambient string” x of which y is a suffix.
$y \mapsto y^ \unicode{x2020} : R \to I(x)$
depends on an “ambient string” x of which y is a suffix.
Definition 23. For any
 $b \in 2$
, let
$b \in 2$
, let
 $b^ \unicode{x2020} = b$
. For any string
$b^ \unicode{x2020} = b$
. For any string
 $x \in 2^\star$
and any nonempty suffix y of x, let
$x \in 2^\star$
and any nonempty suffix y of x, let
 $y^ \unicode{x2020} = |y|$
(as a member of I(x)). Furthermore,
$y^ \unicode{x2020} = |y|$
(as a member of I(x)). Furthermore,
-
Extend the map to tuples of data coordinate-wise, i.e., if
$v=(v_0,\dots,v_{n-1})$
is a decomposition of v into atomic types, then
$v^ \unicode{x2020} = (v_0^ \unicode{x2020},\dots,v_{n-1}^ \unicode{x2020})$
. Note that
$(u \circ v)^ \unicode{x2020} = u^ \unicode{x2020} \circ v^ \unicode{x2020}$
, where
$\circ$
denotes concatenation. -
For an environment
$\rho$
, define the environment
$\rho^ \unicode{x2020}$
by
$\rho(\mathtt{x}) = v \iff \rho^ \unicode{x2020}(\mathtt{x}^ \unicode{x2020}) = v^ \unicode{x2020}$
. (By this, we mean that the domain of
$\rho^ \unicode{x2020}$
is the
$ \unicode{x2020}$
-image of the domain of
$\rho$
.)










Next, we prove correctness of the dagger translation.
Definition 24. Let
 $\rho$
be an RW environment, i.e., a partial, finite map from RW variables to RW data. For a string
$\rho$
be an RW environment, i.e., a partial, finite map from RW variables to RW data. For a string
 $x \in 2^\star$
, we say that
$x \in 2^\star$
, we say that
 $\rho$
is an x-environment in case for every variable
$\rho$
is an x-environment in case for every variable
 $\mathtt{x}$
of type R,
$\mathtt{x}$
of type R,
 $\rho(\mathtt{x})$
is a suffix of x, and similarly, for every variable
$\rho(\mathtt{x})$
is a suffix of x, and similarly, for every variable
 $\mathtt{x}$
of product type
$\mathtt{x}$
of product type
 $\tau_0 \times \dots \tau_{n-1}$
,
$\tau_0 \times \dots \tau_{n-1}$
,
 $\rho(\mathtt{x})[i]$
is a suffix of x whenever
$\rho(\mathtt{x})[i]$
is a suffix of x whenever
 $\tau_i = R$
.
$\tau_i = R$
.
Remark 8. Suppose p is RW-factorizable program,
 $\rho$
is an x-environment, T is a cons-free term, and
$\rho$
is an x-environment, T is a cons-free term, and
 $\rho \vdash_p T \to v$
. Then, every R value that appears in the derivation of
$\rho \vdash_p T \to v$
. Then, every R value that appears in the derivation of
 $\rho \vdash T \to v$
must also be a suffix of x.
$\rho \vdash T \to v$
must also be a suffix of x.
The proof of the next lemma is postponed to Appendix A.
Lemma 2. Suppose p is a cons-free program, x is a string,
 $\rho$
is an x-environment. Then,
$\rho$
is an x-environment. Then,
 $$\rho \vdash_p T \to v \implies x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}} T^ \unicode{x2020} \to v^ \unicode{x2020}.$$
$$\rho \vdash_p T \to v \implies x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}} T^ \unicode{x2020} \to v^ \unicode{x2020}.$$
Example Consider the program p defined by
 \begin{align*} \mathtt{evt}(\mathtt{y}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{hd}(\mathtt{y})\ \mathtt{then}\ \mathtt{odt}(\mathtt{tl}\ \mathtt{y})\ \mathtt{else}\ \mathtt{evt}(\mathtt{tl}\ \mathtt{y}) \\ \mathtt{odt}(\mathtt{y}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{hd}(\mathtt{y})\ \mathtt{then}\ \mathtt{evt}(\mathtt{tl}\ \mathtt{y})\ \mathtt{else}\ \mathtt{odt}(\mathtt{tl}\ \mathtt{y}).\end{align*}
\begin{align*} \mathtt{evt}(\mathtt{y}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{hd}(\mathtt{y})\ \mathtt{then}\ \mathtt{odt}(\mathtt{tl}\ \mathtt{y})\ \mathtt{else}\ \mathtt{evt}(\mathtt{tl}\ \mathtt{y}) \\ \mathtt{odt}(\mathtt{y}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{hd}(\mathtt{y})\ \mathtt{then}\ \mathtt{evt}(\mathtt{tl}\ \mathtt{y})\ \mathtt{else}\ \mathtt{odt}(\mathtt{tl}\ \mathtt{y}).\end{align*}
Then,
 $\mathtt{evt}$
and
$\mathtt{evt}$
and
 $\mathtt{odt}$
compute whether the number of occurrences of the character
$\mathtt{odt}$
compute whether the number of occurrences of the character
 $\mathtt{true}$
in the string
$\mathtt{true}$
in the string
 $\mathtt{y}$
is even or odd, respectively. The program
$\mathtt{y}$
is even or odd, respectively. The program
 $p^ \unicode{x2020}$
is defined by
$p^ \unicode{x2020}$
is defined by
 \begin{align*} \mathtt{evt}^ \unicode{x2020}(\mathtt{y}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{bit}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{odt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020}))\ \mathtt{else}\ \mathtt{evt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020})) \\ \mathtt{odt}^ \unicode{x2020}(\mathtt{y}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{bit}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{evt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020}))\ \mathtt{else}\ \mathtt{odt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020})).\end{align*}
\begin{align*} \mathtt{evt}^ \unicode{x2020}(\mathtt{y}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{if}\ \mathtt{bit}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{odt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020}))\ \mathtt{else}\ \mathtt{evt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020})) \\ \mathtt{odt}^ \unicode{x2020}(\mathtt{y}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{bit}(\mathtt{y}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{evt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020}))\ \mathtt{else}\ \mathtt{odt}^ \unicode{x2020}(\mathtt{P} (\mathtt{y}^ \unicode{x2020})).\end{align*}
Notice that
 $\mathtt{evt}^ \unicode{x2020}$
and
$\mathtt{evt}^ \unicode{x2020}$
and
 $\mathtt{odt}^ \unicode{x2020}$
compute whether the number of occurrences of
$\mathtt{odt}^ \unicode{x2020}$
compute whether the number of occurrences of
 $\mathtt{true}$
with index at most
$\mathtt{true}$
with index at most
 $ \mathtt{y}^ \unicode{x2020}$
in the input string is even or odd respectively. Thus, if
$ \mathtt{y}^ \unicode{x2020}$
in the input string is even or odd respectively. Thus, if
 $\mathtt{y}$
is bound to a suffix y of some string x, then
$\mathtt{y}$
is bound to a suffix y of some string x, then
 $\mathtt{evt}$
and
$\mathtt{evt}$
and
 $\mathtt{odt}$
behave the same on input y as
$\mathtt{odt}$
behave the same on input y as
 $\mathtt{evt}^ \unicode{x2020}$
and
$\mathtt{evt}^ \unicode{x2020}$
and
 $\mathtt{odt}^ \unicode{x2020}$
behave on input
$\mathtt{odt}^ \unicode{x2020}$
behave on input
 $y^ \unicode{x2020}$
(the index
$y^ \unicode{x2020}$
(the index
 $|y|$
) with global input x.
$|y|$
) with global input x.
6.2 The diamond transformation
These next three transformations each extend the dagger transformation from pure cons-free terms to terms of type W in different ways. In the diamond transformation, we will transform terms of type W into terms of type 2, the idea being that the transformed term will encode which of
 $\mathtt{nil}$
or
$\mathtt{nil}$
or
 $\mathtt{w}$
the original term is built up from.
$\mathtt{w}$
the original term is built up from.
Definition 25. . For each recursive function symbol
 $\mathtt{f} : \beta \times W \to W$
, let
$\mathtt{f} : \beta \times W \to W$
, let
 $\mathtt{f}^\diamond$
be a recursive function symbol of type
$\mathtt{f}^\diamond$
be a recursive function symbol of type
 $\beta^ \unicode{x2020} \to 2$
. (We may assume that the map
$\beta^ \unicode{x2020} \to 2$
. (We may assume that the map
 $\mathtt{f} \mapsto \mathtt{f}^\diamond$
is injective.)
$\mathtt{f} \mapsto \mathtt{f}^\diamond$
is injective.)
Definition 26. We define a transformation
 $T \mapsto T^\diamond$
from RW terms of type W to bit-length terms of type 2 as follows:
$T \mapsto T^\diamond$
from RW terms of type W to bit-length terms of type 2 as follows:
-
If
$T \equiv \mathtt{w}$
, then
$T^\diamond \equiv \mathtt{false,}$
. -
If
$T \equiv \mathtt{nil}$
, then
$T^\diamond \equiv \mathtt{true}$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
then
$T^\diamond \equiv \mathtt{if}\ T_0^ \unicode{x2020}\ \mathtt{then}\ T_1^\diamond\ \mathtt{else}\ T_2^\diamond$
. -
If
$T \equiv \mathtt{f}(T')$
for some
$\mathtt{f} : \beta \to W$
, then
$T^\diamond \equiv \mathtt{true} $
. -
If
$T \equiv \mathtt{f}(T',S)$
for some
$\mathtt{f} : \beta \times W \to W$
, then
$T^\diamond \equiv \mathtt{if}\ S^\diamond\ \mathtt{then}\ \mathtt{true} \ \mathtt{else}\ \mathtt{f}^\diamond((T')^ \unicode{x2020})$
-
If
$T \equiv \mathtt{cons}(T',S)$
then
$T^\diamond \equiv S^\diamond$
.






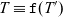







Remark 9. This transformation transforms tail-recursive terms into tail-recursive terms. It never produces a primitive call, and the only things it puts inside recursive calls are outputs of the
 $ \unicode{x2020}$
transformation. The only way it possibly produces a non-tail-recursive term is in the case
$ \unicode{x2020}$
transformation. The only way it possibly produces a non-tail-recursive term is in the case
 $T \equiv \mathtt{f}(T',S)$
, when
$T \equiv \mathtt{f}(T',S)$
, when
 $S^\diamond$
goes in an if clause. But if T is tail-recursive, S is explicit, so
$S^\diamond$
goes in an if clause. But if T is tail-recursive, S is explicit, so
 $S^\diamond$
is explicit, hence contains no recursive function calls.
$S^\diamond$
is explicit, hence contains no recursive function calls.
Definition 27. Given an RW-factorizable program p of type
 $R \to W$
, we define the bit-length program
$R \to W$
, we define the bit-length program
 $p^\diamond$
by extending
$p^\diamond$
by extending
 $p^ \unicode{x2020}$
as follows. For every function symbol
$p^ \unicode{x2020}$
as follows. For every function symbol
 $\mathtt{f}_i$
of type
$\mathtt{f}_i$
of type
 $ \beta \times W \to W$
with definition
$ \beta \times W \to W$
with definition
 $\mathtt{f}_i(\mathtt{x}_i,\mathtt{w}) = T_i$
, we add a new line
$\mathtt{f}_i(\mathtt{x}_i,\mathtt{w}) = T_i$
, we add a new line
 $ \mathtt{f}_i^\diamond(\mathtt{x}_i^ \unicode{x2020}) = T_i^\diamond. $
Note that
$ \mathtt{f}_i^\diamond(\mathtt{x}_i^ \unicode{x2020}) = T_i^\diamond. $
Note that
 $p^\diamond$
is tail-recursive if p is.
$p^\diamond$
is tail-recursive if p is.
We ignore function symbols of type
 $\beta \to W$
. Also, we do not bother to specify a head, because we will only need
$\beta \to W$
. Also, we do not bother to specify a head, because we will only need
 $\vdash_{p^\diamond}$
, not
$\vdash_{p^\diamond}$
, not
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\diamond}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\diamond}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
.
Note that
 $p^\diamond$
is a well-formed program: its recursive function symbols consist exactly of
$p^\diamond$
is a well-formed program: its recursive function symbols consist exactly of
 $\mathtt{f}_i^ \unicode{x2020}$
for
$\mathtt{f}_i^ \unicode{x2020}$
for
 $\mathtt{f}_i$
of type non-W and
$\mathtt{f}_i$
of type non-W and
 $\mathtt{f}_i^\diamond$
for
$\mathtt{f}_i^\diamond$
for
 $\mathtt{f}_i$
of type
$\mathtt{f}_i$
of type
 $\beta \times W \to W$
. For the latter, the term
$\beta \times W \to W$
. For the latter, the term
 $\mathtt{f}_i^\diamond(\mathtt{x}_i^ \unicode{x2020})$
is well-formed and of the same type as
$\mathtt{f}_i^\diamond(\mathtt{x}_i^ \unicode{x2020})$
is well-formed and of the same type as
 $T_i^\diamond$
. The only variable that may occur in
$T_i^\diamond$
. The only variable that may occur in
 $T_i^\diamond$
is
$T_i^\diamond$
is
 $\mathtt{x}_i^ \unicode{x2020}$
. Notice as well that
$\mathtt{x}_i^ \unicode{x2020}$
. Notice as well that
 $p^\diamond$
contains no terms of type C. Hence, when specifying a semantics, we do not need to give a natural number bound n on the upper end of the counting module. Suppose that p is an RW-factorizable program, T is an RW term,
$p^\diamond$
contains no terms of type C. Hence, when specifying a semantics, we do not need to give a natural number bound n on the upper end of the counting module. Suppose that p is an RW-factorizable program, T is an RW term,
 $x, v, v',w \in 2^\star$
,
$x, v, v',w \in 2^\star$
,
 $\rho$
is an x-environment, and
$\rho$
is an x-environment, and
 $\mathtt{w}$
is not bound by
$\mathtt{w}$
is not bound by
 $\rho$
.
$\rho$
.
Lemma 3. Suppose that
 $\rho,[\mathtt{w} = w] \vdash_p T \to v$
and
$\rho,[\mathtt{w} = w] \vdash_p T \to v$
and
 $\rho,[\mathtt{w} = \varepsilon] \vdash_p T \to v'$
.
Footnote 10
Then either
$\rho,[\mathtt{w} = \varepsilon] \vdash_p T \to v'$
.
Footnote 10
Then either
-
$x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to \top $
and
$v = v'$
, or
-
$x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to \bot $
and
$v = v'w$
.




(The proof is postponed to Appendix A.)
In particular, Lemma 3 implies that for any x, x-environment
 $\rho$
, w, and term T, if there exists a v such that
$\rho$
, w, and term T, if there exists a v such that
 $\rho,[\mathtt{w} =w] \vdash T \to v$
, then there exists a boolean b such that
$\rho,[\mathtt{w} =w] \vdash T \to v$
, then there exists a boolean b such that
 $x,\rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to b$
. We will silently use this fact in the remainder of this paper.
$x,\rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to b$
. We will silently use this fact in the remainder of this paper.
Example Consider the program
 $\mathit{id}$
defined by
$\mathit{id}$
defined by
 \begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
\begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
which computes the identity function of type
 $R \to W$
. Both
$R \to W$
. Both
 $\mathtt{id}$
and
$\mathtt{id}$
and
 $\mathtt{cat}$
have output type W; note that
$\mathtt{cat}$
have output type W; note that
 $\mathtt{id}$
always builds its output from
$\mathtt{id}$
always builds its output from
 $\mathtt{nil}$
and
$\mathtt{nil}$
and
 $\mathtt{cat}$
always builds its output from the input
$\mathtt{cat}$
always builds its output from the input
 $\mathtt{w}$
. Then,
$\mathtt{w}$
. Then,
 \begin{align*} \mathtt{id}^\diamond(\mathtt{x}^ \unicode{x2020}) &= \mathtt{true} \\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{false,}\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{cat}^\diamond(\mathtt{P}(\mathtt{x}^ \unicode{x2020})).\end{align*}
\begin{align*} \mathtt{id}^\diamond(\mathtt{x}^ \unicode{x2020}) &= \mathtt{true} \\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{false,}\ \mathtt{then}\ \mathtt{true}\ \mathtt{else}\ \mathtt{cat}^\diamond(\mathtt{P}(\mathtt{x}^ \unicode{x2020})).\end{align*}
We can see that
 $\mathtt{id}^\diamond$
and
$\mathtt{id}^\diamond$
and
 $\mathtt{cat}^\diamond$
compute the always-true and always-false functions, respectively, as they ought to. Note that the dagger and diamond transformations produce C-free BL-terms. By contrast, the subsequent two transformations make crucial use of counting modules.
$\mathtt{cat}^\diamond$
compute the always-true and always-false functions, respectively, as they ought to. Note that the dagger and diamond transformations produce C-free BL-terms. By contrast, the subsequent two transformations make crucial use of counting modules.
6.3 The length transformation
In the length transformation, we will be transforming terms of type W into terms of type C. Since the length of any W output of an RW-factorizable program is bounded by a polynomial in the length of the inputs, it makes sense to try to capture the length within a counting module.
Definition 28. For each recursive function symbol
 $\mathtt{f}$
of type
$\mathtt{f}$
of type
 $\beta \times W \to W$
or
$\beta \times W \to W$
or
 $\beta \to W$
, let
$\beta \to W$
, let
 $\mathtt{f}^\ell$
be a recursive function symbol of type
$\mathtt{f}^\ell$
be a recursive function symbol of type
 $\beta^ \unicode{x2020} \to C$
. (We may assume that the map
$\beta^ \unicode{x2020} \to C$
. (We may assume that the map
 $\mathtt{f} \mapsto \mathtt{f}^\ell$
is injective.)
$\mathtt{f} \mapsto \mathtt{f}^\ell$
is injective.)
Definition 29. We define a transformation
 $T \mapsto T^\ell$
from RW-terms of type W to bit-length terms of type C as follows:
$T \mapsto T^\ell$
from RW-terms of type W to bit-length terms of type C as follows:
-
If
$T \equiv \mathtt{w}$
or
$T \equiv \mathtt{nil}$
, then
$T^\ell \equiv 0$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then
$T^\ell \equiv \mathtt{if}\ T^ \unicode{x2020}_0\ \mathtt{then}\ T_1^\ell\ \mathtt{else}\ T_2^\ell$
. -
If
$T \equiv \mathtt{f}(T')$
, then
$T^\ell \equiv \mathtt{f}^\ell((T')^ \unicode{x2020})$
. -
If
$T \equiv \mathtt{f}(T',S)$
, where S has type W, then
$$ T^\ell \equiv \mathtt{if}\ \mathtt{f}^\diamond((T')^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell((T')^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell((T')^ \unicode{x2020}) + S^\ell.$$
-
If
$T \equiv \mathtt{cons}(T',S)$
, then
$T^\ell \equiv 1 + S^\ell$
.











Remark 10. This transformation does not preserve tail recursion, the problem being
 $\mathtt{f}^\ell((T')^ \unicode{x2020}) + S^\ell$
, where the recursive function symbol
$\mathtt{f}^\ell((T')^ \unicode{x2020}) + S^\ell$
, where the recursive function symbol
 $\mathtt{f}^\ell$
occurs within the primitive
$\mathtt{f}^\ell$
occurs within the primitive
 $+$
. This can be fixed in a couple of ways. For one, we can observe that if T is tail-recursive then
$+$
. This can be fixed in a couple of ways. For one, we can observe that if T is tail-recursive then
 $T^\ell$
is linear recursive, which can always be transformed into an equivalent tail-recursive term (Greibach, 1975).
$T^\ell$
is linear recursive, which can always be transformed into an equivalent tail-recursive term (Greibach, 1975).
But there is an easier fix in this case: just give each
 $\mathtt{f}^\ell$
an extra input of type
$\mathtt{f}^\ell$
an extra input of type
 $\mathtt{c}$
, the idea being that the new
$\mathtt{c}$
, the idea being that the new
 $\mathtt{f}^\ell(T,\mathtt{c})$
is the old
$\mathtt{f}^\ell(T,\mathtt{c})$
is the old
 $\mathtt{f}^\ell(T) + \mathtt{c}$
. We have to change each recursive definition
$\mathtt{f}^\ell(T) + \mathtt{c}$
. We have to change each recursive definition
 $\mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) = T^\ell$
to
$\mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) = T^\ell$
to
 $\mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020},\mathtt{c}) = T^\ell + \mathtt{c}$
. Then
$\mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020},\mathtt{c}) = T^\ell + \mathtt{c}$
. Then
 $\mathtt{f}^\ell((T')^ \unicode{x2020}) + S^\ell$
becomes
$\mathtt{f}^\ell((T')^ \unicode{x2020}) + S^\ell$
becomes
 $\mathtt{f}^\ell((T')^ \unicode{x2020},S^\ell$
), and this solves our problem.
$\mathtt{f}^\ell((T')^ \unicode{x2020},S^\ell$
), and this solves our problem.
Definition 30. Given an RW-factorizable program p of type
 $R \to W$
, we define the bit-length program
$R \to W$
, we define the bit-length program
 $p^\ell$
by extending
$p^\ell$
by extending
 $p^\diamond$
by adding the following lines for each recursive function symbol of output type W:
$p^\diamond$
by adding the following lines for each recursive function symbol of output type W:

Finally, add a new head
 $ \mathtt{h} = \mathtt{f}^\ell_0(\mathtt{max}) .$
The resulting program is
$ \mathtt{h} = \mathtt{f}^\ell_0(\mathtt{max}) .$
The resulting program is
 $p^\ell$
; it is tail-recursive if p is.
$p^\ell$
; it is tail-recursive if p is.
Let us check that
 $p^\ell$
is a well-defined bit-length program. In addition to
$p^\ell$
is a well-defined bit-length program. In addition to
 $p^\diamond$
, it contains recursive function symbols
$p^\diamond$
, it contains recursive function symbols
 $\mathtt{f}_i^\ell$
for
$\mathtt{f}_i^\ell$
for
 $\mathtt{f}_i$
of output type W. If the only variables that may occur in
$\mathtt{f}_i$
of output type W. If the only variables that may occur in
 $T_i$
are
$T_i$
are
 $\mathtt{x}_i$
and
$\mathtt{x}_i$
and
 $\mathtt{w}$
, then the only variable that may occur in
$\mathtt{w}$
, then the only variable that may occur in
 $T^\ell_i$
is
$T^\ell_i$
is
 $\mathtt{x}^ \unicode{x2020}_i$
, and the only recursive function symbols that may occur are the recursive function symbols listed above. Finally, the terms in each line are well-formed and the types of each recursive functions symbol and its definition agree. Finally, notice that since p has type
$\mathtt{x}^ \unicode{x2020}_i$
, and the only recursive function symbols that may occur are the recursive function symbols listed above. Finally, the terms in each line are well-formed and the types of each recursive functions symbol and its definition agree. Finally, notice that since p has type
 $R \to W$
,
$R \to W$
,
 $p^\ell$
has type C.
$p^\ell$
has type C.
Definition 31. For a value v of type W, let
 $v^\ell = |v|$
.
$v^\ell = |v|$
.
Lemma 4. For every RW-program p of type
 $R \to W$
, RW term T from p of type W, strings x, v, and w, natural number
$R \to W$
, RW term T from p of type W, strings x, v, and w, natural number
 $n > |v|$
, and x-environment
$n > |v|$
, and x-environment
 $\rho$
binding
$\rho$
binding
 $\mathtt{w}$
to w:
$\mathtt{w}$
to w:
 $$ \rho \vdash_p T \to v \implies x,n,\rho^ \unicode{x2020} \vdash_{p^\ell} T^\ell \to v^\ell - \delta ,$$
$$ \rho \vdash_p T \to v \implies x,n,\rho^ \unicode{x2020} \vdash_{p^\ell} T^\ell \to v^\ell - \delta ,$$
where
 $\delta = 0$
if
$\delta = 0$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
 $\delta = |w|$
if
$\delta = |w|$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. Moreover, the derivation of the right-hand side is collision-free.
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. Moreover, the derivation of the right-hand side is collision-free.
(The proof is postponed to Appendix A.)
Theorem 4. Suppose that p is an RW-factorizable program of type
 $ R \to W$
and suppose that
$ R \to W$
and suppose that
 $\lambda : \omega \to \omega$
satisfies
$\lambda : \omega \to \omega$
satisfies
 $$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies | w | < \lambda(|x|) . $$
$$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies | w | < \lambda(|x|) . $$
Then,
 $$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |w|; $$
$$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |w|; $$
moreover, without collisions.
Proof Fix x and suppose that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w$
. Suppose
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w$
. Suppose
 $\mathtt{f}_0(\mathtt{x}_0)$
is the head of p. Then,
$\mathtt{f}_0(\mathtt{x}_0)$
is the head of p. Then,
 $ [\mathtt{x}_0 = x] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to w, $
so by Lemma 4, since
$ [\mathtt{x}_0 = x] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to w, $
so by Lemma 4, since
 $\lambda(|x|) > w$
,
$\lambda(|x|) > w$
,
 $$ x, \lambda(|x|), [\mathtt{x}_0^ \unicode{x2020} = x^ \unicode{x2020}] \vdash_{p^\ell} \mathtt{f}_0^\ell(\mathtt{x}_0^ \unicode{x2020}) \to |w|$$
$$ x, \lambda(|x|), [\mathtt{x}_0^ \unicode{x2020} = x^ \unicode{x2020}] \vdash_{p^\ell} \mathtt{f}_0^\ell(\mathtt{x}_0^ \unicode{x2020}) \to |w|$$
by a collision-free derivation. Therefore, since
 $x^ \unicode{x2020} = |x|$
(as a member of I(x)), and since
$x^ \unicode{x2020} = |x|$
(as a member of I(x)), and since
 $|x|$
is the denotation of
$|x|$
is the denotation of
 $\mathtt{max}$
, we have
$\mathtt{max}$
, we have
 $$ x, \lambda(|x|) \vdash_{p^\ell} \mathtt{f}_0^\ell(\mathtt{max}) \to |w|. $$
$$ x, \lambda(|x|) \vdash_{p^\ell} \mathtt{f}_0^\ell(\mathtt{max}) \to |w|. $$
Since
 $\mathtt{f}_0(\mathtt{max})$
is precisely the head of
$\mathtt{f}_0(\mathtt{max})$
is precisely the head of
 $p^\ell$
, we have
$p^\ell$
, we have
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x) = |w|$
, which is what we wanted to prove.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x) = |w|$
, which is what we wanted to prove.
Examples. Consider again the program
 $\mathit{id}$
given by
$\mathit{id}$
given by
 \begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
\begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
Then,
 \begin{align*} \mathtt{id}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020})+0 \\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \big( \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{P}(\mathtt{x}^ \unicode{x2020}))\ \mathtt{then}\ \mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020}))\ \mathtt{else}\\ &\mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020})) + 0\big),\end{align*}
\begin{align*} \mathtt{id}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020})+0 \\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \big( \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{P}(\mathtt{x}^ \unicode{x2020}))\ \mathtt{then}\ \mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020}))\ \mathtt{else}\\ &\mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020})) + 0\big),\end{align*}
which is semantically equivalent to
 \begin{align*} \mathtt{id}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) \\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020})).\end{align*}
\begin{align*} \mathtt{id}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) \\ \mathtt{cat}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{cat}^\ell(\mathtt{P}(\mathtt{x}^ \unicode{x2020})).\end{align*}
It’s now easy to see that for sufficiently large
 $\lambda$
,
$\lambda$
,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x) = |x|$
, as it ought to. (Recall that the head of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda (x) = |x|$
, as it ought to. (Recall that the head of
 $\mathit{id}^\ell$
is
$\mathit{id}^\ell$
is
 $\mathtt{id}^\ell(\mathtt{max})$
.)
$\mathtt{id}^\ell(\mathtt{max})$
.)
Consider the following program
 $\mathit{leap}$
based off of modifying the program from line (1) in Section 1 to string data:
$\mathit{leap}$
based off of modifying the program from line (1) in Section 1 to string data:
 \begin{align*} \mathtt{leap}(\mathtt{x}) &= \mathtt{f}(\mathtt{x},\mathtt{nil}) \\ \mathtt{f}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{cons}(\mathtt{true},\mathtt{w})\ \mathtt{else}\ \mathtt{f}(\mathtt{tl}\ \mathtt{x},\mathtt{f}(\mathtt{tl}\ \mathtt{x},\mathtt{w})).\end{align*}
\begin{align*} \mathtt{leap}(\mathtt{x}) &= \mathtt{f}(\mathtt{x},\mathtt{nil}) \\ \mathtt{f}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{cons}(\mathtt{true},\mathtt{w})\ \mathtt{else}\ \mathtt{f}(\mathtt{tl}\ \mathtt{x},\mathtt{f}(\mathtt{tl}\ \mathtt{x},\mathtt{w})).\end{align*}
Then for any string x,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{leap}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x)$
is a
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{leap}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x)$
is a
 $2^{|x|}$
-length string of only the character
$2^{|x|}$
-length string of only the character
 $\mathtt{true}$
. Now,
$\mathtt{true}$
. Now,
 \begin{align*} \mathtt{leap}^\ell(\mathtt{x}^ \unicode{x2020}) =\ &\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) + 0 \\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 1 + 0\ \mathtt{else}\ \\ &\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + \\ &\big(\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + 0 \big).\end{align*}
\begin{align*} \mathtt{leap}^\ell(\mathtt{x}^ \unicode{x2020}) =\ &\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) + 0 \\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 1 + 0\ \mathtt{else}\ \\ &\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + \\ &\big(\mathtt{if}\ \mathtt{f}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + 0 \big).\end{align*}
This is semantically equivalent to
 \begin{align*} \mathtt{leap}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) \\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 1\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}),\end{align*}
\begin{align*} \mathtt{leap}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) \\ \mathtt{f}^\ell(\mathtt{x}^ \unicode{x2020}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ 1\ \mathtt{else}\ \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}) + \mathtt{f}^\ell(\mathtt{P} \mathtt{x}^ \unicode{x2020}),\end{align*}
which we can see correctly computes the base-2 exponential of the length of the input string (given a sufficiently large counting module).
6.4 The bit transformation
In the bit transformation, we will transform terms of type W into terms of type 2, with an additional type-C input. The idea is that the transformed term encodes the bits of the original W-term.
Definition 32. For each function symbol
 $\mathtt{f}$
of type
$\mathtt{f}$
of type
 $\beta \times W \to W$
or
$\beta \times W \to W$
or
 $\beta \to W$
, let
$\beta \to W$
, let
 $\mathtt{f}^b$
be a recursive function symbol of type
$\mathtt{f}^b$
be a recursive function symbol of type
 $\beta^ \unicode{x2020} \times C \to 2$
. (We may assume that the map
$\beta^ \unicode{x2020} \times C \to 2$
. (We may assume that the map
 $\mathtt{f} \mapsto \mathtt{f}^b$
is injective.)
$\mathtt{f} \mapsto \mathtt{f}^b$
is injective.)
Definition 33. We define a transformation
 $T \mapsto T^b$
from RW terms of type W to bit-length terms of type 2 as follows. Here
$T \mapsto T^b$
from RW terms of type W to bit-length terms of type 2 as follows. Here
 $\mathtt{c}$
is a fixed variable of type C.
$\mathtt{c}$
is a fixed variable of type C.
-
If
$T \equiv \mathtt{w}$
or
$T \equiv \mathtt{nil}$
, then
$T^b \equiv \mathtt{false,}$
.
Footnote 11
-
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then
$T^b \equiv \mathtt{if}\ T_0^ \unicode{x2020}\ \mathtt{then}\ T_1^b\ \mathtt{else}\ T_2^b$
. -
If
$T \equiv \mathtt{f}(T')$
, then
$T^b \equiv \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c})$
-
If
$T \equiv \mathtt{f}(T',S)$
, where S has type W, then
$$ T^b \equiv \mathtt{if}\ \mathtt{f}^\diamond((T')^ \unicode{x2020})\ \mathtt{then}\ \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c} - S^\ell) .$$
-
If
$T \equiv \mathtt{cons}(T',S)$
, then
$T^b \equiv \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ (T')^ \unicode{x2020}$
,











Notice that the only variables that may occur in
 $T^b$
are
$T^b$
are
 $\mathtt{c}$
and
$\mathtt{c}$
and
 $\mathtt{x}^ \unicode{x2020}$
for
$\mathtt{x}^ \unicode{x2020}$
for
 $\mathtt{x}$
which occur in T, and the only recursive function symbols that may occur are
$\mathtt{x}$
which occur in T, and the only recursive function symbols that may occur are
 $\mathtt{f}^b$
for
$\mathtt{f}^b$
for
 $\mathtt{f}$
of output type W, and
$\mathtt{f}$
of output type W, and
 $\mathtt{f}^ \unicode{x2020}$
for
$\mathtt{f}^ \unicode{x2020}$
for
 $\mathtt{f}$
of output type non-W, which occur in T.
$\mathtt{f}$
of output type non-W, which occur in T.
Remark 11 Not only does this transformation preserve tail-recursive terms, but every term it produces is tail-recursive (as long as we regard previously defined subterms like
 $S^\ell$
and
$S^\ell$
and
 $\mathtt{f}^\diamond((T')^ \unicode{x2020})$
as explicit, as usual). No matter what T is, no
$\mathtt{f}^\diamond((T')^ \unicode{x2020})$
as explicit, as usual). No matter what T is, no
 $\mathtt{f}^b$
will occur inside anything other than a then- or else-clause in
$\mathtt{f}^b$
will occur inside anything other than a then- or else-clause in
 $T^b$
.
$T^b$
.
Definition 34. Given an RW-factorizable program p of type
 $R \to W$
, we define the bit-length program
$R \to W$
, we define the bit-length program
 $p^b$
by extending
$p^b$
by extending
 $p^\ell$
as follows
$p^\ell$
as follows

Finally, add a new head
 $ \mathtt{h}(\mathtt{c}) = \mathtt{f}^b_0(\mathtt{max},\mathtt{c}) .$
The resulting program is
$ \mathtt{h}(\mathtt{c}) = \mathtt{f}^b_0(\mathtt{max},\mathtt{c}) .$
The resulting program is
 $p^b$
. It is tail-recursive if p is.
$p^b$
. It is tail-recursive if p is.
Let us check that for any RW-factorizable program p of type
 $R \to W$
,
$R \to W$
,
 $p^b$
is a well-defined bit-length program. It contains the recursive function symbols
$p^b$
is a well-defined bit-length program. It contains the recursive function symbols
 $\mathtt{f}^b$
for
$\mathtt{f}^b$
for
 $\mathtt{f}$
in p of type W, and
$\mathtt{f}$
in p of type W, and
 $\mathtt{f}^ \unicode{x2020}$
for
$\mathtt{f}^ \unicode{x2020}$
for
 $\mathtt{f}$
in p of type non-W. Since the only variable that appears in T is
$\mathtt{f}$
in p of type non-W. Since the only variable that appears in T is
 $\mathtt{x}_i$
, the only variables that may appear in
$\mathtt{x}_i$
, the only variables that may appear in
 $T^b$
are
$T^b$
are
 $\mathtt{x}_i^ \unicode{x2020}$
and
$\mathtt{x}_i^ \unicode{x2020}$
and
 $\mathtt{c}$
. Finally, the types of
$\mathtt{c}$
. Finally, the types of
 $\mathtt{f}^b_i(\mathtt{x}^ \unicode{x2020},\mathtt{c})$
and
$\mathtt{f}^b_i(\mathtt{x}^ \unicode{x2020},\mathtt{c})$
and
 $T_i$
agree.
$T_i$
agree.
Notice that
 $p^b$
contains
$p^b$
contains
 $p^\ell$
, and hence
$p^\ell$
, and hence
 $p^\diamond$
and
$p^\diamond$
and
 $p^ \unicode{x2020}$
, as “subprograms.” Hence, the semantics of
$p^ \unicode{x2020}$
, as “subprograms.” Hence, the semantics of
 $p^b$
extends the semantics of the previous programs. We now prove its correctness; the proof is postponed to Appendix A.
$p^b$
extends the semantics of the previous programs. We now prove its correctness; the proof is postponed to Appendix A.
Lemma 5. For every RW program p of type
 $R \to W$
, RW term T from p of type W, strings x, w and v, natural numbers
$R \to W$
, RW term T from p of type W, strings x, w and v, natural numbers
 $n > |v|$
and
$n > |v|$
and
 $1 \le c \le |v| - \delta$
, and x-environment
$1 \le c \le |v| - \delta$
, and x-environment
 $\rho$
binding
$\rho$
binding
 $\mathtt{w}$
to w,
$\mathtt{w}$
to w,
 $$ \rho \vdash_p T \to v \implies x,n, \rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to v_{c + \delta},$$
$$ \rho \vdash_p T \to v \implies x,n, \rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to v_{c + \delta},$$
where
 $\delta = 0$
if
$\delta = 0$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
 $\delta = |w|$
if
$\delta = |w|$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
.
Footnote 12
Moreover, the computation on the right-hand side is without collisions.
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
.
Footnote 12
Moreover, the computation on the right-hand side is without collisions.
Theorem 5. Suppose that p is an RW-factorizable program of type
 $ R \to W$
and suppose that
$ R \to W$
and suppose that
 $\lambda : \omega \to \omega$
satisfies
$\lambda : \omega \to \omega$
satisfies
 $$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies |w| < \lambda(|x|) . $$
$$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies |w| < \lambda(|x|) . $$
Then,
 $$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies (\forall c \le |w| ) \ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = w_c,$$
$$ (\forall x,w \in 2^\star)\, \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = w \implies (\forall c \le |w| ) \ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = w_c,$$
without collisions.
Proof Fix x, v, and c such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
and
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
and
 $1 \le c \le |v |$
. Suppose that
$1 \le c \le |v |$
. Suppose that
 $\mathtt{f}_0(\mathtt{x}_0)$
is the head of p, so that
$\mathtt{f}_0(\mathtt{x}_0)$
is the head of p, so that
 $[\mathtt{x}_0 = x] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v$
. Therefore,
$[\mathtt{x}_0 = x] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v$
. Therefore,
 $[\mathtt{x}_0 = x,\mathtt{w} = \varepsilon] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v$
. By Lemma 5, since
$[\mathtt{x}_0 = x,\mathtt{w} = \varepsilon] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v$
. By Lemma 5, since
 $\lambda(|x|) > v$
,
$\lambda(|x|) > v$
,
 $$x,\lambda(|x|), [\mathtt{x}_0^ \unicode{x2020} = x^ \unicode{x2020}, \mathtt{c} = c] \vdash_{p^b} \mathtt{f}_0^b(\mathtt{x}_0^ \unicode{x2020},\mathtt{c}) \to v_c,$$
$$x,\lambda(|x|), [\mathtt{x}_0^ \unicode{x2020} = x^ \unicode{x2020}, \mathtt{c} = c] \vdash_{p^b} \mathtt{f}_0^b(\mathtt{x}_0^ \unicode{x2020},\mathtt{c}) \to v_c,$$
without collisions. (Notice that
 $\delta = 0$
as
$\delta = 0$
as
 $\mathtt{w}$
is bound to
$\mathtt{w}$
is bound to
 $\varepsilon$
.)
$\varepsilon$
.)
Since
 $x , \lambda(|x|) \vdash_{p^b} \mathtt{max} \to |x|$
and
$x , \lambda(|x|) \vdash_{p^b} \mathtt{max} \to |x|$
and
 $|x| = x^ \unicode{x2020}$
, we have
$|x| = x^ \unicode{x2020}$
, we have
 $$ x , \lambda(|x|) , [\mathtt{c} = c] \vdash_{p^b} \mathtt{f}_0^b(\mathtt{max},\mathtt{c}) \to v_c .$$
$$ x , \lambda(|x|) , [\mathtt{c} = c] \vdash_{p^b} \mathtt{f}_0^b(\mathtt{max},\mathtt{c}) \to v_c .$$
But since the head of
 $\mathtt{h}(\mathtt{c})$
is defined to be
$\mathtt{h}(\mathtt{c})$
is defined to be
 $\mathtt{f}_0^b(\mathtt{max},\mathtt{c})$
, this implies
$\mathtt{f}_0^b(\mathtt{max},\mathtt{c})$
, this implies
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = v_c$
, which is exactly what we wanted to show.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = v_c$
, which is exactly what we wanted to show.
Theorems 4 and 5 immediately imply the following result, the statement of correctness for the translation from RW-factorizable to bit-length programs.
Theorem 6. Let
 $f:2^\star \to 2^\star$
be a function,
$f:2^\star \to 2^\star$
be a function,
 $\lambda : \omega \to \omega$
satisfy
$\lambda : \omega \to \omega$
satisfy
 $\lambda(|x|) > |f(x)|$
, and p be an RW-factorizable program of type
$\lambda(|x|) > |f(x)|$
, and p be an RW-factorizable program of type
 $R \to W$
computing f. Then,
$R \to W$
computing f. Then,
 $(\lambda,p^\ell,p^b)$
properly computes f.
$(\lambda,p^\ell,p^b)$
properly computes f.
Example Given the program
 $\mathit{id}$
defined by
$\mathit{id}$
defined by
 \begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
\begin{align*} \mathtt{id}(\mathtt{x}) &= \mathtt{cat}(\mathtt{x},\mathtt{nil}) \\ \mathtt{cat}(\mathtt{x},\mathtt{w}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{cons}(\mathtt{hd}\ \mathtt{x},\mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})),\end{align*}
 $\mathit{id}^b$
is defined by
$\mathit{id}^b$
is defined by
 \begin{align*} \mathtt{id}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\\ & \mathtt{else}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c} - 0) \\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ \mathtt{bit}(\mathtt{x}^ \unicode{x2020}) ,\end{align*}
\begin{align*} \mathtt{id}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\\ & \mathtt{else}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c} - 0) \\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ \mathtt{bit}(\mathtt{x}^ \unicode{x2020}) ,\end{align*}
where
 $S \equiv \mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})$
. We know that
$S \equiv \mathtt{cat}(\mathtt{tl}\ \mathtt{x},\mathtt{w})$
. We know that
 $S^\ell$
correctly computes the length of
$S^\ell$
correctly computes the length of
 $\mathtt{tl}(\mathtt{x})$
, which is (abusing notation)
$\mathtt{tl}(\mathtt{x})$
, which is (abusing notation)
 $\mathtt{x}^ \unicode{x2020} - 1$
. Moreover,
$\mathtt{x}^ \unicode{x2020} - 1$
. Moreover,
 $$ S^b \equiv \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^b(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{cat}^b(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c}-0) .$$
$$ S^b \equiv \mathtt{if}\ \mathtt{cat}^\diamond(\mathtt{P} \mathtt{x}^ \unicode{x2020})\ \mathtt{then}\ \mathtt{cat}^b(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{cat}^b(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c}-0) .$$
Recall that
 $\mathtt{cat}^\diamond$
computes the always-false function. Combining this all into semantically equivalent and legible pseudocode, we get
$\mathtt{cat}^\diamond$
computes the always-false function. Combining this all into semantically equivalent and legible pseudocode, we get
 \begin{align*} \mathtt{id}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) = \ &\mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) \\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020}) \vee \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \\ &\mathtt{if}\ \mathtt{c} \le \mathtt{x}^ \unicode{x2020} - 1\ \mathtt{then}\ \mathtt{cat}(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{bit}(\mathtt{x}^ \unicode{x2020}).\end{align*}
\begin{align*} \mathtt{id}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) = \ &\mathtt{if}\ \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) \\ \mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c}) =\ &\mathtt{if}\ \mathtt{null}(\mathtt{x}^ \unicode{x2020}) \vee \mathtt{c} \le 0\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \\ &\mathtt{if}\ \mathtt{c} \le \mathtt{x}^ \unicode{x2020} - 1\ \mathtt{then}\ \mathtt{cat}(\mathtt{P} \mathtt{x}^ \unicode{x2020},\mathtt{c})\ \mathtt{else}\ \mathtt{bit}(\mathtt{x}^ \unicode{x2020}).\end{align*}
We can see that
 $\mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c})$
computes the bit indexed by
$\mathtt{cat}^b(\mathtt{x}^ \unicode{x2020},\mathtt{c})$
computes the bit indexed by
 $\mathtt{c}$
: operationally, it decrements the index
$\mathtt{c}$
: operationally, it decrements the index
 $\mathtt{x}^ \unicode{x2020}$
until it is equal to the counting module
$\mathtt{x}^ \unicode{x2020}$
until it is equal to the counting module
 $\mathtt{c}$
, then spits out the bit indexed by
$\mathtt{c}$
, then spits out the bit indexed by
 $\mathtt{x}^ \unicode{x2020}$
. Hence,
$\mathtt{x}^ \unicode{x2020}$
. Hence,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c)$
computes the bit
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c)$
computes the bit
 $x_c$
for sufficiently large
$x_c$
for sufficiently large
 $\lambda$
and appropriate values of c.
$\lambda$
and appropriate values of c.
Observe that for sufficiently large
 $\lambda$
,
$\lambda$
,
 $(\lambda,\mathit{id}^\ell,\mathit{id}^b)$
correctly bit-length computes the identity function, as
$(\lambda,\mathit{id}^\ell,\mathit{id}^b)$
correctly bit-length computes the identity function, as
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |x|$ and $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = x_c$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^\ell}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = |x|$ and $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{\mathit{id}^b}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,c) = x_c$
.
7 Compiling BL- to RW-factorizable programs
In this section, we show how to compile a pair of bit-length programs into a single RW-factorizable program, thus establishing extensional equivalence for these two notions of computability, at least for total functions. The core of this section consists of two transformations:
-
The more significant of these is a transformation
$\unicode{x2021}$
, which acts as a sort of inverse to
$ \unicode{x2020}$
: it eliminates indices in favor of string suffixes, i.e., R-data, and counting modules in favor of tuples of R-data. (More precisely, this is a family of transformations parameterized by how many R values we need to encode a single counting module.) This process transforms every bit-length program into a cons-free program with a “global input variable.” -
The simpler transformation takes a cons-free program with a global input variable into one without. We do this in most naive way possible, simply by passing the global input as an additional parameter to every recursive call.


The former transformation uses a well-known trick of cons-free programming, namely that we can simulate a counting module of size polynomial in the input length by a tuple of suffixes of the input. If we just think of a suffix of the input as encoding its length (i.e., forgetting about its bits), then we can identify it with some single digit
 $\{0,1,\dots,n\}$
, where n is the length of the input. Therefore, we can identify a k-tuple of suffixes with some k-digit number in base
$\{0,1,\dots,n\}$
, where n is the length of the input. Therefore, we can identify a k-tuple of suffixes with some k-digit number in base
 $n+1$
, which we can identify in turn with some number less than
$n+1$
, which we can identify in turn with some number less than
 $(n+1)^k$
. To implement the full data type of a counting module, it simply suffices to implement the fixed-width arithmetic and comparison operations using cons-free programs. In this way, we can replace polynomially bounded counting modules with fixed-width tuples of R values.
$(n+1)^k$
. To implement the full data type of a counting module, it simply suffices to implement the fixed-width arithmetic and comparison operations using cons-free programs. In this way, we can replace polynomially bounded counting modules with fixed-width tuples of R values.
A complication is the fact that our language does not accommodate nested tuples. For example, suppose that we had to replace every counting module of type C by three R values of type
 $R \times R \times R$
. Then if we had a tuple of type
$R \times R \times R$
. Then if we had a tuple of type
 $I \times C \times 2$
, it should be replaced by a tuple of type
$I \times C \times 2$
, it should be replaced by a tuple of type
 $(R,R^3,2)$
, but since we don’t have nested tuples, we are required to “flatten it out” into a tuple of type (R,R,R,R,2). This makes indexing harder: to get the element of
$(R,R^3,2)$
, but since we don’t have nested tuples, we are required to “flatten it out” into a tuple of type (R,R,R,R,2). This makes indexing harder: to get the element of
 $R^3$
encoding the counting module, we have to extract the middle three coordinates.
$R^3$
encoding the counting module, we have to extract the middle three coordinates.
7.1 Programs with global input
Bit-length programs have a global input value, which is the x in the judgment
 $x , n, \rho \vdash_p T \to v$
. RW-factorizable programs, and cons-free programs in particular, do not. It will be convenient to first transform bit-length programs into cons-free programs with some global input variable
$x , n, \rho \vdash_p T \to v$
. RW-factorizable programs, and cons-free programs in particular, do not. It will be convenient to first transform bit-length programs into cons-free programs with some global input variable
 $\mathtt{in}$
, and then eliminate it, instead of trying to cram both in one transformation.
$\mathtt{in}$
, and then eliminate it, instead of trying to cram both in one transformation.
Definition 35. A RW term term with global input is obtained by extending the formation rules of Figure 1 by the additional axiom
 $\mathtt{in} : R$
. A RW-factorizable program with global input is defined like an ordinary RW-factorizable program, except that the terms
$\mathtt{in} : R$
. A RW-factorizable program with global input is defined like an ordinary RW-factorizable program, except that the terms
 $T_i$
are RW-terms with global input.
$T_i$
are RW-terms with global input.
The semantics relation
 $\vdash$
has the form
$\vdash$
has the form
 $x , \rho \vdash T \to v$
(note the additional x argument on the left-hand side) and is defined by extending the rules of Figure 2 by the axiom
$x , \rho \vdash T \to v$
(note the additional x argument on the left-hand side) and is defined by extending the rules of Figure 2 by the axiom
 $x,\rho \vdash \mathtt{in} \to x$
. If
$x,\rho \vdash \mathtt{in} \to x$
. If
 $\mathtt{f}_0(\mathtt{x}_0)$
is the head of a program p, then we define
$\mathtt{f}_0(\mathtt{x}_0)$
is the head of a program p, then we define
 $$ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,y) = v \iff x,[\mathtt{x}_0 = y] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v . $$
$$ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,y) = v \iff x,[\mathtt{x}_0 = y] \vdash_p \mathtt{f}_0(\mathtt{x}_0) \to v . $$
An RW-factorizable program with global input is cons-free if it contains no term of type W.
We can easily transform a RW program with global input into one without. The basic idea is to pass the global input explicitly into each recursive function symbol as an extra argument which never gets modified. The remainder of this subsection consists of making this intuition formal. Moreover, we will restrict our attention to cons-free programs, because that is the only case we need.
Definition 36. For any RW product term
 $\alpha$
, let
$\alpha$
, let
 $\alpha_R$
be
$\alpha_R$
be
 $\alpha \times R$
. For any RW function term
$\alpha \times R$
. For any RW function term
 $\rho = \beta \to \alpha$
, let
$\rho = \beta \to \alpha$
, let
 $\rho_R$
be
$\rho_R$
be
 $\beta_R \to \alpha$
. Define an injection
$\beta_R \to \alpha$
. Define an injection
 $\mathtt{x} \mapsto \mathtt{x}_R$
,
$\mathtt{x} \mapsto \mathtt{x}_R$
,
 $\mathtt{f} \mapsto \mathtt{f}_R$
from variables and recursive function symbols of type
$\mathtt{f} \mapsto \mathtt{f}_R$
from variables and recursive function symbols of type
 $\alpha$
and
$\alpha$
and
 $\rho$
to type
$\rho$
to type
 $\alpha_R$
and
$\alpha_R$
and
 $\rho_R,$
respectively.
$\rho_R,$
respectively.
The idea of the next transformation is we replace the variable
 $\mathtt{x}$
with the variable
$\mathtt{x}$
with the variable
 $\mathtt{x}_R$
. The last coordinate of
$\mathtt{x}_R$
. The last coordinate of
 $\mathtt{x}_R$
stores the “global input” which gets passed around to all the recursive functions in the program, and the rest of the variable stores the “original variable”
$\mathtt{x}_R$
stores the “global input” which gets passed around to all the recursive functions in the program, and the rest of the variable stores the “original variable”
 $\mathtt{x}$
.
$\mathtt{x}$
.
Suppose T is a term in which only the variable
 $\mathtt{x}$
may occur. (Call this an
$\mathtt{x}$
may occur. (Call this an
 $\mathtt{x}$
-term for brevity.) Let n be the length of the type of
$\mathtt{x}$
-term for brevity.) Let n be the length of the type of
 $\mathtt{x}$
. Define the map
$\mathtt{x}$
. Define the map
 $T \mapsto T^\mathtt{x}_R$
from cons-free terms with global input to cons-free terms as follows (for brevity, we omit the superscript
$T \mapsto T^\mathtt{x}_R$
from cons-free terms with global input to cons-free terms as follows (for brevity, we omit the superscript
 $\mathtt{x}$
):
$\mathtt{x}$
):
-
If
$T \equiv \mathtt{x}$
, then
$T_R \equiv \mathtt{x}_R [0,n-1]$
. -
If
$T \equiv \mathtt{in}$
, then
$T_R \equiv \mathtt{x}_R [n]$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
then
$T_R \equiv \mathtt{if}\ (T_0)_R\ \mathtt{then}\ (T_1)_R\ \mathtt{else}\ (T_2)_R$
. -
If
$T \equiv \mathtt{hd}(S)$
,
$\mathtt{tl}(S)$
, or
$\mathtt{null}(S)$
, then
$T_R \equiv \mathtt{hd}(S_R)$
,
$\mathtt{tl}(S_R)$
, or
$\mathtt{null}(S_R)$
respectively. -
If
$T \equiv T_0 \oplus \dots \oplus T_{n-1}$
, then
$T_R \equiv (T_0)_R \oplus \dots \oplus (T_{n-1})_R$
. -
If
$T \equiv S[i,j]$
, then
$T_R \equiv S_R[i,j]$
. -
If
$T \equiv \mathtt{f}(S)$
, then
$T_R \equiv \mathtt{f}_R(S_R \oplus \mathtt{x}_R[n])$
.


















Notice that for any RW-term with global input T containing only
 $\mathtt{x}$
, then
$\mathtt{x}$
, then
 $T_R^\mathtt{x}$
is a well-formed RW-term of the same type of T. Moreover,
$T_R^\mathtt{x}$
is a well-formed RW-term of the same type of T. Moreover,
 $\mathtt{x}_R$
is the only variable which may occur in
$\mathtt{x}_R$
is the only variable which may occur in
 $T^\mathtt{x}_R$
. This transformation is easily seen to preserve tail recursion.
$T^\mathtt{x}_R$
. This transformation is easily seen to preserve tail recursion.
Definition 38. Suppose the cons-free program with global input p consists of the lines
 $\mathtt{f}_i(\mathtt{x}_i) = T_i$
for
$\mathtt{f}_i(\mathtt{x}_i) = T_i$
for
 $0 \le i \le k$
. Then define the program
$0 \le i \le k$
. Then define the program
 $p_R$
to consist of lines
$p_R$
to consist of lines
 $(\mathtt{f}_i)_R((\mathtt{x}_i)_R) = (T_i)^{\mathtt{x}_i}_R$
for
$(\mathtt{f}_i)_R((\mathtt{x}_i)_R) = (T_i)^{\mathtt{x}_i}_R$
for
 $0 \le i \le k$
.
$0 \le i \le k$
.
Note that
 $p_R$
is a well-defined program. It contains the recursive function symbols
$p_R$
is a well-defined program. It contains the recursive function symbols
 $(\mathtt{f}_i)_R$
for each
$(\mathtt{f}_i)_R$
for each
 $\mathtt{f}_i$
from p. The type of
$\mathtt{f}_i$
from p. The type of
 $(\mathtt{x}_i)_R$
is the input type of
$(\mathtt{x}_i)_R$
is the input type of
 $(\mathtt{f}_i)_R$
. The type of
$(\mathtt{f}_i)_R$
. The type of
 $(T_i)^{\mathtt{x}_i}_R$
is the type of
$(T_i)^{\mathtt{x}_i}_R$
is the type of
 $T_i$
, which is the output type of
$T_i$
, which is the output type of
 $\mathtt{f}_i$
, which is the output type of
$\mathtt{f}_i$
, which is the output type of
 $(\mathtt{f}_i)_R$
. The only variable that may occur in
$(\mathtt{f}_i)_R$
. The only variable that may occur in
 $(T_i)_R$
is
$(T_i)_R$
is
 $(\mathtt{x}_i)_R$
, and the only recursive function symbols that may occur are among
$(\mathtt{x}_i)_R$
, and the only recursive function symbols that may occur are among
 $((\mathtt{f}_0)_R,\dots,(\mathtt{f}_k)_R)$
.
$((\mathtt{f}_0)_R,\dots,(\mathtt{f}_k)_R)$
.
In the next lemma, recall that if
 $(u_0,\dots,u_{n-1})$
is a decomposition of the value u into atomic values, then by
$(u_0,\dots,u_{n-1})$
is a decomposition of the value u into atomic values, then by
 $u \circ x$
we mean
$u \circ x$
we mean
 $(u_0,\dots,u_{n-1},x)$
. Its proof is postponed to Appendix A.
$(u_0,\dots,u_{n-1},x)$
. Its proof is postponed to Appendix A.
Lemma 6. For any cons-free program with global input p, values x u, and v, variable
 $\mathtt{x}$
, and
$\mathtt{x}$
, and
 $\mathtt{x}$
-term T,
$\mathtt{x}$
-term T,
 $$ x,[\mathtt{x} = u] \vdash T \to v \implies [\mathtt{x}_R = u \circ x] \vdash T^\mathtt{x}_R \to v .$$
$$ x,[\mathtt{x} = u] \vdash T \to v \implies [\mathtt{x}_R = u \circ x] \vdash T^\mathtt{x}_R \to v .$$
Hence,
Theorem 7. For any cons-free program with global input p with nullary input, string x and value v, if
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$, then $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$, then $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
.
Proof Let
 $\mathtt{f}_0(\mathtt{x})$
be the head of p. Since p has nullary input,
$\mathtt{f}_0(\mathtt{x})$
be the head of p. Since p has nullary input,
 $\mathtt{x}$
is a variable of type the empty product, and
$\mathtt{x}$
is a variable of type the empty product, and
 $\mathtt{x}_R$
is a variable of type R. If
$\mathtt{x}_R$
is a variable of type R. If
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$, then $x \vdash \mathtt{f}_0 \to v$
. By Lemma 6,
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$, then $x \vdash \mathtt{f}_0 \to v$
. By Lemma 6,
 $[\mathtt{x}_R = x] \vdash (\mathtt{f}_0)_R((\mathtt{x}_0)_R) \to v$
. But since
$[\mathtt{x}_R = x] \vdash (\mathtt{f}_0)_R((\mathtt{x}_0)_R) \to v$
. But since
 $(\mathtt{f}_0)_R((\mathtt{x}_0)_R)$
is the head of
$(\mathtt{f}_0)_R((\mathtt{x}_0)_R)$
is the head of
 $p_R$
,
$p_R$
,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v$
.
7.2 Eliminating indices and counting modules
In this subsection, we show how to compile any bit-length program into a cons-free program with global input. We fix a natural number
 $k \ge 1$
which is the number of copies of R we want to replace every copy of C by. The transformation
$k \ge 1$
which is the number of copies of R we want to replace every copy of C by. The transformation
 $\unicode{x2021}$
defined in this section should be understood as parameterized by this number k. First we will define a map on types, variables, and terms, then values, then programs, and we conclude with a proof of correctness.
$\unicode{x2021}$
defined in this section should be understood as parameterized by this number k. First we will define a map on types, variables, and terms, then values, then programs, and we conclude with a proof of correctness.
The main idea: Bit-length programs contain two types of data that RW-factorizable programs do not: indices and counting modules. We replace indices by single R values and counting modules by k-tuples of R values.
The former correspondence is straightforward: if the input string x has length n, then its bits are
 $x_n \dots x_2 x_1$
. R values range over suffixes of x. We encode the index i by the R value
$x_n \dots x_2 x_1$
. R values range over suffixes of x. We encode the index i by the R value
 $x_i \dots x_2 x_1$
. The “dummy index” 0 is encoded by the empty string. With respect to this encoding, the index primitives
$x_i \dots x_2 x_1$
. The “dummy index” 0 is encoded by the empty string. With respect to this encoding, the index primitives
 $\mathtt{bit}$
,
$\mathtt{bit}$
,
 $\mathtt{P}$
,
$\mathtt{P}$
,
 $\mathtt{null}$
, and
$\mathtt{null}$
, and
 $\mathtt{max}$
correspond to
$\mathtt{max}$
correspond to
 $\mathtt{hd}$
,
$\mathtt{hd}$
,
 $\mathtt{tl}$
,
$\mathtt{tl}$
,
 $\mathtt{null}$
, and
$\mathtt{null}$
, and
 $\mathtt{in}$
(the global input variable) respectively. The only index primitive that needs to be programmed is
$\mathtt{in}$
(the global input variable) respectively. The only index primitive that needs to be programmed is
 $\mathtt{min}$
, which can be replaced by
$\mathtt{min}$
, which can be replaced by
 $\mathtt{f}(\mathtt{in})$
, where
$\mathtt{f}(\mathtt{in})$
, where
 $$ \mathtt{f}(\mathtt{x}) \equiv \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{x}\ \mathtt{else}\ \mathtt{f}(\mathtt{tl}(\mathtt{x})). $$
$$ \mathtt{f}(\mathtt{x}) \equiv \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ \mathtt{x}\ \mathtt{else}\ \mathtt{f}(\mathtt{tl}(\mathtt{x})). $$
Let
 $\mathtt{zero}_I$
be the term
$\mathtt{zero}_I$
be the term
 $\mathtt{f}(\mathtt{in})$
.
$\mathtt{f}(\mathtt{in})$
.
If we ignore the characters in an R-string, it simply encodes a length ranging from 0 to
 $n+1$
; i.e., a single digit base
$n+1$
; i.e., a single digit base
 $n+1$
. Hence, a k-tuple of R-data encodes a k-digit number base
$n+1$
. Hence, a k-tuple of R-data encodes a k-digit number base
 $n+1$
, or alternatively, as a natural number less than
$n+1$
, or alternatively, as a natural number less than
 $(n+1)^k$
. Therefore, k-tuples of R data can be used to simulate counting modules which are polynomially bounded in the length of the input.
Footnote 13
The counting modules primitives
$(n+1)^k$
. Therefore, k-tuples of R data can be used to simulate counting modules which are polynomially bounded in the length of the input.
Footnote 13
The counting modules primitives
 $+$
,
$+$
,
 $-$
, and
$-$
, and
 $\le$
can be replaced by cons-free programs
$\le$
can be replaced by cons-free programs
 $\mathtt{add}$
,
$\mathtt{add}$
,
 $\mathtt{minus}$
, and
$\mathtt{minus}$
, and
 $\mathtt{less}$
, which simulate the corresponding primitives on k-tuples of R values by mimicking any common algorithm for fixed-width arithmetic.
Footnote 14
The cons-free constants 0 and 1 can similarly be replaced with programs
$\mathtt{less}$
, which simulate the corresponding primitives on k-tuples of R values by mimicking any common algorithm for fixed-width arithmetic.
Footnote 14
The cons-free constants 0 and 1 can similarly be replaced with programs
 $\mathtt{zero}$
and
$\mathtt{zero}$
and
 $\mathtt{one}$
, which compute the constant-
$\mathtt{one}$
, which compute the constant-
 $(0,\dots,0,0)$
and constant-
$(0,\dots,0,0)$
and constant-
 $(0,\dots,0,1)$
functions, respectively.
Footnote 15
$(0,\dots,0,1)$
functions, respectively.
Footnote 15
We assume the existence of these five programs without constructing them and note that they can always be made tail-recursive. In fact, all the recursion we need can be collected into a few important subroutines. Thinking of R values as single digits, we can name the largest digit (by the global input variable
 $\mathtt{in}$
) and we can decrement digits (by
$\mathtt{in}$
) and we can decrement digits (by
 $\mathtt{tl}$
). Using these primitives, we can define simple tail-recursive subroutines incrementing a digit, comparing two digits, and naming the digit 0. Then, the programs
$\mathtt{tl}$
). Using these primitives, we can define simple tail-recursive subroutines incrementing a digit, comparing two digits, and naming the digit 0. Then, the programs
 $\mathtt{add}$
,
$\mathtt{add}$
,
 $\mathtt{minus}$
,
$\mathtt{minus}$
,
 $\mathtt{less}$
,
$\mathtt{less}$
,
 $\mathtt{zero}$
, and
$\mathtt{zero}$
, and
 $\mathtt{one}$
are explicit in these subroutines; i.e., can be defined in terms of them using no additional recursion.
$\mathtt{one}$
are explicit in these subroutines; i.e., can be defined in terms of them using no additional recursion.
Definition 39. Let
 $2^\unicode{x2021} = 2$
,
$2^\unicode{x2021} = 2$
,
 $I^\unicode{x2021} = R$
, and
$I^\unicode{x2021} = R$
, and
 $C^\unicode{x2021} = R^k$
. For every bit-length product type
$C^\unicode{x2021} = R^k$
. For every bit-length product type
 $\alpha$
, define the RW product type
$\alpha$
, define the RW product type
 $\alpha^\unicode{x2021}$
by replacing every copy of I by R, replacing every copy of C by
$\alpha^\unicode{x2021}$
by replacing every copy of I by R, replacing every copy of C by
 $R^k$
, and flattening. For example:
$R^k$
, and flattening. For example:
 \begin{align*} C^\unicode{x2021} &= R^k \\ (2 \times I \times C)^\unicode{x2021} &= 2 \times R^{k+1} \\ (2 \times C \times I \times 2 \times C \times C)^\unicode{x2021} &= 2 \times R^{k+1} \times 2 \times R^{2k}. \end{align*}
\begin{align*} C^\unicode{x2021} &= R^k \\ (2 \times I \times C)^\unicode{x2021} &= 2 \times R^{k+1} \\ (2 \times C \times I \times 2 \times C \times C)^\unicode{x2021} &= 2 \times R^{k+1} \times 2 \times R^{2k}. \end{align*}
Extend this to a map on function types by
 $(\beta \to \alpha)^\unicode{x2021} = \beta^\unicode{x2021} \to \alpha^\unicode{x2021}$
.
$(\beta \to \alpha)^\unicode{x2021} = \beta^\unicode{x2021} \to \alpha^\unicode{x2021}$
.
Finally, for each product type
 $\alpha$
, define the map
$\alpha$
, define the map
 $s_\alpha : |\alpha^\unicode{x2021}| \to |\alpha|$
by mapping each coordinate of
$s_\alpha : |\alpha^\unicode{x2021}| \to |\alpha|$
by mapping each coordinate of
 $\alpha^\unicode{x2021}$
to the coordinate “which it comes from” in
$\alpha^\unicode{x2021}$
to the coordinate “which it comes from” in
 $\alpha$
. For example,
$\alpha$
. For example,
 $s_C : k \to 1$
is defined by
$s_C : k \to 1$
is defined by
 $s_C(i) = 0$
for all
$s_C(i) = 0$
for all
 $i \in k$
;
$i \in k$
;
 $s_{2 \times I \times C}:k+2 \to 3$
and
$s_{2 \times I \times C}:k+2 \to 3$
and
 $s_{2 \times I \times C}(i)$
is 0 if
$s_{2 \times I \times C}(i)$
is 0 if
 $i=0$
, 1 if
$i=0$
, 1 if
 $i = 1$
, and 2 otherwise; and
$i = 1$
, and 2 otherwise; and
 $$ s_{2 \times C \times I \times 2 \times C \times C} : 3k + 2 \to 6 $$
$$ s_{2 \times C \times I \times 2 \times C \times C} : 3k + 2 \to 6 $$
is defined by
 $$ s_{2 \times C \times I \times 2 \times C \times C}(i) = \begin{cases} 0 & \text{if } i = 0 \\1 & \text{if } 1 \le i \le k \\2 & \text{if } i = k+1 \\3 & \text{if } i = k+2 \\4 & \text{if } k+3 \le i \le 2k+2 \\5 & \text{otherwise}\end{cases}$$
$$ s_{2 \times C \times I \times 2 \times C \times C}(i) = \begin{cases} 0 & \text{if } i = 0 \\1 & \text{if } 1 \le i \le k \\2 & \text{if } i = k+1 \\3 & \text{if } i = k+2 \\4 & \text{if } k+3 \le i \le 2k+2 \\5 & \text{otherwise}\end{cases}$$
Notice that each such map
 $s_\alpha$
is a monotone (non-decreasing) surjection.
$s_\alpha$
is a monotone (non-decreasing) surjection.
Definition 40. Fix an injection
 $\mathtt{x} \mapsto \mathtt{x}^\unicode{x2021}$
from bit-length variables to RW variables such that if
$\mathtt{x} \mapsto \mathtt{x}^\unicode{x2021}$
from bit-length variables to RW variables such that if
 $\mathtt{x}$
has type
$\mathtt{x}$
has type
 $\alpha$
,
$\alpha$
,
 $\mathtt{x}^\unicode{x2021}$
has type
$\mathtt{x}^\unicode{x2021}$
has type
 $\alpha^\unicode{x2021}$
. Fix an injection
$\alpha^\unicode{x2021}$
. Fix an injection
 $\mathtt{f} \mapsto \mathtt{f}^\unicode{x2021}$
from bit-length recursive function symbols of type
$\mathtt{f} \mapsto \mathtt{f}^\unicode{x2021}$
from bit-length recursive function symbols of type
 $\rho$
to RW function symbols of type
$\rho$
to RW function symbols of type
 $\rho^\unicode{x2021}$
, for every bit-length function type
$\rho^\unicode{x2021}$
, for every bit-length function type
 $\rho$
.
$\rho$
.
In the next definition,
 $\mathtt{in}$
is a fixed variable of type R naming the global input,
$\mathtt{in}$
is a fixed variable of type R naming the global input,
 $\mathtt{zero}$
and
$\mathtt{zero}$
and
 $\mathtt{one}$
are fixed function symbols of type
$\mathtt{one}$
are fixed function symbols of type
 $ C^ \unicode{x2020}$
,
$ C^ \unicode{x2020}$
,
 $\mathtt{add}$
and
$\mathtt{add}$
and
 $\mathtt{minus}$
are fixed function symbols of type
$\mathtt{minus}$
are fixed function symbols of type
 $(C \times C \to C)^\unicode{x2021}$
, and
$(C \times C \to C)^\unicode{x2021}$
, and
 $\mathtt{less}$
is a fixed function symbol of type
$\mathtt{less}$
is a fixed function symbol of type
 $(C \times C \to 2)^\unicode{x2021}$
.
$(C \times C \to 2)^\unicode{x2021}$
.
Definition 41. Define a map
 $T \mapsto T^ \unicode{x2020}$
from bit-length terms to cons-free terms with global input by:
$T \mapsto T^ \unicode{x2020}$
from bit-length terms to cons-free terms with global input by:
-
If
$T \equiv \mathtt{true} $
or
$T \equiv \mathtt{false,}$
then
$T^\unicode{x2021} \equiv T$
. -
If
$T \equiv \mathtt{x}$
, a variable of type
$\alpha$
, then
$T^\unicode{x2021} \equiv \mathtt{x}^\unicode{x2021}$
. -
If
$T \equiv \mathtt{0}$
then
$T^\unicode{x2021} \equiv \mathtt{zero}$
. -
If
$T \equiv \mathtt{1}$
then
$T^\unicode{x2021} \equiv \mathtt{one}$
. -
If
$T \equiv T_0 + T_1$
then
$T^\unicode{x2021} \equiv \mathtt{add}(T_0^\unicode{x2021},T_1^\unicode{x2021})$
. -
If
$T \equiv T_0 - T_1$
then
$T^\unicode{x2021} \equiv \mathtt{minus}(T_0^\unicode{x2021},T_1^\unicode{x2021})$
. -
If
$T \equiv T_0 \le T_1$
, then
$T^\unicode{x2021} \equiv \mathtt{less}(T_0^\unicode{x2021},T_1^\unicode{x2021})$
. -
If
$T \equiv \mathtt{min}$
then
$T^\unicode{x2021} \equiv \mathtt{zero}_I$
. -
If
$T \equiv \mathtt{max}$
then
$T^\unicode{x2021} \equiv \mathtt{in}$
. -
If
$T \equiv \mathtt{P}(S)$
then
$T^\unicode{x2021} \equiv \mathtt{tl}(S^\unicode{x2021})$
. -
If
$T \equiv \mathtt{null}(S)$
then
$T^\unicode{x2021} \equiv \mathtt{null}(S^\unicode{x2021})$
. -
If
$T \equiv \mathtt{bit}(S)$
then
$T^\unicode{x2021} \equiv \mathtt{hd}(S^\unicode{x2021})$
. -
If
$T \equiv T_0 \oplus \dots \oplus T_{n-1}$
then
$T^\unicode{x2021} \equiv T_0^\unicode{x2021} \oplus \dots \oplus T_{n-1}^\unicode{x2021}$
. -
If
$T \equiv S[i,j]$
, let m be the length of S and n the length of
$S^\unicode{x2021}$
. Then,
$T^\unicode{x2021} \equiv S^\unicode{x2021}[\imath,\jmath]$
, where the interval
$[\imath,\jmath] \subseteq m$
is the
$s_\alpha$
-pre-image of
$[i,j] \subseteq n$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
then
$T^\unicode{x2021} \equiv \mathtt{if}\ T_0^\unicode{x2021}\ \mathtt{then}\ T_1^\unicode{x2021}\ \mathtt{else}\ T_2^\unicode{x2021}$
. -
If
$T \equiv \mathtt{f}(S)$
, then
$T \equiv \mathtt{f}^\unicode{x2021}( S^\unicode{x2021} )$
.






































Now we define a map on values. For this definition, recall the bijection
 $$ f : \underbrace{n \times \dots \times n}_{\boldsymbol{k}}{\text{copies}} \to n^k $$
$$ f : \underbrace{n \times \dots \times n}_{\boldsymbol{k}}{\text{copies}} \to n^k $$
defined by
 $(d_0,\dots,d_{k-1}) \mapsto \sum_{i < k} d_i n^i.$
Intuitively, this identifies k-digit numerals base n with the numbers they denote.
$(d_0,\dots,d_{k-1}) \mapsto \sum_{i < k} d_i n^i.$
Intuitively, this identifies k-digit numerals base n with the numbers they denote.
Remark 12. As long as
 $\mathtt{zero}$
,
$\mathtt{zero}$
,
 $\mathtt{one}$
,
$\mathtt{one}$
,
 $\mathtt{add}$
,
$\mathtt{add}$
,
 $\mathtt{minus}$
, and
$\mathtt{minus}$
, and
 $\mathtt{less}$
are implemented by tail-recursive programs, this transformation is easily seen to preserve tail recursion.
$\mathtt{less}$
are implemented by tail-recursive programs, this transformation is easily seen to preserve tail recursion.
Definition 42. For any string
 $x \in 2^\star$
, define the map
$x \in 2^\star$
, define the map
 $v \mapsto v^\unicode{x2021}$
as follows. If
$v \mapsto v^\unicode{x2021}$
as follows. If
 $v \in 2$
, then
$v \in 2$
, then
 $v_x^\unicode{x2021} = v$
. If
$v_x^\unicode{x2021} = v$
. If
 $v \in I(x)$
, then
$v \in I(x)$
, then
 $v_x^\unicode{x2021}$
is the suffix of x of length
$v_x^\unicode{x2021}$
is the suffix of x of length
 $|v|$
. If
$|v|$
. If
 $v \in C((|x|+1)^k)$
, then
$v \in C((|x|+1)^k)$
, then
 $v_x^\unicode{x2021}$
is the unique k-tuple of suffixes
$v_x^\unicode{x2021}$
is the unique k-tuple of suffixes
 $(s_0,\dots,s_{k-1})$
of x such that
$(s_0,\dots,s_{k-1})$
of x such that
 $$ v = \sum_{i < k} |s_i| (|x| + 1)^i .$$
$$ v = \sum_{i < k} |s_i| (|x| + 1)^i .$$
If
 $(v_0,\dots,v_{n-1})$
is a decomposition of v into atomic types, then
$(v_0,\dots,v_{n-1})$
is a decomposition of v into atomic types, then
 $v^\unicode{x2021} = v_0^\unicode{x2021} \circ \dots \circ v_{n-1}^\unicode{x2021}$
. Notice that for any values u and v,
$v^\unicode{x2021} = v_0^\unicode{x2021} \circ \dots \circ v_{n-1}^\unicode{x2021}$
. Notice that for any values u and v,
 $(u \circ v)^\unicode{x2021} = u^\unicode{x2021} \circ v^\unicode{x2021}$
.
$(u \circ v)^\unicode{x2021} = u^\unicode{x2021} \circ v^\unicode{x2021}$
.
Definition 43. Given a bit-length program
 $p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)$
, the cons-free program with global input
$p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)$
, the cons-free program with global input
 $p^\unicode{x2021}$
is defined to be
$p^\unicode{x2021}$
is defined to be
 $(\mathtt{f}_i^\unicode{x2021}(\mathtt{x}^\unicode{x2021}_i) = T_i^\unicode{x2021}) $
.
$(\mathtt{f}_i^\unicode{x2021}(\mathtt{x}^\unicode{x2021}_i) = T_i^\unicode{x2021}) $
.
This program is well-defined: if
 $T_i$
is an
$T_i$
is an
 $\mathtt{x}_i$
-term, then
$\mathtt{x}_i$
-term, then
 $T_i^\unicode{x2021}$
is an
$T_i^\unicode{x2021}$
is an
 $\mathtt{x}_i^\unicode{x2021}$
-term. The only recursive function symbols that may occur in
$\mathtt{x}_i^\unicode{x2021}$
-term. The only recursive function symbols that may occur in
 $T_i^\unicode{x2021}$
, besides the previously defined
$T_i^\unicode{x2021}$
, besides the previously defined
 $\mathtt{zero}_I$
,
$\mathtt{zero}_I$
,
 $\mathtt{zero}$
,
$\mathtt{zero}$
,
 $\mathtt{one}$
,
$\mathtt{one}$
,
 $\mathtt{add}$
,
$\mathtt{add}$
,
 $\mathtt{minus}$
and
$\mathtt{minus}$
and
 $\mathtt{less}$
, are the
$\mathtt{less}$
, are the
 $\mathtt{f}_j^\unicode{x2021}$
. Moreover, it is tail-recursive if p is.
$\mathtt{f}_j^\unicode{x2021}$
. Moreover, it is tail-recursive if p is.
The proof of the next result is postponed to Appendix A.
Lemma 7. For every bit-length program p, bit-length term T from p, string x, x-environment
 $\rho$
, and value v,
$\rho$
, and value v,
 $$ x, (|x|+1)^k, \rho \vdash_p T \to v \implies x, \rho^\unicode{x2021} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}.$$
$$ x, (|x|+1)^k, \rho \vdash_p T \to v \implies x, \rho^\unicode{x2021} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}.$$
Lemma 7 and Theorem 7 have the following corollary. Let
 $p^\unicode{x2021}_R$
be
$p^\unicode{x2021}_R$
be
 $(p^\unicode{x2021})_R$
.
$(p^\unicode{x2021})_R$
.
Theorem 8. For any bit-length program p and polynomially bounded
 $\lambda : \omega \to \omega$
, string x and value v, if
$\lambda : \omega \to \omega$
, string x and value v, if
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = v$
without collisions, then
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = v$
without collisions, then
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
.
Proof Choose k such that
 $\lambda(n) < (n+1)^k$
for all n and define
$\lambda(n) < (n+1)^k$
for all n and define
 $\mu:\omega \to \omega$
by
$\mu:\omega \to \omega$
by
 $\mu(n) = (n+1)^k$
. Suppose that
$\mu(n) = (n+1)^k$
. Suppose that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = v$
without collisions. Then,
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = v$
without collisions. Then,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\mu(x) = v$
by monotonicity of collision-free computation. By Lemma 7 and the definition of
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\mu(x) = v$
by monotonicity of collision-free computation. By Lemma 7 and the definition of
 $p^\unicode{x2021}$
,
$p^\unicode{x2021}$
,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
. By Theorem 7,
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
. By Theorem 7,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = v^\unicode{x2021}$
.
Example. The following program of type
 $C \times C \to C$
multiplies its two inputs. (Or rather, the two coordinates of its single input—recall these are
$C \times C \to C$
multiplies its two inputs. (Or rather, the two coordinates of its single input—recall these are
 $\mathtt{c}[0]$
and
$\mathtt{c}[0]$
and
 $\mathtt{c}[1]$
.)
$\mathtt{c}[1]$
.)
 \begin{align*} \mathtt{f}(\mathtt{c}) = \mathtt{if}\ \mathtt{c}[0] \le 0\ \mathtt{then}\ 0\ \mathtt{else}\ \mathtt{c}[1] + \mathtt{f}(\mathtt{c}[0] - 1, \mathtt{c}[1]).\end{align*}
\begin{align*} \mathtt{f}(\mathtt{c}) = \mathtt{if}\ \mathtt{c}[0] \le 0\ \mathtt{then}\ 0\ \mathtt{else}\ \mathtt{c}[1] + \mathtt{f}(\mathtt{c}[0] - 1, \mathtt{c}[1]).\end{align*}
Suppose that
 $k=2$
, so we replace each occurrence of C by two copies of R. Then, the type of
$k=2$
, so we replace each occurrence of C by two copies of R. Then, the type of
 $\mathtt{c}^\unicode{x2021}$
is
$\mathtt{c}^\unicode{x2021}$
is
 $R^4$
, where the former and latter two copies of R correspond to
$R^4$
, where the former and latter two copies of R correspond to
 $\mathtt{c}[0]$
and
$\mathtt{c}[0]$
and
 $\mathtt{c}[1],$
respectively. Hence,
$\mathtt{c}[1],$
respectively. Hence,
 \begin{align*} \mathtt{f}^\unicode{x2021}(\mathtt{c}^\unicode{x2021}) & = \mathtt{if}\ \mathtt{less}(\mathtt{c}^\unicode{x2021}[0,1],\mathtt{zero})\ \mathtt{then}\ \mathtt{zero}\ \mathtt{else}\ \mathtt{add}(\mathtt{c}^\unicode{x2021}[2,3],\mathtt{f}^\unicode{x2021}(\mathtt{minus}(\mathtt{c}^\unicode{x2021}[0,1],\mathtt{one}),\\ & \qquad \mathtt{c}^\unicode{x2021}[2,3])).\end{align*}
\begin{align*} \mathtt{f}^\unicode{x2021}(\mathtt{c}^\unicode{x2021}) & = \mathtt{if}\ \mathtt{less}(\mathtt{c}^\unicode{x2021}[0,1],\mathtt{zero})\ \mathtt{then}\ \mathtt{zero}\ \mathtt{else}\ \mathtt{add}(\mathtt{c}^\unicode{x2021}[2,3],\mathtt{f}^\unicode{x2021}(\mathtt{minus}(\mathtt{c}^\unicode{x2021}[0,1],\mathtt{one}),\\ & \qquad \mathtt{c}^\unicode{x2021}[2,3])).\end{align*}
7.3 Building type-W output
So far we have shown that we can convert any bit-length program p into an equivalent cons-free RW-factorizable program
 $p^\unicode{x2021}_R$
. Given a polynomially bounded function
$p^\unicode{x2021}_R$
. Given a polynomially bounded function
 $\lambda$
and bit-length programs p and q such that
$\lambda$
and bit-length programs p and q such that
 $(\lambda,p,q)$
properly computes a function f, how do we use the cons-free programs
$(\lambda,p,q)$
properly computes a function f, how do we use the cons-free programs
 $q^\unicode{x2021}_R$
and
$q^\unicode{x2021}_R$
and
 $p^\unicode{x2021}_R$
to form an RW-factorizable program computing f? (As above,
$p^\unicode{x2021}_R$
to form an RW-factorizable program computing f? (As above,
 $\unicode{x2021}$
is dependent on a parameter k, which we choose large enough so that
$\unicode{x2021}$
is dependent on a parameter k, which we choose large enough so that
 $(n+1)^k$
dominates
$(n+1)^k$
dominates
 $\lambda$
.)
$\lambda$
.)
As usual, the basic idea is straightforward. We compute the length of the output string using
 $q^\unicode{x2021}_R$
. We iterate through indices of the output string less than
$q^\unicode{x2021}_R$
. We iterate through indices of the output string less than
 $q^\unicode{x2021}_R$
and compute the corresponding bit of the output string using
$q^\unicode{x2021}_R$
and compute the corresponding bit of the output string using
 $p^\unicode{x2021}_R$
. For each of these computed bits, we
$p^\unicode{x2021}_R$
. For each of these computed bits, we
 $\mathtt{cons}$
-them on to a variable
$\mathtt{cons}$
-them on to a variable
 $\mathtt{w}$
, which “accumulates” the eventual output.
$\mathtt{w}$
, which “accumulates” the eventual output.
If we were to write this in a legible but informal imperative pseudocode, it would look like this:
 \begin{align*} &\mathtt{w} = \mathtt{nil} \\ &\mathtt{for}\ \texttt{1} \le \mathtt{c} \le \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(\mathtt{x}) \\ &\ \ \ \ \mathtt{w} = \mathtt{cons}(\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(\mathtt{x},\mathtt{c}),\mathtt{w}) \\ &\mathtt{return} \ \mathtt{w}\end{align*}
\begin{align*} &\mathtt{w} = \mathtt{nil} \\ &\mathtt{for}\ \texttt{1} \le \mathtt{c} \le \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(\mathtt{x}) \\ &\ \ \ \ \mathtt{w} = \mathtt{cons}(\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(\mathtt{x},\mathtt{c}),\mathtt{w}) \\ &\mathtt{return} \ \mathtt{w}\end{align*}
It is easy to see that this program computes f(x) on input x, as it outputs a string of length
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x)$
(x) whose i-th bit is
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x)$
(x) whose i-th bit is
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,i)$
. Written slightly more carefully, we get this:
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p^\unicode{x2021}_R}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,i)$
. Written slightly more carefully, we get this:
 \begin{align*} \mathtt{out}(\mathtt{x}) &= \mathtt{f}(\mathtt{x} , \mathtt{one},\mathtt{nil}) \\ \mathtt{f}(\mathtt{x},\mathtt{c},\mathtt{w}) &= \mathtt{if}\ \mathtt{c}=\mathtt{h}_q(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{f}(\mathtt{x},\mathtt{add}(\mathtt{c},\mathtt{one}),\mathtt{cons}(\mathtt{h}_p(\mathtt{x},\mathtt{c}),\mathtt{w})),\end{align*}
\begin{align*} \mathtt{out}(\mathtt{x}) &= \mathtt{f}(\mathtt{x} , \mathtt{one},\mathtt{nil}) \\ \mathtt{f}(\mathtt{x},\mathtt{c},\mathtt{w}) &= \mathtt{if}\ \mathtt{c}=\mathtt{h}_q(\mathtt{x})\ \mathtt{then}\ \mathtt{w}\ \mathtt{else}\ \mathtt{f}(\mathtt{x},\mathtt{add}(\mathtt{c},\mathtt{one}),\mathtt{cons}(\mathtt{h}_p(\mathtt{x},\mathtt{c}),\mathtt{w})),\end{align*}
where
 $\mathtt{h}_p$
and
$\mathtt{h}_p$
and
 $\mathtt{h}_q$
denote the heads of the programs
$\mathtt{h}_q$
denote the heads of the programs
 $p^\unicode{x2021}_R$
and
$p^\unicode{x2021}_R$
and
 $q^\unicode{x2021}_R,$
respectively. But even here, we have sacrificed some precision for legibility: for example, we must replace
$q^\unicode{x2021}_R,$
respectively. But even here, we have sacrificed some precision for legibility: for example, we must replace
 $=$
by two occurrences of
$=$
by two occurrences of
 $\mathtt{less}$
, and a term like
$\mathtt{less}$
, and a term like
 $\mathtt{f}(\mathtt{x},\mathtt{0},\mathtt{nil})$
must be understood as
$\mathtt{f}(\mathtt{x},\mathtt{0},\mathtt{nil})$
must be understood as
 $\mathtt{f}(\mathtt{x} \oplus \mathtt{0},\mathtt{nil})$
.
$\mathtt{f}(\mathtt{x} \oplus \mathtt{0},\mathtt{nil})$
.
Thus, we have transformed
 $(\lambda,p,q)$
into an RW-factorizable program computing the same function. Moreover, note that it is non-nested, and tail-recursive if p and q are.
Footnote 16
Combined with Theorem 6, we get the following translation result:
$(\lambda,p,q)$
into an RW-factorizable program computing the same function. Moreover, note that it is non-nested, and tail-recursive if p and q are.
Footnote 16
Combined with Theorem 6, we get the following translation result:
Theorem 9. For every function
 $f : 2^\star \to 2^\star$
whose length is polynomially bounded, there is a non-nested RW-factorizable program of type
$f : 2^\star \to 2^\star$
whose length is polynomially bounded, there is a non-nested RW-factorizable program of type
 $R \to W$
computing f iff there is a polynomially bounded function
$R \to W$
computing f iff there is a polynomially bounded function
 $\lambda$
and bit-length programs p and q such that
$\lambda$
and bit-length programs p and q such that
 $(\lambda,p,q)$
properly computes f.
$(\lambda,p,q)$
properly computes f.
Similarly, there is a tail-recursive RW-factorizable program of type
 $R \to W$
computing f iff there is a polynomially bounded function
$R \to W$
computing f iff there is a polynomially bounded function
 $\lambda$
and tail-recursive bit-length programs p and q such that
$\lambda$
and tail-recursive bit-length programs p and q such that
 $(\lambda,p,q)$
properly computes f.
$(\lambda,p,q)$
properly computes f.
Theorems 9 and 2 have the following immediate consequence, which is the central result of this paper:
Theorem 10. For any function
 $f:2^\star \to 2^\star$
,
$f:2^\star \to 2^\star$
,
 $f \in \mathrm{FP}$
iff f is computed by a non-nested RW-factorizable program of type
$f \in \mathrm{FP}$
iff f is computed by a non-nested RW-factorizable program of type
 $R \to W$
, and
$R \to W$
, and
 $f \in \mathrm{FL}$
iff f is computed by a tail-recursive RW-factorizable program of type
$f \in \mathrm{FL}$
iff f is computed by a tail-recursive RW-factorizable program of type
 $R \to W$
.
$R \to W$
.
A few comments are in order. The proof of this theorem gives us a rather strong normal form for non-nested RW-factorizable programs. Namely, each such program can be written with a single for loop on top of purely cons-free subroutines. We know that those cons-free subroutines can be made non-nested in general, and can furthermore be made tail-recursive if the original program was tail-recursive.
It remains an open question which complexity class general (i.e., possibly nested) RW-factorizable programs capture, but it seems to be intermediate between the class of polynomial time and polynomial space functions. (Recall that the length of the output of the latter functions can grow exponentially in the length of the input.) A plausible candidate is functions whose length is computable in polynomial space, but whose bits are computable in polynomial time.
8 Composing bit-length programs
Finally, we turn to the problem of syntactic composition: producing a program r such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{r}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$} = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$} \circ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
given p and q. In most programming languages this is trivial: we combine programs p and q and add a new head
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{r}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$} = \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$} \circ \mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{q}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}$
given p and q. In most programming languages this is trivial: we combine programs p and q and add a new head
 $\mathtt{h}_p(\mathtt{h}_q(\mathtt{x}))$
, where
$\mathtt{h}_p(\mathtt{h}_q(\mathtt{x}))$
, where
 $\mathtt{h}_p$
and
$\mathtt{h}_p$
and
 $\mathtt{h}_q$
are the recursive function symbols in the heads of p and q respectively. However, this does not work for RW-factorizable programs of type
$\mathtt{h}_q$
are the recursive function symbols in the heads of p and q respectively. However, this does not work for RW-factorizable programs of type
 $R \to W$
, as the term
$R \to W$
, as the term
 $\mathtt{h}_p(\mathtt{h}_q(\mathtt{x}))$
would be ill-typed.
$\mathtt{h}_p(\mathtt{h}_q(\mathtt{x}))$
would be ill-typed.
However, since we can transform RW-factorizable programs to and from equivalent pairs of bit-length programs, it suffices to syntactically compose these. Footnote 17 As we have remarked above, pairs of bit-length programs are compositional in a rough extensional sense: we are given bit- and length-access to the input, and we compute bit- and length-access to the output.
More precisely, suppose we have a triple
 $(\lambda_f,p_f,q_f)$
that properly computes a function f and a triple
$(\lambda_f,p_f,q_f)$
that properly computes a function f and a triple
 $(\lambda_g,p_g,q_g)$
that properly computes g. We want to transform
$(\lambda_g,p_g,q_g)$
that properly computes g. We want to transform
 $p_f$
and
$p_f$
and
 $q_f$
so that they output the bits and length of f(g(x)), as opposed to f(x). Namely, we must “re-interpret” the primitives in
$q_f$
so that they output the bits and length of f(g(x)), as opposed to f(x). Namely, we must “re-interpret” the primitives in
 $p_f$
and
$p_f$
and
 $q_f$
so that it returns the bits of g(x) instead of bits of x, and the constant
$q_f$
so that it returns the bits of g(x) instead of bits of x, and the constant
 $\mathtt{max}$
so that it returns the maximum index of g(x) instead of the maximum index of x. Luckily this is exactly what we have in
$\mathtt{max}$
so that it returns the maximum index of g(x) instead of the maximum index of x. Luckily this is exactly what we have in
 $p_g$
and
$p_g$
and
 $q_g$
.
$q_g$
.
Finally, we have to find a suitable bound for the size of the counting module in the composed program. We assume
 $\lambda_f$
and
$\lambda_f$
and
 $\lambda_g$
are increasing and dominate the identity function. Note that if
$\lambda_g$
are increasing and dominate the identity function. Note that if
 $|f(x)| \le \lambda_f(|x|)$
and
$|f(x)| \le \lambda_f(|x|)$
and
 $|g(x)| \le \lambda_g(|x|)$
, then
$|g(x)| \le \lambda_g(|x|)$
, then
 $|f(g(x))| \le (\lambda_f \circ \lambda_g)(|x|)$
. Hence, we may take
$|f(g(x))| \le (\lambda_f \circ \lambda_g)(|x|)$
. Hence, we may take
 $\lambda_f \circ \lambda_g$
.
$\lambda_f \circ \lambda_g$
.
We now present the formal development, which follows a familiar rhythm: a map on types, on values, terms, and programs, followed by a proof of that the program transformation behaves how we want it to. In this section, let us fix:
-
functions
$f,g: 2^\star \rightharpoonup 2^\star$
, -
increasing functions
$\lambda_f,\lambda_g : \omega \to \omega$
, each dominating the identity function, such that
$\lambda_f(|x|) > |f(x)|$
and
$\lambda_g(|x|) > |g(x)|$
for all x, -
a function
$\mu : \omega \to \omega$
satisfying
$\mu \ge \lambda_f \circ \lambda_g$
, -
a triple
$(\lambda_f,p_f,q_f)$
properly computing f, and -
a triple
$(\lambda_g,p_g,q_g)$
properly computing g.








Note that the map defined in this section will be denoted by a g in the subscript, e.g.,
 $T \mapsto T_g$
. For types, terms, and programs, this g is purely formal; not so for values, where it actually depends on the partial function g.
$T \mapsto T_g$
. For types, terms, and programs, this g is purely formal; not so for values, where it actually depends on the partial function g.
Definition 44. Let
 $2_g = 2$
,
$2_g = 2$
,
 $I_g = C$
, and
$I_g = C$
, and
 $C_g = C$
. Extend this map to a map
$C_g = C$
. Extend this map to a map
 $\alpha \mapsto \alpha_g$
on product types coordinate-wise, and thence to a map
$\alpha \mapsto \alpha_g$
on product types coordinate-wise, and thence to a map
 $(\beta \to \alpha) \mapsto (\beta_g \to \alpha_g)$
on function types.
$(\beta \to \alpha) \mapsto (\beta_g \to \alpha_g)$
on function types.
Definition 45. For each product type
 $\alpha$
, fix an injection
$\alpha$
, fix an injection
 $\mathtt{x} \mapsto \mathtt{x}_g : \mathtt{Var}_\alpha \to \mathtt{Var}_{\alpha _g}$
and an injection
$\mathtt{x} \mapsto \mathtt{x}_g : \mathtt{Var}_\alpha \to \mathtt{Var}_{\alpha _g}$
and an injection
 $\mathtt{f} \mapsto \mathtt{f}_g : \mathtt{RFsymb}_\rho \to \mathtt{RFsymb}_{\rho_g}$
.
$\mathtt{f} \mapsto \mathtt{f}_g : \mathtt{RFsymb}_\rho \to \mathtt{RFsymb}_{\rho_g}$
.
For the next definition, notice that
 $|g(x)| \le \lambda_g(|x|) \le \lambda_f(\lambda_g(|x|)) \le \mu(|x|)$
and
$|g(x)| \le \lambda_g(|x|) \le \lambda_f(\lambda_g(|x|)) \le \mu(|x|)$
and
 $\lambda_f(|g(x)|) \le \lambda_f(\lambda_g(|x|)) \le \mu(|x|)$
, by the assumption that
$\lambda_f(|g(x)|) \le \lambda_f(\lambda_g(|x|)) \le \mu(|x|)$
, by the assumption that
 $\lambda_f$
is increasing and dominates the identity.
$\lambda_f$
is increasing and dominates the identity.
Definition 46. For each
 $x \in 2^\star$
, we define a map
$x \in 2^\star$
, we define a map
 $v \mapsto v_g : I(g(x)) \to C(\mu(|x|))$
and
$v \mapsto v_g : I(g(x)) \to C(\mu(|x|))$
and
 $C(\lambda_f(|g(x)|)) \to C(\mu(|x|))$
by inclusion as initial segments of
$C(\lambda_f(|g(x)|)) \to C(\mu(|x|))$
by inclusion as initial segments of
 $\omega$
. Extend this to a map
$\omega$
. Extend this to a map
 $v \mapsto v_g$
on product types coordinate-wise, fixing boolean values.
$v \mapsto v_g$
on product types coordinate-wise, fixing boolean values.
For the next definition and henceforth, let
 $\mathtt{h}_p(\mathtt{c})$
and
$\mathtt{h}_p(\mathtt{c})$
and
 $\mathtt{h}_q$
be the heads of
$\mathtt{h}_q$
be the heads of
 $p_g$
and
$p_g$
and
 $q_g$
. Notice that these are terms of type 2 and C respectively, and that
$q_g$
. Notice that these are terms of type 2 and C respectively, and that
 $\mathtt{c}$
is a variable of type C.
$\mathtt{c}$
is a variable of type C.
Definition 47. Given a term T of type
 $\alpha$
, we define the term
$\alpha$
, we define the term
 $T_g$
of type
$T_g$
of type
 $\alpha_g$
as follows:
$\alpha_g$
as follows:
-
1. If
$T \equiv \mathtt{x}$
(a variable) then
$T_g \equiv \mathtt{x}_g$
. -
2. If
$T \equiv \mathtt{f}(T')$
, then
$T_g \equiv \mathtt{f}_g(T'_g)$
. -
3. If
$T \equiv \mathtt{true}$
,
$\mathtt{false,}$
,
$\mathtt{0}$
, or
$\mathtt{1}$
, then
$T_g \equiv T$
. -
4. If
$T \equiv T_0 + T_1$
,
$T_0 - T_1$
, or
$T_0 \le T_1$
, then
$T_g \equiv (T_0)_g + (T_1)_g$
,
$(T_0)_g - (T_1)_g$
, or
$(T_0)_g \le (T_1)_g$
respectively. -
5. If
$T \equiv \mathtt{min}$
, then
$T_g \equiv 0$
. -
6. If
$T \equiv \mathtt{max}$
, then
$T_g \equiv \mathtt{h}_q$
. -
7. If
$T \equiv \mathtt{P}(T')$
or
$\mathtt{null}(T')$
, then
$T_g \equiv T'_g -1$
, or
$T'_g \le 0,$
respectively. -
8. If
$T \equiv \mathtt{bit}(T')$
, then
$T_g \equiv \mathtt{h}_p(T'_g)$
. -
9. If
$T \equiv (T_0,\dots,T_{n-1})$
, then
$T_g \equiv ((T_0)_g,\dots,(T_{n-1})_g)$
. -
10. If
$T \equiv T'[i]$
, then
$T_g \equiv (T'_g)[i]$
. -
11. If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then
$T_g \equiv \mathtt{if}\ (T_0)_g\ \mathtt{then}\ (T_1)_g\ \mathtt{else}\ (T_2)_g$
.































Definition 48. Given a program
 $p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)_{0 \le i \le k}$
, let program
$p = (\mathtt{f}_i(\mathtt{x}_i) = T_i)_{0 \le i \le k}$
, let program
 $p_{(g)}$
be defined by combining the programs
$p_{(g)}$
be defined by combining the programs
 $p_g$
and
$p_g$
and
 $q_g$
, then adding new lines
$q_g$
, then adding new lines
 $((\mathtt{f}_i)_g((\mathtt{x}_i)_g) = (T_i)_g)_{0 \le i \le k}$
on top. (The head of
$((\mathtt{f}_i)_g((\mathtt{x}_i)_g) = (T_i)_g)_{0 \le i \le k}$
on top. (The head of
 $p_{(g)}$
is the line
$p_{(g)}$
is the line
 $(\mathtt{f}_0)_g((\mathtt{x}_0)_g) = (T_0)_g$
, where
$(\mathtt{f}_0)_g((\mathtt{x}_0)_g) = (T_0)_g$
, where
 $\mathtt{f}_0(\mathtt{x}_0) = T_0$
is the head of p.)
$\mathtt{f}_0(\mathtt{x}_0) = T_0$
is the head of p.)
Lemma 8. For any program p, environment
 $\rho$
, string x, term T, and value v,
$\rho$
, string x, term T, and value v,
 $$ g(x), \lambda_f(|g(x)|) , \rho \vdash_p T \to v \implies x, \mu(|x|) , \rho_g \vdash_{p_{(g)}} T_g \to v_g,$$
$$ g(x), \lambda_f(|g(x)|) , \rho \vdash_p T \to v \implies x, \mu(|x|) , \rho_g \vdash_{p_{(g)}} T_g \to v_g,$$
without collisions, if the derivation of the left-hand side has no collisions.
(The proof is in Appendix A.)
Theorem 11.
 $(\mu,(p_f)_{(g)},(q_f)_{(g)})$
properly computes
$(\mu,(p_f)_{(g)},(q_f)_{(g)})$
properly computes
 $f \circ g$
.
$f \circ g$
.
Proof. Let
 $\mathtt{h}'_p(\mathtt{c})$
and
$\mathtt{h}'_p(\mathtt{c})$
and
 $\mathtt{h}'_q$
be the left-hand-sides of the heads of
$\mathtt{h}'_q$
be the left-hand-sides of the heads of
 $p_f$
and
$p_f$
and
 $q_f$
respectively. Fix a string x. By definition of
$q_f$
respectively. Fix a string x. By definition of
 $q_f$
,
$q_f$
,
 $$ g(x), \lambda_f(|g(x)|) \vdash_{q_f} \mathtt{h}'_q \to |f(g(x))| $$
$$ g(x), \lambda_f(|g(x)|) \vdash_{q_f} \mathtt{h}'_q \to |f(g(x))| $$
without collisions. Hence by Lemma 8,
 $$ x,\mu(|x|) \vdash_{(q_f)_{(g)}} (\mathtt{h}'_q)_g \to |f(g(x))|,$$
$$ x,\mu(|x|) \vdash_{(q_f)_{(g)}} (\mathtt{h}'_q)_g \to |f(g(x))|,$$
i.e.,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{(q_f)_{(g)}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = |f(g(x))|$
, without collisions.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{(q_f)_{(g)}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x) = |f(g(x))|$
, without collisions.
By definition of
 $p_f$
, for each
$p_f$
, for each
 $i < |f(g(x))|$
,
$i < |f(g(x))|$
,
 $$ g(x), \lambda_f(|g(x)|), [\mathtt{c} = i] \vdash_{p_f} \mathtt{h}'_p(\mathtt{c}) \to (f(g(x)))_i$$
$$ g(x), \lambda_f(|g(x)|), [\mathtt{c} = i] \vdash_{p_f} \mathtt{h}'_p(\mathtt{c}) \to (f(g(x)))_i$$
without collisions. Hence, by Lemma 8,
 $$ x,\mu(|x|), [\mathtt{c}_g = i] \vdash_{(p_f)_g} (p^0_f)_g(\mathtt{c}_g) \to (f(g(x)))_i,$$
$$ x,\mu(|x|), [\mathtt{c}_g = i] \vdash_{(p_f)_g} (p^0_f)_g(\mathtt{c}_g) \to (f(g(x)))_i,$$
i.e.,
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{(p_f)_{(g)}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,i) = (f(g(x)))_i$
, without collisions.
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{(p_f)_{(g)}}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}(x,i) = (f(g(x)))_i$
, without collisions.
Example. Let
 $q_g$
be the program
$q_g$
be the program
 \begin{align*} \mathtt{h}_q &= \mathtt{q}(\mathtt{max}) \\ \mathtt{q}(\mathtt{x}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}(\mathtt{P}(\mathtt{x})),\end{align*}
\begin{align*} \mathtt{h}_q &= \mathtt{q}(\mathtt{max}) \\ \mathtt{q}(\mathtt{x}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}(\mathtt{P}(\mathtt{x})),\end{align*}
and let
 $p_g$
be the program
$p_g$
be the program
 \begin{align*} \mathtt{h}_p(\mathtt{x}) = \mathtt{if}\ \mathtt{bit}(\mathtt{x})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true}.\end{align*}
\begin{align*} \mathtt{h}_p(\mathtt{x}) = \mathtt{if}\ \mathtt{bit}(\mathtt{x})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true}.\end{align*}
In other words, for sufficiently large
 $\lambda$
,
$\lambda$
,
 $(\lambda,p_g,q_g)$
computes the function which flips the bits of the input string. Let us square this function, i.e., create an identical pair of programs
$(\lambda,p_g,q_g)$
computes the function which flips the bits of the input string. Let us square this function, i.e., create an identical pair of programs
 $(p_f,q_f)$
, distinguishing the function symbols of the latter by replacing, e.g.,
$(p_f,q_f)$
, distinguishing the function symbols of the latter by replacing, e.g.,
 $\mathtt{q}$
by
$\mathtt{q}$
by
 $\mathtt{q}'$
, and then composing
$\mathtt{q}'$
, and then composing
 $(p_f,q_f)$
with
$(p_f,q_f)$
with
 $(p_g,q_g)$
. We get for the length component:
$(p_g,q_g)$
. We get for the length component:
 \begin{align*} \mathtt{h}'_q &= \mathtt{q}'(\mathtt{h}_q) \\ \mathtt{q}'(\mathtt{x}_g) &= \mathtt{if}\ \mathtt{x}_g \le 0\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}'(\mathtt{x}_g - 1) \\ \mathtt{h}_q &= \mathtt{q}(\mathtt{max}) \\ \mathtt{q}(\mathtt{x}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}(\mathtt{P}(\mathtt{x})),\end{align*}
\begin{align*} \mathtt{h}'_q &= \mathtt{q}'(\mathtt{h}_q) \\ \mathtt{q}'(\mathtt{x}_g) &= \mathtt{if}\ \mathtt{x}_g \le 0\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}'(\mathtt{x}_g - 1) \\ \mathtt{h}_q &= \mathtt{q}(\mathtt{max}) \\ \mathtt{q}(\mathtt{x}) &= \mathtt{if}\ \mathtt{null}(\mathtt{x})\ \mathtt{then}\ 0\ \mathtt{else}\ 1 + \mathtt{q}(\mathtt{P}(\mathtt{x})),\end{align*}
and for the bits component,
 \begin{align*} \mathtt{h}'_p(\mathtt{x}_g) &= \mathtt{if}\ \mathtt{h}_p(\mathtt{x}_g)\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true} \\ \mathtt{h}_p(\mathtt{x}) &= \mathtt{if}\ \mathtt{bit}(\mathtt{x})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true}.\end{align*}
\begin{align*} \mathtt{h}'_p(\mathtt{x}_g) &= \mathtt{if}\ \mathtt{h}_p(\mathtt{x}_g)\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true} \\ \mathtt{h}_p(\mathtt{x}) &= \mathtt{if}\ \mathtt{bit}(\mathtt{x})\ \mathtt{then}\ \mathtt{false,}\ \mathtt{else}\ \mathtt{true}.\end{align*}
By inspection, we can see that this pair of programs computes the identity function, as it should.
9 Discussion and open questions
We have identified RW-factorizable programs as a simple extension of cons-free programs that captures functional polynomial time and logarithmic space, and we have also shown how to compose two such programs. We introduced the notion of bit-length computability as auxiliary machinery to help us show these results. Our work suggests a number of subsequent questions:
-
1. Higher orders, non-determinism, and other data types. Cons-free programs have been studied in all of these contexts. Jones (Reference Jones2001) showed that deterministic cons-free programs at higher orders capture the deterministic exponential hierarchy, whose union is the class of elementary relations. Kop & Simonsen (Reference Kop and Simonsen2017) showed that whereas non-deterministic first-order cons-free programs are no more expressive than deterministic ones, even non-deterministic second-order programs capture the entire class of elementary relations. Ben-Amram & Petersen (Reference Ben-Amram, Petersen, Larsen, Skyum and Winskel1998) studied cons-free programs over tree data. Does the RW-factorizable paradigm extend smoothly to all of these situations?
-
2. RW-factorizable algorithms Many algorithms seem to be RW-factorizable, in the sense that they have read-only input and write-only output (allowing for some flexibility in what we mean by “read” and “write”). For example, both selection sort and insertion sort seem to follow this paradigm: both algorithms have an input list which gets whittled down over the course of computation while the output list is simultaneously built up. Mergesort, on the other hand, is definitely not RW-factorizable: whereas merge can be consistently typed by
$R \to W$
, the recursive definition
$ \mathit{sort}(u) = \mathit{merge}(\mathit{sort}(u_0),\mathit{sort}(u_1)) $
forces
$\mathit{sort}(u)$
to be of type R and W simultaneously. Are there general techniques or results that apply to RW-factorizable algorithms in general, for example, stronger lower bounds? More generally, can we consider other ways to separate construction from destruction that just variable typing? (e.g., in heapsort we separate them chronologically: the same piece of data is first constructed, then destructed.) -
3. RW-factorizable programs as an indexing of polynomial-time functions. If we fix an encoding of RW-factorizable programs by binary strings, we get an indexing of polynomial-time functions, i.e., an identification of strings with functions. Indexings of partial recursive functions are the central topic in recursion theory, but indexings of complexity classes (or subrecursive indexings) have received a little bit of attention in the context of proving, e.g., speedup phenomena for non-Turing complete languages (Constable & Borodin Reference Constable and Borodin1972; Alton Reference Alton1980). Footnote 18 Kozen (Reference Kozen1978) has identified several simple axioms of subrecursive indexings with significant consequences, for example, Kleene’s second recursion theorem. One of these axioms is the existence of a polynomial-time function which gives a code for
$f \circ g$
given codes for f and g. It seems likely that the transformations in this paper can be computed in polynomial time, and that the natural indexing of FP given by RW-factorizable programs satisfies this and the other axioms. This suggests that we might look for speedup phenomena within the class of RW-factorizable programs itself. Given that cons-free running time corresponds to something like (the exponential of) circuit depth, such speedups might have complexity-theoretic consequences (Bhaskar et al., Reference Bhaskar, Kop and Simonsen2022).




Acknowledgements
We are immensely grateful to Andrzej Filinski, Neil Jones, and Jakob Nordström for their comments on this work. This paper is dedicated to the memory of Neil Jones.
Conflicts of interest
None.
Appendix A: Proofs of correctness
In this section, we collect all the proofs of correctness for transformations defined earlier.
Lemma (Lemma 2). Suppose p is a cons-free program, x is a string,
 $\rho$
is an x-environment. Then,
$\rho$
is an x-environment. Then,
 $$\rho \vdash_p T \to v \implies x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}} T^ \unicode{x2020} \to v^ \unicode{x2020}.$$
$$\rho \vdash_p T \to v \implies x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}} T^ \unicode{x2020} \to v^ \unicode{x2020}.$$
Proof The proof is by induction on the length of the derivation of
 $\rho \vdash T \to v$
. Abbreviate
$\rho \vdash T \to v$
. Abbreviate
 $x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}}$
by
$x, \rho^ \unicode{x2020} \vdash_{p^ \unicode{x2020}}$
by
 $\rho^ \unicode{x2020} \vdash$
.
$\rho^ \unicode{x2020} \vdash$
.
-
If
$T \equiv \mathtt{true}$
or
$T \equiv \mathtt{false,}$
, then
$v = \top$
or
$v = \bot$
, and
$v^ \unicode{x2020} = v$
and
$T^ \unicode{x2020} \equiv T$
. -
If
$T \equiv \mathtt{x}$
, then
$T^ \unicode{x2020} \equiv \mathtt{x}^ \unicode{x2020}$
, and hence,
$\rho^ \unicode{x2020} \vdash T^ \unicode{x2020} \to \rho(\mathtt{x}^ \unicode{x2020})$
, which is
$v^ \unicode{x2020}$
. -
If
$T \equiv \mathtt{hd}(S)$
, then let u satisfy
$\rho \vdash S \to u$
. Then by the suffix property, u is a suffix of x, so the head of u is the bit
$x_{|u|}$
and
$\rho \vdash T \to x_{|u|}$
. By induction,
$\rho^ \unicode{x2020} \vdash S \to u^ \unicode{x2020}$
so
$\rho^ \unicode{x2020} \vdash \mathtt{bit}(S^ \unicode{x2020}) \to x_{u^ \unicode{x2020}}$
, but
$u^ \unicode{x2020} = |u|$
. -
If
$T \equiv \mathtt{tl}(S)$
, then there exists a u and
$b \in 2$
such that
$v = bu$
and
$\rho \vdash S \to u$
. By induction,
$\rho^ \unicode{x2020} \vdash S^ \unicode{x2020} \to |u|$
. Hence,
$\rho^ \unicode{x2020} \vdash \mathtt{P}(S^ \unicode{x2020}) \to |u|-1$
. -
If
$T \equiv \mathtt{null}(S)$
, then v is true or false depending on whether S is the empty string. Similarly,
$\mathtt{null}(S^ \unicode{x2020})$
is true or false depending on whether
$S^ \unicode{x2020}$
is zero, the length of the empty string. -
If
$T \equiv T_0 \oplus \dots \oplus T_{n-1}$
, then there exist
$v_0,\dots,v_{n-1}$
such that
$\rho \vdash T_i \to v_i$
for each
$i < n$
and
$v = v_0 \circ \dots \circ v_{n-1}$
. By induction,
$\rho^ \unicode{x2020} \vdash T_i^ \unicode{x2020} \to v_i^ \unicode{x2020}$
for each
$i< n$
. Since
$v^ \unicode{x2020} = v_0^ \unicode{x2020} \circ \dots \circ v_{n-1}^ \unicode{x2020}$
,
$\rho^ \unicode{x2020} \vdash T_0^ \unicode{x2020} \oplus \dots \oplus T_{n-1}^ \unicode{x2020} \to v^ \unicode{x2020}$
; hence,
$\rho^ \unicode{x2020} \vdash T^ \unicode{x2020} \to v^ \unicode{x2020}$
. -
If
$T \equiv S[i],$
then there exists a value u such that
$\rho \vdash S \to u$
,
$(u_0,\dots,u_{n-1})$
is a decomposition of u into atomic values, and
$v = u_i$
. By induction,
$\rho^ \unicode{x2020} \vdash S^ \unicode{x2020} \to u^ \unicode{x2020}$
, where
$u^ \unicode{x2020} = (u_0^ \unicode{x2020},\dots,u_{n-1}^ \unicode{x2020})$
. Thus,
$\rho^ \unicode{x2020} \vdash S^ \unicode{x2020}[i] \to u_i^ \unicode{x2020}$
, which says
$\rho^ \unicode{x2020} \vdash T^ \unicode{x2020} \to v^ \unicode{x2020}$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, assume
$\rho \vdash T_0 \to \top $
. (The case
$\rho \vdash T_0 \to \bot $
is similar.) Then,
$\rho \vdash T_1 \to v$
. By induction,
$\rho^ \unicode{x2020} \vdash T_0^ \unicode{x2020} \to \top $
and
$\rho^ \unicode{x2020} \vdash T_1^ \unicode{x2020} \to v^ \unicode{x2020}$
. Hence,
$\rho^ \unicode{x2020} \vdash T \to v^ \unicode{x2020}$
. -
If
$T \equiv \mathtt{f}(S)$
, then let
$\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. Then there exists some u such that
$\rho \vdash S \to u$
and
$[\mathtt{x}^\mathtt{f} = u] \vdash T^\mathtt{f} \to v$
. By induction,
$\rho^ \unicode{x2020} \vdash S^ \unicode{x2020} \to u^ \unicode{x2020}$
and
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = u^ \unicode{x2020}] \vdash (T^\mathtt{f}) ^ \unicode{x2020} \to v^ \unicode{x2020}$
. Hence,
$\rho^ \unicode{x2020} \vdash \mathtt{f}^ \unicode{x2020}(S^ \unicode{x2020}) \to v^ \unicode{x2020}$
, and
$\rho^ \unicode{x2020} \vdash T^ \unicode{x2020} \to v^ \unicode{x2020}$
.




























































Lemma (Lemma 3). Suppose that p is an RW-factorizable program, T is an RW-term,
 $x, v, v',w \in 2^\star$
,
$x, v, v',w \in 2^\star$
,
 $\rho$
is an x-environment, and
$\rho$
is an x-environment, and
 $\mathtt{w}$
is not bound by
$\mathtt{w}$
is not bound by
 $\rho$
.
$\rho$
.
Suppose that
 $\rho,[\mathtt{w} = w] \vdash_p T \to v$
and
$\rho,[\mathtt{w} = w] \vdash_p T \to v$
and
 $\rho,[\mathtt{w} = \varepsilon] \vdash_p T \to v'$
.
Footnote 19
Then either
$\rho,[\mathtt{w} = \varepsilon] \vdash_p T \to v'$
.
Footnote 19
Then either
-
$x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to \top $
and
$v = v'$
, or
-
$x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to \bot $
and
$v = v'w$
.




Proof Abbreviate
 $\rho, [\mathtt{w} = w] \vdash_p T \to v$
by
$\rho, [\mathtt{w} = w] \vdash_p T \to v$
by
 $[\rho,w] \vdash T \to v$
, and similarly abbreviate
$[\rho,w] \vdash T \to v$
, and similarly abbreviate
 $\rho, [\mathtt{w} = \varepsilon] \vdash_p T \to v$
by
$\rho, [\mathtt{w} = \varepsilon] \vdash_p T \to v$
by
 $[\rho,\varepsilon] \vdash T \to v$
. Abbreviate
$[\rho,\varepsilon] \vdash T \to v$
. Abbreviate
 $x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to b$
by
$x, \rho^ \unicode{x2020} \vdash_{p^\diamond} T^\diamond \to b$
by
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to b$
. The proof proceeds by induction on the size of the derivation of
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to b$
. The proof proceeds by induction on the size of the derivation of
 $[\rho,w] \vdash T \to v$
and breaks up into cases depending on the form of T.
$[\rho,w] \vdash T \to v$
and breaks up into cases depending on the form of T.
-
If
$T \equiv \mathtt{w}$
, then
$v = w$
,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
, and
$v' = \varepsilon$
. In this case,
$v = w = \varepsilon w = v' w$
, so we’re done. -
If
$T \equiv \mathtt{nil}$
, then
$v = \varepsilon$
,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
, and
$v' = \varepsilon$
. In this case
$v = \varepsilon = v'$
, so we’re done. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, first suppose that
$\rho \vdash T_0 \to \top $
. By Lemma 2,
$\rho^ \unicode{x2020} \vdash_\diamond T_0^ \unicode{x2020} \to \top $
. By definition of T,
$[\rho,w] \vdash T_1 \to v$
and
$[\rho,\varepsilon] \vdash T_1 \to v'$
. By induction, either
$\rho^ \unicode{x2020} \vdash_\diamond T_1^\diamond \to \top $
or
$\rho^ \unicode{x2020} \vdash_\diamond T_1^\diamond \to \bot $
.

















Suppose that
 $\rho^ \unicode{x2020} \vdash_\diamond T_1^\diamond \to \top $
. By induction
$\rho^ \unicode{x2020} \vdash_\diamond T_1^\diamond \to \top $
. By induction
 $v = v'$
. By definition of
$v = v'$
. By definition of
 $T^\diamond$
,
$T^\diamond$
,
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
. Similarly, suppose that
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
. Similarly, suppose that
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. By induction,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. By induction,
 $v = v'w$
. By definition of
$v = v'w$
. By definition of
 $T^\diamond$
,
$T^\diamond$
,
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
, and we’re done.
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
, and we’re done.
(The case
 $\rho \vdash T_0 \to \bot $
is similar.)
$\rho \vdash T_0 \to \bot $
is similar.)
-
Suppose that
$T \equiv \mathtt{f}(T')$
for some
$\mathtt{f} : \beta \to W$
. Then, the variable
$\mathtt{w}$
does not occur in T, so
$v' =v$
. Since
$T^\diamond \equiv \mathtt{true} $
,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
, and we are done. -
Suppose that
$T \equiv \mathtt{f}(T',S)$
for some
$\mathtt{f} : \beta \times W \to W$
. Suppose that
$\mathtt{f}(\mathtt{x}^\mathtt{f}, \mathtt{w}) = T^\mathtt{f}$
is the recursive definition of
$\mathtt{f}$
in p. Then there exist t and s such that
$\rho \vdash T' \to t$
,
$[\rho,w] \vdash S \to s$
, and
$[\mathtt{x}^\mathtt{f} = t, \mathtt{w} = s] \vdash T^\mathtt{f} \to v$
, and there exists s’ such that
$[\rho,\varepsilon] \vdash S \to s'$
and
$[\mathtt{x}^\mathtt{f} = t, \mathtt{w} = s'] \vdash T^\mathtt{f} \to v'$
. By Lemma 2,
$\rho^ \unicode{x2020} \vdash (T')^ \unicode{x2020} \to t^ \unicode{x2020}$
. Since convergence is independent of the binding of
$\mathtt{w}$
, there exists a v” such that
$[\mathtt{x}^\mathtt{f} = t, \mathtt{w} = \varepsilon] \vdash T^\mathtt{f} \to v''$
.Now By induction,
$$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v\ \ \text{and}\ \ [\mathtt{x}^\mathtt{f} = t, \mathtt{w} = \varepsilon] \vdash T^\mathtt{f} \to v''.$$
Similarly,
$$\big( [(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \top \, \wedge \, v = v'' \big) \ \vee \ \big( [(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \bot \, \wedge \, v = v''s \big).$$
By induction,
$$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s'] \vdash T^\mathtt{f} \to v'\ \ \text{and}\ \ [\mathtt{x}^\mathtt{f} = t, \mathtt{w} = \varepsilon] \vdash T^\mathtt{f} \to v''.$$
First assume
$$\big( [(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \top \, \wedge \, v '= v'' \big) \, \vee\ \big( [(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \bot \, \wedge \, v' = v''s' \big).$$
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \top $
. Then,
$v = v'' = v'$
and (by definition of
$T^\diamond$
)
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
, which completes this case. Next assume then that
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\diamond (T^\mathtt{f}) ^\diamond \to \bot $
. In this case,
$v = v''s$
and
$v' = v''s'$
. Now Then by induction,
$$ [\rho,w] \vdash S \to s \ \ \text{and} \ \ [\rho,\varepsilon] \vdash S \to s'. $$
If
$$ \big( \rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \top \, \wedge \, s = s' \big) \ \vee \ \big( \rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \bot \, \wedge \, s = s'w \big). $$
$\rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \top $
, then
$v = v''s = v''s' = v'$
and
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
(by definition of
$T^\diamond$
). If, on the other hand,
$\rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \bot $
, then
$v = v''s = v''s'w = v'w$
and
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
(by definition of
$T^\diamond$
). This finishes the case that
$T \equiv \mathtt{f}(T',S)$
.
-
If
$T \equiv \mathtt{cons}(T',S)$
, then there are strings s and s’ and a character
$c \in 2$
such that
$[\rho,w] \vdash S \to s$
,
$[\rho,\varepsilon] \vdash S \to s'$
,
$v = cs$
, and
$v'= cs'$
. By induction, either
$\rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \top $
and
$s = s'$
or
$\rho^ \unicode{x2020} \vdash_\diamond S^\diamond \to \bot $
and
$s = s'w$
. In the first case,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
and
$v = cs = cs' = v'$
. In the second case,
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
and
$v = cs = cs'w = v'w$
.






















































Lemma (Lemma 4). For every RW program p of type
 $R \to W$
, RW term T from p of type W, strings x, v, and w, natural number
$R \to W$
, RW term T from p of type W, strings x, v, and w, natural number
 $n > |v|$
, and x-environment
$n > |v|$
, and x-environment
 $\rho$
binding
$\rho$
binding
 $\mathtt{w}$
to w:
$\mathtt{w}$
to w:
 $$ \rho \vdash_p T \to v \implies x,n,\rho^ \unicode{x2020} \vdash_{p^\ell} T^\ell \to v^\ell - \delta ,$$
$$ \rho \vdash_p T \to v \implies x,n,\rho^ \unicode{x2020} \vdash_{p^\ell} T^\ell \to v^\ell - \delta ,$$
where
 $\delta = 0$
if
$\delta = 0$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
 $\delta = |w|$
if
$\delta = |w|$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. Moreover, the derivation of the right-hand side is collision-free.
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
. Moreover, the derivation of the right-hand side is collision-free.
Proof Let
 $\rho \vdash T \to v$
abbreviate
$\rho \vdash T \to v$
abbreviate
 $\rho \vdash_p T \to v$
and
$\rho \vdash_p T \to v$
and
 $\rho \vdash_\ell T \to v$
abbreviate
$\rho \vdash_\ell T \to v$
abbreviate
 $x,n,\rho \vdash_{p^\ell} T \to v$
. The proof proceeds by induction on the derivation of
$x,n,\rho \vdash_{p^\ell} T \to v$
. The proof proceeds by induction on the derivation of
 $\rho \vdash T \to v$
and breaks up into cases depending on the form of T. To verify that the derivation is collision-free, we note that any time we add counting modules we do not introduce a new collision. Note that since
$\rho \vdash T \to v$
and breaks up into cases depending on the form of T. To verify that the derivation is collision-free, we note that any time we add counting modules we do not introduce a new collision. Note that since
 $p^\ell$
contains
$p^\ell$
contains
 $p^\diamond$
,
$p^\diamond$
,
 $\vdash_\ell$
extends
$\vdash_\ell$
extends
 $\vdash_\diamond$
.
$\vdash_\diamond$
.
-
If
$T \equiv \mathtt{w}$
, then
$v = w$
and
$v^\ell = |w|$
. Moreover,
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to \bot $
, so
$ \delta = |w|$
and
$v^\ell - \delta = 0$
. But in this case,
$T^\ell \equiv 0$
. -
If
$T \equiv \mathtt{nil}$
, then
$v = \varepsilon$
. Moreover,
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to \top $
, so
$\delta = \varepsilon$
and
$v^\ell - \delta = 0$
. But in this case,
$T^\ell \equiv 0$
as well. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, assume
$\rho \vdash T_0 \to \top $
(the case
$\bot$
is similar). By Lemma 2,
$\rho^ \unicode{x2020} \vdash_\ell T^ \unicode{x2020}_0 \to 1$
, so by definition of
$T^\diamond$
,
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to \top \iff \rho^ \unicode{x2020} \vdash_\ell T_1^\diamond \to \top $
. Therefore, the
$\delta$
associated with
$T_1$
is identical to the
$\delta$
associated with T, and we can simply say
$\delta$
unambiguously.























Since
 $\rho \vdash T_0 \to 1$
,
$\rho \vdash T_0 \to 1$
,
 $\rho \vdash T_1 \to v$
, so (by induction)
$\rho \vdash T_1 \to v$
, so (by induction)
 $\rho^ \unicode{x2020} \vdash_\ell T^\ell_1 \to v^\ell - \delta$
. Since
$\rho^ \unicode{x2020} \vdash_\ell T^\ell_1 \to v^\ell - \delta$
. Since
 $\rho^ \unicode{x2020} \vdash_\ell T^ \unicode{x2020}_0 \to \top $
,
$\rho^ \unicode{x2020} \vdash_\ell T^ \unicode{x2020}_0 \to \top $
,
 $\rho^ \unicode{x2020} \vdash_\ell T^\ell \to v^\ell - \delta$
by definition of
$\rho^ \unicode{x2020} \vdash_\ell T^\ell \to v^\ell - \delta$
by definition of
 $T^\ell$
.
$T^\ell$
.
-
If
$T \equiv \mathtt{f}(T')$
, let
$\mathtt{f}(\mathtt{x}^\mathtt{f}, \mathtt{w}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. There exists a value t such that
$\rho \vdash T' \to t$
and
$[\mathtt{x}^\mathtt{f} = t] \vdash T^\mathtt{f} \to v$
. By induction,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\ell (T^\mathtt{f}) ^\ell \to v^\ell$
. Hence,
$\rho^ \unicode{x2020} \vdash_\ell \mathtt{f}^\ell((T')^ \unicode{x2020}) \to v^\ell$
, and
$\rho^ \unicode{x2020} \vdash_\ell T^\ell \to v^\ell$
. (In this case,
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to \top $
.) -
If
$T \equiv \mathtt{f}(T',S)$
, let
$\mathtt{f}(\mathtt{x}^\mathtt{f}, \mathtt{w}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. There exist values t and s such that
$\rho \vdash T' \to t$
,
$ \rho \vdash S \to s$
, and
$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v$
.Let us first suppose that
$\rho^ \unicode{x2020} \vdash_\diamond \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \top $
. By Lemma 2,
$\rho^ \unicode{x2020} \vdash_\ell (T')^ \unicode{x2020} \to t^ \unicode{x2020}$
. Since the recursive definition of
$\mathtt{f}^\diamond$
is
$\mathtt{f}^\diamond((\mathtt{x}^\mathtt{f}) ^ \unicode{x2020}) = (T^\mathtt{f}) ^\diamond$
, we have that
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\ell (T^\mathtt{f}) ^\diamond \to \top $
. By induction,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\ell (T^\mathtt{f}) ^\ell \to v^\ell$
; hence,
$\rho^ \unicode{x2020} \vdash_\ell \mathtt{f}^\ell((T')^ \unicode{x2020}) \to v^\ell$
. By definition of
$T^\ell$
,
$\rho^ \unicode{x2020} \vdash_\ell T^\ell \to v^\ell$
, which is what we wanted to show. Now suppose that
$\rho^ \unicode{x2020} \vdash_\diamond \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \bot $
. By definition of
$T^\diamond$
,
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to b$
iff
$\rho^ \unicode{x2020} \vdash_\ell S^\diamond \to b$
for both boolean values b. Therefore, since
$\mathtt{w}$
is bound to the same value (w) in S as in T, the value of
$\delta$
can be used unambiguously in both the inductive hypothesis at S and the conclusion at T. Moreover,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\ell (T^\mathtt{f}) ^\diamond \to \bot $
. Thus, by the inductive hypothesis applied to
$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v$
,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_\ell (T^\mathtt{f}) ^\ell \to v^\ell - |s|$
, and therefore,
$\rho^ \unicode{x2020} \vdash_\ell \mathtt{f}^\ell((T')^ \unicode{x2020}) \to v^\ell - |s|$
. By the inductive hypothesis at
$\rho \vdash S \to s$
,
$\rho^ \unicode{x2020} \vdash_\ell S^\ell \to s^\ell - \delta$
. As
$s^\ell = |s|$
,
$\rho^ \unicode{x2020} \vdash_\ell \mathtt{f}^\ell(T^ \unicode{x2020}) + S^\ell \to v^\ell - \delta$
. (Note that this uses the assumption that
$n > |v|$
, which also verifies that this addition does not introduce a new collision.) Finally, since
$\rho^ \unicode{x2020} \vdash_\diamond \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \bot $
and by definition of
$T^\ell$
,
$\rho^ \unicode{x2020} \vdash_\ell T^\ell \to v^\ell - \delta$
, which is what we wanted to show. -
If
$T \equiv \mathtt{cons}(T',S)$
, then there exists a character
$c \in 2$
and a string s such that
$\rho \vdash T' \to b$
,
$\rho \vdash S \to s$
, and
$v = cs$
. As in the previous case, the values of
$\delta$
at S and T are identical. By induction,
$\rho^ \unicode{x2020} \vdash_\ell S^\ell \to |s| - \delta$
, so
$\rho^ \unicode{x2020} \vdash_\ell T^\ell \to |s|+1 - \delta$
, which is
$|v| - \delta$
. (We again use the assumption that
$n > |v|$
here, which again verifies that this addition does not introduce a new collision.)




















































Lemma (Lemma 5) For every RW program p of type
 $R \to W$
, RW term T from p of type W, strings x, w and v, natural numbers
$R \to W$
, RW term T from p of type W, strings x, w and v, natural numbers
 $n > |v|$
and
$n > |v|$
and
 $1 \le c \le |v| - \delta$
, and x-environment
$1 \le c \le |v| - \delta$
, and x-environment
 $\rho$
binding
$\rho$
binding
 $\mathtt{w}$
to w,
$\mathtt{w}$
to w,
 $$ \rho \vdash_p T \to v \implies x,n, \rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to v_{c + \delta},$$
$$ \rho \vdash_p T \to v \implies x,n, \rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to v_{c + \delta},$$
where
 $\delta = 0$
if
$\delta = 0$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \top $
or
 $\delta = |w|$
if
$\delta = |w|$
if
 $\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
.
Footnote 20
Moreover, the computation on the right-hand side is without collisions.
$\rho^ \unicode{x2020} \vdash_\diamond T^\diamond \to \bot $
.
Footnote 20
Moreover, the computation on the right-hand side is without collisions.
Proof Let
 $\rho \vdash T \to v$
abbreviate
$\rho \vdash T \to v$
abbreviate
 $\rho \vdash_p T \to v$
and
$\rho \vdash_p T \to v$
and
 $ [\rho^ \unicode{x2020},c] \vdash_b T^b \to a$
abbreviate
$ [\rho^ \unicode{x2020},c] \vdash_b T^b \to a$
abbreviate
 $x, n ,\rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to a$
. The proof is by induction on the size of the derivation of
$x, n ,\rho^ \unicode{x2020} , [\mathtt{c} = c] \vdash_{p^b} T^b \to a$
. The proof is by induction on the size of the derivation of
 $\rho \vdash T \to v$
and breaks up into cases depending on the form of T.
$\rho \vdash T \to v$
and breaks up into cases depending on the form of T.
-
If
$T \equiv \mathtt{w}$
or
$T \equiv \mathtt{nil}$
, then
$|v| - \delta = 0$
, so the universal quantification over c is empty and the conclusion is vacuously true. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then suppose
$\rho \vdash T_0 \to \top $
(the case
$\rho \vdash T_0 \to \bot $
is similar). Then
$\rho \vdash T_1 \to v$
. By Lemma 2,
$\rho^ \unicode{x2020} \vdash_\ell T_0^ \unicode{x2020} \to \top $
, and hence
$\rho^ \unicode{x2020} \vdash_\ell T^\diamond \to b$
if and only if
$\rho^ \unicode{x2020} \vdash_\ell T_1^\diamond \to b$
.Let us apply the induction hypothesis to
$\rho \vdash T_1 \to v$
. The value of
$\delta$
at the induction hypothesis is identical to the value of
$\delta$
for
$\rho \vdash T \to v$
, so by induction
$[\rho^ \unicode{x2020},c] \vdash_b T^b_1 \to v_{c + \delta}$
, and by definition of
$T^b$
,
$[\rho^ \unicode{x2020},c] \vdash_b T^b \to v_{c + \delta}$
. -
If
$T \equiv \mathtt{f}(T')$
, let
$\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. Then, there exists a value t such that
$\rho \vdash T' \to t$
and
$[\mathtt{x}^\mathtt{f} = t] \vdash T^\mathtt{f} \to v$
. In this case,
$\rho^ \unicode{x2020} \vdash T^\diamond \to \top $
, so
$\delta = 0.$
By Lemma 2,
$\rho^ \unicode{x2020} \vdash_b (T')^ \unicode{x2020} \to t^ \unicode{x2020}$
.Since
$[\mathtt{x}^\mathrm{f}=t] \vdash T^\mathtt{f} \to v$
,
$[\mathtt{x}^\mathtt{f} = t, \mathtt{w} = \varepsilon] \vdash T^\mathtt{f} \to v$
. By induction on the latter,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020},\mathtt{c} = c] \vdash_b (T^\mathtt{f}) ^b \to v_c$
. (Notice that the denotation of
$(T^\mathtt{f}) ^\diamond$
is irrelevant if
$|\mathtt{w}|=0$
.) Hence,
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{f}((T')^ \unicode{x2020},\mathtt{c}) \to v_c$
, i.e.,
$[\rho^ \unicode{x2020},c] \vdash_b T^b \to v_c$
. -
If
$T \equiv \mathtt{f}(T',S)$
, let
$\mathtt{f}(\mathtt{x},\mathtt{w}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. Then, there are values (t,s) such that
$\rho \vdash T' \to s$
,
$\rho \vdash S \to s$
, and
$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v$
.First let us suppose that
$\rho^ \unicode{x2020} \vdash \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \top $
. In this case,
$\rho^ \unicode{x2020} \vdash_b T^\diamond \to \top $
, so
$\delta = 0$
. Moreover,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}] \vdash_b (T^\mathtt{f}) ^\diamond \to \top $
, so by induction applied to
$T^\mathtt{f}$
,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020} = t^ \unicode{x2020}, \mathtt{c} = c] \vdash_b (T^\mathtt{f}) ^b \to v_c$
, and hence,
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c}) \to v_c$
. But by definition of
$T^b$
,
$[\rho^ \unicode{x2020},c] \vdash_b T^b \to v_c$
.Next let us suppose that
$\rho^ \unicode{x2020} \vdash \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \bot $
. In this case,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020}] \vdash_b (T^\mathtt{f}) ^\diamond \to \bot $
, and the denotation of
$T^\diamond$
is equivalent to that of
$S^\diamond$
. Since it is the same environment
$\rho$
at T and S as well, the value of
$\delta = |\rho(\mathtt{w})|$
is identical at both S and T. Therefore, by induction applied to
$\rho \vdash S \to s$
,
$[\rho^ \unicode{x2020},c] \vdash_b S^b \to s_{c+\delta}$
for any
$1 \le c \le |s| - \delta$
. By Lemma 3, since
$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v$
, s appears as a suffix of v, and hence for
$1 \le c \le s - |\delta|$
,
$s_{c+\delta} = v_{c + \delta}$
. Hence for any
$1 \le c \le |s| - \delta$
,
$[\rho^ \unicode{x2020},c] \vdash_b S^b \to v_{c + \delta}$
.By induction applied to
$[\mathtt{x}^\mathtt{f} = t,\mathtt{w} = s] \vdash T^\mathtt{f} \to v$
,
$[(\mathtt{x}^\mathtt{f}) ^ \unicode{x2020},\mathtt{c} = c] \vdash_b (T^\mathtt{f}) ^b \to v_{c + |s|}$
, and hence
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c}) \to v_{c + |s|}$
, for any
$1 \le c \le |v| - |s|$
. Said another way, for any
$|s| - \delta + 1 \le c \le |v| - \delta$
,
$[\rho^ \unicode{x2020},c - |s| + \delta] \vdash_b \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c}) \to v_{c + \delta}$
. By Lemma 4,
$\rho^ \unicode{x2020} \vdash_b S^\ell \to |s| - \delta$
. Hence for any
$|s| - \delta + 1 \le c \le |v| - \delta$
,
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c} - S^\ell) \to v_{c + \delta}$
.Since
$\rho^ \unicode{x2020} \vdash_b S^\ell \to |s| - \delta$
,
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{c} \le S^\ell \to \top $
just in case
$c \le |s| - \delta$
, otherwise
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{c} \le S^\ell \to \bot $
. We have now shown that for all
$1 \le c \le |v| - \delta$
, Since we are in the case
$$ [\rho^ \unicode{x2020},c] \vdash_b \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ \mathtt{f}^b((T')^ \unicode{x2020},\mathtt{c} - S^\ell) \to v_{c + \delta}.$$
$\rho^ \unicode{x2020} \vdash \mathtt{f}^\diamond((T')^ \unicode{x2020}) \to \bot $
, we have now shown that
$[\rho^ \unicode{x2020},c] \vdash_b T^b \to v_{c + \delta}$
, which is what we wanted to show.
-
If
$T \equiv \mathtt{cons}(T',S)$
, then
$T^\diamond$
and
$S^\diamond$
are identical, so we can use
$\delta$
unambiguously at both T and S as in the previous case. Let
$\rho \vdash S \to s$
. By induction, for any
$1 \le c \le |s| - \delta$
,
$[\rho^ \unicode{x2020},c] \vdash S^b \to v_{c + \delta}$
. If
$c = |v| - \delta$
, then
$v_{c + \delta}$
is the first character of v, so
$\rho \vdash T' \to v_{c + \delta}$
. By Lemma 2,
$\rho^ \unicode{x2020} \vdash T' \to v_{c + \delta}$
(
$v_{c+\delta} = v^ \unicode{x2020}_{c+\delta}$
as it is a boolean value). Since
$|v| - \delta = (|s| - \delta) + 1$
and
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{c} \le S^\ell \to \top $
if and only if
$c \le |s| - \delta$
, otherwise
$[\rho^ \unicode{x2020},c] \vdash_b \mathtt{c} \le S^\ell \to \bot $
, then for any
$1 \le c \le |v| - \delta$
, hence
$$ [\rho^ \unicode{x2020},c] \vdash_b \mathtt{if}\ \mathtt{c} \le S^\ell\ \mathtt{then}\ S^b\ \mathtt{else}\ (T')^ \unicode{x2020} \to v_{c+\delta};$$
$[\rho^ \unicode{x2020},c] \vdash_b T^b \to v_{c+\delta}$
, which is what we wanted to show.

































































































That there are no collisions stems from the fact that the transformation
 $T \mapsto T^b$
introduces no new occurrences of counting module addition that were not already contained in the transformation
$T \mapsto T^b$
introduces no new occurrences of counting module addition that were not already contained in the transformation
 $T \mapsto T^\ell$
.
$T \mapsto T^\ell$
.
Lemma (Lemma 6). For any cons-free program with global input p, values x u, and v, variable
 $\mathtt{x}$
, and
$\mathtt{x}$
, and
 $\mathtt{x}$
-term T,
$\mathtt{x}$
-term T,
 $$ x,[\mathtt{x} = u] \vdash T \to v \implies [\mathtt{x}_R = u \circ x] \vdash T^\mathtt{x}_R \to v .$$
$$ x,[\mathtt{x} = u] \vdash T \to v \implies [\mathtt{x}_R = u \circ x] \vdash T^\mathtt{x}_R \to v .$$
Proof. As usual, the proof proceeds by induction on the size of the derivation of the hypothesis and breaks up into cases according to the form of T. Let us abbreviate
 $T^\mathtt{x}_R$
by
$T^\mathtt{x}_R$
by
 $T_R$
.
$T_R$
.
-
If
$T \equiv \mathtt{x}$
, then
$v = u$
, and
$[\mathtt{x}_R = u \circ x] \vdash \mathtt{x}_R[0,n-1] \to u$
. -
If
$T \equiv \mathtt{in}$
, then
$v = x$
, and
$[\mathtt{x}_R = u \circ x] \vdash \mathtt{x}_R[n] \to x$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, suppose that
$x,[\mathrm{x}=u] \vdash T_0 \to \top $
. (The case
$x,[\mathrm{x}=u] \vdash T_0 \to \bot $
is similar.) Then,
$x,[\mathrm{x}=u]\vdash T_1 \to v$
, so by induction,
$[\mathtt{x}_R = u \circ x]\vdash (T_0)_R \to \top $
and
$[\mathtt{x}_R = u\circ x] \vdash (T_1)_R \to v$
. Therefore,
$[\mathtt{x}_R = u \circ x] \vdash T_R \to v$
.Suppose that
$T \equiv \varphi(S)$
, where
$\varphi \in \{\mathtt{hd},\mathtt{tl},\mathtt{null}\}$
. Then, there exists some v’ such that
$x,[\mathrm{x}=u]\vdash S \to v'$
and
$\varphi(v')=v$
. By induction,
$[\mathtt{x}_R = u \circ x] \vdash S_R \to v'$
. Therefore,
$[\mathtt{x}_R = u \circ x ] \vdash T_R \to v$
.Suppose that
$T \equiv T_0 \oplus \dots \oplus T_{n-1}$
. Then, there exist
$v_0,\dots,v_{n-1}$
such that
$x,[\mathrm{x}=u] \vdash T_i \to v_i$
for each
$i < n$
and
$v = v_0 \circ \dots \circ v_{n-1}$
. By induction, for each
$i<n$
,
$[\mathtt{x}_R = u \circ x] \vdash T_i \to v_i$
, so
$[\mathtt{x}_R = u \circ x] \vdash T \to v$
. -
If
$T \equiv S[i,j]$
, there is some v’ such that
$x,[\mathrm{x}=u] \vdash S \to v'$
. Let
$(v_0,\dots,v_{n-1})$
be a decomposition of v’ into a tuple of atomic values; then,
$v = (v_i,\dots,v_j)$
. By induction,
$[\mathtt{x}_R = u \circ x] \vdash S_R \to (v_0,\dots,v_{n-1})$
, so
$[\mathtt{x}_R = u \circ x] \vdash S_R[i,j] \to (v_i,\dots,v_j)$
, i.e.,
$[\mathtt{x}_R = u \circ x]\vdash T_R \to v$
.Finally, suppose
$T \equiv \mathtt{f}(S)$
. Let
$\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
be the definition of
$\mathtt{f}$
in p. Then, there is some v’ such that
$x,[\mathrm{x}=u]\vdash S \to v'$
and
$x,[\mathtt{x}^\mathtt{f} = v'] \vdash T^\mathtt{f} \to v$
. By induction,
$[\mathtt{x}_R = u \circ x] \vdash S_R \to v'$
and
$[\mathtt{x}^\mathtt{f}_R = v' \circ x] \vdash (T^\mathtt{f}) ^{\mathtt{x}^\mathrm{f}}_R \to v$
. Since
$[\mathtt{x}_R = u \circ x] \vdash S_R \to v'$
,
$[\mathtt{x}_R = u \circ x] \vdash S_R \oplus \mathtt{x}_R[n] \to v' \circ x$
.But
$\mathtt{f}_R(\mathtt{x}^\mathtt{f}_R) = (T^\mathtt{f}) ^{\mathtt{x}^\mathrm{f}}_R$
is the recursive definition of
$\mathtt{f}_R$
in
$p_R$
. Hence,
$[\mathtt{x}_R = u \circ x] \vdash \mathtt{f}_R(S_R \oplus \mathtt{x}_R[n]) \to v$
, which is what we wanted to prove.















































Lemma (Lemma 7). For every bit-length program p, bit-length term T from p, string x, x-environment
 $\rho$
, and value v,
$\rho$
, and value v,
 $$ x, (|x|+1)^k, \rho \vdash_p T \to v \implies x, \rho^\unicode{x2021} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}.$$
$$ x, (|x|+1)^k, \rho \vdash_p T \to v \implies x, \rho^\unicode{x2021} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}.$$
Proof The proof is by induction on the length of
 $x, (|x|+1)^k, \rho \vdash_p T \to v$
and then breaks up into cases depending on the form of T. Abbreviate
$x, (|x|+1)^k, \rho \vdash_p T \to v$
and then breaks up into cases depending on the form of T. Abbreviate
 $x, (|x|+1)^k, \rho \vdash_p T \to v$
by
$x, (|x|+1)^k, \rho \vdash_p T \to v$
by
 $\rho \vdash T \to v$
and
$\rho \vdash T \to v$
and
 $x, \rho^ \unicode{x2020} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}$
by
$x, \rho^ \unicode{x2020} \vdash_{p^\unicode{x2021}} T^\unicode{x2021} \to v^\unicode{x2021}$
by
 $\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
.
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
.
-
If
$T \equiv \mathtt{true} $
or
$\mathtt{false,}$
, then
$v = v^\unicode{x2021} = \top$
or
$\bot$
, and
$T^\unicode{x2021} \equiv \mathtt{true} $
or
$\mathtt{false,}$
respectively. -
If
$T \equiv \mathtt{x}$
, then
$v = \rho(x)$
, so
$v^\unicode{x2021} = \rho^\unicode{x2021}(\mathtt{x}^\unicode{x2021})$
,
$T^\unicode{x2021} \equiv \mathtt{x}^\unicode{x2021}$
, and
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{0}$
then
$v = 0$
(as a counting module),
$v^\unicode{x2021} = (0,\dots,0,0)$
(as an element of
$R^k$
), and
$T^\unicode{x2021} \equiv \mathtt{zero}$
. By correctness of
$\mathtt{zero}$
,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
.The case
$T \equiv \mathtt{1}$
is similar to the previous one, replacing
$(0,\dots,0,0)$
by
$(0,\dots,0,1)$
and
$\mathtt{zero}$
by
$\mathtt{one}$
. -
If
$T \equiv T_0 + T_1,$
then
$T^\unicode{x2021} \equiv \mathtt{add}(T_0^\unicode{x2021},T_1^\unicode{x2021})$
. By induction, there exist
$u_0$
and
$u_1$
such that
$\rho \vdash T_i \to u_i$
for
$i < 2$
and
$v = \max\{ u_0 + u_1, (|x|+1)^k -1\}$
. By induction,
$\rho^\unicode{x2021} \vdash T_i^\unicode{x2021} \to u_i^\unicode{x2021}$
for
$i < 2$
. By correctness of
$\mathtt{add}$
,
$[\mathtt{u}_0 = u_0^\unicode{x2021},\mathtt{u} = u_1^\unicode{x2021}] \vdash \mathtt{add}(\mathtt{u}_0,\mathtt{u}_1) \to v^\unicode{x2021}$
. Hence,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
.The cases
$T \equiv T_0 - T_1$
and
$T \equiv T_0 \le T_1$
are similar to the previous one, by the correctness of
$\mathtt{minus}$
and
$\mathtt{less}$
respectively. -
If
$T \equiv \mathtt{min}$
, then
$v=0$
(as an index),
$v^\unicode{x2021} = \varepsilon$
, and
$T^\unicode{x2021} = \mathtt{zero}_I$
. By correctness of
$\mathtt{zero}_I$
,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{max,}$
then
$v = |x|$
,
$v^\unicode{x2021} = x$
,
$T^\unicode{x2021} \equiv \mathtt{in}$
, so
$x,\rho^\unicode{x2021} \vdash \mathtt{in} \to x$
implies
$x,\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{P}(S),$
then there exists some u such that
$\rho \vdash S \to u$
and
$u - 1 = v$
. In this case,
$v^\unicode{x2021}$
is the tail of
$u^\unicode{x2021}$
; by induction,
$\rho^\unicode{x2021} \vdash S^\unicode{x2021} \to u^\unicode{x2021}$
, and thus,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{null}(S),$
then there exists some u such that
$\rho \vdash S \to u$
and
$v = \mathtt{true} \iff u = 0$
. In this case
$v^\unicode{x2021} = v$
and
$u^\unicode{x2021} = \varepsilon \iff u = 0$
; by induction,
$\rho^\unicode{x2021} \vdash S^\unicode{x2021} \to u^\unicode{x2021}$
, and thus
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{bit}(S),$
then there exists some u such that
$\rho \vdash S \to u$
and
$x_u = v$
. In this case,
$v^\unicode{x2021} = v$
and
$u^\unicode{x2021}$
is a suffix of x with head
$x_u = v = v^\unicode{x2021}$
; by induction,
$\rho^\unicode{x2021} \vdash S^\unicode{x2021} \to u^\unicode{x2021}$
, and thus,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv T_0 \oplus \dots \oplus T_{n-1,}$
then there exist
$v_0 ,\dots,v_{n-1}$
such that
$\rho \vdash T_i \to v_i$
for each
$i < n$
; by induction,
$\rho^\unicode{x2021} \vdash T_i^\unicode{x2021} \to v_i^\unicode{x2021}$
and
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v_0^\unicode{x2021} \circ \dots \circ v_{n-1}^\unicode{x2021}$
. But this is exactly
$v^\unicode{x2021}$
. -
If
$T \equiv S[i,j]$
, then there exists a u such that
$\rho \vdash S \to u$
. Let
$(u_0,\dots,u_{m-1})$
be a decomposition of u into atomic values; then
$v = u_i \circ \dots u_j$
. Now
$\rho^\unicode{x2021} \vdash S^\unicode{x2021} \to u^\unicode{x2021}$
by induction, and
$u^\unicode{x2021} = u_0^\unicode{x2021} \circ \dots \circ u_{m-1}^\unicode{x2021}$
. Suppose that
$(t_0,\dots,t_{n-1})$
is a decomposition of
$u^\unicode{x2021}$
into atomic values. By definition of
$s_\alpha$
, where
$\alpha$
is the type of S,
$t_\imath \circ \dots \circ t_\jmath = u_i^\unicode{x2021} \circ \dots u_j^\unicode{x2021} = v^\unicode{x2021}$
. Hence,
$\rho^\unicode{x2021} S^\unicode{x2021}[\imath,\jmath] \to v^\unicode{x2021}$
, which is what we wanted to show. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then suppose that
$\rho \vdash T_0 \to \top $
. (The case
$\rho \vdash T_0 \to \bot $
is similar.) Then,
$\rho \vdash T_1 \to v$
. By induction,
$\rho^\unicode{x2021} T_0^\unicode{x2021} \to \top $
and
$\rho^\unicode{x2021} \vdash T_1^\unicode{x2021} \to v^\unicode{x2021}$
; hence,
$\rho^\unicode{x2021} \vdash T^\unicode{x2021} \to v^\unicode{x2021}$
. -
If
$T \equiv \mathtt{f}(S)$
, let
$\mathtt{f}(\mathtt{x}^\mathtt{f}) = T^\mathtt{f}$
be the recursive definition of
$\mathtt{f}$
in p. Then, there exists a u such that
$\rho \vdash S \to u$
and
$[\mathtt{x}^\mathtt{f} = u] \vdash T^\mathtt{f} \to v$
. By induction
$\rho^\unicode{x2021} \vdash S^\unicode{x2021} \to u^\unicode{x2021}$
and
$[(\mathtt{x}^\mathtt{f}) ^\unicode{x2021} = u^\unicode{x2021}] \vdash (T^\mathtt{f}) ^\unicode{x2021} \to v^\unicode{x2021}$
. Since
$\mathtt{f}^\unicode{x2021}((\mathtt{x}^\mathtt{f}) ^\unicode{x2021}) = (T^\mathtt{f}) ^\unicode{x2021}$
is the definition of
$\mathtt{f}^\unicode{x2021}$
in
$p^\unicode{x2021}$
,
$\rho^\unicode{x2021} \vdash \mathtt{f}^\unicode{x2021}(S^\unicode{x2021}) \to v^\unicode{x2021}$
.














































































































Lemma (Lemma 8). For any program p, environment
 $\rho$
, string x, term T, and value v,
$\rho$
, string x, term T, and value v,
 $$ g(x), \lambda_f(|g(x)|) , \rho \vdash_p T \to v \implies x, \mu(|x|) , \rho_g \vdash_{p_{(g)}} T_g \to v_g,$$
$$ g(x), \lambda_f(|g(x)|) , \rho \vdash_p T \to v \implies x, \mu(|x|) , \rho_g \vdash_{p_{(g)}} T_g \to v_g,$$
without collisions, if the derivation of the left-hand side has no collisions.
Proof For legibility, we will abbreviate
 $g(x),\lambda_f(|g(x)|),\rho \vdash_p$
by
$g(x),\lambda_f(|g(x)|),\rho \vdash_p$
by
 $\rho \vdash$
and
$\rho \vdash$
and
 $x,\mu(|x|),\rho_g \vdash_{p_{(g)}}$
by
$x,\mu(|x|),\rho_g \vdash_{p_{(g)}}$
by
 $\rho_g \vdash_g$
. The proof proceeds by induction on the size of the derivation of
$\rho_g \vdash_g$
. The proof proceeds by induction on the size of the derivation of
 $\rho \vdash T \to v$
and is broken into cases depending on the form of T.
$\rho \vdash T \to v$
and is broken into cases depending on the form of T.
-
If
$T \equiv \mathtt{x}$
, a single variable, then
$T_g \equiv \mathtt{x}_g$
, and
$v = \rho(\mathtt{x})$
, so
$v_g = \rho(\mathtt{x}_g)$
. Hence,
$\rho_g \vdash_g T_g \to v_g$
. -
If
$T \equiv \mathtt{f}(T')$
, let
$\mathtt{f}(\mathtt{x}) = T^\mathtt{f}$
be the recursive definition of
$\mathtt{f}$
in p. Then, there exists a w such that
$ \rho \vdash T' \to w$
and
$ [\mathtt{x} = w] \vdash T^\mathtt{f} \to v$
. By induction,
$\rho_g \vdash_g T'_g \to w_g$
and
$[\mathtt{x}_g = w_g] \vdash T^\mathtt{f}_g \to v_g$
.But
$\mathtt{f}_g(\mathtt{x}_g) = T^\mathtt{f}_g$
is the recursive definition of
$\mathtt{f}_g$
in
$p_g$
. Hence,
$\rho_g \vdash_g \mathtt{f}_g(T'_g) \to v_g$
. But
$T_g \equiv \mathtt{f}_g(T'_g)$
, so
$\rho_g \vdash_g T_g \to v_g$
. -
If
$T \equiv \mathtt{true}$
,
$\mathtt{false,}$
,
$\mathtt{0}$
, or
$\mathtt{1}$
, then the conclusion is immediate. -
If
$T \equiv \varphi(T_0,T_1)$
, for
$\varphi \in \{+,-,\le\}$
, then there exists
$v_0,v_1$
, such that
$\rho \vdash T_i \to v_i$
for
$i < 2$
and
$\varphi(v_0,v_1) = v$
in
$C(\lambda_f(|g(x)|))$
. Since, by assumption, there are no collisions,
$\varphi(v_0,v_1) = v$
in
$C(\mu(|x|))$
. Note that
$v_i = (v_i)_g$
and
$v = v_g$
, when we identify
$C(\lambda_f(|g(x)|))$
as a subset of
$C(\mu(|x|))$
.By induction,
$\rho_g \vdash_g (T_i)_g \to (v_i)_g$
. Since
$T_g \equiv \varphi((T_0)_g,(T_1)_g)$
,
$\rho_g \vdash T_g \to v_g$
. Since
$C(\mu(|x|))$
contains
$C(\lambda_f(|g(x)|)$
, no new collisions are introduced. -
If
$T \equiv \mathtt{min}$
, then v is the index 0, so
$T_g \equiv 0$
, and
$v_g$
is
$0 \in C(\mu(|x|))$
. Hence,
$\rho_g \vdash_g T_g \to v_g$
. -
If
$T \equiv \mathtt{max}$
, then v is the index
$|g(x)|$
, so
$v_g = |g(x)| \in C(\mu(|x|))$
.Since
$x,\lambda_g(|x|) \vdash_{q_g} \mathtt{h}_q \to |g(x)|$
with no collisions,
$x, \mu(|x|) \vdash_{q_g} \mathtt{h}_q \to |g(x)|$
. Since
$q_g$
is a fragment of
$p_g$
,
$x, \mu(|x|) \vdash_{p_g} \mathtt{h}_q \to |g(x)|$
, i.e.,
$\vdash_g \mathtt{h}_q \to |g(x)|$
. Hence,
$\vdash_g \mathtt{h}_q \to v_g$
, but
$T_g \equiv \mathtt{h}_q $
, so
$\vdash_g T_g \to v_g$
. -
If
$T \equiv \varphi(T')$
for
$\varphi \in \{\mathtt{P},\mathtt{null}\}$
, then there exists an index w of g(x) such that
$\rho \vdash T' \to w$
and
$v = \varphi(w)$
. By induction, there exists some
$w_g \in C(\mu(|x|))$
such that
$v_g = w_g -1$
(if
$\varphi = \mathtt{P}$
) or
$v_g \iff w_g =0$
(if
$\varphi = \mathtt{null}$
), and
$\rho_g \vdash_g T'_g \to w_g$
. In the former case,
$\rho_g \vdash_g T'_g - 1 \to v_g$
and in the latter,
$\rho_g \vdash_g (T'_g) \to v_g$
; in either case,
$\rho_g \vdash T_g \to v_g$
.If
$T \equiv \mathtt{bit}(T')$
, then there is some w such that
$\rho \vdash T' \to w$
and
$(g(x))_{w-1} = v$
. Notice that
$v_g = v$
and
$w_g$
is natural number equivalent to w in the counting module
$C(\mu(|x|))$
. If we identify
$C(\lambda_g(|x|))$
as a subtype of
$ C(\mu(|x|))$
,
$w_g$
becomes a member of
$C(\lambda_g(|x| ))$
too. Then, moreover with no collisions. Hence,
$$x,\lambda_g(|x|),[\mathtt{c} = w_g] \vdash_{p_g} \mathtt{h}_p(\mathtt{c}) \to v,$$
and therefore
$$x,\mu(|x|),[\mathtt{c} = w_g] \vdash_{p_g} \mathtt{h}_p(\mathtt{c}) \to v,$$
$[\mathtt{c} = w_g] \vdash_g \mathtt{h}_p(\mathtt{c}) \to v$
.By induction,
$\rho_g \vdash T'_g \to w_g$
. Hence,
$\rho_g \vdash \mathtt{h}_p(T'_g) \to v$
; as
$T_g \equiv \mathtt{h}_p(T'_g)$
and
$v = v_g$
, this is what we wanted to show.
-
If
$T \equiv (T_0,\dots,T_{n-1})$
, then
$v = (v_0,\dots,v_{n-1})$
, where
$\rho \vdash T_i \to v_i$
. By induction,
$\rho_g \vdash (T_i)_g \to (v_i)_g$
, and
$\rho_g \vdash T_g \to v_g$
, as
$T_g \equiv ((T_0)_g,\dots,(T_{n-1})_g)$
and
$v_g = ((v_0)_g,\dots,(v_{n-1})_g)$
. -
If
$T \equiv T'[i]$
, then there exists some
$(v_0,\dots,v_{n-1})$
such that
$v = v_i$
and
$\rho \vdash T' \to (v_0,\dots,v_{n-1})$
. By induction,
$\rho_g \vdash_g T'_g \to ((v_0)_g,\dots,(v_{n-1})_g)$
, and therefore,
$\rho_g \vdash_g T_g \to (v_i)_g$
. -
If
$T \equiv \mathtt{if}\ T_0\ \mathtt{then}\ T_1\ \mathtt{else}\ T_2$
, then there exists some
$b \in 2$
such that
$\rho \vdash T_0 \to b$
and
$\rho \vdash T_b \to v$
. By induction,
$\rho_g \vdash_g (T_0)_g \to b$
(as
$b = b_g$
) and
$\rho_g \vdash (T_b)_g \to v_g$
. Therefore, since
$T_g \equiv \mathtt{if}\ (T_0)_g \ \mathtt{then}\ (T_1)_g\ \mathtt{else}\ (T_2)_g$
,
$\rho_g \vdash T_g \to v_g$
.













































































































Appendix B: Bit-length programs and Turing machines
In this section, we sketch a proof of Theorem 2. We split the recursive/polynomial time correspondence and the tail-recursive/logarithmic space correspondence into two different parts, as they require different constructions. We try to give just enough detail so that these are perspicuous and unburdened by excess notation.
Theorem. For any function
 $f : 2^\star \to 1^\star$
, the following are equivalent:
$f : 2^\star \to 1^\star$
, the following are equivalent:
-
f is computable in polynomial time.
-
There is a polynomially bounded
$\lambda : \omega \to \omega$
and a bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
$x \in 2^\star$
.For any function
$f : 2^\star \times 1^\star \to 2$
and polynomially bounded function
$\pi : \omega \to \omega$
, the following are equivalent:
-
There is a polynomial-time computable function
$g : 2^\star \times 1^\star \to 2$
such that
$g(x,y) = f(x,y)$
for any string
$x \in 2^\star$
and
$y < \pi(|x|)$
. -
There is a polynomially bounded function
$\lambda : \omega \to \omega$
and a bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = f(x,y)$
, without collisions, for any
$x \in 2^\star$
and
$y \le \pi(|x|)$
.













Proof Let f be a function of type
 $2^\star \times (1^\star)^k \to \alpha$
for some
$2^\star \times (1^\star)^k \to \alpha$
for some
 $k \in \omega$
and
$k \in \omega$
and
 $\alpha \in \{1^\star,2\}$
. (This generalizes both cases above.) Suppose that f is computable in polynomial time, and let
$\alpha \in \{1^\star,2\}$
. (This generalizes both cases above.) Suppose that f is computable in polynomial time, and let
 $\mathcal{M} $
be a Turing machine witnessing as much. We may assume that
$\mathcal{M} $
be a Turing machine witnessing as much. We may assume that
 $\mathcal{M}$
has read-only input tapes, a one-way write-only output tape if the output alphabet is
$\mathcal{M}$
has read-only input tapes, a one-way write-only output tape if the output alphabet is
 $1^\star$
, and any finite number of work tapes, each with tape alphabet
$1^\star$
, and any finite number of work tapes, each with tape alphabet
 $\Sigma$
containing a blank character. All tapes of
$\Sigma$
containing a blank character. All tapes of
 $\mathcal{M}$
extend infinitely to the right; the heads of
$\mathcal{M}$
extend infinitely to the right; the heads of
 $\mathcal{M}$
are initialized to the left; the work and output tapes are initialized to all blank.
$\mathcal{M}$
are initialized to the left; the work and output tapes are initialized to all blank.
We now describe a bit-length program simulating
 $\mathcal{M}$
. The global input variable is identified with the single input of type
$\mathcal{M}$
. The global input variable is identified with the single input of type
 $2^\star$
. The tuple
$2^\star$
. The tuple
 $\vec{\mathtt{x}}$
of counting module variables is identified with the remaining unary inputs; these keep getting passed around, unchanged, in each recursive call. For each tape of
$\vec{\mathtt{x}}$
of counting module variables is identified with the remaining unary inputs; these keep getting passed around, unchanged, in each recursive call. For each tape of
 $\mathcal{M}$
we define a recursive functions
$\mathcal{M}$
we define a recursive functions
 $\mathtt{position} : C \to C$
and
$\mathtt{position} : C \to C$
and
 $\mathtt{character} : C \times C \to \Sigma$
. The function
$\mathtt{character} : C \times C \to \Sigma$
. The function
 $\mathtt{position}(\mathtt{t},\vec{\mathtt{x}})$
describes the position of the head after
$\mathtt{position}(\mathtt{t},\vec{\mathtt{x}})$
describes the position of the head after
 $\mathtt{t}$
steps, and
$\mathtt{t}$
steps, and
 $\mathtt{character}(\mathtt{t},\mathtt{p},\vec{\mathtt{x}})$
describes the character on that tape after
$\mathtt{character}(\mathtt{t},\mathtt{p},\vec{\mathtt{x}})$
describes the character on that tape after
 $\mathtt{t}$
steps at position
$\mathtt{t}$
steps at position
 $\mathtt{p}$
. In addition, there is a single recursive function
$\mathtt{p}$
. In addition, there is a single recursive function
 $\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
describing the state of
$\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
describing the state of
 $\mathcal{M}$
after
$\mathcal{M}$
after
 $\mathtt{t}$
steps. The codomain of
$\mathtt{t}$
steps. The codomain of
 $\mathtt{state}$
is a finite type, which we can encode by a sufficiently wide tuple of booleans.
$\mathtt{state}$
is a finite type, which we can encode by a sufficiently wide tuple of booleans.
The surface configuration of
 $\mathcal{M}$
at a given time
$\mathcal{M}$
at a given time
 $\mathtt{t,}$
consists of the current state (
$\mathtt{t,}$
consists of the current state (
 $\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
) and the characters read by the heads (
$\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
) and the characters read by the heads (
 $\mathtt{character}(\mathtt{t},\mathtt{position}(\mathtt{t}),\vec{\mathtt{x}})$
for each tape). The surface configuration tells us what state
$\mathtt{character}(\mathtt{t},\mathtt{position}(\mathtt{t}),\vec{\mathtt{x}})$
for each tape). The surface configuration tells us what state
 $\mathcal{M}$
transitions to, how the heads move, and what they write in each step. (Exactly how this happens is specified by the transition function of
$\mathcal{M}$
transitions to, how the heads move, and what they write in each step. (Exactly how this happens is specified by the transition function of
 $\mathcal{M}$
.) More precisely, for
$\mathcal{M}$
.) More precisely, for
 $\mathtt{t} > 0$
,
$\mathtt{t} > 0$
,
 $\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
is given by the previous surface configuration,
$\mathtt{state}(\mathtt{t},\vec{\mathtt{x}})$
is given by the previous surface configuration,
 $\mathtt{position}(\mathtt{t},\vec{\mathtt{x}})=\mathtt{position}(\mathtt{t-1},\vec{\mathtt{x}}) + \delta$
, where
$\mathtt{position}(\mathtt{t},\vec{\mathtt{x}})=\mathtt{position}(\mathtt{t-1},\vec{\mathtt{x}}) + \delta$
, where
 $\delta = 0,1,\,\text{or}\ -1$
depending on the previous surface configuration, and
$\delta = 0,1,\,\text{or}\ -1$
depending on the previous surface configuration, and
 $\mathtt{character}(\mathtt{t},\mathtt{p},\vec{\mathtt{x}})$
is equal to
$\mathtt{character}(\mathtt{t},\mathtt{p},\vec{\mathtt{x}})$
is equal to
 $\mathtt{character}(\mathtt{t-1},\mathtt{p},\vec{\mathtt{x}})$
unless
$\mathtt{character}(\mathtt{t-1},\mathtt{p},\vec{\mathtt{x}})$
unless
 $\mathtt{position}(\mathtt{t-1}) = \mathtt{p}$
, in which case it is given by the previous surface configuration.
$\mathtt{position}(\mathtt{t-1}) = \mathtt{p}$
, in which case it is given by the previous surface configuration.
The initial position of each head is
 $\mathtt{0}$
. The initial characters all work and output tapes are blank, and the initial characters of the input tapes are given by the
$\mathtt{0}$
. The initial characters all work and output tapes are blank, and the initial characters of the input tapes are given by the
 $\vec{\mathtt{x}}$
. Once
$\vec{\mathtt{x}}$
. Once
 $\mathcal{M}$
reaches a halting state, the state, positions, and characters of the program remain fixed. Therefore, to name the “final” state, tape positions, etc., we need a function
$\mathcal{M}$
reaches a halting state, the state, positions, and characters of the program remain fixed. Therefore, to name the “final” state, tape positions, etc., we need a function
 $\mathtt{seed} : C$
which is big enough to bound the largest possible running time on some given input.
$\mathtt{seed} : C$
which is big enough to bound the largest possible running time on some given input.
Notice that we can always “copy” an index value to a counting module value in a bit-length program. In particular, we can copy the maximum index
 $\mathtt{max}$
into the counting module value n, the length of the input. Using the counting module primitives, we can define multiplication on counting modules. Then, all we need to do is construct
$\mathtt{max}$
into the counting module value n, the length of the input. Using the counting module primitives, we can define multiplication on counting modules. Then, all we need to do is construct
 $(n+1)^k$
for a large enough constant k. All of this is done without collisions in the context of a sufficiently large (but still polynomially bounded) counting module.
Footnote 21
$(n+1)^k$
for a large enough constant k. All of this is done without collisions in the context of a sufficiently large (but still polynomially bounded) counting module.
Footnote 21
The final state is named by
 $\mathtt{state}(\mathtt{seed},\vec{\mathtt{x}})$
, which is the output of
$\mathtt{state}(\mathtt{seed},\vec{\mathtt{x}})$
, which is the output of
 $\mathcal{M}$
if f is boolean-valued. If
$\mathcal{M}$
if f is boolean-valued. If
 $\mathcal{M}$
has output of type
$\mathcal{M}$
has output of type
 $1^\star$
, then the output is
$1^\star$
, then the output is
 $\mathtt{position}(\mathtt{seed},\vec{\mathtt{x}})$
, the final position of the output tape. Since the output tape is one-way and write-only, this position is precisely the output string. Finally, this program contains no collisions, since it contains no counting module additions except those in the construction of
$\mathtt{position}(\mathtt{seed},\vec{\mathtt{x}})$
, the final position of the output tape. Since the output tape is one-way and write-only, this position is precisely the output string. Finally, this program contains no collisions, since it contains no counting module additions except those in the construction of
 $\mathtt{seed}$
.
$\mathtt{seed}$
.
Conversely, suppose that there is a polynomially bounded
 $\lambda : \omega \to \omega$
and a bit-length program p such that
$\lambda : \omega \to \omega$
and a bit-length program p such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
 $x \in 2^\star$
. For a fixed input x, there are at most polynomially many-in-
$x \in 2^\star$
. For a fixed input x, there are at most polynomially many-in-
 $|x|$
possible environments
$|x|$
possible environments
 $\rho$
obtained by binding variables of p to indices of x and counting modules bounded by
$\rho$
obtained by binding variables of p to indices of x and counting modules bounded by
 $\lambda(|x|)$
. We make a table of all pairs
$\lambda(|x|)$
. We make a table of all pairs
 $(\rho,T)$
of environments and possible terms and then, using dynamic programming, evaluate each term on each environment. One of these is the output of the program, and the whole process takes polynomial time.
$(\rho,T)$
of environments and possible terms and then, using dynamic programming, evaluate each term on each environment. One of these is the output of the program, and the whole process takes polynomial time.
Theorem. For any function
 $f : 2^\star \to 1^\star$
, the following are equivalent:
$f : 2^\star \to 1^\star$
, the following are equivalent:
-
f is computable in logarithmic space.
-
There is a polynomially bounded
$\lambda : \omega \to \omega$
and a tail-recursive bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x) = f(x)$
, without collisions, for any
$x \in 2^\star$
.For any function
$f : 2^\star \times 1^\star \to 2$
and polynomially bounded function
$\pi : \omega \to \omega$
, the following are equivalent: -
There is a logarithmic-space computable function
$g : 2^\star \times 1^\star \to 2$
such that
$g(x,y) = f(x,y)$
for any string
$x \in 2^\star$
and
$y < \pi(|x|)$
. -
There is a polynomially bounded function
$\lambda : \omega \to \omega$
and a tail-recursive bit-length program p such that
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = f(x,y)$
, without collisions, for any
$x \in 2^\star$
and
$y < \pi(|x|)$
.













Proof As above, let f be a function of type
 $2^\star \times (1^\star)^k \to \alpha$
for some
$2^\star \times (1^\star)^k \to \alpha$
for some
 $k \in \omega$
and
$k \in \omega$
and
 $\alpha \in \{1^\star,2\}$
, and let
$\alpha \in \{1^\star,2\}$
, and let
 $\mathcal{M}$
be a Turing machine computing f in logarithmic space. In case
$\mathcal{M}$
be a Turing machine computing f in logarithmic space. In case
 $\alpha = 1^\star$
,
$\alpha = 1^\star$
,
 $\mathcal{M}$
has a write-only one-way output tape; note that the logarithmic space bound does not apply to this tape.
$\mathcal{M}$
has a write-only one-way output tape; note that the logarithmic space bound does not apply to this tape.
For a fixed finite alphabet
 $\Delta$
, call a short string a
$\Delta$
, call a short string a
 $\Delta$
-string of length
$\Delta$
-string of length
 $O(\log n)$
, for any given n. We can encode short strings by polynomially bounded-in-n counting modules, roughly, by identifying
$O(\log n)$
, for any given n. We can encode short strings by polynomially bounded-in-n counting modules, roughly, by identifying
 $\Delta$
with some finite initial segment of
$\Delta$
with some finite initial segment of
 $\omega$
, and identifying bounded-width
$\omega$
, and identifying bounded-width
 $\Delta$
-strings with base-
$\Delta$
-strings with base-
 $\Delta$
numerals.
$\Delta$
numerals.
Let the configuration of
 $\mathcal{M}$
at a given time consist of the current state, the positions of each head, and the entire contents of each tape. (Contrast this with the surface configuration above.) The point is, in a logarithmic-space Turing machine on input of length n, the entire configuration of n can be encoded by a short string in n and thus in a polynomially bounded counting module. Moreover, we can compute the next configuration from the previous one by a tail-recursive program using the counting module primitives.
$\mathcal{M}$
at a given time consist of the current state, the positions of each head, and the entire contents of each tape. (Contrast this with the surface configuration above.) The point is, in a logarithmic-space Turing machine on input of length n, the entire configuration of n can be encoded by a short string in n and thus in a polynomially bounded counting module. Moreover, we can compute the next configuration from the previous one by a tail-recursive program using the counting module primitives.
Ultimately, the program p looks something like this. As above, the single binary string input is identified with the (invisible) global input variable, and the string
 $\vec{\mathtt{x}}$
is identified with any remaining variables of type
$\vec{\mathtt{x}}$
is identified with any remaining variables of type
 $1^\star$
.
$1^\star$
.
 \begin{align*} \mathtt{f}_0(\vec{\mathtt{x}}) &= \mathtt{f}_1(\mathtt{init}(\vec{\mathtt{x}})) \\ \mathtt{f}_1(\mathtt{c}) &= \mathtt{if}\ \mathtt{halt}(\mathtt{c})\ \mathtt{then}\ \mathtt{out}(\mathtt{c})\ \mathtt{else}\ \mathtt{f}_1(\mathtt{next}(\mathtt{c})),\end{align*}
\begin{align*} \mathtt{f}_0(\vec{\mathtt{x}}) &= \mathtt{f}_1(\mathtt{init}(\vec{\mathtt{x}})) \\ \mathtt{f}_1(\mathtt{c}) &= \mathtt{if}\ \mathtt{halt}(\mathtt{c})\ \mathtt{then}\ \mathtt{out}(\mathtt{c})\ \mathtt{else}\ \mathtt{f}_1(\mathtt{next}(\mathtt{c})),\end{align*}
where
 $\mathtt{halt}(\mathtt{c})$
detects whether the configuration
$\mathtt{halt}(\mathtt{c})$
detects whether the configuration
 $\mathtt{c}$
is halting,
$\mathtt{c}$
is halting,
 $\mathtt{out}(\mathtt{c})$
correctly returns the output of a halting configuration,
$\mathtt{out}(\mathtt{c})$
correctly returns the output of a halting configuration,
 $\mathtt{init}(\vec{\mathtt{x}})$
is the initial configuration, and
$\mathtt{init}(\vec{\mathtt{x}})$
is the initial configuration, and
 $\mathtt{next}(\mathtt{c})$
is the configuration following
$\mathtt{next}(\mathtt{c})$
is the configuration following
 $\mathtt{c}$
. This program is tail-recursive and correctly computes f.
$\mathtt{c}$
. This program is tail-recursive and correctly computes f.
Conversely, suppose that there is a polynomially bounded
 $\lambda : \omega \to \omega$
and a tail-recursive bit-length program p such that
$\lambda : \omega \to \omega$
and a tail-recursive bit-length program p such that
 $\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = f(x,y)$
, without collisions, for any
$\mbox{$\lbrack\hspace{-0.3ex}\lbrack$}{p}\mbox{$\rbrack\hspace{-0.3ex}\rbrack$}_\lambda(x,y) = f(x,y)$
, without collisions, for any
 $x \in 2^\star$
. It is a well-known fact that every tail-recursive program can be rewritten as a while program with a single while loop and no additional data structures (e.g., a stack). We can directly simulate a program with a single while loop on a Turing machine by, e.g., storing each program variable on a tape of the machine. But it takes only logarithmic space to encode indices and counting modules which are bounded polynomially in the length of the input.
$x \in 2^\star$
. It is a well-known fact that every tail-recursive program can be rewritten as a while program with a single while loop and no additional data structures (e.g., a stack). We can directly simulate a program with a single while loop on a Turing machine by, e.g., storing each program variable on a tape of the machine. But it takes only logarithmic space to encode indices and counting modules which are bounded polynomially in the length of the input.




































































 Open access
Open access
Discussions
No Discussions have been published for this article.