

1. Introduction
When I first started teaching, my students used to bring trolleys-full of dictionaries on exam days. Today's students look up words on their computers or mobile phones instead. It is not just the medium that has changed, however. In terms of content, current state-of-the-art learner dictionaries contain information that goes well beyond spellings, definitions or translations, providing users with valuable empirical, corpus-based data on how to employ words in texts. This includes information on word grammar, lexical collocations and common errors to avoid, as well as typical examples of usage.
Yet despite the remarkable developments that have taken place in the field of lexicography over the past decades, dictionary-user behaviour does not seem to have changed much. People tend to turn to dictionaries mostly to look up meanings, spellings, translations, or as an authority when engaging in games such as crosswords (Atkins & Varantola Reference Atkins and Varantola1997; Frankenberg-Garcia Reference Frankenberg-Garcia2005; Welker Reference Welker2006; Frankenberg-Garcia Reference Frankenberg-Garcia2011; Lew & de Schryver Reference Lew and de Schryver2014; Müller-Spitzer Reference Müller-Spitzer and Müller-Spitzer2014; Nesi Reference Nesi2014; Gromann & Schnitzer Reference Gromann and Schnitzer2016; Jardim Reference Jardim2018). Little do average dictionary users know that they could also consult dictionaries to help them use language more idiomatically.
Considering this reality, it is widely acknowledged that more needs to be done to teach dictionary-consultation skills. However, in an age where authoritative dictionaries are rapidly losing ground to easily accessible free, online language tools and resources (Levy & Steel Reference Levy and Steel2015; Lew Reference Lew2016), it would be hard to convince the public in general of the advantages of learning to become better users of dictionaries.
In this paper, I propose bringing lexicographic information to writers instead of waiting for them to get the information they need from dictionaries. I begin with an overview of how pedagogical dictionaries have evolved, and of some of the challenges of getting writers to become better users of dictionaries and of assisting writers in real-time. Next, I present the ColloCaid project, which combines user needs, lexicographic data and digital writing environments to help writers produce more idiomatic texts.
2. Developments in pedagogical lexicography
Dictionaries in the past were mostly a repository of the words in a language, with a focus on definitions, the standardization of spellings, and etymology (Cowie Reference Cowie2009). In addition, bilingual dictionaries provided translations, but neither monolingual nor bilingual dictionaries were particularly concerned with usability. It was up to the users consulting these resources to decipher their ‘cryptic lexicographic content’ (Lew & de Schryver Reference Lew and de Schryver2014: 341). Interest in the pedagogical function of dictionaries, where the end user began to be taken into account, saw the development of new types of dictionaries for learners. The Idiomatic and syntactic dictionary of English (Hornby, Gatenby & Wakefield Reference Hornby, Gatenby and Wakefield1942) – the precursor to the famous 1974 edition of the Oxford advanced learner's dictionary (OALD) (Hornby, Cowie & Lewis Reference Hornby, Cowie and Lewis1974) – is regarded as the first dictionary to address information such as noun countability and verb complementation, which can help learners use words in language production tasks. The hugely popular 1974 edition of the OALD then added phonetic transcriptions to aid pronunciation and examples to illustrate usage (Cowie Reference Cowie1999). Another significant development in the field of pedagogical lexicography was the introduction of a controlled defining vocabulary in the 1978 edition of the Longman dictionary of contemporary English (Procter Reference Procter1978), where a conscious effort was made to restrict the words used in definitions to those learners are more familiar with, thus increasing the chances of users understanding the meanings of the words they consult without having to look any further.
The next paradigm shift in the history of dictionaries for learners occurred with the publication of the Collins COBUILD English dictionary for advanced learners (Sinclair Reference Sinclair1987a). Among other innovations, such as providing more natural-sounding, full-sentence definitions, COBUILD was the first dictionary to be compiled with the support of a computerized corpus with millions of words of English used in authentic communicative situations. Whereas up to then lexicographers had had to rely on their own partial perceptions and experience, the corpus revolution took language description to new levels, enabling them to capture the combined intuitions of hundreds or even thousands of language users together. Corpus software counts, sorts, ranks and displays words in special ways that facilitate linguistic analysis. For the first time, lexicographers could describe a representative selection of empirical language data systematically. With corpora, it also became possible to take word frequencies into account when establishing defining vocabularies and deciding which senses were more important to present to learners (Sinclair Reference Sinclair1987b). Since the words in a language tend to follow a Zipfian distribution (Zipf Reference Zipf1949), where the top-ranking words cover most of the language (Nation Reference Nation2001), it made sense for dictionaries for learners to prioritize more frequent words and senses.
Corpora also allow lexicographers to analyse how words are used together. This enables them to provide learners with information on not only syntactic patterns or grammatical collocations (e.g. interest in something), but also on lexical collocations, i.e. conventional combinations of lexis like express/take/show an interest in something, which make texts sound natural and idiomatic (Nattinger & DeCarrico Reference Nattinger and DeCarrico1992; Hoey Reference Hoey2005; Nesselhauf Reference Nesselhauf2005; Paquot & Granger Reference Paquot and Granger2012; Wray Reference Wray2013; Boers & Webb Reference Boers and Webb2017).
If you ask experienced language users about lexical collocations, say, what verbs can be used before the noun interest, they may recall around two or three without hesitation, but usually need to think harder to remember more (Frankenberg-Garcia Reference Frankenberg-Garcia2018). With corpora, however, it is possible to extract a long list of verbs that collocate with interest as an object in seconds, as exemplified in Figure 1 with data from the 20 billion-word enTenTen13 corpus, available on Sketch Engine (Kilgarriff et al. Reference Kilgarriff, Baisa, Bušta, Jakubíček, Kovvář, Michelfeit and Suchomel2014). Without getting into too many details, this is done by comparing the overall frequency with which words appear in a corpus (e.g. express/show/take) with the frequency with which they appear in proximity to a target word (in this case, interest), and calculating the likelihood of the two appearing together.
Top 50 verbal collocates of the noun interest in the enTenTen13 corpus

This not only greatly facilitates the work of lexicographers, but is also especially relevant to learners, for collocations have been shown to be particularly difficult to master (Nattinger & DeCarrico Reference Nattinger and DeCarrico1992; Nesselhauf Reference Nesselhauf2005; Paquot & Granger Reference Paquot and Granger2012; Wray Reference Wray2013; Boers & Webb Reference Boers and Webb2017). Since texts that do not make use of appropriate collocations tend to sound less fluent/proficient (Hsu Reference Hsu2007; Crossley, Salsbury & McNamara Reference Crossley, Salsbury and McNamara2015) and are notoriously more difficult to process (Hoey Reference Hoey2005; Ellis, Simpson-Vlach & Maynard Reference Ellis, Simpson-Vlach and Maynard2008; Conklin & Schmitt Reference Conklin and Schmitt2012), the inclusion of information on collocation in dictionaries represents a particularly welcome innovation to help learners use language more idiomatically.
Another significant change brought about by corpora was the replacement of scattered examples to illustrate definitions with a more consistent use of authentic, corpus-based examples selected to further clarify meaning or draw attention to typical usages of words in context (Sinclair Reference Sinclair1987b). This development was extremely important, as dictionary-use research has shown that examples help learners with language production (Frankenberg-Garcia Reference Frankenberg-Garcia2012a, Reference Frankenberg-Garcia2014, Reference Frankenberg-Garcia2015).
Following the corpus revolution, the next leap in pedagogical lexicography took place with the popularization of personal computers, and the possibilities offered by presenting dictionary information in a new medium (Lew & de Schryver Reference Lew and de Schryver2014). Rather than simply transposing the print editions of dictionaries to digital formats – initially as CD-ROMs – the major English dictionaries for learners introduced several innovations. To begin with, finding words has become much easier. Users are no longer required to look up words in alphabetical order, as they can now just type them into a search box. If users do not know exact spellings, they only need to begin typing to be reminded of matching words, or corrected spellings when a word is misspelled. Similarly, users do not have to know the uninflected forms of words to look them up, as inflections are recognized too. The new medium has also made it easier for users to learn how to pronounce words, as they can click on sound files to listen to them instead of having to decipher phonetic symbols. Recently, sound files have also begun to be used to enhance the definitions of words involving sounds. For example, in the Macmillan English dictionary online (Rundell Reference Rundell2009) entry for the verb bark, one can click on a sound icon to hear a dog barking.
Another particularly important advantage of the new electronic medium is space (Lew & de Schryver Reference Lew and de Schryver2014; Rundell Reference Rundell2015). The fact that dictionaries do not need to be printed anymore has meant they are no longer restricted by the weight and cost of paper or of using colour. There is therefore room for unpacking the compact way in which information is traditionally presented in print editions, enhancing the retention of information (Dziemianko Reference Dziemianko2015, Reference Dziemianko2017; Choi Reference Choi2017). There is also room for expanding contents, like adding further examples of usage, as well as vocabulary exercises and games (Lew Reference Lew, Fuertes-Olivera and Bergenholtz2011). However, it could be argued that space is only an advantage if used wisely. Overburdening dictionary users with too much information could be detrimental, as it could make look-ups less efficient or even distract users from the reason why they were consulting a dictionary in the first place.
More recently, with the proliferation of wireless internet access and portable electronic devices, there has been a growing tendency for electronic dictionaries to migrate from static CD-ROM versions to online platforms which can be accessed remotely. In addition to the obvious benefits of portability, the move to online dictionaries has paved the way for further developments in the field. First, dictionaries ‘can be updated as often as needed, and all users can instantly benefit from the improved content or features right from the moment these become available’ (Lew & de Schryver Reference Lew and de Schryver2014: 345). Another advantage of online dictionaries is that log files can offer new insights into user behaviour, which can in turn be fed back into the development of subsequent dictionary updates (de Schryver & Joffe Reference De Schryver and Joffe2004). However, this is more easily said than done, since log files tell us little about the motivations behind individual look-ups or the users themselves (Santos & Frankenberg-Garcia Reference Santos and Frankenberg-Garcia2007). Moreover, in addition to privacy issues, the major players in pedagogical lexicography seem to have kept this type of data to themselves, as there does not seem to be much published research on dictionary-user log files and how they can promote better dictionaries.Footnote 1 On the other hand, this does not mean to say there is no attempt to gain information from actual users. In fact, it is now common for online dictionaries to encourage user-generated content (Rundell Reference Rundell, Hanks and de Schryver2017). A notable initiative is the Macmillan English dictionary online (Rundell Reference Rundell2009), where users are invited to contribute to the addition of new entries whenever they look up words that are yet not part of the dictionary's headword list.
3. Getting writers to use dictionaries
Despite the spectacular advances in dictionary content and format outlined in the previous section, as pointed out in the introduction, dictionaries remain by and large underused, particularly as an aid to writing. I have just come back from examining a Ph.D. thesis on dictionary use (Jardim Reference Jardim2018), and its findings confirm yet again previous research showing that users are generally unaware that dictionaries are not just about meanings, spellings, settling language disputes or L1-L2 equivalence (see Introduction). Few writers realize that dictionaries can also help them use words in context and produce more idiomatic texts.
Although existing research recognizes the need to train users in dictionary-consultation skills (Frankenberg-Garcia Reference Frankenberg-Garcia2011; Ranalli Reference Ranalli2013; Kim Reference Kim2017), the aforementioned studies on dictionary use show that little progress has been made in this arena. What is particularly worrying is the inadequate way in which information about dictionaries is being conveyed to the general public even today. For example, the top result for a quick online search for ‘how to use a dictionary’ carried out when preparing this paper took me to wikihow.com, which outlined the following steps:
a. Choose the right dictionary
b. Read the introduction
c. Learn the abbreviations
d. Learn the guide to pronunciation
e. Find the section of your dictionary with the first letter of your word
f. Read the guide words [i.e. the running head showing the first and last word on each page]
g. Scan down the page for your word
h. Read the definition
i. Alternately, you could use an online dictionary
As can be seen, apart from point (i), the above instructions are totally out of step with recent developments in the field. Yet even if dictionary users were made aware that dictionaries have evolved not just in terms of format, the fact is most language users are not in the habit of consulting references to help them become better writers. As explained in Frankenberg-Garcia (Reference Frankenberg-Garcia2014: 140), ‘one of the main reasons why learners are underusers of dictionaries and other language resources is that they are often not aware of their own language limitations and reference needs’. While people normally realize when language comprehension is an issue, they tend to be less aware about language production problems. In a second language writing workshop at a Portuguese university, where undergraduate students were encouraged to ask for help at any point during writing, ‘the queries posed by the students suggested that they felt all they needed to become successful writers of English was a bilingual dictionary and a spelling checker’ (Frankenberg-Garcia Reference Frankenberg-Garcia1999: 104), although the problems in the texts they produced went far beyond that.
Promoting better dictionary-consultation skills among writers cannot have much impact if they are not sufficiently aware of their reference needs in the first place. Moreover, in an age where authoritative dictionaries are competing with other types of language tools and resources (Levy & Steel Reference Levy and Steel2015; Lew Reference Lew2016), the time is ripe for rethinking pedagogical lexicography. In the next section, I propose bringing lexicographic information to writers instead of expecting them to get the information they need from dictionaries.
4. Bringing dictionaries to writers
While writers know they can look up translations and spellings in dictionaries or dictionary-like tools, one of the greatest challenges of pedagogical lexicography is to get them to use dictionaries for more than that. Collocations are particularly relevant in the context of writing. As referred to in Section 2, collocations have been shown to be notoriously difficult for language learners. Failing to follow the established collocation conventions of a particular language or language variety can lead to error (e.g. *based in something, *to learn knowledge) or less idiomatic text that can be harder to process. For example, compare the collocation deeply entrenched, which proficient language users tend to read as a unit, with a less idiomatic combination of words like incredibly entrenched.
There are many references writers can consult when in doubt about collocations in English. In addition to looking them up in corpus-based, general learner dictionaries, there are also dictionaries that focus specifically on collocations, like the BBI dictionary of English word combinations (Benson, Benson & Ilson Reference Benson, Benson and Ilson1986), the Oxford collocations dictionary (Runcie Reference Runcie2002), the Macmillan collocations dictionary (Rundell Reference Rundell2010), and the Longman collocations dictionary and thesaurus (Mayor Reference Mayor2013).
Language users can also look up English collocations in free online tools like Just the Word and the Flax Library, which process corpus data and provide automatic summaries of collocations. In addition, although there are not many language users familiar with corpora (Frankenberg-Garcia Reference Frankenberg-Garcia2012b), those who are can go directly to the sources where lexicographers get information about collocations in the first place. The British National Corpus (BNC), the Corpus of Contemporary American English (COCA) and more recently Sketch Engine for English Language Learning (SkELL), for example, are all easily accessible corpora of General English which writers can consult to help them with their use of collocations.
While there is no room here for a comprehensive review of all existing collocation aids available for English, there is certainly no lack of resources that writers can utilize to look up ways to combine words so as to improve the idiomaticity of their texts. However, unlike using dictionaries to look up more obvious reference needs like how to say a word in another language or check its spelling, language learners would have no reason to look up collocations if they were not aware of their shortcomings regarding them. In a controlled experiment with Hebrew learners of English, Laufer (Reference Laufer2011) found that they had a tendency to misjudge what they knew about collocations and did not think it necessary to consult dictionaries to look them up. Similar evidence was found in Frankenberg-Garcia (Reference Frankenberg-Garcia1999, Reference Frankenberg-Garcia2014). Moreover, even if writers realized collocations were a problem, they would have to interrupt their writing to look them up and could lose their focus in the process, forgetting what they wanted to say. This can be particularly detrimental to writers struggling with cognitively demanding texts. In a study observing how academic writers interacted with online dictionaries and corpora, Yoon (Reference Yoon2016: 220–221) observed that the participants ‘expressed frustration with the time required to go through the consultation cycle’ and complained that they ‘had their flow of thoughts interrupted’.
A solution to this problem would be to provide writers with real-time help. Writing tools are becoming better and better, with various innovations that can assist writers on the spot. For example, most text editors today can autocorrect spelling or flag up misspelled words. Some writing tools allow users to right-click on a word to look up synonyms. Other useful functionalities include drawing attention to repeated words and missing punctuation. Researchers working on the Danish version of MS-Word are trialling an add-in that integrates a Danish-English bilingual dictionary and predictive text (Tarp, Fisker & Sepstrup Reference Tarp, Fisker and Sepstrup2017). In addition, recent developments in natural language processing and machine learning have given rise to sophisticated writing assistants like Grammarly®, which provide feedback on more complex issues such as verb tenses and word choice. Cambridge English has developed Write&Improve, which sets topics for non-native speakers of English to practise writing and gives them automatic feedback on their texts based on how similar texts were previously marked. Another well-known tool is Hemingway, which aims to inform writers on the readability of their texts based on sentence length and the use of adverbs and the passive voice or rarer words. WriteAway, in turn, processes data from corpora to autocomplete writers’ sentences.
The provision of automated feedback on writing is a very fertile and fast-developing field, and it is hard to keep up with all the writing assistants that are emerging. While there are many truly innovative ways of helping writers in real time being proposed, the programmed advice given by some tools can at times be prescriptive and overly simplistic (e.g. ‘avoid the passive voice’), and there does not seem to be enough research assessing the usability of these tools. Anyone who has used predictive text, for example, will know how annoying it can be. If predictive text can irritate users writing simple text messages on their phones, imagine its effect when writers are trying to cope with more cognitively demanding tasks. Another limitation is that if we exclude the integration of predictive text, writing assistants are mostly limited to offering corrective feedback. The challenge is thus to develop a lexicographic tool that is not just reactive, but which can also help writers proactively, without disrupting their writing. In the next section, I describe the ColloCaid project, which aims to bring collocations to writers instead of waiting for them to look up collocations they may not even be aware they need.
5. The ColloCaid project
ColloCaid is a three-year project led by myself at the University of Surrey, in collaboration with Professor Jonathan Roberts (Bangor University) and Professor Robert Lew (Adam Mickiewicz University), with the assistance of Dr Geraint Rees (Surrey University) and Dr Nirwan Sharma (Bangor University). The project is funded by the UK Arts and Humanities Research Council.
The principles underpinning our research apply to collocation in general, and in future we would like to see similar applications for various languages. However, given the limitations of what can be realistically achieved within the scope of three years, our prototype is being developed specifically to help novice users of English for Academic Purposes (EAP). This enables us to focus on the collocation needs of a well-defined group of real-world users for whom writing is particularly important.
5.1 User needs
The first step in our research was to identify the collocation needs of our target users. Based on the premise that there are no native speakers of academic language (Kosem Reference Kosem2010; Hyland & Shaw Reference Hyland, Shaw, Hyland and Shaw2016; Frankenberg-Garcia Reference Frankenberg-Garcia2018), ColloCaid aims to encourage novice EAP users (including native English speakers) to employ collocations which may not be instinctive to them. We nevertheless acknowledge that EAP users of different first language backgrounds may experience diverse problems regarding the use of collocations. It is well-documented that the ways in which second language writers combine words can be negatively impacted by their first languages (Nesselhauf Reference Nesselhauf2005; Laufer & Waldman Reference Laufer and Waldman2011; Peters Reference Peters2016; Paquot Reference Paquot2017). By the same token, as shown in Frankenberg-Garcia (Reference Frankenberg-Garcia2018), less experienced native English EAP users tend to employ general language words and collocations which may sound out of place in formal academic writing. At a later stage in our research, we will therefore use learner corpora to analyse how such problems manifest themselves and provide targeted feedback to help writers tackle them.
However, before focusing on the comparatively more straightforward problem of corrective feedback, we intend to ‘feed forward’ first, addressing issues that are not as visible in learner corpora. The problem of collocations, after all, is not limited to error, but involves also the underuse and overuse of certain word combinations (Durrant & Schmitt Reference Durrant and Schmitt2009; Paquot Reference Paquot2017). At the root of such problems is not only the previously discussed tendency to overestimate knowledge of collocations (Section 4), but also lexical avoidance strategies (Faerch & Kasper Reference Faerch and Kasper1983), whereby writers alter, reduce or completely abandon what they meant to say when they are unable to find the words they need. The starting point for the lexicographic database behind ColloCaid was therefore the identification of a core set of collocations that will be useful to EAP users, even if they themselves are not initially aware of their worth.
For this purpose, we opted to concentrate our efforts on collocations used across a range of academic disciplines. Without diminishing the importance of discipline-specific collocations, as discussed in Frankenberg-Garcia et al. (Reference Frankenberg-Garcia2018), we believe it is easier for EAP users to acquire such vocabulary incidentally, through ‘a targeted and concentrated exposure to the subject-matter of their studies’. On the other hand, interdisciplinary academic collocations can be harder for novice EAP users to recall, precisely because they tend to be less salient. Although we do not rule out the development, at a later stage, of discipline-specific versions of ColloCaid, a writing assistant that handles interdisciplinary EAP collocations can be more immediately useful to a greater number of users.
5.2 Lexicographic data
Following the Zipfian principles referred to in Section 2, a combination of three well-established general EAP vocabulary lists was used to ensure appropriate coverage was given to words with the potential to improve the collocation repertoire of EAP users: the Academic Keyword List (Paquot Reference Paquot2010), the Academic Collocations List (Ackermann & Chen Reference Ackermann and Chen2013) and a subset of the Academic Vocabulary List (Gardner & Davies Reference Gardner and Davies2014) identified by Durrant (Reference Durrant2016) as being particularly relevant to novice writers. Since the three lists are based on different corpora and different extraction methods, combining them allows us to prioritize what they have in common. As detailed in Frankenberg-Garcia et al. (Reference Frankenberg-Garcia2018), our guiding principles in this selection were to focus on lemmas used across a wide range of disciplines (all three lists), including academic lemmas like table and figure that are also used in non-academic contexts (Academic Keyword List), prioritizing lemmas which evoke strong collocations (Academic Collocations List), and lemmas novice EAP writers actually use (Durrant's subset of the Academic Vocabulary List). The circa 500 noun, verb and adjective lemmas that overlapped in at least two of the three lists helped to determine which collocation nodes to focus on in the compilation of ColloCaid's initial lexicographic framework.Footnote 2
The next step was to research lexical and grammatical collocates for the collocation nodes selected in corpora of expert academic writing. As explained in Frankenberg-Garcia et al. (Reference Frankenberg-Garcia2018), our main source was the 70 million-word Oxford Corpus of Academic English, which was kindly made available to our team on Sketch Engine, although we also consulted the Pearson International Corpus of Academic English (Ackermann, de Jong & Tugwell Reference Ackermann, de Jong, Kilgarriff and Tugwell2011) by kind permission of Pearson Longman and the academic components of the BNC and COCA. The analysis was centred on the logical collocation queries prompted by each node. For example, writers may ask questions like, ‘What adjective can I use with number?’, but are unlikely to ask, ‘What noun can I use with significant?’ because nouns are the foundation for the selection of adjectives, and not the other way around.
When deciding on which collocates to present, we opted to focus on collocations used across a range of academic disciplines. Therefore, discipline-specific collocations like natural/prime number were left out, allowing us to devote more room to interdisciplinary academic collocations like large/increasing/significant/average number. Following studies like Frankenberg-Garcia (Reference Frankenberg-Garcia2012a, Reference Frankenberg-Garcia2014, Reference Frankenberg-Garcia2015) on the value of examples for language production, our collocation framework is also being populated with corpus-based examples. These are being curated to: (a) show how collocations are used in context; (b) expose writers to further collocations (e.g. large number followed by of); (c) emphasize typical colligational, i.e., grammar, patterns (e.g. increasing number, increased numbers); and (d) help users differentiate between semantically similar collocations like increasing/growing number.
5.3 Digital writing environments
As discussed earlier, our main concern when integrating lexicographic data with digital writing environments in ColloCaid is not to distract writers from their writing, while helping them (a) not to give up on collocations through avoidance strategies; (b) find suitable collocates for the words they use without having to consult external resources; (c) notice collocations they may not remember to look up (because they overestimate their knowledge of collocations); and (d) self-correct miscollocations.
To facilitate the smooth integration of the interdisciplinary EAP collocation framework we are compiling, we want to flag up that relevant information on collocation is available in an unobtrusive way. This will be achieved by discreetly highlighting the lemmas that form part of our lexicographic framework in real time. Writers can then click to obtain further information or ignore and carry on writing. While our prototype is still under development, a schematic representation of how we propose to do this is shown in Figure 2. Step 1 in the figure illustrates how the highlighting of collocation nodes could be accomplished.
Incremental display of information on collocations
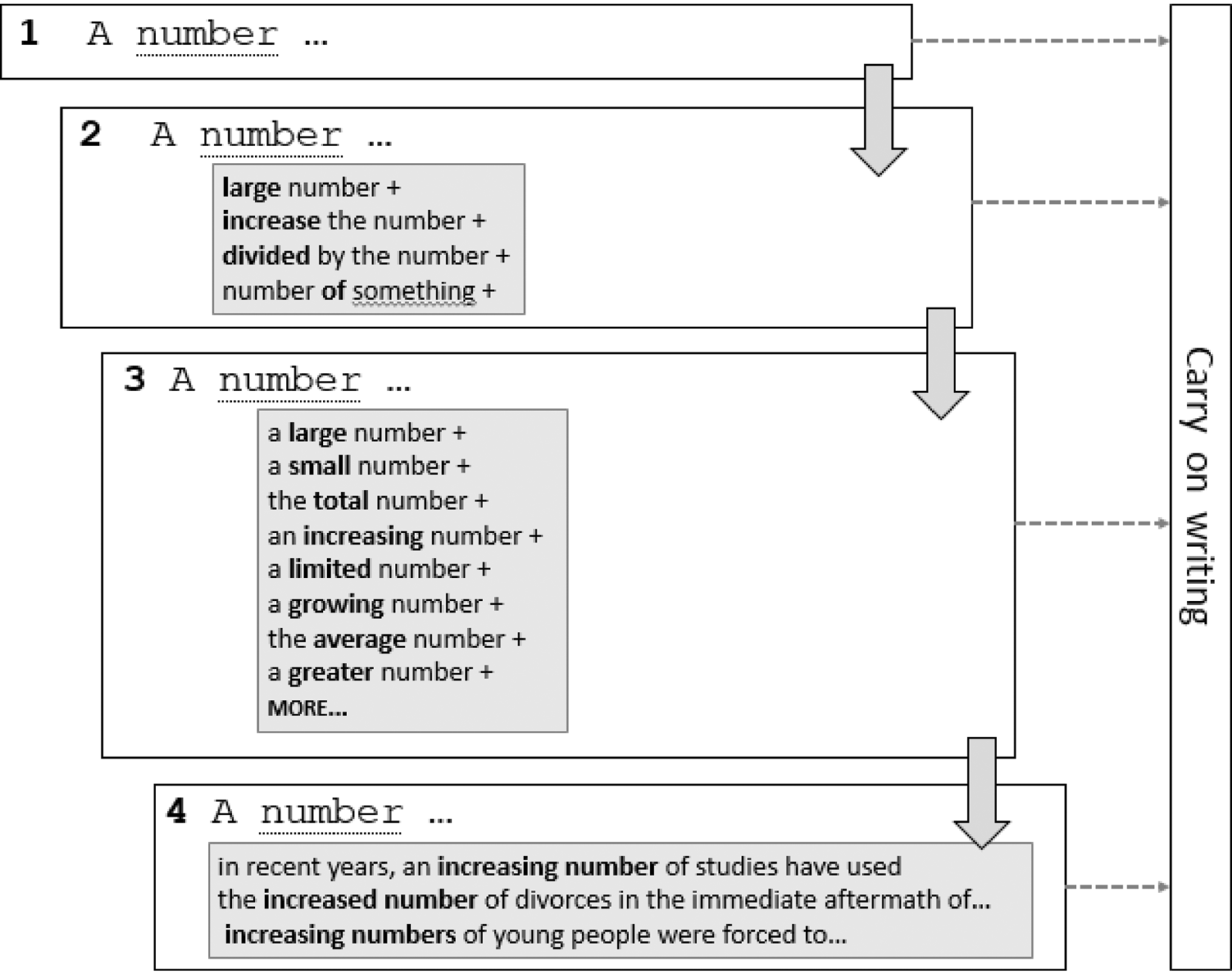
Should writers click on the highlighted lemma, they will be shown different academic collocations associated with it (Figure 2, Step 2). Note that instead of using metalanguage like adjective + number, verb + number, and so on, we have chosen to present this information by displaying the strongest collocate pertaining to each grammatical relation.Footnote 3 This has the double advantage of sheltering less linguistically aware users from grammar and enabling writers to find the collocate they need without any further interaction.
If Step 2 is not enough, users can click on the plus sign to expand a grammatical relation with further options. Step 3 of Figure 2 shows the expansion of large number with further adjectival collocates. Although in theory it would be possible to present a much greater number of suggestions at this point, we have opted to show a maximum of eight because of the known limitations of the working memory (Miller Reference Miller1956), and also so as not to overcrowd the text-editor screen. The collocates displayed are the first eight in terms of logDice strength of association score.Footnote 4 However, they can click on more to view further collocates on a side-bar.
If writers still need more details, in the next interaction they can click on the plus sign to view corpus-based examples showing the selected collocation in context. Step 4 in Figure 2 illustrates this with the expansion of an increasing number. Note that unlike dictionaries, which normally give only one (if any) example to illustrate a particular collocation, we have opted to present three analogous examples, following research showing that multiple examples tend to help more (Frankenberg-Garcia Reference Frankenberg-Garcia2012a, Reference Frankenberg-Garcia2014, Reference Frankenberg-Garcia2015). Since the examples have been curated to display further collocations and typical colligational patterns (see Section 5.2), it is likely that users will find one that can be transferred to their own texts with minimal adaptation. Note also the collocations in the examples are typographically enhanced, following research showing that this facilitates intake (Dziemianko Reference Dziemianko2014; Choi Reference Choi2017). Another benefit of examples is that they can help writers better understand the use of semantically similar collocations like increasing/growing number.
ColloCaid also aims to provide feedback on miscollocations or collocations that sound out of place in formal academic writing. As explained earlier, at a later stage in our research we will use learner corpora to research typical problem areas that can be addressed. Preliminary data from the British Academic Written English (BAWE) corpus of university student assignments (Nesi Reference Nesi, Frankenberg-Garcia, Flowerdew and Aston2011), for example, indicates novice EAP users tend to overuse informal collocations like a lot of time/research/information/effort/criticism, and brings to the surface miscollocations like *an increase of sales/profit/interest/production. To address this kind of problem, our preferred approach is to raise awareness and educate rather than autocorrect, as indicated in Figures 3 and 4.
(Colour online) Suggesting more appropriate collocations

(Colour online) Drawing attention to miscollocations

Finally, we also intend to allow users to customize collocation cues according to their needs. For example, it should be possible for writers to turn off real-time help and check their texts only when they wish, and hide or restore specific collocation prompts.
At the time of writing this paper, we have compiled circa 50% of our target lexicographic database and are working on how to best link it to a text-editing environment. In the next steps of our research, we intend to test an initial prototype with end-users and experts in order to enhance usability and develop appropriate design solutions. Additionally, we aim to forge partnerships with researchers focusing on EAP collocation problems among specific user groups to investigate how ColloCaid can be fine-tuned to their needs.
6. Conclusion
In this paper I have argued that despite the remarkable advances that have taken place in pedagogical lexicography over the past decades, dictionaries fail to address higher-level needs of writers efficiently and are rapidly losing ground to other tools and resources. The way forward would seem to be to bring dictionary information to writers rather than to wait for writers to become better users of dictionaries, hence the necessity to investigate the integration of user needs, lexicographic data and digital writing environments. In response to this challenge, we are taking a step beyond the static dictionary through the ColloCaid project, where we are researching ways to convey information on collocation to writers as they write, with minimal disruption of the writing process. A distinguishing characteristic of ColloCaid is that it is not limited to providing feedback on miscollocations. Its main aim is to ‘feed forward’, raising awareness of collocations writers may not remember or know how to look up. While the prototype we are developing is specifically for EAP users, the implications of our research can be broadened to other languages and beyond academic purposes.
Acknowledgements
I would like to thank the TechLing 2017 committee for inviting me to present this plenary at the University of Bologna in Forlì. The ColloCaid project is funded by the UK Arts and Humanities Research Council Grant AH/P003508/1.
Ana Frankenberg-Garcia is Reader in Translation Studies at the University of Surrey. Her research focuses on applied uses of corpora in translation, lexicography and language learning. She was Principal Investigator of Compara – a 3-million-word, open-access parallel corpus of English and Portuguese fiction – and Chief Editor of the bilingual, corpus-based Oxford Portuguese dictionary (2015). She is currently Principal Investigator of ColloCaid, an AHRC-funded project aimed at helping writers with collocations in real time. Outside the university, Ana has led various hands-on professional development workshops on practical applications of corpora.





 Open access
Open access