

1 Introduction
State-of-the-art syntactic dependency parsing delivers surface-syntactic structures (SSyntSs), which are per force idiosyncratic in that they are defined over the entire vocabulary of a language (including governed prepositions, determiners, support verb constructions, etc.) and language-specific grammatical functions such as, e.g., SBJ, OBJ, PRD, PMOD, etc.; see, among others (McDonald et al. Reference McDonald, Pereira, Ribarov and Hajič2005; Nivre et al. Reference Nivre, Hall, Nilsson, Chanev, Eryiǧit, Kübler, Marinov and Marsi2007b; Kübler, McDonald and Nivre 2009; Bohnet and Kuhn Reference Bohnet and Kuhn2012; Bohnet and Nivre Reference Bohnet and Nivre2012; Dyer et al. Reference Dyer, Ballesteros, Ling, Matthews and Smith2015). On the other hand, semantic (or deep) parsing delivers logical forms (LFs) or semantic structures (SemSs) equivalent to LFs,Footnote 1 PropBank (Palmer, Gildea and Kingsbury Reference Palmer, Gildea and Kingsbury2005) or FrameNet (Fillmore, Baker and Sato Reference Fillmore, Baker and Sato2002) structures (SemSs). See, for instance, Miyao (Reference Miyao2006), Oepen and Lønning (Reference Oepen and Lønning2006), Allen et al. (Reference Allen, Dzikovska, Manshadi and Swift2007), Bos (Reference Bos, Bos and Delmonte2008) and the DM- and PAS-parsers of the SemEval 2014 shared task (Oepen et al. Reference Oepen, Kuhlmann, Miyao, Zeman, Flickinger, Hajic, Ivanova and Zhang2014) for LF outputs. Some approaches deliver PropBank structure output (Johansson and Nugues Reference Johansson and Nugues2008a; Zhao et al. Reference Zhao, Chen, Kity and Zhou2009; Gesmundo et al. Reference Gesmundo, Henderson, Merlo and Titov2009; Henderson et al. Reference Henderson, Merlo, Titov and Musillo2013), and FrameNet structure output (Das et al. Reference Das, Chen, Martins, Schneider and Smith2014).
Parsers working with LFs tend to abstract not only over surface-oriented linguistic information (such as determination, tense, etc.) but also over distinctive (shallow) semantic relations. Thus, in Boxer (Bos Reference Bos, Bos and Delmonte2008) and in other parsers that produce LFs, the phrases the dancing girl and the girl dances will result in the same relation between ‘dance’ and ‘girl’. PropBank and FrameNet structures are forests of trees, defined over disambiguated lexemes or phrasal chunks and thematic roles (A0, A1, . . ., ARGM-DIR, ARGM-LOC, etc., in the case of PropBank structures and Agent, Object, Patient, Value, Time, Beneficiary, etc., in the case of Frame structures), with usually omitted attributive and coordinative relations (be they within chunks or sentential).
For many NLP-applications, including machine translation, paraphrasing, text simplification, etc., neither SSyntSs nor LFs or SemSs are adequate: the high idiosyncrasy of SSyntSs is obstructive because of the recurrent divergence between the source and the target structures, while the high abstraction of LFs and SemSs is problematic because of the loss of linguistic structure information in the case of LFs and dependencies between chunks and the loss of meaningful content elements in the case of SemSs. ‘Syntactico-semantic’ structures in the sense of deep-syntactic structures (DSyntSs) as defined in the Meaning-Text Theory (Mel’čuk Reference Mel’čuk1988) are in this sense arguably more appropriate. DSyntSs are situated between SSyntSs and LFs/SemSs. Compared to SSyntSs, they have the advantage to abstract from language-specific grammatical idiosyncrasies. Compared to LFs, PropBank and Frame structures, they have the advantage to be complete, i.e., capture all and distinguish all argumentative, attributive and coordinative dependencies between the meaning-bearing lexical items of a sentence, and to be connected. As a consequence, for instance, in the context of Machine Translation, DSyntSs help reduce the number and types of divergences between the source language
 ${\cal L}_S$
and destination language
${\cal L}_S$
and destination language
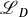 ${\cal L}_D$
structures to the minimum to make the transfer straightforward (Mel’čuk and Wanner Reference Mel’čuk and Wanner2006, Reference Mel’čuk and Wanner2008),Footnote
2
but are still syntactic and thus reflect the communicative intention of the speaker (Steedman Reference Steedman2000). Consider, for instance, a French–English sentence pair in (1).
${\cal L}_D$
structures to the minimum to make the transfer straightforward (Mel’čuk and Wanner Reference Mel’čuk and Wanner2006, Reference Mel’čuk and Wanner2008),Footnote
2
but are still syntactic and thus reflect the communicative intention of the speaker (Steedman Reference Steedman2000). Consider, for instance, a French–English sentence pair in (1).
-
(1) Fr. Qu’il soit l’invité de Mary me dérange
lit. ‘That he be the invited of Mary me bothers.’
≡
His being Mary's invitee bothers me.
In French, the subject has to be a full clause, hence the presence of a subordinating conjunction que ‘that’, which links the embedded verb and the main verb in the SSyntS. In addition, invité ‘invited’ has to bear a determiner, and the genitive construction is realized through the use of the preposition de ‘of’ (which is also possible although less idiomatic in English). Figure 1 shows the corresponding SSyntSs, PropBank structure, and Discourse Representation Structure (DRS) (the Propbank structure and DRS are, in principle, the same for both the French and the English sentence). As can be observed, the SSyntSs differ considerably, while the PropBank structure provides only a partial argumental structure, and the DRS blurs the difference between the main and the embedded clauses.Footnote 3 None of the variants is thus optimal for MT.
SSyntSs, PropBank structure, and DRS of (1).

The respective DSyntSs in Figure 2 avoid the idiosyncrasies of SSyntSs and the over-generalizations of PropBank/DRS. They are isomorphic and facilitate thus a straightforward transfer.
DSyntSs of (1).

Based on these observations, we propose to put on the research agenda of statistical parsing the task of deep-syntactic parsing. This task is not really novel. Thus the idea of the surface → surface syntax → deep syntax pipeline goes back at least to Curry (Reference Curry and Jacobson1961) and is implemented in a number of more recent works; cf. (Klimeš Reference Klimeš2006, Reference Klimeš2007), which produces tectogrammatical structures in the sense of the Prague school,Footnote 4 de Groote (Reference de Groote2001), which obtains a deep categorial grammar structure, and Rambow and Joshi (Reference Rambow, Joshi and Wanner1997), which provide a deep analysis in the TAG-framework. Moreover, in the SemEval 2014 shared task on Broad-Coverage Semantic Dependency Parsing, the target structures (Oepen et al. Reference Oepen, Kuhlmann, Miyao, Zeman, Flickinger, Hajic, Ivanova and Zhang2014) show a similarity with DSyntSs. However, as pointed out above and as will be argued further below in more detail, DSyntSs still show some advantages over most of the other common structures. Nonetheless, the primary goal of this paper is not to push forward the use of DSyntSs. Rather, we aim to propose a novel way to obtain DSyntSs (or structures that are equivalent to DSyntSs) from a SSynt dependency parse using data-driven tree transduction in a pipeline with a syntactic parser.
The paper is an extension of the paper presented by Ballesteros et al. (Reference Ballesteros, Bohnet, Mille and Wanner2014). Compared to Ballesteros et al. (Reference Ballesteros, Bohnet, Mille and Wanner2014), it contains a more detailed discussion of the theoretical background and of the data sets, more exhaustive experiments with more challenging baselines not only on Spanish, but also on Chinese and English, and a deeper analysis of the outcome of these experiments. The latest version of the source code and the package distribution of our DSynt parser are available at https://github.com/talnsoftware/deepsyntacticparsing/wiki.
The remainder of the paper is structured as follows. In Section 2, we introduce DSyntSs and SSyntSs. Section 3 discusses the fundamentals of SSyntS–DSyntS transduction. Section 4 describes the experiments that we carried out on Spanish, Chinese and English material, and Section 5 presents their outcome. Section 6 summarizes the related work, before in Section 7 some conclusions and plans for future work are presented.
2 Linguistic fundamentals of SSyntS–DSynt transduction
Before we set out to discuss the principles of the SSyntS–DSynt transduction, we define the notions of DSyntS and SSyntS as used in our experiments and the types of correspondences between the two.
2.1 The surface- and deep-syntactic structures
SSyntSs and DSyntSs are directed, node- and edge-labeled dependency trees with standard feature-value structures (Kasper and Rounds Reference Kasper and Rounds1986) as node labels and dependency relations as edge labels. Both differ, however, with respect to the abstraction of linguistic information: DSyntSs capture predicate-argument relations between meaning-bearing lexical items, while these relations are not captured by SSyntSs. At the same time, DSyntSs maintain the sentence structure (as SSyntSs do).
The features of the node labels in SSyntSs are lex, which captures the name of the lexical item, and ‘syntactic grammemes’ of this name, i.e., number, gender, case, person for nouns and tense, mood and finiteness for verbs. The value of lex can be any (either full or functional) lexical item. The edge labels of a SSyntS are grammatical functions ‘subj’, ‘dobj’, ‘det’, ‘modif’, etc. In other words, SSyntSs are syntactic structures of the kind as encountered in the standard dependency treebanks: dependency version of the Penn Treebank (PTB) (Johansson and Nugues Reference Johansson, Nugues, Nivre, Kaalep, Muischnek and Koit2007) for English, Prague Dependency Treebank for Czech (Hajič et al. Reference Hajič, Panevová, Hajičová, Sgall, Pajas, Štěpánek, Havelka, Mikulová and Žabokrtský2006), AnCora for Spanish (Taulé, Martí and Recasens Reference Taulé, Martí and Recasens2008), Copenhagen Dependency Treebank for Danish (Buch-Kromann Reference Buch-Kromann2003), etc. In formal terms, which we need for the outline of the transduction below, a SSyntS is defined as follows:
Definition 1 (SSyntS)
An SSyntS of a language
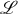 ${\cal L}$
is a quintuple TSS
= ⟨N, A, λ
ls
→ n
, ρ
rs
→ a
, γ
n → g
⟩ defined over all lexical items L of
${\cal L}$
, the set of syntactic grammemes Gsynt
, and the set of grammatical functions Rgr
, where
${\cal L}$
is a quintuple TSS
= ⟨N, A, λ
ls
→ n
, ρ
rs
→ a
, γ
n → g
⟩ defined over all lexical items L of
${\cal L}$
, the set of syntactic grammemes Gsynt
, and the set of grammatical functions Rgr
, where
-
• the set N of nodes and the set A of directed arcs form a connected tree,
-
• λ ls → n assigns to each n ∈ N an ls ∈ L,
-
• ρ rs → a assigns to each a ∈ A an r ∈ Rgr ,
-
• γ n → g assigns to each λ ls → n (n) a set of grammemes Gt ∈ Gsynt .
The top structure in Figure 3 shows a sample SSyntS, where the feature-value information for three nodes is made explicit for illustration. A more common graphical representation of a SSyntS (which does not show explicitly the features and their corresponding values) is displayed in Figure 4(a).
SSyntS (top) and DSyntS (bottom) for the sentence The producer thinks that the new song will be successful soon.

SSyntS and DSyntS for the sentence Almost 1.2 million jobs have been created by the state in that time.

The features of the node labels in DSyntSs are lex and ‘semantic grammemes’ of the value of lex, i.e., number and definiteness for nouns and tense, finiteness, mood, voice and aspect for verbs.Footnote 5 In contrast to lex in SSyntS, DSyntS's lex can be any full, but not a functional lexeme. In accordance with this restriction, in the case of look after a person, after will not appear in the corresponding DSyntS since it is a functional (or governed) preposition. In contrast, after in leave after the meeting will remain in the DSyntS because there it has its own meaning of ‘succession in time’. The edge labels of a DSyntS are ‘deep-syntactic’ relations I,. . .,VI, ATTR, COORD, APPEND. ‘I’,. . .,‘VI’ are argument relations, analogous to A0, A1, etc. in the PropBank annotation. ‘ATTR’ subsumes all (circumstantial) ARGM-x PropBank relations as well as the modifier relations not captured by the PropBank and FrameNet annotations. ‘COORD’ is the coordinative relation as in: John-COORD → and-II → Mary, publish-COORD → or-II → perish, and so on. APPEND subsumes all parentheticals, interjections, direct addresses, etc., as, e.g., in Listen, John!: listen-APPEND → John. DSyntSs thus show a strong similarity with PropBank structures, with four important differences: (i) their lexical labels are not disambiguated;Footnote 6 (ii) instead of circumstantial thematic roles of the kind ARGM-LOC, ARGM-DIR, etc. they use a unique ATTR relation; (iii) they capture all existing dependencies between meaning-bearing lexical nodes and (iv) they are connected. Formally, a DSyntS is defined as follows:
Definition 2 (DSyntS)
A DSyntS of a language
${\cal L}$
is a quintuple TDS
= ⟨N, A, λ
ls
→ n
, ρ
rs
→ a
, γ
n → g
⟩ defined over the full lexical items Ld
of
${\cal L}$
, the set of semantic grammemes Gsem
, and the set of deep-syntactic relations Rdsynt
, where
-
• the set N of nodes and the set A of directed arcs form a connected tree,
-
• λ ls → n assigns to each n ∈ N an ls ∈ Ld ,
-
• ρ rs → a assigns to each a ∈ A an r ∈ Rdsynt ,
-
• γ n → g assigns to each λ ls → n (n) a set of grammemes Gt ∈ Gsem .
The bottom structure in Figures 3 and 4(b) show examples of DSyntSs.
As mentioned, a number of other annotations have resemblance with DSyntSs. In particular, as already pointed out, DSyntSs show some resemblance but also some important differences with PropBank structures, mainly due to the fact that the latter concern phrasal chunks and not individual nodes. Figure 5 shows the PropBank structure that corresponds to the SSyntS and DSyntS in Figure 4. The square brackets in the PropBank structure indicate the constituents that implicitly form part of the arguments of A1 and AM-TMP, respectively.
PropBank structure of the sentence Almost 1.2 million jobs have been created by the state in that time.

The target structures of the SemEval 2014 shared task on Broad-Coverage Semantic Dependency Parsing (Oepen et al. Reference Oepen, Kuhlmann, Miyao, Zeman, Flickinger, Hajic, Ivanova and Zhang2014) also show some similarities with DSyntSs. For instance, the DELPH-IN annotation, which is a rough conversion of the Minimal Recursion Semantics treebank (Oepen and Lønning Reference Oepen and Lønning2006) into bi-lexical dependencies, also captures the lexical argument (or valency) structure and eliminates some functional elements (such as be copula and prepositions). The Enju annotation (Miyao Reference Miyao2006) is a pure predicate-argument graph over all the words of a sentence. However, it distinguishes arguments of functional elements (auxiliaries, infinitive and dative TO, THAT, WHETHER, FOR complementizers, passive BY) in that they are attached to the semantic heads of these elements (rather than to the elements themselves). This facilitates the disregard of functional elements – as in DSyntSs (cf. Ivanova et al. (Reference Ivanova, Oepen, Øvrelid and Flickinger2012) for a more complete overview of Enju and DELPH-IN).
The degree of ‘semanticity’ of DSyntSs can be directly compared to Prague's tectogrammatical structures (PDT-tecto (Hajič et al. Reference Hajič, Panevová, Hajičová, Sgall, Pajas, Štěpánek, Havelka, Mikulová and Žabokrtský2006)), which contain autosemantic words only. Synsemantic elements such as determiners, auxiliaries, prepositions and conjunctions are not kept in tectogrammatical structures. Thanks to the distinction between argumental and non-argumental edges, tectogrammatical structures are trees, not graphs. That is, as in the DSyntSs, they maintain the syntactic structure of the sentence. The main differences between DSyntSs and tectogrammatical structures are: (i) in tectogrammatical structures, no distinction is made between governed and non-governed prepositions and conjunctions, and (ii) in tectogrammatical structures, the vocabulary used for edge labels emphasizes ‘semantic’ content over predicate-argument information. For instance, a label like ADDR (addressee) indicates that the dependent is an argument of its governor, but does not say which slot is occupied in the valency frame of the latter. At the same time, this tag indicates that the dependent is the recipient of a message, which a simple ARG2 label for instance does not encode.Footnote 7 DSyntSs, on the other hand, have the advantage to directly encode predicate-argument structures and thus be straightforwardly connected to existing lexical resources such as PropBank or NomBank, and through these to deeper representation such as VerbNet (Schuler Reference Schuler2005) and FrameNet structures; see Palmer (Reference Palmer2009).
Although the annotations are not really of the same nature, DSyntSs can be furthermore contrasted to the Collapsed Stanford Dependencies (SD) (de Marneffe and Manning Reference de Marneffe and Manning2008). Collapsed SDs differ from DSyntSs (apart from the fact that that they may be (sometimes) disconnected graphs) in that: (i) in the same fashion as in the Prague Dependency Treebank, they collapse only (but all) prepositions, conjunctions and possessive clitics, whereas DSyntSs omit all functional nodes (all auxiliaries, some determiners, and some prepositions and conjunctions); (ii) they do not involve any removal of (syntactic) information since the meaning of the preposition remains encoded in the label of the collapsed dependency, while DSyntSs omit or generalize the purely functional elements; (iii) they do not add semantic information compared to the surface annotation. That is, Collapsed SDs keep the surface-syntactic information, representing it in a different format, while DSyntSs keep only deep-syntactic information. Consider Figure 6 for illustration.Footnote 8
Collapsed Stanford dependency structure of the sentence Almost 1.2 million jobs have been created by the state in that time.

As in all mentioned annotations (except in SD), the opposition between active and passive voice is neutralized in the DSynSs – for instance, both the first object of an active verb and the subject of a passive verb are annotated as second arguments. As in PDT-tecto, PropBank and SD, in DSyntSs multi-word expressions (MWEs) are handled through a specific dependency relation; in DRS and DELPH-IN, special predicates exist, which take as arguments the components of a MWE, while in Enju, MWEs are not annotated. In our current version of the DSyntSs (as in SD, DRS, DELPH-IN, and Enju), predicates are not disambiguated and light verb constructions, which are the most common type of MWEs, are annotated as regular constructions. In contrast, in the PropBank and PDT-tecto annotations, verbs and nouns are disambiguated, and an independent resource with lexical units and their valency frames is compiled (PropBank lexicon and PDT-VALLEX). In PropBank and PDT-tecto, light verb constructions are also annotated: as MWEs in PDT-tecto, and as independent lexical units in the PropBank lexicon. Finally, in DSyntSs, argument sharing is not represented, since at this level the structures must be trees and one node can thus receive one and only one incoming arc. In the Meaning-Text framework, argument sharing is made explicit at the semantic layer, where the structures are predicate-argument graphs. The PDT-tecto annotation is also arborescent, but its authors made the choice to annotate argument sharing by duplicating shared arguments in the tree for control and coordinate structures.Footnote 9 PropBank, SD, DRS, DELPH-IN and Enju, are graph representations, so shared arguments in coordinate and control constructions are not an issue. However, in PropBank and SD, special relations are used in some case of control constructions (and other phenomena), respectively C-AM and xsubj relations.
2.2 SSyntS–DSyntS correspondences
The implementation of the transduction from SSyntS to DSyntS requires a prior detailed analysis of the correspondences between elements of SSyntS and DSyntS. Let us thus discuss the correspondences between the two types of structures, based on the example in Figure 7 (in which the grammemes are not shown for the sake of clarity); we use a Spanish example (instead of, e.g., an English one) because it allows us to illustrate all relevant phenomena.
SSyntS and DSyntS of the sentence el profesor dice que se quejan mucho ‘the professor says that they complain a lot’.

The following correspondences between the SSyntS Sss and DSyntS Sds of a sentence need to be taken into account during the SSyntS–DSyntS transduction:Footnote 10
-
(i) A node in Sss is a node in Sds (Figure 8):
The node mucho ‘a-lot’ has a single correspondent in the DSyntS. This is also the case of the node profesor.
-
(ii) A relation in Sss corresponds to a relation in Sds (Figure 9):
The SSynt relation subj is mapped to the DSynt relation I. Note that the relation-to-relation mapping is not necessarily unique. Thus, subj is mapped to II (rather than to I) if the verb in the SSyntS is in passive.
-
(iii) A fragment of the Sss tree corresponds to a single node in Sds (Figure 10):
The words dice ‘say’ and que ‘that’ and the dependency between them (dobj) correspond to one single node in DSynt (decir ‘say’); in other words, que ‘that’ is not reflected in the DSyntS.
-
(iv) A relation with a dependent or governor node in Sss is a grammeme in Sds (Figure 11):
The relation det and its dependent, the definite determiner el ‘the’, are stored in the DSyntS as the grammeme of definiteness associated to the node profesor ‘professor’. Similarly, the auxiliary relations and their governors correspond to a grammeme of voice, tense, or aspect on the node of the dependent verb.Footnote 11
-
(v) A grammeme in Sss is a grammeme in Sds (Figure 12):
Number grammemes are maintained on nodes which can carry semantic number (that is, on nodes which do not have a number only for agreement reasons, as it can be the case for verbs in English, verbs, determiners and adjectives in Spanish and other languages, etc.), such as singular number on the node profesor ‘professor’. Other grammemes, such as those of tense, mood, or finiteness are mapped the same way.
-
(vi) A node in Sss is conflated with another node in Sds (Figure 13):
For this correspondence, the reflexive pronoun se ‘itself’/‘each other’ is part of the lemma of the verb in the DSyntS. In the SSyntS, it is separated in order to produce the sentence se quejan, lit. ‘themselves they-complain’.
-
(vii) A node in Sds has no correspondence in Sss (Figure 14):
A node in Sss is a node in Sds .

A relation in Sss corresponds to a relation in Sds .

A fragment of the Sss tree corresponds to a single node in Sds .

A relation with a dependent or governor node in Sss is a grammeme in Sds .

A grammeme in Sss is a grammeme in Sds .

A node in Sss is conflated with another node in Sds .

A node in Sds has no correspondence in Sss .

In Spanish, which is a pro-drop language, the subject of a finite verb does not need to be realized, even though there is a node at the DSynt level which accounts for the agreement found on the verb, for instance (third person plural in this case).
3 SSyntS–DSyntS transduction
In this section, we first flesh out the principles of the transduction between SSyntSs and DSyntSs and detail it then step by step.
3.1 Principles of the SSyntS–DSyntS transduction
In the above list of SSynt-DSynt correspondences, the grammeme correspondences (iv) and (v) and the ‘pseudo’ correspondences in (vi) and (vii) are few or idiosyncratic and are best handled in a rule-based post-processing stage; see Section 3.5. The main task of the SSyntS–DSyntS transducer is thus to cope with the correspondences (i)–(iii). For this purpose, we consider SSyntS and DSyntS trees as two-dimensional matrices I = N × N (with N as the set of nodes {1, . . ., m} of a given tree and
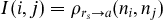 $I(i, j) = \rho _{{r_s}{\rightarrow} a}(n_i, n_j)$
if ni
, nj
∈ N and (ni
, nj
) = a ∈ A (i, j = 1, . . ., m; i ≠ j) and I(i, j) = 0 otherwise.Footnote
12
That is, for a given SSyntS, I(i, j) contains in the cell (i, j), i, j = 1, . . ., m (with i ≠ j) the name of the SSynt-relation that is encountered in the given tree between the nodes ni
and nj
. If no relation holds between ni
and nj
, the cell I(i, j) contains ‘0’. In analogy, for a given DSyntS, the cells contain DSyntS-relations between the corresponding nodes.
$I(i, j) = \rho _{{r_s}{\rightarrow} a}(n_i, n_j)$
if ni
, nj
∈ N and (ni
, nj
) = a ∈ A (i, j = 1, . . ., m; i ≠ j) and I(i, j) = 0 otherwise.Footnote
12
That is, for a given SSyntS, I(i, j) contains in the cell (i, j), i, j = 1, . . ., m (with i ≠ j) the name of the SSynt-relation that is encountered in the given tree between the nodes ni
and nj
. If no relation holds between ni
and nj
, the cell I(i, j) contains ‘0’. In analogy, for a given DSyntS, the cells contain DSyntS-relations between the corresponding nodes.
Starting from the matrix Is of a given SSyntS, the task is therefore to obtain the matrix Id of the corresponding DSyntS, that is, to identify correspondences between is respectively js , (is , js ) and groups of (is , js ) of Is with id respectively jd and (id , jd ) of Id ; see (i)–(iii) above. In other words, the task consists in identifying and removing all functional lexemes, and attach correctly the remaining nodes between them.Footnote 13
As already the projection of a chain of tokens onto an SSyntS, the SSyntS–DSyntS projection can be viewed as a classification task. However, while the ‘chain → surface-syntactic tree’ projection is isomorphic, the latter is not (see (iii)). In order to make it appear as an isomorphic projection, it is convenient to interpret SSyntS and the targeted DSyntS as collection of hypernodes; cf. Definition 3:
Definition 3 (Hypernode)
Given a SSyntS Ss with its matrix Is and a DSyntS Sd with its matrix Id , a node partition p (with ∣p∣ ⩾ 1) of Is /Id is a hypernode h si / h di iff p corresponds to a partition p′ (with ∣p′∣ ⩾ 1) of Sd /Ss .
In other words, a SSyntS hypernode, known as syntagm in linguistics, is any SSyntS configuration with a cardinality ⩾ 1 that corresponds to a single DSyntS node. The notion of hypernode is quite generic. It subsumes several types of correspondences discussed in Section 2.2 (namely, (i), (iii), (iv) and (vi)). For instance, dice que ‘says that’, el profesor ‘the professor’, and se quejan ‘(they) complain’ from the example above constitute hypernodes. Hypernodes can also contain more than two nodes, as in the case of more complex analytical verb forms, e.g., ha sido invitado ‘he-has been invited’, which corresponds to the node invitar ‘invite’ in the DSyntS.
In this way, the SSyntS–DSyntS correspondence boils down to a correspondence between individual hypernodes and between individual arcs, such that the transduction embraces the following three (classification) subtasks: (i) hypernode identification, (ii) DSynt tree reconstruction and (iii) DSynt arc labeling, which are completed by (iv) post-processing.
3.2 Hypernode identification
The hypernode identification consists of a binary classification of the nodes of a given SSyntS as nodes that form a hypernode of cardinality 1 (i.e., nodes that have a one-to-one correspondence to a node in the DSyntS) versus nodes that form part of a hypernode of cardinality > 1. In practice, hypernodes of the first type (henceforth, ‘type 1’ or ‘h1’) will be formed by: (1) noun nodes that do not govern (in)definite determiner or functional preposition nodes, (2) full verb nodes that are not governed by any auxiliary verb nodes and that do not govern any functional preposition node and (3) adjective, adverbial, and semantic preposition nodes which do not govern functional preposition nodes.
Hypernodes of the second type (henceforth, ‘type 2’ or ‘h2’) will be formed by: (1) noun nodes + (in)definite determiner + functional preposition nodes they govern, (2) verb nodes + auxiliary nodes they are governed by + functional preposition nodes they govern + reflexive pronoun se ‘oneself’ when it is part of the lemma of the verb and (3) adjective, adverbial, and semantic preposition nodes + functional preposition nodes they govern.
The following sentence shows different examples of hypernodes of type 1 (h1) and type 2 (h2):
-
(2) [El capitán de] h2 [la embarcación] h2 [se ha puesto a] h2 [cantar] h1 [cuando] h1 [ha visto a] h2 [cuatro] h1 [delfines] h1 [adultos] h1 [saltar] h1 [cerca de] h2 [nosotros] h1.
‘[The captain of] h2 [the boat] h2 [(reflexive+has) started to] h2 [sing] h1 [when] h1 [he-has seen prep] h2 [four] h1 [dolphins] h1 [adults] h1 [jump] h1 [next to] h2 [us] h1.’
3.3 DSynt tree reconstruction
The outcome of the hypernode identification stage is thus the set Hs = H s ∣p∣ = 1 ∪H s ∣p∣ > 1 of hypernodes of two types. With this set at hand, we can define an isomorphic function τ: Hs → H d ∣p∣ = 1 (with hd ∈ H d ∣p∣ = 1 consisting of nd ∈ Nds , i.e., the set of nodes of the target DSyntS). τ is the identity function for hs ∈ H s ∣p∣ = 1 . For hs ∈ H s ∣p∣ > 1 , τ maps the functional nodes in hs onto grammemes (attribute-value tags) of the meaning-bearing node in hd and identifies the meaning-bearing node as governor. Some of the dependencies of the obtained nodes nd ∈ Nds can be recovered from the dependencies of their sources. Due to the node removals (e.g., the projection of functional nodes to grammemes), some dependencies will be also missing and must be introduced. The algorithm in Figure 15 recalculates the dependencies for the target DSyntS Sd , starting from the matrix Is of SSyntS Ss to obtain a connected tree.
DSyntS tree reconstruction algorithm.

BestHead recursively ascends Ss from a given node ni until it encounters one or several governor nodes nd ∈ Nds . In case of several encountered governor nodes, the one which governs the highest frequency dependency is returned. Consider Figure 16 for illustration.
A sentence in its surface representation that shows two paths: [dep1] + [dep2] + [dep3] for the node3 and [dep1] + [dep4] for node4 . The nodes governor, node3 and node4 are kept in the deep structure. The other nodes (node1 and node2 ) are not included in the deep structure. The system has to decide whether node3 or node4 are attached to the governor.

3.4 DSynt arc labeling
The tree reconstruction stage produces a ‘hybrid’ connected dependency tree S s → d with DSynt nodes Nds , and arcs As labeled by SSynt relation labels (cf. left part of Figure 17), i.e., a matrix I −, whose cells (i, j) contain SSynt labels for all ni , nj ∈ Nds : (ni , nj ) ∈ As and ‘0’ otherwise. The next and last stage of SSynt-to-DSyntS transduction is thus the projection of SSynt relation labels of S s → d to their corresponding DSynt labels, or, in other words, the mapping of I − to Id of the target DSyntS (see Tables 2 and 3 for concrete examples).
Input (left) and output (right) of DSynt arc relabeling.

There are some labels that have a direct transduction (see Table 2 for direct SSynt-DSynt label correspondences in Spanish), while others have several candidates. For instance, and as shown in Table 3 for Spanish, the labels coord and copred are always transduced to COORD and ATTR respectively, while obl_obj may be mapped to II, III, IV or VI, depending on the other dependents of the governor of the current node. This is why it is necessary to include higher-order features based on the siblings of the node that is about to be transduced. Figure 17 shows an example of the relabeling: on the left side of the figure, the dependency labels are superficial (dep x ), whereas on the right side of the figure, the labels are the ones usually found in a DSyntS (dep Deepx ).
The system learns the SSynt-to-DSynt label projection (in training time) in order to be able to infer it during the test time. The training procedure outputs a multi-class classifier that detects the best DSynt label for each node, taking into account the features that are included in the procedure. Again, this module allows for two kinds of features: local features related to a node and higher-order features related to the governor node of a node that is being processed and features related to the sibling nodes.
3.5 Postprocessing
As mentioned in Section 2, there is a limited number of idiosyncratic correspondences between elements of SSyntS and DSyntS. The correspondences (iv–vii), depicted in Section 2.2 can be straightforwardly handled by a rule-based post-processor because (a) they are non-ambiguous, i.e., a↔b, c↔b⇒a = c∧a↔b, a↔d⇒b = d, and (b) they are few. The rule-based post-processor creates/copies grammemes and creates respectively collapses some nodes in the DSyntS:
-
(1) Tense and voice grammemes are introduced for verbal lexemes in accordance with the corresponding SSynt dependency relation (e.g., analyt_fut gives rise to ‘tense=FUT(ure)’, analyt_perf to ‘tense=PAST’, analyt_pass to ‘voice=PASS(ive)’, etc.); definiteness grammemes are introduced for nominal lexemes (e.g., the ← det- gives rise to ‘def=DEF’).
-
(2) If a number or tense grammeme is already assigned to a node ns in the SSyntS, it is copied to the node nd corresponding to ns in the DSyntS.
-
(3) A reflexive verb particle that is part of the verb lemma (as e.g., se in Spanish or si in Italian) or a pronoun (as e.g., sich in German) and its verbal governor in the SSyntS are collapsed in the DSyntS into a single node.
-
(4) If a pronoun in the SSyntS of a pro-drop language is omitted, a pronoun node is created and related to its verbal governor in the DSyntS. So far, this case has been implemented only for the zero subject in Spanish, for which the pronoun node is created, furnished with the number and person grammemes derived from the SSyntS and related to its verbal governor by an actantial relation which depends on the voice of the verb: I for active and II for passive, respectively.
4 Experiments
In order to validate the SSyntS–DSyntS transduction described in Section 3 and to assess its performance in combination with a surface dependency parser, i.e., starting from a plain sentence, we carried out a number of experiments in which we implemented the transducer and integrated it into the pipeline. Figure 18 shows the whole pipeline we set up.
Setup of a deep-syntactic parser.

4.1 The SSyntS and DSyntS treebanks
We carried out experiments on Spanish, English and Chinese.Footnote 14
For Spanish, we use the AnCora-UPF SSyntS and DSyntS treebanks (Mille, Burga and Wanner 2013) in CoNLL format,Footnote 15 which we adjusted for our needs. In particular, we removed from the 79-tags SSyntS treebank the semantically and information structure influenced relation tags to obtain an annotation granularity closer to the granularities used for previous parsing experiments (55 relation tags; see Mille et al. (Reference Mille, Burga, Ferraro and Wanner2012)). Unlike, e.g., PTB, in which syntactic (Penn TreeBank) and semantic role (ProbBank/NomBank) annotations are superimposed in the same CoNLL repository, in AnCora-UPF the SSyntSs and DSyntSs are separate treebanks,Footnote 16 which have been validated manually (Mille et al. Reference Mille, Burga and Wanner2013).
The treebanks have been divided into: (i) a training set (3,036 sentences, 57,665 tokens in the DSyntS treebank and 86,984 tokens in the SSyntS treebank); (ii) a development set (219 sentences, 3,271 tokens in the DSyntS treebank and 4,953 tokens in the SSyntS treebank); (iii) a held-out test set for evaluation (258 sentences, 5,641 tokens in the DSyntS treebank and 8,955 tokens in the SSyntS treebank).
For English, we use the PTB 3 (Marcus et al. Reference Marcus, Santorini, Marcinkiewicz, MacIntyre, Bies, Ferguson, Katz and Schasberger1994) dependency version (Hajič et al. Reference Hajič, Ciaramita, Johansson, Kawahara, Martí, Màrquez, Meyers, Nivre, Padó, Štěpánek, Straňák, Surdeanu, Xue and Zhang2009) as SSynt annotation. To derive from it the DSynt annotation,Footnote 17 we implemented graph-transduction grammars in the MATE environment (Bohnet and Wanner Reference Bohnet and Wanner2010).Footnote 18 The derivation removes all determiners, auxiliaries, that complementizers, infinitive markers to, punctuations and functional prepositions of verbs and predicative nouns. In order to obtain a DSynt annotation of a quality that is close to the quality of our annotation of the Spanish corpus, we used existing (manually annotated) lexical resources during the derivation, namely, PropBank (Kingsbury and Palmer Reference Kingsbury and Palmer2002) and NomBank (Meyers et al. Reference Meyers, Reeves, Macleod, Szekely, Zielinska, Young and Grishman2004).Footnote 19 In these two resources, 11,781 disambiguated predicates (5,577 nouns and 6,204 verbs) are described and their semantic roles are listed. For each of them, an important share of functional prepositions can be retrieved. To access the list of arguments of each predicate and for each argument the list of its functional prepositions, we draw upon two fields of the XML files of these resources: the last word of the field ‘descr’in ‘roles’, and the first word of the field of the corresponding role in ‘example’. In this way, we obtain, for instance, for the lexical unit beg.01 (Figure 19), the preposition from for the semantic role 1, and the preposition for for role 2. From the example field, we also retrieve for for role 2.
Sample PropBank entry.

For each disambiguated predicate of PropBank and NomBank, we add a new entry with the semantic roles and associated functional prepositions. The resulting dictionary allows us to obtain a DSynt layer freed from around 25,000 such prepositions.
Table 1 shows the quality of the obtained DSynt layer. The quality figures are based on the comparison of the DSyntSs of 300 sentences (6,979 SSynt and 4,976 DSynt tokens) of the PTB annotated manually with their automatically obtained equivalents. According to our error analysis, most errors of the automatic annotation are due to the fact that during the annotation, the only information that is available concerns verbs and nouns which govern preposition(s). In other words, functional prepositions governed by adjectives, adverbs or prepositions (e.g., thanks to ) cannot be identified automatically. Neither can be identified argument slots in genitive noun compounds, as explained in Sections 4.3.1–3 for Spanish. However, the automatic annotation is still of reasonable quality that allows us to use it for our experiments.
Quality of the automatic annotation of the PTB with the DSyntS layer

For our experiments, we kept the same training and test dataset split as in the CoNLL Shared Task 2009 (Hajič et al. Reference Hajič, Ciaramita, Johansson, Kawahara, Martí, Màrquez, Meyers, Nivre, Padó, Štěpánek, Straňák, Surdeanu, Xue and Zhang2009): 39,279 sentences for the training set and 2,399 sentences for the test set. This meant in the case of the training set 958,167 tokens in the SSyntS treebank and 711,491 tokens in the DSyntS treebank, and in the case of the test set 57,676 tokens in the SSyntS treebank and 42,467 tokens in the DSyntS treebank.
For Chinese, we use the Chinese Dependency Treebank (Xue et al. Reference Xue, Xia, Chiou and Palmer2004), which was mapped to the DSyntSs along the same lines as PTB 3, but using a graph transduction grammar tuned to Chinese syntax and without lexical resources. The mapping removes (i) aspectual markers (PoS AS), (ii) prepositions in beneficiary constructions (PoS BA), in verbal modifier constructions (PoS DER and DEV), in passives (PoS LB), and in verbal and nominal constructions with PoS DEC, DEG, and P in the case of the word jiu, (iii) localizers when they are combined with prepositions, (iv) certain particles (PoS SP and a subclass of MSP) and (v) punctuations.Footnote 20
The Chinese treebank has been divided into a training set of 31,131 sentences (718,716 tokens in the SSyntS treebank and 553,290 tokens in the DSyntS treebank) and a test set of 10,180 sentences (241,247 tokens in the SSyntS treebank and 186,710 tokens in the DSyntS treebank).
4.2 Getting the SSyntS
To obtain the SSyntS of all three languages with which we experiment, we use Bohnet and Nivre (Reference Bohnet and Nivre2012)'s transition-based parser, which combines PoS tagging and syntactic labeled dependency parsing. The parser uses a number of various techniques to obtain competitive accuracy such as beam search, a hash kernel that can employ a large number of features, and a graph-based completion model that re-scores the beam to capture the tree structure in terms of completed structures composed by up to three edges.
The parser was trained in twenty-five training iterations, using in each iteration the model from the preceding iteration for further processing. Given that the parser combines PoS and dependency parsing, we let the parser choose between the two best PoS tags. The threshold for the inclusion of PoS tags was set to a score of 0.25, and the size for the beam of the alternative PoS tags to 4.
4.3 From SSyntS to DSyntS
In what follows, we first present the realization of the SSyntS–DSyntS transducer and then the baseline that we use for the evaluation of the performance of the transducer. Given that we did the main development work on the Spanish treebanks, the examples in this subsection are given for Spanish and the performance reported for the development data set is for Spanish.
4.3.1 SSyntS–DSyntS transducer
As outlined in Section 3, the SSyntS–DSyntS transducer is composed of three main submodules ((1) Hypernode identification, (2) Tree reconstruction and (3) Relation label classification) and a post-processing submodule. Let us discuss each of them separately.
(1) Hypernode identification: For hypernode identification, we trained a binary Support Vector Machine (SVM) with polynomial kernel from The library for Support Vector Machines (LIBSVM) (Chang and Lin Reference Chang and Lin2001). The SVM allows for both features that are related to the processed node and higher-order features, which can be related to the governor node of the processed node or to its sibling nodes. After several feature selection trials, we chose the following features for each node n:
-
• lemma or stem of the label of n,
-
• label of the relation between n and its governor,
-
• surface PoS of n's label,Footnote 21
-
• label of the relation between n's governor to its own governor,
-
• surface PoS of the label of n’ governor node.
After an optimization round of the parameters available in the SVM implementation, the hypernode identification achieved over the Spanish gold development set 99.78% precision and 99.02% recall (and thus 99.4% F1).Footnote 22 That is, only very few hypernodes are not identified correctly. The main (if not the only) error source are governed prepositions; cf. Section 2: the classifier has to learn when to assign a preposition an own hypernode (i.e., when it is lexically meaning-bearing) and when it should be included into the hypernode of the verb/noun (i.e., when it is functional). Our interpretation is that the features we use for this task are appropriate, but that the training data set is too small. As a result, some prepositions are erroneously removed from or left in the DSyntS.
(2) Tree reconstruction: The implementation of the tree reconstruction module shows an unlabeled dependency attachment precision of 98.18% and an unlabeled dependency attachment recall of 97.43% over the Spanish gold development set. Most of the errors produced by this module have their origin in the previous module, that is, in the hypernode identification. When a node has been incorrectly removed, the module errs in the attachment because it cannot use the node in question as the destination or the origin of a dependency, as it is the case in the gold-standard annotation; cf. Figure 20.Footnote 23
Sample gold-standard and predicted DSyntSs: node erroneously removed from the DSyntS.

When a node has erroneously not been removed, no dependencies between its governor and its dependent can be established since DSyntS must remain a tree (which gives the same LAS and UAS errors as when a node has been erroneously removed); cf. Figure 21.
Sample gold-standard and predicted DSyntSs: node erroneously left in the DSyntS.

(3) Relation label classification: For relation label classification, we use a multi-class linear SVM. The label classification procedure depends on the concrete annotation schemata of the SSyntS and DSyntS treebanks on which the parser is trained. Some DSynt relation labels may be easier to derive from the original SSyntS relation labels than others. In Tables 2 and 3, we summarize the DSynt relation label derivation for the Spanish treebank.Footnote 24 Table 2 lists all Spanish SSynt relation labels that have a straightforward mapping to DSyntS relation labels, i.e., (i) neither their dependent nor their governor are removed, and (ii) the SSyntS label always maps to the same DSynt label. Table 3 shows SSyntS relation–DSyntS relation label correspondences that are not straightforward.
Straightforward SSynt to DSyntS DepRel mappings (Spanish)

Complex SSyntS to DSyntS mappings (Spanish); ‘Dep’ = ‘dependent’, ‘Gov’ = ‘governor’, ‘DepRel’ = ‘DSynt dependency relation’

Given that SSyntS is highly language-dependent, the SSyntS–DSyntS mappings must necessarily capture these idiosyncrasies. For instance, for Spanish as a pro-drop language we need to create in the DSyntS nodes that stand for zero subjects (i.e., subjects that do not appear in the SSyntS). Since the data-driven hypernode classifier only removes or keeps nodes, we implemented a simple rule-based approach for node creation. The system adds a node in the DSyntS when there is a finite verb that does not have a dependent which is a subject. This new node inherits the person and number from the verbal governor. This strategy is fully applicable to other languages as well since the system only needs as input the verbal PoS tag and the subjectival dependency relation.
The final set of features selected for label classification includes:
-
• lemma of the dependent node,
-
• dependency relation to the governor of the dependent node,
-
• dependency relation label of the governor node to its own governor,
-
• dependency relation to the governor of the sibling nodes of the dependent node, if any.
After an optimization round of the parameters set of the SVM model, relation labeling achieved 94.00% label precision and 93.28% label recall on the Spanish development set. The recall is calculated considering all the nodes that are included in the gold standard.
The error sources for relation labeling are mostly the dependencies that involve possessives and the various types of objects (see Table 3) due to their differing valency. For instance, the relation det in su ‘his’/‘her’ ← det − coche ‘car’ and su ‘his’/‘her’ ← det − llamada ‘phone call’ have different correspondences in DSyntS: su ← ATTR − coche versus su ← I − llamada. That is, the DSyntS relation depends on the lexical properties of the governor. Once again, more training data is needed in order to classify better those cases.
(4) Post-processing: In the post-processing stage for Spanish, the following rules capture non-ambiguous correspondences between elements of the SSynt matrix Is = Ns × Ns and DSyntS matrix Id = Nd × Nd , with ns ∈ Ns and nd ∈ Nd , and ns and nd corresponding to each other (we do not list here identity correspondences such as between the number grammemes of ns and nd ):
-
• if ns is either dependent of analyt_pass or governor of aux_refl_pass relation, then the voice grammeme in nd is PASS;
-
• if ns is dependent of analyt_progr, then the voice grammeme in nd is PROGR;
-
• if ns is dependent of analyt_fut, then the tense grammeme in nd is FUT;
-
• if ns is governor of aux_refl_lex, then add the particle -se as suffix of node label (word token) of dd ;
-
• if any of the children of ns with the dependency label det is labeled by one of the tokens un, una, unos or unas, then the definiteness grammeme in nd is INDEF; this grammeme is DEF for the tokens el, la, los and las;
-
• if the ns label is a finite verb and ns does not govern a subject relation, then add to Id the relation nd − I → n′ d , with n′ d being a newly introduced node.
4.3.2 Baseline
For the evaluation of the performance of our SSyntS–DSyntS transducer, we use a rule-based SSyntS–DSyntS mapping baseline.
The baseline carries out the most direct SSynt–DSynt relation label projections following the SSyntS–DSyntS relation mapping tables compiled for each language (see Tables 2 and 3 for Spanish). It removes all nodes which are systematically absent from the DSynt corpus (determiners, auxiliaries, infinitive markers, punctuations, etc.), and also prepositions and conjunctions involved in a dependency which indicates the possible presence of a governed preposition (e.g., compar_conj or dobj in Table 3). The baseline always produces connected trees.
The rules of the rule-based baseline look as follows:
-
1 if (deprel==abbrev) then deep_deprel=ATTR
-
2 if (deprel==obl_obj) then deep_deprel=II
-
. . .
-
n if (deprel==punc) then remove(current_node)
5 Results and discussion
To assess the performance of our SSyntS–DSyntS transducer in isolation and in a pipeline with a SSyntS parser, we carried out a number of experiments on Spanish, English and Chinese. Before we report on the performance figures obtained during these experiments, let us first introduce the evaluation measures we use.
5.1 Evaluation measures
To measure the performance of the SSyntS–DSyntS transducer, we came up with a number of evaluation measures for hypernode detection and node attachment.
The measures for hypernode detection are:
-
• Precision of the hypernode detection: ph = ∣Hcorr ∣/∣Hpred ∣ (with ∣Hcorr ∣ as the number of correctly predicted hypernodes and ∣Hpred ∣ as the total number of predicted hypernodes);
-
• Recall of the hypernode detection: rh = ∣Hcorr ∣/∣Hg ∣ (with ∣Hcorr ∣ as the number of correctly predicted hypernodes and ∣Hg ∣ as the number of hypernodes in the gold standard);
-
• F-measure of the hyper-node detection: F1 h = 2ph .rh /(ph + rh ).
The measures to assess the precision of node attachment are:
-
• Unlabeled attachment precision: UAP = ∣Ngovernor ∣/∣N∣ (with ∣Ngovernor ∣ as the number of nodes with a correctly predicted governor, and ∣N∣ as the total number of predicted nodes);
-
• Label assignment precision: LA − P = ∣N gov.rel.label ∣/∣N∣ (with ∣N gov.rel.label ∣ as the number of nodes for whose governing relation the label has been correctly predicted, and ∣N∣ as the total number of predicted nodes);
-
• Labeled attachment precision: LAP = ∣N governor.label ∣/∣N∣ (with ∣N governor.label ∣ as the number of nodes with a correctly predicted governor and governing relation label, and ∣N∣ as the total number of predicted nodes).
The measures to assess the recall of the node attachment are:
-
• Unlabeled attachment recall: UAR = ∣Ngovernor ∣/∣Ng ∣ (with ∣Ngovernor ∣ as the number of nodes with a correctly predicted governor, and ∣Ng ∣ as the total number of gold nodes);
-
• Label assignment recall: LA − R = ∣N gov.rel.label ∣/∣Ng ∣ (with ∣N gov.rel.label ∣ as the number of nodes for whose governing relation the label has been correctly predicted, and ∣Ng ∣ as the total number of gold nodes);
-
• Labeled attachment recall: LAR = ∣N governor.label ∣/∣Ng ∣ (with ∣N governor.label ∣ as the number of nodes with a correctly predicted governor and governing relation label, and ∣Ng ∣ as the total number of gold nodes).
5.2 SSyntS–DSyntS transducer results
In Tables 4–6, the performance of the subtasks of the SSyntS–DSyntS transducer for Spanish, Chinese and English respectively is contrasted to the performance of the rule-based baseline; we do not include the evaluation of the post-processing subtask for Spanish because the one-to-one projection of SSyntS elements to DSyntS captured by the rules of the post-processing submodule guarantees an accuracy of 100% of the operations performed, when starting from gold SSyntS trees.
Performance of the SSyntS–DSyntS transducer and of the rule-based baseline over the Spanish gold-standard held-out test set

Performance of the SSyntS–DSyntS transducer and of the rule-based baseline over the English gold-standard held-out test set

Performance of the SSyntS–DSyntS transducer and of the rule-based baseline over the Chinese gold-standard held-out test set

The transducer has been applied to the gold standard test sets, which are the held-out test sets presented in Section 4.1, with gold standard PoS tags, gold-standard lemmas and gold-standard dependency trees. In the case of Spanish, the transducer outputs in total 5,610 nodes. The rule-based baseline produces an output that contains 5,902 nodes. As mentioned in Section 4.1, our gold standard includes 5,641 nodes. In the case of English, the transducer outputs in total 43,472 nodes. In this case, the rule-based baseline produces an output that contains 43,510 nodes, while the gold standard includes 43,301 nodes. Finally, for Chinese, the transducer outputs in total 186,809 nodes. The rule-based baseline produces an output with 192,078 nodes, while the gold standard has 186,710 nodes.
Our data-driven SSyntS–DSyntS transducer is significantly better than the baseline with respect to all evaluation measures. The transducer relies on distributional patterns identified in the training data set, and makes thus use of information that is not available to the rule-based baseline, which merely takes into account one node and its immediate parent at a time.
However, the rule-based baseline results also show that transduction that would remove a few nodes would obtain a performance close to a 100% recall for the hypernode detection because a DSynt tree is a subtree of the SSynt tree (if we ignore the nodes introduced by post-processing). This is also evidenced by the label and attachment recall scores.
For Spanish, which is the language we used for the system development (Ballesteros et al. Reference Ballesteros, Bohnet, Mille and Wanner2014), the results of the transducer on the test and development sets are quite comparable. For convenience of the reader, the development set figures are repeated in Table 7.
Performance of the SSyntS–DSyntS transducer over the Spanish development set

The hypernode detection is even better on the test set. Label assignment precision and recall are the measures that suffer most from using unseen data during the development of the system. The attachment figures are more or less equivalent on both sets.
It is also worth noting that the Chinese results confirm that the SSyntS–DSyntS Chinese mapping is rather straightforward. This is why the baseline provides very competitive results. However, the data-driven system is capable of improving these results and even achieve figures that are very close to a perfect mapping. In English, the difference between the baseline and the data-driven system is significant, since, unlike in Chinese, the predicates are annotated using a manually supervised resource (see Section 4.1). The difference is even more striking with Spanish, due to the fact that the DSyntS treebank has been revised manually in several iterations (Mille et al. Reference Mille, Burga and Wanner2013).
5.3 Results of deep-syntactic parsing
Let us consider now the performance of the complete DSynt parsing pipeline, i.e., PoS-tagger+surface-dependency parser → SSyntS–DSyntS transducer on the held-out test set. Table 8 displays the figures of the Bohnet and Nivre parser for Spanish, English and Chinese respectively. The figures are in line with the performance of state-of-the-art parsers for Spanish (Mille et al. Reference Mille, Burga, Ferraro and Wanner2012), English and Chinese (Ballesteros and Bohnet Reference Ballesteros and Bohnet2014). Note that for Chinese we did not predict the lemmas (there are no lemmatized forms in the treebank), but rather used gold standard forms instead.
Performance of Bohnet and Nivre's joint PoS-tagger+dependency parser trained on the Ancora-UPF treebank for Spanish, PTB treebank for English, and the CTB treebank for Chinese

Tables 9–11 show the performance of the pipeline when we feed the outputs of the syntactic parser to the rule-based baseline module and the SSyntS–DSyntS transducer for Spanish, English and Chinese, respectively.
Performance of the rule-based baseline and the SSyntS–DSyntS transducer over the Spanish predicted held-out test set

Performance of the rule-based baseline and the SSyntS–DSyntS transducer over the English predicted held-out test set

Performance of the rule-based baseline and the SSyntS–DSyntS transducer over the Chinese predicted held-out test set

In the case of Spanish, we observe a clear error propagation from the dependency parser (which provides 81.45% LAS) to the SSyntS–DSyntS transducer, which loses in tree quality about 18%: the difference between 90.57% (Table 4) and 67.26% LAS (Table 9) is more than 23%. For Chinese and English, we observe a similar behavior, but in this case the system is capable to recover better from the erroneous output of the surface parser. This is because the mapping from SSyntS to DSyntS is simpler, and thus the system achieves a higher performance (closer to the performance of the surface parser).
To observe the influence of the automatic conversion of the DSyntS layer of the English treebank on the quality of the SSyntS–DSyntS transducer, we ran it on a manually annotated DSyntS test set of 300 sentences over the gold surface-standard held-out test set (Table 12) and over the predicted surface-standard held-out test set (Table 13). Compared to the performance on the automatically obtained DSyntS test set (see Tables 5 and 10), the performance is somewhat lower (due to the fact that manually annotated, i.e., ideal, DSyntSs are more diverging from the SSyntSs than automatically derived ones). However, it is still high enough to provide reasonably well-formed and correct DSyntSs for downstream applications.
Performance of the rule-based baseline and the SSyntS–DSyntS transducer over the English surface gold-standard held-out test set and the manually annotated DSyntS test set

Performance of the rule-based baseline and the SSyntS–DSyntS transducer over the English surface predicted held-out test set and the manually annotated DSyntS test set

é tenemos peor recall en el ml system As we observe in Tables 12 and 13, the recall of the rule-based baseline is a little bit higher than the one obtained with the machine learning approach, however the precision is much higher for the machine-learning system. Since the output trees of the rule-based baseline have more nodes, it provides a more recall oriented system, but it suffers more in precision, leading to lower F1 scores for all measures. Moreover, since the machine learning model is trained on partially (and not fully manually) validated sentences, the parser tries to predict the annotation provided in the partially validated sentences.
6 Related work
As already pointed out in Section 1, the idea of deep parsing is not novel: it goes back at least to Curry (Reference Curry and Jacobson1961) and has already been addressed in some depth in the early days of Natural Language Processing in the context of language understanding (Bobrow and Webber Reference Bobrow and Webber1981; Dahlgren Reference Dahlgren1988). Over the years, some authors continued to work on rule-based proposals for deep parsing in different theoretical frameworks. Among others, Rambow and Joshi (Reference Rambow, Joshi and Wanner1997) proposed a deep analysis proposal in the TAG-framework, de Groote (Reference de Groote2001) proposed something similar in the CCG framework. There have also been proposals in the Prague School Dependency framework (Klimeš Reference Klimeš2006). More recently, the importance of deep linguistic processing for parsing has been reiterated, e.g., by Baldwin et al. (Reference Baldwin, Dras, Hockenmaier, King and van Noord2007). However, to the best of our knowledge, data-driven deep-syntactic parsing as proposed in this article is novel.
As data-driven semantic role labeling, frame-semantic analysis, and logical form analysis, DSynt parsing has the goal to obtain more semantically-oriented structures than those delivered by state-of-the-art syntactic parsing (McDonald et al. Reference McDonald, Pereira, Ribarov and Hajič2005; Nivre et al. Reference Nivre, Hall, Nilsson, Chanev, Eryiǧit, Kübler, Marinov and Marsi2007b; Kübler et al. Reference Kübler, McDonald and Nivre2009; Bohnet and Kuhn Reference Bohnet and Kuhn2012; Bohnet and Nivre Reference Bohnet and Nivre2012; Dyer et al. Reference Dyer, Ballesteros, Ling, Matthews and Smith2015). Semantic role labeling received considerable attention in the CoNLL shared tasks for syntactic dependency parsing in 2006 and 2007 (Buchholz and Marsi Reference Buchholz and Marsi2006; Nivre et al. Reference Nivre, Hall, Kübler, McDonald, Nilsson, Riedel and Yuret2007a), the CoNLL shared task for joint parsing of syntactic and semantic dependencies in 2008 (Surdeanu et al. Reference Surdeanu, Johansson, Meyers, Màrquez and Nivre2008) and the shared task in 2009 (Hajič et al. Reference Hajič, Ciaramita, Johansson, Kawahara, Martí, Màrquez, Meyers, Nivre, Padó, Štěpánek, Straňák, Surdeanu, Xue and Zhang2009). The top ranked systems were pipelines that started with a syntactic analysis (as we do) and continued with predicate identification, argument identification, argument labeling, and word sense disambiguation (WSD); cf. Johansson and Nugues (Reference Johansson and Nugues2008b) and Che et al. (Reference Che, Li, Li, Guo, Qin and Liu2009). At the end, a re-ranker that considers jointly all arguments to select the best combination was applied. Some of the systems were based on integrated syntactic and semantic dependency analysis; cf., e.g., Gesmundo et al. (Reference Gesmundo, Henderson, Merlo and Titov2009); see also Lluís, Carreras and Màrquez (Reference Lluís, Carreras and Màrquez2013) for a more recent proposal along similar lines. However, all of them lack the ability to perform necessary structural changes – as, e.g., introduction of nodes or removal of nodes necessary to obtain a DSyntS.
Logical form analyzers such as Boxer (Bos Reference Bos, Bos and Delmonte2008) tend also to pipeline syntactic and deep parsing, as we do. In the case of Boxer, a CCG parser is integrated into a pipeline with the DRS parser. However, they output abstract structures that are void of any syntactic dependencies – which can however be important for some applications (such as Machine Translation).
Finally, even though, as discussed in Section 2.1, the deep structures used in SemEval 2014 (Oepen et al. Reference Oepen, Kuhlmann, Miyao, Zeman, Flickinger, Hajic, Ivanova and Zhang2014) are different from DSyntSs, the systems solve a similar problem. Among the best performing systems, are Priberam (Martins and Almeida Reference Martins and Almeida2014) and CMU (Flanigan et al. Reference Flanigan, Thomson, O’Connor, Bamman, Schneider, Dodge, Swayamdipta, Dyer and Smith2014), which follow graph-based approaches. Alpage (Ribeyre, De La Clergerie and Seddah Reference Ribeyre, De La Clergerie and Seddah2014) and Peking (Du et al. Reference Du, Zhang, Sun and Wan2014) are similar to our approach since they propose transition-based parsing algorithms for DAGs, similar to the one presented by Sagae and Tsujii (Reference Sagae and Tsujii2008), where the usual set of transitions is different in each task. Both Alpage and Peking transform graphs into trees. Turku (Kanerva, Luotolahti and Ginter Reference Kanerva, Luotolahti and Ginter2014) is also similar to our proposal since it works with a cascade of classifiers. In contrast to Turku, however, we present a joint transition-based dependency parser tagger for getting the SSyntS from plain text sentences and a cascade of classifiers to transduce the SSyntS then to the DSyntS.
7 Conclusions and future work
We have presented a novel data-driven deep-syntactic parsing pipeline which consists of a state-of-the-art dependency parser and a SSyntS–DSyntS transducer. The DSyntSs provided by the pipeline can be used in different applications since they abstract from language-specific grammatical idiosyncrasies of the SSynt structures as produced by state-of-the art dependency parsers, but still avoid the complexities of genuine semantic analysis. DSyntS treebanks needed for data-driven applications can be bootstrapped by the pipeline. If required, a SSyntS–DSyntS structure pair can be also mapped to a pure predicate-argument graph such as the Enju conversion (Miyao Reference Miyao2006), to an DRS (Kamp and Reyle Reference Kamp and Reyle1993), or to a PropBank structure. An online demo (Soler-Company et al. Reference Soler-Company, Ballesteros, Bohnet, Mille and Wanner2015) of our DSynt parser is available at http://dparse.multisensor.taln.upf.edu/main.
In the future, we will carry out further in-depth feature engineering for the task of DSynt parsing. It proved to be crucial in semantic role labeling and dependency parsing (Che et al. Reference Che, Li, Li, Guo, Qin and Liu2009; Ballesteros and Nivre Reference Ballesteros and Nivre2012); we expect it be essential for our task as well. Furthermore, we will join surface-syntactic and deep-syntactic parsing we kept so far separately; see, e.g., Zhang and Clark (Reference Zhang and Clark2008), Bohnet and Nivre (Reference Bohnet and Nivre2012), Lluís et al. (Reference Lluís, Carreras and Màrquez2013) for analogous proposals. Further research is required here since although joined models avoid error propagation from the first stage to the second, they need to bridge a broader abstraction moat – which is why pipelined models still prove to be competitive; cf. the outcome of CoNLL shared tasks.
We will try to improve the English and Chinese DSyntS treebanks we obtained by automatic conversion in order to make them genuine DSyntS treebanks (and thus more comparable to the Spanish DSyntS treebank we work with). This will allow our DSynt parser to also provide genuine DSyntSs, with no traces of SSyntSs left in its output.
Finally, our DSynt parser could be exploited in machine translation or summarization by using it jointly with a DSyntS generator such as the one presented by (Ballesteros et al. Reference Ballesteros, Bohnet, Mille and Wanner2015).


































