


1. Introduction
Data-to-text (D2T) generation, the task of automatically generating text from structured nonlinguistic data or meaning representation (MR), is an important research problem for various NLP applications such as task-oriented dialog, question answering, machine translation, image captioning, selective generation systems, and search engines (Reiter Reference Reiter2007). Examples of MRs and their corresponding texts are shown in Fig. 1. In addition to being fluent and coherent, the generated text should cover all and only the information provided in the MRs (Rebuffel et al. Reference Rebuffel, Roberti, Soulier, Scoutheeten, Cancelliere and Gallinari2022). Traditional approaches for solving this problem have used rule-based (Gkatzia, Lemon, and Rieser Reference Gkatzia, Lemon and Rieser2016) or grammar-based (Mille, Dasiopoulou, and Wanner Reference Mille, Dasiopoulou and Wanner2019) methods. Recently, the use of deep learning methods has expanded. These methods have been able to produce more fluent and diverse sentences compared to traditional methods (Wang, Schwing, and Lazebnik Reference Wang, Schwing and Lazebnik2017; Panagiaris, Hart, and Gkatzia Reference Panagiaris, Hart and Gkatzia2020; Schuz, Han, and Zarriess Reference Schuz, Han and Zarriess2021). One of the most common deep learning methods is to use the maximum likelihood estimation (MLE) loss function. D2T models trained with this method, which are generally based on RNN networks (Wen et al. Reference Wen, Gasic, Kim, Mrksic, Su, Vandyke and Young2015a, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Youngb, Reference Wen, Gasic, Mrksic, Su, Vandyke and Youngc, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2016; Dusek and Jurcicek Reference Dusek and Jurcicek2016; Mei, Bansal, and Walter Reference Mei, Bansal and Walter2016; Nayak et al. Reference Nayak, Hakkani-Tur, Walker and Heck2017; Riou et al. Reference Riou, Jabaian, Huet and Lefèvre2017; Gehrmann, Dai, and Elder Reference Gehrmann, Dai and Elder2018; Juraska et al. Reference Juraska, Karagiannis, Bowden and Walker2018; Liu et al. Reference Liu, Wang, Sha, Chang and Sui2018; Oraby et al. Reference Oraby, Reed, Tandon, S., Lukin and Walker2018; Sha et al. Reference Sha, Mou, Liu, Poupart, Li, Chang and Sui2018) or transformers (Gehrmann et al. Reference Gehrmann, Dai and Elder2018; Gong Reference Gong2018; Radford et al. Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019; Kasner and Dušek Reference Kasner and Dušek2020a; Peng et al. Reference Peng, Zhu, Li, Li, Li, Zeng and Gao2020; Harkous, Groves, and Saffari Reference Harkous, Groves and Saffari2020; Chen et al. Reference Chen, Eavani, Liu and Wang2020; Kale and Rastogi Reference Kale and Rastogi2020a; Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020; Chang et al. Reference Chang, Shen, Zhu, Demberg and Su2021; Lee Reference Lee2021), auto-regressively generate each output token based on the sequence of previously generated tokens. Although these methods have achieved good performance on the D2T task, they also have problems. One of the major drawbacks of these methods is exposure bias caused by the difference between the training and testing phases. In the training phase, the ground-truth tokens are used as the model input, but in the test phase, the token generated in the previous step is used as the next step input. In this case, if the previously generated token is incorrect, the tokens that are subsequently generated will also be incorrect. Another problem with these methods, which is related to the nature of MLE, is the sensitivity to rare examples in the training dataset, which leads to a cautious prediction of the real data distribution. As a result of these problems, the produced text could still be dull, unnatural, and also containing incoherent representations. Moreover, since these methods have little control over the semantic flow in the process of generating text, the output sentences have duplicate and redundant information or lack parts of the input information in the output text (Juraska and Walker Reference Juraska and Walker2021).
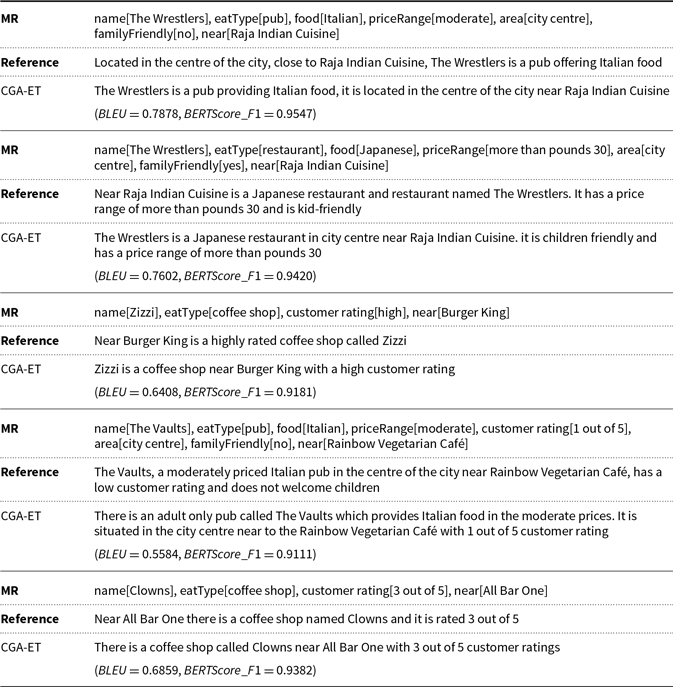
Sample meaning representation (MR) and text chosen from (a) WebNLG, (b) MultiWoz, and (c) E2E datasets.

In contrast to MLE, there is another class of deep learning-based methods called generative adversarial network (GAN) (Goodfellow et al. Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014), which aims to generate texts by an unsupervised learning approach (Kusner and Hernández-Lobato Reference Kusner and Hernández-Lobato2016; Zhang et al. Reference Zhang, Gan, Fan, Chen, Henao, Shen and Carin2017; Yu et al. Reference Yu, Zhang, Wang and Yu2017; Che et al. Reference Che, Li, Zhang, Hjelm, Li, Song and Bengio2017; Lin et al. Reference Lin, Li, He, Zhang and Sun2017; Gou et al. Reference Gou, Lu, Zhang, Yu and Wang2017; Fedus, Goodfellow, and Dai Reference Fedus, Goodfellow and Dai2018; Xu et al. Reference Xu, Ren, Lin and Sun2018; Wang and Wan Reference Wang and Wan2018; Chen et al. Reference Chen, Dai, Tao, Shen, Gan, Zhang, Zhang and Carin2018; Nie, Narodytska, and Patel Reference Nie, Narodytska and Patel2019; Jiao and Ren Reference Jiao and Ren2021). The GAN model includes the generator and discriminator networks. The generator network tries to generate a sample similar to the real sample by taking the noise signal, and the discriminator network moves the generator in the right direction and generates samples closer to real samples by distinguishing real samples from the fake ones. This results in solving the exposure bias problem. However, training of the GANs faces challenges such as the instability of the training process and the mode collapse problem (Ledig et al. Reference Ledig, Theis, Huszar, Caballero, Aitken, Tejani, Totz, Wang and Shi2017). Mode collapse occurs when the generator finds a small number of template that fool the discriminator. Therefore, generator is not able to generate any sentences other than this limited set of templates.
To improve the quality of the generated sentences in terms of semantics, verbal, and diversity, we propose a novel model for D2T generation named conditional generative adversarial with enhanced transformer (CGA-ET). The generator network in the proposed model is our enhanced version of the vanilla transformer encoder and decoder (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). Since input of D2T models is an MR containing a set of distinct slots, which must be expressed in the output text completely without redundancy or repetition, we modified self-attention of each encoder block with a diagonal mask and added history of each slot’s attention weights to multi-head cross-attention of its decoder. Furthermore, for strengthening the generator in order to generate diverse and verbally correct sentences, we use the triplet network (Hoffer and Ailon Reference Hoffer and Ailon2015), including the vanilla transformer encoder blocks, as the discriminator network. The triplet network takes triplet sets of input MR, real and fake sentences as input, extracts sets of rich context vectors from them, and tries to update its parameters in a way that the semantic similarity between the input MR and the real sentence is greater than the semantic similarity between the input MR and the fake sentence. In this way, the discriminator networks guide the generator to generate sentences that are semantically and structurally close to the input MR as well as the real sentence. In addition, in order to stabilize the model training process, the WGAN-GP (Gulrajani et al. Reference Gulrajani, Ahmed, Arjovsky, Dumoulin and Courville2017) loss function is used. To evaluate the performance of the CGA-ET model, experiments are performed on the WebNLG (Castro Ferreira et al. Reference Castro Ferreira, Gardent, Ilinykh, Lee, Mille, Moussallem and Shimorina2020), MultiWoz (Budzianowski et al. Reference Budzianowski, Wen, Tseng, Casanueva, Ultes, Ramadan and Gasic2018), and E2E (Dusek, Howcroft, and Rieser Reference Dusek, Howcroft and Rieser2019) datasets. The results of comparing the CGA-ET with state-of-the-art models demonstrate the superiority and efficiency of our proposed model.
The major contributions of this paper are summarized below:
-
We introduce an enhanced version of the vanilla transformer encoder and decoder for the D2T generation task. In this model, a diagonal mask matrix is added to the self-attention scores of each encoder block, and the history of multi-head cross-attention scores of previously generated tokens between encoder and decoder is used to compute attention weights of the current token in the decoder. This decreases semantic errors in the output sentences.
-
We introduce a new model called CGA-ET, which uses our enhanced version of the vanilla transformer encoder and decoder as the generator and the triplet network containing transformer encoder blocks as the discriminator.
-
We use a combination of the WGAN-GP and triplet loss functions to train the model, so while stabilizing the model training process, by controlling the semantic similarity of the sentences and then generating diverse sentences, the mode collapse problem is prevented.
The rest of our paper is structured as follows: Section 2 presents related works. Section 3 presents the proposed CGA-ET model. Datasets, experimental setups, and evaluation metrics are described in Section 4. The resulting analysis and case studies are presented in Section 5. The paper is concluded in Section 6.
2. Related work
The main focus of our proposed model is on improving the semantic quality of generated sentences in the field of D2T generation. Due to the importance of semantic fidelity to the given input in the output sentences, so far many efforts have been made to preserve the meaning in tasks such as abstractive summarization, dialog generation, and D2T generation, selected works of which are mentioned below.
To prevent the generation of repetitive and redundant phrases and words in abstractive summarization, See et al. (Reference See, Liu and Manning2017) propose a hybrid pointer-generator architecture that copies words from the source text to improve accuracy by handling OOV words along with learning to generate new words. Also, they propose a coverage mechanism (COV) that keeps track of words that have been summarized and that makes a model aware of its attention history. Li et al. (Reference Li, Zhu, Zhang and Zong2018) propose a model that incorporates entailment knowledge into the summarization in an encoder–decoder structure. Their proposed encoder jointly learns summarization generation and entailment recognition, so it can grasp both the gist of the source sentence and be aware of entailment relationships. Furthermore, they train the decoder by entailment reward augmented maximum likelihood training to encourage it to produce a summary entailed by the source. In the same direction, Perez-Beltrachini and Lapata (Reference Perez-Beltrachini and Lapata2021) propose an attention mechanism that encourages the decoder in each time step to pay greater attention to a subset of input representations that are both relevant and diverse.
In the dialog generation task, to reduce missing or misplacing slot values in the generated output, Li et al. (Reference Li, Yao, Qin, Che, Li and Liu2020) propose a dialog state tracker with reinforcement learning (RL). Their model uses a slot consistency reward which is the cardinality of the difference between the generated template and the slot–value pairs extracted from the input dialog act. Rashkin et al. (Reference Rashkin, Reitter, SinghTomar and Das2021) use DialoGPT (Zhang et al. Reference Zhang, Gan, Fan, Chen, Henao, Shen and Carin2017) model and fine-tune it on their dialog dataset. Also, they introduce a set of control codes, entailment, objective voice, and lexical precision and concatenate them with dialog inputs to encourage the model to generate responses that are faithful to the provided evidence.
To improve faithfulness to resources in the D2T generation task, Liu et al. (Reference Liu, Zheng, Chang and Sui2021) propose a two-step generator with a separate text planner, which is augmented by auxiliary entity information. First, the text planner predicts the content plan based on the input data. Second, given the input data and the predicted content plan, the sequence generator generates the text. Tian et al. (Reference Tian, Narayan, Sellam and Parikh2019) first define a confidence score to detect semantic errors in each time step t of the decoder by using an attention score to measure how much the model is attending to the source and a language model to judge if a word conveys source information. Then, they propose a variational Bayes training framework that encourages a model to generate output text with high confidence, while learning the confidence score parameters at the same time. Wang et al. (Reference Wang, Wang, An, Yu and Chen2020) enhance the vanilla transformer model with two content-matching constraints. By using a latent-representation-level matching constraint, they encourage model to generate text semantically consistent with input data. Also, by using an explicit entity-level matching scheme, they control that the entities of input and the corresponding text are identical. PlanGen, proposed by Su et al. (Reference Su, Vandyke, Wang, Fang and Collier2021), consists of a content planner to predict the most probable content plan from the input data and a sequence generator that takes the input data and predicted content plan and generates the output text. Then by training this model using a structure-aware RL objective, the model is encouraged to be faithful to the predicted content plan.
In the proposed model, we used a different approach than the works mentioned above. In the proposed model, to generate sentences with semantic fidelity to the input MRs, an adversarial learning method with an objective function, including constraints on the semantic distance between the generated sentences and their corresponding MRs, is used. The generator network in the proposed model is an enhanced version of the base transformer network. In this enhanced version, attention mask and history information are added to the encoder and decoder self-attention layers, respectively. In this way, this transformer network will be more compatible with D2T generation. The generator network in the proposed model is an enhanced version of the base transformer network. In this enhanced version, attention mask and history information are added to the encoder and decoder self-attention layers, respectively. In this way, this transformer network will be more compatible with D2T generation.
It is necessary to note that efforts have been made before to enhance the transformer model which is completely different from our proposed method. For example, Su et al. (Reference Su, Vandyke, Wang, Fang and Collier2021) introduce a method called Rotary Position Embedding to effectively leverage the positional information into the training process of pretrained language models. In this method, absolute positions are encoded with a rotation matrix and incorporate explicit relative position dependency in self-attention layers formulation. The studies conducted on this method are shown that the objective function of the pretraining process converges faster and dependency between words in very long sentences is better learned by this enhanced model compared to the base transformer model. In order to reduce the training time and floating-point operations of attention-based language models, a new network, named GroupBERT, is introduced by modifying the structure of the transformer network of Chelombiev et al. (Reference Chelombiev, Justus, Orr, Dietrich, Gressmann, Koliousis and Luschi2021). In this model, a dedicated grouped convolution module is added to each self-attention layer to better learn local and global interactions between tokens. Also, the density of fully connected layers is reduced by using grouped transformations. This model has achieved better results compared to the BERT model on language representation learning. Also, its efficiency improved both in terms of floating-point operations and time-to-train. To improve the quality of word alignment in the source text and target text in NMT, Song et al. (Reference Song, Wang, Yu, Zhang, Huang, Luo, Duan and Zhang2020) added a dedicated head to the multi-head transformer, which is supervised during training. The evaluation results show that using this head to derive better word alignment leads to improvement in dictionary-guided decoding. In the field of D2T generation, Gong, Crego and Senellart (Reference Gong, Crego and Senellart2019) apply a classification layer on the output of the encoder to define which slot and values of input MRs should be expressed in the output text and which ones not.
3. Approach
We use a combination of the transformers model and the adversarial learning method to generate text from nonlinguistic, structured input data. The general outline of our proposed model is shown in Fig. 2. The input of the proposed model is the MRs consisting of slot and value pairs and a noise vector drawn from a normal distribution
 $N(0,1)$
, and the output of the model is the descriptive text equivalent to the input MR. The proposed model consists of two parts: a generator and a discriminator. The generator network is the vanilla transformer encoder and decoder (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). This network gets the input MRs and the noise vector, then by using Gumbel-SoftMax (Kusner and Hernández-Lobato Reference Kusner and Hernández-Lobato2016) in the output layer, generates a conditional probabilistic distribution of the vocabulary tokens. Since the generator must be trained to produce sentences that are close to the real sentences, both verbally and semantically, a triplet network (Hoffer and Ailon Reference Hoffer and Ailon2015) consisting of the vanilla transformer encoder blocks is used as the discriminator network. The input to this network is a triplet including the real sentence, the fake sentence generated by the generator, and the input MR. The objective function of this network is defined in such a way that the semantic distances of the input MRs from the real sentences are less than the semantic distances of the input MRs from the fake sentences. In this way, the discriminator teaches the generator how to express the information of the input MRs to generate correct sentences that are semantically close to the real sentences. In addition, to avoid the mode collapse problem and make the model training process more stable, the WGAN-GP (Gulrajani et al. Reference Gulrajani, Ahmed, Arjovsky, Dumoulin and Courville2017) loss function is also used in the discriminator objective function. The details of our proposed model are given in the following subsections.
$N(0,1)$
, and the output of the model is the descriptive text equivalent to the input MR. The proposed model consists of two parts: a generator and a discriminator. The generator network is the vanilla transformer encoder and decoder (Vaswani et al. Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017). This network gets the input MRs and the noise vector, then by using Gumbel-SoftMax (Kusner and Hernández-Lobato Reference Kusner and Hernández-Lobato2016) in the output layer, generates a conditional probabilistic distribution of the vocabulary tokens. Since the generator must be trained to produce sentences that are close to the real sentences, both verbally and semantically, a triplet network (Hoffer and Ailon Reference Hoffer and Ailon2015) consisting of the vanilla transformer encoder blocks is used as the discriminator network. The input to this network is a triplet including the real sentence, the fake sentence generated by the generator, and the input MR. The objective function of this network is defined in such a way that the semantic distances of the input MRs from the real sentences are less than the semantic distances of the input MRs from the fake sentences. In this way, the discriminator teaches the generator how to express the information of the input MRs to generate correct sentences that are semantically close to the real sentences. In addition, to avoid the mode collapse problem and make the model training process more stable, the WGAN-GP (Gulrajani et al. Reference Gulrajani, Ahmed, Arjovsky, Dumoulin and Courville2017) loss function is also used in the discriminator objective function. The details of our proposed model are given in the following subsections.
The block diagram of CGS-ET model. In the generator diagram, improvements made to the transformers-based generator network are shown as blocks with dashed borders. The discriminator diagram shows a triplet network that consists of three vanilla transformer encoders with sharing weights.
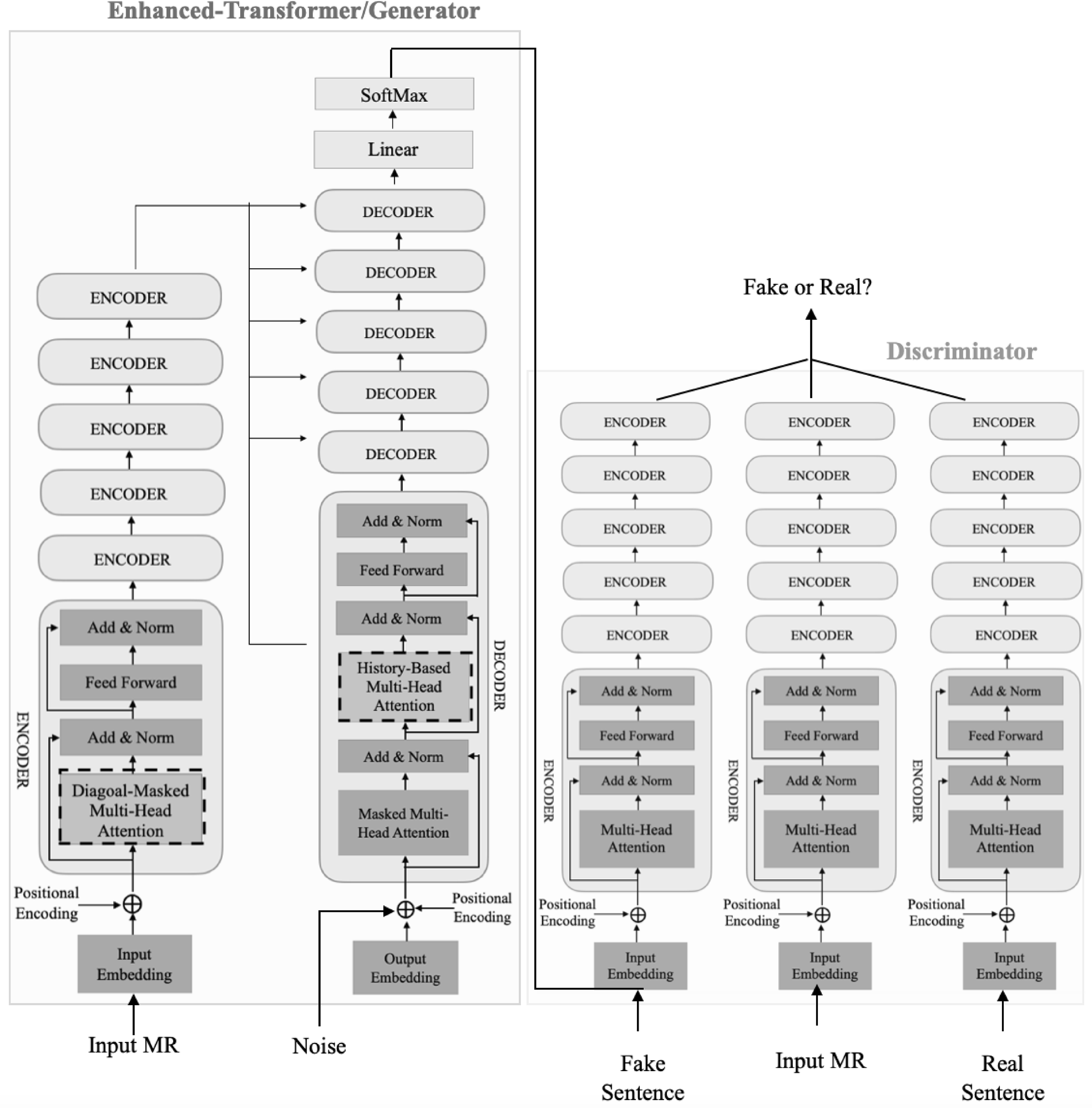
3.1. Generator
As mentioned earlier, the generator network used in this work is the vanilla transformer with six encoder and decoder layers. Encoder layers are made up of blocks with similar structures, including multi-heads self-attention and feed-forward sublayers. For each word of the encoder input sequence, first, the encoding vector resulting from the sum of the word embedding vector and positional encoding vector is produced. The produced encoding vector then is converted into sets of three vectors
 $q$
,
$q$
,
 $k$
, and
$k$
, and
 $v$
depending on the number of heads. Afterward, for each head, vectors
$v$
depending on the number of heads. Afterward, for each head, vectors
 $q$
,
$q$
,
 $k$
, and
$k$
, and
 $v$
of all words are stored in matrices named
$v$
of all words are stored in matrices named
 $Q$
,
$Q$
,
 $K$
, and
$K$
, and
 $V$
with
$V$
with
 $d$
dimension, and they are used to calculate the self-attention vector as follows:
$d$
dimension, and they are used to calculate the self-attention vector as follows:
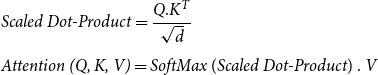 \begin{equation} \begin{aligned} &\textit{Scaled Dot-Product}=\frac{Q.K^T}{\sqrt{d}}\\[5pt] &\textit{Attention (Q, K, V)}=\textit{SoftMax} \ (\textit{Scaled Dot-Product}) \ . \ V \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\textit{Scaled Dot-Product}=\frac{Q.K^T}{\sqrt{d}}\\[5pt] &\textit{Attention (Q, K, V)}=\textit{SoftMax} \ (\textit{Scaled Dot-Product}) \ . \ V \end{aligned} \end{equation}
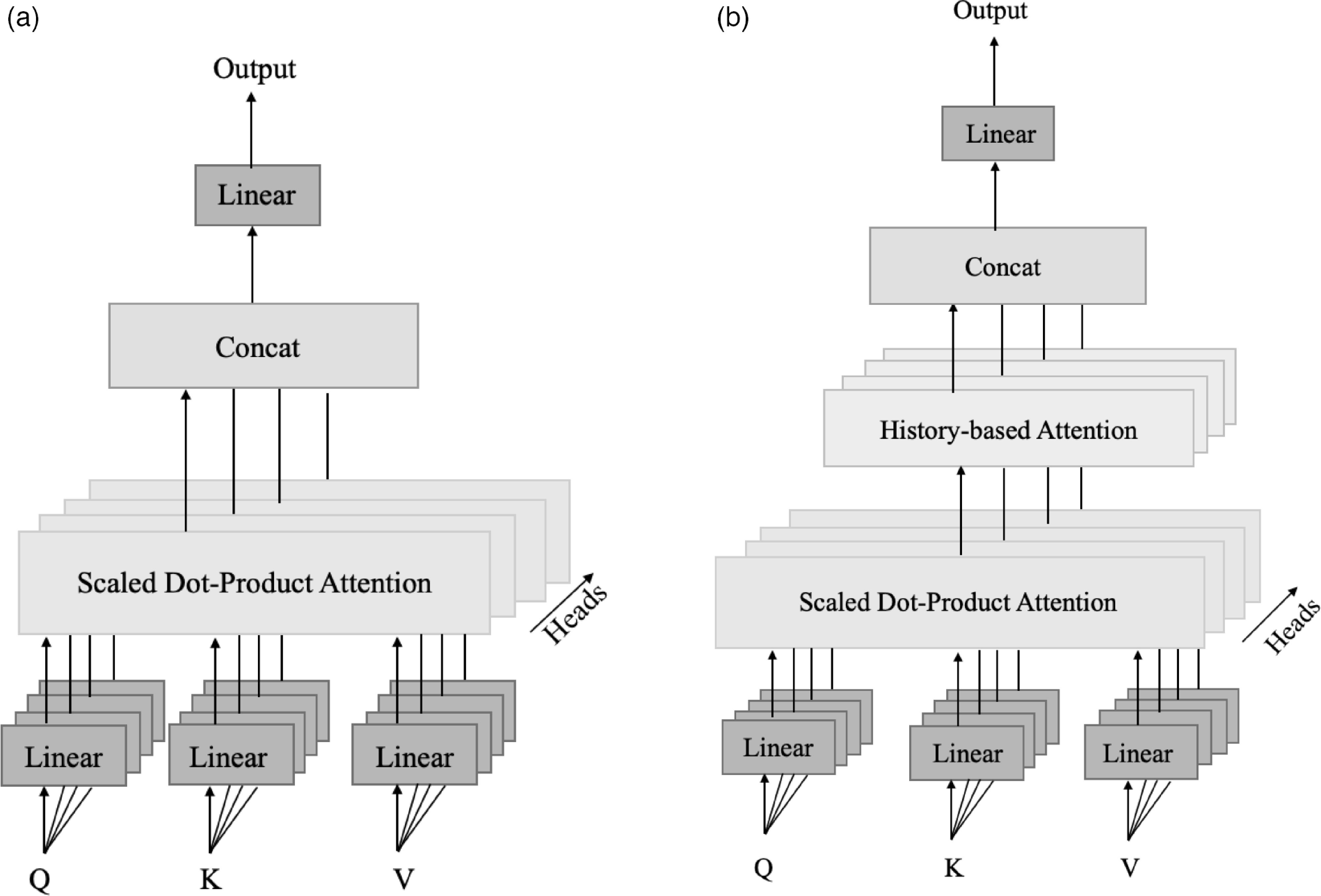
The output of the SoftMax function shows the contribution of the other input sequence words in creating the final attention vector for each word. For example, when the input of the encoder is a sentence like “This morning I went to the bank that is near the river bank to open an account,” words like “open” and “account” contribute more to the attention vector of the first “bank,” and for the second “bank” more attention weight is given to “river.” After attention vectors for all tokens are generated in each layer, the attention vectors of all heads are concatenated and after passing through a feed-forward layer with the linear activation function, the final attention vector is made. This vector is then passed through the normalization layer with residual connection and is given as an input to the next encoder layer. For the D2T generation task, the input of encoder is not a sentence, but an MR includes a number of slots such as “name[The Eagle], eatType[coffee shop], food[Japanese], priceRange[less than 20], customer rating[low], area[riverside], familyFriendly[yes], near[Burger King].” Each slot has its own independent concept. Therefore, it is not right to generate the attention vector for each slot based on other slots in MR. For this reason, before applying the SoftMax function for each head, the output of the scaled dot product step is summed by a Diagonal Mask matrix. In this way, a MR vector is created for each input slot independent of the other slots (Fig. 3). Therefore, the attention vector for the encoder layers is calculated as follows:
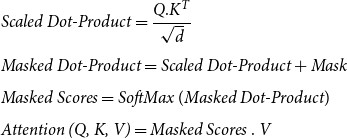 \begin{equation} \begin{aligned} &\textit{Scaled Dot-Product}=\frac{Q.K^T}{\sqrt{d}}\\[5pt] &\textit{Masked Dot-Product}= \textit{Scaled Dot-Product} + \textit{Mask}\\[5pt] &\textit{Masked Scores}=\textit{SoftMax} \ (\textit{Masked Dot-Product})\\[5pt] &\textit{Attention (Q, K, V)}=\textit{Masked Scores} \ . \ V \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\textit{Scaled Dot-Product}=\frac{Q.K^T}{\sqrt{d}}\\[5pt] &\textit{Masked Dot-Product}= \textit{Scaled Dot-Product} + \textit{Mask}\\[5pt] &\textit{Masked Scores}=\textit{SoftMax} \ (\textit{Masked Dot-Product})\\[5pt] &\textit{Attention (Q, K, V)}=\textit{Masked Scores} \ . \ V \end{aligned} \end{equation}
where
 $\textit{Mask}$
is a diagonal matrix whose diagonal elements are 0 and its other elements are
$\textit{Mask}$
is a diagonal matrix whose diagonal elements are 0 and its other elements are
 $\textit{-inf}$
.
$\textit{-inf}$
.
Generating Masked Scores for the self-attention sublayer of each encoder block.

Decoder layers in the vanilla transformer are also made of similar blocks including multi-head cross-attention, feed-forward, and multi-heads encoder–decoder attention sublayers where the last one is responsible for calculating the attention scores between the decoder
 $Q$
and encoder
$Q$
and encoder
 $K$
and
$K$
and
 $V$
vectors. Both decoder attention layers of the vanilla transformer have the same computation as in Equation (1), without the use of a diagonal mask. The output of the last layer of the decoder passing through a feed-forward layer with the RELU activation function and then a feed-forward layer with the linear function generates a token based on the previously generated ones. Since in the D2T generation task, all the encoder input slots, not the redundant ones and also without repetition, must be expressed in the decoder output, it is necessary for the decoder to consider the weights previously given to each slot to calculate the current attention weight scores; as a result, duplicate or lack of expression of the slots in the output text will be prevented. For this purpose, attention vectors generated for previous tokens, which we called History, and the attention vector for the current token are given to a sigmoid gate. So, by using this gate, the attention vector between encoder and decoder is calculated based on a weighted combination of history and current information (Fig. 4):
$V$
vectors. Both decoder attention layers of the vanilla transformer have the same computation as in Equation (1), without the use of a diagonal mask. The output of the last layer of the decoder passing through a feed-forward layer with the RELU activation function and then a feed-forward layer with the linear function generates a token based on the previously generated ones. Since in the D2T generation task, all the encoder input slots, not the redundant ones and also without repetition, must be expressed in the decoder output, it is necessary for the decoder to consider the weights previously given to each slot to calculate the current attention weight scores; as a result, duplicate or lack of expression of the slots in the output text will be prevented. For this purpose, attention vectors generated for previous tokens, which we called History, and the attention vector for the current token are given to a sigmoid gate. So, by using this gate, the attention vector between encoder and decoder is calculated based on a weighted combination of history and current information (Fig. 4):
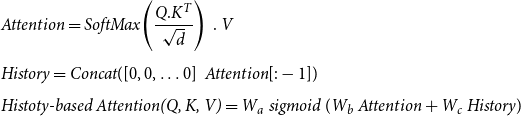 \begin{equation} \begin{aligned} &\textit{Attention}=\textit{SoftMax} \!\left(\frac{Q.K^T}{\sqrt{d}}\right) \ . \ V\\[5pt] &\textit{History}=\textit{Concat}([0,0,\ldots 0] \, \ \textit{Attention}[:-1])\\[5pt] &\textit{Histoty-based Attention}\textit{(Q, K, V)}=W_a \ \textit{sigmoid} \ (W_b \ \textit{Attention}+W_c \ \textit{History}) \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\textit{Attention}=\textit{SoftMax} \!\left(\frac{Q.K^T}{\sqrt{d}}\right) \ . \ V\\[5pt] &\textit{History}=\textit{Concat}([0,0,\ldots 0] \, \ \textit{Attention}[:-1])\\[5pt] &\textit{Histoty-based Attention}\textit{(Q, K, V)}=W_a \ \textit{sigmoid} \ (W_b \ \textit{Attention}+W_c \ \textit{History}) \end{aligned} \end{equation}
where
 $W_a$
,
$W_a$
,
 $W_b$
, and
$W_b$
, and
 $W_c$
are weight matrices that are learned during the model training process. Moreover, to solve the gradient back-propagation problem in adversarial training, in this work, the Gumbel-SoftMax function is used instead of the SoftMax function in the last layer of the decoder.
$W_c$
are weight matrices that are learned during the model training process. Moreover, to solve the gradient back-propagation problem in adversarial training, in this work, the Gumbel-SoftMax function is used instead of the SoftMax function in the last layer of the decoder.
Generating the encoder–decoder self-attention vector in (a) the vanilla transformer and (b) the proposed model.
3.2. Discriminator
The generator network needs a discriminative signal from the discriminator network to be trained. The more information the received signal contains, the more successful the generator training is and the closer the generated sentences are to real sentences. The closeness of real and fake sentences can be defined at two levels: word level and semantic level. Using the MLE objective function, the generator can be trained in a teacher-forcing manner (Bengio et al. Reference Bengio, Vinyals, Jaitly and Shazeer2015) to generate a sentence close to the real sentence at the level of the words. However, due to the MLE drawbacks such as exposure bias and sensitivity to rare examples resulting in conservative learning of real data distribution, this objective function cannot guarantee that the generated sentence is close enough to the real sentence in terms of maintaining the semantic structure and expressing the input MRs information. For this reason, in this work, the task of extracting the semantic features of sentences and estimating the distance between them is entrusted to the discriminator network.
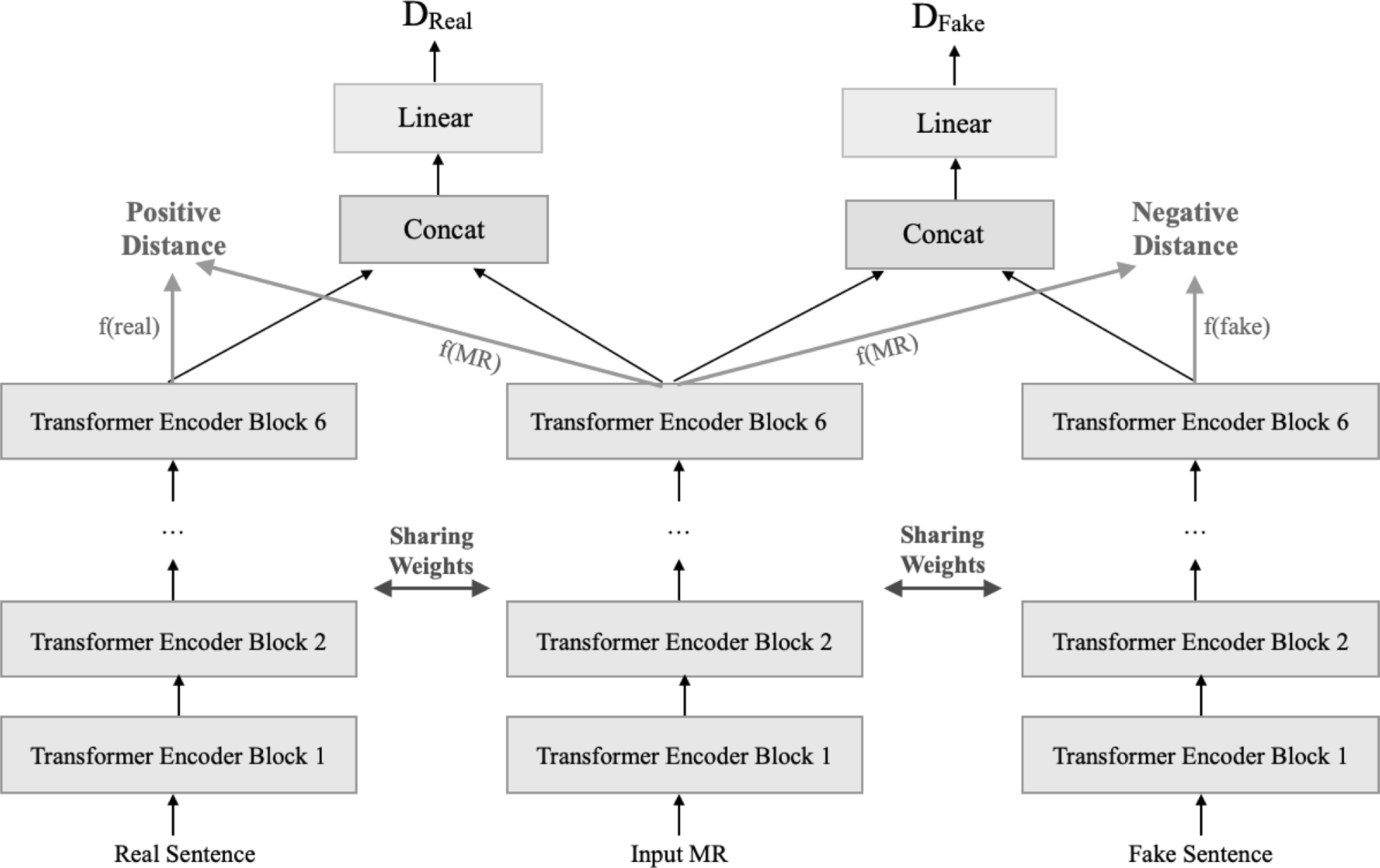
The proposed discriminator is a triplet network composed of the transformer encoder blocks (Fig. 5). This network takes triplets including the input MR, the real sentence, and the generated sentence as an anchor, positive, and negative samples, respectively. Then it extracts the semantic features of each triplet in such a way that in the created semantic space the sum of the distance between the input MR and the real sentence (positive distance) with a margin value is still less than the distance between the input MR and the fake sentence (negative distance) (Hermans, Beyer, and Leibe Reference Hermans, Beyer and Leibe2017). In this work, to calculate the positive and negative distances between the semantic features of sentences, the element-wise cosine distance is used as follows:
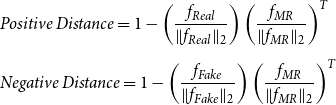 \begin{equation} \begin{aligned} &\textit{Positive Distance}=1- \left (\frac{f_{\textit{Real}}}{\|f_{\textit{Real}}\|_2}\right )\left (\frac{f_{\textit{MR}}}{\|f_{\textit{MR}}\|_2}\right )^T\\[5pt] &\textit{Negative Distance}=1-\left (\frac{f_{\textit{Fake}}}{\|f_{\textit{Fake}}\|_2}\right )\left (\frac{f_{\textit{MR}}}{\|f_{\textit{MR}}\|_2}\right )^T \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\textit{Positive Distance}=1- \left (\frac{f_{\textit{Real}}}{\|f_{\textit{Real}}\|_2}\right )\left (\frac{f_{\textit{MR}}}{\|f_{\textit{MR}}\|_2}\right )^T\\[5pt] &\textit{Negative Distance}=1-\left (\frac{f_{\textit{Fake}}}{\|f_{\textit{Fake}}\|_2}\right )\left (\frac{f_{\textit{MR}}}{\|f_{\textit{MR}}\|_2}\right )^T \end{aligned} \end{equation}
where
 $f_{\text{Real}},f_{\text{Fake}}$
, and
$f_{\text{Real}},f_{\text{Fake}}$
, and
 $f_{\text{MR}}$
indicate the semantic feature vector extracted by the encoder blocks from the real sentence, fake sentence, and input MR, respectively. In addition, in order to make the training process of the model more stable, the extracted semantic feature vectors are concatenated in pairs of real and anchor sentences as well as fake and anchor sentences, then these concatenated vectors are passed through a feed-forward layer with one output neuron and the linear activation function. The value of the output neuron is considered as the output discriminator for real and fake sentences, and their distances show how close their distributions are. In this way, in addition to discovering which sentence is better, the discriminator teaches the generator how to generate sentences that are semantically close to the real sentences.
$f_{\text{MR}}$
indicate the semantic feature vector extracted by the encoder blocks from the real sentence, fake sentence, and input MR, respectively. In addition, in order to make the training process of the model more stable, the extracted semantic feature vectors are concatenated in pairs of real and anchor sentences as well as fake and anchor sentences, then these concatenated vectors are passed through a feed-forward layer with one output neuron and the linear activation function. The value of the output neuron is considered as the output discriminator for real and fake sentences, and their distances show how close their distributions are. In this way, in addition to discovering which sentence is better, the discriminator teaches the generator how to generate sentences that are semantically close to the real sentences.
Discriminator network. The hidden state vectors obtained from the encoders contain the semantic information of the input sentences. The discriminator network is trained in such a way that the distance between the semantic vectors of the real sentence and MR (positive distance) is less than the distance between the semantic vectors of the fake sentence and MR (negative distance). The discriminator network also tries to increase the distance between the real and predicted distributions of data
 $(D_{Real}, D_{Fake})$
.
$(D_{Real}, D_{Fake})$
.
3.3. Objective functions and training process
To train the discriminator network with the aim of increasing the semantic distance between real and fake sentences, the discriminator objective function is defined as follows:
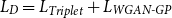 \begin{equation} \begin{aligned} &L_D=L_{\textit{Triplet}}+L_{\textit{WGAN-GP}} \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &L_D=L_{\textit{Triplet}}+L_{\textit{WGAN-GP}} \end{aligned} \end{equation}
where discriminator tries to minimize this objective function by calculating
 $L_{\textit{Triplet}}$
and
$L_{\textit{Triplet}}$
and
 $L_{\textit{WGAN-GP}}$
as follows:
$L_{\textit{WGAN-GP}}$
as follows:
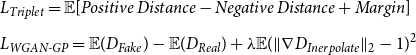 \begin{equation} \begin{aligned} & L_{\textit{Triplet}}=\mathbb{E}[\textit{Positive Distance}-\textit{Negative Distance}+\textit{Margin}]\\[5pt] & L_{\textit{WGAN-GP}}=\mathbb{E}(D_{Fake})-\mathbb{E}(D_{Real})+\lambda \mathbb{E}(\|\nabla D_{Inerpolate}\|_2-1)^2 \end{aligned} \end{equation}
\begin{equation} \begin{aligned} & L_{\textit{Triplet}}=\mathbb{E}[\textit{Positive Distance}-\textit{Negative Distance}+\textit{Margin}]\\[5pt] & L_{\textit{WGAN-GP}}=\mathbb{E}(D_{Fake})-\mathbb{E}(D_{Real})+\lambda \mathbb{E}(\|\nabla D_{Inerpolate}\|_2-1)^2 \end{aligned} \end{equation}
where
 $\nabla$
denotes gradient and
$\nabla$
denotes gradient and
 $D_{Inerpolate}$
is a linear mixture of the real and generated sentences. Accordingly, the generative objective function is also defined as follows:
$D_{Inerpolate}$
is a linear mixture of the real and generated sentences. Accordingly, the generative objective function is also defined as follows:
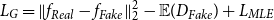 \begin{equation} \begin{aligned} &L_G=\|f_{\textit{Real}}-f_{\textit{Fake}} \|_2^2 -\mathbb{E}(D_{Fake})+L_{\textit{MLE}} \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &L_G=\|f_{\textit{Real}}-f_{\textit{Fake}} \|_2^2 -\mathbb{E}(D_{Fake})+L_{\textit{MLE}} \end{aligned} \end{equation}
where
 $\|f_{\textit{Real}}-f_{\textit{Fake}} \|_2^2$
is the Euclidean distance between real and fake sentences semantic features. Also,
$\|f_{\textit{Real}}-f_{\textit{Fake}} \|_2^2$
is the Euclidean distance between real and fake sentences semantic features. Also,
 $L_{\textit{MLE}}$
is a regularization term that calculates by using categorical cross-entropy between the real sentence and the sentence generated by generator network in a teacher-forcing manner. So by minimizing this loss, the value of the discriminator objective function is increasing.
$L_{\textit{MLE}}$
is a regularization term that calculates by using categorical cross-entropy between the real sentence and the sentence generated by generator network in a teacher-forcing manner. So by minimizing this loss, the value of the discriminator objective function is increasing.
Training process of our proposed model.
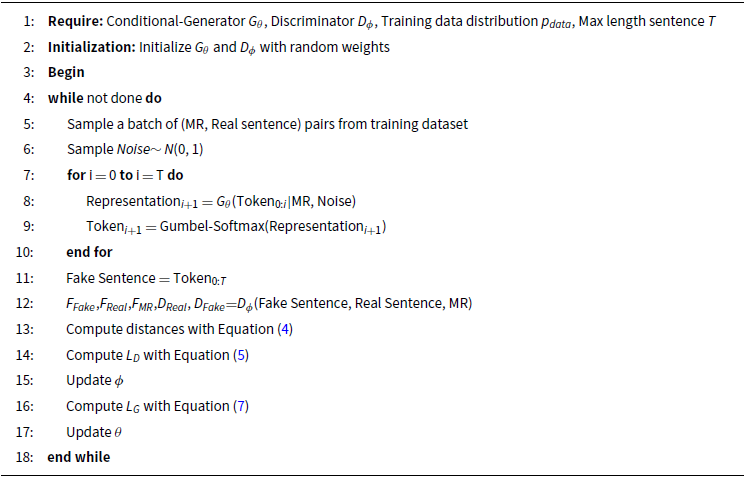
The whole training process of the proposed method is illustrated in Algorithm 1. As observed, to calculate the
 $L_{\textit{MLE}}$
, the generator network generates the output sentence in a teacher-forcing manner for the given MR, while to generate a fake sentence the tokens generated at each step are used as the input of the next step. Moreover, the generator and discriminator networks in the proposed model do not require any pretraining and both networks are trained adversarially from the beginning.
$L_{\textit{MLE}}$
, the generator network generates the output sentence in a teacher-forcing manner for the given MR, while to generate a fake sentence the tokens generated at each step are used as the input of the next step. Moreover, the generator and discriminator networks in the proposed model do not require any pretraining and both networks are trained adversarially from the beginning.
4. Experiments
Experiments to evaluate the performance of the proposed CGA-ET model and compare it with other state-of-the-art models are described in this section. The used datasets, experimental setups, evaluation metrics, experiments results, and their analysis are described below.
4.1. Datasets
To qualitatively evaluate the proposed CGA-ET model, we used three datasets: (1) the enriched version of WebNLG + 2020 (Castro-Ferreira et al. Reference Castro-Ferreira, Moussallem, Krahmer and Wubben2018; Castro Ferreira et al. Reference Castro Ferreira, Gardent, Ilinykh, Lee, Mille, Moussallem and Shimorina2020), which is the modified version of the original WebNLG dataset (Gardent et al. Reference Gardent, Shimorina, Narayan and Perez-Beltrachini2017), containing sets of RDF triples (Subject, Predicate, and Object) extracted from DBPedia and their corresponding texts of 10 seen domains in the training data and 5 unseen domains of the test data; (2) Multiwoz 2.1 (Budzianowski et al. Reference Budzianowski, Wen, Tseng, Casanueva, Ultes, Ramadan and Gasic2018) consisting of conversation sequences and their equivalent semantic representations in seven domains; and (3) cleaned version of E2E dataset (Dusek et al. Reference Dusek, Howcroft and Rieser2019) containing descriptions of restaurants with their equivalent MR in form slots and values. Details of these datasets are given in Table 1.
Datasets statistics. Attributes shows the total number of slot types and Avg-Len indicates average length of sentences in each dataset

4.2. Experimental setups
The proposed CGA-ET model is implemented using the TensorFlow library and trained on Google Colaboartory with one Tesla P100-PCIE-16 GB GPU for 20k steps. Encoder and decoder in both generator and discriminator networks include six multi-head attention layers with eight heads. The model dimensions and fully connected layers size are set to 256, the batch size is set to 10, and the dropout rate is set to 10%. The CGA-ET model at first is initialized with random weights and then optimized using an Adam optimizer with a learning rate of 1e-4. This process is terminated by early stopping based on the validation loss. Moreover, for every 50 steps, L2-regularization with
 $\lambda =1e-5$
is added to loss values. In the inference phase, beam search with width 10 is used, and for each MR, then the top sentence is selected based on its negative log-likelihood value.Footnote
a
$\lambda =1e-5$
is added to loss values. In the inference phase, beam search with width 10 is used, and for each MR, then the top sentence is selected based on its negative log-likelihood value.Footnote
a
4.3. Automatic evaluation metrics
To automatically evaluate the quality of sentences produced by the proposed CGA-ET model and compare them with baseline models on the E2E dataset, as in the E2E challenge, BLEU (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), METEOR (Lavie, Sagae, and Jayaraman Reference Lavie, Sagae and Jayaraman2004), NIST (Martin and Przybocki Reference Martin and Przybocki2000), ROUGE-L (Lin Reference Lin2004), and CIDEr (Vedantam, Zitnick, and Parikh Reference Vedantam, Zitnick and Parikh2015) metrics are used. The BLEU, METEOR, and BERTScore (Zhang et al. Reference Zhang, Sun, Galley, Chen, Brockett, Gao, Gao, Liu and Dolan2020) metrics used in the WebNLG + 2020 challenge are also used for the WebNLG dataset. For the MultiWoz dataset, BLEU and slot error rate (SER) metrics are used. SER is the fraction of times where at least one slot value from the input MR is not expressed or incorrectly expressed in the output sentence (Wen et al. Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c).
4.4. Human evaluation
Human evaluation is performed to evaluate the semantic quality of the generated sentences by our proposed model in terms of faithfulness (How many of the semantic units in the given sentence can be found/recognized in the given MR/RDF), coverage (How many of the given MRs slots values/RDF triples can be found/recognized in the given sentence), and fluency (whether the given sentence is clear, natural, grammatically correct, and understandable). For fluency, we asked the judges to evaluate the given sentence and then give it a score: 1 (with many errors and hardly understandable), 2 (with a few errors, but mostly understandable), and 3 (clear, natural, grammatically correct, and completely understandable). As judges, 20 English speakers are chosen (Fleiss’s
 $\kappa = 0.65$
Landis and Koch Reference Landis and Koch1977 and Krippendorff’s
$\kappa = 0.65$
Landis and Koch Reference Landis and Koch1977 and Krippendorff’s
 $\alpha = 0.58$
Krippendorff Reference Krippendorff2011) for evaluating 50 tests MRs that were randomly selected from each dataset. To avoid any bias, judges are shown a randomly selected MR at a time, together with its gold sentence and the generated models. The judges were not aware of the model each output sentence is generated by and the sentences are presented each time in a different order.
$\alpha = 0.58$
Krippendorff Reference Krippendorff2011) for evaluating 50 tests MRs that were randomly selected from each dataset. To avoid any bias, judges are shown a randomly selected MR at a time, together with its gold sentence and the generated models. The judges were not aware of the model each output sentence is generated by and the sentences are presented each time in a different order.
4.5. Results and analysis
4.5.1. Results on WebNLG
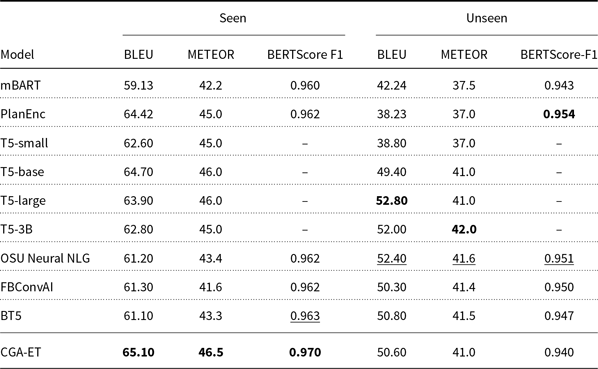
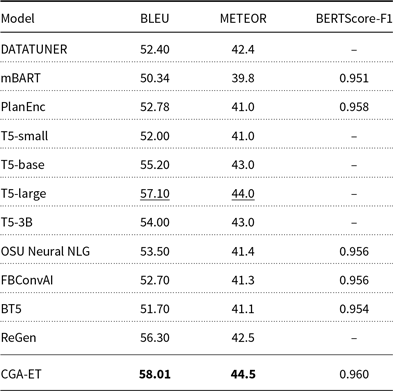
The results of the BLEU and METEOR automatic metrics for the output of the CGA-ET and baseline models on the seen, unseen, and full test data are given in Tables 2 and 3. The baseline models used for comparison include the following:
Results on WebNLG seen and unseen test data. The best and second-best models are highlighted in bold and underline face, respectively
Results on WebNLG full test data. The best and second-best models are highlighted in bold and underline face, respectively
-
DATATUNER (Harkous et al. Reference Harkous, Groves and Saffari2020), which first fine-tuned the GPT-2 pretrained language model on the WebNLG dataset and then by using the RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019) model as a semantic fidelity classifier it detects and avoids generation errors.
-
mBART (Kasner and Dušek Reference Kasner and Dušek2020b), which is fine-tuned on the WebNLG dataset.
-
T5-small, T5-large, T5-base, and T5-3B (Kale and Rastogi Reference Kale and Rastogi2020b), which are different versions of T5 pretrained model that are fine-tuned on the WebNLG dataset.
-
ReGen (Dognin et al. Reference Dognin, Padhi, Melnyk and Das2021), which is the T5 model that fine-tuned using REINFORCE method (Williams Reference Williams1992)
The top models participating in the WebNLG + 2020 challenge (Castro Ferreira et al. Reference Castro Ferreira, Gardent, Ilinykh, Lee, Mille, Moussallem and Shimorina2020) are also selected for comparison:
-
PlanEnc (Zhao, Walker, and Chaturvedi Reference Zhao, Walker and Chaturvedi2020), which consists of two graph convolution network-based encoders to extract both structural information and sequential content of the input graph. The decoder in this model is an LSTM conditioned on both encoder outputs, with attention and copy mechanism.
-
OSU Neural NLG (Li et al. Reference Li, Yao, Qin, Che, Li and Liu2020), which fine-tuned the T5 pretrained language model on the WebNLG dataset.
-
FBConvAI (Yang et al. Reference Yang, Einolghozati, Inan, Fan, Donmez and Gupta2020), which fine-tuned the BART (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020) model on the WebNLG dataset and proposed two different methods for giving a graph as input to the BART model.
-
BT5(Agarwal et al. Reference Agarwal, Kale, Ge, Shakeri and Al-Rfou2020), which is the T5 model that is trained and fine-tuned bilingually on the WebNLG dataset.
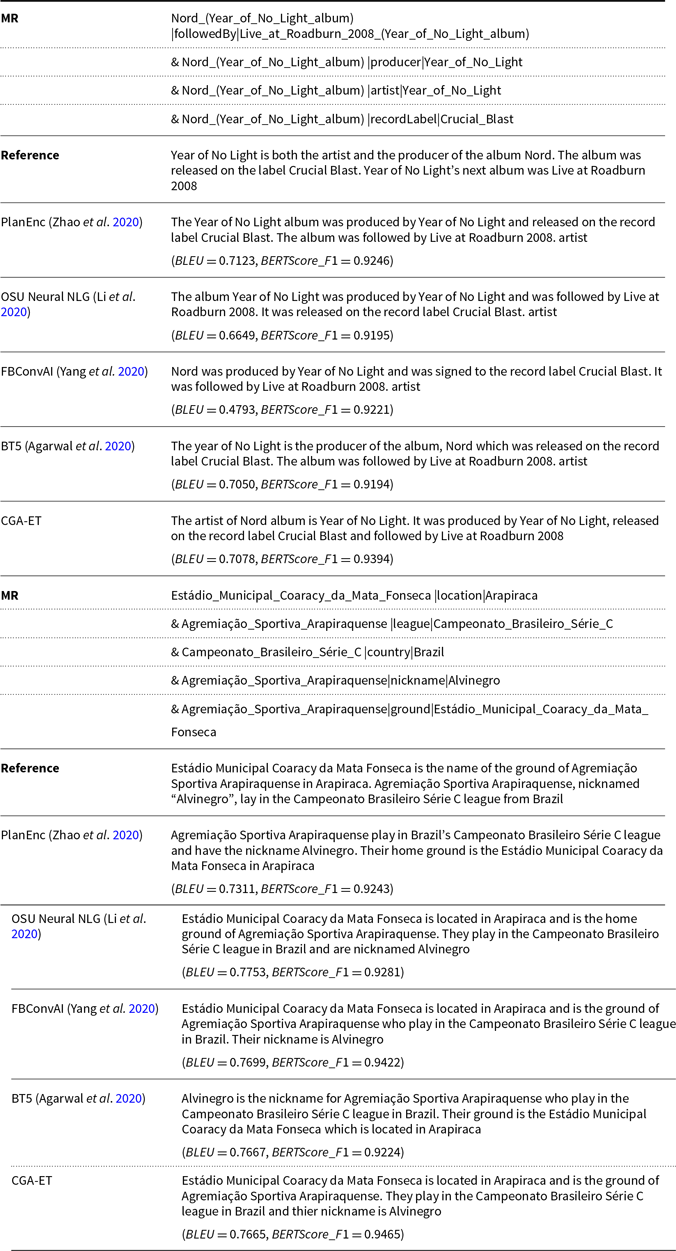
As shown, the proposed model has outperformed all the baselines on seen and full test data and got the highest BLEU, METEOR, and BERTScore values. This advantage is due to the fact that in the process of training our CGA-ET model’s generator and discriminator, by forcing the reduction of the semantic distance of the generated sentences with the input RDF triples, the generator has been successful in learning how to express all semantic elements of the given RDF triples in the output sentences. But for the unseen test set, our model performed moderately, because the generator has not trained in generating tokens for expressing unseen concepts. Moreover, as subjective evaluations, we compared the outputs generated by our CGA-ET model, with the published outputs of baseline models in terms of faithfulness (precision), coverage (recall), and fluency and reported its results in Table 4. Since the proposed model has a better ability to express the predicates in the input RDF than baseline models, it has achieved higher faithfulness and coverage values. Also, controlling the output of the generator using similarity in both levels of words and semantic has resulted in more fluent outputs. An example of the input RDF and output sentences generated by the CGA-ET and baseline models is given in Table 5.
Results of human evaluations on WebNLG dataset in terms of Faithfulness, Coverage, and Fluency (rating out of 3). The symbols
 $\ast$
and
$\ast$
and
 $\dagger$
indicate statistically significant improvement with
$\dagger$
indicate statistically significant improvement with
 $p \lt 0.05$
and
$p \lt 0.05$
and
 $p \lt 0.01$
, based on the paired t-test and the ANOVA test, respectively
$p \lt 0.01$
, based on the paired t-test and the ANOVA test, respectively

Comparison of the generated sentences from the WebNLG dataset for our proposed model and baselines. The missed meaning labels for each generated sentence are shown in red
4.5.2. Results on MultiWoz
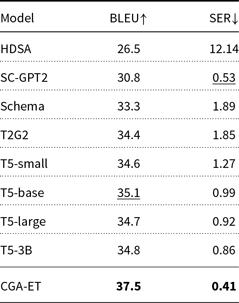
The experiments performed on the MultiWoz dataset are aimed at generating sentences from the input MRs. The results of the BLEU and SER automatic metrics for the output of the CGA-ET and transformer-based baseline models are given in Table 6. The baseline models used for comparison include the following:
Results on MultiWoz for generating sentence form input MR. The best and second-best models are highlighted in bold and underline face, respectively
-
Hierarchically disentangled self-attention or HDSA (Chen et al. Reference Chen, Chen, Qin, Yan and Wang2019), a transformer-based model that encodes the input MR into a multilayer hierarchical graph and assigns separate head attentions to each node in the generated graph.
-
SC-GPT2 (Peng et al. Reference Peng, Zhu, Li, Li, Li, Zeng and Gao2020) is the GPT-2 model pretrained on a large D2T corpus and are fine-tuned on the MultiWoz dataset.
-
Schema and T2G2 (Kale and Rastogi Reference Kale and Rastogi2020a) are two methods of generating text using a common model. In this model, the semantically correct but possibly incoherent and ungrammatical utterances are first generated for an input MR by using schema-guided or template-guided approaches. These utterances are then rewritten into natural sentences using T5.
-
T5-small, T5-large, T5-base, and T5-3B (Kale and Rastogi Reference Kale and Rastogi2020b) that are different versions of the T5 pretrained language model fine-tuned on the MultiWoz dataset.
As one can observe from Table 7, the proposed model is able to obtain the lowest value of SER and the highest value of BLEU compared to the baseline models. A lower value of SER, which means fewer semantic defects in the generated sentences, leads to an improvement in the value of BLEU. Moreover, we evaluated the output sentences of our model using BERTScore for which a value of 0.915 was obtained indicating that the outputs of our proposed model are semantically close to the reference sentences. Since the outputs of the baseline models are not available, the reference sentences in the test set and the sentences generated by the CGA-ET model are used for subjective evaluation with results given in Table 7. In this dataset, some reference sentences in test data contain semantic errors and do not contain all concepts of the MR. For this reason, the proposed model has achieved higher coverage and faithfulness scores than the reference sentences. However, the score of fluency of the proposed model is lower compared to the reference sentences (about 0.07 units), which is an acceptable difference considering that the reference sentences are written by humans. Examples of input MRs and sentences generated by the CGA-ET model are given in Table 8.
Results of human evaluations on MultiWoz dataset in terms of Faithfulness, Coverage, and Fluency (rating out of 3)

Comparison of the generated sentences from the MultiWoz dataset for our proposed model

4.5.3. Results on E2E
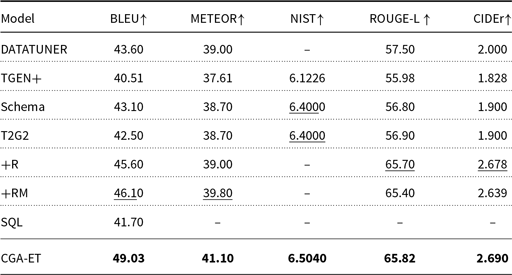
The results of the automatic metrics for the output of the CGA-ET and baseline models on the E2E dataset are given in Table 9. The baseline models used for comparison include the following:
Results on E2E. The best and second-best models are highlighted in bold and underline face, respectively
-
DATATUNER (Harkous et al. Reference Harkous, Groves and Saffari2020), which first fine-tuned the GPT-2 pretrained language model on the E2E dataset and then by using the RoBERTa (Liu et al. Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019) model as a semantic fidelity classifier it detects and avoids generation errors.
-
TGEN+ (Dusek et al. Reference Dusek, Howcroft and Rieser2019), which is an LSTM-based sequence-to-sequence model with attention that uses slot matching script directly.
-
Schema and T2G2 (Kale and Rastogi Reference Kale and Rastogi2020a) are two methods of generating text using a common model. In this model, the semantically correct but possibly incoherent and ungrammatical utterances are first generated for an input MR by using schema-guided or template-guided approaches. These utterances are then rewritten into natural sentences using T5.
-
+R and +RM (Shen et al. Reference Shen, Chang, Su, Zhou and Klakow2020), which automatically extract the segmental structures of texts and learn to align them with their data correspondences. For reducing hallucination, they used constraints to prevent repetition (+R) and further reduce information missing (+RM).
-
SQL (Guo et al. Reference Guo, Tan, Liu, Xing and Hu2021), which is GPT-2 pretrained language model fine-tuned using soft Q-learning (Schulman, Chen, and Abbeel Reference Schulman, Chen and Abbeel2017)
The results in Table 10 show that the proposed model has outperformed all the baseline models in terms of the n-grams-based evaluation metrics. Also, we evaluated the output sentences of our model using BERTScore for which a value of 0.930 was obtained indicating that the outputs of our proposed model are semantically close to the reference sentences. As subjective evaluations, we compared the outputs generated by our CGA-ET model, with their gold reference, since the baseline outputs are not published. Table 10 shows the scores of each human evaluation factor for the E2E dataset. In the cleaned version of the E2E dataset, the semantic deficiencies that existed in previous versions have been fixed so that the concept of all input slots is expressed in the reference sentences. For this reason, the faithfulness and coverage scores for reference sentences are both 100%. The difference between the fluency scores of the CGA-ET model and the references is due to the fact that the reference sentences are written by humans. Examples of input MRs and sentences generated by the CGA-ET model are given in Table 11.
Results of human evaluations on E2E dataset in terms of Faithfulness, Coverage, and Fluency (rating out of 3)

Comparison of the generated sentences from the E2E dataset for our proposed model
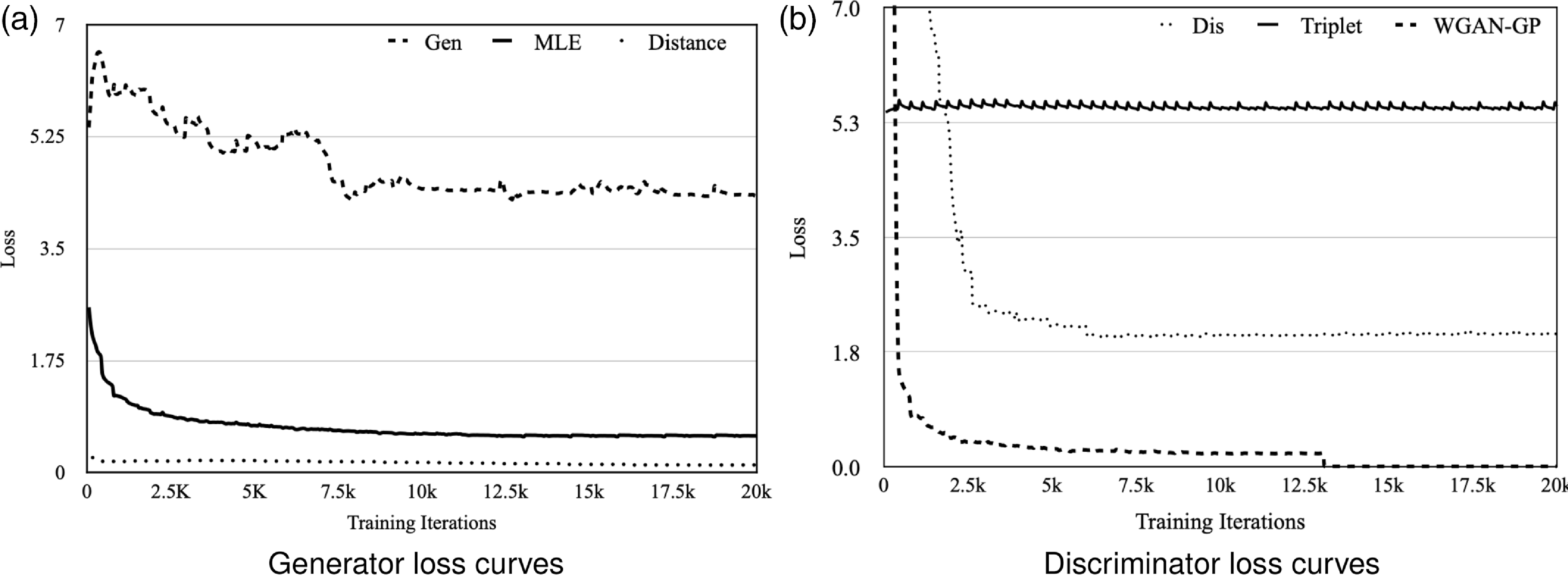
The loss curves of our CGA-ET model during the adversarial training process are shown in Fig. 6. As illustrated, the adversarial process between generator (Gen) and discriminator (Dis) is quite stable. Initially, the value for the WGAN-GP loss function is high and prevents the error gradient for the fake sentence from being zero. During the training process, the amount of WGAN-GP is reduced, while triplet loss controls the semantic similarity of real and fake sentences with the input MR. Fluctuations in generator loss value indicate a productive attempt to mislead the discriminator under the control of MLE (similarity at the word level) and Distance (semantic similarity of sentences).
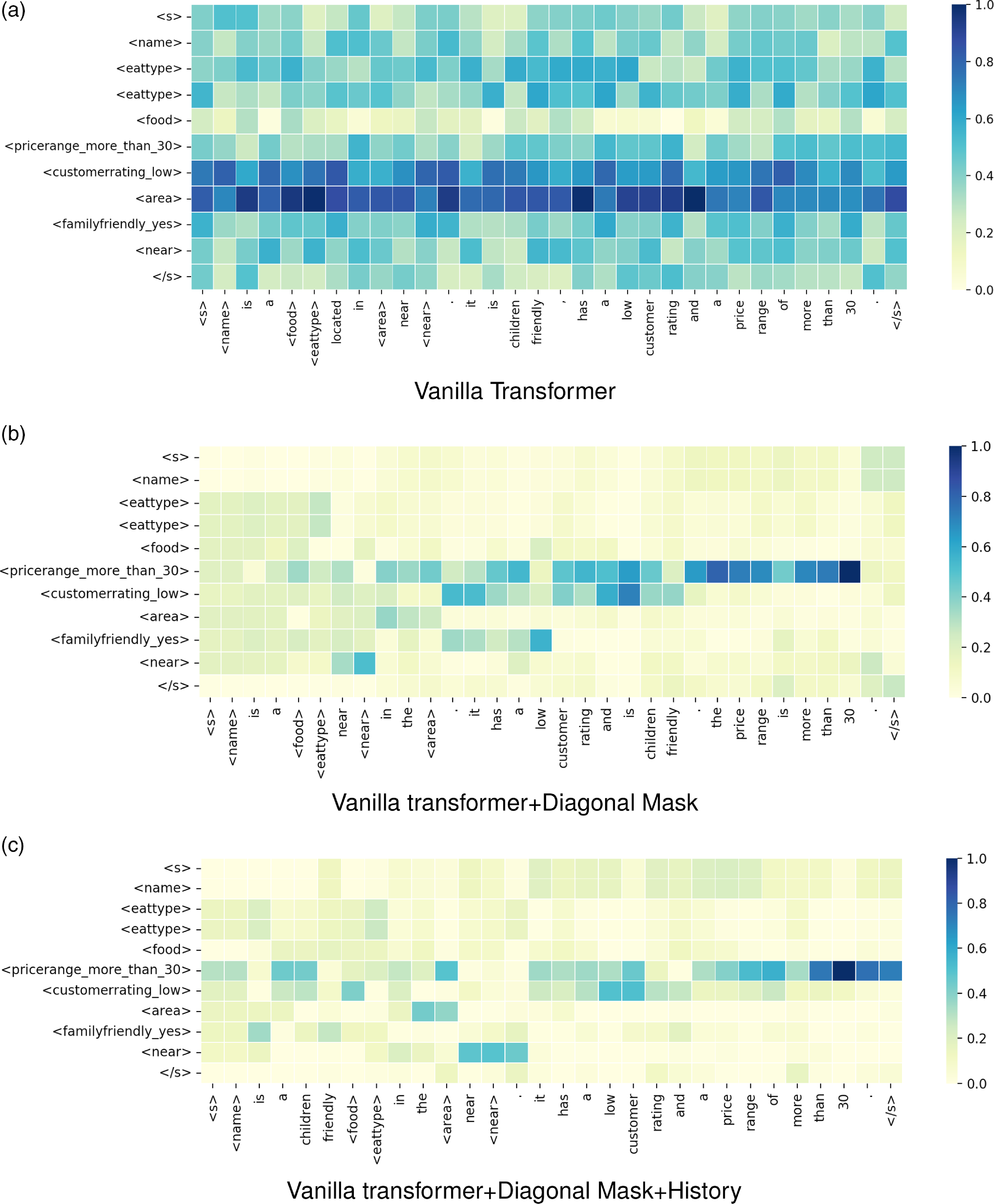
Encoder–decoder attention weights for an E2E MR and the equivalent sentence generated by (a) Vanilla transformer, (b) Vanilla transformer+Diagonal Mask. and (c) Vanilla transformer+Diagonal Mask+History.
4.6. Ablation study
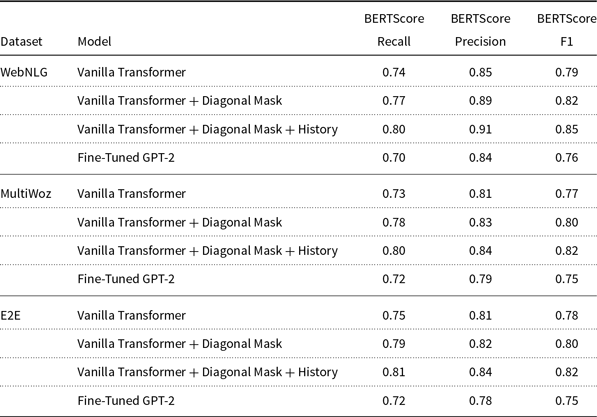
As mentioned earlier, we made modifications to the vanilla transformer encoder and decoder to create an enhanced transformer model that is more compatible with the task D2T, and we used this enhanced model for the generator network of our CGA-ET model. To evaluate the effect of the modifications and compare them with the vanilla transformer, experiments are performed. In these experiments, the vanilla transformer, vanilla transformer + Diagonal Mask, and vanilla transformer + Diagonal Mask + History are trained separately on the training sets of E2E, WebNLG, and MultiWoz datasets using MLE. We also fine-tuned the GPT2 model on all three training datasets to compare it with the vanilla and enhanced transformer. For this purpose, we gave the sequence of pairs slots and values in the form
 $\lt slot\_value\gt$
to the GPT-2 and adjusted the weights of all 12 layers of it so that the equivalent sentence would be generated at the output. We also used beam search with a width of 5 and temperature 0.7 to generate the sentences in the inference phase. The results obtained on each test dataset are given in Table 12. As observed, when the vanilla transformer is trained and tested on a dataset, its generated output sentences got a higher value for F1 than when the pretrained models are used. Furthermore, as previously mentioned, the use of the diagonal mask in calculating the weights of attention in the encoder results in separate generation of input slots without considering the order of slots in the input MR. This makes the model less restricted in expressing slots in a particular order or in relation to other slots in equivalent sentences; so as a result, its F1 score is increased. Moreover, the use of history in calculating encoder–decoder attention weights causes the decoder to always pay attention to the sequence of slots previously expressed in the output when generating output tokens. Hence, semantic similarity with gold test sentences is increased. To illustrate the effect of using diagonal mask and history in output sentences, the encoder–decoder attention weights for an MR input from the E2E dataset and the generated sentences by enhanced and vanilla transformers are shown in Fig. 7.
$\lt slot\_value\gt$
to the GPT-2 and adjusted the weights of all 12 layers of it so that the equivalent sentence would be generated at the output. We also used beam search with a width of 5 and temperature 0.7 to generate the sentences in the inference phase. The results obtained on each test dataset are given in Table 12. As observed, when the vanilla transformer is trained and tested on a dataset, its generated output sentences got a higher value for F1 than when the pretrained models are used. Furthermore, as previously mentioned, the use of the diagonal mask in calculating the weights of attention in the encoder results in separate generation of input slots without considering the order of slots in the input MR. This makes the model less restricted in expressing slots in a particular order or in relation to other slots in equivalent sentences; so as a result, its F1 score is increased. Moreover, the use of history in calculating encoder–decoder attention weights causes the decoder to always pay attention to the sequence of slots previously expressed in the output when generating output tokens. Hence, semantic similarity with gold test sentences is increased. To illustrate the effect of using diagonal mask and history in output sentences, the encoder–decoder attention weights for an MR input from the E2E dataset and the generated sentences by enhanced and vanilla transformers are shown in Fig. 7.
Comparison of the effect of modifications on the vanilla transformer in data-to-text generation
Different loss curves of CGA-ET model during adversarial training process.
4.7. Case study
Examples of generated texts for a certain MR from the WebNLG, MultiWoz, and E2E datasets by CGA-ET and baseline models are shown in Tables 8, 9, and 10, respectively. The MR chosen from the WebNLG dataset has two similar objects and subjects but with two different predicates artist and producer, which is a challenge for the D2T models to express both predicates in their output sentences. As shown in Table 5, for the first example, unlike our proposed model, neither of the baseline models could express both predicates in the output. In the second example, all the input concepts are expressed in the sentences generated by baseline and our models. But the structures of the produced sentences are different, and this has caused the sentences to have different levels of fluency. Since the sentences generated by the baseline models are not published for the MultiWoz and E2E datasets, the outputs of the CGA-ET model for five MRs from these datasets are shown in Tables 8 and 9. These sentences show that the proposed model is able to express all the required concepts in the input MR.
Apart from the faithfulness and coverage, the other differences between the sentences generated by our models, references, and baseline outputs are in their structure, syntax, and length. This diversity in the selection of phrases and words to express the input concepts is the effect of using an adversarial method for training the proposed model. Because, unlike the MLE-based baseline models, the generator in the proposed model does not generate sentences based on frequent patterns in the training data. As can be seen from the BLEU scores given in the tables obtained by comparing each sentence with the reference, this difference in the structure of the sentences generated by our proposed model led to getting a lower score when evaluated by the n-gram-based evaluation metrics, despite the semantic and structural correctness. But the BERTScore metric clearly shows the semantic similarity of the generated sentences to the reference sentence.
5. Conclusion
In this paper, we present a novel conditional generative adversarial method for D2T generation. The generator network in this model is our enhanced version of the vanilla transformer encoder and decoder. In this enhanced version, which is created to reduce semantic errors in the output sentences, a diagonal mask matrix is added to the self-attention computation step of the vanilla transformer encoder. Moreover, in the encoder–decoder multi-head cross-attention computation step of the vanilla transformer decoder, the history of attention scores for the previously generated tokens is considered. The discriminator network in the proposed model is a triplet network that consists of three vanilla transformer encoders with sharing weights. The loss function of the discriminator network includes WGAN-GP loss and triplet loss function between the real and generated output sentences and the input MR; as a result, while stabilizing the model training process, the semantic similarity between the generated sentence and the real sentence is maintained. Experimental results demonstrate that our proposed model can generate higher-quality sentences than transformer-based baseline models, in terms of BLEU, METEOR, NIST, ROUGE-L, CIDEr, BERTScore, and SER evaluation metrics.


























 Open access
Open access