

1 Introduction
Graphs are ubiquitous in Natural Language Processing (NLP). They are relatively obvious when imagining words in a lexical resource or concepts in a knowledge network, or even words within a sentence that are connected to each other through what is formalized as syntactic relations. They are less obvious, however still there, when thinking about correcting typos, sentiment analysis, machine translation, figuring out the structure of a document or language generation.
Graphs are a powerful representation formalism. In language, this is probably most apparent in graph-based representations of words’ meanings through their relations with other words (Quillian Reference Quillian and Minsky1968), which has resulted in WordNet (Fellbaum Reference Fellbaum1998) – a semantic network that after more than 20 years is still heavily used for a variety of tasks (word sense disambiguation, semantic similarity, question answering, and others). Interestingly, some tasks are concerned with updating or expanding it, proof of the usefulness of this representation for capturing lexical semantics, or connecting it to the numerous resources that have joined it lately in the NLP resource box, as can be seen in Open Linked DataFootnote 1 – a large graph connecting information from various resources.
The standard graphs – consisting of a set of nodes and edges that connect pairs of nodes – have quickly grown into more powerful representations such as heterogeneous graphs, hypergraphs, graphs with multi-layered edges, to fit more and more complex problems or data, and to support computational approaches.
With a proper choice of nodes and edge drawing criteria and weighing, graphs can be extremely useful for revealing regularities and patterns in the data, allowing us to bypass the bottleneck of data annotations. Graph formalisms have been adopted as an unsupervised learning approach to numerous problems – such as language identification, part-of-speech (POS) induction, or word sense induction – and also in semi-supervised settings, where a small set of annotated seed examples are used together with the graph structure to spread their annotations throughout the graph. Graphs’ appeal is also enhanced by the fact that using them as a representation method can reveal characteristics and be useful for human inspection, and thus provide insights and ideas for automatic methods.
All is not perfect in the world of graphs, however. Many graph-based algorithms are NP-hard, and do not scale to current data sizes. As a well-studied field in mathematics, there are proofs that the graph problems encountered converge, or have a solution. Finding it computationally is another issue altogether, and scalability is an important attribute for algorithms, as they have to process larger and larger amounts of data. There are also problems that pertain specifically to computational approaches in NLP – for example, streaming graphs – graphs that change (some of them very fast) in time, like the graphs built from social media, where the networks representing the users, their tweets and the relations between them change rapidly.
This all shows that graph construction is a critical issue – its structure must correctly model the data such that it will allow not only to solve the target NLP problem, but to solve it in a computationally acceptable manner (finite, and as reduced as possible, use of computation time and memory).
In this paper, we aim to present a broad overview of the status of graphs in NLP. We will focus in particular on the graph representations adopted, and show how the NLP task was mapped onto a graph-based problem. To cover as many different approaches as possible, we will not go into details that are not strictly connected to graphs. The included references are all available for exploring in more detail the approaches that the readers find most interesting.
Note that we focus on core NLP tasks, and will not delve into research topics that do not have a major NLP component (for example link prediction in social networks). We do not include descriptions of resources represented as graphs (e.g., WordNet, conceptual graphs). We also do not include graph methods used in sequence analysis, such as HMMs and related frameworks.
2 Notations and definitions
A graph G = (V, E) is a structure consisting of a set of vertices (or nodes) V = {vi|i = 1, n}, some of which are connected through a set of edges E = {(vi, vj)|vi, vj ∈ V}. In a weighted graph Gw = (V, E, W), edges have associated a weight or cost wij: W = {wij|wij is the weight/cost associated with edge } 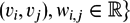 $(v_i,v_j), w_{i,j} \in \mathbb {R}\rbrace$. Edges can be directed or undirected.
$(v_i,v_j), w_{i,j} \in \mathbb {R}\rbrace$. Edges can be directed or undirected.
Depending on the NLP application, the nodes and edges may represent a variety of language-related units and links. Vertices can represent text units of various sizes and characteristics, e.g., words, collocations, word senses, sentences or even documents. Edges can encode relationships like co-occurrence (two words appearing together in a text unit), collocation (two words appearing next to each other or separated by a function word), syntactic structure (e.g., the parent and child in a syntactic dependency), lexical similarity (e.g., cosine between the vector representations of two sentences).
In a heterogeneous graph the vertices may correspond to different types of entities, and the edges to different types of links between vertices of the same or different type: V = V 1∪V 2∪⋅⋅⋅∪Vt, where each Vi is the set of nodes representing one type of entity.
An example of a heterogeneous graph is a graph consisting of articles, their authors and bibliographic references. Edges between authors could correspond to co-authorship/collaboration, citation, edges between authors and their papers represent authorship, and links between two papers could represent citation/reference relations.
A hypergraph expands the notion of graph by having edges – called hyperedges – that cover an arbitrary number of vertices: E = {E 1, …, Em} with Ek⊆V, ∀k = 1, m. When |Ek| = 2, ∀k = 1, m the hypergraph is a standard graph (Gallo et al. Reference Gallo, Longo, Nguyen and Pallotino1993). The incidence matrix A(n × m) = [aik] of a hypergraph associates each row i with vertex vi and each column k with hyperedge Ek. aik = 1 if vi ∈ Ek.
A directed hypergraph has directed hyperedges, which are represented as ordered pairs Ek = (Xk, Yk), where Xk, Yk are disjoint subsets of vertices, possibly empty. Xk is the head of Ek ( H(Ek) ), and Yk is the tail ( T(Ek) ). The incidence matrix of the hypergraph can encode directionality:
 $$
\begin{equation*}
a_{ik} = \left\lbrace
\begin{array}{@{}l@{\quad }l@{}}-1 & \quad \mbox{ if } v_i \in H(E_k)\\
~1 & \quad \mbox{ if } v_i \in T(E_k)\\
~0 & \quad \mbox{ otherwise } \\
\end{array}\right.
\end{equation*}$$
$$
\begin{equation*}
a_{ik} = \left\lbrace
\begin{array}{@{}l@{\quad }l@{}}-1 & \quad \mbox{ if } v_i \in H(E_k)\\
~1 & \quad \mbox{ if } v_i \in T(E_k)\\
~0 & \quad \mbox{ otherwise } \\
\end{array}\right.
\end{equation*}$$An example of a hypergraph in language is the grammar, where the nodes are nonterminals and words, and each hyperedge corresponds to a grammatical rule, with the left-hand side of the rule forming the head of the hyperedge, and the body of the rule forming the tail.
3 Books and surveys
The most comprehensive book on the topic is Mihalcea and Radev (Reference Mihalcea and Radev2011), which gives an introduction to graph theory, and presents in detail algorithms particularly relevant to various aspects of language processing, texts and linguistic knowledge as networks, and the combination of the two leading to elegant solutions for information retrieval, various problems related to lexical semantics (synonym detection, word sense disambiguation, semantic class detection, semantic distance), syntax (POS tagging, dependency parsing, prepositional phrase attachment), discourse (co-reference resolution), as well as high-end applications like summarization, segmentation, machine translation.
Graphs and graph-based algorithms are particularly relevant for unsupervised approaches to language tasks. Choosing what the vertices represent, what their features are, and how edges between them should be drawn and weighted, leads to uncovering salient regularities and structure in the language or corpora data represented. Such formalisms are detailed in Biemann (Reference Biemann2012), with emphasis on the usefulness of the graph framework to tasks superficially very different: language separation, POS tagging, word sense induction and word sense disambiguation. At the bottom of all these varied tasks is the phenomenon of clustering, for which the graph representation and algorithms are particularly appropriate. Chen and Ji (Reference Chen and Ji2010) present a survey of clustering approaches useful for tasks in computational linguistics.
Transforming a graph representation allows different characteristics of the data to come into focus – for example imposing a certain threshold on the weights of edges in a graph will change the topology of the structure, leading to different results in clustering. Rossi et al. (Reference Rossi, McDowell, Aha and Neville2012) examine and categorize techniques for transforming graph-based relational data – transformation of nodes/edges/features – to improve statistical relational learning. Rossi et al. present a taxonomy for data representation transformation in relational domains that incorporates link transformation and node transformation as symmetric representation tasks. Relational representation transformation is defined as any change to the space of links, nodes and/or features used to represent the data. The particular transformation applied depends on the application, and may lead to improving the accuracy, speed or complexity of the final application – e.g., adding links between similar nodes may increase performance in classification/clustering. Transformation tasks for both nodes and links include (i) predicting their existence, (ii) predicting their label or type, (iii) estimating their weight or importance, (iv) constructing their relevant features.
Some of the most used techniques in graph-based learning approaches include min-cut (Blum and Chawla Reference Blum and Chawla2001), spectral graph transducer (Joachims Reference Joachims2003), random walk-based approaches (Szummer and Jaakkola Reference Szummer and Jaakkola2001), and label propagation (Zhu and Ghahramani Reference Zhu and Ghahramani2002). Label propagation in particular is frequently used: it is a method of self-supervision, by allowing the labels of a small set of annotated data to spread in consistent fashion (according to the underlying similarity method) to unlabeled data.
4 Text structure, discourse, and generation
While traditionally we work with clean, edited text, the increasing amounts and the appeal of data produced through social media (like Tweeter and Facebook) raises the need for text normalization and typo correction to provide clean data to NLP tools further down the processing chain. This section reviews a few approaches that address this issue with graph-based methods.
Once a clean text is obtained, a potential next step is inducing its structure, to detect semantically coherent segments. This structuring can further aid tasks such as summarization and alignment. The idea that a summary should consist of the most semantically rich and representative sentences of a document has led to the development of approaches that aim to detect simultaneously the keyphrases and the most important sentences of a document/set of documents. Graph representations can capture this duality, and bipartite or heterogeneous graphs have been used to model both keyphrase and sentence nodes, and the relations between them. Keyphrases are themselves a desired result, as they can contribute to document classification or clustering.
Texts also have a discourse structure, whether they are a simple text or a multi-party dialog. The set of entity mentions in the text and the coreference relations between them can themselves be modeled through different graph representations, either to make local decisions about a pair of entity mentions, or to induce clusters representing coreference chains that group all mentions of an entity together.
4.1 Text normalization
The language of social media is very dynamic, and alternative spellings (and errors) for words based on ad-hoc or customized abbreviations, phonetic substitutions or slang language are continuously created. Text normalization could be used to increase the performance of subsequent processing such as Machine Translation, Text-to-Speech, Information Extraction. Hassan et al. (Reference Hassan and Menezes2013) proposed a method that relies on a method similar to label propagation – from correct word forms found in dictionaries – to alternative spellings. This approach relies on a bipartite graph G = (W, C, E) which represents words W = {wi|i = 1, N} and contexts C = {Cj|j = 1, M} which are n-gram patterns. Frequency-based weighted edges connect words with the contexts in which they appear. The graph is built based on social media noisy text, and a large clean corpus. Correct words are marked based on frequency information from the clean corpus. These are the ‘correctly labeled’ words. Unlabeled nodes will adopt the ‘label’ (i.e., spelling) of the their closest (highest ranking) labeled node based on a random walk in graph G.
Interaction with social media from portable devices like smartphones brings up particular problems for languages with logographic scripts, like Chinese, as the small screen cannot display the hundreds of available characters. The solution is the usage of input method engines (IME) of which pinyin-to-Chinese conversion is a core part. This manages the conversion from (Roman alphabet) letter sequences to logograms (Chinese characters), but is prone to errors on two levels: (i) the sequence of letters input has a typo – caused by limited familiarity with the language or dialect, or mistake – and the system cannot produce the correct character, (ii) the wrong Chinese character was selected for the correct input letters. Jia and Zhao (Reference Jia and Zhao2014) address these problems through a combination of two graph-based methods. The first method is applied to a graph consisting of the linear sequence of letters input by the user, and aims to produce legal syllables (as sequences of nodes) that have a corresponding Chinese character using a dictionary. Each detected syllable will form a new node, and it will be connected to other adjacent candidate syllables. A new graph will be built based on the detected syllables candidates, plus syllables that are similar to these candidates based on a Levenshtein distance. The shortest path that covers the string is taken as the best typo correction result. To determine the correct mapping onto Chinese characters, an HMM is applied to the sequence of typo-corrected syllables, as each syllable can be mapped onto different characters.
4.2 Text structure and summarization
Despite the fact that often when reading a text we intuitively detect functional structures – an introduction, the elaboration/main content, a conclusion – texts often have at most a structuring in terms of paragraphs that may or may not reflect a shared topic of the sentences included.
Among the first to explore the structure of a text computationally through graph-based methods, Salton et al. (Reference Salton, Singhal, Mitra and Buckley1997) apply techniques previously used to determining inter-document link to determine links between sentences or paragraphs within a document. The weights of the edges are essentially similarity scores between the nodes, filtered using a threshold value. The first aim of the work is to determine the structure of a text as a sequence of coherent units. This emerges when edges are further limited to connect nodes corresponding to sentences or paragraphs no more than five positions away. Summarization is an extension of the analysis of the text structure in terms of segments. They propose that this structure of segments can be used to produce the generic summary of a text by selecting a subset of the sentences/paragraphs that cover all the topics of the document. Three methods are explored, based on the ‘bushiness’ of nodes – what current graph formalisms call the degree of nodes. The best performing was the ‘bushy path’ method, that selected the top k bushy nodes, where k is the targeted number of paragraphs in the summary.
Zha (Reference Zha2002) proposes a new graph representation of a document based on the intuition that important terms and sentences should reinforce each other. Instead of linking together sentences through an edge representing the similarity of the two, Zha differentiates between sentences and keyphrases, and build an undirected bipartite graph that captures the occurrence of keyphrases in sentences. The aim is to score each node in this graph based on its links and the weights of these links, and this score will be the ‘salience’ of the node. The scores of the nodes are computed in a manner very similar to the HITS algorithm (Kleinberg Reference Kleinberg1999), where the keyphrases and sentences are scored iteratively depending on each others’ scores until convergence. This approach determines a ranking of keyphrases (and sentences) that can be used to describe the document. The next step is to leverage this information to build a summary. The first operation is to cluster sentences. The weight of an edge between two sentences depends on the number and weight of the keyphrases they share. Recognizing that the order in which sentences appear is important, the weight of the edge has an additional (fix) factor (α) which is added when two sentences ‘are near-by’ or not. To cluster the sentences, spectral clustering is applied to the incidence matrix of the sentence graph. This is used to produce a hierarchical clustering of sentences. Depending on the level of summarization (more detailed or more general), clusters at different levels can be used, and then representative sentences selected from each cluster.
In Erkan and Radev (Reference Erkan and Radev2004) and Mihalcea and Tarau (Reference Mihalcea and Tarau2004), they take the idea of graph-based summarization further by introducing the concept of lexical centrality. Lexical centrality is a measure of importance of nodes in a graph formed by linking semantically or lexically related sentences or documents. A random walk is then executed on the graph and the nodes that are visited the most frequently are selected as the summary of the input graph (which, in some cases, consists of information from multiple documents). One should note however, that in order to avoid nodes with duplicate or near duplicate content, the final decision about including a node in the summary also depends on its maximal marginal relevance as defined in Carbonell and Goldstein (Reference Carbonell and Goldstein1998). An example from Erkan and Radev (Reference Erkan and Radev2004) is shown in Figure 1. The input consists of eleven sentences from several news stories on related topics. Figure 2 shows the resulting weighted graph.

Fig. 1. A cluster of 11 related sentences.
Fig. 2. Weighted cosine similarity graph for the cluster in Figure 1.
To boost scores for the most relevant or important sentences, the sentence-based graph representations for documents can be enhanced with additional information such as relative position of sentences within a document (Wan Reference Wan2008). Word-based graph representations could include POS information, sentences in which they occurred and position in these sentences. Ganesan, Zhai and Han (Reference Ganesan, Zhai and Han2010) use such a representation, in which words are linked based on their sequence in the sentence (adjacent words are connected with directed edges). Three properties of this graph – redundancy; gapped subsequence; collapsible structure – are used to explore and score subpaths that help generating abstractive summaries (as they have elements of sentence fusion and compression based on the selected paths).
Zhu et al. (Reference Zhu, Gao, Pan, Li, Deng and Shahabi2013) formulate the informative-sentence problem in opinion summarization as a community-leader detection problem, where a community consists of a cluster of sentences towards the same aspect of an entity. The graph consists of sentences linked by edges whose weight combines term similarity and adjective orientation similarity. In this graph, an interactive process builds communities of sentences and determines their leaders: a set of leaders is selected initially (from the top nodes based on their degree, select a set of k nodes such that no two are connected), then iteratively communities and leaders are updated in a manner similar to link propagation: starting with the current set of leaders the communities are determined (one per leader), and after generating the community, leaders are reassigned based on ranking their in-community degree. After the process converges, a set of informative sentences are selected from each community to generate the summary.
A different approach to summarization is presented by Mani and Bloedorn (Reference Mani and Bloedorn1997), who start with the goal of building summaries from several documents. They build a graph for each document, whose nodes are word instances at specific positions (such that names and phrases spanning more than one word are formed by the respective word instances). Words are weighted and filtered using tf-idf, and are connected through several types of relations, presented in order of weight: same (linking different instances of the same word); coreference (link names or phrases that are the same – names and phrases span more than one word/node); name (link nodes that together form a name); phrase (link nodes that are part of the same phrase); alpha (various lexical relations such as synonymy, hypernymy/hyponymy obtained from an early version of WordNet); adj (adjacency – words that are adjacent in the text, but filtering out intervening words). On this graph with weighted nodes and edges, is applied a step of spreading activation. First, a set of words expressing a topic of interest is selected. All nodes in the graph except those matching the topic words receive a weight of 0. Starting from the selected topic words the spreading activation will reassign weights to the nodes, based on the signal coming from connected nodes, the weight of the edges, and a dampening effect caused by distance from a starting node. After activation, segments are selected from the reweighted graph. A segment can either consist of the set of nodes (and underlying text) within a weight within a given delta from the peak values, or all nodes within a user-defined distance in the text from a peak value.
Spreading activation for topic-driven summarization was also used by Nastase (Reference Nastase2008). The set of documents is used to build a graph in which open-class words are nodes connected through dependency relations. In this graph, open words from the topic and their related terms obtained from Wikipedia and WordNet are given a starting weight which is then propagated using spreading activation to enhance the weight of other related terms and the edges that connect them. The weighted nodes and relations are used to score the sentences in which they appear, and the highest scoring ones will form the summary.
Related to the problem of summarization is the issue of passage retrieval: given a query in the form of a natural language question, return a set of passages from a set of input documents that contain the answer. Otterbacher, Erkan and Radev (Reference Otterbacher, Erkan and Radev2005) propose a solution that combines the sentence-based graph representation of Erkan and Radev (Reference Erkan and Radev2004) with biased random walk and implement a label propagation method: the graph is seeded with known positive and negative examples and then each node is labeled in proportion to the percentage of times a random walk on the graph ends at that node. Given the presence of the initially labeled nodes, the nodes with the highest score eventually are the ones that are both similar to the seed nodes and are central to the document set. In other words, they are chosen as the answer set by a mixture model that takes into account the known seeds (positive or negative) and the lexical centrality score as in the previous section. The graph consists of both sentences (paragraphs) and features (content words that appear in these sentences). The graph is bipartite as a sentence can only link to a feature and vice versa.
4.3 Discourse
Coreference resolution aims to group mentions of entities such that all mentions in a group refer to the same entity. This problem can be cast into a graph-based framework in various ways. For instance, Ng (Reference Ng2009) uses a graph formalism to filter non-anaphoric mentions, as previous work has shown that eliminating isolated mentions (singletons) leads to better coreference resolution results. The solution proposed partitions a graph in two parts corresponding to anaphoric and non-anaphoric mentions. The graph’s nodes are the mentions discovered in the text, plus two special nodes – s (source) and t (sink) – representing the two classes (anaphoric/non-anaphoric). The graph is built in two steps. First, each mention node n is connected to the s and t nodes through edges whose weights are a function of the probability that n is anaphoric or not. In the next step, mention nodes ni and nj are connected through an edge weighted by a similarity measure between ni and nj, reflecting the probability that the two are coreferent. Partitioning this graph in two is a minimum cut problem, which seeks to minimize the partition cost, i.e., the cost of ‘cut’ edges, where the nodes they link belong to the different subsets. Training data is used to estimate probabilities and thresholds on these probabilities for weighing/drawing the graph.
Other approaches aim to cluster the mentions based on connections between them. (Nicolae and Nicolae Reference Nicolae and Nicolae2006) build a graph whose vertices are mentions, connected with edges whose weights are confidence values obtained from a coreference classification model. This graph is then partitioned into clusters using a variation of the min-cut algorithm that iteratively removes edges between subgraphs that have low weights, and are thus interpreted as representing different entities.
Cai and Strube (Reference Cai and Strube2010) present a one-step coreference method that builds coreference chains directly by clustering nodes in a hypergraph. Hypergraph nodes are mentions detected in the text, and the edges group nodes that can be connected through relational features (e.g., alias – the mentions are aliases of each other: proper names with partial match, full names and acronyms or organizations, etc.; synonyms; etc.) The edges of the hypergraph correspond roughly to features used in other coreference work. This hypergraph covering the mentions in the entire document is split into sub-hypergraphs (i.e., clusters) by partitioning using two-way recursive spectral clustering.
Local text coherence can also be cast into a graph framework. Occurrence of entities in sentences can be viewed as a bipartite graph, and used to model local coherence (Guinaudeau and Strube Reference Guinaudeau and Strube2013). Links between entities and sentences can encode grammatical information (e.g., entity is subject/object in the sentence), and be weighted accordingly. This bipartite graph is used to generate sentence graphs, where two sentences are connected if they have at least one entity in common. Depending on how the weights of the graph are computed, several variants of the sentence graphs are obtained. Compared to alternative approaches for sentence ordering, summary coherence rating and readability assessment, the graph-based approach is computationally lighter at state-of-the-art performance levels.
Another discourse problem is dialog analysis, of which disentanglement – determining to which conversation thread each utterance belongs to – is an essential step. Elsner and Charniak (Reference Elsner and Charniak2010) approach this as a clustering problem on a graph. A machine learning step is first used to predict probabilities for pairs of utterances as belonging to the same conversation thread or not based on lexical, timing and discourse-based features. The graph covering the conversation is then built, with a node for each utterance, and edges between utterances having as weight a function of the probability score assigned by the classifier (the log odds). On this graph is applied a greedy voting algorithm, adding an utterance j to an existing cluster based on the weight of the edge between j and nodes in the existing cluster, or put it into a new cluster if no weights greater than 0 exist.
4.4 Language generation
From the point of view of graphs, paraphrases can be seen as matching graphs – there is a mapping between the graphs (as dependency graphs or syntactic trees) corresponding to the paraphrases. Barzilay and Lee (Reference Barzilay and Lee2003) build word latices to find commonalities within automatically derived groups of structurally similar sentences. They then identify pairs of lattices from different corpora that are paraphrases of each other – the identification process checks whether the lattices take similar arguments; given an input sentence to be paraphrased, they match it to a lattice and use a paraphrase from the matched lattice’s mate to generate an output sentence.
Konstas and Lapata (Reference Konstas and Lapata2012) generate descriptions of database records in natural language. Given a corpus of database records and textual descriptions (for some of them), they define a PCFG that captures the structure of the database and how it can be rendered into natural language. This grammar, representing a set of trees, is encoded as a weighted hypergraph. Generation is equivalent to finding the best derivation tree in the hypergraph using Viterbi.
5 Syntax and tagging
Regarding syntax, we have identified two main directions – graphs used to represent the dependency relations between words, and graphs for representing the grammar, used ultimately in generative contexts (in machine translation or language generation).
Tagging involves assigning (one of the given) tags to words or expressions in a collection. Approaches using graphs rely on the fact that they are useful for providing a global view on the data and enforce coherence at the level of the entire dataset. This characteristic is exploited to induce consistent labeling over a set of nodes, either by clustering, propagating the tags starting from a small set of seeds, or by obtaining features that capture a larger context of the targeted entity for supervised learning.
5.1 Syntactic parsing
Dependency relations linking words in a sentence form a directed acyclic graph. This view of the result of syntactic parsing can be used to cast the problem of dependency parsing into searching for a maximum spanning tree (MST) in a directed graph that covers the given sentence/text (Hirakawa Reference Hirakawa2001; McDonald et al. Reference McDonald, Pereira, Ribarov and Hajic2005): given a directed graph G = (V, E), the MST problem is to find the highest scoring subgraph of G that satisfies the tree constraint over the set of vertices V.
Graph literature provides various algorithms for determining the MST of a directed graph. Choosing an algorithm depends on characteristics of the dependency graph: for projective dependenciesFootnote 2 choose one based on the Eisner algorithm (Eisner Reference Eisner1996); for non-projective dependencies choose one based on Chi-Liu-Edmonds (Chu and Liu Reference Chu and Liu1965; Edmonds Reference Edmonds1967).
Another important aspect is scoring the MST candidates. There are several variations, based on the way the scoring of the tree is done: first-order – the score of the tree is based on the scores of single edges; second-order – the score of the tree is factored into the sum of adjacent edge-pair scores.
Graph-based models take into account the score for the entire structure, but this score is computed based on local features of each edge, to make the parsing tractable. Nivre and McDonald (Reference Nivre and McDonald2008), Zhang and Clark (Reference Zhang and Clark2008) and Chen and Ji (Reference Chen and Ji2010) show methods to improve the graph-based parsing by including additional features, possibly produced by alternative parsing models. Nivre and McDonald (Reference Nivre and McDonald2008) and Zhang and Clark (Reference Zhang and Clark2008) use features produced by transition models – learned by scoring transitions from one parser state to the next – which have a complementary approach to parsing compared to the graph-based models – they use local training, and greedy inference algorithms, while using richer features that capture the history of parsing decisions. It is interesting to note that the transition-based and the graph-based parsing have the same end states – the set of dependency relations graphs that cover the input sentence – which they reach through different search strategies. Combining features that guide the search strategies for the two methods leads to improved results.
The definition of directed hyperarcs in terms of heads and tails matches the view of grammatical rules – which have a head and a body, and therefore can be used to encode (probabilistic) grammars (Klein and Manning Reference Klein and Manning2001). Building a hypergraph that encodes a grammar and an input, the paths in the hypergraph correspond to parses of the given input. The shortest path will correspond to the best parse. Klein and Manning (Reference Klein and Manning2001) present PCFG-specific solutions in the hypergraph framework, including an approach that constructs the grammar hypergraph dynamically as needed, and a Dijkstra’s algorithm style shortest path computation. Other solutions were proposed by Huang and Chiang (Reference Huang and Chiang2005) and Huang (Reference Huang2008), which can also be integrated in the decoding step of phrase-based or syntax-based machine translation (Huang and Chiang Reference Huang and Chiang2007), where grammar rules are combined with language models.
5.2 Tagging
Using graph methods for tagging relies on the intuition that similar entities should have the same tag. The nodes in these graph will represent words or phrases (depending on the type of targets and their tags), and the edges will be drawn and weighted based on a similarity metric between the nodes.
Watanabe, Asahara and Matsumoto (Reference Watanabe, Asahara and Matsumoto2007) aim to tag named entities in Wikipedia. A graph structure covers linked anchor texts of hyperlinks in structured portions in Wikipedia articles – in particular lists and tables. A CRF variation is used to categorize nodes in the graph as one of twelve Named Entity types. Three types of links are defined between anchor texts, based on their relationships in the structured portions of the text – siblings, cousins, relatives. These relations define three types of cliques. The potential function for cliques is introduced to define conditional probability distribution over CRFs (over label set y given observations x). These potential functions are expressed in terms of features that capture co-occurrences between labels. Experiments show that a configuration using cousin and relative relations leads to the best results (also compared to a non-graph method – i.e., unconnected nodes).
Subramanya, Petrov and Pereira (Reference Subramanya, Petrov and Pereira2010) tag words with POS information through a label-propagation algorithm that builds upon a word similarity graph and the assumption that words that are similar have the same POS. The similarity graph is used during the training of a CRF to smooth the state posteriors on the target domain. Local sequence contexts (n-grams) are graph vertices, exploiting the empirical observation that the POS of a word occurrence is mostly determined by its local context. For each n-gram they extract a set of context features, whose values are the pointwise mutual information between the n-gram and its features. The similarity function between graph nodes is the cosine distance between the pointwise mutual information vectors representing each node. The neighbors of a node are used as features for the CRF, thus embedding larger contextual information in the model. CRFs cannot enforce directly constraints that similar n-grams appearing in different contexts should have similar POS tags. The graphs are used to discover new features, to propagate adjustments to the weights of known features, and to train the CRF in a semi-supervised manner.
Bollegala, Matsuo and Ishizuka (Reference Bollegala, Matsuo and Ishizuka2008) detect aliases based on a word (anchor text) co-occurrence graph in which they compute node rankings, combined using SVMs. The nodes consist of words that appear in anchor texts, which are linked through an edge if the anchor texts in which they appear point to the same URL. The association strength between a name and a candidate alias is computed using several measures (link frequency – the number of different URLs in which the name and candidate co-occur), tf-idf (to downrank high frequency words), log-likelihood ratio, chi-squared measure, pointwise mutual information and hypergeometric distribution), also considering the importance of each URL target.
6 Semantics
Within the area of lexical and text semantics, the most common representation is a graph having words as nodes. The way edges are drawn and weighted varies much, depending on the task. They may represented directed/undirected relations, and may be derived from other networks (e.g., as similarity/distance from WordNet), from distributional representations of words, or directly from evidence found in corpora (e.g., corresponding to conjunctions of the form X (and|or|but) Y).
The purpose of the tasks also varies. The focus may be to build a lexical network, to transfer annotations from one lexical network to another, or to induce higher level information, such as semantic classes or even ontologies.
6.1 Lexicon and language models
One of the largest graph representations constructed to support an NLP task is perhaps the graph model proposed by Widdows and Dorow for unsupervised lexical acquisition (Widdows and Dorow Reference Widdows and Dorow2002). The goal of their work is to build semantic classes, by automatically extracting from raw corpora all the elements belonging to a certain semantic category such as fruits or musical instruments. The method first constructs a large graph consisting of all the nouns in a large corpus (British National Corpus, in their case), linked by the conjunction and or or. A cutoff value is used to filter out rare words, resulting in a graph of almost 1,00,000 nouns, linked by more than half-million edges. To identify the elements of a semantic class, first a few representative nouns are manually selected and used to form a seed set. In an iterative process, the node found to have the largest number of links with the seed set in the co-occurrence graph is selected as potentially correct, and thus added to the seed set. The process is repeated until no new elements can be reliably added to the seed set. Figure 3 shows a sample of a graph built to extract semantic classes. An evaluation against ten semantic classes from WordNet indicated an accuracy of 82 per cent which, according to the authors, was an order of magnitude better than previous work in semantic class extraction. The drawback of their method is the low coverage which is limited to those words found in a conjunction relation. However, whenever applicable, the graph representation has the ability to precisely identify the words belonging to a semantic class.

Fig. 3. Lexical network constructed for the extraction of semantic classes.
Another research area is the study of lexical network properties carried out by Ferrer-i-Cancho and Sole (Reference Ferrer i Cancho and Sole2001). By building very large lexical networks of nearly half-million nodes, with more than ten million edges, constructed by linking words appearing in English sentences within a distance of at most two words, they proved that complex system properties hold on such co-occurrence networks. Specifically, they observed a small-world effect, with a relatively small number of 2–3 jumps required to connect any two words in the lexical network. Additionally, it has also been observed that the distribution of node degrees inside the network is scale-free, which reflects the tendency of a link to be formed with an already highly connected word. Perhaps not surprisingly, the small-world and scale-free properties observed over lexical networks automatically acquired from corpora are were also observed on manually-constructed semantic networks such as WordNet (Sigman and Cecchi Reference Sigman and Cecchi2002; Steyvers and Tenenbaum Reference Steyvers and Tenenbaum2005).
In a more recent work on acquiring semantic classes and their instances, Talukdar et al. (Reference Talukdar, Reisinger, Pasca, Ravichandran, Bhagat and Pereira2008) use a graph formalism to encode information from unstructured and structured texts and then induce and propagate labels. Nodes representing instances or classes are extracted from free text using clustering techniques and structured sources (like HTML tables). A small set of nodes is annotated with class labels (which also appear as class nodes in the graph), and these labels are propagated in the graph using Adsorption label propagation, which computes for each node a probability distribution over the set of labels. Talukdar and Pereira (Reference Talukdar and Pereira2010) continues this work by comparing several label propagation algorithms for this problem, determining that Modified Adsorption gives the best results. Modified Adsorption is a variation of the Adsorption algorithm, formalized like an optimization problem.
Velardi, Faralli and Navigli (Reference Velardi, Faralli and Navigli2013) learn concepts and relations via automated extraction of terms, definitions and hypernyms to obtain a dense hypernym graph. A taxonomy is induced from this (potentially disconnected and cyclic) graph via optimal branching and weighting.
As seen above, corpus information can be exploited to obtain structured information. One downside of information derived from corpora is the fact that it captures information at the word level and connecting to other linguistic resources such as WordNet or FrameNet requires word-sense distinctions. Johansson and Nieto Piña (Reference Johansson and Nieto Piña2015) present a framework for deriving vector representations for word senses from continuous vector-space representations of the words and word sense information (and their connections) from a semantic network. The work is based on word-sense constraints in the semantic network – neighbors in the semantic network should have similar vector representations – and the fact that the vector for a polysemous word is a combination of the vectors of its senses.
Numerous lexical resources, including those automatically derived, have a graph structure. To combine such resources Matuschek and Gurevych (Reference Matuschek and Gurevych2013) iteratively determine an alignment using the graphs representing these resources and an initial set of trivial alignments consisting of monosemous nodes in both resources. Further alignments are based on the shortest path in the connected graph that links a pair of candidate nodes, one from each of the initial resources.
From monolingual lexical networks we can transition to multi-lingual networks by linking together monolingual networks. Issues like inducing new connections starting from a seed of relations that link the networks, and disambiguating ambiguous entries are seamlessly tackled in the graph-based framework. Laws et al. (Reference Laws, Michelbacher, Dorow, Scheible, Heid and Schütze2010) build separate graphs for two languages, representing words and their lexical relations (e.g., adjectival modification). The two monolingual graphs are linked starting with a set of seeds. Nodes from the two graphs are compared and linked using a similarity measure to determine translations. Flati and Navigli (Reference Flati and Navigli2012) disambiguate ambiguous translations in the lexical entries of a bilingual machine-readable dictionary using cycles and quasi-cycles. The dictionary is represented as a graph and cyclic patterns are sought in this graph to assign an appropriate sense tag to each translation in a lexical entry. The output is also used to correct the dictionary by improving alignments and missing entries.
6.2 Similarity and relatedness measures
A large class of methods for semantic similarity consists of metrics calculated on existing semantic networks such as WordNet and Roget, by applying, for instance, shortest path algorithms that identify the closest semantic relation between two input concepts (Leacock, Miller and Chodorow Reference Leacock, Miller and Chodorow1998). Tsatsaronis, Varlamis and Nørvåg (Reference Tsatsaronis, Varlamis and Nørvåg2010) present a method for computing word relatedness based on WordNet that exploits several types of information in the network: depth of nodes, relations and relation weights, relations crossing POS boundaries. The computation is extended from word-to-word to relatedness between texts.
Hughes and Ramage (Reference Hughes and Ramage2007) propose an algorithm based on random walks. Briefly, in their method, the PageRank algorithm is used to calculate the stationary distribution of the nodes in the WordNet graph, biased on each of the input words in a given word pair. Next, the divergence between these distributions is calculated, which reflects the relatedness of the two words. When evaluated on standard word relatedness data sets, the method was found to improve significantly over previously proposed algorithms for semantic relatedness. In fact, their best performing measure came close to the upper bound represented by the inter-annotator agreement on these data sets.
Tsang and Stevenson (Reference Tsang and Stevenson2010) introduce a measure of the semantic distance between texts that integrates distributional information with a network flow formalism. Texts are represented as a collection of frequency weighted concepts within an ontology. The network flow method provides an efficient way of explicitly measuring the frequency-weighted ontological distance between concepts across two texts.
A different approach to similarity computation that combines co-occurrence information from a parsed corpus is presented by Minkov and Cohen (Reference Minkov and Cohen2008). The starting point is a graph with two types of vertices and two types of edges that covers a dependency parsed corpus: nodes are work tokens and word types (terms), edges representing grammatical dependencies connect word token vertices, the inverse relation is then added, and there are also edges linking word tokens with the corresponding word type (term). The working assumption is that terms that are more semantically related will be linked by a larger number of paths in this corpus graph, and shorter paths are more meaningful. The similarity between two nodes in this graph is derived through a weighted random walk. The edges may have uniform weights, or they can be tuned in a learning step. For specific tasks, additional information from the graph can be used to rerank the terms with the highest similarity to terms in the given query (for example) – the sequence of edges on the connecting path, unigrams that appear on the path, and the number of words in the query that are connected to the term that is being ranked. Minkov and Cohen also propose a dynamic version of graph-walk, which is constrained at each new step by previous path information. This is achieved by reevaluating the weights of the outgoing edges from the current edge based on the history of the walk up to this node.
6.3 Word sense induction and word sense disambiguation
The surface level of a text consists of words, but what a reader perceives, and what we’d ideally want a system to access, are the meanings of words, or word senses. It is commonly accepted that the context of a word – within a window of a given size/sentence/larger text fragment – influences its interpretation and thus determines its sense. Mapping words onto specific senses can be done relative to a given inventory of senses, or a system may determine itself the set of senses that occur in a given text collection, or something in between when a partial set of senses can be provided for a small set of seed words. Depending on the task and the availability of labeled data, various graph-based methods can be applied, including clustering on unlabeled data, label propagation starting from a small set of labeled data, ranking of given word senses to determine which applies to specific instances in the data.
Work related to word senses has been encouraged by recurring word sense induction and word sense disambiguation tasks within the SensEval/SemEval/*SEM semantic evaluation campaigns. The variety of approaches has been recorded in the events’ proceedings. We will present an overview of graph-based methods successfully used to tackle these tasks by modeling the relations between words, their contexts and their senses, and using these models in different manners.
A graph-based method that has been successfully used for semi-supervised word sense disambiguation is the label propagation algorithm (Niu, Ji and Tan Reference Niu, Ji and Tan2005). In their work, Niu and colleagues start by constructing a graph consisting of all the labeled and unlabeled examples provided for a given ambiguous word. The word sense examples are used as nodes in the graph, and weighted edges are drawn by using a pairwise metric of similarity. On this graph, all the known labeled examples (the seed set) are assigned with their correct labels, which are then propagated throughout the graph across the weighted links. In this way, all the nodes are assigned with a set of labels, each with a certain probability. The algorithm is repeated through convergence, with the known labeled examples being reassigned with their correct label at each iteration. In an evaluation carried out on a standard word sense disambiguation data set, the performance of the algorithm was found to exceed the one obtained with monolingual or bilingual bootstrapping. The algorithm was also found to perform better than SVM when only a few labeled examples were available.
Graph-based methods have also been used for knowledge-based word sense disambiguation. In Mihalcea, Tarau and Figa (Reference Mihalcea, Tarau and Figa2004), Mihalcea and colleagues proposed a method based on graphs constructed based on WordNet. Given an input text, a graph is built by adding all the possible senses for the words in the text, which are then connected on the basis of the semantic relations available in the WordNet lexicon. For instance, Figure 4 shows an example of a graph constructed over a short sentence of four words.

Fig. 4. Graph constructed over the word senses in a sentence, to support automatic word sense disambiguation.
A random-walk applied on this graph results in a set of scores that reflects the ‘importance’ of each word sense in the given text. The word senses with the highest score are consequently selected as potentially correct. An evaluation on sense-annotated data showed that this graph-based algorithm was superior to alternative knowledge-based methods that did not make use of such rich representations of word sense relationships.
In follow-up work, Mihalcea developed a more general graph-based method that did not require the availability of semantic relations such as those defined in WordNet. Instead, she used derived weighted edges determined by using a measure of similarity among word sense definitions (Mihalcea Reference Mihalcea2005), which brought generality, as the method is not restricted to semantic networks such as WordNet but it can be used on any electronic dictionaries, as well as improvements in disambiguation accuracy.
Along similar lines with (Mihalcea et al. Reference Mihalcea, Tarau and Figa2004), Navigli and Lapata carried out a comparative evaluation of several graph connectivity algorithms applied on word sense graphs derived from WordNet (Navigli and Lapata Reference Navigli and Lapata2007). They found that the best word sense disambiguation accuracy is achieved by using a closeness measure, which was found superior to other graph centrality algorithms such as in-degree, PageRank, and betweenness. Navigli and Lapata (Reference Navigli and Lapata2010) present an updated survey of graph-based methods for word sense disambiguation. Agirre, de Lacalle and Soroa (Reference Agirre, de Lacalle and Soroa2014) present a random walk-based disambiguation method on a combination of WordNet and extended WordNet. Extended WordNet (Mihalcea and Moldovan Reference Mihalcea and Moldovan2001) brings in relations between synsets and disambiguated words in the synset glosses. This additional information makes the graph more dense, which leads to better results of the PageRank algorithm for word sense disambiguation than WordNet alone.
In the related task of entity linking – essentially disambiguating a named entity relative to an inventory of possible interpretations/concepts – Fahrni, Nastase and Strube (Reference Fahrni, Nastase and Strube2011) starts from an n-partite graph similar to Mihalcea et al. (Reference Mihalcea, Tarau and Figa2004), where each part corresponds to the possible interpretations of the corresponding text mention. Edges between potential interpretations are weighted based on a combination of relatedness measures that capture relatedness information between these interpretations from Wikipedia (if they can be mapped onto a Wikipedia article), as well as context selectional preference. Concepts are then chosen using a maximum edge weighted clique algorithm – choose the interpretations that have the highest scored subgraph. The method achieved highest scores in the NTCIR-9 entity linking task for several languages (Japanese, Korean, Chinese) and evaluation methods. For the same task, Moro, Raganato and Navigli (Reference Moro, Raganato and Navigli2014) use a densest subgraph heuristic together with entity candidate meanings to select high-coherence semantic interpretations. The graph consists of terms in the texts and their candidate meanings, whose edges are reweighted using random walks and triangles. The highest density subgraph heuristic provides the joint disambiguation solution.
Graph connectivity can also be used to tackle the complementary problem of word sense induction. Word sense induction is often modeled as a clustering problem, with word occurrences – represented through their contexts – that share the same word sense grouped together. Graph-based word sense induction rely usually on the co-occurrence graph, where (open-class, or just nouns) words are nodes. Nodes corresponding to words that occur together within a pre-specified span (e.g., document, sentence, or a specific window size) are connected with edges whose weights reflect co-occurrence frequency, pointwise mutual information between the two words, or other co-occurrence measures. The assumption is that clusters in this network will correspond to different word senses (Biemann Reference Biemann2012). Nodes could also represent word pairs (target word,collocate) to better separate subgraphs pertaining to different senses of the same target word. Nodes are weighted based on the frequency of the corresponding word pair, and nodes that come from the same context are connected (Klapaftis and Manandhar Reference Klapaftis and Manandhar2008). Clustering using the Chinese whispers algorithm proceeds iteratively, with vertices all assigned to different classes, and then reassigned at every step based on the strongest class in its local neighborhood (Biemann Reference Biemann2012). Building the graph relies on several parameters, that threshold and weight the nodes and edges. Korkontzelos, Klapaftis and Manandhar (Reference Korkontzelos, Klapaftis and Manandhar2009) explore eight graph connectivity measures that evaluate the connectivity of clusters produced by a graph-based word sense induction method based on a set of parameters. The evaluation allows the system to estimate the sets of parameters that lead to high performance. Di Marco and Navigli (Reference Di Marco and Navigli2013) investigate the effect of different similarity measures used to draw and weigh edges in a word-based co-occurrence graph.
The previously mentioned approaches to word sense disambiguation either pair a target word with its collocates within the same node, or connects two co-occurring words together. Different models of the problem are proposed in Klapaftis and Manandhar (Reference Klapaftis and Manandhar2007) and Qian et al. (Reference Qian, Ji, Zhang, Teng and Xia2014), who use hypergraphs – actually hyperedges – to capture shared semantic context. Klapaftis and Manandhar (Reference Klapaftis and Manandhar2007) build a hypergraph where nodes are words, and hyperedges connect words within the same context. In Qian et al. (Reference Qian, Ji, Zhang, Teng and Xia2014)’s hypergraph, the nodes represent instances of the context where a target word appears, hyperedges represent higher-order semantic relatedness among these instances – particularly lexical chains. This representation captures a more global perspective as different contexts can be connected through a lexical chain. To induce word senses (Klapaftis and Manandhar Reference Klapaftis and Manandhar2007; Qian et al. Reference Qian, Ji, Zhang, Teng and Xia2014) use hypergraph clustering methods such as Normalized Hypergraph Cut (Zhou, Huang and Schölkopf Reference Zhou, Huang and Schölkopf2006), Hyperedge Expansion Clustering (Shashua, Zass and Hazan Reference Shashua, Zass, Hazan, Leonardis, Bischof and Pinz2006), or a maximal density clustering algorithm (Michoel and Nachtergaele Reference Michoel and Nachtergaele2012).
For processing semantic roles, Lang and Lapata (Reference Lang and Lapata2014) represent argument instances of a verb as vertices in a graph whose edges express similarities between these instances. The graph consists of multiple edge layers, each capturing a different aspect of argument-instance similarity. This graph is partitioned based on extensions of standard clustering algorithms.
7 Sentiment analysis and social networks
Sentiment and subjectivity analysis is an area related to both semantics and pragmatics, which has received a lot of attention from the research community. An interesting approach based on graphs has been proposed by Pang and Lee (Reference Pang and Lee2004), where they show that a min-cut graph-based algorithm can be effectively applied to build subjective extracts of movie reviews.
First, they construct a graph by adding all the sentences in a review as nodes, and by drawing edges based on sentence proximity. Each node in the graph is initially assigned with a score indicating the probability of the corresponding sentence being subjective or objective, based on an estimate provided by a supervised subjectivity classifier. A min-cut algorithm is then applied on the graph and used to separate the subjective sentences from the objective ones. Figure 5 illustrates the graph constructed over the sentences in a text, on which the min-cut algorithm is applied to identify and extract the subjective sentences.

Fig. 5. A min-cut algorithm applied on a graph constructed over the sentences in a text, which is used to separate subjective from objective sentences.
The precision of this graph-based subjectivity classifier was found to be better than the labeling obtained with the initial supervised classifier. Moreover, a polarity classifier relying on the min-cut subjective extracts was found to be more accurate than one applied on entire reviews.
Recent research on sentiment and subjectivity analysis has also considered the relation between word senses and subjectivity (Wiebe and Mihalcea Reference Wiebe and Mihalcea2006). In work targeting the assignment of subjectivity and polarity labels to WordNet senses, Esuli and Sebastiani applied a biased PageRank algorithm on the entire WordNet graph (Esuli and Sebastiani Reference Esuli and Sebastiani2007). Similar to some extent to the label propagation method, their random-walk algorithm was seeded with nodes labeled for subjectivity and polarity. When compared to a simpler classification method, their random-walk was found to result in more accurate annotations of subjectivity and polarity of word senses.
One of the first methods of inducing the semantic orientation of words is Hatzivassiloglou and McKeown (Reference Hatzivassiloglou and McKeown1997). They build a graph of adjectives, and draw edges based on conjunctions found in corpora, following the observation that if they appear in a conjunctions, the adjectives will have the same orientation (e.g., ‘happy and healthy’). Adjectives are clustered based on the connectivity of the graph, and those in the same cluster will have the same label, thus expanding from an initial set of labeled seeds.
Graph methods for semantic orientation rely on a graph of words, seeded with semantic orientation information for a small subset of the nodes. The edges are drawn based on a variety of similarity metrics, relying on lexical resources (such as WordNet) or distributional representation from a corpus or the Web. Inducing the labels of unlabeled nodes is done in various manners such as label propagation (Blair-Goldensohn et al. Reference Blair-Goldensohn, Neylon, Hannan, Reis, McDonald and Reynar2008; Rao and Ravichandran Reference Rao and Ravichandran2009; Velikovich et al. Reference Velikovich, Blair-Goldensohn, Hannan and McDonald2010), or random walks (Xu, Meng and Wang Reference Xu, Meng and Wang2010; Hassan et al. Reference Hassan, Abu-Jbara, Lu and Radev2014). Blair-Goldensohn et al. (Reference Blair-Goldensohn, Neylon, Hannan, Reis, McDonald and Reynar2008) and Rao and Ravichandran (Reference Rao and Ravichandran2009) apply the label propagation algorithm on a graph built based on WordNet’s synonymy and antonymy links. Velikovich et al. (Reference Velikovich, Blair-Goldensohn, Hannan and McDonald2010) apply a variation on the label propagation algorithm (which considers only the highest scoring path from a labeled node to an unlabeled one) on a large graph of n-grams built based on the information in four billion pages. Context vectors and cosine similarity were used to draw edges. Hassan et al. (Reference Hassan, Abu-Jbara, Lu and Radev2014) apply random walks from unlabeled nodes to labeled ones, and estimate the orientation of the unlabeled nodes based on its relative proximity to positive/negative words. Xu et al. (Reference Xu, Meng and Wang2010) use random walks for ranking words based on the seed words. The method can be applied on a multilingual graph, to transfer sentiment information from one language to another through random walks (Hassan et al. Reference Hassan, Abu-Jbara, Lu and Radev2014) or label propagation (Gao et al. Reference Gao, Wei, Li, Liu and Zhou2015).
Semantic orientation can be transferred between languages using graph alignments. Scheible et al. (Reference Scheible, Laws, Michelbacher and Schütze2010) build monolingual sentiment graphs for the source and target language respectively, and then align nodes in the two graphs based on a similarity measure that relies on the topology of each graph and a set of seed links between them, as in the SimRank algorithm (Jeh and Widom Reference Jeh and Widom2002; Dorow et al. Reference Dorow, Laws, Michelbacher, Scheible and Utt2009). The influence of different phenomena (coordinations through ‘and’ and ‘but’, adjective-noun modification) can be computed separately and then averaged to obtain the final similarity score for two compared nodes. Similar nodes will have similar orientation. Gao et al. (Reference Gao, Wei, Li, Liu and Zhou2015) present a similar approach, building a graph consisting of two monolingual subgraphs for the source and target languages respectively. The link between the two graphs consists of an inter-language subgraph that connects the two based on word alignment information in a parallel corpus. The edges in the monolingual subgraphs can have positive or negative weights, corresponding to synonymy/antonymy relations between the words. Label propagation is used to propagate sentiment polarity labels from the source language (English) to the target language (Chinese).
To build a tweet recommendation system that presents users with items they may have an interest in, Yan, Lapata and Li (Reference Yan, Lapata and Li2012) build a heterogeneous graph, which is used to rank both tweeters and tweets simultaneously. This graph covers the network of tweeters, the network of tweets linked based on content similarity, and includes additional edges that link these two based on posting and retweeting information. Nodes are ranked based on coupling two random walks, one on the graph representing the tweeters, the other the tweets. The framework was also extended to allow for personalized recommendations, by ranking tweets relative to individual users.
Another interesting task related to social media is determining the polarity of the users and the content they produce. Zhu et al. (Reference Zhu, Galstyan, Cheng and Lerman2014) build a tripartite graph with the purpose of determining the polarity of tweets and tweeters. The graph nodes represent users, their tweets, and features of the users and the tweets (as words in the user profile and in the tweets). Edges between user nodes and tweet nodes represent posting or retweeting, and feature nodes are linked to the user and tweet nodes with which they appear. Co-clustering in this graph will produce simultaneously sentiment clusters of users, tweets and features. Recognizing that such graphs change fast over time, leads to an online setting where an initial graph is updated with new network information (new users, tweets and features), which allows them to study the dynamic factor of user-level sentiments and the evolution of latent feature factors.
8 Machine translation
Label propagation approaches are based on the smoothness assumption (Chapelle, Schölkopf and Zien Reference Chapelle, Schölkopf and Zien2006) which states that if two nodes are similar according to the graph, their output labels should also be similar. We have seen in previous sections the label propagation algorithm – which usually relies on a small set of labels (e.g., binary) that will be propagated – applied to text normalization, passage retrieval, semantic class acquisition, word sense induction and disambiguation, semantic orientation. The goal of the label propagation algorithm is to compute soft labels for unlabeled vertices from the labeled vertices. The edge weight encodes (intuitively) the degree of belief about the similarity of the soft labeling for the connected vertices.
Labels to be propagated need not be atomic, but can also be ‘structured’ – e.g., the label is a translation of the node’s string. In this format, the technique can be applied to machine translation, particularly to encourage smooth translation probabilities for similar inputs.
The first machine translation approach using graph-based learning is presented by Alexandrescu and Kirchhoff (Reference Alexandrescu and Kirchhoff2009). They build a graph consisting of train and test data (word strings) connected through edges that encode pairwise similarities between samples. The training data will have labels – i.e., translations – that will be propagated to the unlabeled data based on the similarity relations between nodes. Label options for unlabeled nodes (i.e., candidate translations) are first produced using an SMT system, and the label propagation algorithm is used to rerank the candidates, ensuring that similar nodes (i.e., input strings) will have similar labels. The similarity measure used to compute edge weights is crucial to the success of the method, and can be used to incorporate domain knowledge. Alexandrescu and Kirchhoff compare two measures – the BLEU score (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002) and a score based on string kernels. On different datasets, different similarity measures perform better. An important issue facing graph-based learning is scalability, because the working graph combines training and test data. To address this issue, a separate graph is built for each test sentence, as a transitive closure of the edge set over the nodes containing all hypotheses for that test sentence. A similar approach is presented in Liu et al. (Reference Liu, Li, Li and Zhou2012).
One of the causes of errors in machine translation are out-of-vocabulary words. Razmara et al. (Reference Razmara, Siahbani, Haffari and Sarkar2013) use label propagation to find translations (as labels) for out-of-vocabulary words. A graph is constructed from source language monolingual texts, and the source side of the available parallel data. Each phrase type represents a vertex in the graph, and is connected to other vertices with a weight defined by a similarity measure between the two profiles (and filtered based on a threshold value). There are three types of vertices: labeled, unlabeled, and out-of-vocabulary. Nodes for which translations are available (from the parallel data/phrase tables) are annotated with target-side translations and their feature values. A label propagation algorithm is used to propagate translations form labeled nodes to unlabeled nodes. This handles several types of out-of-vocabulary words, including morphological variants, spelling variants and synonyms. The graph constructed is very large, the experiments show that the methods proposed are scalable.
Graphs can be used to combine different translation models in one structure, where the models can complement or strengthen each other’s choices. Cmejrek, Mi and Zhou (Reference Cmejrek, Mi and Zhou2013) introduce the ‘flexible interaction of hypergraphs’ where translation rules from a tree-to-string and hierarchical phrase-based model are combined in a hypergraph, which is then used for decoding. Tree-to-string translation rules – consisting of a tree fragment on the left-hand side, and a string on the right-hand side in the target language – are considered to be good at non-local reorderings, while hierarchical phrase-based rules – consisting of a source-language string on the left-hand side and a target-language string on the right – are good at providing reliable lexical coverage. The hypergraph is built from these rules: left and right sides of these rules will become nodes with an associated span (start and end point in the source or target language string). Nodes from different rules that cover the same span are merged – forming interaction supernodes. Nodes within an interaction supernode are connected through interaction edges. Interaction hyperedges within each supernode allow the decoder to switch between models.
9 Information extraction/Knowledge extraction and representation/Events
Information extraction and representation is a multi-faceted problem, and this is reflected in the variety of graph-based approaches proposed. One characteristic of the problem which makes it particularly appropriate for a graph approach is the redundancy in the data – the same type of information can appear in numerous contexts or forms. Redundancy can be explored to boost particular patterns – as vertices or edges or paths within the representation graph.
For identifying topics of a given document, Coursey and Mihalcea (Reference Coursey and Mihalcea2009) use high ranking nodes in a very large graph built based on Wikipedia articles and categories, scored through a biased graph centrality algorithm started from Wikipedia concepts identified in the input document. Several variations regarding the structure of the graph are tested, with the best performance obtained from a graph that has as nodes both Wikipedia articles and categories. Within the ranking process, the best performing bias takes into account the nodes in the graph that have been identified in the input document (through a wikification process).
A popular approach to information extraction is bootstrapping – start with a few seed relation examples or patterns, and iteratively grow the set of relations and patterns based on occurrence in a large corpus (Hearst Reference Hearst1992). This view of bootstrapping as a mutual dependency between patterns and relation instances can be modeled through a bipartite graph. Hassan, Hassan and Emam (Reference Hassan, Hassan and Emam2006) cast the relation pattern detection as a hubs (instances) and authorities (patterns) problem, solved using the HITS algorithm (Kleinberg Reference Kleinberg1999). The method relies on redundancy in large datasets and graph-based mutual reinforcement to induce generalized extraction patterns. The mutual reinforcement between patterns and instances will lead to increased weight for authoritative patterns, which will then be used for information extraction. To reduce the space of instances and induce better patterns, instances are clustered based on a similarity/relatedness measure based on WordNet between the entities in the same position in a pair of instances.
Bootstrapping algorithms are prone to semantic drift – where patterns that encode relations different that the target one are started to be extracted, which leads to the extraction of noisy instances, which in turn lead to more noisy patterns, and so on. Komachi et al. (Reference Komachi, Kudo, Shimbo and Matsumoto2008) show that semantic drift observed in bootstrapping algorithms is essentially the same phenomenon as topic drift in the HITS algorithm through an analysis of HITS-based algorithm performance in word sense disambiguation. Comparison of the ranking of instances (text fragments containing a target word) obtained through bootstrapping and the HITS algorithm show that the two methods arrive at the same results. To address the issue of semantic drift, they propose two graph-based algorithms (von-Neumann kernels and regularized Laplacian), for scoring the instances relative to the patterns, which will keep the extraction algorithm more semantically focused.
While semantic networks and ontologies that include knowledge about words/ word senses/concept as a hierarchy are quite common, similar knowledge structures that encode relations between larger text units are just starting to appear. One such knowledge structure is an entailment graph (Berant, Dagan and Goldberger Reference Berant, Dagan and Goldberger2010). The entailment graph is a graph structure over propositional templates, which are propositions comprising a predicate and arguments, possibly replaced by variables – e.g., alcohol reduces blood pressure, X reduces Y. Berant et al. (Reference Berant, Dagan and Goldberger2010) present a global algorithm for learning entailment relations between propositional templates. The optimal set of edges is learned using Integer Linear Programming – they define a global function and aim to find the graph that maximizes the function under a transitivity constraint.
Representing temporal interactions between events in a text is another problem where graphs are a good fit. The problem is how to build them. Bramsen et al. (Reference Bramsen, Deshpande, Lee and Barzilay2006) compare three different approaches to building directed acyclic that encode temporal relations found in texts. They are all based on predictions for pairs of events (edges) – forward, backward, null – learned from manually annotated data. These local decisions though can be combined in different ways to arrive at the big picture. From the three methods investigated – (i) Natural Reading Order – start with an empty graph and add the highest scoring edge for a new node (event) that appears in text without violating the consistency of the direct acyclic graph; (ii) Best-First – add edges to obtain the highest scoring graph, by always adding the highest scoring edge that doesn’t violate the direct acyclic graph condition; (iii) exact inference with Integer Linear Programming – build a globally optimal temporal direct acyclic graph as an optimization problem, subject to the following constraints: there is exactly one relation (edge) between two events (nodes), the transitivity constraint is respected, and the direct acyclic graph is connected. The graph construction method using Integer Linear Programming provides the best results.
Events have multiple facets, e.g., the outcome, its causes, aftermath. To detect the facets of an event and group together blog posts about a facet of the same event, Muthukrishnan, Gerrish and Radev (Reference Muthukrishnan, Gerrish and Radev2008) use KL divergence and the Jaccard coefficient to generate topic labels (as keyphrases) and then build a topic graph which represents the community structure of different facets. The graph built has keyphrases as nodes, linked with edges weighted with an overlap measure (Jaccard similarity coefficient, defined as a ratio of the documents covered by both keyphrases and the total number of documents covered by the two keyphrases). A greedy algorithm is used to iteratively extract a Weighted Set Cover using a cost function for each node (i.e., keyphrase) that combines coverage information and coverage overlap with other keyphrases.
Popular application areas for event extraction are the medical and biological domains, to help find and aggregate data from an ever increasing number of studies. To find events and their arguments in biological texts, Björne et al. (Reference Björne, Heimonen, Ginter, Airola, Pahikkala and Salakoski2009) represent texts as semantic graphs – entities and events connected by edges corresponding to event arguments.
Notions like minimal graphs of a graph are useful for casting a difficult evaluation problem into a manageable formalism. Evaluation of NLP problems can be difficult – e.g., the evaluation of temporal graphs that capture temporal relations between events in text. Allen’s relations (seven direct + six inverse) have been adopted for annotation of events’ temporal relations. Evaluating the annotations against a gold standard is difficult because the level of the relations may vary: the same ordering of events may be expressed in different ways, or they may include relation closures that may artificially increase a score. Tannier and Muller (Reference Tannier and Muller2011) propose a method to address these issues and provide an objective evaluation metric. First, based on fact that the Allen relations are defined in terms of the ends of the time interval corresponding to an event, they transform the graph where events are nodes connected by the Allen relations into a graph where the nodes are the start and end points of events, and the relations between them can be equality, before or after. From this graph, the ‘gold standard’ reference graph is extracted as the minimal graph of constraints. A minimal graph has the following two properties: (1) its (relation) closure leads to the full graph; (2) removing any relation leads to breaking the first property. Minimal graphs of a candidate temporal events annotation can be compared to the reference minimal graph objectively.
10 Further reading
General graph and network analysis papers. The following papers describe the relevant graph theory: (Doyle and Snell Reference Doyle and Snell1984; Bollobás Reference Bollobás1985Reference Bollobás1998; Brin and Page Reference Brin and Page1998; Grimmett Reference Grimmett1999; Langville and Meyer Reference Langville and Meyer2003). Lexical networks. The following readings are essential: (Dorogovtsev and Mendes Reference Dorogovtsev and Mendes2001; Motter et al. Reference Motter, de Moura, Lai and Dasgupta2002; de Moura, Lai and Motter Reference de Moura, Lai and Motter2003; Ferrer i Cancho Reference Ferrer i Cancho, Levickij and Altmann2005; Caldeira et al. Reference Caldeira, Petit Lobão, Andrade, Neme and Miranda2006; Masucci and Rodgers Reference Masucci and Rodgers2006; Pardo et al. Reference Alexandre, Pardo, Antiqueira, das Graças Volpe Nunes, Oliveira and da Fontoura Costa2006; Ferrer i Cancho et al. Reference Ferrer i Cancho, Mehler, Pustylnikov and Díaz-Guilera2007), and (Mehler Reference Mehler, Lüdeling and Kytö2007). Language processing applications. A list includes (Haghighi, Ng and Manning Reference Haghighi, Ng and Manning2005; Wolf and Gibson Reference Wolf and Gibson2005; Zens and Ney Reference Zens and Ney2005; Erkan Reference Erkan2006; Malioutov and Barzilay Reference Malioutov and Barzilay2006), and (Biemann Reference Biemann2006). Random walks and learning on graphs. Some readings include (Zhu and Ghahramani Reference Zhu and Ghahramani2002; Radev Reference Radev2004; Zhu and Lafferty Reference Zhu and Lafferty2005; Goldberg and Zhu Reference Goldberg and Zhu2006), and (Zhu Reference Zhu2007).
The lists above are by far not exhaustive. A large bibliography appears on Dragomir Radev’s web site http://clair.si.umich.edu/~radev/webgraph/webgraph-bib.html.
11 Conclusions
In this paper, we presented an overview of the current state-of-the-art in research work on graphs in NLP. We addressed the relevant work in the main areas of NLP, including text structure and discourse, semantics and syntax, summarization and generation, machine translation, and information and knowledge extraction. We covered both the graph representations used to model the problems, as well as the graph algorithms applied on these representations. We believe the intersection of the fields of natural language processing and graph theory has proven to be a rich source of interesting solutions that has just been untapped. We expect that future work in this space will bring many more exciting findings.





