


1. Introduction
Networks have been used broadly in biology, the social sciences, and many other fields to model and analyze the relational structure of individual units in a complex system. In a network model, nodes or vertices represent the units of the system, and edges connect the vertices if the corresponding units share a relationship. It is desirable, in many applications, to study the change in connections among the vertices of a network over time. Stochastic actor-oriented models (SAOMs), designed specifically for longitudinally observed networks (i.e. network panel data), are a class of models that were developed for this purpose in the social network setting by Snijders et al., Snijders (Reference Snijders1996); Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010); Snijders (Reference Snijders2017).
The SAOM framework revolves around the notion that the vertices control the connections they make to other vertices. This approach is different from other models, such as the temporal exponential random graph model (TERGM) developed by Hanneke et al., Hanneke et al. (Reference Hanneke, Fu and Xing2010). The assumption is that the network evolves as a continuous time Markov chain and that the networks one has observed are snapshots of this stochastic process. Network changes are assumed to happen by one vertex making a change in one of its connections at a time. Vertices seek to change these connections such that their “personal satisfaction” with the network configuration is maximized. This “satisfaction” is captured by an objective function, in the form of a linear combination of effects, which can be both endogenous (i.e. functions of the network itself) and exogenous (i.e. functions of vertex characteristics). Parameters indicating the strength of each effect are estimated using either a method of moments or maximum likelihood simulation-based approach, and hypotheses associated with each effect can be tested, similar to a linear regression framework Snijders (Reference Snijders2017); Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010).
SAOMs have been shown to be useful in a variety of applications, but a key assumption is that the networks one has observed are error-free. In other words, one is assuming that the vertices present in the network and the relationships observed among them are all accurate at the time the network data were measured. However, what if this is not the case? Network analysis has long been plagued by issues of measurement error Wang et al. (Reference Wang, Shi, McFarland and Leskovec2012). For instance, survey respondents may not report the correct spellings of their friends’ names. This not only leads to erroneous vertices, but also to an absence of an edge to the correct vertex in the social network. Furthermore, even if everyone reports the correct spellings of their friends’ names, the understanding of what qualifies as a friendship tie can vary by respondent. Other settings, such as co-authorship networks, which represent collaborative relationships, can also contain false positive and false negative edges Wuchty et al. (Reference Wuchty, Jones and Uzzi2007). In this case, false edges may exist because of failure to account for edge decay. One can deal with this issue by setting a pre-specified time window under which the established relationship is thought to be meaningful Fleming and Frenken (Reference Fleming and Frenken2007). However, setting too narrow of a window might overlook important relationships and introduce false negatives, while setting too wide of a window can introduce false positives Wang et al. (Reference Wang, Shi, McFarland and Leskovec2012).
In addition to SAOMs being used extensively in a social network context, in our own work we have recently adapted these models to resting-state fMRI complex brain networks. We sought to answer questions such as, “If two brain regions are in the same cortical lobe, are they more likely to connect?” In this case, a connection represents a similar pattern of brain activity. In the neuroscience setting, functional network edges are almost always defined based on some measure of association between patterns of activation between distinct brain regions Simpson et al. (Reference Simpson, Bowman and Laurienti2013). Therefore, it is unreasonable to assume that the observed networks are always the truth. Instead, we expect some level of type I error (false positives) and type 2 error (false negatives) to exist in the inferred networks.
Motivated by scenarios such as these, our goal is to account for false positive and false negative edges while analyzing observed networks with SAOMs. To capture the notion of false positive and false negative rates, along with the parameters in the SAOM, we propose a hidden Markov model (HMM) based approach. This modeling approach consists of two components - the latent Markov model and the measurement model. The latent Markov model specifies that the unobserved hidden networks evolve according to a Markov process, as they did in the original SAOM framework. The measurement model describes the conditional distribution of the observed networks given the true networks.
HMMs, developed by Baum and colleagues in the 1960s Baum et al. (Reference Baum, Petrie, Soules and Weiss1970), are a natural modeling approach to take given that we have an observable sequence of a system in which the hidden state is governed by a Markov process. They have been widely studied in statistics Ephraim and Merhav (Reference Ephraim and Merhav2002) and have been applied extensively in many applications, such as in speech recognition and biological sequence analysis Gales and Young (Reference Gales and Young2008); Yoon (Reference Yoon2009). While HMMs have been used much less frequently in the dynamic network analysis literature, there is some work where they have been incorporated. For example, Guo et al., developed the hidden TERGM, which utilizes a hidden Markov process to model and recover temporally rewiring networks from time series of node characteristics Guo et al. (Reference Guo, Hanneke, Fu and Xing2007). Dong et al., present the Graph-Coupled Hidden Markov Model, a discrete-time model for analyzing the interactions between individuals in a dynamic social network Dong et al. (Reference Dong, Pentland and Heller2012). Their method incorporates dynamic social network structure into a hidden Markov Model to predict how the spread of illness occurs and can be avoided on an individual level. Similarly, Raghavan et al., propose a coupled Hidden Markov Model, where each user’s activity in a social network evolves according to a Markov chain with a hidden state that is influenced by the collective activity of the friends of the user Raghavan et al. (Reference Raghavan, Ver Steeg, Galstyan and Tartakovsky2014).
HMMs for SAOMs have not been published in a peer-reviewed journal, but they have been published in a dissertation Lospinoso and Lospinoso (Reference Lospinoso and Lospinoso2012). Lospinoso worked to tackle this same problem of accounting for error on the observed networking edges in the SAOM setting. We take a similar approach in this paper, but instead of using a full MCMC algorithm for performing maximum likelihood estimation of the model parameters, we take an MCMC within an Expectation-Maximization approach to parameter estimation. We also focus on a brain network application, whereas Lospinoso applies the methodology to social networks. We touch further on the similarities and differences to Lospinoso’s approach in the Discussion section.
The remainder of this paper is organized as follows. In section 2, we introduce our HMM-SAOM set-up. Section 3 provides necessary background information on the SAOM model set-up, as well as the estimation routine traditionally used to fit the SAOM parameters. Our framework incorporates the methods described in this section. Section 4 describes our Expectation-Maximum algorithm for maximum likelihood estimation of the false positive and false negative error rates, along with the SAOM parameters. We assess the performance of our method on a series of simulated dynamic networks in Section 5, comparing it to the case of fitting only a standard SAOM to noisy networks. In Section 6, we apply our method to functional brain networks inferred from electroencephalogram (EEG) data. We conclude with a discussion of our method and open directions for future research.
Hidden Markov Model Set-Up. The unobserved hidden networks evolve according to a Markov process, as they did in the original stochastic actor-oriented models framework. The true networks are then observed with measurement error.
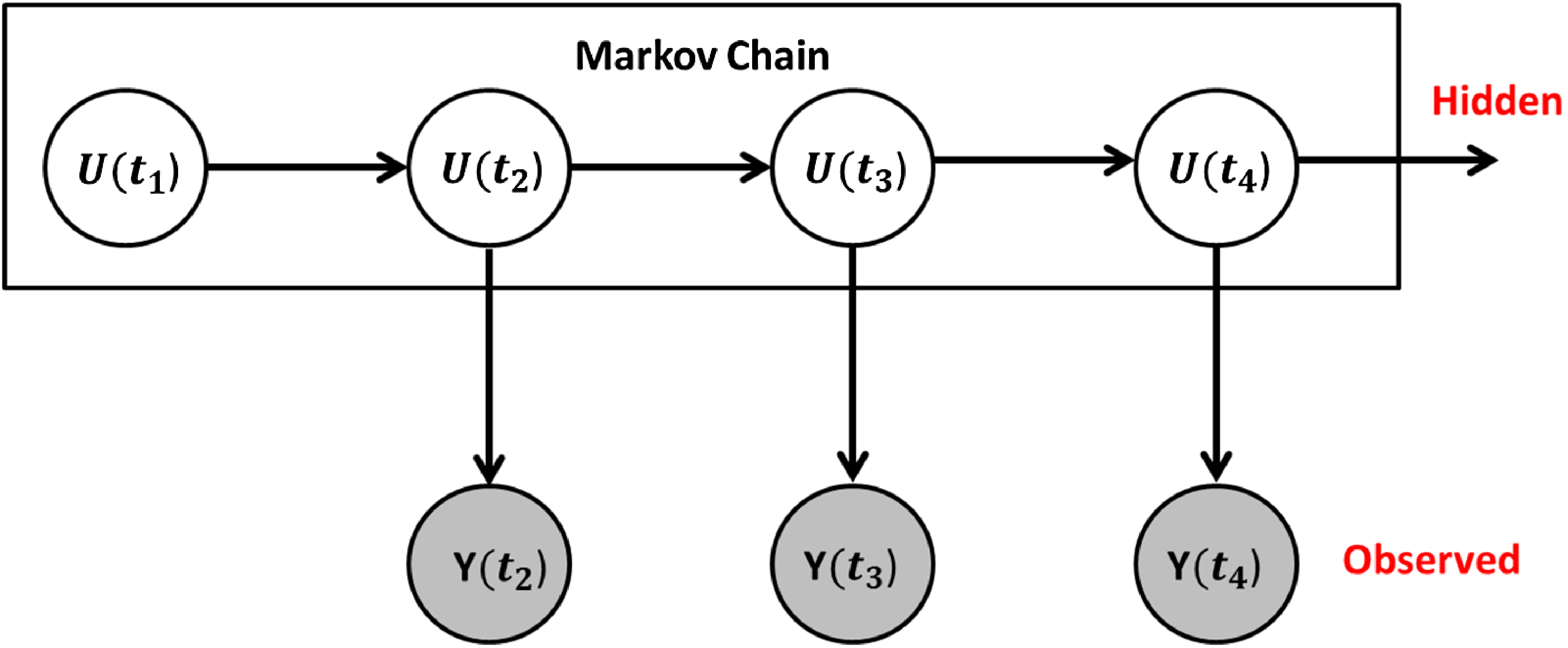
2. The SAOM hidden Markov model set-up
We consider repeated observations of a directed network on a given set of vertices
 $\mathcal{N}={1,\ldots ,N}$
, observed according to a panel design. The observations are represented as a sequence of digraphs
$\mathcal{N}={1,\ldots ,N}$
, observed according to a panel design. The observations are represented as a sequence of digraphs
 $y(t_{m})$
for
$y(t_{m})$
for
 $m=1,\ldots ,M$
, where
$m=1,\ldots ,M$
, where
 $t_{1} \lt \ldots \lt t_{M}$
are the observation times and the node set is the same for all observation times. A digraph is defined as a subset
$t_{1} \lt \ldots \lt t_{M}$
are the observation times and the node set is the same for all observation times. A digraph is defined as a subset
 $y$
of
$y$
of
 $\big \{(i,j) \in \mathcal{N}^2|i \neq j\big \}$
Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010); Snijders (Reference Snijders2017). When
$\big \{(i,j) \in \mathcal{N}^2|i \neq j\big \}$
Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010); Snijders (Reference Snijders2017). When
 $(i,j) \in y$
, there is an edge from vertex
$(i,j) \in y$
, there is an edge from vertex
 $i$
to vertex
$i$
to vertex
 $j$
. The observations
$j$
. The observations
 $y(t_{m})$
are realizations of random digraph/network variables
$y(t_{m})$
are realizations of random digraph/network variables
 $Y(t_{m})$
. This random vector of observed network variables
$Y(t_{m})$
. This random vector of observed network variables
 $Y(t_{1}),\ldots , Y(t_{M})$
is denoted by
$Y(t_{1}),\ldots , Y(t_{M})$
is denoted by
 $\tilde {Y}$
. We represent a true/hidden network variable underlying the observed network at a particular observation time by
$\tilde {Y}$
. We represent a true/hidden network variable underlying the observed network at a particular observation time by
 $U(t_{m})$
. The vector of true network variables,
$U(t_{m})$
. The vector of true network variables,
 $U(t_{1}),\ldots , U(t_{M})$
is denoted by
$U(t_{1}),\ldots , U(t_{M})$
is denoted by
 $\tilde {U}$
. See Figure 1 for a visual representation. We also assume that
$\tilde {U}$
. See Figure 1 for a visual representation. We also assume that
-
1. The vector of true networks follows a first order Markov chain.
 \begin{equation*}f(\tilde {u})=f(u(t_{1}))\prod \limits _{m=2}^M f(u(t_{m})|u(t_{m-1}))\end{equation*}
\begin{equation*}f(\tilde {u})=f(u(t_{1}))\prod \limits _{m=2}^M f(u(t_{m})|u(t_{m-1}))\end{equation*}
-
2. The observed networks are conditionally independent given the latent process.
\begin{equation*}f(y(t_{m})|u(t_{1:M}), y(t_{1:(m-1)}), y(t_{(m+1):M}))=f(y(t_{m})|u(t_{m}))\end{equation*}
-
3. We condition on the first observed network
$y(t_{1})$
, and we assume the first true network
$u(t_{1})$
is observed error-free.
\begin{equation*} f(u(t_{1}))= \begin{cases} 1 & u(t_{1})=y(t_{1}) \\ 0 & otherwise \end{cases} \end{equation*}





Therefore, the complete data log-likelihood, conditional on
 $y(t_{1})$
, can be written as:
$y(t_{1})$
, can be written as:
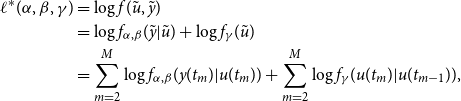 \begin{align} \ell ^{*}(\alpha , \beta , \gamma )&=\log f(\tilde {u},\tilde {y}) \nonumber \\ &=\log f_{\alpha ,\beta }(\tilde {y}|\tilde {u}) + \log f_{\gamma }(\tilde {u}) \nonumber \\ &=\sum _{m=2}^{M} \log f_{\alpha ,\beta }(y(t_{m})|u(t_{m})) + \sum _{m=2}^{M} \log f_{\gamma }(u(t_{m})|u(t_{m-1})), \end{align}
\begin{align} \ell ^{*}(\alpha , \beta , \gamma )&=\log f(\tilde {u},\tilde {y}) \nonumber \\ &=\log f_{\alpha ,\beta }(\tilde {y}|\tilde {u}) + \log f_{\gamma }(\tilde {u}) \nonumber \\ &=\sum _{m=2}^{M} \log f_{\alpha ,\beta }(y(t_{m})|u(t_{m})) + \sum _{m=2}^{M} \log f_{\gamma }(u(t_{m})|u(t_{m-1})), \end{align}
where
 $\alpha$
is the false positive rate,
$\alpha$
is the false positive rate,
 $\beta$
is the false negative rate, and
$\beta$
is the false negative rate, and
 $\gamma$
consists of the objective function parameters and rate parameters in the SAOM. Additional details on the SAOM and its parameters are provided in Section 3.
$\gamma$
consists of the objective function parameters and rate parameters in the SAOM. Additional details on the SAOM and its parameters are provided in Section 3.
The first term in
 $\ell ^{*}(\alpha , \beta , \gamma )$
derives from the conditional distribution of the observed networks given the true networks and takes the form
$\ell ^{*}(\alpha , \beta , \gamma )$
derives from the conditional distribution of the observed networks given the true networks and takes the form
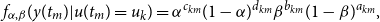 \begin{align} f_{\alpha ,\beta }(y(t_{m})|u(t_{m})=u_{k})=\alpha ^{c_{km}}(1-\alpha )^{d_{km}}\beta ^{b_{km}}(1-\beta )^{a_{km}}, \end{align}
\begin{align} f_{\alpha ,\beta }(y(t_{m})|u(t_{m})=u_{k})=\alpha ^{c_{km}}(1-\alpha )^{d_{km}}\beta ^{b_{km}}(1-\beta )^{a_{km}}, \end{align}
where
 $a_{km},b_{km},c_{km},$
and
$a_{km},b_{km},c_{km},$
and
 $d_{km}$
(for a given true network
$d_{km}$
(for a given true network
 $u_{m}$
at observation time
$u_{m}$
at observation time
 $t_{m}$
) represent counts of false positive and false negative edges (see Table 1).
$t_{m}$
) represent counts of false positive and false negative edges (see Table 1).
Counts corresponding to false positive and false negative edges

The second term in
 $\ell ^{*}(\alpha , \beta , \gamma )$
, deriving from the network transition probability distribution, cannot be calculated in closed form. Additional details will be provided in the Section 3.
$\ell ^{*}(\alpha , \beta , \gamma )$
, deriving from the network transition probability distribution, cannot be calculated in closed form. Additional details will be provided in the Section 3.
3. Background on SAOM framework
3.1 Modeling framework
We adopt the SAOM framework of Snijders et al., Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010) for the evolution of our true networks, which are underlying the sequence of our observed networks,
 $y(t_{m})$
. In this framework, it is assumed that the changing network is the outcome of a continuous time Markov process with time parameter
$y(t_{m})$
. In this framework, it is assumed that the changing network is the outcome of a continuous time Markov process with time parameter
 $t \in T$
where the
$t \in T$
where the
 $u(t_{m})$
, underlying the
$u(t_{m})$
, underlying the
 $y(t_{m})$
, are realizations of stochastic digraphs
$y(t_{m})$
, are realizations of stochastic digraphs
 $U(t_{m})$
embedded in a continuous-time stochastic process
$U(t_{m})$
embedded in a continuous-time stochastic process
 $U(t)$
,
$U(t)$
,
 $t_{1} \le t \le t_{M}$
. The totality of possible networks is the state space and the discrete set of true networks are snapshots of the true network state during the continuous period of time. In other words, many changes are assumed to happen in the true networks between observation times, and the process unfolds in time steps of potentially varying lengths Snijders (Reference Snijders1996); Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010); Snijders (Reference Snijders2017).
$t_{1} \le t \le t_{M}$
. The totality of possible networks is the state space and the discrete set of true networks are snapshots of the true network state during the continuous period of time. In other words, many changes are assumed to happen in the true networks between observation times, and the process unfolds in time steps of potentially varying lengths Snijders (Reference Snijders1996); Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010); Snijders (Reference Snijders2017).
Each
 $U(t)$
is made up of
$U(t)$
is made up of
 $N\times (N-1)$
possible edge status variables
$N\times (N-1)$
possible edge status variables
 $u_{ij}$
, where
$u_{ij}$
, where
 $u_{ij}=1$
if there exists a directed edge from vertex
$u_{ij}=1$
if there exists a directed edge from vertex
 $i$
to vertex
$i$
to vertex
 $j$
and
$j$
and
 $u_{ij}=0$
otherwise. At a given moment, one probabilistically selected vertex may change an edge, where the decision is modeled according to a random utility model, requiring the specification of a utility function (i.e., objective function) depending on a set of explanatory variables and parameters. Therefore, we are reduced to modeling the change of one edge status variable
$u_{ij}=0$
otherwise. At a given moment, one probabilistically selected vertex may change an edge, where the decision is modeled according to a random utility model, requiring the specification of a utility function (i.e., objective function) depending on a set of explanatory variables and parameters. Therefore, we are reduced to modeling the change of one edge status variable
 $u_{ij}$
by one vertex at a time (a network micro step) and modeling the occurrence of all these micro steps over time. The first true network
$u_{ij}$
by one vertex at a time (a network micro step) and modeling the occurrence of all these micro steps over time. The first true network
 $u(t_{1})$
serves as a starting value of the evolution process. At any time point
$u(t_{1})$
serves as a starting value of the evolution process. At any time point
 $t$
with current network
$t$
with current network
 $u(t) = u$
, each of the vertices has a rate function
$u(t) = u$
, each of the vertices has a rate function
 $\lambda _{i}(\delta ,u)$
, where
$\lambda _{i}(\delta ,u)$
, where
 $\delta$
is a parameter. Therefore, the waiting time until occurrence of the next micro step by any vertex is exponentially distributed with parameter
$\delta$
is a parameter. Therefore, the waiting time until occurrence of the next micro step by any vertex is exponentially distributed with parameter
 \begin{align} \lambda (\delta , u)=\sum _{i=1}^{N}\lambda _{i}(\delta , u). \end{align}
\begin{align} \lambda (\delta , u)=\sum _{i=1}^{N}\lambda _{i}(\delta , u). \end{align}
Given that an opportunity for change occurs, the probability that it is vertex
 $i$
who gets the opportunity is given by
$i$
who gets the opportunity is given by
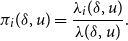 \begin{align} \pi _{i}(\delta , u)=\frac {\lambda _{i}(\delta , u)}{\lambda (\delta ,u)}. \end{align}
\begin{align} \pi _{i}(\delta , u)=\frac {\lambda _{i}(\delta , u)}{\lambda (\delta ,u)}. \end{align}
The micro step that vertex
 $i$
takes is determined probabilistically by a linear combination of effects. For example, let’s assume that
$i$
takes is determined probabilistically by a linear combination of effects. For example, let’s assume that
 $u$
is the current network and vertex
$u$
is the current network and vertex
 $i$
has the opportunity to make a network change. The next network state
$i$
has the opportunity to make a network change. The next network state
 $u'$
then must be either equal to
$u'$
then must be either equal to
 $u$
or deviate from
$u$
or deviate from
 $u$
by one edge. Vertex
$u$
by one edge. Vertex
 $i$
chooses the value of
$i$
chooses the value of
 $u'$
for which
$u'$
for which
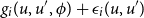 \begin{align} g_{i}(u,u',\phi ) + \epsilon _{i}(u,u') \end{align}
\begin{align} g_{i}(u,u',\phi ) + \epsilon _{i}(u,u') \end{align}
is maximal, where
 $\epsilon _{i}(u,u')$
is a Gumbel-distributed random disturbance that captures the uncertainty stemming from unknown factors, and
$\epsilon _{i}(u,u')$
is a Gumbel-distributed random disturbance that captures the uncertainty stemming from unknown factors, and
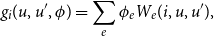 \begin{align} g_{i}(u,u',\phi ) =\sum \limits _{e} \phi _{e} W_{e}(i,u,u'), \end{align}
\begin{align} g_{i}(u,u',\phi ) =\sum \limits _{e} \phi _{e} W_{e}(i,u,u'), \end{align}
where
 $\phi _{e}$
represent parameters and
$\phi _{e}$
represent parameters and
 $W_{e}(i,u,u')$
represent the corresponding effects. There are many types of effects one can place in the model. See Ripley et al., Ripley et al. (Reference Ripley, Snijders, Boda, Vörös and Preciado2024) for a full list. Some are purely structural effects, such as triangle formation and reciprocity. Other effects may involve vertex traits, such as gender or smoking status of the individuals in a social network.
$W_{e}(i,u,u')$
represent the corresponding effects. There are many types of effects one can place in the model. See Ripley et al., Ripley et al. (Reference Ripley, Snijders, Boda, Vörös and Preciado2024) for a full list. Some are purely structural effects, such as triangle formation and reciprocity. Other effects may involve vertex traits, such as gender or smoking status of the individuals in a social network.
Equation 3.4 is the objective function. It can be thought of as a function of the network perceived by the focal vertex. Probabilities are higher for moving towards network states with a high value of the objective function. The objective function depends on the personal network position of vertex
 $i$
, vertex
$i$
, vertex
 $i$
’s exogenous covariates, and the exogenous covariates of all of the vertices in
$i$
’s exogenous covariates, and the exogenous covariates of all of the vertices in
 $i$
’s personal network. Due to distributional assumptions placed on
$i$
’s personal network. Due to distributional assumptions placed on
 $\epsilon _{i}(u,u')$
, the probability of choosing
$\epsilon _{i}(u,u')$
, the probability of choosing
 $u'$
can be expressed in multinomial logit form as
$u'$
can be expressed in multinomial logit form as
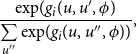 \begin{align} \frac {\exp\!(g_{i}(u,u',\phi )}{\sum \limits _{u''}\exp\!(g_{i}(u,u'',\phi ))}, \end{align}
\begin{align} \frac {\exp\!(g_{i}(u,u',\phi )}{\sum \limits _{u''}\exp\!(g_{i}(u,u'',\phi ))}, \end{align}
where the sum of the denominator extends over all possible next network states
 $u''$
.
$u''$
.
For each set of model parameters, there exists a stationary distribution of probabilities over the state space of all possible network configurations for the Markov process that governs the SAOM. The complexity of the model does not allow for the equilibrium distribution (nor the likelihood of the network “snapshots”) to be calculated in closed form. Therefore, parameter estimates need to be obtained via an iterative stochastic approximation version of a maximum likelihood approach based on data augmentation.
3.2 SAOM maximum likelihood framework
The distribution of the true networks
 $U(t_{1}),\ldots , U(t_{M})$
conditional on
$U(t_{1}),\ldots , U(t_{M})$
conditional on
 $U(t_{1})$
cannot generally be expressed in closed form. Therefore, the true networks are augmented with data such that an easily computable likelihood is obtained Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). The data augmentation can be done for each period
$U(t_{1})$
cannot generally be expressed in closed form. Therefore, the true networks are augmented with data such that an easily computable likelihood is obtained Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). The data augmentation can be done for each period
 $(U(t_{m-1}),U(t_{m}))$
separately, and therefore, it is explained below only for
$(U(t_{m-1}),U(t_{m}))$
separately, and therefore, it is explained below only for
 $U(t_{1})$
and
$U(t_{1})$
and
 $U(t_{2})$
.
$U(t_{2})$
.
Denote the time points of an opportunity for change by
 $T_{r}$
and their total number between
$T_{r}$
and their total number between
 $t_{1}$
and
$t_{1}$
and
 $t_{2}$
by
$t_{2}$
by
 $R$
, the time points being ordered increasingly so that
$R$
, the time points being ordered increasingly so that
 $t_{1}= T_{0} \lt T_{1} \lt T_{2} \lt \ldots \lt T_{R} \leq t_{2}$
. The model assumptions imply that at each time
$t_{1}= T_{0} \lt T_{1} \lt T_{2} \lt \ldots \lt T_{R} \leq t_{2}$
. The model assumptions imply that at each time
 $T_{r}$
, there is one vertex, denoted
$T_{r}$
, there is one vertex, denoted
 $I_{r}$
, who gets an opportunity for change at this time moment. Define
$I_{r}$
, who gets an opportunity for change at this time moment. Define
 $J_{r}$
as the vertex toward whom the edge status variable is changed, and define
$J_{r}$
as the vertex toward whom the edge status variable is changed, and define
 $J_{r}=I_{r}$
if there is no change. Given
$J_{r}=I_{r}$
if there is no change. Given
 $u(t_{1})$
, the outcome of the stochastic process
$u(t_{1})$
, the outcome of the stochastic process
 $(T_{r},I_{r},J_{r})$
,
$(T_{r},I_{r},J_{r})$
,
 $r=1,\ldots ,R$
completely determines
$r=1,\ldots ,R$
completely determines
 $u(t)$
,
$u(t)$
,
 $t_{1}\lt t \leq t_{2}$
.
$t_{1}\lt t \leq t_{2}$
.
The stochastic process
 $V=((I_{r},J_{r}),r=1,\ldots ,R$
) will be referred to as the sample path. Define
$V=((I_{r},J_{r}),r=1,\ldots ,R$
) will be referred to as the sample path. Define
 $u^{(r)}=u(T_{r})$
. The graphs
$u^{(r)}=u(T_{r})$
. The graphs
 $u^{(r)}$
and
$u^{(r)}$
and
 $u^{(r-1)}$
differ in element
$u^{(r-1)}$
differ in element
 $(I_{r},J_{r})$
, provided
$(I_{r},J_{r})$
, provided
 $I_{r}\neq J_{r}$
and in no other elements. Snijders et al., show that in the case where the vertex-level rates of change
$I_{r}\neq J_{r}$
and in no other elements. Snijders et al., show that in the case where the vertex-level rates of change
 $\lambda _{i}(\delta , u)$
are constant (which is an assumption typically recommended in using SAOMs), denoted by
$\lambda _{i}(\delta , u)$
are constant (which is an assumption typically recommended in using SAOMs), denoted by
 $\delta _{1}$
, the probability function of the sample path, conditional on
$\delta _{1}$
, the probability function of the sample path, conditional on
 $u(t_{1})$
, is given by
$u(t_{1})$
, is given by
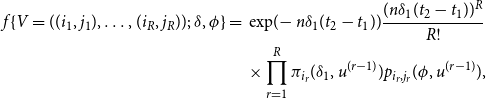 \begin{align} f\{V=((i_{1},j_{1}),\ldots ,(i_{R},j_{R}));\;\delta ,\phi \}= {} & \exp\!{(\!-n\delta _{1}(t_{2}-t_{1}))}\frac {(n\delta _{1}(t_{2}-t_{1}))^{R}}{R!} \nonumber \\ & \times \prod \limits _{r=1}^R \pi _{i_{r}}(\delta _{1},u^{(r-1)})p_{i_{r},j_{r}}(\phi ,u^{(r-1)}), \end{align}
\begin{align} f\{V=((i_{1},j_{1}),\ldots ,(i_{R},j_{R}));\;\delta ,\phi \}= {} & \exp\!{(\!-n\delta _{1}(t_{2}-t_{1}))}\frac {(n\delta _{1}(t_{2}-t_{1}))^{R}}{R!} \nonumber \\ & \times \prod \limits _{r=1}^R \pi _{i_{r}}(\delta _{1},u^{(r-1)})p_{i_{r},j_{r}}(\phi ,u^{(r-1)}), \end{align}
where
 $\pi _{i}$
is defined in (3.2), and
$\pi _{i}$
is defined in (3.2), and
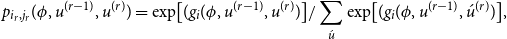 \begin{align} p_{i_{r},j_{r}}(\phi ,u^{(r-1)},u^{(r)})=\exp\!\big [(g_{i}(\phi ,u^{(r-1)},u^{(r)})\big ]/ \sum _{\acute {u}}\exp\!\big [(g_{i}(\phi ,u^{(r-1)},\acute {u}^{(r)})\big ], \end{align}
\begin{align} p_{i_{r},j_{r}}(\phi ,u^{(r-1)},u^{(r)})=\exp\!\big [(g_{i}(\phi ,u^{(r-1)},u^{(r)})\big ]/ \sum _{\acute {u}}\exp\!\big [(g_{i}(\phi ,u^{(r-1)},\acute {u}^{(r)})\big ], \end{align}
where the summation extends over all possible next network states
 $\acute {u}$
.
$\acute {u}$
.
Therefore, for two possible true networks
 $(u(t_{1}),u(t_{2}))$
augmented by a sample path, the likelihood conditional on
$(u(t_{1}),u(t_{2}))$
augmented by a sample path, the likelihood conditional on
 $u(t_{1})$
can be expressed exactly. An MCMC algorithm is used to find the maximum likelihood estimator based on the augmented data. The algorithm Snijders et al., implements, proposed by Gu and Kong Gu and Kong (Reference Gu and Kong1998), is based on the missing information principle, which can be summarized as follows. Let the rate and objective function parameters
$u(t_{1})$
can be expressed exactly. An MCMC algorithm is used to find the maximum likelihood estimator based on the augmented data. The algorithm Snijders et al., implements, proposed by Gu and Kong Gu and Kong (Reference Gu and Kong1998), is based on the missing information principle, which can be summarized as follows. Let the rate and objective function parameters
 $(\delta , \phi )$
be denoted by
$(\delta , \phi )$
be denoted by
 $\gamma$
. Suppose
$\gamma$
. Suppose
 $\tilde {u}$
is given and having probability density
$\tilde {u}$
is given and having probability density
 $f(\tilde {u}; \;\gamma )$
. Then, suppose it is augmented by extra data
$f(\tilde {u}; \;\gamma )$
. Then, suppose it is augmented by extra data
 $v$
, such that the joint density is
$v$
, such that the joint density is
 $f(\tilde {u}, v;\; \gamma )$
. Denote the incomplete data score function
$f(\tilde {u}, v;\; \gamma )$
. Denote the incomplete data score function
 $\frac {\partial }{\partial \gamma }\log f(\tilde {u};\; \gamma )$
by
$\frac {\partial }{\partial \gamma }\log f(\tilde {u};\; \gamma )$
by
 $S(\gamma ;\;\tilde {u})$
and the complete data score function
$S(\gamma ;\;\tilde {u})$
and the complete data score function
 $\frac {\partial }{\partial \gamma }\log f(\tilde {u}, v;\; \gamma )$
by
$\frac {\partial }{\partial \gamma }\log f(\tilde {u}, v;\; \gamma )$
by
 $S(\gamma ;\;\tilde {u}, v)$
. It can be shown
$S(\gamma ;\;\tilde {u}, v)$
. It can be shown
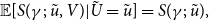 \begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=S(\gamma ;\;\tilde {u}), \end{align}
\begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=S(\gamma ;\;\tilde {u}), \end{align}
which implies that maximum likelihood estimates can be determined as the solution to
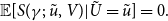 \begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=0. \end{align}
\begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=0. \end{align}
In the SAOM context,
 $U(t_{1})$
is treated as fixed, and data are augmented between the true networks at each observed time point
$U(t_{1})$
is treated as fixed, and data are augmented between the true networks at each observed time point
 $m=1,\ldots ,M$
by a sample path that could have brought each true network to the next. Each period
$m=1,\ldots ,M$
by a sample path that could have brought each true network to the next. Each period
 $(t_{m-1}, t_{m})$
is treated separately, and draws from the probability distribution of the sample path,
$(t_{m-1}, t_{m})$
is treated separately, and draws from the probability distribution of the sample path,
 $v_{m}$
, conditional on
$v_{m}$
, conditional on
 $U(t_{m})=u(t_{m})$
,
$U(t_{m})=u(t_{m})$
,
 $U(t_{m-1})=u(t_{m-1})$
, are generated by the Metropolis Hastings Algorithm. These sample paths for each period combined constitute
$U(t_{m-1})=u(t_{m-1})$
, are generated by the Metropolis Hastings Algorithm. These sample paths for each period combined constitute
 $v$
. The complete data score function can be written as
$v$
. The complete data score function can be written as
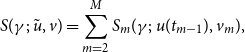 \begin{align} S(\gamma ;\;\tilde {u}, v)=\sum _{m=2}^{M}S_{m}(\gamma ;\;u(t_{m-1}),v_{m}), \end{align}
\begin{align} S(\gamma ;\;\tilde {u}, v)=\sum _{m=2}^{M}S_{m}(\gamma ;\;u(t_{m-1}),v_{m}), \end{align}
and (3.8) can now be written as
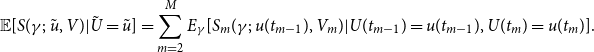 \begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=\sum _{m=2}^{M}E_{\gamma }[S_{m}(\gamma ;\;u(t_{m-1}),V_{m})|U(t_{m-1})=u(t_{m-1}), U(t_{m})=u(t_{m})]. \end{align}
\begin{align} \mathbb{E}[S(\gamma ;\;\tilde {u}, V)|\tilde {U}=\tilde {u}]=\sum _{m=2}^{M}E_{\gamma }[S_{m}(\gamma ;\;u(t_{m-1}),V_{m})|U(t_{m-1})=u(t_{m-1}), U(t_{m})=u(t_{m})]. \end{align}
The maximum likelihood estimate is the value of
 $\gamma$
for which (3.11) equals 0. The solution is obtained by stochastic approximation via a Robbins Monro Algorithm with updating step
$\gamma$
for which (3.11) equals 0. The solution is obtained by stochastic approximation via a Robbins Monro Algorithm with updating step
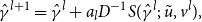 \begin{align} \hat {\gamma }^{l+1}= \hat {\gamma }^{l} + a_{l}D^{-1}S(\hat {\gamma }^{l};\;\tilde {u},v^{l}), \end{align}
\begin{align} \hat {\gamma }^{l+1}= \hat {\gamma }^{l} + a_{l}D^{-1}S(\hat {\gamma }^{l};\;\tilde {u},v^{l}), \end{align}
where
 $v^{l}$
is generated according to the conditional distribution of
$v^{l}$
is generated according to the conditional distribution of
 $V$
, given
$V$
, given
 $\tilde {U}=\tilde {u}$
, with parameter value
$\tilde {U}=\tilde {u}$
, with parameter value
 $\hat {\gamma }^{l}$
.
$\hat {\gamma }^{l}$
.
 $a_{l}$
is a sequence of positive numbers tending to 0, and
$a_{l}$
is a sequence of positive numbers tending to 0, and
 $D$
is a positive definite matrix. See Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) and https://www.stats.ox.ac.uk/∼snijders/siena/Siena_algorithms.pdf[stats.ox.ac.uk] for additional details on this algorithm.
$D$
is a positive definite matrix. See Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) and https://www.stats.ox.ac.uk/∼snijders/siena/Siena_algorithms.pdf[stats.ox.ac.uk] for additional details on this algorithm.
4. Maximum likelihood estimation for the SAOM-HMM
In this section we present an algorithm to calculate the maximum likelihood estimates of the parameters
 $\alpha$
,
$\alpha$
,
 $\beta$
, and
$\beta$
, and
 $\gamma$
in our SAOM-HMM described in Section 2. Let
$\gamma$
in our SAOM-HMM described in Section 2. Let
 $\Gamma$
consist of
$\Gamma$
consist of
 $(\alpha , \beta , \gamma )$
. We develop a variation of the EM algorithm, an iterative method which alternates between performing an expectation (E) step and a maximization (M) step Dempster et al. (Reference Dempster, Laird and Rubin1977). We first find the expected value of the complete data log-likelihood
$(\alpha , \beta , \gamma )$
. We develop a variation of the EM algorithm, an iterative method which alternates between performing an expectation (E) step and a maximization (M) step Dempster et al. (Reference Dempster, Laird and Rubin1977). We first find the expected value of the complete data log-likelihood
 $\ell ^{*}(\Gamma )=\log f(\tilde {u},\tilde {y})$
, with respect to the unknown, true networks
$\ell ^{*}(\Gamma )=\log f(\tilde {u},\tilde {y})$
, with respect to the unknown, true networks
 $\tilde {u}$
, given the observed networks
$\tilde {u}$
, given the observed networks
 $\tilde {y}$
and the current parameter estimates for
$\tilde {y}$
and the current parameter estimates for
 $\Gamma$
. We then maximize the expected log-likelihood found in the E-step. Our M-step framework embeds the SAOM estimation routine described in Section 3.2. The overall schematic of our estimation routine (that we will describe in detail in the remainder of this section) is as follows:
$\Gamma$
. We then maximize the expected log-likelihood found in the E-step. Our M-step framework embeds the SAOM estimation routine described in Section 3.2. The overall schematic of our estimation routine (that we will describe in detail in the remainder of this section) is as follows:
Given a series of observed networks
 $\tilde {y}$
and a number of effects one wishes to include in the SAOM, a SAOM is fit (via the maximum likelihood estimation routine described in Section 3.2) to get initial estimates of the parameters associated with each effect. We also make the choice, for this current implementation, to assume a constant rate parameter across all vertices. This is a fairly standard choice and is recommended in the SAOM literature, unless one has strong reason to believe otherwise. Set
$\tilde {y}$
and a number of effects one wishes to include in the SAOM, a SAOM is fit (via the maximum likelihood estimation routine described in Section 3.2) to get initial estimates of the parameters associated with each effect. We also make the choice, for this current implementation, to assume a constant rate parameter across all vertices. This is a fairly standard choice and is recommended in the SAOM literature, unless one has strong reason to believe otherwise. Set
 $\hat {\gamma }^{1}$
equal to these estimates. The
$\hat {\gamma }^{1}$
equal to these estimates. The
 $p^{th}$
updating step of our EM algorithm then proceeds as follows:
$p^{th}$
updating step of our EM algorithm then proceeds as follows:
-
1. Using
$\hat {\Gamma }^{p-1}$
, perform Algorithms1, 2, and 3 described in Section 1.3 to sample a series of true networks. This step corresponds to the E-step in the EM algorithm and is necessary due to the incredibly large state space present in our Expectation. -
2. Perform the maximization step using the formulas in section 4.2.1 to obtain
$\hat {\alpha }^{p}$
and
$\hat {\beta }^{p}$
. -
3. Perform the maximization routine outlined in section 4.2.2 to obtain
$\hat {\gamma }^{p}$
. -
4. Repeat steps 1-3 until convergence.




Additional details are presented below.
4.1 E-step
The expected value of the complete data log-likelihood (2.1) with respect to the true networks
 $\tilde {u}$
given the observed networks
$\tilde {u}$
given the observed networks
 $\tilde {y}$
is:
$\tilde {y}$
is:
 \begin{align} Q(\Gamma , \Gamma ^{p-1})&=\mathbb{E}[\!\log f(\tilde {u},\tilde {y}|\Gamma )|\tilde {y},\Gamma ^{p-1}] \nonumber \\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{m=2}^{M}\log f_{\alpha ,\beta }(y(t_{m})|u(t_{m}))\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) + \sum _{\tilde {u} \in \tilde {U}}^{}\log f_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}), \end{align}
\begin{align} Q(\Gamma , \Gamma ^{p-1})&=\mathbb{E}[\!\log f(\tilde {u},\tilde {y}|\Gamma )|\tilde {y},\Gamma ^{p-1}] \nonumber \\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{m=2}^{M}\log f_{\alpha ,\beta }(y(t_{m})|u(t_{m}))\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) + \sum _{\tilde {u} \in \tilde {U}}^{}\log f_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}), \end{align}
where
 $p$
is the iteration number,
$p$
is the iteration number,
 $\Gamma ^{p-1}$
are the current parameter estimates that we use to evaluate the expectation, and
$\Gamma ^{p-1}$
are the current parameter estimates that we use to evaluate the expectation, and
 $\Gamma ^{p}$
are the new parameters that we want to optimize to increase
$\Gamma ^{p}$
are the new parameters that we want to optimize to increase
 $Q(\Gamma , \Gamma ^{p-1})$
. This expectation is difficult to calculate due to the magnitude of the state space. In order to address this computational challenge, we employ a particle filtering based sampling scheme (i.e. a sequential Monte Carlo method), which will be described in detail in Section 4.3.
$Q(\Gamma , \Gamma ^{p-1})$
. This expectation is difficult to calculate due to the magnitude of the state space. In order to address this computational challenge, we employ a particle filtering based sampling scheme (i.e. a sequential Monte Carlo method), which will be described in detail in Section 4.3.
4.2 M-step
The second step of the EM algorithm is to maximize the expectation, i.e. to calculate
 $\Gamma ^p = \arg \max _{\Gamma } Q(\Gamma , \Gamma ^{p-1})$
. Since the parameters we wish to optimize are independently split into two terms in
$\Gamma ^p = \arg \max _{\Gamma } Q(\Gamma , \Gamma ^{p-1})$
. Since the parameters we wish to optimize are independently split into two terms in
 $Q(\Gamma , \Gamma ^{p-1})$
, we can optimize each separately.
$Q(\Gamma , \Gamma ^{p-1})$
, we can optimize each separately.
4.2.1 Maximizing in
$\alpha$
and
$\beta$


We write the first term in
 $Q(\Gamma , \Gamma ^{p-1})$
as:
$Q(\Gamma , \Gamma ^{p-1})$
as:
 \begin{align} \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{m=2}^{M} & \log f_{\alpha ,\beta }(y(t_{m})|u(t_{m}))\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})= \nonumber \\ & \sum _{k=1}^{K}\sum _{m=2}^{M}\log \big [ \alpha ^{c_{km}}(1-\alpha )^{d_{km}}\beta ^{b_{km}}(1-\beta )^{a_{km}}\big ] f(u(t_{m})=u_{k}|\tilde {y},\Gamma ^{p-1}), \end{align}
\begin{align} \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{m=2}^{M} & \log f_{\alpha ,\beta }(y(t_{m})|u(t_{m}))\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})= \nonumber \\ & \sum _{k=1}^{K}\sum _{m=2}^{M}\log \big [ \alpha ^{c_{km}}(1-\alpha )^{d_{km}}\beta ^{b_{km}}(1-\beta )^{a_{km}}\big ] f(u(t_{m})=u_{k}|\tilde {y},\Gamma ^{p-1}), \end{align}
where
 $a,b,c,$
and
$a,b,c,$
and
 $d$
for a given true network
$d$
for a given true network
 $u_{k}$
at observation time
$u_{k}$
at observation time
 $t_{m}$
are defined in Table 1. Let
$t_{m}$
are defined in Table 1. Let
 $A,B,C,$
and
$A,B,C,$
and
 $D$
correspond to the random variables for each. Maximizing in
$D$
correspond to the random variables for each. Maximizing in
 $\alpha$
and
$\alpha$
and
 $\beta$
yields the following:
$\beta$
yields the following:
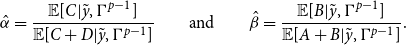 \begin{align} \hat {\alpha }=\dfrac {\mathbb{E}[C|\tilde {y},\Gamma ^{p-1}]}{\mathbb{E}[C+D|\tilde {y},\Gamma ^{p-1}]} \qquad \text{and}\qquad \hat {\beta }=\dfrac {\mathbb{E}[B|\tilde {y},\Gamma ^{p-1}]}{\mathbb{E}[A+B|\tilde {y},\Gamma ^{p-1}]}. \end{align}
\begin{align} \hat {\alpha }=\dfrac {\mathbb{E}[C|\tilde {y},\Gamma ^{p-1}]}{\mathbb{E}[C+D|\tilde {y},\Gamma ^{p-1}]} \qquad \text{and}\qquad \hat {\beta }=\dfrac {\mathbb{E}[B|\tilde {y},\Gamma ^{p-1}]}{\mathbb{E}[A+B|\tilde {y},\Gamma ^{p-1}]}. \end{align}
The formula for
 $\hat {\alpha }$
is the expected number of false edges in the observed network divided by the expected number of non-edges in the true network, given the observed networks
$\hat {\alpha }$
is the expected number of false edges in the observed network divided by the expected number of non-edges in the true network, given the observed networks
 $\tilde {y}$
and current parameter estimates
$\tilde {y}$
and current parameter estimates
 $\Gamma ^{p-1}$
. The formula for
$\Gamma ^{p-1}$
. The formula for
 $\hat {\beta }$
is the expected number of false non-edges in the observed network divided by the expected number of edges in the true network, given the observed networks
$\hat {\beta }$
is the expected number of false non-edges in the observed network divided by the expected number of edges in the true network, given the observed networks
 $\tilde {y}$
and current parameter estimates
$\tilde {y}$
and current parameter estimates
 $\Gamma ^{p-1}$
.
$\Gamma ^{p-1}$
.
4.2.2 Maximizing in
$\gamma$

The second term in our
 $Q$
function is
$Q$
function is
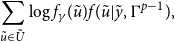 \begin{align*} \sum _{\tilde {u} \in \tilde {U}}^{}\log f_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}), \end{align*}
\begin{align*} \sum _{\tilde {u} \in \tilde {U}}^{}\log f_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}), \end{align*}
where
 $\gamma$
consists of the SAOM parameters. We adopt the SAOM framework of Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) described in Section 2. Note that taking the derivative of the second term in our
$\gamma$
consists of the SAOM parameters. We adopt the SAOM framework of Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) described in Section 2. Note that taking the derivative of the second term in our
 $Q$
function yields
$Q$
function yields
 \begin{align*} \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \text{ where } S(\gamma ;\;\tilde {u})=\frac {\partial }{\partial \gamma }\log f_{\gamma }(\tilde {u}). \end{align*}
\begin{align*} \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \text{ where } S(\gamma ;\;\tilde {u})=\frac {\partial }{\partial \gamma }\log f_{\gamma }(\tilde {u}). \end{align*}
Since
 $f_{\gamma }(\tilde {u})$
cannot be calculated in closed form, neither can
$f_{\gamma }(\tilde {u})$
cannot be calculated in closed form, neither can
 $\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. To aid in maximization, we augment each true network series
$\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. To aid in maximization, we augment each true network series
 $\tilde {u}$
with a possible sample path that could have led one true network to the next in the series. We define the random variable
$\tilde {u}$
with a possible sample path that could have led one true network to the next in the series. We define the random variable
 $V$
to be a sample path associated with a true network series
$V$
to be a sample path associated with a true network series
 $\tilde {u}$
. Drawing upon the missing information principle and the work of Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) and Gu et al., Gu and Kong (Reference Gu and Kong1998), we write the equation above as
$\tilde {u}$
. Drawing upon the missing information principle and the work of Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) and Gu et al., Gu and Kong (Reference Gu and Kong1998), we write the equation above as
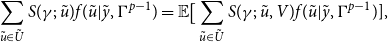 \begin{align} \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})=\mathbb{E}\big [\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})], \end{align}
\begin{align} \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})=\mathbb{E}\big [\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})], \end{align}
where the expectation on the right-hand side of the equation is with respect to
 $V$
. Maximum likelihood estimates for
$V$
. Maximum likelihood estimates for
 $\gamma$
can be determined, under regularity conditions, as the solution for (4.4) equaling 0. The proof of (4.4) is shown in Appendix A.
$\gamma$
can be determined, under regularity conditions, as the solution for (4.4) equaling 0. The proof of (4.4) is shown in Appendix A.
In our approach, the solution to (4.4) is obtained by stochastic approximation via a Robbins Monro algorithm, which is similar to that used in Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010) and described in Section 3.2. At each iteration of the Robbins Monro algorithm, a possible
 $V$
, i.e. a path connecting each possible true network, in each possible latent network series, is sampled. This sampling is done via a Metropolis Hastings algorithm Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). Next,
$V$
, i.e. a path connecting each possible true network, in each possible latent network series, is sampled. This sampling is done via a Metropolis Hastings algorithm Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). Next,
 $\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
is calculated and used in an updating step in the algorithm. It is unreasonable, given the prohibitively large state space of true network series, to sum over every possible true network series in this calculation. Therefore, we note that
$\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
is calculated and used in an updating step in the algorithm. It is unreasonable, given the prohibitively large state space of true network series, to sum over every possible true network series in this calculation. Therefore, we note that
 $\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
is an expectation, and we sample a smaller number (denoted by
$\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
is an expectation, and we sample a smaller number (denoted by
 $H$
) of true network series from
$H$
) of true network series from
 $f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. The average of
$f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. The average of
 $S(\gamma ;\;\tilde {u}, v)$
for this smaller sample is what is used in the updating step of the Robbins Monro algorithm in place of
$S(\gamma ;\;\tilde {u}, v)$
for this smaller sample is what is used in the updating step of the Robbins Monro algorithm in place of
 $\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. The updating step is
$\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, v)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. The updating step is
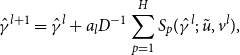 \begin{align} \hat {\gamma }^{l+1}= \hat {\gamma }^{l} + a_{l}D^{-1}\sum _{p=1}^{H}S_{p}(\hat {\gamma }^{l};\;\tilde {u},v^{l}) , \end{align}
\begin{align} \hat {\gamma }^{l+1}= \hat {\gamma }^{l} + a_{l}D^{-1}\sum _{p=1}^{H}S_{p}(\hat {\gamma }^{l};\;\tilde {u},v^{l}) , \end{align}
where the sum is over the total number of sampled true network series
 $\tilde {u}$
,
$\tilde {u}$
,
 $D$
is the matrix of partial derivatives, and
$D$
is the matrix of partial derivatives, and
 $a_{l}$
is a sequence of positive numbers tending to 0.
$a_{l}$
is a sequence of positive numbers tending to 0.
Our actual implementation of the above algorithm again borrows from that of Snijders et al., Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010), which follows directly from the work of Gue and Kong Gu and Kong (Reference Gu and Kong1998). The algorithm performed consists of two phases. In the first phase a small number of simulations are used to obtain a rough estimate of the matrix of partial derivatives (defined as D in our updating step), which are estimated by a score-function method Schweinberger and Snijders (Reference Schweinberger and Snijders2007). The second phase determines the estimate of
 $\gamma$
by simulating
$\gamma$
by simulating
 $V$
and performing the updating step.
$V$
and performing the updating step.
4.3 Particle filtering
The expectation in the E-step of our E-M algorithm is difficult to calculate largely due to the magnitude of the state space. There are
 $2^{N*(N-1)}$
possible true networks at each observation time, and to calculate
$2^{N*(N-1)}$
possible true networks at each observation time, and to calculate
 $f(u(t_{m})|\tilde {y}, \Gamma ^{p-1})$
for a given observation moment
$f(u(t_{m})|\tilde {y}, \Gamma ^{p-1})$
for a given observation moment
 $m$
, one needs to sum over all possible combinations of
$m$
, one needs to sum over all possible combinations of
 $u$
at the previous
$u$
at the previous
 $m-1$
observation times. The forward-backward algorithm can in principle be used to compute these posterior marginals of all hidden state variables given a sequence of observations Rabiner and Juang (Reference Rabiner and Juang1986). The algorithm makes use of the principle of dynamic programing to efficiently compute the values in two passes. The first pass goes forward in time, while the second goes backward in time. However, given the magnitude of our network space, direct use of this approach is not computationally feasible in any but the smallest of problems. Also, as described in the previous section, the transition probabilities,
$m-1$
observation times. The forward-backward algorithm can in principle be used to compute these posterior marginals of all hidden state variables given a sequence of observations Rabiner and Juang (Reference Rabiner and Juang1986). The algorithm makes use of the principle of dynamic programing to efficiently compute the values in two passes. The first pass goes forward in time, while the second goes backward in time. However, given the magnitude of our network space, direct use of this approach is not computationally feasible in any but the smallest of problems. Also, as described in the previous section, the transition probabilities,
 $f_{\gamma }(u(t_{m})|u(t_{m-1}))$
, cannot be calculated in closed form.
$f_{\gamma }(u(t_{m})|u(t_{m-1}))$
, cannot be calculated in closed form.
In order to address this computational challenge, we employ a particle filtering based sampling scheme (i.e. a Sequential Monte Carlo method) Doucet and Lee (Reference Doucet and Lee2018). Particle filtering methods provide a way to sample from an approximation of
 $f(u(t_{m})|\tilde {y}, \Gamma ^{p-1})$
through time. Our adaptation of particle filtering principles to the current content is described in Algorithms1– 3 and follows almost exactly from Doucet and Lee (Reference Doucet and Lee2018). In this context, we let the particle
$f(u(t_{m})|\tilde {y}, \Gamma ^{p-1})$
through time. Our adaptation of particle filtering principles to the current content is described in Algorithms1– 3 and follows almost exactly from Doucet and Lee (Reference Doucet and Lee2018). In this context, we let the particle
 $\zeta ^{k}$
be a provisional, hypothetical value of true network
$\zeta ^{k}$
be a provisional, hypothetical value of true network
 $u$
, with respective elements
$u$
, with respective elements
 $\zeta ^{k}_{m}$
and
$\zeta ^{k}_{m}$
and
 $u(t_{m})$
. Algorithm1 mirrors the forward portion of the forward-backward algorithm referred to above. Algorithm2 describes the ancestral simulation of
$u(t_{m})$
. Algorithm1 mirrors the forward portion of the forward-backward algorithm referred to above. Algorithm2 describes the ancestral simulation of
 $\star$
in 1.1, and Algorithm3 is used to sample full sequences of latent network variables, i.e., to obtain an approximate sample from the conditional distribution of the latent networks given the observed networks (
$\star$
in 1.1, and Algorithm3 is used to sample full sequences of latent network variables, i.e., to obtain an approximate sample from the conditional distribution of the latent networks given the observed networks (
 $f(\tilde {u}|\tilde {y}, \Gamma ^{p-1}))$
. For more details on the particle filtering method we have applied in our algorithm, refer to Doucet and Lee (Reference Doucet and Lee2018).
$f(\tilde {u}|\tilde {y}, \Gamma ^{p-1}))$
. For more details on the particle filtering method we have applied in our algorithm, refer to Doucet and Lee (Reference Doucet and Lee2018).
A mirror of the Forward Algorithm

Ancestral simulation of (⋆)

Sampling an ancestral line (i.e., a true network series)
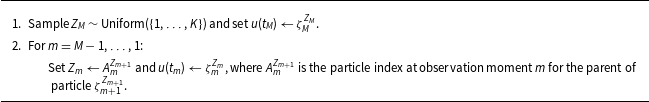
Of special note is that
 $(\!\star\!)$
in step 2 is sampled in two stages and is outlined in Algorithm2. The first stage samples a mixture parameter,
$(\!\star\!)$
in step 2 is sampled in two stages and is outlined in Algorithm2. The first stage samples a mixture parameter,
 $\zeta ^{k}_{m-1}$
, with probability proportional to
$\zeta ^{k}_{m-1}$
, with probability proportional to
 $f(y(t_{m-1})|u(t_{m-1})=\zeta _{m-1})$
. The second stage samples from
$f(y(t_{m-1})|u(t_{m-1})=\zeta _{m-1})$
. The second stage samples from
 $f(u(t_{m})|u(t_{m-1})=\zeta _{m-1})$
. This two-stage process provides a genealogical interpretation of the particles that are produced by the algorithm. For
$f(u(t_{m})|u(t_{m-1})=\zeta _{m-1})$
. This two-stage process provides a genealogical interpretation of the particles that are produced by the algorithm. For
 $m \in \{1,\ldots ,M \}$
and
$m \in \{1,\ldots ,M \}$
and
 $k \in \{1,\ldots ,K \}$
, we denote by
$k \in \{1,\ldots ,K \}$
, we denote by
 $A^{k}_{m-1}$
the ancestor index of particle
$A^{k}_{m-1}$
the ancestor index of particle
 $\zeta ^{k}_{m}$
.
$\zeta ^{k}_{m}$
.
One can view Algorithms1 and 2 as a kind of evolutionary system where at observation moment
 $m \lt M$
each particle has exactly one parent, and at each observation moment
$m \lt M$
each particle has exactly one parent, and at each observation moment
 $m \gt 1$
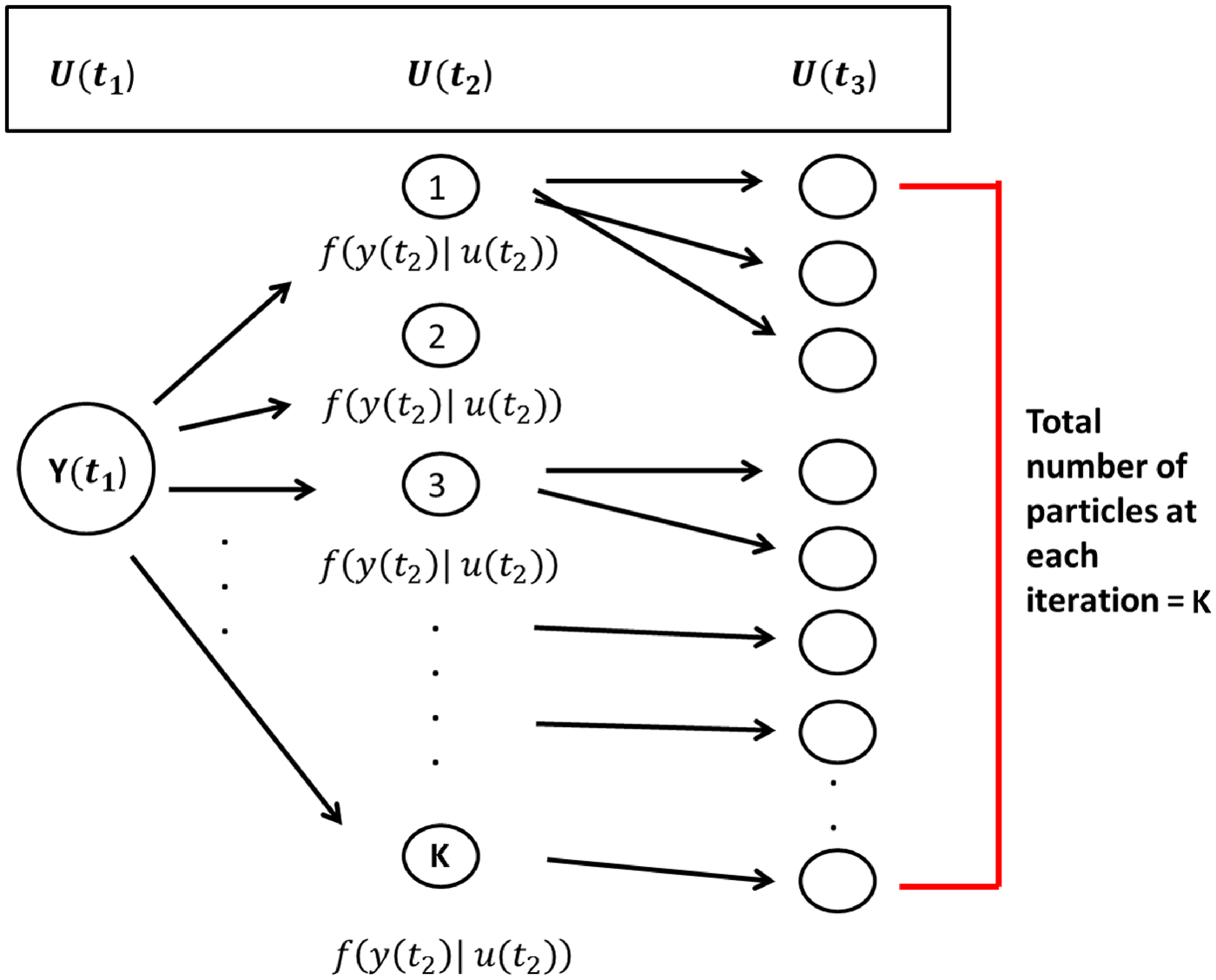
, each particle has some number of offspring. Algorithms1 and 2 create a collection of possible true networks at each observation moment. Figure 2 provides a visual description of the scheme. The total number of observation moments
$m \gt 1$
, each particle has some number of offspring. Algorithms1 and 2 create a collection of possible true networks at each observation moment. Figure 2 provides a visual description of the scheme. The total number of observation moments
 $M$
are fixed. At each observation moment, particles from the previous observation moment
$M$
are fixed. At each observation moment, particles from the previous observation moment
 $m-1$
are assigned probabilities that are proportional to
$m-1$
are assigned probabilities that are proportional to
 $f(y(t_{m-1})|u(t_{m-1}))$
(i.e., parameterized by the false positive and false negative error rate estimates). An independent random sample of these particles is drawn according to these probabilities. For each of these particles, a next true network
$f(y(t_{m-1})|u(t_{m-1}))$
(i.e., parameterized by the false positive and false negative error rate estimates). An independent random sample of these particles is drawn according to these probabilities. For each of these particles, a next true network
 $u(t_{m})$
(i.e., particle
$u(t_{m})$
(i.e., particle
 $\zeta _{m}^{k}$
) is simulated as evolving from the current SAOM with parameter estimates
$\zeta _{m}^{k}$
) is simulated as evolving from the current SAOM with parameter estimates
 $\hat {\gamma }^{p-1}$
, conditional on
$\hat {\gamma }^{p-1}$
, conditional on
 $u(t_{m-1})$
(i.e., particle
$u(t_{m-1})$
(i.e., particle
 $\zeta _{m-1}^{k}$
). However, we ultimately would like a sample of possible true network
$\zeta _{m-1}^{k}$
). However, we ultimately would like a sample of possible true network
 $\it{series}$
. Algorithm3 describes how to sample such a series. By sampling an ancestral line, we are effectively sampling from
$\it{series}$
. Algorithm3 describes how to sample such a series. By sampling an ancestral line, we are effectively sampling from
 $f(\tilde {u}|\tilde {y}, \Gamma ^{p-1})$
.
$f(\tilde {u}|\tilde {y}, \Gamma ^{p-1})$
.
Particle filtering sampling scheme.
 $K$
particles are sampled at each observation moment following a two-stage process. First, particles are selected from the previous observation moment with probability proportional to the conditional distribution of the true network given the observed network at that time point. Then, a true network (i.e., particle) at the next observation moment is sampled/simulated, starting from the current selected particle network, and according to the parameter estimates in the stochastic actor-oriented models.
$K$
particles are sampled at each observation moment following a two-stage process. First, particles are selected from the previous observation moment with probability proportional to the conditional distribution of the true network given the observed network at that time point. Then, a true network (i.e., particle) at the next observation moment is sampled/simulated, starting from the current selected particle network, and according to the parameter estimates in the stochastic actor-oriented models.
4.4 Putting it all together
We now combine the elements presented in the previous sections to define a complete algorithm for the estimation of
 $\alpha$
,
$\alpha$
,
 $\beta$
, and
$\beta$
, and
 $\gamma$
in our SAOM-HMM.
$\gamma$
in our SAOM-HMM.
Given a series of observed networks
 $\tilde {y}$
and a number of effects one wishes to include in the SAOM, a SAOM is fit (via maximum likelihood estimation) to get initial estimates of the parameters associated with each effect. We also make the choice, for this current implementation, to assume a constant rate parameter across all vertices. This is a fairly standard choice and is recommended in the SAOM literature, unless one has strong reason to believe otherwise. Set the initial SAOM parameter estimates,
$\tilde {y}$
and a number of effects one wishes to include in the SAOM, a SAOM is fit (via maximum likelihood estimation) to get initial estimates of the parameters associated with each effect. We also make the choice, for this current implementation, to assume a constant rate parameter across all vertices. This is a fairly standard choice and is recommended in the SAOM literature, unless one has strong reason to believe otherwise. Set the initial SAOM parameter estimates,
 $\hat {\gamma }^{1}$
, equal to these estimates.
$\hat {\gamma }^{1}$
, equal to these estimates.
The
 $p^{th}$
updating step of our EM algorithm then proceeds as follows:
$p^{th}$
updating step of our EM algorithm then proceeds as follows:
-
1. Using
$\hat {\Gamma }^{p-1}$
, perform Algorithm2 to get
$K$
possible true networks at each observation moment. -
2. Sample
$H$
number of true network series from an approximation of
$f(\tilde {u}|\tilde {y}, \Gamma ^{p-1})$
using the ancestral sampling scheme in Algorithm3. -
3. Perform the maximization step using Equations 4.3 to obtain
$\hat {\alpha }^{p}$
and
$\hat {\beta }^{p}$
. This step obtains estimates of the false positive and false negative rates. -
4. Perform the maximization routine outlined in section 4.2.2 to obtain
$\hat {\gamma }^{p}$
. This step provides estimates of the SAOM parameters and can be done using the multi-group option of RSiena Ripley et al. (Reference Ripley, Snijders, Boda, Vörös and Preciado2024). -
5. Repeat steps 1-4 until convergence. The convergence criteria we have used in our simulation study is based on a moving average and is the following:
where
\begin{equation*} \frac {\mid \mid \hat {\Gamma }^{*p} - \hat {\Gamma }^{*p-1} \mid \mid _{1}}{\mid \mid \hat {\Gamma }^{*p-1} \mid \mid _{1}}\lt 0.01 , \end{equation*}
$\hat {\Gamma }^{*p} = \frac {\sum _{i=p-4}^{p} \hat {\Gamma _{i}}}{5}$
and
$\hat {\Gamma }^{*p-1} = \frac {\sum _{i=p-5}^{p-1} \hat {\Gamma _{i}}}{5}$
.
However, in other instances, some parameter coordinates may have a different scale than others, and the true estimate may be close to 0. Therefore, the convergence criterion may need to be adapted.










The choice of
 $K$
in step 1 (i.e. the number of particles sampled at each observation moment) and the choice of
$K$
in step 1 (i.e. the number of particles sampled at each observation moment) and the choice of
 $H$
(i.e. the sample of true network series to sample) in step 2 should depend on the size of the network, the number of observation moments, and the amount of noise and strength of the SAOM parameter signals one suspects to be present. For example, when working with network sizes of 10 vertices, 4 observation moments, and 5 parameters in our SAOM, we have used a K of 50,000 and an
$H$
(i.e. the sample of true network series to sample) in step 2 should depend on the size of the network, the number of observation moments, and the amount of noise and strength of the SAOM parameter signals one suspects to be present. For example, when working with network sizes of 10 vertices, 4 observation moments, and 5 parameters in our SAOM, we have used a K of 50,000 and an
 $H$
of 3000 for the maximization of
$H$
of 3000 for the maximization of
 $\alpha$
and
$\alpha$
and
 $\beta$
. For the maximization of
$\beta$
. For the maximization of
 $\gamma$
, we have worked with an
$\gamma$
, we have worked with an
 $H$
of 50.
$H$
of 50.
We deliberately keep
 $H$
relatively small (in this case, 50) because this step involves finding
$H$
relatively small (in this case, 50) because this step involves finding
 $\hat {\gamma }$
that maximizes data from
$\hat {\gamma }$
that maximizes data from
 $H$
number of network series. As has often been remarked by the developers of SAOMs, even estimating
$H$
number of network series. As has often been remarked by the developers of SAOMs, even estimating
 $\gamma$
for one series of networks can be time consuming, depending on the size of the network and the number of parameters in the model. This step of our algorithm consumes much of the run time, and to try and estimate
$\gamma$
for one series of networks can be time consuming, depending on the size of the network and the number of parameters in the model. This step of our algorithm consumes much of the run time, and to try and estimate
 $\gamma$
for many more
$\gamma$
for many more
 $H$
will require significantly more time.
$H$
will require significantly more time.
4.5 Calculation of standard errors
The algorithm outlined thus far only produces the parameter estimates. Additional work is required if one wants the standard errors associated with the estimates. Since inference is likely the end goal in practice, a method for calculating standard errors of the estimates is needed. We propose performing a parametric bootstrap where the maximum likelihood estimates from the above algorithm are collected and a number of network series from the estimated model are sampled. The proposed algorithm is then run on each of the sampled network series to obtain a new collection of parameter estimates, which are then used to calculate the standard errors. The more samples we take, the more accurate the estimates of the standard error will be. However, again, there is a computational trade-off, since our algorithm needs to be run for each of the sampled network series.
4.6 Algorithm modifications
The focus of the framework discussed thus far has been on directed networks since SAOMs were initially developed for directed networks. It should be noted, though, that SAOMs are now capable of handling undirected networks, and so is our methodology. The only caveat is that one needs to define how edges are assumed to form in the SAOM model Snijders and Pickup (Reference Snijders, Pickup, Victor, Montgomery and Lubell2017). For example, does one vertex unilaterally impose that an edge is created or dissolved? Or, do both vertices have to “agree”? We present an example of an application to undirected networks in Section 6.
Another modification one may choose to make is with regards to how
 $\gamma$
is estimated in the maximization step in the algorithm we propose. In section 4.2.2, we outline a Robbins Monro algorithm to maximize the complete data log likelihood. Our approach borrows from the algorithm Snijders et al., use for the maximum likelihood estimation of the SAOM parameters for the evolution of one observed network series Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). The computation for this step is time consuming. As a way to reduce the maximization time for
$\gamma$
is estimated in the maximization step in the algorithm we propose. In section 4.2.2, we outline a Robbins Monro algorithm to maximize the complete data log likelihood. Our approach borrows from the algorithm Snijders et al., use for the maximum likelihood estimation of the SAOM parameters for the evolution of one observed network series Snijders et al. (Reference Snijders, Koskinen and Schweinberger2010). The computation for this step is time consuming. As a way to reduce the maximization time for
 $\gamma$
, one could instead perform a method of moments based estimation routine. This approach also utilizes a Robbins Monro algorithm. In the maximum likelihood based routine, at each iteration of the Robbins Monro algorithm, possible paths leading from one network to the next are augmented for each of our sampled true network series. A complete data score function is then calculated and used in the updating step. The method of moments based routine instead simulates the SAOM evolution process, calculates statistics corresponding to each parameter in the model on both the observed and simulated networks, and then takes the difference of these to be used in the updating step of the Robbins Monro algorithm. In other words, parameter estimates are determined as the parameter value for which the expected value of the statistics equals the observed value at each observation point and for each sampled true network series Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010).
$\gamma$
, one could instead perform a method of moments based estimation routine. This approach also utilizes a Robbins Monro algorithm. In the maximum likelihood based routine, at each iteration of the Robbins Monro algorithm, possible paths leading from one network to the next are augmented for each of our sampled true network series. A complete data score function is then calculated and used in the updating step. The method of moments based routine instead simulates the SAOM evolution process, calculates statistics corresponding to each parameter in the model on both the observed and simulated networks, and then takes the difference of these to be used in the updating step of the Robbins Monro algorithm. In other words, parameter estimates are determined as the parameter value for which the expected value of the statistics equals the observed value at each observation point and for each sampled true network series Snijders et al. (Reference Snijders, Van de Bunt and Steglich2010).
Although the method of moment based estimation for
 $\gamma$
does not produce formal maximum likelihood estimates, it it still a viable estimation method and has been shown to provide similar results in our setting. We demonstrate this in section 5.2 through a small simulation study. In larger networks, the savings in run time may justify the use of method of moments as an approximation.
$\gamma$
does not produce formal maximum likelihood estimates, it it still a viable estimation method and has been shown to provide similar results in our setting. We demonstrate this in section 5.2 through a small simulation study. In larger networks, the savings in run time may justify the use of method of moments as an approximation.
4.7 Algorithm implementation
The algorithm outlined in this paper is implemented in R. We have written code for steps 1–3 outlined in Section 4.4. For step 4, we call upon the RSiena package Ripley et al. (Reference Ripley, Snijders, Boda, Vörös and Preciado2024), which was developed by R. Ripley, K. Boitmanis, and T.A. Snijders for the implementation of SAOMs. Version 1.1-232 was used for our modeling framework. Minor modifications were made to the source files of this package (saved locally) to allow for our specific algorithm outlined in Section 4.2.2 to be implemented.
One iteration of our E-M algorithm for the networks used in our simulation study explained in the following section takes approximately 45 minutes to run on a high performance Linux computing cluster using 5 cores. The algorithm converged, on average, after 15-20 iterations.
5. Simulation study
5.1 Study design
We present a small simulation study to demonstrate the accuracy of our method and draw a comparison between the behavior of our HMM-SAOM ML estimator and the ML estimator obtained from only fitting a SAOM (i.e. the naive approach). For this study, we simulate 10 node directed networks at 4 observation moments, referred to as
 $t_{1}$
,
$t_{1}$
,
 $t_{2}$
,
$t_{2}$
,
 $t_{3}$
, and
$t_{3}$
, and
 $t_{4}$
. We also create 2 vertex covariates, called Covariate A and Covariate B. Both are indicator variables and are defined as:
$t_{4}$
. We also create 2 vertex covariates, called Covariate A and Covariate B. Both are indicator variables and are defined as:
Simulation model effects and parameters

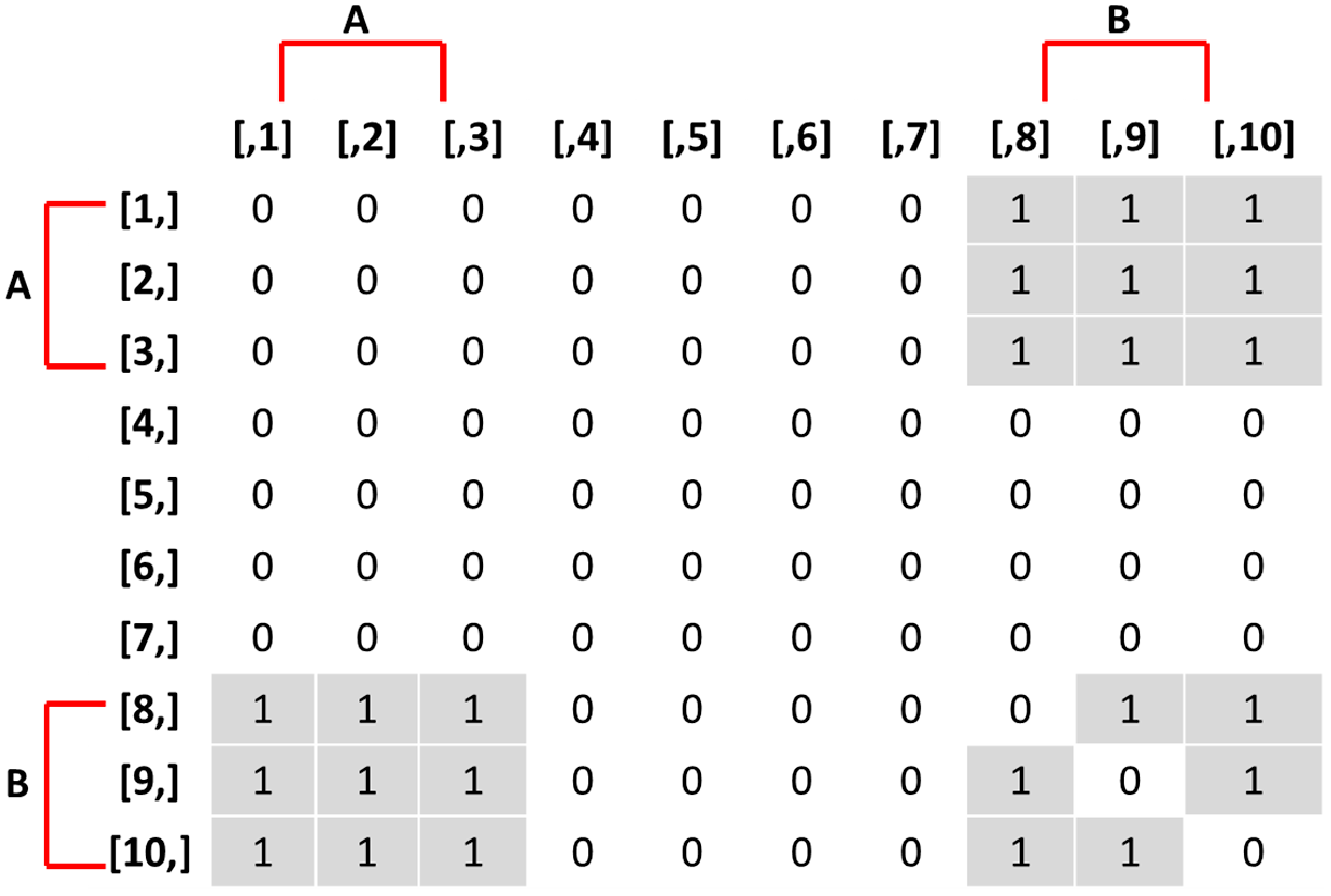
Adjacency matrix of true networks encouraged by the stochastic actor-oriented models in the simulation study. An entry of 1 in row
 $i$
and column
$i$
and column
 $j$
represents a directed edge from vertex
$j$
represents a directed edge from vertex
 $i$
to vertex
$i$
to vertex
 $j$
.
$j$
.
 \begin{equation*} \text{Covariate A}= a = \begin{cases} 1 & \text{Vertex Index} = 1,2,3 \\ 0 & \text{Vertex Index} = 4,5,6,7,8,9,10 \end{cases} \end{equation*}
\begin{equation*} \text{Covariate A}= a = \begin{cases} 1 & \text{Vertex Index} = 1,2,3 \\ 0 & \text{Vertex Index} = 4,5,6,7,8,9,10 \end{cases} \end{equation*}
 \begin{equation*} \text{Covariate B}= b = \begin{cases} 1 & \text{Vertex Index} = 8,9,10 \\ 0 & \text{Vertex Index} = 1,2,3,4,5,6,7 \end{cases} \end{equation*}
\begin{equation*} \text{Covariate B}= b = \begin{cases} 1 & \text{Vertex Index} = 8,9,10 \\ 0 & \text{Vertex Index} = 1,2,3,4,5,6,7 \end{cases} \end{equation*}
The objective function in the SAOM for the evolution of the true networks,
 $u(t_{m})$
, contains 5 effects (2 endogenous and 3 exogenous). Table 2 lists these effects, their mathematical definitions, and their descriptions. The large, negative value for outdegree, keeps our simulated true networks fairly sparse. It sets the probability of connections forming low, unless the other parameters in the function influence specific vertices in a more positive way. For example, the large positive value for reciprocated edges encourages a directed edge to form if one already exists in the reverse direction. These parameters, in conjunction with the parameters assigned to the three covariate related effects, promote the network structure demonstrated in Figure 3. In other words, the Covariate A Ego effect makes it highly likely that vertices 1, 2, and 3 will initiate out-connections to other vertices, outweighing the negative density parameter, as long as these connections form with vertices 8, 9, and 10 since the Covariate B Alter effect parameter is high. Furthermore, the Covariate B Ego effect parameter is large, encouraging vertices 8, 9, and 10 to connect to other vertices, but they will mainly choose to connect amongst each other and to vertices 1, 2, and 3 due to the large reciprocity parameter.
$u(t_{m})$
, contains 5 effects (2 endogenous and 3 exogenous). Table 2 lists these effects, their mathematical definitions, and their descriptions. The large, negative value for outdegree, keeps our simulated true networks fairly sparse. It sets the probability of connections forming low, unless the other parameters in the function influence specific vertices in a more positive way. For example, the large positive value for reciprocated edges encourages a directed edge to form if one already exists in the reverse direction. These parameters, in conjunction with the parameters assigned to the three covariate related effects, promote the network structure demonstrated in Figure 3. In other words, the Covariate A Ego effect makes it highly likely that vertices 1, 2, and 3 will initiate out-connections to other vertices, outweighing the negative density parameter, as long as these connections form with vertices 8, 9, and 10 since the Covariate B Alter effect parameter is high. Furthermore, the Covariate B Ego effect parameter is large, encouraging vertices 8, 9, and 10 to connect to other vertices, but they will mainly choose to connect amongst each other and to vertices 1, 2, and 3 due to the large reciprocity parameter.
Mean and standard deviation of parameter estimates based on 100 simulations
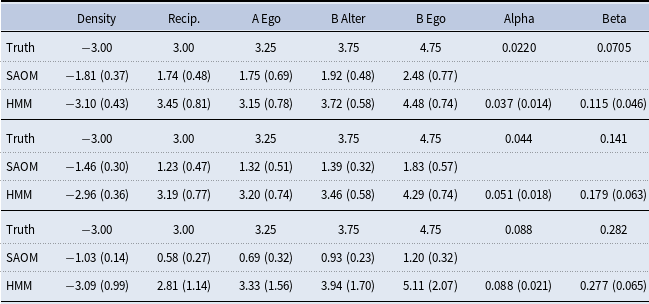
To create an initial true directed network without error at time
 $t_{1}$
for the evolution process to begin at, we first created a random network of approximately one quarter of the possible edges. We chose this density to be in line with the density of the encouraged network structure of the simulation model. We then simulated a next network state, evolving from this network, with a small rate parameter of 1 and the true parameter values we set for our SAOM objective function. By doing this, we created a network that had begun to drift towards a network state that has a high probability under the stationary distribution. This network was used as the first observed and true network for every simulation in our study.
$t_{1}$
for the evolution process to begin at, we first created a random network of approximately one quarter of the possible edges. We chose this density to be in line with the density of the encouraged network structure of the simulation model. We then simulated a next network state, evolving from this network, with a small rate parameter of 1 and the true parameter values we set for our SAOM objective function. By doing this, we created a network that had begun to drift towards a network state that has a high probability under the stationary distribution. This network was used as the first observed and true network for every simulation in our study.
We performed 100 simulations each, for 3 different error rate scenarios, while holding the first network constant and keeping the same SAOM objective function parameters. For each simulation, we simulated true networks at the
 $2^{nd}$
,
$2^{nd}$
,
 $3^{rd}$
, and
$3^{rd}$
, and
 $4^{th}$
observation moments, according to our true SAOM and with a constant rate parameter of 3. This rate was small enough that the networks gradually approached dynamic equilibrium, thus simulating a realistic evolution process. However, it is large enough that the network at
$4^{th}$
observation moments, according to our true SAOM and with a constant rate parameter of 3. This rate was small enough that the networks gradually approached dynamic equilibrium, thus simulating a realistic evolution process. However, it is large enough that the network at
 $t_{4}$
was a network in (or nearly in) dynamic equilibrium. We then created “observed” networks by introducing error to the edges of each true network. True edges remained edges in the observed network with probability equal to
$t_{4}$
was a network in (or nearly in) dynamic equilibrium. We then created “observed” networks by introducing error to the edges of each true network. True edges remained edges in the observed network with probability equal to
 $1-\beta$
and non-edges in the true networks remained non-edges in the observed network with probability
$1-\beta$
and non-edges in the true networks remained non-edges in the observed network with probability
 $1-\alpha$
. We then fit the HMM-SAOM to the observed networks, as well as just the SAOM by itself.
$1-\alpha$
. We then fit the HMM-SAOM to the observed networks, as well as just the SAOM by itself.
To determine the error-rates, we first ran 200 simulations of our true network evolution process to determine the expected number of edges and non-edges. The expected edges were calculated to be 21.31 and the expected non-edges to be 68.69. Therefore, we chose three error-rate scenarios. We performed 100 simulations with an expected number of 3 false edges and 3 false non-edges, which equates to an
 $\alpha$
of 0.044 and a
$\alpha$
of 0.044 and a
 $\beta$
of 0.141. We performed an additional 100 simulations where we reduced
$\beta$
of 0.141. We performed an additional 100 simulations where we reduced
 $\alpha$
and
$\alpha$
and
 $\beta$
to half of what we originally defined them to be, giving us
$\beta$
to half of what we originally defined them to be, giving us
 $\alpha =.022$
and
$\alpha =.022$
and
 $\beta =.0705$
, and lastly, we performed 100 simulations where we doubled the original
$\beta =.0705$
, and lastly, we performed 100 simulations where we doubled the original
 $\alpha$
and
$\alpha$
and
 $\beta$
, equating to
$\beta$
, equating to
 $\alpha =.088$
and
$\alpha =.088$
and
 $\beta =.282$
.
$\beta =.282$
.
5.2 Simulation study results
Table 3 reports the average estimates and the standard deviations for each estimate, under each scenario, based on 100 simulations. The root mean square errors (RMSE) are presented in Table 4, as well as the estimated relative mean square error (MSE). RMSE was calculated as the square root of the sum of the variance of the estimator and the squared bias, where bias was calculated to be the difference between the average estimated parameter value and the true parameter value. Relative MSE was calculated by dividing the squared RMSE value of the HMM-SAOM estimator by that of the SAOM only estimator. Side-by-side boxplots of the distribution of each parameter estimate are also included (Figures 4--6). Our results demonstrate that the HMM-SAOM estimator outperforms the SAOM-Only estimator under various error rates. The estimated relative MSE for these five SAOM parameters ranges from 0.053 to 0.468, indicating that the HMM-SAOM parameters are much more accurate than the SAOM parameters when we have observed networks with error. The bias observed in our estimators is not unexpected. The same is shown in the maximum likelihood estimates in the standard SAOM framework. When we simulate 100 error-free networks with our true parameters and then estimate the parameters via the standard MLE SAOM routine, we obtain mean estimates that are similar to those obtained under our HMM-SAOM estimator, despite our method needing to account for noise, as well. Table 5 displays these results. Note, however, that the bias shown in our estimator is substantially smaller than that for the SAOM fit to these same noisy data. When we increase our network size to 30 vertices, we still see a great improvement in the SAOM-HMM compared to the standard SAOM (see Supplementary Appendix B for additional details).
Root mean squared error and relative MSE for the SAOM objective function parameter estimates. The SAOM only estimates are the reference group for the relative MSE
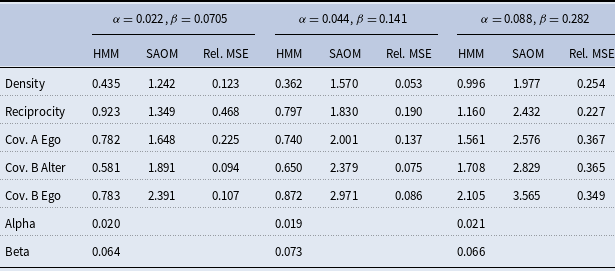
Boxplots for density and reciprocity parameter estimate distributions obtained from 100 simulations for our HMM-SAOM model and also for the SAOM only (i.e. the naive approach). The dashed line represents the true parameter value.
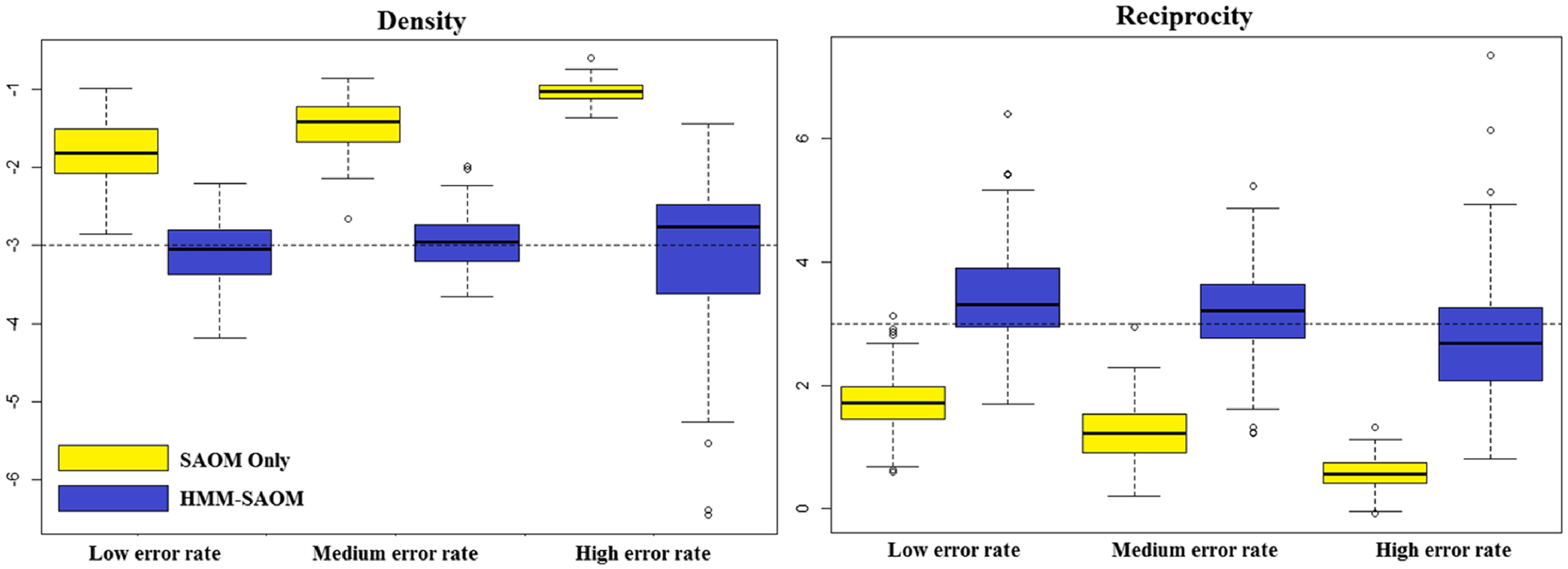
Boxplots for covariate B alter and ego parameter estimate distributions obtained from 100 simulations for our HMM-SAOM model and also for the SAOM only (i.e. the naive approach). The dashed line represents the true parameter value.
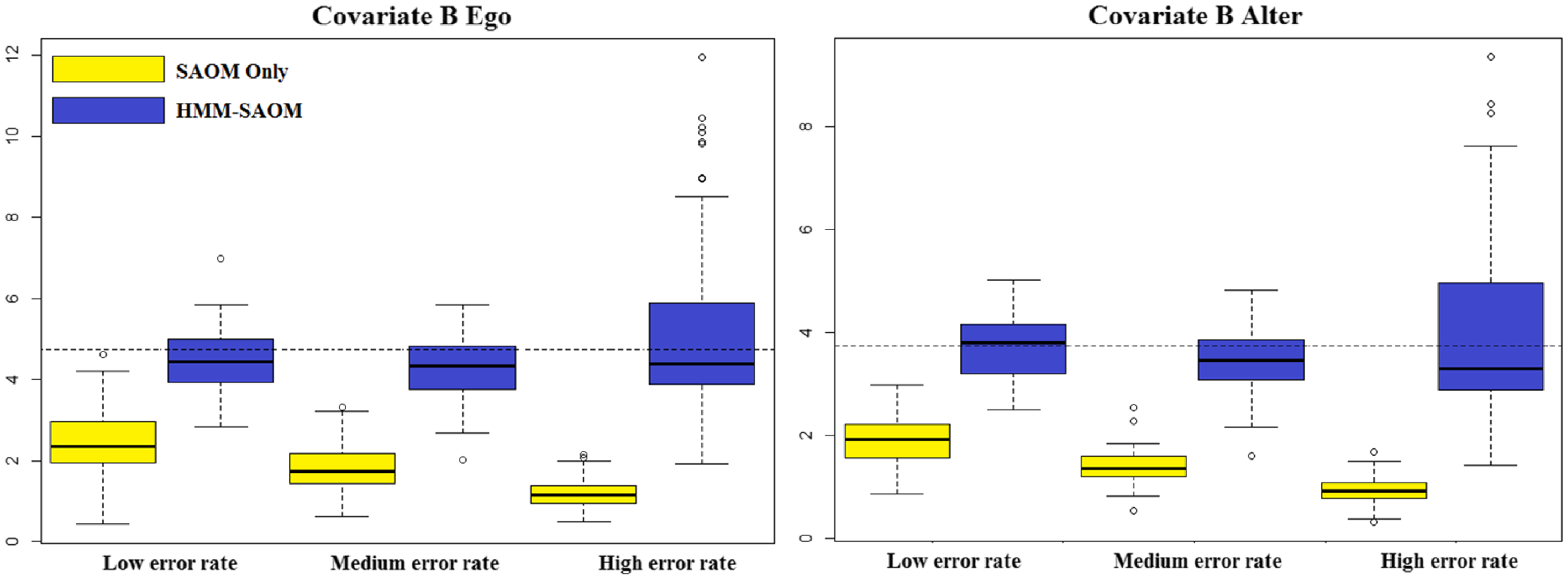
Boxplots for covariate a ego parameter estimate distributions obtained from 100 simulations for our HMM-SAOM model and also for the SAOM only (i.e. the naive approach). The dashed line represents the true parameter value.
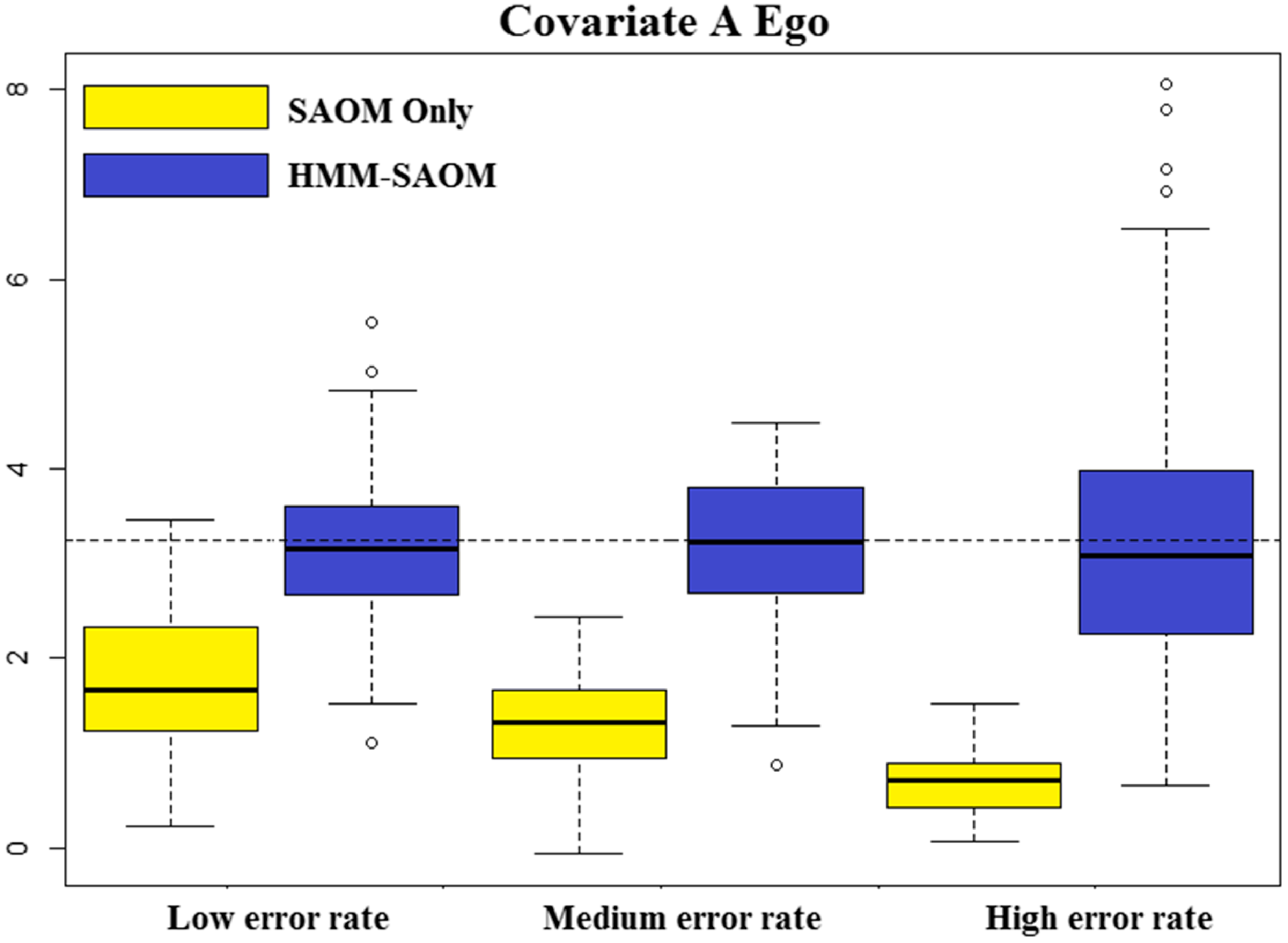
Mean and standard deviation of parameter estimates based on the standard SAOM MLE routine for 10 node noise-free networks

We see an increase in variability in the estimates for our larger error rate scenario, which is expected. Interestingly, the opposite phenomena appears to be true when only fitting a SAOM. We suspect this is due to the fact that true signal becomes more diluted as more error is introduced, encouraging the parameter estimates to consistently stay right above the 0 mark (i.e there is a consistent weakening of the signal since there a large amount of noise). Whereas, when smaller amounts of error are introduced, which edges end up being affected by the error play a major role in the estimates the SAOM model produce. It may be the case that the small amount of noise impacts edges in a way that do not dilute the signal as much.
We also perform 100 simulations under our middle error rate scenario where we use the SAOM method of moments estimation routine for
 $\gamma$
in place of the maximum likelihood estimation routine in our M-step of the E-M algorithm (as discussed in section 4.6). Results are presented in Table 6. We see that substitution of the method-of-moments approach within our algorithm yields results similar to the originally described algorithm in the sense that the absolute bias is not much larger. However, several of the parameters have bias in the opposite direction. There is also some increase in variability of the estimates. We suspect that the method-of-moments approach will produce estimates that are more accurate than the ones displayed in Table 6 for larger network sizes. Despite the increase in variability observed when performing the method-of-moments estimation routine for
$\gamma$
in place of the maximum likelihood estimation routine in our M-step of the E-M algorithm (as discussed in section 4.6). Results are presented in Table 6. We see that substitution of the method-of-moments approach within our algorithm yields results similar to the originally described algorithm in the sense that the absolute bias is not much larger. However, several of the parameters have bias in the opposite direction. There is also some increase in variability of the estimates. We suspect that the method-of-moments approach will produce estimates that are more accurate than the ones displayed in Table 6 for larger network sizes. Despite the increase in variability observed when performing the method-of-moments estimation routine for
 $\gamma$
, it may be worthwhile to use when working with larger networks or many observation moments.
$\gamma$
, it may be worthwhile to use when working with larger networks or many observation moments.
Mean and standard deviation of parameter estimates for MLE vs. MoM for estimation of
 $\gamma$
$\gamma$
6. Analysis of EEG complex functional networks
We apply this methodology in an analysis of dynamic EEG complex functional networks. Networks are becoming a popular model to illustrate both the physiological/anatomical connections (structural networks) and the coupling of dynamic brain activity (functional networks) linking different areas of the brain Bassett and Sporns (Reference Bassett and Sporns2017). Deviations in the expected behavior and organization of brain networks have been observed in several diseases Kramer and Cash (Reference Kramer and Cash2012); Voytek and Knight (Reference Voytek and Knight2015); Stam (Reference Stam2014); Silasi and Murphy (Reference Silasi and Murphy2014). Although physiological coupling between brain regions must be mediated by underlying structural connectivity, previous studies have found little relationship between large scale structural and functional brain networks Chu et al. (Reference Chu, Tanaka, Diaz, Edlow, Wu, Hämäläinen, Stufflebeam, Cash and Kramer2015); Mišić et al. (Reference Mišić, Betzel, De Reus, Van Den Heuvel, Berman, McIntosh and Sporns2016); Messé et al. (Reference Messé, Rudrauf, Benali and Marrelec2014); Honey et al. (Reference Honey, Kötter, Breakspear and Sporns2007). We hypothesize that this may be due to the inherent false positive and false negative error rates present in inferring functional brain networks using current techniques, and therefore that the effect size of structural connectivity and other observed parameters will be increased using our approach. We explored this relationship by relating functional networks inferred from statistical associations between source imaging of EEG activity and underlying cortico-cortical structural brain connectivity determined by probabilistic white matter tractography.
A patient with high density EEG (70 electrodes), digitized electrode coordinates, and high resolution diffusion tensor imaging (DTI; 60 diffusion-encoding directions, 1.85 mm isotropic voxels) was retrospectively identified from clinical evaluations performed at the Massachusetts General Hospital Athinoula A. Martinos Center for Biomedical Imaging between 1/2009 and 12/2012, where she was undergoing evaluation due to epilepsy. The EEG was recorded with a 70-channel electrode cap, based on the 10-10 electrode-placement system (Easycap, Vectorview, ElektaNeuromag, Helsinki, Finland) in the quiet resting state. The positions of the EEG sensors were determined prior to data acquisition with a 3D digitizer (Fastrak, Polhemus Inc., Colchester, VA). The sampling rate was 600 Hz and the data were filtered with high- and low-pass filters from 1–50 Hz for analysis using the MATLAB Signal Processing Toolbox and custom software. Source analysis of EEG data was performed using the MNE software package Gramfort et al. (Reference Gramfort, Luessi, Larson, Engemann, Strohmeier, Brodbeck, Parkkonen and Hämäläinen2014) with anatomical surfaces reconstructed using Freesurfer Fischl (Reference Fischl2012) with 70 vertices distributed across the cortical surface.
Functional undirected binary networks based on the source EEG data were constructed for each contiguous 1 s interval, using cross-correlation as the measure of coupling, as described in Chu et al. (Reference Chu, Tanaka, Diaz, Edlow, Wu, Hämäläinen, Stufflebeam, Cash and Kramer2015). For our analysis, binary networks were averaged across 10 s segments to create a representative weighted network reflecting the average properties of the functional networks over time, where the edge weight or strength reveals the consistency of an edge appearance across time. We then binarized these weighted matrices to obtain a single 70 node, binary network for 4 consecutive 10 s intervals. The average degree, along with the inter quartile range of the degree, for each of the 4 networks are 22.686 [12,36], 23.971 [12,37], 23.943 [12.25, 34.75], and 22.743 [10,36]. The Jaccard similarity coefficients, which are a measure of network stability, are 0.668, 0.576, and 0.588. Jaccard values of .3 and higher are considered optimal for fitting a SAOM. If the Jaccard indices are low and the average degree isn’t increasing significantly, it suggests that the network’s turnover might be too high to treat the data as an evolving network Ripley et al. (Reference Ripley, Snijders, Boda, Vörös and Preciado2024).
To infer structural connectivity networks, probabilistic tractography (Probtrackx2 through FSL 5.0.4/FDT- FMRIB’s Diffusion Toolbox 3.0; FMRIB’s Software Library) was used to process the DTI data obtained from a 3 T Magnetom Trio scanner, choosing as seed and target regions of interest (ROIs) the same cortical vertices used to infer functional networks, and a weighted structural connectivity matrix was constructed. Please see Chu et al., for a more detailed description of data acquisition and network construction Chu et al. (Reference Chu, Tanaka, Diaz, Edlow, Wu, Hämäläinen, Stufflebeam, Cash and Kramer2015).
Since we are working with undirected networks, we will work under the assumption that one ROI takes the initiative and unilaterally imposes that an edge is created or dissolved. Table 7 lists the effects we chose to place into the objective function of our SAOM. We would like to test hypotheses involving how each of these effects drives change in this individual’s functional EEG networks. Moreover, we would like to investigate which of these effects are detectable in HMM-SAOM approach, but not the SAOM alone. A short description of these effects is given below.
Mathematical definition of SAOM effects for EEG functional network analysis

Endogenous Effects
-
• Density: Represents the basic tendency for vertices to form connections. It is similar to an intercept in a regression model. For sparser networks, this parameter will often be negative.
-
• Transitive Triads: Represents the tendency for vertices to form connections that position them within triangular structures. Triangles serve as a representation of clustering and clustering serves as an indicator of segregation within the network. When examining functional connectivity data in healthy individuals, network analysis has revealed a notable high clustering coefficient. This coefficient is linked to elevated local efficiency in information transfer, specifically facilitating specialized processing Schulz et al. (Reference Schulz, Bédard, Fan, Clerkin, Dima, Newcorn and Halperin2014). Triangles also hold significance from a motif perspective. Network motifs are intriguing in functional brain networks as they signify distinct topological connection patterns, essentially serving as the“building blocks” of the entire network Sporns (Reference Sporns2016, Reference Sporns2013).
-
• Number of Vertices at Distance Two: Defined by the number of ROIs to whom
$i$
is indirectly connected (through at least one intermediary). When this effect has a negative parameter, vertices will have a preference for having few others at a geodesic distance of 2. Short path lengths play a crucial role in fostering functional integration and efficiency by facilitating communication with minimal intermediate steps, thereby reducing the impact of noise or signal degradation Sporns (Reference Sporns2013). Research has demonstrated that functional networks in diverse brain disorders exhibit longer path lengths, suggesting a less efficient organization of connectivity Sanz-Arigita et al. (Reference Sanz-Arigita, Schoonheim, Damoiseaux, Rombouts, Maris, Barkhof, Scheltens and Stam2010); Xiang et al. (Reference Xiang, Guo, Cao, Liang and Chen2013).

Exogenous Effects
-
• Electrode Distance: Represents the tendency for vertex pairs with higher values of electrode distance to form connections. A negative parameter implies that vertex pairs with a larger distance separating them, have a smaller probability of connecting.
-
• Structural Connectivity: Reflects the tendency for vertex pairs with higher values of structural connectivity to form connections. A positive parameter implies that vertex pairs with more structural connectivity, have a higher probability of connecting.
We first fit a SAOM to our series of 4 observed functional networks. We then fit our HMM-SAOM to the same series of functional networks. Standard errors for the HMM-SAOM were approximated via parametric bootstrap in the manner described in section 4.5 with 10 sampled network series. The estimated parameters, standard errors, and t-ratios for both models are reported in Table 8. We must interpret the results cautiously, based on the relative magnitude of t-ratios, as formal grounds for comparison to the t distribution are not well established. It is also important to note that the parameter estimates allow for a caricature of the rules governing the dynamic change in the network Steglich et al. (Reference Steglich, Snijders and West2006). Because the temporal progression is taken care of by the rate functions, the parameters in the objective function are static and are comparable across periods of different lengths of time. As the SAOM authors point out Steglich et al. (Reference Steglich, Snijders and West2006), a common misunderstanding is that the parameter estimates express tendencies over time. Instead, they should be interpreted as quantitative measures that are suitable for explaining the observed changes.
EEG functional network analysis results from fitting our HMM-SAOM and from only fitting a SAOM
As hypothesized, we find a positive estimate (and a large t-ratio) for the structural connectivity effect in both models. This indicates that regions with increased structural connectivity are more likely to form functional connections. The difference between the estimates produced by the two models for this effect is quite large. We conclude that the true signal for this effect is strong and may be diluted by measurement error on the network edges. The false positive rate is estimated to be
 $13.5\%$
, while the false negative rate is estimated to be
$13.5\%$
, while the false negative rate is estimated to be
 $19\%$
. Furthermore, as one would expect, the electrode distance effect is associated with a negative parameter estimate, suggesting that the further apart two regions are, the less likely they are to connect. The estimate produced by the SAOM-HMM is approximately 1.57 times the magnitude of that estimated by the SAOM. In addition, the parameter estimate associated with the transitive triads effect is positive and 1.7 times larger in the HMM-SAOM model. The t-ratio is also very large. This indicates that triangle formation is favored as the network evolves. The distance 2 parameter estimate is negative in both models. However, it is half the magnitude and has a much smaller t-ratio in the HMM-SAOM, suggesting a weaker signal than what would have been inferred in the naive method of fitting just a SAOM.
$19\%$
. Furthermore, as one would expect, the electrode distance effect is associated with a negative parameter estimate, suggesting that the further apart two regions are, the less likely they are to connect. The estimate produced by the SAOM-HMM is approximately 1.57 times the magnitude of that estimated by the SAOM. In addition, the parameter estimate associated with the transitive triads effect is positive and 1.7 times larger in the HMM-SAOM model. The t-ratio is also very large. This indicates that triangle formation is favored as the network evolves. The distance 2 parameter estimate is negative in both models. However, it is half the magnitude and has a much smaller t-ratio in the HMM-SAOM, suggesting a weaker signal than what would have been inferred in the naive method of fitting just a SAOM.
7. Discussion
Our framework shows an increase of MSE over the naive approach of only fitting a SAOM when noise is present in network edges. Therefore, we feel it is a more appropriate modeling choice if error is believed to be present. In our fitting of the HMM-SAOM on EEG functional networks, we find stronger effect sizes in the transitive triads, electrode distance, and structural connectivity effects than what is found when fitting the standard SAOM to the networks. We also obtain an estimate of the false positive and false negative rates on edge status of the inferred networks, which we would not have obtained by simply fitting the standard SAOM. While we feel that the stronger effect sizes are capturing a more accurate depiction of these effects compared to only fitting the SAOM model (due to the noisy edges), it should be noted that it is possible that the parameters for the SAOM-only model and the HMM-SAOM are not necessarily on the same scale due to the error rates potentially being confounded with the non-estimable variance of
 $\epsilon _{i}$
in Equation 3.3.
$\epsilon _{i}$
in Equation 3.3.
As mentioned in the Introduction Section, we take a similar approach to Lospinoso Lospinoso and Lospinoso (Reference Lospinoso and Lospinoso2012), but instead of using a full MCMC algorithm for performing maximum likelihood estimation of the model parameters, we took an MCMC within an E-M approach to parameter estimation. Both approaches have their limitations. In either case, there may be multimodality of the likelihood, potentially causing the E-M to converge to local maxima or for there to be poor mixing of MCMC samplers. Additionally, Lospinoso proposes three potential models for the measurement model, while we focus on one measurement model. Our framework is certainly able to handle more complicated measurement models, but we focused on a model that enumerates false positive and false negative edges in a very simple case given the popularity of quantifying false positive and false negative edges in the brain network science community. One may easily extend our model to another measurement model framework as long as the model parameters can be estimated in closed form. Moreover, the SAOM building block portion of our framework may be exchanged for another dynamic network model abiding by the Markov chain properties, such as the Temporal Exponential Random Graph Model (TERGM) Hanneke et al. (Reference Hanneke, Fu and Xing2010). To do so, one would need to incorporate techniques for MCMC sampling in that setting with our overall framework to enable approximate maximum likelihood estimation. We leave this for future work.
Additionally, in order to perform the particle filtering algorithm, we made an assumption of an error-free first network in the sequence of observed networks. Functionally, this means that the first network is used in the particle filtering algorithm and is conditioned upon when estimating the SAOM parameters, but it is not used in the maximum likelihood estimation routine for the false positive and false negative error rates. To explore how violations of this assumption affect our results, we performed a small simulation study. We repeated the simulation study described in Section 5.1 of the manuscript (for the low error rates), but with error on the network edges for our first observed network, and we did not find a reduction in model performance. What we anticipate is that error on the first observed network will not have a major impact on the performance of our algorithm, as long as there are at least 4 networks in the sequence of observed networks. Having less than 4 networks would decrease the sample size, hurting the algorithm’s ability to accurately estimate parameters, especially with a violation of the error-free assumption on the first network.
Just as Lospinoso reported in his dissertation, and as previously mentioned in this section, we found that higher false positive rates shrink the parameter estimates to 0, falsely suggesting no significant effect on network change. Unlike Lospinoso, though, we did not study the effect of having a non-zero false positive rate (or false negative rate) while holding the other error rate constant at 0. This was simply because in the brain network application, we typically expect there to be comparable levels of false positive and false negative edges.
Lastly, in his dissertation, Lospinoso focuses on the application of his methodology to social networks, whereas we focus on a brain network application. While the entire SAOM framework was developed for the social network setting, we feel extending the models to brain network science is justified. Given existing literature that indicates brain regions often change functional connections as a compensatory mechanism Gardini et al. (Reference Gardini, Venneri, Sambataro, Cuetos, Fasano, Marchi, Crisi and Caffarra2015); Etkin et al. (Reference Etkin, Prater, Schatzberg, Menon and Greicius2009); Simpson and Laurienti (Reference Simpson and Laurienti2016) or that “hub” regions shift which regions they communicate with based on instructions for the task at hand Cole et al. (Reference Cole, Reynolds, Power, Repovs, Anticevic and Braver2013), an “actor-oriented” or “node-oriented” approach is well-motivated and appealing. With that being said, obviously model interpretation with regards to “actor” preferences and decision-making should not be interpreted too literally. The key is that the model expresses tendencies for connections to form based on each brain region’s current connections/network, its own properties, and the properties of all other brain regions.
Stochastic Actor Oriented Models offer great flexibility in that they are able to represent network dynamics as being driven by many factors/influences. Furthermore, the models allow for the accounting of several different explanations of network change, which may be competing and even complementary. This allows for the testing of effects driving the changes, while controlling for other factors, which better enables researchers to delve in, disentangle, and identify which mechanisms are playing a role (as opposed to focusing on different network characteristics individually). We feel that our contribution complements this framework well and is important, especially for network data that is known to contain large amounts of noise. When this is the case, signal becomes so diluted that the naive approach of fitting only a SAOM, gives very inaccurate estimates. Our HMM-SAOM method gives much more accurate estimates of the SAOM parameters, while also providing estimates of the false positive and false negative rates. SAOMs are already very prominent in the social network literature, but we feel this extension to an HMM setting may potentially spark interest in other research fields (e.g. neuroscience) where noisy data is much more of a concern.
Acknowledgments.
This work was supported by NIH awards 1R01NS095369-01 and K25-EB032903-01, Canadian NSERC RGPIN-2023-03566 and NSERC DGDND-2023-03566, and by the National Institute of General Medical (NIGMS) Interdisciplinary Training Grant for Biostatisticians (T32 GM74905). The authors would like to thank Steven M. Stufflebeam, MD for acquisition of the MRI and EEG data used to generate the human functional and structural brain networks. The computational work reported in this paper was performed on the Shared Computing Cluster which is administered by Boston University’s Research Computing Services. (www.bu.edu/tech/support/research/). Data will be made available upon request.
Competing interests.
The authors have no competing interests to declare.
A. Appendix
A. proof of missing information principle in
$\hat {\gamma }$
derivation

Recall that we denote each possible unique true network series by
 $\tilde {u}$
. We define the random variable
$\tilde {u}$
. We define the random variable
 $V$
to be a sample path associated with a true network series
$V$
to be a sample path associated with a true network series
 $\tilde {u}$
. We prove below that
$\tilde {u}$
. We prove below that
 $E\big [\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})]= \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. By calculating this expectation, we are able to maximize
$E\big [\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})]= \sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})$
. By calculating this expectation, we are able to maximize
 $\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y}, \Gamma ^{p-1})$
, which would otherwise be intractable.
$\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y}, \Gamma ^{p-1})$
, which would otherwise be intractable.
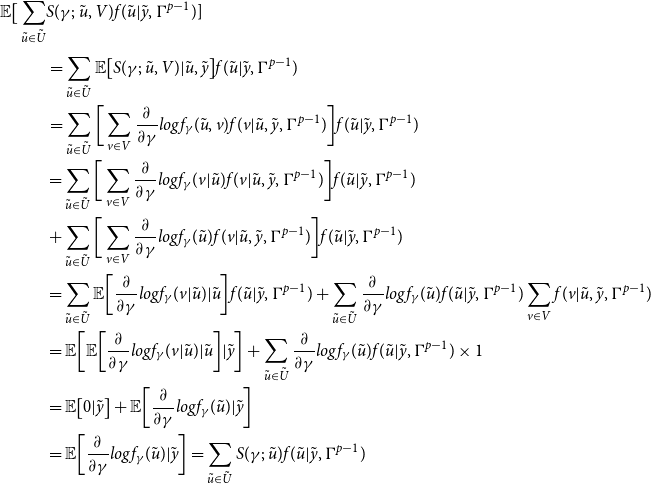 \begin{align*} \mathbb{E}\big [\sum _{\tilde {u} \in \tilde {U}}^{}&S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})] \\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\mathbb{E}\big [S(\gamma ;\;\tilde {u}, V)|\tilde {u},\tilde {y}\big ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &= \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u}, v)f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &= \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &+ \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\mathbb{E}\bigg[\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})|\tilde {u}\bigg]f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) + \sum _{\tilde {u} \in \tilde {U}}^{}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\sum _{v \in V}f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\\ &=\mathbb{E}\bigg [\mathbb{E}\bigg[\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})|\tilde {u}\bigg]|\tilde {y}\bigg ] + \sum _{\tilde {u} \in \tilde {U}}^{}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \times 1\\ &= \mathbb{E}\big [0|\tilde {y}\big ] + \mathbb{E}\bigg [\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})|\tilde {y}\bigg ]\\ &=\mathbb{E}\bigg [\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})|\tilde {y}\bigg ] =\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \end{align*}
\begin{align*} \mathbb{E}\big [\sum _{\tilde {u} \in \tilde {U}}^{}&S(\gamma ;\;\tilde {u}, V)f(\tilde {u}|\tilde {y},\Gamma ^{p-1})] \\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\mathbb{E}\big [S(\gamma ;\;\tilde {u}, V)|\tilde {u},\tilde {y}\big ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &= \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u}, v)f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &= \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &+ \sum _{\tilde {u} \in \tilde {U}}^{}\bigg [\sum _{v \in V}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\bigg ]f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\\ &=\sum _{\tilde {u} \in \tilde {U}}^{}\mathbb{E}\bigg[\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})|\tilde {u}\bigg]f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) + \sum _{\tilde {u} \in \tilde {U}}^{}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1})\sum _{v \in V}f(v|\tilde {u},\tilde {y},\Gamma ^{p-1})\\ &=\mathbb{E}\bigg [\mathbb{E}\bigg[\frac {\partial }{\partial \gamma }logf_{\gamma }(v|\tilde {u})|\tilde {u}\bigg]|\tilde {y}\bigg ] + \sum _{\tilde {u} \in \tilde {U}}^{}\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \times 1\\ &= \mathbb{E}\big [0|\tilde {y}\big ] + \mathbb{E}\bigg [\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})|\tilde {y}\bigg ]\\ &=\mathbb{E}\bigg [\frac {\partial }{\partial \gamma }logf_{\gamma }(\tilde {u})|\tilde {y}\bigg ] =\sum _{\tilde {u} \in \tilde {U}}^{}S(\gamma ;\;\tilde {u})f(\tilde {u}|\tilde {y},\Gamma ^{p-1}) \end{align*}
B. 30 Node network simulation study
We present a small simulation study to demonstrate the accuracy of our method on slightly larger network sizes. For this study, we simulate 30 node directed networks at 4 observation moments, referred to as
 $t_{1}, t_{2}, t_{3},$
and
$t_{1}, t_{2}, t_{3},$
and
 $t_{4}$
. We also create 2 vertex covariates, called Covariate A and Covariate B. Both are indicator variables and are defined as:
$t_{4}$
. We also create 2 vertex covariates, called Covariate A and Covariate B. Both are indicator variables and are defined as:
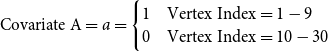 \begin{equation*} \text{Covariate A}= a = \begin{cases} 1 & \text{Vertex Index} = 1-9 \\ 0 & \text{Vertex Index} = 10-30 \end{cases} \end{equation*}
\begin{equation*} \text{Covariate A}= a = \begin{cases} 1 & \text{Vertex Index} = 1-9 \\ 0 & \text{Vertex Index} = 10-30 \end{cases} \end{equation*}
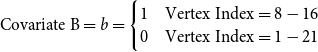 \begin{equation*} \text{Covariate B}= b = \begin{cases} 1 & \text{Vertex Index} = 8-16 \\ 0 & \text{Vertex Index} = 1-21 \end{cases} \end{equation*}
\begin{equation*} \text{Covariate B}= b = \begin{cases} 1 & \text{Vertex Index} = 8-16 \\ 0 & \text{Vertex Index} = 1-21 \end{cases} \end{equation*}
The objective function in the SAOM for the evolution of the true networks,
 $u(t_{m})$
, contains 5 effects (2 endogenous and 3 exogenous). Table B1 lists these effects, their mathematical definitions, and their descriptions. The large, negative value for outdegree, keeps our simulated true networks fairly sparse. It sets the probability of connections forming low, unless the other parameters in the function influence specific vertices in a more positive way. For example, the large positive value for reciprocated edges encourages a directed edge to form if one already exists in the reverse direction. These parameters, in conjunction with the parameters assigned to the three covariate related effects, promote the network structure demonstrated in Figure 3 in the manuscript, but with 30 nodes as opposed to 10 nodes and
$u(t_{m})$
, contains 5 effects (2 endogenous and 3 exogenous). Table B1 lists these effects, their mathematical definitions, and their descriptions. The large, negative value for outdegree, keeps our simulated true networks fairly sparse. It sets the probability of connections forming low, unless the other parameters in the function influence specific vertices in a more positive way. For example, the large positive value for reciprocated edges encourages a directed edge to form if one already exists in the reverse direction. These parameters, in conjunction with the parameters assigned to the three covariate related effects, promote the network structure demonstrated in Figure 3 in the manuscript, but with 30 nodes as opposed to 10 nodes and
 $9 \times 9$
block sizes, as opposed to
$9 \times 9$
block sizes, as opposed to
 $3 \times 3$
block sizes.
$3 \times 3$
block sizes.
To create an initial true directed network without error at time
 $t_{1}$
for the evolution process to begin at, we first created a random network of approximately one quarter of the possible edges. We chose this density to be in line with the density of the encouraged network structure of the simulation model. We then simulated a next network state, evolving from this network, with a small rate parameter of 1 and the true parameter values we set for our SAOM objective function. By doing this, we created a network that had begun to drift towards a network state that has a high probability under the stationary distribution. This network was used as the first observed and true network for every simulation in our study.
$t_{1}$
for the evolution process to begin at, we first created a random network of approximately one quarter of the possible edges. We chose this density to be in line with the density of the encouraged network structure of the simulation model. We then simulated a next network state, evolving from this network, with a small rate parameter of 1 and the true parameter values we set for our SAOM objective function. By doing this, we created a network that had begun to drift towards a network state that has a high probability under the stationary distribution. This network was used as the first observed and true network for every simulation in our study.
Simulation model effects and parameters

Mean and standard deviation of parameter estimates based on 30 simulations

We performed 30 simulations for the smallest error rate scenario in our paper, while holding the first network constant and the SAOM objective function parameters constant. For each simulation, we simulated true networks at the
 $2^{nd}, 3^{rd},$
and
$2^{nd}, 3^{rd},$
and
 $4^{th}$
observation moments, according to our true SAOM and with a constant rate parameter of 3. This rate was small enough that the networks gradually approached dynamic equilibrium, thus simulating a realistic evolution process. However, it is large enough that the network at
$4^{th}$
observation moments, according to our true SAOM and with a constant rate parameter of 3. This rate was small enough that the networks gradually approached dynamic equilibrium, thus simulating a realistic evolution process. However, it is large enough that the network at
 $t_{4}$
was a network in (or nearly in) dynamic equilibrium. We then created “observed” networks by introducing error to the edges of each true network. True edges remained edges in the observed network with probability equal to 1-
$t_{4}$
was a network in (or nearly in) dynamic equilibrium. We then created “observed” networks by introducing error to the edges of each true network. True edges remained edges in the observed network with probability equal to 1-
 $\beta$
and non-edges in the true networks remained non-edges in the observed network with probability 1-
$\beta$
and non-edges in the true networks remained non-edges in the observed network with probability 1-
 $\alpha$
. We then fit the HMM-SAOM to the observed networks.
$\alpha$
. We then fit the HMM-SAOM to the observed networks.
Table B2 reports the average estimates and the standard deviations for each estimate based on 30 simulations. Our results demonstrate that the HMM-SAOM estimator out performs the SAOMOnly estimator, just as it did in the 10 node networks presented in the main manuscript.


























 Open access
Open access