


1. Introduction
This paper aims to generalize the classical model due to DeGroot (see e.g. DeGroot (Reference DeGroot1974) or Jackson (Reference Jackson2008)) to the case when the update of beliefs is nonlinear. A set of agents corresponds to the set of nodes of the network, and a directed edge denotes the belief flow between two nodes. Each of them has his/her own aggregation function, which depends on the belief of (not necessarily all) other agents. The question is, will a consensus develop after a while on a given network? Is this belief unique if we know the initial situation (agents’ initial beliefs and aggregation functions)? If not, when can the formation of a unique common belief be guaranteed and when not?
In this work, we seek to answer these questions using the theory of invariant means. The simplest case is when the aggregation functions are weighted arithmetic means, then our model reduces to the above mentioned DeGroot model. The weights show how much impact a given agent has on other beliefs.
The foundational model of network interactions concerning information dissemination, belief development, and consensus achievement was introduced by DeGroot (Reference DeGroot1974) (see Jackson (Reference Jackson2008), sect. 8.3 for the details). This quite straightforward and intuitive model provides a basic framework that aids in comprehending how a network’s structure affects belief propagation and the shaping of beliefs.
Here we follow Section 8.3 of Jackson’s book (Reference Jackson2008) to introduce DeGroot’s model.
Agents in a society start with initial beliefs on a subject. Let these be represented by an
 $n$
-dimensional vector of numbers,
$n$
-dimensional vector of numbers,
 $p(0) = (p_1(0)),\ldots , p_n(0))$
. Each
$p(0) = (p_1(0)),\ldots , p_n(0))$
. Each
 $p_i(0)$
lies in the interval
$p_i(0)$
lies in the interval
 $I$
, and might be thought of as, for example, the probability that a given statement is true, or the quality of a given product, or the likelihood that the agent might engage in a given activity, etc. The interaction patterns are represented by an
$I$
, and might be thought of as, for example, the probability that a given statement is true, or the quality of a given product, or the likelihood that the agent might engage in a given activity, etc. The interaction patterns are represented by an
 $n \times n$
nonnegative matrix
$n \times n$
nonnegative matrix
 $T$
, which may be weighted (it is not required that positive entries in a row are equal to each other) and directed (we do not claim
$T$
, which may be weighted (it is not required that positive entries in a row are equal to each other) and directed (we do not claim
 $T_{ij}=T_{ji}$
). Specifically, suppose
$T_{ij}=T_{ji}$
). Specifically, suppose
 $T$
is a (row) stochastic matrix, meaning the sum of the entries in each row equals one. The element
$T$
is a (row) stochastic matrix, meaning the sum of the entries in each row equals one. The element
 $T_{ij}$
can be understood as the degree of weight or trust that agent
$T_{ij}$
can be understood as the degree of weight or trust that agent
 $i$
assigns to agent
$i$
assigns to agent
 $j$
’s current belief when updating their belief for the subsequent period. The beliefs are updated over time so that we obtain a sequence
$j$
’s current belief when updating their belief for the subsequent period. The beliefs are updated over time so that we obtain a sequence
 $(p(t))_{t=0}^\infty$
of elements in
$(p(t))_{t=0}^\infty$
of elements in
 $I^n$
defined as follows
$I^n$
defined as follows
 \begin{equation*} p(t) = T p(t-1) = T^t p(0). \end{equation*}
\begin{equation*} p(t) = T p(t-1) = T^t p(0). \end{equation*}
The DeGroot model can be seen as a version of the aggregation process with bounded rationality, where agents maintain constant weightings over time. However, repeating the update process enables agents to integrate more remote belief and potentially achieve consensus. Additionally, this straightforward updating method can still lead agents to arrive at a completely accurate belief over time in certain cases.
Indeed, following Golub and Jackson (Reference Golub and Jackson2010), convergence of this process is related to the properties of the directed graph
 $P_T$
with vertices
$P_T$
with vertices
 $V_T=\{1,\ldots ,n\}$
and vertices
$V_T=\{1,\ldots ,n\}$
and vertices
 $E_T\,:\!=\,\{(i,j)\in V_T \,\colon T_{ij}\gt 0\}$
. Remarkably, in the mentioned paper it was not explicitly stated in the graph setup, however, this approach is equivalent.
$E_T\,:\!=\,\{(i,j)\in V_T \,\colon T_{ij}\gt 0\}$
. Remarkably, in the mentioned paper it was not explicitly stated in the graph setup, however, this approach is equivalent.
We say that a group of nodes
 $B \subset V_T$
is closed (with relative to
$B \subset V_T$
is closed (with relative to
 $T$
) if
$T$
) if
 $i \in B$
and
$i \in B$
and
 $T_{ij}\gt 0$
yields
$T_{ij}\gt 0$
yields
 $j \in B$
. Then Golub and Jackson (Reference Golub and Jackson2010), applying Perkins (Reference Perkins1961), states that
$j \in B$
. Then Golub and Jackson (Reference Golub and Jackson2010), applying Perkins (Reference Perkins1961), states that
 $\ell (p)\,:\!=\,\lim _{t \to \infty } T^tp$
exists for all vectors
$\ell (p)\,:\!=\,\lim _{t \to \infty } T^tp$
exists for all vectors
 $p \in I^n$
if, and only if,
$p \in I^n$
if, and only if,
 $T$
is strongly aperiodic (that is, it is aperiodic restricted to every close group of nodes).
$T$
is strongly aperiodic (that is, it is aperiodic restricted to every close group of nodes).
Note that the DeGroot model possesses significant limitations. Namely, the update of beliefs relies only on the stochastic matrix
 $T$
. As an immediate consequence, not only all iterates
$T$
. As an immediate consequence, not only all iterates
 $T^t$
but also the limit
$T^t$
but also the limit
 $\ell$
is a linear function (of the initial beliefs). Meanwhile, our new approach involves the following additional aspects:
$\ell$
is a linear function (of the initial beliefs). Meanwhile, our new approach involves the following additional aspects:
-
- there is no reason to claim that the update is a linear function of the beliefs;
-
- aggregation function may not represent only the trust of the agents but also other aspects, for instance, preferences between beliefs (fear, hope, risk-aversion, etc.);
-
- a set of a special group of agents (the root) is carefully defined, characterized (see Section 4.1, in particular Theorem4.4), which has a key role in the existence of a unique common belief on the network;
-
- under the mild assumptions on the averaging functions the impact of the initial belief of an agent to the final agreement depends mostly on its position in the social network (not on the belief itself).
As a result, we reinstate the leader–follower model in such processes (see for example Shen et al. (Reference Shen, He, Wu, Zhu and Shen2023)). To be more precise, we show that there exists a group of agents (whose membership depends exclusively on their position in the graph) that establishes the consensus among themselves. All the remaining agents attain this consensus in the limit, regardless of their initial belief.
This study was started in Pasteczka (Reference Pasteczka2023) under the additional assumption that the social graph is irreducible which means that for every two agents there exists a chain of neighbors connecting them (in both directions). This assumption, however, seems to be quite restrictive in the real world. There is plenty of one-sided communication, for example: influencers
 $\to$
followers, politicians
$\to$
followers, politicians
 $\to$
voters, newspapers
$\to$
voters, newspapers
 $\to$
readers, etc. This paper shows how such directed ways of communication impact the spreading of the beliefs.
$\to$
readers, etc. This paper shows how such directed ways of communication impact the spreading of the beliefs.
Comparison to the DeGroot model
DeGroot model enables the description of achieving consensus in the limited case when all agents update their beliefs based on a weighted arithmetic mean. Using the standard conjugacy method, one can easily extend this model to the case when updates are obtained via the expected utility model with the same utility function. This generalization, however, does not convey any additional information. The only difference is that the averaging concerns utilities instead of original inputs. The core remains unchanged.
Meanwhile, several recent studies require a more general approach. The most natural one (which we will discuss later on) is the expected utility model with agent-dependent utility functions. This represents the situation where each agent has a different risk aversion.
Our approach rephrases the principles of DeGroot in the new framework. Namely, we start with a sedentary social graph. Then, each agent has a fixed list of neighbors and updates his/her belief based on an agent’s own averaging function (which is a mean). For the purpose of this paper, for a given
 $p\in \mathbb{N}$
and an interval
$p\in \mathbb{N}$
and an interval
 $I \subset \mathbb{R}$
, a
$I \subset \mathbb{R}$
, a
 $p$
-variable mean on
$p$
-variable mean on
 $I$
is an arbitrary function
$I$
is an arbitrary function
 $M \,\colon I^p \to I$
satisfying the inequality
$M \,\colon I^p \to I$
satisfying the inequality
 \begin{equation*} \min \!(x)\le M(x)\le \max \!(x)\text{ for all }x \in I^p. \end{equation*}
\begin{equation*} \min \!(x)\le M(x)\le \max \!(x)\text{ for all }x \in I^p. \end{equation*}
In a sense, this generalization is in Nash’s spirit, where an agent is unaware of the structure of the social graph and the behavior of other agents. Contrary to the DeGroot model, our only assumptions are continuity and strictness (which, roughly speaking, claims that the aggregating function can return neither the minimum nor the maximum value of the input vector) of the aggregating functions. This will not only cover all cases described above, but also several very natural further extensions. For example, the trust can be associated with beliefs instead of agents, which would lead to the class of Bajraktarević means; see Bajraktarević (Reference Bajraktarević1958, Reference Bajraktarević1963). Another meaningful example comes from the prospect theory by Kahneman and Tversky (Reference Kahneman and Tversky1979), the CPT model by Tversky and Kahneman (Reference Tversky and Kahneman1992), Bonferroni means (see Bonferroni (Reference Bonferroni1950)), generalized Bonferroni means (see Chen et al. (Reference Chen, Yang, Jin, Dutta, Martínez, Pedrycz, Mesiar and Bustince2024)), or a mix of the above (which reflects the agent-dependent choice of the model). The freedom to choose the corresponding mean for each agent separately also allows us to simulate psychological phenomena, such as the confirmation bias, and verify how levels of self-confidence affect the consensus.
Outline of the paper
The remaining part of the paper is organized as follows. In the second section, we introduce the main concepts beyond the model, the third section provides several remarks to provide its better support. This section does not explicitly include any meaningful results, but delivers an insight to the model.
The next section, Section 4, is devoted to introduce the mathematical tools that will be used later on and several easy examples. The main results are contained in the fifth section jointly with several further examples. Finally, we set the conclusions. All proofs are postponed to the appendix.
2. The model
Contrary to the classical DeGroot model we allow aggregation functions to be arbitrary (continuous and strict) means. We claim the following principles:
-
(a) each agent has its initial belief;
-
(b) there is a discrete-time measurement, in every time frame each agent may modify his/her belief. A discrete-time measurement implies that it is reasonable to tell about the next or previous time frames which naturally leads to a sort of iteration process;
-
(c) beliefs in each step depend only on beliefs in the previous step (Markov principle);
-
(d) each agent has a time-independent aggregation function and a list of neighbors, which are given a’priori and remain unchanged during the process; It means that the list of neighbors could be modified in the course of time however this phenomenon is not covered by the model similarly to DeGroot’s one;
-
(e) once the process begins, agents are isolated from external data. This means that there will be no new information during the iteration process.
All these principles are valid for the DeGroot model, however this approach is much more general.
Let us also mention some of these principles void in some variations of DeGroot model (see for example Parsegov et al. (Reference Parsegov, Proskurnikov, Tempo and Friedkin2017)).
Principle (d) can be made more realistic with the assumption that a certain agent can modify its neighbors and change its aggregation function. However, in real networks this happens only during a longer time period presumably with little changes. It is quite unusual that somebody completely changes his/her belief sources and his/her belief of their authenticity. So assuming principle (b) with tiny time frames, principle (d) becomes completely reasonable.
Axiom (e) is also natural when the iteration is taken in small time frames (for example daily or hourly). In such a case the knowledge of each agent remains unchanged and, as a consequence, no external data impacts the process.
The principles above give us some insight into the mathematical model of this setting.
Since the necessary notation system is not trivial, we will devote a whole section (see the first part of Section 3 for the details) to introduce it through an example, and then, in connection with this, we will also present the necessary mathematical apparatus in general.
Based on the principle (d), our basic object is a directed graph
 $G=(V,E)$
where
$G=(V,E)$
where
 $V$
denotes the vertices of the graph and
$V$
denotes the vertices of the graph and
 $E\subset V\times V$
denotes the directed edges, which is an abstract visualization of a network. A number is assigned to all vertices, which symbolizes the initial “belief” of the vertex (agents) in question. The directed edges will be induced by the neighbors (see Section 3).
$E\subset V\times V$
denotes the directed edges, which is an abstract visualization of a network. A number is assigned to all vertices, which symbolizes the initial “belief” of the vertex (agents) in question. The directed edges will be induced by the neighbors (see Section 3).
Following the principle (a) initial beliefs could be represented by a function
 $m_0\,\colon V\to D$
, where
$m_0\,\colon V\to D$
, where
 $D$
is some abstract set of beliefs (among this paper we will assume that
$D$
is some abstract set of beliefs (among this paper we will assume that
 $D$
is a subset of the reals). Following (b), we can also associate a similar function to each (
$D$
is a subset of the reals). Following (b), we can also associate a similar function to each (
 $k$
-th) time frame, we denote it as
$k$
-th) time frame, we denote it as
 $m_k\,\colon V\to D$
.
$m_k\,\colon V\to D$
.
Property (c) mimics discrete-time Markov chain rule. Indeed, based on properties (b)–(d), there exists a modification function
 $\mathbf{M} \,\colon D^V \to D^V$
(validating additional requirements implied by assertions above) such that
$\mathbf{M} \,\colon D^V \to D^V$
(validating additional requirements implied by assertions above) such that
 $m_{k+1}=\mathbf{M}\circ m_k$
, that is
$m_{k+1}=\mathbf{M}\circ m_k$
, that is
 $m_k=\mathbf{M}^k$
(see Example 3.5). In the following
$m_k=\mathbf{M}^k$
(see Example 3.5). In the following
 $D$
always denotes an interval. Then we have two possible behaviors:
$D$
always denotes an interval. Then we have two possible behaviors:
-
-
 $(m_k)_{k=1}^\infty$
is not convergent which means that this process does not achieve an equilibrium in the limit,
$(m_k)_{k=1}^\infty$
is not convergent which means that this process does not achieve an equilibrium in the limit, -
-
$(m_k)_{k=1}^\infty$
is convergent to
$m_\infty \,\colon V \to D$
which refers to the fact that each agent achieves a final belief in the limit. Then
$m_\infty$
can be considered as a limit beliefs of the whole network.




It is natural to expect that
 $m_\infty$
is an equilibrium, that is,
$m_\infty$
is an equilibrium, that is,
 $m_\infty =\mathbf{M} \circ m_\infty$
in the second case. It turns out that the convergence (or convergence to some equilibrium) cannot be easily characterized (see examples in Section 5). Therefore we study a bit more restricted problem: convergence to an equilibrium which is a total agreement.
$m_\infty =\mathbf{M} \circ m_\infty$
in the second case. It turns out that the convergence (or convergence to some equilibrium) cannot be easily characterized (see examples in Section 5). Therefore we study a bit more restricted problem: convergence to an equilibrium which is a total agreement.
The key tool is the existence of invariant means, and their uniqueness (which is a mathematical model of the situation described above). This highly depends on the structure of the incidence graph of the aggregating functions of root elements (see Section 4.1 for the exact definition), and on the structure of the root.
Contrary to the authors listed above, we assume that the set of admissible beliefs (that is
 $D$
) is an arbitrary interval and each aggregation function is a mean. However, this approach has already been studied by Pasteczka (Reference Pasteczka2023), with an important restriction. That is, all the results contained in Pasteczka (Reference Pasteczka2023) were proved under the assumption that the social graph is aperiodic and irreducible. Aperidodicity of social graphs seems to be just a technical assumption which is easy to validate (for example if a graph contains a totally connected subgraph with three vertices, or there is at least one agent who takes into account its own belief, that is, there is at least one loop in the graph). Irreducibily assumption is, however, the one which should be avoided to cover (real) social networks.
$D$
) is an arbitrary interval and each aggregation function is a mean. However, this approach has already been studied by Pasteczka (Reference Pasteczka2023), with an important restriction. That is, all the results contained in Pasteczka (Reference Pasteczka2023) were proved under the assumption that the social graph is aperiodic and irreducible. Aperidodicity of social graphs seems to be just a technical assumption which is easy to validate (for example if a graph contains a totally connected subgraph with three vertices, or there is at least one agent who takes into account its own belief, that is, there is at least one loop in the graph). Irreducibily assumption is, however, the one which should be avoided to cover (real) social networks.
Essentially, we distinguish the subset of vertices which, from the point of view of the graph, have a privileged position – we call them root elements (or influencers). The idea beyond the root is that each vertex is reachable (possibly indirectly) from some root elements, and if the root set is reachable from some other vertex, then it must also be an element of the root. Note that the initial belief of a root could have an impact on non root elements. Root elements can be influenced only by other (not necessarily all of them) root elements.
3. Introductory remarks and examples
The aim of this section is to deliver toy examples to provide a better understanding of our model. For the sake of simplicity, we will use a notation which will be formally introduced in the next section (in this section they will be only announced).
Example 3.1.
Let us consider first the following simple (academic) example. Assume that there are four agents symbolized by
 $\{1,2,3,4\}$
.
$\{1,2,3,4\}$
.
In our case, their aggregation functions are equal to the following weighted-arithmetic means:
 \begin{align*} M_1(x_1,x_2,x_3,x_4)&=\tfrac {x_1+x_2}{2}, & M_2(x_1,x_2,x_3,x_4)&=\tfrac {3x_1+4x_2}{7},\\ M_3(x_1,x_2,x_3,x_4)&=\tfrac {x_2+2x_3+x_4}{4},& M_4(x_1,x_2,x_3,x_4)&=\tfrac {x_1+x_3+2x_4}{4}. \end{align*}
\begin{align*} M_1(x_1,x_2,x_3,x_4)&=\tfrac {x_1+x_2}{2}, & M_2(x_1,x_2,x_3,x_4)&=\tfrac {3x_1+4x_2}{7},\\ M_3(x_1,x_2,x_3,x_4)&=\tfrac {x_2+2x_3+x_4}{4},& M_4(x_1,x_2,x_3,x_4)&=\tfrac {x_1+x_3+2x_4}{4}. \end{align*}
It is clear that an agent does not necessarily take into account all the other agents’ beliefs. For example the first agent aggregates only its own belief and the second agent’s belief with equal weights. The second one takes into account the first agent’s belief and its own belief but with different weights (with
 $\tfrac 37$
and
$\tfrac 37$
and
 $\tfrac 47$
, respectively), and so on.
$\tfrac 47$
, respectively), and so on.
We have to introduce some notation to handle this problem (make everything precise) from mathematical point of view.
Firstly, all the aggregation functions are four variables means, but practically they depend on less variables only. In what follows we denote by
 $p$
the number of the agents and at the same time the number of the variables, and by
$p$
the number of the agents and at the same time the number of the variables, and by
 $d_i$
the number of the variables for which the
$d_i$
the number of the variables for which the
 $i$
th aggregation function really depends on. Unfortunately, this is not enough. We also have to designate exactly which variables are involved in the
$i$
th aggregation function really depends on. Unfortunately, this is not enough. We also have to designate exactly which variables are involved in the
 $i$
th mean, and this will be denoted by
$i$
th mean, and this will be denoted by
 $\alpha _i$
.
$\alpha _i$
.
In our example, we have
 \begin{equation} \begin{aligned} p&=4,\\ d_1&=2,\qquad & d_2 &= 2,\qquad & d_3&=3,\qquad & d_4&=3,\\ \alpha _1&=(1,2),\qquad & \alpha _2&=(1,2),\qquad &\alpha _3&=(2,3,4),\qquad &\alpha _4&=(1,3,4). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} p&=4,\\ d_1&=2,\qquad & d_2 &= 2,\qquad & d_3&=3,\qquad & d_4&=3,\\ \alpha _1&=(1,2),\qquad & \alpha _2&=(1,2),\qquad &\alpha _3&=(2,3,4),\qquad &\alpha _4&=(1,3,4). \end{aligned} \end{equation}
This means that
 $\alpha _i\in \{1,\ldots ,p\}^{d_i}$
.
$\alpha _i\in \{1,\ldots ,p\}^{d_i}$
.
Now, we introduce some notations concerning the aggregation functions using the previously introduced notations.
If
 $M_i$
is a
$M_i$
is a
 $d_i$
variables mean, then
$d_i$
variables mean, then
 $M_i^{(p,\alpha _i)}$
will be a
$M_i^{(p,\alpha _i)}$
will be a
 $p$
variables mean (which actually depends on only
$p$
variables mean (which actually depends on only
 $d_i$
variables) defined in the following way:
$d_i$
variables) defined in the following way:
 \begin{equation*} M_i^{(p,\alpha _i)}(x_1,\ldots ,x_p)=M_{i}(x_{\alpha _{i,1}},\ldots ,x_{\alpha _{i,d_i}}). \end{equation*}
\begin{equation*} M_i^{(p,\alpha _i)}(x_1,\ldots ,x_p)=M_{i}(x_{\alpha _{i,1}},\ldots ,x_{\alpha _{i,d_i}}). \end{equation*}
For example, in the above introduced example if
 $i=1$
and
$i=1$
and
 $M(u,v)=\frac {u+v}{2}$
is the ordinary two variables arithmetic mean, then
$M(u,v)=\frac {u+v}{2}$
is the ordinary two variables arithmetic mean, then
 \begin{eqnarray*} p=4,\qquad d_1=2,\qquad \alpha _{1,1}=1,\qquad \alpha _{1,2}=2,\\[5pt] M^{(4,(1,2))}(x_1,x_2,x_3,x_4)=M(x_1,x_2)=\frac {x_1+x_2}{2}. \end{eqnarray*}
\begin{eqnarray*} p=4,\qquad d_1=2,\qquad \alpha _{1,1}=1,\qquad \alpha _{1,2}=2,\\[5pt] M^{(4,(1,2))}(x_1,x_2,x_3,x_4)=M(x_1,x_2)=\frac {x_1+x_2}{2}. \end{eqnarray*}
For the sake of simplicity and shorter notation, we collect all the
 $d_i$
s,
$d_i$
s,
 $\alpha _i$
s and
$\alpha _i$
s and
 $M_i$
s in one. So, using the brief notation
$M_i$
s in one. So, using the brief notation
 $\mathbb{N}_p\,:\!=\,\{1,\ldots ,p\}$
, we set
$\mathbb{N}_p\,:\!=\,\{1,\ldots ,p\}$
, we set
 \begin{align*} \textbf {d}&\,:\!=\,(d_1,\ldots ,d_p)\in \mathbb{N}^p, &\qquad \mathbb{N}_p^{\textbf {d}}&\,:\!=\,\mathbb{N}_p^{d_1}\times \cdots \mathbb{N}_p^{d_p},\\[5pt] \alpha &\phantom {:}=(\alpha _1,\ldots ,\alpha _p)\in \mathbb{N}_p^{\textbf {d}},&\qquad \textbf {M}_\alpha &\phantom {:}=(M_1^{(p,\alpha _1)},\cdots ,M_p^{(p,\alpha _p)}). \end{align*}
\begin{align*} \textbf {d}&\,:\!=\,(d_1,\ldots ,d_p)\in \mathbb{N}^p, &\qquad \mathbb{N}_p^{\textbf {d}}&\,:\!=\,\mathbb{N}_p^{d_1}\times \cdots \mathbb{N}_p^{d_p},\\[5pt] \alpha &\phantom {:}=(\alpha _1,\ldots ,\alpha _p)\in \mathbb{N}_p^{\textbf {d}},&\qquad \textbf {M}_\alpha &\phantom {:}=(M_1^{(p,\alpha _1)},\cdots ,M_p^{(p,\alpha _p)}). \end{align*}
In our example we set the
 $\mathbf{d}$
-averaging mapping
$\mathbf{d}$
-averaging mapping
 $\mathbf{M}\,:\!=\,(M_1,M_2,M_3,M_4)$
(see Definition 4.7 for the details) by
$\mathbf{M}\,:\!=\,(M_1,M_2,M_3,M_4)$
(see Definition 4.7 for the details) by
 \begin{equation*} \begin{aligned} M_1\,\colon \mathbb{R}^2\to \mathbb{R} &\qquad M_1(x,y)\,:\!=\,\frac {x+y}2;\\[5pt] M_2\,\colon \mathbb{R}^2\to \mathbb{R} &\qquad M_2(x,y)\,:\!=\,\frac {3x+4y}7;\\[5pt] M_3\,\colon \mathbb{R}^3\to \mathbb{R} &\qquad M_3(x,y,z)\,:\!=\,\frac {x+2y+z}4;\\[5pt] M_4\,\colon \mathbb{R}^3\to \mathbb{R} &\qquad M_4(x,y,z)\,:\!=\,\frac {x+y+2z}4.\\ \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} M_1\,\colon \mathbb{R}^2\to \mathbb{R} &\qquad M_1(x,y)\,:\!=\,\frac {x+y}2;\\[5pt] M_2\,\colon \mathbb{R}^2\to \mathbb{R} &\qquad M_2(x,y)\,:\!=\,\frac {3x+4y}7;\\[5pt] M_3\,\colon \mathbb{R}^3\to \mathbb{R} &\qquad M_3(x,y,z)\,:\!=\,\frac {x+2y+z}4;\\[5pt] M_4\,\colon \mathbb{R}^3\to \mathbb{R} &\qquad M_4(x,y,z)\,:\!=\,\frac {x+y+2z}4.\\ \end{aligned} \end{equation*}
Then this averaging mapping jointly with the vector
 $\alpha =(\alpha _1,\ldots ,\alpha _4)\in \mathbb{N}_4^{\mathbf{d}}$
defined in (3.1)induces the mean-type mapping
$\alpha =(\alpha _1,\ldots ,\alpha _4)\in \mathbb{N}_4^{\mathbf{d}}$
defined in (3.1)induces the mean-type mapping
 $\mathbf{M}_\alpha \,\colon \mathbb{R}^4 \to \mathbb{R}^4$
defined by
$\mathbf{M}_\alpha \,\colon \mathbb{R}^4 \to \mathbb{R}^4$
defined by
 \begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x_1,x_2,x_3,x_4)&=\left (\frac {x_1+x_2}{2},\frac {3x_1+4x_2}{7},\frac {x_2+2x_3+x_4}{4},\frac {x_1+x_3+2x_4}{4}\right )\\[5pt] &=\left [\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right ] \left (\begin{array}{c} x_1\\x_2\\x_3\\x_4 \end{array}\right ) \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x_1,x_2,x_3,x_4)&=\left (\frac {x_1+x_2}{2},\frac {3x_1+4x_2}{7},\frac {x_2+2x_3+x_4}{4},\frac {x_1+x_3+2x_4}{4}\right )\\[5pt] &=\left [\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right ] \left (\begin{array}{c} x_1\\x_2\\x_3\\x_4 \end{array}\right ) \end{aligned} \end{equation*}
is the collected aggregation function, which is a mean-type mapping. Its properties have a central role in our investigation.
Let us review this process. First, we are given
 $p \in \mathbb{N}$
and a vector
$p \in \mathbb{N}$
and a vector
 $\mathbf{d} \in \mathbb{N}^p$
. Then we independently set a
$\mathbf{d} \in \mathbb{N}^p$
. Then we independently set a
 $\mathbf{d}$
-averaging mapping
$\mathbf{d}$
-averaging mapping
 $\mathbf{M}$
and a vector
$\mathbf{M}$
and a vector
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
. Next, they are combined to obtain a mean-type mapping
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
. Next, they are combined to obtain a mean-type mapping
 $\mathbf{M}_\alpha \,\colon \mathbb{R}^p \to \mathbb{R}^p$
. This separation has an impact on our research. More precisely some properties depend mostly on a (
$\mathbf{M}_\alpha \,\colon \mathbb{R}^p \to \mathbb{R}^p$
. This separation has an impact on our research. More precisely some properties depend mostly on a (
 $\mathbf{d}$
-averaging) mapping
$\mathbf{d}$
-averaging) mapping
 $\mathbf{M}$
while other properties depend on a vector
$\mathbf{M}$
while other properties depend on a vector
 $\alpha$
(belonging to
$\alpha$
(belonging to
 $\mathbb{N}_p^{\mathbf{d}}$
). Surprisingly, it turns out that most of the properties are vector-dependent while only a few of them are mapping-dependent. As a consequence, in most of our results, we will have natural assumptions for the mapping and very specific assumptions for the vector.
$\mathbb{N}_p^{\mathbf{d}}$
). Surprisingly, it turns out that most of the properties are vector-dependent while only a few of them are mapping-dependent. As a consequence, in most of our results, we will have natural assumptions for the mapping and very specific assumptions for the vector.
We see that each entry in a
 $\mathbf{d}$
-averaging mapping could have a different domain, however, they are fully described by an interval and a vector
$\mathbf{d}$
-averaging mapping could have a different domain, however, they are fully described by an interval and a vector
 $\mathbf{d}$
.
$\mathbf{d}$
.
The aggregation function of a given network (denoted above as
 $\alpha$
) generates a directed graph as well, which will be also important in our inquiries.
$\alpha$
) generates a directed graph as well, which will be also important in our inquiries.
The nodes of this graph will be the agents and there is a directed edge from the
 $j$
th agent to the
$j$
th agent to the
 $i$
th agent if the
$i$
th agent if the
 $i$
th agent takes the
$i$
th agent takes the
 $j$
th agent’s belief into account, more precisely, if
$j$
th agent’s belief into account, more precisely, if
 $j\in \alpha _i$
.
$j\in \alpha _i$
.
In the case of the above mentioned
 $\mathbf{M}_\alpha$
the corresponding graph, which is the generated network as well, is
$\mathbf{M}_\alpha$
the corresponding graph, which is the generated network as well, is

The most important concept here is the root set of a graph (see the Section 4.1).
Remark 3.2. The issue is to obtain total agreement at the end. Such a state is not expected in the real world; on the other hand, it is not very surprising when we take into account that, following the principle (e), the aggregation is isolated from the external data except for fixing the initial values. As a consequence, no new information is delivered to the network, and the only evolution of beliefs is caused by aggregating the beliefs of others. It turned out that such convergence of iterations (taking shape of a narrative) is naturally connected to the notion of invariant means.
Remark 3.3. Note that if we restrict admissible means to weighted arithmetic means then our approach reduces to the DeGroot model. However, the belief is conveyed in the weights associated with each edge.
In our setup, this belief is shifted to the averaging function. As a result, there is no need to consider weighted graphs.
As we saw in Example 3.1 the matrix belonging to the aggregation function of the network is
 \begin{equation*} \left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right], \end{equation*}
\begin{equation*} \left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right], \end{equation*}
and the result of the limiting process is
 \begin{equation*} \lim \limits _{n\to \infty }\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right]^n=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0 \end{array}\right]. \end{equation*}
\begin{equation*} \lim \limits _{n\to \infty }\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac 12 &\dfrac 12 & 0 & 0\\[5pt] \dfrac 37 & \dfrac 47 & 0 & 0\\[5pt] 0 & \dfrac 14 & \dfrac 12 & \dfrac 14\\[5pt] \dfrac 14 & 0 & \dfrac 14 & \dfrac 12 \end{array}\right]^n=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0\\[5pt] \dfrac {6}{13}&\dfrac {7}{13}&0&0 \end{array}\right]. \end{equation*}
So, the consensus depends only on the starting belief of the first two agents. As we see later, they constitute the root set of the corresponding graph, and the root here is ergodic.
Example 3.4.
Let
 $D=[0,1]$
,
$D=[0,1]$
,
 $V=\{1,2,3\}$
and
$V=\{1,2,3\}$
and
 $\mathbf{M} \,\colon D^V \to D^V$
be given by
$\mathbf{M} \,\colon D^V \to D^V$
be given by
 \begin{equation*} \mathbf{M}(a,b,c)\,:\!=\,\left (\frac {b+c}2,\frac {a+c}2,\frac {a+b}2\right ). \end{equation*}
\begin{equation*} \mathbf{M}(a,b,c)\,:\!=\,\left (\frac {b+c}2,\frac {a+c}2,\frac {a+b}2\right ). \end{equation*}
Then
 \begin{align*} \mathbf{M}^n(a,b,c)=\frac {1}{3} \left [\begin{array}{c@{\quad}c@{\quad}c} 2^{-n+1}({-}1)^n +1&({-}1)^{n+1}2^{-n}+1&({-}1)^{n+1}2^{-n}+1\\[3pt] ({-}1)^{n+1}2^{-n}+1& 2^{-n+1}({-}1)^n +1&({-}1)^{n+1}2^{-n}+1\\[3pt] ({-}1)^{n+1}2^{-n}+1&({-}1)^{n+1}2^{-n}+1 &2^{-n+1}({-}1)^n +1 \end{array} \right ] \left (\begin{array}{c} a \\ b \\ c \end{array} \right ) \end{align*}
\begin{align*} \mathbf{M}^n(a,b,c)=\frac {1}{3} \left [\begin{array}{c@{\quad}c@{\quad}c} 2^{-n+1}({-}1)^n +1&({-}1)^{n+1}2^{-n}+1&({-}1)^{n+1}2^{-n}+1\\[3pt] ({-}1)^{n+1}2^{-n}+1& 2^{-n+1}({-}1)^n +1&({-}1)^{n+1}2^{-n}+1\\[3pt] ({-}1)^{n+1}2^{-n}+1&({-}1)^{n+1}2^{-n}+1 &2^{-n+1}({-}1)^n +1 \end{array} \right ] \left (\begin{array}{c} a \\ b \\ c \end{array} \right ) \end{align*}
Therefore
 \begin{equation*} \lim _{n\to \infty }\mathbf{M}^n(a,b,c)=\left (\frac {a+b+c}3,\frac {a+b+c}3,\frac {a+b+c}3\right ). \end{equation*}
\begin{equation*} \lim _{n\to \infty }\mathbf{M}^n(a,b,c)=\left (\frac {a+b+c}3,\frac {a+b+c}3,\frac {a+b+c}3\right ). \end{equation*}
The corresponding matrix here is
 \begin{equation*} A= \left[\begin{array}{c@{\quad}c@{\quad}c} 0& \dfrac {1}{2}&\dfrac {1}{2}\\[5pt] \dfrac {1}{2}&0&\dfrac {1}{2}\\[5pt] \dfrac {1}{2}&\dfrac {1}{2}&0 \end{array}\right],\qquad \mbox{and the limit is} \lim \limits _{n\to \infty }A^n=\left[\begin{array}{c@{\quad}c@{\quad}c} \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3}\\[5pt] \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3}\\[5pt] \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3} \end{array}\right]. \end{equation*}
\begin{equation*} A= \left[\begin{array}{c@{\quad}c@{\quad}c} 0& \dfrac {1}{2}&\dfrac {1}{2}\\[5pt] \dfrac {1}{2}&0&\dfrac {1}{2}\\[5pt] \dfrac {1}{2}&\dfrac {1}{2}&0 \end{array}\right],\qquad \mbox{and the limit is} \lim \limits _{n\to \infty }A^n=\left[\begin{array}{c@{\quad}c@{\quad}c} \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3}\\[5pt] \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3}\\[5pt] \dfrac {1}{3}&\dfrac {1}{3}&\dfrac {1}{3} \end{array}\right]. \end{equation*}
So, everybody’s belief takes with equal weights in the consensus.
Example 3.5.
In the next example, we assume that we have five agents (
 $n=5$
), they aggregate their belief using the certainty equivalent under the expected utility model (see for example Föllmer and Schied (Reference Föllmer and Schied2016)), and the Arrow-Pratt index of risk aversion (see Arrow (Reference Arrow1965)) is constant (but agent-dependent). Assume that the risk aversions equal
$n=5$
), they aggregate their belief using the certainty equivalent under the expected utility model (see for example Föllmer and Schied (Reference Föllmer and Schied2016)), and the Arrow-Pratt index of risk aversion (see Arrow (Reference Arrow1965)) is constant (but agent-dependent). Assume that the risk aversions equal
 $r=(1.7,2.3,0,-1,1)$
, respectively. Furthermore, not all agents are aware of each other belief, say
$r=(1.7,2.3,0,-1,1)$
, respectively. Furthermore, not all agents are aware of each other belief, say
 \begin{equation*} \alpha =\big ((1,2),(1,2),(1,2,3),(3,1),(3,4)) \end{equation*}
\begin{equation*} \alpha =\big ((1,2),(1,2),(1,2,3),(3,1),(3,4)) \end{equation*}
which has the following interpretation: the first two agents are aware of each other’s beliefs and take their own belief into account; the third agent takes the belief of the first two and its own, etc. In a social-network manner, one agent takes others’ beliefs into account if, and only if, there is a direct connection between them in a social network (which will be formally introduced on page 23). In this particular case,
 $\alpha$
describes the social network presented at Figure
1
. For the sake of simplicity we assume that all impacters or a given agent are equally treated.
$\alpha$
describes the social network presented at Figure
1
. For the sake of simplicity we assume that all impacters or a given agent are equally treated.

Figure 1. A directed graph corresponding to the social network
 $\alpha$
.
$\alpha$
.
The update of beliefs is described by the following mapping
 $\mathbf{M} \,\colon \mathbb{R}^5\to \mathbb{R}^5$
$\mathbf{M} \,\colon \mathbb{R}^5\to \mathbb{R}^5$
 \begin{equation*} \begin{aligned} \mathbf{M}(x_1,x_2,x_3,x_4,x_5)&\,:\!=\,\bigg (\frac {1}{-1.7}\ln \Big (\frac {e^{-1.7x_1}+e^{-1.7x_2}}{2}\Big ),\\ &\qquad \frac {1}{-2.3}\ln \Big (\frac {e^{-2.3x_1}+e^{-2.3x_2}}{2}\Big ),\frac {x_1+x_2+x_3}3,\\ &\qquad \ln \Big (\frac {e^{x_1}+e^{x_3}}{2}\Big ),-\ln \Big (\frac {e^{-x_3}+e^{-x_4}}{2}\Big ) \bigg ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}(x_1,x_2,x_3,x_4,x_5)&\,:\!=\,\bigg (\frac {1}{-1.7}\ln \Big (\frac {e^{-1.7x_1}+e^{-1.7x_2}}{2}\Big ),\\ &\qquad \frac {1}{-2.3}\ln \Big (\frac {e^{-2.3x_1}+e^{-2.3x_2}}{2}\Big ),\frac {x_1+x_2+x_3}3,\\ &\qquad \ln \Big (\frac {e^{x_1}+e^{x_3}}{2}\Big ),-\ln \Big (\frac {e^{-x_3}+e^{-x_4}}{2}\Big ) \bigg ). \end{aligned} \end{equation*}
Starting from the beliefs
 $x=(3,10,7,5,8)$
we obtain the following sequence of iterations
$x=(3,10,7,5,8)$
we obtain the following sequence of iterations
 \begin{align*} \mathbf{M}^0(x)&= x=(3, 10, 7, 5, 8);\\ \mathbf{M}^{1}(x)&= (3.40773, 3.30137, 6.66667, 6.32500, 5.56622);\\ \mathbf{M}^{2}(x)&= (3.35215, 3.35130, 4.45859, 6.01123, 6.48131);\\ \mathbf{M}^{3}(x)&= (3.35173, 3.35173, 3.72068, 4.05117, 4.95972);\\ \mathbf{M}^{4}(x)&= (3.35173, 3.35173, 3.47471, 3.55312, 3.87233);\\ \mathbf{M}^{5}(x)&= (3.35173, 3.35173, 3.39272, 3.41511, 3.51315);\\ \mathbf{M}^{6}(x)&= (3.35173, 3.35173, 3.36539, 3.37243, 3.40385);\\ \mathbf{M}^{7}(x)&= (3.35173, 3.35173, 3.35628, 3.35858, 3.36891);\\ \mathbf{M}^{8}(x)&= (3.35173, 3.35173, 3.35324, 3.35401, 3.35743);\\ \mathbf{M}^{9}(x)&= (3.35173, 3.35173, 3.35223, 3.35249, 3.35363);\\ \mathbf{M}^{10}(x)&= (3.35173, 3.35173, 3.35189, 3.35198, 3.35236);\\ \mathbf{M}^{11}(x)&= (3.35173, 3.35173, 3.35178, 3.35181, 3.35194);\\ \mathbf{M}^{12}(x)&= (3.35173, 3.35173, 3.35175, 3.35175, 3.35180);\\ \mathbf{M}^{13}(x)&= (3.35173, 3.35173, 3.35173, 3.35174, 3.35175);\\ \mathbf{M}^{14}(x)&= (3.35173, 3.35173, 3.35173, 3.35173, 3.35173);\\ &\ldots \end{align*}
\begin{align*} \mathbf{M}^0(x)&= x=(3, 10, 7, 5, 8);\\ \mathbf{M}^{1}(x)&= (3.40773, 3.30137, 6.66667, 6.32500, 5.56622);\\ \mathbf{M}^{2}(x)&= (3.35215, 3.35130, 4.45859, 6.01123, 6.48131);\\ \mathbf{M}^{3}(x)&= (3.35173, 3.35173, 3.72068, 4.05117, 4.95972);\\ \mathbf{M}^{4}(x)&= (3.35173, 3.35173, 3.47471, 3.55312, 3.87233);\\ \mathbf{M}^{5}(x)&= (3.35173, 3.35173, 3.39272, 3.41511, 3.51315);\\ \mathbf{M}^{6}(x)&= (3.35173, 3.35173, 3.36539, 3.37243, 3.40385);\\ \mathbf{M}^{7}(x)&= (3.35173, 3.35173, 3.35628, 3.35858, 3.36891);\\ \mathbf{M}^{8}(x)&= (3.35173, 3.35173, 3.35324, 3.35401, 3.35743);\\ \mathbf{M}^{9}(x)&= (3.35173, 3.35173, 3.35223, 3.35249, 3.35363);\\ \mathbf{M}^{10}(x)&= (3.35173, 3.35173, 3.35189, 3.35198, 3.35236);\\ \mathbf{M}^{11}(x)&= (3.35173, 3.35173, 3.35178, 3.35181, 3.35194);\\ \mathbf{M}^{12}(x)&= (3.35173, 3.35173, 3.35175, 3.35175, 3.35180);\\ \mathbf{M}^{13}(x)&= (3.35173, 3.35173, 3.35173, 3.35174, 3.35175);\\ \mathbf{M}^{14}(x)&= (3.35173, 3.35173, 3.35173, 3.35173, 3.35173);\\ &\ldots \end{align*}
Therefore the consensus would be approximately
 $3.35173$
. Note that this value was first established (with this precision) for the first two agents (already in the third iteration!) and then spread to the remaining ones. It is visible that only the first two agents have an impact on the consensus. It is important to emphasize that the beliefs of all agents differ, however, the difference between them is getting so small that it goes beyond the precision presented in this numerical example. Nevertheless, we could observe two processes: establishing the consensus between the first two agents, and spreading it to the remaining ones. We see that establishing consensus is a much faster process than spreading it, which faithfully reflects real situations; see for example Yamaguchi (Reference Yamaguchi1994). A relatively small value of the consensus is due to the position of the first agent in the social graph and the high risk aversion of the first two agents.
$3.35173$
. Note that this value was first established (with this precision) for the first two agents (already in the third iteration!) and then spread to the remaining ones. It is visible that only the first two agents have an impact on the consensus. It is important to emphasize that the beliefs of all agents differ, however, the difference between them is getting so small that it goes beyond the precision presented in this numerical example. Nevertheless, we could observe two processes: establishing the consensus between the first two agents, and spreading it to the remaining ones. We see that establishing consensus is a much faster process than spreading it, which faithfully reflects real situations; see for example Yamaguchi (Reference Yamaguchi1994). A relatively small value of the consensus is due to the position of the first agent in the social graph and the high risk aversion of the first two agents.
Here we used a mean type mapping where the coordinate functions are not weighted-arithmetic means, so this situation cannot fit into the DeGroot model.
So, the calculation of the consensus can not be executed by a single matrix iteration. We used here a computer program to get the exact result, which exists for an arbitrary starting belief because of our main theorem (Theorem 5.1 ), since the root in this case is irreducible.
Example 3.6.
Let’s assume that an agent (agent
 $1$
) wants to form a belief about a washing powder, for which he takes into account the beliefs of two other agents (agent
$1$
) wants to form a belief about a washing powder, for which he takes into account the beliefs of two other agents (agent
 $2$
and agent
$2$
and agent
 $3$
). One (agent 2) is an employee of the washing powder company in question, and the other (agent
$3$
). One (agent 2) is an employee of the washing powder company in question, and the other (agent
 $3$
) works for a competing washing powder company. In this case, the weights of the beliefs taken into account are influenced not only by the agent, but also by the belief itself. For example, if an employee (agent
$3$
) works for a competing washing powder company. In this case, the weights of the beliefs taken into account are influenced not only by the agent, but also by the belief itself. For example, if an employee (agent
 $1$
) of the washing powder company makes a negative statement about their own product, agent
$1$
) of the washing powder company makes a negative statement about their own product, agent
 $1$
considers it with more weight than if she makes a positive statement about it. For the belief of the competing company, the weighting is exactly the opposite, with the negative belief having a lower weight and the positive one having a higher weight. This simple model can be made even more realistic if the weights of the beliefs in question also depend on each other. For example, suppose employees (agent
$1$
considers it with more weight than if she makes a positive statement about it. For the belief of the competing company, the weighting is exactly the opposite, with the negative belief having a lower weight and the positive one having a higher weight. This simple model can be made even more realistic if the weights of the beliefs in question also depend on each other. For example, suppose employees (agent
 $2$
and agent
$2$
and agent
 $3$
) of both companies make a positive statement about the washing powder. In that case, the positive statement of agent
$3$
) of both companies make a positive statement about the washing powder. In that case, the positive statement of agent
 $3$
strengthens the statement of agent
$3$
strengthens the statement of agent
 $2$
, so in this case it is worth using a weight function that depends on all the beliefs in the network.
$2$
, so in this case it is worth using a weight function that depends on all the beliefs in the network.
The above situation does not fit the deGroot model because the aggregation function is nonlinear. In this case we can use the following aggregation function:
 \begin{equation*} \frac {p_1(x_1,x_2,x_3)x_1+p_2(x_1,x_2,x_3)x_2+p_3(x_1,x_2,x_3)x_3}{p_1(x_1,x_2,x_3)+p_2(x_1,x_2,x_3)+p_3(x_1,x_2,x_3)}, \end{equation*}
\begin{equation*} \frac {p_1(x_1,x_2,x_3)x_1+p_2(x_1,x_2,x_3)x_2+p_3(x_1,x_2,x_3)x_3}{p_1(x_1,x_2,x_3)+p_2(x_1,x_2,x_3)+p_3(x_1,x_2,x_3)}, \end{equation*}
where
 $I$
is an interval and
$I$
is an interval and
 \begin{equation*} p_i\,\colon I^3\to \mathbb{R}_+,\qquad i=1,2,3 \end{equation*}
\begin{equation*} p_i\,\colon I^3\to \mathbb{R}_+,\qquad i=1,2,3 \end{equation*}
are weight functions.
4. Needed mathematical tools
We proceed now with the description of the mathematical toolkit which is used in our investigation.
It has two main groups. The first contains tools from the theory of graphs and the second contains tools from the theory of means.
4.1 Graph theory and the concept of the root
Now we recall some elementary facts concerning graphs. For details, we refer the reader to the classical book Graham et al. (Reference Graham, Knuth and Patashnik1989).
A digraph is a pair
 $G=(V,E)$
, where
$G=(V,E)$
, where
 $V$
is a finite (possibly empty) set of vertices, and
$V$
is a finite (possibly empty) set of vertices, and
 $E\subset V \times V$
is a set of edges. For each
$E\subset V \times V$
is a set of edges. For each
 $v \in V$
we denote by
$v \in V$
we denote by
 $N_G^-(v)$
and
$N_G^-(v)$
and
 $N_G^+(v)$
sets of in-neighbors and out-neighbors, respectively. More precisely
$N_G^+(v)$
sets of in-neighbors and out-neighbors, respectively. More precisely
 $N_G^-(v)=\{w \in V \,\colon (w,v)\in E\}$
and
$N_G^-(v)=\{w \in V \,\colon (w,v)\in E\}$
and
 $N_G^+(v)=\{w \in V \,\colon (v,w)\in E\}$
. The edges of the form
$N_G^+(v)=\{w \in V \,\colon (v,w)\in E\}$
. The edges of the form
 $(v,v)$
for
$(v,v)$
for
 $v \in V$
are called loops. Let us observe that in view of the above definition the null graph (empty graph)
$v \in V$
are called loops. Let us observe that in view of the above definition the null graph (empty graph)
 $\varnothing \,:\!=\,(\emptyset ,\emptyset )$
is a well-defined digraph.
$\varnothing \,:\!=\,(\emptyset ,\emptyset )$
is a well-defined digraph.
A sequence
 $(v_0,\ldots ,v_n)$
of elements in
$(v_0,\ldots ,v_n)$
of elements in
 $V$
such that
$V$
such that
 $(v_{i-1},v_{i})\in E$
for all
$(v_{i-1},v_{i})\in E$
for all
 $i \in \{1,\ldots ,n\}$
is called a walk from
$i \in \{1,\ldots ,n\}$
is called a walk from
 $v_0$
to
$v_0$
to
 $v_n$
. The number
$v_n$
. The number
 $n$
is a length of the walk. If for
$n$
is a length of the walk. If for
 $v, w \in V$
there exists a walk from
$v, w \in V$
there exists a walk from
 $v$
to
$v$
to
 $w$
in
$w$
in
 $G$
, then we denote it by
$G$
, then we denote it by
 $v \leadsto _G w$
(abbreviated to
$v \leadsto _G w$
(abbreviated to
 $v \leadsto w$
whenever
$v \leadsto w$
whenever
 $G$
is known). A graph
$G$
is known). A graph
 $G$
is called irreducible provided
$G$
is called irreducible provided
 $v \leadsto w$
for all
$v \leadsto w$
for all
 $v, w \in V$
.
$v, w \in V$
.
A cycle in a graph is a nonempty walk in which only the first and last vertices are equal. A directed graph is said to be aperiodic if there is no integer
 $k \gt 1$
that divides the length of every cycle of the graph. A graph that is nonempty, irreducible, and aperiodic is called ergodic.
$k \gt 1$
that divides the length of every cycle of the graph. A graph that is nonempty, irreducible, and aperiodic is called ergodic.
A topological ordering of a digraph
 $G=(V,E)$
is a linear ordering of its vertices such that for every directed edge
$G=(V,E)$
is a linear ordering of its vertices such that for every directed edge
 $(v,w) \in E$
,
$(v,w) \in E$
,
 $v$
precedes
$v$
precedes
 $w$
in the ordering. It is known that if
$w$
in the ordering. It is known that if
 $G$
has no cycles, then there exists its topological ordering (see, for example Cormen et al. (Reference Cormen, Leiserson, Rivest and Stein2009, Section 22.4)). Obviously, it is not uniquely determined.
$G$
has no cycles, then there exists its topological ordering (see, for example Cormen et al. (Reference Cormen, Leiserson, Rivest and Stein2009, Section 22.4)). Obviously, it is not uniquely determined.
We also need a lemma which will be useful in the remaining part of this paper.
Lemma 4.1 (Pasteczka (Reference Pasteczka2023), Lemma 1). Let
 $G=(V,E)$
be an ergodic digraph. Then there exists
$G=(V,E)$
be an ergodic digraph. Then there exists
 $q_0 \in \mathbb{N}$
such that for all
$q_0 \in \mathbb{N}$
such that for all
 $q \in \mathbb{N}$
with
$q \in \mathbb{N}$
with
 $q \ge q_0$
, and
$q \ge q_0$
, and
 $v,w \in V$
there exists a walk from
$v,w \in V$
there exists a walk from
 $v$
to
$v$
to
 $w$
of length exactly
$w$
of length exactly
 $q$
.
$q$
.
Let us now introduce the decomposition of a directed graph into a directed acyclic graph of its strongly connected components (see, for example (Cormen et al. (Reference Cormen, Leiserson, Rivest and Stein2009, section 22.5)). More precisely, for a directed graph
 $G=(V,E)$
we define a relation
$G=(V,E)$
we define a relation
 $\sim$
on its vertices in the following way:
$\sim$
on its vertices in the following way:
 $v \sim w$
if and only if they are both in the same strongly connected component (that is
$v \sim w$
if and only if they are both in the same strongly connected component (that is
 $v=w$
or there is a walk from
$v=w$
or there is a walk from
 $v$
to
$v$
to
 $w$
and from
$w$
and from
 $w$
to
$w$
to
 $v$
). Obviously
$v$
). Obviously
 $\sim$
is an equivalence relation on
$\sim$
is an equivalence relation on
 $V$
, thus we define the quotient graph
$V$
, thus we define the quotient graph
 $G^{SCC}\,:\!=\,G/_{\sim }$
. In more details
$G^{SCC}\,:\!=\,G/_{\sim }$
. In more details
 $G^{SCC}=(V^{SCC},E^{SCC})$
, where
$G^{SCC}=(V^{SCC},E^{SCC})$
, where
 $V^{SCC}=V/_\sim$
and
$V^{SCC}=V/_\sim$
and
 \begin{eqnarray*} E^{SCC}=\big \{ (P,Q)\in V^{SCC} \times V^{SCC} \,\colon P \ne Q \text{ and }(p,q) \in E\\ \text{ for some } p \in P\text{ and }q\in Q\big \}. \end{eqnarray*}
\begin{eqnarray*} E^{SCC}=\big \{ (P,Q)\in V^{SCC} \times V^{SCC} \,\colon P \ne Q \text{ and }(p,q) \in E\\ \text{ for some } p \in P\text{ and }q\in Q\big \}. \end{eqnarray*}
It can be shown that
 $G^{SCC}$
has no cycles. Now we define the set of sources of a directed graph
$G^{SCC}$
has no cycles. Now we define the set of sources of a directed graph
 $G=(V,E)$
as follows
$G=(V,E)$
as follows
 \begin{eqnarray*} \textrm {source}(G)\,:\!=\,\{v \in V \,\colon \text{ there is no edge in }E\text{ which ends in }v\}\\ =\{v \in V \,\colon N_G^-(v)=\emptyset \}. \end{eqnarray*}
\begin{eqnarray*} \textrm {source}(G)\,:\!=\,\{v \in V \,\colon \text{ there is no edge in }E\text{ which ends in }v\}\\ =\{v \in V \,\colon N_G^-(v)=\emptyset \}. \end{eqnarray*}
Obviously, there are no edges between elements in the source. Furthermore, since
 $G^{SCC}$
is acyclic, that is, it has no cycles, we know that
$G^{SCC}$
is acyclic, that is, it has no cycles, we know that
 $\textrm {source}(G^{SCC})$
is nonempty. In fact, it contains the first element of (any) topological ordering of
$\textrm {source}(G^{SCC})$
is nonempty. In fact, it contains the first element of (any) topological ordering of
 $G^{SCC}$
(see the definition above). In the next step, we go backward (to the initial graph
$G^{SCC}$
(see the definition above). In the next step, we go backward (to the initial graph
 $G$
) and define the root of
$G$
) and define the root of
 $G$
by
$G$
by
 \begin{equation} R(G)\,:\!=\,\bigcup \textrm {source} (G^{SCC}) \subset V. \end{equation}
\begin{equation} R(G)\,:\!=\,\bigcup \textrm {source} (G^{SCC}) \subset V. \end{equation}
Example 4.2. Let
 \begin{equation*} \begin{aligned} G&=(V,E),\qquad V=\{a,b,c,d,e,f\},\\ E&=\{(a,d),(d,a),(b,c),(c,b),(d,e),(b,e),(e,f),(c,f)\}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} G&=(V,E),\qquad V=\{a,b,c,d,e,f\},\\ E&=\{(a,d),(d,a),(b,c),(c,b),(d,e),(b,e),(e,f),(c,f)\}. \end{aligned} \end{equation*}
Then
 \begin{equation*} \begin{aligned} G^{SCC}&= (V^{SCC},E^{SCC}),\qquad V^{SCC}=\{P,Q,R,S\},\\ E^{SCC}&=\{(P,R),(Q,R),(Q,S),(R,S)\}, \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} G^{SCC}&= (V^{SCC},E^{SCC}),\qquad V^{SCC}=\{P,Q,R,S\},\\ E^{SCC}&=\{(P,R),(Q,R),(Q,S),(R,S)\}, \end{aligned} \end{equation*}
where the equivalence classes
 $P,Q,R,S$
correspond to the sets
$P,Q,R,S$
correspond to the sets
 $\{a,d\},$
$\{a,d\},$
 $\{b,c\},\{e\},\{f\}$
respectively (see Figure
2
).
$\{b,c\},\{e\},\{f\}$
respectively (see Figure
2
).

Figure 2. A directed graph
 $G$
and the corresponding
$G$
and the corresponding
 $G^{SCC}$
.
$G^{SCC}$
.
So, the source of
 $G^{SCC}=\{P,Q\}$
, which entails that the root of
$G^{SCC}=\{P,Q\}$
, which entails that the root of
 $G$
is
$G$
is
 \begin{equation*} R(G)=\{a,b,c,d\}. \end{equation*}
\begin{equation*} R(G)=\{a,b,c,d\}. \end{equation*}
Here the root is not ergodic.
Example 4.3. Let $G$ be the graph presented in Figure 3, that is
 \begin{equation*} \begin{aligned} G&= (V,E),\qquad V=\{1,2,3,4\},\\ E&=\{(1,1),(2,2),(4,4),(1,2),(2,1),(2,3),(3,4),(4,3)\}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} G&= (V,E),\qquad V=\{1,2,3,4\},\\ E&=\{(1,1),(2,2),(4,4),(1,2),(2,1),(2,3),(3,4),(4,3)\}. \end{aligned} \end{equation*}
Then
 \begin{equation*} G^{SCC}= (V^{SCC},E^{SCC}),\qquad V^{SCC}=\{I,II\},\quad E^{SCC}=\{(I,II)\}, \end{equation*}
\begin{equation*} G^{SCC}= (V^{SCC},E^{SCC}),\qquad V^{SCC}=\{I,II\},\quad E^{SCC}=\{(I,II)\}, \end{equation*}
where the equivalence classes
 $I,II$
correspond to the sets
$I,II$
correspond to the sets
 $\{1,2\},\{3,4\}$
respectively (see Figure
3
).
$\{1,2\},\{3,4\}$
respectively (see Figure
3
).

Figure 3. Graph
 $G_\alpha$
related to Example 4.3.
$G_\alpha$
related to Example 4.3.
So, the source of
 $G^{SCC}$
equals to
$G^{SCC}$
equals to
 $\{I\}$
, which entails that the root of
$\{I\}$
, which entails that the root of
 $G$
is
$G$
is
 \begin{equation*} R(G)=\{1,2\}. \end{equation*}
\begin{equation*} R(G)=\{1,2\}. \end{equation*}
Here the root is ergodic.
Now we show the equivalent definition of the root.
Theorem 4.4. (Characterization theorem of
 $R(G)$
). Let
$R(G)$
). Let
 $G=(V,E)$
be a directed graph. Then
$G=(V,E)$
be a directed graph. Then
 $R(G)$
is the smallest subset
$R(G)$
is the smallest subset
 $S \subset V$
such that the following conditions are valid:
$S \subset V$
such that the following conditions are valid:
-
(i) For all
$v\in V$
such that there exists a path
$w \leadsto _G v$
for some
$w \in S$
; -
(ii) if
$v \in S$
and there is an edge
$(wv)\in E$
for some
$w \in V$
, then
$w \in S$
.







Proof. see Appendix A.1.
Now, we define a root graph
 $\mathcal{R}(G)$
as the graph induced by the root of
$\mathcal{R}(G)$
as the graph induced by the root of
 $G$
. Thus, purely formally,
$G$
. Thus, purely formally,
 $\mathcal{R}(G)\,:\!=\,(R(G),E\cap (R(G) \times R(G))$
.
$\mathcal{R}(G)\,:\!=\,(R(G),E\cap (R(G) \times R(G))$
.
We underline a few easy observations related to this definition.
Observation 1.
-
(1) Since
$\textrm {source}(G^{SCC})$
is nonempty, we get that
$\mathcal{R}(G)$
is nonempty if
$V$
is nonempty.
-
(2) A graph
$G$
is irreducible if, and only if, all its vertices belong to the root, that is
$\mathcal{R}(G)=G$
. -
(3) There are no edges in
$G$
that start outside the root and end inside it.
-
(4)
$\mathcal{R}(G)$
is a union of irreducible graphs. Consequently,
$\mathcal{R}(G)$
is irreducible if, and only if,
$\textrm {source}(G^{SCC})$
is a singleton.









A subset of the roots for which the generated graph is irreducible is called a component of the root.
The simplest situation is when the root graph is ergodic. In particular, there is only one component of the root set. We will see later, that in this case the effect of the common belief of the root elements, which exists in this case, will be the common belief of the whole network (see Theorem5.1).
A more challenging case is, when there is more than one component of
 $\mathcal{R}(G)$
. This can happen when the root contains more than one independent group that are not aware of each other (that is belief is not spreading between the groups). This issue is illustrated in Example 5.6.
$\mathcal{R}(G)$
. This can happen when the root contains more than one independent group that are not aware of each other (that is belief is not spreading between the groups). This issue is illustrated in Example 5.6.
4.2 Means, mean-type mappings, and invariant means
Before we proceed further recall that, for a given
 $p\in \mathbb{N}$
and an interval
$p\in \mathbb{N}$
and an interval
 $I \subset \mathbb{R}$
, a
$I \subset \mathbb{R}$
, a
 $p$
-variable mean on
$p$
-variable mean on
 $I$
is an arbitrary function
$I$
is an arbitrary function
 $M \,\colon I^p \to I$
satisfying the inequality
$M \,\colon I^p \to I$
satisfying the inequality
 \begin{equation} \begin{aligned} \min (x)\le M(x)\le \max (x)\text{ for all }x \in I^p. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \min (x)\le M(x)\le \max (x)\text{ for all }x \in I^p. \end{aligned} \end{equation}
Property (4.2) is referred as a mean property. If the inequalities in (4.2) are strict for every nonconstant vector
 $x$
, then we say that a mean
$x$
, then we say that a mean
 $M$
is strict. Moreover, for such objects, we define natural properties like continuity, symmetry (when the value of a mean does not depend on the order of its arguments), monotonicity (which states that
$M$
is strict. Moreover, for such objects, we define natural properties like continuity, symmetry (when the value of a mean does not depend on the order of its arguments), monotonicity (which states that
 $M$
is nondecreasing in each of its variables), etc. A mean
$M$
is nondecreasing in each of its variables), etc. A mean
 $M$
on
$M$
on
 $\mathbb{R}_+$
is positively homogeneous provided
$\mathbb{R}_+$
is positively homogeneous provided
 $cM(x)=M(cx)$
for all
$cM(x)=M(cx)$
for all
 $c \in \mathbb{R}_+$
and
$c \in \mathbb{R}_+$
and
 $x \in \mathbb{R}_+^p$
.
$x \in \mathbb{R}_+^p$
.
A mean-type mapping is a self-mapping of
 $I^p$
which has a
$I^p$
which has a
 $p$
-variable mean on each of its coordinates. More precisely,
$p$
-variable mean on each of its coordinates. More precisely,
 $\mathbf{M} \,\colon I^p \to I^p$
is called a mean-type mapping if
$\mathbf{M} \,\colon I^p \to I^p$
is called a mean-type mapping if
 $\mathbf{M}=(M_1,\ldots ,M_p)$
for some
$\mathbf{M}=(M_1,\ldots ,M_p)$
for some
 $p$
-variable means
$p$
-variable means
 $M_1,\ldots ,M_p$
on
$M_1,\ldots ,M_p$
on
 $I$
. In this framework, a function
$I$
. In this framework, a function
 $K \,\colon I^p\to \mathbb{R}$
is called
$K \,\colon I^p\to \mathbb{R}$
is called
 $\mathbf{M}$
-invariant if it solves the functional equation
$\mathbf{M}$
-invariant if it solves the functional equation
 $K \circ \mathbf{M}=K$
. Usually, we restrict solutions of this equation to the family of means and say about
$K \circ \mathbf{M}=K$
. Usually, we restrict solutions of this equation to the family of means and say about
 $\mathbf{M}$
-invariant means. Several authors studied invariant means during years, let us just mention the book Borwein and Borwein (Reference Borwein and Borwein1987), a comprehensive survey paper Jarczyk and Jarczyk (Reference Jarczyk and Jarczyk2018) and the references therein.
$\mathbf{M}$
-invariant means. Several authors studied invariant means during years, let us just mention the book Borwein and Borwein (Reference Borwein and Borwein1987), a comprehensive survey paper Jarczyk and Jarczyk (Reference Jarczyk and Jarczyk2018) and the references therein.
Example 4.5.
Let
 $\mathbf{M}\,\colon \mathbb{R}^2_+\to \mathbb{R}^2_+$
be given by
$\mathbf{M}\,\colon \mathbb{R}^2_+\to \mathbb{R}^2_+$
be given by
 \begin{equation*} \mathbf{M}(x,y)=\left (\frac {x+y}{2},\frac {2xy}{x+y}\right ), \end{equation*}
\begin{equation*} \mathbf{M}(x,y)=\left (\frac {x+y}{2},\frac {2xy}{x+y}\right ), \end{equation*}
then it is easy to see that
 \begin{equation*} K\,\colon \mathbb{R}^2_+\to \mathbb{R}_+,\qquad K(x,y)=\sqrt {xy} \end{equation*}
\begin{equation*} K\,\colon \mathbb{R}^2_+\to \mathbb{R}_+,\qquad K(x,y)=\sqrt {xy} \end{equation*}
will be
 $\mathbf{M}$
-invariant. Indeed,
$\mathbf{M}$
-invariant. Indeed,
 \begin{equation*} K\circ \mathbf{M}(x,y)=\sqrt {\frac {x+y}{2}\cdot \frac {2xy}{x+y}}=\sqrt {xy}=K(x,y). \end{equation*}
\begin{equation*} K\circ \mathbf{M}(x,y)=\sqrt {\frac {x+y}{2}\cdot \frac {2xy}{x+y}}=\sqrt {xy}=K(x,y). \end{equation*}
We get a more sophisticated example, when
 \begin{equation*} \mathbf{M}(x,y)=\left (\frac {x+y}{2},\sqrt {xy}\right ). \end{equation*}
\begin{equation*} \mathbf{M}(x,y)=\left (\frac {x+y}{2},\sqrt {xy}\right ). \end{equation*}
Then the corresponding invariant mean (see for example Borwein and Borwein (Reference Borwein and Borwein1987)) is
 \begin{equation*} K(x,y)=\frac {\pi }{2}\left (\int \limits _0^{\frac {\pi }{2}}\frac {d\theta }{\sqrt {x^2\cos ^2\theta +y^2\sin ^2\theta }}\right )^{-1}. \end{equation*}
\begin{equation*} K(x,y)=\frac {\pi }{2}\left (\int \limits _0^{\frac {\pi }{2}}\frac {d\theta }{\sqrt {x^2\cos ^2\theta +y^2\sin ^2\theta }}\right )^{-1}. \end{equation*}
For a given
 $d,p \in \mathbb{N}$
, a sequence
$d,p \in \mathbb{N}$
, a sequence
 \begin{equation*} \alpha \,:\!=\,(\alpha _1,\ldots ,\alpha _d) \in \{1,\ldots ,p\}^d, \end{equation*}
\begin{equation*} \alpha \,:\!=\,(\alpha _1,\ldots ,\alpha _d) \in \{1,\ldots ,p\}^d, \end{equation*}
and a
 $d$
-variable mean
$d$
-variable mean
 $M \,\colon I^d\to I$
we define the mean
$M \,\colon I^d\to I$
we define the mean
 $M^{(p;\alpha )}\,\colon I^p\to I$
by
$M^{(p;\alpha )}\,\colon I^p\to I$
by
 \begin{equation} \begin{aligned} M^{(p;\alpha )}(x_1,\ldots ,x_p)\,:\!=\,M(x_{\alpha _1},\ldots ,x_{\alpha _d}) \text{ for all }(x_1,\ldots ,x_p)\in I^p. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} M^{(p;\alpha )}(x_1,\ldots ,x_p)\,:\!=\,M(x_{\alpha _1},\ldots ,x_{\alpha _d}) \text{ for all }(x_1,\ldots ,x_p)\in I^p. \end{aligned} \end{equation}
Example 4.6.
Let
 $d=2$
and
$d=2$
and
 ${\mathscr{A}}\,\colon \mathbb{R}^2\to \mathbb{R}$
be the bivariate arithemetic mean,
${\mathscr{A}}\,\colon \mathbb{R}^2\to \mathbb{R}$
be the bivariate arithemetic mean,
 $p \ge 3$
and
$p \ge 3$
and
 $\alpha =(2,3)$
then
$\alpha =(2,3)$
then
 ${\mathscr{A}}^{\, \, \, (p;\alpha )}\,\colon I^p \to I$
is given by
${\mathscr{A}}^{\, \, \, (p;\alpha )}\,\colon I^p \to I$
is given by
 \begin{equation*} \begin{aligned} {\mathscr{A}}^{\, (p;\alpha )}(x_1,\ldots ,x_p)={\mathscr{A}}^{\, (p;2,3)}(x_1,\ldots ,x_p)=\tfrac {x_2+x_3}2\text{ for all }(x_1,\ldots ,x_p)\in I^p. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} {\mathscr{A}}^{\, (p;\alpha )}(x_1,\ldots ,x_p)={\mathscr{A}}^{\, (p;2,3)}(x_1,\ldots ,x_p)=\tfrac {x_2+x_3}2\text{ for all }(x_1,\ldots ,x_p)\in I^p. \end{aligned} \end{equation*}
For the sake of completeness, let us introduce formally
 $\mathbb{N}\,:\!=\,\{1,\ldots \}$
, and
$\mathbb{N}\,:\!=\,\{1,\ldots \}$
, and
 $\mathbb{N}_p\,:\!=\,\{1,\ldots ,p\}$
(where
$\mathbb{N}_p\,:\!=\,\{1,\ldots ,p\}$
(where
 $p\in \mathbb{N}$
). Then, for
$p\in \mathbb{N}$
). Then, for
 $p \in \mathbb{N}$
and a vector
$p \in \mathbb{N}$
and a vector
 $\mathbf{d}=(d_1,\ldots ,d_p)\in \mathbb{N}^p$
, let
$\mathbf{d}=(d_1,\ldots ,d_p)\in \mathbb{N}^p$
, let
 $\mathbb{N}_p^{\mathbf{d}}\,:\!=\,\mathbb{N}_p^{d_1}\times \ldots \times \mathbb{N}_p^{d_p}$
.
$\mathbb{N}_p^{\mathbf{d}}\,:\!=\,\mathbb{N}_p^{d_1}\times \ldots \times \mathbb{N}_p^{d_p}$
.
Definition 4.7.
Using this notations, a sequence of means
 $\mathbf{M}=(M_1,\ldots ,M_p)$
is called
$\mathbf{M}=(M_1,\ldots ,M_p)$
is called
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
if each
$I$
if each
 $M_i$
is a
$M_i$
is a
 $d_i$
-variable mean on
$d_i$
-variable mean on
 $I$
.
$I$
.
For a
 $\mathbf{d}$
-averaging mapping (for an example see Example 5.3)
$\mathbf{d}$
-averaging mapping (for an example see Example 5.3)
 $\mathbf{M}$
and a vector of indexes
$\mathbf{M}$
and a vector of indexes
 $\alpha =(\alpha _1,\ldots ,\alpha _p)\in \mathbb{N}_p^{d_1}\times \ldots \times \mathbb{N}_p^{d_p}=\mathbb{N}_p^{\mathbf{d}}$
define a mean-type mapping
$\alpha =(\alpha _1,\ldots ,\alpha _p)\in \mathbb{N}_p^{d_1}\times \ldots \times \mathbb{N}_p^{d_p}=\mathbb{N}_p^{\mathbf{d}}$
define a mean-type mapping
 $\mathbf{M}_\alpha \,\colon I^p \to I^p$
by
$\mathbf{M}_\alpha \,\colon I^p \to I^p$
by
 \begin{equation*} \begin{aligned} \mathbf{M}_\alpha \,:\!=\,\Big (M_1^{(p;\alpha _1)},\ldots ,M_p^{(p;\alpha _p)}\Big ); \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}_\alpha \,:\!=\,\Big (M_1^{(p;\alpha _1)},\ldots ,M_p^{(p;\alpha _p)}\Big ); \end{aligned} \end{equation*}
recall that
 $M_i^{(p,\alpha _i)}$
-s were defined in (4.3). In the more explicit form we have
$M_i^{(p,\alpha _i)}$
-s were defined in (4.3). In the more explicit form we have
 \begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x_1,\ldots ,x_p)&=\Big (M_i^{(p,\alpha _i)}(x_1\ldots ,x_p)\Big )_{i=1}^p\\ &=\Big (M_i\big (x_{\alpha _{i,1}},\ldots ,x_{\alpha _{i,d_i}}\big )\Big )_{i=1}^p\\ &=\Big (M_1\big (x_{\alpha _{1,1}},\ldots ,x_{\alpha _{1,d_1}}\big ),\ldots ,M_p\big (x_{\alpha _{p,1}},\ldots ,x_{\alpha _{p,d_p}}\big )\Big ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x_1,\ldots ,x_p)&=\Big (M_i^{(p,\alpha _i)}(x_1\ldots ,x_p)\Big )_{i=1}^p\\ &=\Big (M_i\big (x_{\alpha _{i,1}},\ldots ,x_{\alpha _{i,d_i}}\big )\Big )_{i=1}^p\\ &=\Big (M_1\big (x_{\alpha _{1,1}},\ldots ,x_{\alpha _{1,d_1}}\big ),\ldots ,M_p\big (x_{\alpha _{p,1}},\ldots ,x_{\alpha _{p,d_p}}\big )\Big ). \end{aligned} \end{equation*}
For a given
 $p\in \mathbb{N}$
,
$p\in \mathbb{N}$
,
 $\mathbf{d}=(d_1,\ldots ,d_p)\in \mathbb{N}^p$
, and
$\mathbf{d}=(d_1,\ldots ,d_p)\in \mathbb{N}^p$
, and
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, we define the
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, we define the
 $\alpha$
-incidence graph
$\alpha$
-incidence graph
 $G_\alpha =(V_\alpha ,E_\alpha )$
as follows:
$G_\alpha =(V_\alpha ,E_\alpha )$
as follows:
 $V_\alpha \,:\!=\,\mathbb{N}_p$
and
$V_\alpha \,:\!=\,\mathbb{N}_p$
and
 $E_\alpha \,:\!=\,\{(\alpha _{i,j},i) \,\colon i \in \mathbb{N}_p \text{ and }j \in \mathbb{N}_{d_i}\}$
.
$E_\alpha \,:\!=\,\{(\alpha _{i,j},i) \,\colon i \in \mathbb{N}_p \text{ and }j \in \mathbb{N}_{d_i}\}$
.
For the readers’ convenience and for the better understandability of the paper we recall two results from Pasteczka (Reference Pasteczka2023) and Matkowski and Pasteczka (Reference Matkowski and Pasteczka2021), which will be used later.
Theorem 4.8 (Pasteczka (Reference Pasteczka2023), Theorem 2 (a)-(d)). Let
 $I \subset \mathbb{R}$
be an interval,
$I \subset \mathbb{R}$
be an interval,
 $p \in \mathbb{N}$
,
$p \in \mathbb{N}$
,
 $\mathbf{d} \in \mathbb{N}^p$
,
$\mathbf{d} \in \mathbb{N}^p$
,
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
 $\mathbf{M}=(M_1,\ldots ,M_p)$
be a
$\mathbf{M}=(M_1,\ldots ,M_p)$
be a
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
. Assume that
$I$
. Assume that
 $G_\alpha$
is an ergodic graph, and
$G_\alpha$
is an ergodic graph, and
 $M_i$
-s are continuous and strict for all
$M_i$
-s are continuous and strict for all
 $i \in \{1,\ldots ,p\}$
.
$i \in \{1,\ldots ,p\}$
.
There exists the unique, continuous, and strict
 $\mathbf{M}_\alpha$
-invariant mean
$\mathbf{M}_\alpha$
-invariant mean
 $K_\alpha \,\colon I^p \to I$
. Moreover
$K_\alpha \,\colon I^p \to I$
. Moreover
 $\lim \limits _{n\to \infty }\mathbf{M}_\alpha ^n=\mathbf{K}_\alpha$
, where
$\lim \limits _{n\to \infty }\mathbf{M}_\alpha ^n=\mathbf{K}_\alpha$
, where
 $\mathbf{K}_\alpha \,\colon I^p \to I^p$
is defined as
$\mathbf{K}_\alpha \,\colon I^p \to I^p$
is defined as
 $\mathbf{K}_\alpha =(K_\alpha ,\ldots ,K_\alpha )$
.
$\mathbf{K}_\alpha =(K_\alpha ,\ldots ,K_\alpha )$
.
Let us now recall (Matkowski and Pasteczka, Reference Matkowski and Pasteczka2021, Theorem 1) which provides the necessary and sufficient condition of the uniqueness of the invariant mean.
Proposition 4.9 (Invariance principle). Let
 $\mathbf{M}\,\colon I^p\to I^p$
be a mean-type mapping and
$\mathbf{M}\,\colon I^p\to I^p$
be a mean-type mapping and
 $K\,:\,I^{p}\rightarrow I$
be an arbitrary mean.
$K\,:\,I^{p}\rightarrow I$
be an arbitrary mean.
 $K$
is a unique
$K$
is a unique
 $\mathbf{M}$
-invariant mean if and only if the sequence of iterates
$\mathbf{M}$
-invariant mean if and only if the sequence of iterates
 $\left ( \mathbf{M}^{n}\right ) _{n\in \mathbb{N}}$
of the mean-type mapping
$\left ( \mathbf{M}^{n}\right ) _{n\in \mathbb{N}}$
of the mean-type mapping
 $\mathbf{M}$
converges to
$\mathbf{M}$
converges to
 $\mathbf{K}\,:\!=\,\left ( K,\ldots ,K\right )$
pointwise on
$\mathbf{K}\,:\!=\,\left ( K,\ldots ,K\right )$
pointwise on
 $I^{p}$
.
$I^{p}$
.
5. Main result
The message of Theorem4.8 is if everybody takes into account everybody’s belief (at least implicitly, that is, in the generated graph by the aggregation function of the network all the agents are available from all the agents by a directed path), then there will be a unique consensus at the end of the limit process. However, this assumption is not realistic.
So, our aim is to generalize Theorem4.8. The most significant advantage over Theorem4.8 is that only the root
 $\mathcal{R}(G_\alpha )$
is assumed to be ergodic (instead of the whole graph
$\mathcal{R}(G_\alpha )$
is assumed to be ergodic (instead of the whole graph
 $G_\alpha$
).
$G_\alpha$
).
Clearly, if
 $G_\alpha$
is ergodic, then the root coincides with the whole graph which means that this case is also covered by the result below.
$G_\alpha$
is ergodic, then the root coincides with the whole graph which means that this case is also covered by the result below.
There arises a natural question, how far is this assumption being necessary. As we show in Theorem5.4, this assumption is optimal in some sense. Namely, the existence of a unique consensus can be ensured only in the case when the root is ergodic (see Theorem5.4).
The outcome of this theorem (and the forthcoming corollary) from the point of view of aggregating the beliefs is very understandable. It says that:
-
(1) the consensus is obtained if and only if the set of influencers (roots) is ergodic;
-
(2) the consensus depends only on the influencers’ beliefs.
Theorem 5.1.
Let
 $I \subset \mathbb{R}$
be an interval,
$I \subset \mathbb{R}$
be an interval,
 $p \in \mathbb{N}$
,
$p \in \mathbb{N}$
,
 $\mathbf{d} \in \mathbb{N}^p$
,
$\mathbf{d} \in \mathbb{N}^p$
,
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
 $\mathbf{M}=(M_1,\ldots ,M_p)$
be a
$\mathbf{M}=(M_1,\ldots ,M_p)$
be a
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
. Assume that
$I$
. Assume that
 $\mathcal{R}(G_\alpha )$
is an ergodic graph, and
$\mathcal{R}(G_\alpha )$
is an ergodic graph, and
 $M_i$
-s are continuous and strict for all
$M_i$
-s are continuous and strict for all
 $i \in \{1,\ldots ,p\}$
. Then, there exists a unique and continuous
$i \in \{1,\ldots ,p\}$
. Then, there exists a unique and continuous
 $\mathbf{M}_\alpha$
-invariant mean
$\mathbf{M}_\alpha$
-invariant mean
 $K_\alpha \,\colon I^p \to I$
such that
$K_\alpha \,\colon I^p \to I$
such that
 \begin{equation} \lim _{n\to \infty }\mathbf{M}_\alpha ^n=\mathbf{K}_\alpha ,\qquad \mbox{(existence of a consensus)} \end{equation}
\begin{equation} \lim _{n\to \infty }\mathbf{M}_\alpha ^n=\mathbf{K}_\alpha ,\qquad \mbox{(existence of a consensus)} \end{equation}
where
 \begin{equation*} \mathbf{K}_\alpha \,\colon I^p \to I^p,\qquad \mathbf{K}_\alpha =(K_\alpha ,\ldots ,K_\alpha ), \end{equation*}
\begin{equation*} \mathbf{K}_\alpha \,\colon I^p \to I^p,\qquad \mathbf{K}_\alpha =(K_\alpha ,\ldots ,K_\alpha ), \end{equation*}
which depends on the root elements only. That is to say, there exists a mean
 $K_\alpha ^* \,\colon I^{|R(G_\alpha )|} \to I$
such that
$K_\alpha ^* \,\colon I^{|R(G_\alpha )|} \to I$
such that
 \begin{equation*}K_\alpha (x_1,\ldots ,x_p)=K_\alpha ^*(x_i \,\colon i \in R(G_\alpha )).\end{equation*}
\begin{equation*}K_\alpha (x_1,\ldots ,x_p)=K_\alpha ^*(x_i \,\colon i \in R(G_\alpha )).\end{equation*}
(The consensus depends only on the beliefs of the root agents).
Proof. see Appendix A.2.
Some properties are inherited during the limiting process, which can be useful if we cannot guess the resulting invariant mean. However, we would like to get some belief related to the consensus.
For example, if the aggregation functions are nondecreasing with respect to each variable, then so is the corresponding consensus (if it exists). Translated into the language of spreading belief in networks with ergodic roots, if the root members give a higher value to something, then this occurs with a higher value in the consensus (part (b) of Corollary 5.2).
Corollary 5.2.
Let
 $I \subset \mathbb{R}$
be an interval,
$I \subset \mathbb{R}$
be an interval,
 $p \in \mathbb{N}$
,
$p \in \mathbb{N}$
,
 $\mathbf{d} \in \mathbb{N}^p$
,
$\mathbf{d} \in \mathbb{N}^p$
,
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
 $\mathbf{M}=(M_1,\ldots ,M_p)$
be a
$\mathbf{M}=(M_1,\ldots ,M_p)$
be a
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
. Assume that
$I$
. Assume that
 $\mathcal{R}(G_\alpha )$
is an ergodic graph, and
$\mathcal{R}(G_\alpha )$
is an ergodic graph, and
 $M_i$
-s are continuous and strict for all
$M_i$
-s are continuous and strict for all
 $i \in \{1,\ldots ,p\}$
. Define
$i \in \{1,\ldots ,p\}$
. Define
 $K_\alpha$
and
$K_\alpha$
and
 $\mathbf{K}_\alpha$
according to Theorem
5.1
. Then
$\mathbf{K}_\alpha$
according to Theorem
5.1
. Then
-
(a)
$\mathbf{K}_\alpha \,\colon I^p \to I^p$
is
$\mathbf{M}_\alpha$
-invariant, that is
$\mathbf{K}_\alpha =\mathbf{K}_\alpha \circ \mathbf{M}_\alpha$
; -
(b) if
$M_1,\ldots ,M_p$
are nondecreasing with respect to each variable, then so is
$K_\alpha$
; -
(c) if
$I=(0,+\infty )$
and
$M_1,\ldots ,M_p$
are positively homogeneous, then every iterate of
$\mathbf{M}_\alpha$
and
$K_\alpha$
are positively homogeneous.









Proof. see Appendix A.3.
We continue with an application of our main theorem. This example was already mentioned in Pasteczka (Reference Pasteczka2023) and, in some sense, was the motivation for this investigation. Since all means in the example below are positively homogeneous, we obtain the homogeneous invariant mean, which is implied by the above corollary.
Example 5.3. (Pasteczka (Reference Pasteczka2023), Example 5). Let
 $p=4$
,
$p=4$
,
 $\mathbf{d}=(2,2,2,2)$
,
$\mathbf{d}=(2,2,2,2)$
,
 \begin{equation*} \begin{aligned} \alpha =\big ((1,2),(1,2),(2,4),(3,4)\big )\in \mathbb{N}_4^{\mathbf{d}} \quad \text{ and }\quad \mathbf{M}=(\mathcal{P}_{-1},\mathcal{P}_1,\mathcal{P}_{-1},\mathcal{P}_1), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \alpha =\big ((1,2),(1,2),(2,4),(3,4)\big )\in \mathbb{N}_4^{\mathbf{d}} \quad \text{ and }\quad \mathbf{M}=(\mathcal{P}_{-1},\mathcal{P}_1,\mathcal{P}_{-1},\mathcal{P}_1), \end{aligned} \end{equation*}
where
 $\mathcal{P}_r$
are
$\mathcal{P}_r$
are
 $r$
-th Hölder (power) means. Then
$r$
-th Hölder (power) means. Then
 $\mathbf{M}_\alpha$
is of the form
$\mathbf{M}_\alpha$
is of the form
 \begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x,y,z,t)&=\bigg (\frac {2xy}{x+y},\frac {x+y}2,\frac {2yt}{y+t},\frac {z+t}2\:\bigg ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x,y,z,t)&=\bigg (\frac {2xy}{x+y},\frac {x+y}2,\frac {2yt}{y+t},\frac {z+t}2\:\bigg ). \end{aligned} \end{equation*}
Clearly
 $\mathcal{R}(G_\alpha )$
is ergodic as it is shown on Figure 4. Thus, by Theorem
5.1
, we obtain that there exists the unique
$\mathcal{R}(G_\alpha )$
is ergodic as it is shown on Figure 4. Thus, by Theorem
5.1
, we obtain that there exists the unique
 $\mathbf{M}_\alpha$
-invariant mean
$\mathbf{M}_\alpha$
-invariant mean
 $K_\alpha \,\colon \mathbb{R}_+^4 \to \mathbb{R}_+$
, and it is of the form
$K_\alpha \,\colon \mathbb{R}_+^4 \to \mathbb{R}_+$
, and it is of the form
 $K_\alpha (x,y,z,t)=K^*_\alpha (x,y)$
, where
$K_\alpha (x,y,z,t)=K^*_\alpha (x,y)$
, where
 $K^*_\alpha \,\colon \mathbb{R}_+^2 \to \mathbb{R}_+$
. By
$K^*_\alpha \,\colon \mathbb{R}_+^2 \to \mathbb{R}_+$
. By
 $K_\alpha \circ \mathbf{M}_\alpha =K_\alpha$
for all
$K_\alpha \circ \mathbf{M}_\alpha =K_\alpha$
for all
 $x,y,z,t \in \mathbb{R}_+$
we obtain,
$x,y,z,t \in \mathbb{R}_+$
we obtain,
 \begin{equation*} \begin{aligned} K_\alpha ^*(x,y)&=K_\alpha (x,y,z,t)=K_\alpha \circ \mathbf{M}_\alpha (x,y,z,t)\\ &=K_\alpha \big (\tfrac {2xy}{x+y},\tfrac {x+y}2,\tfrac {2yt}{y+t},\tfrac {z+t}2\big ) =K_\alpha ^* \big (\tfrac {2xy}{x+y},\tfrac {x+y}2\big ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} K_\alpha ^*(x,y)&=K_\alpha (x,y,z,t)=K_\alpha \circ \mathbf{M}_\alpha (x,y,z,t)\\ &=K_\alpha \big (\tfrac {2xy}{x+y},\tfrac {x+y}2,\tfrac {2yt}{y+t},\tfrac {z+t}2\big ) =K_\alpha ^* \big (\tfrac {2xy}{x+y},\tfrac {x+y}2\big ). \end{aligned} \end{equation*}
Now we can use the folklore result stating that the arithmetic-harmonic mean is the geometric mean (see for example Schoenberg (Reference Schoenberg1982), p. 156) to obtain
 $K_\alpha ^*(x,y)=\sqrt {xy}$
for
$K_\alpha ^*(x,y)=\sqrt {xy}$
for
 $x,y \in \mathbb{R}_+$
. Finally
$x,y \in \mathbb{R}_+$
. Finally
 \begin{equation*} \begin{aligned} K_\alpha (x,y,z,t)=K^*_\alpha (x,y)=\sqrt {xy}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} K_\alpha (x,y,z,t)=K^*_\alpha (x,y)=\sqrt {xy}. \end{aligned} \end{equation*}

Figure 4. Graph
 $G_\alpha$
related to Example 5.3.
$G_\alpha$
related to Example 5.3.
Therefore, we have shown that the consensus is the geometric mean of the initial beliefs of the first two agents. This is not surprising because only the first two agents are in the root of this network.
So, we have a complete description if the root is ergodic. An immediate question is implied by this situation: Is something similar true if the root is not connected? In other words, it has more than one component, more precisely, what happens if the root is not ergodic.
The following theorem says, that the nice characterization (see Theorem5.1) is available if and only if the root is ergodic.
Theorem 5.4.
Let
 $I \subset \mathbb{R}$
be an interval,
$I \subset \mathbb{R}$
be an interval,
 $p \in \mathbb{N}$
,
$p \in \mathbb{N}$
,
 $\mathbf{d} \in \mathbb{N}^p$
,
$\mathbf{d} \in \mathbb{N}^p$
,
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
, and
 $\mathbf{M}=(M_1,\ldots ,M_p)$
be a
$\mathbf{M}=(M_1,\ldots ,M_p)$
be a
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
such that all
$I$
such that all
 $M_i$
-s are continuous and strict. Then there exists the unique
$M_i$
-s are continuous and strict. Then there exists the unique
 $\mathbf{M}_\alpha$
-invariant mean (the consensus) if and only if
$\mathbf{M}_\alpha$
-invariant mean (the consensus) if and only if
 $\mathcal{R}(G_\alpha )$
is ergodic.
$\mathcal{R}(G_\alpha )$
is ergodic.
Proof. see Appendix A.4.
Now we justify what happens if
 $\mathcal{R}(G_\alpha )$
is not connected. Then the iteration of elements in the root can be split into (at least two) independent iteration processes. There appears a natural problem: if convergence of elements in the root yields the convergence in the whole graph.
$\mathcal{R}(G_\alpha )$
is not connected. Then the iteration of elements in the root can be split into (at least two) independent iteration processes. There appears a natural problem: if convergence of elements in the root yields the convergence in the whole graph.
Example 5.5. We assume that the involved means are weighted arithmetic means (trivial weights, so projections are allowed). In this case, our model reduces to the DeGroot model.
Even, if the root is not ergodic, the limit of the iteration is unique; however, there is no unique invariant mean in this case (see Theorem 5.4 ).
Let’s consider the following numerical example.
Let
 $d=4$
and the
$d=4$
and the
 $d$
-averaging mapping
$d$
-averaging mapping
 $M\,\colon \mathbb{R}^4\to \mathbb{R}^4$
given by
$M\,\colon \mathbb{R}^4\to \mathbb{R}^4$
given by
 \begin{equation*} M(x_1,x_2,x_3,x_4)=\left (x_1,x_2,\frac {x_1+2x_2+3x_3+3x_4}{9},\frac {2x_1+x_2+x_3+2x_4}{6}\right ). \end{equation*}
\begin{equation*} M(x_1,x_2,x_3,x_4)=\left (x_1,x_2,\frac {x_1+2x_2+3x_3+3x_4}{9},\frac {2x_1+x_2+x_3+2x_4}{6}\right ). \end{equation*}
Then the corresponding graph of incidence is presented at Figure 5, and the corresponding row stochastic matrix is
 \begin{equation*} A\,:\!=\,\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} 1&0&0&0\\ 0&1&0&0\\ \dfrac {1}{9}&\dfrac {2}{9}&\dfrac {3}{9}&\dfrac {3}{9}\\[7pt] \dfrac {2}{6}&\dfrac {1}{6}&\dfrac {1}{6}&\dfrac {2}{6} \end{array}\right]. \end{equation*}
\begin{equation*} A\,:\!=\,\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} 1&0&0&0\\ 0&1&0&0\\ \dfrac {1}{9}&\dfrac {2}{9}&\dfrac {3}{9}&\dfrac {3}{9}\\[7pt] \dfrac {2}{6}&\dfrac {1}{6}&\dfrac {1}{6}&\dfrac {2}{6} \end{array}\right]. \end{equation*}
Then we can see that
 $M(x)=Ax$
for all
$M(x)=Ax$
for all
 $x \in \mathbb{R}^4$
. The limit of the iteration process is
$x \in \mathbb{R}^4$
. The limit of the iteration process is
 \begin{equation*} \lim \limits _{n\to \infty }A^n=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} 1&0&0&0\\ 0&1&0&0\\[3pt] \dfrac {10}{21}&\dfrac {11}{21}&0&0\\[7pt] \dfrac {13}{21}&\dfrac {8}{21}&0&0 \end{array}\right] \end{equation*}
\begin{equation*} \lim \limits _{n\to \infty }A^n=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} 1&0&0&0\\ 0&1&0&0\\[3pt] \dfrac {10}{21}&\dfrac {11}{21}&0&0\\[7pt] \dfrac {13}{21}&\dfrac {8}{21}&0&0 \end{array}\right] \end{equation*}
This means that the consensus of the agents will be the mixtures of the beliefs of the two components of the root with weights
 $\tfrac {10}{21},\tfrac {11}{21}$
and
$\tfrac {10}{21},\tfrac {11}{21}$
and
 $\tfrac {13}{21},\tfrac {8}{21}$
respectively.
$\tfrac {13}{21},\tfrac {8}{21}$
respectively.

Figure 5. Graph
 $G_\alpha$
related to Example 5.5.
$G_\alpha$
related to Example 5.5.
We would like to emphasize again the fact that the resulted limit is a possible consensus (invariant mean) and surely not the only one (see Theorem 5.2). Indeed, all means
 $K \,\colon \mathbb{R}^4 \to \mathbb{R}$
of the form
$K \,\colon \mathbb{R}^4 \to \mathbb{R}$
of the form
 \begin{equation} \begin{aligned} K(x_1,x_2,x_3,x_4)=K^*(x_1,x_2), \end{aligned} \end{equation}
\begin{equation} \begin{aligned} K(x_1,x_2,x_3,x_4)=K^*(x_1,x_2), \end{aligned} \end{equation}
where
 $K^* \,\colon \mathbb{R}^2 \to \mathbb{R}$
is a bivariate mean are
$K^* \,\colon \mathbb{R}^2 \to \mathbb{R}$
is a bivariate mean are
 $\mathbf{M}_\alpha$
-invariant. However, the description of the structure and properties of the remaining set of invariant means (common narratives, which are not the limit of the iteration process) in the general case could be a nice goal of further research.
$\mathbf{M}_\alpha$
-invariant. However, the description of the structure and properties of the remaining set of invariant means (common narratives, which are not the limit of the iteration process) in the general case could be a nice goal of further research.
This problem can be formulated in the following way. Do the non-root vertices impact the final consensus in a case when we have no final consensus in the root?
In the next example, we show that this is not the case. This example is much different from the previous approaches. Namely, we are going to study the iterations (and invariant means) only for two vectors. Furthermore, in this example, the mean-type mapping contains a mean (denoted by
 $F$
) which is not given explicitly.
$F$
) which is not given explicitly.
Example 5.6.
Let
 $I \subset \mathbb{R}$
be an interval and
$I \subset \mathbb{R}$
be an interval and
 $a,b,c,d \in I$
with
$a,b,c,d \in I$
with
 $a\lt b\lt c\lt d$
. There exists a symmetric, continuous, and strict mean
$a\lt b\lt c\lt d$
. There exists a symmetric, continuous, and strict mean
 $F \,\colon I^3 \to I$
such that
$F \,\colon I^3 \to I$
such that
 $F(a,d,b)=c$
and
$F(a,d,b)=c$
and
 $F(a,d,c)=b$
.
$F(a,d,c)=b$
.
Set
 $\mathbf{d}\,:\!=\,(1,1,3,3)$
,
$\mathbf{d}\,:\!=\,(1,1,3,3)$
,
 $\mathbf{d}$
-averaging mapping
$\mathbf{d}$
-averaging mapping
 $\mathbf{M}\,:\!=\,(\mathrm{id},\mathrm{id},F,F)$
(here
$\mathbf{M}\,:\!=\,(\mathrm{id},\mathrm{id},F,F)$
(here
 $\mathrm{id} \,\colon I \to I$
stands for the identical function) and set
$\mathrm{id} \,\colon I \to I$
stands for the identical function) and set
 \begin{equation*} \alpha \,:\!=\,\big ((1),(2),(1,2,4),(1,2,3)\big ) \in \mathbb{N}_4^{\mathbf{d}}, \end{equation*}
\begin{equation*} \alpha \,:\!=\,\big ((1),(2),(1,2,4),(1,2,3)\big ) \in \mathbb{N}_4^{\mathbf{d}}, \end{equation*}
which corresponds to the graph shown on Figure 6. Then we have
 \begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x,y,z,t)=\big (x,y,F(x,y,t),F(x,y,z)\big ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{M}_\alpha (x,y,z,t)=\big (x,y,F(x,y,t),F(x,y,z)\big ). \end{aligned} \end{equation*}
In particular for
 $v_1\,:\!=\,(a,d,b,c)$
and
$v_1\,:\!=\,(a,d,b,c)$
and
 $v_2\,:\!=\,(a,d,c,b)$
we have
$v_2\,:\!=\,(a,d,c,b)$
we have
 $\mathbf{M}_\alpha (v_i)=v_{3-i}$
(
$\mathbf{M}_\alpha (v_i)=v_{3-i}$
(
 $i \in \mathbb{N}_2$
).
$i \in \mathbb{N}_2$
).

Figure 6. Graph
 $G_\alpha$
related to Example 5.6.
$G_\alpha$
related to Example 5.6.
Observe that
 $R(G_\alpha )=\{1,2\}$
and thus
$R(G_\alpha )=\{1,2\}$
and thus
 $[\mathbf{M}_\alpha ^n]_i$
is convergent for all
$[\mathbf{M}_\alpha ^n]_i$
is convergent for all
 $i \in R(G_\alpha )$
, although it is (in general) not convergent for indexes which do not belong to the root.
$i \in R(G_\alpha )$
, although it is (in general) not convergent for indexes which do not belong to the root.
Now we define means
 $L_i,U_i \,\colon I^4\to I$
(
$L_i,U_i \,\colon I^4\to I$
(
 $i \in \mathbb{N}_4$
) by
$i \in \mathbb{N}_4$
) by
 \begin{equation*} \begin{aligned} L_i(v)=\liminf _{n \to \infty } [\mathbf{M}_\alpha ^n(v)]_i\qquad \text{ and }\qquad U_i(v)=\limsup _{n \to \infty } [\mathbf{M}_\alpha ^n(v)]_i. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} L_i(v)=\liminf _{n \to \infty } [\mathbf{M}_\alpha ^n(v)]_i\qquad \text{ and }\qquad U_i(v)=\limsup _{n \to \infty } [\mathbf{M}_\alpha ^n(v)]_i. \end{aligned} \end{equation*}
Clearly, for all
 $i \in \mathbb{N}_4$
, we have
$i \in \mathbb{N}_4$
, we have
 $L_i\circ \mathbf{M}_\alpha =L_i$
and
$L_i\circ \mathbf{M}_\alpha =L_i$
and
 $U_i\circ \mathbf{M}_\alpha =U_i$
, that is
$U_i\circ \mathbf{M}_\alpha =U_i$
, that is
 $L_i$
-s and
$L_i$
-s and
 $U_i$
-s are
$U_i$
-s are
 $\mathbf{M}_\alpha$
-invariant. For vectors
$\mathbf{M}_\alpha$
-invariant. For vectors
 $v_i$
(
$v_i$
(
 $i \in \mathbb{N}_2$
) these means are
$i \in \mathbb{N}_2$
) these means are
 \begin{equation*} \begin{aligned} L_1(v_i)=U_1(v_i)=a,\hskip 13.3mm&\quad L_2(v_i)=U_2(v_i)=d,\\ L_3(v_i)=L_4(v_i)=\min \! (b,c),&\quad U_3(v_i)=U_4(v_i)=\max \! (b,c). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} L_1(v_i)=U_1(v_i)=a,\hskip 13.3mm&\quad L_2(v_i)=U_2(v_i)=d,\\ L_3(v_i)=L_4(v_i)=\min \! (b,c),&\quad U_3(v_i)=U_4(v_i)=\max \! (b,c). \end{aligned} \end{equation*}
We can also manually verify that all these means are
 $\mathbf{M}_\alpha$
-invariant.
$\mathbf{M}_\alpha$
-invariant.
6. Conclusion and further research
We gave a general model of the spread of beliefs on networks, which contains the classical DeGroot model (DeGroot, Reference DeGroot1974) as a particular case. The key concept in our investigation was the notion of invariant means of certain averaging mappings. The root in the network has a special role, as we proved. Actually, the accepted narrative of the network depends on the belief of root agents only.
Pasteczka (Reference Pasteczka2023) proved that the
 $\mathbf{M}_\alpha$
-invariant mean is uniquely determined whenever each coordinate of
$\mathbf{M}_\alpha$
-invariant mean is uniquely determined whenever each coordinate of
 $\mathbf{M}$
is a continuous, strict mean and
$\mathbf{M}$
is a continuous, strict mean and
 $G_\alpha$
is an ergodic graph. Here we improved this statement to the case when
$G_\alpha$
is an ergodic graph. Here we improved this statement to the case when
 $\mathcal{R}(G_\alpha )$
is ergodic (Theorem5.1). Clearly, this generalizes the previous setup, since the root of an irreducible graph contains all vertices. We were also able to show some related properties of this invariant mean (Corollary 5.2). It is also worth mentioning that the ergodicity of the root is unavoidable due to the uniqueness of the invariant mean (Theorem5.4).
$\mathcal{R}(G_\alpha )$
is ergodic (Theorem5.1). Clearly, this generalizes the previous setup, since the root of an irreducible graph contains all vertices. We were also able to show some related properties of this invariant mean (Corollary 5.2). It is also worth mentioning that the ergodicity of the root is unavoidable due to the uniqueness of the invariant mean (Theorem5.4).
To the best of our knowledge, this general approach is new in the literature. So, several open problems can be posed concerning this new approach.
Let us mention just a few. One of the most important questions in our belief is the better understanding of the case when the root is not ergodic. There is no unique invariant mean in this case (see Theorem5.4). However, the iteration process results in a unique limit, which can be considered as a possible consensus at the end. It is not clear what the role of the other invariant means are in this case.
A good start for the investigation of this would be
 $d$
-averaging mappings containing only weighted arithmetic means (see Example 5.5).
$d$
-averaging mappings containing only weighted arithmetic means (see Example 5.5).
Another important question, which can simplify further investigations, is the following. If the root contains
 $k$
different components with
$k$
different components with
 $\alpha _i,\ i=1,\ldots ,k$
variables. And the corresponding invariant means are
$\alpha _i,\ i=1,\ldots ,k$
variables. And the corresponding invariant means are
 $K_1,\ldots , K_k$
, then do we get the same situation or not, if we substitute the aggregation process of root elements with the corresponding invariant mean at the very beginning?
$K_1,\ldots , K_k$
, then do we get the same situation or not, if we substitute the aggregation process of root elements with the corresponding invariant mean at the very beginning?
Furthermore, based on Example 5.6, we know that the convergence on sequence of iterates on the root set (in general) does not imply that it is convergent on remaining elements. On the other hand, we conjecture that it would be the case under some additional assumptions. For example, if we additionally assume that all means are monotone in their parameters.
Another possible direction to make the model more realistic is to assume that the agents and the influencers change their aggregation process in time. A possible approach to grab this is to use random means defined by Barczy and Burai (Reference Barczy and Burai2022).
Finally, it is not known how a modification of the mean in one vertex impacts to the whole iteration process. More precisely, is it true that if a single agent slightly changes the way of aggregating the belief then it will not have a big impact to the remaining part of the graph?
Acknowledgements
We would like to express our gratitude to the anonymous reviewers for their detailed and careful efforts. Specifically, we acknowledge the importance of focusing on DeGroot’s model, which provides substantial motivation for this research. The recommended modifications have greatly and significantly enhanced the quality of our work.
Funding statement
P. Burai acknowledges the support of the Hungarian National Research Development and Innovation Office (NKFIH) through the grant TKP2021-NVA-02.
Data availability
The authors confirm that the data supporting the findings of this study are available within the article.
Competing interests
The authors declare that they have no conflict of interest.
Appendix A. Proofs
A.1 Proof of Theorem4.4
This proof is split into three steps.
A.1.1
We prove that the root set is a set of minimal elements with respect to a certain ordering in V.
Let us introduce the relation on
 $V$
as follows
$V$
as follows
 \begin{equation*} \begin{aligned} p \prec q :\iff p\ne q,\ p \leadsto _G q \text{ and }q \not \leadsto _G p. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} p \prec q :\iff p\ne q,\ p \leadsto _G q \text{ and }q \not \leadsto _G p. \end{aligned} \end{equation*}
First, observe that
 $\prec$
is a strict partial ordering of elements in
$\prec$
is a strict partial ordering of elements in
 $V$
.
$V$
.
Second, if
 $p$
and
$p$
and
 $q$
are in the same SCC then
$q$
are in the same SCC then
 $p \not \prec q$
. Whence each element of
$p \not \prec q$
. Whence each element of
 $R(G)$
is minimal with respect to
$R(G)$
is minimal with respect to
 $\prec$
in
$\prec$
in
 $V$
.
$V$
.
Conversely, if
 $p$
is not a minimal element (with respect to
$p$
is not a minimal element (with respect to
 $\prec$
) then there exists a
$\prec$
) then there exists a
 $\bar p$
such that
$\bar p$
such that
 $\bar p \prec p$
. Then
$\bar p \prec p$
. Then
 $\bar p$
is in the different SCC than
$\bar p$
is in the different SCC than
 $p$
and there exists a path
$p$
and there exists a path
 $\bar p \leadsto p$
. Consequently
$\bar p \leadsto p$
. Consequently
 $[p]_\sim \notin \textrm {source}(G^{SCC})$
, and whence
$[p]_\sim \notin \textrm {source}(G^{SCC})$
, and whence
 $p \notin R(G)$
. That is,
$p \notin R(G)$
. That is,
 $R(G)$
is exactly the set of minimal elements in the ordering
$R(G)$
is exactly the set of minimal elements in the ordering
 $\prec$
.
$\prec$
.
A.1.2
We show that conditions (i) and (ii) hold for
 $S=R(G)$
.
$S=R(G)$
.
Indeed, for every
 $v \in V$
there exists
$v \in V$
there exists
 $w \in R(G)$
such
$w \in R(G)$
such
 $w \prec v$
, which implies that condition (i) holds for
$w \prec v$
, which implies that condition (i) holds for
 $S=R(G)$
.
$S=R(G)$
.
Now assume that
 $v \in R(G)$
and
$v \in R(G)$
and
 $(wv) \in E$
for some
$(wv) \in E$
for some
 $w \in G \setminus \{v\}$
. Then, since
$w \in G \setminus \{v\}$
. Then, since
 $v$
is minimal we have
$v$
is minimal we have
 $w \not \prec v$
. Whence one of three cases hold:
$w \not \prec v$
. Whence one of three cases hold:
 $w=v$
(which we can exclude),
$w=v$
(which we can exclude),
 $w \not \leadsto _G v$
(which is impossible since
$w \not \leadsto _G v$
(which is impossible since
 $(wv) \in E$
) or
$(wv) \in E$
) or
 $v \leadsto _G w$
which implies that
$v \leadsto _G w$
which implies that
 $v$
and
$v$
and
 $w$
are in the same SCC. Whence
$w$
are in the same SCC. Whence
 $w \in R(G)$
, which implies that (ii) holds for
$w \in R(G)$
, which implies that (ii) holds for
 $S=R(G)$
.
$S=R(G)$
.
A.1.3
Now take any set
 $S \subset V$
such that conditions (i) and (ii) hold. Observe that if
$S \subset V$
such that conditions (i) and (ii) hold. Observe that if
 $v \in S$
and
$v \in S$
and
 $w \prec v$
then
$w \prec v$
then
 $w \leadsto _G v$
and (applying condition (ii) inductively) we get
$w \leadsto _G v$
and (applying condition (ii) inductively) we get
 $w \in S$
.
$w \in S$
.
Now take any
 $v \in R(G)$
. Applying condition (i), there exists
$v \in R(G)$
. Applying condition (i), there exists
 $v^* \in S$
such that
$v^* \in S$
such that
 $v^* \leadsto _G v$
. Then, since
$v^* \leadsto _G v$
. Then, since
 $v^* \not \prec v$
we have that
$v^* \not \prec v$
we have that
 $v=v^*$
or
$v=v^*$
or
 $v \leadsto _G v^*$
, and therefore
$v \leadsto _G v^*$
, and therefore
 $v \in S$
. Thus
$v \in S$
. Thus
 $R(G) \subseteq S$
.
$R(G) \subseteq S$
.
A.2 Proof of Theorem5.1
Let us assume without loss of generality that
 $R(G_\alpha )=(1,\ldots ,q)$
for some
$R(G_\alpha )=(1,\ldots ,q)$
for some
 $q \in \{1,\ldots ,p\}$
.
$q \in \{1,\ldots ,p\}$
.
If
 $q=p$
then all vertices of
$q=p$
then all vertices of
 $G_\alpha$
belong to the root. Whence
$G_\alpha$
belong to the root. Whence
 $G_\alpha$
is irreducible, and
$G_\alpha$
is irreducible, and
 $G_\alpha =\mathcal{R}(G_\alpha )$
is aperiodic. So,
$G_\alpha =\mathcal{R}(G_\alpha )$
is aperiodic. So,
 $G_\alpha$
is ergodic and this theorem is implied by Theorem4.8. For the remaining part of the proof we assume that
$G_\alpha$
is ergodic and this theorem is implied by Theorem4.8. For the remaining part of the proof we assume that
 $q\in \{1,\ldots ,p-1\}$
.
$q\in \{1,\ldots ,p-1\}$
.
For
 $v \in V$
define
$v \in V$
define
 ${\textrm {rank}}(v)$
as the distance of
${\textrm {rank}}(v)$
as the distance of
 $v$
from the closest vertex in
$v$
from the closest vertex in
 $R(G_\alpha )$
. If
$R(G_\alpha )$
. If
 $v \in R(G_\alpha )$
then we set
$v \in R(G_\alpha )$
then we set
 ${\textrm {rank}}(v)\,:\!=\,0$
.
${\textrm {rank}}(v)\,:\!=\,0$
.
For
 $k \ge 0$
define
$k \ge 0$
define
 $V_k\,:\!=\,\{v \in V \,\colon {\textrm {rank}}(v)\le k\}$
. Obviously,
$V_k\,:\!=\,\{v \in V \,\colon {\textrm {rank}}(v)\le k\}$
. Obviously,
 $R(G_\alpha )=V_0 \subseteq V_1 \subseteq V_2 \subseteq \cdots$
and there exists
$R(G_\alpha )=V_0 \subseteq V_1 \subseteq V_2 \subseteq \cdots$
and there exists
 $k_0$
such that
$k_0$
such that
 $V=V_{k_0}$
.
$V=V_{k_0}$
.
A.2.1 Means with coordinates in
$V_0$

Since
 $V_0=(1,\ldots ,q)$
is the root of
$V_0=(1,\ldots ,q)$
is the root of
 $G_\alpha$
, we obtain that all means
$G_\alpha$
, we obtain that all means
 $[\mathbf{M}_\alpha ]_1,\ldots ,[\mathbf{M}_\alpha ]_q$
depend on the first
$[\mathbf{M}_\alpha ]_1,\ldots ,[\mathbf{M}_\alpha ]_q$
depend on the first
 $q$
variables only. Therefore let
$q$
variables only. Therefore let
 $\pi \,\colon I^p \to I^q$
be the projection to the first
$\pi \,\colon I^p \to I^q$
be the projection to the first
 $q$
variables.
$q$
variables.
Thus, if we define
 $\mathbf{M}^*=(M_1,\ldots ,M_q)$
and
$\mathbf{M}^*=(M_1,\ldots ,M_q)$
and
 $\alpha ^*=(\alpha _1,\ldots ,\alpha _q)$
we get
$\alpha ^*=(\alpha _1,\ldots ,\alpha _q)$
we get
 \begin{align*} [\mathbf{M}_\alpha ]_s (x)&=[\mathbf{M}_\alpha ]_s (x_1,\ldots ,x_p)=M_s^{(p;\alpha _s)}(x_1,\ldots ,x_p)=M_s^{(q;\alpha _s)}(x_1,\ldots ,x_q)\\ &=[\mathbf{M}^*_{\alpha ^*}]_s(x_1,\ldots ,x_q)=[\mathbf{M}^*_{\alpha ^*}]_s \circ \pi (x_1,\ldots ,x_p)=[\mathbf{M}^*_{\alpha ^*}]_s \circ \pi (x) \end{align*}
\begin{align*} [\mathbf{M}_\alpha ]_s (x)&=[\mathbf{M}_\alpha ]_s (x_1,\ldots ,x_p)=M_s^{(p;\alpha _s)}(x_1,\ldots ,x_p)=M_s^{(q;\alpha _s)}(x_1,\ldots ,x_q)\\ &=[\mathbf{M}^*_{\alpha ^*}]_s(x_1,\ldots ,x_q)=[\mathbf{M}^*_{\alpha ^*}]_s \circ \pi (x_1,\ldots ,x_p)=[\mathbf{M}^*_{\alpha ^*}]_s \circ \pi (x) \end{align*}
for all
 $s \in V_0$
and
$s \in V_0$
and
 $x=(x_1,\ldots ,x_p) \in I^p$
. If we apply this equality to all admissible
$x=(x_1,\ldots ,x_p) \in I^p$
. If we apply this equality to all admissible
 $s$
we get
$s$
we get
 $\pi \circ \mathbf{M}_\alpha =\mathbf{M}^*_{\alpha ^*}\circ \pi$
. This, by easy induction, yields
$\pi \circ \mathbf{M}_\alpha =\mathbf{M}^*_{\alpha ^*}\circ \pi$
. This, by easy induction, yields
 \begin{equation} \begin{aligned} \pi \circ \mathbf{M}_\alpha ^n=(\mathbf{M}^*_{\alpha ^*})^n\circ \pi \text{ for all }n \in \mathbb{N}. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} \pi \circ \mathbf{M}_\alpha ^n=(\mathbf{M}^*_{\alpha ^*})^n\circ \pi \text{ for all }n \in \mathbb{N}. \end{aligned} \end{equation}
However
 $G_{\alpha ^*}$
is a graph
$G_{\alpha ^*}$
is a graph
 $G_\alpha$
restricted to
$G_\alpha$
restricted to
 $V_0$
, whence we obtain
$V_0$
, whence we obtain
 $G_{\alpha ^*}=\mathcal{R}(G_\alpha )$
. Since
$G_{\alpha ^*}=\mathcal{R}(G_\alpha )$
. Since
 $\mathcal{R}(G_\alpha )$
is ergodic, by Theorem4.8, there exists the unique
$\mathcal{R}(G_\alpha )$
is ergodic, by Theorem4.8, there exists the unique
 $\mathbf{M}^*_{\alpha ^*}$
-invariant mean
$\mathbf{M}^*_{\alpha ^*}$
-invariant mean
 $K \,\colon I^q \to I$
and the sequence of iterates
$K \,\colon I^q \to I$
and the sequence of iterates
 $((\mathbf{M}^*_{\alpha ^*})^n)_{n=1}^\infty$
converges to
$((\mathbf{M}^*_{\alpha ^*})^n)_{n=1}^\infty$
converges to
 $\mathbf{K}^*\,:\!=\,(K,\ldots ,K) \,\colon I^q \to I^q$
. Then, by (A.1),
$\mathbf{K}^*\,:\!=\,(K,\ldots ,K) \,\colon I^q \to I^q$
. Then, by (A.1),
 $(\pi \circ \mathbf{M}_\alpha ^n)_{n=1}^\infty$
converges to
$(\pi \circ \mathbf{M}_\alpha ^n)_{n=1}^\infty$
converges to
 $\mathbf{K}^* \circ \pi$
. In other words
$\mathbf{K}^* \circ \pi$
. In other words
 \begin{equation} \begin{aligned} ([\mathbf{M}_\alpha ^n]_i)_{n=1}^\infty \text{ converges to }K\circ \pi \text{ on }I^p \text{ for all }i \in V_0. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} ([\mathbf{M}_\alpha ^n]_i)_{n=1}^\infty \text{ converges to }K\circ \pi \text{ on }I^p \text{ for all }i \in V_0. \end{aligned} \end{equation}
A.2.2 General case
Take
 $x \in I^p$
arbitrary and set
$x \in I^p$
arbitrary and set
 $u_i\,:\!=\, \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)$
(
$u_i\,:\!=\, \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)$
(
 $i \in \{1,\ldots ,p\}$
). Property (A.2) implies
$i \in \{1,\ldots ,p\}$
). Property (A.2) implies
 \begin{equation} \begin{aligned} u_i=K \circ \pi (x) \text{ for all }i \in V_0. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} u_i=K \circ \pi (x) \text{ for all }i \in V_0. \end{aligned} \end{equation}
Let
 $i_0 \in \{1,\ldots p\}$
be a number that satisfies
$i_0 \in \{1,\ldots p\}$
be a number that satisfies
 $u_{i_0}=\max \{u_i \,\colon i \in \{1,\ldots ,p\}\}$
with the minimal rank. We show that
$u_{i_0}=\max \{u_i \,\colon i \in \{1,\ldots ,p\}\}$
with the minimal rank. We show that
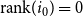 ${\textrm {rank}}(i_0)=0$
.
${\textrm {rank}}(i_0)=0$
.
A.2.3
${\textrm {rank}}(i_0)=0$

Assume to the contrary that
 $k\,:\!=\,{\textrm {rank}}(i_0)\gt 0$
. Then
$k\,:\!=\,{\textrm {rank}}(i_0)\gt 0$
. Then
 $i_0 \in V_k \setminus V_{k-1}$
and, since
$i_0 \in V_k \setminus V_{k-1}$
and, since
 $i_0$
have a minimal rank, we get
$i_0$
have a minimal rank, we get
 $\rho \,:\!=\,\max \{u_i \,\colon i \in V_{k-1}\}\lt u_{i_0}$
. Whence for all
$\rho \,:\!=\,\max \{u_i \,\colon i \in V_{k-1}\}\lt u_{i_0}$
. Whence for all
 $\varepsilon \in (0,+\infty )$
there exists
$\varepsilon \in (0,+\infty )$
there exists
 $n_\varepsilon$
such that
$n_\varepsilon$
such that
 \begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \le \rho +\varepsilon \text{ for all }n\ge n_\varepsilon \text{ and } i \in V_{k-1}. \end{equation*}
\begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \le \rho +\varepsilon \text{ for all }n\ge n_\varepsilon \text{ and } i \in V_{k-1}. \end{equation*}
Then we have that
 \begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \in [\! \min x,\rho +\varepsilon ] \cap I \,=\!:\, A_\varepsilon \text{ for all }n \ge n_\varepsilon \text{ and } i \in V_{k-1}. \end{equation*}
\begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \in [\! \min x,\rho +\varepsilon ] \cap I \,=\!:\, A_\varepsilon \text{ for all }n \ge n_\varepsilon \text{ and } i \in V_{k-1}. \end{equation*}
Moreover, there exists
 $m_\varepsilon$
such that
$m_\varepsilon$
such that
 \begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \in [\! \min x,u_i+\varepsilon ] \cap I \subset [\! \min x,u_{i_0}+\varepsilon ] \cap I =:B_\varepsilon \end{equation*}
\begin{equation*} [\mathbf{M}_\alpha ^n]_i(x) \in [\! \min x,u_i+\varepsilon ] \cap I \subset [\! \min x,u_{i_0}+\varepsilon ] \cap I =:B_\varepsilon \end{equation*}
for all
 $n\ge m_\varepsilon$
and
$n\ge m_\varepsilon$
and
 $i \in V.$
$i \in V.$
Clearly
 $A_\varepsilon \subseteq B_\varepsilon$
for all
$A_\varepsilon \subseteq B_\varepsilon$
for all
 $\varepsilon \gt 0$
. Now for
$\varepsilon \gt 0$
. Now for
 $\varepsilon \ge 0$
, let us define the set
$\varepsilon \ge 0$
, let us define the set
 $\Lambda _\varepsilon \,:\!=\,\prod _{i =1}^p H_\varepsilon (i) \subset I^p$
, where
$\Lambda _\varepsilon \,:\!=\,\prod _{i =1}^p H_\varepsilon (i) \subset I^p$
, where
 \begin{equation*} H_\varepsilon (i)=\begin{cases} A_\varepsilon &\text{ for }i\in V_{k-1};\\ B_\varepsilon &\text{ for }i \in V \setminus V_{k-1}. \end{cases} \end{equation*}
\begin{equation*} H_\varepsilon (i)=\begin{cases} A_\varepsilon &\text{ for }i\in V_{k-1};\\ B_\varepsilon &\text{ for }i \in V \setminus V_{k-1}. \end{cases} \end{equation*}
Then
 $\mathbf{M}_\alpha ^n(x) \in \Lambda _\varepsilon$
for all
$\mathbf{M}_\alpha ^n(x) \in \Lambda _\varepsilon$
for all
 $n \ge \max (n_\varepsilon ,m_\varepsilon )$
. Moreover for all
$n \ge \max (n_\varepsilon ,m_\varepsilon )$
. Moreover for all
 $i \in \{1,\ldots ,p\}$
the mapping
$i \in \{1,\ldots ,p\}$
the mapping
 $[0,+\infty ) \ni \varepsilon \mapsto H_\varepsilon (i)$
is topologically continuous. Thus, so is
$[0,+\infty ) \ni \varepsilon \mapsto H_\varepsilon (i)$
is topologically continuous. Thus, so is
 $[0,+\infty ) \ni \varepsilon \mapsto \Lambda _\varepsilon$
. Therefore, the function
$[0,+\infty ) \ni \varepsilon \mapsto \Lambda _\varepsilon$
. Therefore, the function
 \begin{equation*} \begin{aligned} \varphi \,\colon [0,+\infty ) \ni \varepsilon \mapsto \sup \big \{[\mathbf{M}_\alpha ]_{i_0}(y) \,\colon y \in \Lambda _\varepsilon \big \} \in [\min (x),\infty ) \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \varphi \,\colon [0,+\infty ) \ni \varepsilon \mapsto \sup \big \{[\mathbf{M}_\alpha ]_{i_0}(y) \,\colon y \in \Lambda _\varepsilon \big \} \in [\min (x),\infty ) \end{aligned} \end{equation*}
is also continuous. But, since
 ${\textrm {rank}}(i_0)=k$
, there exists
${\textrm {rank}}(i_0)=k$
, there exists
 $j \in V_{k-1}$
such that
$j \in V_{k-1}$
such that
 $(j,i_0) \in E$
. Equivalently, the mean
$(j,i_0) \in E$
. Equivalently, the mean
 $[\mathbf{M}_\alpha ]_{i_0}$
depends on the
$[\mathbf{M}_\alpha ]_{i_0}$
depends on the
 $j$
-th variable, say
$j$
-th variable, say
 $\alpha _{i_0,q}=j$
for some
$\alpha _{i_0,q}=j$
for some
 $q \in \{1,\ldots ,d_{i_0}\}$
.
$q \in \{1,\ldots ,d_{i_0}\}$
.
Therefore, for all
 $\varepsilon \gt 0$
, we have
$\varepsilon \gt 0$
, we have
 \begin{align*} \varphi (\varepsilon )&= \sup \big \{[\mathbf{M}_\alpha ]_{i_0}(y) \,\colon y \in \Lambda_\varepsilon \big \} \\ &= \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon (y_1,\ldots ,y_p) \in \Lambda _\varepsilon \big \} \\ &= \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon y_1 \in H_\varepsilon (1),\ldots ,y_p \in H_\varepsilon (p)\big \} \\ &\le \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon y_j \in A_\varepsilon ,\text{ and } y_i \in B_\varepsilon \text{ for }i \ne j\big \} \\ &\le \sup \big \{M_{i_0}(z_1,z_2,\ldots ,z_{d_{i_0}}) \,\colon z_q \in A_\varepsilon ,\text{ and } z_k \in B_\varepsilon \text{ for }k \ne q\big \}\\ &= \sup \big \{M_{i_0}(z) \,\colon z \in B_\varepsilon ^{d_{i_0}}, z_q \in A_\varepsilon \big \} =:\psi (\varepsilon ). \end{align*}
\begin{align*} \varphi (\varepsilon )&= \sup \big \{[\mathbf{M}_\alpha ]_{i_0}(y) \,\colon y \in \Lambda_\varepsilon \big \} \\ &= \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon (y_1,\ldots ,y_p) \in \Lambda _\varepsilon \big \} \\ &= \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon y_1 \in H_\varepsilon (1),\ldots ,y_p \in H_\varepsilon (p)\big \} \\ &\le \sup \big \{M_{i_0}(y_{\alpha _{i_0,1}},\ldots ,y_{\alpha _{i_0,d_{i_0}}}) \,\colon y_j \in A_\varepsilon ,\text{ and } y_i \in B_\varepsilon \text{ for }i \ne j\big \} \\ &\le \sup \big \{M_{i_0}(z_1,z_2,\ldots ,z_{d_{i_0}}) \,\colon z_q \in A_\varepsilon ,\text{ and } z_k \in B_\varepsilon \text{ for }k \ne q\big \}\\ &= \sup \big \{M_{i_0}(z) \,\colon z \in B_\varepsilon ^{d_{i_0}}, z_q \in A_\varepsilon \big \} =:\psi (\varepsilon ). \end{align*}
However, since it is a supremum of a continuous function over a compact set, it attaches its maximum. Thus, for all
 $\varepsilon \gt 0$
, there exists
$\varepsilon \gt 0$
, there exists
 $z^{(\varepsilon )} \in C_\varepsilon \,:\!=\,\{ z\in B_\varepsilon ^{d_{i_0}} \,\colon z_q \in A_\varepsilon \}$
such that
$z^{(\varepsilon )} \in C_\varepsilon \,:\!=\,\{ z\in B_\varepsilon ^{d_{i_0}} \,\colon z_q \in A_\varepsilon \}$
such that
 $\psi (\varepsilon )=M_{i_0}(z^{(\varepsilon )})$
. Since
$\psi (\varepsilon )=M_{i_0}(z^{(\varepsilon )})$
. Since
 $M_{i_0}$
is continuous, we obtain that
$M_{i_0}$
is continuous, we obtain that
 $\psi$
is nondecreasing and continuous.
$\psi$
is nondecreasing and continuous.
Let
 $\bar z$
be any accumulation point of the set
$\bar z$
be any accumulation point of the set
 $\{z^{(1/n)} \,\colon n \in \mathbb{N}\}$
. Clearly
$\{z^{(1/n)} \,\colon n \in \mathbb{N}\}$
. Clearly
 $\bar z$
belongs to the topological limit of
$\bar z$
belongs to the topological limit of
 $C_\varepsilon$
, that is
$C_\varepsilon$
, that is
 $\bar z \in \{ z \in [\min x,u_{i_0}]^{d_{i_0}} \,\colon z_q \in [\min x,\rho ]\}$
.
$\bar z \in \{ z \in [\min x,u_{i_0}]^{d_{i_0}} \,\colon z_q \in [\min x,\rho ]\}$
.
Since
 $M_{i_0}$
is a strict mean and
$M_{i_0}$
is a strict mean and
 $\rho \lt u_{i_0}$
, we get
$\rho \lt u_{i_0}$
, we get
 $M_{i_0}(\bar z)\lt u_{i_0}$
. Whence, since
$M_{i_0}(\bar z)\lt u_{i_0}$
. Whence, since
 $\varphi$
and
$\varphi$
and
 $\psi$
are nonincreasing and
$\psi$
are nonincreasing and
 $\varphi \le \psi$
we get
$\varphi \le \psi$
we get
 \begin{equation*} \begin{aligned} \lim _{\varepsilon \to 0^+}\varphi (\varepsilon ) \le \lim _{\varepsilon \to 0^+}\psi (\varepsilon ) =\liminf _{n \to \infty }\psi (\tfrac 1n) =\liminf _{n \to \infty }M_{i_0}(z^{(1/n)})\le M_{i_0}(\bar z)\lt u_{i_0}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \lim _{\varepsilon \to 0^+}\varphi (\varepsilon ) \le \lim _{\varepsilon \to 0^+}\psi (\varepsilon ) =\liminf _{n \to \infty }\psi (\tfrac 1n) =\liminf _{n \to \infty }M_{i_0}(z^{(1/n)})\le M_{i_0}(\bar z)\lt u_{i_0}. \end{aligned} \end{equation*}
Consequently, there exists
 $\varepsilon _0$
such that
$\varepsilon _0$
such that
 $\varphi (\varepsilon _0)\lt u_{i_0}$
. Then, for all
$\varphi (\varepsilon _0)\lt u_{i_0}$
. Then, for all
 $n \ge \max (n_{\varepsilon _0},m_{\varepsilon _0})$
we have
$n \ge \max (n_{\varepsilon _0},m_{\varepsilon _0})$
we have
 $\mathbf{M}_\alpha ^n(x) \in \Lambda _{\varepsilon _0}$
, that is
$\mathbf{M}_\alpha ^n(x) \in \Lambda _{\varepsilon _0}$
, that is
 $[\mathbf{M}_\alpha ^n]_{i_0}(x)\le \varphi (\varepsilon _0)$
. Therefore
$[\mathbf{M}_\alpha ^n]_{i_0}(x)\le \varphi (\varepsilon _0)$
. Therefore
 \begin{equation*} \begin{aligned} \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_{i_0}(x)\le \varphi (\varepsilon _0)\lt u_{i_0}=\limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_{i_0}(x), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_{i_0}(x)\le \varphi (\varepsilon _0)\lt u_{i_0}=\limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_{i_0}(x), \end{aligned} \end{equation*}
a contradiction. Thus
 ${\textrm {rank}}(i_0)=0$
.
${\textrm {rank}}(i_0)=0$
.
A.2.4 Conclusion
Since
 ${\textrm {rank}}(i_0)=0$
we have
${\textrm {rank}}(i_0)=0$
we have
 $i_0 \in V_0$
. Whence, by (A.3), we get
$i_0 \in V_0$
. Whence, by (A.3), we get
 \begin{equation*} \begin{aligned} \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)=u_i \le u_{i_0}=K\circ \pi (x) \text{ for any } i \in V. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \limsup _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)=u_i \le u_{i_0}=K\circ \pi (x) \text{ for any } i \in V. \end{aligned} \end{equation*}
Analogously, we can show the property
 \begin{equation*} \begin{aligned} \liminf _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x) \ge K\circ \pi (x) \text{ for any } i \in V, \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \liminf _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x) \ge K\circ \pi (x) \text{ for any } i \in V, \end{aligned} \end{equation*}
Whence (5.1) holds with
 $K_\alpha =K \circ \pi (x)$
. If we set
$K_\alpha =K \circ \pi (x)$
. If we set
 $K_\alpha ^*\,:\!=\,K$
then, for all
$K_\alpha ^*\,:\!=\,K$
then, for all
 $i \in V$
and
$i \in V$
and
 $x \in I^p$
, we have
$x \in I^p$
, we have
 \begin{equation*} \begin{aligned} \lim _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)=K\circ \pi (x)=K_\alpha ^* \circ \pi (x)=\end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \lim _{n \to \infty } [\mathbf{M}_\alpha ^n]_i(x)=K\circ \pi (x)=K_\alpha ^* \circ \pi (x)=\end{aligned} \end{equation*}
 \begin{equation*} \begin{aligned} =K_\alpha ^*(x_i \,\colon i \in R(G_\alpha ))=K_\alpha (x_1,\ldots ,x_p), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} =K_\alpha ^*(x_i \,\colon i \in R(G_\alpha ))=K_\alpha (x_1,\ldots ,x_p), \end{aligned} \end{equation*}
which completes the proof.
A.3 Proof of Corollary 5.2
Applying Theorem5.1 twice, for all
 $x \in I^p$
we have
$x \in I^p$
we have
 \begin{equation*} \begin{aligned} \mathbf{K}_\alpha (x)=\lim _{n \to \infty } \mathbf{M}_\alpha ^n (x)=\lim _{n \to \infty } \mathbf{M}_\alpha ^n \big (\mathbf{M}_\alpha (x)\big )=\mathbf{K}_\alpha \circ \mathbf{M}_\alpha (x), \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \mathbf{K}_\alpha (x)=\lim _{n \to \infty } \mathbf{M}_\alpha ^n (x)=\lim _{n \to \infty } \mathbf{M}_\alpha ^n \big (\mathbf{M}_\alpha (x)\big )=\mathbf{K}_\alpha \circ \mathbf{M}_\alpha (x), \end{aligned} \end{equation*}
which yields (a).
Properties (b) and (c) are consequences of Theorem5.1 too. Indeed, if all
 $M_i$
-s are nondecreasing (resp. homogenous) then so are all entries in
$M_i$
-s are nondecreasing (resp. homogenous) then so are all entries in
 $\mathbf{M}_\alpha$
. Then all entries in the sequence of iterates
$\mathbf{M}_\alpha$
. Then all entries in the sequence of iterates
 $\mathbf{M}_\alpha ^n$
also possess this property. Since it is inherited by the limit procedure, in view of (5.1) we obtain that
$\mathbf{M}_\alpha ^n$
also possess this property. Since it is inherited by the limit procedure, in view of (5.1) we obtain that
 $K$
is nondecreasing (resp. homogenous).
$K$
is nondecreasing (resp. homogenous).
A.4 Proof of Theorem5.4
If
 $\mathcal{R}(G_\alpha )$
is ergodic then, as an immediate consequence of Theorem5.1, we obtain that
$\mathcal{R}(G_\alpha )$
is ergodic then, as an immediate consequence of Theorem5.1, we obtain that
 $\mathbf{M}_\alpha$
-invariant mean is uniquely determined.
$\mathbf{M}_\alpha$
-invariant mean is uniquely determined.
For the converse implication, let us take
 $p \in \mathbb{N}$
,
$p \in \mathbb{N}$
,
 $\mathbf{d} \in \mathbb{N}^p$
, and
$\mathbf{d} \in \mathbb{N}^p$
, and
 $\alpha \in \mathbb{N}_p^{\mathbf{d}}$
so that
$\alpha \in \mathbb{N}_p^{\mathbf{d}}$
so that
 $\mathcal{R}(G_\alpha )$
is not connected or periodic. Moreover, let
$\mathcal{R}(G_\alpha )$
is not connected or periodic. Moreover, let
 $\mathbf{M}=(M_1,\ldots ,M_p)$
be an arbitrary
$\mathbf{M}=(M_1,\ldots ,M_p)$
be an arbitrary
 $\mathbf{d}$
-averaging mapping on
$\mathbf{d}$
-averaging mapping on
 $I$
such that all
$I$
such that all
 $M_i$
-s are continuous and strict. This splits our proof into two parts.
$M_i$
-s are continuous and strict. This splits our proof into two parts.
A.4.1
If
 $\mathcal{R}(G_\alpha )$
is not connected then for all
$\mathcal{R}(G_\alpha )$
is not connected then for all
 $v \in V$
there exists
$v \in V$
there exists
 $\bar v \in V$
such that there is no path from
$\bar v \in V$
such that there is no path from
 $v$
to
$v$
to
 $\bar v$
. Let us define, for all
$\bar v$
. Let us define, for all
 $v \in V$
, sets
$v \in V$
, sets
 \begin{equation*} \begin{aligned} {\textrm {succ}}(v)\,:\!=\,\{v\}\cup \{w \in V \,\colon v \leadsto w\}; \quad {\textrm {prec}}(v)\,:\!=\,\{v\} \cup \{w \in V\,\colon w \leadsto v\}. \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} {\textrm {succ}}(v)\,:\!=\,\{v\}\cup \{w \in V \,\colon v \leadsto w\}; \quad {\textrm {prec}}(v)\,:\!=\,\{v\} \cup \{w \in V\,\colon w \leadsto v\}. \end{aligned} \end{equation*}
Clearly, for every
 $v \in V$
we have
$v \in V$
we have
 ${\textrm {succ}}(v) \cap {\textrm {prec}}(\bar v)=\emptyset$
. Moreover
${\textrm {succ}}(v) \cap {\textrm {prec}}(\bar v)=\emptyset$
. Moreover
 ${\textrm {prec}}(v) \ne \emptyset$
for all
${\textrm {prec}}(v) \ne \emptyset$
for all
 $v \in V$
.
$v \in V$
.
Moreover, each vertex has an in-neighbor and
 \begin{equation} \begin{aligned} {\textrm {succ}}(w) \supseteq {\textrm {succ}}(v) \text{ for all }w \in N_G^-(v). \end{aligned} \end{equation}
\begin{equation} \begin{aligned} {\textrm {succ}}(w) \supseteq {\textrm {succ}}(v) \text{ for all }w \in N_G^-(v). \end{aligned} \end{equation}
Now let
 $V_0$
be the maximal element of
$V_0$
be the maximal element of
 $\{{\textrm {succ}}(v) \,\colon v \in V\}$
. Then, in view of (A.4) we have
$\{{\textrm {succ}}(v) \,\colon v \in V\}$
. Then, in view of (A.4) we have
 ${\textrm {succ}}(w)=V_0$
for all
${\textrm {succ}}(w)=V_0$
for all
 $w \in N_G^-(v)$
. This implies that there are no edges from
$w \in N_G^-(v)$
. This implies that there are no edges from
 $V_0$
to
$V_0$
to
 $V \setminus V_0$
(that is,
$V \setminus V_0$
(that is,
 $E \cap (V_0 \times (V \setminus V_0))=\emptyset$
).
$E \cap (V_0 \times (V \setminus V_0))=\emptyset$
).
Moreover, by simple induction, we have
 ${\textrm {succ}}(w)=V_0$
for all
${\textrm {succ}}(w)=V_0$
for all
 $w \in {\textrm {prec}}(v_0)$
. Since
$w \in {\textrm {prec}}(v_0)$
. Since
 $v \in {\textrm {succ}}(v)$
for all
$v \in {\textrm {succ}}(v)$
for all
 $v\in V$
we get
$v\in V$
we get
 ${\textrm {prec}}(v) \subset V_0$
for all
${\textrm {prec}}(v) \subset V_0$
for all
 $v \in V_0$
(that is,
$v \in V_0$
(that is,
 $E \cap ((V \setminus V_0) \times V_0) =\emptyset$
).
$E \cap ((V \setminus V_0) \times V_0) =\emptyset$
).
Finally, we have
 $E \subset V_0^2 \cup (V \setminus V_0)^2$
. Therefore every vector
$E \subset V_0^2 \cup (V \setminus V_0)^2$
. Therefore every vector
 $x \in I^p$
of the form
$x \in I^p$
of the form
 \begin{equation*} x_i = \begin{cases} \gamma & \text{ if } i \in V_0\\ \delta & \text{ if } i \in V \setminus \! V_0 \end{cases} \end{equation*}
\begin{equation*} x_i = \begin{cases} \gamma & \text{ if } i \in V_0\\ \delta & \text{ if } i \in V \setminus \! V_0 \end{cases} \end{equation*}
(where
 $\gamma ,\delta \in I$
) is a fixed point of
$\gamma ,\delta \in I$
) is a fixed point of
 $\mathbf{M}_\alpha$
. By Proposition 4.9 we obtain that
$\mathbf{M}_\alpha$
. By Proposition 4.9 we obtain that
 $\mathbf{M}_\alpha$
-invariant mean is not unique.
$\mathbf{M}_\alpha$
-invariant mean is not unique.
A.4.2
If
 $\mathcal{R}(G_\alpha )=(V_0,E_0)$
is nonempty and periodic then there exists
$\mathcal{R}(G_\alpha )=(V_0,E_0)$
is nonempty and periodic then there exists
 $c\ge 2$
and a partition
$c\ge 2$
and a partition
 $W_0,\ldots W_{c-1}$
of
$W_0,\ldots W_{c-1}$
of
 $V_0$
such that
$V_0$
such that
 $E_0 \subseteq \bigcup _{i=0}^{c-1} W_i \times W_{i+1}$
(we set
$E_0 \subseteq \bigcup _{i=0}^{c-1} W_i \times W_{i+1}$
(we set
 $W_{c+i}\,:\!=\,W_i$
for all
$W_{c+i}\,:\!=\,W_i$
for all
 $i \in \mathbb{Z}$
). Take
$i \in \mathbb{Z}$
). Take
 $\gamma ,\delta \in I$
with
$\gamma ,\delta \in I$
with
 $\gamma \ne \delta$
and define
$\gamma \ne \delta$
and define
 $x \in I^p$
as follows
$x \in I^p$
as follows
 \begin{equation*} x_i=\begin{cases} \gamma & \text{ if } i \in W_0, \\ \delta & \text{ if } i \in V_0 \! \setminus \! W_0. \end{cases} \end{equation*}
\begin{equation*} x_i=\begin{cases} \gamma & \text{ if } i \in W_0, \\ \delta & \text{ if } i \in V_0 \! \setminus \! W_0. \end{cases} \end{equation*}
But for all
 $i \in W_k$
means
$i \in W_k$
means
 $[\mathbf{M}_\alpha ]_i$
depends only on arguments with indexes
$[\mathbf{M}_\alpha ]_i$
depends only on arguments with indexes
 $W_{k-1}$
. By the simple introduction, for all
$W_{k-1}$
. By the simple introduction, for all
 $n \in \mathbb{N}$
we get
$n \in \mathbb{N}$
we get
 \begin{equation*} [\mathbf{M}_\alpha ^n]_i (x)=\begin{cases} \gamma & \text{ if } i \in W_n,\\ \delta & \text{ if } i \in V_0 \! \setminus \! W_n. \end{cases} \end{equation*}
\begin{equation*} [\mathbf{M}_\alpha ^n]_i (x)=\begin{cases} \gamma & \text{ if } i \in W_n,\\ \delta & \text{ if } i \in V_0 \! \setminus \! W_n. \end{cases} \end{equation*}
Whence
 \begin{equation*} \begin{aligned} \lim _{n \to \infty } \max _{i \in \{1,\ldots ,p\}} [\mathbf{M}_\alpha ^n (x)]_i=\max (\gamma ,\delta );\quad \lim _{n \to \infty } \min _{i \in \{1,\ldots ,p\}} [\mathbf{M}_\alpha ^n (x)]_i=\min (\gamma ,\delta ). \end{aligned} \end{equation*}
\begin{equation*} \begin{aligned} \lim _{n \to \infty } \max _{i \in \{1,\ldots ,p\}} [\mathbf{M}_\alpha ^n (x)]_i=\max (\gamma ,\delta );\quad \lim _{n \to \infty } \min _{i \in \{1,\ldots ,p\}} [\mathbf{M}_\alpha ^n (x)]_i=\min (\gamma ,\delta ). \end{aligned} \end{equation*}
By Proposition 4.9, this yields that the
 $\mathbf{M}_\alpha$
-invariant mean is not uniquely determined.
$\mathbf{M}_\alpha$
-invariant mean is not uniquely determined.














 Open access
Open access