


1. Introduction
The Latent Position Model (LPM) was introduced for social network analysis by Hoff et al. (Reference Hoff, Raftery and Handcock2002). An important feature of the LPM is that it facilitates network visualization via latent space modeling. The LPM assumes that the data distribution depends on the stochastic latent positions of the nodes of the network. Usually these latent positions are assumed to lie in a Euclidean space. We refer the reader to Kaur et al. (Reference Kaur, Rastelli and Friel2023); Rastelli et al. (Reference Rastelli, Friel and Raftery2016); Salter-Townshend et al. (Reference Salter-Townshend, White, Gollini and Murphy2012) for detailed reviews of this model. Clustering of nodes plays a central role in statistical network analysis: the LPM can be extended to this context following the pioneering work of Handcock et al. (Reference Handcock, Raftery and Tantrum2007). This leads us to the well-known Latent Position Cluster Model (LPCM) whereby the latent positions of the nodes are assumed to follow a mixture of multivariate normal distributions. With these assumptions, the network model can better support the presence of communities and assortative mixing.
A limitation of the original LPM and LPCM models is that they are only defined for the networks with binary interactions between the individuals. An interesting extension of these models to the weighted setting is provided by Sewell and Chen (Reference Sewell and Chen2015, Reference Sewell and Chen2016), where the authors extend the LPM to dynamic unipartite networks with weighted edges and propose a general link function for the expectation of the edge weights. In this paper, we focus on non-dynamic unipartite networks with non-negative discrete weighted edges, corresponding to networks where the edge values are typically integer counts.
Missing data is a common issue in statistical data analysis which generally leads to an overabundance of zeros. In this paper, we classify zero entries in a dataset either as “true” zeros or as “unusual” zeros. A zero-inflated model proposed by Lambert (Reference Lambert1992) assumes a probability model for the occurrence of unusual zeros, which can be paired with the Poisson distribution as a canonical choice for count weighted data. In this situation, an unusual zero may correspond to an edge that although present, the corresponding edge weight is not recorded.
Zero-inflation is well-explored in the area of regression models with many extensions, for example, Hall (Reference Hall2000), Ridout et al. (Reference Ridout, Hinde and Demétrio2001), Ghosh et al. (Reference Ghosh, Mukhopadhyay and Lu2006), Lemonte et al. (Reference Lemonte, Moreno-Arenas and Castellares2019) to cite a few. By contrast, zero-inflated models are not widely applied in the statistical analysis of network data. Zero-inflation is mentioned in Sewell and Chen (Reference Sewell and Chen2016): while their dynamic latent space model may be extended to the zero-inflated case for sparse networks, their applications do not cover this extension. Some advancements in this line of literature include Marchello et al. (Reference Marchello, Corneli and Bouveyron2024), which incorporate the zero-inflated model within the Latent Block Model (LBM) (Govaert and Nadif, Reference Govaert and Nadif2003) for dynamic bipartite networks, and Lu et al. (Reference Lu, Durante and Friel2025), which adopts the zero-inflation to the Stochastic Block Model (SBM) for unipartite networks. The SBM is widely used clustering model for network analysis that shares some similarities with the LPM, since both models are based on a latent variable framework. Differently from the LPM, the SBM is capable of representing disassortative patterns, but, on the other hand, the LPM can provide clearer and more interpretable network visualizations.
In this paper, we propose to incorporate a Zero-Inflated Poisson (ZIP) distribution within the LPCM leading to the Zero-Inflated Poisson Latent Position Cluster Model (ZIP-LPCM), and, in doing so, we create a simultaneous framework that can be used to characterize zero inflation, clustering and the latent space visualization. Similar model assumptions can be found in Ma (Reference Ma2024) where a Latent Space Zero-Inflated Poisson (LS-ZIP) model is proposed. However, differently from our model structure, their LS-ZIP embeds an inner-product latent space model (Hoff, Reference Hoff2003; Ma et al., Reference Ma, Ma and Yuan2020) and proposes two different sets of latent positions for the Poisson rate and for the probability of unusual zeros, respectively. Furthermore, their model does not account for the clustering of nodes, which is a central feature of our proposed model.
We employ a Bayesian framework to infer the model parameters and the latent variables of our ZIP-LPCM. Our inferential framework takes inspiration from the literature on the LPCM, the Mixture of Finite Mixtures (MFM) model (Miller and Harrison, Reference Miller and Harrison2018; Geng et al., Reference Geng, Bhattacharya and Pati2019), and collapsed Gibbs sampling, and we combine some key ideas from the available literature to create our own original procedure. As regards the LPCM, commonly used inference methods include a variational expectation maximization algorithm (Salter-Townshend and Murphy, Reference Salter-Townshend and Murphy2013), and Markov chain Monte Carlo methods (Handcock et al., Reference Handcock, Raftery and Tantrum2007). A contribution close to our own is that of Ryan et al. (Reference Ryan, Wyse and Friel2017) where the authors exploit conjugate priors to calculate a marginalized posterior in analytic form, and then target this distribution using a so-called “collapsed” sampler. Similar parameter-collapsing ideas are also employed in McDaid et al. (Reference McDaid, Murphy, Friel and Hurley2012); Wyse and Friel (Reference Wyse and Friel2012). In this paper, we propose to follow a similar strategy as that presented in Lu et al. (Reference Lu, Durante and Friel2025) for the inference task leveraging the partially collapsed Gibbs sampler introduced by Van Dyk and Park (Reference Van Dyk and Park2008); Park and Van Dyk (Reference Park and Van Dyk2009).
As regards the choice of the number of clusters, we also make an original contribution by combining some approaches and ideas available from the literature. We highlight Nobile and Fearnside (Reference Nobile and Fearnside2007), where the authors introduced an Absorb-Eject (AE) move to automatically choose the number of clusters. Here we propose a variant of this move to better match our framework. Indeed, as a prior distribution for the clustering variables and number of clusters, we adopt a MFM model, along with the supervision idea introduced by Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022). In this case, the AE move can further facilitate the estimation of clusters, but such a step can only be defined if the framework allows for the existence of empty clusters. Unfortunately, this is not the case for MFMs, and so the move and the model are incompatible. To address this impasse, we propose a new Truncated Absorb-Eject (TAE) move which allows us to efficiently explore the sample space thus obtaining good estimates of the clustering variables and of the number of groups.
This paper is organized as follows. Section 2 provides a detailed introduction of our proposed ZIP-LPCM. Section 3 explains how we design the Bayesian inference process of our model where the incorporation of a mixture of finite mixtures model as well as its supervised version is included in Section 2.3. The idea of partially collapsing the model parameters in the posterior distribution, and the newly proposed TAE move, are introduced in Sections 3.1 and 3.2, respectively. The detailed steps and designs of the Partially Collapsed Metropolis-within-Gibbs (PCMwG) algorithm for the inference are illustrated in Section 3.3. In Section 4, we show the performance of our strategy via three carefully designed simulation studies within which different scenarios are proposed to tackle different real world situations. Applications on four different real social networks with different network sizes are included in Section 5. Finally, Section 6 concludes this paper and provides a few possible future directions.
2. Model
In this paper we focus on weighted networks with non-negative discrete edges, and denote
 $N$
as the total number of individuals in the network. This framework is particularly common in observed real datasets, most notably whereby edges indicate the intensity or frequency of interactions. Examples include some types of friendship and professional networks, email networks, phone call networks, proximity networks. In this paper we consider several real datasets, including a summit co-attendance network which records the number of times that two criminal suspects co-attended summits within a specified period. Since the edges indicate the number of co-attendances, these are observed as non-negative integers. The model introduced in this section is designed for directed networks, however it is straightforward to apply it to the undirected case. A network is usually observed by an
$N$
as the total number of individuals in the network. This framework is particularly common in observed real datasets, most notably whereby edges indicate the intensity or frequency of interactions. Examples include some types of friendship and professional networks, email networks, phone call networks, proximity networks. In this paper we consider several real datasets, including a summit co-attendance network which records the number of times that two criminal suspects co-attended summits within a specified period. Since the edges indicate the number of co-attendances, these are observed as non-negative integers. The model introduced in this section is designed for directed networks, however it is straightforward to apply it to the undirected case. A network is usually observed by an
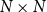 $N \times N$
adjacency matrix denoted as
$N \times N$
adjacency matrix denoted as
 ${\boldsymbol{Y}}$
, where each element
${\boldsymbol{Y}}$
, where each element
 $y_{ij}$
is a non-negative integer indicating the interaction from node
$y_{ij}$
is a non-negative integer indicating the interaction from node
 $i$
to node
$i$
to node
 $j$
, and reflecting the corresponding interaction strength. An element
$j$
, and reflecting the corresponding interaction strength. An element
 $y_{ij}=0$
corresponds to a non-interaction or a zero interaction. Self-loops are not allowed.
$y_{ij}=0$
corresponds to a non-interaction or a zero interaction. Self-loops are not allowed.
2.1 Zero-inflated Poisson model
In real networks which are observed in practice, there is often an overabundance of zeros. It is possible that these zeros are due to the nature of the network’s sparse architecture, but they may also be due to missing data or misreported data. Since practitioners are typically not aware of the presence of unusual zeros, we aim to provide a model-based solution that helps detecting any unusual zeros in the observed data.
We consider the ZIP model (Lambert, Reference Lambert1992), which is a commonly used framework to deal with an excessive number of zeros in
 ${\boldsymbol{Y}}$
. The ZIP model assumes that each observed interaction
${\boldsymbol{Y}}$
. The ZIP model assumes that each observed interaction
 $y_{ij}$
follows
$y_{ij}$
follows
 \begin{align} \text{P}(y_{ij}|\lambda _{ij},p_{ij}) = \begin{cases} p_{ij} + (1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij}),&\text{if } y_{ij}=0;\\[3pt] (1-p_{ij})f_{\text{Pois}}(y_{ij}|\lambda _{ij}),&\text{if } y_{ij}=1,2,\dots , \end{cases} \end{align}
\begin{align} \text{P}(y_{ij}|\lambda _{ij},p_{ij}) = \begin{cases} p_{ij} + (1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij}),&\text{if } y_{ij}=0;\\[3pt] (1-p_{ij})f_{\text{Pois}}(y_{ij}|\lambda _{ij}),&\text{if } y_{ij}=1,2,\dots , \end{cases} \end{align}
for
 $i,j=1,2,\dots ,N;\; i\neq j$
, where
$i,j=1,2,\dots ,N;\; i\neq j$
, where
 $f_{\text{Pois}}(\!\cdot |\lambda _{ij})$
is the probability mass function of the Poisson distribution with parameter
$f_{\text{Pois}}(\!\cdot |\lambda _{ij})$
is the probability mass function of the Poisson distribution with parameter
 $\lambda _{ij}$
. Here, the zeros assigned with probability mass
$\lambda _{ij}$
. Here, the zeros assigned with probability mass
 $p_{ij} + (1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij})$
can be classified into two types: “structural” zeros, which are observed with probability
$p_{ij} + (1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij})$
can be classified into two types: “structural” zeros, which are observed with probability
 $p_{ij}$
, and Poisson zeros, which naturally arise from the Poisson distribution, and are observed with probability
$p_{ij}$
, and Poisson zeros, which naturally arise from the Poisson distribution, and are observed with probability
 $(1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij})$
, respectively. If we treat the Poisson zeros as the conventional zeros, then we refer to the other observed zeros as the “structural” or “unusual” zeros, since these are not determined according to the natural distribution that we assume on the data. We formalize the two possibilities by augmenting the model in Eq. (1) with a new indicator variable,
$(1-p_{ij})f_{\text{Pois}}(0|\lambda _{ij})$
, respectively. If we treat the Poisson zeros as the conventional zeros, then we refer to the other observed zeros as the “structural” or “unusual” zeros, since these are not determined according to the natural distribution that we assume on the data. We formalize the two possibilities by augmenting the model in Eq. (1) with a new indicator variable,
 $\nu _{ij}$
, indicating whether the corresponding
$\nu _{ij}$
, indicating whether the corresponding
 $y_{ij}$
is a structural zero or not, and thus the data distribution is determined separately for the two cases below:
$y_{ij}$
is a structural zero or not, and thus the data distribution is determined separately for the two cases below:
 \begin{align} y_{ij}|\lambda _{ij},\nu _{ij} \sim \begin{cases} \unicode {x1D7D9}(y_{ij}=0),&\text{if } \nu _{ij}=1;\\[3pt] \text{Pois}(\lambda _{ij}),&\text{if } \nu _{ij}=0, \end{cases} \end{align}
\begin{align} y_{ij}|\lambda _{ij},\nu _{ij} \sim \begin{cases} \unicode {x1D7D9}(y_{ij}=0),&\text{if } \nu _{ij}=1;\\[3pt] \text{Pois}(\lambda _{ij}),&\text{if } \nu _{ij}=0, \end{cases} \end{align}
where, for every
 $i$
and
$i$
and
 $j$
, the collection of
$j$
, the collection of
 $\nu _{ij}\sim \text{Bernoulli}(p_{ij})$
constitutes the
$\nu _{ij}\sim \text{Bernoulli}(p_{ij})$
constitutes the
 $N \times N$
structural zero indicator matrix
$N \times N$
structural zero indicator matrix
 $\boldsymbol{\nu }$
. The function
$\boldsymbol{\nu }$
. The function
 $\unicode {x1D7D9}(y_{ij}=0)$
is an indicator function returning
$\unicode {x1D7D9}(y_{ij}=0)$
is an indicator function returning
 $1$
if
$1$
if
 $y_{ij}=0$
and returning
$y_{ij}=0$
and returning
 $0$
otherwise.
$0$
otherwise.
As far as
 $\nu _{ij}=1$
, the observed
$\nu _{ij}=1$
, the observed
 $y_{ij}$
is a structural zero with probability
$y_{ij}$
is a structural zero with probability
 $1$
. Here, we interpret such a “structural” zero as an “unusual” zero or missing data that replaces a true interaction weight which follows the corresponding
$1$
. Here, we interpret such a “structural” zero as an “unusual” zero or missing data that replaces a true interaction weight which follows the corresponding
 $\text{Pois}(\lambda _{ij})$
distribution. A zero arising from
$\text{Pois}(\lambda _{ij})$
distribution. A zero arising from
 $f_{\text{Pois}}(\!\cdot |\lambda _{ij})$
is thus treated as a “true” zero. We denote the covert true interaction as
$f_{\text{Pois}}(\!\cdot |\lambda _{ij})$
is thus treated as a “true” zero. We denote the covert true interaction as
 $x_{ij}$
: we assume that this value is not observed when
$x_{ij}$
: we assume that this value is not observed when
 $\nu _{ij}=1$
, and that it follows the same Poisson distribution of
$\nu _{ij}=1$
, and that it follows the same Poisson distribution of
 $y_{ij}|\lambda _{ij},\nu _{ij}=0$
. Thus, based on the augmented zero-inflated model in Eq. (2) as well as the observed
$y_{ij}|\lambda _{ij},\nu _{ij}=0$
. Thus, based on the augmented zero-inflated model in Eq. (2) as well as the observed
 ${\boldsymbol{Y}}$
, the augmented data
${\boldsymbol{Y}}$
, the augmented data
 ${\boldsymbol{X}}$
, which is a
${\boldsymbol{X}}$
, which is a
 $N \times N$
matrix with entries
$N \times N$
matrix with entries
 $\{x_{ij}\}$
, is in the form
$\{x_{ij}\}$
, is in the form
 \begin{align} \begin{cases} x_{ij}\sim \text{Pois}(\lambda _{ij}),&\text{if } \nu _{ij}=1;\\[3pt] x_{ij}=y_{ij},&\text{if } \nu _{ij}=0. \end{cases} \end{align}
\begin{align} \begin{cases} x_{ij}\sim \text{Pois}(\lambda _{ij}),&\text{if } \nu _{ij}=1;\\[3pt] x_{ij}=y_{ij},&\text{if } \nu _{ij}=0. \end{cases} \end{align}
Here, the case
 $x_{ij}=y_{ij}$
is equivalent to
$x_{ij}=y_{ij}$
is equivalent to
 $x_{ij} \sim \unicode {x1D7D9}(x_{ij}=y_{ij})$
when
$x_{ij} \sim \unicode {x1D7D9}(x_{ij}=y_{ij})$
when
 $\nu _{ij}=0$
. A similar data augmentation framework has appeared in other works, for example, Tanner and Wong (Reference Tanner and Wong1987), Ghosh et al. (Reference Ghosh, Mukhopadhyay and Lu2006). The augmented
$\nu _{ij}=0$
. A similar data augmentation framework has appeared in other works, for example, Tanner and Wong (Reference Tanner and Wong1987), Ghosh et al. (Reference Ghosh, Mukhopadhyay and Lu2006). The augmented
 ${\boldsymbol{X}}$
is known as the missing data imputed adjacency matrix.
${\boldsymbol{X}}$
is known as the missing data imputed adjacency matrix.
2.2 Zero-inflated Poisson latent position cluster model
To characterize the Pois(
 $\lambda _{ij}$
) distribution under the
$\lambda _{ij}$
) distribution under the
 $\nu _{ij}=0$
case of the augmented ZIP model in Eq. (2), we employ the LPCM (Handcock et al., Reference Handcock, Raftery and Tantrum2007), which is an extended version of the Latent Position Model (LPM) (Hoff et al., Reference Hoff, Raftery and Handcock2002). Each node
$\nu _{ij}=0$
case of the augmented ZIP model in Eq. (2), we employ the LPCM (Handcock et al., Reference Handcock, Raftery and Tantrum2007), which is an extended version of the Latent Position Model (LPM) (Hoff et al., Reference Hoff, Raftery and Handcock2002). Each node
 $i\,:\, i=1,2,\dots ,N$
in the network is assumed to have a latent position
$i\,:\, i=1,2,\dots ,N$
in the network is assumed to have a latent position
 ${\boldsymbol{u}}_i\in \mathbb{R}^d$
, and we denote the collection of all latent positions as
${\boldsymbol{u}}_i\in \mathbb{R}^d$
, and we denote the collection of all latent positions as
 ${\boldsymbol{U}} \, :\!= \, \{{\boldsymbol{u}}_i\}$
. A generalization of the latent position model without considering covariates can be expressed in the form
${\boldsymbol{U}} \, :\!= \, \{{\boldsymbol{u}}_i\}$
. A generalization of the latent position model without considering covariates can be expressed in the form
 $g[\mathbb{E}(y_{ij})]=h({\boldsymbol{u}}_i,{\boldsymbol{u}}_j)$
, where
$g[\mathbb{E}(y_{ij})]=h({\boldsymbol{u}}_i,{\boldsymbol{u}}_j)$
, where
 $g(\! \cdot \!)$
is some link function, and
$g(\! \cdot \!)$
is some link function, and
 $h\,:\,\mathbb{R}^d\times \mathbb{R}^d\rightarrow \mathbb{R}$
is a function of two nodes’ latent positions. Here, we make standard assumptions on the functions
$h\,:\,\mathbb{R}^d\times \mathbb{R}^d\rightarrow \mathbb{R}$
is a function of two nodes’ latent positions. Here, we make standard assumptions on the functions
 $g(\! \cdot \!)$
and
$g(\! \cdot \!)$
and
 $h(\cdot ,\cdot )$
, which link the Poisson rate
$h(\cdot ,\cdot )$
, which link the Poisson rate
 $\lambda _{ij}$
in Eq. (2) with the latent positions
$\lambda _{ij}$
in Eq. (2) with the latent positions
 ${\boldsymbol{U}}$
as follows:
${\boldsymbol{U}}$
as follows:
 \begin{equation} \text{log}(\lambda _{ij})=\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||. \end{equation}
\begin{equation} \text{log}(\lambda _{ij})=\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||. \end{equation}
In the equation above,
 $||\cdot ||$
is the Euclidean distance, while
$||\cdot ||$
is the Euclidean distance, while
 $\beta \in \mathbb{R}$
can be interpreted as an intercept term where higher values bring larger interaction weights as well as lower chance of a true zero. Note that the model characterization in Eq. (4) is symmetric for directed edges in directed networks, that is,
$\beta \in \mathbb{R}$
can be interpreted as an intercept term where higher values bring larger interaction weights as well as lower chance of a true zero. Note that the model characterization in Eq. (4) is symmetric for directed edges in directed networks, that is,
 $\log (\lambda _{ij}) = \log (\lambda _{ji})$
. This may be seen as a limitation of the framework, but it can be overcome when additional information, such as covariates, are available and thus are characterized in Eq. (4). We note that also other variations of latent space models, such as the projection model discussed in Hoff et al. (Reference Hoff, Raftery and Handcock2002) or the random effects model of Krivitsky et al. (Reference Krivitsky, Handcock, Raftery and Hoff2009), can be formulated in ways that allow for non-symmetric patterns. However, in this paper, we do not pursue this characteristic directly, but our model can certainly be adapted to deal with non-symmetric patterns.
$\log (\lambda _{ij}) = \log (\lambda _{ji})$
. This may be seen as a limitation of the framework, but it can be overcome when additional information, such as covariates, are available and thus are characterized in Eq. (4). We note that also other variations of latent space models, such as the projection model discussed in Hoff et al. (Reference Hoff, Raftery and Handcock2002) or the random effects model of Krivitsky et al. (Reference Krivitsky, Handcock, Raftery and Hoff2009), can be formulated in ways that allow for non-symmetric patterns. However, in this paper, we do not pursue this characteristic directly, but our model can certainly be adapted to deal with non-symmetric patterns.
The LPCM further assumes that each latent position
 ${\boldsymbol{u}}_i$
is drawn from a finite mixture of
${\boldsymbol{u}}_i$
is drawn from a finite mixture of
 $\bar {K}$
multivariate normal distributions, each corresponding to a different group:
$\bar {K}$
multivariate normal distributions, each corresponding to a different group:
 \begin{equation} {\boldsymbol{u}}_i\sim \sum _{k=1}^{\bar {K}}\pi _k\text{MVN}_d(\boldsymbol{\mu }_k,1/\tau _k\mathbb{I}_d). \end{equation}
\begin{equation} {\boldsymbol{u}}_i\sim \sum _{k=1}^{\bar {K}}\pi _k\text{MVN}_d(\boldsymbol{\mu }_k,1/\tau _k\mathbb{I}_d). \end{equation}
Here, each
 $\pi _k$
is the probability that a node is clustered into group
$\pi _k$
is the probability that a node is clustered into group
 $k$
, and
$k$
, and
 $\sum _{k=1}^{\bar {K}}\pi _k=1$
. The combination of Eqs. (2), (4) and (5) defines our ZIP-LPCM.
$\sum _{k=1}^{\bar {K}}\pi _k=1$
. The combination of Eqs. (2), (4) and (5) defines our ZIP-LPCM.
Letting
 $z_i \in \{1,2,\dots ,\bar {K}\}$
denote the group membership of node
$z_i \in \{1,2,\dots ,\bar {K}\}$
denote the group membership of node
 $i$
, the mixture in Eq. (5) can be augmented as
$i$
, the mixture in Eq. (5) can be augmented as
 \begin{equation*} {\boldsymbol{u}}_i|z_i=k\sim \text{MVN}_d(\boldsymbol{\mu }_k,1/\tau _k\mathbb{I}_d), \end{equation*}
\begin{equation*} {\boldsymbol{u}}_i|z_i=k\sim \text{MVN}_d(\boldsymbol{\mu }_k,1/\tau _k\mathbb{I}_d), \end{equation*}
where a multinomial
 $(1,\boldsymbol{\Pi })$
distribution is assumed for each
$(1,\boldsymbol{\Pi })$
distribution is assumed for each
 $\boldsymbol{z}_{\boldsymbol{i}}$
, and
$\boldsymbol{z}_{\boldsymbol{i}}$
, and
 $\boldsymbol{\Pi } \, :\!= \, (\pi _1,\pi _2,\dots ,\pi _{\bar {K}})$
. The notation
$\boldsymbol{\Pi } \, :\!= \, (\pi _1,\pi _2,\dots ,\pi _{\bar {K}})$
. The notation
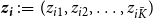 $\boldsymbol{z}_{\boldsymbol{i}} \, :\!= \, (z_{i1},z_{i2},\dots ,z_{i\bar {K}})$
is equivalent to
$\boldsymbol{z}_{\boldsymbol{i}} \, :\!= \, (z_{i1},z_{i2},\dots ,z_{i\bar {K}})$
is equivalent to
 $z_i=k$
if we let
$z_i=k$
if we let
 $z_{ig}=\unicode {x1D7D9}(g=k)$
for
$z_{ig}=\unicode {x1D7D9}(g=k)$
for
 $g=1,2,\dots ,\bar {K}$
, and thus
$g=1,2,\dots ,\bar {K}$
, and thus
 $f_{\text{multinomial}}(\boldsymbol{z}_{\boldsymbol{i}}|1,\boldsymbol{\Pi }) = \pi _{z_i}$
. Note that
$f_{\text{multinomial}}(\boldsymbol{z}_{\boldsymbol{i}}|1,\boldsymbol{\Pi }) = \pi _{z_i}$
. Note that
 $\bar {K}$
here denotes the total number of possible groups that the network is assumed to have, even though some groups may be empty. Further, we denote
$\bar {K}$
here denotes the total number of possible groups that the network is assumed to have, even though some groups may be empty. Further, we denote
 ${\boldsymbol{z}} \, :\!= \, (z_1,z_2,\dots ,z_N)$
as a vector of group membership indicators for all
${\boldsymbol{z}} \, :\!= \, (z_1,z_2,\dots ,z_N)$
as a vector of group membership indicators for all
 $\{z_i\}$
, while
$\{z_i\}$
, while
 $\boldsymbol{\mu } \, :\!= \, \{\boldsymbol{\mu }_k\,:\,k=1,2,\dots ,\bar {K}\}$
, and
$\boldsymbol{\mu } \, :\!= \, \{\boldsymbol{\mu }_k\,:\,k=1,2,\dots ,\bar {K}\}$
, and
 $\boldsymbol{\tau } \, :\!= \, (\tau _1,\tau _2,\dots ,\tau _{\bar {K}})$
.
$\boldsymbol{\tau } \, :\!= \, (\tau _1,\tau _2,\dots ,\tau _{\bar {K}})$
.
The indicator of unusual zero
 $\nu _{ij}$
in Eq. (2) is proposed to instead follow a
$\nu _{ij}$
in Eq. (2) is proposed to instead follow a
 $\text{Bernoulli}(p_{z_iz_j})$
, that is, a typical Stochastic Block Model (SBM) structure is further assumed for
$\text{Bernoulli}(p_{z_iz_j})$
, that is, a typical Stochastic Block Model (SBM) structure is further assumed for
 $\boldsymbol{\nu }$
, where we replace the probability of unusual zero
$\boldsymbol{\nu }$
, where we replace the probability of unusual zero
 $p_{ij}$
with a cluster-dependent counterpart
$p_{ij}$
with a cluster-dependent counterpart
 $p_{z_iz_j}$
, as in a network block-structure. One intuition behind this is that the probability of an unusual zero observed between two nodes is expected to vary depending on their respective groups. Taking the summit co-attendance real network for criminal suspects as an example here, the occurrences of unusual zeros possibly correspond to different group-level secrecy strategies applied by the group leaders where some summits are intentionally hidden to the law enforcement investigations (Lu et al., Reference Lu, Durante and Friel2025), leading to different levels of unusual zero probability within and between different groups.
$p_{z_iz_j}$
, as in a network block-structure. One intuition behind this is that the probability of an unusual zero observed between two nodes is expected to vary depending on their respective groups. Taking the summit co-attendance real network for criminal suspects as an example here, the occurrences of unusual zeros possibly correspond to different group-level secrecy strategies applied by the group leaders where some summits are intentionally hidden to the law enforcement investigations (Lu et al., Reference Lu, Durante and Friel2025), leading to different levels of unusual zero probability within and between different groups.
There are other possible ways to model the probability of unusual zeros. A homogeneous setup where the probability is the same for all pairs of nodes is also possible, albeit naive. This would correspond to a special case of our framework. Alternatively, one may characterize the probability of unusual zeros using the latent distances. However, we eventually decided not to pursue this type of model formulation in this paper. One could argue: should the unusual zero probability be larger or smaller when the nodes are close to each other? Intuitively one could choose that a large distance would make it more likely that there is an unusual zero. However, it turns out that the Poisson distribution would also be more likely to give a zero in that case. So, the logic behind this assumption does not seem particularly convincing. On the other hand, a SBM structure can give disassortative patterns which can be more flexible for this particular task. In any case, we emphasize again that there is no one solution to this, and alternative approaches to ours may be perfectly valid. We denote
 ${\boldsymbol{P}}$
as a
${\boldsymbol{P}}$
as a
 $\bar {K} \times \bar {K}$
matrix with each entry
$\bar {K} \times \bar {K}$
matrix with each entry
 $p_{gh}$
denoting the probability of unusual zeros for the interactions from group
$p_{gh}$
denoting the probability of unusual zeros for the interactions from group
 $g$
to group
$g$
to group
 $h$
, where
$h$
, where
 $g,h=1,2,\dots ,\bar {K}$
.
$g,h=1,2,\dots ,\bar {K}$
.
The following Directed Acyclic Graph (DAG) provides a clear visualization of the relationships between the observed adjacency matrix data
 ${\boldsymbol{Y}}$
and all the model latent variables and parameters as well as the augmented missing data imputed adjacency matrix
${\boldsymbol{Y}}$
and all the model latent variables and parameters as well as the augmented missing data imputed adjacency matrix
 ${\boldsymbol{X}}$
for our proposed ZIP-LPCM:
${\boldsymbol{X}}$
for our proposed ZIP-LPCM:

The complete likelihood of the ZIP-LPCM is thus written as:
 \begin{align} & f({\boldsymbol{Y}}, \boldsymbol{\nu },{\boldsymbol{U}},{\boldsymbol{z}}|\beta , {\boldsymbol{P}}, \boldsymbol{\mu }, \boldsymbol{\tau }, \boldsymbol{\Pi }) = f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu }, \boldsymbol{\tau }, {\boldsymbol{z}})f({\boldsymbol{z}}|\boldsymbol{\Pi }) \nonumber \\[2pt] &= \prod ^N_{\substack {i,j\,:\, i \neq j, \nonumber \\[2pt] \nu _{ij} = 0}}f_{\text{Pois}}(y_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)) \prod ^N_{i,j\,:\,i \neq j} f_{\text{Bern}}(\nu _{ij}|p_{z_iz_j}) \nonumber \\[2pt] &\hspace {1em}\times \prod ^N_{i =1} f_{\text{MVN}_d}({\boldsymbol{u}}_i|\boldsymbol{\mu }_{z_i},1/\tau _{z_i}\mathbb{I}_d) \prod ^N_{i =1} f_{\text{multinomial}}(\boldsymbol{z}_{\boldsymbol{i}}|1,\boldsymbol{\Pi }), \end{align}
\begin{align} & f({\boldsymbol{Y}}, \boldsymbol{\nu },{\boldsymbol{U}},{\boldsymbol{z}}|\beta , {\boldsymbol{P}}, \boldsymbol{\mu }, \boldsymbol{\tau }, \boldsymbol{\Pi }) = f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu }, \boldsymbol{\tau }, {\boldsymbol{z}})f({\boldsymbol{z}}|\boldsymbol{\Pi }) \nonumber \\[2pt] &= \prod ^N_{\substack {i,j\,:\, i \neq j, \nonumber \\[2pt] \nu _{ij} = 0}}f_{\text{Pois}}(y_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)) \prod ^N_{i,j\,:\,i \neq j} f_{\text{Bern}}(\nu _{ij}|p_{z_iz_j}) \nonumber \\[2pt] &\hspace {1em}\times \prod ^N_{i =1} f_{\text{MVN}_d}({\boldsymbol{u}}_i|\boldsymbol{\mu }_{z_i},1/\tau _{z_i}\mathbb{I}_d) \prod ^N_{i =1} f_{\text{multinomial}}(\boldsymbol{z}_{\boldsymbol{i}}|1,\boldsymbol{\Pi }), \end{align}
which can be calculated analytically and efficiently for all choices of parameter values.
2.3 Mixture of finite mixtures and supervision
Instead of the multinomial distribution, we further consider the Mixture-of-Finite-Mixtures (MFM) model for the clustering
 ${\boldsymbol{z}}$
, because such a model is actually an extension of the Dirichlet-multinational conjugacy and allows the corresponding inference procedure to automatically choose the number of clusters.
${\boldsymbol{z}}$
, because such a model is actually an extension of the Dirichlet-multinational conjugacy and allows the corresponding inference procedure to automatically choose the number of clusters.
A natural conjugate prior for the multinomial parameters is
 \begin{equation*}\boldsymbol{\Pi } \sim \text{Dirichlet}(\alpha ,\dots ,\alpha ).\end{equation*}
\begin{equation*}\boldsymbol{\Pi } \sim \text{Dirichlet}(\alpha ,\dots ,\alpha ).\end{equation*}
By further proposing a prior
 $\bar {K}\sim \pi _{\bar {K}}(\! \cdot \!)$
, the MFM marginalizes both
$\bar {K}\sim \pi _{\bar {K}}(\! \cdot \!)$
, the MFM marginalizes both
 $\boldsymbol{\Pi }$
and
$\boldsymbol{\Pi }$
and
 $\bar {K}$
, leading to the probability mass function of a MFM, which is defined for the unlabeled clustering and reads as follows:
$\bar {K}$
, leading to the probability mass function of a MFM, which is defined for the unlabeled clustering and reads as follows:
 \begin{equation} \begin{split} f({\boldsymbol{C}}({\boldsymbol{z}}))= \sum _{k=1}^{\infty } \frac {k_{(K)}}{(k\alpha )^{(N)}}\pi _{\bar {K}}(k)\prod _{G\in {\boldsymbol{C}}({\boldsymbol{z}})} \alpha ^{(|G|)}, \end{split} \end{equation}
\begin{equation} \begin{split} f({\boldsymbol{C}}({\boldsymbol{z}}))= \sum _{k=1}^{\infty } \frac {k_{(K)}}{(k\alpha )^{(N)}}\pi _{\bar {K}}(k)\prod _{G\in {\boldsymbol{C}}({\boldsymbol{z}})} \alpha ^{(|G|)}, \end{split} \end{equation}
where
 ${\boldsymbol{C}}({\boldsymbol{z}}) \, :\!= \, \{G_k\,:\, k=1,2,\dots ,\bar {K};\;|G_k|\gt 0\}$
is a set of non-empty unordered collections of nodes with each collection
${\boldsymbol{C}}({\boldsymbol{z}}) \, :\!= \, \{G_k\,:\, k=1,2,\dots ,\bar {K};\;|G_k|\gt 0\}$
is a set of non-empty unordered collections of nodes with each collection
 $G_k \, :\!= \, \{i\,:\,i=1,2,\dots ,N;\;z_i=k\}$
containing all the nodes from group
$G_k \, :\!= \, \{i\,:\,i=1,2,\dots ,N;\;z_i=k\}$
containing all the nodes from group
 $k$
. Here,
$k$
. Here,
 $|G_k|$
denotes the number of nodes inside the collection, and the number of non-empty collections/groups
$|G_k|$
denotes the number of nodes inside the collection, and the number of non-empty collections/groups
 $K \, :\!= \, |{\boldsymbol{C}}({\boldsymbol{z}})|$
. In the case that
$K \, :\!= \, |{\boldsymbol{C}}({\boldsymbol{z}})|$
. In the case that
 $G_k$
is the empty set, we have
$G_k$
is the empty set, we have
 $|G_k|=0$
. The ascending factorial notation
$|G_k|=0$
. The ascending factorial notation
 $\alpha ^{(n)} \, :\!= \, \alpha (\alpha +1)\cdots (\alpha +n-1)$
, while the descending factorial notation
$\alpha ^{(n)} \, :\!= \, \alpha (\alpha +1)\cdots (\alpha +n-1)$
, while the descending factorial notation
 $k_{(K)} \, :\!= \, k(k-1)\cdots (k-(K-1))$
. The parameter
$k_{(K)} \, :\!= \, k(k-1)\cdots (k-(K-1))$
. The parameter
 $\bar {K}$
is collapsed by summing over all the possible
$\bar {K}$
is collapsed by summing over all the possible
 $\bar {K}=k$
values from
$\bar {K}=k$
values from
 $k=1$
to
$k=1$
to
 $k=\infty$
. Note that
$k=\infty$
. Note that
 ${\boldsymbol{C}}({\boldsymbol{z}})$
is invariant under any relabeling of
${\boldsymbol{C}}({\boldsymbol{z}})$
is invariant under any relabeling of
 ${\boldsymbol{z}}$
. The
${\boldsymbol{z}}$
. The
 $k_{(K)}\equiv \binom {k}{K}K!$
term in Eq. (7) is the number of ways to relabel a specific
$k_{(K)}\equiv \binom {k}{K}K!$
term in Eq. (7) is the number of ways to relabel a specific
 ${\boldsymbol{z}}$
or to label the unlabeled partition
${\boldsymbol{z}}$
or to label the unlabeled partition
 ${\boldsymbol{C}}({\boldsymbol{z}})$
provided with
${\boldsymbol{C}}({\boldsymbol{z}})$
provided with
 $\bar {K}=k$
. The natural choice of
$\bar {K}=k$
. The natural choice of
 $\bar {K}$
prior is a zero-truncated Poisson(1) distribution (Geng et al., Reference Geng, Bhattacharya and Pati2019; Nobile, Reference Nobile2005; McDaid et al., Reference McDaid, Murphy, Friel and Hurley2012) that is assumed throughout this paper.
$\bar {K}$
prior is a zero-truncated Poisson(1) distribution (Geng et al., Reference Geng, Bhattacharya and Pati2019; Nobile, Reference Nobile2005; McDaid et al., Reference McDaid, Murphy, Friel and Hurley2012) that is assumed throughout this paper.
To ensure that the clustering
 ${\boldsymbol{z}}$
is invariant under any relabeling of it, we adopt a particular labeling method following the procedure used in Rastelli and Friel (Reference Rastelli and Friel2018). We assign node
${\boldsymbol{z}}$
is invariant under any relabeling of it, we adopt a particular labeling method following the procedure used in Rastelli and Friel (Reference Rastelli and Friel2018). We assign node
 $1$
to group
$1$
to group
 $1$
by default, and then iteratively assign the next node either to a new empty group or to an existing group. In this way, the defined
$1$
by default, and then iteratively assign the next node either to a new empty group or to an existing group. In this way, the defined
 ${\boldsymbol{z}}$
only contains
${\boldsymbol{z}}$
only contains
 $K$
occupied groups and is one-to-one correspondence to
$K$
occupied groups and is one-to-one correspondence to
 ${\boldsymbol{C}}({\boldsymbol{z}})$
regardless of whether the clustering before label-switching has empty groups or not. The clustering dependent parameters,
${\boldsymbol{C}}({\boldsymbol{z}})$
regardless of whether the clustering before label-switching has empty groups or not. The clustering dependent parameters,
 $\boldsymbol{\mu },\boldsymbol{\tau }$
and
$\boldsymbol{\mu },\boldsymbol{\tau }$
and
 ${\boldsymbol{P}}$
are relabeled accordingly and the entries relevant to empty groups are treated as redundant. The probability mass function of the MFM in Eq. (7) may be rewritten as
${\boldsymbol{P}}$
are relabeled accordingly and the entries relevant to empty groups are treated as redundant. The probability mass function of the MFM in Eq. (7) may be rewritten as
 \begin{equation} \begin{split} f({\boldsymbol{z}})= \mathcal{W}_{N,K}\prod ^K_{g=1} \alpha ^{(n_g)}, \end{split} \end{equation}
\begin{equation} \begin{split} f({\boldsymbol{z}})= \mathcal{W}_{N,K}\prod ^K_{g=1} \alpha ^{(n_g)}, \end{split} \end{equation}
where
 $n_g$
is the number of nodes in group
$n_g$
is the number of nodes in group
 $g$
. The non-negative weight
$g$
. The non-negative weight
 \begin{equation*} \mathcal{W}_{N,K} \, :\!= \, \sum _{k=1}^{\infty } \frac {k_{(K)}}{(k\alpha )^{(N)}}\pi _{\bar {K}}(k) \end{equation*}
\begin{equation*} \mathcal{W}_{N,K} \, :\!= \, \sum _{k=1}^{\infty } \frac {k_{(K)}}{(k\alpha )^{(N)}}\pi _{\bar {K}}(k) \end{equation*}
satisfies the recursion
 $\mathcal{W}_{N,K} \, :\!= \, (N+K\alpha )\mathcal{W}_{N+1,K}+\alpha \mathcal{W}_{N+1,K+1}$
with
$\mathcal{W}_{N,K} \, :\!= \, (N+K\alpha )\mathcal{W}_{N+1,K}+\alpha \mathcal{W}_{N+1,K+1}$
with
 $\mathcal{W}_{1,1}=1/\alpha$
, and we refer to Miller and Harrison (Reference Miller and Harrison2018) for the details of the computation of
$\mathcal{W}_{1,1}=1/\alpha$
, and we refer to Miller and Harrison (Reference Miller and Harrison2018) for the details of the computation of
 $\mathcal{W}_{N,K}$
.
$\mathcal{W}_{N,K}$
.
One could proceed to determine a generative/predictive urn scheme by checking the formulae differences between the
 $f({\boldsymbol{z}})$
and each
$f({\boldsymbol{z}})$
and each
 $f(\{{\boldsymbol{z}},z_{N+1}\})$
for
$f(\{{\boldsymbol{z}},z_{N+1}\})$
for
 $z_{N+1}=1,2,\dots ,K,K+1$
. Then, sampling from Eq. (8) can be performed using the following procedure: assuming that the first node labeled as node
$z_{N+1}=1,2,\dots ,K,K+1$
. Then, sampling from Eq. (8) can be performed using the following procedure: assuming that the first node labeled as node
 $1$
is assigned to group
$1$
is assigned to group
 $1$
by default, then the probability of the subsequent node being assigned to existing non-empty groups or to a new empty group is defined as:
$1$
by default, then the probability of the subsequent node being assigned to existing non-empty groups or to a new empty group is defined as:
 \begin{align} \text{P}(z_{N+1}=k|{\boldsymbol{z}}) \propto \begin{cases} n_k+\alpha , & \text{for}\;k = 1,2,\dots ,K;\\[8pt] \dfrac {\mathcal{W}_{N+1,K+1}}{\mathcal{W}_{N+1,K}}\alpha , & \text{for}\;k = K+1, \end{cases} \end{align}
\begin{align} \text{P}(z_{N+1}=k|{\boldsymbol{z}}) \propto \begin{cases} n_k+\alpha , & \text{for}\;k = 1,2,\dots ,K;\\[8pt] \dfrac {\mathcal{W}_{N+1,K+1}}{\mathcal{W}_{N+1,K}}\alpha , & \text{for}\;k = K+1, \end{cases} \end{align}
that is conditional on the current clustering
 ${\boldsymbol{z}}$
with parameters
${\boldsymbol{z}}$
with parameters
 $N$
and
$N$
and
 $K$
, where
$K$
, where
 $n_k$
is defined as the number of nodes in group
$n_k$
is defined as the number of nodes in group
 $k$
. We refer to Theorem 4.1 of Miller and Harrison (Reference Miller and Harrison2018) for a more detailed discussion on this generative procedure. This generative scheme also belongs to the Ewens-Pitman two-parameter family of Exchangeable Partitions (Gnedin et al., Reference Gnedin, Haulk and Pitman2009; Pitman, Reference Pitman2006).
$k$
. We refer to Theorem 4.1 of Miller and Harrison (Reference Miller and Harrison2018) for a more detailed discussion on this generative procedure. This generative scheme also belongs to the Ewens-Pitman two-parameter family of Exchangeable Partitions (Gnedin et al., Reference Gnedin, Haulk and Pitman2009; Pitman, Reference Pitman2006).
Some exogenous node attributes may be available when analyzing real datasets, and, in this case, we leverage the idea of supervised priors proposed by Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022) to account for such information in the modeling. We use
 ${\boldsymbol{c}} = \{c_1,c_2,\dots ,c_N\}$
to denote the categorical node attributes in our context where each
${\boldsymbol{c}} = \{c_1,c_2,\dots ,c_N\}$
to denote the categorical node attributes in our context where each
 $c_i\in \{1,2,\dots ,C\}$
, and propose that
$c_i\in \{1,2,\dots ,C\}$
, and propose that
 \begin{align} f({\boldsymbol{z}}|{\boldsymbol{c}}) &\propto \mathcal{W}_{N,K}\prod ^{K}_{g=1}\text{P}({\boldsymbol{c}}_g)\alpha ^{(n_g)}, \end{align}
\begin{align} f({\boldsymbol{z}}|{\boldsymbol{c}}) &\propto \mathcal{W}_{N,K}\prod ^{K}_{g=1}\text{P}({\boldsymbol{c}}_g)\alpha ^{(n_g)}, \end{align}
where
 ${\boldsymbol{c}}_g \, :\!= \, \{c_i\,:\, z_i = g\}$
and where the distribution
${\boldsymbol{c}}_g \, :\!= \, \{c_i\,:\, z_i = g\}$
and where the distribution
 $\text{P}({\boldsymbol{c}}_g)$
is chosen as the Dirichlet-multinomial cohesion of Müller et al. (Reference Müller, Quintana and Rosner2011), which is given by:
$\text{P}({\boldsymbol{c}}_g)$
is chosen as the Dirichlet-multinomial cohesion of Müller et al. (Reference Müller, Quintana and Rosner2011), which is given by:
 \begin{align} \text{P}({\boldsymbol{c}}_g) = \frac {\prod ^C_{c=1}\Gamma \left (n_{g,c}+\omega _c\right )}{\Gamma \left (n_g+\omega _0\right )}\frac {\Gamma \left (\omega _0\right )}{\prod ^C_{c=1}\Gamma \left (\omega _c\right )}. \end{align}
\begin{align} \text{P}({\boldsymbol{c}}_g) = \frac {\prod ^C_{c=1}\Gamma \left (n_{g,c}+\omega _c\right )}{\Gamma \left (n_g+\omega _0\right )}\frac {\Gamma \left (\omega _0\right )}{\prod ^C_{c=1}\Gamma \left (\omega _c\right )}. \end{align}
Here,
 $n_{g,c}$
denotes the number of nodes in group
$n_{g,c}$
denotes the number of nodes in group
 $g$
that have the node attribute
$g$
that have the node attribute
 $c$
, whereas
$c$
, whereas
 $\omega _c$
is the cohesion parameter for each level
$\omega _c$
is the cohesion parameter for each level
 $c$
of the node attributes and
$c$
of the node attributes and
 $\omega _0 = \sum ^C_{c=1}\omega _c$
. Similar to Eq. (9), we can determine an urn scheme also for the supervised MFM as:
$\omega _0 = \sum ^C_{c=1}\omega _c$
. Similar to Eq. (9), we can determine an urn scheme also for the supervised MFM as:
 \begin{align} \text{P}(z_{N+1}=k|{\boldsymbol{z}},{\boldsymbol{c}},c_{N+1}) \propto \begin{cases} \dfrac {n_{k,c_{N+1}}+\omega _{c_{N+1}}}{n_k+\omega _0}(n_k+\alpha ), & \text{for } k=1,2,\dots ,K; \\[12pt] \dfrac {\omega _{c_{N+1}}}{\omega _0}\dfrac {\mathcal{W}_{N+1,K+1}}{\mathcal{W}_{N+1,K}}\alpha , & \text{for } k = K+1, \end{cases} \end{align}
\begin{align} \text{P}(z_{N+1}=k|{\boldsymbol{z}},{\boldsymbol{c}},c_{N+1}) \propto \begin{cases} \dfrac {n_{k,c_{N+1}}+\omega _{c_{N+1}}}{n_k+\omega _0}(n_k+\alpha ), & \text{for } k=1,2,\dots ,K; \\[12pt] \dfrac {\omega _{c_{N+1}}}{\omega _0}\dfrac {\mathcal{W}_{N+1,K+1}}{\mathcal{W}_{N+1,K}}\alpha , & \text{for } k = K+1, \end{cases} \end{align}
which, compared to Eq. (9), is inflated or deflated by a term that favors allocating the new node
 $N+1$
to the group with higher fraction of the same node attribute as the
$N+1$
to the group with higher fraction of the same node attribute as the
 $c_{N+1}$
, that is, the allocation is supervised by
$c_{N+1}$
, that is, the allocation is supervised by
 ${\boldsymbol{c}}$
.
${\boldsymbol{c}}$
.
Note that, in the case that some categorical node attributes
 ${\boldsymbol{c}}$
are available, these can be considered as a reference clustering under the MFM framework. For example, individuals in a social network can be clustered into different groups based on their affiliations, while they can also be clustered in a different way according to their job categories. However, none of these reference clusterings might be the “true” clustering or the “best” clustering for the network. Our supervised MFM framework can be treated as a type of supervised prior, in the sense of Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022), with a reference clustering
${\boldsymbol{c}}$
are available, these can be considered as a reference clustering under the MFM framework. For example, individuals in a social network can be clustered into different groups based on their affiliations, while they can also be clustered in a different way according to their job categories. However, none of these reference clusterings might be the “true” clustering or the “best” clustering for the network. Our supervised MFM framework can be treated as a type of supervised prior, in the sense of Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022), with a reference clustering
 ${\boldsymbol{c}}$
: this should not be confused with the general idea of supervised learning, which is often used in similar contexts. We refer to Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022) for more details on the use and terminology of supervised priors.
${\boldsymbol{c}}$
: this should not be confused with the general idea of supervised learning, which is often used in similar contexts. We refer to Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022) for more details on the use and terminology of supervised priors.
3. Partially collapsed Bayesian inference
In this section, we illustrate our original inference processes which aim to jointly infer the intercept
 $\beta$
, the indicator of unusual zeros
$\beta$
, the indicator of unusual zeros
 $\boldsymbol{\nu }$
, the latent positions
$\boldsymbol{\nu }$
, the latent positions
 ${\boldsymbol{U}}$
, the latent clustering indicator
${\boldsymbol{U}}$
, the latent clustering indicator
 ${\boldsymbol{z}}$
and the number of occupied groups
${\boldsymbol{z}}$
and the number of occupied groups
 $K$
. The model includes other parameters, such as
$K$
. The model includes other parameters, such as
 $\boldsymbol{\mu }$
and
$\boldsymbol{\mu }$
and
 $\boldsymbol{\tau }$
, which are dealt with via marginalization, as shown in Section 3.1. We emphasize that
$\boldsymbol{\tau }$
, which are dealt with via marginalization, as shown in Section 3.1. We emphasize that
 $K$
indicates the number of occupied groups for the clustering
$K$
indicates the number of occupied groups for the clustering
 ${\boldsymbol{z}}$
, and thus can be calculated directly from
${\boldsymbol{z}}$
, and thus can be calculated directly from
 ${\boldsymbol{z}}$
. This should not be confused with the total number of groups
${\boldsymbol{z}}$
. This should not be confused with the total number of groups
 $\bar {K}$
. This distinction is crucial since we leverage mixture-of-finite-mixtures (Miller and Harrison, Reference Miller and Harrison2018; Geng et al., Reference Geng, Bhattacharya and Pati2019) to marginalize
$\bar {K}$
. This distinction is crucial since we leverage mixture-of-finite-mixtures (Miller and Harrison, Reference Miller and Harrison2018; Geng et al., Reference Geng, Bhattacharya and Pati2019) to marginalize
 $\bar {K}$
in Section 2.3. As a result, we only need to focus on non-empty groups during the inference procedures.
$\bar {K}$
in Section 2.3. As a result, we only need to focus on non-empty groups during the inference procedures.
3.1 Inference and collapsing
In the case that the exogenous node attributes
 ${\boldsymbol{c}}$
are available, adopting the supervised MFM introduced in Eq. (10) as well as the missing data imputation shown in Eq. (3) leads to the posterior distribution of our ZIP-LPCM being written as:
${\boldsymbol{c}}$
are available, adopting the supervised MFM introduced in Eq. (10) as well as the missing data imputation shown in Eq. (3) leads to the posterior distribution of our ZIP-LPCM being written as:
 \begin{align} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta ,{\boldsymbol{P}},\boldsymbol{\mu },\boldsymbol{\tau }|{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}}) f({\boldsymbol{z}}|{\boldsymbol{c}}) \nonumber \\[4pt]&\hspace {1em}\times \pi ({\boldsymbol{P}})\pi (\boldsymbol{\mu })\pi (\boldsymbol{\tau })\pi (\beta ) \nonumber \\[4pt] &=f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\boldsymbol{\mu })\pi (\boldsymbol{\tau })\pi (\beta ), \end{align}
\begin{align} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta ,{\boldsymbol{P}},\boldsymbol{\mu },\boldsymbol{\tau }|{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}}) f({\boldsymbol{z}}|{\boldsymbol{c}}) \nonumber \\[4pt]&\hspace {1em}\times \pi ({\boldsymbol{P}})\pi (\boldsymbol{\mu })\pi (\boldsymbol{\tau })\pi (\beta ) \nonumber \\[4pt] &=f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\boldsymbol{\mu })\pi (\boldsymbol{\tau })\pi (\beta ), \end{align}
where the
 $f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
, the
$f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
, the
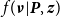 $f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})$
and the
$f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})$
and the
 $f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}})$
are exactly the same as the ones shown in the complete likelihood in Eq. (6). Furthermore, similar to the
$f({\boldsymbol{U}}|\boldsymbol{\mu },\boldsymbol{\tau },{\boldsymbol{z}})$
are exactly the same as the ones shown in the complete likelihood in Eq. (6). Furthermore, similar to the
 $f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
, the
$f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
, the
 $f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
above can be obtained based on its sampling process in Eq. (3). The combination of the
$f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
above can be obtained based on its sampling process in Eq. (3). The combination of the
 $f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
and the
$f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })$
and the
 $f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
in Eq. (13) is equivalent to the
$f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
in Eq. (13) is equivalent to the
 $f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})$
which reads as follows:
$f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})$
which reads as follows:
 \begin{align*}f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})&=\prod ^N_{i,j\,:\,i \neq j}f_{\text{Pois}}(x_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)). \end{align*}
\begin{align*}f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})&=\prod ^N_{i,j\,:\,i \neq j}f_{\text{Pois}}(x_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)). \end{align*}
However, in our context, not all the real networks that we work on provide exogenous node attributes. In the case that
 ${\boldsymbol{c}}$
is not available, the unsupervised prior
${\boldsymbol{c}}$
is not available, the unsupervised prior
 $f({\boldsymbol{z}})$
from Eq. (8) is instead proposed in Eq. (13) to replace the
$f({\boldsymbol{z}})$
from Eq. (8) is instead proposed in Eq. (13) to replace the
 $f({\boldsymbol{z}}|{\boldsymbol{c}})$
.
$f({\boldsymbol{z}}|{\boldsymbol{c}})$
.
We leverage conjugate prior distributions to marginalize a number of model parameters from the posterior distribution in (13). This methodology is also known as “collapsing” and has already been exploited in, for example, McDaid et al. (Reference McDaid, Murphy, Friel and Hurley2012); Wyse and Friel (Reference Wyse and Friel2012); Ryan et al. (Reference Ryan, Wyse and Friel2017); Rastelli et al. (Reference Rastelli, Latouche and Friel2018); Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022); Lu et al. (Reference Lu, Durante and Friel2025). By proposing the conjugate prior distributions:
 \begin{align} \tau _k\sim \text{Gamma}(\alpha _1,\alpha _2/2)\ \text{for}\ k=1,\dots ,K, \\[-6pt] \nonumber \end{align}
\begin{align} \tau _k\sim \text{Gamma}(\alpha _1,\alpha _2/2)\ \text{for}\ k=1,\dots ,K, \\[-6pt] \nonumber \end{align}
 \begin{align} \boldsymbol{\mu }_k|\tau _k \sim \text{MVN}_d(\boldsymbol{0},1/(\omega \tau _k)\mathbb{I}_d)\ \text{for}\ k=1,\dots ,K, \\[12pt] \nonumber \end{align}
\begin{align} \boldsymbol{\mu }_k|\tau _k \sim \text{MVN}_d(\boldsymbol{0},1/(\omega \tau _k)\mathbb{I}_d)\ \text{for}\ k=1,\dots ,K, \\[12pt] \nonumber \end{align}
where
 $(\alpha _1,\alpha _2,\omega )$
are hyperparameters to be specified a priori, the collapsed posterior distribution of the ZIP-LPCM is obtained as:
$(\alpha _1,\alpha _2,\omega )$
are hyperparameters to be specified a priori, the collapsed posterior distribution of the ZIP-LPCM is obtained as:
 \begin{equation} \begin{split} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta ,{\boldsymbol{P}}|{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\beta ),\\ \end{split} \end{equation}
\begin{equation} \begin{split} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta ,{\boldsymbol{P}}|{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\beta ),\\ \end{split} \end{equation}
where the
 $f({\boldsymbol{U}}|{\boldsymbol{z}})$
is calculated according to the methodology explored in Ryan et al. (Reference Ryan, Wyse and Friel2017):
$f({\boldsymbol{U}}|{\boldsymbol{z}})$
is calculated according to the methodology explored in Ryan et al. (Reference Ryan, Wyse and Friel2017):
 \begin{align} f({\boldsymbol{U}}|{\boldsymbol{z}}) = \prod ^{K}_{k=1} \!\left \{\frac {\alpha _2^{\alpha _1}}{\Gamma (\alpha _1)}\frac {\Gamma \big(\alpha _1+\frac {d}{2}n_k\big)}{\pi ^{\frac {d}{2}n_k}}\left (\frac {\omega }{\omega +n_k}\right )^{\frac {d}{2}}\!\left [\alpha _2-\frac {{\left \|{\sum _{i\,:\,z_i=k}{\boldsymbol{u}}_i}\right \|}^2}{n_k+\omega }+\!\!\sum _{i\,:\,z_i=k}\left \|{{\boldsymbol{u}}_i}\right \|^2\right ]^{-(\frac {d}{2}n_k+\alpha _1)}\right \}\!. \end{align}
\begin{align} f({\boldsymbol{U}}|{\boldsymbol{z}}) = \prod ^{K}_{k=1} \!\left \{\frac {\alpha _2^{\alpha _1}}{\Gamma (\alpha _1)}\frac {\Gamma \big(\alpha _1+\frac {d}{2}n_k\big)}{\pi ^{\frac {d}{2}n_k}}\left (\frac {\omega }{\omega +n_k}\right )^{\frac {d}{2}}\!\left [\alpha _2-\frac {{\left \|{\sum _{i\,:\,z_i=k}{\boldsymbol{u}}_i}\right \|}^2}{n_k+\omega }+\!\!\sum _{i\,:\,z_i=k}\left \|{{\boldsymbol{u}}_i}\right \|^2\right ]^{-(\frac {d}{2}n_k+\alpha _1)}\right \}\!. \end{align}
Now that we have our target collapsed posterior distribution, we apply a partially collapsed Markov chain Monte Carlo approach (Van Dyk and Park, Reference Van Dyk and Park2008; Park and Van Dyk, Reference Park and Van Dyk2009) aiming to infer the latent clustering
 ${\boldsymbol{z}}$
, the latent indicators of unusual zeros
${\boldsymbol{z}}$
, the latent indicators of unusual zeros
 $\boldsymbol{\nu }$
, the intercept
$\boldsymbol{\nu }$
, the intercept
 $\beta$
and the latent positions
$\beta$
and the latent positions
 ${\boldsymbol{U}}$
from the posterior in Eq. (16). This is accomplished by constructing a sampler which consists of multiple steps for each of the target variables and parameters, and for the number of occupied groups
${\boldsymbol{U}}$
from the posterior in Eq. (16). This is accomplished by constructing a sampler which consists of multiple steps for each of the target variables and parameters, and for the number of occupied groups
 $K$
simultaneously. The sampling of the imputed adjacency matrix
$K$
simultaneously. The sampling of the imputed adjacency matrix
 ${\boldsymbol{X}}$
straightforwardly follows from Eq. (3), and we leverage ideas similar to those in Lu et al. (Reference Lu, Durante and Friel2025) to infer
${\boldsymbol{X}}$
straightforwardly follows from Eq. (3), and we leverage ideas similar to those in Lu et al. (Reference Lu, Durante and Friel2025) to infer
 $\boldsymbol{\nu }$
and
$\boldsymbol{\nu }$
and
 ${\boldsymbol{z}}$
. Another layer of conjugacy is proposed for the inference procedure of the probability of unusual zeros
${\boldsymbol{z}}$
. Another layer of conjugacy is proposed for the inference procedure of the probability of unusual zeros
 ${\boldsymbol{P}}$
that is required by the sampling step of
${\boldsymbol{P}}$
that is required by the sampling step of
 $\boldsymbol{\nu }$
, and we further develop a new TAE move tailored for the clustering without empty groups to facilitate the clustering inference. The sampling of
$\boldsymbol{\nu }$
, and we further develop a new TAE move tailored for the clustering without empty groups to facilitate the clustering inference. The sampling of
 ${\boldsymbol{U}}$
and
${\boldsymbol{U}}$
and
 $\beta$
are performed via two standard Metropolis-Hastings steps. More details of all these sampling steps are carefully discussed and provided next.
$\beta$
are performed via two standard Metropolis-Hastings steps. More details of all these sampling steps are carefully discussed and provided next.
3.1.1 Inference for
 $\boldsymbol\nu$
$\boldsymbol\nu$

Recall that each of the latent indicators of unusual zeros
 $\{\nu _{ij}\}$
is assumed to follow the
$\{\nu _{ij}\}$
is assumed to follow the
 $\text{Bern}(p_{z_iz_j})$
distribution. However, note that each
$\text{Bern}(p_{z_iz_j})$
distribution. However, note that each
 $\nu _{ij}$
must be zero by assumption when the corresponding observed
$\nu _{ij}$
must be zero by assumption when the corresponding observed
 $y_{ij}\gt 0$
, so only those
$y_{ij}\gt 0$
, so only those
 $\{\nu _{ij}\,:\,y_{ij}=0\}$
are required to be inferred during the inference. Conditional on that the observed interaction
$\{\nu _{ij}\,:\,y_{ij}=0\}$
are required to be inferred during the inference. Conditional on that the observed interaction
 $y_{ij}$
is a zero interaction, the probability of such an interaction being an unusual zero is:
$y_{ij}$
is a zero interaction, the probability of such an interaction being an unusual zero is:
 \begin{equation} \text{P}(\nu _{ij}=1|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)=\frac {p_{z_iz_j}}{p_{z_iz_j}+(1-p_{z_iz_j})f_{\text{Pois}}(0|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)}, \end{equation}
\begin{equation} \text{P}(\nu _{ij}=1|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)=\frac {p_{z_iz_j}}{p_{z_iz_j}+(1-p_{z_iz_j})f_{\text{Pois}}(0|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)}, \end{equation}
and, on the contrary, the conditional probability of it not being an unusual zero is
 $\text{P}(\nu _{ij}=0|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)=1-\text{P}(\nu _{ij}=1|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)$
. This motivates the sampling of each
$\text{P}(\nu _{ij}=0|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)=1-\text{P}(\nu _{ij}=1|y_{ij}=0,p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j)$
. This motivates the sampling of each
 $\nu _{ij}$
to follow:
$\nu _{ij}$
to follow:
 \begin{align} \nu _{ij}|y_{ij},p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j &\sim \begin{cases} \text{Bern}\left (\dfrac {p_{z_iz_j}}{p_{z_iz_j}+(1-p_{z_iz_j})f_{\text{Pois}}(0|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)}\right ), & \text{if}\;y_{ij}=0; \\[12pt] \unicode {x1D7D9}(\nu _{ij}=1), & \text{if}\; y_{ij} \gt 0. \end{cases} \end{align}
\begin{align} \nu _{ij}|y_{ij},p_{z_iz_j},\beta ,{\boldsymbol{u}}_i,{\boldsymbol{u}}_j &\sim \begin{cases} \text{Bern}\left (\dfrac {p_{z_iz_j}}{p_{z_iz_j}+(1-p_{z_iz_j})f_{\text{Pois}}(0|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)}\right ), & \text{if}\;y_{ij}=0; \\[12pt] \unicode {x1D7D9}(\nu _{ij}=1), & \text{if}\; y_{ij} \gt 0. \end{cases} \end{align}
This distribution is actually the full-conditional distribution of
 $\nu _{ij}$
under the posterior:
$\nu _{ij}$
under the posterior:
 \begin{align} \pi (\boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta , {\boldsymbol{P}}|{\boldsymbol{Y}},{\boldsymbol{c}}) \propto f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\beta ), \end{align}
\begin{align} \pi (\boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta , {\boldsymbol{P}}|{\boldsymbol{Y}},{\boldsymbol{c}}) \propto f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi ({\boldsymbol{P}})\pi (\beta ), \end{align}
which further marginalizes the augmented missing data imputed elements from Eq. (16), that is, collapsing the
 $f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
therein. The sampling in Eq. (19) requires the inference of the probability of unusual zeros defined for the interactions between and within those occupied groups. This can be accomplished by further proposing the conjugate prior distributions:
$f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })$
therein. The sampling in Eq. (19) requires the inference of the probability of unusual zeros defined for the interactions between and within those occupied groups. This can be accomplished by further proposing the conjugate prior distributions:
 \begin{align} p_{gh}\sim \text{Beta}(\beta _1,\beta _2)\ \text{for}\ g,h=1,\dots ,K, \end{align}
\begin{align} p_{gh}\sim \text{Beta}(\beta _1,\beta _2)\ \text{for}\ g,h=1,\dots ,K, \end{align}
leading to a typical Gibbs sampling step for each non-redundant probability of unusual zeros:
 \begin{equation} p_{gh}|\boldsymbol{\nu },{\boldsymbol{z}} \sim \text{Beta}\left (\boldsymbol{\nu }_{gh} + \beta _1,n_{gh}-\boldsymbol{\nu }_{gh}+\beta _2\right ),\;\text{for}\; g,h=1,2,\dots ,K, \end{equation}
\begin{equation} p_{gh}|\boldsymbol{\nu },{\boldsymbol{z}} \sim \text{Beta}\left (\boldsymbol{\nu }_{gh} + \beta _1,n_{gh}-\boldsymbol{\nu }_{gh}+\beta _2\right ),\;\text{for}\; g,h=1,2,\dots ,K, \end{equation}
where
 $(\beta _1,\beta _2)$
are hyperparameters, and
$(\beta _1,\beta _2)$
are hyperparameters, and
 $n_{gh} \, :\!= \, \sum _{i,j\,:\,i\neq j}^N\unicode {x1D7D9}(z_i=g, z_j=h)$
. The notation
$n_{gh} \, :\!= \, \sum _{i,j\,:\,i\neq j}^N\unicode {x1D7D9}(z_i=g, z_j=h)$
. The notation
 $\boldsymbol{\nu }_{gh}$
denotes the sum of all the
$\boldsymbol{\nu }_{gh}$
denotes the sum of all the
 $\nu _{ij}|z_i=g, z_j=h, i \neq j$
. Note that the conditional probability of unusual zero provided that the corresponding observed interaction is a zero interaction shown in Eq. (18) is of key interest for practitioners to explore when observing a zero interaction. We refer to Lu et al. (Reference Lu, Durante and Friel2025) for a detailed discussion of the
$\nu _{ij}|z_i=g, z_j=h, i \neq j$
. Note that the conditional probability of unusual zero provided that the corresponding observed interaction is a zero interaction shown in Eq. (18) is of key interest for practitioners to explore when observing a zero interaction. We refer to Lu et al. (Reference Lu, Durante and Friel2025) for a detailed discussion of the
 $\boldsymbol{\nu }$
sampling in Eq. (19).
$\boldsymbol{\nu }$
sampling in Eq. (19).
3.1.2 Inference for
$\boldsymbol{z}$

Carrying out inference for the clustering variable
 ${\boldsymbol{z}}$
based on the supervised MFM prior in Eq. (12) simultaneously infers the clustering allocations and automatically chooses the number of groups. However, the dimension of the model parameter matrix
${\boldsymbol{z}}$
based on the supervised MFM prior in Eq. (12) simultaneously infers the clustering allocations and automatically chooses the number of groups. However, the dimension of the model parameter matrix
 ${\boldsymbol{P}}$
becomes problematic when the nodes are proposed to be assigned to a new empty group. Thus, following the prior distribution introduced in Eq. (21), we can marginalize the target posterior in Eq. (16) in a different way compared to the posterior in Eq. (20). Here, we collapse the parameter
${\boldsymbol{P}}$
becomes problematic when the nodes are proposed to be assigned to a new empty group. Thus, following the prior distribution introduced in Eq. (21), we can marginalize the target posterior in Eq. (16) in a different way compared to the posterior in Eq. (20). Here, we collapse the parameter
 ${\boldsymbol{P}}$
from Eq. (16) following, for example, McDaid et al. (Reference McDaid, Murphy, Friel and Hurley2012); Lu et al. (Reference Lu, Durante and Friel2025), and this leads to a posterior:
${\boldsymbol{P}}$
from Eq. (16) following, for example, McDaid et al. (Reference McDaid, Murphy, Friel and Hurley2012); Lu et al. (Reference Lu, Durante and Friel2025), and this leads to a posterior:
 \begin{equation} \begin{split} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta |{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi (\beta ),\\ \end{split} \end{equation}
\begin{equation} \begin{split} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, {\boldsymbol{U}}, {\boldsymbol{z}},\beta |{\boldsymbol{Y}},{\boldsymbol{c}}) &\propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi (\beta ),\\ \end{split} \end{equation}
where the collapsed likelihood function
 $f(\boldsymbol{\nu }|{\boldsymbol{z}})$
reads as follows:
$f(\boldsymbol{\nu }|{\boldsymbol{z}})$
reads as follows:
 \begin{align} f(\boldsymbol{\nu }|{\boldsymbol{z}}) &= \prod ^{K}_{g=1,h=1}\left [\frac {\text{B}\left (\boldsymbol{\nu }_{gh} + \beta _1,n_{gh}-\boldsymbol{\nu }_{gh}+\beta _2\right )}{\text{B}(\beta _1,\beta _2)}\right ]. \end{align}
\begin{align} f(\boldsymbol{\nu }|{\boldsymbol{z}}) &= \prod ^{K}_{g=1,h=1}\left [\frac {\text{B}\left (\boldsymbol{\nu }_{gh} + \beta _1,n_{gh}-\boldsymbol{\nu }_{gh}+\beta _2\right )}{\text{B}(\beta _1,\beta _2)}\right ]. \end{align}
Here, B(
 $\cdot ,\cdot$
) is the beta function. The sampling of each
$\cdot ,\cdot$
) is the beta function. The sampling of each
 $z_i$
is based on the normalized probability proportional to its full-conditional distribution of the posterior in Eq. (23) (Legramanti et al., Reference Legramanti, Rigon, Durante and Dunson2022), that is,
$z_i$
is based on the normalized probability proportional to its full-conditional distribution of the posterior in Eq. (23) (Legramanti et al., Reference Legramanti, Rigon, Durante and Dunson2022), that is,
 \begin{equation} \begin{split} \text{P}(z_i = k|\boldsymbol{\nu }, {\boldsymbol{U}},{\boldsymbol{c}}, {\boldsymbol{z}}^{-i}) &\propto \text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})f(\boldsymbol{\nu }|z_i = k, {\boldsymbol{z}}^{-i})f({\boldsymbol{U}}|z_i = k, {\boldsymbol{z}}^{-i}),\\ \end{split} \end{equation}
\begin{equation} \begin{split} \text{P}(z_i = k|\boldsymbol{\nu }, {\boldsymbol{U}},{\boldsymbol{c}}, {\boldsymbol{z}}^{-i}) &\propto \text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})f(\boldsymbol{\nu }|z_i = k, {\boldsymbol{z}}^{-i})f({\boldsymbol{U}}|z_i = k, {\boldsymbol{z}}^{-i}),\\ \end{split} \end{equation}
where the notation
 ${\boldsymbol{z}}^{-i} \, :\!= \, {\boldsymbol{z}}\backslash \{z_i\}$
contains all the clustering indicators except
${\boldsymbol{z}}^{-i} \, :\!= \, {\boldsymbol{z}}\backslash \{z_i\}$
contains all the clustering indicators except
 $z_i$
, and the
$z_i$
, and the
 $\text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})$
follows the supervised MFM urn scheme in Eq. (12) by assuming that the node
$\text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})$
follows the supervised MFM urn scheme in Eq. (12) by assuming that the node
 $i$
is removed from the network and then is treated as a new node to be assigned a group in the network. More specifically, we have
$i$
is removed from the network and then is treated as a new node to be assigned a group in the network. More specifically, we have
 \begin{align} \text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i}) \propto \begin{cases} \dfrac {n^{-i}_{k,c_i}+\omega _{c_i}}{n^{-i}_k+\omega _0} \big(n^{-i}_k+\alpha \big), & \text{for}\; k=1,2,\dots ,K^{-i}; \\[14pt] \dfrac {\omega _{c_i}}{\omega _0}\dfrac {\mathcal{W}_{N^{-i}+1,K^{-i}+1}}{\mathcal{W}_{N^{-i}+1,K^{-i}}}\alpha & \text{for}\; k = K^{-i}+1, \end{cases} \end{align}
\begin{align} \text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i}) \propto \begin{cases} \dfrac {n^{-i}_{k,c_i}+\omega _{c_i}}{n^{-i}_k+\omega _0} \big(n^{-i}_k+\alpha \big), & \text{for}\; k=1,2,\dots ,K^{-i}; \\[14pt] \dfrac {\omega _{c_i}}{\omega _0}\dfrac {\mathcal{W}_{N^{-i}+1,K^{-i}+1}}{\mathcal{W}_{N^{-i}+1,K^{-i}}}\alpha & \text{for}\; k = K^{-i}+1, \end{cases} \end{align}
where
 $(\! \cdot \!)^{-i}$
denotes the corresponding statistics obtained after removing node
$(\! \cdot \!)^{-i}$
denotes the corresponding statistics obtained after removing node
 $i$
from the network. If removing node
$i$
from the network. If removing node
 $i$
makes one of the groups empty, the remaining non-empty groups in
$i$
makes one of the groups empty, the remaining non-empty groups in
 ${\boldsymbol{z}}^{-i}$
should be relabeled in ascending order by letting
${\boldsymbol{z}}^{-i}$
should be relabeled in ascending order by letting
 $z_j=z_j-1$
for all the
$z_j=z_j-1$
for all the
 $\{z_j\,:\,j=1,2,\dots ,N;\, j\neq i;\, z_j\gt z_i\}$
during the inference procedures. If
$\{z_j\,:\,j=1,2,\dots ,N;\, j\neq i;\, z_j\gt z_i\}$
during the inference procedures. If
 ${\boldsymbol{c}}$
is not available, the
${\boldsymbol{c}}$
is not available, the
 $\text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})$
should be replaced with the
$\text{P}(z_i = k|{\boldsymbol{c}}, {\boldsymbol{z}}^{-i})$
should be replaced with the
 $\text{P}(z_i = k|{\boldsymbol{z}}^{-i})$
which instead follows the unsupervised MFM urn scheme in Eq. (9), that is, the specific form can be obtained by removing the
$\text{P}(z_i = k|{\boldsymbol{z}}^{-i})$
which instead follows the unsupervised MFM urn scheme in Eq. (9), that is, the specific form can be obtained by removing the
 $(n^{-i}_{k,c_i}+\omega _{c_i})/(n^{-i}_k+\omega _0)$
and the
$(n^{-i}_{k,c_i}+\omega _{c_i})/(n^{-i}_k+\omega _0)$
and the
 $\omega _{c_i}/\omega _0$
terms in Eq. (26). We refer to Miller and Harrison (Reference Miller and Harrison2018), Geng et al. (Reference Geng, Bhattacharya and Pati2019), Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022), Lu et al. (Reference Lu, Durante and Friel2025) for more details of the inference procedure of
$\omega _{c_i}/\omega _0$
terms in Eq. (26). We refer to Miller and Harrison (Reference Miller and Harrison2018), Geng et al. (Reference Geng, Bhattacharya and Pati2019), Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022), Lu et al. (Reference Lu, Durante and Friel2025) for more details of the inference procedure of
 ${\boldsymbol{z}}$
.
${\boldsymbol{z}}$
.
3.2 Truncated absorb-eject move
Since the latent clustering variable
 ${\boldsymbol{z}}$
is updated one element at a time based on Eq. (25), the inference algorithm is susceptible to getting stuck in local posterior modes. Thus, we propose to leverage an Absorb-Eject (AE) move proposed by Nobile and Fearnside (Reference Nobile and Fearnside2007) to facilitate the clustering inference and to deal with such a sampling issue. However, the AE move, as suggested by Nobile and Fearnside (Reference Nobile and Fearnside2007), may create empty groups, and this does not work well with our method, which requires non-empty groups. Thus we instead propose a TAE move which specifically addresses this issue by no longer creating empty groups, as we describe more in detail here below.
${\boldsymbol{z}}$
is updated one element at a time based on Eq. (25), the inference algorithm is susceptible to getting stuck in local posterior modes. Thus, we propose to leverage an Absorb-Eject (AE) move proposed by Nobile and Fearnside (Reference Nobile and Fearnside2007) to facilitate the clustering inference and to deal with such a sampling issue. However, the AE move, as suggested by Nobile and Fearnside (Reference Nobile and Fearnside2007), may create empty groups, and this does not work well with our method, which requires non-empty groups. Thus we instead propose a TAE move which specifically addresses this issue by no longer creating empty groups, as we describe more in detail here below.
Similar to a typical AE move, we have two reversible moves in each iteration of the inference algorithm: a truncated
 $eject$
move, denoted as
$eject$
move, denoted as
 $eject^T$
, and an
$eject^T$
, and an
 $absorb$
move. In general, with probability
$absorb$
move. In general, with probability
 $\text{P}(eject^T)$
, the
$\text{P}(eject^T)$
, the
 $eject^T$
move is applied and, with probability
$eject^T$
move is applied and, with probability
 $1-\text{P}(eject^T)$
, the
$1-\text{P}(eject^T)$
, the
 $absorb$
move is applied. As an exception, the
$absorb$
move is applied. As an exception, the
 $eject^T$
move is applied with probability
$eject^T$
move is applied with probability
 $1$
if
$1$
if
 $K=1$
, while the
$K=1$
, while the
 $absorb$
move is applied with probability
$absorb$
move is applied with probability
 $1$
when
$1$
when
 $K=N$
.
$K=N$
.
-
•
$Eject^T$
move: first randomly pick one of the
$K$
non-empty groups, say group
$g$
. Then, we sample an ejection probability from a prior distribution,
$p_e\sim \text{Beta}(a,a)$
, and each node in group
$g$
has probability
$p_e$
to be reallocated to the new group labeled as
$K+1$
. Thus, on the contrary, each node stays in group
$g$
with probability
$1-p_e$
. The proposed state is denoted as
$({\boldsymbol{z}}',K'=K+1)$
after the reallocation. If this process creates an empty group, that is, either the proposed group
$g$
or the proposed group
$K+1$
in
${\boldsymbol{z}}'$
is an empty group, we propose to abandon this truncated AE move and remains at the current state,
$({\boldsymbol{z}},K)$
.If the reallocation does not create an empty group, we propose:
with the proposal probability
\begin{equation*}\{{\boldsymbol{z}},K\}\rightarrow \{{\boldsymbol{z}}',K'=K+1\},\end{equation*}
(27)where
\begin{align} &\text{P}(\{{\boldsymbol{z}},K\}\rightarrow \{{\boldsymbol{z}}',K'\})=\dfrac {\int ^1_0 p_e^{n'_{K'}}(1-p_e)^{n'_g}\pi _{\text{beta}}(p_e|a,a)\text{d}p_e}{1-p_0}\text{P}(eject^T)\frac {1}{K}, \end{align}
$n'_{g}$
and
$n'_{K'}$
, respectively, denotes the number of nodes in group
$g$
and in group
$K'$
of the proposed clustering
${\boldsymbol{z}}'$
. Here, the reallocation probability
$p_e$
is collapsed leading to:(28)where
\begin{align} &\int ^1_0 p_e^{n'_{K'}}(1-p_e)^{n'_g}\pi _{\text{beta}}(p_e|a,a)\text{d}p_e = \int ^1_0 p_e^{n'_{K'}}(1-p_e)^{n'_g}\frac {\Gamma (2a)}{\Gamma (a)^2}(1-p_e)^{a-1}p_e^{a-1}\text{d}p_e \nonumber \\[8pt] & \quad\quad =\frac {\Gamma (2a)}{\Gamma (a)^2}\int ^1_0p_e^{n'_{K'}+a-1}(1-p_e)^{n'_g+a-1}=\frac {\Gamma (2a)}{\Gamma (a)^2}\frac {\Gamma (a+n'_g)\Gamma (a+n'_{K'})}{\Gamma (2a+n_g)}, \end{align}
$n_g$
is the number of nodes in group
$g$
of the current clustering
${\boldsymbol{z}}$
, and note here that
$n_g = n'_{K'} + n'_{g}$
. The
$p_0$
in Eq. (27) is the probability that all the selected nodes are reallocated in one group leaving another group empty, and is calculated following the similar way as Eq. (28), that is,The prior parameter
\begin{align*} \text{P}\big(n'_{K'}=0\big)=\text{P}\big(n'_{g}=0\big)=\frac {p_0}{2}= \int _0^1p_e^0(1-p_e)^{n_{g}}\pi _{\text{beta}}(p_e|a,a)\text{d}p_e=\frac {\Gamma (2a)}{\Gamma (a)}\frac {\Gamma (a+n_{g})}{\Gamma (2a+n_{g})}. \end{align*}
$a$
for the reallocation probability
$p_e$
is set by checking the pre-computed look-up table of
$p_0$
with respect to
$a$
and
$n_{g}$
. According to our simulation studies, since we do not expect too many moves to be abandoned due to creating empty groups, we propose to set
$p_0=0.02$
in our experiments.On the contrary, the reverse proposal probability is
\begin{align*} &\text{P}(\{{\boldsymbol{z}}',K'\}\rightarrow \{{\boldsymbol{z}},K\})=\frac {\text{P}(absorb)}{K}. \end{align*}
Thus this
$eject^T$
move is accepted with probability(29)where the details of the
\begin{align} &\text{min}\left (1,\frac {f(\boldsymbol{\nu }|{\boldsymbol{z}}')f({\boldsymbol{U}}|{\boldsymbol{z}}')f({\boldsymbol{z}}'|{\boldsymbol{c}})}{f(\boldsymbol{\nu }|{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})}\frac {\text{P}(\{{\boldsymbol{z}}',K'\}\rightarrow \{{\boldsymbol{z}},K\})}{\text{P}(\{{\boldsymbol{z}},K\}\rightarrow \{{\boldsymbol{z}}',K'\})}\right )\!, \end{align}
$f(\boldsymbol{\nu }|{\boldsymbol{z}}), f({\boldsymbol{U}}|{\boldsymbol{z}})$
and
$f({\boldsymbol{z}}|{\boldsymbol{c}})$
terms are, respectively, provided in Eqs. (24), (17) and (10). Otherwise, we remain at the current state
$({\boldsymbol{z}},K)$
.
-
•
$Absorb$
move: first randomly select two groups, say groups
$g,h$
with
$g\lt h$
, from the
$K$
groups and merge them together into cluster
$g$
. Then relabel all the groups in ascending order from group
$1$
to group
$K' \, :\!= \, K-1$
. We accept this
$absorb$
move with the same probability scheme in Eq. (29) but with different proposal probability:while the reverse proposal probability is
\begin{align*} &\text{P}(\{{\boldsymbol{z}},K\}\rightarrow \{{\boldsymbol{z}}',K'\})=\frac {\text{P}(absorb)}{K(K-1)}, \end{align*}
The proof of the above formula is similar to Eq. (28). If the absorb move is not accepted, we remain at the current state.
\begin{align*} \text{P}(\{{\boldsymbol{z}}',K'\}\rightarrow \{{\boldsymbol{z}},K\})=\dfrac {\dfrac {\Gamma (2a)}{\Gamma (a)^2}\dfrac {\Gamma (a+n_g)\Gamma (a+n_h)}{\Gamma (2a+n'_g)}}{1-2\dfrac {\Gamma (2a)}{\Gamma (a)}\dfrac {\Gamma \big(a+n'_{g}\big)}{\Gamma \big(2a+n'_{g}\big)}}\dfrac {\text{P}(eject^T)}{K'(K'+1)}. \end{align*}



















































Note that our proposed TAE move is a Metropolis-Hastings move that extends the typical AE move proposed in Nobile and Fearnside (Reference Nobile and Fearnside2007), wherein a complete study and discussion on these moves are provided.
3.3 Partially collapsed metropolis-within-Gibbs
Inferring the indicators of unusual zeros
 $\boldsymbol{\nu }$
and the latent clustering indicators
$\boldsymbol{\nu }$
and the latent clustering indicators
 ${\boldsymbol{z}}$
from different posteriors does not guarantee the convergence to the same target distribution. However, note that both posteriors in Eq. (20) and in Eq. (23) are different partially collapsed forms of the posterior in Eq. (16) which is further a partially collapsed form of the posterior:
${\boldsymbol{z}}$
from different posteriors does not guarantee the convergence to the same target distribution. However, note that both posteriors in Eq. (20) and in Eq. (23) are different partially collapsed forms of the posterior in Eq. (16) which is further a partially collapsed form of the posterior:
 \begin{equation} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, \bar {{\boldsymbol{P}}}, {\boldsymbol{U}}, {\boldsymbol{z}},\beta |{\boldsymbol{Y}},{\boldsymbol{c}}) \propto f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|\bar {{\boldsymbol{P}}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi (\beta )\pi (\bar {{\boldsymbol{P}}}), \end{equation}
\begin{equation} \pi ({\boldsymbol{X}}, \boldsymbol{\nu }, \bar {{\boldsymbol{P}}}, {\boldsymbol{U}}, {\boldsymbol{z}},\beta |{\boldsymbol{Y}},{\boldsymbol{c}}) \propto f({\boldsymbol{X}}|{\boldsymbol{Y}}, \beta , {\boldsymbol{U}},\boldsymbol{\nu })f({\boldsymbol{Y}}|\beta , {\boldsymbol{U}},\boldsymbol{\nu })f(\boldsymbol{\nu }|\bar {{\boldsymbol{P}}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\pi (\beta )\pi (\bar {{\boldsymbol{P}}}), \end{equation}
where
 $\bar {{\boldsymbol{P}}}$
is defined as a
$\bar {{\boldsymbol{P}}}$
is defined as a
 $N \times N$
matrix of which
$N \times N$
matrix of which
 ${\boldsymbol{P}}$
is a submatrix. The joint prior distribution
${\boldsymbol{P}}$
is a submatrix. The joint prior distribution
 $\pi (\bar {{\boldsymbol{P}}}) \propto \prod _{g=1,h=1}^Nf_{\text{Beta}}(\bar {p}_{gh}|\beta _1,\beta _2)$
is proposed to be the product up to the maximum reachable value of
$\pi (\bar {{\boldsymbol{P}}}) \propto \prod _{g=1,h=1}^Nf_{\text{Beta}}(\bar {p}_{gh}|\beta _1,\beta _2)$
is proposed to be the product up to the maximum reachable value of
 $K$
, that is,
$K$
, that is,
 $N$
, and the
$N$
, and the
 $\{\bar {p}_{gh}\}$
here are the entries of
$\{\bar {p}_{gh}\}$
here are the entries of
 $\bar {{\boldsymbol{P}}}$
. Thus we leverage the partially collapsed Gibbs approach proposed by Van Dyk and Park (Reference Van Dyk and Park2008); Park and Van Dyk (Reference Park and Van Dyk2009) to ensure the correct target stationary distribution. Our Algorithm 1 further adopts the Metropolis-Hastings (M-H) steps of inferring
$\bar {{\boldsymbol{P}}}$
. Thus we leverage the partially collapsed Gibbs approach proposed by Van Dyk and Park (Reference Van Dyk and Park2008); Park and Van Dyk (Reference Park and Van Dyk2009) to ensure the correct target stationary distribution. Our Algorithm 1 further adopts the Metropolis-Hastings (M-H) steps of inferring
 $\beta$
and
$\beta$
and
 ${\boldsymbol{U}}$
leading to the Partially Collapsed Metropolis-within-Gibbs (PCMwG) algorithm. Note that the full-conditional distribution of
${\boldsymbol{U}}$
leading to the Partially Collapsed Metropolis-within-Gibbs (PCMwG) algorithm. Note that the full-conditional distribution of
 $\beta$
remains the same under either the posterior in Eq. (16) or the posterior in Eq. (30), that is,
$\beta$
remains the same under either the posterior in Eq. (16) or the posterior in Eq. (30), that is,
 \begin{align} p(\beta |{\boldsymbol{X}},{\boldsymbol{U}}) \propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})\pi (\beta ) = \left [\prod ^N_{i,j\,:\,i \neq j}f_{\text{Pois}}(x_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||))\right ]\pi (\beta ), \end{align}
\begin{align} p(\beta |{\boldsymbol{X}},{\boldsymbol{U}}) \propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})\pi (\beta ) = \left [\prod ^N_{i,j\,:\,i \neq j}f_{\text{Pois}}(x_{ij}|\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||))\right ]\pi (\beta ), \end{align}
while the full-conditional distribution of each
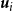 ${\boldsymbol{u}}_i$
is also invariant under the two different posteriors:
${\boldsymbol{u}}_i$
is also invariant under the two different posteriors:
 \begin{align} &\hspace {1.2em}p({\boldsymbol{u}}_i|z_i=k, \beta ,{\boldsymbol{X}},{\boldsymbol{U}}\backslash \{{\boldsymbol{u}}_i\}) \propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f({\boldsymbol{U}}|{\boldsymbol{z}}^{-i},z_i=k) \nonumber \\ & \propto \left [\prod ^N_{j\,:\,j \neq i}f_{\text{Pois}}(x_{ij},x_{ji}\mid \text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||))\right ] \left [\alpha _2-\frac {\left \|{\sum _{j\,:\,z_j=k}{\boldsymbol{u}}_j}\right \|^2}{n_k+\omega }+\sum _{j\,:\,z_j=k}\left \|{{\boldsymbol{u}}_j}\right \|^2\right ]^{-(\frac {d}{2}n_k+\alpha _1)}. \end{align}
\begin{align} &\hspace {1.2em}p({\boldsymbol{u}}_i|z_i=k, \beta ,{\boldsymbol{X}},{\boldsymbol{U}}\backslash \{{\boldsymbol{u}}_i\}) \propto f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f({\boldsymbol{U}}|{\boldsymbol{z}}^{-i},z_i=k) \nonumber \\ & \propto \left [\prod ^N_{j\,:\,j \neq i}f_{\text{Pois}}(x_{ij},x_{ji}\mid \text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||))\right ] \left [\alpha _2-\frac {\left \|{\sum _{j\,:\,z_j=k}{\boldsymbol{u}}_j}\right \|^2}{n_k+\omega }+\sum _{j\,:\,z_j=k}\left \|{{\boldsymbol{u}}_j}\right \|^2\right ]^{-(\frac {d}{2}n_k+\alpha _1)}. \end{align}
Here we set normal proposal distribution with variance
 $\sigma ^2_{\beta }$
for the M-H step of
$\sigma ^2_{\beta }$
for the M-H step of
 $\beta$
, while we propose a multivariate normal proposal distribution for each latent position
$\beta$
, while we propose a multivariate normal proposal distribution for each latent position
 ${\boldsymbol{u}}_i$
with covariance
${\boldsymbol{u}}_i$
with covariance
 $\sigma ^2_{{\boldsymbol{U}}}\mathbb{I}_d$
. Both proposal distributions are centered at the previous state of the corresponding parameter or latent variables.
$\sigma ^2_{{\boldsymbol{U}}}\mathbb{I}_d$
. Both proposal distributions are centered at the previous state of the corresponding parameter or latent variables.
A partially collapsed Metropolis-within-Gibbs sampler for ZIP-LPCM.

According to Van Dyk and Park (Reference Van Dyk and Park2008); Park and Van Dyk (Reference Park and Van Dyk2009), the ordering of the steps in Algorithm 1 matters in that the sampling of
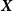 ${\boldsymbol{X}}$
must be performed after the sampling on
${\boldsymbol{X}}$
must be performed after the sampling on
 $\boldsymbol{\nu }$
; also, the inference on
$\boldsymbol{\nu }$
; also, the inference on
 ${\boldsymbol{P}}$
must be performed after the step on
${\boldsymbol{P}}$
must be performed after the step on
 ${\boldsymbol{z}}$
and after the truncated AE move. If these requirements are not satisfied, the algorithm would yield a Markov chain targeting an unknown stationary distribution.
${\boldsymbol{z}}$
and after the truncated AE move. If these requirements are not satisfied, the algorithm would yield a Markov chain targeting an unknown stationary distribution.
The posterior samples of interests are those of
 $\boldsymbol{\nu }, \beta , {\boldsymbol{U}}, {\boldsymbol{z}}$
and
$\boldsymbol{\nu }, \beta , {\boldsymbol{U}}, {\boldsymbol{z}}$
and
 $K$
. Since the sampled values of each
$K$
. Since the sampled values of each
 $\nu _{ij}$
are either 0s or 1s, the posterior mean of the
$\nu _{ij}$
are either 0s or 1s, the posterior mean of the
 $\nu _{ij}$
, denoted as
$\nu _{ij}$
, denoted as
 $\hat {\nu }_{ij}$
, provides an approximation of the conditional probability in Eq. (18). Such an approximation takes into account the uncertainty generated by
$\hat {\nu }_{ij}$
, provides an approximation of the conditional probability in Eq. (18). Such an approximation takes into account the uncertainty generated by
 $\beta , {\boldsymbol{U}},{\boldsymbol{z}}$
and
$\beta , {\boldsymbol{U}},{\boldsymbol{z}}$
and
 ${\boldsymbol{P}}$
, where
${\boldsymbol{P}}$
, where
 $p_{z_iz_j}$
varies along with different posterior clustering
$p_{z_iz_j}$
varies along with different posterior clustering
 ${\boldsymbol{z}}$
throughout the posterior samples. Similarly, the posterior mean is also calculated for the intercept
${\boldsymbol{z}}$
throughout the posterior samples. Similarly, the posterior mean is also calculated for the intercept
 $\beta$
to obtain its summary statistic,
$\beta$
to obtain its summary statistic,
 $\hat {\beta }$
.
$\hat {\beta }$
.
As concerns the latent clustering variable, we may obtain a point estimate via
 \begin{equation} \hat {{\boldsymbol{z}}}=\underset {{\boldsymbol{z}}'}{\arg \min }\;\mathbb{E}_{\text{post}}[\mathcal{L}_{VI}({\boldsymbol{z}},{\boldsymbol{z}}')|{\boldsymbol{Y}},{\boldsymbol{c}}], \end{equation}
\begin{equation} \hat {{\boldsymbol{z}}}=\underset {{\boldsymbol{z}}'}{\arg \min }\;\mathbb{E}_{\text{post}}[\mathcal{L}_{VI}({\boldsymbol{z}},{\boldsymbol{z}}')|{\boldsymbol{Y}},{\boldsymbol{c}}], \end{equation}
within which
 $\mathcal{L}_{VI}$
is the Variation of Information (VI) loss function (Meilă, Reference Meilă2007; Wade and Ghahramani, Reference Wade and Ghahramani2018) defined as
$\mathcal{L}_{VI}$
is the Variation of Information (VI) loss function (Meilă, Reference Meilă2007; Wade and Ghahramani, Reference Wade and Ghahramani2018) defined as
 $\mathcal{L}_{VI}({\boldsymbol{z}},{\boldsymbol{z}}') = 2H({\boldsymbol{z}},{\boldsymbol{z}}')-H({\boldsymbol{z}})-H({\boldsymbol{z}}')$
, measuring the log-ratio of the mutual and the individual entropies of the clusterings. Here,
$\mathcal{L}_{VI}({\boldsymbol{z}},{\boldsymbol{z}}') = 2H({\boldsymbol{z}},{\boldsymbol{z}}')-H({\boldsymbol{z}})-H({\boldsymbol{z}}')$
, measuring the log-ratio of the mutual and the individual entropies of the clusterings. Here,
 $H({\boldsymbol{z}})$
is the entropy of
$H({\boldsymbol{z}})$
is the entropy of
 ${\boldsymbol{z}}$
, and
${\boldsymbol{z}}$
, and
 $H({\boldsymbol{z}},{\boldsymbol{z}}')$
is the joint entropy of
$H({\boldsymbol{z}},{\boldsymbol{z}}')$
is the joint entropy of
 ${\boldsymbol{z}}$
and
${\boldsymbol{z}}$
and
 ${\boldsymbol{z}}'$
. Such a method is widely used in the literature and is shown to perform well for obtaining a point estimate of the clustering from a set of posterior samples, for example, Rastelli and Friel (Reference Rastelli and Friel2018); Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022); Lu et al. (Reference Lu, Durante and Friel2025). An estimated
${\boldsymbol{z}}'$
. Such a method is widely used in the literature and is shown to perform well for obtaining a point estimate of the clustering from a set of posterior samples, for example, Rastelli and Friel (Reference Rastelli and Friel2018); Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022); Lu et al. (Reference Lu, Durante and Friel2025). An estimated
 $\hat {K}$
can thus be obtained based on the number of non-empty groups in
$\hat {K}$
can thus be obtained based on the number of non-empty groups in
 $\hat {{\boldsymbol{z}}}$
. A natural approach to summarize posterior samples of latent positions
$\hat {{\boldsymbol{z}}}$
. A natural approach to summarize posterior samples of latent positions
 ${\boldsymbol{U}}$
is to first apply Procrustes transformation (Borg and Groenen, Reference Borg and Groenen2005) on each posterior sample with respect to a reference
${\boldsymbol{U}}$
is to first apply Procrustes transformation (Borg and Groenen, Reference Borg and Groenen2005) on each posterior sample with respect to a reference
 ${\boldsymbol{U}}$
, and then to calculate the posterior mean from the posterior samples of each
${\boldsymbol{U}}$
, and then to calculate the posterior mean from the posterior samples of each
 ${\boldsymbol{u}}_i$
. However, we find that, under LPCMs, the latent positions can still keep rotating within each individual group, especially when the groups are well separated. This creates further complications that are not resolved by the standard Procrustes transformations. For this reason, we opt for a more pragmatic approach and resort to obtain a point estimate of
${\boldsymbol{u}}_i$
. However, we find that, under LPCMs, the latent positions can still keep rotating within each individual group, especially when the groups are well separated. This creates further complications that are not resolved by the standard Procrustes transformations. For this reason, we opt for a more pragmatic approach and resort to obtain a point estimate of
 ${\boldsymbol{U}}$
via
${\boldsymbol{U}}$
via
 \begin{equation} \hat {{\boldsymbol{U}}}=\underset {{\boldsymbol{U}}}{\arg {\max }}{}_{\text{post}}\left [f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\unicode {x1D7D9}({\boldsymbol{z}}=\hat {{\boldsymbol{z}}})\right ], \end{equation}
\begin{equation} \hat {{\boldsymbol{U}}}=\underset {{\boldsymbol{U}}}{\arg {\max }}{}_{\text{post}}\left [f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}})\unicode {x1D7D9}({\boldsymbol{z}}=\hat {{\boldsymbol{z}}})\right ], \end{equation}
which is the posterior latent positions from the posterior state which maximizes the complete likelihood function of the posterior in Eq. (30) among those states whose corresponding posterior clustering is identical to
 $\hat {{\boldsymbol{z}}}$
. In the case that no posterior clustering agrees with
$\hat {{\boldsymbol{z}}}$
. In the case that no posterior clustering agrees with
 $\hat {{\boldsymbol{z}}}$
, the posterior states after burn-in process are all considered. However, this is not the case of any experiments we illustrate in the next sections.
$\hat {{\boldsymbol{z}}}$
, the posterior states after burn-in process are all considered. However, this is not the case of any experiments we illustrate in the next sections.
3.4 Choice of the number of latent dimensions
In our simulations and applications, we generally propose
 $d=3$
for the latent positions, aiming to provide 3-d visualizations of the complex networks. Latent spaces with higher dimensions cannot be visualized in practice and are generally not required to represent most typical real networks, so
$d=3$
for the latent positions, aiming to provide 3-d visualizations of the complex networks. Latent spaces with higher dimensions cannot be visualized in practice and are generally not required to represent most typical real networks, so
 $d=2$
or
$d=2$
or
 $d=3$
dimensions are usually more than sufficient. In fact, in Hoff et al. (Reference Hoff, Raftery and Handcock2002), the authors defined (for binary networks) a concept of representability that determines by which dimension
$d=3$
dimensions are usually more than sufficient. In fact, in Hoff et al. (Reference Hoff, Raftery and Handcock2002), the authors defined (for binary networks) a concept of representability that determines by which dimension
 $d$
of the latent positions a network is representable. However, it is not easy to theoretically evaluate the value
$d$
of the latent positions a network is representable. However, it is not easy to theoretically evaluate the value
 $d$
, especially for complex networks, regardless of whether such a concept can be well extended to weighted networks. In any case, the authors argue that a small value of
$d$
, especially for complex networks, regardless of whether such a concept can be well extended to weighted networks. In any case, the authors argue that a small value of
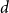 $d$
can be sufficient to represent a large variety of common social networks. In this spirit, we perform our simulation studies in three dimensions, and, in the real data applications of Section 5, we compare the
$d$
can be sufficient to represent a large variety of common social networks. In this spirit, we perform our simulation studies in three dimensions, and, in the real data applications of Section 5, we compare the
 $d=3$
performance to the corresponding
$d=3$
performance to the corresponding
 $d=2$
performance for each real network we focus on, giving some nuanced views for the different cases. We note that model choice for LPMs remains a critical research question. Our work contributes in this research direction by providing additional examples of the typical results that can be obtained in two and three dimensional LPMs.
$d=2$
performance for each real network we focus on, giving some nuanced views for the different cases. We note that model choice for LPMs remains a critical research question. Our work contributes in this research direction by providing additional examples of the typical results that can be obtained in two and three dimensional LPMs.
4. Simulation studies
In this section, we show the performance of the newly proposed ZIP-LPCM + MFM model in both a supervised and unsupervised setting. For clarity, the inference algorithm of the unsupervised case is obtained by simply replacing Eq. (12) with Eq. (9) in Eq. (25) within the Algorithm 1 Step 5, and by replacing Eq. (10) with Eq. (8) in Step 6 of the algorithm. Further, we also make comparisons with the binary LPCM explored in Ryan et al. (Reference Ryan, Wyse and Friel2017), which we suitably extend to the non-negative weighted networks framework. The extension of the binary LPCM to the weighted case is done by replacing the Bernoulli logistic link function with the Poisson distribution equipped with the link function in Eq. (4), leading to the Poisson LPCM (Pois-LPCM). Note that the Pois-LPCM is a specific case of the ZIP-LPCM if we let the probability of unusual zeros for each pair of nodes be zero, corresponding to the situation that no unusual zero or missing data is assumed for the model. Both supervised and unsupervised MFM priors are also proposed for the Pois-LPCM along with the truncated AE move to achieve a more fair performance comparison. Thus the corresponding inference processes for the Pois-LPCM also follow Algorithm 1, the only differences being the removal of Steps 1, 2, 7, as well as all the
 $\boldsymbol{\nu }$
terms in Steps 5, 6, and also treating
$\boldsymbol{\nu }$
terms in Steps 5, 6, and also treating
 ${\boldsymbol{X}}$
as
${\boldsymbol{X}}$
as
 ${\boldsymbol{Y}}$
instead.
${\boldsymbol{Y}}$
instead.
We propose three simulation studies. In simulation study 1, we randomly generate two artificial networks: one from a ZIP-LPCM (scenario 1) and one from a Pois-LPCM (scenario 2). We implement the supervised and the unsupervised versions of ZIP-LPCM and of Pois-LPCM on the artificial network in each scenario, aiming to show that our newly proposed ZIP-LPCM is able to perform well when it is mis-specified to networks without unusual zeros or missing data. We also aim to illustrate that the capability of modeling unusual zeros plays a key role during the inference, leading to better performance of the ZIP-LPCM compared to the Pois-LPCM when we fit them to networks with unusual zeros.
Instead, in simulation study 2, we focus on synthetic networks which are generated from the Zero-Inflated Poisson Stochastic Block Model (ZIP-SBM) explored in Lu et al. (Reference Lu, Durante and Friel2025). Also for this second simulation study, we consider two scenarios. In the first scenario we have a basic community structure, whereas in the second we also include hubs and thus disassortative patterns. Our goal is to analyze whether the ZIP-LPCM is able to fit well to networks that generated from a different model, that is, the ZIP-SBM. Indeed, it is known that the ZIP-SBM is able to characterize specific structures which are not possible to represent with the latent positions of the ZIP-LPCM (due to the inherent transitivity of the latent space), and thus may be more flexible when compared to the ZIP-LPCM. However, the ZIP-SBM cannot capture much variability within the blocks, and cannot provide the latent space views of the networks, thus making the ZIP-LPCM a viable modeling choice. Note that the simulation settings of all the models in this section mimic the structures of the real networks from our real data applications, thus, the simulation study performance provide valuable benchmarks for the analyses of real networks.
In simulation study 3, we further explore the robustness of our ZIP-LPCM approach performance by replicated experiments on different sampled networks with the same model settings. We also investigate the generalization of our results to networks with larger network sizes.
4.1 Simulation study 1
We propose synthetic networks with
 $N=75$
nodes and
$N=75$
nodes and
 $K=5$
clusters, where the true clustering
$K=5$
clusters, where the true clustering
 ${\boldsymbol{z}}^*$
has group sizes:
${\boldsymbol{z}}^*$
has group sizes:
 $n_1=5,n_2=10,n_3=15,n_4=20$
and
$n_1=5,n_2=10,n_3=15,n_4=20$
and
 $n_5=25$
. The network that we generate for scenario 1 is randomly simulated from a ZIP-LPCM with settings:
$n_5=25$
. The network that we generate for scenario 1 is randomly simulated from a ZIP-LPCM with settings:
 $\beta =3$
,
$\beta =3$
,
 $\boldsymbol{\tau } = \big(\frac {1}{0.25},\frac {1}{0.50},\frac {1}{0.75},1,\frac {1}{1.25} \big)$
and
$\boldsymbol{\tau } = \big(\frac {1}{0.25},\frac {1}{0.50},\frac {1}{0.75},1,\frac {1}{1.25} \big)$
and
 \begin{equation*} \boldsymbol{\mu } = \left [ \begin{pmatrix} -1.5 \\-1.5\\-1.5 \end{pmatrix}, \begin{pmatrix} -2\\ 2\\ 0 \end{pmatrix}, \begin{pmatrix} 2\\ -2\\ 0 \end{pmatrix}, \begin{pmatrix} 2\\ 2\\ -2 \end{pmatrix}, \begin{pmatrix} -2\\ -2\\ 2 \end{pmatrix}\right ], {\boldsymbol{P}}=\begin{pmatrix} 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05 &\quad 0.10 \\ 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05 \\ 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 \\ 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 \\ 0.05 &\quad 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40 \end{pmatrix}. \end{equation*}
\begin{equation*} \boldsymbol{\mu } = \left [ \begin{pmatrix} -1.5 \\-1.5\\-1.5 \end{pmatrix}, \begin{pmatrix} -2\\ 2\\ 0 \end{pmatrix}, \begin{pmatrix} 2\\ -2\\ 0 \end{pmatrix}, \begin{pmatrix} 2\\ 2\\ -2 \end{pmatrix}, \begin{pmatrix} -2\\ -2\\ 2 \end{pmatrix}\right ], {\boldsymbol{P}}=\begin{pmatrix} 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05 &\quad 0.10 \\ 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05 \\ 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 \\ 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 \\ 0.05 &\quad 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40 \end{pmatrix}. \end{equation*}
The network in scenario 2 is simulated from a Pois-LPCM with the same set of parameters shown above, but excluding the probability of unusual zeros
 ${\boldsymbol{P}}$
. In order to assess the performance of the estimation procedure, the above parameter values, which are used for generating the networks, are treated as the reference values to be compared to the corresponding posterior samples. We further use
${\boldsymbol{P}}$
. In order to assess the performance of the estimation procedure, the above parameter values, which are used for generating the networks, are treated as the reference values to be compared to the corresponding posterior samples. We further use
 $(\! \cdot \!)^*$
to denote these reference values, that is,
$(\! \cdot \!)^*$
to denote these reference values, that is,
 $(K^*,{\boldsymbol{z}}^*,\beta ^*,\boldsymbol{\tau }^*,\boldsymbol{\mu }^*,{\boldsymbol{P}}^*)$
indicate the true parameter values that have generated the data. However, not all of these parameters are actually used, for example, the parameters
$(K^*,{\boldsymbol{z}}^*,\beta ^*,\boldsymbol{\tau }^*,\boldsymbol{\mu }^*,{\boldsymbol{P}}^*)$
indicate the true parameter values that have generated the data. However, not all of these parameters are actually used, for example, the parameters
 $\boldsymbol{\tau }$
and
$\boldsymbol{\tau }$
and
 $\boldsymbol{\mu }$
are marginalized out during the inference and thus they are not taken into account. Figure 1 illustrates the latent positions and the clustering used for generating the networks in two scenarios. The pattern of the latent positions for the second scenario are similar to the first scenario one but with denser edges because no missing data is assumed. We refer to https://github.com/Chaoyi-Lu/ZIP-LPCM for more details including the 3-d interactive plots of the latent positions as well as all the implementation code of the experiments in this paper. Figure 2 shows the heatmap plots of the adjacency matrices for both synthetic networks.
$\boldsymbol{\mu }$
are marginalized out during the inference and thus they are not taken into account. Figure 1 illustrates the latent positions and the clustering used for generating the networks in two scenarios. The pattern of the latent positions for the second scenario are similar to the first scenario one but with denser edges because no missing data is assumed. We refer to https://github.com/Chaoyi-Lu/ZIP-LPCM for more details including the 3-d interactive plots of the latent positions as well as all the implementation code of the experiments in this paper. Figure 2 shows the heatmap plots of the adjacency matrices for both synthetic networks.
Simulation study 1 synthetic networks. The 1st row plots correspond to the scenario 1 network, while the 2nd row plots correspond to the scenario 2 network. The 1st column plots show the 3-dimensional plots of the latent positions with different node colors denoting the corresponding true clustering. Node sizes are proportional to node betweenness, whereas edge widths and colors are proportional to edge weights. The 2nd column plots are the rotated plots of the 1st column latent position plots that are rotated for
 $90^{\circ }$
clockwise with respect to the vertical axis.
$90^{\circ }$
clockwise with respect to the vertical axis.

Simulation study 1. Synthetic networks’ adjacency matrix heatmap plots. Darker entries correspond to higher edge weights. The side-bars indicate the reference clustering
 ${\boldsymbol{z}}^*$
. Left plot: scenario 1 network, generated from a ZIP-LPCM. Right plot: scenario 2 network, generated from a Pois-LPCM.
${\boldsymbol{z}}^*$
. Left plot: scenario 1 network, generated from a ZIP-LPCM. Right plot: scenario 2 network, generated from a Pois-LPCM.

Prior settings similar to those of Handcock et al. (Reference Handcock, Raftery and Tantrum2007), Ryan et al. (Reference Ryan, Wyse and Friel2017) are applied for all the experiments of this paper:
 $\alpha =3$
for the MFM and
$\alpha =3$
for the MFM and
 $\alpha _1=1,\alpha _2=0.103$
in Eq. (14). The tuning parameter
$\alpha _1=1,\alpha _2=0.103$
in Eq. (14). The tuning parameter
 $\omega$
in Eq. (15) is instead set as
$\omega$
in Eq. (15) is instead set as
 $0.01$
, encouraging more split clusters in the latent space. A common prior distribution of
$0.01$
, encouraging more split clusters in the latent space. A common prior distribution of
 $\bar {K}$
in MFM is assumed as we discussed in Section 2.3, that is,
$\bar {K}$
in MFM is assumed as we discussed in Section 2.3, that is,
 $\bar {K}\sim \text{Pois}(1)|\bar {K}\gt 1$
. Based on the ZIP-SBM results illustrated in Lu et al. (Reference Lu, Durante and Friel2025), we also propose to set a
$\bar {K}\sim \text{Pois}(1)|\bar {K}\gt 1$
. Based on the ZIP-SBM results illustrated in Lu et al. (Reference Lu, Durante and Friel2025), we also propose to set a
 $\text{Beta}(1,9)$
prior for the probability of unusual zeros by default in Eq. (21), but we also check in the simulation studies the sensitivity of this prior setting by considering four other different options, that is,
$\text{Beta}(1,9)$
prior for the probability of unusual zeros by default in Eq. (21), but we also check in the simulation studies the sensitivity of this prior setting by considering four other different options, that is,
 $\text{Beta}(1,1),\text{Beta}(1,3),\text{Beta}(1,19)$
and
$\text{Beta}(1,1),\text{Beta}(1,3),\text{Beta}(1,19)$
and
 $\text{Beta}(1,99)$
.
$\text{Beta}(1,99)$
.
As regards the node attributes, a contaminated version of the true clustering
 ${\boldsymbol{z}}^*$
is used as the exogenous node attributes
${\boldsymbol{z}}^*$
is used as the exogenous node attributes
 ${\boldsymbol{c}}$
where the clustering of 20 out of 75 nodes are randomly reallocated. This setting aims to check whether the output are robust when noise exists in the node attributes. The prior of
${\boldsymbol{c}}$
where the clustering of 20 out of 75 nodes are randomly reallocated. This setting aims to check whether the output are robust when noise exists in the node attributes. The prior of
 $\beta$
is proposed to be a continuous uniform distribution defined on a large enough interval centered around zero so that the corresponding probability density function can always be canceled in the acceptance ratio of Step 3.2 of Algorithm 1. The cohesion parameter of the supervised MFM is canonically set as
$\beta$
is proposed to be a continuous uniform distribution defined on a large enough interval centered around zero so that the corresponding probability density function can always be canceled in the acceptance ratio of Step 3.2 of Algorithm 1. The cohesion parameter of the supervised MFM is canonically set as
 $\omega _c=1$
for
$\omega _c=1$
for
 $c=1,2,\dots ,C$
.
$c=1,2,\dots ,C$
.
With regard to the MCMC posterior samples, we run the algorithm for 12,000 iterations, where the first 2000 iterations are discarded as burn-in for each setting that we consider. The convergence and mixing of the posterior samples of the ZIP-LPCM is monitored by checking the trace plots of the corresponding values of the complete likelihood function of the posterior in Eq. (16), that is,
 \begin{equation*}f({\boldsymbol{Y}},{\boldsymbol{X}},\boldsymbol{\nu },{\boldsymbol{U}},{\boldsymbol{z}}|\beta ,{\boldsymbol{P}},{\boldsymbol{c}})= f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}}).\end{equation*}
\begin{equation*}f({\boldsymbol{Y}},{\boldsymbol{X}},\boldsymbol{\nu },{\boldsymbol{U}},{\boldsymbol{z}}|\beta ,{\boldsymbol{P}},{\boldsymbol{c}})= f({\boldsymbol{X}}|\beta , {\boldsymbol{U}})f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})f({\boldsymbol{U}}|{\boldsymbol{z}})f({\boldsymbol{z}}|{\boldsymbol{c}}).\end{equation*}
The complete likelihood of the Pois-LPCM is obtained by simply removing the
 $f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})$
term and by replacing
$f(\boldsymbol{\nu }|{\boldsymbol{P}},{\boldsymbol{z}})$
term and by replacing
 ${\boldsymbol{X}}$
with
${\boldsymbol{X}}$
with
 ${\boldsymbol{Y}}$
in the above equation. In practice, we observe that the posterior samples of all implementations in simulation study 1 and simulation study 2 quickly converge to the stationary distribution within approximately 2000 iterations, however we conservatively use a much larger number of iteration to ensure satisfactory convergence.
${\boldsymbol{Y}}$
in the above equation. In practice, we observe that the posterior samples of all implementations in simulation study 1 and simulation study 2 quickly converge to the stationary distribution within approximately 2000 iterations, however we conservatively use a much larger number of iteration to ensure satisfactory convergence.
The initial clustering is proposed to be the trivial clustering where each node occupies a different group. This leads to higher computational burden required in early iterations of the implementations: on a laptop equipped with a Intel Core i7 1.80 GHz CPU, the supervised ZIP-LPCM algorithm implemented for 2000 iterations in this simulation study 1 take around 5.5 mins to finish, the 6000-iteration implementations take approximately 14 mins, and the 12,000-iteration implementations that we mainly focus on in practice take around 24 mins. The execution time of the unsupervised implementations is generally 20% less than that of the supervised implementations, and the time spent by Pois-LPCM algorithm executions is approximately 12.5% less than that of the ZIP-LPCM cases.
Latent positions are initialized by a natural approach where classical multidimensional scaling (Gower, Reference Gower1966) is applied on the geodesic distance matrix of the observed adjacency matrix, in the same style as Hoff et al. (Reference Hoff, Raftery and Handcock2002). The proposal variances of M-H steps of
 $\beta$
and
$\beta$
and
 ${\boldsymbol{U}}$
are tuned so that the corresponding acceptance rates are approximately 0.23. The probability of applying an
${\boldsymbol{U}}$
are tuned so that the corresponding acceptance rates are approximately 0.23. The probability of applying an
 $eject^T$
move is set as
$eject^T$
move is set as
 $\text{P}(eject^T)=0.5$
by default.
$\text{P}(eject^T)=0.5$
by default.
Recall that a point estimate of the posterior clustering and of the latent positions is, respectively, obtained by Eqs. (33) and (34). The set of distances
 $\{d_{ij}=||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||\,:\,i,j=1,2,\dots ,N;\,i\gt j\}$
between each pair of nodes are invariant under any rotation or translation of
$\{d_{ij}=||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||\,:\,i,j=1,2,\dots ,N;\,i\gt j\}$
between each pair of nodes are invariant under any rotation or translation of
 ${\boldsymbol{U}}$
, so that the set of
${\boldsymbol{U}}$
, so that the set of
 $\{\hat {d}_{ij}\}$
can be obtained via posterior mean of each
$\{\hat {d}_{ij}\}$
can be obtained via posterior mean of each
 $d_{ij}$
in the posterior samples, accounting for the uncertainty of all other model parameters and latent variables. We treat the distances obtained from
$d_{ij}$
in the posterior samples, accounting for the uncertainty of all other model parameters and latent variables. We treat the distances obtained from
 ${\boldsymbol{U}}^*$
as the corresponding reference values to be compared to those
${\boldsymbol{U}}^*$
as the corresponding reference values to be compared to those
 $\{\hat {d}_{ij}\}$
, that is,
$\{\hat {d}_{ij}\}$
, that is,
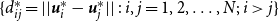 $\{d^*_{ij}=||{\boldsymbol{u}}_i^*-{\boldsymbol{u}}_j^*||\,:\,i,j=1,2,\dots ,N;\,i\gt j\}$
. Similarly, the probability of unusual zeros
$\{d^*_{ij}=||{\boldsymbol{u}}_i^*-{\boldsymbol{u}}_j^*||\,:\,i,j=1,2,\dots ,N;\,i\gt j\}$
. Similarly, the probability of unusual zeros
 ${\boldsymbol{P}}$
is, by definition, composed by
${\boldsymbol{P}}$
is, by definition, composed by
 $\{p_{gh}\,:\,g,h=1,2,\dots ,K\}$
for each pair of non-empty clusters and is dependent on the clustering. Due to the fact that the posterior clustering keeps mixing during the inference leading to different number of clusters, the identifiability problem occurs in the posterior samples of
$\{p_{gh}\,:\,g,h=1,2,\dots ,K\}$
for each pair of non-empty clusters and is dependent on the clustering. Due to the fact that the posterior clustering keeps mixing during the inference leading to different number of clusters, the identifiability problem occurs in the posterior samples of
 ${\boldsymbol{P}}$
. However, instead of such a group-level parameter, we focus on an individual-level
${\boldsymbol{P}}$
. However, instead of such a group-level parameter, we focus on an individual-level
 $N \times N$
matrix,
$N \times N$
matrix,
 $\boldsymbol{p}$
, within which each
$\boldsymbol{p}$
, within which each
 $ij$
th entry is the probability of unusual zero
$ij$
th entry is the probability of unusual zero
 $p_{z_iz_j}$
, and we obtain the corresponding
$p_{z_iz_j}$
, and we obtain the corresponding
 $\hat {p}_{z_iz_j}$
via posterior mean accounting for the uncertainty of the posterior clustering. The
$\hat {p}_{z_iz_j}$
via posterior mean accounting for the uncertainty of the posterior clustering. The
 $p^*_{z_iz_j}$
is proposed to be zero for each pair of nodes
$p^*_{z_iz_j}$
is proposed to be zero for each pair of nodes
 $i,j$
in scenario 2 by considering that the Pois-LPCM is a specific case of the ZIP-LPCM.
$i,j$
in scenario 2 by considering that the Pois-LPCM is a specific case of the ZIP-LPCM.
The performance of eight different cases are illustrated in Table 1. The table shows that the supervised implementations are able to provide better clustering performance with lower uncertainty in both scenarios as expected, even though there is significant contamination existing in the exogenous node attributes. The Pois-LPCM cases fail to recover the true clustering and are shown to be unable to fit well to the network generated from the ZIP-LPCM in scenario 1. On the contrary, the ZIP-LPCM provides good performance in both scenario 1 and 2, especially when the parameter
 $\beta _2$
of the prior of the probability of unusual zeros is set to be around
$\beta _2$
of the prior of the probability of unusual zeros is set to be around
 $9$
. In the case that
$9$
. In the case that
 $\beta _2=99$
, the prior encourages very small probability of unusual zeros, and this makes the ZIP-LPCM become close to the Pois-LPCM leading to small
$\beta _2=99$
, the prior encourages very small probability of unusual zeros, and this makes the ZIP-LPCM become close to the Pois-LPCM leading to small
 $\{\hat {p}_{z_iz_j}\}$
shown as, for example,
$\{\hat {p}_{z_iz_j}\}$
shown as, for example,
 $\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd] where
$\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd] where
 $p^*_{z_iz_j}=0$
in scenario 2 of Table 1. Moreover, the inferred
$p^*_{z_iz_j}=0$
in scenario 2 of Table 1. Moreover, the inferred
 $\hat {{\boldsymbol{z}}}$
from the cases of “ZIP-LPCM Sup Beta(1,99)” and “Pois-LPCM Sup” is also very similar in scenario 1. Though the estimated clustering is not detailed here, the materials can be provided upon request or following the provided code in the Data availability statement section to reproduce the output.
$\hat {{\boldsymbol{z}}}$
from the cases of “ZIP-LPCM Sup Beta(1,99)” and “Pois-LPCM Sup” is also very similar in scenario 1. Though the estimated clustering is not detailed here, the materials can be provided upon request or following the provided code in the Data availability statement section to reproduce the output.
Simulation study 1. Performance of eight different implementations where (i)
 $\hat {K}$
: the number of clusters in
$\hat {K}$
: the number of clusters in
 $\hat {{\boldsymbol{z}}}$
; (ii)
$\hat {{\boldsymbol{z}}}$
; (ii)
 $\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}^*)$
: the VI distance between the point estimate
$\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}^*)$
: the VI distance between the point estimate
 $\hat {{\boldsymbol{z}}}$
and the true clustering
$\hat {{\boldsymbol{z}}}$
and the true clustering
 ${\boldsymbol{z}}^*$
; (iii)
${\boldsymbol{z}}^*$
; (iii)
 $\mathbb{E}_{{\boldsymbol{z}}}[\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}) \mid {\boldsymbol{Y}}]$
: the minimized expected posterior VI loss of the clustering with respect to
$\mathbb{E}_{{\boldsymbol{z}}}[\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}) \mid {\boldsymbol{Y}}]$
: the minimized expected posterior VI loss of the clustering with respect to
 $\hat {{\boldsymbol{z}}}$
. This statistic measures the uncertainty of the posterior clustering around the
$\hat {{\boldsymbol{z}}}$
. This statistic measures the uncertainty of the posterior clustering around the
 $\hat {{\boldsymbol{z}}}$
; (iv)
$\hat {{\boldsymbol{z}}}$
; (iv)
 $\mathbb{E}(\{|\hat {d}_{ij}-d^*_{ij}|\})$
[sd]: the mean of
$\mathbb{E}(\{|\hat {d}_{ij}-d^*_{ij}|\})$
[sd]: the mean of
 $\{|\hat {d}_{ij}-d^*_{ij}|\,:\, i,j=1,2,\dots ,N; i\gt j\}$
with the corresponding standard deviation (sd) shown in the square bracket; (v)
$\{|\hat {d}_{ij}-d^*_{ij}|\,:\, i,j=1,2,\dots ,N; i\gt j\}$
with the corresponding standard deviation (sd) shown in the square bracket; (v)
 $\hat {\beta }$
: the posterior mean of
$\hat {\beta }$
: the posterior mean of
 $\beta$
; (vi)
$\beta$
; (vi)
 $\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd]: the mean of
$\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd]: the mean of
 $\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\,:\, i,j=1,2,\dots ,N; i\gt j\}$
with sd in the square bracket. More details are included in Section 4.1. The best performance within each column are highlighted in bold font
$\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\,:\, i,j=1,2,\dots ,N; i\gt j\}$
with sd in the square bracket. More details are included in Section 4.1. The best performance within each column are highlighted in bold font

The results also highlight that the ZIP-LPCM implementations with higher prior mean of the probability of unusual zeros tend to overestimate
 $K$
on ZIP-LPCM networks. For example, in scenario 1 the posterior clustering of the “ZIP-LPCM Sup Beta(1,1)” tends to split some of the groups into smaller subgroups, leading to
$K$
on ZIP-LPCM networks. For example, in scenario 1 the posterior clustering of the “ZIP-LPCM Sup Beta(1,1)” tends to split some of the groups into smaller subgroups, leading to
 $\hat {K}=7$
against
$\hat {K}=7$
against
 $K^*=5$
, even though such an implementation is supervised and thus uses some extra information. On the contrary, the unsupervised Pois-LPCM underestimates
$K^*=5$
, even though such an implementation is supervised and thus uses some extra information. On the contrary, the unsupervised Pois-LPCM underestimates
 $K$
: the posterior clustering of the “Pois-LPCM unSup” merges several groups together and provides
$K$
: the posterior clustering of the “Pois-LPCM unSup” merges several groups together and provides
 $\hat {K}=2$
. Considering that the Pois-LPCM is in fact an extreme case of the ZIP-LPCM wherein all the probability of unusual zeros is set to be zero, this overestimated/underestimated
$\hat {K}=2$
. Considering that the Pois-LPCM is in fact an extreme case of the ZIP-LPCM wherein all the probability of unusual zeros is set to be zero, this overestimated/underestimated
 $K$
performance correspond to the fact that the probability of unusual zeros controls the sparsity of the network, where larger probability corresponds to sparser latent positions bringing more separated clusters, and vice-versa.
$K$
performance correspond to the fact that the probability of unusual zeros controls the sparsity of the network, where larger probability corresponds to sparser latent positions bringing more separated clusters, and vice-versa.
Simulation study 1 scenario 1. Performance of the posterior mean
 $\hat {\boldsymbol{\nu }}$
, which approximates the conditional probability in Eq. (18). The top-left plot is the heatmap of the reference values of Eq. (18), obtained by leveraging the reference model parameters used for simulating the network, whereby darker entry colors correspond to higher values. The other four heatmap plots describe
$\hat {\boldsymbol{\nu }}$
, which approximates the conditional probability in Eq. (18). The top-left plot is the heatmap of the reference values of Eq. (18), obtained by leveraging the reference model parameters used for simulating the network, whereby darker entry colors correspond to higher values. The other four heatmap plots describe
 $\hat {\boldsymbol{\nu }}$
as inferred by the corresponding priors indicated on top of the heatmap. The rows and columns of the matrices are rearranged and separated according to
$\hat {\boldsymbol{\nu }}$
as inferred by the corresponding priors indicated on top of the heatmap. The rows and columns of the matrices are rearranged and separated according to
 $\hat {{\boldsymbol{z}}}$
while the side-bars indicate the true clustering of each individual. The last plot shows the Receiver Operating Characteristic (ROC) curves for all the supervised ZIP-LPCM cases, where the reference
$\hat {{\boldsymbol{z}}}$
while the side-bars indicate the true clustering of each individual. The last plot shows the Receiver Operating Characteristic (ROC) curves for all the supervised ZIP-LPCM cases, where the reference
 $\boldsymbol{\nu }^*$
is the response variable.
$\boldsymbol{\nu }^*$
is the response variable.

Each element
 $\nu _{ij}$
of the indicators of unusual zeros
$\nu _{ij}$
of the indicators of unusual zeros
 $\boldsymbol{\nu }$
is defined to be either 1 or 0. Hence, the posterior mean of each
$\boldsymbol{\nu }$
is defined to be either 1 or 0. Hence, the posterior mean of each
 $\nu _{ij}$
measures the proportion of the times that the corresponding
$\nu _{ij}$
measures the proportion of the times that the corresponding
 $y_{ij}$
is inferred as an unusual zero. In the case that
$y_{ij}$
is inferred as an unusual zero. In the case that
 $y_{ij}\gt 0$
, the posterior samples of
$y_{ij}\gt 0$
, the posterior samples of
 $\nu _{ij}$
are all inferred to zero by default. Denoting
$\nu _{ij}$
are all inferred to zero by default. Denoting
 $\hat {\nu }_{ij}$
as the posterior mean of
$\hat {\nu }_{ij}$
as the posterior mean of
 $\nu _{ij}$
, then
$\nu _{ij}$
, then
 $\hat {\nu }_{ij}$
becomes an approximation of the conditional probability of the unusual zeros in Eq. (18) accounting for the posterior uncertainty of all other model parameters and latent variables. The performance of
$\hat {\nu }_{ij}$
becomes an approximation of the conditional probability of the unusual zeros in Eq. (18) accounting for the posterior uncertainty of all other model parameters and latent variables. The performance of
 $\hat {\nu }_{ij}$
for the supervised ZIP-LPCM cases from scenario 1 are shown in Figure 3. We note that the
$\hat {\nu }_{ij}$
for the supervised ZIP-LPCM cases from scenario 1 are shown in Figure 3. We note that the
 $\text{Beta}(1,1)$
case is excluded because its summarized clustering is not satisfactory. The figure shows that the
$\text{Beta}(1,1)$
case is excluded because its summarized clustering is not satisfactory. The figure shows that the
 $\text{Beta}(1,9)$
case provide the best matching and the best ROC curves with respect to the references, while slightly tuning the
$\text{Beta}(1,9)$
case provide the best matching and the best ROC curves with respect to the references, while slightly tuning the
 $\beta _2$
provides comparable performance. However, it is also interesting that the
$\beta _2$
provides comparable performance. However, it is also interesting that the
 $\text{Beta}(1,99)$
prior also successfully and correctly prioritizes many zero interactions which are more likely to be unusual zeros compared to other zeros. In fact, more non-zero interactions exist in a particular block, more accurate the pairwise distances between the nodes inside are, hence bringing more robust inference results of how likely the zero interactions in the block are unusual zeros. Note here that in general smaller
$\text{Beta}(1,99)$
prior also successfully and correctly prioritizes many zero interactions which are more likely to be unusual zeros compared to other zeros. In fact, more non-zero interactions exist in a particular block, more accurate the pairwise distances between the nodes inside are, hence bringing more robust inference results of how likely the zero interactions in the block are unusual zeros. Note here that in general smaller
 $p_{ij}$
does not imply smaller value of Eq. (18): that also depends on
$p_{ij}$
does not imply smaller value of Eq. (18): that also depends on
 $\beta$
and
$\beta$
and
 ${\boldsymbol{U}}$
. Hence, from a practical standpoint we suggest the
${\boldsymbol{U}}$
. Hence, from a practical standpoint we suggest the
 $\text{Beta}(1,9)$
as the default prior setting for the probability of unusual zeros, whereas priors with smaller means can be considered when practitioners expect a more clustered network or prefer to learn more towards true zeros rather than unusual zeros. By contrast, higher prior mean is encouraged if practitioners expect sparser network architecture bringing more subgroup features. However, moderate tuning of the prior parameters does not significantly affect the overall performance as shown in both Figure 3 and Table 1.
$\text{Beta}(1,9)$
as the default prior setting for the probability of unusual zeros, whereas priors with smaller means can be considered when practitioners expect a more clustered network or prefer to learn more towards true zeros rather than unusual zeros. By contrast, higher prior mean is encouraged if practitioners expect sparser network architecture bringing more subgroup features. However, moderate tuning of the prior parameters does not significantly affect the overall performance as shown in both Figure 3 and Table 1.
4.2 Simulation study 2
In this second simulation study, the network size
 $N$
and the clustering
$N$
and the clustering
 ${\boldsymbol{z}}^*$
of the synthetic networks are the same as those proposed in the first simulation study. The networks are randomly simulated from the ZIP-SBM which can be obtained by removing the latent position parts in Eq. (4) and in Eq. (5) from the ZIP-LPCM, and directly proposing a
${\boldsymbol{z}}^*$
of the synthetic networks are the same as those proposed in the first simulation study. The networks are randomly simulated from the ZIP-SBM which can be obtained by removing the latent position parts in Eq. (4) and in Eq. (5) from the ZIP-LPCM, and directly proposing a
 $\text{Pois}(\lambda _{z_iz_j})$
in Eq. (2). The model parameter
$\text{Pois}(\lambda _{z_iz_j})$
in Eq. (2). The model parameter
 $\boldsymbol{\lambda }$
is a
$\boldsymbol{\lambda }$
is a
 $K \times K$
matrix with entries
$K \times K$
matrix with entries
 $\{\lambda _{gh}\,:\,g,h=1,2,\dots ,K\}$
being the Poisson rates defined for the interactions between any two occupied groups.
$\{\lambda _{gh}\,:\,g,h=1,2,\dots ,K\}$
being the Poisson rates defined for the interactions between any two occupied groups.
In scenario 1 of simulation study 2, the values of
 $\boldsymbol{\lambda }$
used for generating the network are indicated with
$\boldsymbol{\lambda }$
used for generating the network are indicated with
 $\boldsymbol{\lambda _1}$
in the equation shown below, whereas the probability of unusual zeros
$\boldsymbol{\lambda _1}$
in the equation shown below, whereas the probability of unusual zeros
 ${\boldsymbol{P}}$
is the same as the one in Section 4.1.
${\boldsymbol{P}}$
is the same as the one in Section 4.1.
 \begin{align*} \boldsymbol{\lambda _1} & =\begin{pmatrix}7.0 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 0.5 \\ 0.5 &\quad 4.5 &\quad 0.5 &\quad 0.5 &\quad 0.5\\ 0.5 &\quad 0.5 &\quad 3.5 &\quad 0.5 &\quad 0.5 \\ 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.0 &\quad 0.5 \\ 0.5 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.5\end{pmatrix},\boldsymbol{\lambda _2}=\begin{pmatrix}7.0 &\quad 2.0 &\quad 2.0 &\quad 2.0 &\quad 2.0 \\ 2.0 &\quad 4.5 &\quad 0.5 &\quad 0.5 &\quad 0.5\\ 2.0 &\quad 0.5 &\quad 3.5 &\quad 0.5 &\quad 0.5 \\ 2.0 &\quad 0.5 &\quad 0.5 &\quad 2.0 &\quad 0.5 \\ 2.0 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.5\end{pmatrix},\\ \boldsymbol{P_2} & =\begin{pmatrix}0.40 &\quad 0.60 &\quad 0.20 &\quad 0.60 &\quad 0.20 \\ 0.20 &\quad 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05\\ 0.60 &\quad 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 \\ 0.20 &\quad 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 \\ 0.60 &\quad 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40\end{pmatrix}. \end{align*}
\begin{align*} \boldsymbol{\lambda _1} & =\begin{pmatrix}7.0 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 0.5 \\ 0.5 &\quad 4.5 &\quad 0.5 &\quad 0.5 &\quad 0.5\\ 0.5 &\quad 0.5 &\quad 3.5 &\quad 0.5 &\quad 0.5 \\ 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.0 &\quad 0.5 \\ 0.5 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.5\end{pmatrix},\boldsymbol{\lambda _2}=\begin{pmatrix}7.0 &\quad 2.0 &\quad 2.0 &\quad 2.0 &\quad 2.0 \\ 2.0 &\quad 4.5 &\quad 0.5 &\quad 0.5 &\quad 0.5\\ 2.0 &\quad 0.5 &\quad 3.5 &\quad 0.5 &\quad 0.5 \\ 2.0 &\quad 0.5 &\quad 0.5 &\quad 2.0 &\quad 0.5 \\ 2.0 &\quad 0.5 &\quad 0.5 &\quad 0.5 &\quad 2.5\end{pmatrix},\\ \boldsymbol{P_2} & =\begin{pmatrix}0.40 &\quad 0.60 &\quad 0.20 &\quad 0.60 &\quad 0.20 \\ 0.20 &\quad 0.40 &\quad 0.05 &\quad 0.10 &\quad 0.05\\ 0.60 &\quad 0.10 &\quad 0.40 &\quad 0.05 &\quad 0.10 \\ 0.20 &\quad 0.05 &\quad 0.10 &\quad 0.40 &\quad 0.05 \\ 0.60 &\quad 0.10 &\quad 0.05 &\quad 0.10 &\quad 0.40\end{pmatrix}. \end{align*}
The values indicated with
 $\boldsymbol{\lambda _2}$
and
$\boldsymbol{\lambda _2}$
and
 $\boldsymbol{P_2}$
describe instead the setup for the second scenario of this simulation study, whereby the interaction rate matrix
$\boldsymbol{P_2}$
describe instead the setup for the second scenario of this simulation study, whereby the interaction rate matrix
 $\boldsymbol{\lambda _2}$
includes a group of hubs, that is, nodes that have relatively high connection rates to all other groups. The heatmap plots of the networks’ adjacency matrices from both scenarios are shown in Figure 4. In practice, we observe that the execution time of our approach is affected by the complexity of the observed networks, whereby all the simulation study 2 implementations require approximately 10% less time compared to those in simulation study 1.
$\boldsymbol{\lambda _2}$
includes a group of hubs, that is, nodes that have relatively high connection rates to all other groups. The heatmap plots of the networks’ adjacency matrices from both scenarios are shown in Figure 4. In practice, we observe that the execution time of our approach is affected by the complexity of the observed networks, whereby all the simulation study 2 implementations require approximately 10% less time compared to those in simulation study 1.
Figure 5 illustrates the inferred
 $\hat {{\boldsymbol{U}}}$
obtained by the supervised ZIP-LPCM with the default
$\hat {{\boldsymbol{U}}}$
obtained by the supervised ZIP-LPCM with the default
 $\text{Beta}(1,9)$
prior setting, whereas Table 2 illustrates the performance of all the implementations that we take into account in this second simulation study. The latent positions show well-separated clusters when they are inferred for ZIP-SBM networks, with significant hubs exiting in the center for scenario 2. Based on the
$\text{Beta}(1,9)$
prior setting, whereas Table 2 illustrates the performance of all the implementations that we take into account in this second simulation study. The latent positions show well-separated clusters when they are inferred for ZIP-SBM networks, with significant hubs exiting in the center for scenario 2. Based on the
 $\boldsymbol{\lambda }^*$
s used for simulating the networks, it is also shown that smaller
$\boldsymbol{\lambda }^*$
s used for simulating the networks, it is also shown that smaller
 $\{\lambda ^*_{gh}\}$
correspond to sparser inferred latent positions between and within the clusters. The presence of the hubs leads to slightly more clustered latent positions in scenario 2, which in turn brings slightly higher
$\{\lambda ^*_{gh}\}$
correspond to sparser inferred latent positions between and within the clusters. The presence of the hubs leads to slightly more clustered latent positions in scenario 2, which in turn brings slightly higher
 $\hat {\beta }$
in scenario 2 as shown in Table 2.
$\hat {\beta }$
in scenario 2 as shown in Table 2.
Simulation study 2. Synthetic networks’ adjacency matrix heatmap plots. Darker entries correspond to higher edge weights. The side-bars indicate the reference clustering
 ${\boldsymbol{z}}^*$
. Left plot: scenario 1 network, generated from a ZIP-SBM without hubs. Right plot: scenario 2 network, generated from a ZIP-SBM with hubs.
${\boldsymbol{z}}^*$
. Left plot: scenario 1 network, generated from a ZIP-SBM without hubs. Right plot: scenario 2 network, generated from a ZIP-SBM with hubs.

Simulation study 2. The 1st and the 2nd rows illustrate the inferred point estimate
 $\hat {{\boldsymbol{U}}}$
obtained by ZIP-LPCM Sup Beta(1,9) implementations for Scenario 1 and Scenario 2, respectively. The 2nd column plots are rotated version of the 1st column plots where each inferred latent position rotated for
$\hat {{\boldsymbol{U}}}$
obtained by ZIP-LPCM Sup Beta(1,9) implementations for Scenario 1 and Scenario 2, respectively. The 2nd column plots are rotated version of the 1st column plots where each inferred latent position rotated for
 $90^{\circ }$
clockwise with respect to the vertical axis. Different node colors correspond to different inferred groups according to the corresponding
$90^{\circ }$
clockwise with respect to the vertical axis. Different node colors correspond to different inferred groups according to the corresponding
 $\hat {{\boldsymbol{z}}}$
. Node sizes are proportional to node betweenness while edge widths and colors are proportional to edge weights.
$\hat {{\boldsymbol{z}}}$
. Node sizes are proportional to node betweenness while edge widths and colors are proportional to edge weights.

In the ZIP-LPCM, the
 $\lambda _{ij}$
can be obtained based on
$\lambda _{ij}$
can be obtained based on
 $\beta$
and
$\beta$
and
 ${\boldsymbol{U}}$
following Eq. (4) for each pair of nodes
${\boldsymbol{U}}$
following Eq. (4) for each pair of nodes
 $i,j$
: we use this to construct the posterior samples of
$i,j$
: we use this to construct the posterior samples of
 $\lambda _{ij}$
for each ZIP-LPCM implementation. The posterior mean of these samples forms the
$\lambda _{ij}$
for each ZIP-LPCM implementation. The posterior mean of these samples forms the
 $\hat {\lambda }_{ij}$
which contributes to the statistic,
$\hat {\lambda }_{ij}$
which contributes to the statistic,
 $\mathbb{E}(\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\})$
[sd], shown in Table 2. The corresponding reference parameter
$\mathbb{E}(\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\})$
[sd], shown in Table 2. The corresponding reference parameter
 $\lambda _{ij}^*$
is obtained according to
$\lambda _{ij}^*$
is obtained according to
 $\lambda ^*_{z^*_iz^*_j}$
.
$\lambda ^*_{z^*_iz^*_j}$
.
In general, our ZIP-LPCM still performs reasonably well in situations where the data are generated using a ZIP-SBM. However, we note that in this case the best performance is provided by the Beta(1,19) prior instead of the default Beta(1,9). The Pois-LPCM fails to recover the true clustering of the scenario 2 network when the inference is unsupervised. The same deteriorated performance is also observed for the supervised ZIP-LPCM with
 $\text{Beta}(1,99)$
prior, the performance of which is considered to be close to that of the Pois-LPCM. After a careful analysis of the resulting posterior samples, we noticed that even though these two settings are able to recover the true clustering, it is easy for them to get stuck around some local posterior mode of the clustering, whereby the hubs are merged into another group. We find that these simulation results highlight that the zero-inflation feature of the model becomes critical to efficiently characterize the group differences and thus recover the correct partitioning of the nodes.
$\text{Beta}(1,99)$
prior, the performance of which is considered to be close to that of the Pois-LPCM. After a careful analysis of the resulting posterior samples, we noticed that even though these two settings are able to recover the true clustering, it is easy for them to get stuck around some local posterior mode of the clustering, whereby the hubs are merged into another group. We find that these simulation results highlight that the zero-inflation feature of the model becomes critical to efficiently characterize the group differences and thus recover the correct partitioning of the nodes.
Figure 6 further illustrates the performance of
 $\hat {\boldsymbol{\nu }}$
for the ZIP-LPCM. Though the elements in the diagonal blocks are well approximated, the elements in the off-diagonal blocks are difficult to infer. This shows that, in some cases, it is difficult for the ZIP-LPCM in the latent space to capture specific network architectures produced by those freely chosen model parameters of ZIP-SBM. This is especially significant for the asymmetric patterns of the upper-diagonal and the lower-diagonal blocks shown in Figure 6. However, we can still observe remarkably many elements in the off-diagonal blocks of
$\hat {\boldsymbol{\nu }}$
for the ZIP-LPCM. Though the elements in the diagonal blocks are well approximated, the elements in the off-diagonal blocks are difficult to infer. This shows that, in some cases, it is difficult for the ZIP-LPCM in the latent space to capture specific network architectures produced by those freely chosen model parameters of ZIP-SBM. This is especially significant for the asymmetric patterns of the upper-diagonal and the lower-diagonal blocks shown in Figure 6. However, we can still observe remarkably many elements in the off-diagonal blocks of
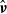 $\hat {\boldsymbol{\nu }}$
from scenario 2 that have significantly higher values than others, especially for those blocks associated to the hubs. The patterns of these elements generally agree with the corresponding reference patterns, thus successfully and correctly highlighting non-negligible many zero interactions that are more likely to be unusual zeros compared to others.
$\hat {\boldsymbol{\nu }}$
from scenario 2 that have significantly higher values than others, especially for those blocks associated to the hubs. The patterns of these elements generally agree with the corresponding reference patterns, thus successfully and correctly highlighting non-negligible many zero interactions that are more likely to be unusual zeros compared to others.
Simulation study 2. Performance of eight different implementations where (i)
 $\hat {K}$
: the number of clusters in
$\hat {K}$
: the number of clusters in
 $\hat {{\boldsymbol{z}}}$
; (ii)
$\hat {{\boldsymbol{z}}}$
; (ii)
 $\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}^*)$
: the VI distance between the point estimate
$\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}^*)$
: the VI distance between the point estimate
 $\hat {{\boldsymbol{z}}}$
and the true clustering
$\hat {{\boldsymbol{z}}}$
and the true clustering
 ${\boldsymbol{z}}^*$
; (iii)
${\boldsymbol{z}}^*$
; (iii)
 $\mathbb{E}_{{\boldsymbol{z}}}[\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}) \mid {\boldsymbol{Y}}]$
: the minimized expected posterior VI loss of the clustering with respect to
$\mathbb{E}_{{\boldsymbol{z}}}[\text{VI}(\hat {{\boldsymbol{z}}},{\boldsymbol{z}}) \mid {\boldsymbol{Y}}]$
: the minimized expected posterior VI loss of the clustering with respect to
 $\hat {{\boldsymbol{z}}}$
. This statistic measures the uncertainty of the posterior clustering around the
$\hat {{\boldsymbol{z}}}$
. This statistic measures the uncertainty of the posterior clustering around the
 $\hat {{\boldsymbol{z}}}$
; (iv)
$\hat {{\boldsymbol{z}}}$
; (iv)
 $\hat {\beta }$
: the posterior mean of
$\hat {\beta }$
: the posterior mean of
 $\beta$
; (v)
$\beta$
; (v)
 $\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd]: the mean of
$\mathbb{E}(\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\})$
[sd]: the mean of
 $\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\,:\, i,j=1,2,\dots ,N;\, i\gt j\}$
with the corresponding standard deviation (sd) shown in the square bracket; (vi)
$\{|\hat {p}_{z_iz_j}-p^*_{z_iz_j}|\,:\, i,j=1,2,\dots ,N;\, i\gt j\}$
with the corresponding standard deviation (sd) shown in the square bracket; (vi)
 $\mathbb{E}(\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\})$
[sd]: the mean of
$\mathbb{E}(\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\})$
[sd]: the mean of
 $\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\,:\, i,j=1,2,\dots ,N;\, i\gt j\}$
with the corresponding sd in the square bracket. More details are included in Section 4.2. The best performance within each column excluding the
$\{|\hat {\lambda }_{ij}-\lambda ^*_{ij}|\,:\, i,j=1,2,\dots ,N;\, i\gt j\}$
with the corresponding sd in the square bracket. More details are included in Section 4.2. The best performance within each column excluding the
 $\hat {\beta }$
column are highlighted in bold font
$\hat {\beta }$
column are highlighted in bold font

Simulation study 3. Performance of the replication simulation study (top table) and the simulation studies for networks with larger network sizes (bottom table). The same set of summary statistics used in Table 1 is also leveraged here for performance explorations. The values in each row of the top table below correspond to the median, 10% and 90% quantiles of the corresponding summary statistics for all 50 replicated implementations. The values in the bottom table below correspond to the output values of the corresponding summary statistics for the two simulation studies of larger networks

Simulation study 2. Performance of
 $\hat {\boldsymbol{\nu }}$
based on the
$\hat {\boldsymbol{\nu }}$
based on the
 $\text{Beta}(1,9)$
and
$\text{Beta}(1,9)$
and
 $\text{Beta}(1,19)$
prior settings. The 1st and 2nd rows, respectively, correspond to scenarios 1 and 2. Darker colors indicate higher (approximate) probability of unusual zero conditional on the fact that the corresponding observed interaction is a zero interaction. The rows and columns of the matrices are rearranged and separated according to
$\text{Beta}(1,19)$
prior settings. The 1st and 2nd rows, respectively, correspond to scenarios 1 and 2. Darker colors indicate higher (approximate) probability of unusual zero conditional on the fact that the corresponding observed interaction is a zero interaction. The rows and columns of the matrices are rearranged and separated according to
 $\hat {{\boldsymbol{z}}}$
while the side-bars indicate the true clustering of each individual.
$\hat {{\boldsymbol{z}}}$
while the side-bars indicate the true clustering of each individual.

As a final note, we also applied the supervised ZIP-SBM with the Beta(1,9) prior and a Ga(1,1) Poisson rate prior, which extend the applications in Lu et al. (Reference Lu, Durante and Friel2025) to directed networks, on both ZIP-SBM networks from the two different scenarios. We indicate these as “ZIP-SBM Sup” here. Since the network data was generated from the ZIP-SBM, it is expected that the “ZIP-SBM Sup” implementations have natural advantages over ZIP-LPCM implementations in this case. However, we note that, though the results of the “ZIP-SBM Sup” implementations are even better than the best “ZIP-LPCM Sup Beta(1,19)” cases illustrated in Table 2 and Figure 4, the discrepancies in performance between them are not substantial. Especially for the inferred approximate conditional probability of unusual zeros
 $\{\hat {\nu }_{ij}\}$
, the mean absolute error of which between the “ZIP-SBM Sup” case and the “ZIP-LPCM Sup Beta(1,19)” case is
$\{\hat {\nu }_{ij}\}$
, the mean absolute error of which between the “ZIP-SBM Sup” case and the “ZIP-LPCM Sup Beta(1,19)” case is
 $0.0403$
in scenario 1, and is
$0.0403$
in scenario 1, and is
 $0.0301$
in scenario 2, while the corresponding standard deviation is
$0.0301$
in scenario 2, while the corresponding standard deviation is
 $0.0320$
and
$0.0320$
and
 $0.0756$
, respectively. Considering that the ZIP-SBM is not able to visualize networks, these deterioration can be fairly neglected compared to the gains in the ability of network visualization for the ZIP-LPCM.
$0.0756$
, respectively. Considering that the ZIP-SBM is not able to visualize networks, these deterioration can be fairly neglected compared to the gains in the ability of network visualization for the ZIP-LPCM.
4.3 Simulation study 3
In this third simulation study, we first replicate the simulation study 1 scenario 1 experiments for multiple times to check the robustness of the ZIP-LPCM performance. We repeatedly draw 50 different networks with the same model settings introduced therein, and we leverage the same implementation settings for the inference. The performance of this replication simulation study is shown as the top table of Table 3, wherein we use the same set of summary statistics as being used in Table 1 for the performance exploration. The median, 10% and 90% quantiles of the corresponding statistics for all the 50 replication experiments are provided. The results show that all the 50 implementations successfully select the true number of groups
 $K^*=5$
for the 50 different networks, respectively, and provide similar performance of the distance matrix
$K^*=5$
for the 50 different networks, respectively, and provide similar performance of the distance matrix
 $\{d_{ij}\}$
, the intercept
$\{d_{ij}\}$
, the intercept
 $\beta$
, and the individual-level probability of unusual zeros
$\beta$
, and the individual-level probability of unusual zeros
 $\boldsymbol{p}$
, which are as good as those illustrated in simulation study 1. However, we observe that not all the implementations successfully recover the true clustering. In fact, there are 60% implementations which perfectly recover the true clustering; 32% implementations misclassified 1 node; 6% implementations misclassified 2 nodes, and there is only 1 output clustering which clusters two true groups together leading to the final 4-group clustering.
$\boldsymbol{p}$
, which are as good as those illustrated in simulation study 1. However, we observe that not all the implementations successfully recover the true clustering. In fact, there are 60% implementations which perfectly recover the true clustering; 32% implementations misclassified 1 node; 6% implementations misclassified 2 nodes, and there is only 1 output clustering which clusters two true groups together leading to the final 4-group clustering.
The above observed misclassifications are due to the model assumption that the clustering is highly dependent on the latent positions
 ${\boldsymbol{U}}$
. Figure 7 provides a more challenging simulation study to explain this situation. The synthetic network shown in the figure has
${\boldsymbol{U}}$
. Figure 7 provides a more challenging simulation study to explain this situation. The synthetic network shown in the figure has
 $N=50$
nodes, which are evenly assigned to
$N=50$
nodes, which are evenly assigned to
 $K=2$
groups. The network is randomly generated from a ZIP-LPCM with settings:
$K=2$
groups. The network is randomly generated from a ZIP-LPCM with settings:
 $\beta =3, \boldsymbol{\mu }=[(2,0,0)^T,(\!-2,0,0)^T], \boldsymbol{\tau } = (0.75,0.75)$
, and the unusual zero probability is set to be
$\beta =3, \boldsymbol{\mu }=[(2,0,0)^T,(\!-2,0,0)^T], \boldsymbol{\tau } = (0.75,0.75)$
, and the unusual zero probability is set to be
 $0.6$
and
$0.6$
and
 $0.4$
, respectively, for diagonal and off-diagonal elements. These settings make the two groups of the network in the latent space be close to each other, forming some mixed nodes in the middle that are challenging to classify as shown in Figure 7. By treating the reference clustering
$0.4$
, respectively, for diagonal and off-diagonal elements. These settings make the two groups of the network in the latent space be close to each other, forming some mixed nodes in the middle that are challenging to classify as shown in Figure 7. By treating the reference clustering
 ${\boldsymbol{z}}^*$
with 15 nodes’ clustering contaminated (randomly reallocated) as the node attributes
${\boldsymbol{z}}^*$
with 15 nodes’ clustering contaminated (randomly reallocated) as the node attributes
 ${\boldsymbol{c}}$
, our supervised inference approach misclassified three nodes which should belong to group 1 (dark reds) but which are inferred to be in group 2 (dark blues) according to the reference clustering used for generating such a network. However, this “misclassification” might not be wrong based on the network architecture. In fact, the complete likelihood value evaluated based on the reference values of those model parameters and variables used for generating the network is −3114.734, whereas that of our inferred output is −2771.003, indicating a better fitting to such a synthetic network. Considering also the fact that 98% of the replication simulation studies provide either true clustering or the clustering that is very close to the reference clustering, our proposed method is shown to work well in this robustness checking experiment.
${\boldsymbol{c}}$
, our supervised inference approach misclassified three nodes which should belong to group 1 (dark reds) but which are inferred to be in group 2 (dark blues) according to the reference clustering used for generating such a network. However, this “misclassification” might not be wrong based on the network architecture. In fact, the complete likelihood value evaluated based on the reference values of those model parameters and variables used for generating the network is −3114.734, whereas that of our inferred output is −2771.003, indicating a better fitting to such a synthetic network. Considering also the fact that 98% of the replication simulation studies provide either true clustering or the clustering that is very close to the reference clustering, our proposed method is shown to work well in this robustness checking experiment.
Simulation study 3. A two-group synthetic network example of showing possible misclassifications of nodes’ clustering. The 2nd plot is the rotated plot of the 1st latent positions’ plot that is rotated for
 $45^{\circ }$
anti-clockwise with respect to the vertical axis. The latent positions are those used for generating the network, whereas the dark red (group 1) and dark blue (group 2) nodes correspond to the nodes which are inferred to have true clustering. The three light red nodes are the ones which should belong to group 1 according to the reference clustering
$45^{\circ }$
anti-clockwise with respect to the vertical axis. The latent positions are those used for generating the network, whereas the dark red (group 1) and dark blue (group 2) nodes correspond to the nodes which are inferred to have true clustering. The three light red nodes are the ones which should belong to group 1 according to the reference clustering
 ${\boldsymbol{z}}^*$
but they are instead inferred to be misclassified to group 2 based on their network structure. No misclassification observed for group 2 nodes’ clustering. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights.
${\boldsymbol{z}}^*$
but they are instead inferred to be misclassified to group 2 based on their network structure. No misclassification observed for group 2 nodes’ clustering. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights.

We also experiment on two more synthetic networks with larger network sizes in this simulation study 3. The first network has double of the number of nodes of the simulation study 1 networks, that is,
 $N=150$
, whereas the second network has triple of the number, that is,
$N=150$
, whereas the second network has triple of the number, that is,
 $N=225$
. Both networks are randomly generated from the ZIP-LPCMs that have settings which are the same as those proposed in simulation study 1 scenario 1, except that the latent space group centers are scaled to be larger and are 1.25 and 1.375 of the
$N=225$
. Both networks are randomly generated from the ZIP-LPCMs that have settings which are the same as those proposed in simulation study 1 scenario 1, except that the latent space group centers are scaled to be larger and are 1.25 and 1.375 of the
 $\boldsymbol{\mu }^*$
therein, respectively, in order to maintain similar or less network sparsity. The supervised inference is applied on both networks where 40 and 60 nodes’ clustering is contaminated in the reference clustering to, respectively, form the corresponding node attributes. The inference results on such two networks are shown as the bottom table of Table 3, where the performance which are comparable as those illustrated in Sections 4.1 and 4.2 are observed. However, though it is shown that our good performance can be generalized to larger networks, we found that the practical implementations are more challenging, where the 12,000-iteration executions of our approach for the
$\boldsymbol{\mu }^*$
therein, respectively, in order to maintain similar or less network sparsity. The supervised inference is applied on both networks where 40 and 60 nodes’ clustering is contaminated in the reference clustering to, respectively, form the corresponding node attributes. The inference results on such two networks are shown as the bottom table of Table 3, where the performance which are comparable as those illustrated in Sections 4.1 and 4.2 are observed. However, though it is shown that our good performance can be generalized to larger networks, we found that the practical implementations are more challenging, where the 12,000-iteration executions of our approach for the
 $N=150$
network take approximately 43 mins to finish. The execution time spent by fitting the
$N=150$
network take approximately 43 mins to finish. The execution time spent by fitting the
 $N=225$
network is much longer and is around 1.2 hr, even when a k-means algorithm is used to initialize the partition with a 25-group solution. The convergence of posterior samples of the
$N=225$
network is much longer and is around 1.2 hr, even when a k-means algorithm is used to initialize the partition with a 25-group solution. The convergence of posterior samples of the
 $N=225$
network simulation study are shown to require more than 4000 iterations, which is significantly longer than all our previous experiments and thus 4000-iteration burn-in is instead proposed in this case.
$N=225$
network simulation study are shown to require more than 4000 iterations, which is significantly longer than all our previous experiments and thus 4000-iteration burn-in is instead proposed in this case.
5. Real data applications
In this section, we illustrate the ZIP-LPCM performance on four different real networks. The experiment priors and proposal variance settings are similar to those applied in the simulation studies in Section 4 with the default prior setting of the probability of unusual zeros being
 $\text{Beta}(1,9)$
. Since the real networks have different network sizes and complexity, a conservative
$\text{Beta}(1,9)$
. Since the real networks have different network sizes and complexity, a conservative
 $60,000$
iterations are used for each real network, with the first
$60,000$
iterations are used for each real network, with the first
 $30,000$
iterations treated as burn-in. We find that this leads to satisfactory mixing and convergence in all the applications considered.
$30,000$
iterations treated as burn-in. We find that this leads to satisfactory mixing and convergence in all the applications considered.
In this section, we introduce an extra summary statistic to help with the illustration of the results. Recall that the posterior mean
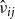 $\hat {\nu }_{ij}$
approximates Eq. (18), which is the conditional probability of
$\hat {\nu }_{ij}$
approximates Eq. (18), which is the conditional probability of
 $y_{ij}$
being an unusual zero provided that
$y_{ij}$
being an unusual zero provided that
 $y_{ij}$
is observed as a zero. However, once an observed
$y_{ij}$
is observed as a zero. However, once an observed
 $y_{ij}=0$
is inferred as an unusual zero, the corresponding missing weight
$y_{ij}=0$
is inferred as an unusual zero, the corresponding missing weight
 $x_{ij}\sim \text{Pois}(\lambda _{ij})$
can be assumed following Eq. (3), where
$x_{ij}\sim \text{Pois}(\lambda _{ij})$
can be assumed following Eq. (3), where
 $\lambda _{ij}=\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)$
. This allows us to construct the conditional probability of an observed zero interaction that should actually be a non-zero interaction by using the product of
$\lambda _{ij}=\text{exp}(\beta -||{\boldsymbol{u}}_i-{\boldsymbol{u}}_j||)$
. This allows us to construct the conditional probability of an observed zero interaction that should actually be a non-zero interaction by using the product of
 $\text{P}(x_{ij}\gt 0|\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j)=1-f_{\text{Pois}}(0|\lambda _{ij})$
and Eq. (18), confirmed by:
$\text{P}(x_{ij}\gt 0|\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j)=1-f_{\text{Pois}}(0|\lambda _{ij})$
and Eq. (18), confirmed by:
 \begin{equation*} \text{P}(x_{ij}\gt 0|y_{ij}=0,\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j, p_{z_iz_j})=\text{P}(x_{ij}\gt 0|\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j)\text{P}(\nu _{ij}=1|y_{ij}=0,\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j, p_{z_iz_j}). \end{equation*}
\begin{equation*} \text{P}(x_{ij}\gt 0|y_{ij}=0,\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j, p_{z_iz_j})=\text{P}(x_{ij}\gt 0|\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j)\text{P}(\nu _{ij}=1|y_{ij}=0,\beta , {\boldsymbol{u}}_i, {\boldsymbol{u}}_j, p_{z_iz_j}). \end{equation*}
The above probability can be approximated by
 $\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )=[1-f_{\text{Pois}}(0|\hat {\lambda }_{ij})]\hat {\nu }_{ij}$
accounting for the uncertainty of the posterior samples. From a practical standpoint, this statistic is usually the one that the practitioners are more interested in, compared to Eq. (18). Here, the
$\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )=[1-f_{\text{Pois}}(0|\hat {\lambda }_{ij})]\hat {\nu }_{ij}$
accounting for the uncertainty of the posterior samples. From a practical standpoint, this statistic is usually the one that the practitioners are more interested in, compared to Eq. (18). Here, the
 $\hat {\lambda }_{ij}$
can be obtained by the posterior mean of Eq. (4) accounting for the uncertainty of posterior samples of
$\hat {\lambda }_{ij}$
can be obtained by the posterior mean of Eq. (4) accounting for the uncertainty of posterior samples of
 $\beta$
and
$\beta$
and
 ${\boldsymbol{U}}$
.
${\boldsymbol{U}}$
.
5.1 Sampson monks network
The social interactions among a group of
 $18$
monks were recorded by Sampson (Reference Sampson1968) during his stay in a monastery. A political “crisis in the cloister” occurred in that period, leading to the expulsion of four monks and the voluntary departure of several others. The interactions were recorded as follows: each monk was asked at three different time points whether they had positive relations to each of other monks and to rank the three monks they were closest to. The dataset has been studied on many previous works, including Hoff et al. (Reference Hoff, Raftery and Handcock2002). We aggregated the three time points leading to a directed non-negative discrete weighted social network describing different levels of friendships between the monks.
$18$
monks were recorded by Sampson (Reference Sampson1968) during his stay in a monastery. A political “crisis in the cloister” occurred in that period, leading to the expulsion of four monks and the voluntary departure of several others. The interactions were recorded as follows: each monk was asked at three different time points whether they had positive relations to each of other monks and to rank the three monks they were closest to. The dataset has been studied on many previous works, including Hoff et al. (Reference Hoff, Raftery and Handcock2002). We aggregated the three time points leading to a directed non-negative discrete weighted social network describing different levels of friendships between the monks.
The heatmap plots for the Sampson monks real network where the grays are used for zero values in order to highlight other non-zero elements. Left plot: original observed adjacency matrix,
 ${\boldsymbol{Y}}$
. Middle plot: plot of
${\boldsymbol{Y}}$
. Middle plot: plot of
 ${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
 ${\boldsymbol{z}}^*$
. The different colors in the side-bars of this and the last plot correspond to different reference clustering of each individual. Right plot: inferred
${\boldsymbol{z}}^*$
. The different colors in the side-bars of this and the last plot correspond to different reference clustering of each individual. Right plot: inferred
 $\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.
$\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.

The observed adjacency matrix
 ${\boldsymbol{Y}}$
is shown as the first plot of Figure 8, within which the non-negative discrete values of each entry ranges from 0 to 3. Each monk was classified by Sampson to be within one of the three groups: “Turks”, “Outcasts” or “Loyal”, and such a clustering is treated as the reference clustering
${\boldsymbol{Y}}$
is shown as the first plot of Figure 8, within which the non-negative discrete values of each entry ranges from 0 to 3. Each monk was classified by Sampson to be within one of the three groups: “Turks”, “Outcasts” or “Loyal”, and such a clustering is treated as the reference clustering
 ${\boldsymbol{z}}^*$
for this network. The plot of
${\boldsymbol{z}}^*$
for this network. The plot of
 ${\boldsymbol{Y}}$
rearranged based on
${\boldsymbol{Y}}$
rearranged based on
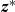 ${\boldsymbol{z}}^*$
is shown as the second plot of Figure 8, where we use red, blue and green colors to represent the three reference groups, respectively. An extra true-or-false variable “Cloisterville” from De Nooy et al. (Reference De Nooy, Mrvar and Batagelj2018) was also added to this dataset to indicate whether or not each monk attended the minor seminary of “Cloisterville” before coming to the monastery. In our experiments, we leverage the combination of the
${\boldsymbol{z}}^*$
is shown as the second plot of Figure 8, where we use red, blue and green colors to represent the three reference groups, respectively. An extra true-or-false variable “Cloisterville” from De Nooy et al. (Reference De Nooy, Mrvar and Batagelj2018) was also added to this dataset to indicate whether or not each monk attended the minor seminary of “Cloisterville” before coming to the monastery. In our experiments, we leverage the combination of the
 ${\boldsymbol{z}}^*$
and the “Cloisterville” information as the exogenous node attributes indicated with
${\boldsymbol{z}}^*$
and the “Cloisterville” information as the exogenous node attributes indicated with
 ${\boldsymbol{c}}$
, to implement the supervised version of the ZIP-LPCM on this network. For example, the monks in the “Turks” group are separated into two different levels in
${\boldsymbol{c}}$
, to implement the supervised version of the ZIP-LPCM on this network. For example, the monks in the “Turks” group are separated into two different levels in
 ${\boldsymbol{c}}$
depending on whether each of them attended the minor seminary or not. Similar for the other two groups leading to a total of
${\boldsymbol{c}}$
depending on whether each of them attended the minor seminary or not. Similar for the other two groups leading to a total of
 $C=6$
levels in
$C=6$
levels in
 ${\boldsymbol{c}}$
.
${\boldsymbol{c}}$
.
The inferred latent positions,
 $\hat {{\boldsymbol{U}}}$
, shown in Figure 9 illustrate a typical SBM structure which resembles the ones shown in our simulation study 2 in Section 4.2. The inferred clustering
$\hat {{\boldsymbol{U}}}$
, shown in Figure 9 illustrate a typical SBM structure which resembles the ones shown in our simulation study 2 in Section 4.2. The inferred clustering
 $\hat {{\boldsymbol{z}}}$
perfectly agrees with the reference clustering
$\hat {{\boldsymbol{z}}}$
perfectly agrees with the reference clustering
 ${\boldsymbol{z}}^*$
, even consider the more informative exogenous node attributes
${\boldsymbol{z}}^*$
, even consider the more informative exogenous node attributes
 ${\boldsymbol{c}}$
during inference. It is shown that the exogenous “Cloisterville” information does not bring more subgroup features to the clustering of this network under the ZIP-LPCM. Our unsupervised ZIP-LPCM implementation, which is not detailed here, also returns the same inferred clustering but with higher uncertainty of the posterior clustering.
${\boldsymbol{c}}$
during inference. It is shown that the exogenous “Cloisterville” information does not bring more subgroup features to the clustering of this network under the ZIP-LPCM. Our unsupervised ZIP-LPCM implementation, which is not detailed here, also returns the same inferred clustering but with higher uncertainty of the posterior clustering.
The red “Turks” group is shown to be more tightly clustered than the blue “Outcasts” group, which is itself more clustered than the green “Loyal” group. According to the analysis of the conditional probability of observed zeros that should actually be non-zero interactions shown in the last plot of Figure 8, the within-group zero interactions of the “Loyal” group are more likely to be non-zeros compared to other zero interactions, though the corresponding inferred probability is around 0.4 which is not particularly high. The number of zero interactions from “Turks” to “Outcasts” are shown to be significantly less than that in the reverse direction, leading to slightly higher conditional probability of those zero-interactions being unusual zeros. However, considering the far latent distance between the two groups illustrated in Figure 9, the corresponding conditional probability of being non-zeros shown in the last plot of Figure 8 remains relatively small and negligible.
The Sampson monks real network. Left plot: inferred latent positions,
 $\hat {{\boldsymbol{U}}}$
. The three inferred groups in
$\hat {{\boldsymbol{U}}}$
. The three inferred groups in
 $\hat {{\boldsymbol{z}}}$
are distinguished by different colors, and perfectly agree with the reference clustering. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
$\hat {{\boldsymbol{z}}}$
are distinguished by different colors, and perfectly agree with the reference clustering. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
 $90^{\circ }$
clockwise with respect to the vertical axis.
$90^{\circ }$
clockwise with respect to the vertical axis.

Windsurfers real network. Left plot: inferred latent positions,
 $\hat {{\boldsymbol{U}}}$
. The three inferred groups in
$\hat {{\boldsymbol{U}}}$
. The three inferred groups in
 $\hat {{\boldsymbol{z}}}$
are distinguished by different colors. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
$\hat {{\boldsymbol{z}}}$
are distinguished by different colors. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
 $90^{\circ }$
clockwise with respect to the vertical axis.
$90^{\circ }$
clockwise with respect to the vertical axis.

5.2 Windsurfers network
This is an undirected non-negative discrete weighted network (Freeman et al., Reference Freeman, Webster and Kirke1998, Reference Freeman, Freeman and Michaelson1988; Kunegis, Reference Kunegis2013) recording the interpersonal contacts between
 $43$
windsurfers in southern California during the fall of 1986. The values of interaction weights range from 0 to 47 recorded in the adjacency matrix. As the network size is larger than the Sampson monks network, the
$43$
windsurfers in southern California during the fall of 1986. The values of interaction weights range from 0 to 47 recorded in the adjacency matrix. As the network size is larger than the Sampson monks network, the
 $\text{Beta}(1,19)$
prior of the probability of unusual zeros is proposed to encourage more clustering. Further, no reference clustering and exogenous node attributes are available for this network, so the unsupervised ZIP-LPCM is used.
$\text{Beta}(1,19)$
prior of the probability of unusual zeros is proposed to encourage more clustering. Further, no reference clustering and exogenous node attributes are available for this network, so the unsupervised ZIP-LPCM is used.
Figure 10 shows that the whole network may generally be split into two main groups. However, it is interesting that our inferred clustering
 $\hat {{\boldsymbol{z}}}$
returns
$\hat {{\boldsymbol{z}}}$
returns
 $\hat {K}=3$
inferred groups, one of which is likely to be a core group since it sits at the center of another group. We use dark red color to represent the core group while the light red and light blue colors are used, respectively, for the corresponding non-core group and another group. In combination with the middle plot of Figure 11, it is shown that there are four windsurfers clustered into the red core group: they frequently interact with each other thus leading to very strong connections. This core group also actively interacts with all other windsurfers from the red non-core group, within which a few windsurfers seem to be the “close friends” of the core windsurfers. These findings indicate that the members from the core group may have a central or leader role or generally high reputation across the whole network.
$\hat {K}=3$
inferred groups, one of which is likely to be a core group since it sits at the center of another group. We use dark red color to represent the core group while the light red and light blue colors are used, respectively, for the corresponding non-core group and another group. In combination with the middle plot of Figure 11, it is shown that there are four windsurfers clustered into the red core group: they frequently interact with each other thus leading to very strong connections. This core group also actively interacts with all other windsurfers from the red non-core group, within which a few windsurfers seem to be the “close friends” of the core windsurfers. These findings indicate that the members from the core group may have a central or leader role or generally high reputation across the whole network.
The heatmap plots for the windsurfers real network where the grays are used for zero values in order to highlight other non-zero elements. Left plot: original observed adjacency matrix,
 ${\boldsymbol{Y}}$
. Middle plot: plot of
${\boldsymbol{Y}}$
. Middle plot: plot of
 ${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
 $\hat {{\boldsymbol{z}}}$
. The different colors on the side-bars correspond to different inferred clustering of each individual. Right plot: inferred
$\hat {{\boldsymbol{z}}}$
. The different colors on the side-bars correspond to different inferred clustering of each individual. Right plot: inferred
 $\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.
$\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.

It can also be observed in Figure 10 that four blue windsurfers are also well connected with each other and tend to form a core of the blue group, but their connection patterns tend to be significantly weaker than the red core group, and thus our model prefers not to distinguish them from the whole blue group. The zero interactions which are more likely to be non-zeros are mainly those within the red non-core group: some of them have very high probability to be non-zero interactions. This result indicates that either the corresponding interpersonal contact data was lost, or that those pairs of windsurfers might have other forms of interactions which were not recorded in this dataset.
5.3 Train bombing network
This dataset (Hayes, Reference Hayes2006; Kunegis, Reference Kunegis2013) aims at reconstructing the contacts between suspected terrorists involved in the train bombing of Madrid on 11th March, 2004. The corresponding undirected network records 64 suspects, and the pair-wise interaction strengths, which range from 0 to 4, indicate the aggregation of friendship and co-participating in training camps or previous attacks. For this dataset, we propose a
 $\text{Beta}(1,9)$
prior and we use the unsupervised setting.
$\text{Beta}(1,9)$
prior and we use the unsupervised setting.
The inferred latent positions and clustering shown in Figure 12 illustrate that a small red group containing five suspects forms the core of the whole network: strong connections between each pair of members inside this core group can be observed. The big blue group contains the non-core suspects and, based on the middle plot of Figure 13, some of them seem to be more “central” than others in light of the significantly stronger connections with each other and with the core nodes. By contrast, the other “non-central” blue members do not interact with the core nodes and only interact with these “central” blue members. Though this “central” and “non-central” feature of the inferred blue group can be illustrated by the plots, our inference results suggest not to split them into two separate groups.
Train bombing real network. Left plot: inferred latent positions,
 $\hat {{\boldsymbol{U}}}$
. The inferred clustering distinguished by different colors. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
$\hat {{\boldsymbol{U}}}$
. The inferred clustering distinguished by different colors. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights. Right plot: rotated version of the latent positions shown in the left plot where the whole latent space is rotated by
 $90^{\circ }$
clockwise with respect to the vertical axis.
$90^{\circ }$
clockwise with respect to the vertical axis.

The heatmap plots for the train bombing real network where the grays are used for zero values in order to highlight other non-zero elements. Left plot: original observed adjacency matrix,
 ${\boldsymbol{Y}}$
. Middle plot: the plot of
${\boldsymbol{Y}}$
. Middle plot: the plot of
 ${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
${\boldsymbol{Y}}$
where the rows and columns of the matrices are rearranged and separated according to
 $\hat {{\boldsymbol{z}}}$
. The different colors in the side-bars of this and the last plot correspond to different inferred clustering of each individual. Right plot: inferred
$\hat {{\boldsymbol{z}}}$
. The different colors in the side-bars of this and the last plot correspond to different inferred clustering of each individual. Right plot: inferred
 $\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.
$\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.

It is interesting that we also observe a small green group which contains five suspects who interact strongly with each other. This special group is shown to only interact well with the core red group and has very few connections with the non-core blue group. According to the corresponding inferred latent positions shown in Figure 12, these features are unusual and in agreement with the results shown in the last plot of Figure 13 where there are significantly many zero interactions, which are more likely to be non-zeros compared to other zero interactions, between this special green group and the non-core blue group. Finally, a small purple group seems to form a separate small network by themselves and only has few weak connections with the blue group.
5.4 Summit co-attendance criminality network
The last real network that we propose in this paper was obtained from https://sites.google.com/site/ucinetsoftware/datasets/covert-networks, and was previously analyzed in a number of works, including Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022) and Lu et al. (Reference Lu, Durante and Friel2025). This is an undirected network recording the co-attendance of summits for 84 criminal suspects operating in the north of Italy. The edge weights represent the number of summits that any two individuals co-attended, and the maximum edge weight is 13. We consider a ground-truth partition of the nodes as in Lu et al. (Reference Lu, Durante and Friel2025), which we indicate with
 ${\boldsymbol{z}}^*$
. This reference clustering is made of 10 groups, which describe the roles and affiliations of the suspects.
${\boldsymbol{z}}^*$
. This reference clustering is made of 10 groups, which describe the roles and affiliations of the suspects.
The network also contains additional exogenous node attributes, which we indicate with
 ${\boldsymbol{c}}$
, and use for the supervised implementations. The additional node information is also a partition with
${\boldsymbol{c}}$
, and use for the supervised implementations. The additional node information is also a partition with
 $C=7$
clusters. Since these partitions contain more levels compared to the ones explored in the previous sections, we propose to apply a
$C=7$
clusters. Since these partitions contain more levels compared to the ones explored in the previous sections, we propose to apply a
 $\text{Beta}(1,6)$
as the prior of the probability of the unusual zeros, so that we encourage the network sparsity, thus bringing more subgroup features.
$\text{Beta}(1,6)$
as the prior of the probability of the unusual zeros, so that we encourage the network sparsity, thus bringing more subgroup features.
Figure 14 illustrates the inferred latent positions plotted along with a set of different node colors and shapes. The clustering in the 1st row plots is the reference clustering,
 ${\boldsymbol{z}}^*$
, where different node colors correspond to different affiliations. Darker squares indicate individuals with more central roles within the organization. Figure 15 shows the heatmaps for this network, with sidebars indicating
${\boldsymbol{z}}^*$
, where different node colors correspond to different affiliations. Darker squares indicate individuals with more central roles within the organization. Figure 15 shows the heatmaps for this network, with sidebars indicating
 ${\boldsymbol{z}}^*$
, and row and column gaps indicating
${\boldsymbol{z}}^*$
, and row and column gaps indicating
 $\hat {{\boldsymbol{z}}}$
. We note that there is a fairly strong agreement between the ground truth partition and the inferred one.
$\hat {{\boldsymbol{z}}}$
. We note that there is a fairly strong agreement between the ground truth partition and the inferred one.
Summit co-attendance criminality network. The 1st row plots illustrate the inferred latent positions,
 $\hat {{\boldsymbol{U}}}$
, along with the different dark or light node colors indicating the reference clustering
$\hat {{\boldsymbol{U}}}$
, along with the different dark or light node colors indicating the reference clustering
 ${\boldsymbol{z}}^*$
. Darker square nodes indicate a more central role in the organization. The same
${\boldsymbol{z}}^*$
. Darker square nodes indicate a more central role in the organization. The same
 $\hat {{\boldsymbol{U}}}$
is shown in the 2nd row plots but the node colors denote instead the inferred partition
$\hat {{\boldsymbol{U}}}$
is shown in the 2nd row plots but the node colors denote instead the inferred partition
 $\hat {{\boldsymbol{z}}}$
. The 2nd column plots are the rotated version of the latent positions shown in the 1st column plots where the whole latent space is rotated by
$\hat {{\boldsymbol{z}}}$
. The 2nd column plots are the rotated version of the latent positions shown in the 1st column plots where the whole latent space is rotated by
 $60^{\circ }$
clockwise with respect to the vertical axis. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights.
$60^{\circ }$
clockwise with respect to the vertical axis. Node sizes are proportional to node betweenness. Edge widths and colors are proportional to edge weights.

The output heatmap plots for the summit co-attendance criminality network where the grays are used for zero values in order to highlight other non-zero elements. The different colors in the side-bars correspond to the role-affiliation information,
 ${\boldsymbol{z}}^*$
. The rows and columns of the matrices are rearranged and separated according to
${\boldsymbol{z}}^*$
. The rows and columns of the matrices are rearranged and separated according to
 $\hat {{\boldsymbol{z}}}$
, where the inferred groups containing central nodes are placed at the bottom while the others are placed at the top. Left plot: adjacency matrix
$\hat {{\boldsymbol{z}}}$
, where the inferred groups containing central nodes are placed at the bottom while the others are placed at the top. Left plot: adjacency matrix
 ${\boldsymbol{Y}}$
. Middle plot: inferred
${\boldsymbol{Y}}$
. Middle plot: inferred
 $\hat {\boldsymbol{\nu }}$
. Right plot: inferred
$\hat {\boldsymbol{\nu }}$
. Right plot: inferred
 $\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.
$\hat {\text{P}}(x_{ij}\gt 0|y_{ij}=0,\dots )$
.

Combining both Figure 14 and 15, significant core-periphery structure can be observed. Based on the inferred latent positions, the core groups, consisting mainly of the criminal suspects with central roles shown as darker groups in the 2nd row plots of Figure 14, mostly sit at the center of the network, while the non-core groups are at the periphery. The core groups generally show a flat structure as they roughly lie within a flat plane, whereas the periphery non-core groups are more tridimensional and more pervasive. But the members of the non-core groups mainly have connections within their own group or with the corresponding core groups, indicating a lack of interactions between the non-core groups for this network. This is further confirmed by visualizing the first plot of Figure 15. The members within each core group are densely connected with each other, but significant sparsity between the cores can be observed, as exemplified by those relatively sparse between-group interactions of the cores at the center of the latent positions in Figure 14. However, most of the corresponding zeros within and between these core groups are not likely to be non-zeros according to the right plot of Figure 15.
It is worthwhile to note that our inferred clustering,
 $\hat {{\boldsymbol{z}}}$
, is similar to the inferred clustering (denoted as
$\hat {{\boldsymbol{z}}}$
, is similar to the inferred clustering (denoted as
 ${\boldsymbol{z}}^\dagger$
here) obtained by ZIP-SBM in Lu et al. (Reference Lu, Durante and Friel2025). However, one key difference between
${\boldsymbol{z}}^\dagger$
here) obtained by ZIP-SBM in Lu et al. (Reference Lu, Durante and Friel2025). However, one key difference between
 $\hat {{\boldsymbol{z}}}$
and
$\hat {{\boldsymbol{z}}}$
and
 ${\boldsymbol{z}}^\dagger$
is relevant to some of the central nodes, including two orange nodes, one blue and one green, whose inferred latent positions are close to each other and are near the center of the network as shown in Figure 14.
${\boldsymbol{z}}^\dagger$
is relevant to some of the central nodes, including two orange nodes, one blue and one green, whose inferred latent positions are close to each other and are near the center of the network as shown in Figure 14.
5.5 Comparisons to inference on 2-dimensional latent space
We finish this section of real data applications by comparing the inference output obtained in a 3-dimensional latent space to the output obtained in a 2-dimensional latent space for the real datasets. The analyses are performed in an analogous way, with the obvious exception that the dimension of the latent positions is instead set as
 $d=2$
. Figure 16 illustrates the inferred 2-dimensional latent positions for the real networks. In summary, these results show that the plot of the 2-d inferred latent positions is roughly like a screenshot of the corresponding 3-d inferred latent positions from a specific angle, for example, if we compare the top-left plot of Figure 16, which illustrates the 2-dimensional
$d=2$
. Figure 16 illustrates the inferred 2-dimensional latent positions for the real networks. In summary, these results show that the plot of the 2-d inferred latent positions is roughly like a screenshot of the corresponding 3-d inferred latent positions from a specific angle, for example, if we compare the top-left plot of Figure 16, which illustrates the 2-dimensional
 $\hat {{\boldsymbol{U}}}$
of the windsurfers network, to the left plot of Figure 10. Similarly, the bottom-left plot of Figure 16, which shows the 2-dimensional
$\hat {{\boldsymbol{U}}}$
of the windsurfers network, to the left plot of Figure 10. Similarly, the bottom-left plot of Figure 16, which shows the 2-dimensional
 $\hat {{\boldsymbol{U}}}$
and the reference clustering
$\hat {{\boldsymbol{U}}}$
and the reference clustering
 ${\boldsymbol{z}}^*$
of the criminality network, generally follow the pattern which is similar to that of the top-left plot of Figure 14 which is a screenshot of the 3-dimensional
${\boldsymbol{z}}^*$
of the criminality network, generally follow the pattern which is similar to that of the top-left plot of Figure 14 which is a screenshot of the 3-dimensional
 $\hat {{\boldsymbol{U}}}$
of this network.
$\hat {{\boldsymbol{U}}}$
of this network.
The windsurfers, train bombing and summit co-attendance criminality network in 2-dimensional latent space. The plot settings regarding node sizes, colors, types and edge colors, widths are similar to those applied in the previous subsections. Top-left: inferred 2-d latent positions’ plot of the windsurfers network. Different node colors correspond to different inferred groups in
 $\hat {{\boldsymbol{z}}}$
. Top-right: inferred 2-d latent positions’ plot of the train bombing network where the inferred clustering has only 1 group. Bottom plots: inferred 2-d latent positions of the summit co-attendance criminality network, where the different node colors in the left plot indicate the reference clustering
$\hat {{\boldsymbol{z}}}$
. Top-right: inferred 2-d latent positions’ plot of the train bombing network where the inferred clustering has only 1 group. Bottom plots: inferred 2-d latent positions of the summit co-attendance criminality network, where the different node colors in the left plot indicate the reference clustering
 ${\boldsymbol{z}}^*$
, while those in the right plot correspond to different inferred groups in
${\boldsymbol{z}}^*$
, while those in the right plot correspond to different inferred groups in
 $\hat {{\boldsymbol{z}}}$
.
$\hat {{\boldsymbol{z}}}$
.

However, this does not mean that the third dimension is redundant, actually, there is good evidence that a 2-dimensional latent space is not sufficient to characterize the architectures of these complex networks. For example, in the summit co-attendance criminality network, the green nodes are distributed pervasively and tend to overlap with red and blue nodes in 2-d latent space as shown in the bottom-left plot of Figure 16. In comparison, this group of nodes can be well separated along the extra 3rd dimension in 3-d latent space according to Figure 14. Furthermore, it is also shown that the networks are generally inferred to be more aggregated in 2-d space compared to the corresponding 3-d cases, making it harder to well infer the network clustering.
Similarly for the train bombing network, the 2-dimensional
 $\hat {{\boldsymbol{U}}}$
and the corresponding
$\hat {{\boldsymbol{U}}}$
and the corresponding
 $\hat {{\boldsymbol{z}}}$
are plotted at top-right of Figure 16. The core red group and the special green group are well inferred in the 3-d space shown in Figure 12, but can no longer be well separated and be identified in the 2-d space, bringing a trivial inferred clustering which only has one singleton group. Our experiments show that the illustrated unsatisfactory clustering of the summit co-attendance criminality network and the train bombing network inferred in 2-d space also brings unreasonable performance of inferred probability of unusual zeros. On the other hand, we point out that the inference performance of the windsurfers network and the Sampson monks network in 2-d space are shown to be comparable with those in 3-d space. Similar inferred latent positions’ patterns and inferred clustering are observed in both 2-d and 3-d space, though the inferred probability of unusual zeros is generally higher in 2-d cases due to the more aggregated patterns of the 2-d latent positions. The plot of inferred 2-d latent positions of the Sampson monks network, which is not included in Figure 16, is similar to the plots shown in Figure 9. We refer to https://github.com/Chaoyi-Lu/ZIP-LPCM for more details of all the 2-d implementations for the four real networks.
$\hat {{\boldsymbol{z}}}$
are plotted at top-right of Figure 16. The core red group and the special green group are well inferred in the 3-d space shown in Figure 12, but can no longer be well separated and be identified in the 2-d space, bringing a trivial inferred clustering which only has one singleton group. Our experiments show that the illustrated unsatisfactory clustering of the summit co-attendance criminality network and the train bombing network inferred in 2-d space also brings unreasonable performance of inferred probability of unusual zeros. On the other hand, we point out that the inference performance of the windsurfers network and the Sampson monks network in 2-d space are shown to be comparable with those in 3-d space. Similar inferred latent positions’ patterns and inferred clustering are observed in both 2-d and 3-d space, though the inferred probability of unusual zeros is generally higher in 2-d cases due to the more aggregated patterns of the 2-d latent positions. The plot of inferred 2-d latent positions of the Sampson monks network, which is not included in Figure 16, is similar to the plots shown in Figure 9. We refer to https://github.com/Chaoyi-Lu/ZIP-LPCM for more details of all the 2-d implementations for the four real networks.
The above findings show that 3-dimensional latent positions are capable of giving a more nuanced model-based representation compared to 2-d latent spaces. The choice of the number of latent space dimensions remains a challenging problem. According to our results, 3-dimensional latent spaces can allow for a better model fit while still maintaining visualizations that are easy to interpret. Thus, our work emphasizes once more the criticality of this model-choice research question within the scope of latent space modeling.
6. Conclusion and discussion
This paper describes an original ZIP-LPCM which leverages several recent ideas from the literature on computational statistics to analyze non-negative weighted networks with unusual zeros or missing data. Our methodology combines ZIP distributions, clustering (via mixture of finite mixtures), and optional nodes attributes to be used within the clustering structure, when available. As regards the inferential procedure, our novel approach relies on a partially collapsed sampler which features a new TAE move, and leads to an automatic and computationally efficient selection of the optimal number of groups. One fundamental output of our proposed procedure is that it provides new model-based visualizations of the complex network data using a 3-dimensional latent space.
The results that we obtain using this methodology include the latent space visualizations, the clustering of the nodes, and the detection of unusual zeros, that is, missing or non-reported data. As we demonstrate via various examples on simulated datasets, the model has great flexibility and can generalize well to a variety of data patterns. In addition, the inferential procedure is scalable and is able to discover the accurate estimates for the model parameters and model structure. Applications on various real networks show that we are able to uncover multiple complex and interesting architectures for the social networks, which provide new perspectives on the analyses of these datasets.
Future work will focus on computational scalability, since we are interested in estimating networks with much larger sizes that are common in real world. Moreover, instead of our proposed partially collapsed MCMC approach, the variational Bayesian methods (for example, Salter-Townshend and Murphy, Reference Salter-Townshend and Murphy2013; Gollini and Murphy, Reference Gollini and Murphy2016; Marchello et al., Reference Marchello, Corneli and Bouveyron2024) are also viable approaches for inference tasks, and it will be interesting to compare the performance of these two widely-used classes of inference methods. As motivated by Legramanti et al. (Reference Legramanti, Rigon, Durante and Dunson2022), instead of a mixture of finite mixtures clustering prior, one could compare different forms of Gibbs-type priors (Gnedin and Pitman, Reference Gnedin and Pitman2006) to complement our framework. If exogenous node attributes are not categorical, one may consider a more generalized structure of the clustering prior, as suggested by Shen et al. (Reference Shen, Amini, Josephs and Lin2024), which can accommodate continuous or categorical or mixed type attributes. Another viable modification is to replace Eq. (4), which is one of the simplest forms to link between the
 $\mathbb{E}(y_{ij})$
and the corresponding latent positions, with a more sophisticated choice, for example, considering a different metric between pair-wise nodes on a different latent geometric space (Smith et al., Reference Smith, Asta and Calder2019). Similarly, count data distributions beyond the Poisson may also be considered. Finally, following Sewell and Chen (Reference Sewell and Chen2015), a natural and ambitious extension for this network model would be to consider a dynamic setting, for the interactions, the clustering, and the missing data specifications.
$\mathbb{E}(y_{ij})$
and the corresponding latent positions, with a more sophisticated choice, for example, considering a different metric between pair-wise nodes on a different latent geometric space (Smith et al., Reference Smith, Asta and Calder2019). Similarly, count data distributions beyond the Poisson may also be considered. Finally, following Sewell and Chen (Reference Sewell and Chen2015), a natural and ambitious extension for this network model would be to consider a dynamic setting, for the interactions, the clustering, and the missing data specifications.
Acknowledgements
The authors would like to gratefully thank the anonymous reviewers for the constructive comments to help improve this article.
Competing interests
None.
Funding statement
The Insight Research Ireland Centre for Data Analytics is supported by Science Foundation Ireland under Grant Number 12/RC/2289
 $\_$
P2.
$\_$
P2.
Data availability statement
The application code and data for the simulation studies and the real data applications shown in Sections 4 and 5 is available at https://github.com/Chaoyi-Lu/ZIP-LPCM.



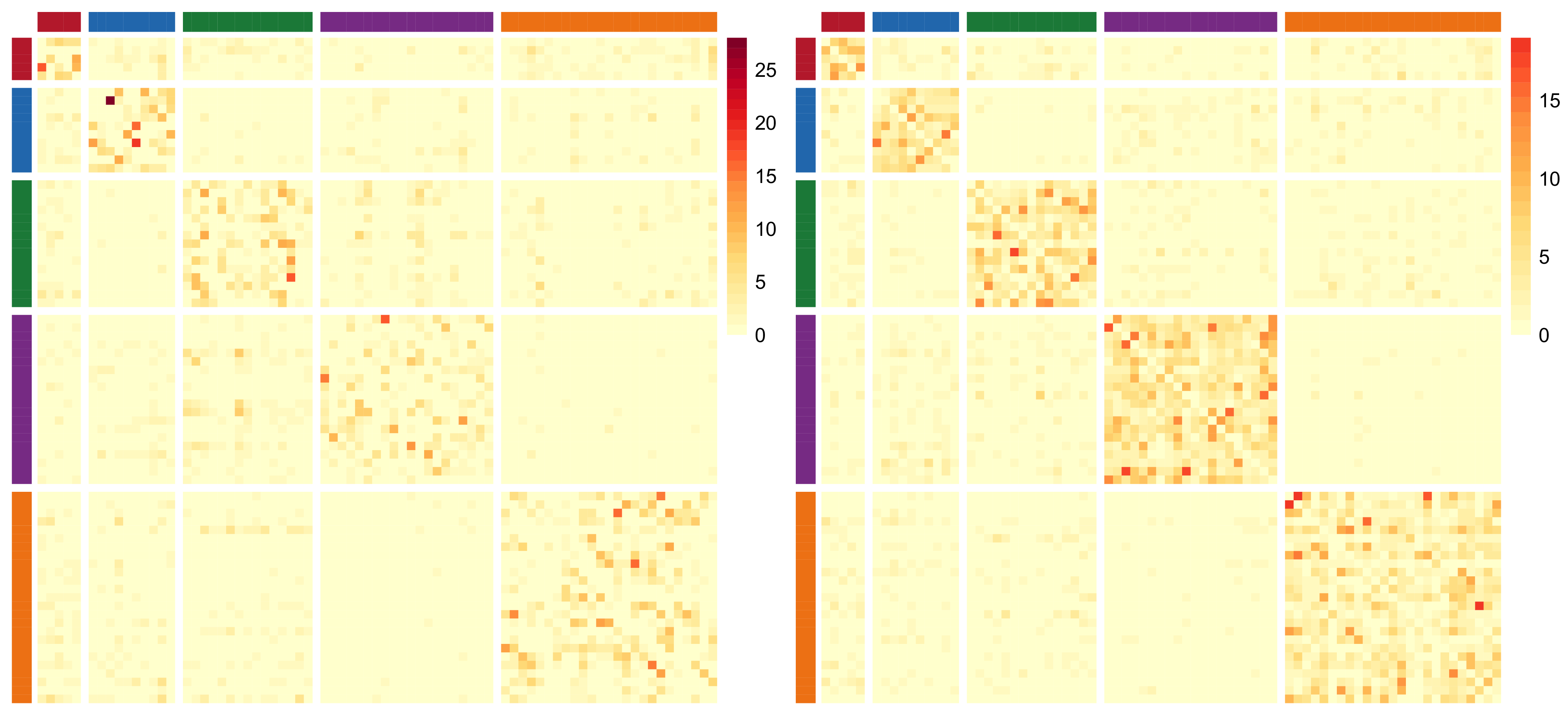

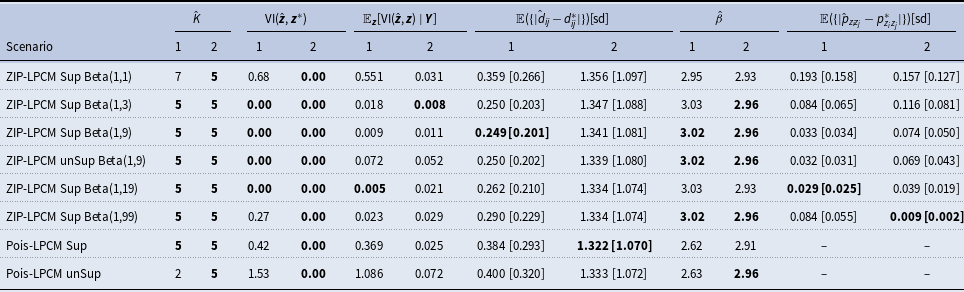



















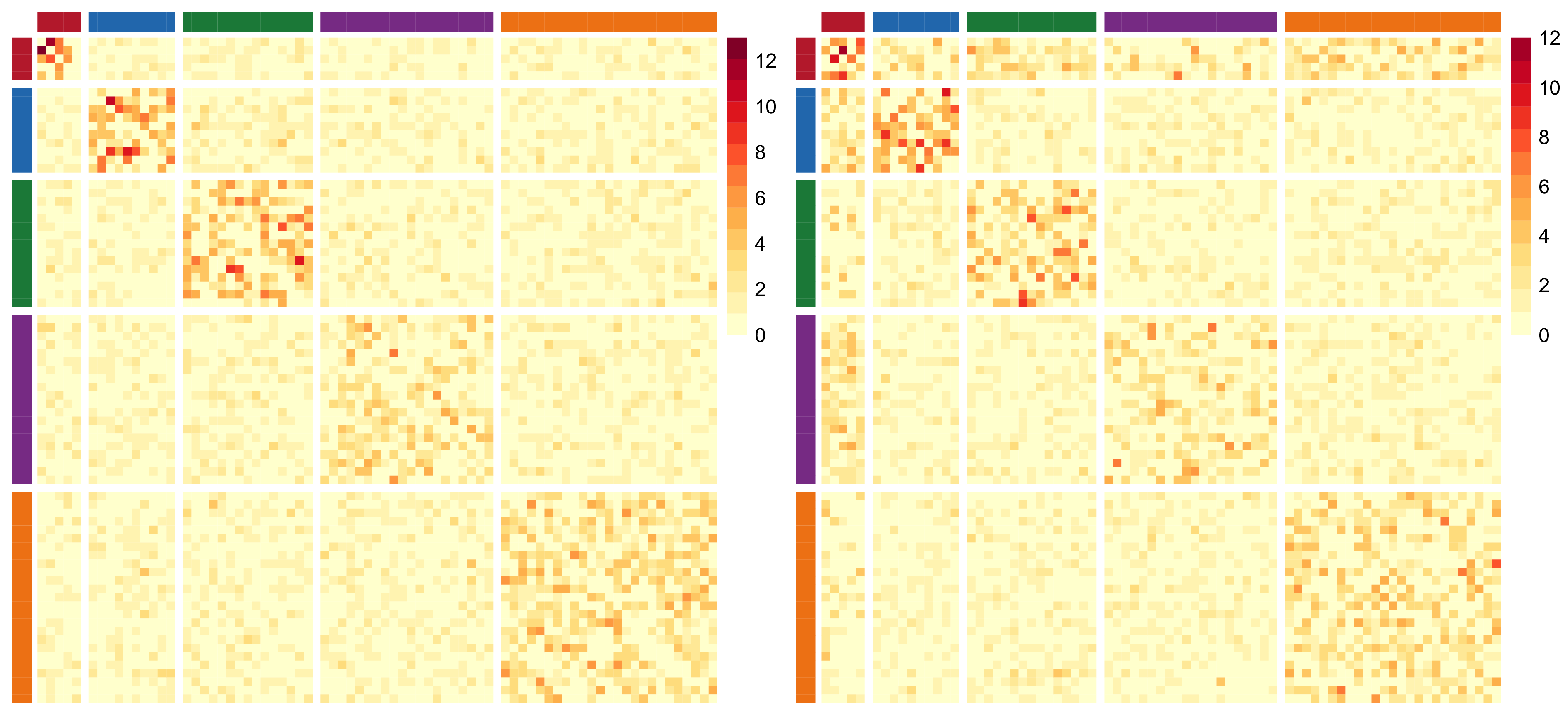





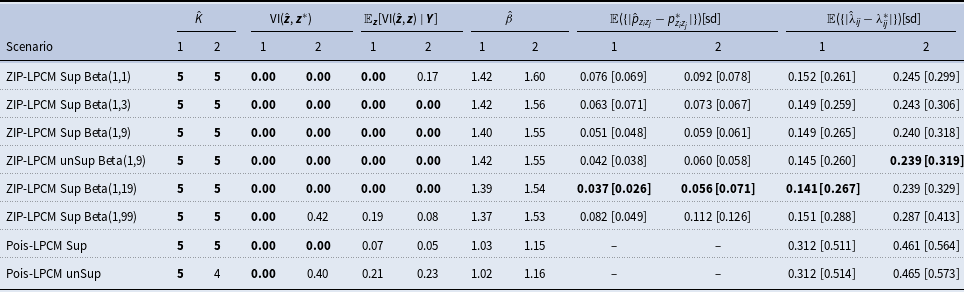
























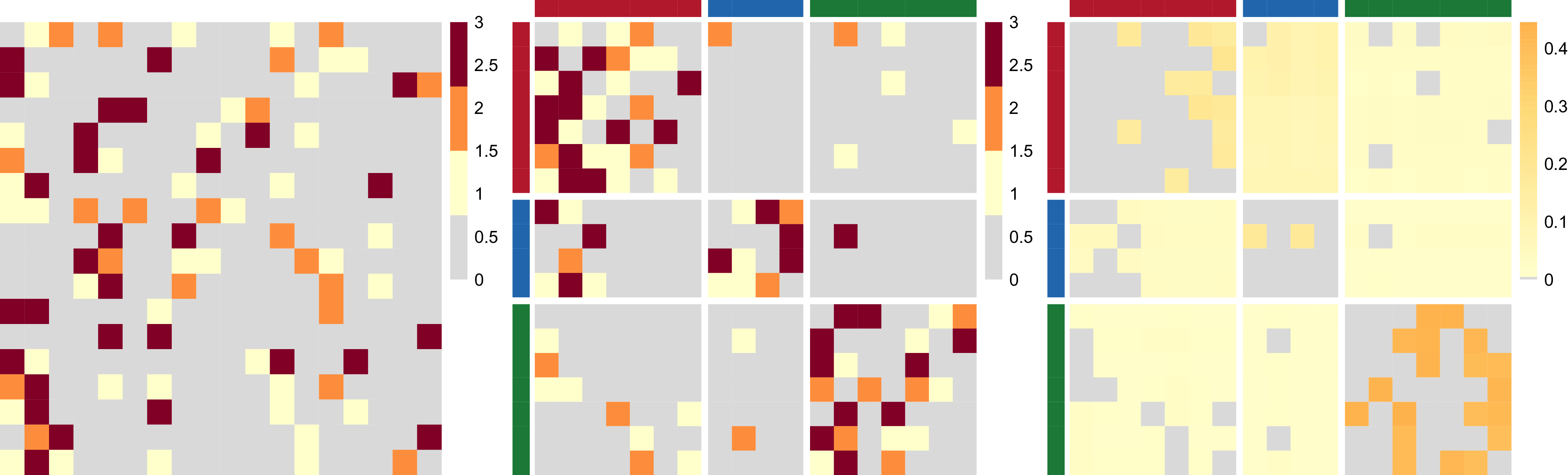












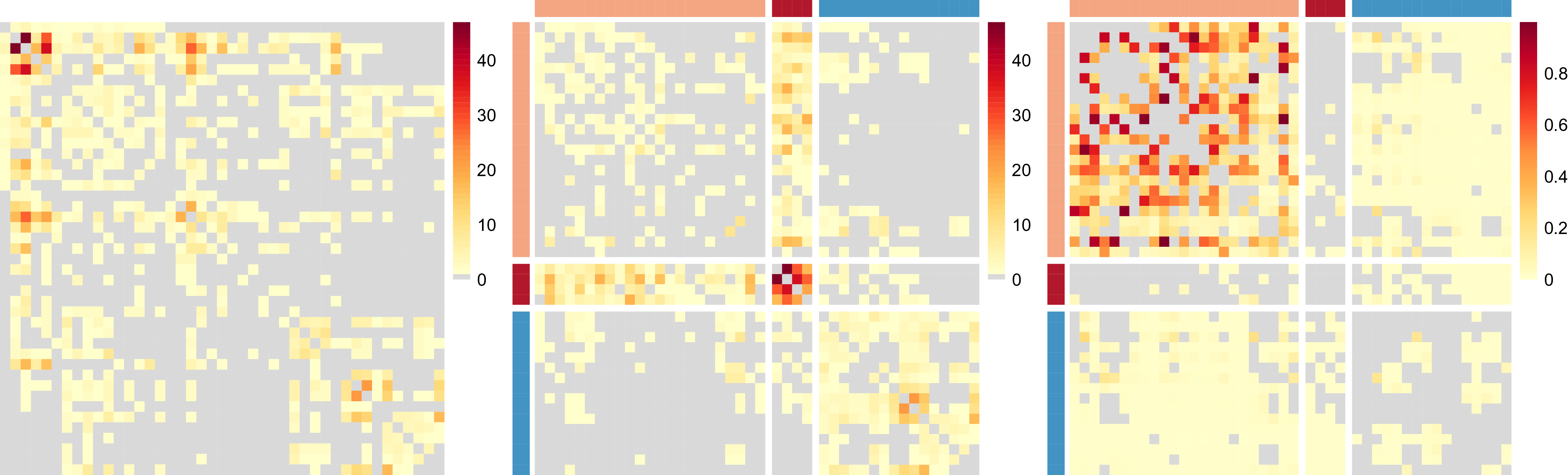







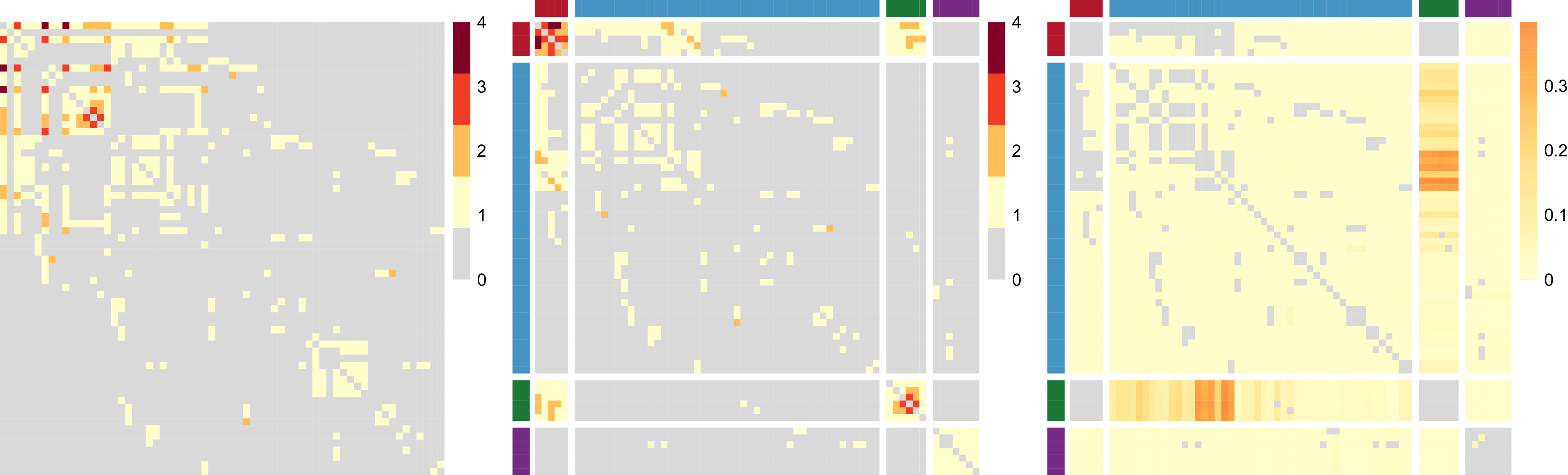





















 Open access
Open access