

1 Introduction
Racial discrimination affects numerous aspects of social and political life (DeSante Reference DeSante2013; Hutchings and Piston Reference Hutchings, Piston, Druckman, Green, Kuklinski and Lupia2011; Pager Reference Pager2007). Social scientists interested in understanding and reducing this bias frequently use experiments because doing so allows them to hold other factors constant when measuring racial bias (e.g., Hutchings and Piston Reference Hutchings, Piston, Druckman, Green, Kuklinski and Lupia2011). While these experiments take a variety of forms, and are conducted on surveys, in the lab, and in the field, researchers will often use racially distinctive names (i.e., names that are much more likely to be associated with a given racial group) as a key tool to measure racial bias (e.g., Bertrand and Mullainathan Reference Bertrand and Mullainathan2004). For example, surveys will often present respondents with a vignette about an individual, randomizing whether the individual has a name that is distinctively black or distinctively white, and then ask them to evaluate that individual (e.g., DeSante Reference DeSante2013). Similarly, field experiments will ask politicians for help, using the name of the individual to signal the putative race of the one sending the email (e.g., Broockman Reference Broockman2013; McClendon Reference McClendon2016; Mendez and Grose Reference Mendez and Grose2014; White, Faller and Nathan Reference White, Faller and Nathan2015). The researchers then use the differences in respondents’ reactions to the putatively white individuals versus the putative minorities as a measure of racial bias.
The ability of these experiments to inform us about racial discrimination depends in large part on the excludability assumption (Gerber and Green Reference Gerber and Green2012). In the majority of studies using names to signal the race of a subject, the excludability assumption is that the research subjects’ response to the name is driven solely by the signal that the name provides about race. In other words, these studies assume (at least implicitly) that the research subjects are not responding to some other relevant information that might be signaled with racially distinctive names. In economics, the validity of using names to measure the effect of ethnic/racial bias has been a matter of active debate because of concerns about excludability. Most prominently, Fryer and Levitt (Reference Fryer and Levitt2004) argue that racially distinctive names are also strong signals about socioeconomics. The issue is not just that black and Latino individuals have lower incomes than white individuals. But that even among black and Latino individuals, those with distinctively black and Latino names tend to be different than others of their race. Fryer and Levitt argue that once you control for the initial differences at birth, names do not have an impact on a wide range of outcomes (see also Heckman and Siegelman Reference Heckman, Siegelman, Fix and Struyk1992; Heckman Reference Heckman1998). However, several recent studies have taken extensive steps to control for such background characteristics and find that names can have very sizable effects on outcomes (Abramitzky, Boustan and Eriksson Reference Abramitzky, Boustan and Eriksson2016; Biavaschi, Giulietti and Siddique Reference Biavaschi, Giulietti and Siddique2013; Goldstein and Stecklov Reference Goldstein and Stecklov2016).
Concerns about excludability are equally important for political science because racially distinctive names can also signal politically relevant information. For example, Latinos and blacks in the United States, especially those with racially distinctive names, are more likely to have a lower SES (Fryer and Levitt Reference Fryer and Levitt2004). Similarly, and very important for many political science studies, Latinos and blacks are much more likely than whites to vote for a Democratic candidate. The concern is that the signal about race is confounded with these other signals and that people are responding to these other pieces of information and not the race of the individual. Of course, in some projects, researchers’ conceptualization of the race treatment will include these differences (see discussion in Sen and Wasow Reference Sen and Wasow2016). However, many projects using racially distinctive names are interested in identifying how race, separate from signals about partisanship and political resources, affects subjects’ responses to the individual with the racially distinctive name.
One approach for mitigating concerns about confounding the effect of race with these other factors is to convey additional information to the research subjects about the individuals with racially distinctive names. If the experiment is a survey vignette, researchers can incorporate the relevant pieces of information into the vignette (e.g., Hainmueller, Hopkins and Yamamoto Reference Hainmueller, Hopkins and Yamamoto2014). If one includes the relevant pieces of information, this can be effective at mitigating confounding concerns (Dafoe, Zhang and Caughey Reference Dafoe, Zhang and Caughey2015). However, it is not always possible to convey additional information to the research subject in the study. There may be time and space constraints which make it difficult to convey the necessary information. For example, in audit studies it may be hard or impossible to also convey the additional information in the communication using the racially distinctive name. Thankfully, it may not be necessary to convey additional information. The key assumption is that race is the only signal associated with the racially distinctive name that the research subjects are responding to. Even if a racially distinctive name signals other information, research subjects may not respond to this information. In other words, if research subjects are only responding to the signal about race, then the excludability assumption still holds.
We evaluate the excludability assumption undergirding the use of racially distinctive names in experiments by reanalyzing data from an audit study of how public officials respond to email requests from putative Latino, black, and white constituents (Butler Reference Butler2014). In the audit study, state legislative offices were sent emails requesting information with the alias used in the email being randomly chosen from a set of over 100 different names. Each of these names signals information not only about race, but also about other factors. For our study, we merged the results from the audit study with detailed information from public records on individuals who share the first name with the aliases in the email experiment (as a robustness check we also run the analysis using full names). We thus have information about the specific signals that each name sends about the political resources and the partisan preferences of the putative individual sending the request.
We focus on political resources (in the form of turnout and one’s SES) and partisanship because these are likely to be particularly important for most political science studies. Elections are decided by votes and the financial contributions used to seek after votes. Thus actors in the political arena are likely to care about individuals’ partisan preferences (because it affects who they vote for) as well as their political resources (i.e., their likelihood of voting and their ability to donate financial resources to candidates). In the study we reanalyze, the state legislators are deciding whether to give help to a constituent who contacts them. The original study concludes that white state legislators are less responsive to minorities because they are minorities. The concern is that this conclusion may be misplaced. Instead, officials may have used the names to make inferences about the political resources of the individual contacting them and then responded according to those inferences. If they are doing so, then what looks like racial bias would in fact be driven by their concerns for these other relevant factors.
In this letter we conduct two tests. First, we calculate the bivariate correlations between legislative responsiveness and signals that each name sends about political resources and partisan preferences. If officials are actually responding to these factors when they decide whether to respond to an email, then these factors should also be correlated with the levels of responsiveness observed within race. However, we find that these factors are uncorrelated with responsiveness. Second, we replicate the original analysis and then add in the information about the political resource and partisan preferences signals as additional controls. Adding in these controls has no effect on how the aliases are treated. We thus find no evidence that the political resource and partisan preference signals drove the elected officials’ responses. This in turn provides empirical support for the exclusion restriction with regard to the most important confounders for studies of politics.
2 Data
We use results from a previously conducted audit study (Butler Reference Butler2014) and information on voters from a large-scale nationwide database to empirically test key parts of the excludability assumption in experiments with racially distinctive names.Footnote 1 In the original study, a total of 6,951 emails requesting information were sent to state legislators during the summer of 2010. Importantly, the experiment used a total of 123 different email aliases: 35 of them had a putatively black name, 42 had Latino names, and 46 had white names. Each alias was used to send between 51 and 66 different emails.Footnote 2 In line with other studies (Butler and Broockman Reference Butler and Broockman2011), the audit found that state legislators were more likely to respond to individuals from their own racial group. In order to analyze whether these effects could be driven by confounding factors such as socioeconomic status or political characteristics, we calculated the average response rate for each email alias’ first name used in the audit study and then merged this information with socioeconomic and political data of individuals who actually have that name. We also examined the results when matching based on each email alias’ exact full name. The results of this robustness check confirm the findings reported below and can be found in Tables SA.1 and SA.2 in the Appendix.
Our information on voters’ socioeconomic status and political characteristics comes from the company L2.Footnote 3 L2’s database contains over 166 million regularly updated voter records and includes data from state and county level registered voter files, current U.S. Census Data, telephone source files, election return data with results from every county in the U.S., and L2’s own lifestyle and issue data.Footnote 4 For our analysis, we received information on almost 9.3 million individuals in L2’s database that have matching first names with the 123 aliases used in the audit study.Footnote 5
For the analysis we used information from the L2 database to get estimates of each alias’ partisanship and political resources. For partisanship we use the percent of individuals in the sample who belong to each respective party. For political resources, we use data from L2 on income, education, housing and turnout to compute a Political Resources factor score for each first name.Footnote 6 This score refers to the first dimension extracted from a factor analysis including these variables and reflects the idea that the concept of political resources is multidimensional. Using a factor score also increases the power of our test and reduces the danger of a Type II error.Footnote 7
3 Analysis
We begin by confirming the original results in Butler (Reference Butler2014) regarding legislators’ average response rates.Footnote 8 In particular, the first row of Table 1 looks at the correlation between the response rates and putative race of the alias for white legislators.Footnote 9 The correlation coefficient is positive and significant, confirming the main finding from Butler (Reference Butler2014): white legislators are significantly more likely to respond to emails from white constituents than from nonwhite constituents.
The original interpretation assumes that email aliases experience different response rates because of the respective aliases’ putative race. Thus the excludability assumption would be violated if the legislators in the experiment inferred some kind of information from the email aliases that is distinct from race (i.e., socioeconomic or political characteristics) and based their behavior on that additional information. For example, this would be the case if legislators responded less to a Precious or a DeAndre in the experiment, because they assumed that they were less likely to donate money than an Emily or a Luke.
If socioeconomic and political information were the driving determinant of whether a legislator responds to constituents with racially distinctive names, we would expect there to also be large correlations between the variables capturing these characteristics and response rates in the audit study. Further, the correlations with political resources should be positive because individuals with better financial resources would be able to donate more money and legislators have incentives to provide more help to individuals with higher turnout rates (Verba, Schlozman and Brady Reference Verba, Schlozman and Brady1995). Similarly, individuals who share the legislators’ partisanship should be more likely to receive answers because they are more likely to vote and support the candidate at the polls. If these confounding characteristics explain the differences in how racial groups are treated, then differences in these characteristics should also predict how different individuals within racial groups are treated. To test whether this is the case, we computed a series of correlation coefficients to test for these potential effects. The tests are done within racial categories and the results are displayed in Table 1. We analyze correlations within racial categories because comparing across racial categories would confound these characteristics with race.Footnote 10
Table 1. Correlation results for political resources and partisanship.

Note: The table reports Pearson’s correlation coefficients for a two-sided test. 95% confidence intervals in square brackets. Significant correlations are highlighted in bold. Political Resources refers to the first dimension extracted from a factor analysis including the variables for income, education, housing, and turnout. The eigenvalue of the first factor is 2.73.
The different columns in the bottom portion of Table 1 report the correlations between average response rates and political resources as well as partisanship respectively for different subsets of our data. The first results column reports the correlations for the white aliases in the study, the next column for black aliases, and the third results column for Latino aliases.Footnote 11
The results show that all 15 of these correlations are statistically insignificant. In fact, the two correlation coefficients that come closest to being statistically significant and that have the highest absolute value are negative – a finding in the opposite direction of what a violation of the excludability assumption would predict. And given that we are testing 15 different correlations, we would almost expect to observe at least one correlation to be significant at the 95% confidence level just by chance.
Of course this is a small dataset so we might not expect the results to be statistically significant; however, the results are also substantively small. To get an idea of the substantive meaning of these correlations, we can also interpret them as the square root of the
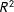 $R^{2}$
values of the respective bivariate regressions. In other words, if we were to regress the average response rate among white aliases on the political resources factor score, the
$R^{2}$
values of the respective bivariate regressions. In other words, if we were to regress the average response rate among white aliases on the political resources factor score, the
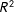 $R^{2}$
value for that regression would be
$R^{2}$
value for that regression would be
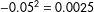 $-0.05^{2}=0.0025$
, indicating that the variance in political resources would only manage to explain 0.25% of the variation in response rates. It turns out that the mean (absolute) value for the 15 correlations is 0.099 (and the median is 0.1). Accordingly, the average amount of response rate variation explained by the socioeconomic and political variables is less than one percentage point. By contrast, the amount of variation explained by race is
$-0.05^{2}=0.0025$
, indicating that the variance in political resources would only manage to explain 0.25% of the variation in response rates. It turns out that the mean (absolute) value for the 15 correlations is 0.099 (and the median is 0.1). Accordingly, the average amount of response rate variation explained by the socioeconomic and political variables is less than one percentage point. By contrast, the amount of variation explained by race is
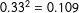 $0.33^{2}=0.109$
, which is 10.9% or more than 10 times the amount explained by the mean correlation across the potential confounders. Also, of the 15 correlation coefficients, none is larger in magnitude than the correlation between response rate and race.
$0.33^{2}=0.109$
, which is 10.9% or more than 10 times the amount explained by the mean correlation across the potential confounders. Also, of the 15 correlation coefficients, none is larger in magnitude than the correlation between response rate and race.
The results in Table 1 provide support for the notion that the potential socioeconomic and political confounders are not related to response rates among the legislators. However, an even more direct way to test whether these potential confounders would affect this finding is to directly control for them in the analysis. In Table 2 we therefore present a series of logit regressions that first replicate the original analysis by Butler (Reference Butler2014), and then also add in the new information about political resources and partisan signals of the aliases as additional controls.
More specifically, we used the original dataset of sent emails, and merged in the new information about the aliases’ political resources and partisanship. For the latter, we created a new variable called Copartisan which indicates the probability that email sender and recipient share the same partisan identification. For example, 59% of all Alfonsos in our voter file data are Democrats. For an email received by a Democratic legislator and sent by the Alfonso alias, the Copartisan variable would therefore take on the value of 0.59.Footnote 12
Table 2. Pooled effects of race, political resources, and partisanship.

Note: Table entries are logit regression coefficients with standard errors in parentheses. Only white legislators are included in the analysis. Political Resources refers to the first dimension extracted from a factor analysis including the variables for income, education, housing, and turnout. The eigenvalue of the first factor is 2.73. Significance at the 95% level is highlighted in bold, one-tailed tests.

Figure 1. Relationship between average response rates (white legislators) and political resources factor score.
Model 1 of Table 2 only includes dummy variables to indicate emails sent using a black or Latino alias. Model 2 adds the Political Resources factor score for each name, Model 3 the Copartisan variable, and Model 4 both of these potential confounders. The results across all model specifications are very consistent. Both the black and Latino dummy variables have negative and statistically significant coefficient estimates in all four models, confirming the finding of the original study and suggesting that black and Latino aliases were less likely to receive an email response. At the same time, both the Political Resources and Copartisan variables fail to reach statistical significance and are relatively close to zero, regardless of whether they are included separately or jointly.
The results in Table 2 thus confirm the findings reported in Table 1. Together, these two analyses provide strong support for the excludability assumption as they suggest that the different response rates between white and nonwhite aliases are indeed driven by the putative race, and not by their putative political resources or partisanship.
Figure 1 illustrates the findings graphically by showing the relationship between the political resources factor scores and the average response rates among white legislators for each group of aliases. Overall, there is not a strong relationship between political resources and the likelihood of receiving a response from the state legislators. The three respective regression lines are all relatively flat indicating no substantive associations.Footnote 13 And to the extent that there is a relationship, it is in the wrong direction.
Finally, the patterns reported in Tables 1 and 2 are robust to limiting the analysis to voter information based on full name matches (see Tables SA.1 and SA.2 in the Appendix), or to aliases that had more than 2,000 matches in the voter database (see Tables SA.3 and SA.4 in the Appendix). The results are also robust when analyzing the audit study’s other outcome variables: responding in a timely manner, and answering the original question (see Tables SA.6 to SA.9 in the Appendix). We also control for the possibility that examining the average levels of a characteristic for each name could mask important variation. For example, a given alias could have the same average income as another name, but also include a larger share of relatively poor and relatively rich people. In Table SA.11 in the Appendix, we therefore also include standard deviation measures of each indicator, and arrive at the same conclusions reported above.Footnote 14 All these results provide strong empirical evidence that the exclusion restriction (with regard to important political confounders) is not violated in experiments with racially distinct names.
4 Conclusion
Excludability is a key assumption in all experimental work (Gerber and Green Reference Gerber and Green2012). In the context of studies using racially distinctive names, excludability is the assumption that subjects are responding to the putative race of the individual and not to something else. We tested this assumption with data from an audit study of state legislators. While the names used in the audit study signal race, they could also signal information about the individuals’ socioeconomic and political characteristics. We used the L2 company’s voter database to learn what signals each name might send. We first looked within each of the three racial groups of aliases whether these other pieces of information predicted legislators’ likelihood of responding in the original audit study. If the public officials were responding less to blacks because they were using race as a shortcut for other characteristics, then we should have observed that they were also treating aliases differentially based on those characteristics within each group. However, the evidence we present suggests that politicians are not responding to these characteristics when deciding how to respond to constituents. We also showed that the original results were similar when directly controlling for these potential confounders. Our findings are robust to a number of alternative model specifications and assumptions, and thus support the excludability assumption that politicians are not using racially distinctive names as a signal of potentially confounding factors. Most importantly, our results provide empirical support for the use of racially distinctive names as a way of signaling race. Knowing that racially distinctive names can be used as a tool to measure racial bias will allow researchers to continue to focus on other aspects of the experimental design in order to contribute to measuring, understanding and minimizing racial bias.
Supplementary material
For supplementary material accompanying this paper, please visithttps://doi.org/10.1017/pan.2016.15.







