1 Introduction
Over the past decade, a number of new measures have been developed that attempt to capture the political ideology of both incumbent and nonincumbent candidates for Congress, as well as other offices, on the same scale. These measures pose the tantalizing possibility of being able to answer a host of fundamental questions about political accountability and representation. Are ideologically extreme candidates punished at the ballot box (Black Reference Black1948; Downs Reference Downs1957; Enelow and Hinich Reference Enelow and Hinich1984; Canes-Wrone et al. Reference Canes-Wrone, Brady and Cogan2002; Hall Reference Hall2015)? How much do the policy preferences of a district influence the political orientation of candidates that run for Congress (Ansolabehere et al. Reference Ansolabehere, Snyder and Stewart2001)? How much does the available pool of candidates affect the degree of legislative polarization (Thomsen Reference Thomsen2014)? Does variation in electoral rules in primaries affect the policy positions of candidates that run for office (Kousser et al. Reference Kousser, Phillips and ShorForthcoming; Rogowski and Langella Reference Rogowski and Langella2014; Ahler et al. Reference Ahler, Citrin and Lenz2016)? Do ideologically extreme candidates raise less money than centrist candidates (Ensley Reference Ensley2009)?
In this paper, we examine the properties of six recent measures of candidates’ political orientations in different domains.Footnote 1 Specifically, we examine the properties of measures based on candidates’ National Political Awareness Test (NPAT) responses from Project Vote Smart (Ansolabehere et al. Reference Ansolabehere, Snyder and Stewart2001; Montagnes and Rogowski Reference Montagnes and Rogowski2014), their state legislative voting records (Shor and McCarty Reference Shor and McCarty2011), their Twitter followers (Barberá Reference Barberá2015), their campaign donor networks (Bonica Reference Bonica2013b, Reference Bonica2014), the perceptions of survey respondents (Aldrich and McKelvey Reference Aldrich and McKelvey1977; Hare et al. Reference Hare, Armstrong, Bakker, Carroll and Poole2015; Ramey Reference Ramey2016), and expert assessments (Stone and Simas Reference Stone and Simas2010; Joesten and Stone Reference Joesten and Stone2014; Maestas et al. Reference Maestas, Buttice and Stone2014).
The original papers that develop these six measurement models all assert that their estimates measure “ideology,” and a large body of new work has used these measures as proxies for candidate ideology in order to evaluate theories of representation and accountability (e.g., Simas Reference Simas2013; Joesten and Stone Reference Joesten and Stone2014; Montagnes and Rogowski Reference Montagnes and Rogowski2014; Rogowski and Langella Reference Rogowski and Langella2014; Thomsen Reference Thomsen2014; Hall Reference Hall2015; Ahler et al. Reference Ahler, Citrin and Lenz2016). Each paper uses the word “ideology” to describe its estimates. For example, Barberá (Reference Barberá2015, 77) states that its model based on Twitter followers “represents an additional measurement tool that can be used to estimate [the] ideology” of both elites and the mass public. Likewise, Bonica (Reference Bonica2014, 367) describes its model based on campaign-finance (CF) data as a “method to measure the ideology of candidates and contributors using campaign-finance data.” Hare et al. (Reference Hare, Armstrong, Bakker, Carroll and Poole2015, 769) claim that their model based on the perceptions of survey respondents produces “ideological estimates of political stimuli.” Moreover, applied empirical studies almost uniformly use the estimates from these models as measures of candidates’ ideology. For instance, Rogowski and Langella’s (Reference Rogowski and Langella2014, 2) study of the effect of primary systems on polarization in state legislatures describes the foundation of its study as Bonica’s (Reference Bonica2014) “estimates of ideology generated from campaign-finance records.”
However, the assertion that these measures all capture a common dimension of ideology has never been rigorously evaluated. In fact, there are a number of reasons to believe that each of these types of political behavior are driven by domain-specific political orientations rather than ideology. Each of these domains involves very different choices, incentives, contexts, and actors. In order to examine the dimensional structure of these measures, we first examine the correlation between each domain-specific measure of candidates’ political orientation. We find that each measure is highly correlated with candidates’ party. However, there is only a modest correlation across measures within each party. This suggests that a common dimension of political ideology is probably not the primary driver of each domain-specific measure of political orientation.
Next we evaluate how well each measure predicts candidates’ roll call positions in Congress. Roll call votes are an important mechanism for political accountability and representation. If elections are a meaningful constraint, they must constrain what legislators do, not just what legislators say during the campaign. For this reason, roll call behavior has been used as a standard for convergent validity for nearly all of the measurement models of political orientation that we assess (Barberá Reference Barberá2015, 82, Bonica Reference Bonica2014, 370–371, Hare et al. Reference Hare, Armstrong, Bakker, Carroll and Poole2015, 769–770, Joesten and Stone Reference Joesten and Stone2014, 745).
Our findings, however, indicate that none of these measures of political orientation are good predictors of candidates’ roll call voting patterns within their party. For instance, Republican congressman Dave Reichert’s DW-Nominate score places him among the most liberal members of his party in 2010, while measures of his political orientation based upon his CF contributions (Bonica Reference Bonica2014) place him in the conservative wing of his party. Peter King’s roll call record also places him among the most liberal members of his party. Both survey respondents and his Twitter score, however, place him in the more conservative half of the Republican party. On the Democratic side, Henry Waxman’s DW-Nominate score placed him among the most liberal of Democrats. But his dynamic CF-score placed him in the more conservative half of the Democratic Party in several recent Congresses. Chris Van Hollen’s DW-Nominate score places him in the middle of his party, but experts rated him as one of the most liberal members of the Democratic caucus. Overall, the measures we examine only marginally improve on candidates’ party identification for predicting their roll call behavior.Footnote 2
In the penultimate sections, we demonstrate that substituting these measures for a measure based on roll call votes can lead to misleading conclusions to important research questions. As examples, we examine the conclusions that would be reached by using these measures to study polarization and the tendency of extreme candidates to lose their reelection. We find that the measures often lead to inconsistent conclusions. While it may be the case that these measures capture interesting variation in political orientations within their specific domains, future research should seek to explain this variation rather than equating these measures with ideology or roll call voting. Care is warranted in the evaluation and use of new measures as well.
2 Background
Measuring the preferences and behavior of political officeholders and candidates is central to the study of American Politics. Many of our most important explanations of political phenomena involve choices in an underlying policy space, with Black’s median voter theorem being the canonical example (Black Reference Black1948). Although few scholars think that the median voter theorem should be taken literally, its basic intuition is the bedrock of studies of accountability and representation. Simply put: given voters with certain policy desires, they must have a tendency to select candidates who will push policy in their direction. Otherwise elections will not have any tendency to select candidates who represent the policy desires of voters.
A fundamental part of this notion of preferences is the idea of an underlying policy space in which policies can be closer or farther away from what someone desires. If political actors have a shared understanding of this policy space and the space is low-dimensional, then the literature on measuring policy preferences refers to it as an “ideological space.” All of the measures under examination in this paper use the word “ideology” in their abstract, and typically use it throughout as a shorthand for “preferences.” A political actor’s “ideal point” is the unique point in this underlying space that represents that set of policies that they prefer above all others.Footnote 3 A person’s “ideal point” is often said to be a measure of their “ideology” or equivalently, their preferences.
This terminology is problematic because it implies that the measures that arise from various applications of “ideal point estimation” are all measures of the same underlying phenomenon: ideology. Take the most influential work in this literature, which concerns legislative roll call voting (e.g., Poole and Rosenthal Reference Poole and Rosenthal2011). Roll call voting is central to theories of representation and accountability because roll call voting forces legislators to take a public stand on an issue, and to reap the consequences. Roll call voting is constitutionally linked to policy outcomes: if legislators change their votes, different policy can result. Legislators can then be held accountable for these votes by their constituents.
However, a legislator’s ideal point in the space of roll call votes arises from a complex set of calculations which are specific to that context. It is not necessarily the case that this same set of factors defines the policy space that underlies other political choices. Roll call voting only captures one component of legislators’ broader political orientations.
The challenge for empirical scholars of representation and accountability is that roll call behavior is only available for incumbents. In order to test a number of important theories, scholars need measures of the positions of both incumbents and nonincumbents. For example, in order to examine why polarization in Congress is increasing, it is important to know whether the ideological positions of Democratic and Republican candidates in each district are diverging over time (Ansolabehere et al. Reference Ansolabehere, Snyder and Stewart2001). To examine theories of spatial voting in elections, we need to know whether voters are more likely to vote for the more spatially proximate candidate, which requires measures of the ideological positions of both Democratic and Republican candidates (e.g., Jessee Reference Jessee2012; Joesten and Stone Reference Joesten and Stone2014; Shor and Rogowski Reference Shor and RogowskiForthcoming).
In order to meet this challenge scholars have developed a variety of models that estimate ideal points using disparate data sets. These are usually called models of “ideology.” We use the term “political orientation” because it captures the idea that individuals may have different considerations which come in to play in different political contexts. Voters are presumed to have only one ideology, but their choice, for instance, of which politicians to follow on social media may reflect a different political orientation than their decision of who to vote for.
Measures of candidates’ ideal points fall into three broad categories, shown in Table 1. These measurement models all assume that some observed behavior is primarily generated by candidates’ unobserved, latent political orientation.Footnote
4
Roll call voting is an insufficient data source because nonincumbents do not get to vote. In each case, the political orientation of a given individual is summarized by a single number, which we denote as the variable
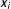 $x_{i}$
where
$x_{i}$
where
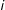 $i$
indexes candidates.Footnote
5
$i$
indexes candidates.Footnote
5
Table 1. Methods for estimating candidate preferences.

a We downloaded Shor and McCarty’s data from the Dataverse (Shor and McCarty Reference Shor and McCarty2015), and manually matched the estimates of state legislators’ ideal points to their ICPSR numbers that Poole and Rosenthal use to index their DW-Nominate scores. Because state legislative ideal points are only available before legislators take office, we use them in the validation below for nonincumbents.
b Jon Rogowski generously shared an expanded version of the data used in Montagnes and Rogowski (Reference Montagnes and Rogowski2014).
c In our evaluation, we focus on the estimates from Ramey (Reference Ramey2016), which uses 109,935 survey responses from 2010 and 2012 to estimate the positions of House and Senate candidates. We downloaded the replication data from the dataverse (Ramey Reference Ramey2015), and used this to analyze the ability of Aldrich–McKelvey scores to predict contemporaneous roll call positions. However, the replication data for Ramey (Reference Ramey2015) does not include estimates for nonincumbent candidates. So we used what we believe to be the same data, from the 2010 and 2012 Cooperative Congressional Election Studies, and the same method, to compute our own estimates based on an identical measurement model.
d We downloaded the replication data from the Dataverse (Maestas et al. Reference Maestas, Buttice and Stone2013). We use the inclc_pc09 variable for incumbent placements, dlc_pc10 for Democratic candidates’ placements, and rlc_pc10 for Republican candidates’ placements.
e We downloaded the replication data from the Dataverse (Barbera Reference Barbera2014).
f We downloaded each congressional candidates’ dynamic and static CF-score data from Adam Bonica’s DIME website (Bonica Reference Bonica2013a). We use the dynamic CF-scores in each of the analyses that follow. However, the results are very similar using static CF-scores.
2.1 Models of political orientation based on political positions outside Congress
One potential approach for measuring the political orientation of candidates is to use information from their political positions outside of Congress. For instance, we could estimate the political orientation of state legislators that run for Congress based on their roll call votes in state legislatures (e.g., Shor and McCarty Reference Shor and McCarty2011) or their responses to political questionnaires from interest groups (e.g., Ansolabehere et al. Reference Ansolabehere, Snyder and Stewart2001; Montagnes and Rogowski Reference Montagnes and Rogowski2014).
In this model, legislators choose the outcome on each bill,
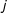 $j$
, that gives them greater utility: either the status quo,
$j$
, that gives them greater utility: either the status quo,
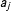 $a_{j}$
or the policy that would be enacted if the bill were passed,
$a_{j}$
or the policy that would be enacted if the bill were passed,
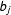 $b_{j}$
. Their utility for any outcome is a function of the distance between their ideal point,
$b_{j}$
. Their utility for any outcome is a function of the distance between their ideal point,
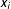 $x_{i}$
, and the outcome in question,
$x_{i}$
, and the outcome in question,
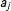 $a_{j}$
or
$a_{j}$
or
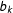 $b_{k}$
, plus a random error that represents idiosyncratic or random features of the legislator’s utility. If the status quo point is “closer” to what the legislator wants, then she votes nay. If the bill is closer, she votes yea. The only exception is if the random shock to her utility is enough to make her prefer the less close option more. This will be more likely when the legislator is close to indifferent between the two options. If we make a few simplifying assumptions, we can write the probability that a legislator votes in favor of a bill (yea) as follows:Footnote
6
$b_{k}$
, plus a random error that represents idiosyncratic or random features of the legislator’s utility. If the status quo point is “closer” to what the legislator wants, then she votes nay. If the bill is closer, she votes yea. The only exception is if the random shock to her utility is enough to make her prefer the less close option more. This will be more likely when the legislator is close to indifferent between the two options. If we make a few simplifying assumptions, we can write the probability that a legislator votes in favor of a bill (yea) as follows:Footnote
6
 $$\begin{eqnarray}P(y_{ij}=\mathit{Yea})=P((x_{i}-b_{j})^{2}-(x_{i}-a_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>0).\end{eqnarray}$$
$$\begin{eqnarray}P(y_{ij}=\mathit{Yea})=P((x_{i}-b_{j})^{2}-(x_{i}-a_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>0).\end{eqnarray}$$
The probability of a vote against (nay) is one minus the probability of a vote in favor. The likelihood of the model is simply the product of the likelihoods of every vote. This model is often referred to as the quadratic utility item response model. The “ideal point” summarizes a legislator’s preferences in the sense that legislators will tend to prefer bills that are closer to their ideal points on average. Observing simply the
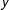 $y$
matrix of vote choices, we can estimate the latent
$y$
matrix of vote choices, we can estimate the latent
 $x$
’s that underlie those choices.
$x$
’s that underlie those choices.
Shor and McCarty (Reference Shor and McCarty2011) estimate the ideal points of each state legislature separately, and then bridge together the ideal points of state legislators in different states using Project Vote Smart’s NPAT survey of legislators from 1996 to 2009. In total, they estimate the positions of 18,000 state legislators from the mid-1990s to 2014.Footnote 7 A related approach is to use only candidates’ responses to questionnaires about their positions. The most widely used questionnaire is again the NPAT survey conducted by Project Vote Smart.Footnote 8 Ansolabehere et al. (Reference Ansolabehere, Snyder and Stewart2001) use factor analysis to estimate candidates’ spatial positions based on the NPAT survey. More recently, Montagnes and Rogowski (Reference Montagnes and Rogowski2014), Shor and Rogowski (Reference Shor and RogowskiForthcoming), and others use a spatial utility model similar to Equation (1) to estimate candidates’ ideal points based on their NPAT responses. These estimates have been widely used in the applied, empirical literature for studies on polarization, spatial voting, elections, and other topics.
Of course, only a fraction of state legislators become candidates for Congress, and even fewer win election to Congress. Moreover, a changing constituency in Congress may lead candidates to adapt their behavior (Stratmann Reference Stratmann2000). Finally, the institutional context of Congress is very different from state legislatures in a variety of ways, depending on the state. For example, partisan gatekeeping power varies substantially (Anzia and Jackman Reference Anzia and Jackman2013), and the level of party pressure may vary as well (Lee Reference Lee2009; Bateman et al. Reference Bateman, Clinton and LapinskiForthcoming).
2.2 Models of political orientation based on perceptions of candidate positions
Another approach is to estimate candidates’ political orientation from survey respondents’ or experts’ perceptions of candidates’ ideological positions. This approach has the benefit of providing estimates for candidates that did not serve in the state legislature or complete Project Vote Smart’s questionnaire. Indeed, conceptually one could imagine survey respondents or experts rating thousands of candidates for all levels of office.
Stone and Simas (Reference Stone and Simas2010) and Joesten and Stone (Reference Joesten and Stone2014) pioneered the use of experts to rate candidates’ ideological positions. These studies survey a sample of state legislators and party convention delegates and ask them to place their congressional candidates on a 7-point scale.Footnote 9 These “expert informants” can label candidates as either very liberal, liberal, somewhat liberal, moderate, somewhat conservative, conservative, or very conservative. The resulting scores are adjusted by subtracting/adding the average difference between partisans and independents. Averaging responses is a sensible approach if we assume that errors in perceptions are symmetrically distributed.
Although Joesten and Stone (Reference Joesten and Stone2014) correct for the average “bias” from partisanship, they do not attempt to correct for the fact that individuals often use scales differently. For instance, some individuals may think that “very liberal” is an appropriate term for anyone who is not a Republican whereas others may reserve the term for revolutionary socialists. When individuals are asked to rate a variety of politicians and political entities, their own tendencies in the use of the scale can be accounted for. This observation led Aldrich and McKelvey (Reference Aldrich and McKelvey1977) to the following model:
 $$\begin{eqnarray}\tilde{x}_{ij}=w_{j}(x_{i}-c_{j})+\unicode[STIX]{x1D716}_{ij},\end{eqnarray}$$
$$\begin{eqnarray}\tilde{x}_{ij}=w_{j}(x_{i}-c_{j})+\unicode[STIX]{x1D716}_{ij},\end{eqnarray}$$
where
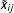 $\tilde{x}_{ij}$
is person
$\tilde{x}_{ij}$
is person
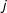 $j$
’s placement of candidate
$j$
’s placement of candidate
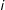 $i$
;
$i$
;
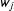 $w_{j}$
and
$w_{j}$
and
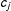 $c_{j}$
are coefficients that capture person
$c_{j}$
are coefficients that capture person
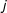 $j$
’s individual use of the scale, which can be estimated because each person places multiple candidates and political entities; and
$j$
’s individual use of the scale, which can be estimated because each person places multiple candidates and political entities; and
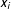 $x_{i}$
is again the actual, latent political orientation of candidate
$x_{i}$
is again the actual, latent political orientation of candidate
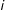 $i$
. Hare et al. (Reference Hare, Armstrong, Bakker, Carroll and Poole2015) and Ramey (Reference Ramey2016) use a Bayesian variant of this model to estimate candidate locations based on the perceptions of survey respondents.Footnote
10
$i$
. Hare et al. (Reference Hare, Armstrong, Bakker, Carroll and Poole2015) and Ramey (Reference Ramey2016) use a Bayesian variant of this model to estimate candidate locations based on the perceptions of survey respondents.Footnote
10
However, there are a number of nonideological factors that could influence survey respondents’ and experts’ perceptions of candidates’ ideology. For instance, more bombastic candidates could be perceived as more ideologically extreme, and candidates with more establishment support could be perceived as more moderate. In addition, candidates’ campaign positions, press releases, and television advertisements might not be an accurate reflection of legislators’ roll call record, or their underlying ideology (see, e.g., Grimmer Reference Grimmer2013; Henderson Reference Henderson2013; Rogowski Reference Rogowski2014; Cormack Reference Cormack2016). All of these factors could lead voters and experts to perceive candidates to be more liberal or conservative than the candidates are in practice. Thus, it is important to evaluate how well these measures actually capture legislators’ roll call behavior and other measures of candidates’ political orientation.
2.3 Models of political orientation based on spatial models of citizen behavior
Another approach is to measure candidates’ political orientation based on the idea that some set of behavior by voters or citizens is driven by a spatial model which is a function of candidate positions. For instance, we could assume that citizens donate to spatially proximate candidates. Likewise, we could assume that social network users follow spatially proximate candidates on Facebook and Twitter.
In Barberá (Reference Barberá2015), the choice by Twitter users of whether or not to follow political candidates is assumed to be a function of the policy distance between the Twitter user and the candidate.Footnote
11
The Twitter user follows the candidate if the utility of doing so is greater than some threshold,
 $t$
, where utility is once again quadratic. Barberá uses a logistically distributed random error, which is very similar to the normal distribution. So the probability that user
$t$
, where utility is once again quadratic. Barberá uses a logistically distributed random error, which is very similar to the normal distribution. So the probability that user
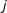 $j$
follows candidate
$j$
follows candidate
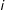 $i$
is:
$i$
is:
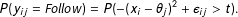 $$\begin{eqnarray}P(y_{ij}=\mathit{Follow})=P(-(x_{i}-\unicode[STIX]{x1D703}_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>t).\end{eqnarray}$$
$$\begin{eqnarray}P(y_{ij}=\mathit{Follow})=P(-(x_{i}-\unicode[STIX]{x1D703}_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>t).\end{eqnarray}$$
In order to allow for arbitrary levels of sensitivity to this distance, Barberá (Reference Barberá2015) adds a scaling parameter,
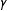 $\unicode[STIX]{x1D6FE}$
, as well as two different intercepts, recognizing that any given user can only follow so many accounts, and that many candidates have limited name recognition and thus few followers. The term
$\unicode[STIX]{x1D6FE}$
, as well as two different intercepts, recognizing that any given user can only follow so many accounts, and that many candidates have limited name recognition and thus few followers. The term
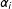 $\unicode[STIX]{x1D6FC}_{i}$
captures candidate
$\unicode[STIX]{x1D6FC}_{i}$
captures candidate
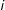 $i$
’s overall popularity with users, and
$i$
’s overall popularity with users, and
 $\unicode[STIX]{x1D6FD}_{j}$
captures user
$\unicode[STIX]{x1D6FD}_{j}$
captures user
 $j$
’s propensity for following people on Twitter. These intercepts are arbitrarily scaled, so we can replace the threshold
$j$
’s propensity for following people on Twitter. These intercepts are arbitrarily scaled, so we can replace the threshold
 $t$
with an arbitrary fixed number, in this case 0. The following specification results:
$t$
with an arbitrary fixed number, in this case 0. The following specification results:
 $$\begin{eqnarray}P(y_{ij}=\mathit{Follow})=P(\unicode[STIX]{x1D6FC}_{i}+\unicode[STIX]{x1D6FD}_{j}-\unicode[STIX]{x1D6FE}(x_{i}-\unicode[STIX]{x1D703}_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>0).\end{eqnarray}$$
$$\begin{eqnarray}P(y_{ij}=\mathit{Follow})=P(\unicode[STIX]{x1D6FC}_{i}+\unicode[STIX]{x1D6FD}_{j}-\unicode[STIX]{x1D6FE}(x_{i}-\unicode[STIX]{x1D703}_{j})^{2}+\unicode[STIX]{x1D716}_{ij}>0).\end{eqnarray}$$
Based on this model, Barberá (Reference Barberá2015) estimates the latent ideology of several hundred House and Senate candidates using data on 301,537 Twitter users from November of 2012.
In a related paper, Bonica (Reference Bonica2014) uses correspondence analysis to estimate candidates’ political orientation based on their campaign contributors.Footnote 12 The main difference between Barberá (Reference Barberá2015)’s model and the correspondence analysis model in Bonica (Reference Bonica2014) is that when it comes to campaign contributions, donors must choose both who to give to and how much to give. Bonica recodes all contribution amounts as categories of $100s of dollars, and uses correspondence analysis to recover ideal points.Footnote 13
However, there is no reason to necessarily believe that politicians’ political orientation on Twitter, or the profile of their Twitter followers or donors, are based on the same underlying factors that drive legislative behavior or other aspects of candidates’ political orientation. There are a number of nonideological factors that could influence both donations and social media following. For instance, ideologically extreme voters may be more likely to donate to, and follow on Twitter, more outspoken candidates. Similarly, ideologically extreme voters may be more likely to donate to, or follow on social media, candidates who specialize in attacking the opposing party.
Of course, distinct factors could also drive donations and social media following. As a result, candidates’ donation networks (Bonica Reference Bonica2014) and social media following (Barberá Reference Barberá2015) may not capture a common political orientation. For example, past research has shown that geography influences donation patterns (Gimpel et al. Reference Gimpel, Lee and Kaminski2006; Tam Cho and Gimpel Reference Tam Cho and Gimpel2007), while geography probably has more modest effects on Twitter networks. Also, many donors are strategic—seeking to direct contributions to “competitive districts where the parties’ control of legislative seats is in doubt” (Gimpel et al. Reference Gimpel, Lee and Pearson-Merkowitz2008). In contrast, citizens’ behavior on social media is likely expressive rather than strategic.
3 Do these Domain-Specific Measures Capture a Common Dimension of Political Ideology?
Empirical scholars have typically assumed that the measures of political orientation that emerge from these models are synonymous with candidates’ underlying political ideology. However, each of these forms of political behavior involves very different choices, incentives, contexts, and actors. There is no reason that they are necessarily equivalent to ideology.
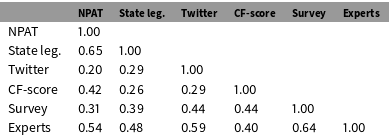
We find that all of the domain-specific measures of political orientation accurately capture candidates’ partisan identification.Footnote 14 In fact, they typically classify candidates into the correct party over 95% of the time. However, this does not necessarily indicate that the measures are structured by a common ideological dimension. Instead, it is possible that they are structured by a combination of partisanship and domain-specific factors. To assess this possibility, Tables 2 and 3 show the within-party correlations between the six domain-specific measures for Democrats and Republicans.Footnote 15 In general, the within-party correlation between the various measures of political orientation is low. The average correlation between the various measures is 0.57 for Democrats and 0.42 for Republicans.Footnote 16 This means that two measures can be expected to explain only 33% of the variance in one another for Democrats and 18% for Republicans. This leads to two potential conclusions. One is that a common dimension of political ideology may not be the primary component underlying these measures. This would indicate that the individual measures are best viewed as capturing domain-specific political orientations rather than a common dimension of political ideology. Alternatively, it is possible that each measure is capturing an underlying dimension of ideology, but with a great deal of measurement error. In other words, either the accuracy or the precision of the measures is in question.
Table 2. Within-party correlation between measures of political orientations in different domains for Democrats.
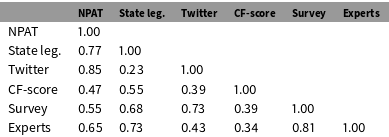
Table 3. Within-party correlation between measures of political orientations in different domains for Republicans.
4 The Usage of Domain-Specific Political Orientation as a Proxy for Roll Call Votes in Congress
Despite the low correlations between these measures, it is possible that some of them are good predictors of candidates’ roll call votes in Congress. It is important to examine whether they are accurate predictors of roll call votes because these votes are the most obvious means by which legislators can fulfill the obligations of accountability. If elections are a meaningful constraint, they must constrain what legislators do, not just what legislators say during the campaign.Footnote 17 This is probably the reason why roll call behavior is used as a metric of validation by nearly all of the existing measurement models of candidate positions that we assess below (Barberá Reference Barberá2015, 82, Bonica Reference Bonica2014, 370–371, Hare et al. Reference Hare, Armstrong, Bakker, Carroll and Poole2015, 769–770, Joesten and Stone Reference Joesten and Stone2014, 745).
Clearly, it is not enough to equate roll call voting itself with ideology. We know already that the measures in question do not have much convergent validity, but roll call voting itself may encapsulate many considerations as well (Poole and Rosenthal Reference Poole and Rosenthal2011). For instance, many of the most important debates in Congress may be rooted in partisan competition for power rather than ideological disagreements (Lee Reference Lee2009). The endogeneity of the choice set (e.g., the roll call agenda) may also influence the mapping between legislators’ ideology and their revealed behavior in different domains (Lee Reference Lee2008). It is worth noting, however, that Hirsch (Reference Hirsch2011) shows that some important aspects of the legislative process do not bias ideal point estimates based on roll call data.
We examine how much each measure increases the predictive classification of candidates’ roll call votes compared to their party identification alone. We focus on each measure’s within-party explanatory power for two reasons. First, a good measure of candidates’ political orientation should also be able to outperform measures that are much simpler and more parsimonious. In recent years, over 90% of the variation in roll call behavior can be predicted by the party identification of the legislator. Polarization in Congress has been on the rise since the 1970s (Poole and Rosenthal Reference Poole and Rosenthal2011). As the parties have become more extreme and more homogeneous, across-party prediction of roll call behavior has become easier and within-party prediction more difficult. Thus, many measures are able to report very high correlations with DW-Nominate and other scaled measures of roll call behavior because they have very high correlations with party ID. The empirical problem with such a measure is not just that it might as well be replaced with party identification. Understanding within-party variation in political orientation is vitally important for understanding polarization, accountability, and spatial voting. Polarization is a process by which extreme legislators are replacing moderates within each party. In order to identify instances of this process, we need measures of preferences that can accurately identify which candidates in nomination contests are more extreme than others within their party. Likewise, spatial voting involves judgments about which candidates are closer in some sense to particular voters, which requires accurate measures of the spatial location of candidates within their party.
For our primary empirical analysis, we run univariate logistic regressions for every vote cast in the House of Representatives from 2001 to 2012. We focus on this period because many empirical studies focus on recent Congresses, and these Congresses may be particularly hard to predict because they are so polarized. Moreover, many of the measures that we evaluate are only available for recent Congresses. For instance, Twitter scores are only available for the 112th Congress (Barberá Reference Barberá2015, 82).
For each measure, we calculate predicted votes and compare them to the actual votes. Next, we calculate the Percent Correctly Predicted (PCP) which is simply the percent of all nonmissing votes that are correctly predicted. Then, we calculate how much each model improves over a naive model that only uses a dummy variable for the party identification of the legislator to predict their roll call votes. The “Improvement over Party” is the percent reduction in error where the error from the party model is in the denominator.
 $$\begin{eqnarray}\text{Improvement over Party}=\frac{\displaystyle \mathop{\sum }_{\text{votes}}\text{Party Model Errors}-\text{Errors From This Model}}{\displaystyle \mathop{\sum }_{\text{votes}}\text{Party Model Errors}}.\end{eqnarray}$$
$$\begin{eqnarray}\text{Improvement over Party}=\frac{\displaystyle \mathop{\sum }_{\text{votes}}\text{Party Model Errors}-\text{Errors From This Model}}{\displaystyle \mathop{\sum }_{\text{votes}}\text{Party Model Errors}}.\end{eqnarray}$$
We validate each measure against both candidates’ contemporaneous roll call behavior and, for nonincumbents, their future roll call behavior after they win election to Congress. Accurate measures of nonincumbents’ positions are crucial for studies of spatial voting and representation. Indeed, we already have good estimates of incumbent legislators’ behavior based on their roll call positions. Thus, the most common use of the estimates from the recent wave of models is to provide estimates of nonincumbents’ spatial positions. Few of the existing papers validate their measures of nonincumbents’ positions against their future roll call positions.Footnote 18
There are a variety of reasons to think that pre-election measures of candidates’ political orientation may not be accurate predictors of their future roll call records. Although candidates make commitments and promises during their campaigns, these commitments are rarely enforceable (Alesina Reference Alesina1988). Incumbent legislators are widely believed to be in a highly advantageous position to win reelection (Gelman and King Reference Gelman and King1990; Lee et al. Reference Lee, Moretti and Butler2004), so punishing legislators for unkept promises may be difficult, and may even risk electing a legislator from the opposite party. The quirks of political geography are also important in shaping candidate’s support bases. Social media commentators, donors, and the public are limited in the choice of viable candidates to support in any particular district. Information gleaned from these relationships may be a feature of the limited choice set rather than true similarity. As a result, we should not assume that measures based on these sources will ultimately reflect actual legislative behavior.
4.1 Roll call votes in U.S. House
In order to visualize the relationship between each measure and candidates’ contemporaneous roll call behavior, we first examine the correlation between each measure and legislators’ DW-Nominate scores. Figure 1 shows the relationship between each measure and DW-Nominate scores. Each panel contains a scatterplot of individual measurements as well as a LOESS line to allow a more flexible comparison between the measure and DW-Nominate.

Figure 1. The relationship between DW-Nominate and various measures of candidate positions in the House between 2001 and 2012.
The top panel of Figure 1 shows that none of the measures explain more than 60% of the variation in DW-Nominate scores within the Democratic party, and most of the measures perform much worse than that. The bottom panel of Figure 1 indicates that none of the measures explain more than about a third of the variation in Republicans’ DW-Nominate scores. These figures do not inspire much confidence in the ability of the measures we examine to explain roll call behavior. Of course, our ultimate object is to predict roll call votes, rather than a scaled measure of roll call votes such as DW-Nominate. So, next, we conduct a more detailed evaluation of each model’s ability to provide accurate estimates of the roll call votes of incumbents in the U.S. House between 2001 and 2012 (Table 4). This table also shows the number of legislator sessions analyzed, which varies due to the availability of the measures in question. For comparison, we examine how much each measure improves on party ID as a predictor of roll call votes.Footnote 19
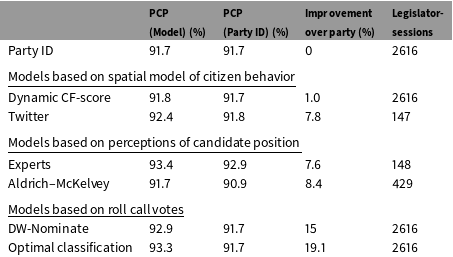
Unsurprisingly, the results of Table 4 mirror the earlier graphs using DW-Nominate scores. Despite the very high importance of party in recent years, DW-Nominate scores substantially improve the classification of votes. This is why we use DW-Nominate scores as a general measure of legislator behavior. It should be noted, however, that DW-Nominate is based on a parametric model. We also include Poole’s Optimal Classification (OC), which maximizes that number of votes correctly classified. OC provides an upper bound for how well a single dimension can classify roll call votes (Poole Reference Poole2000). In each case, DW-Nominate performs close to as well as OC.
In contrast, the remaining measures vary significantly in their explanatory power, which is often close to 0, and sometimes even negative. No measure besides DW-Nominate and OC substantially reduces error above and beyond party. Twitter scores and survey-based Aldrich–McKelvey scores explain 7.8% and 8.4% of the variation left unexplained by party in the one Congress where they are available. This is still only 56% of the reduction in error achieved by DW-Nominate, and less half of the reduction in error achieved through OC (Poole Reference Poole2000). Moreover, these are contemporaneous comparisons. We will show that they likely overestimate the predictive power of these measures for nonincumbents’ future roll call voting behavior.
Table 4. Accuracy of various models at predicting contemporaneous roll call votes in the U.S. House (107–113 Congresses).
Next, we repeat the statistics from Figure 1 and Table 4, but this time each measure is taken from a candidate for the House of Representatives who has not previously held office. Their roll call votes are from the next Congress after they win election. This give us leverage on an important counterfactual: how well do these measures capture how nonincumbent candidates would vote in Congress if they were sitting legislators?
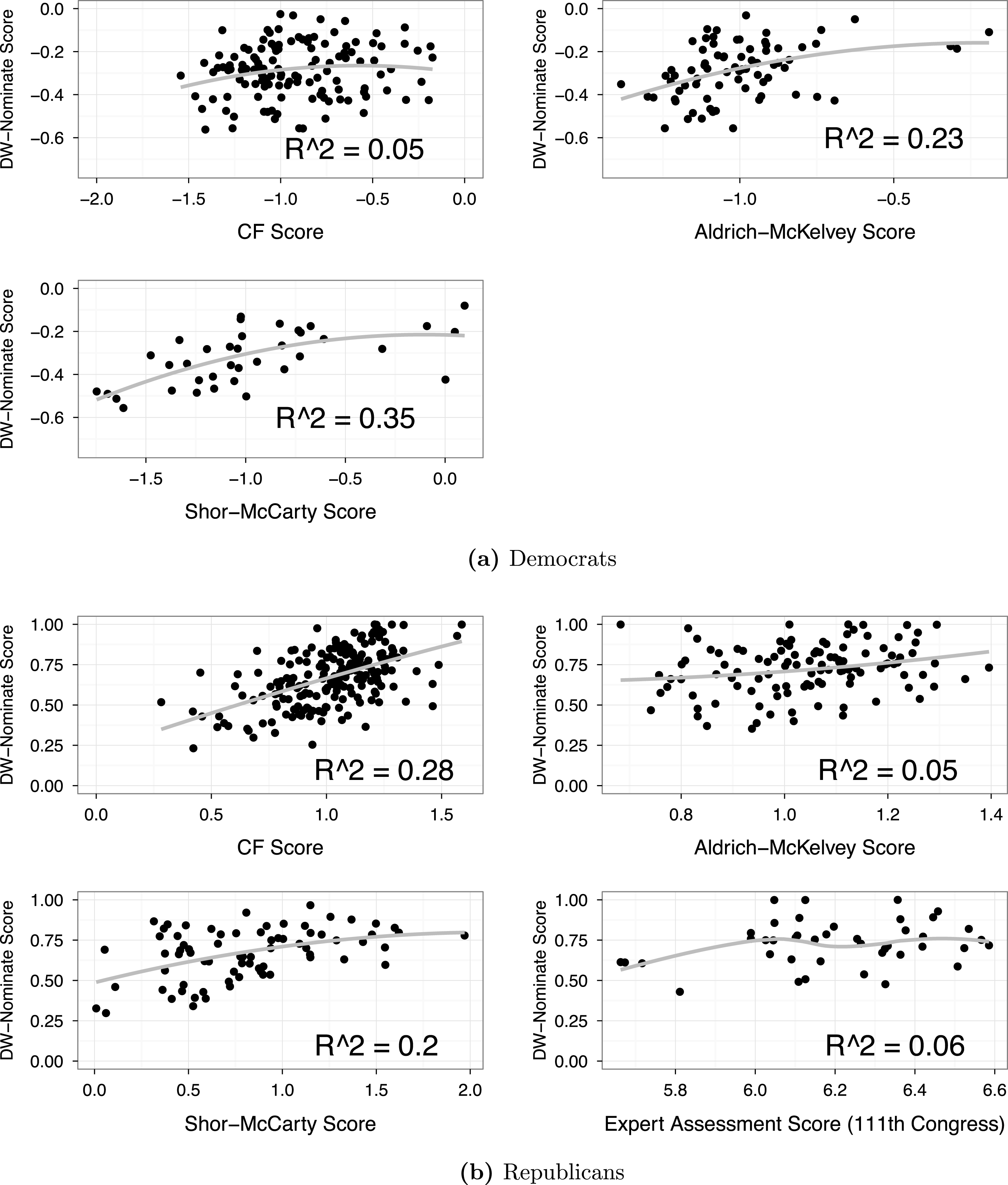
Figure 2. The relationship between DW-Nominate and various measures of candidate positions in the House in the election before their first term in the House between 2001 and 2012.
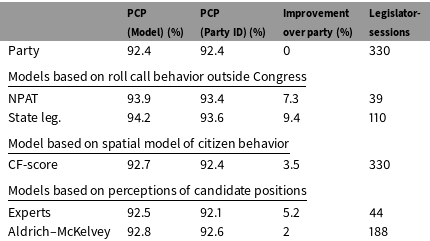
Figure 2 shows that none of the measures that were taken before legislators served in Congress predict more than about a third of the variation in DW-Nominate scores within their party after they took office, and most of the measures perform much worse than that. Table 5 shows the predictive results for individual roll call votes.
For the observations we do have, the results are much weaker than they were for the contemporaneous comparisons. The exception is Shor and McCarty’s estimates of the ideal points of state legislators. It makes sense that these scores are reasonably good predictors of subsequent roll call behavior in Congress since they are themselves based on roll call behavior. However, they are only available for the very small number of legislators that served in a state legislature prior to sitting in Congress.
Table 5. Accuracy of various models at predicting prospective roll call votes in the U.S. House (107–113 Congresses).
Overall, the average accuracy of the six models we examine at explaining within-party variation in roll call votes in Congress is very low. In fact, no model performs much better than a model that assumes one ideal point per party. At the very least, this degree of measurement error should give applied researchers pause. Moreover, this measurement error could be even more problematic if these measures are biased, rather than just noisy. We will revisit the potential for bias in the applications below.
4.2 Roll call votes in U.S. Senate
Of course, it is possible that these measures perform poorly for the House of Representatives because it is inherently difficult to predict the voting records of House members. House members tend to have lower visibility to donors, members of the public, and experts. Some House candidates are political novices, and may not have formed their own views on a variety of issues. The experience of operating in a chamber where majority party control is strong may alter candidate positions once they begin serving.
In contrast, the United States Senate is a much more visible body, and candidates for the Senate tend to have longer experience in the public eye. Once elected, Senators participate in a legislative body that is noted for its individualism rather than overbearing party control. For these reasons we might expect non-roll-call based measures to have better accuracy in the Senate than in the House of Representatives.
The disadvantage of the Senate is a greatly reduced sample size. There are fewer total Senators (100 instead of 435), fewer Senatorial elections (each Senator is up for election every six years instead of two), and lower turnover. We lack enough data from two of the models (NPAT and Experts) to test these models at all. For the other measures, we have lower sample sizes for the contemporaneous comparison. For the predictive comparison involving candidates who win, we will not be able to test the Twitter-based measure either.
Table 6. Accuracy of various models at predicting contemporaneous roll call votes in the U.S. Senate (107–113 Congresses).

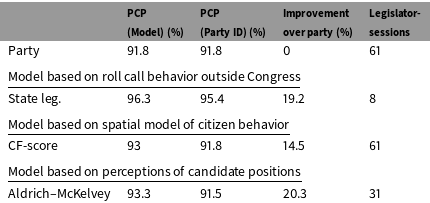
Table 6 shows the contemporaneous comparison for the Senate. In most cases, the fit is substantially higher for these measures than in the case of the House of Representatives. Aldrich–McKelvey scores perform particularly well. However, the overall predictive power of these measures is still limited.
Table 7 repeats the analysis above using the candidate scores for candidates who have not yet held Senate seats and their later roll call behavior as Senators. Unfortunately, due to the small amount of turnover in the Senate during this period, we have very small sample sizes to work with. We begin with only sixty-one new senators. All of these have CF-scores. CF-scores have better predictive value here than in previous cases. Aldrich–McKelvey and Shor–McCarty scores show more promise, but with only thirty-one and eight observations, respectively, we cannot draw any firm conclusions. Legislators who appear in these data are not necessarily representative of the broader set of Senators.
Table 7. Accuracy of various models at predicting prospective roll call votes in the U.S. Senate.
4.3 Polarization
There is a vast literature that examines changes in polarization over time among legislators and candidates. In their authoritative study, McCarty et al. (Reference McCarty, Poole and Rosenthal2006) show that legislators’ roll call records have polarized asymmetrically, with virtually all of the polarization occurring among Republicans. In line with this finding, the upper panel of Figure 3 shows that between 1980 and 2012 the two parties’ DW-Nominate scores drifted steadily apart, with nearly all of the polarization in DW-Nominate scores occurring among Republicans. The middle panel shows polarization in incumbents’ CF-scores over this time period. A number of recent empirical studies have used CF-scores to examine the causal factors that drive polarization in state legislatures and Congress (e.g., Rogowski and Langella Reference Rogowski and Langella2014; Thomsen Reference Thomsen2014; Ahler et al. Reference Ahler, Citrin and Lenz2016). This panel indicates that unlike their roll call records, the two parties’ campaign donor scores did not start moving apart until the mid-1990s. Moreover, the bulk of the polarization appears to have occurred among Democrats. Finally, the bottom panel shows polarization in NPAT-scores. It indicates that virtually all of the polarization in NPAT-scores occurs among Democrats. Moreover, the two parties’ NPAT-scores only modestly moved apart during the time period when these data are available.

Figure 3. The evolution of DW-Nominate and various measures of candidate positions for Democrats and Republicans in the House between 1980 and 2012 (NPAT-scores are only available from 1996 to 2006). Gray dots show the mean spatial position of Democrats and black dots show the mean spatial position of Republicans.
Overall, these plots indicate that DW-Nominate scores, NPAT-scores, and CF-scores each show a different story regarding the relative changes in polarization in recent Congresses. Most problematically, the results show that NPAT- and CF-scores are not just noisy measures of candidates’ roll call positions. They are actually biased. For instance, in contrast to DW-Nominate, Democrats’ NPAT responses and CF-scores are growing more extreme much more rapidly.
This suggests that scholars should use caution in using non-roll-call based measures of candidate political orientation to make inferences about hypotheses that implicate actual legislative behavior.
4.4 The effect of political orientation on elections
An important question in the study of representation and accountability is how various metrics of political orientation are associated with election results. There is a large literature that argues that legislators that take extreme roll call positions are penalized at the ballot box (e.g., Canes-Wrone et al. Reference Canes-Wrone, Brady and Cogan2002). However, there is less work concerning how other metrics of political orientation are related to election results (cf., Hall Reference Hall2015).
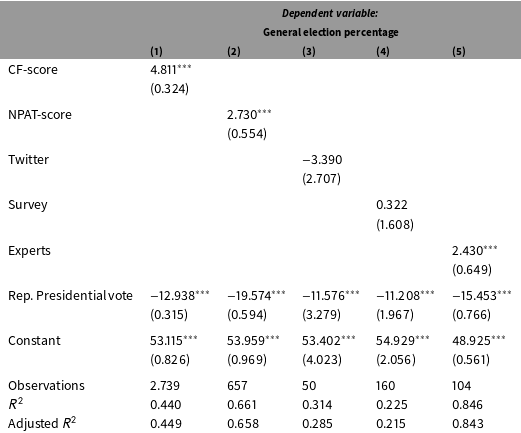
Table 8. Relationship between political orientation and election results for Democratic candidates.
Note:
 $^{\ast }p<0.1$
;
$^{\ast }p<0.1$
;
 $^{\ast \ast }p<0.05$
;
$^{\ast \ast }p<0.05$
;
 $^{\ast \ast \ast }p<0.01$
.
$^{\ast \ast \ast }p<0.01$
.
In this section, we examine whether the conclusions of this literature vary depending on which measure of political orientation is used. Following the literature, we examine how measures of political orientation in different domains are correlated with election results after controlling for constituency preferences. We standardize all the independent variables to make the results easily comparable across models. All independent variables are oriented such that higher values are more conservative. Table 8 shows the results for Democrats and Table 9 shows the results for Republicans.
Table 9. Relationship between political orientation and election results for Republican candidates.

Note:
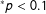 $^{\ast }p<0.1$
;
$^{\ast }p<0.1$
;
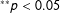 $^{\ast \ast }p<0.05$
;
$^{\ast \ast }p<0.05$
;
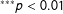 $^{\ast \ast \ast }p<0.01$
.
$^{\ast \ast \ast }p<0.01$
.
In general, candidates with more extreme political orientations across the various domains suffer at the ballot box, and more moderate political orientations are rewarded, following the conclusions of the literature. For instance, a one-standard deviation to the right in Democrats’ CF-scores corresponds to a 4.8% increase in their general election vote share. For Republicans, a one-standard deviation to the left in their CF-scores (i.e., their donor network) corresponds to a 3.4% increase in their general election vote share.
However, the effect magnitude varies substantially across measures. CF-scores always have the largest effect despite the fact that they are consistently among the weakest predictors of roll call voting. The effects of scores based on Twitter, surveys, and expert ratings are inconsistent in terms of sign and significance, although smaller sample sizes are one source of this uncertainty. Once again there is not enough evidence to justify the use of these scores in a study of accountability without abundant caution in interpretation. Most of these measures appear to be related to election outcomes, suggesting that they may be measuring something of political importance. The question for future research is how these phenomena affect politics given that they are only weakly related to legislative behavior or a common ideological space.
5 Conclusion
Despite the development of a variety of innovative strategies for measuring the political positions of candidates for Congress, existing measures do not measure the same underlying dimension, and have only limited predictive power in terms of the voting records that candidates establish once elected. Even contemporaneous measures, which use data on legislators as they are currently serving in Congress, typically fail to explain even half the variation in legislator’ roll call voting, and usually closer to a third. The performance of these measures varies across parties, with no measure clearly dominant. As a result, the usage of these measures of candidate positions could lead to serious inferential errors for substantive, applied research. For instance, we have shown that different measures of candidate positions lead to dramatically different inferences for studies of polarization and representation. These findings have important implications for academic research, as well as for our understanding of democracy. Prospective voting requires voters, not just political scientists, to know what candidates will do if elected, and these results suggest that this predictive exercise is very difficult.
Overall, our findings call into question the usefulness of these measures for examining questions that depend on the relative spatial distance between candidates, such as tests of spatial voting theories or the causes of Congressional polarization.Footnote 20 There are a variety of explanations that may account for the fact that constituents’ implicit (e.g., campaign donations or twitter following) and explicit (e.g., survey responses) perceptions of candidates’ political orientation are both only weakly associated with candidates’ roll call behavior inside of Congress. Although candidates make commitments and promises during their campaigns, these commitments are rarely enforceable (Alesina Reference Alesina1988). Moreover, candidates have a variety of reasons to distort their positions during the campaign. This may weaken the relationship between candidates’ campaign platforms and their roll call positions (Rogowski Reference Rogowski2014). The ability of constituents to predict roll call behavior may be further distorted by political geography. Indeed, social media commentators, donors, and the public are limited in the choice of viable candidates to support in any particular district. Information gleaned from these relationships may be a feature of the limited choice set rather than true similarity. Finally, there are a variety of factors that could influence candidates’ roll call votes (e.g., lobbying, agenda control, party leaders).
While these measures perform poorly at predicting legislators’ roll call positions, they may have other valuable uses. They could potentially be used to impute the partisanship of candidates and voters when other information on their partisanship is not readily available (Hill and Huber Reference Hill and Huber2017). If interpreted and validated properly, they may be useful for examining potential explanations for the mismatch between survey respondents’ perceptions and candidates’ actual roll call positions (e.g., Grimmer Reference Grimmer2013; Henderson Reference Henderson2013; Cormack Reference Cormack2016). These measures also have a number of potential applications for specific substantive questions outside the realm of legislative behavior. For instance, CF-scores could be used to examine the campaign donations of bureaucrats (Bonica et al. Reference Bonica, Jowei and Tim2015) and Barberá (Reference Barberá2015)’s measures of candidates’ Twitter followers could be used to examine the effect of candidates’ roll call positions on their followings on social networks. However, even in these applications the authors must answer some difficult questions for the results to be meaningful. What is it that these measures are capturing, why is this kind of measure necessary, and why is the underlying latent variable important to study?
It is important to note that our findings do not imply that it is impossible to find a better measure of candidates’ spatial positions. On the contrary, we hope that new data sources and statistical tools will facilitate more accurate estimates of the positions of candidates than extant measures (e.g., Bonica Reference Bonica2016). However, future researchers should measure success by a high standard given the importance of these measures for a variety of fundamental substantive questions.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2017.5.