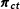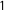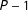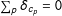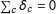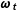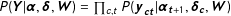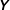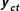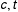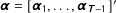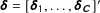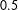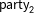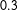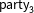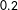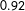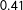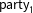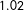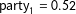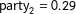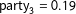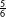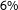The majority of countries worldwide feature an electoral system for their main legislative body that is proportional or mixed in nature.Footnote 1 Most of these systems—as well as a considerable number of plurality-based systems, such as India, Canada, or the United Kingdom—generate multiparty politics, i.e., more than two parties being regularly represented in parliament. With rising interest in data-based coverage of campaign dynamics, there is a demand for models that deliver forecasts in such multiparty systems. However, existing dynamic forecasting models that have been developed for the US (Silver Reference Silver2012; Erikson and Wlezien Reference Erikson and Wlezien2013; Linzer Reference Linzer2013)—a setting that is hallmarked by two-party races with long historical records—do not easily translate to multiparty systems.
In this letter, we present a general dynamic model to forecast party vote shares and other related quantities of interest in multiparty elections. To that end, we suggest to combine data from pre-election public opinion polls with information from fundamentals-based forecasting models. We extend the existing backward random-walk approach that has been proposed to forecast US presidential elections (Strauss Reference Strauss2007; Linzer Reference Linzer2013), to account for the compositional nature of party support in multiparty systems. In addition, we develop a Bayesian approach that combines information from fundamentals with polls in a fully integrated model. The model, moreover, allows predicting a number of quantities of interest important to multiparty elections, such as the probability with which coalitions of parties might secure a majority of seats and the likelihood that a party can overcome an electoral threshold. These methodological innovations contribute to an emerging literature on synthetic forecasting models (Lewis-Beck and Dassonneville Reference Lewis-Beck and Dassonneville2015; Lewis-Beck, Nadeau, and Bélanger Reference Lewis-Beck, Nadeau and Bélanger2016).
We present results of real-time step-ahead forecasts of two multiparty elections in September 2017: the German (in the main text) as well as the New Zealand election (in the Online Appendix C). In both instances, our dynamic ex ante forecast outperformed the fundamental forecast models.
1 A Dynamic Bayesian Measurement Model for Multiparty Elections
Our modeling strategy to forecast vote shares in multiparty elections comprises two components.Footnote
2
The first is a fundamentals-based model that provides a forecast for each (relevant) party’s vote share long before the election campaign starts. For this purpose, previous contributions employ party-level predictors based on regularities of elections to forecast the election outcome (see, e.g., Norpoth and Gschwend Reference Norpoth and Gschwend2010; Magalhães, Aguiar-Conraria, and Lewis-Beck Reference Magalhães, Aguiar-Conraria and Lewis-Beck2012; Jérôme, Jérôme-Speziari, and Lewis-Beck Reference Jérôme, Jérôme-Speziari and Lewis-Beck2013). Most of those regression-based fundamentals models can be defined by the election results of all parties in past elections
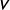 $\mathbf{V}$
, a matrix of predictors
$\mathbf{V}$
, a matrix of predictors
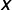 $\mathbf{X}$
, and a vector of parameters
$\mathbf{X}$
, and a vector of parameters
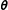 $\boldsymbol{\unicode[STIX]{x1D703}}$
, which link the predictors to the election results. Two distributions of those models are of central interest for Bayesian forecasting. First, the posterior density of the parameter estimates that infers from the relationship between predictors and election results. It is proportional to the likelihood derived from the statistical model and the priors for the parameters:
$\boldsymbol{\unicode[STIX]{x1D703}}$
, which link the predictors to the election results. Two distributions of those models are of central interest for Bayesian forecasting. First, the posterior density of the parameter estimates that infers from the relationship between predictors and election results. It is proportional to the likelihood derived from the statistical model and the priors for the parameters:
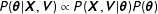 $P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{X},\mathbf{V})\propto P(\mathbf{X},\mathbf{V}|\boldsymbol{\unicode[STIX]{x1D703}})P(\boldsymbol{\unicode[STIX]{x1D703}})$
. Second, the posterior predictive distribution that provides a forecast for the upcoming election results
$P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{X},\mathbf{V})\propto P(\mathbf{X},\mathbf{V}|\boldsymbol{\unicode[STIX]{x1D703}})P(\boldsymbol{\unicode[STIX]{x1D703}})$
. Second, the posterior predictive distribution that provides a forecast for the upcoming election results
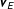 $\mathbf{v}_{E}$
given the predictors
$\mathbf{v}_{E}$
given the predictors
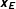 $\mathbf{x}_{\mathbf{E}}$
. This distribution takes “coefficient uncertainty” (Lauderdale and Linzer Reference Lauderdale and Linzer2015, p.967) into account by integrating over the posterior distribution of the parameters from the predictive distribution for the upcoming election:
$\mathbf{x}_{\mathbf{E}}$
. This distribution takes “coefficient uncertainty” (Lauderdale and Linzer Reference Lauderdale and Linzer2015, p.967) into account by integrating over the posterior distribution of the parameters from the predictive distribution for the upcoming election:
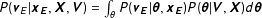 $P(\mathbf{v}_{E}|\mathbf{x}_{\mathbf{E}},\mathbf{X},\mathbf{V})=\int _{\unicode[STIX]{x1D703}}P(\mathbf{v}_{\mathbf{E}}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{x}_{\mathbf{E}})P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{V},\mathbf{X})d\boldsymbol{\unicode[STIX]{x1D703}}$
. Unlike common implementations of fundamentals models, we integrate our fundamentals model into a dynamic Bayesian measurement model, which we describe below. For brevity, we discuss our application-specific Dirichlet regression model in detail in Online Appendix A.1.
$P(\mathbf{v}_{E}|\mathbf{x}_{\mathbf{E}},\mathbf{X},\mathbf{V})=\int _{\unicode[STIX]{x1D703}}P(\mathbf{v}_{\mathbf{E}}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{x}_{\mathbf{E}})P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{V},\mathbf{X})d\boldsymbol{\unicode[STIX]{x1D703}}$
. Unlike common implementations of fundamentals models, we integrate our fundamentals model into a dynamic Bayesian measurement model, which we describe below. For brevity, we discuss our application-specific Dirichlet regression model in detail in Online Appendix A.1.
In the following, we focus on the second component, which provides the core contribution of our approach: A dynamic Bayesian measurement model that estimates the current level of party support based on pre-election polls published during the election campaign, and that combines it with the forecasts from the fundamentals-based model. To that end, we draw on poll results published by different polling companies.
Let
 $y_{ctp}$
be the reported vote share of party
$y_{ctp}$
be the reported vote share of party
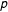 $p$
(
$p$
(
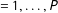 $=1,\ldots ,P$
) at time
$=1,\ldots ,P$
) at time
 $t$
(
$t$
(
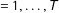 $=1,\ldots ,T$
) as published by polling company
$=1,\ldots ,T$
) as published by polling company
 $c$
(
$c$
(
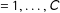 $=1,\ldots ,C$
). Let
$=1,\ldots ,C$
). Let
 $t$
represent the days of the campaign, whereby
$t$
represent the days of the campaign, whereby
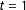 $t=1$
corresponds to the first day and
$t=1$
corresponds to the first day and
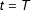 $t=T$
to Election Day. Each poll has a sample size of
$t=T$
to Election Day. Each poll has a sample size of
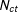 $N_{ct}$
. We conceptualize each published poll result
$N_{ct}$
. We conceptualize each published poll result
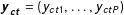 $\mathbf{y}_{\mathbf{c}\mathbf{t}}=(y_{ct1},\ldots ,y_{ctP})$
as a
$\mathbf{y}_{\mathbf{c}\mathbf{t}}=(y_{ct1},\ldots ,y_{ctP})$
as a
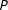 $P$
-dimensional random variable that is generated by a multinomial process, where
$P$
-dimensional random variable that is generated by a multinomial process, where
 $\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast }=(\unicode[STIX]{x1D70B}_{ct1}^{\ast },\ldots ,\unicode[STIX]{x1D70B}_{ctP}^{\ast })$
is a vector of expected support at day
$\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast }=(\unicode[STIX]{x1D70B}_{ct1}^{\ast },\ldots ,\unicode[STIX]{x1D70B}_{ctP}^{\ast })$
is a vector of expected support at day
 $t$
in company
$t$
in company
 $c$
’s poll:
$c$
’s poll:
 $$\begin{eqnarray}\mathbf{y}_{\mathbf{c}\mathbf{t}}\sim \text{Multinomial}(\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast },N_{ct}).\end{eqnarray}$$
$$\begin{eqnarray}\mathbf{y}_{\mathbf{c}\mathbf{t}}\sim \text{Multinomial}(\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast },N_{ct}).\end{eqnarray}$$
The vote shares of each poll sum to 100 percent. To account for this, and to map the proportions into a vector of unbounded, real-valued quantities, we employ a log-ratio transformation (Aitchison Reference Aitchison1986). Each entry of the expected support share vectors
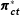 $\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast }$
at time
$\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast }$
at time
 $t$
for company
$t$
for company
 $c$
is divided by the expected party support for the last party
$c$
is divided by the expected party support for the last party
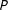 $P$
,
$P$
,
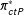 $\unicode[STIX]{x1D70B}_{ctP}^{\ast }$
, before taking the log:Footnote
3
$\unicode[STIX]{x1D70B}_{ctP}^{\ast }$
, before taking the log:Footnote
3
 $$\begin{eqnarray}\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}=\text{alr}(\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast })=\left(\log \left(\frac{\unicode[STIX]{x1D70B}_{ct1}^{\ast }}{\unicode[STIX]{x1D70B}_{ctP}^{\ast }}\right),\ldots ,\log \left(\frac{\unicode[STIX]{x1D70B}_{ct(P-1)}^{\ast }}{\unicode[STIX]{x1D70B}_{ctP}^{\ast }}\right)\right)=\left(\unicode[STIX]{x1D70B}_{ct1},\ldots ,\unicode[STIX]{x1D70B}_{ct(P-1)}\right).\end{eqnarray}$$
$$\begin{eqnarray}\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}=\text{alr}(\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}^{\ast })=\left(\log \left(\frac{\unicode[STIX]{x1D70B}_{ct1}^{\ast }}{\unicode[STIX]{x1D70B}_{ctP}^{\ast }}\right),\ldots ,\log \left(\frac{\unicode[STIX]{x1D70B}_{ct(P-1)}^{\ast }}{\unicode[STIX]{x1D70B}_{ctP}^{\ast }}\right)\right)=\left(\unicode[STIX]{x1D70B}_{ct1},\ldots ,\unicode[STIX]{x1D70B}_{ct(P-1)}\right).\end{eqnarray}$$
In a next step, using classical reliability theory, we decompose the transformed vector of expected support shares for each party into a latent party support vector
 $\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}=(\unicode[STIX]{x1D6FC}_{t_{1}},\ldots ,\unicode[STIX]{x1D6FC}_{t_{P}})$
, the so-called “true” support of each party among voters, as well as a vector of house effects
$\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}=(\unicode[STIX]{x1D6FC}_{t_{1}},\ldots ,\unicode[STIX]{x1D6FC}_{t_{P}})$
, the so-called “true” support of each party among voters, as well as a vector of house effects
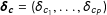 $\boldsymbol{\unicode[STIX]{x1D6FF}}_{\mathbf{c}}=(\unicode[STIX]{x1D6FF}_{c_{1}},\ldots ,\unicode[STIX]{x1D6FF}_{c_{P}})$
that might systematically bias the published vote shares of each company (Jackman Reference Jackman2005), such that
$\boldsymbol{\unicode[STIX]{x1D6FF}}_{\mathbf{c}}=(\unicode[STIX]{x1D6FF}_{c_{1}},\ldots ,\unicode[STIX]{x1D6FF}_{c_{P}})$
that might systematically bias the published vote shares of each company (Jackman Reference Jackman2005), such that
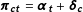 $\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}=\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}+\boldsymbol{\unicode[STIX]{x1D6FF}}_{\mathbf{c}}$
.Footnote
4
$\boldsymbol{\unicode[STIX]{x1D70B}}_{\mathbf{c}\mathbf{t}}=\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}+\boldsymbol{\unicode[STIX]{x1D6FF}}_{\mathbf{c}}$
.Footnote
4
In the context of dynamic forecasting of vote shares, i.e., updating existing forecasts with incoming information, a core quantity of interest is the evolution of party support over time. We model the level of support
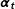 $\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}$
as a backward random walk,Footnote
5
starting at Election Day and moving backwards in time to the start of the campaign, i.e.,
$\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}$
as a backward random walk,Footnote
5
starting at Election Day and moving backwards in time to the start of the campaign, i.e.,
 $$\begin{eqnarray}\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}=\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}+1}+\boldsymbol{\unicode[STIX]{x1D714}}_{\mathbf{t}},\boldsymbol{\unicode[STIX]{x1D714}}_{\mathbf{t}}\sim N(\mathbf{0},\mathbf{W}).\end{eqnarray}$$
$$\begin{eqnarray}\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}=\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}+1}+\boldsymbol{\unicode[STIX]{x1D714}}_{\mathbf{t}},\boldsymbol{\unicode[STIX]{x1D714}}_{\mathbf{t}}\sim N(\mathbf{0},\mathbf{W}).\end{eqnarray}$$
This allows us to estimate party support levels for each day even if no new poll is released. Furthermore, this process assumes that the (log-ratio of the) party support level today depends on the respective level of the following day and a random error term. The variance of this random error, the so-called evolution variance
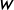 $\mathbf{W}$
(West and Harrison Reference West and Harrison1997), describes the rate of change between any two consecutive days. We constrain
$\mathbf{W}$
(West and Harrison Reference West and Harrison1997), describes the rate of change between any two consecutive days. We constrain
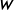 $\mathbf{W}$
to be constant over time, but explicitly allow the latent states to covary:
$\mathbf{W}$
to be constant over time, but explicitly allow the latent states to covary:
 $$\begin{eqnarray}\mathbf{W}=\left[\begin{array}{@{}ccc@{}}w_{1}^{2} & \cdots \, & w_{1,(P-1)}\\ \vdots & \ddots & \vdots \\ w_{1,(P-1)} & \cdots \, & w_{(P-1)}^{2}\end{array}\right].\end{eqnarray}$$
$$\begin{eqnarray}\mathbf{W}=\left[\begin{array}{@{}ccc@{}}w_{1}^{2} & \cdots \, & w_{1,(P-1)}\\ \vdots & \ddots & \vdots \\ w_{1,(P-1)} & \cdots \, & w_{(P-1)}^{2}\end{array}\right].\end{eqnarray}$$
The key advantage of deploying the random walk backwards (Strauss Reference Strauss2007; Linzer Reference Linzer2013) rather than forwards (see, e.g., Walther Reference Walther2015) is that it allows integrating party-level forecasts from fundamentals-based models in the dynamic polls model.Footnote 6 The backward random-walk process in the joint posterior distribution isolates the prior on Election Day. This, in turn, allows us to integrate the forecast from the fundamentals model into the dynamic polls model by setting the latent state of party support on Election Day equal to the log-ratio-transformed posterior predictive distribution from the fundamentals model:
 $$\begin{eqnarray}P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{T}}|\mathbf{x}_{\mathbf{E}})=\text{alr}\left(\int _{\unicode[STIX]{x1D703}}P(\mathbf{v}_{\mathbf{E}}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{x}_{\mathbf{E}})P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{V},\mathbf{X})d\boldsymbol{\unicode[STIX]{x1D703}}\right).\end{eqnarray}$$
$$\begin{eqnarray}P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{T}}|\mathbf{x}_{\mathbf{E}})=\text{alr}\left(\int _{\unicode[STIX]{x1D703}}P(\mathbf{v}_{\mathbf{E}}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{x}_{\mathbf{E}})P(\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{V},\mathbf{X})d\boldsymbol{\unicode[STIX]{x1D703}}\right).\end{eqnarray}$$
With this integration, we can write a joint posterior distribution of both the fundamentals model and the dynamic polls model, which is proportional to the product of the two likelihoods,Footnote 7 the posterior predictive distribution, the backward random walk and priors for the parameters from two model components. Integrating and estimating all parts of the model in a joint specification has a set of advantages. Most importantly, it automatically considers the complete uncertainty from the fundamentals model, which is relevant when aiming at accurately weighting the polls and the fundamentals for a synthetic forecast.
 $$\begin{eqnarray}\displaystyle P(\boldsymbol{\unicode[STIX]{x1D6FC}},\boldsymbol{\unicode[STIX]{x1D6FF}},\mathbf{W},\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{Y},\mathbf{V},\mathbf{X}) & \propto & \displaystyle \underbrace{P(\mathbf{Y}|\boldsymbol{\unicode[STIX]{x1D6FC}},\boldsymbol{\unicode[STIX]{x1D6FF}},\mathbf{W})}_{\begin{array}{@{}c@{}}\text{dynamic}~\text{polls}\\ \text{likelihood}\end{array}}\underbrace{P(\mathbf{V}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{X})}_{\begin{array}{@{}c@{}}\text{fundamentals}\\ \text{likelihood}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{T}}|\mathbf{x}_{\mathbf{E}})}_{\begin{array}{@{}c@{}}\text{posterior}~\text{predictive}\\ \text{distribution}\end{array}}\nonumber\\ \displaystyle & & \displaystyle \mathop{\prod }_{t=1}^{T-1}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}|\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}+1},\mathbf{W})}_{\begin{array}{@{}c@{}}\text{backward}~\text{random}\\ \text{walk}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D703}})}_{\begin{array}{@{}c@{}}\text{fundamentals}\\ \text{prior}\end{array}}\underbrace{P(\mathbf{W})}_{\begin{array}{@{}c@{}}\text{evolution}\\ \text{variance}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FF}})}_{\begin{array}{@{}c@{}}\text{house}\\ \text{effects}\end{array}}\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle P(\boldsymbol{\unicode[STIX]{x1D6FC}},\boldsymbol{\unicode[STIX]{x1D6FF}},\mathbf{W},\boldsymbol{\unicode[STIX]{x1D703}}|\mathbf{Y},\mathbf{V},\mathbf{X}) & \propto & \displaystyle \underbrace{P(\mathbf{Y}|\boldsymbol{\unicode[STIX]{x1D6FC}},\boldsymbol{\unicode[STIX]{x1D6FF}},\mathbf{W})}_{\begin{array}{@{}c@{}}\text{dynamic}~\text{polls}\\ \text{likelihood}\end{array}}\underbrace{P(\mathbf{V}|\boldsymbol{\unicode[STIX]{x1D703}},\mathbf{X})}_{\begin{array}{@{}c@{}}\text{fundamentals}\\ \text{likelihood}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{T}}|\mathbf{x}_{\mathbf{E}})}_{\begin{array}{@{}c@{}}\text{posterior}~\text{predictive}\\ \text{distribution}\end{array}}\nonumber\\ \displaystyle & & \displaystyle \mathop{\prod }_{t=1}^{T-1}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}}|\boldsymbol{\unicode[STIX]{x1D6FC}}_{\mathbf{t}+1},\mathbf{W})}_{\begin{array}{@{}c@{}}\text{backward}~\text{random}\\ \text{walk}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D703}})}_{\begin{array}{@{}c@{}}\text{fundamentals}\\ \text{prior}\end{array}}\underbrace{P(\mathbf{W})}_{\begin{array}{@{}c@{}}\text{evolution}\\ \text{variance}\end{array}}\underbrace{P(\boldsymbol{\unicode[STIX]{x1D6FF}})}_{\begin{array}{@{}c@{}}\text{house}\\ \text{effects}\end{array}}\end{eqnarray}$$
The complete specification of the dynamic Bayesian forecasting model further requires priors for the evolution variance and the house effects. For this purpose, we decompose the covariance matrix into a
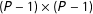 $(P-1)\times (P-1)$
correlation matrix
$(P-1)\times (P-1)$
correlation matrix
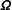 $\boldsymbol{\unicode[STIX]{x1D6FA}}$
and a diagonal matrix with standard deviations on the main diagonal:
$\boldsymbol{\unicode[STIX]{x1D6FA}}$
and a diagonal matrix with standard deviations on the main diagonal:
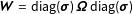 $\mathbf{W}=\text{diag}(\boldsymbol{\unicode[STIX]{x1D70E}})\,\boldsymbol{\unicode[STIX]{x1D6FA}}\,\text{diag}(\boldsymbol{\unicode[STIX]{x1D70E}})$
(Lewandowski, Kurowicka, and Joe Reference Lewandowski, Kurowicka and Joe2009). The prior on the correlation matrix is a weakly informative LKJ prior with
$\mathbf{W}=\text{diag}(\boldsymbol{\unicode[STIX]{x1D70E}})\,\boldsymbol{\unicode[STIX]{x1D6FA}}\,\text{diag}(\boldsymbol{\unicode[STIX]{x1D70E}})$
(Lewandowski, Kurowicka, and Joe Reference Lewandowski, Kurowicka and Joe2009). The prior on the correlation matrix is a weakly informative LKJ prior with
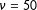 $\unicode[STIX]{x1D708}=50$
, reflecting our prior belief that moderate correlations between the parties are possibleFootnote
8
. The priors on the standard deviations
$\unicode[STIX]{x1D708}=50$
, reflecting our prior belief that moderate correlations between the parties are possibleFootnote
8
. The priors on the standard deviations
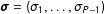 $\boldsymbol{\unicode[STIX]{x1D70E}}=(\unicode[STIX]{x1D70E}_{1},\ldots ,\unicode[STIX]{x1D70E}_{P-1})$
are independent weakly informative half-normal priors with
$\boldsymbol{\unicode[STIX]{x1D70E}}=(\unicode[STIX]{x1D70E}_{1},\ldots ,\unicode[STIX]{x1D70E}_{P-1})$
are independent weakly informative half-normal priors with
 $\unicode[STIX]{x1D70E}_{j}\sim {\mathcal{N}}_{+}(0,0.1)$
. This reflects our prior belief of a modest random walk for the log-ratio-transformed vote shares/polls.Footnote
9
$\unicode[STIX]{x1D70E}_{j}\sim {\mathcal{N}}_{+}(0,0.1)$
. This reflects our prior belief of a modest random walk for the log-ratio-transformed vote shares/polls.Footnote
9
The priors for the house effects are defined such that, on average, we expect no house effects (i.e.,
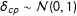 $\unicode[STIX]{x1D6FF}_{cp}\sim {\mathcal{N}}(0,1)$
). The priors we chose in our application for the fundamentals Dirichlet regression model,
$\unicode[STIX]{x1D6FF}_{cp}\sim {\mathcal{N}}(0,1)$
). The priors we chose in our application for the fundamentals Dirichlet regression model,
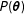 $P(\boldsymbol{\unicode[STIX]{x1D703}})$
, are discussed in Online Appendix A.1. We estimate the model by sampling from the posterior distribution via Markov Chain Monte Carlo algorithms, employing the No-U-Turn sampler (Hoffman and Gelman Reference Hoffman and Gelman2014), the default HMC variant in Stan. The code is written in
Stan and implemented in rstan 2.17.3 (Stan Development Team 2018).Footnote
10
$P(\boldsymbol{\unicode[STIX]{x1D703}})$
, are discussed in Online Appendix A.1. We estimate the model by sampling from the posterior distribution via Markov Chain Monte Carlo algorithms, employing the No-U-Turn sampler (Hoffman and Gelman Reference Hoffman and Gelman2014), the default HMC variant in Stan. The code is written in
Stan and implemented in rstan 2.17.3 (Stan Development Team 2018).Footnote
10

Figure 1. Forecast of the 2017 election 2 days prior to the election. Point estimates along with
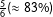 $\frac{5}{6}({\approx}83\%)$
(dark gray) credible intervals and
$\frac{5}{6}({\approx}83\%)$
(dark gray) credible intervals and
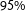 $95\%$
(light gray) credible intervals, the light gray histogram bars represent the election results.
$95\%$
(light gray) credible intervals, the light gray histogram bars represent the election results.
2 Application to the German Federal Election 2017
To demonstrate the virtues of our dynamic Bayesian measurement model, we set it out to an out-of-sample test and applied it to the 2017 German general election.Footnote
11
We use polling data from the major German polling companies.Footnote
12
Figure 1 provides our final forecasts published as of 2 days before the election, along with the respective
 $\frac{5}{6}({\approx}83\%)$
credible intervals.Footnote
13
Accordingly, we predicted that the CDU/CSU would reach 36.2% [30.7%; 41.5%], the SPD 22.1% [19.8%; 24.2%], the Left Party 9.2% [7.2%; 11.4%], the Greens 7.8% [5.9%; 9.6%], the FDP 9.2% [7.2%; 11.4%], the AfD 9.8% [7.4%; 12.5%], and Others 5.7% [3.8%; 7.8%]. As Figure 1 shows, those final forecasts are reasonably close to the final results: Six out of seven
$\frac{5}{6}({\approx}83\%)$
credible intervals.Footnote
13
Accordingly, we predicted that the CDU/CSU would reach 36.2% [30.7%; 41.5%], the SPD 22.1% [19.8%; 24.2%], the Left Party 9.2% [7.2%; 11.4%], the Greens 7.8% [5.9%; 9.6%], the FDP 9.2% [7.2%; 11.4%], the AfD 9.8% [7.4%; 12.5%], and Others 5.7% [3.8%; 7.8%]. As Figure 1 shows, those final forecasts are reasonably close to the final results: Six out of seven
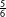 $\frac{5}{6}$
-credible intervals include the final outcome and our final forecast has an RMSE of
$\frac{5}{6}$
-credible intervals include the final outcome and our final forecast has an RMSE of
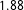 $1.88$
, which is a comparably small error in multiparty forecasting scenarios.Footnote
14
$1.88$
, which is a comparably small error in multiparty forecasting scenarios.Footnote
14
How did the forecast develop over the campaign? Figure 2 highlights a central feature of our model. Early in the campaign, the fundamentals-based model’s forecast (dashed horizontal line) still has a substantial impact on the election-day forecast, with the predictive distributions being centered around it. Closer to Election Day, the polls become more informative and can pull the forecast away from the fundamentals-based model. In instances where the final election result (horizontal line) deviates from the fundamentals-based model, this strongly improves the predictive performance (see, e.g., for SPD or AfD), in cases where they coincide, the forecast does not change much (see, e.g., Left Party). In other words, the dynamic component filters new information from the polls, which reflect short-term dynamics unaccounted for by the fundamentals-based component.
Our model is at least as good as the predictions from a pure fundamentals-based model, but closer to the election it gains in predictive accuracy. We show this in more detail with an application to previous elections in Online Appendix B.3.1. In comparison to monthly averages of the poll results (dark points in Figure 2), our model does better in cases where the fundamentals forecast draws our prediction away from the polls and toward the final result, which can happen particularly early in the campaign (see, e.g., for the CDU/CSU 116–36 days before the election). In the case of a strong decline in public support for the SPD, our model adopted more conservatively to the new level, which in this instance led to weaker predictions 116–36 days before the election. A more detailed comparison of the RMSE of the polls compared to our forecast is given in the Appendix B.3.2.

Figure 2. Development of the dynamic Bayesian forecasting model’s vote share predictions over time for the Federal election 2017, starting 148 days until the final prediction 2 days before the election. The light points show the mean prediction; dark gray bars depict the
 $\frac{5}{6}$
credible intervals and light gray bars the
$\frac{5}{6}$
credible intervals and light gray bars the
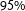 $95\%$
credible intervals. Each party’s observed vote share is indicated by the solid horizontal line. The mean forecast of the fundamentals Dirichlet regression model is marked by the dashed horizontal line. The dark points plot the monthly poll averages.
$95\%$
credible intervals. Each party’s observed vote share is indicated by the solid horizontal line. The mean forecast of the fundamentals Dirichlet regression model is marked by the dashed horizontal line. The dark points plot the monthly poll averages.
Another feature of the implemented Bayesian setup is that deriving other quantities of interest is straightforward. This is particularly useful in multiparty settings, where relative strengths of parties have important implications for government formation. Drawing on the MCMC simulations, we derived such quantities of interest and correctly predicted that (1) seven partiesFootnote
15
entered parliament (with a probability of
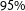 $95\%$
), (2) the AfD had by far the highest probability for becoming the third strongest parliamentary group (
$95\%$
), (2) the AfD had by far the highest probability for becoming the third strongest parliamentary group (
 $43\%$
)Footnote
16
, and (3), most importantly, that merely two of the plausible coalition options had a reasonable chance to gain a parliamentary majority: the Grand coalition (CDU/CSU–SPD) (
$43\%$
)Footnote
16
, and (3), most importantly, that merely two of the plausible coalition options had a reasonable chance to gain a parliamentary majority: the Grand coalition (CDU/CSU–SPD) (
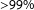 ${>}99\%$
) as well as the “Jamaica coalition” of CDU/CSU, Greens, and FDP (
${>}99\%$
) as well as the “Jamaica coalition” of CDU/CSU, Greens, and FDP (
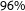 $96\%$
).
$96\%$
).
3 Discussion
We developed a dynamic Bayesian forecasting model for multiparty elections. For the first time, we implemented a backward random-walk strategy in this context. This approach allows us to, first, integrate predictions from a fundamentals-based model as priors on Election Day, and second, to mix it with the information we gain through pooling the polls during the election campaign.
To illustrate the generalizability of the approach, we successfully deployed the same model for another step-ahead forecast in the context of the New Zealand general election 2017, the results of which are presented in Online Appendix C. Our model correctly predicted the strong increase in Labour vote share and the resulting post-electoral bargaining options.
Finally, a caveat: We believe that while the described model provides an attractive and generic framework for dynamic forecasting of electoral outcomes in many multiparty settings, it should not be applied blindly in other contexts. First, although we found some striking similarities in the performance of fundamentals predictors in both the German and the New Zealand setting, the variable choice for the fundamentals component is likely to be context-specific, which is why we did not consider the details of this modeling step in the main text. Second, our model leverages national-level polling results only. In systems that tend to show strong disproportionality between votes and seats, reliable estimates of parliamentary majorities often require district-level forecasts. If district-level polling data are at hand, it should pay off to integrate these into the dynamic component—similar to the original application (Linzer Reference Linzer2013) or other approaches (e.g., Hanretty, Lauderdale, and Vivyan Reference Hanretty, Lauderdale and Vivyan2016).
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2018.49.