


1 Introduction
The idea that parties occupy different positions on an ideological continuum is fundamental to theories of the political process. The need for scoring parties on such a continuum is evidenced by the sheer diversity of approaches and the creativity political scientists devote to obtaining such scores, which range from expert codings of party manifestos (Volkens et al. Reference Volkens, Bara, Budge, McDonald and Klingemann2013), to left–right placements of parties by expert judges (Kitschelt Reference Kitschelt2014) or voters (Lo, Proksch, and Gschwend Reference Lo, Proksch and Gschwend2014), to supervised scaling of word frequencies in party manifestos (Laver, Benoit, and Garry Reference Laver, Benoit and Garry2003), to unsupervised scaling approaches that extract positions from expert-coded manifesto content (Däubler and Benoit Reference Däubler and Benoit2017) or raw word frequencies (Slapin and Proksch Reference Slapin and Proksch2008) in political manifestos, and to analyses of roll call votes (Bräuninger, Müller, and Stecker Reference Bräuninger, Müller and Stecker2016) and parliamentary speech (Lauderdale and Herzog Reference Lauderdale and Herzog2016; Peterson and Spirling Reference Peterson and Spirling2018). Together, these approaches enable the measurement of party positions across time, space, levels of government, and policy areas.Footnote 1
We propose a new measure of party left–right position, one that offers greater party and country coverage than any existing measure. The measure is derived from semistandardized information about party ideology available on the English Wikipedia.Footnote 2 In particular, we draw on ideological keywords (e.g., socialism) that Wikipedia editors use to tag parties and to link them with Wikipedia articles on those ideologies. We develop an ideal point model of how these tags are assigned and use it to scale over 2,000 parties and their associated ideologies on a latent dimension. Our scaling approach is based on the idea that co-occurrences of ideological keywords across parties reveal information about the closeness of parties and ideologies. Keywords that often occur in the same parties (e.g., socialism vs. social democracy) should be closer in space than keywords that rarely occur together (e.g., socialism vs. conservatism). Likewise, parties sharing the same ideological keywords should occupy more similar positions in political space than parties sharing few keywords. To capture these dependencies, we formulate a model in which parties are more likely to get tagged with keywords that are close to them. In a second step, we extend the model to address the fact that some keywords on Wikipedia are inherently ordered.
Our analysis demonstrates that keyword summaries provided by Wikipedia editors enable valid and reliable inferences about party left–right position. Based on our model of keyword assignment, which allows for misclassification and differences in keyword informativeness, we recover a scale from Wikipedia classifications that conforms with common intuitions of left versus right. We show that estimates of party position on this scale correlate with ratings of party position from the largest available expert surveys, and most strongly with ratings of general left–right position. We further demonstrate the reliability of our estimates over repeated measurements with Wikipedia data collected months apart. Together, our results indicate that Wikipedia classifications allow for extracting left–right scores comparable to scores obtained via conventional expert coding methods.
Our findings are in line with studies showing that political information on Wikipedia is often factually correctFootnote 3 (Brown Reference Brown2011; Göbel and Munzert Reference Göbel and Munzert2021; Poschmann and Goldenstein Reference Poschmann and Goldenstein2019), and that Wikipedia can be used for extending political science measurement to a much larger universe of cases (Munzert Reference Munzert2018). Our results also tie in with studies demonstrating the validity of crowd-sourcing information in political research (e.g., Sumner, Farris, and Holman Reference Sumner, Farris and Holman2020; Winter, Hughes, and Sanders Reference Winter, Hughes and Sanders2020). In particular, a number of studies find that assessments by large groups of nonexpert coders (i.e., crowd-coding) of the content of party manifestos or parliamentary debates can give estimates of political position as good as assessments by expert coders (cf. Benoit et al. Reference Benoit, Conway, Lauderdale, Laver and Mikhaylov2016; Haselmayer and Jenny Reference Haselmayer and Jenny2017; Lehmann and Zobel Reference Lehmann and Zobel2018; Horn Reference Horn2019).
Compared to existing approaches, a Wikipedia-based approach offers potentially unlimited coverage of parties. To get some sense of the scope afforded by our measure, note that the largest available databases in political science together include over 4,000 unique parties (Döring and Regel Reference Döring and Regel2019). Extant measures of party left–right position cover only a minority of these. For example, the largest data source in terms of countries covered, the Democratic Accountability and Linkages Project (DALP), provides expert ratings of left–right position for 506 parties from 88 electoral democracies (see Table 1). The data source with the largest party coverage, the Manifesto Project, includes 1,170 parties from 60 countries. The use of Wikipedia allows us to expand that coverage considerably: based on the largest available compilation of parties, drawn from major political science datasets (Party Facts: Döring and Regel Reference Döring and Regel2019), we identify about 3,900 parties (third column) that possess a Wikipedia article. Of these, about 2,100 (fourth column) contain scalable information on party ideology. With the steady expansion of Wikipedia, this number is likely to grow.
Table 1 Coverage of the largest data source on parties (Party Facts), the largest data sources on party left–right positions (MAP: Manifesto Project, DALP: Democratic Accountability and Linkages Project, and CHES: Chapel Hill Expert Survey), and our measure.

While our focus in this paper is on Wikipedia data, the measurement approach we pursue is applicable more generally. For example, selected experts or hired crowd-coders could be tasked with the indexing of parties with keywords. The keywords could be predetermined by the researcher or chosen by the coders. Aside from parties, researchers could also scale other actors, be it politicians, judges, or interest groups. Our approach should be applicable whenever political entities are being indexed with keywords that relate them to some unobserved latent dimension.
2 Party Ideology Classifications on Wikipedia
We focus on information from “party infoboxes” (see Figure 1 for an example). Infoboxes are placed at the top of a Wikipedia article and give a quick summary of facts on a topic. According to Wikipedia guidelines, they

Figure 1 Infobox in the Wikipedia article for La République En Marche! and associated tags.
“contain important facts and statistics of a type which are common to related articles. For instance, all animals have a scientific classification (species, family and so on), as well as a conservation status. Adding an [infobox] to articles on animals therefore makes it easier to quickly find such information and to compare it with that of other articles.”Footnote 4
Unlike the textual format of a basic Wikipedia page, infoboxes restrict editors to submitting information for a defined set of categories; for parties, these are, for instance, the party’s name, its founding year, or the name of its leader. The categories of a party infobox are fixed and cannot be altered by editors.Footnote 5 Their content should be “comparable,” “concise,” “relevant to the subject,” and “already cited elsewhere in the article.”4 While the categories of a party infobox are predefined, their use is optional. Hence, some categories, or even the entire infobox, may be missing from a party’s Wikipedia article.4
Of interest to us are the infobox entries (henceforth tags) provided in the categories “ideology” (henceforth ideology) and “political position” (henceforth lr-position). As can be seen from Figure 1, these categories enable Wikipedia editors to index parties with political philosophies and inclinations, and to establish links between their respective Wikipedia pages. For example, the French party La République En Marche!, formed by Emmanuel Macron in the run-up to his bid for presidency, is tagged with the ideologies liberalism, social liberalism, and pro-Europeanism, with links given for all tags. In terms of lr-position, the party is tagged as centre, including a link to an associated Wikipedia page.
There are no restrictions (that we know of) on which or how many ideology tags a party can have. Our data suggest that editors use tags sparingly, and that they often draw on existing tags rather than generating new ones. The large majority of parties in our data only receive between one and four ideology tags. Furthermore, some tags are assigned much more often than others (see Figures 2 and 3).

Figure 2 Number of tags per party.

Figure 3 Frequency of usage for tags that are used at least 20 times.
In the political position category, editors mostly draw upon a set of seven tags for classifying a party as far-left, left-wing, centre-left, centre, centre-right, right-wing, or far-right (see Online Appendix E for details). Compared to ideology tags, lr-position tags tend to get used somewhat less often: among all parties that exhibit a tag, four out of five have an lr-position tag, while nearly all (97%) have an ideology tag. Roughly three out of five parties receive one lr-position tag, and roughly one out of five parties receive two such tags (see Figure 2). In the latter case, the assigned tags nearly always represent adjacent positions on the political spectrum. Only very few parties receive more than two lr-position tags.
3 A Model of Tag Assignment
We assume that tag assignment is driven by similarity: a party gets tagged if its platform is perceived to be in agreement with the tagged ideology’s basic tenets. We further assume that agreement between party platforms and ideologies can be represented as distances on a latent dimension. Let
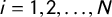 $i = 1, 2,\ldots , N$
be an index of parties, let
$i = 1, 2,\ldots , N$
be an index of parties, let
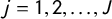 $j = 1, 2,\ldots , J$
be an index of ideology tags, and let y be an N by J matrix with binary entries
$j = 1, 2,\ldots , J$
be an index of ideology tags, and let y be an N by J matrix with binary entries
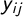 $y_{ij}$
indicating the occurrence of tag j in party is Wikipedia article. We represent these occurrences by an ideal point model similar to the one suggested in Lowe (Reference Lowe2008),
$y_{ij}$
indicating the occurrence of tag j in party is Wikipedia article. We represent these occurrences by an ideal point model similar to the one suggested in Lowe (Reference Lowe2008),
 $$ \begin{align} \Pr(y_{ij} = 1) = F(\alpha_j - \beta_j (o_j - x_i) ^ 2), \end{align} $$
$$ \begin{align} \Pr(y_{ij} = 1) = F(\alpha_j - \beta_j (o_j - x_i) ^ 2), \end{align} $$
where F is the inverse logit transformation,
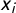 $x_i$
and
$x_i$
and
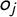 $o_j$
are the positions of party i and ideology j on the latent dimension,
$o_j$
are the positions of party i and ideology j on the latent dimension,
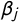 $\beta _j$
is a tag-specific discrimination parameter, and
$\beta _j$
is a tag-specific discrimination parameter, and
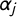 $\alpha _j$
is a tag-specific constant.
$\alpha _j$
is a tag-specific constant.
As can be seen, the probability of observing tag j in party i is maximized when their positions on the latent dimension coincide (i.e., when
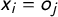 $x_i = o_j$
). Thus,
$x_i = o_j$
). Thus,
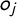 $o_j$
is the modal value of the response function, and the maximum probability at
$o_j$
is the modal value of the response function, and the maximum probability at
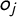 $o_j$
is
$o_j$
is
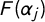 $F(\alpha _j)$
. The discrimination parameter
$F(\alpha _j)$
. The discrimination parameter
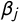 $\beta _j$
measures how strongly the probability of observing tag j in party i depends on their closeness on the latent dimension, that is, how rapidly the probability of observing j decreases as we move away from
$\beta _j$
measures how strongly the probability of observing tag j in party i depends on their closeness on the latent dimension, that is, how rapidly the probability of observing j decreases as we move away from
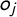 $o_j$
. A high value of
$o_j$
. A high value of
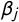 $\beta _j$
implies a peaked response curve in which a party’s probability of exhibiting tag j decreases quickly with increasing distance from j; a low value implies a wide response curve in which the probability that a party exhibits tag j does not depend much on its position on the latent dimension. Tags with low
$\beta _j$
implies a peaked response curve in which a party’s probability of exhibiting tag j decreases quickly with increasing distance from j; a low value implies a wide response curve in which the probability that a party exhibits tag j does not depend much on its position on the latent dimension. Tags with low
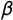 $\beta $
are thus less informative about party position. If
$\beta $
are thus less informative about party position. If
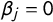 $\beta _j = 0$
, tag j occurs with probability
$\beta _j = 0$
, tag j occurs with probability
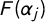 $F(\alpha _j)$
, regardless of party position. Parameters
$F(\alpha _j)$
, regardless of party position. Parameters
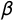 $\beta $
and
$\beta $
and
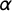 $\alpha $
thus allow tags to differ in their informativeness and prevalence.
$\alpha $
thus allow tags to differ in their informativeness and prevalence.
The above ideal point model is closely connected to extant approaches to scaling word frequencies in political manifestos.Footnote 6 Lowe (Reference Lowe2008, 365f) discusses how the Wordscores and Wordfish approaches can be subsumed under an ideal point model with the same parametric structure as Equation (1). Our application of the model is different in that we only observe binary word presences and absences.Footnote 7 The main substantive difference to the commonly used Wordfish approach is that Equation (1) allows words to have distinct locations. As explained in Lowe (Reference Lowe2008), Wordfish implements a reduced version of the ideal point model that allows word usage only to rise or fall along the latent dimension. By contrast, we assume that keywords (i.e., ideologies) occupy positions on the underlying dimension such that their occurrence may rise and fall, that is, parties may be too far to the right as well as too far to the left for being tagged with a particular ideology. Word frequency scaling approaches typically also include constant terms for the manifestos to correct for the obvious fact that longer manifestos contain more words (Slapin and Proksch Reference Slapin and Proksch2008). We do not apply such a correction as parties do not vary much in their propensity of being tagged: inspection of the marginal distribution shows that the number of tags per party varies little (see Figure 2) and is small compared to the number of available tags (see Figure 3 for the most prominent ones).
As explained in the previous section, Wikipedia offers two kinds of tags: ideology and lr-position. Unlike ideology tags, lr-position tags directly encode regions (i.e., far-left, left-wing, centre-left, etc.) on the underlying scale. We shall treat these tags as coarse, graded indicators of party position in one of seven consecutive intervals along the latent dimension and assume that a party gets tagged if its position is perceived to fall within the interval implied by the tag. To achieve this, we represent the assignment of lr-position tags by an ordered logit model with unknown x (Treier and Jackman Reference Treier and Jackman2008; Caughey and Warshaw Reference Caughey and Warshaw2015). Numbering tags from left to right, and letting
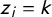 $z_i = k$
denote the presence of tag
$z_i = k$
denote the presence of tag
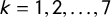 $k = 1, 2,\ldots , 7$
in party is Wikipedia article,
$k = 1, 2,\ldots , 7$
in party is Wikipedia article,
 $$ \begin{align} \Pr(z_i = k) = F(\tau_k - \gamma x_i) - F(\tau_{k - 1} - \gamma x_i), \end{align} $$
$$ \begin{align} \Pr(z_i = k) = F(\tau_k - \gamma x_i) - F(\tau_{k - 1} - \gamma x_i), \end{align} $$
where
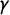 $\gamma $
is a discrimination parameter and
$\gamma $
is a discrimination parameter and
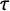 $\tau $
are tag-specific cut points with
$\tau $
are tag-specific cut points with
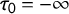 $\tau _0 = -\infty $
,
$\tau _0 = -\infty $
,
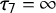 $\tau _7 = \infty $
, and
$\tau _7 = \infty $
, and
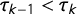 $\tau _{k - 1} < \tau _k$
, for all k.
$\tau _{k - 1} < \tau _k$
, for all k.
Our ordered logit model in Equation (2) is essentially a one-item version of the graded response model from item response theory (Samejima Reference Samejima1969). In this model, the probabilities of tag assignment are single-peaked, except for the left- and rightmost tags. The model parameterizes these outcome probabilities via
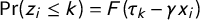 $\Pr (z_i \leq k) = F(\tau _k - \gamma x_i)$
, the cumulative probability of observing tag k or lower (i.e., the probability that party i is tagged as k or further to the left). These cumulative probabilities define a set of binary logit models, each with its own intercept
$\Pr (z_i \leq k) = F(\tau _k - \gamma x_i)$
, the cumulative probability of observing tag k or lower (i.e., the probability that party i is tagged as k or further to the left). These cumulative probabilities define a set of binary logit models, each with its own intercept
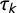 $\tau _k$
and a common slope parameter
$\tau _k$
and a common slope parameter
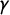 $\gamma $
. The slope parameter
$\gamma $
. The slope parameter
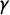 $\gamma $
measures how rapidly the probability of tag assignment changes in response to party position on the latent dimension. Values of
$\gamma $
measures how rapidly the probability of tag assignment changes in response to party position on the latent dimension. Values of
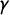 $\gamma $
further from zero imply steeper cumulative response curves and more peaked outcome response curves.
$\gamma $
further from zero imply steeper cumulative response curves and more peaked outcome response curves.
The intercepts
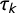 $\tau _k$
define a set of adjacent intervals on the latent dimension, corresponding to the outcome values. The boundaries of these intervals can be interpreted as the points at which the cumulative probabilities are tied, and they are given by
$\tau _k$
define a set of adjacent intervals on the latent dimension, corresponding to the outcome values. The boundaries of these intervals can be interpreted as the points at which the cumulative probabilities are tied, and they are given by
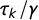 $\tau _k / \gamma $
, for
$\tau _k / \gamma $
, for
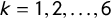 $k = 1, 2,\ldots , 6$
. For example, a party located at
$k = 1, 2,\ldots , 6$
. For example, a party located at
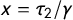 $x = \tau _2 / \gamma $
has
$x = \tau _2 / \gamma $
has
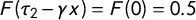 $F(\tau _2 - \gamma x) = F(0) = 0.5$
, and thus a
$F(\tau _2 - \gamma x) = F(0) = 0.5$
, and thus a
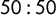 $50:50$
chance of being tagged as left-wing or something further to the left, as opposed to being tagged as centre-left or something further to the right. By construction, the interval boundaries are defined with respect to the cumulative responses, not the observed responses. However, the boundaries are also related to the observed responses in that the probability of outcome k peaks in the middle of the interval associated with it.
$50:50$
chance of being tagged as left-wing or something further to the left, as opposed to being tagged as centre-left or something further to the right. By construction, the interval boundaries are defined with respect to the cumulative responses, not the observed responses. However, the boundaries are also related to the observed responses in that the probability of outcome k peaks in the middle of the interval associated with it.
As explained in the previous section, for some parties, we observe more than one lr-position tag. In these instances, we treat each outcome value as an independent realization of z, conditional on x, and model their joint probability. Formally, this means that instead of
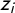 $z_i$
in Equation (2), we model the outcome variable
$z_i$
in Equation (2), we model the outcome variable
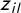 $z_{il}$
, where
$z_{il}$
, where
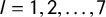 $l = 1, 2,\ldots , 7$
indexes a party’s first, second, and so on observed lr-position tag.
$l = 1, 2,\ldots , 7$
indexes a party’s first, second, and so on observed lr-position tag.
In what follows, we pursue two approaches to recovering party positions from Wikipedia articles:
-
1. Estimating Equation (1) with data on ideology tag assignment.
-
2. Jointly estimating Equations (1) and (2) with data on ideology and lr-position tag assignment.
The first approach recovers the positions of parties and tags solely from their co-occurrences without any prior assumptions about their locations on the latent dimension. This approach has applicability beyond Wikipedia. It can be used whenever political entities are indexed with a set of keywords, following a logic of “pick any(-thing that applies)” (Levine Reference Levine1979).
When applied to Wikipedia tags, a downside of the approach is that it discards the additional information contained in lr-position tags. Since we know the ordering of these tags, their relative locations on the latent dimension do not need to be estimated. This allows us to constrain the estimation problem and recover the locations of parties and tags with greater precision. The fact that we know the ordering of lr-position tags also helps with the identification of the latent dimension. To see why, note that a scaling of ideology tags alone can reveal such a dimension only if neighboring tags occur jointly in some parties. The inclusion of lr-position tags makes this precondition unnecessary: even if ideology tags occurred in completely separate (i.e., nonoverlapping) groups of parties, their ordering could still be inferred from the lr-position tags with which they co-occur.Footnote 8 The key assumption behind combining ideology and lr-position tags in this way is that both sets of tags can be placed on the same latent dimension. As a simple check of this assumption, we compare the placement of ideology tags under both estimation approaches. Strong differences in results would be an indication that the two sets of tags might not form a common scale.
4 Estimation
We employ Bayesian Markov Chain Monte Carlo (MCMC) methods to obtain a posterior distribution for all model parameters (Albert and Chib Reference Albert and Chib1993). MCMC simulations are performed with JAGS, Version 4.3.0 (Plummer Reference Plummer2017). JAGS code used to estimate both models is provided in Online Appendix C.Footnote 9
4.1 Identification and parameterization
Like all latent variable models, Equations (1) and (2) are not identified without some restrictions on the parameters. Three constraints are necessary to identify all parameters in a unidimensional model (Rivers Reference Rivers2003). To resolve invariance to addition, we center the underlying scale at 0; to resolve invariance to multiplication, we standardize the scale to units of
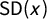 $\text {SD}(x)$
; and to resolve invariance to reflection, we impose the constraint
$\text {SD}(x)$
; and to resolve invariance to reflection, we impose the constraint
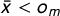 $\bar {x} < o_m$
, where m is the index value for the tag conservatism. The identifying restrictions are imposed on each posterior draw, with offsetting transformations on the other parameters to keep outcome probabilities unchanged (see Online Appendix B for further details).
$\bar {x} < o_m$
, where m is the index value for the tag conservatism. The identifying restrictions are imposed on each posterior draw, with offsetting transformations on the other parameters to keep outcome probabilities unchanged (see Online Appendix B for further details).
To facilitate convergence to the target distribution, we estimate a reparameterized version of Equation (1). As shown in Lowe (Reference Lowe2008, 366), Equation (1) can be equivalently stated as
 $$ \begin{align} \Pr(y_{ij} = 1) = F(\delta_j + \lambda_j x_i - \beta_j x_i ^ 2), \end{align} $$
$$ \begin{align} \Pr(y_{ij} = 1) = F(\delta_j + \lambda_j x_i - \beta_j x_i ^ 2), \end{align} $$
where
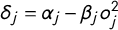 $\delta _j = \alpha _j - \beta _j o_j ^ 2$
and
$\delta _j = \alpha _j - \beta _j o_j ^ 2$
and
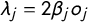 $\lambda _j = 2 \beta _j o_j$
, and where the negative sign on
$\lambda _j = 2 \beta _j o_j$
, and where the negative sign on
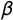 $\beta $
follows from the assumption of concavity (i.e., the response function must be single peaked, not single dipped). Equation (3) has the same number of parameters as Equation (1) but is quadratic only in x, while Equation (1) is quadratic in x and o. In practice, we find that parameterizing the model as in Equation (3) yields faster convergence to the target distribution both in terms of iterations and runtime.Footnote
10
We therefore use Equation (3) as our estimation equation. To obtain estimates of the parameters in Equation (1), we transform posterior draws of
$\beta $
follows from the assumption of concavity (i.e., the response function must be single peaked, not single dipped). Equation (3) has the same number of parameters as Equation (1) but is quadratic only in x, while Equation (1) is quadratic in x and o. In practice, we find that parameterizing the model as in Equation (3) yields faster convergence to the target distribution both in terms of iterations and runtime.Footnote
10
We therefore use Equation (3) as our estimation equation. To obtain estimates of the parameters in Equation (1), we transform posterior draws of
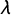 $\lambda $
,
$\lambda $
,
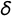 $\delta $
, and
$\delta $
, and
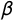 $\beta $
into posterior draws of
$\beta $
into posterior draws of
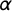 $\alpha $
,
$\alpha $
,
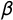 $\beta $
, and o, using the reparameterization relations stated above, and subsequently apply the identifying restrictions.
$\beta $
, and o, using the reparameterization relations stated above, and subsequently apply the identifying restrictions.
4.2 Priors
We assign standard normal priors to x (Albert and Johnson Reference Albert and Johnson1999), and normal priors with mean zero and variance 5 to
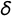 $\delta $
and
$\delta $
and
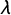 $\lambda $
. To enforce the concavity constraint in Equation (3), we assign log-normal priors with log-mean zero and log-variance parameter 2 to
$\lambda $
. To enforce the concavity constraint in Equation (3), we assign log-normal priors with log-mean zero and log-variance parameter 2 to
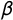 $\beta $
, which implies a prior variance on
$\beta $
, which implies a prior variance on
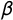 $\beta $
of about 47. To see what these priors mean, consider the prior variation of o relative to x (cf. Clinton and Jackman Reference Clinton and Jackman2009, 601–602): Monte Carlo simulation shows that the prior variances on
$\beta $
of about 47. To see what these priors mean, consider the prior variation of o relative to x (cf. Clinton and Jackman Reference Clinton and Jackman2009, 601–602): Monte Carlo simulation shows that the prior variances on
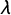 $\lambda $
and
$\lambda $
and
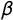 $\beta $
imply a prior 95% credibility interval for o of about
$\beta $
imply a prior 95% credibility interval for o of about
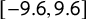 $[-9.6, 9.6]$
. Party positions are thus a priori interior to ideologies with the prior variance of ideologies being large relative to that of party positions. Since the locations of ideologies and parties are only identified relative to each other, because the scale of the latent dimension is unknown, the wide range of ideologies relative to party positions suggests that the priors are permissive enough to allow the data to inform the estimation result. Using wider priors on ideologies leaves results unchanged (but slows down convergence). Likewise, using somewhat tighter priors also yields similar results.
$[-9.6, 9.6]$
. Party positions are thus a priori interior to ideologies with the prior variance of ideologies being large relative to that of party positions. Since the locations of ideologies and parties are only identified relative to each other, because the scale of the latent dimension is unknown, the wide range of ideologies relative to party positions suggests that the priors are permissive enough to allow the data to inform the estimation result. Using wider priors on ideologies leaves results unchanged (but slows down convergence). Likewise, using somewhat tighter priors also yields similar results.
For
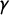 $\gamma $
in the ordered logit model, we use a normal prior with mean zero and variance 25. For the category cut points, we choose normal priors with mean zero and variance 25, subject to the order constraint
$\gamma $
in the ordered logit model, we use a normal prior with mean zero and variance 25. For the category cut points, we choose normal priors with mean zero and variance 25, subject to the order constraint
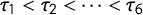 $\tau _1 < \tau _2 <\cdots < \tau _6$
.
$\tau _1 < \tau _2 <\cdots < \tau _6$
.
4.3 Starting Values
We employ correspondence analysis (CA) to generate starting values for party positions. CA is a deterministic dimension-reduction technique, similar to principal components analysis (Greenacre Reference Greenacre2010). Our use of it is motivated by a result in ter Braak (Reference ter Braak1985) proving that first-dimension coordinates from a CA of the binary data matrix yield approximate maximum likelihood (ML) estimates of x and o if the data-generating process adheres to Equation (1).Footnote 11 This property of CA has made it particularly popular in scaling applications involving sparse data matrices (i.e., matrices with many more zeroes than ones), which are common in other fields (see, e.g., Smith and Neiman Reference Smith and Neiman2007; ter Braak and Šmilauer Reference ter Braak and Šmilauer2015) and which we also encounter in our application. ML estimators tend to be numerically unstable in these situations, while CA is guaranteed to yield a solution regardless of how large or sparse the data matrix is (ter Braak and Šmilauer Reference ter Braak and Šmilauer2015). Moreover, CA tends to approximate ML more closely when the data are sparse (ter Braak Reference ter Braak1985, 863).Footnote 12 In our MCMC estimation approach, numerical instability is not an issue; however, convergence to the target distribution can be slow with sparse data. To facilitate convergence, we follow the proposal in ter Braak (Reference ter Braak1985) and use CA estimates of x and o as starting values. Online Appendix G compares our initial CA estimates to the final Bayesian estimates.
To generate starting values for the remaining parameters, we first estimate logistic regression models—one for each ideology—of the form given in Equation (1) using CA estimates of o and x as inputs. This gives us estimates of
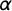 $\alpha $
and
$\alpha $
and
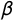 $\beta $
. We then transform those estimates, using the reparameterization relations given in Section 4.1, to obtain starting values for
$\beta $
. We then transform those estimates, using the reparameterization relations given in Section 4.1, to obtain starting values for
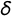 $\delta $
and
$\delta $
and
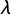 $\lambda $
. To obtain starting values for
$\lambda $
. To obtain starting values for
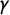 $\gamma $
and
$\gamma $
and
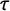 $\tau $
, we estimate the ordered logistic regression model in Equation (2) using CA estimates of x as inputs.
$\tau $
, we estimate the ordered logistic regression model in Equation (2) using CA estimates of x as inputs.
4.4 Convergence
We set up four parallel chains and run each model for 22,000 iterations, discarding the first 2,000 draws as burn-in. We thin the result, keeping every 10th draw, to obtain 8,000 samples from the posterior distribution. Assessment of posterior draws via traceplots and potential scale reduction factors suggest convergence of all parameters to their target distribution (see Online Appendix D for details).
5 Selection of Parties and Tags
Collecting information from Wikipedia requires a list of parties that defines our target population. To maximize coverage, we draw on the largest list of parties that is currently available in political science: the Party Facts database (version 2019a; Döring and Regel Reference Döring and Regel2019; Bederke, Döring, and Regel Reference Bederke, Döring and Regel2019).
Party Facts is a collaborative project that aims to solve the problem of delineating the universe of political parties. It offers an authoritative reference list of relevant parties in the world, based on the parties included in the CLEA, ParlGov, Manifesto Project, PolCon, and a number of smaller datasets. Party Facts includes nearly all parties that won at least 5% seat share in a national election, as well as parties with at least 1% vote share for some countries. Of all political science datasets, it currently provides the largest coverage of political parties worldwide, with over 4,500 parties and URLs to the Wikipedia pages of about 3,900 of these (see Table 1).
We collect all ideology and lr-position tags for parties that have a Wikipedia URL in Party Facts and an infobox on Wikipedia. Data collection took place on April 27, 2019. We consider only tags that are linked to an associated Wikipedia article and code a party as tagged with the ideology or lr-position to which the link refers (see Online Appendix E for further details).
To get some insight into the variety of tags and their usage, Figures 2 and 3 give a breakdown of the raw numbers. The first thing to note is that tags are used sparingly. As Figure 2 shows, Wikipedia editors typically use one to four tags to describe party ideology; only a small fraction of parties show more than seven ideology tags. For lr-position tags, the modal frequency is one, but a considerable number of parties also receive two such tags. A closer inspection of these latter cases reveals that editors almost always assign adjacent lr-position tags to parties (e.g., centre-right and right-wing).
In addition to being used sparingly, tags are also used unequally: the 20 most often-used ideology tags, which make up less than 5% of all observed tags, account for over 50% of total tag usage. Among this core of widely applied tags, we find well-known, major ideologies such as liberalism, conservatism, and social democracy (see Figure 3).
To reduce the potential for bias and inaccuracy in our data, we focus on tags that are widely used on Wikipedia, as such tags should get more exposure and, as a result, be better known and more easily scrutinized than tags referring to rare or obscure ideologies. To achieve this, we implement a threshold of 50-tag occurrences. Tags observed in fewer parties are omitted from the analysis. This restriction allows us to rule out narrow ideologies that depend on national context (e.g., Basque nationalism), as well as peculiar ones (e.g., eurocommunism) about which only a small number of editors probably know enough to be able to apply them adequately, and spot and correct mistakes.Footnote 13 For parties, we choose an inclusive threshold of at least two tags. In sum, this gives us scalable information for more than 2,100 parties (see Table 1).
6 The Resulting Scale
We begin by inspecting the scale that we obtain for its face validity. Figures 4 and 5 summarize the estimation result via the estimated response curves and party positions for Models 1 and 2. Each response curve indicates the probability that a particular tag is assigned to a party with a given position on the underlying dimension. For example, a party at position 0 in Figure 5 has an estimated probability of about 60% of being tagged with liberalism, about 30% probability of being tagged with social liberalism, about 20% probability of being tagged with pro Europeanism, and so on.Footnote 14 The use of politically informative keywords thus lends a substantive interpretation to areas of the scale based on the ideologies that are particularly prominent there. In turn, this is reflected in party positions.
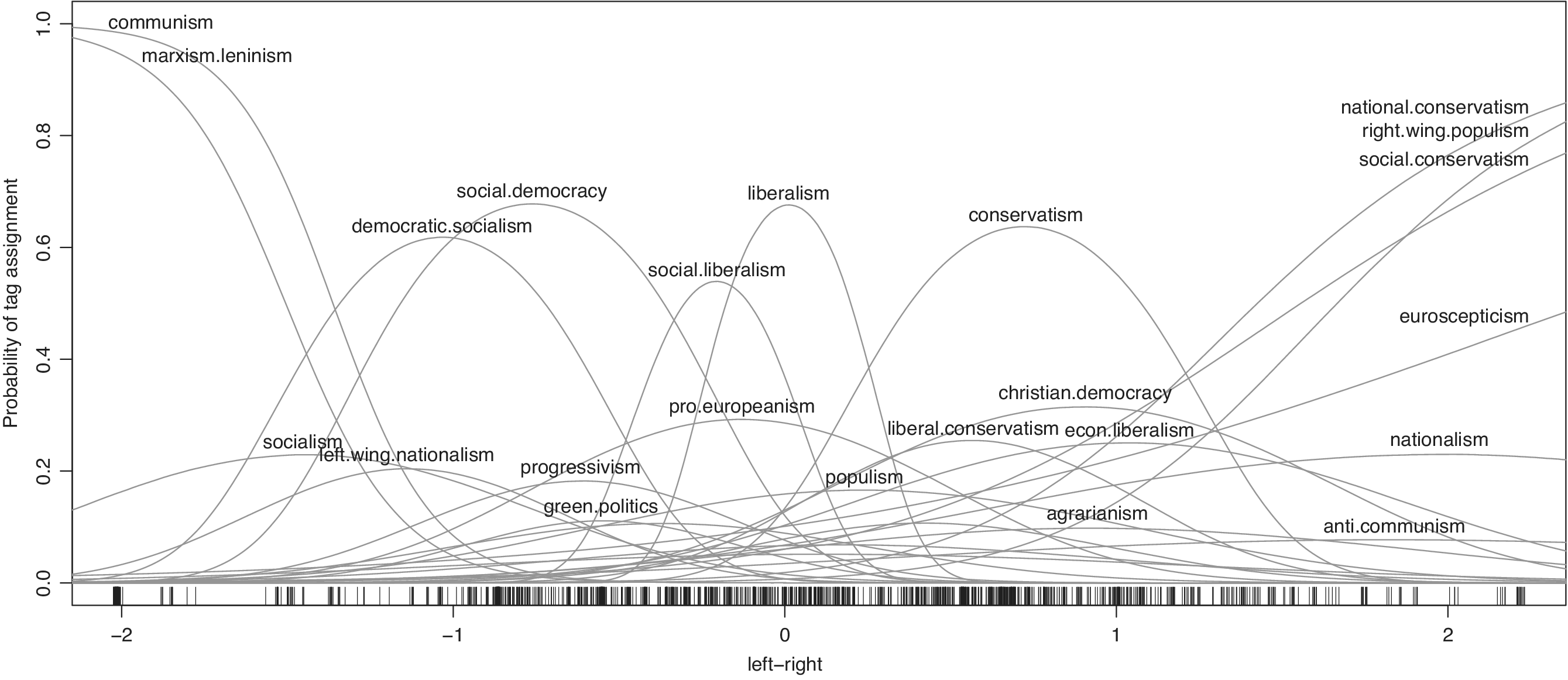
Figure 4 Response curves and estimated party positions (indicated by tick marks) from a scaling of ideology tags only; 1,367 parties and 27 tags (some response curves are unlabeled to avoid clutter).

Figure 5 Response curves for ideology tags, estimated intervals for lr-position tags, and estimated party positions (indicated by tick marks) from a joint scaling of ideology and lr-position tags; 2,147 parties and 35 tags (some response curves are unlabeled to avoid clutter).
Figures 4 and 5 generally support the idea of a global left–right dimension underlying Wikipedia classifications of party ideology. Ideologies that are traditionally associated with the labels “left” and “right” (e.g., communism, socialism, social democracy, liberalism, conservatism, and national conservatism) line up in the familiar order. These ideologies’ response curves are also steep in the sense that their probability of being assigned to a party rises and falls quickly along the underlying spectrum. The ideologies thus help discriminate parties on the underlying dimension. By contrast, ideologies such as agrarianism or regionalism have flat response curves and thus contribute less information on where to place parties on the underlying dimension. The fact that major ideologies line up in the familiar order suggests that party position estimates can be interpreted in terms of left versus right. In other words, the scale has face validity.
We emphasize that we obtain substantively the same result, regardless of whether we include lr-position tags or not (compare Figures 4 and 5). Ideology tags alone are thus sufficient to obtain a meaningful left–right scale. However, the fact that the assignment of ideology tags follows a familiar left–right reasoning suggests that Wikipedia’s lr-position tags can be used to tighten our inferences about the underlying scale (besides allowing us to include even more parties in the estimation) by construing them as ordered indicators of adjacent intervals on the underlying dimension—the assumption that gives rise to Model 2.
As Figure 5 shows, the inclusion of lr-position tags leaves the ordering of ideologies largely unchanged but helps distinguish some ideologies more clearly from one another. For example, social democracy and democratic socialism are now separated more clearly, with the former falling firmly into the centre-left bracket and the latter into the left-wing bracket. Likewise, Christian democracy now clearly peaks left of conservatism and within the centre-right bracket. Lastly, the inclusion of lr-position tags reduces the probability of tag assignment for most ideology tags, especially for some on the far-right end (i.e., right-wing populism, national conservatism, etc.). This is due to the higher frequency with which lr-position tags are observed compared to most ideology tags, as well as their patterns of co-occurrence. In particular, the rightmost ideology tags often occur in conjunction with the far-right tag as well as the right-wing tag. This leads to more equal probabilities of far-right and right-wing parties being tagged with one of these ideologies.
7 Validation with Expert Surveys
Having established our estimates’ face validity, we now consider their convergent and discriminant validity (cf. Adcock and Collier Reference Adcock and Collier2001). Accordingly, a valid measure should correlate highly with other measures of the same construct, while showing lower correlations with measures of related but different constructs.
To test this, we draw on expert ratings of party left–right position as well as party position on other dimensions from the two largest existing expert surveys, the DALP (Kitschelt Reference Kitschelt2014) and the Chapel Hill Expert Survey (CHES) (Polk et al. Reference Polk2017). The DALP covers 506 parties from 88 electoral democracies worldwide. Ratings were collected between 2008 and 2009 and may not be entirely accurate with respect to parties that have recently altered their position significantly. Nevertheless, no other expert survey provides broader country coverage. From the CHES, we use the most recent set of ratings, which were collected in 2014 and cover 268 parties from 31 European democracies.
Regarding convergent validity, Figure 6 shows that our estimates correlate well with expert ratings of party left–right position. Estimates from Model 2 generally fit expert ratings more closely than those of Model 1, suggesting that the inclusion of lr-position tags adds useful information above and beyond ideology tags. Table 2 further shows how the correlation between our scores and expert ratings varies over countries. Since expert surveys ask for placements of parties only within a given polity (i.e., each expert rates parties from his or her country), pooling of ratings across countries may introduce measurement error due to differential item functioning (Hare et al. Reference Hare, Armstrong, Bakker, Carroll and Poole2014; Struthers, Hare, and Bakker Reference Struthers, Hare and Bakker2019).Footnote 15 Comparing estimates on a country-by-country basis, the median correlation is above 0.9 and the 25th percentile is above 0.75 in all four comparisons. Thus, for three-quarters of the countries covered by either the DALP or the CHES, our estimates of party positions accord well—and for half the countries covered, they accord very well—with the judgment of country experts.
Table 2 Country-wise correlations with expert ratings (means and percentiles).


Figure 6 Comparison of party position estimates to expert ratings from the Democratic Accountability and Linkages Project (top row) and from the 2014 Chapel Hill Expert Survey (bottom row). Model 1: N = 321 and N = 203; Model 2: N = 435 and N = 247.
Regarding discriminant validity, we compare our estimates to expert ratings of party position on economic policy, redistribution, GAL–TAN, and identity politics. As Table 3 (first column) shows, experts’ perceptions of party left–right position are substantially correlated with their perceptions of party stances on all other measured dimensions. This suggests that each of the more specific dimensions reflects some aspect of left versus right. Reassuringly, our estimates also correlate with every other dimension measured in expert surveys. However, the correlations remain weaker than those with left–right, suggesting that our estimates most likely represent general left–right position, as opposed to more specific policy stances.
Table 3 Correlations with expert ratings on other dimensions.

Closer inspection of Table 3 reveals further nuances. While experts’ judgments of party left–right position relate most strongly to their perceptions of parties’ stances on economic or redistributive policy, Wikipedia-based estimates are more strongly associated with expert ratings of parties’ positions on GAL–TAN or identity politics than on economic policy. With the inclusion of lr-position tags, correlations increase somewhat between our estimates and ratings of parties’ economic and redistributive stances (compare Model 1 and Model 2), but, overall, our scores remain slightly more associated with social and identity politics. Although small, these differences suggests that Wikipedia editors’ understanding of left versus right is driven more by value considerations than by economic considerations, whereas experts tend to view left versus right somewhat more in terms of economic policy and redistribution than social policy.
8 Reliability
As content on Wikipedia is open to instant updating and revision by anyone, the raw data are constantly evolving. Any day, new tags might get added to a party’s infobox, others deleted. This raises the question of how robust our estimation is to Wikipedia’s openness: Can we rely on estimates of party positions from a single point in time, when the raw data are subject to constant revision (i.e., additions, refinements, mistakes, and corrections of tags)?
To gauge this uncertainty, we estimate party positions using ideology and lr-position tags observed at different points in time. Specifically, we compare our current scores to scores obtained in the same way using data collected some 15 weeks earlier (on January 11, 2019). The assumption is that during this short period of time, the underlying party positions remain the same. Changes in tags will be due to editors adding new classifications or modifying what they see as incorrect classifications, either through deletion or replacement. Given Wikipedia’s 500 million monthly visitors, there should be ample opportunity for observing such changes in the given time period. By comparing the positions of parties that experience a change in their tags, we gain some insight on the sensitivity of our measure to ongoing editing activity. A reliable measure should yield similar position estimates despite overt variation in tags.
Across the 15-week period considered, we find that 111 and 279 of the parties included in the estimation of Models 1 and 2 see a change in their tags. Comparing those parties’ estimated scores, we find a close correspondence between them (Figure 7). The average absolute differences between scores are only 0.20 and 0.17, respectively. If we take a difference of 0.5 as the minimum for a substantial change—a difference of 0.5 roughly corresponds to a move from one left–right bracket to the next (see Figure 5)—we find that 10 and 13 parties, respectively, experience such a change in their positions (see Online Appendix H for a detailed inspection of these cases). The strong correlation between both sets of scores indicates a high test–retest reliability.

Figure 7 Reliability of party position estimates. The x-axis shows party position estimates obtained from Wikipedia classifications collected 15 weeks prior to those on which our current estimates are based, which are shown on the y-axis. A
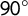 $90^{\circ }$
line is superimposed. Model 1:
$90^{\circ }$
line is superimposed. Model 1:
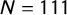 $N = 111$
; Model 2:
$N = 111$
; Model 2:
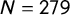 $N = 279$
.
$N = 279$
.
The fact that changes in tags lead to small variation in party positions suggests that the observed edits are mostly refinements rather than sweeping revisions of parties’ infobox classifications.Footnote 16 Perhaps this result should not be too surprising. After all, if there was little stability in parties’ infobox tags, we would not expect a scaling of tags collected at an arbitrary point in time to yield a strong and coherent left–right dimension. Nonetheless, the result is reassuring. Monitoring the evolution of party scores in the long run will, of course, be necessary for maintaining confidence in the measure.
9 Generalizing Beyond Expert Surveys
Parties differ greatly in how much attention they receive by the public, with some parties being much better known than others. This could affect how much attention and scrutiny they receive on Wikipedia. Prominent parties are likely to attract greater interest from Wikipedia editors, and with more resources going into the creation and monitoring of those parties’ articles, their tags are likely to be more accurate than those of less well-known parties.Footnote 17 Our above comparisons with expert ratings might thus represent a best-case scenario, as expert surveys tend to include the most important parties in a polity. For parties not included in expert surveys, the accuracy of our scores might be lower.
To assess this possibility, we formulate two hypotheses. Hypothesis one is that greater scrutiny of a party’s Wikipedia article improves the accuracy of its estimated left–right score. Hypothesis two is that articles of parties included in expert surveys are scrutinized more than those of other parties. If both hypotheses hold true, we can expect our scores to be less accurate for parties not included in expert surveys, and more so the stronger the observed relationships are. We use two indicators for an article’s level of scrutiny (see Online Appendix I for details): its number of editors; and the (average) experience of its 50 most active editors, where experience is defined as an editor’s total number of live edits on Wikipedia. For comparison, we also include two indicators of party prominence in the analysis: article pageviews and vote share as recorded in Party Facts.
To assess the first hypothesis, we study the closeness of fit between our scores and the expert ratings shown in Figure 6. If more editors and greater editor experience improve the accuracy of information on a party’s Wikipedia page, one would expect the party’s estimated position to correspond more closely to the experts’ views and hence be closer to the regression line than that of other parties. We employ a linear regression model with variance heterogeneity (Verbyla Reference Verbyla1993; King Reference King1998) to examine this conjecture (see Online Appendix J for a description of the model). This approach allows us to model the residual variation around the regression line as a function of additional covariates, thus providing a natural way to study correlates of inaccuracy in party scores.
We find that more editors and greater editor experience are associated with a tighter fit between our scores and both the DALP and the CHES ratings (see Table 4). By contrast, pageviews and vote share are not consistently associated with greater accuracy of party scores (the correlation between pageviews and the number of editors is 0.79). Similar results hold if we test each predictor in isolation. In both models, editor experience shows the strongest effect: the standard error of the regression decreases by 8% (i.e., by a factor of
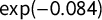 $\exp (-0.084)$
) and by 10%, respectively, for a one-unit increase in (the log of) editor experience. Given the observed ranges and variances on all the variables (see Table 5), editor experience is thus associated with the biggest reduction in regression error.
$\exp (-0.084)$
) and by 10%, respectively, for a one-unit increase in (the log of) editor experience. Given the observed ranges and variances on all the variables (see Table 5), editor experience is thus associated with the biggest reduction in regression error.
Table 4 Predictors of party position estimates (DALP:
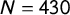 $N = 430$
; CHES:
$N = 430$
; CHES:
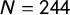 $N = 244$
).
$N = 244$
).
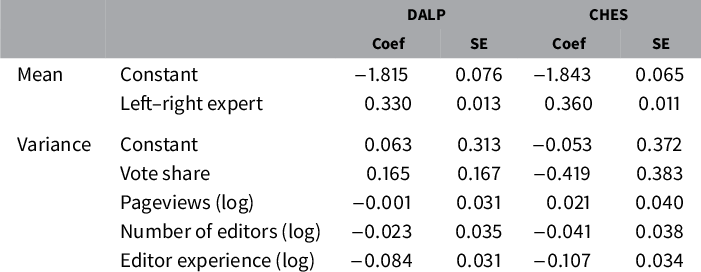
Table 5 Comparing parties included in expert surveys (
 $N = 610$
) to other parties on Wikipedia (
$N = 610$
) to other parties on Wikipedia (
 $N = 3,275$
).
$N = 3,275$
).
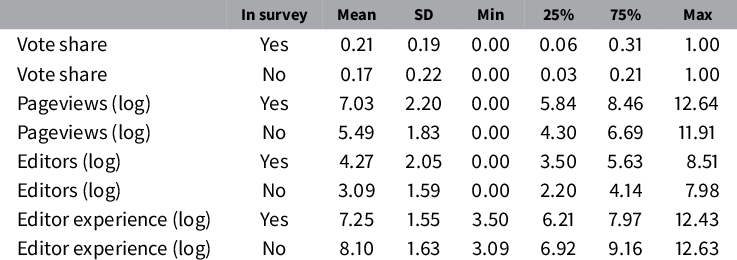
To assess the second hypothesis, Table 5 compares parties covered either by the CHES or the DALP surveys to all other parties that have a Wikipedia page. Consistent with the fact that expert surveys deliberately select the most important parties in a polity, we find that the parties included in expert surveys tend to have a higher vote share and receive more pageviews, on average, than other parties on Wikipedia. Consistent with the notion of greater interest, these parties also attract more editors, on average, than other parties on Wikipedia. For editor experience, we find the opposite pattern with parties not included in expert surveys having more seasoned article editors, on average. Apart from these differences, we find that the two samples are surprisingly similar in terms of variation and spread. In fact, the samples overlap to a large extent on each of the indicators.
The results suggests that both groups of parties have something speaking for them. Parties included in expert surveys tend to attract more editors than other parties on Wikipedia. Yet, their editors tend to be less experienced. Since editor experience contributes to the accuracy of tag assignment, Wikipedia-based scores need not be less accurate for parties not covered by expert surveys. For example, we would expect in-survey parties’ scores to be 5% more accurate, on average, based on their higher number of editors, but we would expect out-of-survey parties’ scores to be 9% more accurate, on average, based on their editors’ greater experience.Footnote
18
The observed correlation between a party’s number of editors and the average experience of its editors is about
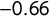 $-0.66$
, so a party with fewer editors tends to have more experienced editors and vice versa. This as well as the large overlap between the two samples on each of the relevant indicators gives us reason to expect a Wikipedia-based measure not to perform worse (than expert surveys would) in estimating positions for parties for which we currently lack such estimates.
$-0.66$
, so a party with fewer editors tends to have more experienced editors and vice versa. This as well as the large overlap between the two samples on each of the relevant indicators gives us reason to expect a Wikipedia-based measure not to perform worse (than expert surveys would) in estimating positions for parties for which we currently lack such estimates.
10 Conclusion and Outlook
Party positions are central to explanations of politics. In this paper, we entertained the hypothesis that semistandardized classifications of party ideology provided on Wikipedia carry valid and reliable information about party position. We stipulated an ideal point model that allows us to exploit variation in ideological keywords across parties and obtained scores of party position on a latent dimension whose substantive interpretation fits common intuitions of left versus right. In line with our hypothesis, we found party scores to correlate well with independent expert judgments of party left–right position and we found them to be reliable in a test–retest scenario. This demonstrates that our approach yields a novel measure of party left–right position.
As a proof of concept, our results hold great promise for future research. Party ideology and the notion of ideological differences between parties are key causal factors in explanations of the political process. They feature prominently in theories of political change and stability, legislative decision making, coalition politics, public policy, economic growth, inequality and redistribution, as well as in accounts of democratization, state building, and violent conflict. Conversely, parties’ ideological positions are the object of study in many research areas, from electoral competition to the quality of representation to political fragmentation and polarization. With its potentially unlimited coverage, our measure of party position opens up new possibilities for researchers to study these and other topics on a much larger universe of cases. This includes many parties for which we currently lack ideological placements, as well as new countries not covered by extant data sources.
Our measure is not limited to parties that currently exist. Unlike many expert surveys, our scaling includes parties of the past, provided they have a Wikipedia article, and provided Wikipedia editors assign to these parties some of the same tags that they assign to other parties. In addition, our Wikipedia-based approach may provide estimates for parties founded just recently, which expert surveys may not (yet) cover. One database that does include past parties and also regularly updates its sample is the Manifesto Project. Compared to manifesto-based measures of party position, our measure does not depend on the existence of an electoral manifesto. This allows for the inclusion of parties that do not produce such documents, including nascent parties, nondemocratic parties, or parties in regimes with restricted electoral competition.
Acknowledgments
The authors would like to thank panelists at the 2019 Annual MPSA Conference, and participants in research colloquia at the Universities of Bremen, Konstanz, and Mannheim for their feedback, especially Christopher Hare, Christopher Wratil, Samuel Baltz, Markus Tepe, Dominic Nyhuis, SaschaGöbel, Thomas Malang, Benjamin Guinaudeau, Paul Bederke, Susumu Shikano, Konstantin Käppner, Christian Breunig, Thomas Gschwend, and Hans-Dieter Klingemann.
Data Availability Statement
All replication materials are available on Dataverse (Herrmann and Döring 2021).
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2021.28.





















 Open access
Open access